Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
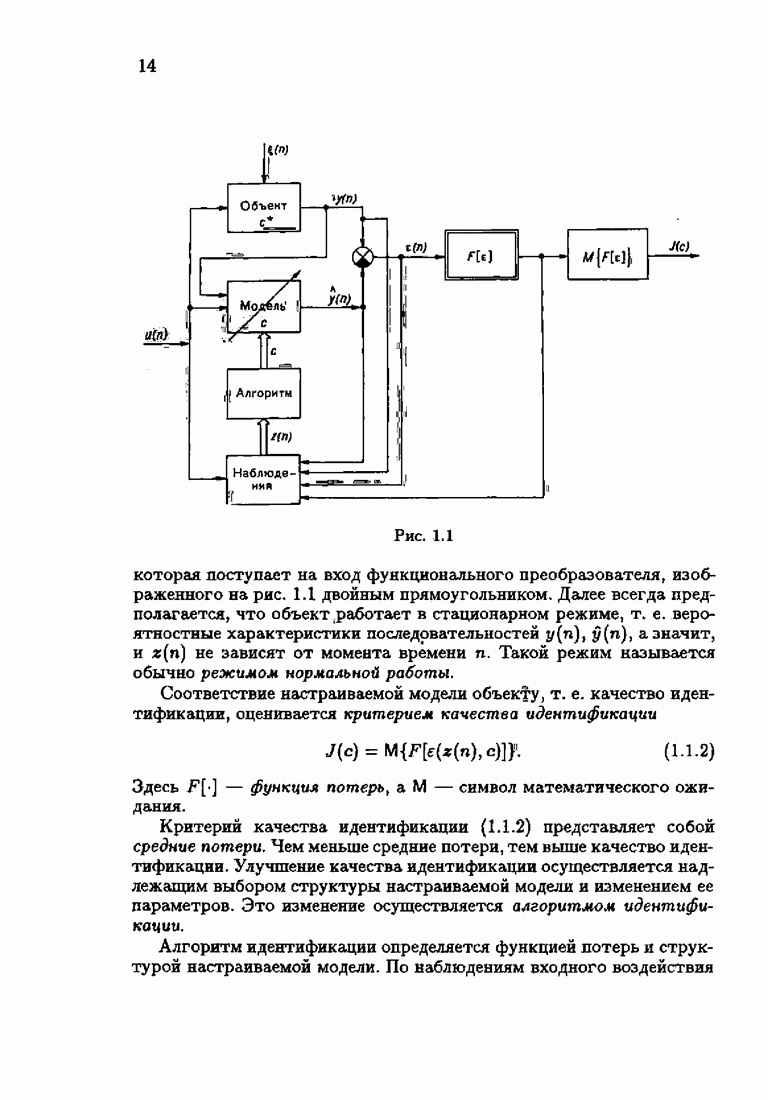
ГЛАВА 1. Задача идентификации и ее особенности§ 1.1. О методах идентификацииИдентификация динамических объектов в общем случае состоит в определении их структуры и параметров по наблюдаемым данным — входному воздействию и выходной величине. Идентификация осуществляется при помощи настраиваемой модели той или иной структуры, параметры которой могут изменяться. Функциональную схему идентификации можно представить в виде, изображенном на рис. 1.1. В каждый момент времени Разность выходных величин объекта и настраиваемой модели образует невязку
Рис. 1.1 которая поступает на вход функционального преобразователя, изображенного на рис. 1.1 двойным прямоугольником. Далее всегда предполагается, что объект работает а стационарном режиме, т. е. вероятностные характеристики последовательностей Соответствие настраиваемой модели объекту, т. е. качество идентификации, оценивается критерием качества идентификации
