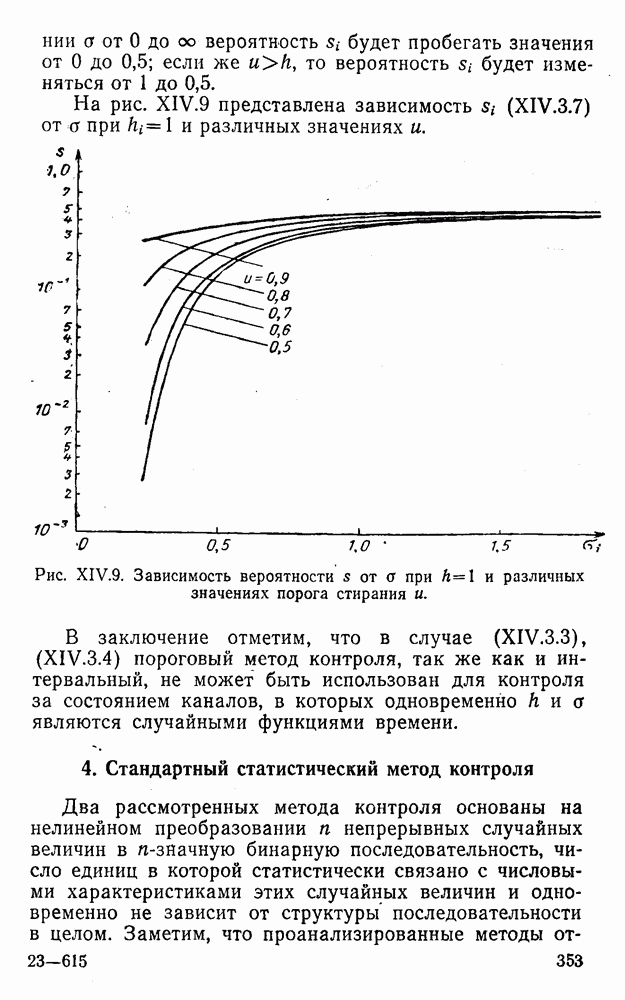
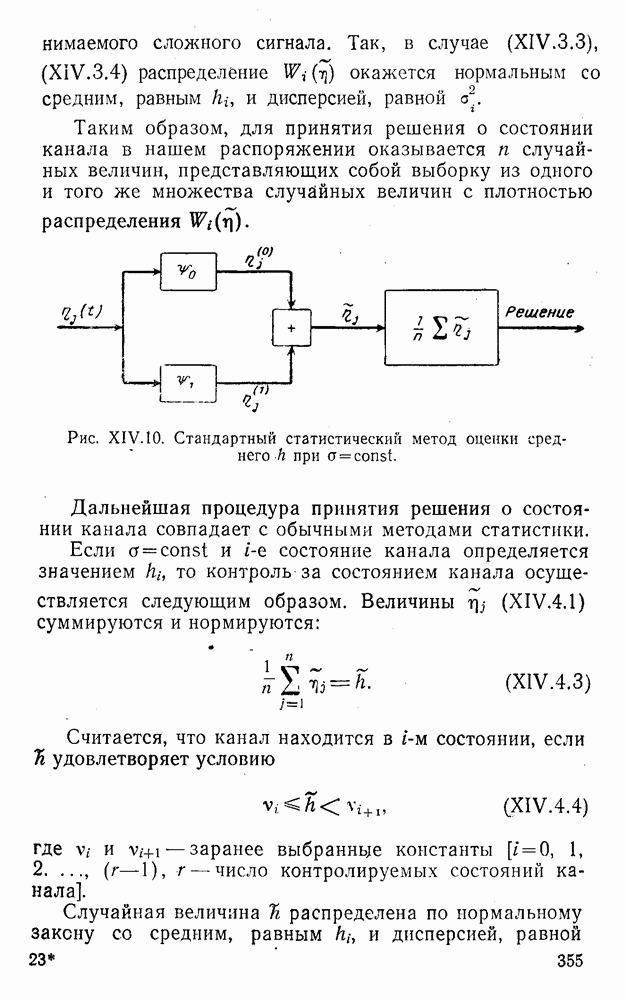
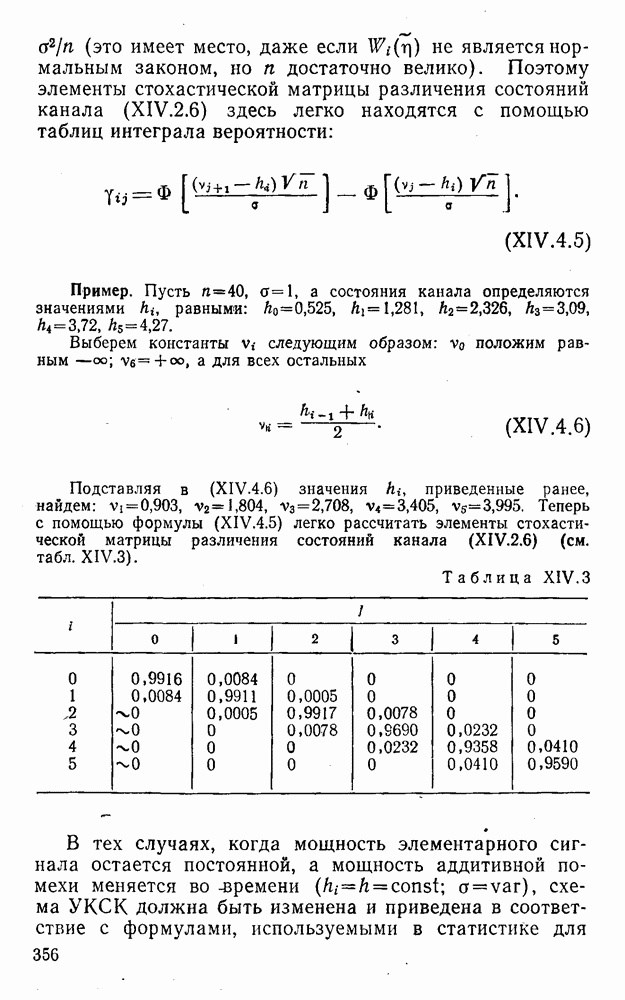
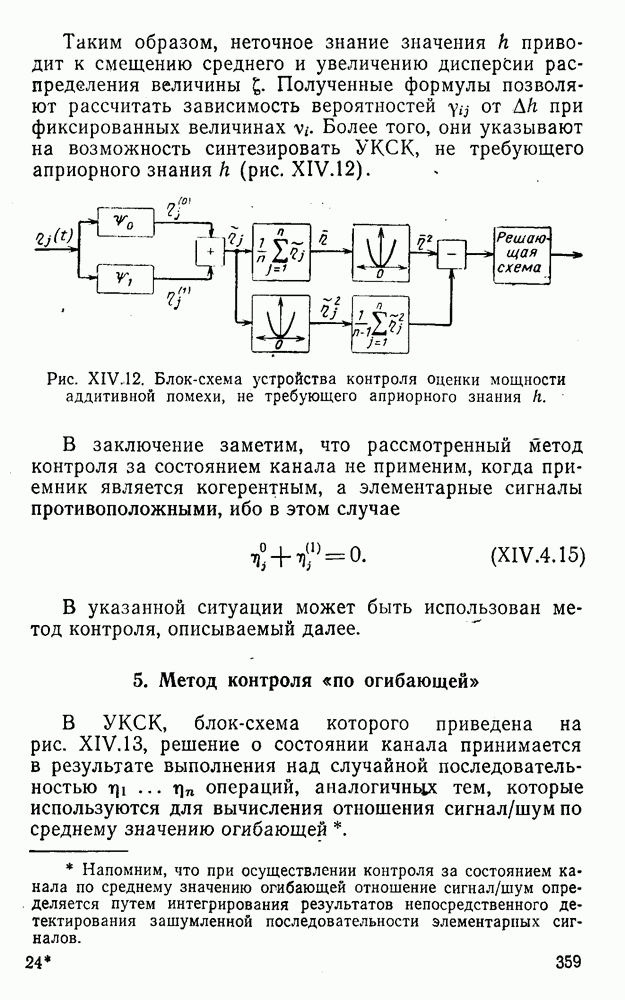
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
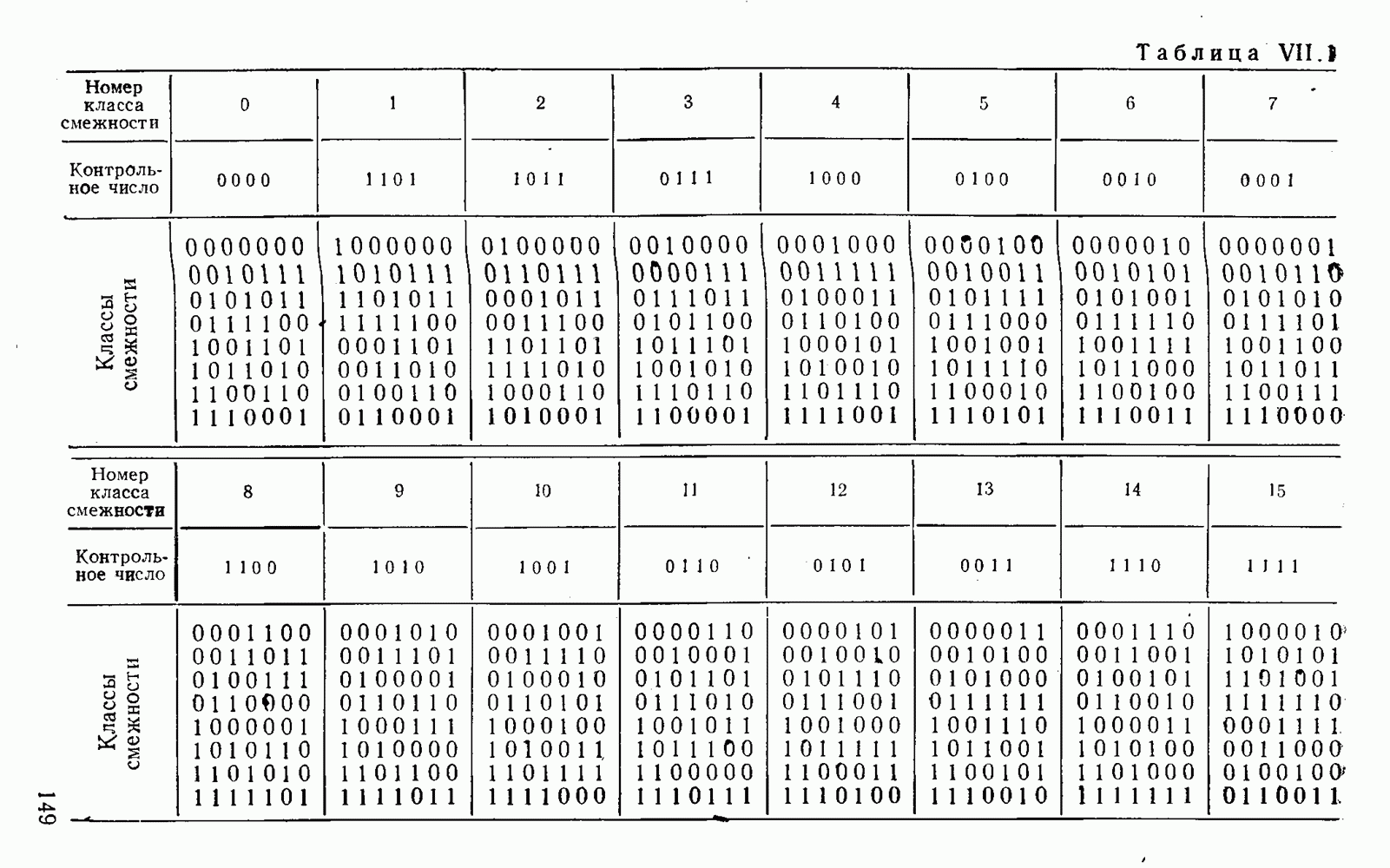
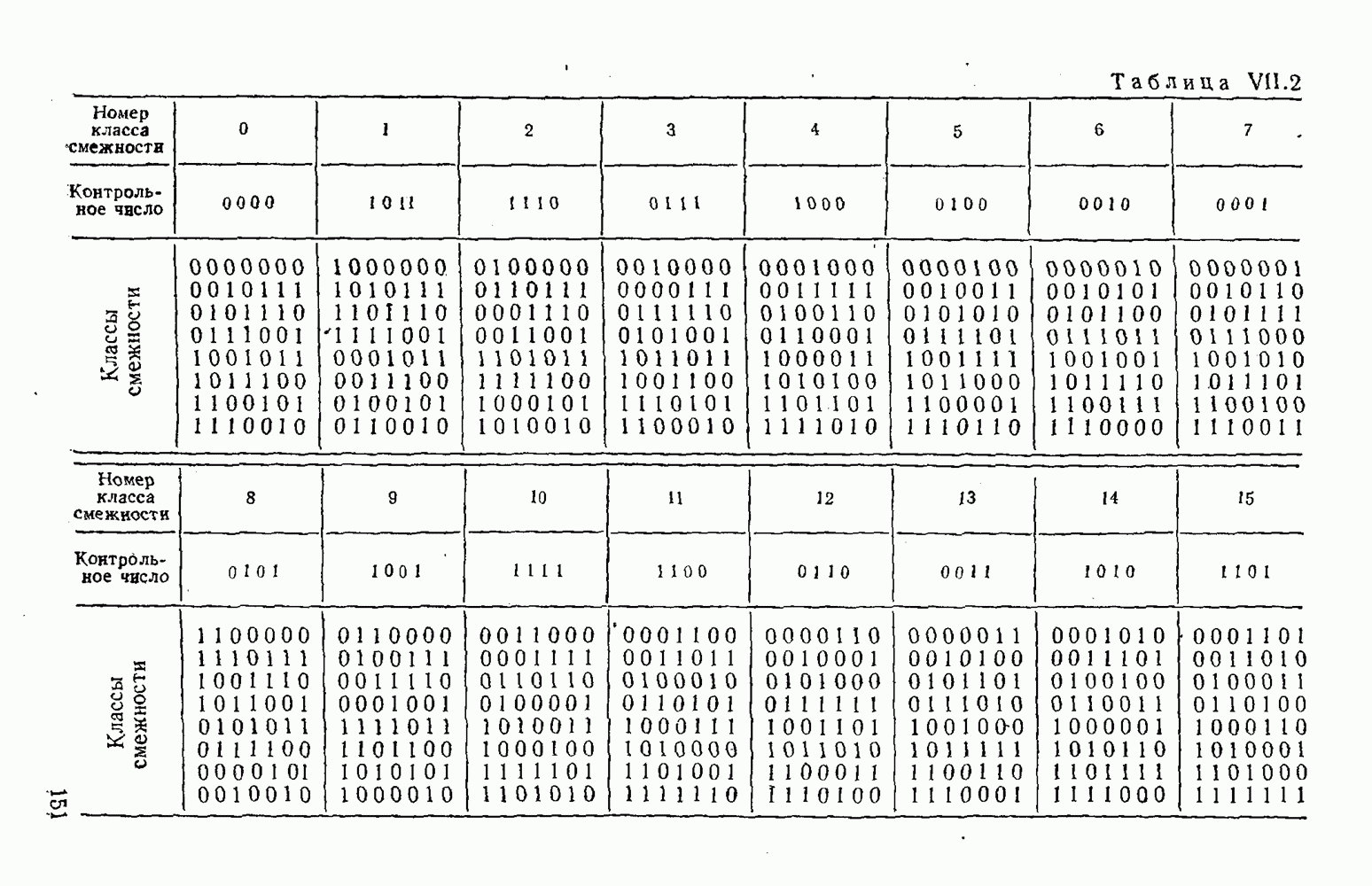
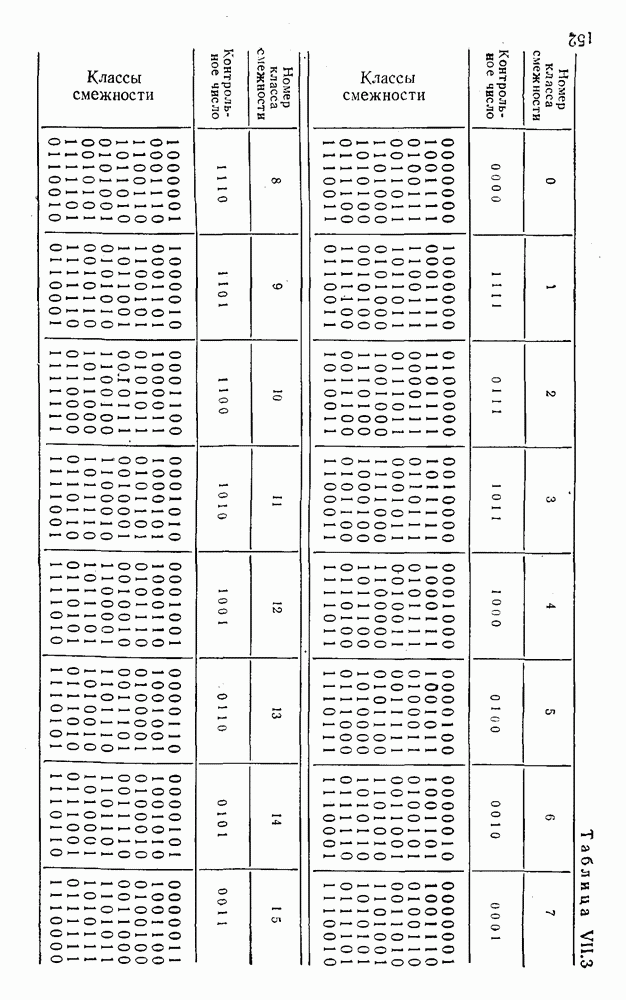
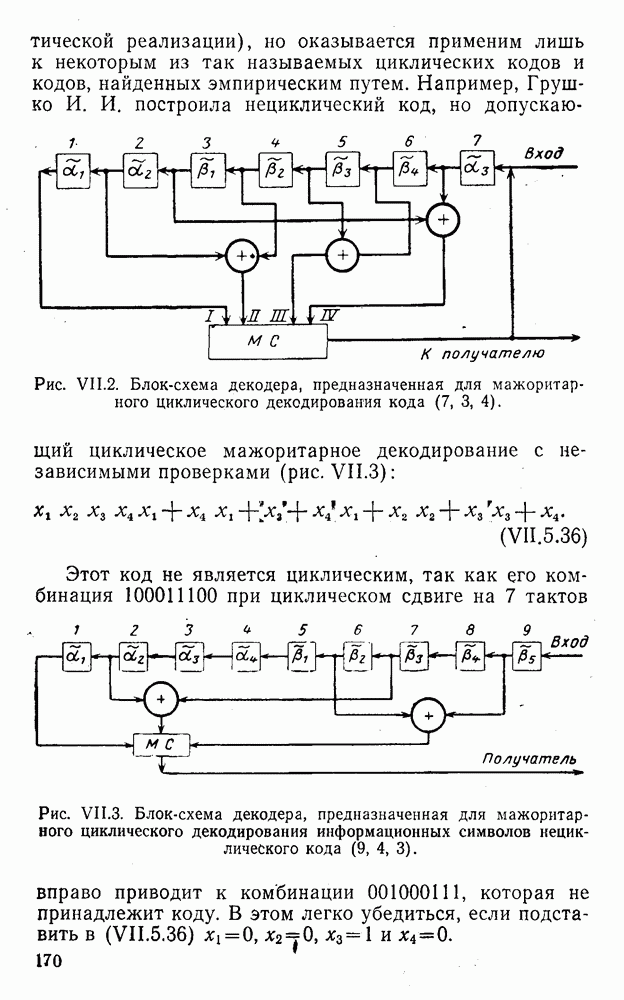
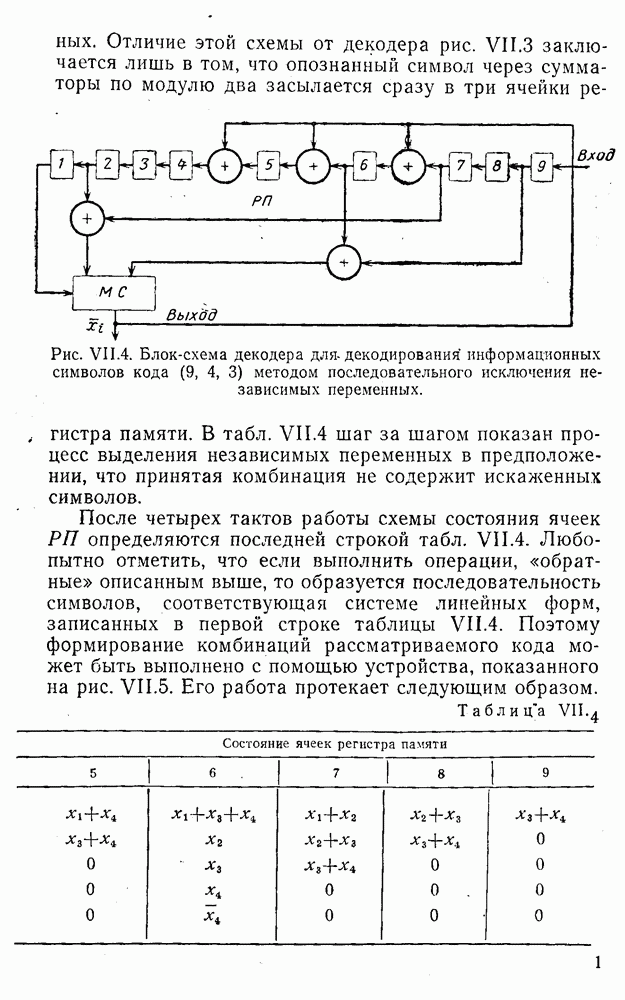
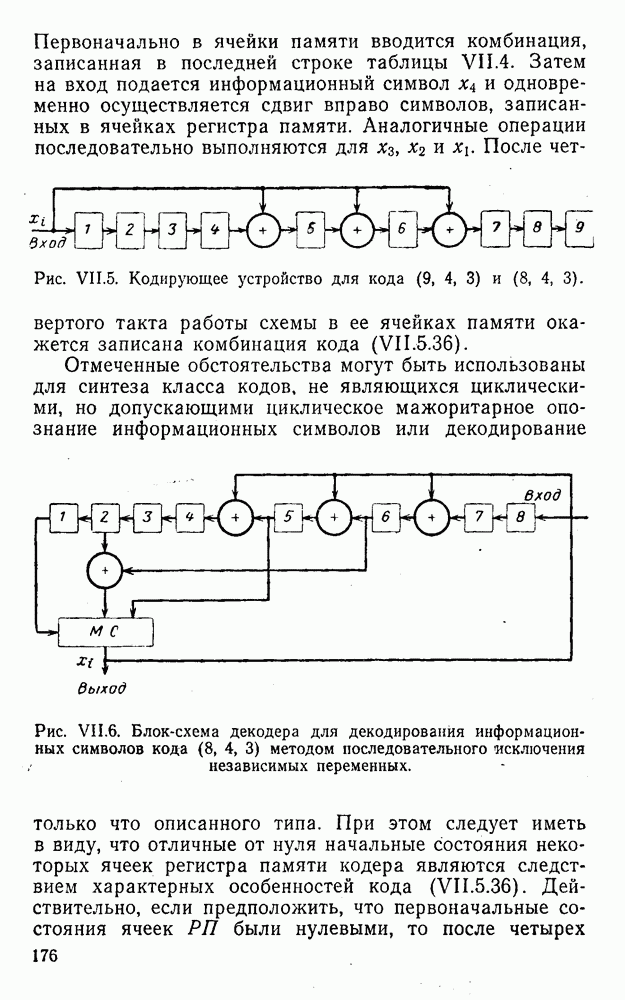
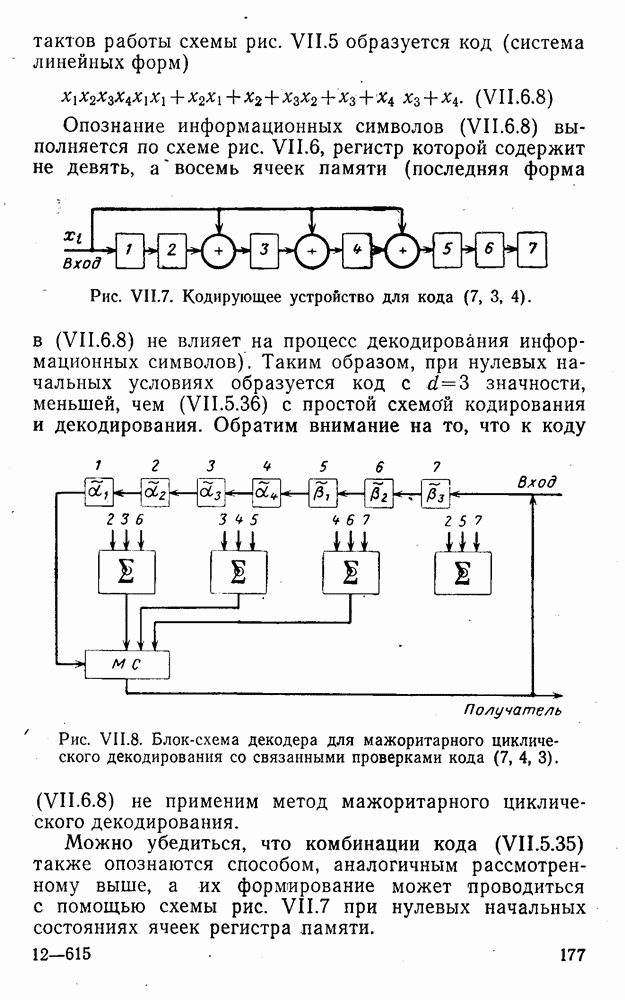
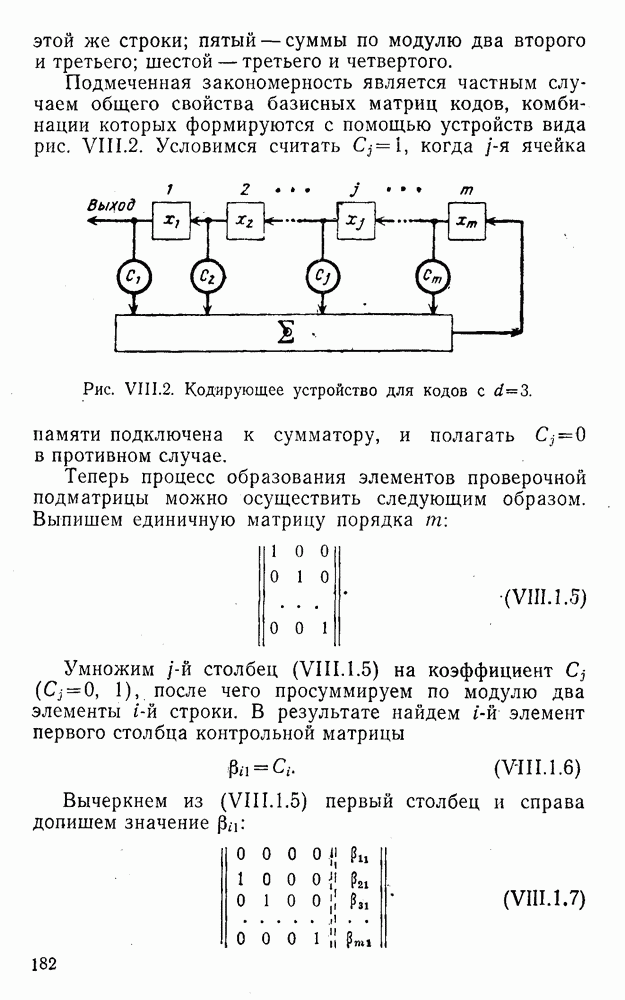
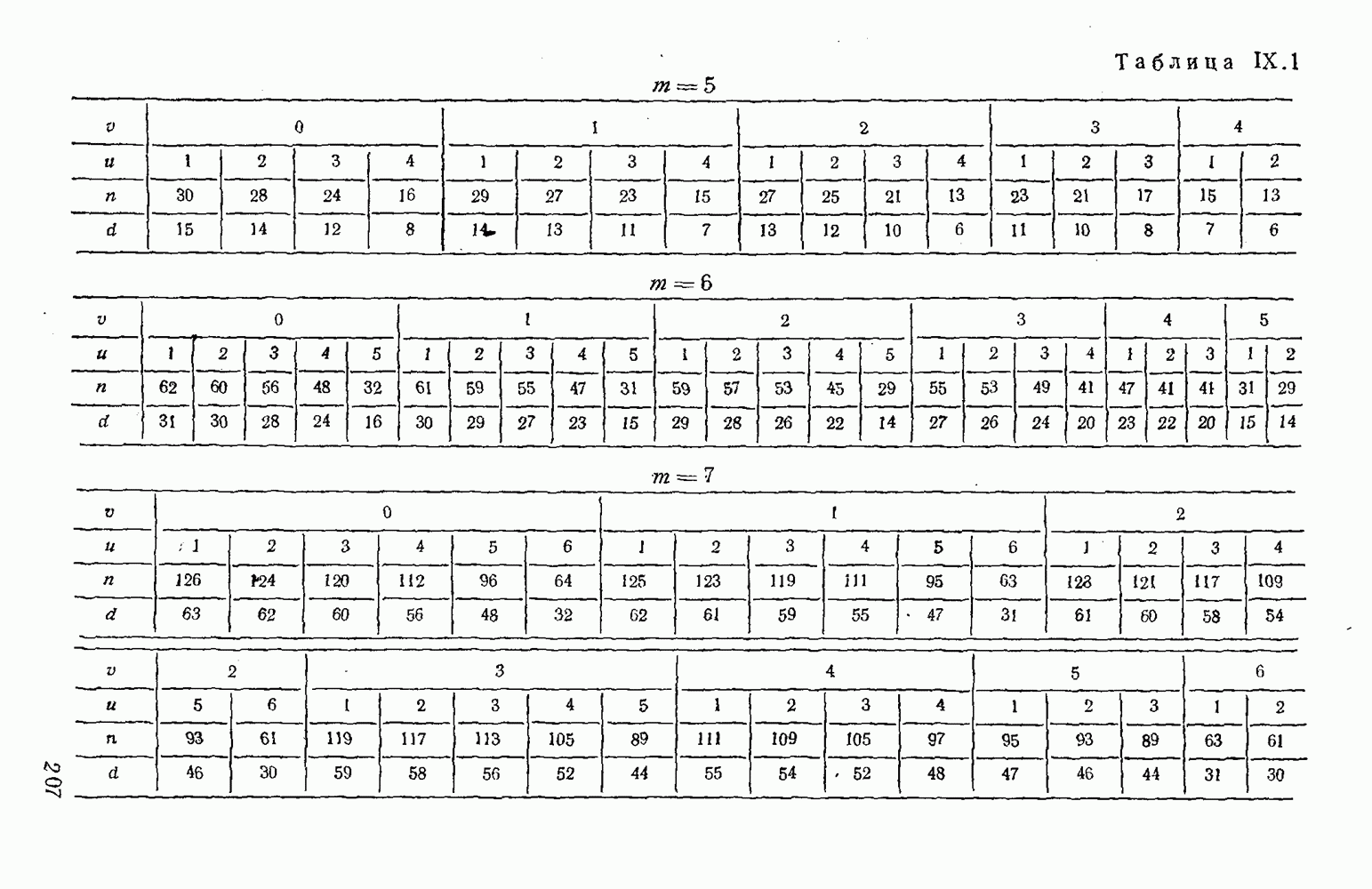
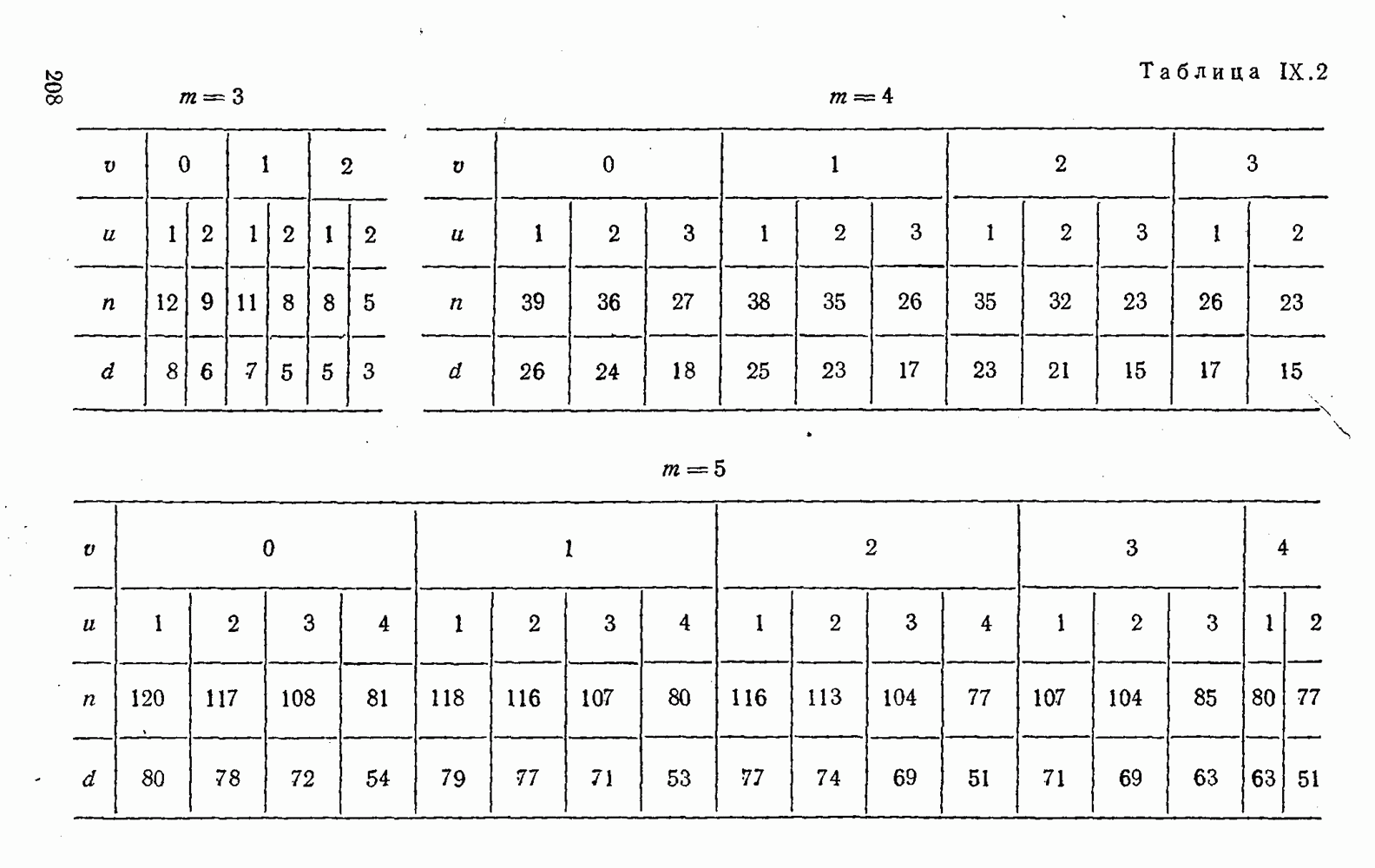
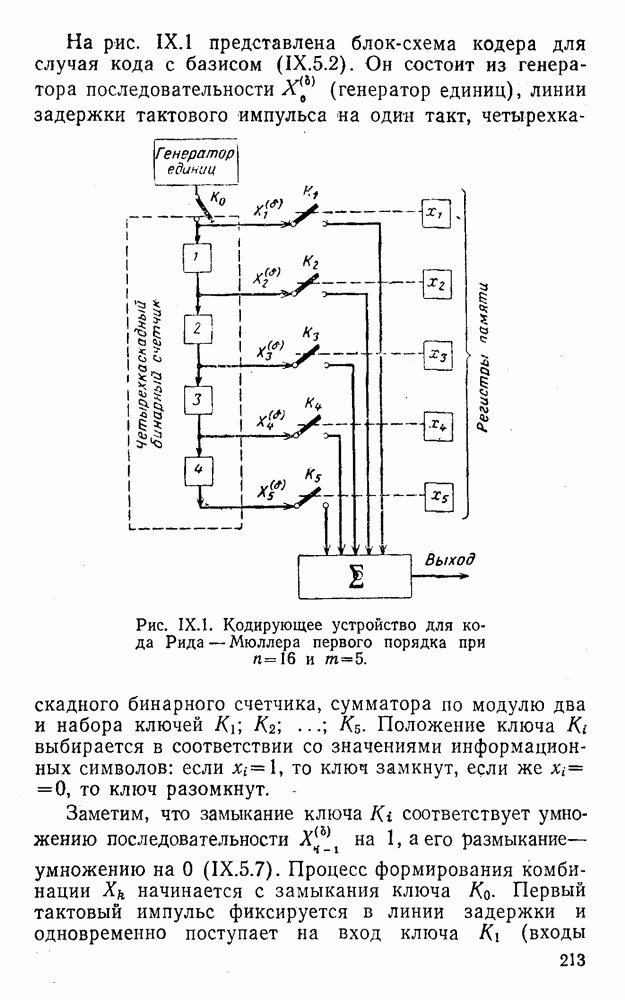
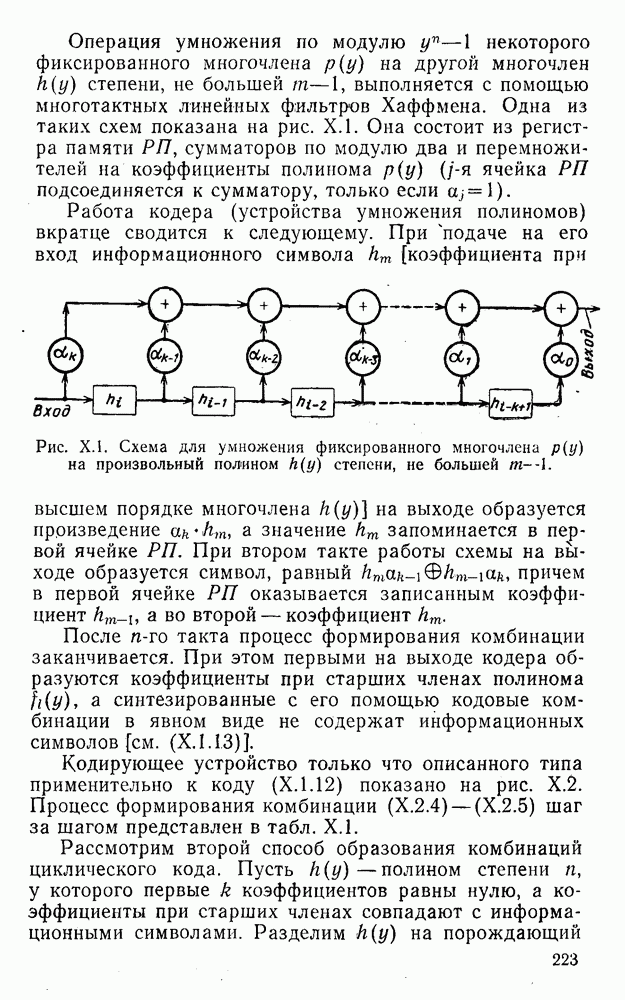
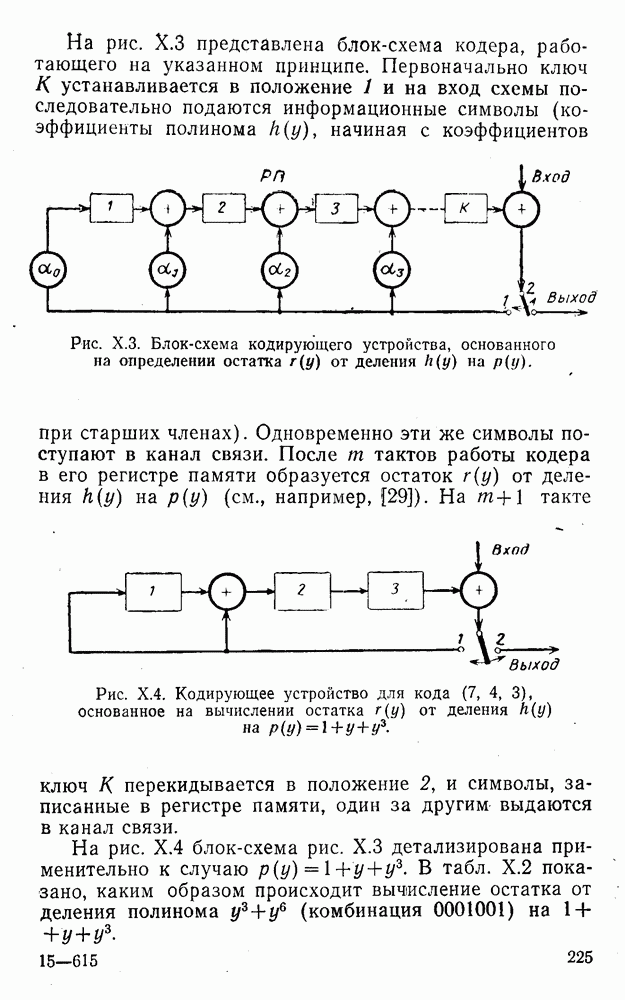
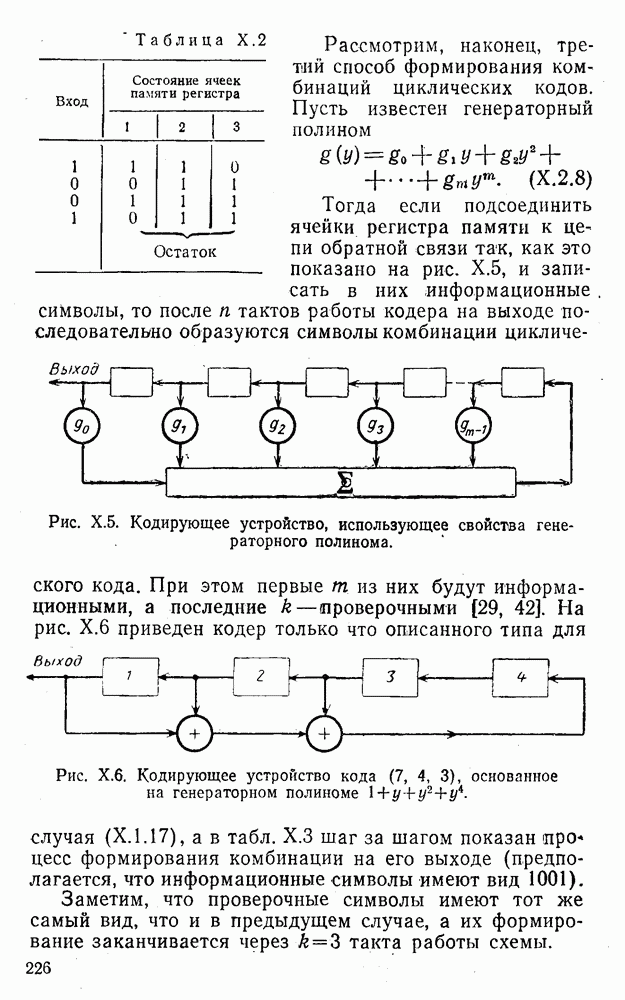
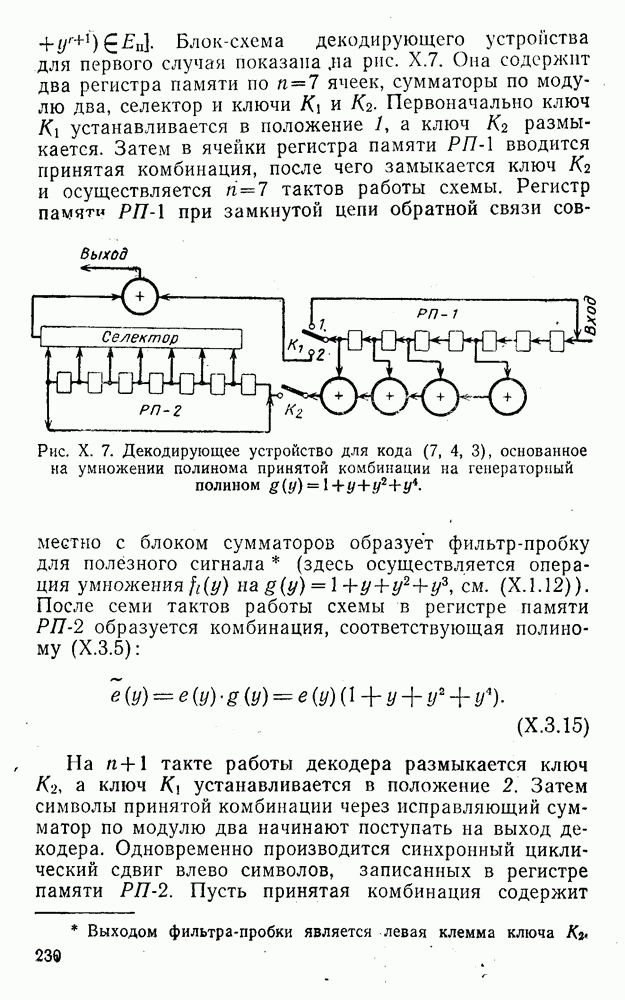
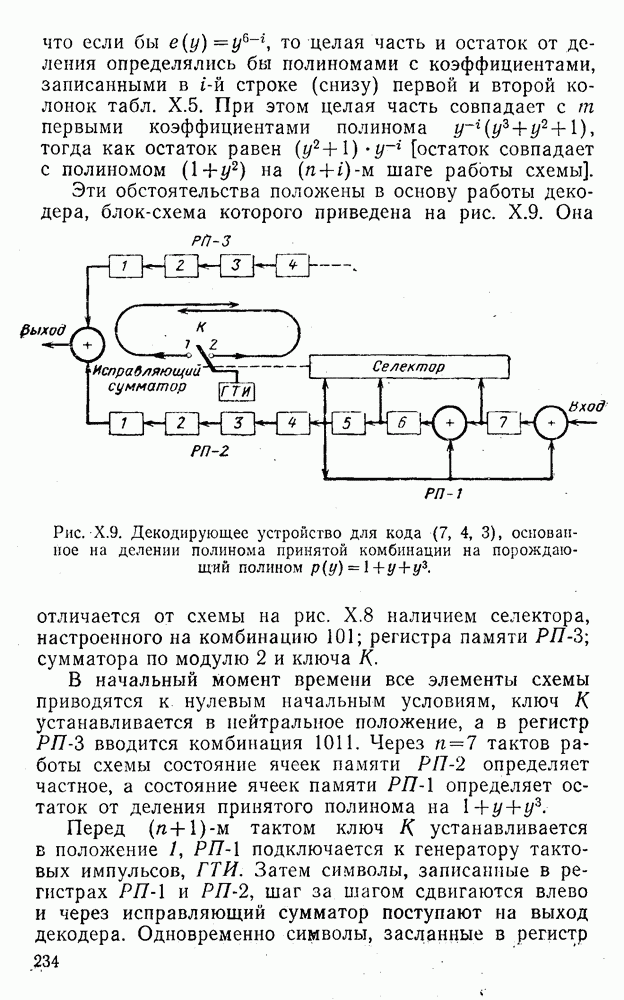
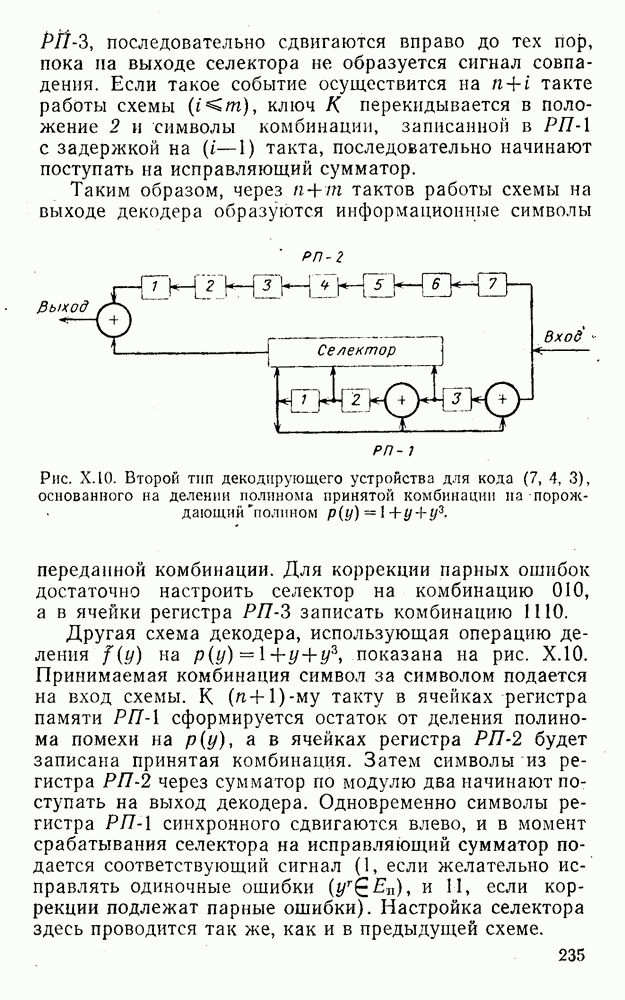
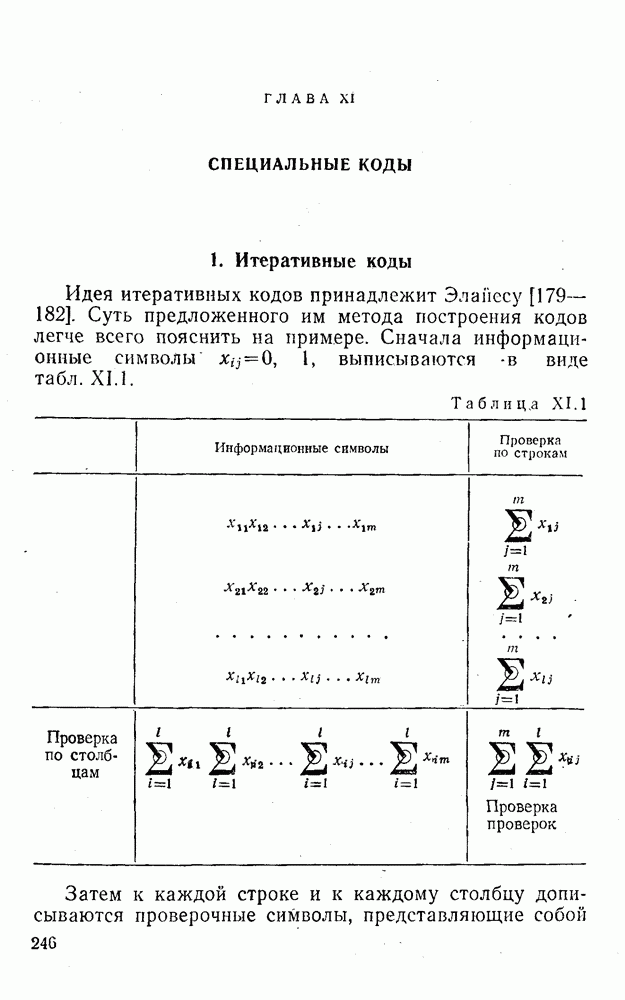
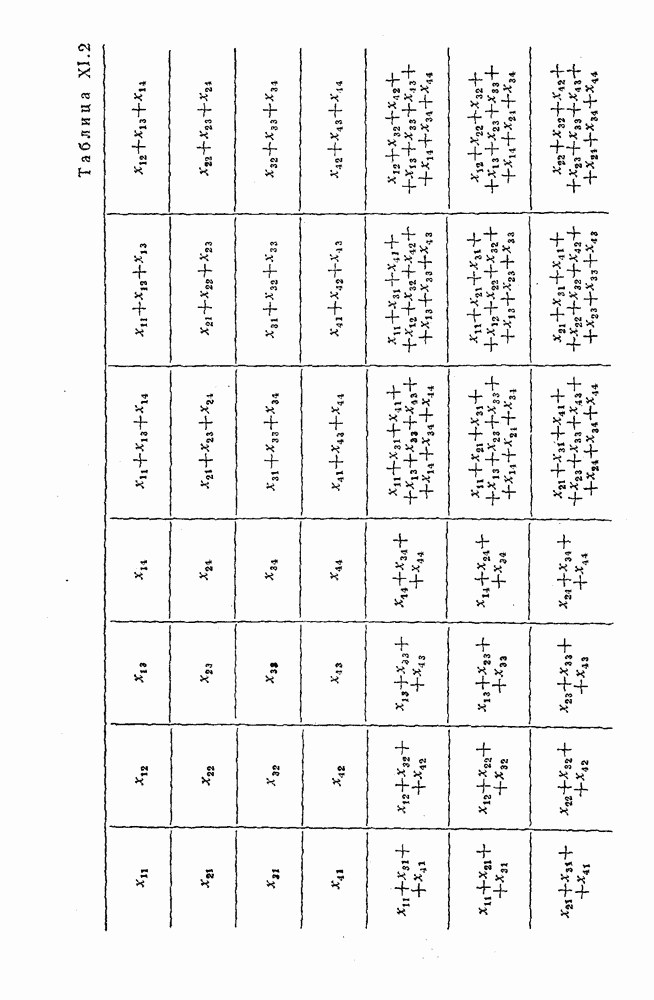
