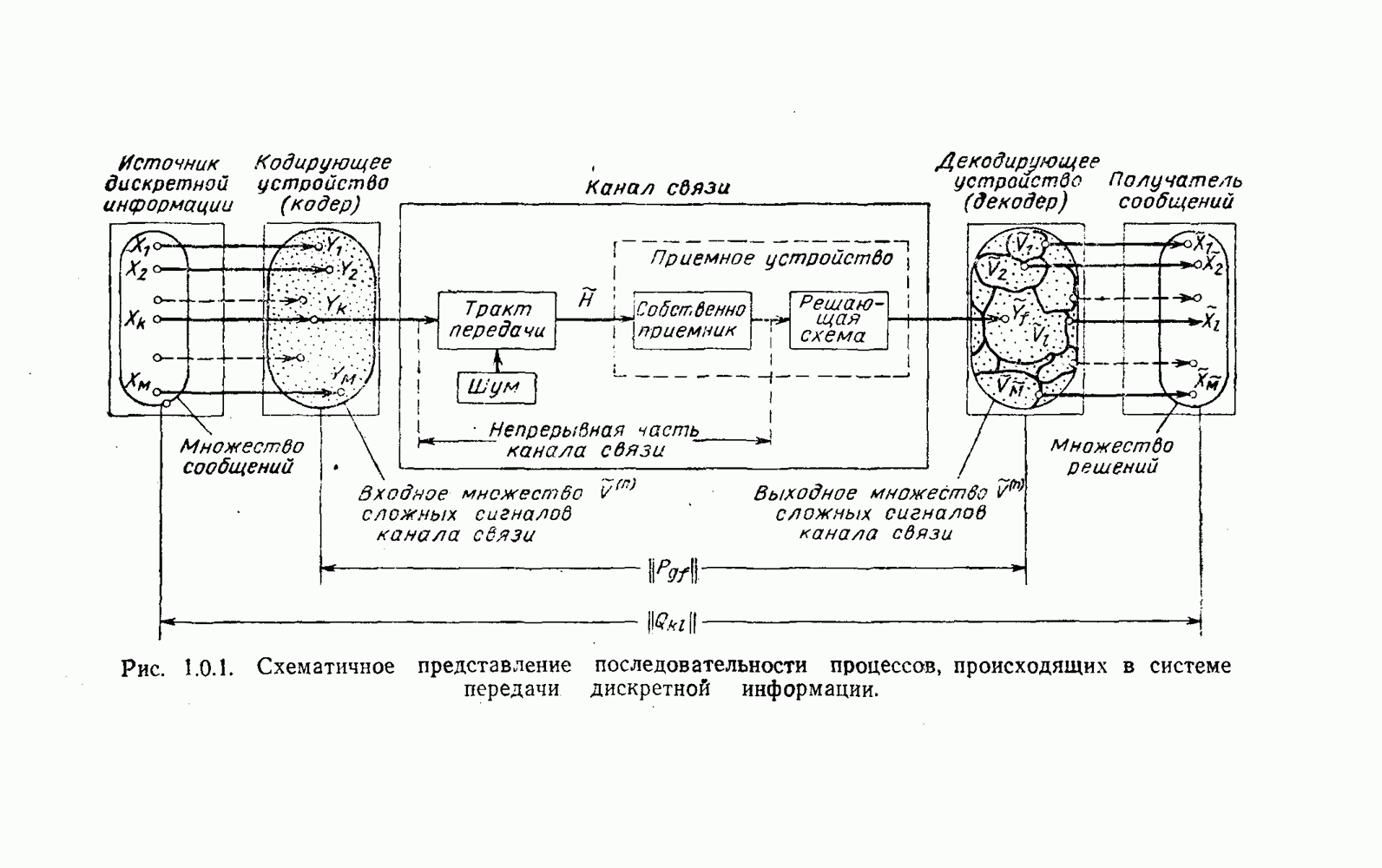
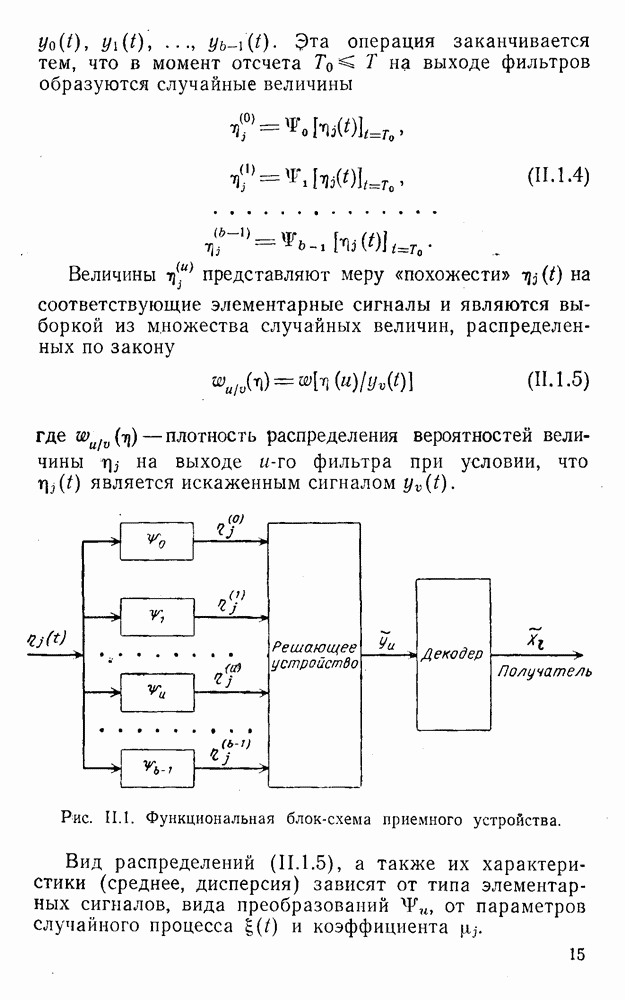
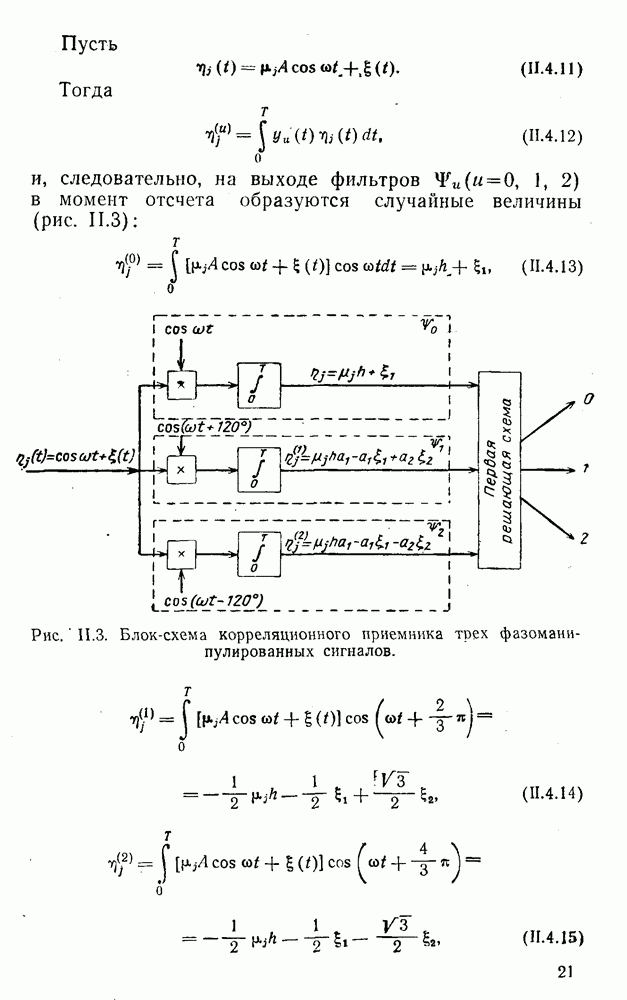
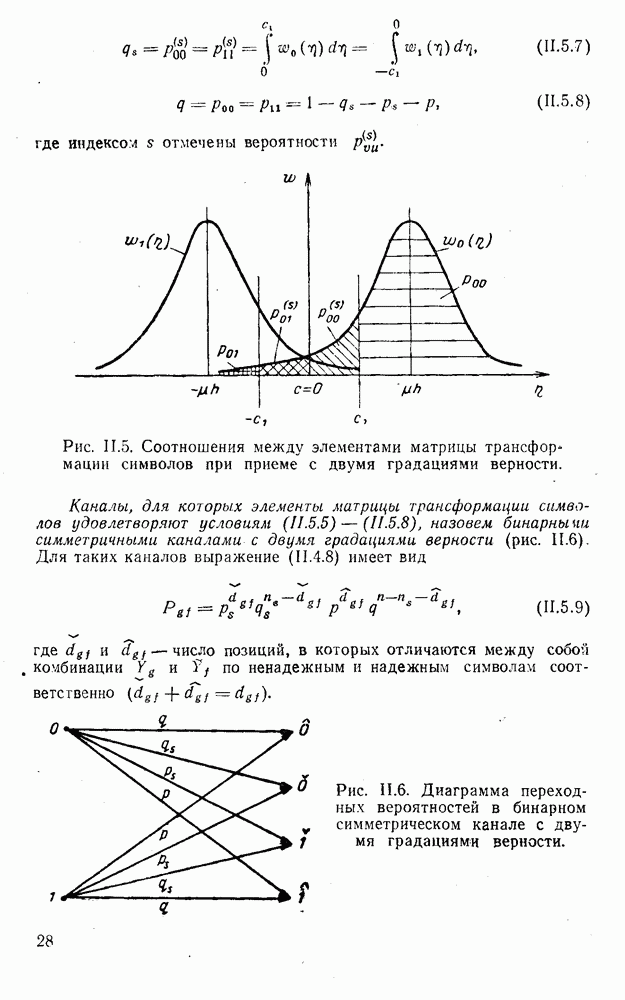
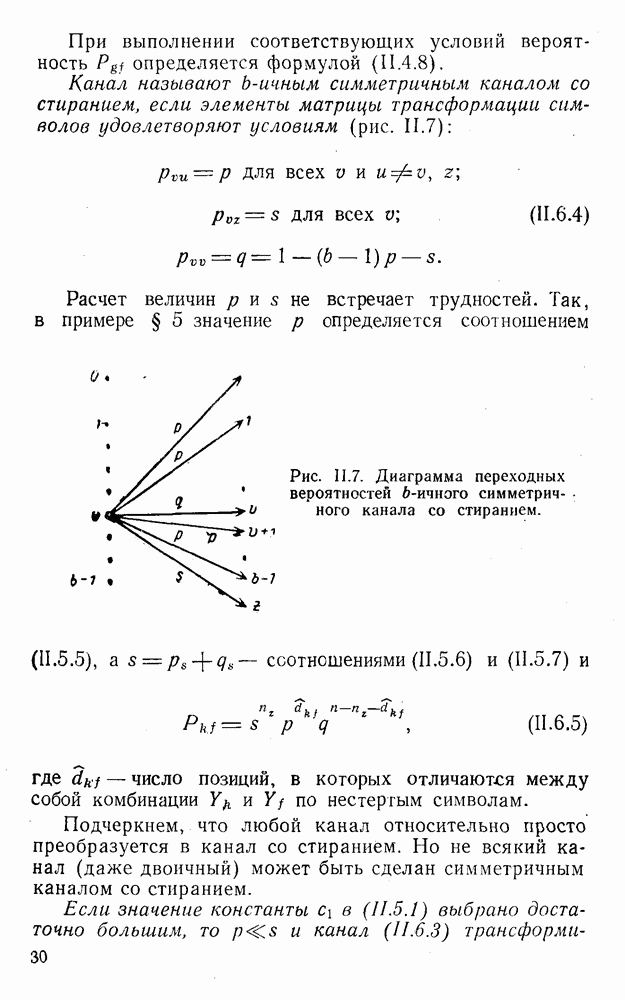
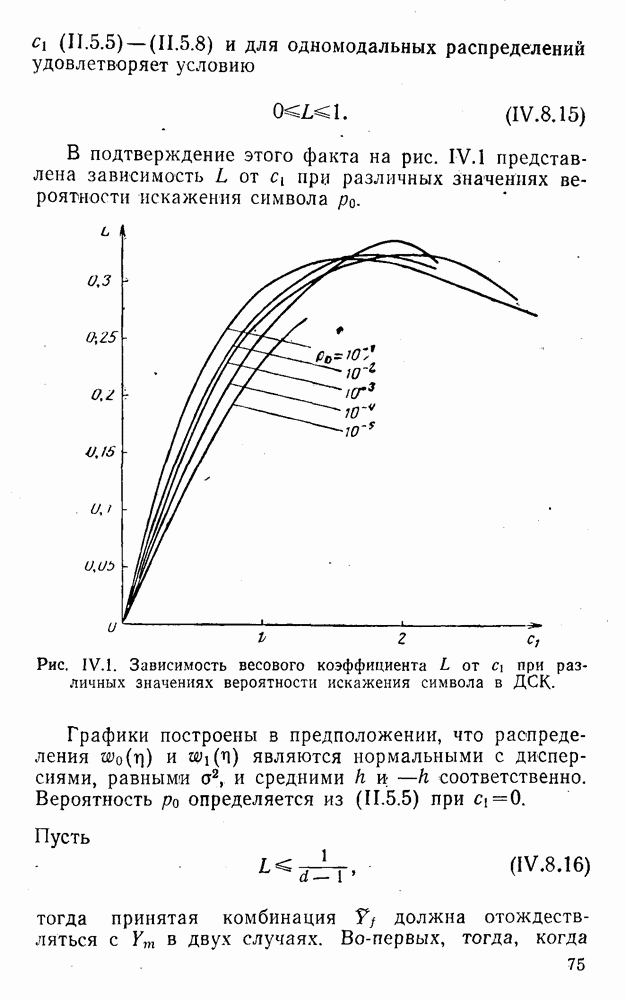
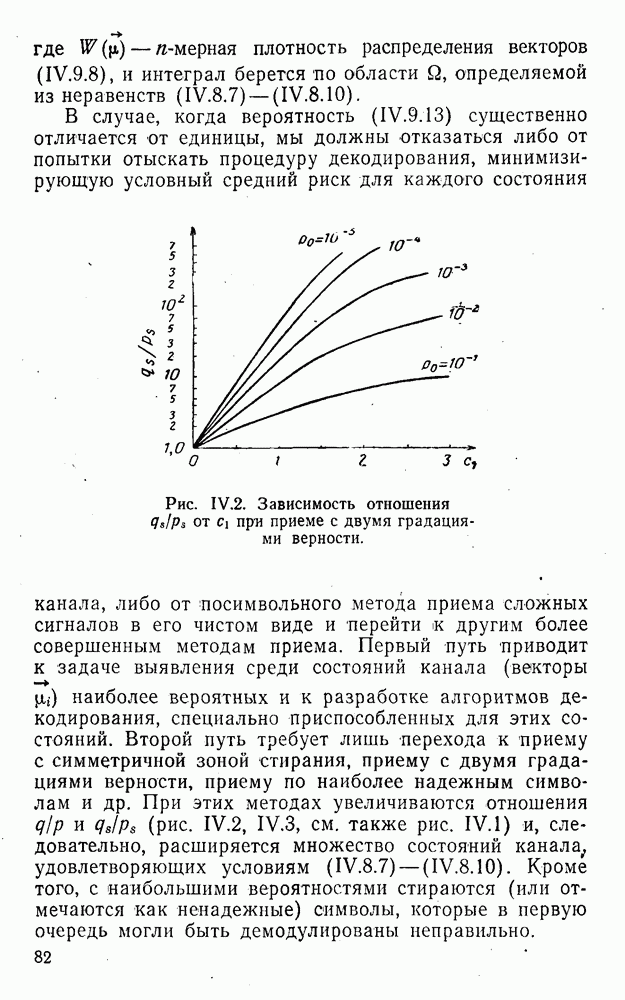
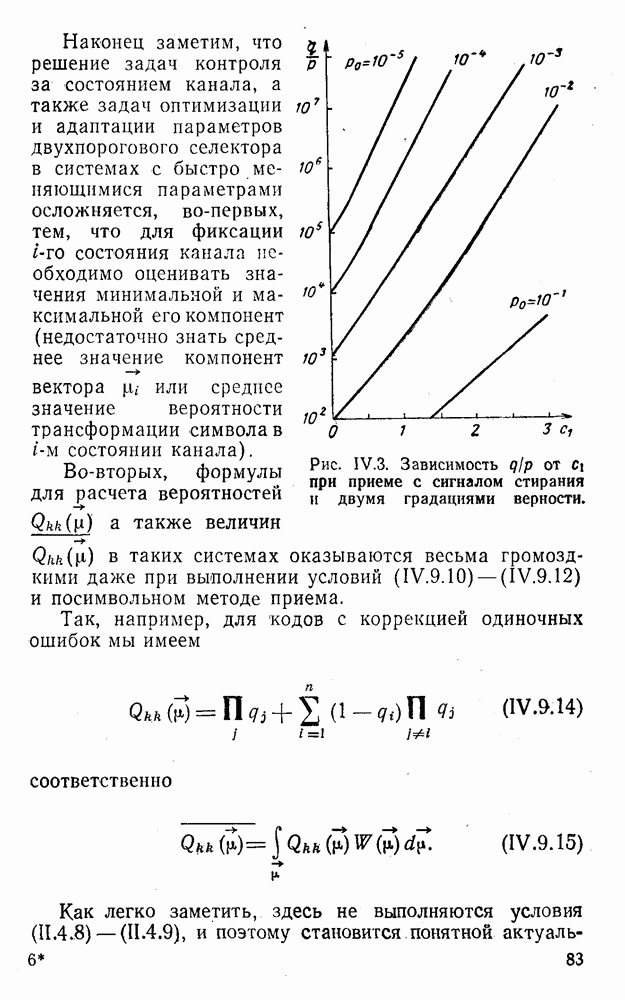
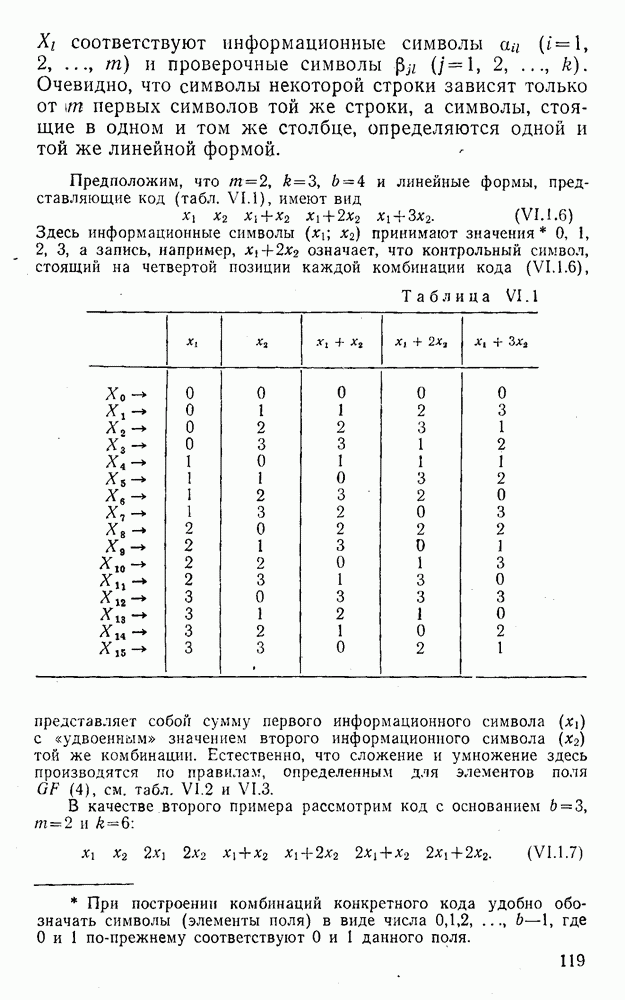
