Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
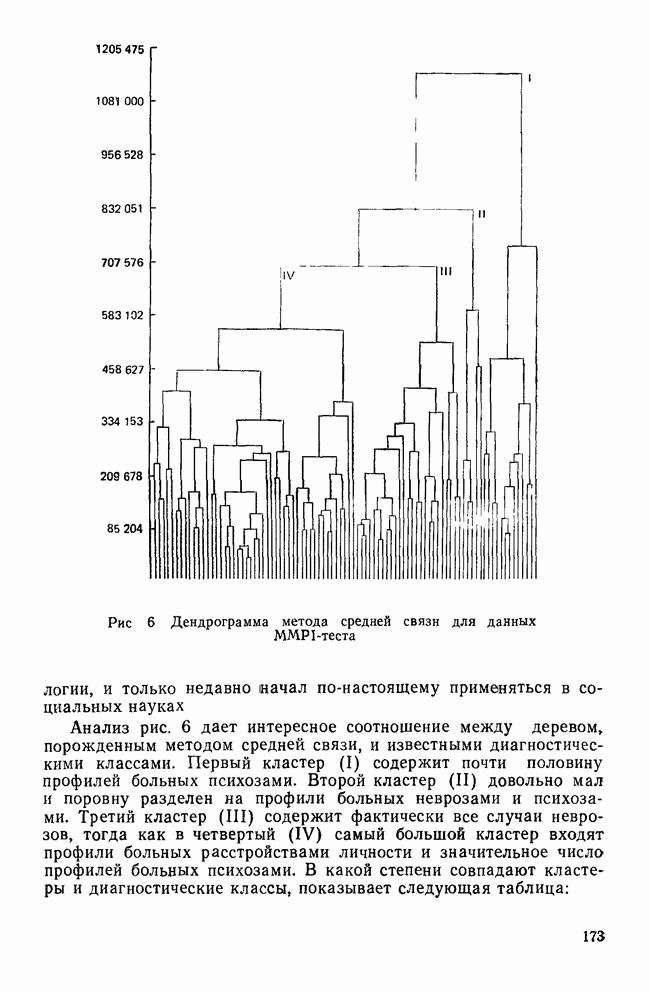
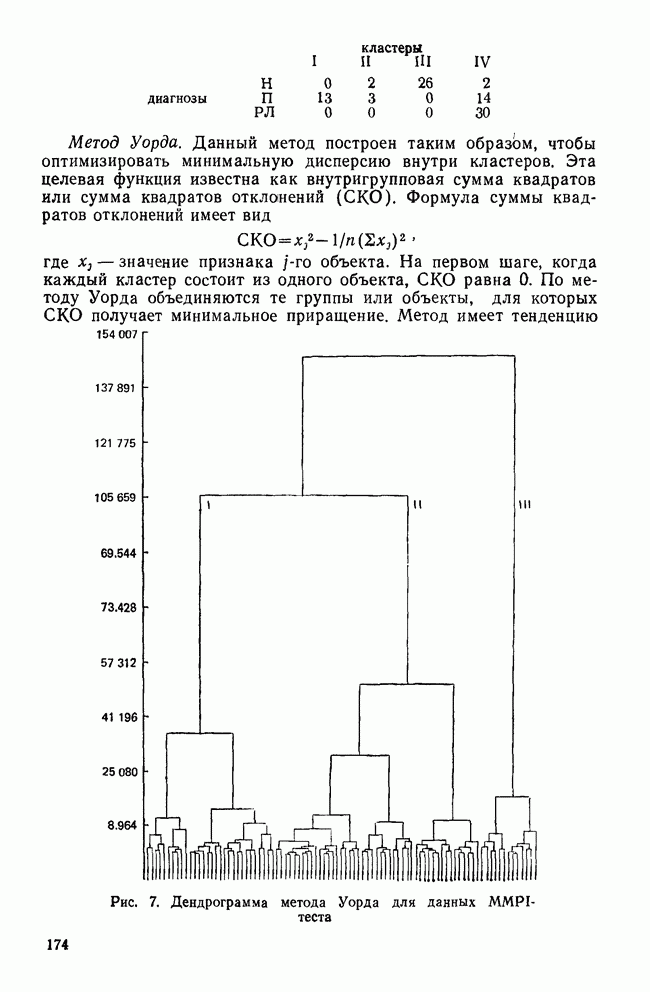
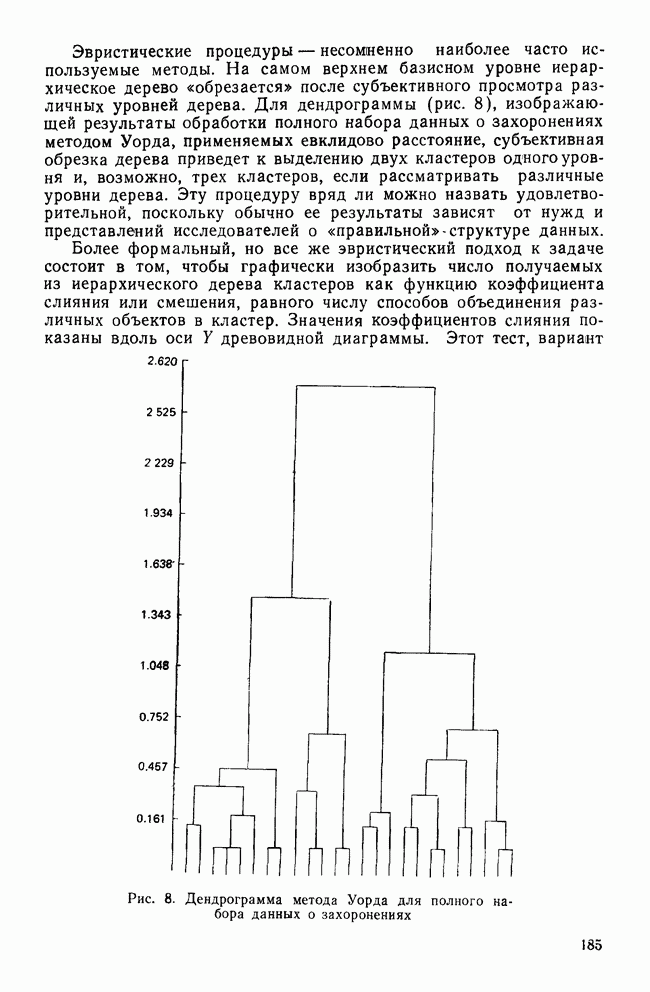
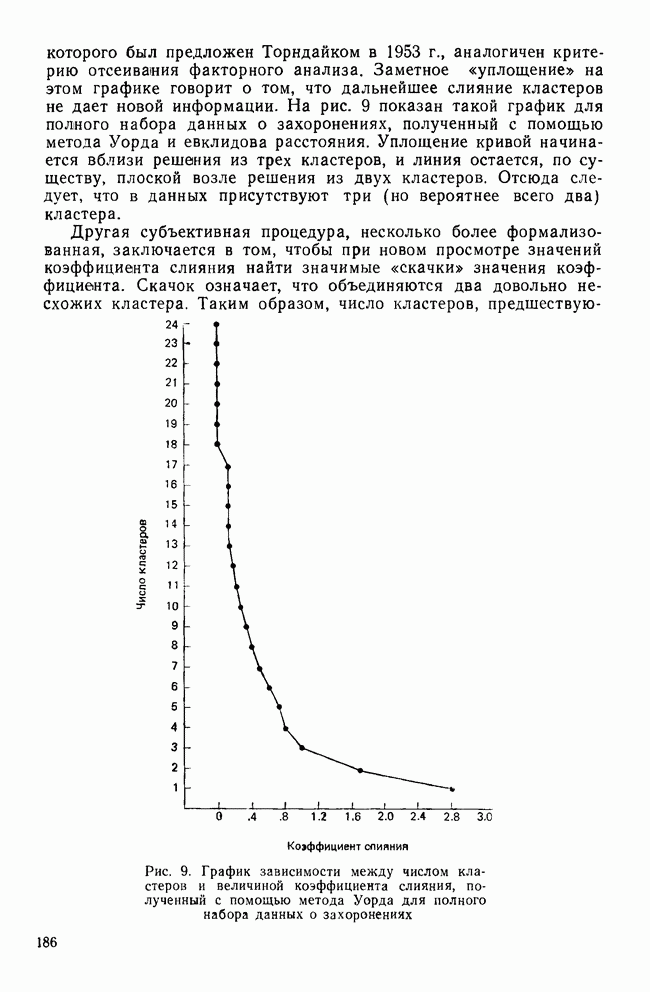
VI. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯНАРУШЕНИЕ ПРЕДПОЛОЖЕНИИМы уже немного говорили о проблемах, возникающих, когда данные не удовлетворяют математическим предположениям дискриминантного анализа. Труднее всего удовлетворить требованиям о нормальности многомерного распределения дискриминантных переменных и равенстве ковариационных матриц классов. Некоторые исследователи (см., в частности, Lachenbruch, 1975) показали, что дискриминантный анализ является достаточно устойчивым методом, допускающим некоторые отклонения от этих предположений. Кроме того, не все выводы дискриминантного анализа требуют их выполнения. Предположение о нормальности многомерного распределения важно для проверки значимости, где сопоставляются статистики, вычисленные по выборочным данным, с теоретическим вероятностным распределением для этой статистики. Можно вычислить теоретическое распределение, сделав некоторые удобные математические предположения (например, такие, как требование, чтобы генеральная совокупность имела многомерное нормальное распределение). Если интересующая нас генеральная совокупность не удовлетворяет этому требованию, истинное выборочное распределение статистики будет отличаться от распределения, полученного теоретически. Различия между этими двумя распределениями могут быть очень малыми или очень большими в зависимости от степени нарушения предположений. Лахенбрук (1975) показал, что дискриминантный анализ не очень чувствителен к небольшим нарушениям предположения о нормальности. Это приводит лишь к некоторым потерям в эффективности и точности. Предположение о нормальности играет важную роль в классификации, основанной на использовании вероятности принадлежности к классу. Эти вероятности вычисляются исходя из распределения хи-квадрат, что оправдано лишь, когда дискриминантные