Пред.
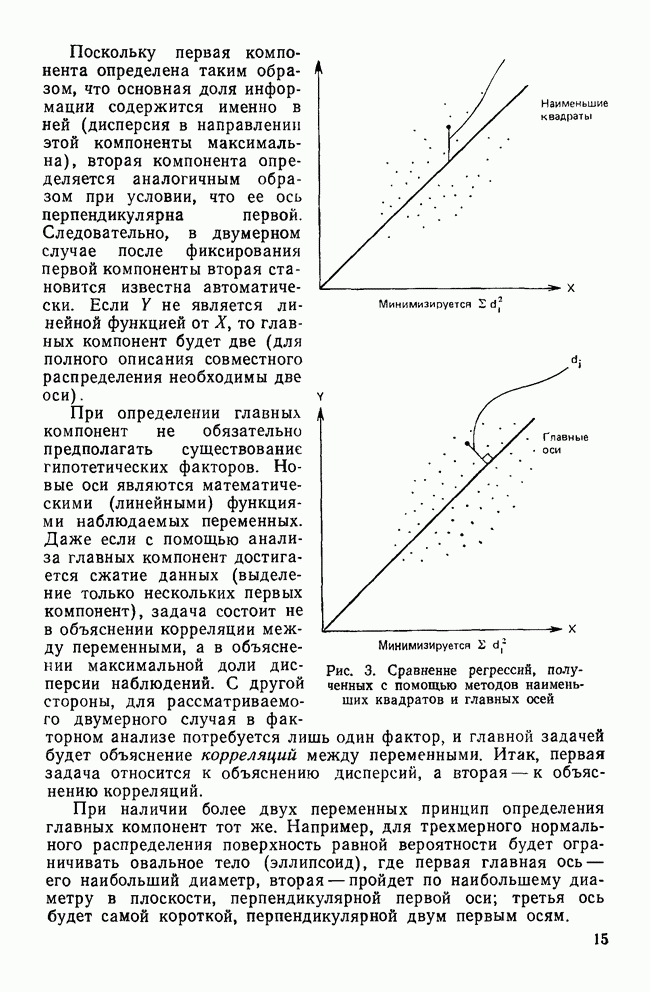
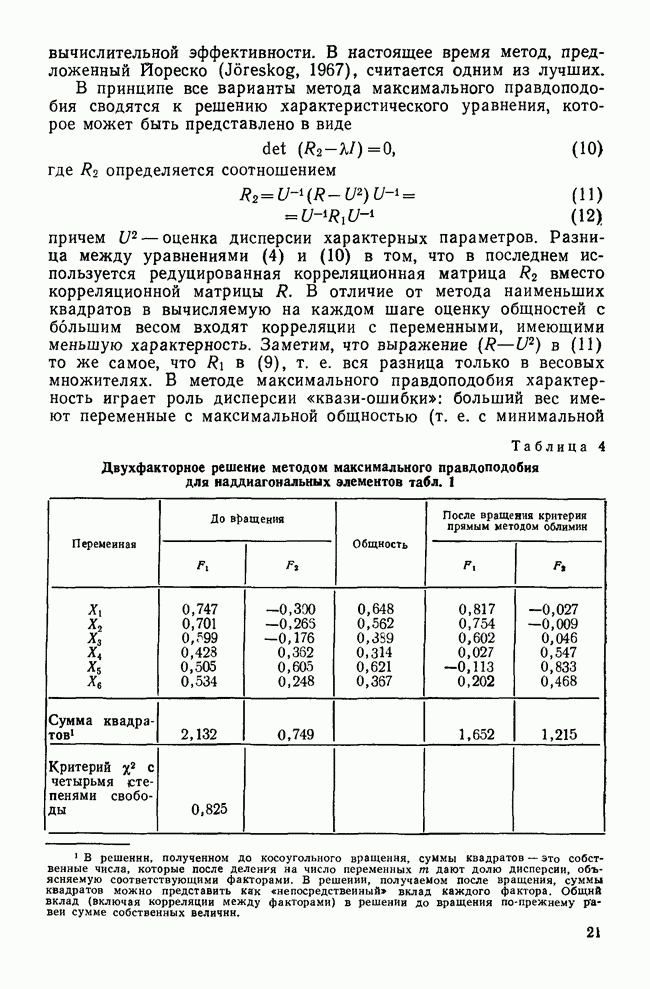
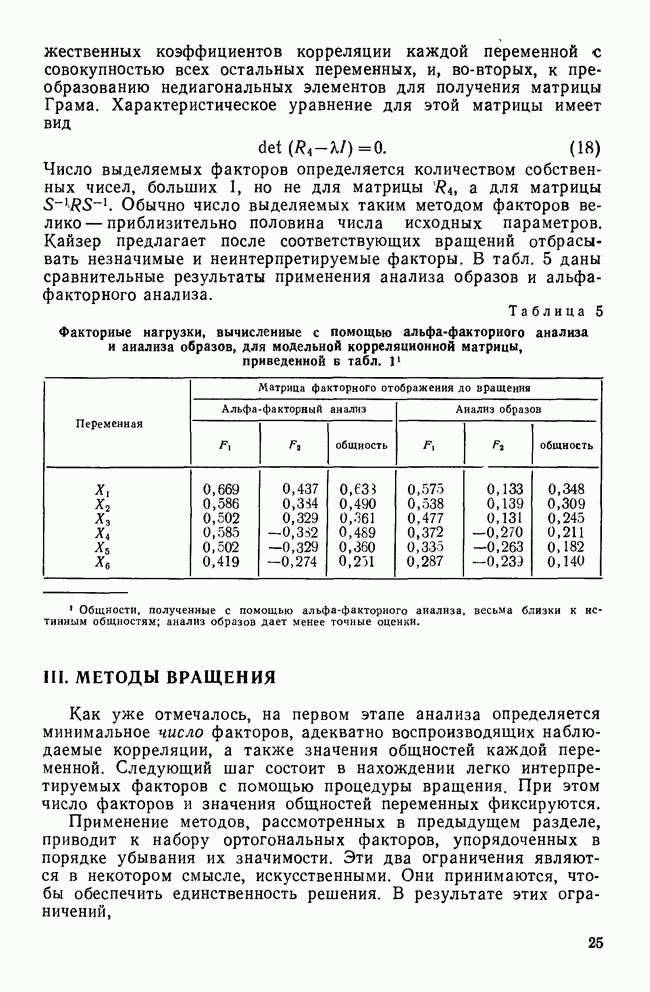
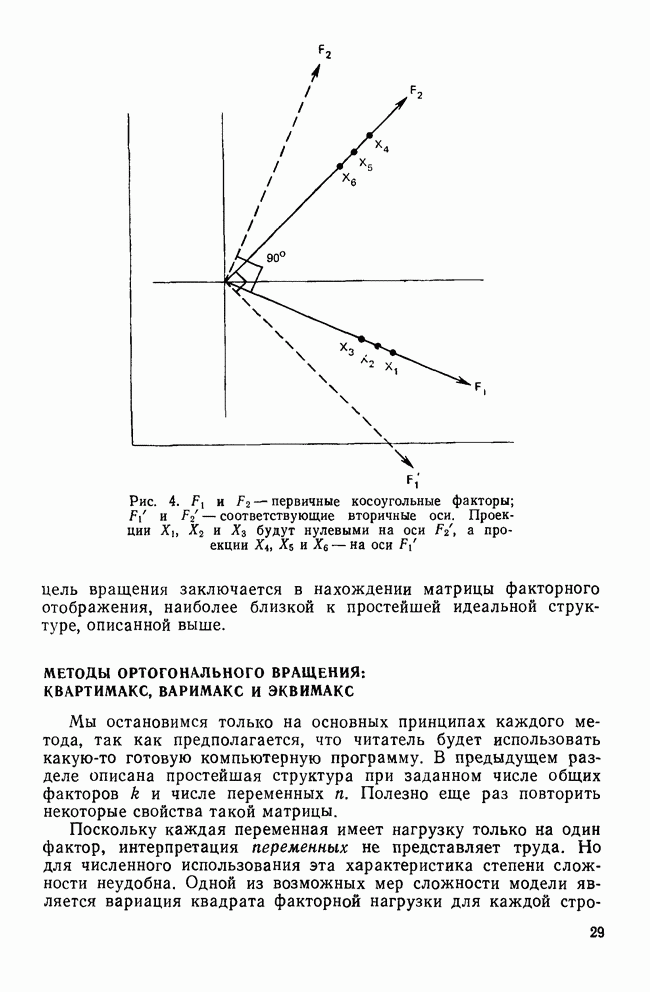
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
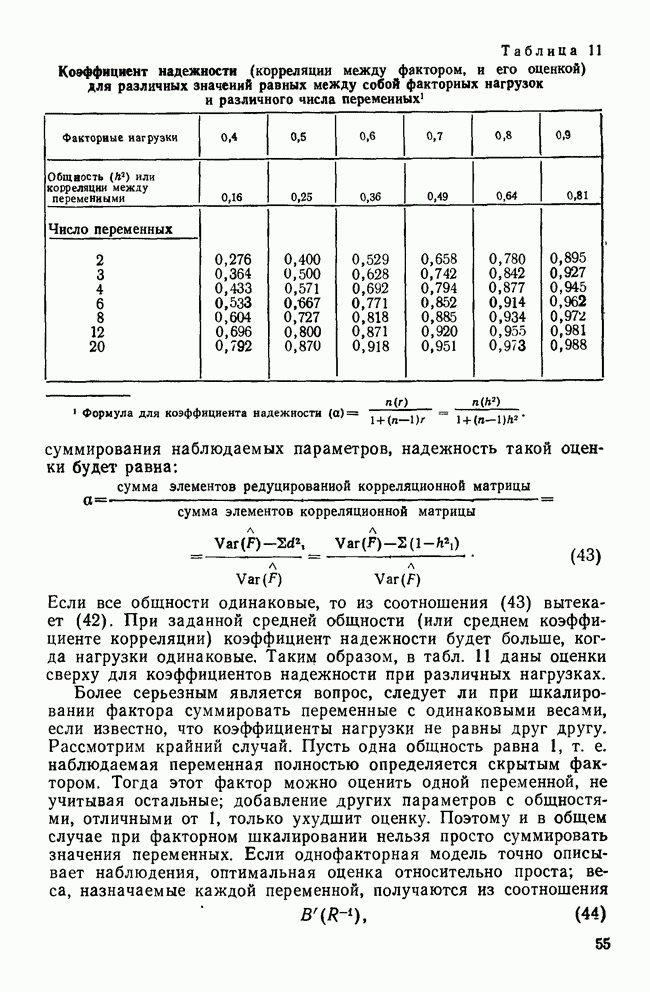
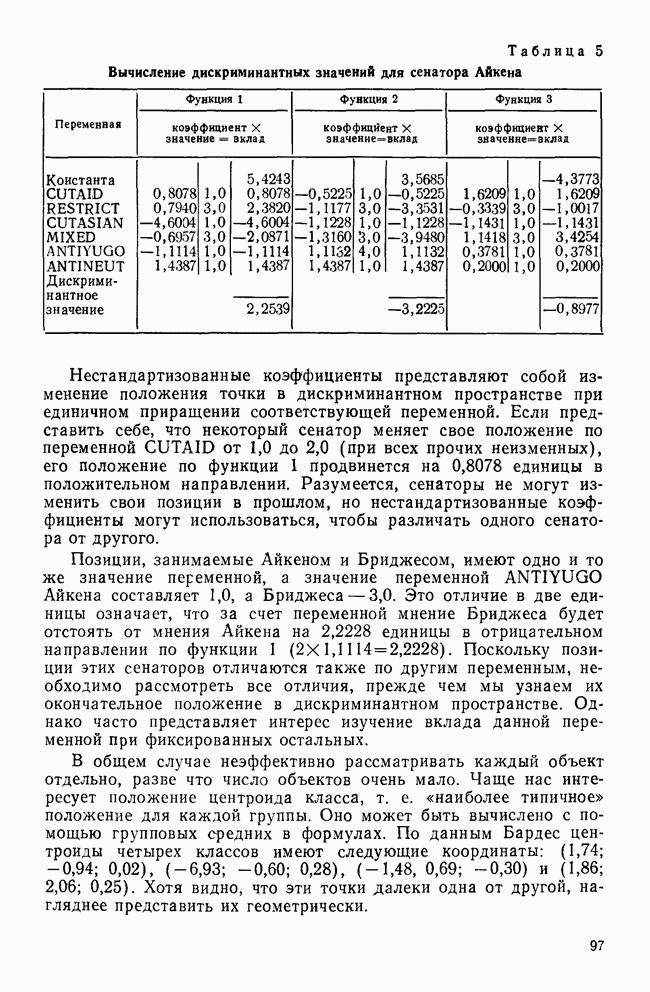
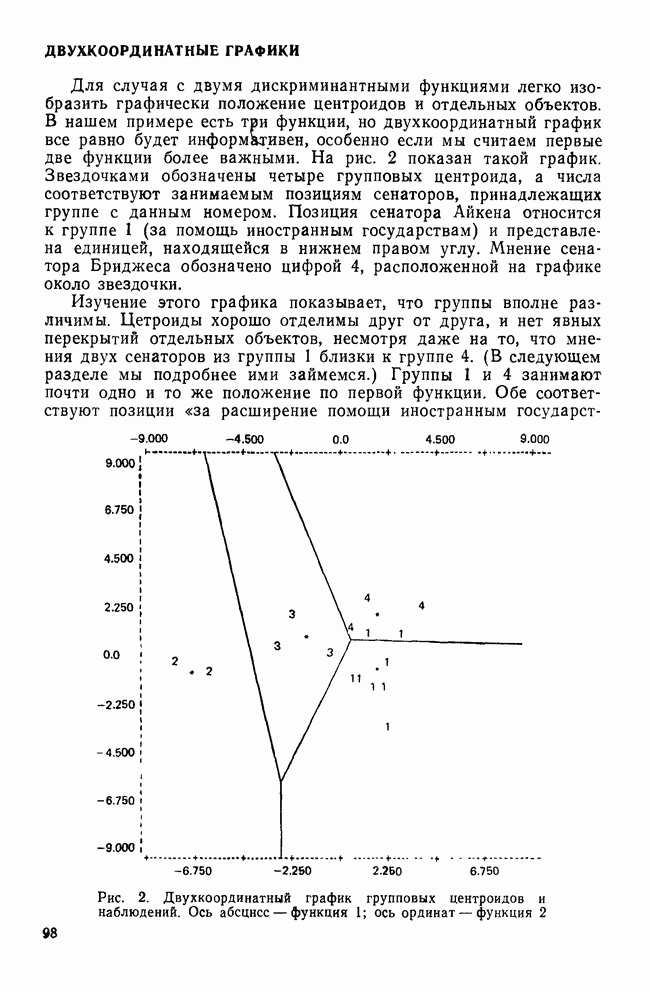
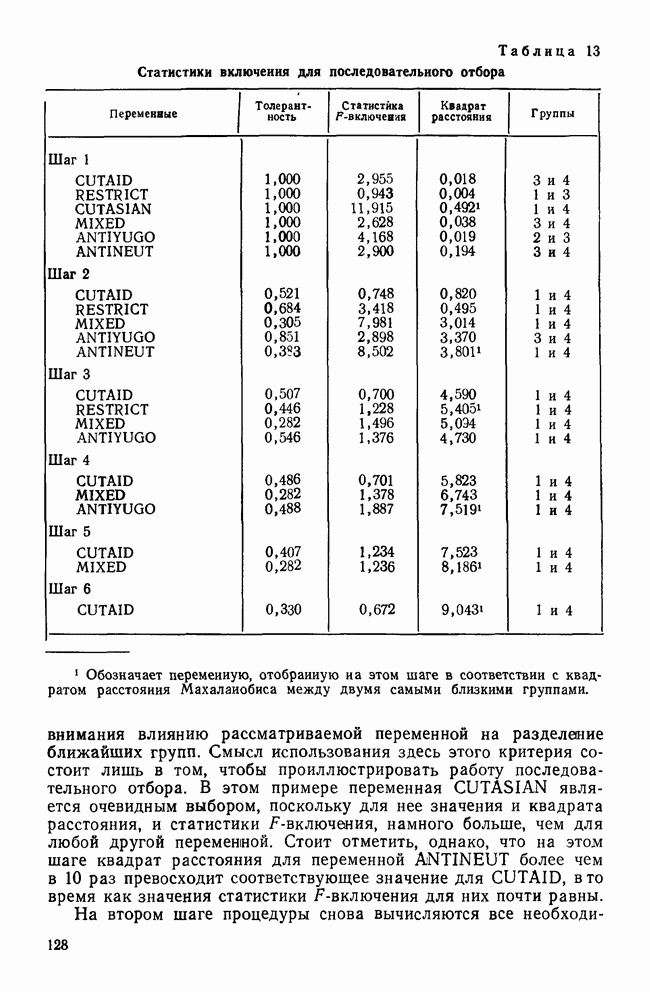
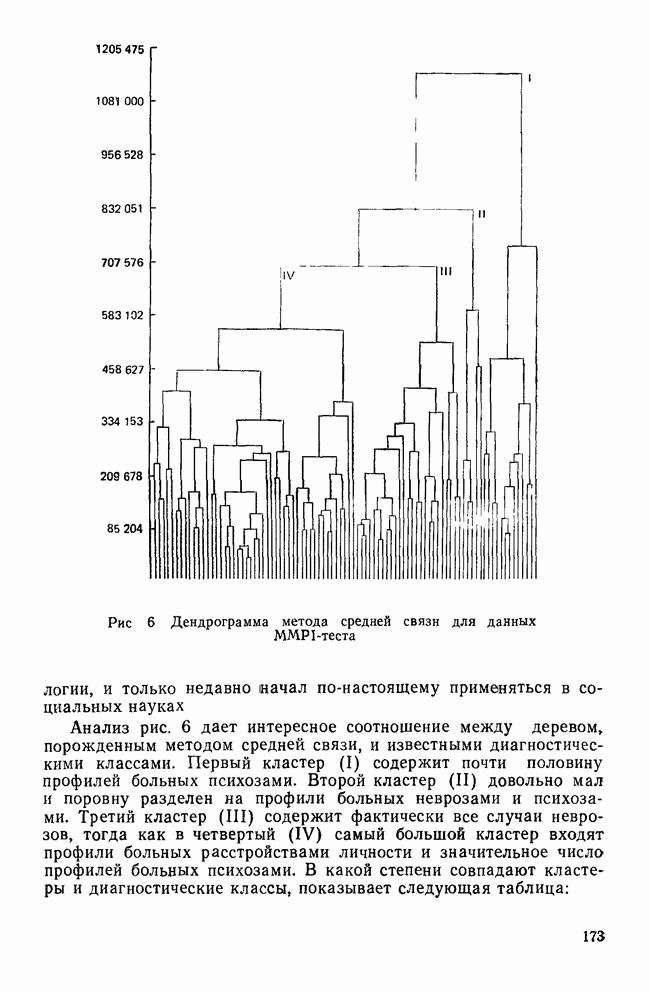
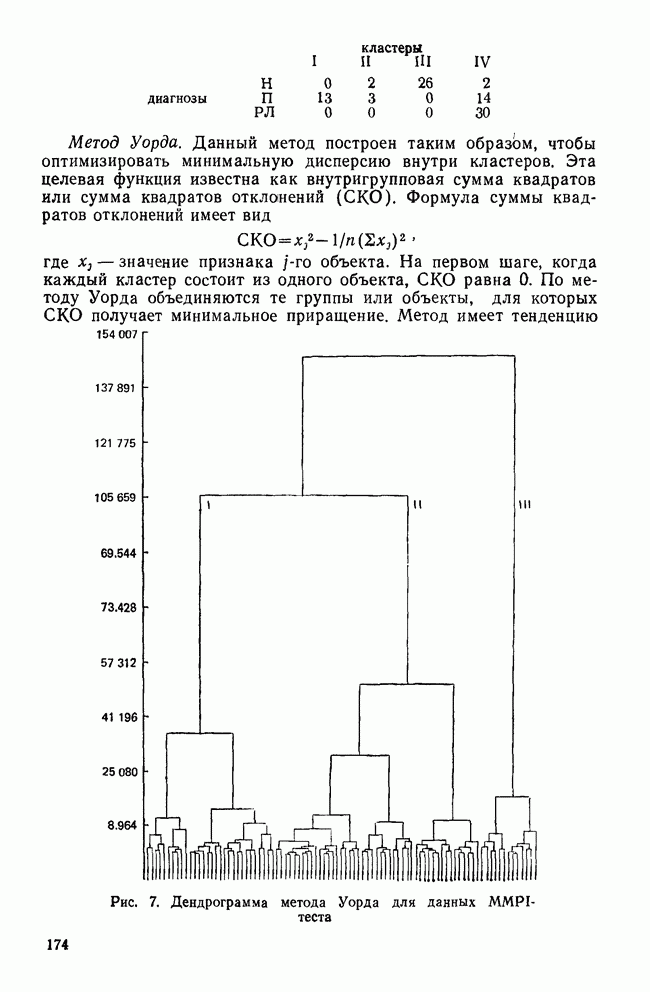
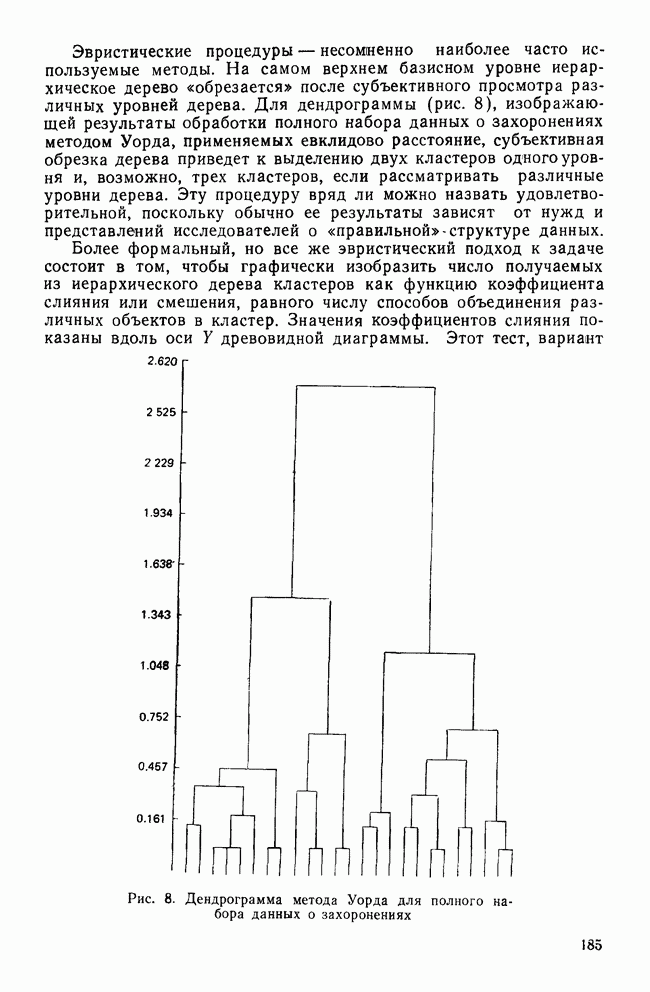
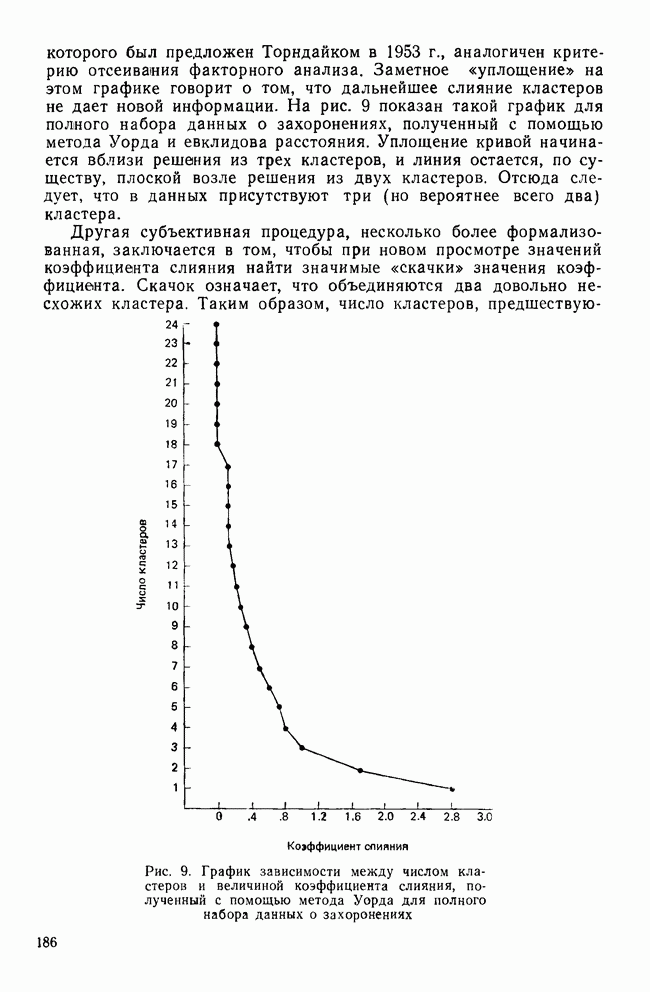
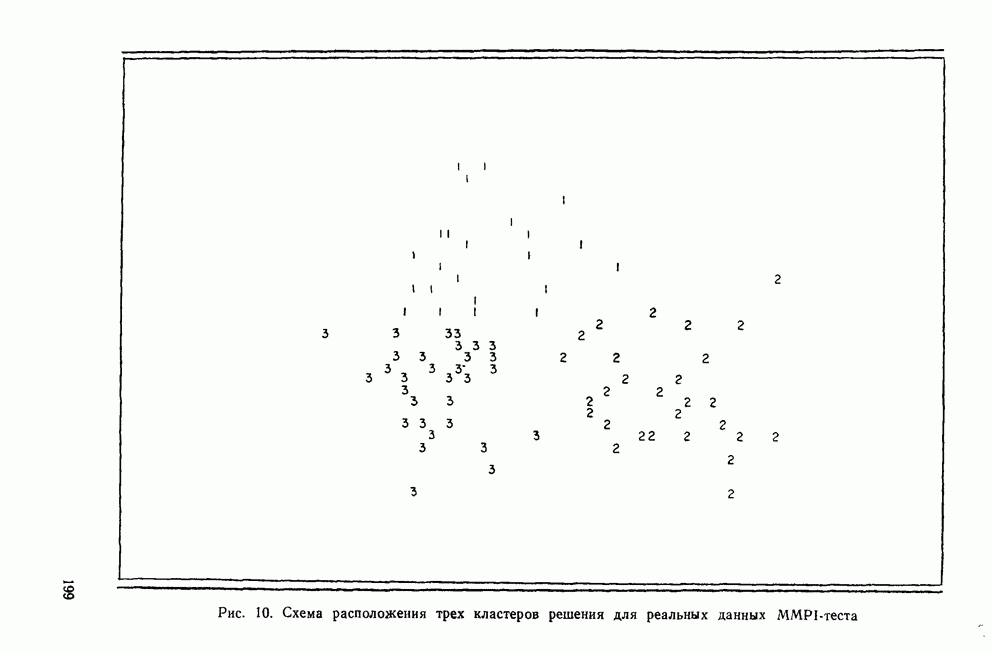
КЛАССИФИКАЦИОННАЯ МАТРИЦАХотя обычно исследователи обращаются к классификации как к средству предсказания