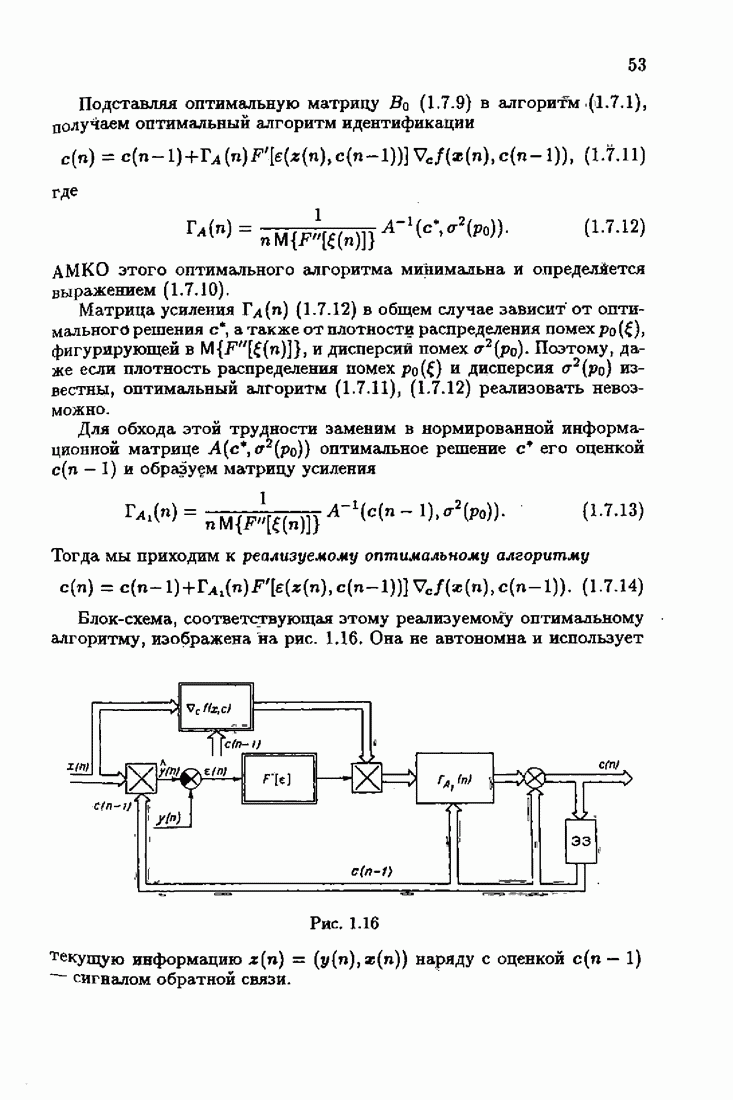
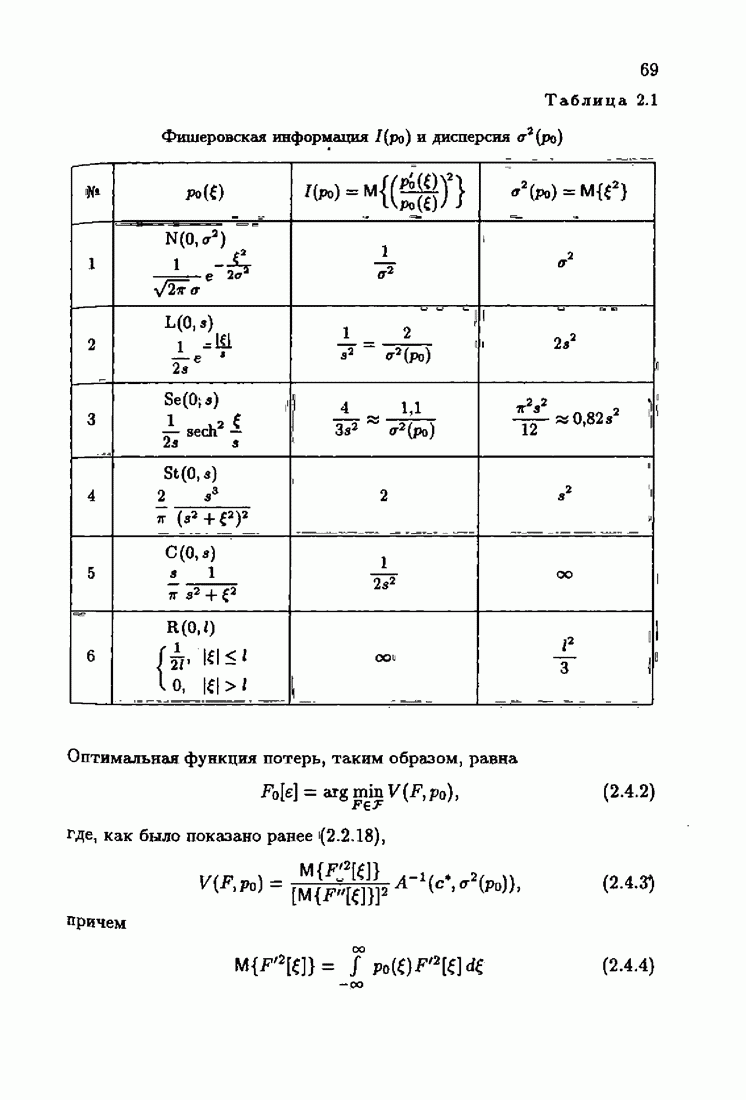
