Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
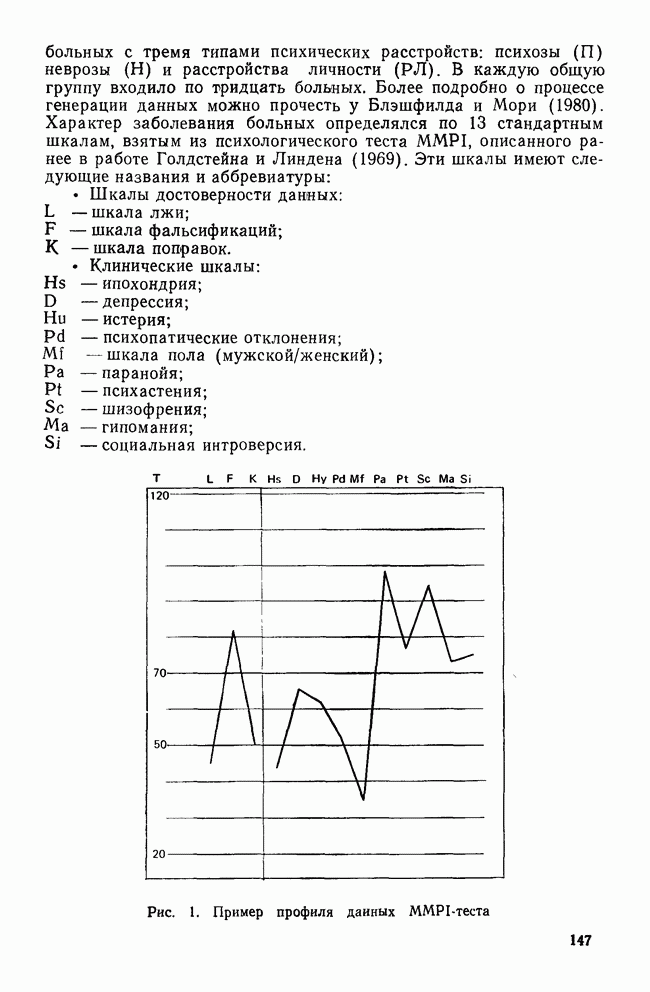
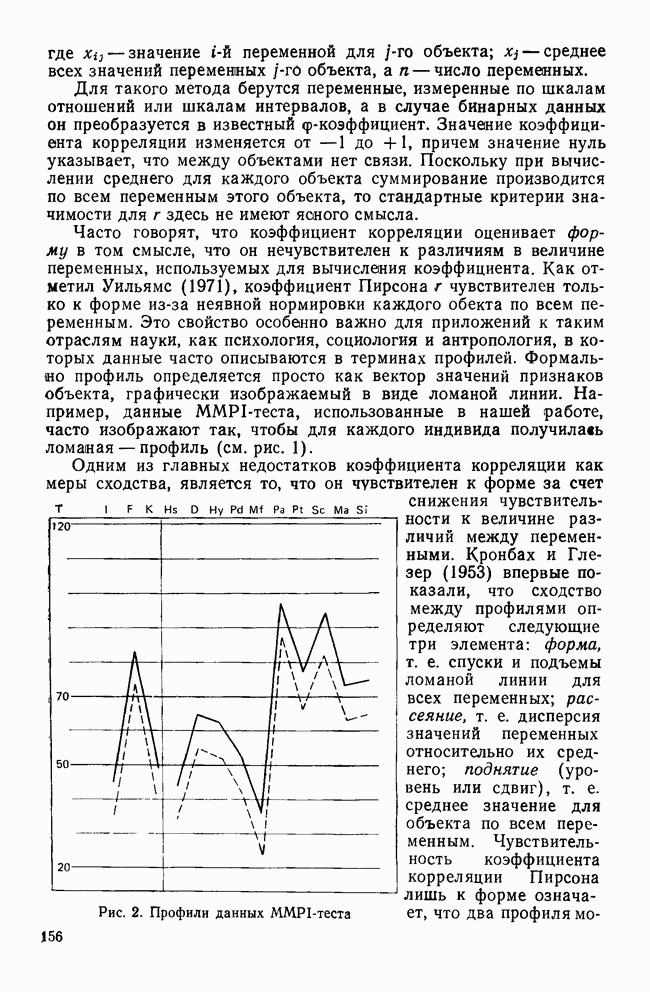
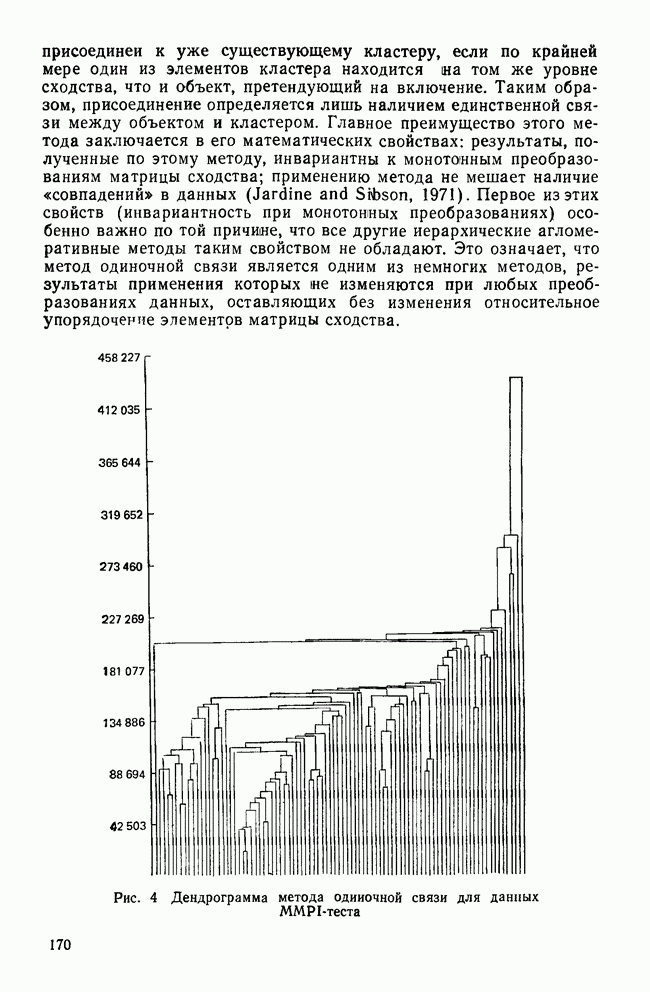
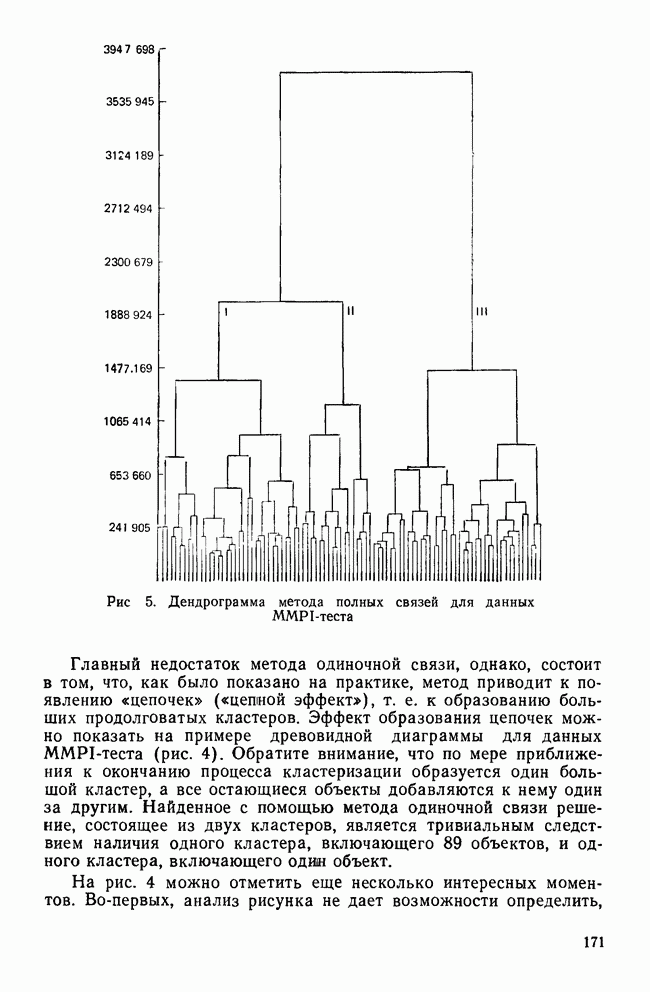
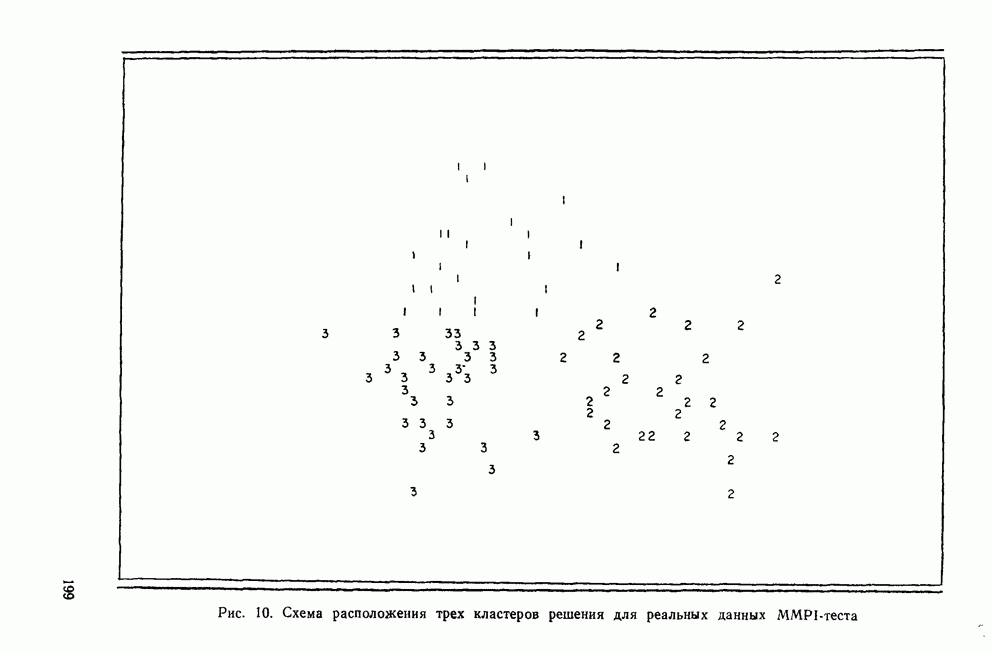
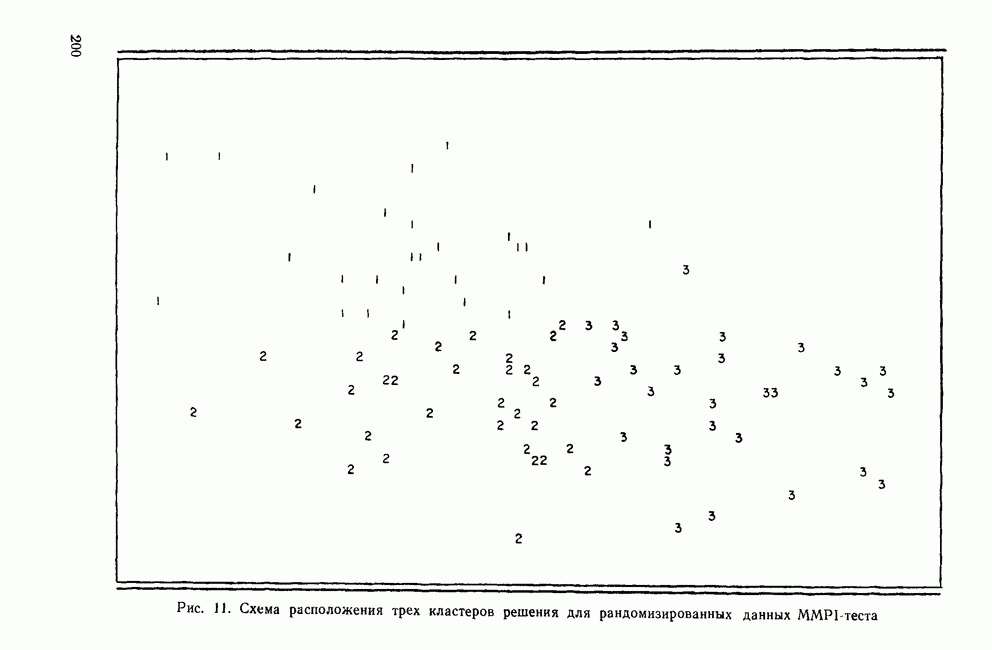
ДРУГИЕ МЕТОДЫИерархические дивизимные методы являются логической противоположностью агломеративным методам. В начале процедуры (при Монотетические дивизимные методы применяют в первую очередь к бинарным данным, а процедура деления совокупности объектов на подгруппы основана на определении признака, максимизирующего несходство между кластерами, получающимися в результате. Часто дивизимные критерии основаны на использовании статистики Методы поиска модальных значений плотности рассматривают кластер как область пространства с «высокой» плотностью точек по сравнению с окружающими областями. Они «обследуют» пространство в поисках скоплений в данных, которые и представляют собой области высокой плотности. Существуют два основных вида методов поиска модальных значений плотности: методы, основанные на кластеризации по одиночной связи, и методы разделения «смесей» многомерных вероятностных распределений. Как отметил Эверитт (1980), методы поиска модальных значений плотности, основанные на кластеризации по одиночной связи, препятствуют образованию цепочек. В отличие от метода одиночной связи методы поиска модальных значений плотности подчинены строгому правилу, согласно которому предпочтение отдается образованию нового кластера, а не присоединению очередного объекта к уже существующей группе. Обычно это правило основано на измерении расстояния между