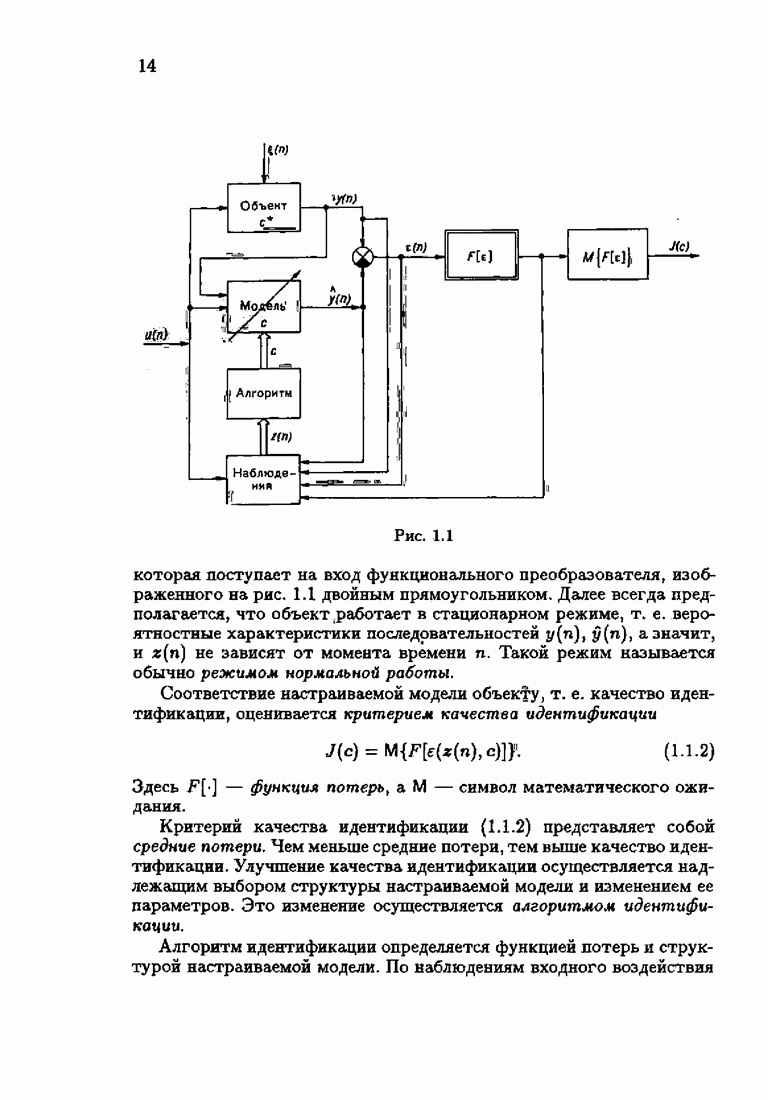
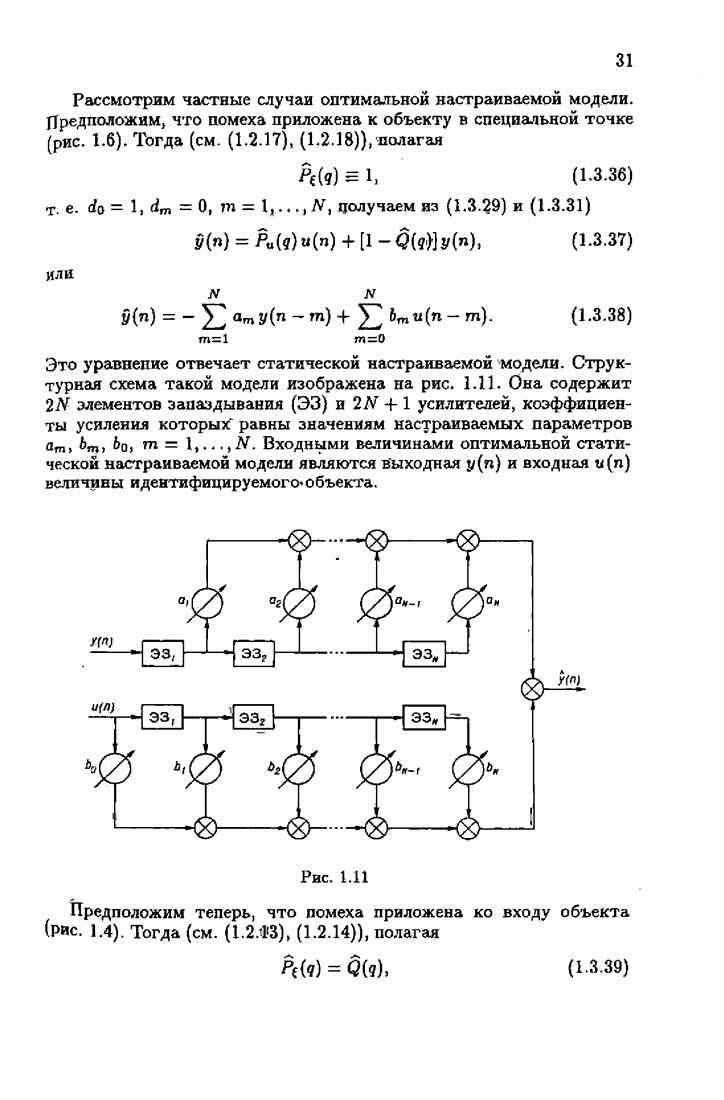
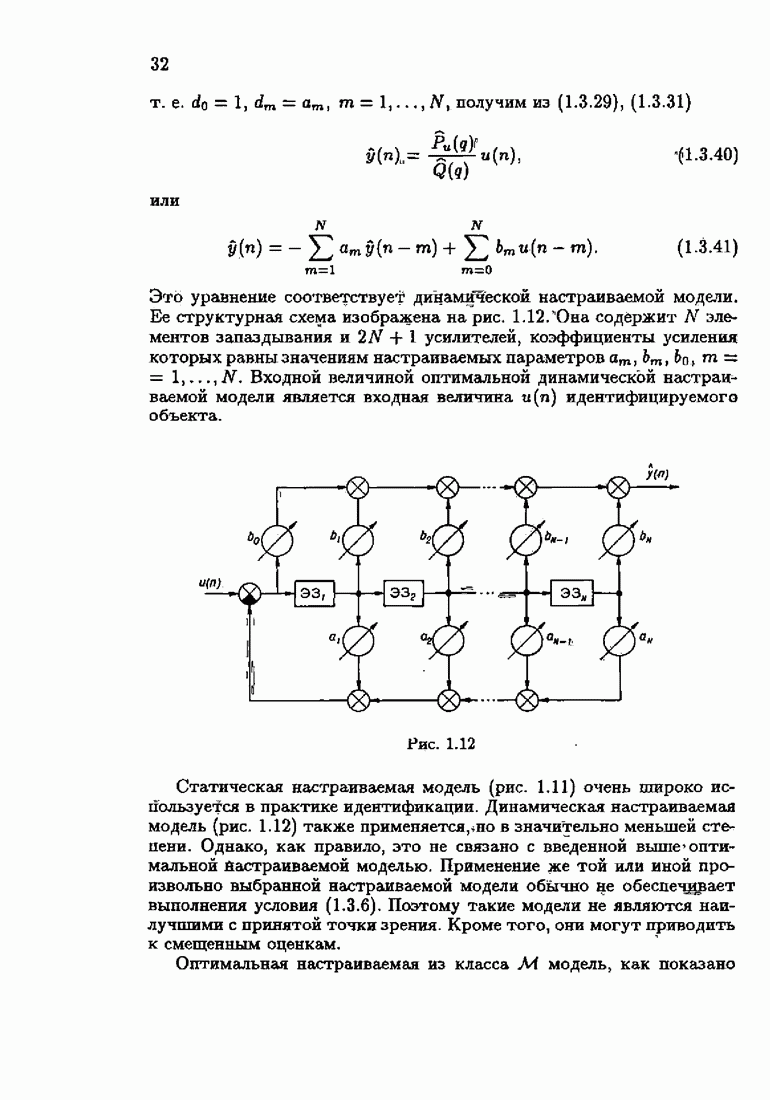
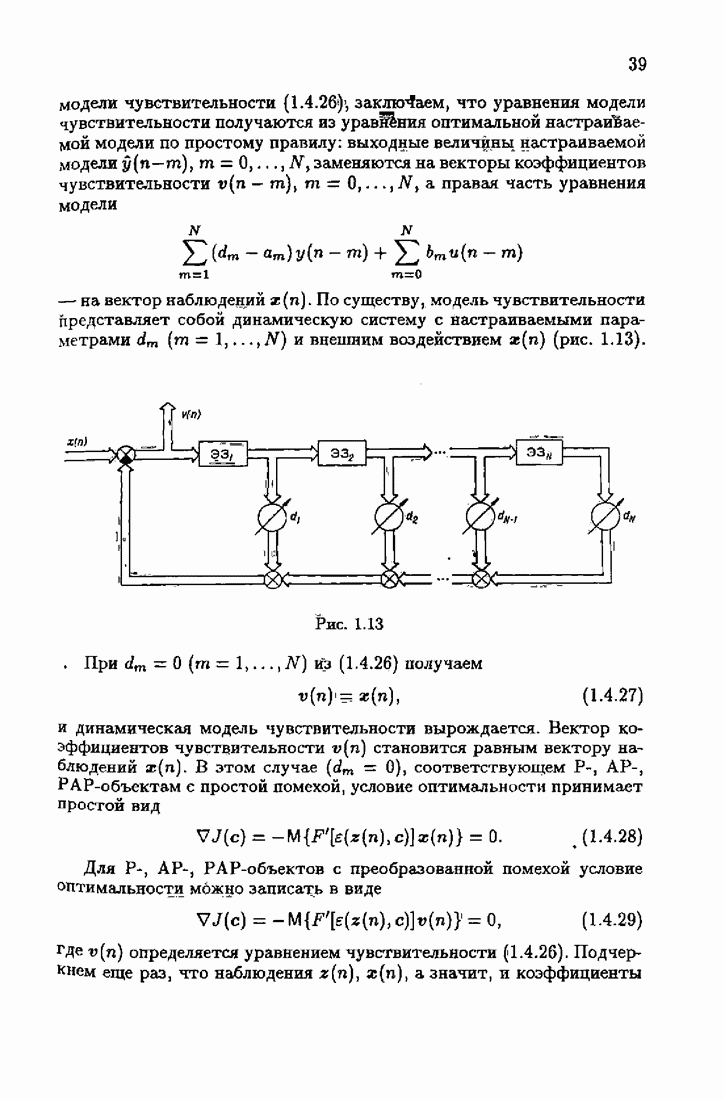
