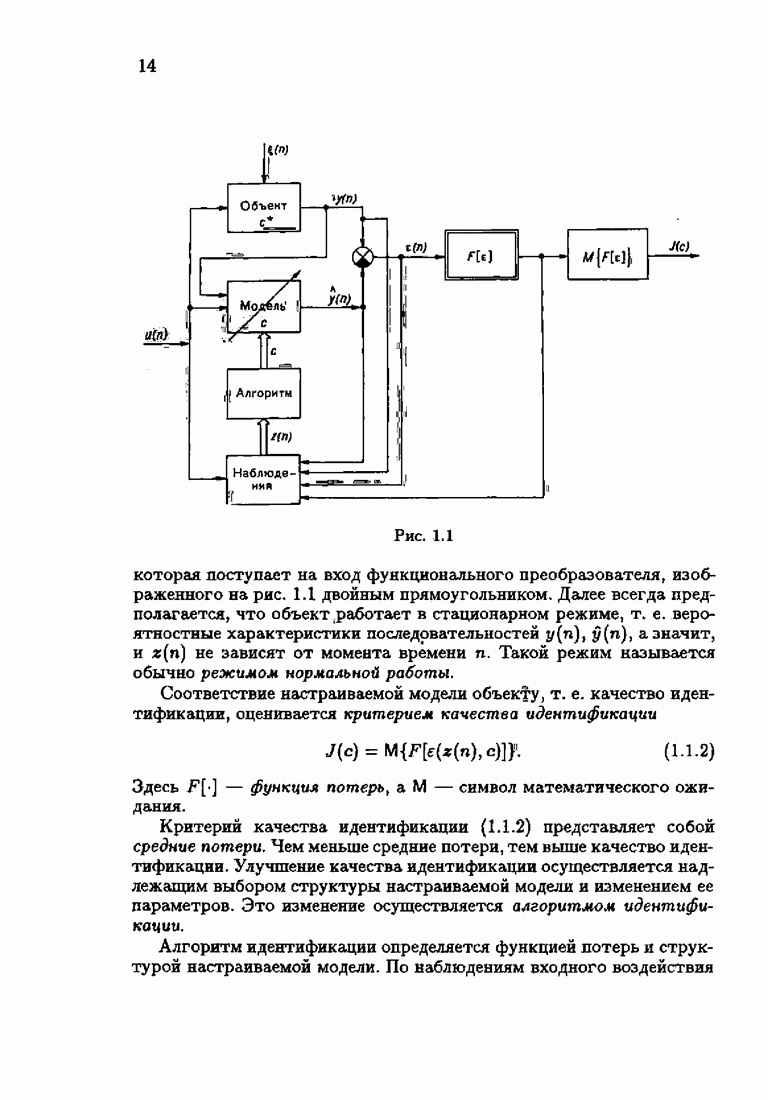
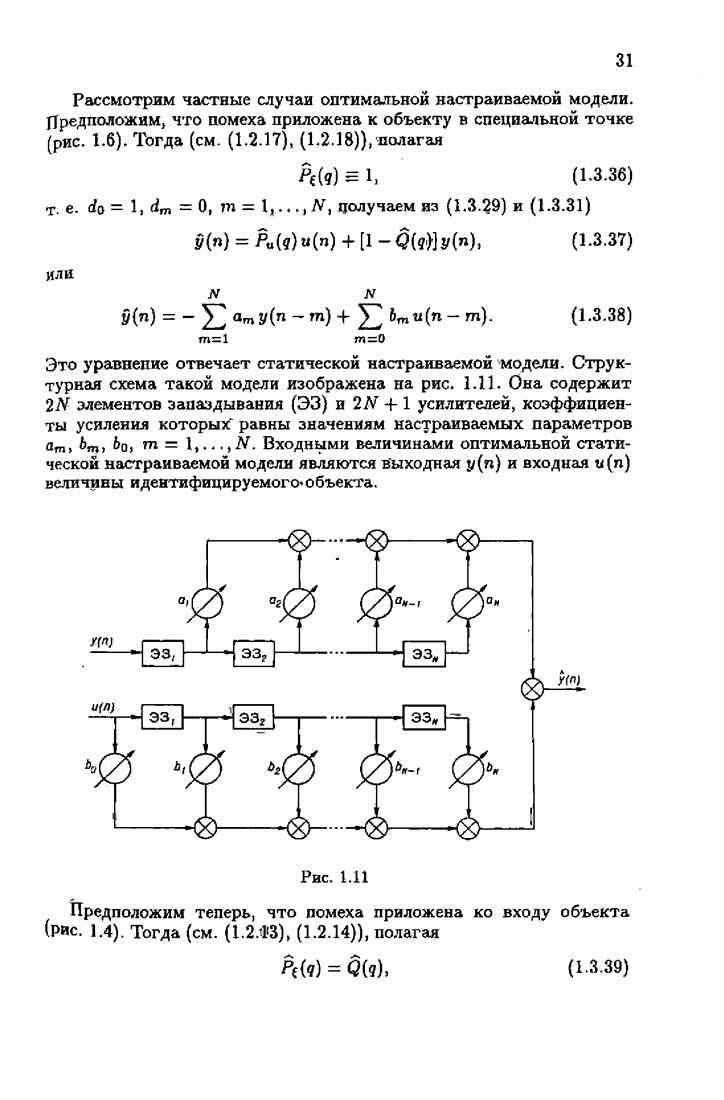
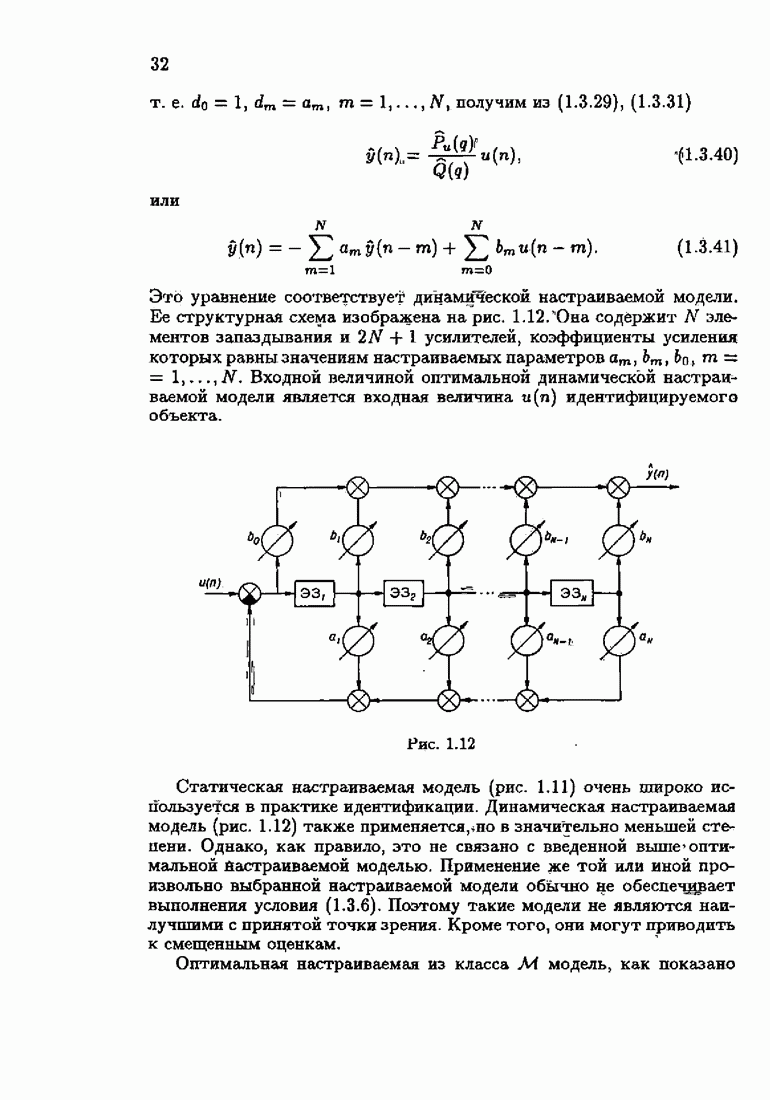
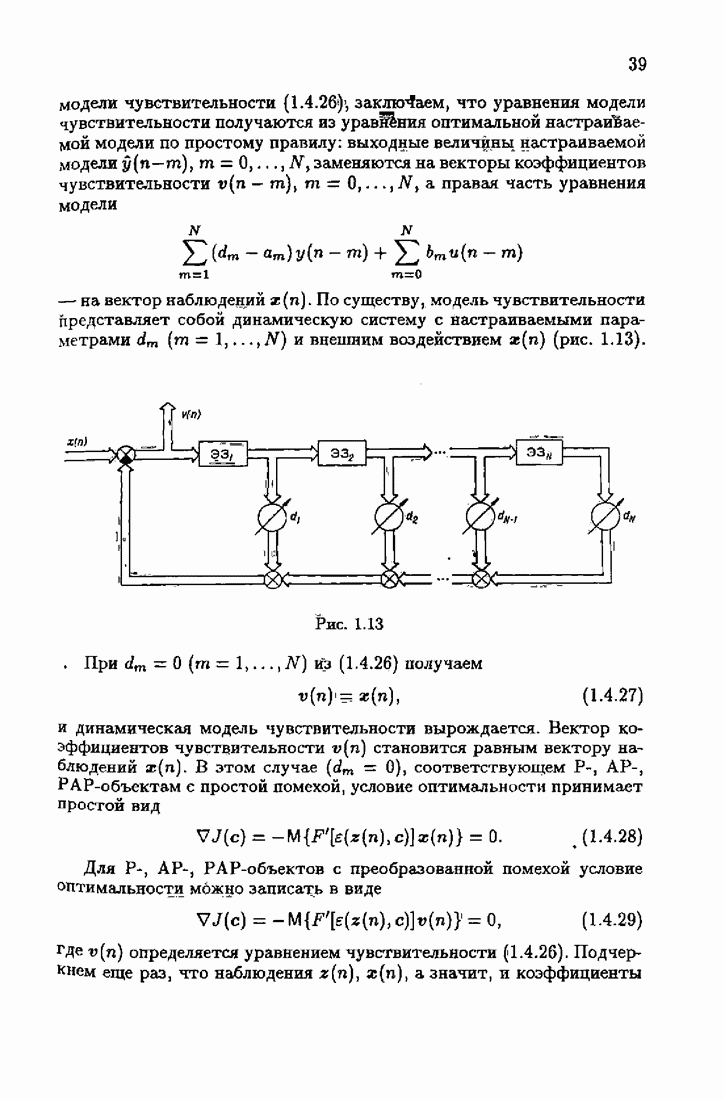
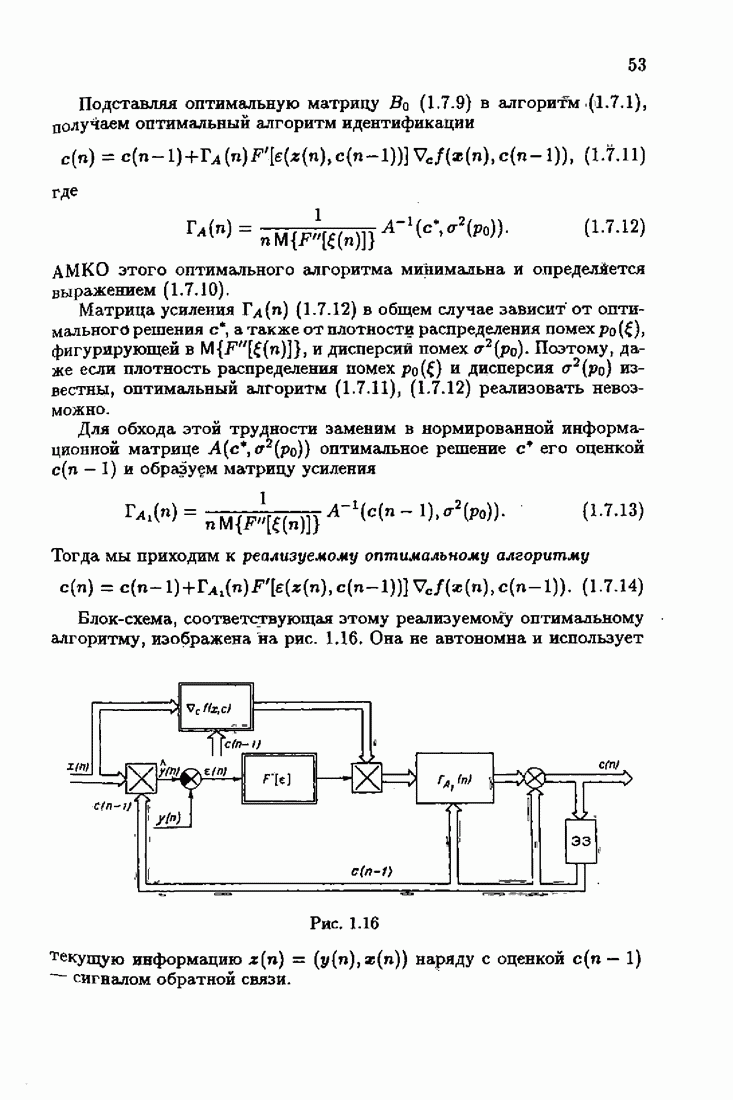
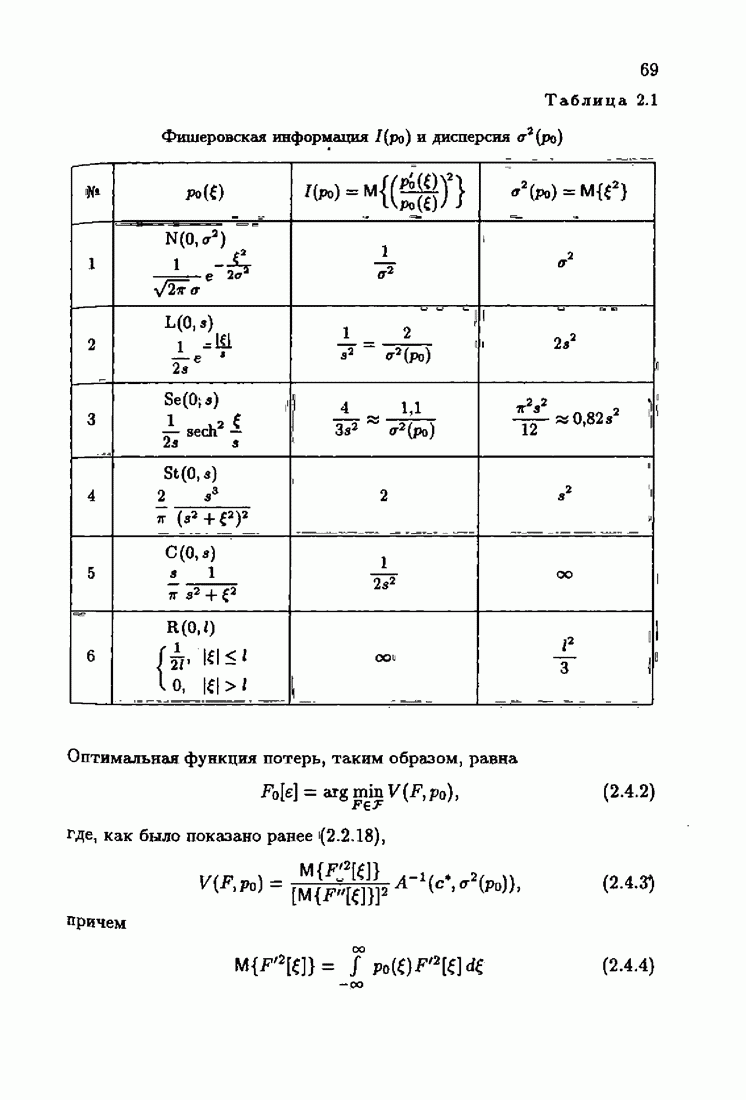
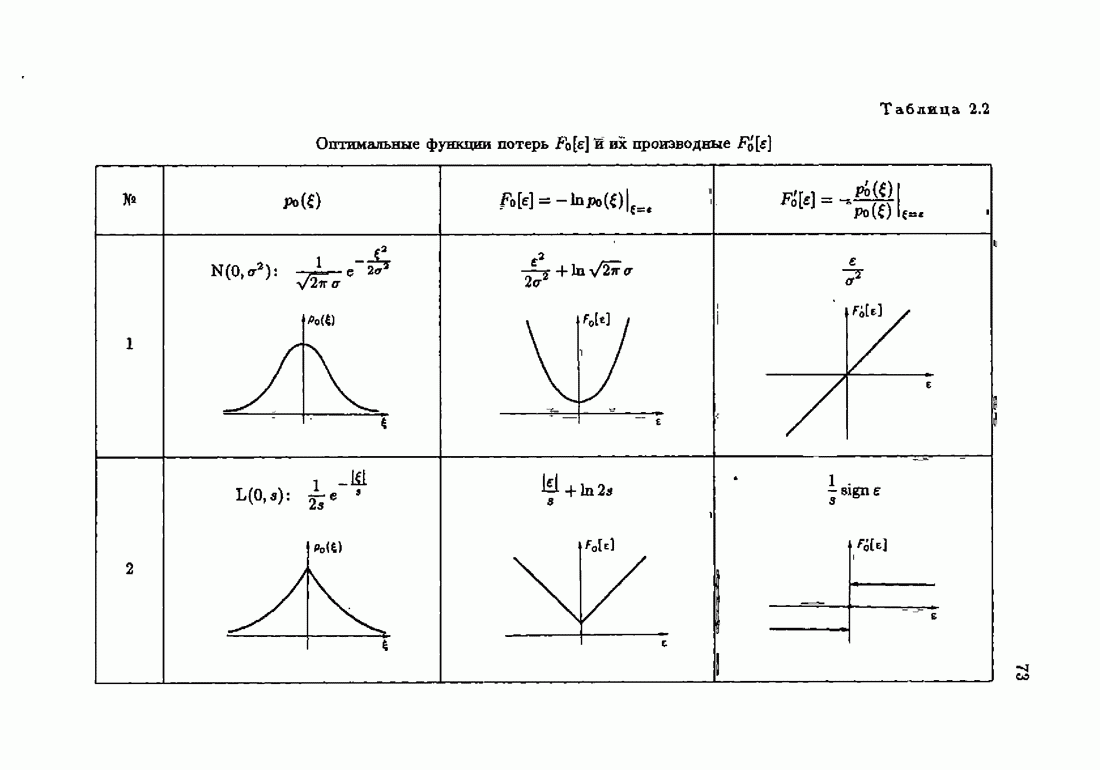
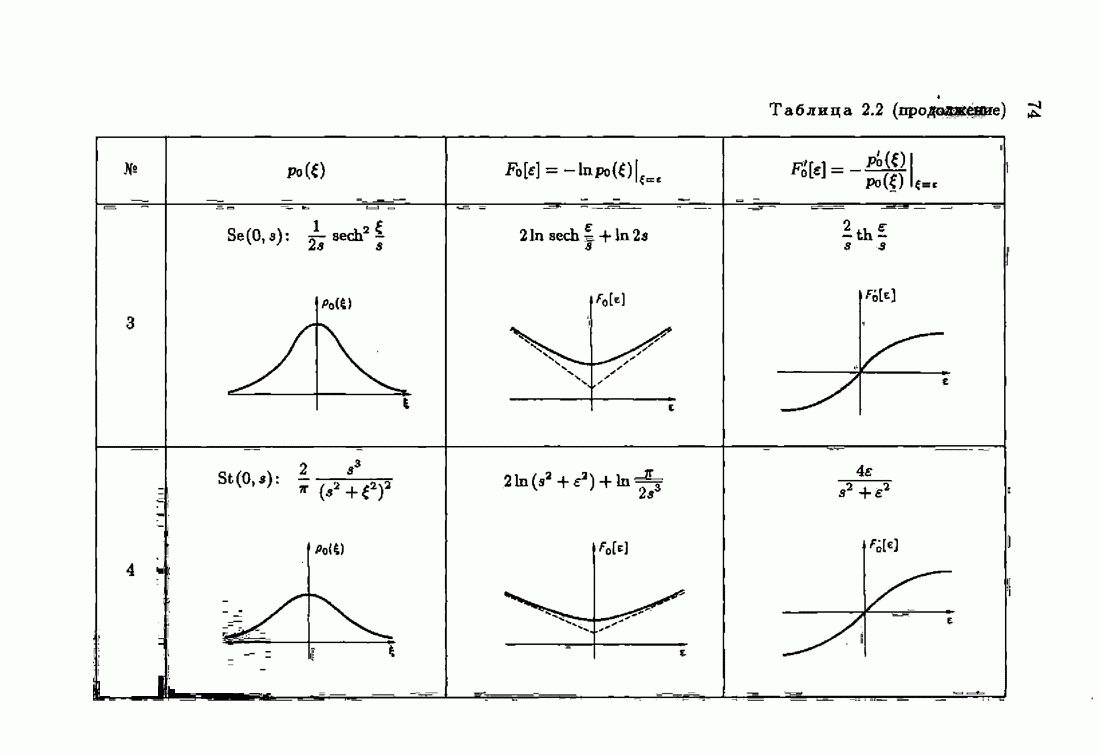
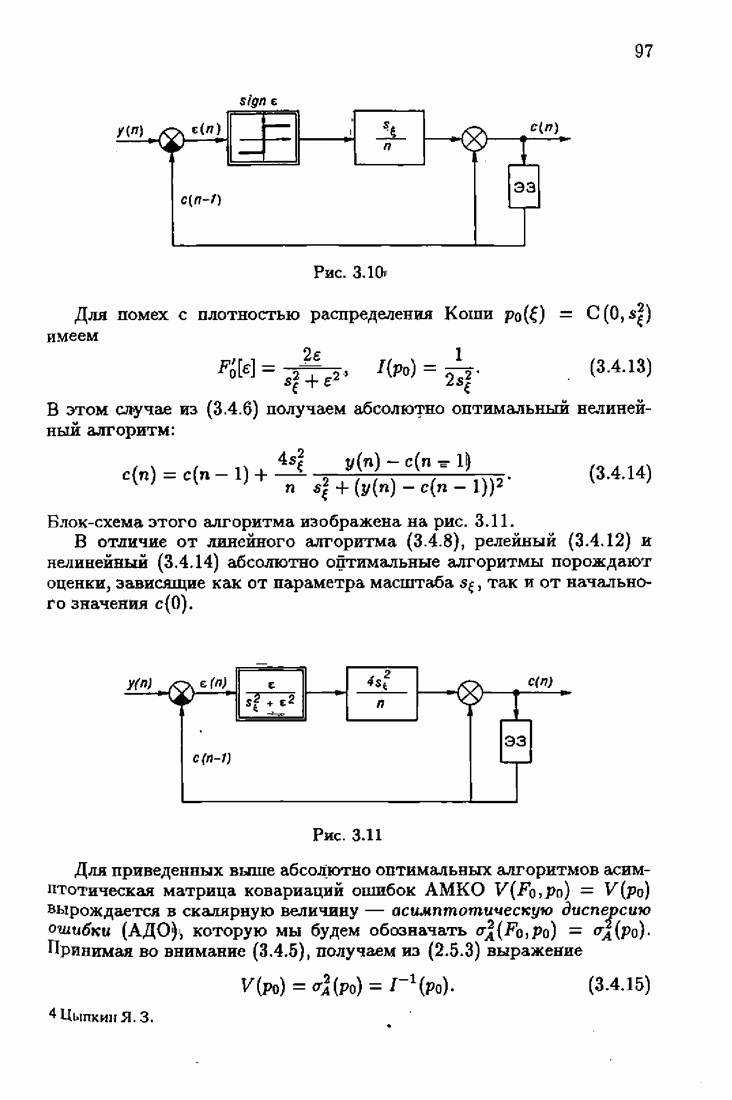
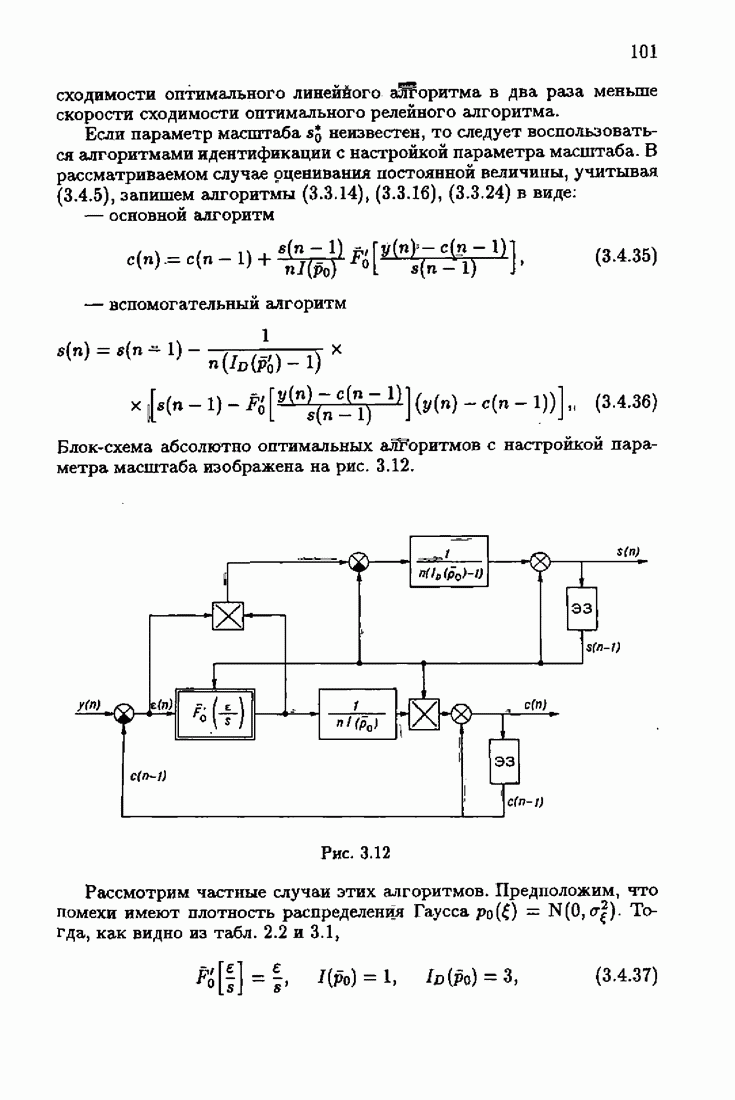
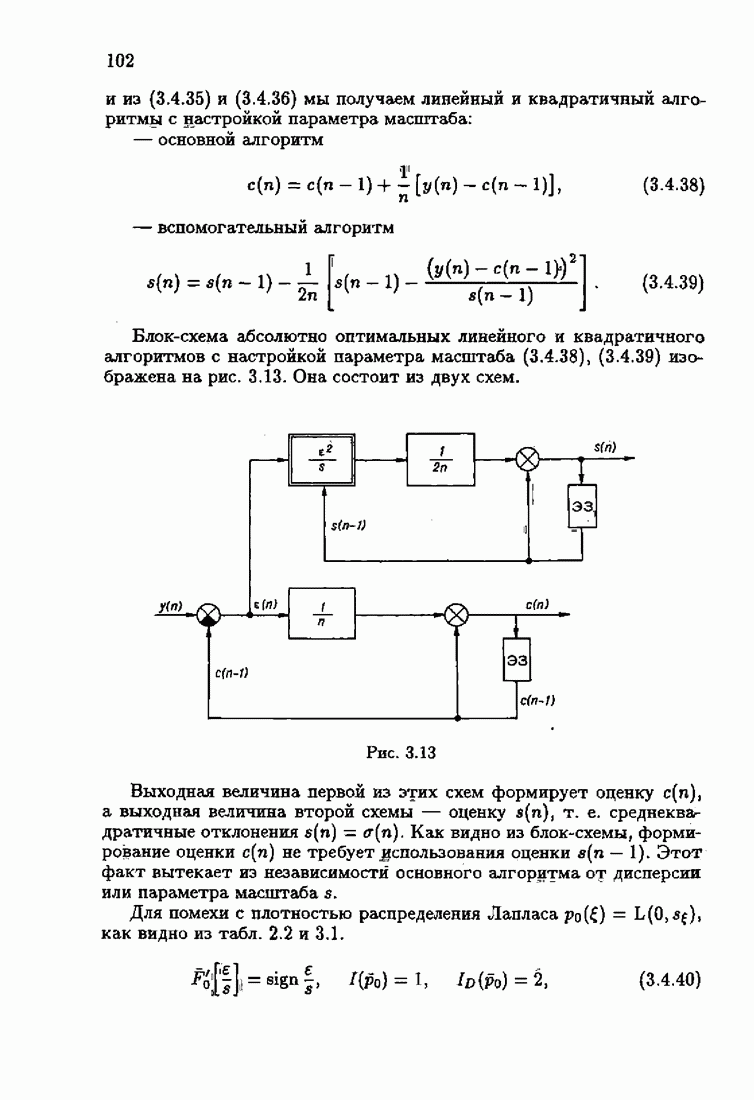
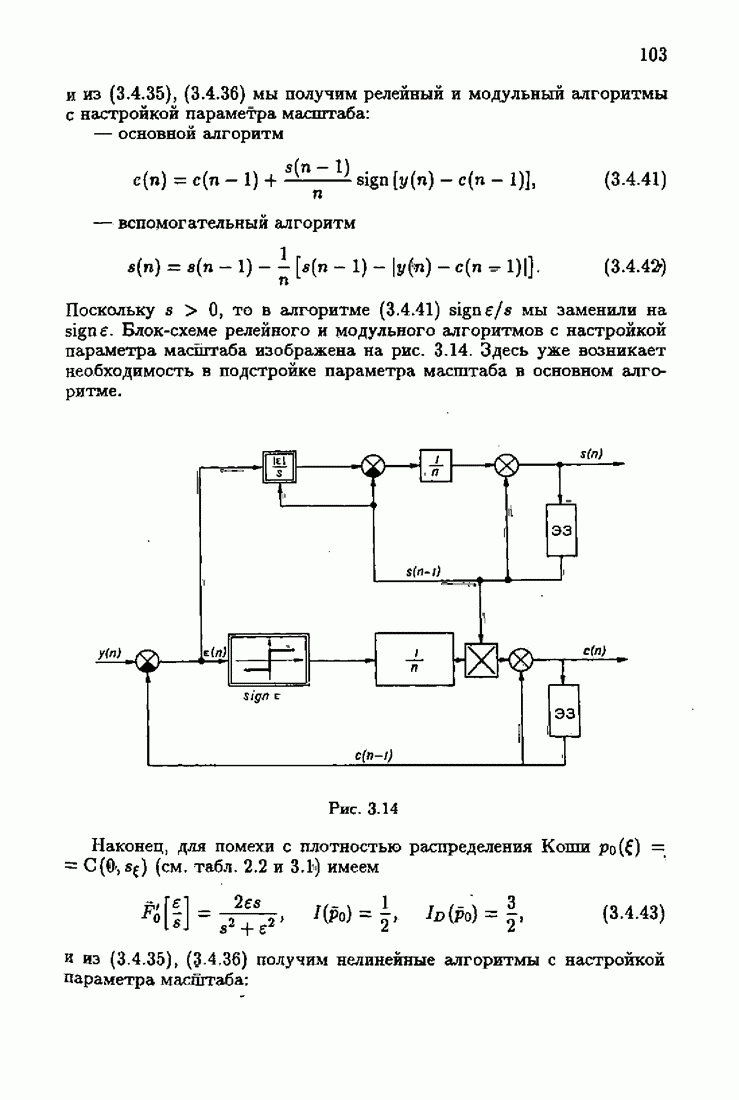
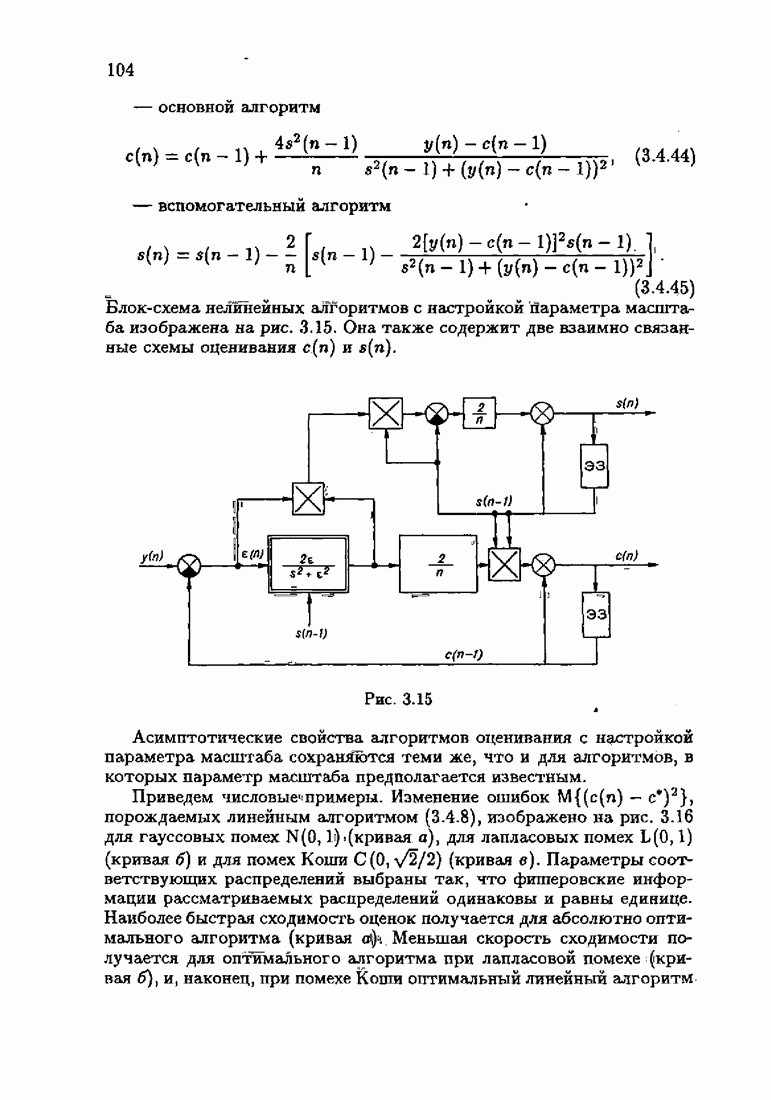
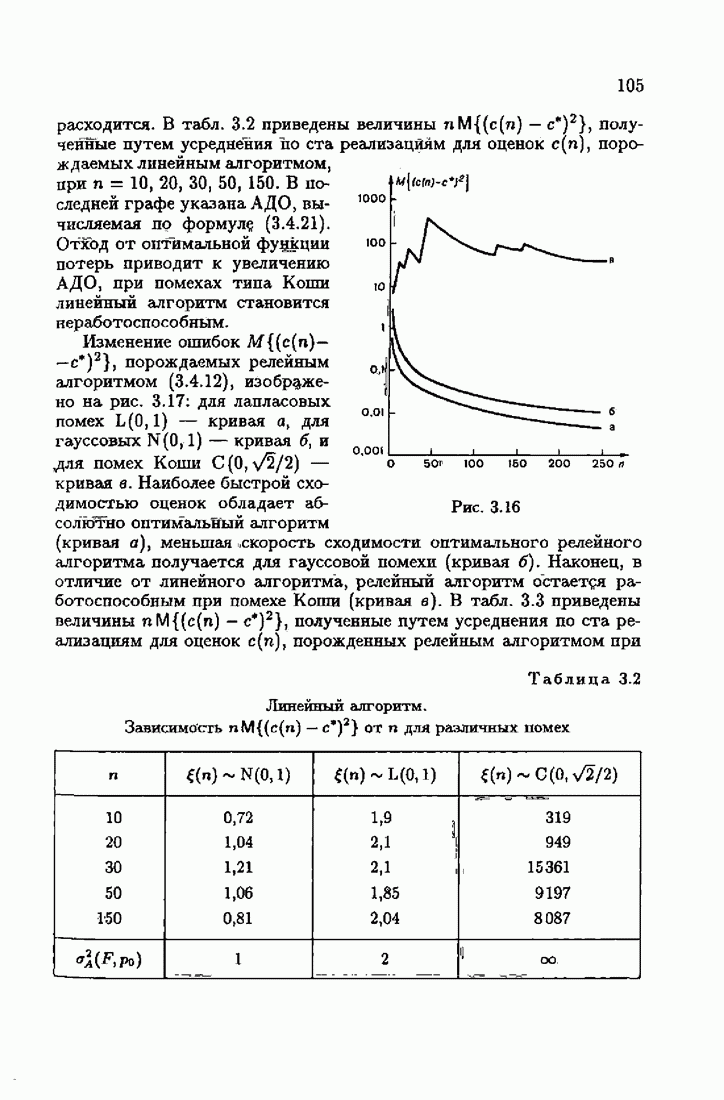
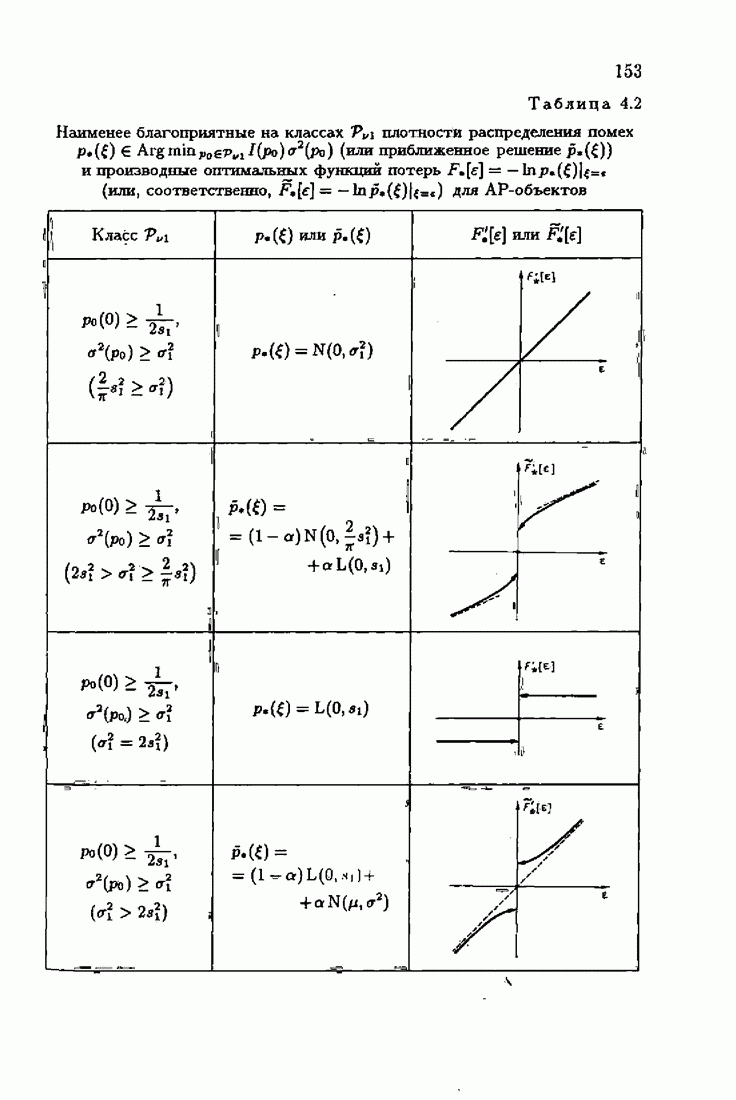
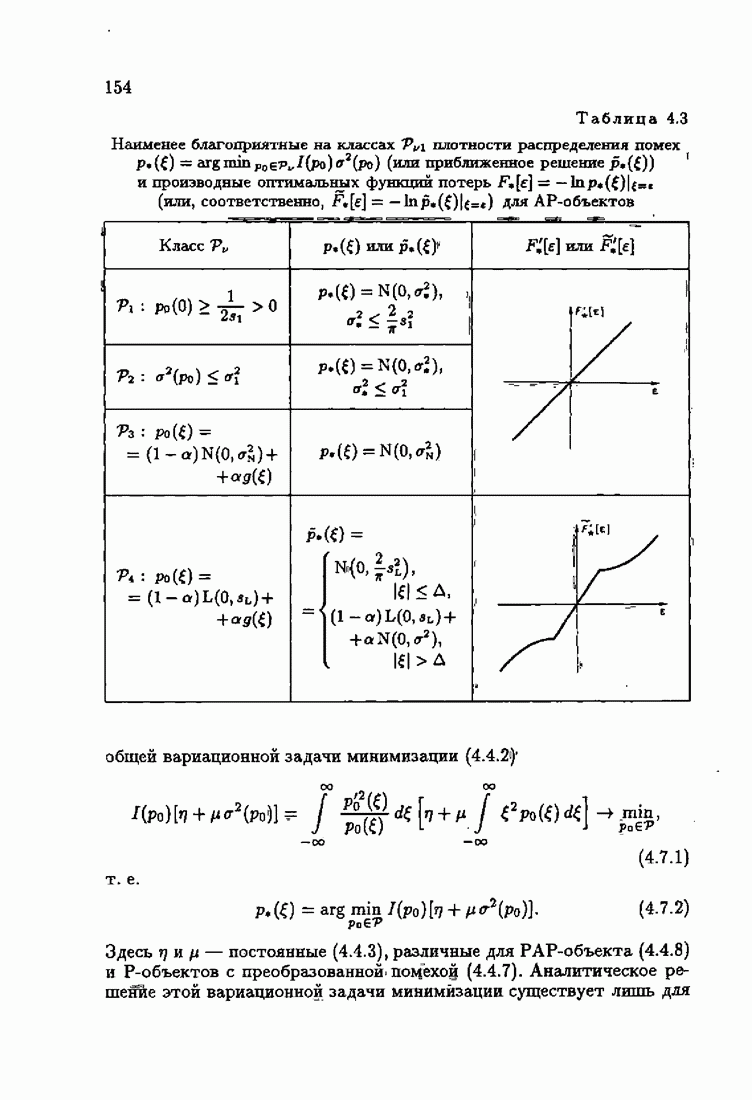