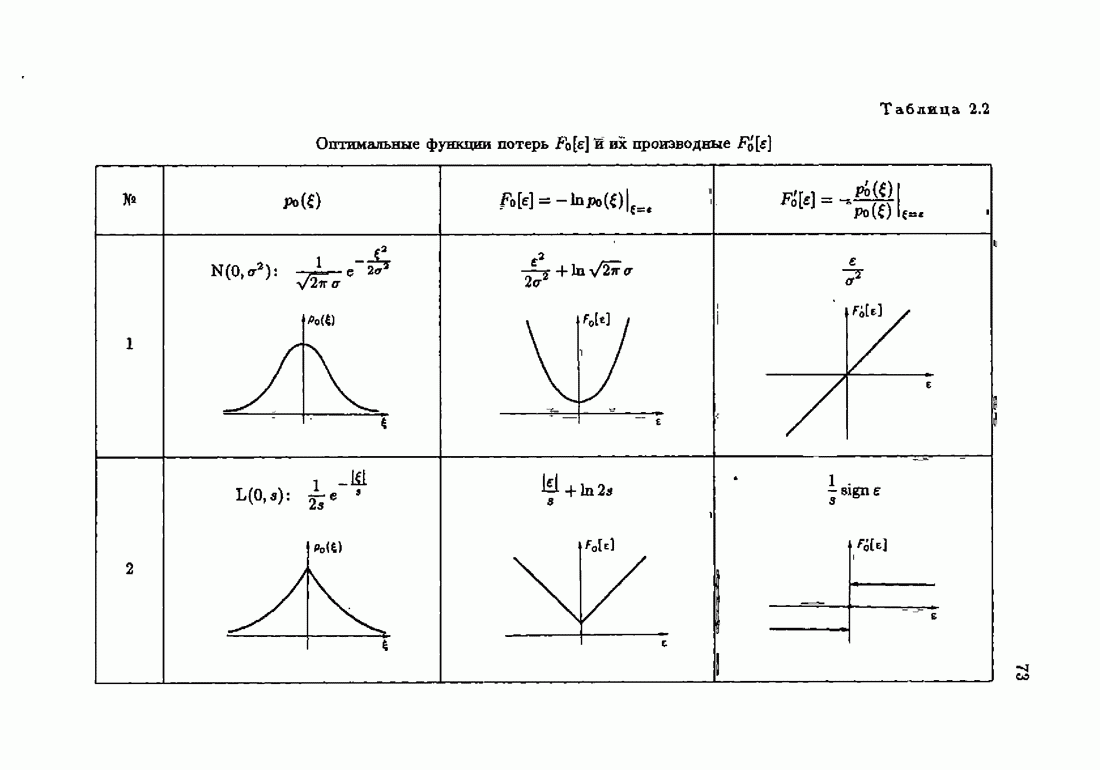
