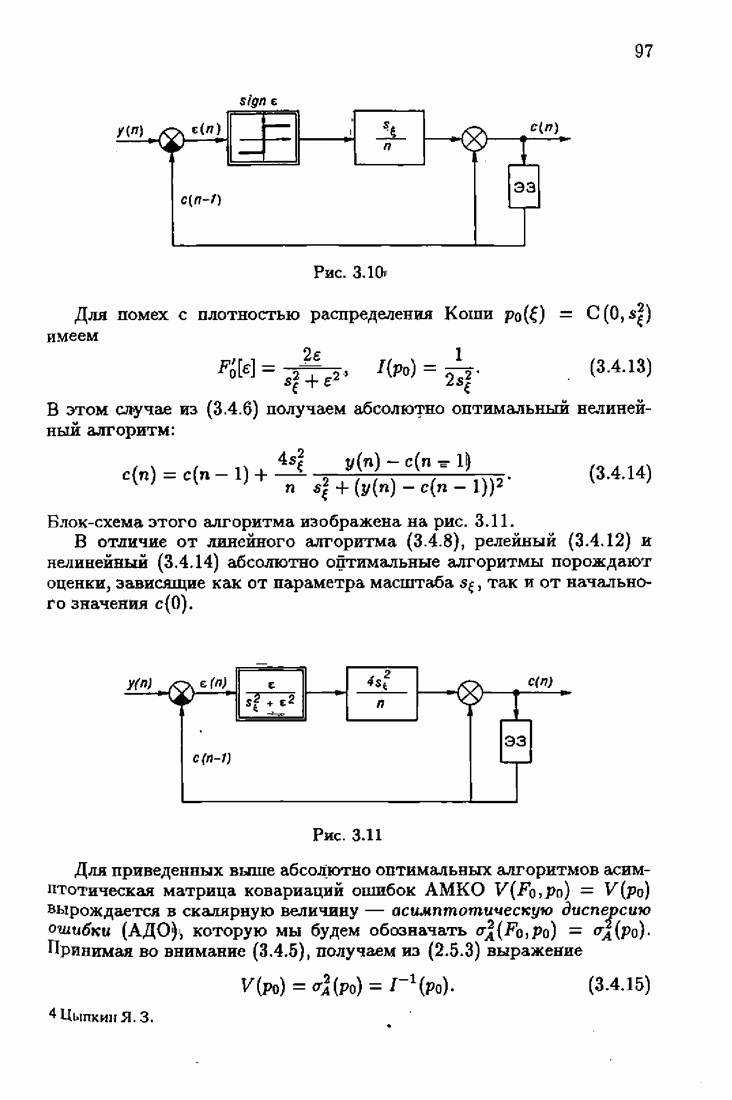
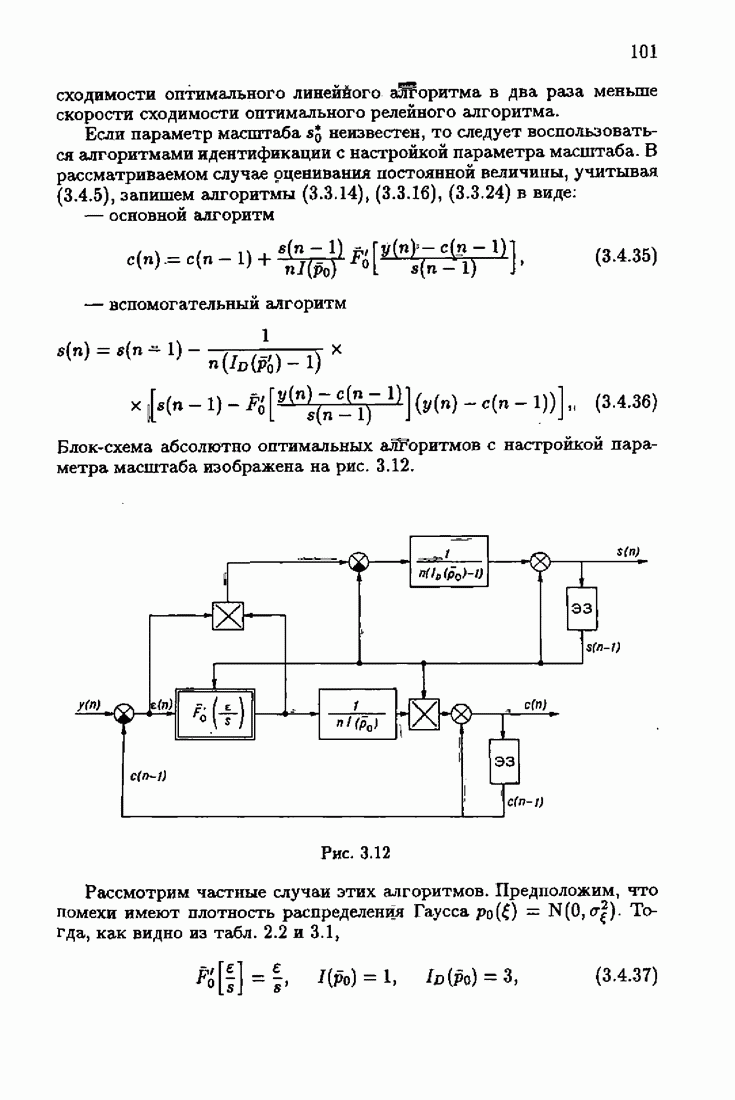
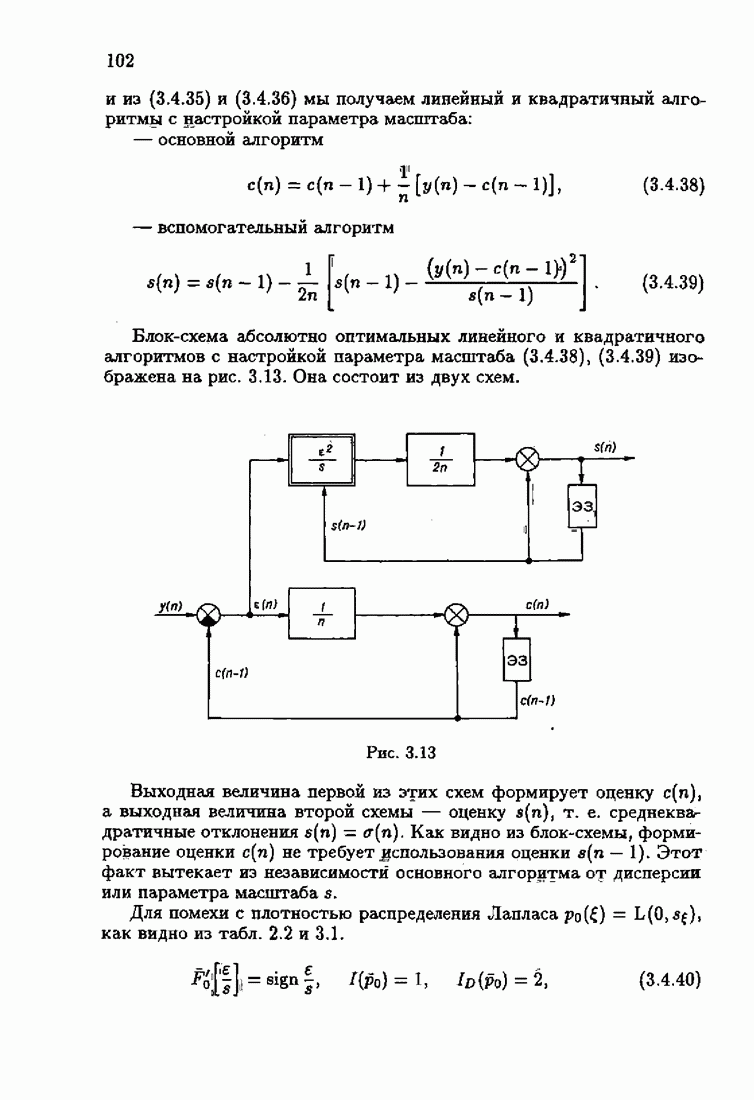
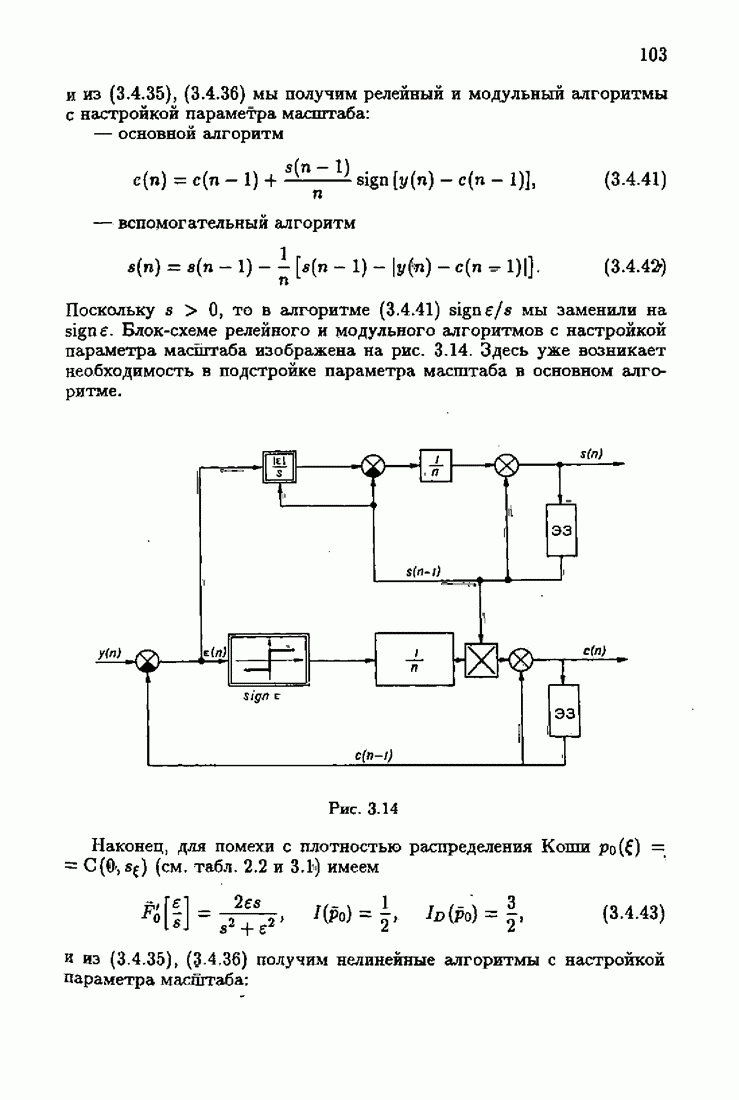
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
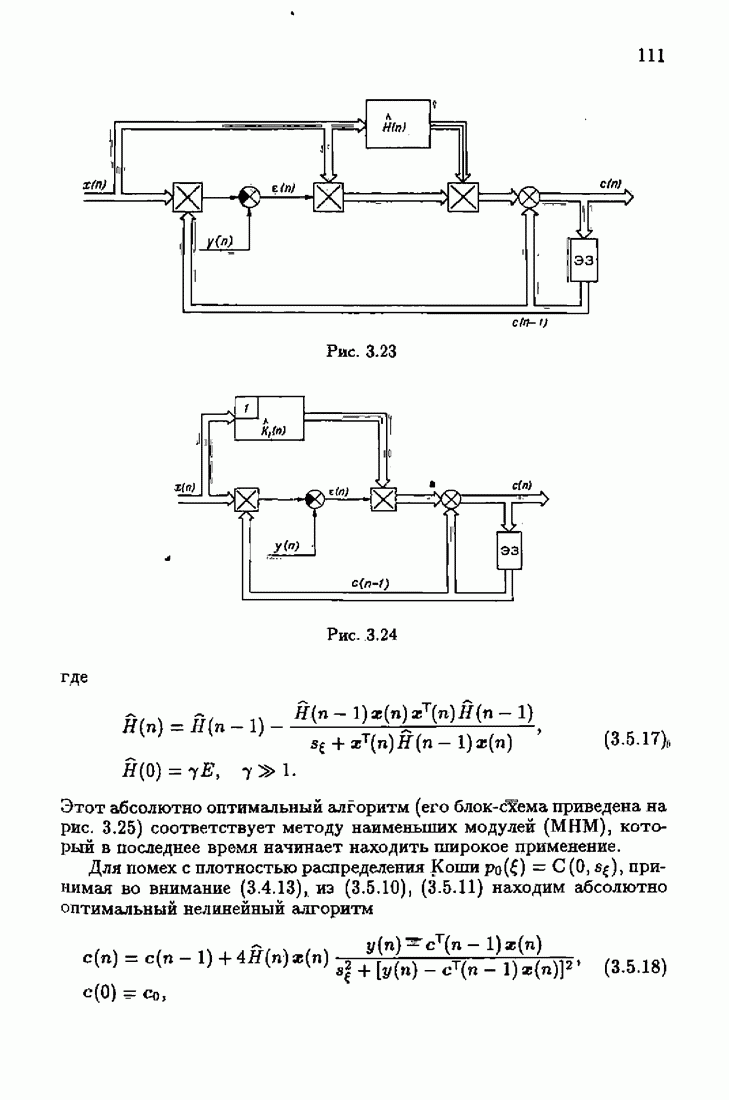
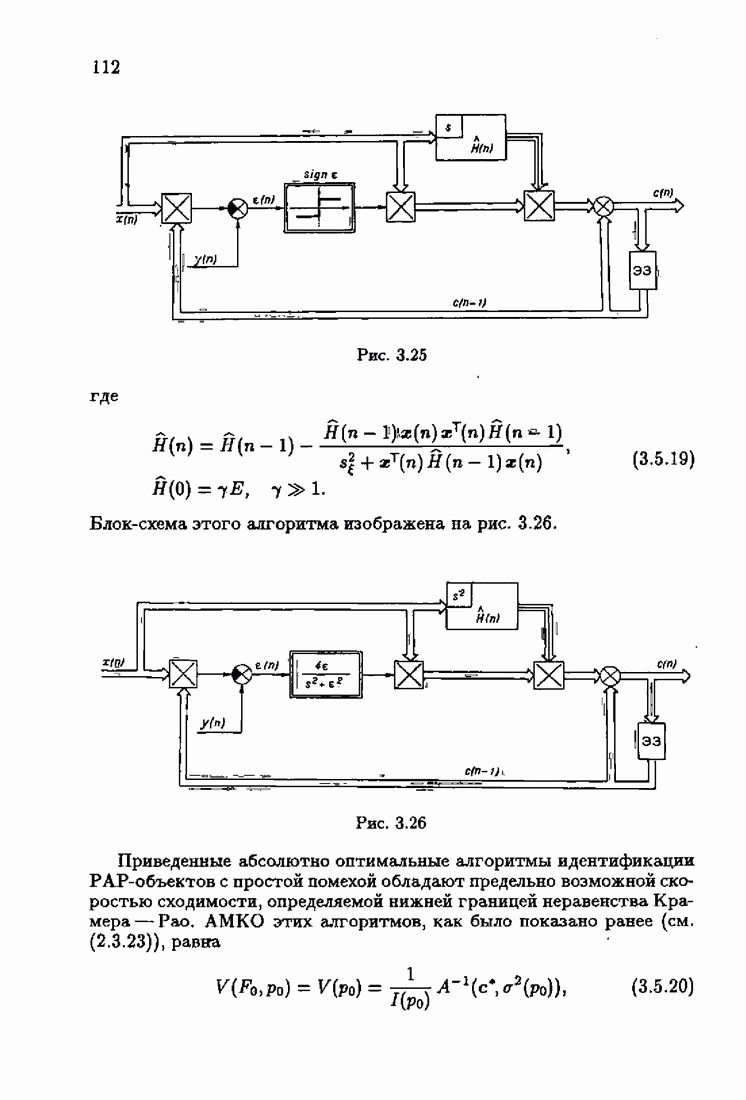
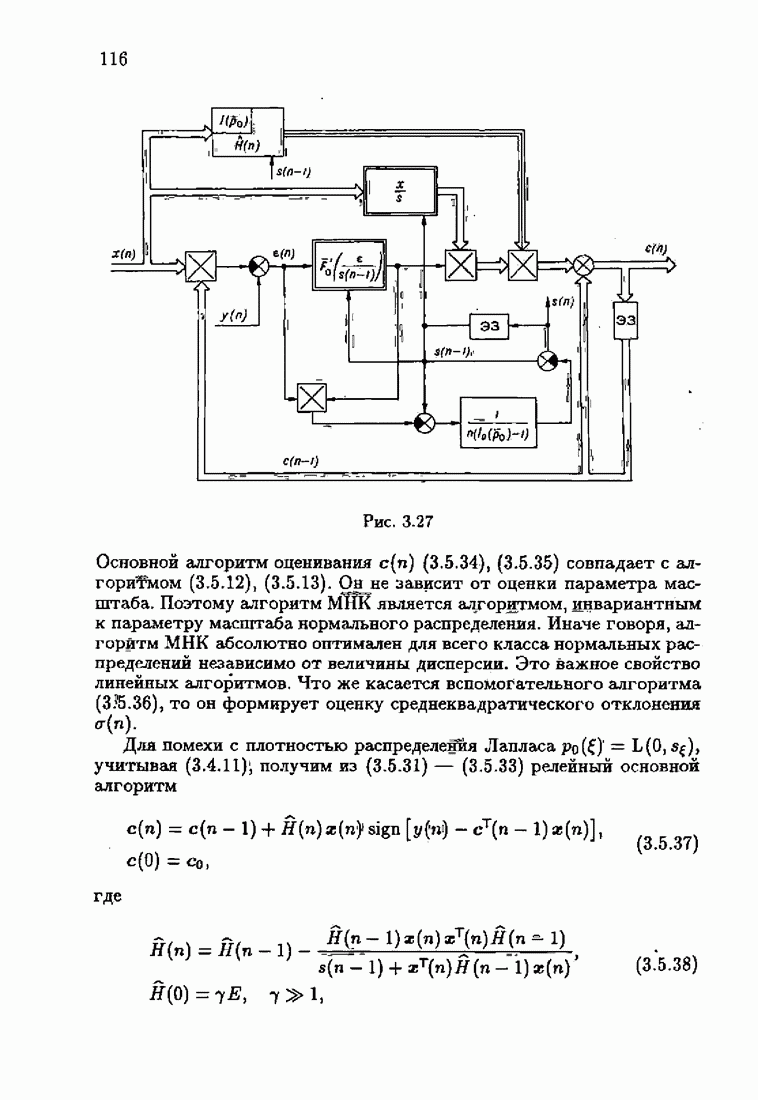
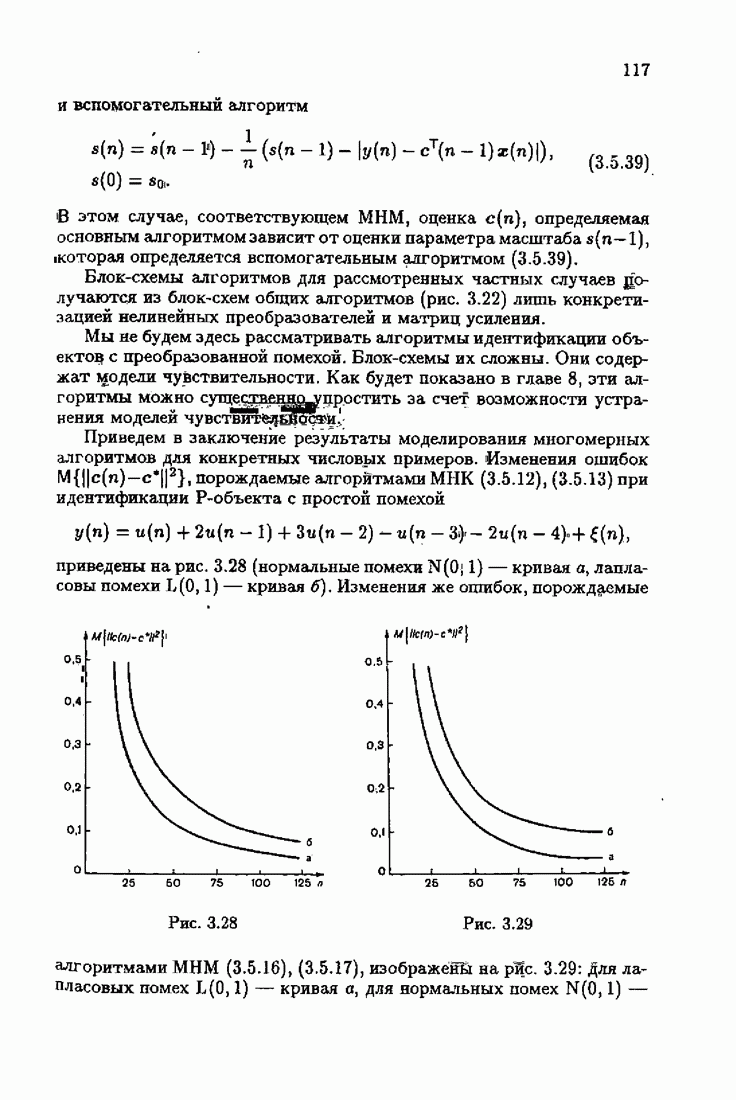
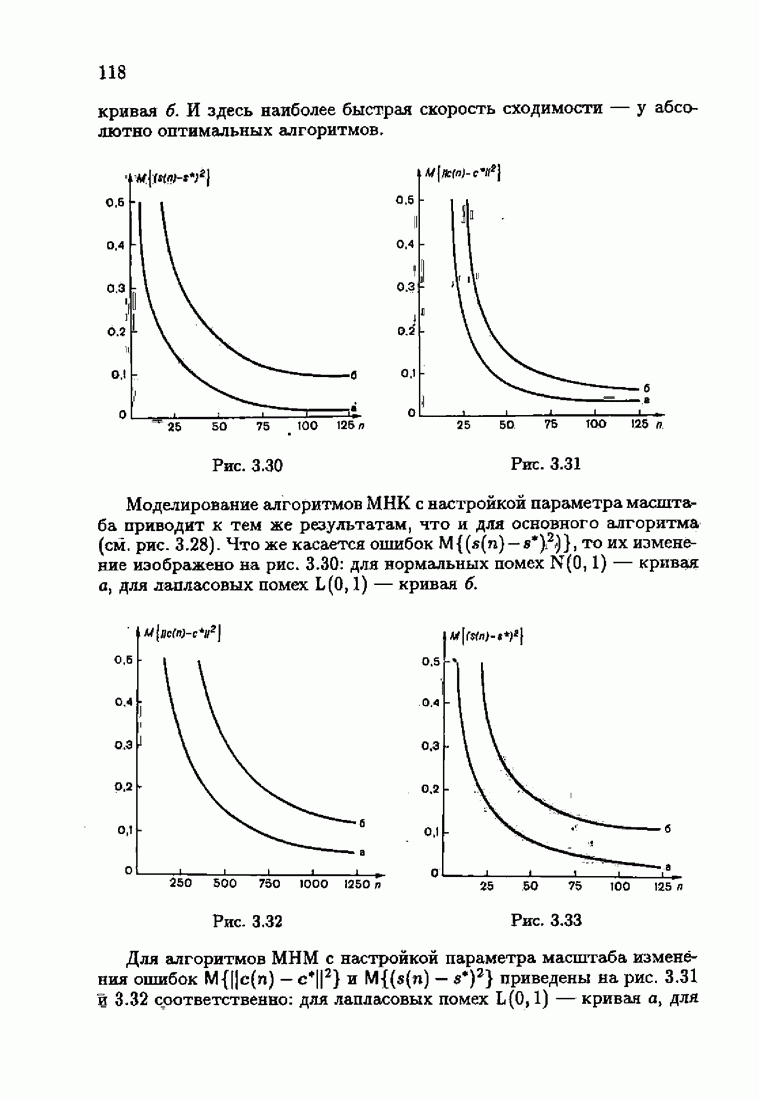
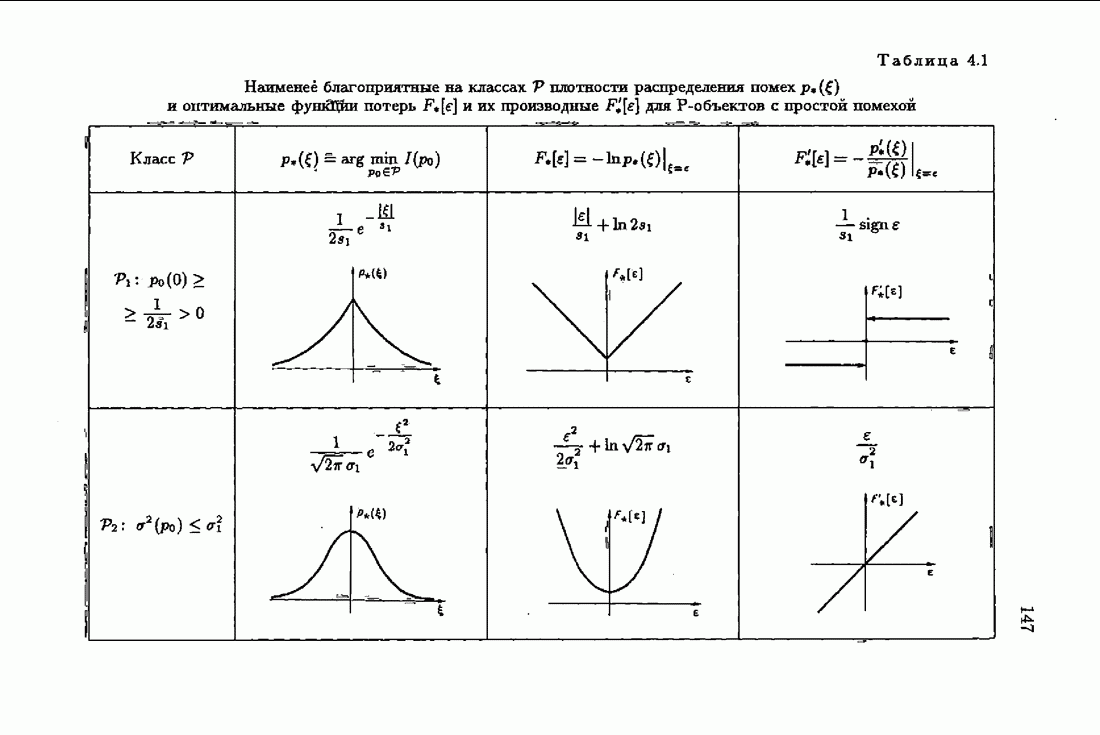
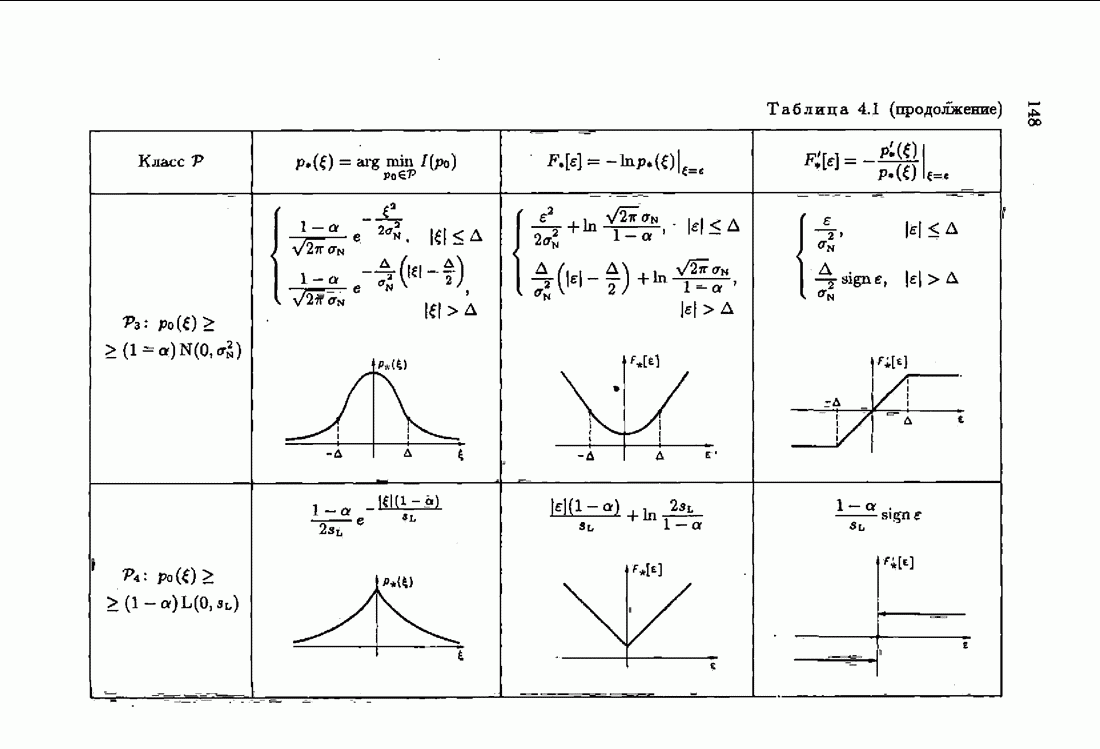
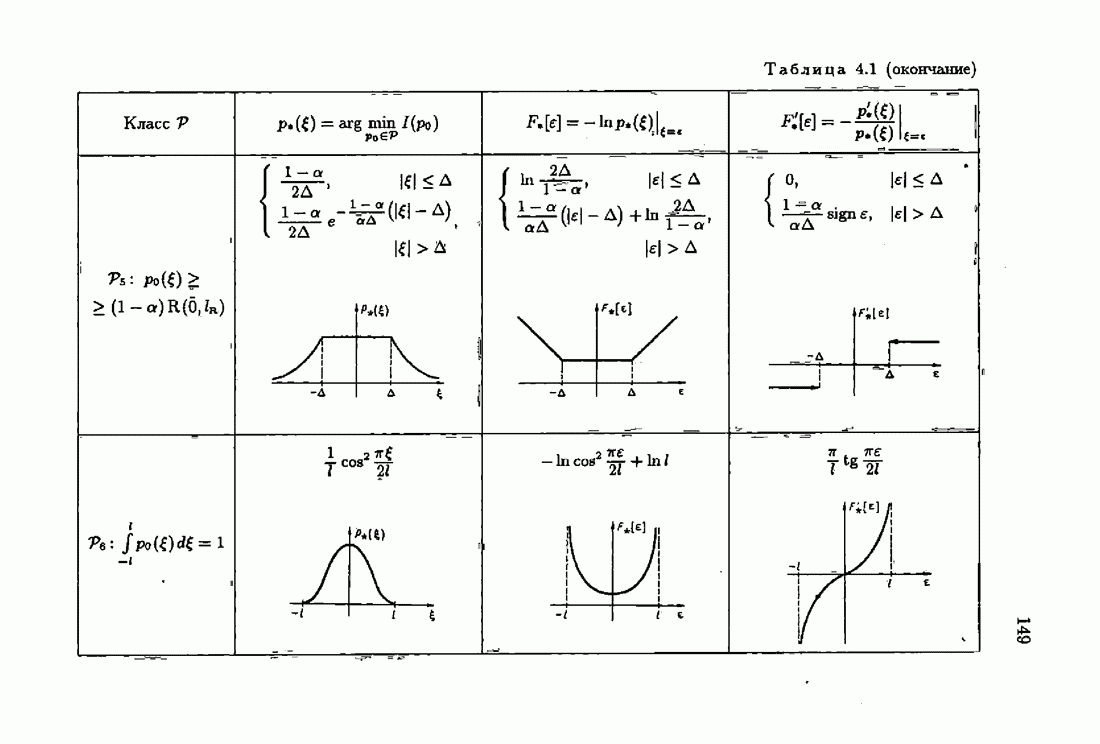
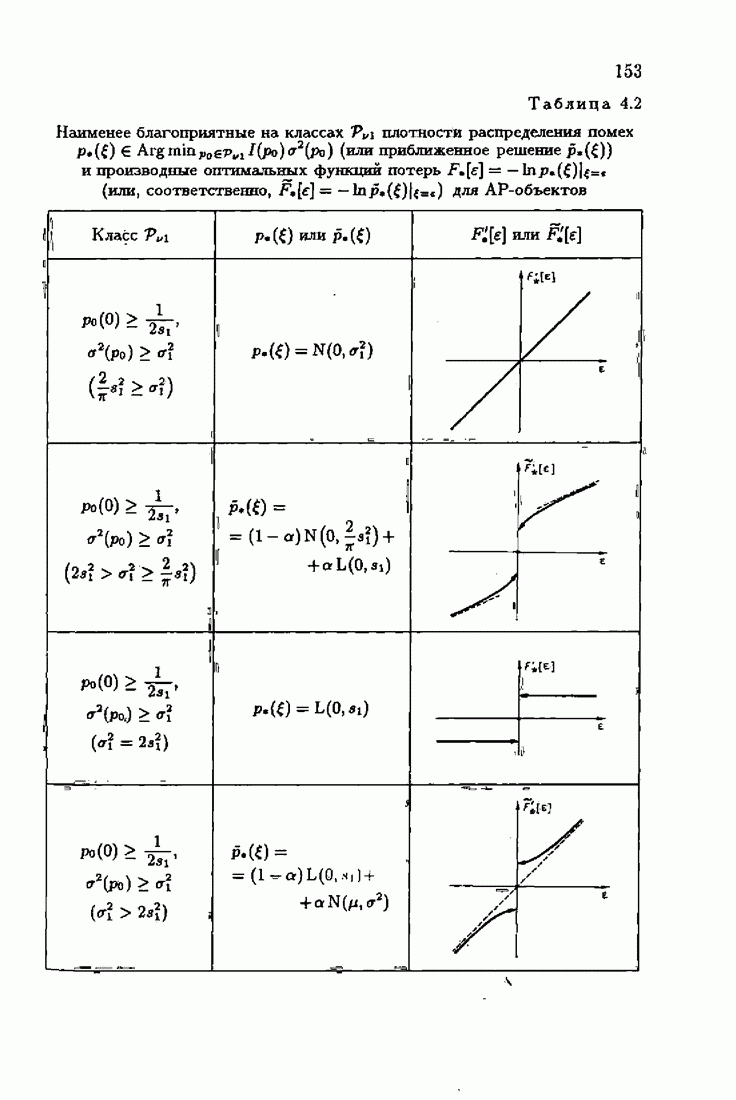
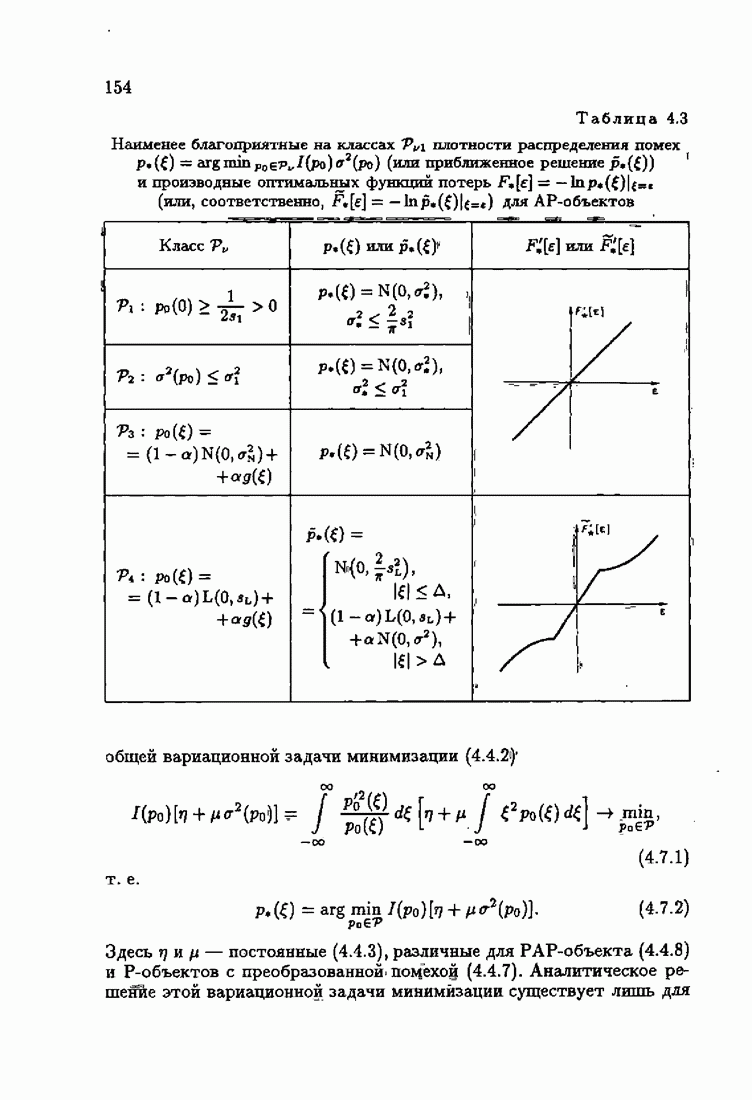
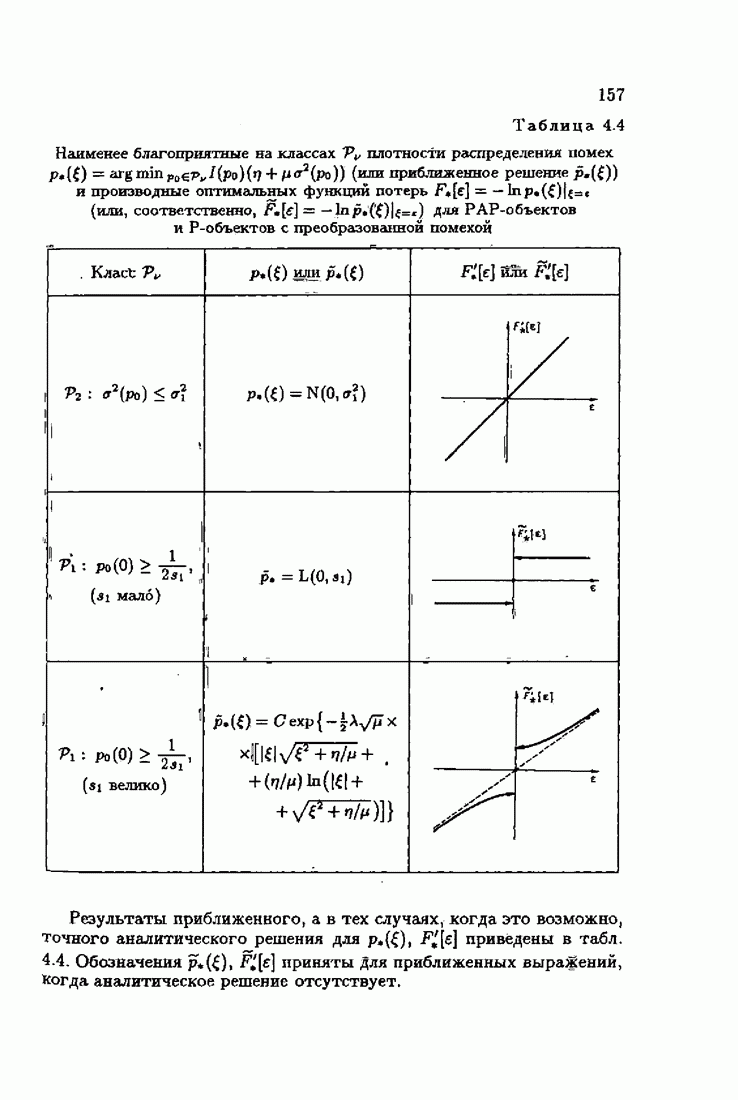
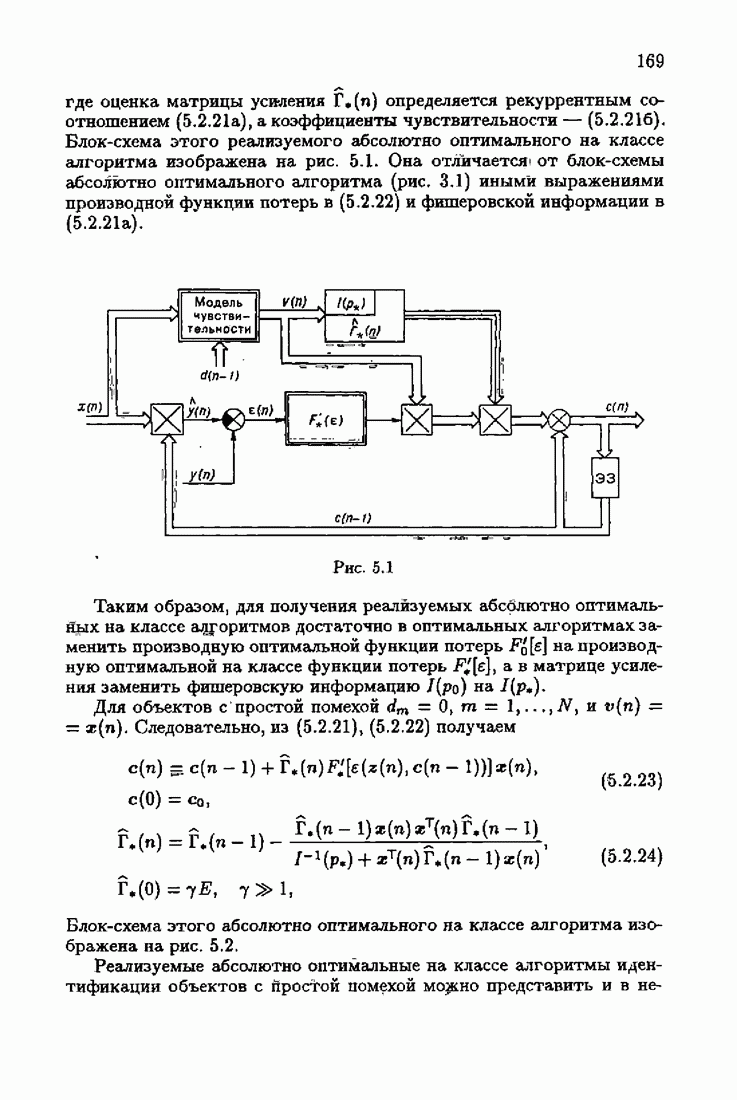
ВведениеЗадача идентификации систем, т. е. определение структуры и параметров систем по наблюдениям, является одной из основных задач современной теории и техники автоматического управления. Эта задача