существующим кластером и новым объектом или кластером (Wishart, 1969) или же на измерении среднего сходства, как в методе ТАХМАР, предложенном Кармайклом и Снитом (1969). Если правило не выполняется, объединение объектов и кластеров не производится. Из этих методов широкое распространение получил модальный анализ, впервые предложенный Уишартом (1969) и позднее встроенный в пакет Другая основная группа методов поиска модальных значений плотности — методы по определению параметров смеси распределений. Смесь определяется как совокупность выборок, представляющих различные популяции объектов. Например, множество данных MMPI-теста является смесью потому, что оно содержит выборки из трех популяций: больных неврозами, психозами и расстройствами личности. Этот подход к кластерному анализу явно основан на статистической модели, в которой элементы разных групп или классов должны иметь различные вероятностные распределения признаков. Цель кластеризации данных состоит в определении параметров, описывающих распределения для популяций. Важные частные случаи разделения смесей реализованы в процедурах NORM1X и NORMAP, разработанных Вульфом (1970, 1971). Процедура NORM1X получает оценки максимального правдоподобия для параметров многомерных смесей нормальных распределений. Настоящий метод предполагает, что основные популяции различаются средними и ковариационными структурами Процедура NORMAP построена на более простом предположении, что структуры внутригрупповых ковариаций одинаковы. Уникальность обеих процедур NORMIX и NORMAP состоит в том, что они не распределяют объекты по кластерам, а вместо этого дают вероятность принадлежности каждого объекта к каждому