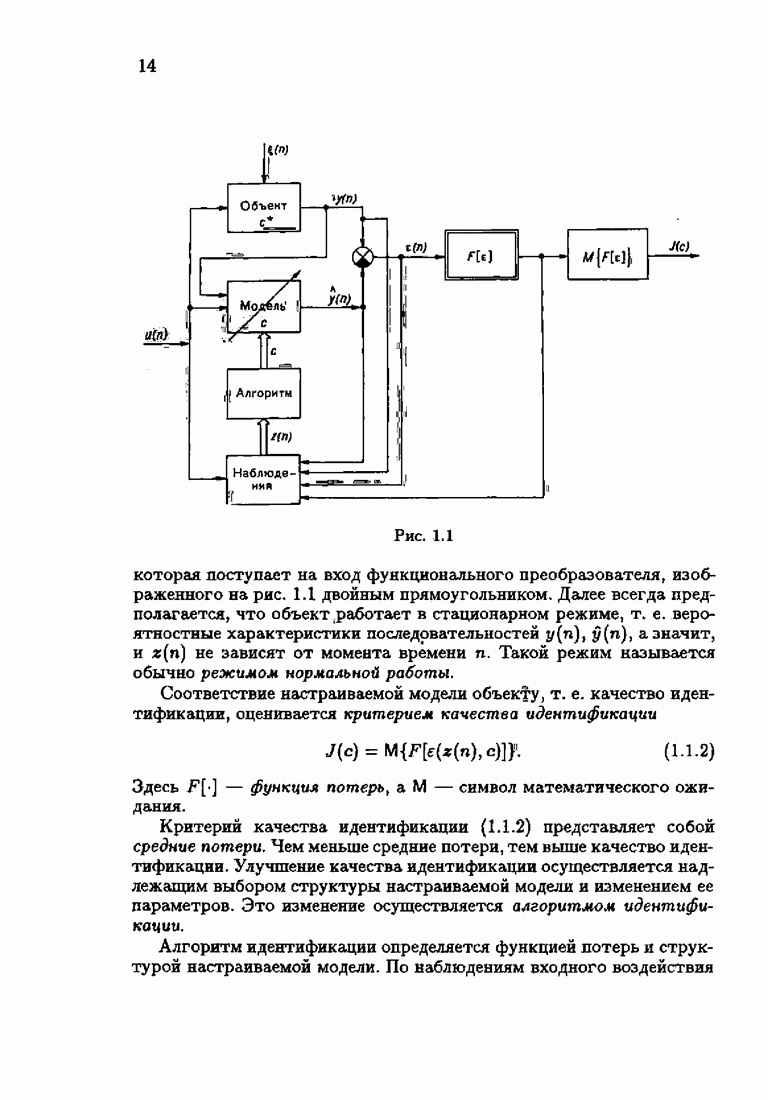
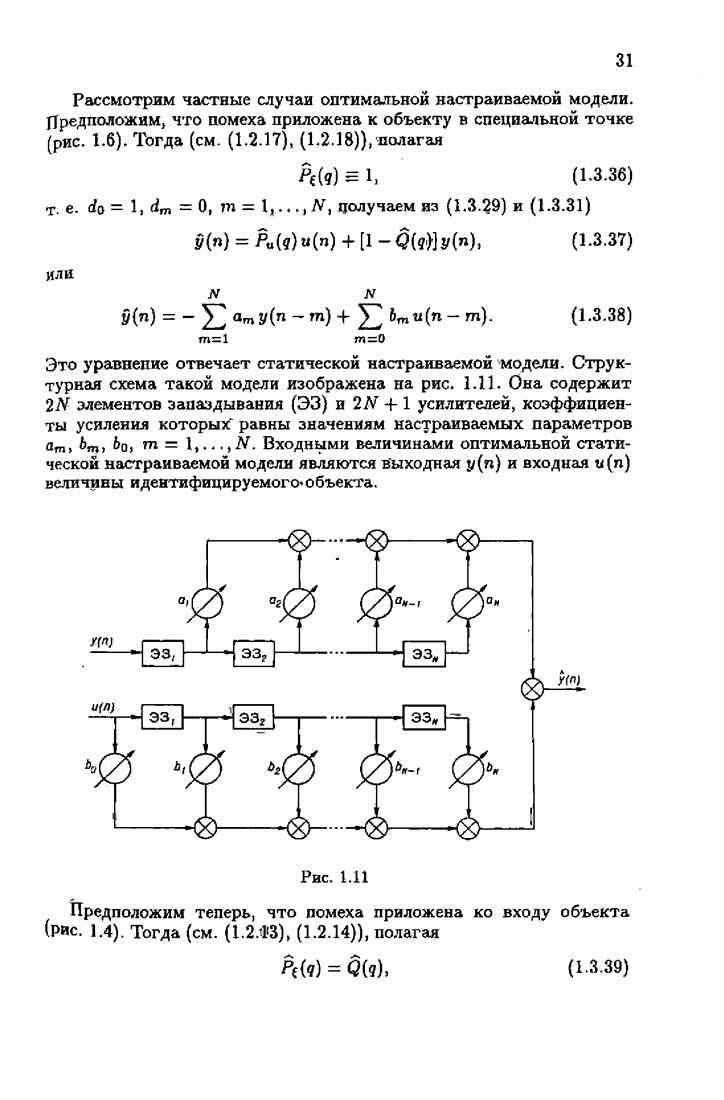
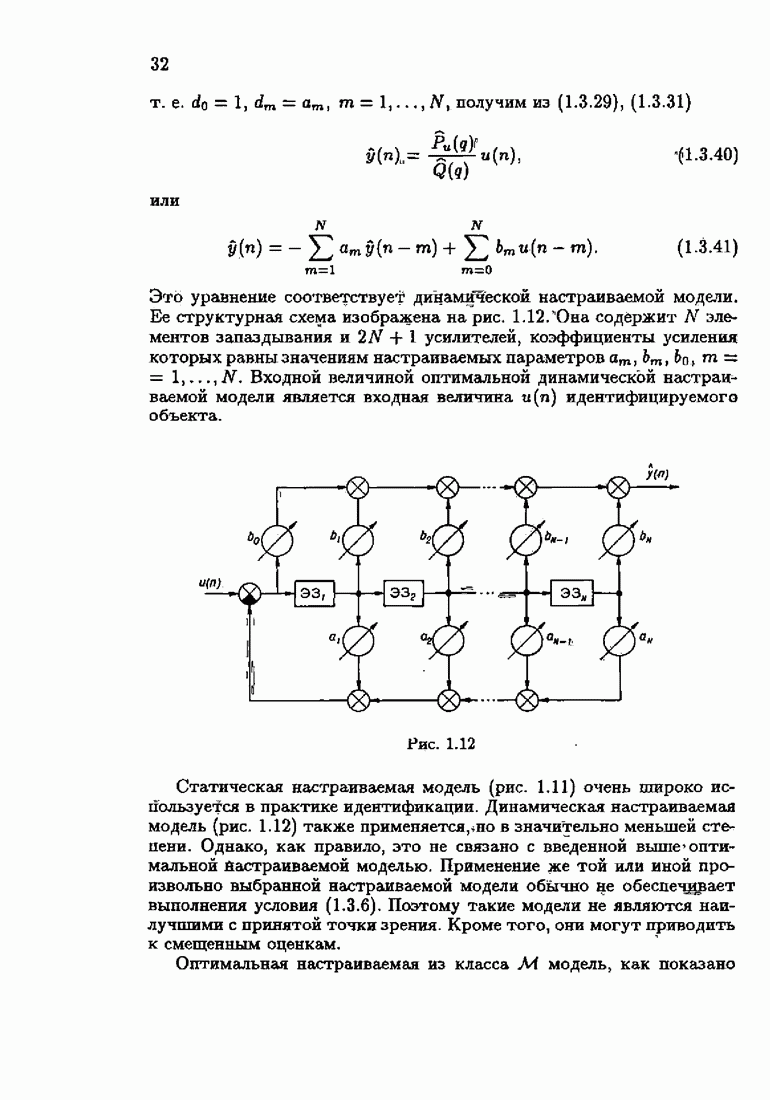
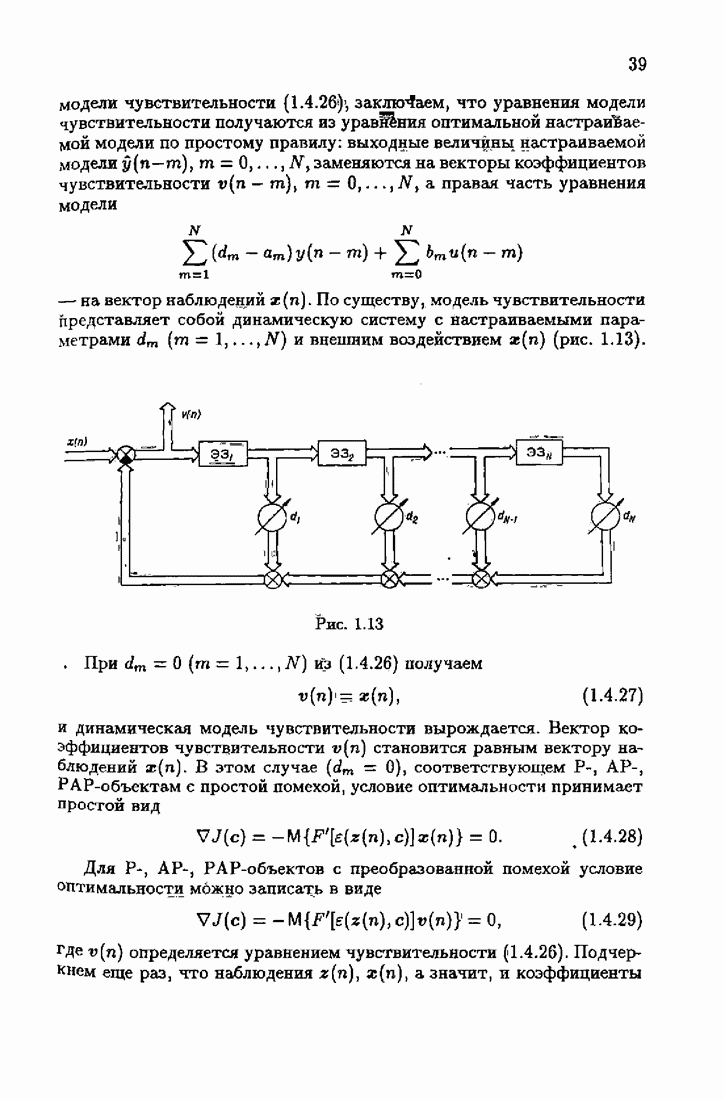
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
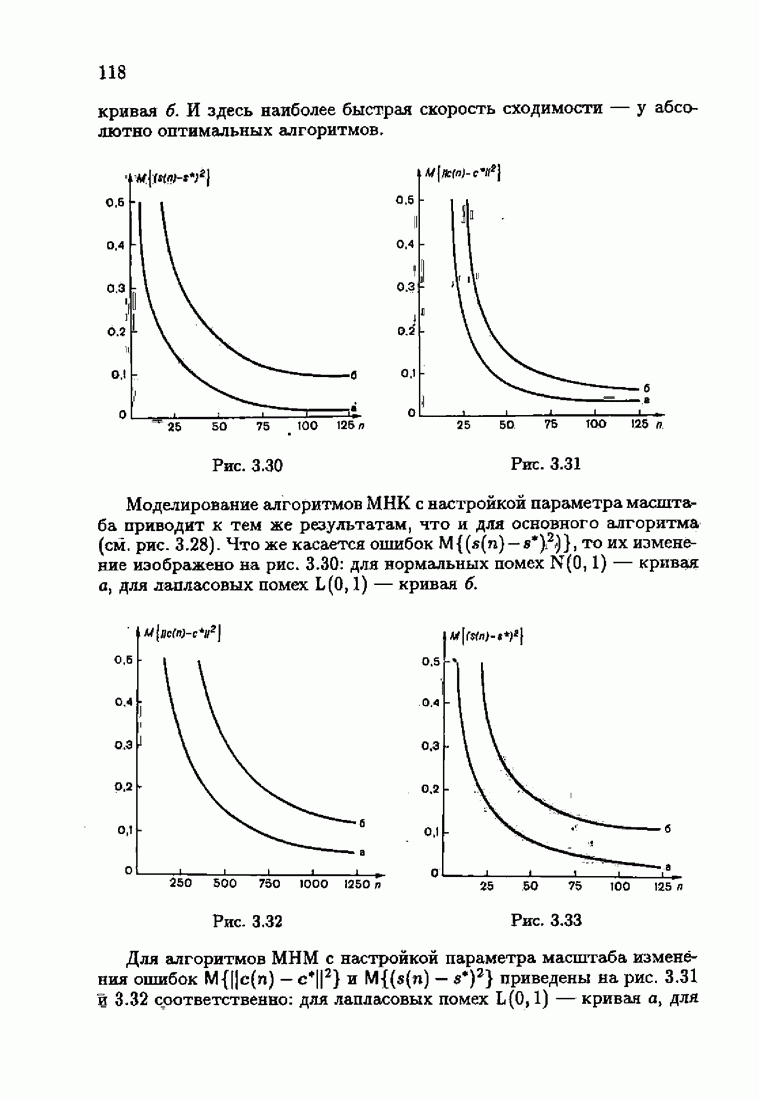
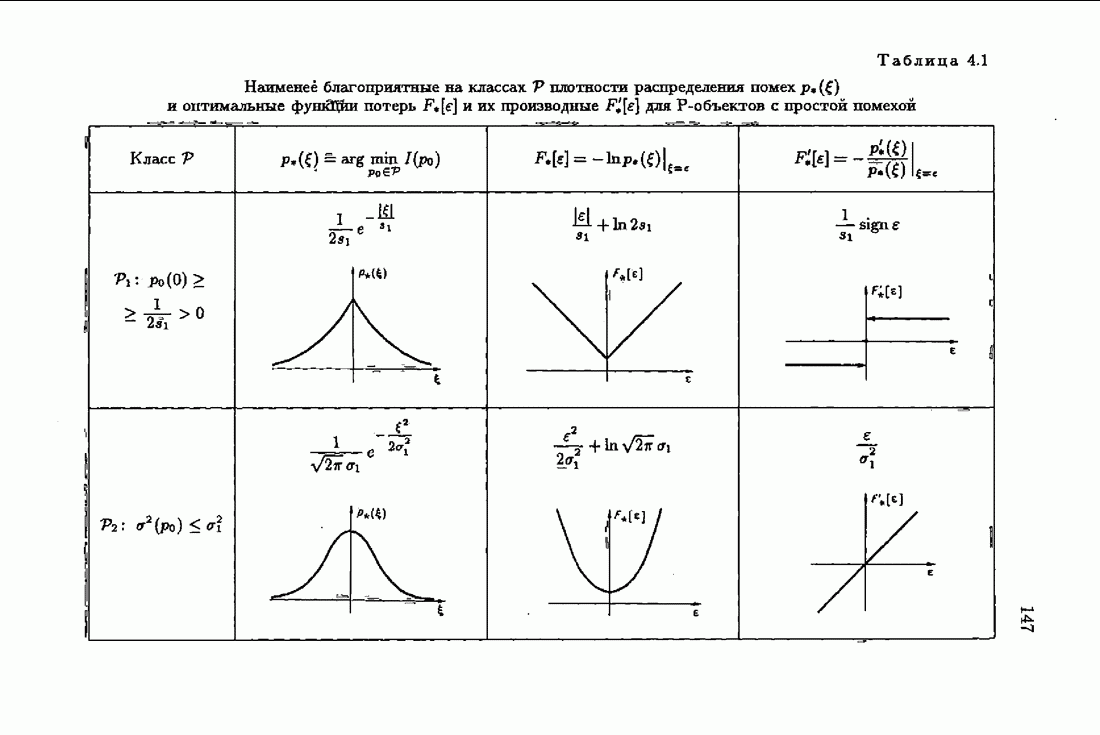
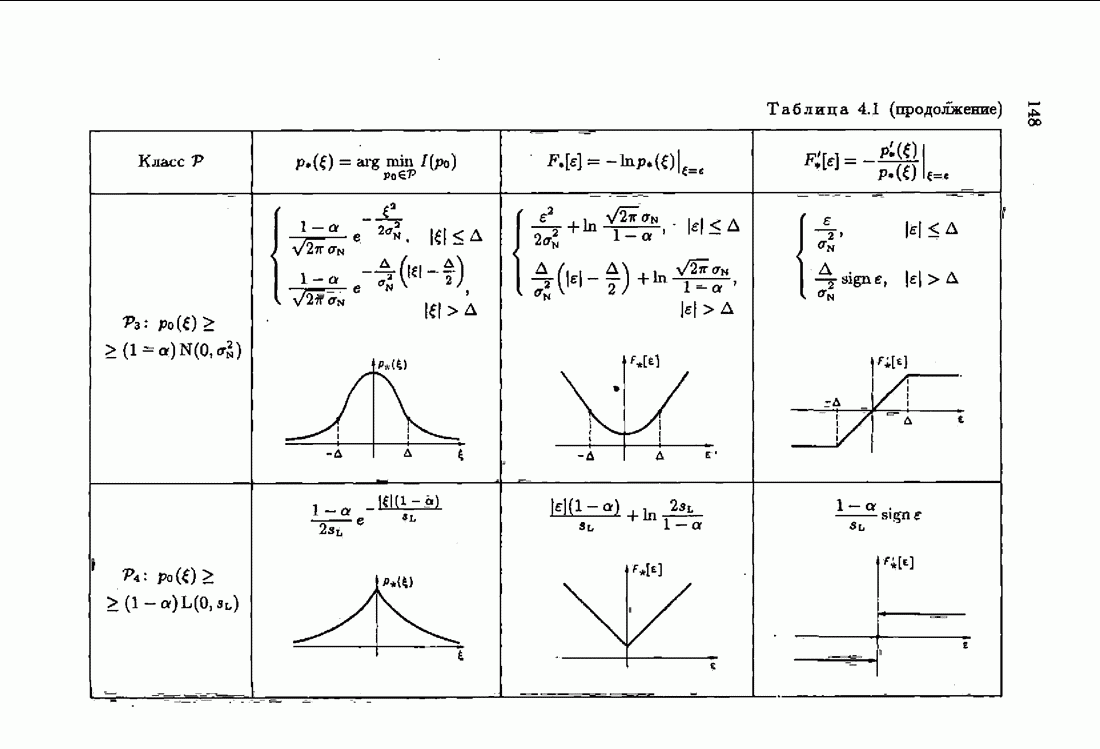
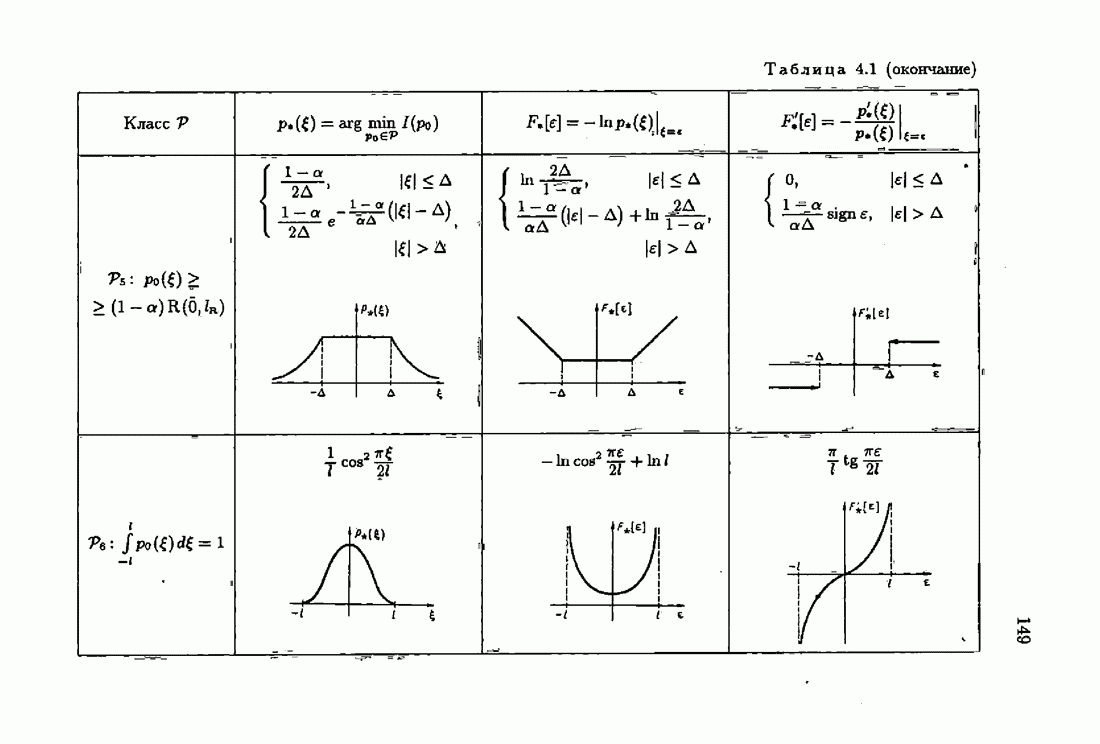
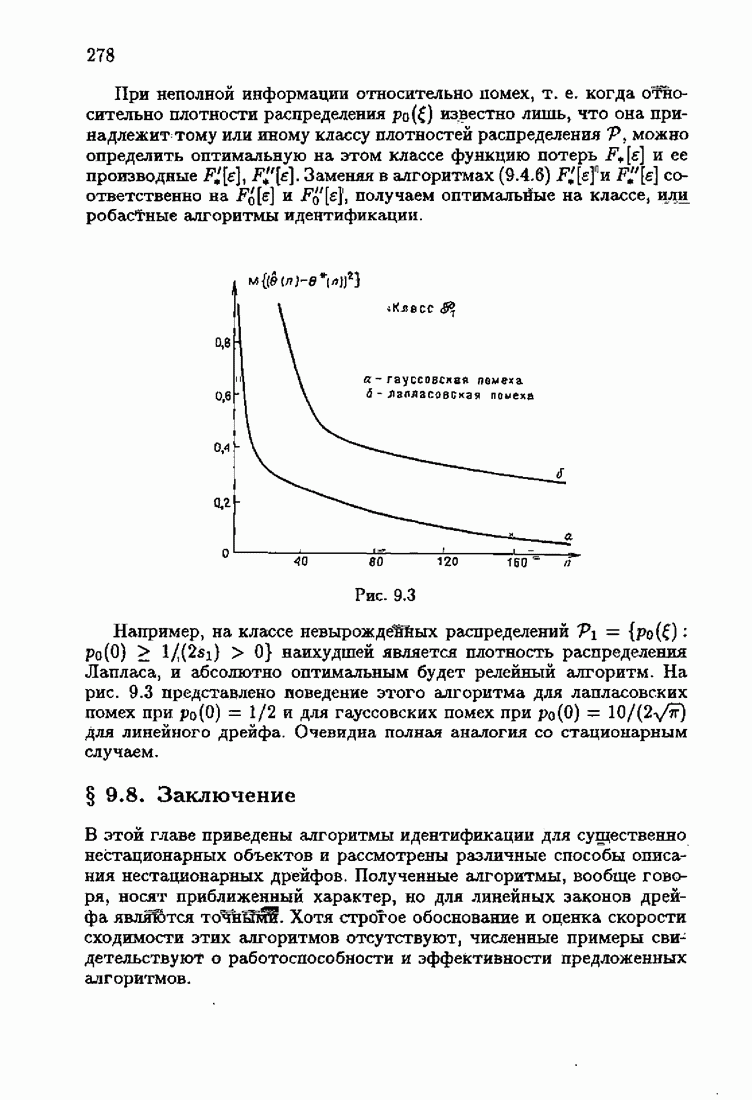
§ 4.2. Понятие оптимальности на классеПри неполной априорной информации о помехах плотность распределения их неизвестна и поэтому определить оптимальную функцию потерь невозможно. А это значит, что невозможно сформировать абсолютно оптимальные алгоритмы идентификации. Предположим теперь, что нам известен лишь класс распределений помех V, характеризующий имеющийся уровень априорной информации относительно истинной плотности распределения Рассмотрим АМКО при произвольной функции потерь (2.4.7)
Функцию потерь без ограничения общности удобно представить в виде
где
Подставляя из (4.2.3) в (4.2.1) и обозначая для простоты
Введем обозначения
Назовем
При
и из (4.2.6) следует уже знакомое нам выражение АМКО для оптимальной функции потерь
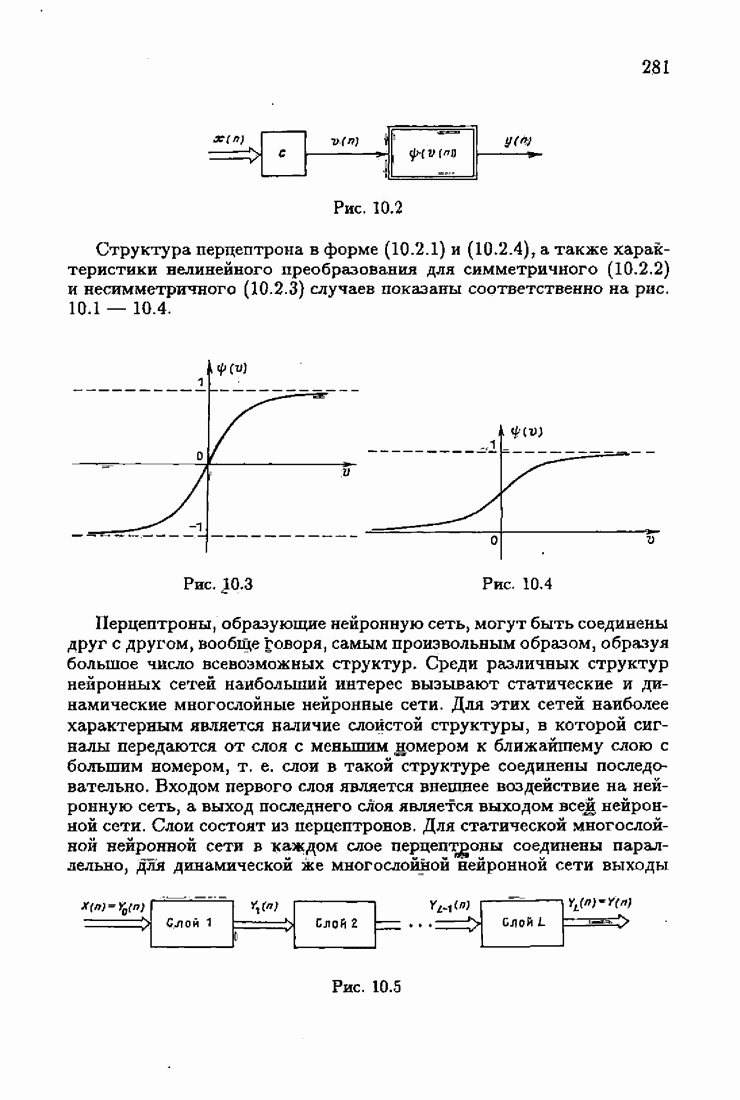
В каждом классе распределений V таких «оптимальных» функций потерь
