и, как следует из (2.3.18),

где  фишеровская информация, находим минимальное значение
фишеровская информация, находим минимальное значение 

Таким образом, для любых 

т. е. отклонение функции потерь  от оптимальной функции
от оптимальной функции  приводит к увеличению АМКО. Более того, замечая, что правая часть (2.5.3) совпадает с нижней границей АМКО (2.3.21), заключаем, что при оптимальной функции потерь достигается предельно возможная максимальная скорость сходимости как оптимальной выборочной оценки
приводит к увеличению АМКО. Более того, замечая, что правая часть (2.5.3) совпадает с нижней границей АМКО (2.3.21), заключаем, что при оптимальной функции потерь достигается предельно возможная максимальная скорость сходимости как оптимальной выборочной оценки

где

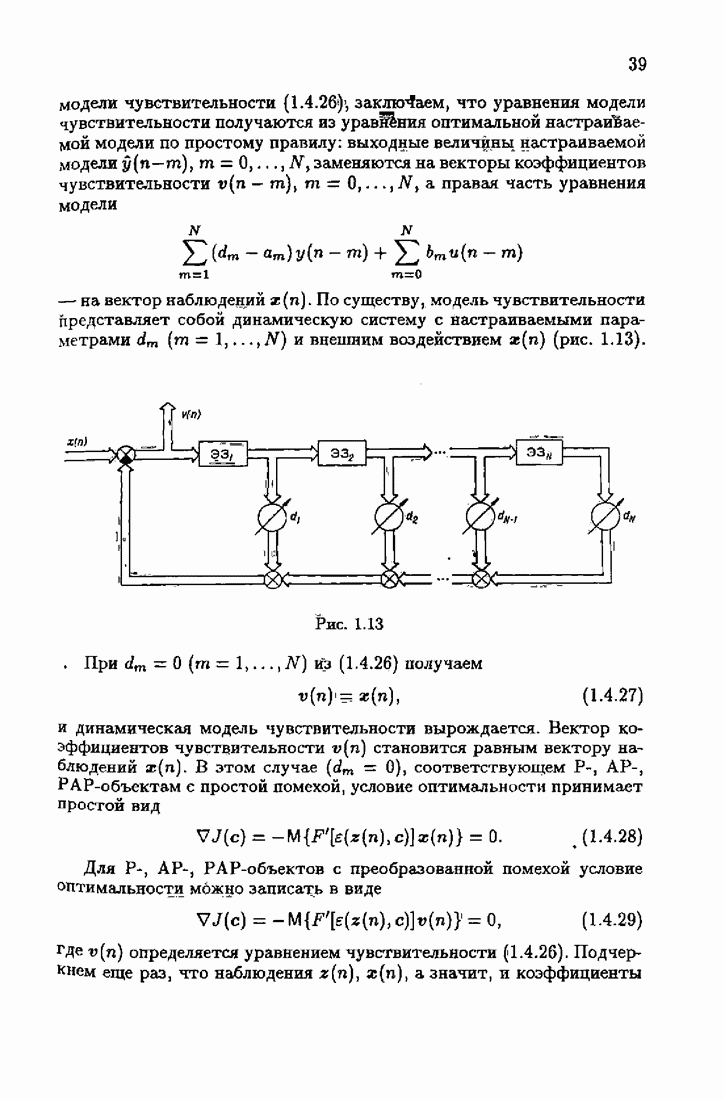
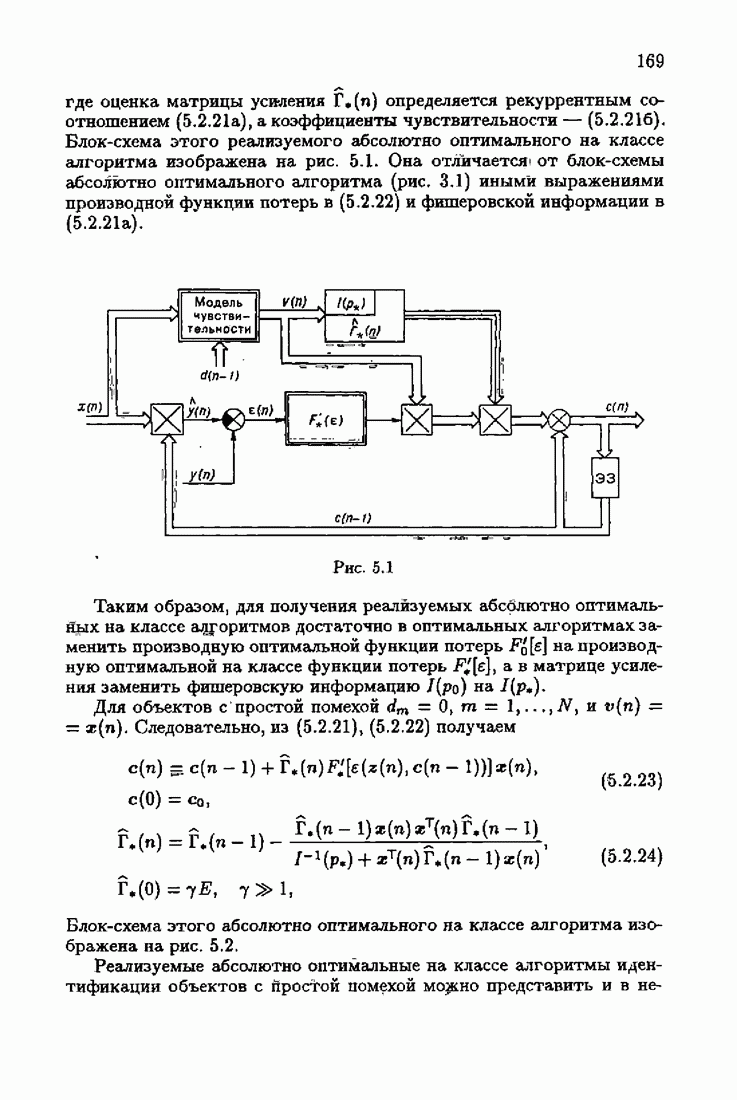
так и оценки  порождаемой оптимальным рекуррентным алгоритмом (1.7.11), (1.7.12) при
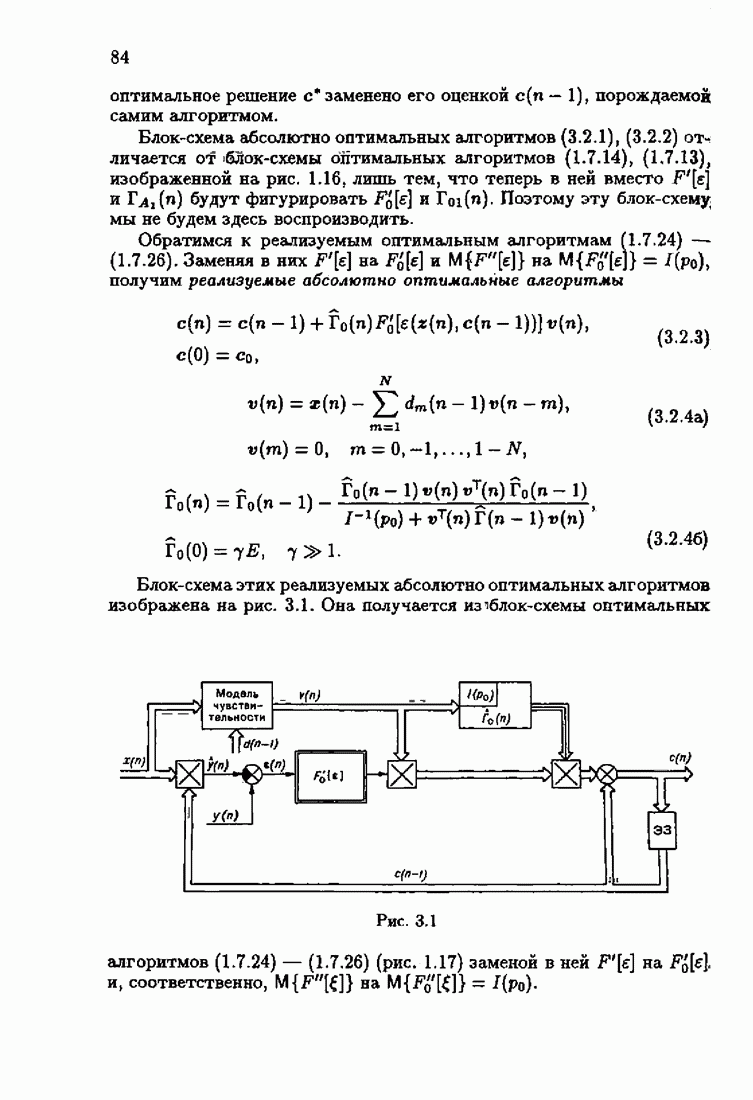
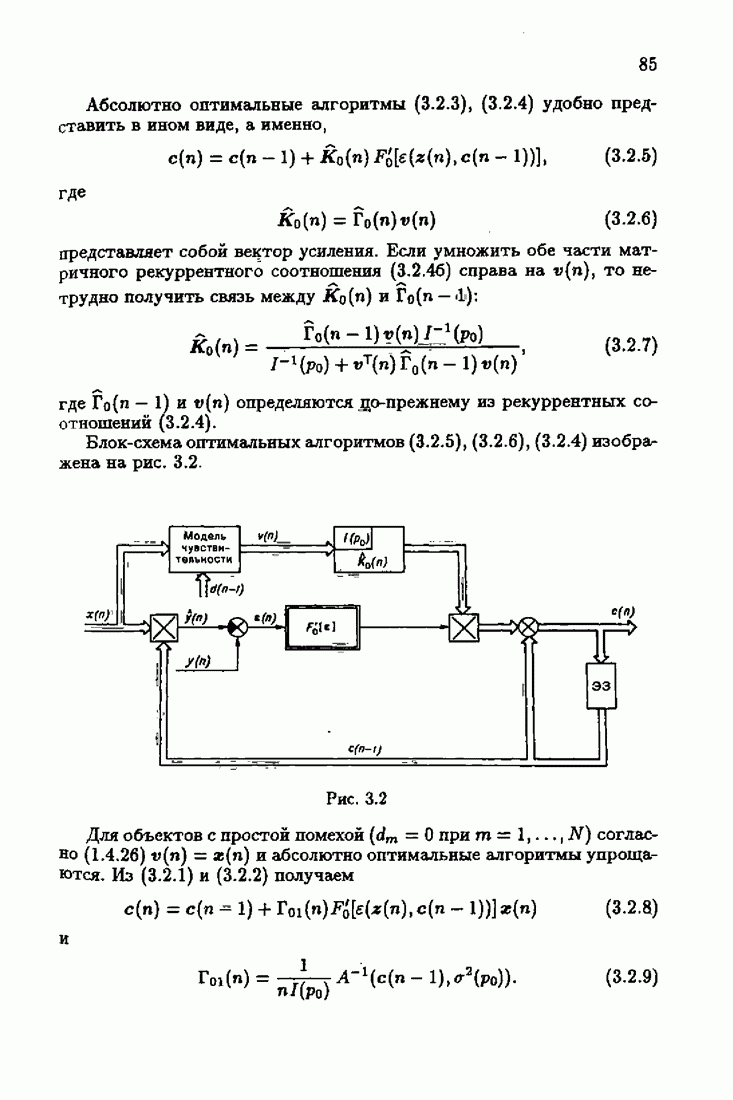
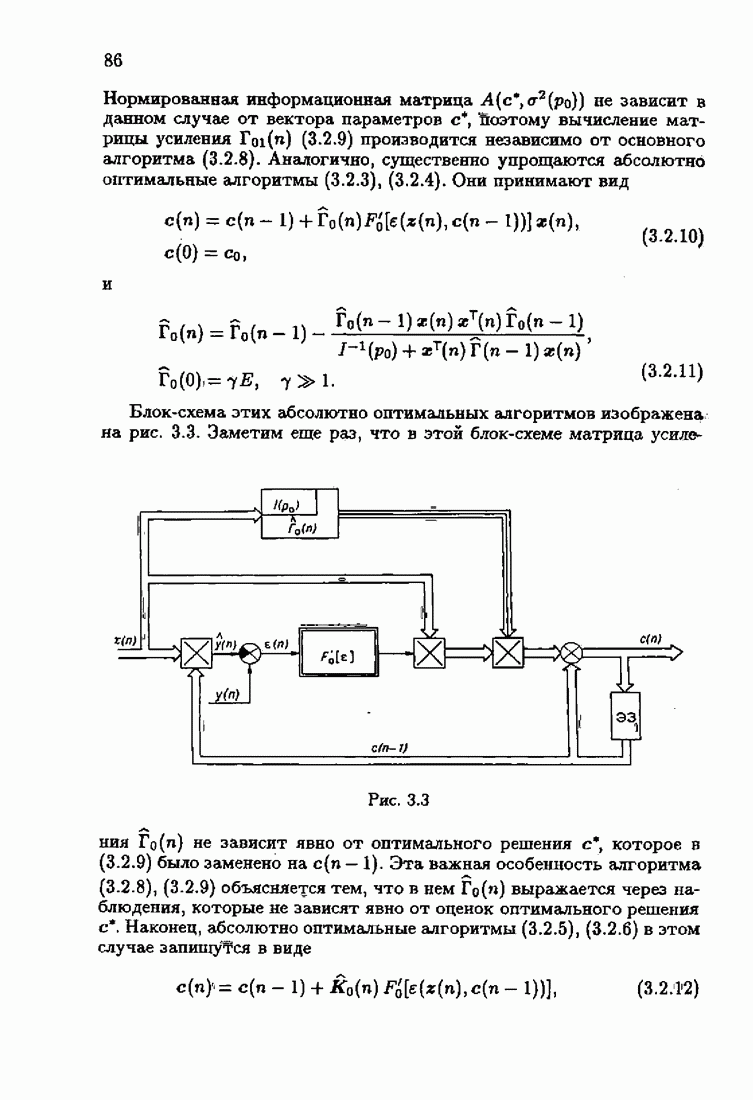
порождаемой оптимальным рекуррентным алгоритмом (1.7.11), (1.7.12) при  Этот алгоритм мы подробно рассмотрим в главе 3.
Этот алгоритм мы подробно рассмотрим в главе 3.
Нетрудно видеть из (2.5.1), (2.5.2) и (2.4.6), что для оптимальной функции потерь имеет место равенство левых частей (2.4.4) и (2.4.5), т. е.