из кластеров. Например, в случае перекрывающихся кластеров вероятность того, что объект принадлежит обоим кластерам, равна 0,5 (Wishart, 1982). Методы поиска модальных значений плотности особенно чувствительны к проблеме субоптимальных решений (Everitt, 1980), поскольку уравнение максимального правдоподобия в общем случае может иметь несколько решений. Хотя в принципе можно сравнить оценки для различных неоптимальных решений, однако это нелегко сделать (или вовсе невозможно) даже для небольших задач. Другой недостаток данных методов в том, что все компоненты смеси являются многомерными нормальными распределениями. Очевидно, возможны и другие виды распределений, но неясно, насколько устойчивы к нарушению предположения о нормальности. Методы сгущения уникальны в том смысле, что они позволяют создавать перекрывающиеся кластеры. В отличие от иерархических методов, это семейство кластерных методов не порождает иерархические классификации; объектам разрешается быть членами нескольких кластеров. Многие ранние разработки методов сгущения относятся к лингвистическим исследованиям, поскольку именно там важно учитывать, что некоторые слова имеют различные значения. Методы сгущения требуют вычисления матрицы сходства между объектами и определения оптимального значения статистического критерия, называемого специалистами «функцией когезии» («функция сцепления»). Затем объекты перемещаются до тех пор, пока функция не достигнет оптимального значения. Поскольку эти методы одновременно создают лишь две группы, то обычно первичные данные случайным образом разделяются на несколько начальных конфигураций, каждая из которых в дальнейшем может быть рассмотрена с