Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
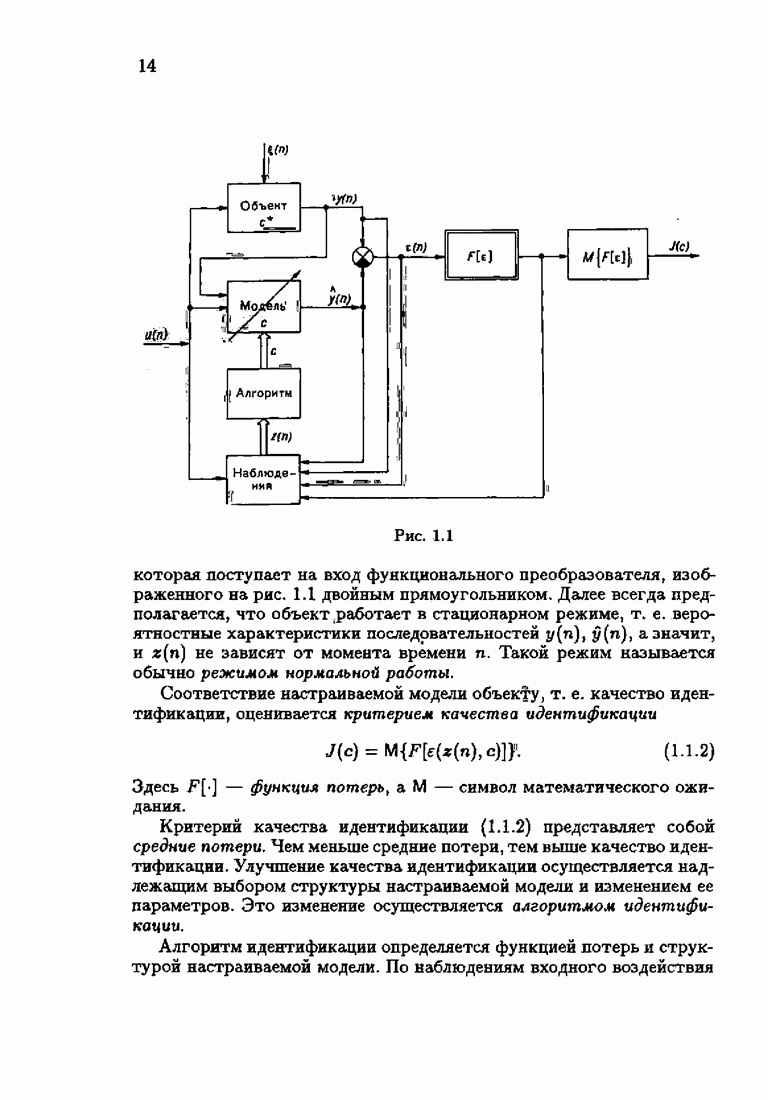
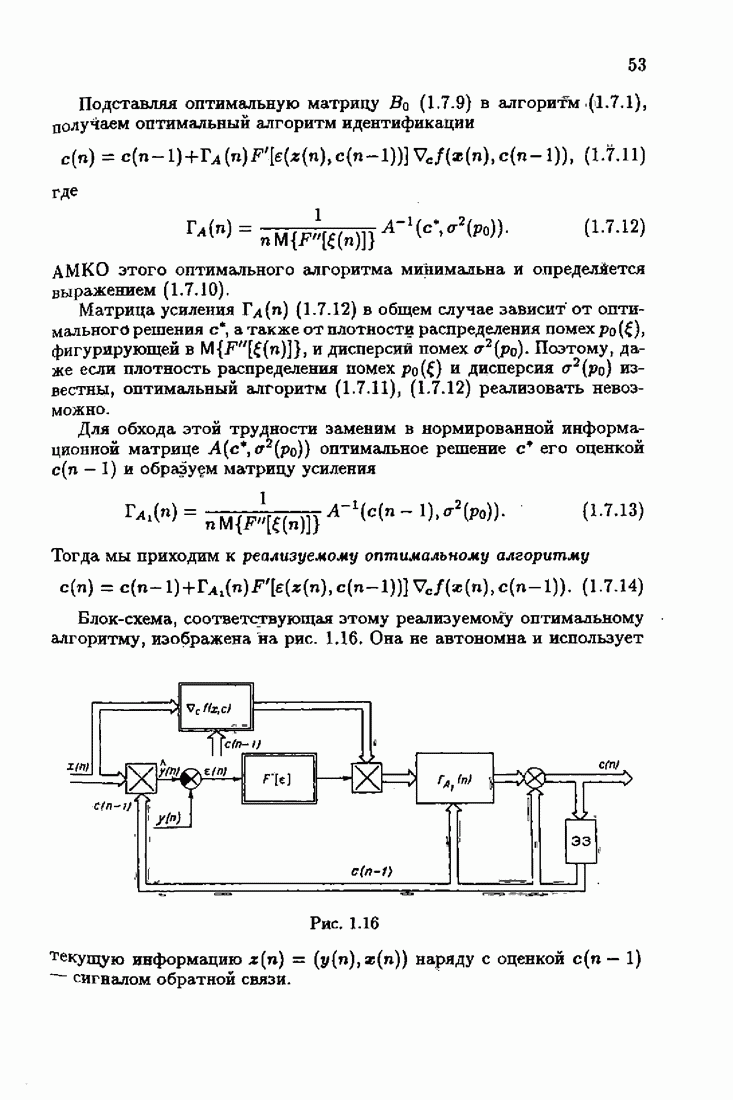
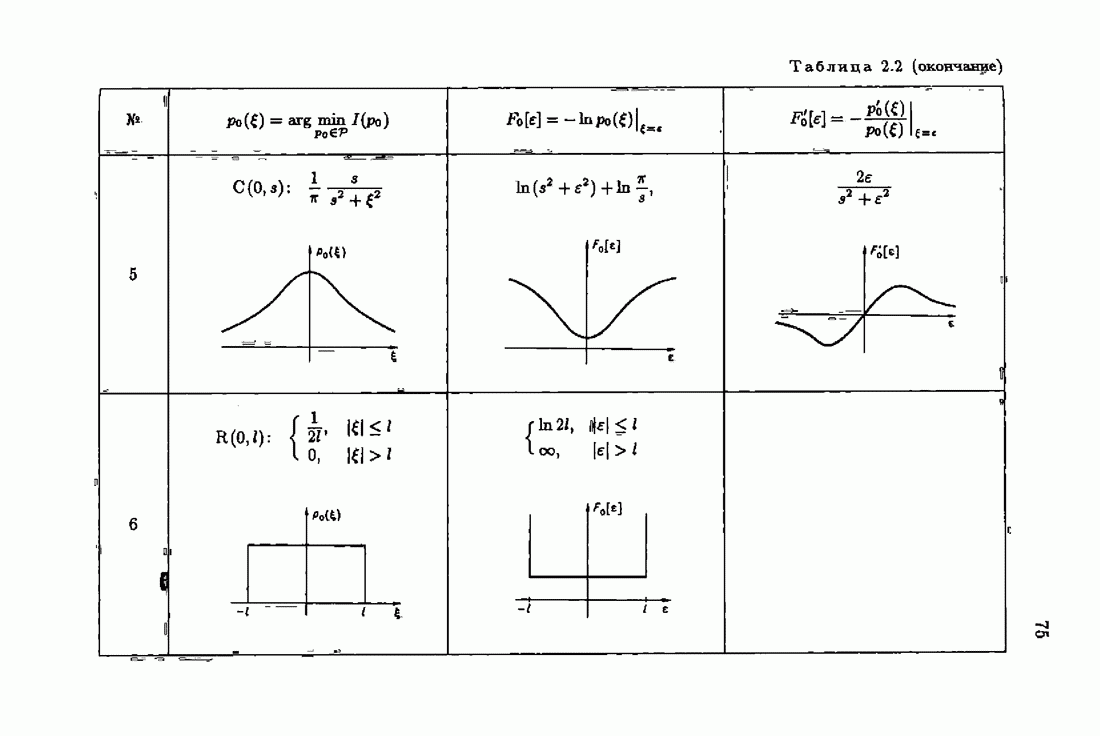
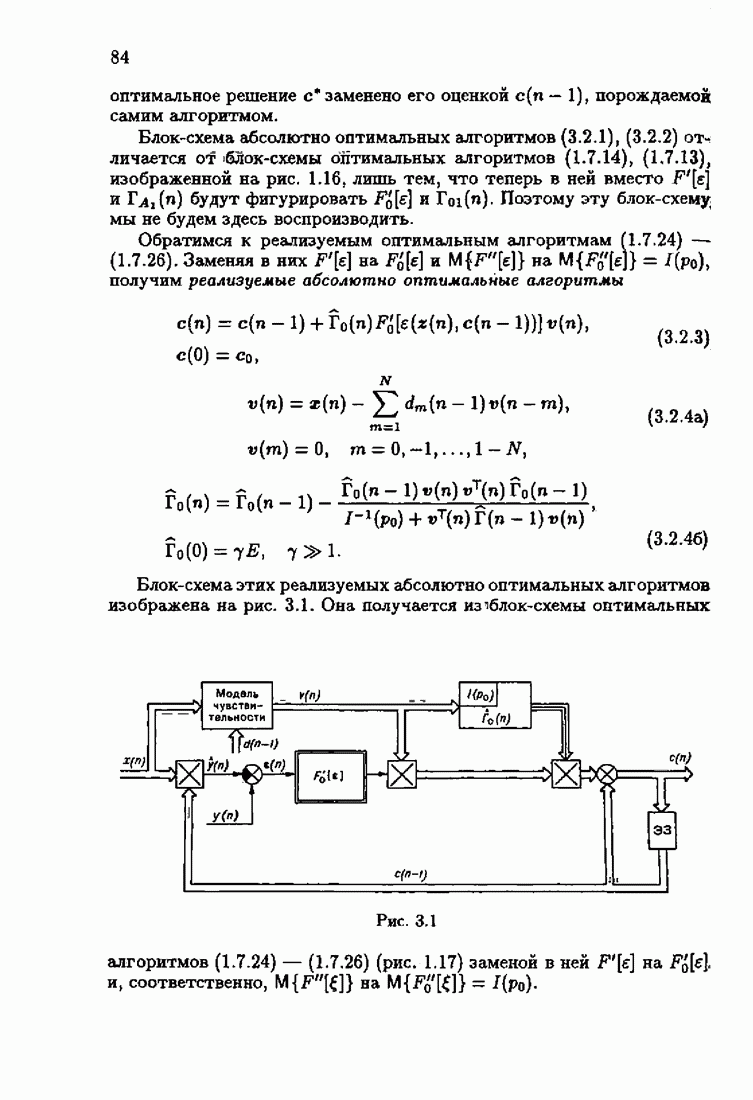
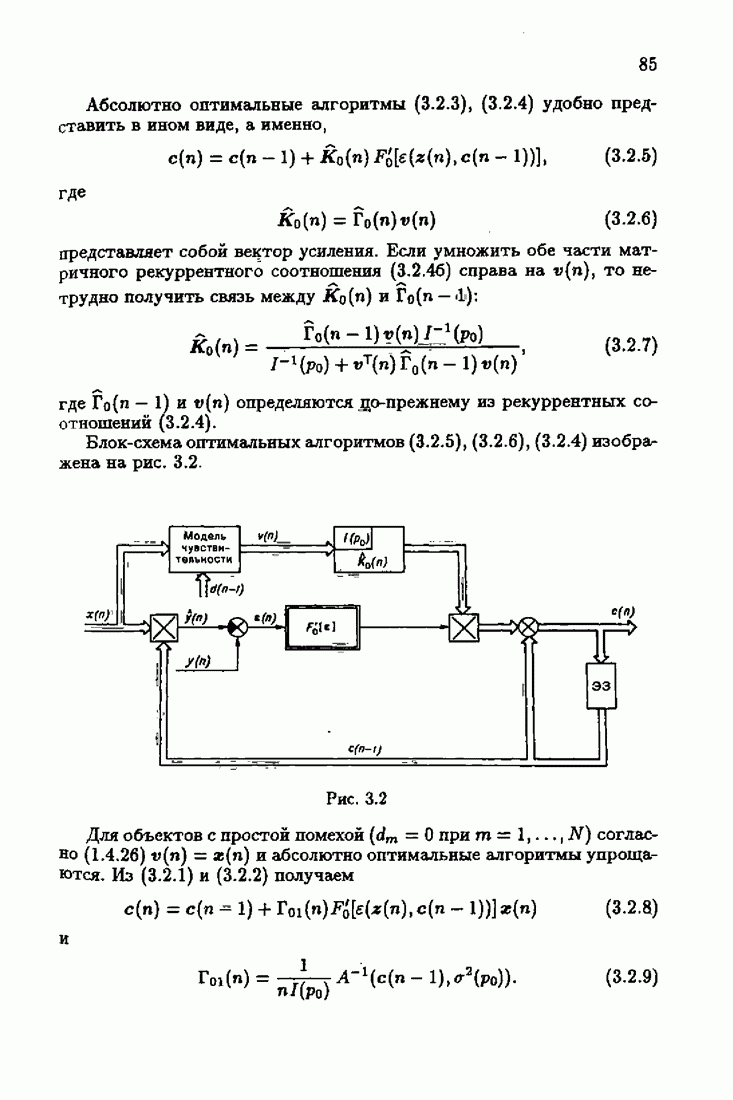
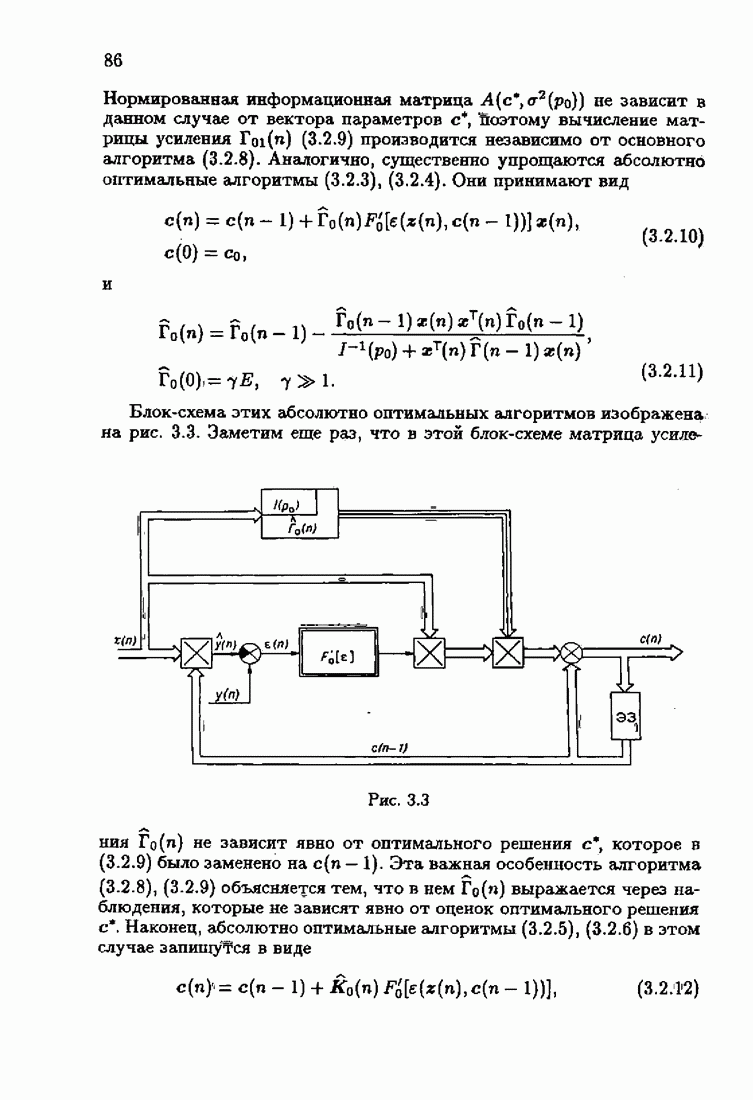
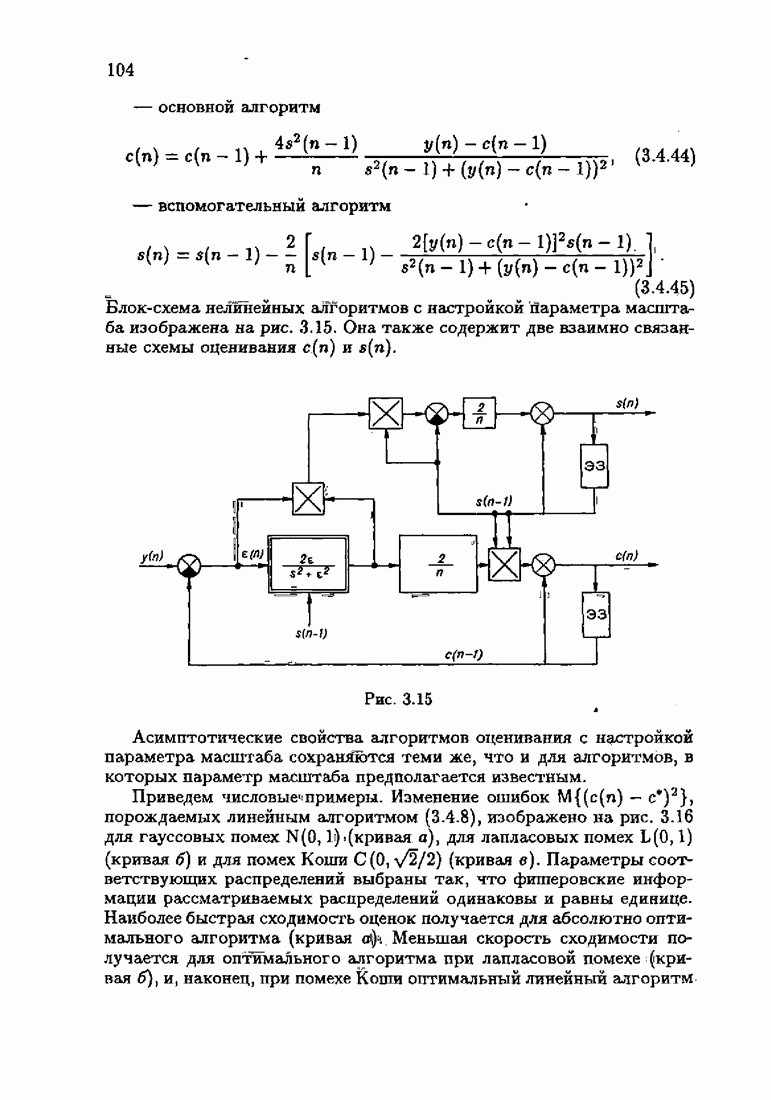
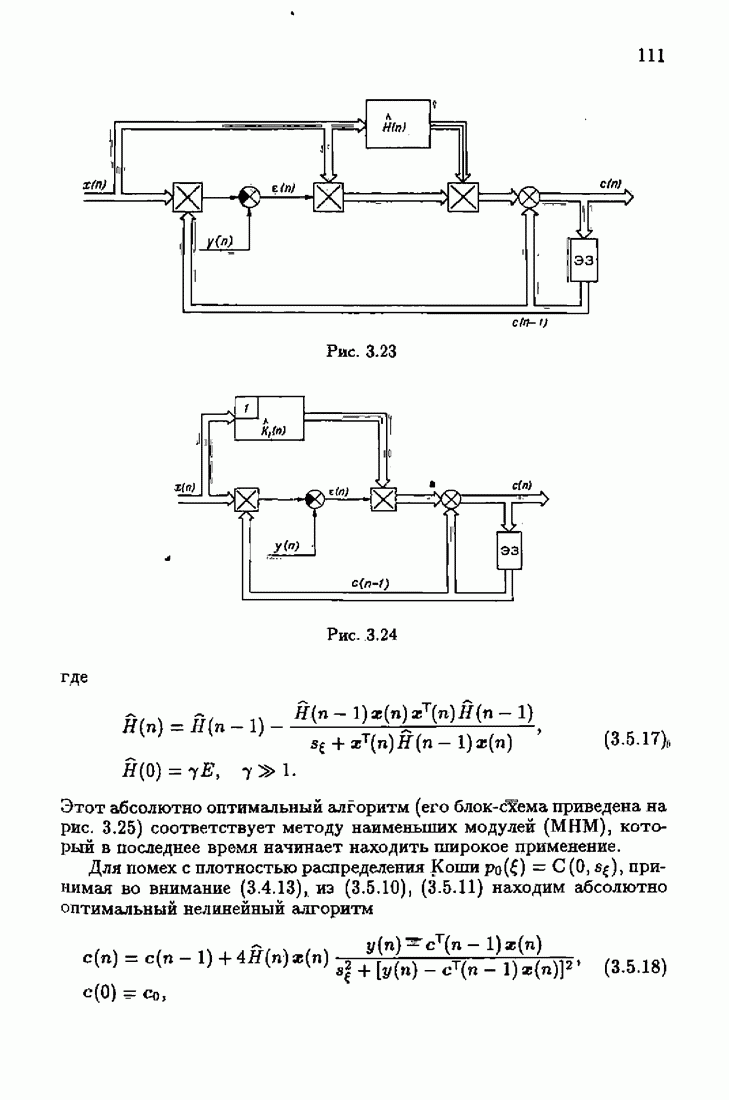
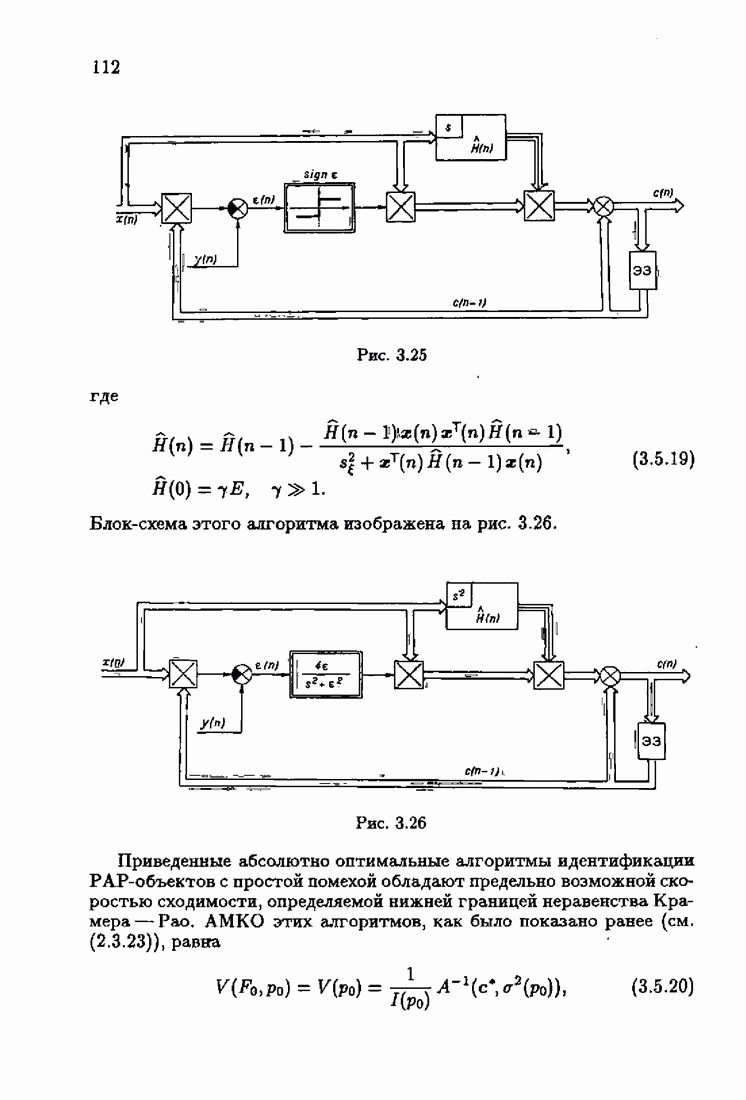
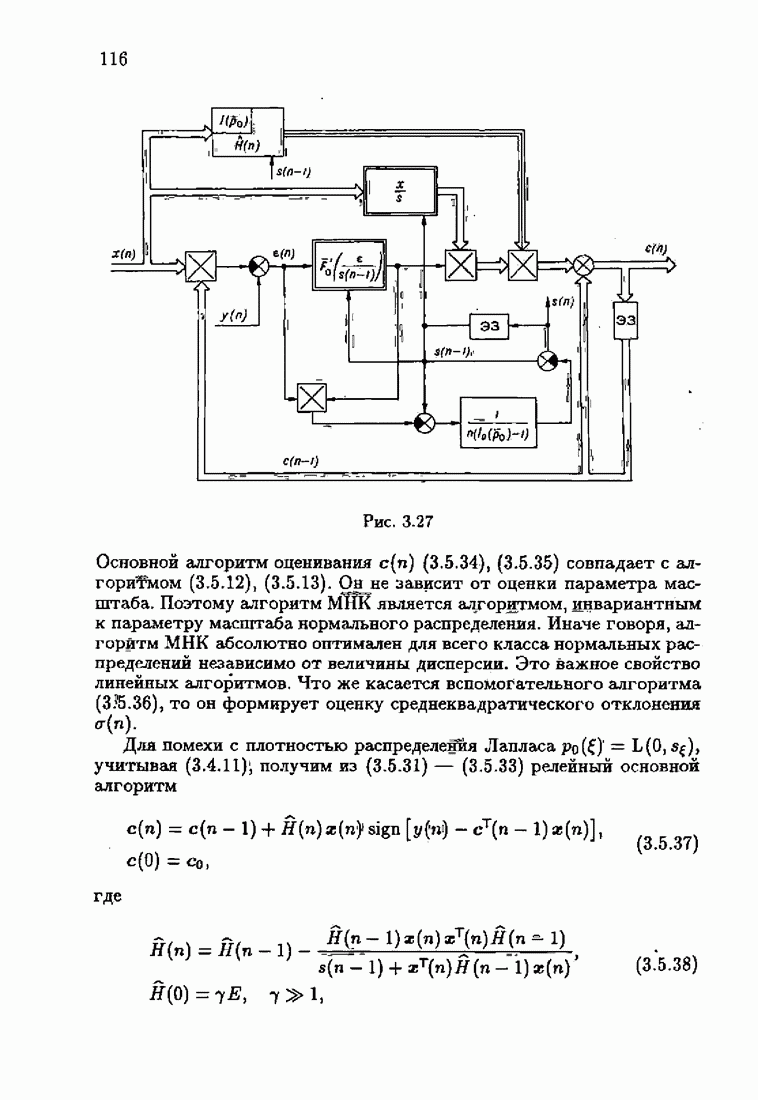
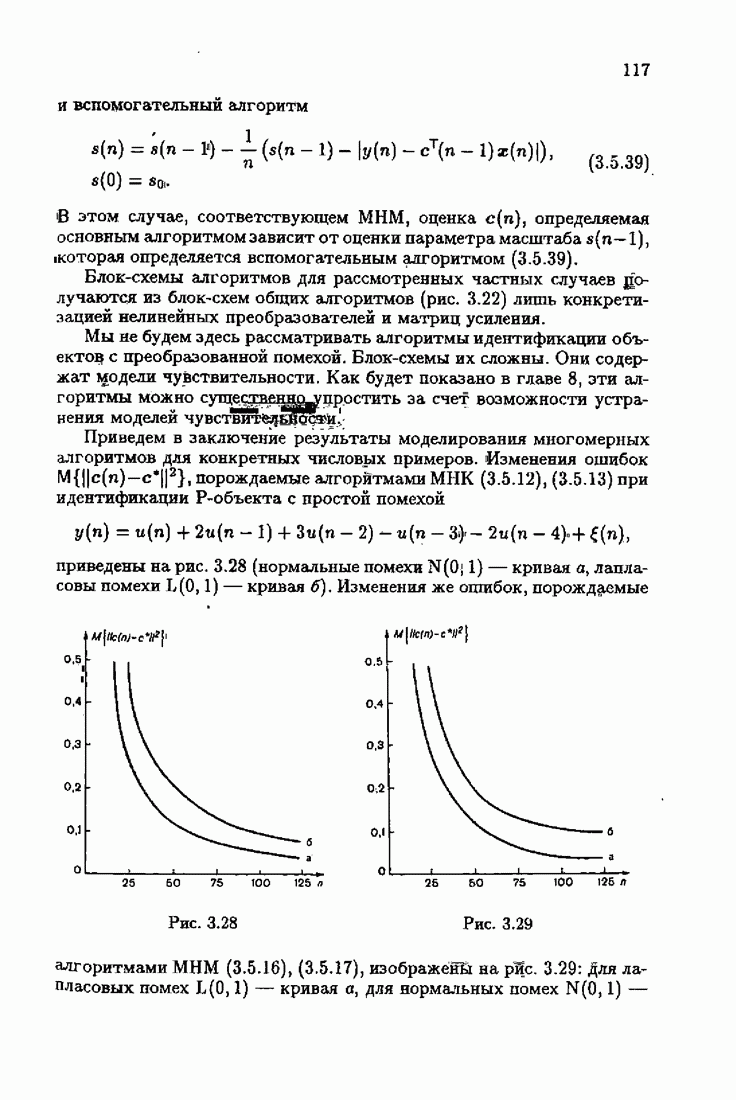
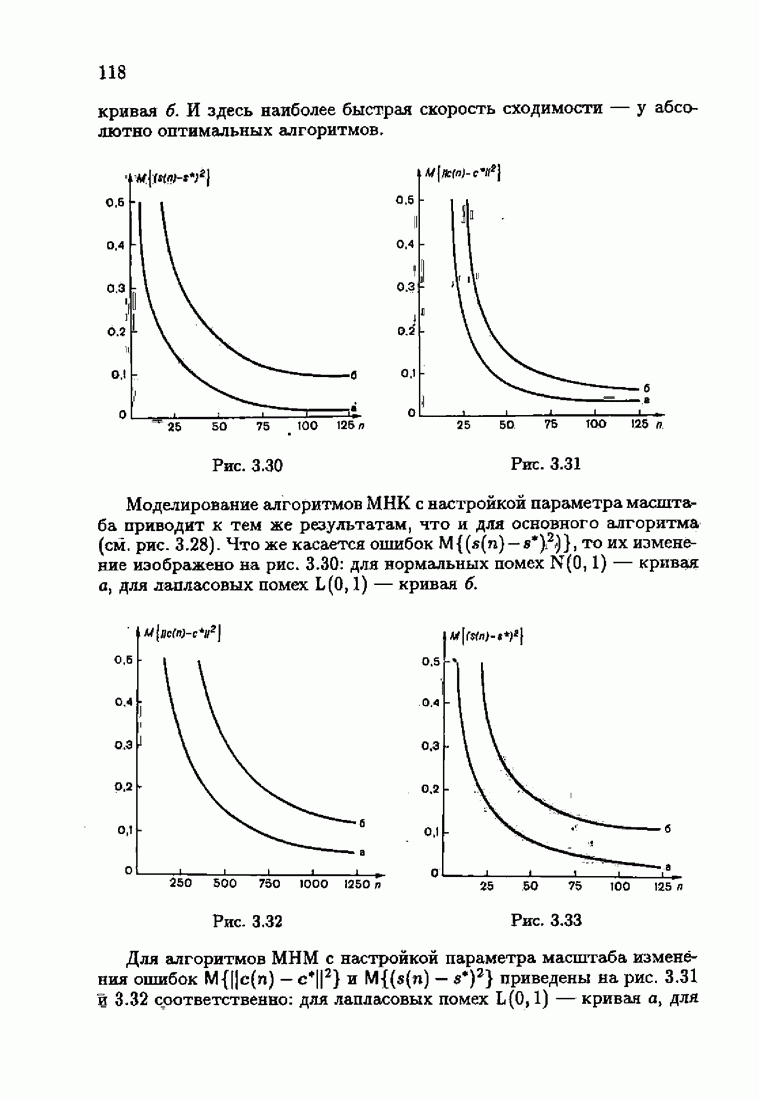
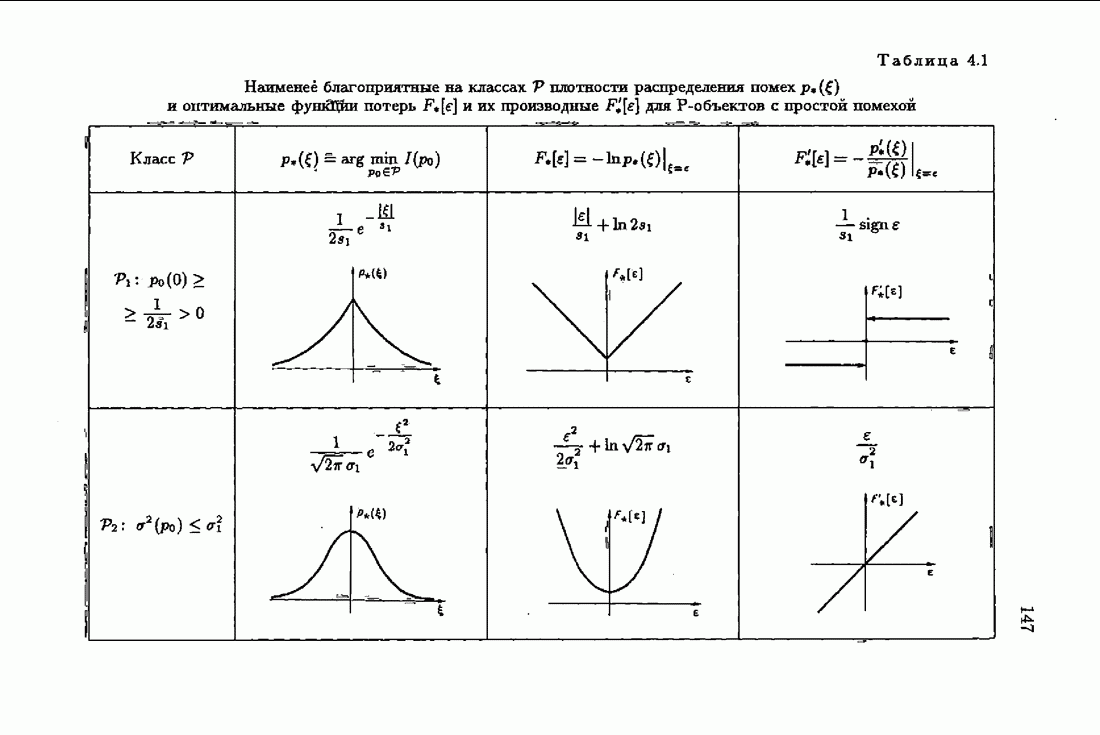
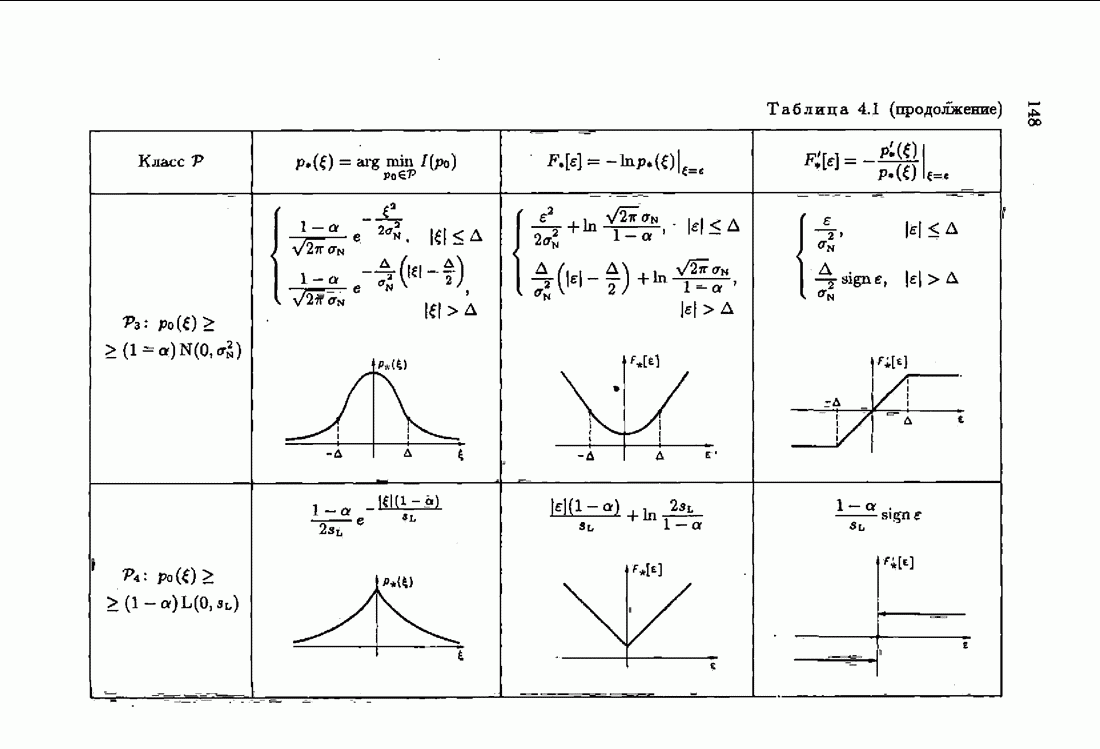
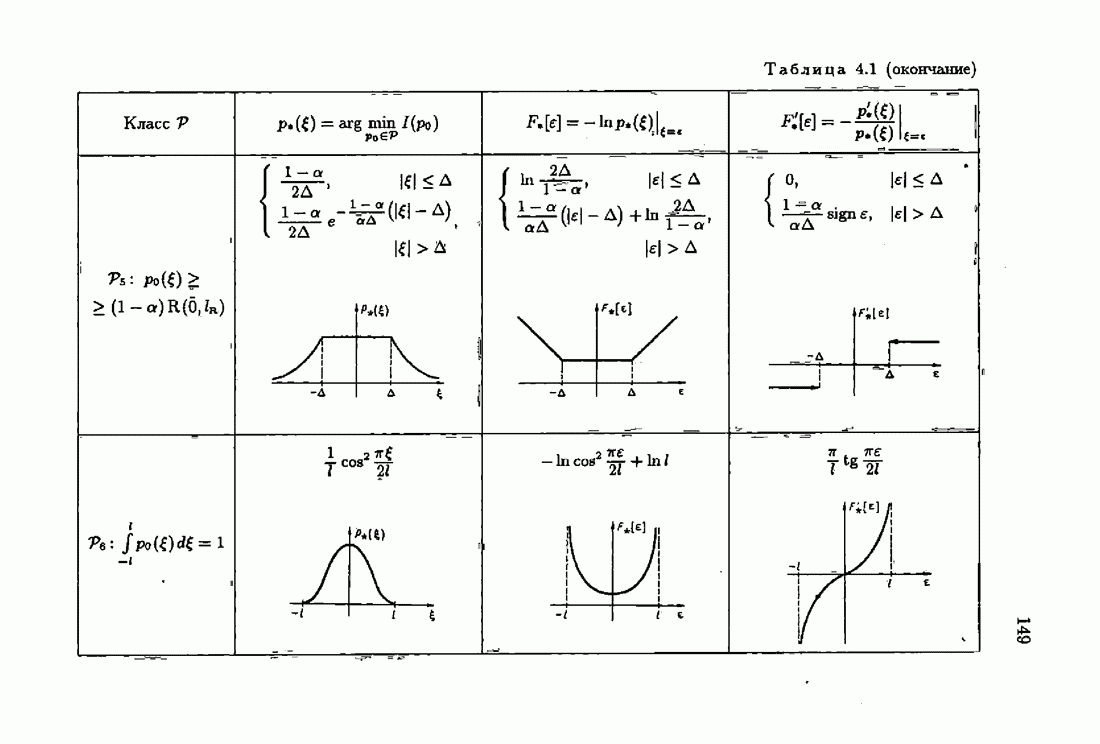
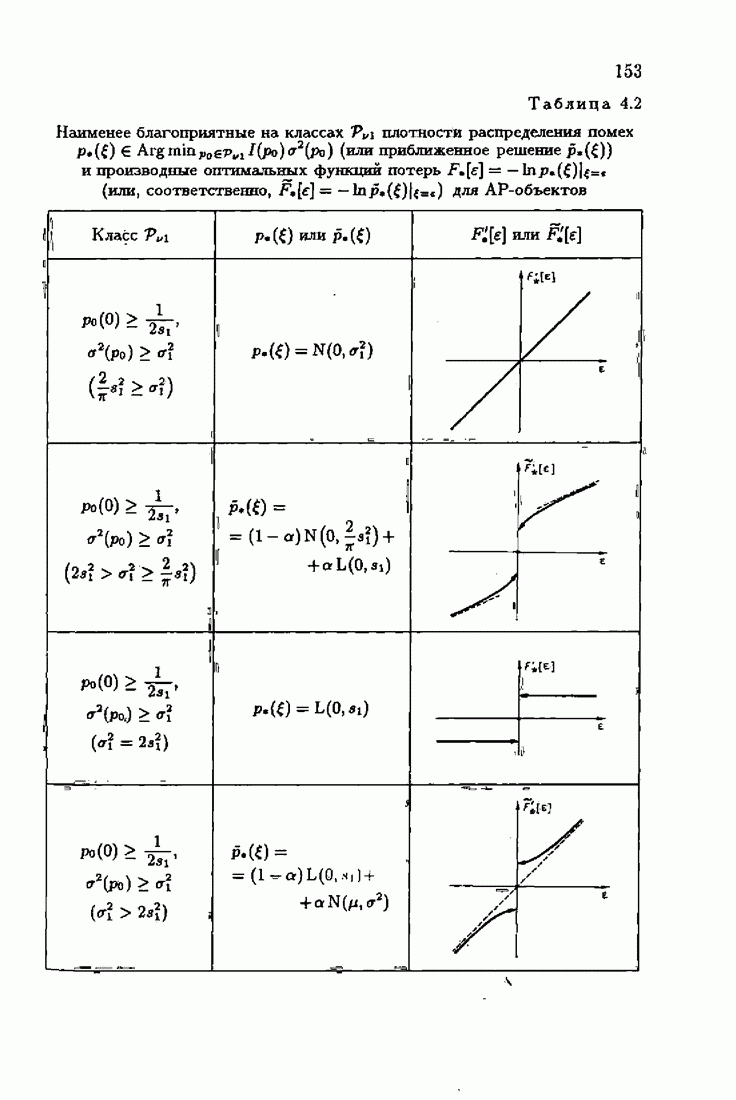
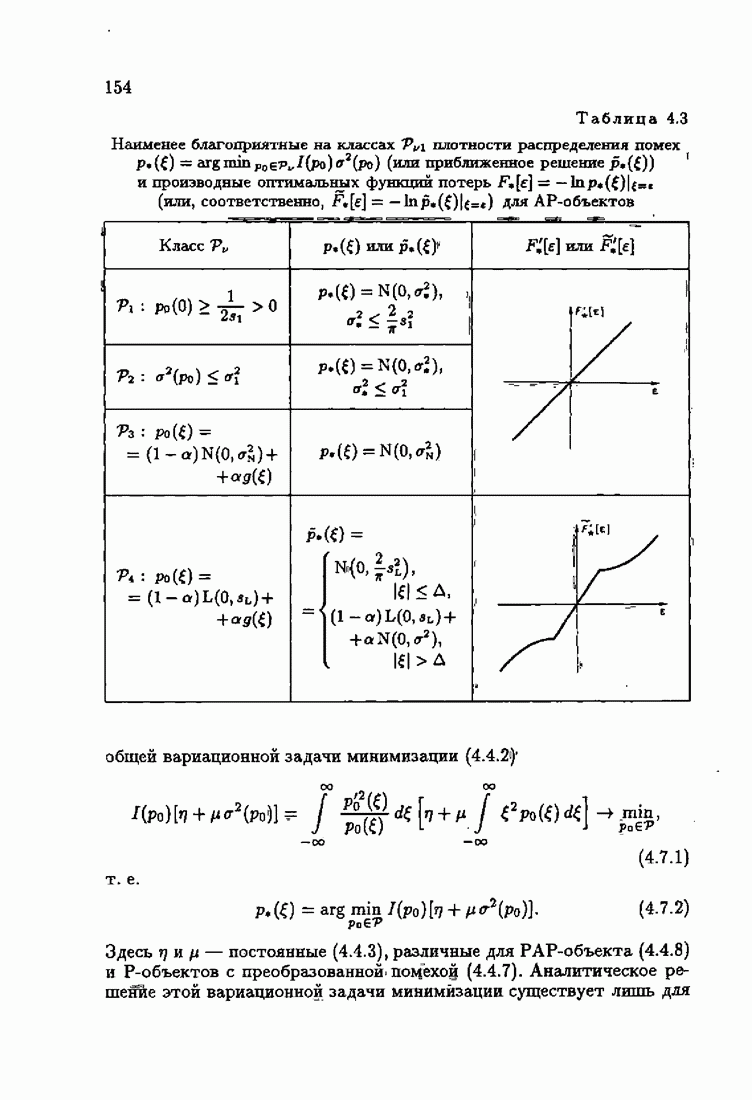
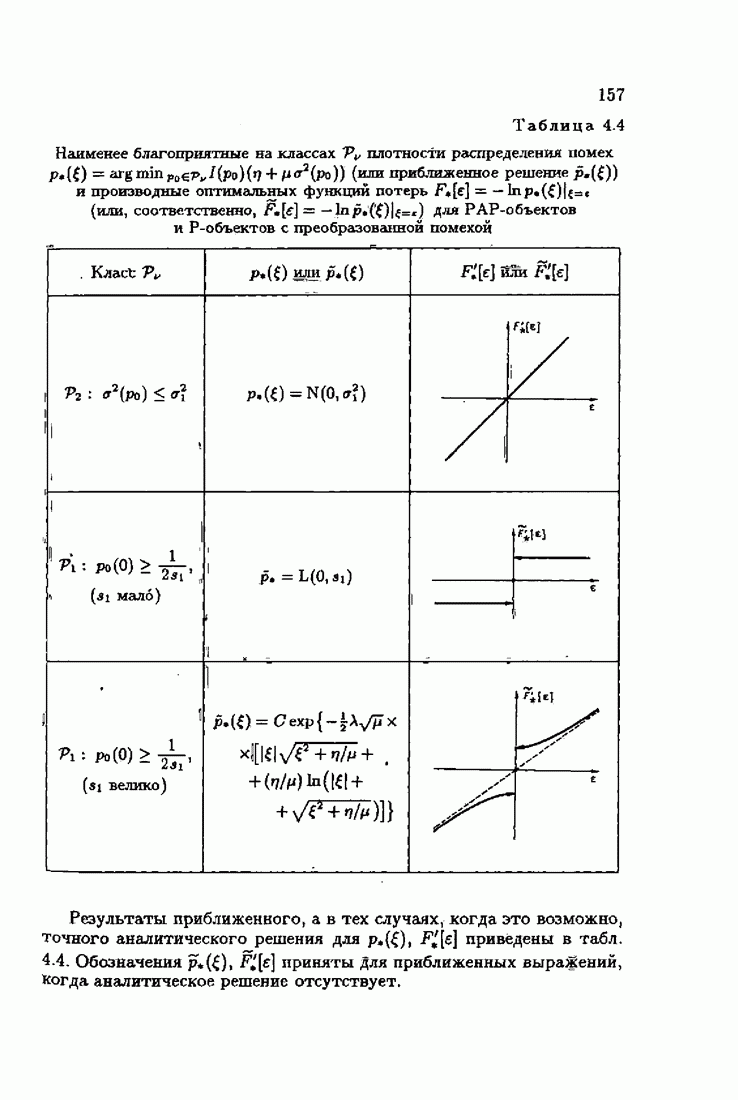
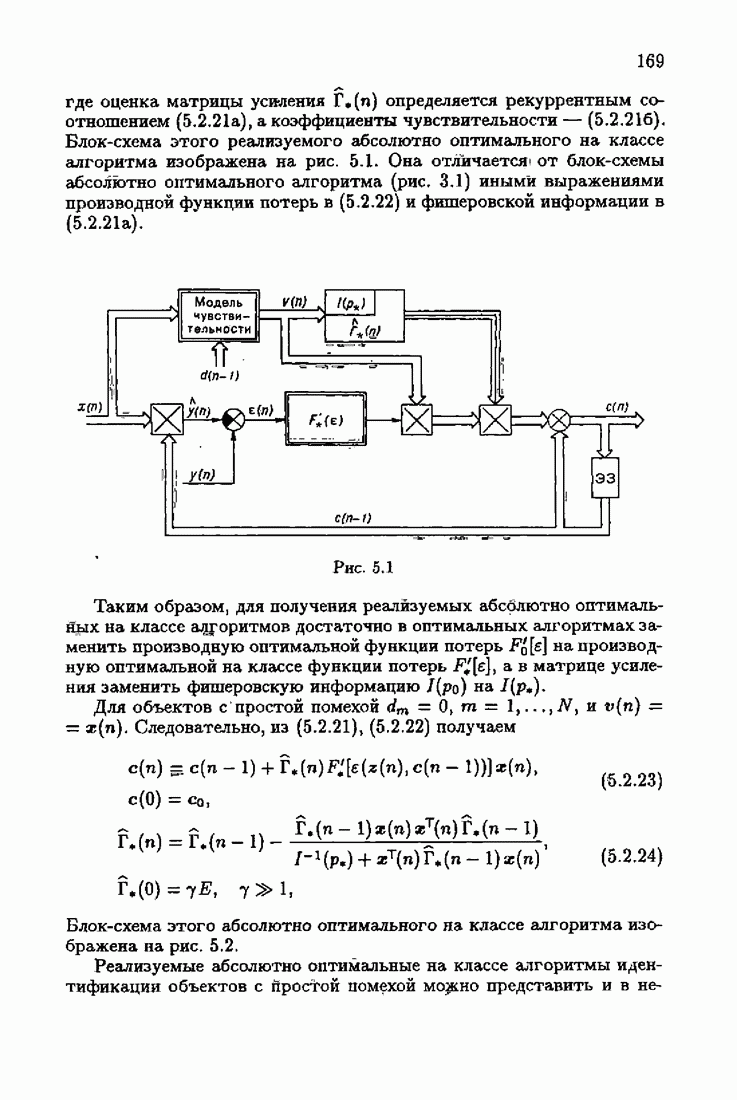
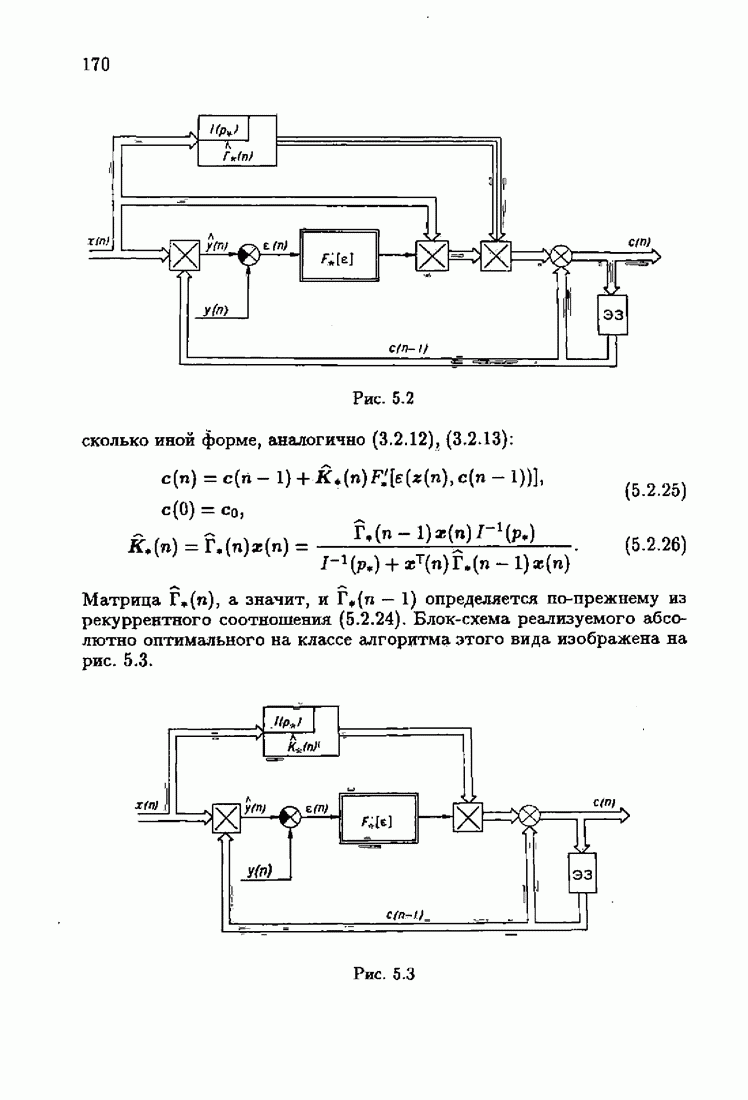
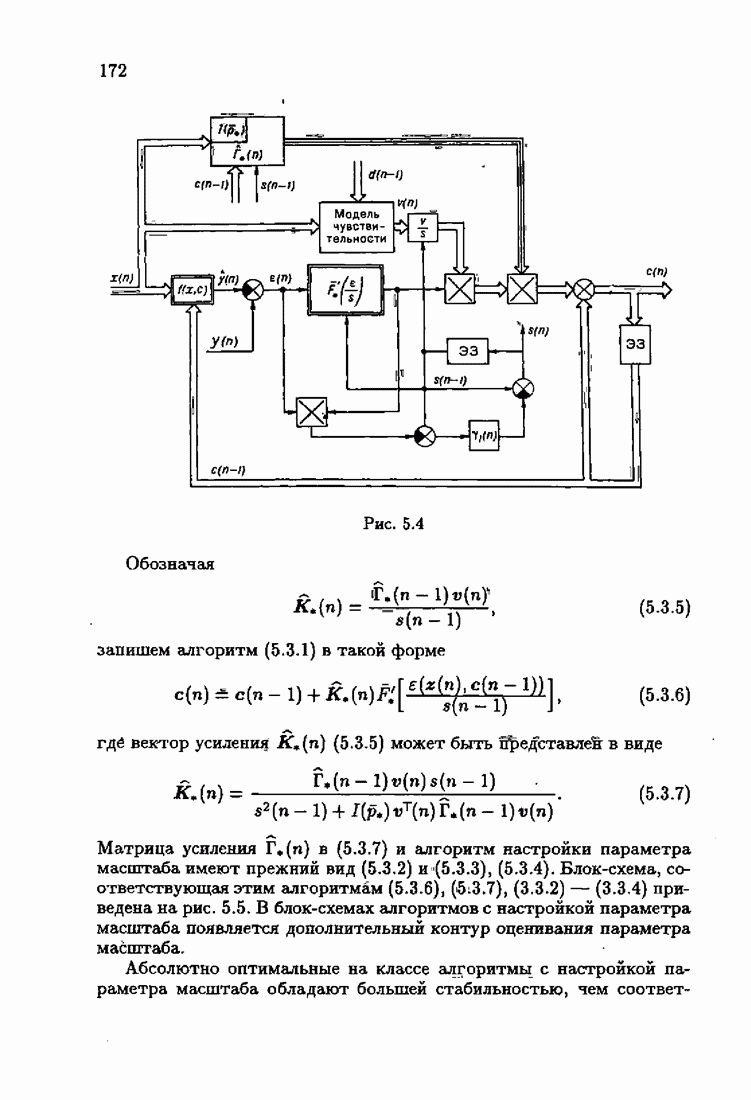