опшылаьмой на классе V, если для любой плотности распределения помех
Выясним смысл этого неравенства, для чего воспользуемся неравенством (2.5.4), определяющим оптимальную функцию потерь. В принятых здесь обозначениях оно запишется в виде
В частности, при
Но в силу неравенства (4.2.10)
Отсюда следует, что
т. е.
Таким образом, Оптимальная на классе функция потерь (4.2.9), как видно из (4.2.10), гарантирует
и знчит
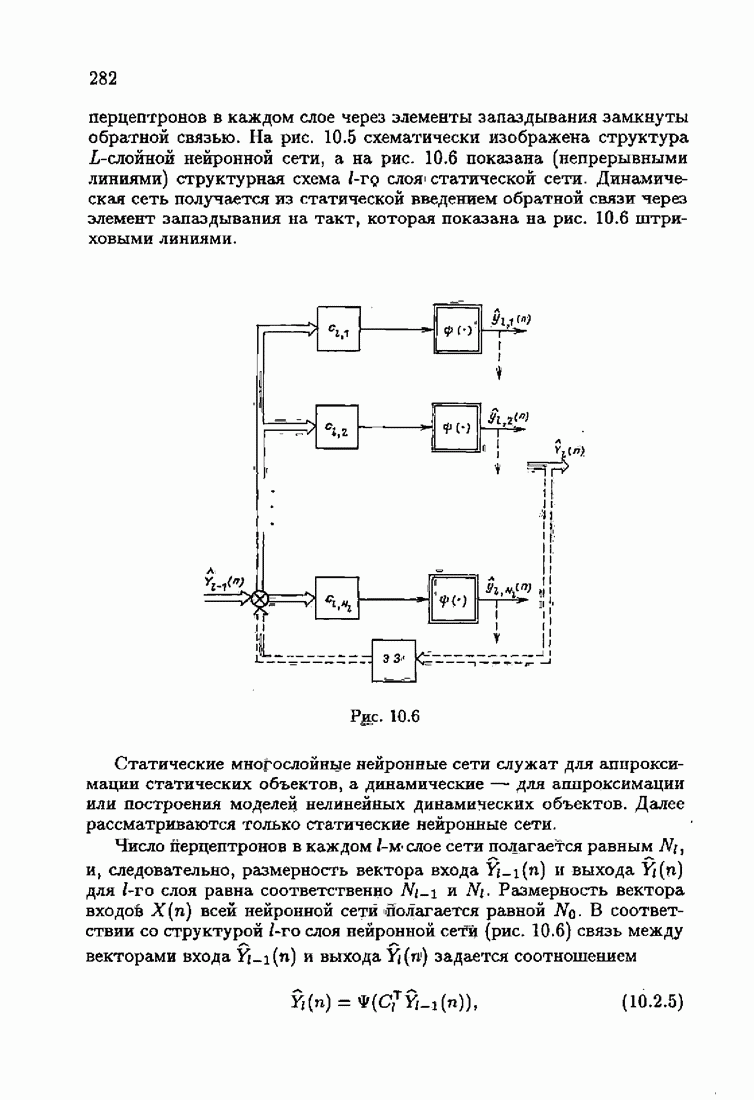
Разумеется, предложенное определение (4.2.10), (4.2.15) или (4.2.16), (4.2.17) оптимальной на классе функции потерь (4.2.9) будет иметь смысл лишь тогда, когда, матричные неравенства (4.2.16) и, значит, (4.2.10) будут действительно иметь место для Вспоминая, что в общем случае для динамического объекта нормированная информационная матрица имеет вид (см.
представим обратные
и
Пусть плотность распределения принадлежит классу распределений
будет также принадлежать классу V при
где теперь
и
Поскольку
то условие минимума запишется в виде
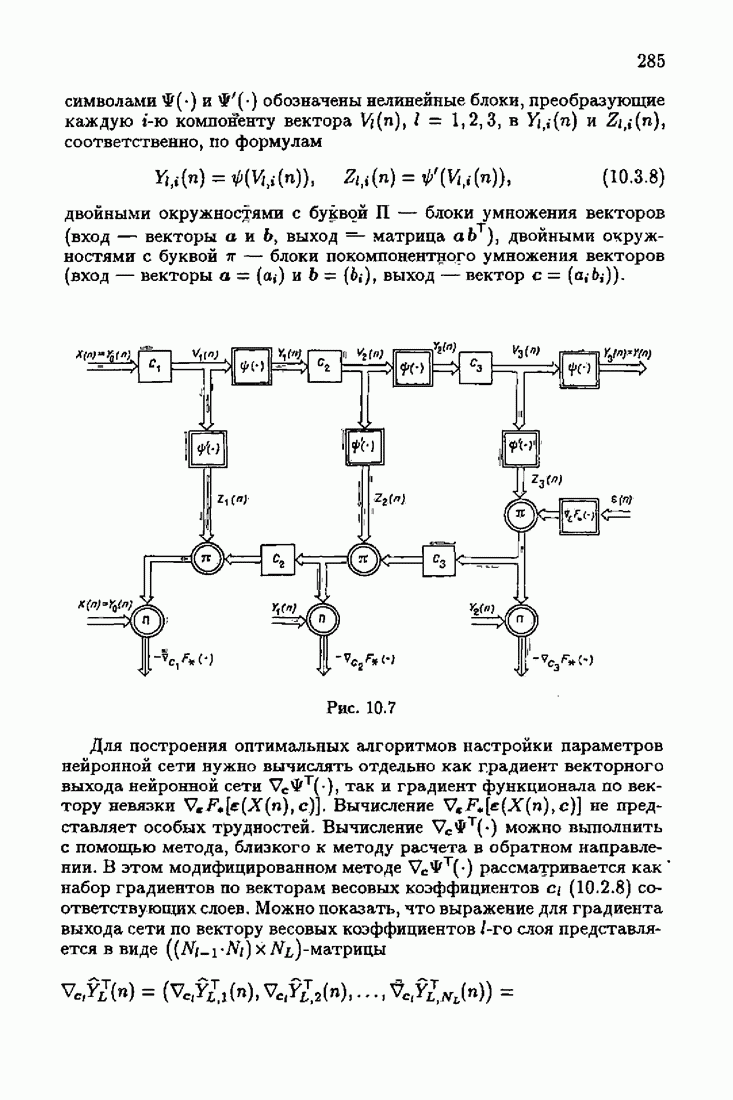
Дифференцируя
Рассмотрим теперь
где теперь
а
Сопоставляя Отсюда и следует справедливость матричного неравенства (4.2.16). Таким образом, мы обосновали понятие оптимальности на классе.
|
 |
Оглавление
|












