Здесь Критерий качества идентификации (1.1.2) представляет собой средние потери. Чем меньше средние потери, тем выше качество идентификации. Улучшение качества идентификации осуществляется надлежащим выбором структуры настраиваемой модели и изменением ее параметров. Это изменение осуществляется алгоритмом идентификации. Алгоритм идентификации определяется функцией потерь и структурой настраиваемой модели. По наблюдениям входного воздействия и выходных величин объекта и настраиваемой модели алгоритм идентификации изменяет параметры последней так, чтобы средние потери достигали с ростом Идентификацию можно осуществить иным способом, а именно: провести специальные эксперименты на объекте, затем полученные результаты этих экспериментов обработать, приближенно восстановить средние потери и далее тем или иным способом минимизировать восстановленные средние потери. Такие алгоритмы минимизации не позволяют обрабатывать поступающие наблюдения последовательно, в режиме нормальной работы. Их мы не будем подробно рассматривать. В дальнейшем, говоря об идентификации, мы всегда будем иметь в виду идентификацию в режиме нормальной работы, если нет специальных оговорок. Для решения задачи идентификации, как это следует из функциональной схемы (рис. 1.1), необходимо: 1) очертить класс объектов; 2) выбрать для этого класса объектов настраиваемую модель, т. е. модель, параметры которой можно изменять; 3) выбрать критерий качества идентификации — средние потери, которые бы характеризовали различие между выходными величинами объекта и настраиваемой модели; 4) сформировать алгоритм идентификации, который, используя доступные для наблюдения значения входных и выходных величин, изменял бы параметры настраиваемой модели так, чтобы средние потери с ростом Динамические объекты описываются дифференциальными уравнениями (обыкновенными или в частных производных) с неизвестными коэффициентами, либо интегральными уравнениями с неизвестным ядром. Динамические объекты, управляемые цифровыми вычислительными машинами (ЦВМ), а также разнообразные процессы, характеризуемые временными рядами, описываются разностными уравнениями, которые являются дискретными аналогами дифференциальных уравнений, либо уравнениями типа свертки (с неизвестным ядром). Как правило, объекты подвержены воздействию помех, которые непосредственно не измеряются. Эти мешающие воздействия фигурируют в уравнениях динамического объекта. Коэффициенты этих Уравнений неизвестны. На основании сведений об объекте формируется настраиваемая модель. Настраиваемая модель описывается