Это свойство оптимальной функции потерь будет далее использовано.
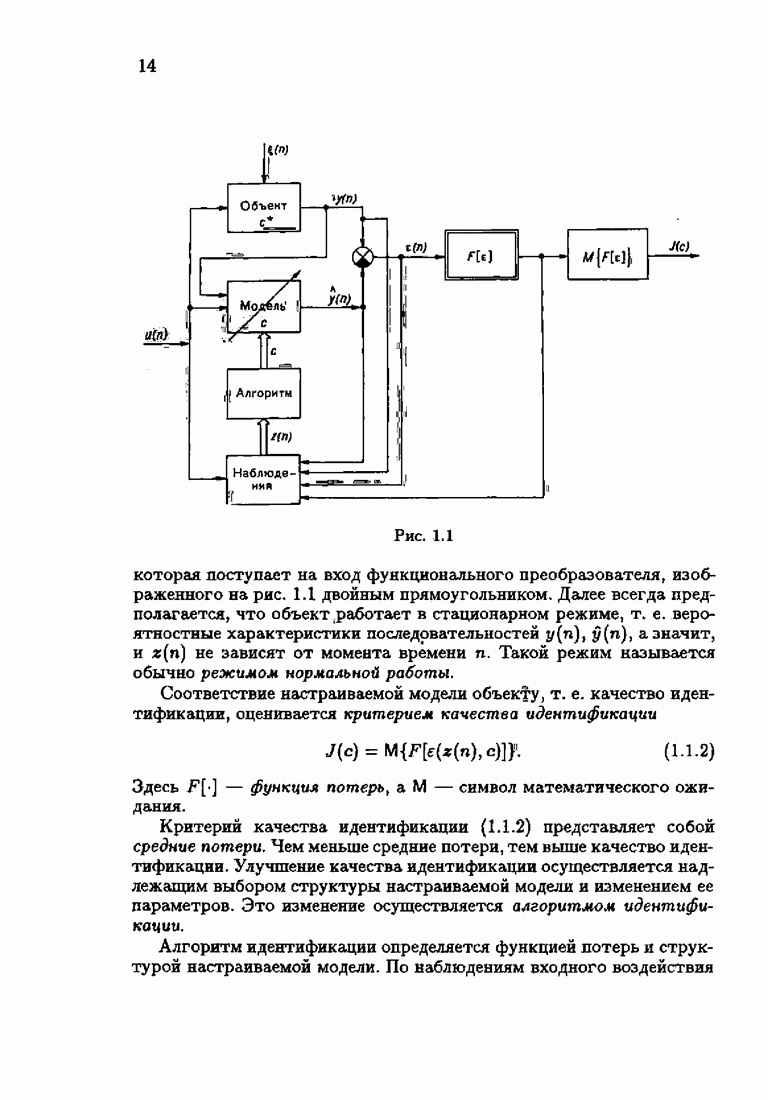
Рассмотрим в заключение, как влияет выбор оптимальной функции потерь  на критерий качества идентификации — средние потери
на критерий качества идентификации — средние потери  при
при  При оптимальном решении
При оптимальном решении  достигает минимума, равного
достигает минимума, равного

Но величина

представляет собой энтропию, или шенноновскую информацию. Таким образом, минимально возможные средние  оптимальной функции потерь равны шенноновской информации.
оптимальной функции потерь равны шенноновской информации.
Для любой иной, не оптимальной, функции потерь, которая может быть представлена в виде

 минимальные средние потери (при
минимальные средние потери (при  будут равны
будут равны

Назовем величину

квазишенноновской информацией. Покажем, что всегда имеет место неравенство

т. е. квазишенноновская информация всегда  шенноновской информации:
шенноновской информации:

Для этой цели рассмотрим кульбаковскую информацию, представляющую собой уклонение средних потерь  и произвольной функций потерь:
и произвольной функций потерь:

При  кульбаковская информация,
кульбаковская информация,  обращается в нуль:
обращается в нуль: 
Замечая, что

получаем из (2.5.15)

Но

Поэтому из (2.5.16) получаем

а значит, неравенства (2.5.13), (2.5.14) справедливы.
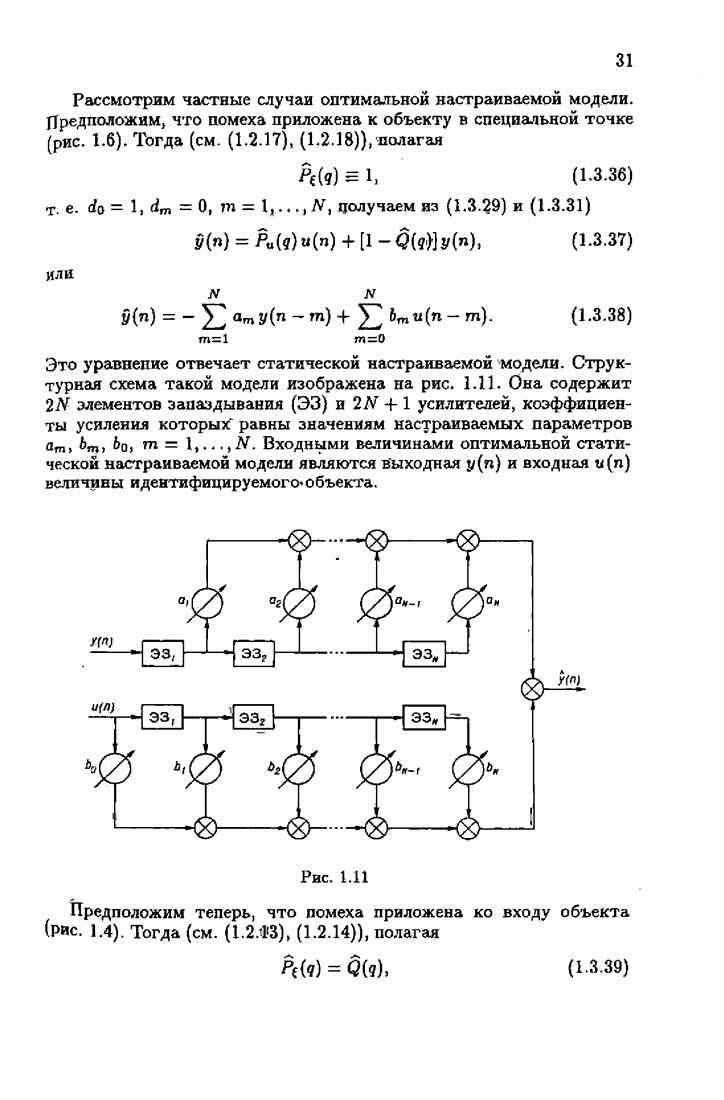
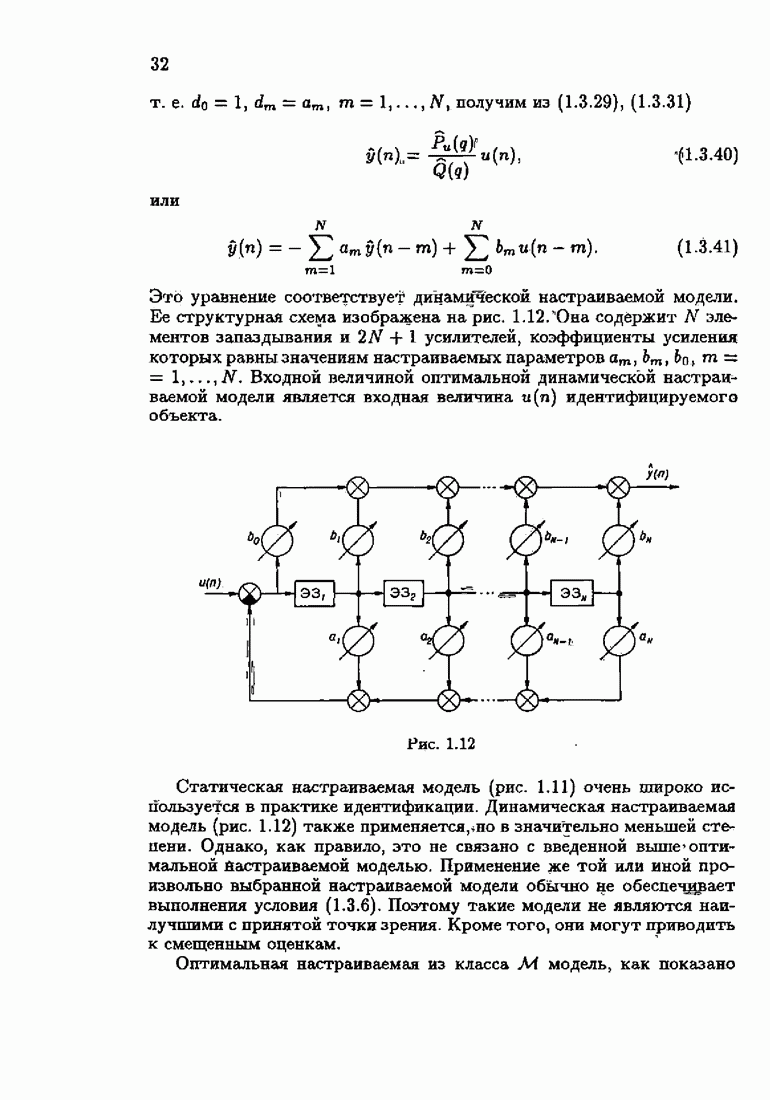
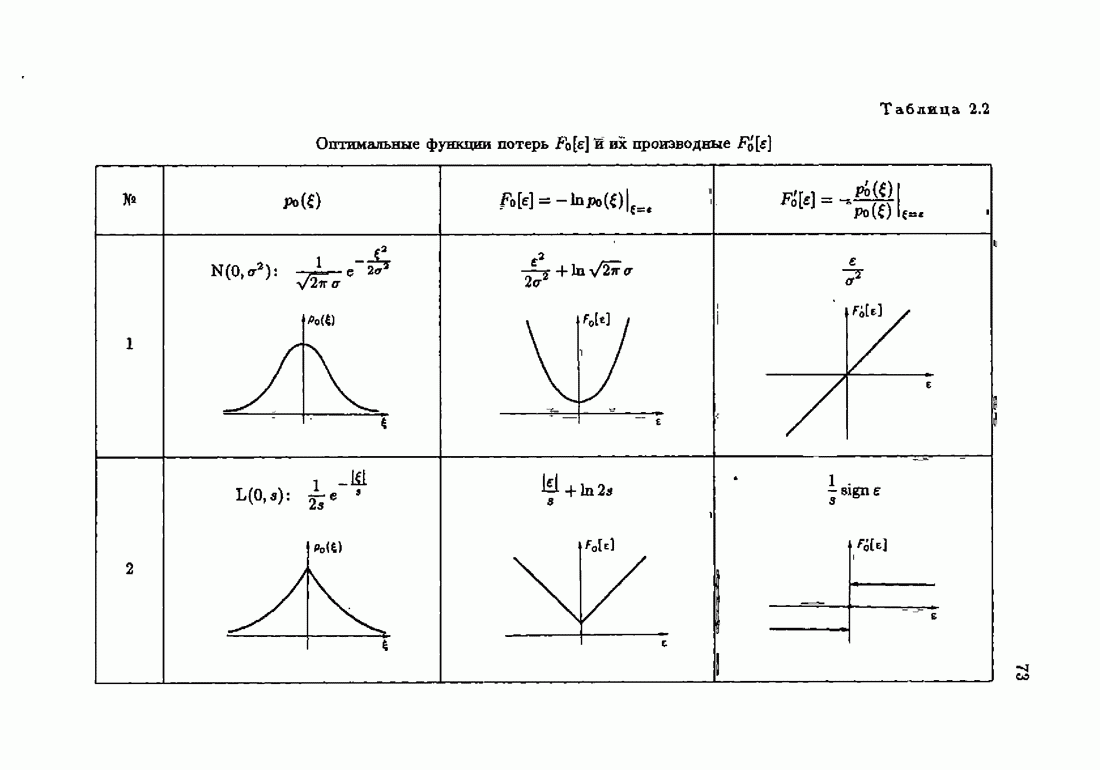
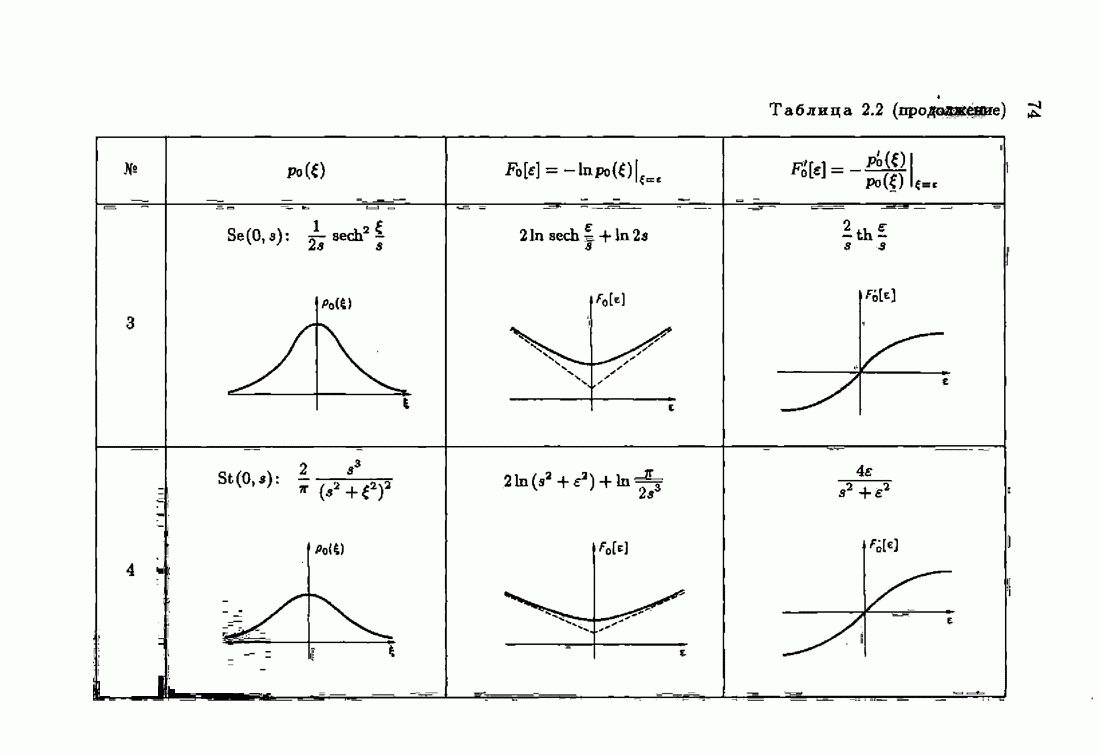
Из этих неравенств следует, что при оптимальной функции потерь средние потери для оптимального решения достигают минимум-миниморума. Отклонение функции потерь от оптимальной приводит к увеличению соответствующего минимума средних потерь. Оптимальная функция потерь минимизирует минимальные потери по всем функциям потерь типа логарифмических функций неправдоподобия. В силу результатов § 1.3 это значит, что для оптимальной настраиваемой модели и оптимальной функции потерь

