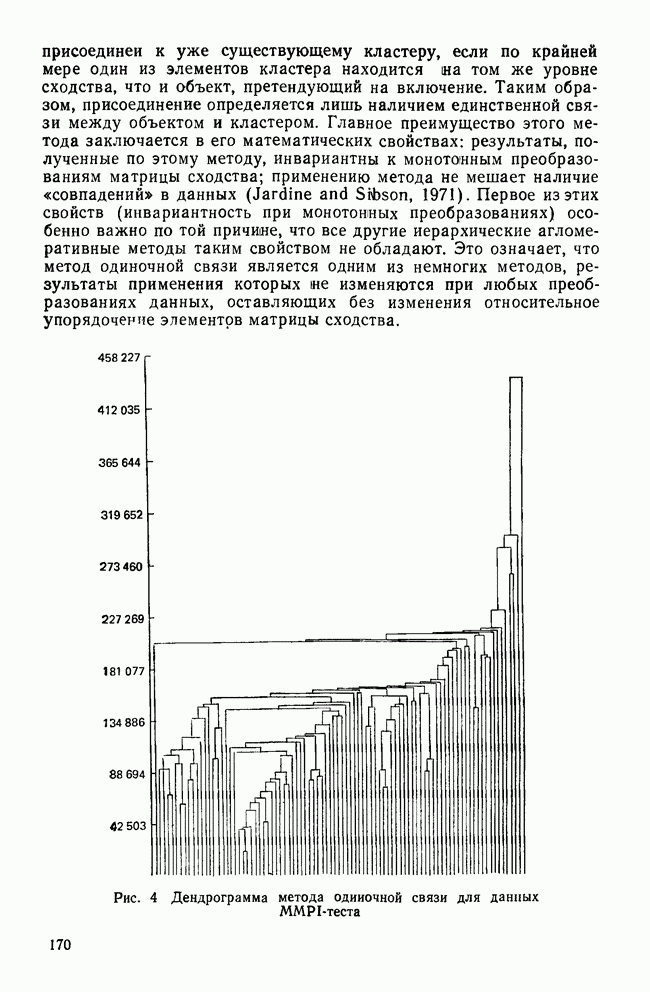
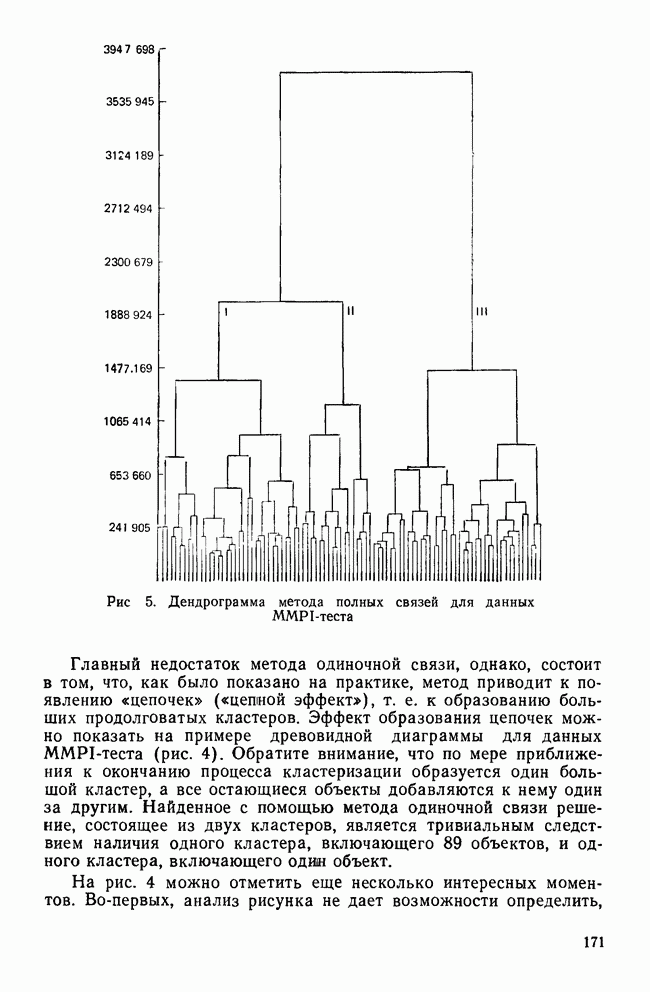
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
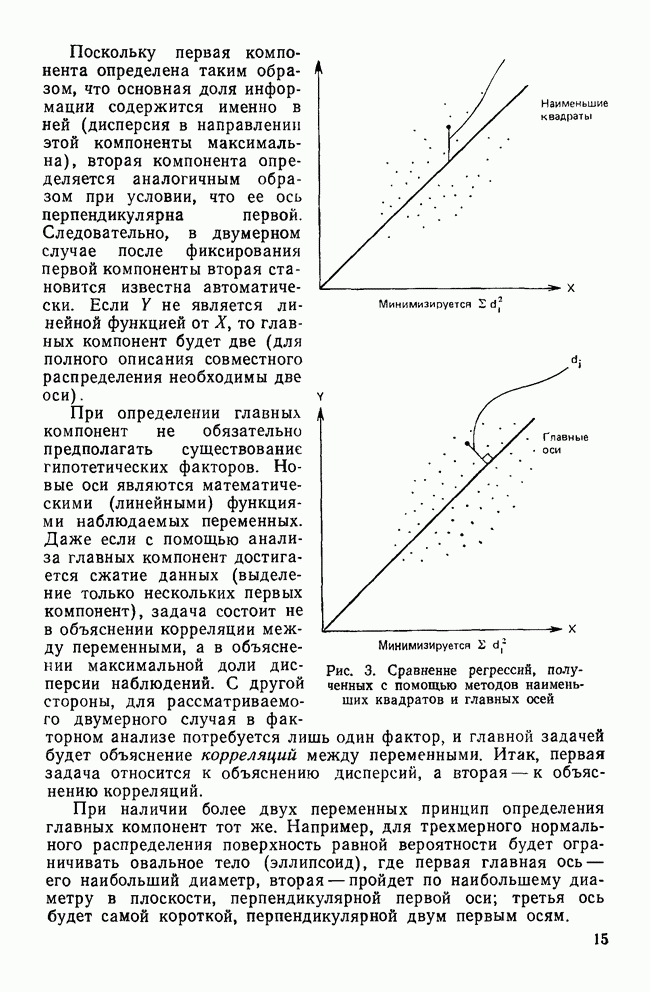
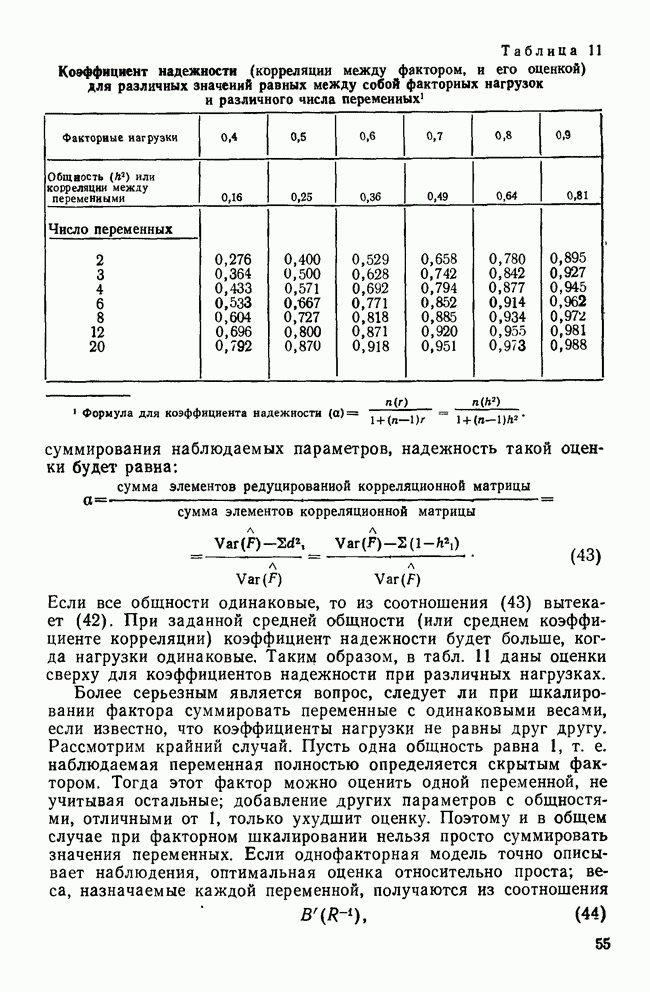
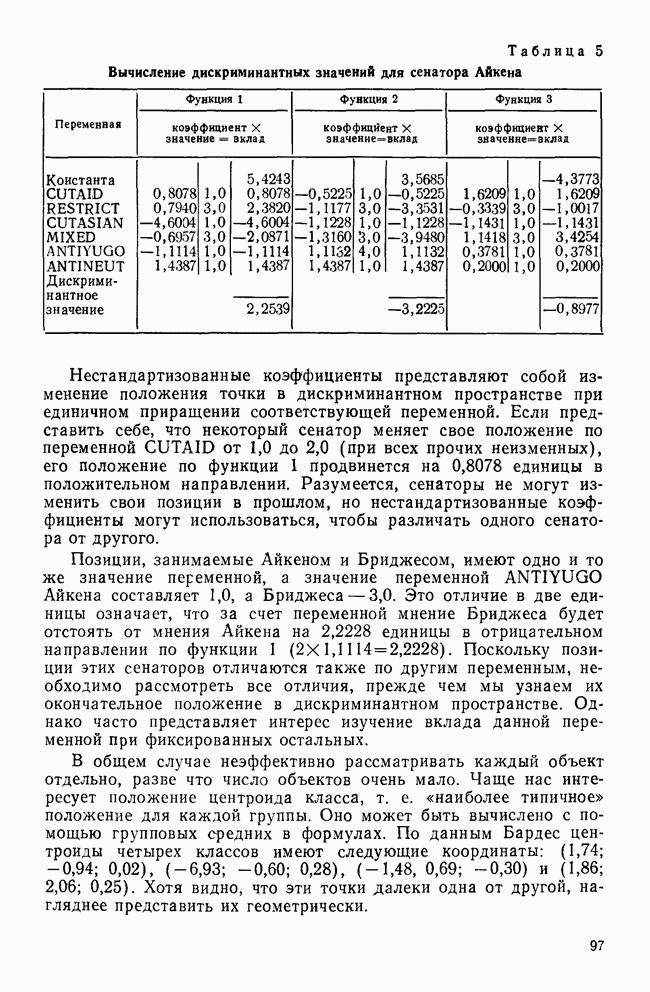
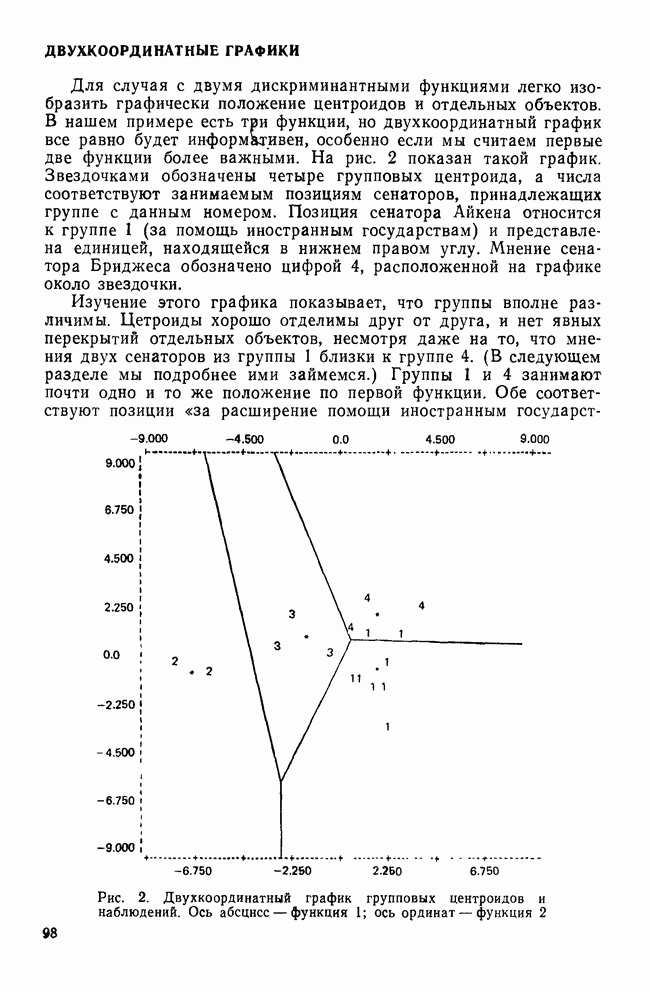
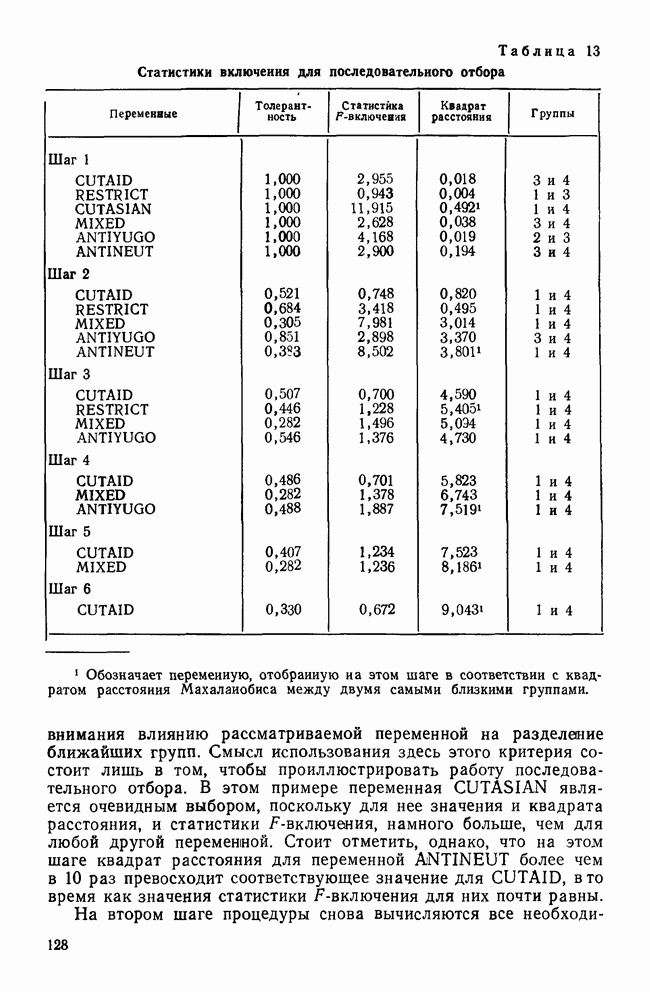
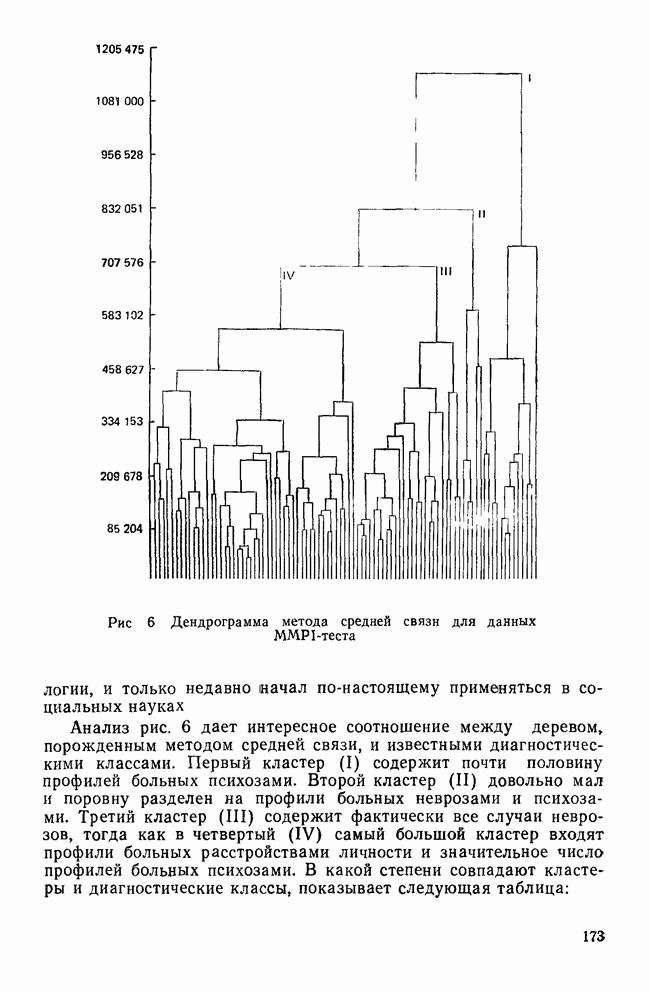
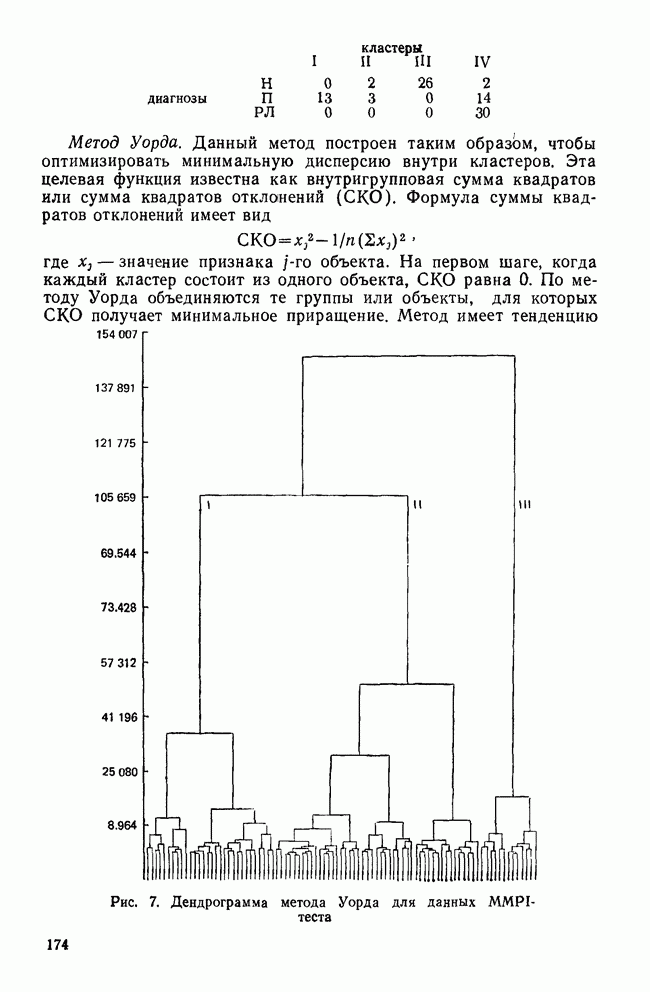
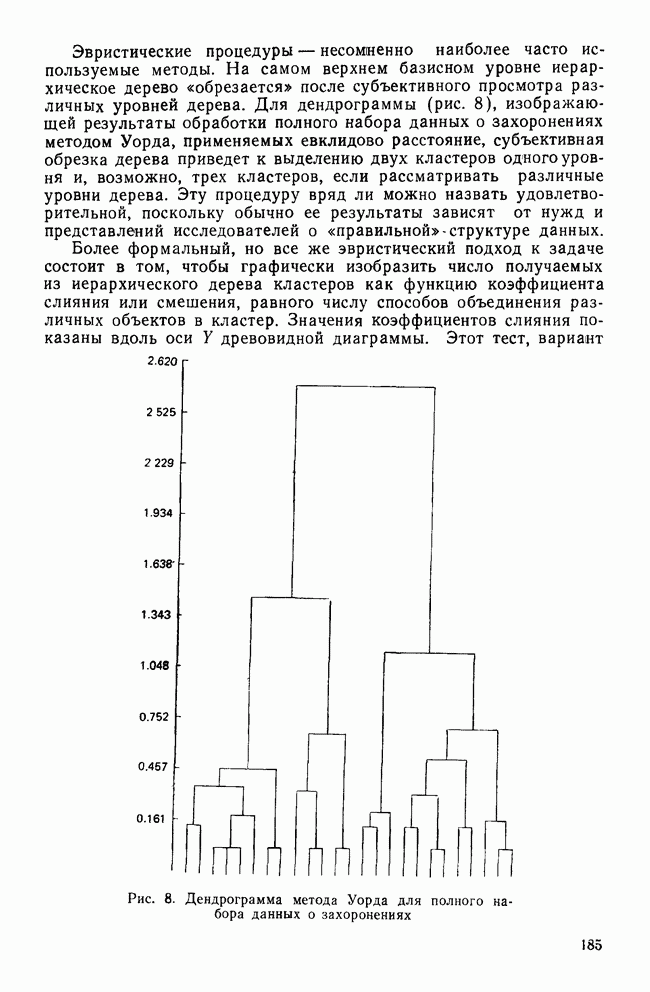
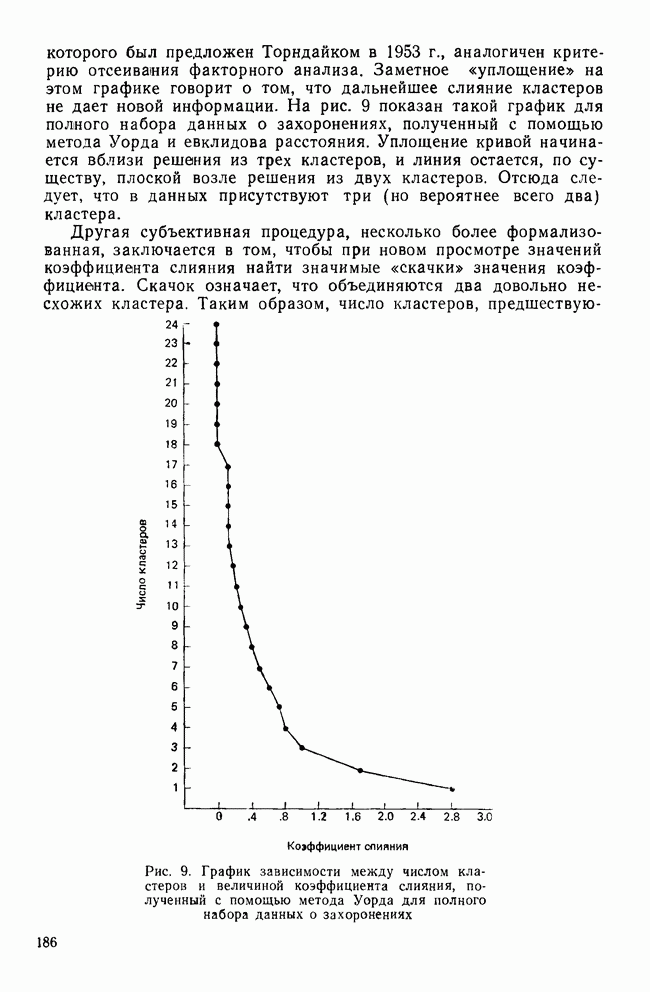
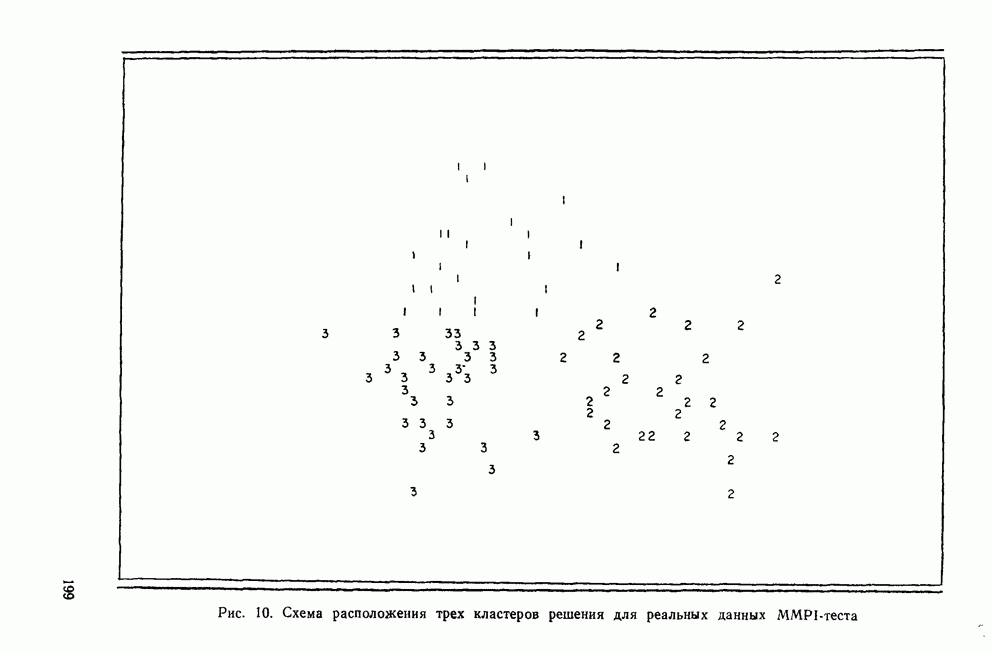
МЕРЫ СХОДСТВАТеперь, когда задача выбора переменных и преобразования данных обсуждены, можно познакомиться с наиболее известными коэффициентами сходства. Как уже отмечалось, существует четыре их вида: коэффициенты корреляции; меры расстояния; коэффициенты ассоциативности и вероятностные коэффициенты сходства. Каждый из этих видов имеет свои достоинства и недостатки, которые следует рассматривать прежде, чем будет принято решение использовать один из них. Хотя все четыре вида мер сходства широко применялись специалистами в численной таксономии и в биологии, лишь коэффициенты корреляции и расстояния получили широкое распространение в области социальных наук. Поэтому мы уделим больше внимания этим двум типам мер. Коэффициенты корреляцииКоэффициенты корреляции, часто называемые угловыми мерами ввиду их геометрической интерпретации, — самый распространенный тип сходства в области социальных наук. Наиболее известным является смешанный момент корреляции, предложенный Карлом Пирсоном. Первоначально использованный в качестве метода определения зависимости переменных, он был применен в количественной классификации при вычислении корреляции между объектами. В связи с этим коэффициент вычисляется следующим образом:
где Для такого метода берутся переменные, измеренные по шкалам отношений или шкалам интервалов, а в случае бинарных данных он преобразуется в известный Часто говорят, что коэффициент корреляции оценивает форму в том смысле, что он нечувствителен к различиям в величине переменных, используемых для вычисления коэффициента. Как отметил Уильямс (1971), коэффициент Пирсона
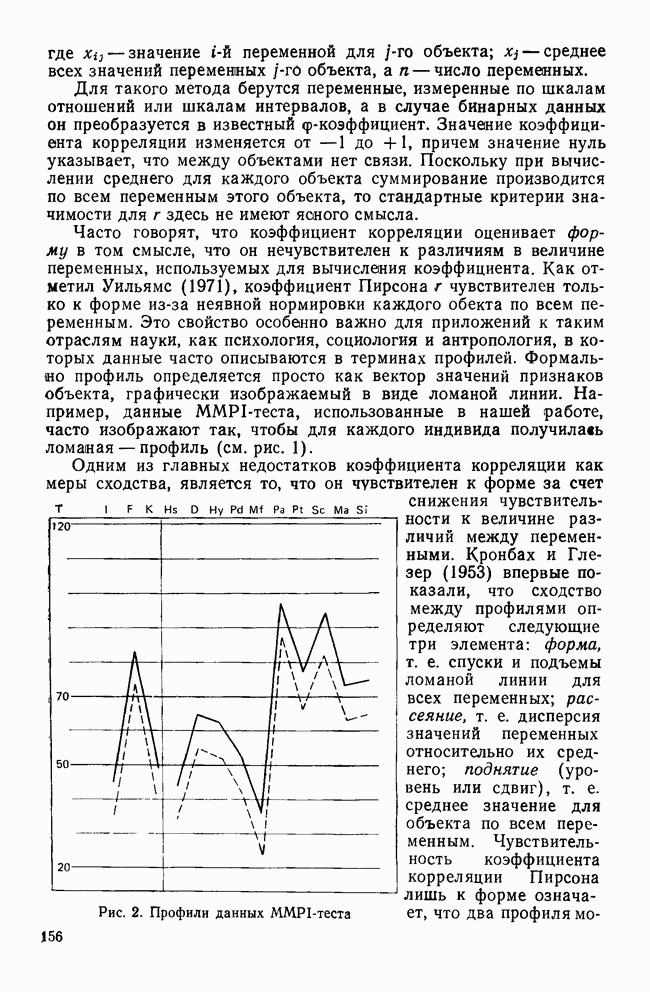