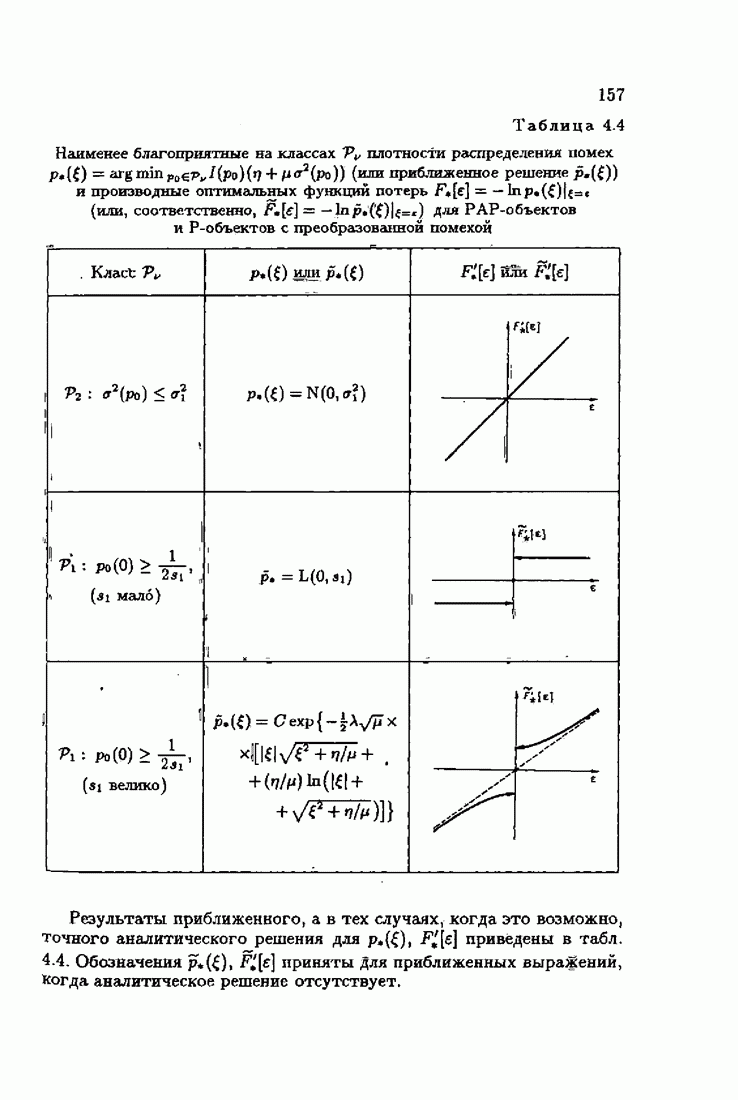
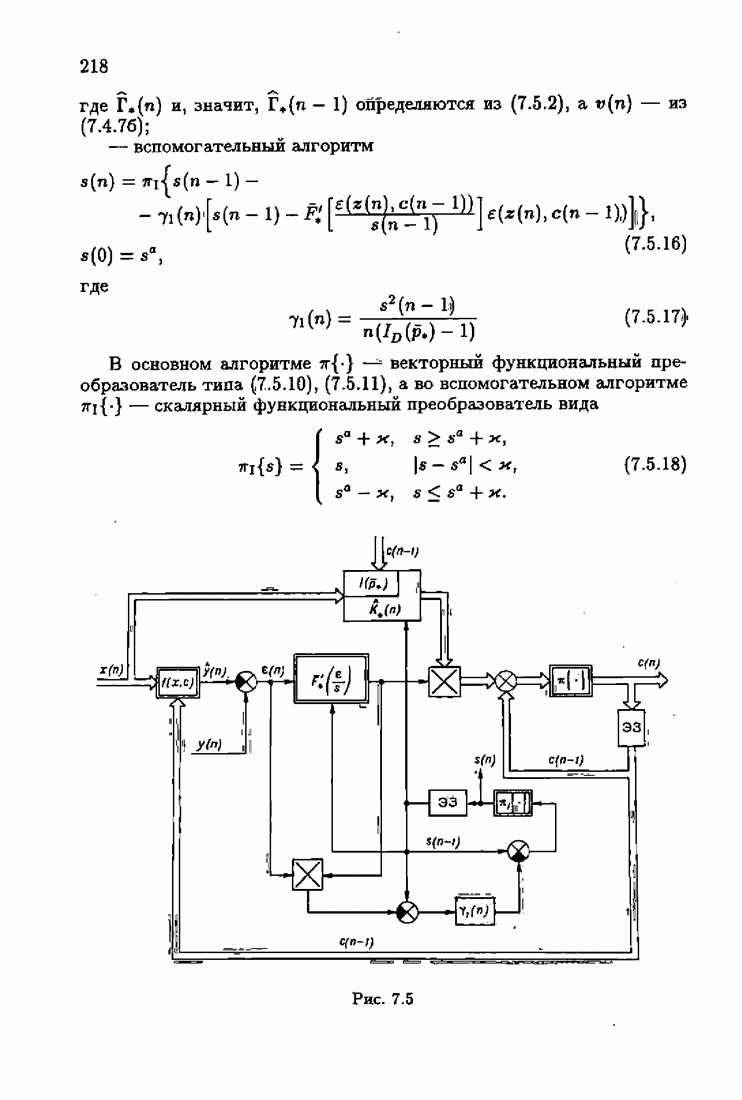
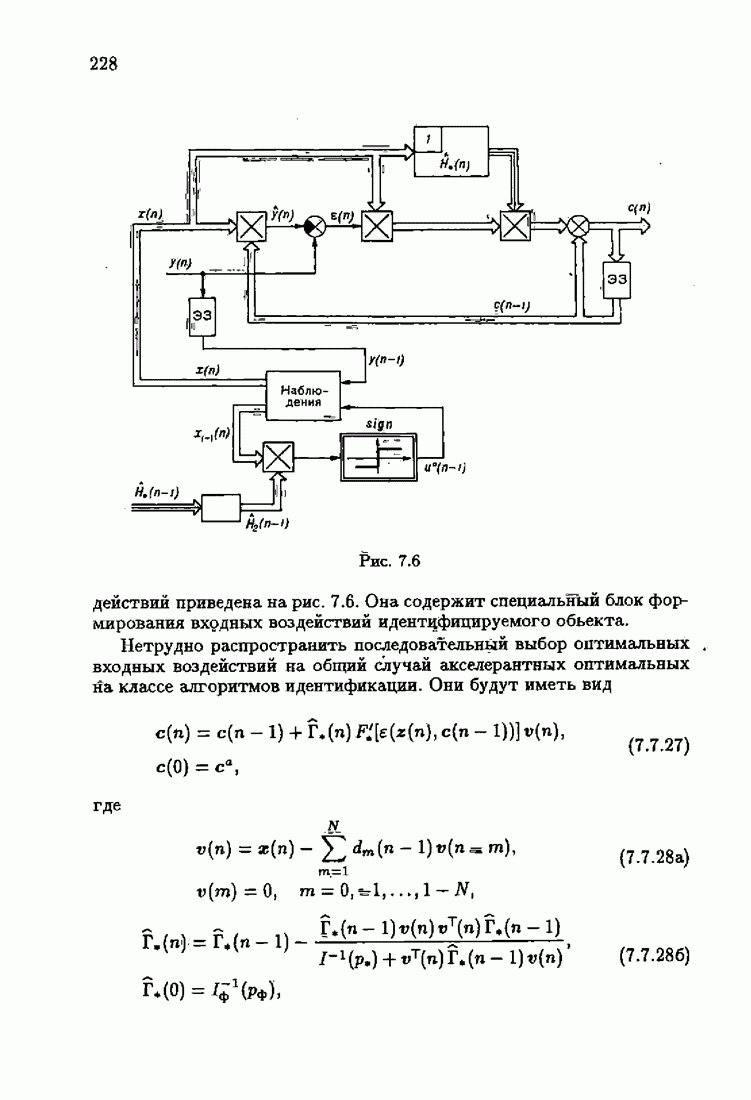
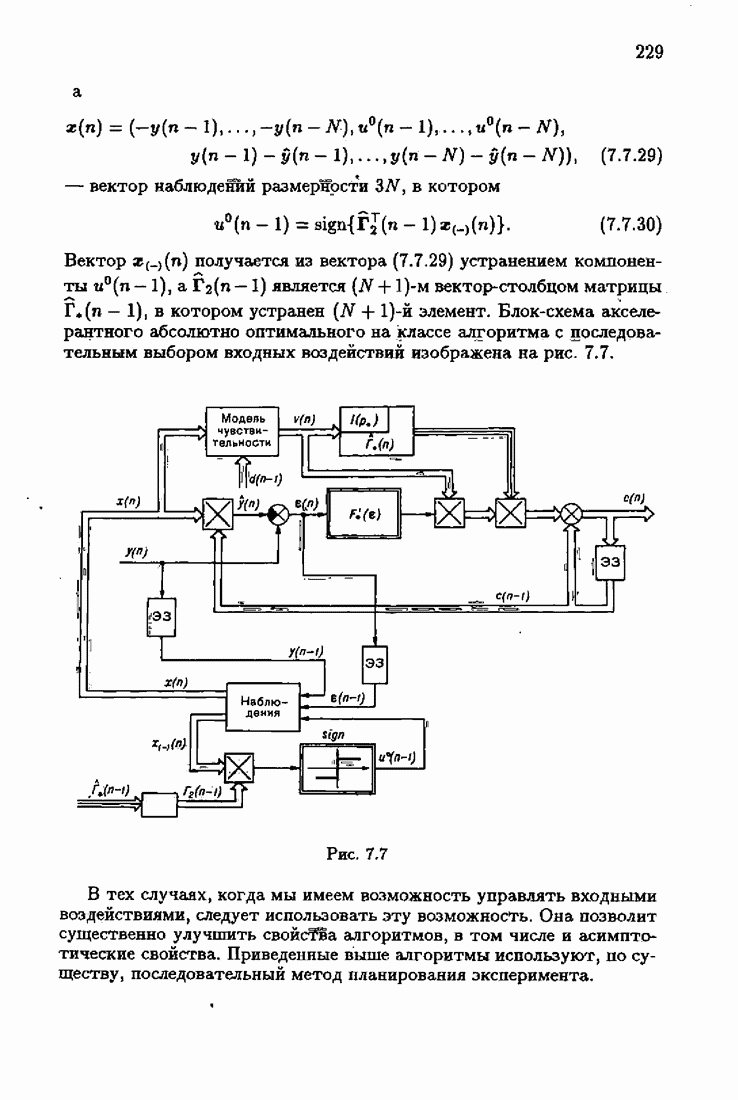
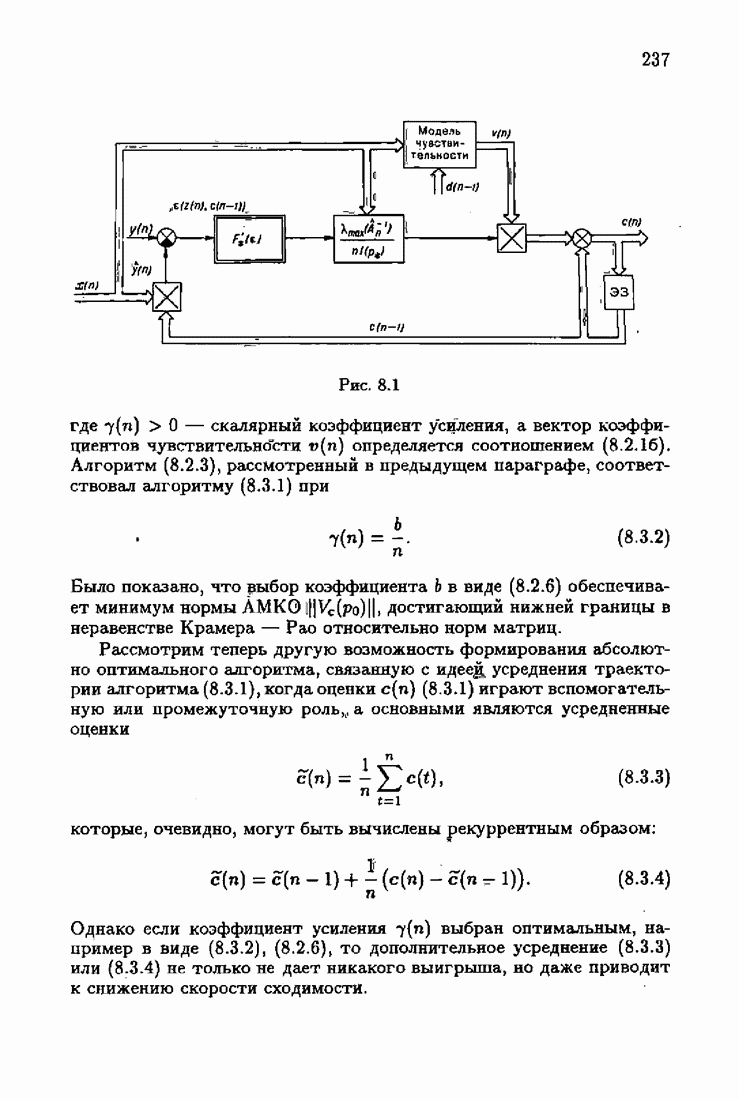
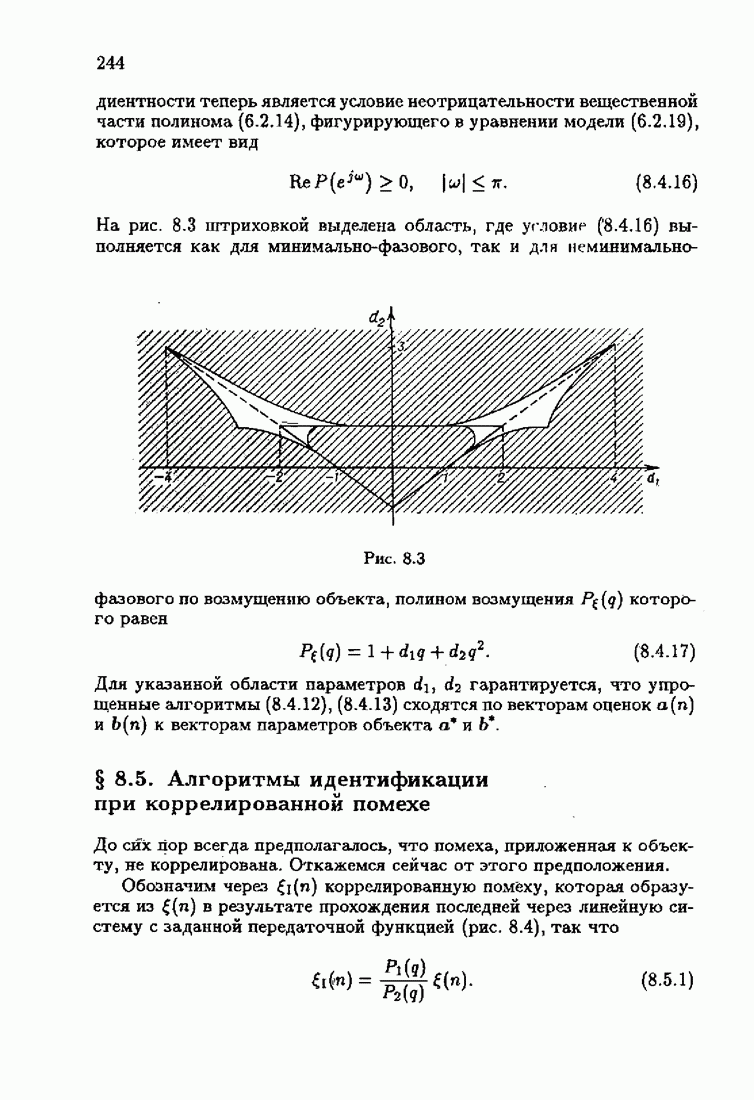
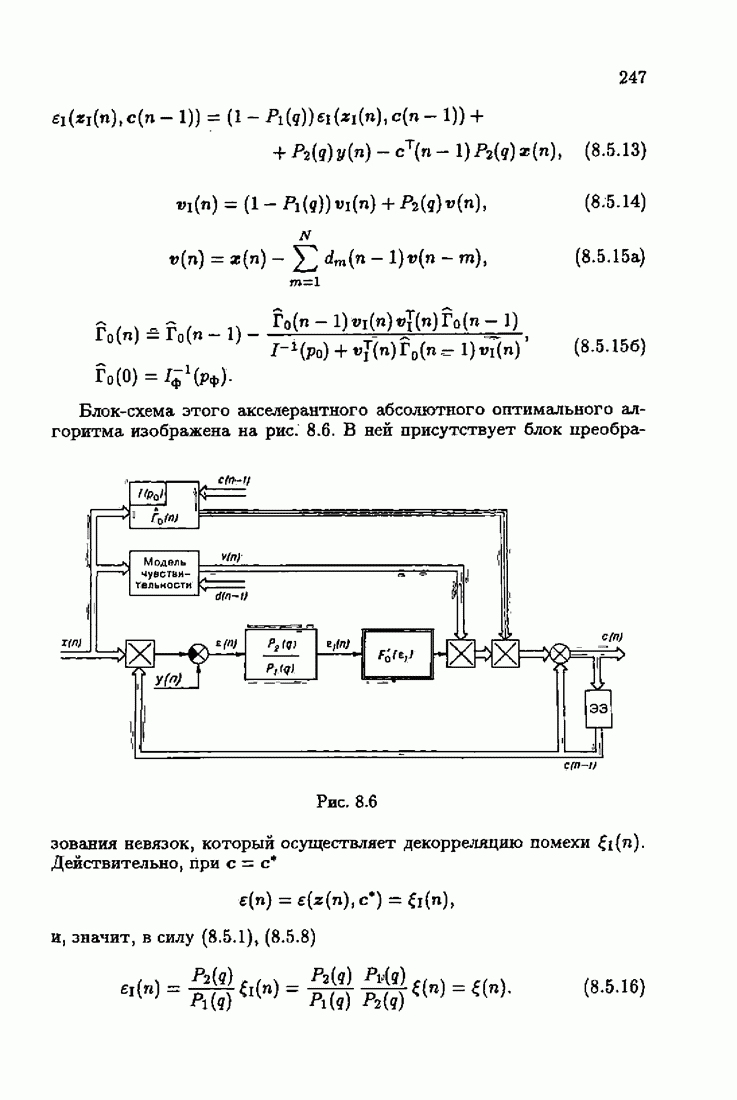
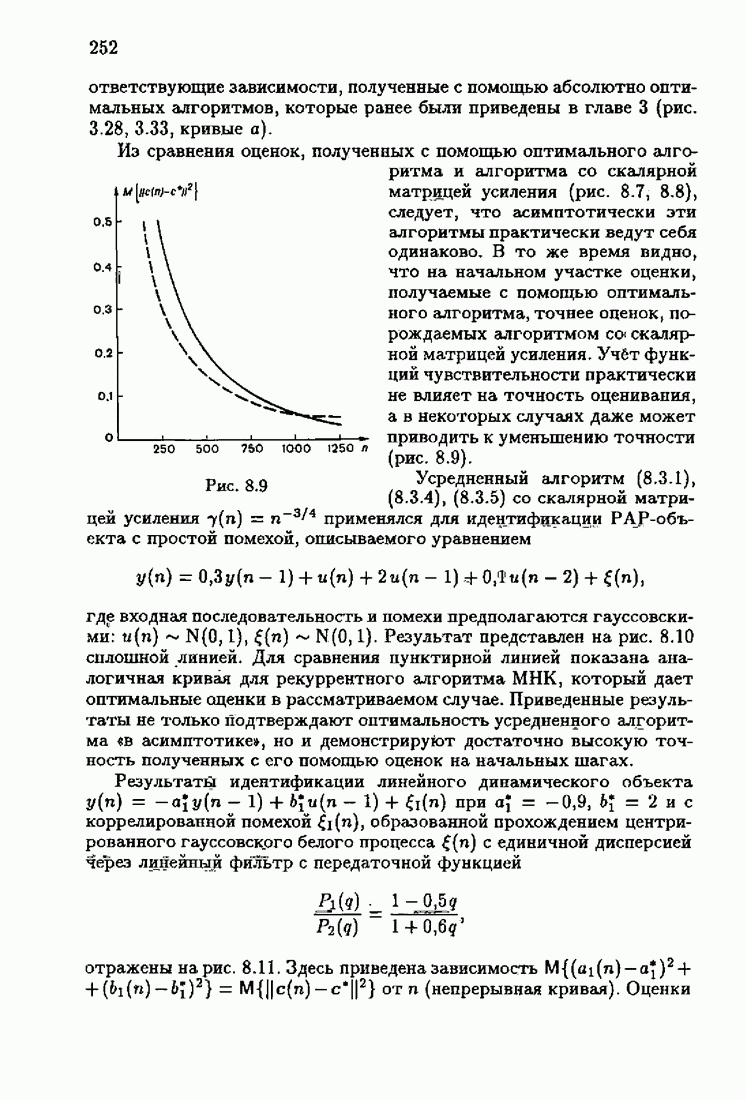
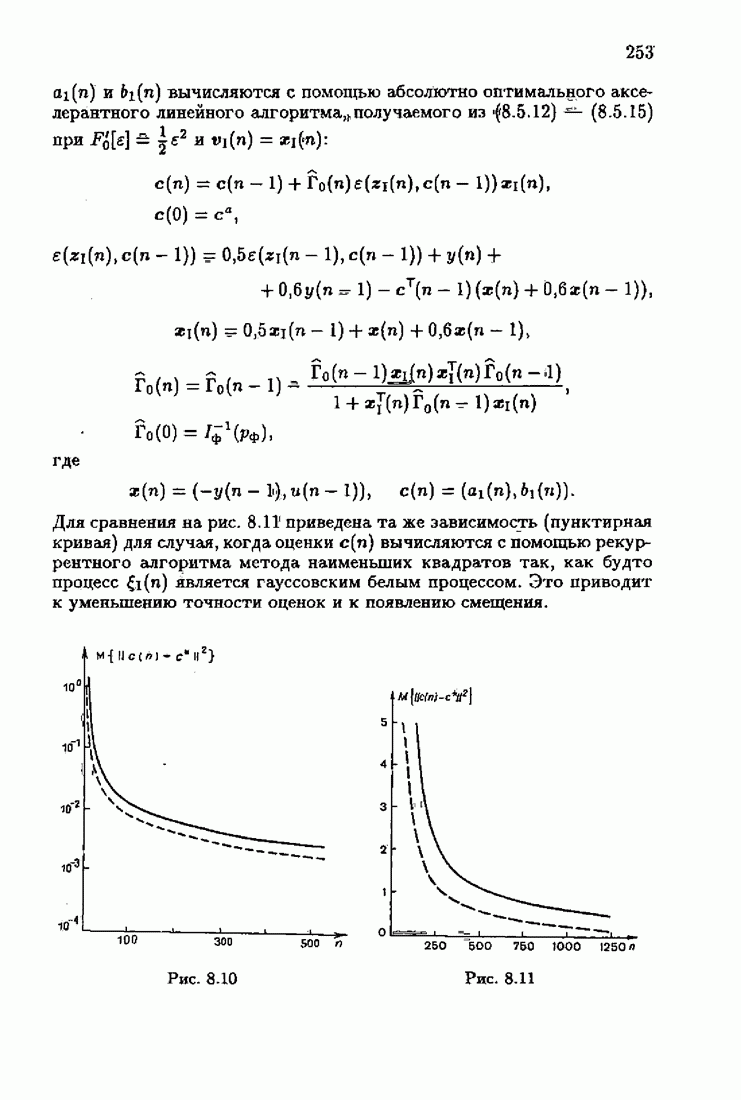
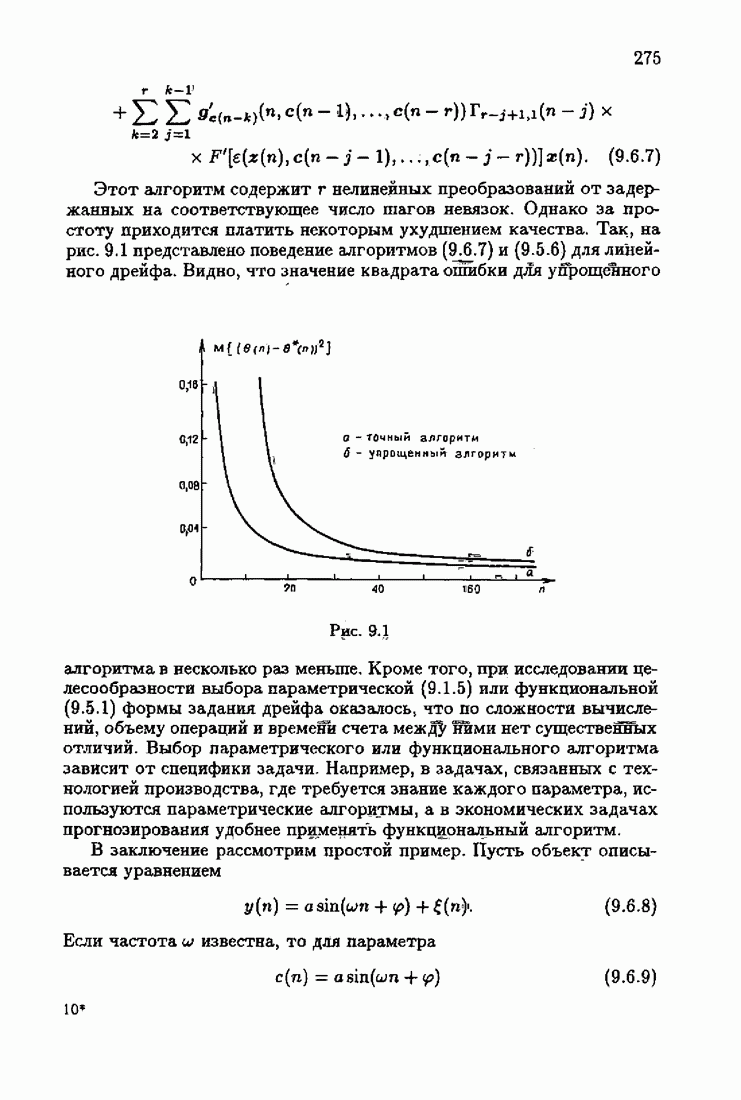
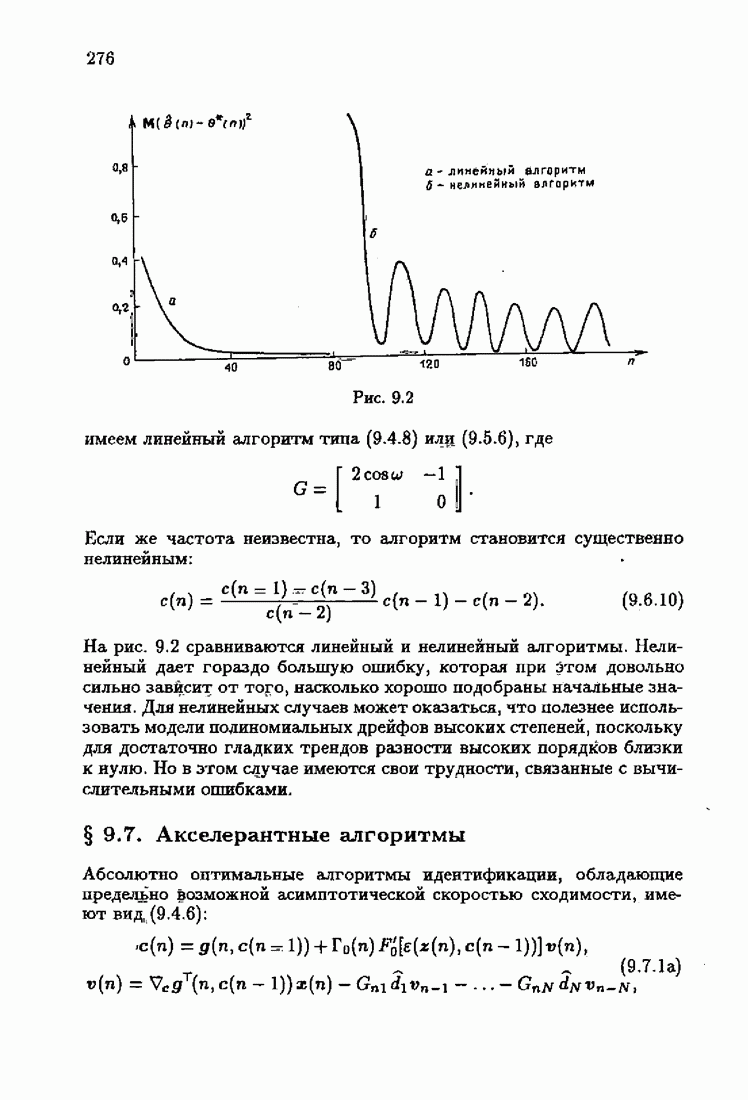
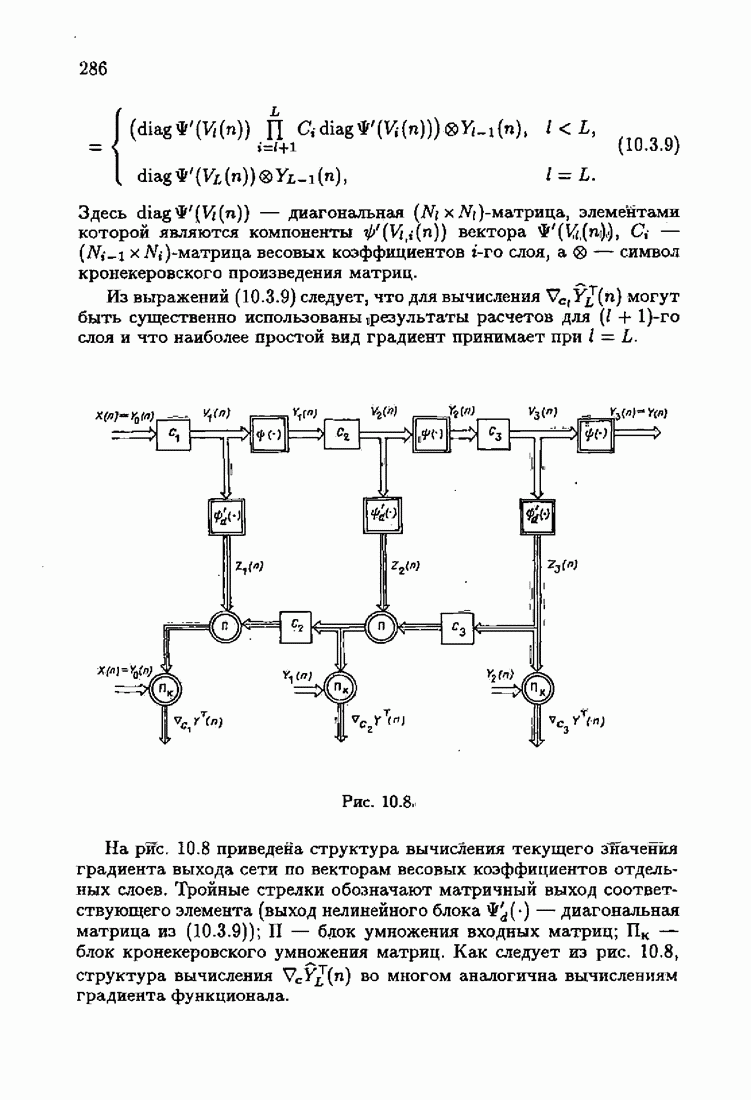
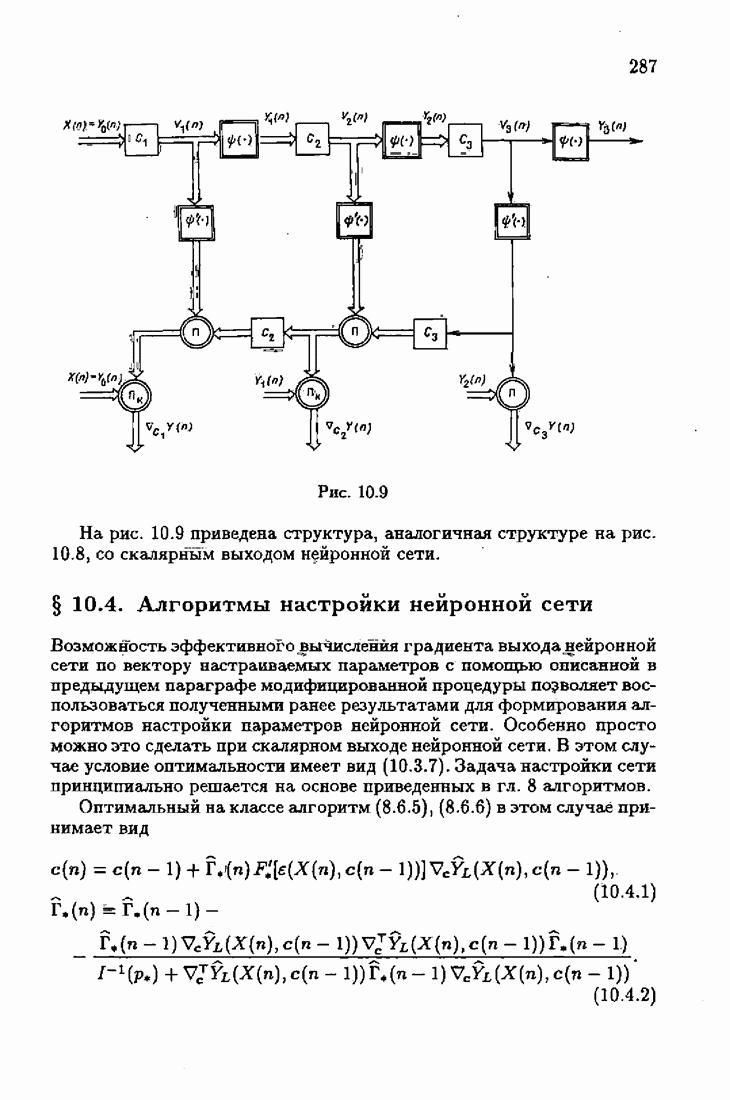
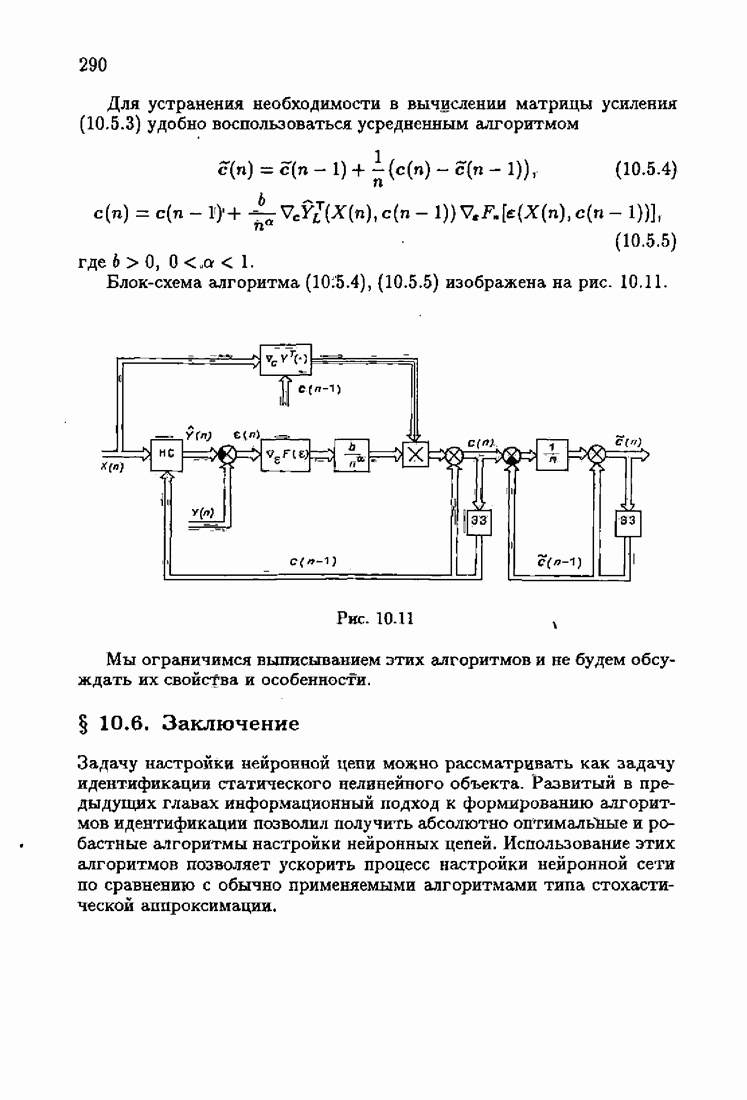
§ 7.8. Примеры
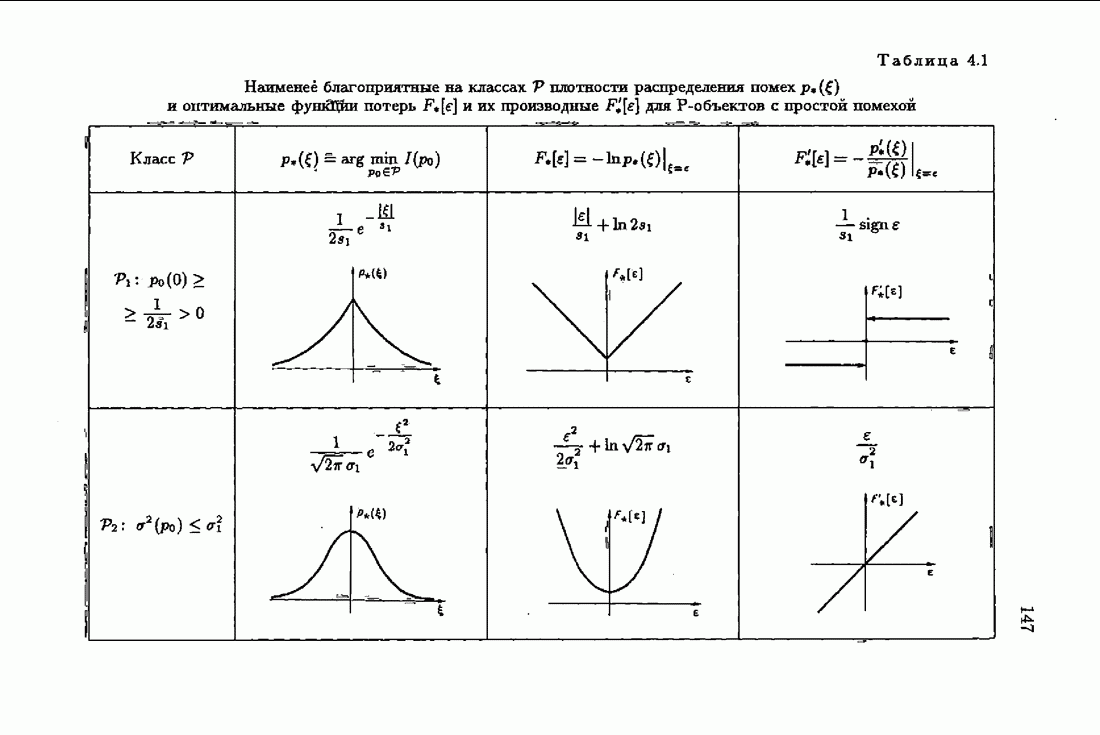