возникает при изучении свойств и особенностей объектов с целью последующего управления имя, либо при создании адаптивных систем, в которых на основе идентификации объекта вырабатываются оптимальные управляющие воздействия. К различным вариантам задачи идентификации, по существу, приводят статистические методы обработки экономической, биологической, медицинской информации. Наиболее часто используется идентификация в режиме нормальной работы. По наблюдаемым входным воздействиям и выходным величинам объекта подбираются параметры настраиваемой модели, обеспечивающие экстремум некоторого критерия, характеризующего качество идентификации. Изменение параметров настраиваемой модели осуществляется при помощи адаптивных устройств, реализующих алгоритмы идентификации. К настоящему времени предложены различные адаптивные алгоритмы идентификации. Многочисленность и разнообразие настраиваемых моделей, критериев и алгоритмов, естественно, затрудняет решение конкретных задач идентификации. Это обстоятельство вызвало к жизни специальные работы по экспериментальному исследованию и сравнению алгоритмов идентификации для типовых задач. К сожалению, результаты этих работ, кроме констатации отдельных фактов, не позволяют установить какие-либо общие закономерности. Практика применения адаптивных алгоритмов идентификации обнаружила, что алгоритмы простейшей формы — типа стохастической аппроксимации — часто оказывались неработоспособными. Оценки параметров настраиваемой модели, даваемые этими алгоритмами, во многих случаях зависели от произвола в выборе начальных значений, а сходимость алгоритмов часто была очень медленной. Попытки улучшения или оптимизации этих алгоритмов за счет замены скалярного коэффициента усиления матричным и подбора элементов этой матрицы, как это делается в рекуррентной форме метода наименьших