Рис. 2. Профили данных MMPI-теста Одним из главных недостатков коэффициента корреляции как меры сходства, является то, что он чувствителен к форме за счет снижения чувствительности к величине различий между переменными. Кронбах и Глезер (1953) впервые показали, что сходство между профилями определяют следующие три элемента: форма, т. е. спуски и подъемы ломаной линии для всех переменных; рассеяние, т. е. дисперсия значений переменных относительно их среднего; поднятие (уровень или сдвиг), т. е. среднее значение для объекта по всем переменным. Чувствительность коэффициента корреляции Пирсона лишь к форме означает, что два профиля могут иметь корреляцию На рис. 2 показаны два профиля данных для MMPI-теста; один изображен сплошной линией, а другой — пунктирной. Формы их одинаковы. Хотя корреляция между этими двумя профилями равна +1,0, они все же не совпадают, потому что один из них приподнят. Таким образом, высокая корреляция между профилями будет наблюдаться, когда измерения одного из профилей будут линейно зависеть от измерений другого. Следовательно, при использовании коэффициента корреляции теряется некоторая информация, что может привести к неверным результатам, если не будет учтено влияние рассеяния и поднятия профиля. Коэффициент корреляции имеет и другие недостатки. Он часто не удовлетворяет неравенству треугольника, и, как многие указывали, корреляция, вычисленная этим способом, не имеет статистического смысла, поскольку среднее значение определяется по совокупности всевозможных разнотипных переменных, а не по совокупности объектов. Смысл «среднего» по разнотипным переменным далеко не ясен. Несмотря на эти недостатки, коэффициент широко использовался в приложениях кластерного анализа. Хаммер и Каннингхем (1981) показали, что при правильном применении кластерного метода коэффициент корреляции превосходит другие коэффициенты сходства, так как позволяет уменьшить число неверных классификаций. Парадоксально, но ценность корреляции заключается именно в том, что она не зависит от различий между переменными из-за рассеяния и сдвига. Существенную роль в успехе работы Хаммера и Каннингхема сыграло, однако, то, что исследователи смогли понять, что им нужен именно коэффициент формы, поскольку они считали, что влияние рассеяния и сдвига данных объясняется лишь субъективизмом критиков, а не недостатками, присущими этим классификациям. Меры расстоянияМеры расстояния пользуются широкой популярностью. На практике их лучше бы называть мерами несходства; для большинства используемых коэффициентов большие значения соответствуют большему сходству, в то время как для мер расстояния дело обстоит наоборот. Два объекта идентичны, если описывающие их переменные принимают одинаковые значения. В этом случае расстояние между ними равно нулю. Меры расстояния обычно не ограничены сверху и зависят от выбора шкалы (масштаба) измерений. Одним из наиболее известных расстояний является евклидово расстояние, определяемое как
