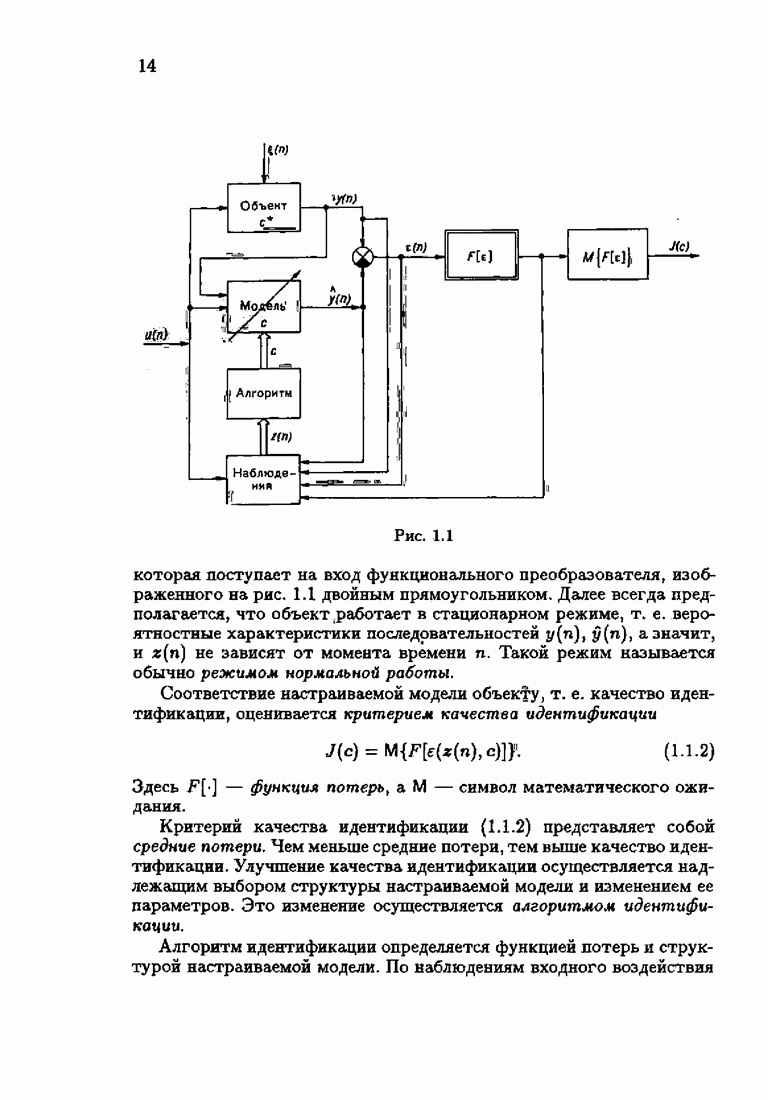
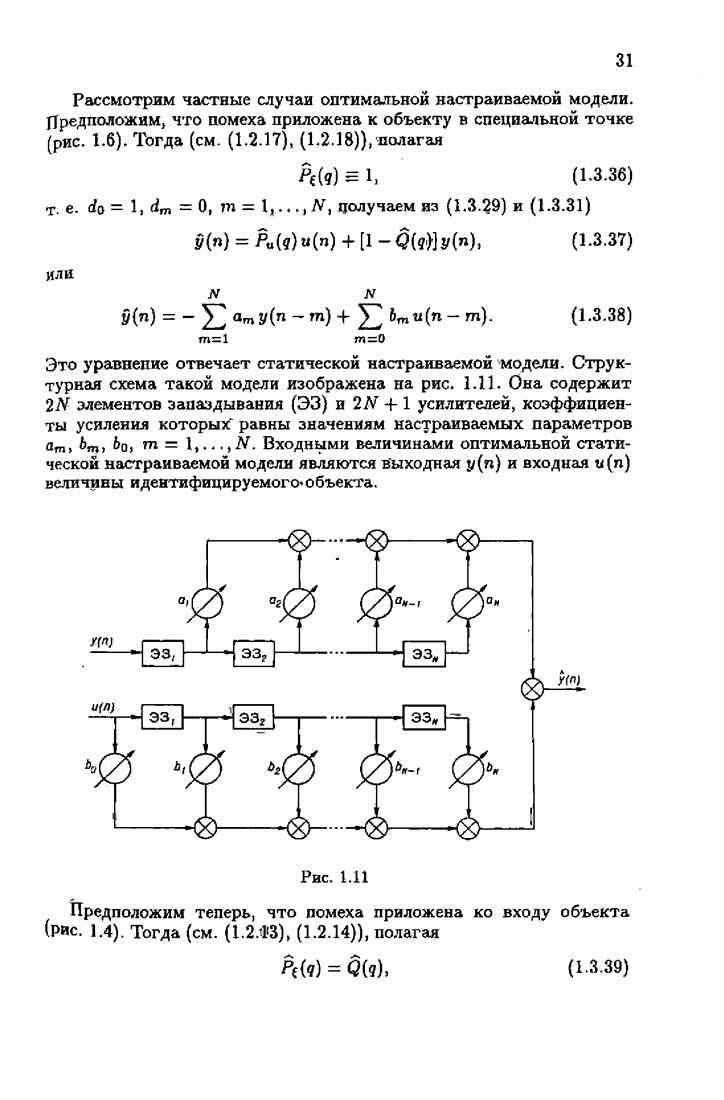
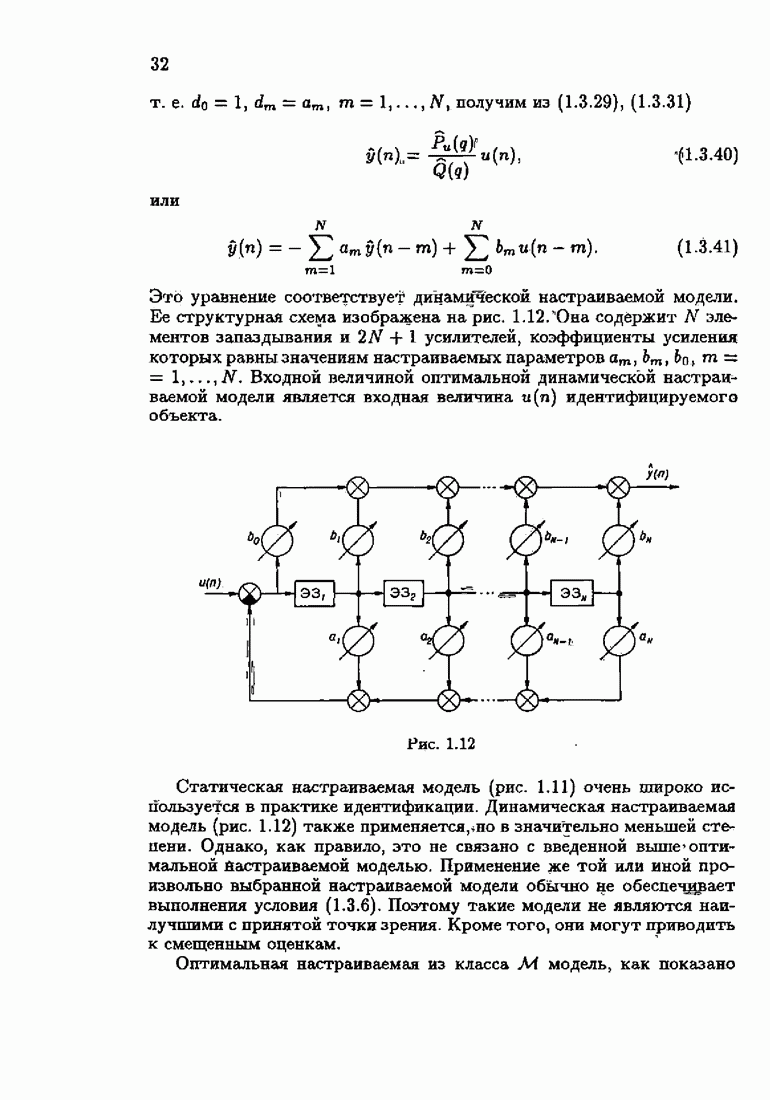
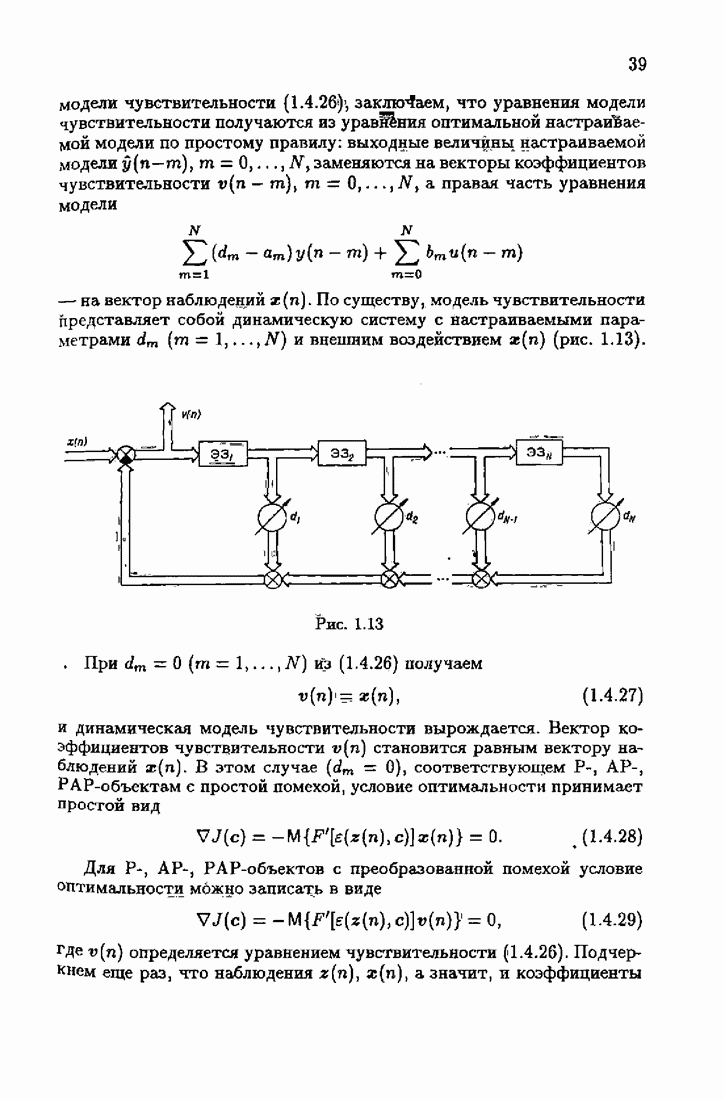
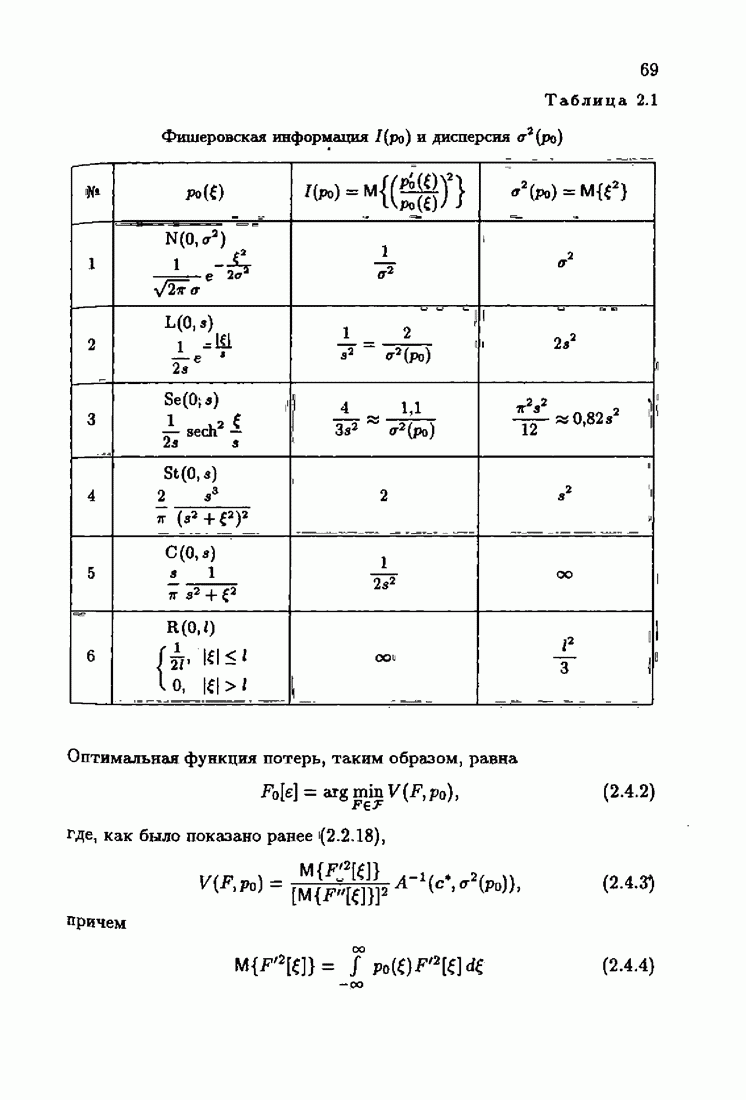
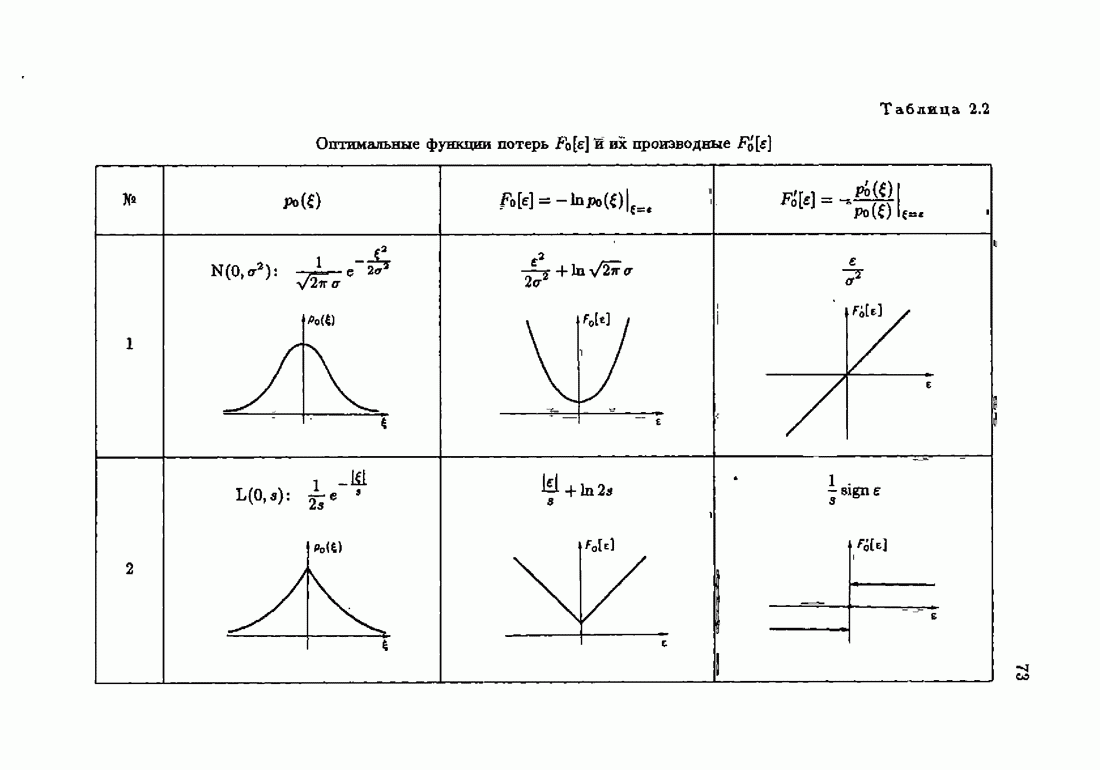
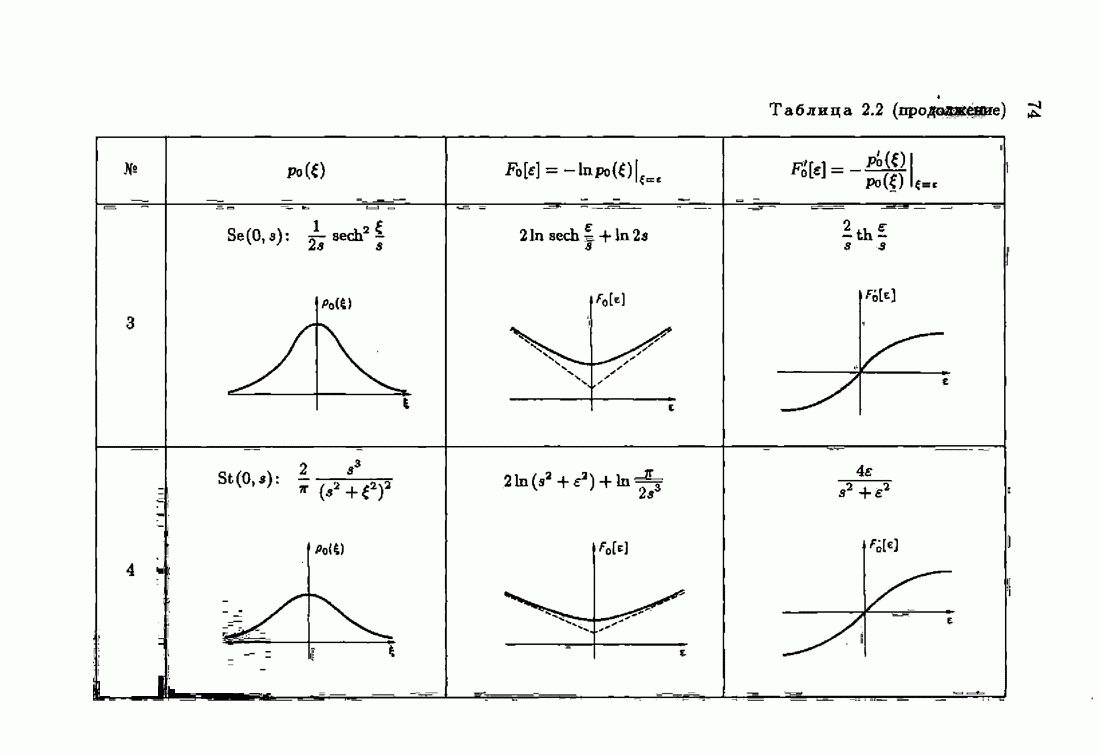
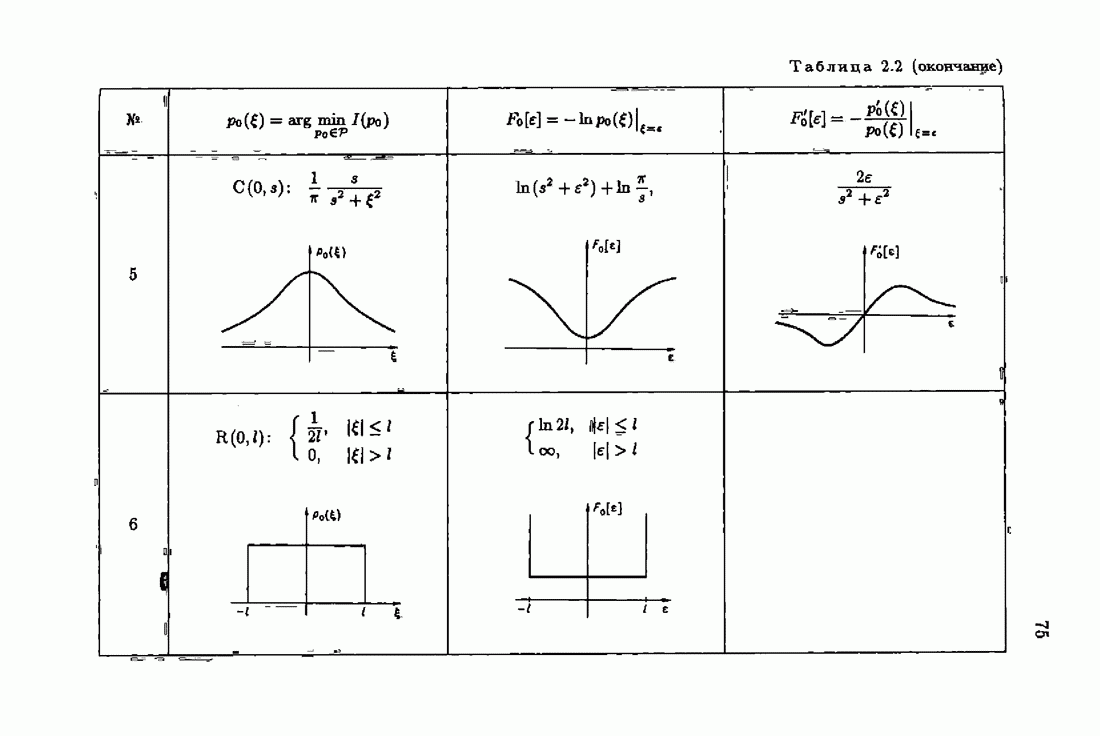
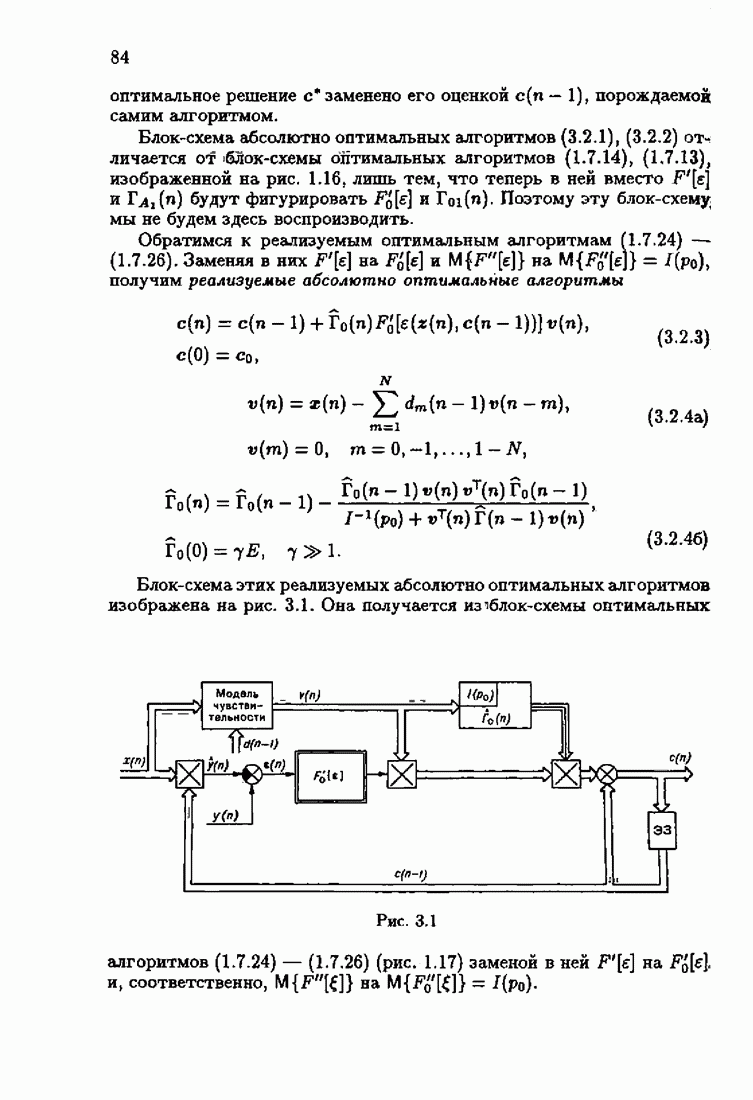
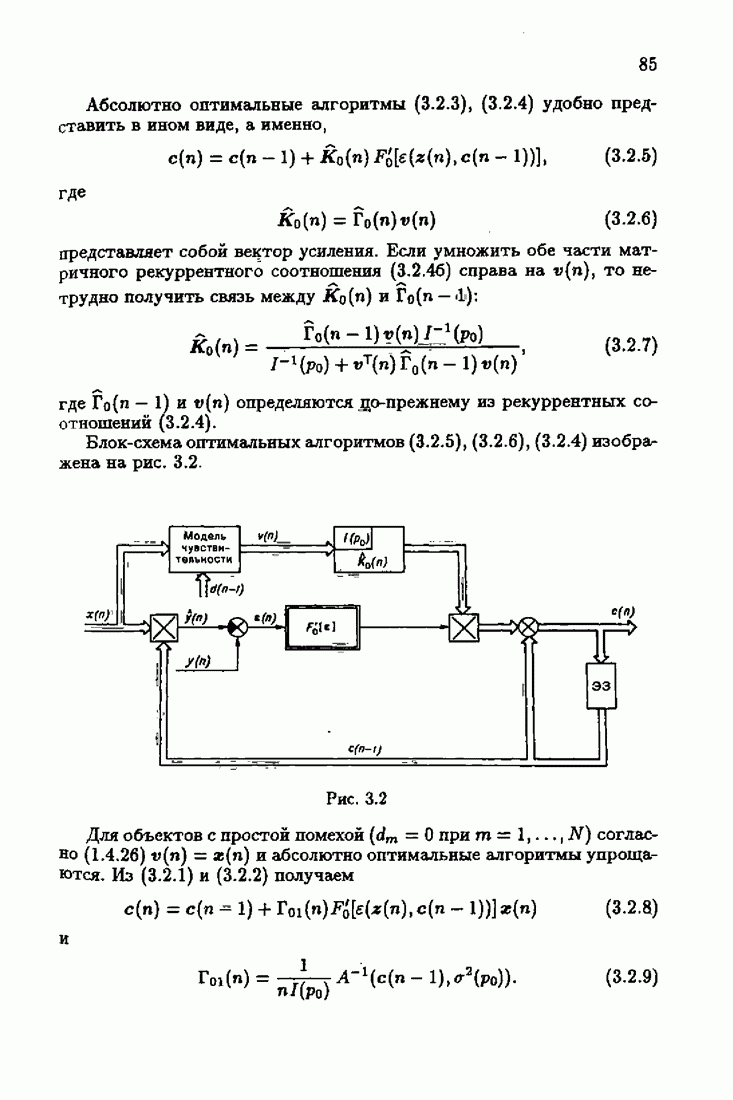
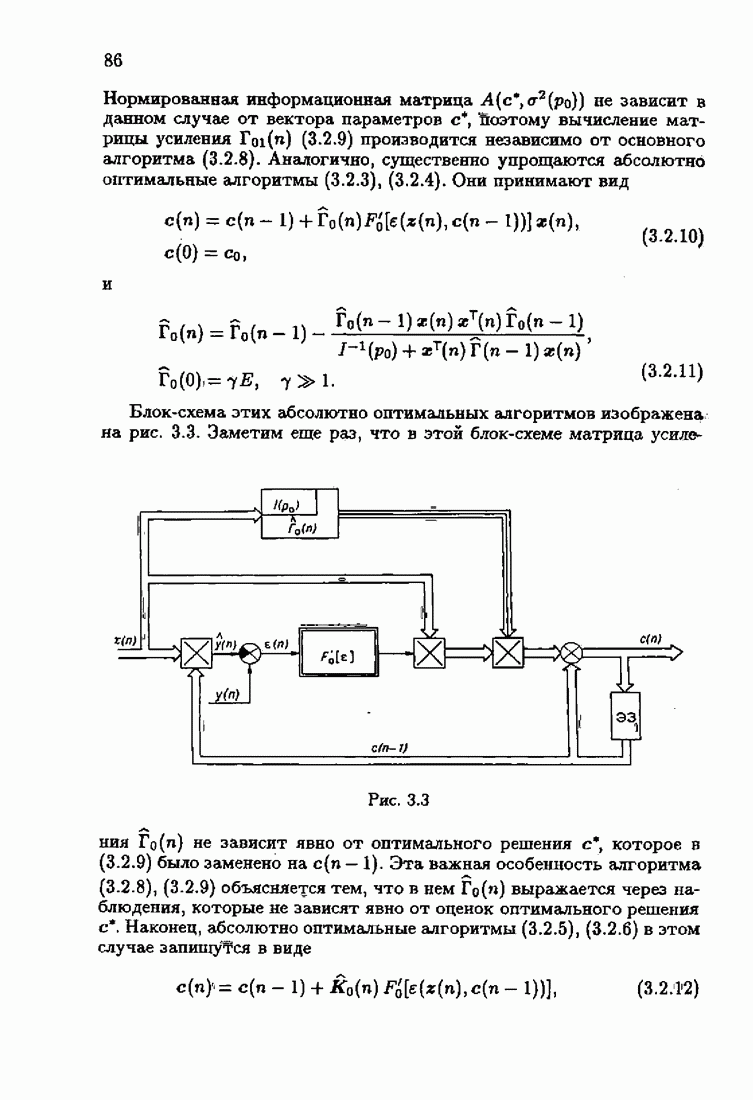
