Пред.
След.
Макеты страниц
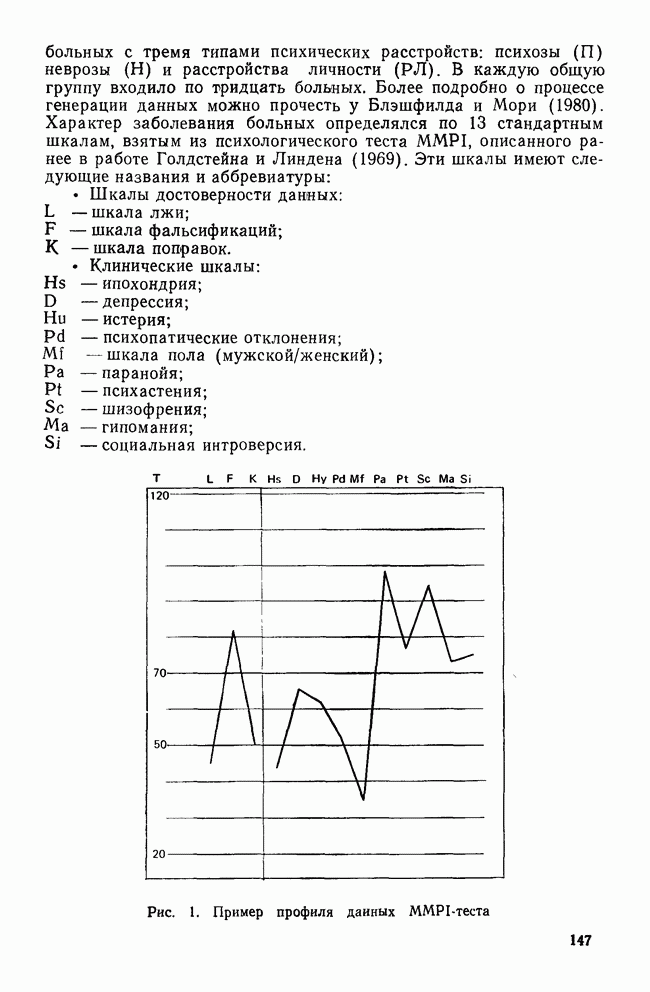
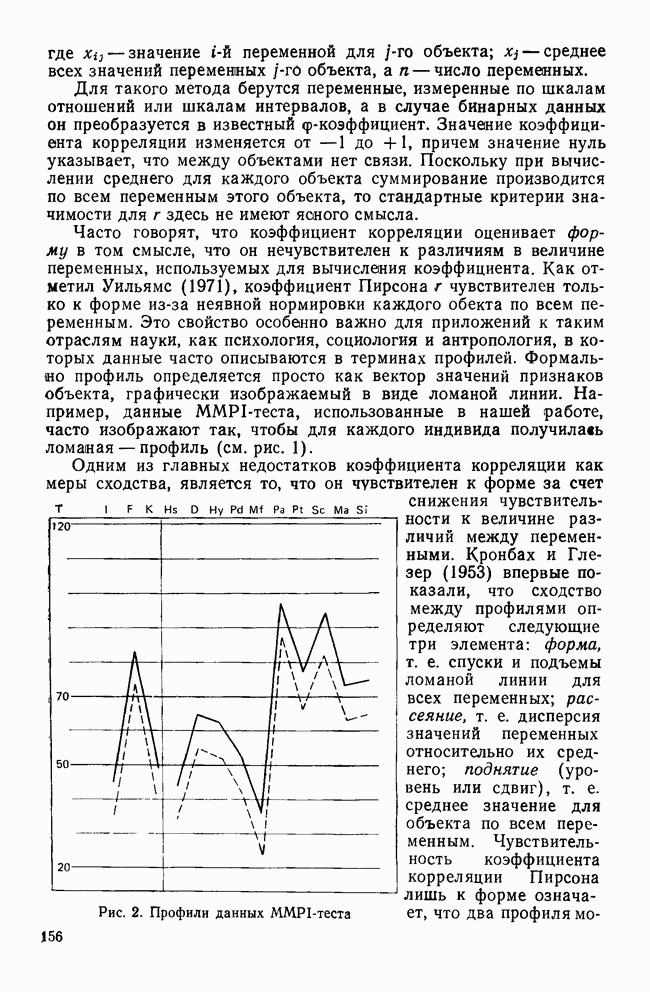
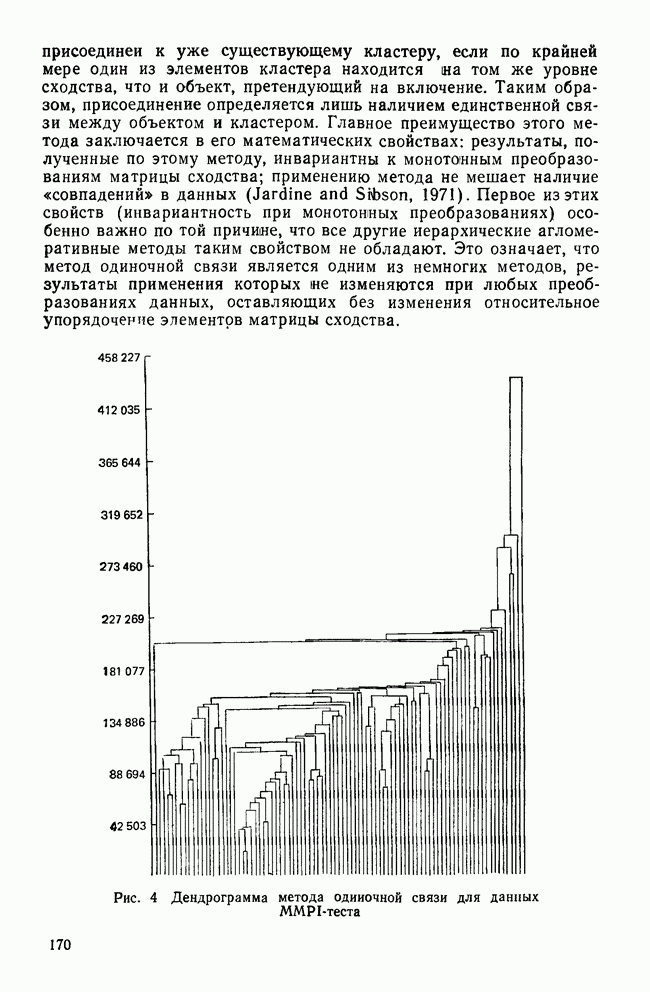
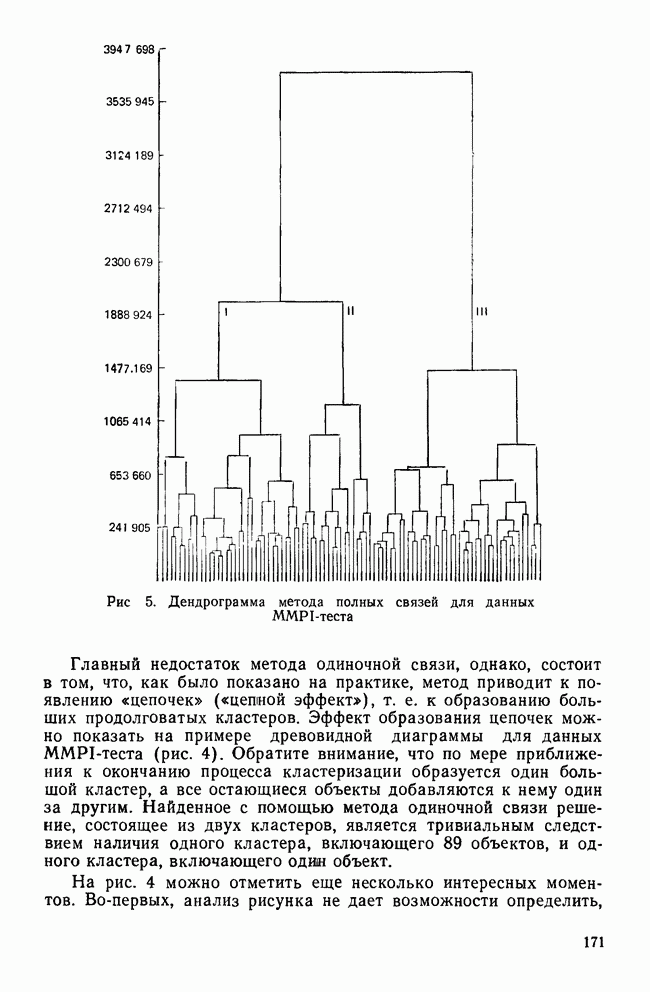
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
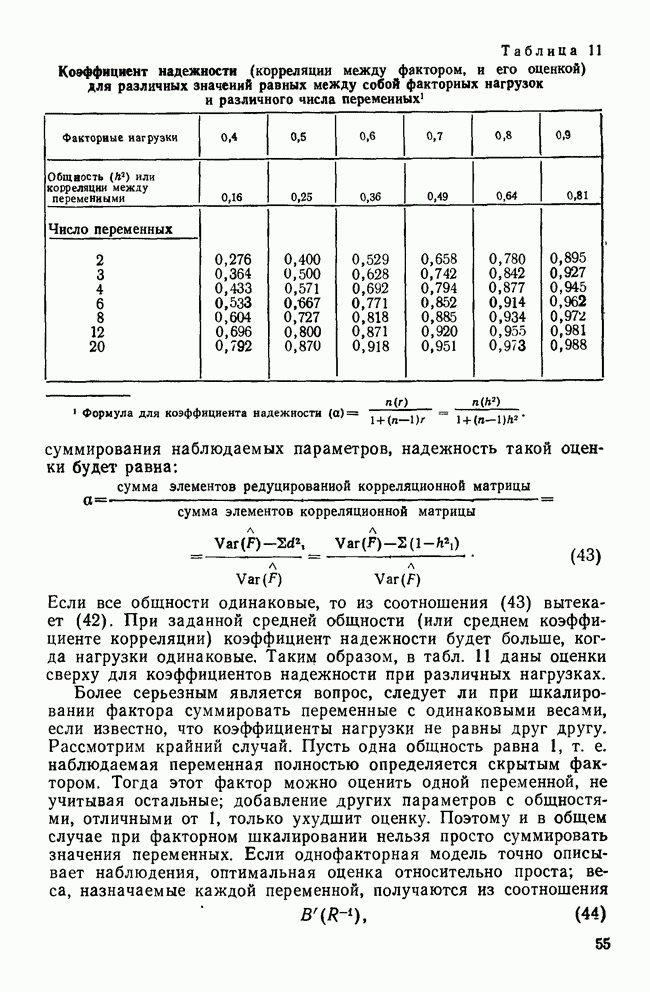
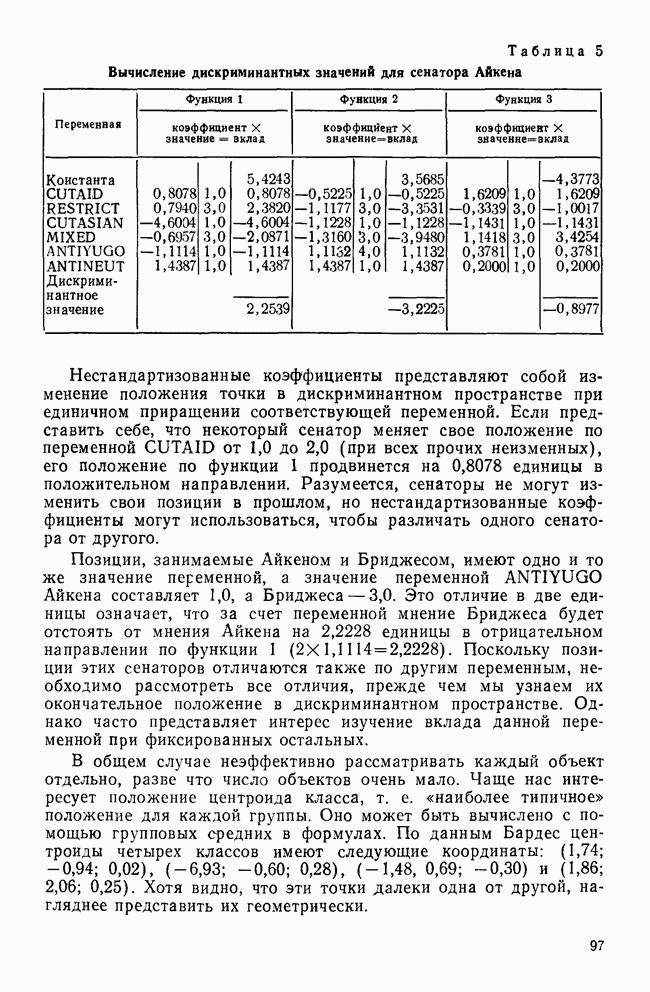
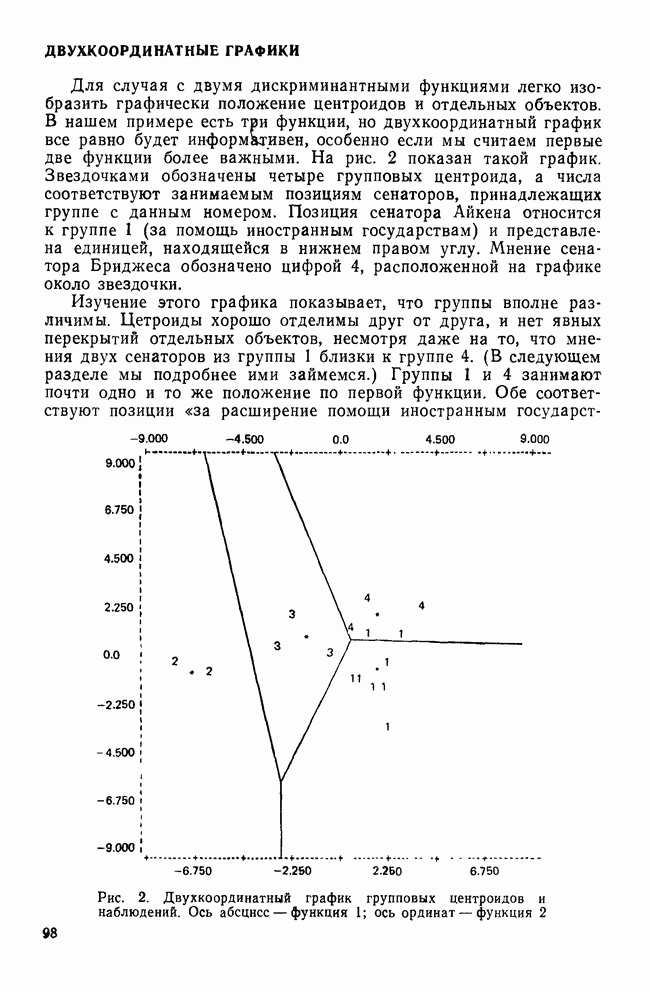
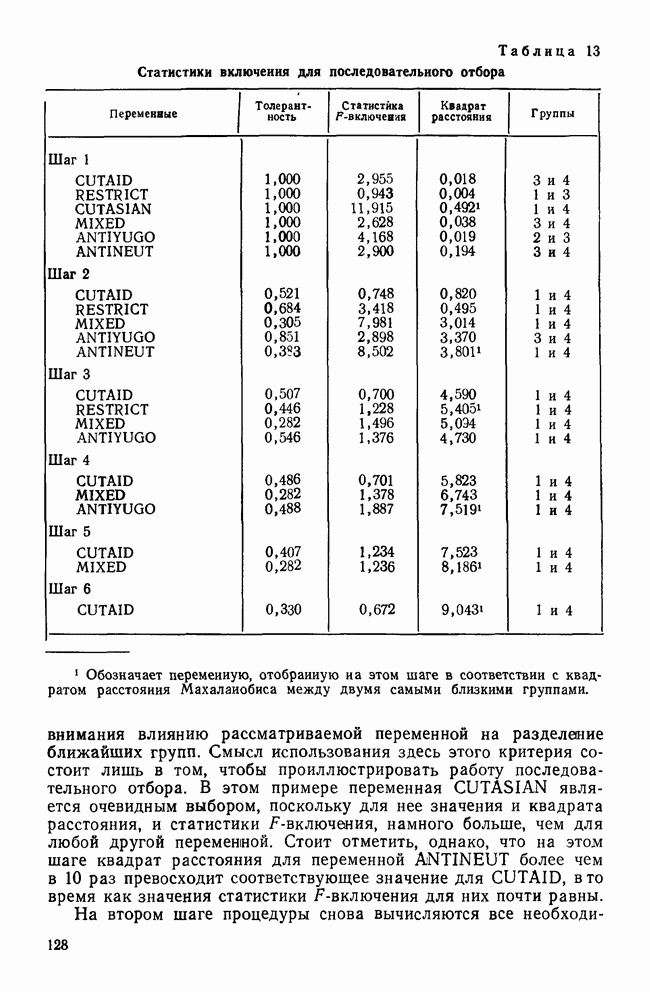
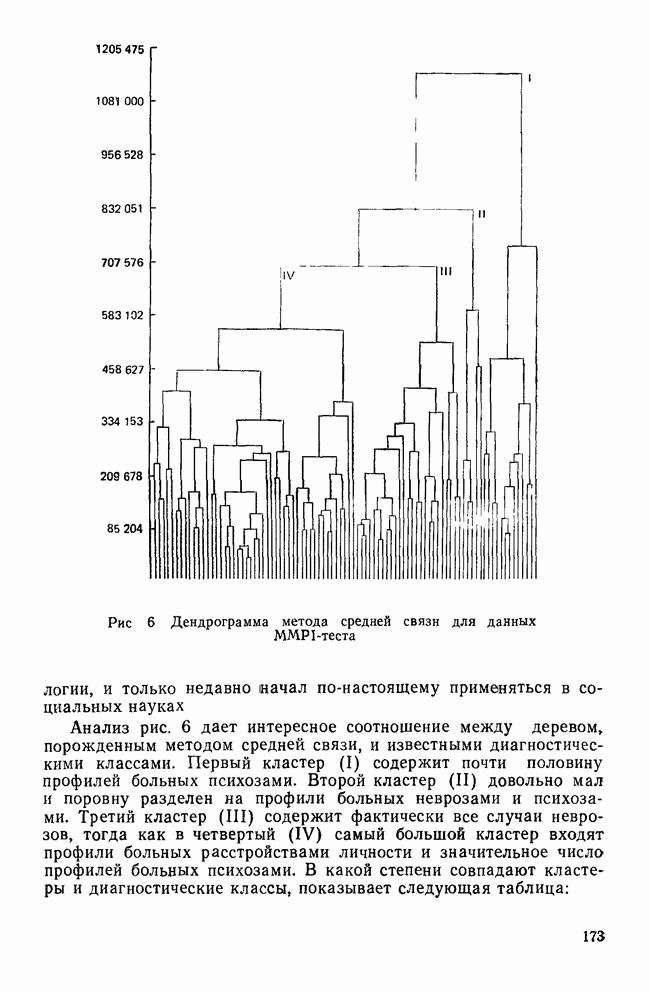
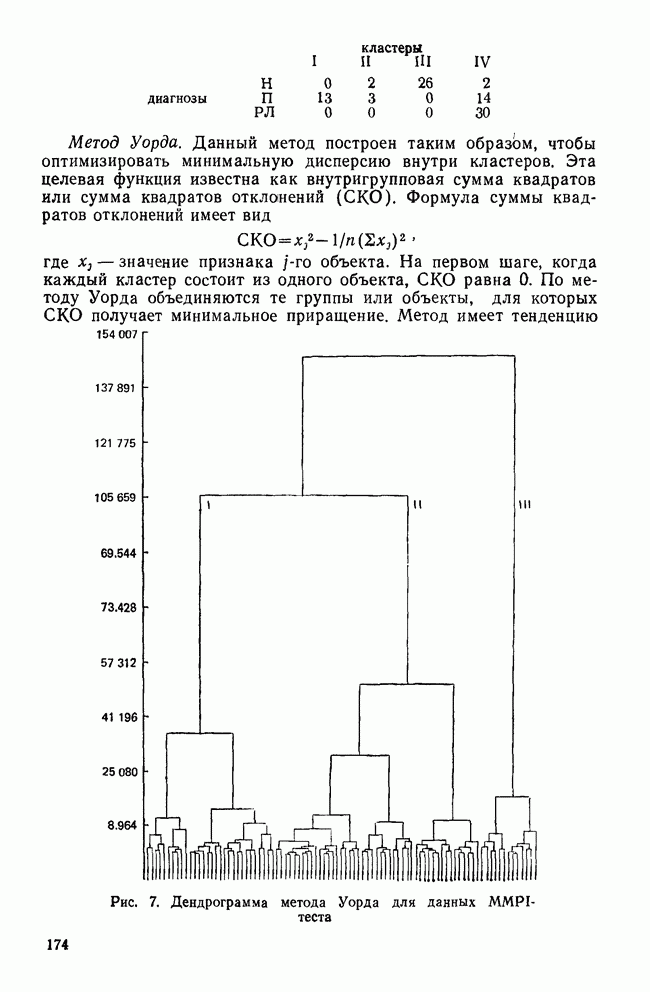
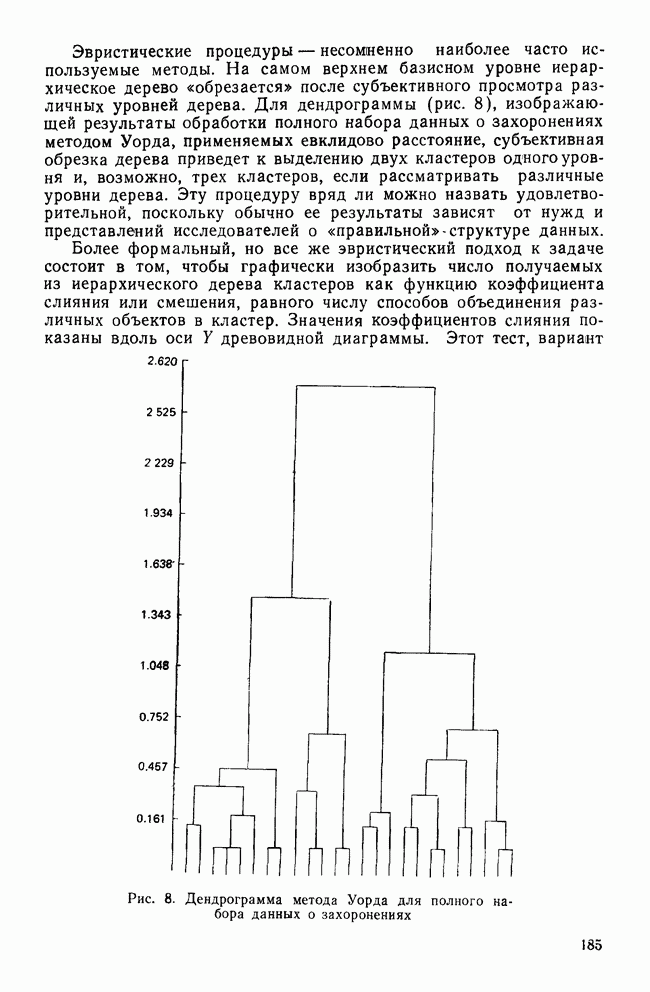
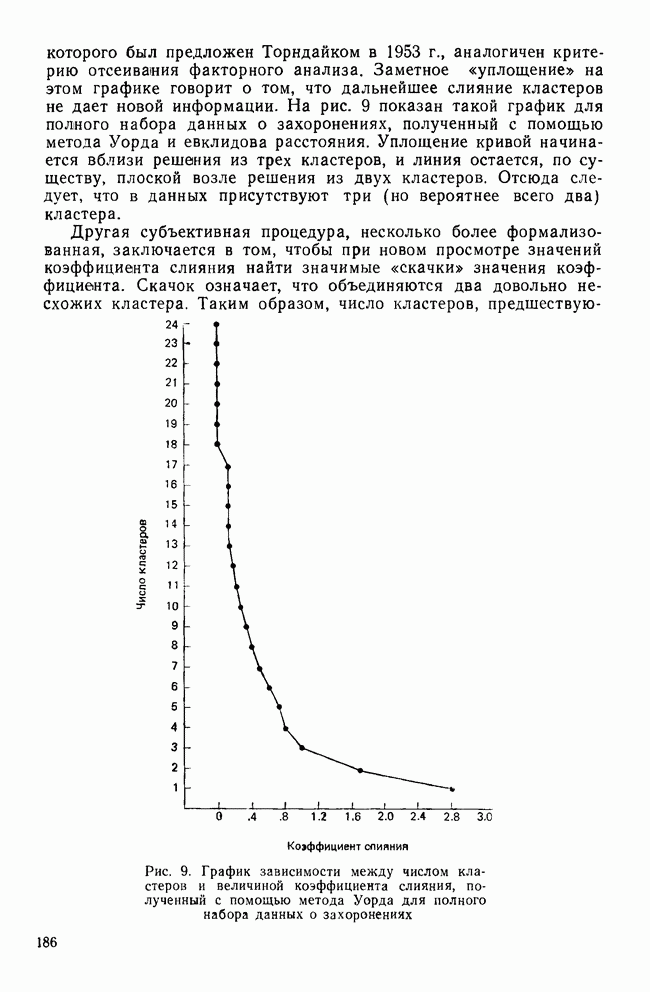
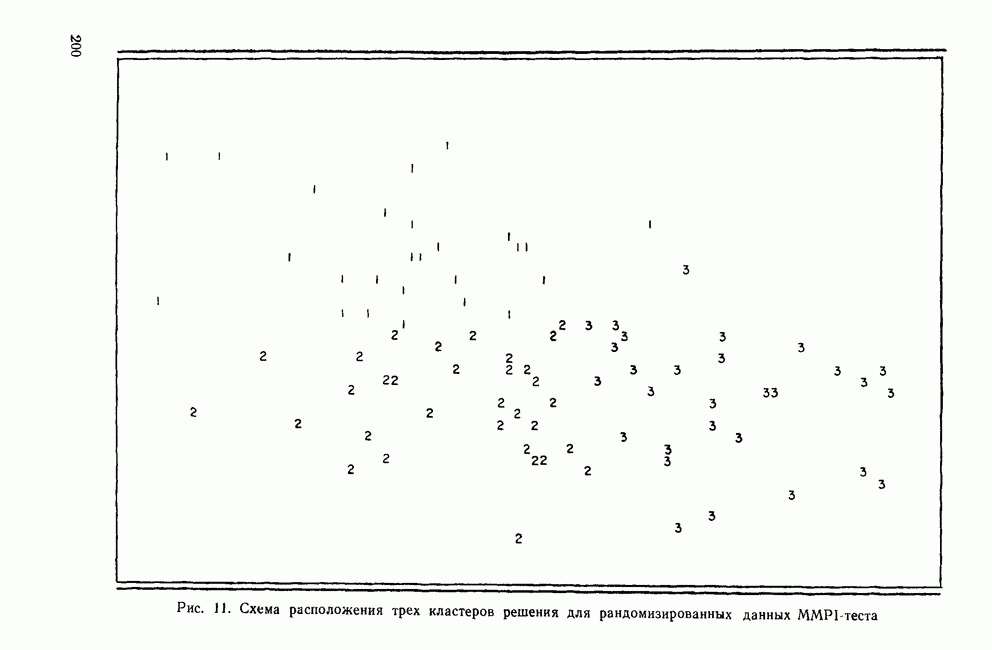
ИТЕРАТИВНЫЕ МЕТОДЫ ГРУППИРОВКИВ отличие от иерархических агломеративных методов итеративные методы группировки кластерного анализа не имели широкого применения, и специфика использования этих методов не до конца понимается их потенциальными пользователями. Большинство итеративных методов группировки работает следующим образом: 1. Начать с исходного разбиения данных на некоторое заданное число кластеров; вычислить центры тяжести этих кластеров. 2. Поместить каждую точку данных в кластер с ближайшим центром тяжести. 3. Вычислить новые центры тяжести кластеров; кластеры не заменяются на новые до тех пор, пока не будут просмотрены полностью все данные. 