уравнениями, подобными Уравнениям объекта, либо соотношениями, содержащими измеряемые входные и выходные величины, характеризующие состояние динамического объекта. Коэффициенты этих уравнений или соотношений являются параметрами настраиваемой модели. Близость настраиваемой модели к динамическому объекту характеризуется функционалом невязки — средними потерями В современной теории идентификации выбор структуры настраиваемой модели для заданного класса динамических объектов в значительной мере произволен. Так, широко используются статические настраиваемые модели, описываемые соотношениями типа линейной комбинации измеряемых входных и выходных величин динамического объекта. Несколько реже применяются динамические настраиваемые модели, описываемые уравнениями, подобными уравнениям объекта. Часто такие настраиваемые модели приводят к смещенным оценкам параметров. Тогда для устранения смещенности в настраиваемую модель вводят оценки ненаблюдаемых помех, либо используют преобразованные тем или иным способом наблюдаемые величины (инструментальные переменные). Критерий качества идентификации в подавляющем большинстве работ выбирался квадратичным в виде среднего значения квадрата невязки. Минимизация такого квадратичного критерия во многих случаях сводилась к решению системы линейных алгебраических уравнений. Возможность получения теоретически точного результата на основе различных вариантов метода наименьших квадратов обеспечила господствующее положение квадратичному критерию идентификации. Значительно реже использовались критерии качества идентификации, отличные от квадратичных, например, модульный критерий типа среднего значения абсолютной величины невязки. Что же касается алгоритмов идентификации, то здесь широкое распространение получили рекуррентный метод наименьших квадратов, а также различные варианты метода стохастической аппроксимации. Простота и универсальность последнего метода позволила не ограничиваться квадратичными критериями идентификации и формировать разнообразные как линейные, так и нелинейные алгоритмы идентификации. Появление большого числа различных алгоритмов идентификации вызвало к жизни работы по их сравнительному анализу. Разумеется, такой анализ иногда позволял выделить лучший из сравниваемых алгоритмов. Но является ли этот алгоритм наилучшим в рассматриваемой задаче идентификации, — на этот вопрос пока