точки зрения пригодности. Серьезный недостаток рассматриваемых методов состоит в том, что из-за неудачной поисковой процедуры время от времени происходит повторное обнаружение одних и тех же групп, а это не дает новой информации. Другим практическим недостатком является то, что их характеристики малоизвестны, так как эти методы не имеют широкого распространения. Джардайн и Сибсон (1968) предложили метод сгущения, основанный на теории графов, который, хотя и лишен серьезного недостатка повторного обнаружения групп, все же ограничен анализом лишь очень малых групп По многим причинам методы теории графов оказались среди новых методов, доступных исследователю. Значительный интерес для теоретиков (а также для пользователей) представляет то, что кластерные методы этого семейства основаны на хорошо разработанных теоремах и аксиомах теории графов. А поскольку из теорем теории графов вытекает большое количество полезных следствий, то возможно, что эта теория станет альтернативой преимущественно эвристическому характеру других кластерных методов. Например, иерархические агломеративные методы могут быть сжато описаны в терминах теории графов (Dubes and Jain, 1980). Теория графов ведет также к созданию нуль-гипотезы, которая может быть использована при проверке наличия кластеров в матрице сходства. Она известна как «гипотеза случайного графа», утверждающая, что все ранжированные матрицы близости являются равновероятными (Ling, 1975). Кроме того, теория графов применяется при разработке более эффективных вычислительных алгоритмов для известных методов кластеризации и в некоторых случаях позволяет сделать число анализируемых объектов довольно большим.
