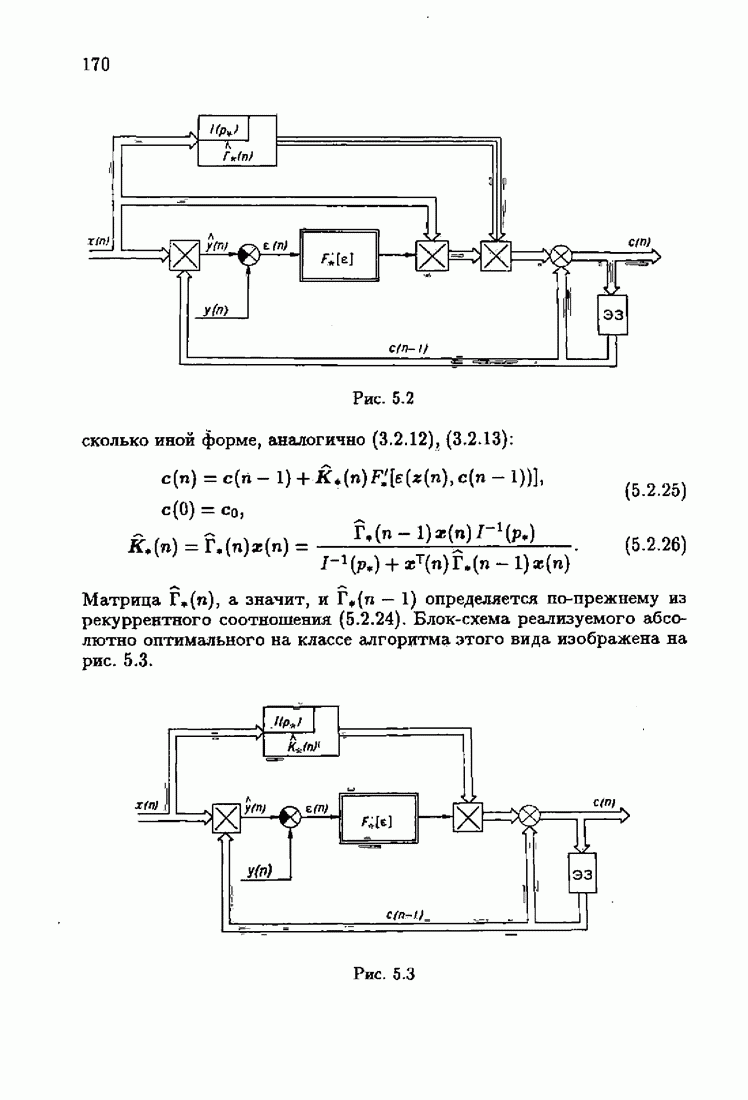
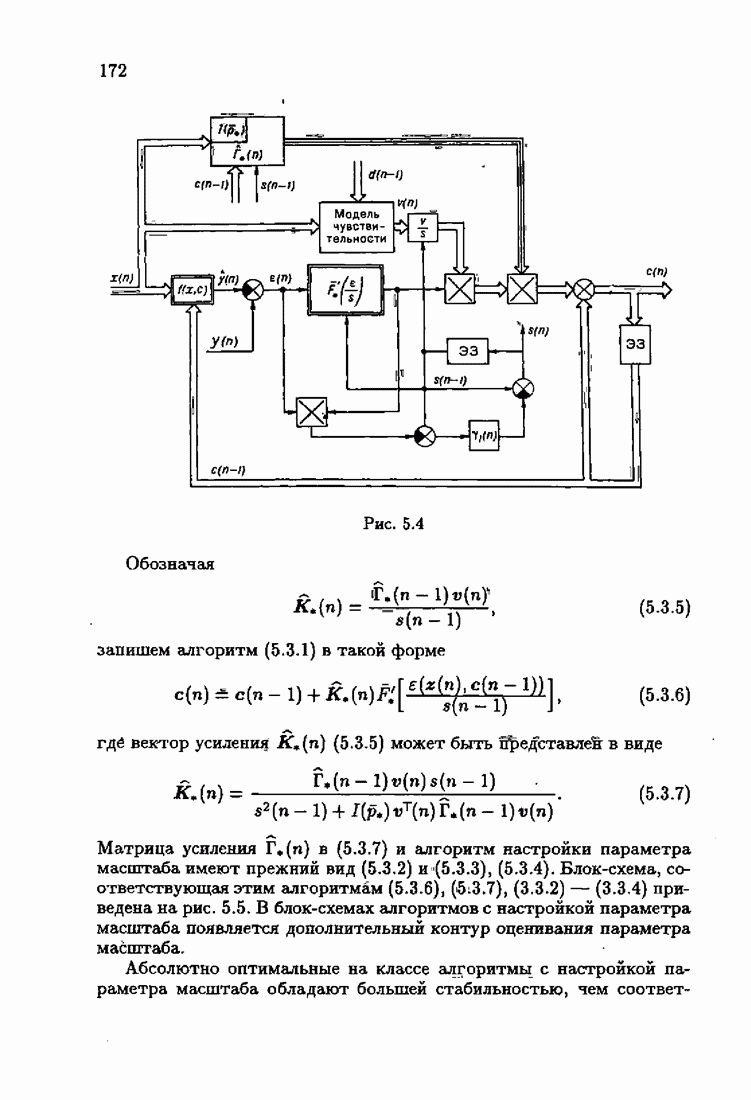
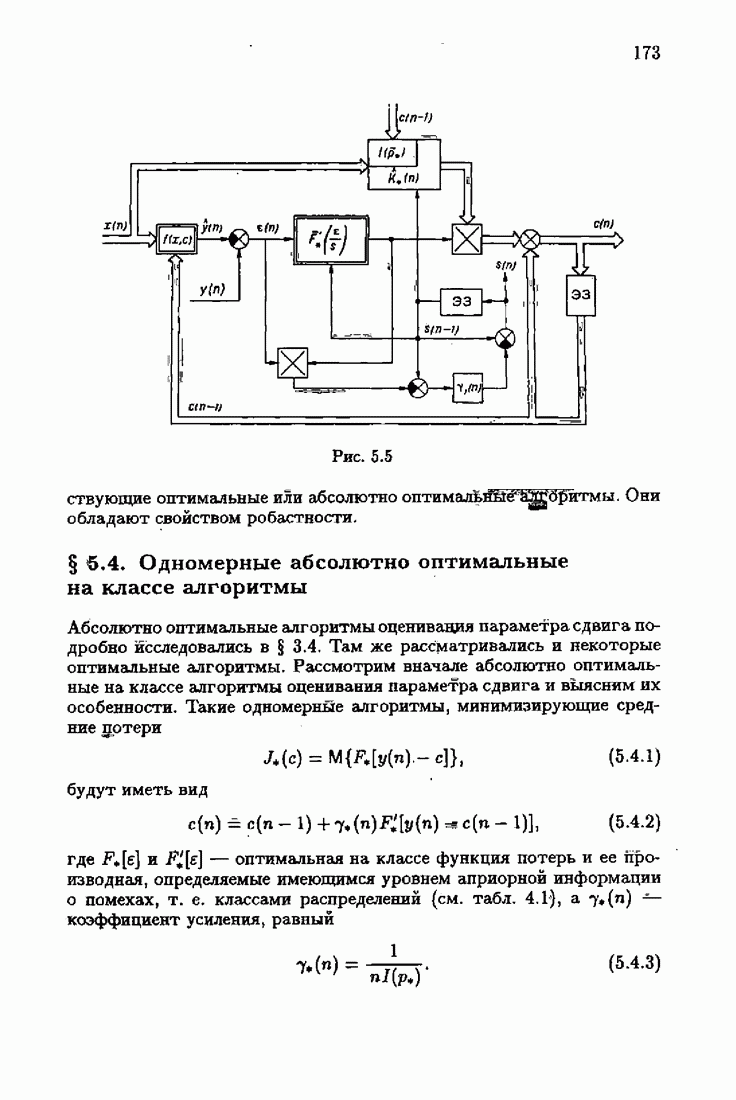
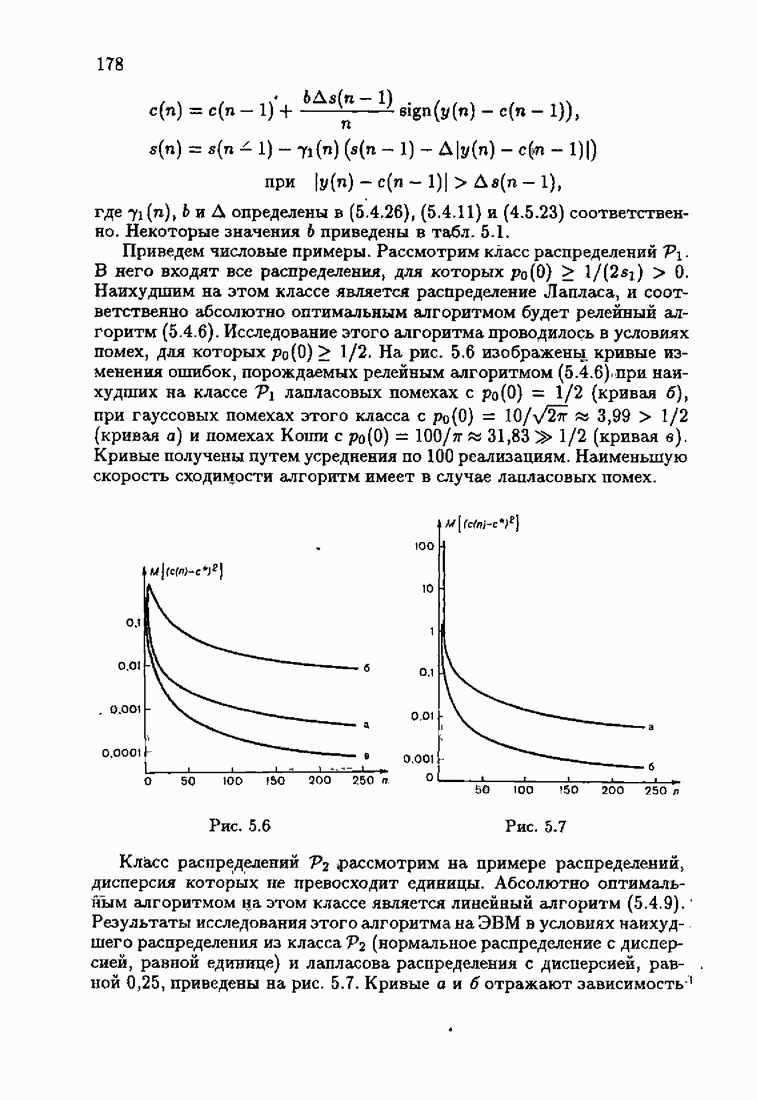
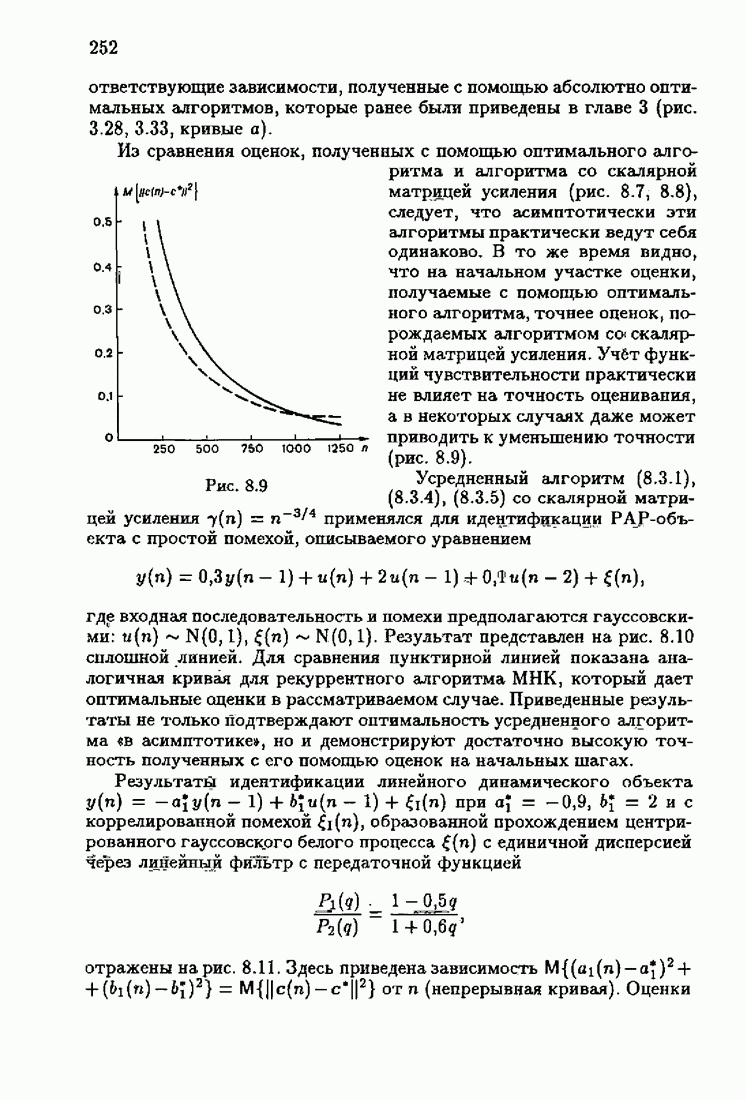
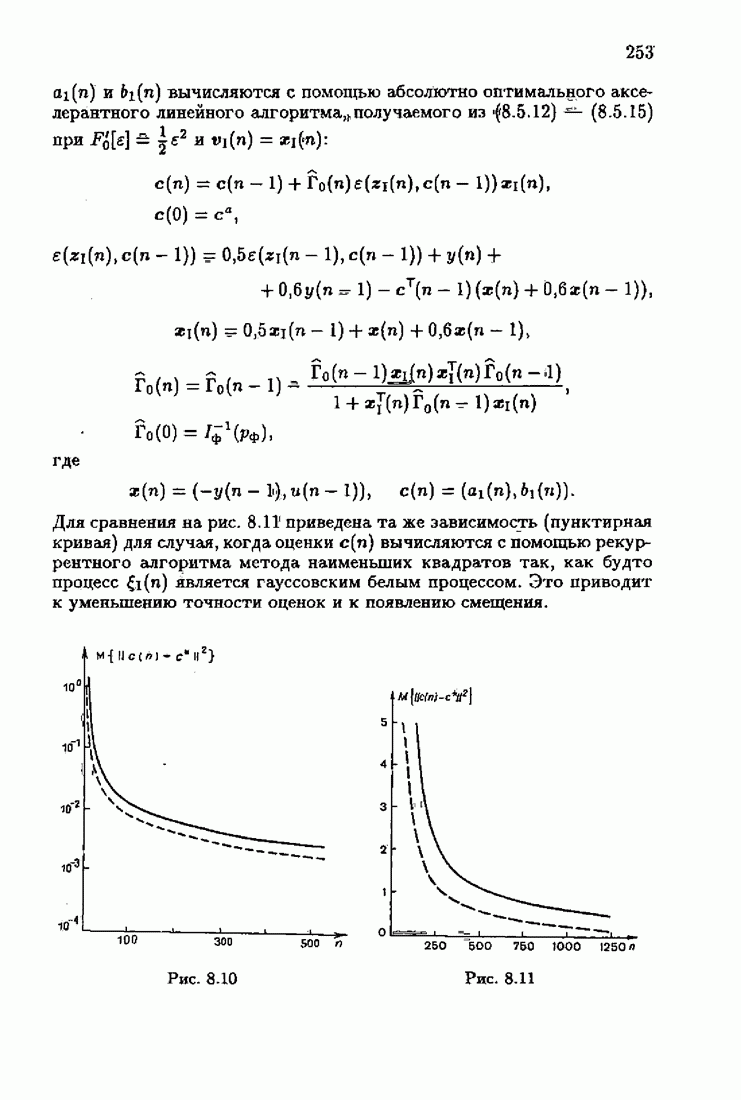
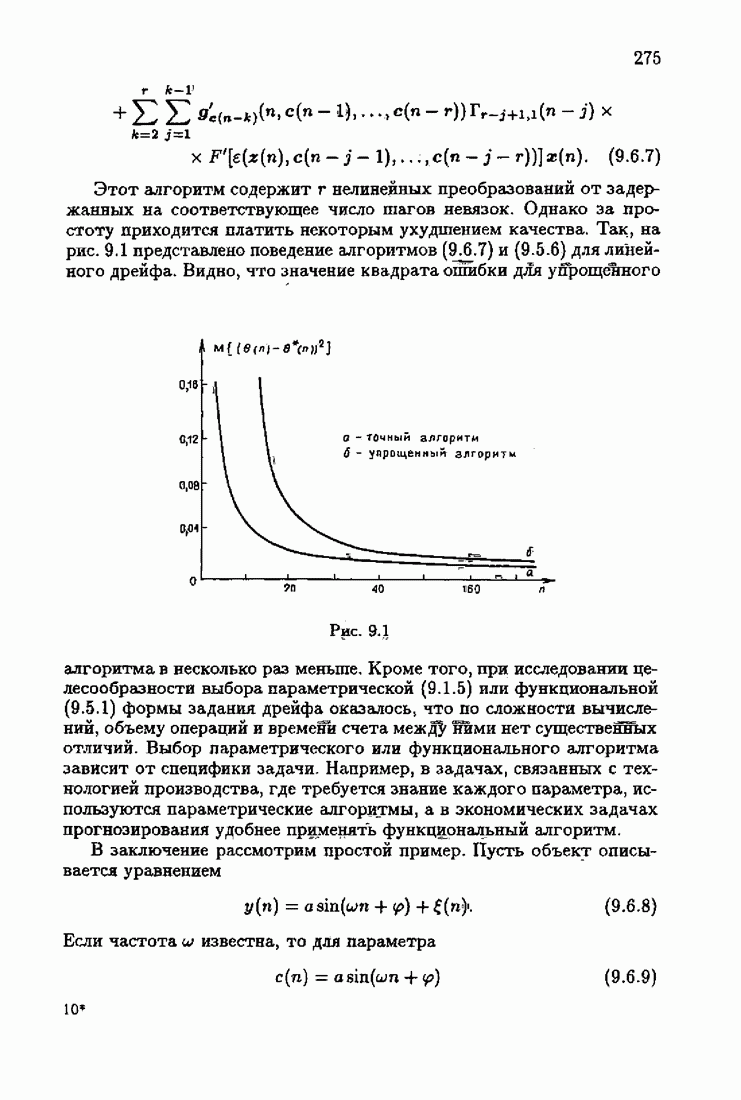
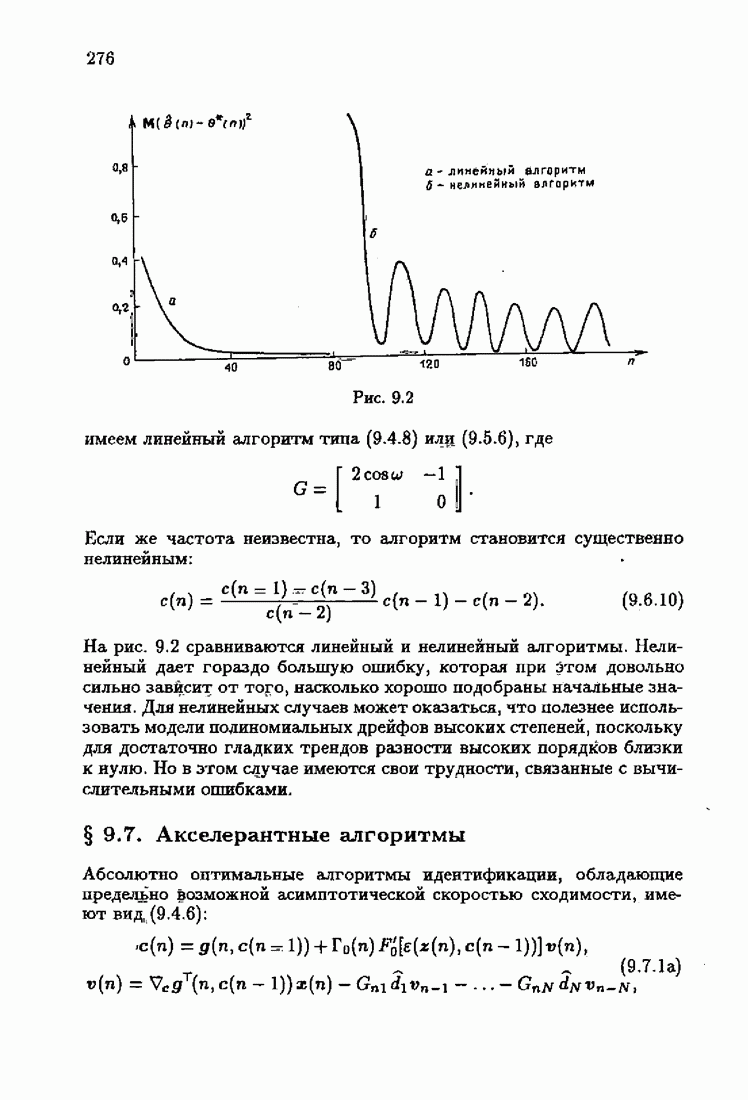
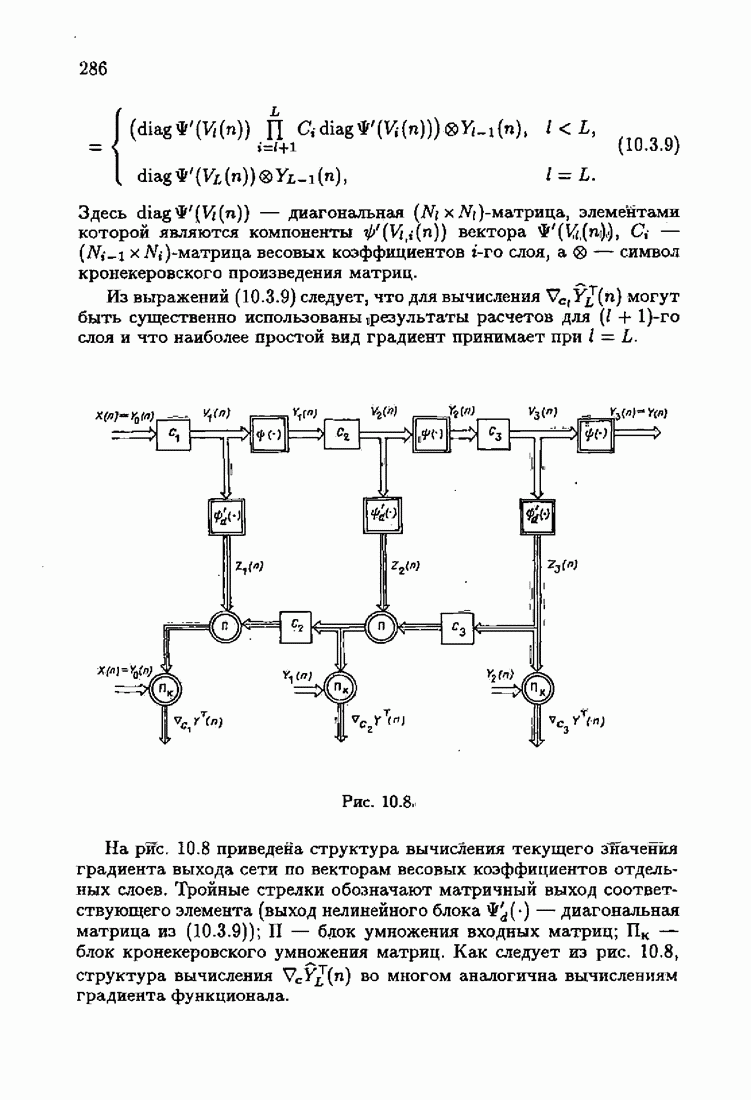
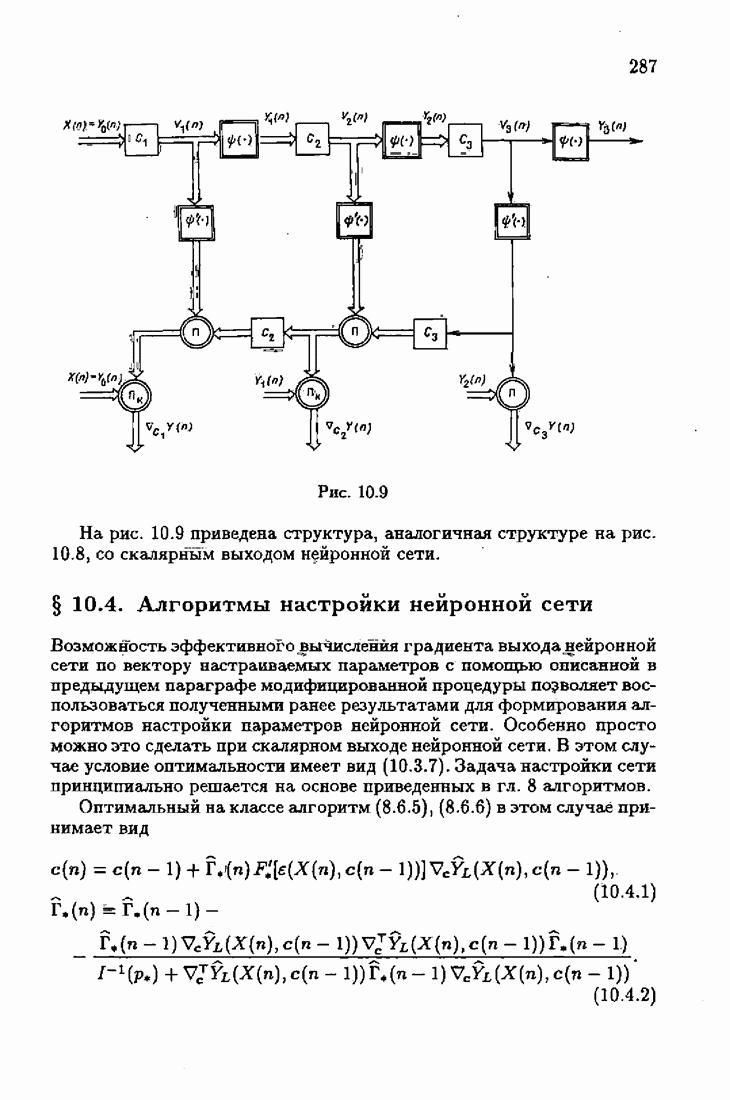
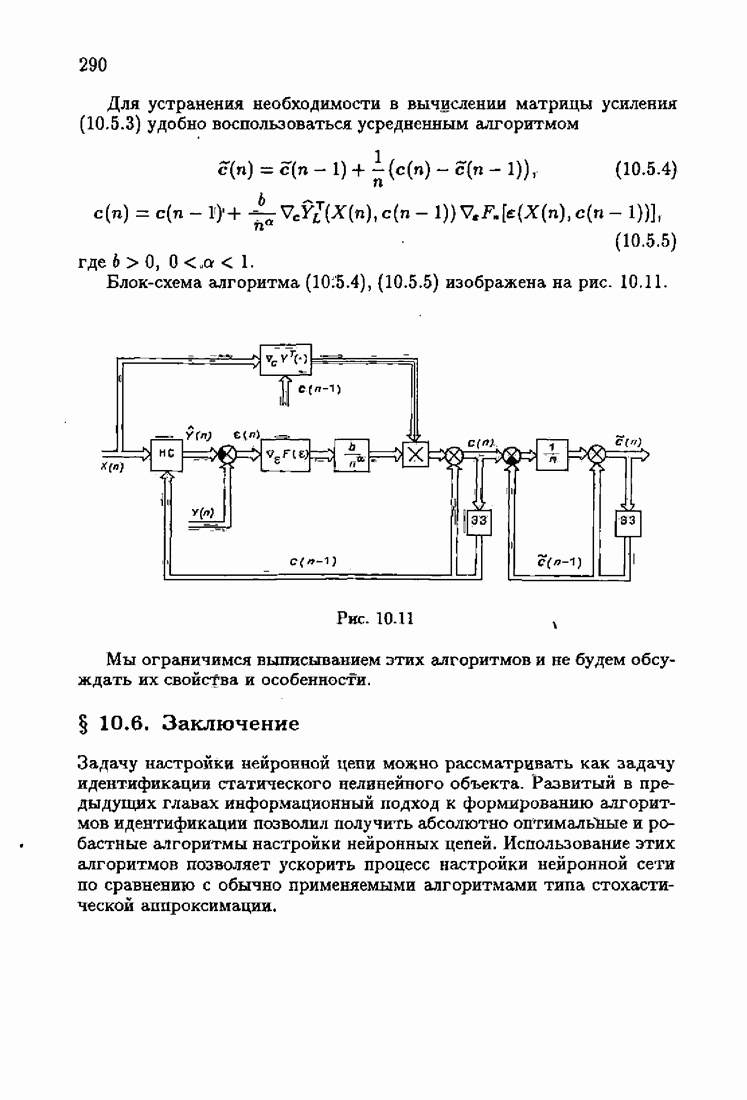
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
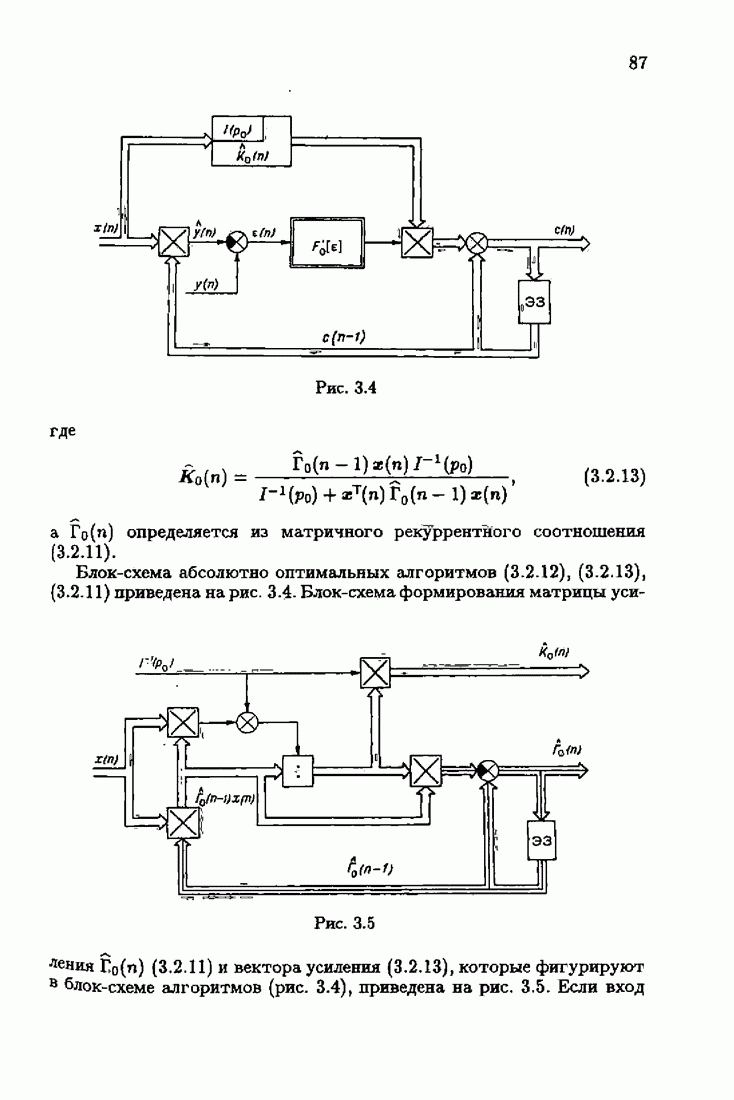
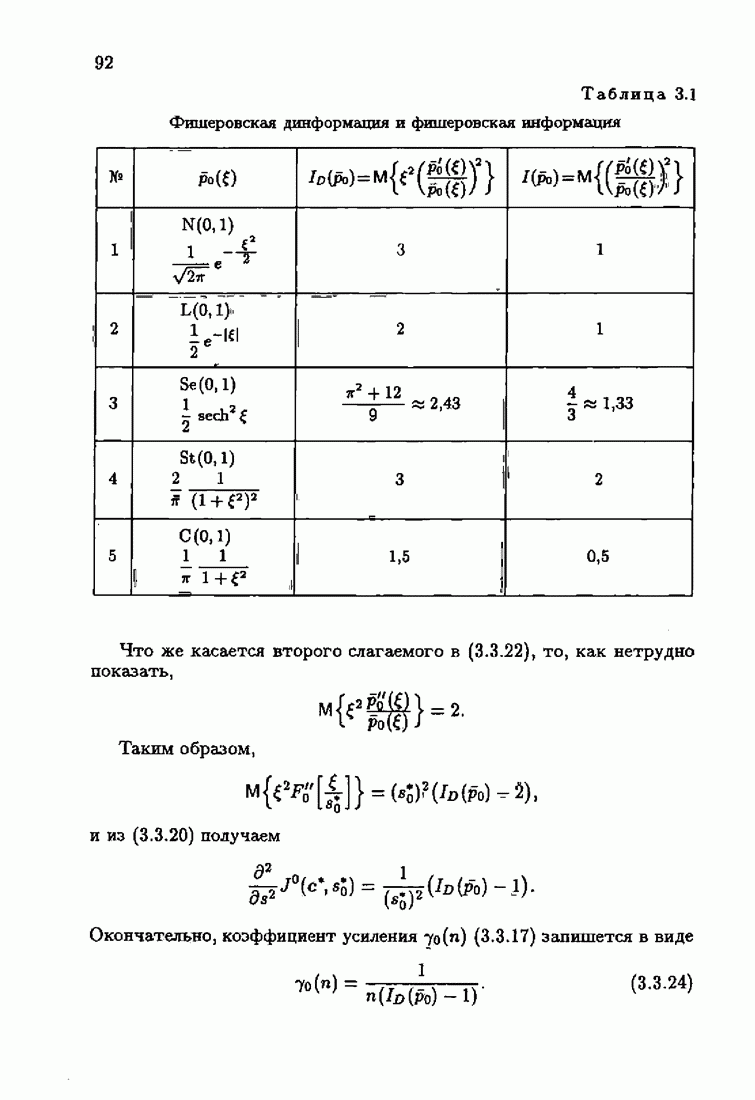
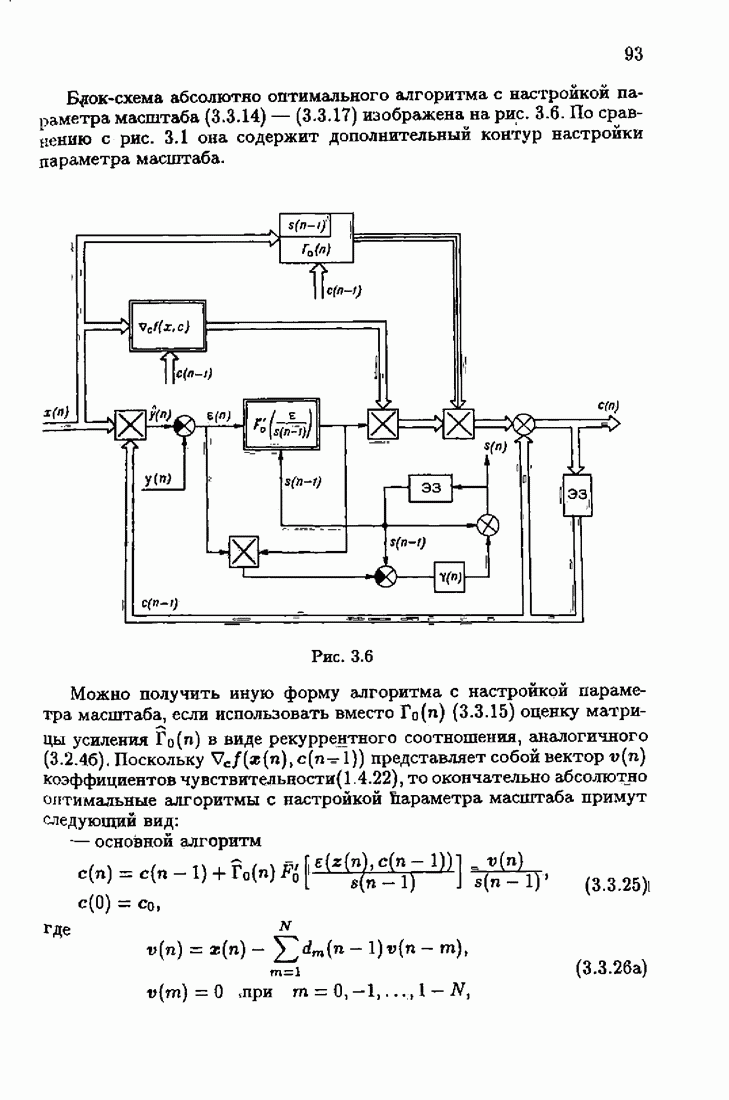
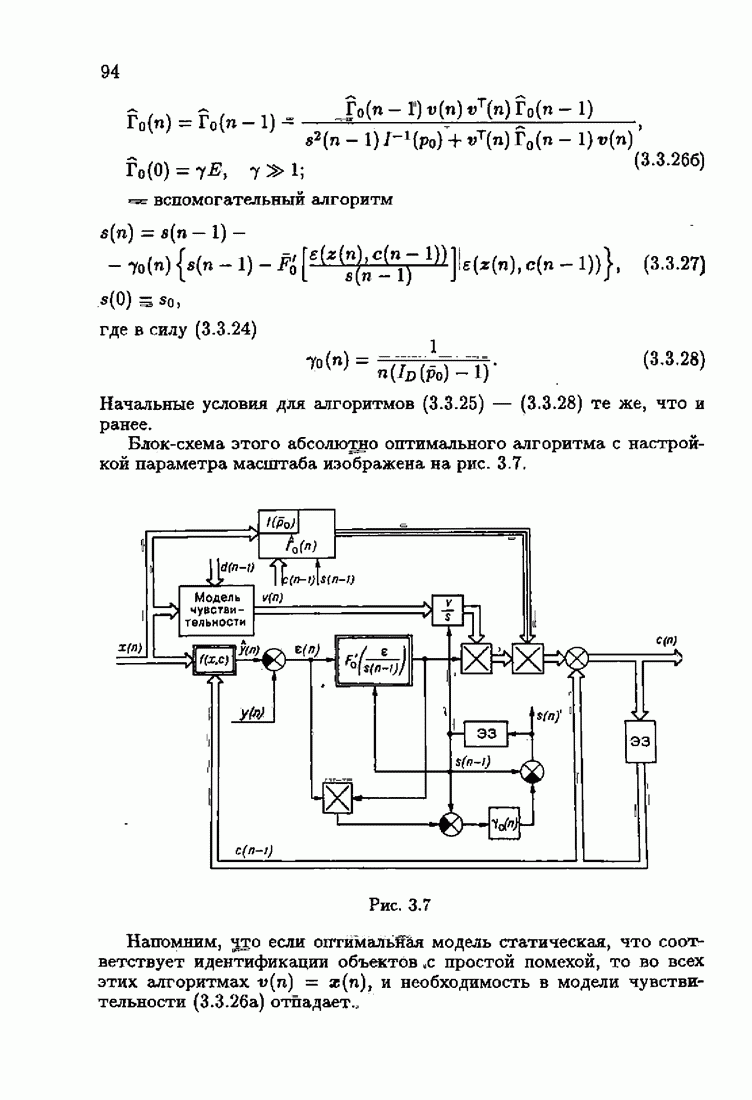
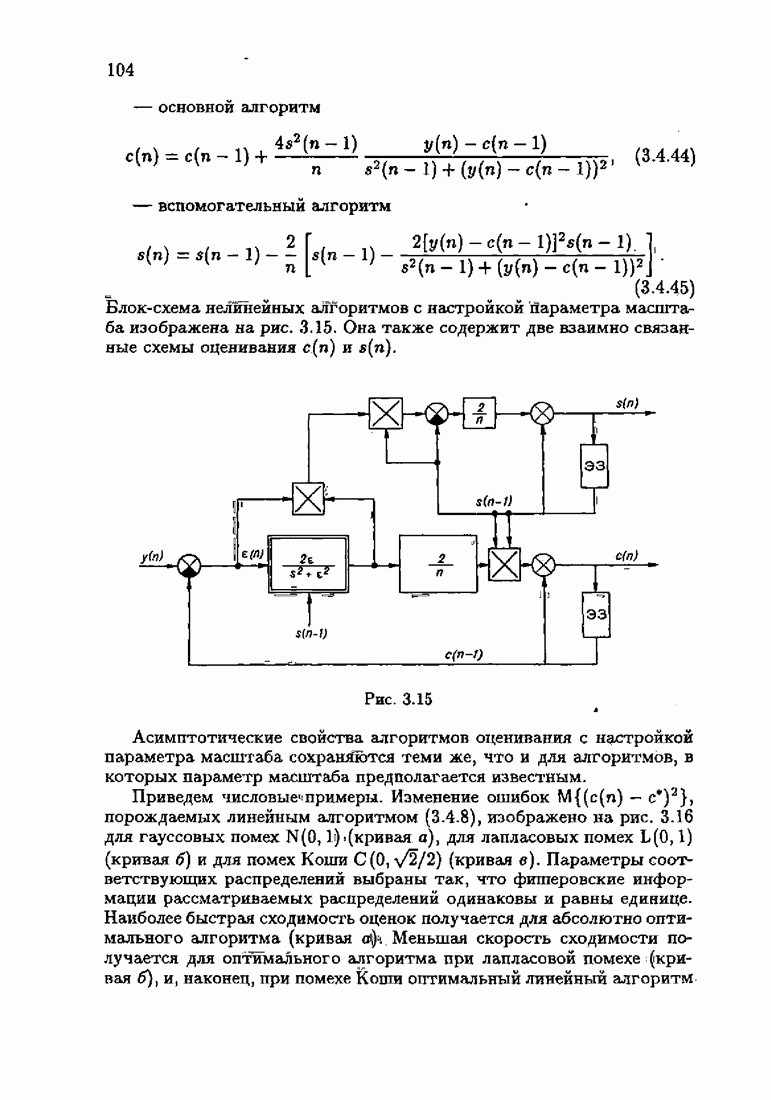
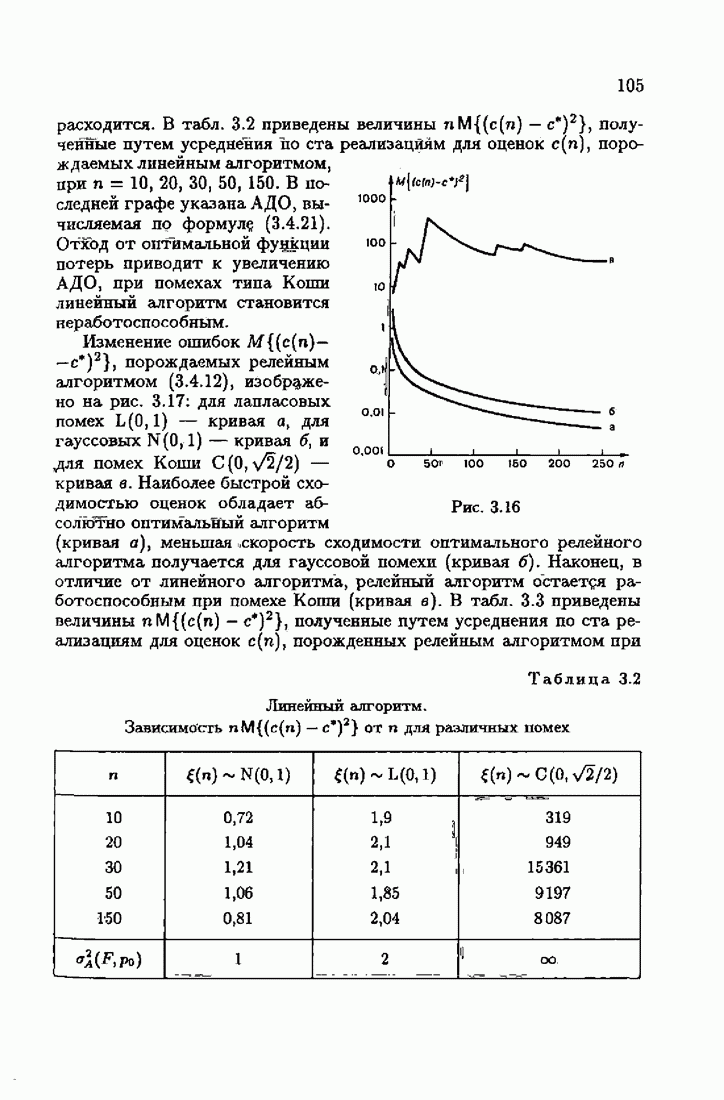
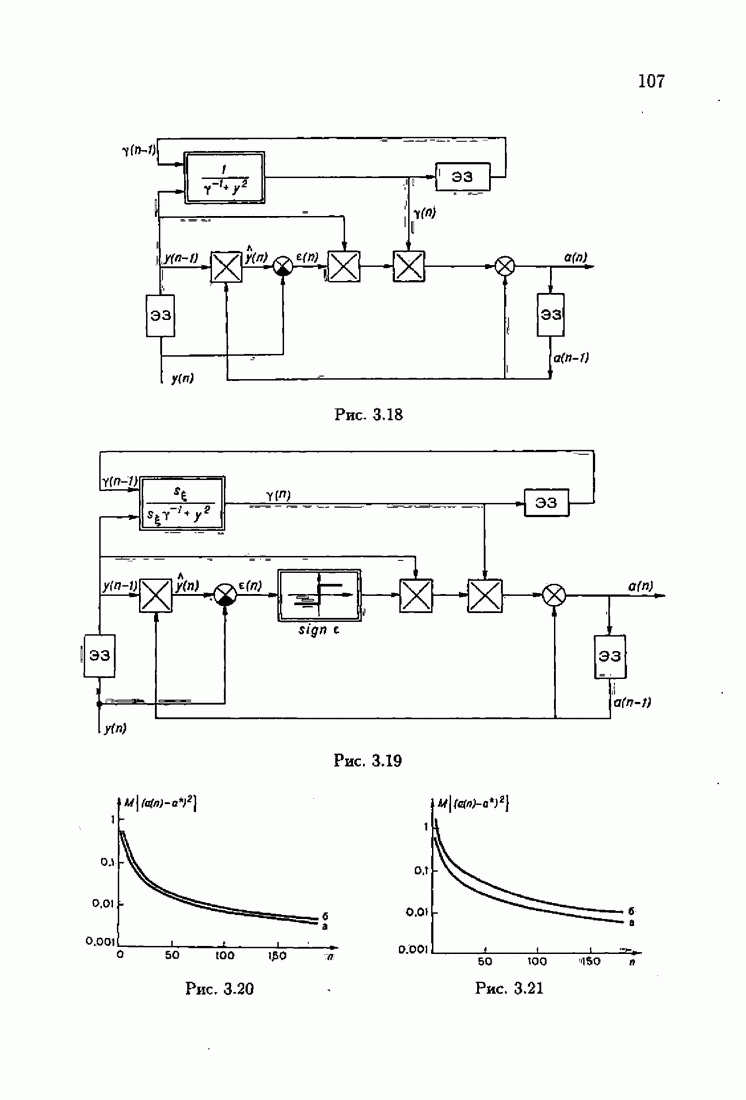
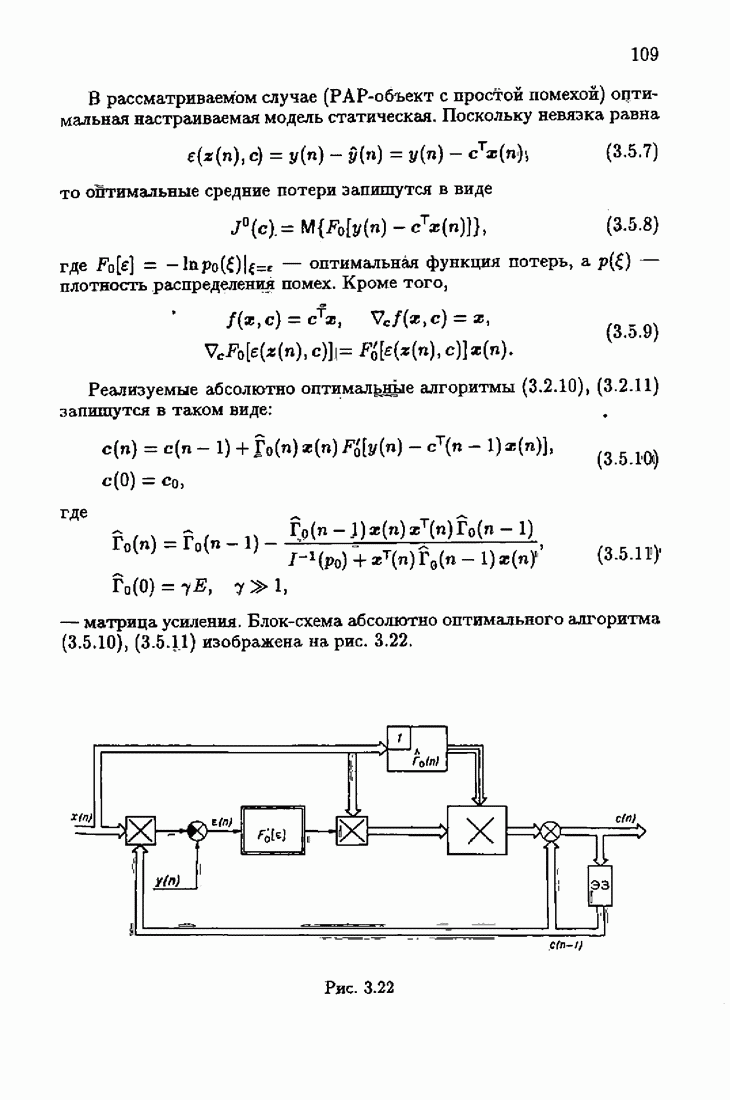
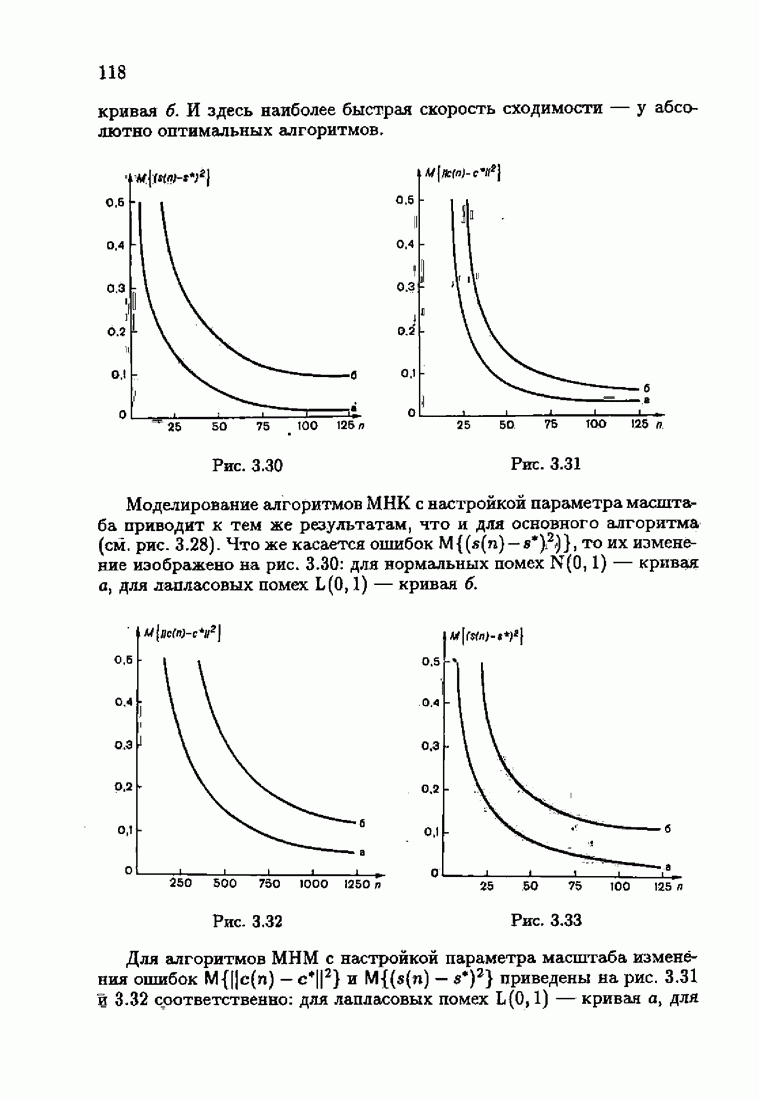
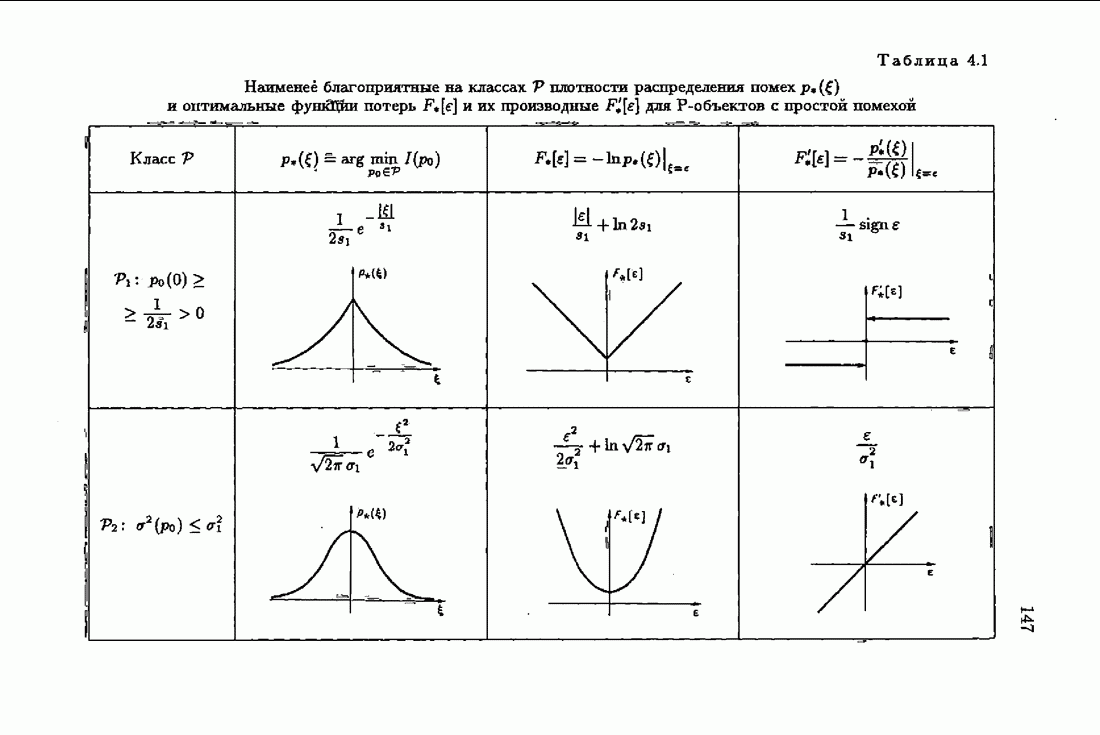
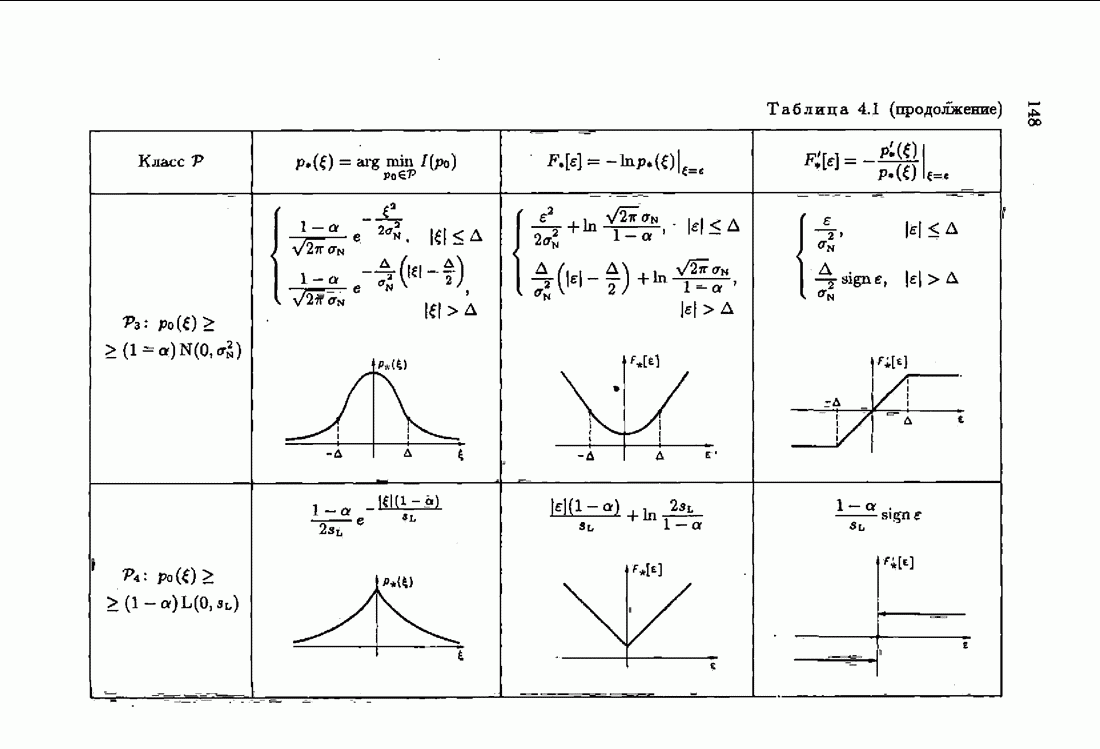
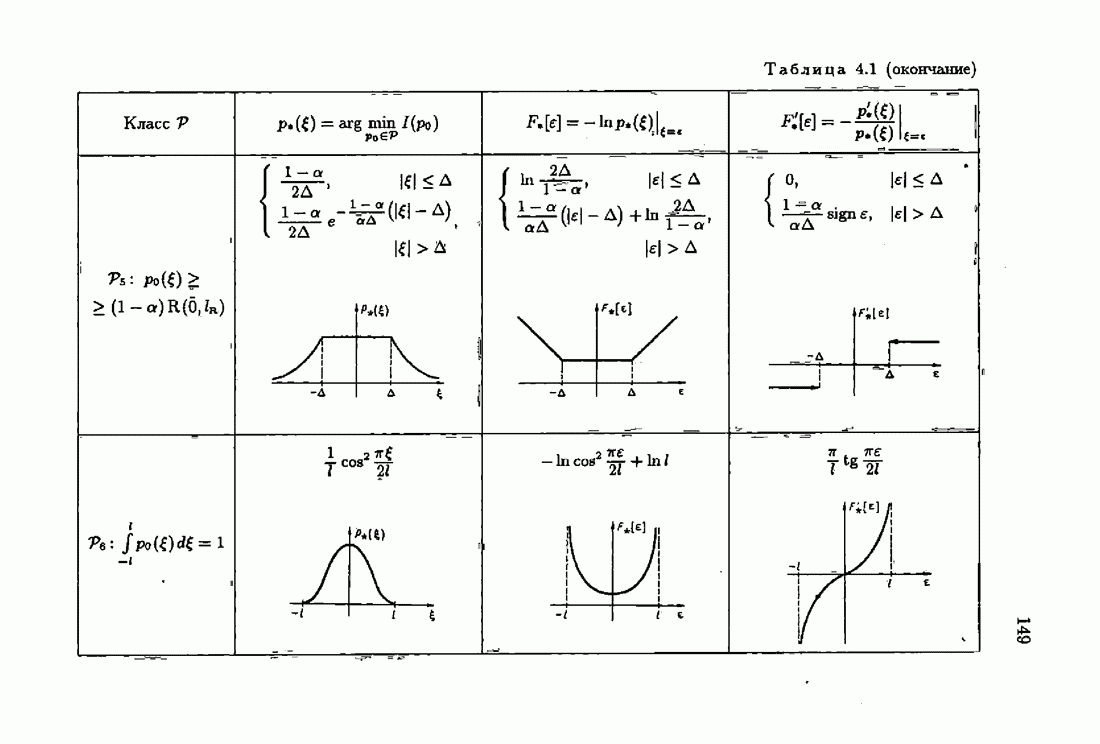
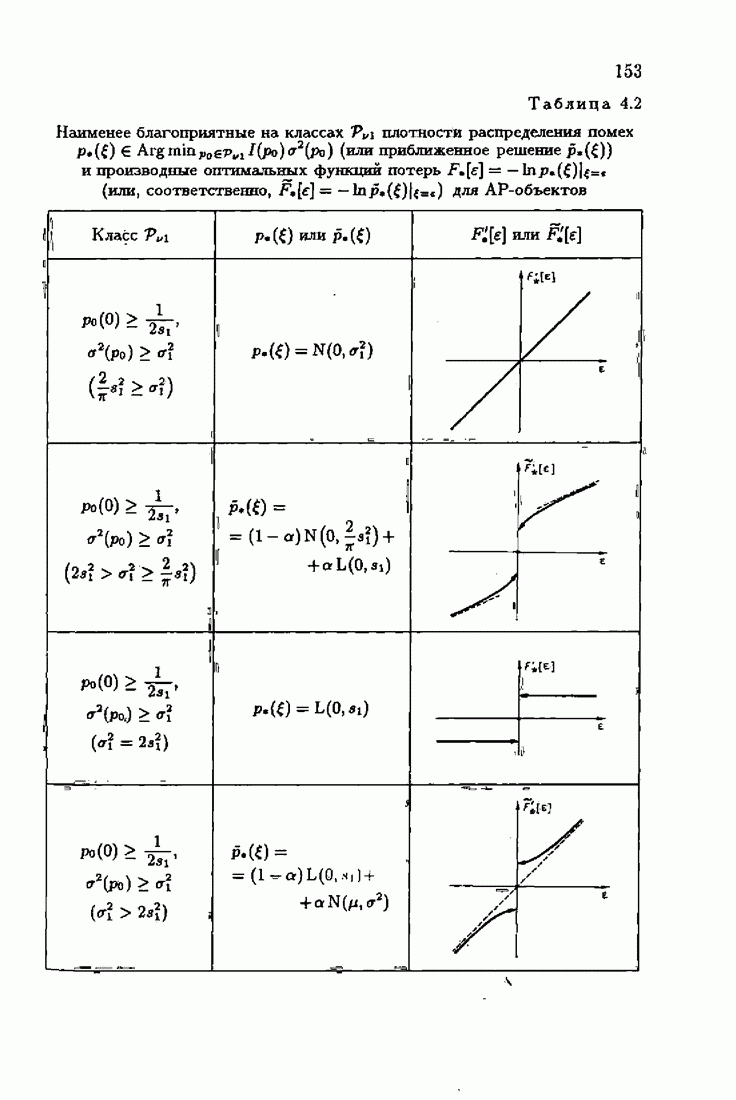
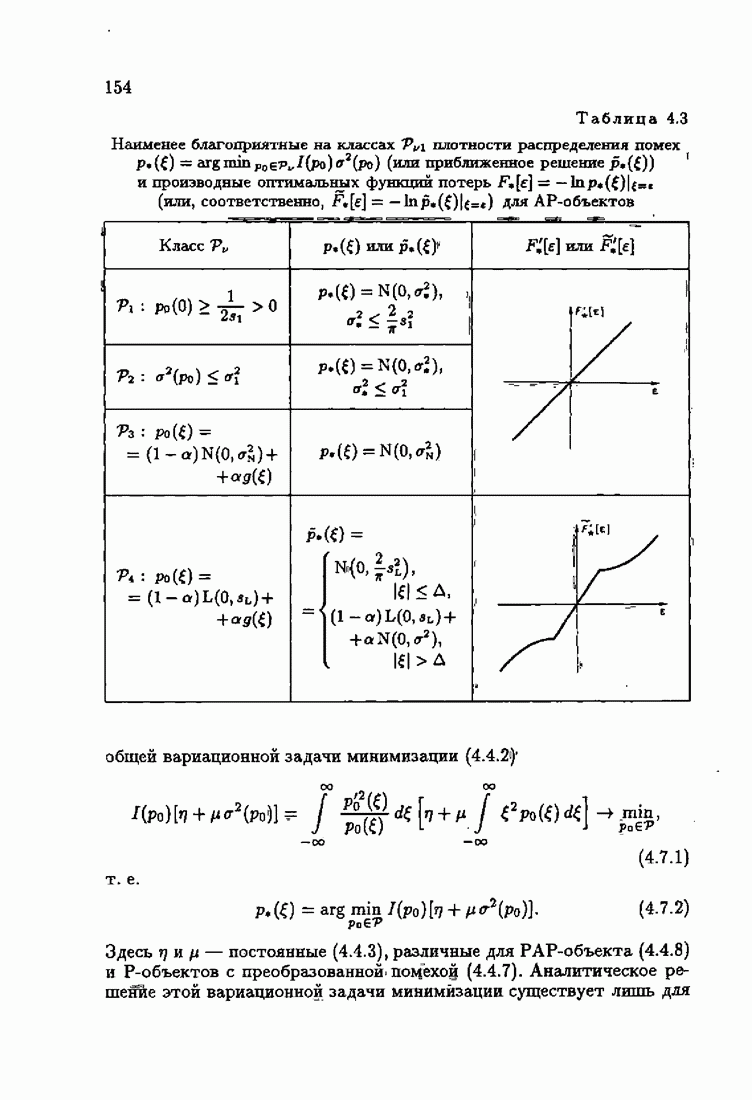
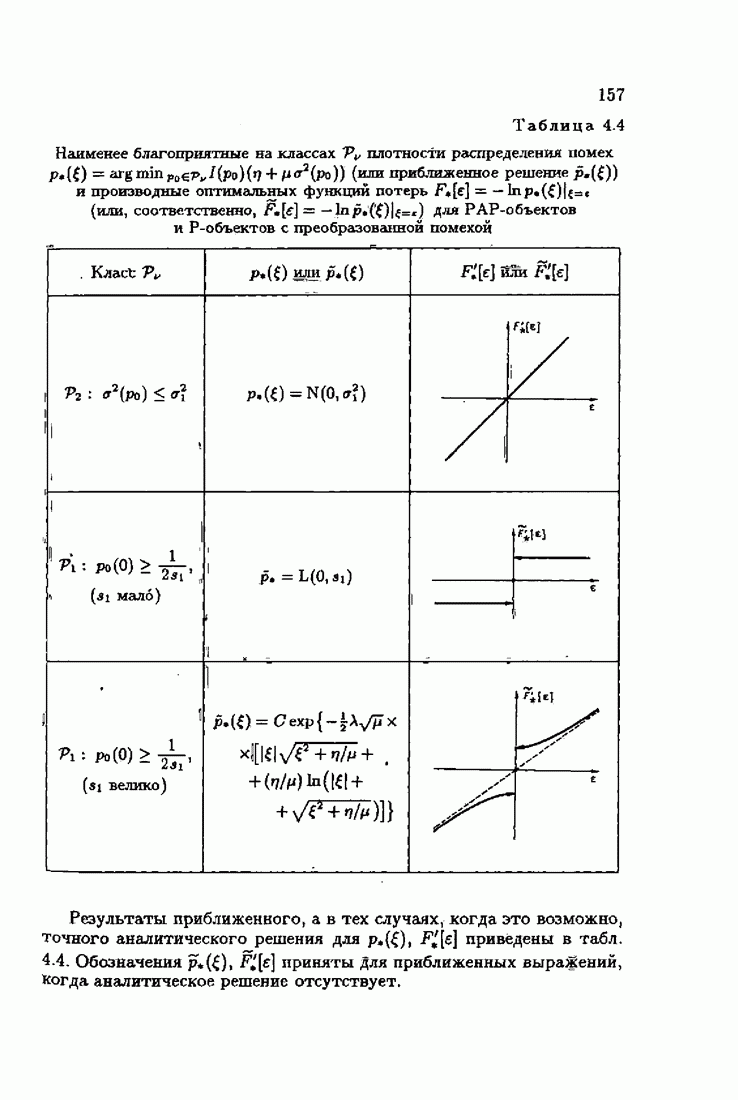
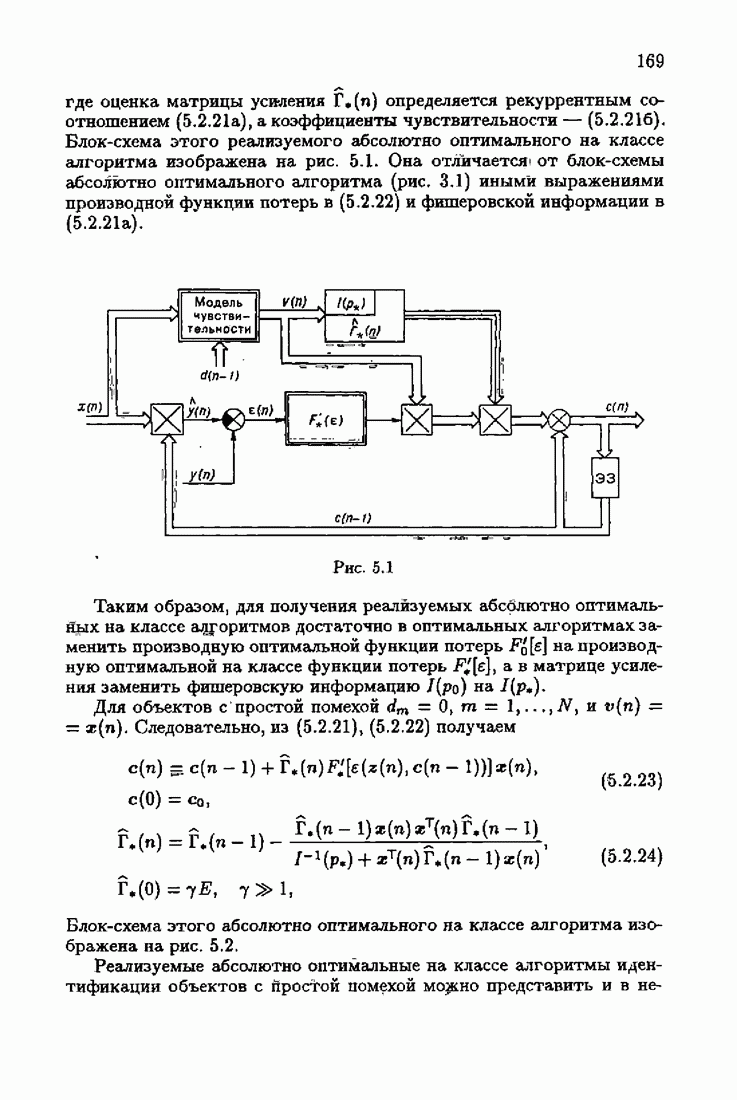
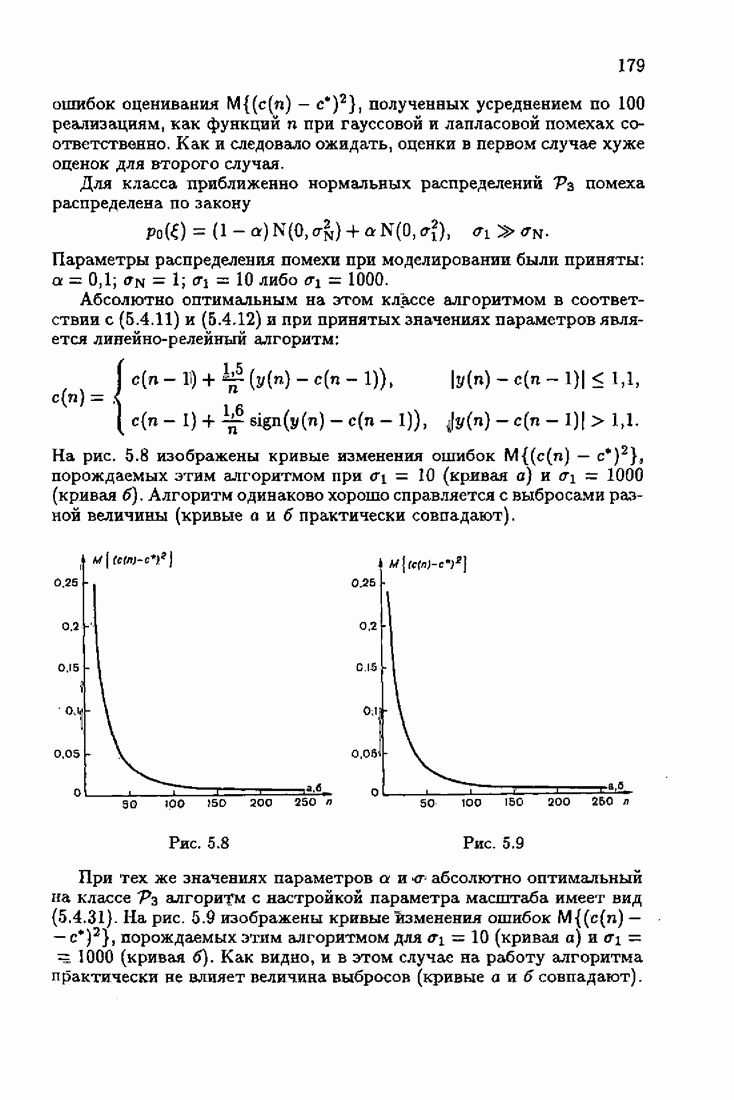
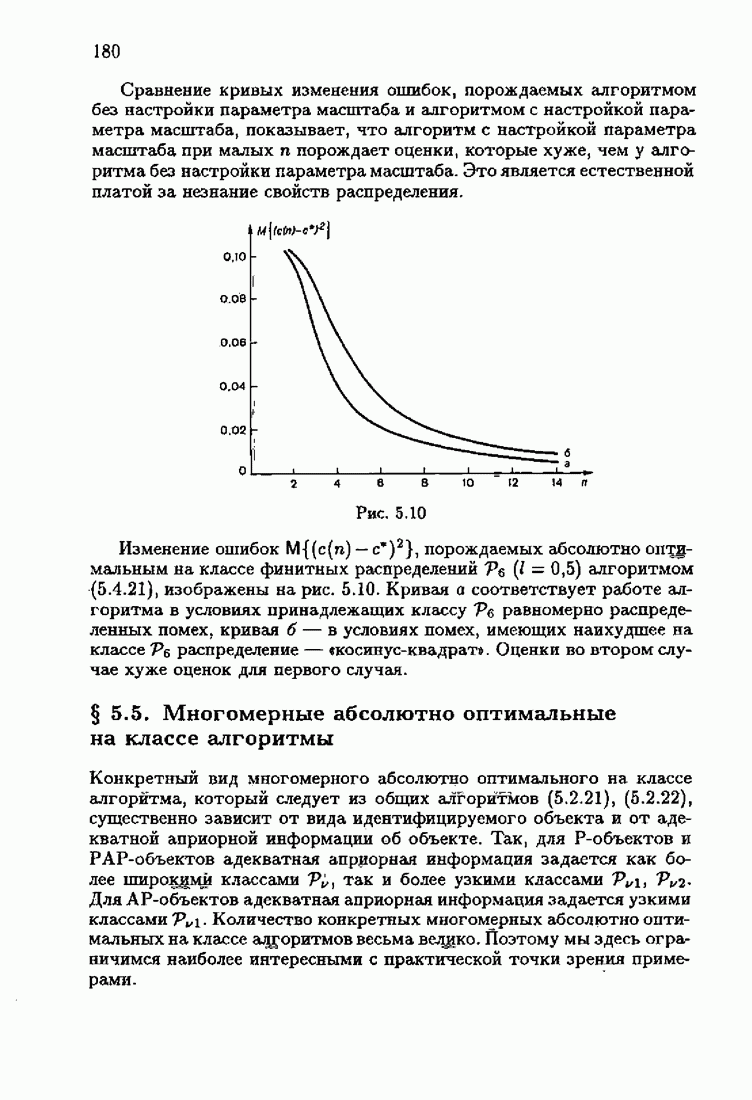
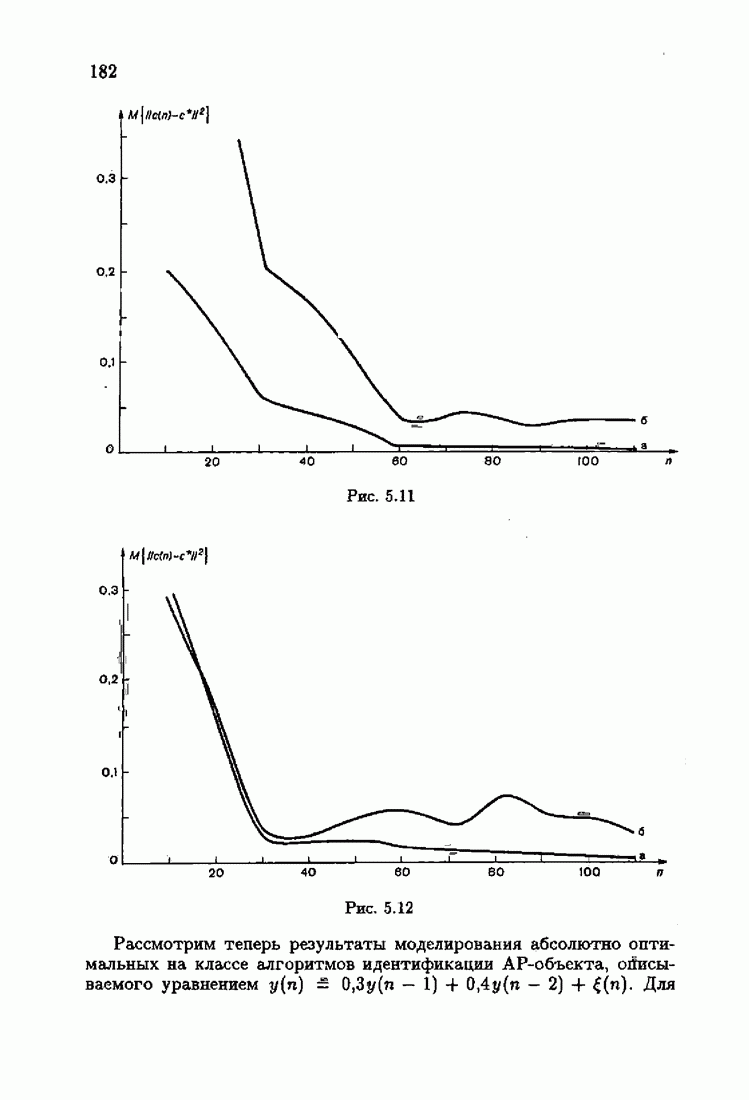
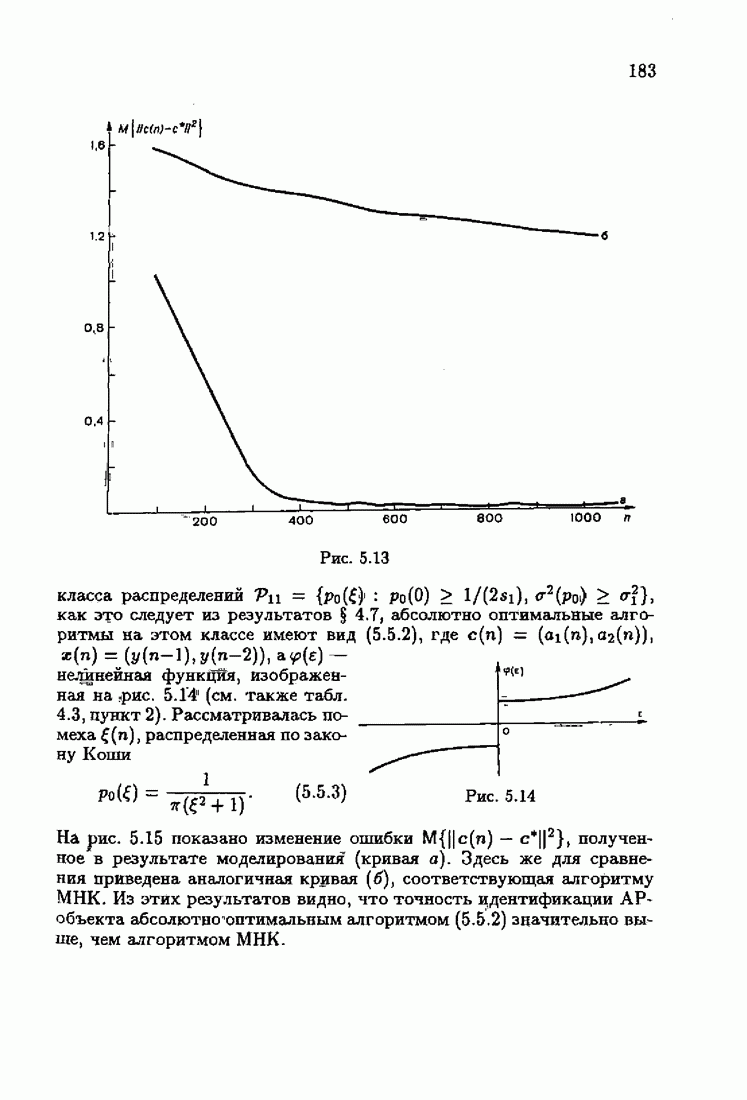