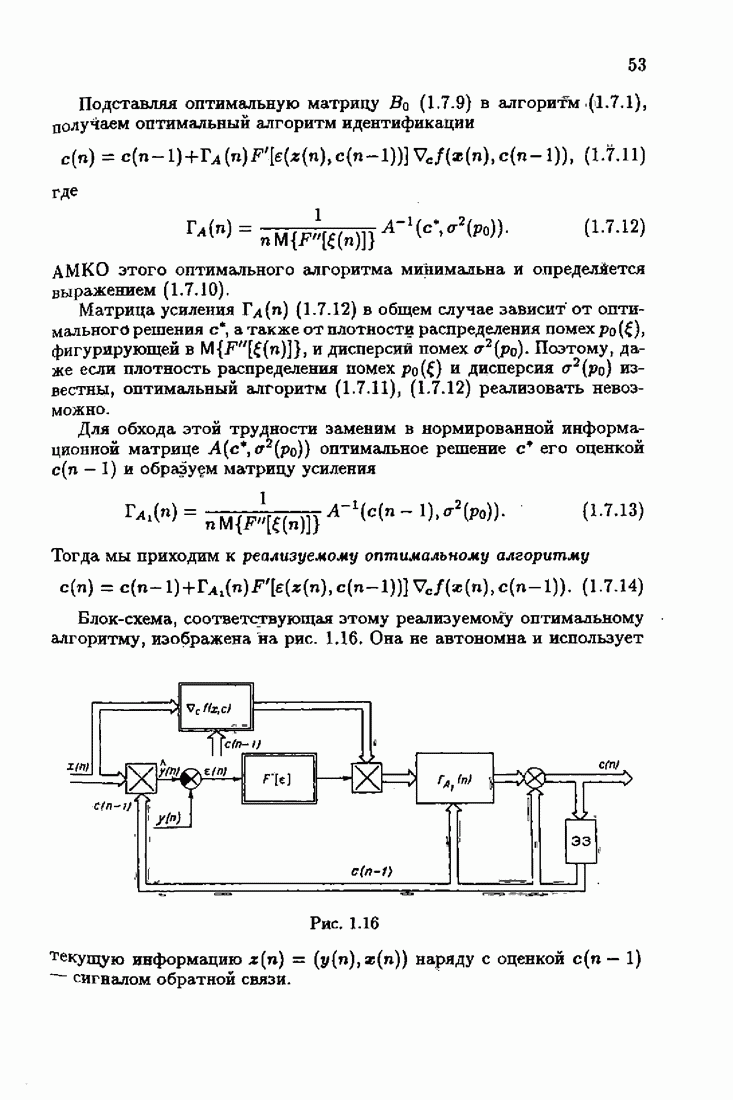















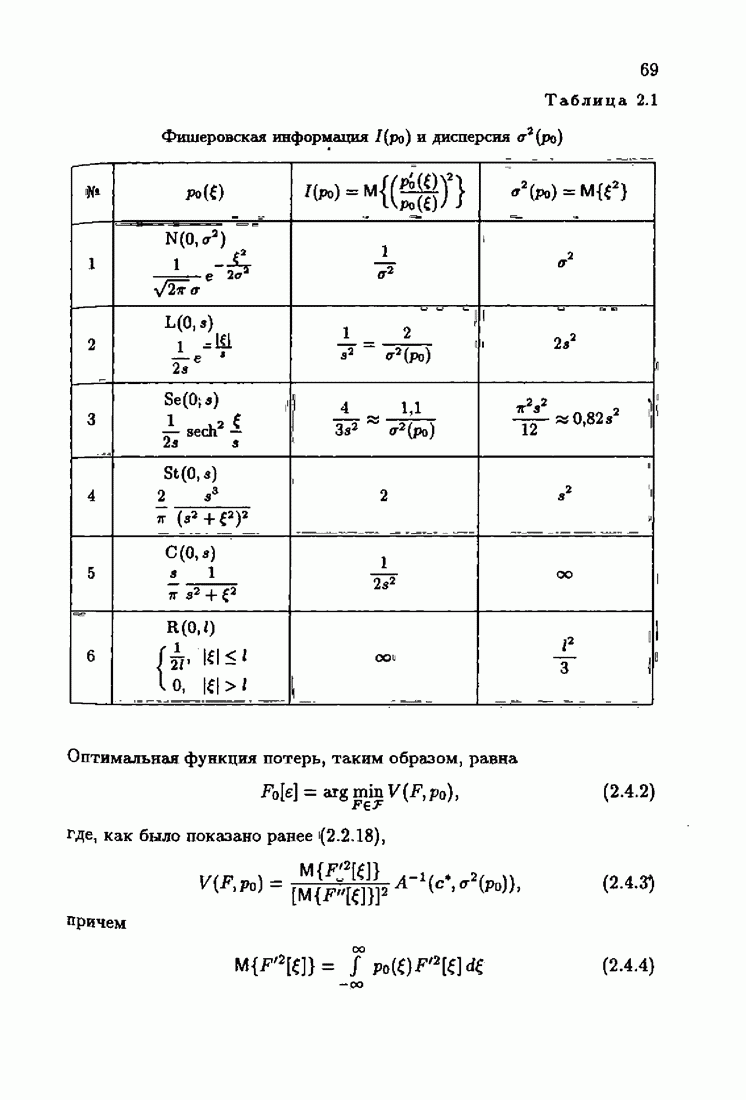



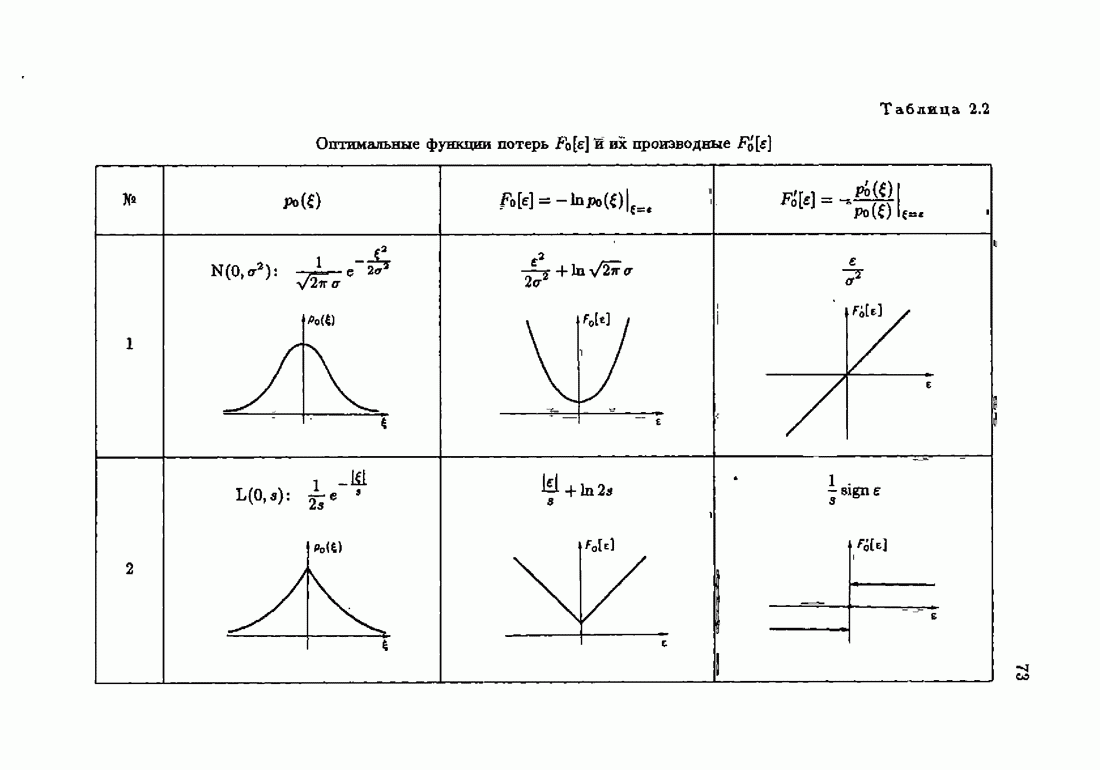
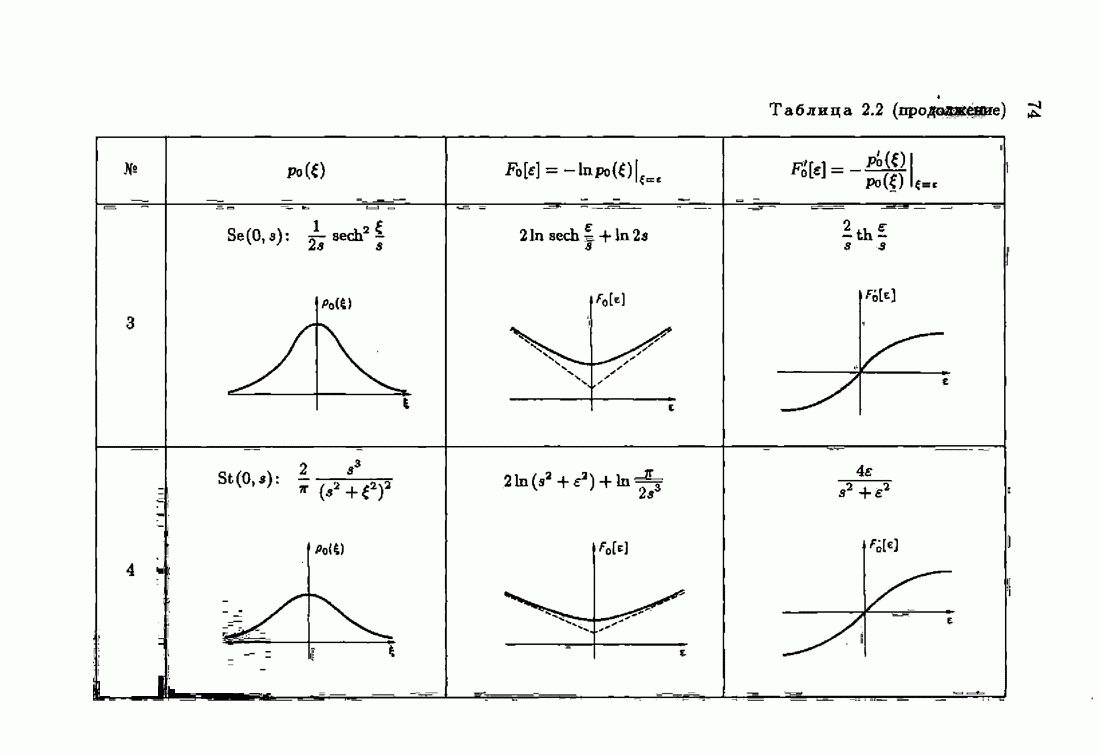














