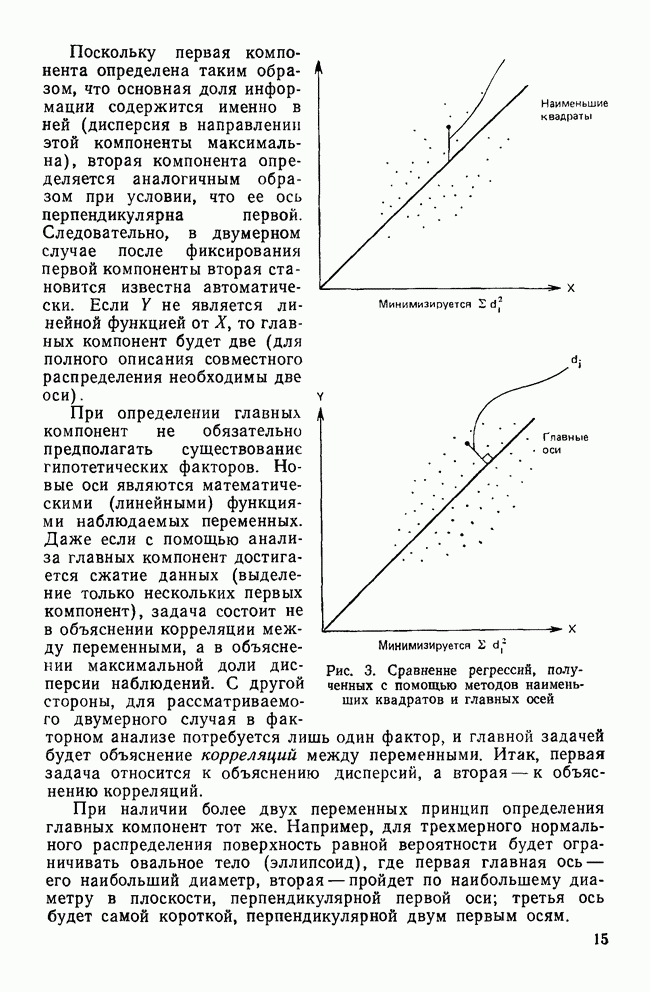
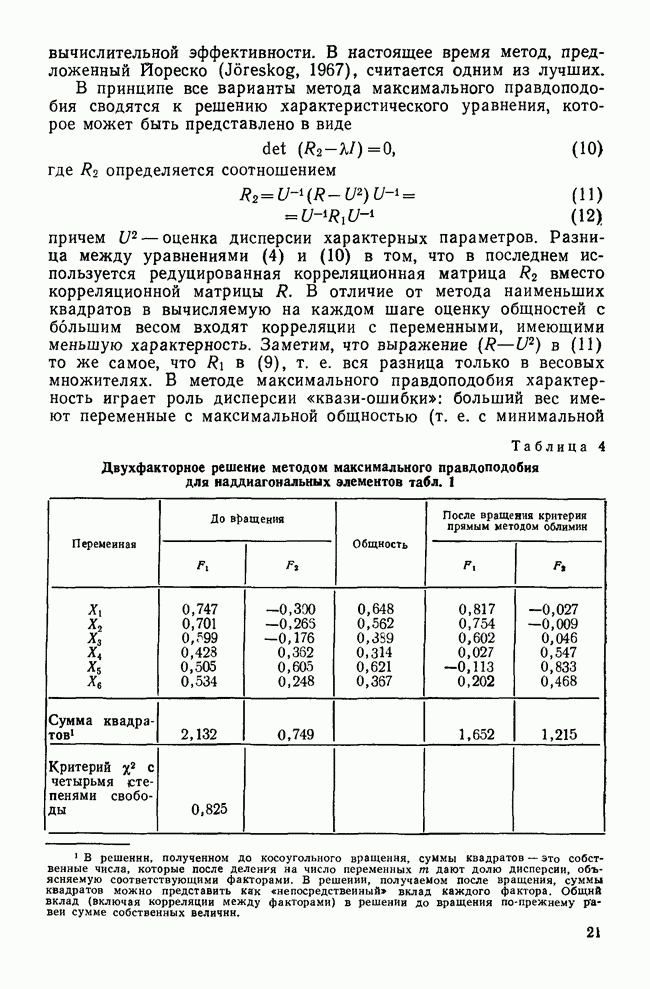
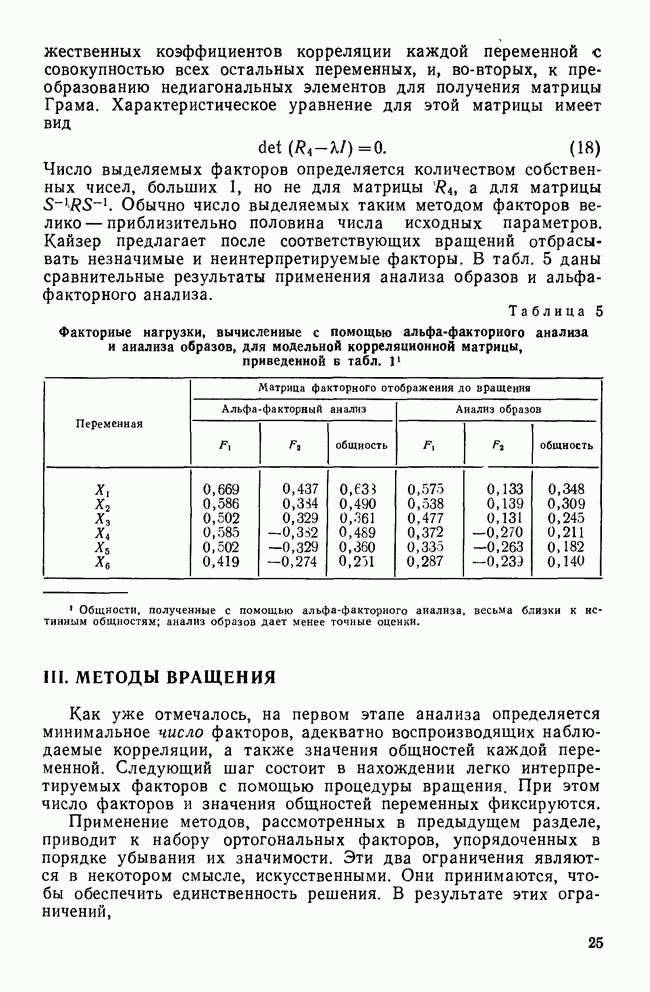
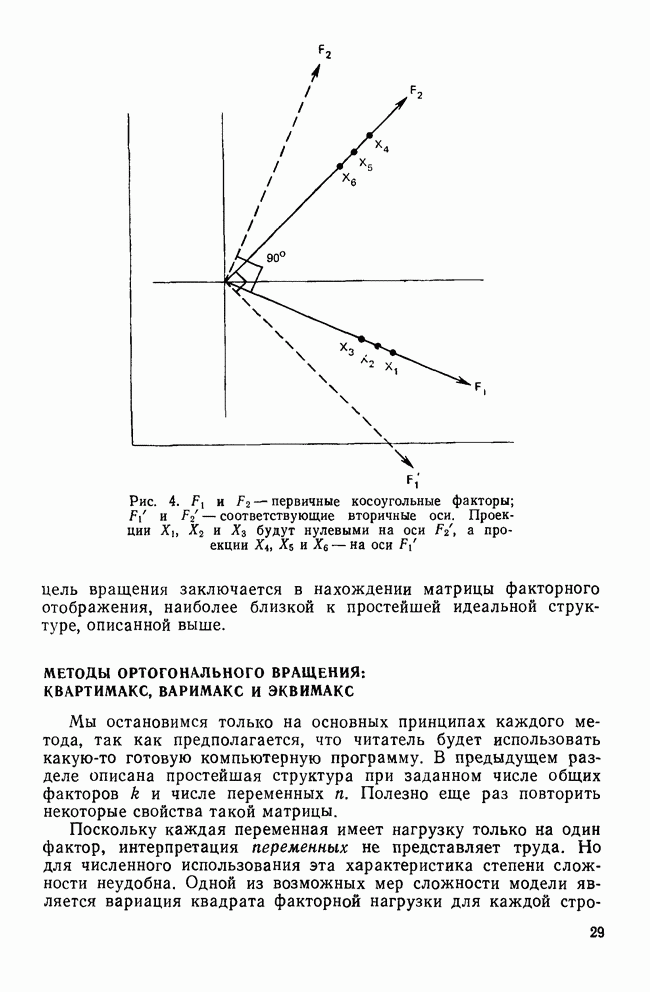
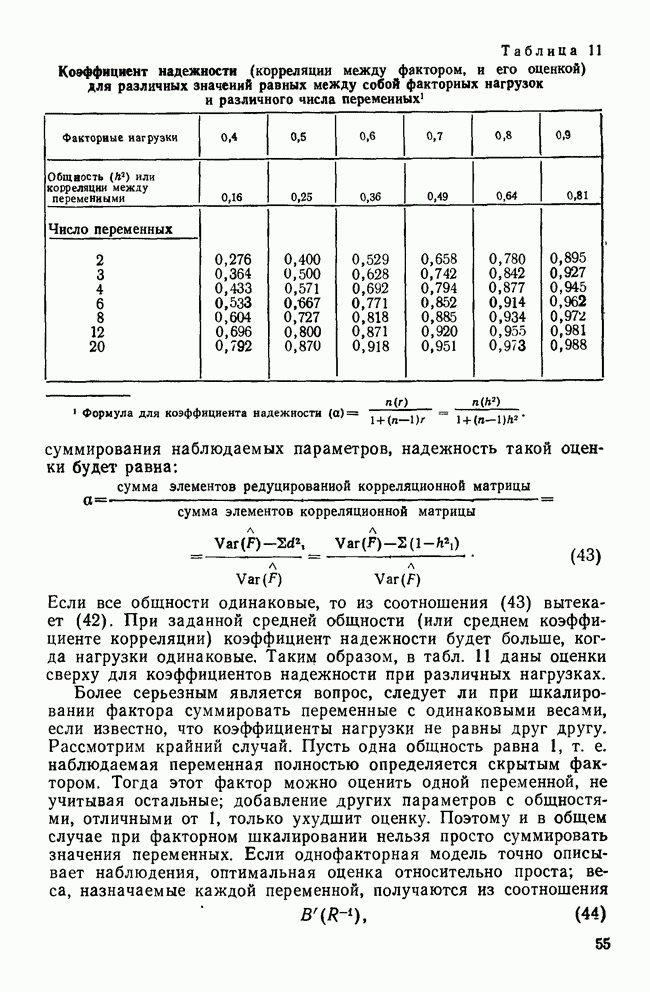
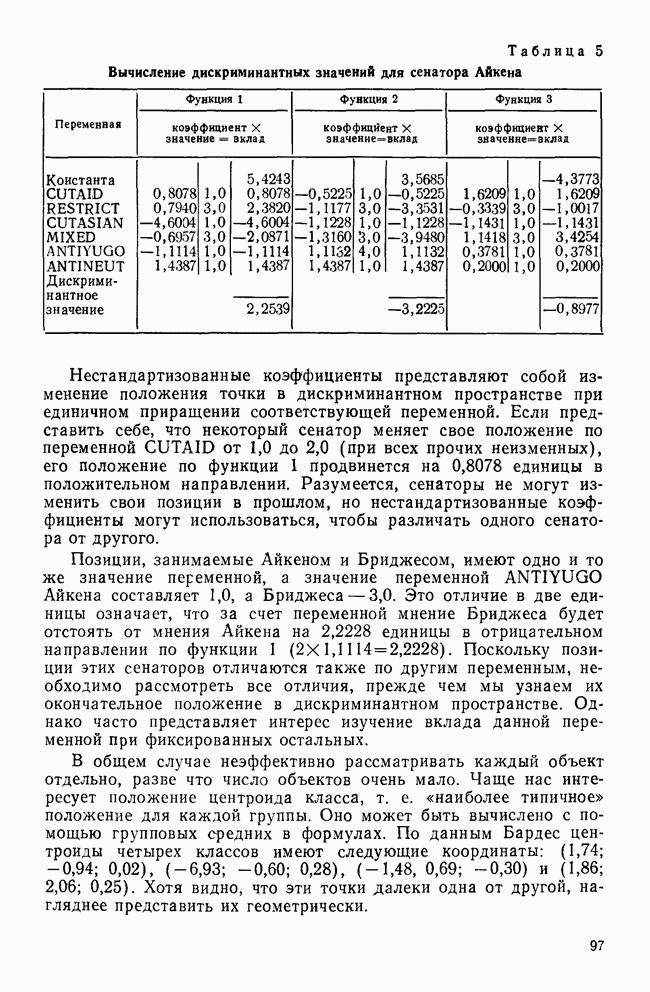
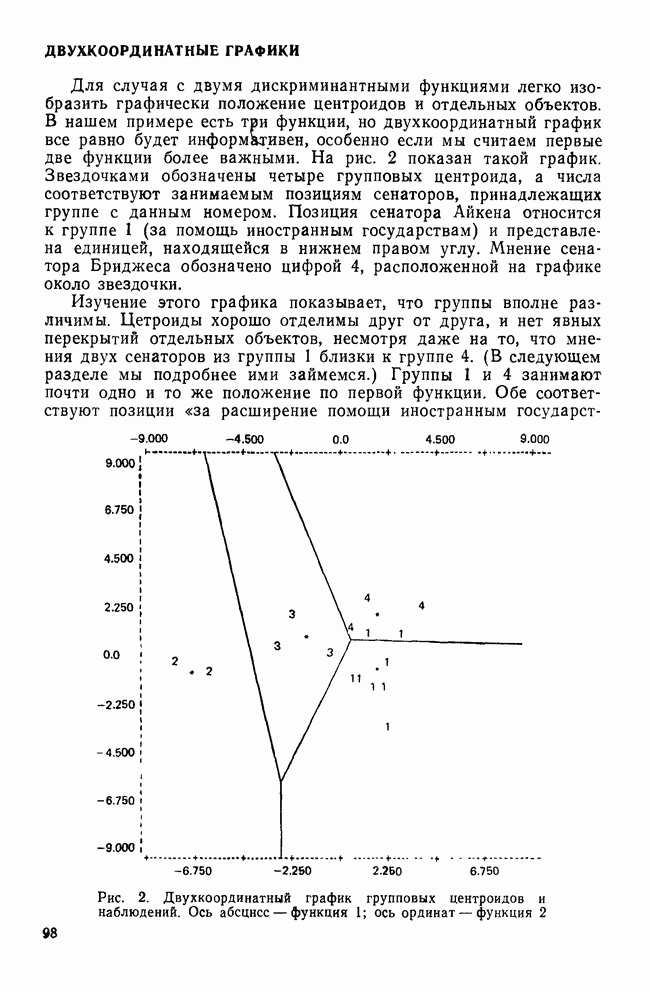
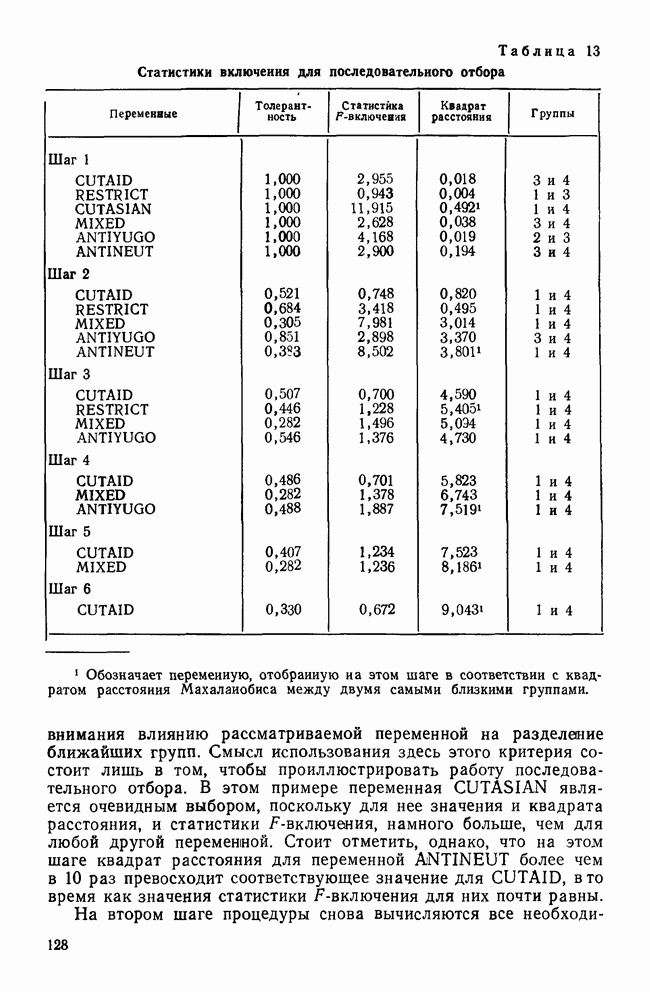
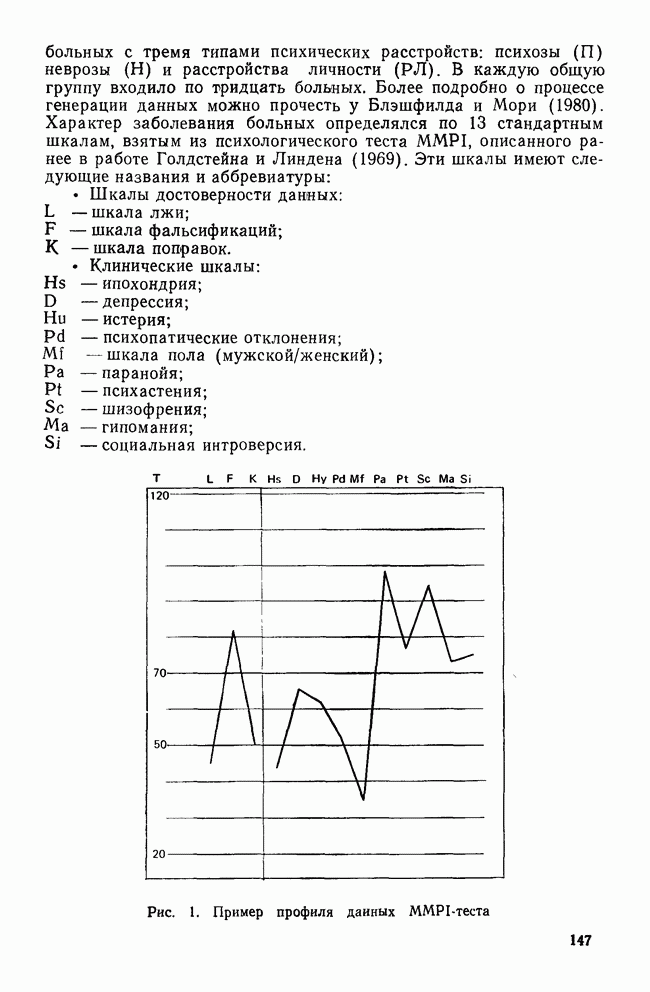
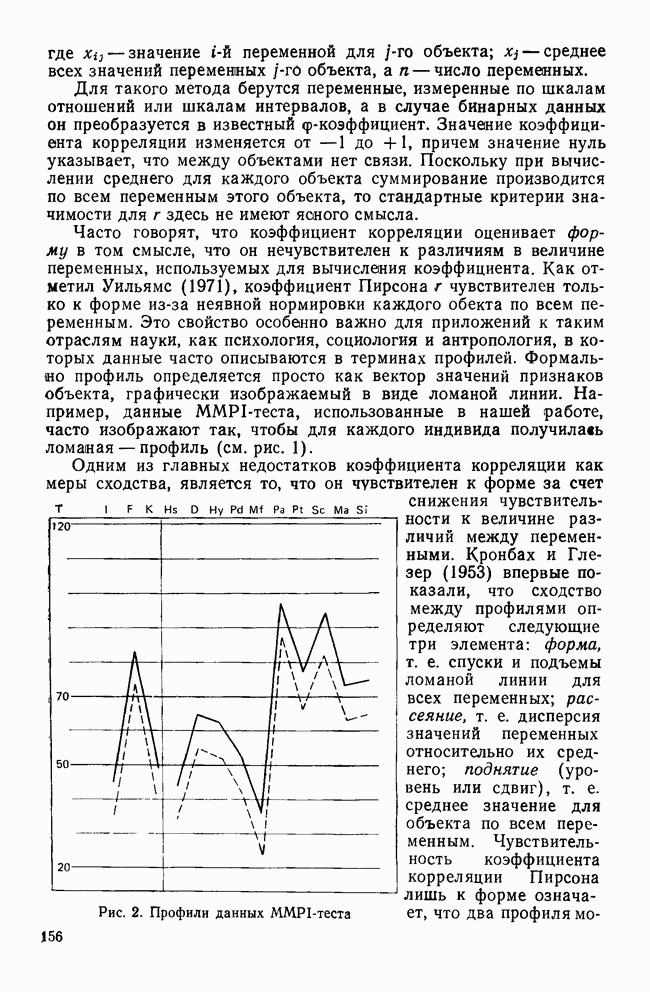
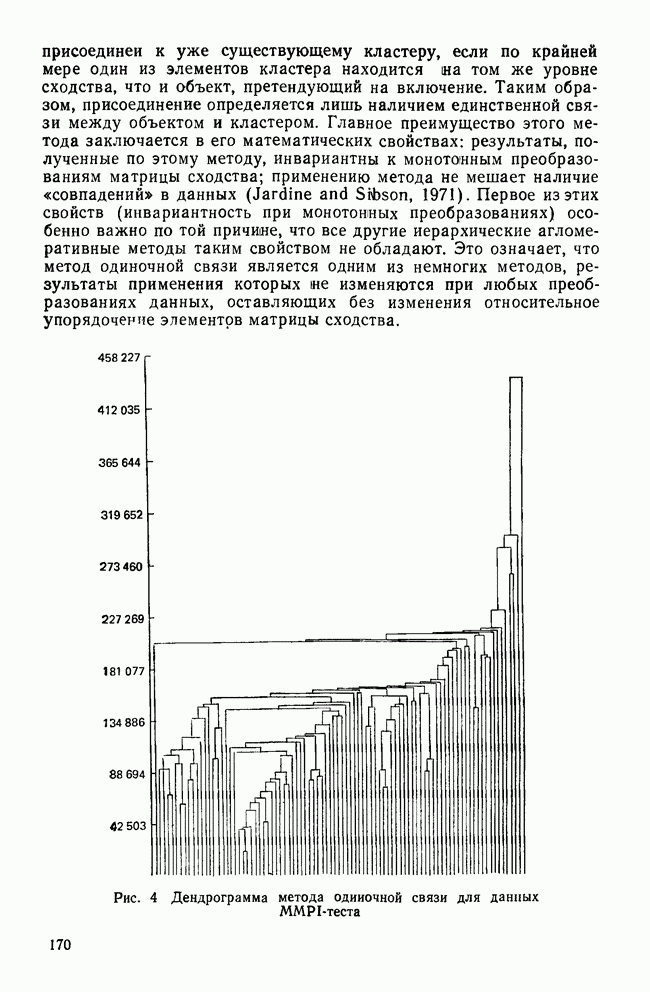
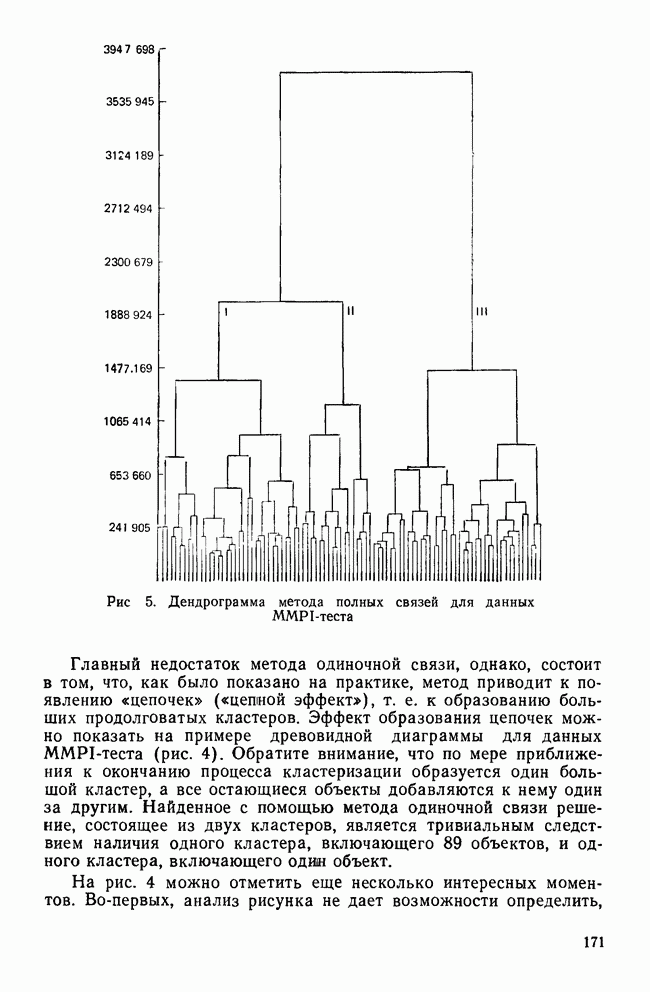