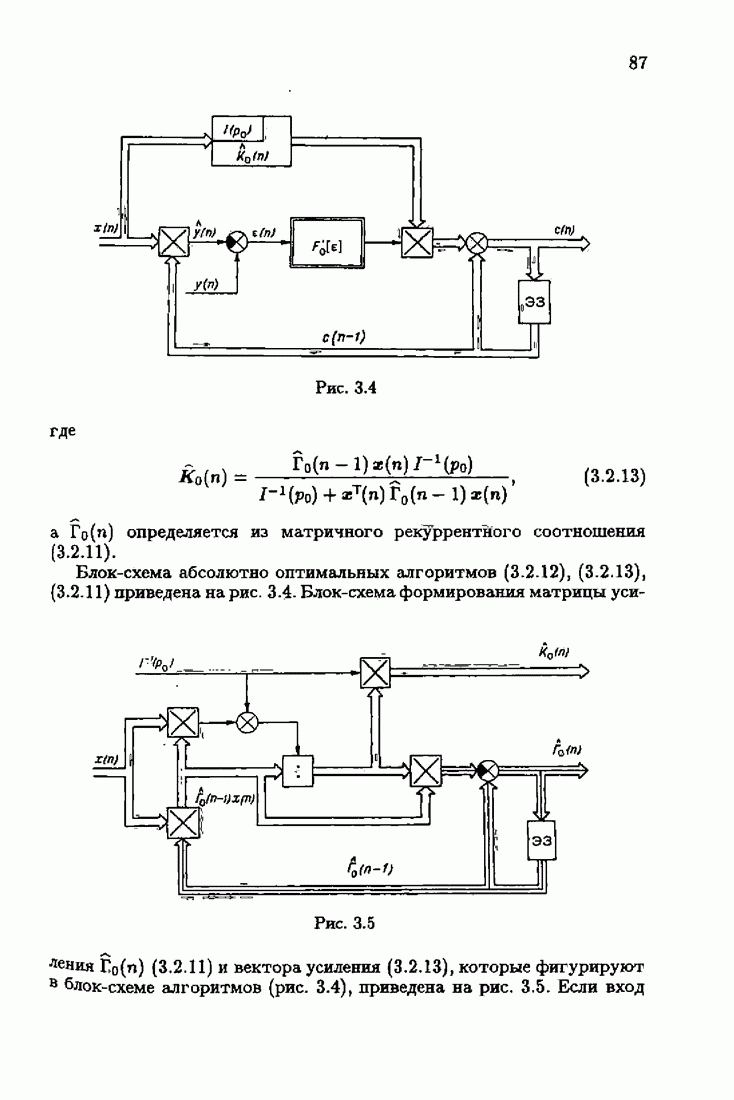
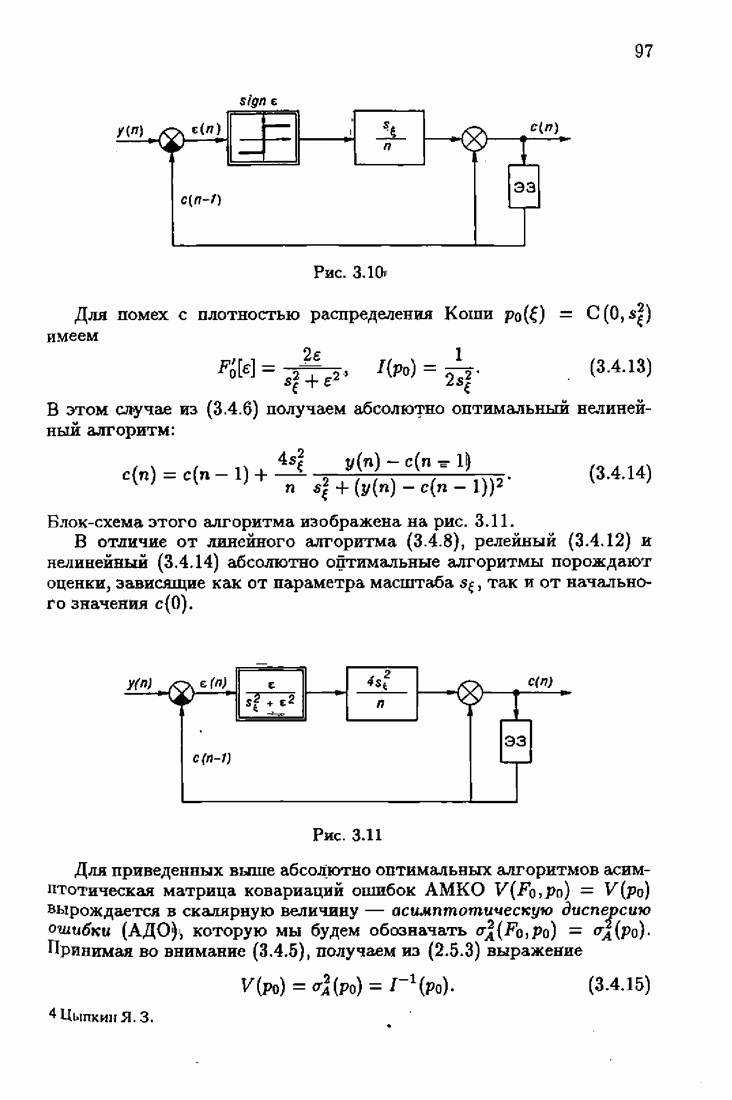
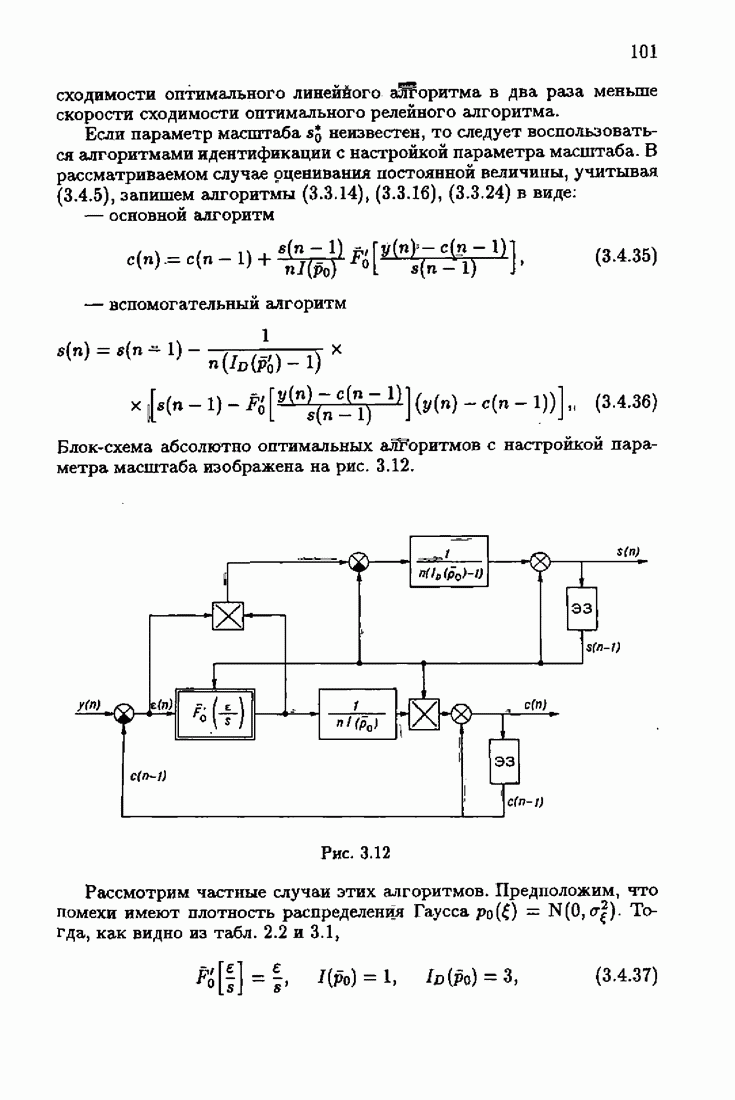
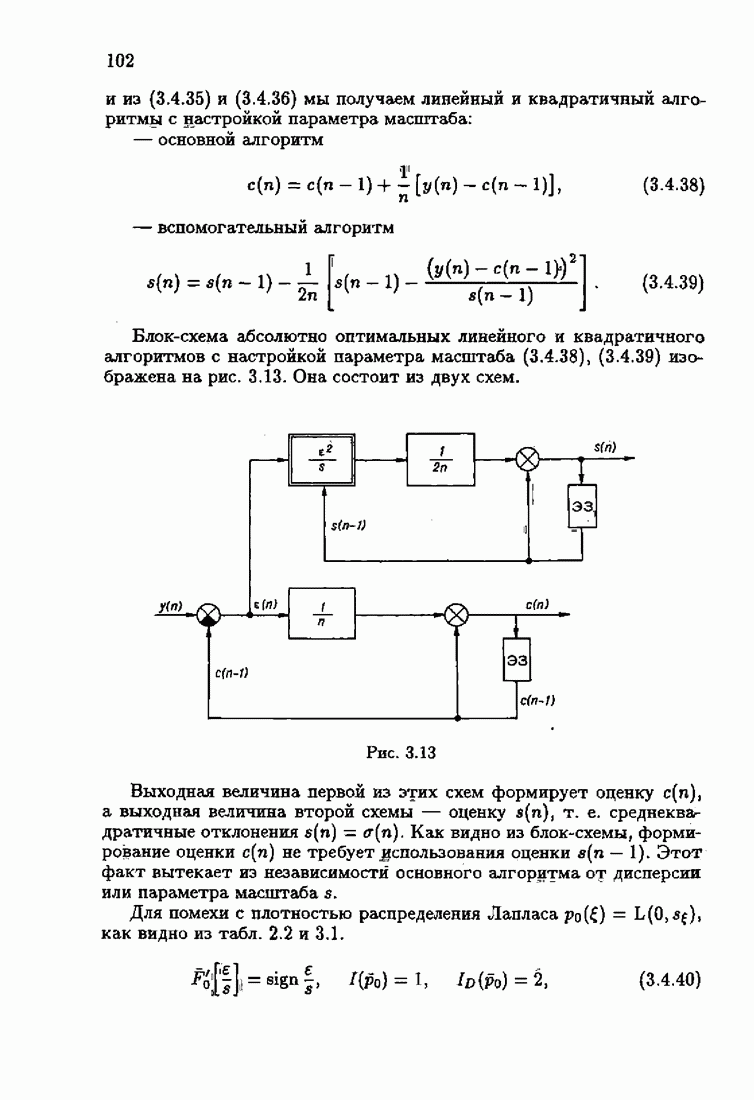
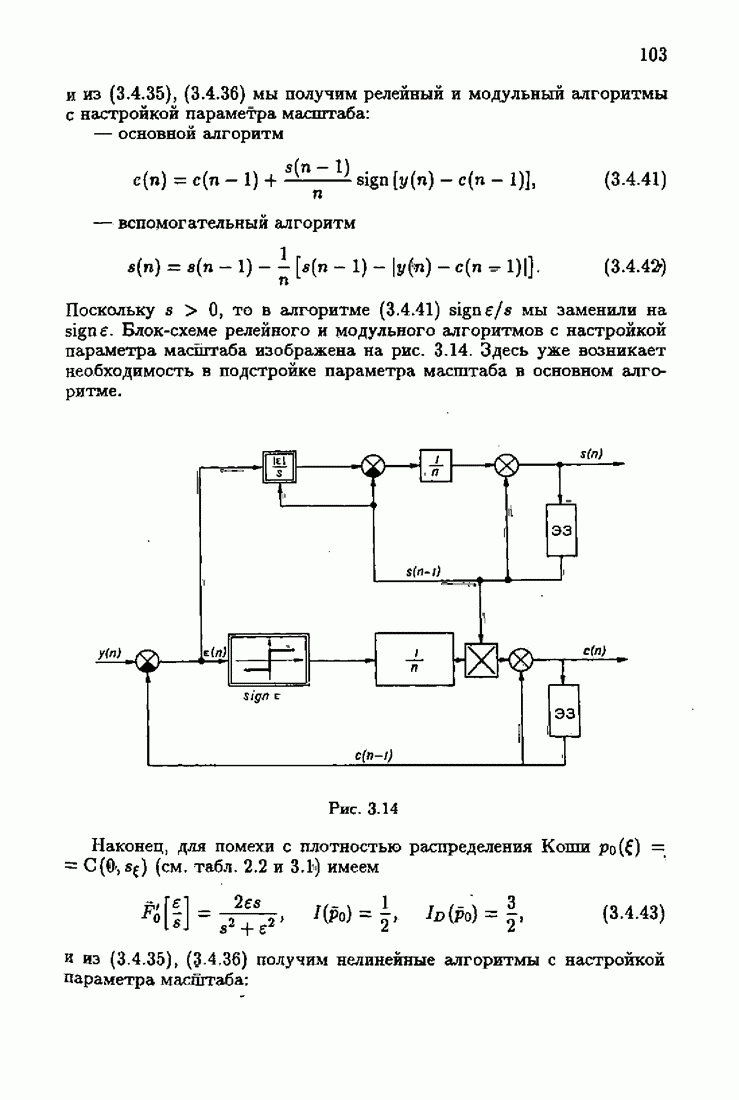
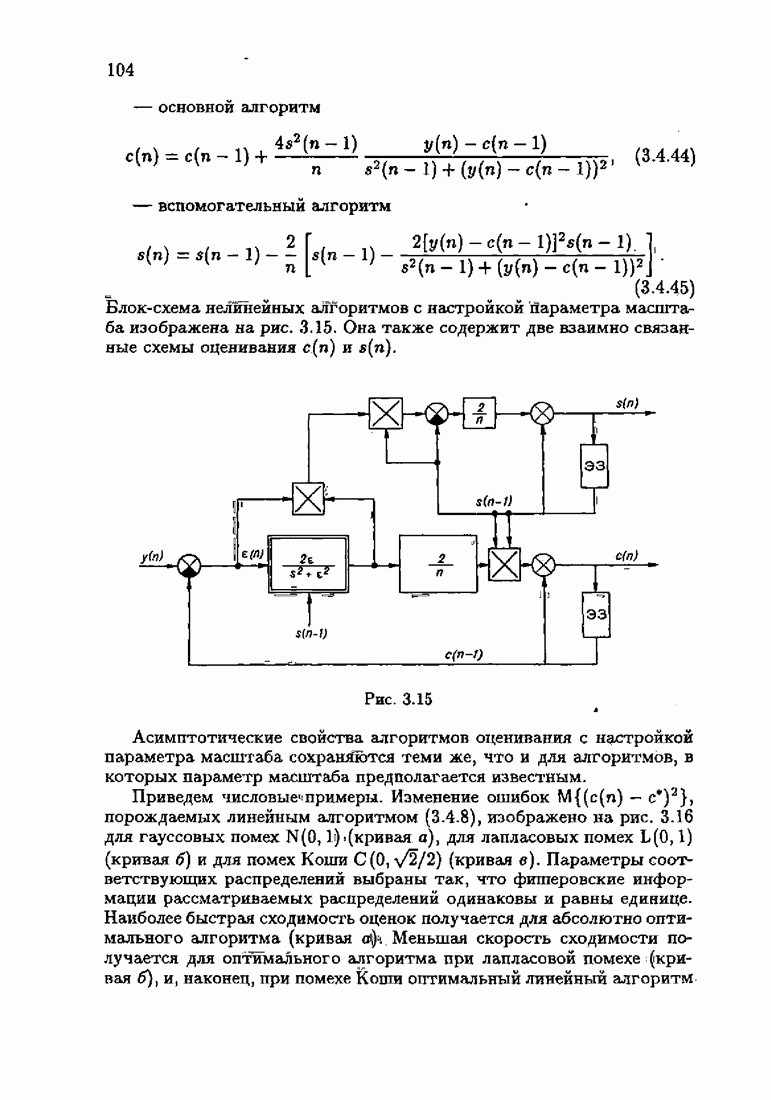
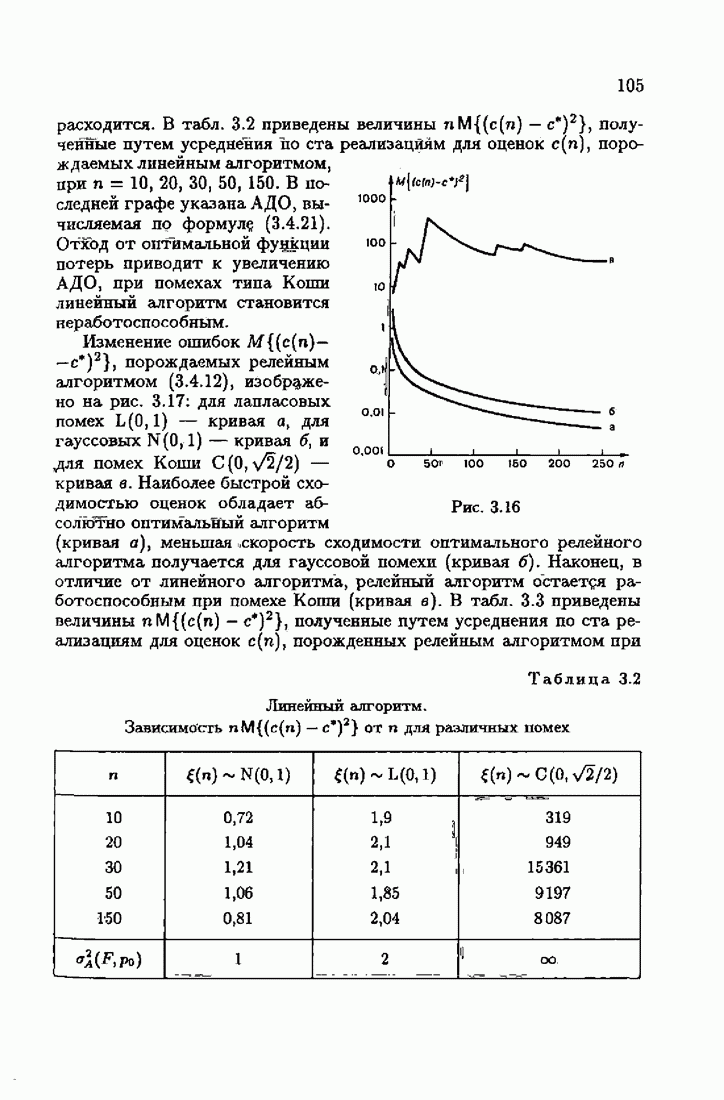
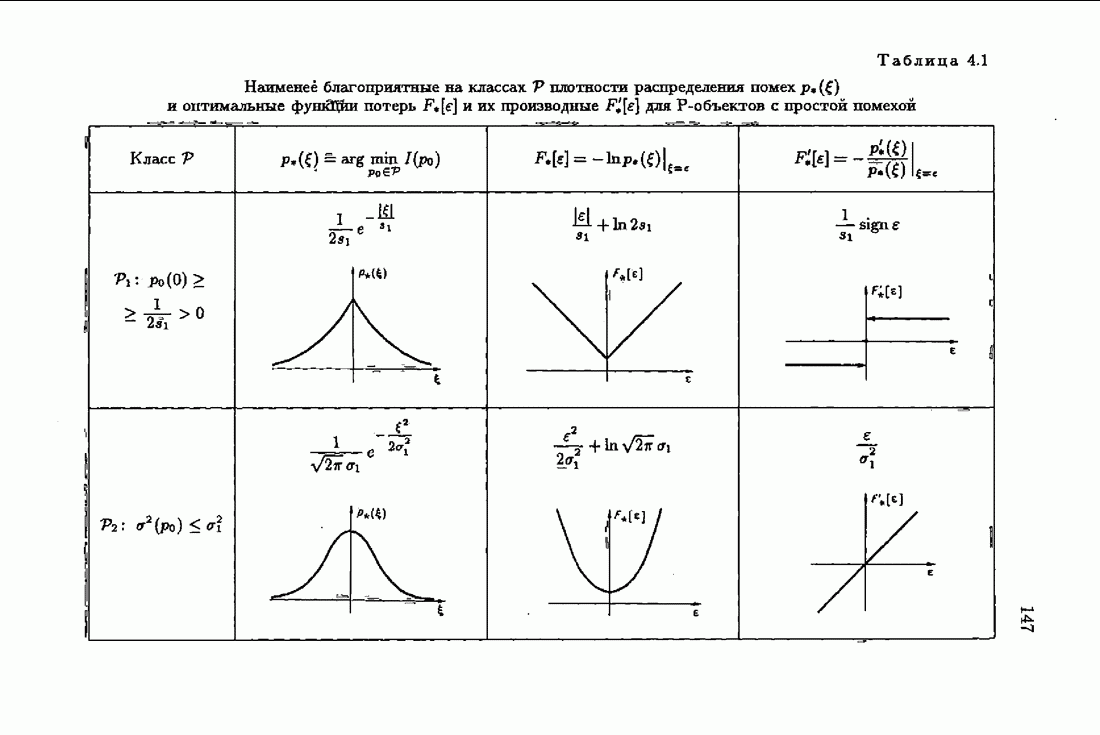
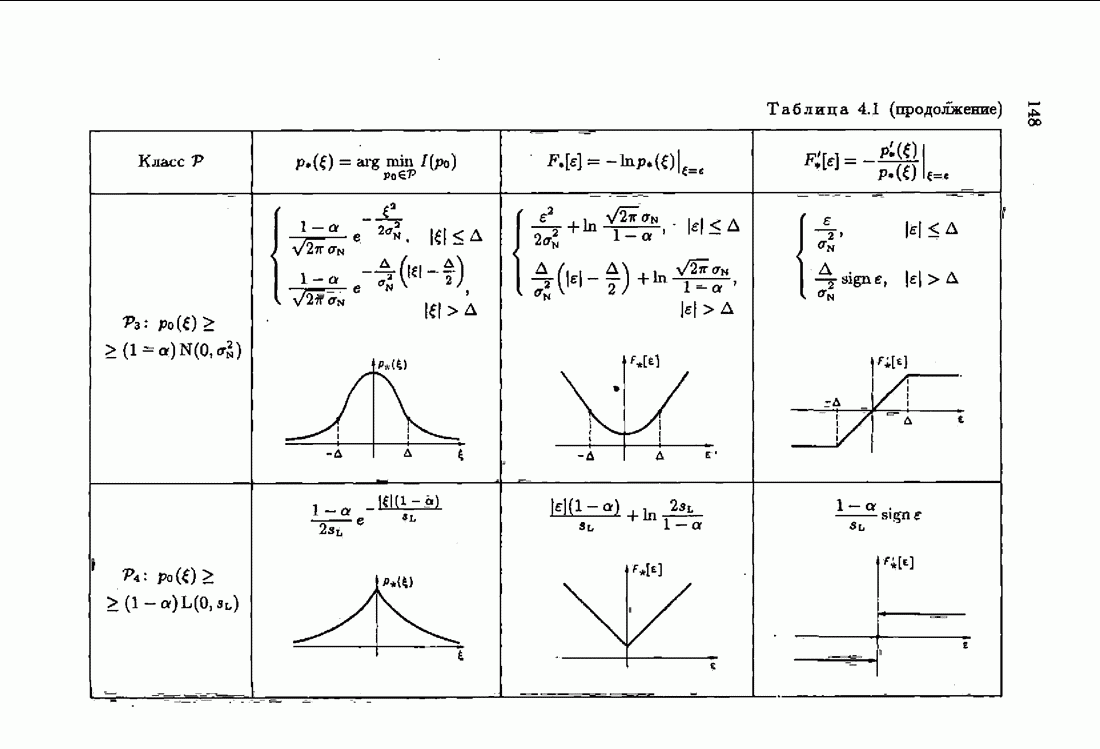
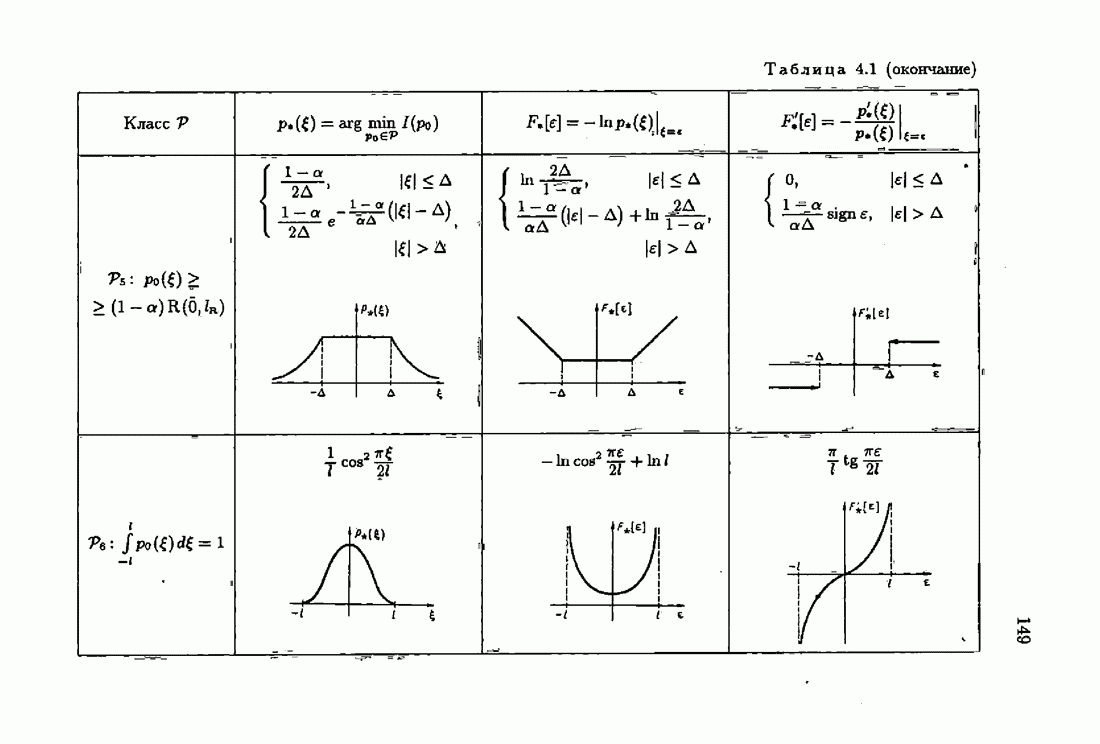
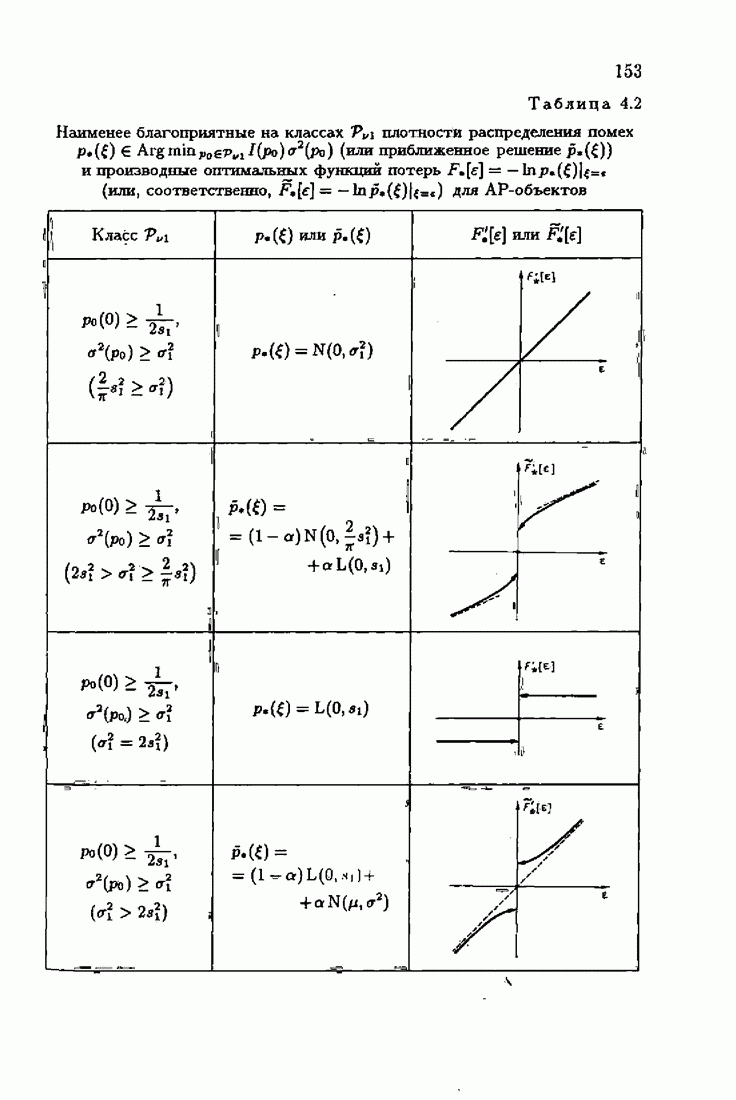