4. Шаги 2 и 3 повторяются до тех пор, пока не перестанут меняться кластеры. Данные MMPI-теста были подвергнуты кластеризации с помощью процедуры k-средних процедурой GLUSTAN (Wishart, 1982) для того, чтобы продемонстрировать основные черты итеративных методов. Первый шаг состоит в формировании исходного разбиения данных. Процедура CLUSTAN произвольно распределяет 90 объектов по трем кластерам После этого определяются евклидовы расстояния между всеми объектами и центрами тяжести трех кластеров и объекты приписываются к ближайшему центру тяжести. Для данных MMPI-теста это означает, что 51 объект перемещается из кластера, в котором они находились первоначально, в кластер с ближайшим центром тяжести. После всех перемещений вычисляются центры тяжести новых кластеров. Эти центры тяжести уже совсем другие и приближаются к реальным центрам трех групп в данных В отличие от иерархических агломеративных методов, которые требуют вычисления и хранения матрицы сходств между объектами размерностью Эти методы порождают кластеры одного ранга, которые не являются вложенными, и поэтому не могут быть частью иерархии. Большинство итеративных методов не допускает перекрытия кластеров. Несмотря на свои привлекательные черты, итеративные методы группировки имеют существенное ограничение. Наиболее простой способ отыскать оптимальное разбиение множества данных с помощью итеративного метода заключается в образовании всевозможных разбиений этого множества данных. Но такое, казалось бы, простое с точки зрения математических вычислений решение возможно лишь для очень небольших и тривиальных задач. Для 15 объектов и 3 кластеров этот подход требует рассмотрения 217 945 728 000 конкретных разбиений, что, очевидно, за пределами возможностей современных вычислительных машин. Поскольку все допустимые разбиения даже для маленьких наборов данных не могут быть рассмотрены, исследователи разработали широкий круг эвристических процедур которые можно использовать для выбора небольшого подмножества из всех разбиений данных, чтобы найти или хотя бы приблизиться к оптимальному разбиению набора данных. Эта ситуация подобна той, с которой сталкиваются при эвристическом подходе к разработке правил объединения для иерархических агломеративных методов. Процедуры выбора разумны и правдоподобны, но только малая часть из них имеет достаточное статистическое обоснование. Большинство эвристических, вычислительных и статистических свойств итеративных методов группировки могут быть описаны с помощью трех основных факторов: 1) выбора исходного разбиения; 2) типа итерации и 3) статистического