Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
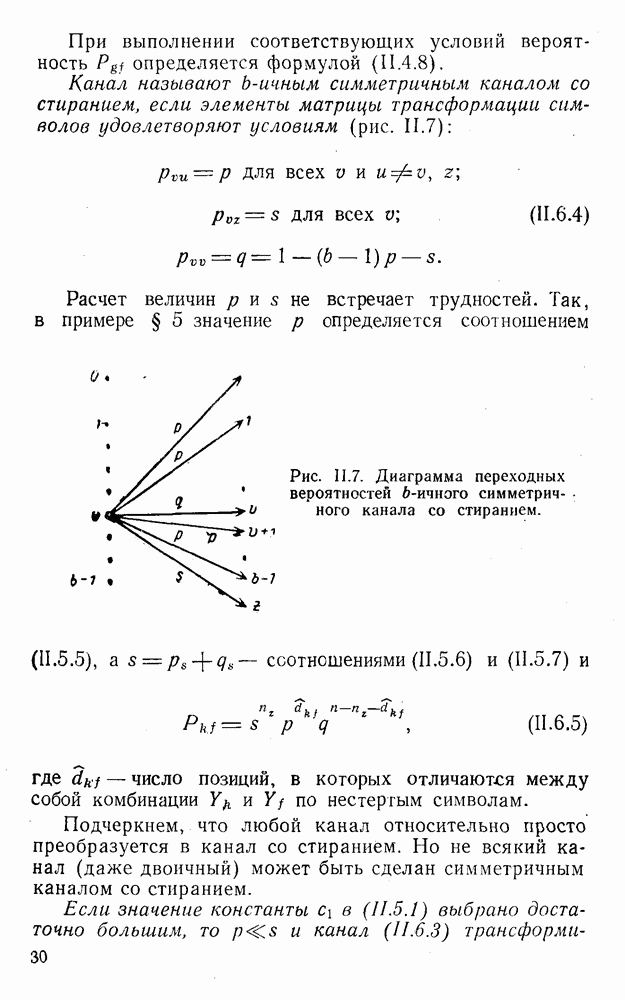
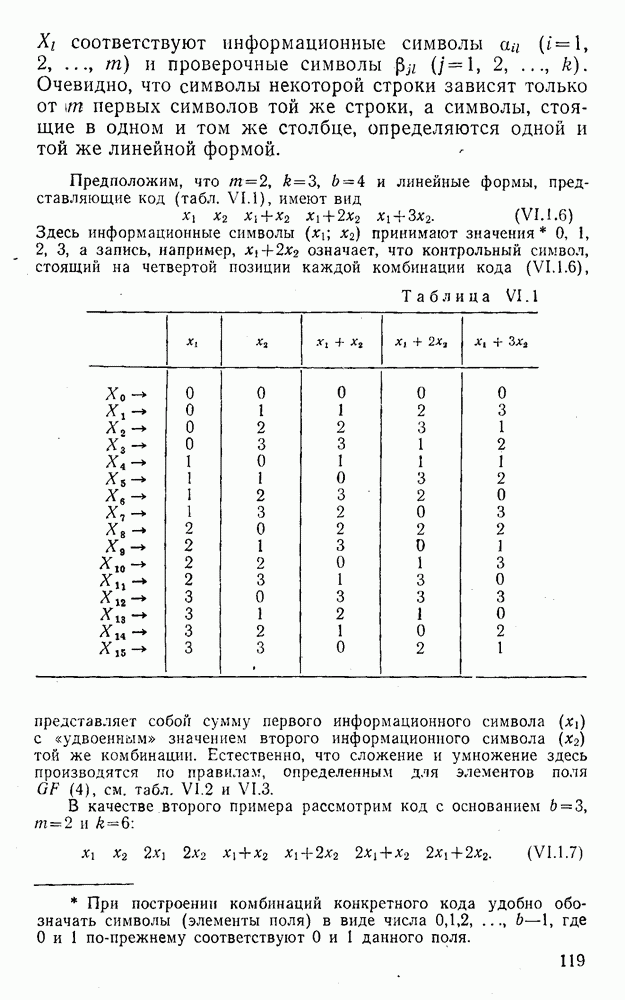
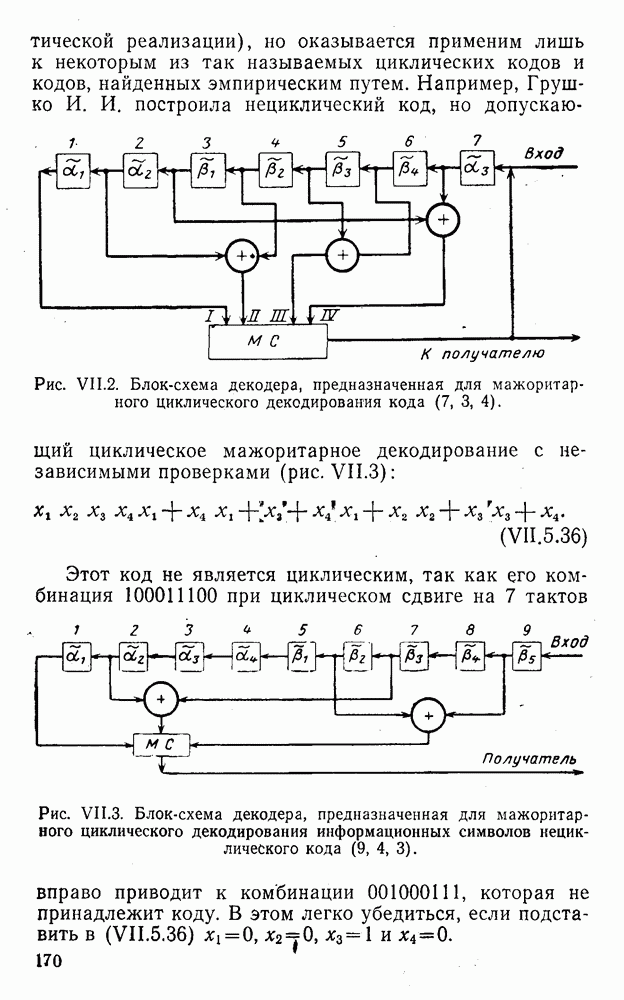
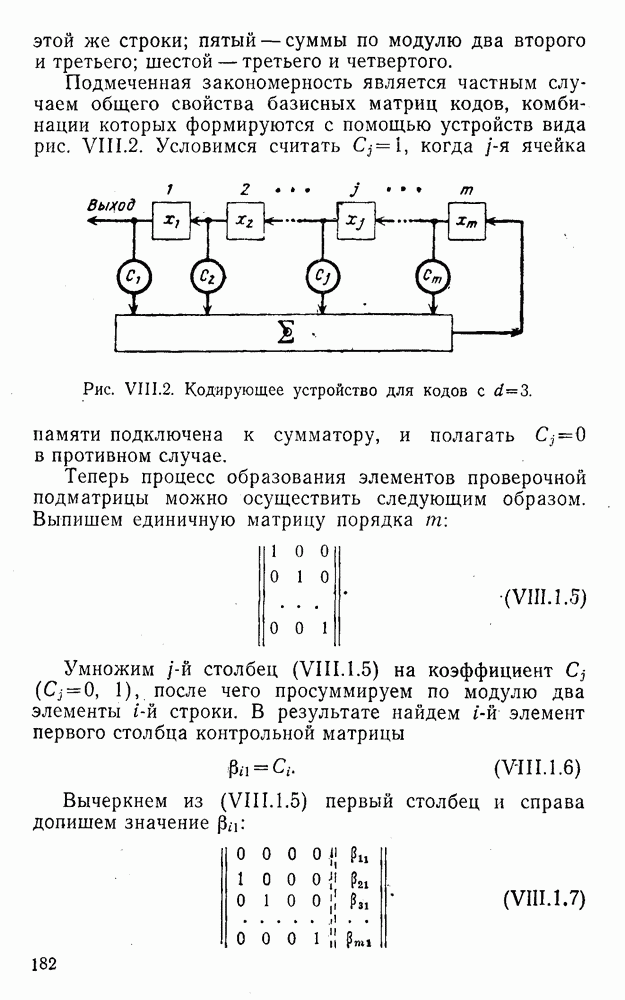
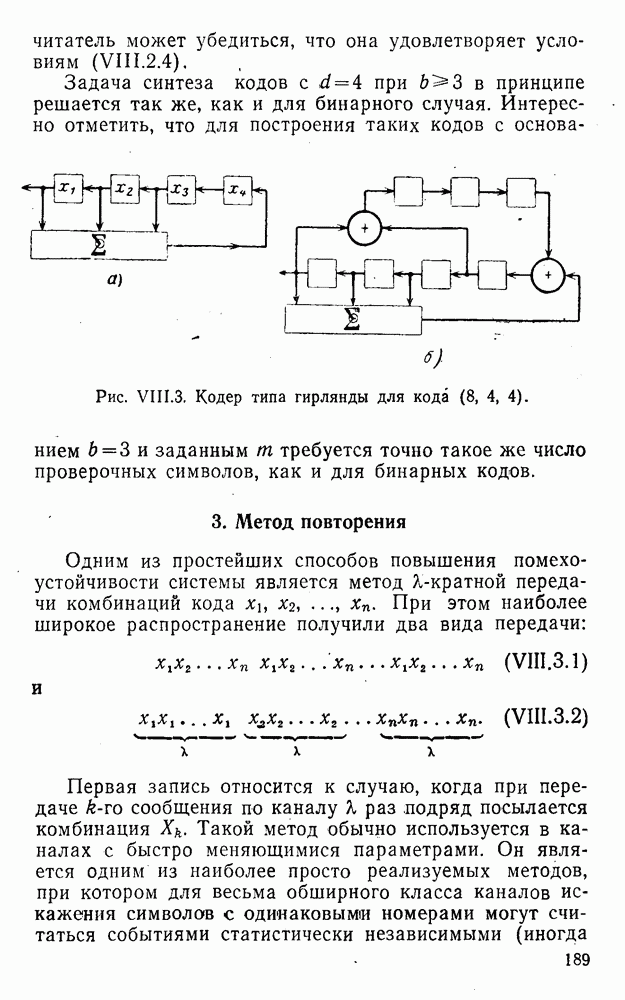
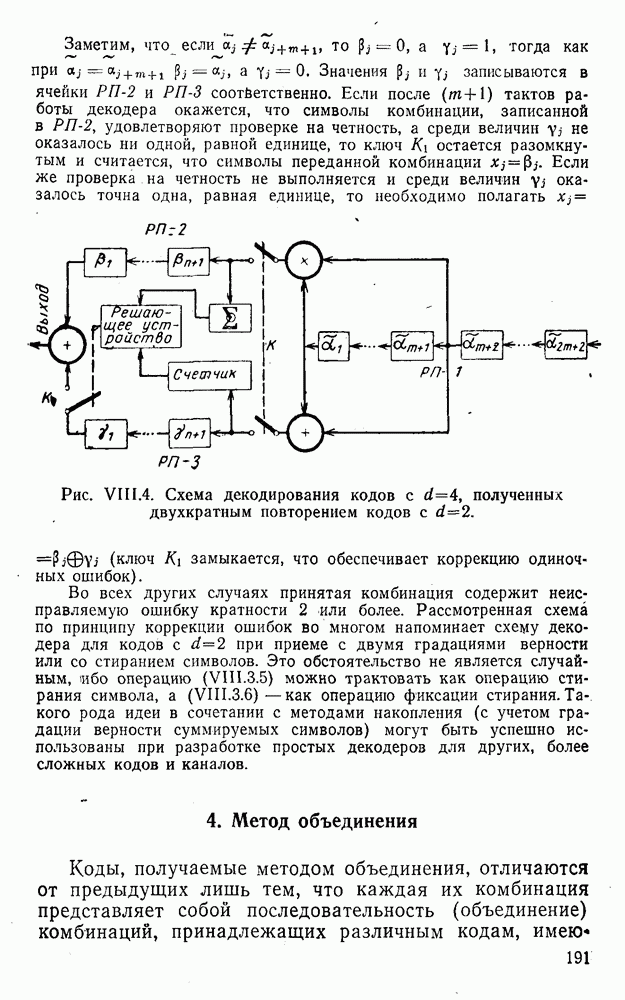
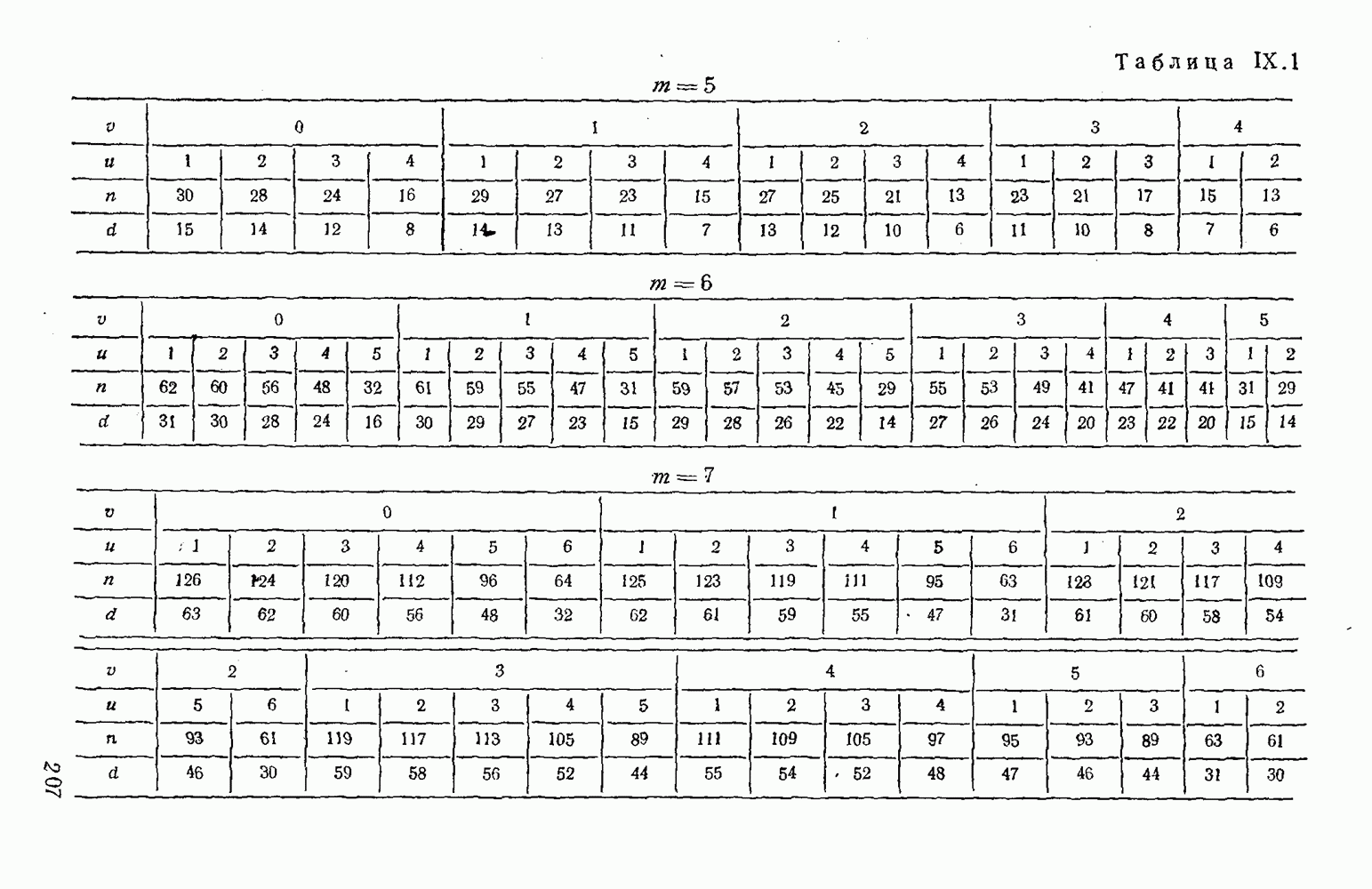
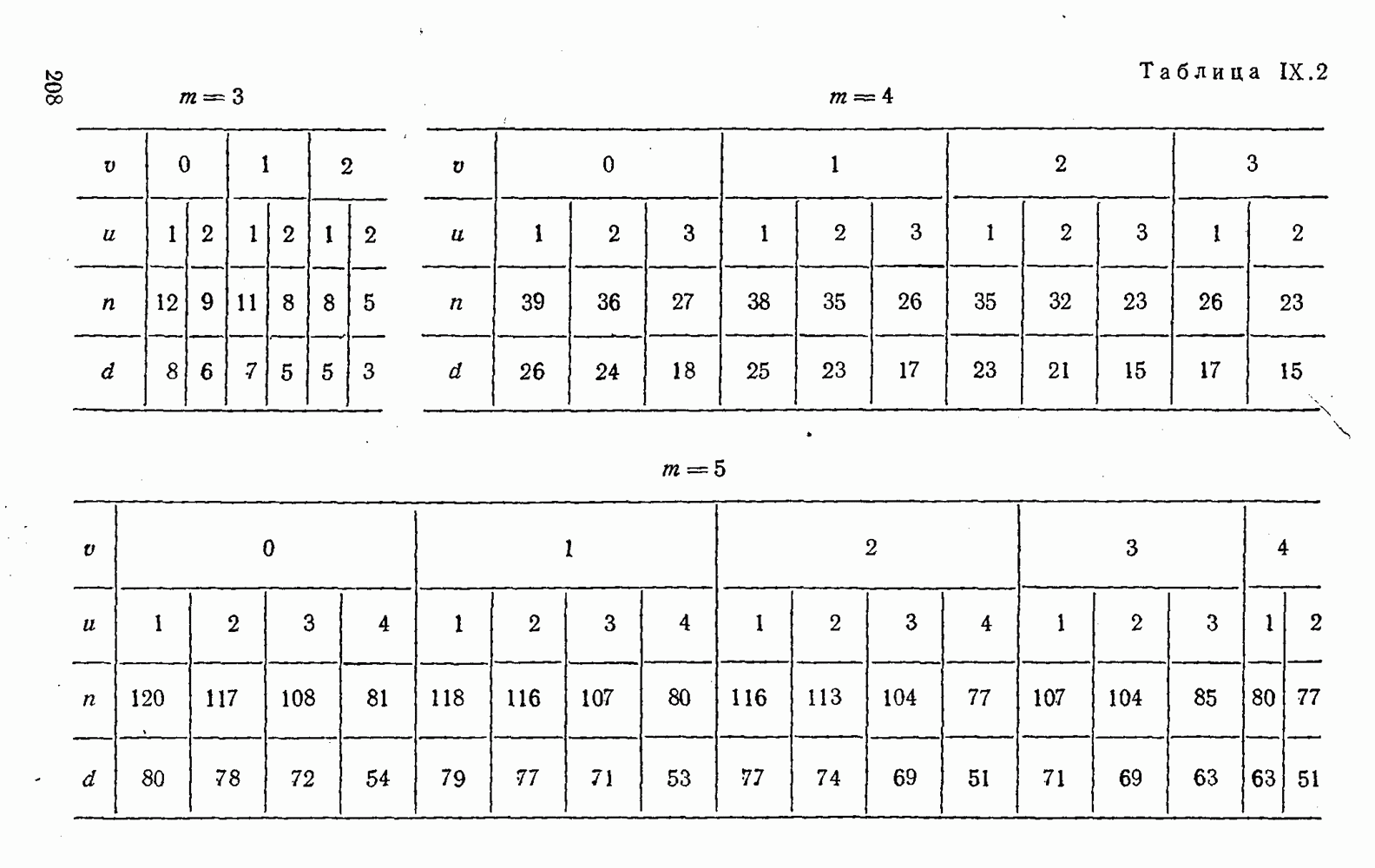
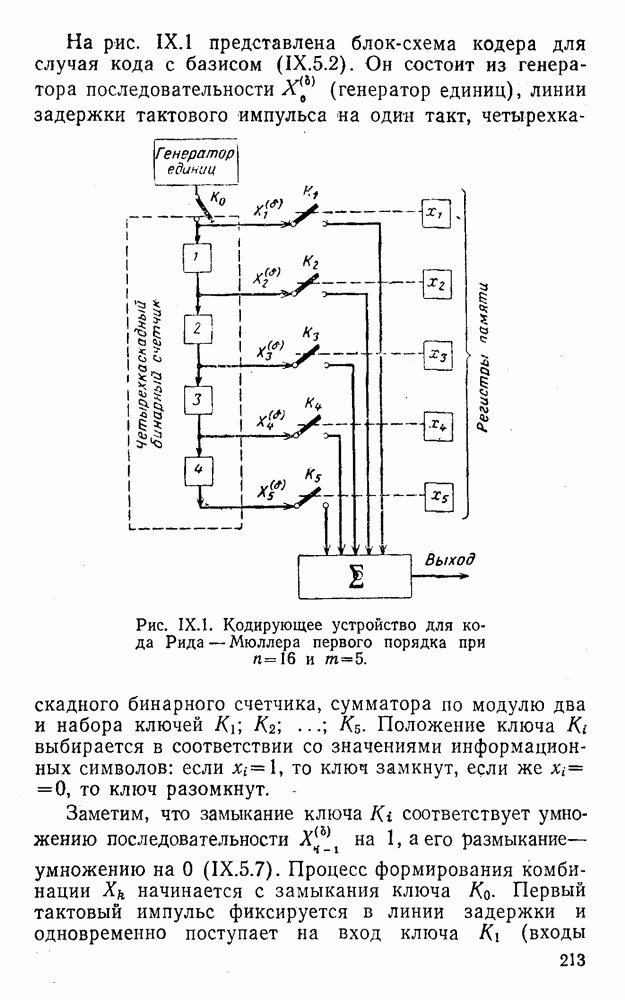
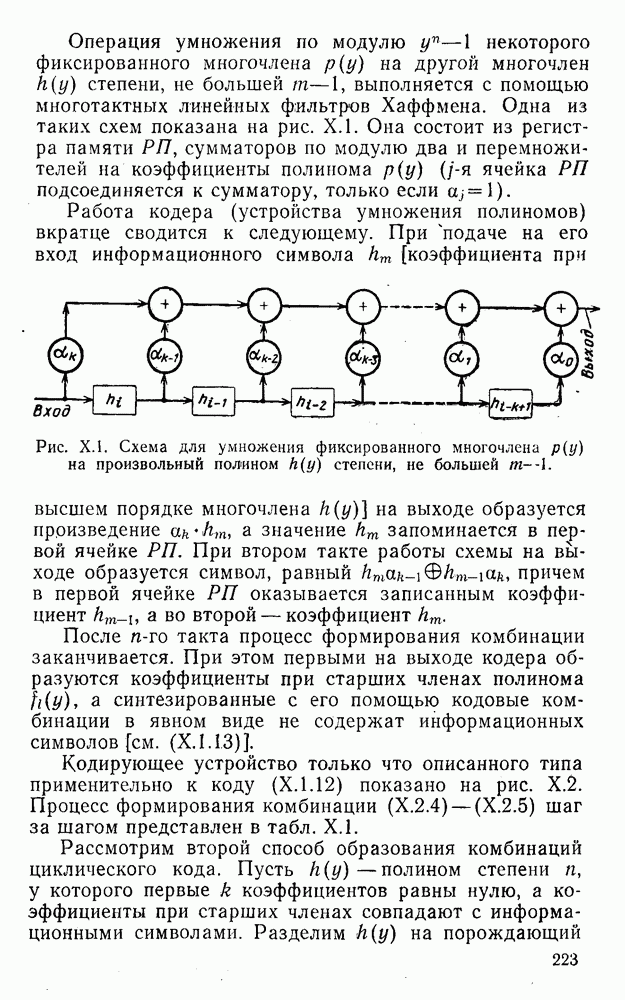
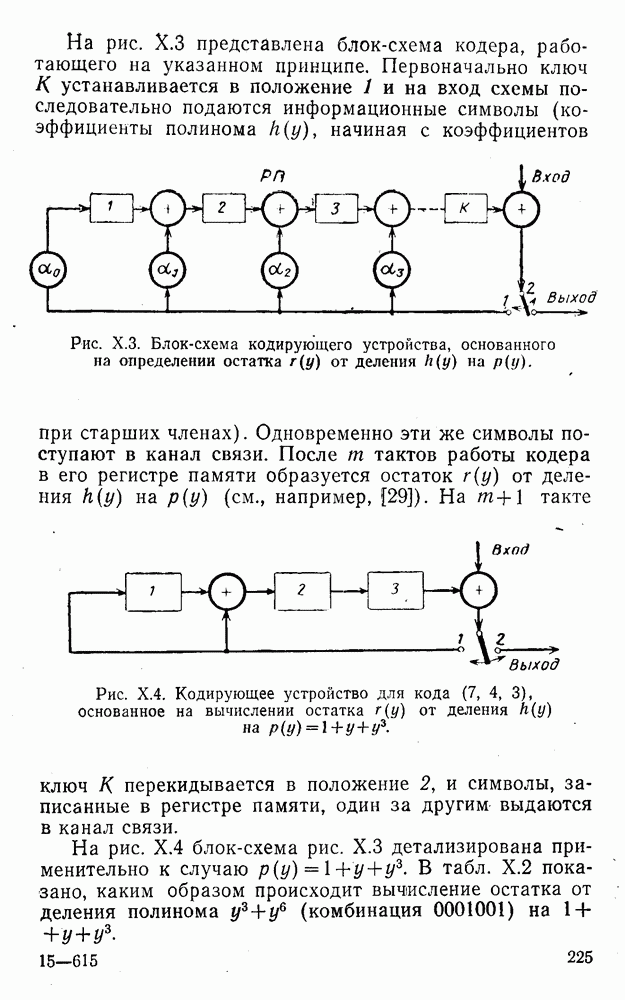
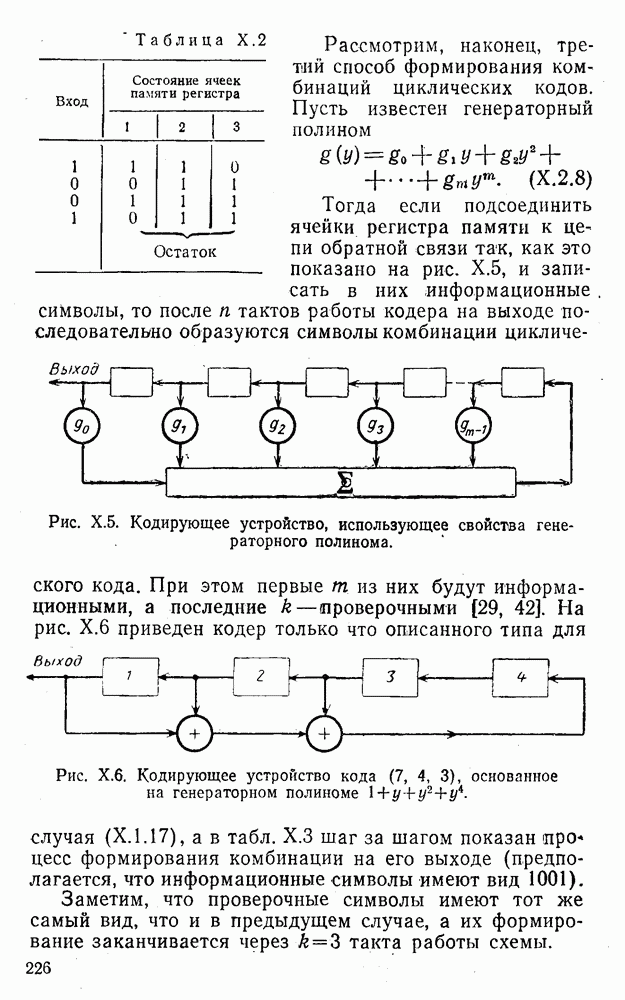
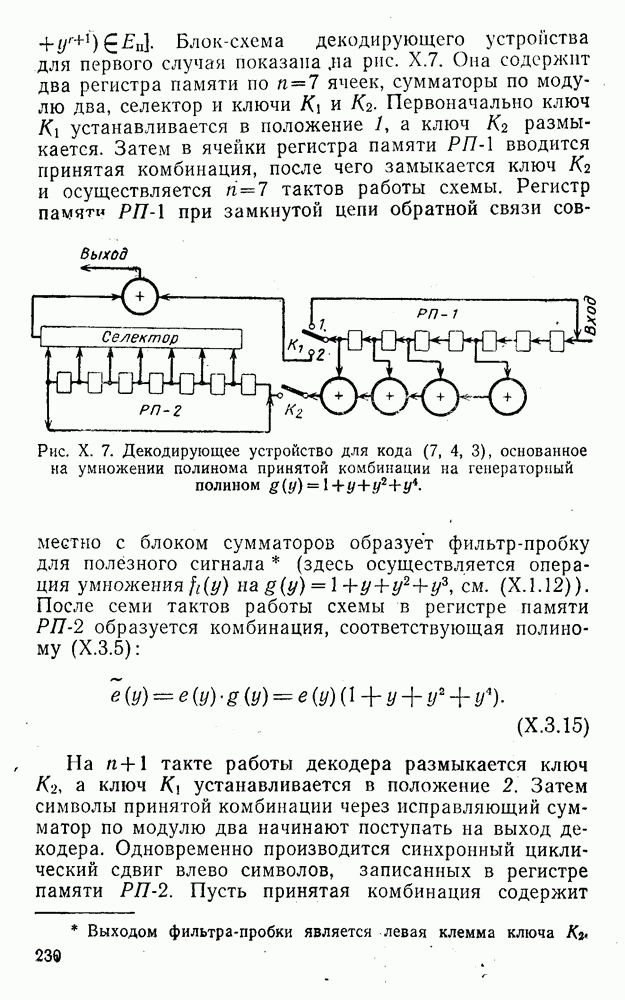
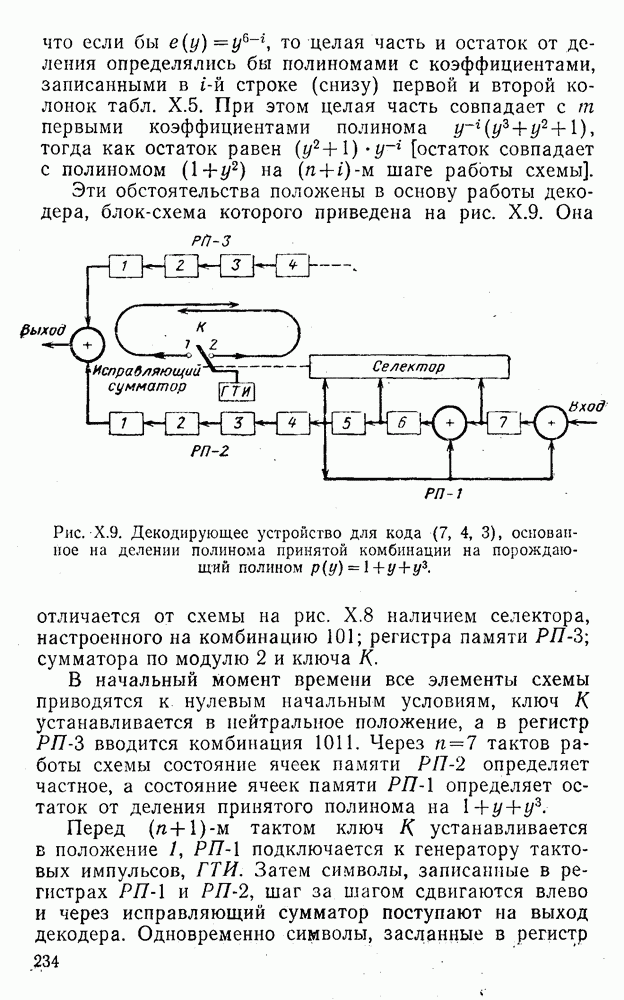
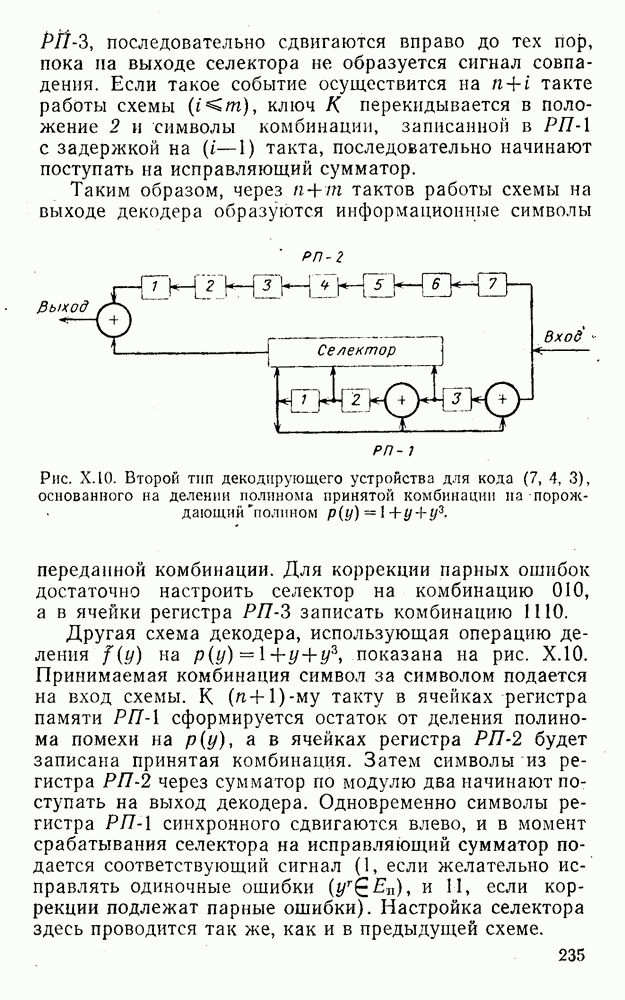
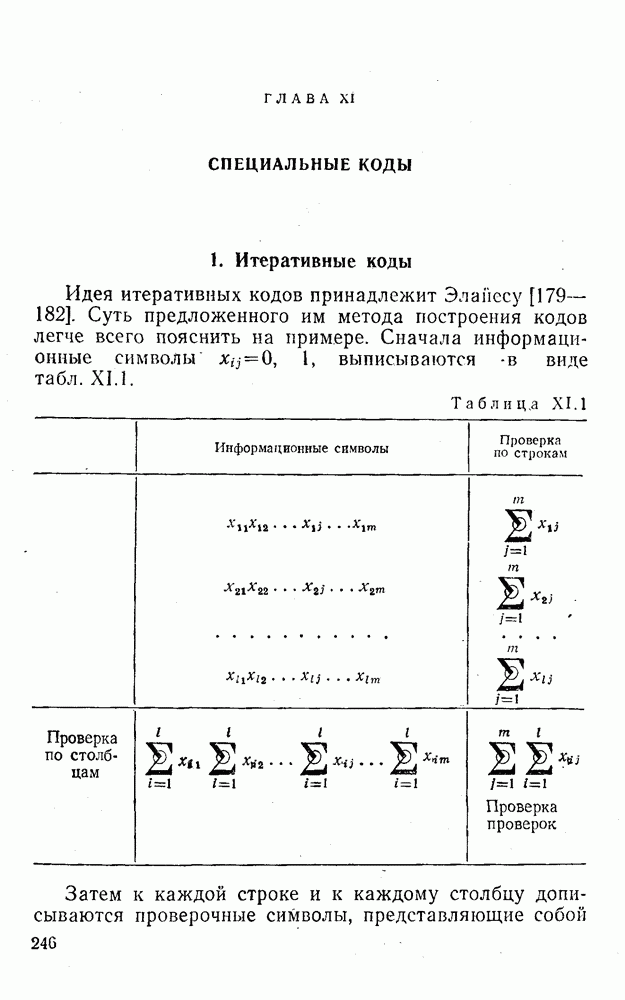
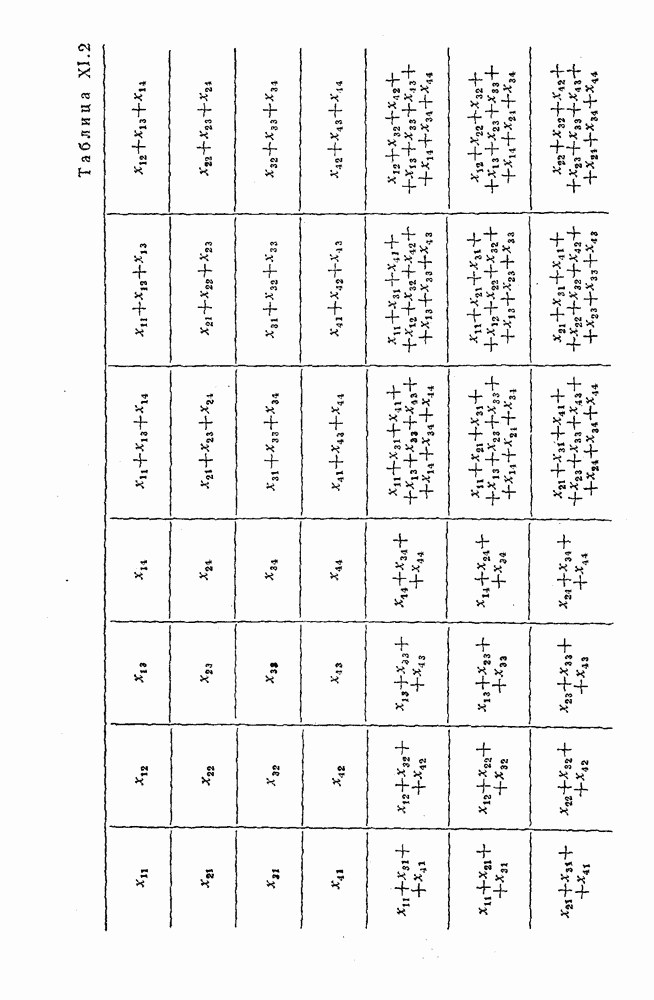
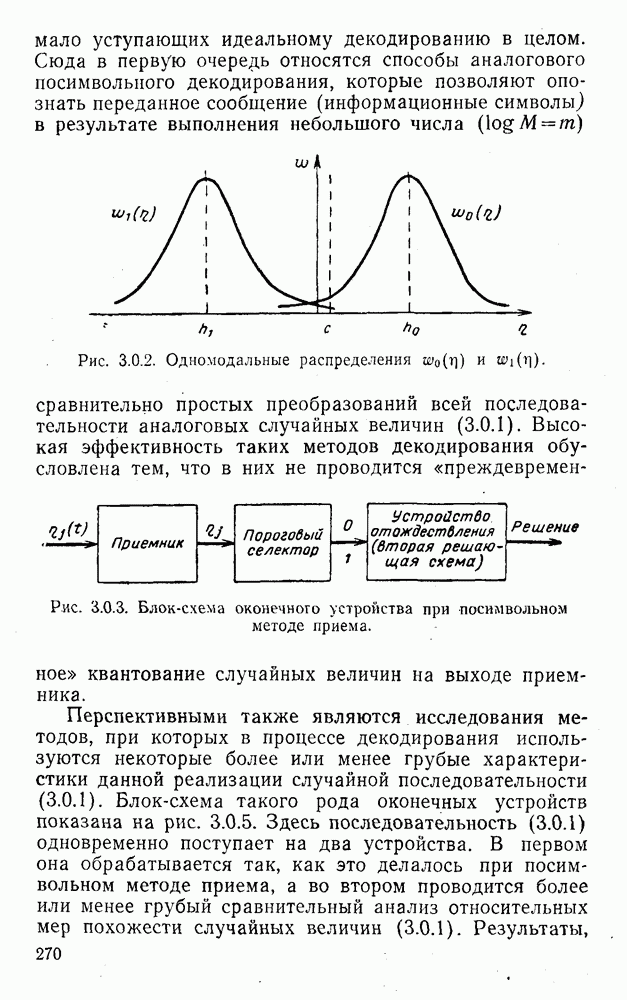
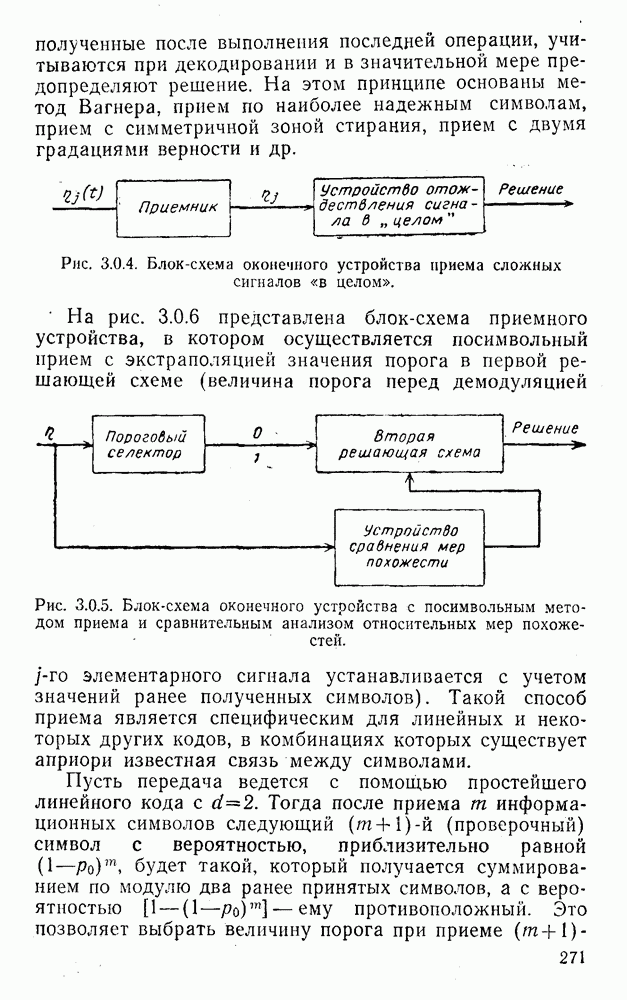
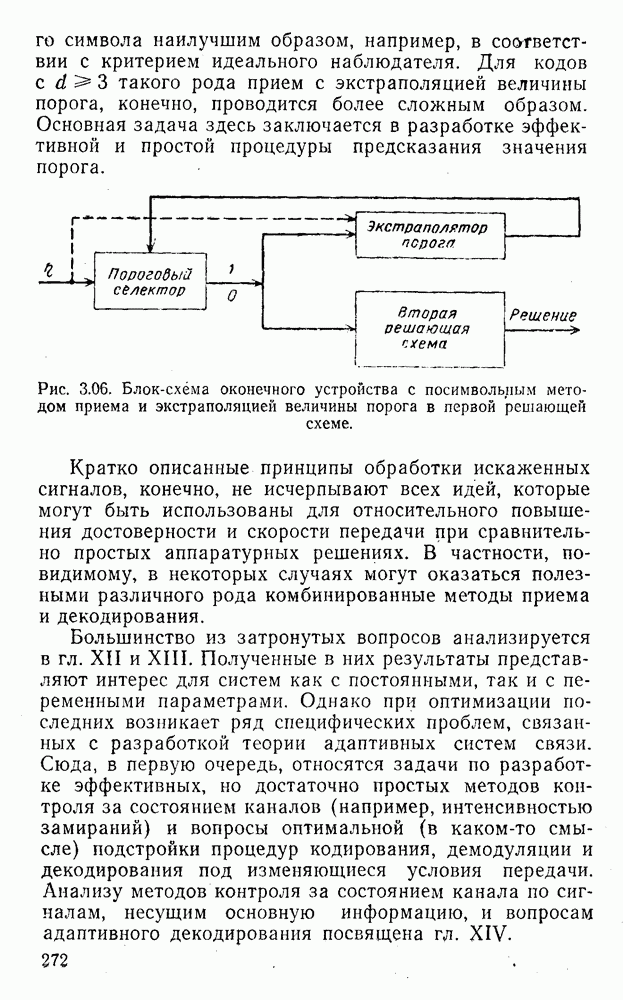
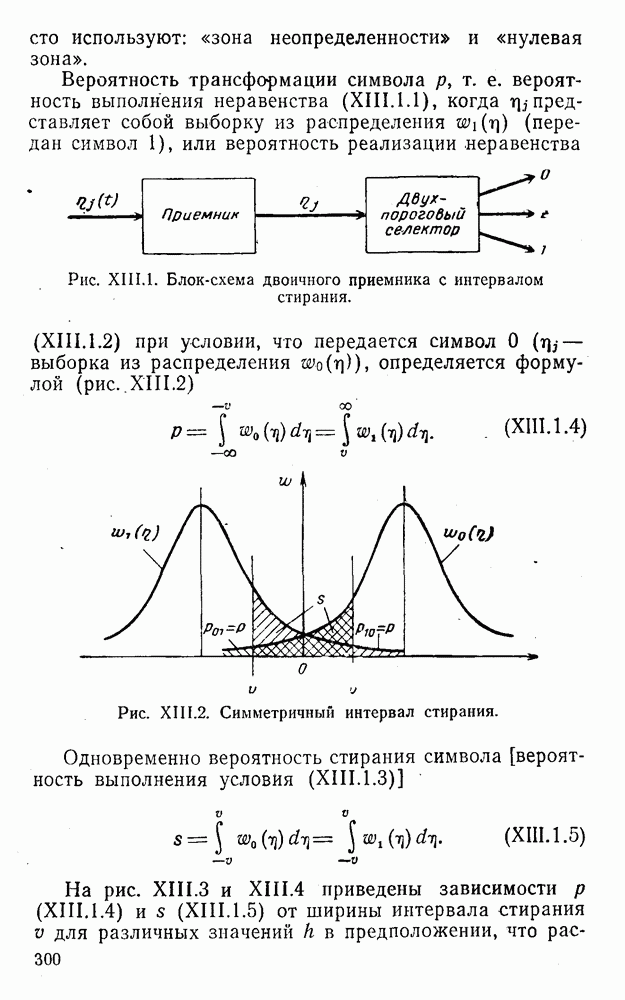
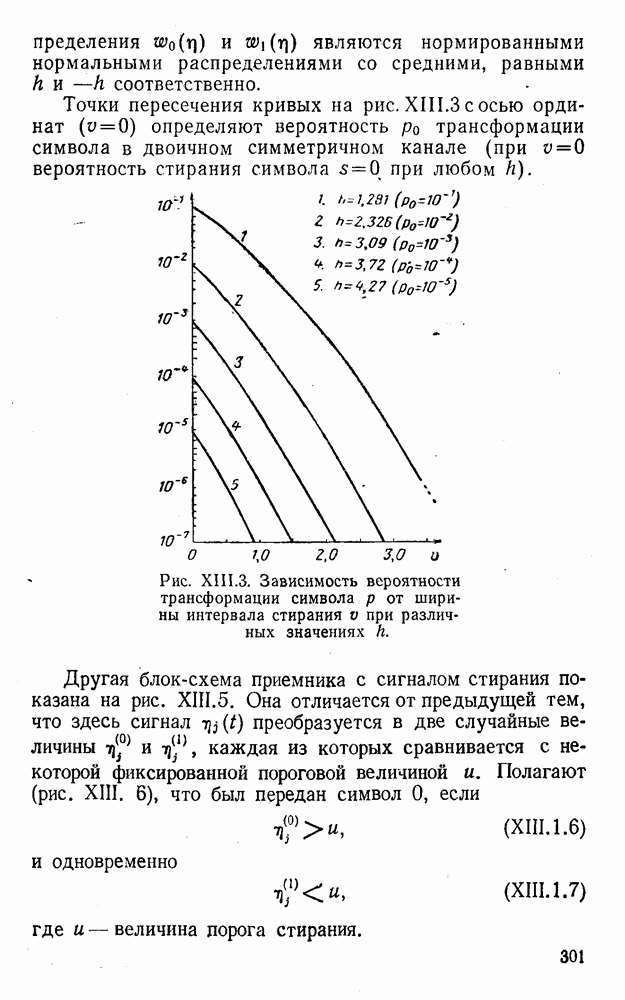
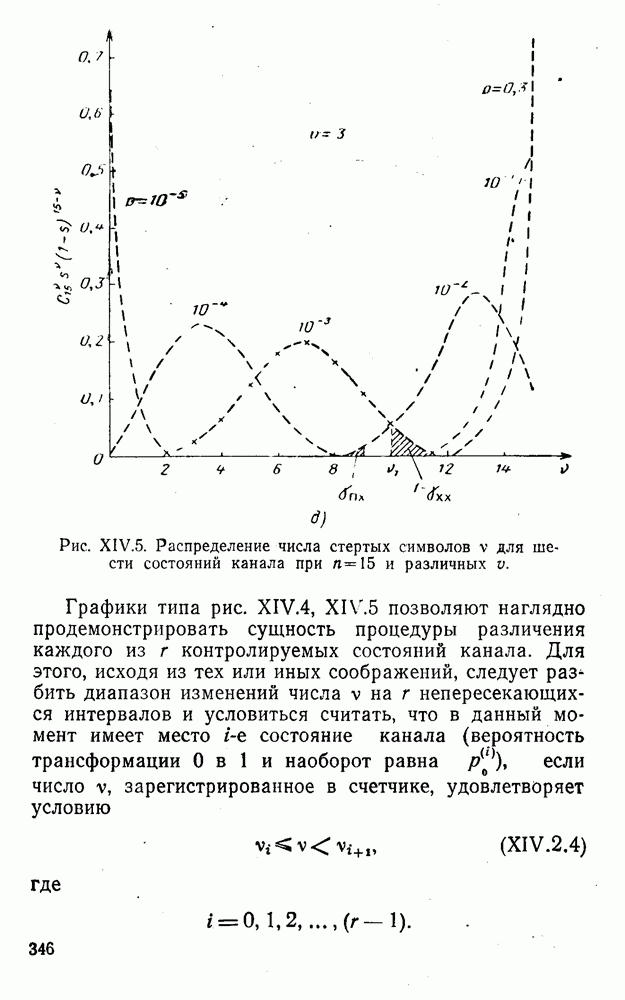
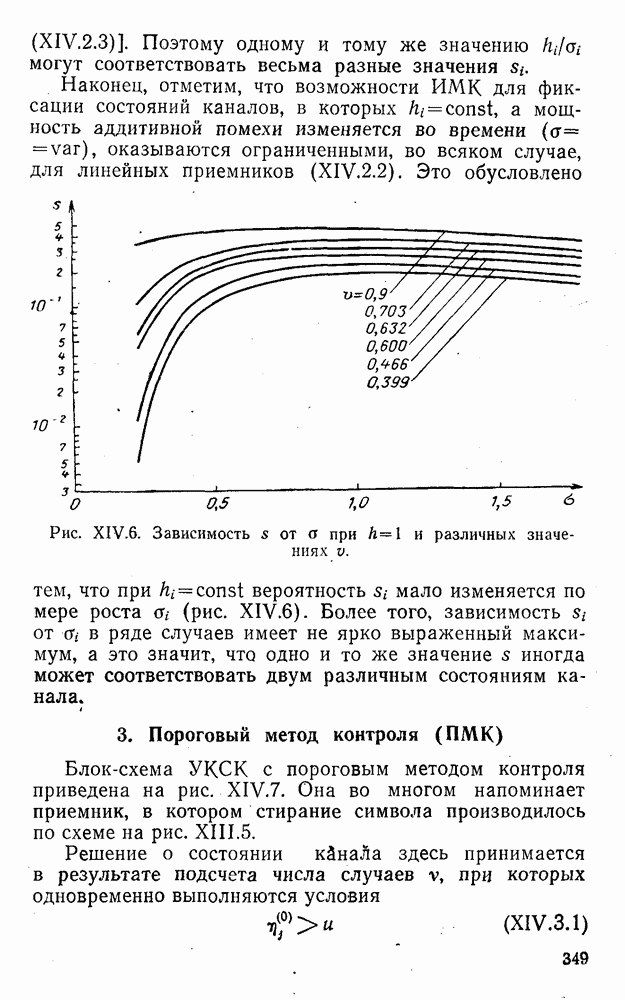
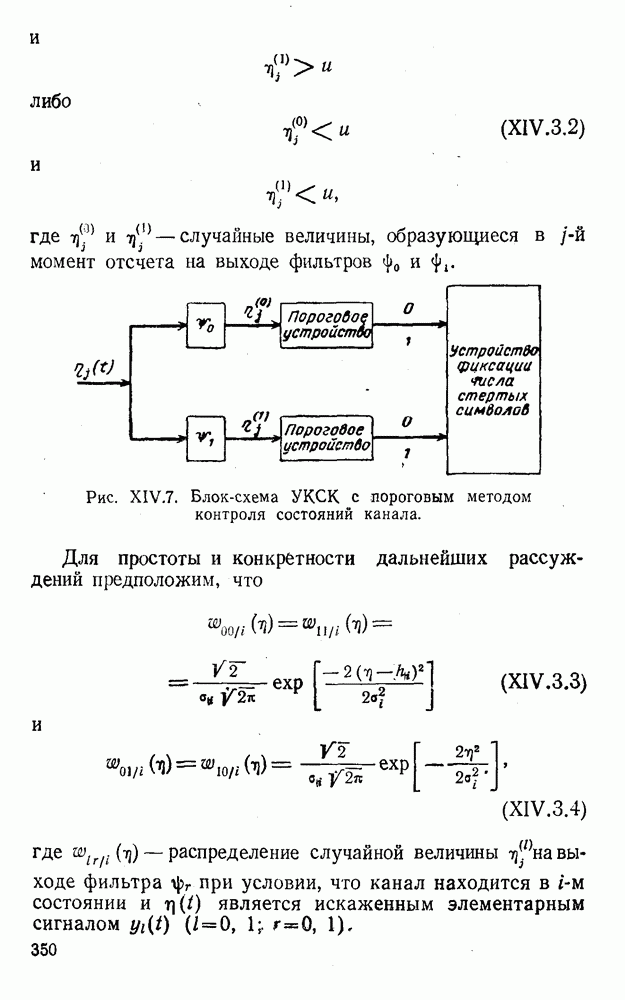
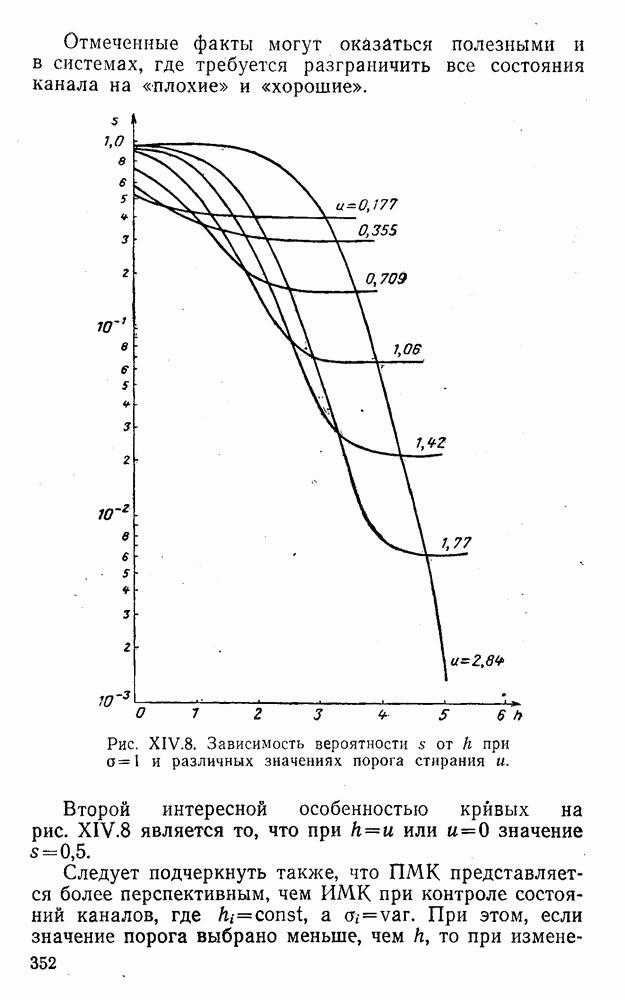
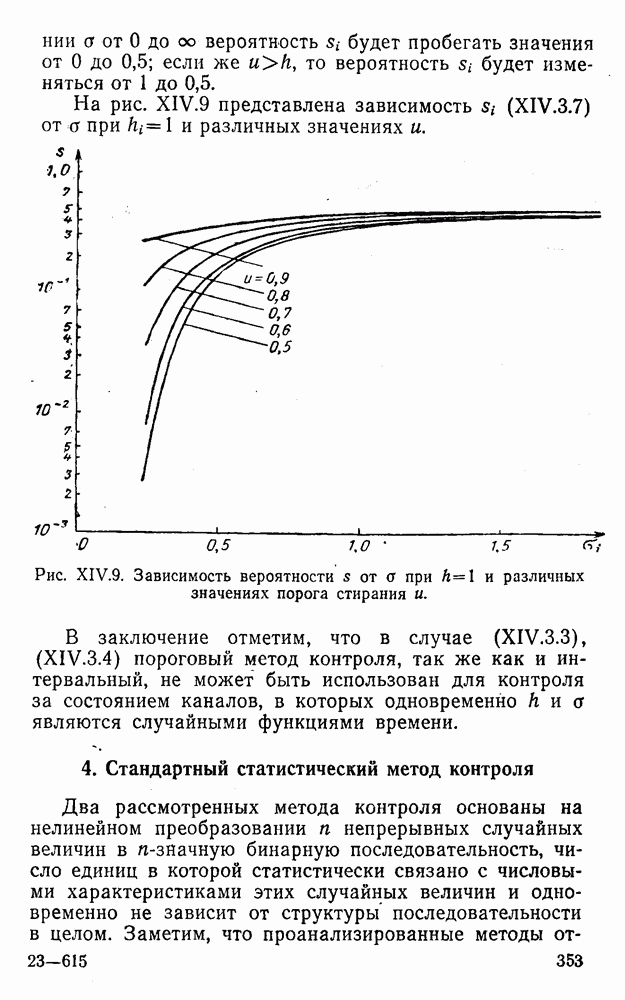
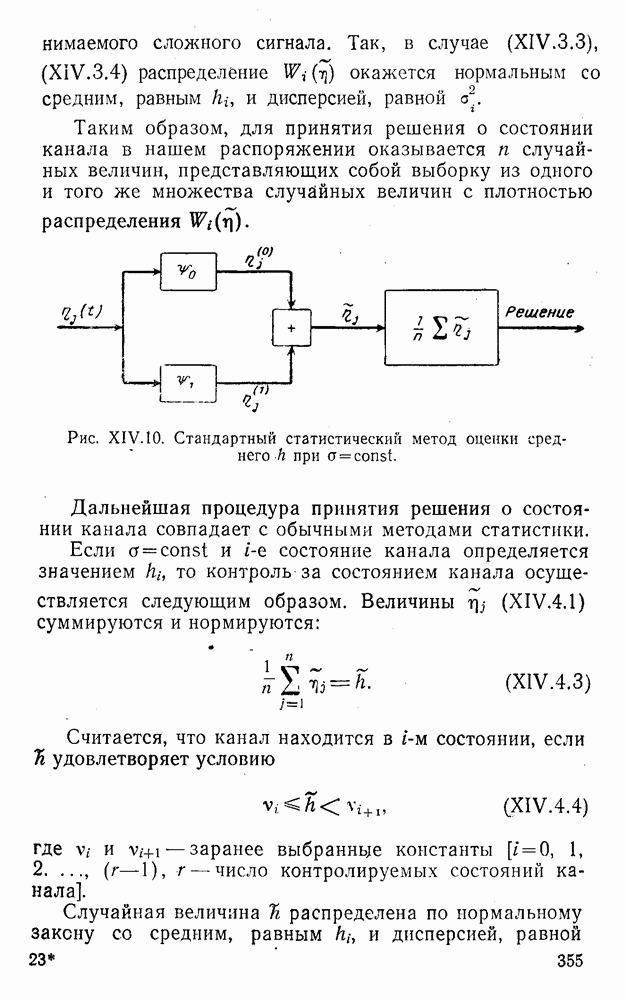
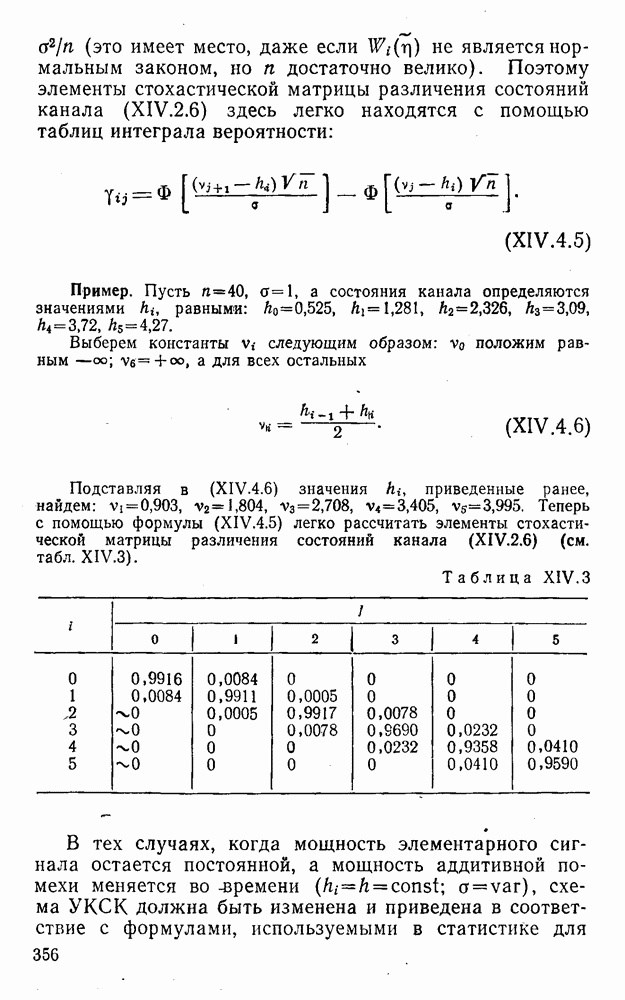
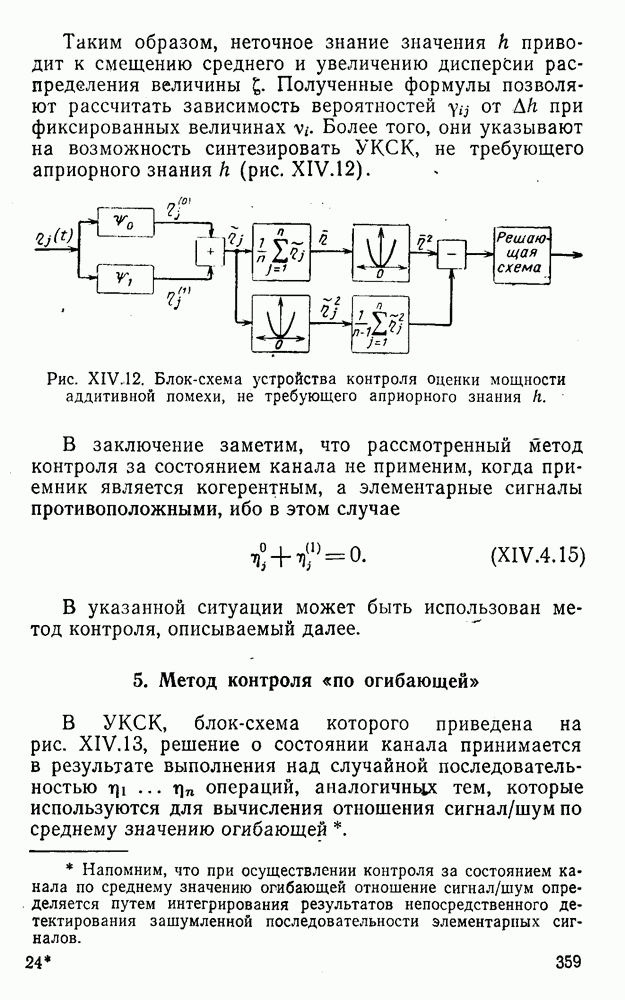
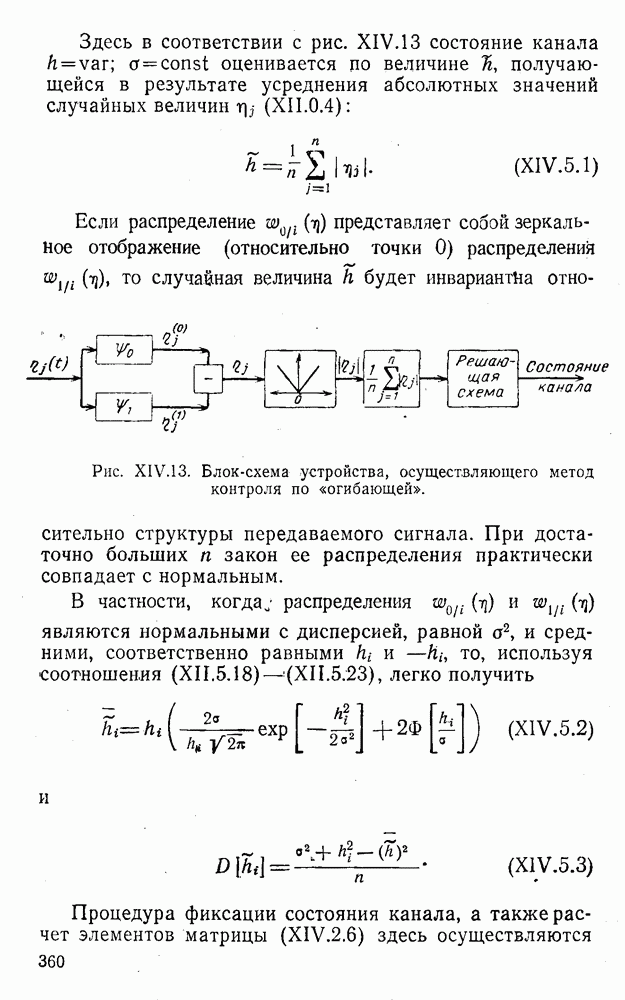
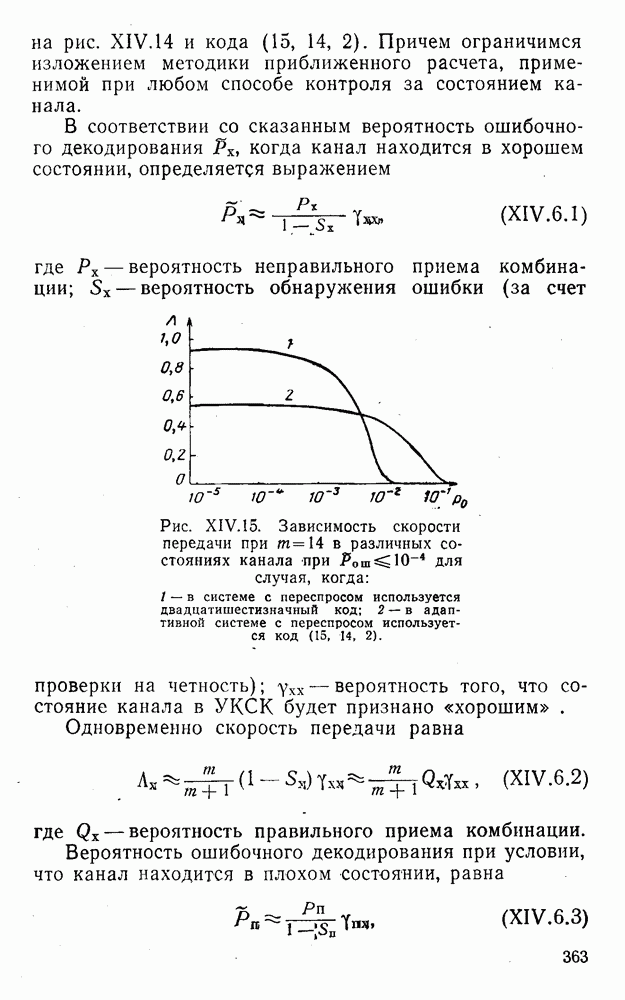
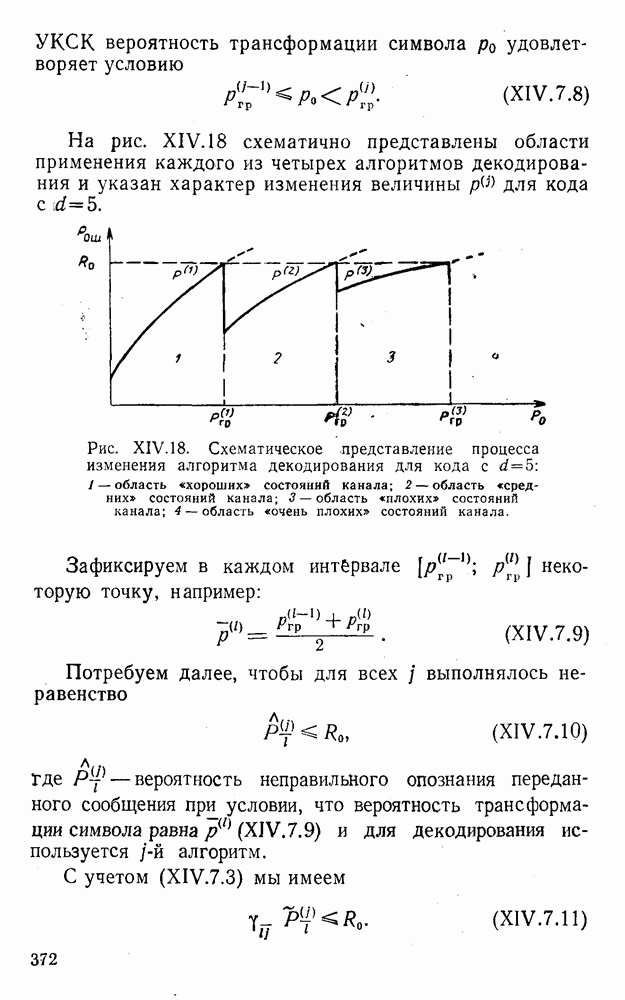
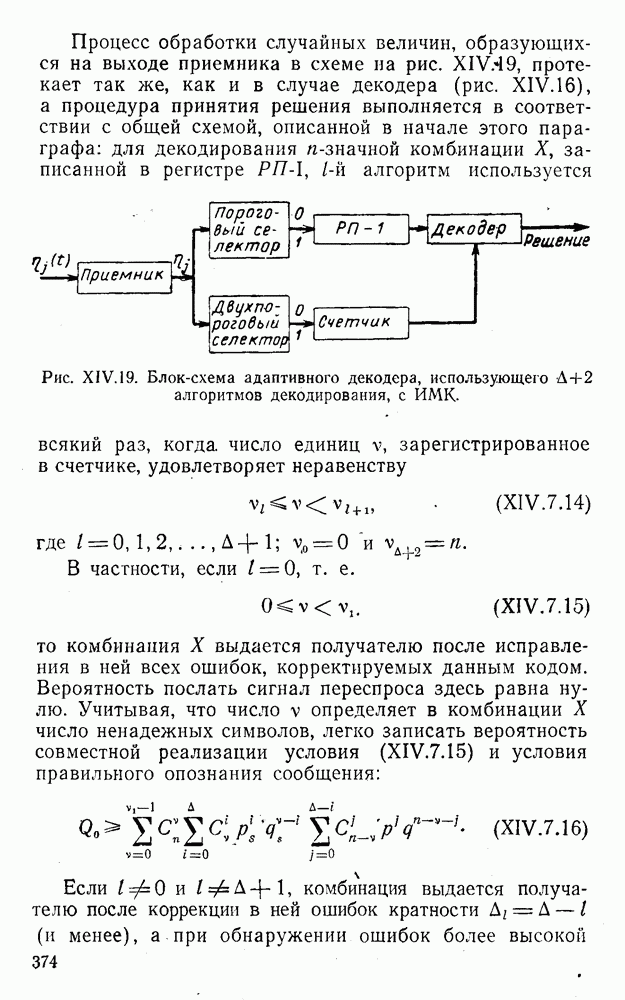
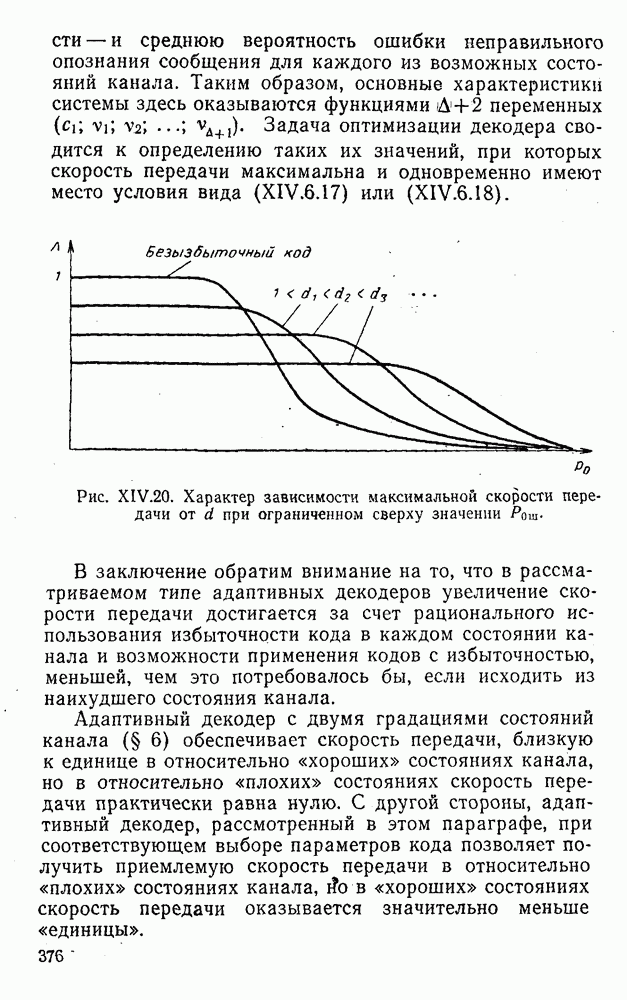
4. Коды для обнаружения и исправления малых ошибокПусть символы
а канал таков, что наиболее вероятными являются единичные (малые) ошибки, т. е. такие, при которых символ
