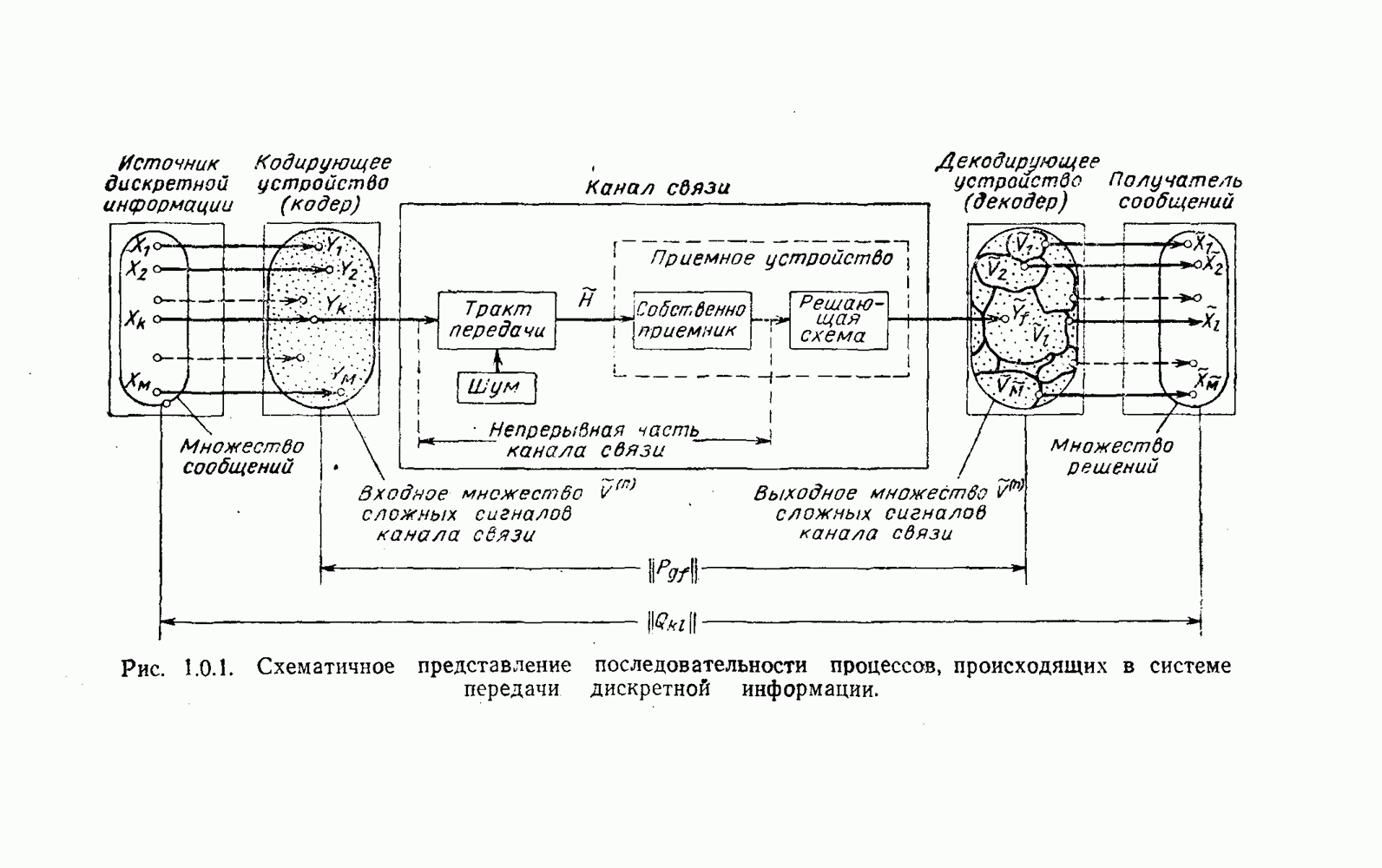
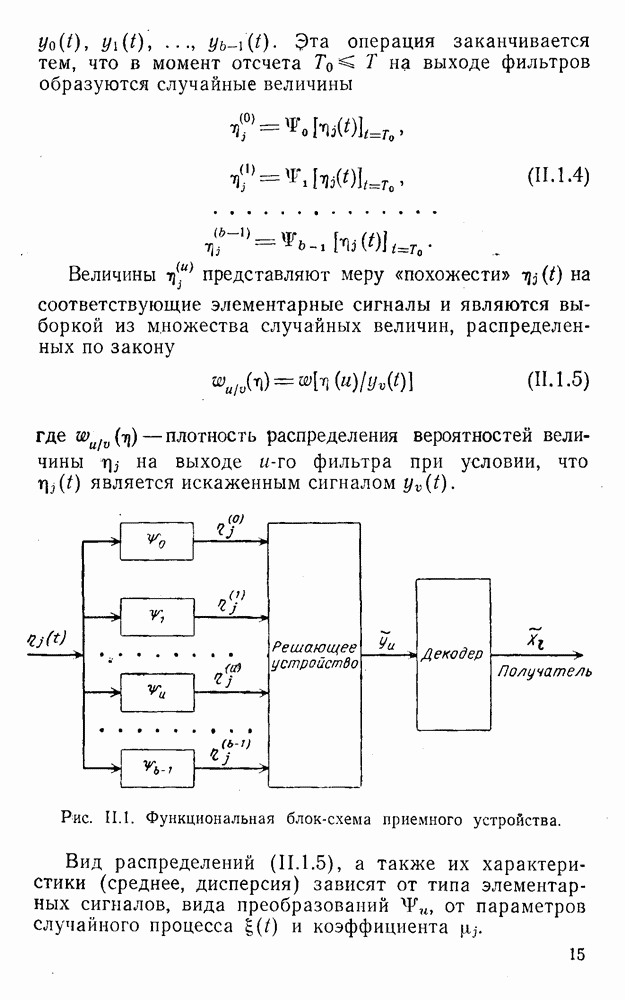
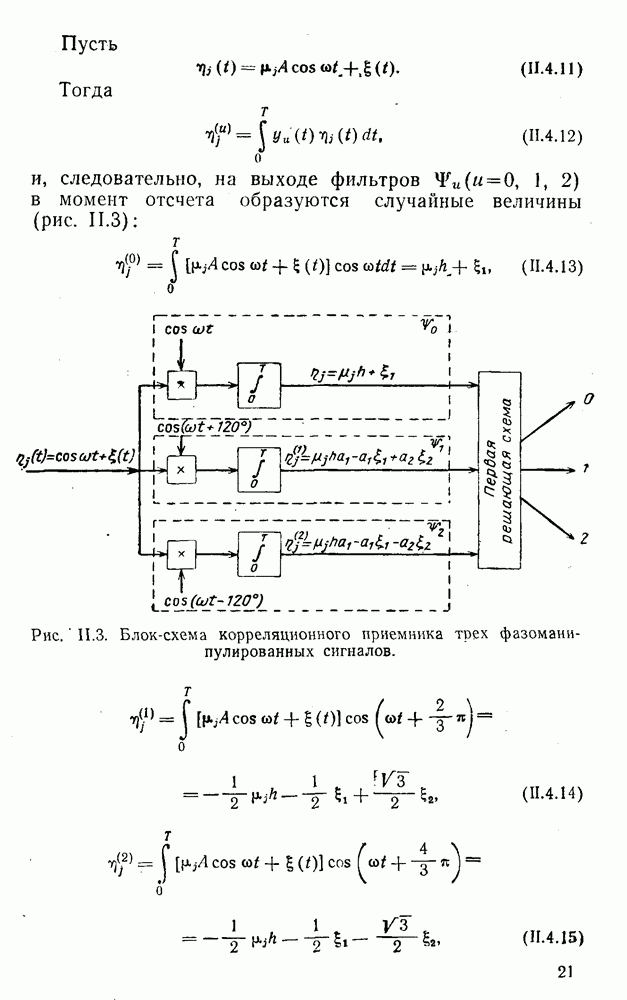
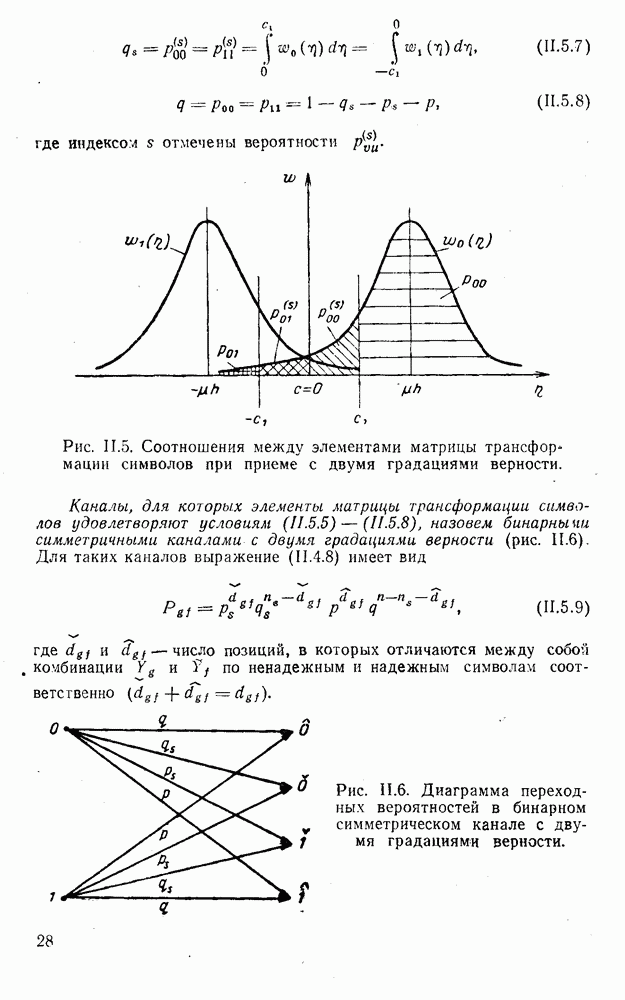
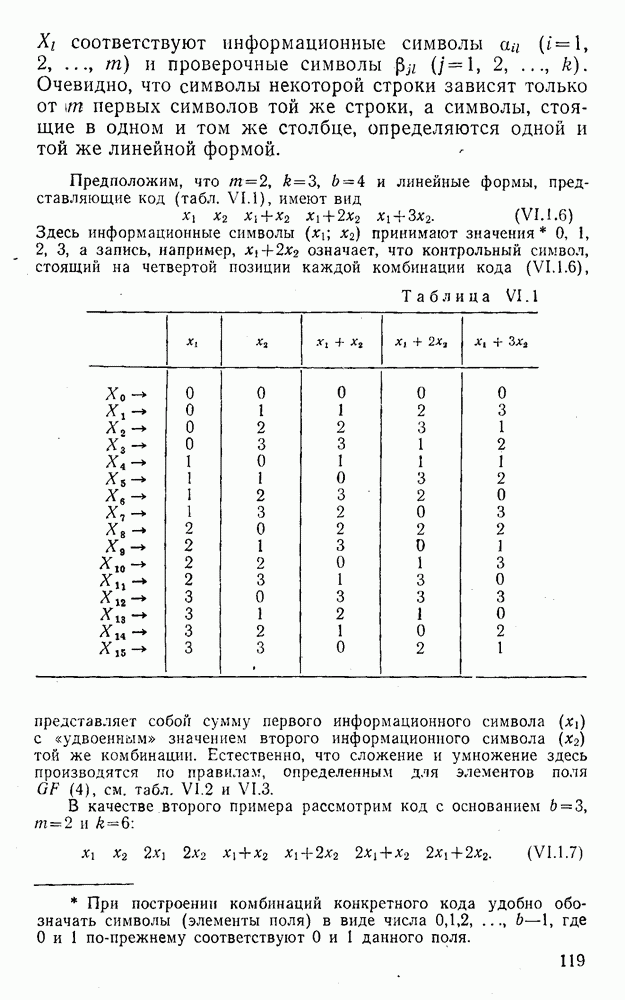
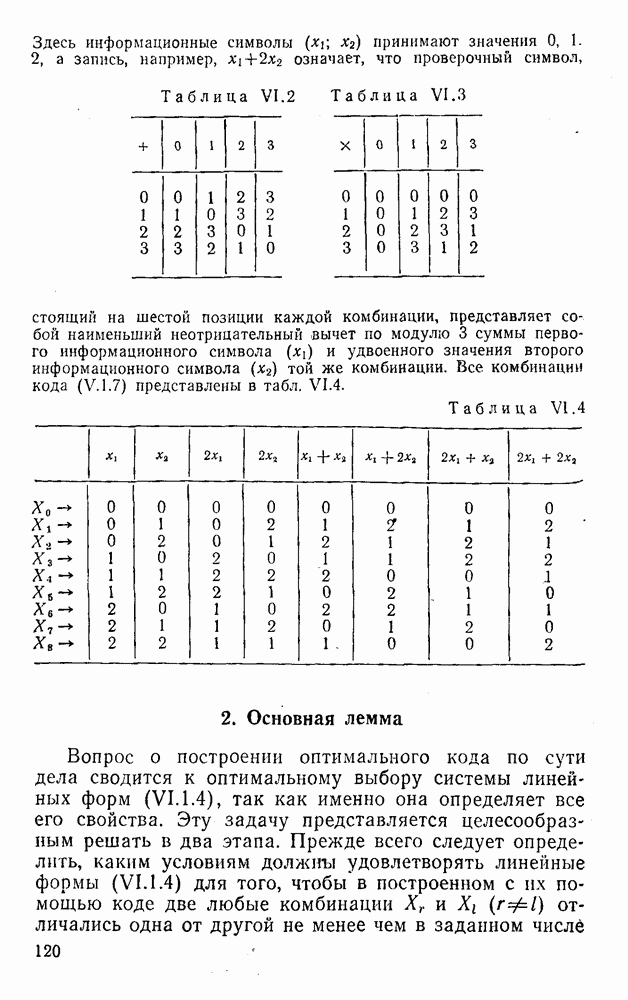
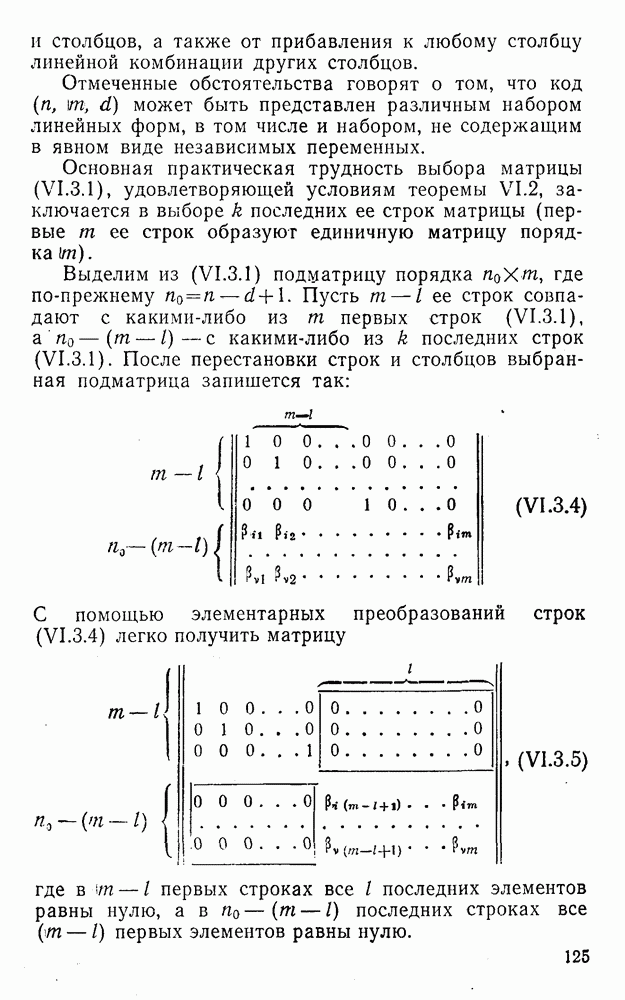
