Пред.
След.
Макеты страниц
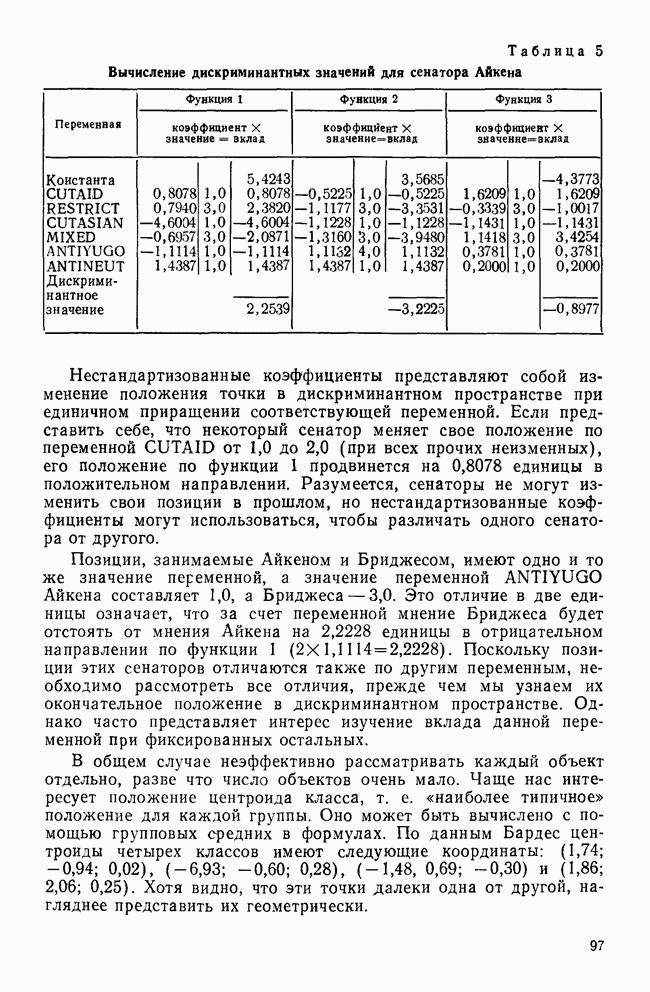
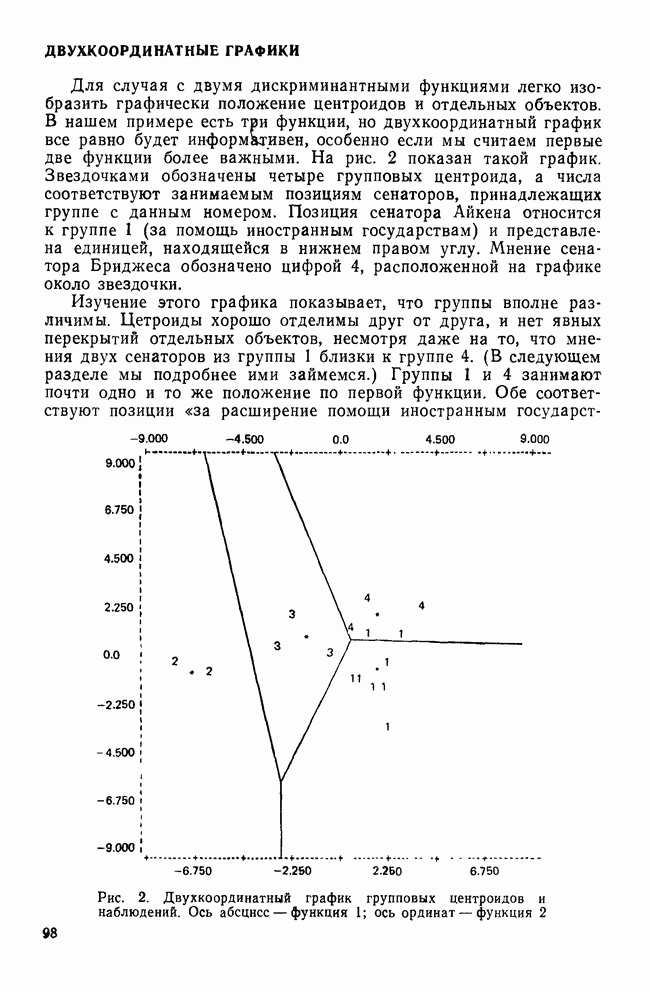
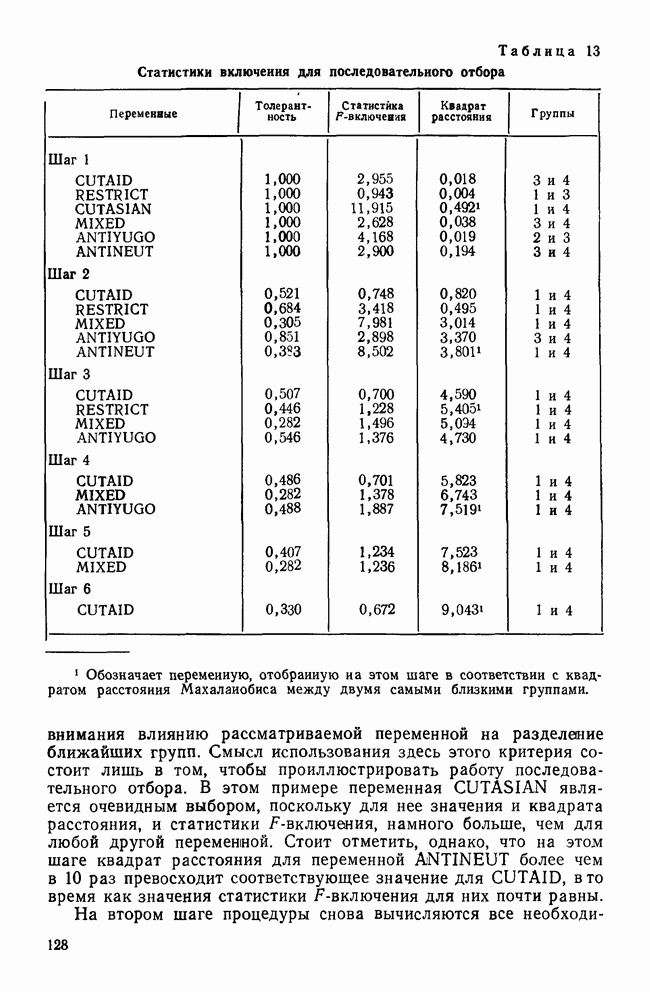
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
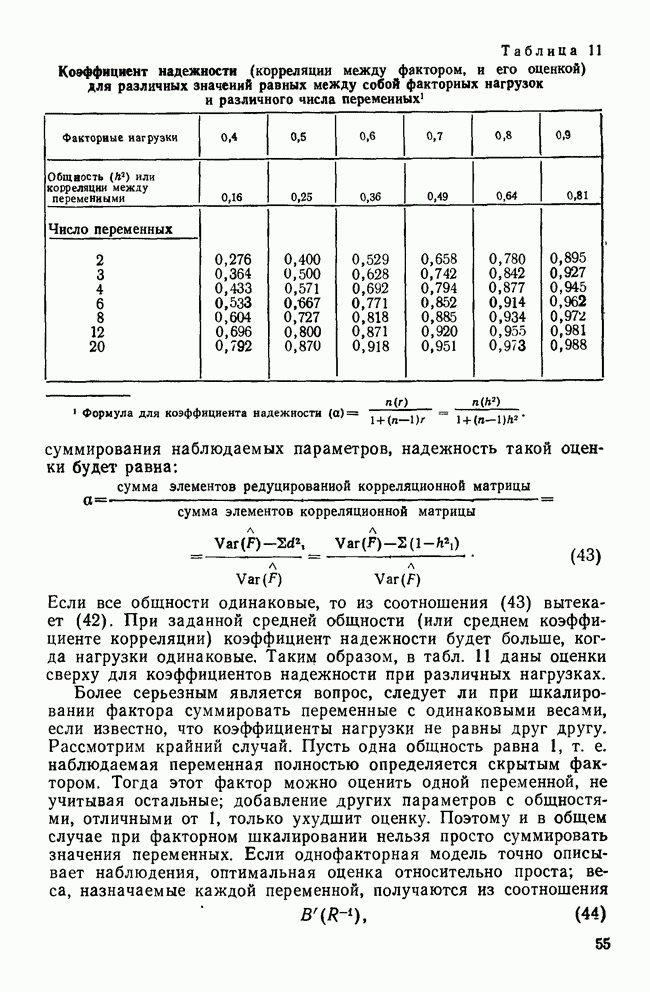
ПРИМЕЧАНИЯ1. В работах (Stevens, 1946; 1951) даны определения четырех шкал измерений, принятых в статистике: наименований, порядковая, интервальная и отношений. Для интервальных измерений характерно то, что истинная разность последовательных единиц шкалы равна разности двух любых последовательных целых единиц этой шкалы. Вообще говоря, измерения по интервальной шкале соответствуют непрерывному случаю, но это ограничение совершенно не обязательно. В дискриминантном анализе требуется вычисление средних вариаций и ковариаций, поэтому измерения должны производиться на интервальном уровне. Дальнейшие сведения о шкалах измерений можно найти в работах (Blalock, 1979; Nie, 1975) и в любом вводном статистическом курсе. 2. Коварнация двух переменных является мерой их совместного изменения. Ковариация аналогична коэффициенту корреляции, но без приведения к стандартизованному виду при различных масштабах в измеряемых переменных. Соответственно ковариация может принимать любые значения и не ограничена константами —1 снизу и +1 сверху. Часто ковариации представляются в виде матриц. Каждой переменной в матрице соответствует одна строка и один столбец. На пересечении данной строки и данного столбца находится ковариация двух переменных. На главной диагонали находятся вариации. Если данные разделены на группы, можно вычислить ковариационную матрицу для каждой группы в отдельности, используя наблюдения, принадлежащие только данной группе. Для того чтобы две ковариационные матрицы были равны, должны быть равны все соответствующие нм элементы. Понятия вариации и ковариации даются во всех вводных статистических курсах, например (Blalock, 1979). 