Пред.
След.
Макеты страниц
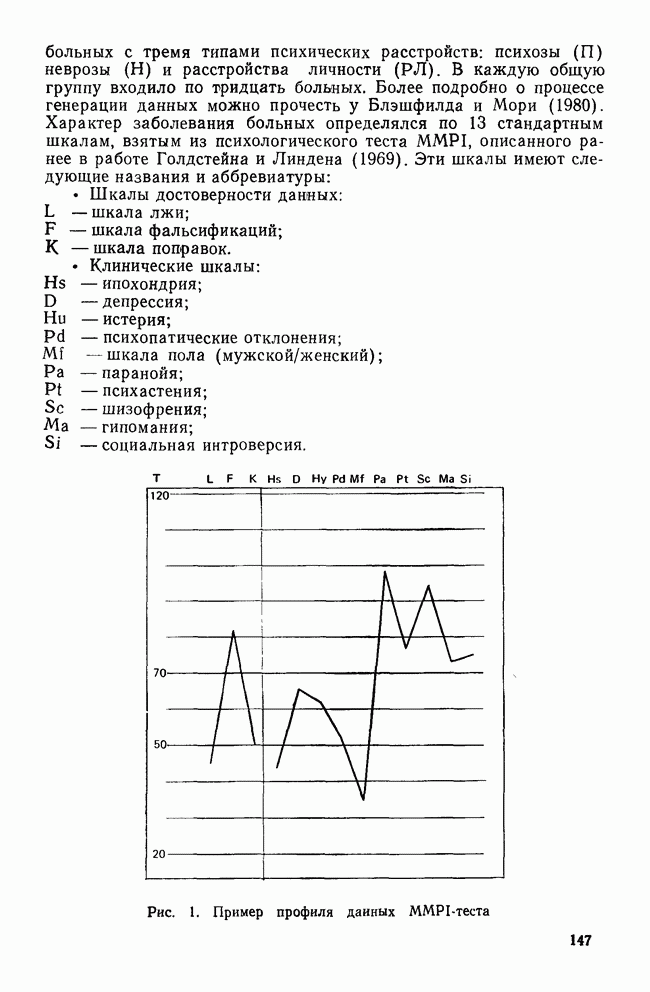
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ИЕРАРХИЧЕСКИЕ АГЛОМЕРАТИВНЫЕ МЕТОДЫИз семи семейств кластерных методов наиболее часто в приложениях употребляются иерархические агломеративные методы. Проанализировав все опубликованные в 1973 г. работы, в которых использовался кластерный анализ, Блэшфилд и Олдендерфер (1978b) нашли, что в 2/3 этих статей применяется какой-либо из иерархических агломеративных методов. Самым легким для понимания из иерархических агломеративных методов является метод одиночной связи. Рассмотрим матрицу сходства размерностью 6х6, которая была получена в разд. II с помощью коэффициента Жаккара для данных о захоронениях. Метод одиночной связи начинает процесс кластеризации с поиска двух наиболее похожих объектов в матрице сходства. В этом примере наиболее схожими являются объекты ПЖЭ (подросток, женский пол, элитарный) и ВЖЭ (взрослый, женский пол, элитарный) с уровнем сходства
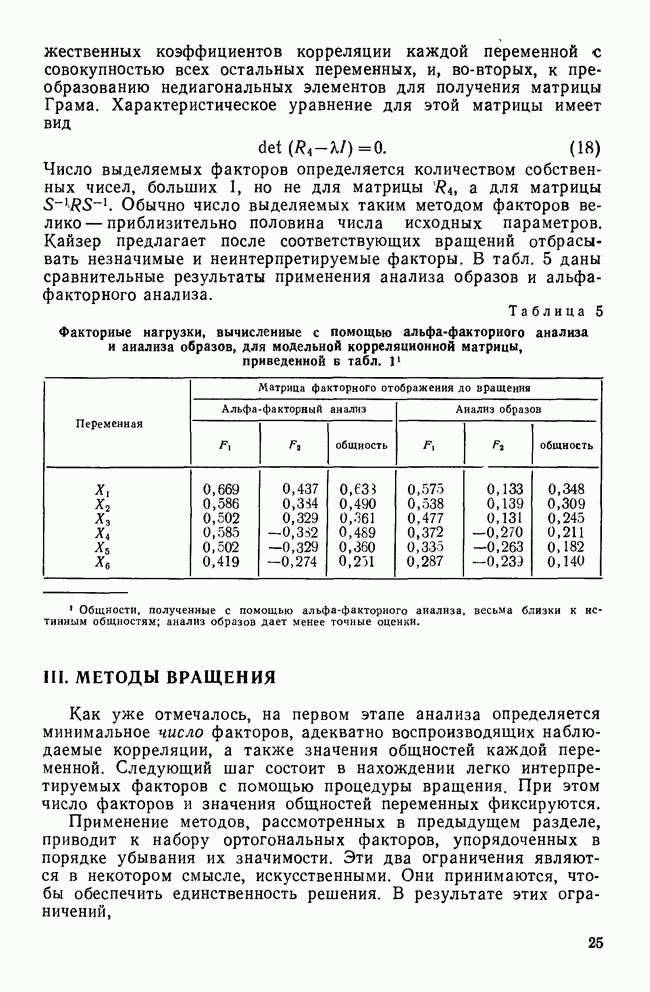
Рис. 3 Дендрограмма для данных о шести захоронениях Из этого примера можно вывести четыре важных наблюдения относительно иерархических агломеративных методов. Первое — все эти методы просматривают матрицу сходства размерностью NxN (где N — число объектов) и последовательно объединяют наиболее схожие объекты. Именно поэтому они называются алгомеративными (объединяющими). Второй важный момент, на который стоит обратить внимание, состоит в том, что последовательность объединений кластеров можно представить визуально в виде древовидной диаграммы, часто называемой дендрограммой. Древовидная диаграмма, отражающая применение метода одиночной связи к данным о шести захоронениях, показана на рис. 3. Каждый шаг, на котором объединялась пара объектов, представляется ветвью этого дерева. Заметьте, что дерево изображает иерархическую организацию связей между шестью точками данных. На самом нижнем уровне все шесть точек независимы; на следующем уровне они объединяются в одну группу и три независимых объекта; наконец, на самом верхнем уровне они все объединяются в одну большую группу. Третьим важным моментом является то, что для полной кластеризации этими методами на основе матрицы сходства размерностью NxN требуется ровно Наконец, для понимания иерархических агломеративных методов не нужны обширные знания. Так, метод одиночной связи не требует понимания матричной алгебры или обширной подготовки по многомерной статистике. Вместо этого дается правило, указывающее, каким образом, исходя из матрицы сходства, объекты могут объединяться в кластеры. Хотя