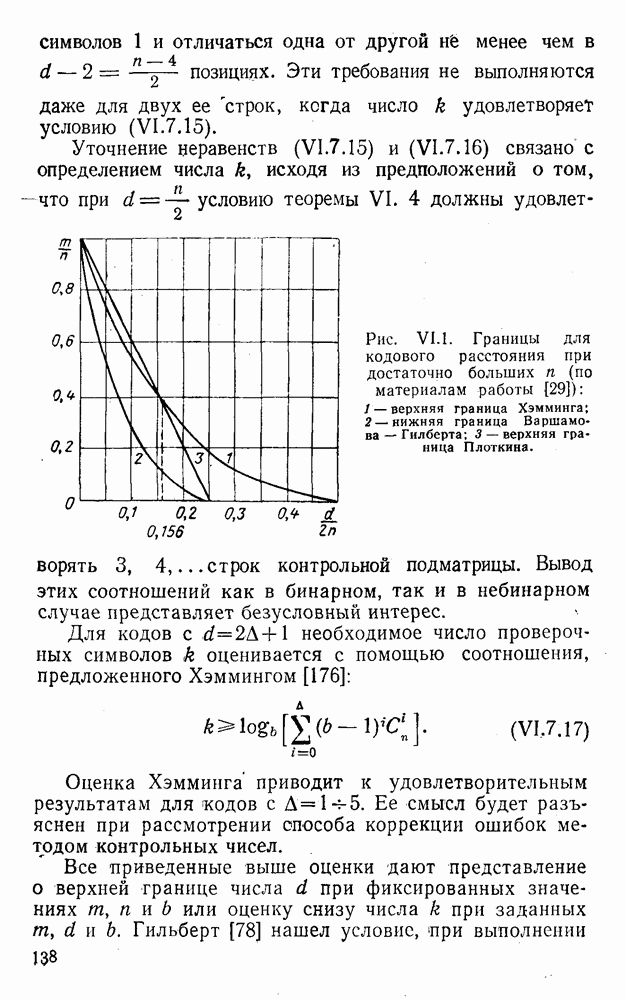
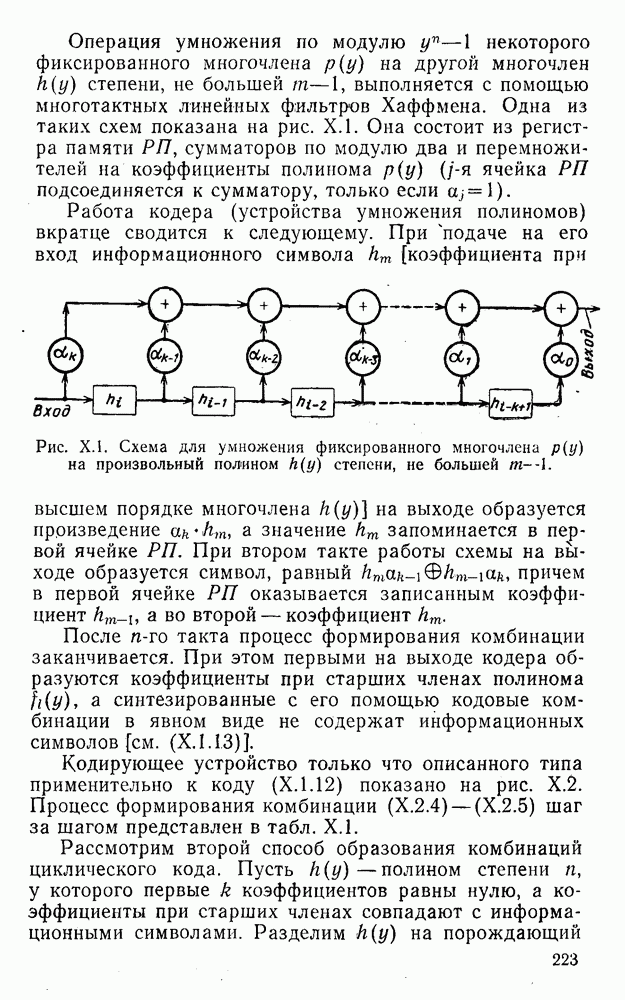
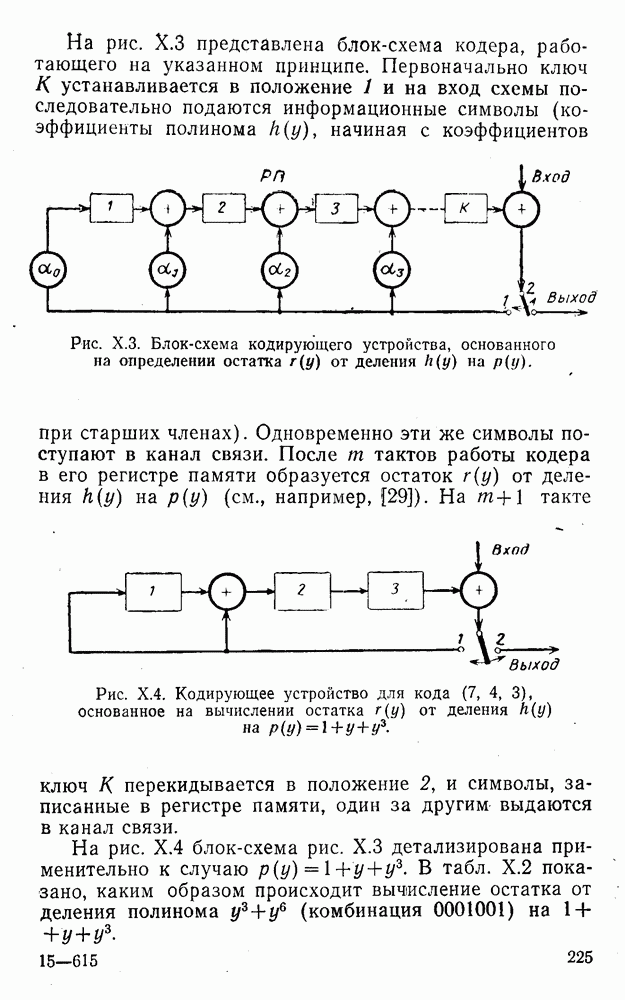
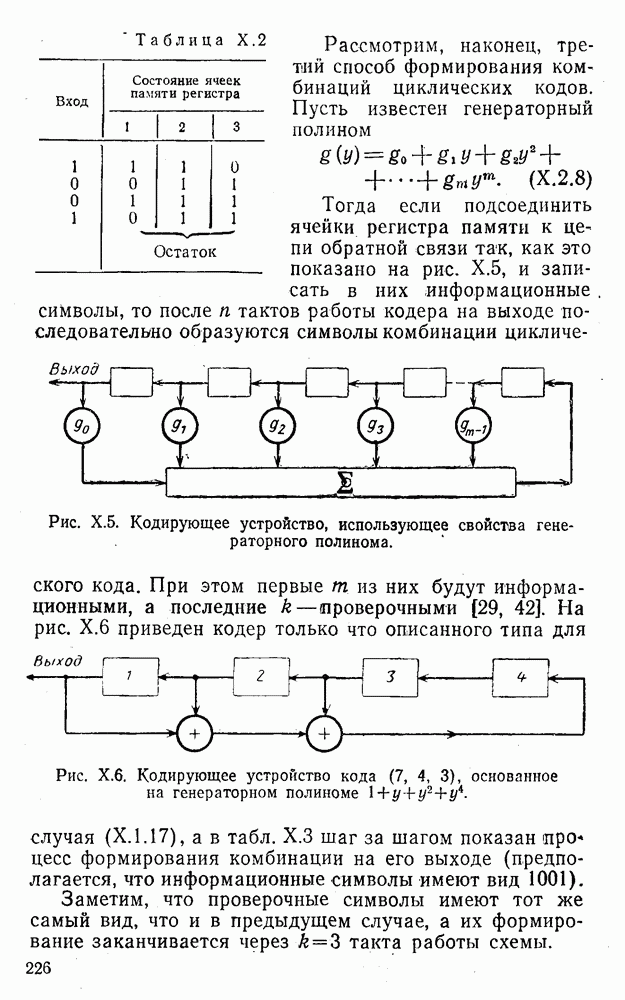
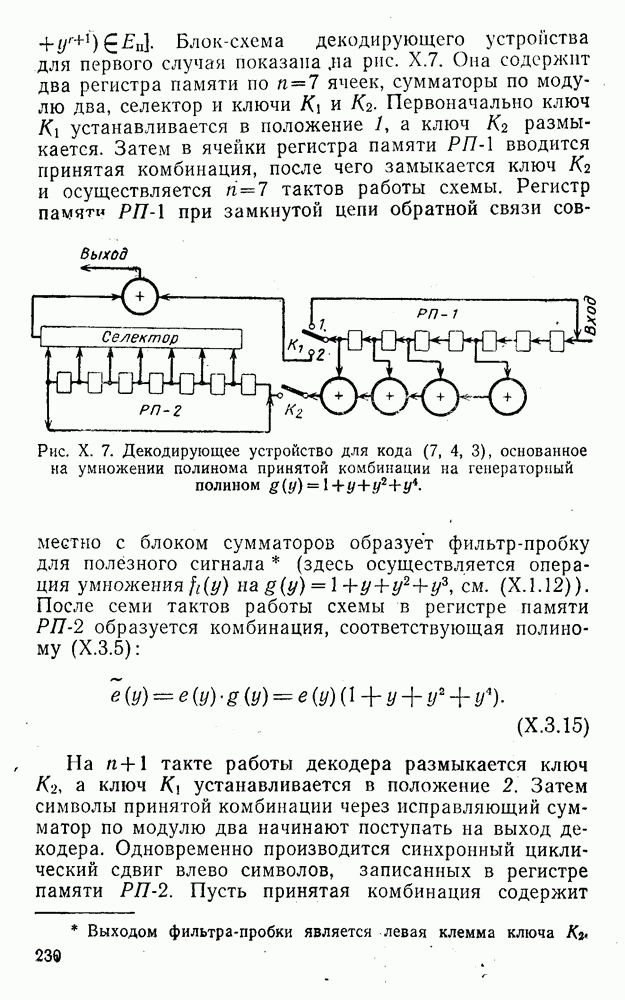
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