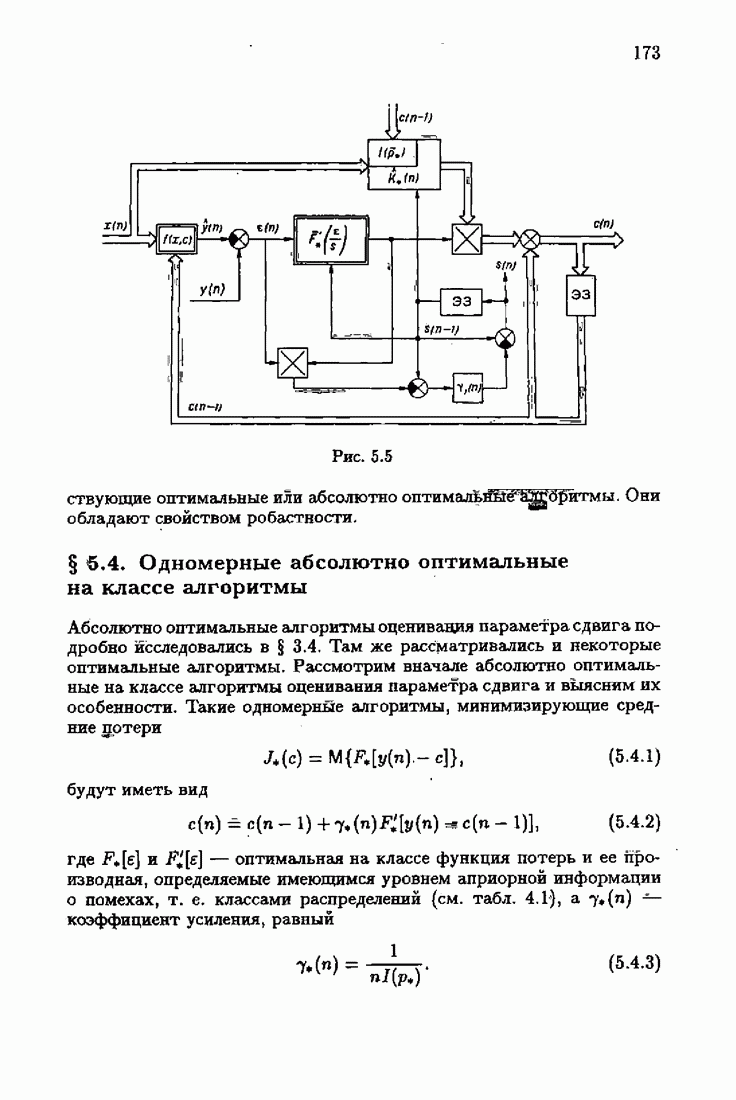
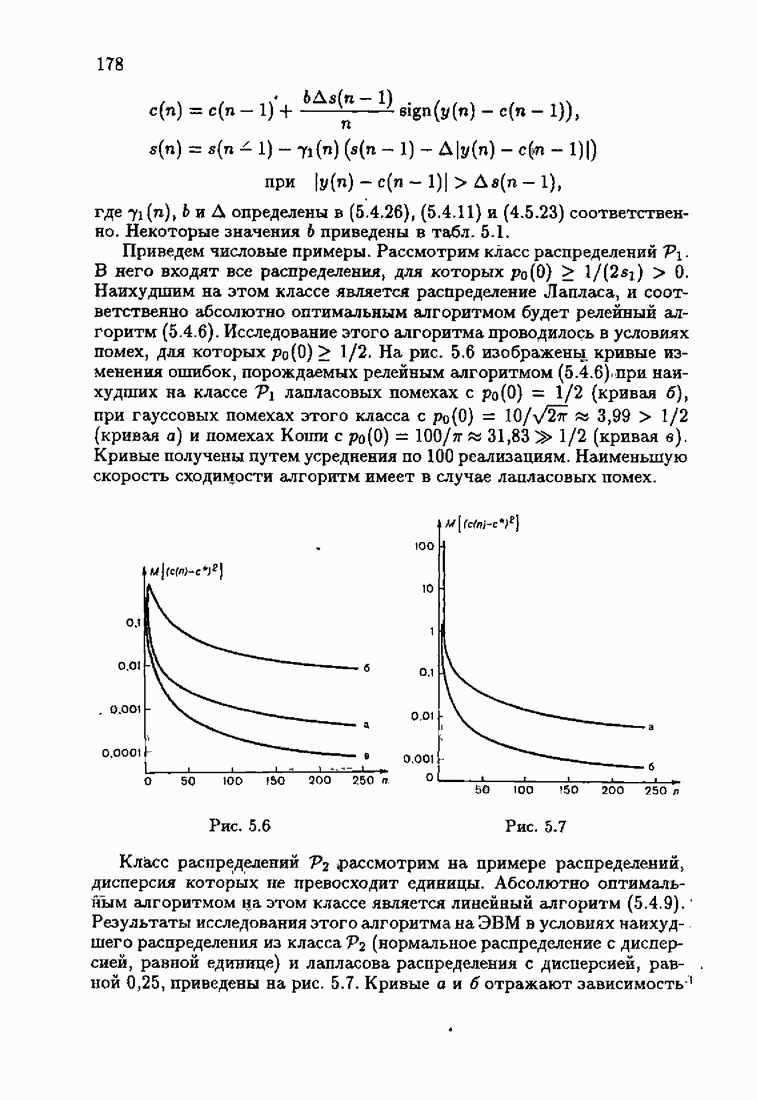
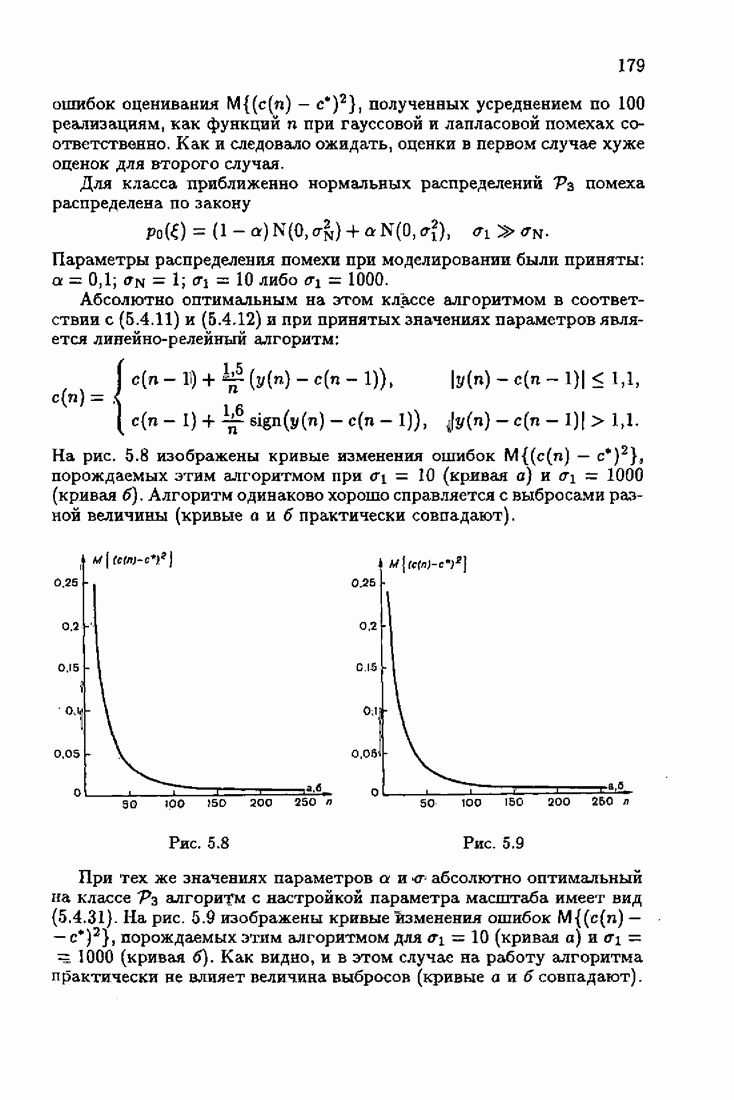
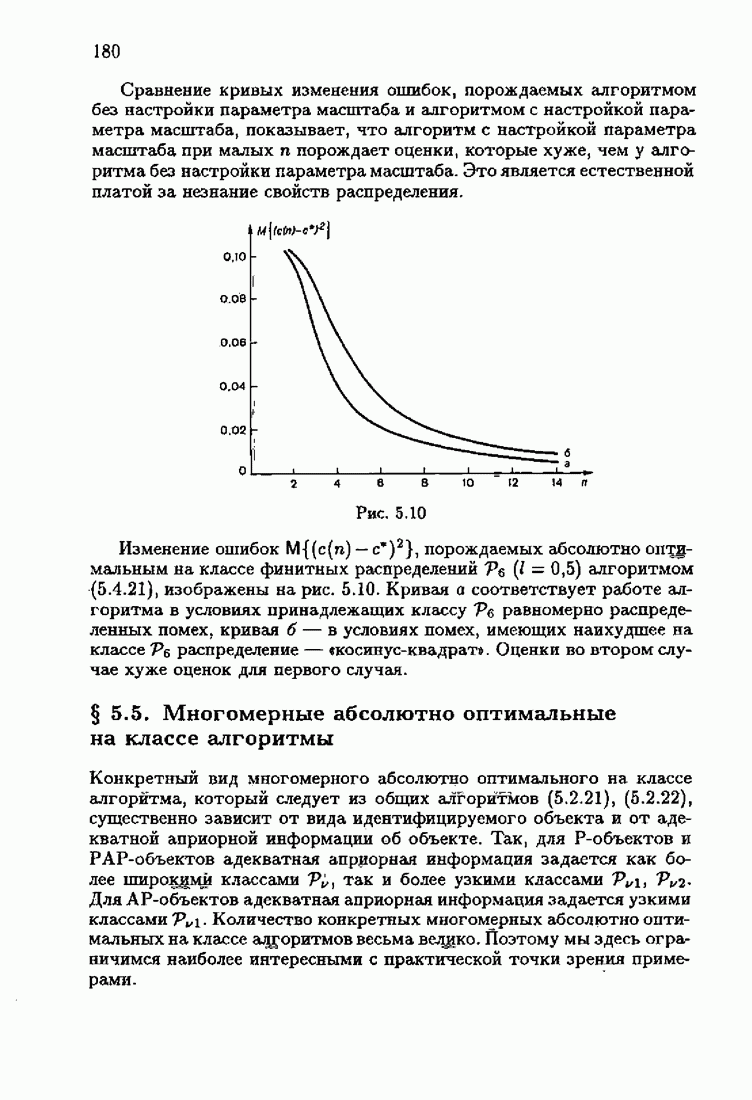
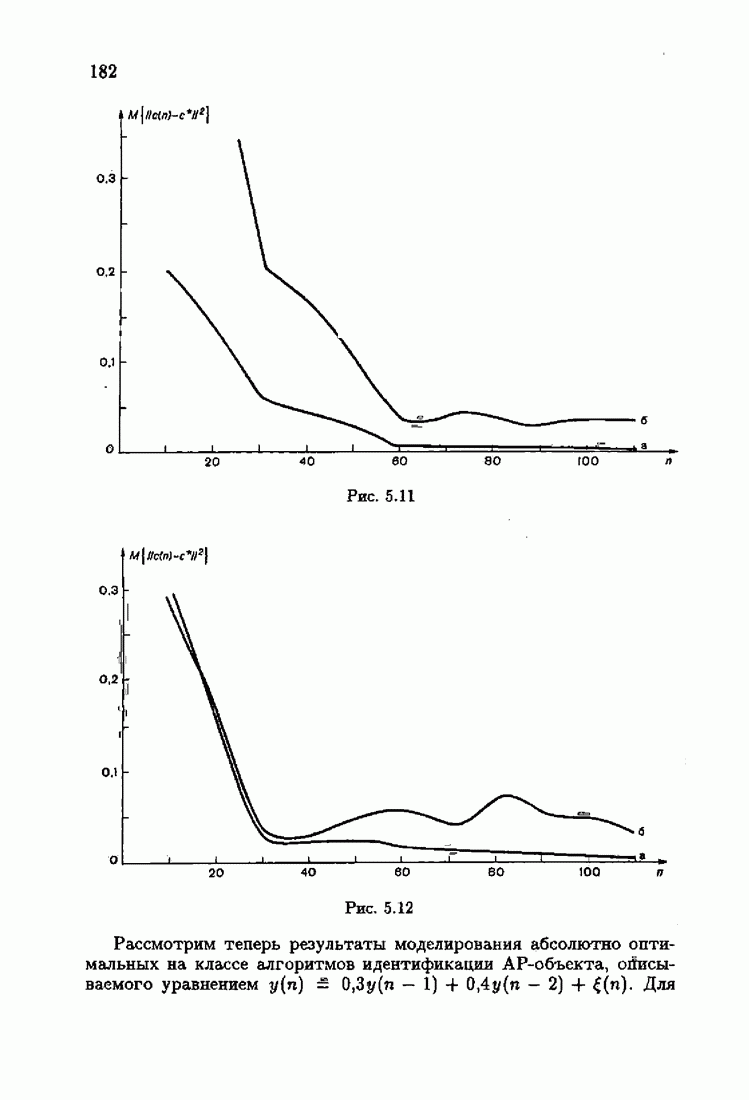
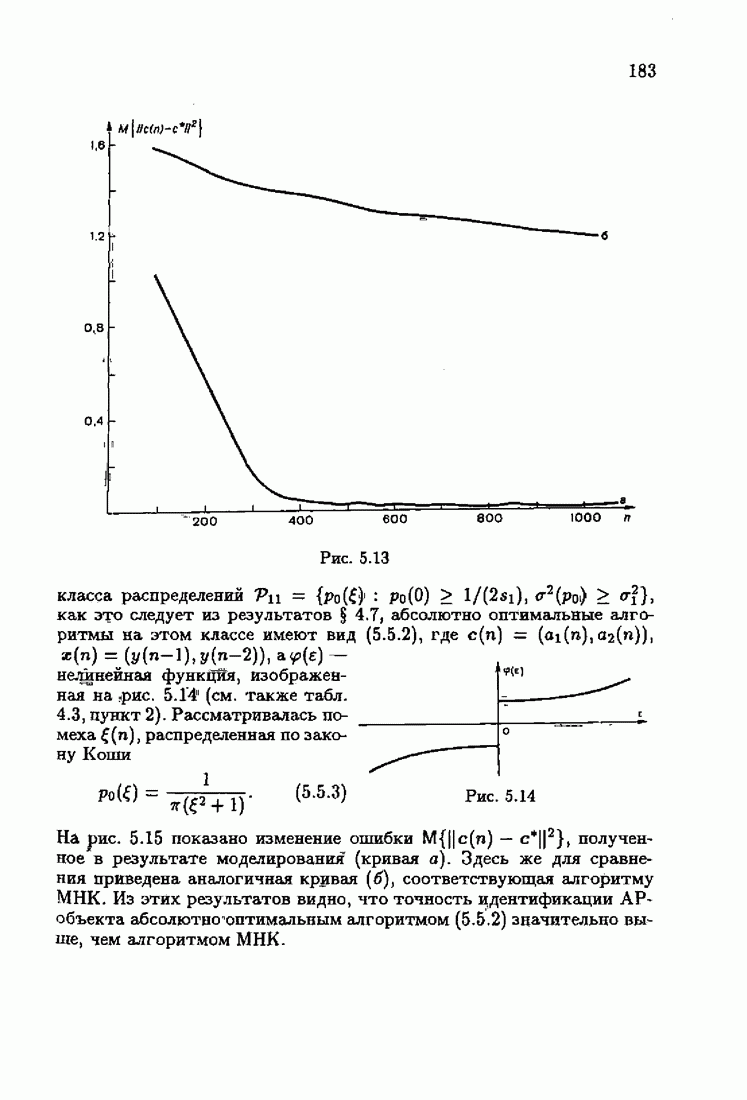
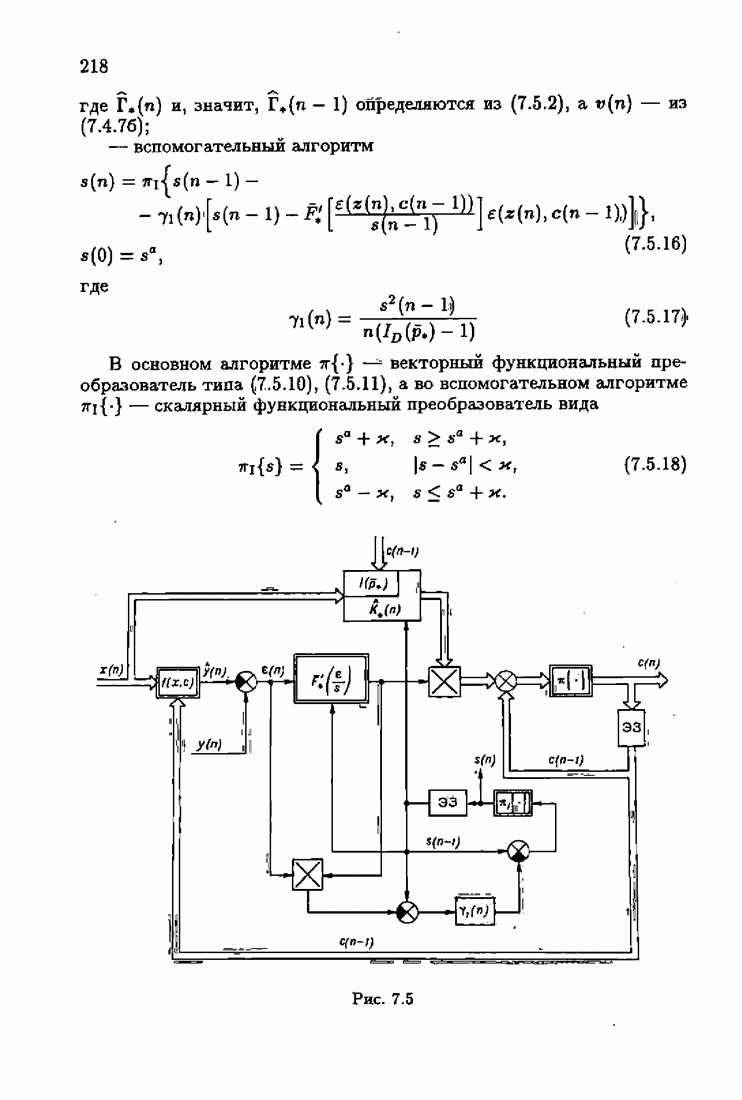
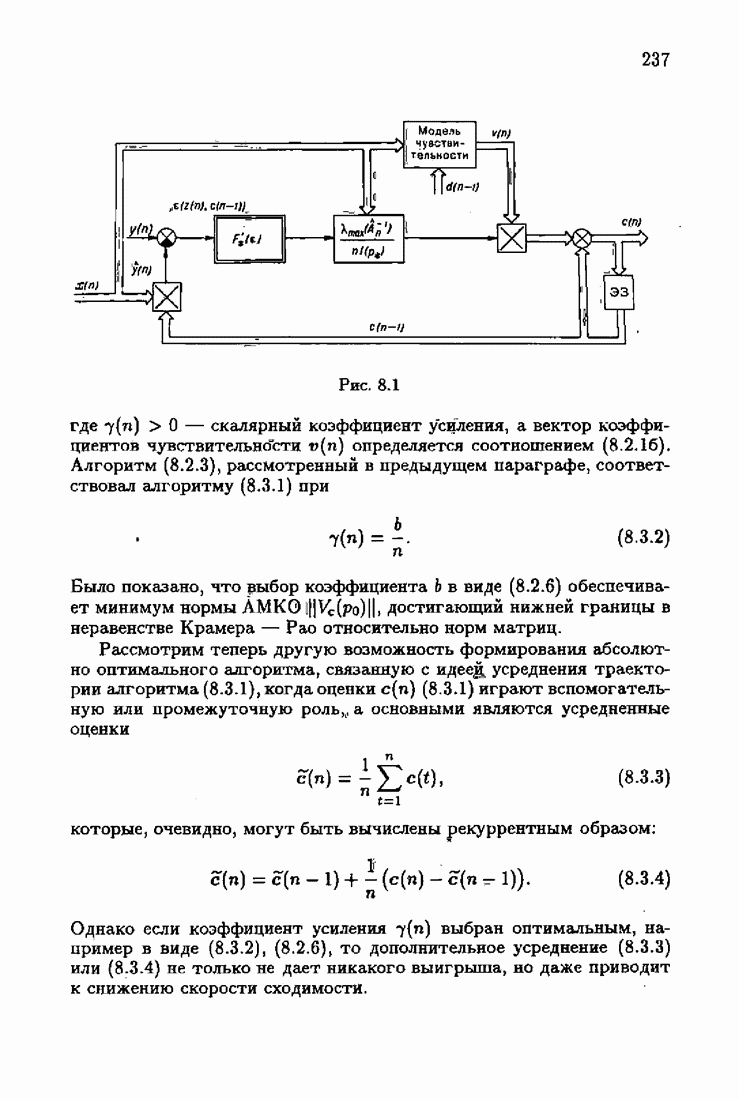
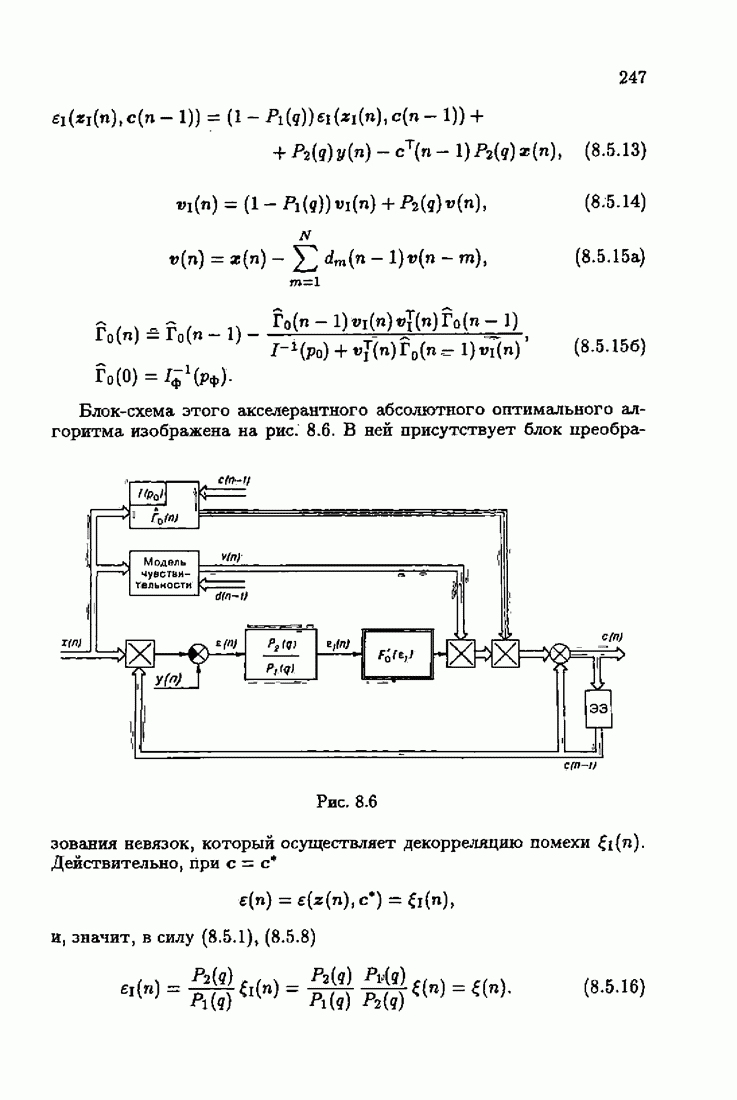
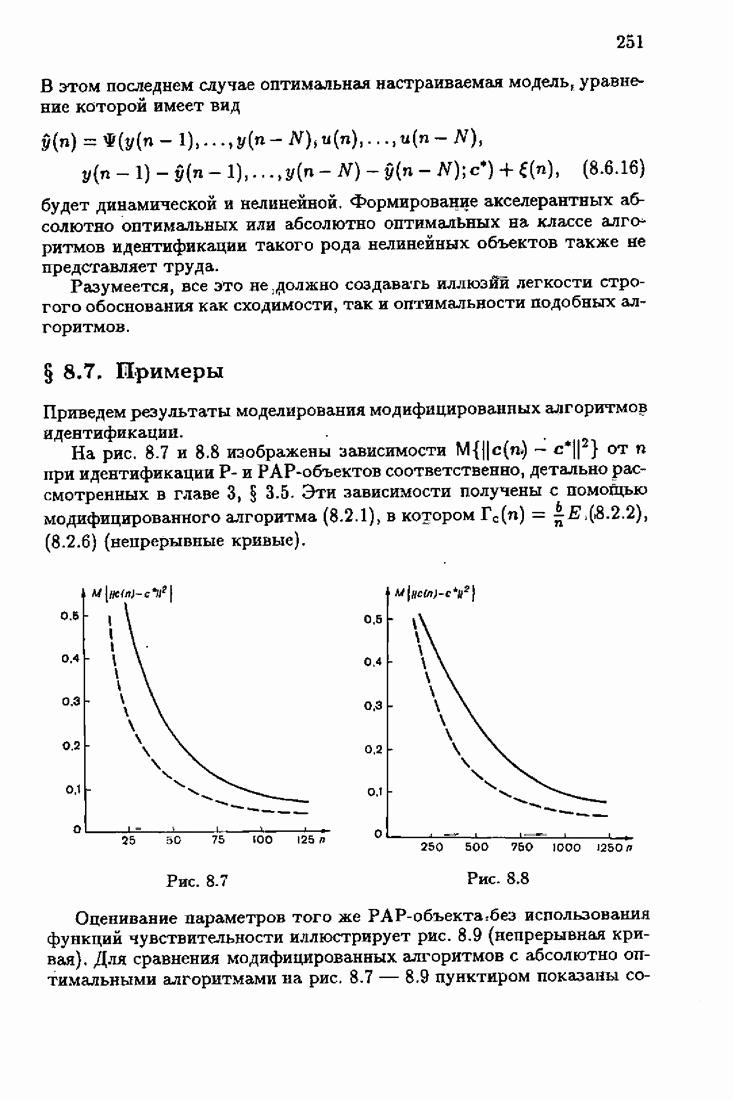
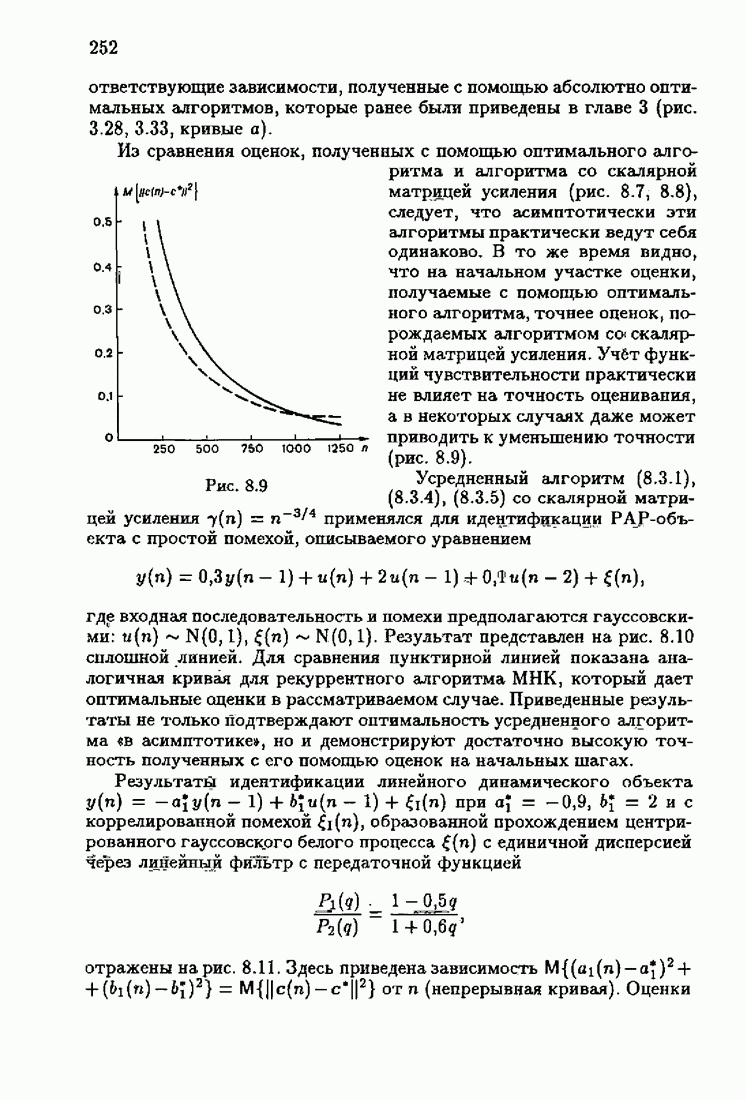
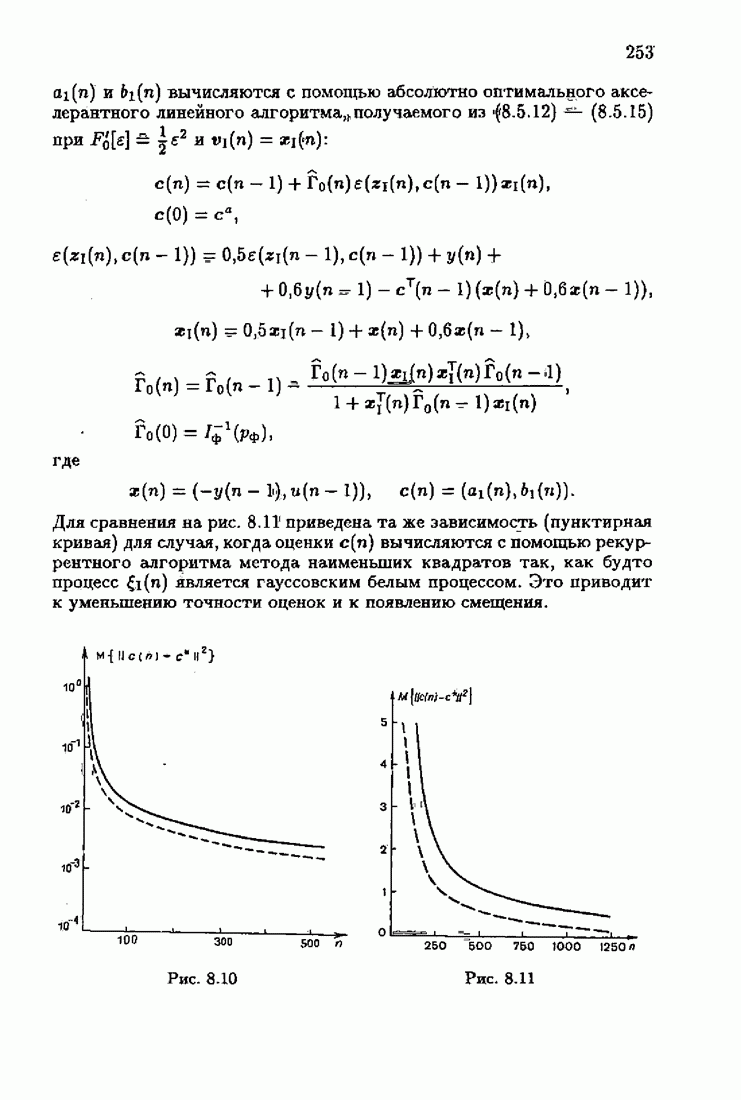
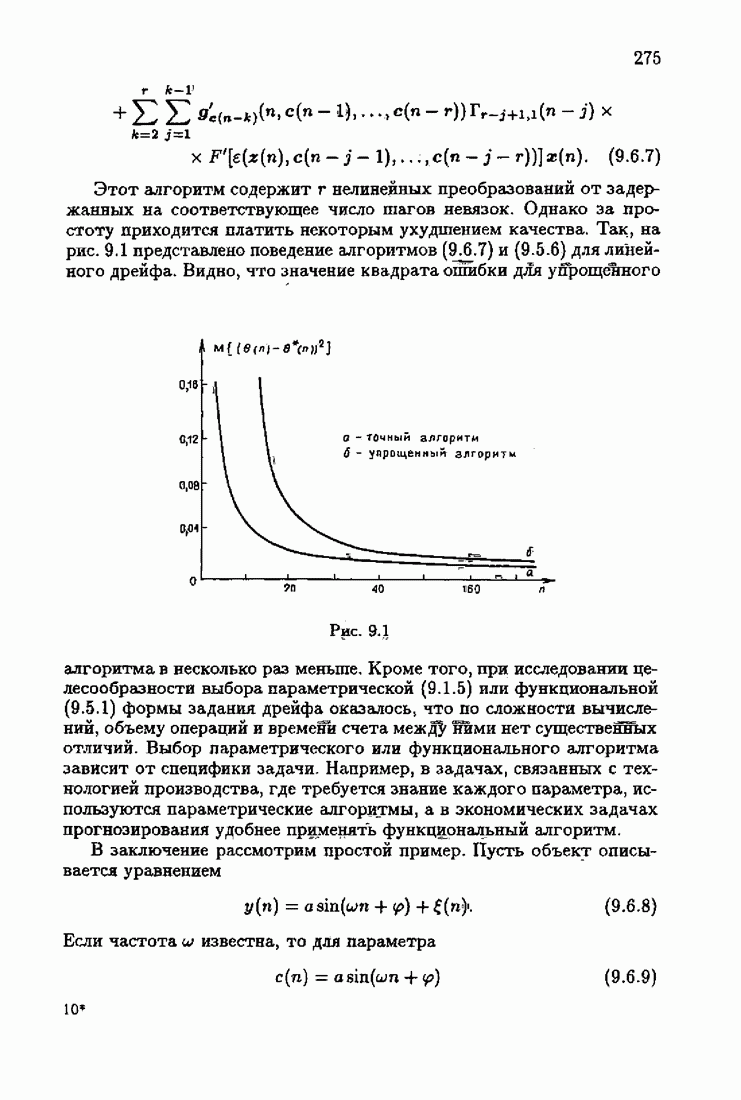
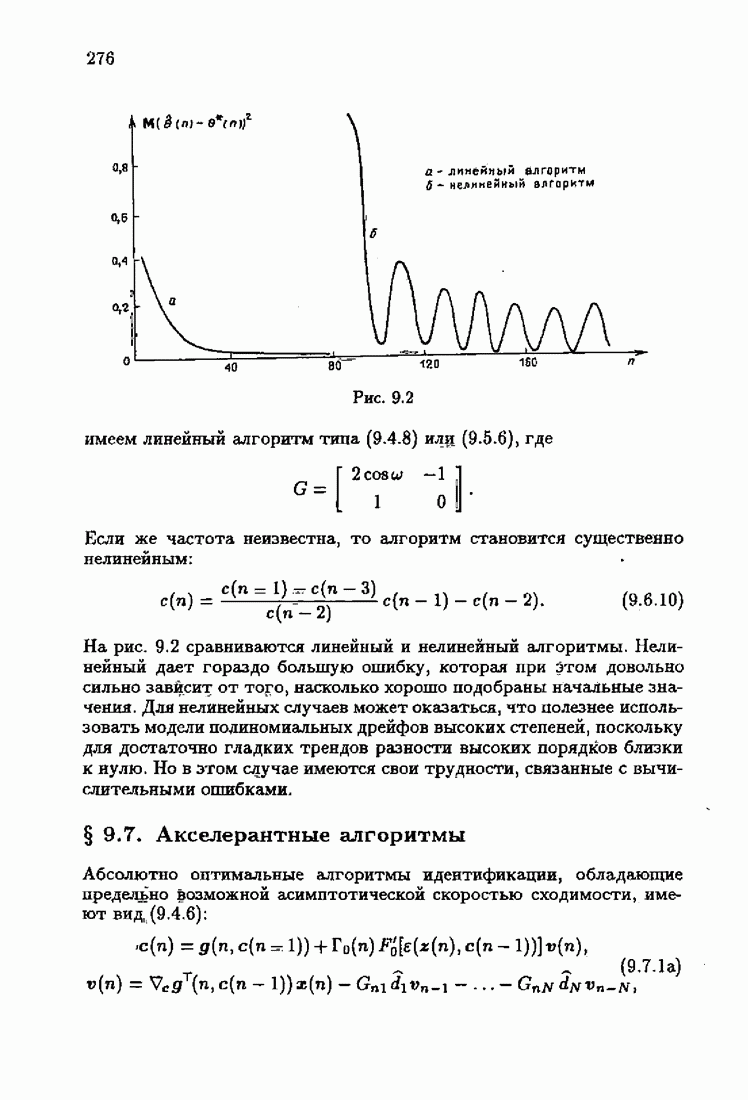
§ 7.6. Лилейные акселерантные алгоритмыВ общем случае как оптимальные, так и оптимальные на классе функции потерь не квадратичны и, следовательно, условие оптимальности представляет собой нелинейную систему уравнений относительно оптимального решения. Формируемые на основе условий оптимальности алгоритмы получаются в результате ряда приближений, поэтому