другие иерархические агломеративные методы несколько сложнее, все они довольно просты и различаются правилами объединения объектов (которые в литературе часто называются видами связи объектов). По определению в результате работы этих кластерных методов получаются неперекрывающиеся кластеры, которые, однако, являются вложенными в том смысле, что каждый кластер может рассматриваться как элемент другого, более широкого кластера на более высоком уровне сходства. Самым распространенным способом представления результатов этих кластерных методов является дендрограмма (древновидная диаграмма), которая графически изображает иерархическую структуру, порожденную матрицей сходства и правилом объединения объектов в кластеры. Несмотря на простоту методов, они обладают некоторыми недостатками. Если не используются специально разработанные алгоритмы, то применение иерархических алгомеративных методов может потребовать вычисления и хранения большой матрицы сходства. Необходимость в хранении такой матрицы фактически ограничивает сверху число объектов, участвующих в процессе кластеризации. Например, для набора данных из 500 объектов потребуются хранение и неоднократный просмотр матрицы, содержащей около 125 000 элементов. Другим недостатком кластерных методов является то, что в них объекты распределяются по кластерам лишь за один проход, а поэтому плохое начальное разбиение множества данных не может быть изменено на последующих шагах процесса кластеризации (Gower, 1967). Третий недостаток всех этих методов (за исключением метода одиночной связи) состоит в том, что они могут порождать разные решения в результате простого переупорядочения объектов в матрице сходства и, кроме того, их результаты изменяются, если некоторые объекты исключаются из рассмотрения. Устойчивость — это важное свойство любой классификации, так как устойчивые группы с большим правдоподобием представляют собой «естественные» группировки по сравнению с теми группами, которые исчезают, если некоторые объекты переупорядочены или исключены из анализа. Вопрос об устойчивости становится особенно существенным, когда мы имеем дело с малыми выборками объектов (Jardine and Sibson, 1071). Иерархические агломеративные методы различаются главным образом по правилам построения кластеров. Некоторые авторы для обозначения способа группировки используют термин «стратегия классификации». Существует много различных правил группировки, каждое из которых порождает специфический иерархический метод. Известно по крайней мере двенадцать различных методов группировки, четыре из них наиболее распространенные: одиночной связи, полной связи, средней связи и метод Уорда. Ланс и Уильямс (1967) получили формулу, которая позволяет описать правила группировки в общем виде для любого иерархического агломеративного метода. Формула имеет вид