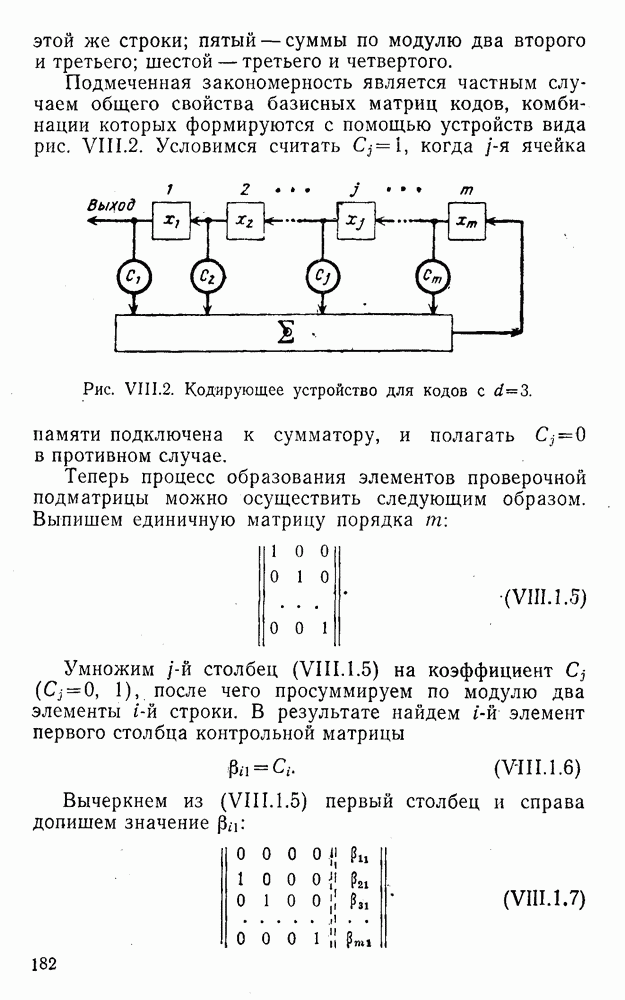
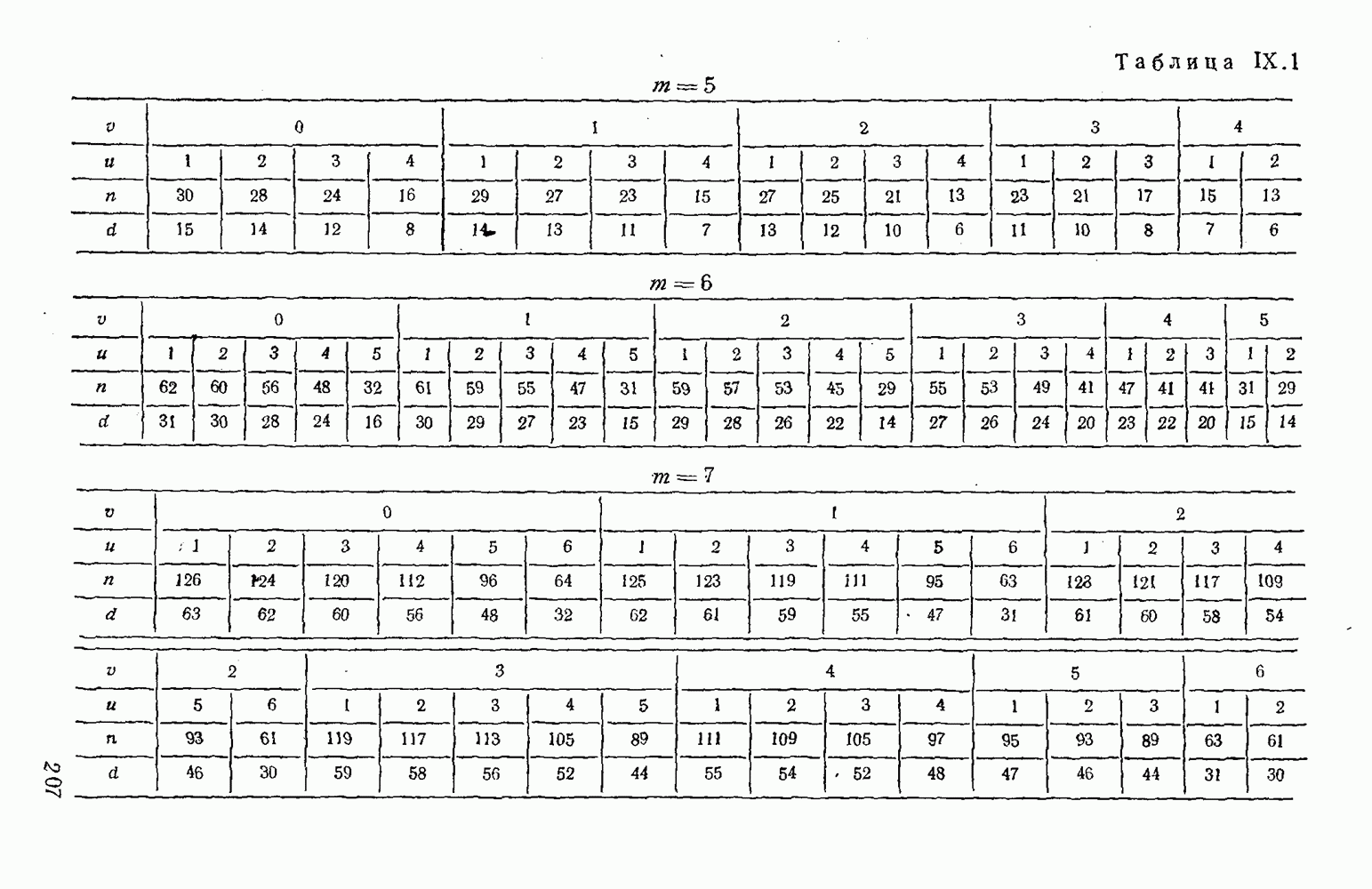
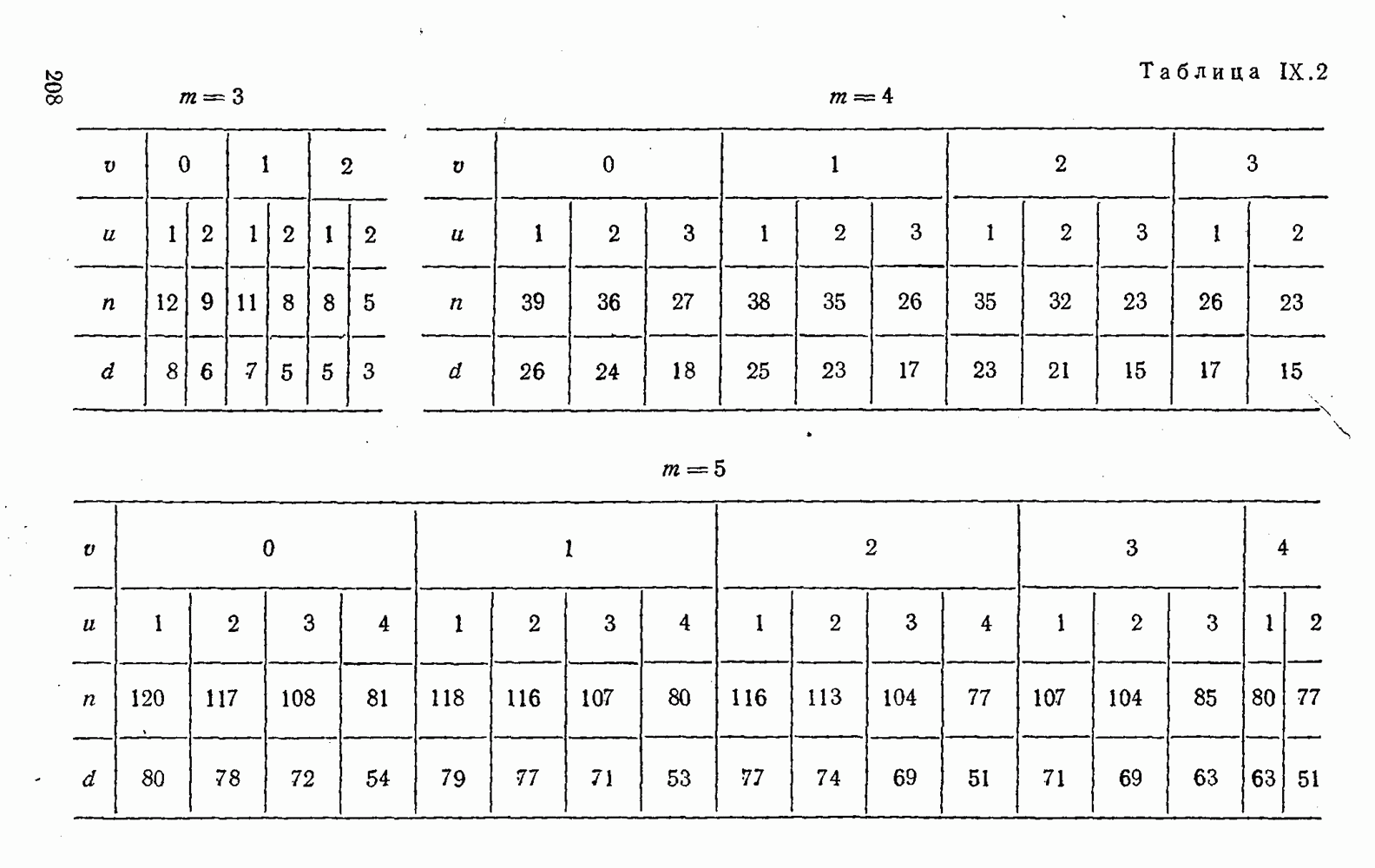
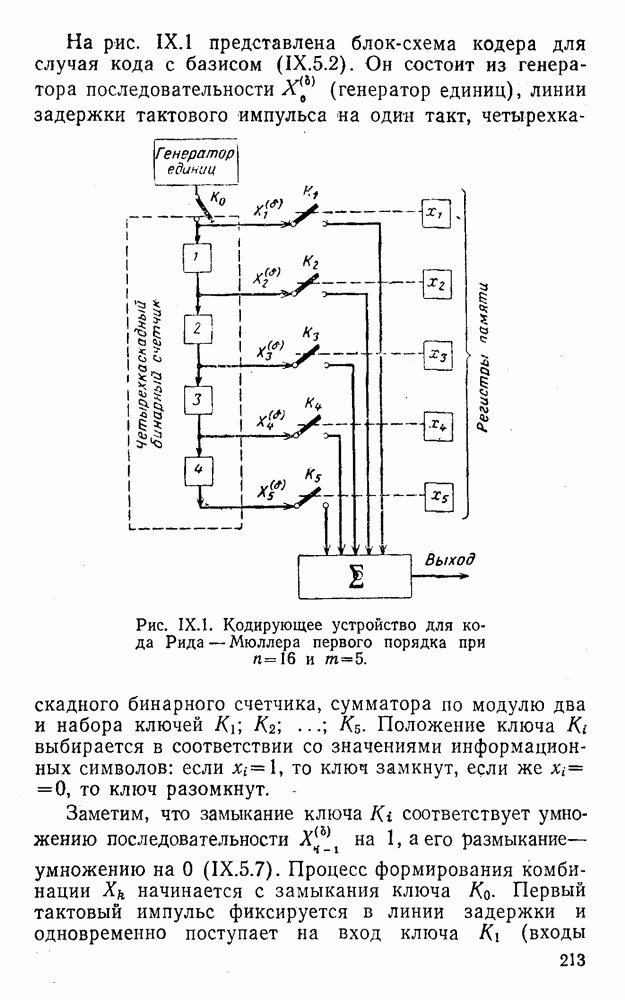
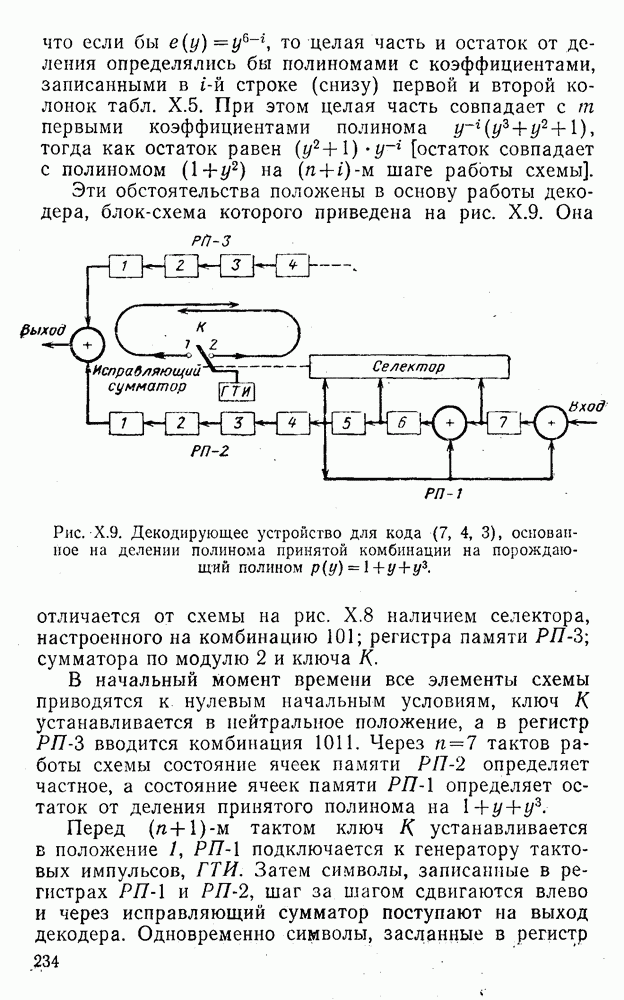
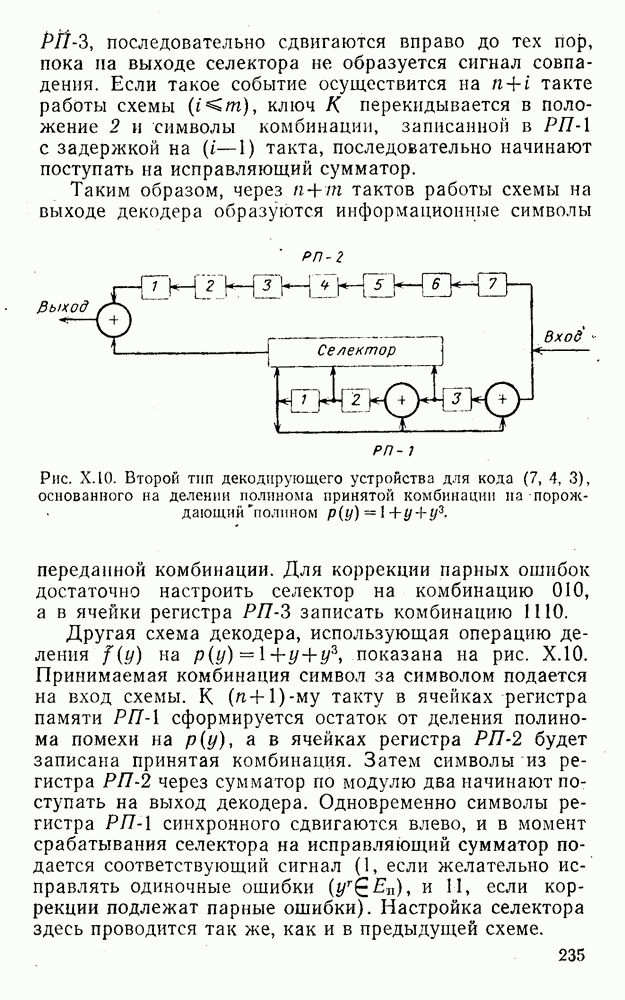
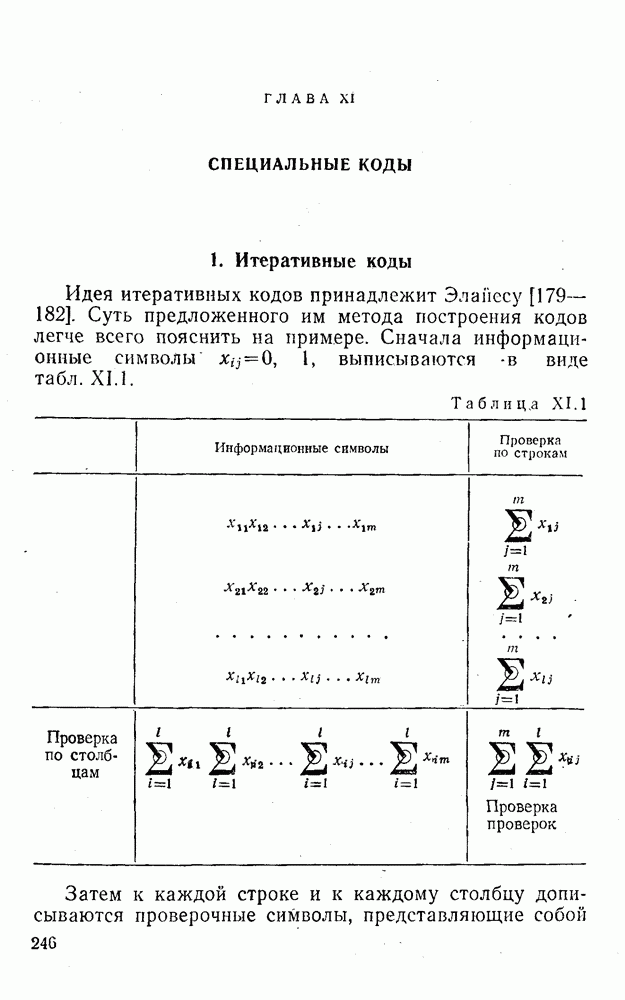