|
 |
Оглавление
|











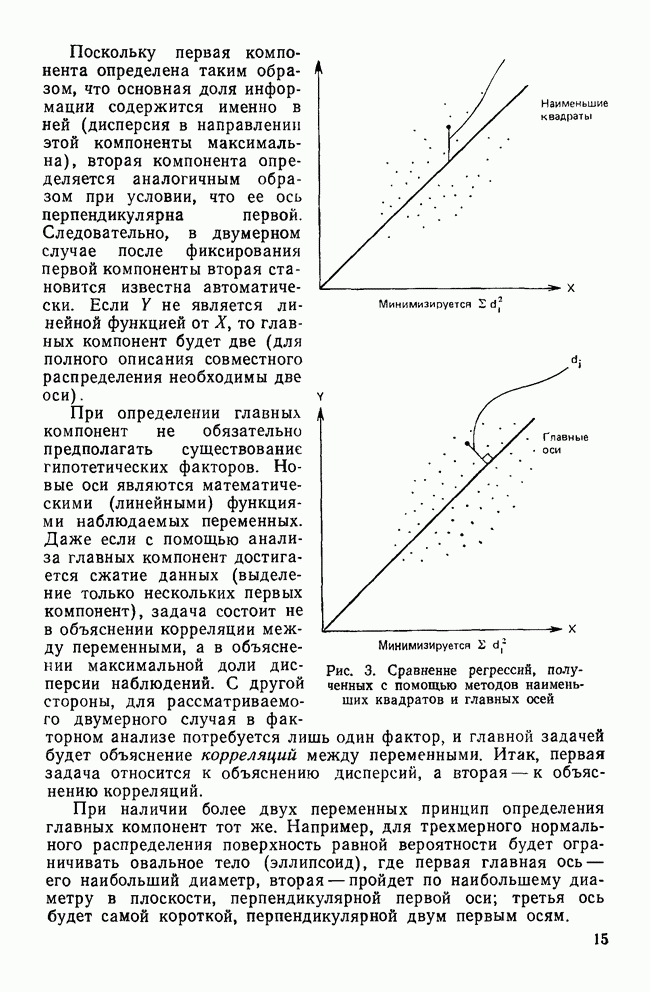





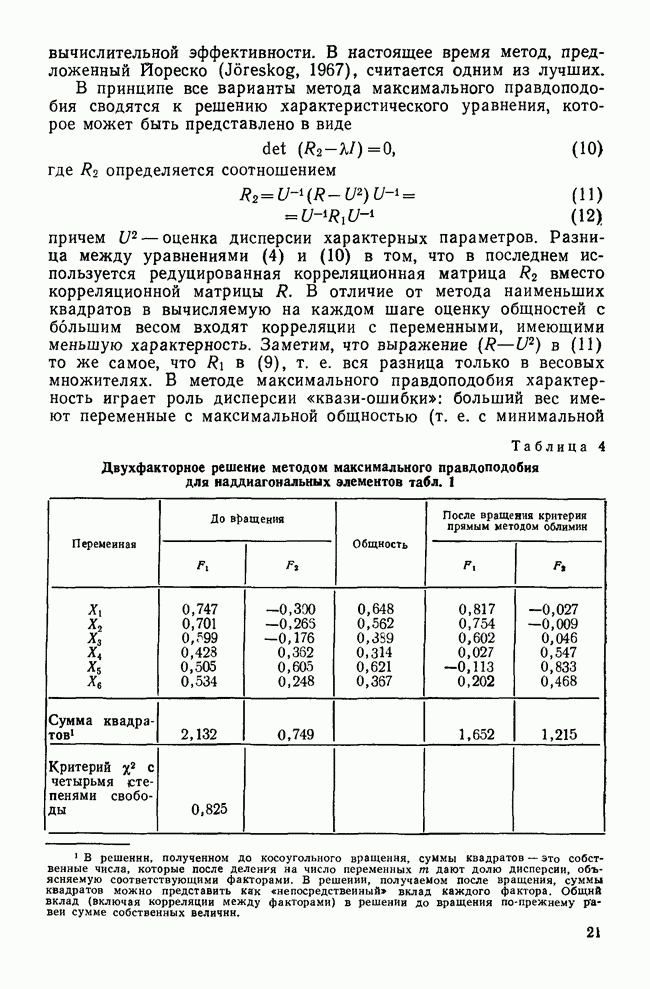



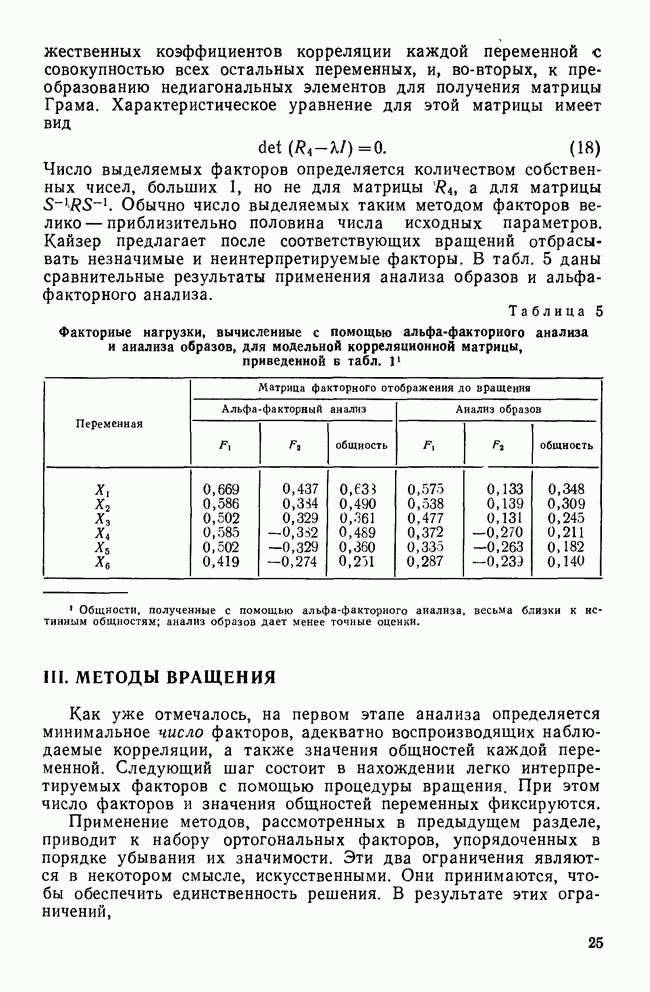



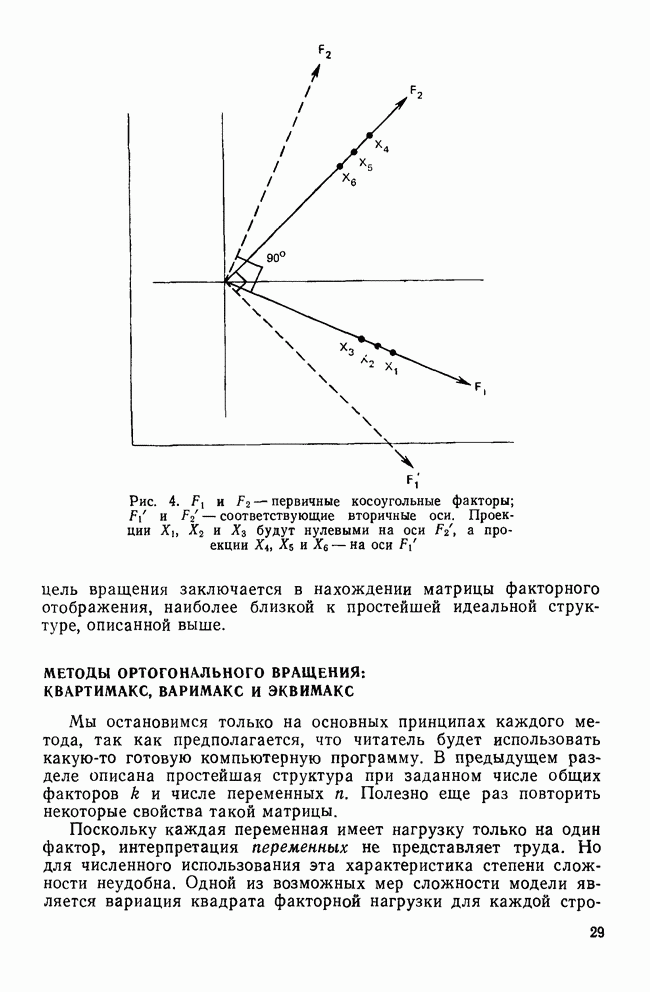







































































































































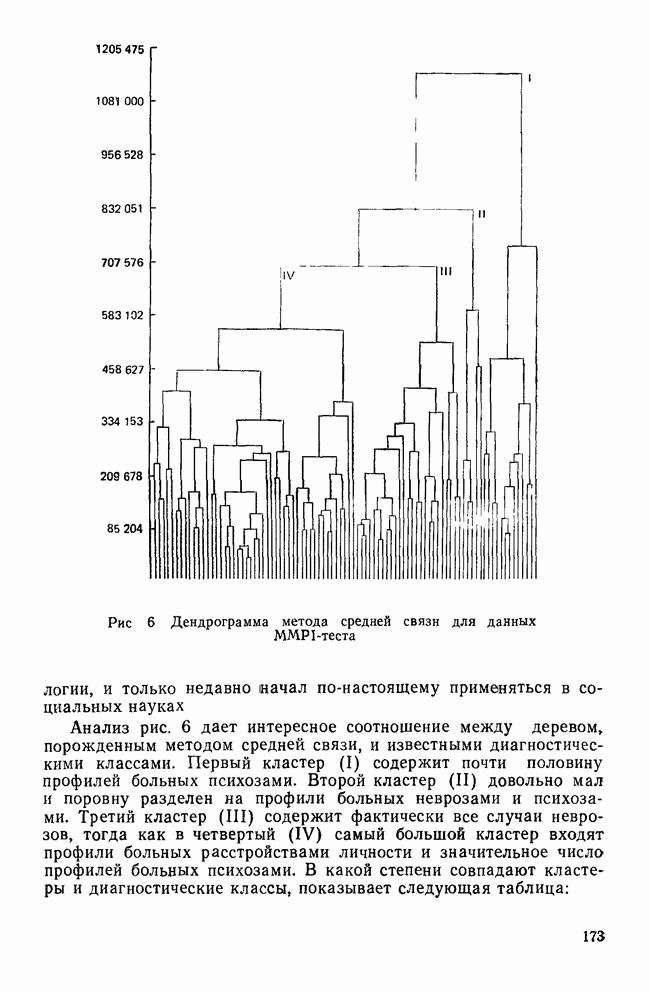
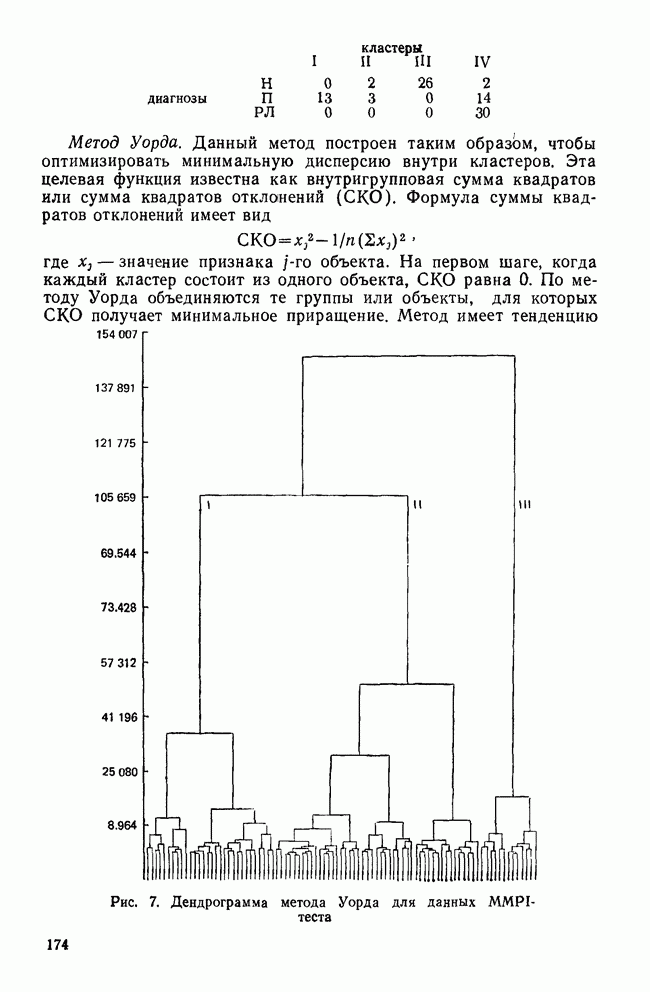










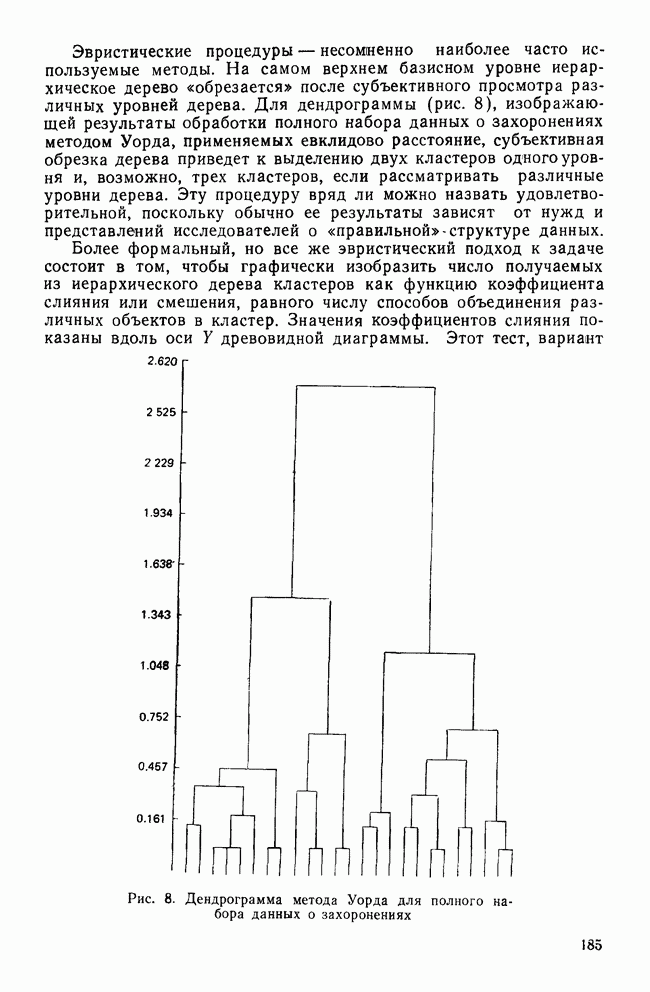
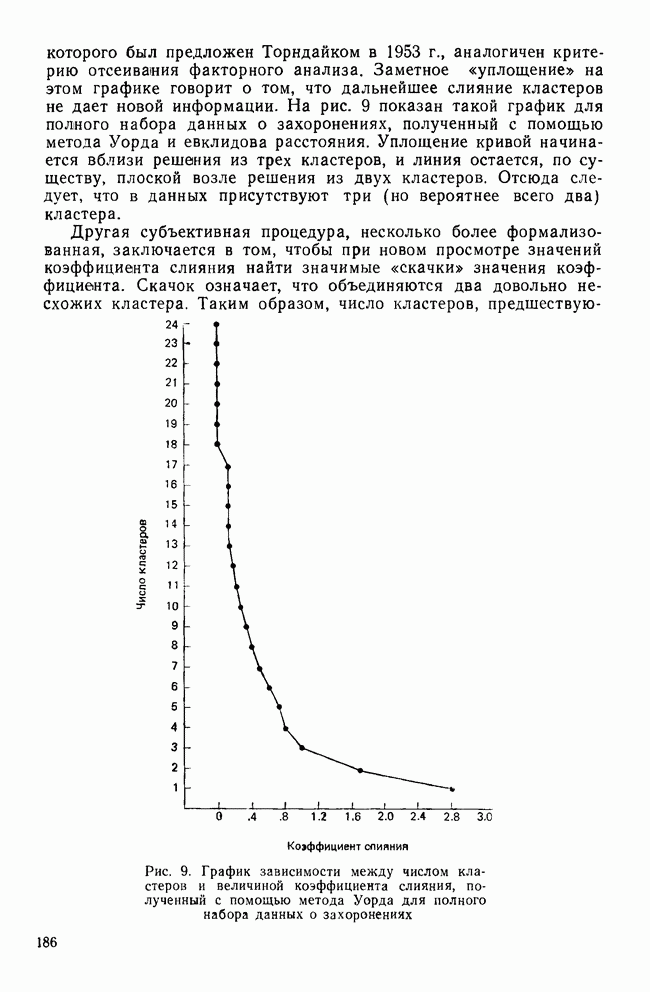



























 все объекты принадлежат одному кластеру, а затем этот всеобъемлющий кластер разрезается на последовательно уменьшающиеся «ломтики». Есть два дивизимных вида: монотетический и политетический. Монотетический кластер — это группа, все объекты которой имеют приблизительно одно и то же значение некоторого конкретного признака. Таким