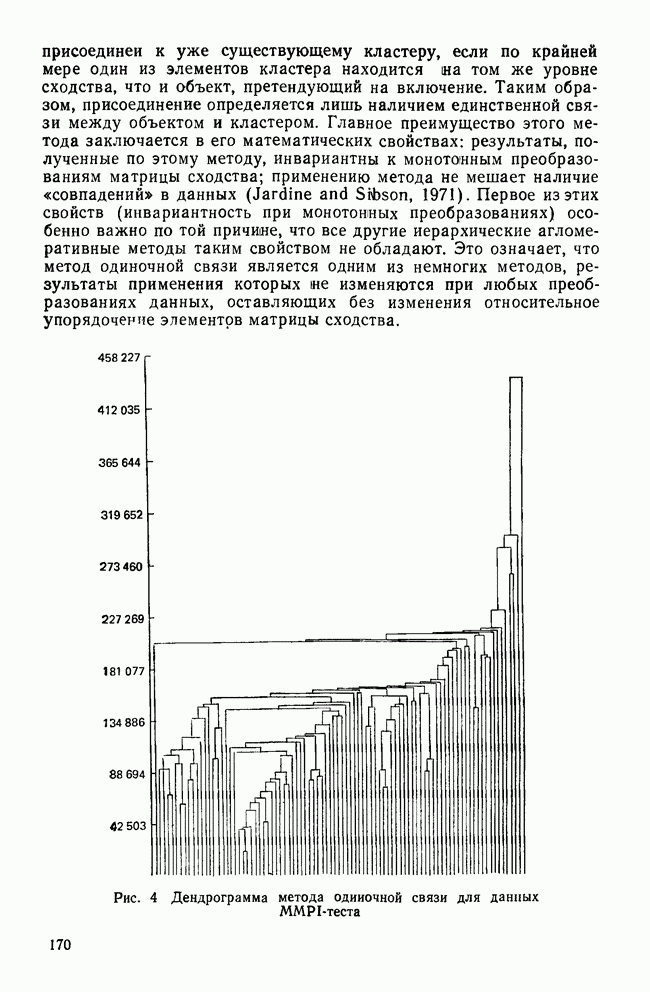
где Чтобы проиллюстрировать работу иерархических методов и показать действие разных правил группировки, данные MMPI-теста были обработаны с помощью четырех наиболее известных методов. Метод одиночной связи. В этом методе, описанном Снитом (1957), кластер образуется по следующему правилу: объект будет присоединен к уже существующему кластеру, если по крайней мере один из элементов кластера находится на том же уровне сходства, что и объект, претендующий на включение. Таким образом, присоединение определяется лишь наличием единственной связи между объектом и кластером. Главное преимущество этого метода заключается в его математических свойствах: результаты, полученные по этому методу, инвариантны к монотонным преобразованиям матрицы сходства; применению метода не мешает наличие «совпадений» в данных (Jardine and Sibson, 1971). Первое из этих свойств (инвариантность при монотонных преобразованиях) особенно важно по той причине, что все другие иерархические агломеративные методы таким свойством не обладают. Это означает, что метод одиночной связи является одним из немногих методов, результаты применения которых не изменяются при любых преобразованиях данных, оставляющих без изменения относительное упорядочение элементов матрицы сходства.
Рис. 4 Дендрограмма метода одиночной связи для данных MMPI-теста
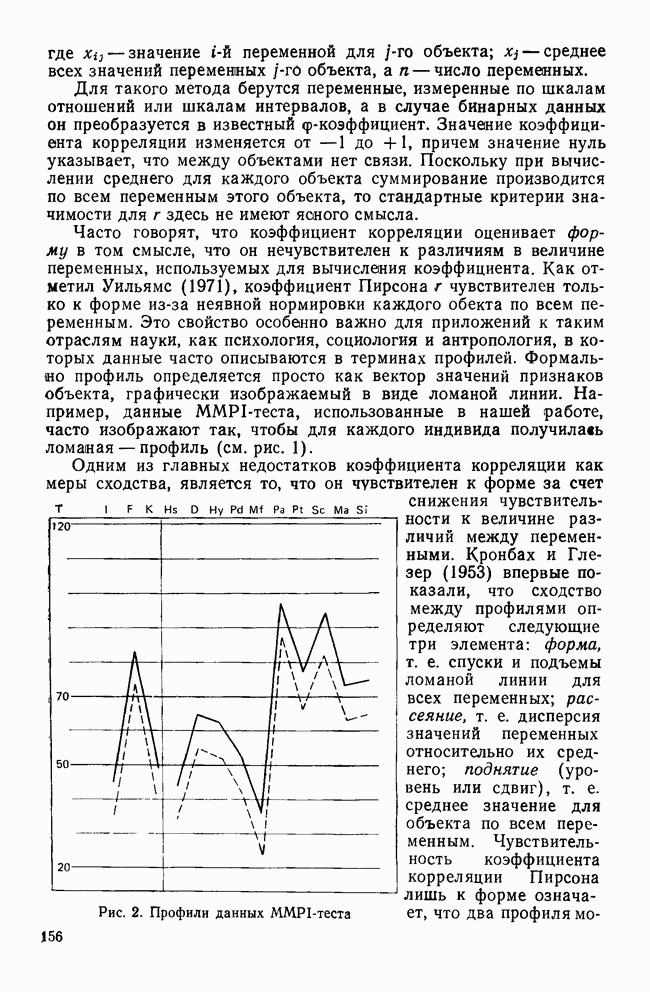
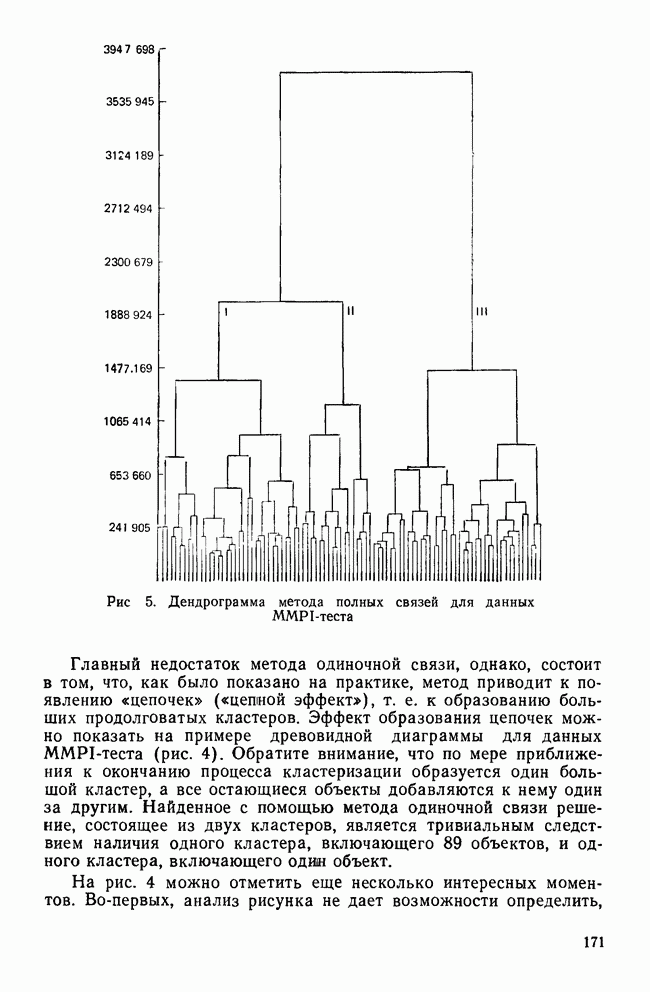
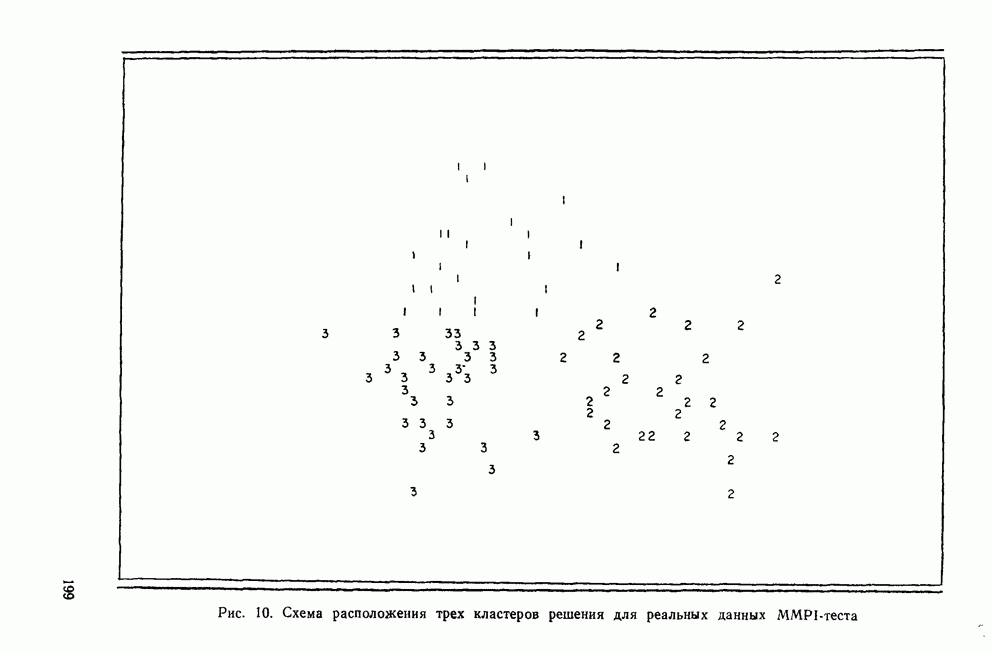
Рис. 5. Дендрограмма метода полных связей для данных MMPI-теста Главный недостаток метода одиночной связи, однако, состоит в том, что, как было показано на практике, метод приводит к появлению «цепочек» («цепной эффект»), т. е. к образованию больших продолговатых кластеров. Эффект образования цепочек можно показать на примере древовидной диаграммы для данных MMPI-теста (рис. 4). Обратите внимание, что по мере приближения к окончанию процесса кластеризации образуется один большой кластер, а все остающиеся объекты добавляются к нему один за другим. Найденное с помощью метода одиночной связи решение, состоящее из двух кластеров, является тривиальным следствием наличия одного кластера, включающего 89 объектов, и одного кластера, включающего один объект. На рис. 4 можно отметить еще несколько интересных моментов. Во-первых, анализ рисунка не дает возможности определить, как много