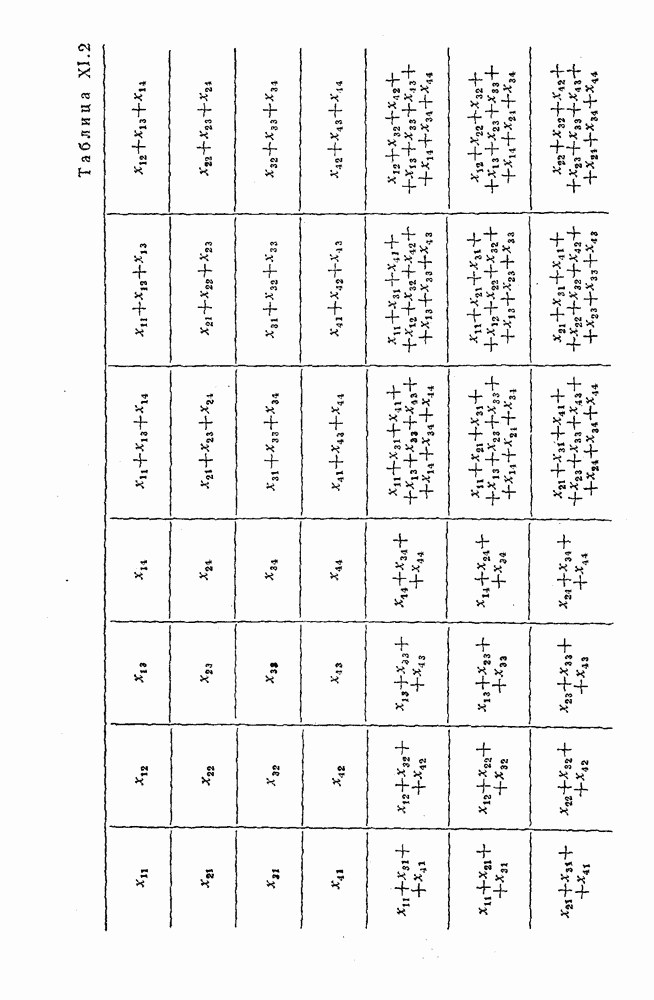
Оптимальное по критерию максимума обобщенного отношения правдоподобия преобразование вида (XII.5.7)-(XII.5.8) было найдено Финком Л. М. и исследовано им совместно с Каганом Б. Д. Далее такой метод опознания информационных символов называется разностно-модульным декодированием. Согласно [100] величины вычисляются следующим образом [применительно к коду (XII.5.1) и в предположении, что распределения и являются нормальными и отличаются лишь знаком среднего]:
(XII.6.1)
При этом, если , то если же , то .