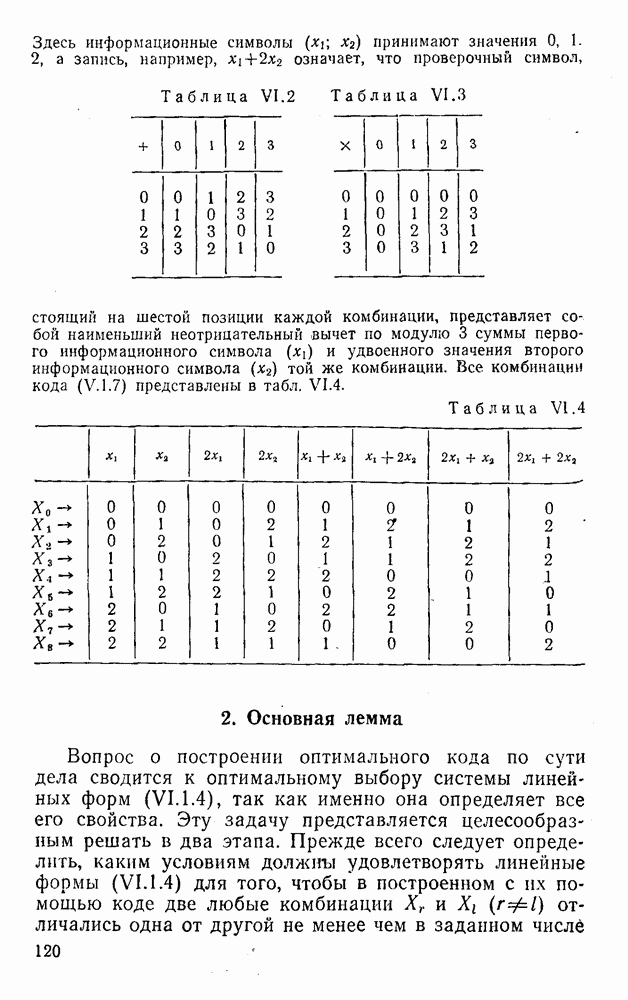
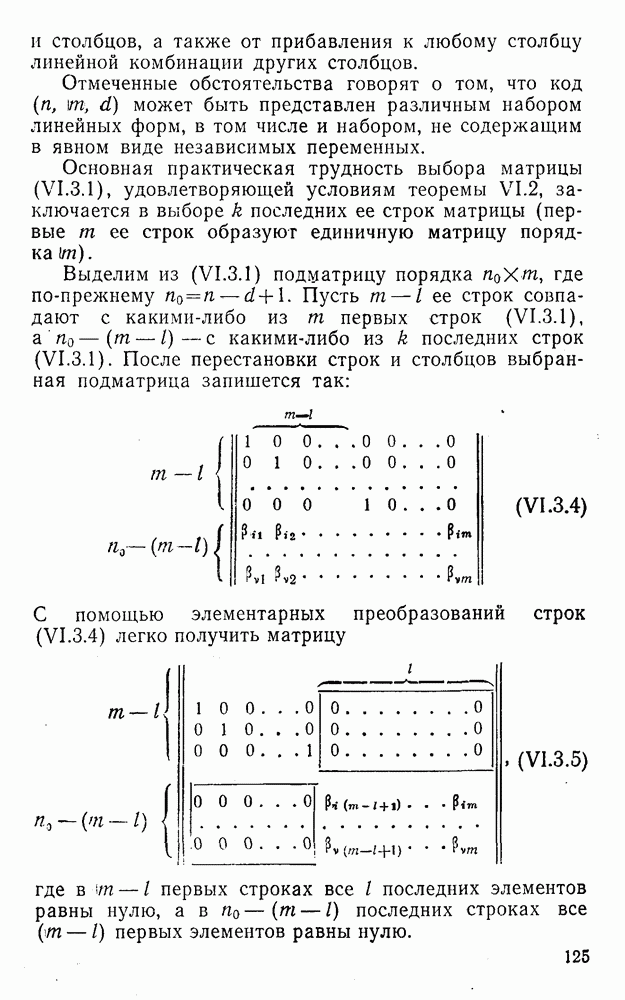
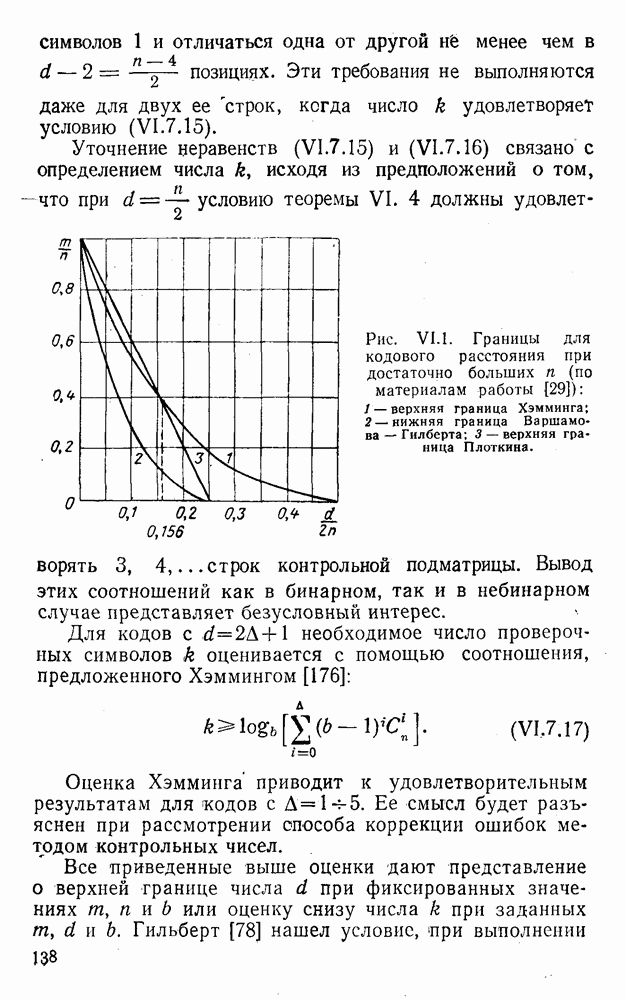
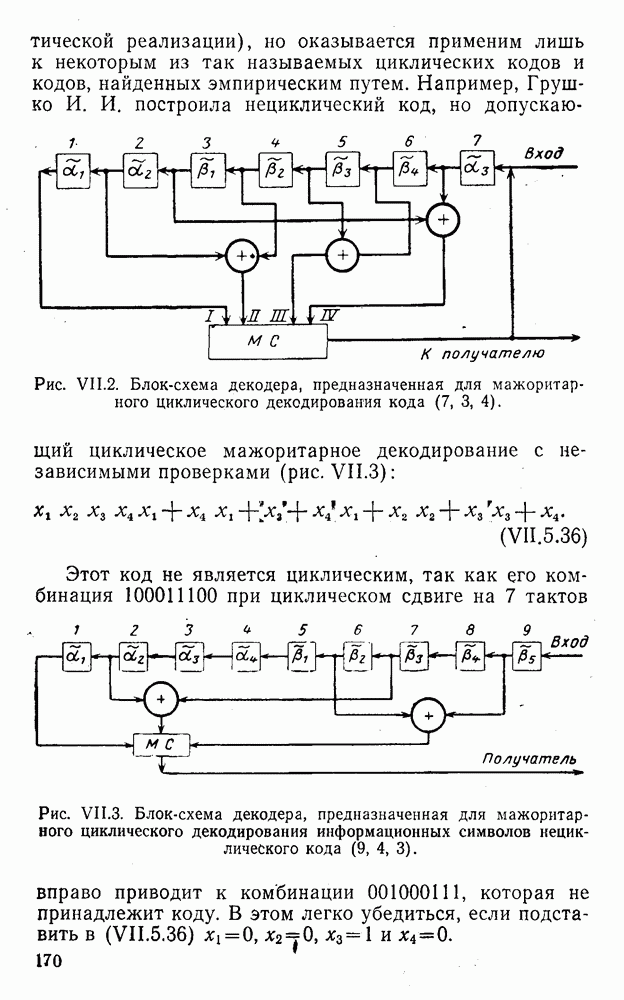
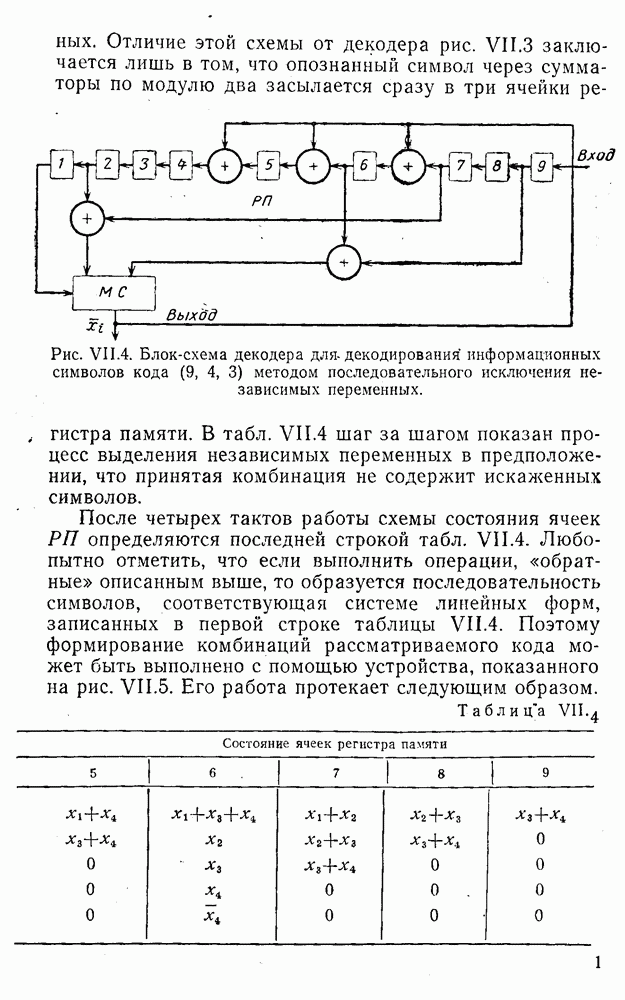
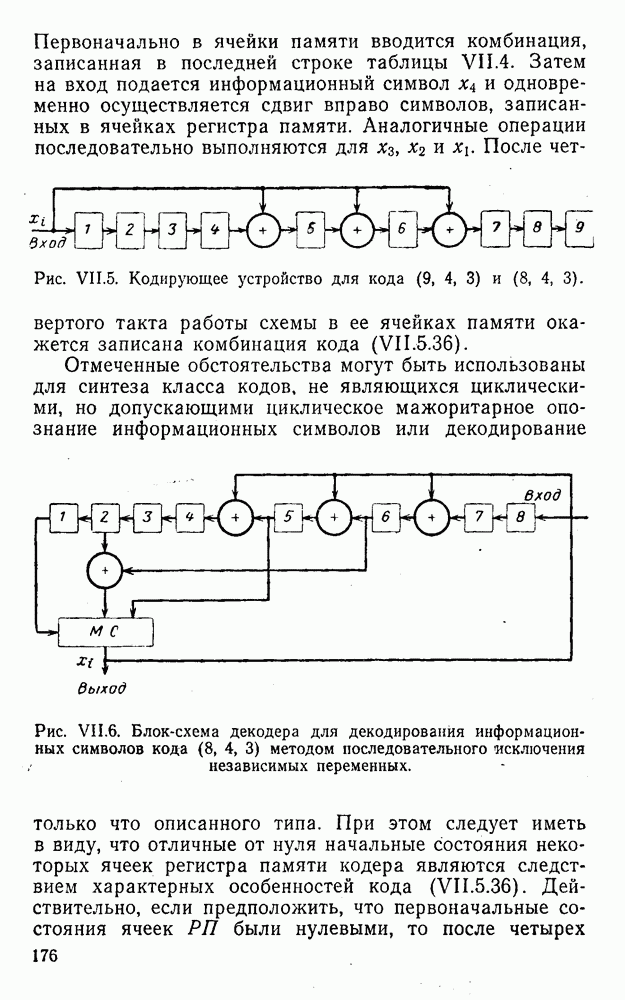
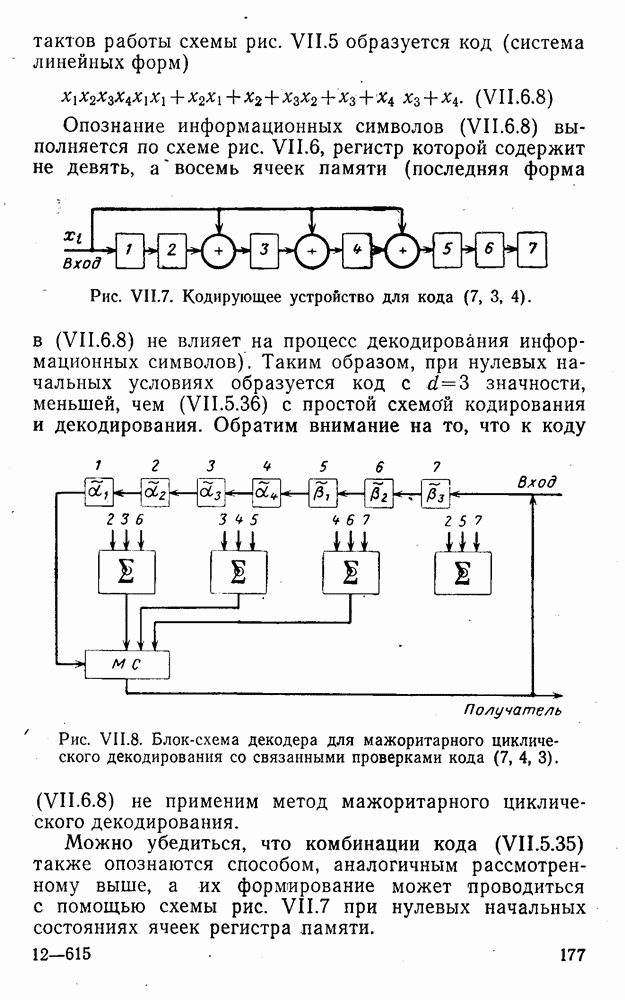
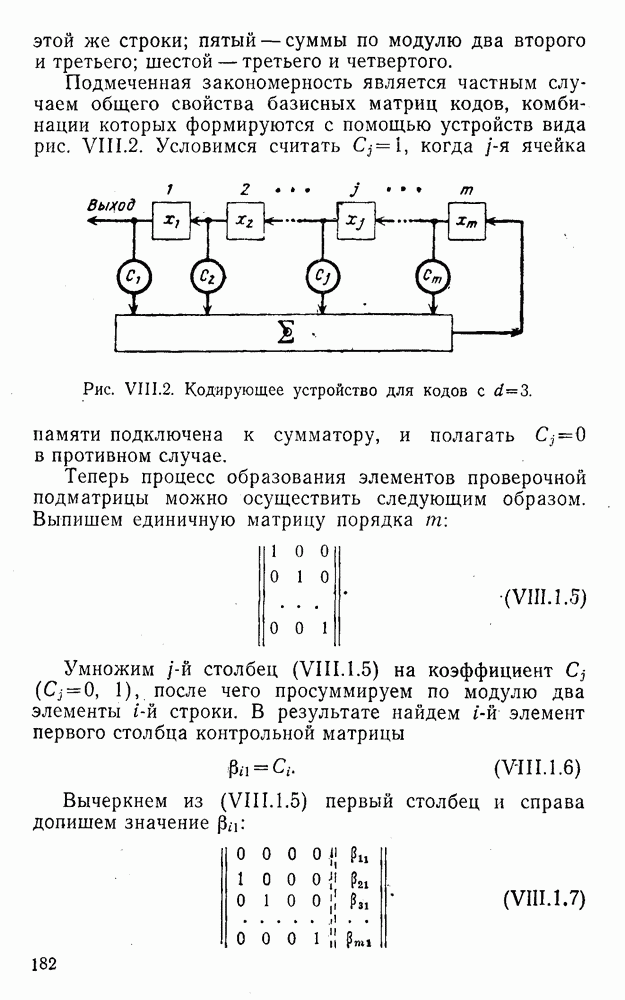
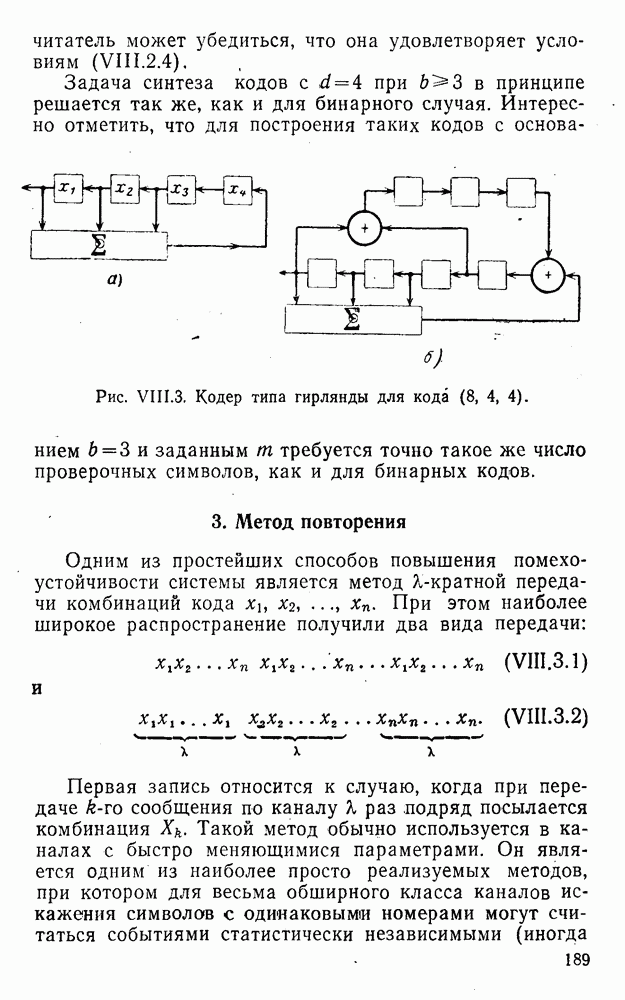
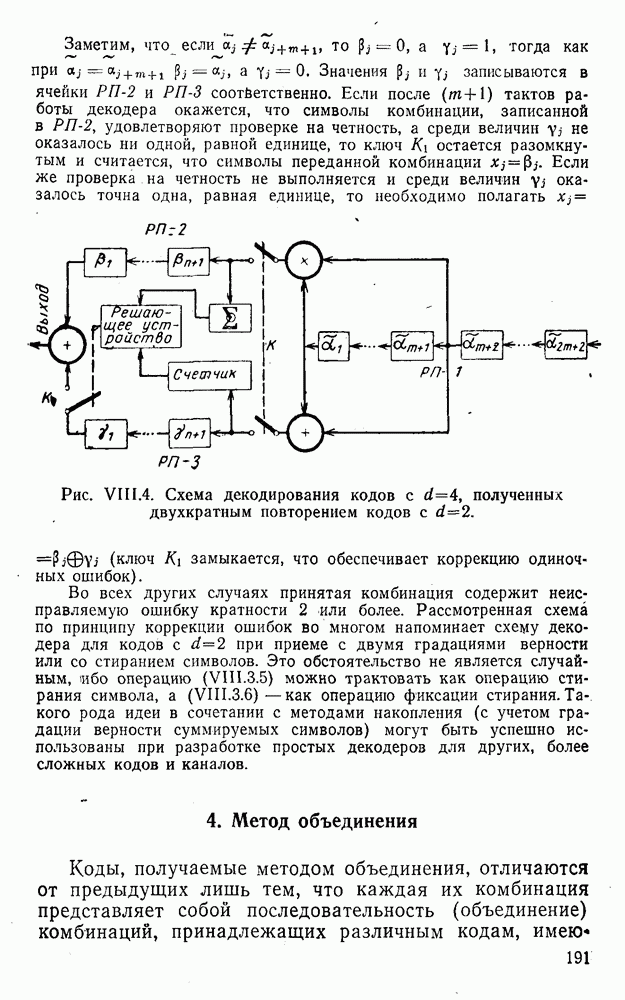