3. Большинство представленных здесь таблиц заимствовано из работы (Bardes, 1975). Везде, где это было необходимо, мы сами обработали экспериментальные данные, которые были любезно предоставлены нам Бардес. Численные значения, приведенные в работе Бардес для коэффициентов, центроидов и дискриминантных значений, не совпадают с представленными в данной работе из-за отличия способов стандартизации дискриминантных функций. Однако это не влияет на результаты интерпретации и классификации. Была использована компьютерная программа SPSS DISCRIMINANT, реализованная на ЭВМ типа IBM 360/370. 4. Можно выполнить анализ вариаций по каждой переменной в отдельности для того, чтобы выявить статистическую значимость межгрупповых отличий (см. работу Inversen, Norpoth, 1976). Переменные, которые не дают значимых межгрупповых отлнчий, нужно исключить из дискриминантного анализа. Следует иметь в виду, что критерии значимости (в строгом статистическом смысле) неприменимы к данным Бардес, поскольку она изучает генеральную совокупность, а не выборку. 5. Матрица является двумерным массивом чисел. Обозначая матрицу одним символом, мы подразумеваем сразу множество чисел, объединенных в эту матрицу. Каждое число, принадлежащее матрице, называется ее элементом. Обозначением для элемента является буква с двумя индексами, первый из которых обозначает строку, где расположен элемент, а второй — столбец. Так, например, Если 6. Дальнейшие детали, касающиеся нахождения собственных векторов и приведения дискриминантных функций к стандартному виду, можно найти в работе (Cooley, Lohnes, 