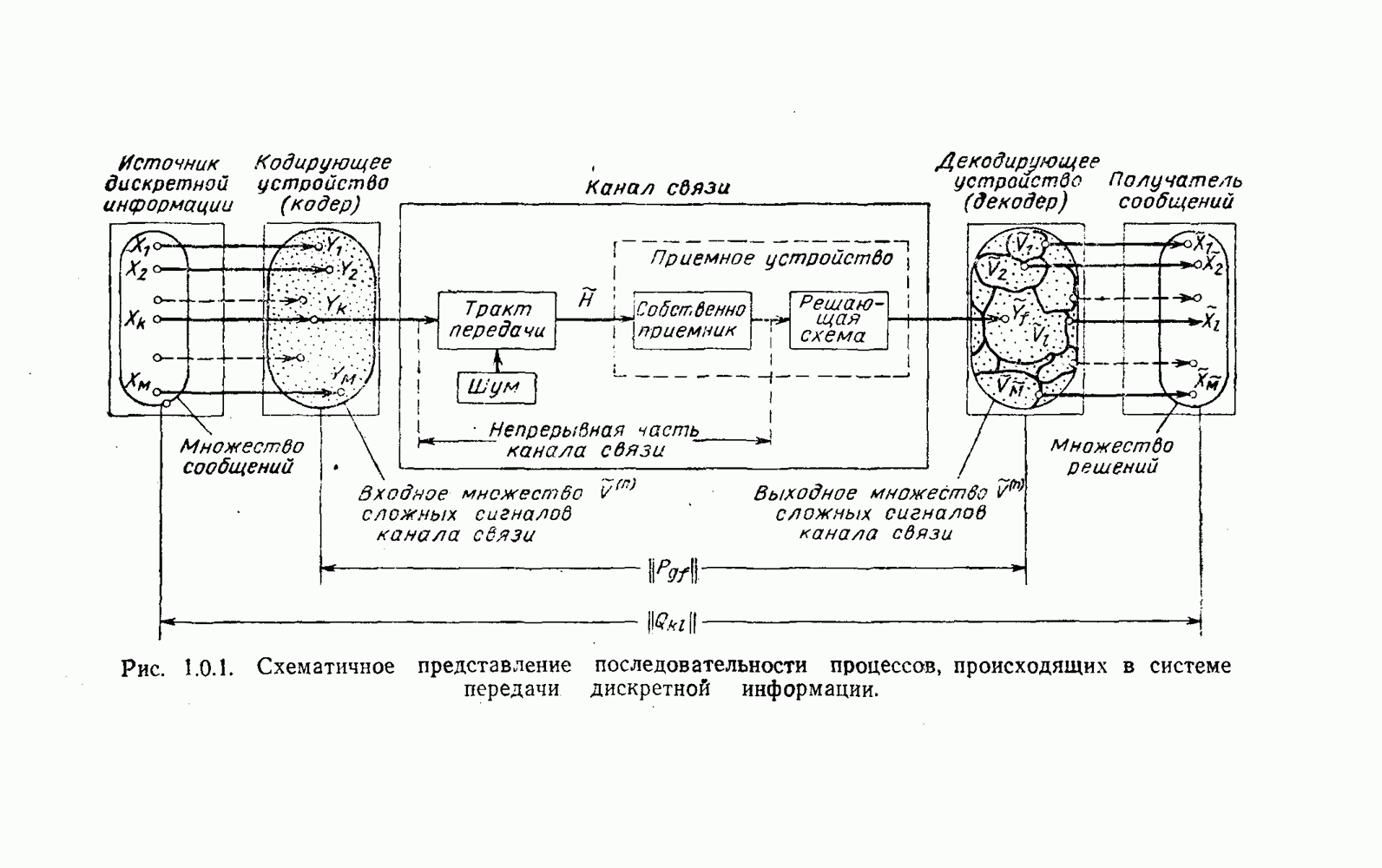
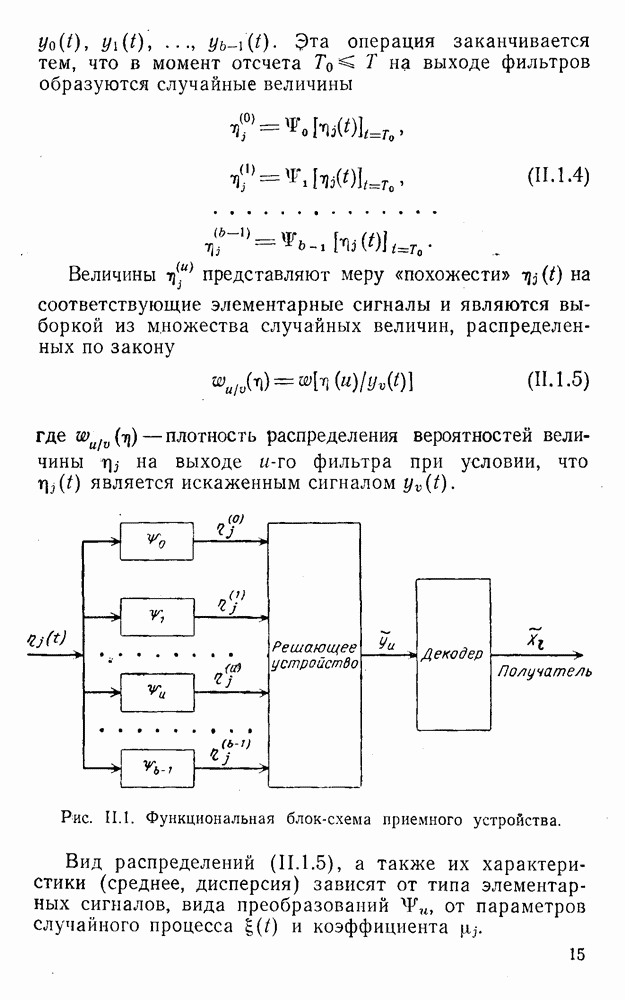
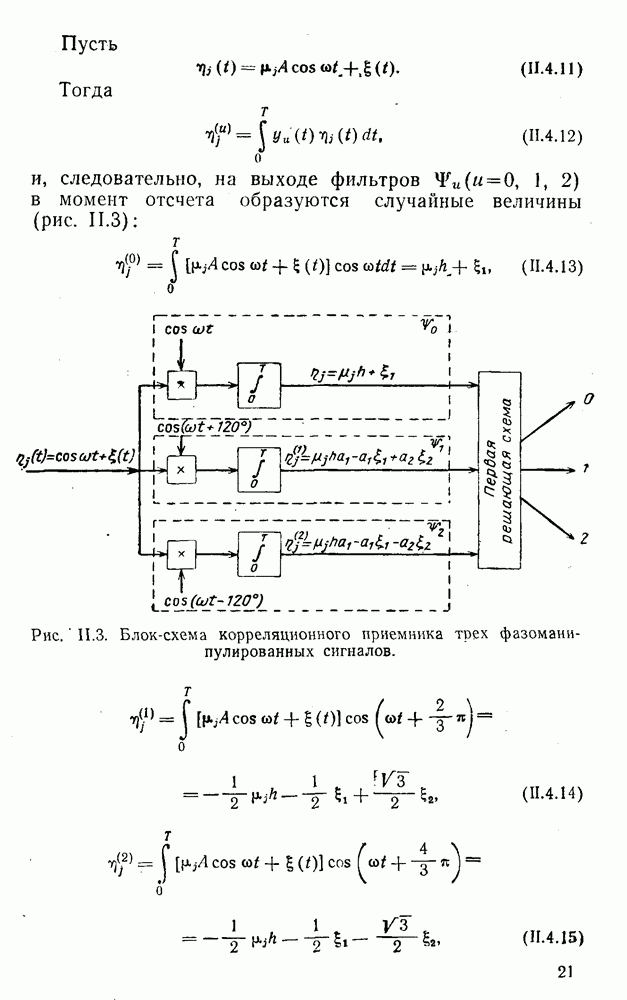
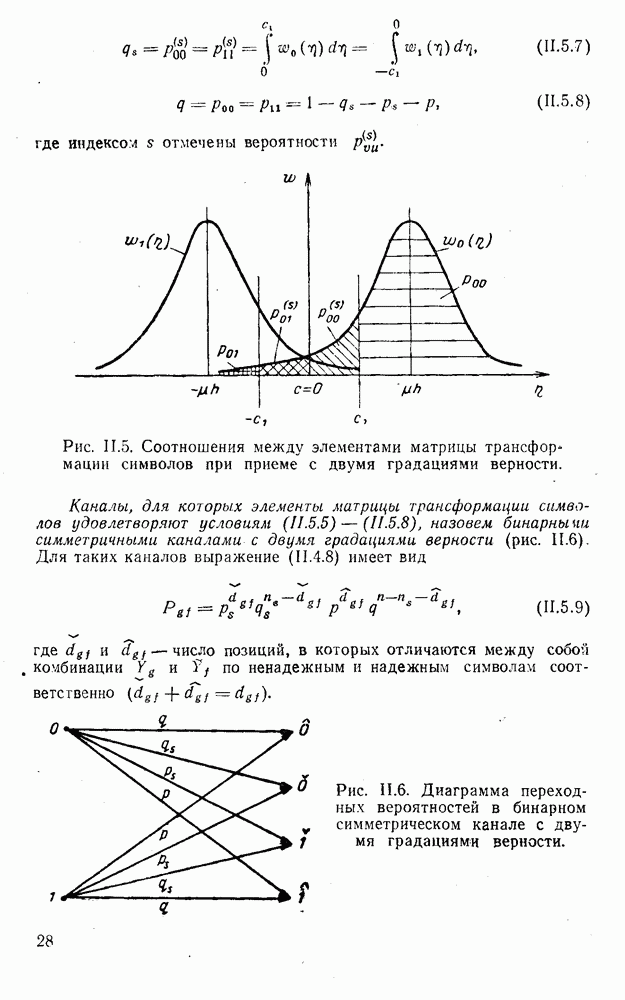
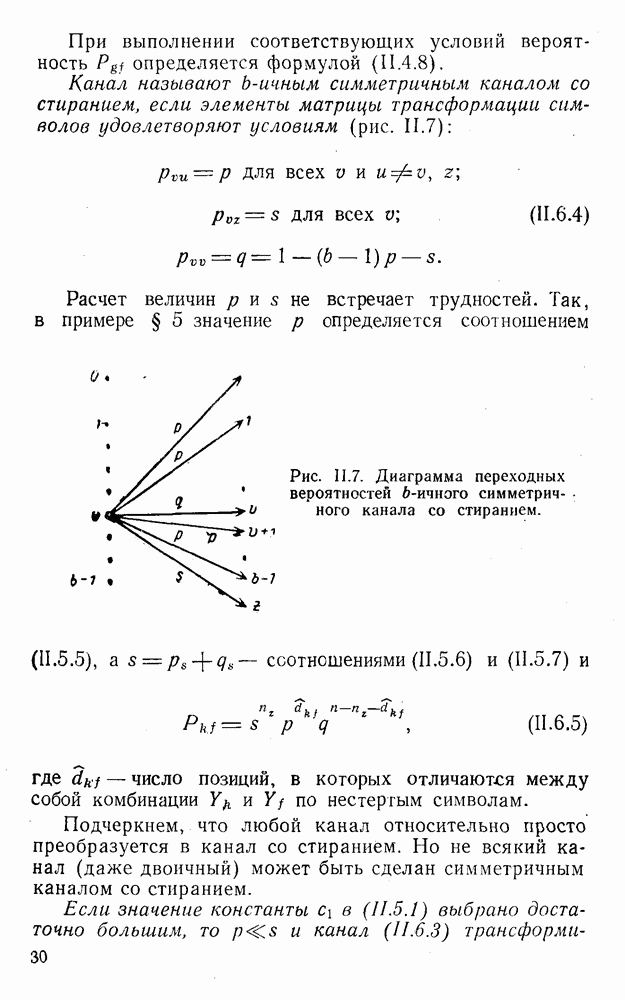
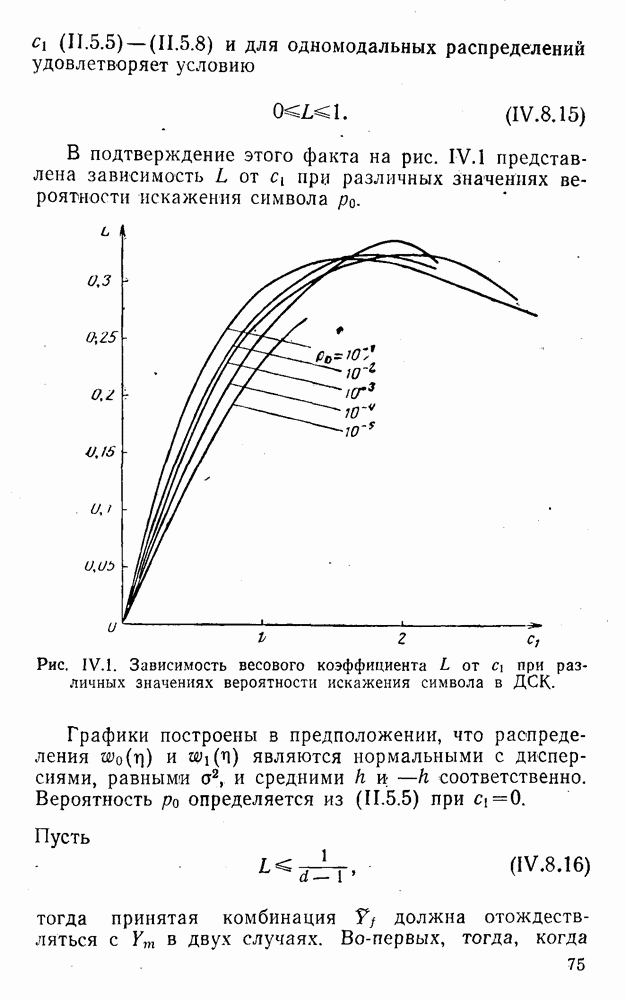
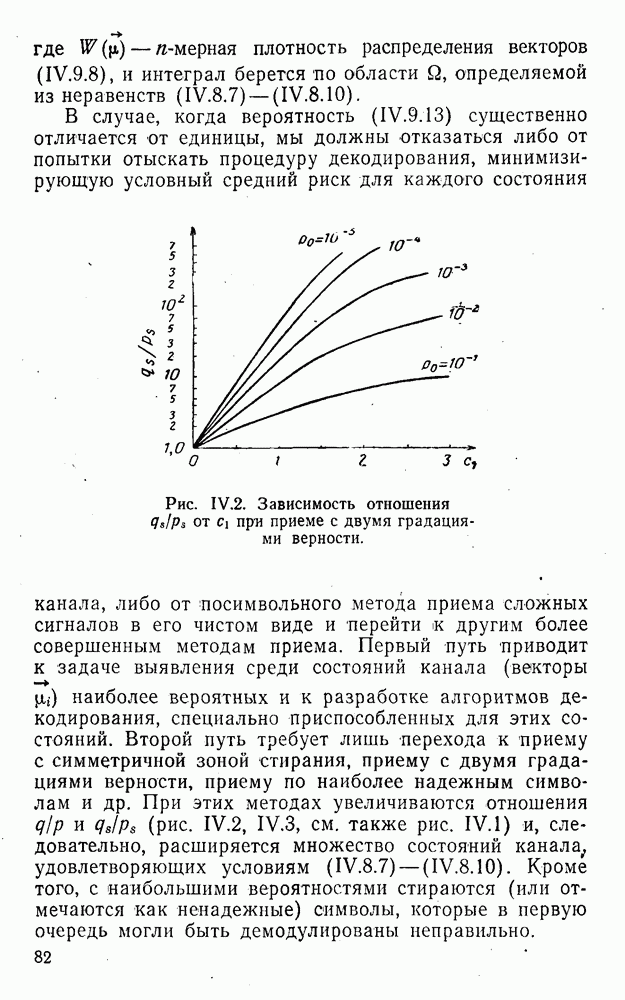
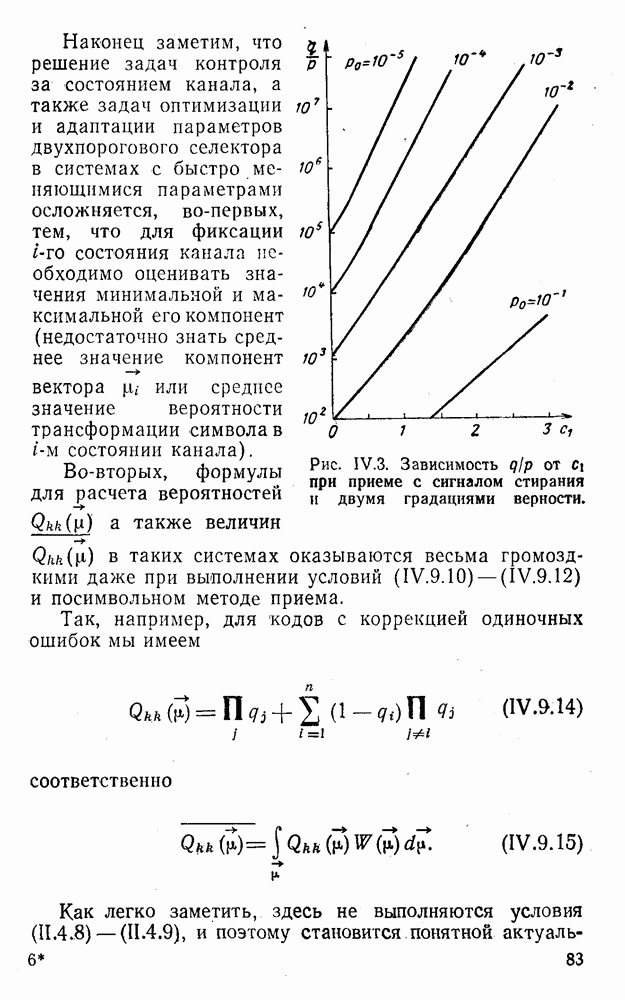
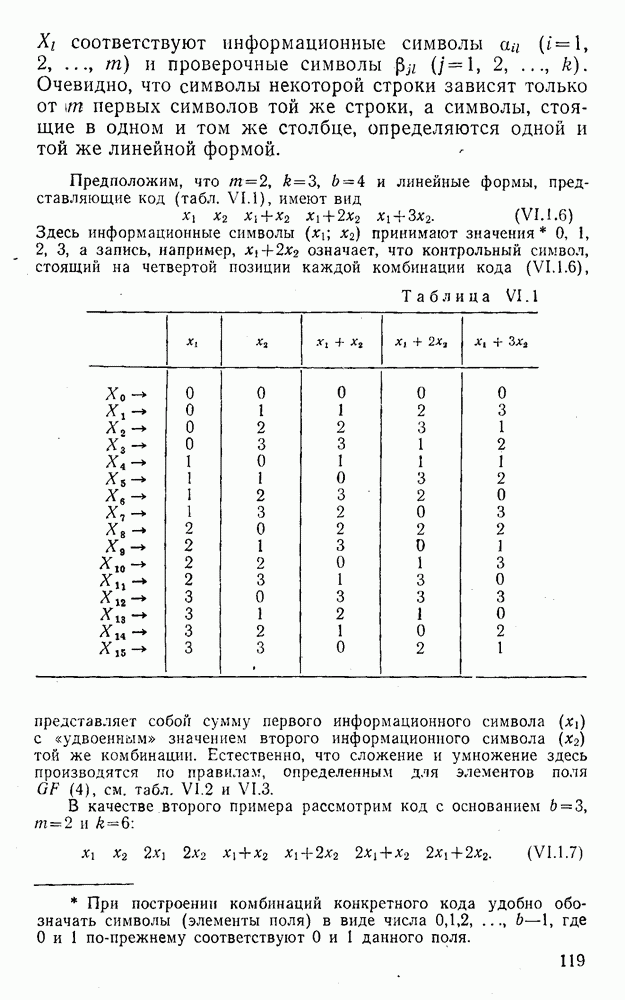
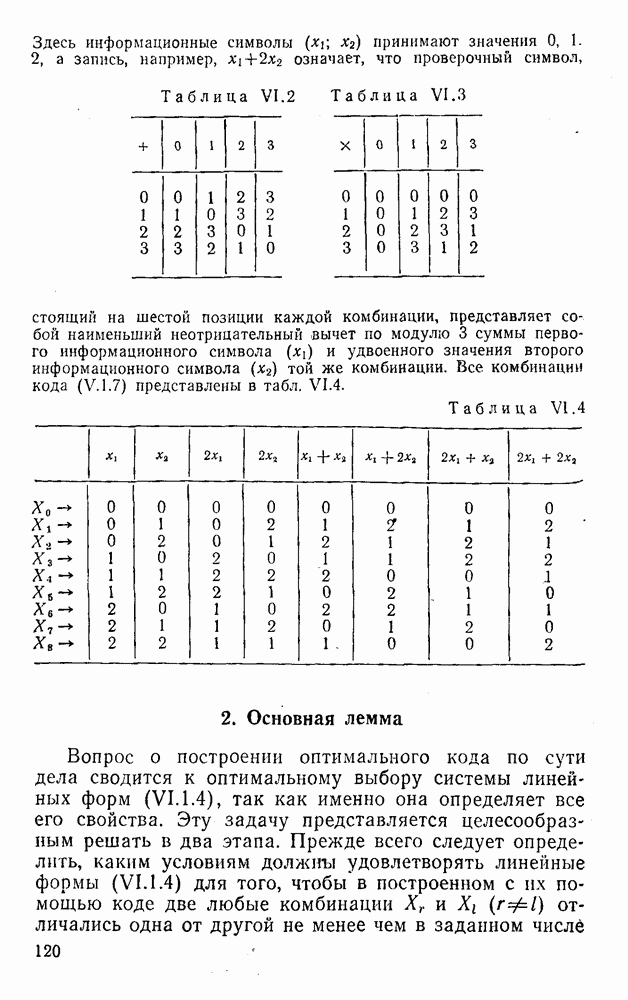
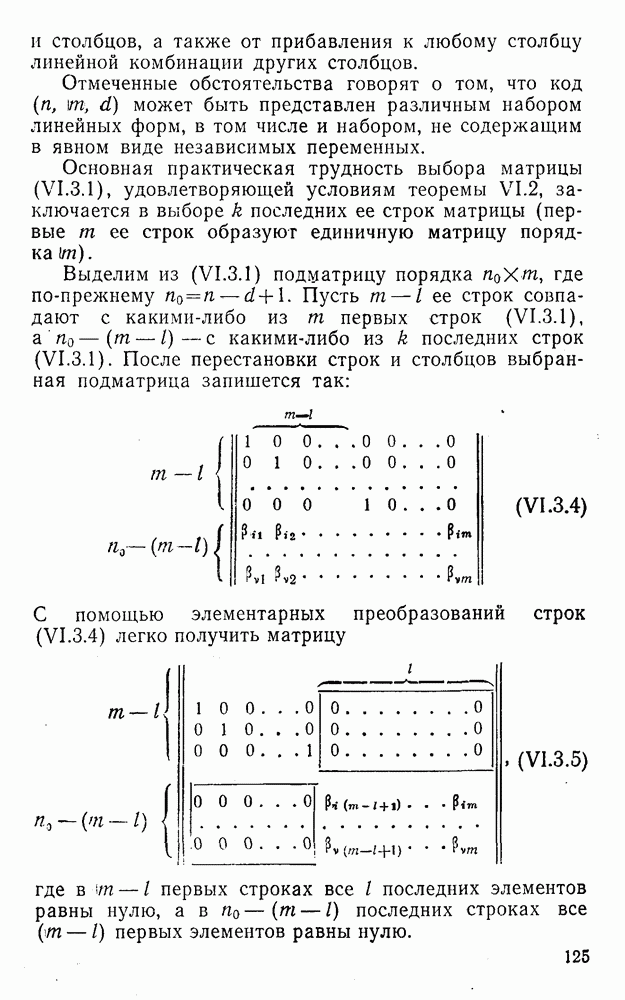
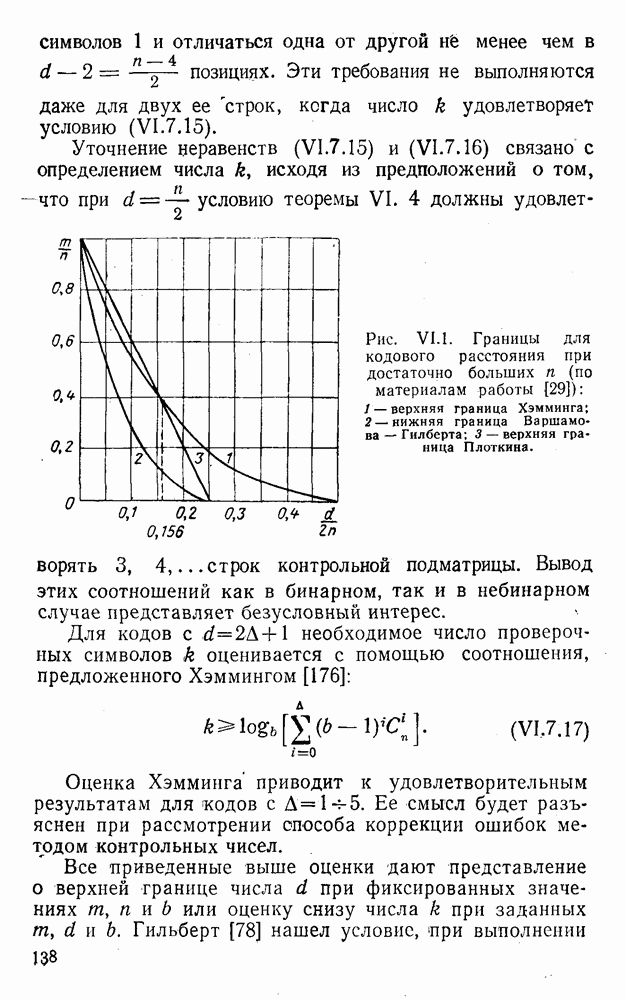
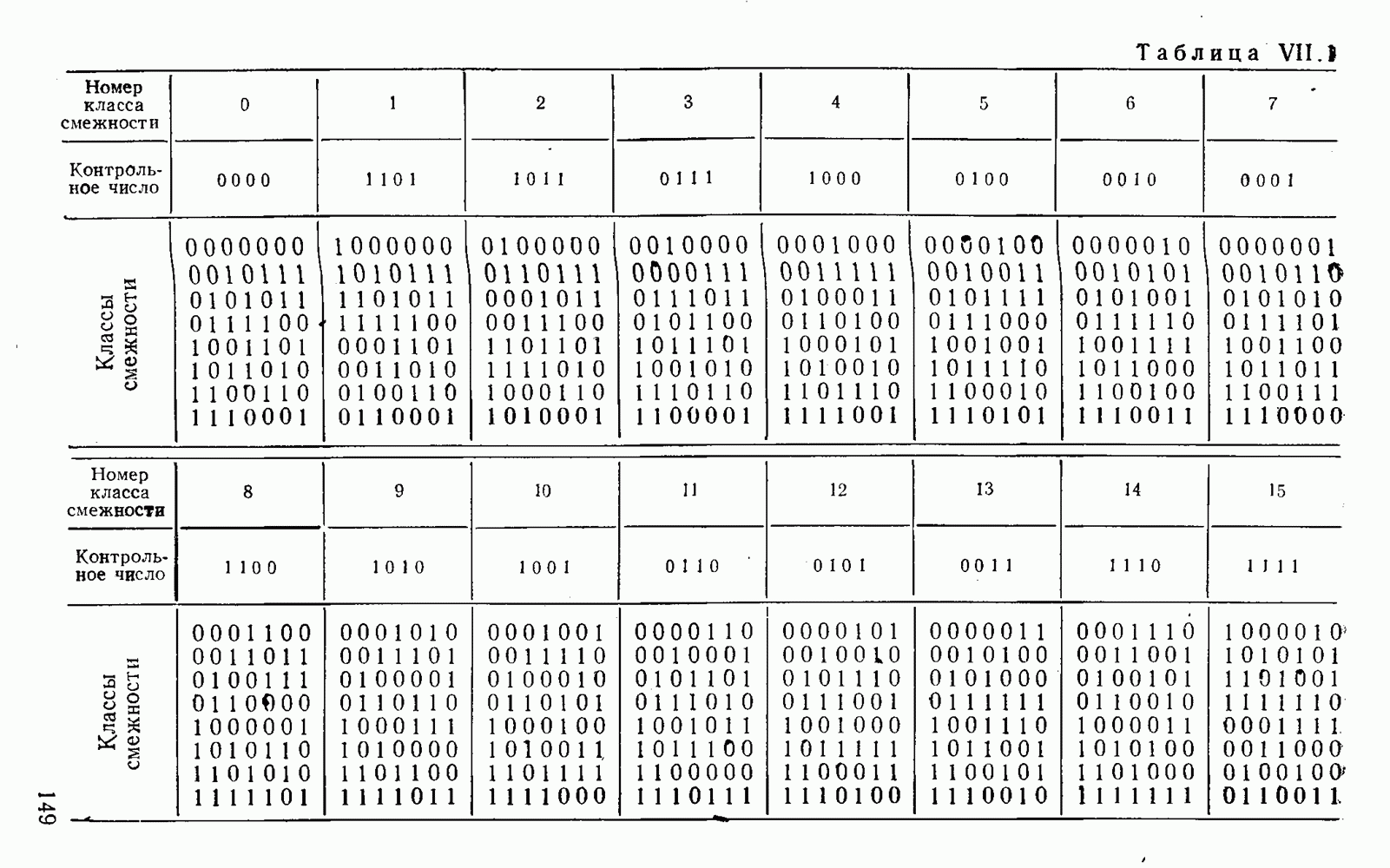
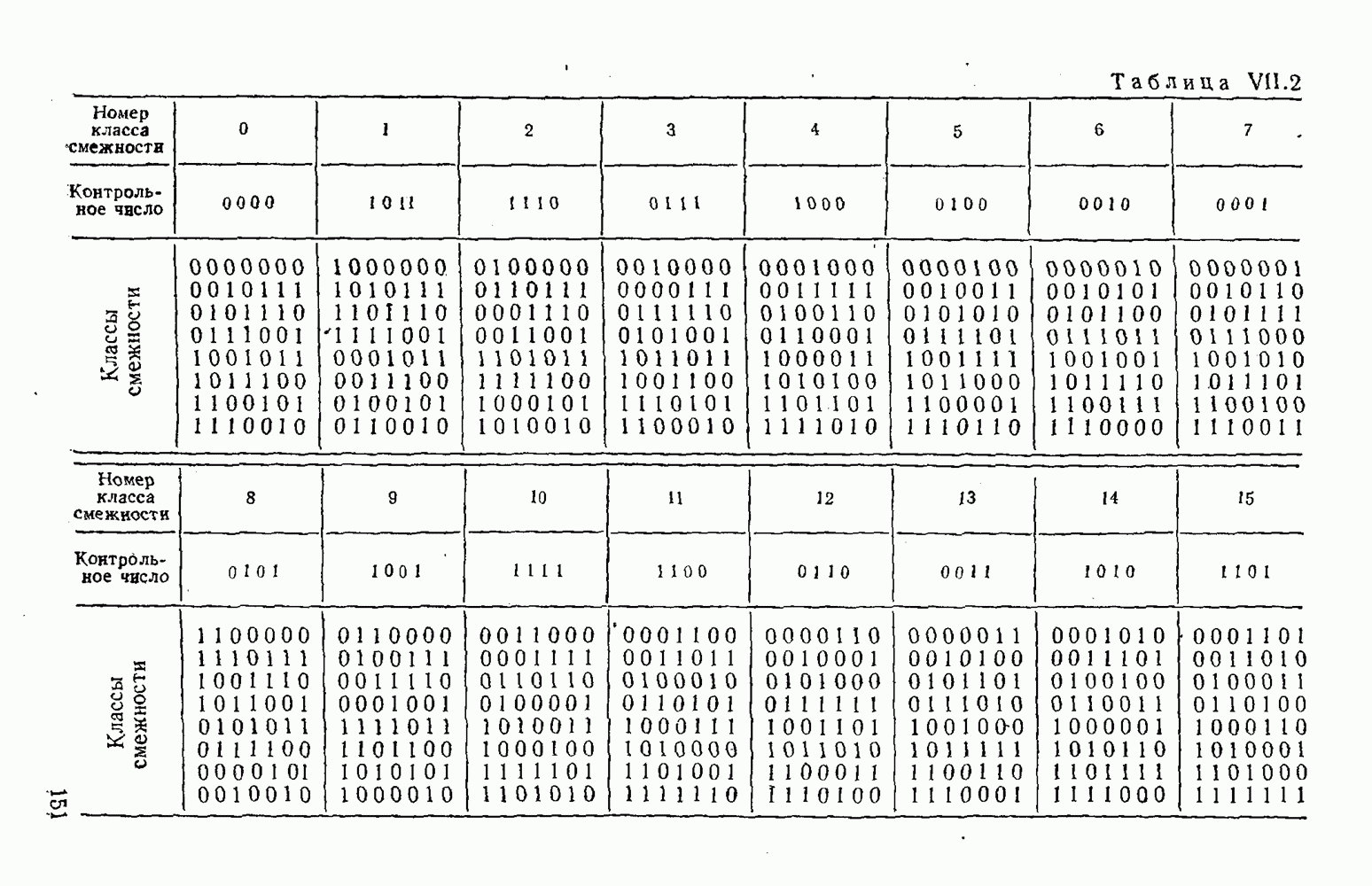
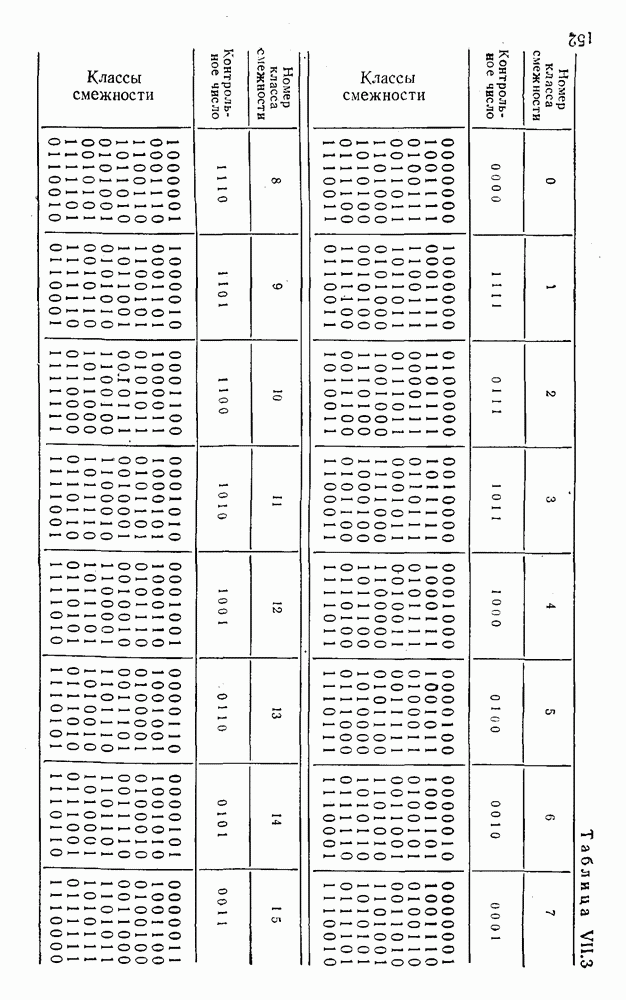
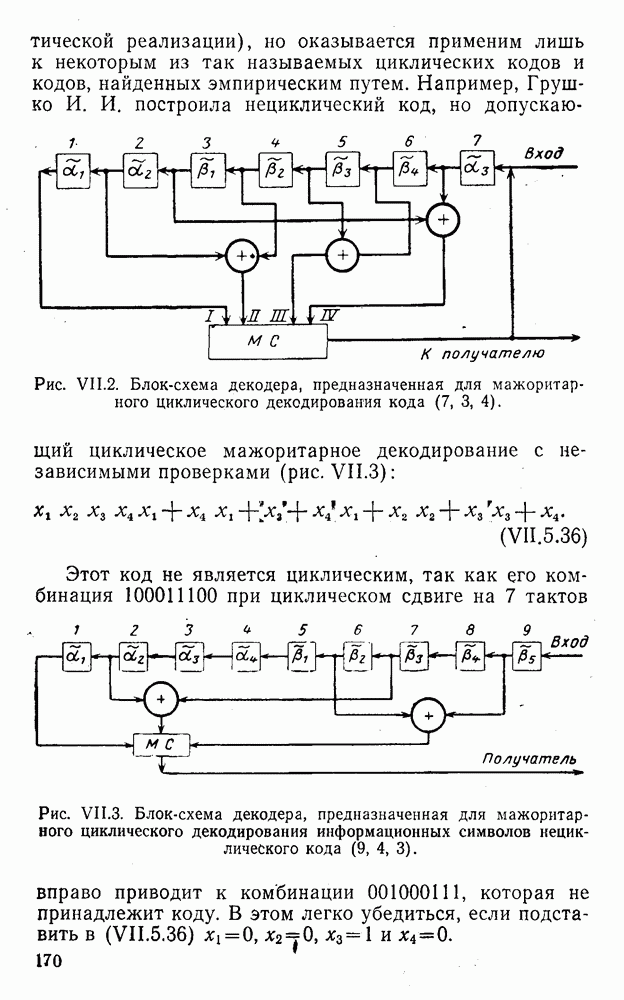
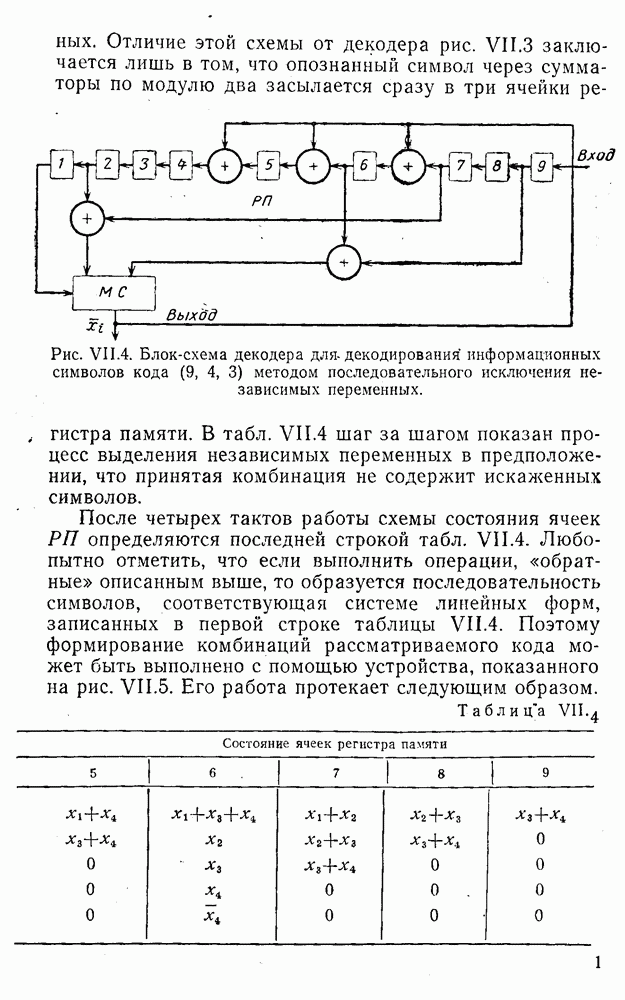
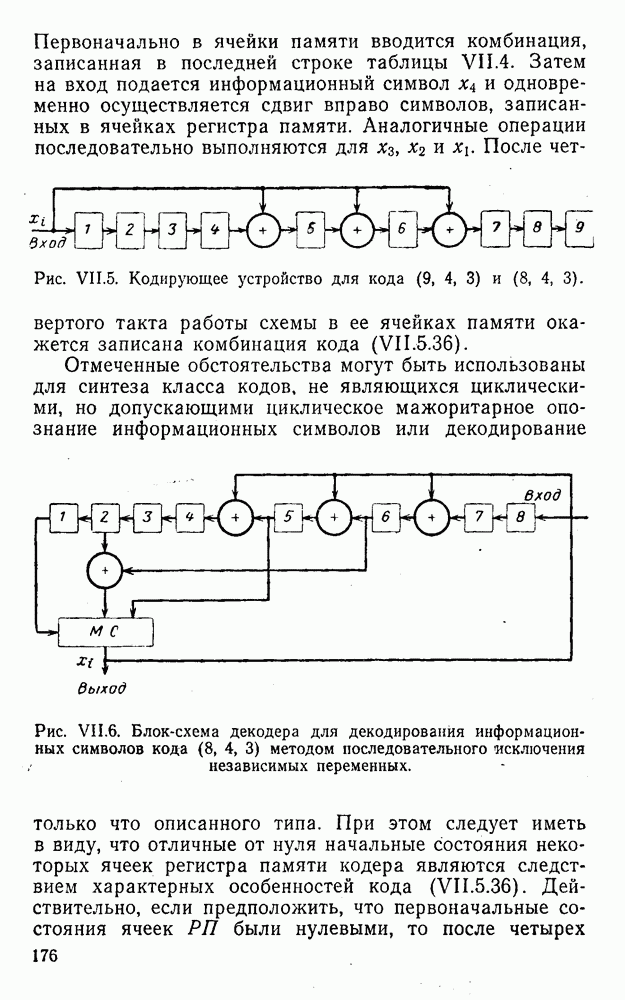
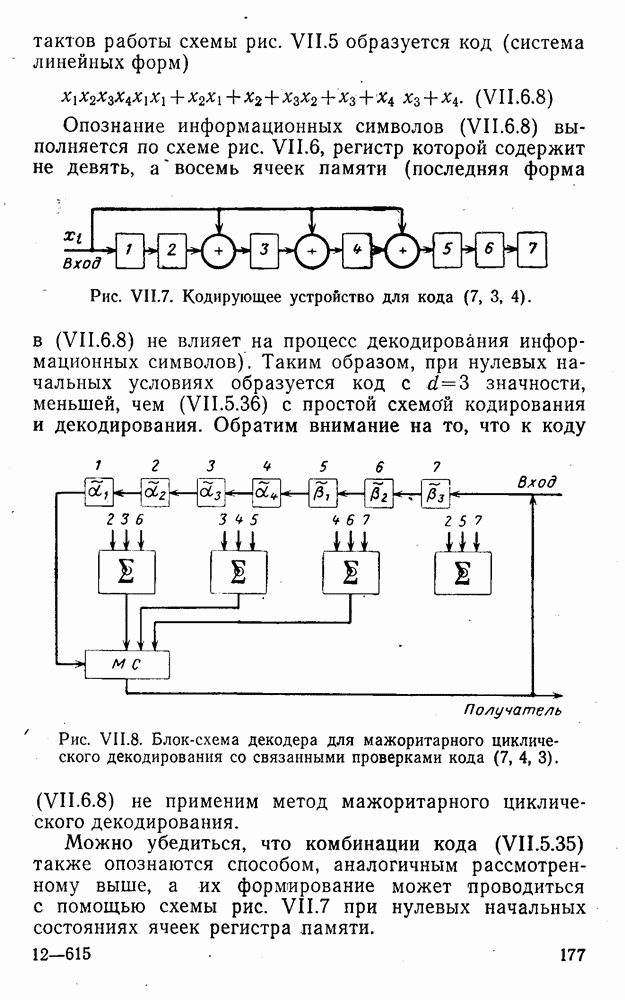
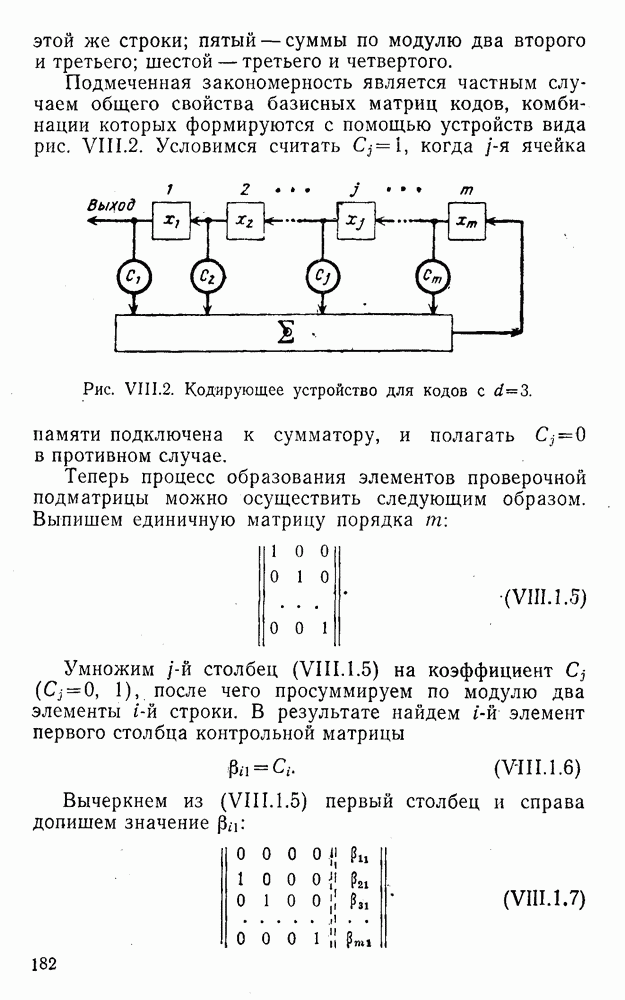
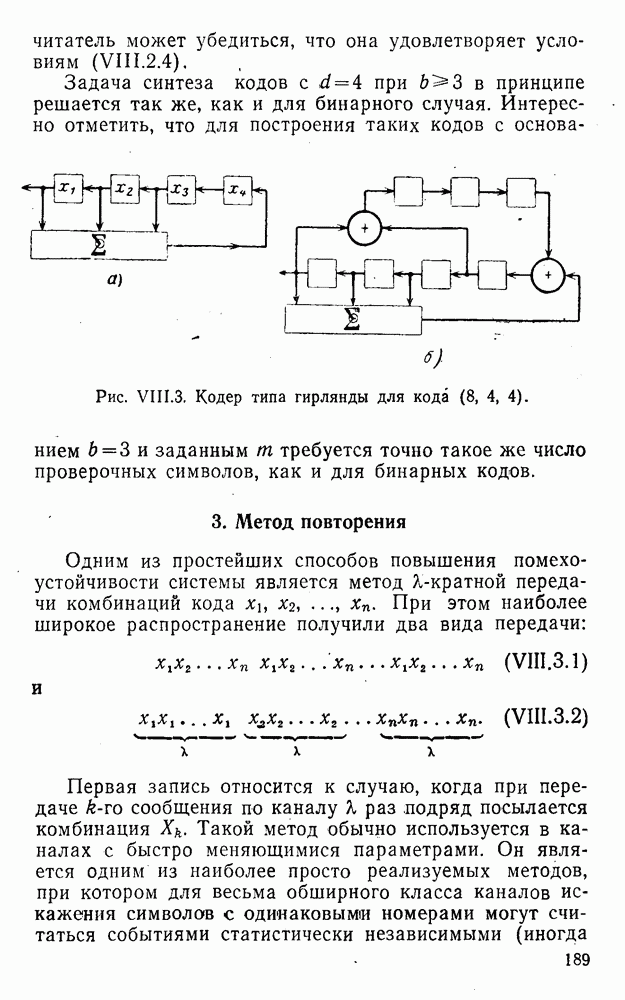
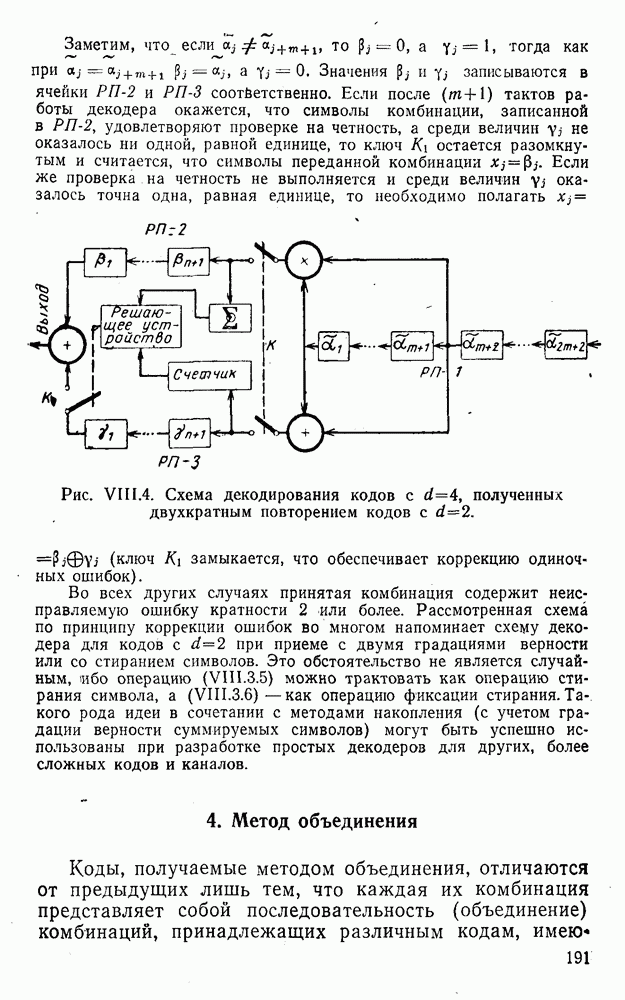
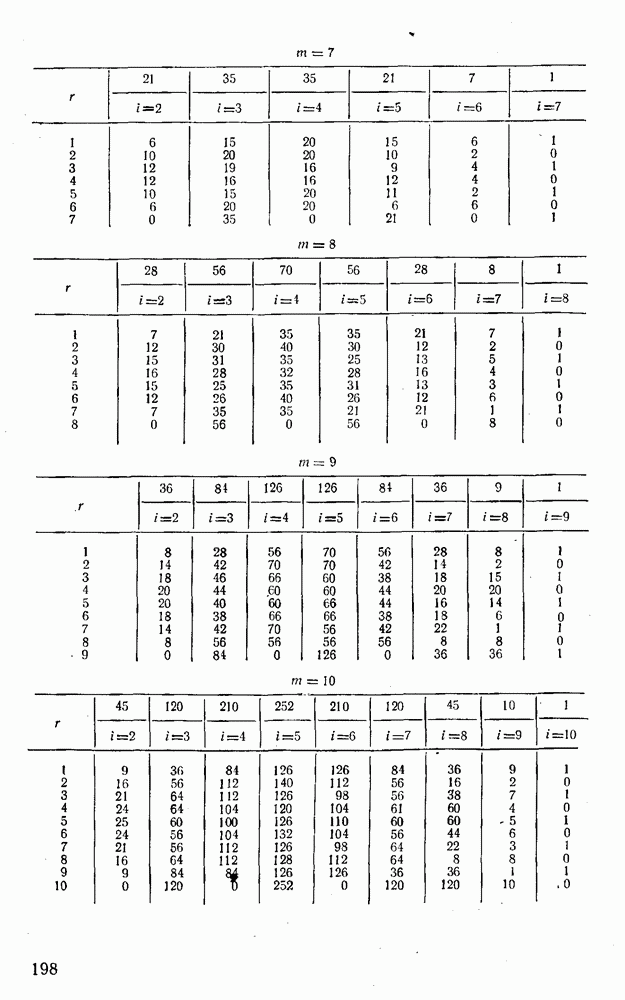
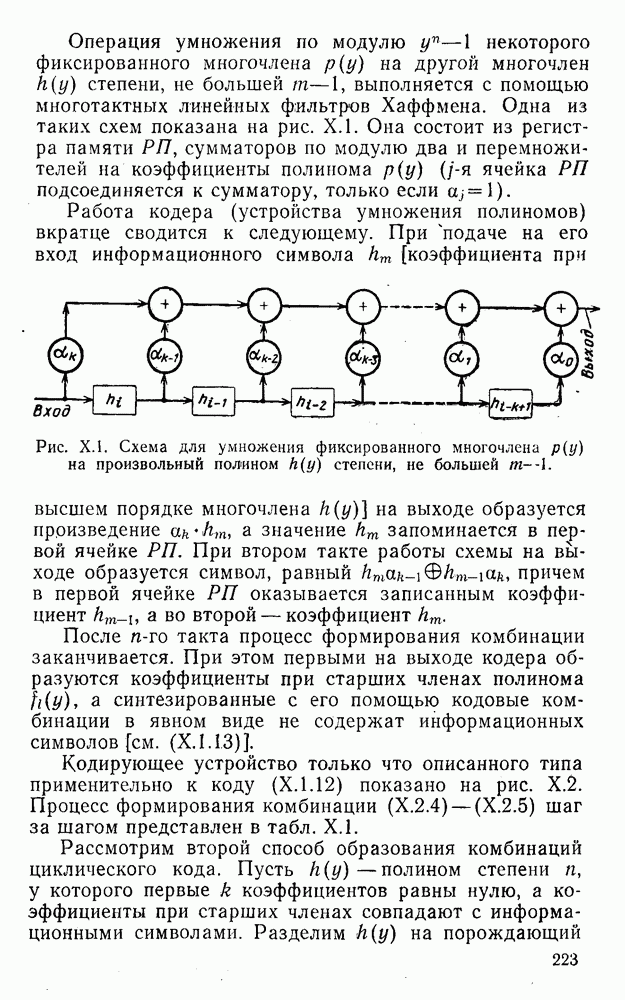
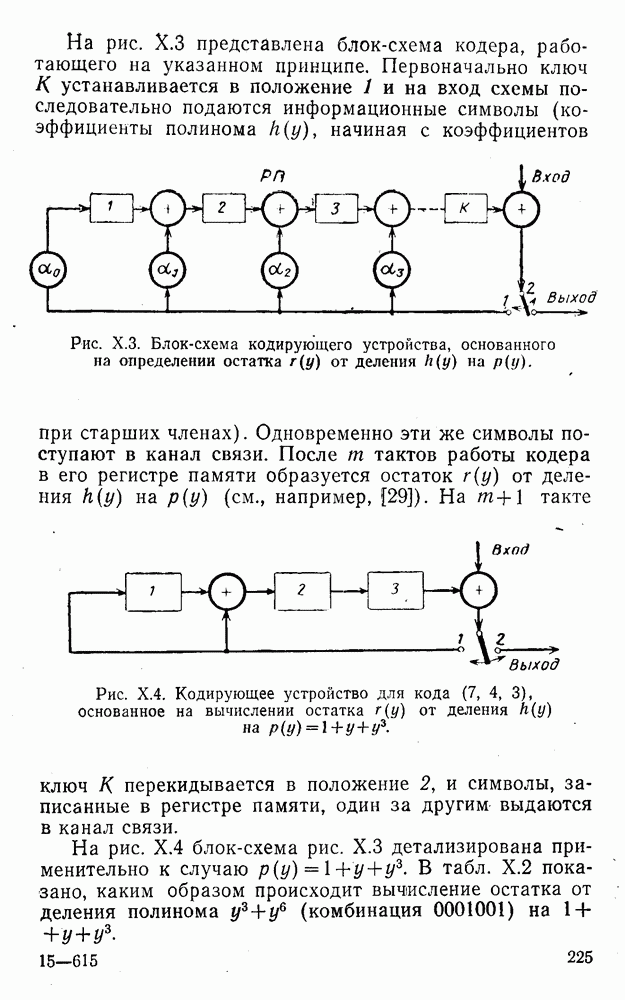
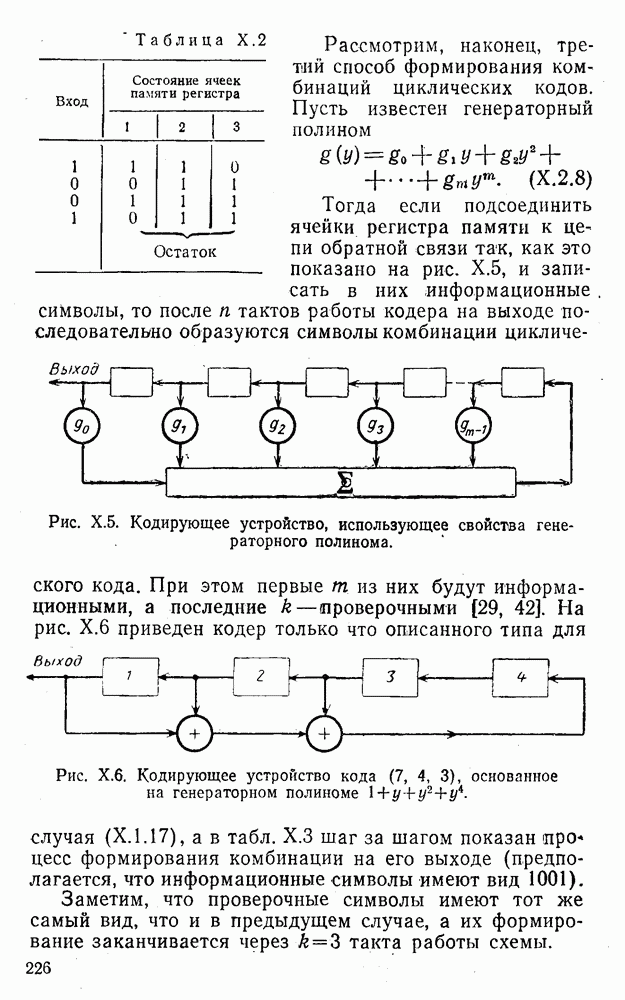
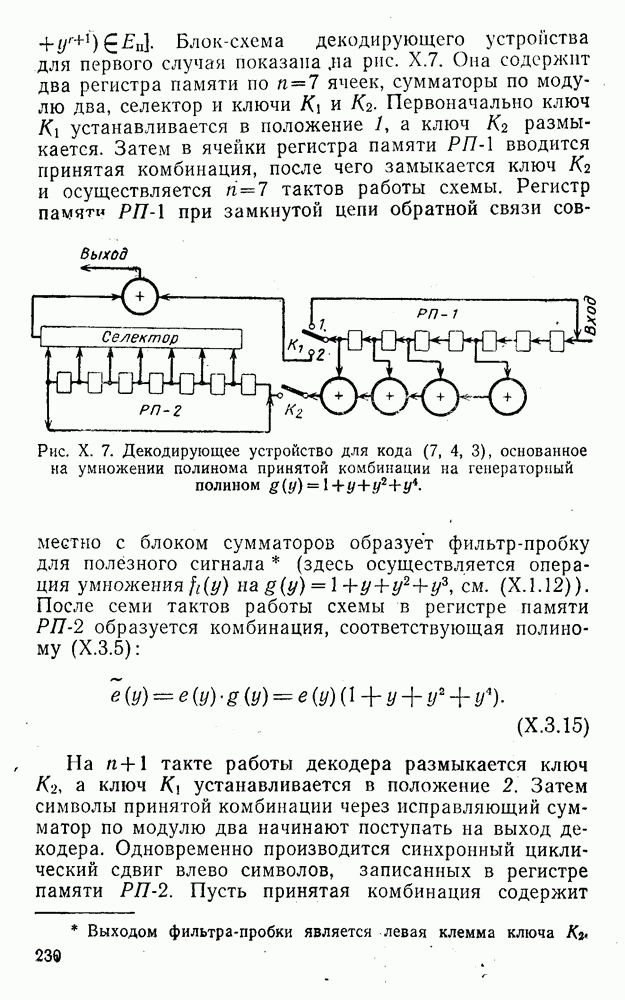
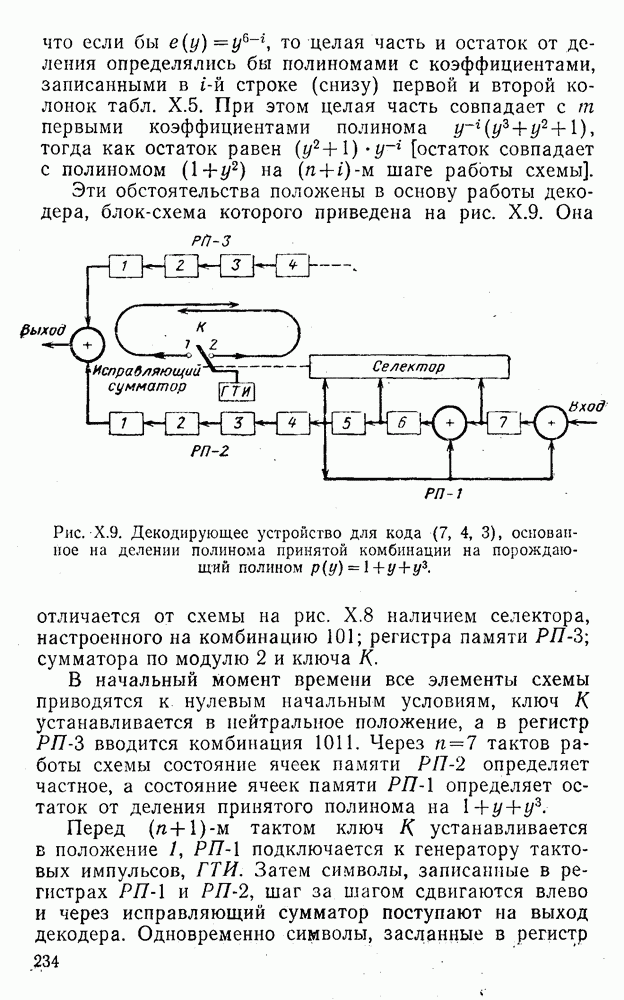
