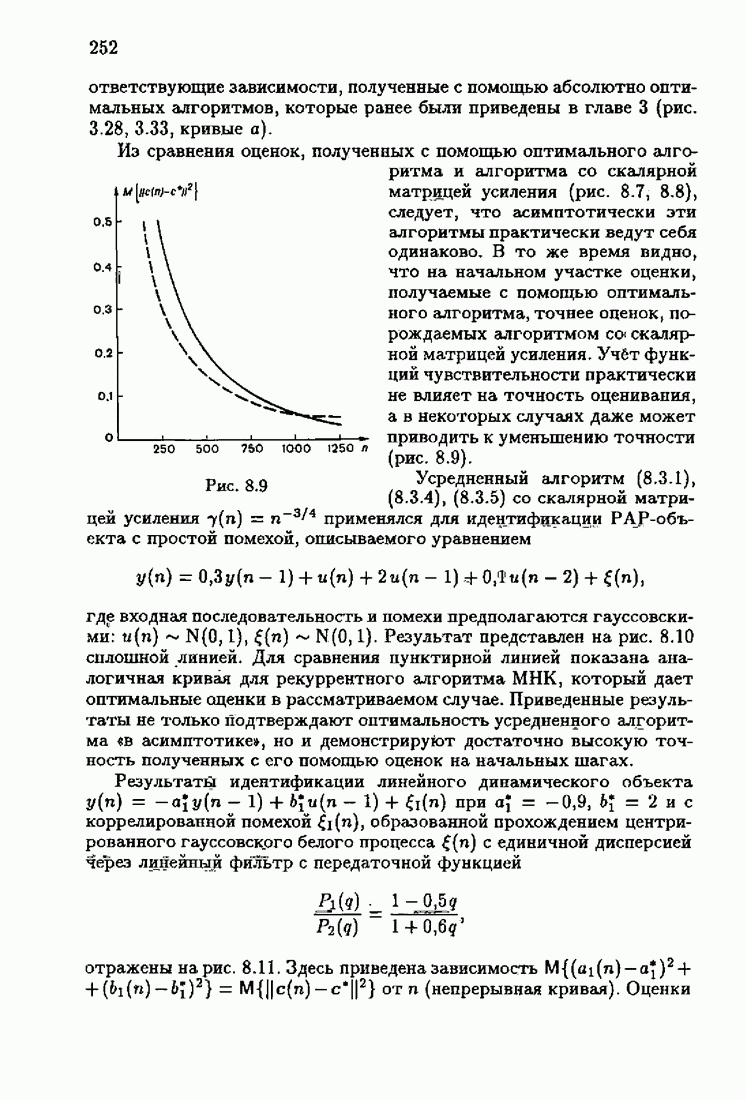
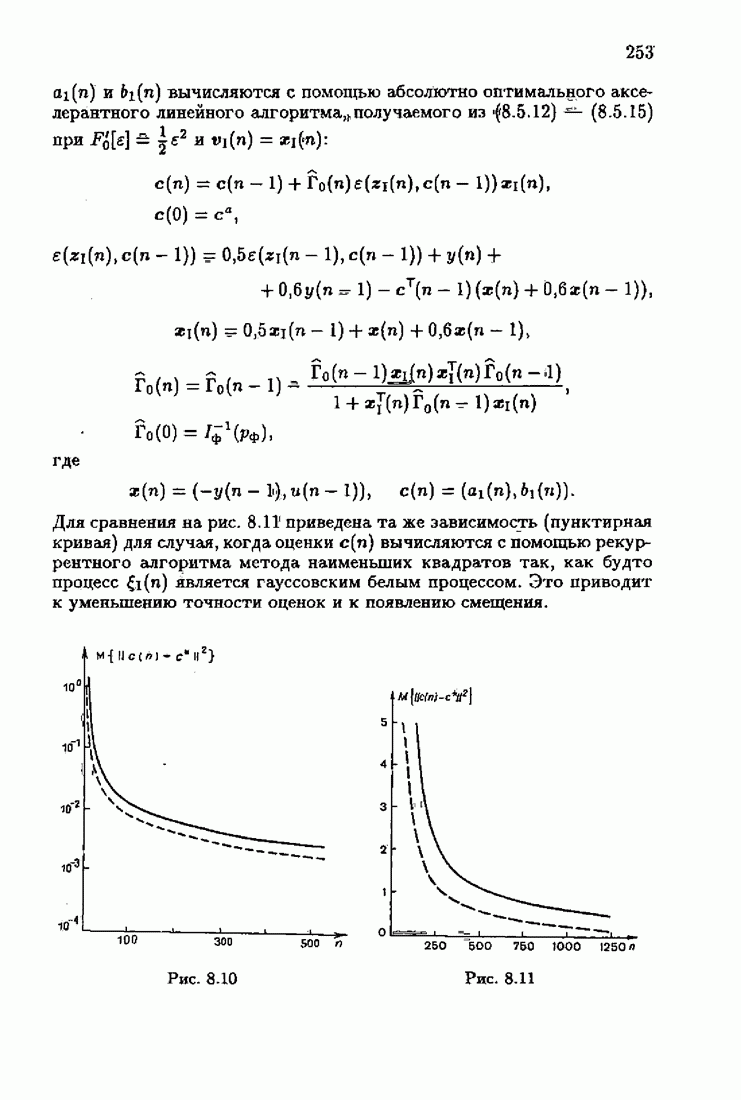
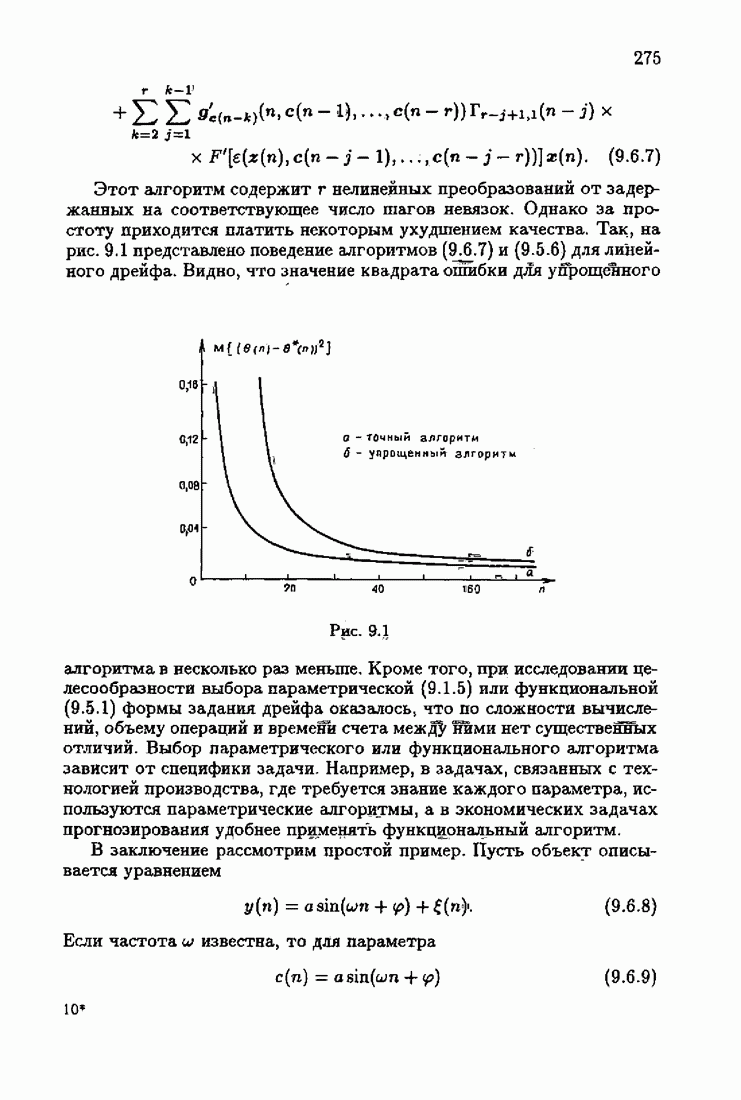
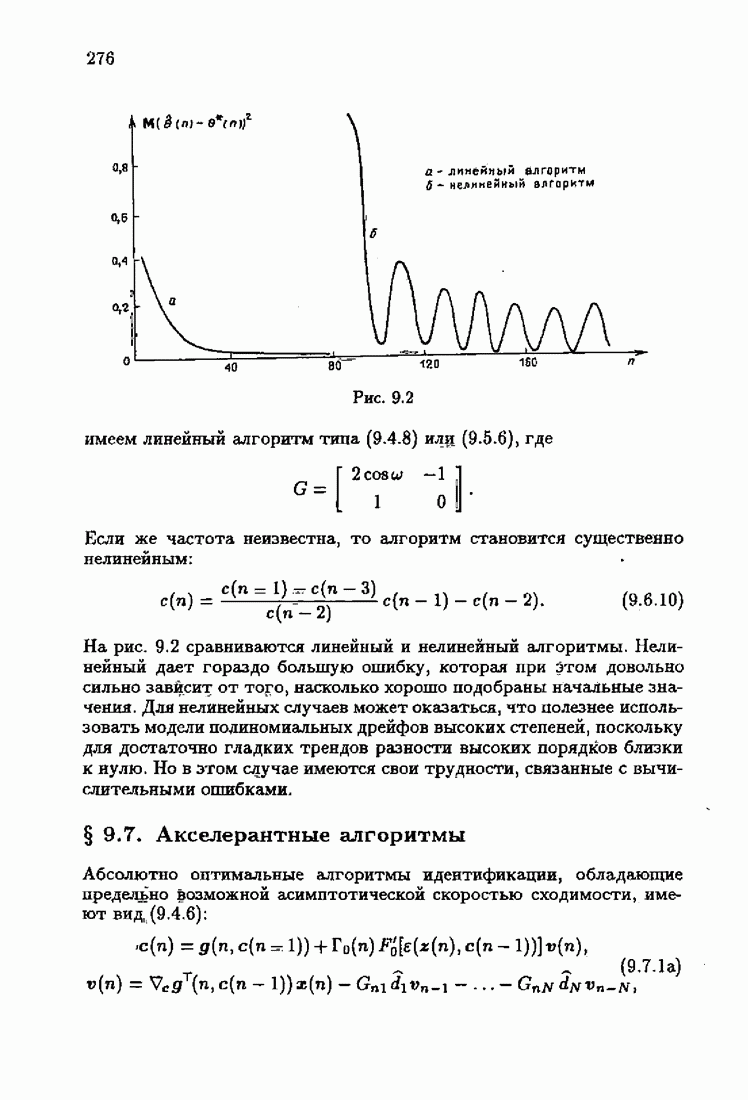
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
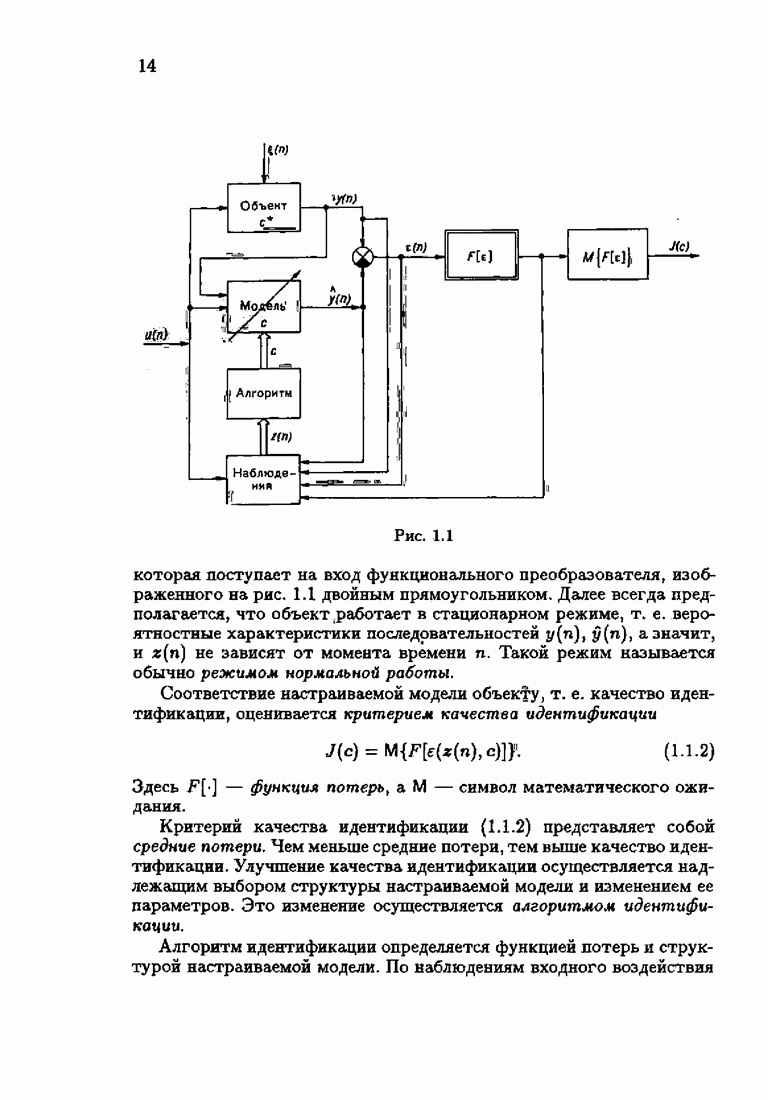
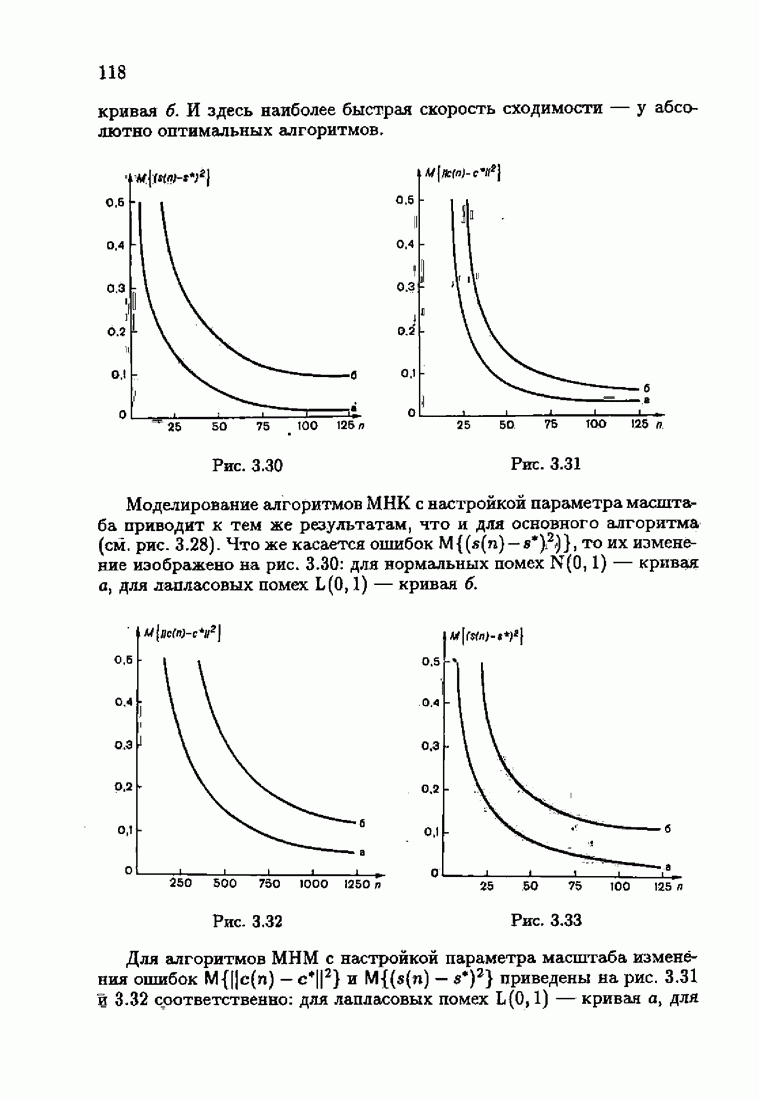
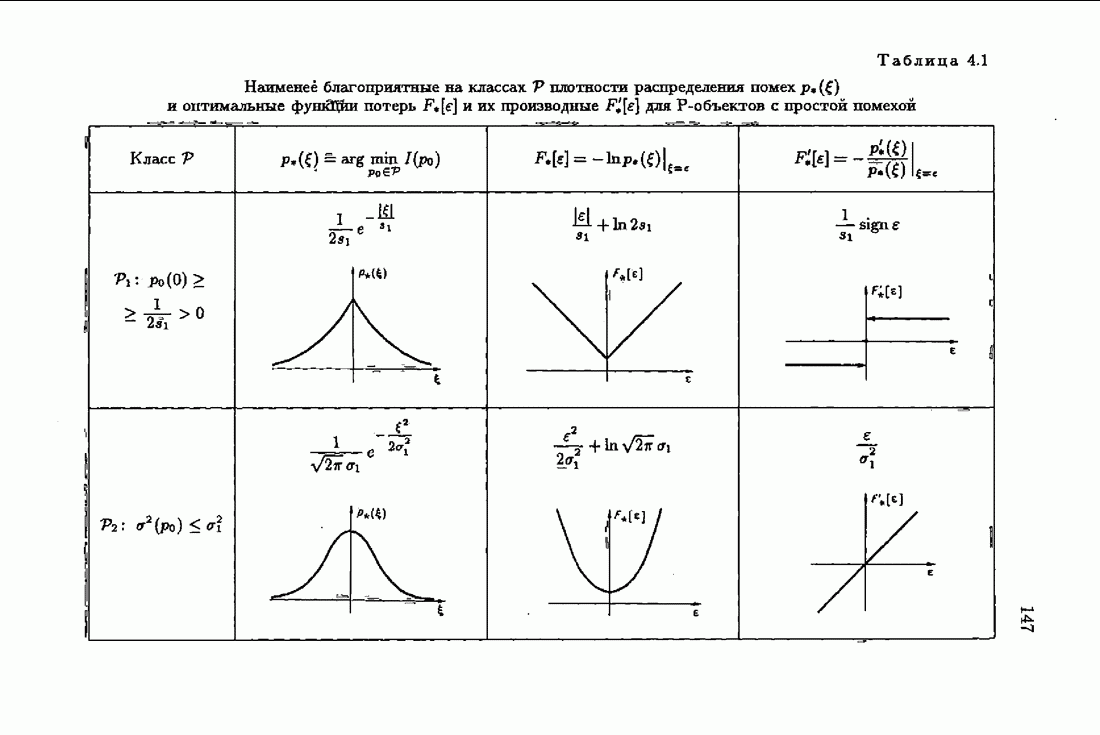
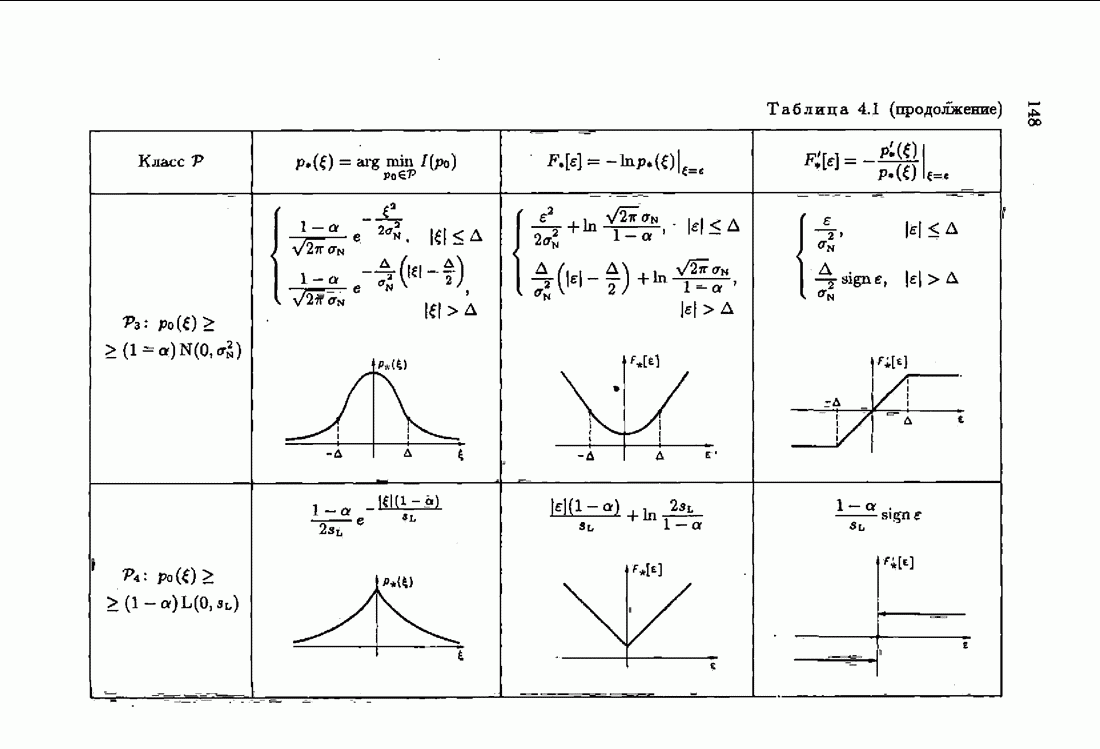
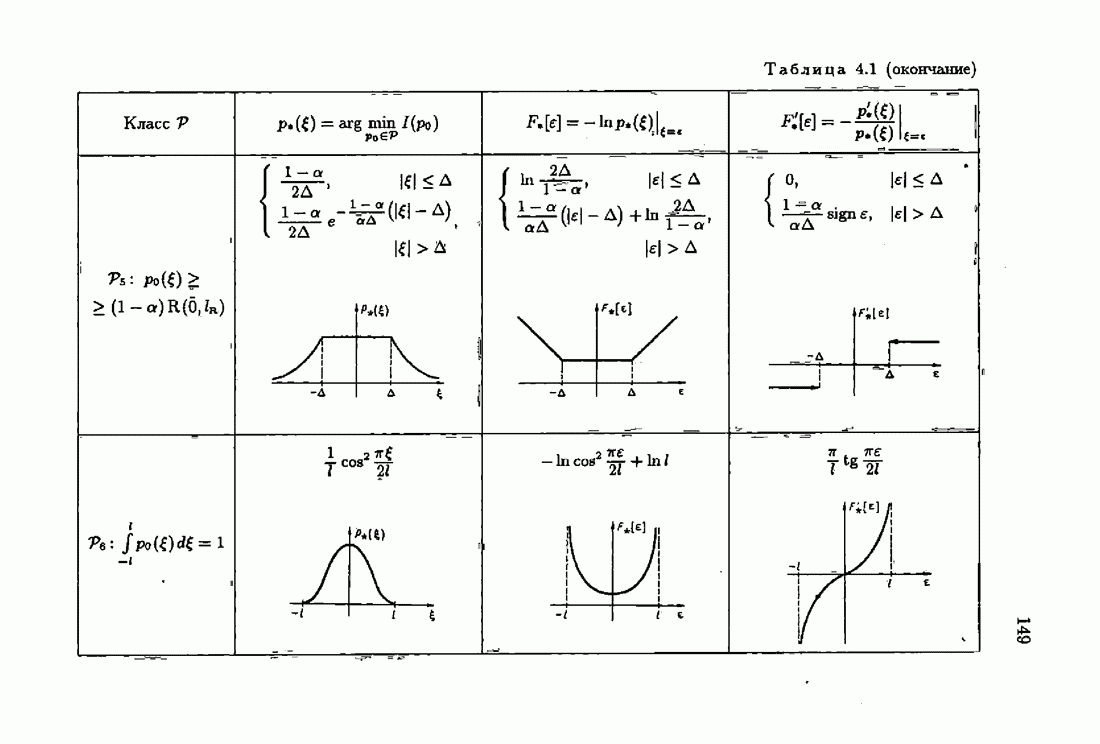
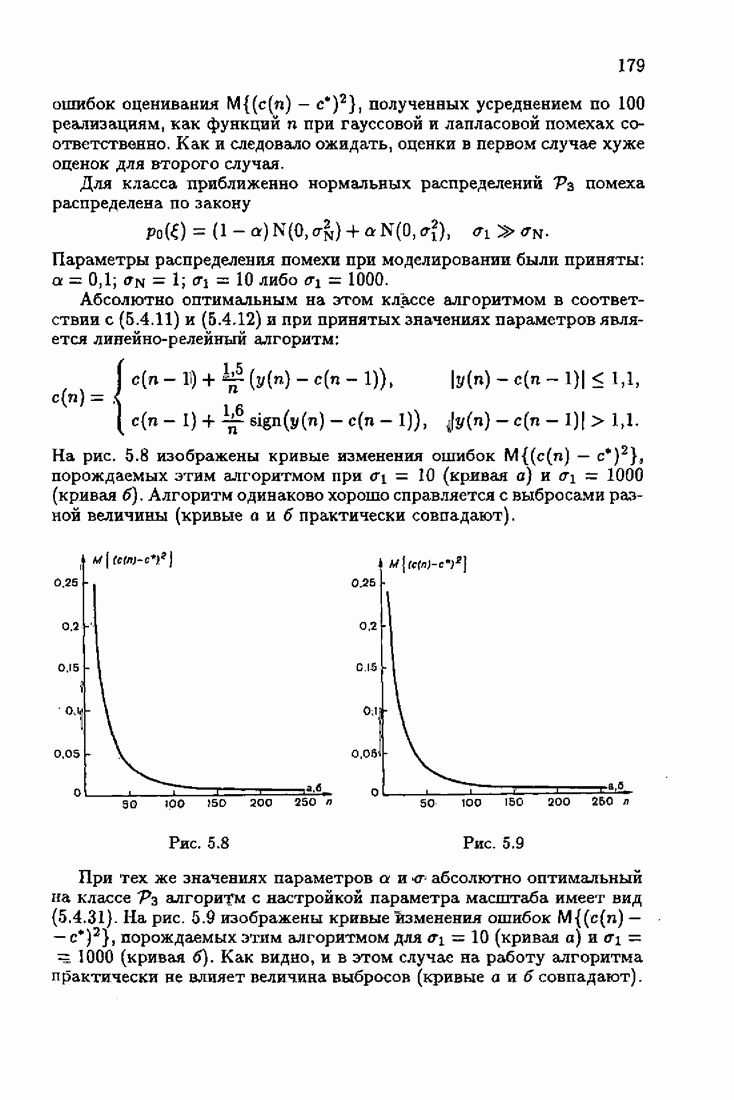
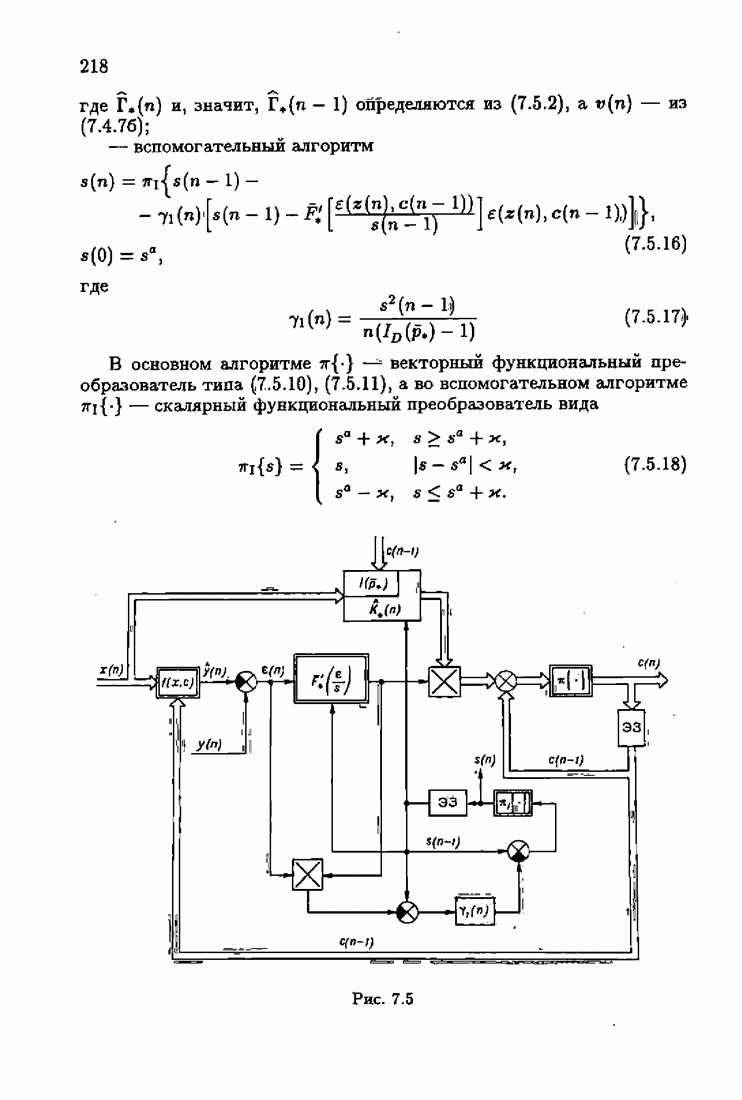
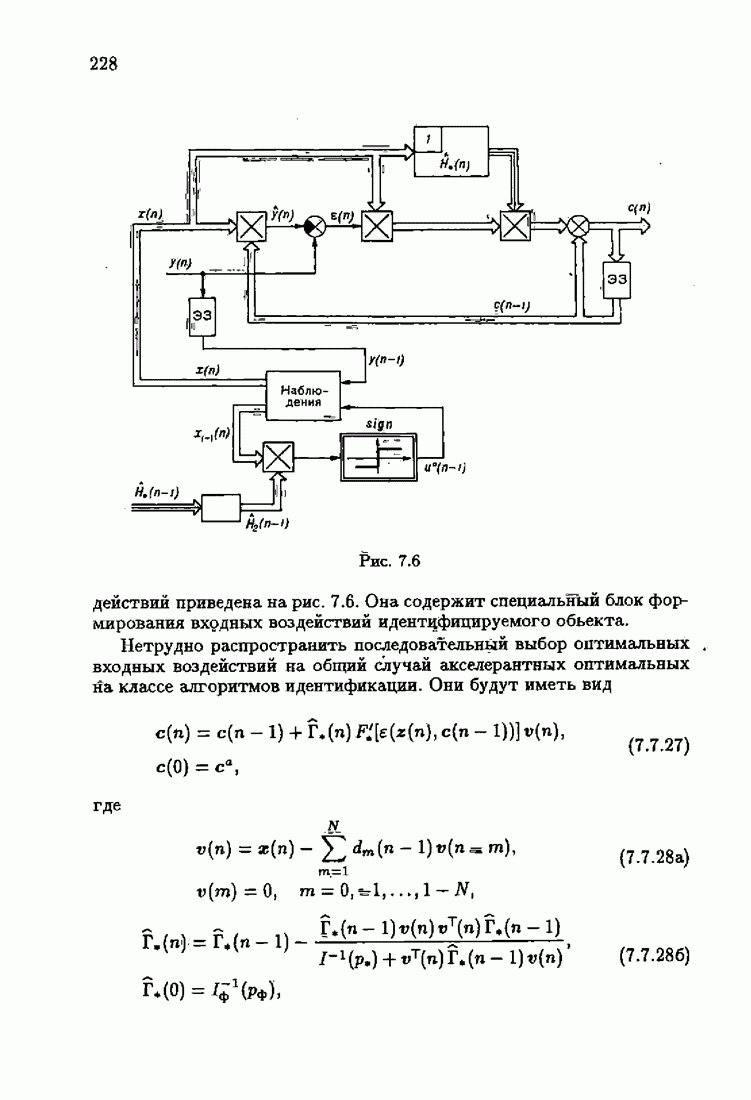
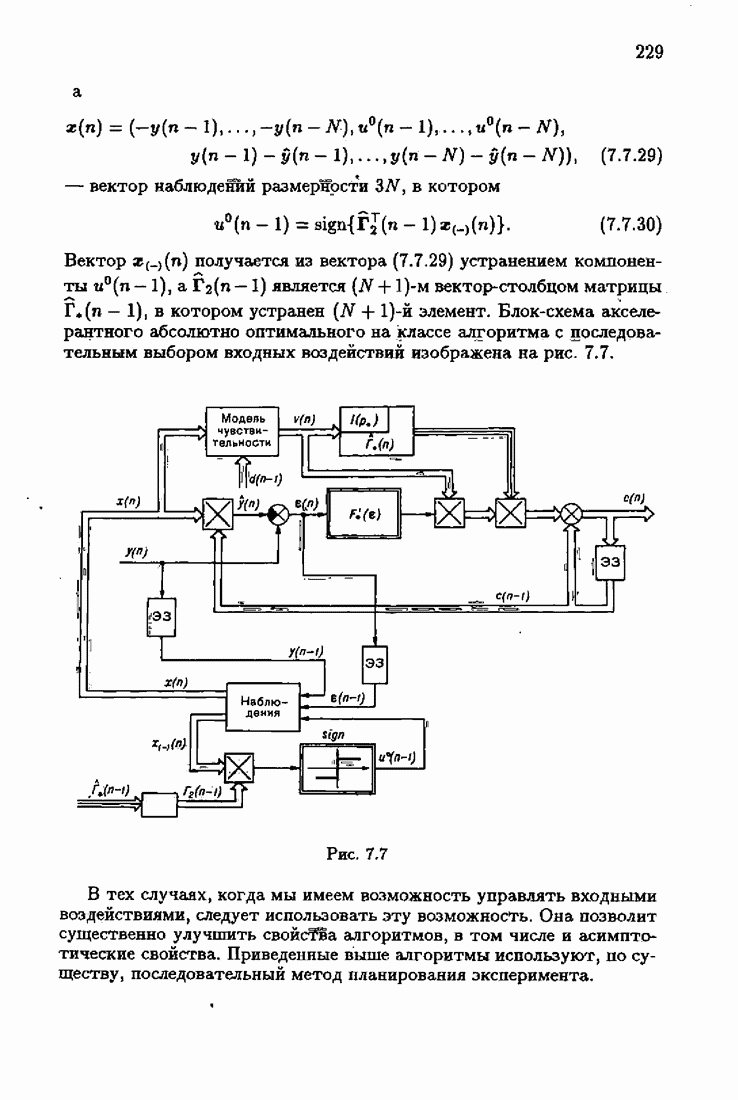
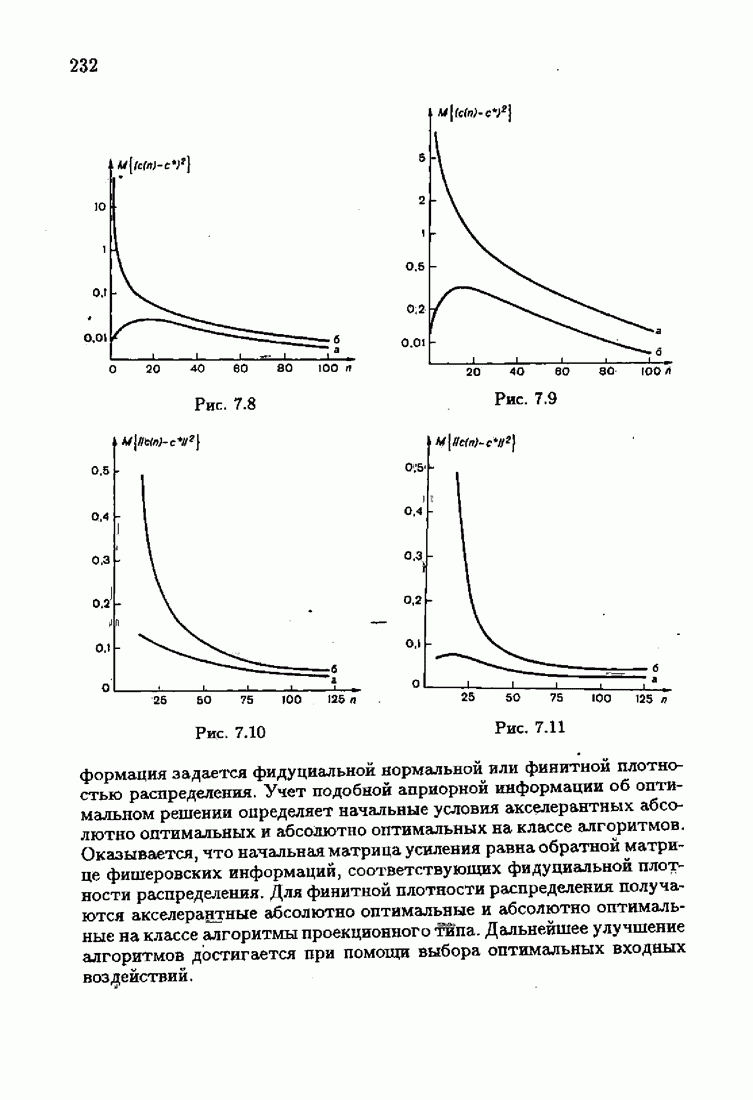
§ 1.4. Критерий качества идентификации и оптимальное решениеКачество идентификации, как уже упоминалось в § 1.1, определяется средними потерями
где функция потерь
Наиболее распространенные функции потерь — квадратичные, Метод минимизации квадратичного критерия