акселерантные абсолютно оптимальные на классе алгоритмы в общем случае являются приближенными алгоритмами. И только для объектов с простой помехой, обладающей ограниченной дисперсией (т. е. с плотностью распределения, принадлежащей классу
и
Вспоминая еще, что для оптимальной статической настраиваемой модели (см. § 1.3)
и
получим из (7.5.1), (7.5.2) после очевидных преобразований линейные акселерантные алгоритмы
Здесь фидуциальное распределение считается нормальным с независимыми компонентами, так что в силу (7.4.14) и (7.2.9) начальное значение матрицы
или
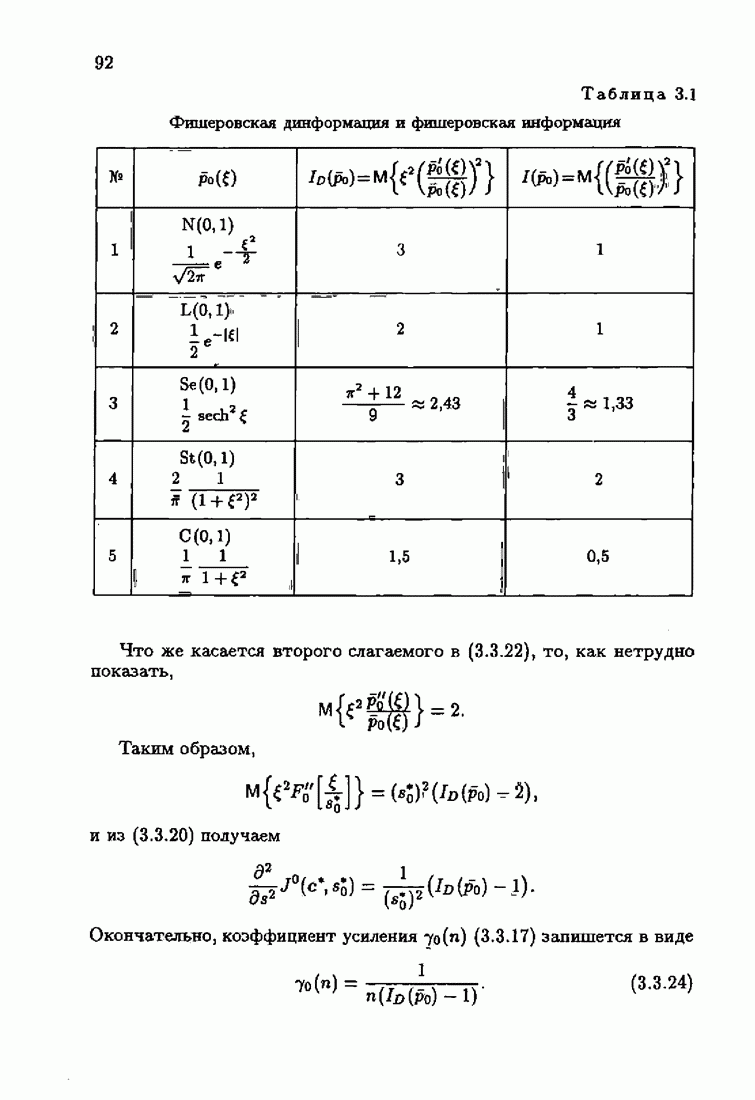
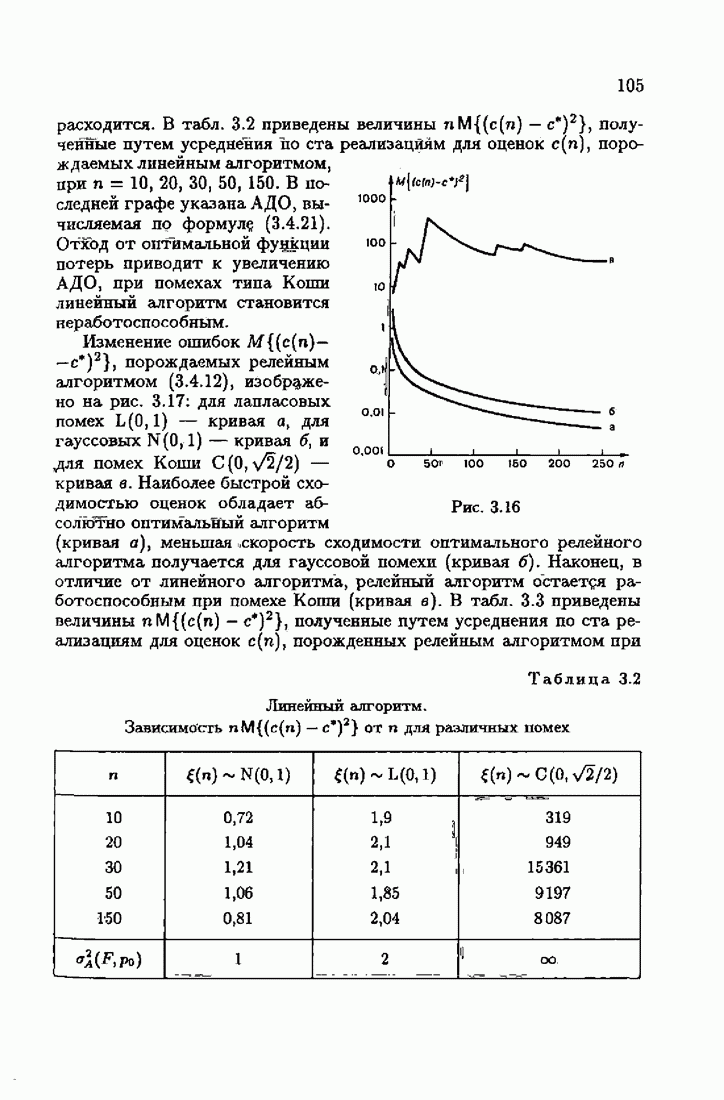
Элементы этой диагональной матрицы равны отношению фидуциальных дисперсий к дисперсии помех. Линейные алгоритмы идентификации (7.6.4) — (7.6.6) соответствуют рекуррентной форме метода наименьших квадратов. Как уже было установлено, линейные алгоритмы абсолютно оптимальны при помехе, плотность