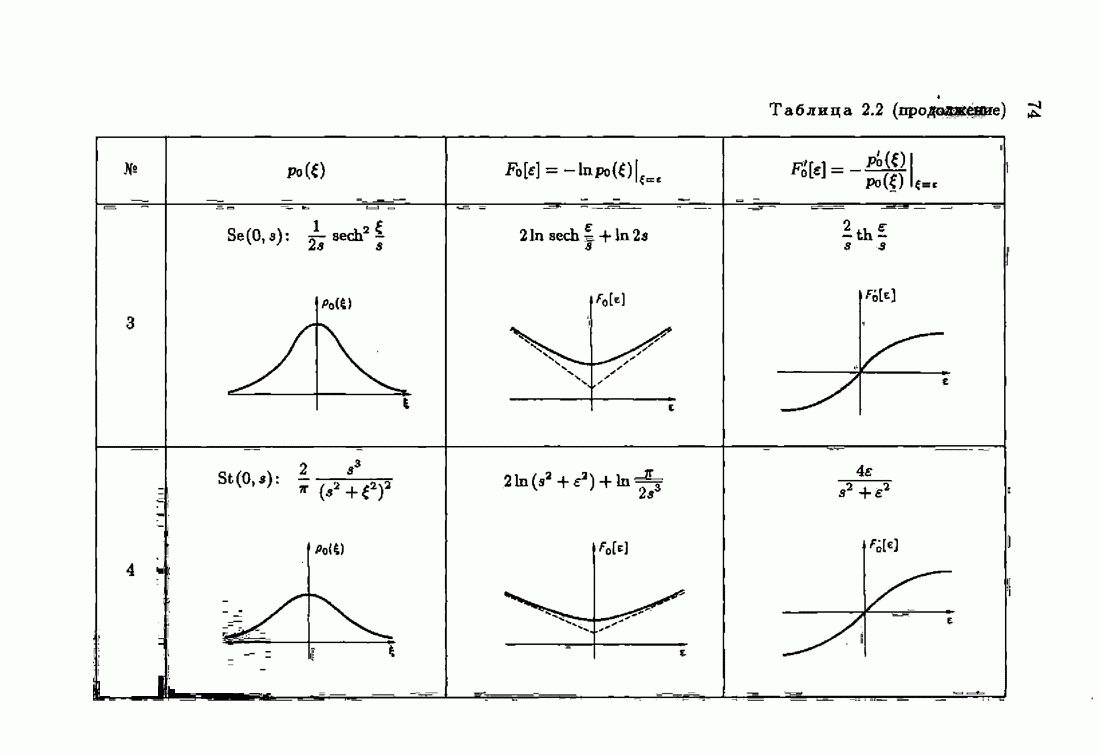
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