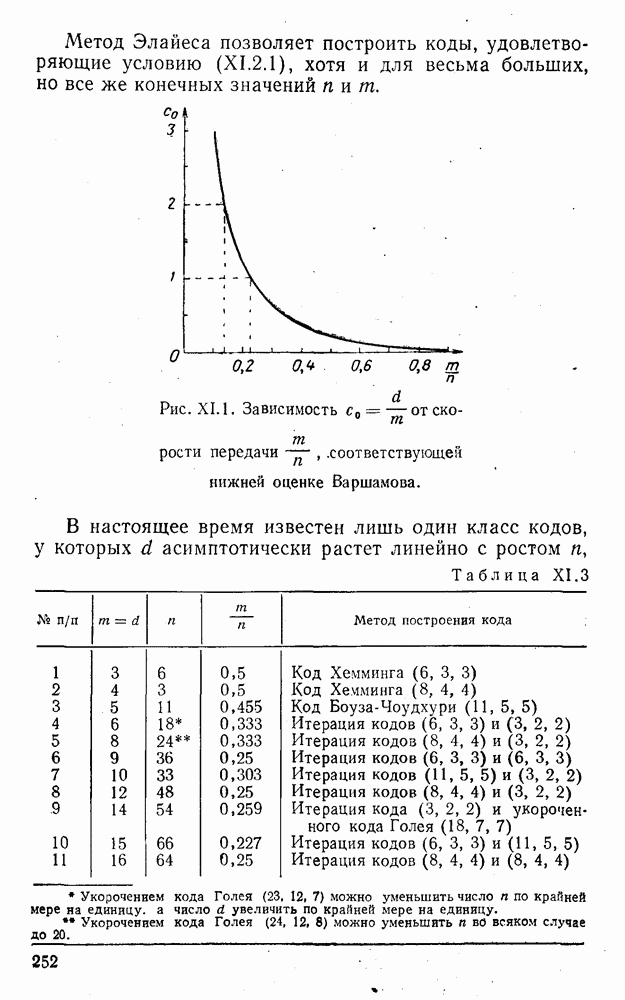
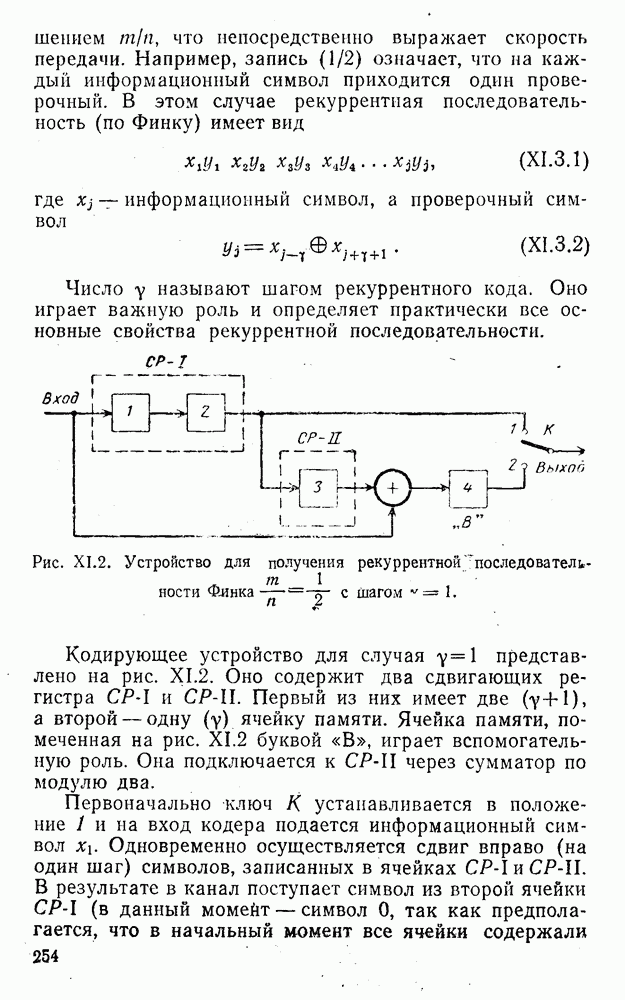
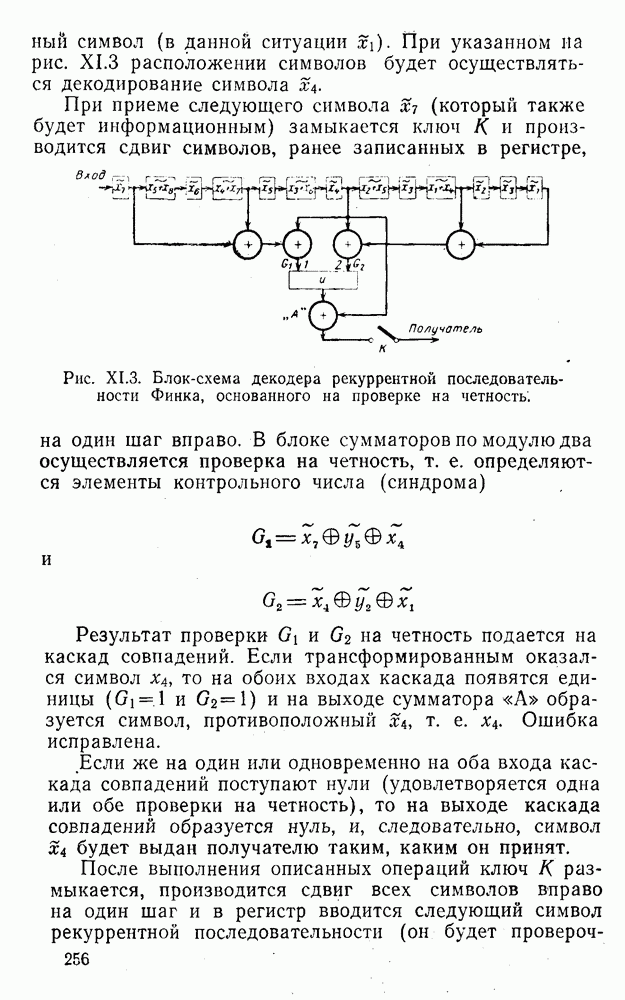
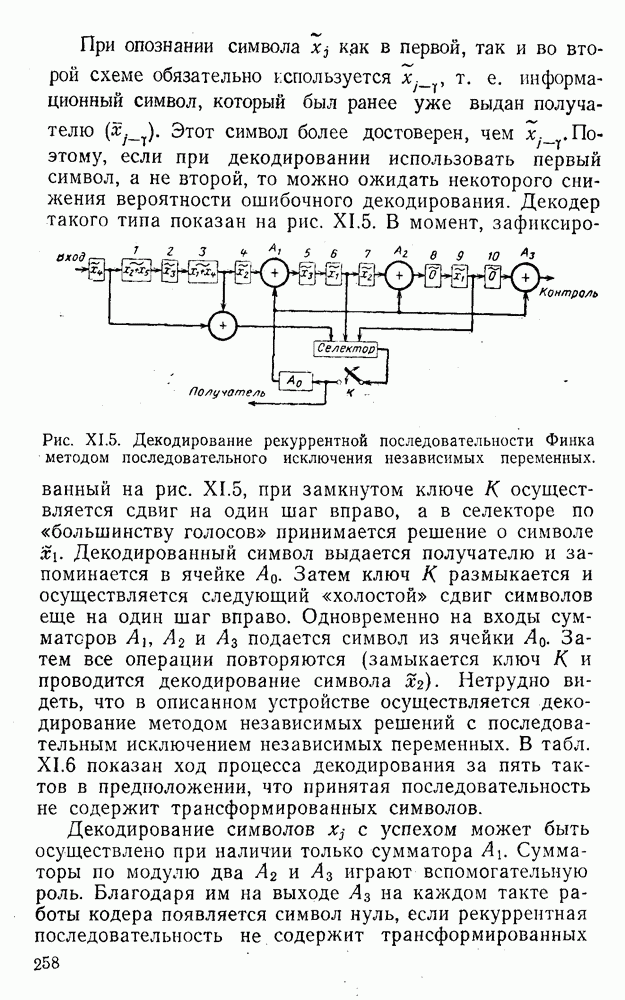
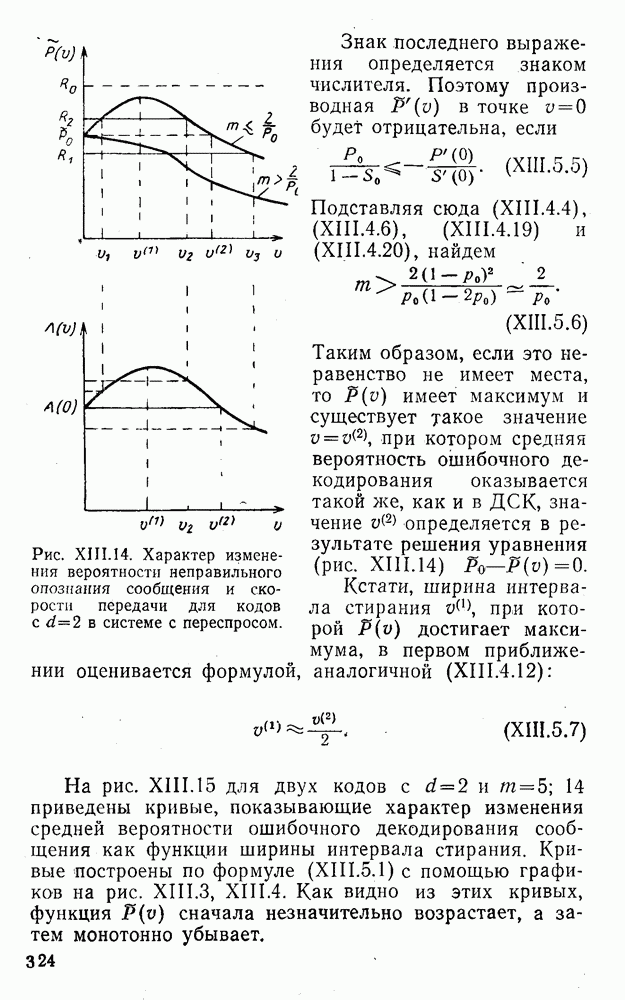
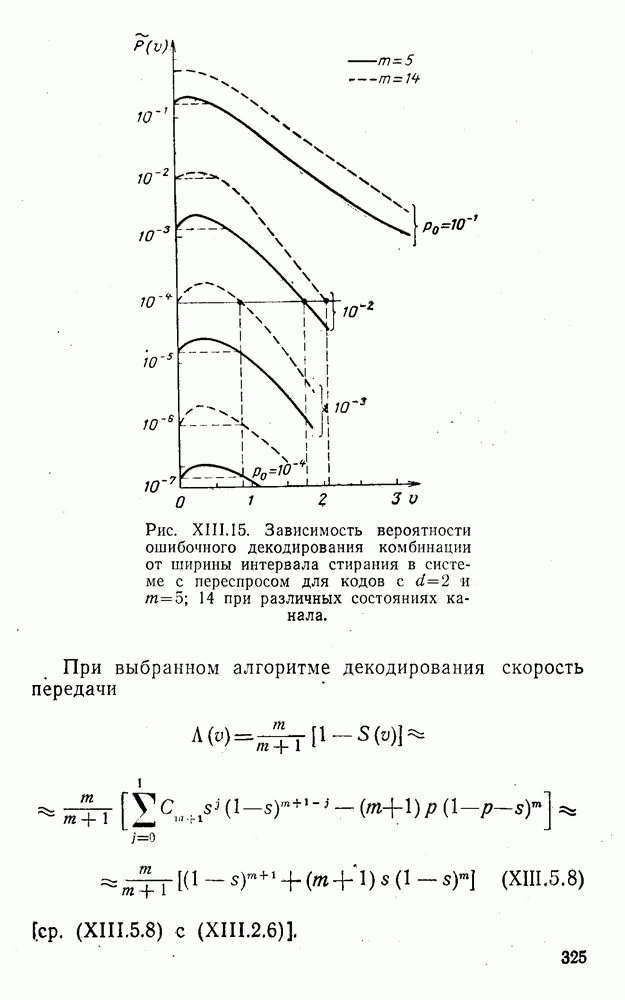
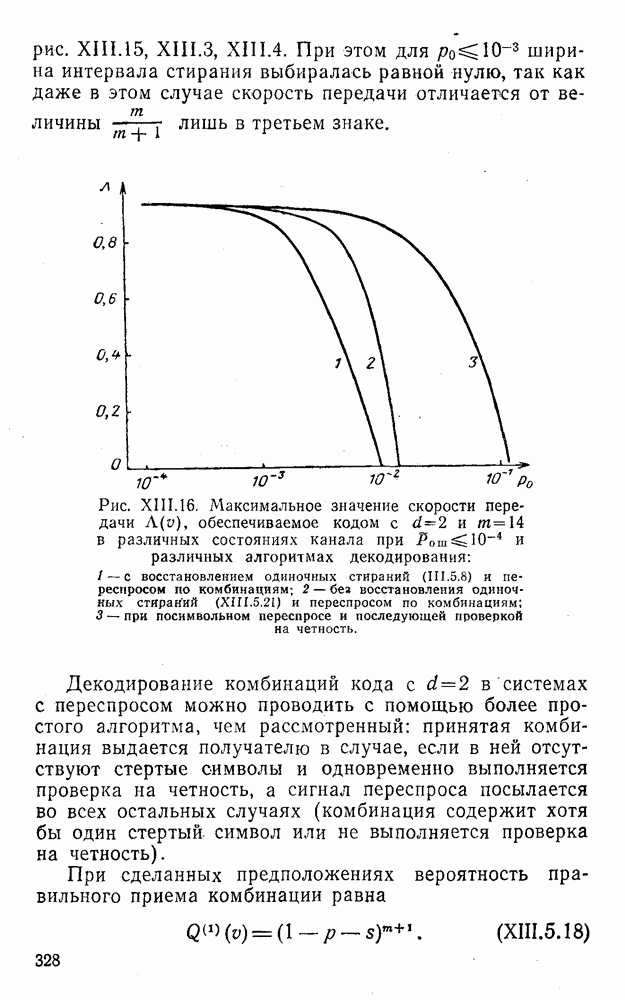
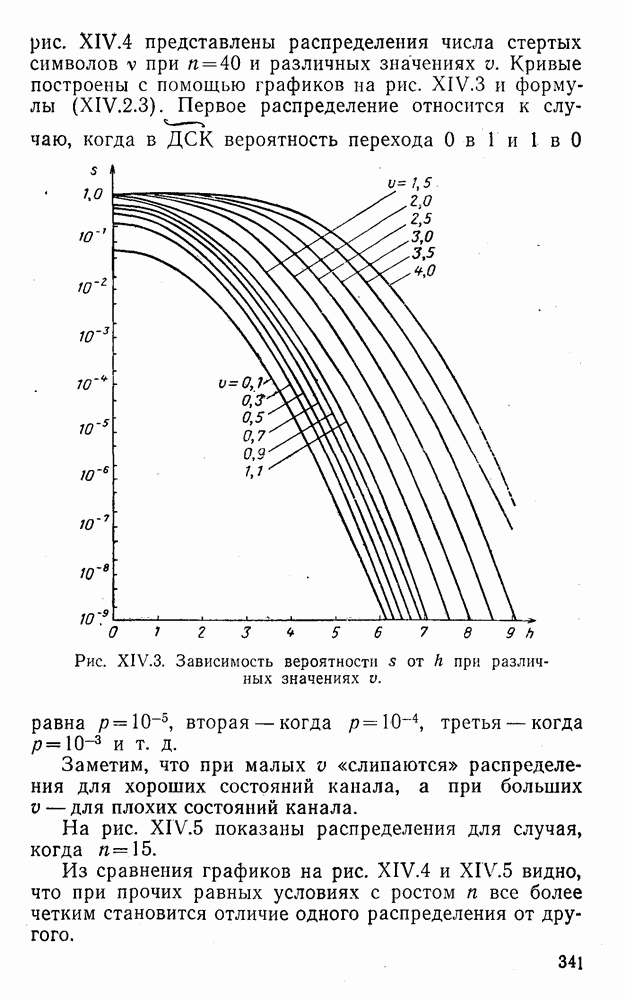
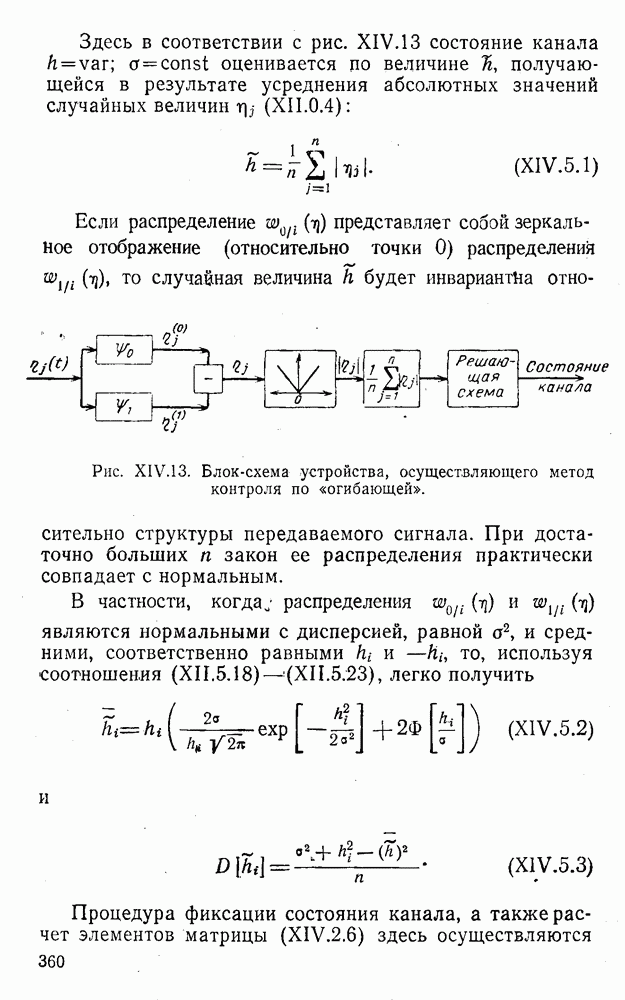
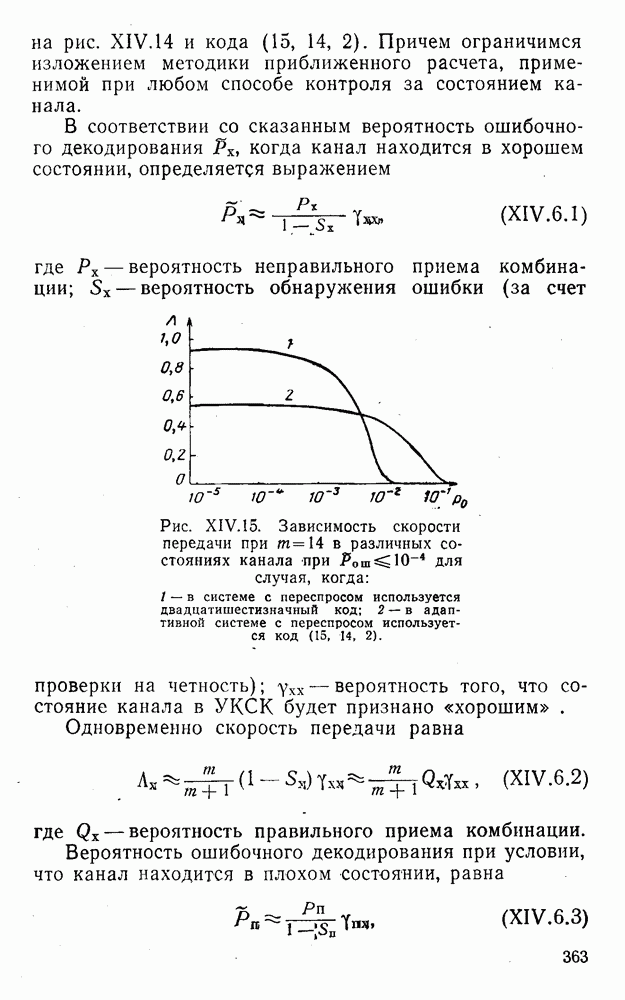
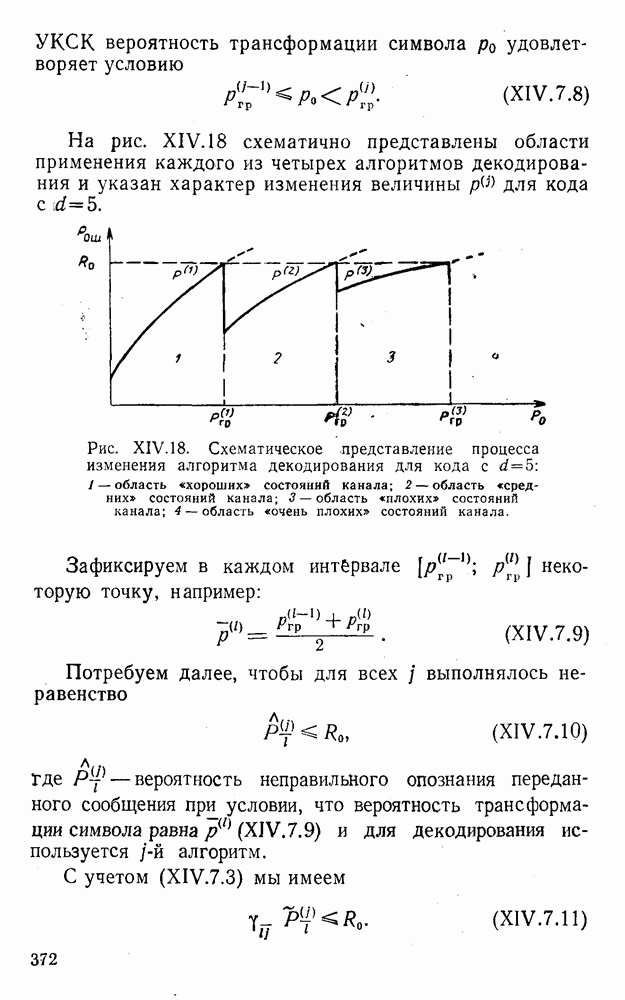
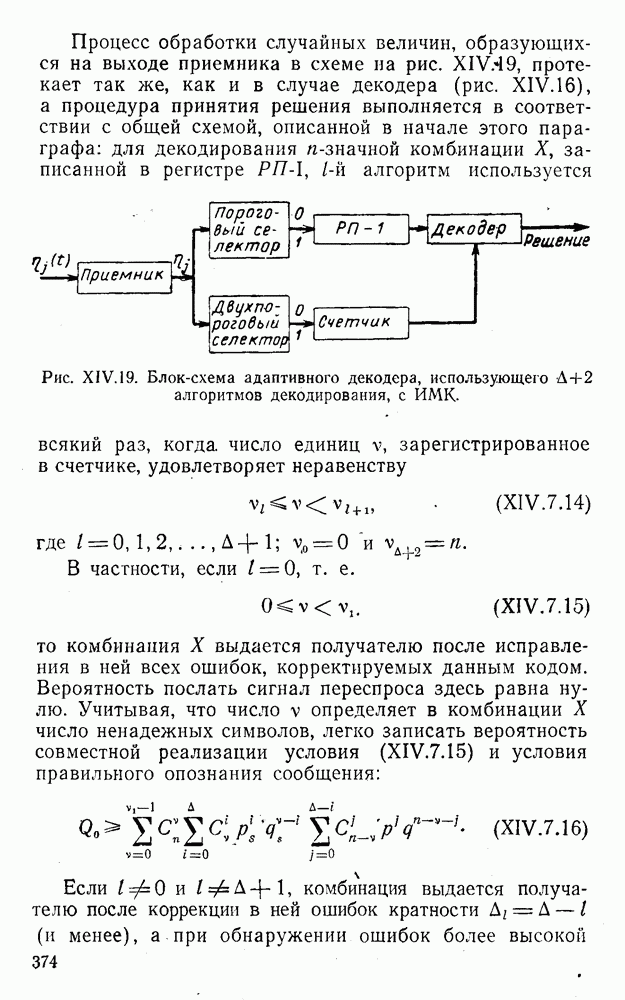
8. Смешанное декодирование и некоторые дополнительныезамечания Методом, рассмотренным в § 5—7, могут быть определены значения всех символов переданной комбинация. Так, применительно к коду (XII.7.1) для отыскания значений проверочных символов методом модульного декодирования прежде всего необходимо вычислить величины:
В первое уравнение под знак модуля входят две случайные величины (XII.5.4) с номерами, определяющими линейные формы в (XII.5.1), сумма которых по модулю два приводит к линейной форме (XII.5.1). Во второе под знак модуля