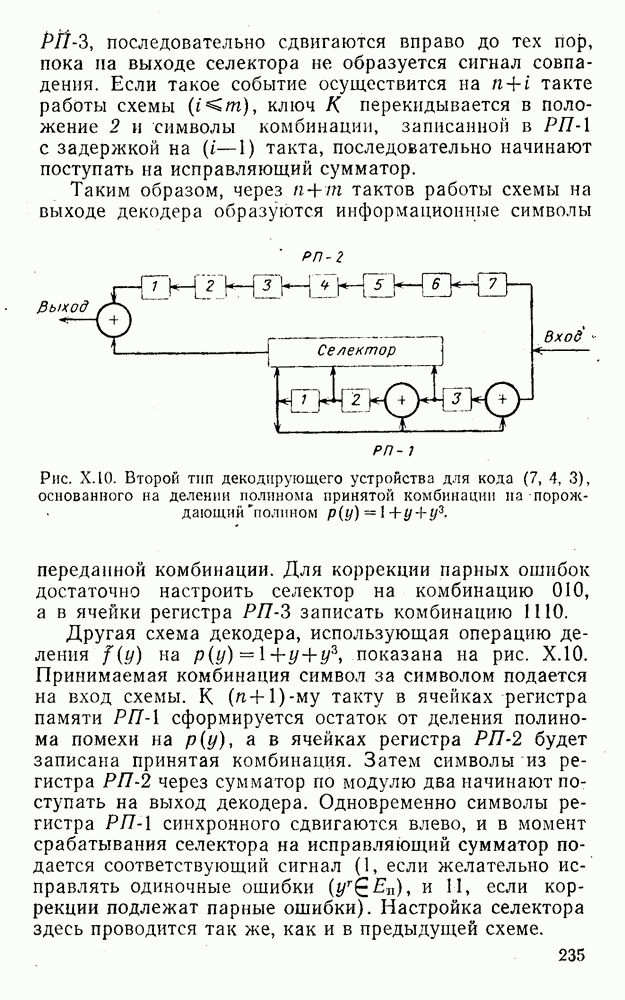
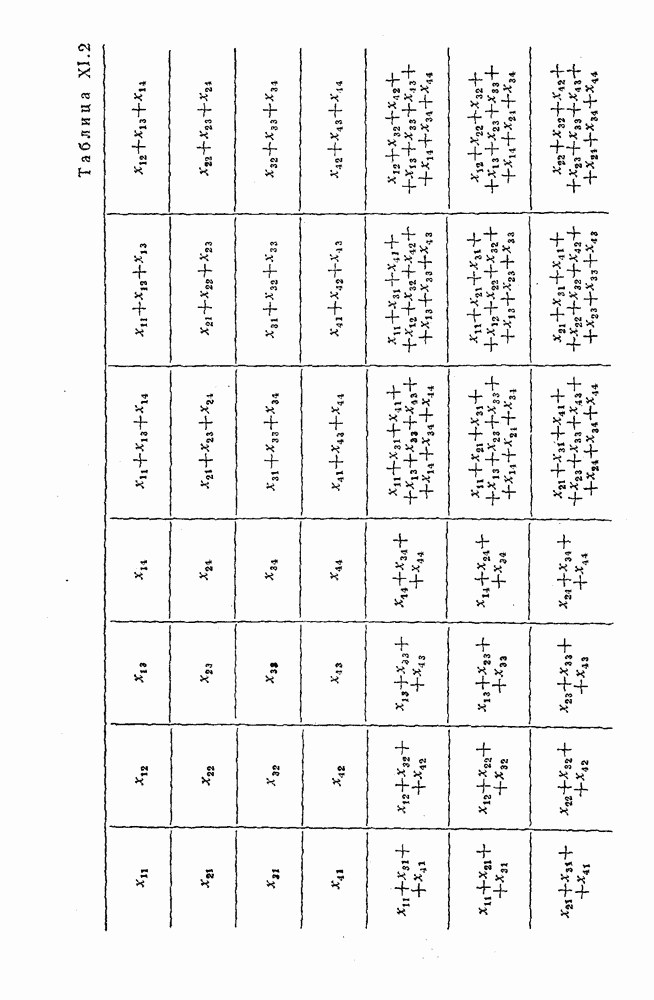
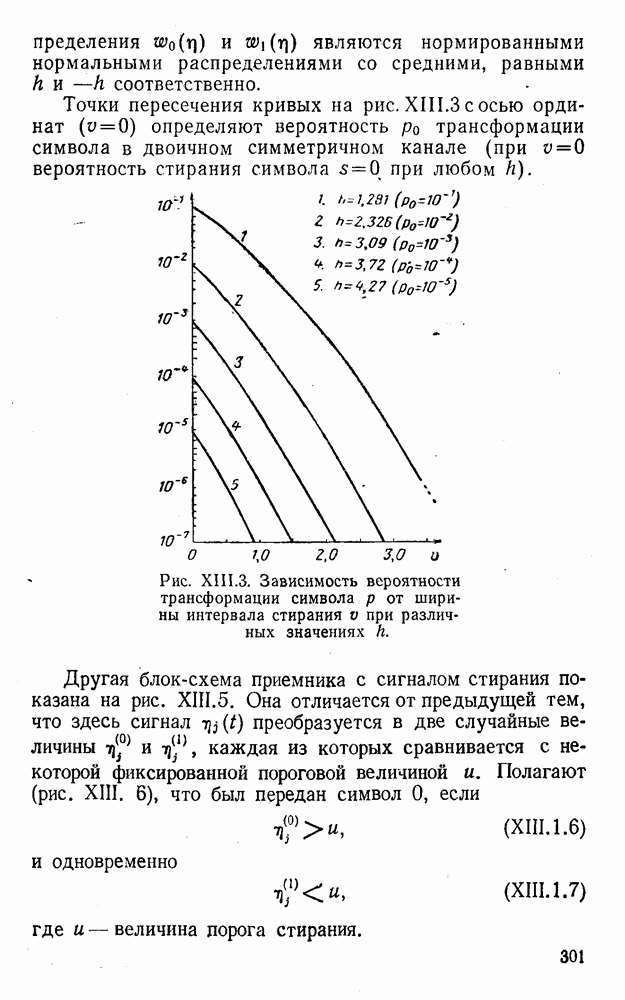
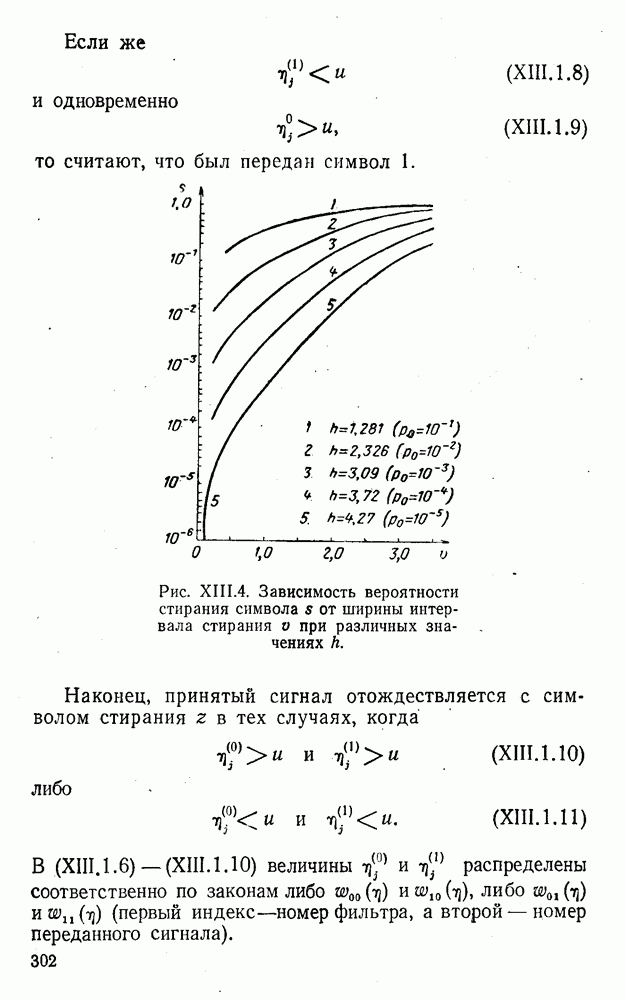
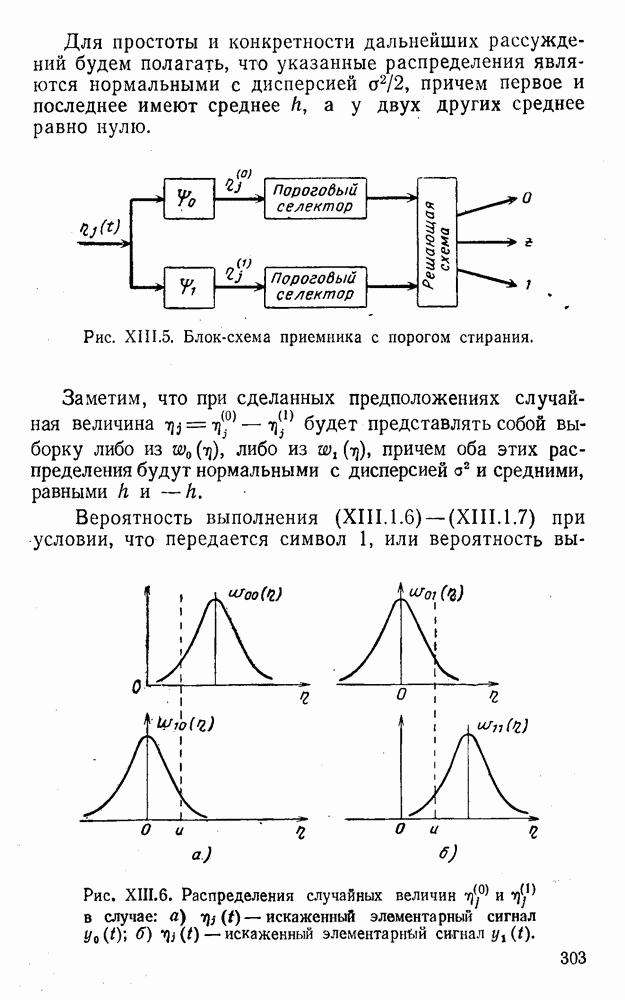
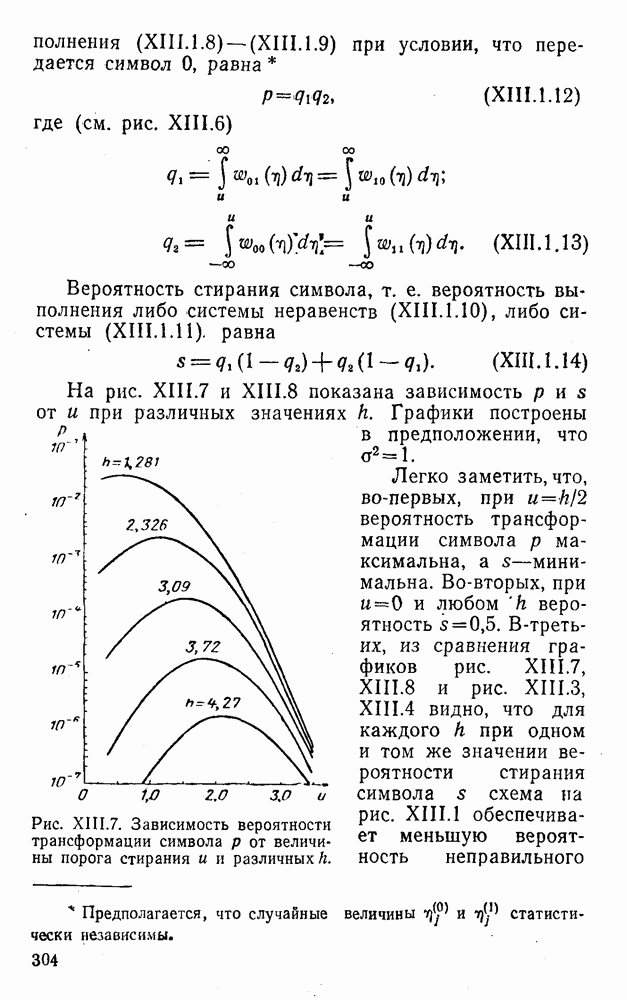
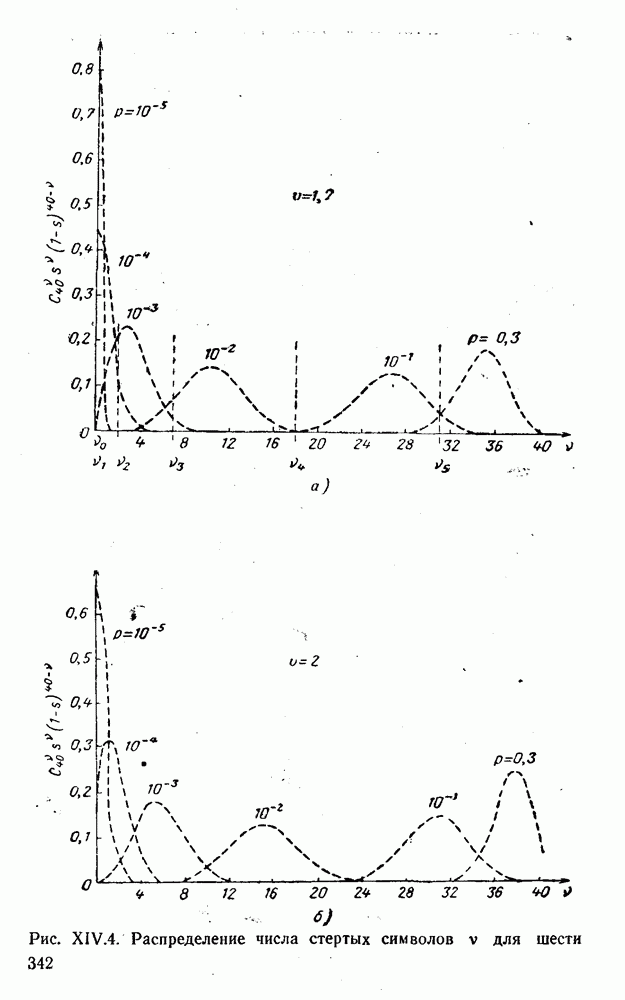
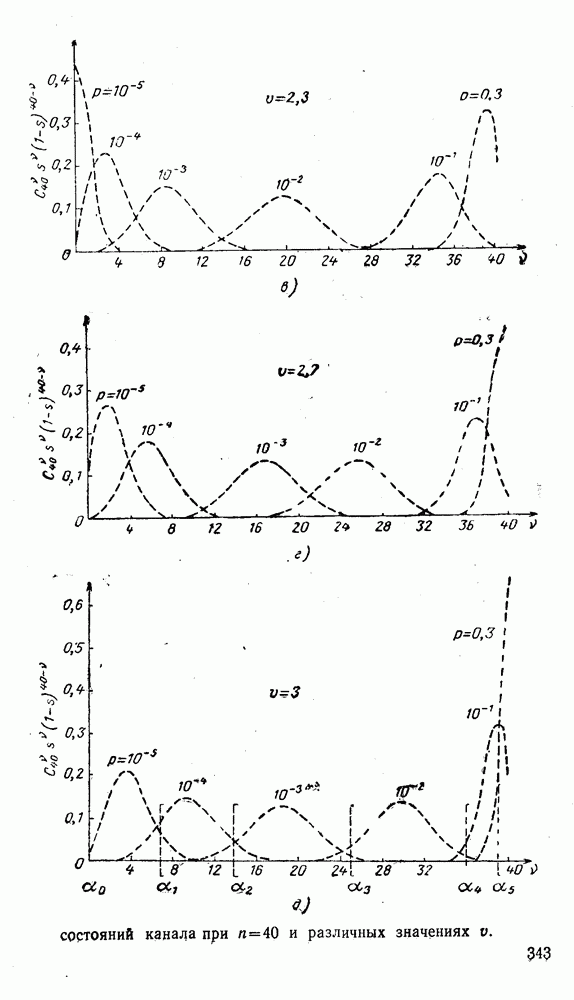
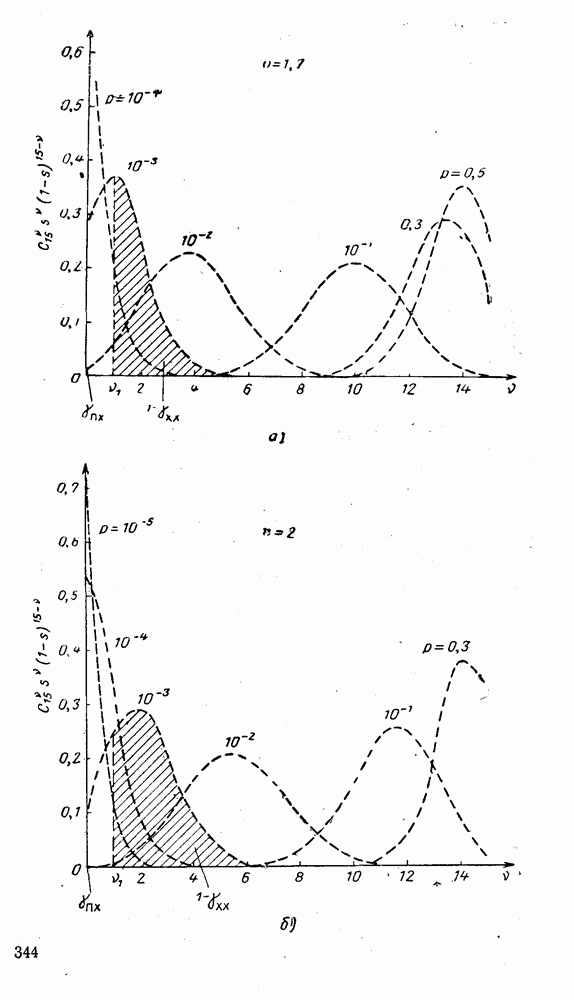
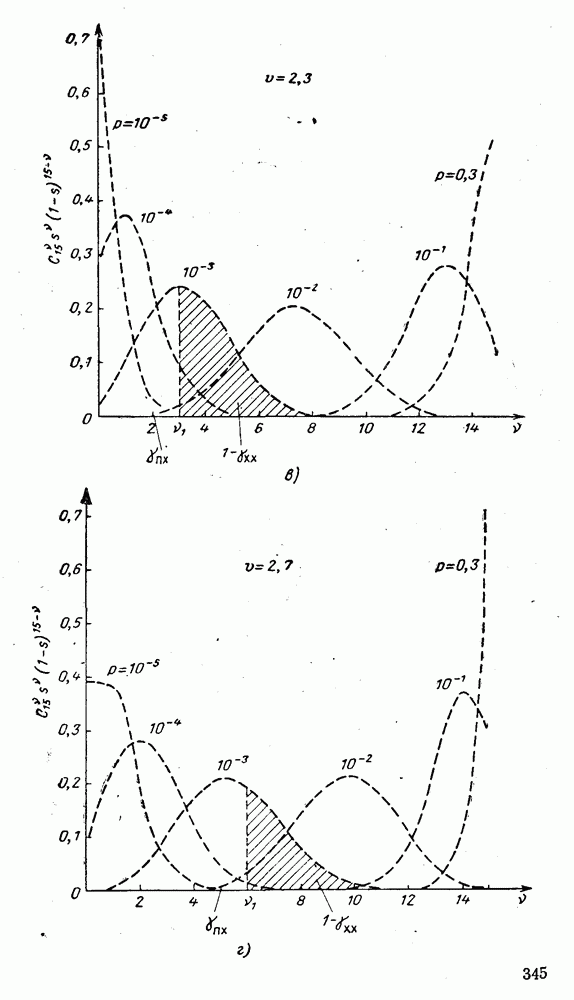
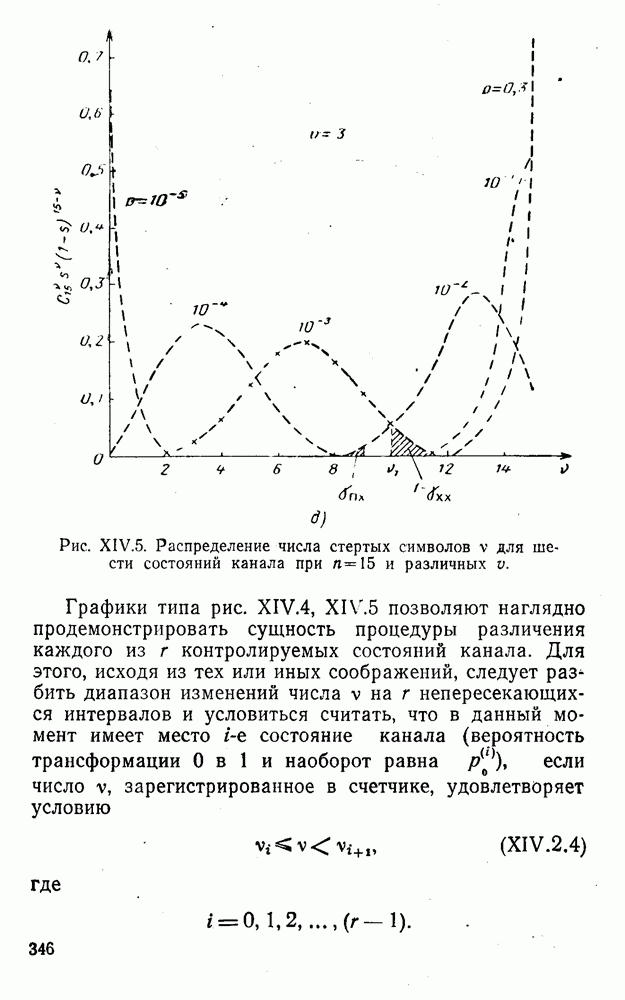
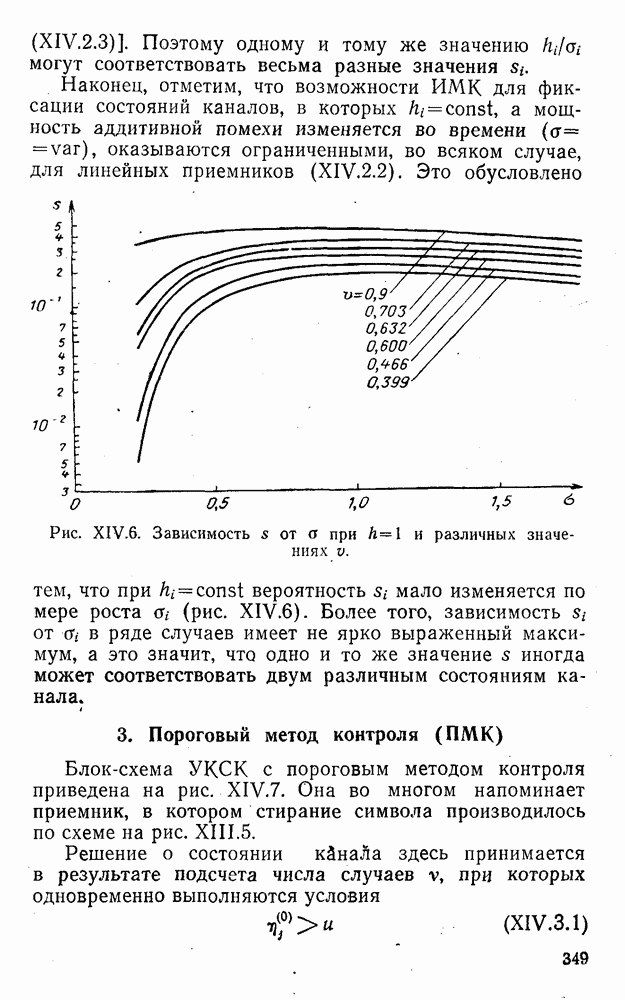
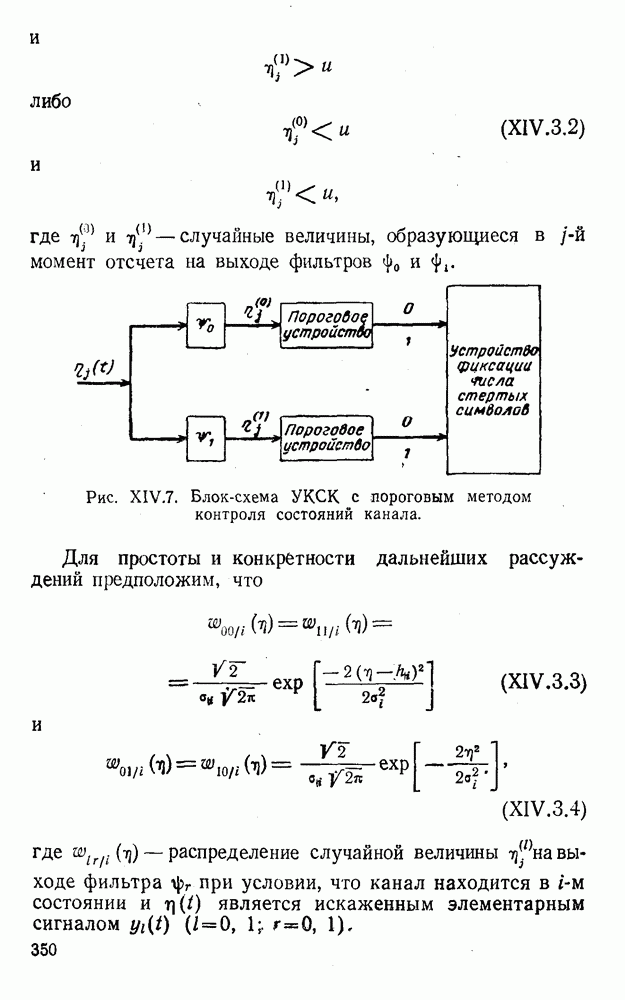
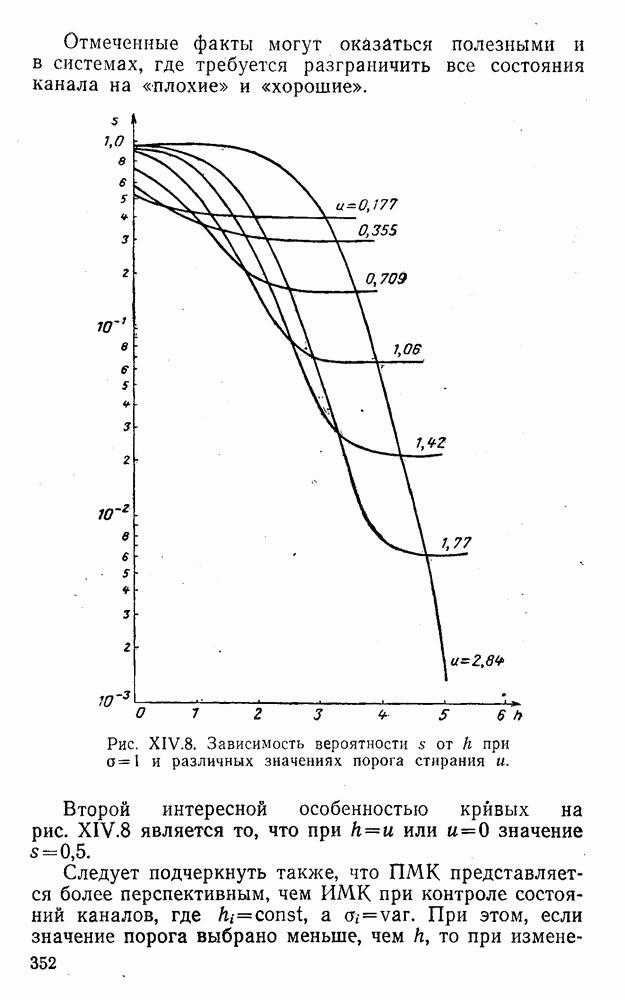
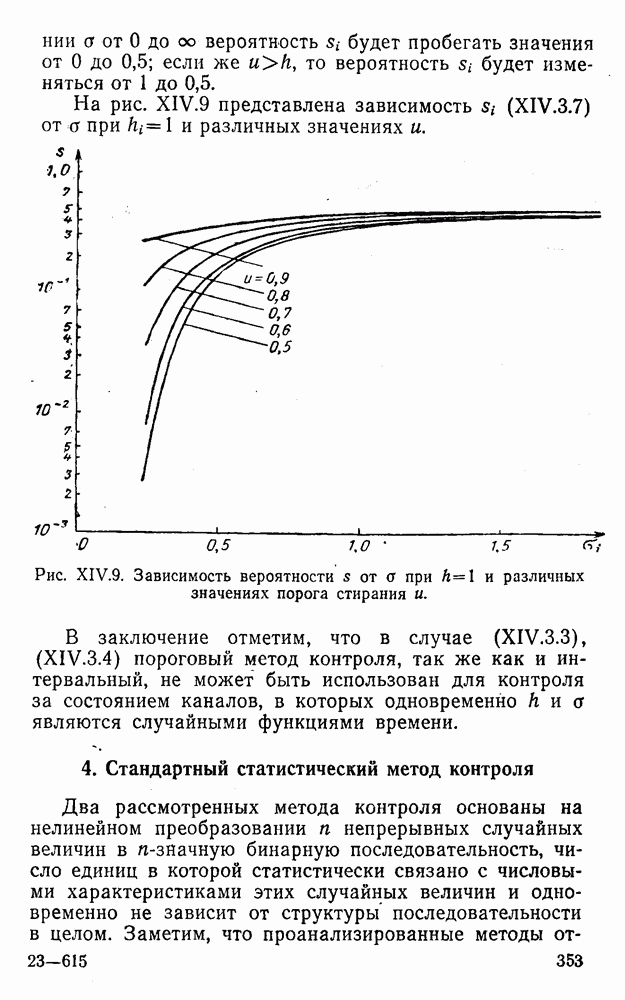
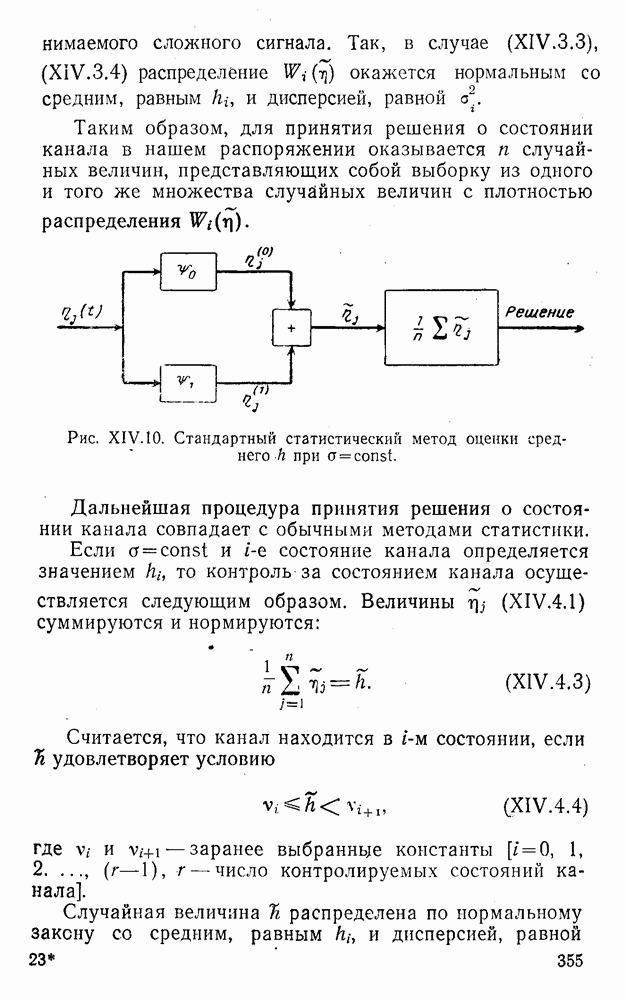
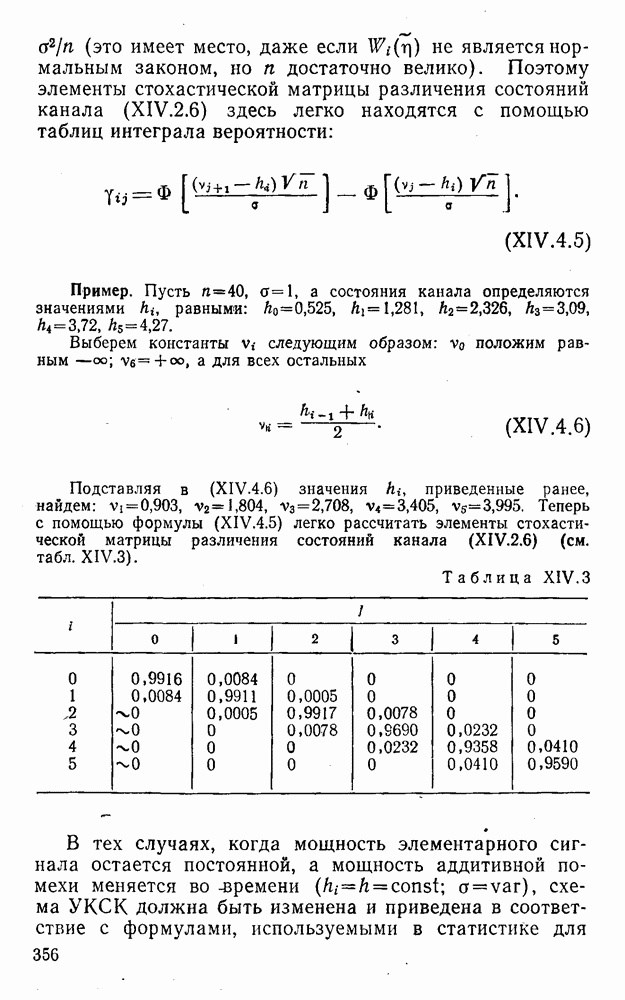
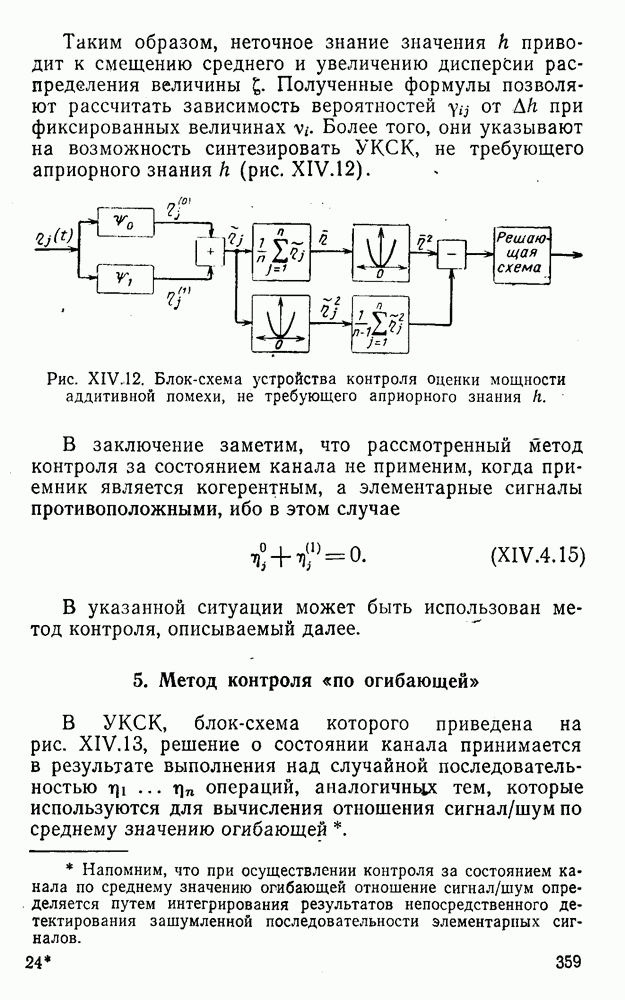
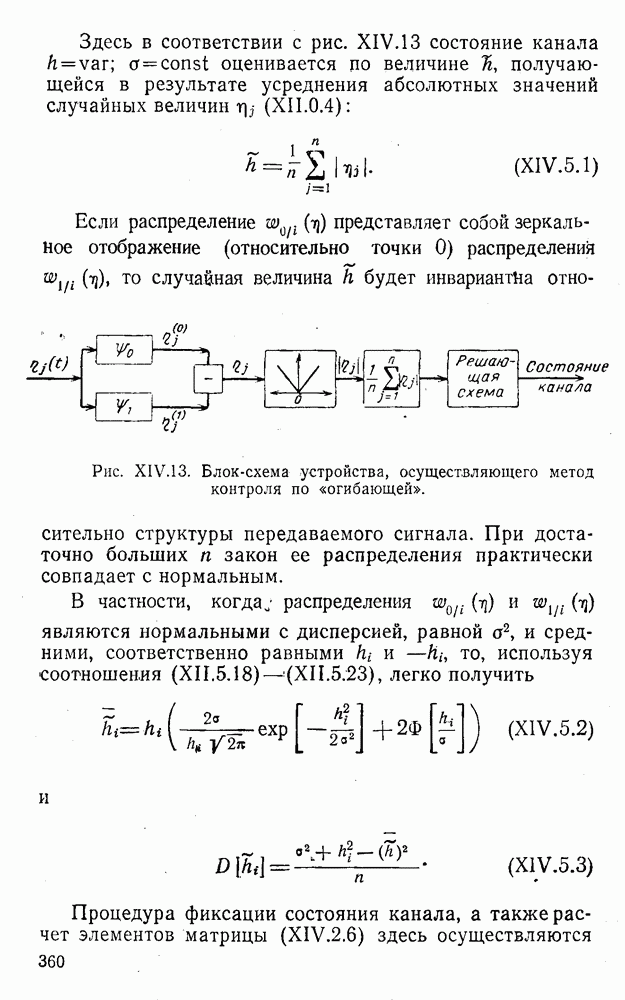
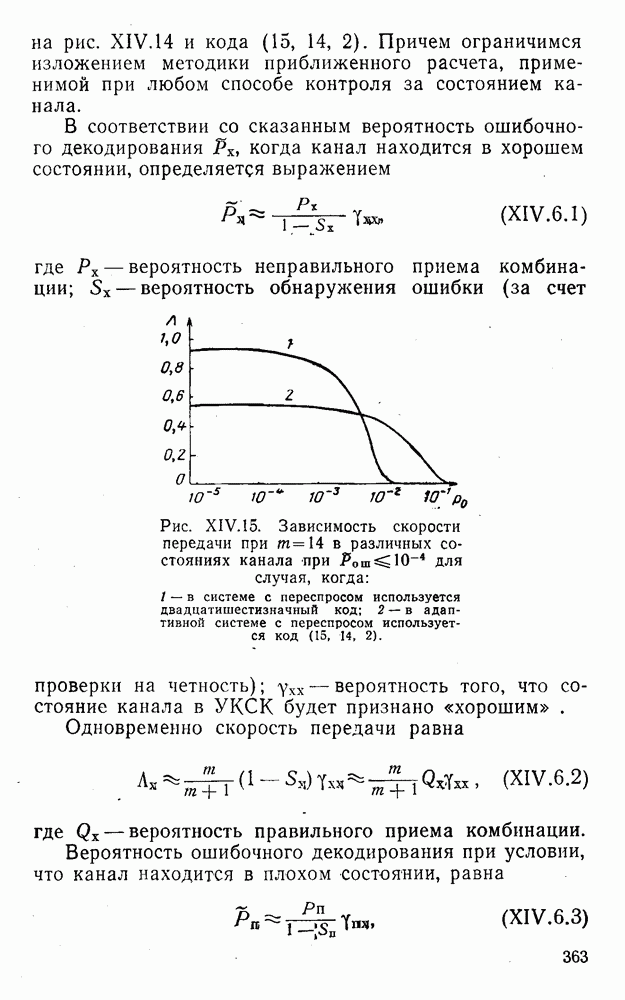
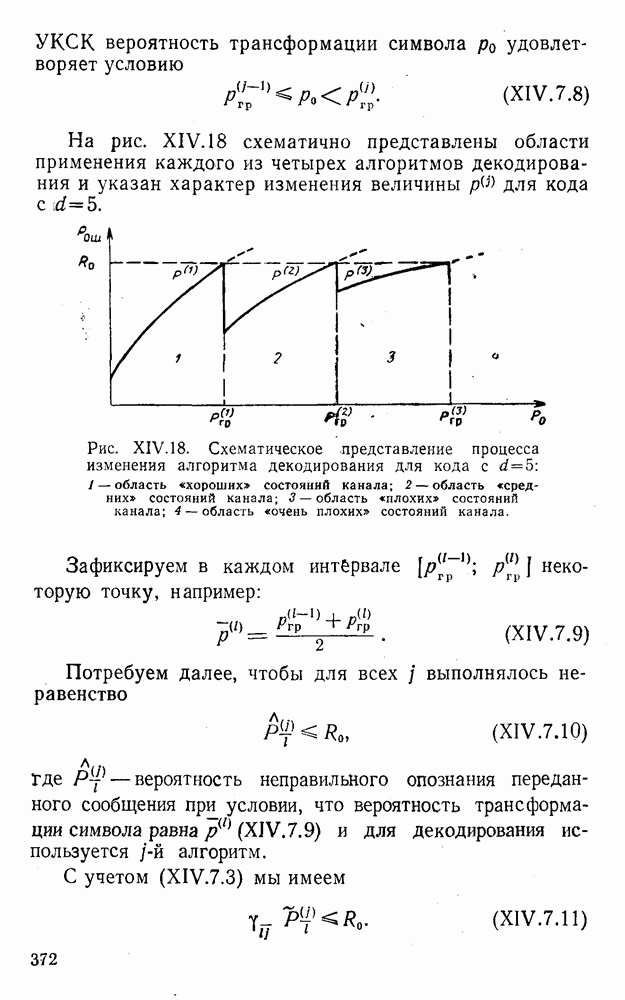
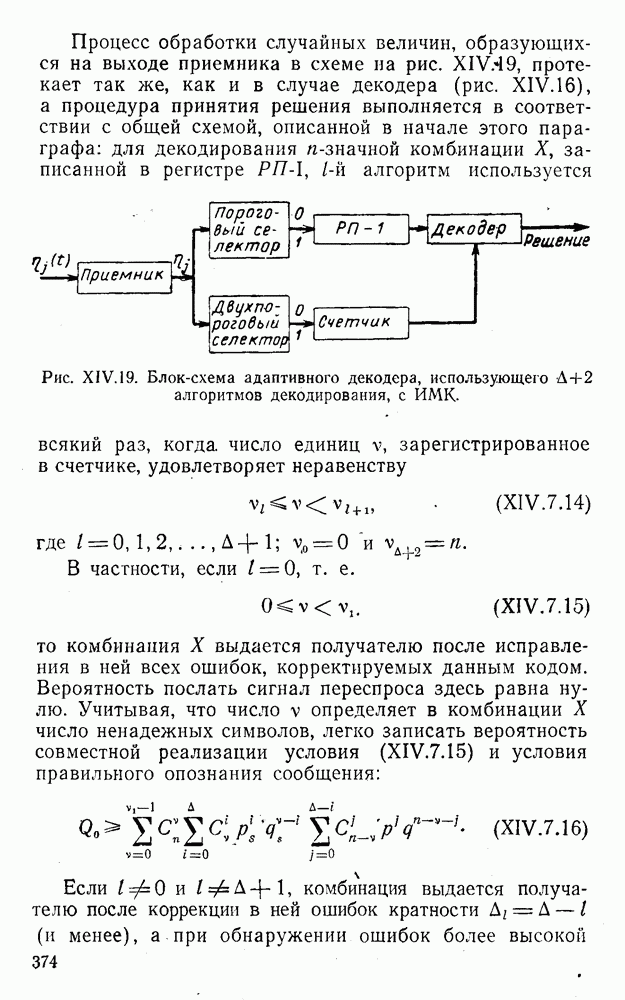
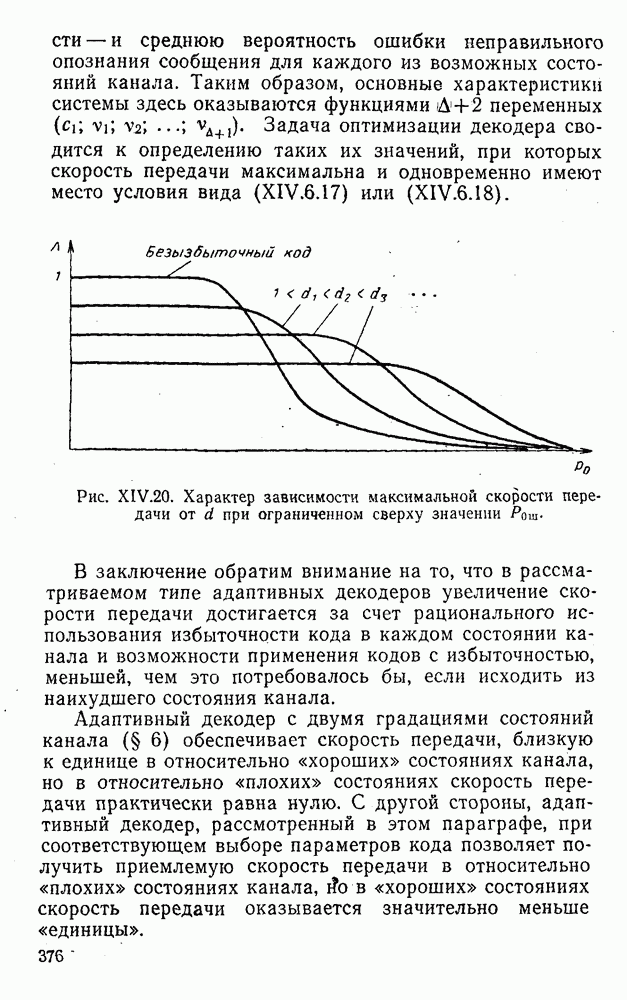
5. Декодирование по критерию максимума отношения правдоподобия и коды, оптимальные в смысле Хэмминга
Пусть система типа М является простой в том смысле, что элементы обобщенной матрицы потерь (IV.2.1) удовлетворяют условию