где Чтобы избежать применения квадратного корня, часто величина расстояния возводится в квадрат, на что обычно указывает обозначение Можно определить и другие виды расстояния. Так, хорошо известной мерой является манхеттенское расстояние, или «расстояние городских кварталов» (city-block), которое определяется следующим образом:
Можно определить и другие метрики, но большинство из них являются частными формами специального класса метрических функций расстояния, известных как метрики Минковского, которые можно найти по формуле
Существуют расстояния, не являющиеся метриками Минковского, и наиболее важное из них — расстояние Махаланобиса
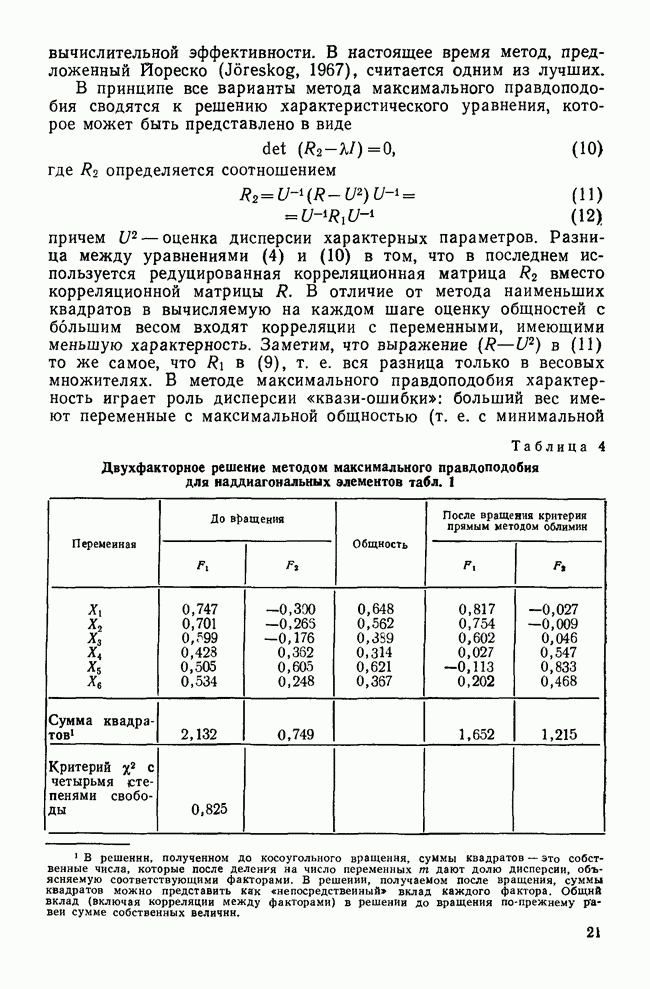
где Несмотря на важность евклидовой и других метрик, они имеют серьезные недостатки, из которых наиболее важный состоит в том, что оценка сходства сильно зависит от различий в сдвигах данных. Переменные, у которых одновременно велики абсолютные значения и стандартные отклонения, могут подавить влияние переменных с меньшими абсолютными размерами и стандартными отклонениями. Более того, метрические расстояния изменяются под воздействием преобразований шкалы измерения переменных, при которых не сохраняется ранжирование по евклидову расстоянию. Чтобы уменьшить влияние относительных величин переменных, обычно перед вычислением расстояния нормируют переменные к единичной дисперсии и нулевому среднему. Как уже отмечалось, такое преобразование данных может вызвать затруднения. Скиннер (1978) для вычисления сходства данных, представляемых профилями, предложил совместно использовать корреляцию и евклидово расстояние. При этом можно определить, какой из факторов (форма, сдвиг или дисперсия) делает вклад в оценку сходства. Метод Скиннера похож на метод, предложенный Гуэртином (1966), согласно которому сначала, взяв за основу форму, с помощью корреляции создаются однородные группы объектов, а затем каждая из этих групп с помощью меры расстояния разбивается на подгруппы со схожими сдвиговыми и дисперсионными характеристиками (Skinner, 1978). Однако в методе Скиннера строится сложная функция сходства, которая объединяет расстояние и корреляцию в вычислительной