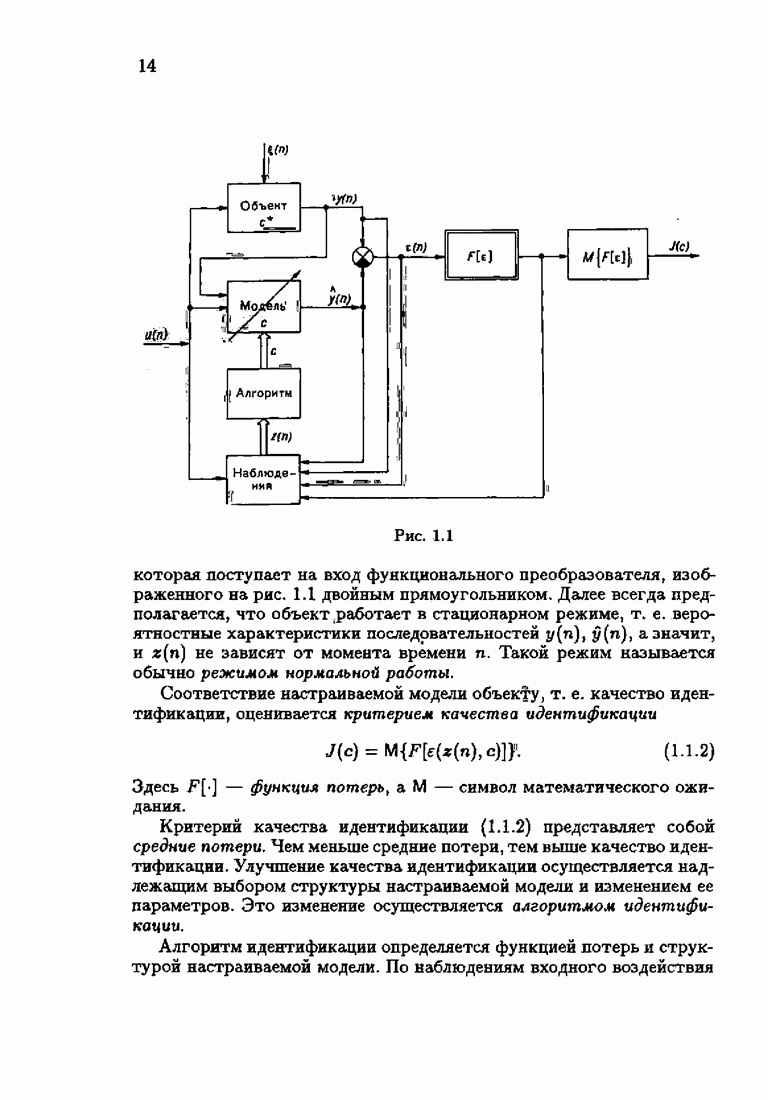
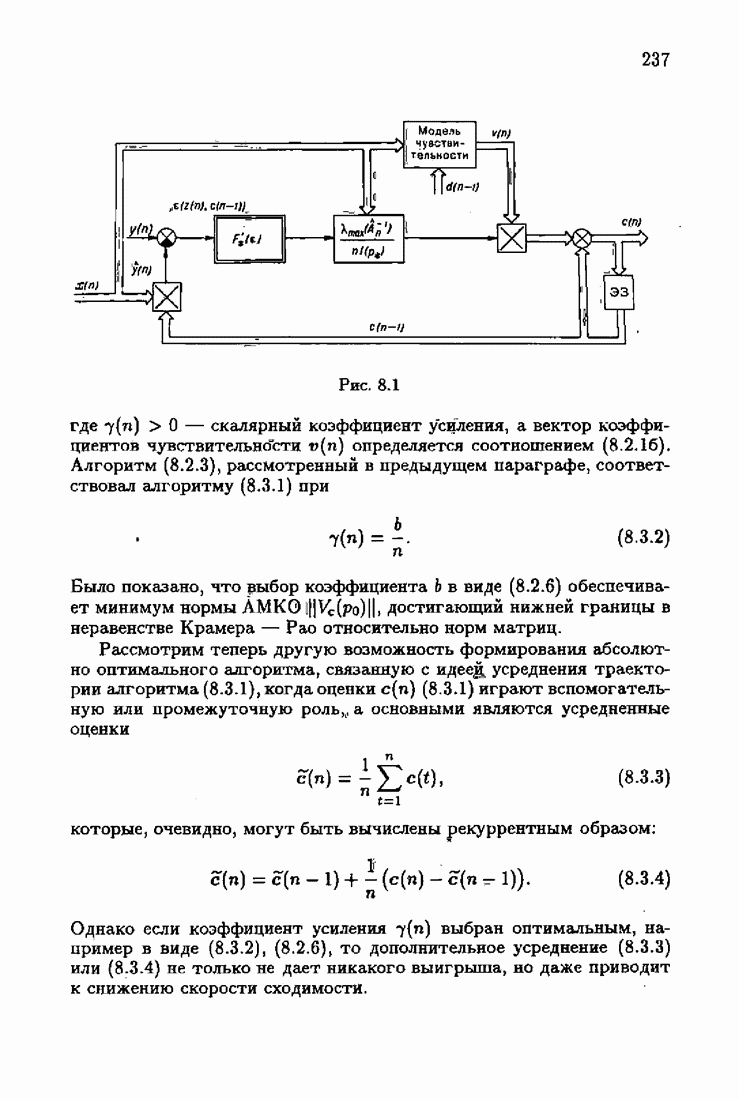
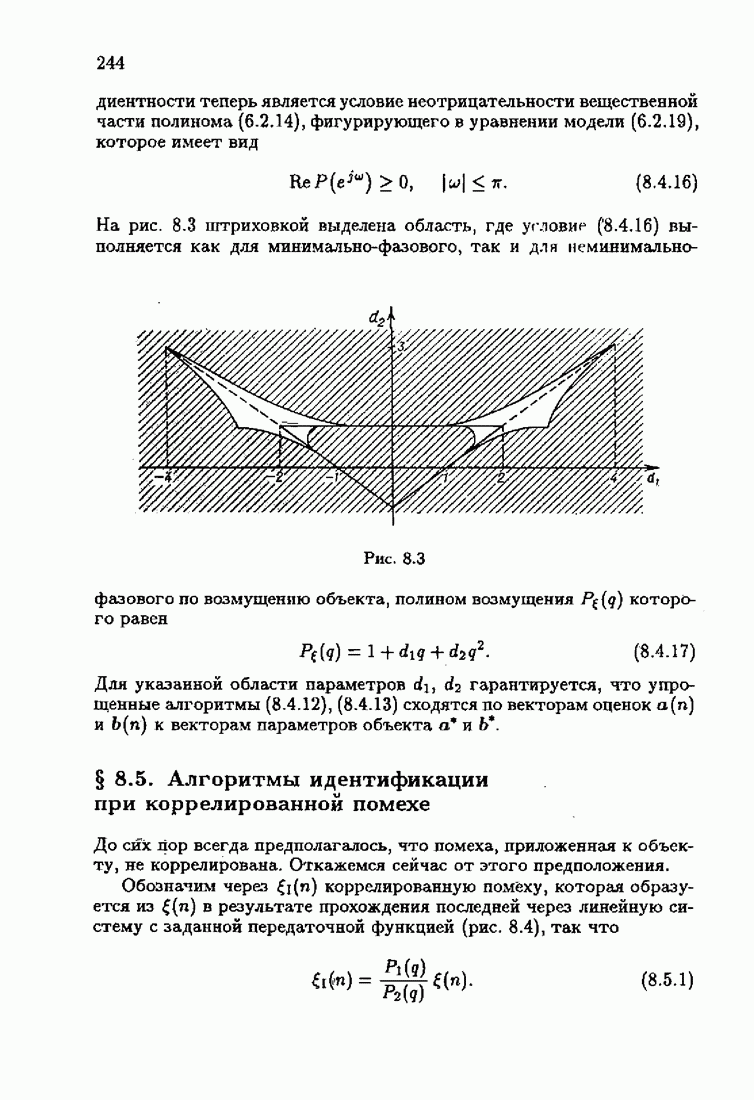
