Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
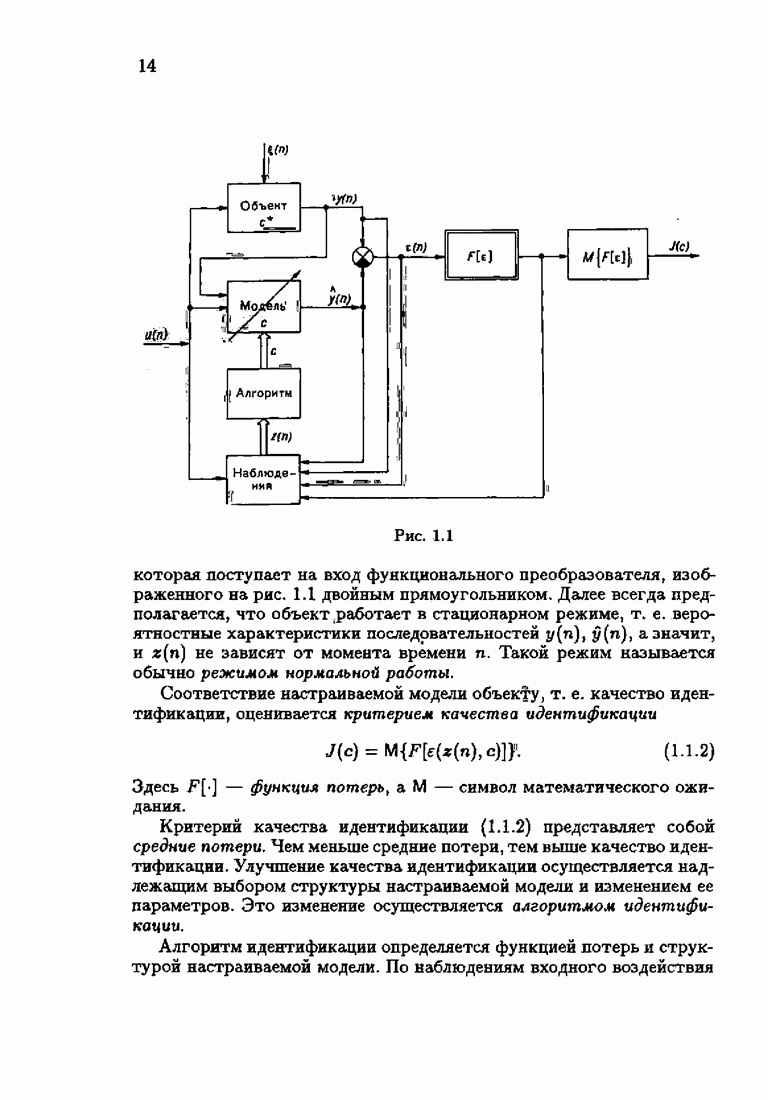
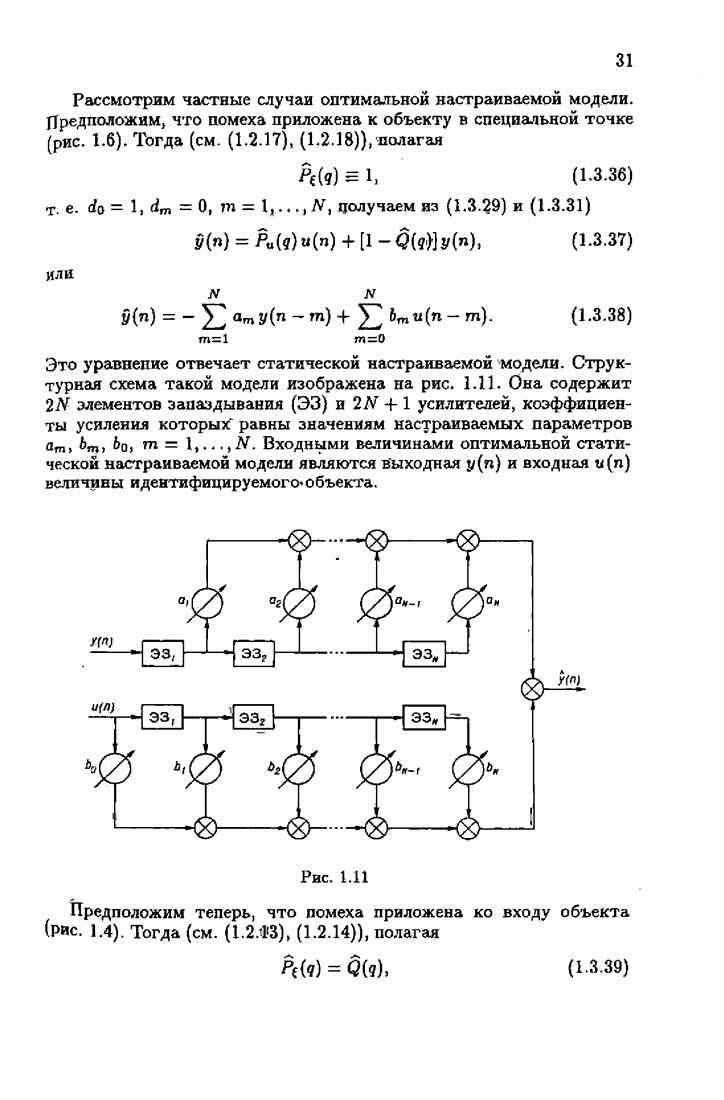
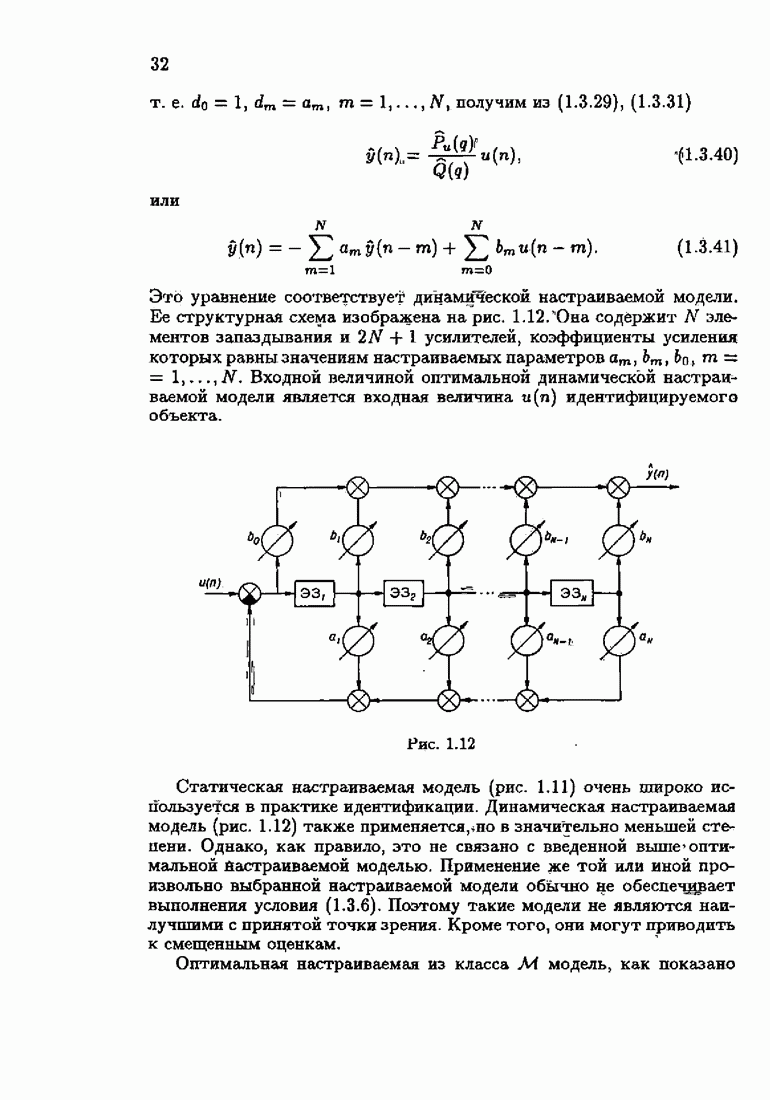
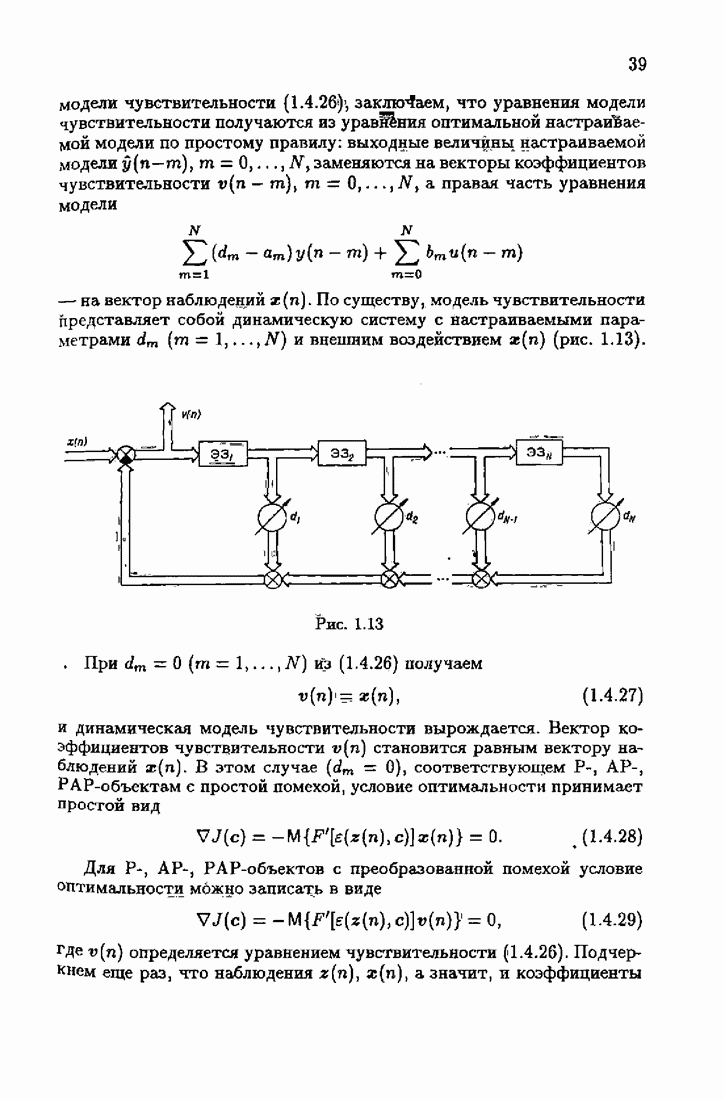
§ 2.2. Асимптотические свойства оценок и средних потерьВыясним асимптотические свойства оценок
где
и
Обозначим, как и ранее в (1.6.13),
Тогда матрица
а из (2.1.12) получим
Но при больших
поэтому
Полагая в
Используя обозначение (1.6.23)
запишем
Что же касается матрицы Гессе
где
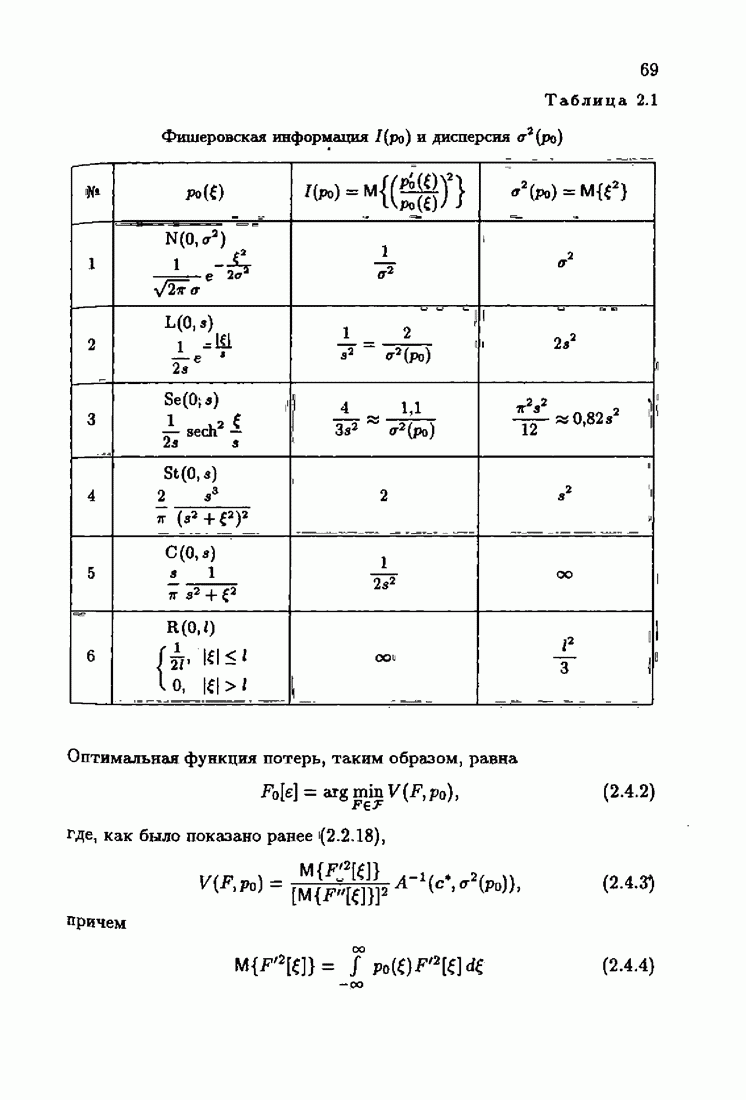
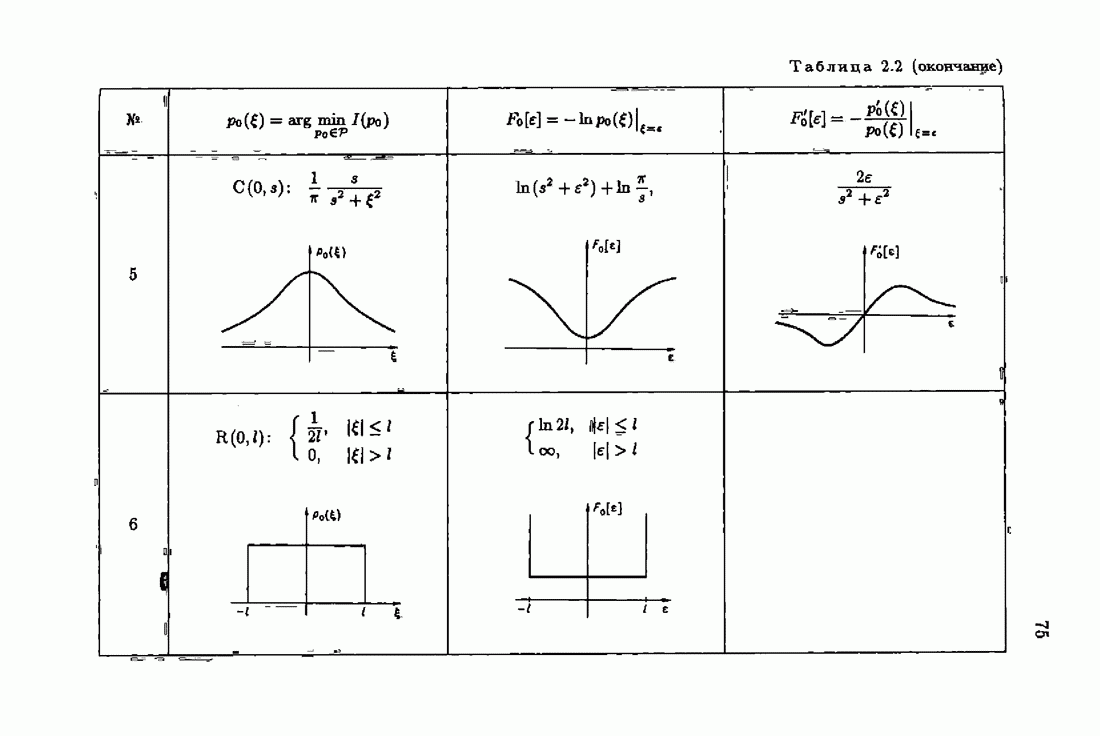
нормированная информационная матрица. Примеры информационных матриц приведены в 5 1.6 (см. табл. 1.1). Подставляя
Теперь уже нетрудно вычислить АМКО (2.2.1). После простых преобразований находим из (2.2.5), (2.2.13)
И хотя равенство (2.2.13) приближенное, полученная формула для АМКО (2.2.14) является точной. Поскольку строгий вывод этой формулы слишком громоздок, мы не будем его здесь приводить. Преобразуем правую часть формулы (2.2.14). Учитывая (1.6.10), (1.6.11) и независимость помех, получим
А из (2.2.9), (2.2.12) следует, что
По в силу стационарности помехи
Поэтому АМКО (2.2.14) представляется в виде
Здесь обозначение Сопоставляя найденное выражение АМКО (1.7.12), то асимптотическая скорость сходимости алгоритма уменьшается. Таким образом, при заданной функции потерь асимптотически оптимальный алгоритм имеет максимальную скорость сходимости, которая совпадает со скоростью сходимости оптимальной выборочной оценки Выясним еще асимптотические свойства средних потерь. Рассмотрим уклонение средних потерь
где, напомним, Разложим
Замечая, что в силу условия оптимальности
Беря от обеих частей математическое ожидание, получаем приближенное выражение для уклонения средних потерь
Но, как нетрудно проверить,
где
И, следовательно, уклонение средних потерь
Назовем по аналогии с (2.2.1) величину
асимптотическим уклонением средних потерь
Здесь
Производя очевидные сокращения и замечая, что
Отсюда следует, что АУСП пропорционально размерности вектора оценок.
|
 |
Оглавление
|












