1971). Кули и Лохиес предложили приводить к стандартному виду матрицу Т вместо матрицы W. Вообще говоря, эта операция является корректной, хотя дискриминантное значение некоторым образом изменяется. Как указывалось, W дает дискриминантное значение, измеренное в единицах стандартного отклонения по каждой группе в отдельности. Использование матрицы Т приводит к дискриминантным значениям в единицах стандартного отклонения по всему пространству, поэтому эти значения являются меньшими числами. Выбор Т и W не влияет на результаты интерпретации или классификации. Однако значения вероятностей Все примеры, рассмотренные в данной работе, основаны на стандартизации матрицы W. 7. Если коэффициенты дискриминантных функций приводятся к стандартному виду с использованием матрицы W, значение 1,0 соответствует одному стандартному отклонению по данной группе. Другими словами, если рассмотреть наблюдения, принадлежащие данной группе и вычислить их стандартное отклонение от группового среднего дискриминантной функции, то полученные значения будут равны единице. Подразумевается, что групповые ковариационные матрицы равны между собой и точно представляются межгрупповой ковариационной матрицей. Если, например, нужно вычислить стандартное отклонение для всех наблюдений по отношению к главному среднему, то результирующие значения будут больше единицы (исключение — когда групповые центроиды совпадают). Причина этого заключается в том, что именно группы, а не вся система в совокупности определяют единицы измерения расстояний. Как отмечалось ранее, можно приводить к стандартному виду матрицу Т, при этом стандартное отклонение от общего главного среднего по всем наблюдениям будет единичным. 