Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
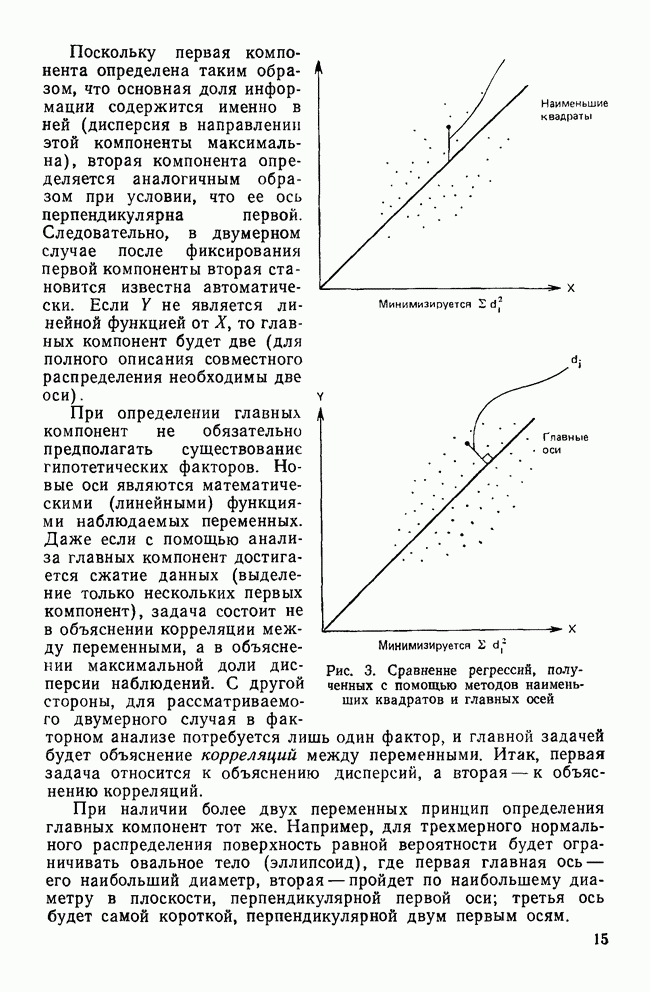
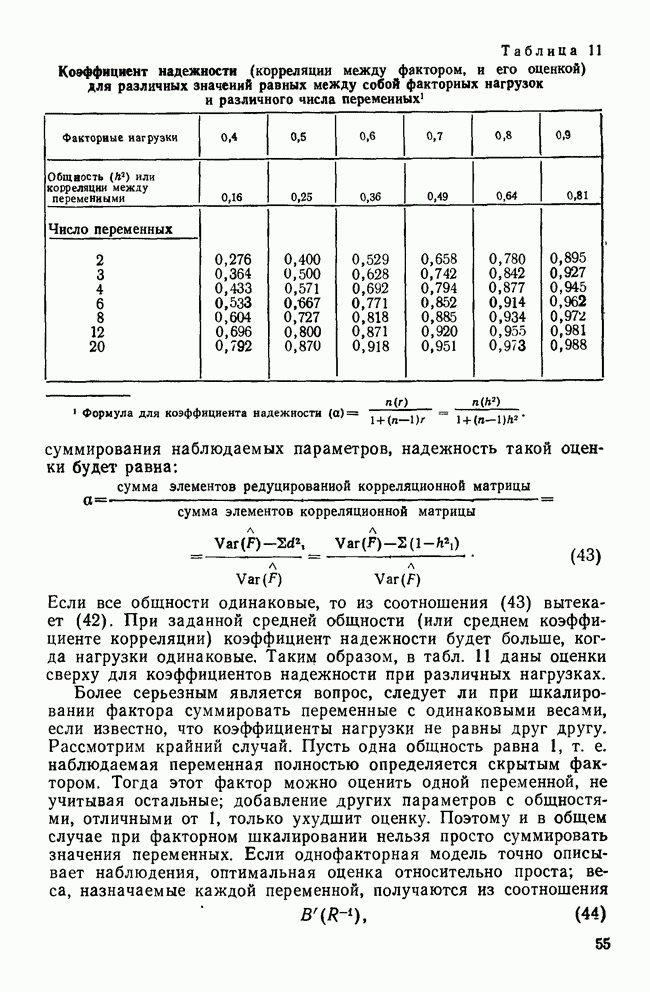
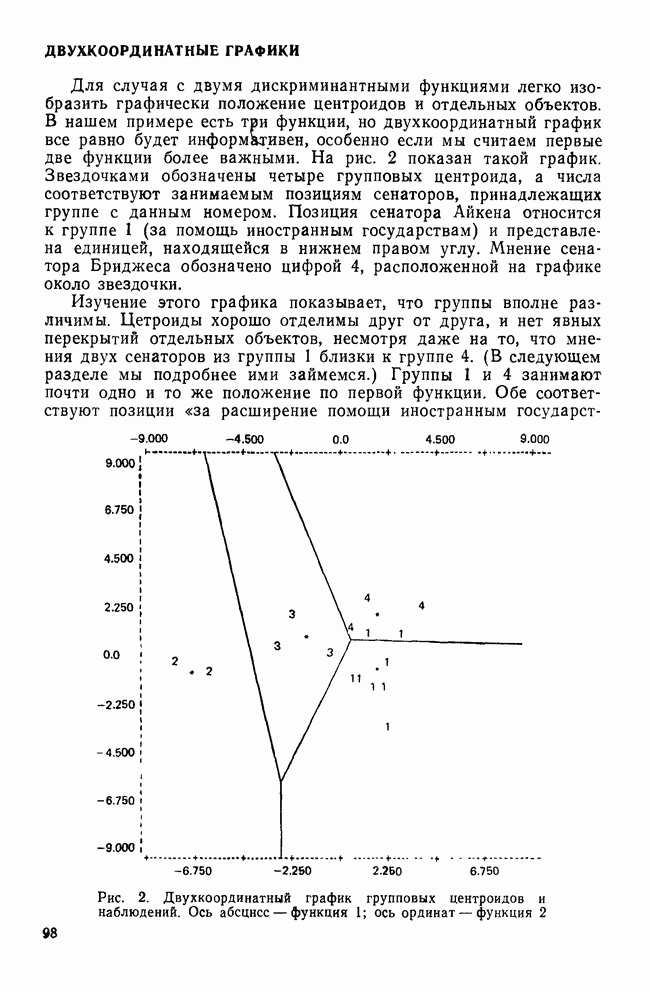
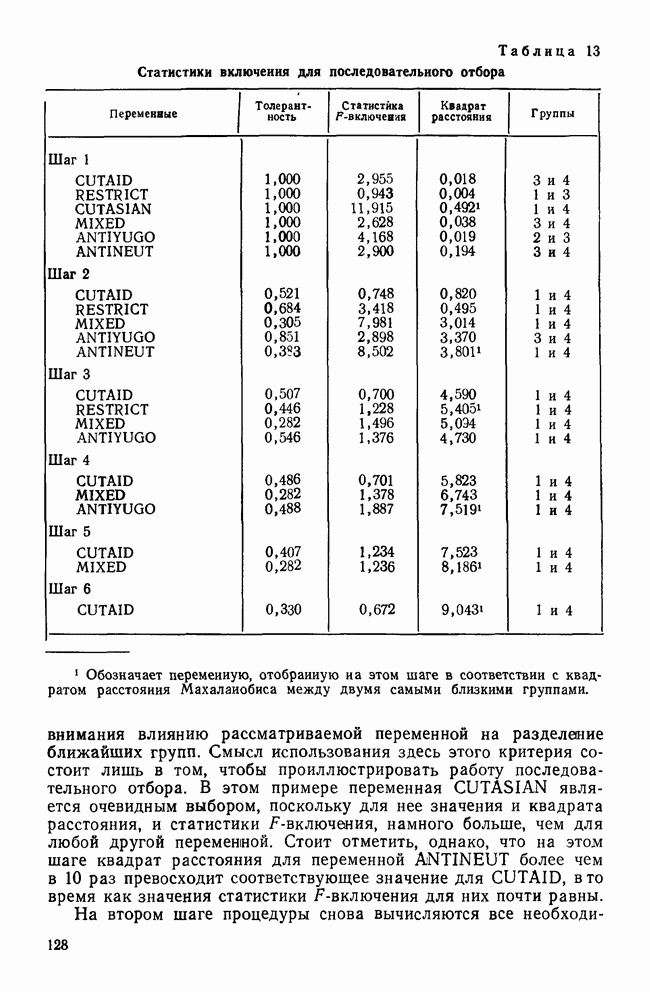
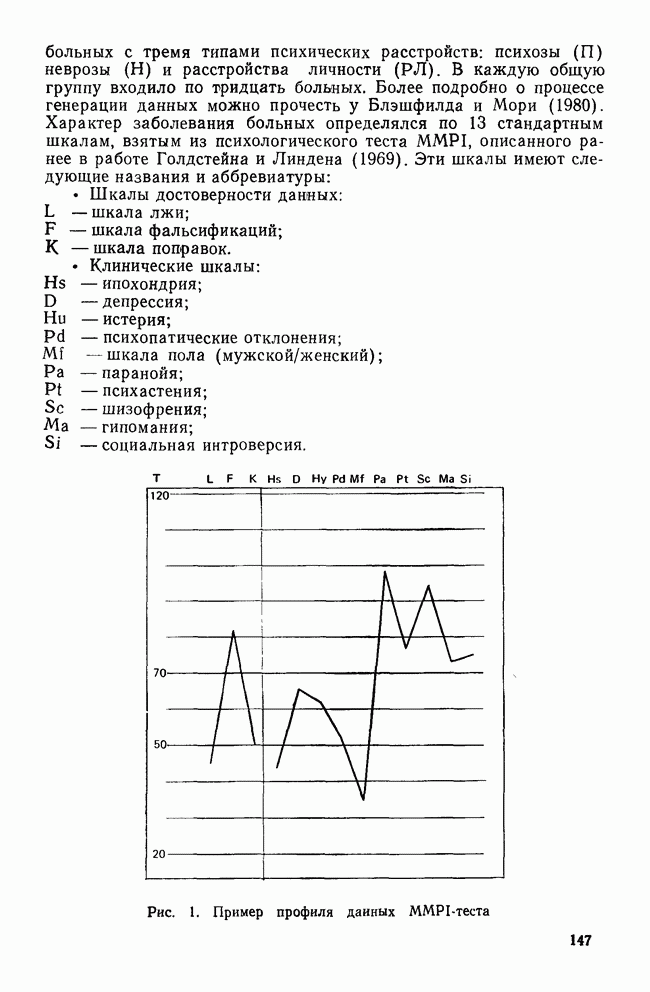
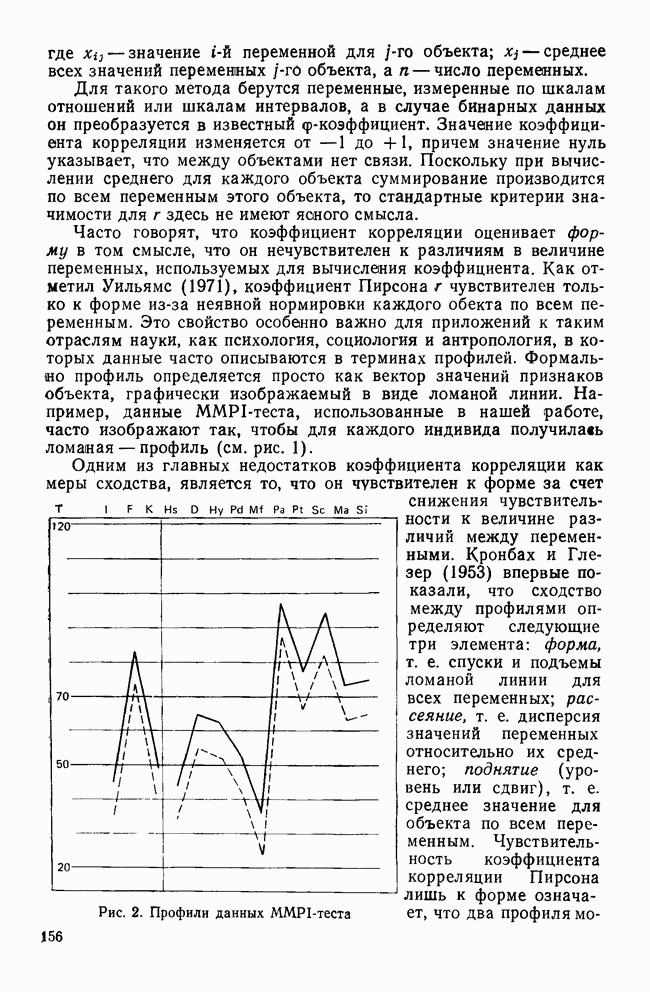
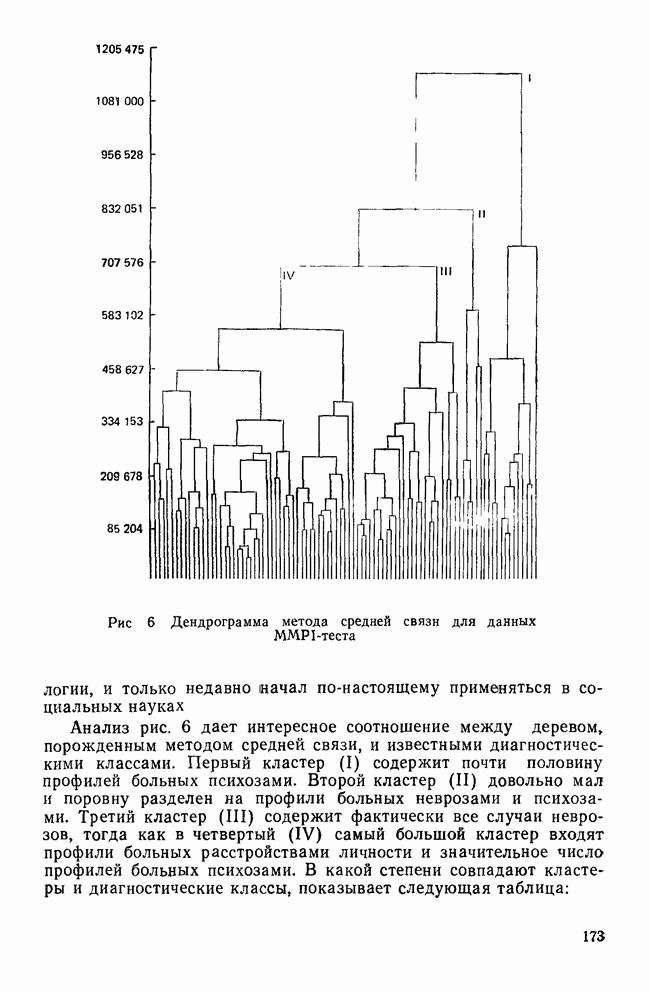
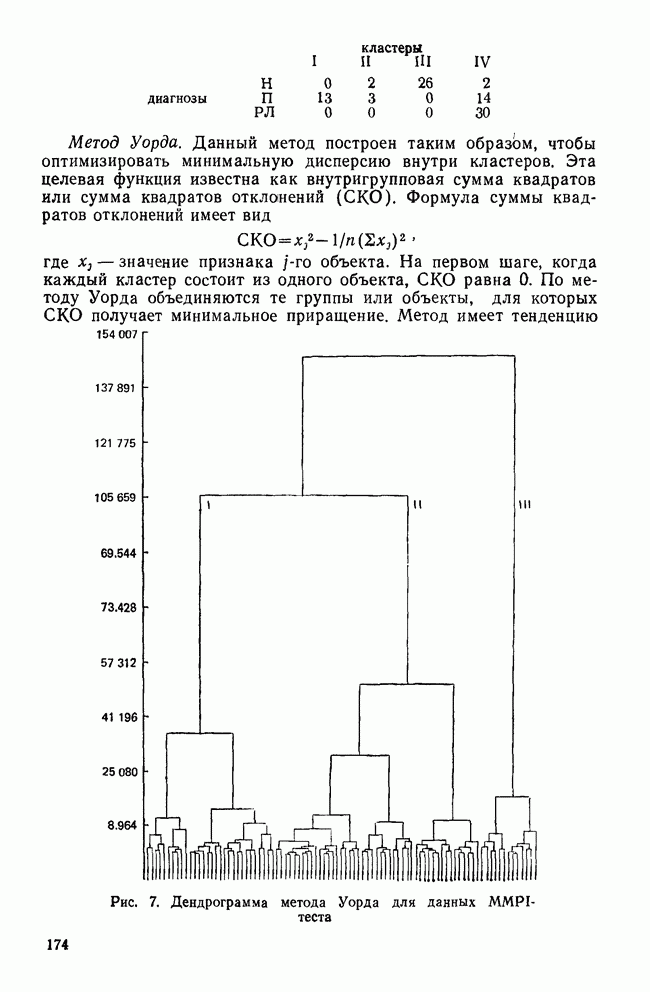
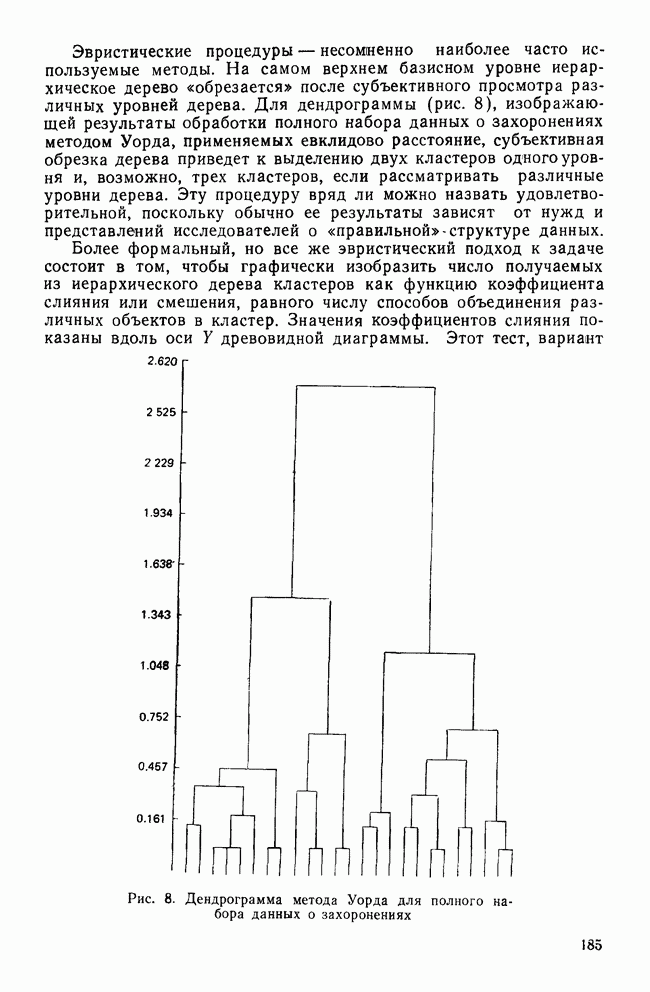
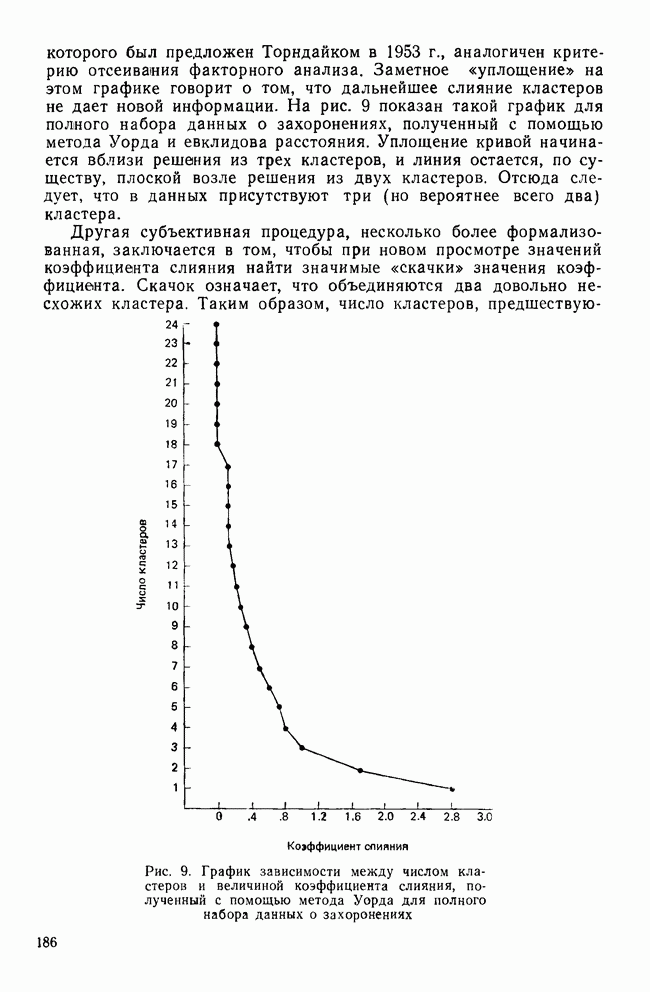
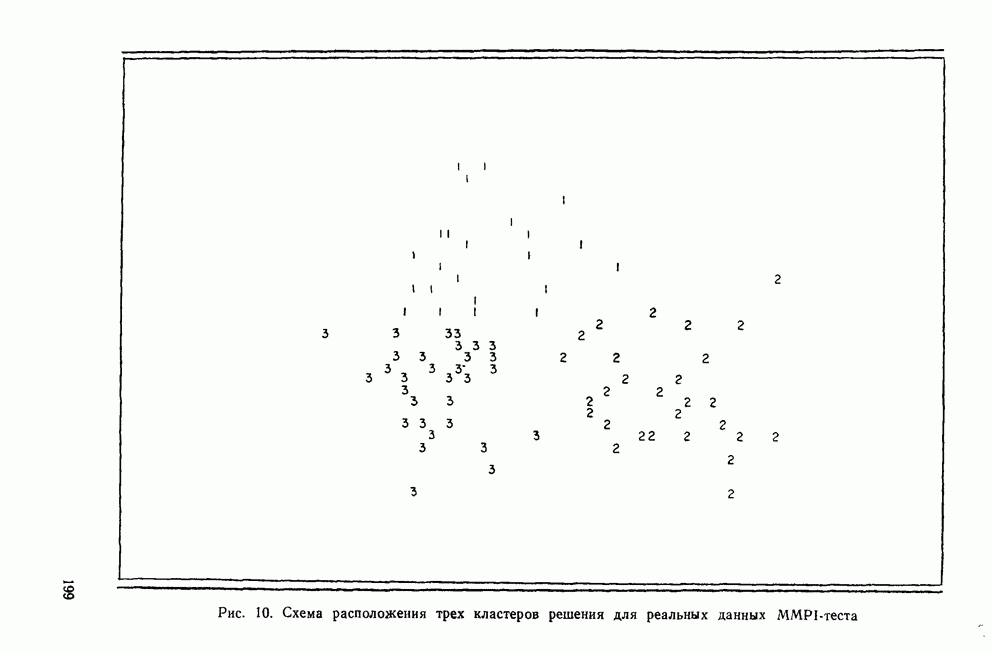
IV. ПРОЦЕДУРЫ КЛАССИФИКАЦИИКак уже было сказано, целью дискриминантного анализа является решение двух задач: интерпретации и классификации. До сих пор внимание фокусировалось в основном на задаче интерпретации, которая связана с определением числа и значимости канонических дискриминантных функций и с выяснением их значений для объяснения различий между классами. Классификация — это особый вид деятельности исследователя, в котором либо дискриминантные переменные, либо канонические дискриминантные функции используются для предсказания класса, к которому более вероятно принадлежит некоторый