переменные имеют многомерное нормальное распределение. Если это предположение не выполняется, вычисленные вероятности будут неточными. Может оказаться, например, что вероятности для некоторых групп будут преувеличены, в то время как вероятности для других групп — недооценены. Следовательно, эта процедура не будет оптимальной в смысле уменьшения числа неправильных классификаций. Если ковариационные матрицы классов не равны, мы стараемся установить искажения дискриминантных функций и уравнений классификации. Один источник ошибок связан с вычислением внутригрупповой ковариационной матрицы (или других, имеющих отношение к матрице W). Внутригрупповая ковариационная матрица служит оценкой общей ковариационной матрицы классов для генеральной совокупности, образованной выборками из нескольких классов. Если матрицы для всей генеральной совокупности не равны, матрицу W все еще можно вычислить, но она уже не будет способствовать упрощению различных формул. Следовательно, канонические дискриминантные функции не дадут максимального разделения классов и вероятности принадлежности к классам будут искажены. Хотя, кажется, нет никаких процедур улучшения свойств канонических дискриминантных функций в некоторых цитированных выше работах предлагается использовать ковариационные матрицы отдельных классов для вычисления вероятности принадлежности к классу (так называемая «квадратичная дискриминация»). Дискриминантный анализ может быть проведен и когда предположения о нормальности многомерного распределения и равенстве ковариационных матриц классов не выполняются. Задача при этом состоит в интерпретации результатов. Что они означают? И какое количество ошибок считается допустимым? В некоторых учебниках предлагаются возможные процедуры, но они приводят лишь к минимальным улучшениям, поскольку исходные отклонения не были большими. Конечно, нам трудно узнать, сколько ошибок было сделано в связи с конкретными нарушениями предположений. Однако здесь могут оказаться полезными некоторые статистики, не зависящие от этих