критерия. Эти факторы могут сочетаться огромным количеством способов образуя алгоритмы отбора данных при определении оптимального разбиения. Не удивительна, что их различные комбинации ведут к разработке методов, порождающих разные результаты при работе с одними и теми же данными. Исходное разбиение. Есть два основных способа начать итеративный процесс: определить начальные точки или подобрать подходящее начальное разбиение. Начальные точки определяют центры тяжести кластеров (Anderberg, 1973). Когда используются начальные точки, то при первом просмотре точки данных приписываются к ближайшим центрам тяжести кластеров. Задание начального разбиения требует детального распределения данных по кластерам. В этой процедуре центр тяжести каждого кластера определяется как многомерное среднее объектов кластера. Начальные разбиения могут выбираться случайным образом (как это было в примере с данными MMPI-теста) или же задаваться каким-либо образом самим пользователем (например, пользователь может взять в качестве исходного разбиения решение, полученное иерархической кластеризацией). Тип итерации. Данный момент итерационного процесса связан со способом распределения объектов по кластерам. И опять имеются два основных вида итераций: по принципу Итерации по принципу В итерациях, работающих по принципу «восхождения на холм», вместо присоединения объектов к кластеру в зависимости от расстояния между объектом и центром тяжести кластера, перемещение объектов производится исходя из того, будет или нет предполагаемое перемещение оптимизировать значение некоторого статистического критерия. Статистический критерий. Методы, основанные на принципе «восхождения на холм», используют один или несколько следующих критериев (функций качества кластеризации): Подобно иерархическим агломеративным методам каждый из статистических критериев находит кластеры определенного вида. Критерий Его использование, однако, предполагает, что у кластеров будет одна и та же форма, и это может вызвать некоторые затруднения в прикладном анализе данных. Скотт и Саймонс (1971) показали, что критерий Одна из главных проблем, присущая всем итеративным методам, — проблема субоптимального решения. Поскольку эти методы могут выбрать лишь очень малую часть всех возможных разбиений, есть определенная вероятность, что будет выбрано субоптимальное разбиение. Такую проблему называют также проблемой локального (в противоположность глобальному) оптимума. Действительно, объективного способа определить, является ли полученное с помощью итеративного метода группировки решение глобально