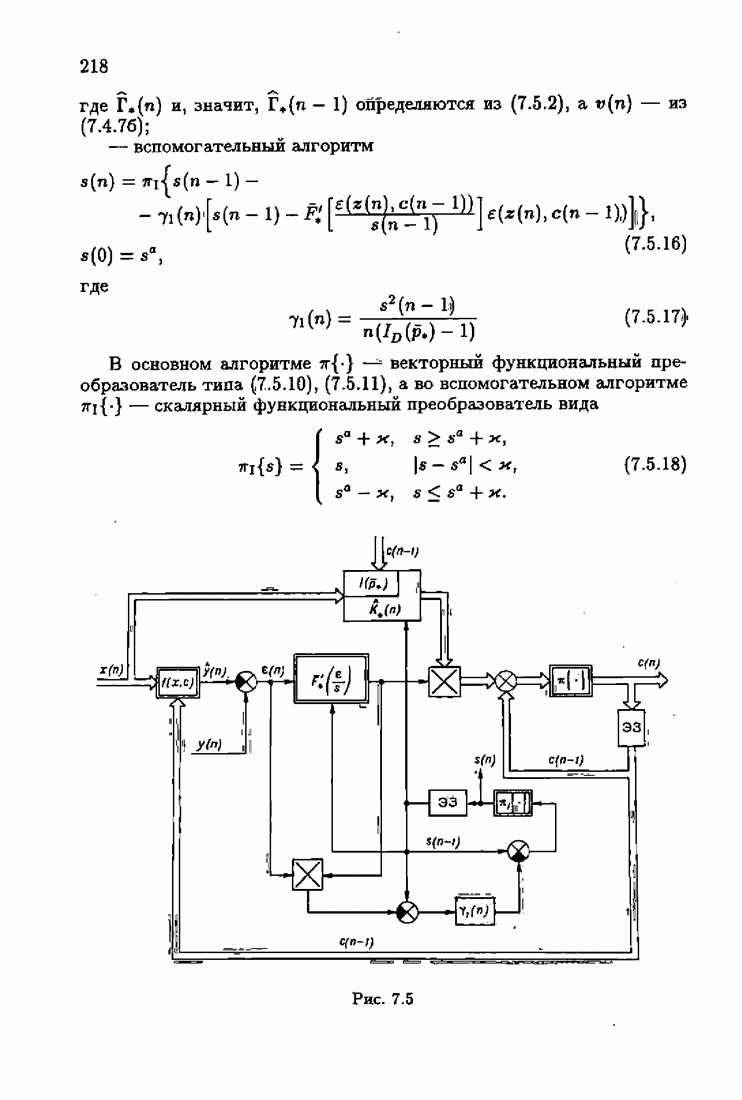
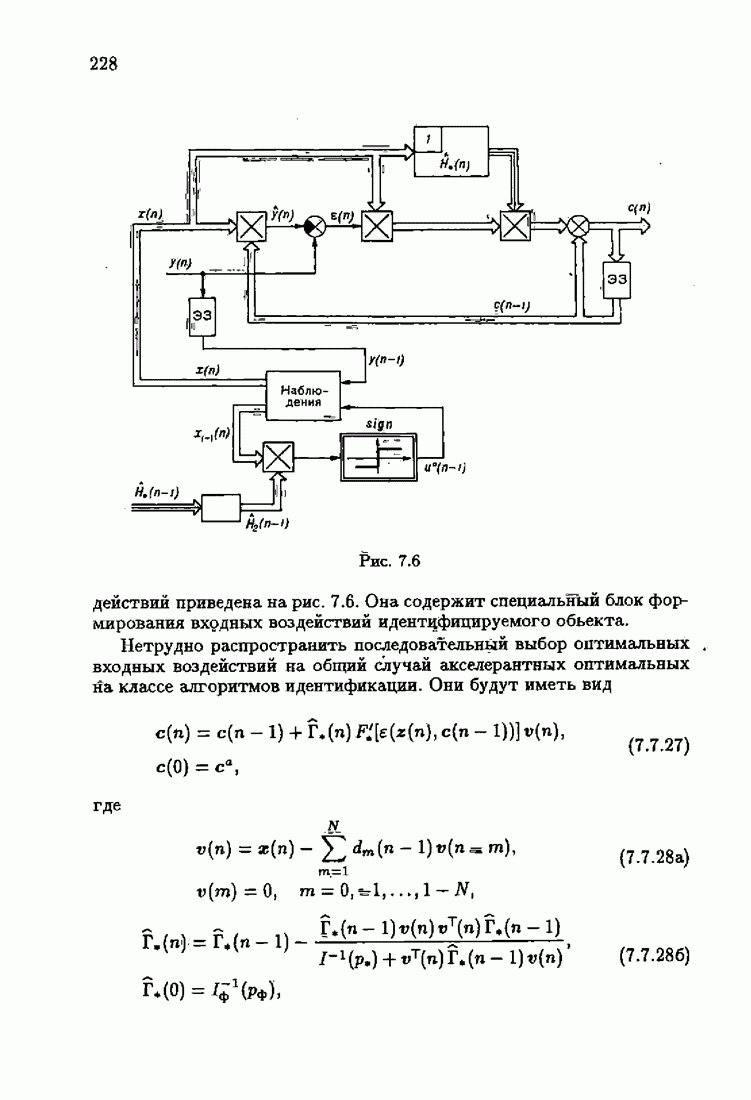
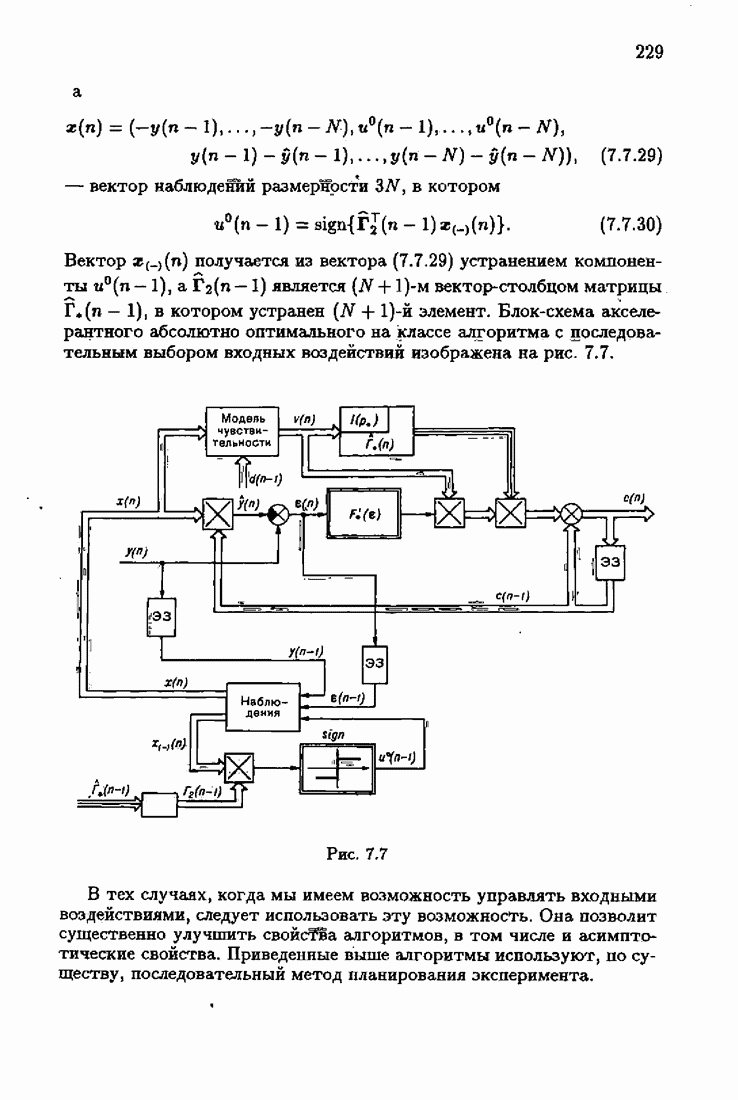
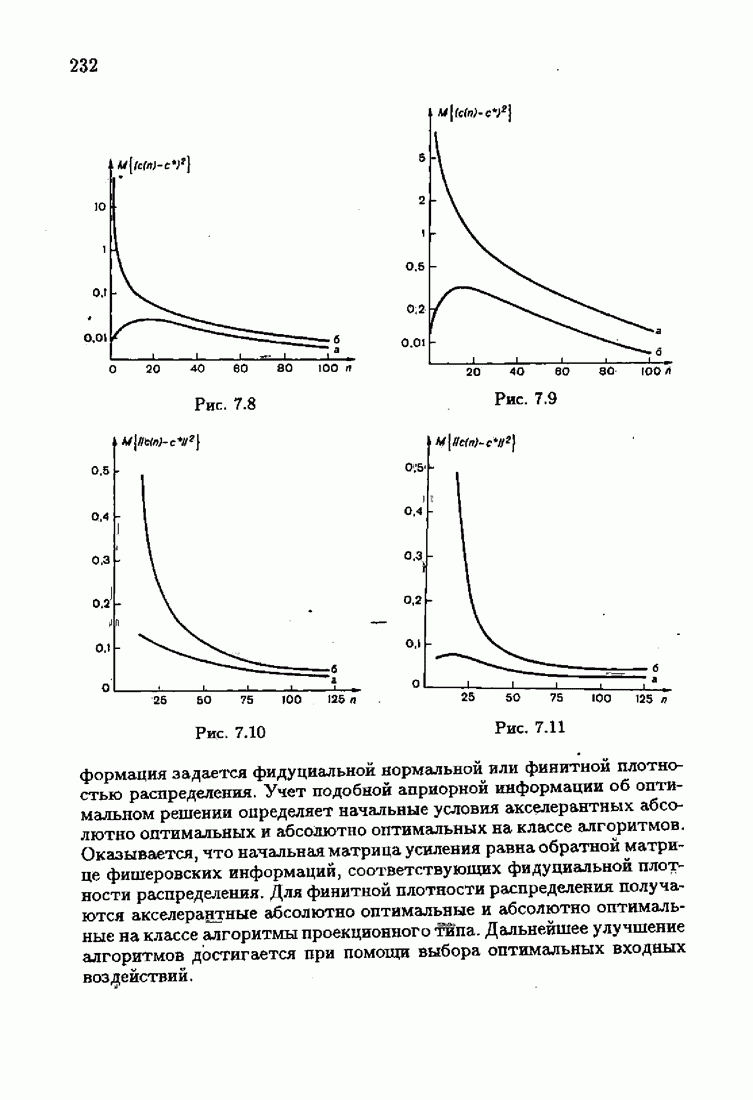
ПредисловиеЗадаче идентификации посвящено необозримое число работ, отличающихся не только типами объектов, которые необходимо идентифицировать, но и самими методами и алгоритмами идентификации. Большое внимание в этих работах уделяется идентификации линейных динамических объектов, описывающихся дифференциальными или разностными уравнениями с неизвестными коэффициентами. Среди разнообразных алгоритмов идентификации, предназначенных для оценивания коэффициентов уравнений по наблюдаемым данным, чаще всего используются рекуррентные алгоритмы, позволяющие осуществить идентификацию в режиме нормальной работы объекта. Принципы формирования алгоритмов идентификации тесно связаны с выбором уравнения, использующего наблюдаемые данные и аппроксимирующего уравнения объекта, выбором критерия качества этой аппроксимации (функции потерь) и, наконец, выбором метода оптимизации критерия. Эти принципы до самого последнего времени были в значительной мере произвольны и зависели во многом от вкусов и возможностей исследователя. Они вырабатывались и утверждались на основе различных эвристических соображений и, в частности, удобства работы с выбираемыми уравнениями