Легко видеть, что соотношения (XII.6.1) получаются в результате умножения первого слагаемого каждого уравнения (XII.5.16) на 2 и замены в нем на
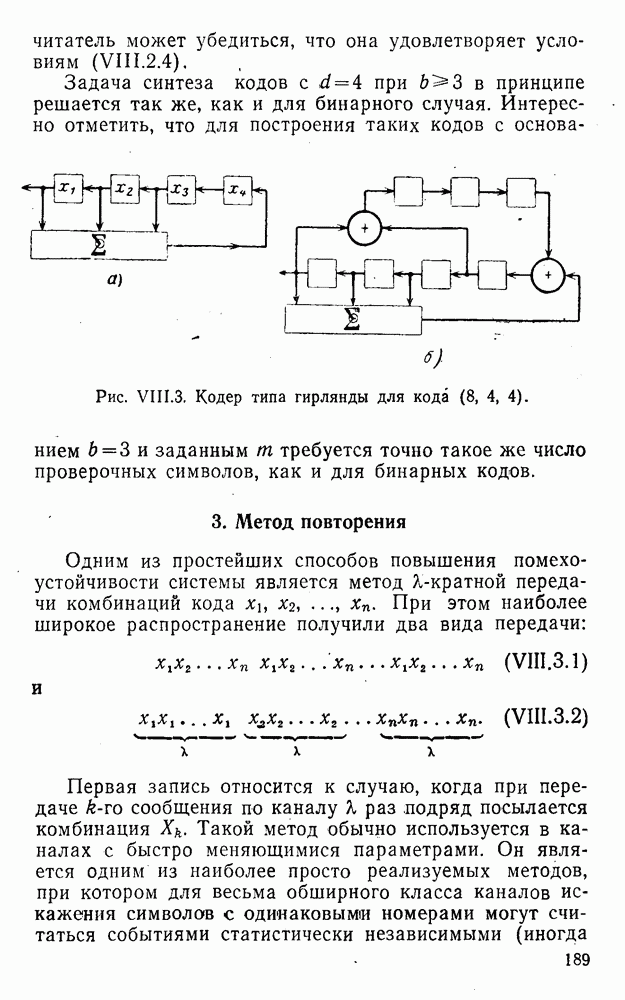
Для вычисления вероятности неправильного опознания информационного символа Цветков А. Н. совместно с автором детально проанализировали статистические свойства преобразования
(XII.6.2)
Выяснилось, что знак величины может быть определен как знак произведения а равен удвоенному значению наименьшего из модулей исходных величин
(XII.6.3)
Такая запись облегчает анализ (XII.6.2) и в ряде случаев, по-видимому, позволит технически просто вычислять значения . Далее, если распределения и являются нормальными с одинаковыми дисперсиями и средними, равными h и , то величины и некоррелированны. В соответствии с этим и формулами (XII.5.20) и (XII.5.22) дисперсия равна
(XII.6.4)
Среднее значение [см. (XII.5.19) и (XII.5.21)]:
(XII.6.5)
где берется знак плюс, если и — выборки из одного и того же распределения, и знак минус, когда они являются выборками из разных распределений.
Таким образом:
(XII.6.6)
(XII.6.7)
(XII.6.8)
По аналогии с предыдущим вероятность ошибочного декодирования информационного символа определится формулой (XII.5.29), если в ней положить
(XII.6.9)
при вероятность неправильного декодирования равна
(XII.6.10)
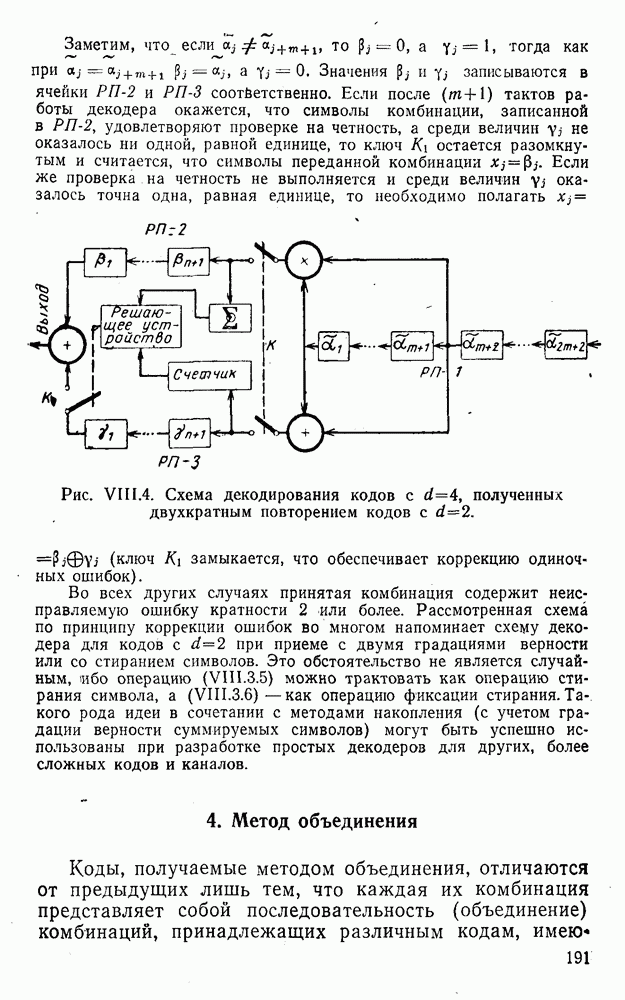
Из (XII.6.1)-(XII.6.3) видно, что если знаки и совпадают со знаками средних этих величин, то данная реализация как одного из слагаемых величины (XII.6.1) благоприятствует правильному опознанию символа . В противном случае способствует принятию неправильного решения. При этом в подавляющем большинстве ситуаций приобретает «ложный» знак благодаря тому, что знак не совпадает со знаком ее среднего значения. Таким образом, знак играет в помехоустойчивости данного метода определяющую роль, а наименьший из модулей исходных величин задает лишь меру его «ненадежности». Основываясь на этом факте можно найти целый ряд сравнительно простых и эффективных методов