Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
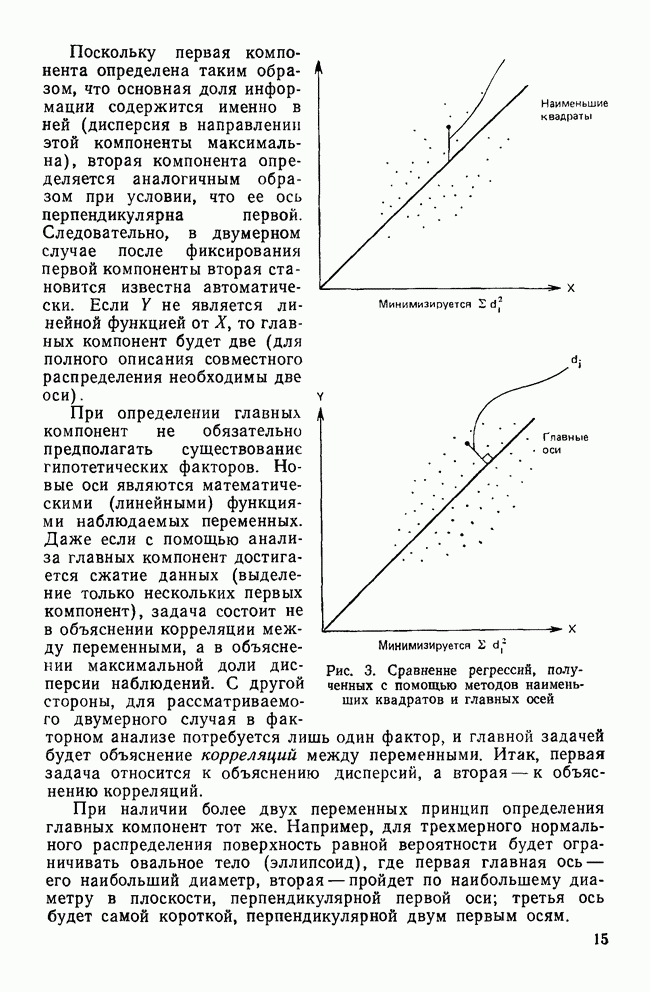
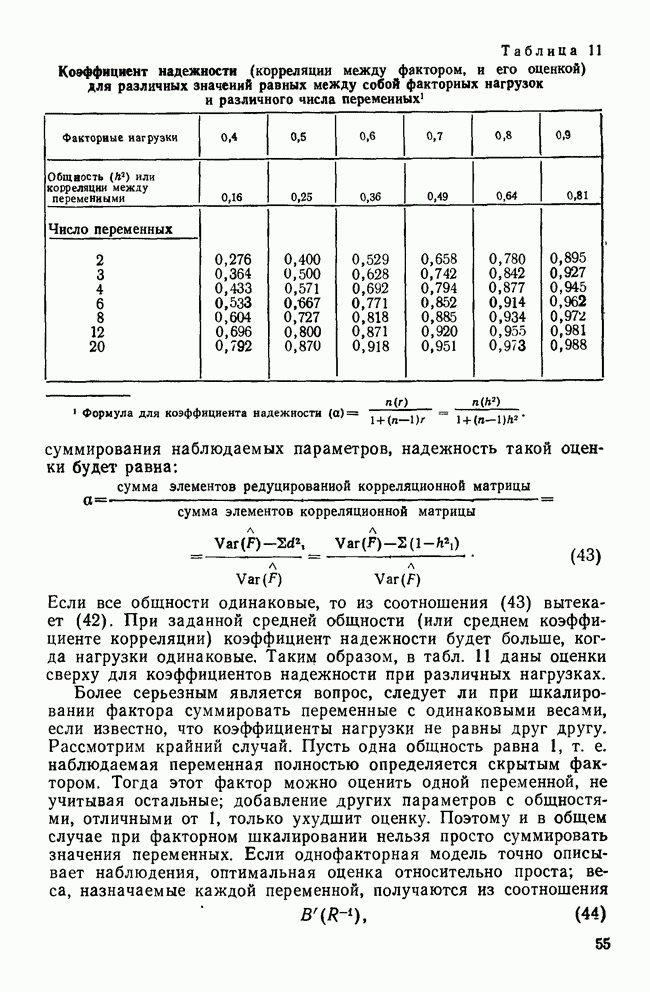
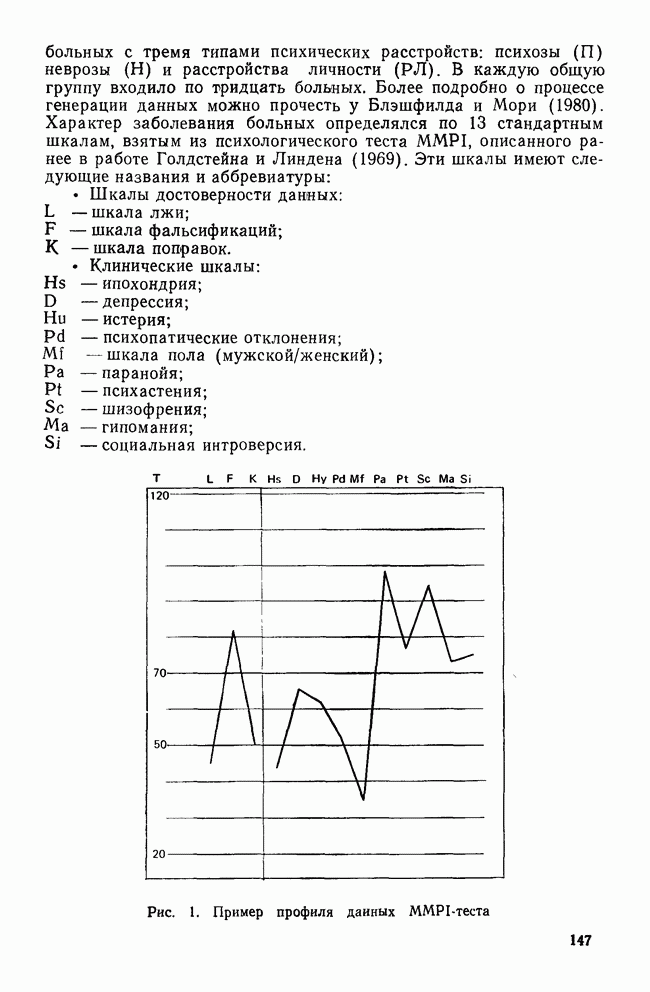
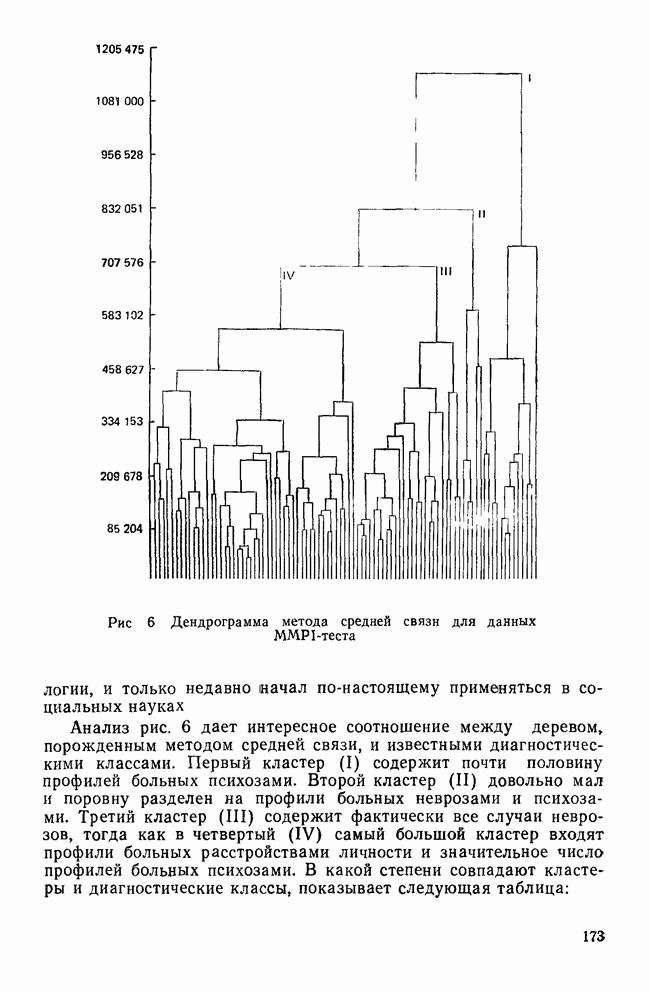
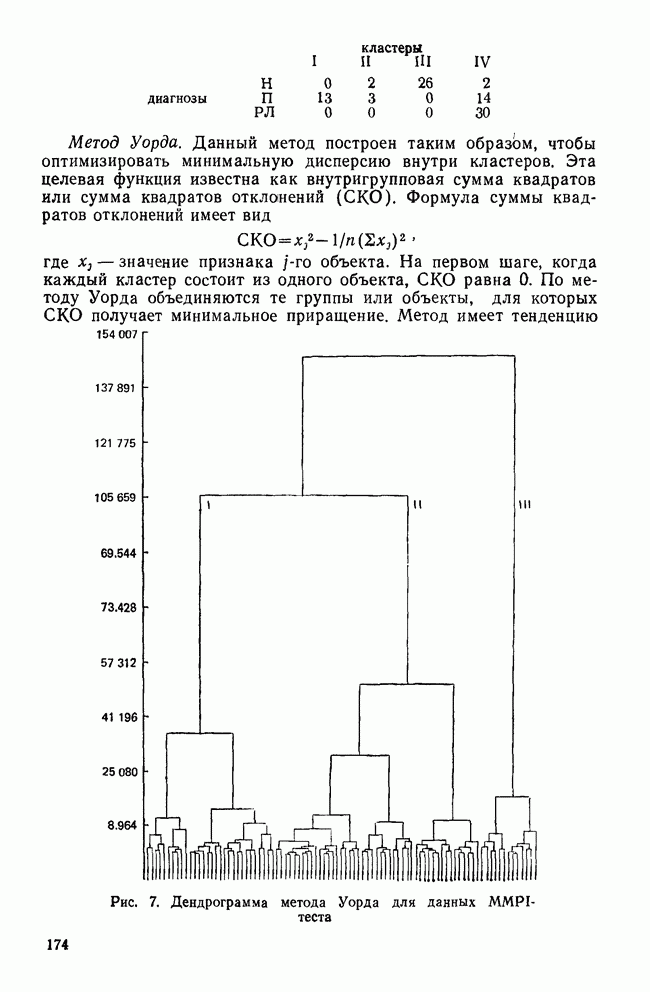
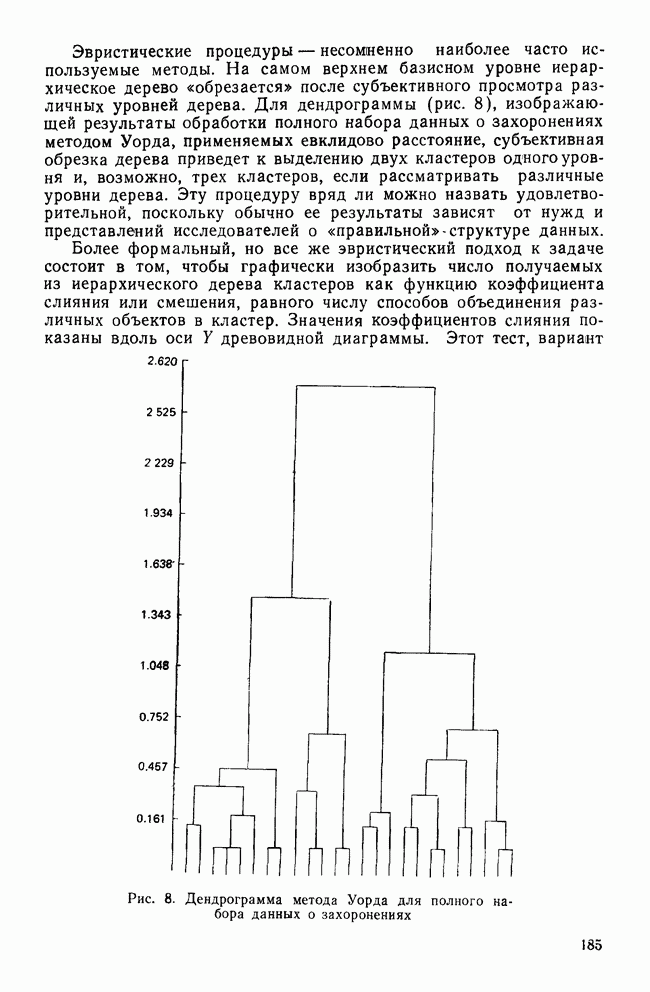
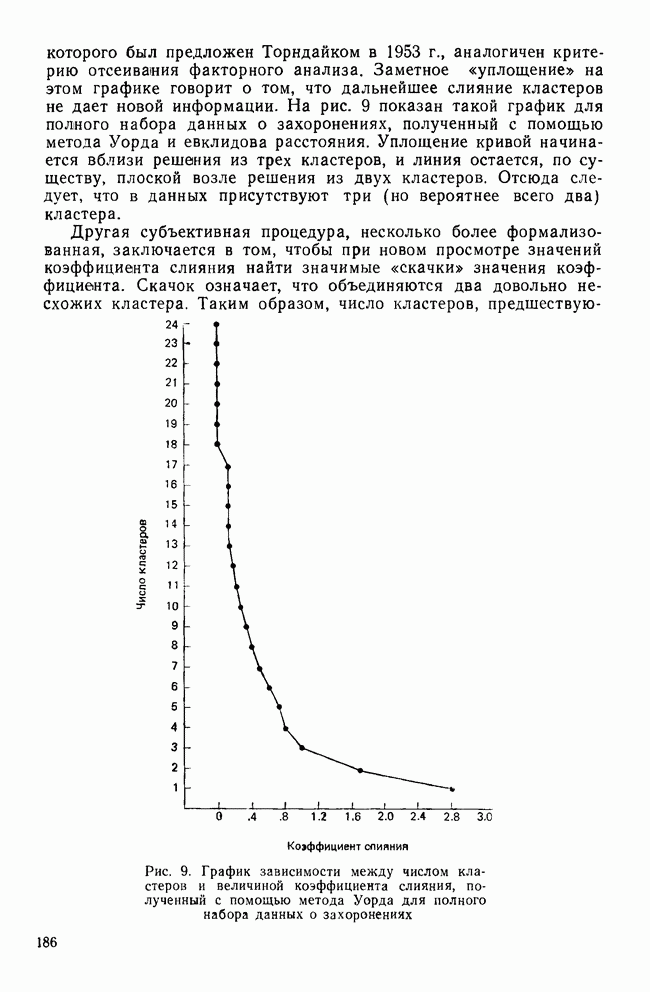
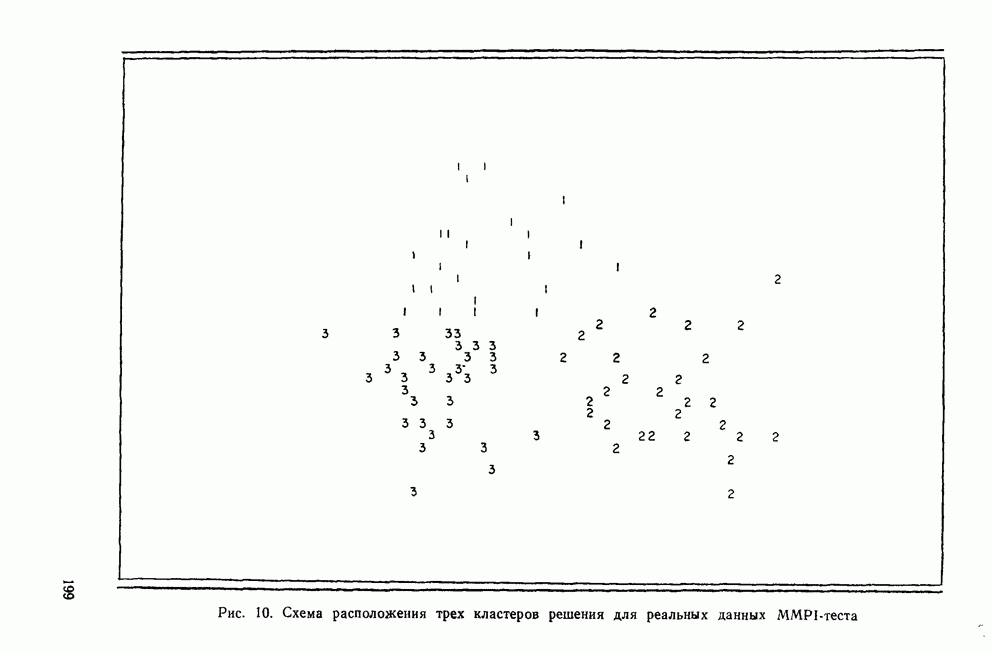
СКОЛЬКО ФУНКЦИЙ НАДО УЧИТЫВАТЬВ разд. II было показано, что решению уравнения (4) соответствует собственное значение (лямбда) и множество коэффициентов для каждой канонической дискриминантной функции. Число возможных решений общей задачи в действительности равно числу дискриминантных переменных р. Однако некоторые из них будут математически тривиальными решениями, а другие — статистически малозначимыми. Все собственные значения лямбды будут положительными или равными нулю, причем чем больше значение лямбды, тем больше групп будет разделять соответствующая функция. Таким образом, функция с самым большим собственным значением является и самым мощным дискриминатором, а функция с наименьшим собственным значением — самым слабым дискриминатором. Число функцийПредположив, что значение лямбда равно нулю, получим решение уравнения (4), которое не представляет интереса. Такое решение оказывается бесполезным, потому что оно допускает отсутствие различий между группами по этой функции. Однако, когда Прежде чем научиться проверять значимость, рассмотрим собственные значения функции, воспользовавшись примером о голосовании в сенате. Эти результаты приведены в табл. 9. Как и ожидалось, имеются три собственных значения, не равных нулю. Они даются в порядке убывания их величин. Так обычно делают потому, что величина собственного значения связана с дискриминирующими возможностями этой функции: чем больше собственное значение, тем лучше различение. Располагая их в порядке убывания, мы знаем, что первая функция обладает наибольшими возможностями: вторая функция обеспечивает максимальное различение после первой функции; третья дает наилучшее дополнительное различение после первой и второй и т. д. Все функции не обязательно дают идеальное различение, но мы, по крайней мере, знаем их порядок значимости. Таблица 9. Собственные значения, соответствующие функции, имеры значимости