аппроксимации, критериями и алгоритмами. Такой произвол обусловил безраздельное господство линейной аппроксимации уравнения объекта и квадратичного критерия. В результате задача идентификации часто сводилась к решению системы линейных уравнений. Но практика показала, что не всегда такой выбор уравнения аппроксимации и критерия приводит к утешительным результатам. Естественно, возникли вопросы: как выбирать уравнение аппроксимации критерий, а затем и алгоритм, которые бы гарантировали получение удовлетворительного, а если возможно, то и наилучшего в рассматриваемых условиях решения задачи идентификации? Цель излагаемой в данной книге информационной теории идентификации состоит в том, чтобы дать ответ на эти вопросы. Книга состоит из десяти глав. В первой главе приводится формулировка задачи идентификации и дается краткая характеристика известной методологии. Описываются типичные линейные объекты и приводятся их уравнения. Эти уравнения положены в основу классификации объектов. Обсуждается вопрос о выборе уравнений аппроксимации, определяющих ту или иную настраиваемую модель. Естественно потребовать, чтобы эта настраиваемая модель наилучшим, в каком-то смысле, образом предсказывала выходную величину объекта. Оказывается, что такая оптимальная модель существует; ее структура зависит от точки приложения к объекту помех. Далее рассмотрены свойства критериев аппроксимации, характеризующих качество идентификации. Приводятся условия оптимальности и выясняются свойства оптимального решения, определяющего неизвестные параметры идентифицируемого объекта. Наконец, приводятся алгоритмы идентификации и указываются их особенности. Определяется асимптотическая скорость сходимости алгоритмов идентификации и устанавливаются оптимальные по скорости сходимости алгоритмы идентификации. Вторая глава посвящена выяснению влияния функции потерь на асимптотические свойства оценок оптимального решения и средних потерь. Здесь изучается вопрос о предельно возможной скорости сходимости оценок оптимального решения и определяется, оптимальная функция потерь, при которой эта предельно возможная скорость сходимости максимальна. В третьей главе показано, что оптимальная функция потерь позволяет сформировать алгоритмы, обладающие предельно возможной скоростью сходимости. Эти алгоритмы названы абсолютно оптимальными. Они оптимальны не только по матрице усиления, но и по функции потерь. Здесь же приводятся абсолютно оптимальные алгоритмы с настройкой параметра масштаба. Подробно исследуются свойства конкретных одномерных и многомерных алгоритмов. Отметим, что оптимальная функция потерь, а значит, и абсолютно оптимальные алгоритмы могут быть определены лишь при полной априорной информации относительно помех, т. е. когда плотность распределения помех известна. В четвертой главе рассматриваются случаи, когда априорная информация о помехах не полна, т. е. плотность распределения помехи полностью не известна. Здесь вводится понятие оптимальной на классе функции потерь. Описываются классы распределения помех, характеризующие различные уровни априорной информации о помехах. Формулируется принцип оптимальности на классе и обсуждаются методы решения вариационных задач минимизации на классе. Приводятся примеры оптимальных на классе функций потерь. Устанавливается связь между оптимальностью на классе и робастностью, т. е. нечувствительностью свойств оценок при малых отклонениях функций потерь от оптимальных. Пятая глава посвящена формированию абсолютно оптимальных на классе алгоритмов идентификации, в том числе и алгоритмов с настройкой параметра масштаба. Выясняются свойства абсолютно оптимальных на классе алгоритмов. В шестой главе рассмотрен сравнительно новый вопрос, связанный с идентификацией неминимально-фазовых по возмущению объектов. Обсуждается специфика неминимально-фазовых объектов и показывается, как использовать полученные в предыдущих главах результаты, чтобы охватить и этот класс объектов, весьма важный для приложений. Здесь, однако, возникают новые задачи, которые к настоящему времени полностью не решены. Седьмая глава посвящена учету априорной информации об искомом решении. Эта априорная информация не влияет на асимптотические свойства алгоритмов, но она обеспечивает ускорение получения оценок оптимального решения. Такие алгоритмы уместно называть акселерантными. Они осуществляют также регуляризацию получаемых оценок. Акселерантные абсолютно оптимальные на классе алгоритмы полностью учитывают имеющуюся в наличии априорную информацию о решении и о помехах и являются оптимальными в условиях неполной априорной информации. Подробно рассмотрены линейные акселерантные абсолютно оптимальные на классе алгоритмы. Указано на возможность улучшения алгоритмов за счет управления входными воздействиями. В восьмой главе приводятся различные модификации акселерантных абсолютно оптимальных на классе алгоритмов. Эти модификации, с одной стороны, касаются упрощения алгоритмов (упрощения матрицы усиления или градиента функции потерь), а с другой стороны, они охватывают более сложные задачи идентификации (учет коррелированности помех и идентификация нелинейных объектов). Рассмотрены также критериальные алгоритмы. В девятой главе, написанной совместно с М. В. Бондаренко, изложены алгоритмы идентификации нестационарных объектов, параметры которых являются функциями времени. Десятая глава, написанная совместно с Э. Д. Аведьяном, посвящена нейронным сетям и их применению для идентификации объектов. В ней показано, что приведенные в предшествующих главах алгоритмы по существу используются в нейронных сетях. Почти во всех главах приведены конкретные числовые примеры, иллюстрирующие свойства и особенности алгоритмов идентификации, а также эффективность абсолютно оптимальных на классе алгоритмов. Излагаемая в книге информационная теория идентификации основана на общем подходе, связанном с вероятностными рекуррентными алгоритмами оптимизации в условиях неопределенности. Этому подходу были посвящены предшествующие книги автора: «Адаптация и обучение в автоматических системах» (М.: Наука, 1968) и «Основы теории обучающихся систем» (М.: Наука, 1970). Вопросы оптимизации моделей, функций потерь и алгоритмов были впервые систематически рассмотрены в книге автора «Основы информационной теории идентификации» (М.: Наука, 1984). Для настоящего издания материал этой книги был существенно переработан и дополнен рассмотрением ряда новых вопросов. Из всех задач оптимизации в условиях неопределенности мы ограничились в настоящей книге лишь одной задачей — задачей идентификации. Это позволило наиболее рельефно показать, какие возможности открывает учет априорной информации различного уровня как при формулировке, так и при решении задач идентификации. Прежде всего, учет этой априорной информации вносит в теорию идентификации определенность, однозначность. Такая однозначность непривычна, но очень удобна, и автор надеется, что заинтересованный читатель к этому быстро привыкнет. В настоящей книге, как и в упомянутых выше книгах, нет последовательности лемм, теорем и их подробных доказательств. Это сделано не только потому, что нам хотелось в основном тексте рельефно изложить главные идеи, закономерности и методы, но и потому, что не все высказанные положения могут быть в настоящее время формально обоснованы. В основном тексте отсутствуют литературные ссылка. Они приводятся в комментариях, помещенных в конце книги. Там же можно познакомиться с обсуждением и сравнением полученных результатов с ранее известными, а также с различного рода замечаниями по рассматриваемому кругу вопросов. Известен афоризм: «Чистая математика делает то, что можно, так, как нужно; прикладная — то, что нужно, так, как можно». Эта книга следует принципу прикладной математики. При подготовке книги к печати неоценимая помощь мне была оказана ее редактором А. В. Назиным. Я очень благодарен Э. Д. Аведьяну, М. В. Бондаренко, А. В. Наэину и Л. В. Богачеву за помощь, которая позволила завершить эту книгу. Москва, 1995 Я. Цыпкин
|
 |
Оглавление
|