где  класс моделей, которому принадлежит оптимальная модель,
класс моделей, которому принадлежит оптимальная модель,  класс функций потерь, которому принадлежит оптимальная функция потерь.
класс функций потерь, которому принадлежит оптимальная функция потерь.
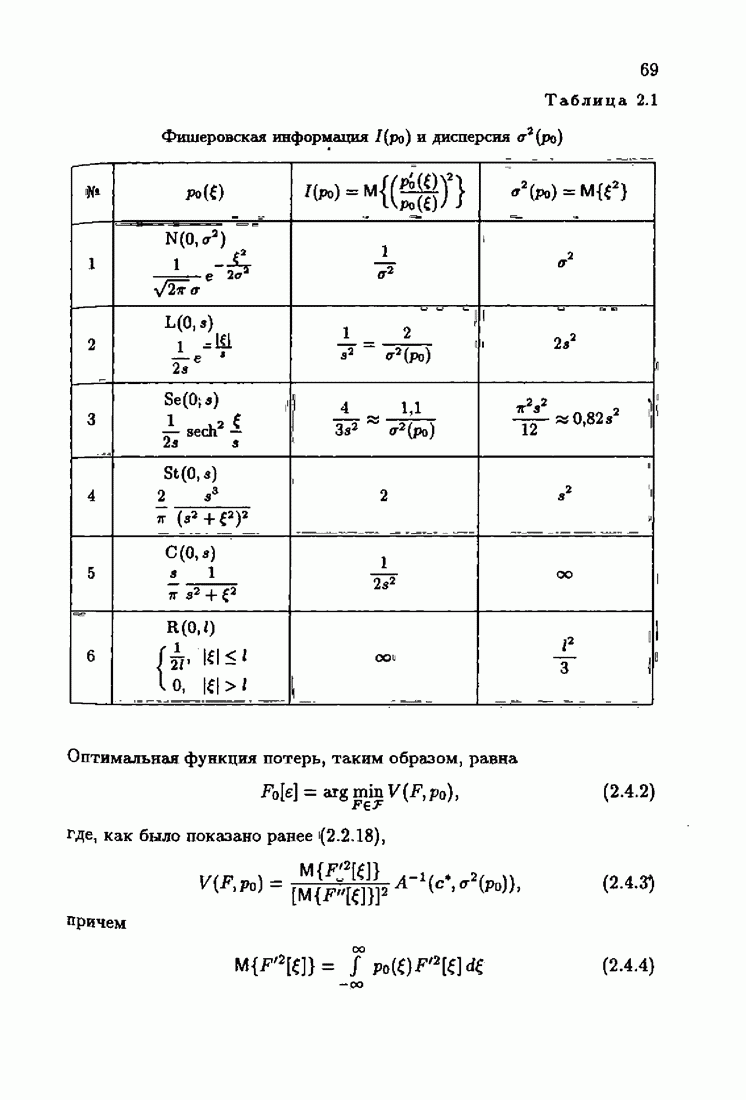
При оптимальной модели и оптимальной функции потерь средние потери достигают минимально возможного значения, равного шенноновской информации  Значения шенноновской информации для типовых плотностей распределения помех
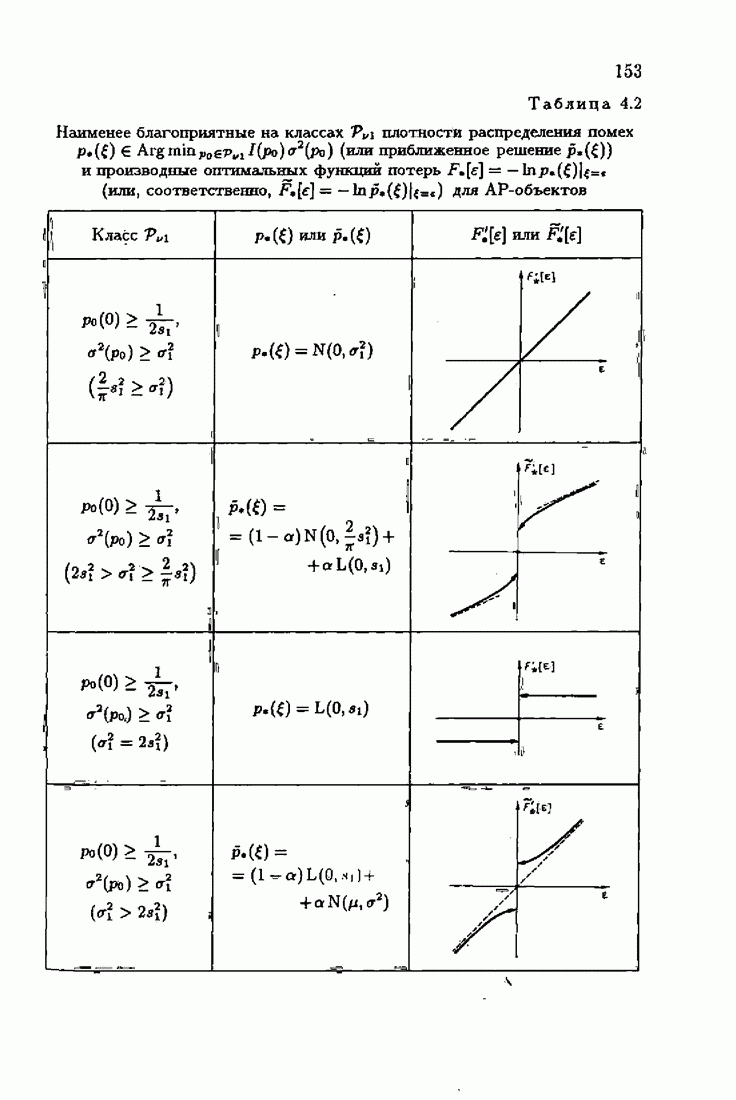
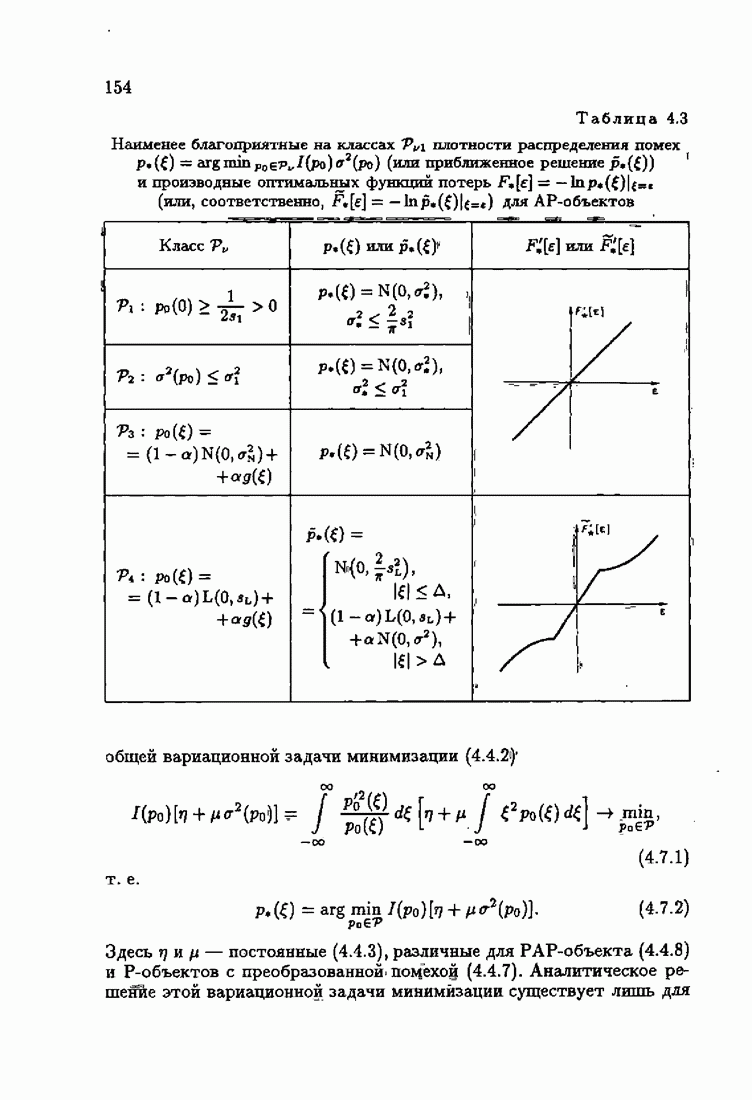
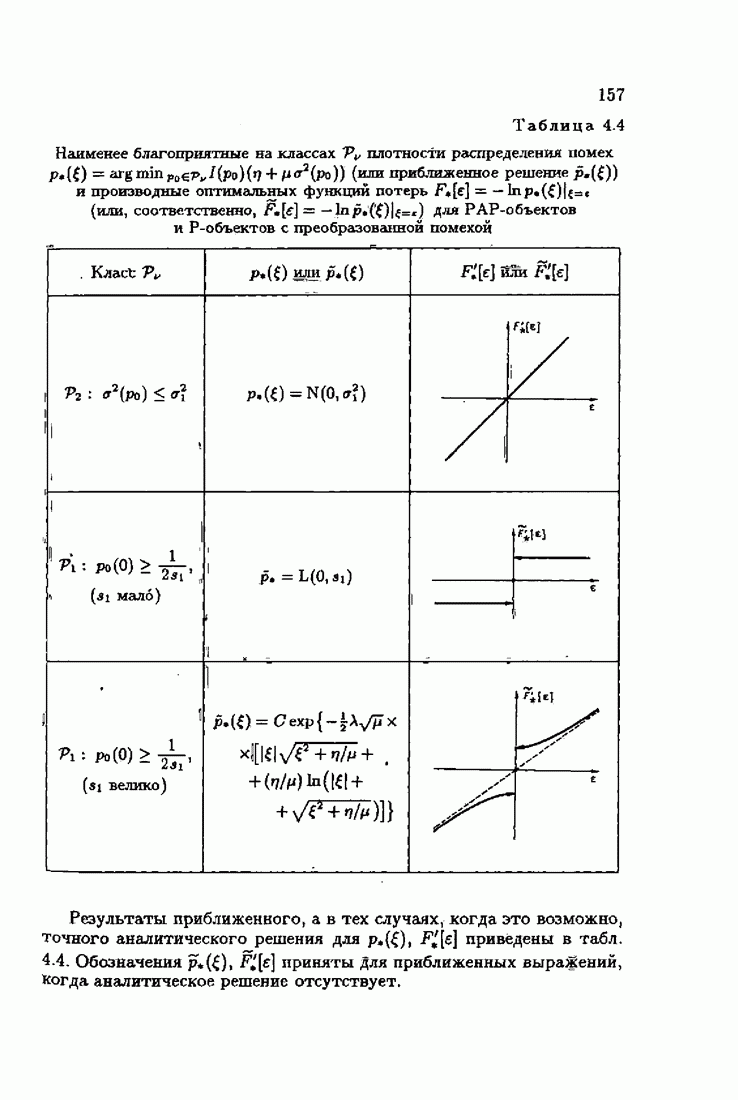
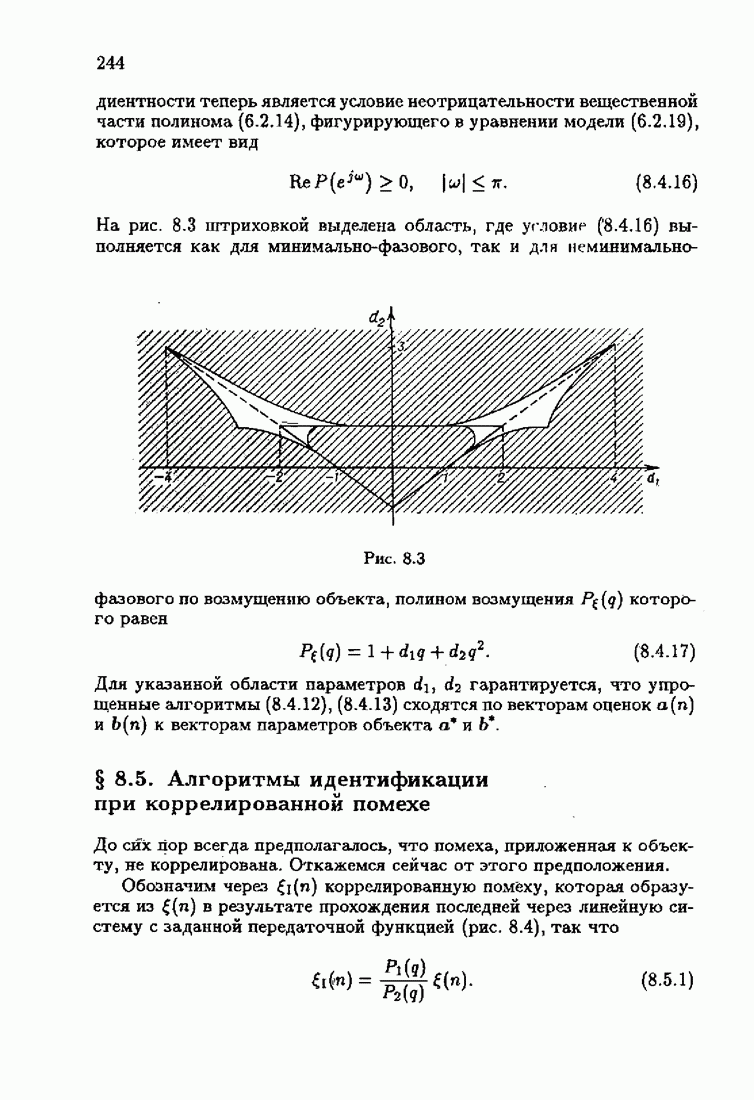
Значения шенноновской информации для типовых плотностей распределения помех  приведены в табл. 2.3.
приведены в табл. 2.3.
Найдем в заключение  для оптимальной функции потерь. В этом случае, как следует из (2.5.7),
для оптимальной функции потерь. В этом случае, как следует из (2.5.7),  значит, из
значит, из  получаем
получаем

т. е. для оптимальной функции потерь  равно половине размерности вектора оценок.
равно половине размерности вектора оценок.












