процедуре, осуществляющей минимизацию ошибки измерения при оценке сходства профилей. Поскольку в прикладном анализе данных часто возникает необходимость в нормировке, полезно рассмотреть небольшой пример, показывающий влияние нормировки на коэффициенты корреляции и расстояния. В качестве данных были взяты четыре профиля MMPI-теста. Каждому из этих профилей соответствует больной с сильной психопатологией. В качестве исходной меры сходства для профилей был взят смешанный момент корреляции Пирсона. Результаты приведены в следующей матрице:
В верхней треуголыной части матрицы приведены значения корреляции, которые показывают, что все четыре профиля имеют очень схожие формы, а профили С и D даже почти идентичны После вычисления евклидовых расстояний получается матрица:
Заметьте, как различаются масштабирования коэффициентов расстояния и коэффициентов корреляции. Вспомните, что абсолютные значения коэффициентов расстояния не имеют смысла. Однако и здесь обнаруживается сходство пациентов С и Чтобы внести еще большую путаницу, предположим, что мы решили нормировать данные. (Нормировка была действительно выполнена на основе статистики для всего множества данных, состоящего из 90 объектов). Если для оценки сходства четырех профилей после нормировки используется смешанный момент корреляции, то матрица сходства принимает вид
Обратите внимание, как различаются коэффициенты корреляции для нормированных и ненормированных данных. Для ненормированных данных Наконец, в нижеприведенной матрице несходства показаны евклидовы расстояния между пациентами в случае нормированных данных:
Снова величины изменяются в зависимости от того, нормированы или нет данные. Однако поскольку значение коэффициента евклидова расстояния не имеет естественного смысла, постольку эти изменения не очень важны. Что действительно важно, так это относительное изменение. Наиболее драматическим моментом является то, что коэффициент евклидова расстояния для нормированных данных показывает, что пациенты Л и Б — пара с наибольшим сходством, между тем, как три другие матрицы сходства указывают на то, что наиболее похожие пациенты — это С и D. В заключение важно отметить, что все четыре матрицы порождают разные ранжирования коэффициентов сходства. Это замечание важно, так как оно показывает, что выбор коэффициента сходства и преобразования данных может плохо повлиять на соотношения, содержащиеся в итоговой матрице сходства. Коэффициенты ассоциативностиКоэффициенты ассоциативности применяются, когда необходимо установить сходство между объектами, описываемыми бинарными переменными. Легче всего рассмотреть эти коэффициенты, обратившись к