квадратов, не всегда приводили к удаче. Подобные оптимальные алгоритмы, несмотря на теоретическую сходимость и минимальность асимптотической дисперсии, в ряде случаев практически оказывались несходящимися. Такое поведение адаптивных алгоритмов идентификации вызывав лось несоответствием используемых алгоритмов условиям, характеризующим конкретные задачи идентификации. Так, алгоритмы типа стохастической аппроксимации слишком универсальны. Они не учитывают имеющуюся априорную информацию как о помехах, так и о самом решении, т. е. о параметрах объекта. Оптимальные же алгоритмы рекуррентной формы метода наименьших квадратов не всегда оказываются адекватными априорной информации о помехах и области принадлежности параметров идентифицируемого объекта. В итоге выбираемые — посуществу, наугад — алгоритмы идентификации часто не приводили к надежным и обоснованным результатам. Поэтому возникла важная задача обоснованного выбора или, точнее говоря, формирования алгоритмов идентификации. Решеиие этой задачи тесно связано с возможностью учета в настраиваемых моделях, в критериях качества и, наконец, в алгоритмах идентификации имеющейся в нашем распоряжении априорной информации. Поскольку адаптивные алгоритмы идентификации определяются принятой настраиваемой моделью идентифицируемого объекта и критерием качества идентификации, оценивающим близость модели и объекта, то однозначный выбор алгоритма возможен лишь при однозначном выборе настраиваемой модели и критерия. Таким образом, задача обоснованного, а значит, и однозначного формирования адаптивного алгоритма сводится прежде всего к задачам выбора настраиваемой модели и выбора критерия идентификации. Современная теория идентификации предоставляет в распоряже ние исследователя возможность широкого выбора настраиваемых моделей и критериев качества идентификации, а