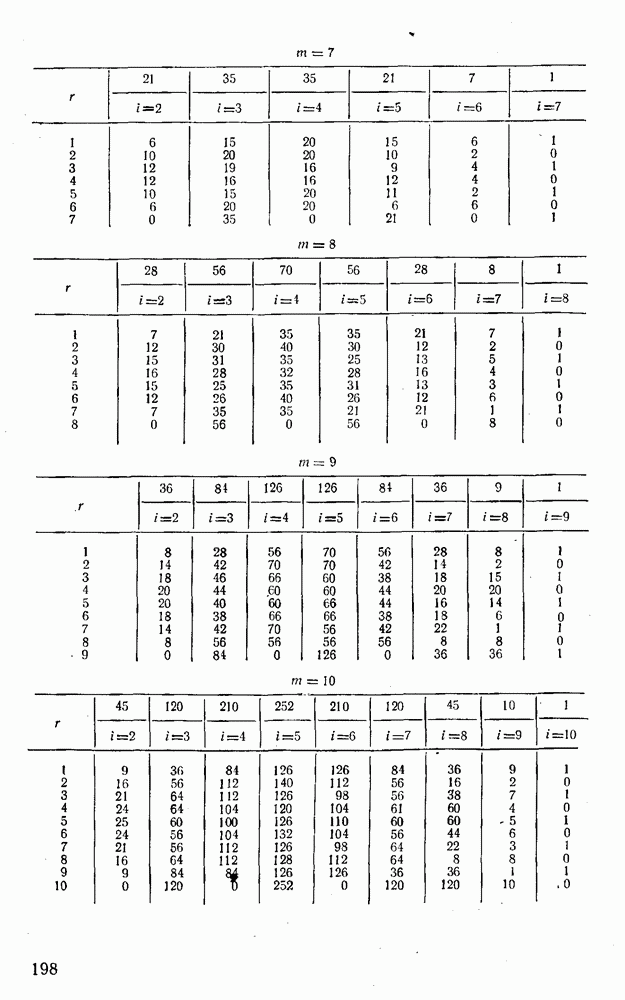
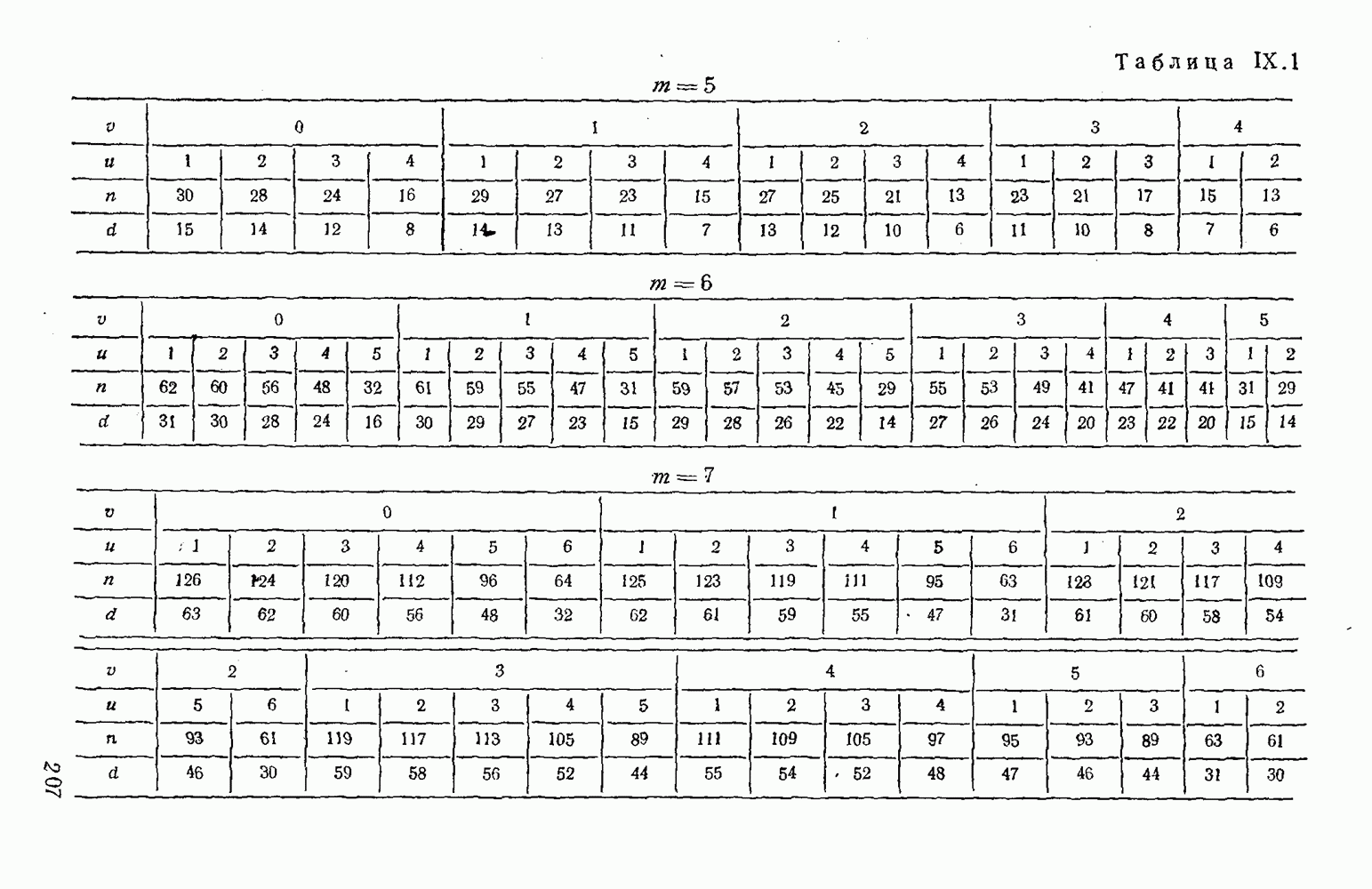
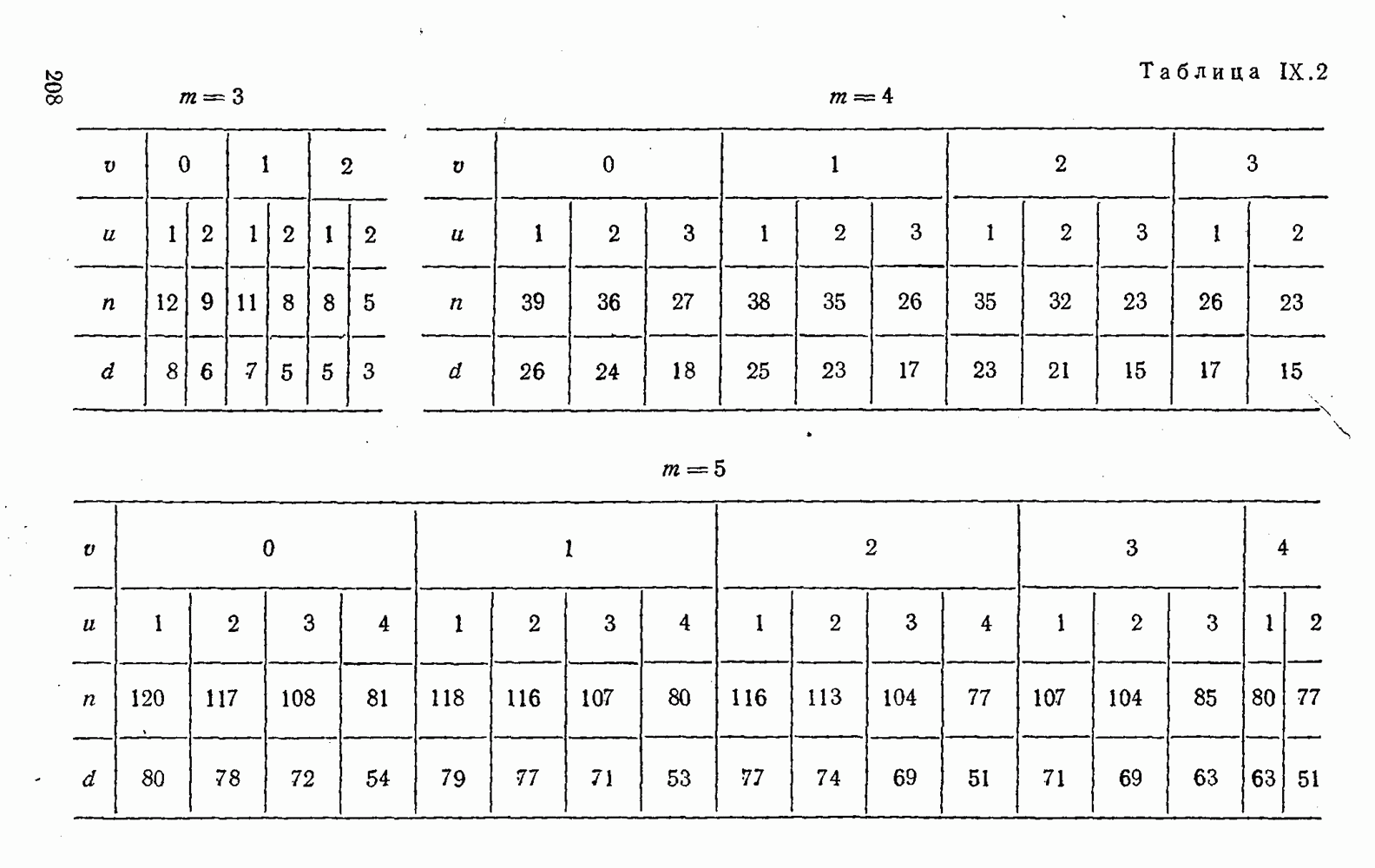
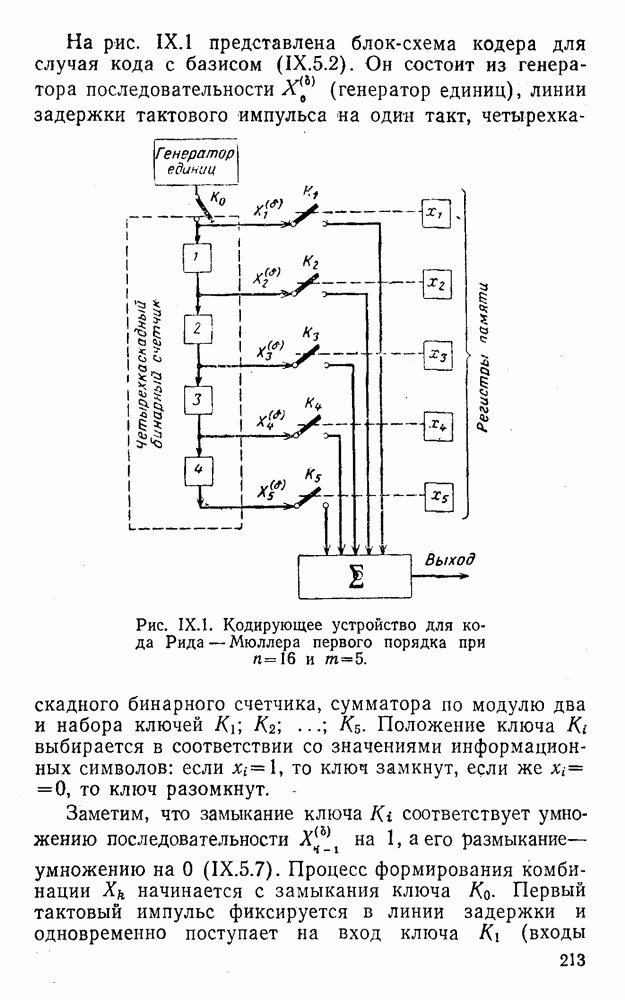
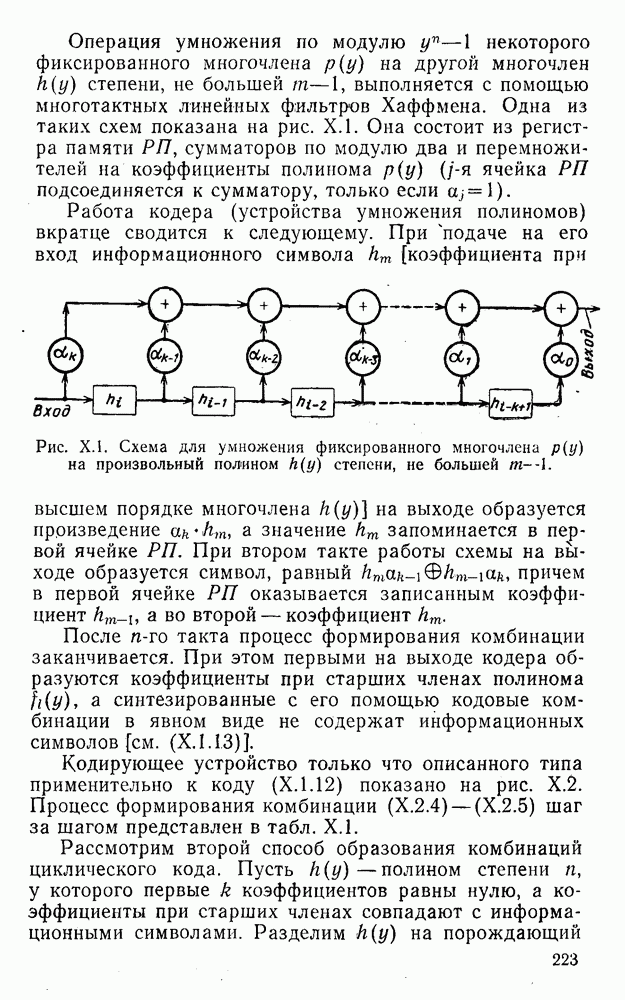
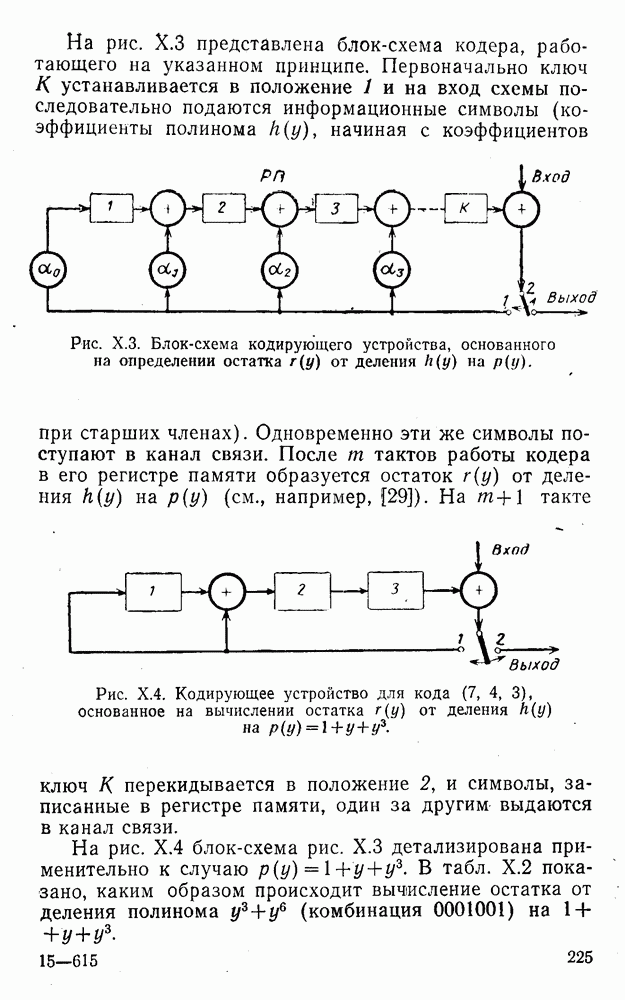
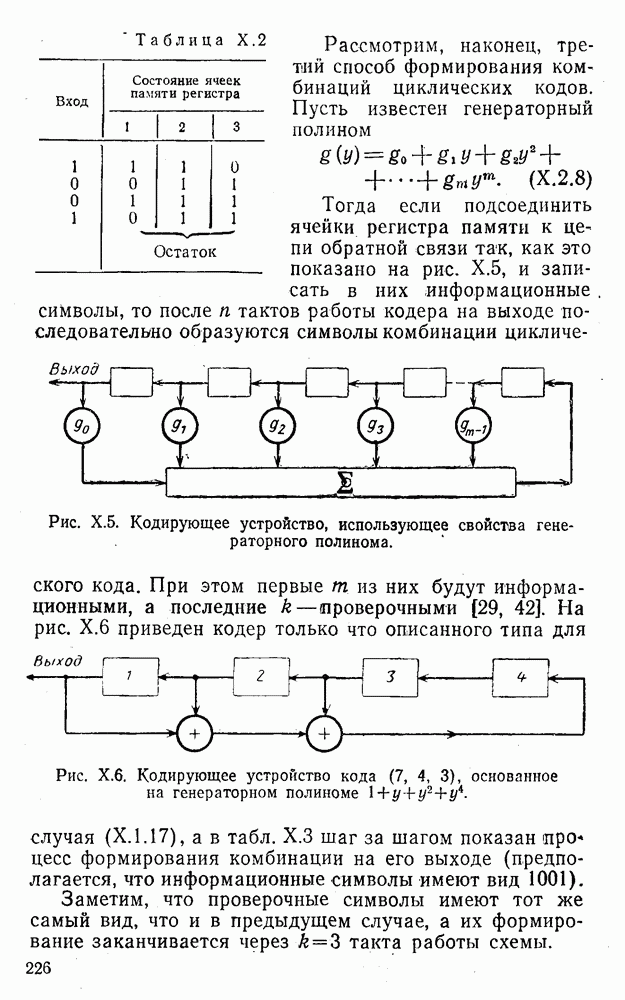
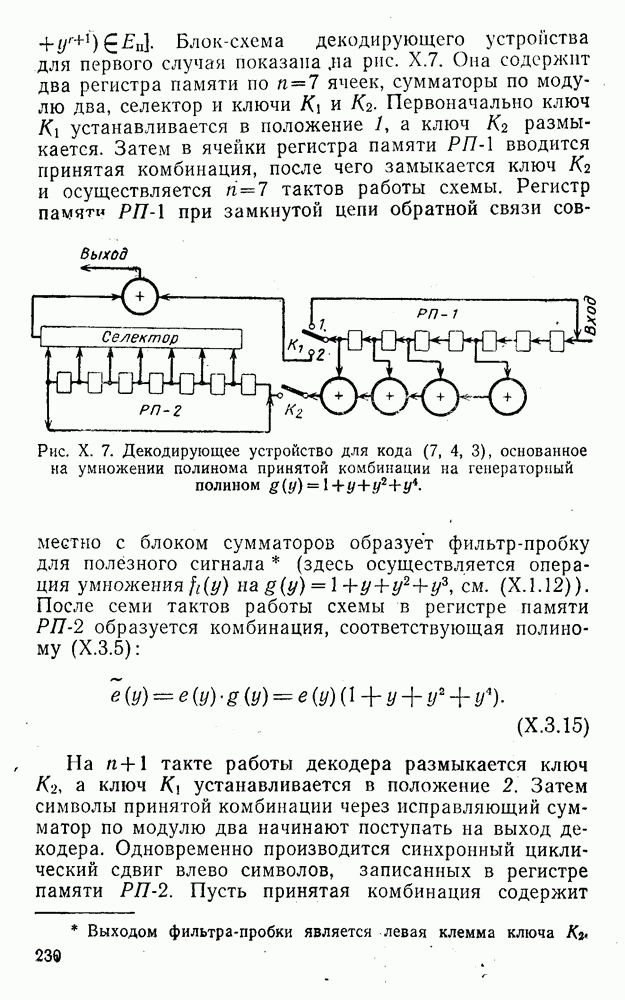
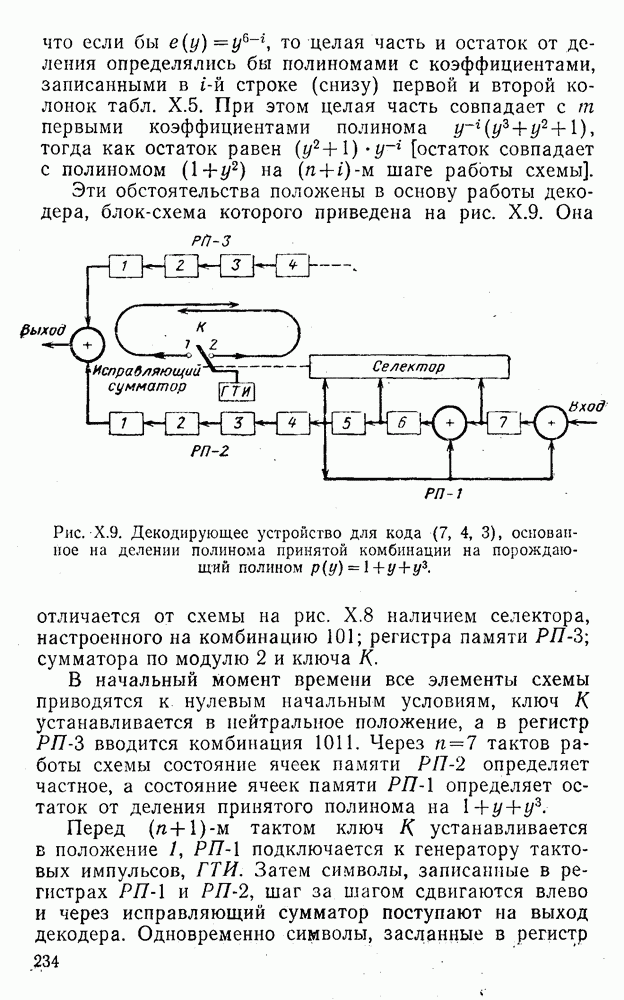