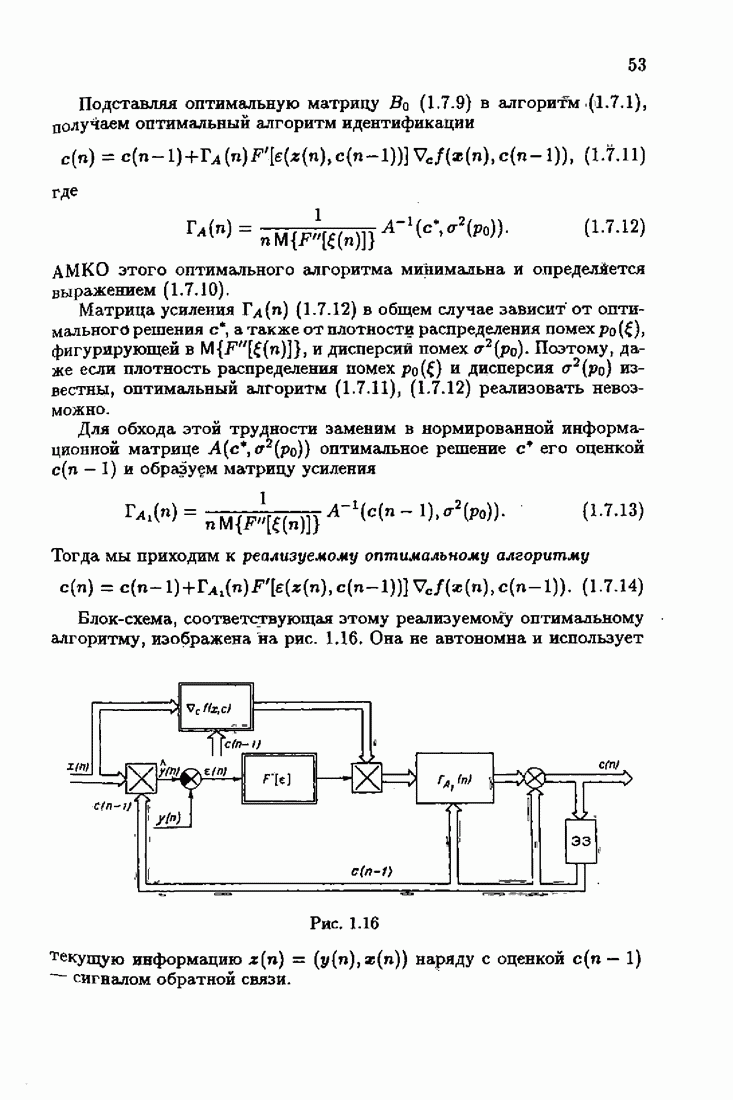


















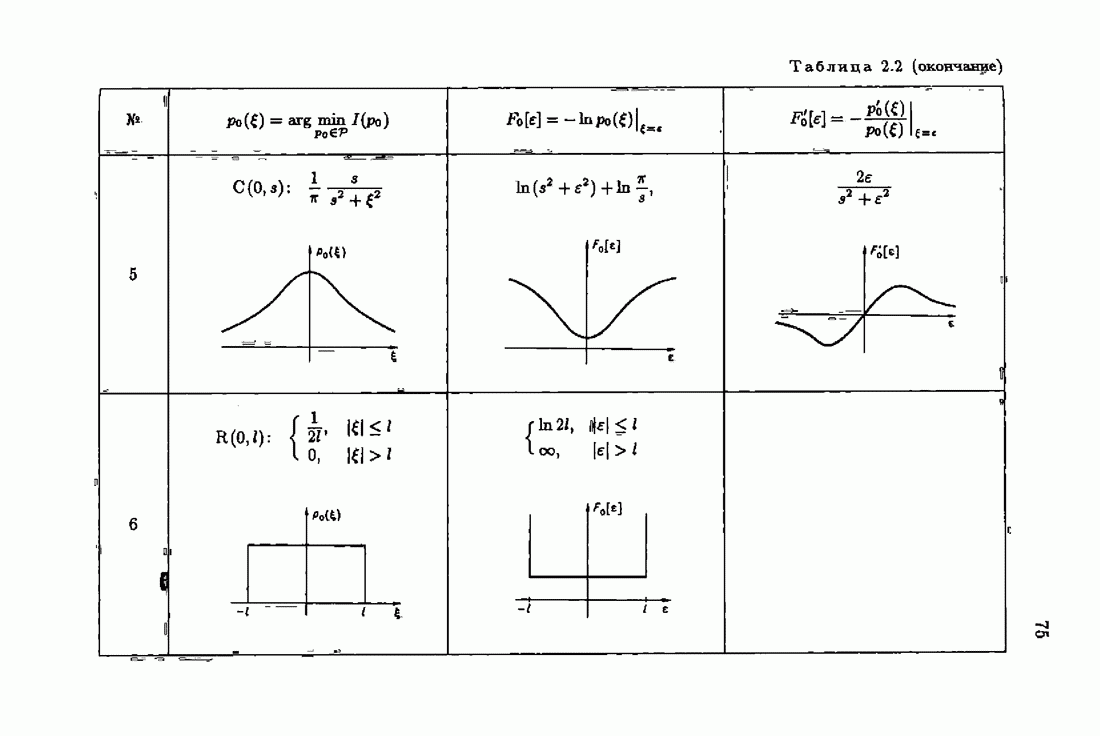








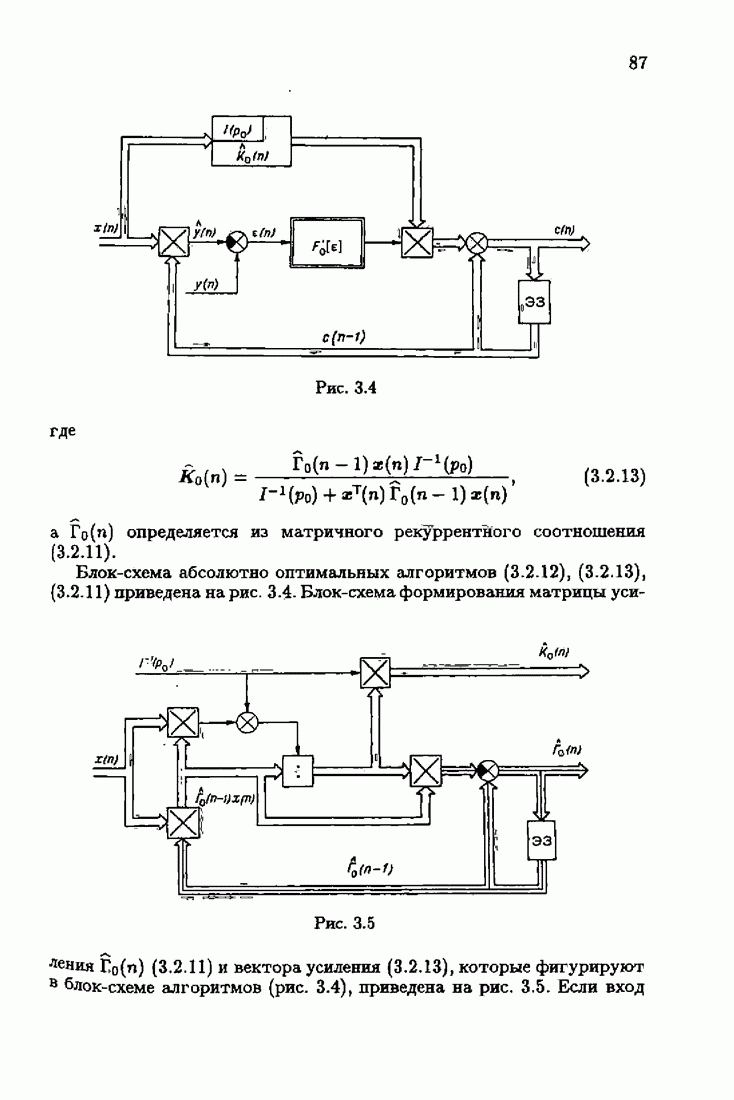




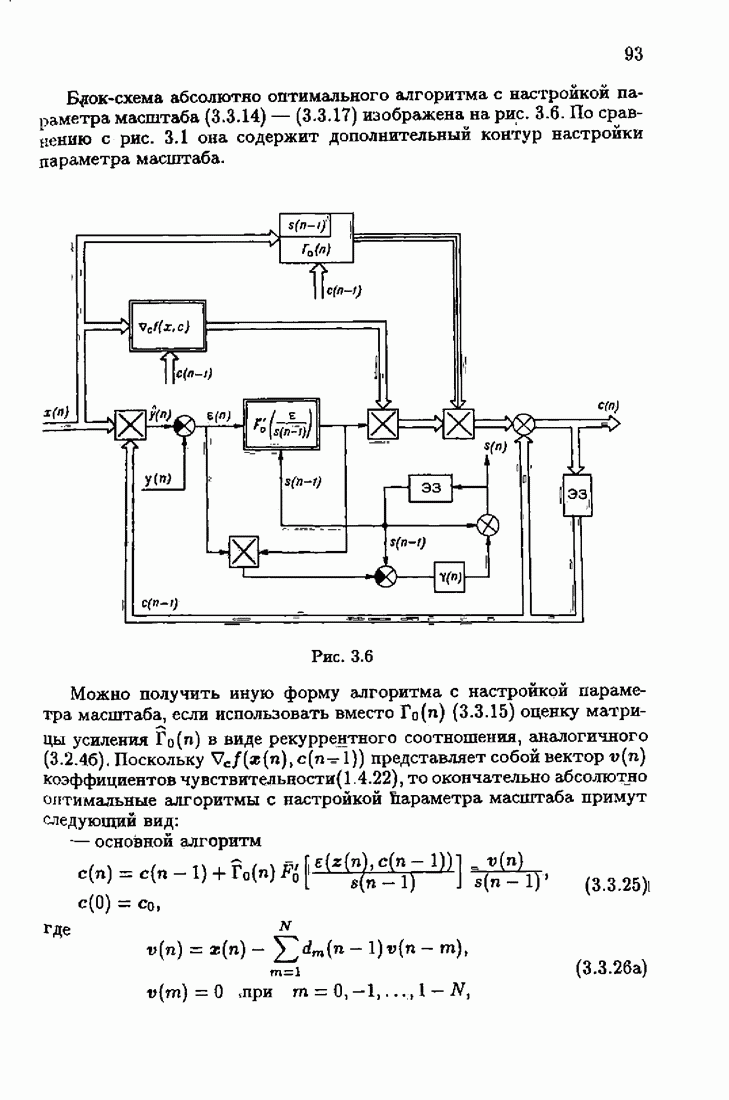
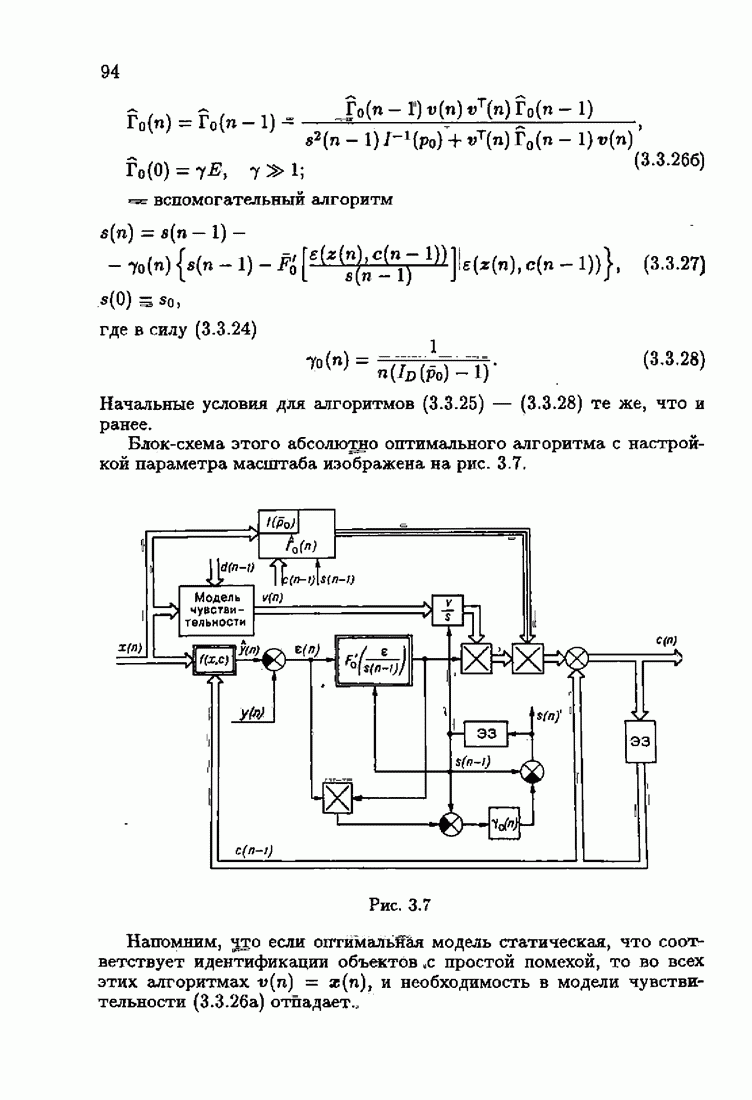