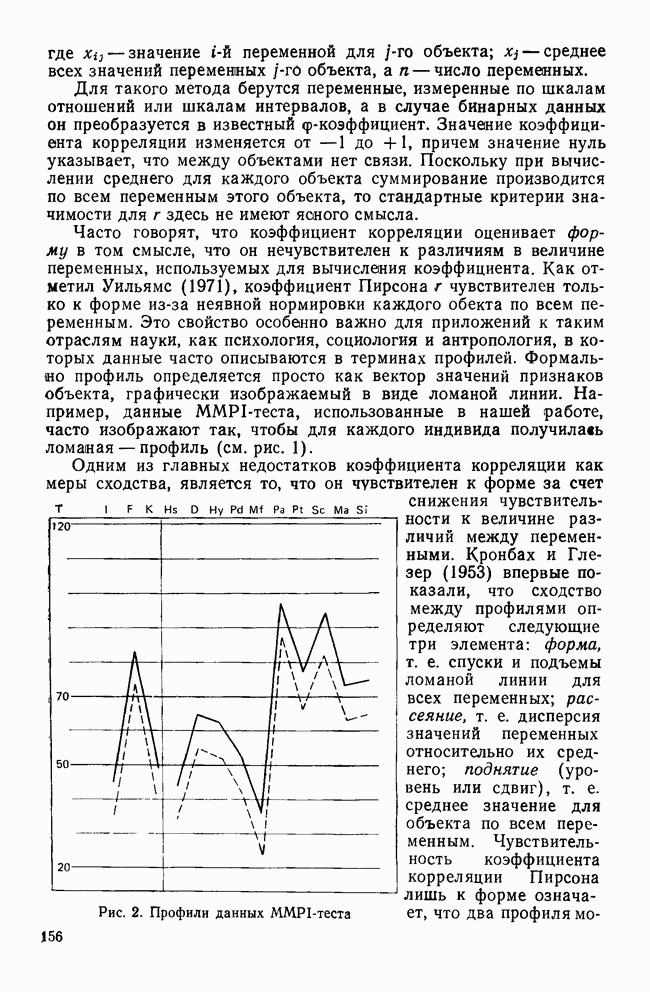
Относительное процентное содержаниеФактические числа, представляющие собственные значения, ни о чем нам не говорят. Их нельзя интерпретировать непосредственно. Если имеется более одной функции, желательно уметь сравнивать их дискриминантные возможности. Так, например, число 9,65976 для собственного значения, соответствующего первой функции, больше собственного значения, соответствующего второй, более чем в шесть раз. В случае когда первое собственное значение в 180 раз превосходит третье, то это доказывает, что третья функция обладает очень незначительными возможностями. Чтобы облегчить такое сравнение, мы припишем собственным значениям относительное процентное содержание. Для этого сначала суммируем все собственные значения, чтобы установить размер общих возможностей различения. Затем разделим каждое собственное значение на общую сумму. Так, в приведенной системе уравнений первая функция содержит 85,54% общих дискриминантных возможностей. Третья функция в этом примере иллюстрирует тот случай, когда она оказывается настолько мало значимой, что, по-видимому, ею можно пренебречь. К сожалению, нет правила, которое помогло бы определить, как велико должно быть относительное процентное содержание, чтобы функция представляла для исследователя интерес. Поэтому при дальнейшем рассмотрении может оказаться, что и функция 2 не удовлетворяет нас. Даже функция 1 иногда не имеет реальной значимости (согласно критерию, который рассматривается ниже), хотя она наиболее мощная. Относительное процентное содержание только показывает что функция настолько слабее по сравнению с другими, что вряд ли она добавит что-либо к определению различий между группами. Каноническая корреляцияДругой способ оценки реальной полезности дискриминантной функции можно получить, рассматривая коэффициент канонической корреляции, который является мерой связи (степени зависимости между группами и дискриминантной функцией). Нулевое значение говорит об отсутствии связи, а большие числа (всегда положительные) означают большую степень зависимости (максимальное значение равно 1,0). Каноническая корреляция (обозначаем ее