8. Заметим, что направление функции является произвольным. Изменение знаков коэффициентов данной функции эквивалентно изменению направления соответствующей оси. В общем случае все направления равноправны. Но в некоторых случаях все-таки можно выделить направления, к которым «тяготеют» отдельные наблюдения. Например, для данных Бардес позиции либералов соответствует отрицательная область данных, а позиции консерваторов — положительная. 9. Отметим, что значения переменных — одни и те же для всех дискриминантных функций. Дело в том, что объекты имеют только одно значение по каждой переменной. 10. Под стандартной, или 11. Для читателей, знакомых с понятием множественной регрессии, должна быть ясна аналогия интерпретации нестандартизованных и стандартизованных дискриминантных коэффициентов с регулярным и стандартизованным коэффициентом множественной регрессии. В рассматриваемом примере стандартное отклонение шести переменных приблизительно равно. Соответственно относительная величина коэффициентов при их стандартизации изменяется незначительно. Иная ситуация наблюдается, когда стандартные отклонения отличаются друг от Друга. 12. Если для приведения коэффициентов к стандартному виду используется матрица W, то дискриминантные переменные должны быть стандартизованы к общему среднему и межгрупповым стандартным отклонениям. Если же применяется матрица Т — переменные должны быть приведены к общему среднему и к общему стандартному отклонению. На практике для вычисления дискриминантных значений мы обычно имеем дело с наблюдаемыми значениями переменных и нестандартизованиыми коэффициентами дискриминантной функции. Стандартизованные коэффициенты используются только для проведения интерпретации. 