объект. Существует несколько процедур классификации, но все они сравнивают положение объекта с каждым из центроидов классов, чтобы найти «ближайший». Например, целью исследования Бардес было сформировать подпространство, определяемое канонической дискриминантной функцией, используя данные о 19 сенаторах и выделенных фракциях. Затем она, воспользовавшись результатами их голосования, вычислила значения дискриминантной функции для позиций остальных сенаторов и смогла отнести позицию каждого сенатора к одной из четырех групп. Таким образом, она определила размеры и состав фракций и выяснила, как они изменяются со временем. КЛАССИФИЦИРУЮЩИЕ ФУНКЦИИКлассификация — это процесс, который помогает исследователю принять решение: указанный объект «принадлежит к» или «очень похож на» данную группу (класс). Такое решение принимается на основе информации, содержащейся в дискриминантных переменных. Существует несколько способов проведения классификации. Обычно они требуют определения понятия «расстояния» между объектом и каждым центроидом группы, чтобы можно было приписать объект к «ближайшей» группе. Процедуры классификации могут использовать или самими дискриминантные переменные, или канонические дискриминантные функции. В первом случае дискриминантный анализ вовсе не проводится. Здесь просто применяется подход максимизации различий между классами для получения функции классификации. Различение классов или размерность дискриминантного пространства на значимость не проверяется. Если же сначала определяются канонические дискриминантные функции и классификация проводится с их помощью, можно провести более глубокий анализ. К этому мы вернемся позднее, а сейчас продолжим рассмотрение классификации, когда дискриминантные переменные используются непосредственно. Простые классифицированные функцииФишер (1936) был первым, кто предположил, что классификация должна проводиться с помощью линейной комбинации дискриминантных переменных. Он предложил применять линейную комбинацию, которая максимизирует различия между классами, но минимизирует дисперсию внутри классов. Разработка его предложения приводит нас к определению особой линейной комбинации для каждого класса, которая называется «классифицирующая функция». Она имеет следующий вид:
где
где
Мы обычно не интерпретируем эти коэффициенты классифицирующей функции, потому что они не стандартизованы и каждому классу соответствует своя функция. Таблица 11. Коэффициенты простой классифицирующей функции
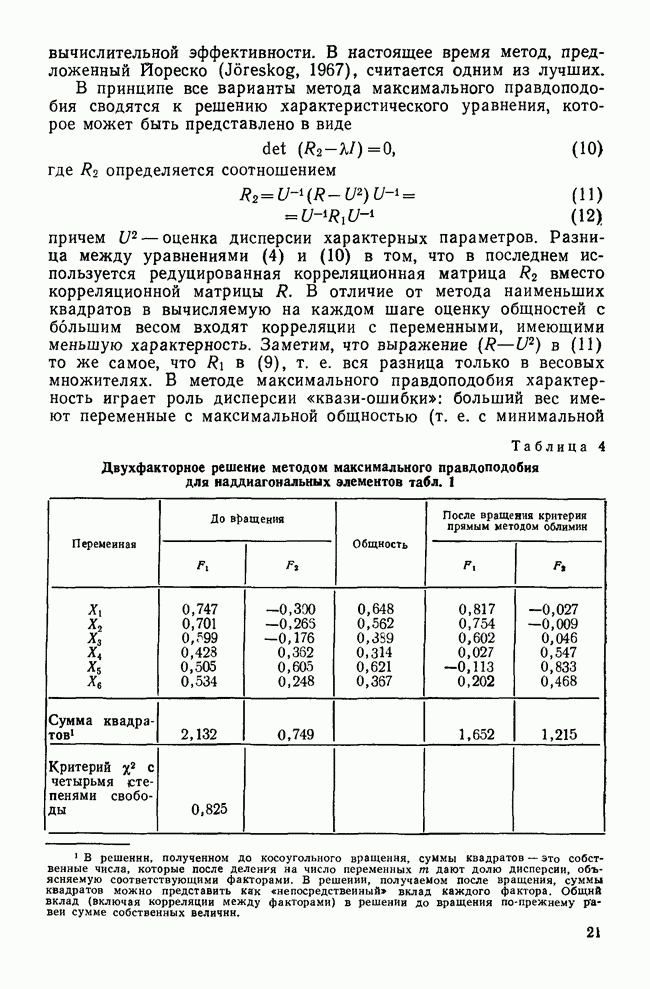
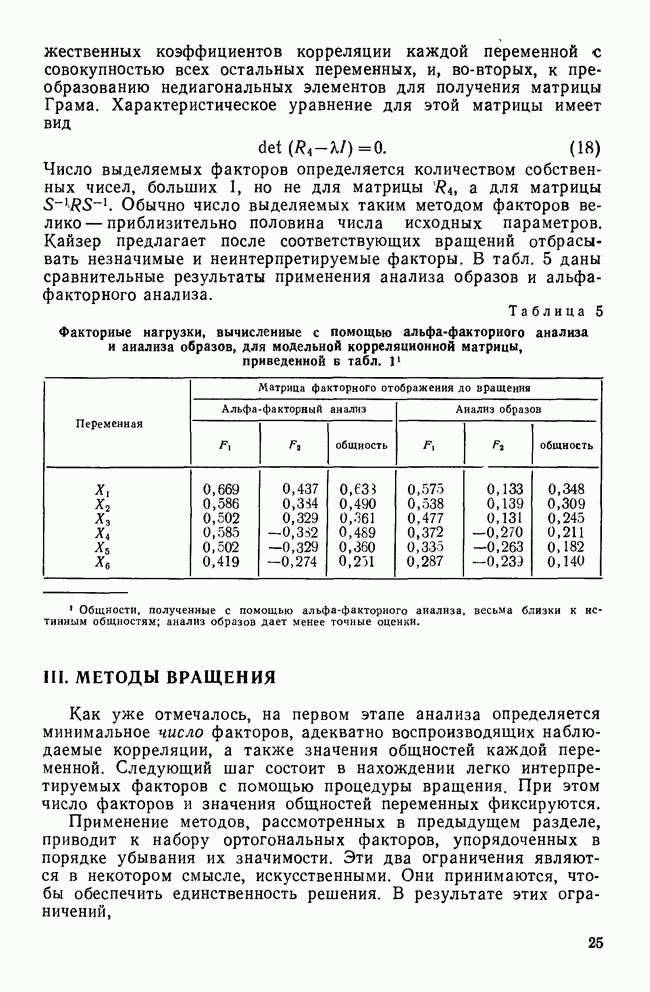
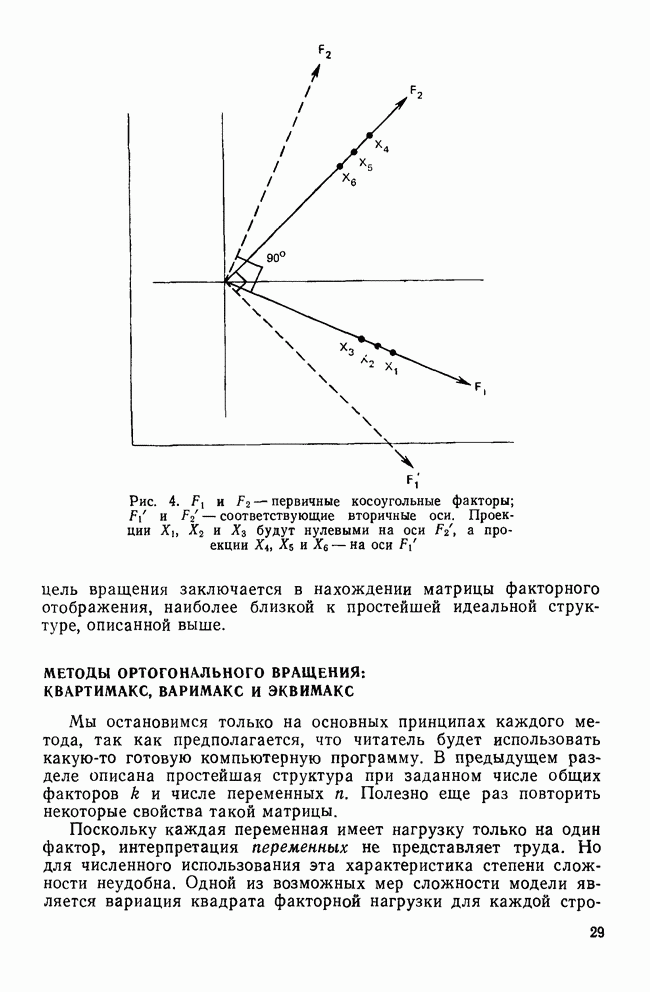
Точные значения функции роли не играют: нам нужно знать лишь, для какого класса это значение наибольшее. Именно к нему объект ближе всего. Функции, описываемые соотношением (12), называются «простыми классифицирующими функциями» потому, что они предполагают лишь равенство групповых ковариационных матриц и не требуют никаких дополнительных свойств, обсуждаемых далее. Рассмотрим табл. 11, в которой приведены коэффициенты классифицирующих функций для данных о голосовании в сенате, чтобы проиллюстрировать использование этих функций. Применив такую функцию к первичным данным по позиции сенатора Айкена, мы получим следующие значения для четырех групп: 89,742; 46,578; 78,101 и 78,221. Поскольку первое значение — наибольшее, мы отнесем позицию