Было предложено большое число Простой коэффициент совстречаемости имеет вид
где S — сходство между двумя объектами, которое меняется в пределах от 0 до 1. Как отмечают Снит и Сокэл (1973), этот коэффициент нелегко преобразовать в метрику. Тем не менее большие усилия были направлены на то, чтобы установить приблизительные доверительные пределы. Один из небольшого числа таких методов отмечает Гудолл (1967). Этот коэффициент учитывает также и одновременное отсутствие признака у обоих объектов (как указано в клетке d матрицы ассоциативности). Коэффициент Жаккара, определенный следующим образом
не учитывает одновременного отсутствия признака при вычислении сходства (клетка d не рассматривается). Подобно простому коэффициенту совстречаемости он изменяется от 0 до 1. Коэффициент Жаккара широко применялся в биологии при необходимости рассмотрения так называемых негативных пар (с одновременным отсутствием признака). Как заметили биологи, используя простой коэффициент совстречаемости, некоторые объекты оказываются в значительной степени схожими главным образом за счет того, что им обоим не свойственны некоторые признаки, а не за счет наличия общих характеристик. В противоположность этому коэффициент Жаккара принимает в расчет лишь те признаки, которые характерны хотя бы для одного из объектов. Во многих областях социологических наук не стоит вопрос об учете негативных пар, но такая проблема возникает в археологии Если предмет не был найден в захоронении, то его отсутствие может быть обусловлено либо культурными традициями, либо естественными процессами распада и изнашивания. Было бы неправильно давать оценку сходства двух захоронений исходя из отсутствия и них какого-то предмета, если невозможно узнать, какое из двух возможных объяснений действительно имеет место. Рассмотрим шесть точек из множества данных о захоронениях, чтобы кратко проиллюстрировать различия между простым коэффициентом совстречаемости и коэффициентом Жаккара:
Возьмем объекты 1 (ребенок, мужской пол, неэлитарное общественное положение — РМН) и 8 (подросток, мужской пол, неэлитарное общественное положение — ПМН). Матрица ассоциативности общих признаков для двух объектов размерностью 2х2 имеет вид