Коды с обнаружением единичной ошибки. Такого рода коды позволяют передавать информацию одновременно от двух источников с разными числовыми основаниями. Достигается это путем использования, во-первых, так называемых смешанных символов и, во-вторых, того очевидного факта, что для обнаружения ошибки вида Пятеричная компонента смешанной цифры берется непосредственно от соответствующего источника и объединяется с двоичной компонентой в соответствии с правилами, указанными в табл.XI.7. В результате этой операции образуется смешанный символ по основанию Таблица XI.7
Как легко заметить (см. табл. XI.7), значение смешанного символа
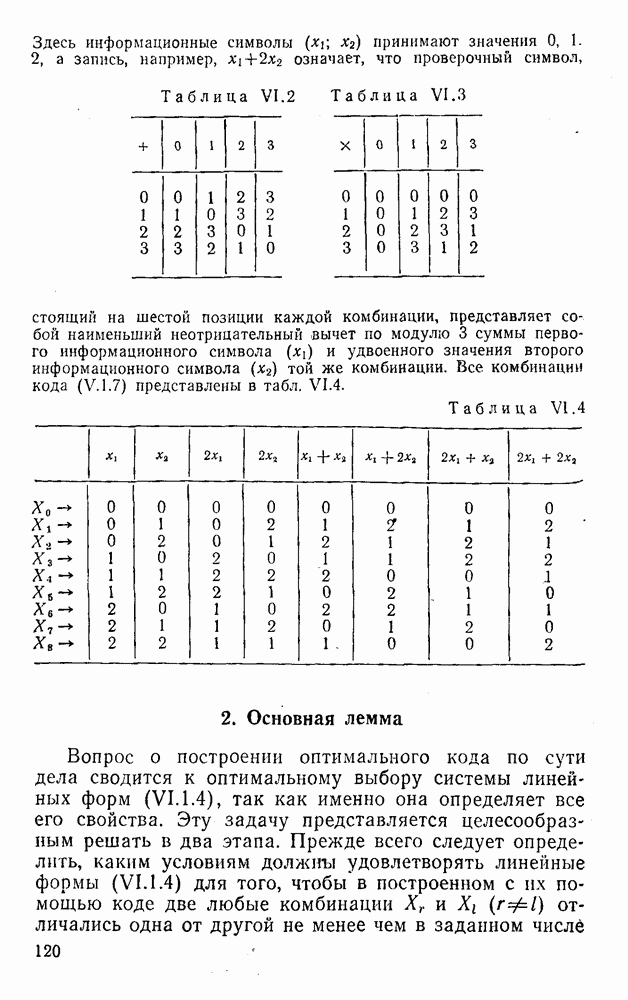
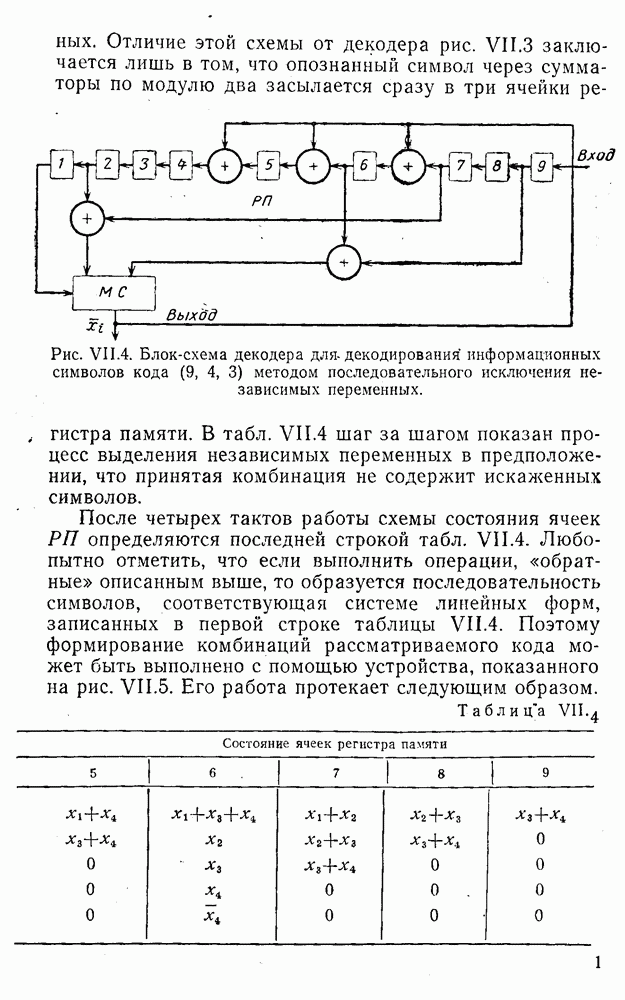
Например, если информационные символы равны 1, 8, 5, а пятеричная компонента равна 4, то С учетом сказанного кодовая комбинация примет вид 1858. Изменение величины любого ее символа на Рассмотренный метод синтеза кодов обобщается на любое основание и на случай обнаружения других малых ошибок, не превосходящих Коды с коррекцией единичных ошибок. Согласно [50] формально такие коды записываются в стандартной форме:
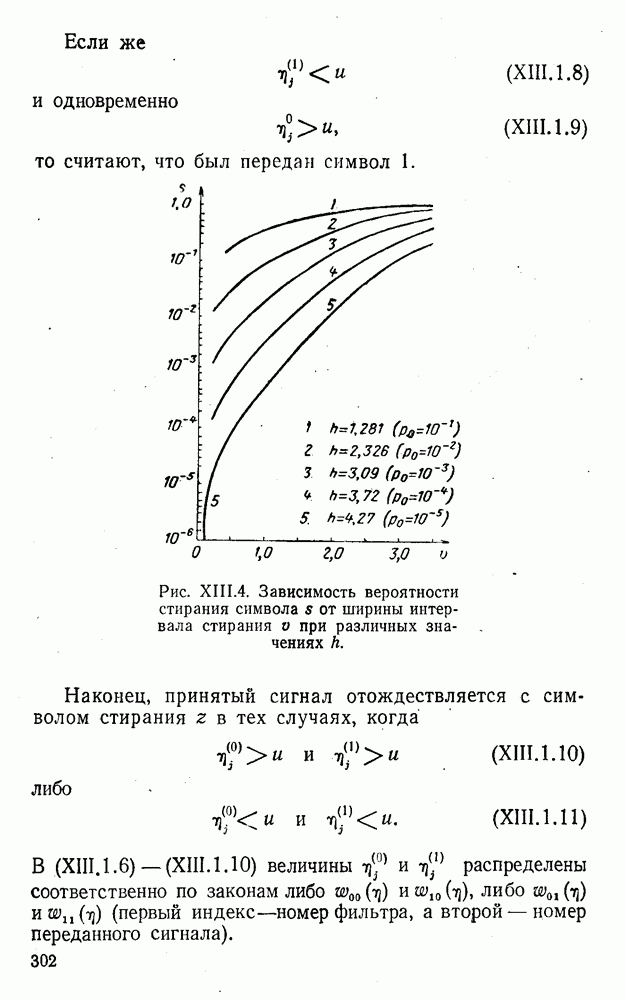
где
Здесь Коррекция ошибки в коде (XI.4.4) может быть осуществлена, например, методом контрольных чисел. При этом, как и ранее, требуется, чтобы каждой из возможных. единичных ошибок соответствовало (взаимно однозначно) контрольное число. Каждый символ комбинации (XI.4.4) может быть искажен двояким образом*. Следовательно, число возможных единичных искажений в
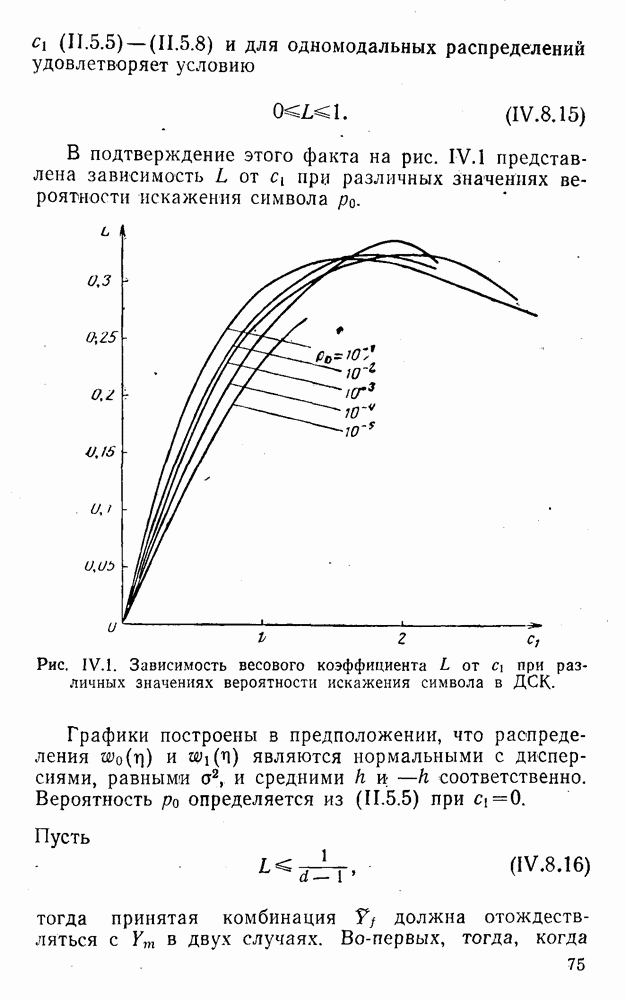