кластеров содержится в данных. В противоположность этому древовидная диаграмма, полученная методом полной связи (см. рис. 5), четко указывает на наличие двух кластеров. Во-вторых, диагностируемые классы больных, тесно связанные с профилями данных MMPI-теста, не образуют четко выделенных кластеров на рисунке. В левой части дерева имеется скопление профилей больных с невротическими заболеваниями (Н), а в середине дерева скопление профилей больных с расстройствами личности (РЛ). Оставшаяся часть дерева состоит из профилей больных психозами (П), неврозами (Н) и нескольких профилей РЛ. Короче говоря, решение, порожденное методом одиночной связи, не является точным воспроизведением известной структуры данных. Метод полных связей. В этом методе в противоположность методу одиночной связи правило объединения указывает, что сходство между кандидатами на включение в существующий кластер и любым из элементов этого кластера не должно быть меньше некоторого порогового уровня (Sokal and Michener, 1958). Настоящее правило более жесткое, чем правило для метода одиночной связи, и поэтому здесь имеется тенденция к обнаружению относительно компактных гиперсферических кластеров, образованных объектами с большим сходством. Хотя дерево, порожденное методом полных связей (рис. 5), дает наглядное представление о найденных кластерах данных, все же сравнение полученной классификации с известной не говорит о хорошем их соответствии. Приведенная ниже информация показывает распределение объектов по кластерам и диагностическим классам. Точное решение давало бы взаимооднозначное соответствие между кластерами и диагностическими классами. Однако в решении, полученном по методу полных связей, оно явно отсутствует. Как распределены объекты по классам и кластерам, показано в таблице:
Метод средней связи. Предложенный Сокэлом и Миченером (1958) метод средней связи разрабатывался в качестве «средства борьбы» с крайностями как метода одиночной связи, так и метода полной связи. Хотя есть несколько вариантов метода, по существу, в каждом из них вычисляется среднее сходство рассматриваемого объекта со всеми объектами в уже существующем кластере, а затем, если найденное среднее значение сходства достигает или превосходит некоторый заданный пороговый уровень сходства, объект присоединяется к этому кластеру. Чаще всего используется вариант метода средней связи, в котором вычисляется среднее арифметическое сходство между объектами кластера и кандидатом на включение. В других вариантах метода средней связи вычисляется сходство между центрами тяжести двух кластеров, подлежащих объединению.