принадлежности к классу «неизвестных» объектов, мы можем использовать ее также для проверки точности процедур классификации. Для этого возьмем «известные» объекты (которыми мы пользовались при выводе классифицирующих функций) и применим к ним правила классификации. Доля правильно классифицированных объектов говорит о точности процедуры и косвенно подтверждает степень разделения классов. Можно составить таблицу, или «классификационную матрицу», описывающую результаты. Это поможет нам увидеть, какие ошибки совершаются чаще. Таблица 12. Классификационная матрица
Таблица 12 представляет собой классификационную матрицу для данных о голосовании в сенате. Шесть переменных Бардес правильно предсказывают распределение по фракциям всех сенаторов (кроме Кейпхарта), чья фракционная принадлежность «известна». Точность предсказания в этом случае — 94,7% (сумма правильных предсказаний — 18, поделенная на общее число «известных» объектов). Мы также видим, что ошибки в этом примере связаны с плохим разделением групп 1 и 4. В нижней строке табл. 12 дано распределение по группам «неизвестных» объектов. Это те сенаторы, чью фракционную принадлежность Бардес не смогла определить по имеющимся у нее данным. Ее главной целью было использовать дискриминантный анализ для классификации позиций этих сенаторов по результатам их голосования, после чего она продолжила исследование отношения сената к различным вариантам помощи