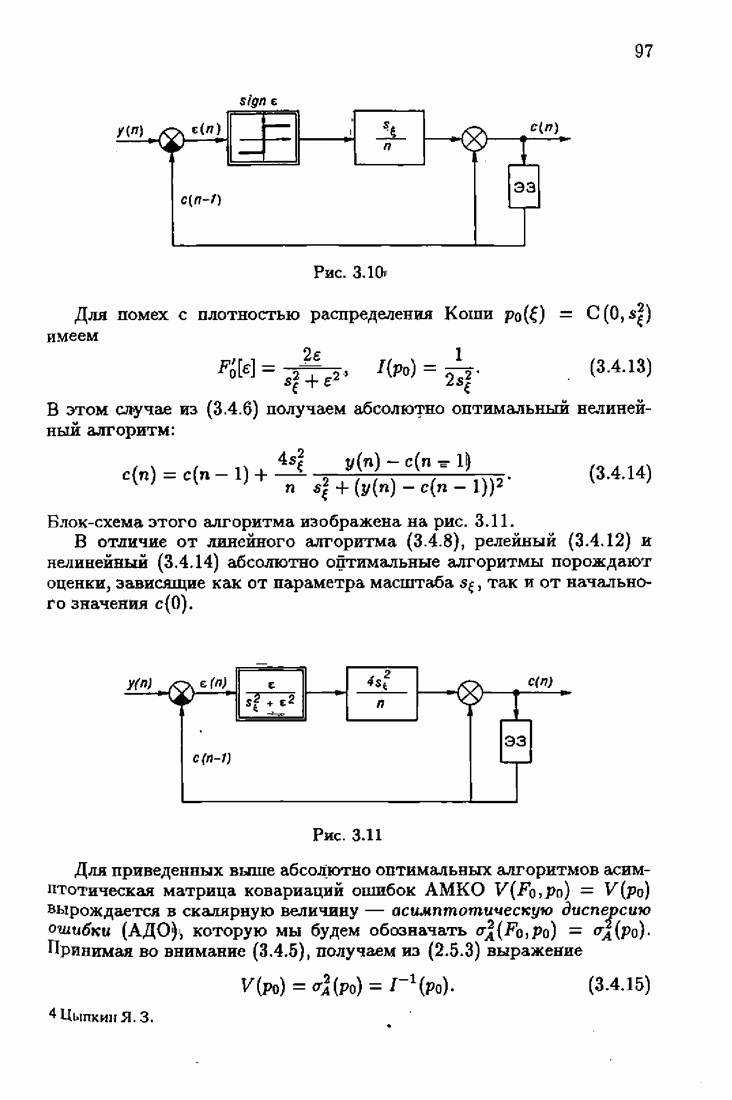



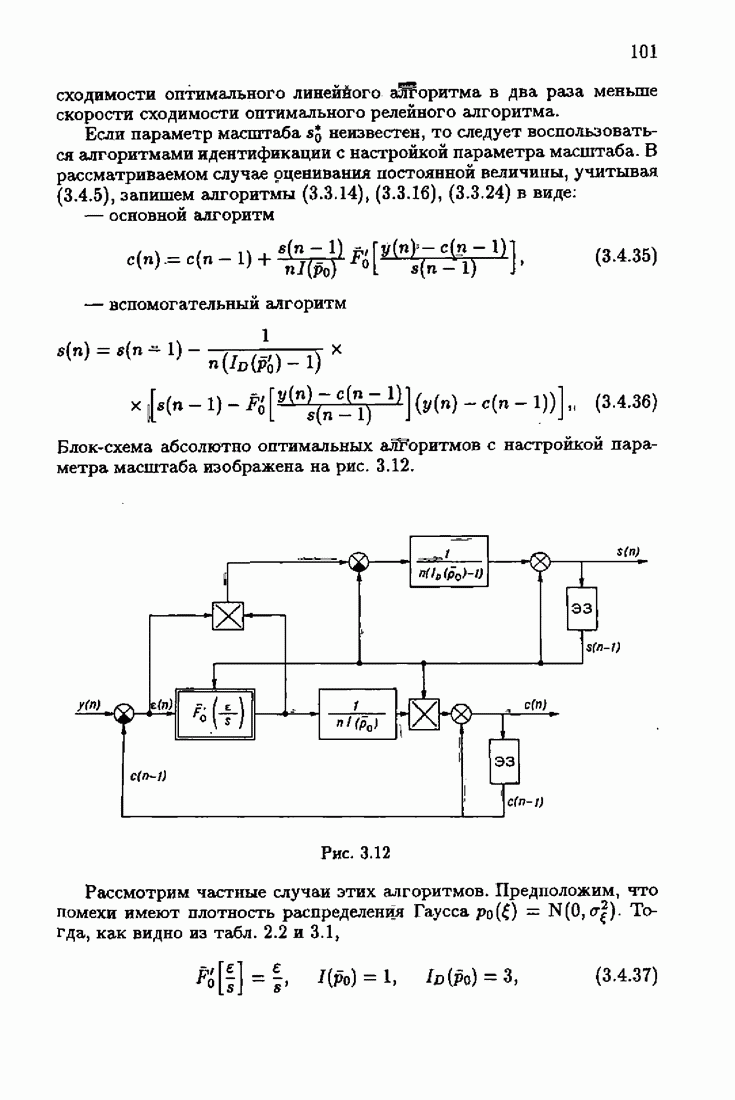
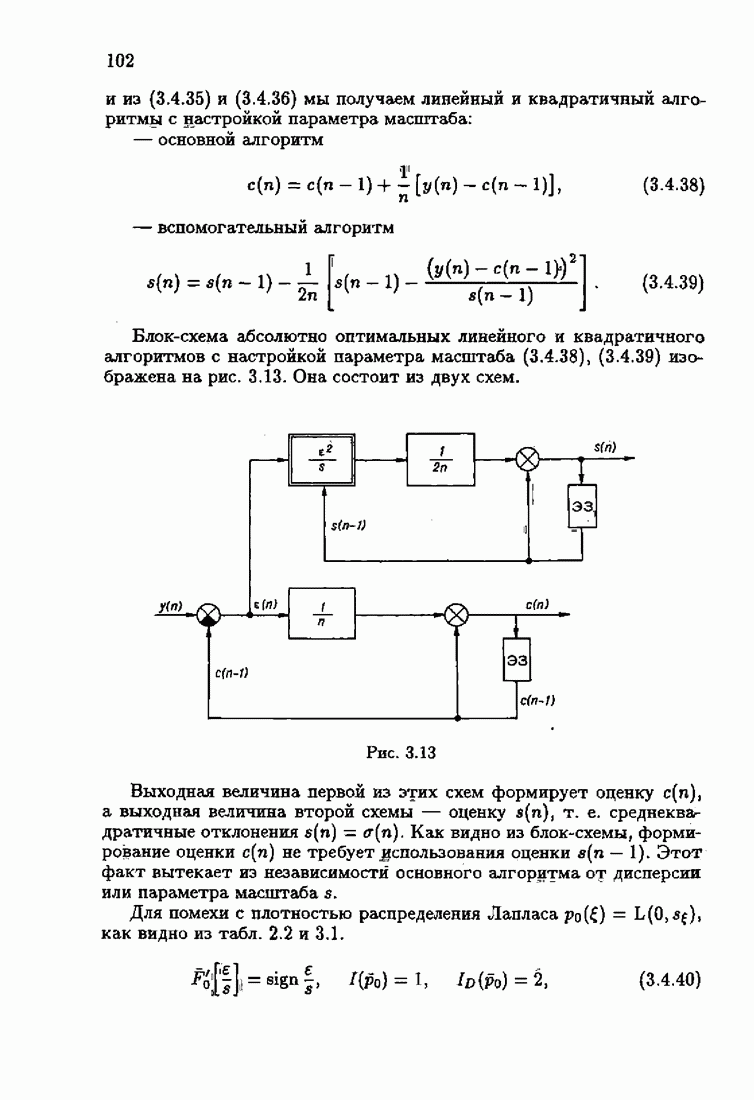
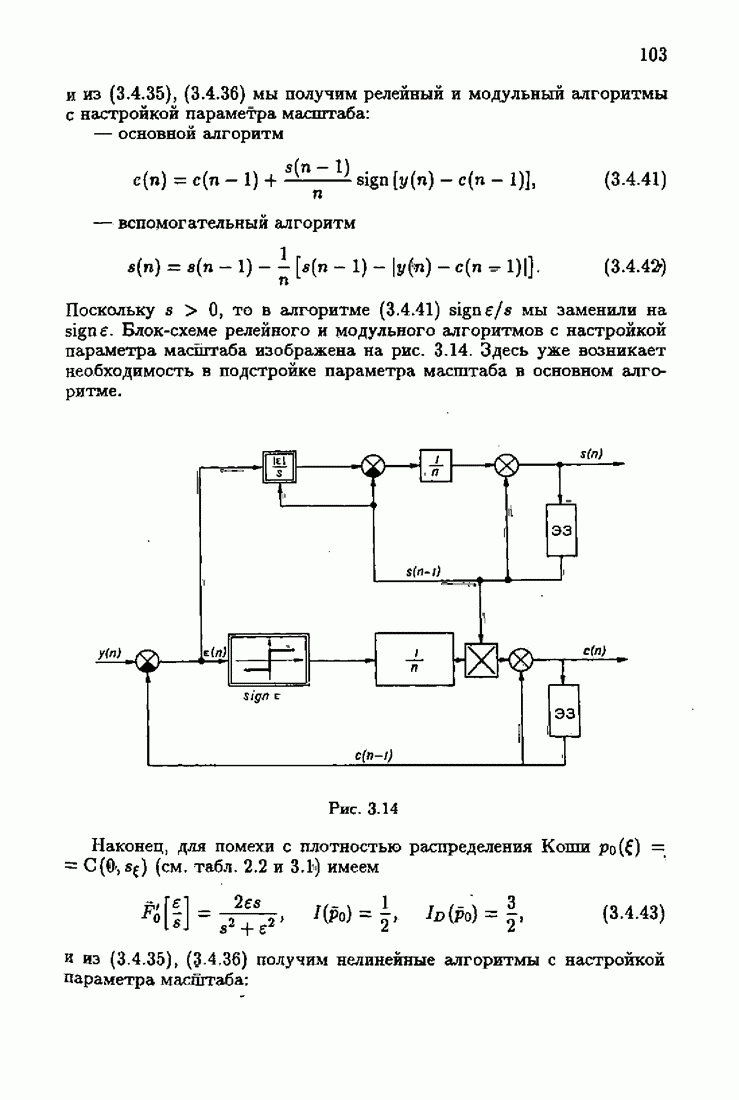



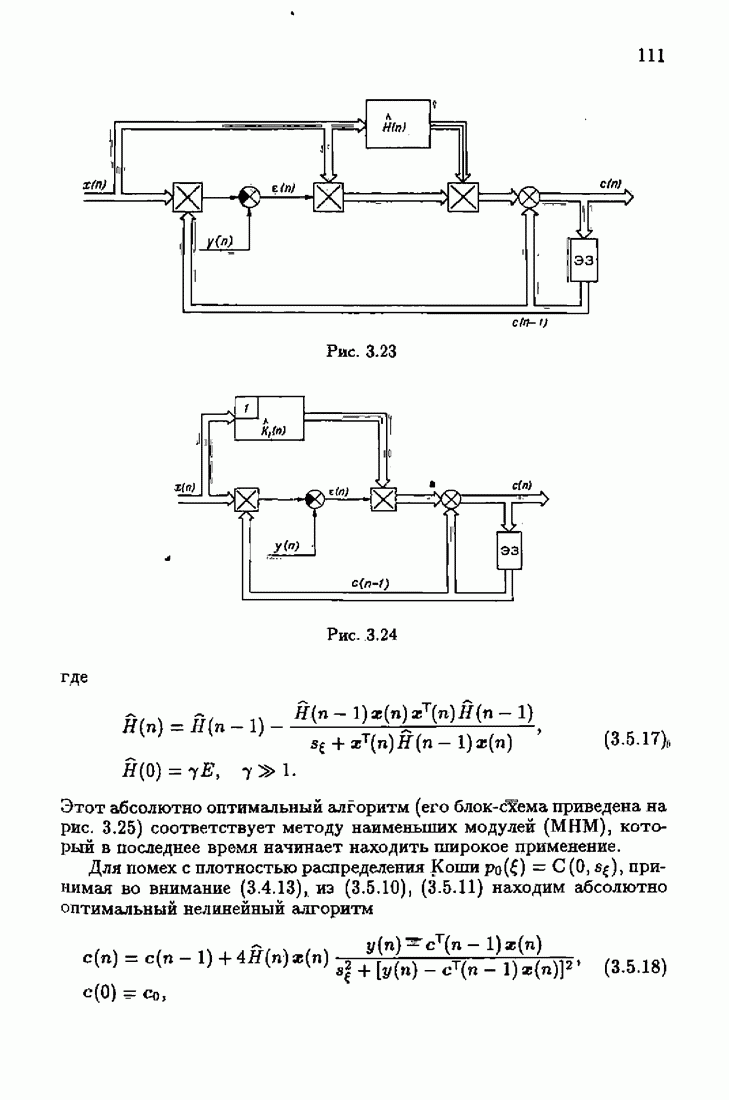
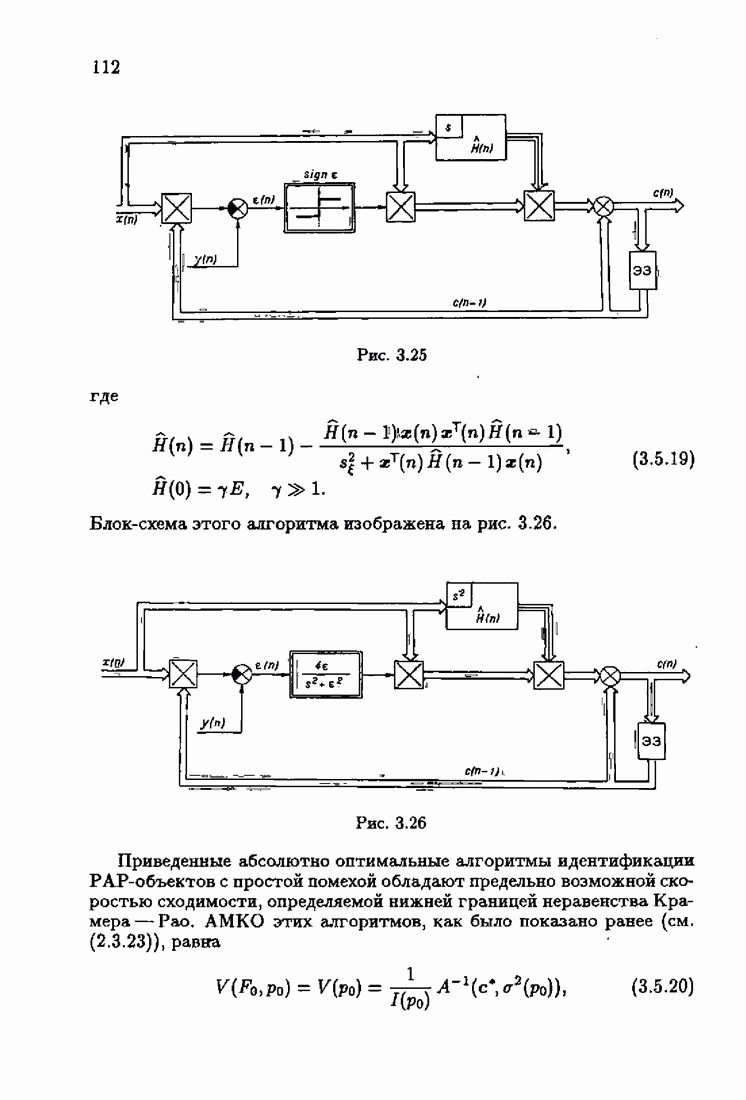