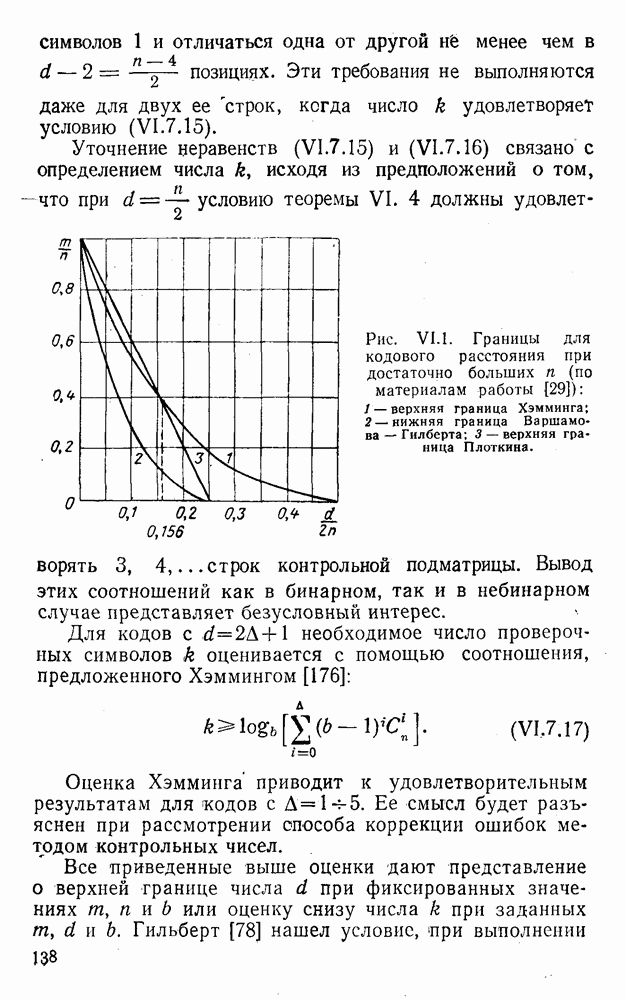
Эта оценка, как показано Алричем, имеет место лишь для нечетных
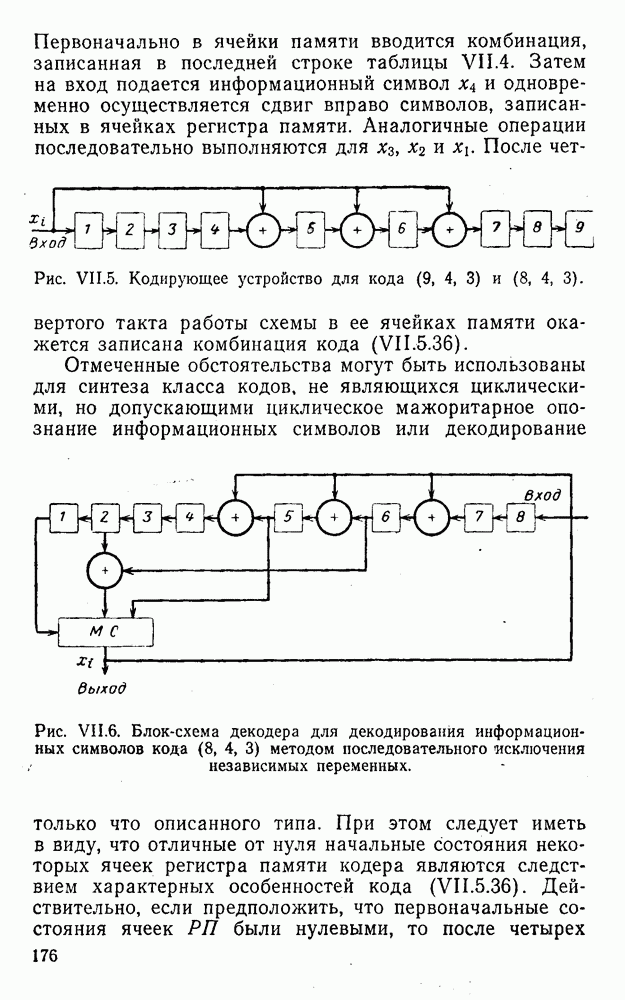
Для обобщения и уточнения этих оценок весьма полезными представляются результаты работ [133—136, 163]. Примером простейшего кода с коррекцией единичных ошибок является четырехзначный код с одним проверочным символом:
где проверочный символ
Контрольное число G находится по формуле
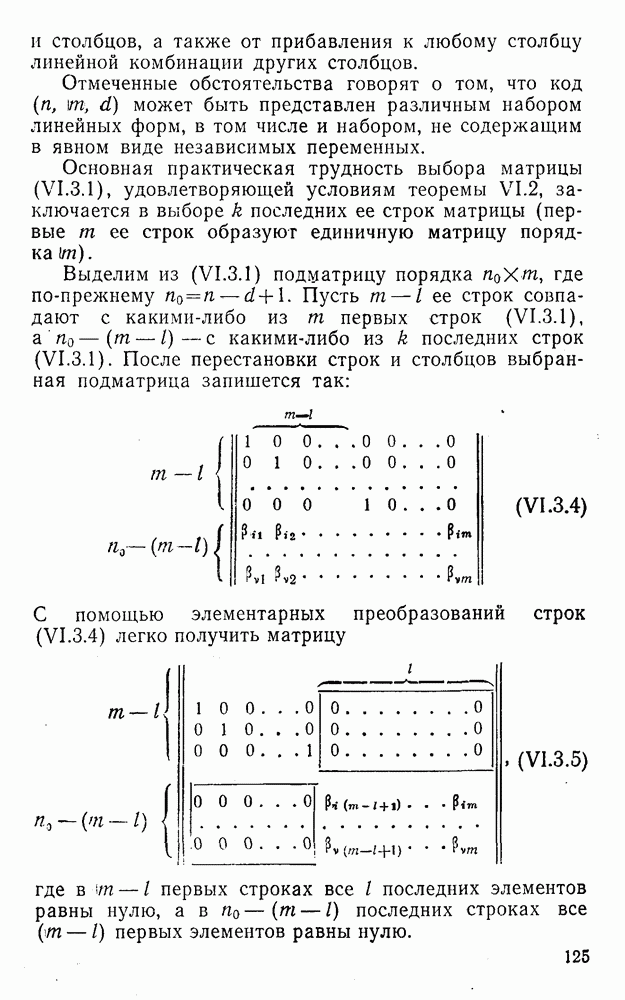
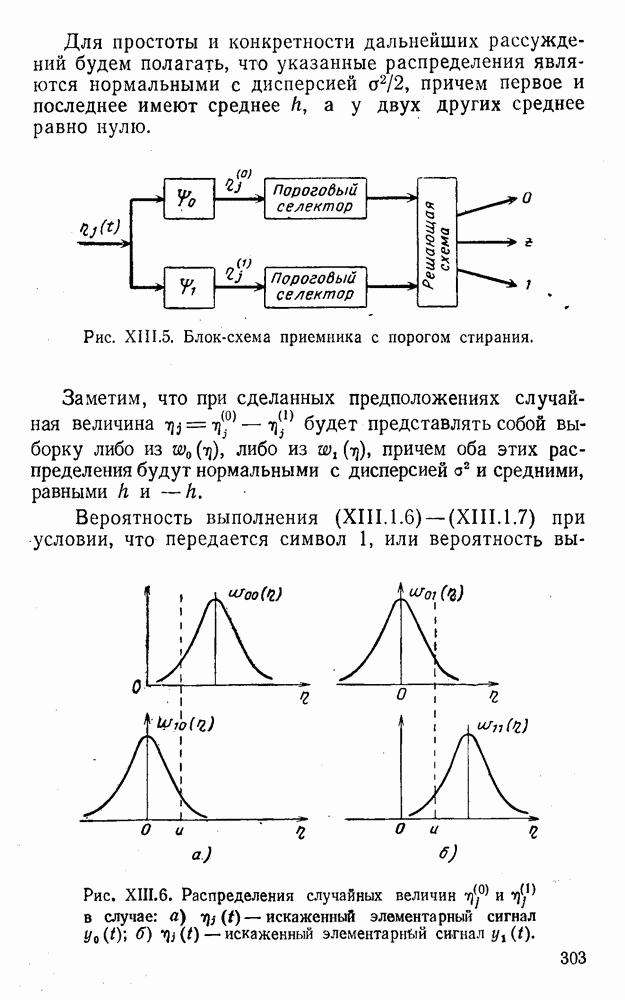
здесь знак а) если б) если в) если г) если Рассмотренные коды являются простейшими линейными кодами с модульной метрикой. При попытке развить общую теорию таких кодов возникает ряд ранее не наблюдавшихся особенностей. Кратко остановимся на некоторых из них. На основе соотношений (2.0.2) — (2.0.4), (2.0.6) и (2.0.8) для кодов с модульной метрикой можно ввести понятия, аналогичные тем, которые имели место в кодах с метрикой Хэмминга, т. е. понятия:
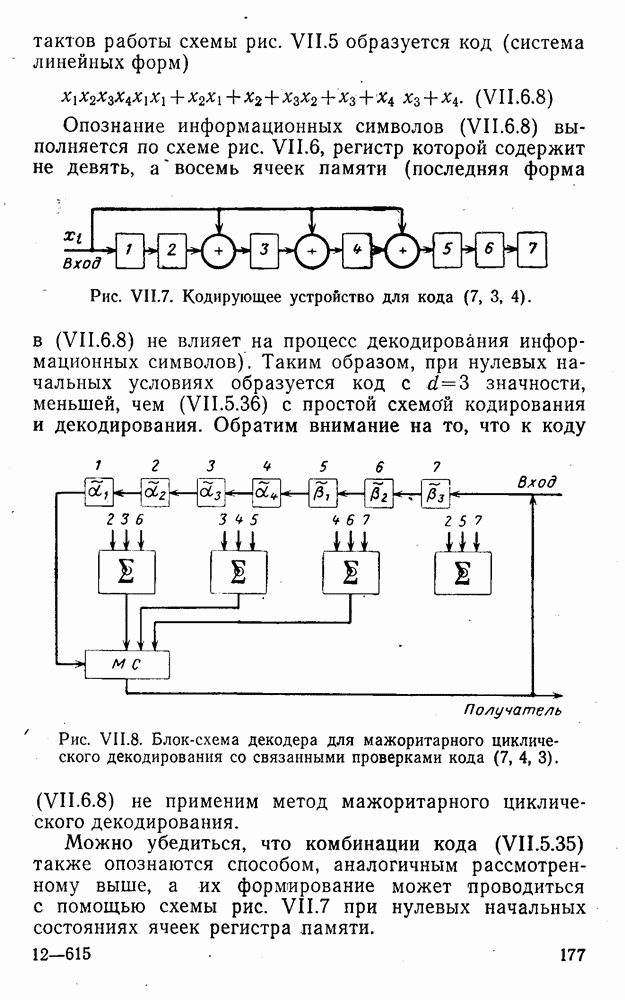
Естественно, что понятие Вторая особенность линейных кодов с модульной метрикой заключается в том, что кодовое расстояние не определяется комбинацией, имеющей минимальный вес:
Пример. Выпишем все комбинации линейного трехзначного кода с основанием
Комбинации этого кода имеют вес между Рассмотрим двузначный код с основанием
Кодовое расстояние
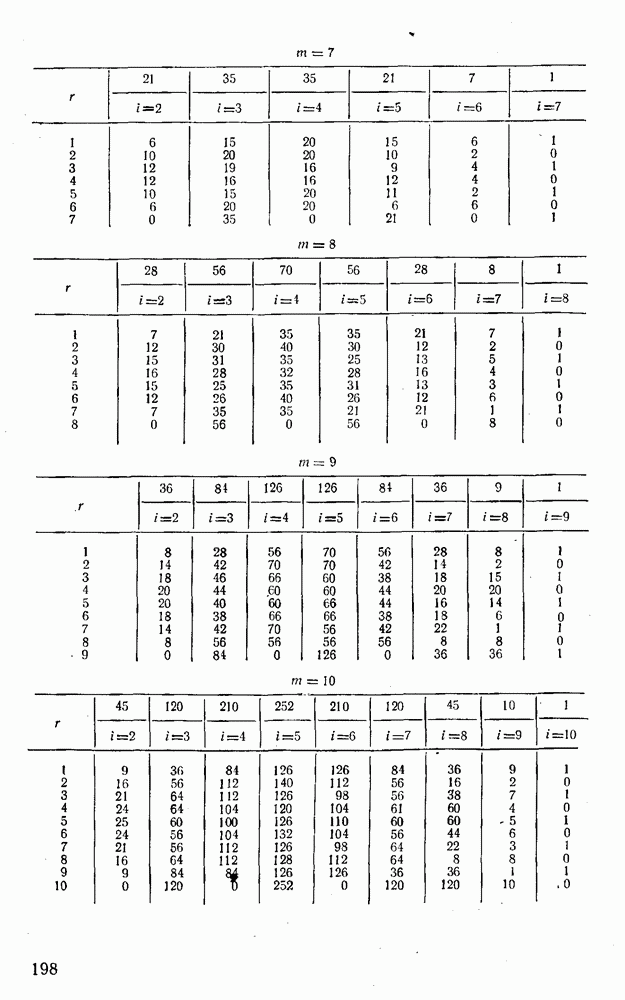
Определим область правильного приема комбинации Таблица XI.8
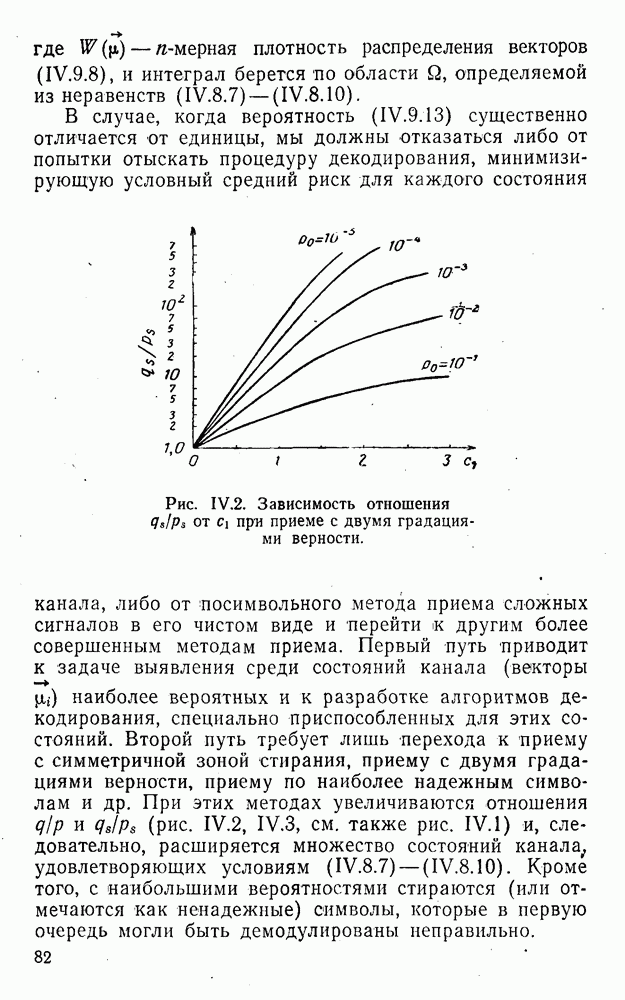
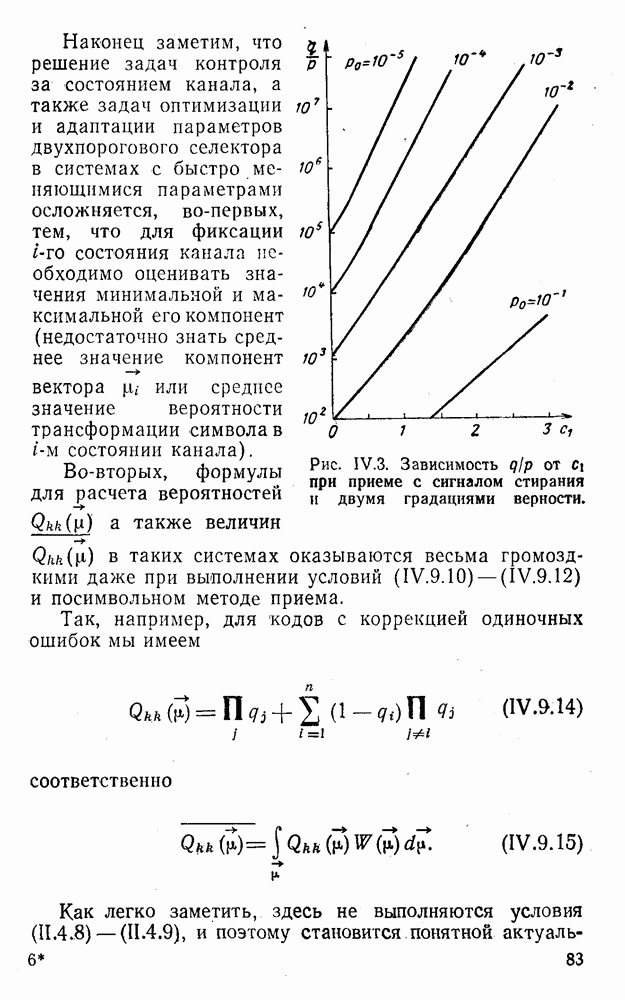
Подмножества Отмеченные и некоторые другие особенности линейных кодов с модульной метрикой, в частности статистические, обусловлены указанными выше обстоятельствами.