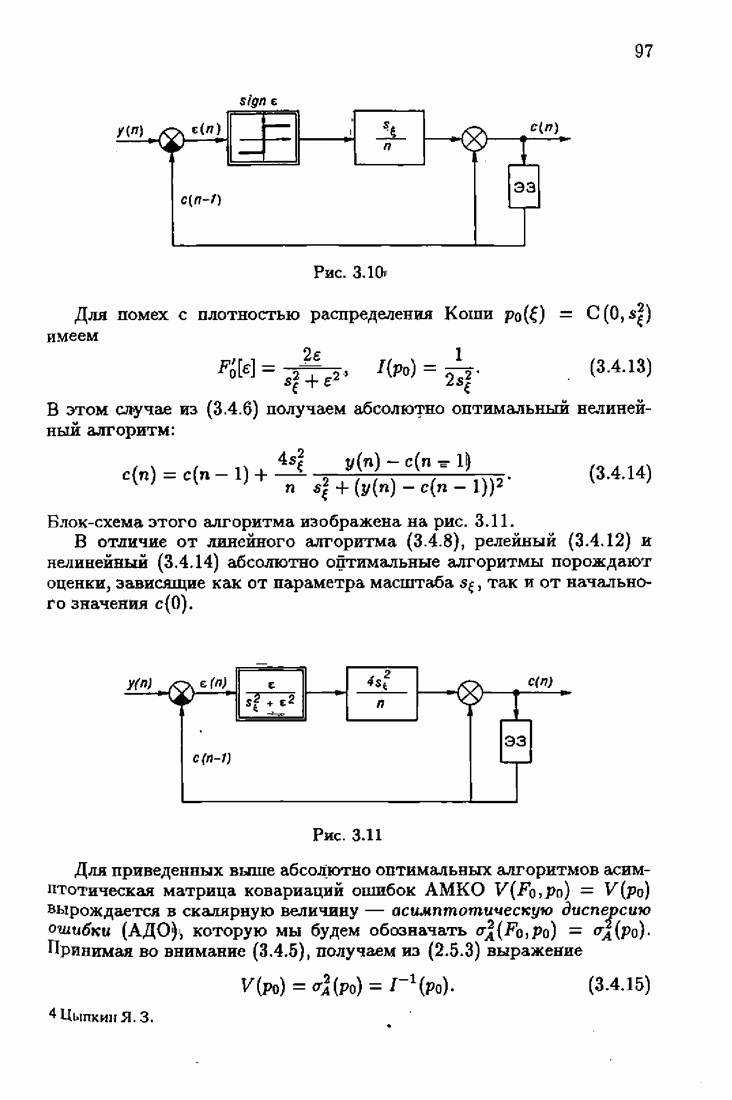



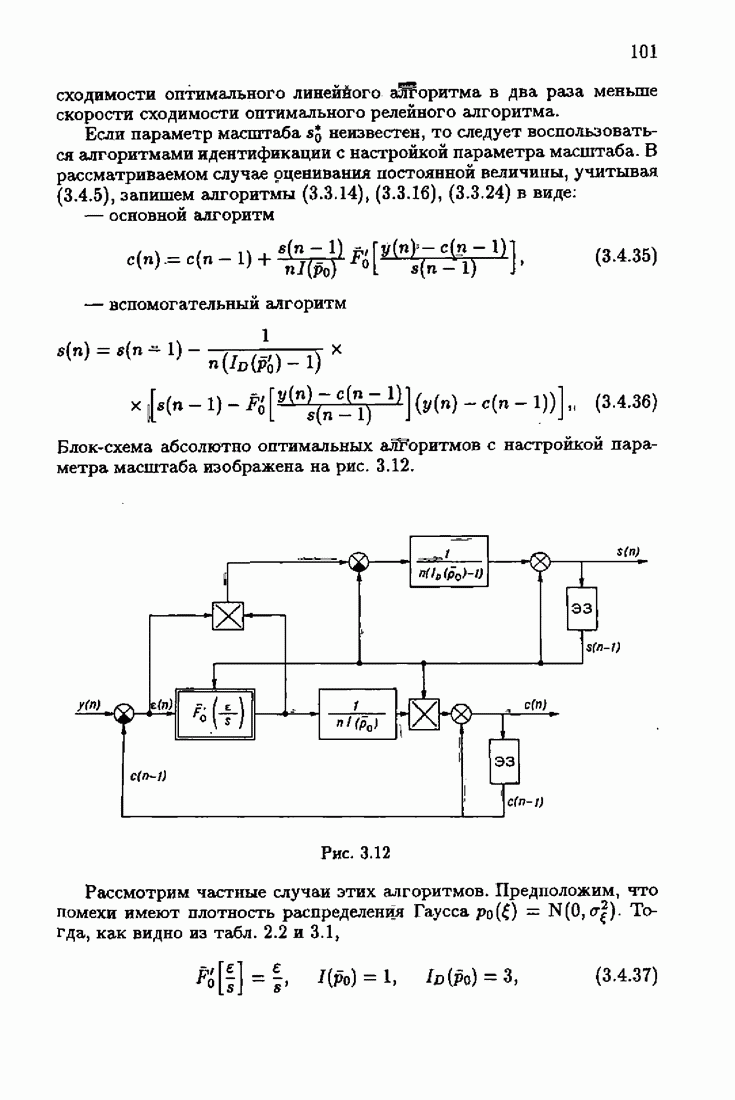
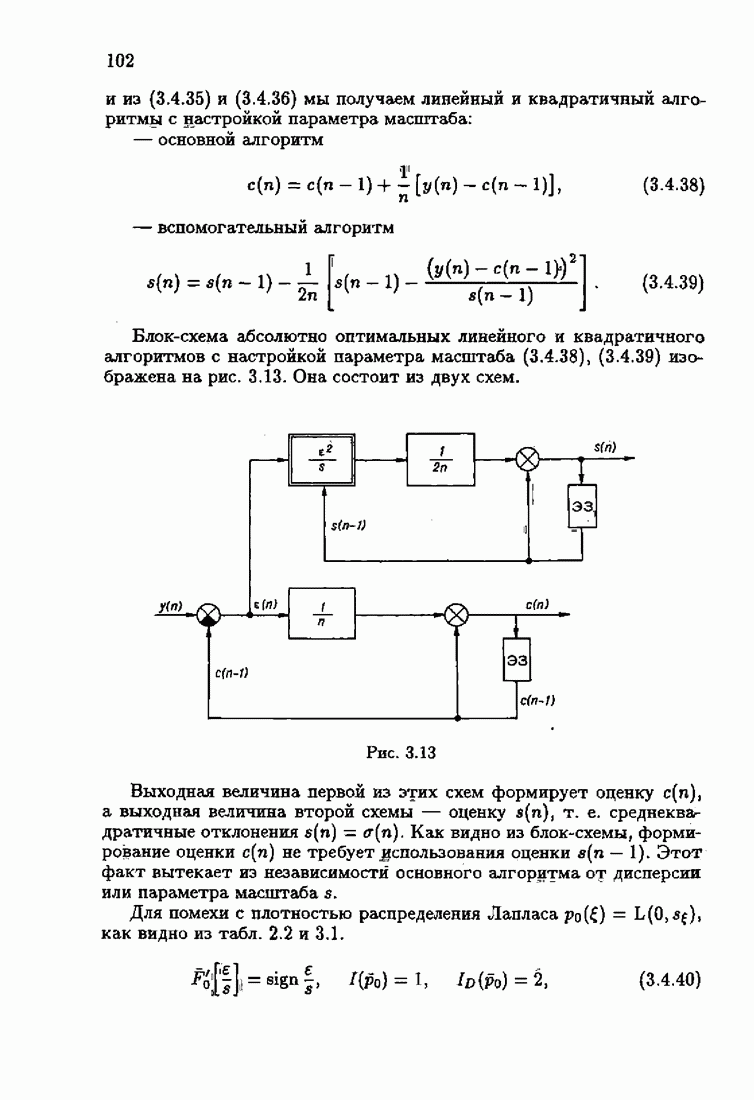
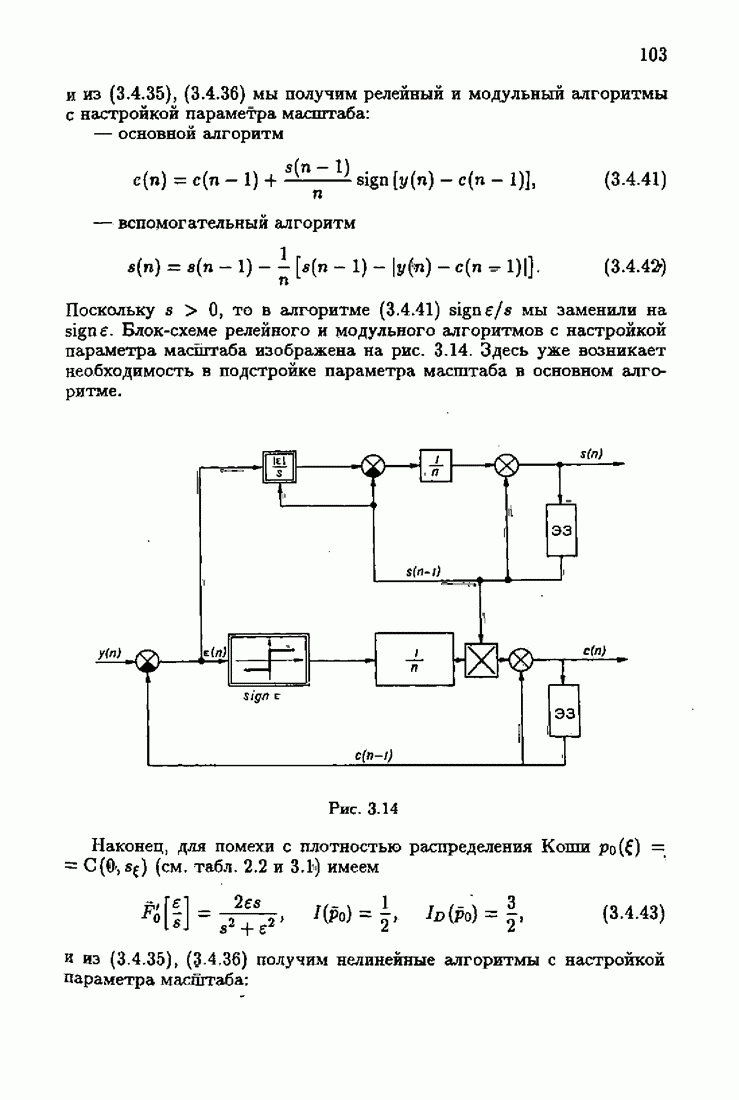
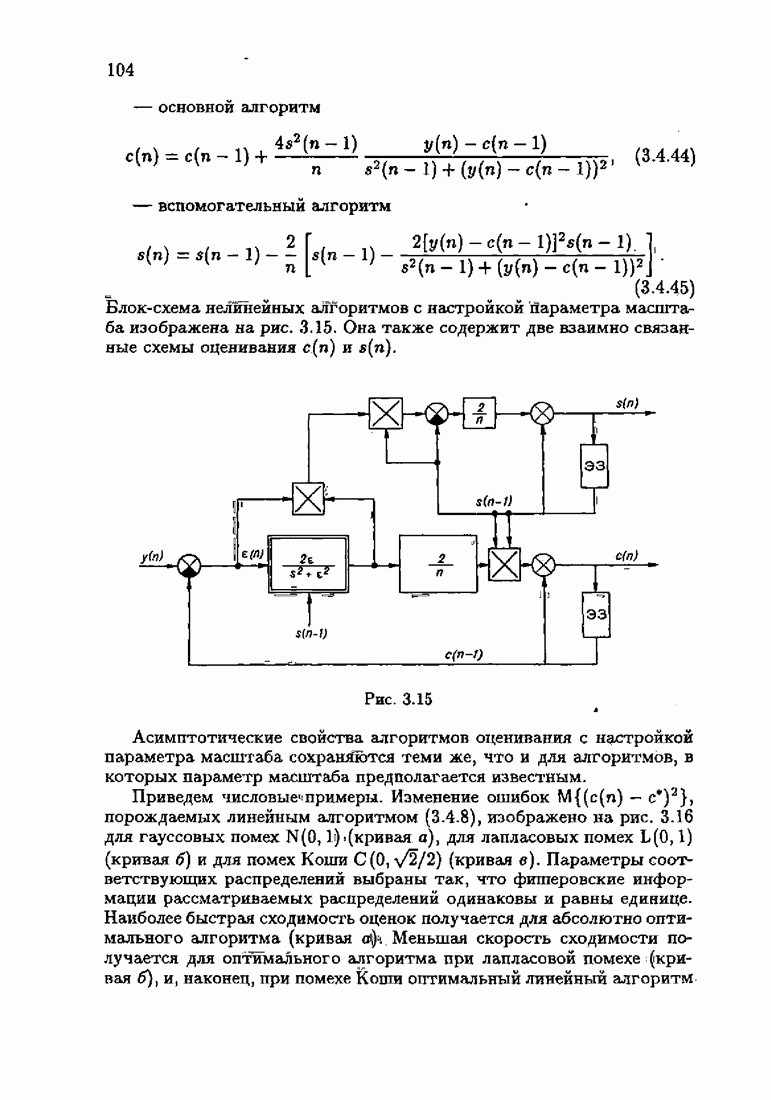
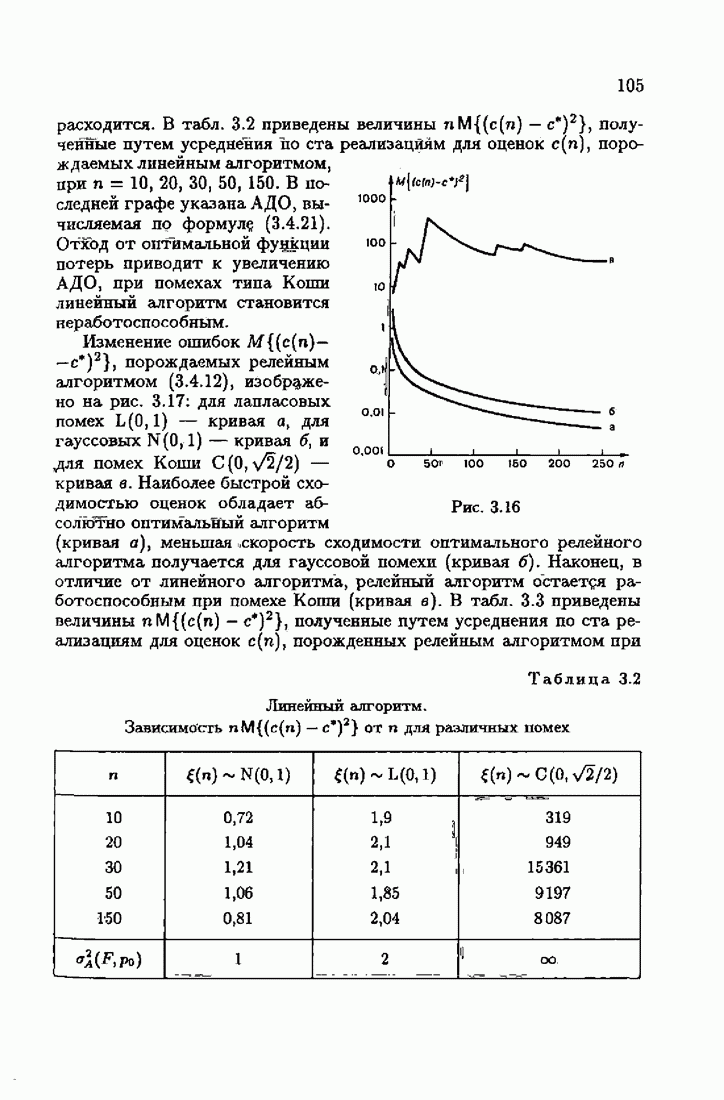

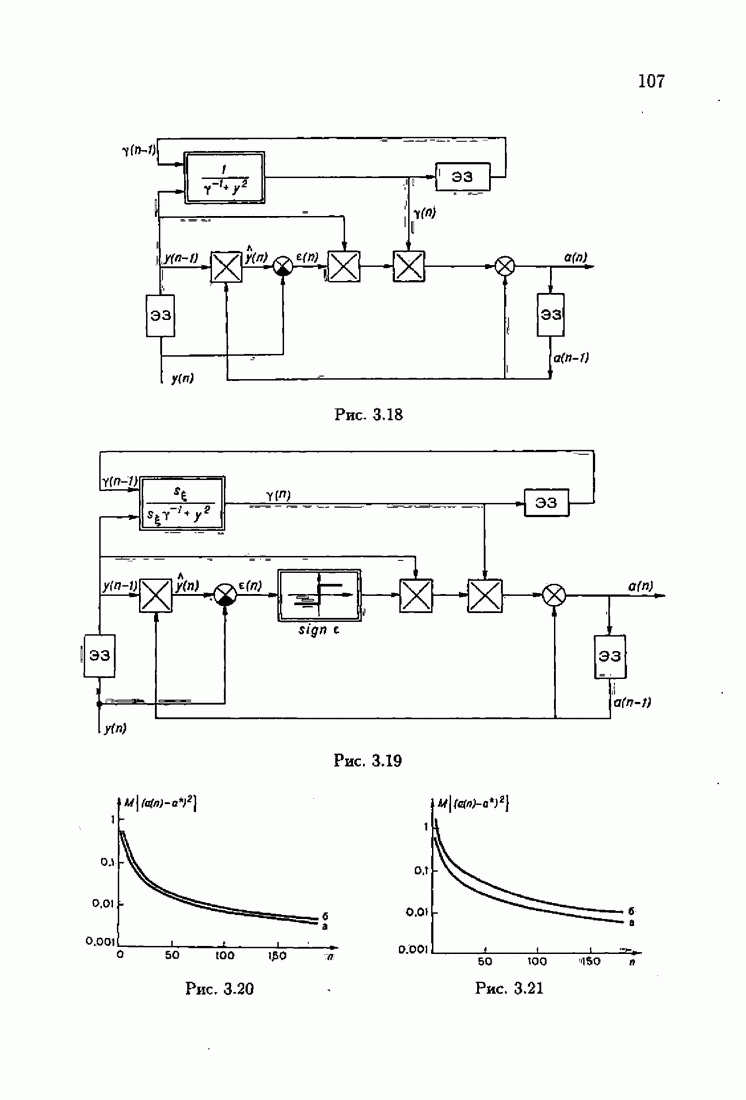

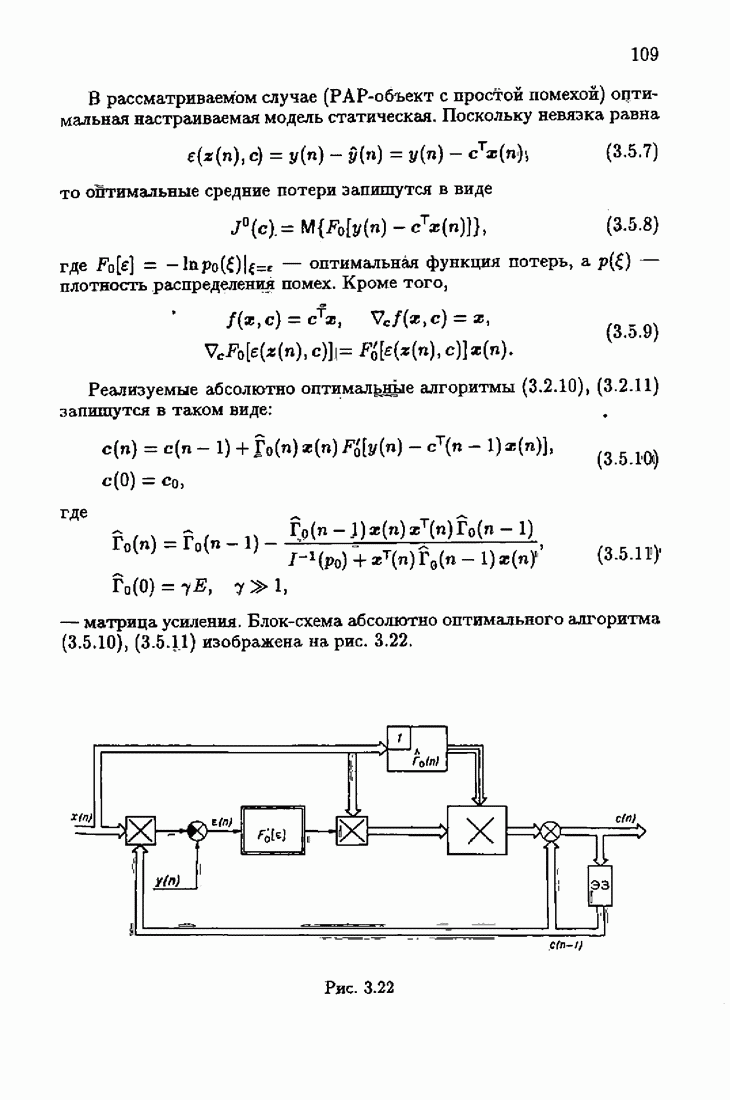

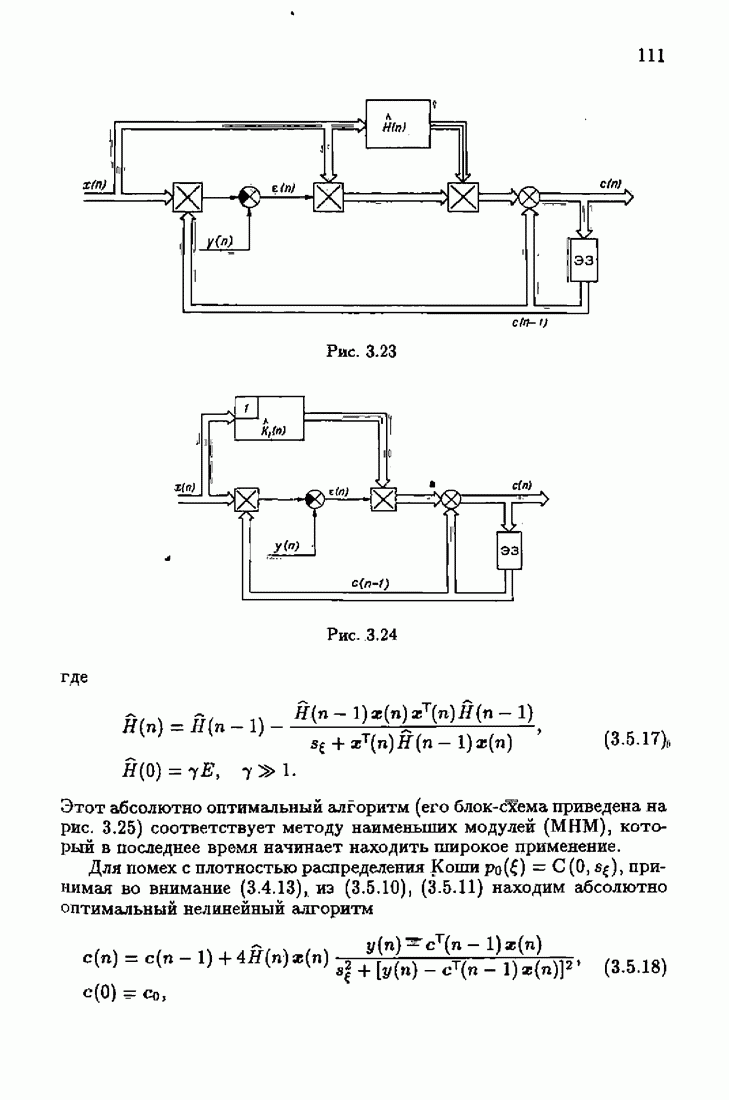
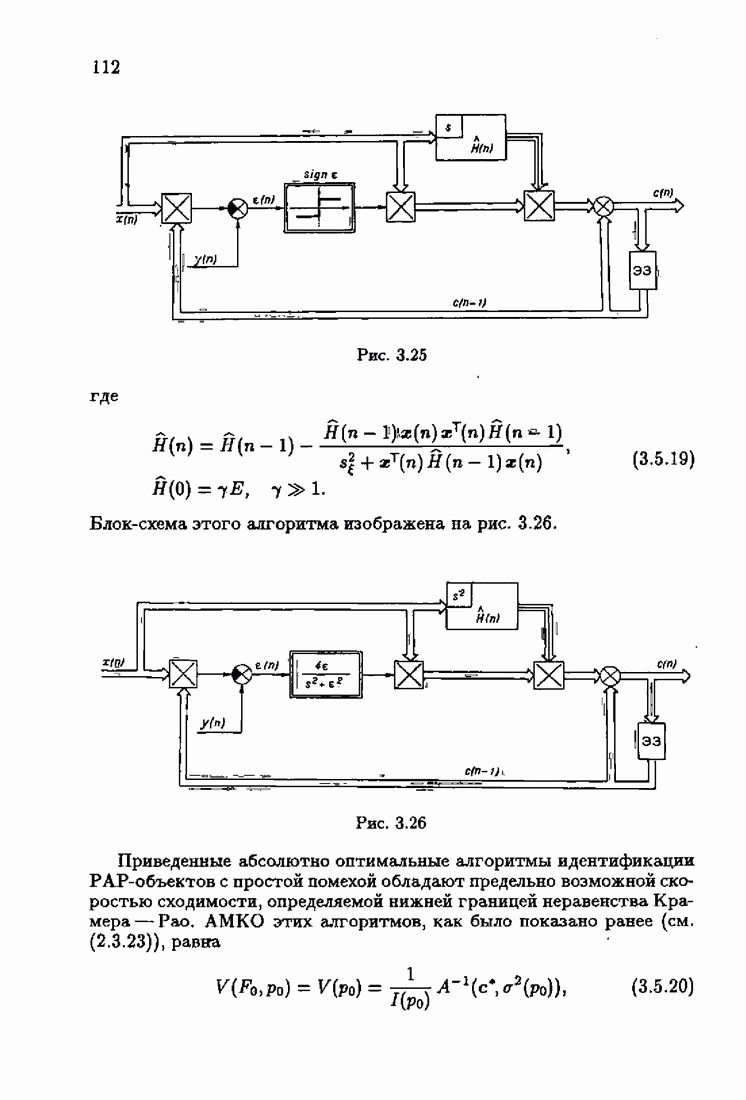