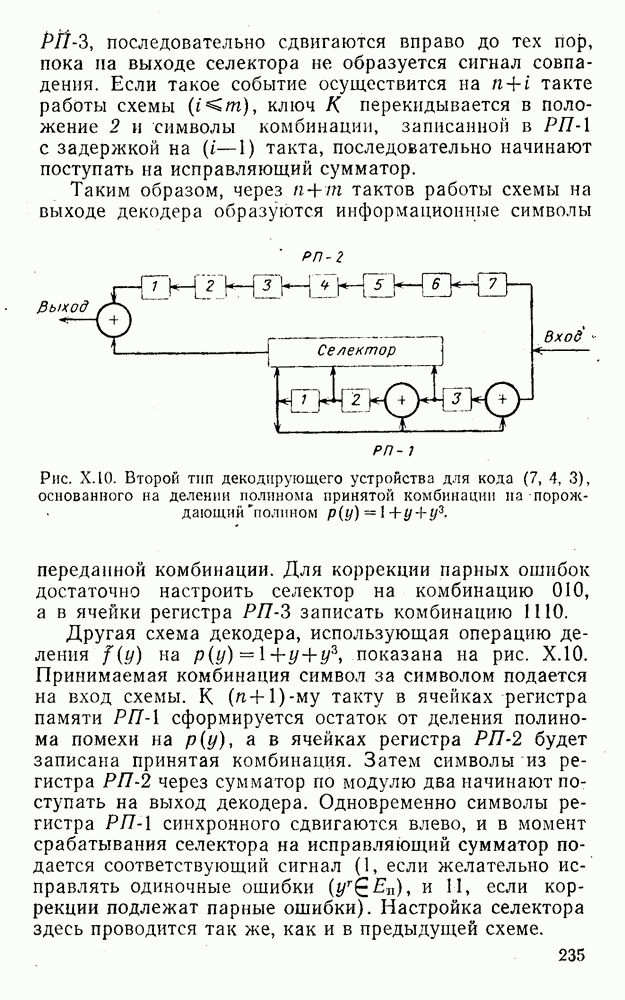
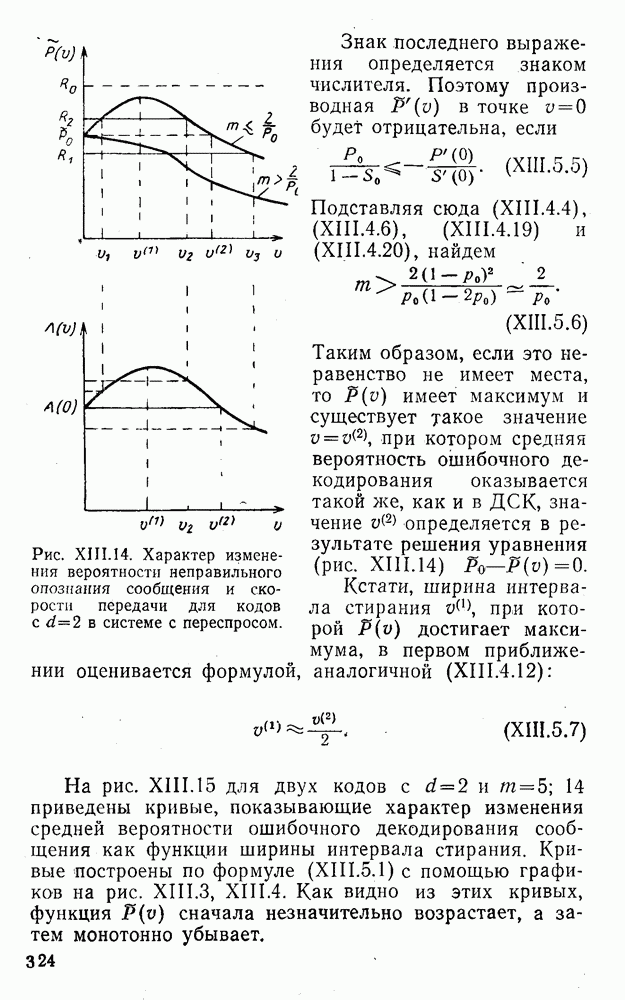
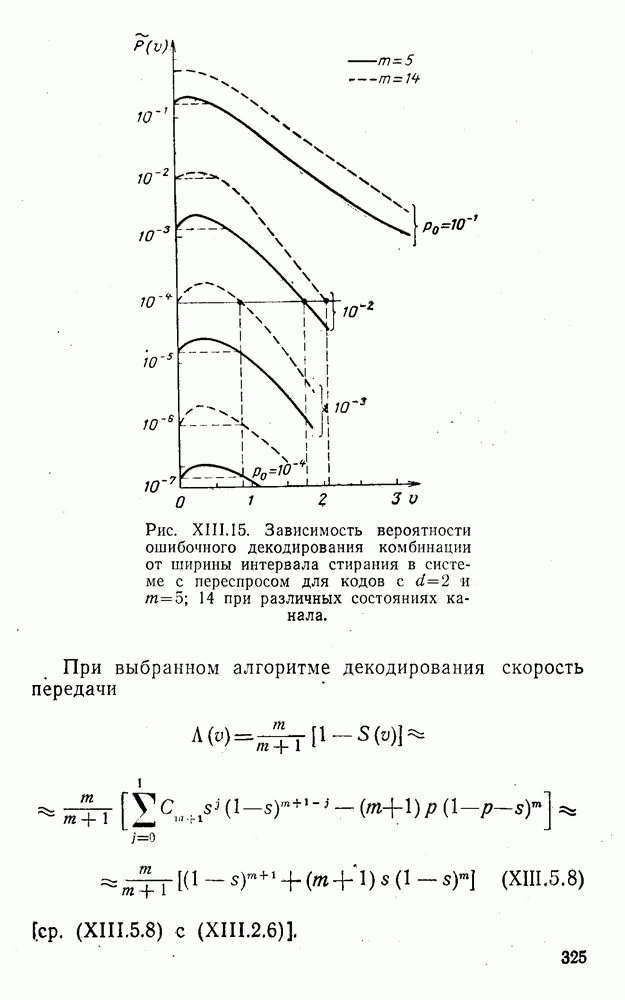
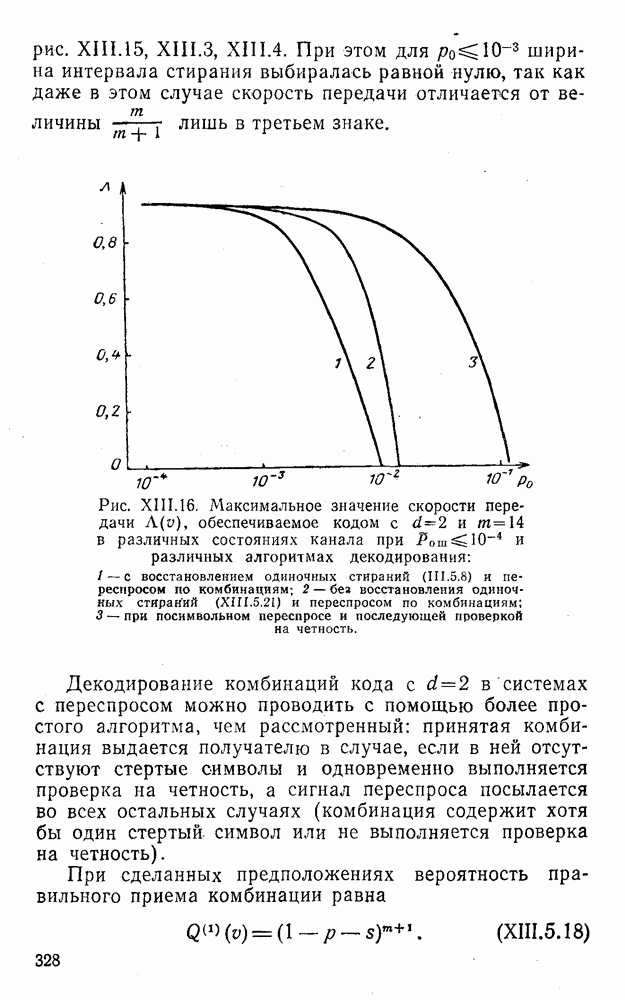
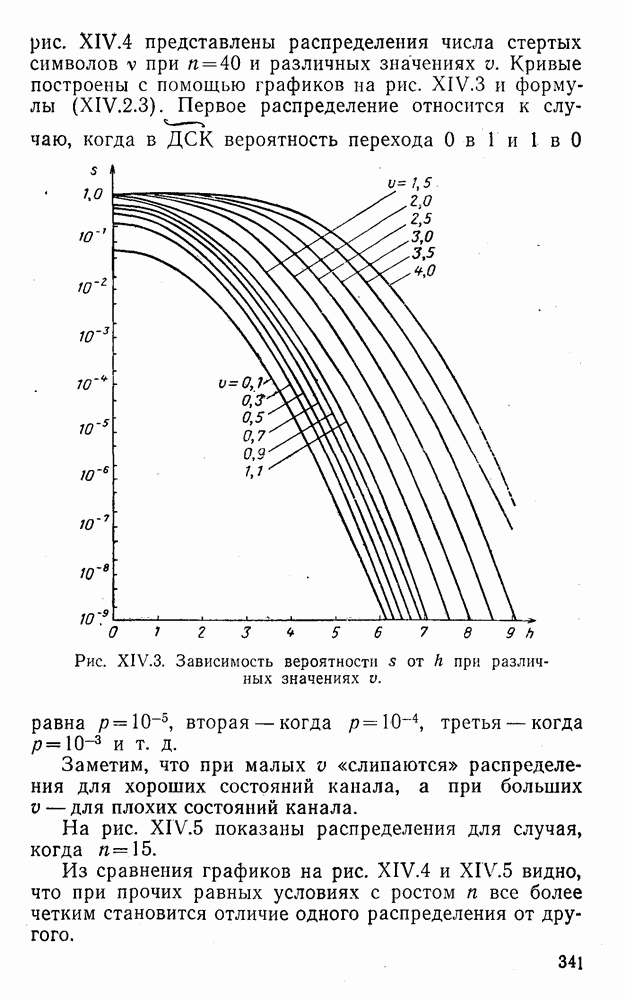
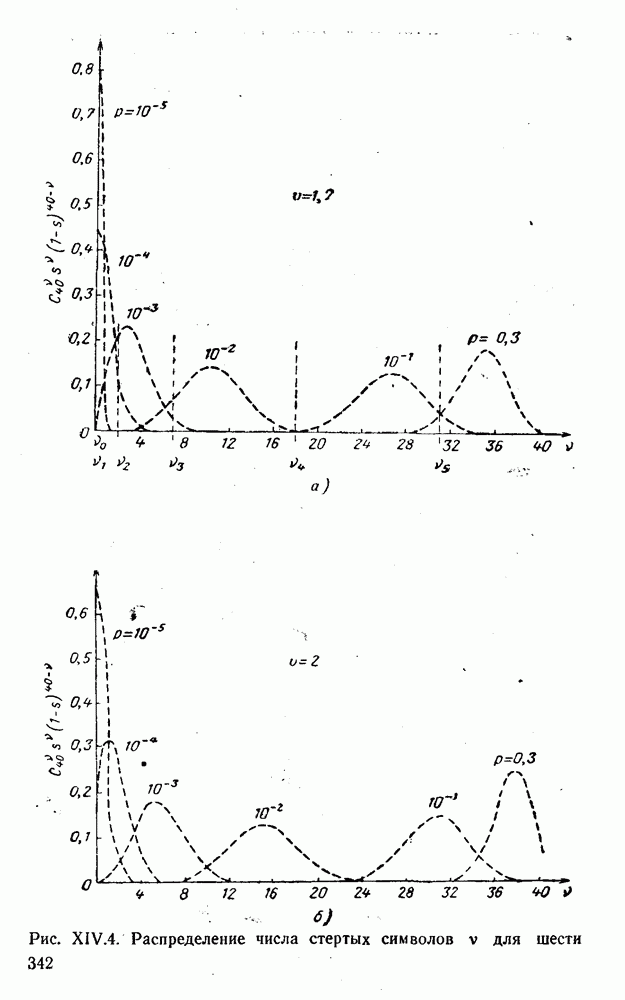
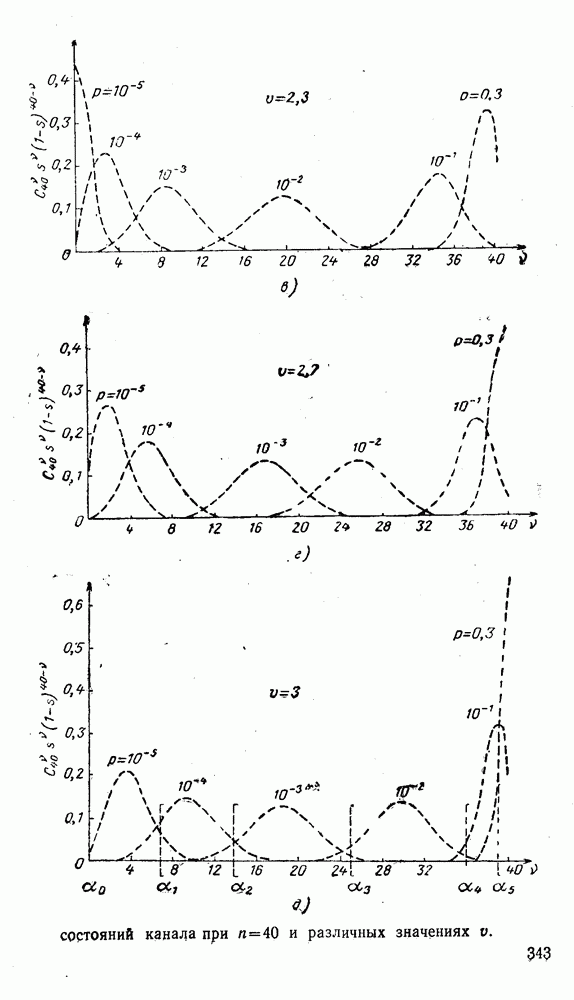
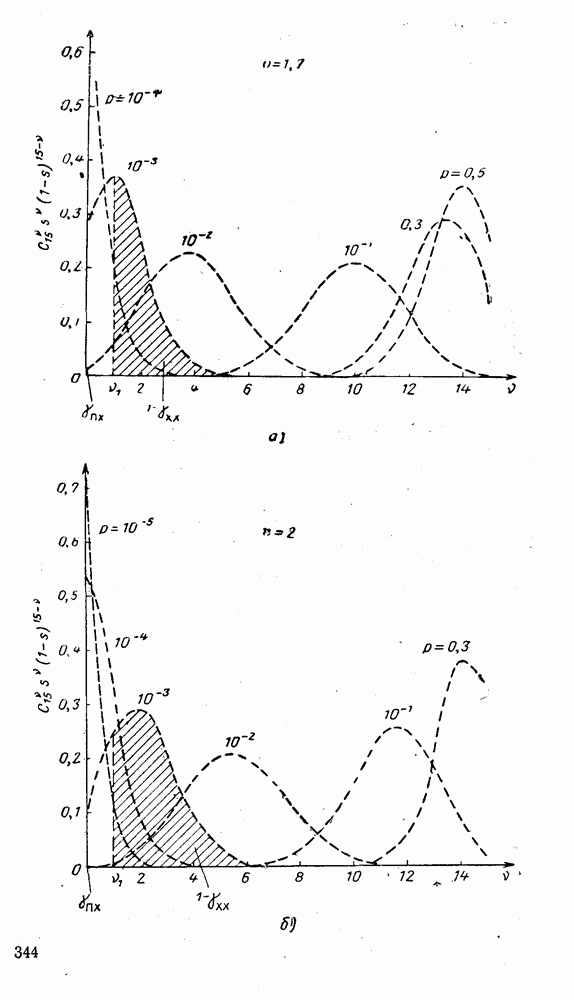
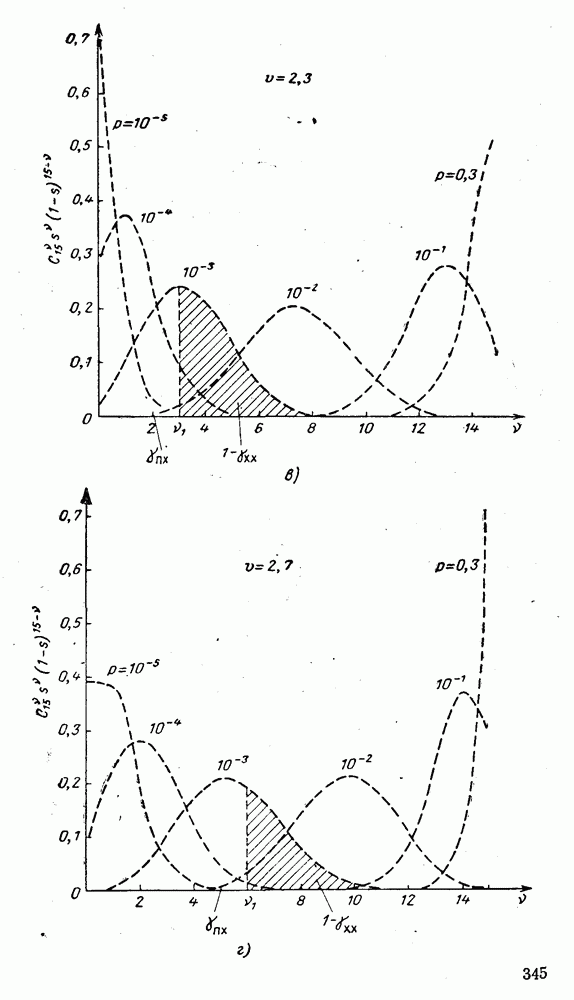
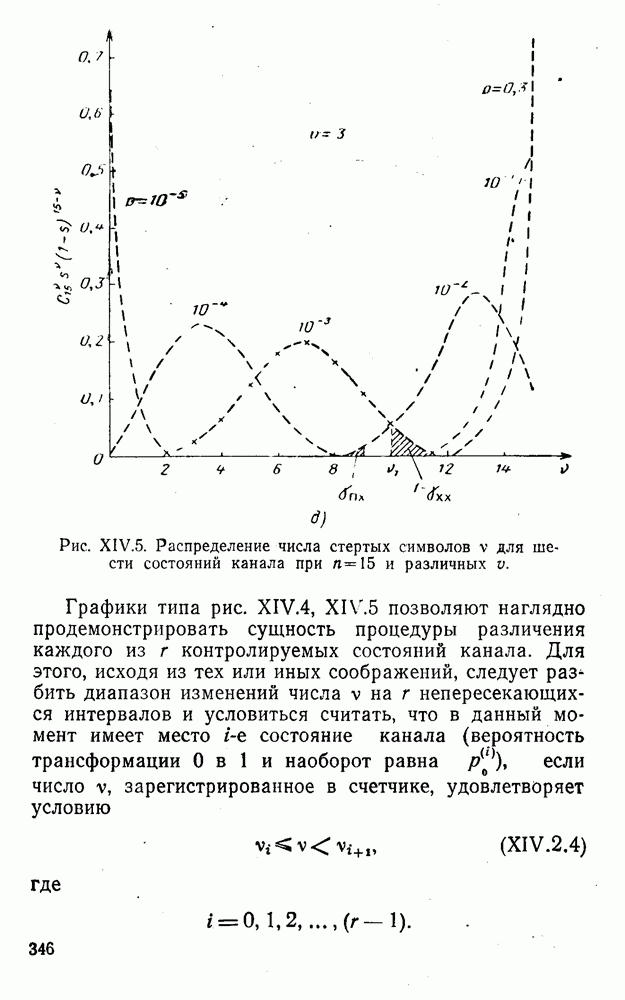