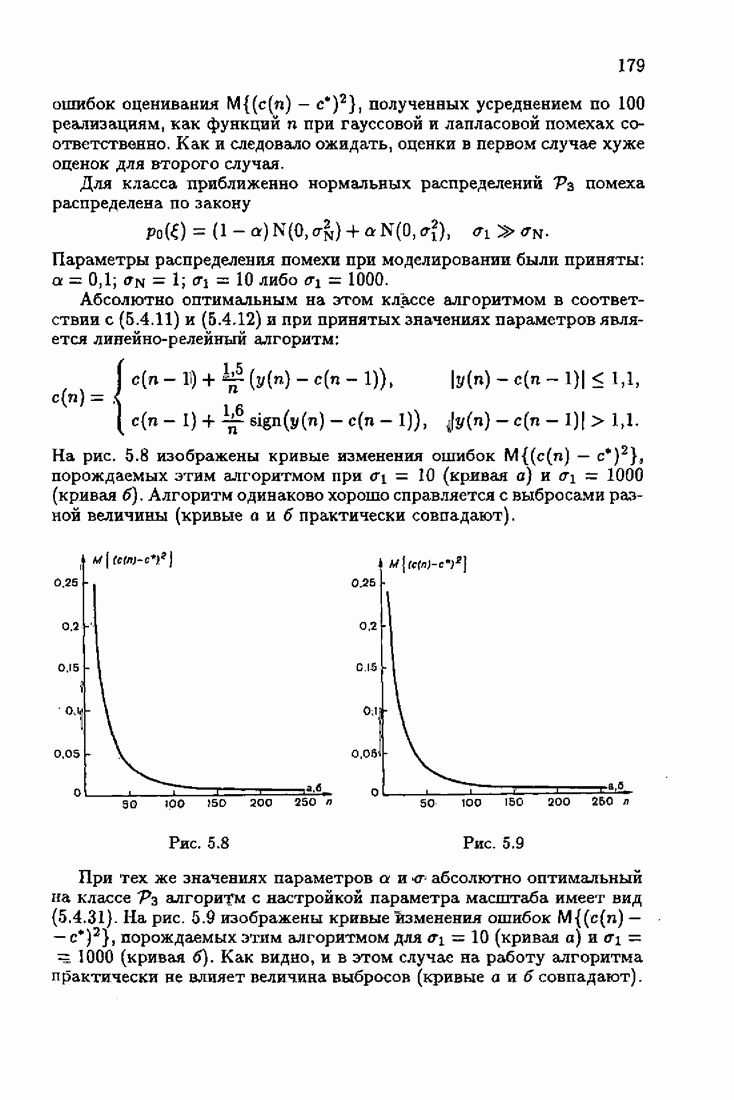
Одномерные абсолютно оптимальные и абсолютно оптимальные на классе алгоритмы оценивания параметра сдвига были приведены и подробно изучены в § 3.4 и § 5.4. Рассмотрим здесь соответствующие им акселерантные алгоритмы. В этом случае (см. (3.4.1), (3.4.4))

Полагая в акселерантных алгоритмах (7.4.18) и  значит,
значит,  получим
получим

где матрица усиления  теперь вырождается в скаляр
теперь вырождается в скаляр

Подставляя  из (7.8.4) в (7.8.3), окончательно получаем акселерантный абсолютно оптимальный алгоритм оценивания параметра сдвига:
из (7.8.4) в (7.8.3), окончательно получаем акселерантный абсолютно оптимальный алгоритм оценивания параметра сдвига:

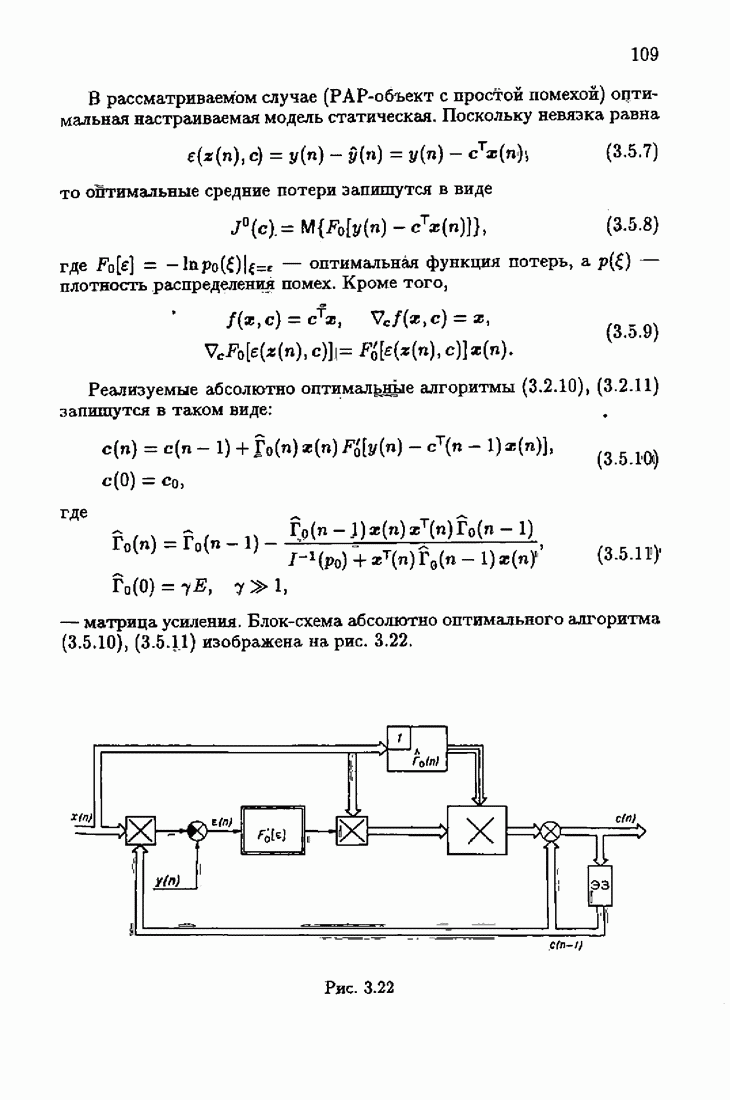
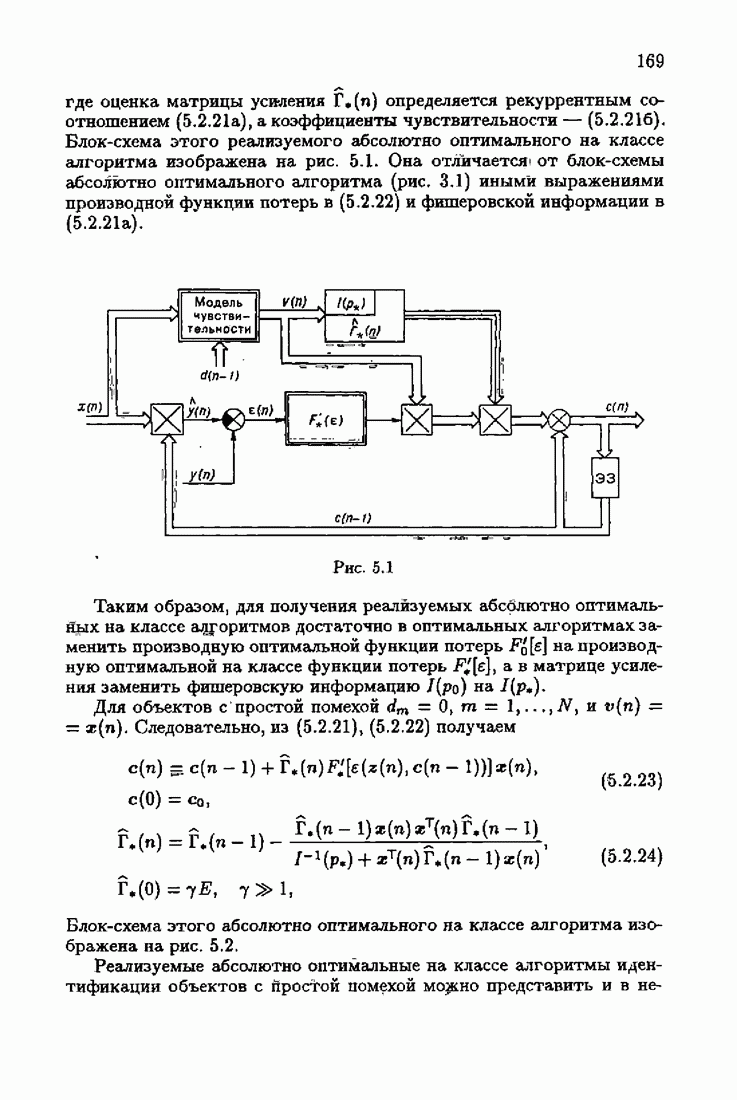
Он отличается от абсолютно оптимального алгоритма (3.4.6) учетом априорной информации об оптимальном решении в виде начального условия  и фишеровской информации
и фишеровской информации 
Аналогичным образом, из (7.5.1) и  при
при  нетрудно получить акселерантный абсолютно оптимальный на классе алгоритм
нетрудно получить акселерантный абсолютно оптимальный на классе алгоритм

В алгоритмах (7.8.5) и (7.8.6), как это следует 
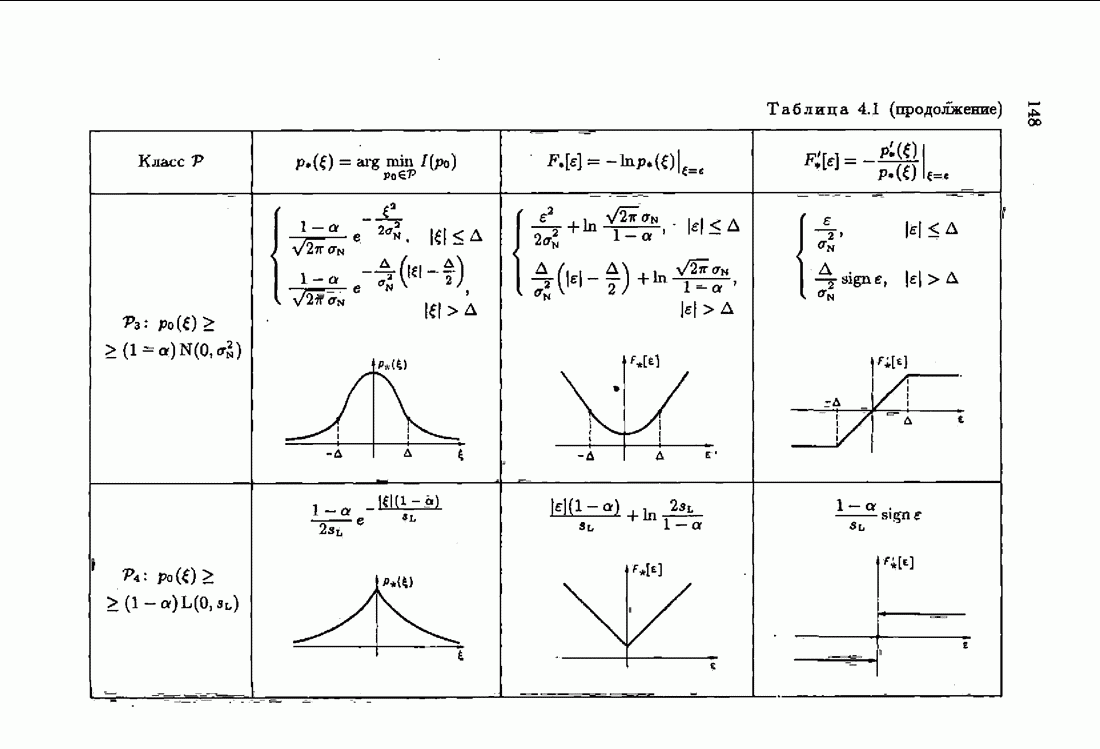
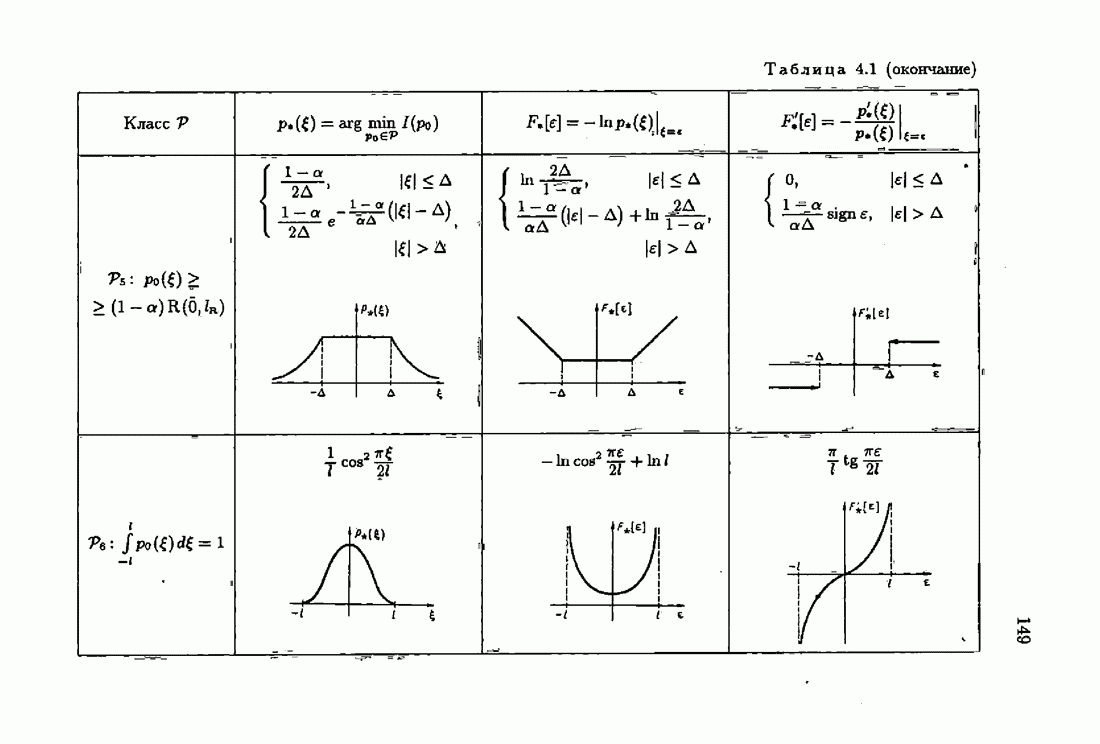