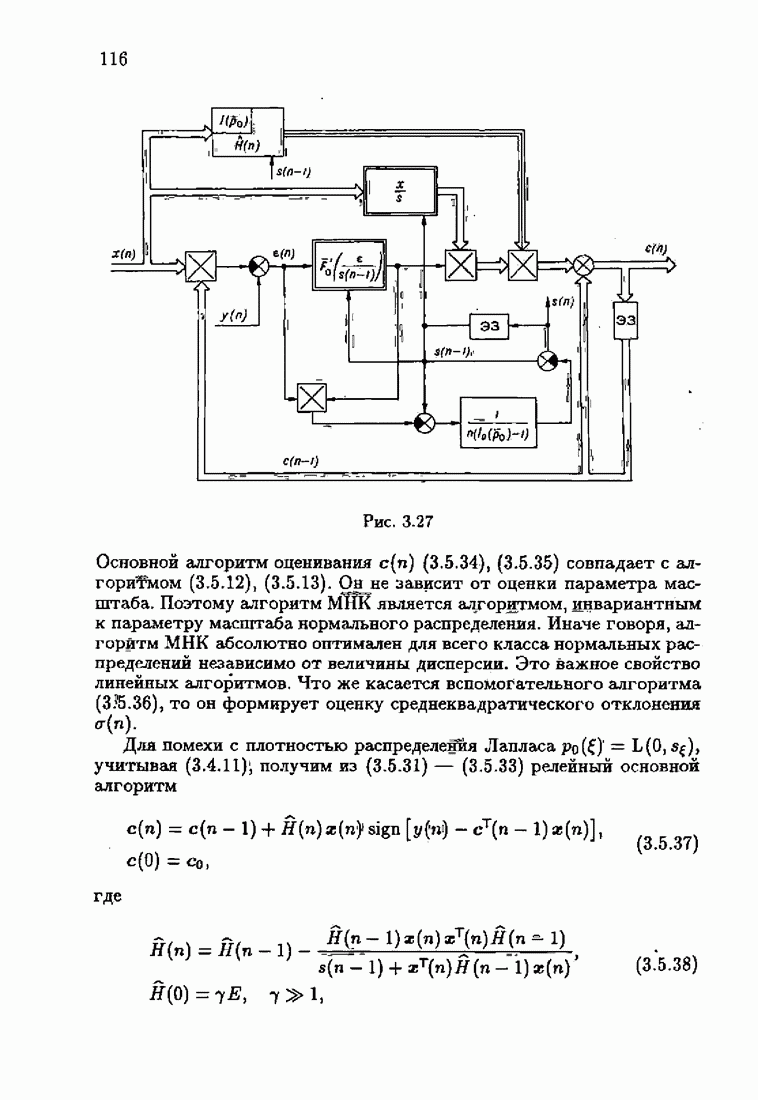
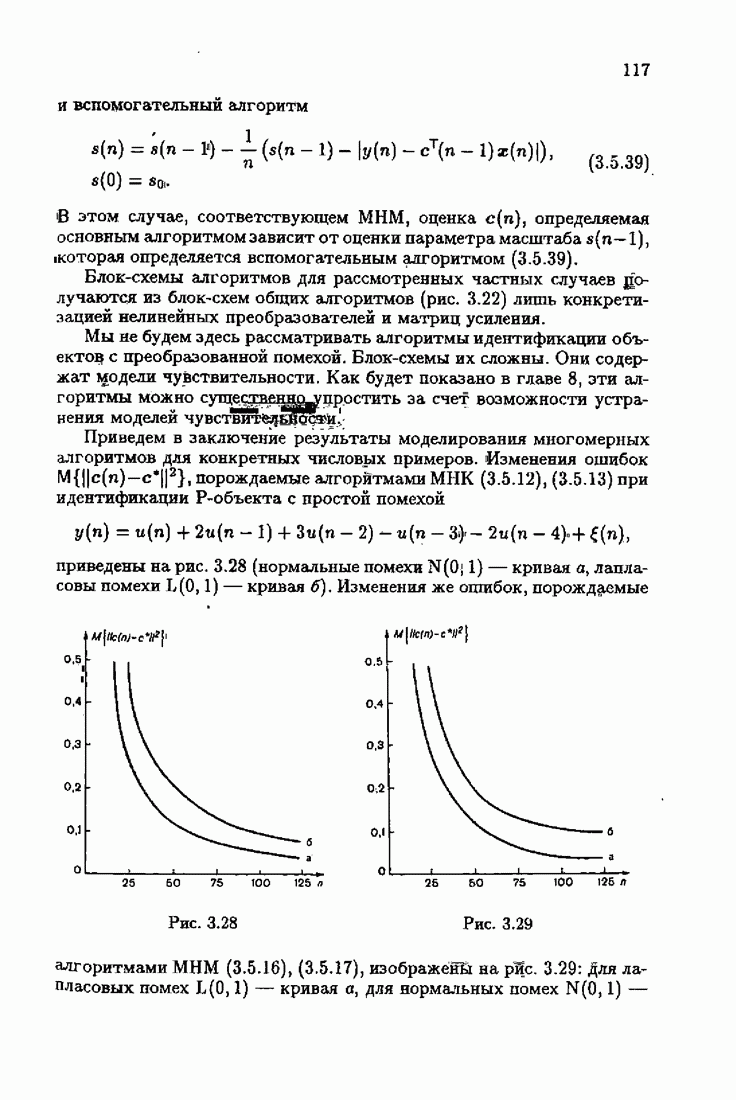












































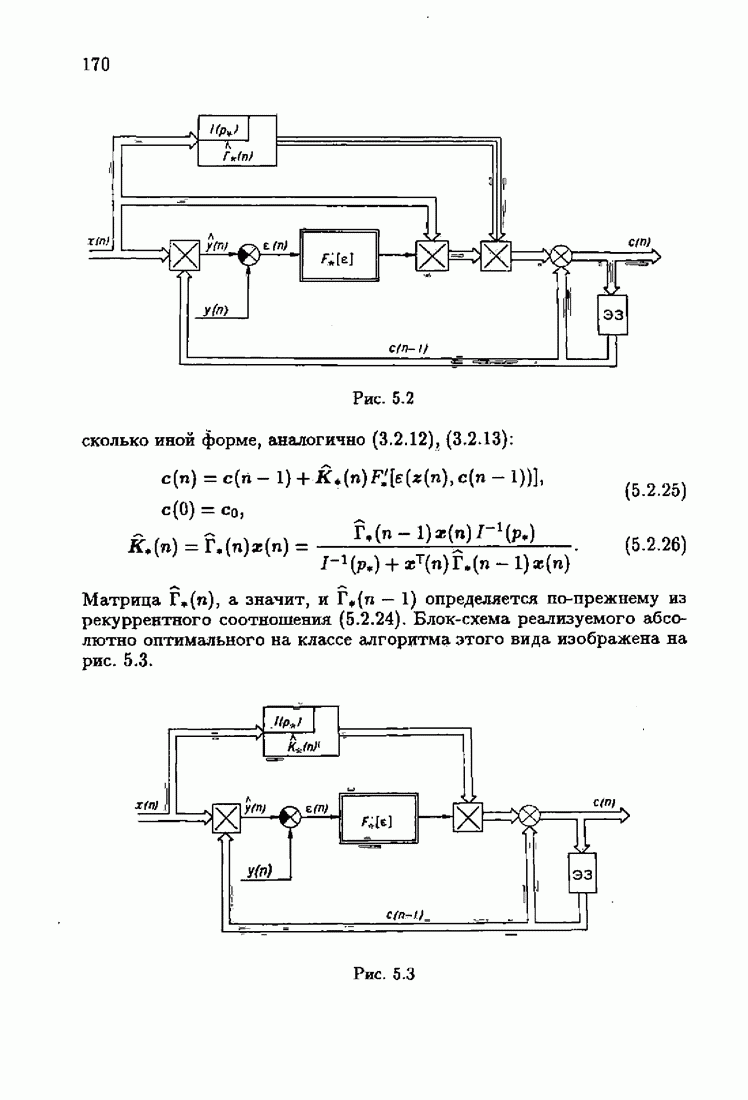

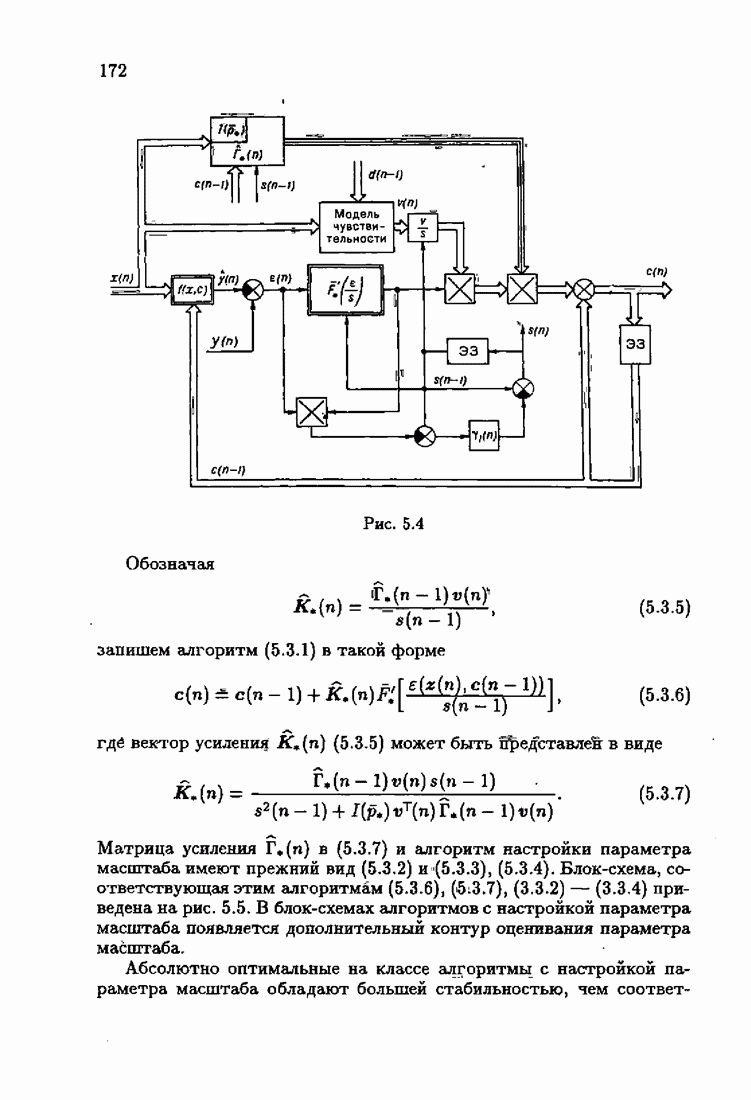
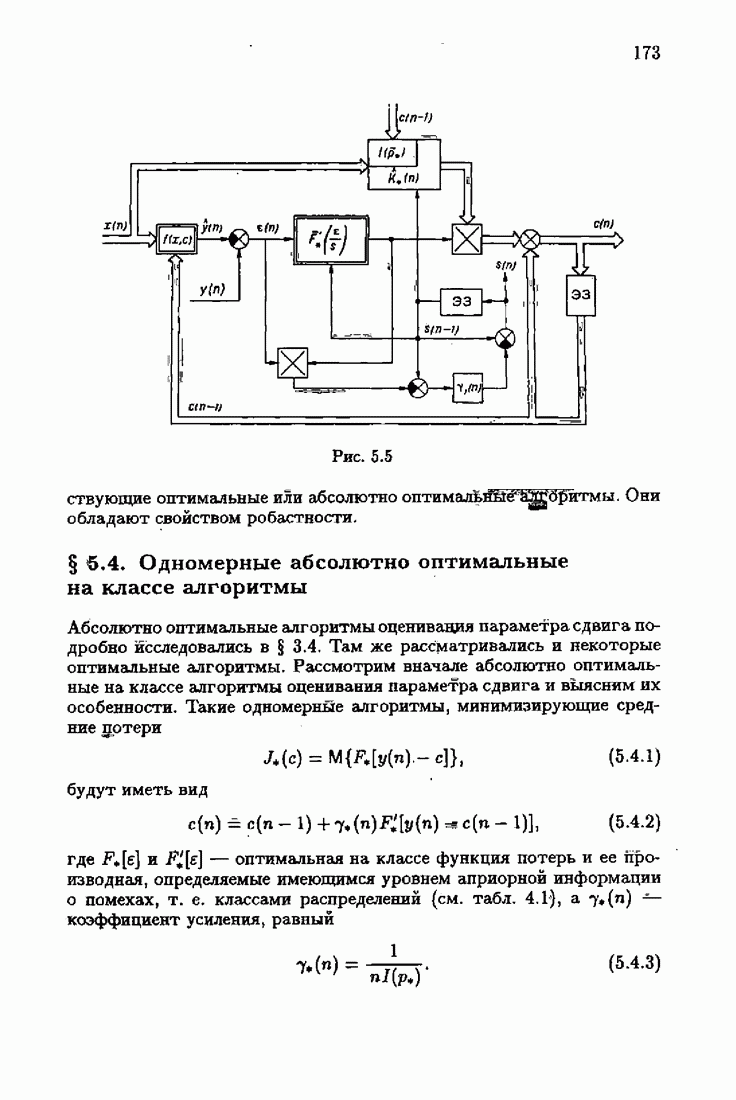