соответствует широко распространенному методу наименьших квадратов (МНК). Этот метод приводит к решению системы линейных алгебраических уравнений (так называемой системы нормальных уравнений), и поэтому оптимальное решение с минимизирующее функционал (1.4.3), может быть выражено в явной аналитической форме Через корреляционные функции. Минимизация же неквадратичных критериев приводит к необходимости решения нелинейной системы уравнений. В этом случае оптимальное решение с, как правило, может быть найдено лишь приближенно. Найдем условия, определяющие оптимальное решение с. Вудем предполагать, что функция потерь решение
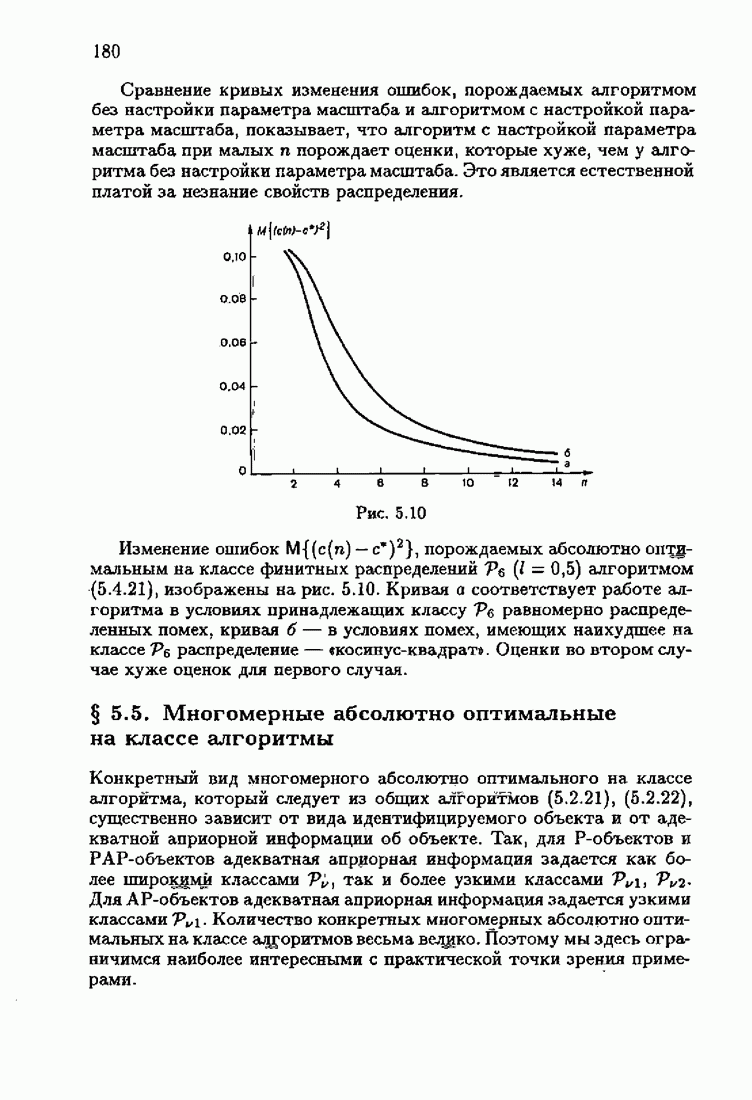
Здесь и далее оператор
является вектор-столбцом,
и
Векторы, фигурирующие в (1.4.4),
и
представляют собой градиенты средних потерь и функции потерь соответственно. Матрицы, фигурирующие в (1.4.5),
представляют собой матрицы Гессе — матрицы вторых производных функции средних потерь и функции потерь соответственно. Частные производные в (1.4.8), (1.4.10) понимаются как обобщенные функции. Матричное неравенство (1.4.5) означает положительную определенность матрицы Гессе средних потерь; оно представляет собой условие