|
 |
Оглавление
|














































































































































































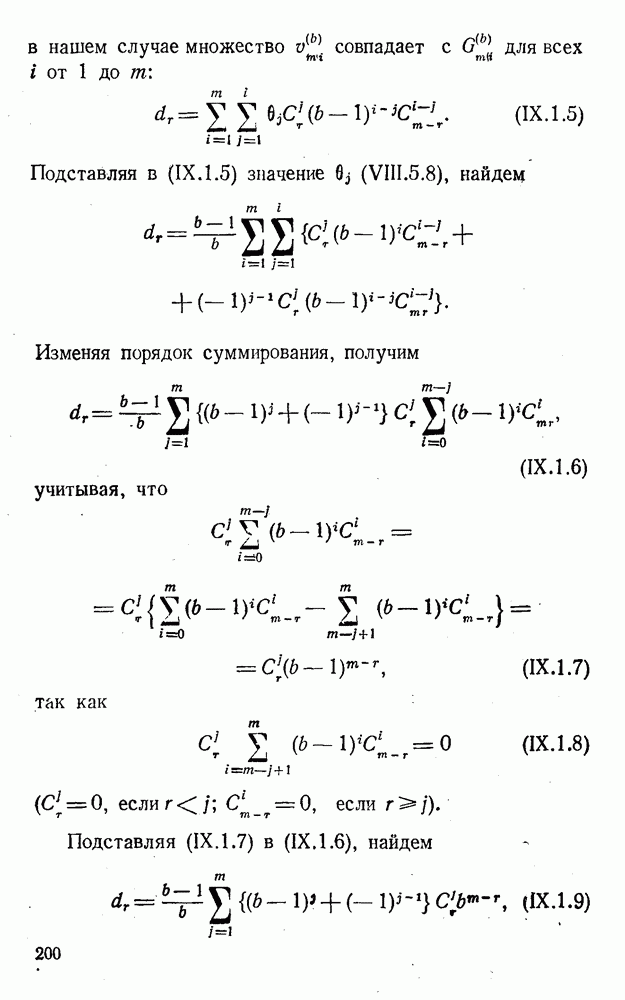














































































































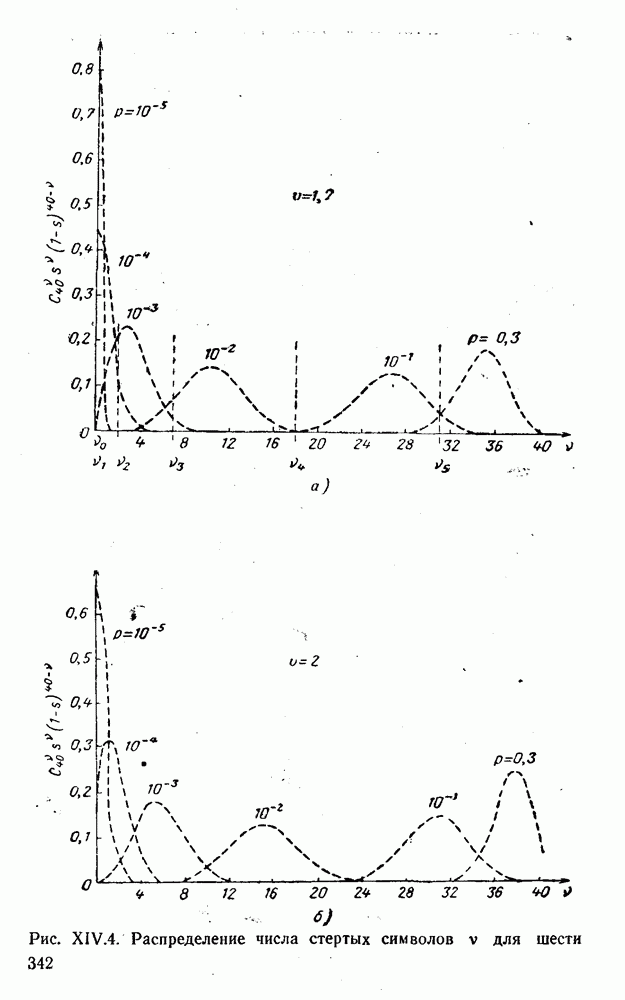
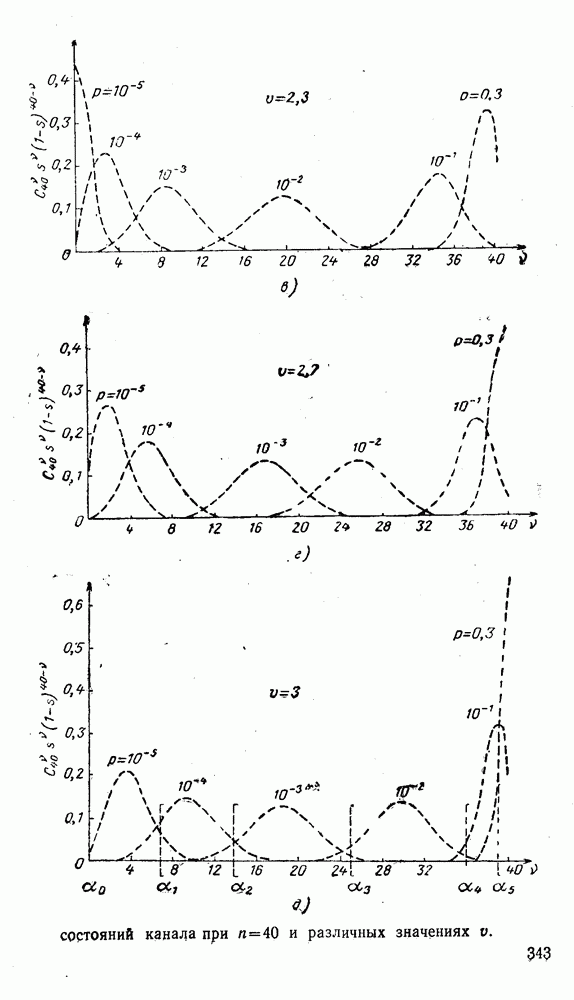
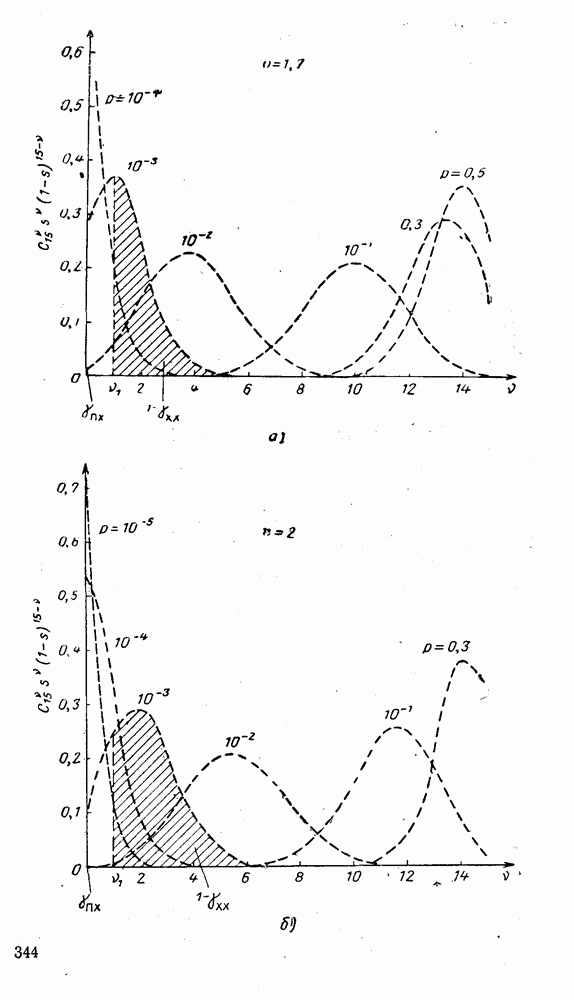
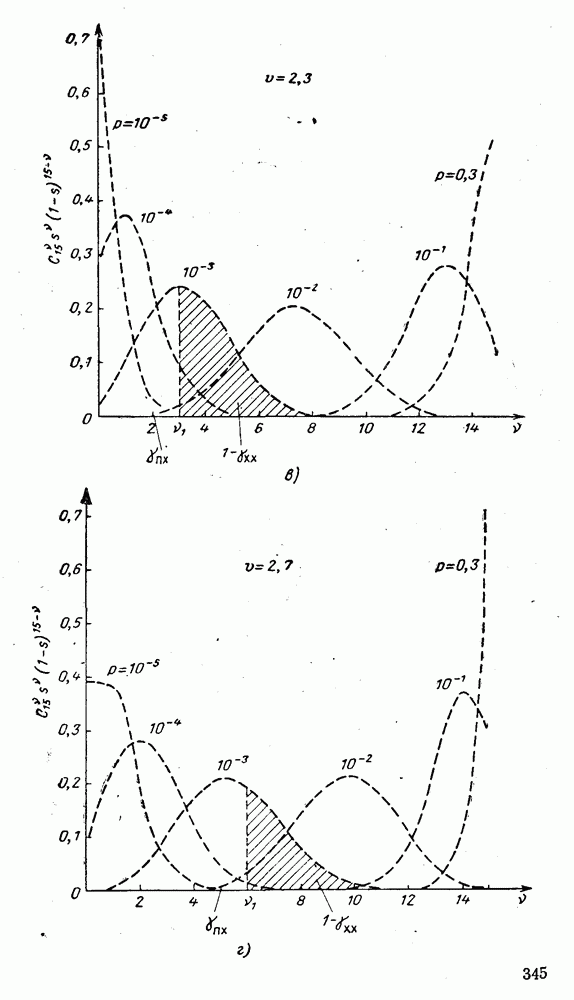










































 представляют собой числа, равные порядковому номеру символа:
представляют собой числа, равные порядковому номеру символа:
 (XI.4.1)
(XI.4.1)
 на приемном конце будет интерпретирован либо как
на приемном конце будет интерпретирован либо как  (ошибка
(ошибка  ), либо как
), либо как  (ошибка -1). Заметим, что символ
(ошибка -1). Заметим, что символ  может трансформироваться лишь в
может трансформироваться лишь в  , а символ
, а символ  лишь в
лишь в  . Ошибки указанного рода имеют место, например, в каналах связи, где в качестве элементарных сигналов
. Ошибки указанного рода имеют место, например, в каналах связи, где в качестве элементарных сигналов  используются сигналы, отличающиеся лишь постоянным множителем (значением амплитуды)
используются сигналы, отличающиеся лишь постоянным множителем (значением амплитуды)
 (XI.4.2)
(XI.4.2)
 достаточно сделать сумму цифр комбинации четной. Смешанным символом