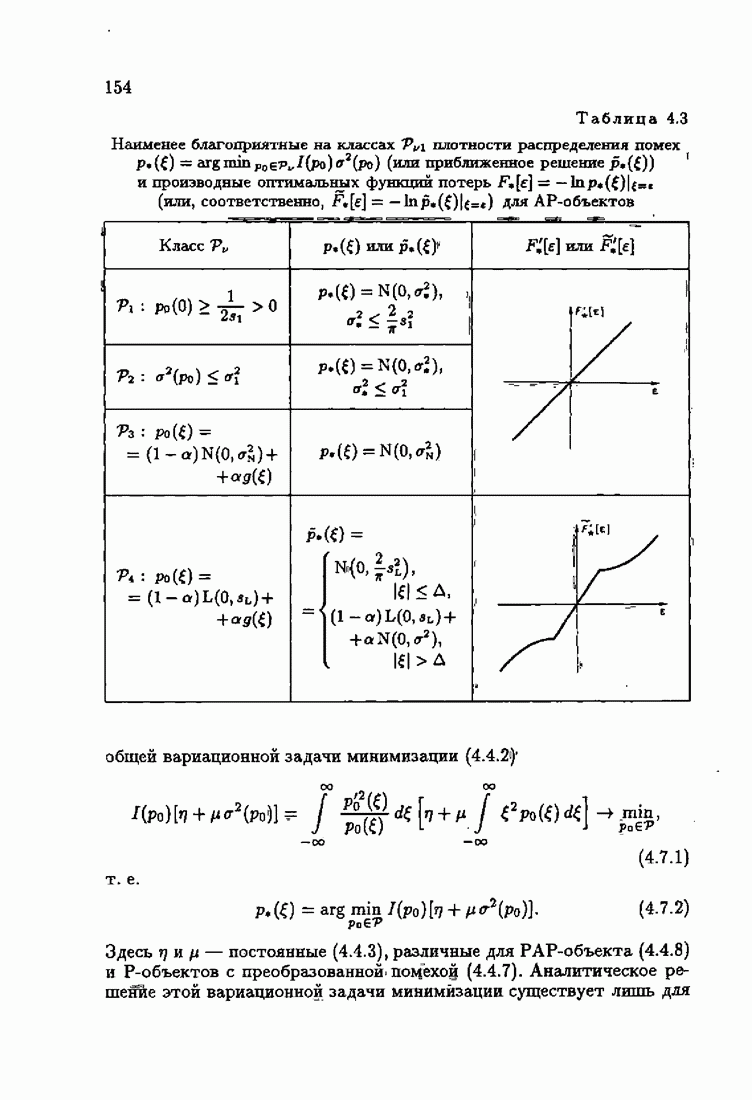
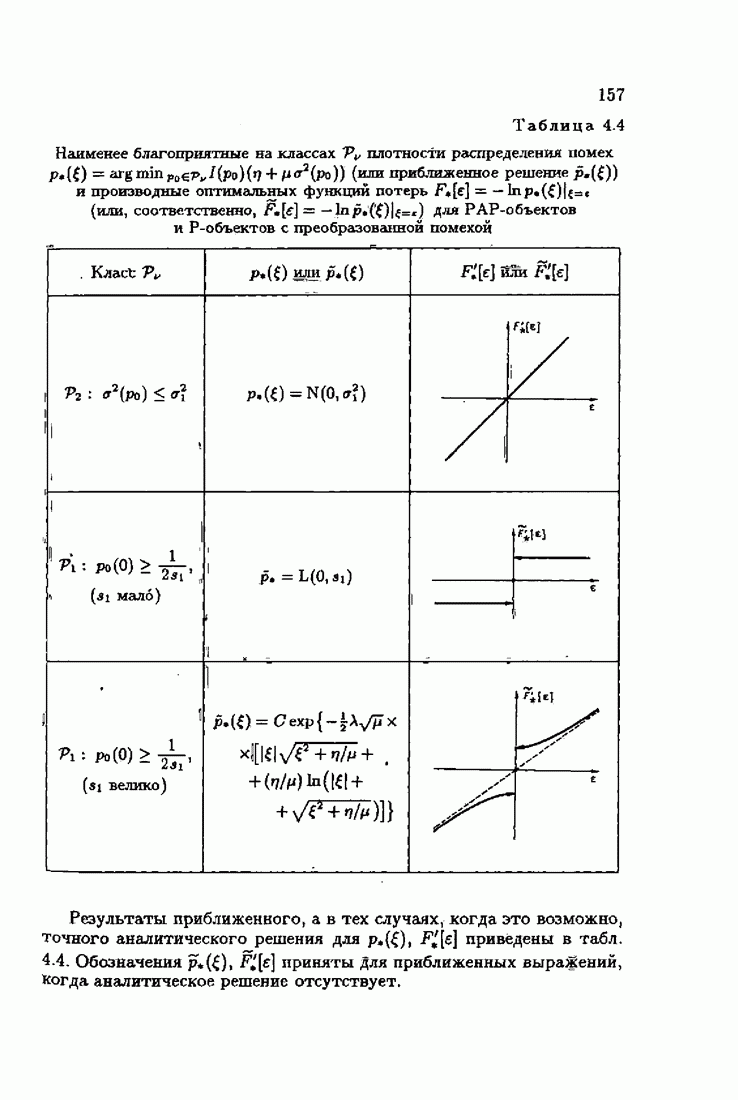
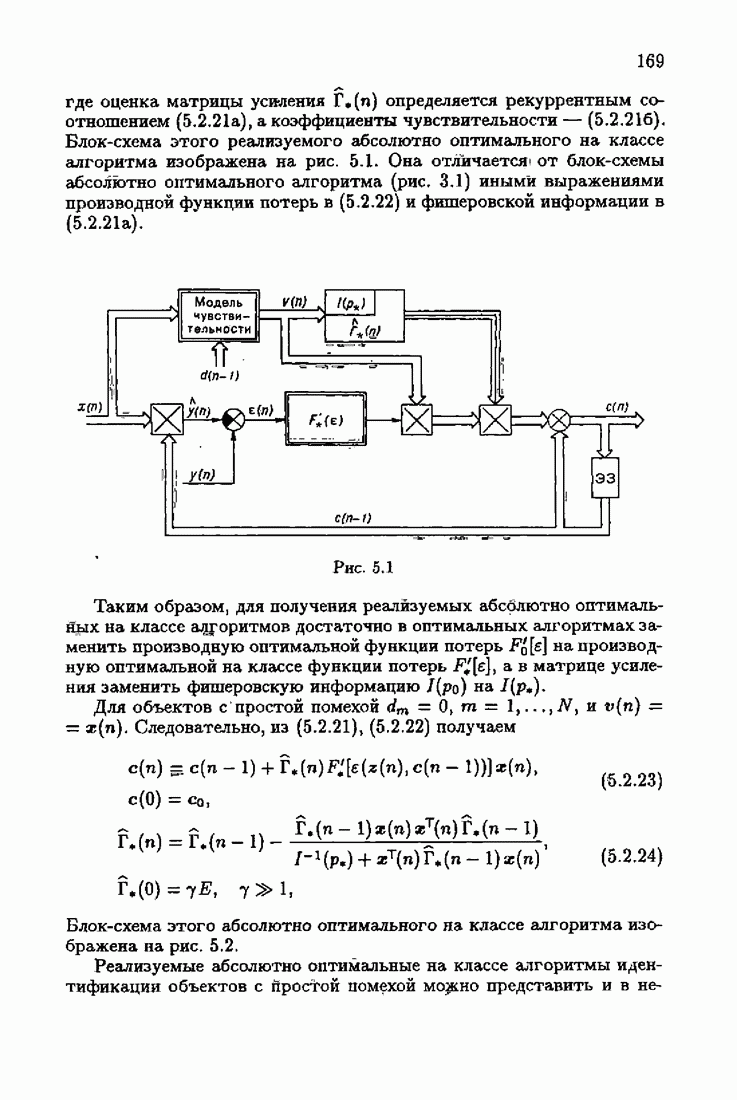
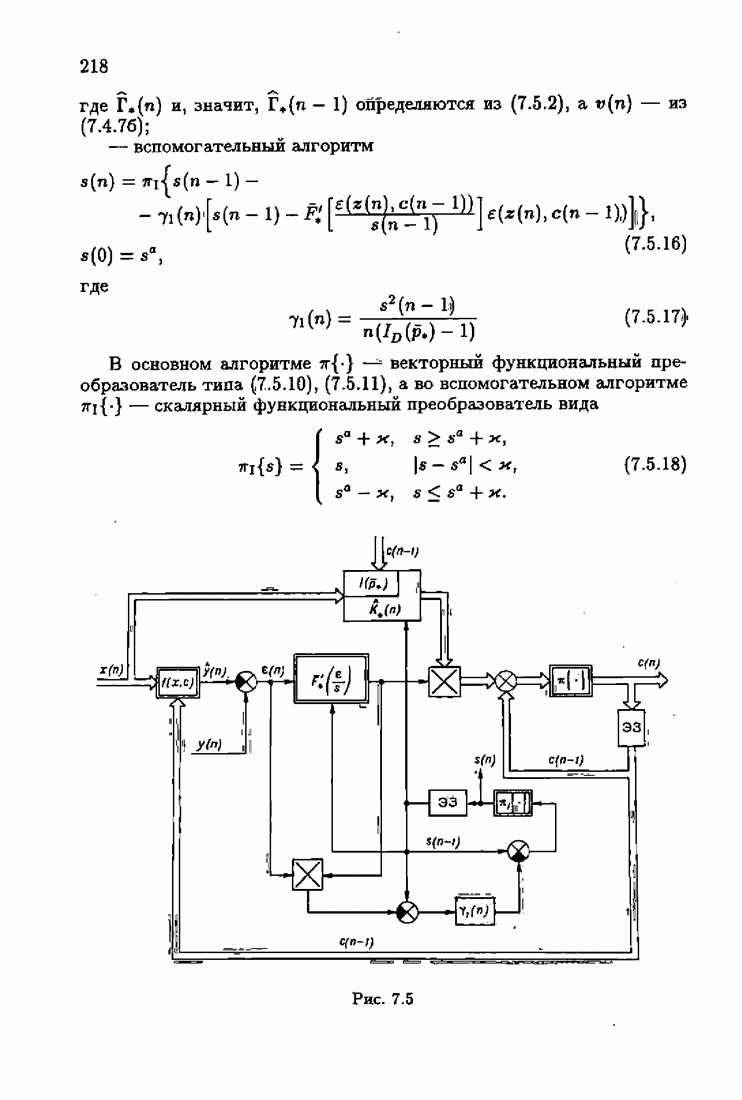
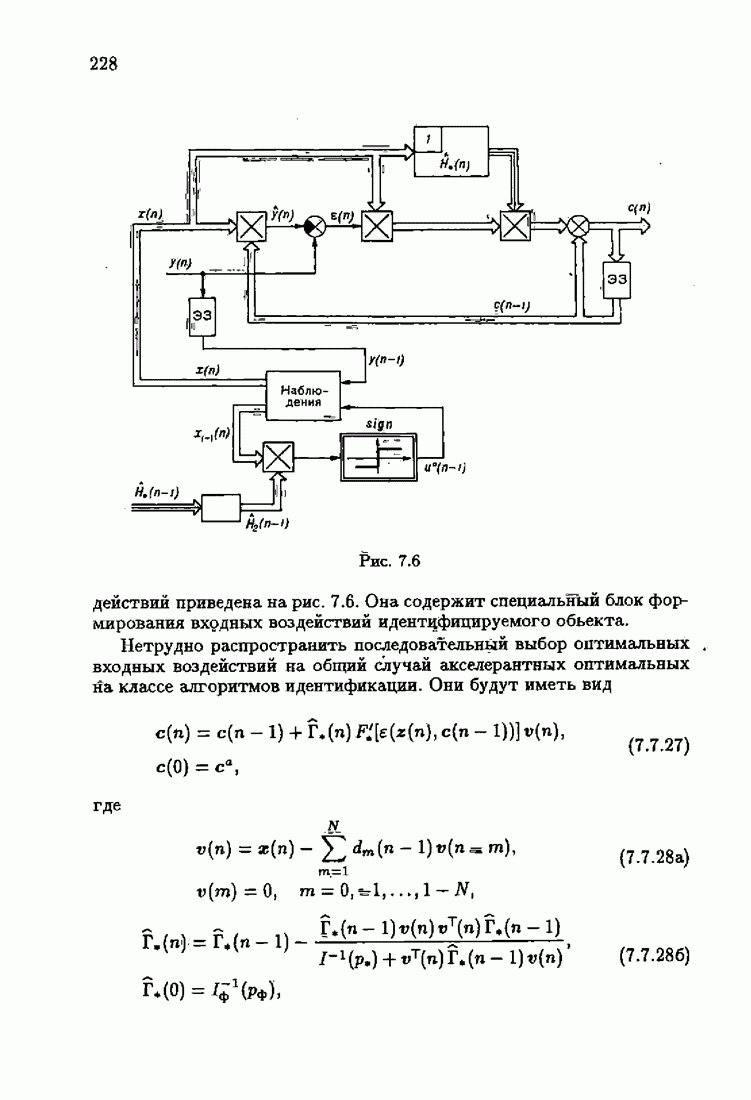
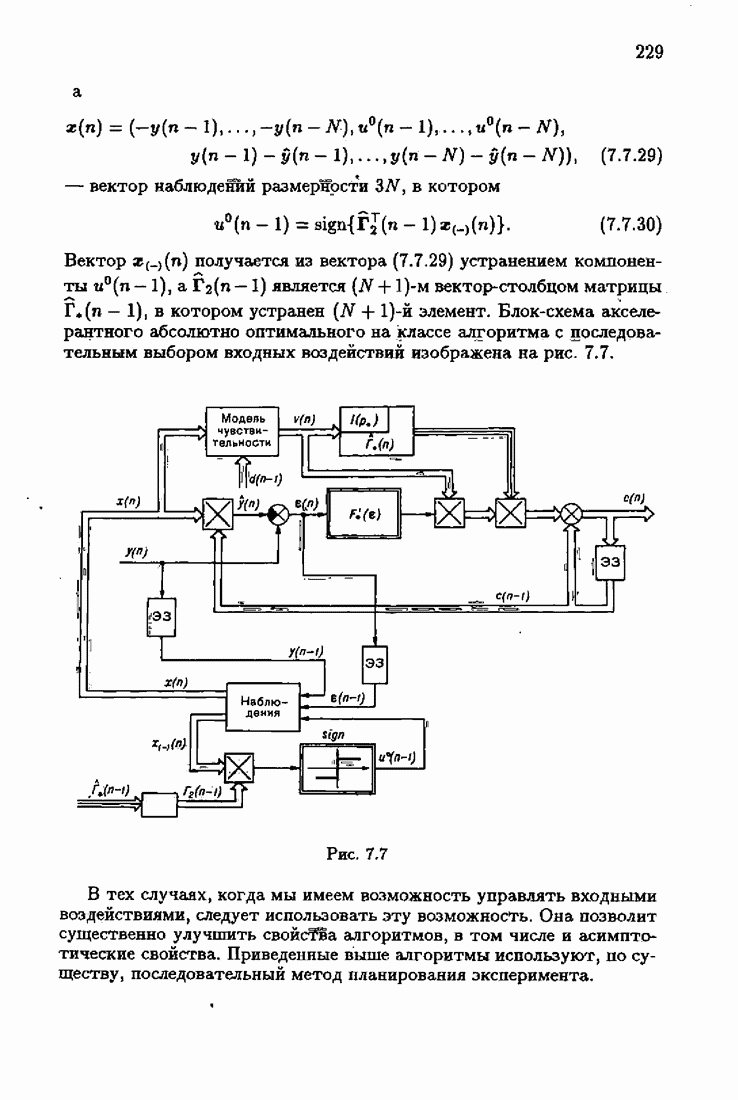
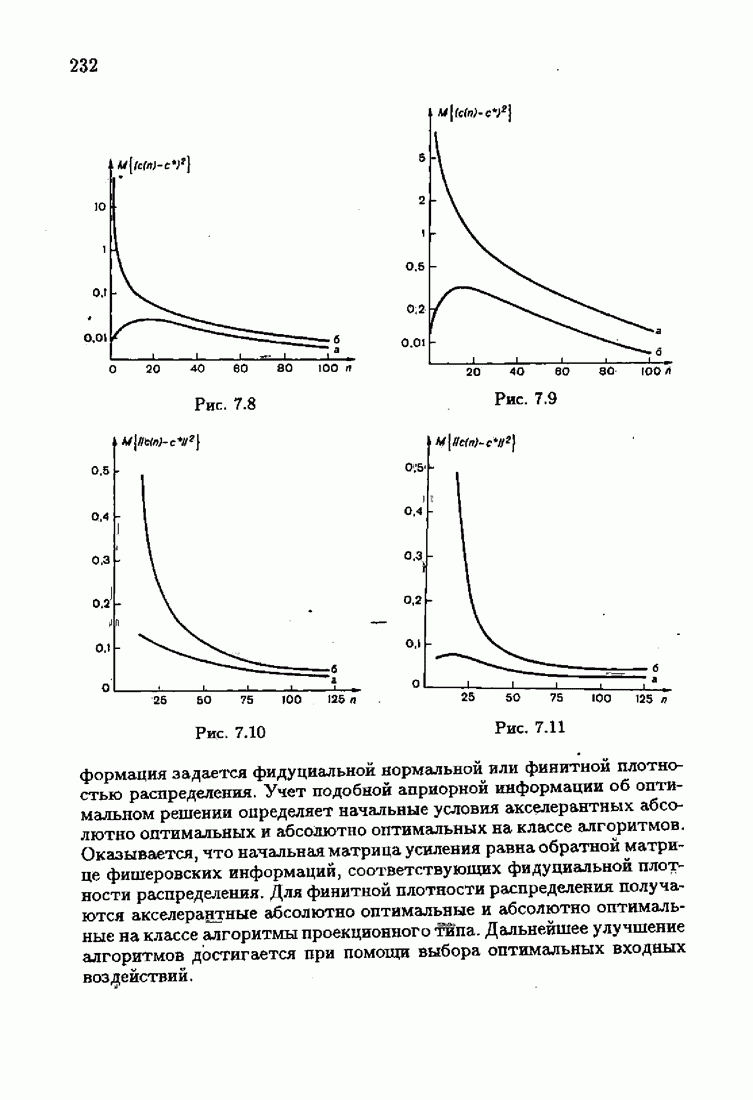
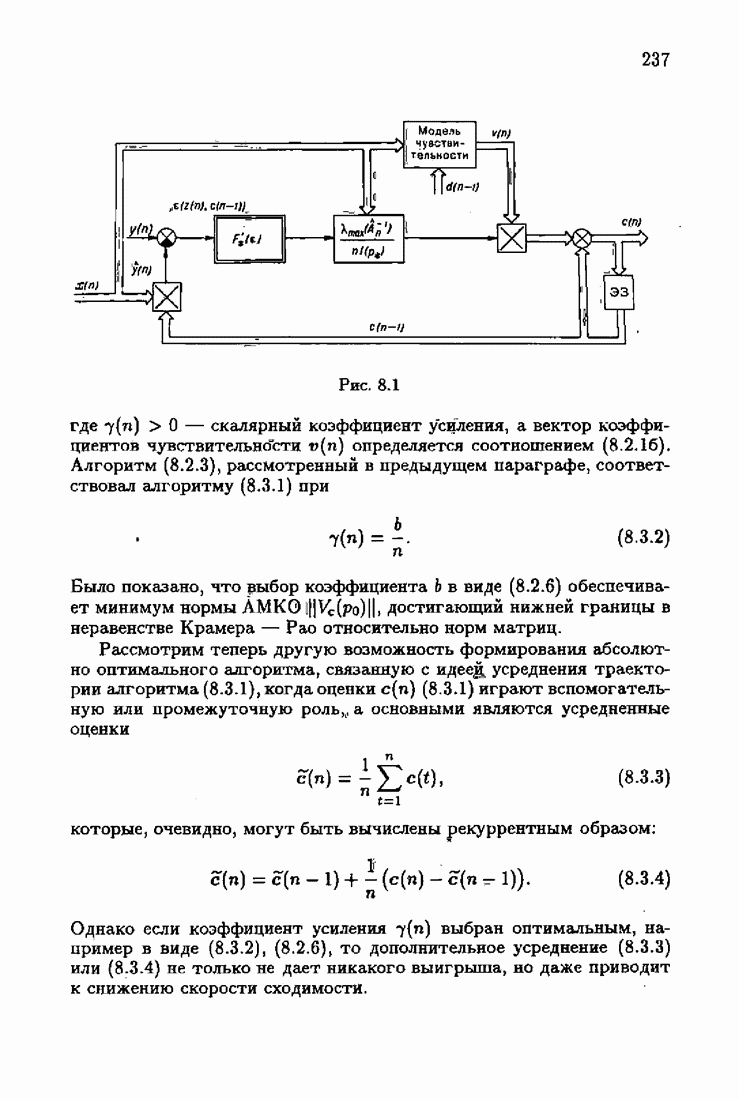
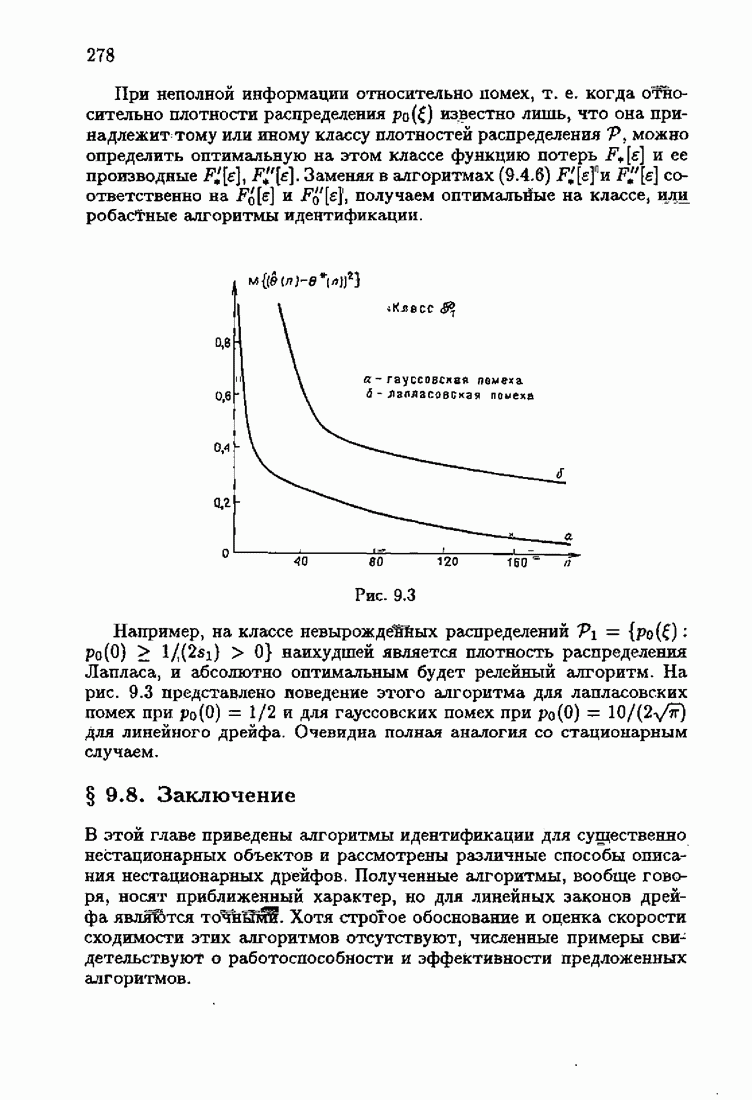
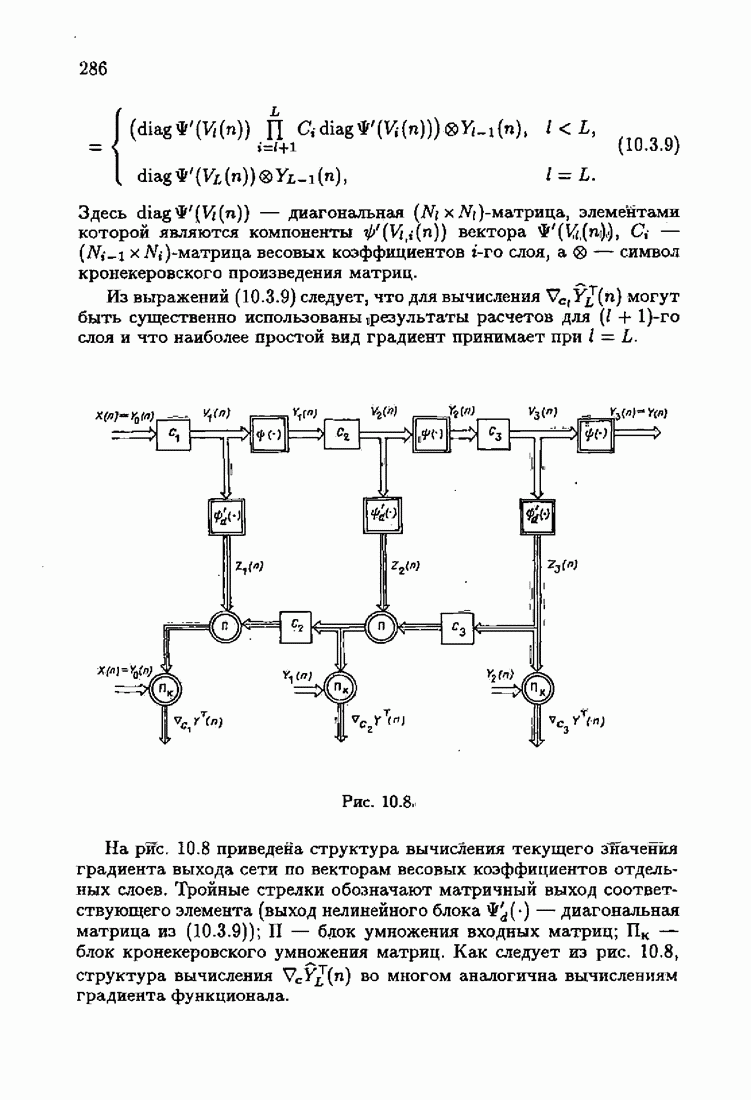
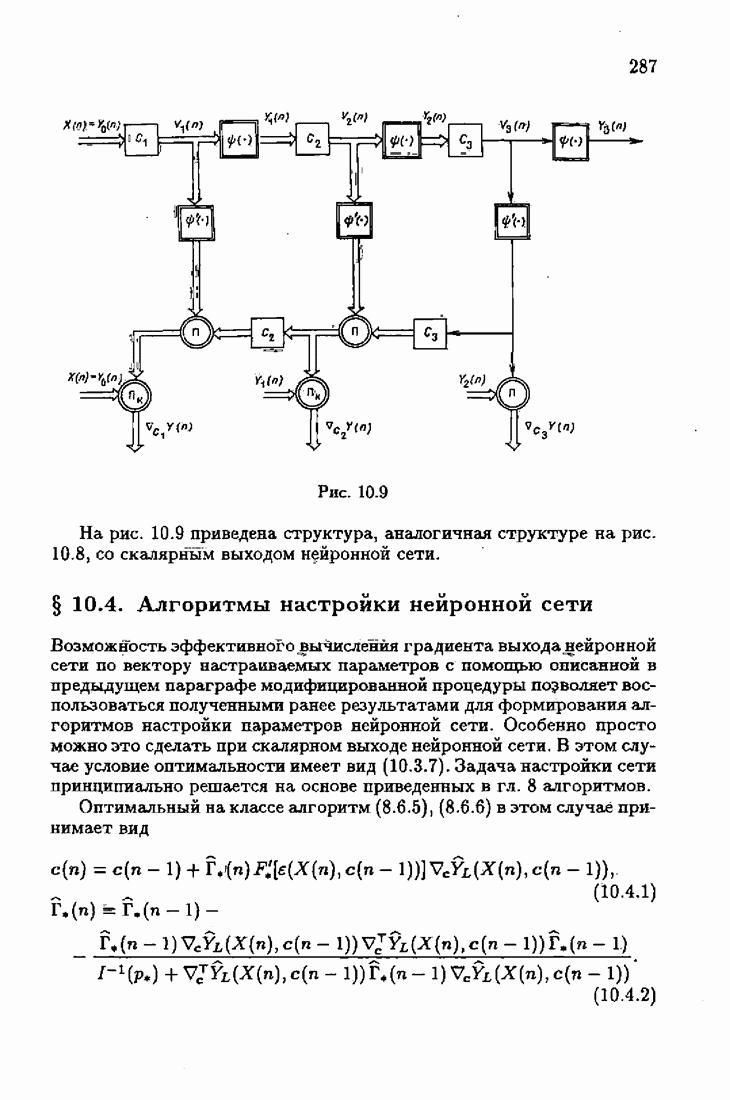
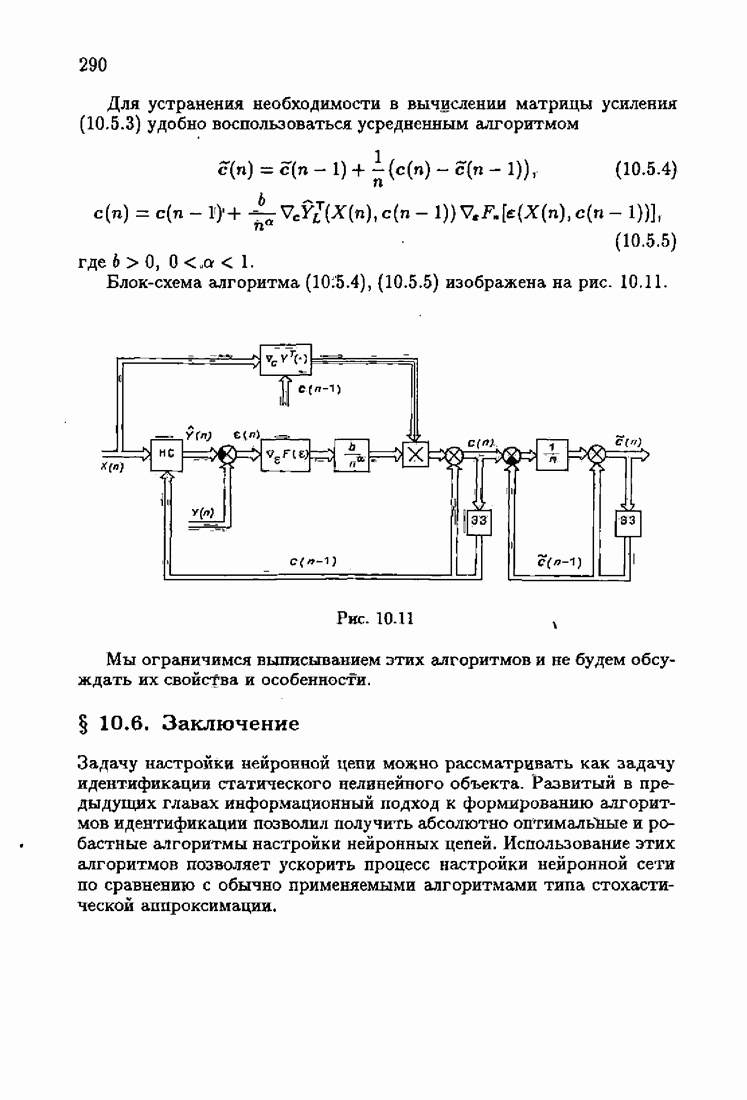