идентифицируемости, которое подробно обсуждается ниже. Далее, как правило, мы будем рассматривать лишь тот случай, когда условия оптимальности (1.4.4), (1.4.5) определяют единственное решение с не оговаривая этого каждый раз. Замечая, что
где штрих у означает производную по аргументу
Для оптимальной настраиваемой модели невязка равна (1.3.50)
следовательно,
поэтому условие оптимальности (1.4.4) запишется в виде
Вспоминая, что (см. (1.3.47))
получаем в общем случае
Заменив в условии оптимальности
Этому условию удовлетворяет оптимальное решение
Поэтому из (1.4.18) при
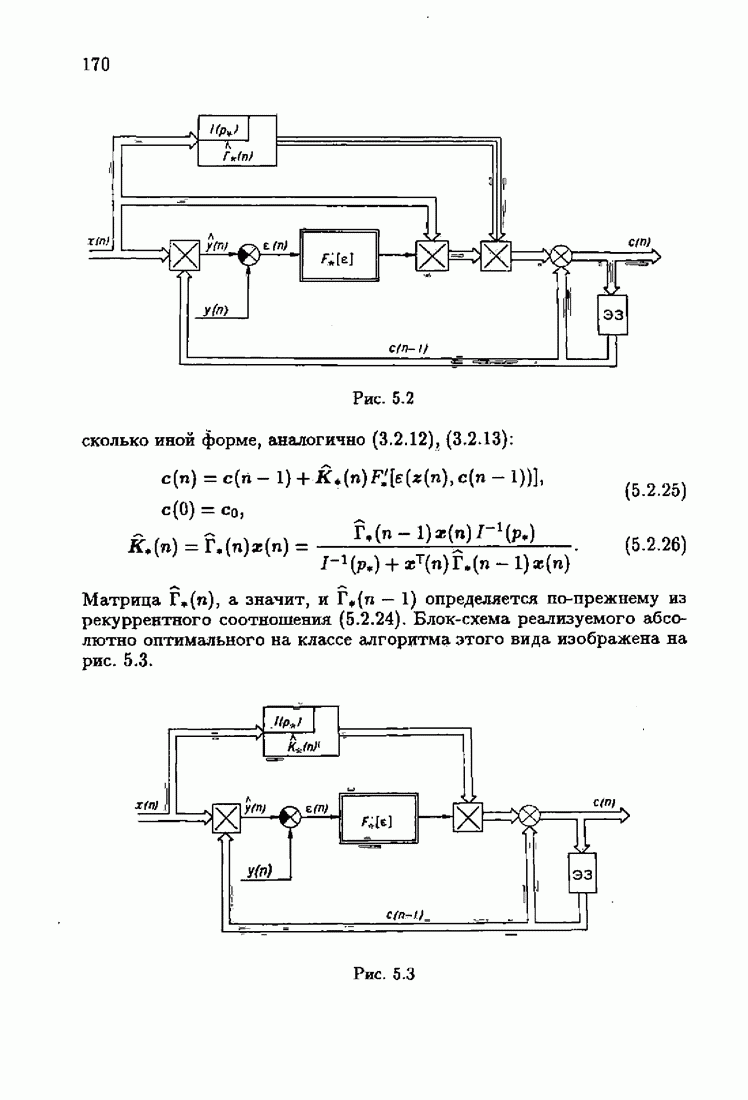
Гак как
Это равенство имеет место для любых четных функций потерь:
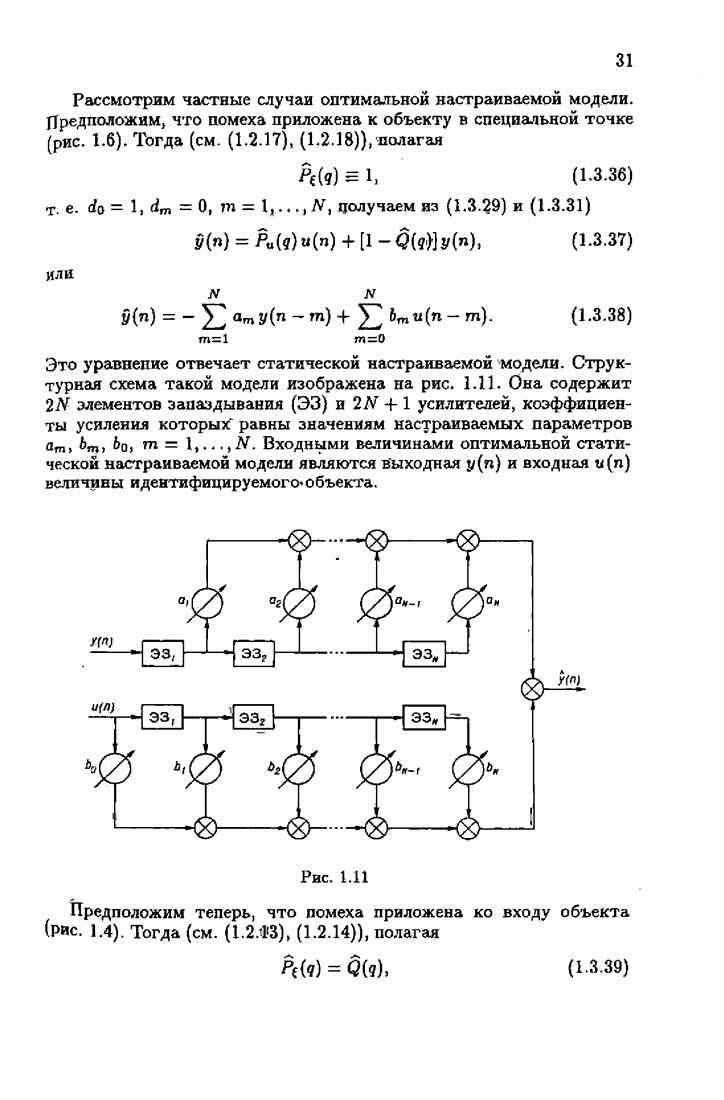
Таким образом, оптимальное решение с удовлетворяет условию оптимальности (1.4.18) при любых четных функциях потерь. Иначе говоря, оптимальное решение с инвариантно относительно четных функций потерь. Именно это обстоятельство часто используется для обоснования выбора квадратичной функции потерь как наиболее простой и допускающей часто нахождение оптимального решения или его оценок в аналитической форме. Вектор
