Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
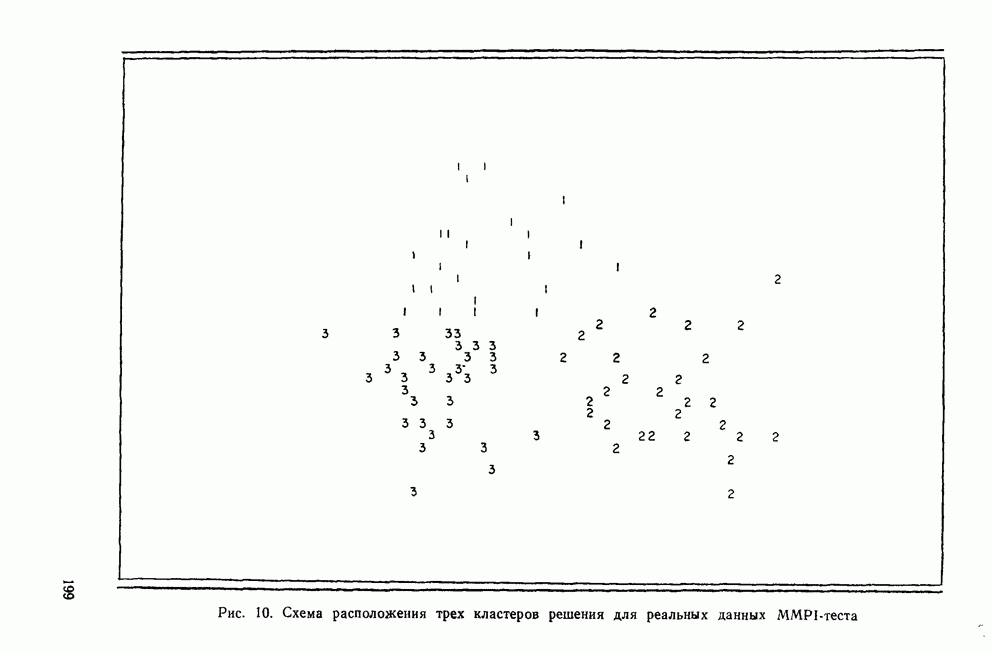
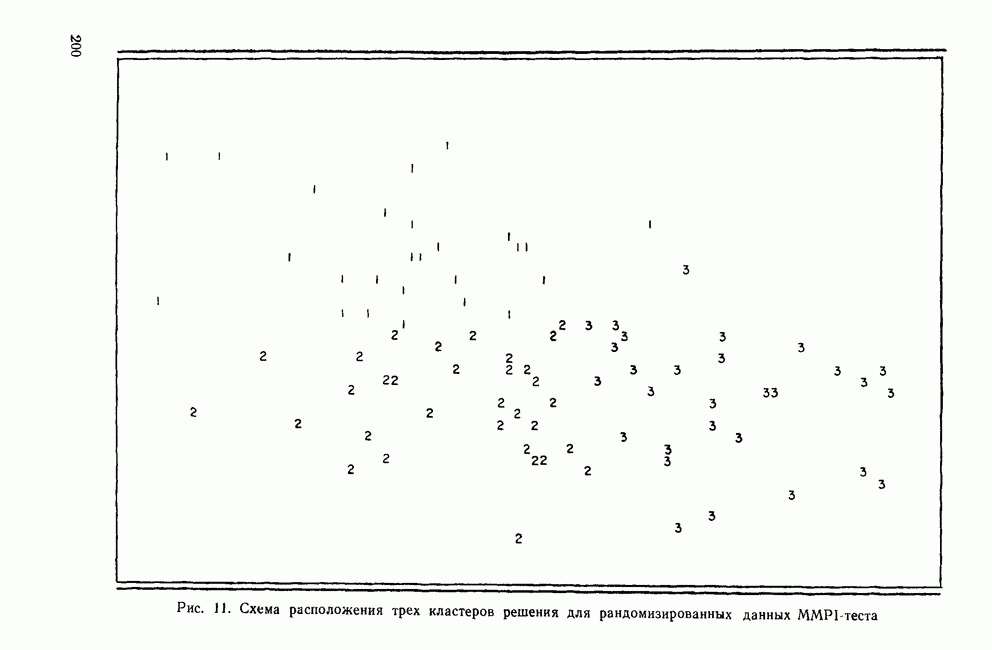
ТЕСТЫ ЗНАЧИМОСТИ ДЛЯ ПРИЗНАКОВ, НЕОБХОДИМЫЕ ПРИ СОЗДАНИИ КЛАСТЕРОВДругой процедурой, которая часто используется в прикладных исследованиях с применением кластерного анализа, является многомерный дисперсионный анализ (MANOVA) признаков, необходимых для получения решения. Цель анализа — выяснить с помощью тестов для проверки гипотезы однородности, значимо ли разбиение данных на кластеры. В отличие от кофенетической корреляции, применяемой для анализа правильности иерархического дерева, выполнение стандартных тестов значимости связано с качеством кластерного решения, представляющего собой разбиение множества данных. Таким образом, процедуру MANOVA можно применять к решениям, полученным любым методом кластеризации, лишь бы