где i — номер соответствующей дискриминантной функции. Понятие канонической корреляции взято из так называемого канонического корреляционного анализа (см. Levine, 1977). Каноническая корреляция используется при изучении связей между двумя различными множествами переменных, измеренных по интервальной шкале. Анализ заключается в формировании q пар линейных комбинаций, где q — число переменных в меньшем множестве. Линейные комбинации в каждой паре (по одной из каждого множества) подбираются так, чтобы получить максимальную корреляцию между ними. Первая пара имеет самую высокую степень зависимости; вторая пара — следующую по величин не степень зависимости при условии, что ее составляющие не коррелируют с первой парой и т. д. Канонический коэффициент корреляции, конечно, является мерой зависимости и идентичен смешанному моменту корреляции Пирсона между двумя линейными комбинациями в паре. С помощью простого математического «фокуса» мы можем превратить дискриминантный анализ (по крайней мере, обсуждаемую часть его) в канонический корреляционный анализ. Очевидно, дискриминантные переменные образуют одно из «множеств». Тогда, если мы представим классы с помощью Другая интерпретация канонического коэффициента корреляции заимствована из дисперсионного анализа (Iversen и Norpoth, 1976, 30—32), где он известен под именами «эта» Независимо от того, какой подход выбран, каноническая корреляция помогает получить представление о реальной полезности дискриминантной функции. Большая величина коэффициента, как например, у функции 1 в табл. 9, указывает на сильную зависимость между классами и первой дискриминантной функцией. С другой стороны, коэффициент для функции 3 имеет довольно малую величину, которая говорит о слабой связи, что и предсказывалось относительным процентным содержанием этой функции. Анализируя данные табл. 9, не следует делать поспешного заключения о том, что первая дискриминантная функция будет всегда иметь большую каноническую корреляцию. Даже если функция 1 