или, учитывая (1.4.17),
Здесь Используя уравнение оптимальной настраиваемой модели (1.3.44), которое мы перепишем в виде
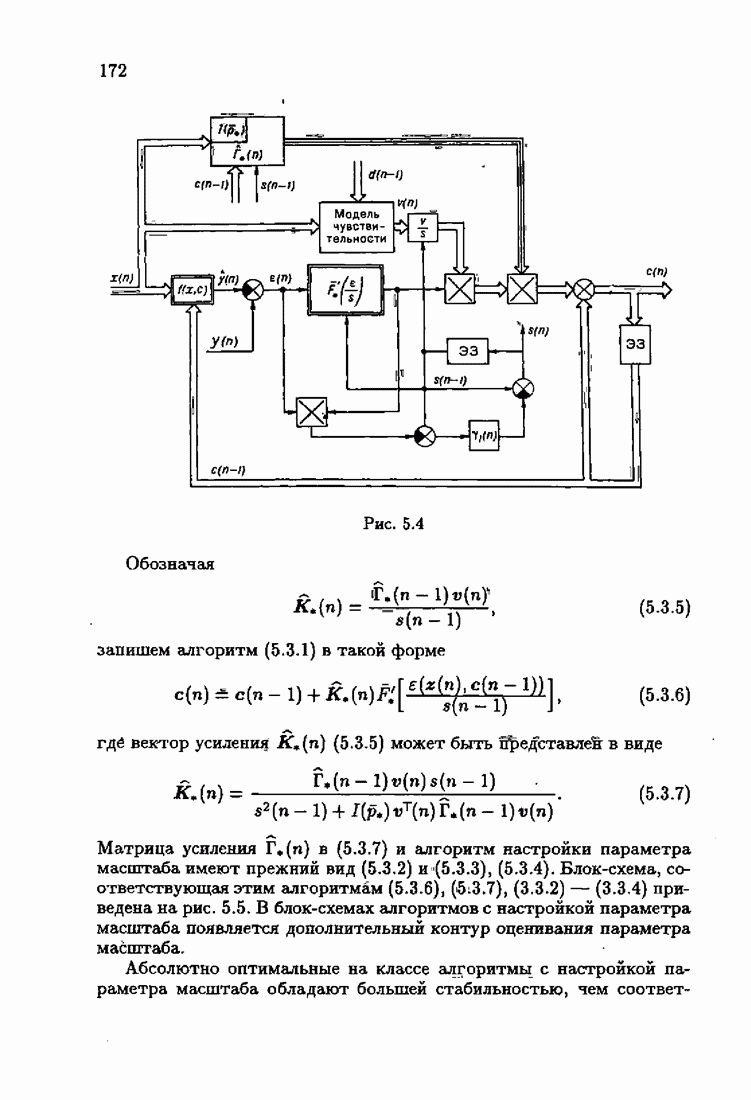
и определение вектора наблюдений
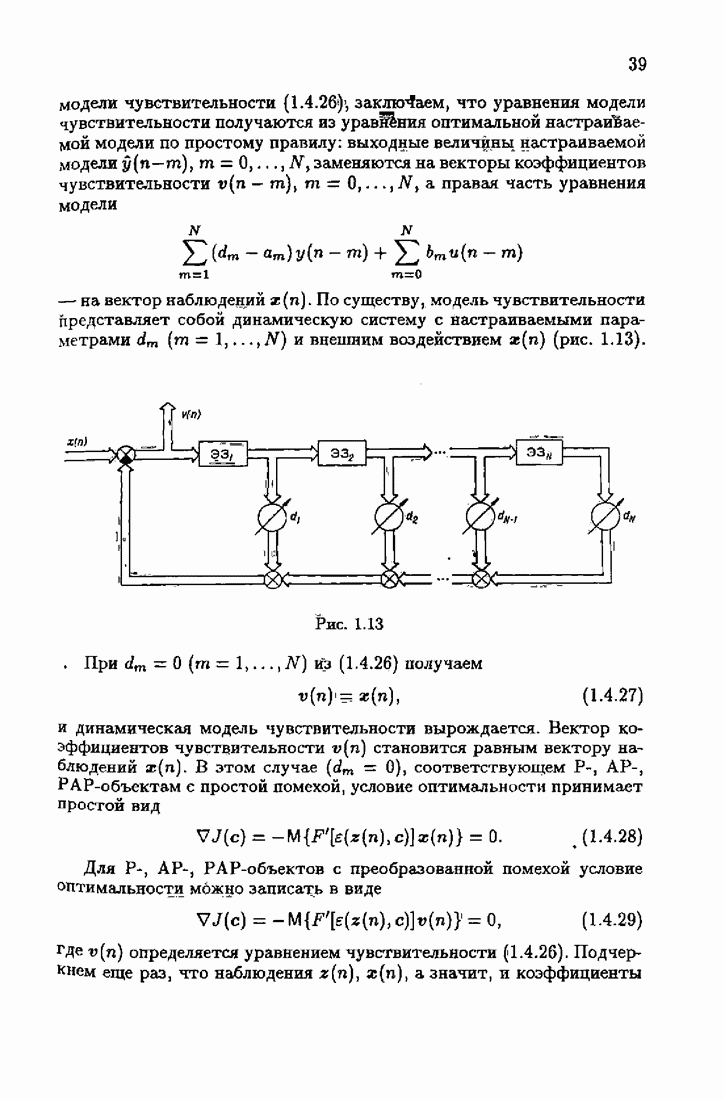
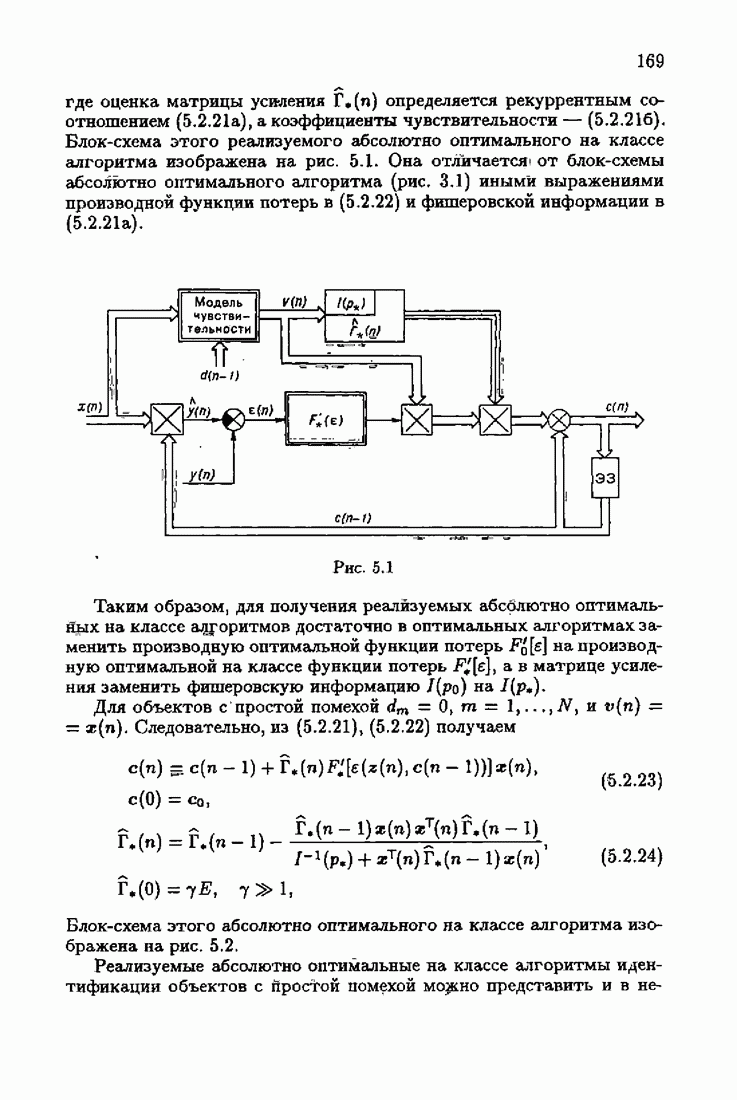
Подставляя (1.4.25) в (1.4.23), получим разностное уравнение относительно векторов коэффициентов чувствительности
Это уравнение определяет модель чувствительности. Сопоставляя уравнение оптимальной настраиваемой модели (1.4.24) и уравнение модели чувствительности (1.4.26), заключаем, что уравнения модели чувствительности получаются из уравнения оптимальной настраиваемой модели по простому правилу: выходные величины настраиваемой модели
— на вектор наблюдений
Рис. 1.13 При
и динамическая модель чувствительности вырождается. Вектор коэффициентов чувствительности
Для
где чувствительности
|
 |
Оглавление
|












































