оптимальным, нет. Однако один подход к решению этой проблемы состоит в том, чтобы применять метод кластеризации совместно с подходящей процедурой проверки результата на достоверность (см. разд. IV). Исследование методом Монте-Карло работы итеративных методов показало, что главная причина появления субоптимальных решений заключается в плохом исходном разбиении набора данных (Blashfield and AJdenderfer, 1978а; Milligan, 1980). Итерации по принципу А-средних чрезвычайно чувствительны к плохим начальным разбиениям и дело еще более усложняется, когда начальное приближение выбирается случайным образом (очень распространенная возможность, предоставляемая многими пакетами программного обеспечения итеративных методов). Блэшфилд и Ол-дендерфер (1978а) показали, что разумный выбор начального разбиения лишь ненамного улучшает положение дел, но Миллиган (1980) продемонстрировал, что итерационный процесс по принципу
|
 |
Оглавление
|











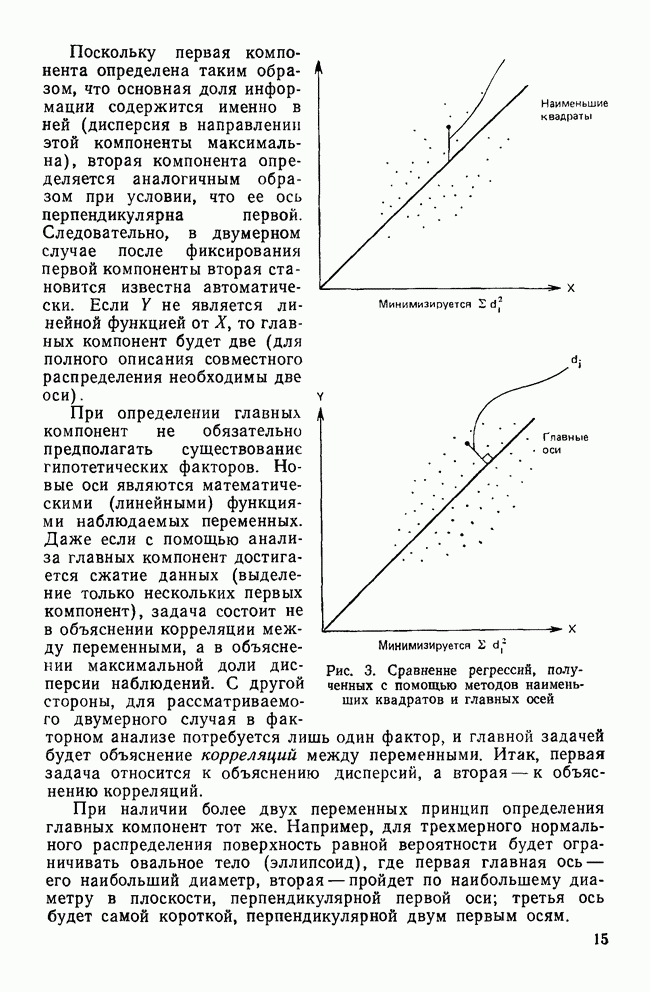








































































































































































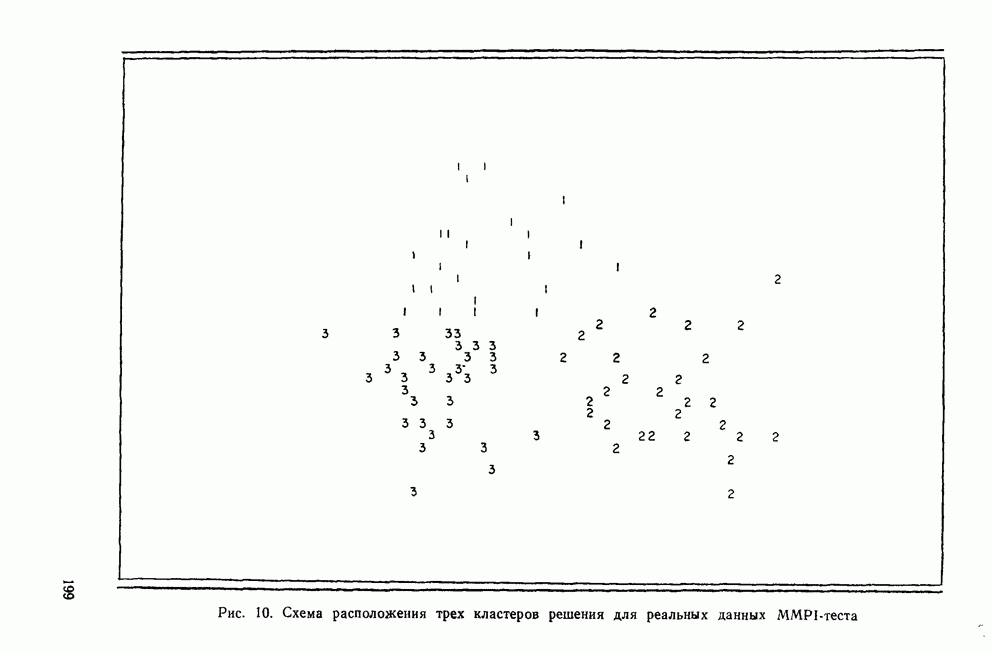















 Значение k задается пользователем. Затем вычисляются центры тяжести кластеров.