13. Структурные коэффициенты могут быть получены двумя способами. Первый применяет компьютерную программу вычислении дискриминантных значений каждой функции по соотношению (1), а затем — программу для вычислений коэффициентов корреляции Пирсона между функциями и переменными. Другой способ заключается в вычислении стандартизованных коэффициентов канонической дискриминантной функции по следующей формуле:
где Структурные коэффициенты получаются из соотношения:
где 14. Эти результаты подразумевают наличие положительной коррелицни между парами переменных. Если корреляция отрицательна, может наблюдаться противоположный эффект. На практике наличие множественных корреляций сильно затрудняет интеграцию стандартизованных коэффициентов. 15. Реальная значимость - это соответствие результата исследования физическому смыслу (содержанию) задачи. 16. Во многих учебниках по статистике применяются термины каноническая переменная для обозначения того, что мы называем «канонической дискриминантной функцией» и дискриминантная функция, которую мы в разд. IV называем «классифицирующей функцией». Другие авторы, например Кули и Лохнес (1971), применяют термин дискриминантная функция к «канонической дискриминантной функции». Чтобы избежать этой терминологической путаницы, мы будем пользоваться терминами «каноническая дискриминантная функция» и «классифицирующая функция). 17. Читатель должен заметить, что канонические корреляции в табл. 9 получены для небольшого числа объектов (19). Большие выборки (1000 объектов и более) затрудняют получение больших корреляций, поскольку обычно они являются более однородными. 18. Под «генеральными данными» понимается, что рассматриваемые данные об объектах исчерпывают всю генеральную совокупность. Они не являются выборкой. 