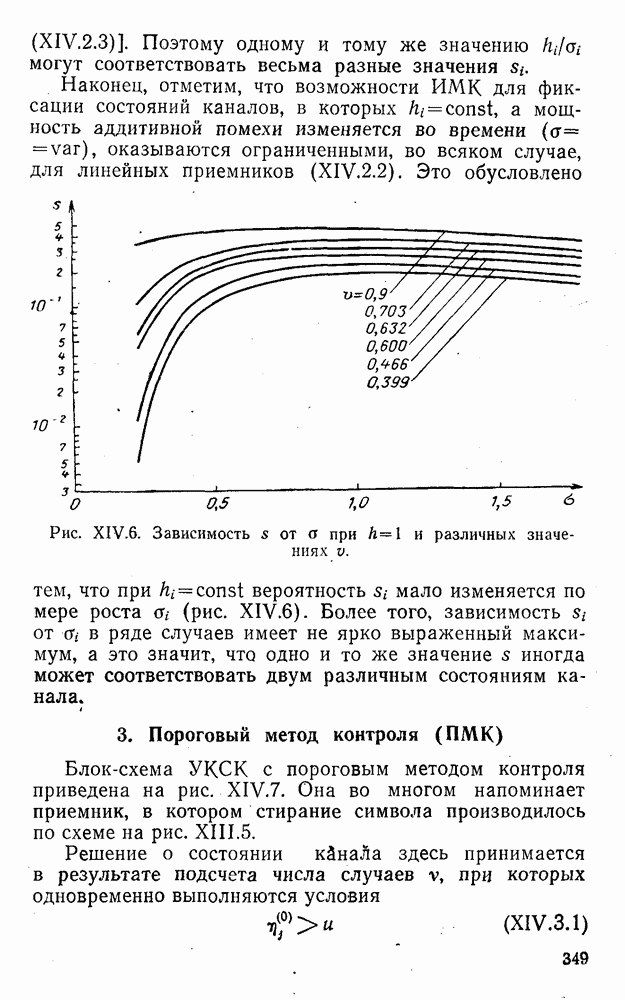
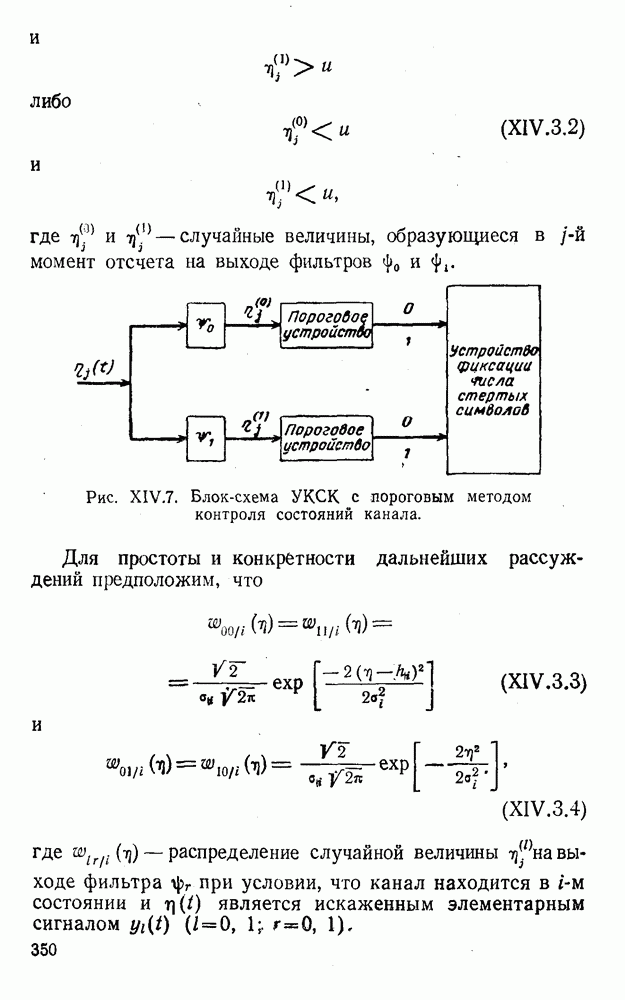
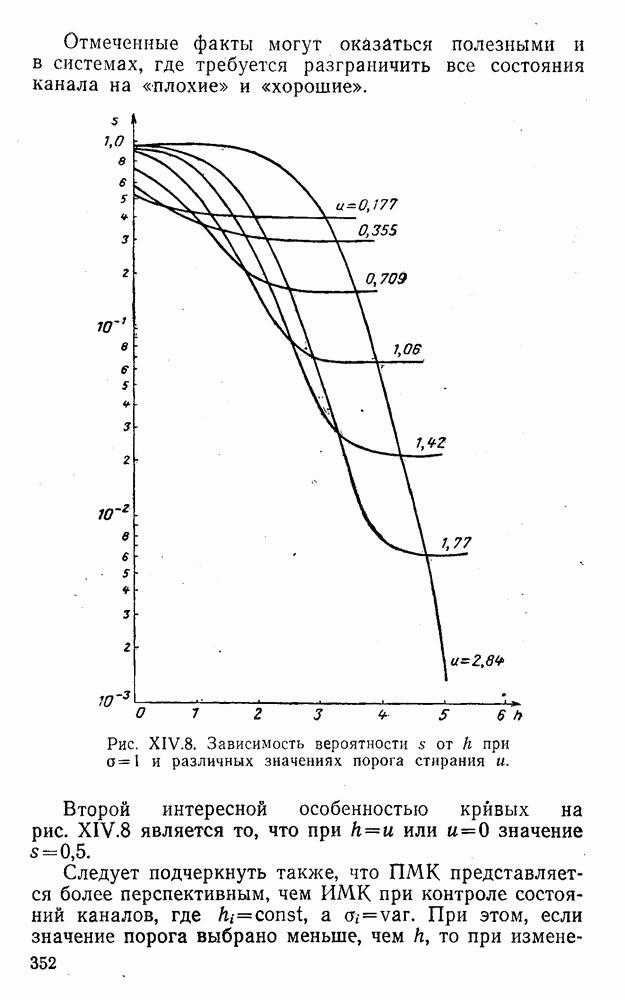
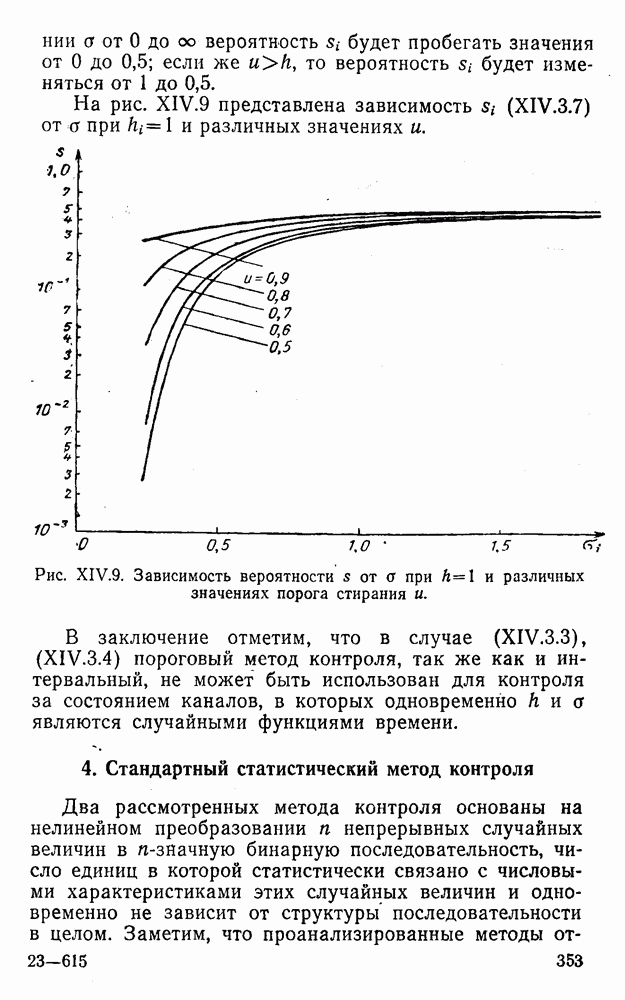
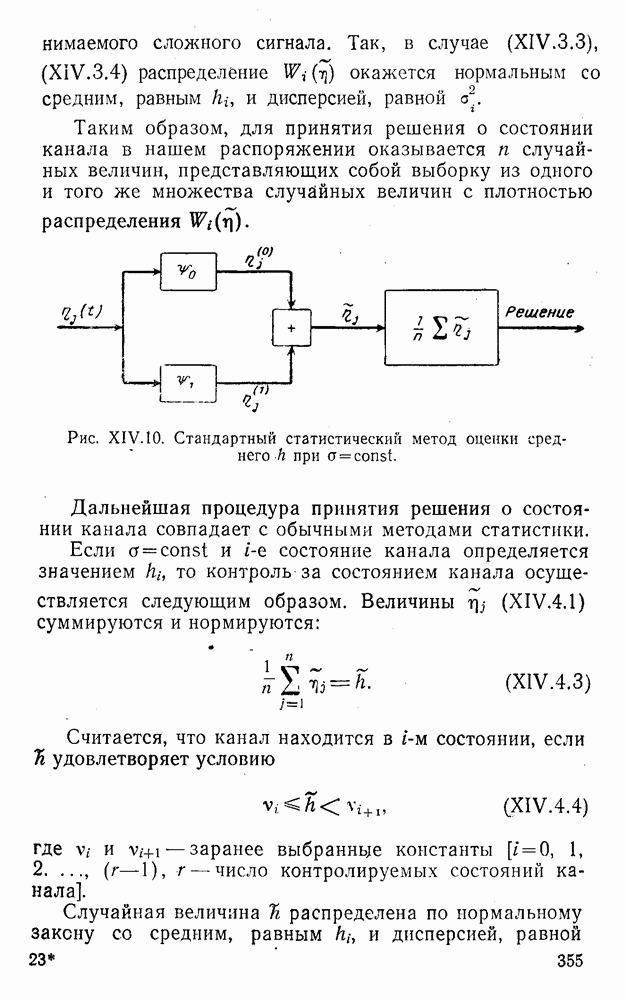
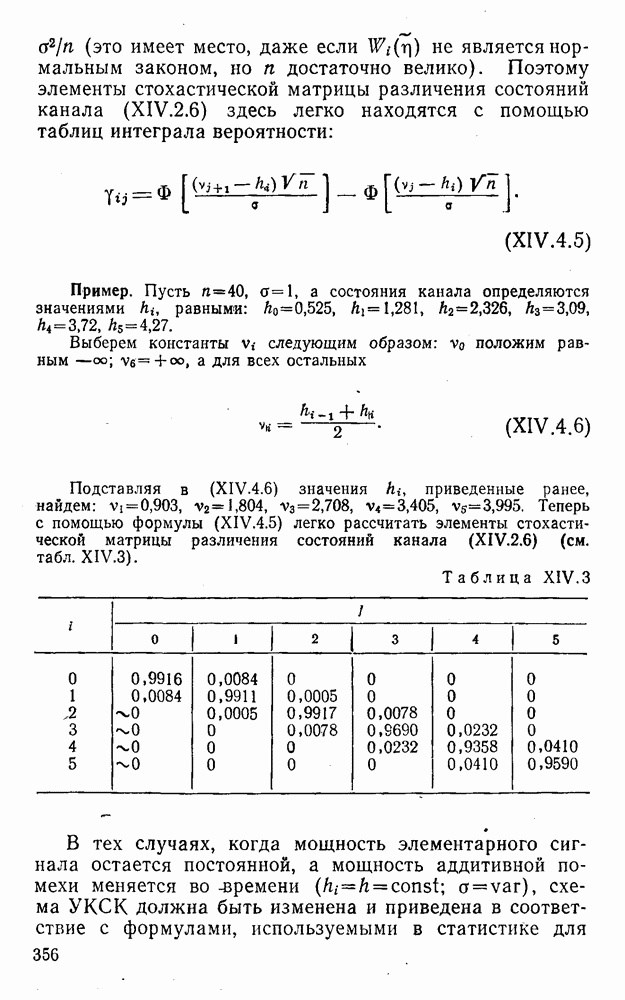
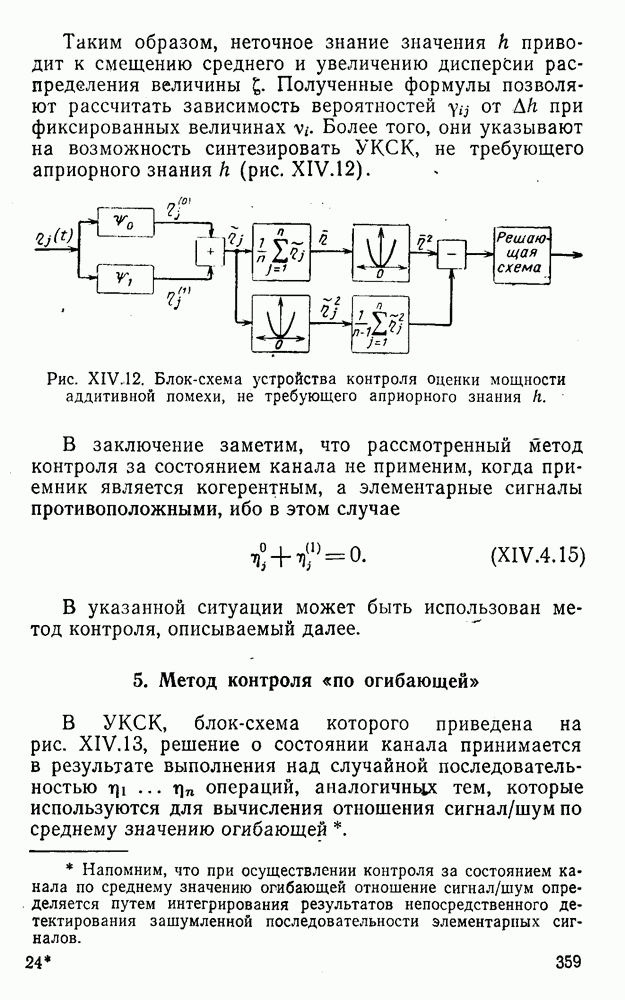
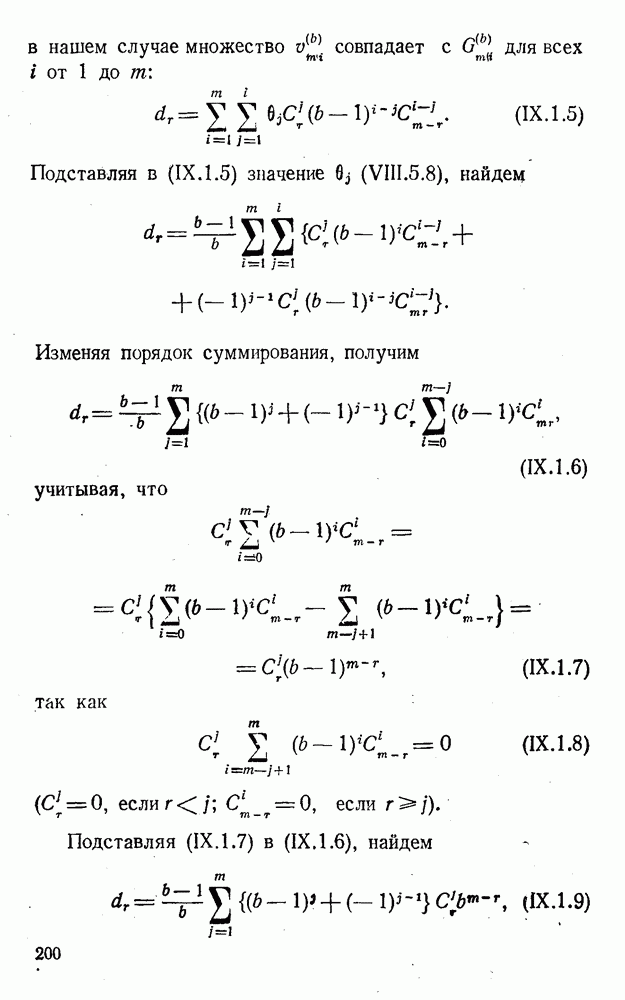5. Модульное декодирование
В этом и следующих параграфах обсуждаются аналоговые посимвольные методы декодирования, представляющие собой своеобразное сочетание идей декодирования в целом и декодирования по способу независимых решений [62]. Для конкретности все дальнейшие рассуждения будут проводиться на примере эквидистатного кода (7, 3, 4):
 (XII.5.1)
(XII.5.1)
Зафиксируем одну из его комбинаций:
 (XII.5.2)
(XII.5.2)
где  и
и  — либо 0, либо 1, и согласно (XII.5.1)
— либо 0, либо 1, и согласно (XII.5.1)
 (XII.5.3)
(XII.5.3)
В соответствии с принятой моделью при передаче (XII.5.2) на выходе приемника образуются случайные величины
 (XII.5.4)
(XII.5.4)
После обработки (XII.5.4) в первой решающей схеме на входе декодера образуется комбинация
 (XII.5.5)
(XII.5.5)
где  принимает значение либо 0, либо 1.