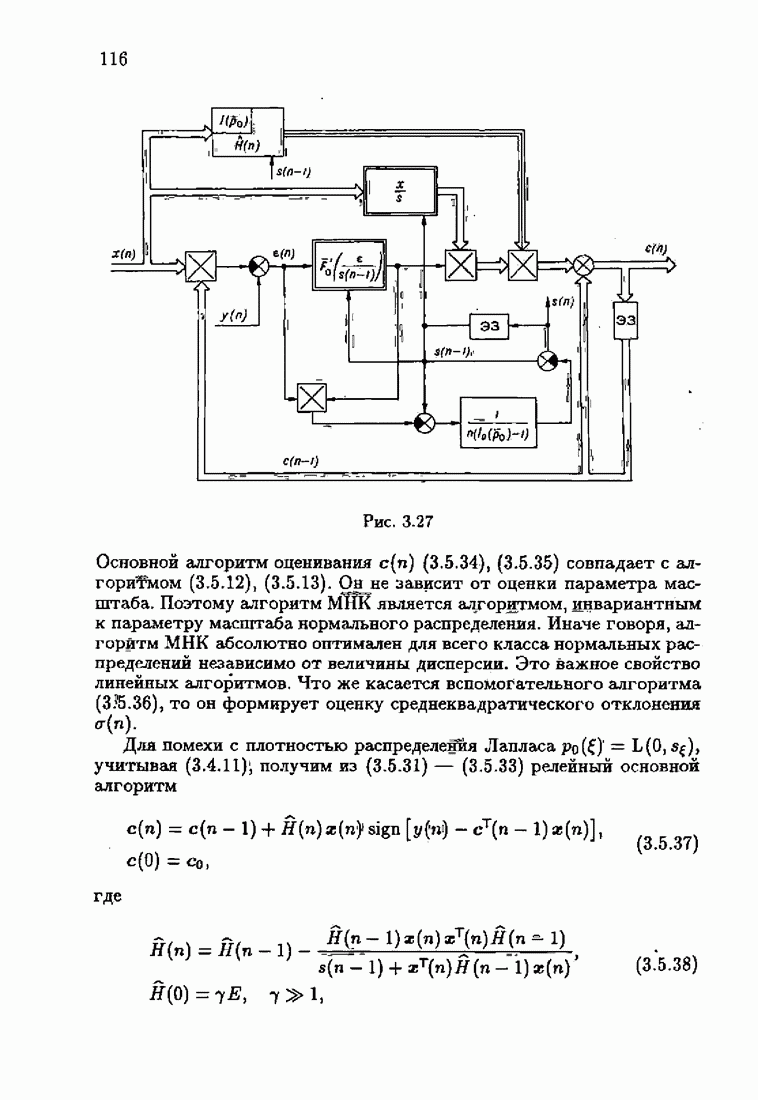
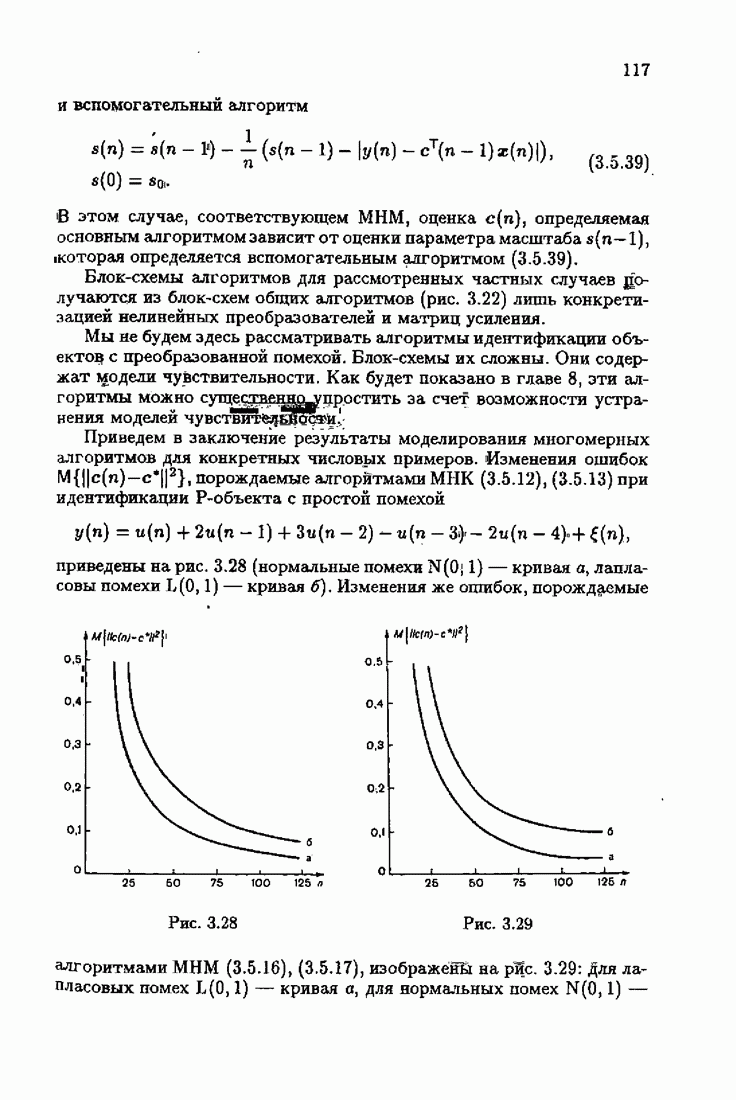































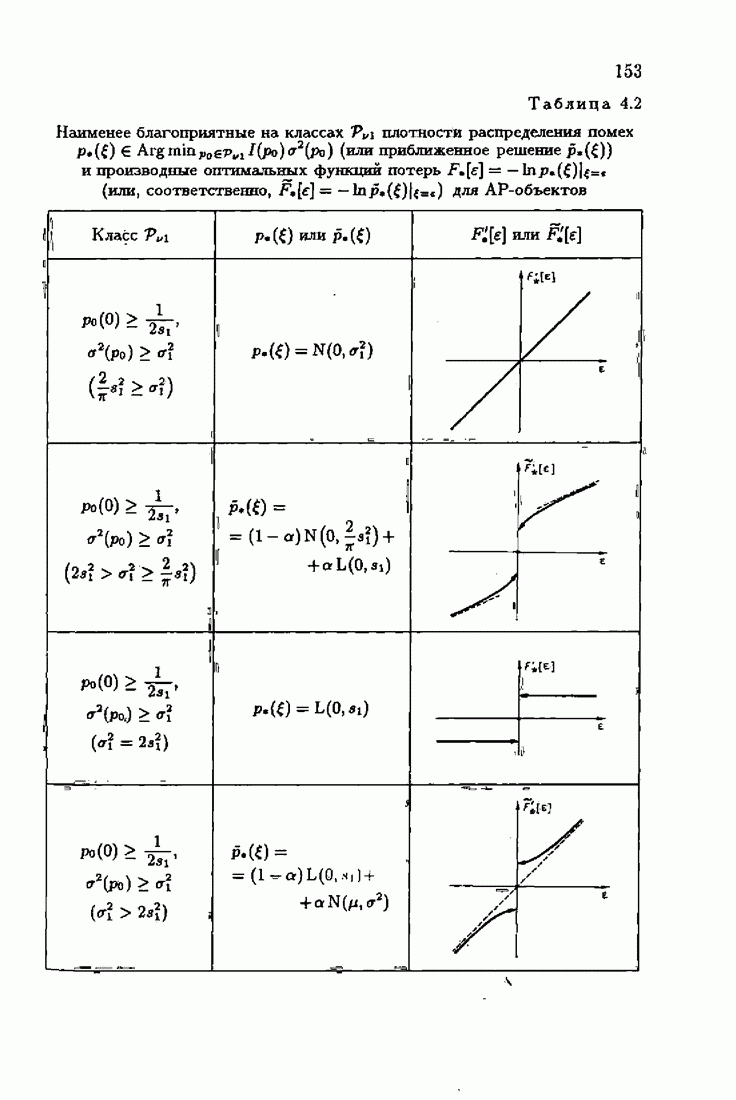
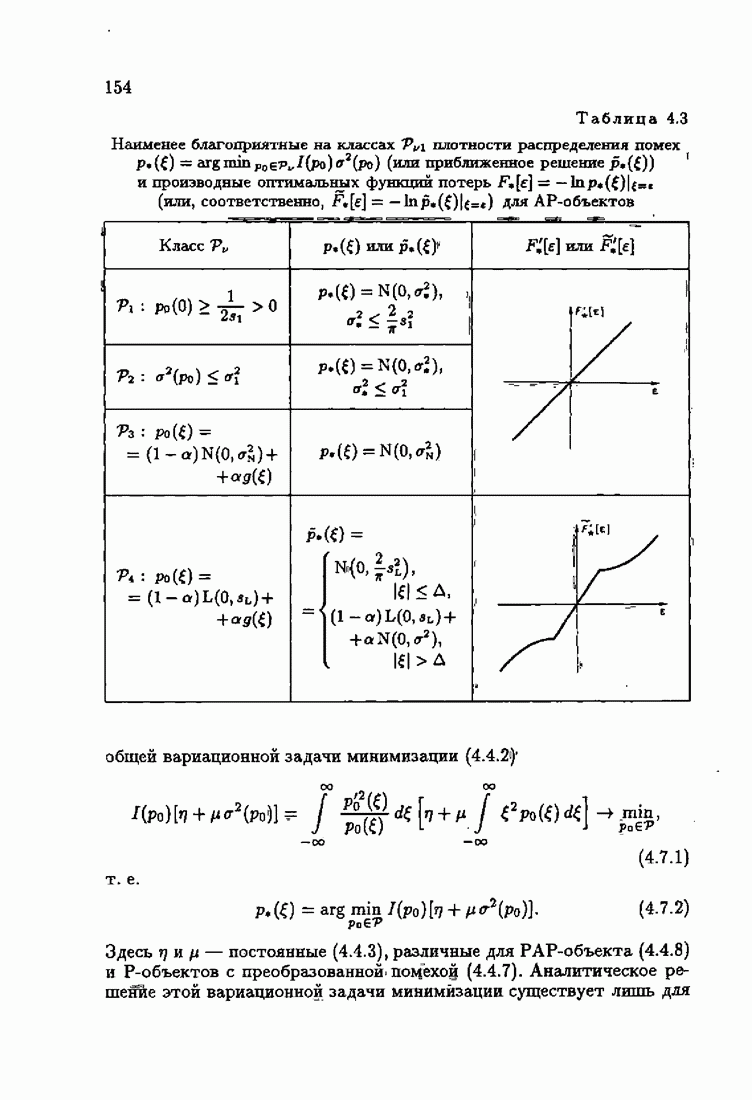


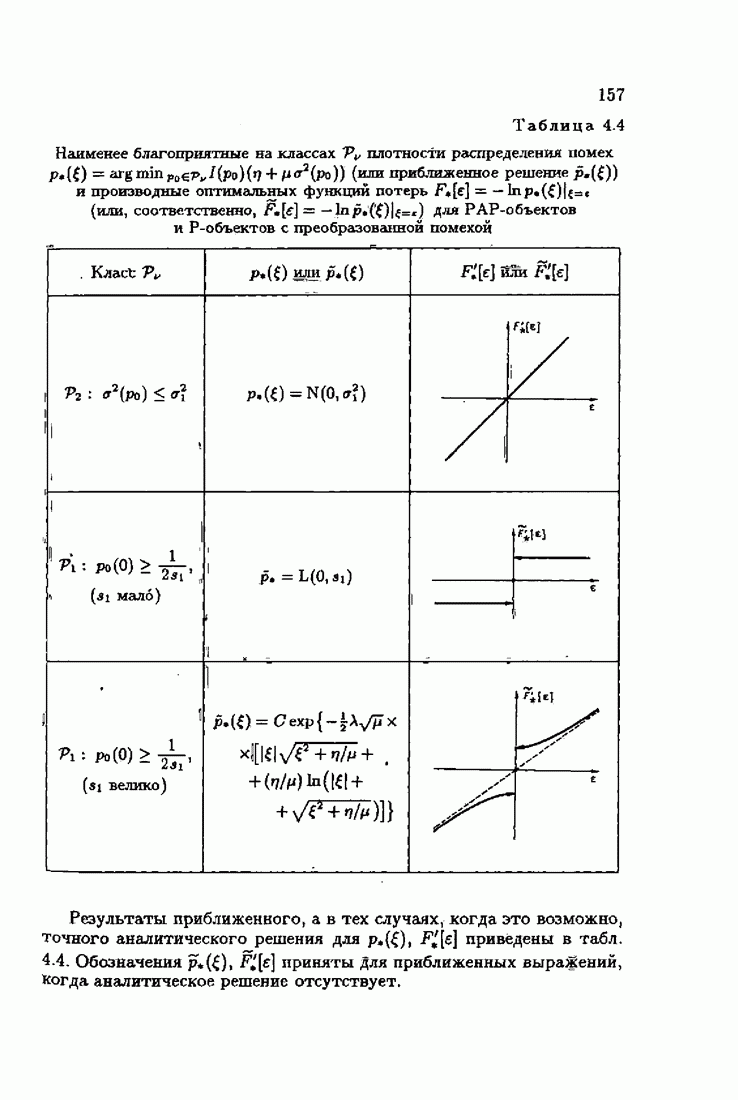











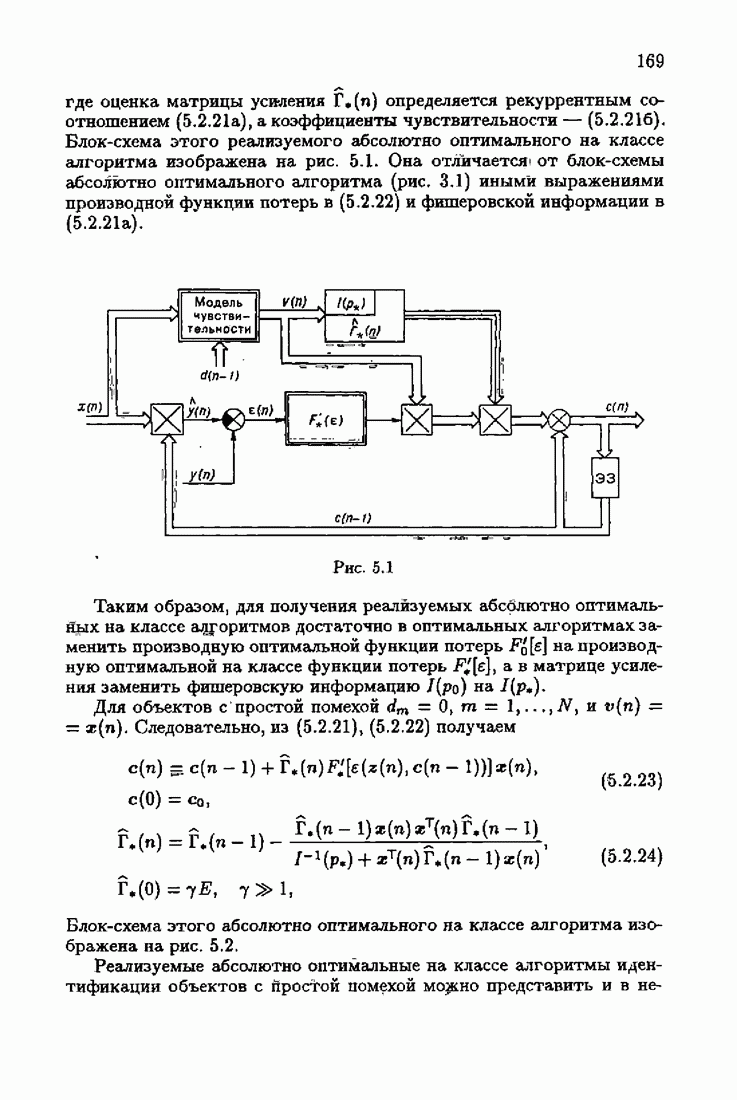
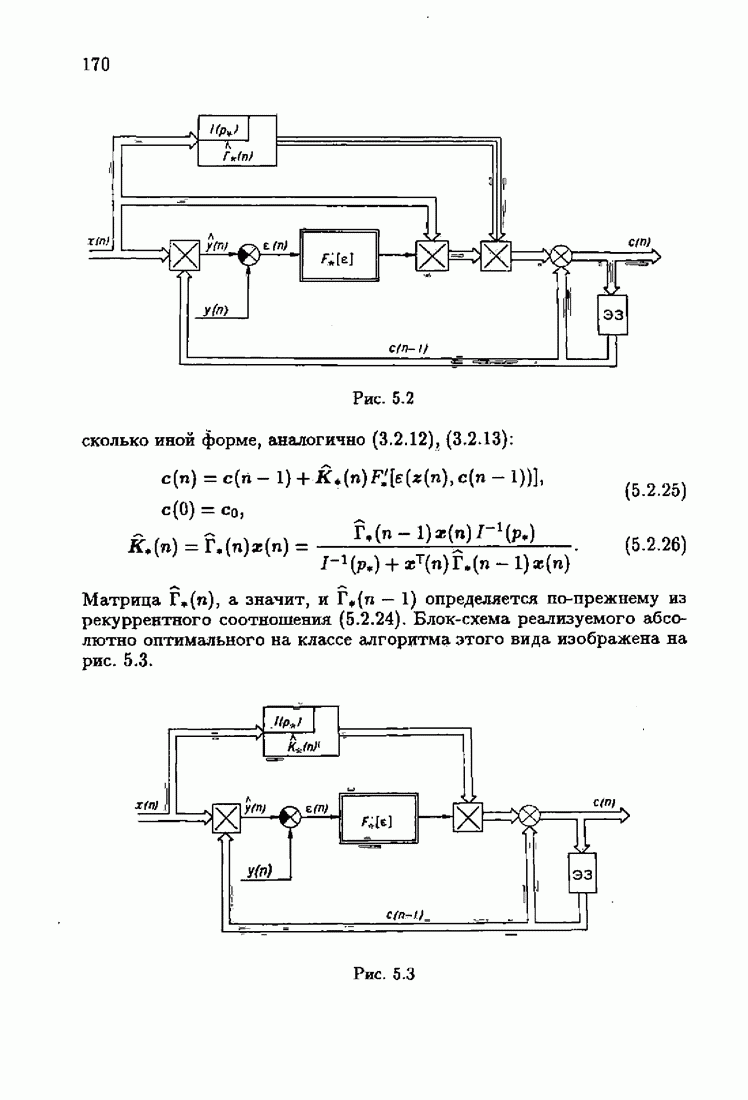