всегда «наиболее» значимая по сравнению с другими (судя по величине ее относительного процентного содержания), у нее может быть лишь слабая связь с классами (измеренная величиной канонической корреляции). По этой причине каноническая корреляция для нас более полезна, потому что она показывает насколько удачно выбрана дискриминантная функция. Если классы не очень хорошо различаются по исследуемым, переменным, то все корреляции будут иметь малые значения, поскольку нельзя найти различия там, где их нет. Оценивая и относительное процентное содержание, и канонические корреляции, можно довольно точно узнать, как много дискриминантных функций имеют реальный смысл, и какую пользу они принесут при определении различий между группами. Измерение остаточной дискриминации с помощью Л-статистики УилксаДо сих пор нас интересовало, сколько дискриминантных функций надо брать с точки зрения математических ограничений и их действительной значимости. В наших рассуждениях не учитывались выборочные свойства данных. Они равно справедливы как для генеральных данных (данных о генеральной совокупности), так и для различных видов отбора (выборок). Когда мы анализируем генеральные данные, то ответы на вопросы о числе функций и их значимости даются с помощью относительного процентного содержания и канонической корреляции. В пределах ошибок измерения эти статистики полностью описывают различия между группами и дискриминантными функциями. Когда же данные берутся из выборки (в противоположность данным, представляющим всю генеральную совокупность), то возникают дополнительные вопросы. Какова вероятность того, что данные о выборке покажут значительную степень различия, тогда как в генеральной совокупности различий между группами нет? Это вопрос статистической значимости, возникающей только в том случае, когда мы имеем дело с выборками. Действительно, ответить на вопрос о статистической значимости можно, если выборочный процесс имеет вероятностную основу. Для многих статистик тесты значимости применимы лишь к простым случайным выборкам ввиду сложности получения тестов для других видов выборок. Таким образом, мы будем рассматривать