достаточно сделать сумму цифр комбинации четной. Смешанным символом  по основанию b Алрич [50] называет символ, состоящий из двух компонент: информационной у по основанию
по основанию b Алрич [50] называет символ, состоящий из двух компонент: информационной у по основанию  и контрольной z по основанию
и контрольной z по основанию  . Так, например, для источников
. Так, например, для источников  и
и  формирование смешанного символа происходит следующим образом. Блок из
формирование смешанного символа происходит следующим образом. Блок из  десятичных цифр образует информационные символы. Затем для каждого из них находится сумма. Если она четна, то двоичная компонента смешанной цифры
десятичных цифр образует информационные символы. Затем для каждого из них находится сумма. Если она четна, то двоичная компонента смешанной цифры  , в противном случае
, в противном случае  .
.
 .
.

 (XI.4.3)
(XI.4.3)
 и согласно табл.XI.7
и согласно табл.XI.7  .
.
 нарушает четность их суммы.
нарушает четность их суммы.
 .
.
 (XI.4.4)
(XI.4.4)
 — информационные символы, а
— информационные символы, а
 (XI.4.5)
(XI.4.5)
 -неотрицательные числа, не большие
-неотрицательные числа, не большие  .
.
 -значной комбинации не превосходит
-значной комбинации не превосходит  , и поэтому при числе проверочных символов k значность кода
, и поэтому при числе проверочных символов k значность кода
 (XI.4.6)
(XI.4.6)
 . В силу линейности форм (XI.4.5) для четных оснований кода
. В силу линейности форм (XI.4.5) для четных оснований кода
 (XI.4.7)
(XI.4.7)
 (XI.4.8)
(XI.4.8)
 (XI.4.9)
(XI.4.9)
 (XI.4.10)
(XI.4.10)
 означает, что значение символа, возможно, изменено на величину