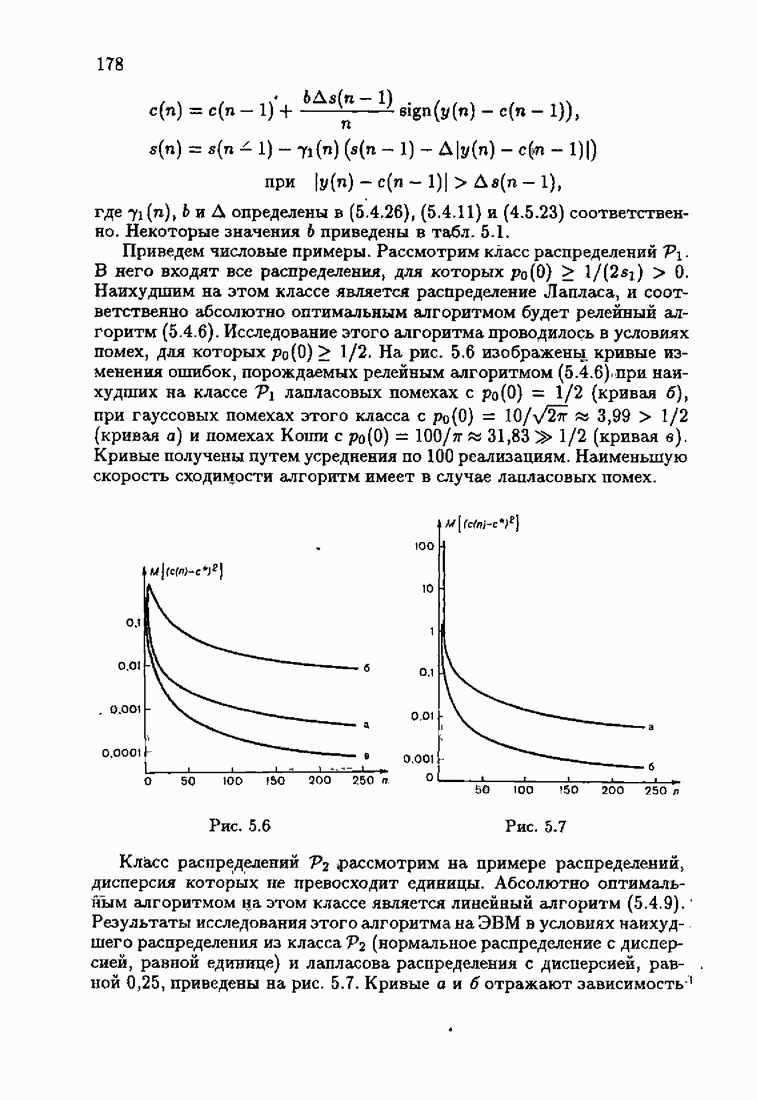
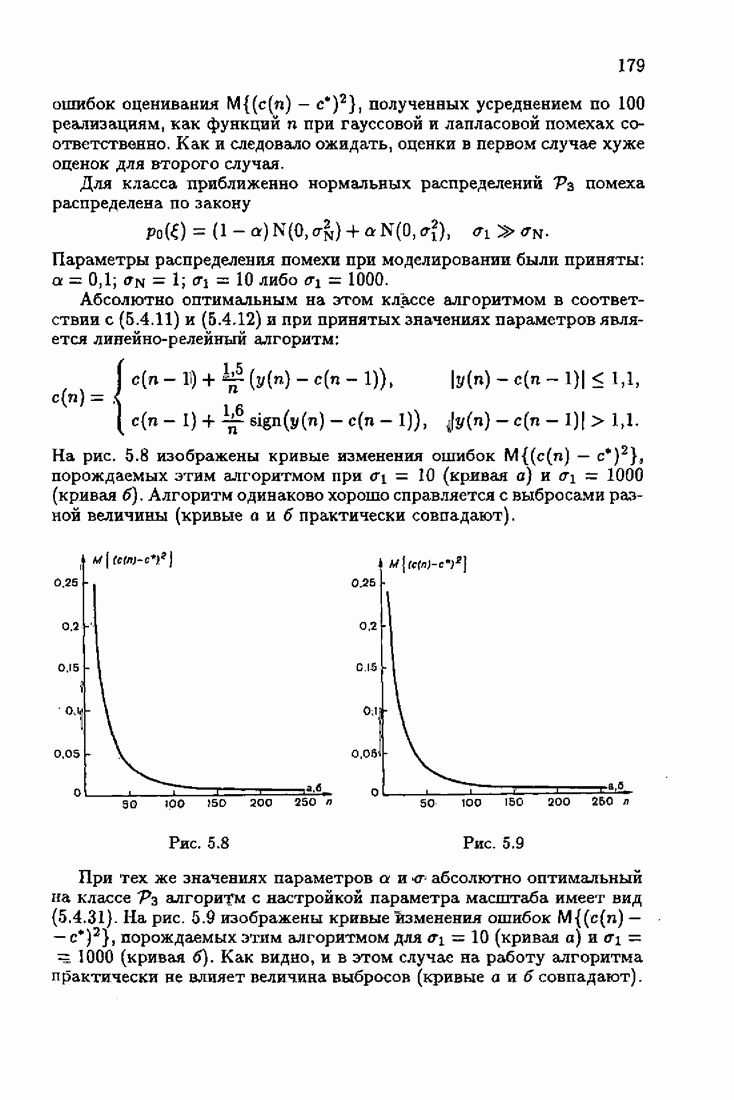
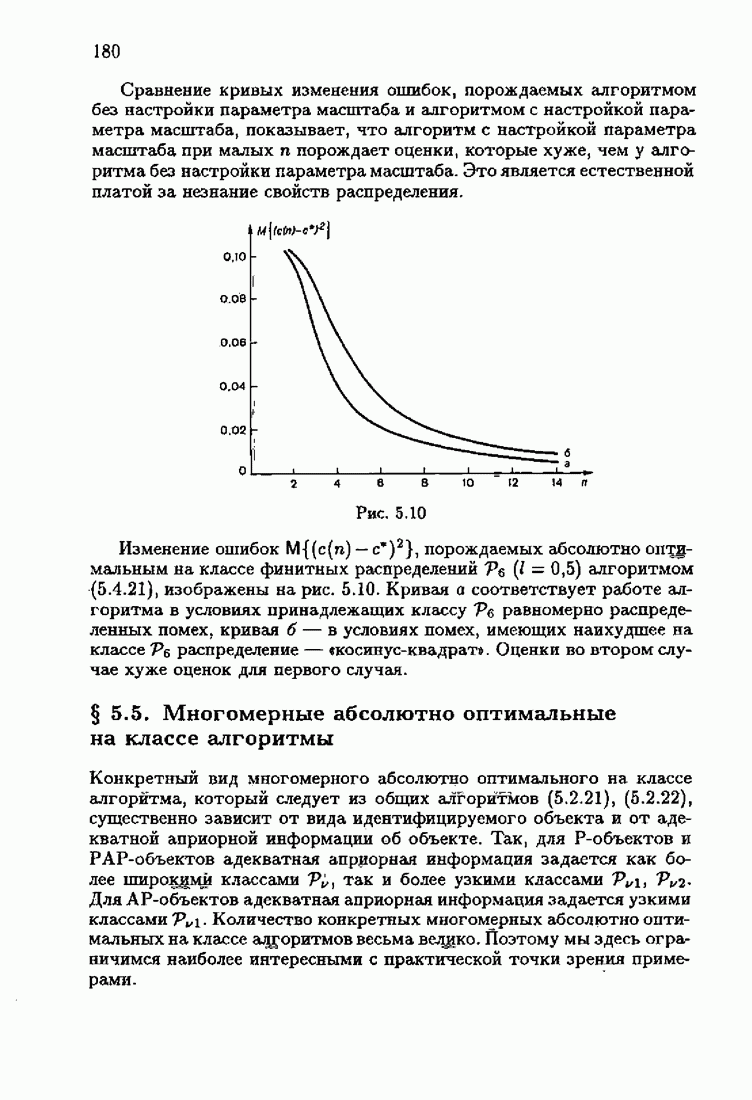

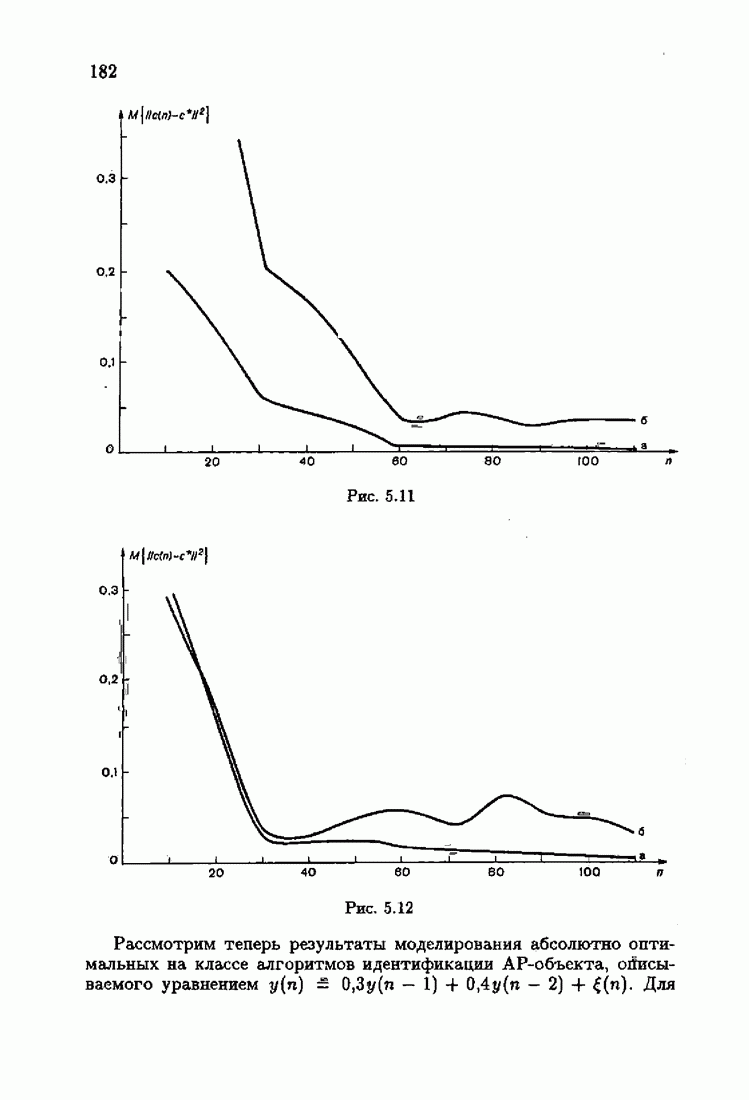
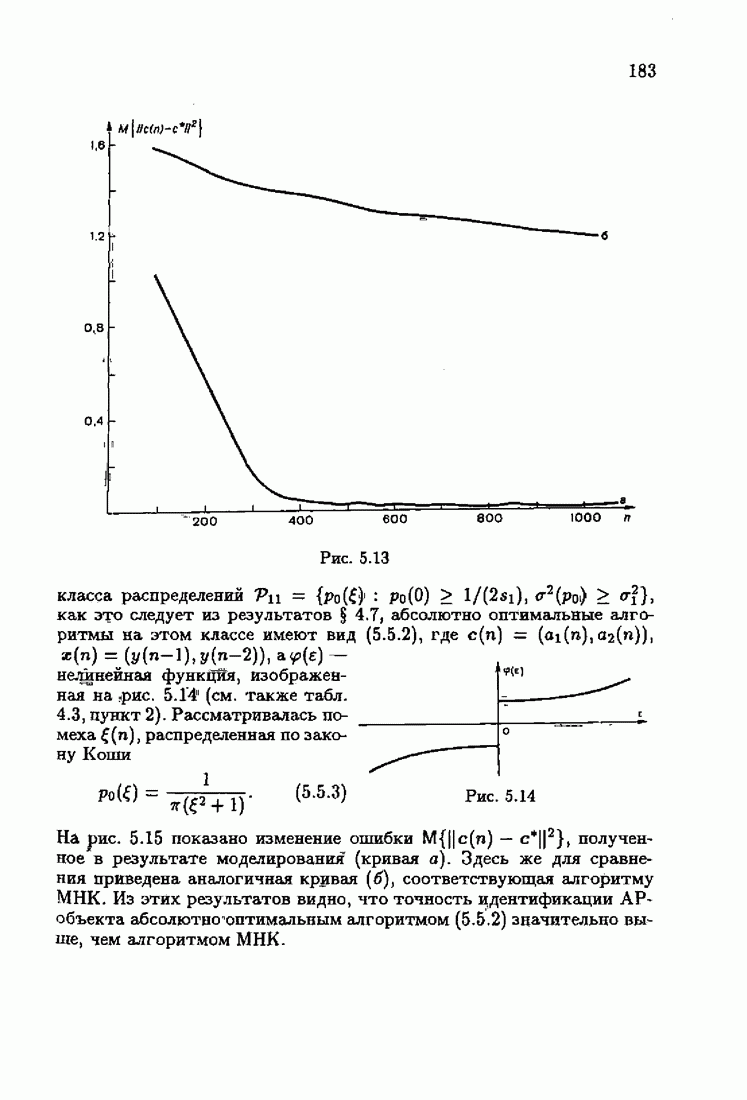













