лишь простые случайные выборки. При использовании каких-либо других процедур отбора, лучше всего к интерпретации тестов подходить консервативно и уделять больше внимания реальной значимости результатов. Чаще всего статистическая значимость дискриминантных функций проверяется косвенным путем. Вместо проверки самой функции рассматривается остаточная дискриминантная способность системы до определения этой функции. Под «остаточной дискриминантной способностью» мы понимаем способность переменных различать классы, если исключить информацию, полученную с помощью ранее вычисленных функций. Если остаточная дискрими-, нация очень мала,
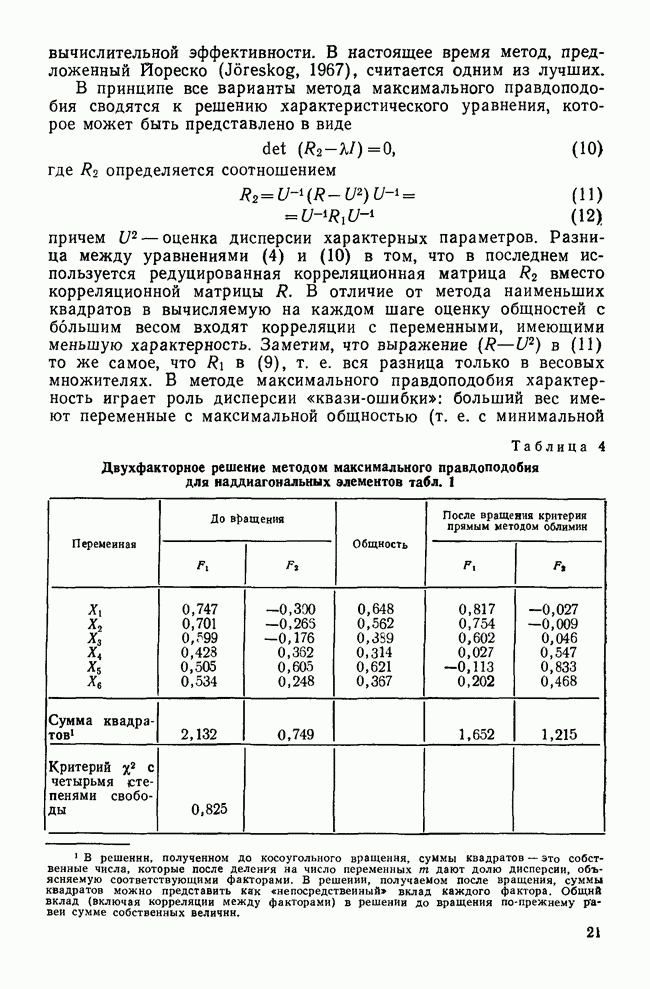
где k — число уже вычисленных функций, а символ П означает, что для получения окончательного результата необходимо перемножить все члены. Проиллюстрируем применение символа П. Сначала вычислим величину Л-статистики Уилкса, для данных о голосовании в сенате до вычисления всех дискриминантных функций. Предположим, что k = 0. Из табл. 9 мы получаем:
Поскольку Л является «обратной» мерой, этот результат означает, что шесть используемых переменных чрезвычайно эффективно участвуют в различении классов. Величины Л, близкие к нулю, говорят о высоком различении (т. е. центроиды классов хорошо разделены и сильно отличаются друг от друга по отношению к степени разброса внутри классов). Увеличение Очевидно, что позиции четырех групп сенаторов сильно различаются по выбранным переменным, так что имеет смысл найти дискриминантную функцию. После получения первой (и самой значимой) функции становится доступным большое количество информации, необходимой для различения групп. Теперь попытаемся ответить на вопрос: достаточен ли уровень остаточной дискриминантной способности для определения второй функции? Из табл. 10 видно, что Л-статистика Уилкса равна 0,3680 (для Таблица 10. Остаточная дискриминантная способность и проверка значимости
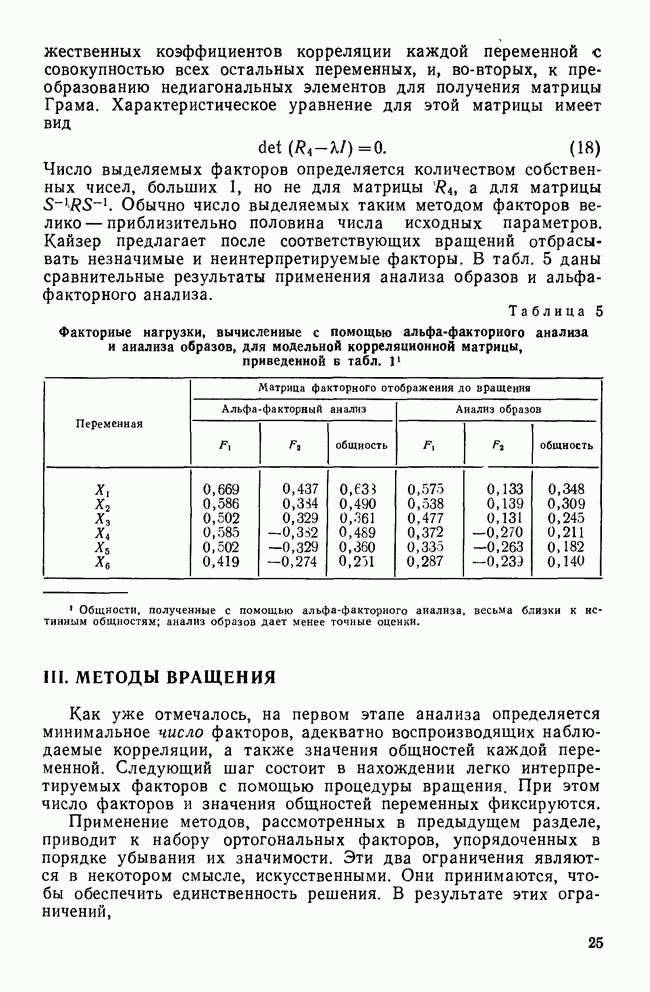
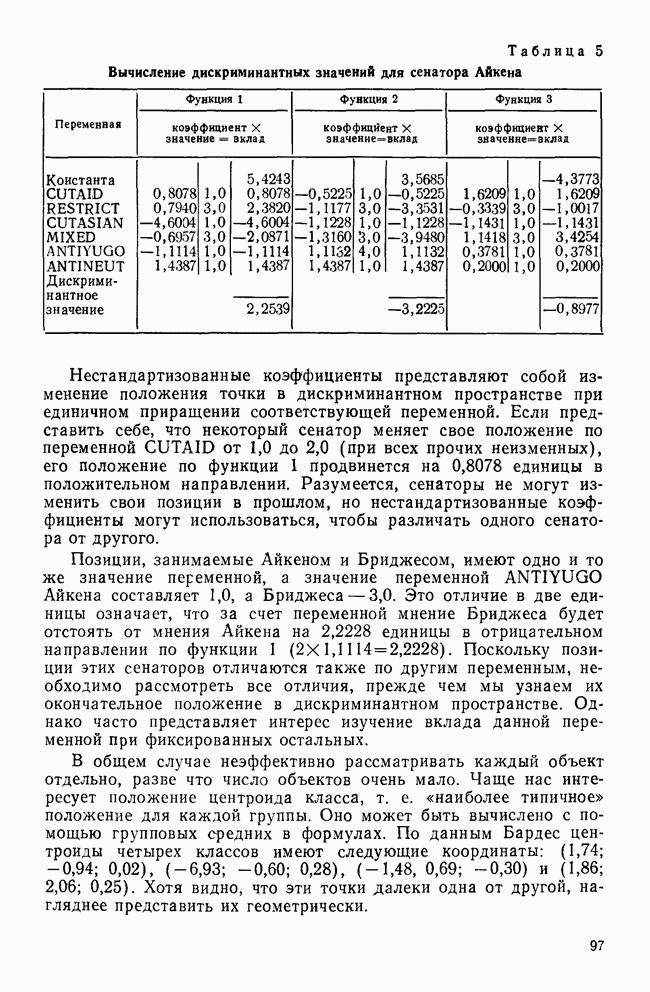
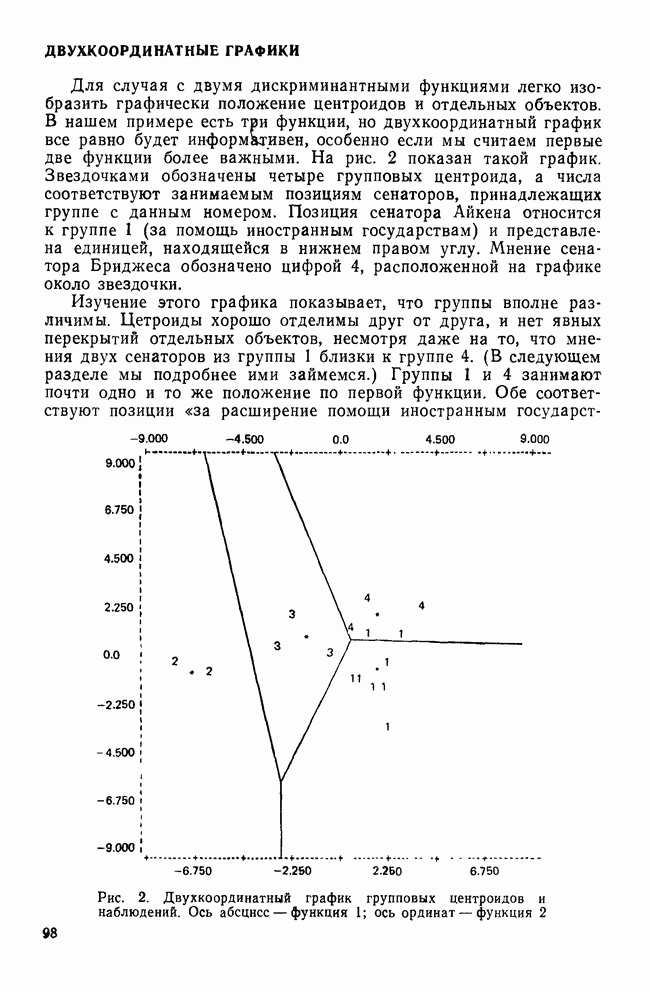
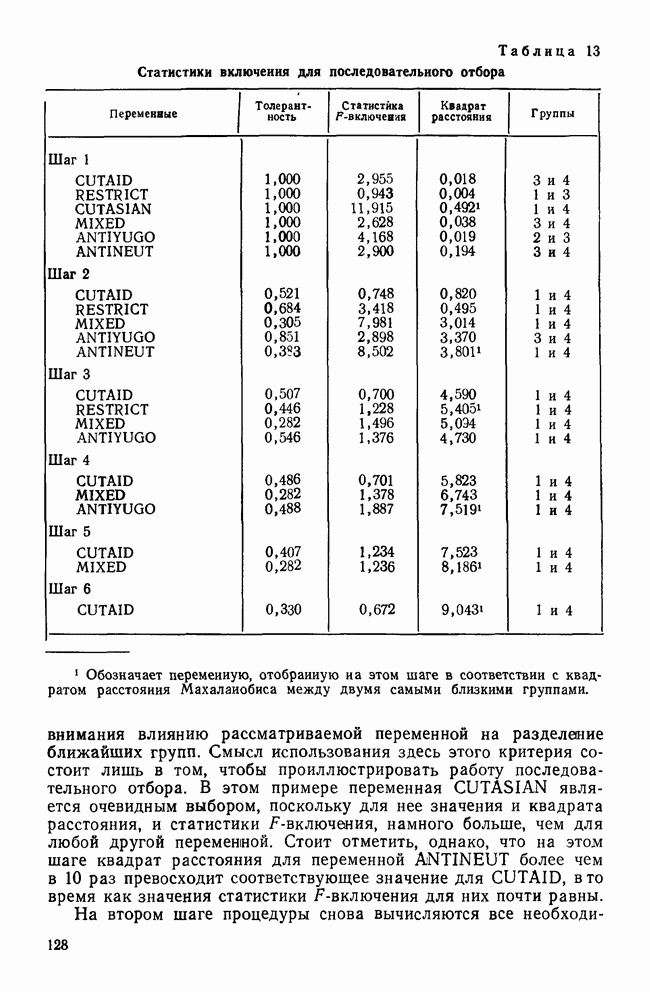