Другими словами, эти объекты имеют только один общий предмет. Одиако четыре предмета отсутствуют в обоих захоронениях. Таким образом,
Тем не менее
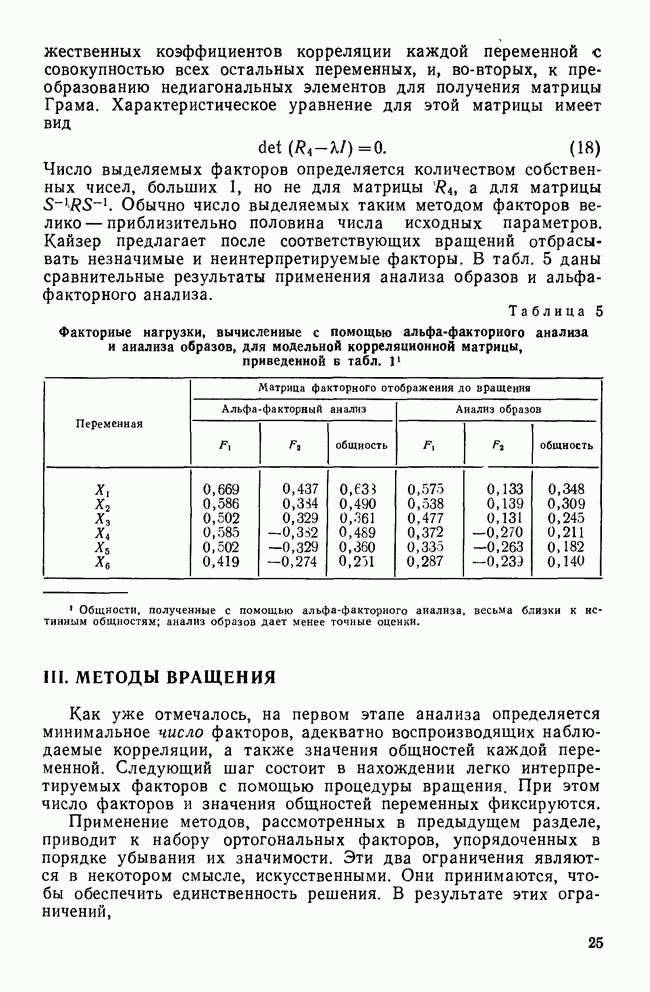
Иначе говоря, в то время как простой коэффициент совстречаемости показывает, что объекты РМН и ПМН достаточно схожи, из величины коэффициента Жаккара следует, что такого сходства нет. Полная матрица сходства размерностью 6x6 в случае простого коэффициента совстречаемости имеет вид
В случае коэффициента Жаккара полная матрица сходства принимает следующий вид:
Как видим, эти матрицы довольно похожи. Например, они показывают, что объекты ПЖЭ, ВМЭ и ВЖЭ (недетские элитарные захоронения) имеют наибольшее сходство. Однако существуют и различия. Два детских захоронения (объекты РМН и РЖЭ) согласно коэффициенту Жаккара совсем не имеют сходства, но, судя по простому коэффициенту совстречаемости, они сравительно похожи. Другой характерной чертой этих матриц является число «совпадений». В случае простого коэффициента совстречаемости имеется пять пар объектов, для которых Коэффициент Гауэра — единственный в своем роде, так как при оценке сходства допускает одновременное использование переменных, измеренных по различным шкалам. Коэффициент был предложен Гауэром (1971) и имеет вид
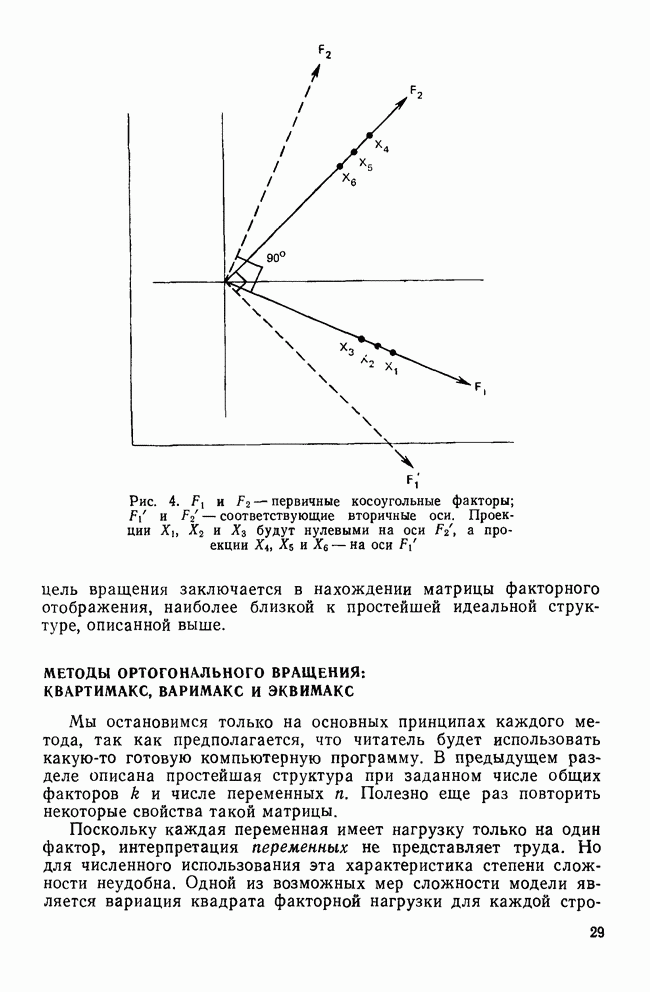
где Чтобы показать, как работает этот коэффициент, расширим множество данных о захоронениях, добавив два новых признака: рост (измеренный в сантиметрах; это количественная переменная) и величину энергетических затрат, связанных с погребением (измеренных по порядковой шкале с рангами 1, 2 и 3 или соответственно низкие, средние и высокие). Матрица сходства для четырех объектов примет вид
Для двоичных данных
Для порядковых данных равно 1, если сравниваемые значения равны, и 0 — в противном случае. Наконец, для количественных данных имеет место уравнение
где
Кроме возможности работать с разнотипными данными, у коэффициента есть еще несколько привлекательных особенностей. Например то, что его метрические свойства и гибкость дают возможность после простого изменения системы бинарных весов при оценке сходства учитывать и негативные пары. К сожалению, коэффициент Гауэра можно редко найти в пакетах прикладных программ по кластерному анализу, так как он практически не применяется в области социальных наук. Вероятностные коэффициенты сходстваРадикальное отличие коэффициентов этого типа от описанных выше заключается в том, что, по сути дела, сходство между двумя