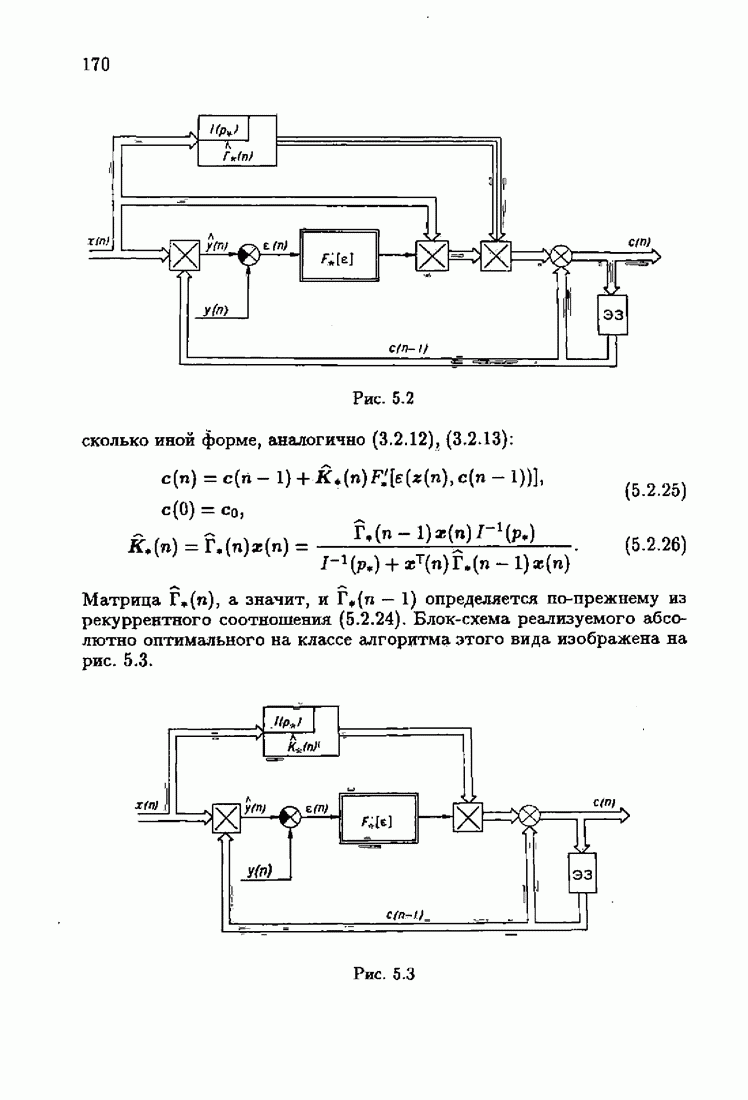