Значение k задается пользователем. Затем вычисляются центры тяжести кластеров.
 -теста. На втором шаге все повторяется, но на этот раз производится восемь перемещений. Находятся новые центры тяжести и переходим к следующему шагу. На третьем шаге никаких перемещений не происходит. Все объекты приписываются к ближайшим центрам тяжести кластеров.
-теста. На втором шаге все повторяется, но на этот раз производится восемь перемещений. Находятся новые центры тяжести и переходим к следующему шагу. На третьем шаге никаких перемещений не происходит. Все объекты приписываются к ближайшим центрам тяжести кластеров.
 , итеративные методы работают непосредственно с первичными данными. Поэтому с их помощью возможно обрабатывать довольно большие множества данных. Более того, итеративные методы делают несколько просмотров данных и могут компенсировать последствия плохого исходного разбиения данных, тем самым устраняя самый главный недостаток иерархических агломеративных методов.
, итеративные методы работают непосредственно с первичными данными. Поэтому с их помощью возможно обрабатывать довольно большие множества данных. Более того, итеративные методы делают несколько просмотров данных и могут компенсировать последствия плохого исходного разбиения данных, тем самым устраняя самый главный недостаток иерархических агломеративных методов.
 -средних и по принципу «восхождения на холм».
-средних и по принципу «восхождения на холм».
 -средних (они называются также «итерациями по принципу ближайшего центра» и «перемещающими итерациями») заключаются просто в перемещении объектов в кластер с ближайшим центром тяжести. Итерации по принципу
-средних (они называются также «итерациями по принципу ближайшего центра» и «перемещающими итерациями») заключаются просто в перемещении объектов в кластер с ближайшим центром тяжести. Итерации по принципу  -средних могут быть либо комбинаторными, либо некомбинаторными. В первом случае перевычисление центра тяжести кластера производится после каждого изменения его состава, а во втором случае — лишь после того, как будет завершен просмотр всех данных. Кроме того, итерации по принципу -средних подразделяются на исключающие и включающие. В итерациях исключающего типа после вычисления центра тяжести кластера рассматриваемый объект удаляется из кластера, а в итерациях включающего типа — помещается в кластер.
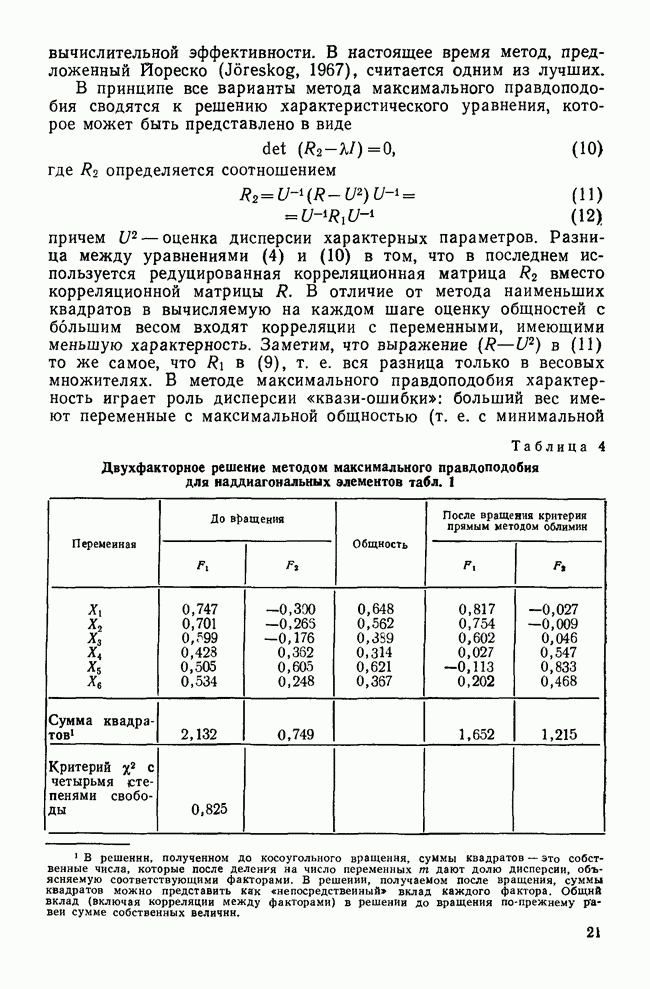
-средних могут быть либо комбинаторными, либо некомбинаторными. В первом случае перевычисление центра тяжести кластера производится после каждого изменения его состава, а во втором случае — лишь после того, как будет завершен просмотр всех данных. Кроме того, итерации по принципу -средних подразделяются на исключающие и включающие. В итерациях исключающего типа после вычисления центра тяжести кластера рассматриваемый объект удаляется из кластера, а в итерациях включающего типа — помещается в кластер.
 и наибольшее собственное значение матрицы WB, где № — объединенная внутригрупповая ковариационная матрица, в В — объединенная межгрупповая ковариационная матрица. Каждая из этих статистик часто рассматривается в многомерном дисперсионном анализе (MANOVA); их применение выводится из статистической теории, заложенной в MANOVA. Фактически все четыре критерия связаны с обнаружением однородности кластеров в многомерном пространстве. Хотя в явном виде итерации по принципу
и наибольшее собственное значение матрицы WB, где № — объединенная внутригрупповая ковариационная матрица, в В — объединенная межгрупповая ковариационная матрица. Каждая из этих статистик часто рассматривается в многомерном дисперсионном анализе (MANOVA); их применение выводится из статистической теории, заложенной в MANOVA. Фактически все четыре критерия связаны с обнаружением однородности кластеров в многомерном пространстве. Хотя в явном виде итерации по принципу  -средних не применяют статистический критерий при перемещении объектов, неявно они оптимизируют критерий
-средних не применяют статистический критерий при перемещении объектов, неявно они оптимизируют критерий  Таким образом, процедура
Таким образом, процедура  -средних минимизирует дисперсию внутри каждого кластера. Важно отметить, однако, что итерации по принципам
-средних минимизирует дисперсию внутри каждого кластера. Важно отметить, однако, что итерации по принципам  -средних и «восхождения на холм», используя критерий
-средних и «восхождения на холм», используя критерий  приведут к различным результатам при одних и тех же исходных данных.