объектами не вычисляется. Вместо этого мера такого типа прилагается непосредственно к исходным данным до их обработки. При образовании кластеров вычисляется информационный выигрыш (по определению Шеннона) от объединения двух объектов, а затем те объединения, которые дают минимальный выигрыш, рассматриваются как один объект. Другой особенностью вероятностных мер является то, что они пригодны лишь для бинарных данных. До сих пор не было разработано ни одной схемы использования меры этого вида для качественных и количественных переменных. Вероятностные коэффициенты сходства еще не нашли своего применения в социальных науках, но уже в течение десятилетия ими широко пользуются специалисты по численной таксономии и экологии. Более подробно об этом см. (Sneath and Sokal, 1973; Clifford and Stephenson, 1975).
|
 |
Оглавление
|



































































































































































































 — значение
— значение  переменной для
переменной для  объекта;
объекта;  среднее всех значений переменных
среднее всех значений переменных  объекта, а
объекта, а  — число переменных.
— число переменных.
 -коэффициент. Значение коэффициента корреляции изменяется от —1 до +1, причем значение нуль указывает, что между объектами нет связи. Поскольку при вычислении среднего для каждого объекта суммирование производится по всем переменным этого объекта, то стандартные критерии значимости для
-коэффициент. Значение коэффициента корреляции изменяется от —1 до +1, причем значение нуль указывает, что между объектами нет связи. Поскольку при вычислении среднего для каждого объекта суммирование производится по всем переменным этого объекта, то стандартные критерии значимости для  здесь не имеют ясного смысла.
здесь не имеют ясного смысла.
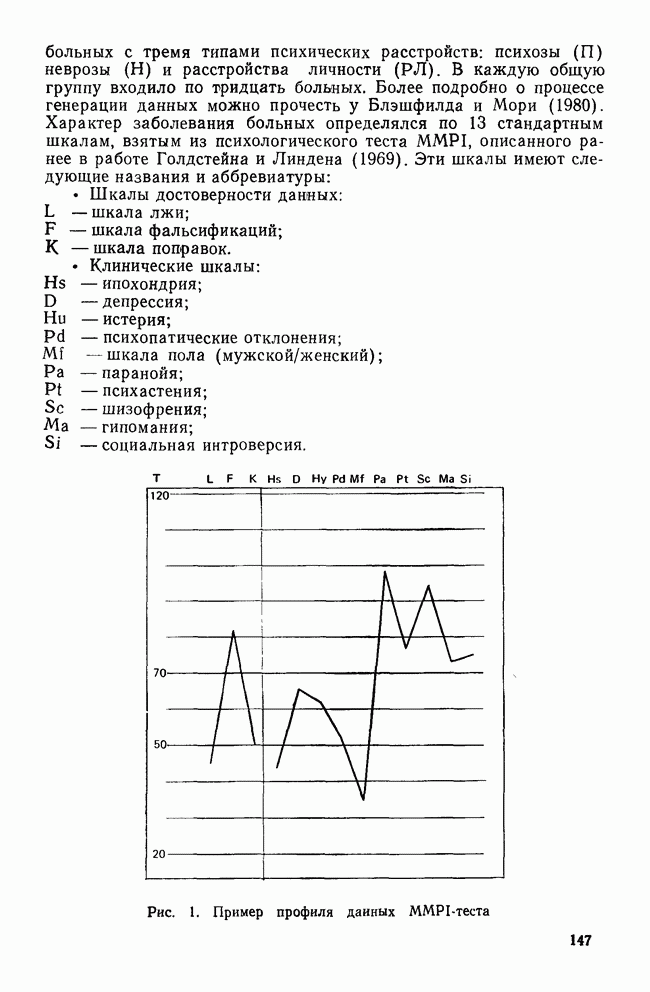
 чувствителен только к форме из-за неявной нормировки каждого обекта по всем переменным. Это свойство особенно важно для приложений к таким отраслям науки, как психология, социология и антропология, в которых данные часто описываются в терминах профилей. Формально профиль определяется просто как вектор значений признаков объекта, графически изображаемый в виде ломаной линии. Например, данные MMPI-теста, использованные в нашей работе, часто изображают так, чтобы для каждого индивида получилась ломаная — профиль (см. рис. 1).