входят случайные величины (XII.5.4) с номерами, определяющими линейные формы (XII.5.1), сумма которых по модулю два приводит к линейной форме Отождествление случайных величин (XII.8.1) с выходными символами канала проводится в соответствии с процедурой, описанной в § 5. После ее выполнения на приемном конце помимо значений информационных символов будут зафиксированы и значения проверочных символов, т. е. окажется известной комбинация
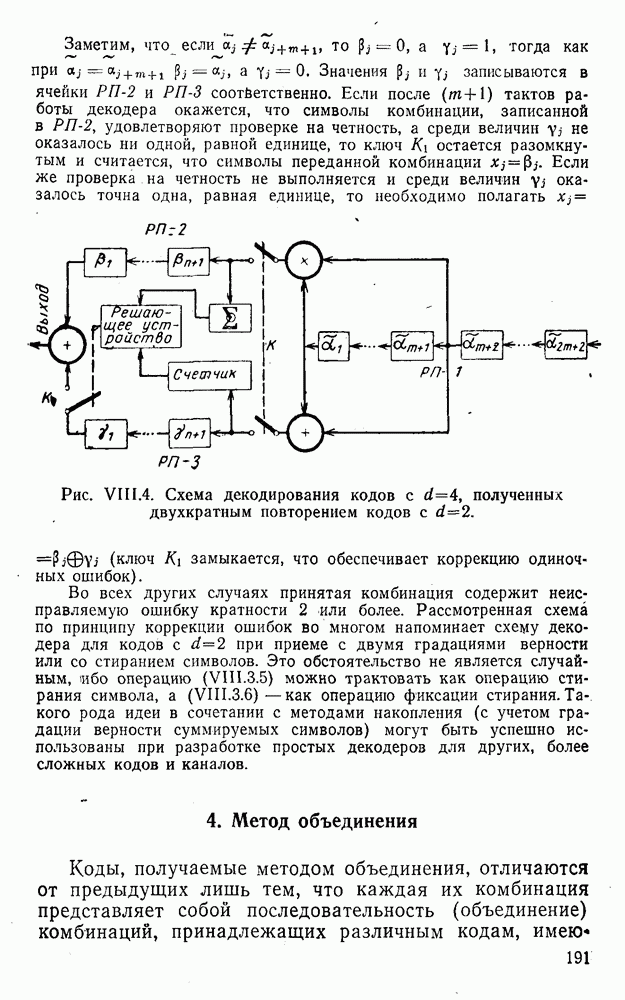
Заметим, что при иеидеальных методах декодирования в целом эта комбинация может не совпадать с кодовыми (здесь имеется определенная аналогия со случаем, когда все символы переданной комбинации определяются на основе соотношений вида (XII.5.6). Поэтому в анализируемой ситуации вычисление проверочных символов не лишено смысла, так как их значения позволяют осуществить в (XII.8.2) коррекцию ошибок одним из известных способов, в частности, на основе соотношений (XII.5.6). Любопытно отметить, что величины В связи со сказанным намечается