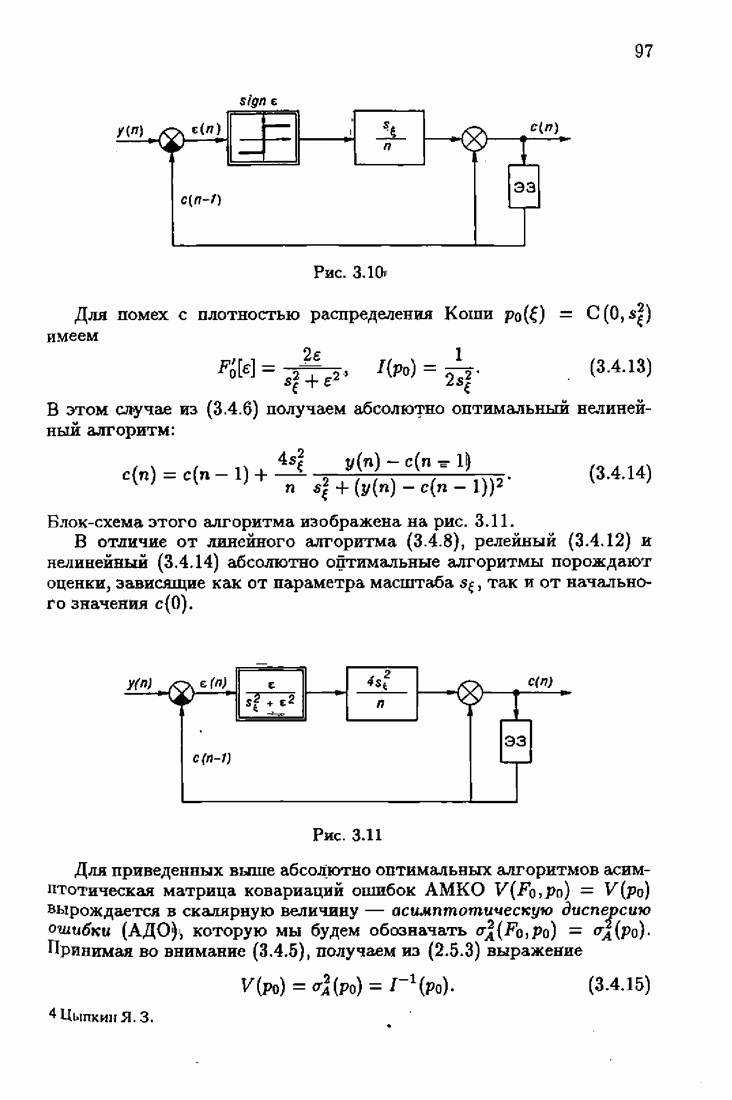



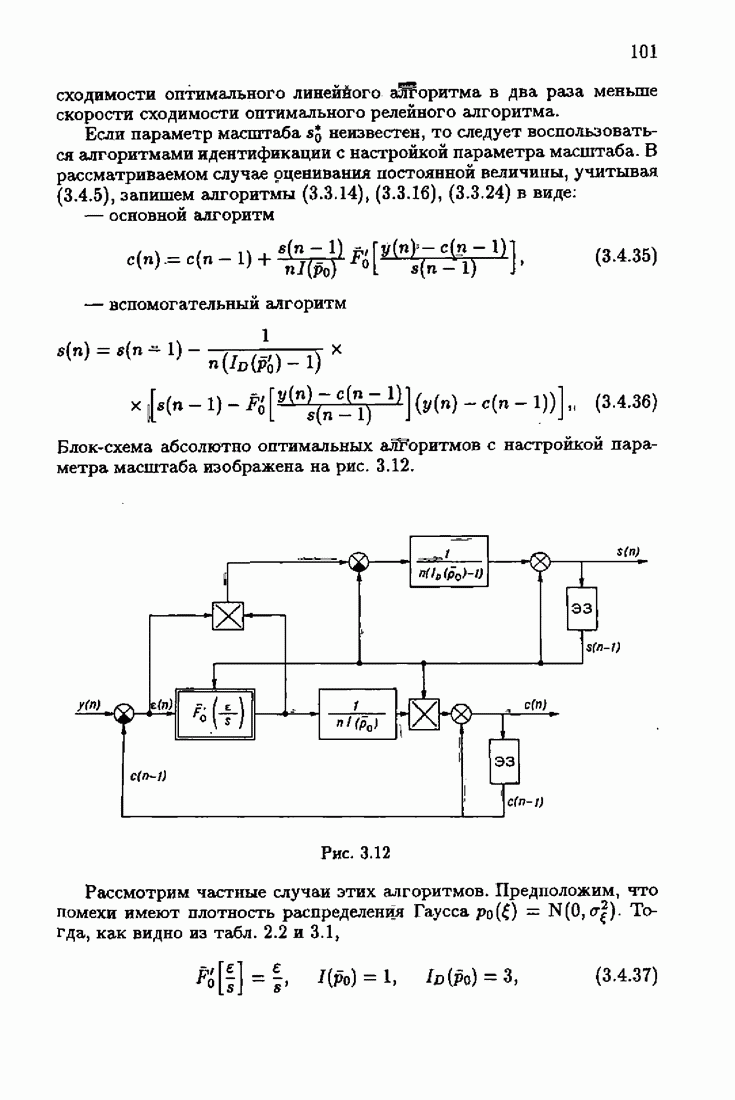
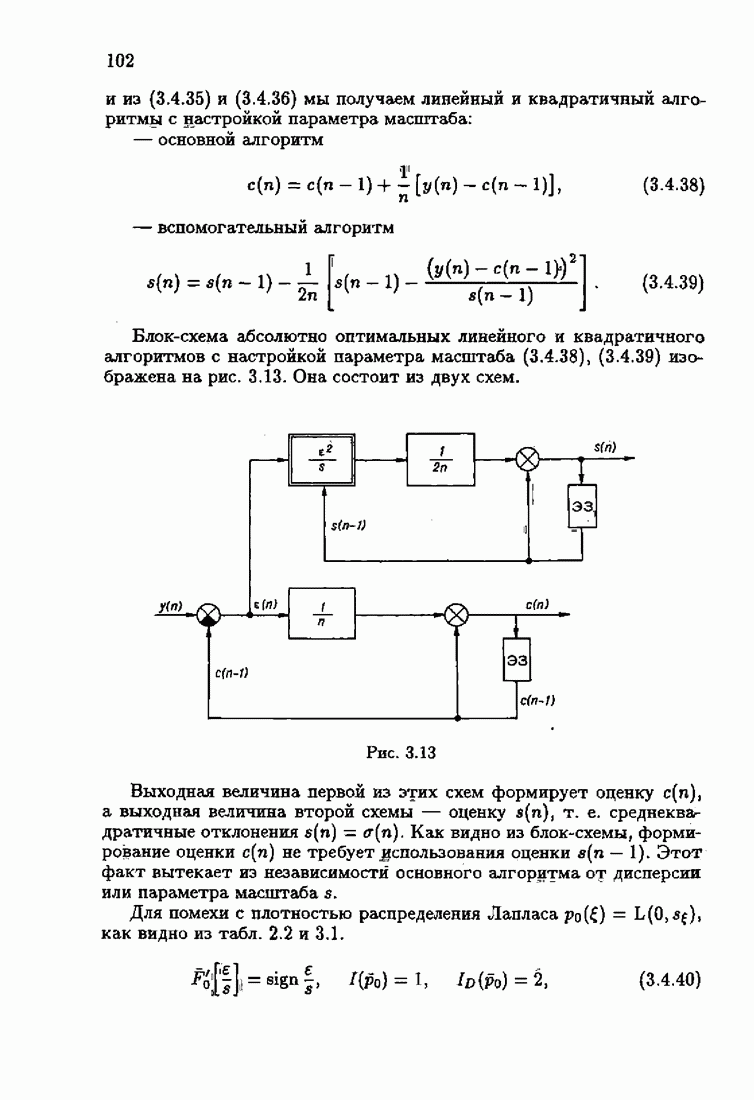
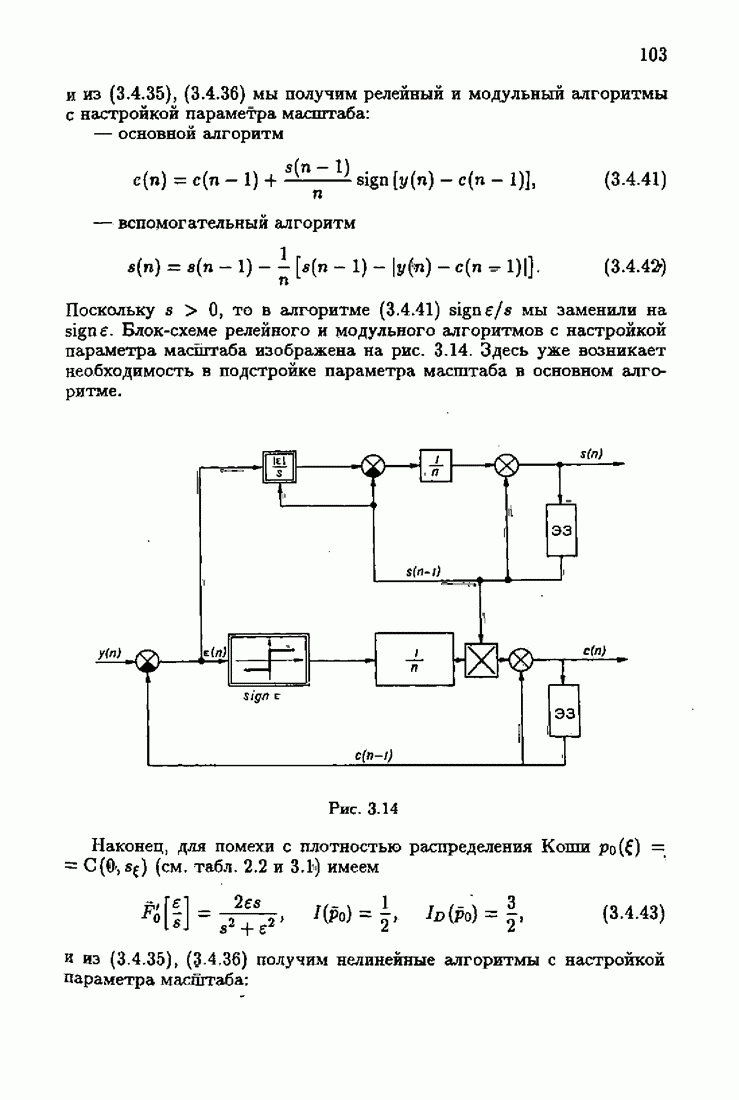





