распределения которой нормальна. Они также абсолютно оптимальны на классе помех с ограниченной дисперсией. Рассмотрим теперь поведение акселерантных линейных алгоритмов при конечных значениях
Обозначая, как обычно, ошибку
выведем уравнение относительно МКО
в силу линейного акселерантного алгоритма (7.6.4), (7.6.5). Алгоритм (7.6.4), учитывая (7.6.9), можно представить в виде
или
Нетрудно найти решение этого векторного линейного разностного уравнения:
Матрица
где
и значит
Отсюда, после умножения слева на
Полагая здесь
Это соотношение позволяет упростить выражение для
Рассмотрим вначале от помехи
Учитывая соотношение (7.6.15) и принимая во внимание независимость
или, после несложных преобразований,
МКО
либо когда
Но при учете фидуциального распределения
Следовательно, вместо (7.6.24) будем иметь
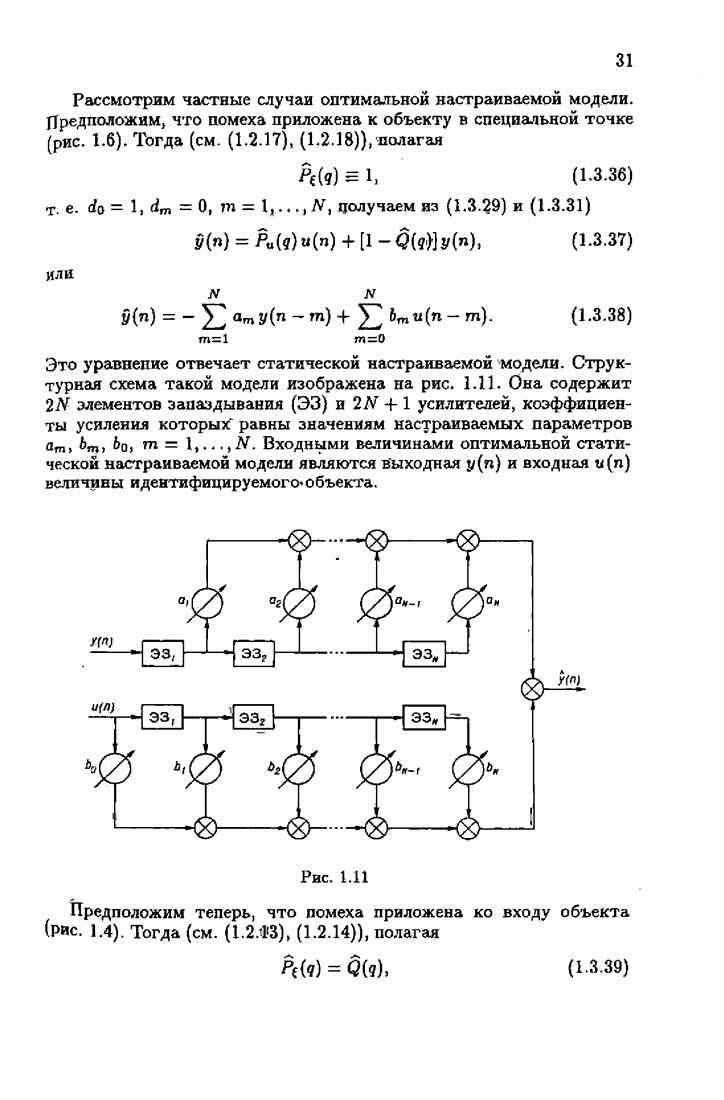
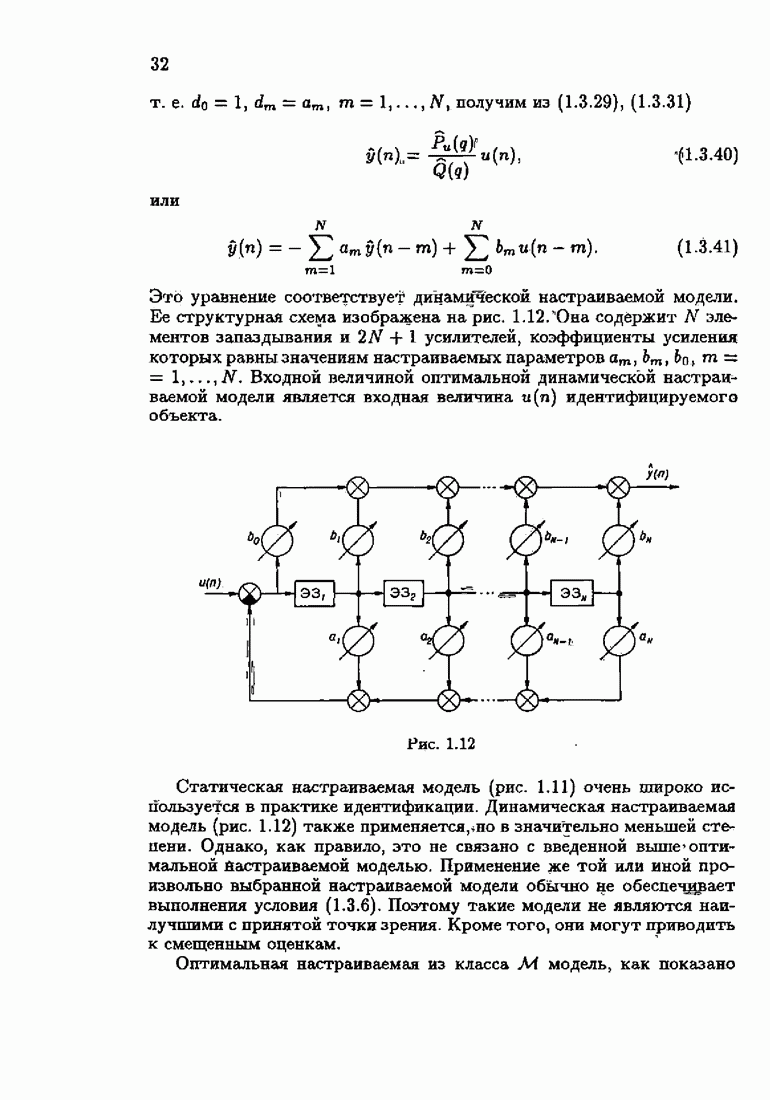