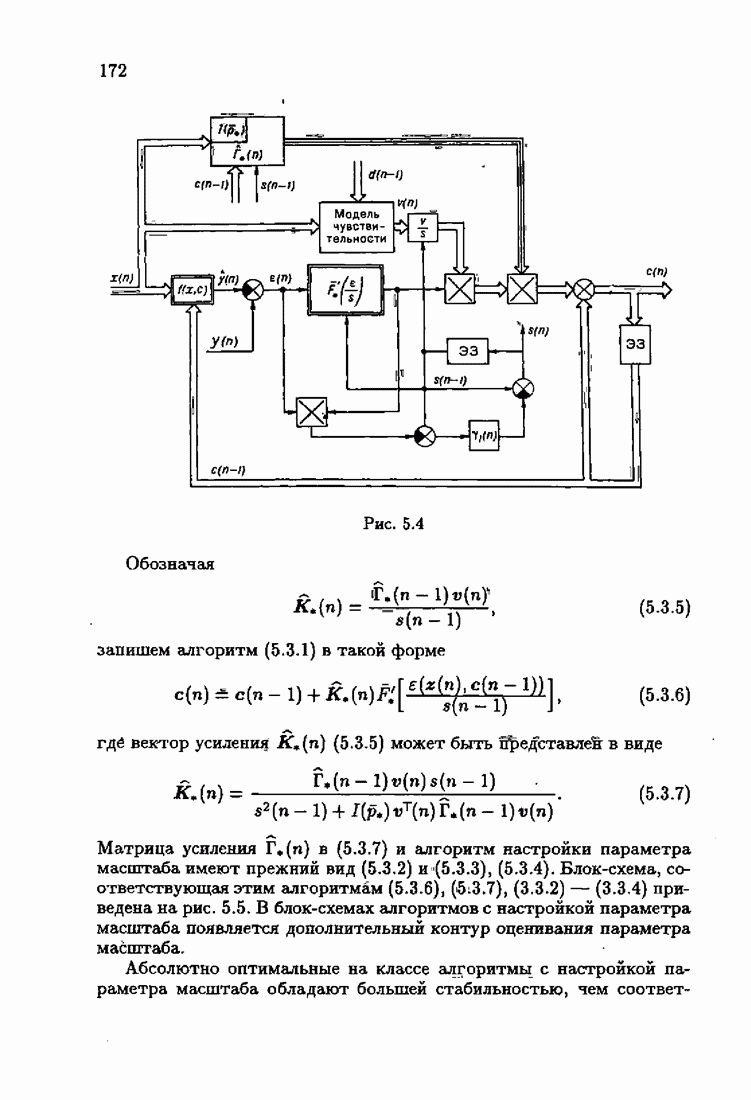
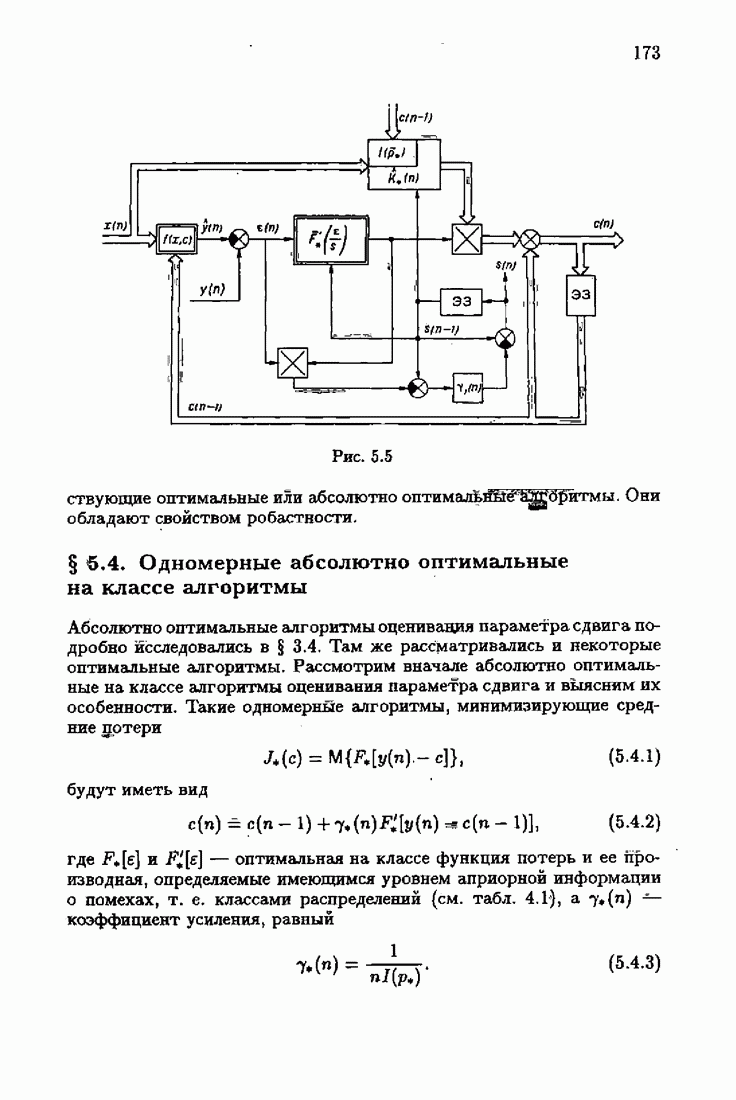