19. Читатели, незнакомые с понятием статистической значимости, должны обратиться к работе (Henkel, 1976) или любому учебнику по статистике, в котором рассматриваются статистические выводы. Важно понимать, что статистическая значимость и реальная значимость-—это разные понятия Статистическая значимость в первую очередь связана с проверкой, является ли выборка достаточно большой, чтобы можно было с уверенностью сказать, что рассматриваемая статистика действительно отличается от гипотетической величины (обычно нуль или «нет отличия»). Для больших выборок статистика может быть статистически значимой и не иметь реальной значимости (например, небольшое значение канонической корреляции). 20. Распределение хи-квадрат и 21. Объекты в этом примере не являются простой случайной выборкой. Следовательно, тест значимости при строгой интерпретации основных предположений неприменим. 22. Некоторые программы «дискриминантного анализа» (такие, как BMD05M и подпрограмма в SAS76) выполняют только классификацию и не вычисляют канонические дискриминантные функции. 23. Матрица, обратная квадратной, 24. Эта проблема обсуждается в (Lachenbruch, 1975; 29—36). 25. Формулы для толерантности, статистик
|
 |
Оглавление
|





























































































































































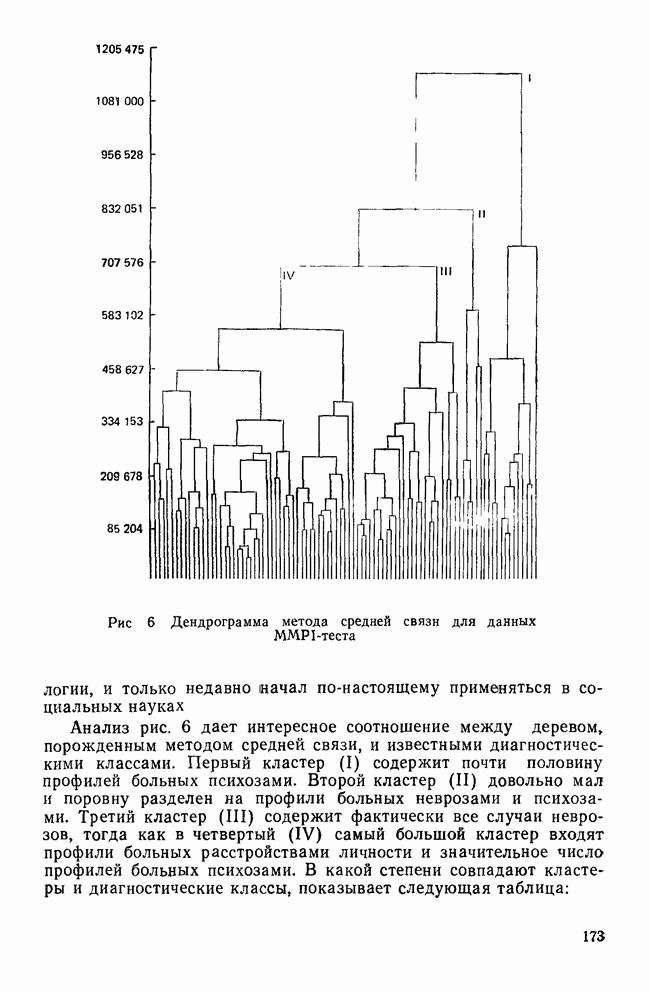
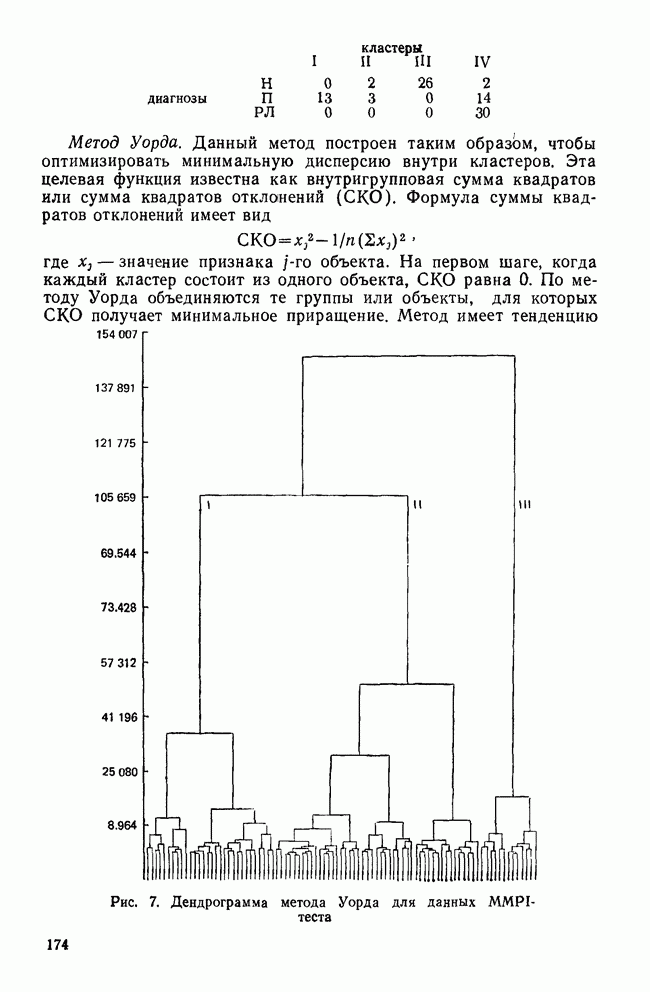










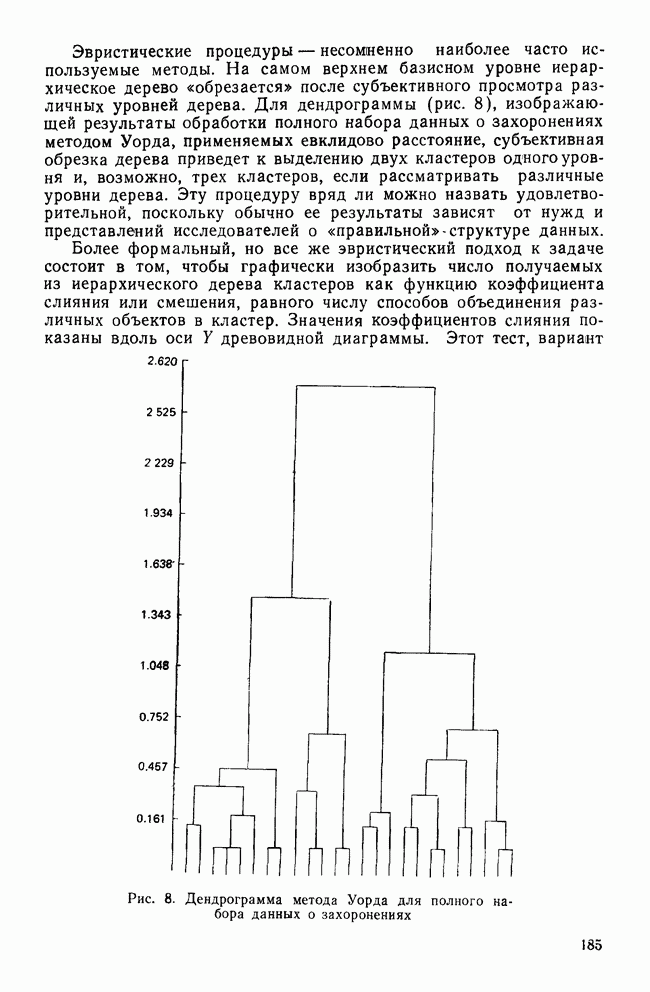
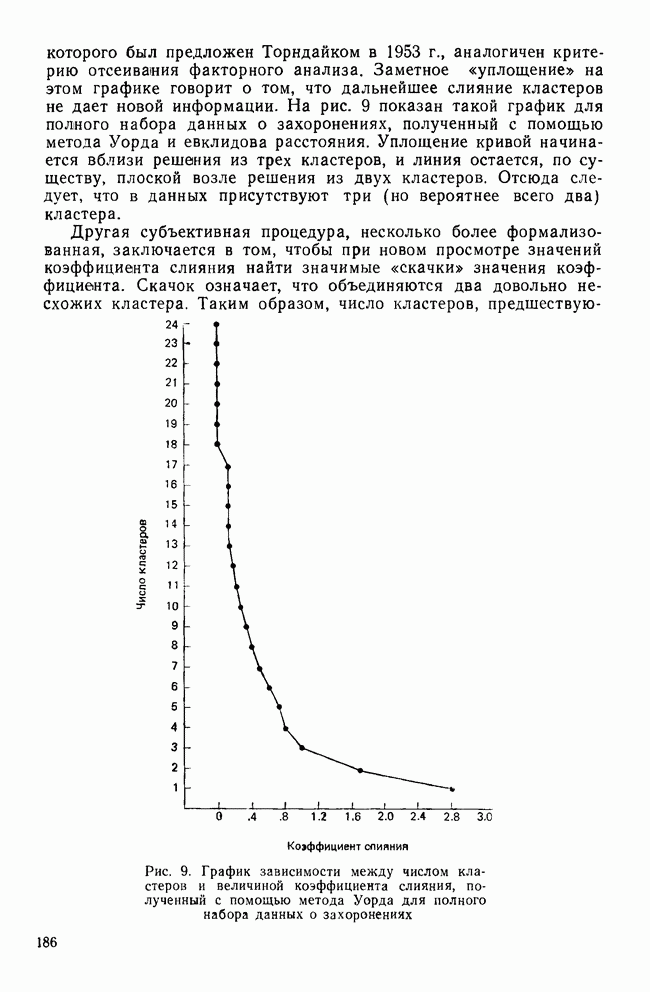












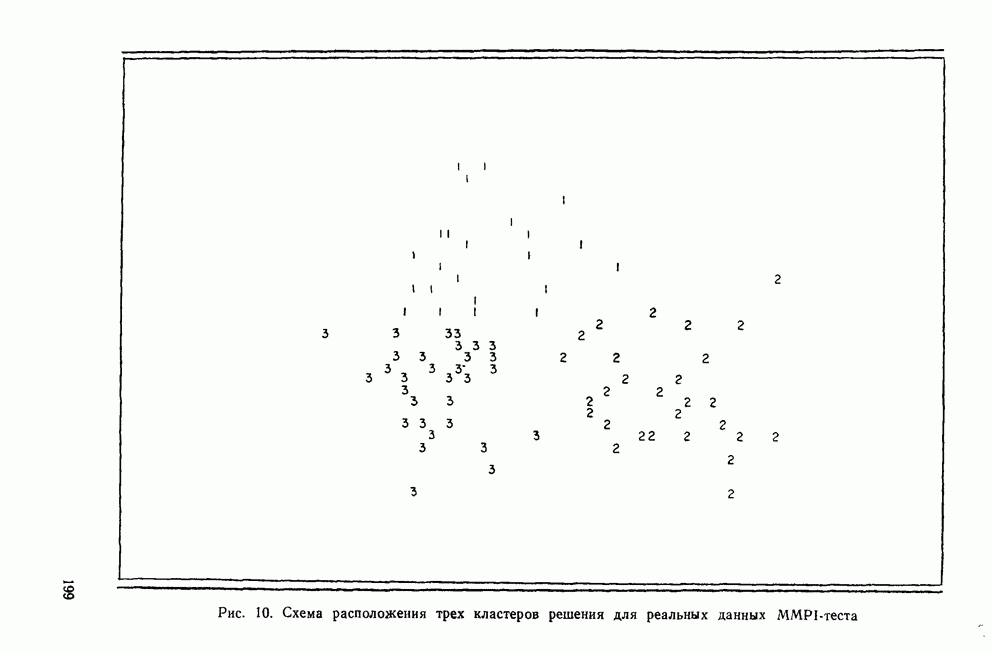
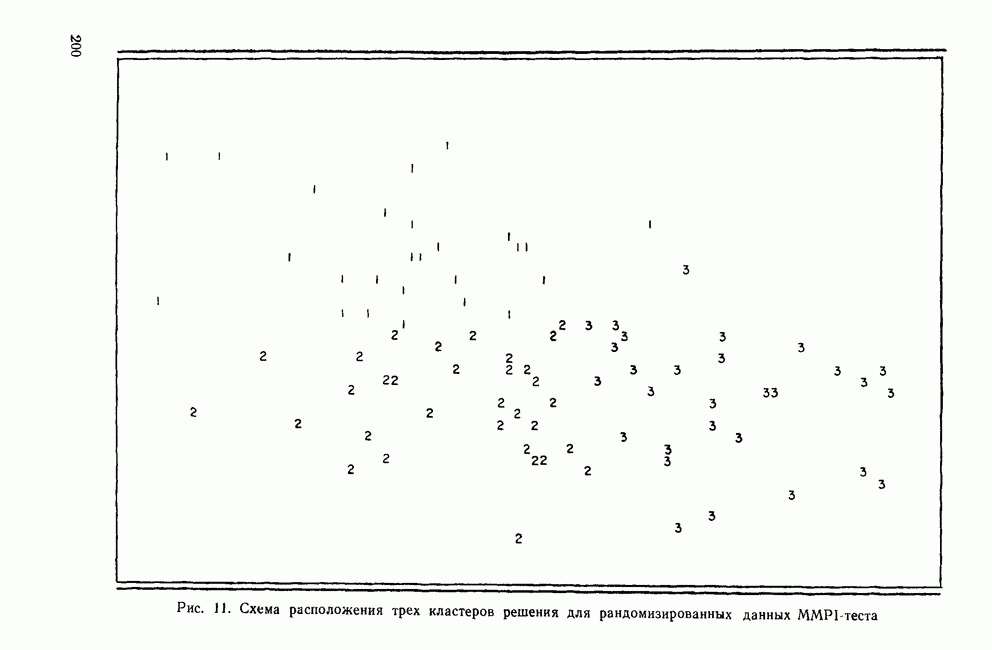















 элемент матрицы Т, расположенный на пересечении строки i и столбца
элемент матрицы Т, расположенный на пересечении строки i и столбца 