ответа не было. Развитая к настоящему времени теория идентификации предлагает огромное число методов и способов, но эта теория не касается вопросов обоснованного выбора метода, т. е. выбора настраиваемой модели, критерия качества идентификации и алгоритмов. Выбор настраиваемых моделей и алгоритмов является скорее искусством, чем наукой. Поэтому много усилий затрачивается на экспериментальное исследование выбранных настраиваемых моделей и алгоритмов и сравнение их с ранее предложенными. Теория идентификации также не пытается объяснить причины неудовлетворительной работы тех или иных конкретных алгоритмов. Поэтому особенно важно рассмотреть возможности обоснования выбора настраиваемой модели, критерия и алгоритма идентификации, которые бы гарантировали не только удовлетворительную работу алгоритмов, но и наилучшее, в том или ином смысле, решение конкретных задач идентификации. Все это и составляет содержание информационной теории идентификации.
|
 |
Оглавление
|

























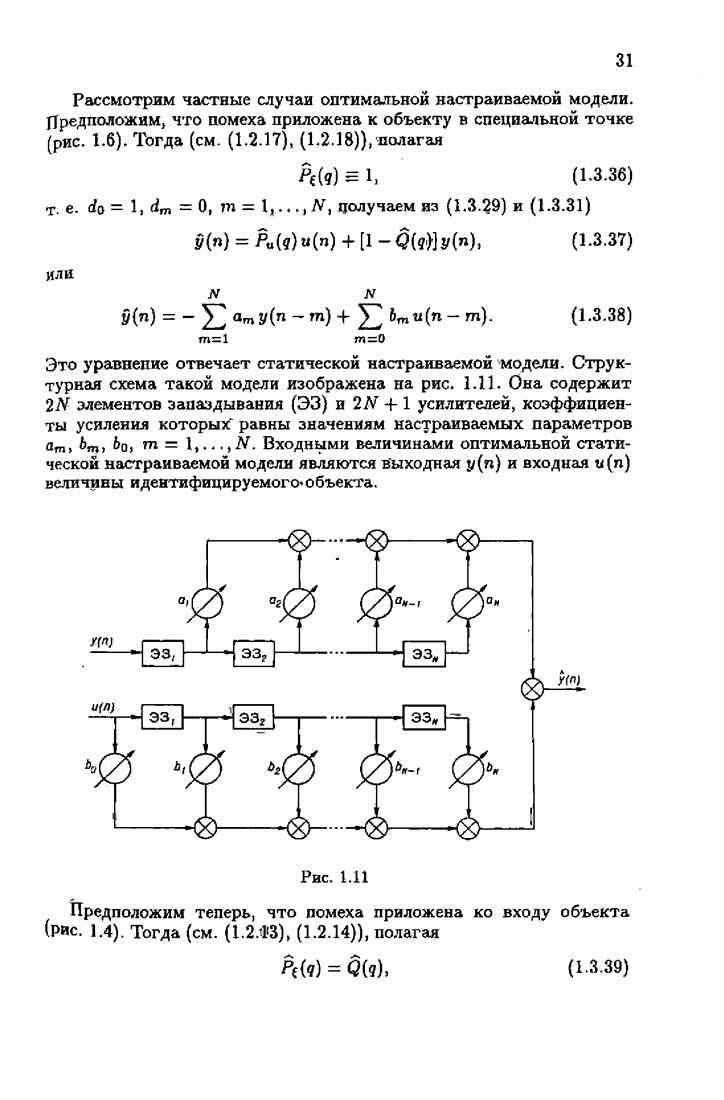
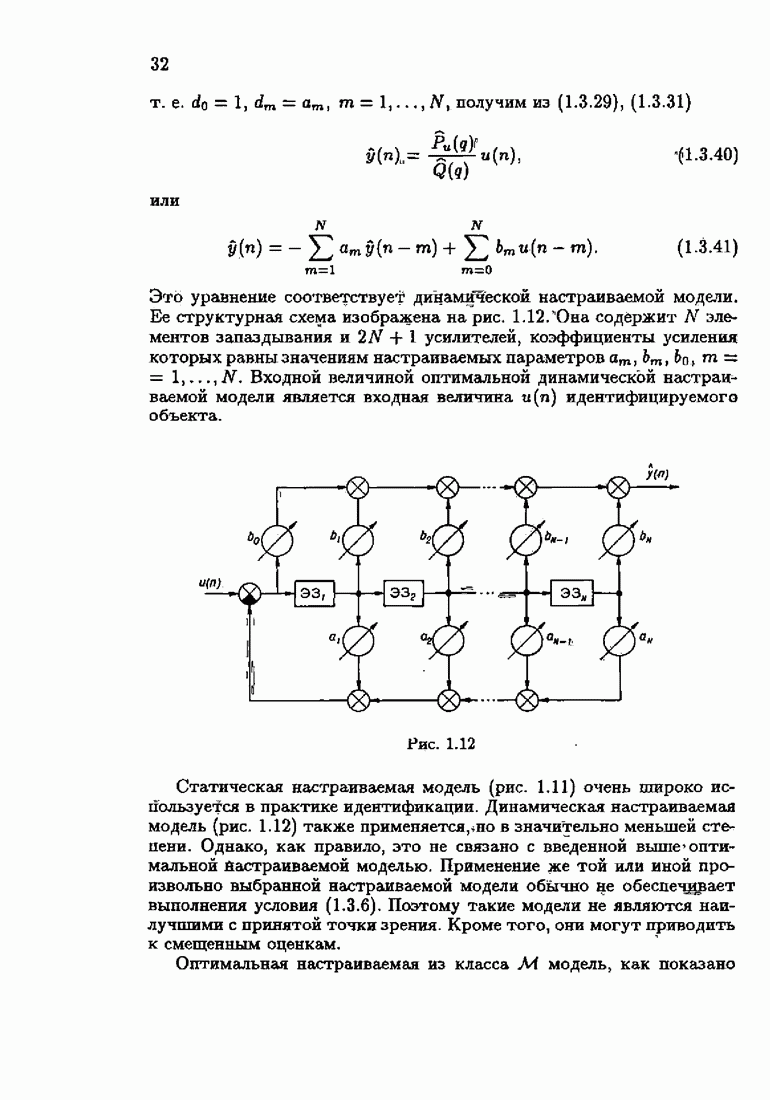






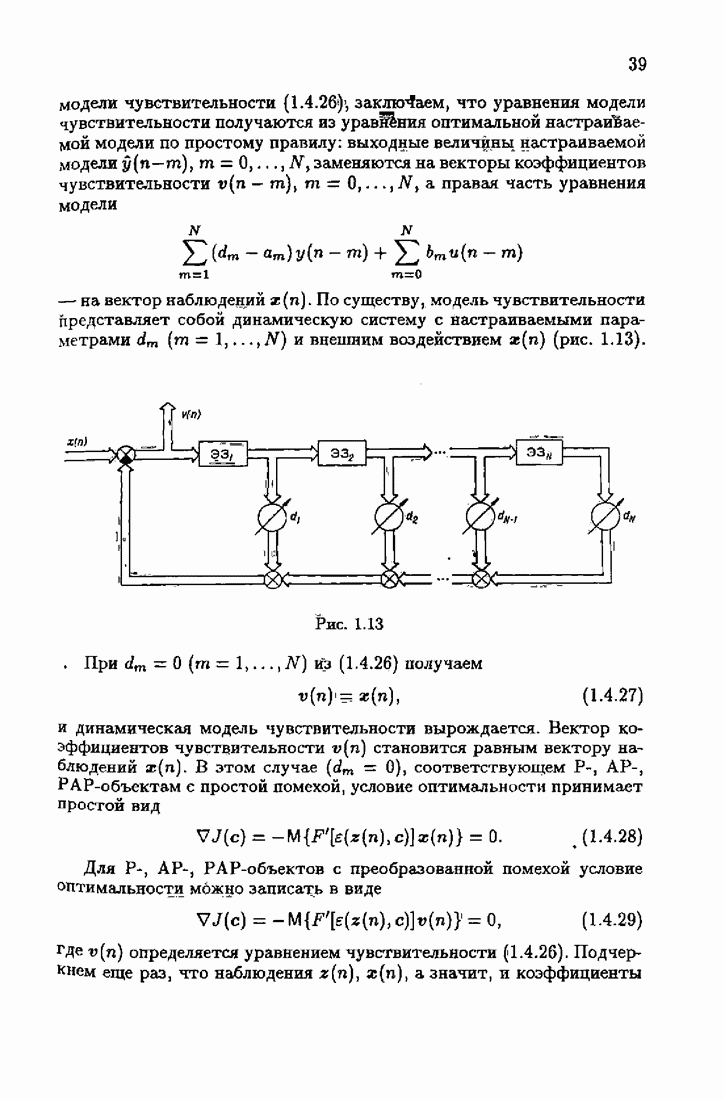







