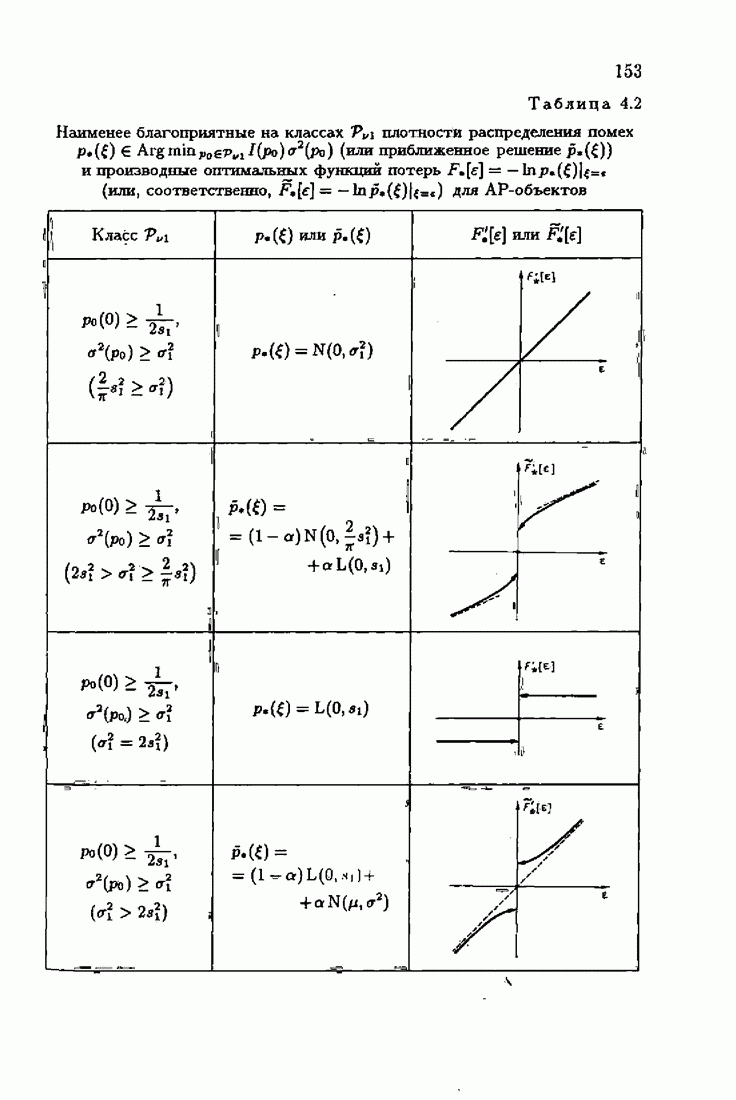
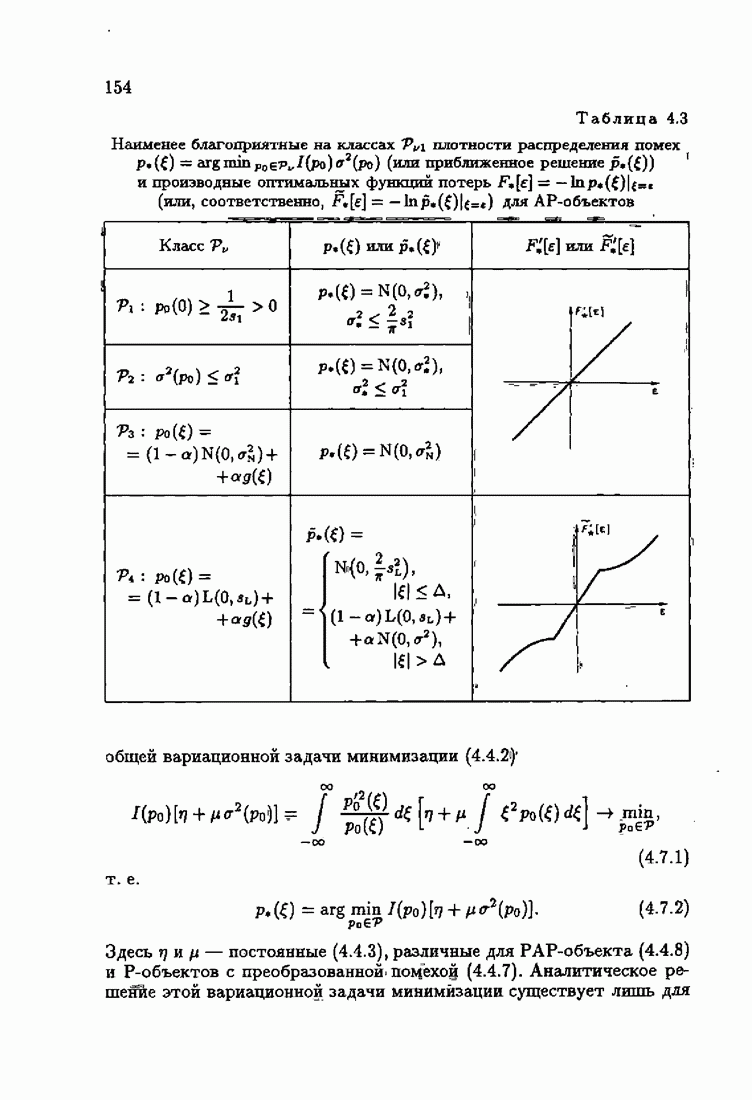


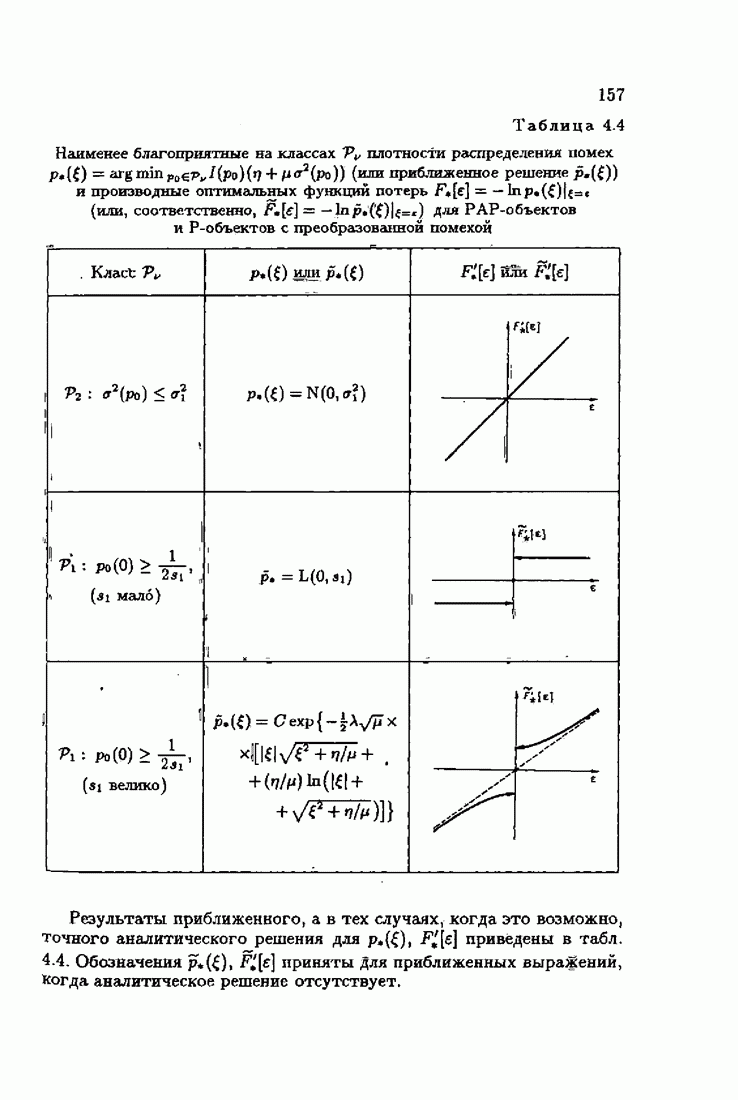



































































































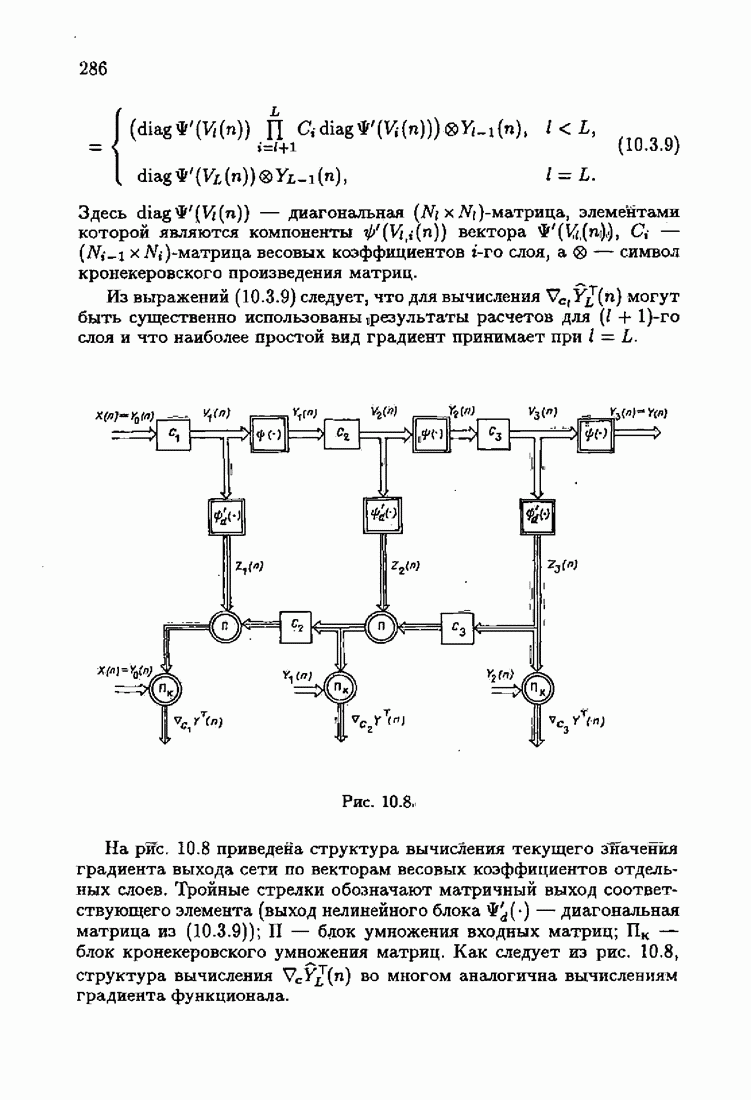
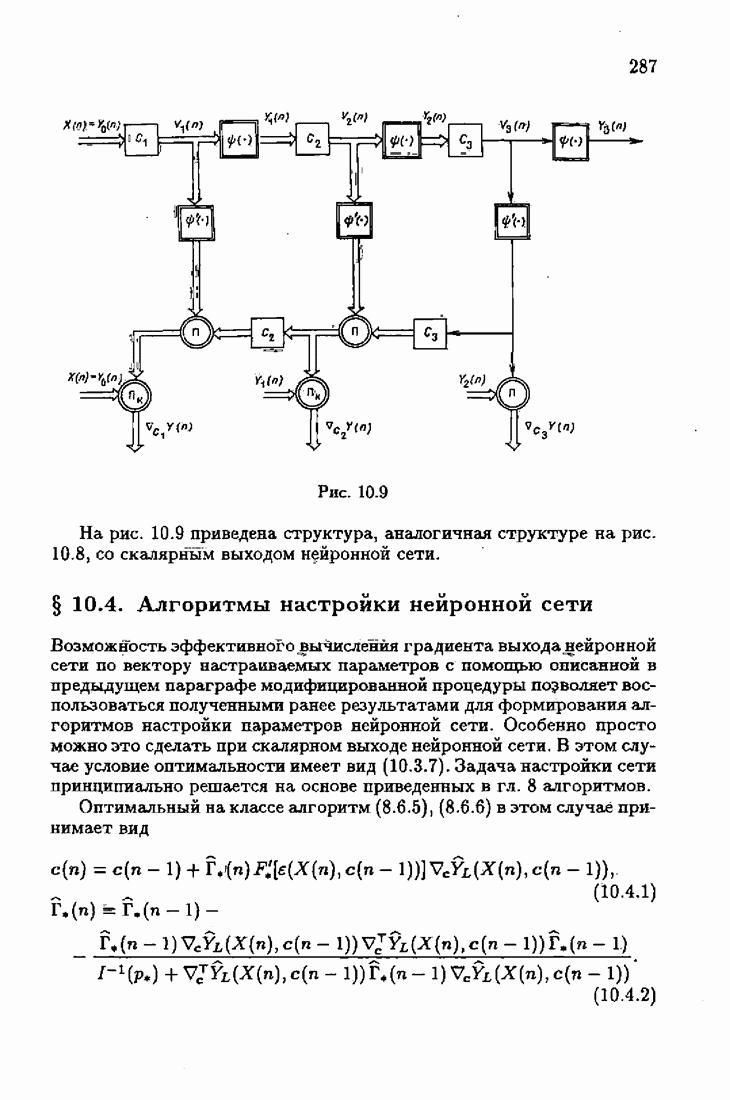


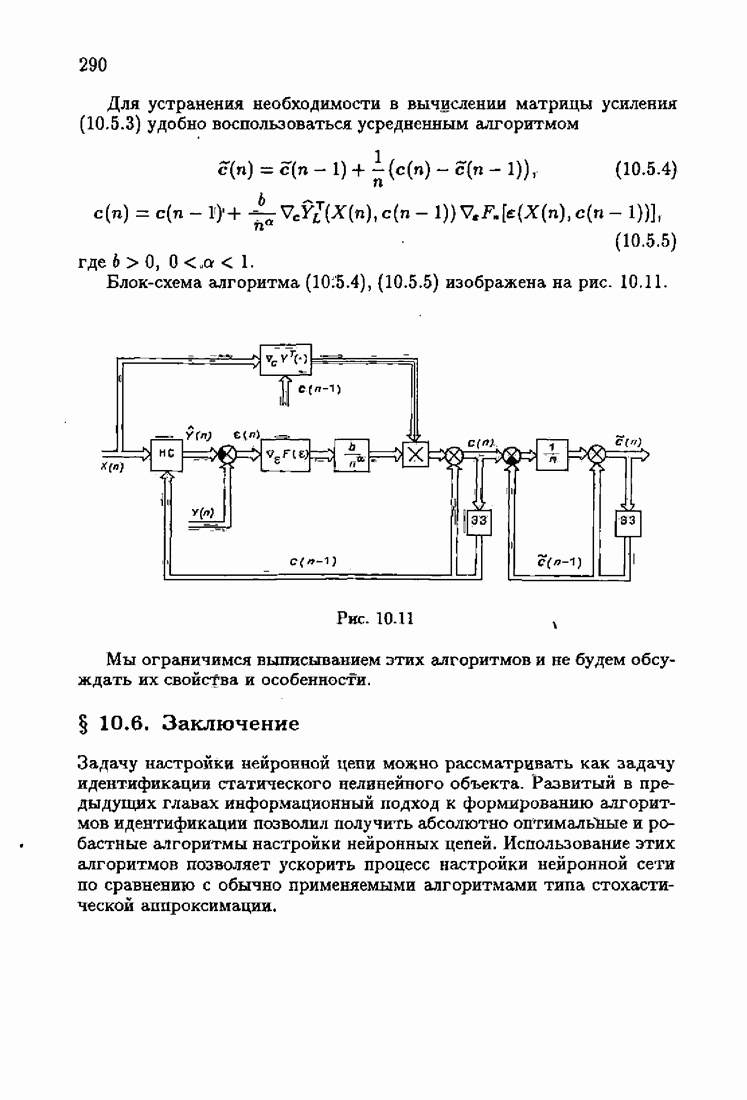















































 обычно представляет собой четную функцию невязки:
обычно представляет собой четную функцию невязки:

 Реже применяются модульные функции потерь
Реже применяются модульные функции потерь  Еще реже используют иные функции потерь, отличные от квадратичных и модульных.
Еще реже используют иные функции потерь, отличные от квадратичных и модульных.