Найдем теперь МКО для этих двух случаев. В первом случае при выборе
Во втором случае, выбирая
Сопоставляя (7.6.28) и (7.6.27), заключаем, что
Из этого неравенства следует, что учет априорной информации об оптимальном решении уменьшает МКО линейных алгоритмов на каждом шаге Для РАР-объектов и АР-объектов с простыми помехами ситуация изменяется. В этих случаях наблюдения
откуда после несложных преобразований получаем
При выполнении условия (7.6.23) или (7.6.24) второе слагаемое здесь обращается в нуль, так что
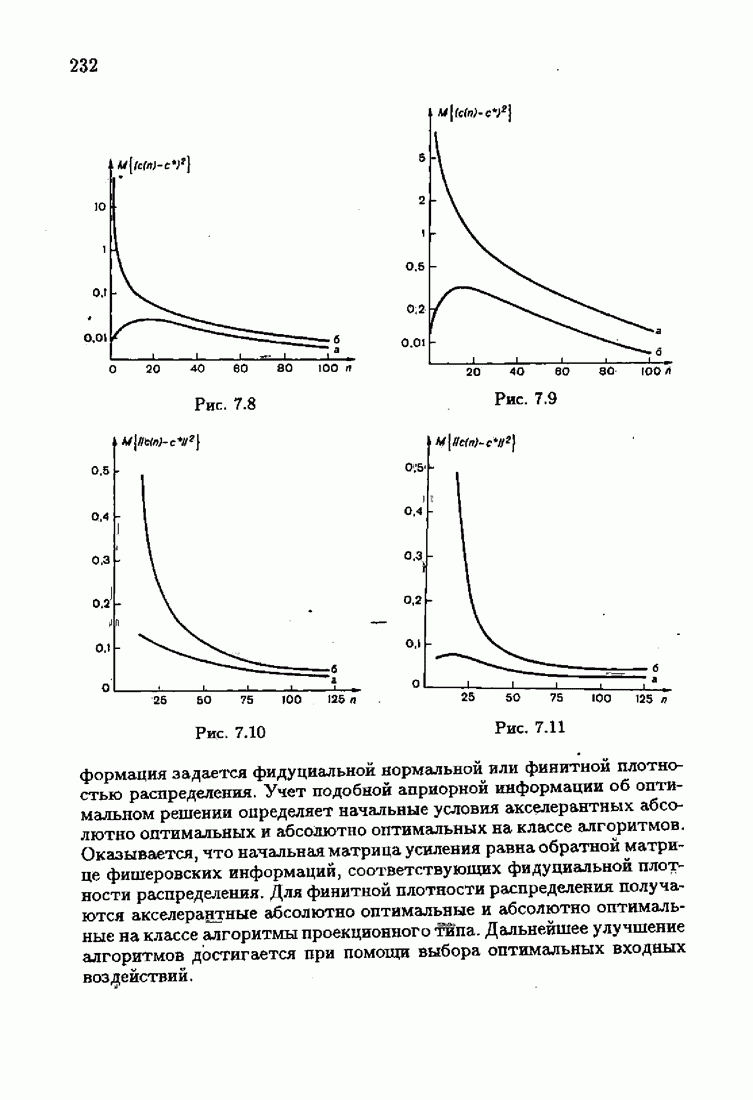
Из (7.6.32) следует, что матрицы Можно ожидать, что эффект акселеризации, достигаемый соответствующим выбором начальных значений оптимальных на классе алгоритмов. Однако мы пока не владеем формальным доказательством этого факта. Природа эффекта акселеризации, как следует из изложенного выше, состоит в увеличении матрицы
где
|
 |
Оглавление
|



























