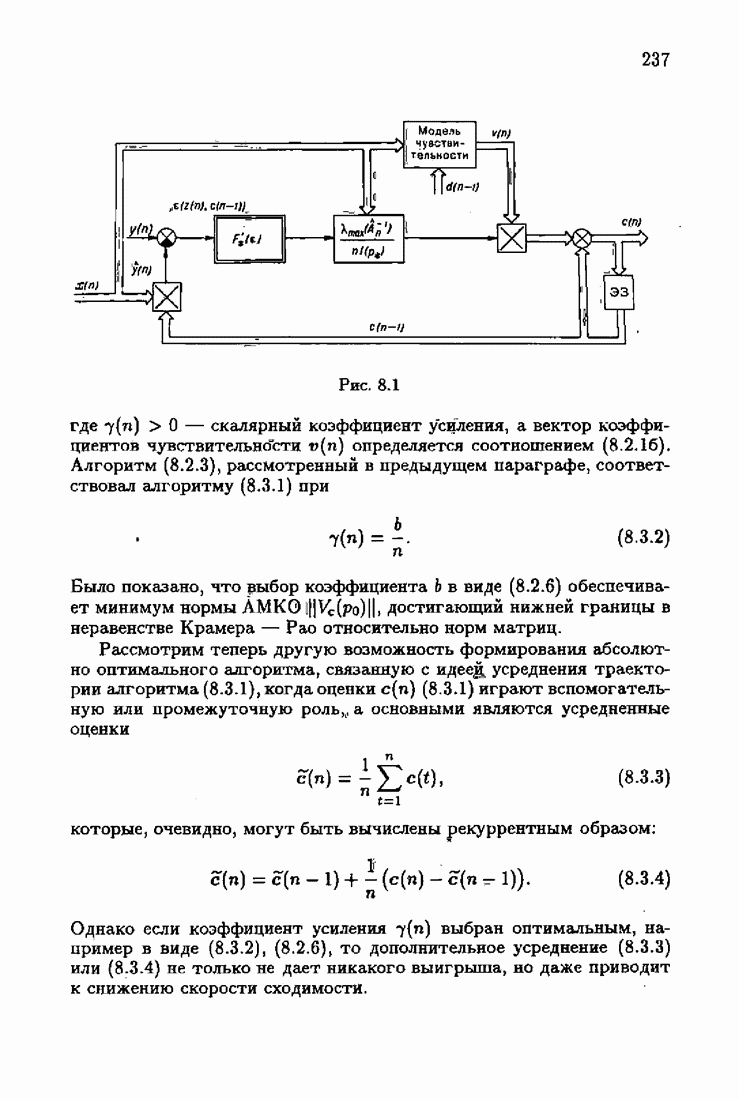








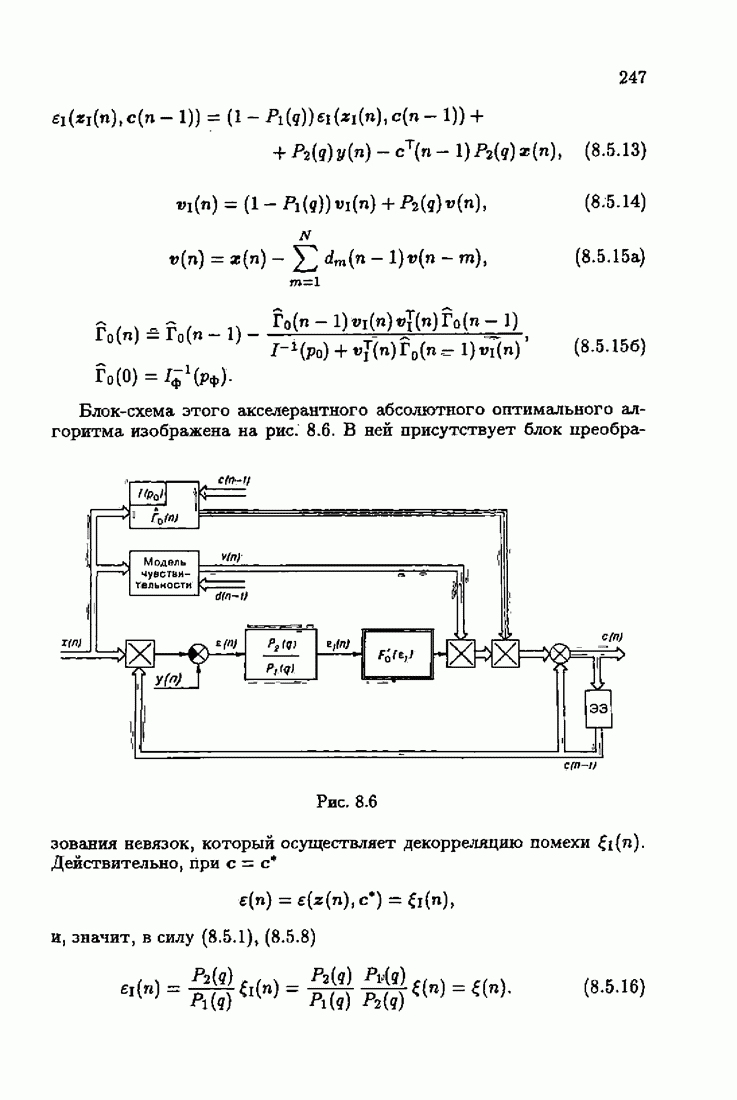



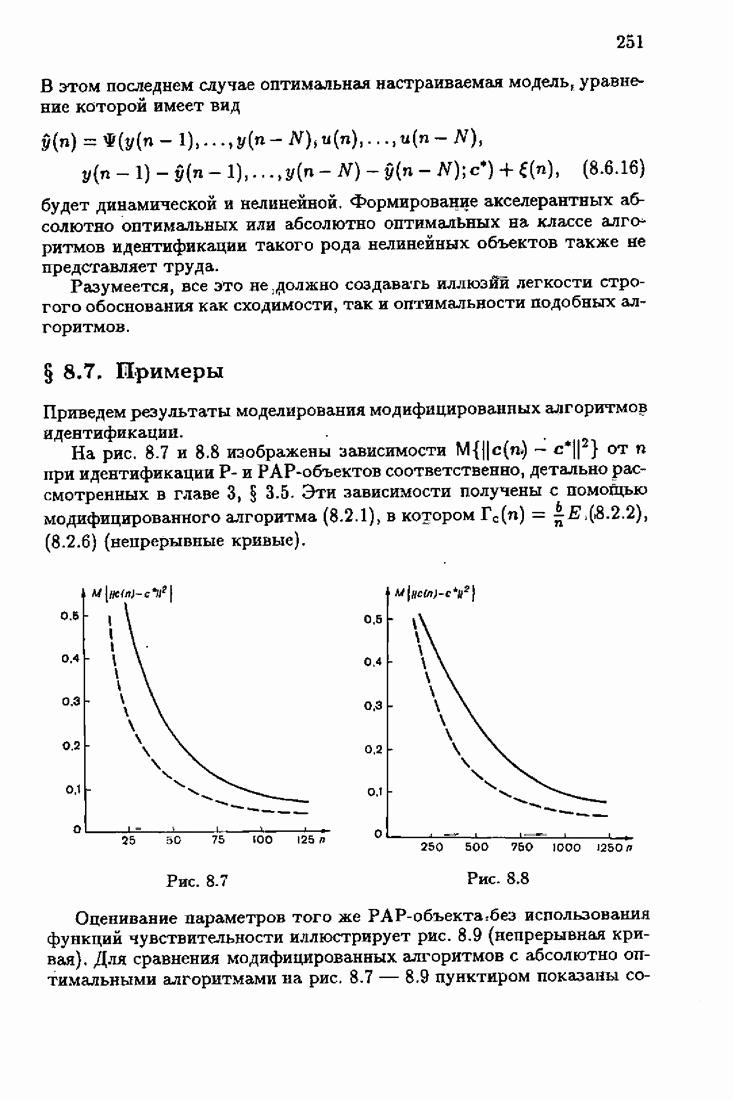






















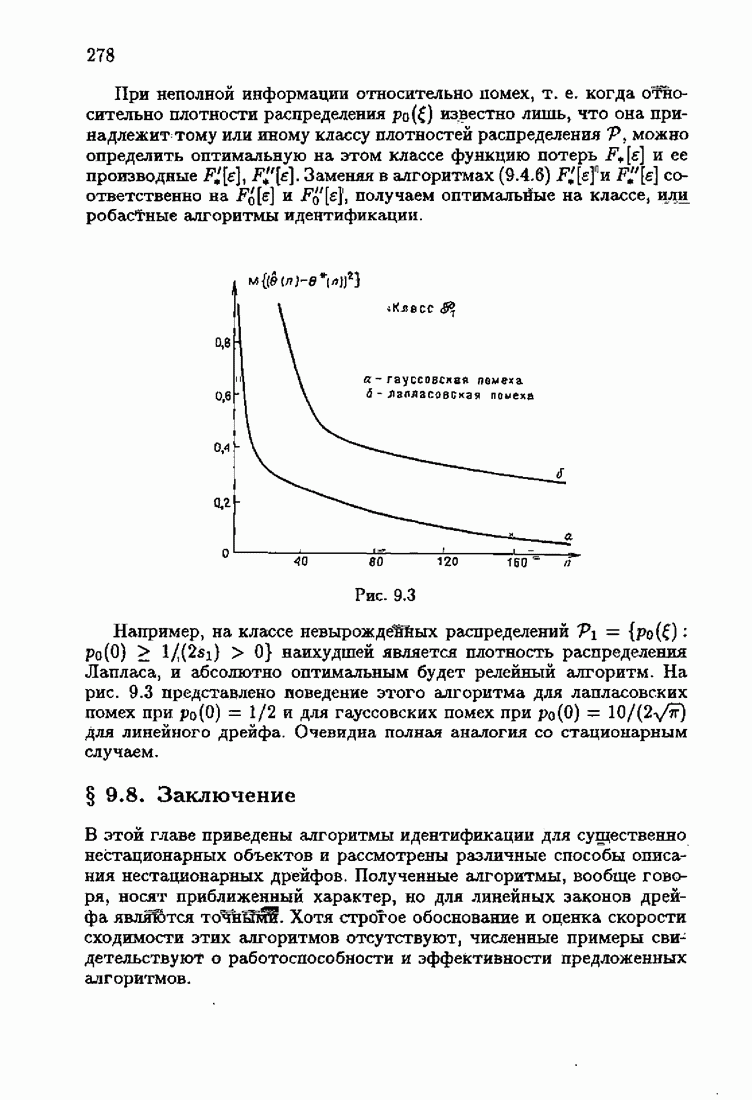


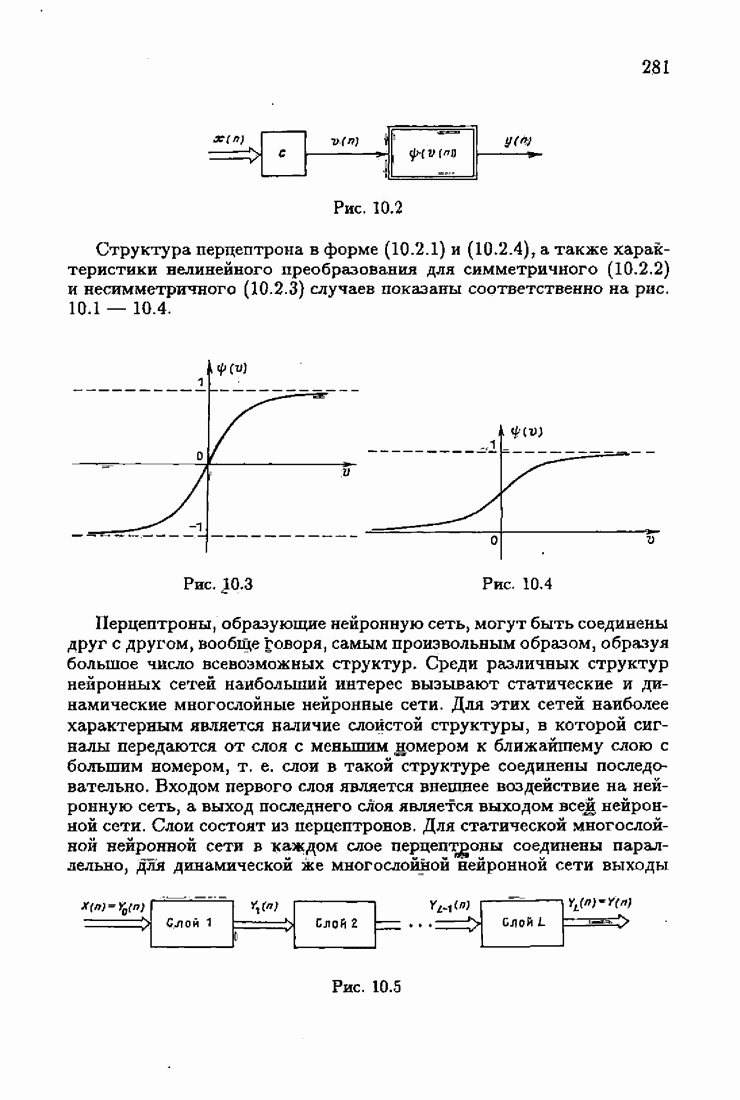
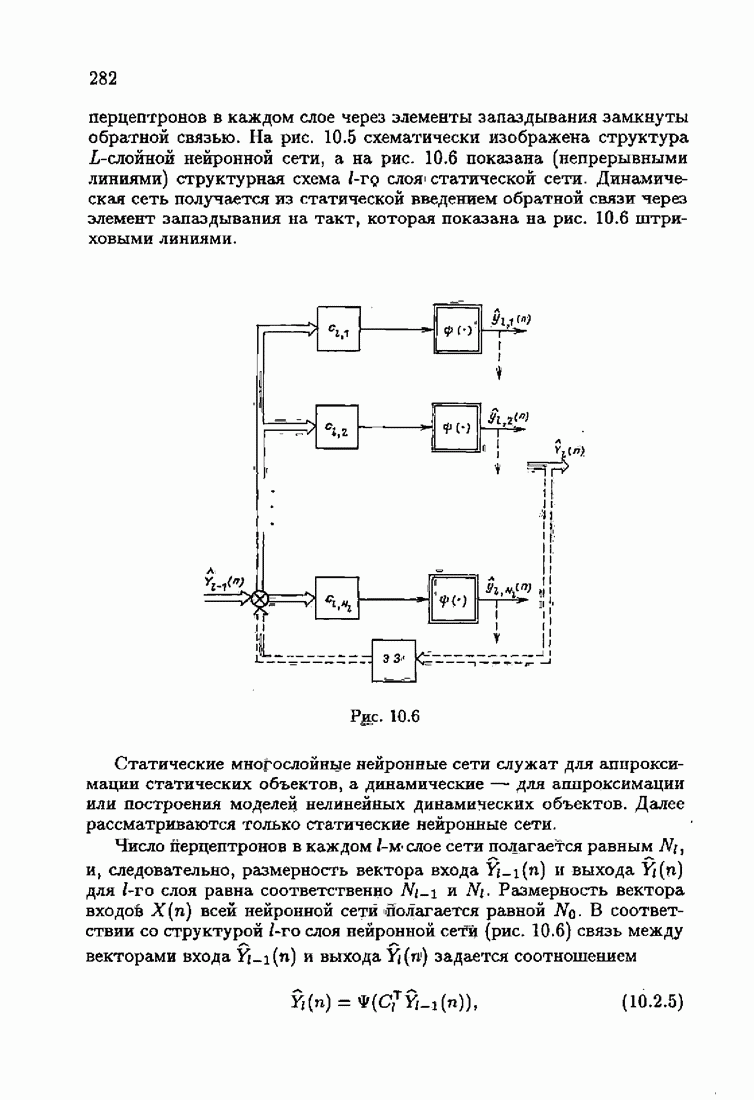


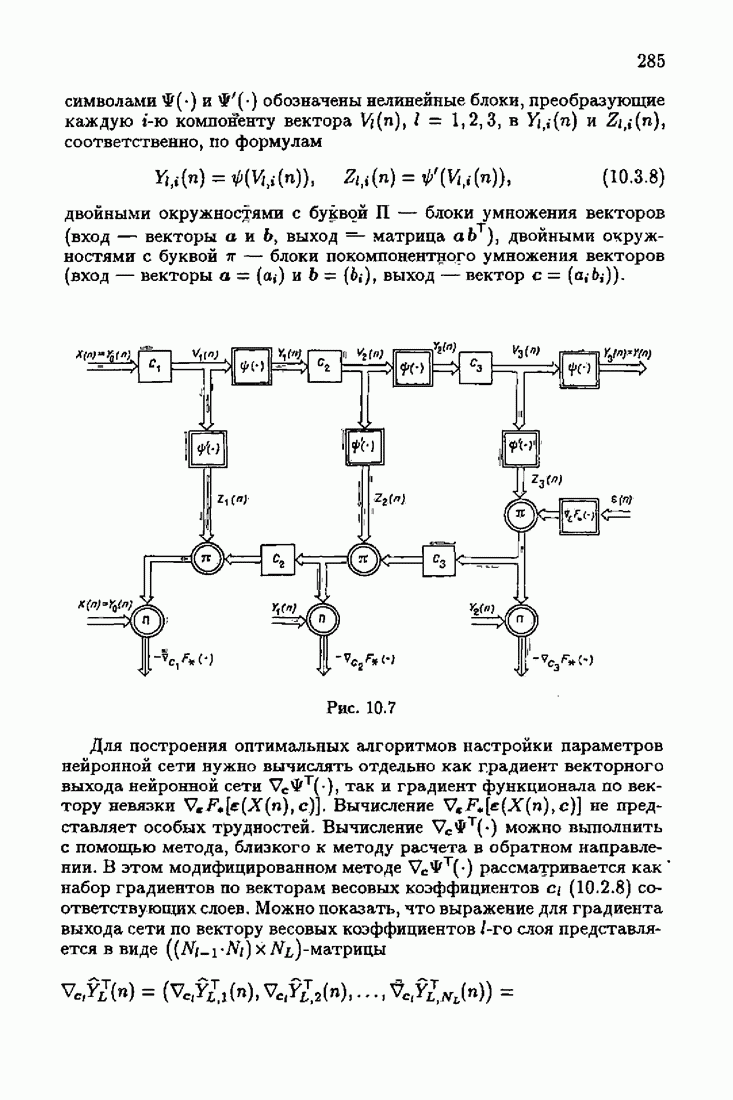
















































 минимизирует АМКО
минимизирует АМКО  (2.4.7). Найдем минимальную АМКО. Для этого подставим
(2.4.7). Найдем минимальную АМКО. Для этого подставим  при
при  из (2.4.19) в
из (2.4.19) в  Замечая, что
Замечая, что