приведут к различным результатам при одних и тех же исходных данных.
 благоприятствует образованию гиперсферических, очень однородных кластеров. Более важно, что этот критерий чувствителен к простым преобразованиям первичных данных, например, таких, как нормировка. Поскольку критерий
благоприятствует образованию гиперсферических, очень однородных кластеров. Более важно, что этот критерий чувствителен к простым преобразованиям первичных данных, например, таких, как нормировка. Поскольку критерий  не зависит от преобразований или от выбора масштаба, порождаемые им кластеры не обязаны иметь гиперсферическую форму.
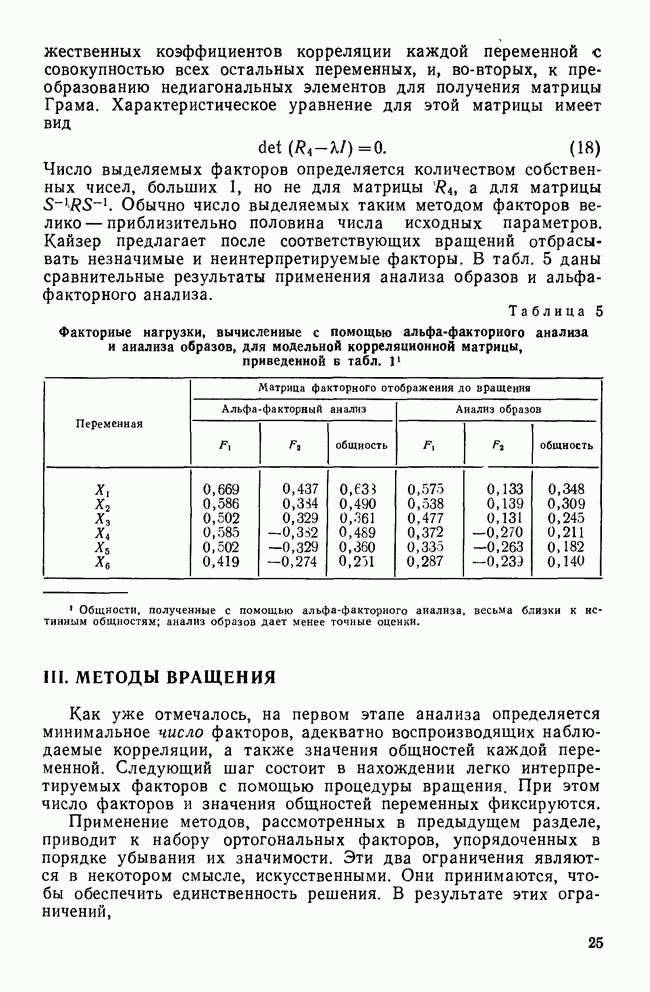
не зависит от преобразований или от выбора масштаба, порождаемые им кластеры не обязаны иметь гиперсферическую форму.
 имет тенденцию к созданию кластеров приблизительно одинаковых размеров, даже если таких кластеров нет в данных. К сожалению, характеристики других критериев известны плохо, так как они не подвергались широкому изучению и сравнению.
имет тенденцию к созданию кластеров приблизительно одинаковых размеров, даже если таких кластеров нет в данных. К сожалению, характеристики других критериев известны плохо, так как они не подвергались широкому изучению и сравнению.
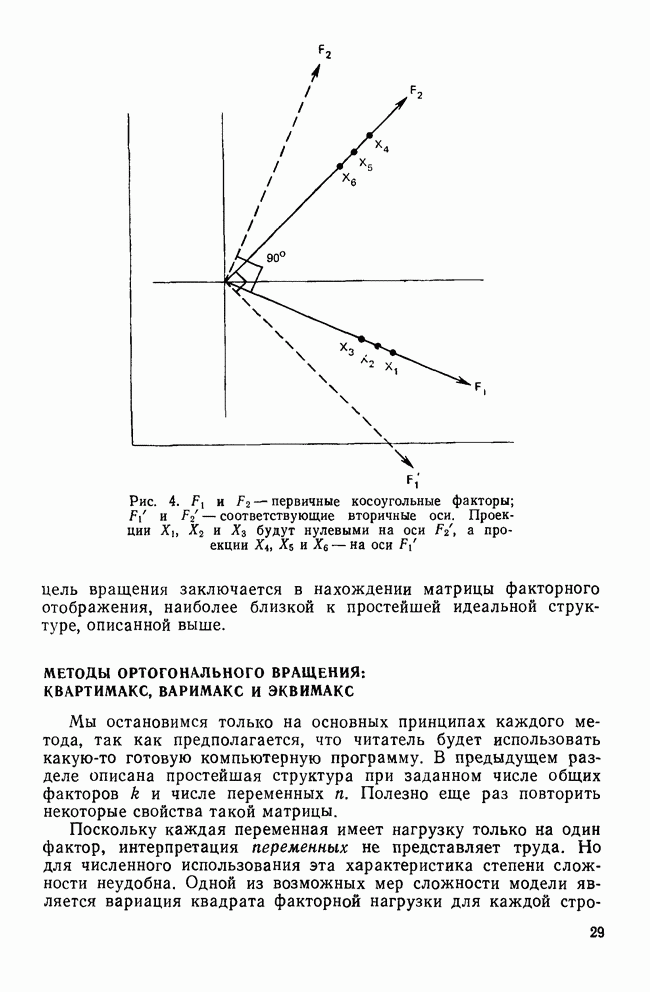
 -средних, использующий начальное разбиение, полученное кластеризацией по методу средней связи, приводит к лучшему восстановлению известной структуры данных по сравнению с прочими итеративными и иерархическими методами кластеризации. Другими исследователями было доказано, что итеративные методы дают оптимальное решение при любом начальном разбиении, если данные имеют хорошую структуру (Everitt, 1980; Bayne etal., 1980). Как видим, для решения этой задачи нужно провести больше исследований с помощью метода Монте-Карло.
-средних, использующий начальное разбиение, полученное кластеризацией по методу средней связи, приводит к лучшему восстановлению известной структуры данных по сравнению с прочими итеративными и иерархическими методами кластеризации. Другими исследователями было доказано, что итеративные методы дают оптимальное решение при любом начальном разбиении, если данные имеют хорошую структуру (Everitt, 1980; Bayne etal., 1980). Как видим, для решения этой задачи нужно провести больше исследований с помощью метода Монте-Карло.