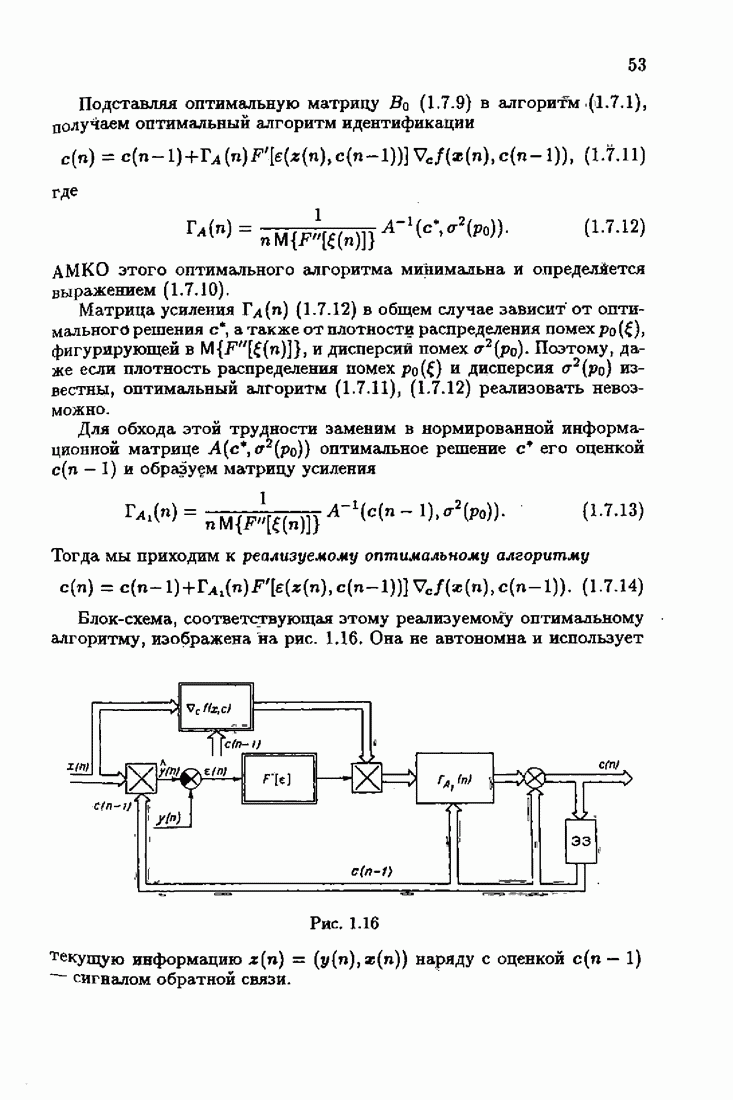


























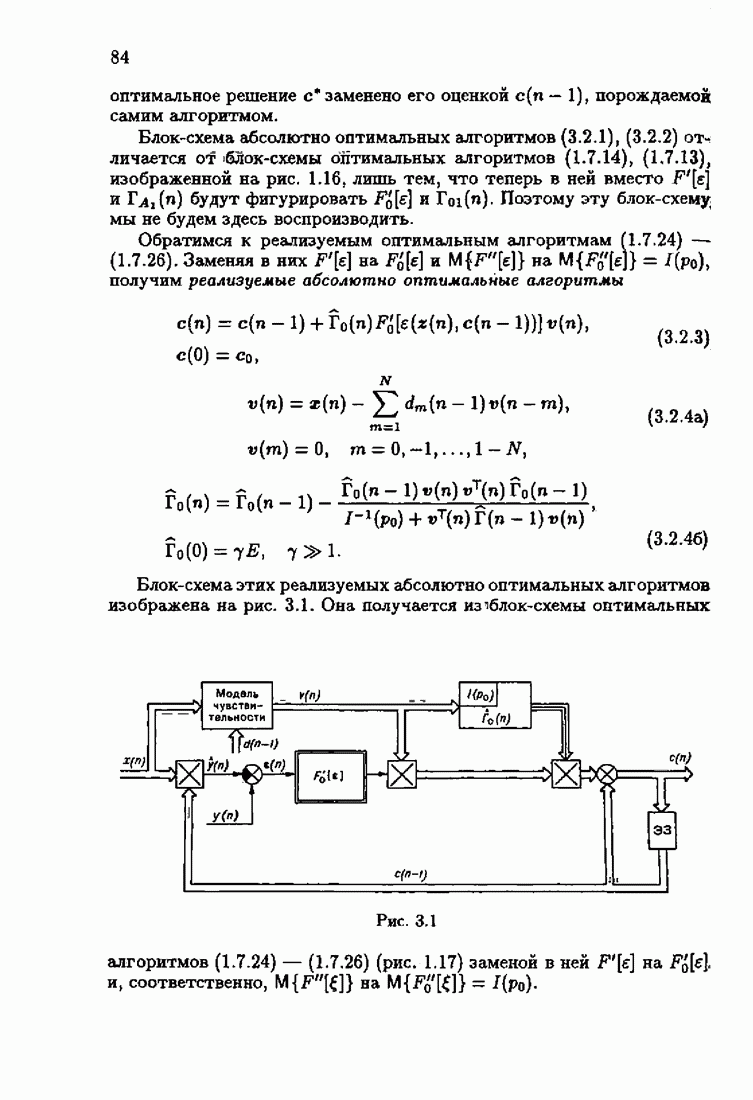
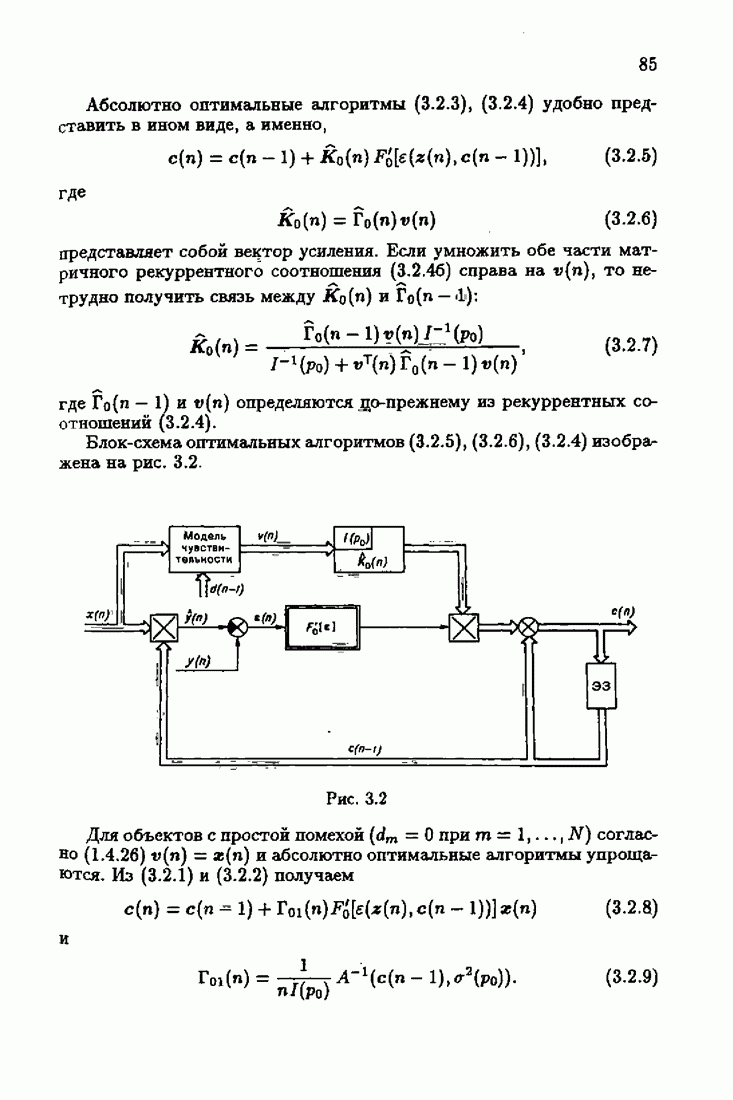
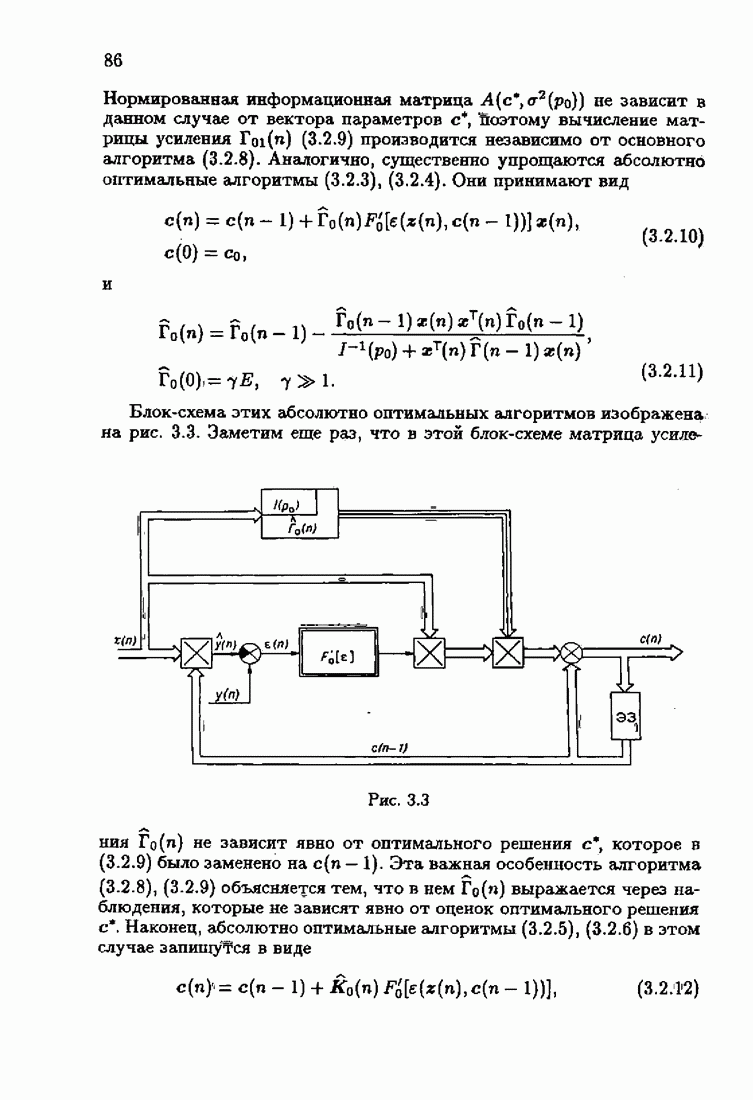
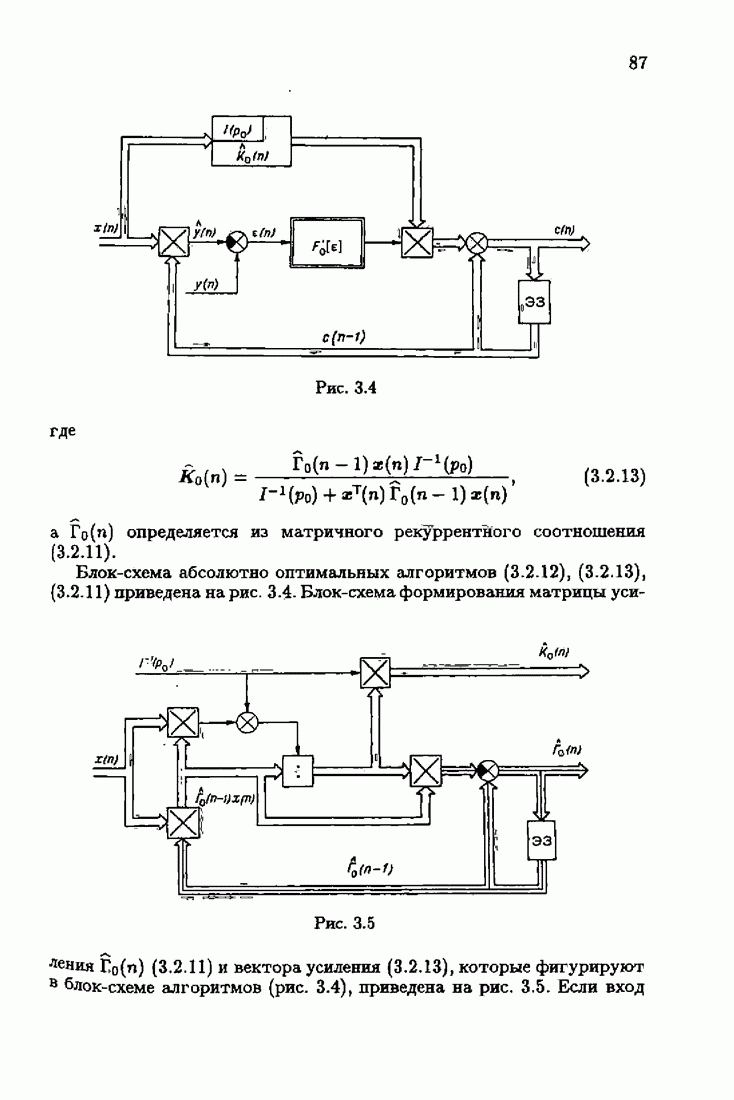




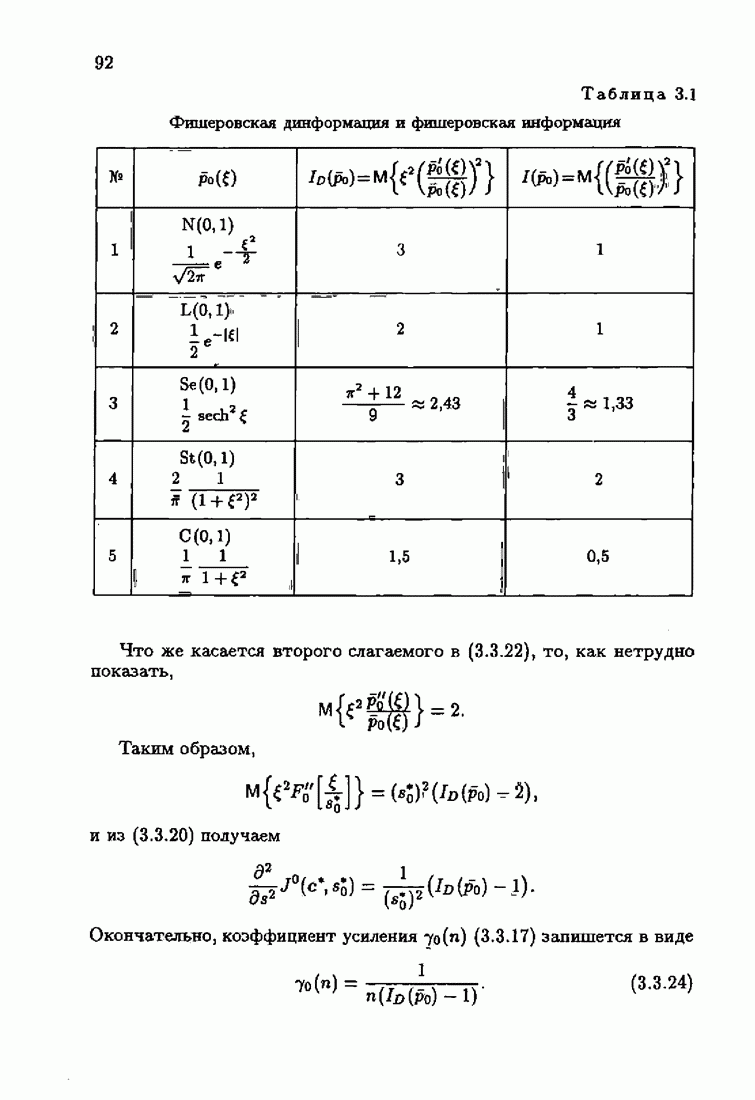
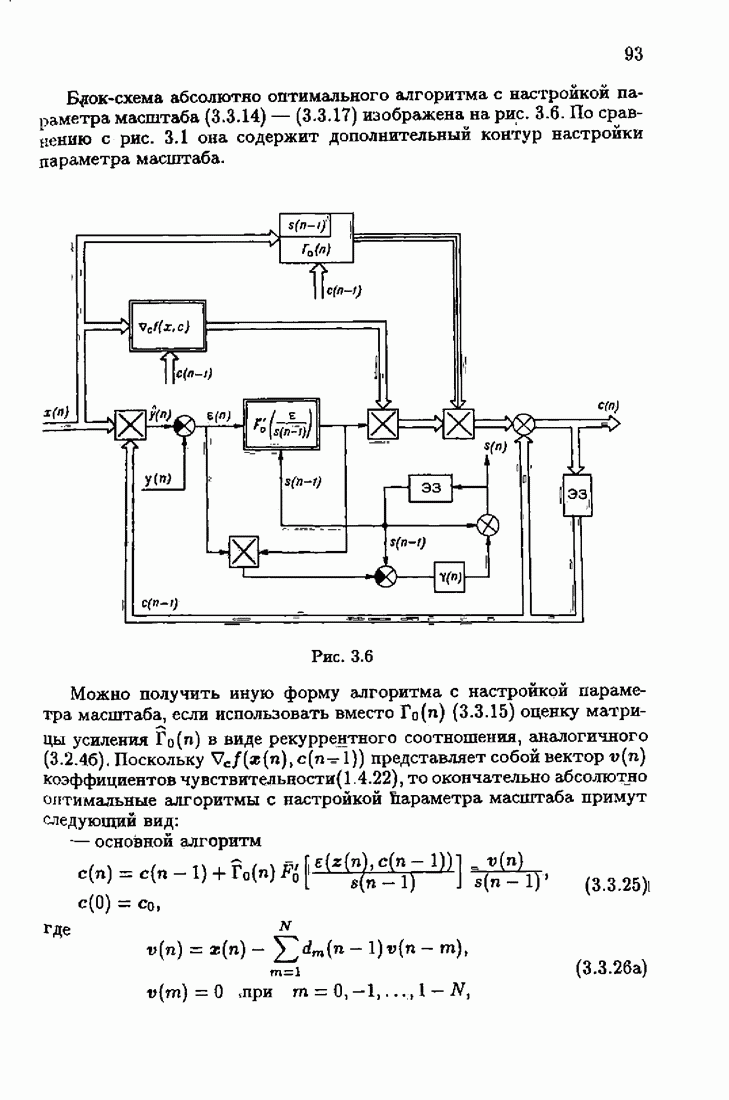
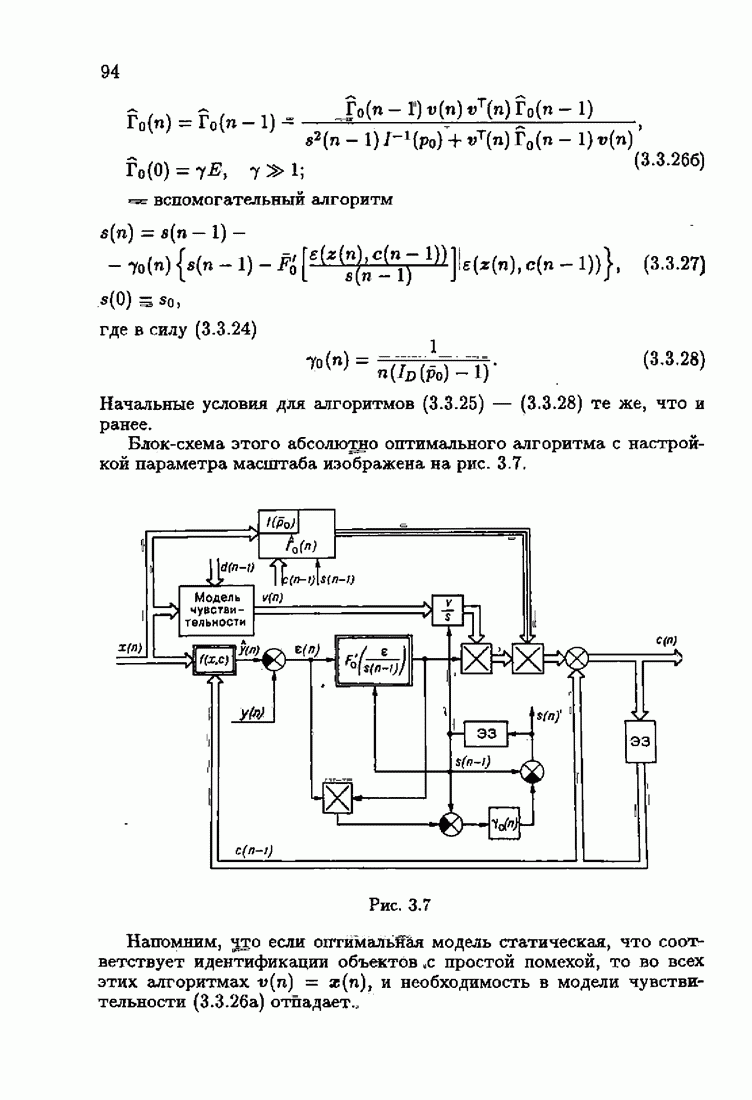