Если априорная информация об оптимальном решении характеризуется финитной фидуциальной плотностью распределения (7.2.3), (7.2.7), то  алгоритмов (7.5.8), (7.5.2) в этом случае получаем акселерантный проекционный алгоритм
алгоритмов (7.5.8), (7.5.2) в этом случае получаем акселерантный проекционный алгоритм

где, как следует из (7.2.10), 
Рассмотрим линейные алгоритмы. Они соответствуют абсолютно оптимальным алгоритмам при нормальной плотности распределения помех и алгоритмам, абсолютно оптимальным на классе распределений с ограниченной дисперсией. Полагая в  получим линейный акселерантный алгоритм
получим линейный акселерантный алгоритм

При  что соответствует отсутствию априорной информации об оптимальном решении, он совпадает с линейным абсолютно оптимальным на классе
что соответствует отсутствию априорной информации об оптимальном решении, он совпадает с линейным абсолютно оптимальным на классе  алгоритмом (5.4.9). Отметим, что в акселерантном алгоритме (7.8.8) последующие оценки
алгоритмом (5.4.9). Отметим, что в акселерантном алгоритме (7.8.8) последующие оценки  уже зависят от начального условия
уже зависят от начального условия  и степень этой зависимости определяется величиной отношения
и степень этой зависимости определяется величиной отношения 