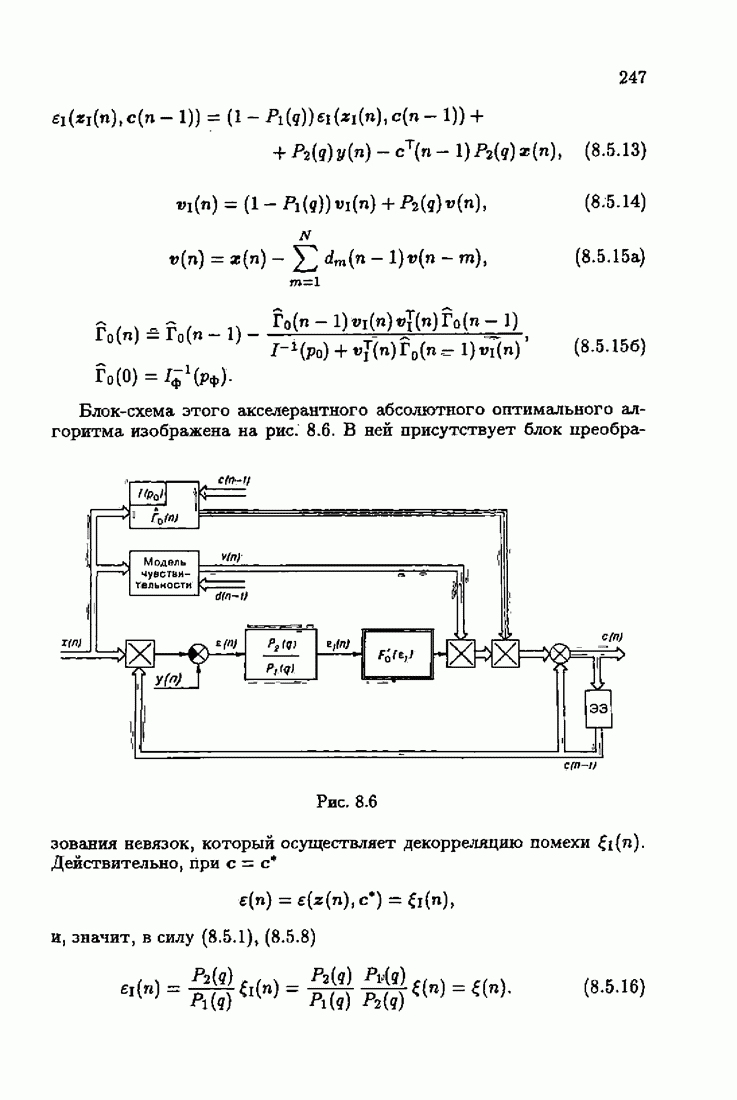
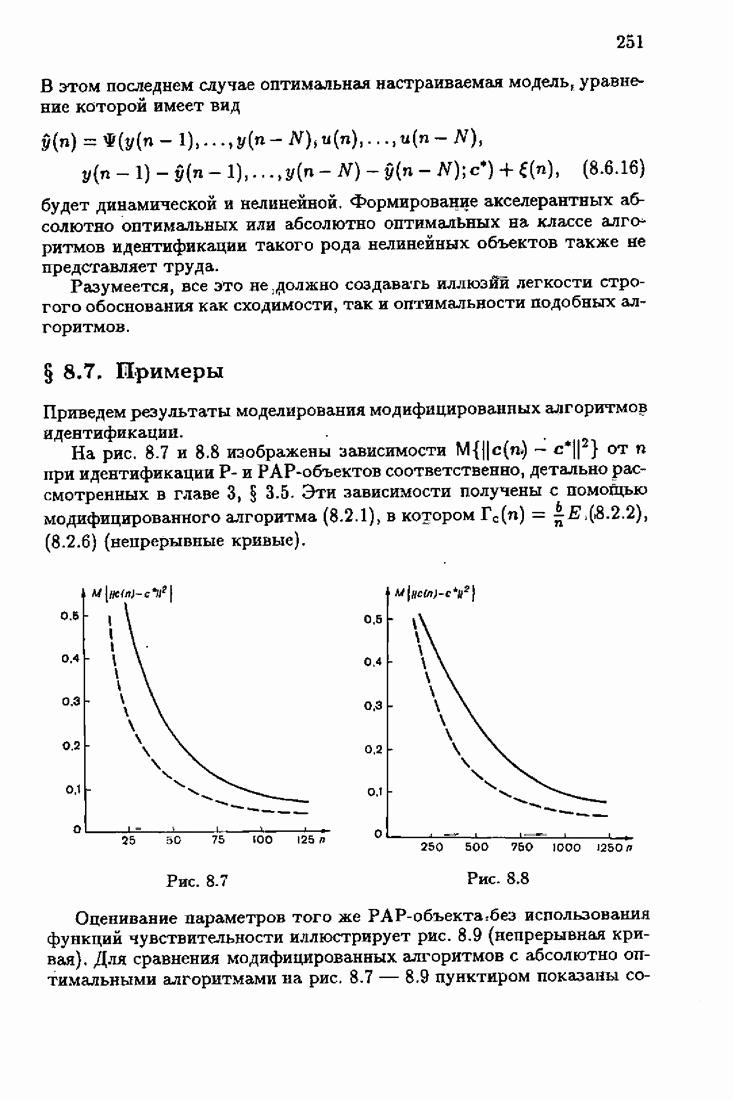
§ 4.3. Принцип оптимальности на классе
Рассмотрим некоторые свойства наименее благоприятной плотности распределения