 (IV.5.1)
(IV.5.1)
и, естественно, см. (IV.2.3) и (III.5.2),
 (IV.5.2)
(IV.5.2)
В простых системах типа М средний риск численно совпадает со средней вероятностью неправильного опознания сообщения:
 (IV.5.3)
(IV.5.3)
Согласно теореме IV.I это выражение достигает минимума, если решение  принимается всякий раз, когда
принимается всякий раз, когда
полученный сигнал  таков, что
таков, что
 (IV.5.4)
(IV.5.4)
Таким образом, вероятность  минимальна, если каждое из подмножеств
минимальна, если каждое из подмножеств  содержит все сигналы
содержит все сигналы  , вероятность реализации которых при передаче сообщения
, вероятность реализации которых при передаче сообщения  (сигнала
(сигнала  ) больше, чем при передаче любого другого сообщения, что и доказывает следующее утверждение.
) больше, чем при передаче любого другого сообщения, что и доказывает следующее утверждение.
Теорема IV.2. В простых системах типа М при любом фиксированном способе кодирования процесс оптимизации процедуры декодирования сводится к разбиению множества  на М подмножеств по критерию максимума отношения правдоподобия.
на М подмножеств по критерию максимума отношения правдоподобия.
В простых системах типа М с симметричными каналами без памяти
 (IV.5.5)
(IV.5.5)
а отношение правдоподобия приводится к виду
 (IV.5.6)
(IV.5.6)
В реальных ситуациях  , поэтому неравенство (IV.5.6) выполняется лишь тогда, когда
, поэтому неравенство (IV.5.6) выполняется лишь тогда, когда  .
.
Теорема IV.3. В простых системах типа М с симметричными каналами без памяти при любой фиксированной процедуре кодирования вероятность  (IV.5.3) минимальна, если декодирование проводится по критерию минимума числа несовпадающих позиций, т. е. если
(IV.5.3) минимальна, если декодирование проводится по критерию минимума числа несовпадающих позиций, т. е. если
решение  (передано сообщение
(передано сообщение  ) принимается всякий раз, когда принятая комбинация
) принимается всякий раз, когда принятая комбинация  отличается от
отличается от  в числе позиций
в числе позиций  , меньшем, чем от любой другой кодовой комбинации:
, меньшем, чем от любой другой кодовой комбинации:
 (IV.5.7)
(IV.5.7)
или, что то же самое,
 (IV.5.8)
(IV.5.8)