Мы пришли к такому же выводу, когда рассматривали относительное процентное содержание и канонические корреляции. Итак, остающиеся дискриминантные функции (в нашем случае только одна) либо не являются значимыми, либо они статистически недостоверны. Проверка значимости с помощью Л-статистики УилксаМы рассматривали На основе
то полученное распределение и будет хи-квадрат распределением с В табл. 10 приведены значения статистики хи-квадрат для данных примера о голосовании. Как мы и предвидели, между позициями групп есть значимые различия еще до вычисления какой-либо из дискриминантных функций Кроме того, это доказывает, что наша первая функция статистически значима. После определения первой функции, снова проверим значимость оставшихся различий. Как и следовало ожидать, значение статистики хи-квадрат стало меньше, а уровень значимости стал равным Но если бы вместо этого была установлена значимость остаточной дискриминантной способности, то мы приступили бы к определению второй функции. Затем проверка значимости для новой остаточной дискриминантной способности была бы повторена В рассматриваемом примере число статистически значимых функций меньше того, которое допускается математикой. Однако так бывает не всегда. Во многих ситуациях остаточная дискриминантная способность для Здесь мы рассмотрели все то, что обычно делает исследователь, но для лучшего усвоения — в обратном порядке. Логически исследователь должен начать с вопроса: «Какая из моих функций является статистически и реально значимой?» Нет необходимости продолжать анализ любой функции, исключенной из рассмотрения. Для выбранных функций исследователь должен сочетать рассмотрение структурных коэффициентов с определением положений центроидов классов, чтобы выявить значение каждой функции. Структурные коэффициенты дают, кроме того, информацию о том, как каждая из переменных участвует в различении классов в этой системе координат. В некоторых исследованиях работа аналитика заканчивается вместе с окончанием интерпретации канонических дискриминантных функций. Более вероятно, исследователь продолжит классификацию объектов — либо для практических, либо для аналитических целей, что и является темой следующего раздела.