§ 9.6. Упрощенные алгоритмы
Рассмотрим следующий класс объектов:

Для него алгоритм (9.5.6) выглядит так:

В этом алгоритме приходится вычислять вспомогательные величины  Исключим эти величины. Подставляя по очереди последующее уравнение в предыдущее, получим
Исключим эти величины. Подставляя по очереди последующее уравнение в предыдущее, получим

Пользуясь (9.6.4), линеаризуем первое уравнение:

Отсюда получаем упрощенный алгоритм


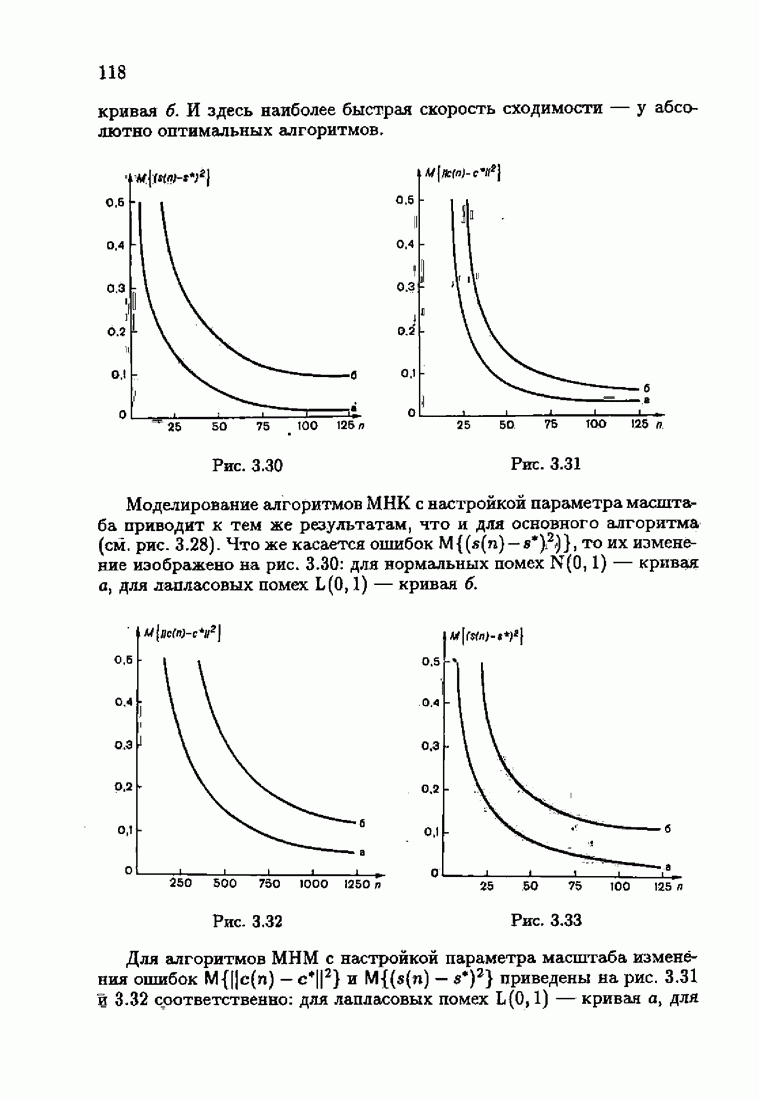
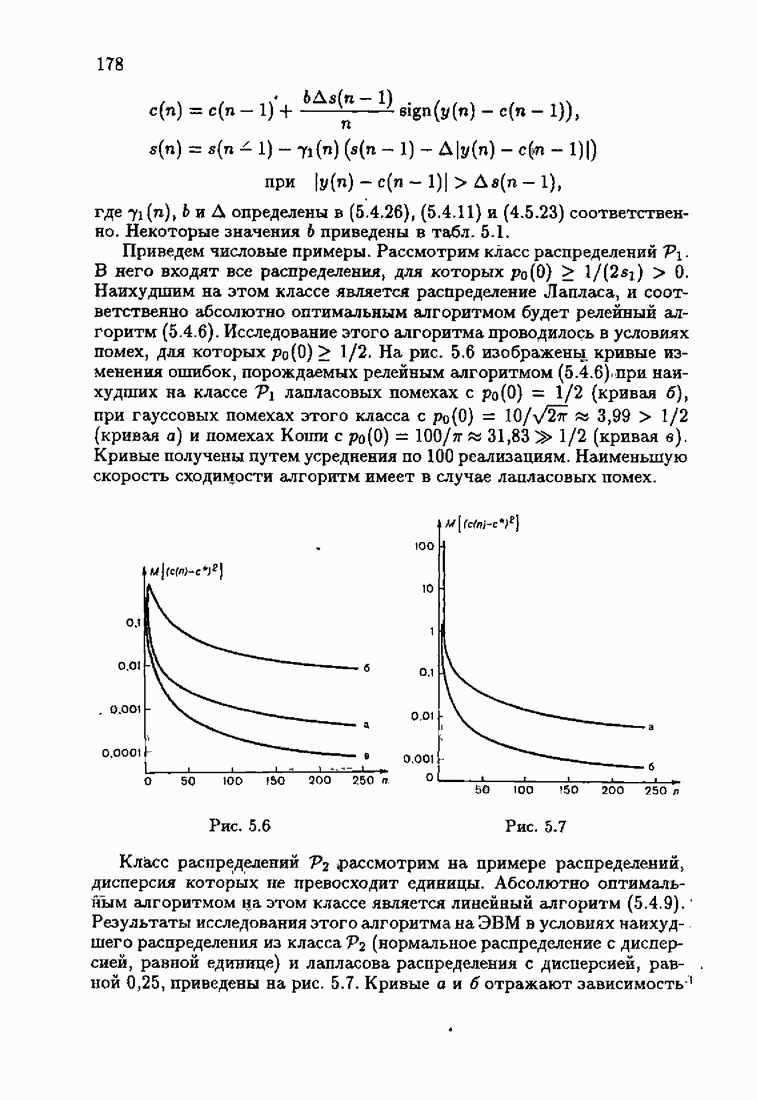
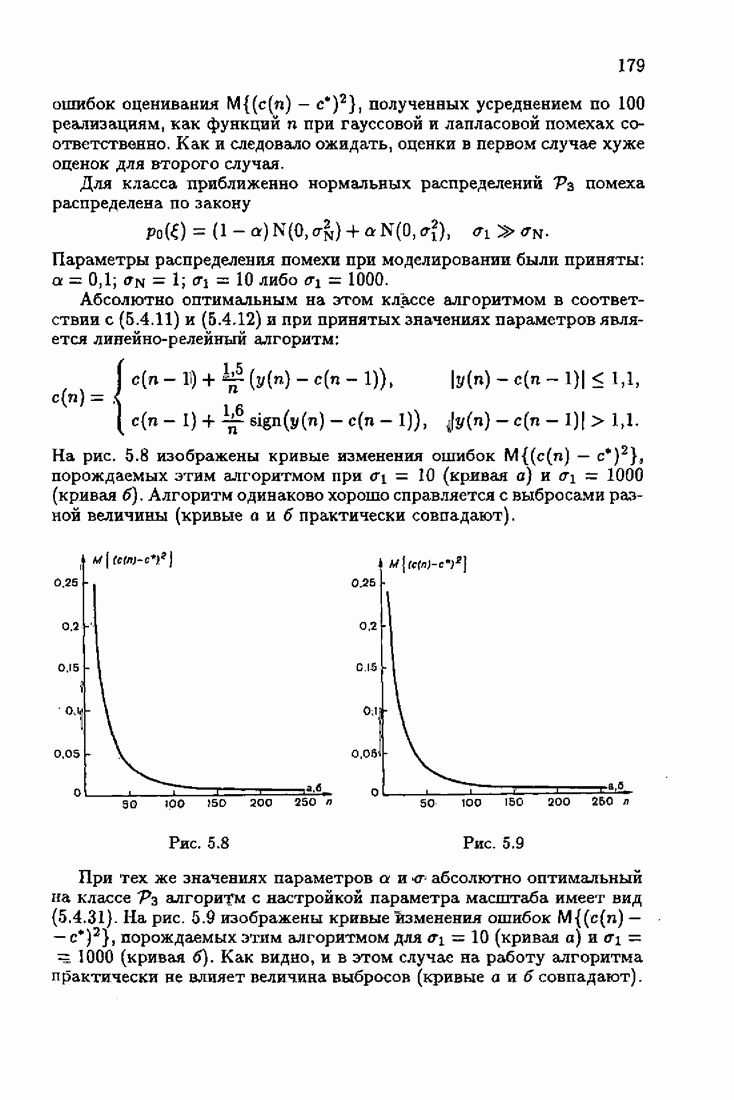
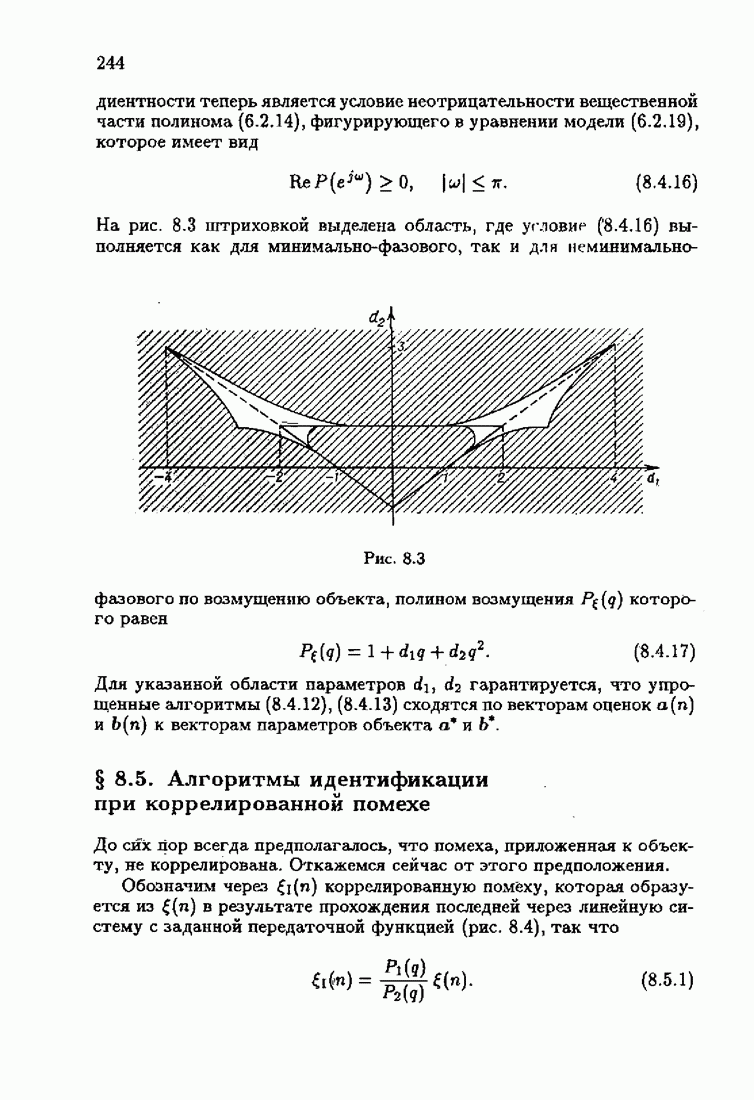
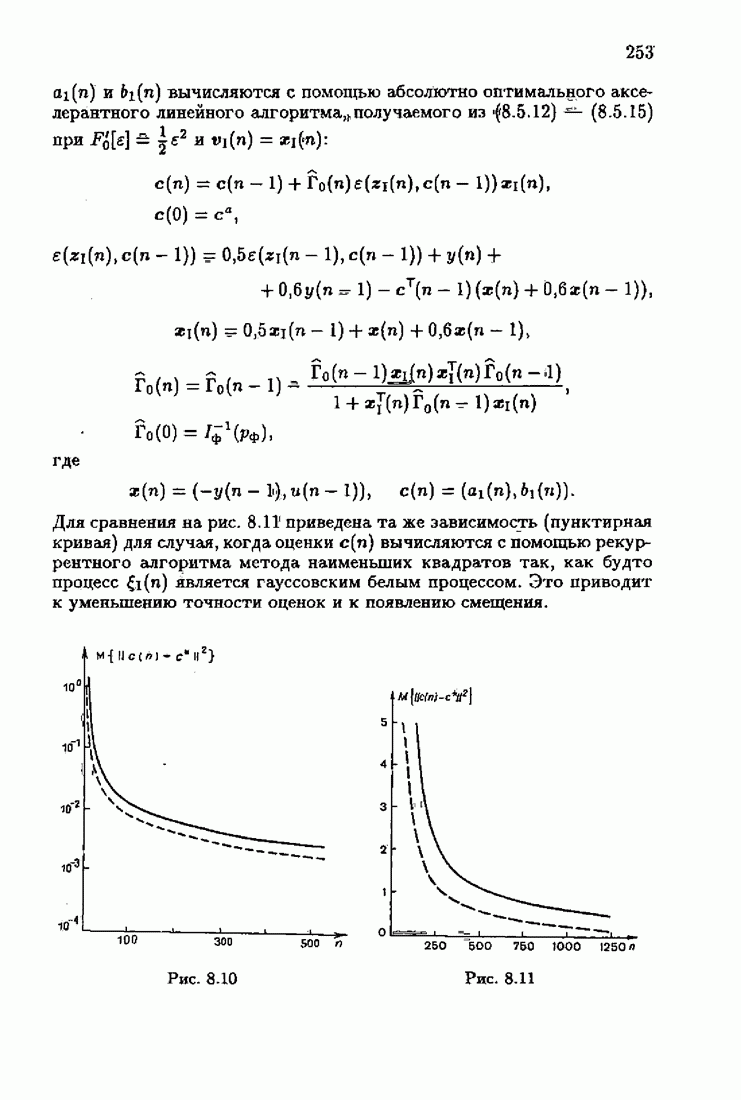
Этот алгоритм содержит  нелинейных преобразований от задержанных на соответствующее число шагов невязок. Однако за простоту приходится платить некоторым ухудшением качества. Так, на рис. 9.1 представлено поведение алгоритмов (9.6.7) и (9.5.6) для линейного дрейфа.