Заметим, что если комбинация  отличается в одинаковом числе позиций от кодовых комбинаций
отличается в одинаковом числе позиций от кодовых комбинаций  и
и  с равным успехом может быть принято как решение
с равным успехом может быть принято как решение  , так и решение
, так и решение  .
.
Попытаемся установить, каким образом следует осуществить процедуру кодирования, чтобы она оказалась оптимальной или хотя бы близкой к таковой. Комбинации любого кода  и
и  (сложные сигналы
(сложные сигналы  и
и  подмножества
подмножества  ) отличаются между собой в определенном числе позиций
) отличаются между собой в определенном числе позиций  Наименьшее из них d называют кодовым расстоянием Хэмминга. Из теоремы IV.3 непосредственно вытекает: каждое подмножество
Наименьшее из них d называют кодовым расстоянием Хэмминга. Из теоремы IV.3 непосредственно вытекает: каждое подмножество  помимо кодовой комбинации
помимо кодовой комбинации  содержит по крайней мере все комбинации, отличающиеся от нее в одной, двух и т. д.
содержит по крайней мере все комбинации, отличающиеся от нее в одной, двух и т. д.  позициях:
позициях:
 (IV.5.9)
(IV.5.9)
где знак [ ] означает целую часть  . Другими словами, при оптимальном декодировании правильное решение принимается по крайней мере тогда, когда после демодуляции сложного сигнала окажется, что
. Другими словами, при оптимальном декодировании правильное решение принимается по крайней мере тогда, когда после демодуляции сложного сигнала окажется, что  (или менее) его элементарных сигналов были опознаны неправильно. В этом случае говорят, что выбранный код
(или менее) его элементарных сигналов были опознаны неправильно. В этом случае говорят, что выбранный код  корректирует все ошибки кратностью Д и менее. На основании сказанного можно сформулировать следующую теорему.
корректирует все ошибки кратностью Д и менее. На основании сказанного можно сформулировать следующую теорему.
Теорема IV.4. Для того чтобы код корректировал все ошибки кратности  и менее, необходимо и достаточно, чтобы кодовое расстояние Хэмминга:
и менее, необходимо и достаточно, чтобы кодовое расстояние Хэмминга:
 (IV.5.10)
(IV.5.10)
Вероятность  того, что при передаче сообщения
того, что при передаче сообщения  будет принято правильное решение, определяется неравенством