Приведем еще акселерантный абсолютно оптимальный алгоритм на классе 

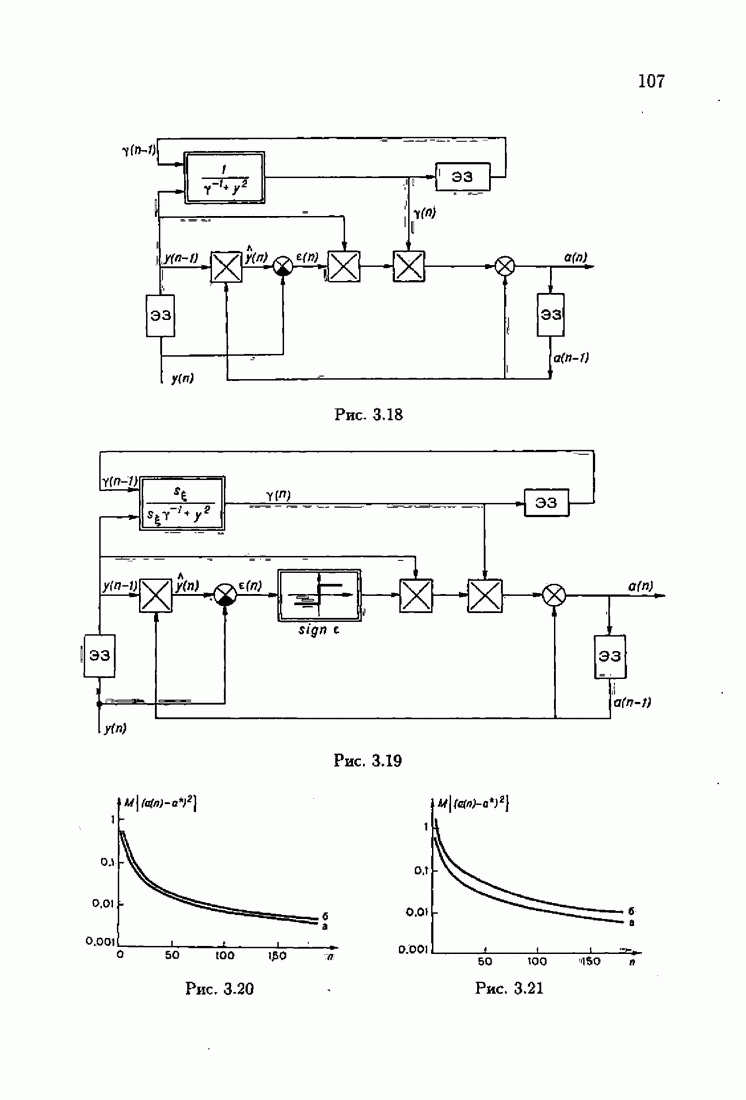
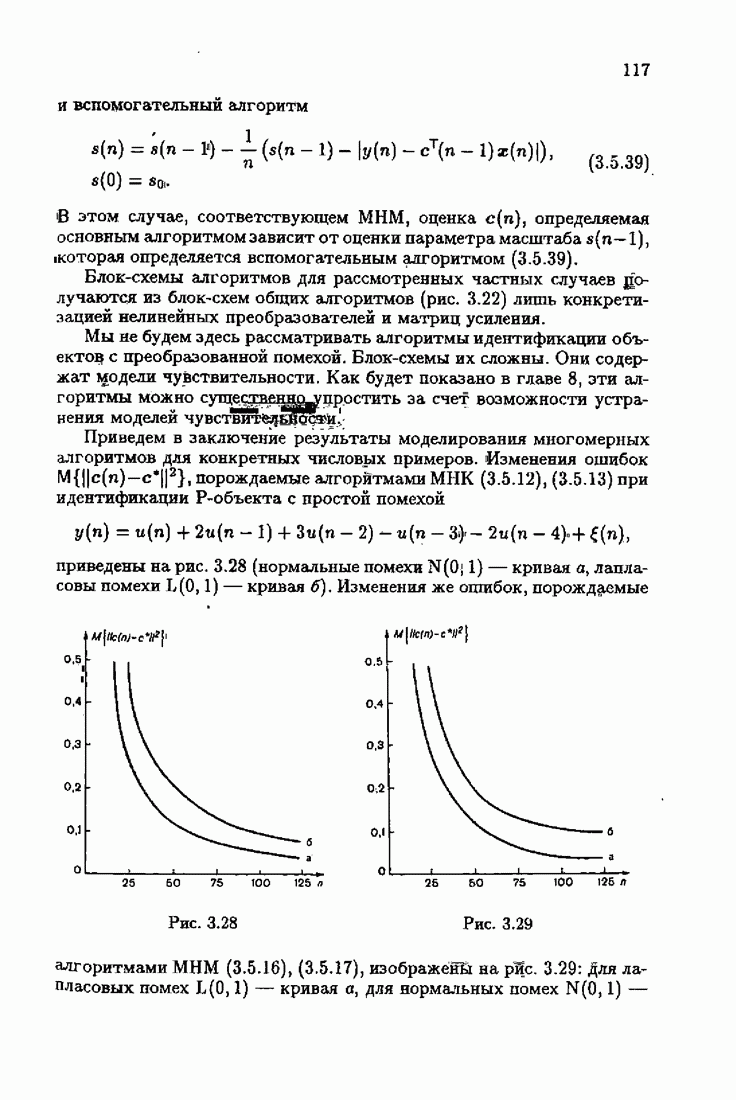
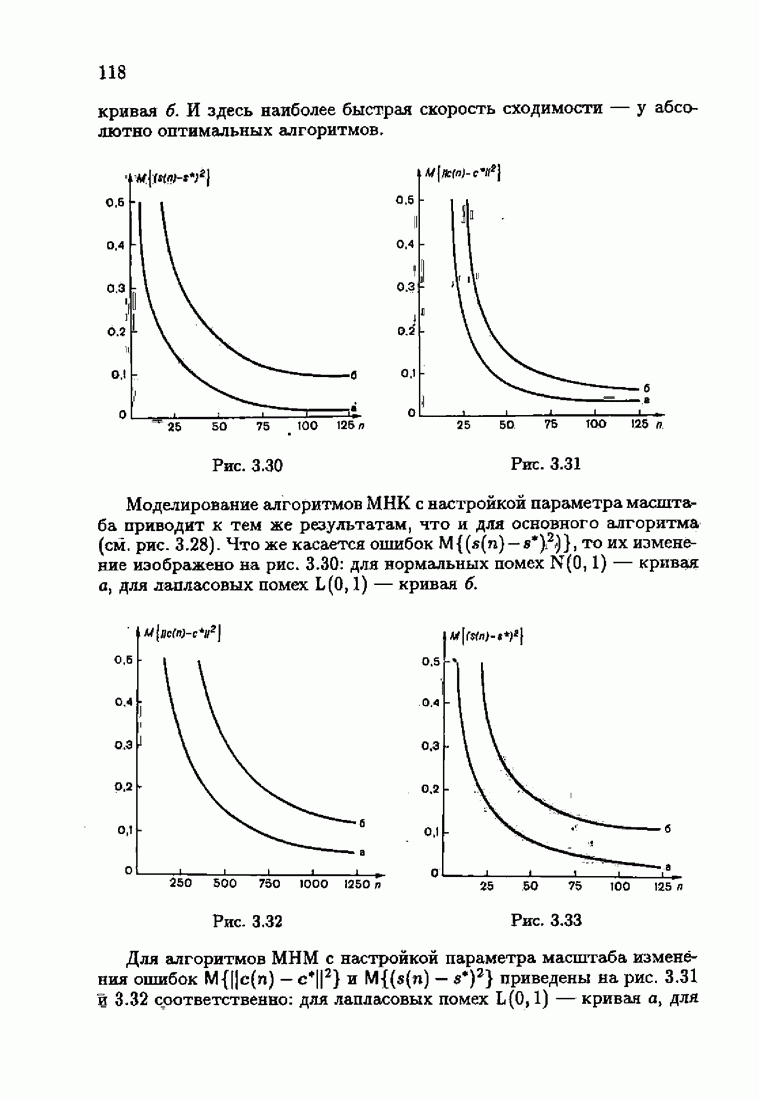
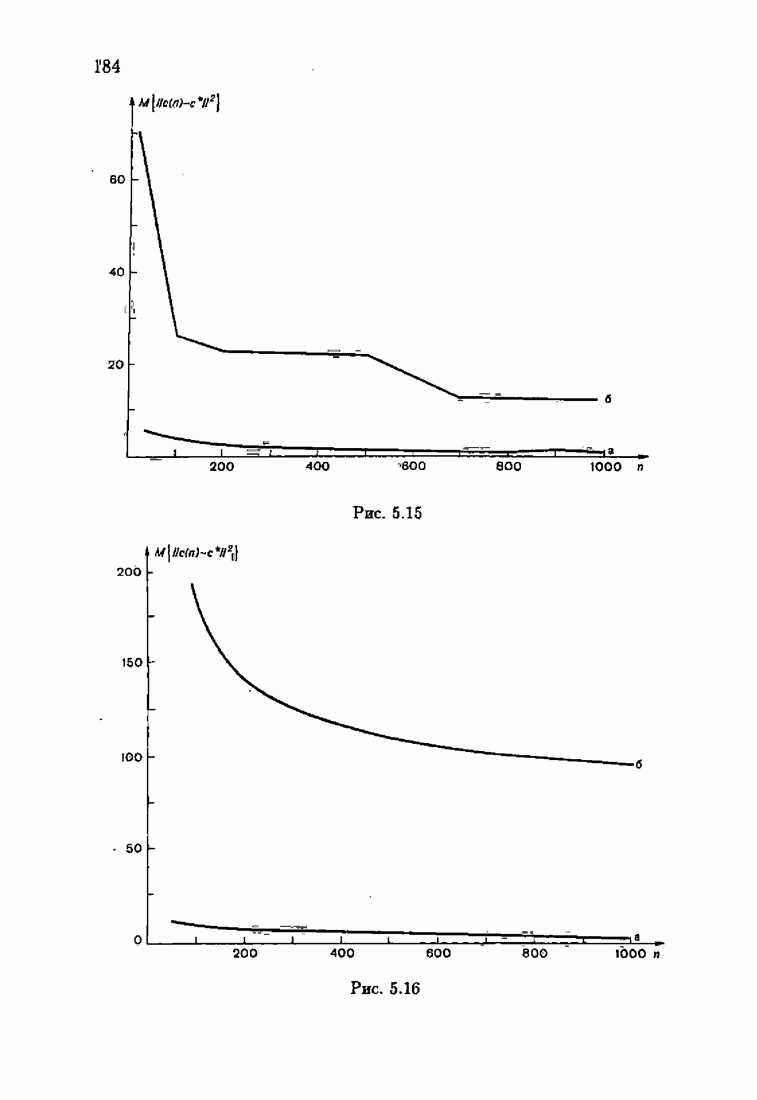
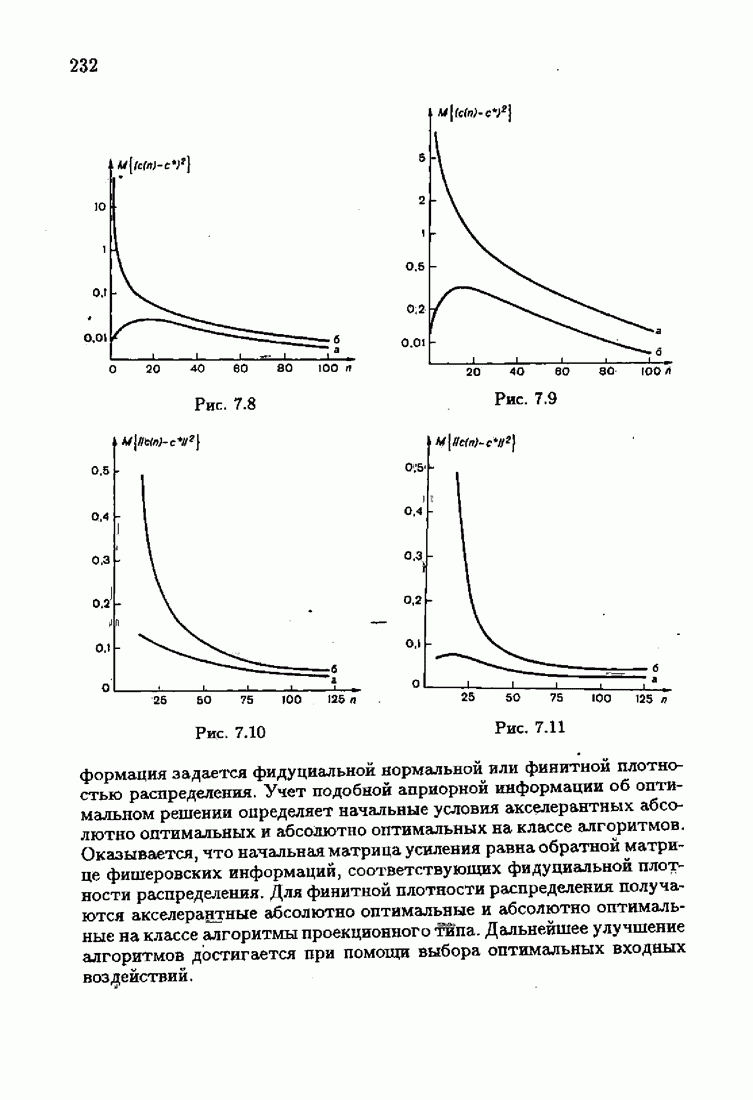
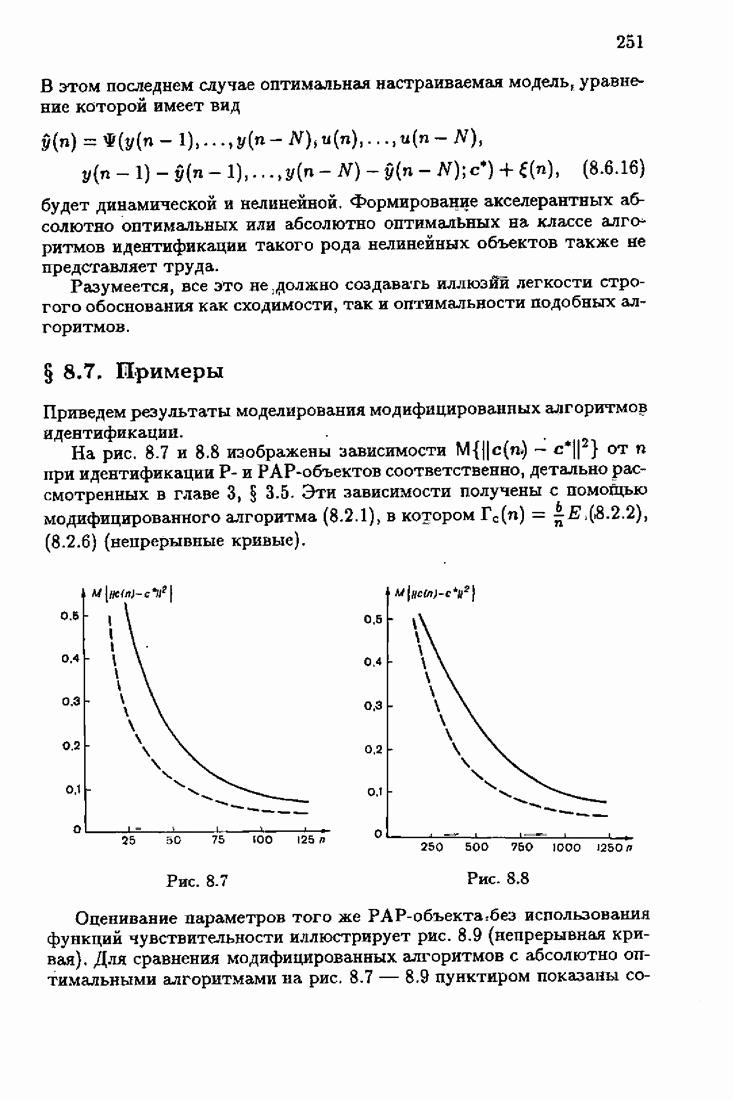
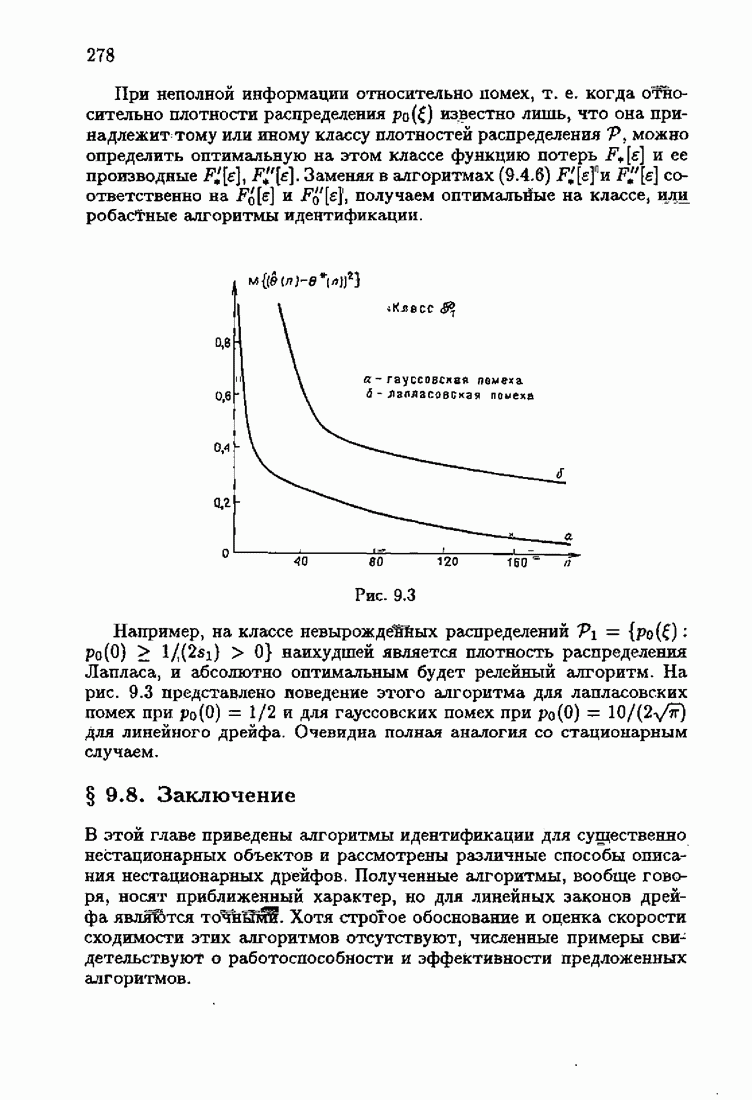
Результаты моделирования алгоритмов (7.8.8), (7.8.9) при тех же условиях, которые были приняты в § 3.4, приведены на рис. 7.8 и 7.9 (кривые а). Для сравнения здесь же приведены результаты из § 3.4 (кривые б). Заметно, что оценки, порождаемые ими на начальных шагах, более точны, чем для произвольных начальных значений.