 в квадратной матрице, соответствующий элемент находится на главной диагонали. Матрица называется квадратной, если число столбцов равно числу строк. Для симметричной матрицы
в квадратной матрице, соответствующий элемент находится на главной диагонали. Матрица называется квадратной, если число столбцов равно числу строк. Для симметричной матрицы  т. е. элементы над главной диагональю равны соответствующим элементам, расположенным ниже главной диагонали.
т. е. элементы над главной диагональю равны соответствующим элементам, расположенным ниже главной диагонали.
 , введенных в разд. IV, могут быть вычислены только, если используется матрица
, введенных в разд. IV, могут быть вычислены только, если используется матрица 
 -формой подразумевается, что переменная должна иметь нулевое среднее и единичное стандартное отклонение.
-формой подразумевается, что переменная должна иметь нулевое среднее и единичное стандартное отклонение.

 — коэффициент
— коэффициент  дискриминантной функции по
дискриминантной функции по  переменной. (Знаменатель этого равенства является константой и может быть вычислен один раз.)
переменной. (Знаменатель этого равенства является константой и может быть вычислен один раз.)

 — структурный коэффициент корреляции переменной i и функции
— структурный коэффициент корреляции переменной i и функции  — корреляция между переменными
— корреляция между переменными 
 -распределение — теоретические вероятностные распределения, которые измеряют вероятность, что различия в групповых средних, отмеченные в выборке, вызваны случайными выборочными отклонениями, а не действительными различиями в генеральной совокупности. Каждое из этих распределений имеет свою собственную форму, зависящую от числа «степеней свободы», связанного с конкретной задачей. Необходимо знать число степеней свободы, прежде чем по таблице определить уровень вероятности с вычисленными значениями распределения хи-квадрат или