 дважды дифференцируема по аргументу. Тогда условия, определяющие оптимальное
дважды дифференцируема по аргументу. Тогда условия, определяющие оптимальное
 запишутся при
запишутся при  в виде:
в виде:


 размерность вектора
размерность вектора  ; для упрощения записи мы полагаем
; для упрощения записи мы полагаем






 запишем условие оптимальности (1.4.4) в такой форме:
запишем условие оптимальности (1.4.4) в такой форме:






 из (1.4.17), будем иметь
из (1.4.17), будем иметь

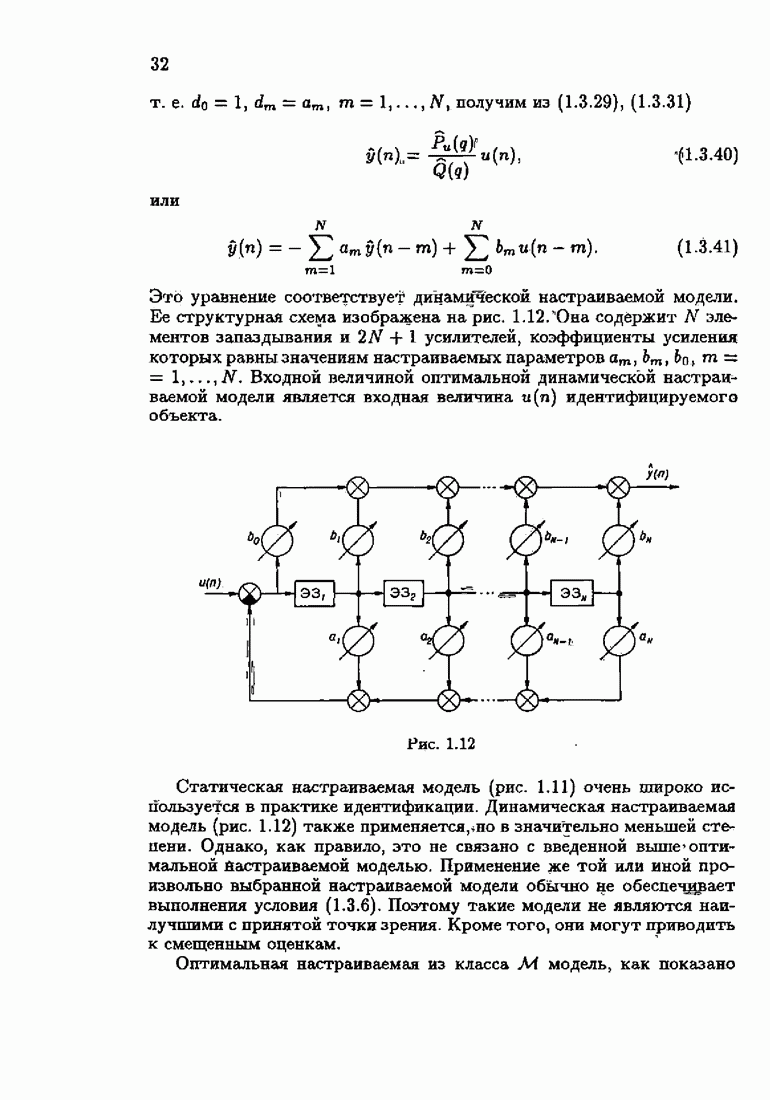
 т. е. вектор параметров настраиваемой модели равен с. При
т. е. вектор параметров настраиваемой модели равен с. При  как уже упоминалось (см. (1.3.52)), невязка равна помехе:
как уже упоминалось (см. (1.3.52)), невязка равна помехе:

 находим
находим

 а значит, и
а значит, и  взаимно независимы, то из (1.4.20) следует
взаимно независимы, то из (1.4.20) следует

 поскольку для них
поскольку для них  и поэтому (см. (1.2.44))
и поэтому (см. (1.2.44))

 фигурирующий в условии оптимальности (1.4.15), представляет собой вектор коэффициентов чувствительности. Обозначим его через
фигурирующий в условии оптимальности (1.4.15), представляет собой вектор коэффициентов чувствительности. Обозначим его через  так что
так что


 матрица коэффициентов чувствительности.
матрица коэффициентов чувствительности.

 нетрудно показать, что матрицу коэффициентов чувствительности можно представить в виде блочной матрицы, содержащей нулевые векторы и векторы коэффициентов чувствительности
нетрудно показать, что матрицу коэффициентов чувствительности можно представить в виде блочной матрицы, содержащей нулевые векторы и векторы коэффициентов чувствительности  т. е.
т. е.


 заменяются на векторы коэффициентов чувствительности
заменяются на векторы коэффициентов чувствительности  а правая часть уравнения модели
а правая часть уравнения модели

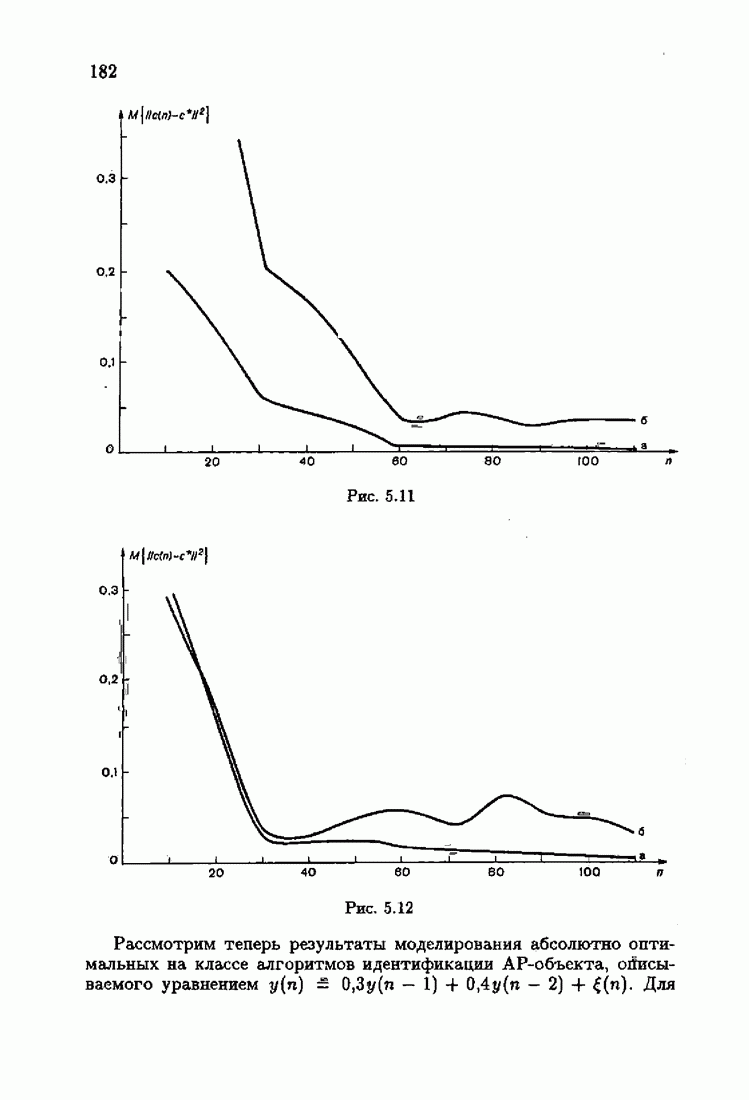
 По существу, модель чувствительности представляет собой динамическую систему с настраиваемыми параметрами
По существу, модель чувствительности представляет собой динамическую систему с настраиваемыми параметрами  и внешним воздействием
и внешним воздействием  (рис. 1.13).
(рис. 1.13).

 из (1.4.26) получаем
из (1.4.26) получаем

 становится равным вектору наблюдений
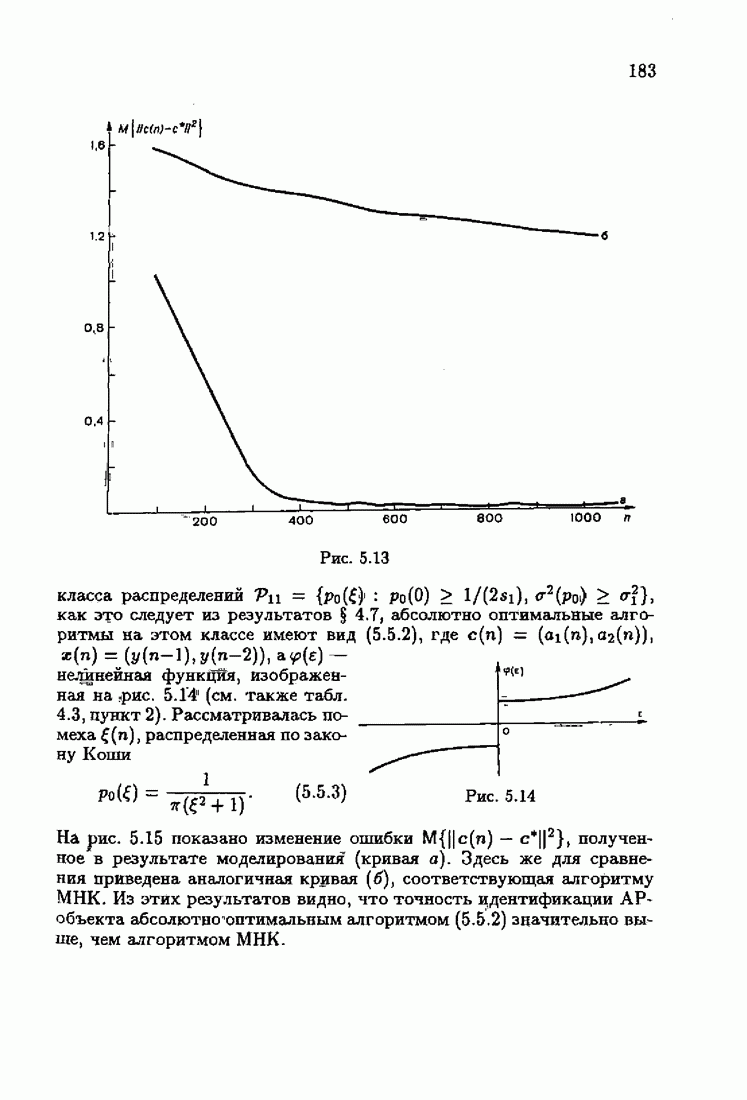
становится равным вектору наблюдений  В этом случае
В этом случае  соответствующем
соответствующем  РАР-объектам с простой помехой, условие оптимальности принимает простой вид
РАР-объектам с простой помехой, условие оптимальности принимает простой вид

 РАР-объектов с преобразованной помехой условие оптимальности можно записать в виде
РАР-объектов с преобразованной помехой условие оптимальности можно записать в виде