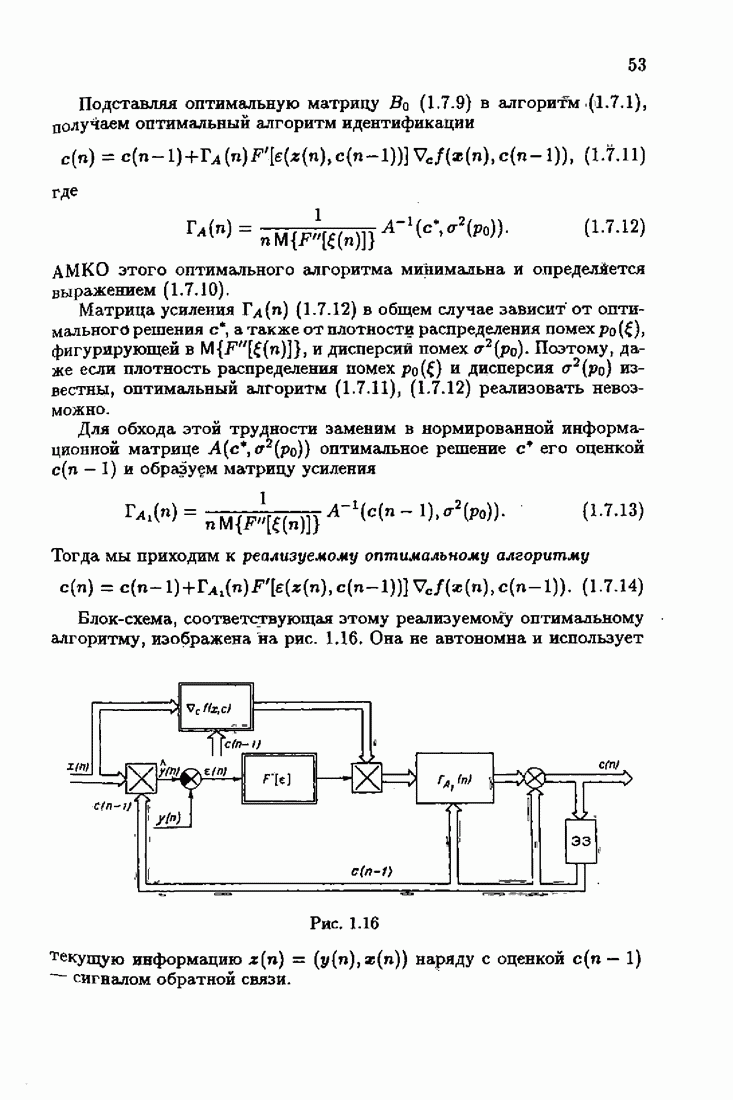
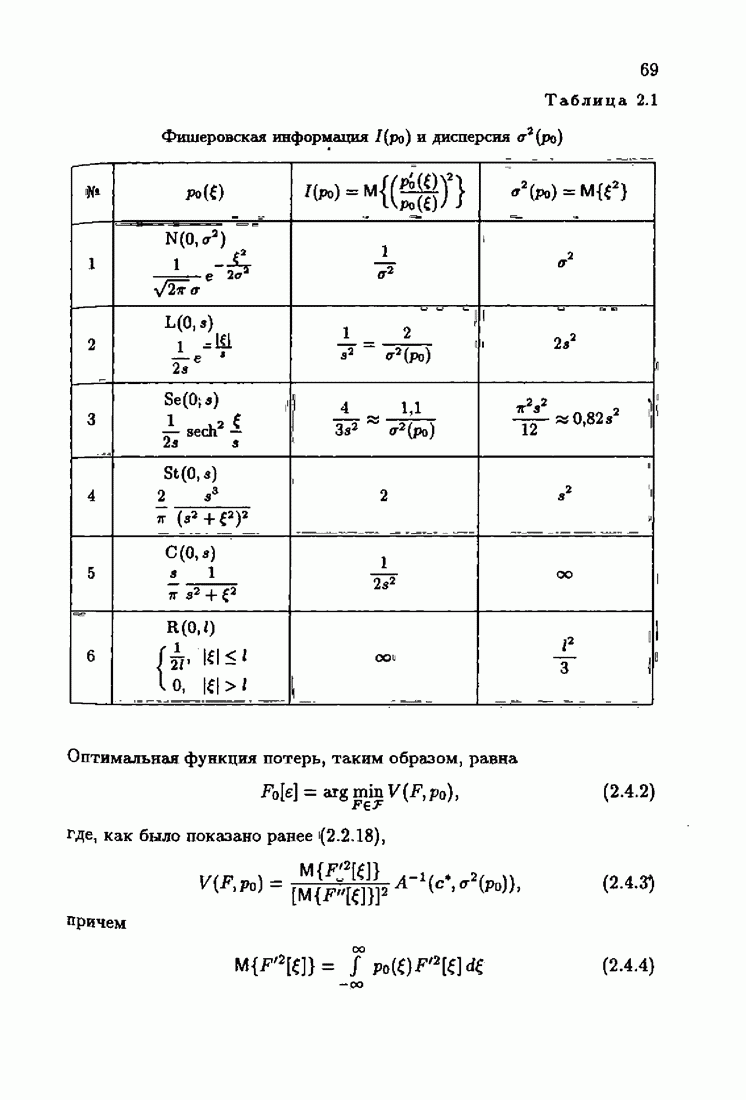
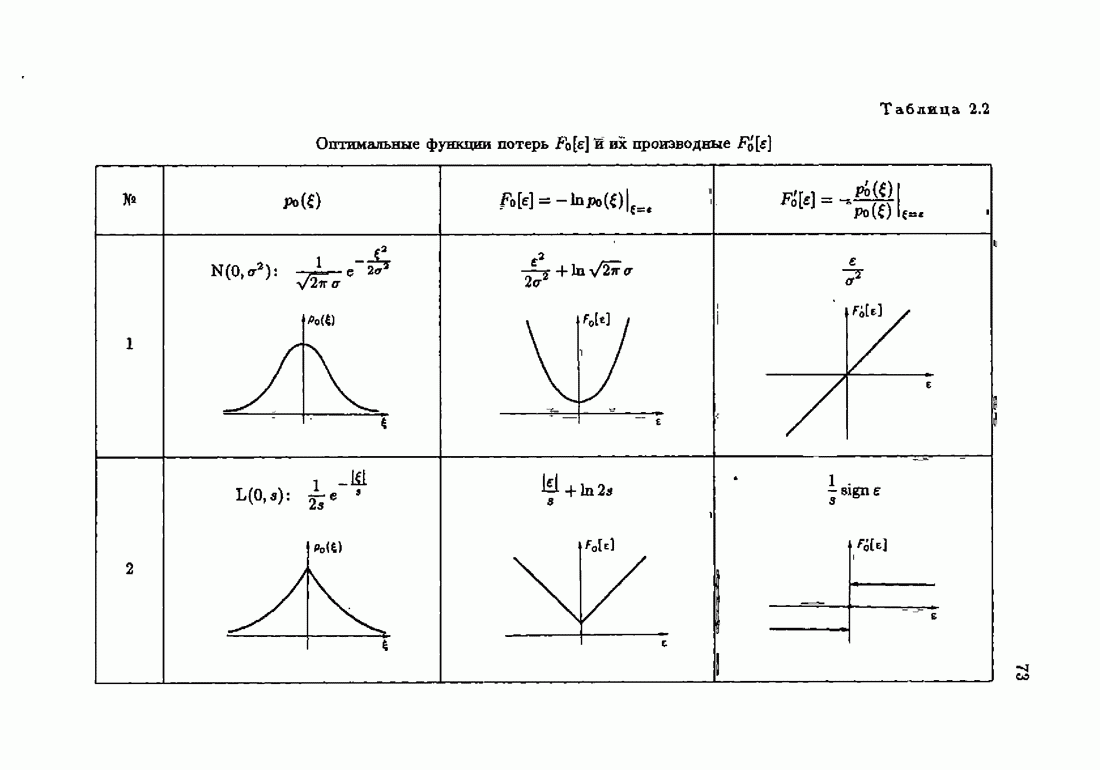