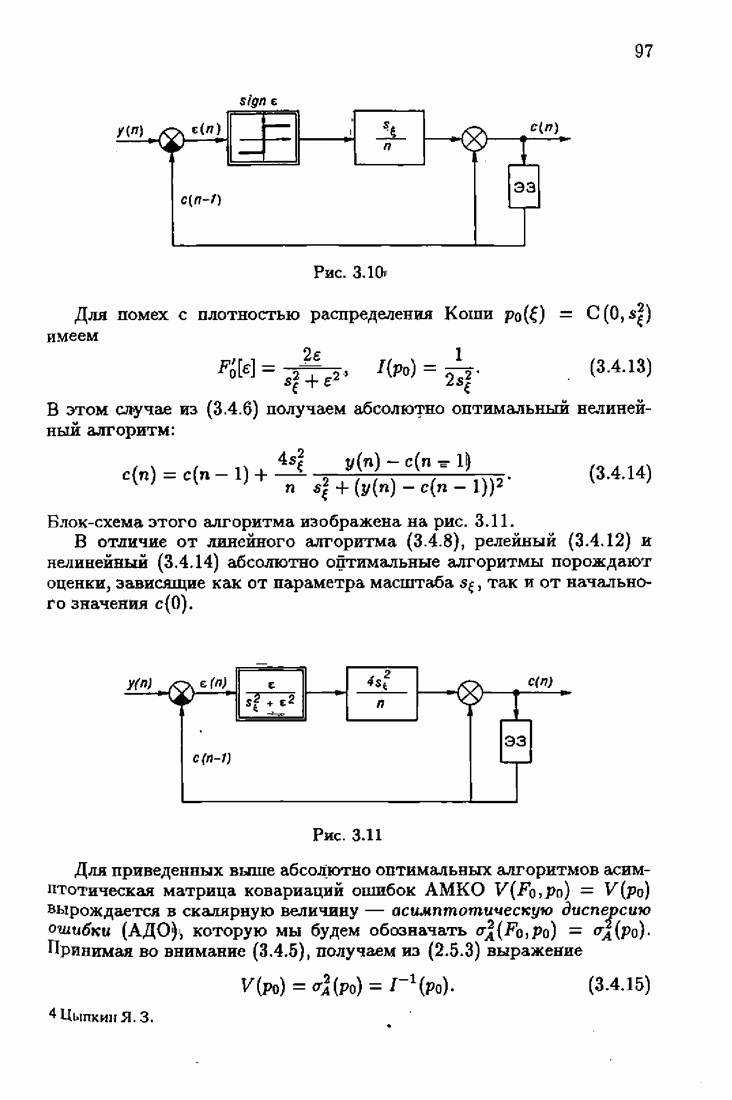



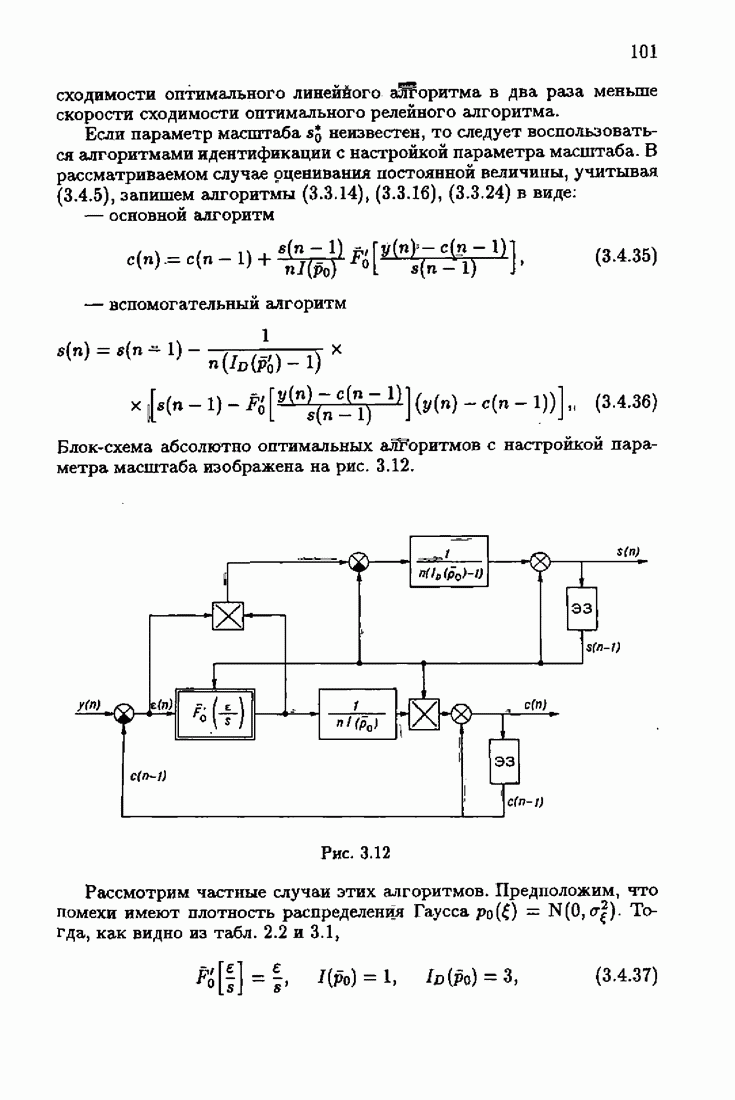
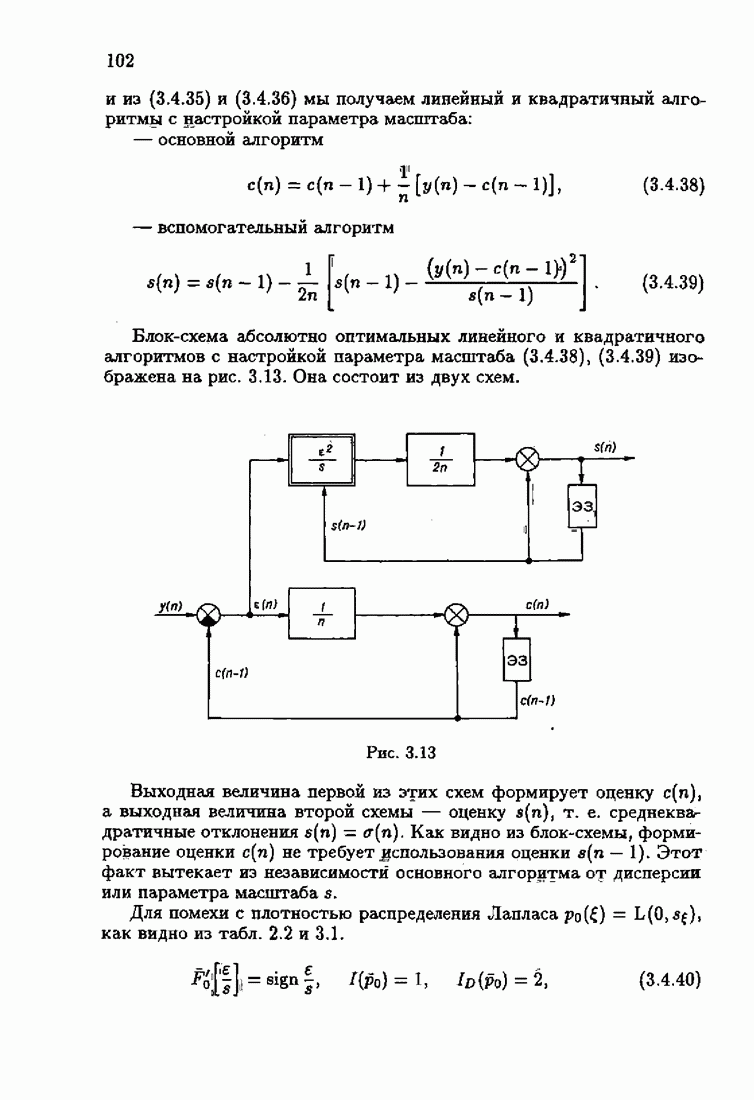
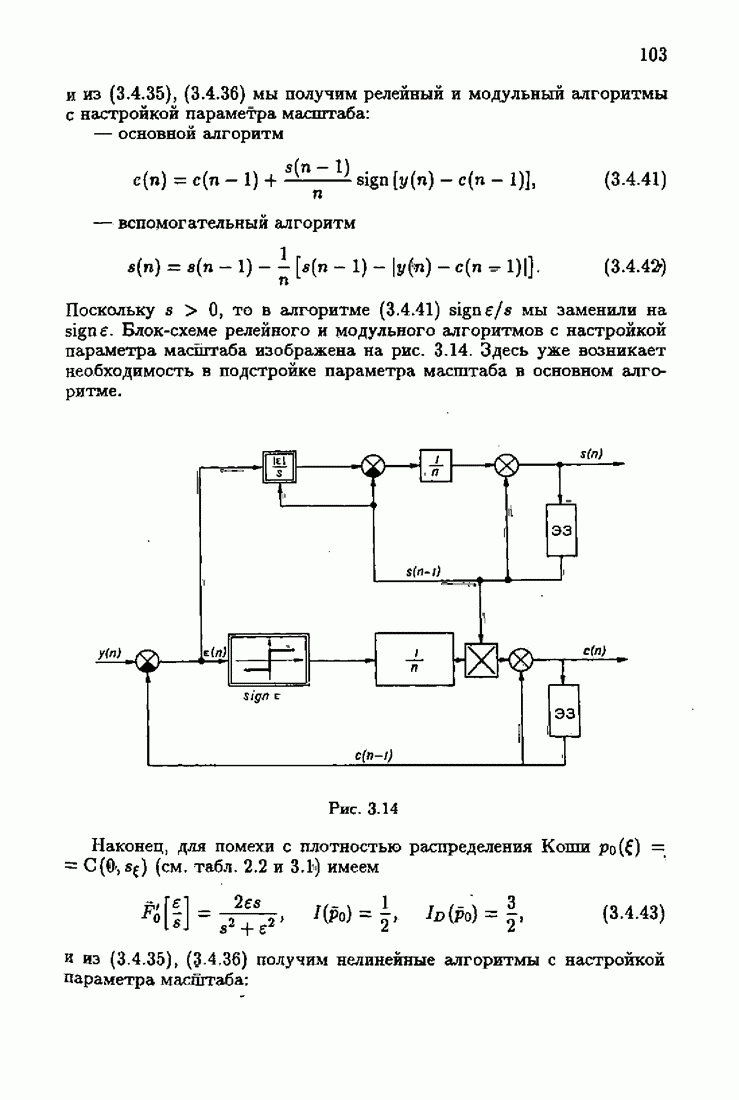
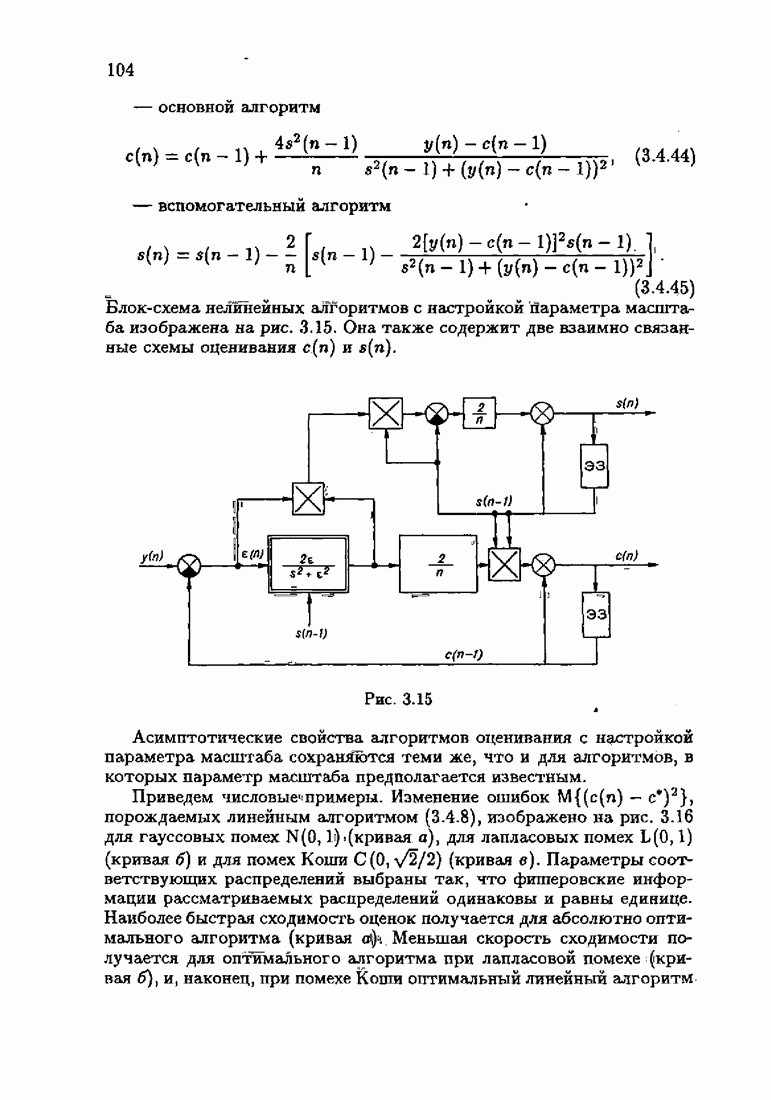