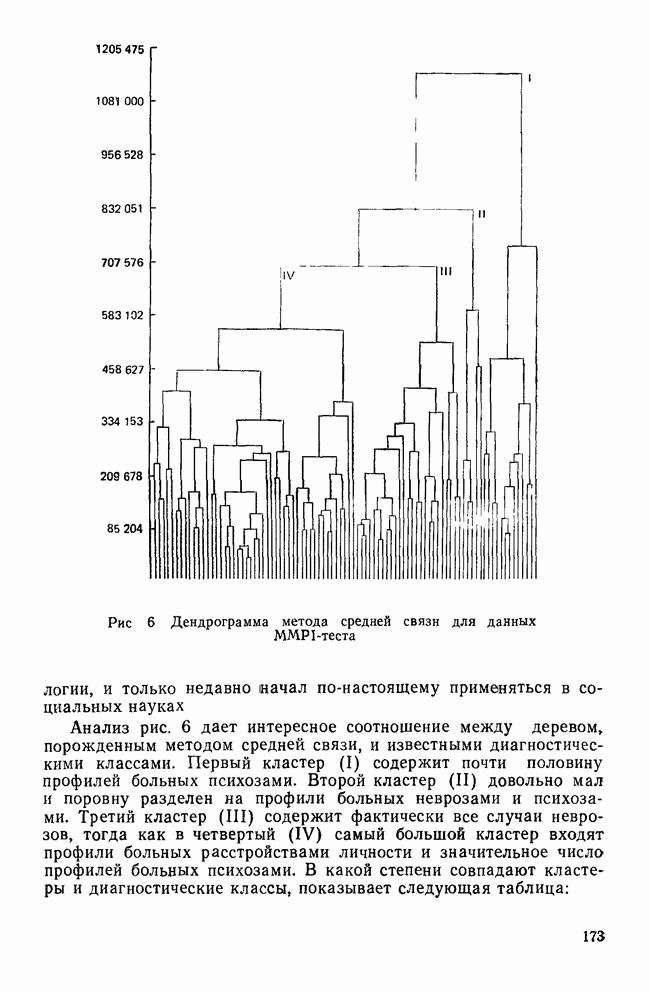
Рис. 6 Дендрограмма метода средней связи для данных MMPI-теста Метод средней связи широко использовался в биологии, и только недавно начал по-настоящему применяться в социальных науках Анализ рис. 6 дает интересное соотношение между деревом, порожденным методом средней связи, и известными диагностическими классами. Первый кластер (I) содержит почти половину профилей больных психозами. Второй кластер (II) довольно мал и поровну разделен на профили больных неврозами и психозами. Третий кластер (III) содержит фактически все случаи неврозов, тогда как в четвертый (IV) самый большой кластер входят профили больных расстройствами личности и значительное число профилей больных психозами. В какой степени совпадают кластеры и диагностические классы, показывает следующая таблица:
Метод Уорда. Данный метод построен таким образом, чтобы оптимизировать минимальную дисперсию внутри кластеров. Эта целевая функция известна как внутригрупповая сумма квадратов или сумма квадратов отклонений (СКО). Формула суммы квадратов отклонений имеет вид
где
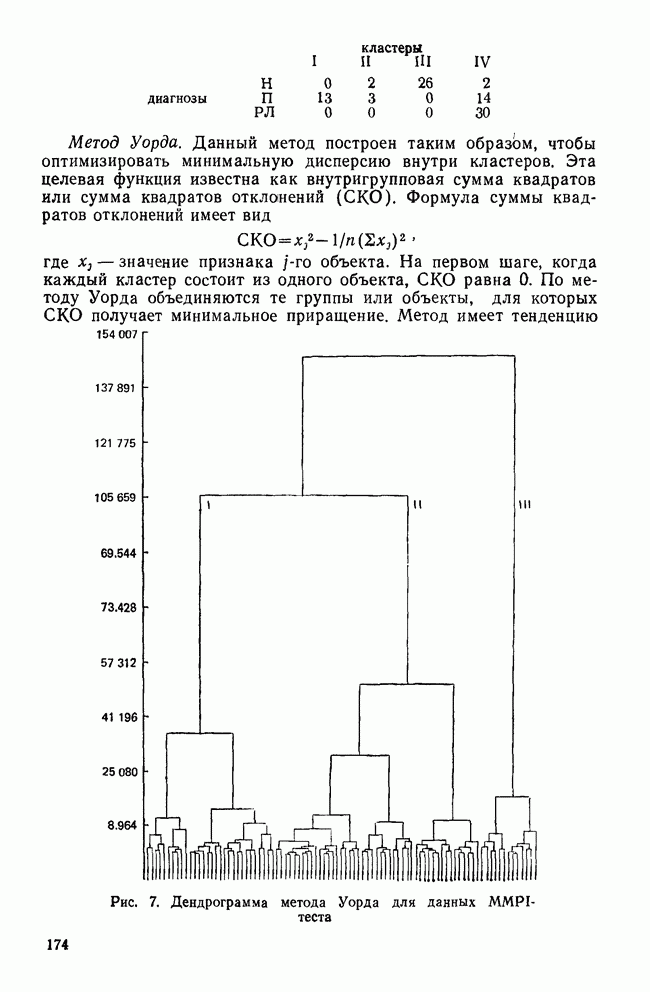
Рис. 7. Дендрограмма метода Уорда для данных MMPI-теста Метод Уорда фактически не нашел применения в биологии, но широко используется во многих социальных науках (Blashfield, 1980). Дерево, порожденное методом Уорда (рис. 7), ясно показывает, что найденное решение состоит из трех кластеров. Как и в случае метода средней связи, здесь имеется взаимосвязь между кластерами и диагностическими классами. Однако и метод Уорда не порождает точного решения. Нише приводится таблица распределения объектов по кластерам и классам:
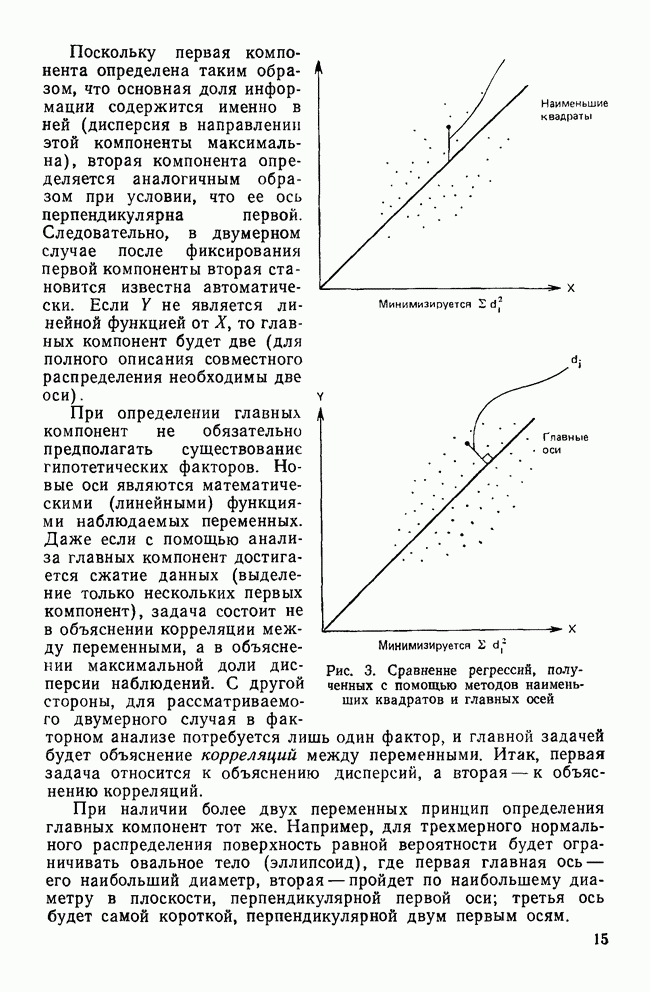
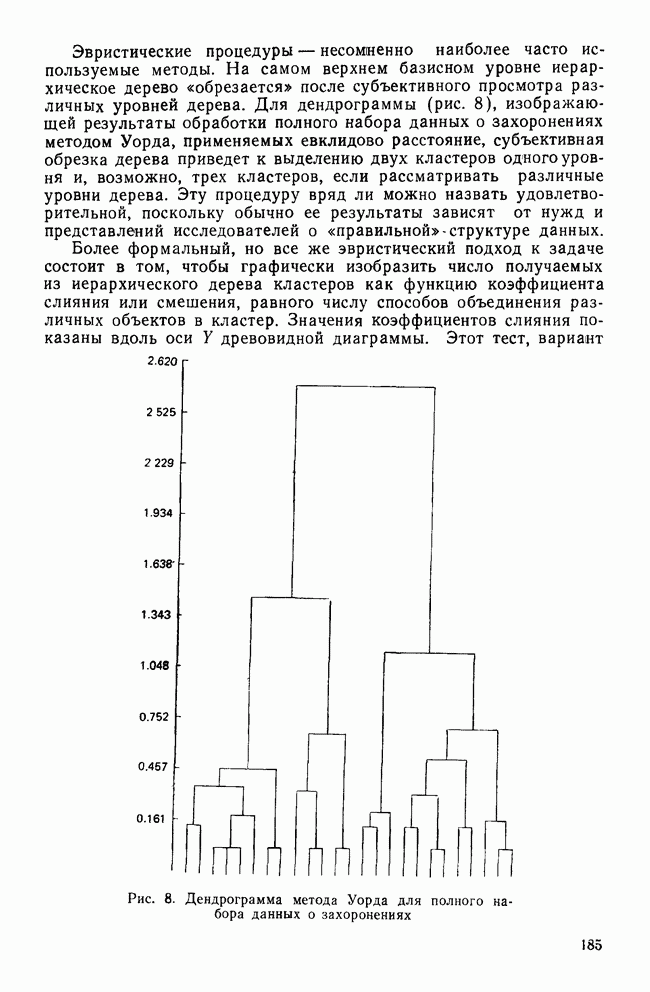
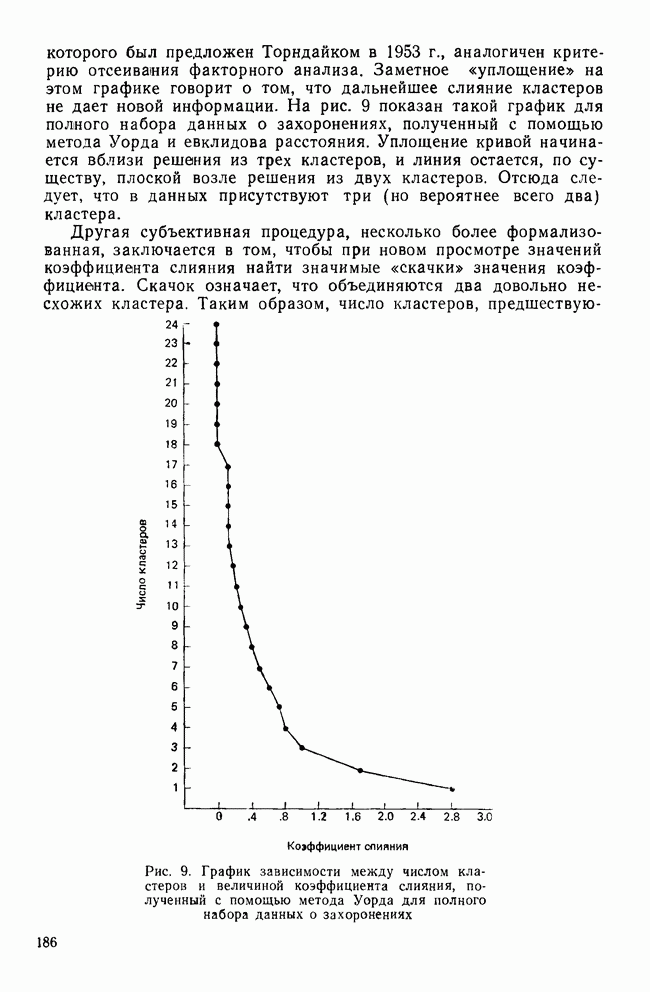
Обычная трудность, связанная с использованием метода Уорда, заключается в том, что найденные с его помощью кластеры можно упорядочить по величине профильного сдвига. Так, в приведенном решении профили кластера III являются наиболее приподнятыми, тогда как кластер II содержит наименее приподнятые кластеры. Практическое применение метода Уорда в социологических исследованиях показало, что он порождает решения, которые находятся под сильным воздействием величины профильного сдвига. Имеется несколько способов сравнения различных иерархических агломеративных методов. С помощью одного из них можно проанализировать, как эти методы преобразуют соотношения между точками в многомерном пространстве. Сжимающие пространство методы изменяют эти соотношения, «уменьшая» пространство между любыми группами в данных. Когда очередная точка подвергается обработке таким методом, она скорее всего будет присоединена к уже существующей группе, а не послужит началом нового кластера. Расширяющие пространство методы действуют противоположным образом. Здесь кластеры как бы «расступаются»; таким образом в пространстве образуются мелкие, более «отчетливые» кластеры. Этот способ группировки также склонен к созданию кластеров гиперсферической формы и приблизительно равных размеров. Методы Уорда и полных связей являются методами, расширяющими пространство. И наконец, сохраняющие пространство методы, такие, как метод средней связи, оставляют без изменения свойства исходного пространства. Уильямс и др. (1971) рассматривают свойства сужающих пространство методов как недостатки, особенно в прикладном анализе данных, тогда как, по мнению других авторов, — среди них наиболее известны Джардайн и Сибсон (1968) — эти методы предпочтительнее ввиду их хороших математических свойств, невзирая на результаты их практического использования. Эверитт (1980) уравновешивает эти две крайности замечанием, что успех применения рассматриваемых методов в анализе данных в большой степени зависит от априорных представлений об ожидаемом виде кластеров и действительной структуре данных. Проблема, которая будет подробно обсуждаться в одном из последующих разделов, состоит в том, чтобы определить, когда один из этих методов привносит в данные не свойственную им структуру.