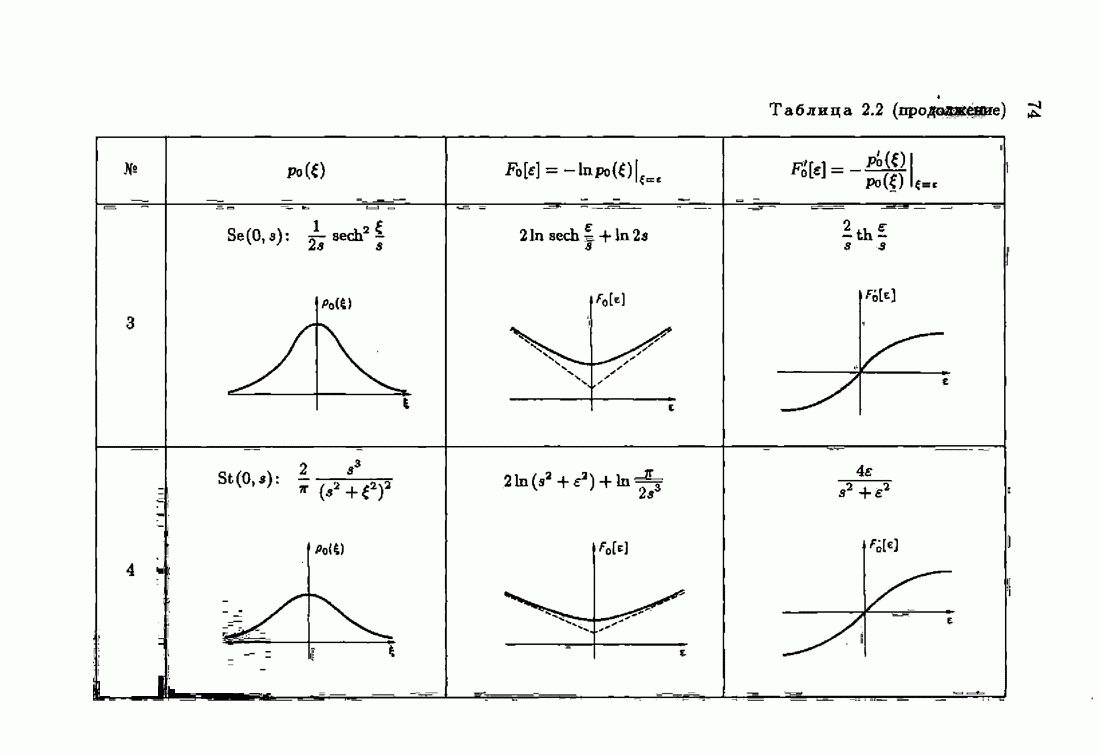
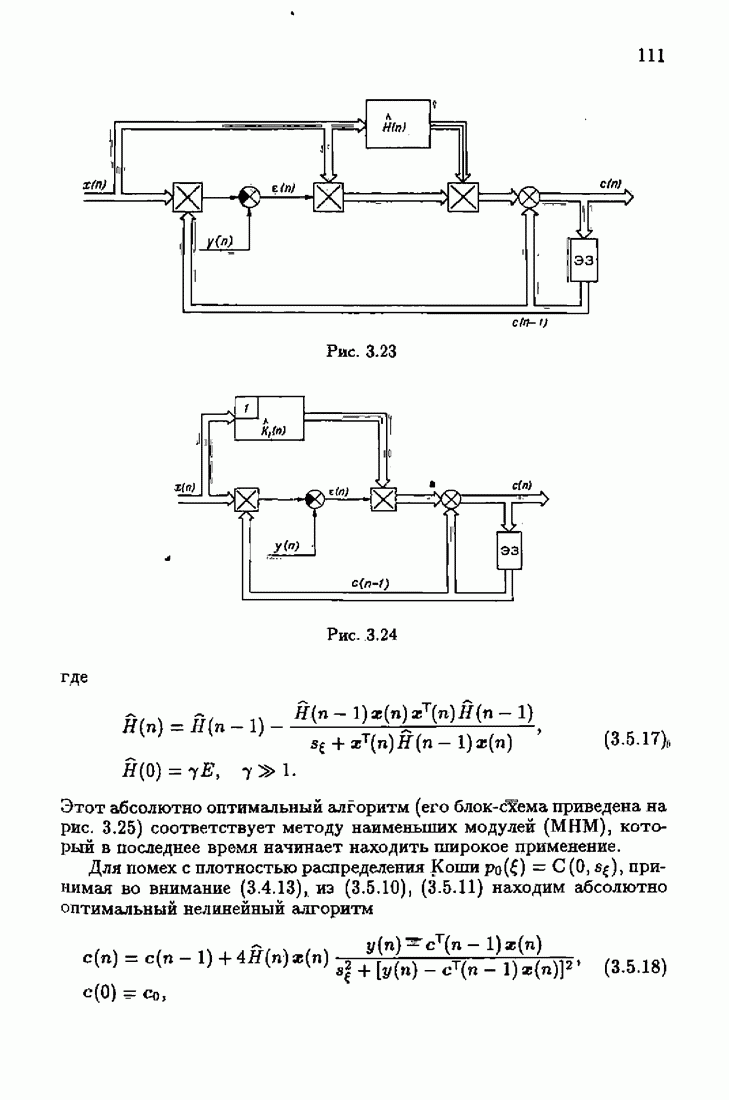
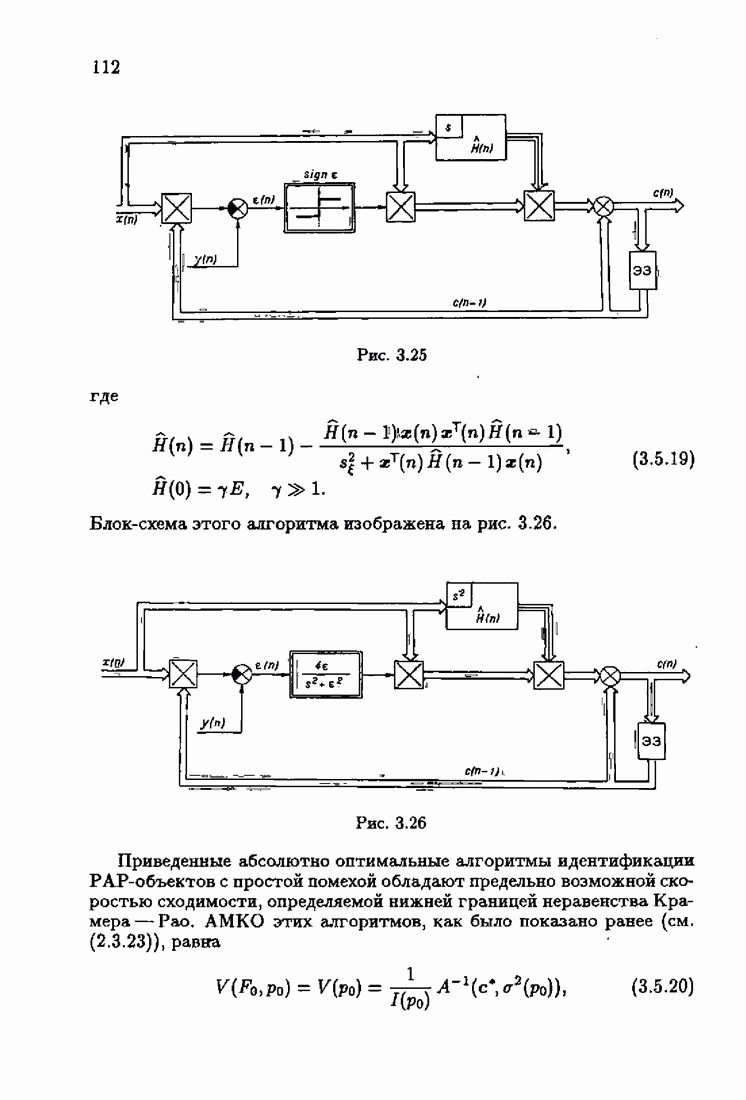
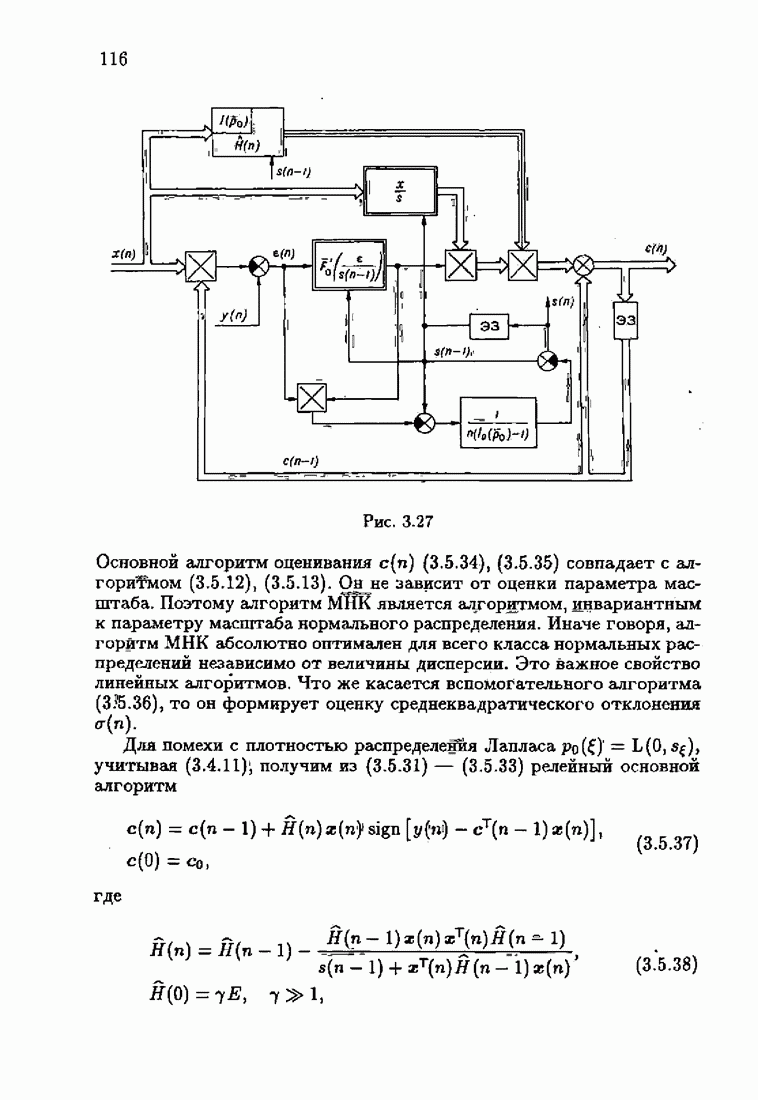