будет принято правильное решение, определяется неравенством
 (IV.5.11)
(IV.5.11)
Правая часть (IV.5.11) - это лишь оценка снизу вероятности  так как при оптимальном декодировании исправляется часть ошибок кратности, большей, чем
так как при оптимальном декодировании исправляется часть ошибок кратности, большей, чем  (подмножество
(подмножество  содержит ряд комбинаций, которые отличаются от
содержит ряд комбинаций, которые отличаются от  в числе позиций, большем чем
в числе позиций, большем чем  ). Задача минимизации средней вероятности неправильного декодирования
). Задача минимизации средней вероятности неправильного декодирования  тождественна задаче максимизации вероятности
тождественна задаче максимизации вероятности  но, как следует из соотношения (IV.5.11), последняя во всяком случае будет тем больше, чем больше
но, как следует из соотношения (IV.5.11), последняя во всяком случае будет тем больше, чем больше  .
.
Теорема IV.5. В простых системах типа М с симметричными каналами без памяти и оптимальной процедурой декодирования коды, оптимальные в смысле максимума  , минимизируют верхнюю границу средней вероятности неправильного декодирования
, минимизируют верхнюю границу средней вероятности неправильного декодирования  .
.
Величина  тем больше, чем больше
тем больше, чем больше  (IV.5.11), поэтому задача поиска кодов, максимизирующих верхнюю границу, сводится к поиску кодов, оптимальных в смысле Хэмминга (обладающих максимальным кодовым расстоянием d). При этом среди кодов с одним и тем же
(IV.5.11), поэтому задача поиска кодов, максимизирующих верхнюю границу, сводится к поиску кодов, оптимальных в смысле Хэмминга (обладающих максимальным кодовым расстоянием d). При этом среди кодов с одним и тем же  могут оказаться коды, применение которых с точки зрения минимизации вероятности
могут оказаться коды, применение которых с точки зрения минимизации вероятности  (а не верхней ее границы) окажется предпочтительнее. Более того, существуют коды с одним и тем же
(а не верхней ее границы) окажется предпочтительнее. Более того, существуют коды с одним и тем же  , но разными
, но разными  такие, что код с меньшим
такие, что код с меньшим  обеспечивает вероятность
обеспечивает вероятность  , меньшую, чем код с большим d [56].
, меньшую, чем код с большим d [56].