также большое число алгоритмов идентификации. К сожалению, какие-либо указания о выборе настраиваемых моделей, критериев и алгоритмов, кроме соображении простоты, отсутствуют. Развиваемая в настоящей книге информационная теория идентификации дает возможность устранить эту неопределенность и для каждого конкретного класса задач идентификации, характеризуемого тем или иным уровнем априорной информации, однозначно определить настраиваемую модель, критерий качества идентификации и алгоритм идентификации, обеспечивающий в определенном смысле наилучшее использование обрабатываемых данных для целей идентификации. Такой подход привлекателен не только с точки зрения внесения большей определенности в задачу идентификации и устранения необходимости в проведении сравнительного анализа разнообразных алгоритмов, но также и потому, что он позволяет установить общие закономерности. Учет априорной информации в задаче идентификации связан с широким использованием основных понятий теории информации и статистики, таких, как информационные меры Шеннона, Кульбака, Фишера и разновидностей этих понятий. Поэтому развиваемую теорию идентификации уместно назвать информационной теорией идентификации. Информационная теория идентификации позволяет не только внести определенность в постановку и решение разнообразных задач идентификации, но и по-новому взглянуть на традиционные методы идентификации, методы робастного (стабильного) оценивания, методы регуляризации и методы планирования эксперимента. На этом пути формируются асимптотически оптимальные алгоритмы идентификации, т. е. алгоритмы, обладающие предельно возможной, максимальной скоростью сходимости, если известна плотность распределения помехи. В том случае, когда плотность распределения помехи неизвестна, а известен лишь класс, которому она принадлежит, формируются асимптотически оптимальные на классе алгоритмы идентификации, обладающие гарантированной скоростью сходимости. Замена в этих алгоритмах нормированной информационной матрицы и фишеровской информации выборочными позволяет, не изменяя асимптотических свойств алгоритмов, придать им нужные свойства на конечных шагах. Конечно, на пути развития информационной теории идентификации возникает множество трудностей как формального характера, связанных с теми или иными доказательствами, так и не формального характера, связанных с используемыми предположениями. Но, как сказал С. Джонсон: «Если прежде, чем начать дело, было бы необходимо найти пути преодоления всех возможных препятствий, которые могут встретиться в ходе его выполнения, то ни одно дело не было бы начато». Поэтому в комментариях читатель найдет множество вопросов, которые ждут ответа, и множество задач, ждущих своего решения.
|
 |
Оглавление
|