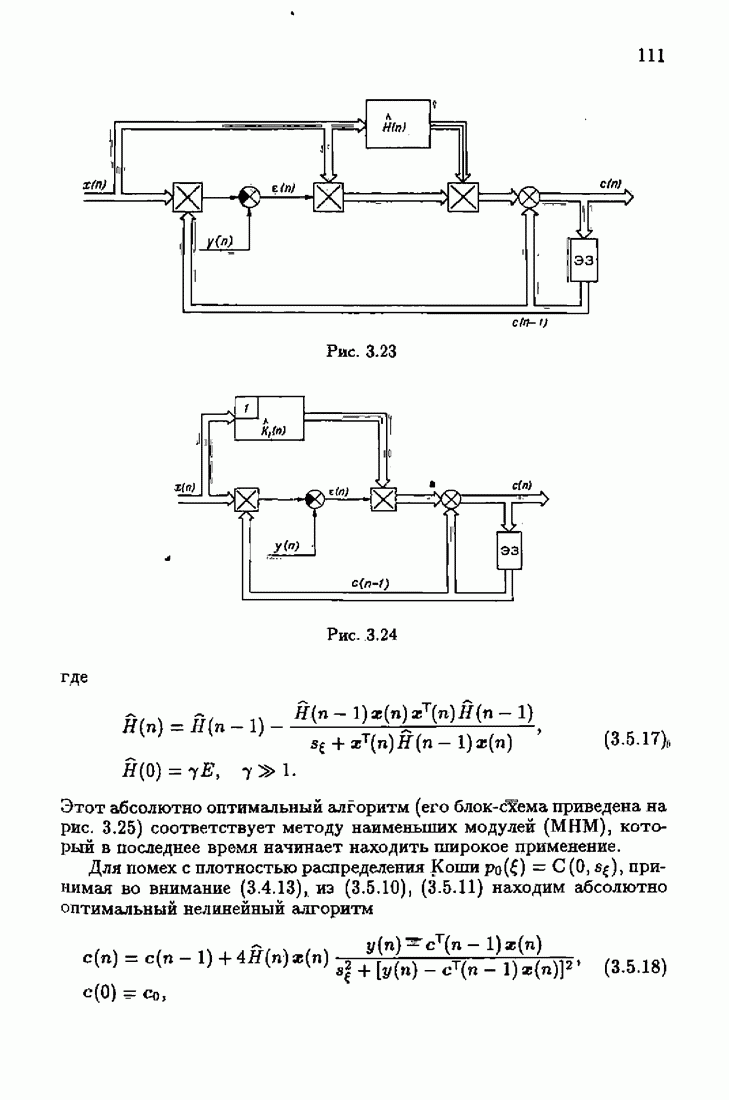
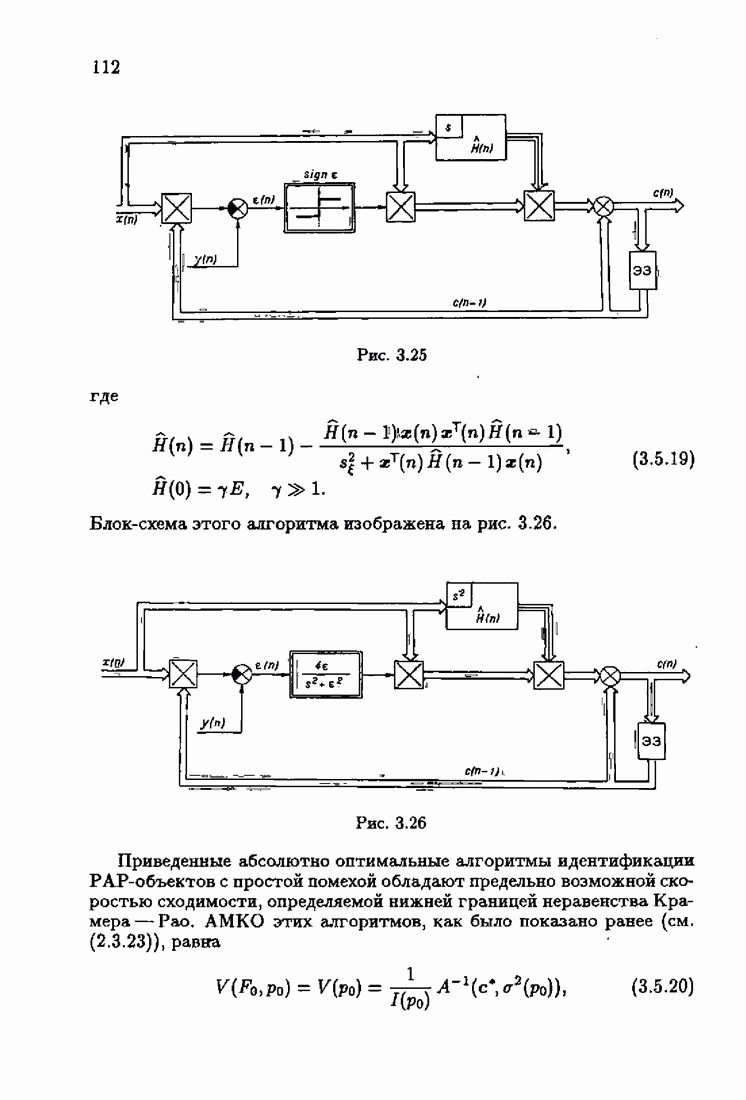



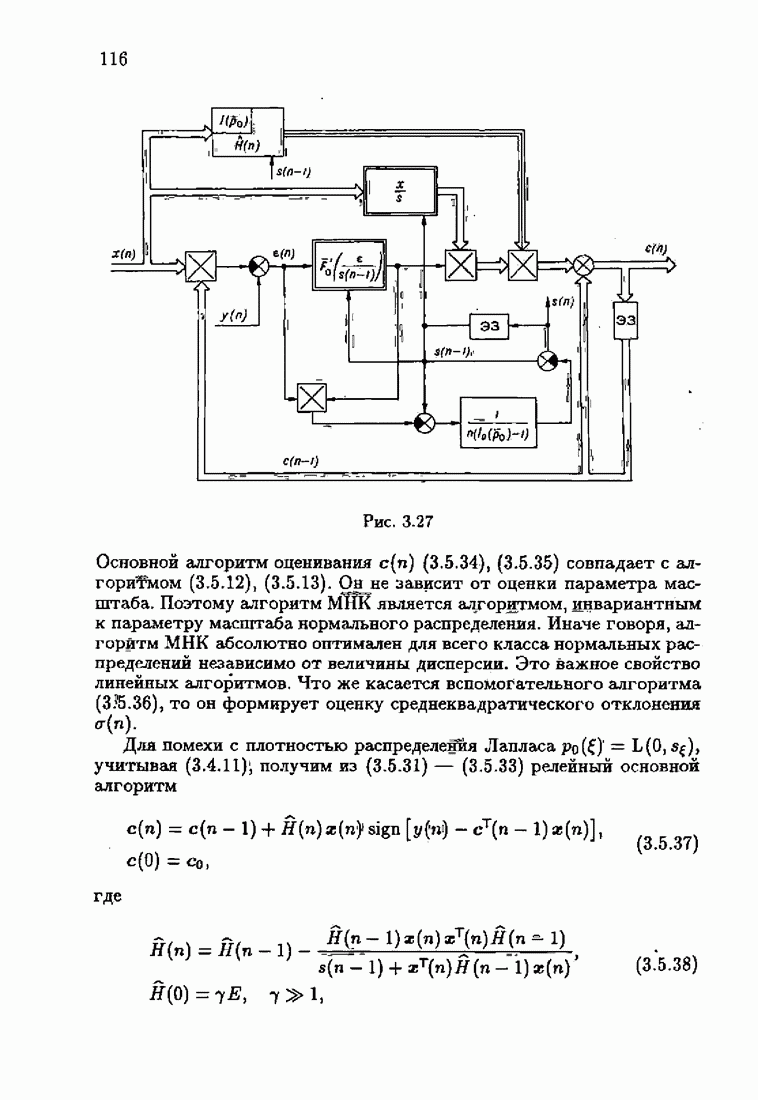
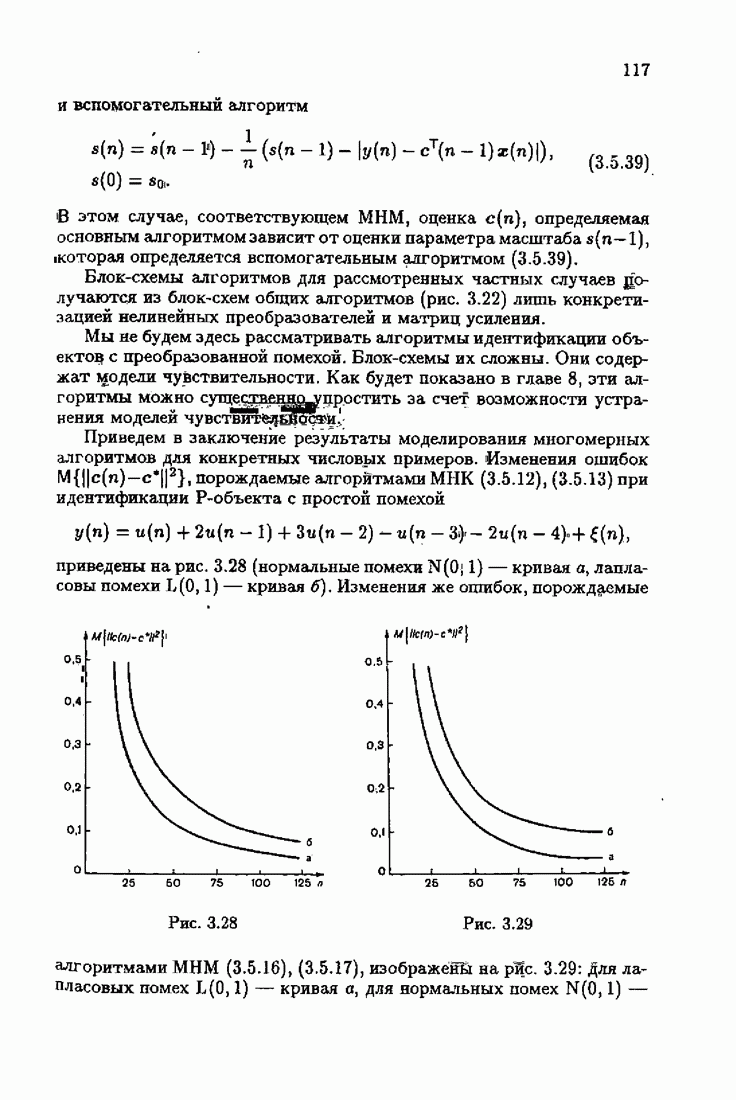
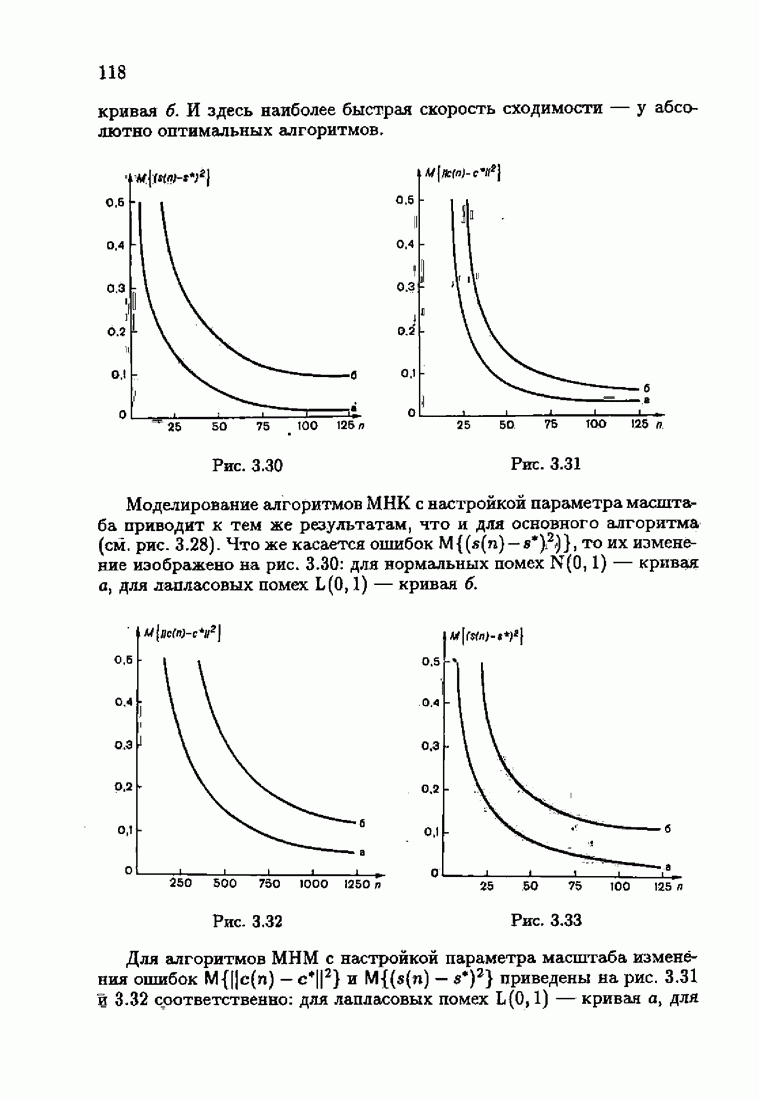




























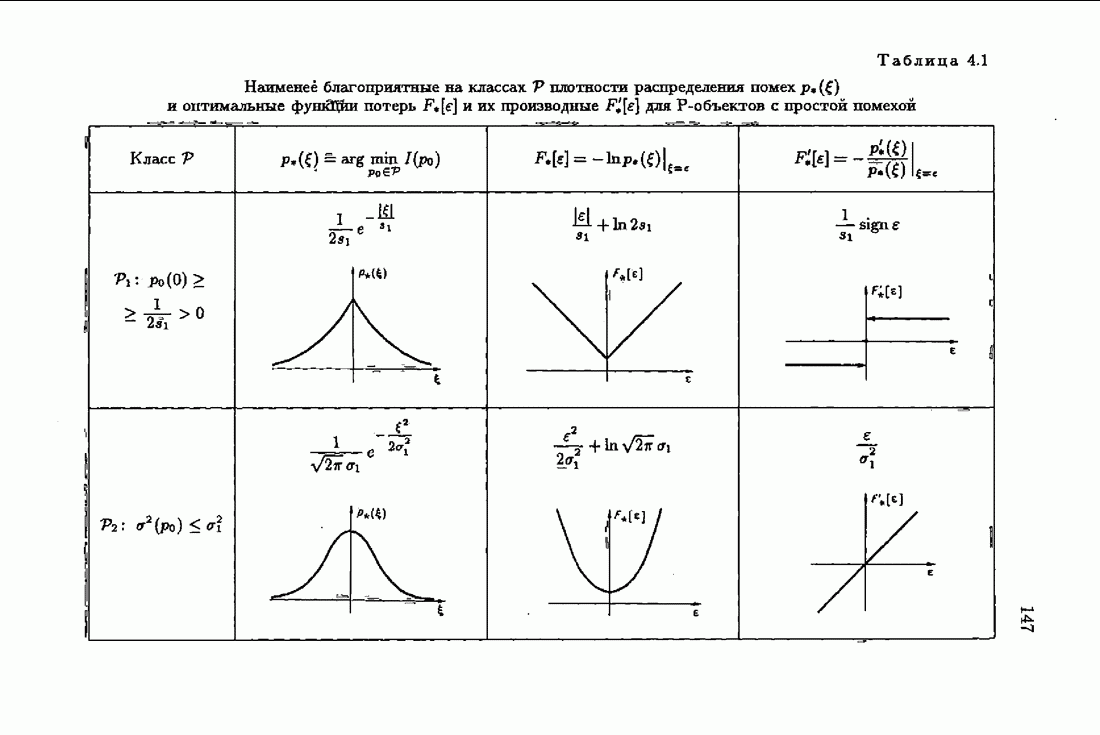
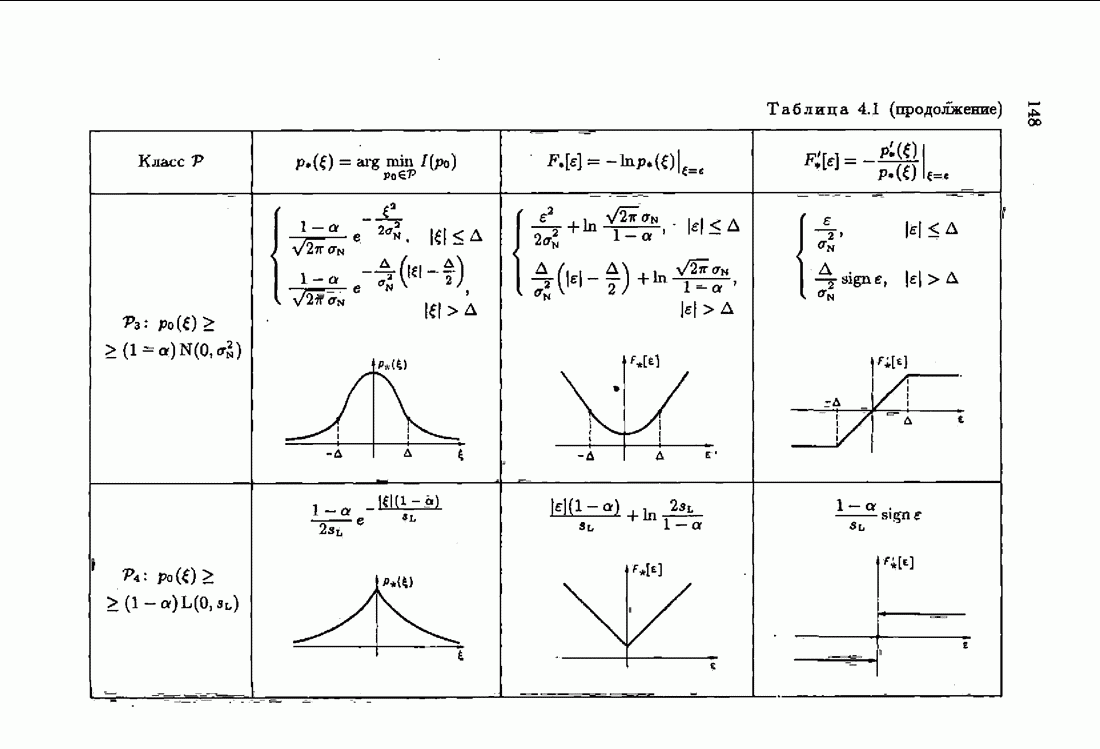
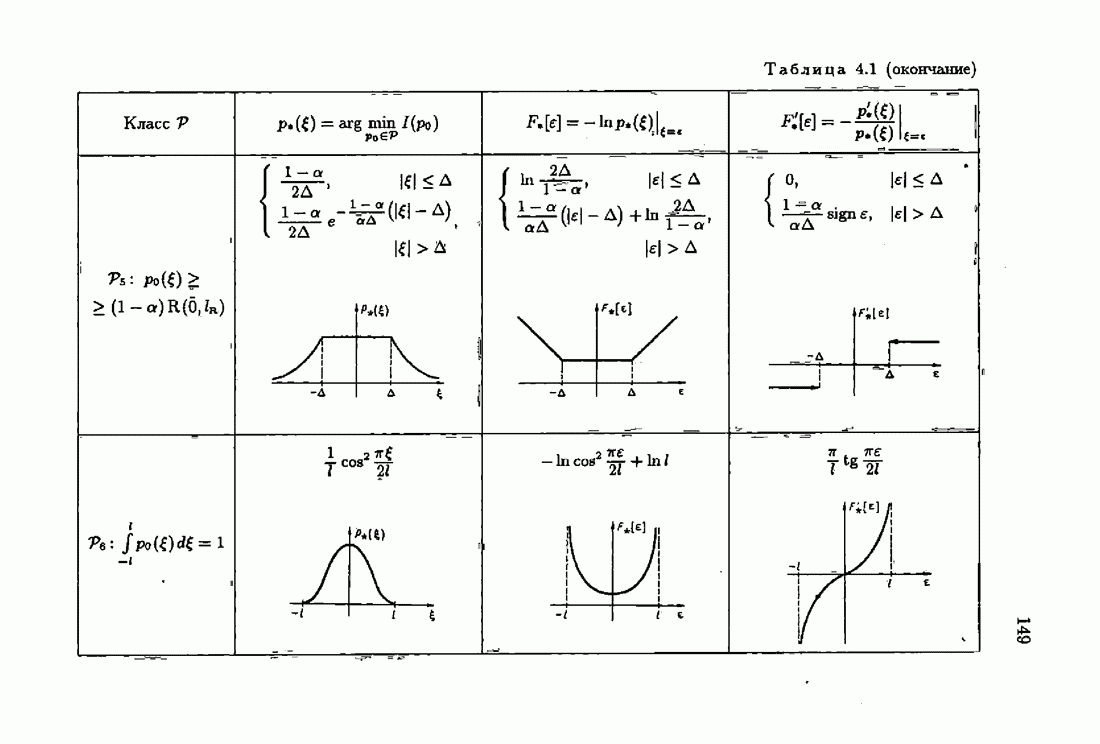
