принимает значение либо 0, либо 1.
Для опознания информационных символов комбинаций (XII.5.2) по методу независимых решений прежде всего вычисляются величины
 (XII.5.6)
(XII.5.6)
Если окажется, что  , то следует полагать, что
, то следует полагать, что  информационный символ переданной комбинации
информационный символ переданной комбинации  . Если же
. Если же  , то
, то  . Наконец,
. Наконец,  в ситуациях, когда
в ситуациях, когда  (принятая комбинация содержит по крайней мере
(принятая комбинация содержит по крайней мере  кратную ошибку).
кратную ошибку).
Характерной особенностью процедуры декодирования (XII.5.6) является то, что здесь значение каждого информационного символа определяется «независимо» из анализа всей комбинации (XII.5.5). Применение этой идеи непосредственно к случайной последовательности (XII.5.4) составляет основное существо анализируемых здесь и в следующих параграфах аналоговых посимвольных методов декодирования. Синтез такого рода методов по своему существу сводится к поиску преобразований
 (XII.5.7)
(XII.5.7)
при которых непрерывная величина  оказывается распределенной по закону
оказывается распределенной по закону  , когда
, когда  , и по закону
, и по закону  , если
, если  . При выполнении этих условий задача о значении
. При выполнении этих условий задача о значении  -го информационного символа переданной комбинации решается как задача различения гипотез о принадлежности
-го информационного символа переданной комбинации решается как задача различения гипотез о принадлежности  к первому или второму распределению: следует полагать
к первому или второму распределению: следует полагать  и
и  , если соответственно окажется, что
, если соответственно окажется, что
 (XII.5.8)
(XII.5.8)
где  - некоторая константа (для конкретности предполагается, что среднее распределения
- некоторая константа (для конкретности предполагается, что среднее распределения  больше, чем среднее распределения
больше, чем среднее распределения  ).
).
При известных распределениях  и выбранном значении порога
и выбранном значении порога  не представляет труда рассчитать условные вероятности и неправильного опознания символа
не представляет труда рассчитать условные вероятности и неправильного опознания символа  , когда его истинное значение равно 0 и 1 соответственно:
, когда его истинное значение равно 0 и 1 соответственно:
 (XII.5.9)
(XII.5.9)
 (XII.5.9)
(XII.5.9)
Расчет вероятности  неправильного опознания переданного сообщения осложнен в силу того, что правильное или неправильное опознание информационных символов
неправильного опознания переданного сообщения осложнен в силу того, что правильное или неправильное опознание информационных символов  и
и  являются событиями не независимыми. Оценка
являются событиями не независимыми. Оценка  находится с помощью неравенства Буля.
находится с помощью неравенства Буля.
В основе анализируемых здесь преобразований (XII.5.7) лежат следующие очевидные факты.
1. Случайная величина  представляет собой выборку из распределения
представляет собой выборку из распределения  , когда символ переданной комбинации
, когда символ переданной комбинации
 (XII.5.11)
(XII.5.11)
то
 (XII.5.12)
(XII.5.12)
2. Из (XII.5.3) и (XII.5.6) непосредственно следует, что если  информационный символ комбинации (XII.5.2)
информационный символ комбинации (XII.5.2)
 (XII.5.13)
(XII.5.13)
то каждые два символа  и
и  , суммируемые по модулю два в
, суммируемые по модулю два в  уравнении (XII.5.6), были одновременно равны либо 0, либо 1. Поэтому в соответствии с (XII.5.12) случайные величины
уравнении (XII.5.6), были одновременно равны либо 0, либо 1. Поэтому в соответствии с (XII.5.12) случайные величины  и
и  последовательности (XII.5.4) являются одновременно выборками либо из
последовательности (XII.5.4) являются одновременно выборками либо из  , либо из
, либо из  :
:
 (XII.5.14)
(XII.5.14)
3. Если же  информационный символ
информационный символ
 (XII.5.15)
(XII.5.15)
то, как это следует из (XII.5.3) и (XII.5.6), символы  и
и  каждой нары суммируемых по модулю два символов в
каждой нары суммируемых по модулю два символов в  уравнении (XII.5.6) были не равны друг другу. Следовательно, случайные величины
уравнении (XII.5.6) были не равны друг другу. Следовательно, случайные величины  и
и  являются выборками из разных распределений [см. (XII.5.112), т. е. если
являются выборками из разных распределений [см. (XII.5.112), т. е. если
 (XII.5.16)
(XII.5.16)
то

и наоборот.
Решение задач синтеза и анализа преобразований вида (XII.5.7) начнем с рассмотрения модульного декодирования. Применительно к коду (XII.5.1) оно записывается так:
 (XII.5.17)
(XII.5.17)
Заметим, что (XII.5.16) получается из (XII.5.16) простой заменой ( ) на
) на  и
и  на
на  . Поэтому, во-первых, число слагаемых правой части каждого равенства (XII.5.17) равно d (в нашем случае
. Поэтому, во-первых, число слагаемых правой части каждого равенства (XII.5.17) равно d (в нашем случае  ). Во-вторых, согласно (XII.5.11) — (XII.5.13), если
). Во-вторых, согласно (XII.5.11) — (XII.5.13), если  , то в
, то в  равенстве (XII.5.17) является выборкой из
равенстве (XII.5.17) является выборкой из  , а случайные величины
, а случайные величины  и
и  , входящие в выражение
, входящие в выражение  , являются выборками либо из
, являются выборками либо из  , либо из
, либо из  .
.
Если же  , то
, то  — выборка из
— выборка из  а величины
а величины  и
и  будут выборками из разных распределений.
будут выборками из разных распределений.
При модульном и ему подобных методах декодирования для расчета вероятности (XII.5.9)-(XII.5.10) неправильного опознания  -го информационного символа необходимо знать распределения
-го информационного символа необходимо знать распределения  и
и  (задача определения законов распределения функций случайных аргументов [22]). Оценки интересующих нас вероятностей связаны с определением вероятностей больших уклонений суммы случайных величин (для решения этой задачи могут быть использованы результаты работы [137, 138]). Однако в первом приближении эти оценки находятся исходя из предположения, что распределение суммы случайных величин асимптотически сходится к нормальному закону. Такой подход широко используется ниже, ибо он существенно упрощает задачу и требует вычисления лишь значений средних и дисперсий
(задача определения законов распределения функций случайных аргументов [22]). Оценки интересующих нас вероятностей связаны с определением вероятностей больших уклонений суммы случайных величин (для решения этой задачи могут быть использованы результаты работы [137, 138]). Однако в первом приближении эти оценки находятся исходя из предположения, что распределение суммы случайных величин асимптотически сходится к нормальному закону. Такой подход широко используется ниже, ибо он существенно упрощает задачу и требует вычисления лишь значений средних и дисперсий  . Найдем эти величины, полагая для конкретности, что случайные величины (XII.5.4) статистически независимы, а распределения
. Найдем эти величины, полагая для конкретности, что случайные величины (XII.5.4) статистически независимы, а распределения  и
и  являются нормальными с дисперсией
являются нормальными с дисперсией  и средними, соответственно равным h и
и средними, соответственно равным h и  .
.
Прежде всего, как известно, среднее значение и дисперсия модуля случайной величины v, распределенной по нормальному закону с дисперсией  и средним
и средним  , определяются выражениями
, определяются выражениями
 (XII.5.18)
(XII.5.18)
 (XII.5.19)
(XII.5.19)
Отметим, что численное значение среднего (XII.5.18) не зависит от знака  .
.
В тех ситуациях, когда  , среднее суммы случайных величин, входящее под знак модуля каждого из слагаемых
, среднее суммы случайных величин, входящее под знак модуля каждого из слагаемых  -го равенства (XII.5.17), равно либо
-го равенства (XII.5.17), равно либо  , либо
, либо  , а дисперсия суммы равна
, а дисперсия суммы равна  .
.
Поэтому среднее и дисперсия  соответственно равны
соответственно равны
 (XII.5.10)
(XII.5.10)
и
 (XII.5.21)
(XII.5.21)
Если  , то среднее суммы случайных величин, входящих под знак модуля каждого из слагаемых
, то среднее суммы случайных величин, входящих под знак модуля каждого из слагаемых  -гo равенства (XII.5.17), равно 0, а дисперсия, как и прежде, равна
-гo равенства (XII.5.17), равно 0, а дисперсия, как и прежде, равна  .
.
Следовательно, в такой ситуации среднее и дисперсия  соответственно равны
соответственно равны
 (XII.5.22)
(XII.5.22)
и
 (XII.5.23)
(XII.5.23)
Среднее значение случайной величины  равно сумме средних значений слагаемых и при условии, что
равно сумме средних значений слагаемых и при условии, что  и
и  , определяется выражениями
, определяется выражениями
 (XII.5.24)
(XII.5.24)
 (XII.5.25)
(XII.5.25)
Дисперсия случайной величины  равна сумме дисперсий слагаемых, поэтому
равна сумме дисперсий слагаемых, поэтому
 (XII.5.26)
(XII.5.26)
и
 (XII.5.27)
(XII.5.27)
В нашем случае вид распределений  и
и  не зависит от
не зависит от  , поэтому вероятность неправильного опознания
, поэтому вероятность неправильного опознания  будет инвариантна относительно его значения, если величина порога
будет инвариантна относительно его значения, если величина порога  удовлетворяет условию
удовлетворяет условию
 (XII.5.28)
(XII.5.28)
где  и
и  по условию — нормальные распределения, причем среднее и дисперсия первого определяются выражениями (XII.5.24) и (XII.5.26), а второго — (XII.5.25) и (XII.5.27).
по условию — нормальные распределения, причем среднее и дисперсия первого определяются выражениями (XII.5.24) и (XII.5.26), а второго — (XII.5.25) и (XII.5.27).
Решая (XII.5.27), находим, что
 (XII.5.29)
(XII.5.29)
а вероятность неправильного опознания символа
 (XII.5.30)
(XII.5.30)
где
 (XII.5.31)
(XII.5.31)
В тех случаях, когда  , как это следует из (XII.5.24),
, как это следует из (XII.5.24),  и поэтому
и поэтому
 (XII.5.32)
(XII.5.32)
Таким образом, модульное декодирование при  обеспечивает (по оценке снизу) практически такую же вероятность
обеспечивает (по оценке снизу) практически такую же вероятность  , как и идеальное [см. (XII.2.1) и (XII.1.15).
, как и идеальное [см. (XII.2.1) и (XII.1.15).
Рассмотренный аналоговый посимвольный метод декодирования далеко не исчерпывает всех возможностей в этом направлении. Так, например, информационные символы переданной комбинации могут быть определены из выражения типа (XII.5.16), если в них заменить  на
на  или на
или на  , или на
, или на  .
.
Использование этих операций и их различных комбинаций позволяет распространить изложенные идеи на системы, где среднее одного из распределений величины  равно нулю или средние обоих распределений совпадают по знаку. Кроме того, применение операций вида
равно нулю или средние обоих распределений совпадают по знаку. Кроме того, применение операций вида  может оказаться полезным для борьбы со всякого рода систематическими ошибками, например, в ситуациях, когда среднее аддитивной помехи отлично от нуля.
может оказаться полезным для борьбы со всякого рода систематическими ошибками, например, в ситуациях, когда среднее аддитивной помехи отлично от нуля.