означает, что значение символа, возможно, изменено на величину  . Легко проверить следующие правила сопоставления значений G возможным ошибкам:
. Легко проверить следующие правила сопоставления значений G возможным ошибкам:
 , то кодовая комбинация не содержит единичных ошибок;
, то кодовая комбинация не содержит единичных ошибок;
 , то нужно уменьшить значение символа
, то нужно уменьшить значение символа  , на 1, т. е. считать, что переданный символ
, на 1, т. е. считать, что переданный символ 
 , то необходимо увеличить на 1 значение символа с номером
, то необходимо увеличить на 1 значение символа с номером  , т. е. полагать, что переданный символ
, т. е. полагать, что переданный символ 
 , то это означает, что принятая комбинация содержит две единичные ошибки или более, либо ошибки, по абсолютной величине больше 1.
, то это означает, что принятая комбинация содержит две единичные ошибки или более, либо ошибки, по абсолютной величине больше 1.
 — расстояние между комбинациями
— расстояние между комбинациями  и
и 
 - вес (норма) комбинации
- вес (норма) комбинации  и d — кодовое расстояние. При этом для того, чтобы иметь возможность обнаруживать ошибки кратности
и d — кодовое расстояние. При этом для того, чтобы иметь возможность обнаруживать ошибки кратности  (и менее) и .исправлять из них все ошибки кратности
(и менее) и .исправлять из них все ошибки кратности  (и менее), необходимо и достаточно, чтобы кодовое расстояние удовлетворяло условию
(и менее), необходимо и достаточно, чтобы кодовое расстояние удовлетворяло условию
 (XI.4.11)
(XI.4.11)