-распределение — теоретические вероятностные распределения, которые измеряют вероятность, что различия в групповых средних, отмеченные в выборке, вызваны случайными выборочными отклонениями, а не действительными различиями в генеральной совокупности. Каждое из этих распределений имеет свою собственную форму, зависящую от числа «степеней свободы», связанного с конкретной задачей. Необходимо знать число степеней свободы, прежде чем по таблице определить уровень вероятности с вычисленными значениями распределения хи-квадрат или  -распределения.
-распределения.
 это матрица, в которой при умножении ее на исходную диагональные элементы становятся равными единице, а все остальные — нулю. Чтобы получить более полную информацию об обратных матрицах и о том, как их вычислять, необходимо обратиться к учебнику статистики, где используется матричная алгебра (см. (Cooley and Lohnes, 1971)).
это матрица, в которой при умножении ее на исходную диагональные элементы становятся равными единице, а все остальные — нулю. Чтобы получить более полную информацию об обратных матрицах и о том, как их вычислять, необходимо обратиться к учебнику статистики, где используется матричная алгебра (см. (Cooley and Lohnes, 1971)).
 -включения и
-включения и  -удаления довольно сложны и здесь не приводятся. Заинтересовавшийся читатель может обратиться к работе (Norusis, 1979; 73—74).
-удаления довольно сложны и здесь не приводятся. Заинтересовавшийся читатель может обратиться к работе (Norusis, 1979; 73—74).