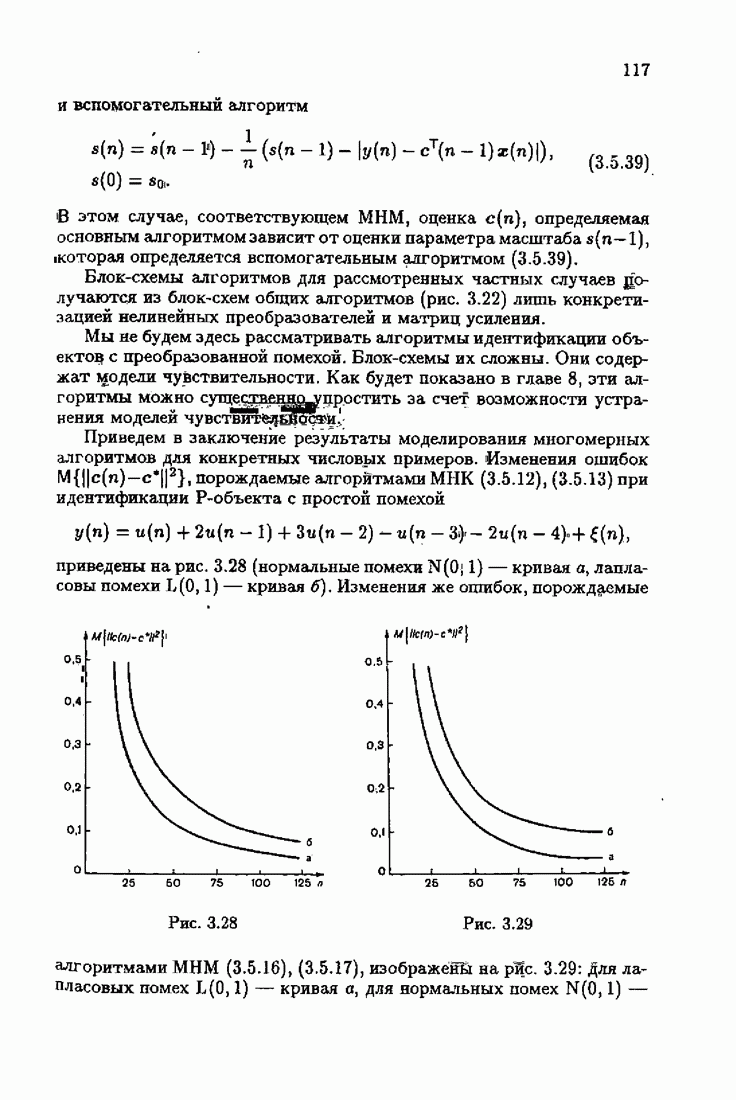
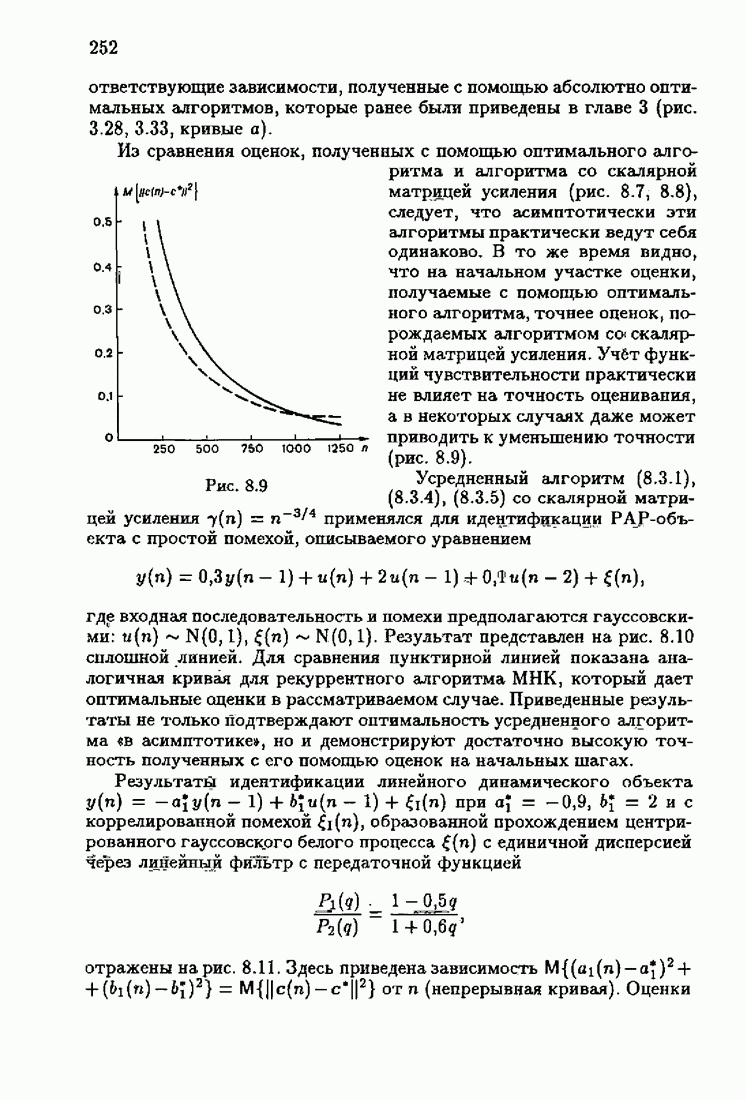
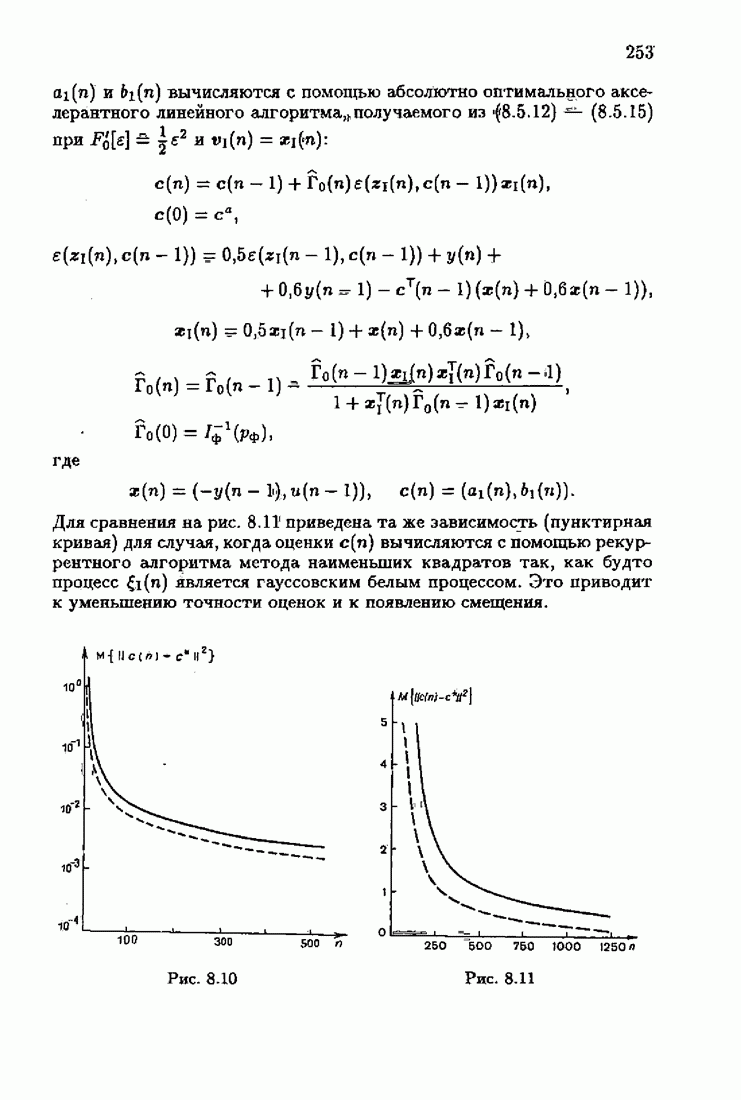
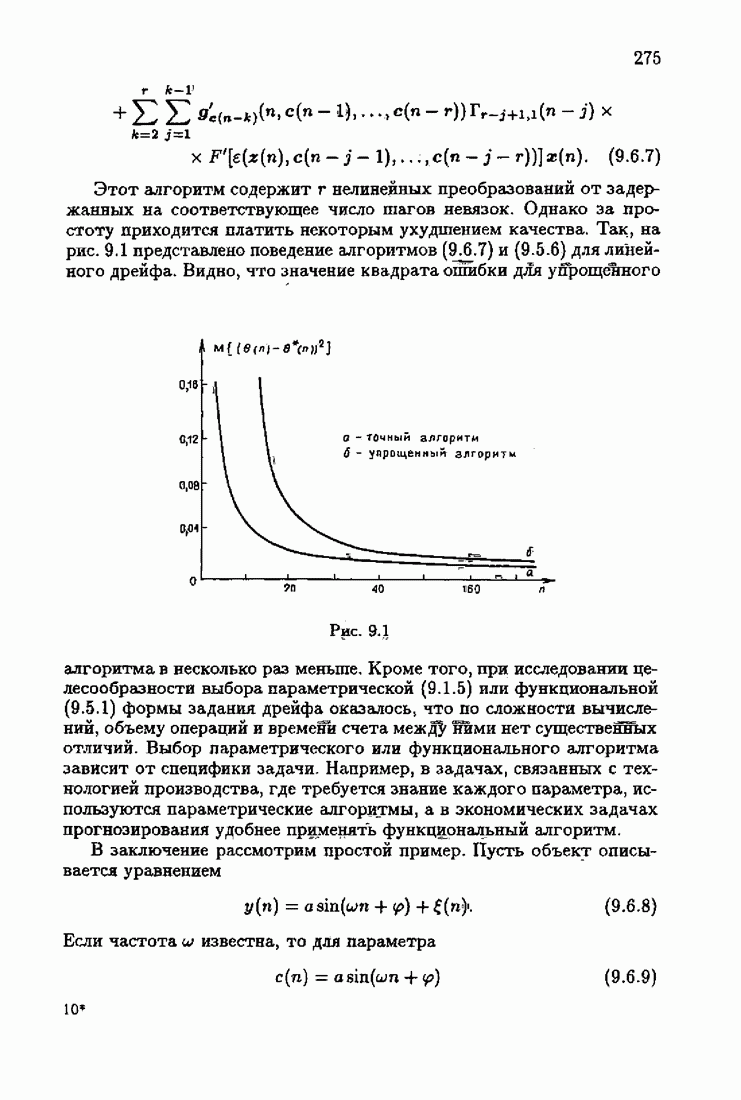