нелинейных преобразований от задержанных на соответствующее число шагов невязок. Однако за простоту приходится платить некоторым ухудшением качества. Так, на рис. 9.1 представлено поведение алгоритмов (9.6.7) и (9.5.6) для линейного дрейфа.

Рис. 9.1
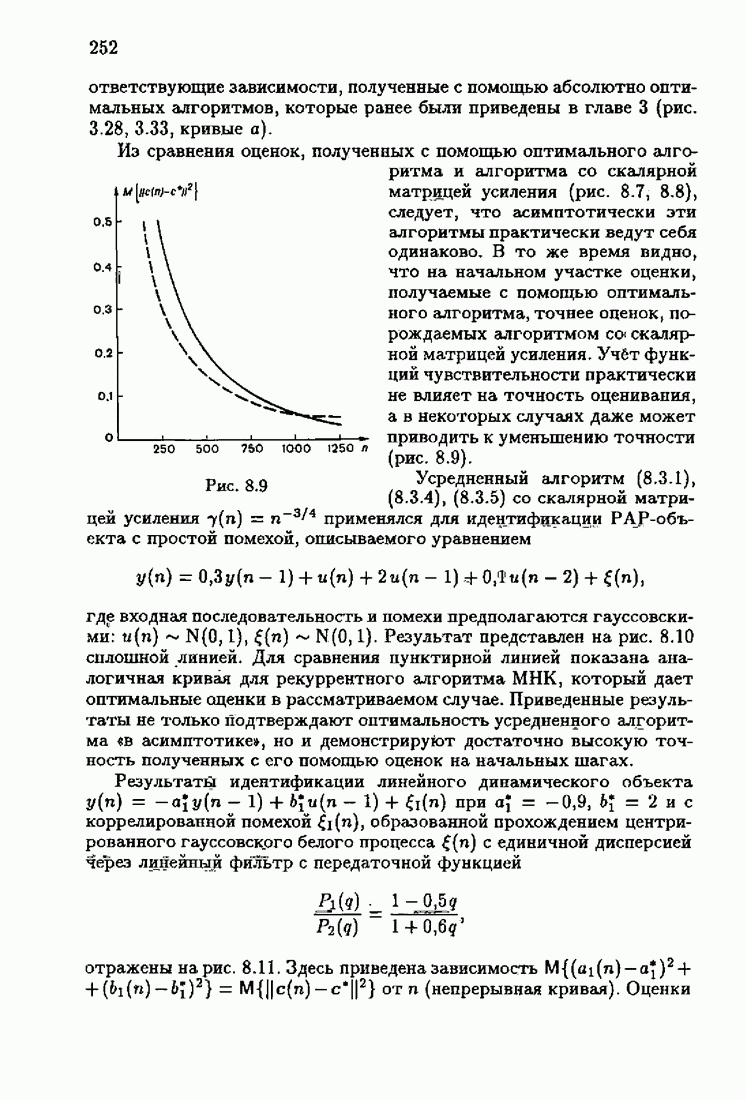
Видно, что значение квадрата ошибки для упрощенного алгоритма в несколько раз меньше. Кроме того, при исследовании целесообразности выбора параметрической (9.1.5) или функциональной (9.5.1) формы задания дрейфа оказалось, что по сложности вычислений, объему операций и времени счета между ними нет существенных отличий. Выбор параметрического или функционального алгоритма зависит от специфики задачи. Например, в задачах, связанных с технологией производства, где требуется знание каждого параметра, используются параметрические алгоритмы, а в экономических задачах прогнозирования удобнее применять функциональный алгоритм.