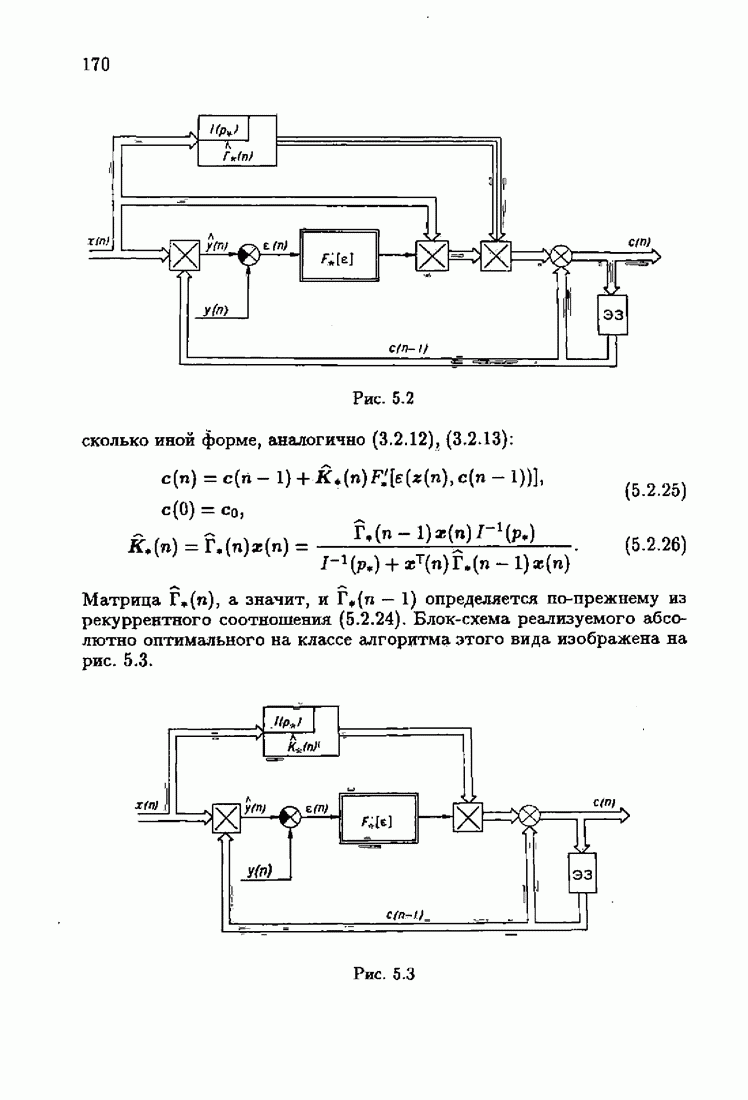

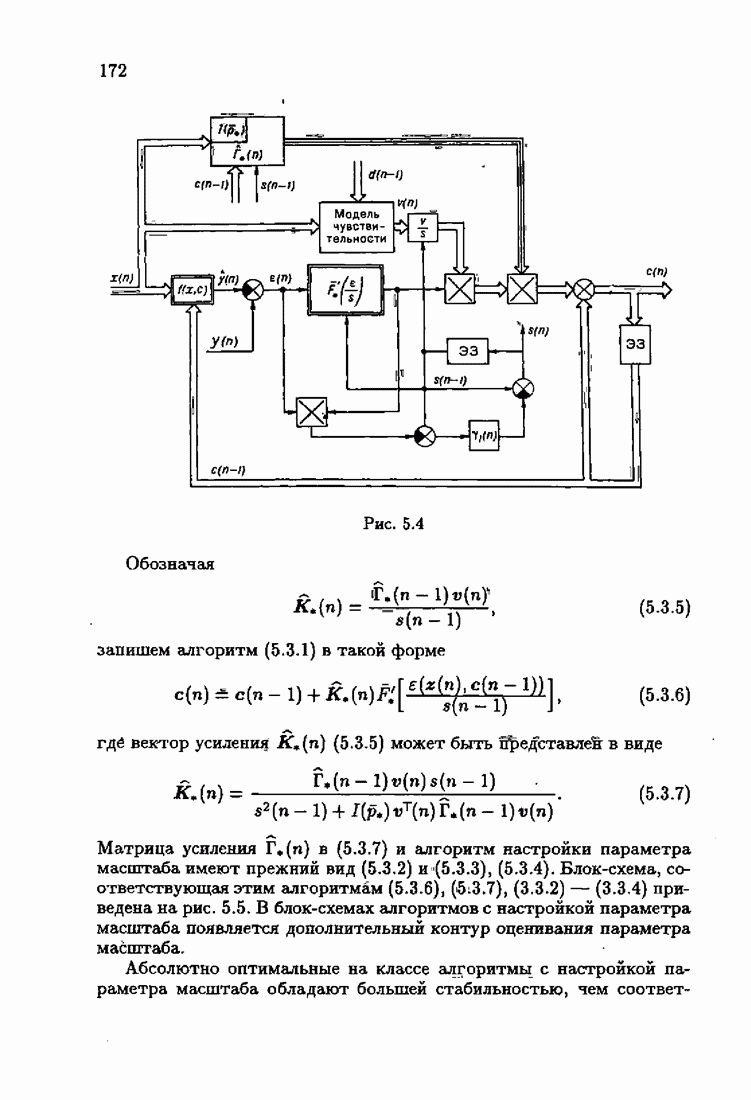
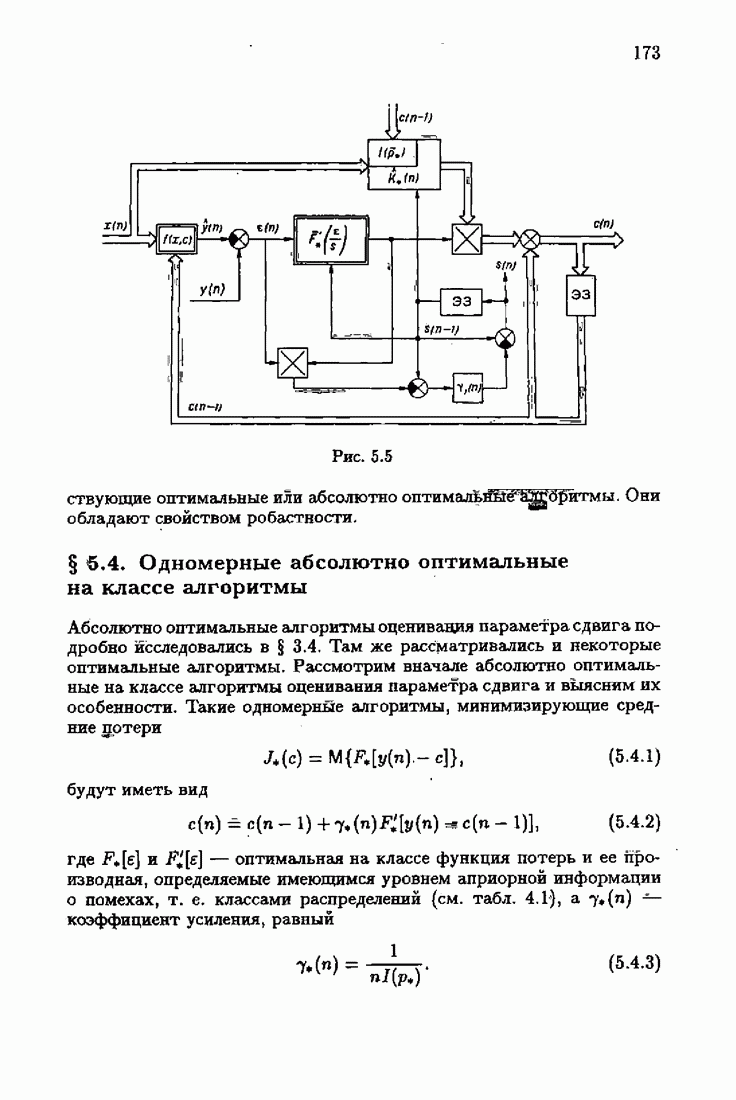




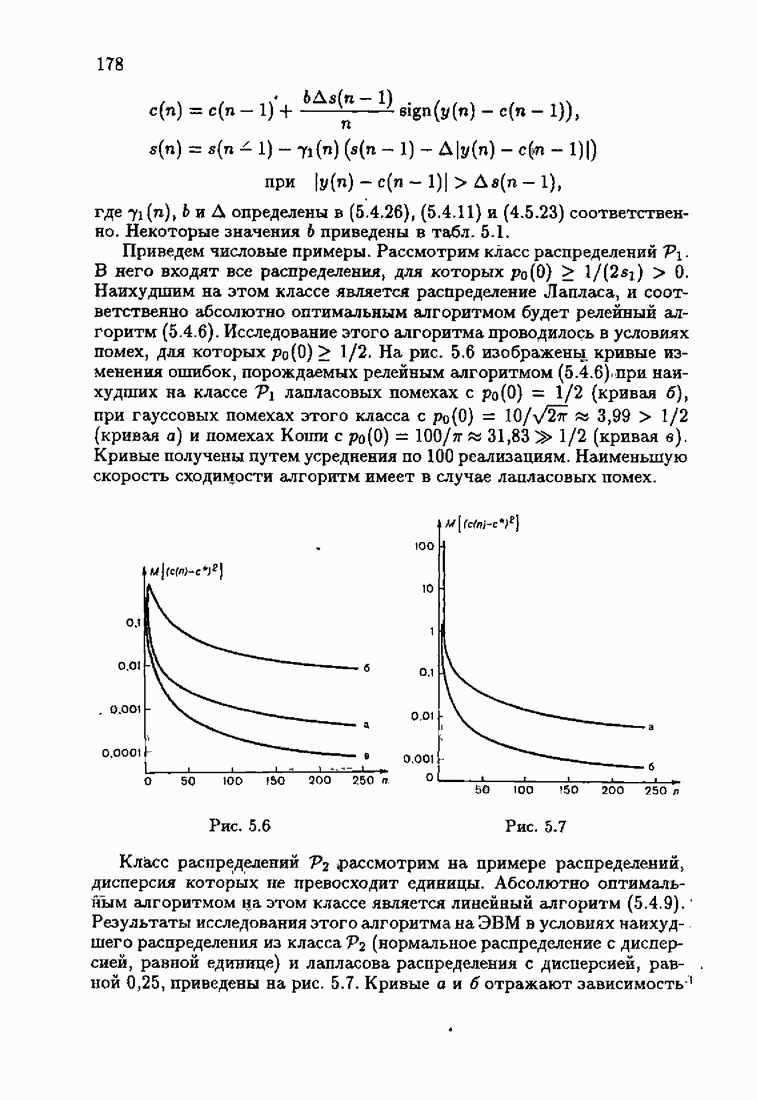
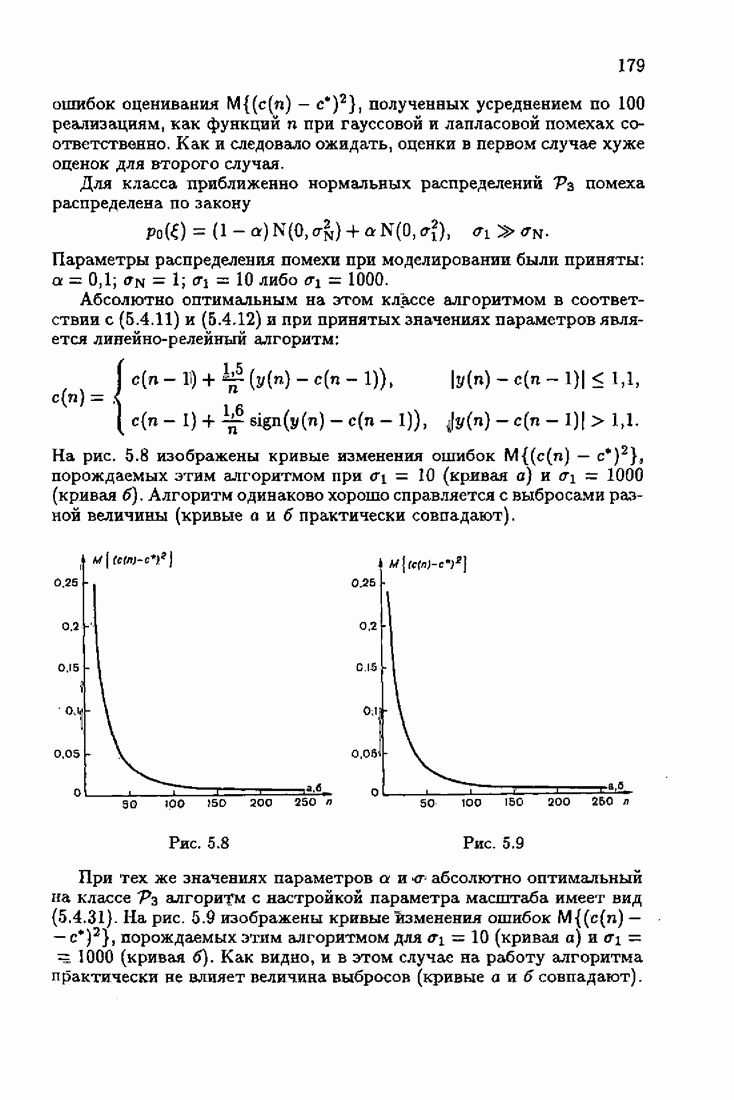
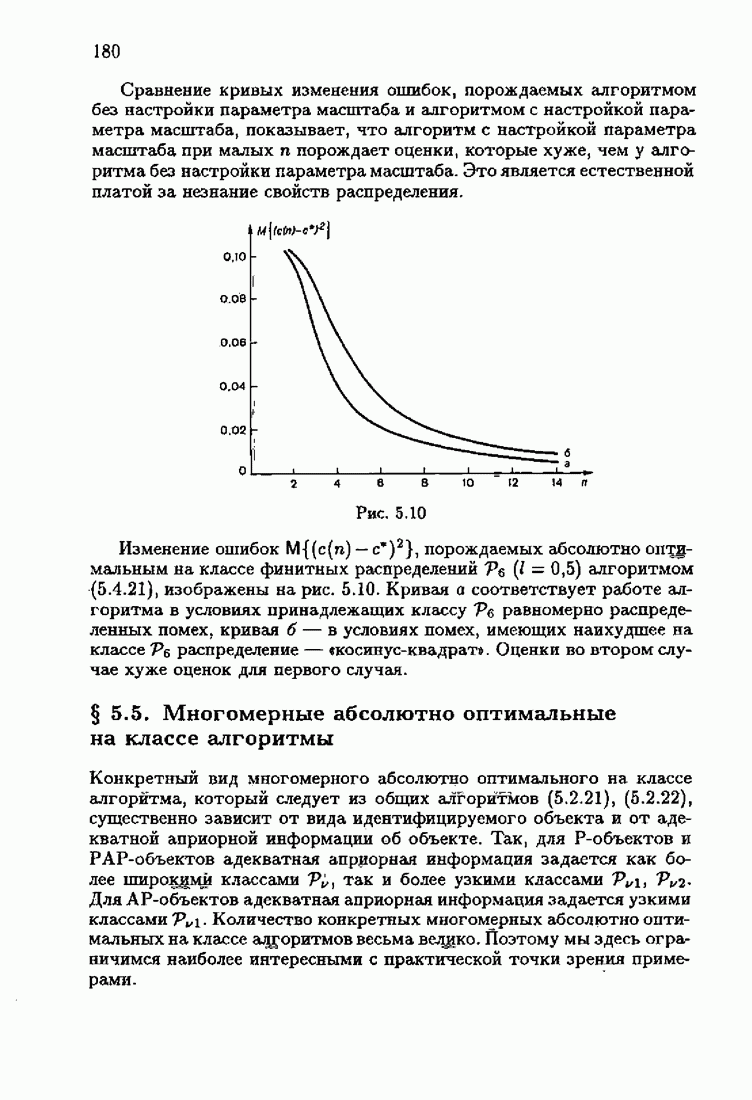