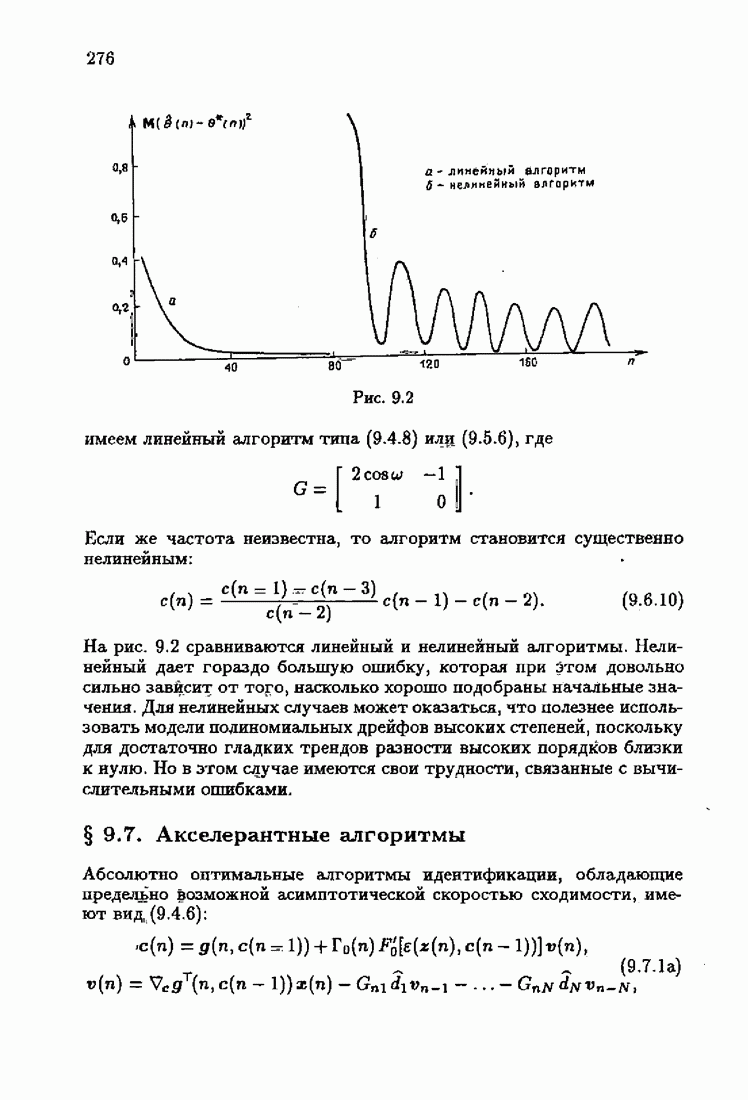
§ 1.8. Заключение
В этой главе была кратко изложена, может быть, в несколько упорядоченной форме, современная теория идентификации линейных динамических объектов, а также введено понятие оптимальности и построена оптимальная настраиваемая модель.