|
 |
Оглавление
|
















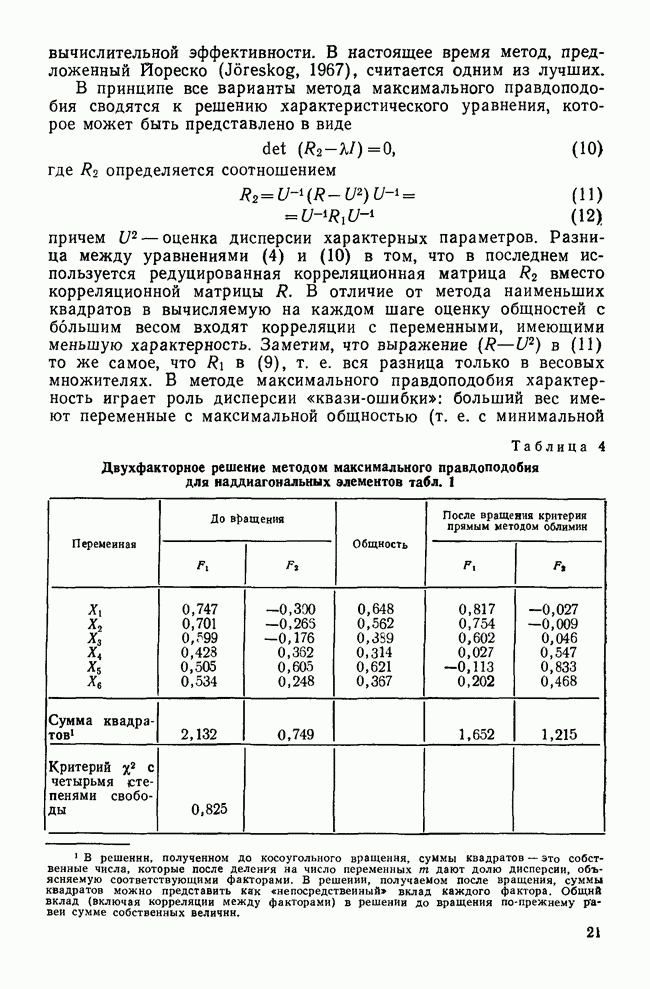


















































































































































































 . На следующем шаге к этой группе присоединяется объект ВМЭ, так как его коэффициент сходства с ПЖО равен 0,500. Дело в том, что по правилу объединения для метода одиночной связи новый кандидат на включение в состав кластера присоединяется к существующей группе в том случае, если он имеет наивысший уровень сходства с каким-либо из членов этой группы. Другими словами, для объединения двух объектов требуется только одна связь между ними. Третий шаг присоединяет объект ПМН к кластеру, содержащему объекты ВЖЭ, ВМЭ и ПЖЭ, потому что он тоже имеет коэффициент сходства с ВМЭ, равный 0,500. Четвертый шаг процесса кластеризации присоединяет объект РМН к группе, образованной объектами ПЖЭ, ВМЭ, ВЖЭ и ПМН с уровнем сходства
. На следующем шаге к этой группе присоединяется объект ВМЭ, так как его коэффициент сходства с ПЖО равен 0,500. Дело в том, что по правилу объединения для метода одиночной связи новый кандидат на включение в состав кластера присоединяется к существующей группе в том случае, если он имеет наивысший уровень сходства с каким-либо из членов этой группы. Другими словами, для объединения двух объектов требуется только одна связь между ними. Третий шаг присоединяет объект ПМН к кластеру, содержащему объекты ВЖЭ, ВМЭ и ПЖЭ, потому что он тоже имеет коэффициент сходства с ВМЭ, равный 0,500. Четвертый шаг процесса кластеризации присоединяет объект РМН к группе, образованной объектами ПЖЭ, ВМЭ, ВЖЭ и ПМН с уровнем сходства  .
.

 шагов. На первом шаге события (объекты) рассматриваются как самостоятельные кластеры. На последнем шаге все события объединяются в одну большую группу.
шагов. На первом шаге события (объекты) рассматриваются как самостоятельные кластеры. На последнем шаге все события объединяются в одну большую группу.

 - различие (расстояние) между кластерами h и k, причем кластер k является результатом объединения кластеров (или объектов) i и
- различие (расстояние) между кластерами h и k, причем кластер k является результатом объединения кластеров (или объектов) i и  в ходе агломеративного шага. С помощью этой формулы можно вычислить расстояние между некоторым объектом
в ходе агломеративного шага. С помощью этой формулы можно вычислить расстояние между некоторым объектом  и новым кластером (k), полученным объединением объектов i и j в единый кластер. Прописными буквами обозначены параметры, которые определяют конкретный вид группировки; в методе одиночной связи, например, эти параметры принимают следующие значения:
и новым кластером (k), полученным объединением объектов i и j в единый кластер. Прописными буквами обозначены параметры, которые определяют конкретный вид группировки; в методе одиночной связи, например, эти параметры принимают следующие значения:  Полученная формула оказала большую помощь при разработке вычислительных алгоритмов для этих методов.
Полученная формула оказала большую помощь при разработке вычислительных алгоритмов для этих методов.






 — значение признака
— значение признака  объекта. На первом шаге, когда каждый кластер состоит из одного объекта, СКО равна 0. По методу Уорда объединяются те группы или объекты, для которых СКО получает минимальное приращение. Метод имеет тенденцию к нахождению (или созданию) кластеров приблизительно равных размеров и имеющих гиперсферическую форму.
объекта. На первом шаге, когда каждый кластер состоит из одного объекта, СКО равна 0. По методу Уорда объединяются те группы или объекты, для которых СКО получает минимальное приращение. Метод имеет тенденцию к нахождению (или созданию) кластеров приблизительно равных размеров и имеющих гиперсферическую форму.