он порождал разбиения (например, итеративные методы группировки, иерархические методы, варианты факторного анализа). Ясно, что использование MANOVA для проверки гипотезы однородности кластеров вполне разумно. Более того, она становится весьма популярной процедурой, потому что ее результаты всегда имеют высокую значимость. Так, при исследовании типов верующих (Filsinger et. al., 1979), обсуждавшемся в разд. I, были обнаружены значимые различия между кластерами после проведения дискриминантного анализа признаков, необходимых при создании кластеров. В действительности дискриминантный анализ правильно классифицировал 96% субъектов. Эти результаты свидетельствуют, что кластерное решение, полученное Филсингером и другими, хорошо описывает типы верующих людей. Однако такое использование дискриминантного анализа (или MANOVA, или многократно ANOVA) оказывается статистически неправомерным. Чтобы понять это, рассмотрим следующий пример. Предположим, что группа исследователей проводит
|
 |
Оглавление
|







































































































































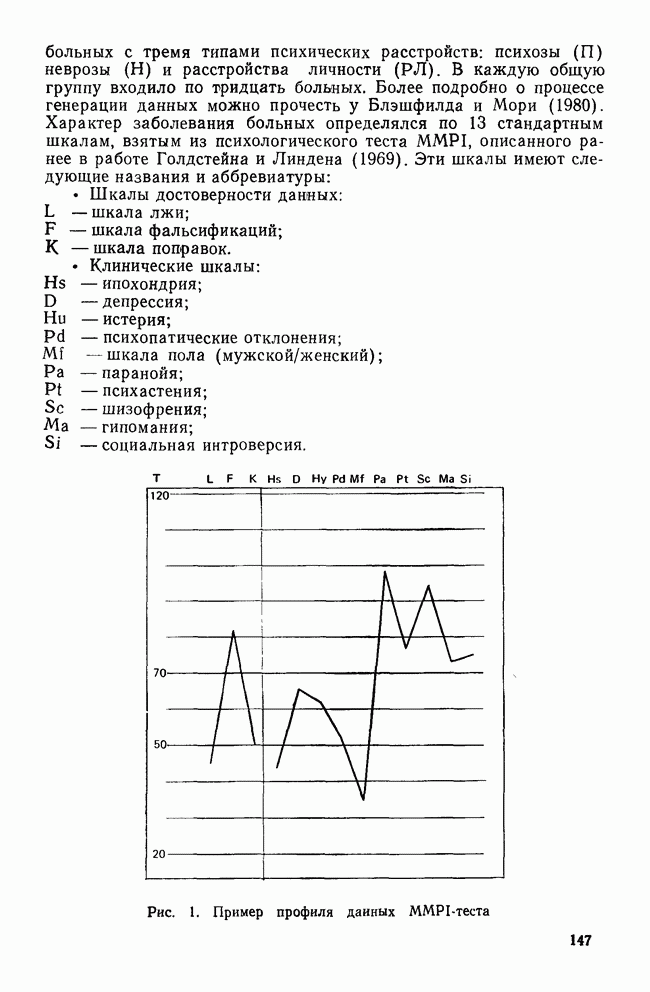








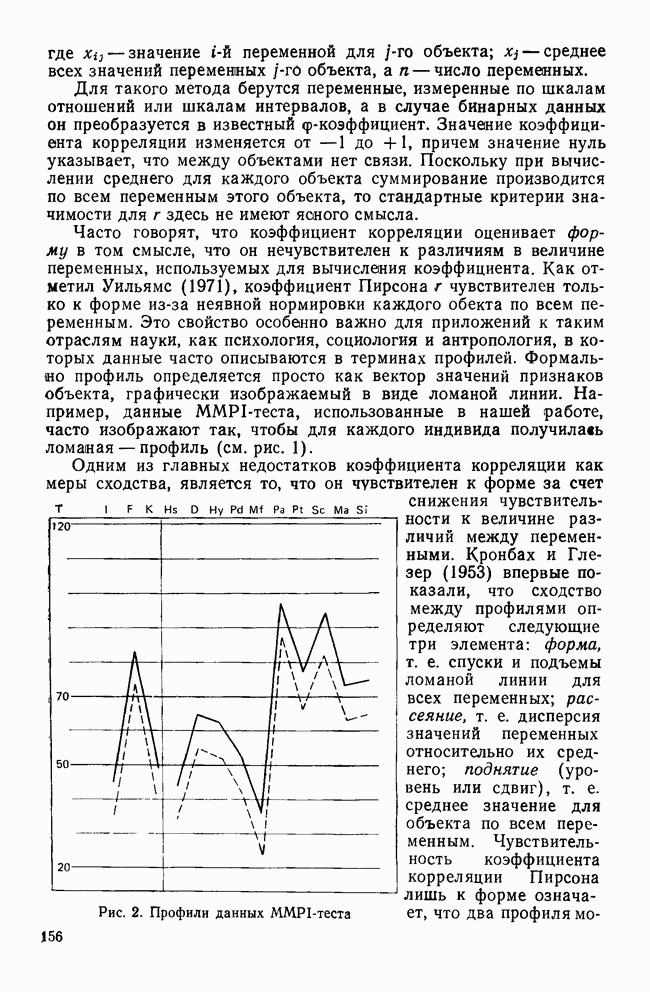













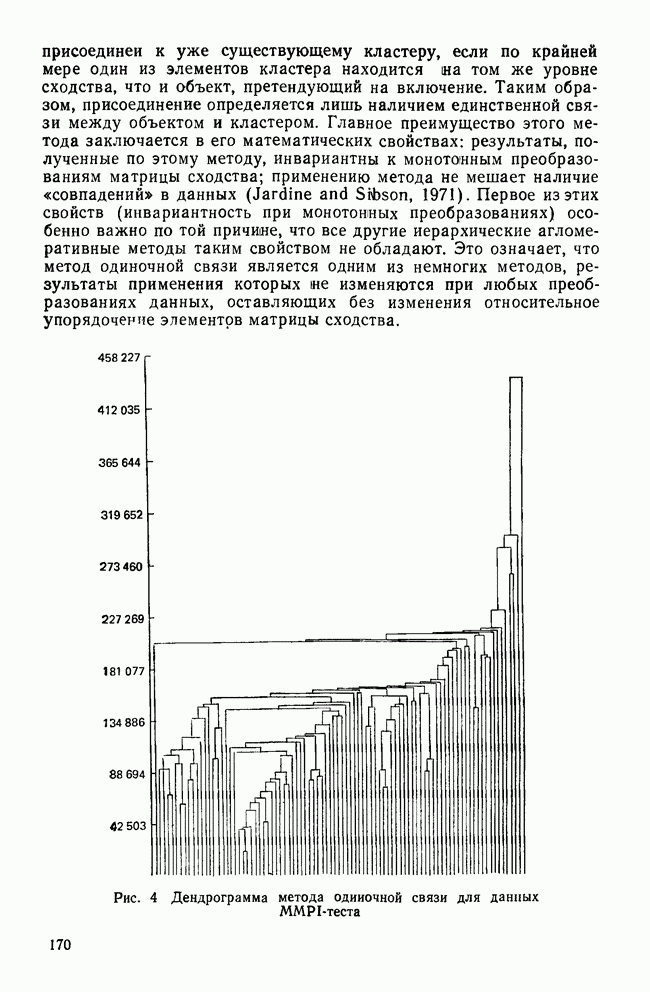
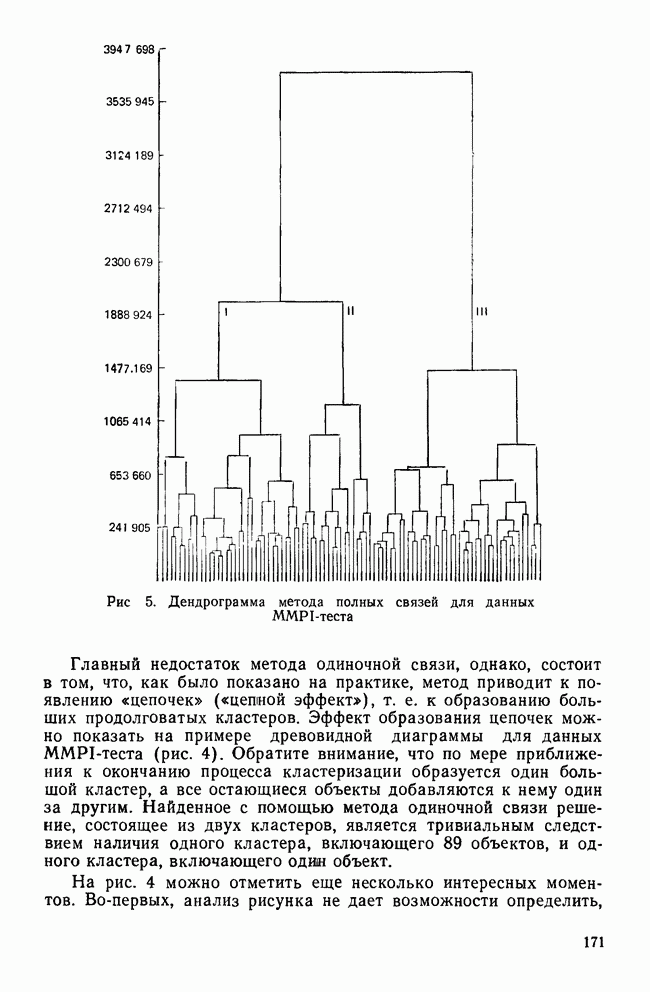

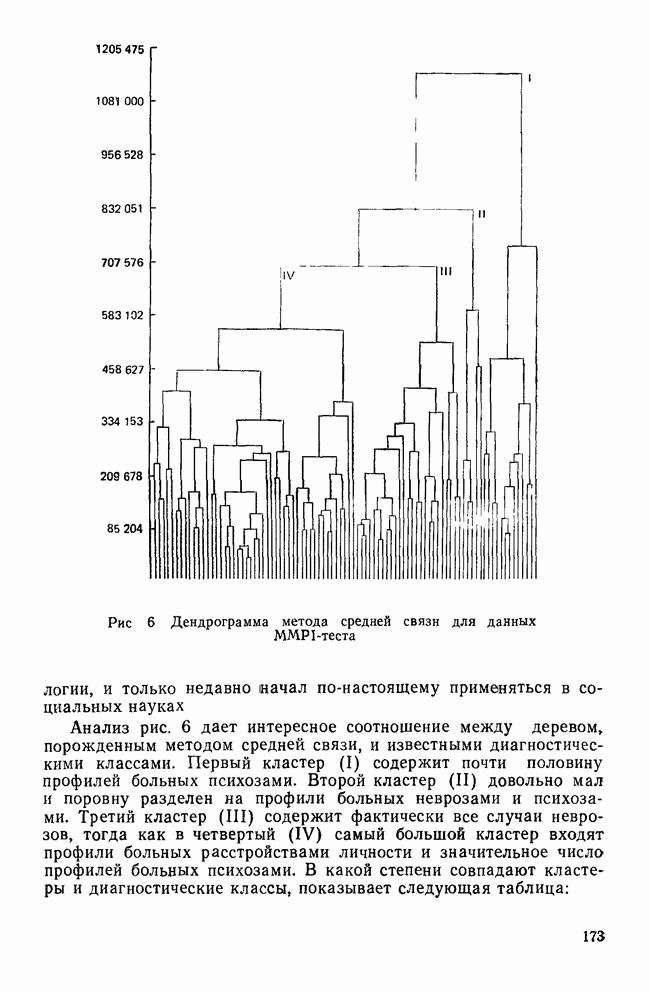
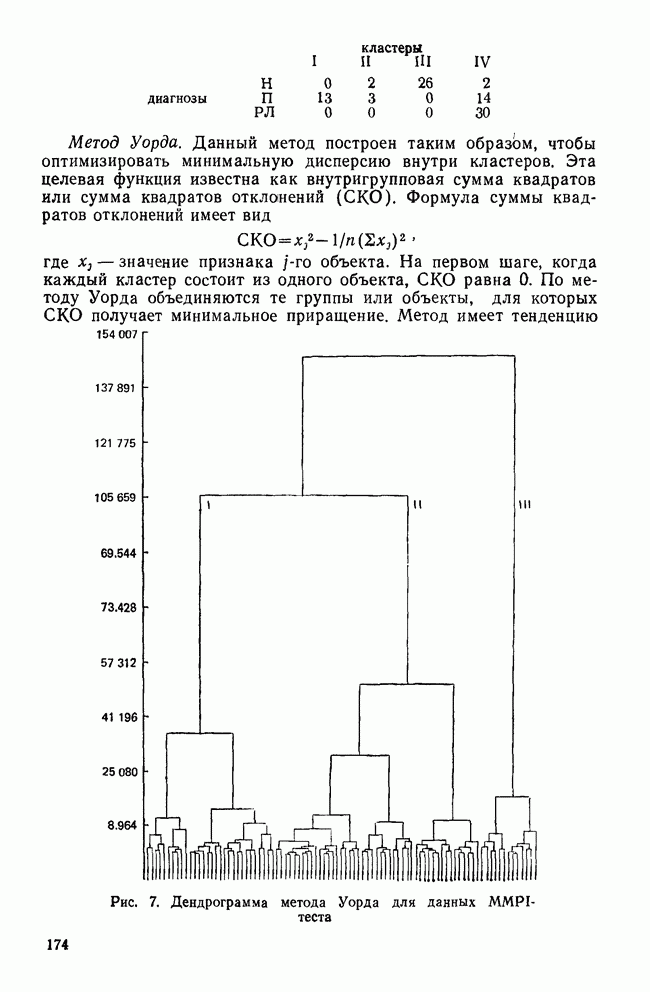










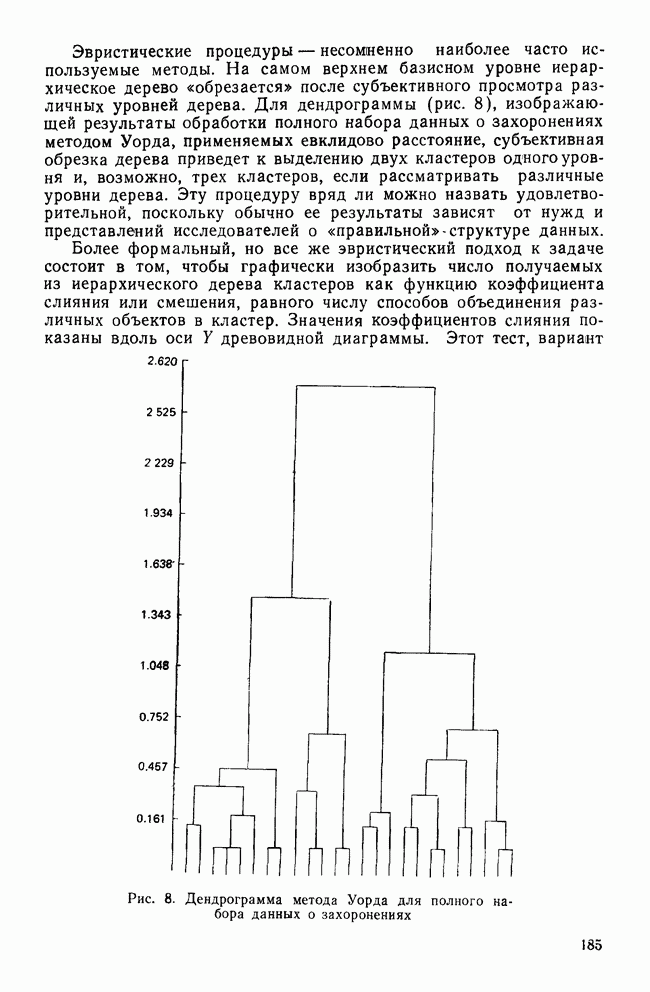
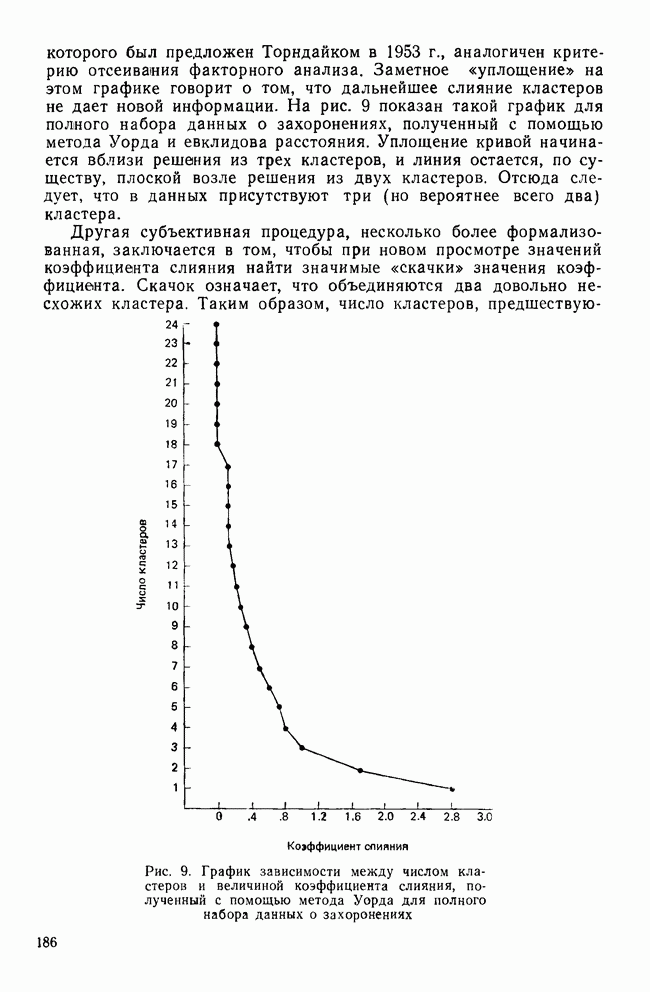



























 -тест среди случайно отобранных детей из одного класса по всей школьной системе. Далее предположим, что в этом наборе данных на самом деле нет кластеров. После того как будет построена диаграмма вдоль оси