Для современной теории идентификации характерен большой произвол в выборе для заданного объекта настраиваемой модели, функции потерь, определяющей критерий качества идентификации, и особенно алгоритмов идентификации. Чаще всего при решении конкретных задач идентификации использовались статические настраиваемые модели и квадратичные функции потерь. Это существенно упрощало решение задачи идентификации. Обоснованием выбора квадратичной функции потерь часто служила инвариантность оптимального решения относительно симметричных функций потерь. Однако такой произвол в выборе модели, критерия и алгоритмов далеко не всегда приводил к хорошим или даже сколь-нибудь приемлемым результатам. Так, алгоритмы типа стохастической аппроксимации со скалярными матрицами усиления слишком медленно сходятся.
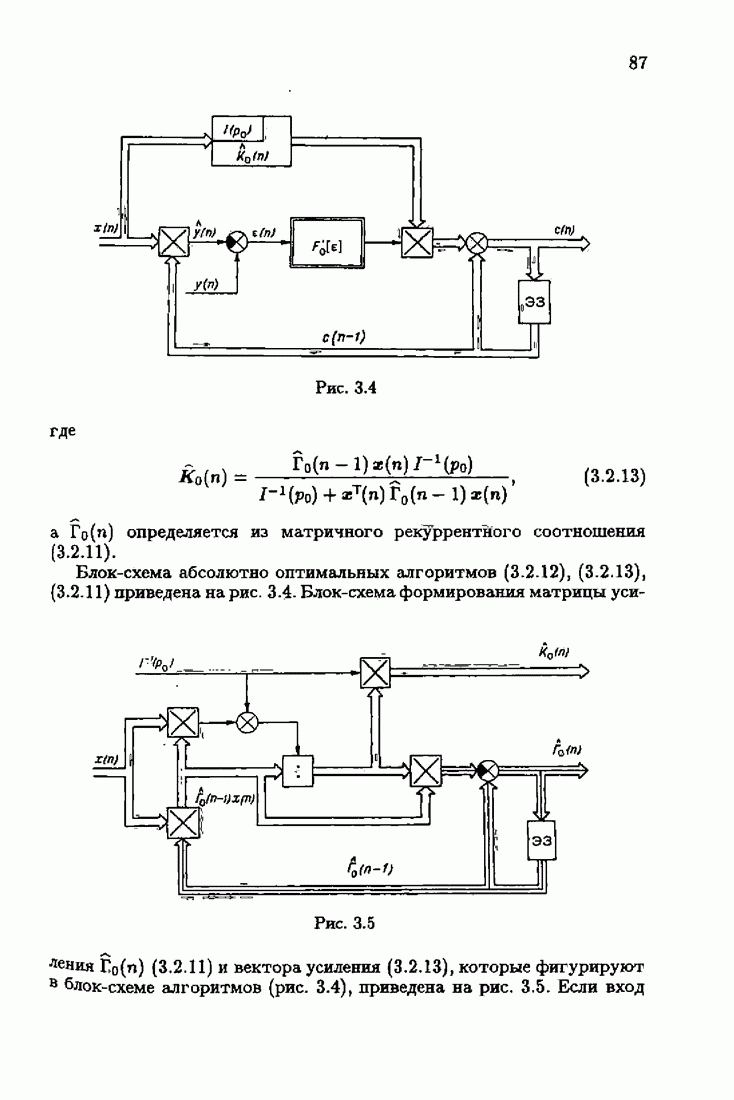
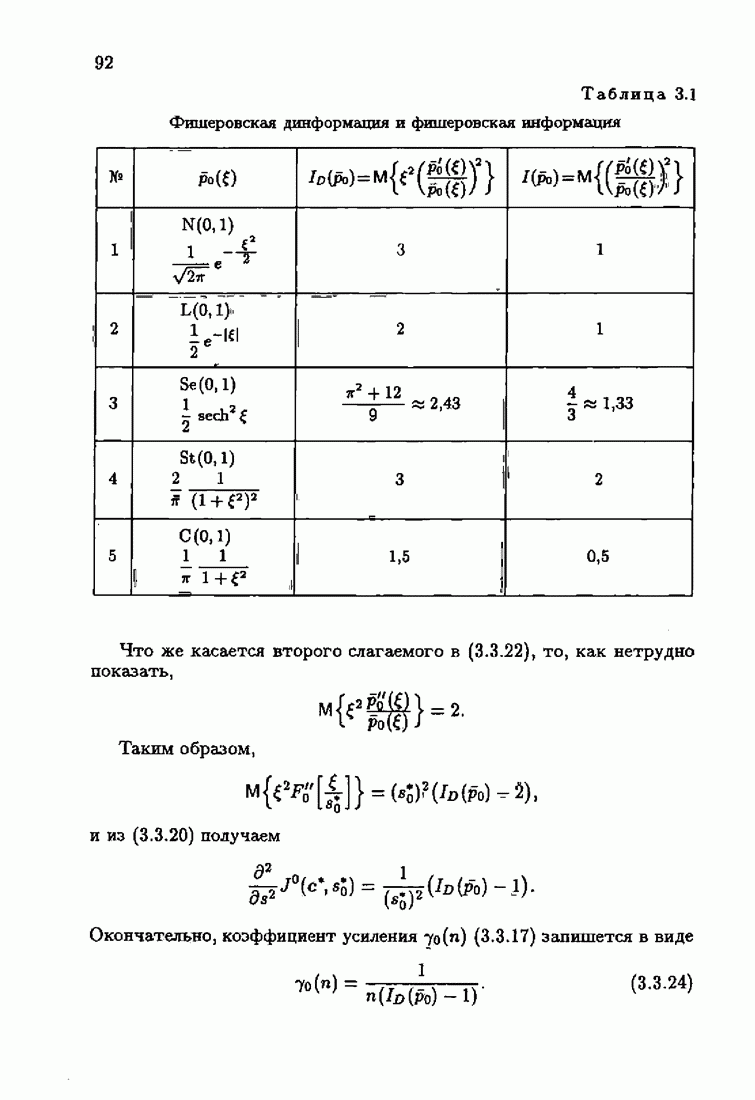
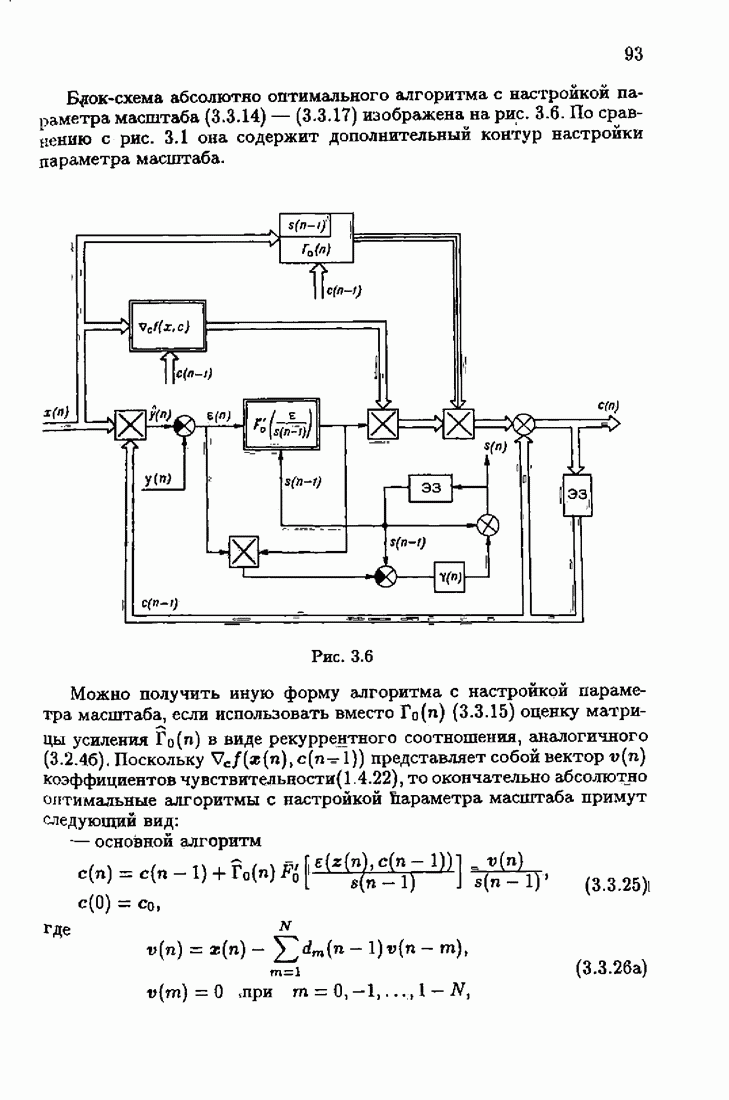
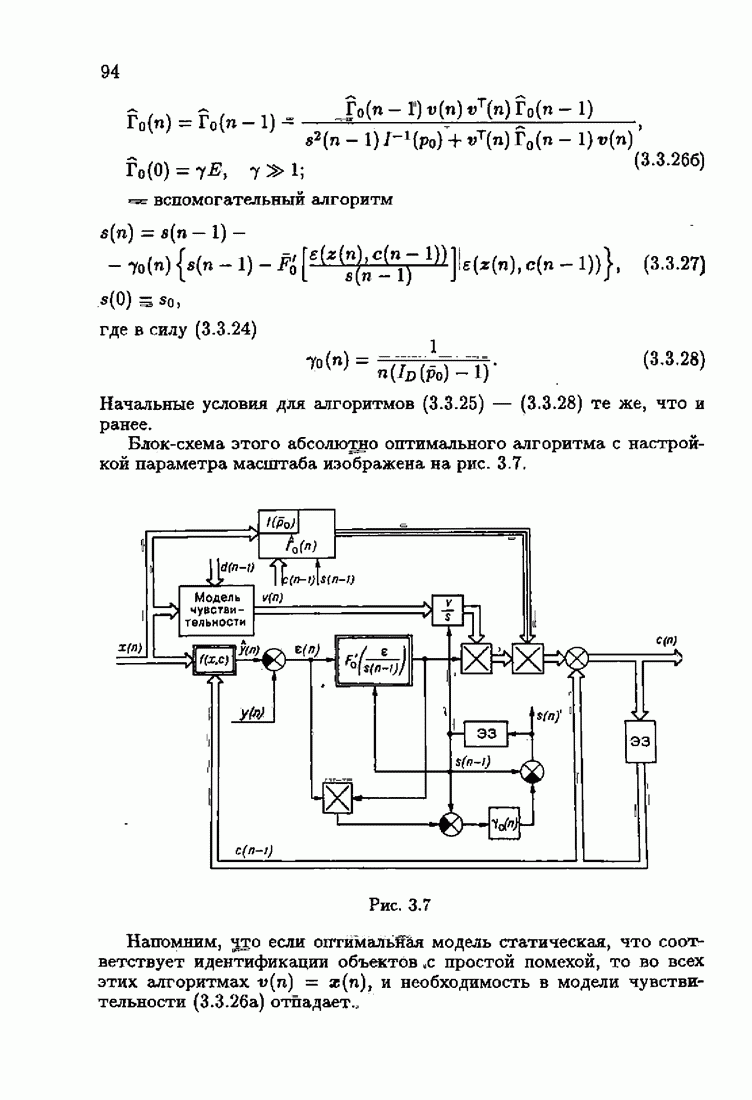
Уменьшение произвола за счет использования оптимальной настраиваемой модели и учета априорной информации о помехе в матрице усиления позволило получить оптимальные алгоритмы, обладающие максимальной в этих условиях скоростью сходимости. Возникает вопрос: предельна ли эта максимальная скорость сходимости или ее еще можно увеличить? Ответу на этот вопрос посвящены главы 2 и 3.
Как показывает опыт, в ряде случаев оптимальные алгоритмы не оправдывают возлагавшихся на них надежд: на практике они не только не оказываются быстро сходящимися, но и могут расходиться. Возникает задача объяснения такого поведения рекуррентных алгоритмов идентификации, разработки путей устранения этих недостатков и дальнейшего совершенствования алгоритмов идентификации. Решение этой задачи возможно лишь на основе учета имеющейся в нашем распоряжении априорной информации об объекте, помехе и оптимальном решении, какого бы уровня она ни была. Этому посвящены последующие главы 4-6.