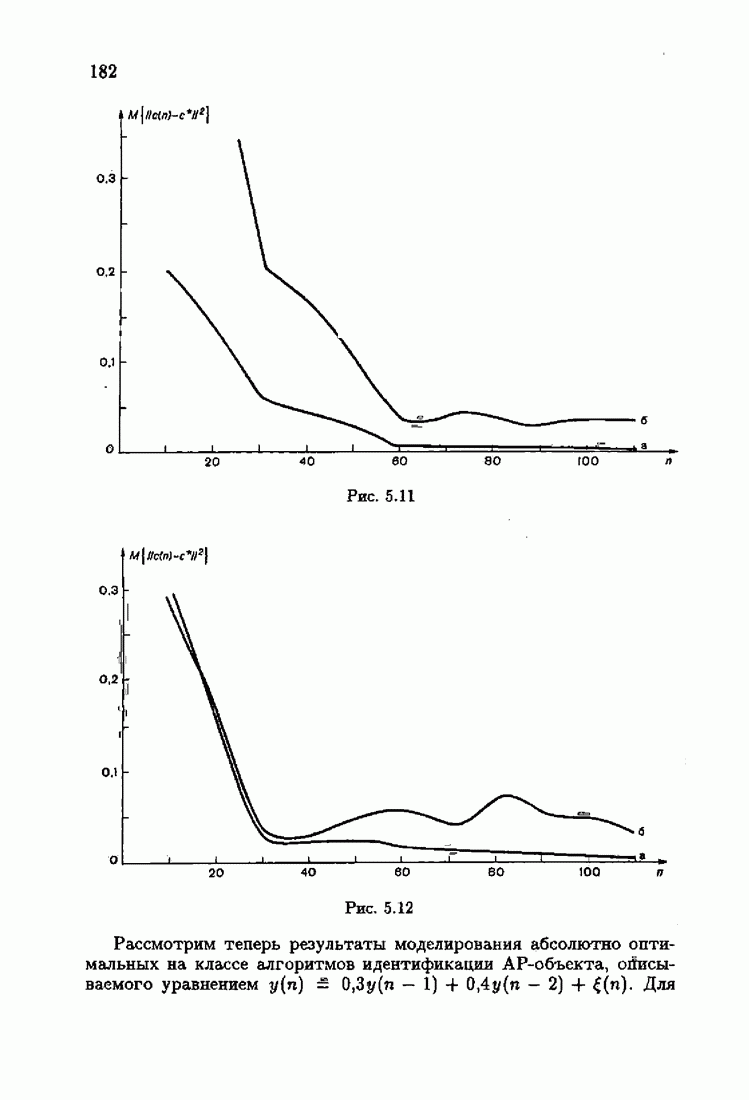
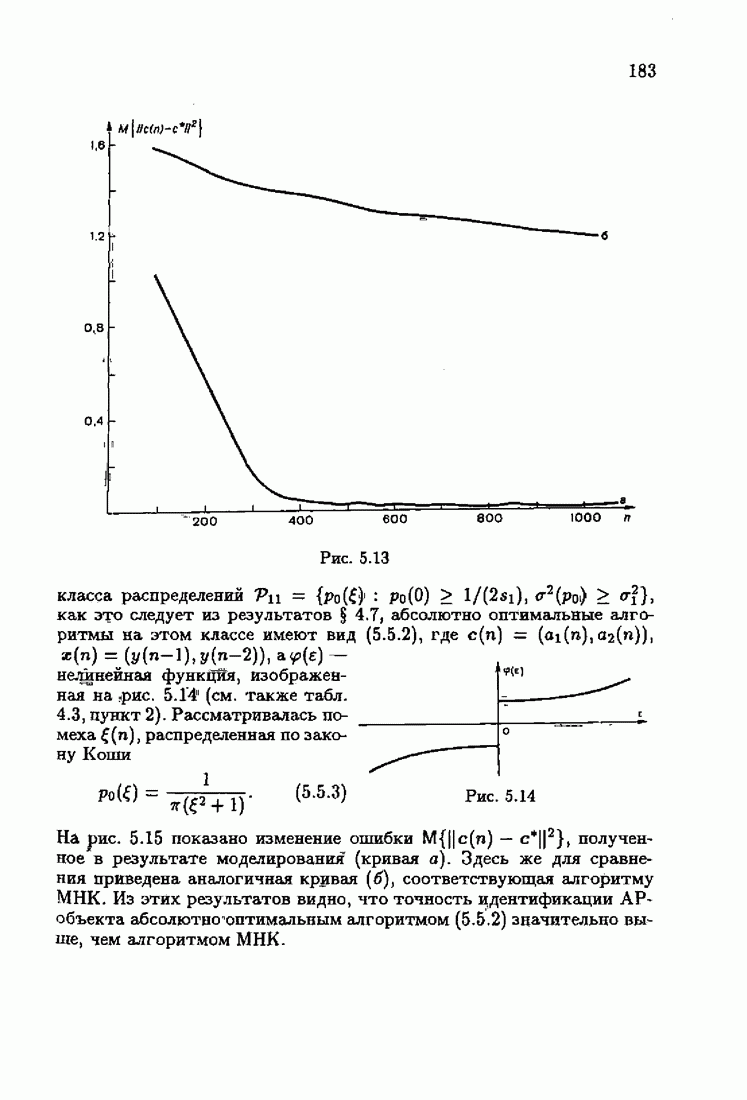
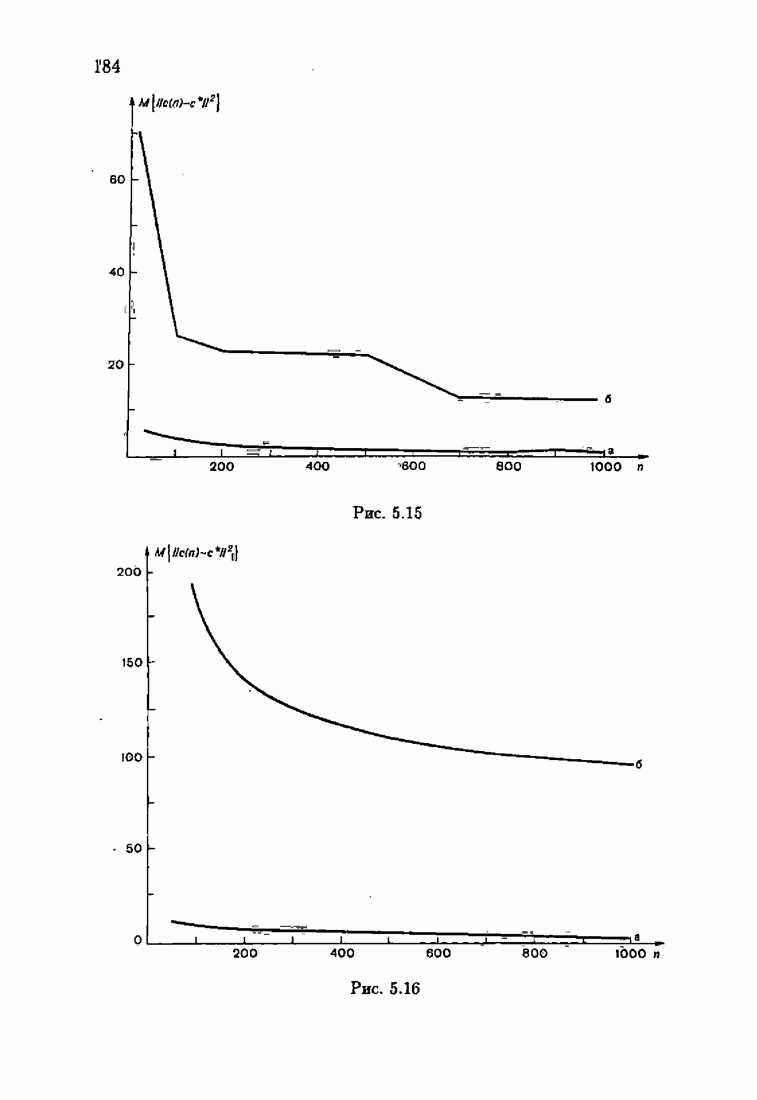















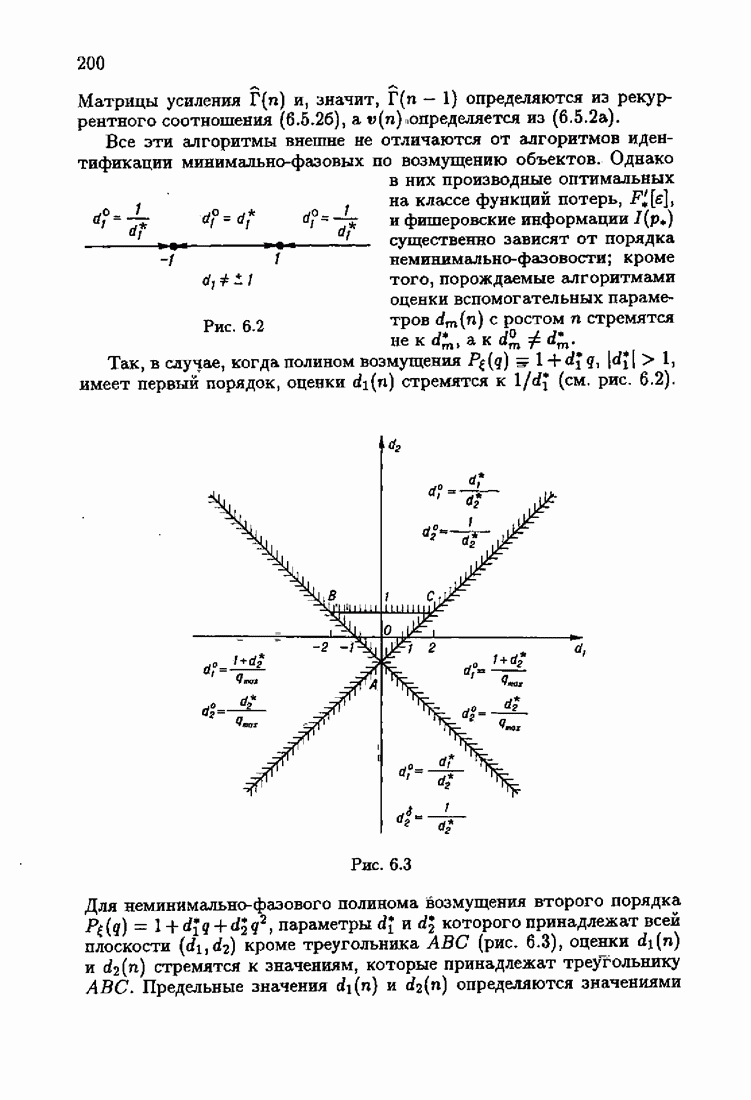

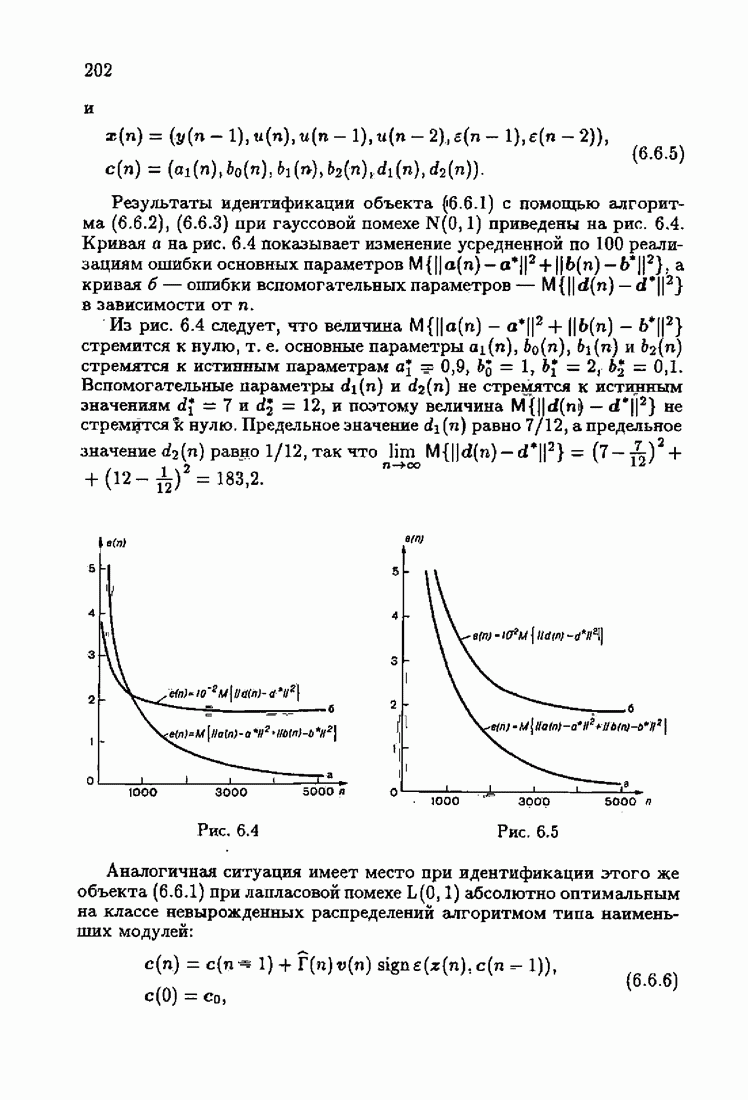














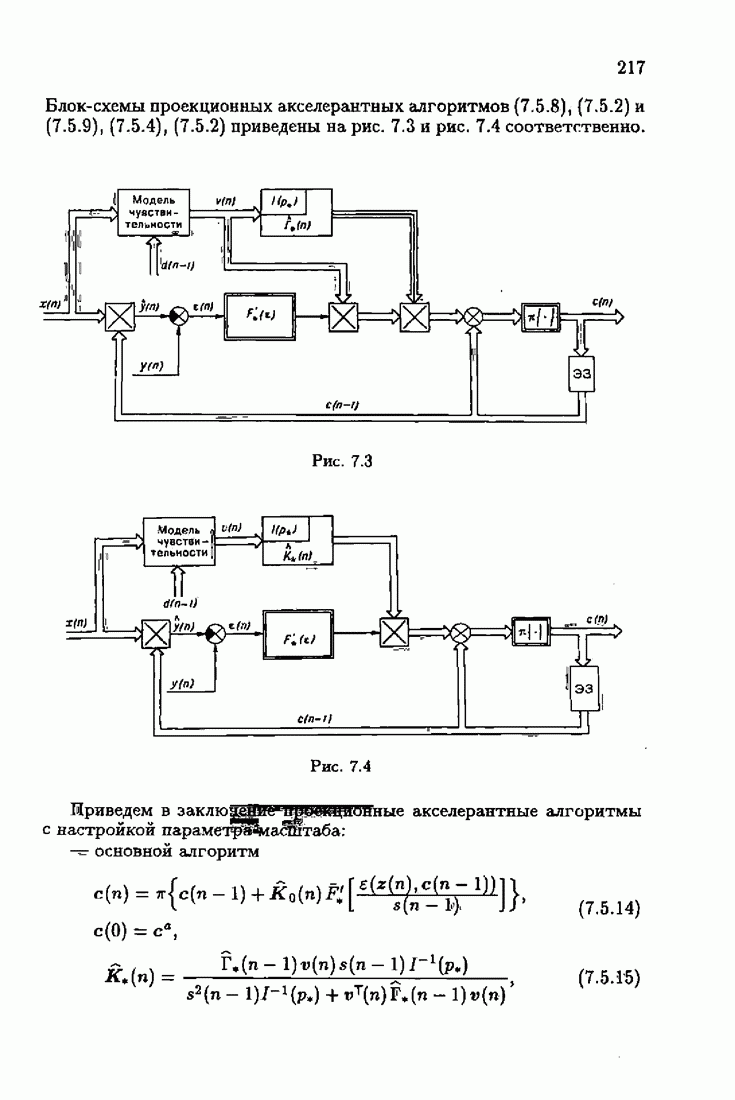
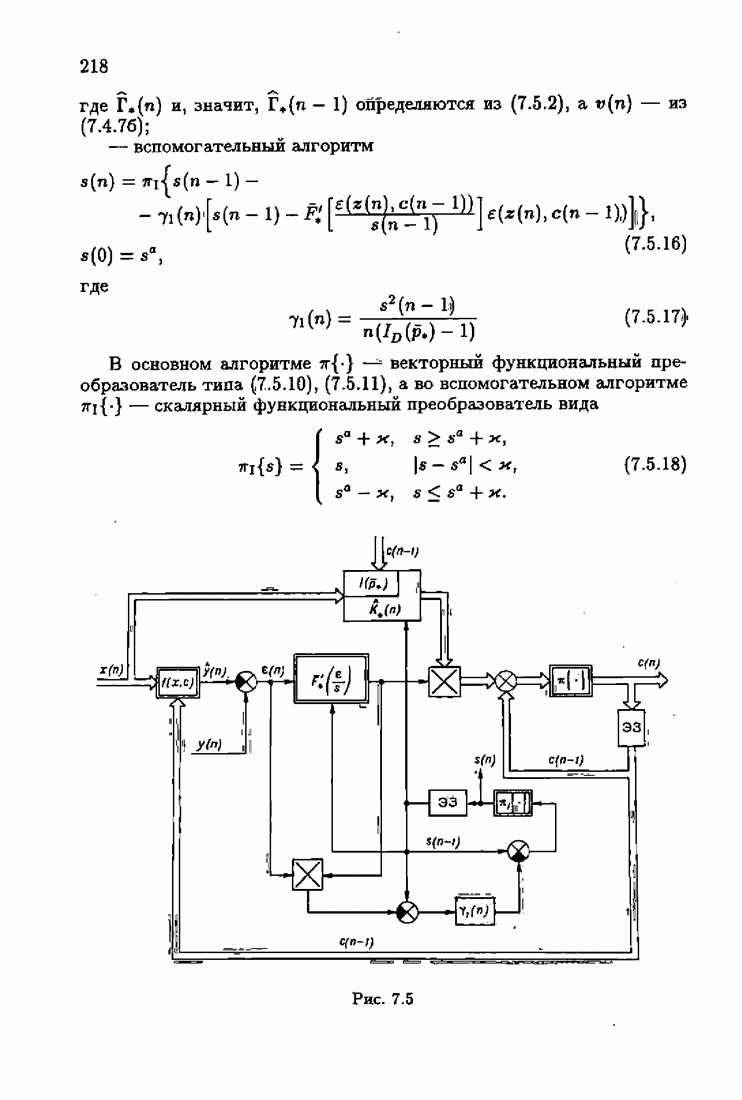