или, что эквивалентно,

Из определения оптимальной на классе функции потерь (4.2.10), (4.2.16) следует

С другой стороны, из матричного неравенства (4.2.11), которое лежало в основе определения оптимальной функции потерь (см. (2.5.4)),

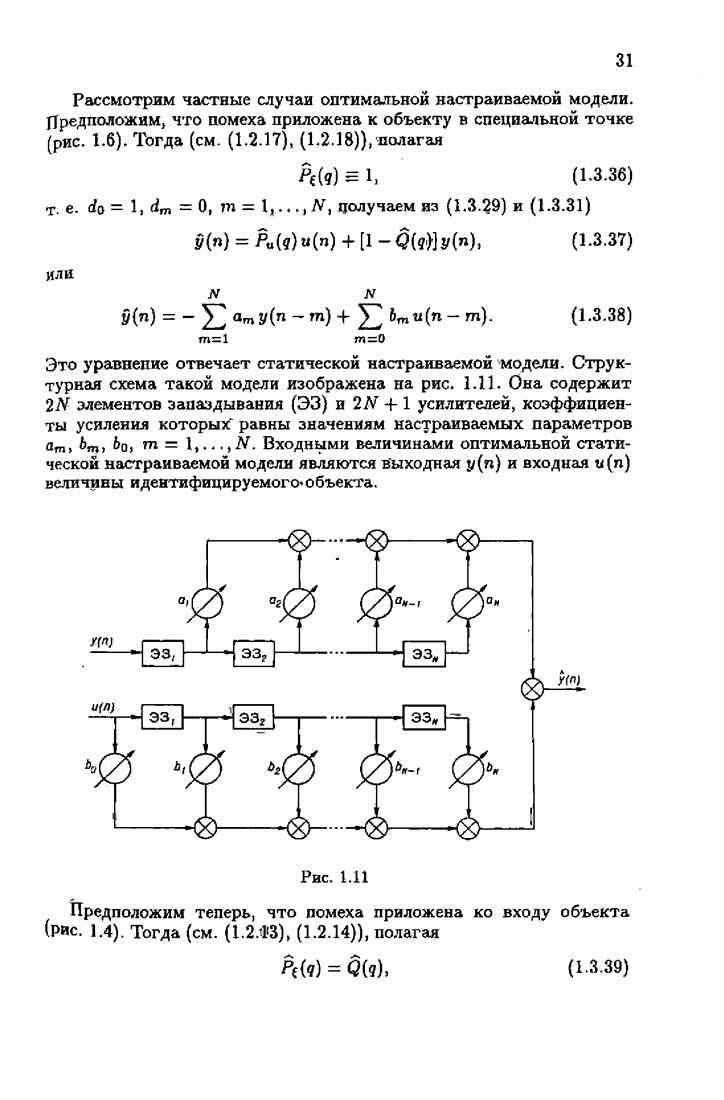
при  из
из  следует
следует

Объединяя матричные неравенства (4.3.3) и (4.3.5), получаем

Для обратной  справедливы матричные неравенства обратного знака
справедливы матричные неравенства обратного знака