Айкена к первой группе (что является верным предсказанием). Обобщенные функции расстоянияБолее понятным способом классификации является измерение расстояний между объектом и каждым из центроидов классов, чтобы затем отнести объект в ближайший класс. Однако в тех случаях, когда переменные коррелированы, измерены в разных единицах и имеют различные стандартные отклонения, бывает трудно определить понятие «расстояния». Индийский статистик Махаланобис (1963) предложил обобщенную меру растояния, которая устраняет эти трудности. Мы можем использовать ее в следующей форме:
где Если расстояние до ближайшего класса велико, то согласие между профилями будет плохим, но по сравнению с любым другим классом — хорошим. Соотношение (15) предполагает, что классы имеют равные ковариационные матрицы. Если это предположение не выполняется, то выражение можно модифицировать, как предлагает Татсуока (1971; 222). Вероятность принадлежности к классуОказывается Относя объект к ближайшему классу в соответствии со значением Ясно, что для любого объекта сумма этих вероятностей по всем классам не обязательно равна 1. Однако если мы предположим, что каждый объект должен принадлежать одной из групп, то можно вычислить вероятность принадлежности для любой из групп. Вероятность того, что объект X является членом класса k, равна:
Сумма этих вероятностей, часто называемых апостериорными вероятностями, по всем классам равна 1. Классификация наибольшей из этих величин тоже эквивалентна использованию наименьшего расстояния. Позиция сенатора Айкена с апостериорной вероятностью 1,0 принадлежит к группе 1, а позиция Бриджеса имеет апостериорную вероятность 0,99 для группы 4. Обратите внимание и а различие между этими двумя вероятностями. Апостериорная величина
|
 |
Оглавление
|



































































































































































































 — значение функции для класса
— значение функции для класса  — коэффициенты, которые необходимо определить. Объект относится к классу с наибольшим значением (наибольшим h). Коэффициенты для классифицирующих функций определяются с помощью таких вычислений:
— коэффициенты, которые необходимо определить. Объект относится к классу с наибольшим значением (наибольшим h). Коэффициенты для классифицирующих функций определяются с помощью таких вычислений:

 — коэффициент для переменной i в выражении, соответствующему классу k, а
— коэффициент для переменной i в выражении, соответствующему классу k, а  — элемент матрицы, обратной к внутригрупповой матрице сумм попарных произведений
— элемент матрицы, обратной к внутригрупповой матрице сумм попарных произведений  . Постоянный член определяется так:
. Постоянный член определяется так:


 (15)
(15)
 - квадрат расстояния от точки X (данный объект) до центроида класса k. После вычисления
- квадрат расстояния от точки X (данный объект) до центроида класса k. После вычисления  для каждого класса классифицируем объект в группу с наименьшим
для каждого класса классифицируем объект в группу с наименьшим  . Это класс, чей типичный профиль по дискриминантным переменным больше похож на профиль для этого объекта.
. Это класс, чей типичный профиль по дискриминантным переменным больше похож на профиль для этого объекта.