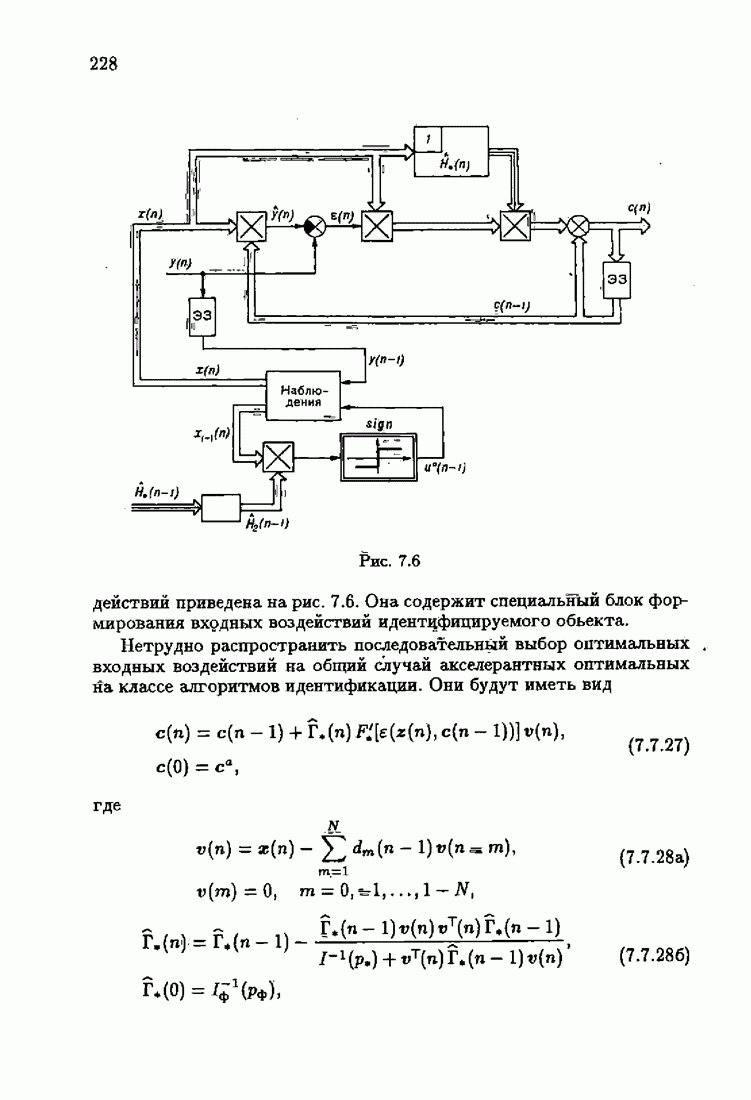
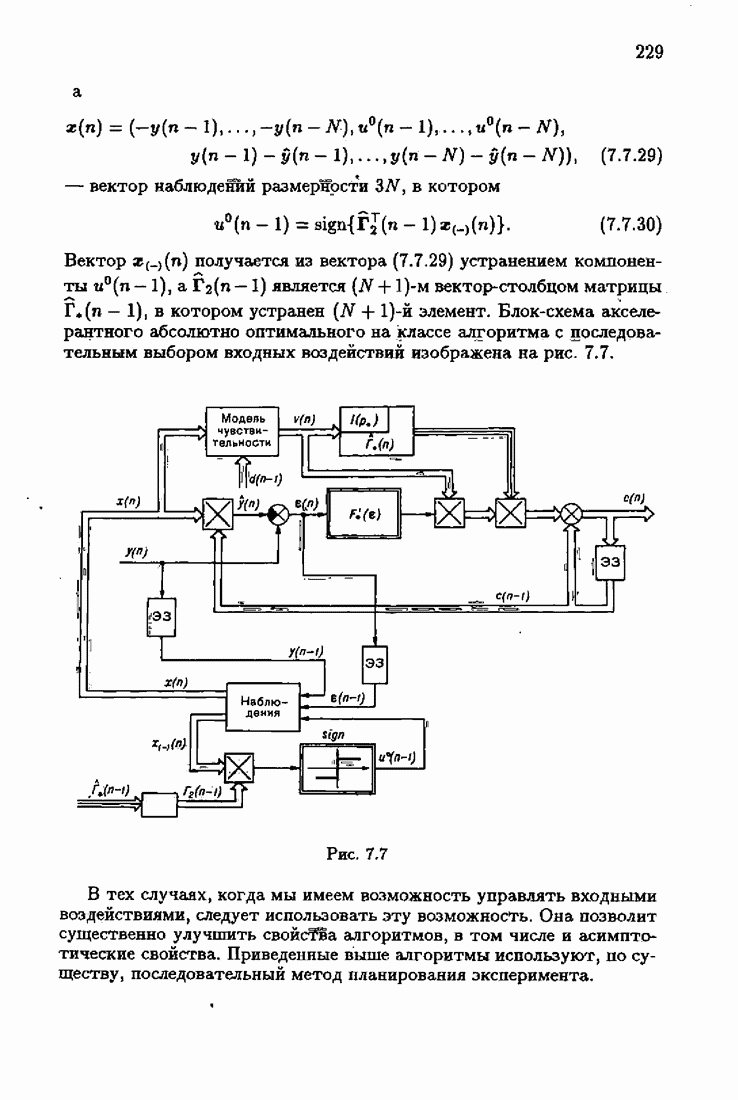


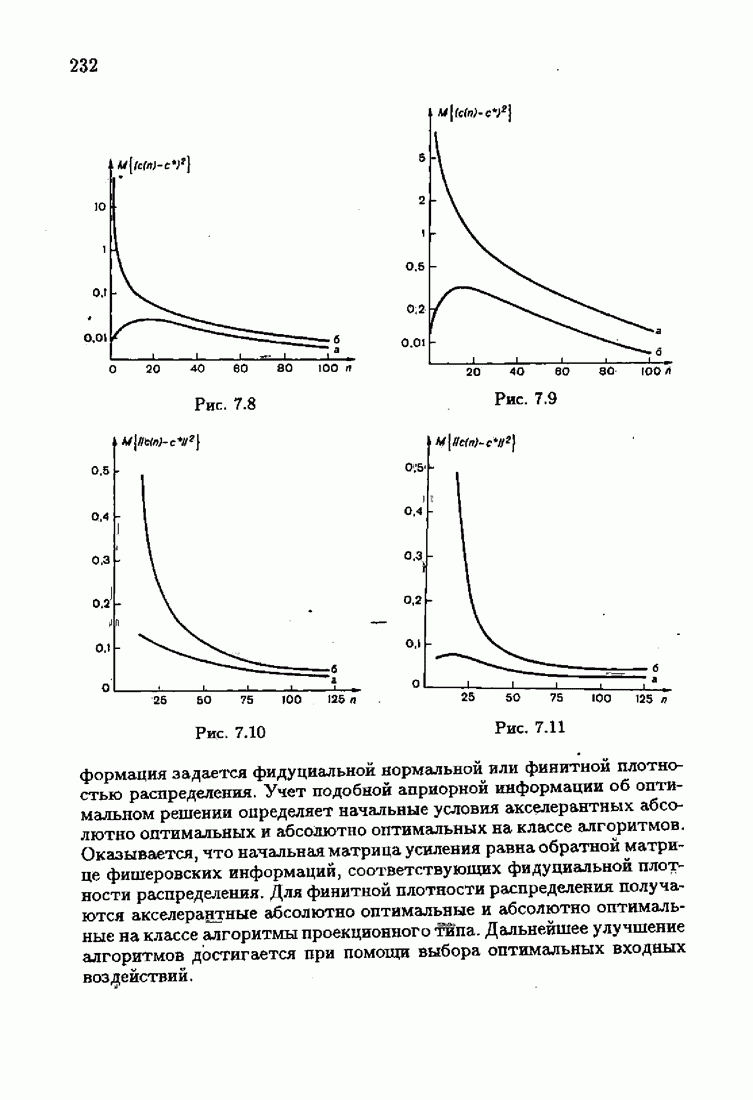




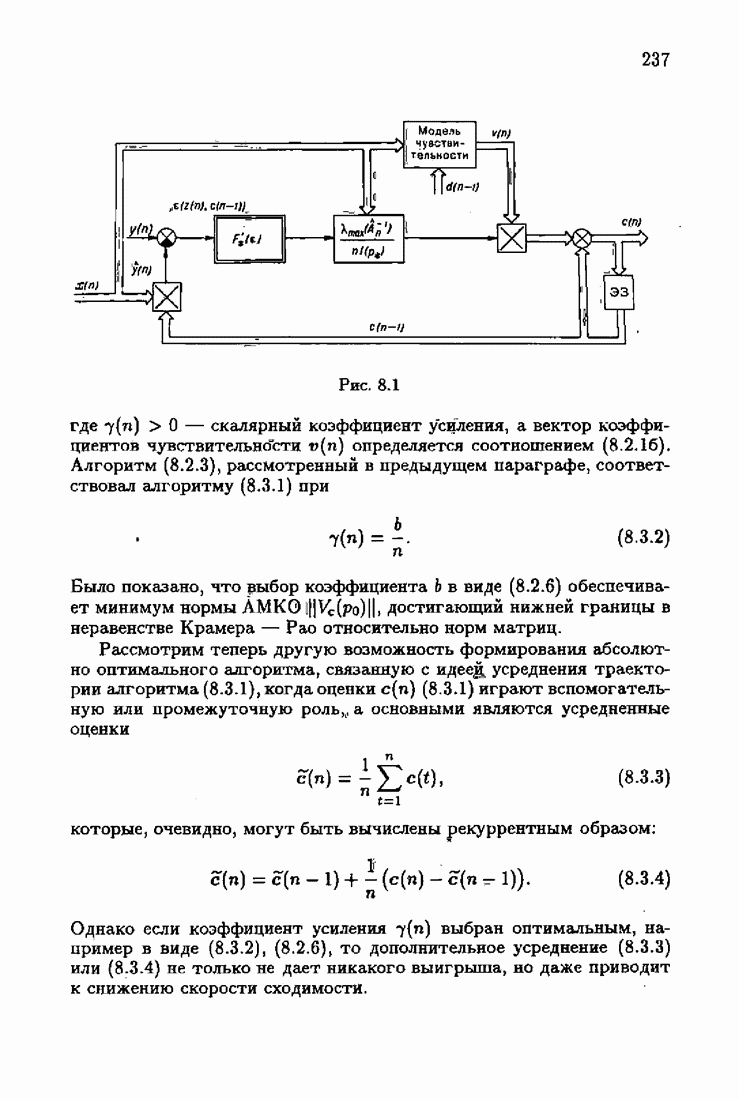






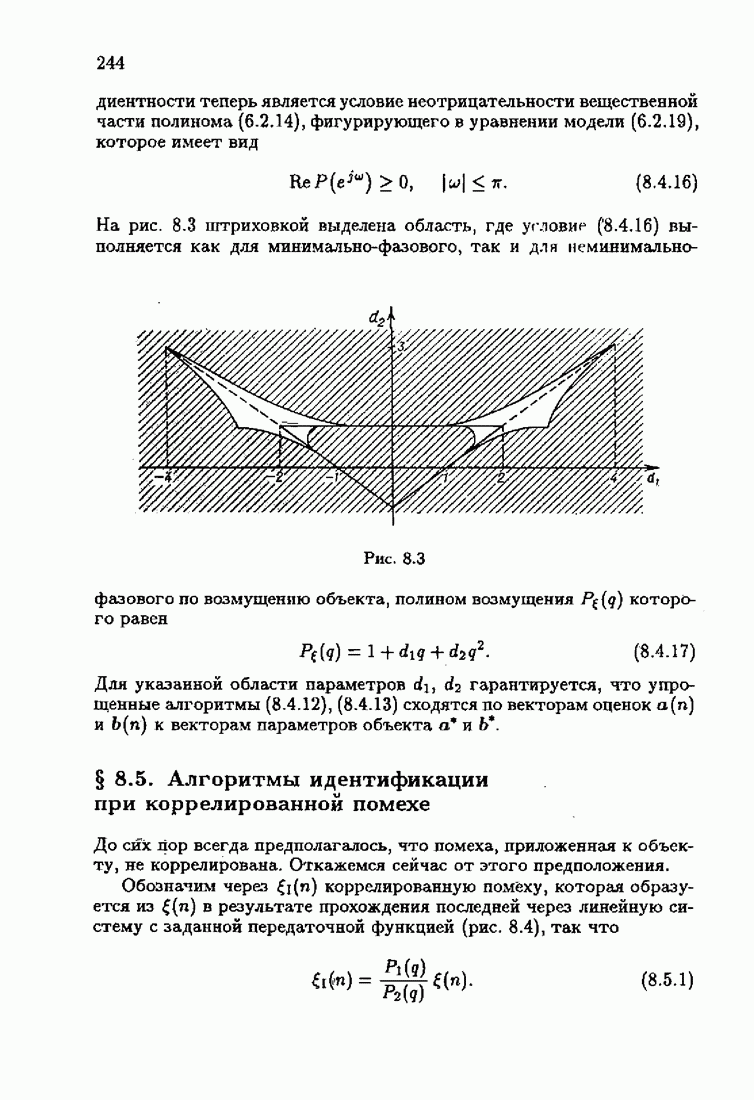


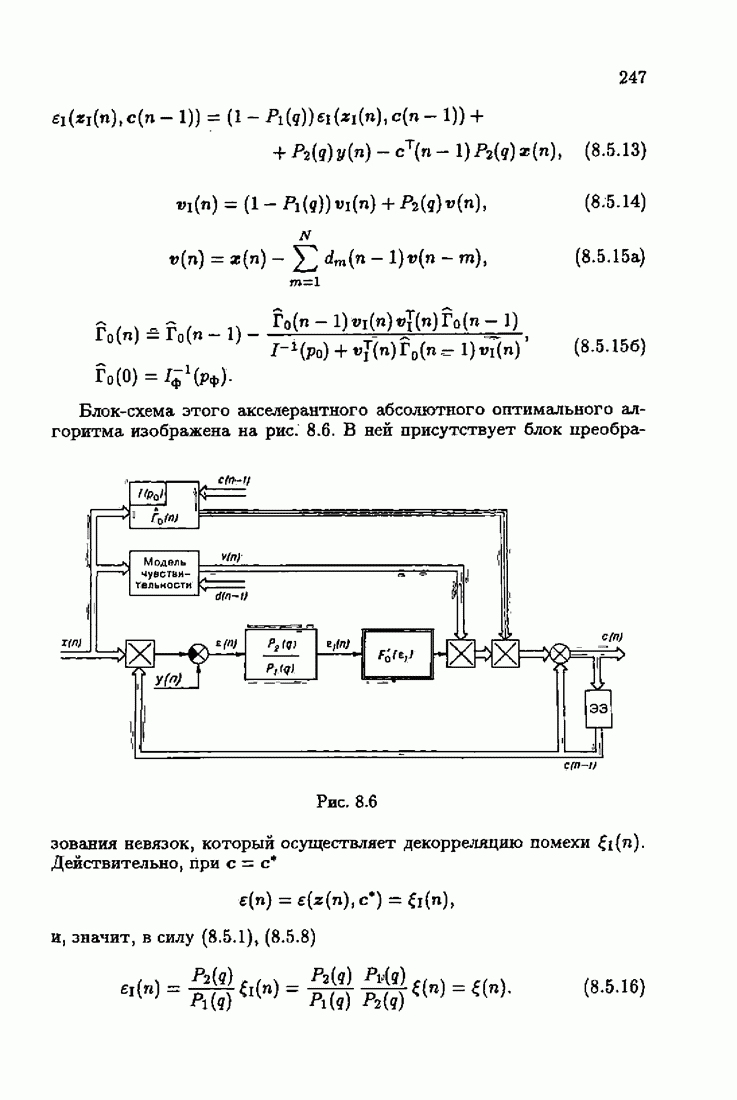



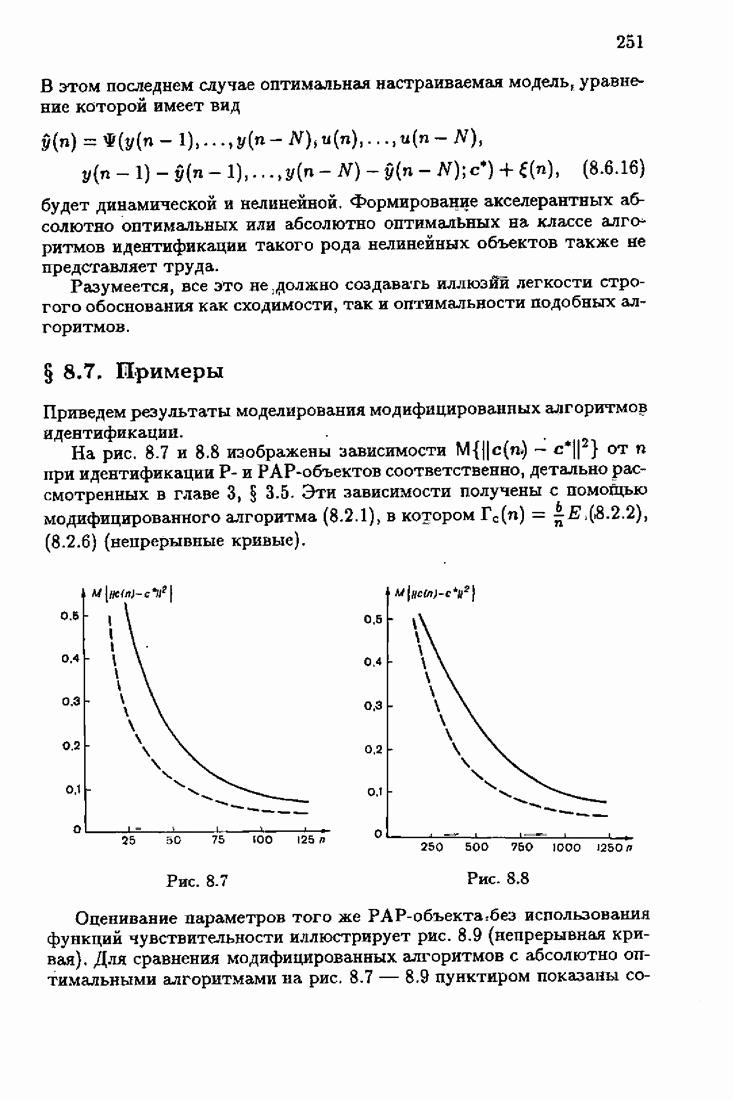
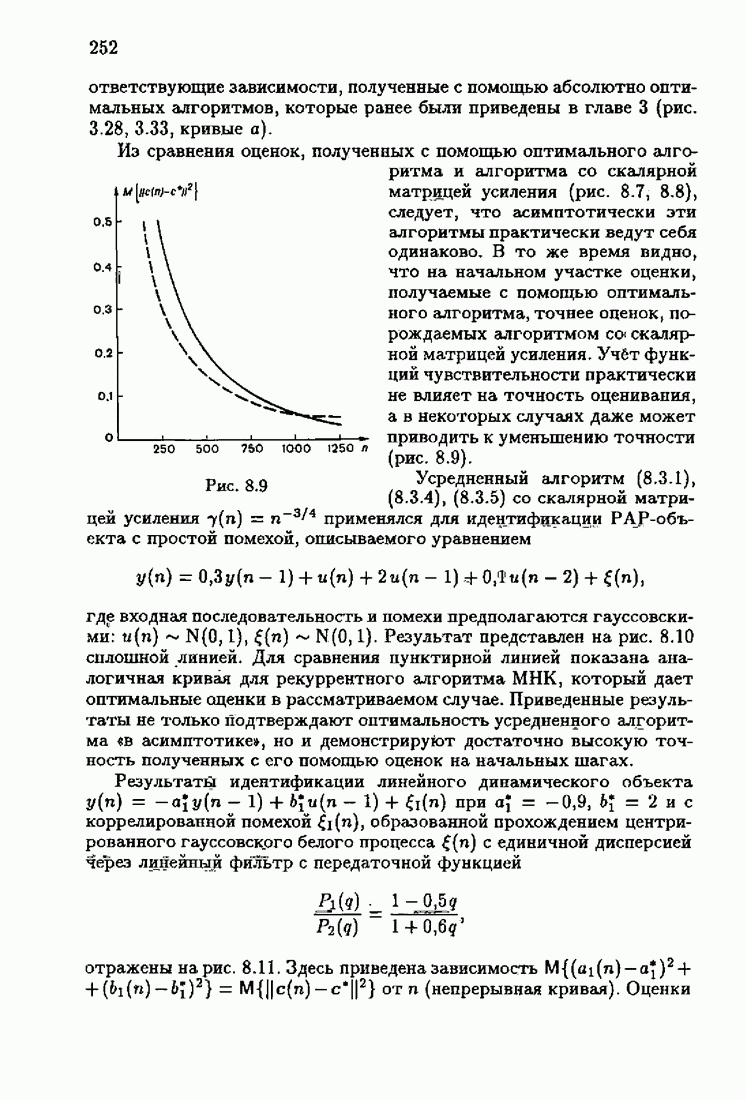
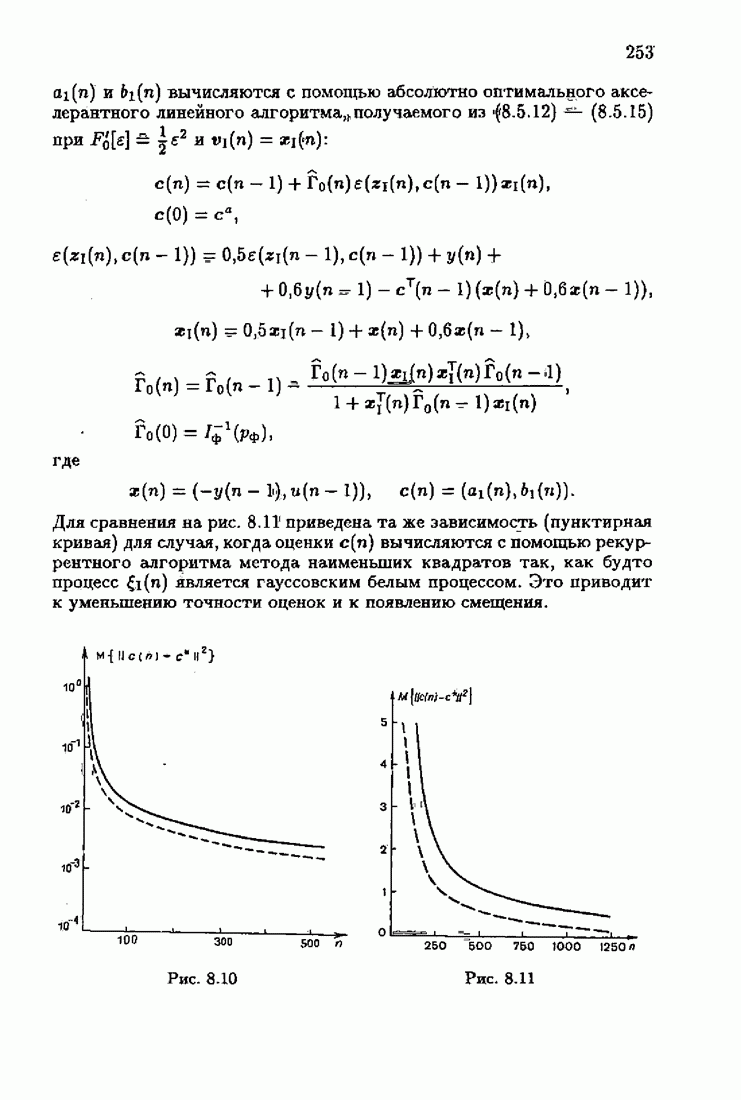





