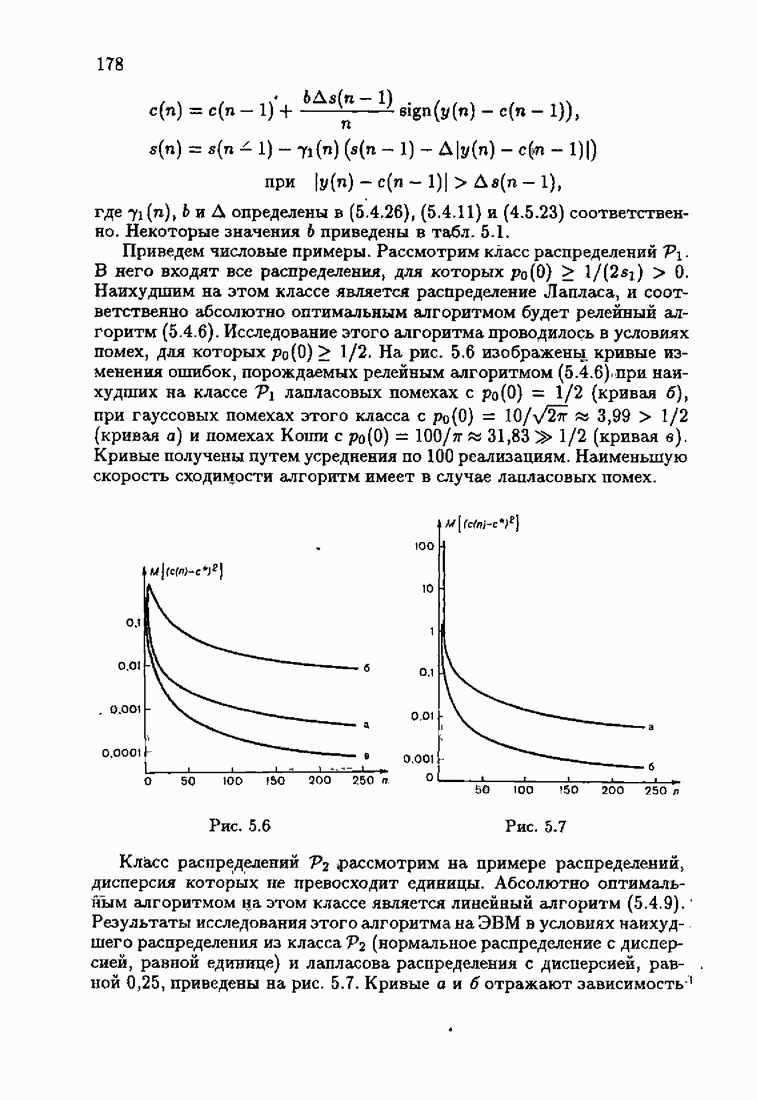