интересный круг задач по разработке способов опознания переданной комбинации путем многократного последовательного (или параллельного) применения указанных операций для обработки случайных величин (XII.5.4) с последующим позиционным весовым суммированием полученных результатов, а также задач рационального сопряжения различных способов декодирования в целом (в том числе многократного) с известными методами коррекции ошибок, например, с процедурой коррекции ошибок по Элайесу в итерационной таблице. Можно полагать, что такого рода смешанные методы декодирования позволят дополнительно снизить вероятность неправильного декодирования комбинации и окажутся полезными в случае, когда канал помимо белого шума подвержен действию других помех, например импульсных (с этой точки зрения особого внимания заслуживают методы декодирования, рассмотренные в двух предыдущих параграфах). Аналоговые посимвольные методы декодирования легко обобщаются на все коды, допускающие коррекцию ошибок методом независимых решений. Они особенно легко реализуются в системах, где кодовая комбинация формируется вдоль оси частот (многоканальные системы). Наконец, они могут быть приспособлены для опознания символов с двумя градациями верности. Для этого достаточно дополнить процедуру принятия решения еще одной операцией: считать, что символ Из оценок, приведенных в § 5—7, следует, что вероятность
или, что то же самое,
здесь и определяется соотношениями вида (XII.5.30) и (XII.6.9) и в общем случае записывается так:
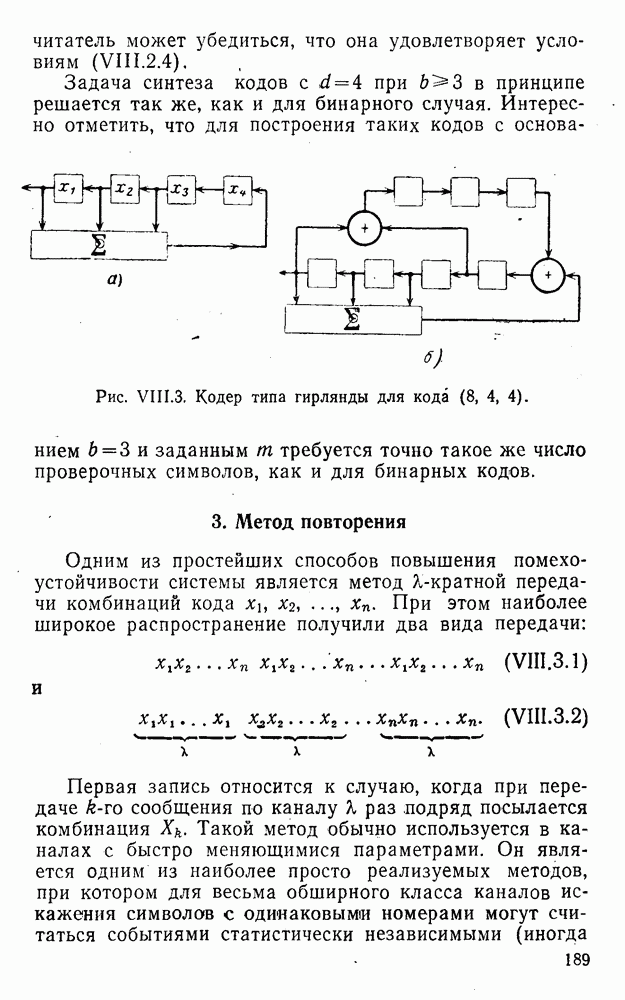
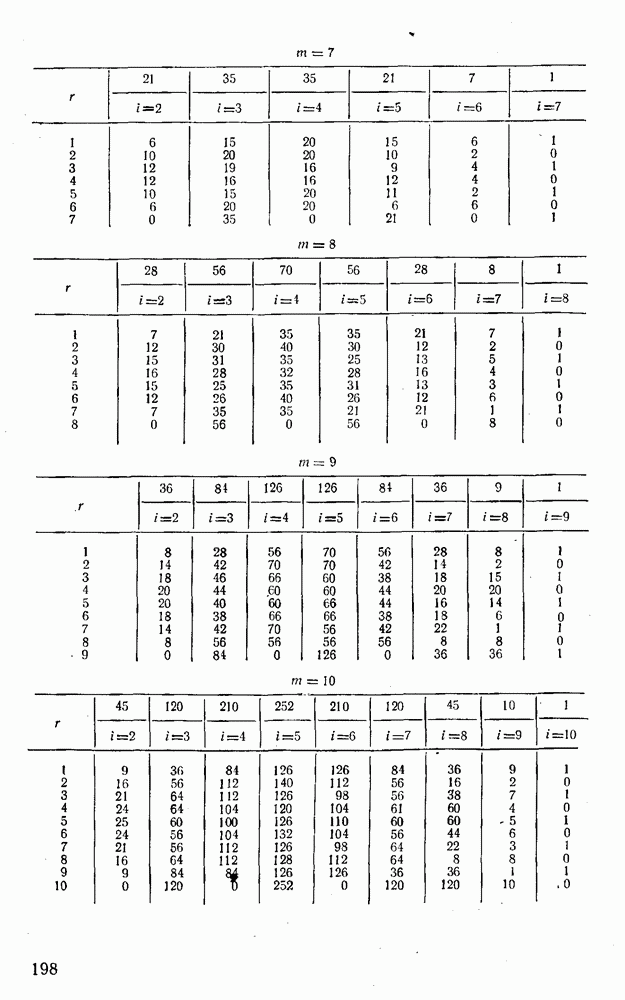
Легко показать, что функция В заключение отметим, что сравнительный анализ различных методов декодирования затруднен из-за отсутствия точных аналитических выражений, пригодных для таких вычислений. Всевозможные оценки зачастую не позволяют достаточно полно судить о преимуществах одного метода перед другим. Поэтому для сравнения различных способов приема и декодирования удобно использовать метод статистического эксперимента на электронно-вычислительных