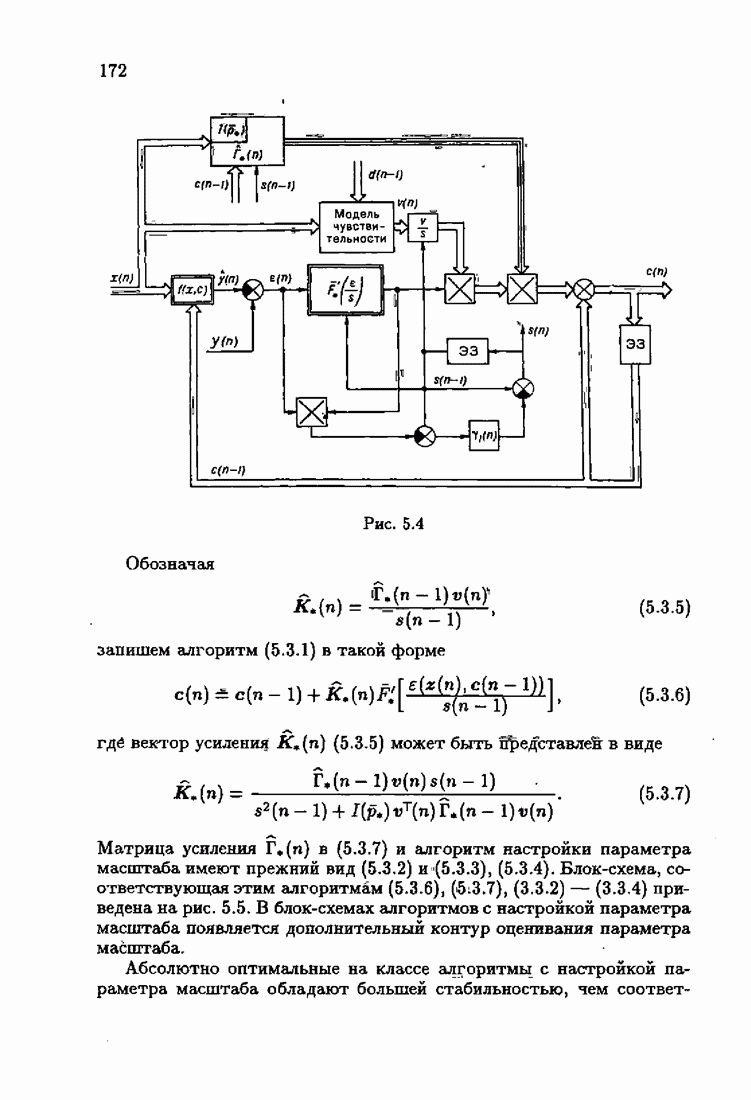
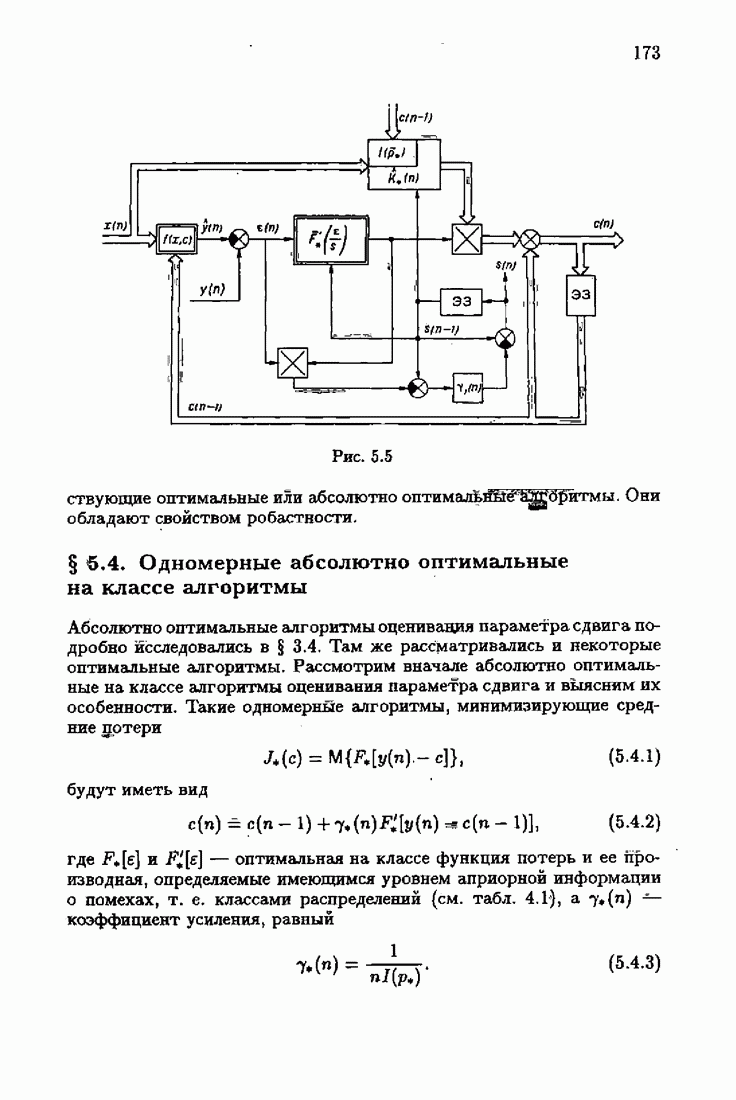




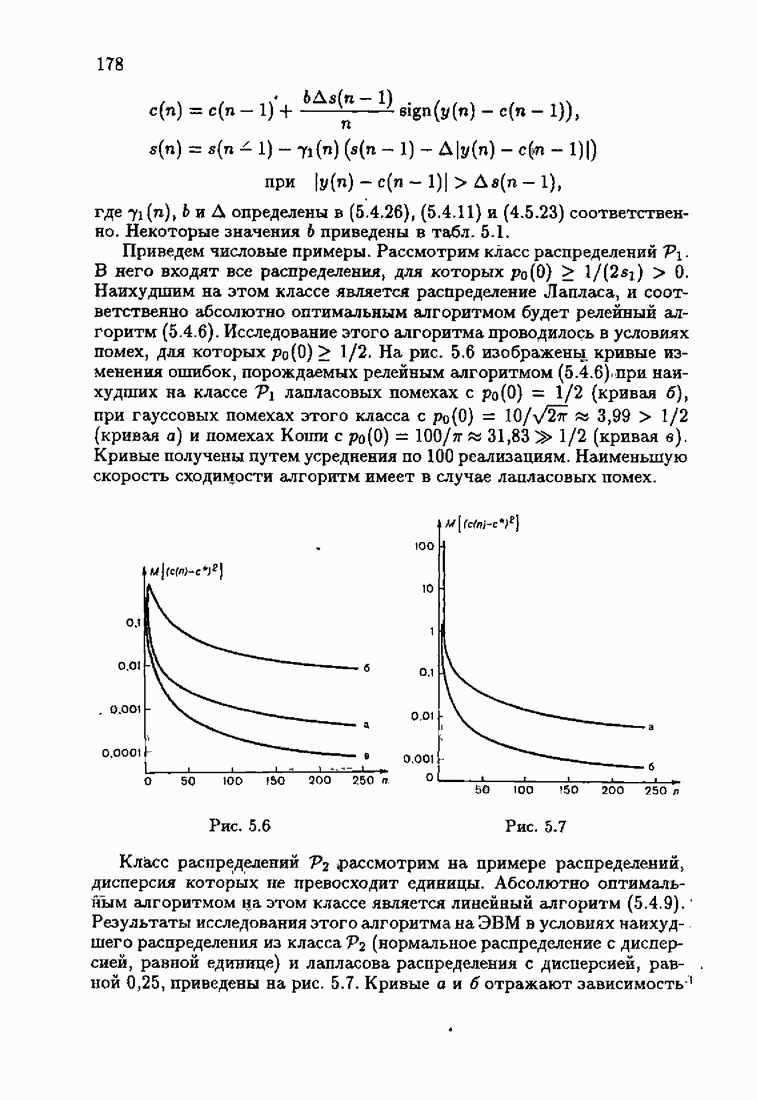































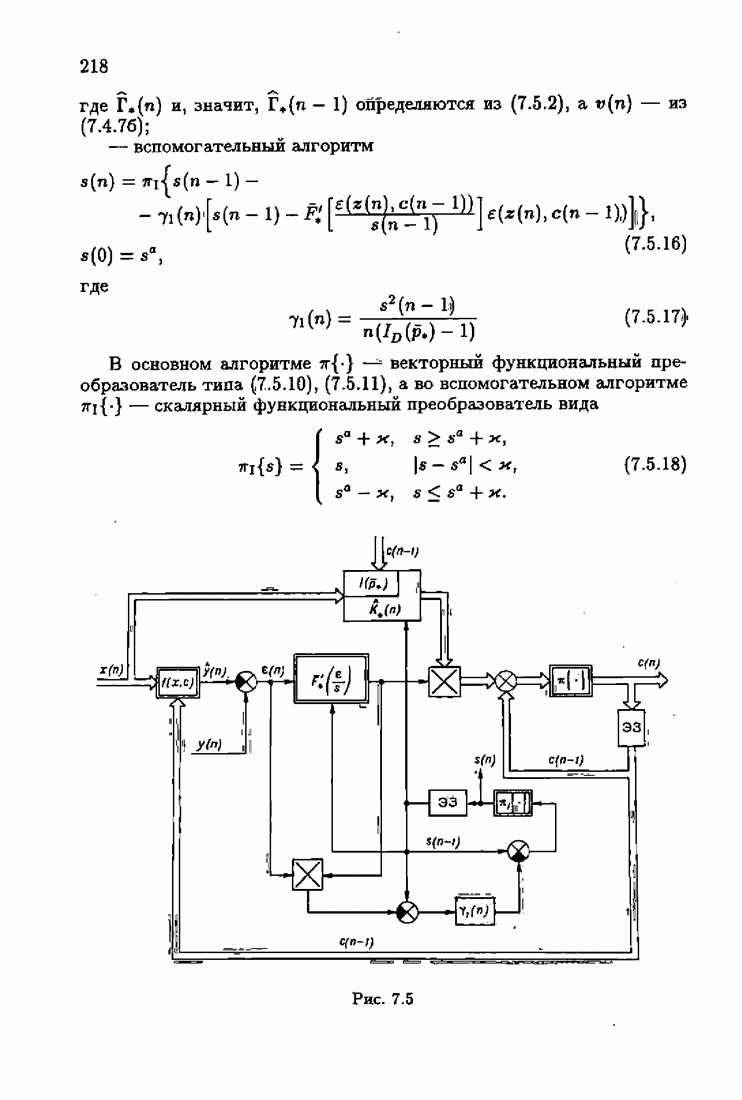









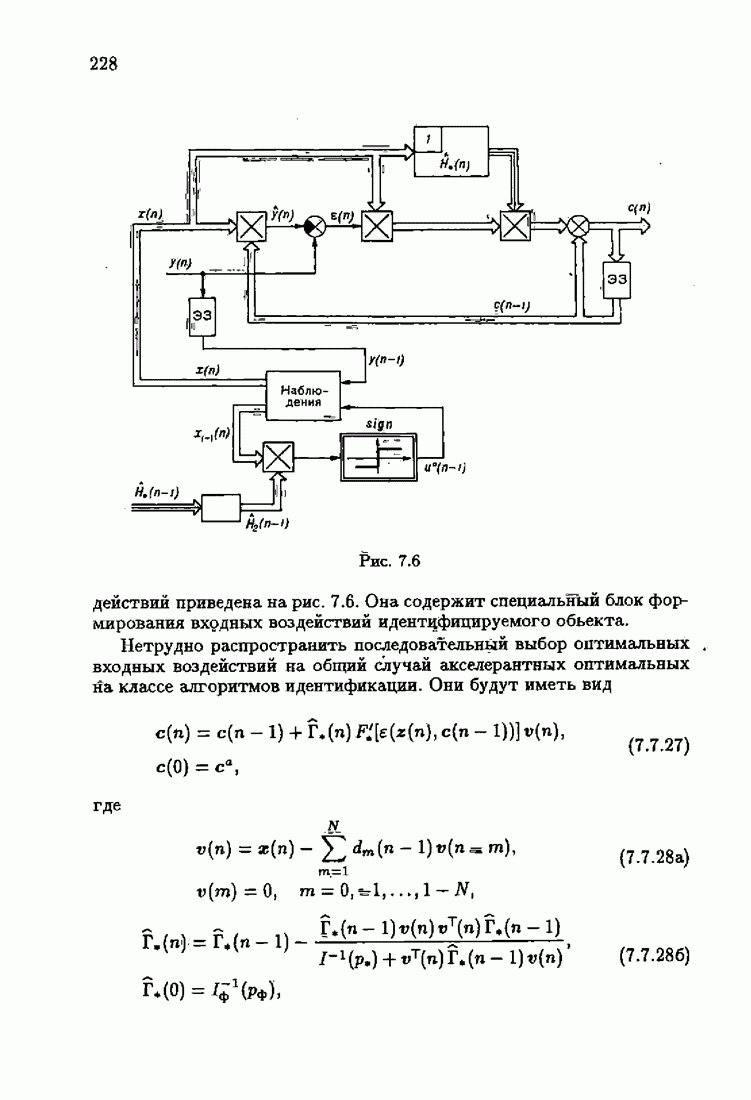
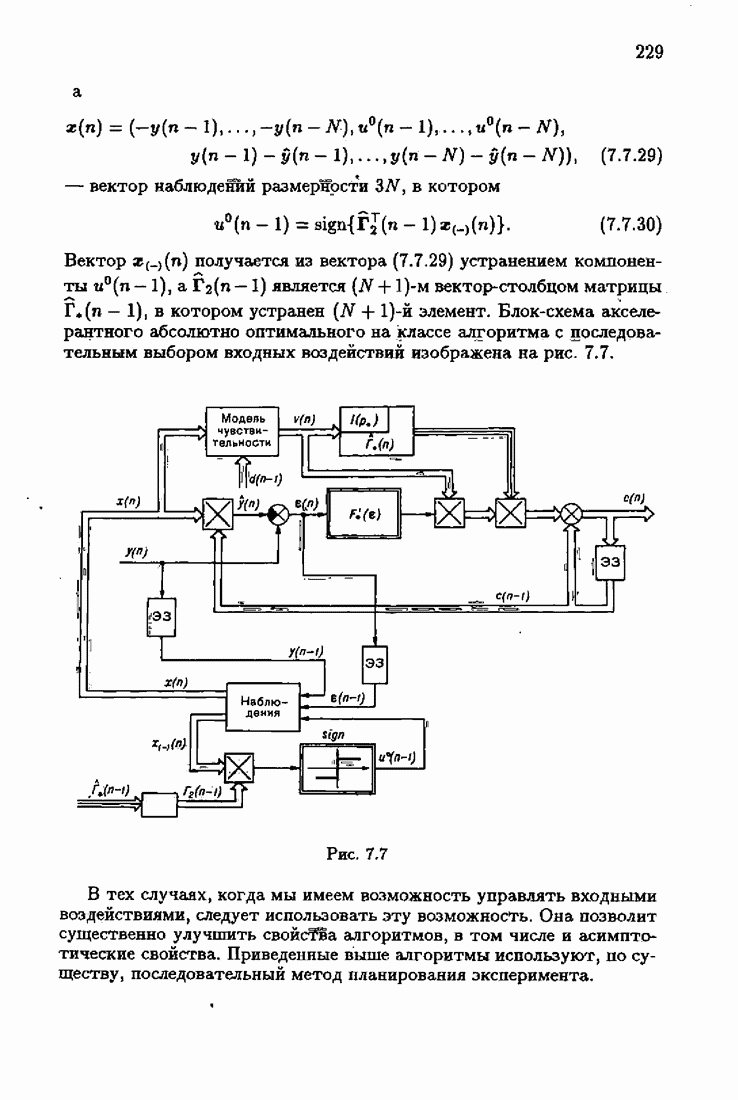