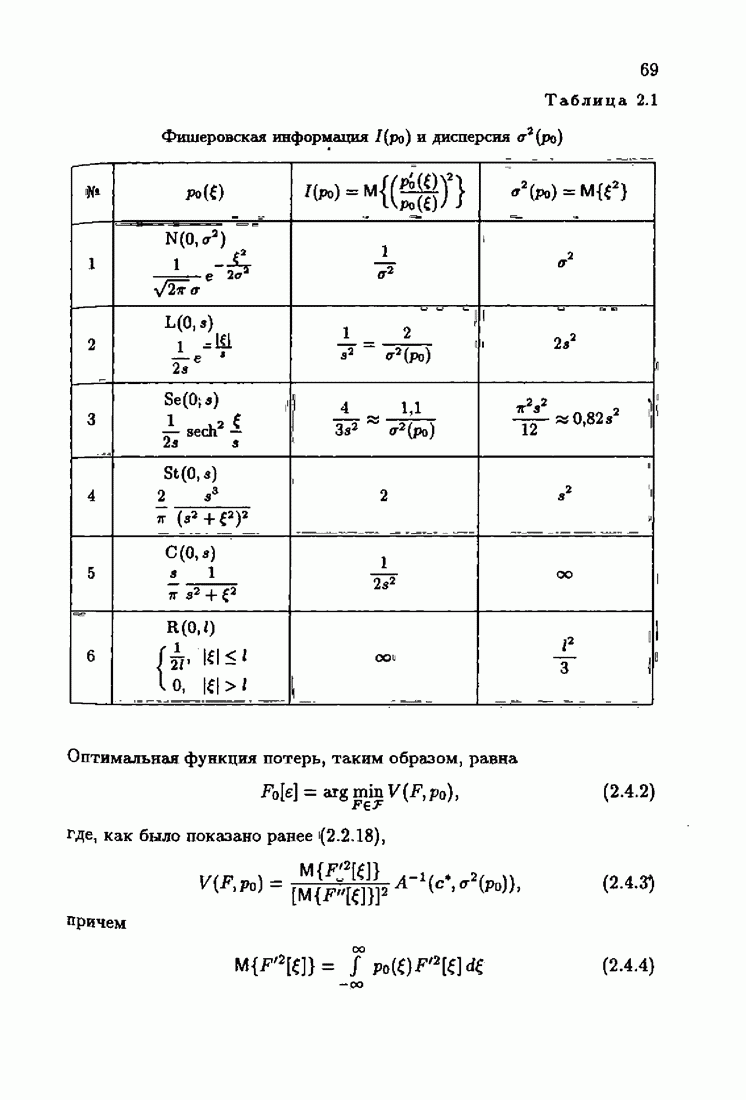



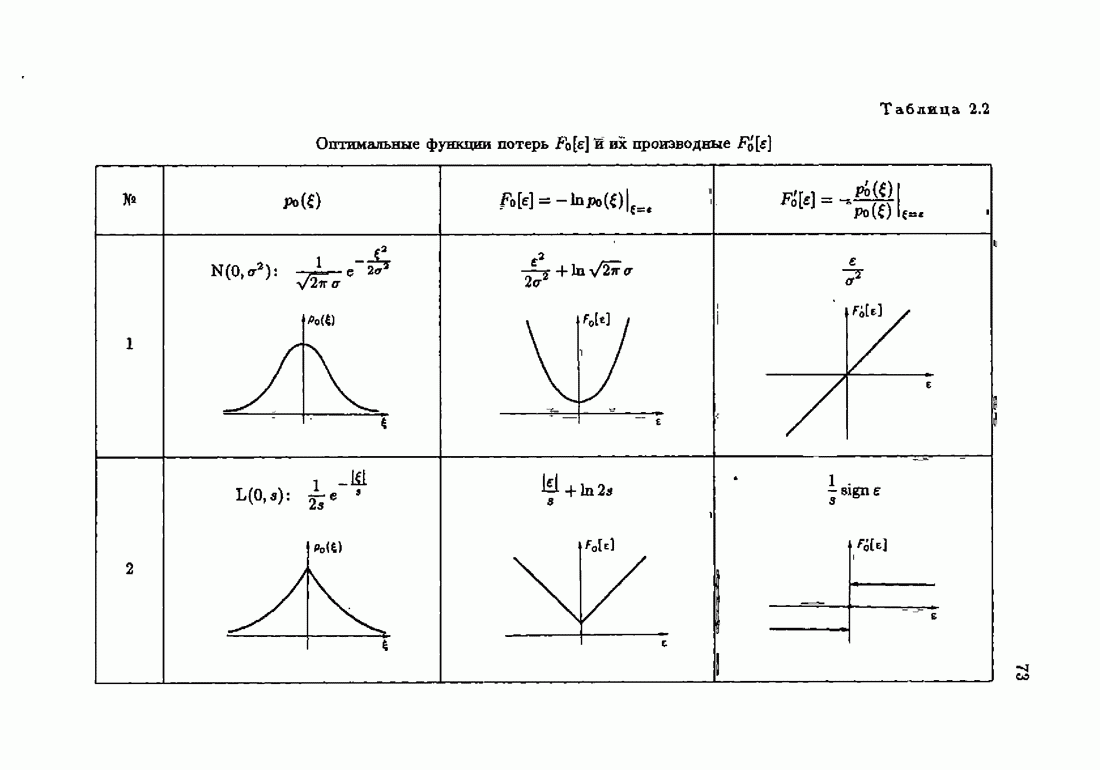
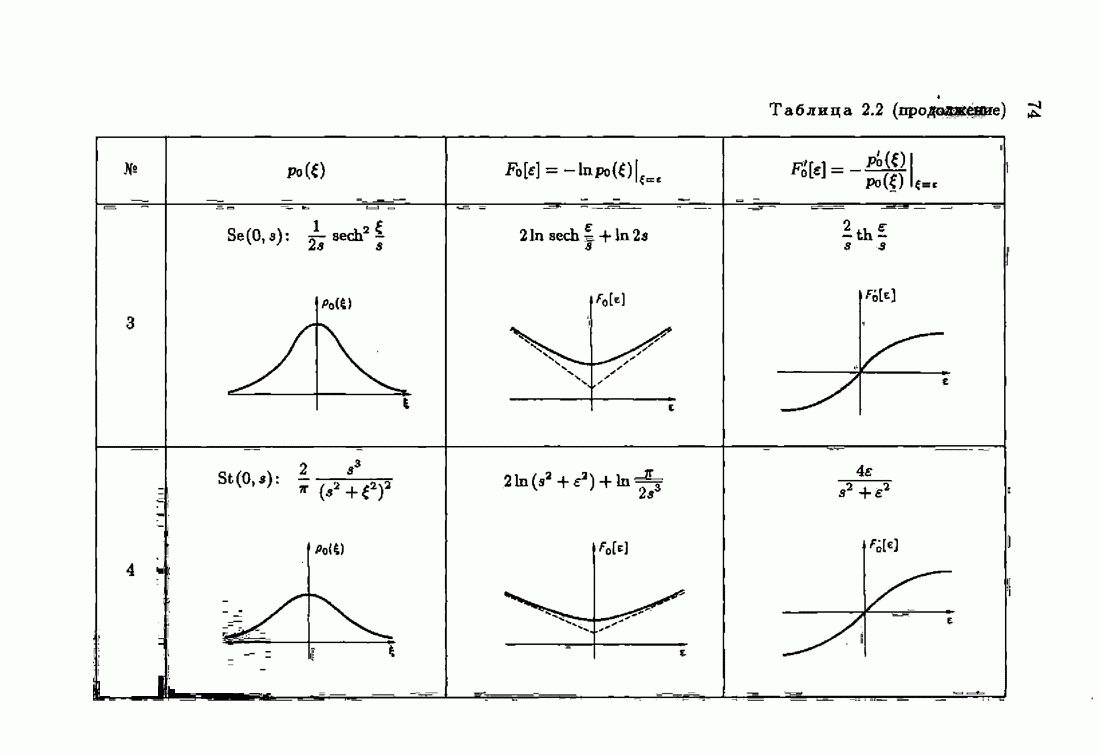








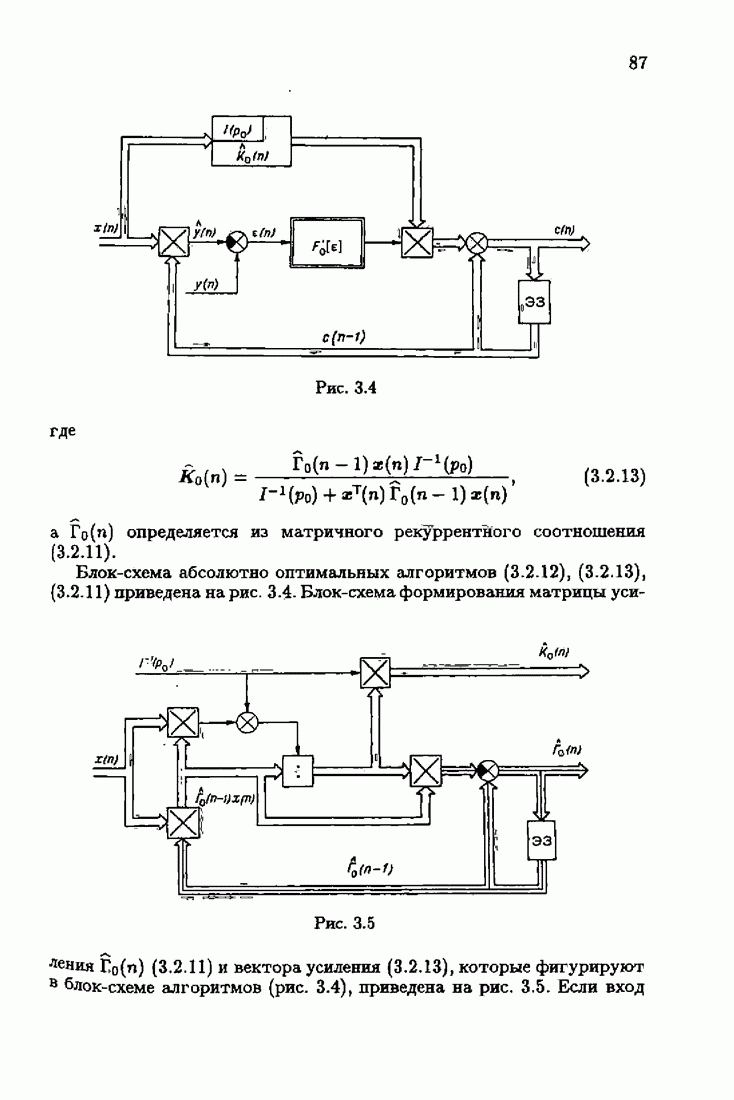




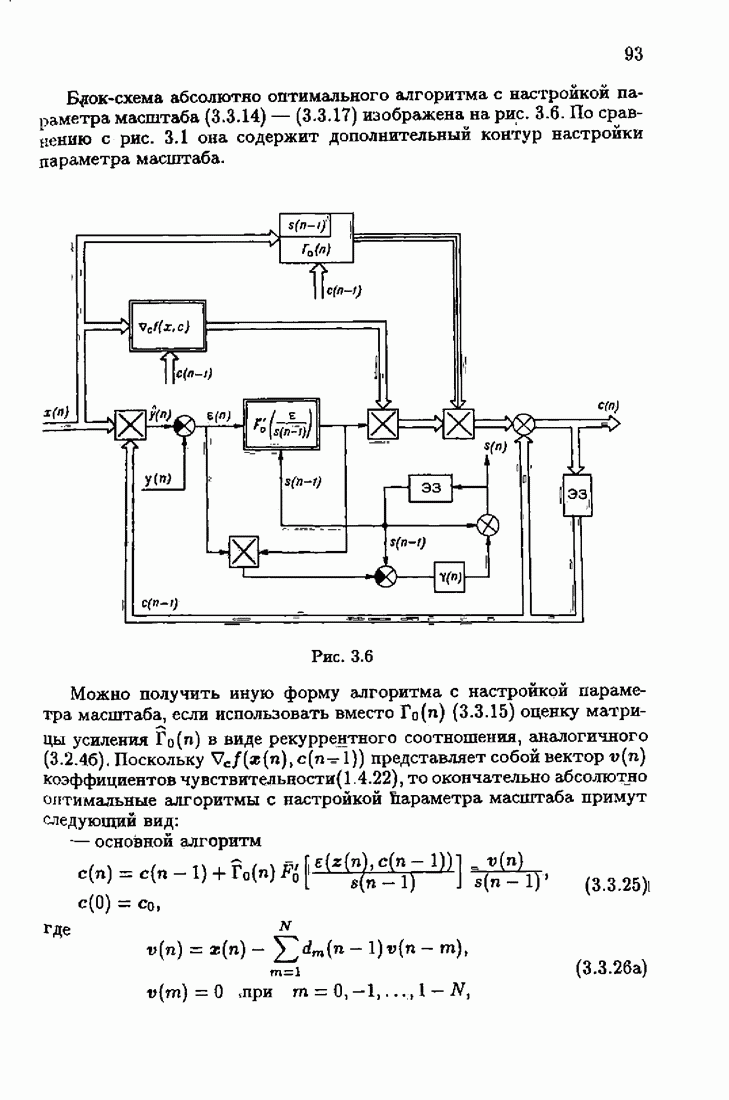
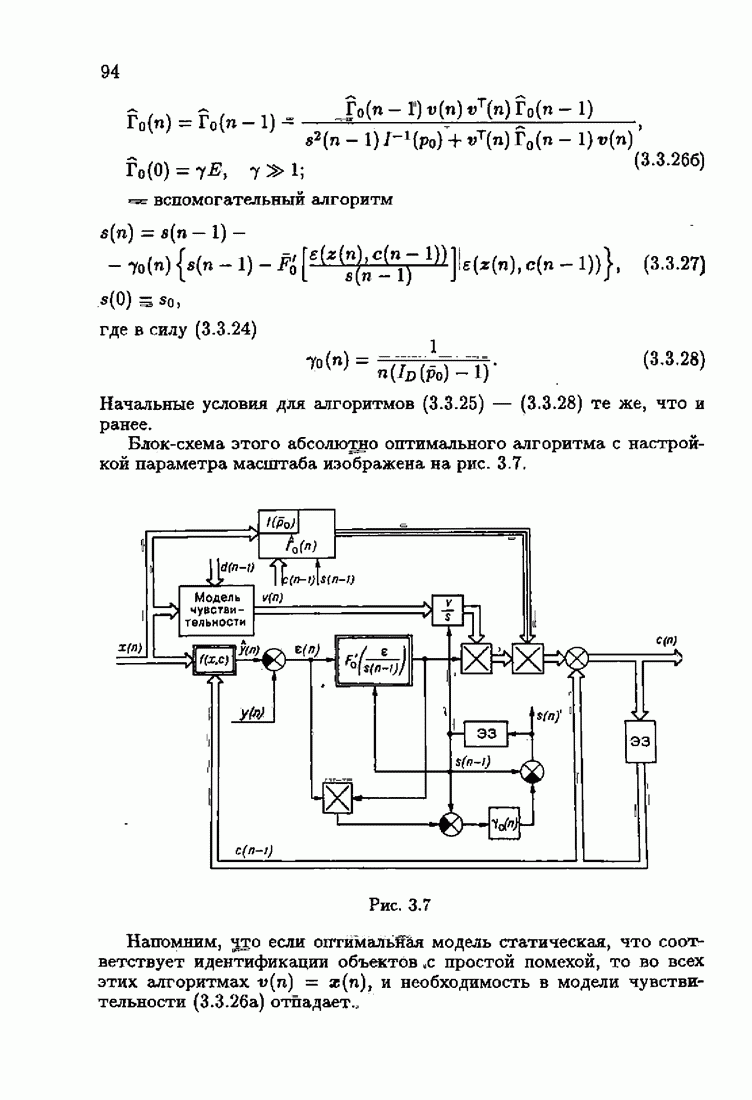