машинах. Такой подход весьма перспективен, так как моделирование процесса заданной обработки случайной последовательности типа (XII.5.4) на современных машинах не вызывает трудности, а полученные результаты позволяют достаточно быстро принимать обоснованные решения [59, 60, 27].
|
 |
Оглавление
|













































































































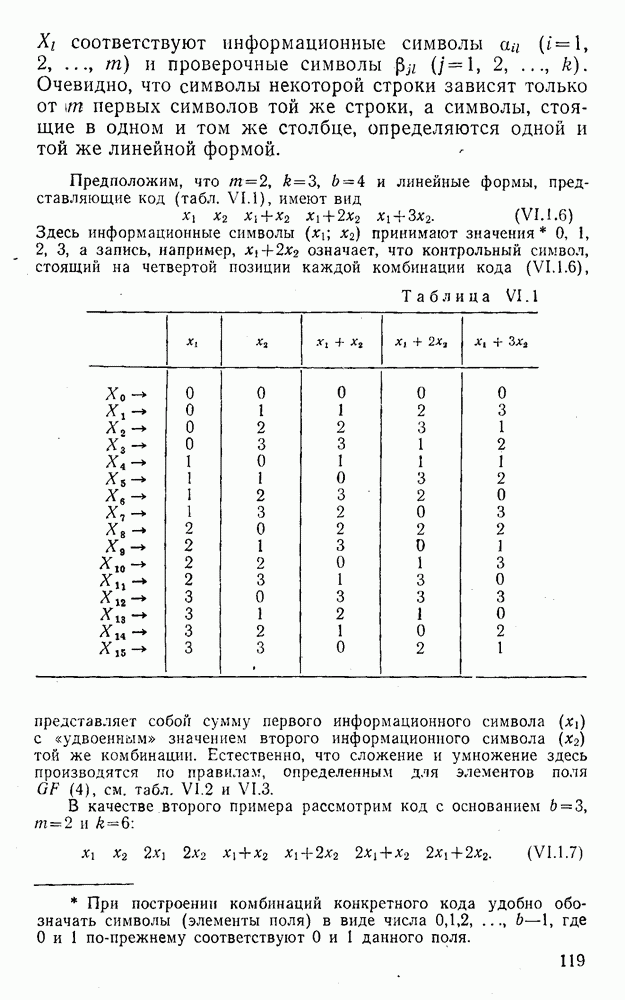
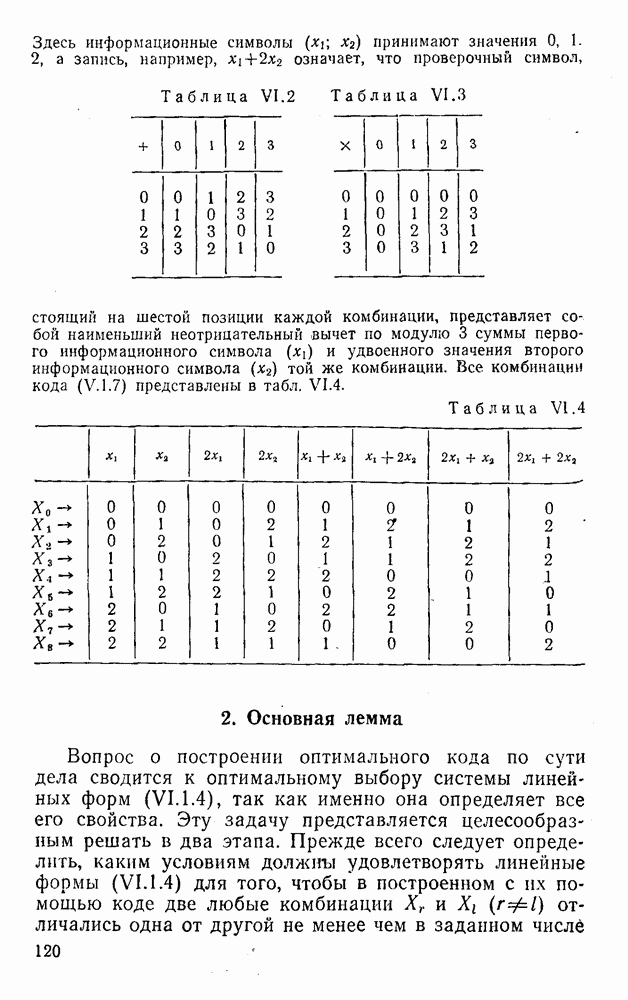




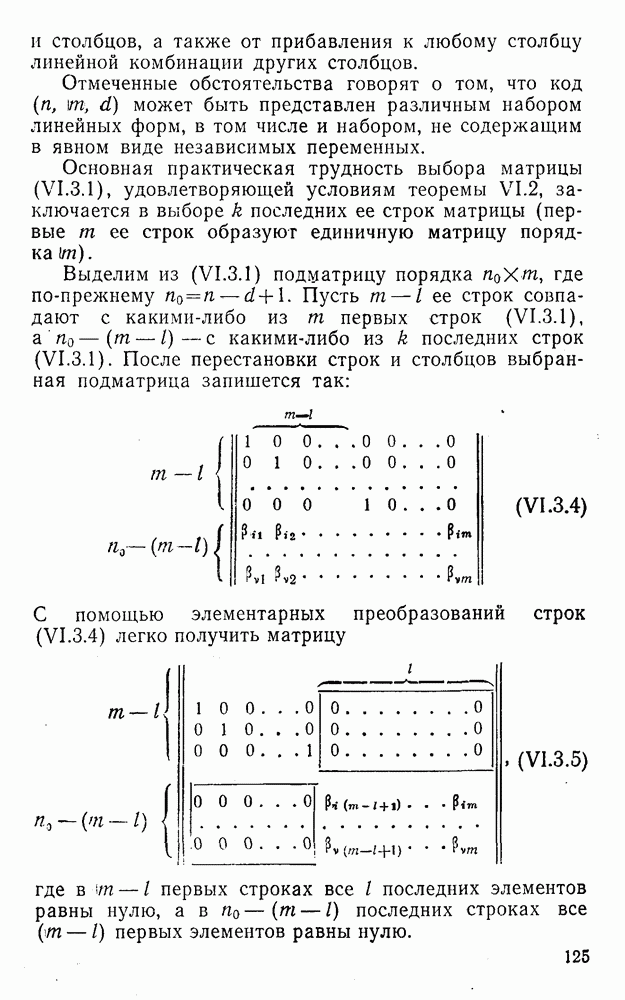












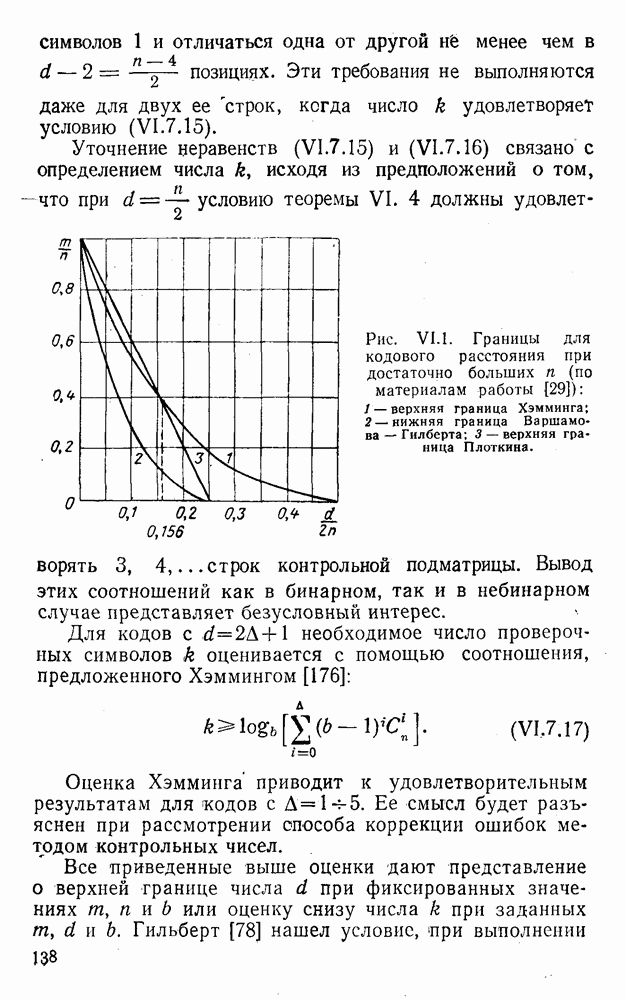

















































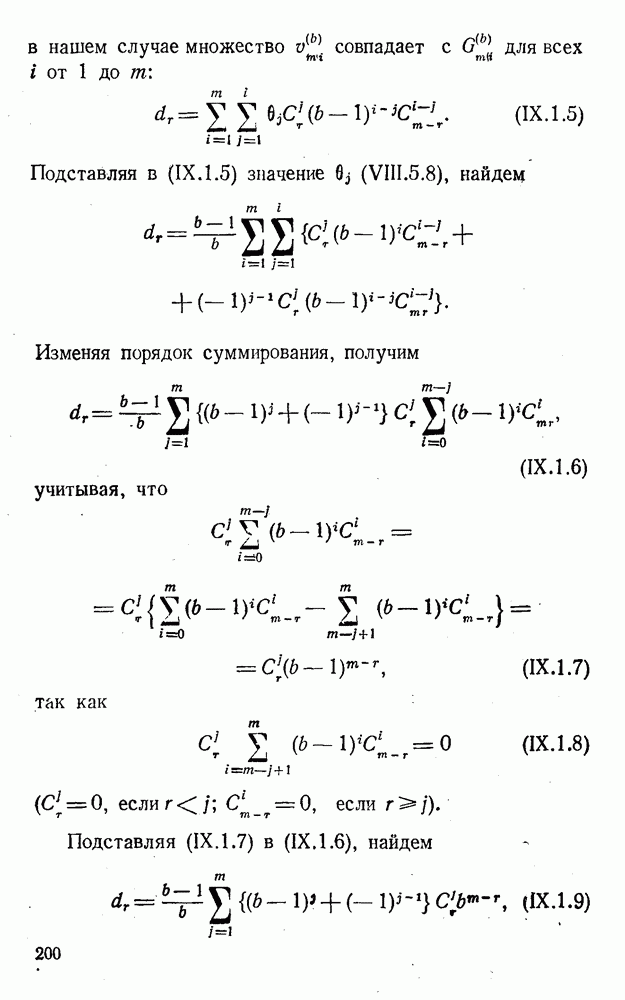














































































































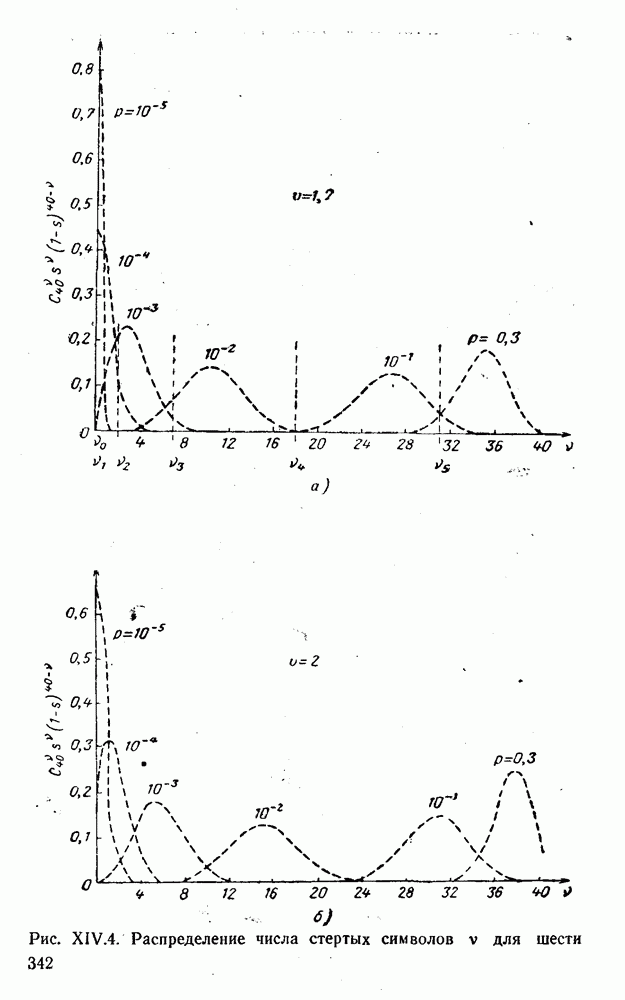
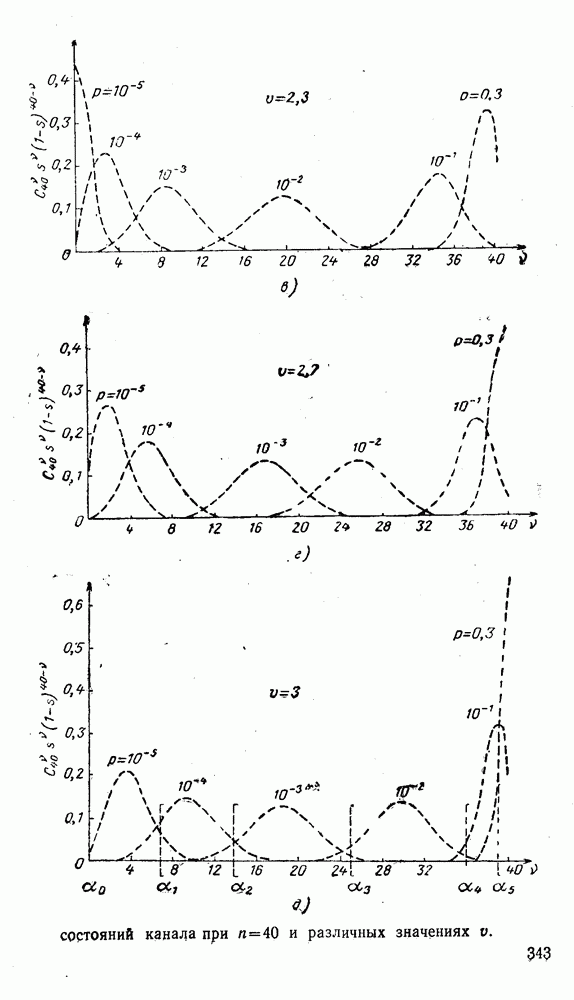
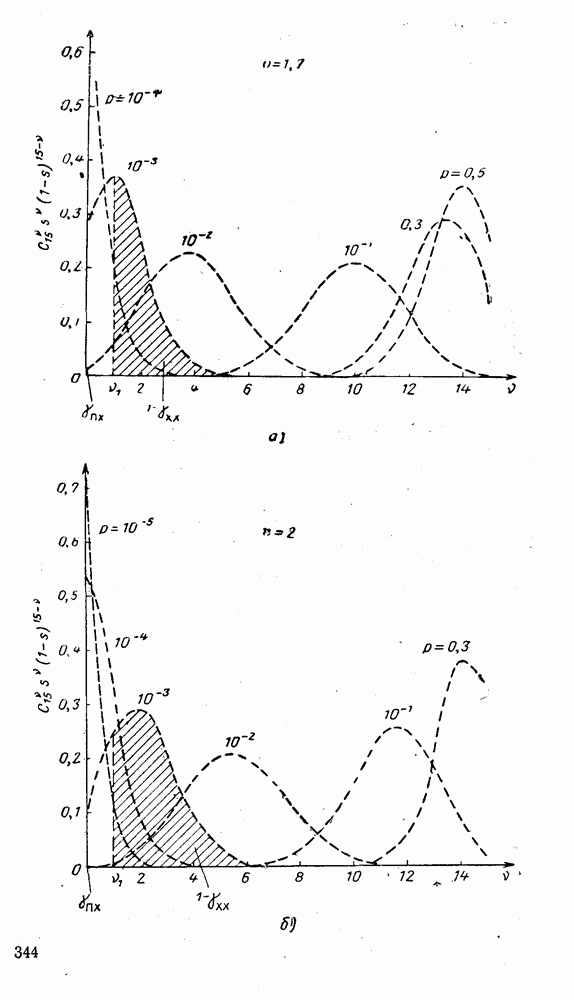
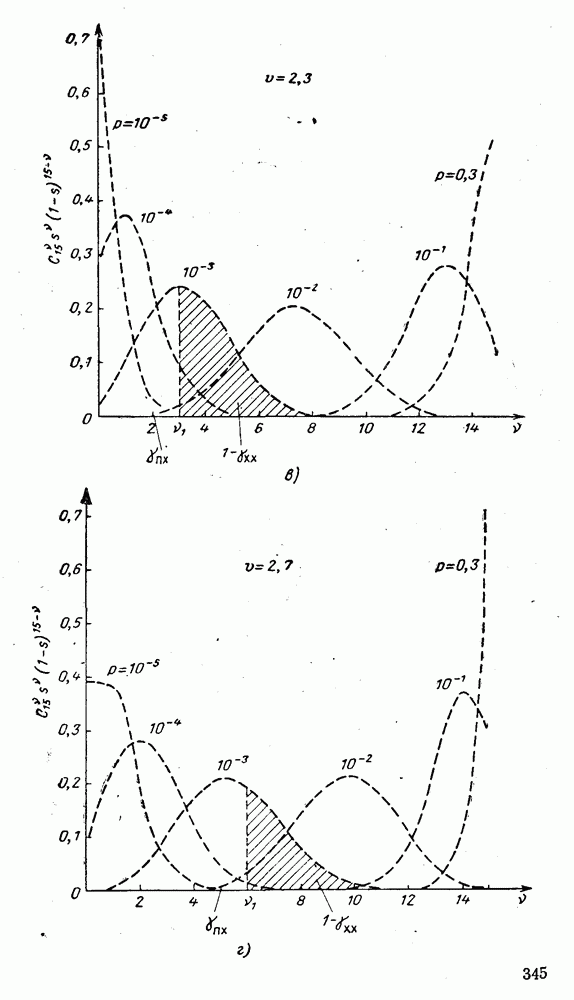










































 (XII.8.1)
(XII.8.1)