|
 |
Оглавление
|


































































































































































































 меньше
меньше  мы получаем
мы получаем  решений, которые имеют нулевые собственные значения. По этой причине максимальное число канонических дискриминантных функций q меньше любого из чисел
решений, которые имеют нулевые собственные значения. По этой причине максимальное число канонических дискриминантных функций q меньше любого из чисел  . Возвращаясь к примеру о голосовании в сенате, имеем
. Возвращаясь к примеру о голосовании в сенате, имеем  , так что
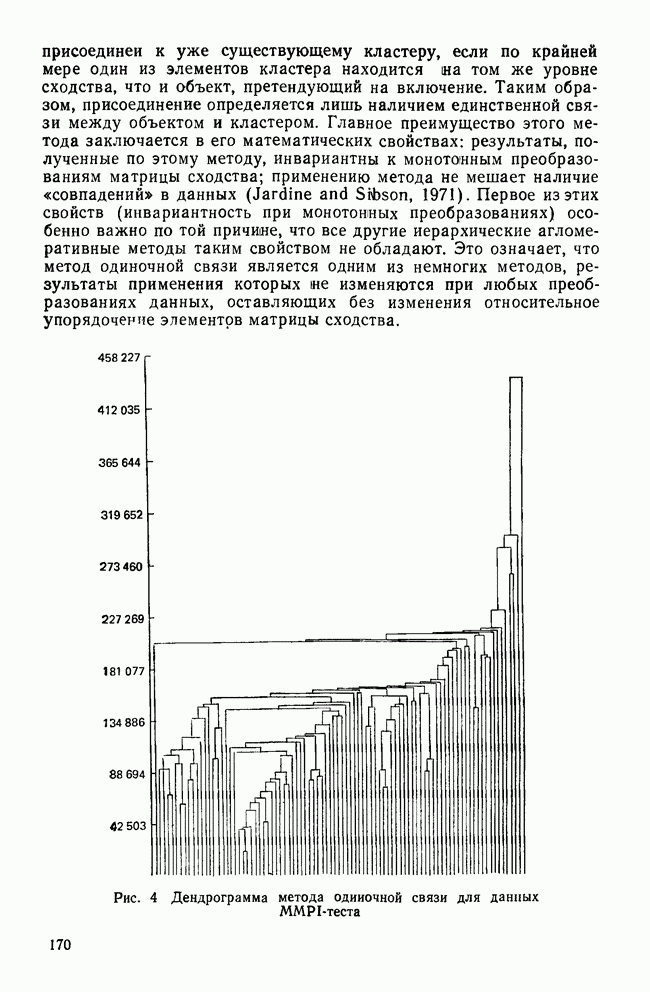
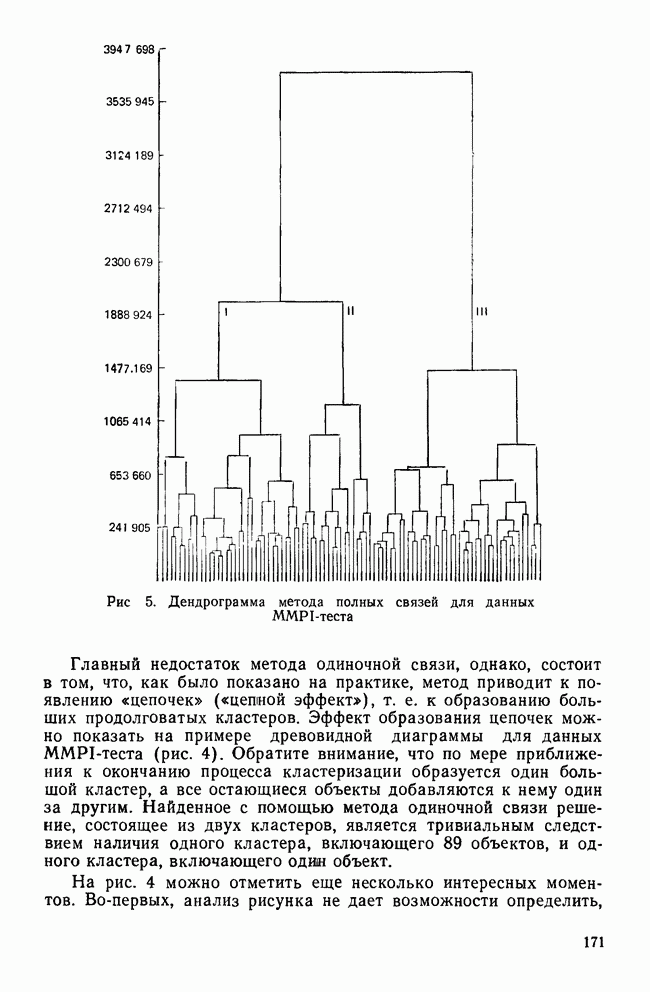
, так что  . Среди этих q возможных решений мы все еще можем найти собственные значения, равные нулю. Это бывает в тех вырожденных случаях, когда один или несколько центроидов совпадают в пространстве, определенном другими центроидами. Более типичен случай не полного совпадения из-за ошибок выборки или ошибок измерения. Скорее всего, такое собственное значение функции будет малой величиной. Вопрос в следующем: как мала должна быть величина собственного значения лямбда, чтобы мы рассматривали ее как результат ошибки выборки или измерения, а не результат измерения величины, действительно отличной от нуля? Это вопрос о статистической значимости. Но даже если функция статистически значима, мы можем решить, что она не имеет самостоятельного значения, поскольку с ее помощью недостаточно хорошо различаются группы.
. Среди этих q возможных решений мы все еще можем найти собственные значения, равные нулю. Это бывает в тех вырожденных случаях, когда один или несколько центроидов совпадают в пространстве, определенном другими центроидами. Более типичен случай не полного совпадения из-за ошибок выборки или ошибок измерения. Скорее всего, такое собственное значение функции будет малой величиной. Вопрос в следующем: как мала должна быть величина собственного значения лямбда, чтобы мы рассматривали ее как результат ошибки выборки или измерения, а не результат измерения величины, действительно отличной от нуля? Это вопрос о статистической значимости. Но даже если функция статистически значима, мы можем решить, что она не имеет самостоятельного значения, поскольку с ее помощью недостаточно хорошо различаются группы.

 связана с собственным значением следующей формулой:
связана с собственным значением следующей формулой: 

 дихотомических переменных (известных так же, как «бинарные переменные» или «фиктивные переменные»), то получим другое «множество». Из них мы образуем q пар линейных комбинаций. В этом случае канонические коэффициенты корреляции можно интерпретировать в соответствии с приведенным выше определением как меру зависимости двух множеств переменных, найденную с помощью линейных комбинаций. Такой подход дает повод некоторым статистикам называть каноническую дискриминантную функцию «канонической переменной».
дихотомических переменных (известных так же, как «бинарные переменные» или «фиктивные переменные»), то получим другое «множество». Из них мы образуем q пар линейных комбинаций. В этом случае канонические коэффициенты корреляции можно интерпретировать в соответствии с приведенным выше определением как меру зависимости двух множеств переменных, найденную с помощью линейных комбинаций. Такой подход дает повод некоторым статистикам называть каноническую дискриминантную функцию «канонической переменной».
 и «корреляционное отношение». Здесь классы рассматриваются как независимые переменные, которые влияют на величину дискриминантной функции, являющейся зависимой переменной. Коэффициент
и «корреляционное отношение». Здесь классы рассматриваются как независимые переменные, которые влияют на величину дискриминантной функции, являющейся зависимой переменной. Коэффициент  измеряет степень различия средних значений дискриминантной функции для разных групп. Можно облегчить интуитивное понимание коэффициента
измеряет степень различия средних значений дискриминантной функции для разных групп. Можно облегчить интуитивное понимание коэффициента  если возвести его в квадрат. Коэффициент
если возвести его в квадрат. Коэффициент  (т. е. каноническая корреляция в квадрате) является долей дисперсии дискриминантной функции, которая объясняется разбиением на классы.