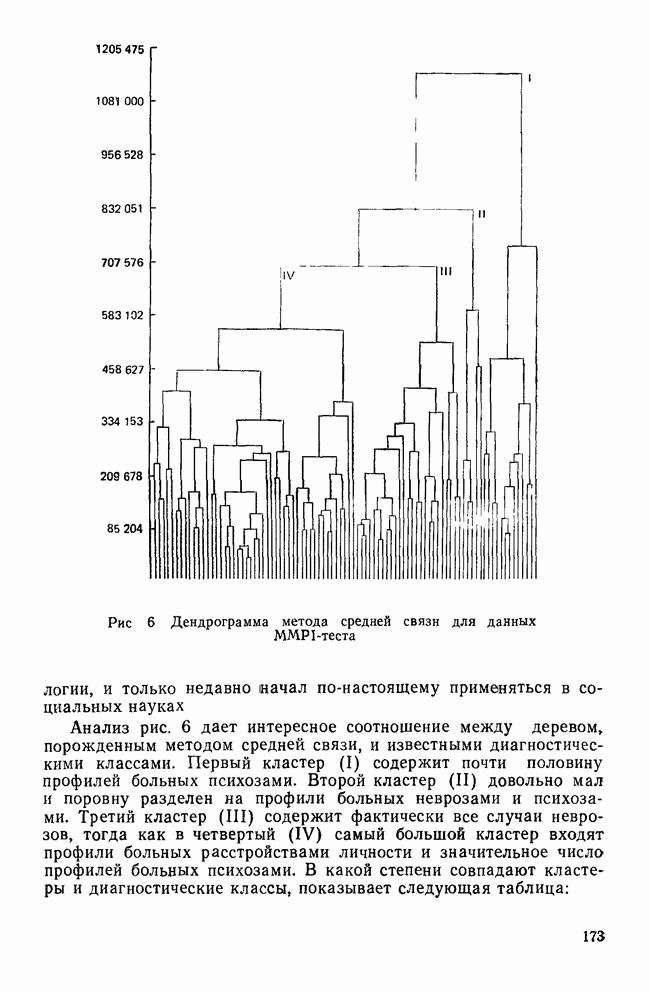
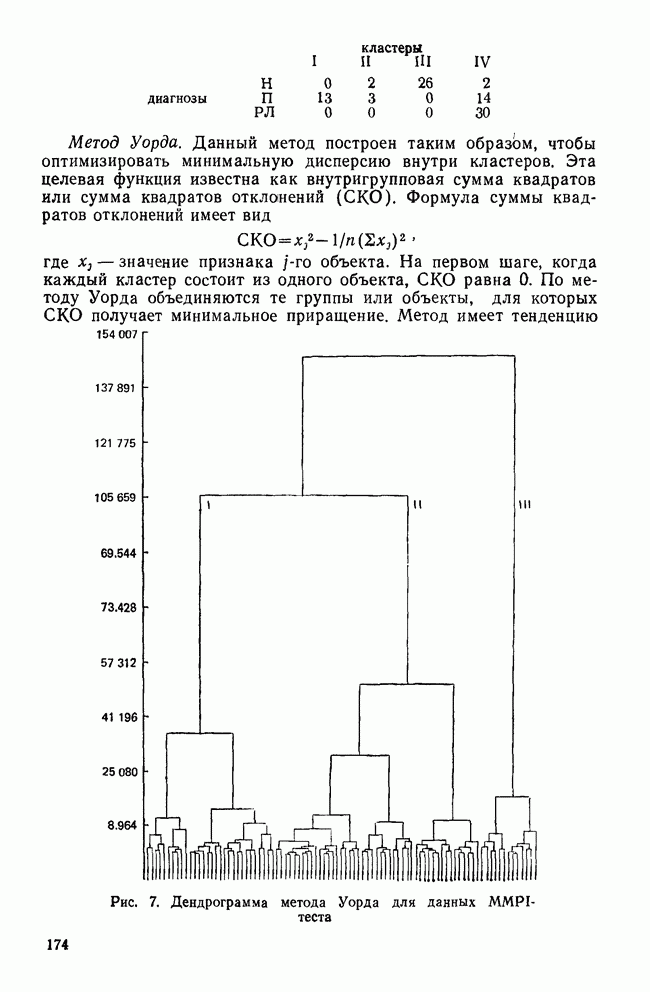
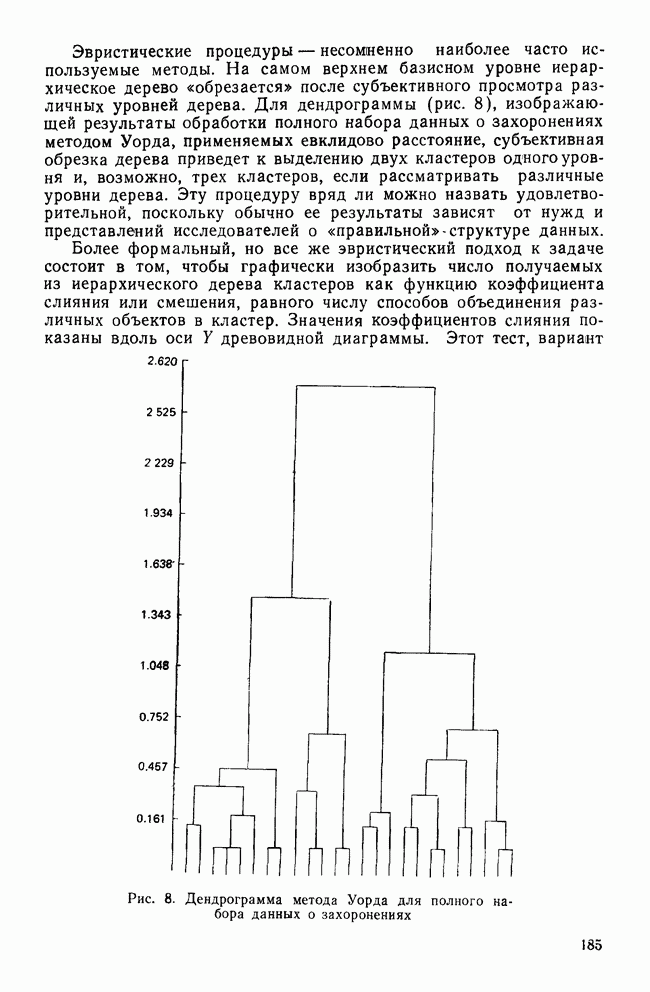
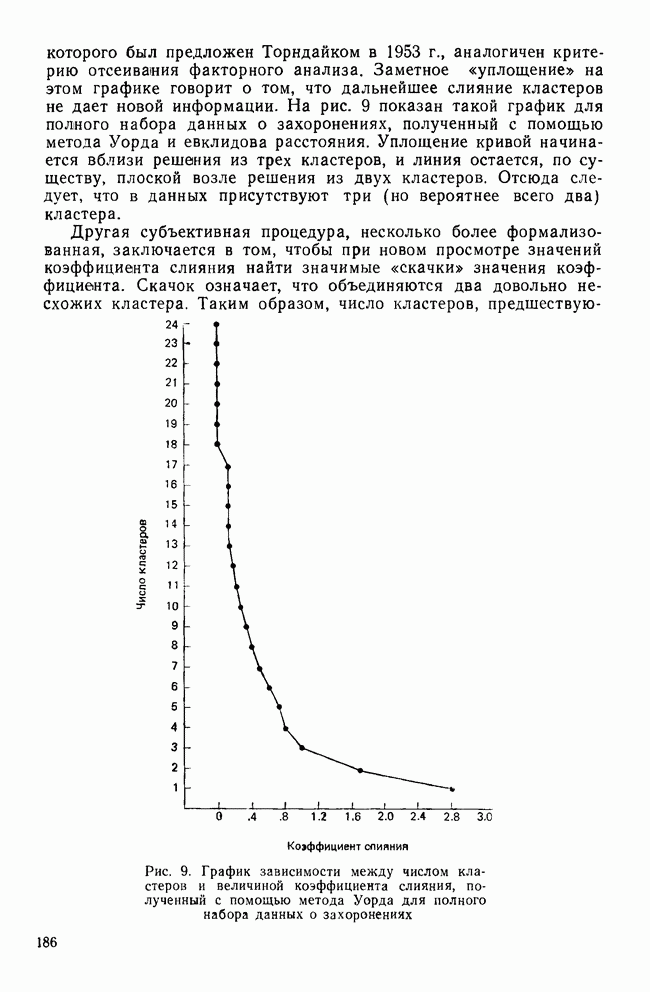
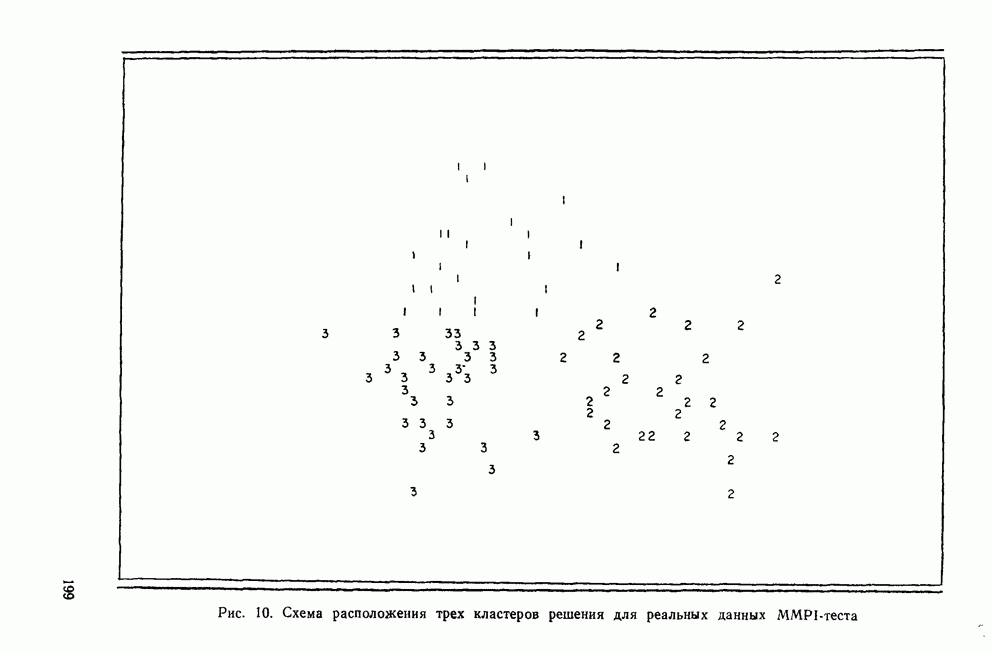
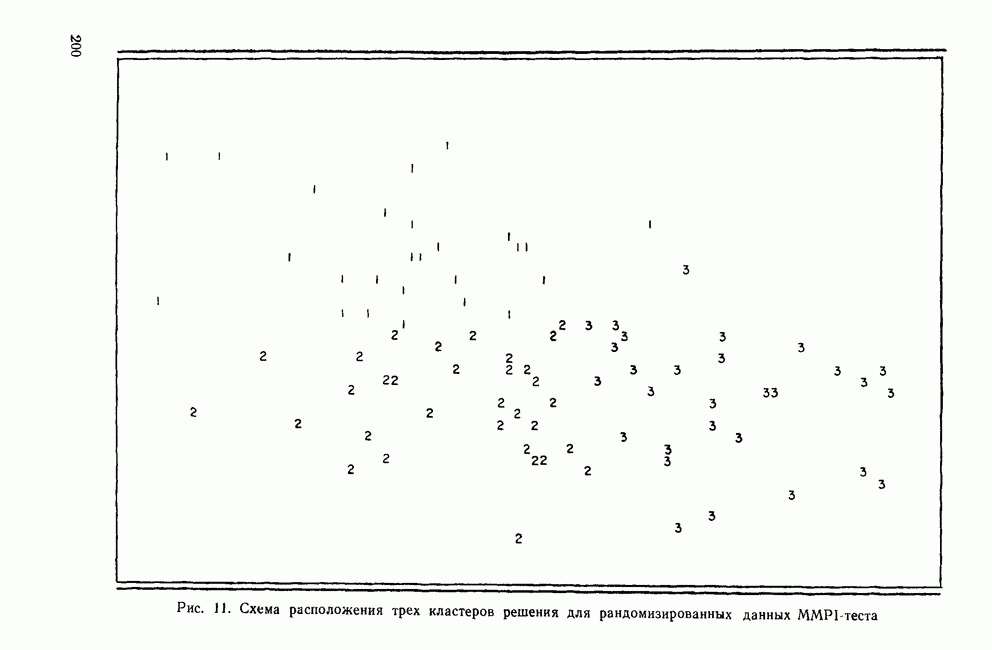
II. МЕРЫ СХОДСТВА
ТЕРМИНОЛОГИЯ
Для описания особенностей оценивания сходства создавалась специальная терминология. Как мы покажем позднее (см. разд. V), развитие жаргона кластерного анализа в различных отраслях науки