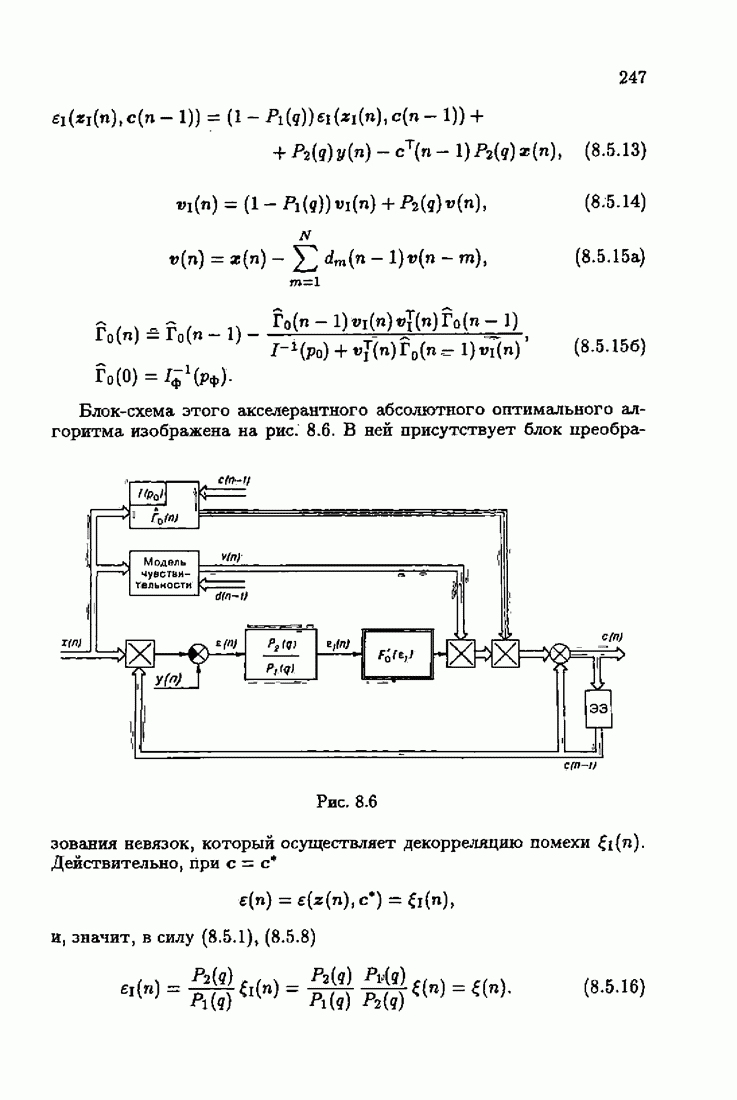
В заключение рассмотрим простой пример. Пусть объект описывается уравнением

Если частота  известна, то для параметра
известна, то для параметра


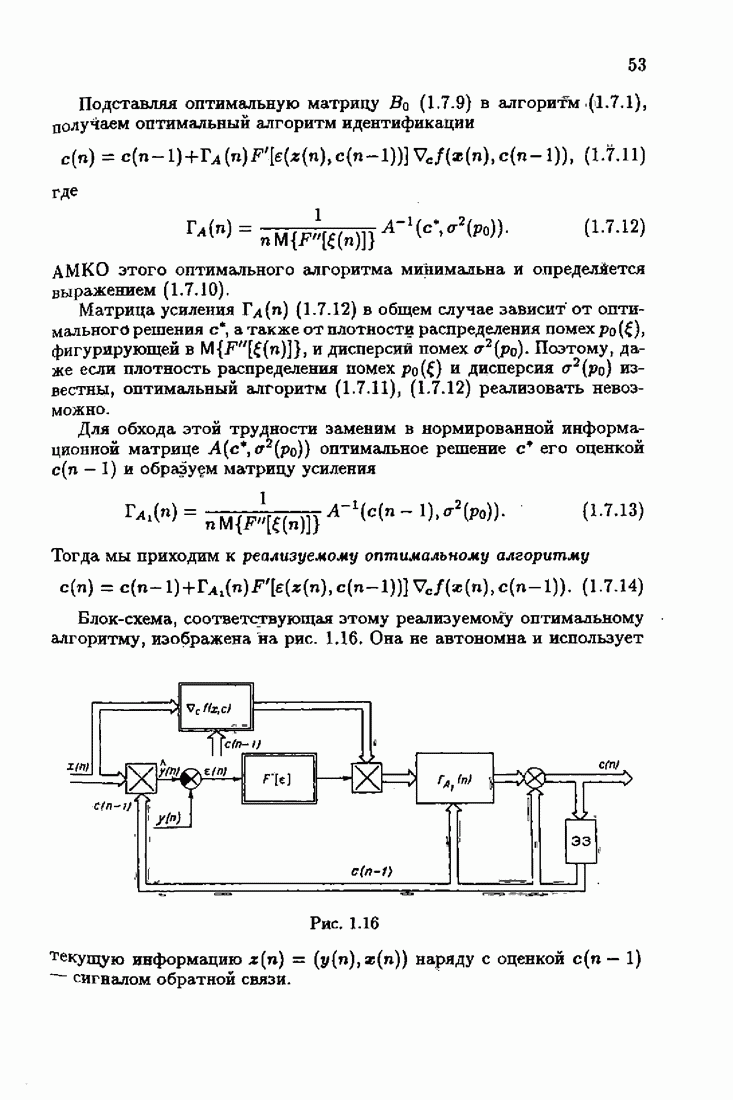
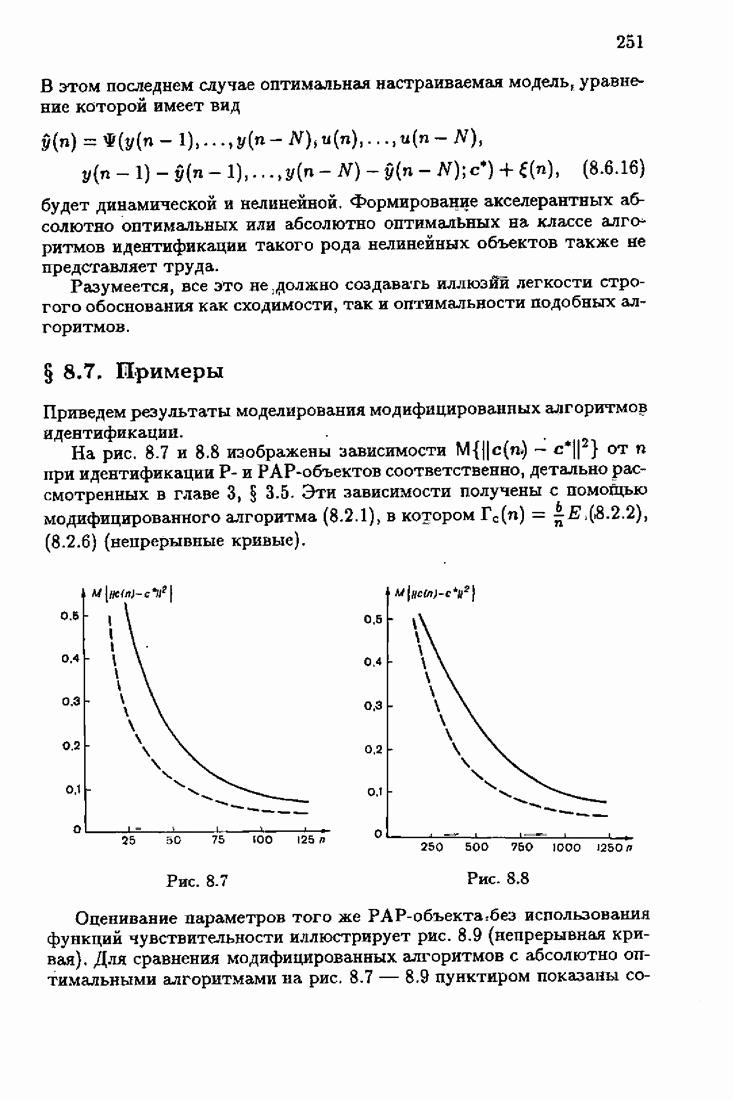
Рис. 9.2
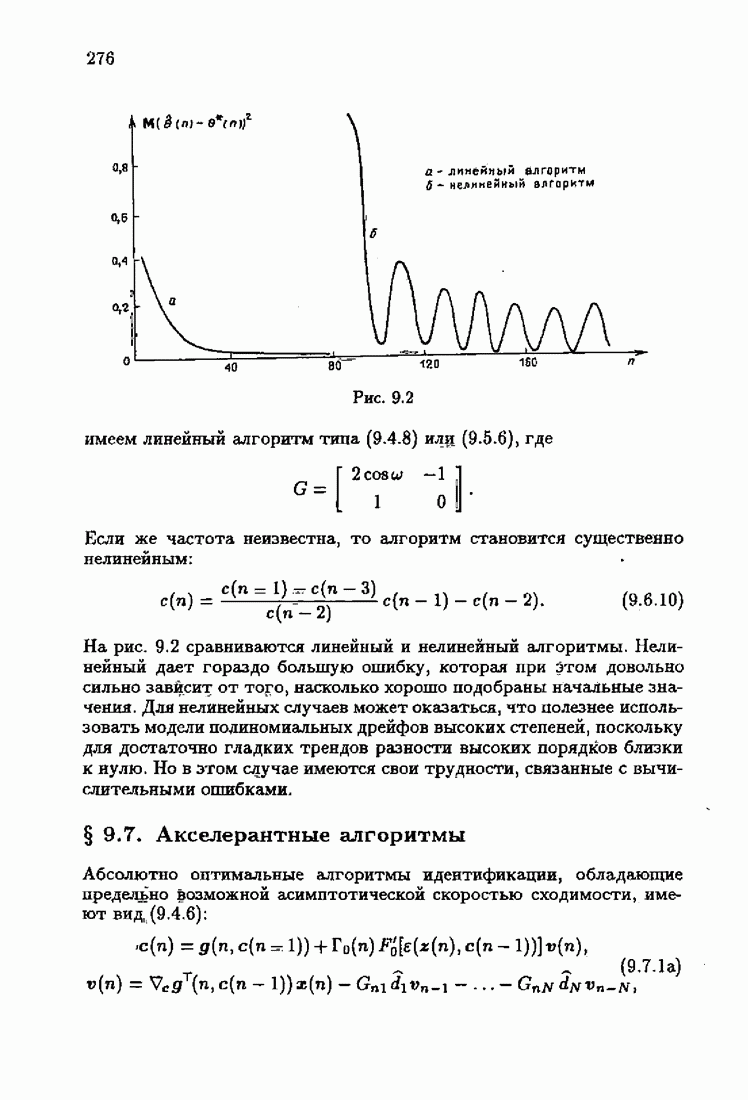
имеем линейный алгоритм типа (9.4.8) или (9.5.6), где

Если же частота неизвестна, то алгоритм становится существенно нелинейным:

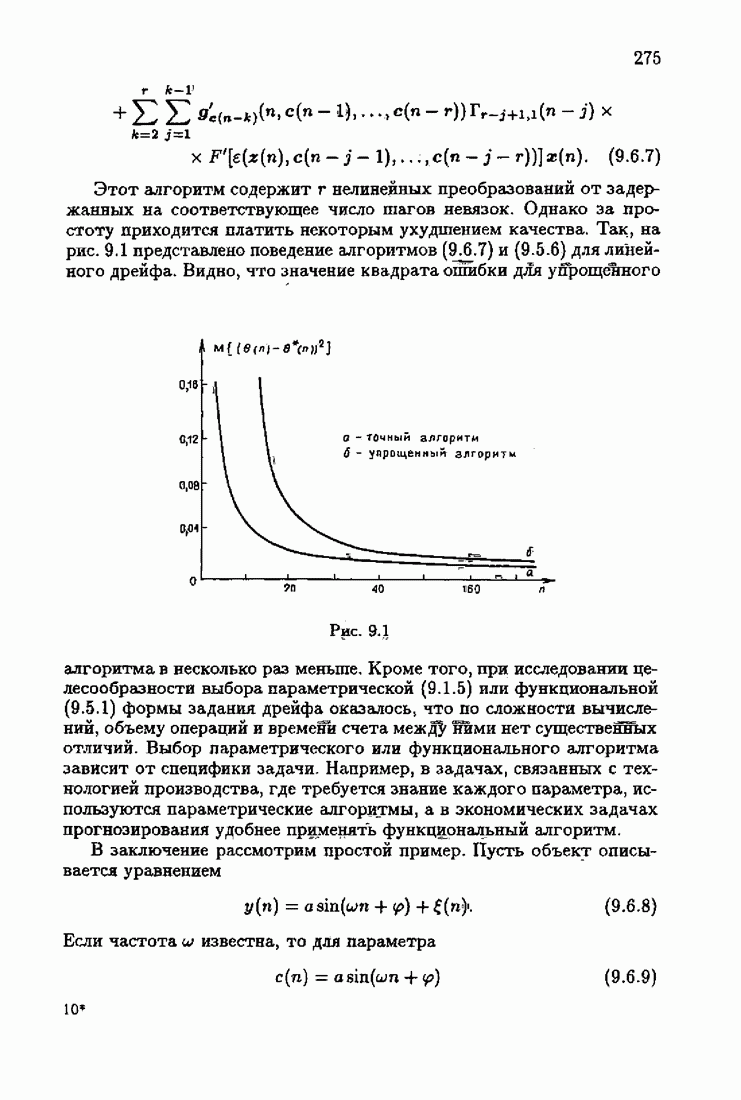
На рис. 9.2 сравниваются линейный и нелинейный алгоритмы. Нелинейный дает гораздо большую ошибку, которая при этом довольно сильно зависит от того, насколько хорошо подобраны начальные значения. Для нелинейных случаев может оказаться, что полезнее использовать модели полиномиальных дрейфов высоких степеней, поскольку для достаточно гладких трендов разности высоких порядков близки к нулю. Но в этом случае имеются свои трудности, связанные с вычислительными ошибками.