 и т. д.
и т. д.
 (XII.8.2)
(XII.8.2)
 (XII.5.17) и (XII.8.1) по своему существу не отличаются от величин последовательности (XII.5.4) и оказываются наделенными свойствами типа (XII.5.9)-(XII.5.16). Поэтому они сами могут быть использованы для определения символов переданной комбинации методом аналогового посимвольного декодирования.
(XII.5.17) и (XII.8.1) по своему существу не отличаются от величин последовательности (XII.5.4) и оказываются наделенными свойствами типа (XII.5.9)-(XII.5.16). Поэтому они сами могут быть использованы для определения символов переданной комбинации методом аналогового посимвольного декодирования.
 опознается как надежный, если
опознается как надежный, если  и полагать его ненадежным, если
и полагать его ненадежным, если  . Такого рода модификация может оказаться полезной при декодировании итерационных таблиц методом Элайеса.
. Такого рода модификация может оказаться полезной при декодировании итерационных таблиц методом Элайеса.
 неправильного опознания переданного сообщения при том или ином аналоговом посимвольном методе декодирования удовлетворяет условию, аналогичному (XII.5.22)
неправильного опознания переданного сообщения при том или ином аналоговом посимвольном методе декодирования удовлетворяет условию, аналогичному (XII.5.22)
 (XII.8.3)
(XII.8.3)
 (XII.8.4)
(XII.8.4)
 (XII.8.5)
(XII.8.5)
 , когда
, когда  . Это обстоятельство отличает аналоговые посимвольные методы декодирования от идеального декодирования в целом, при котором
. Это обстоятельство отличает аналоговые посимвольные методы декодирования от идеального декодирования в целом, при котором  . В связи с этим представляет определенный интерес найти более точные оценки, чем приведенные выше, а также разработать алгоритм опознания символа
. В связи с этим представляет определенный интерес найти более точные оценки, чем приведенные выше, а также разработать алгоритм опознания символа  , учитывающий результаты, полученные при опознании символов
, учитывающий результаты, полученные при опознании символов  .
.