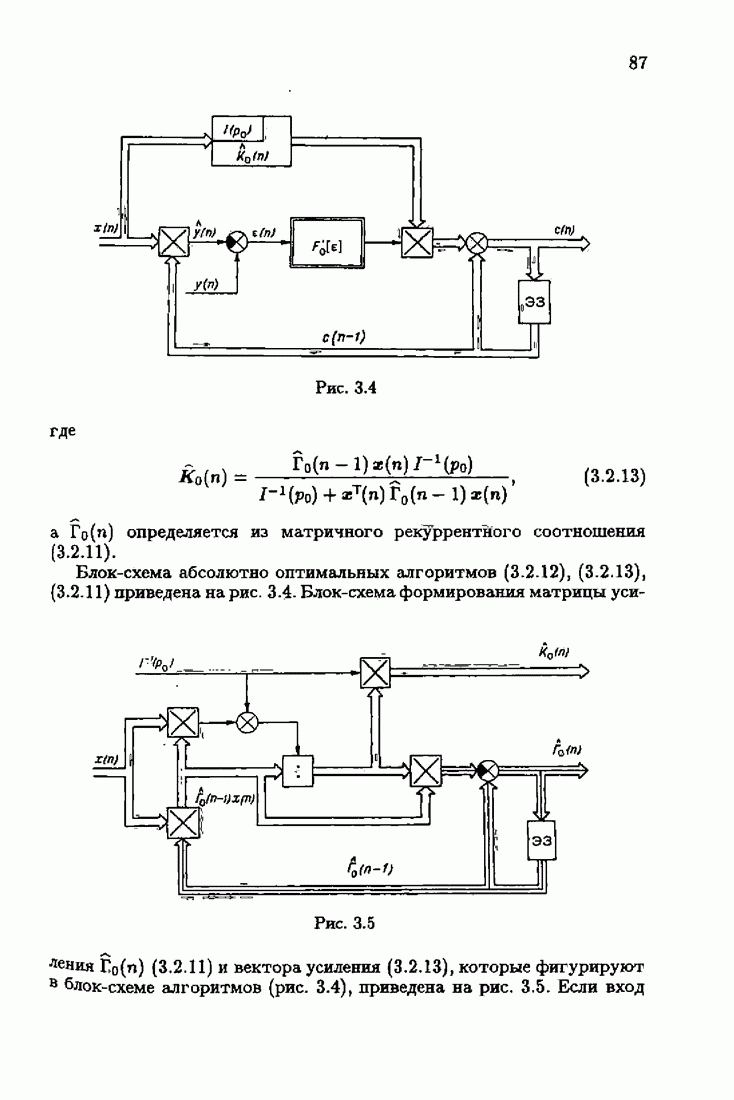




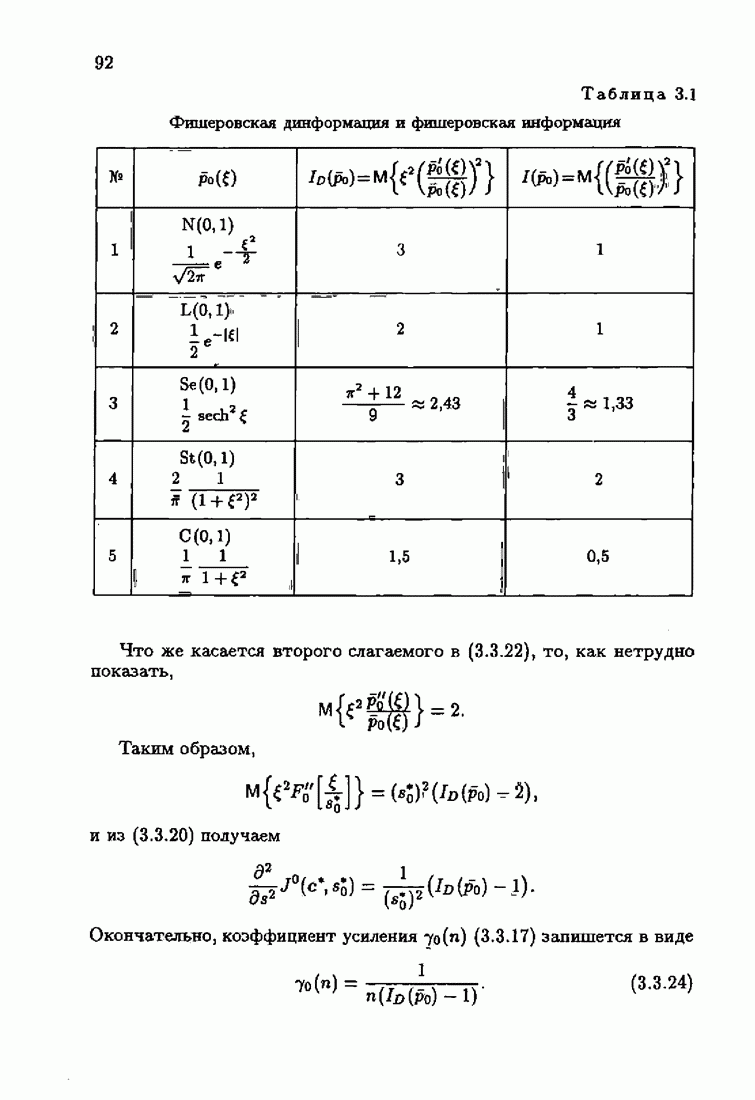
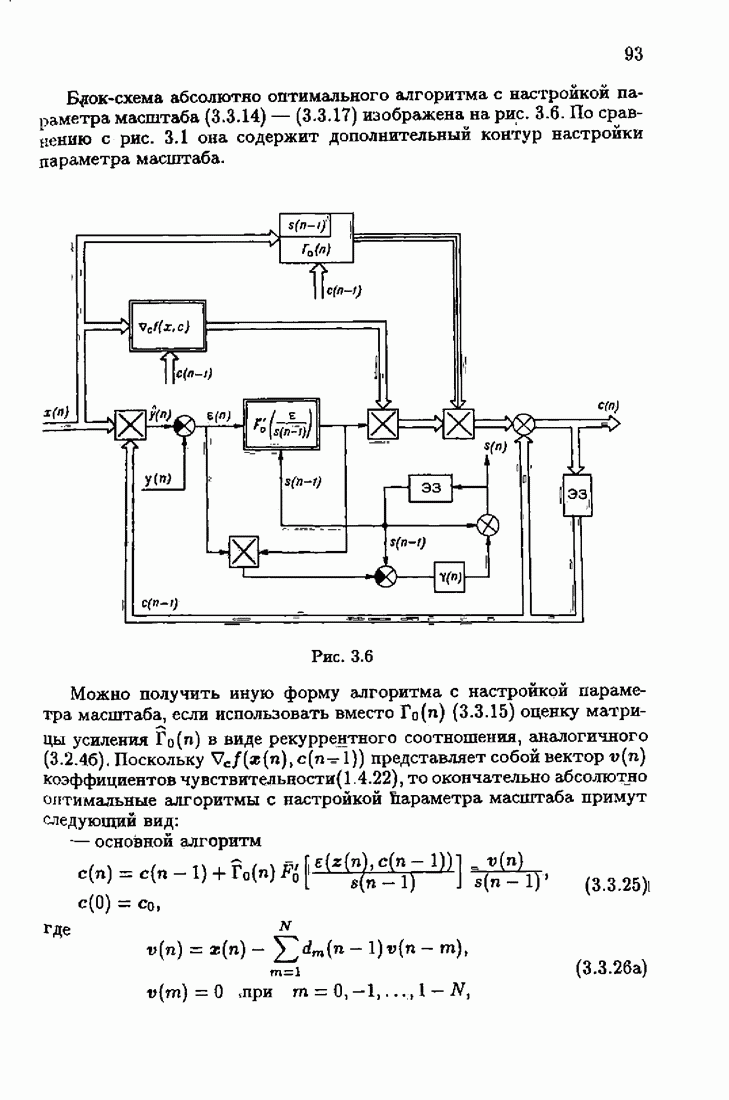
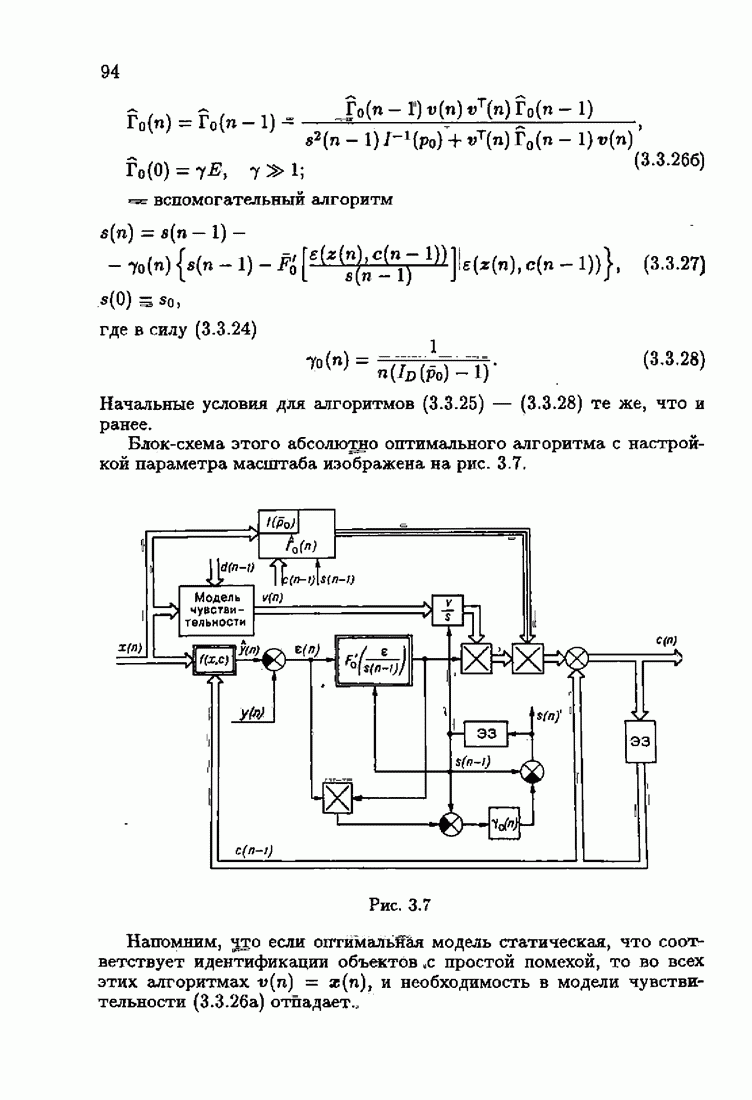


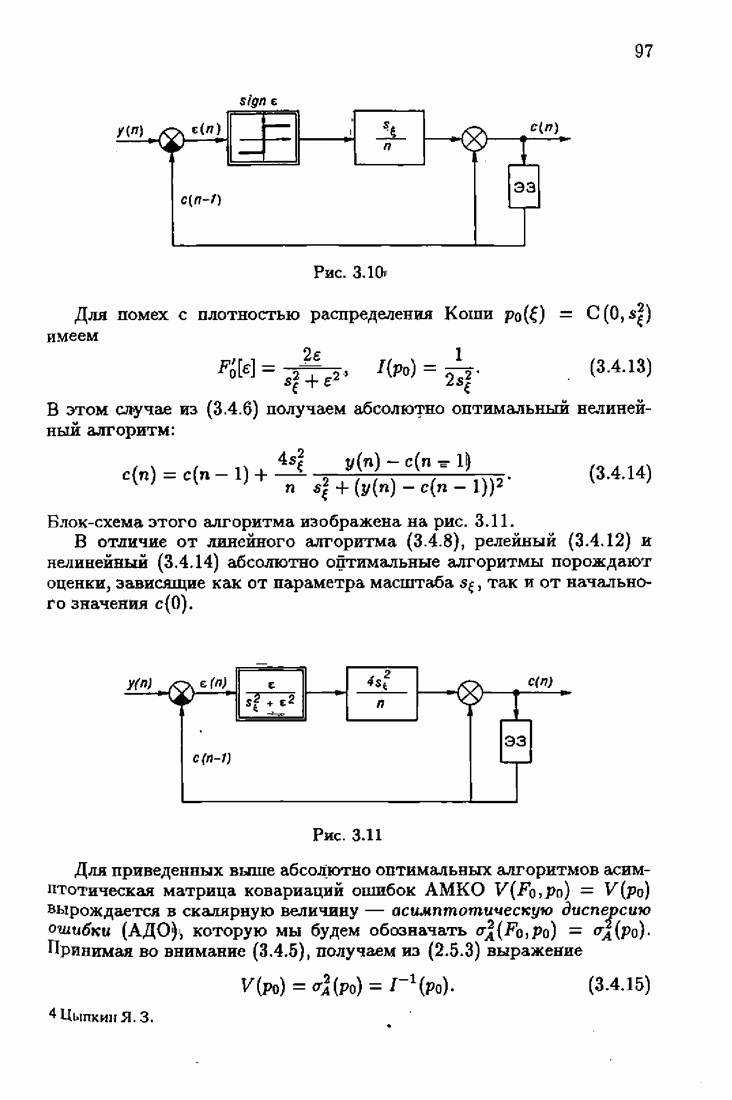



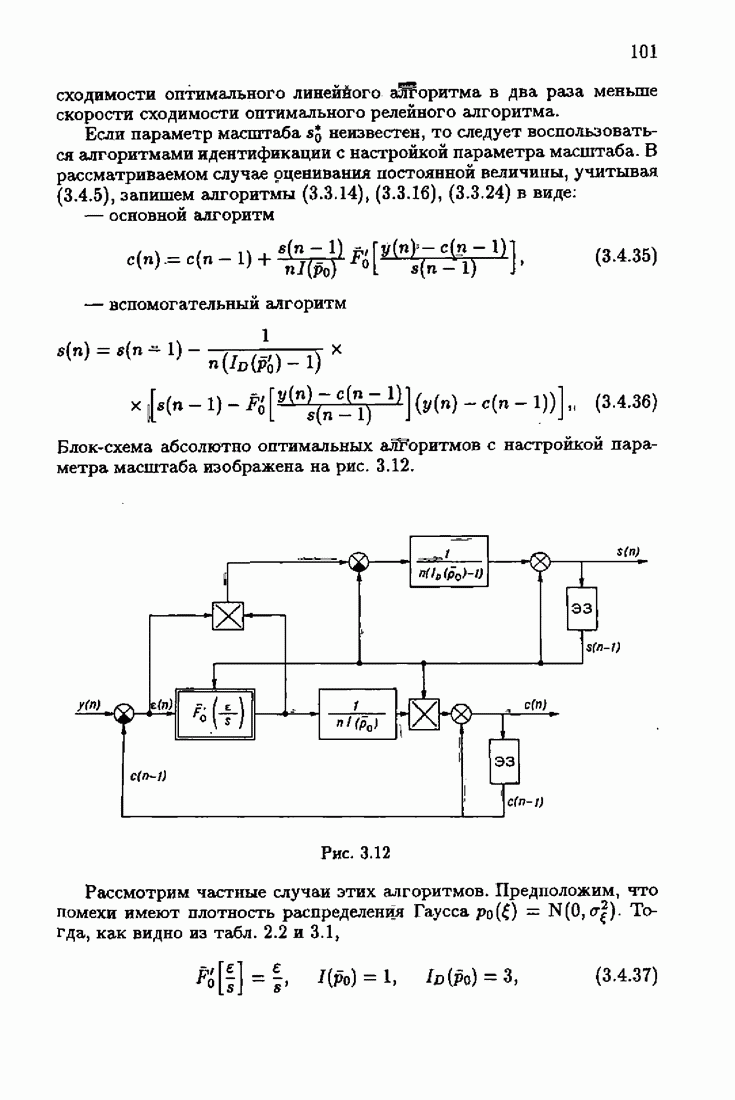
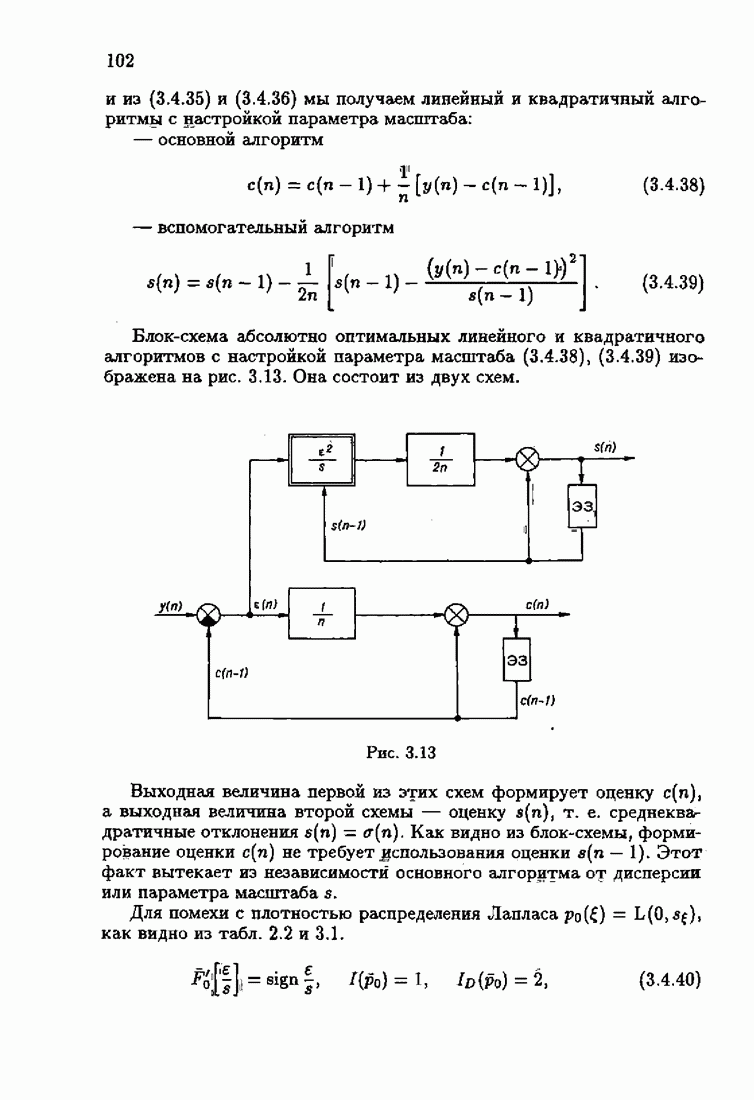
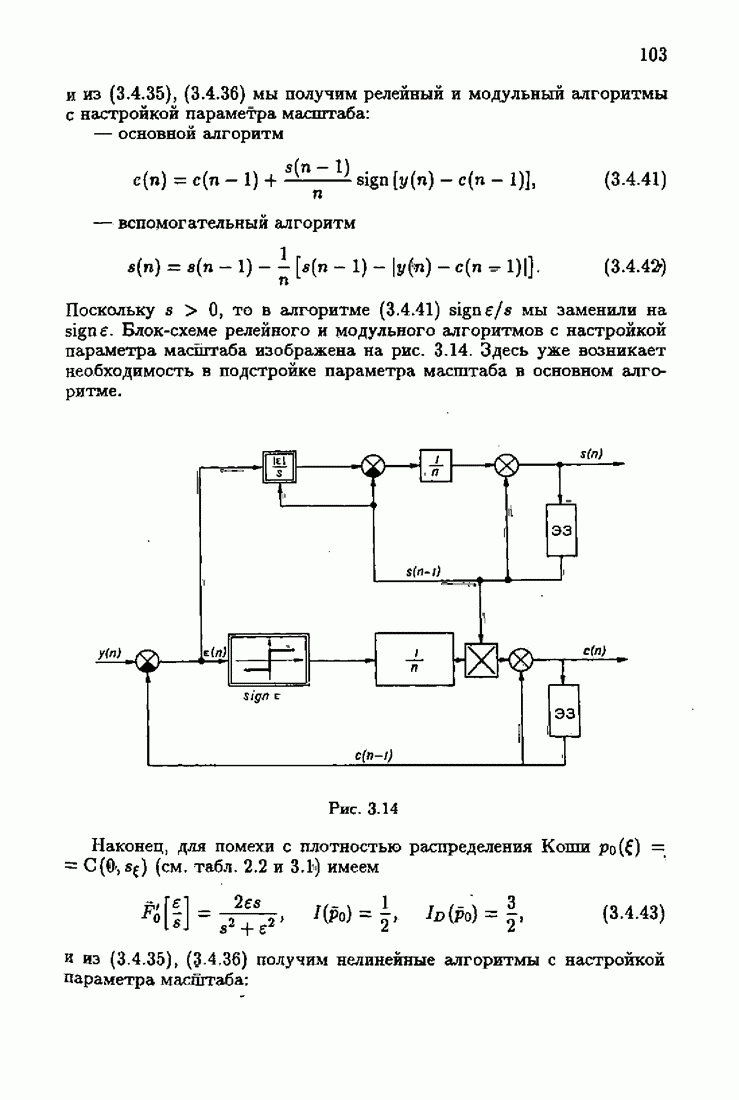










































































































































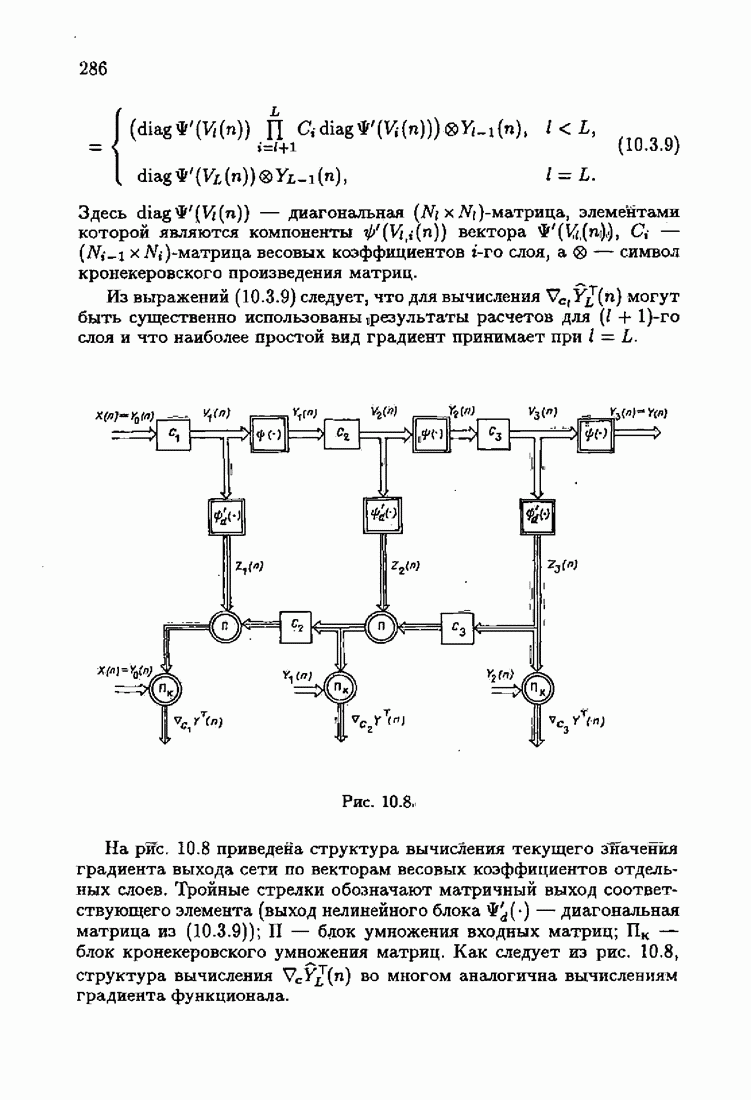
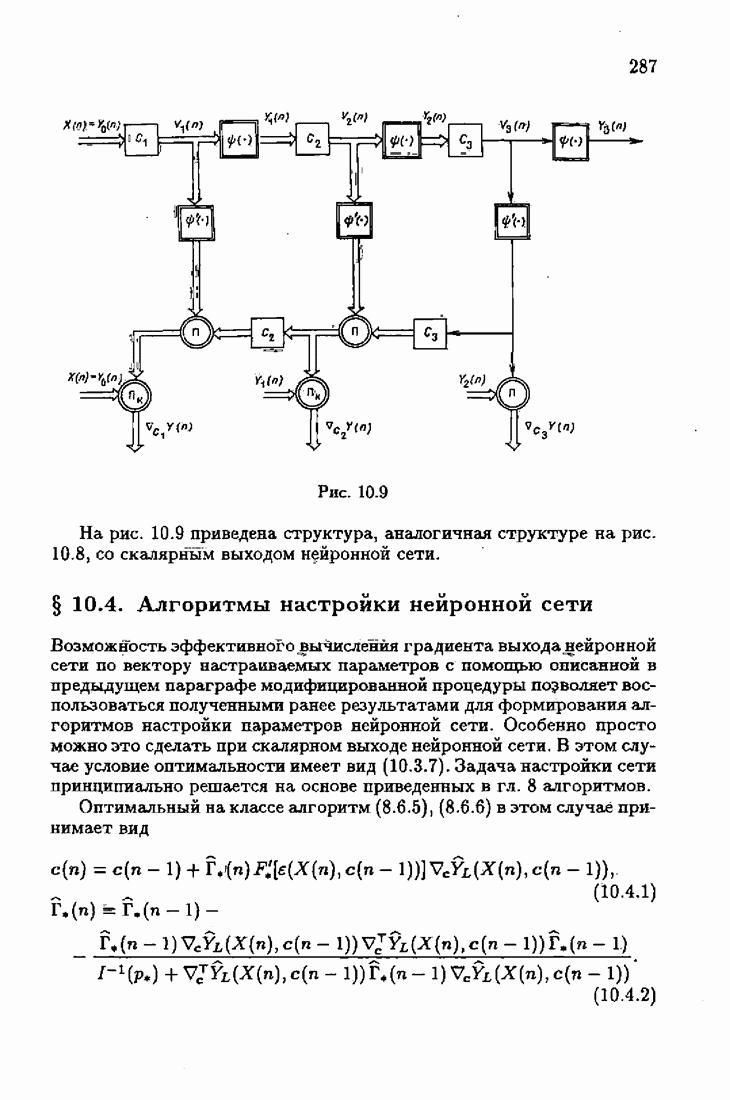


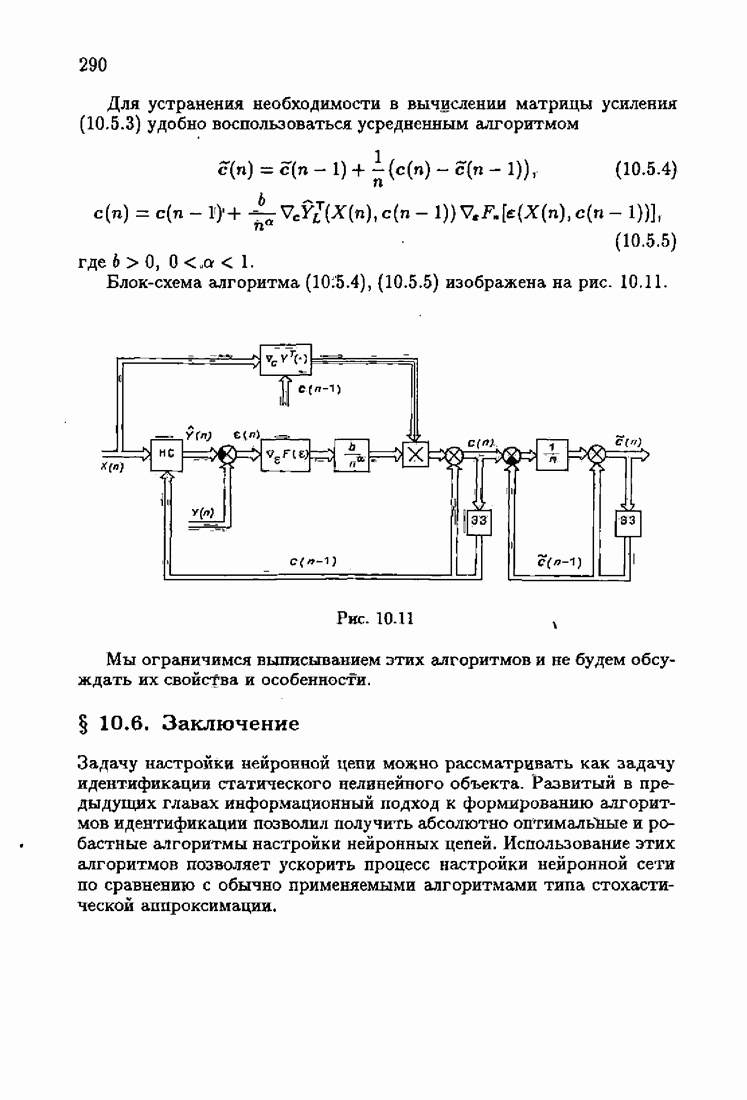














































 ко входам объекта и настраиваемой модели приложено внешнее воздействие
ко входам объекта и настраиваемой модели приложено внешнее воздействие  Объект возмущается также некоторой случайной ненаблюдаемой помехой
Объект возмущается также некоторой случайной ненаблюдаемой помехой  Выходная величина объекта
Выходная величина объекта  зависит как от внешнего воздействия и помехи, так и от неизвестного вектора параметров с. Выходная величина настраиваемой модели
зависит как от внешнего воздействия и помехи, так и от неизвестного вектора параметров с. Выходная величина настраиваемой модели  зависит от вектора настраиваемых параметров с, который пересчитывается в силу алгоритма, обрабатывающего вектор всех наблюдений
зависит от вектора настраиваемых параметров с, который пересчитывается в силу алгоритма, обрабатывающего вектор всех наблюдений  Набор этих наблюдений зависит от конкретных задач идентификации.
Набор этих наблюдений зависит от конкретных задач идентификации.


 а значит, и
а значит, и  не зависят от момента времени
не зависят от момента времени  Такой режим называется обычно режимом нормальной работы.
Такой режим называется обычно режимом нормальной работы.

 функции потерь,
функции потерь,  символ математического ожидания.
символ математического ожидания.
 минимума. Эти условия соответствуют идентификации в режиме нормальной работы объекта.
минимума. Эти условия соответствуют идентификации в режиме нормальной работы объекта.
 достигали минимума.
достигали минимума.
 Минимизация средних потерь достигается изменением параметров настраиваемой модели при помощи алгоритмов идентификации.
Минимизация средних потерь достигается изменением параметров настраиваемой модели при помощи алгоритмов идентификации.