образом, монотетические кластеры определяются фиксированными признаками, определенные значения которых необходимы для принадлежности к кластерам. В противоположность этому политетические кластеры являются группами объектов, для принадлежности к которым достаточно наличия определенных сочетаний из некоторого подмножества признаков. Все три метода — иерархические, агломеративные и итеративные — будут образовывать только политетические кластеры.
все объекты принадлежат одному кластеру, а затем этот всеобъемлющий кластер разрезается на последовательно уменьшающиеся «ломтики». Есть два дивизимных вида: монотетический и политетический. Монотетический кластер — это группа, все объекты которой имеют приблизительно одно и то же значение некоторого конкретного признака. Таким образом, монотетические кластеры определяются фиксированными признаками, определенные значения которых необходимы для принадлежности к кластерам. В противоположность этому политетические кластеры являются группами объектов, для принадлежности к которым достаточно наличия определенных сочетаний из некоторого подмножества признаков. Все три метода — иерархические, агломеративные и итеративные — будут образовывать только политетические кластеры.
 или некоторых информационных статистик (Clifford and Stephenson, 1975; Everitt, 1980). Монотетический подход к дивизимной кластеризации, известный также как ассоциативный анализ, широко распространен в экологии, но применение этого метода в социальных науках ограничено археологией (Peebles, 1972; Whallon, 1971; 1972).
или некоторых информационных статистик (Clifford and Stephenson, 1975; Everitt, 1980). Монотетический подход к дивизимной кластеризации, известный также как ассоциативный анализ, широко распространен в экологии, но применение этого метода в социальных науках ограничено археологией (Peebles, 1972; Whallon, 1971; 1972).
 программ по кластерному анализу CLUSTAN (Wishart, 1982). Несмотря на привлекательность, этот метод обладает некоторыми недостатками, из которых наиболее важным является его зависимость от выбора шкал измерений. Кроме того, предполагается, что искомые в пространстве кластеры имеют сферическую форму.
программ по кластерному анализу CLUSTAN (Wishart, 1982). Несмотря на привлекательность, этот метод обладает некоторыми недостатками, из которых наиболее важным является его зависимость от выбора шкал измерений. Кроме того, предполагается, что искомые в пространстве кластеры имеют сферическую форму.
 , что обусловленно чрезвычайной вычислительной трудоемкостью (см. также Cole and Wishart, 1970).
, что обусловленно чрезвычайной вычислительной трудоемкостью (см. также Cole and Wishart, 1970).