 обладает теми же свойствами, что и статистика хи-квадрат с
обладает теми же свойствами, что и статистика хи-квадрат с  степенями свободы. Таким образом, мы измеряем расстояние в «хи-квадрат единицах». Если предположить, что каждый класс является частью генеральной совокупности с многомерным нормальным распределением, то большинство объектов будет группироваться вблизи центроида, и их плотность будет убывать по мере удаления от центроида. Зная расстояние от центроида, можно сказать, какая часть класса находится ближе к центроиду, а какая — дальше от него. Следовательно, можно оценить вероятность того, что объект, настолько-то удаленный от центроида, принадлежит классу. Поскольку наши расстояния измеряются в хи-квадрат единицах, то попробуем иайти значимость получения этой вероятности. Обозначим через
степенями свободы. Таким образом, мы измеряем расстояние в «хи-квадрат единицах». Если предположить, что каждый класс является частью генеральной совокупности с многомерным нормальным распределением, то большинство объектов будет группироваться вблизи центроида, и их плотность будет убывать по мере удаления от центроида. Зная расстояние от центроида, можно сказать, какая часть класса находится ближе к центроиду, а какая — дальше от него. Следовательно, можно оценить вероятность того, что объект, настолько-то удаленный от центроида, принадлежит классу. Поскольку наши расстояния измеряются в хи-квадрат единицах, то попробуем иайти значимость получения этой вероятности. Обозначим через  вероятность того, что объект, находящийся далеко от центроида, действительно принадлежит классу
вероятность того, что объект, находящийся далеко от центроида, действительно принадлежит классу 
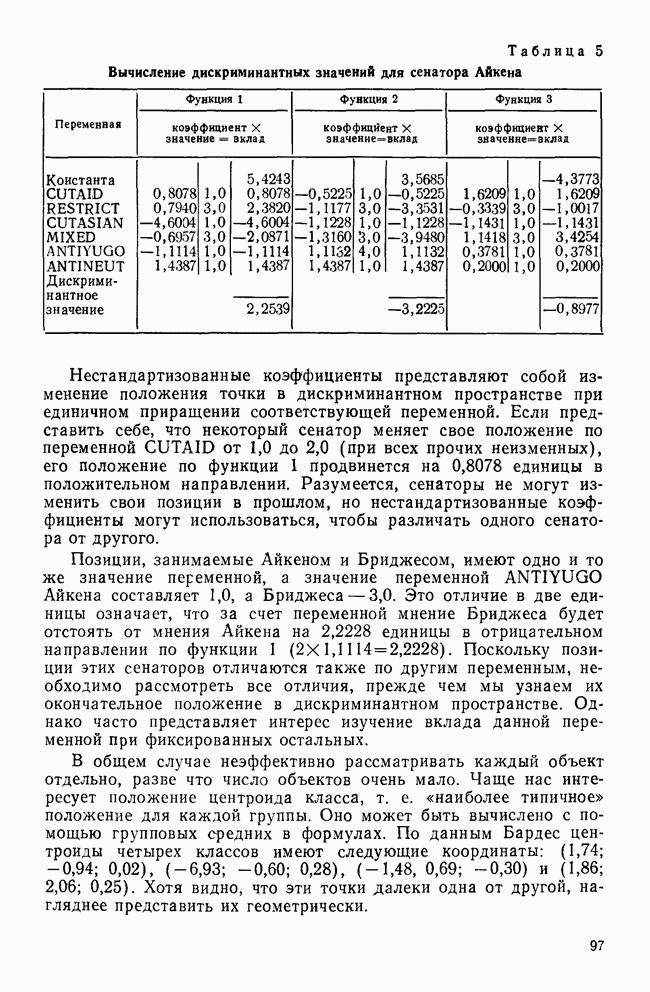
 мы неявно приписываем его к тому классу, для которого он имеет наибольшую вероятность принадлежности. Благодаря вероятностям, об объекте можно сказать больше простого утверждения, что он является «ближайшим» к какому-то конкретному классу. В действительности объект может с большими вероятностями принадлежать более чем одному классу или не принадлежать ни одному из них. Рассмотрим ситуацию с низким различением и высоким перекрытием классов. В этом случае объект, близкий к центроиду класса 1, будет с большой вероятностью «принадлежать» классу 2, поскольку он также «близок» к этому классу. Другая важная ситуация: объект находится на большом расстоянии от всех классов, иначе говоря — все вероятности малы. Решение приписать этот объект к ближайшему классу, может оказаться лишенным смысла, поскольку он мало похож на любой объект из этого класса. В качестве примера такой ситуации возьмем позицию сенатора Айкена. Она принадлежит к группе 1 (ближайшей группе) с вероятностью 0,1, которая очень мала. С другой стороны, позиция сенатора Бриджес с довольно высокой вероятностью (0,48) принадлежит ближайшей к нему группе (группа 4).
мы неявно приписываем его к тому классу, для которого он имеет наибольшую вероятность принадлежности. Благодаря вероятностям, об объекте можно сказать больше простого утверждения, что он является «ближайшим» к какому-то конкретному классу. В действительности объект может с большими вероятностями принадлежать более чем одному классу или не принадлежать ни одному из них. Рассмотрим ситуацию с низким различением и высоким перекрытием классов. В этом случае объект, близкий к центроиду класса 1, будет с большой вероятностью «принадлежать» классу 2, поскольку он также «близок» к этому классу. Другая важная ситуация: объект находится на большом расстоянии от всех классов, иначе говоря — все вероятности малы. Решение приписать этот объект к ближайшему классу, может оказаться лишенным смысла, поскольку он мало похож на любой объект из этого класса. В качестве примера такой ситуации возьмем позицию сенатора Айкена. Она принадлежит к группе 1 (ближайшей группе) с вероятностью 0,1, которая очень мала. С другой стороны, позиция сенатора Бриджес с довольно высокой вероятностью (0,48) принадлежит ближайшей к нему группе (группа 4).

 дает вероятность, что объект принадлежит классу k. А величина
дает вероятность, что объект принадлежит классу k. А величина  оценивает долю объектов в этом классе, которые отстоят от центроида дальше, чем X.
оценивает долю объектов в этом классе, которые отстоят от центроида дальше, чем X.