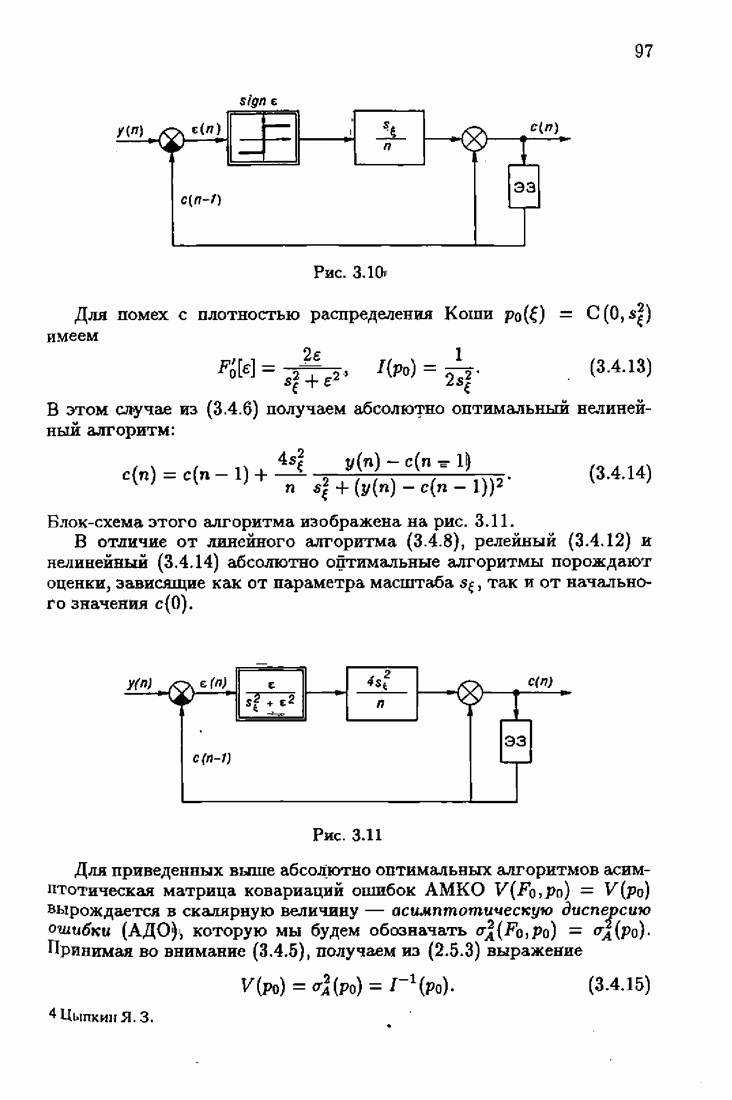



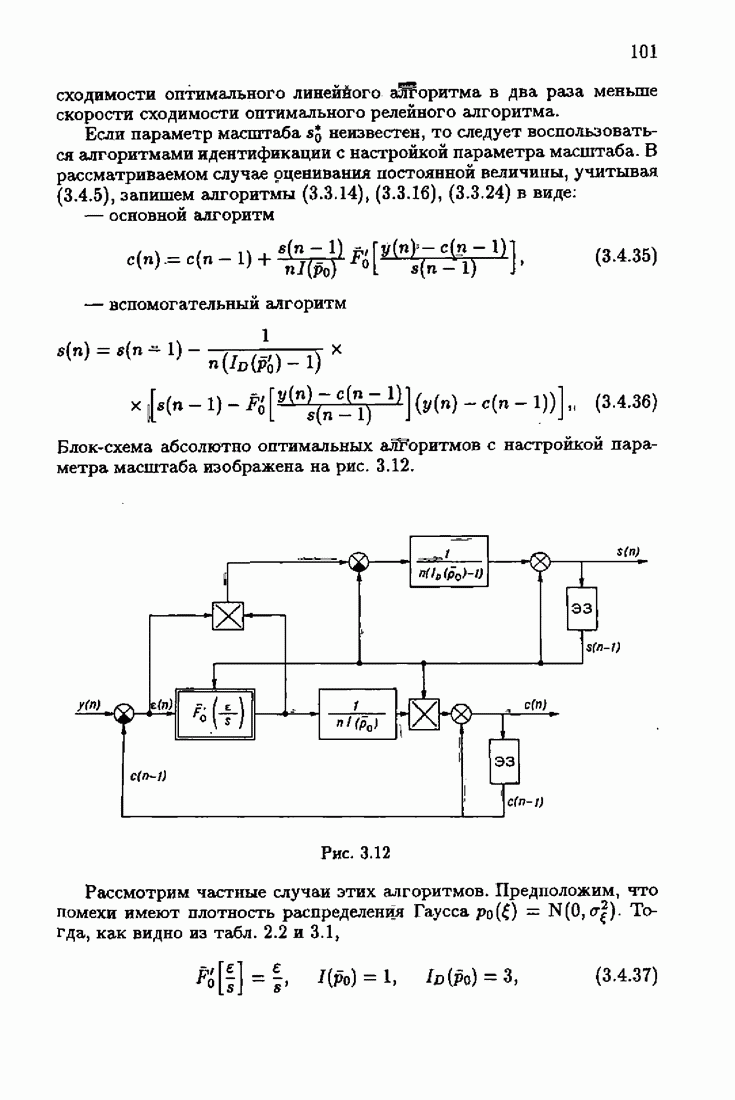
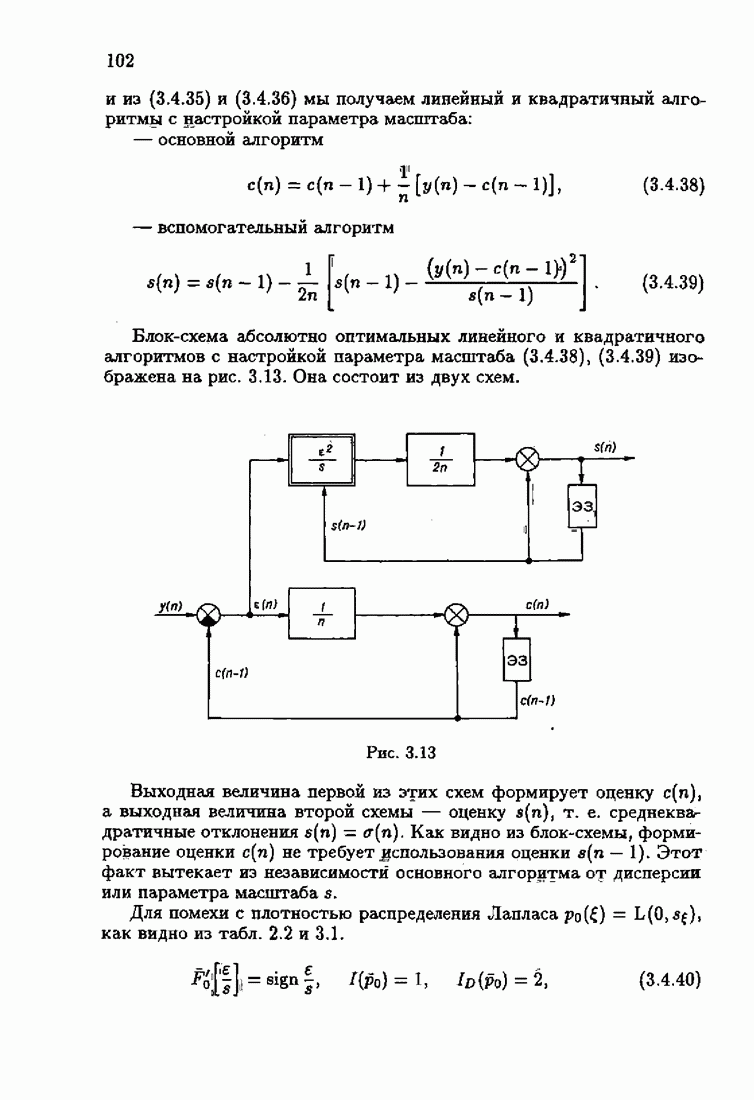
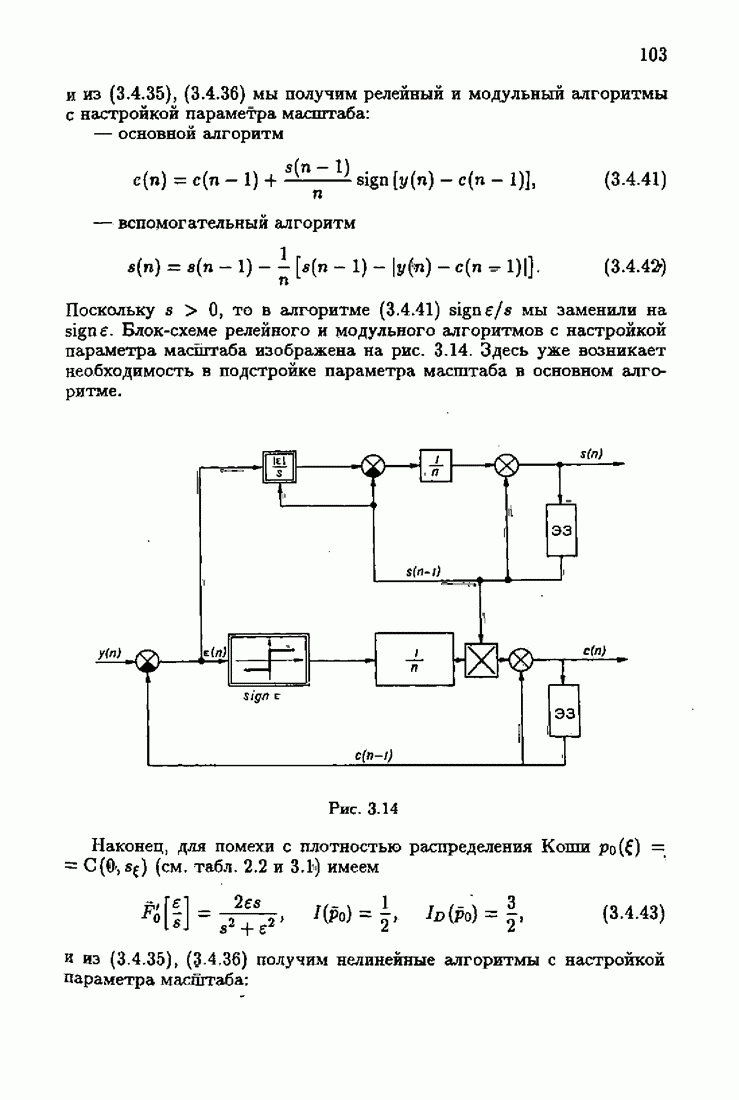






































































































































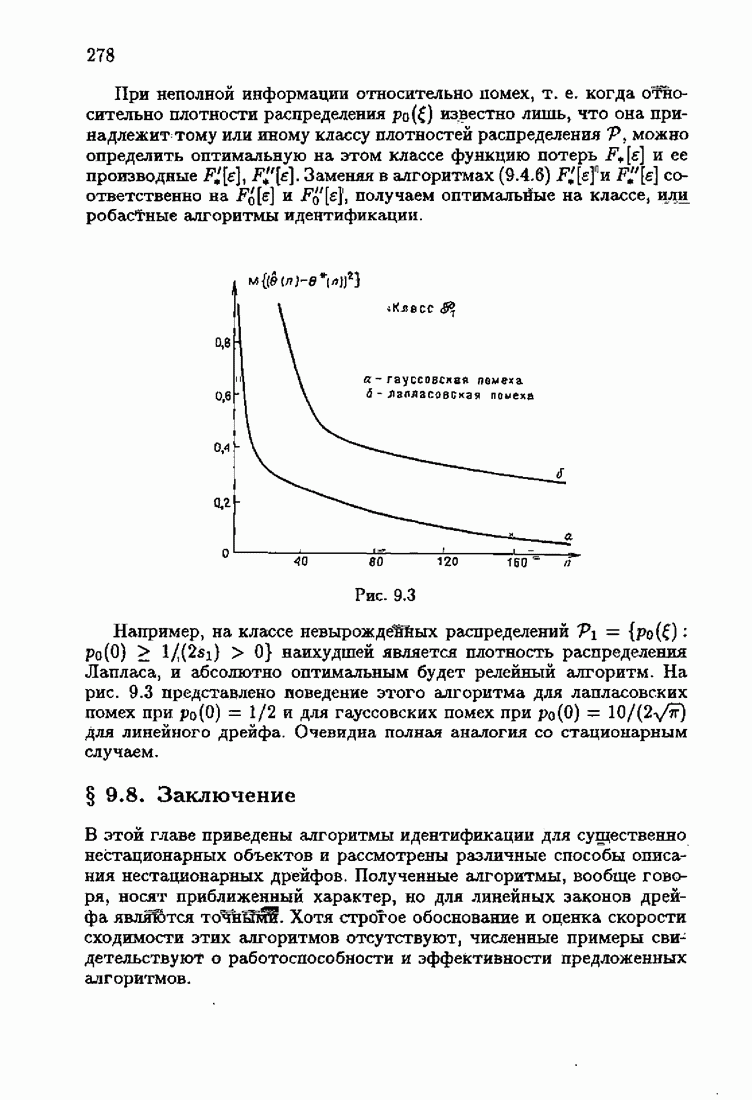


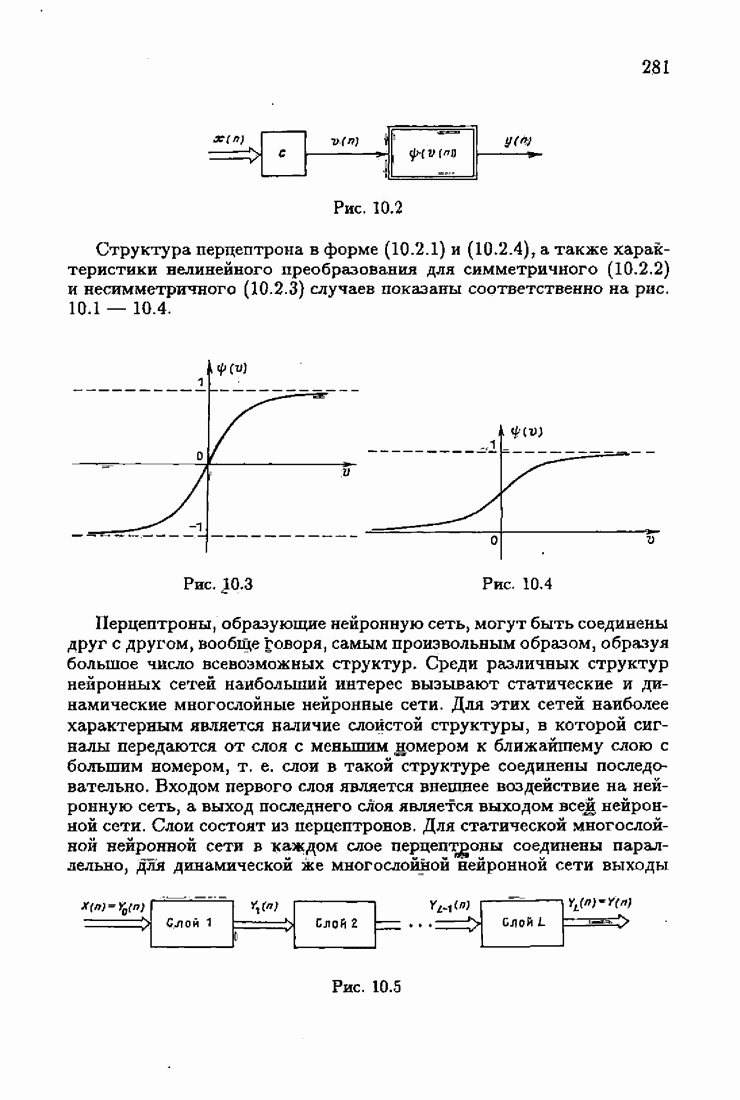
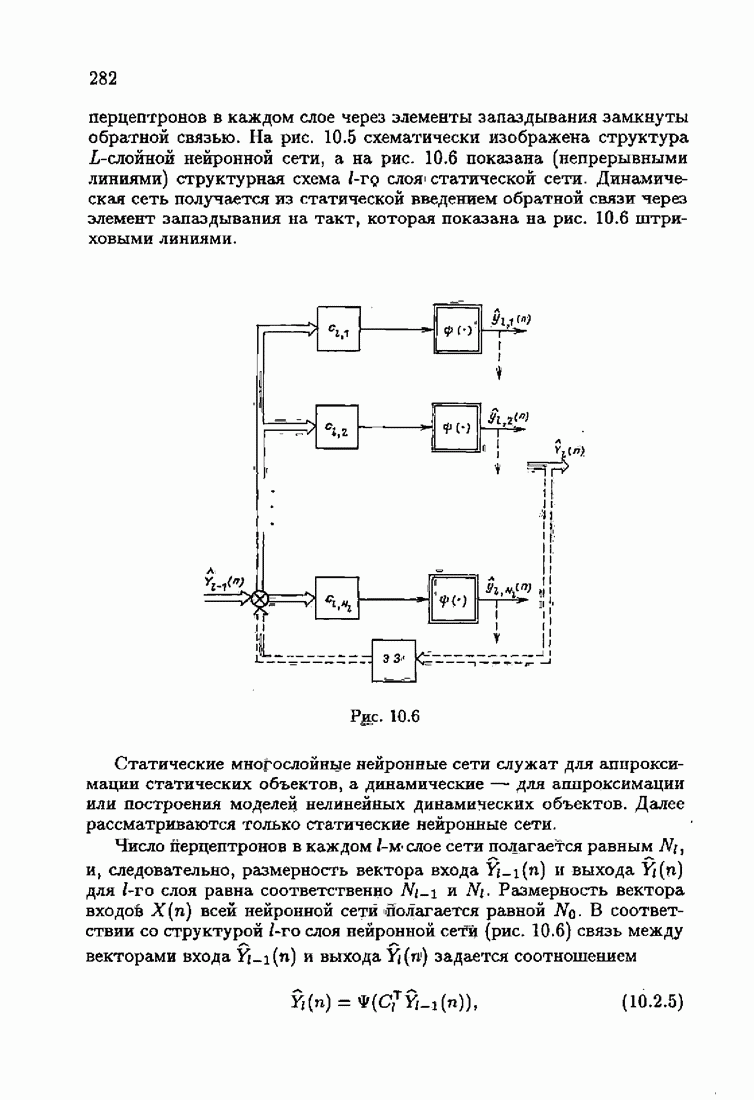