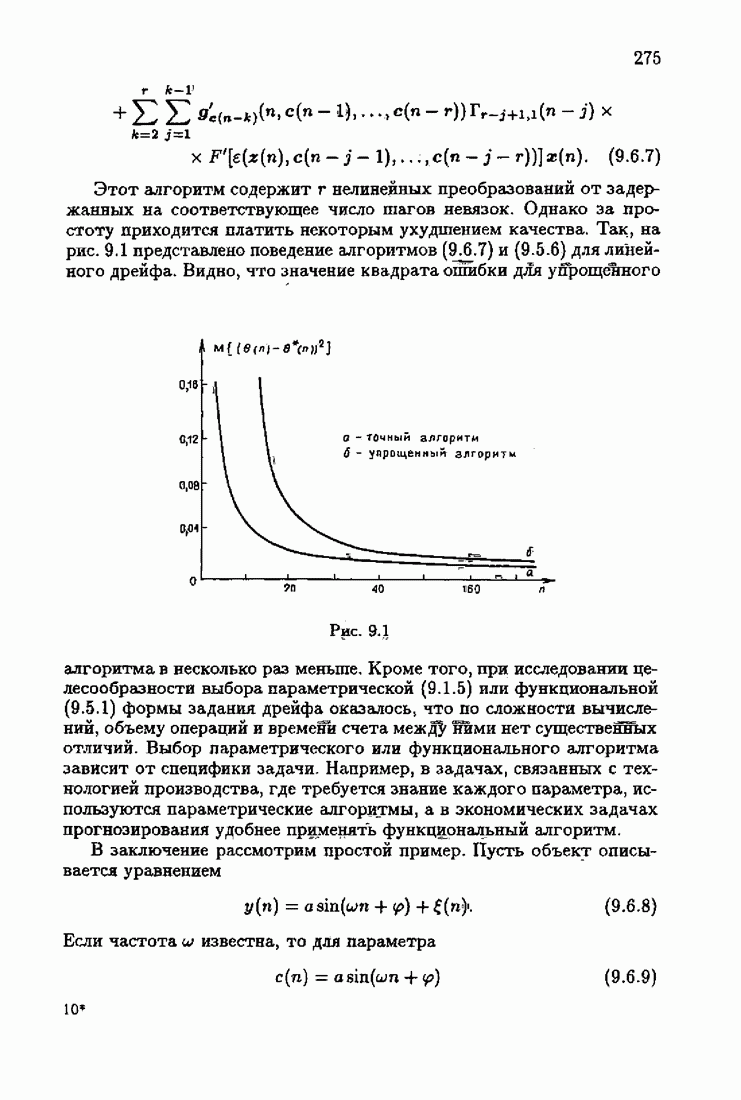
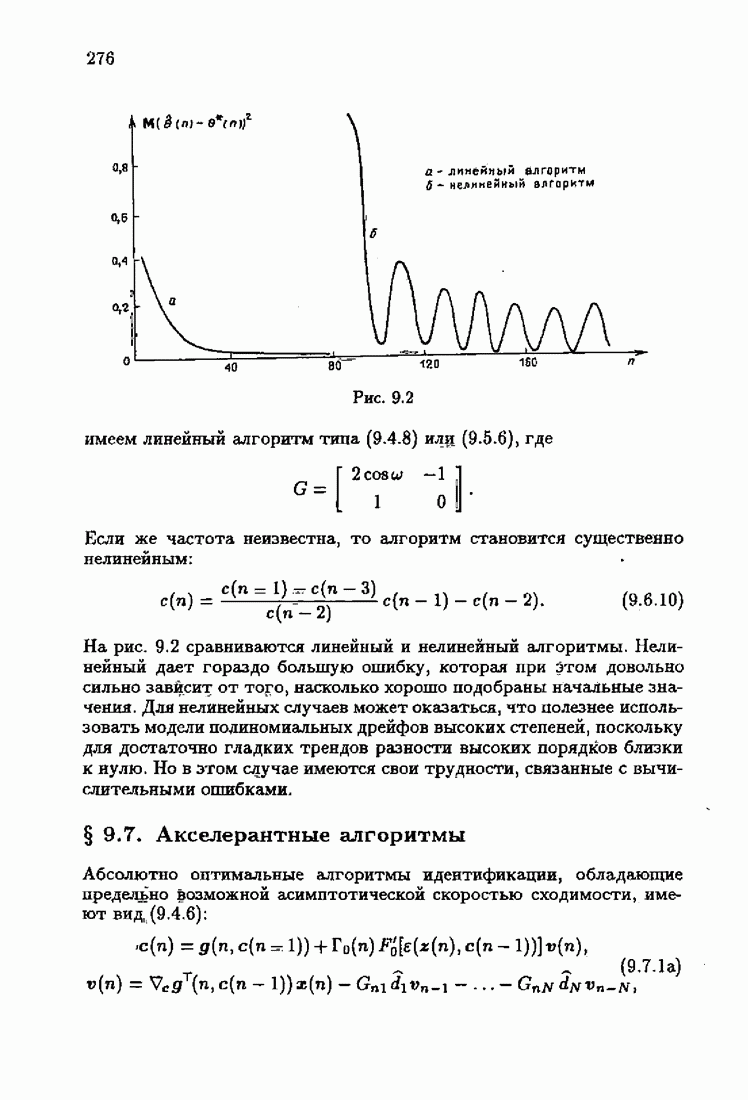





















































 Для этой цели найдем асимптотическую матрицу ковариаций ошибок — АМКО
Для этой цели найдем асимптотическую матрицу ковариаций ошибок — АМКО




 запишется в виде
запишется в виде


 в силу (2.1.14)
в силу (2.1.14)

 можно представить в виде
можно представить в виде

 и учитывая, что
и учитывая, что  находим градиент эмпирических средних потерь при с — с
находим градиент эмпирических средних потерь при с — с


 (с в виде
(с в виде

 то, как было установлено ранее в § 1.6 (см. (1.6.31)),
то, как было установлено ранее в § 1.6 (см. (1.6.31)),


 из (2.2.10) и
из (2.2.10) и  из (2.2.11) в (2.2.7), получим
из (2.2.11) в (2.2.7), получим







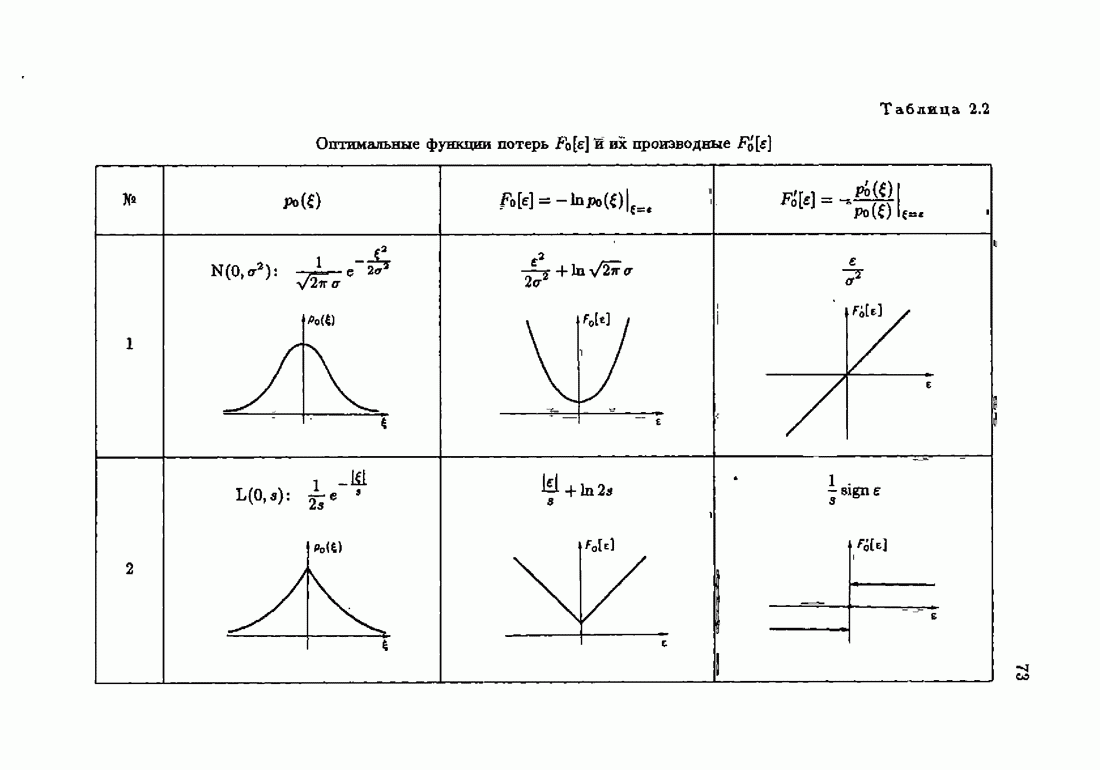
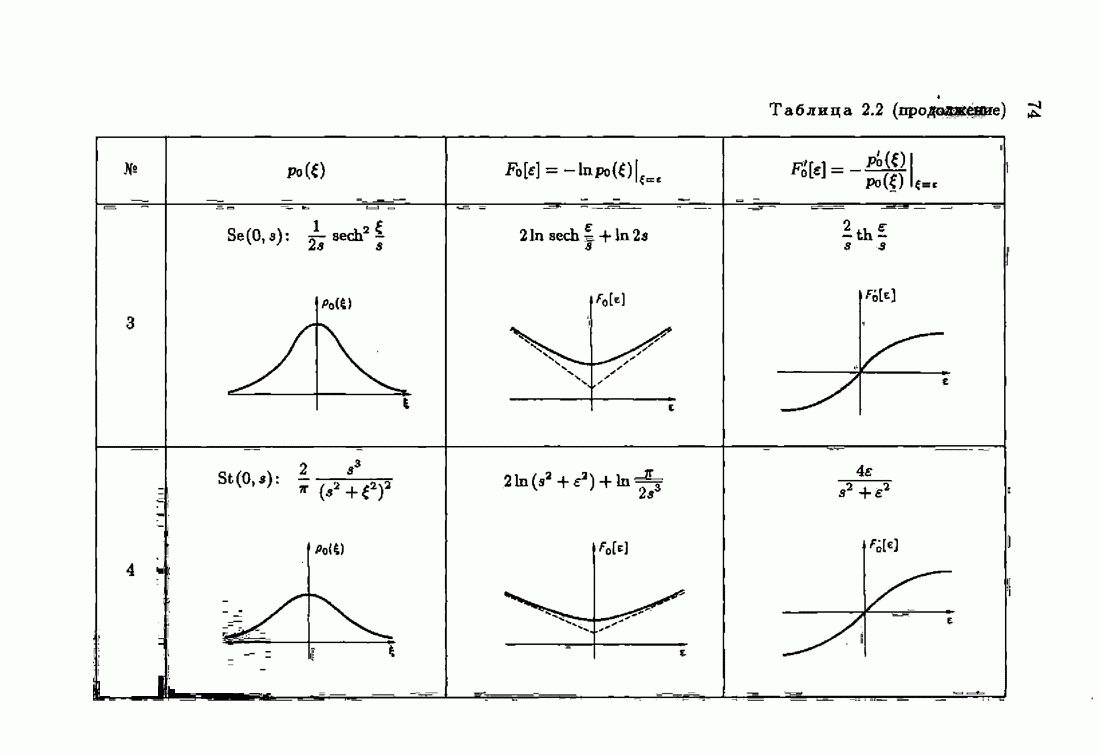
 фиксирует тот факт, что АМКО зависит как от функции потерь так и от плотности распределения помех
фиксирует тот факт, что АМКО зависит как от функции потерь так и от плотности распределения помех 
 (2.2.18) оптимальной выборочной оценки (2.1.4) с
(2.2.18) оптимальной выборочной оценки (2.1.4) с  оптимального алгоритма (1.7.11), (1.7.12), заключаем, что они равны друг другу. А это значит, что оценки, порождаемые асимптотически оптимальным алгоритмом (1.7.11), (1.7.12), и оптимальные выборочные оценки
оптимального алгоритма (1.7.11), (1.7.12), заключаем, что они равны друг другу. А это значит, что оценки, порождаемые асимптотически оптимальным алгоритмом (1.7.11), (1.7.12), и оптимальные выборочные оценки  являющиеся решением уравнения (2.1.5), имеют одинаковую асимптотическую скорость сходимости. Если же матрица в в рекуррентном алгоритме (1.7.1) или, что то же, матрица усиления
являющиеся решением уравнения (2.1.5), имеют одинаковую асимптотическую скорость сходимости. Если же матрица в в рекуррентном алгоритме (1.7.1) или, что то же, матрица усиления  в рекуррентном алгоритме (1.5.7) будет отлична от
в рекуррентном алгоритме (1.5.7) будет отлична от 
 Но если рекуррентные алгоритмы явно определяют оценки
Но если рекуррентные алгоритмы явно определяют оценки  то оптимальную выборочную оценку
то оптимальную выборочную оценку  яужно еще найти. А это сводится к непростой задаче — решению, вообще говоря, нелинейного уравнения.
яужно еще найти. А это сводится к непростой задаче — решению, вообще говоря, нелинейного уравнения.

 минимальное значение средних потерь.
минимальное значение средних потерь.
 по степеням
по степеням  с, ограничившись квадратичным приближением:
с, ограничившись квадратичным приближением:

 а матрица Гессе определяется выражением (2.2.11), представим
а матрица Гессе определяется выражением (2.2.11), представим  в
в



 обозначает след матрицы. Принимая во внимание обозначение
обозначает след матрицы. Принимая во внимание обозначение  получаем
получаем

 можно записать в виде
можно записать в виде


 характеризует асимптотическую скорость сходимости средних потерь
характеризует асимптотическую скорость сходимости средних потерь  к минимальным средним потерям
к минимальным средним потерям  Умножая обе часта (2.2.24) на
Умножая обе часта (2.2.24) на  и переходя к пределу при
и переходя к пределу при  находим, учитывая (1.6.6) или (2.2.1):
находим, учитывая (1.6.6) или (2.2.1):

 представляет собой АМКО и определяется выражением (2.2.18). Подставляя из (2.2.18) в (2.2.26), получим
представляет собой АМКО и определяется выражением (2.2.18). Подставляя из (2.2.18) в (2.2.26), получим

 где
где  размерность вектора оценок, окончательно получаем
размерность вектора оценок, окончательно получаем