 -кратной ошибки здесь отличается от того, которое имело место в кодах с метрикой Хэмминга. Так, двукратная ошибка означает, что либо в комбинации одновременно изменена на единицу величина двух символов, либо значение одного символа изменено сразу на две градации.
-кратной ошибки здесь отличается от того, которое имело место в кодах с метрикой Хэмминга. Так, двукратная ошибка означает, что либо в комбинации одновременно изменена на единицу величина двух символов, либо значение одного символа изменено сразу на две градации.
 (XI.4.12)
(XI.4.12)
 и
и  , у которого проверочный символ опреДеляется как удвоенная сумма по модулю 3 информационных символов:
, у которого проверочный символ опреДеляется как удвоенная сумма по модулю 3 информационных символов:
 (XI.4.13)
(XI.4.13)
 однако расстояние
однако расстояние
 и
и  равно двум, и поэтому
равно двум, и поэтому  , что и подтверждает неравенство (XI.4.12). Приведенный код асимметричен в том смысле, что для каждой его комбинации
, что и подтверждает неравенство (XI.4.12). Приведенный код асимметричен в том смысле, что для каждой его комбинации  существует свой набор величин
существует свой набор величин  . Это вытекает хотя бы уже из того, что комбинация имеет вес 6, и оказывается невозможным найти в (XI.4.13) комбинацию, которая располагалась бы от
. Это вытекает хотя бы уже из того, что комбинация имеет вес 6, и оказывается невозможным найти в (XI.4.13) комбинацию, которая располагалась бы от  на расстоянии, равном шести.
на расстоянии, равном шести.
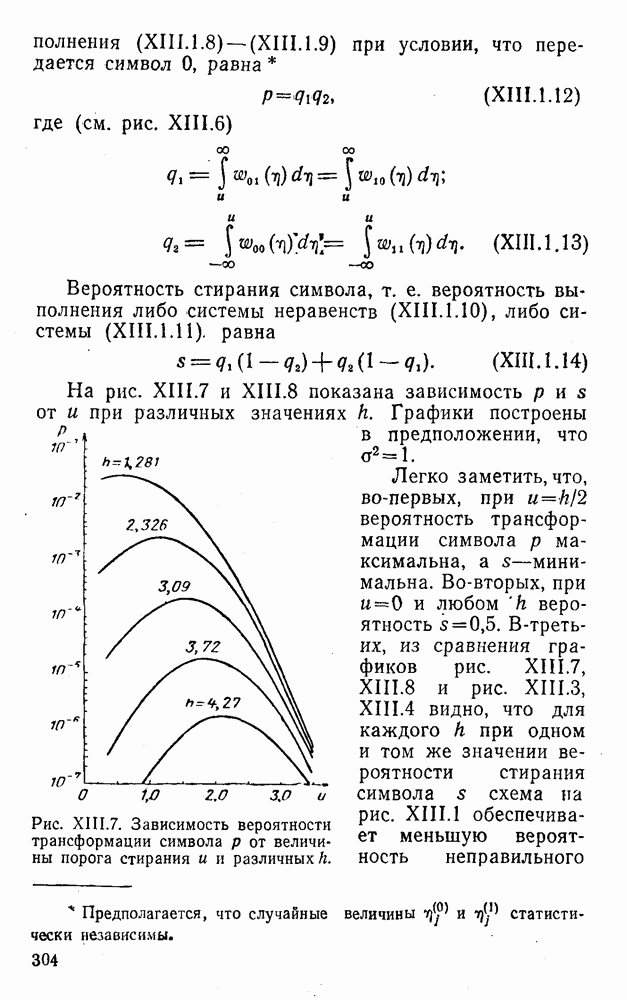
 , у которого проверочный символ представляет собой наименьший неотрицательный вычет по модулю пять удвоенного значения информационного символа:
, у которого проверочный символ представляет собой наименьший неотрицательный вычет по модулю пять удвоенного значения информационного символа:
 (XI.4.14)
(XI.4.14)
 , что позволяет корректировать все единичные ошибки
, что позволяет корректировать все единичные ошибки  . Заметим, что параметры кода (XI.4.14) формально удовлетворяют условию, характерному для плотно упакованных кодов (см. §6 гл. IX):
. Заметим, что параметры кода (XI.4.14) формально удовлетворяют условию, характерному для плотно упакованных кодов (см. §6 гл. IX):
 (XI.4.15)
(XI.4.15)
 . В силу того, что
. В силу того, что  , каждая из таких областей
, каждая из таких областей  содержит все комбинации, располагающиеся от
содержит все комбинации, располагающиеся от  на расстоянии 1 (табл. (XI.8).
на расстоянии 1 (табл. (XI.8).

 содержат неодинаковое число комбинаций, более того, комбинации 20; 03; 04 и 40 не вошли ни в одно из приведенных в табл. XI.8 подмножеств (для каждой из них можно указать по крайней мере две комбинации кода (XI.4.14), расположенные на расстоянии, большем 1). Таким образом, этот код не является плотно упакованным, несмотря на то, что формально соблюдены все необходимые для этого условия.
содержат неодинаковое число комбинаций, более того, комбинации 20; 03; 04 и 40 не вошли ни в одно из приведенных в табл. XI.8 подмножеств (для каждой из них можно указать по крайней мере две комбинации кода (XI.4.14), расположенные на расстоянии, большем 1). Таким образом, этот код не является плотно упакованным, несмотря на то, что формально соблюдены все необходимые для этого условия.