 определяется уравнением чувствительности (1.4.26). Подчеркнем еще раз, что наблюдения
определяется уравнением чувствительности (1.4.26). Подчеркнем еще раз, что наблюдения  а значит, и коэффициенты
а значит, и коэффициенты
 входящие в условия оптимальности, предполагаются стационарными. Их вероятностные характеристики не зависят от момента времени
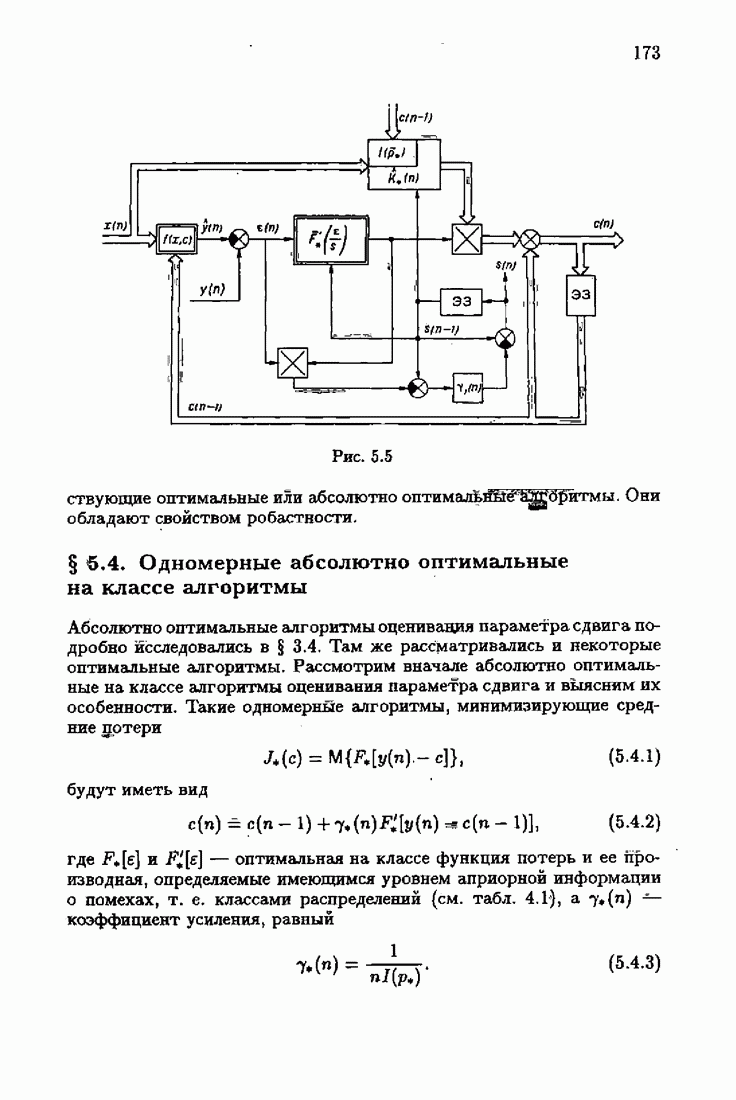
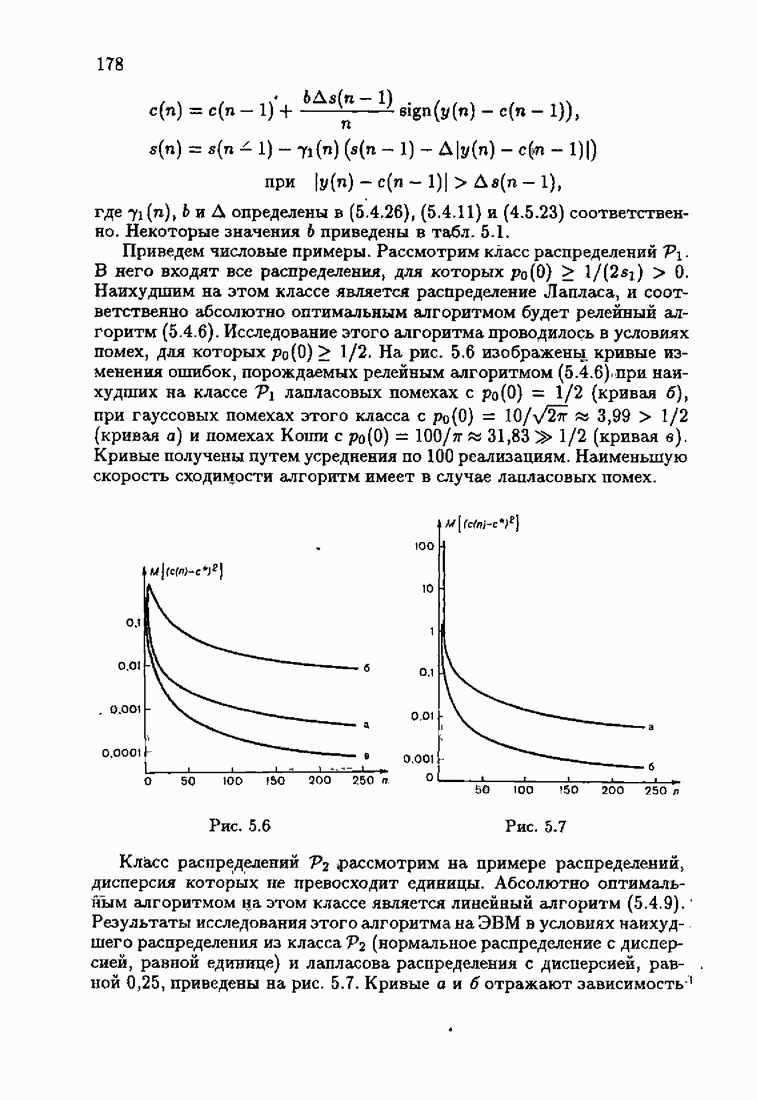
входящие в условия оптимальности, предполагаются стационарными. Их вероятностные характеристики не зависят от момента времени  Условия оптимальности позволяют не только установить ряд важных свойств оптимального решения с, но и, как будет показано далее, сформировать наилучшие, в определенном смысле, алгоритмы оценивания оптимального решения,
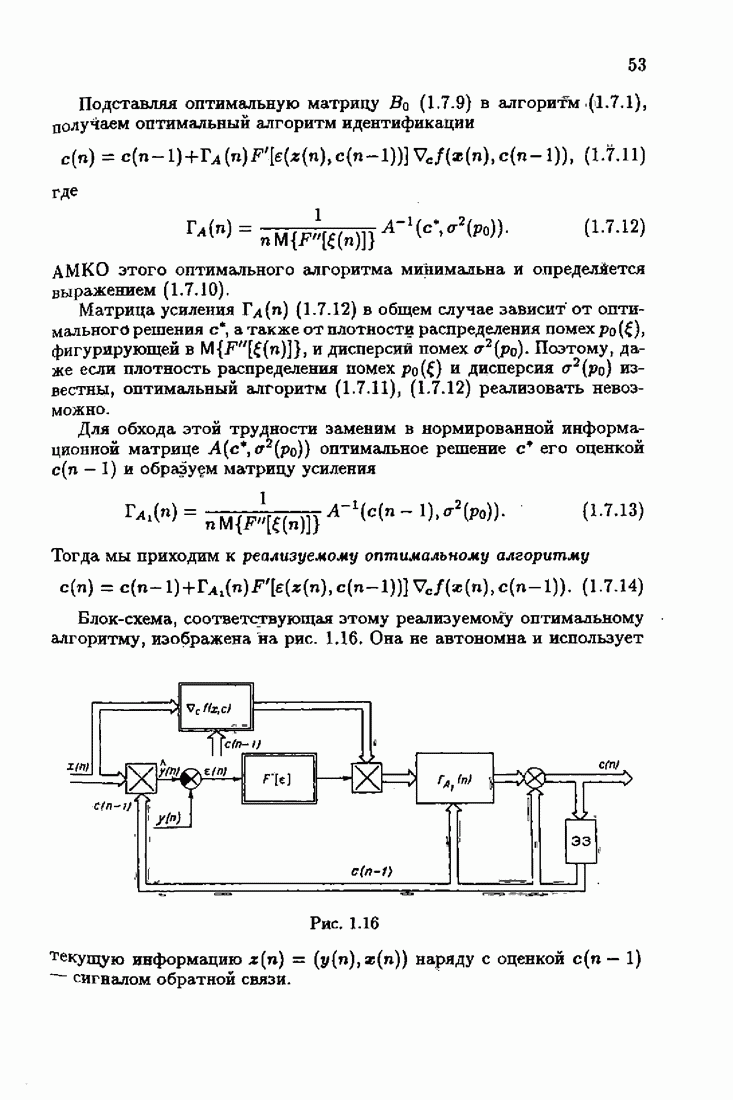
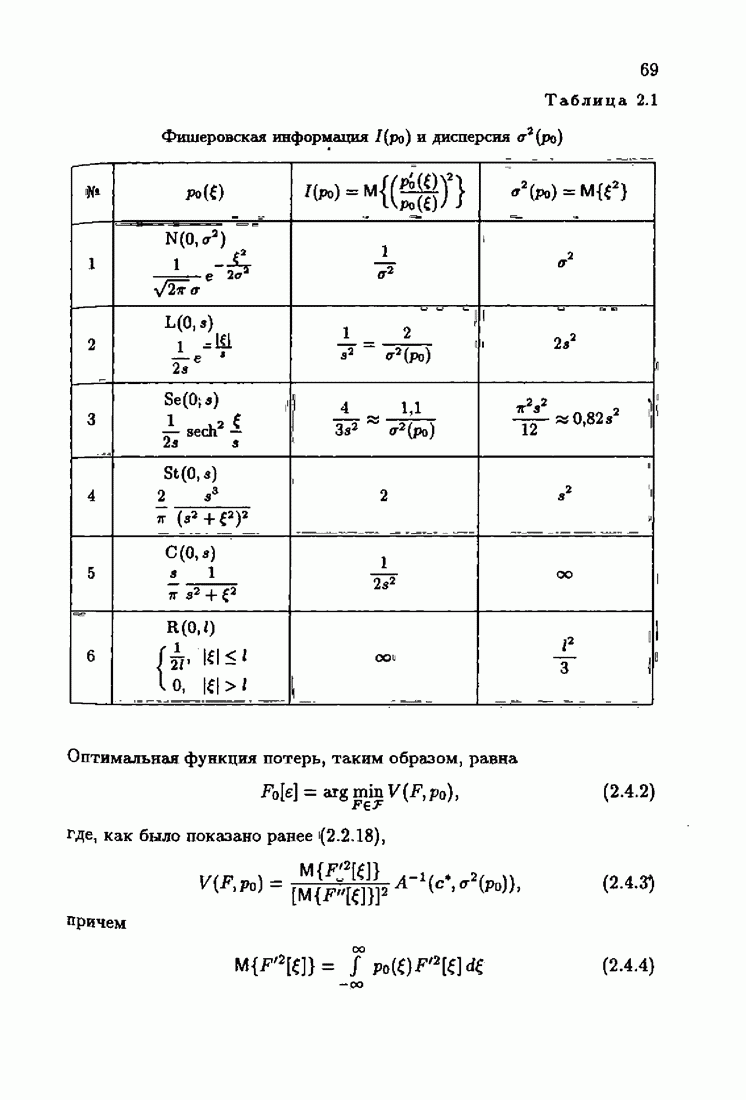
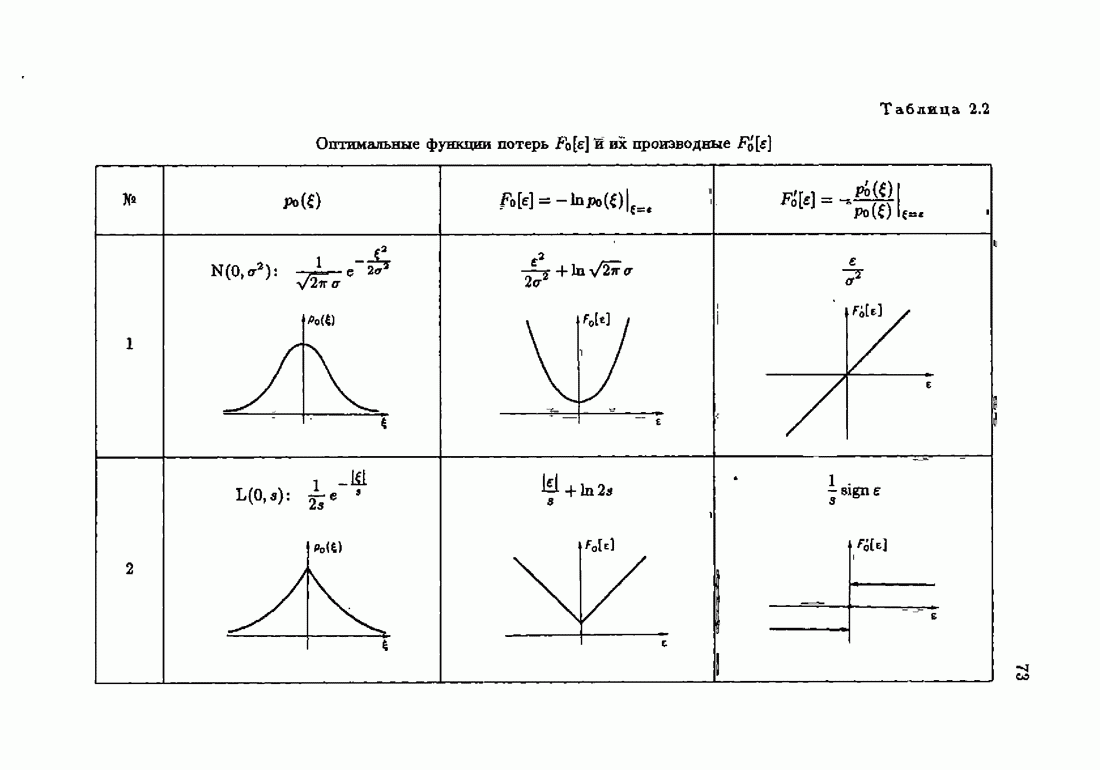
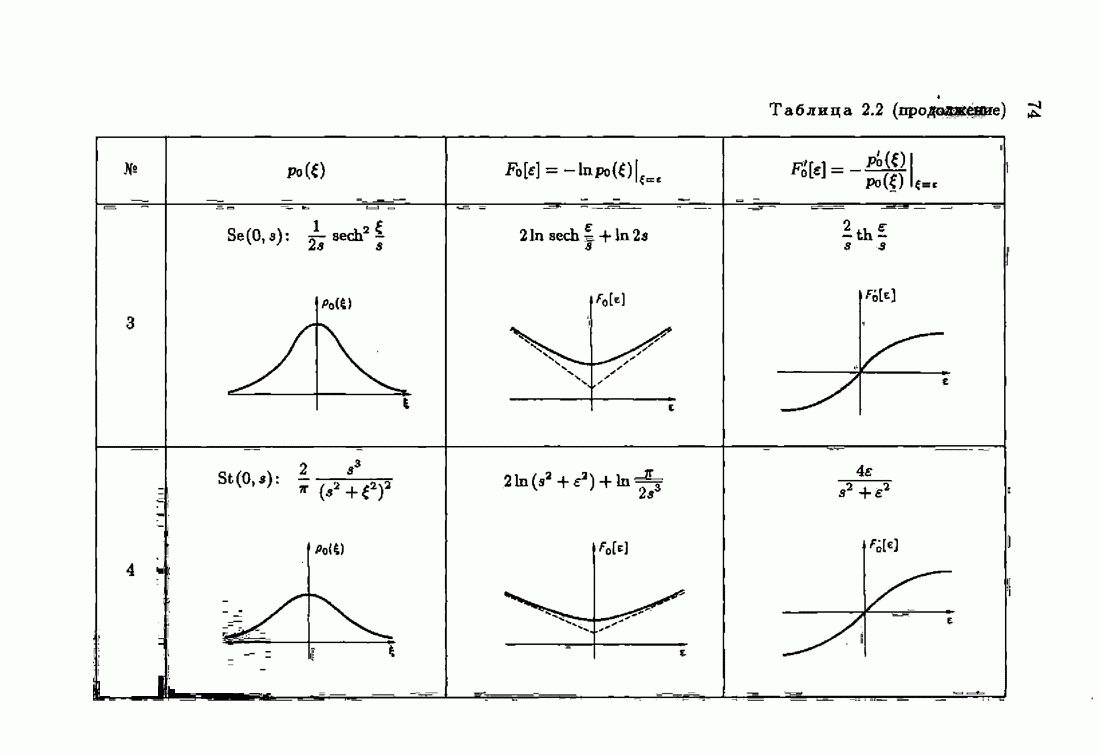
Условия оптимальности позволяют не только установить ряд важных свойств оптимального решения с, но и, как будет показано далее, сформировать наилучшие, в определенном смысле, алгоритмы оценивания оптимального решения,