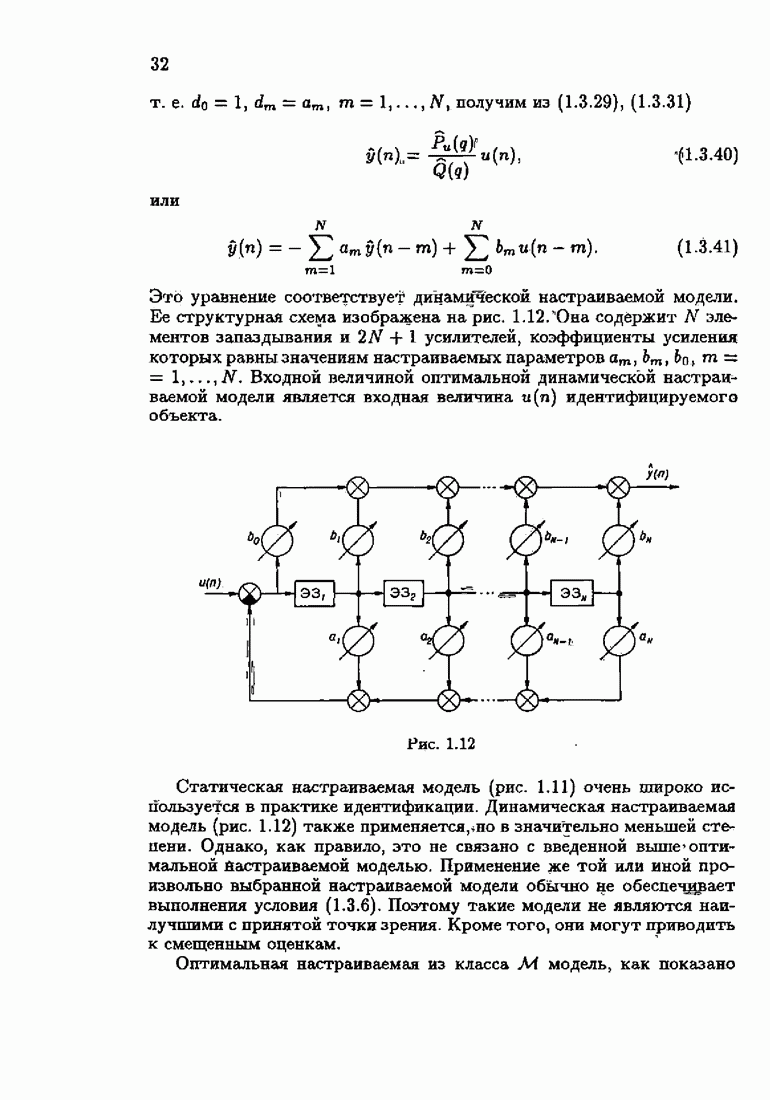
Но эти неравенства являются не чем иным, как определением седловой точки  матричных функционалов. Таким образом, наименее благоприятная плотность распределения
матричных функционалов. Таким образом, наименее благоприятная плотность распределения  является седловой точкой АМКО и обратной АМКО. Однако седловая точка матричного функционала не всегда существует. Поэтому целесообразно вместо матричных неравенств
является седловой точкой АМКО и обратной АМКО. Однако седловая точка матричного функционала не всегда существует. Поэтому целесообразно вместо матричных неравенств  ввести аналогичные неравенства относительно такой скалярной функции матрицы, для которой седловая точка уже существовала бы (для интересующих нас классов распределений), а в тех случаях, когда существует и седловая точка матричных функционалов, совпадала бы с ней. Такой скалярной функцией матрицы является след латрицы
ввести аналогичные неравенства относительно такой скалярной функции матрицы, для которой седловая точка уже существовала бы (для интересующих нас классов распределений), а в тех случаях, когда существует и седловая точка матричных функционалов, совпадала бы с ней. Такой скалярной функцией матрицы является след латрицы 
Если выполняется матричное неравенство относительно обратных АМКО (4,3.7), то выполняется и неравенство относительно следов обратных АМКО

В этом случае наименее благоприятная плотность распределения определяется как решение вариационной задачи минимизации

т. е.