аналогового посимвольного декодирования комбинаций различных линейных кодов, в частности кодов, допускающих мажоритарное декодирование со связанными проверками.
























































































































































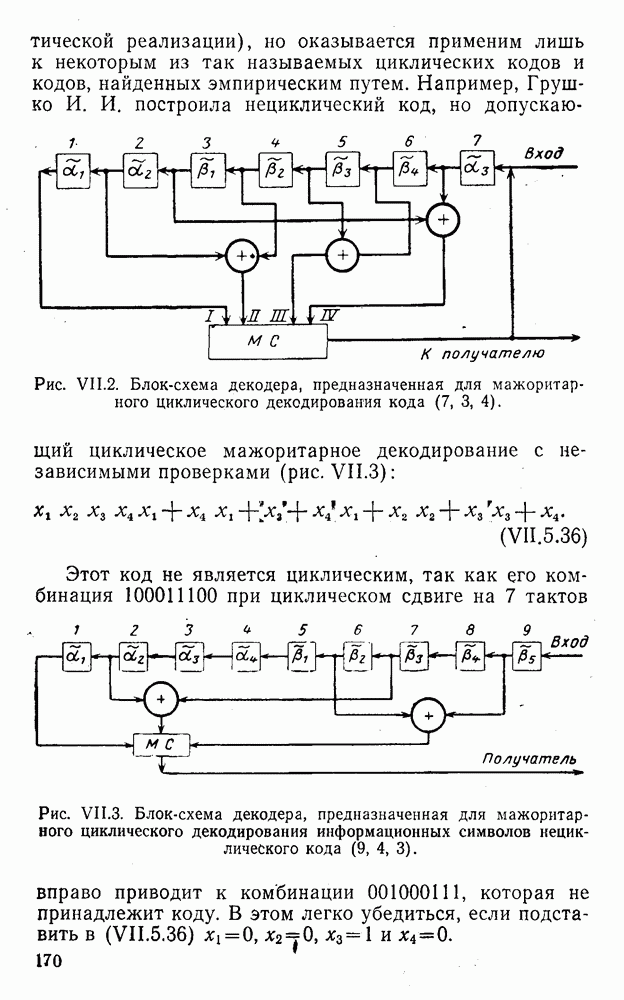




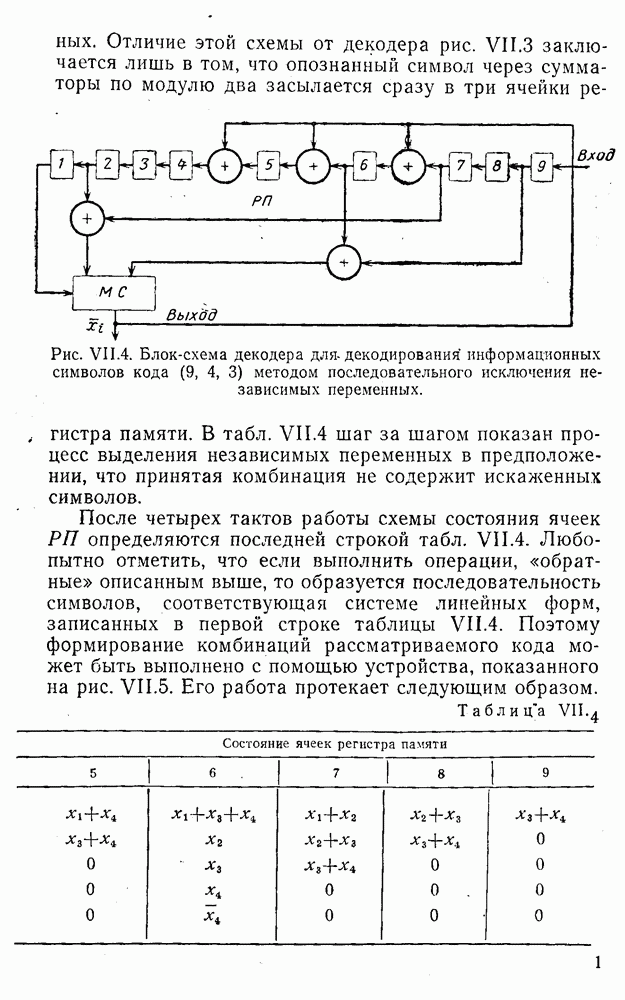
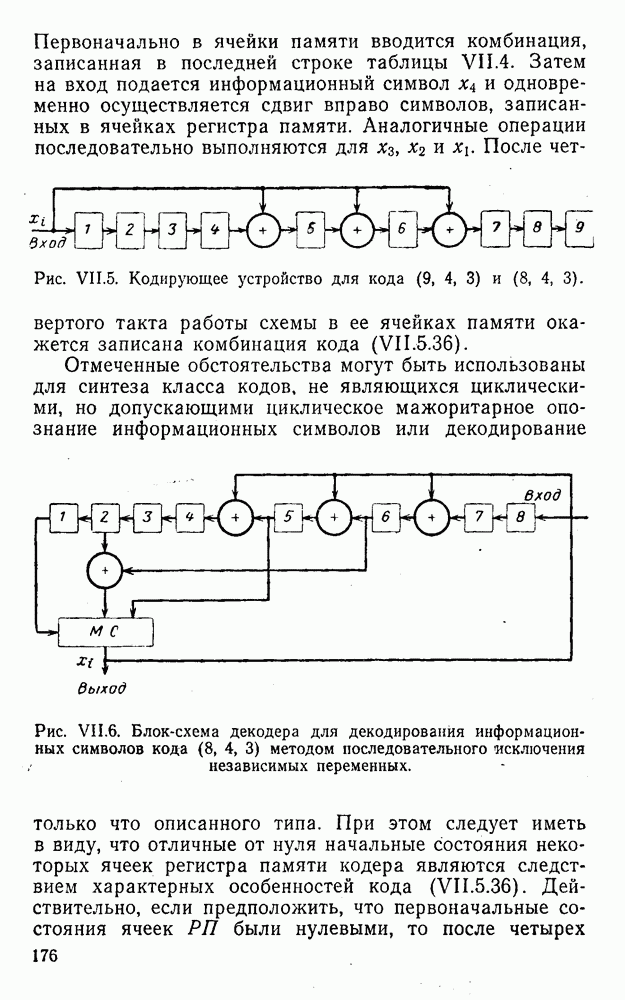
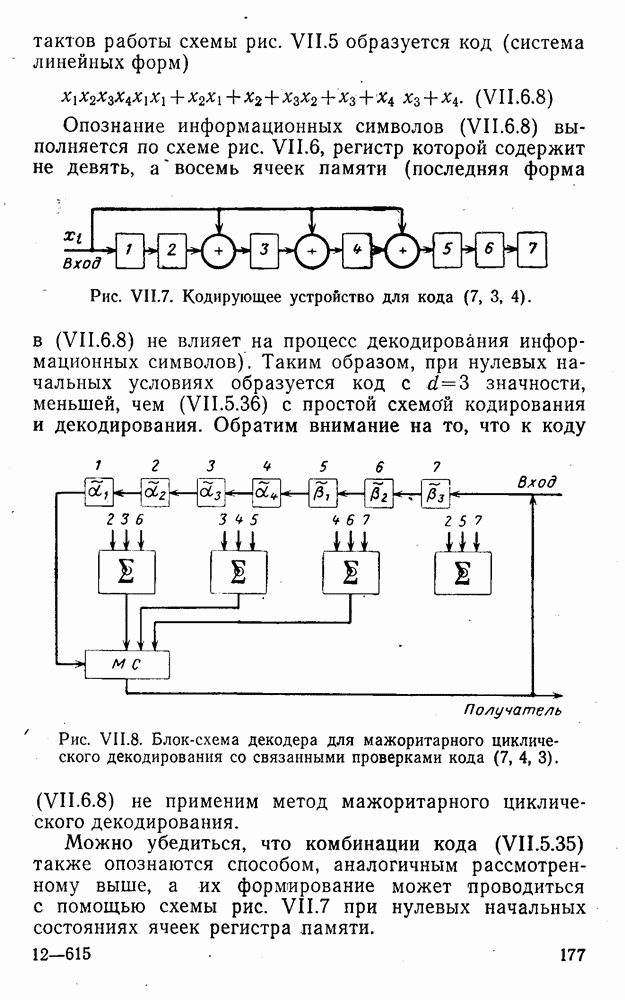


















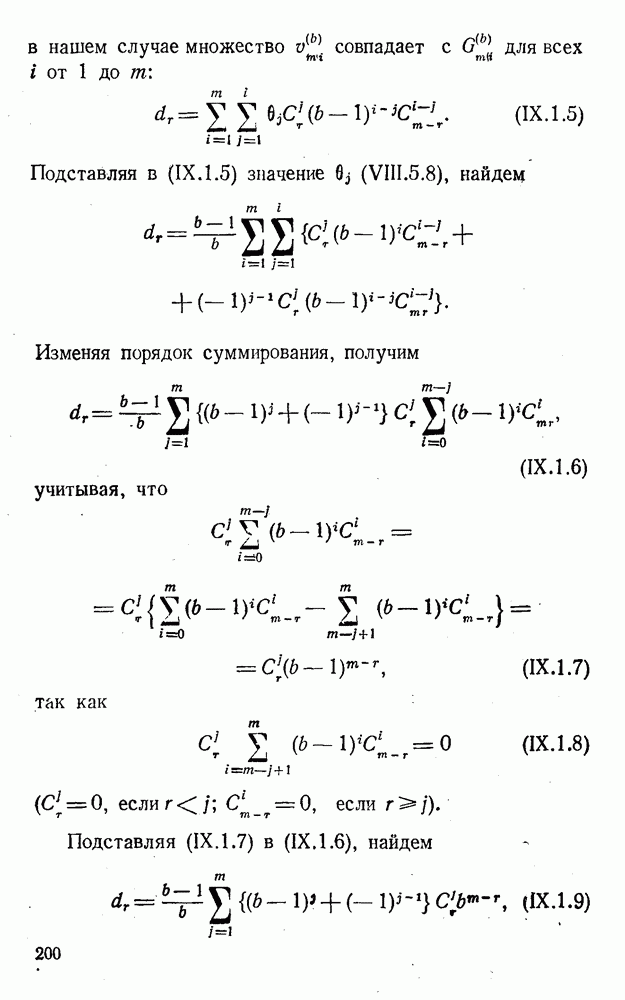














































































































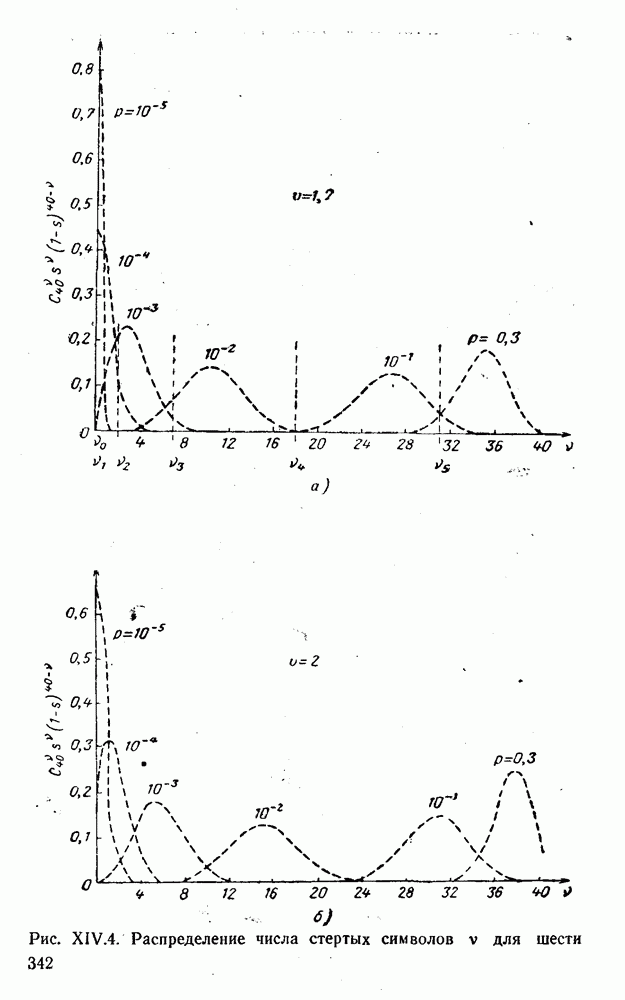
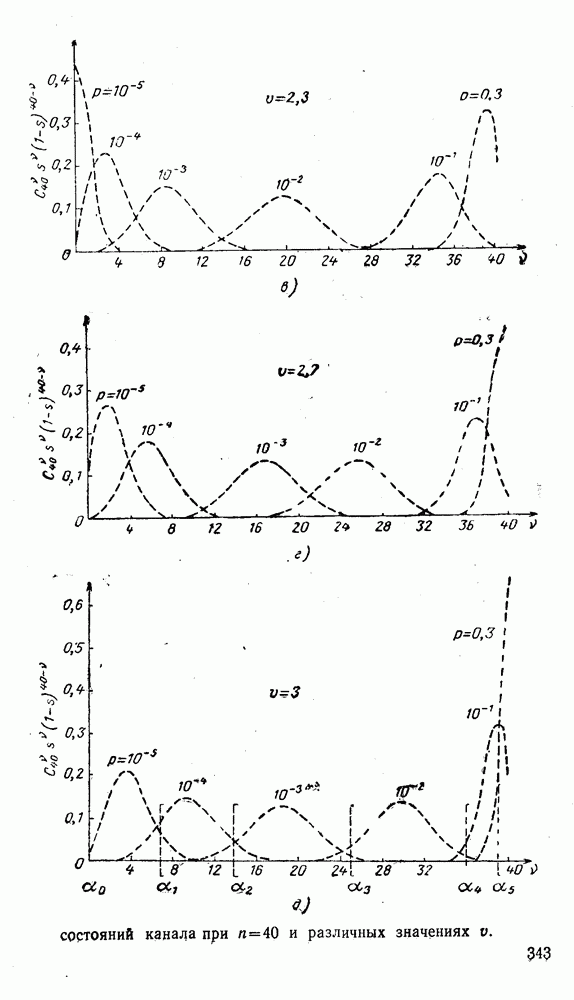
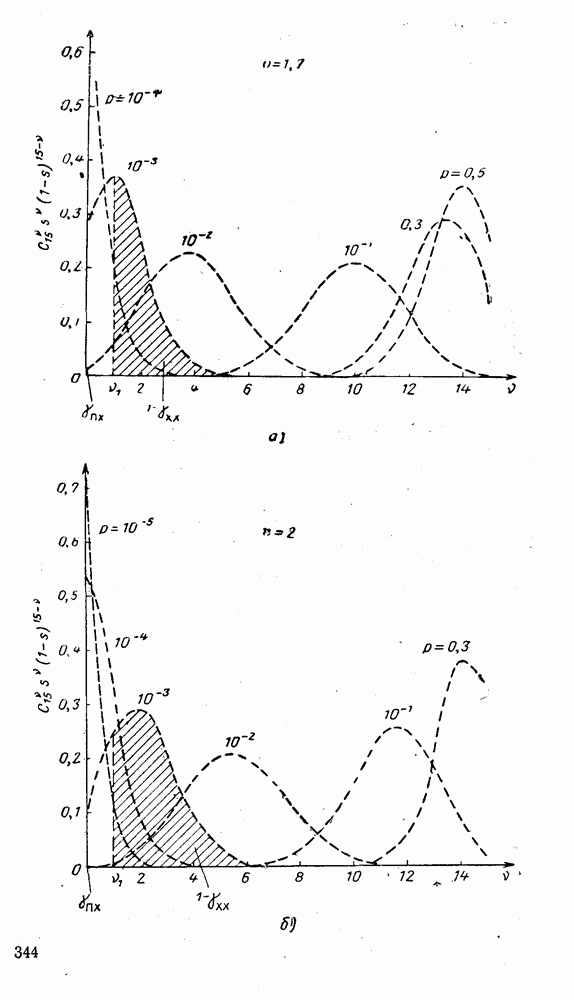
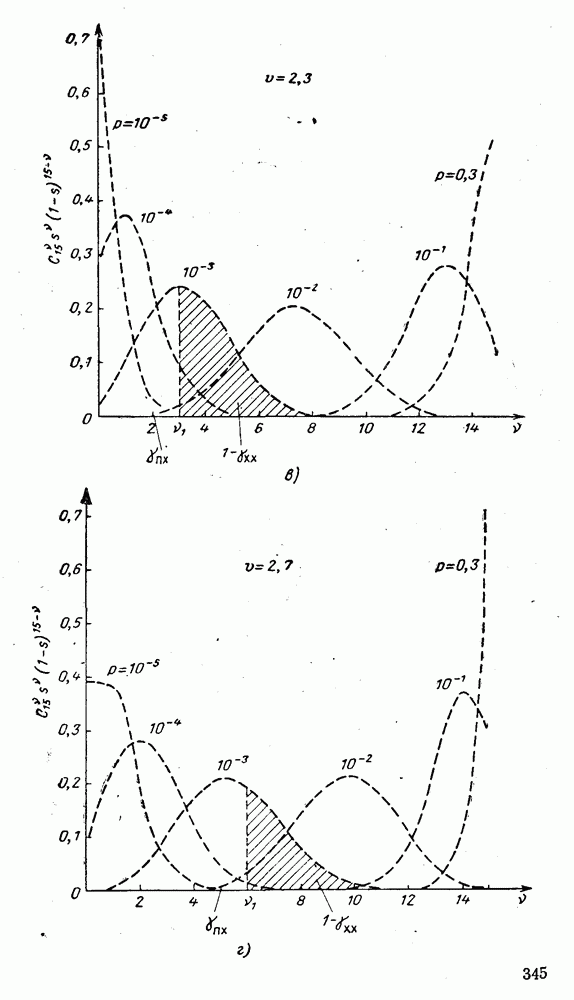










































 вычисляются следующим образом [применительно к коду (XII.5.1) и в предположении, что распределения
вычисляются следующим образом [применительно к коду (XII.5.1) и в предположении, что распределения  и
и  являются нормальными и отличаются лишь знаком среднего]:
являются нормальными и отличаются лишь знаком среднего]:
 (XII.6.1)
(XII.6.1)
 , то
, то  если же
если же  , то
, то  .
.
 на
на 
 (XII.6.2)
(XII.6.2)
 может быть определен как знак произведения
может быть определен как знак произведения  а
а  равен удвоенному значению наименьшего из модулей исходных величин
равен удвоенному значению наименьшего из модулей исходных величин
 (XII.6.3)
(XII.6.3)
 . Далее, если распределения
. Далее, если распределения  и
и  являются нормальными с одинаковыми дисперсиями
являются нормальными с одинаковыми дисперсиями  и средними, равными h и
и средними, равными h и  , то величины
, то величины  и
и  некоррелированны. В соответствии с этим и формулами (XII.5.20) и (XII.5.22) дисперсия равна
некоррелированны. В соответствии с этим и формулами (XII.5.20) и (XII.5.22) дисперсия равна
 (XII.6.4)
(XII.6.4)
 [см. (XII.5.19) и (XII.5.21)]:
[см. (XII.5.19) и (XII.5.21)]:
 (XII.6.5)
(XII.6.5)
 и
и  — выборки из одного и того же распределения, и знак минус, когда они являются выборками из разных распределений.
— выборки из одного и того же распределения, и знак минус, когда они являются выборками из разных распределений.
 (XII.6.6)
(XII.6.6)
 (XII.6.7)
(XII.6.7)
 (XII.6.8)
(XII.6.8)
 (XII.6.9)
(XII.6.9)
 вероятность неправильного декодирования равна
вероятность неправильного декодирования равна
 (XII.6.10)
(XII.6.10)
 и
и  совпадают со знаками средних этих величин, то данная реализация
совпадают со знаками средних этих величин, то данная реализация  как одного из слагаемых величины
как одного из слагаемых величины  (XII.6.1) благоприятствует правильному опознанию символа
(XII.6.1) благоприятствует правильному опознанию символа  . В противном случае
. В противном случае  способствует принятию неправильного решения. При этом в подавляющем большинстве ситуаций
способствует принятию неправильного решения. При этом в подавляющем большинстве ситуаций  приобретает «ложный» знак благодаря тому, что знак
приобретает «ложный» знак благодаря тому, что знак  не совпадает со знаком ее среднего значения. Таким образом, знак
не совпадает со знаком ее среднего значения. Таким образом, знак  играет в помехоустойчивости данного метода определяющую роль, а наименьший из модулей исходных величин задает лишь меру его «ненадежности». Основываясь на этом факте можно найти целый ряд сравнительно простых и эффективных методов аналогового посимвольного декодирования комбинаций различных линейных кодов, в частности кодов, допускающих мажоритарное декодирование со связанными проверками.
играет в помехоустойчивости данного метода определяющую роль, а наименьший из модулей исходных величин задает лишь меру его «ненадежности». Основываясь на этом факте можно найти целый ряд сравнительно простых и эффективных методов аналогового посимвольного декодирования комбинаций различных линейных кодов, в частности кодов, допускающих мажоритарное декодирование со связанными проверками.