предположений. При определении значимости и минимального числа канонических дискриминантных функций мы не полагаемся на А-статистику Уилкса или связанный с ней тест значимости, основанный на хи-квадрат распределении. Вместо этого мы можем рассмотреть каноническую корреляцию и относительное процентное содержание, как было показано в разд. II. Если любая из данных величин окажется небольшой, функция будет для нас малоинтересной, даже если она — статистически значима. Тесты значимости представляют наибольший интерес в случае малых выборок. Таким образом, имея с ними дело, мы должны с большим вниманием отнестись к удовлетворению предположений. Однако в случае больших выборок мы может обойтись без тестов значимости или использовать их «консервативно», когда наши данные нарушают предположения. При классификации точность предсказания наиболее важна для объектов, расположенных вблизи границы. Если некоторый объект с вероятностью 0,90 принадлежит к классу 1 и только с вероятностью 0,10 — к классу 2, то нам нечего беспокоиться о небольших неточностях, возникающих из-за нарушения предположений. Хотя определенная вероятность принадлежности к классу может быть неверной, наше решение приписать объект к классу 1 будет правильным, если ошибка в вычислении вероятностей не будет большой. С другой стороны, если объект имеет вероятности 0,51 для класса 1 и 0,49 для класса 2, мы должны быть очень осторожны, принимая решение. Здесь небольшая ошибка из-за нарушения предположений может привести к неправильной классификации. Если исследователя интересует математическая модель, с помощью которой можно точно предсказывать принадлежность к классу или которая служит разумным описанием реального мира, то лучше всего воспользоваться процентом правильных классификаций. Если этот процент высок, то нарушение предположений не нанесет большого вреда. Однако, если процент правильных классификаций низок, мы не можем сказать, является ли причиной этого нарушение предположений или использование плохих дискриминантных переменных.
|
 |
Оглавление
|