иностранным государствам. Процент «известных» объектов, которые были классифицированы правильно является дополнительной мерой различий между группами. Им мы воспользуемся наряду с общей Л-статистикой Уилкса и каноническими корреляциями для указания количества дискриминантной информации, содержащейся в переменных. Как непосредственная мера точности предсказания это процентное содержание является наиболее подходящей мерой дискриминантной информации. Однако о величине процентного содержания можно судить лишь относительно ожидаемого процента правильных классификаций, когда распределение по классам производилось случайным образом. Если есть два класса, то при случайной классификации можно ожидать 50% правильных предсказаний. Для четырех классов ожидаемая точность составит только 25%. Если для двух классов процедура классификации дает 60% правильных предсказаний, то ее эффективность довольна мала, но для четырех классов такой же результат говорит о значительной эффективности, потому что случайная классификация дала бы лишь 25% правильных предсказаний. Это приводит нас к
где Выражение Для данных Бардес каждая группа имеет априорную вероятность, равную 0,25. Следователыно, сумма в
Это означает, что классификация с помощью дискриминантных функций делает на 93% ошибок меньше, чем ожидалось при случайной классификации (т. е. одна действительная ошибка на 14,25 ожидаемых).
|
 |
Оглавление
|



































































































































































































 -статистике ошибок, которая будет стандартизованной мерой эффективности для любого количества классов:
-статистике ошибок, которая будет стандартизованной мерой эффективности для любого количества классов:

 — число правильно классифицированных объектов, а
— число правильно классифицированных объектов, а  — априорная вероятность принадлежности к классу.
— априорная вероятность принадлежности к классу. 
 представляет собой число объектов, которые будут правильно предсказаны при случайной классификации их по классам пропорционально априорным вероятностям. Если все классы считаются равноправными, то априорные вероятности полагаются равными единице, деленной на число классов. Максимальное значение
представляет собой число объектов, которые будут правильно предсказаны при случайной классификации их по классам пропорционально априорным вероятностям. Если все классы считаются равноправными, то априорные вероятности полагаются равными единице, деленной на число классов. Максимальное значение  -статистики равно 1 и оно достигается в случае безошибочного предсказания. Нулевое значение указывает на неэффективность процедуры,
-статистики равно 1 и оно достигается в случае безошибочного предсказания. Нулевое значение указывает на неэффективность процедуры,  -статистика может принимать и отрицательные значения, что свидетельствует о плохом различении или вырожденном случае. Поскольку
-статистика может принимать и отрицательные значения, что свидетельствует о плохом различении или вырожденном случае. Поскольку  должно быть целым числом, числитель может стать отрицательным чисто случайно, когда нет различий между классами.
должно быть целым числом, числитель может стать отрицательным чисто случайно, когда нет различий между классами.
 -статистике равна
-статистике равна  Для 18 правильных предсказаний из 19 возможных
Для 18 правильных предсказаний из 19 возможных  -статистика составит:
-статистика составит:
