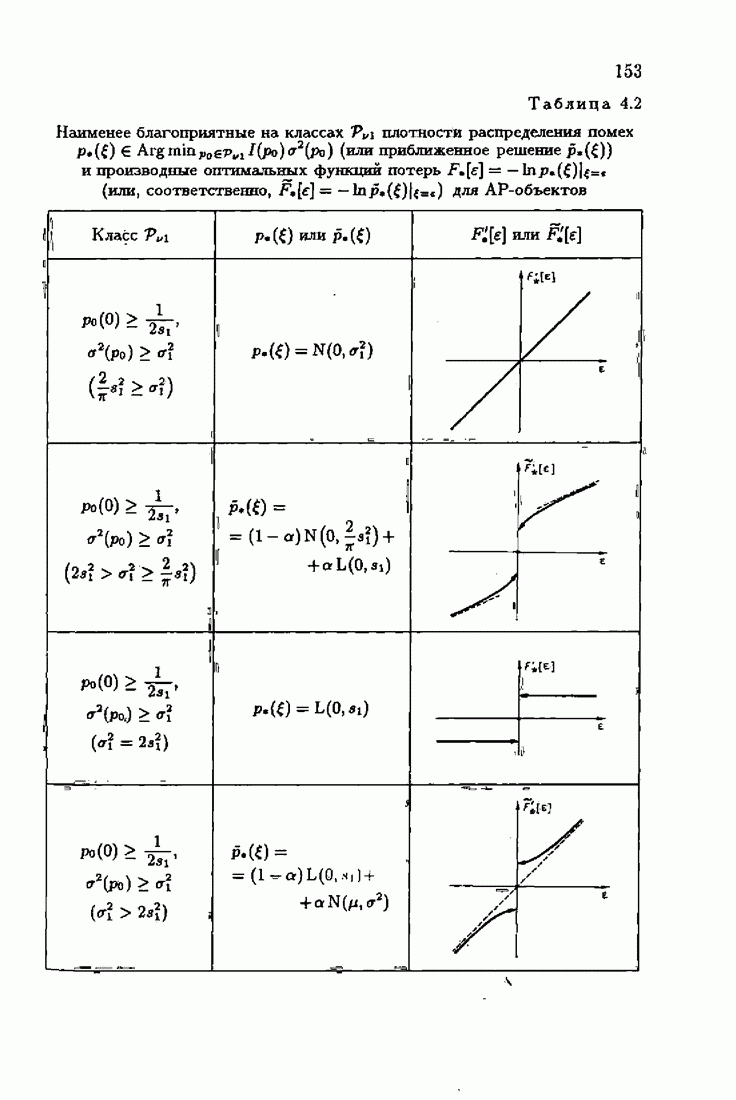
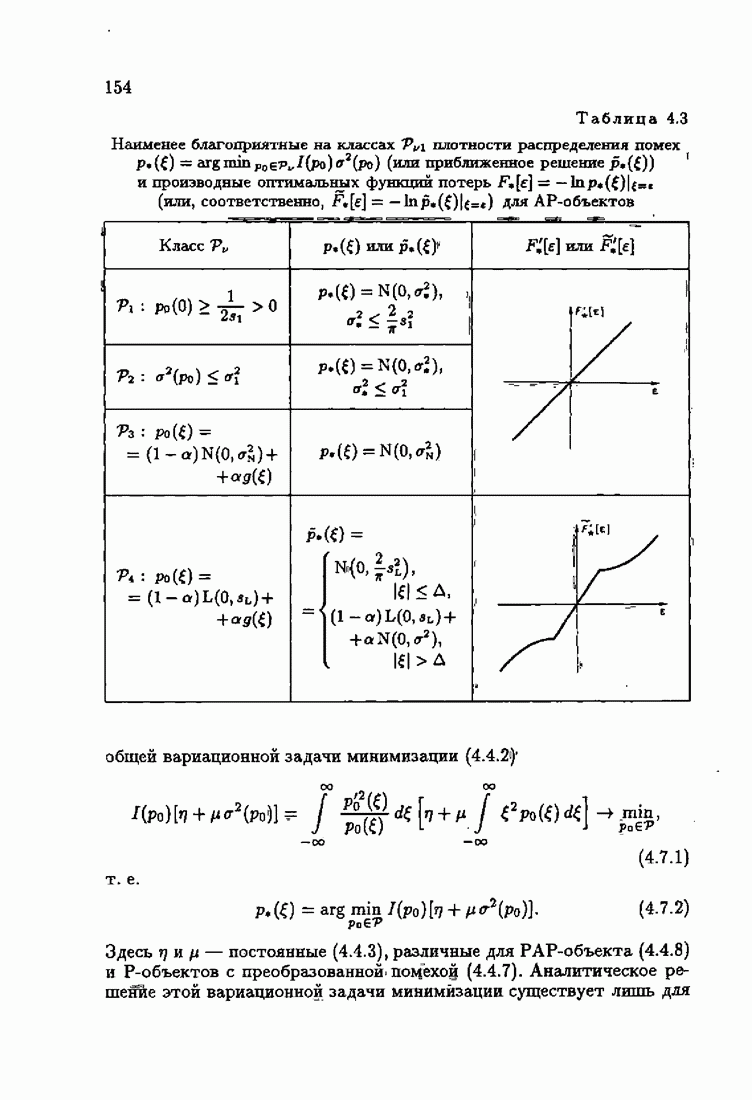
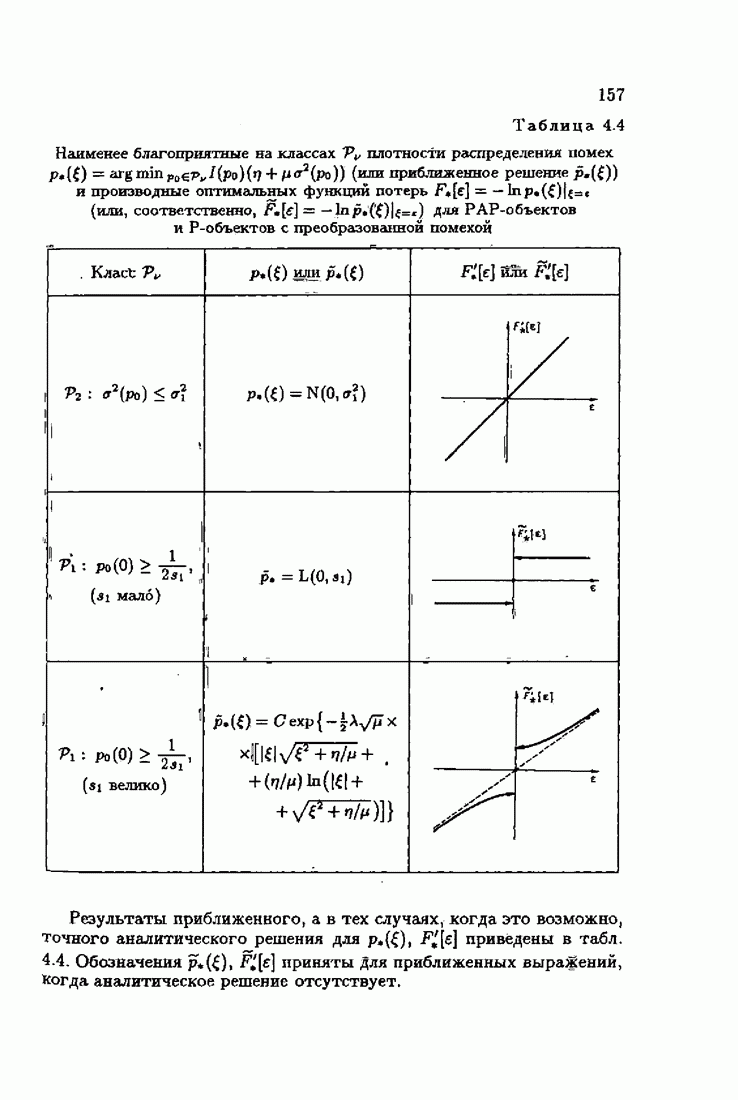
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
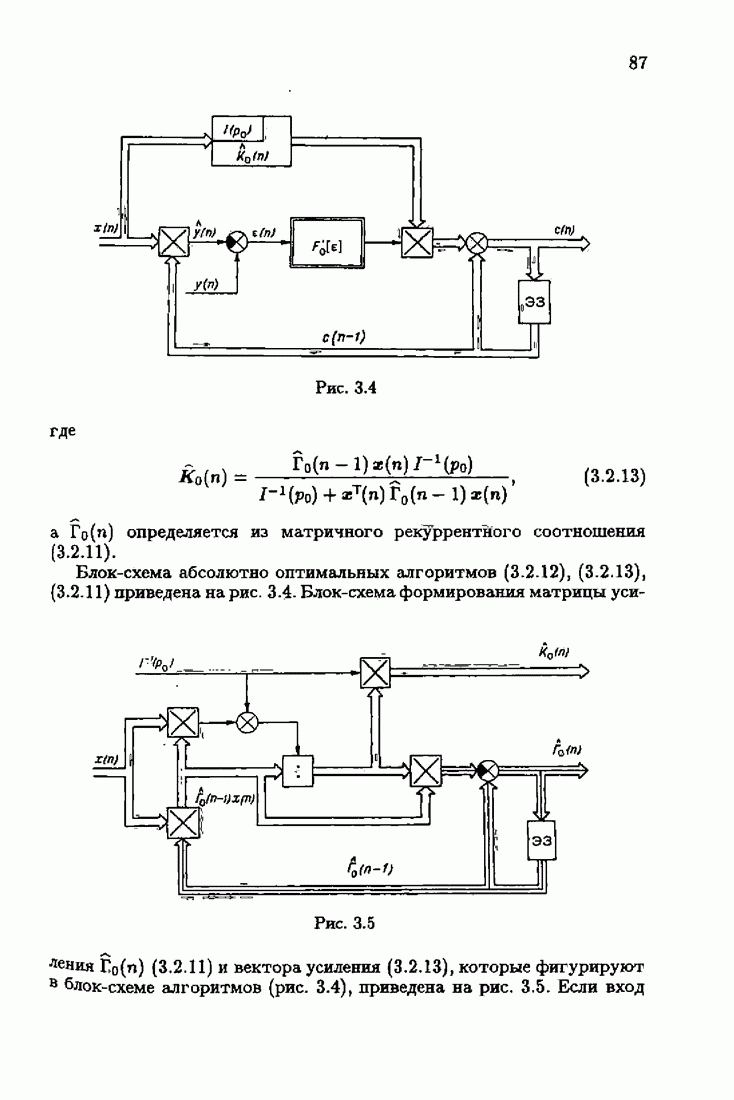
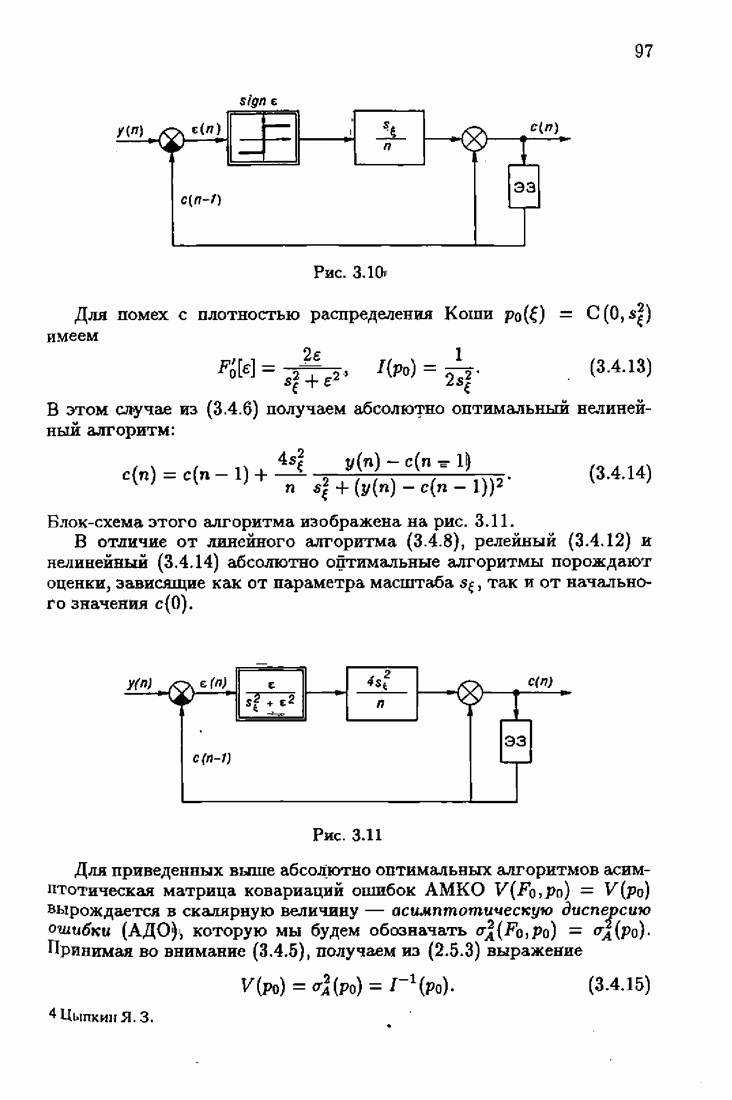
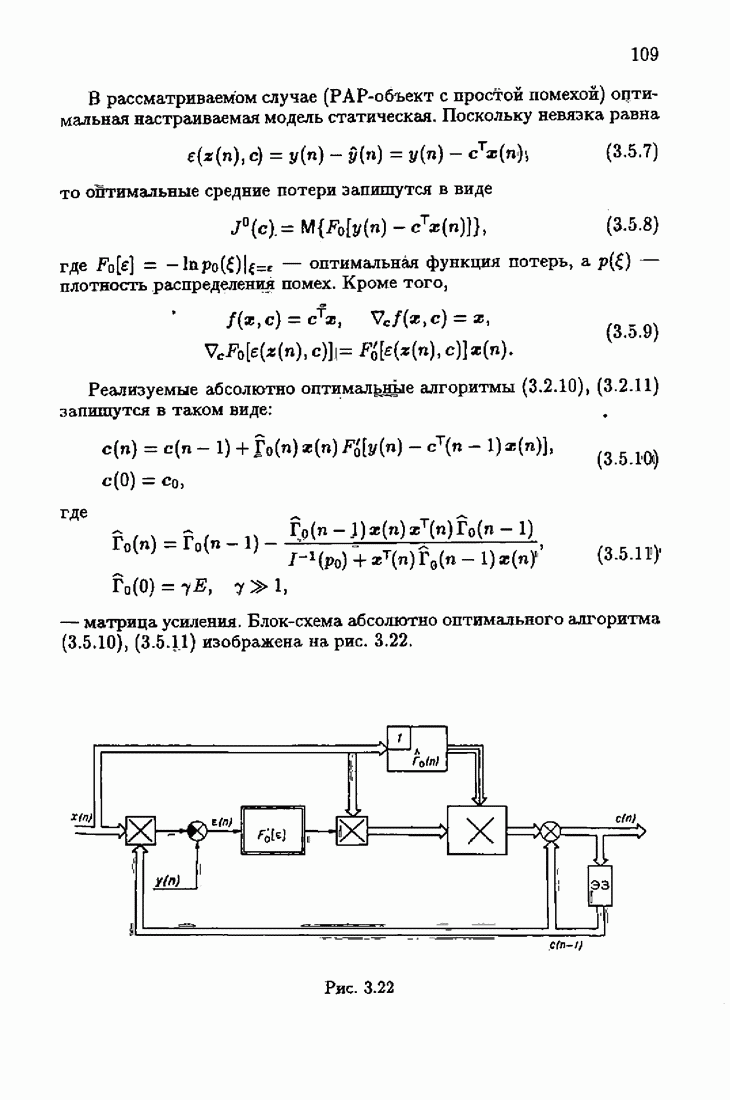
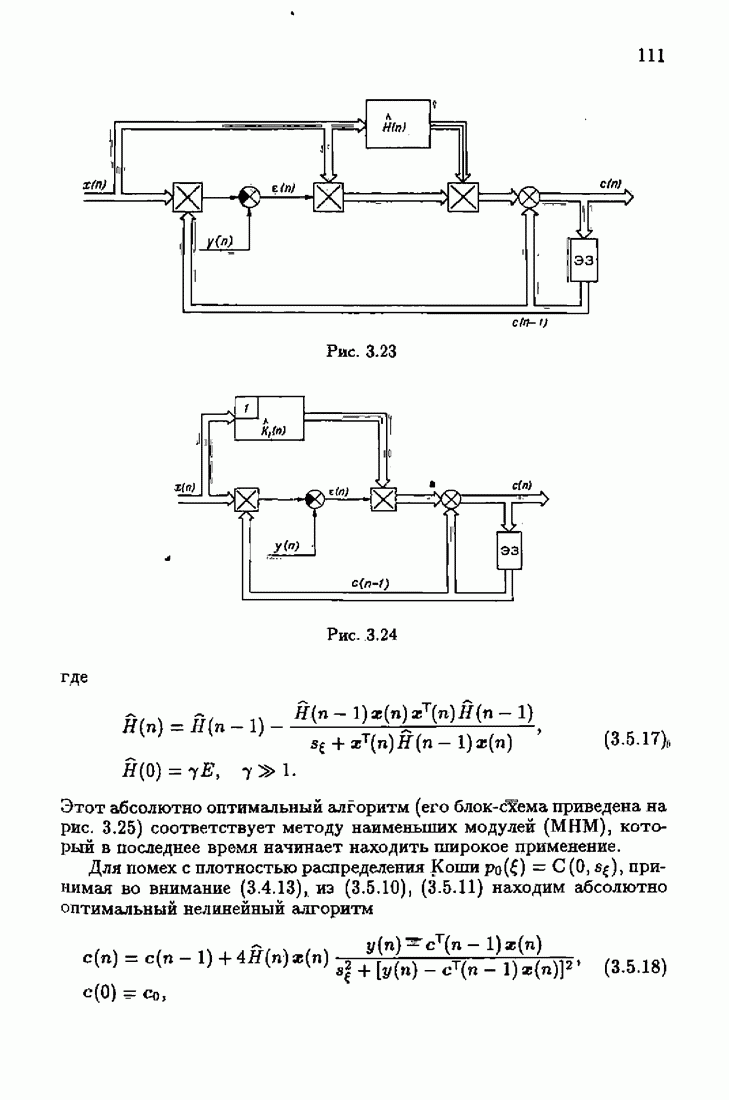
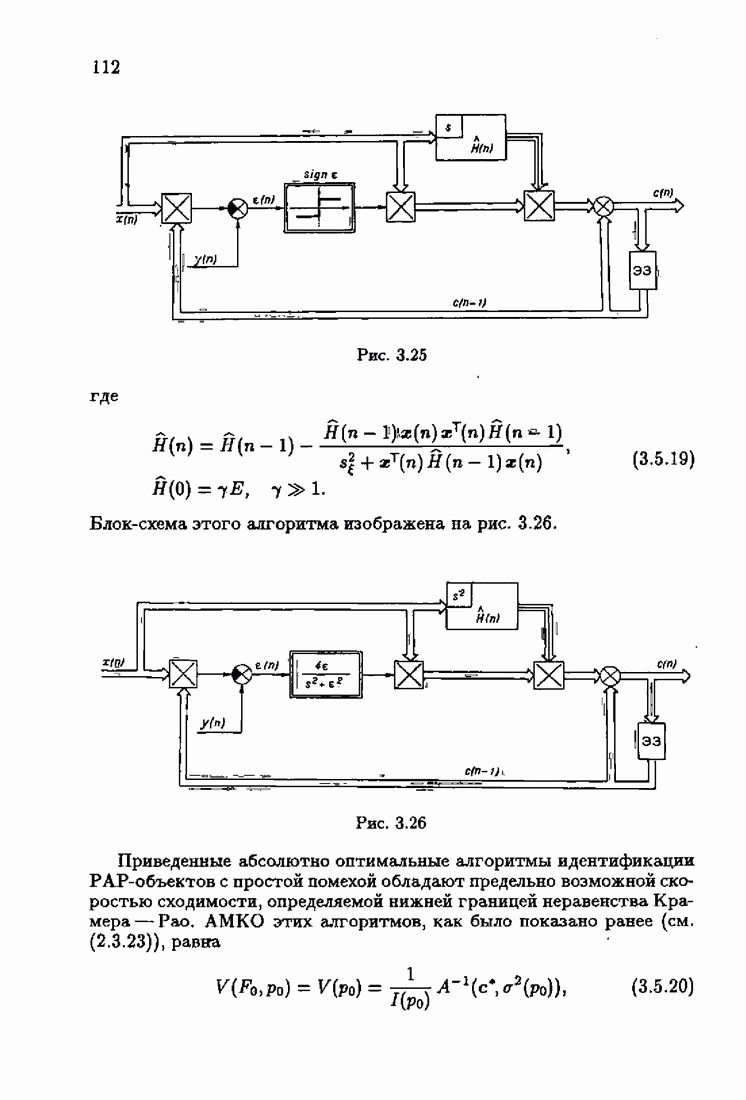
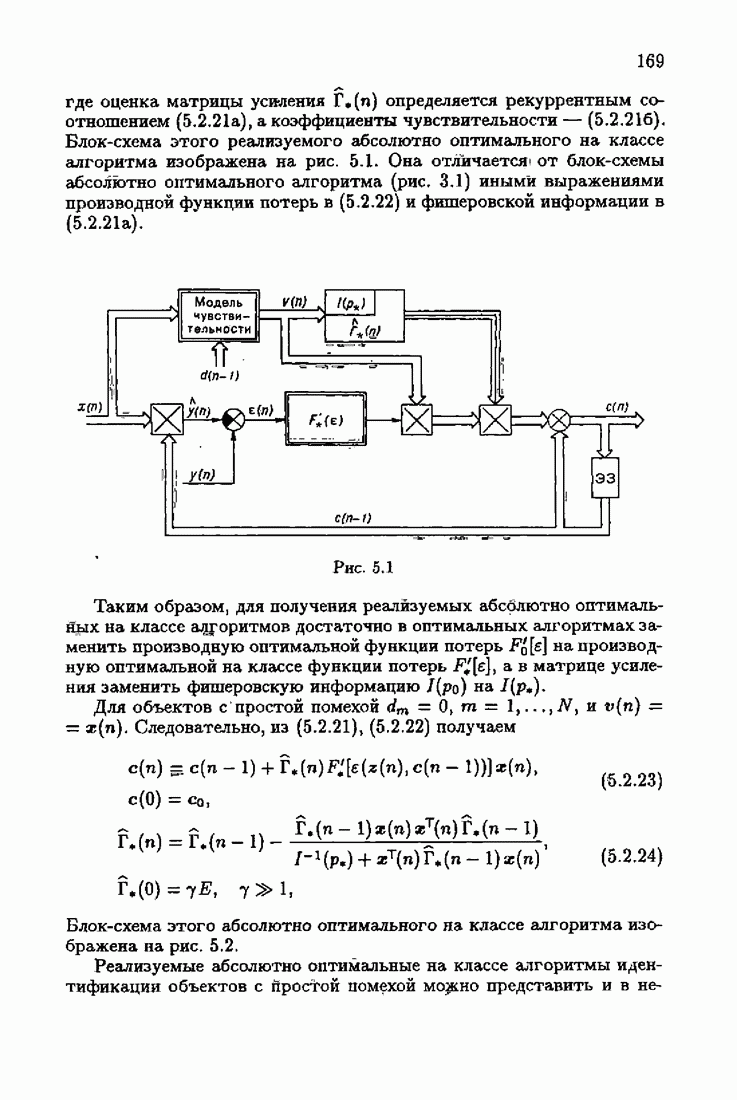
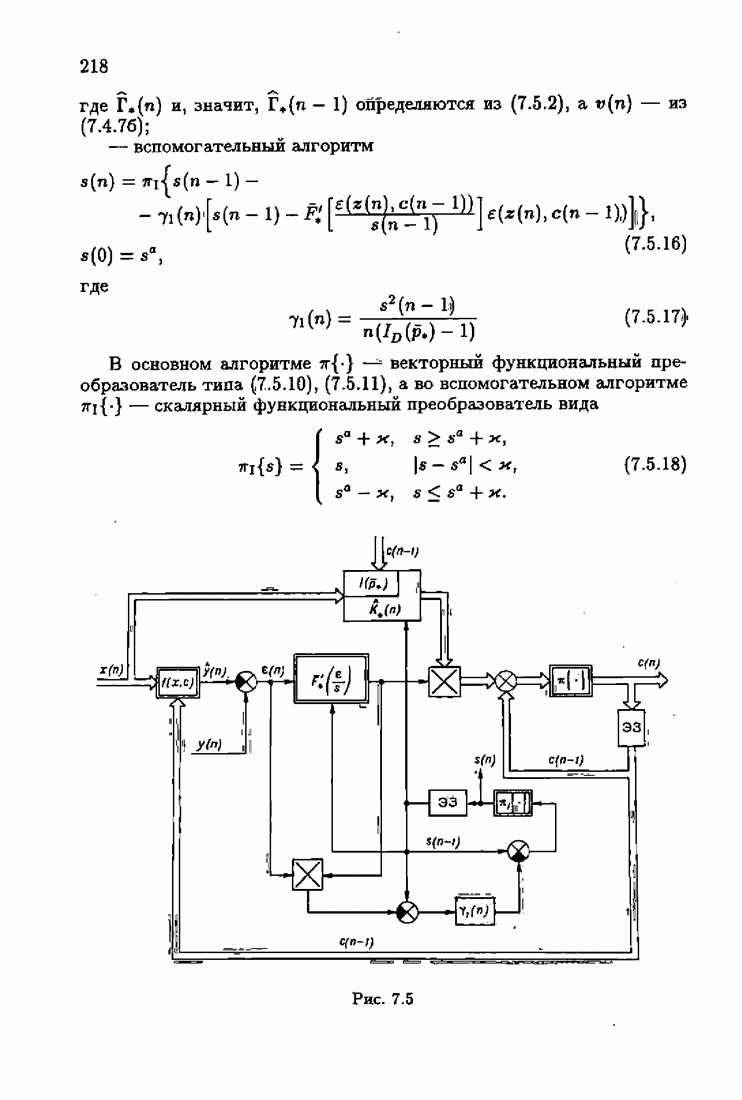
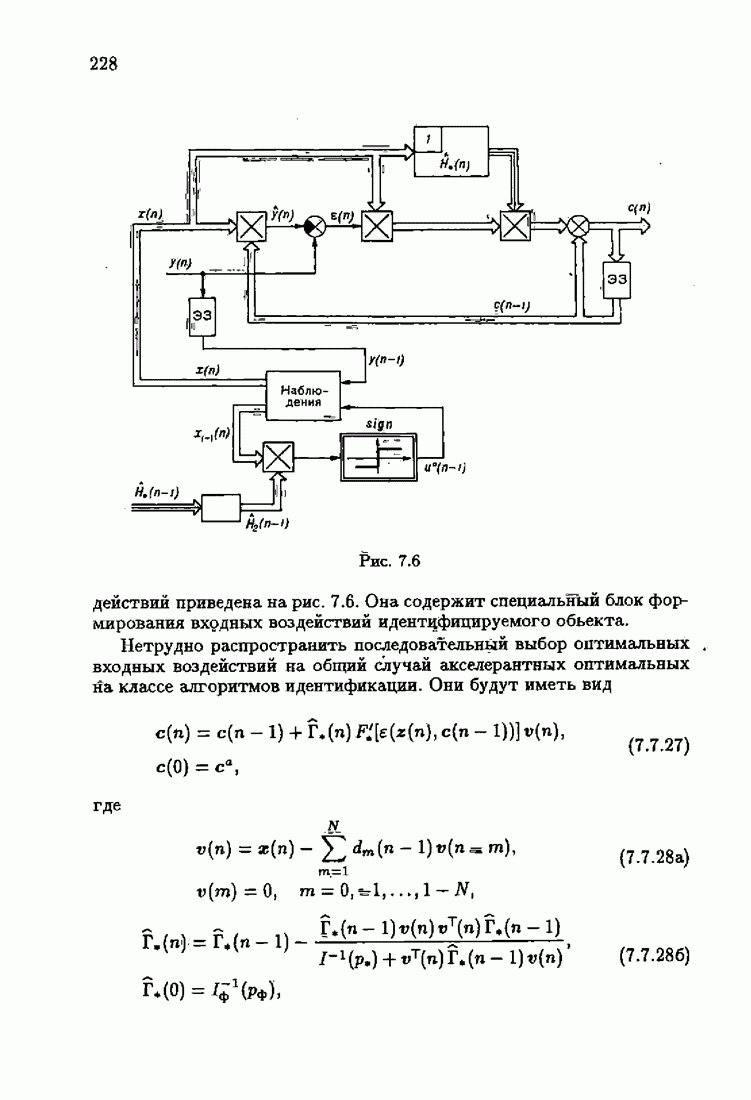
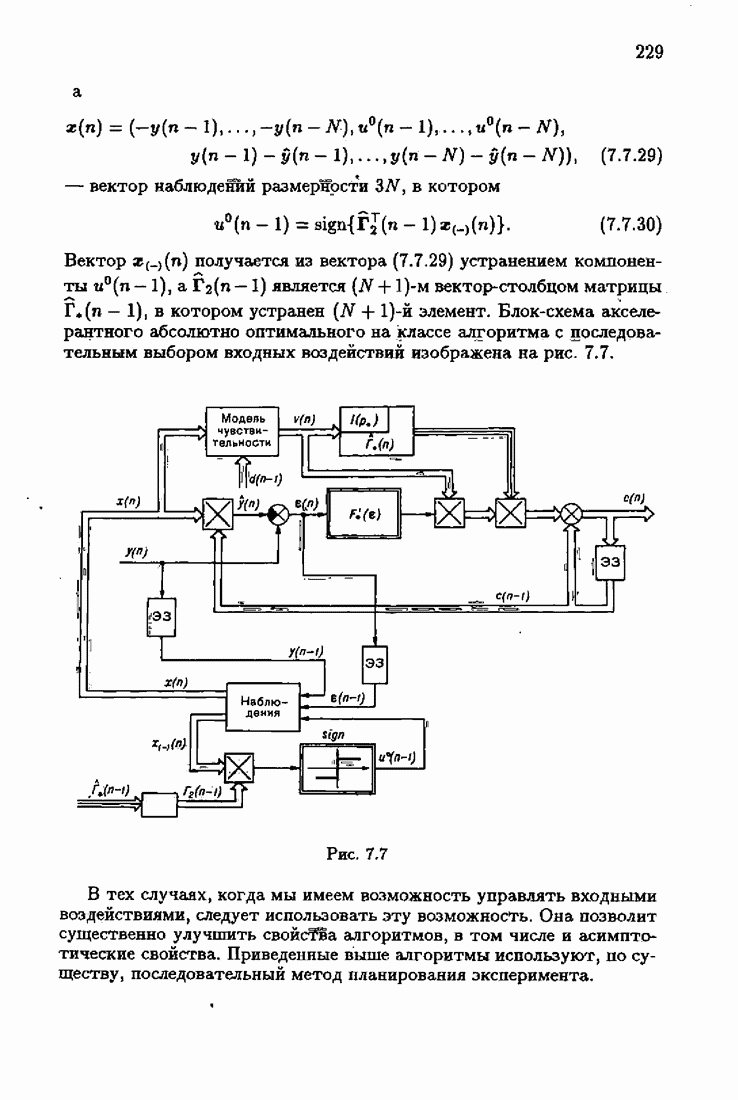
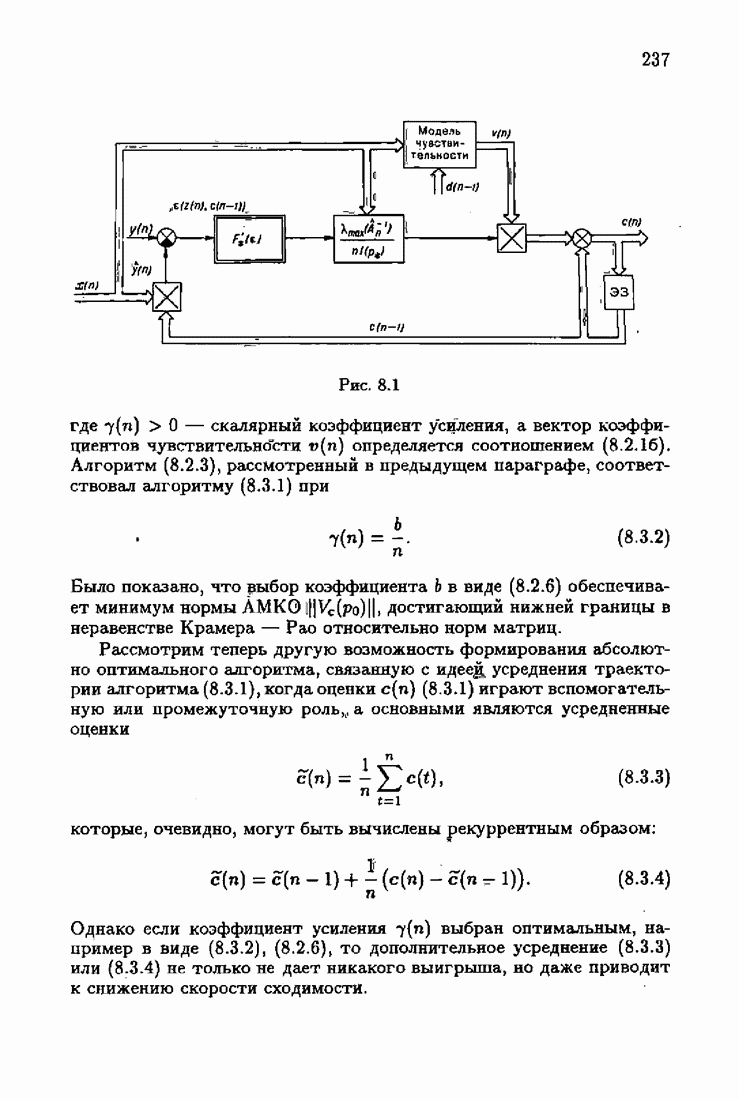
7.4. Акселерантные абсолютно оптимальные алгоритмыАлгоритмы, порождаемые условием оптимальности вида (7.3.8), учитывающим априорную информацию об оптимальном решении, как выше было условлено, назовем акселерантными. Для формирования акселерантных алгоритмов воспользуемся одной из разновидностей алгоритмов Ньютона — Рафсона для решения системы нелинейных уравнений. В общем случае
Выбор вектора с в матрице Гессе
При
Наконец, при
Сделаем еще один шаг. Заменим в (7.4.4) матрицу Гессе
Тогда эта модификация алгоритма Ньютона—Рафсона окончательно представится в виде
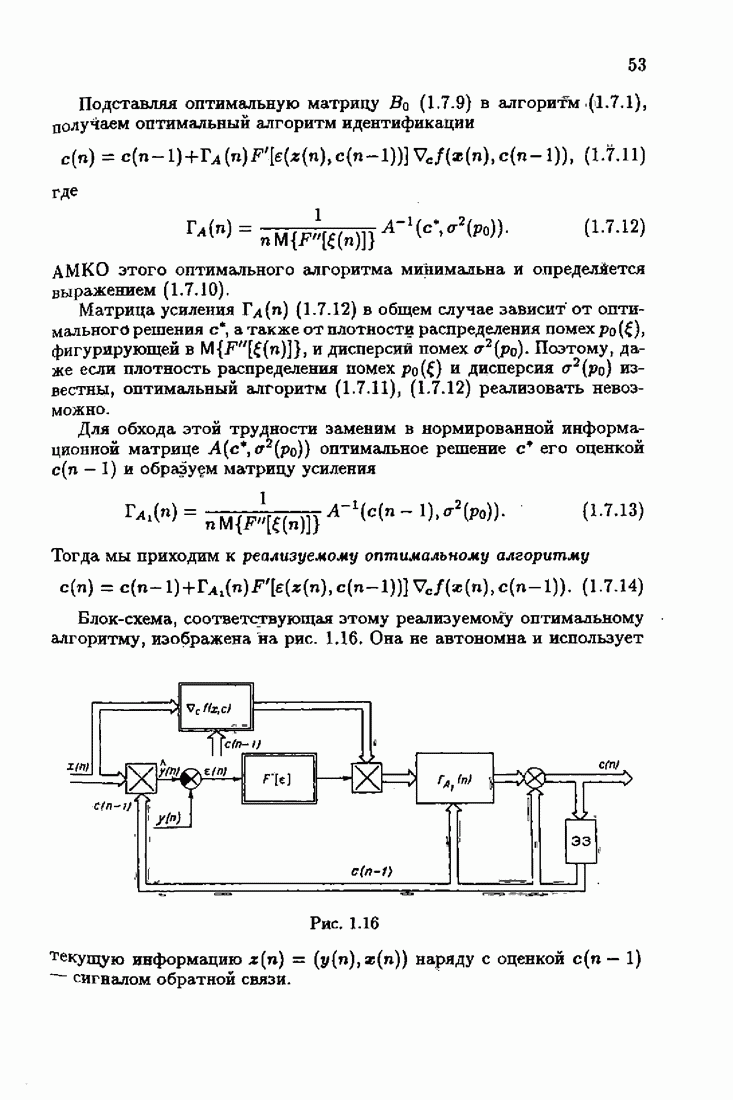
Этим алгоритмом мы и воспользуемся для формирования акселерантных алгоритмов идентификации. Рассмотрим вначале градиент обобщенных эмпирических средних потерь, входящий в алгоритм (7.4.6):
где
Его можно представить в виде
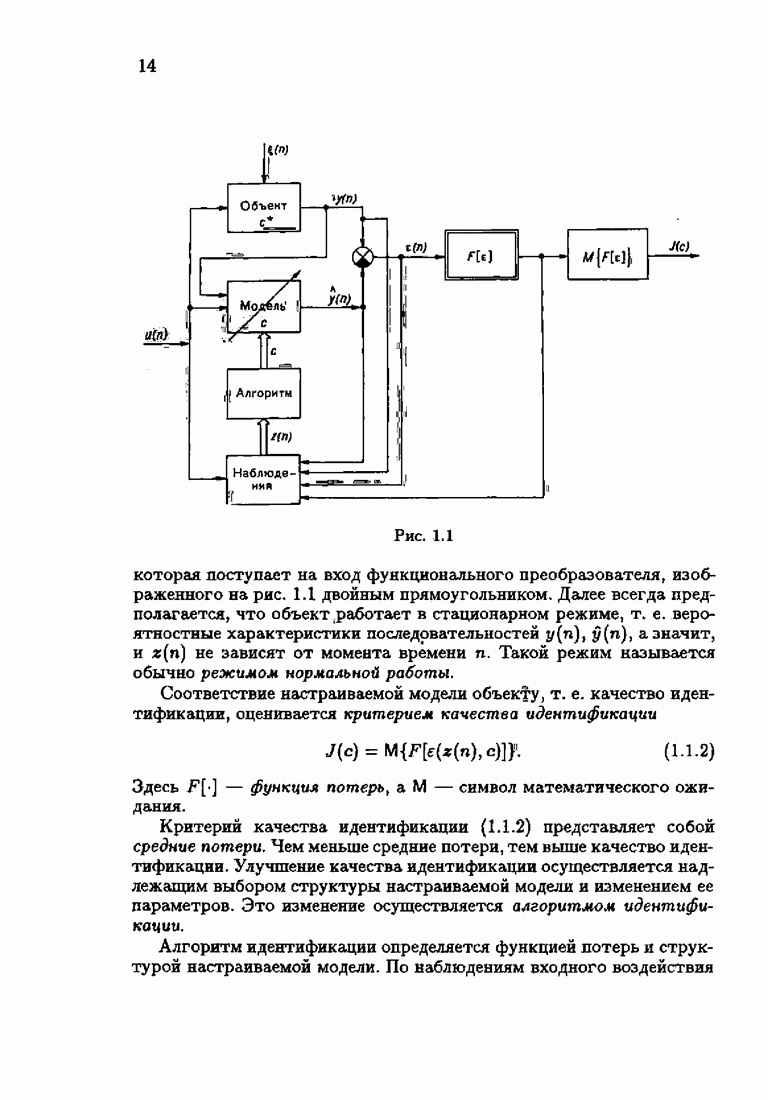
Предположим, что приближенно
Тогда из (7.4.8) получим
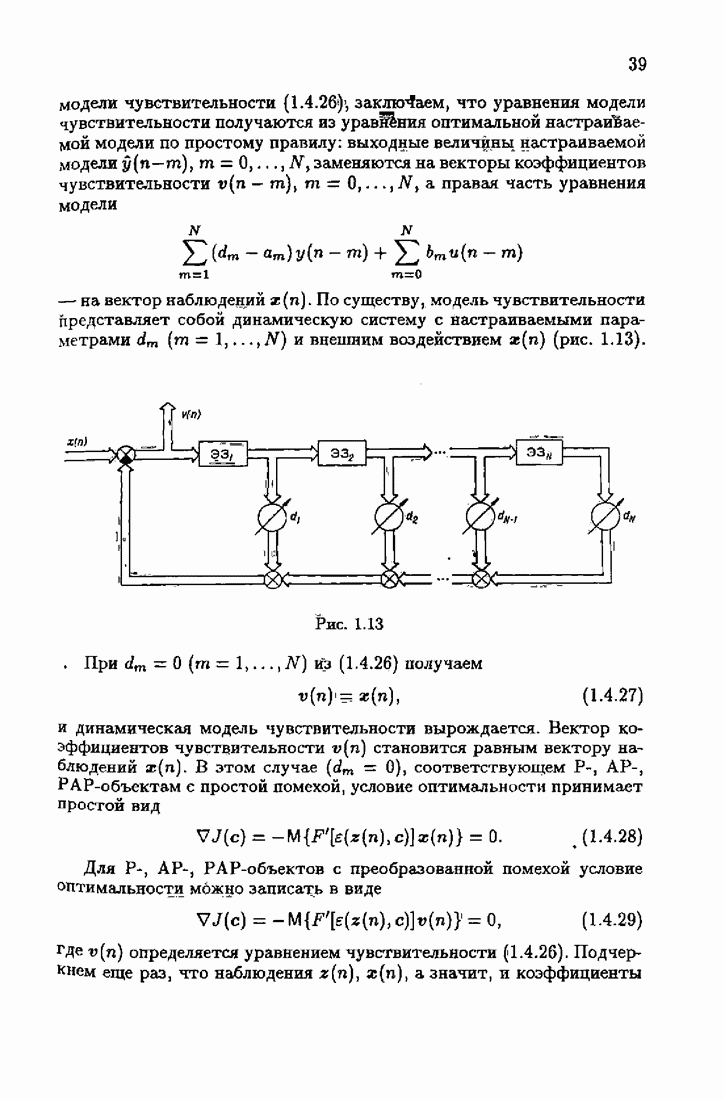
Таким образом определяется градиент Теперь займемся вычислением матрицы Гессе
Но в силу (7.3.4), (7.2.1)
где
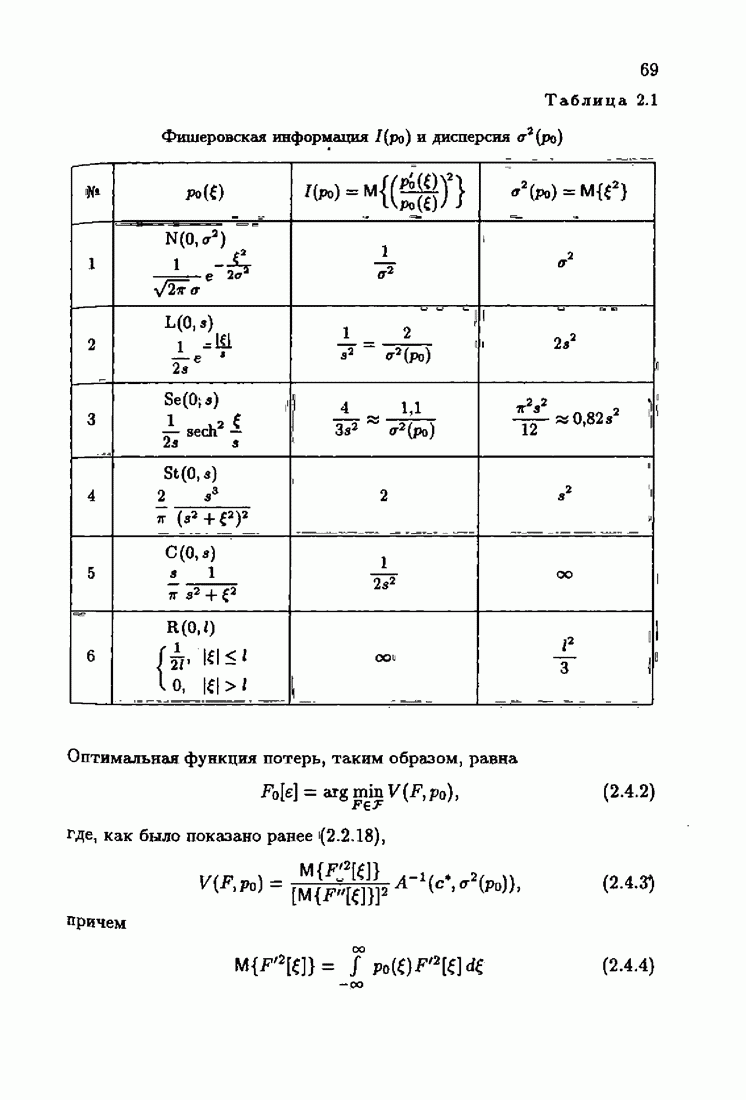
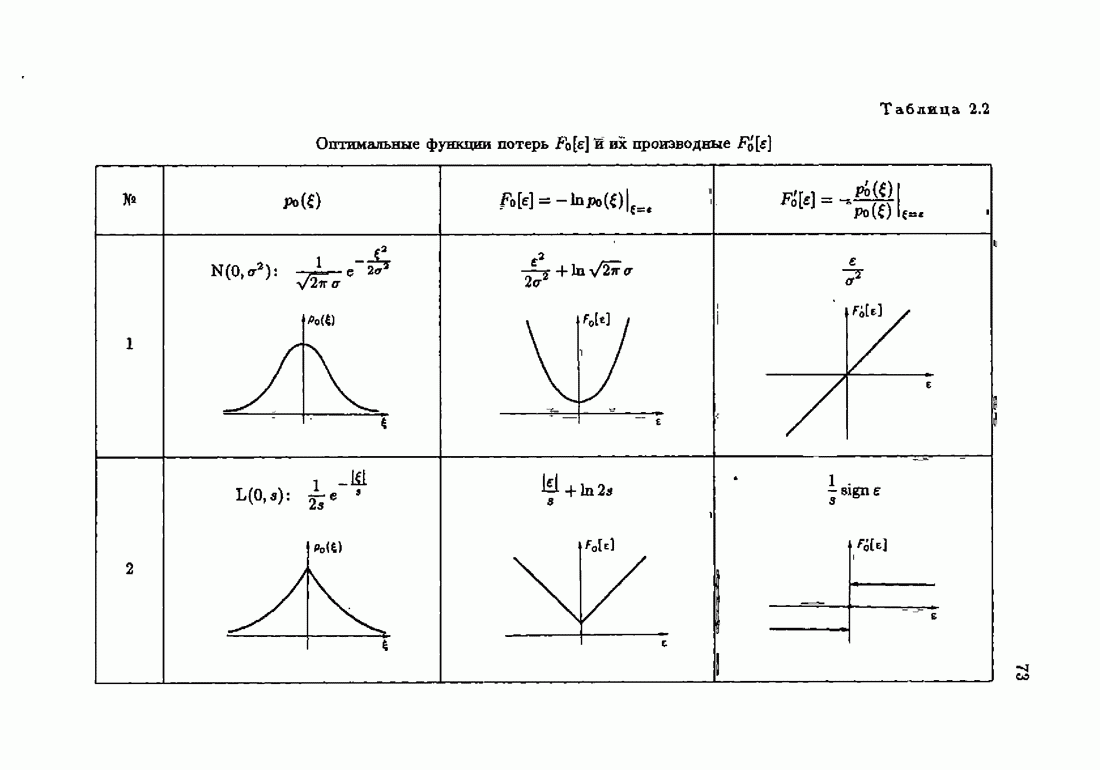
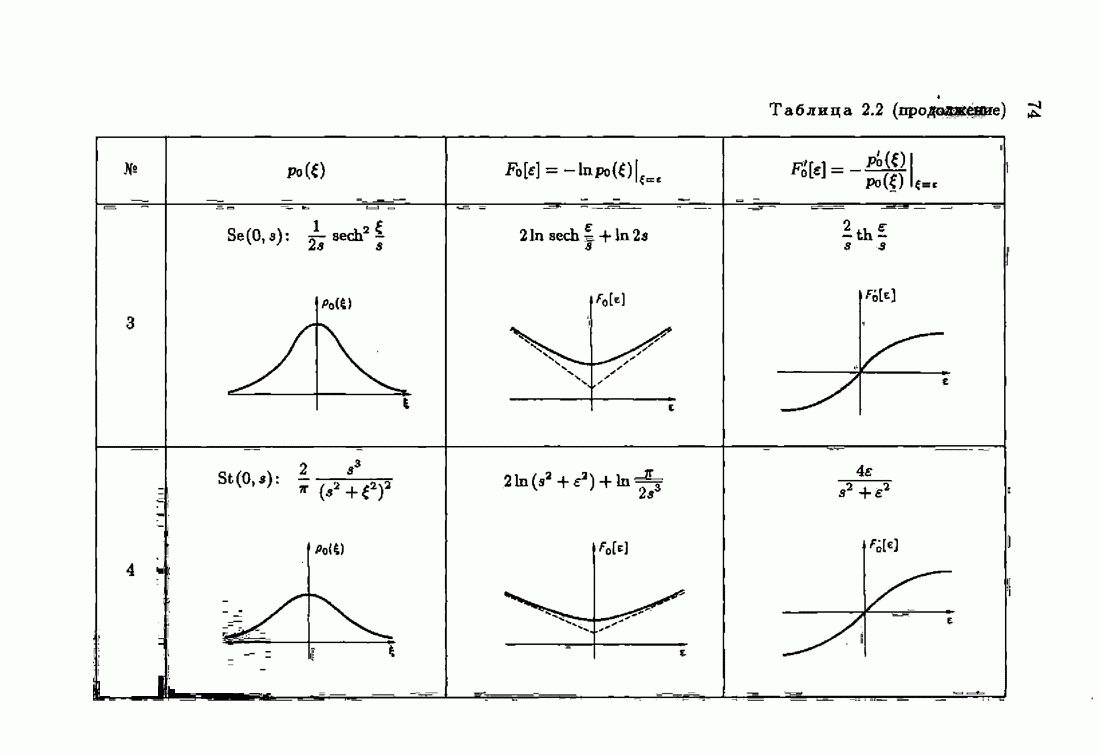
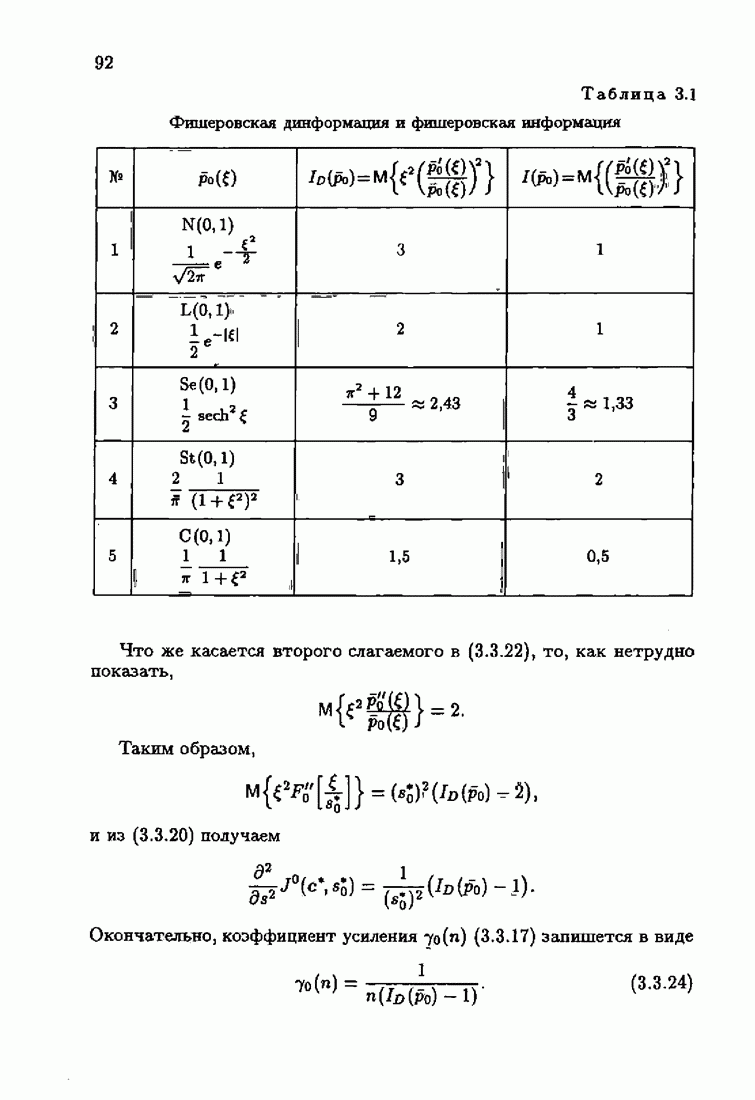
Если принять, что компоненты вектора рандомизации (7.2.3) независимы, то матрица фишеровских информаций (7.4.12) будет диагональной положительно определенной матрицей вида
Здесь
— фишеровские информации, соответствующие фидуциальным плотностям распределения компонент вектора рандомизации. Заменяя в формуле (7.4.13) нормированную информационную матрицу
где
Подставляя выражение градиента (7.4.10) и матрицы Гессе (7.4.17) в алгоритм (7.4.6), получим после уже знакомых преобразований
где
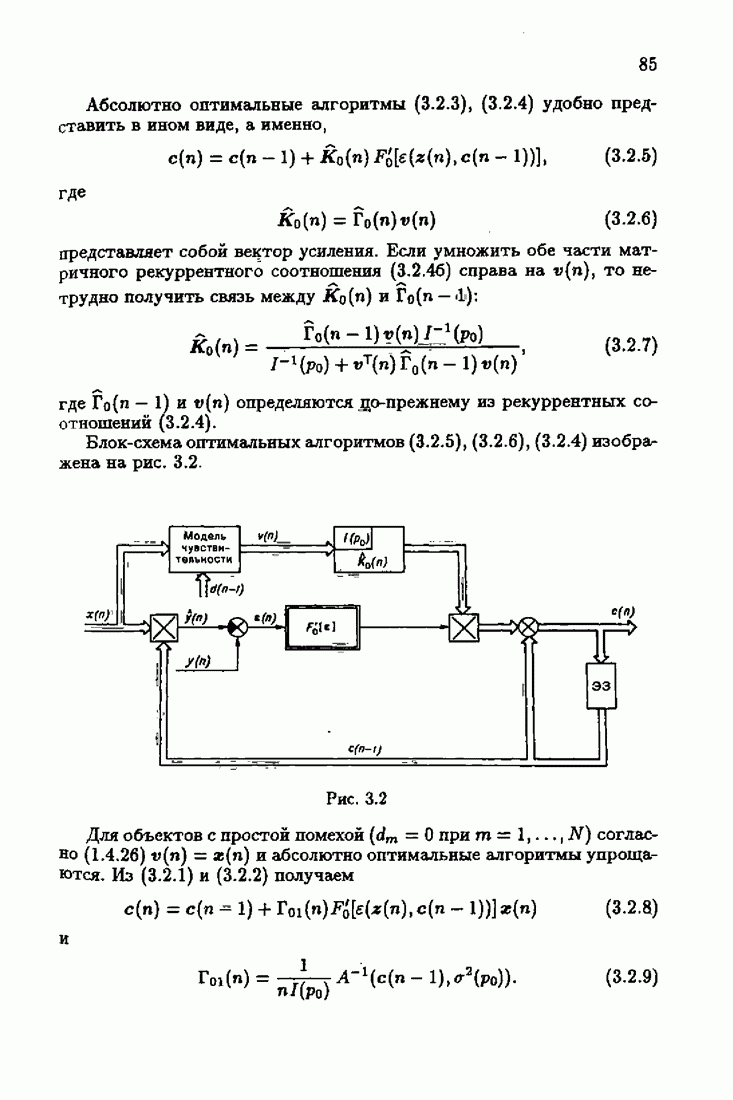
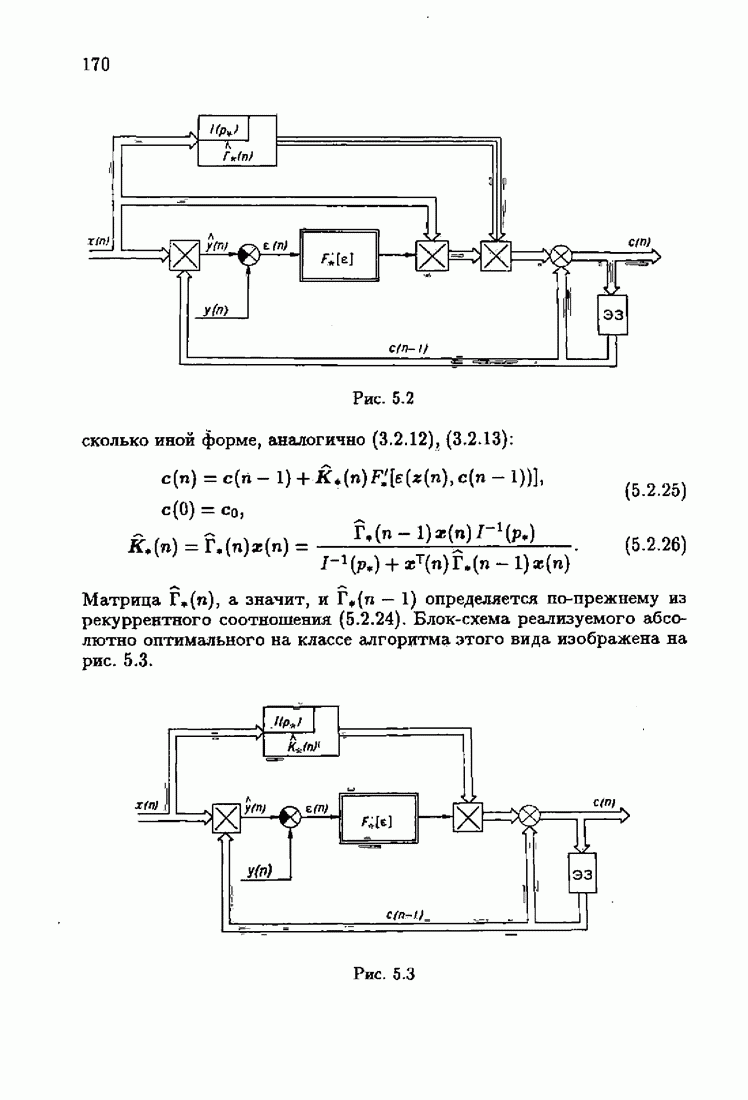
Применяя к матрице усиления
Начальное значение матрицы усиления
Таким образом, мы приходим к акселерантным абсолютно оптимальным алгоритмам Акселерантные алгоритмы (7.4.18), (7.4.19) можно представить и в несколько иной форме:
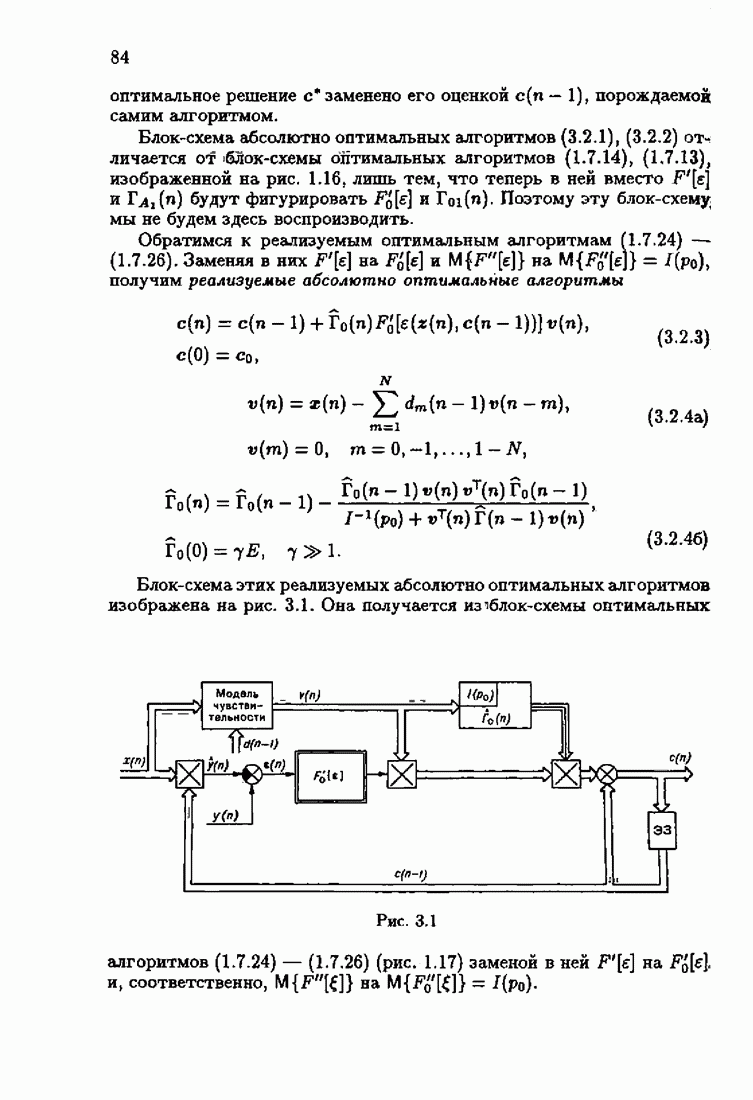
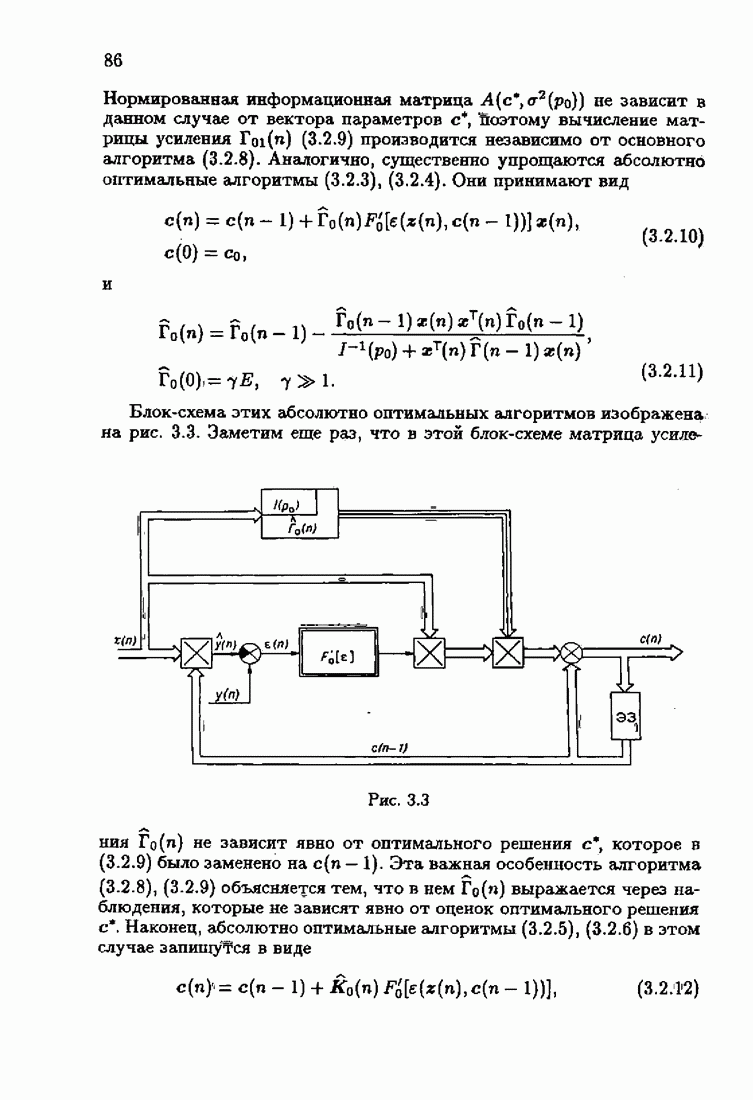
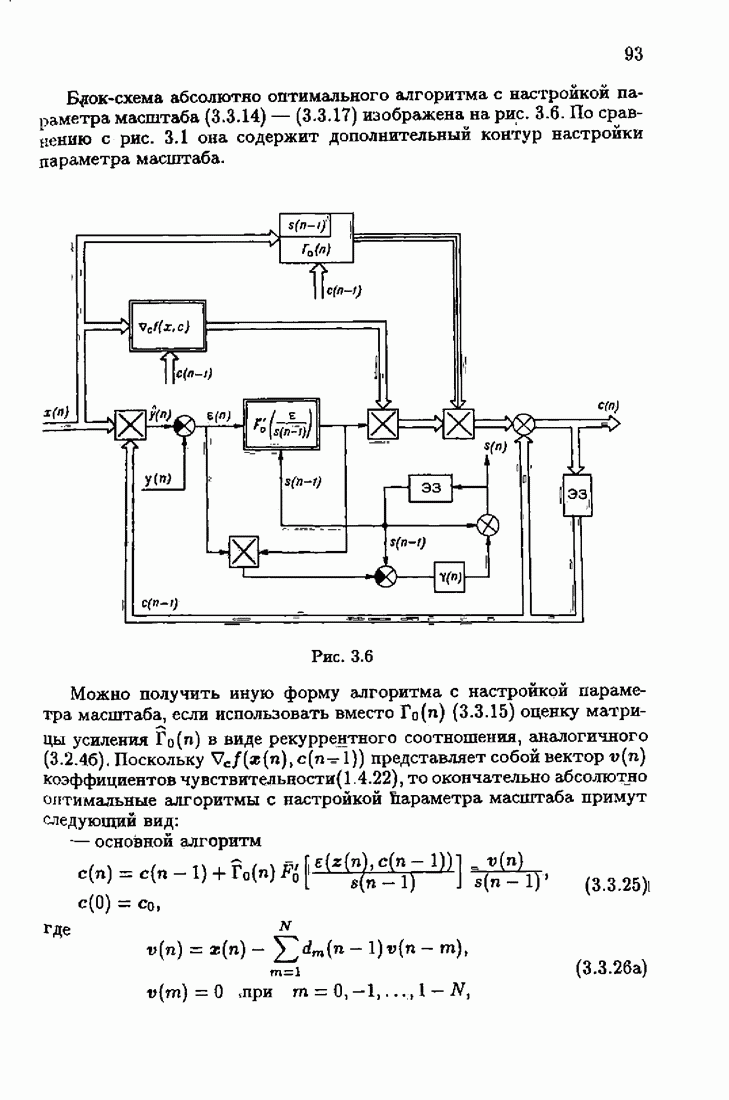
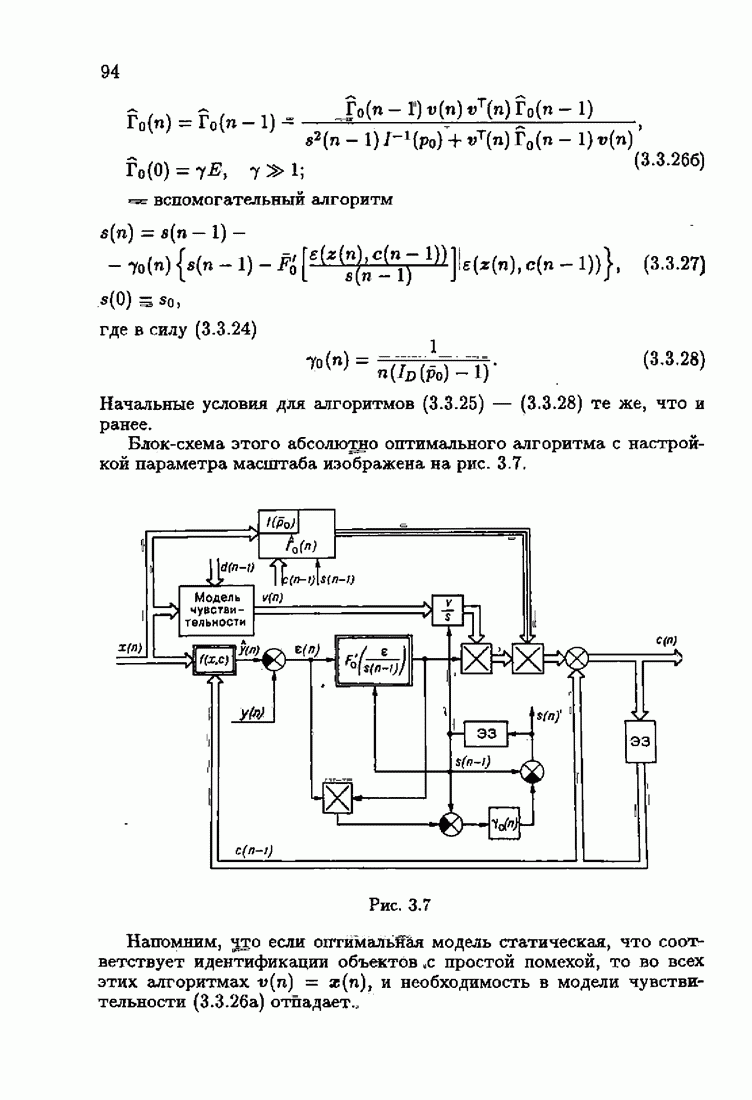
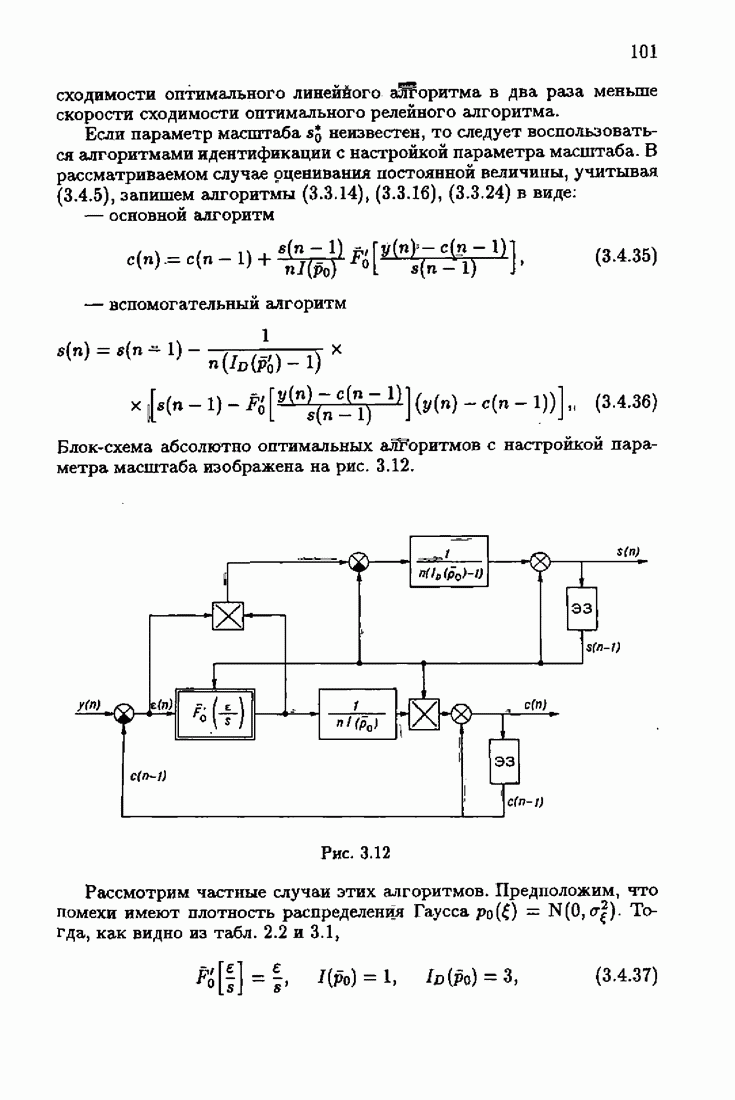
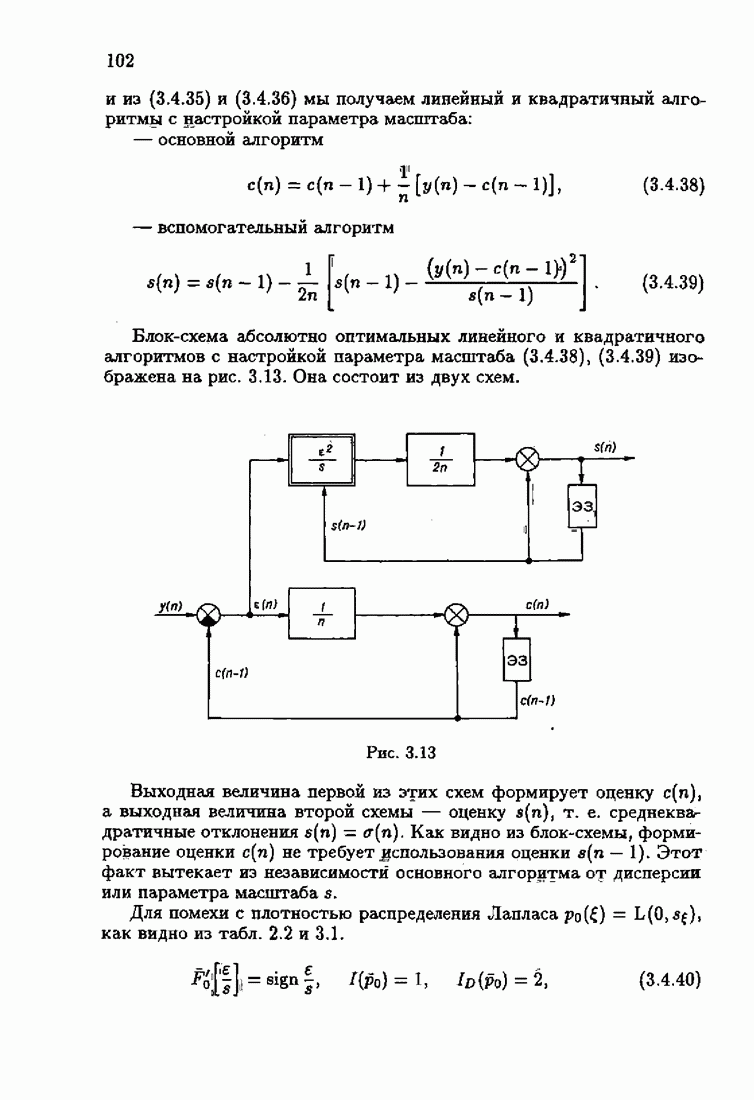
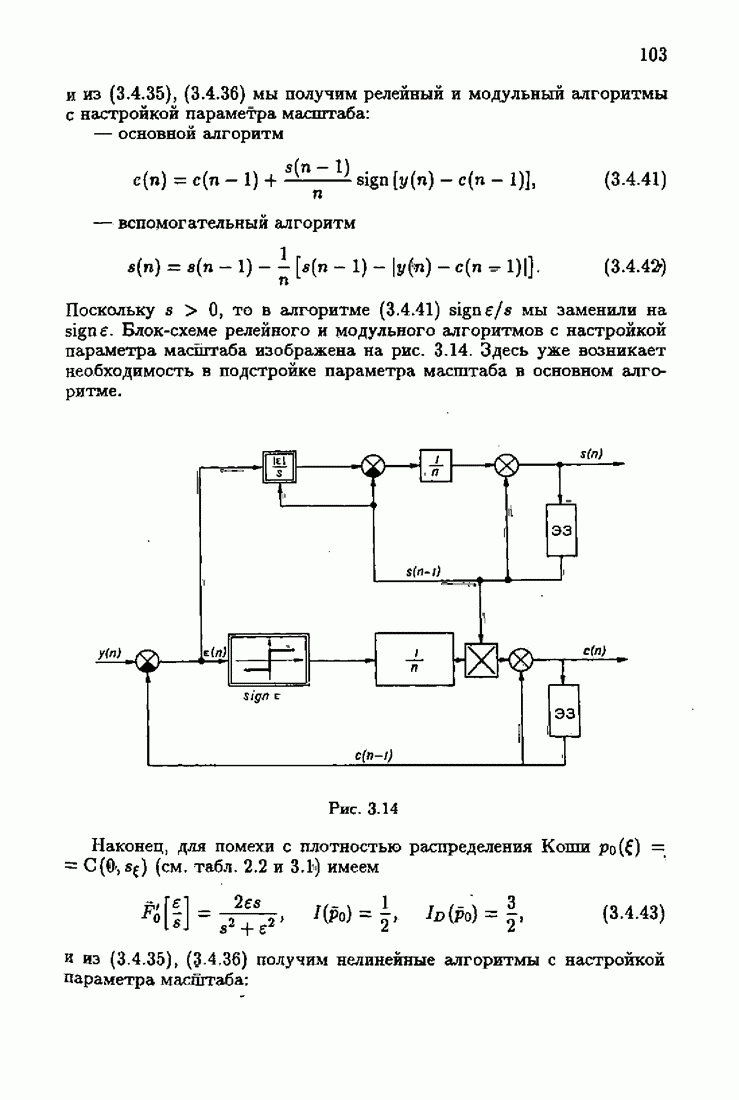
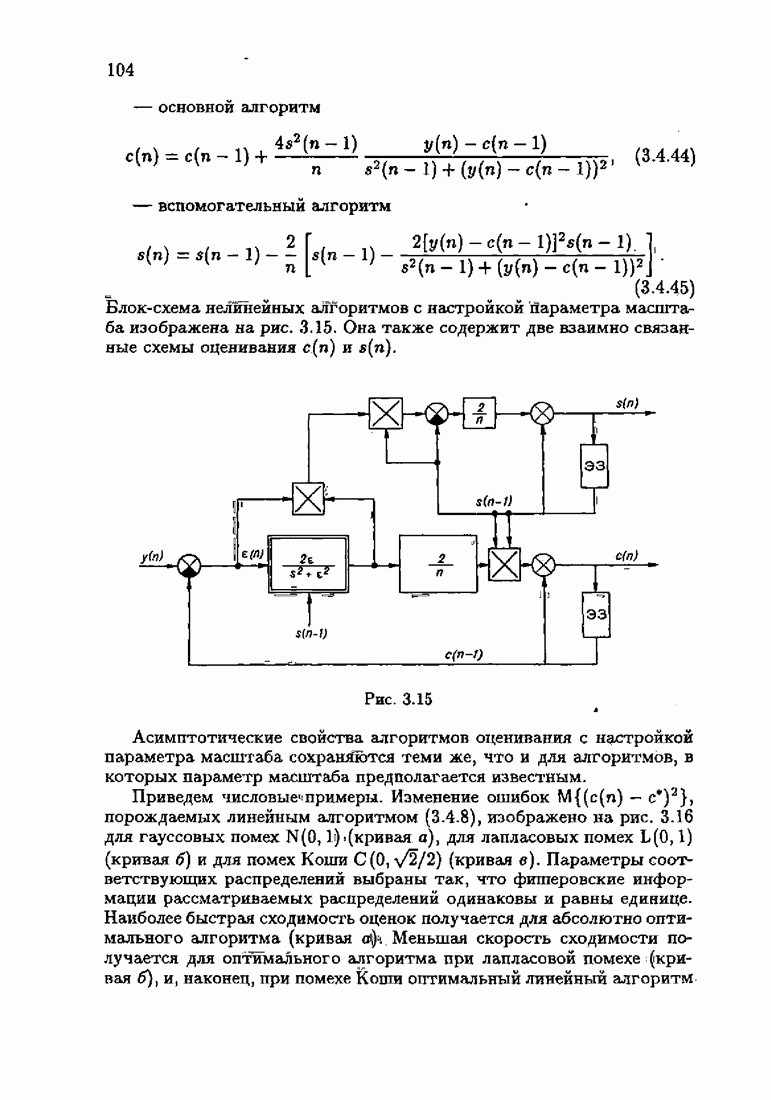
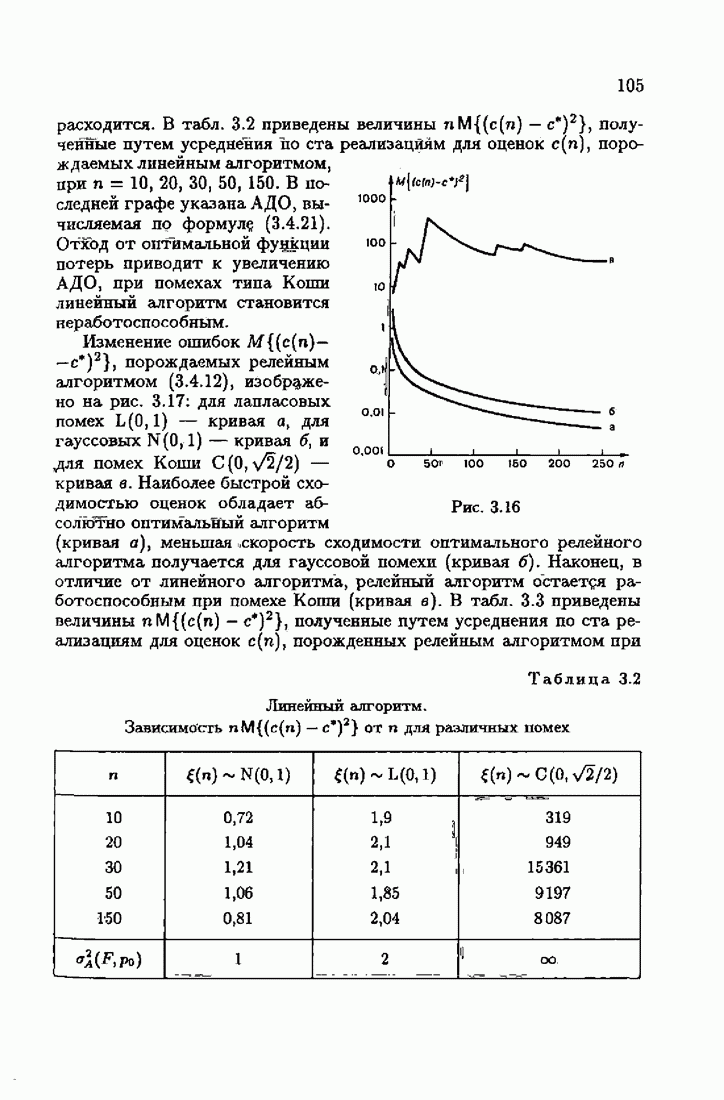
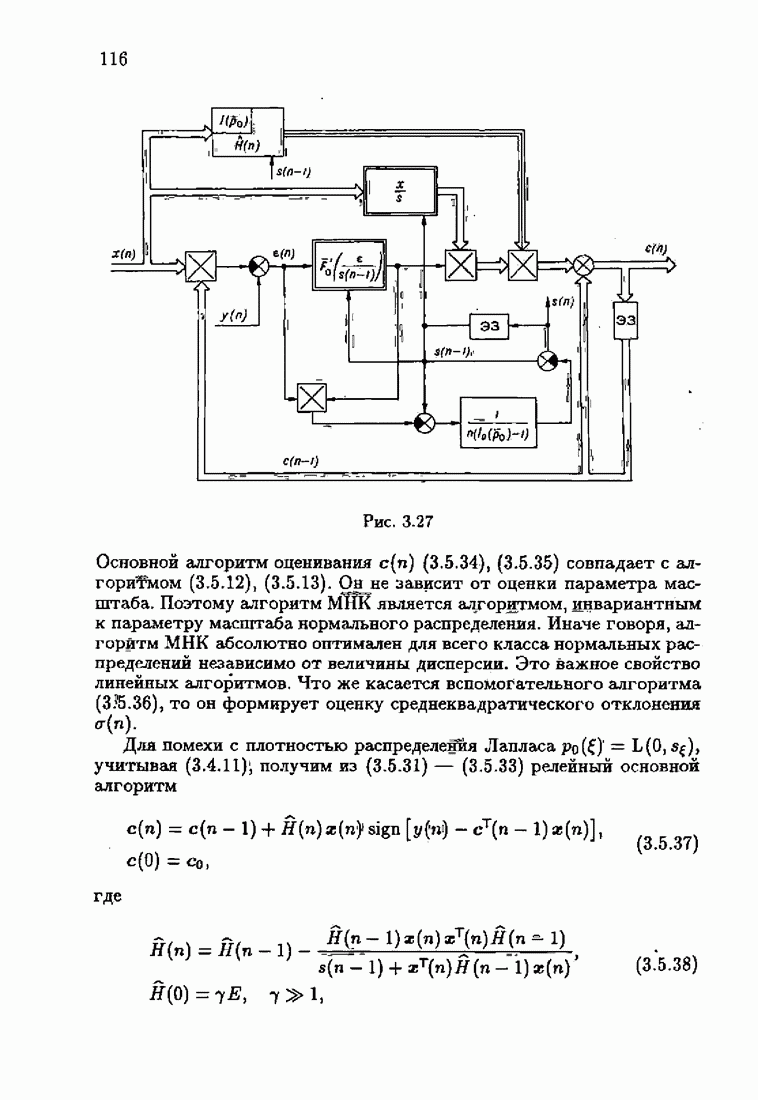
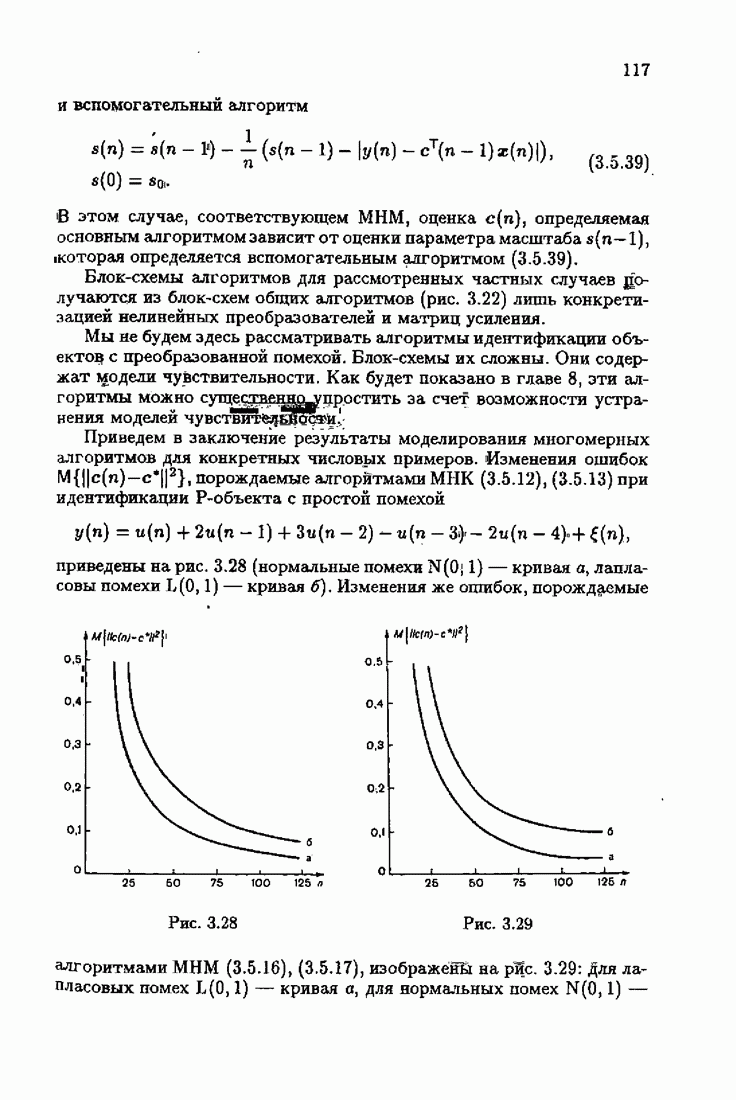
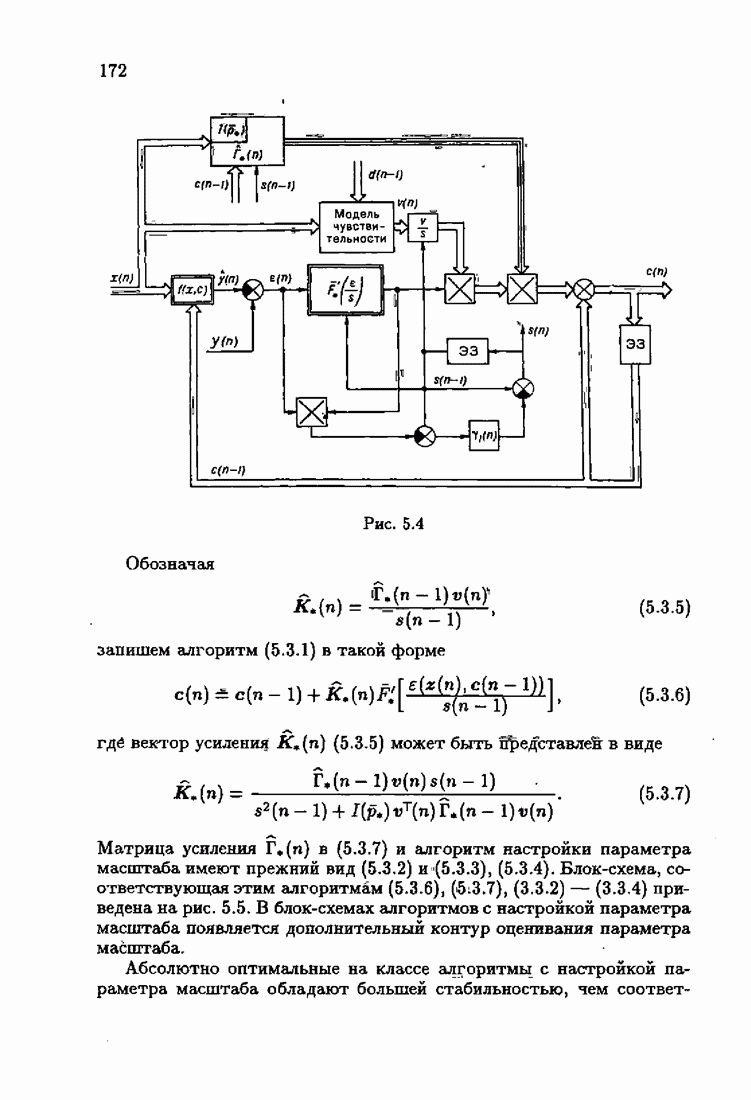
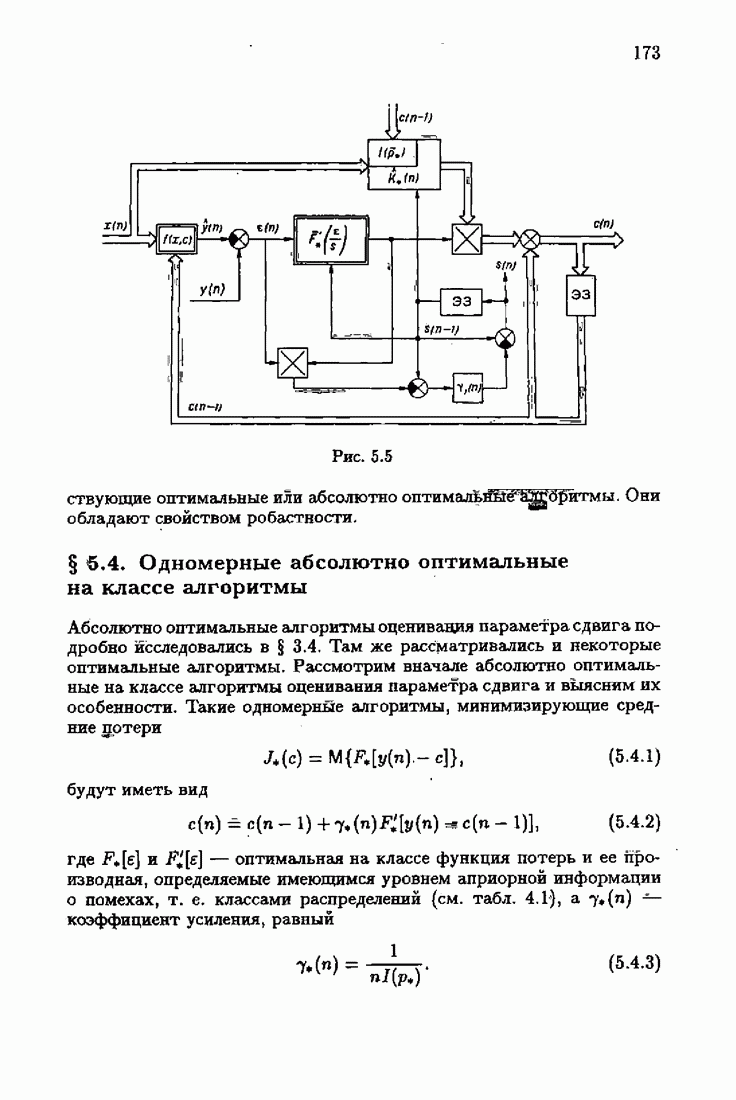
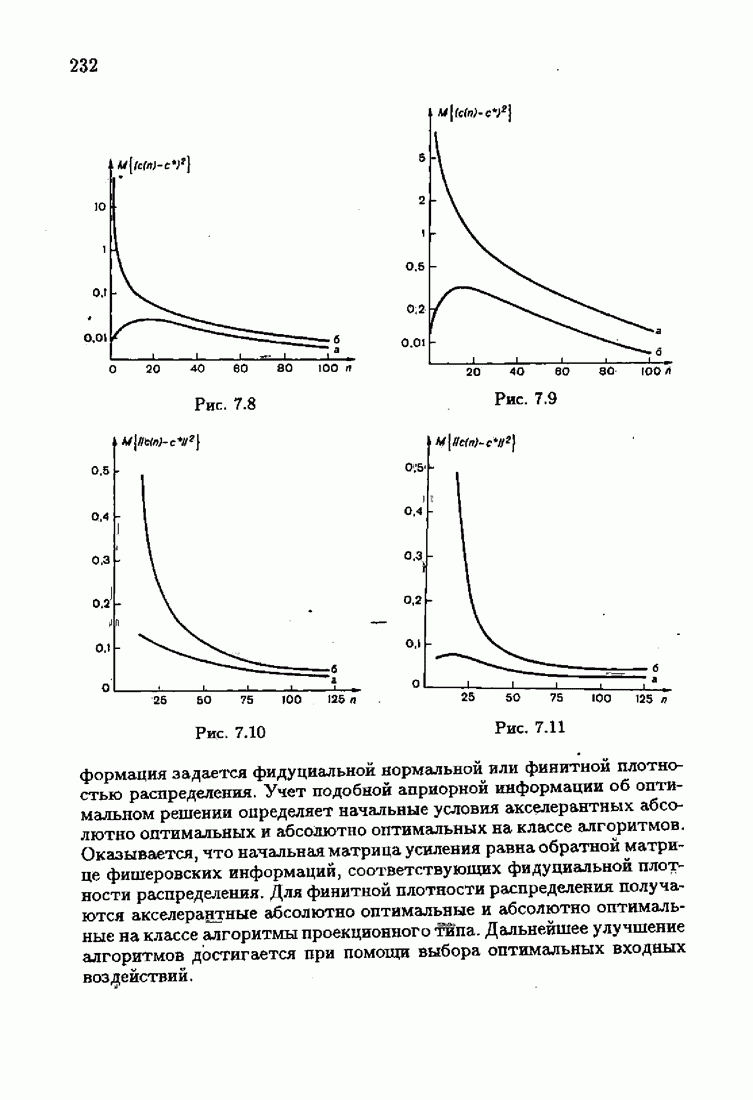
где Сопоставляя акселерантные абсолютно оптимальные алгоритмы (7.4.76), (7.4.18), (7.4.20), (7.4.21) или (7.4.22), (7.4.23), (7.4.20), (7.4.76), (7.4.21) с соответствующими абсолютно оптимальными алгоритмами (3.2.3), (3.2.4) или (3.2.5), (3.2.7), (3.2.4), заключаем, что они отличаются лишь начальными значениями. В акселерантных абсолютно оптимальных алгоритмах начальные значения Таким образом, акселеризация алгоритмов идентификации сводится к замене в них произвольных начальных значений начальными значениями, определенными априорной информацией об оптимальном решении. Блок-схемы акселерантных алгоритмов совпадают с блок-схемами абсолютно оптимальных алгоритмов рис. 1.16 (см. § 3.2) и рис. 3.1 при конкретных начальных значениях. Мы не будем приводить здесь выражения акселерантных алгоритмов с настройкой параметра масштаба. Они образуются из оптимальных алгоритмов с настройкой параметра масштаба (3.3.25) — (3.3.27) заменой произвольных начальных значений начальными значениями, определяемыми априорной информацией об оптимальном решении и параметре масштаба, а именно:
Блок-схемы этих акселерантных алгоритмов совпадают с блок-схемами алгоритмов с настройкой параметра масштаба рис. 3.12 при конкретных начальных значениях (7.4.24).
|
 |
Оглавление
|





































































































































































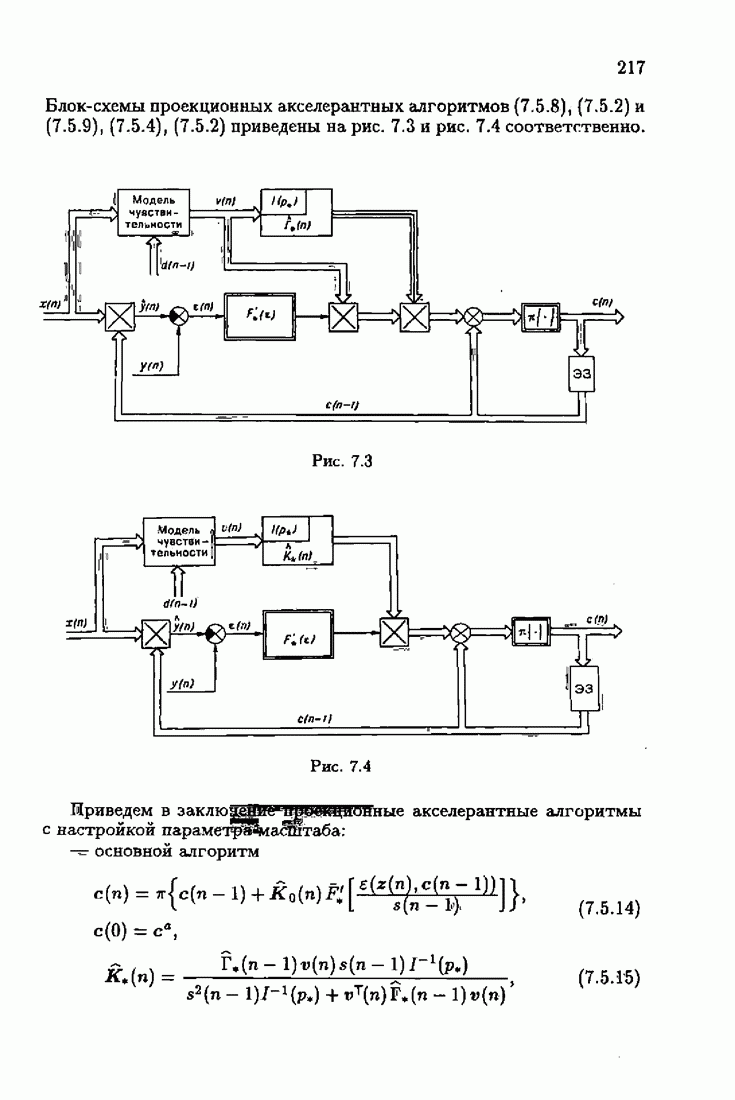




















































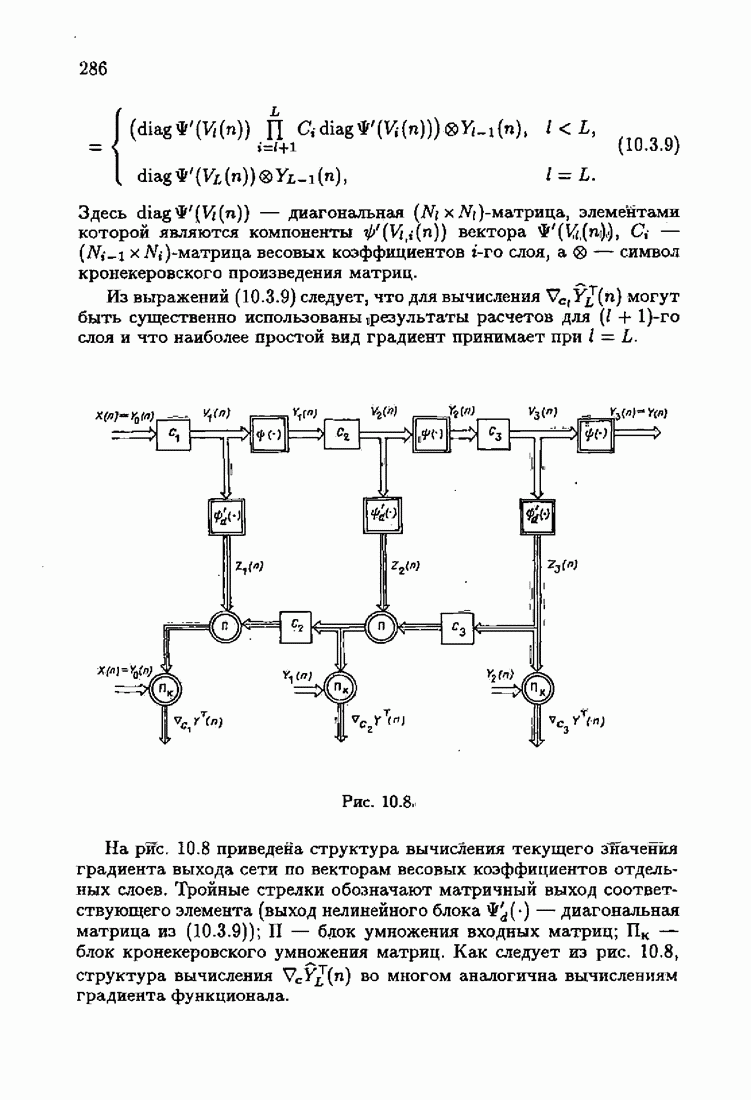

















































 определяет ту или иную разновидность алгоритма Ньютона — Рафсона. При
определяет ту или иную разновидность алгоритма Ньютона — Рафсона. При  из (7.4.1) получаем классический алгоритм Ньютона — Рафсона
из (7.4.1) получаем классический алгоритм Ньютона — Рафсона

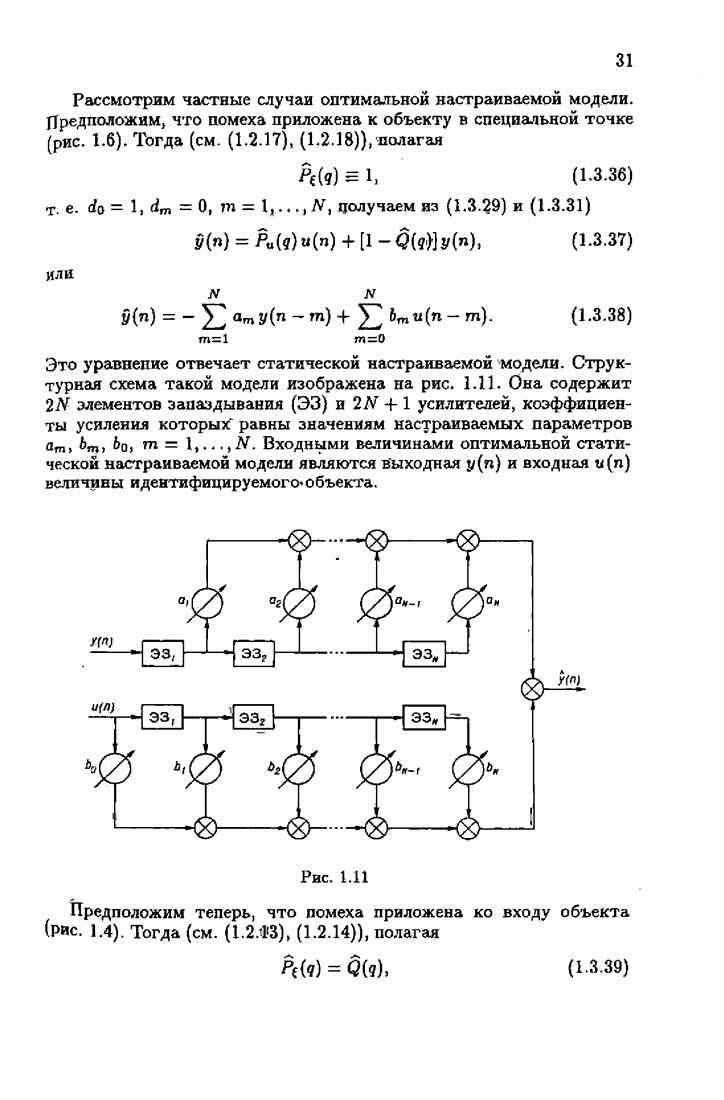
 из (7.4.1) следует модифицированный алгоритм Ньютона — Рафсона
из (7.4.1) следует модифицированный алгоритм Ньютона — Рафсона

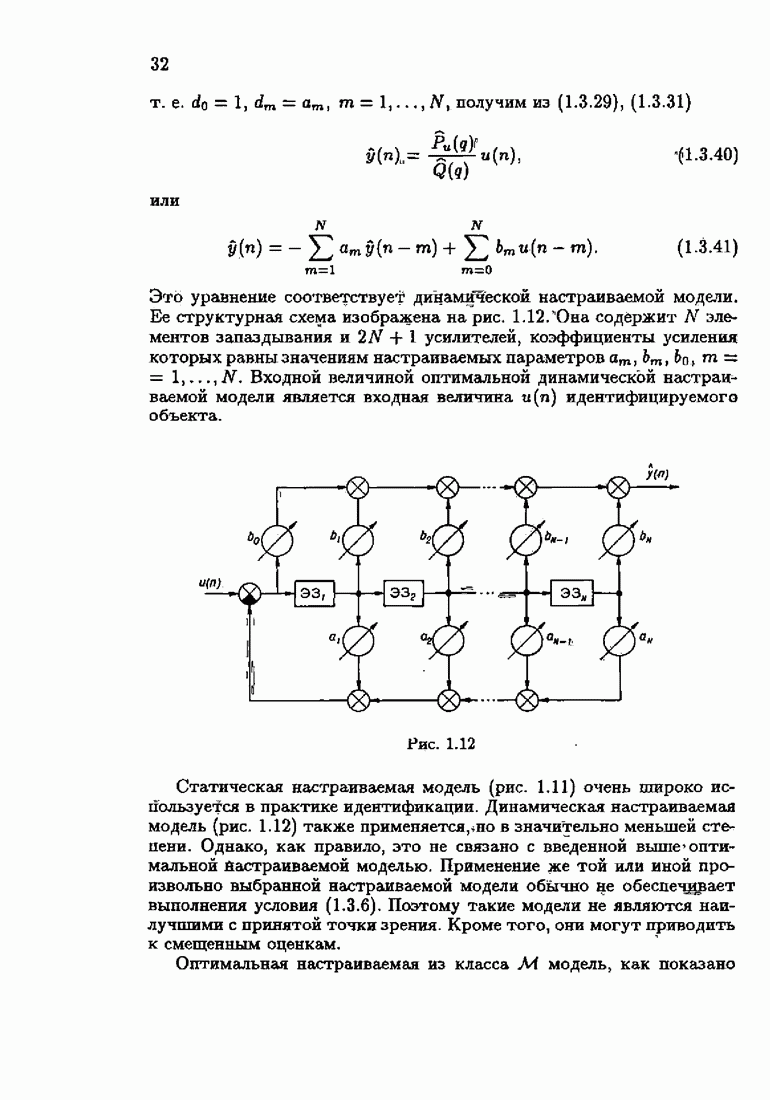
 из (7.4.1) получим необычную модификацию алгоритма Ньютона — Рафсона
из (7.4.1) получим необычную модификацию алгоритма Ньютона — Рафсона







 удовлетворяет условию оптимальности (7.3.8), т. е.
удовлетворяет условию оптимальности (7.3.8), т. е.


 входящий в алгоритм (7.4.6). Оказывается, он зависит явно лишь от наблюдений
входящий в алгоритм (7.4.6). Оказывается, он зависит явно лишь от наблюдений  для
для  момента времени.
момента времени.
 входящей в алгоритм (7.4.6). Принимая во внимание выражение для
входящей в алгоритм (7.4.6). Принимая во внимание выражение для  заключаем, что
заключаем, что


 представляет собой матрицу фишеровских информаций. Таким образом,
представляет собой матрицу фишеровских информаций. Таким образом,



 ее оценкой
ее оценкой

 определяется
определяется  получим приближенное выражение матрицы Гессе:
получим приближенное выражение матрицы Гессе:



 лемму об обращении матриц (1.7.17), (1.7.18) с последующей заменой, если в этом есть необходимость,
лемму об обращении матриц (1.7.17), (1.7.18) с последующей заменой, если в этом есть необходимость,  на
на  (см. § 1.7), получим рекуррентное соотношение
(см. § 1.7), получим рекуррентное соотношение

 которое в абсолютно оптимальных алгоритмах (3.2.3), (3.2.4) принималось имеющим вид
которое в абсолютно оптимальных алгоритмах (3.2.3), (3.2.4) принималось имеющим вид  где 7 1, теперь становится вполне определенным. Как видно из (7.4.19), начальное значение
где 7 1, теперь становится вполне определенным. Как видно из (7.4.19), начальное значение  равно обратной матрице фишеровских информации
равно обратной матрице фишеровских информации



 определяется из (7.4.76).
определяется из (7.4.76).
 не произвольны, а определяются априорной информацией об оптимальном решении:
не произвольны, а определяются априорной информацией об оптимальном решении: 