-тест среди случайно отобранных детей из одного класса по всей школьной системе. Далее предположим, что в этом наборе данных на самом деле нет кластеров. После того как будет построена диаграмма вдоль оси  -оценок, исследователи получат нормальное распределение со средним, равным 100 (именно такое значение можно было предсказать исходя из нормативных данных по этому признаку). Тем не менее допустим, что они все же решили провести кластерный анализ полученных данных, несмотря на унимодальное распределение по
-оценок, исследователи получат нормальное распределение со средним, равным 100 (именно такое значение можно было предсказать исходя из нормативных данных по этому признаку). Тем не менее допустим, что они все же решили провести кластерный анализ полученных данных, несмотря на унимодальное распределение по  -признакам. Найденное кластерное решение делит выборку на две группы: с коэффициентом IQ, превышающим 100, и с коэффициентом IQ не выше 100. Если затем исследователи проведут дисперсионный анализ для сравнения групп по величине их
-признакам. Найденное кластерное решение делит выборку на две группы: с коэффициентом IQ, превышающим 100, и с коэффициентом IQ не выше 100. Если затем исследователи проведут дисперсионный анализ для сравнения групп по величине их  -оценок, применение .
-оценок, применение . -теста покажет высокую значимость! Этот «высокозначимый» результат будет иметь место, несмотря на то, что в данных не существует ни одного кластера. С помощью методов кластерного анализа (по определению) объекты разделяются на кластеры, которые фактически не перекрываются по признакам, применявшимся при создании кластеров. Проверки значимости различий между кластерами по этим признакам будут всегда давать положительные результаты, поскольку результаты таких проверок всегда положительны независимо от того, есть в данных кластеры или нет. Описанное использование тестов в лучшем случае бесполезно, в худшем — ведет к заблуждениям.
-теста покажет высокую значимость! Этот «высокозначимый» результат будет иметь место, несмотря на то, что в данных не существует ни одного кластера. С помощью методов кластерного анализа (по определению) объекты разделяются на кластеры, которые фактически не перекрываются по признакам, применявшимся при создании кластеров. Проверки значимости различий между кластерами по этим признакам будут всегда давать положительные результаты, поскольку результаты таких проверок всегда положительны независимо от того, есть в данных кластеры или нет. Описанное использование тестов в лучшем случае бесполезно, в худшем — ведет к заблуждениям.