связано с быстрым ростом и распространением самого кластерного анализа.
Терминология какой-либо дисциплины образуется таким образом, что она может перекрывать терминологию других дисциплин, даже если термины используются для описания одних и тех же предметов. Если потенциальный пользователь кластерного анализа не осведомлен о таких терминологических различиях, это может привести к большой путанице.
Термин «событие», «единица», «случай», «паттерн», «предмет», ОТЕ (операционная таксономическая единица) обозначают объект, тогда как «переменная», «признак», «свойство», «характеристика» обозначают те черты «объектов», которые позволяют оценить их сходство. Другая группа важных терминов — « -анализ» и «
-анализ» и « -анализ»; первый из них относится к связям между переменными. Кластерный анализ, например, традиционно рассматривается как «
-анализ»; первый из них относится к связям между переменными. Кластерный анализ, например, традиционно рассматривается как « -техника», в то время как факторный анализ — как «
-техника», в то время как факторный анализ — как « -техника».
-техника».
Потенциальный пользователь кластерного анализа должен также обратить внимание на то, что матрицы данных часто формируются различными способами. В общественных науках обычно совокупность данных изображают в виде матрицы, образованной N событиями (строки матрицы), которые определяются Р переменными (столбцы матрицы). В биологии имеет место обратный порядок, что приводит к матрице данных размерностью PXN. В этой работе мы воспользуемся термином «первичные данные» для описания исходной матрицы событий размерностью NxP и их переменных до вычисления сходства. В соответствии с этим мы будем употреблять термины «матрица сходства» или «матрица близости» для описания матрицы сходств событий размерностью NxN, вычисленной с помощью некоторой меры сходства по первичным данным.
Даже термин «сходство» не свободен от смыслового многообразия, а его синонимами являются «подобие», «близость», «связанность», «ассоциативность». Однако другие авторы ограничивают использование термина «коэффициент сходства». Например, Эве-ритт (1980) пользуется термином «коэффициент сходства» для обозначения тех мер, которые Сиит и Сокэл (1973) называют «коэффициентами ассоциативности». Клиффорд и Стефенсон (1975) для еще большей путаницы сводят применение термина «коэффициент ассоциативности» к значению, которое является частным случаем определений, даиных Эвериттом, а также Снитом и Сокэлом. Мы будем пользоваться термином «коэффициент сходства» (или «мера сходства») и придерживаться классификации коэффициентов сходства, предложенной Снитом и Сокэлом (1973), которые подразделили эти коэффициенты на четыре группы:
1) коэффициенты корреляции;
2) меры расстояния;
3) коэффициенты ассоциативности;
4) вероятностные коэффициенты сходства.
Позже каждая из групп будет кратко описана.