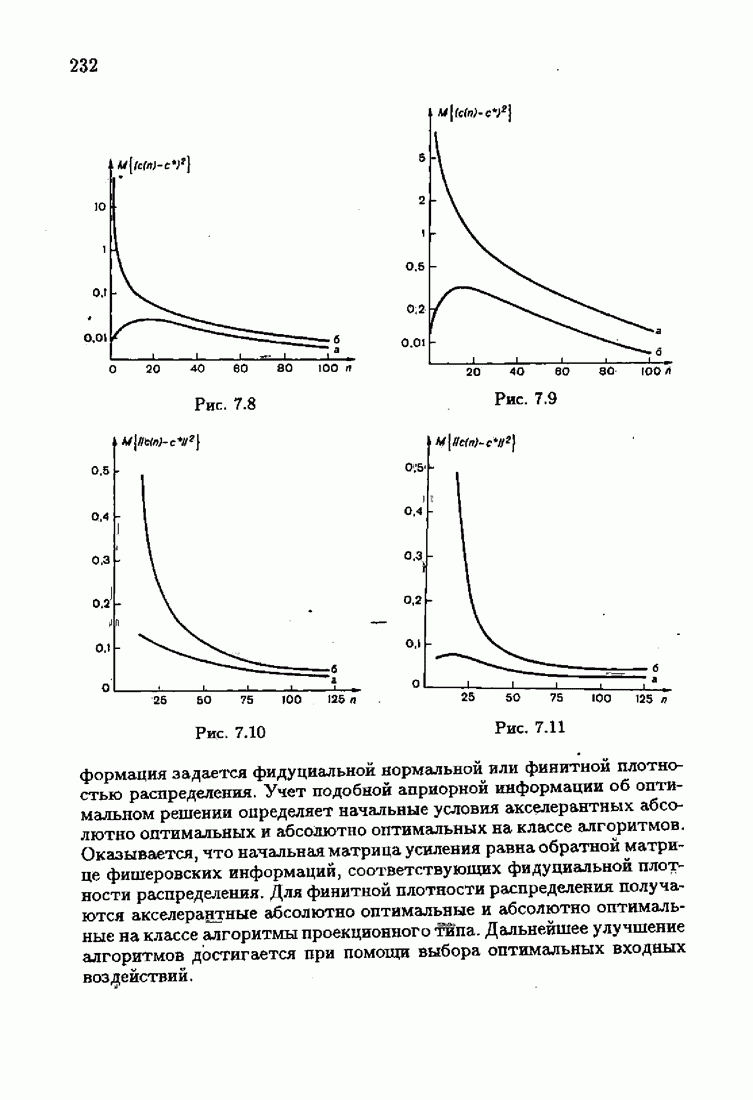




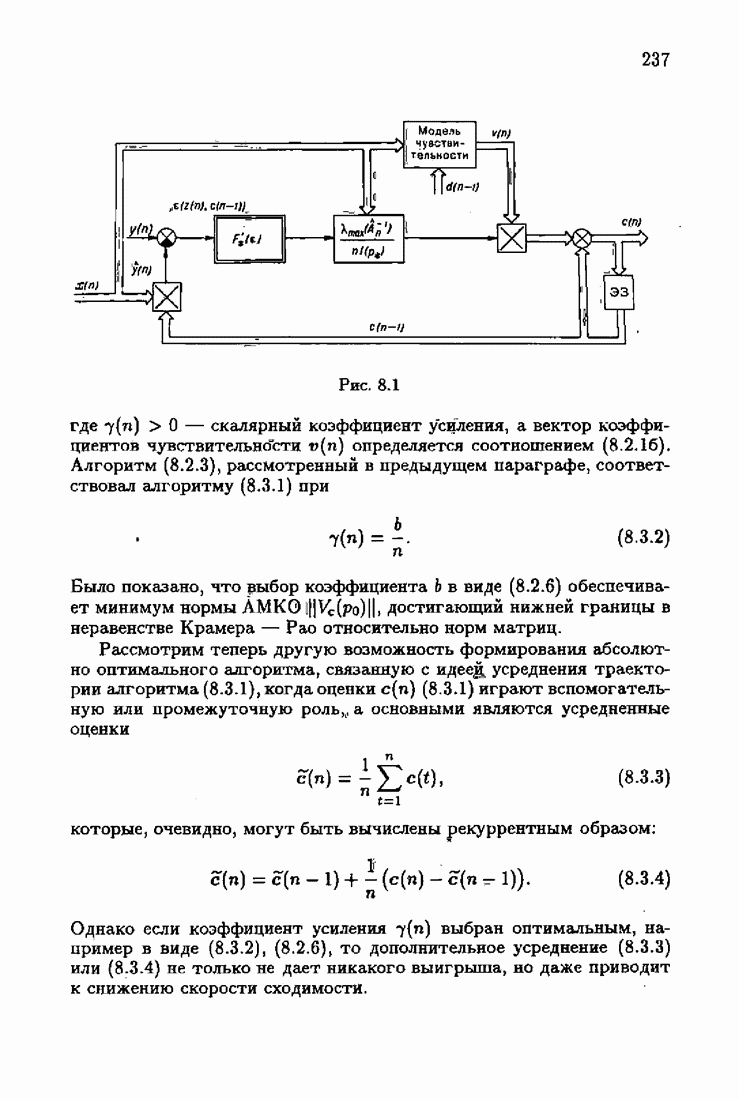






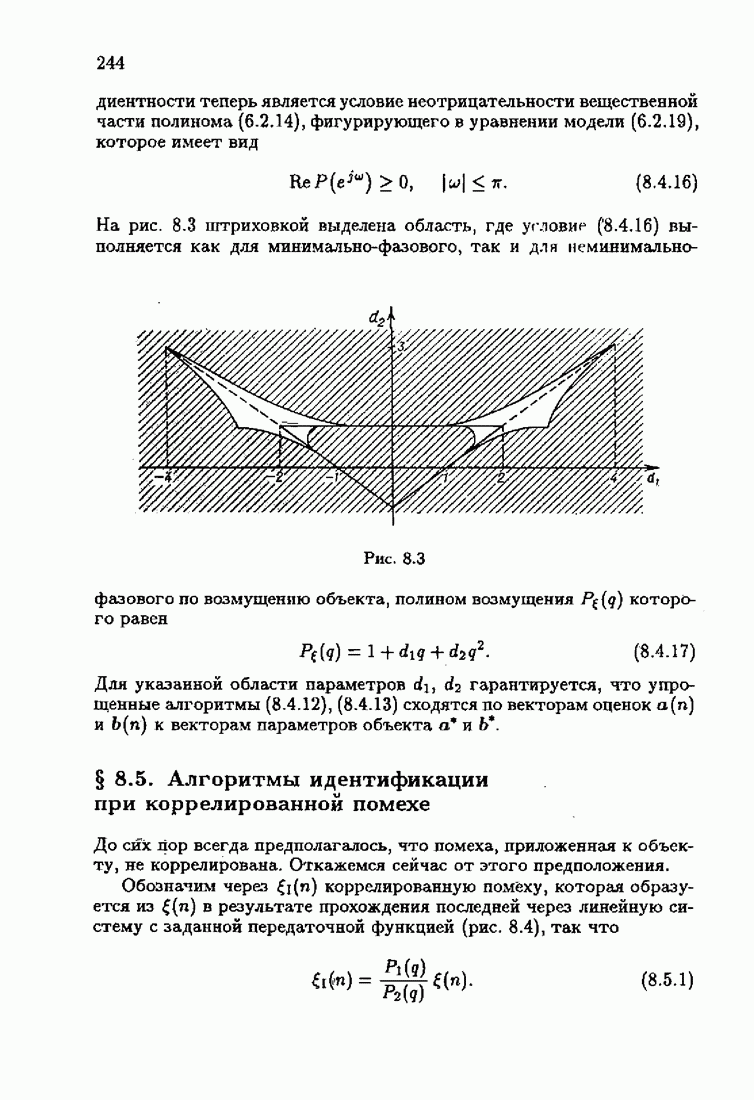


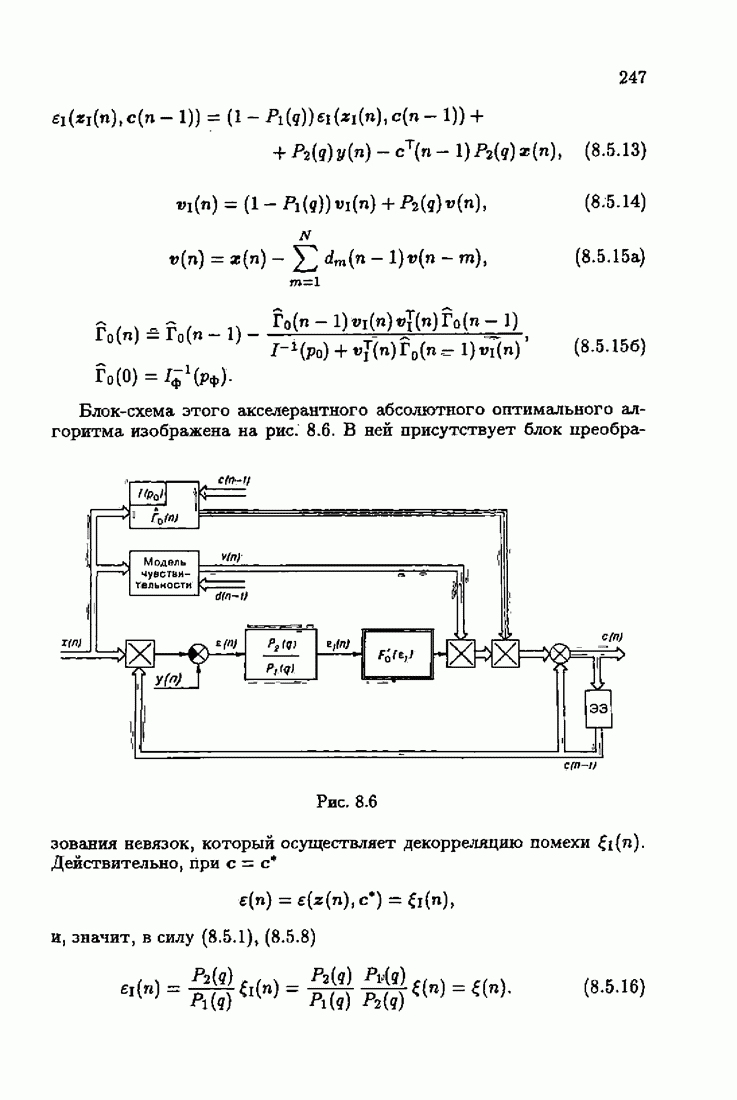



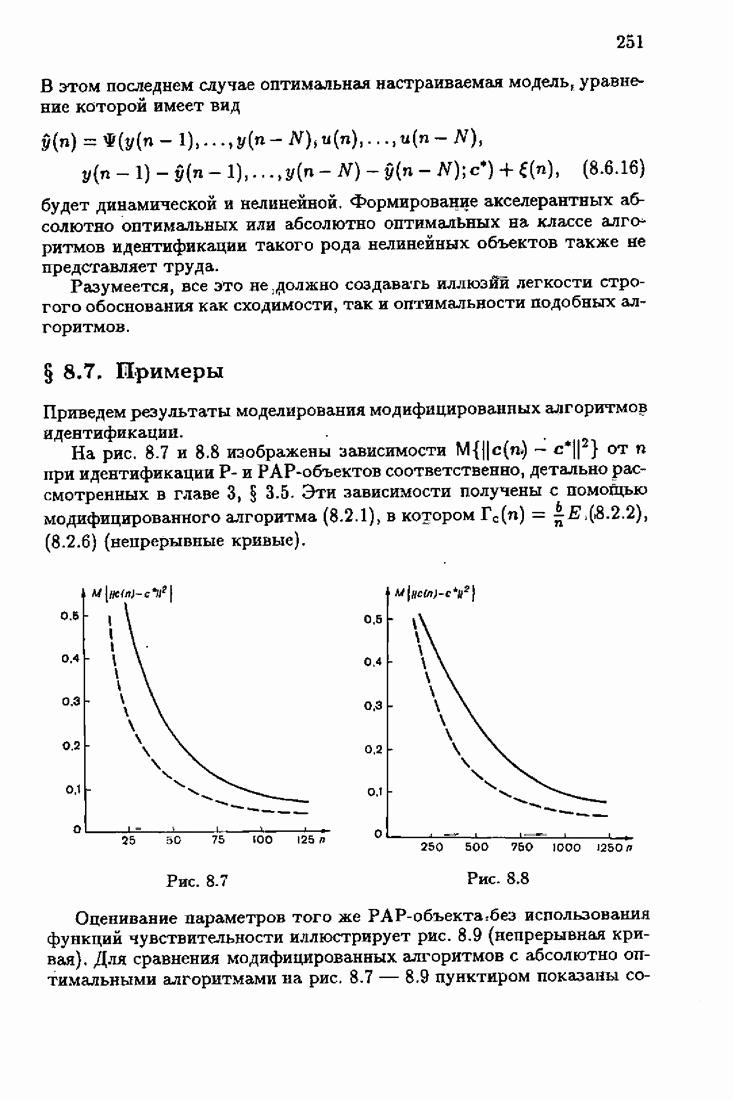
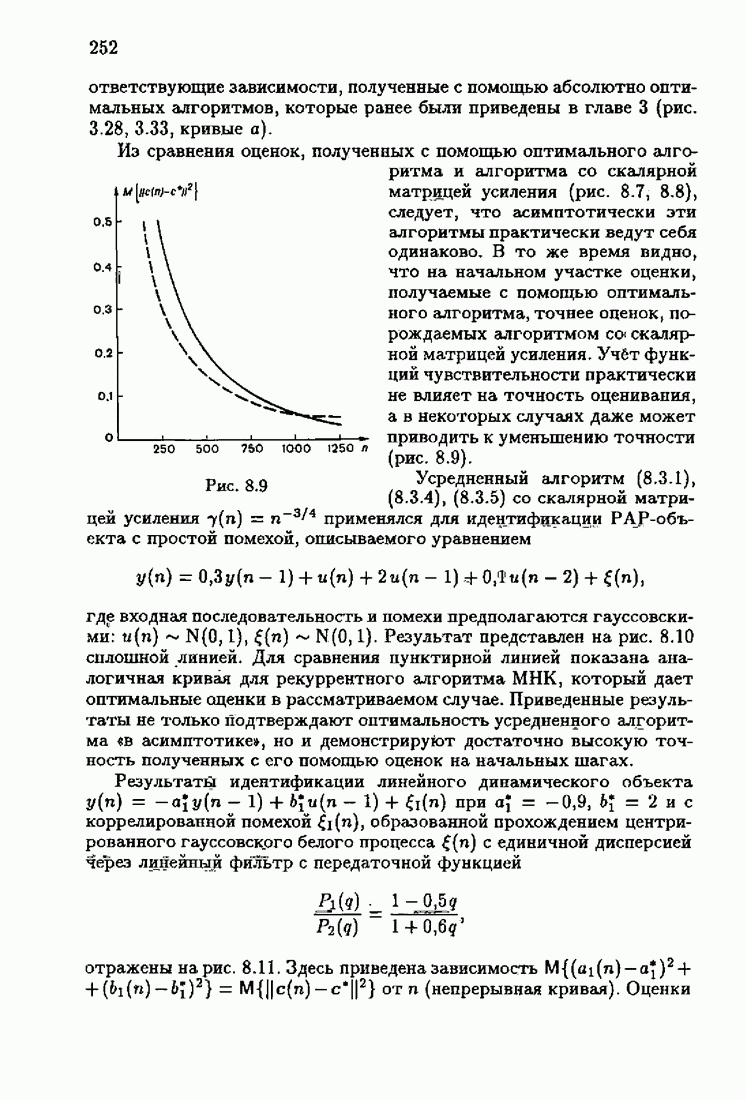
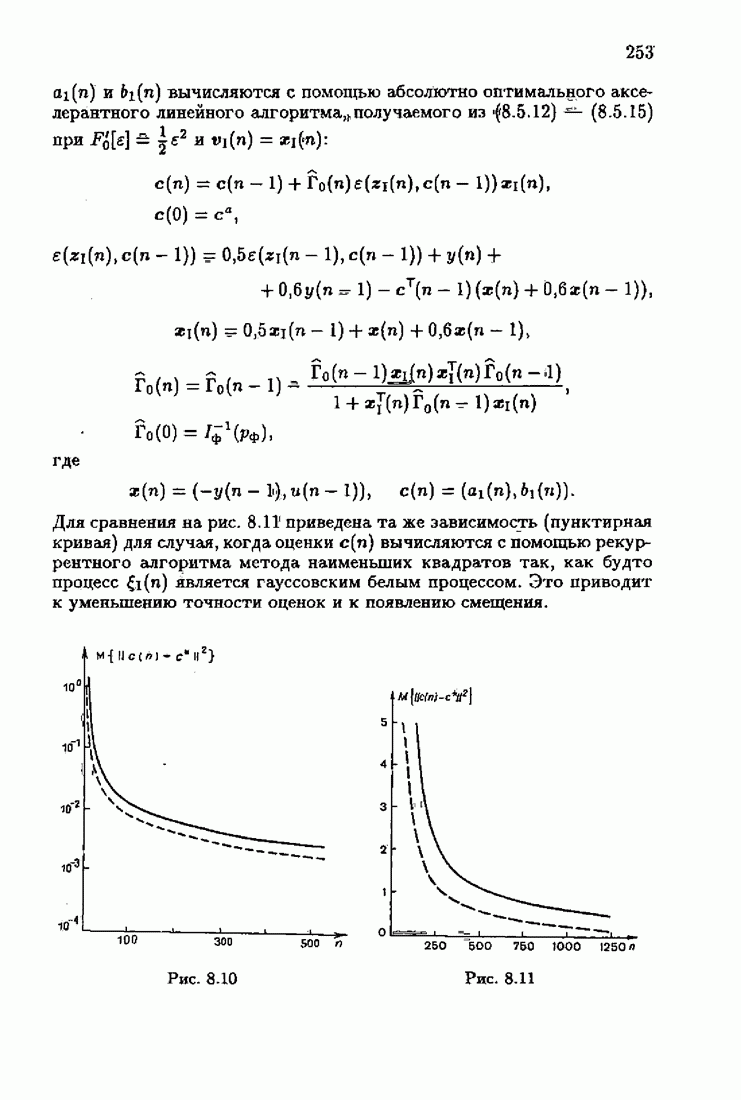





