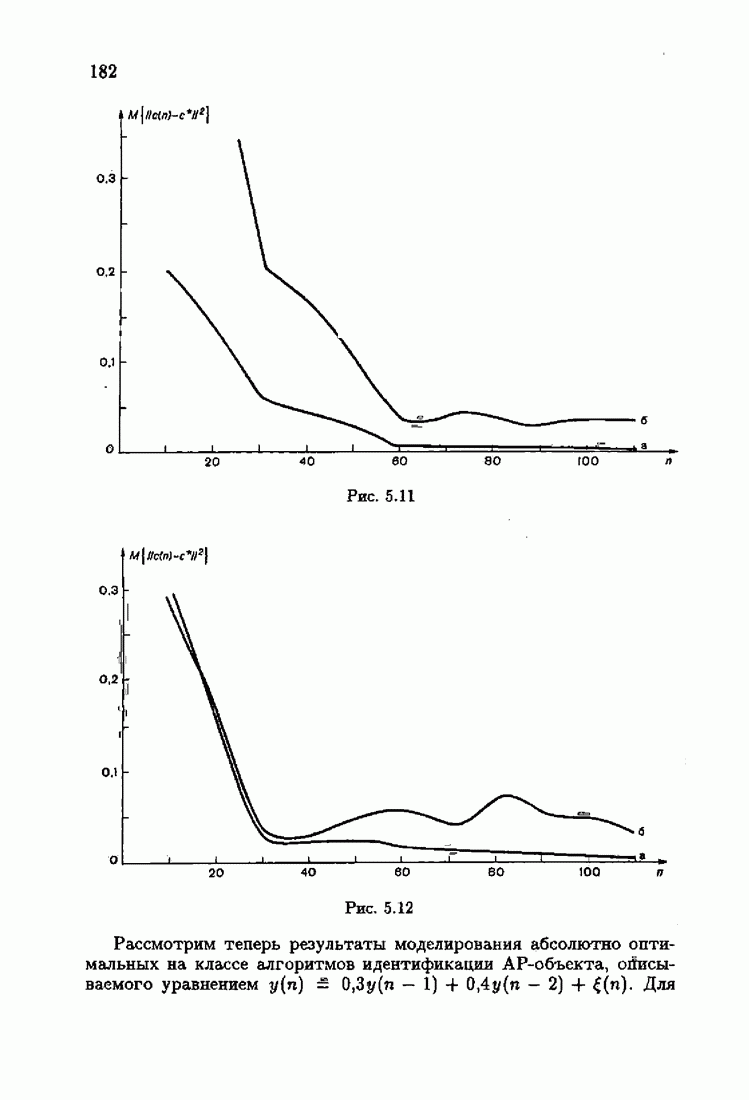
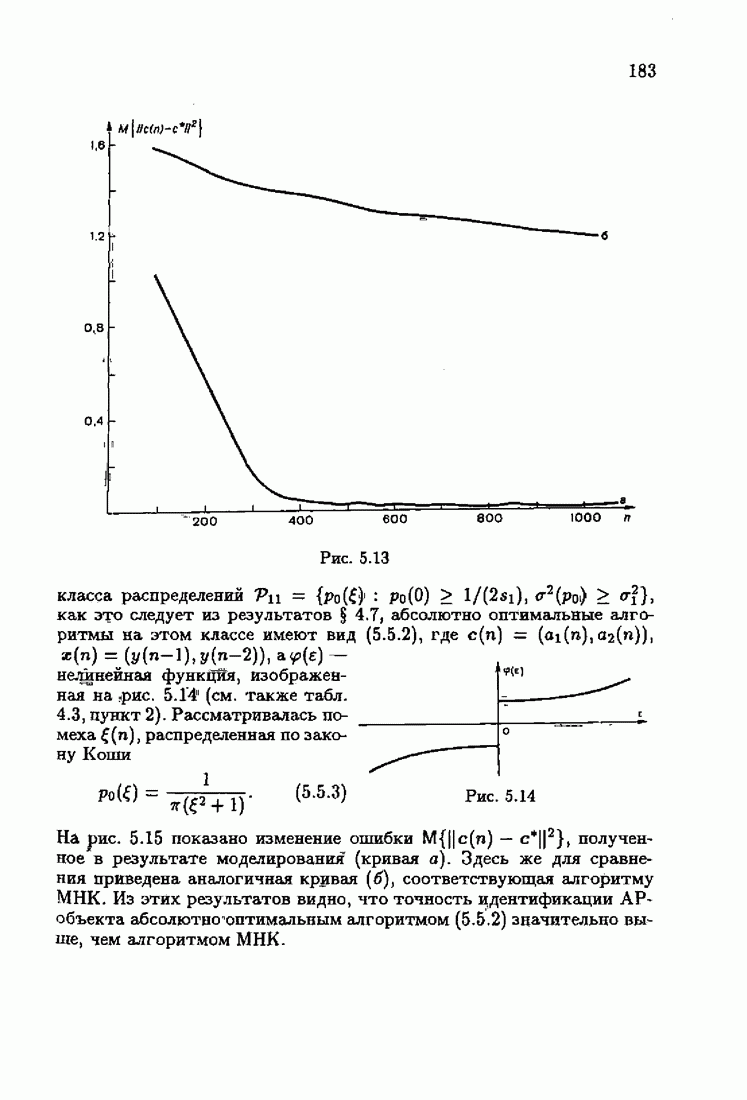
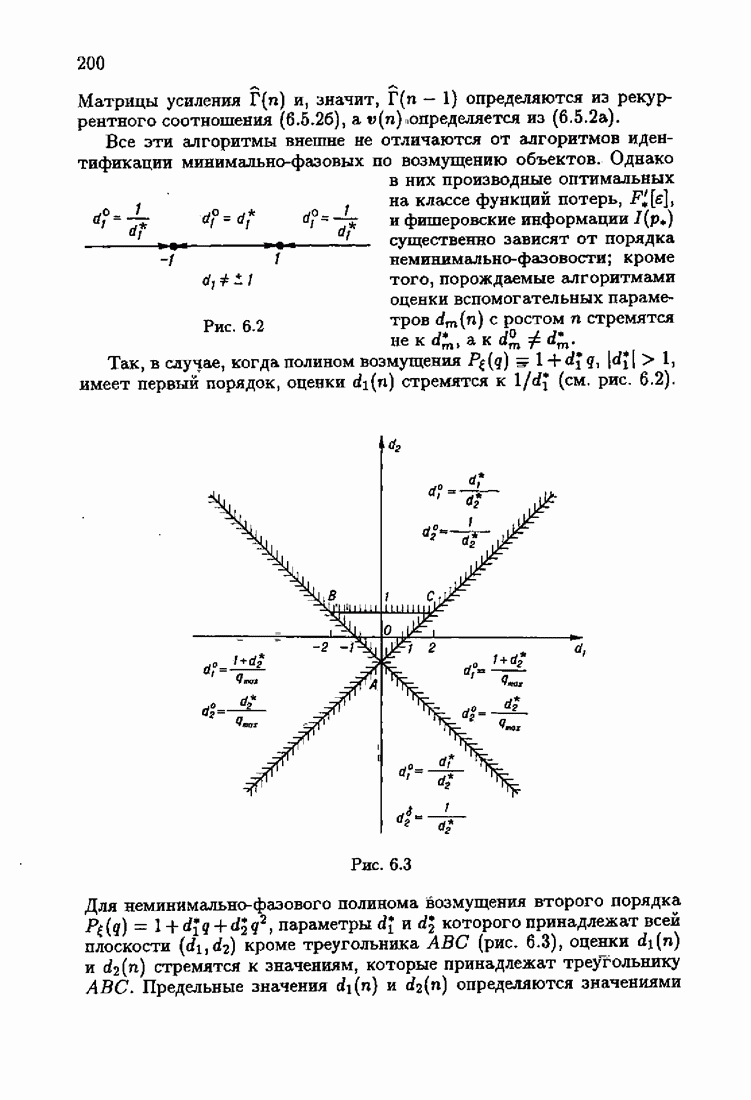
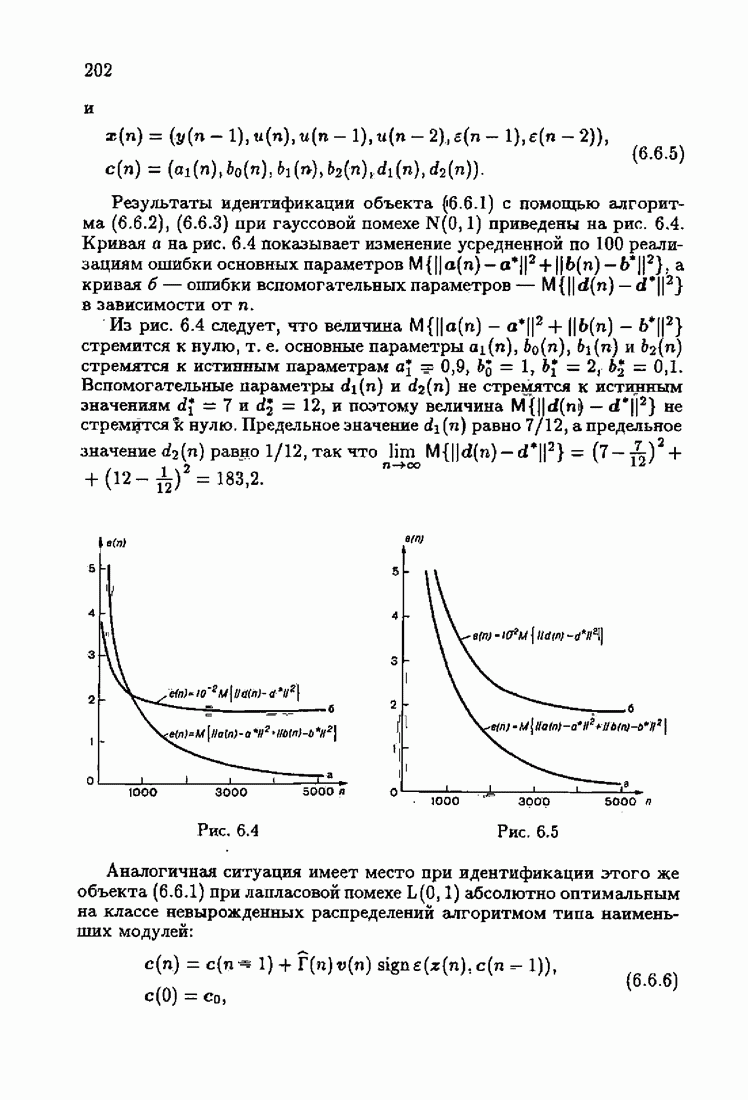
Что же касается многомерных алгоритмов, то, как это неоднократно подчеркивалось, акселерантность в них достигается также за счет выбора соответствующих начальных значений  Так, для рассмотренных в § 3.5 примеров идентификации
Так, для рассмотренных в § 3.5 примеров идентификации  и РАР-объектов алгоритмом
и РАР-объектов алгоритмом  (3.5.13) учет априорной информации в начальных условиях
(3.5.13) учет априорной информации в начальных условиях  позволяет получать на начальных шагах оценки
позволяет получать на начальных шагах оценки  более точные, чем без учета начальных условий. На рис. 7.10 и 7.11 приведены зависимости
более точные, чем без учета начальных условий. На рис. 7.10 и 7.11 приведены зависимости  от
от  для
для  и РАР-объектов соответственно. Кривые а соответствуют учету априорной информации, кривые
и РАР-объектов соответственно. Кривые а соответствуют учету априорной информации, кривые  отсутствию априорной информации.
отсутствию априорной информации.