совпадает с решением матричной вариационной задачи минимизации
































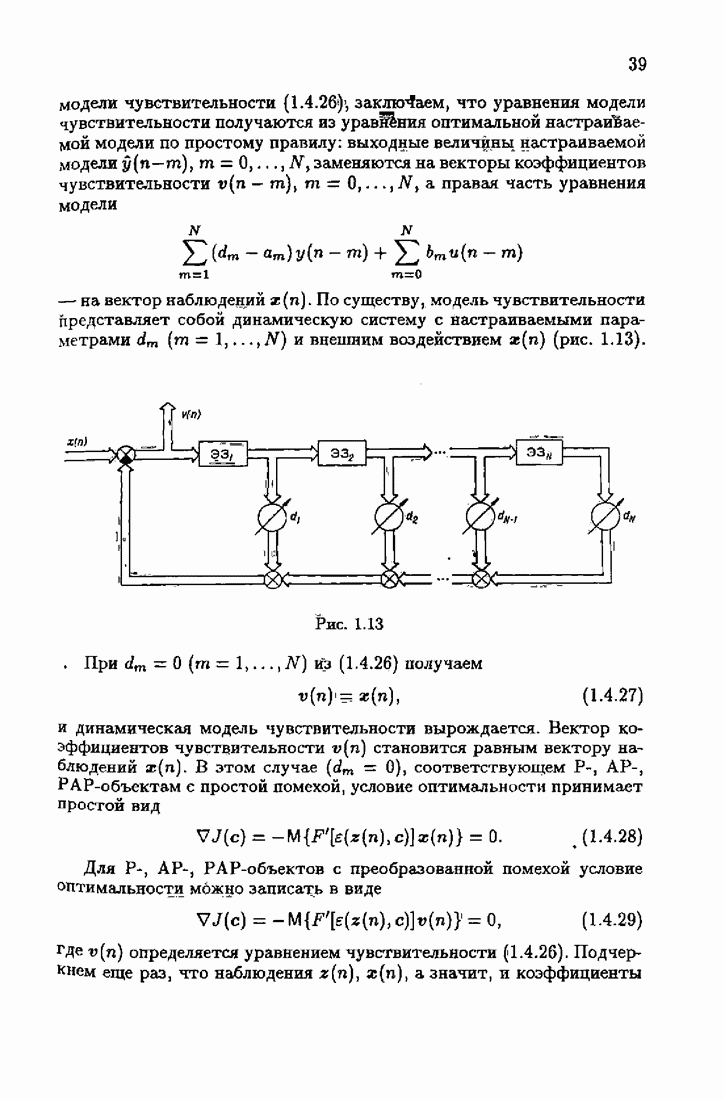










































































































































































































































 не существует, т. е. когда матричная вариационная задача минимизации (4.3.2) не имеет решения, седловая точка ее следа, т. е. решение вариационной задачи минимизации (4.3.9), в интересующих нас случаях существует. Эта седловая точка определяет наименее благоприятное распределение
не существует, т. е. когда матричная вариационная задача минимизации (4.3.2) не имеет решения, седловая точка ее следа, т. е. решение вариационной задачи минимизации (4.3.9), в интересующих нас случаях существует. Эта седловая точка определяет наименее благоприятное распределение  а значит, и оптимальную на классе функцию потерь
а значит, и оптимальную на классе функцию потерь  Однако теперь оптимальная на классе функция потерь
Однако теперь оптимальная на классе функция потерь  гарантирует не обратную
гарантирует не обратную  не меньшую
не меньшую  а только след обратной
а только след обратной  не меньший следа обратной
не меньший следа обратной  Доказательство этого факта полностью аналогично проведенному в § 4.2 доказательству при замене матриц
Доказательство этого факта полностью аналогично проведенному в § 4.2 доказательству при замене матриц  на их следы.
на их следы.
 определяющая оптимальную на классе функцию потерь
определяющая оптимальную на классе функцию потерь  представляет собой седловую точку следа обратной
представляет собой седловую точку следа обратной 

 . В принципе оптимальности (4.3.8) оптимальные стратегии совпадают друг с другом, т. е.
. В принципе оптимальности (4.3.8) оптимальные стратегии совпадают друг с другом, т. е. 