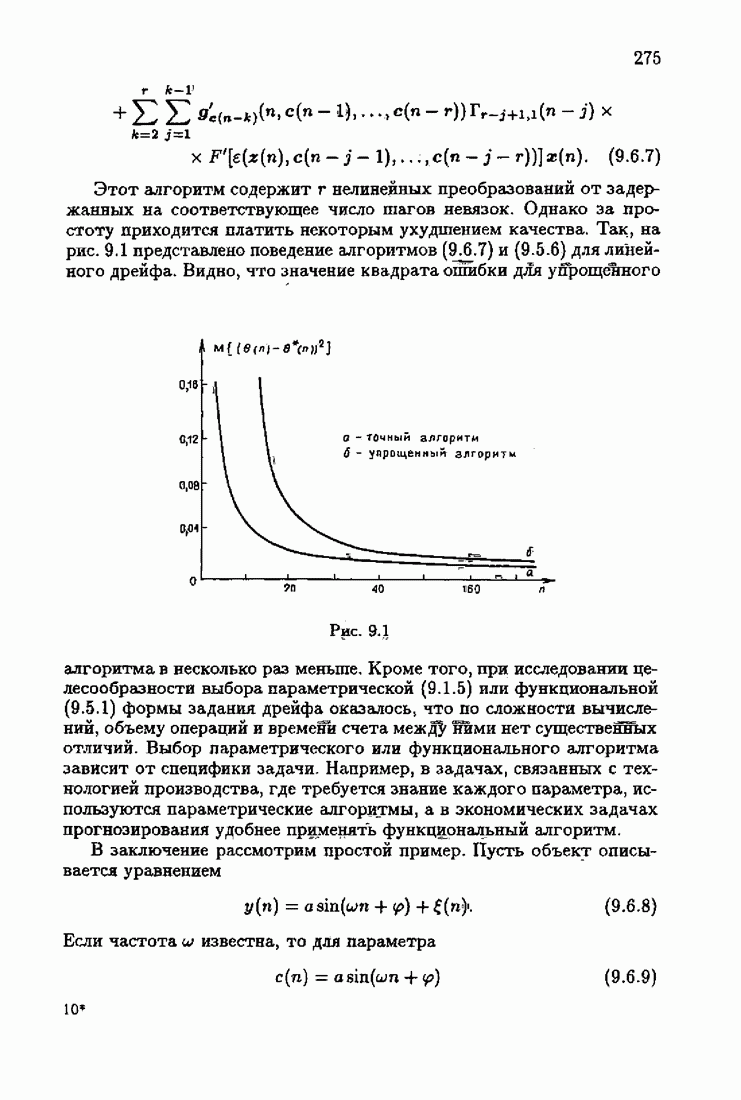
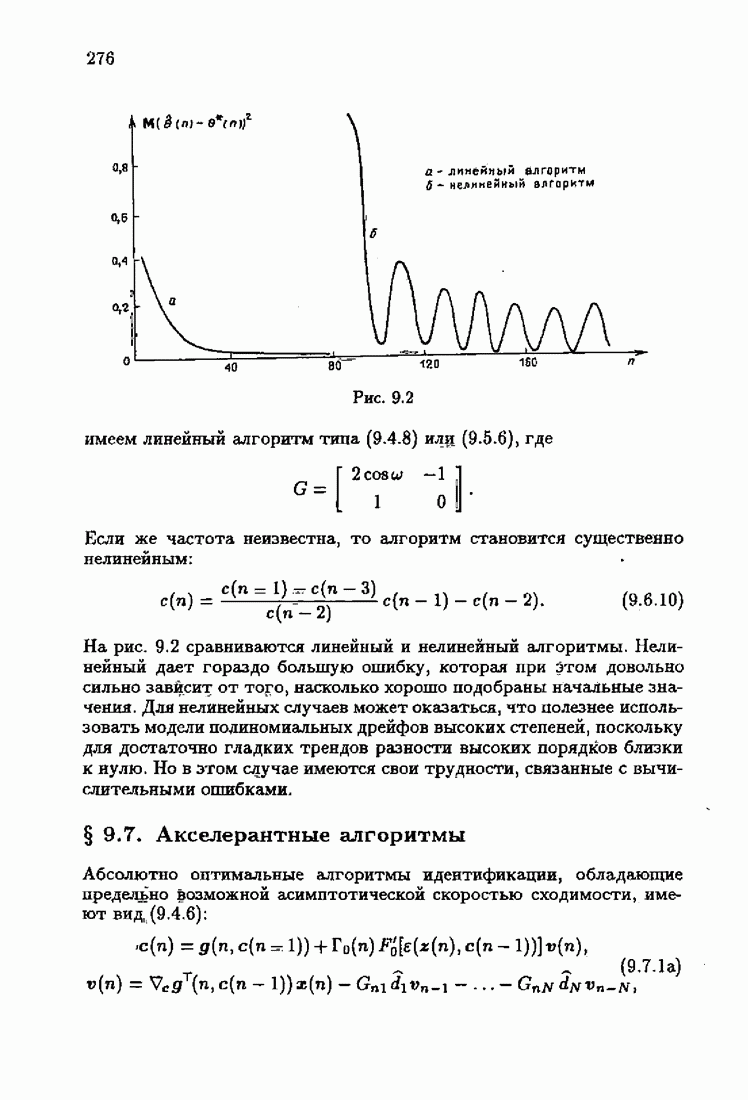





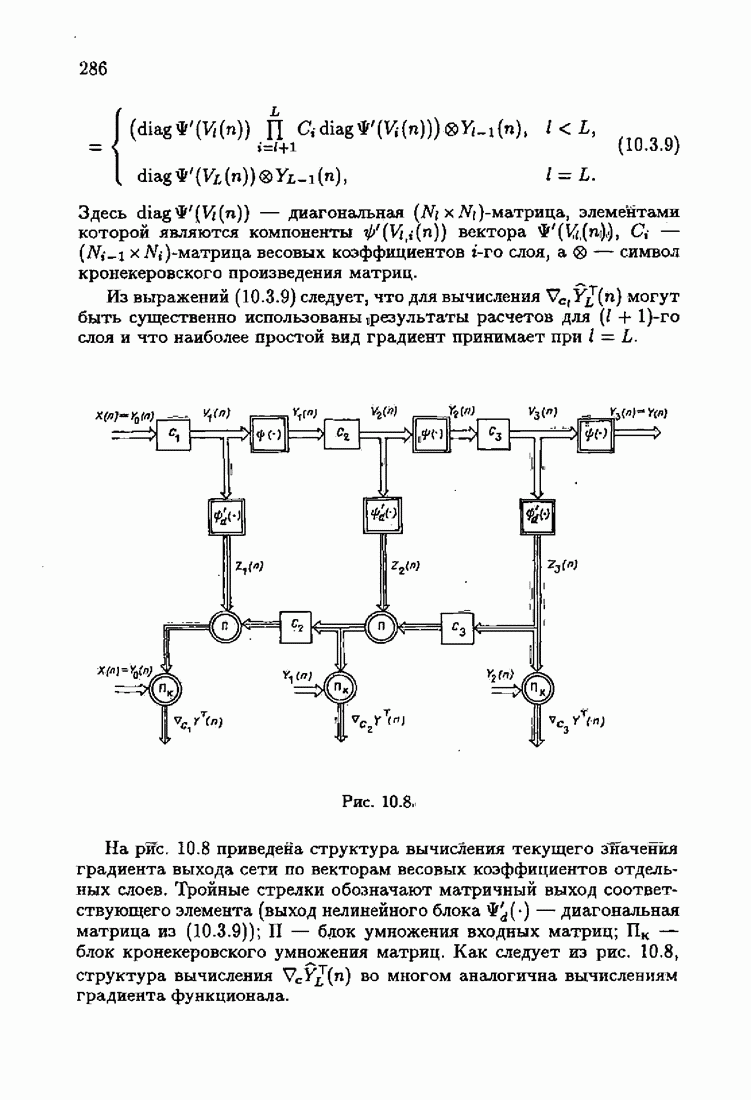
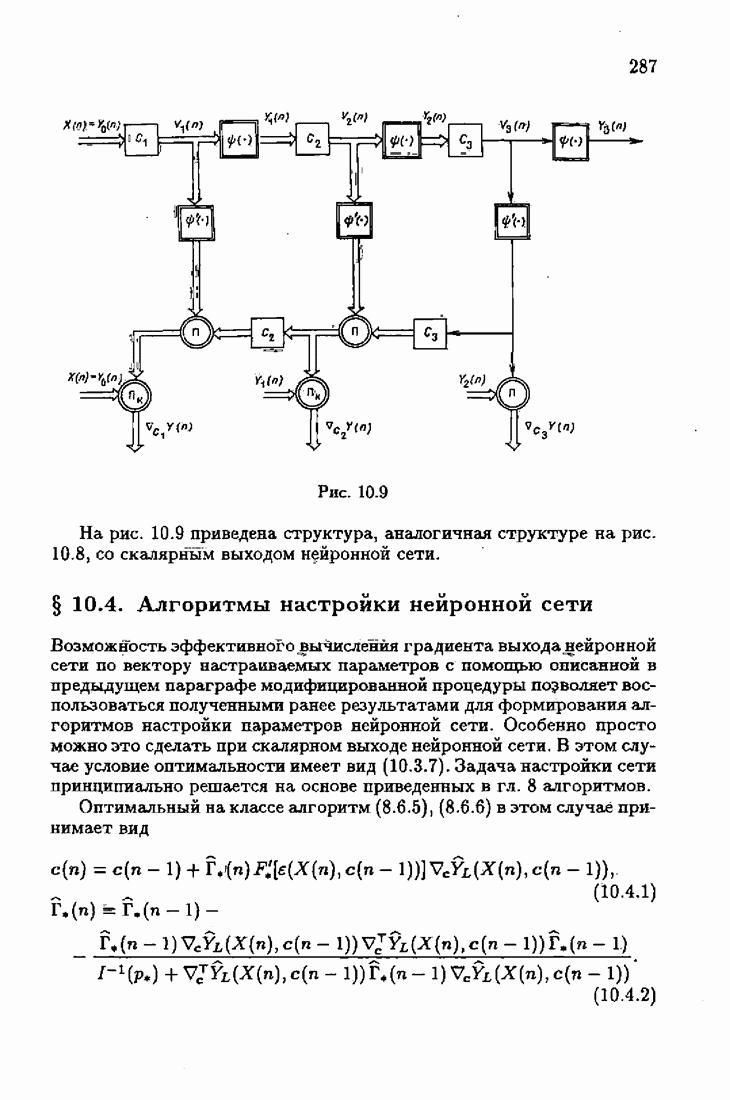


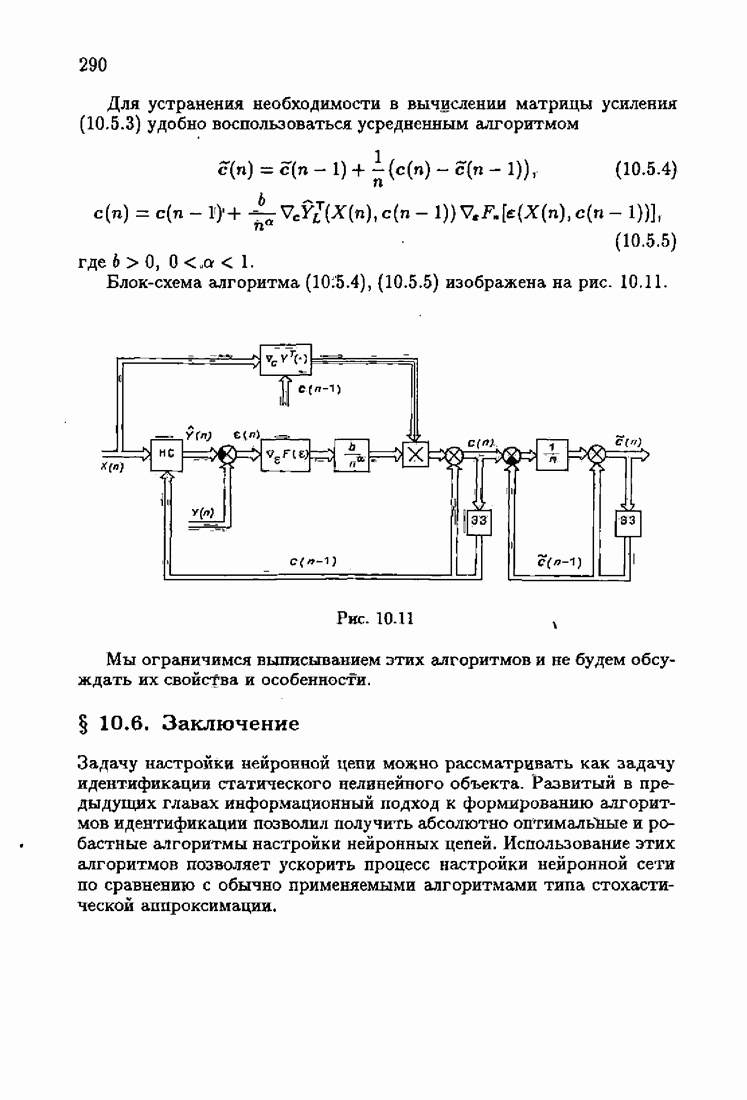














































 Возникает вопрос: как определить оптимальную функцию потерь в этих условиях? Для ответа на этот вопрос введем понятие оптимальной функции потерь на классе распределений
Возникает вопрос: как определить оптимальную функцию потерь в этих условиях? Для ответа на этот вопрос введем понятие оптимальной функции потерь на классе распределений 


 некоторая плотность, удовлетворяющая условиям (4.1.1), (4,1,2). В этом случае
некоторая плотность, удовлетворяющая условиям (4.1.1), (4,1,2). В этом случае

 через
через  получим выражение АМКО
получим выражение АМКО


 квазифишеровскими информациями 1-го и 2-го рода соответственно. Тогда АМКО представится в виде
квазифишеровскими информациями 1-го и 2-го рода соответственно. Тогда АМКО представится в виде

 что соответствует выбору оптимальной функции потерь
что соответствует выбору оптимальной функции потерь  квазифишеровские информации 1-го и 2-го рода становятся равными фишеровской информации
квазифишеровские информации 1-го и 2-го рода становятся равными фишеровской информации


 бесконечное множество. Наша задача — выбрать среди них такую, которая с определенной точки зрения была бы оптимальной на рассматриваемом классе
бесконечное множество. Наша задача — выбрать среди них такую, которая с определенной точки зрения была бы оптимальной на рассматриваемом классе  -Назовем функцию потерь
-Назовем функцию потерь

 удовлетворяет матричному неравенству
удовлетворяет матричному неравенству







 представляет собой плотность распределения из класса V, для которой
представляет собой плотность распределения из класса V, для которой  достигает максимума. Эту плотность распределения уместно назвать наименее благоприятной плотностью распределения. Оптимальная на классе функция потерь (4.2.9) представляет собой оптимальную функцию потерь для наименее благоприятной плотности распределения из заданного класса.
достигает максимума. Эту плотность распределения уместно назвать наименее благоприятной плотностью распределения. Оптимальная на классе функция потерь (4.2.9) представляет собой оптимальную функцию потерь для наименее благоприятной плотности распределения из заданного класса.
 не превосходящую
не превосходящую  т. е.
т. е.  Принимая во внимание, что АМКО представляет собой симметрические положительно определенные матрицы, матричное неравенство (4.2.10) можно записать относительно обратных АМКО
Принимая во внимание, что АМКО представляет собой симметрические положительно определенные матрицы, матричное неравенство (4.2.10) можно записать относительно обратных АМКО


 и всех
и всех  принадлежащих заданному классу
принадлежащих заданному классу  Покажем, что если решение задачи (4.2.17) существует, то оно удовлетворяет неравенству (4.2.16), а следовательно, и неравенству (4.2.10).
Покажем, что если решение задачи (4.2.17) существует, то оно удовлетворяет неравенству (4.2.16), а следовательно, и неравенству (4.2.10).


 и (4.2.6) в форме
и (4.2.6) в форме


 тогда и плотность распределения
тогда и плотность распределения

 Напомним, что все интересующие нас классы распределений выпуклы. Подставляя
Напомним, что все интересующие нас классы распределений выпуклы. Подставляя  вместо
вместо  в (4.2.19), получим
в (4.2.19), получим





 по А и полагая затем
по А и полагая затем  получим после несложных преобразований
получим после несложных преобразований

 при
при  Производя замену
Производя замену  получим
получим


 по-прежнему определяется выражением (4.2.24). Дифференцируя (4.2.28) по А и полагая затем
по-прежнему определяется выражением (4.2.24). Дифференцируя (4.2.28) по А и полагая затем  получим после преобразований
получим после преобразований

 (4.2.31), заключаем, что
(4.2.31), заключаем, что  поэтому необходимые условия минимума
поэтому необходимые условия минимума  по
по  совпадают. Если бы функционалы
совпадают. Если бы функционалы  были выпуклыми на классе V, то можно было бы сделать вывод, что они достигают минимума при одной и той же плотности распределения
были выпуклыми на классе V, то можно было бы сделать вывод, что они достигают минимума при одной и той же плотности распределения  Но выпуклость этих функционалов можно обеспечить, если рассмотреть их на произвольном однопараметрическом подклассе
Но выпуклость этих функционалов можно обеспечить, если рассмотреть их на произвольном однопараметрическом подклассе  Произведя минимизацию
Произведя минимизацию  сначала на подклассе
сначала на подклассе  при произвольном допустимом значении а, а затем по параметру
при произвольном допустимом значении а, а затем по параметру  получим, что эти функционалы достигают минимума одновременно.
получим, что эти функционалы достигают минимума одновременно.