(т. е. каноническая корреляция в квадрате) является долей дисперсии дискриминантной функции, которая объясняется разбиением на классы.
 нет смысла продолжать вычисление очередных функций, даже если математически это возможно. Чтобы лучше усвоить это понятие, рассмотрим «Л-статистику Уилкса», используемую для измерения дискриминации (так называемую
нет смысла продолжать вычисление очередных функций, даже если математически это возможно. Чтобы лучше усвоить это понятие, рассмотрим «Л-статистику Уилкса», используемую для измерения дискриминации (так называемую  -статистику). Л-статистика Уилкса — это мера различий между классами по нескольким переменным (дискриминантным переменным). Хотя существует несколько способов ее вычисления, мы воспользуемся следующей формулой:
-статистику). Л-статистика Уилкса — это мера различий между классами по нескольким переменным (дискриминантным переменным). Хотя существует несколько способов ее вычисления, мы воспользуемся следующей формулой:


 до ее максимального значения, равного 1, приводит к постепенному ухудшению различения, так как центроиды групп совпадают (нет групповых различий).
до ее максимального значения, равного 1, приводит к постепенному ухудшению различения, так как центроиды групп совпадают (нет групповых различий).
 ), т. е. все еще мала. Вычисление второй функции уменьшает количество оставшейся информации, и величина Л становится равной 0,9492 (для
), т. е. все еще мала. Вычисление второй функции уменьшает количество оставшейся информации, и величина Л становится равной 0,9492 (для  ). Это значение (довольно высокое) говорит о том, что оставшуюся информацию о различиях классов уже не стоит искать.
). Это значение (довольно высокое) говорит о том, что оставшуюся информацию о различиях классов уже не стоит искать.

 -статистику Уилкса как еще одну меру зависимости, но то, что она принимает значения, обратные привычным, и оценивает остаточную дискриминантную способность, делает ее менее полезной, чем относительное процентное содержание и каноническая корреляция. Однако Л-статистика может быть превращена в тест значимости. Таким образом, мы будем использовать ее скорее как вспомогательную статистику, а не как искомый конечный продукт.
-статистику Уилкса как еще одну меру зависимости, но то, что она принимает значения, обратные привычным, и оценивает остаточную дискриминантную способность, делает ее менее полезной, чем относительное процентное содержание и каноническая корреляция. Однако Л-статистика может быть превращена в тест значимости. Таким образом, мы будем использовать ее скорее как вспомогательную статистику, а не как искомый конечный продукт.
 -статистики Уилкса можно получить тест значимости, аппроксимируя распределение некоторой функции от нее либо распределением хи-квадрат
-статистики Уилкса можно получить тест значимости, аппроксимируя распределение некоторой функции от нее либо распределением хи-квадрат  либо
либо  -распределением. В дальнейшем можно пользоваться стандартными таблицами для этих распределений, чтобы определить уровень значимости, а некоторые компьютерные программы позволяют распечатать его точные значения. Если воспользоваться формулой
-распределением. В дальнейшем можно пользоваться стандартными таблицами для этих распределений, чтобы определить уровень значимости, а некоторые компьютерные программы позволяют распечатать его точные значения. Если воспользоваться формулой

 степенями свободы.
степенями свободы.
 Уровень значимости 0,001 показывает, что если в действительности между центроидами нет различий, то такое или большее значение статистики хи-квадрат мы получим только в одной из тысячи выборок (имеются в виду независимые, простые случайные выборки). Отбрасывая это невероятное событие, мы можем уверенно считать, что результаты получены из генеральной совокупности с различиями между группами.
Уровень значимости 0,001 показывает, что если в действительности между центроидами нет различий, то такое или большее значение статистики хи-квадрат мы получим только в одной из тысячи выборок (имеются в виду независимые, простые случайные выборки). Отбрасывая это невероятное событие, мы можем уверенно считать, что результаты получены из генеральной совокупности с различиями между группами.
 Большинство исследователей будут считать этот результат незначимым, поэтому определять вторую и третью функции не следует, полагая таким образом, что вся значимая информация о различиях групп уже извлечена. Другими словами, одного-единственного измерения достаточно для представления всех замеченных различий между группами. Второе измерение (которое вместе с первым образует плоскость) не добавит никаких существенных различий.
Большинство исследователей будут считать этот результат незначимым, поэтому определять вторую и третью функции не следует, полагая таким образом, что вся значимая информация о различиях групп уже извлечена. Другими словами, одного-единственного измерения достаточно для представления всех замеченных различий между группами. Второе измерение (которое вместе с первым образует плоскость) не добавит никаких существенных различий.
 . В нашем примере уровень значимости так велик (0,954), что никто не посчитал бы оставшиеся различия значимыми. Следовательно, нет абсолютно никакой необходимости вычислять третью функцию, так как она вряд ли что-либо добавит к объяснению различий между группами. Найденный результат помогает понять, почему у нас было так много трудностей при интерпретации структурных коэффициентов функции 3 и почему не было обнаружено больших различий между центроидами групп по этой функции.
. В нашем примере уровень значимости так велик (0,954), что никто не посчитал бы оставшиеся различия значимыми. Следовательно, нет абсолютно никакой необходимости вычислять третью функцию, так как она вряд ли что-либо добавит к объяснению различий между группами. Найденный результат помогает понять, почему у нас было так много трудностей при интерпретации структурных коэффициентов функции 3 и почему не было обнаружено больших различий между центроидами групп по этой функции.
 оказывается значимой. В таком случае нужно вычислить все возможные функции (вплоть до
оказывается значимой. В таком случае нужно вычислить все возможные функции (вплоть до  ), если, конечно, нет других причин не делать этого (таких, например, как низкая каноническая корреляция). Примем разумное решение — продолжить определение функций до тех пор, пока остаточная дискриминантная способность перестанет быть значимой. Таким образом, мы можем быть уверены в том, что полученные функции являются статистически значимыми в целом как система. Это не доказывает значимость какой-либо одной функции (если, конечно, она не была получена специально), а скорее дает значимость всех полученных функций. А поскольку мы используем функции как систему и наша цель — привести информацию, необходимую для разделения, к наименьшему числу размерностей, то этого вполне достаточно. Единственная реальная проблема, которая может быстро уничтожить любой исследовательский проект, возникает, если общее количество информации является незначимым, т. е. при
), если, конечно, нет других причин не делать этого (таких, например, как низкая каноническая корреляция). Примем разумное решение — продолжить определение функций до тех пор, пока остаточная дискриминантная способность перестанет быть значимой. Таким образом, мы можем быть уверены в том, что полученные функции являются статистически значимыми в целом как система. Это не доказывает значимость какой-либо одной функции (если, конечно, она не была получена специально), а скорее дает значимость всех полученных функций. А поскольку мы используем функции как систему и наша цель — привести информацию, необходимую для разделения, к наименьшему числу размерностей, то этого вполне достаточно. Единственная реальная проблема, которая может быстро уничтожить любой исследовательский проект, возникает, если общее количество информации является незначимым, т. е. при  (если только не нужно показать, что между классами нет различий).
(если только не нужно показать, что между классами нет различий).