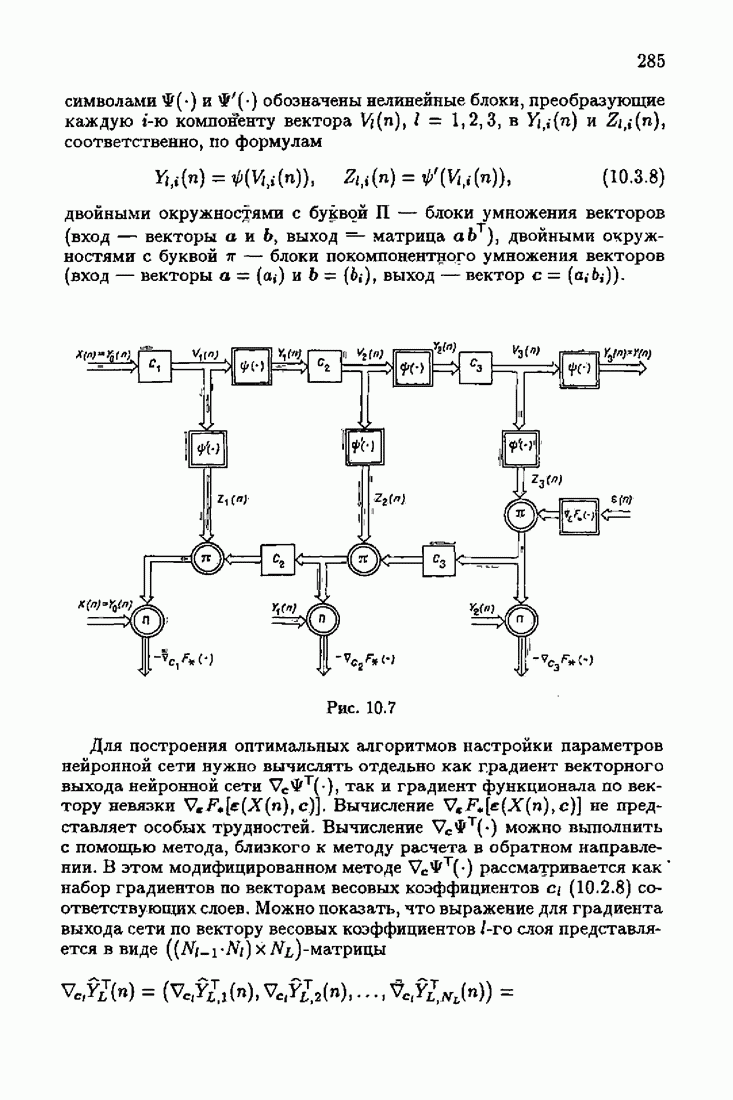
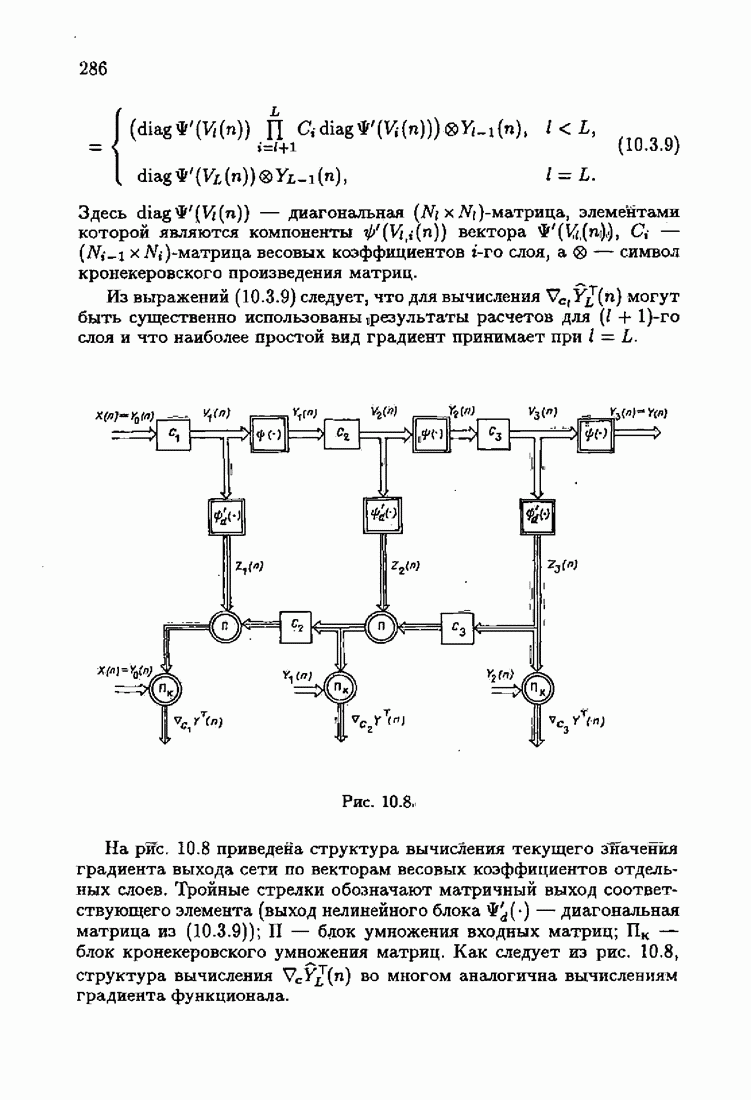
















































 и, значит, для статической оптимальной настраиваемой модели акселерантные абсолютно оптимальные на классе алгоритмы становятся точными. В этом случае оптимальная на классе функция потерь и ее производная равны соответственно
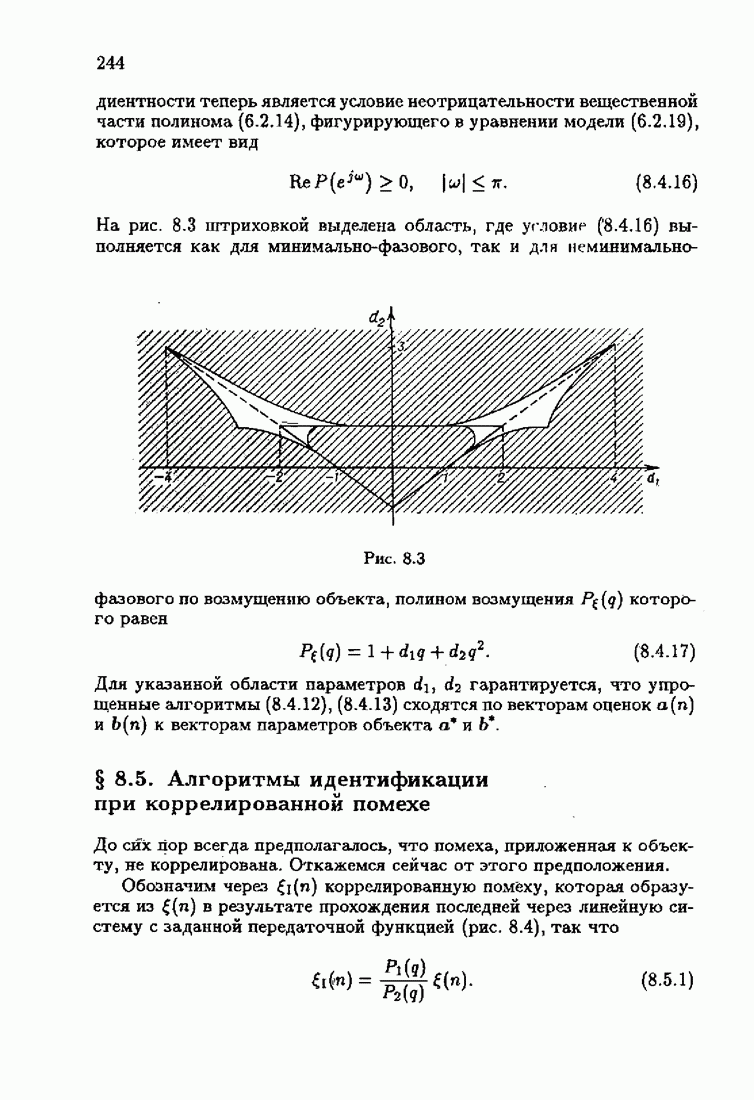
и, значит, для статической оптимальной настраиваемой модели акселерантные абсолютно оптимальные на классе алгоритмы становятся точными. В этом случае оптимальная на классе функция потерь и ее производная равны соответственно






 при
при  можно представить в виде
можно представить в виде


 и покажем, что они являются оптимальными как по оценкам обобщенных эмпирических средних потерь
и покажем, что они являются оптимальными как по оценкам обобщенных эмпирических средних потерь  так и по матрице ковариаций ошибок МКО
так и по матрице ковариаций ошибок МКО






 определяется выражением (7.6.5). Однако сейчас запишем ее в несколько более общей форме
определяется выражением (7.6.5). Однако сейчас запишем ее в несколько более общей форме

 в отличие от (7.6.6), — произвольное начальное значение матрицы
в отличие от (7.6.6), — произвольное начальное значение матрицы  Из (7.6.14) следует, что
Из (7.6.14) следует, что


 получим
получим

 и перемножая почленно эти равенства, будем иметь
и перемножая почленно эти равенства, будем иметь

 и представить его в виде
и представить его в виде

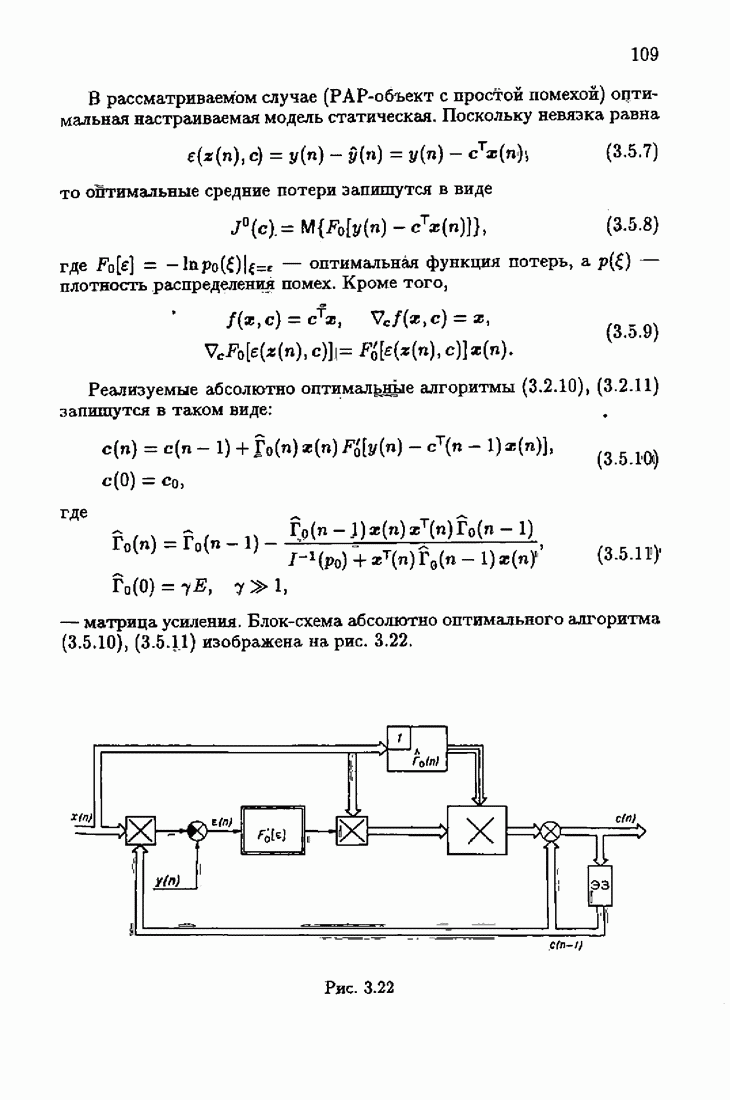
 -обьект с простой помехой. В этом случае вектор наблюдений
-обьект с простой помехой. В этом случае вектор наблюдений  не зависит
не зависит
 Найдем для этого случая
Найдем для этого случая  Подставляя в
Подставляя в  из (7.6.19), получим
из (7.6.19), получим

 преобразуем
преобразуем  к виду
к виду


 состоит из двух слагаемых. Второе слагаемое зависит от начального значения
состоит из двух слагаемых. Второе слагаемое зависит от начального значения  которое определяется априорной информацией о решении, и от начального значения матрицы усиления
которое определяется априорной информацией о решении, и от начального значения матрицы усиления  которое мы можем выбирать. Естественно выбрать
которое мы можем выбирать. Естественно выбрать  так, чтобы второе слагаемое в выражении МКО (7.6.22) обратилось в нуль. Это возможно лишь в двух случаях: когда
так, чтобы второе слагаемое в выражении МКО (7.6.22) обратилось в нуль. Это возможно лишь в двух случаях: когда


 совпадает с обратной матрицей фишеровских информаций (7.4.14), (7.4.15), т. е.
совпадает с обратной матрицей фишеровских информаций (7.4.14), (7.4.15), т. е.


 в виде (7.6.23) и (7.6.14) из (7.6.22) получаем
в виде (7.6.23) и (7.6.14) из (7.6.22) получаем

 в соответствии с (7.6.26), из (7.6.22) и (7.6.14) получаем
в соответствии с (7.6.26), из (7.6.22) и (7.6.14) получаем



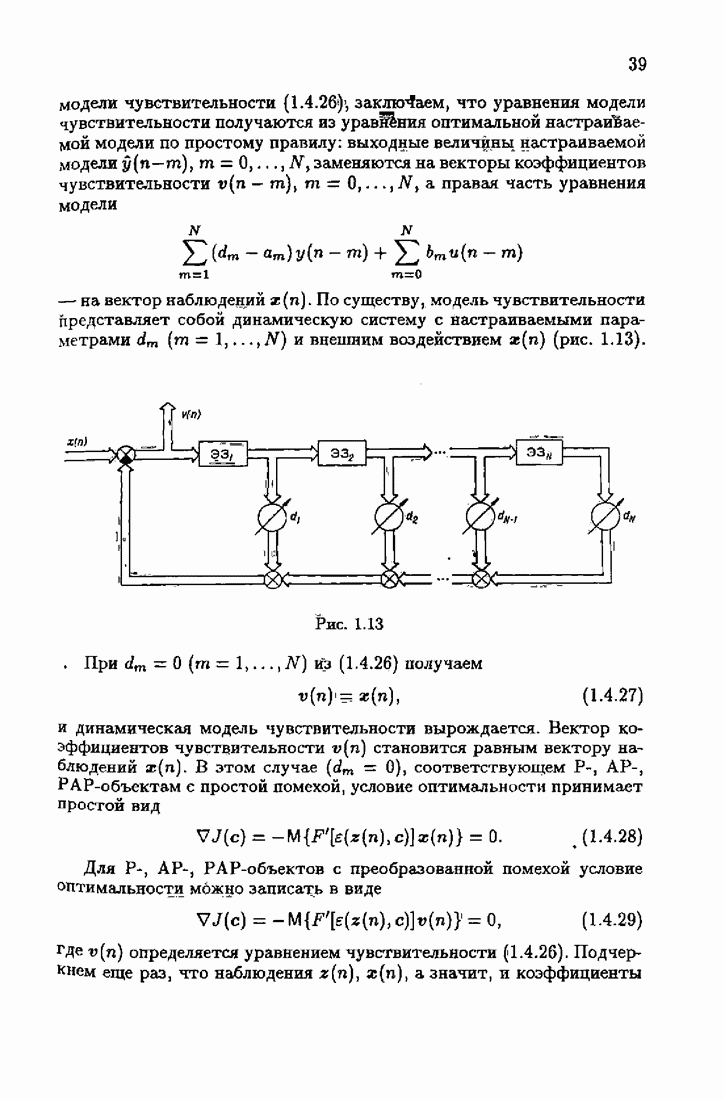
 зависят от
зависят от  при
при  Но сделанный выше вывод остается справедливым и в этих случаях. Действительно, из (7.6.19) следует, что
Но сделанный выше вывод остается справедливым и в этих случаях. Действительно, из (7.6.19) следует, что




 «слабо в среднем» эквивалентны (в отличие от «средней» эквивалентности в случае
«слабо в среднем» эквивалентны (в отличие от «средней» эквивалентности в случае  -обьектов) при всех
-обьектов) при всех  что свидетельствует о том, что для РАР-обьектов и АР-обьектов с простыми помехами учет априорной информации об оптимальном решении улучшает оценивание при конечном
что свидетельствует о том, что для РАР-обьектов и АР-обьектов с простыми помехами учет априорной информации об оптимальном решении улучшает оценивание при конечном  т. е. что и в этих случаях имеет место эффект акселеризации.
т. е. что и в этих случаях имеет место эффект акселеризации.
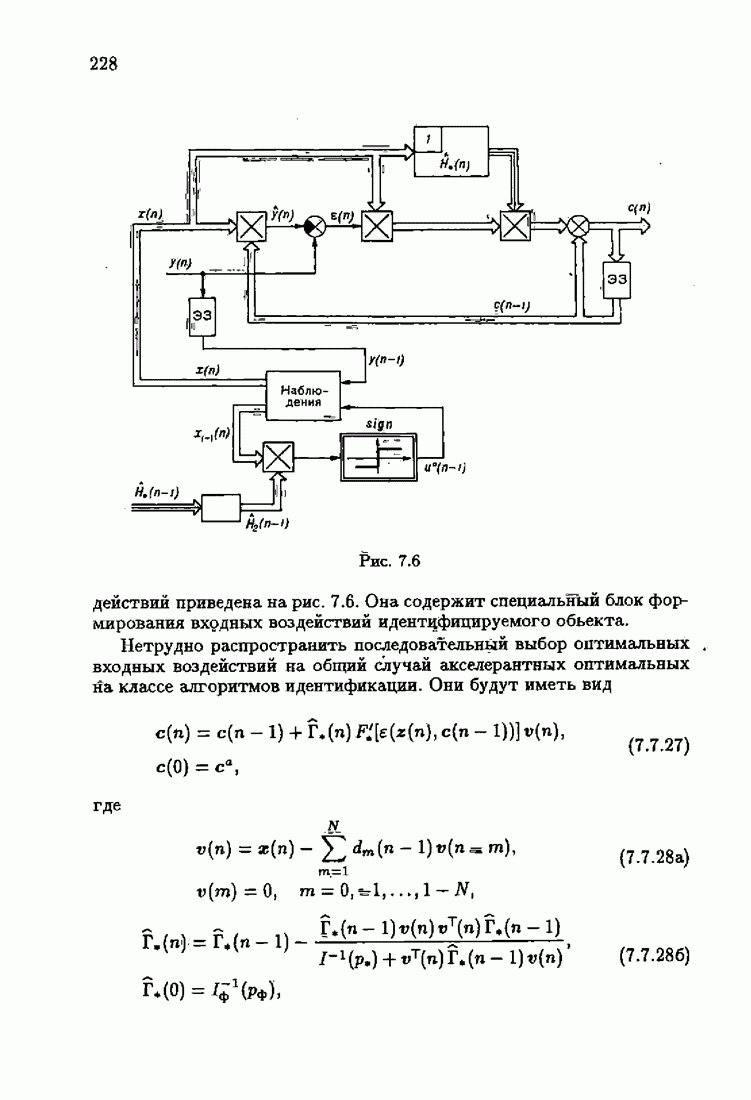
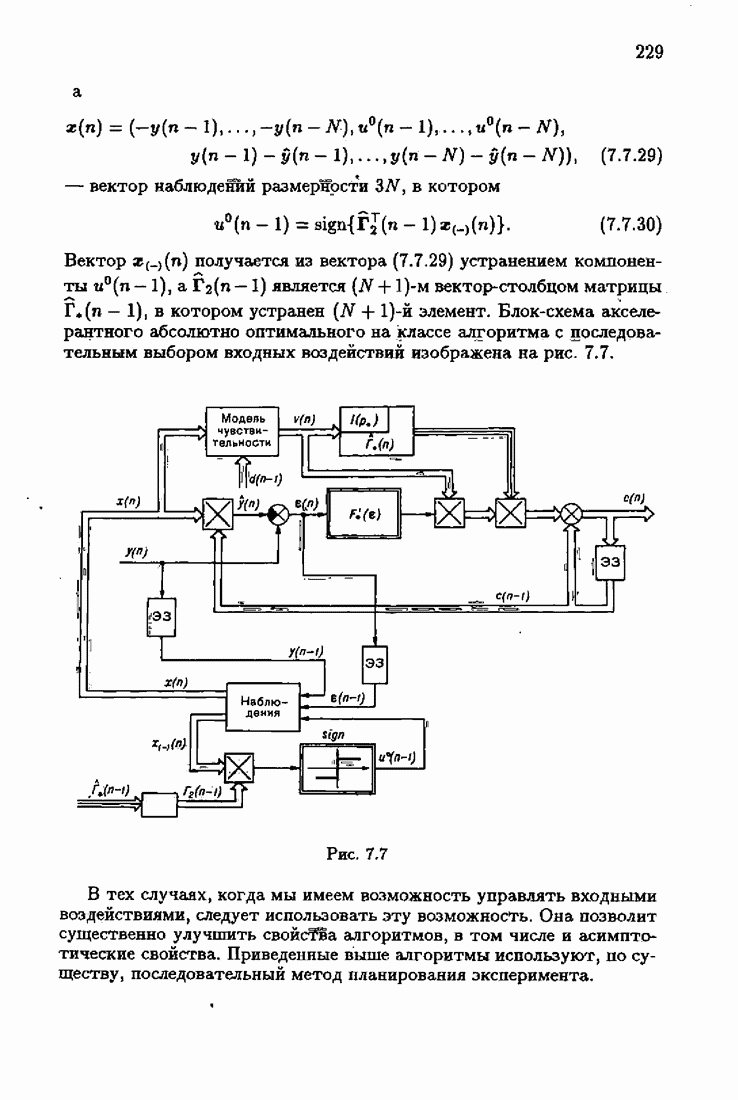
 имеет место и для динамических объектов с преобразованными помехами, а также в общем случае нелинейных абсолютно
имеет место и для динамических объектов с преобразованными помехами, а также в общем случае нелинейных абсолютно
 на матрицу
на матрицу  определяемую априорной информацией об оптимальном решении. С ростом
определяемую априорной информацией об оптимальном решении. С ростом 

 (см. 4.2.4)). Отсюда следует, что асимптотика акселерантных оптимальных и оптимальных на классе алгоритмов одна и та же. Иначе говоря, учет априорной информации об оптимальном решении не влияет на асимптотические свойства оценок, формируемых алгоритмами.
(см. 4.2.4)). Отсюда следует, что асимптотика акселерантных оптимальных и оптимальных на классе алгоритмов одна и та же. Иначе говоря, учет априорной информации об оптимальном решении не влияет на асимптотические свойства оценок, формируемых алгоритмами.