чувствителен только к форме из-за неявной нормировки каждого обекта по всем переменным. Это свойство особенно важно для приложений к таким отраслям науки, как психология, социология и антропология, в которых данные часто описываются в терминах профилей. Формально профиль определяется просто как вектор значений признаков объекта, графически изображаемый в виде ломаной линии. Например, данные MMPI-теста, использованные в нашей работе, часто изображают так, чтобы для каждого индивида получилась ломаная — профиль (см. рис. 1).

 и все же не быть идентичными (т. е. профили объектов не проходят через одни и те же точки).
и все же не быть идентичными (т. е. профили объектов не проходят через одни и те же точки).

 расстояние между объектами i и
расстояние между объектами i и  значение
значение  переменной для
переменной для  объекта.
объекта.
 . Как и следовало ожидать, это выражение называют «квадратичным евклидовым расстоянием».
. Как и следовало ожидать, это выражение называют «квадратичным евклидовым расстоянием».


 которое также носит название обобщенного расстояния (Mahalane-bis, 1936). Эта метрика определяется выражением
которое также носит название обобщенного расстояния (Mahalane-bis, 1936). Эта метрика определяется выражением

 — общая внутригрупповая дисперсионно-ковариационная матрица,
— общая внутригрупповая дисперсионно-ковариационная матрица,  — векторы значений переменных для объектов
— векторы значений переменных для объектов  . В отличие от евклидовой и метрик Минковского, эта метрика с помощью матрицы дисперсий-ковариаций связана с корреляциями переменных. Когда корреляция между переменными равна нулю, расстояние Махаланобиса эквивалентно квадратичному евклидову расстоянию.
. В отличие от евклидовой и метрик Минковского, эта метрика с помощью матрицы дисперсий-ковариаций связана с корреляциями переменных. Когда корреляция между переменными равна нулю, расстояние Махаланобиса эквивалентно квадратичному евклидову расстоянию.

 . В нижней треугольной части матрицы показаны ранги, полученные в результате упорядочения по величине значений сходства от наибольшего (1) к наименьшему (6). Необходимость в ранговом упорядочении будет объяснена ниже.
. В нижней треугольной части матрицы показаны ранги, полученные в результате упорядочения по величине значений сходства от наибольшего (1) к наименьшему (6). Необходимость в ранговом упорядочении будет объяснена ниже.

 хотя не ясно, насколько хорошим является значение 144). Общая картина сходства кажется почти одинаковой и для корреляции, и для расстояния, но существуют и различия. В частности, при использовании корреляции в качестве меры сходства наименее похожими оказались пациенты
хотя не ясно, насколько хорошим является значение 144). Общая картина сходства кажется почти одинаковой и для корреляции, и для расстояния, но существуют и различия. В частности, при использовании корреляции в качестве меры сходства наименее похожими оказались пациенты  Однако евклидова метрика показывает, что наименее схожими являются пациенты
Однако евклидова метрика показывает, что наименее схожими являются пациенты 

 , а для нормированных
, а для нормированных  . В обоих случаях
. В обоих случаях  — наименьшая величина в матрице, но для нормированных данных величина коэффициента корреляции показывает, что между пациентами А и С нет никакого сходства, в то время как для ненормированных данных абсолютное значение корреляции
— наименьшая величина в матрице, но для нормированных данных величина коэффициента корреляции показывает, что между пациентами А и С нет никакого сходства, в то время как для ненормированных данных абсолютное значение корреляции  свидетельствует, что пациенты Л и С довольно похожи.
свидетельствует, что пациенты Л и С довольно похожи.

 -таблице ассоциативности, в которой 1 указывает на наличие переменной, а 0 — на ее отсутствие.
-таблице ассоциативности, в которой 1 указывает на наличие переменной, а 0 — на ее отсутствие.

 таких коэффициентов, а поэтому нереально пытаться дать исчерпывающее описание всей совокупности этих мер. В основном коэффициенты ассоциативности были впервые определены в биологии, хотя, вероятно, некоторые, наиболее простые из них были найдены и в ряде других отраслей науки. Лишь небольшое число мер подверглось широкой проверке, многие вышли из употребления из-за свойств сомнительного характера. Более подробно об этом см. (Sneath and Sokal, 1973; Clifford and Stephenson, 1975; Everitt, 1980). Однако существуют три меры, которые широко используются и заслуживают специального рассмотрения. Это — простой коэффициент совстречаемости, коэффициент Жаккара и коэффициент Гауэра.
таких коэффициентов, а поэтому нереально пытаться дать исчерпывающее описание всей совокупности этих мер. В основном коэффициенты ассоциативности были впервые определены в биологии, хотя, вероятно, некоторые, наиболее простые из них были найдены и в ряде других отраслей науки. Лишь небольшое число мер подверглось широкой проверке, многие вышли из употребления из-за свойств сомнительного характера. Более подробно об этом см. (Sneath and Sokal, 1973; Clifford and Stephenson, 1975; Everitt, 1980). Однако существуют три меры, которые широко используются и заслуживают специального рассмотрения. Это — простой коэффициент совстречаемости, коэффициент Жаккара и коэффициент Гауэра.








 и пять пар, для которых
и пять пар, для которых  На самом деле среди пятнадцати клеток матрицы сходства размерностью 6х6 только в пяти есть неповторяющиеся значения S. Как мы позже покажем, некоторые кластерные методы не годятся для матриц сходства, у которых так много «совпадений».
На самом деле среди пятнадцати клеток матрицы сходства размерностью 6х6 только в пяти есть неповторяющиеся значения S. Как мы позже покажем, некоторые кластерные методы не годятся для матриц сходства, у которых так много «совпадений».

 — весовая переменная, принимающая значение 1, если сравнение объектов по признаку k следует учитывать, и 0 — в противном случае;
— весовая переменная, принимающая значение 1, если сравнение объектов по признаку k следует учитывать, и 0 — в противном случае;  — «вклад» в сходство объектов, зависящий от того, учитывается ли признак k при сравнении объектов
— «вклад» в сходство объектов, зависящий от того, учитывается ли признак k при сравнении объектов  . В случае бинарных признаков
. В случае бинарных признаков  если признак k отсутствует у одного или обоих сопоставляемых объектов (Everitt, 1980). Для так называемых негативных переменных 0. Понятно, что если все данные — двоичные, то коэффициент Гауэра сводится к коэффициенту Жаккара.
если признак k отсутствует у одного или обоих сопоставляемых объектов (Everitt, 1980). Для так называемых негативных переменных 0. Понятно, что если все данные — двоичные, то коэффициент Гауэра сводится к коэффициенту Жаккара.

 вычисляется в соответствии со следующей системой подсчета:
вычисляется в соответствии со следующей системой подсчета:


 — значение
— значение  переменной для объекта
переменной для объекта  размах значений этой переменной (разность между максимальным и минимальным значениями). В результате итоговую матрицу сходства для четырех объектов можно представить как
размах значений этой переменной (разность между максимальным и минимальным значениями). В результате итоговую матрицу сходства для четырех объектов можно представить как