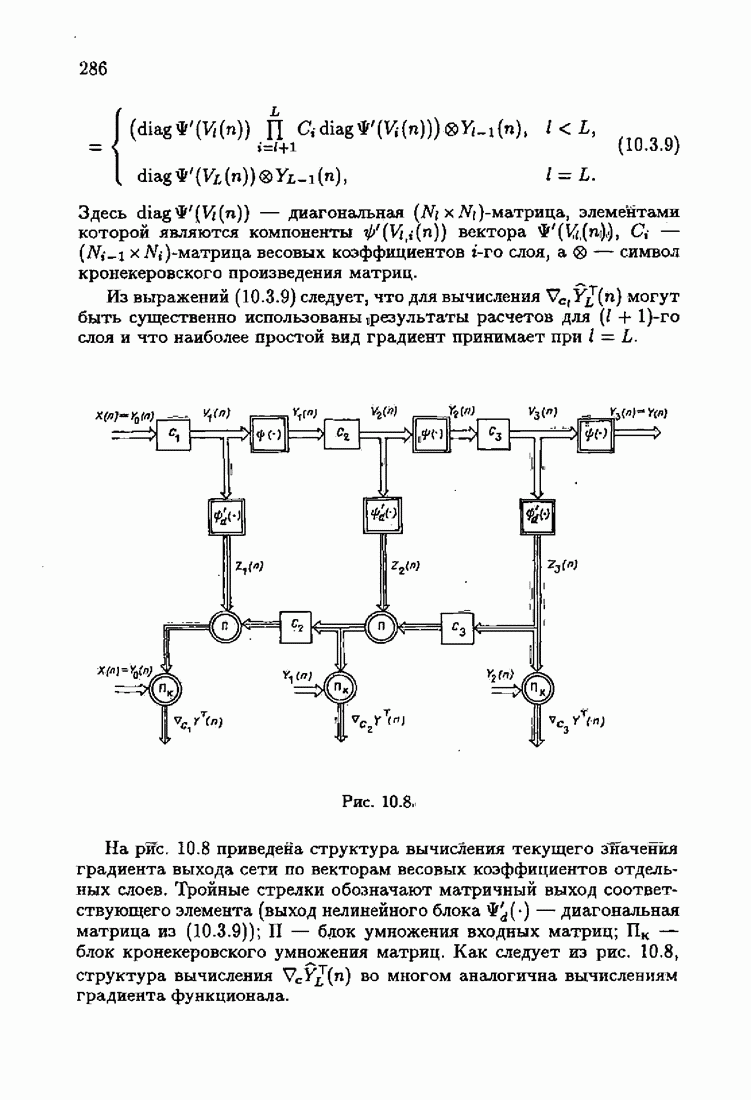
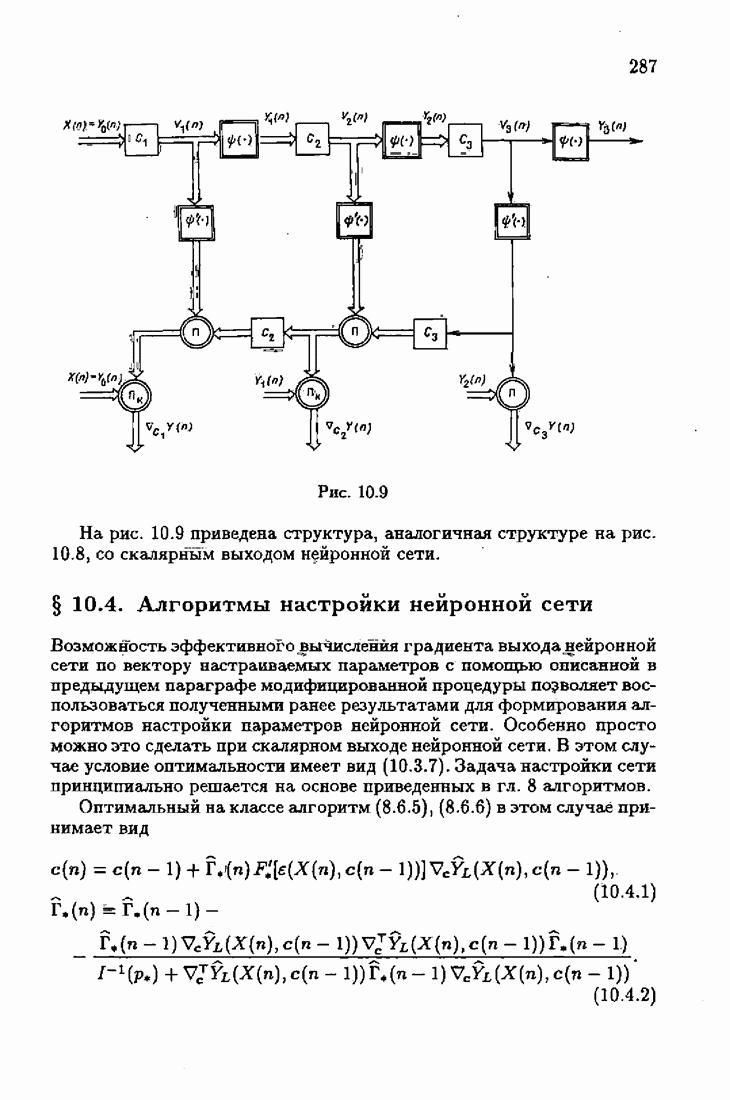
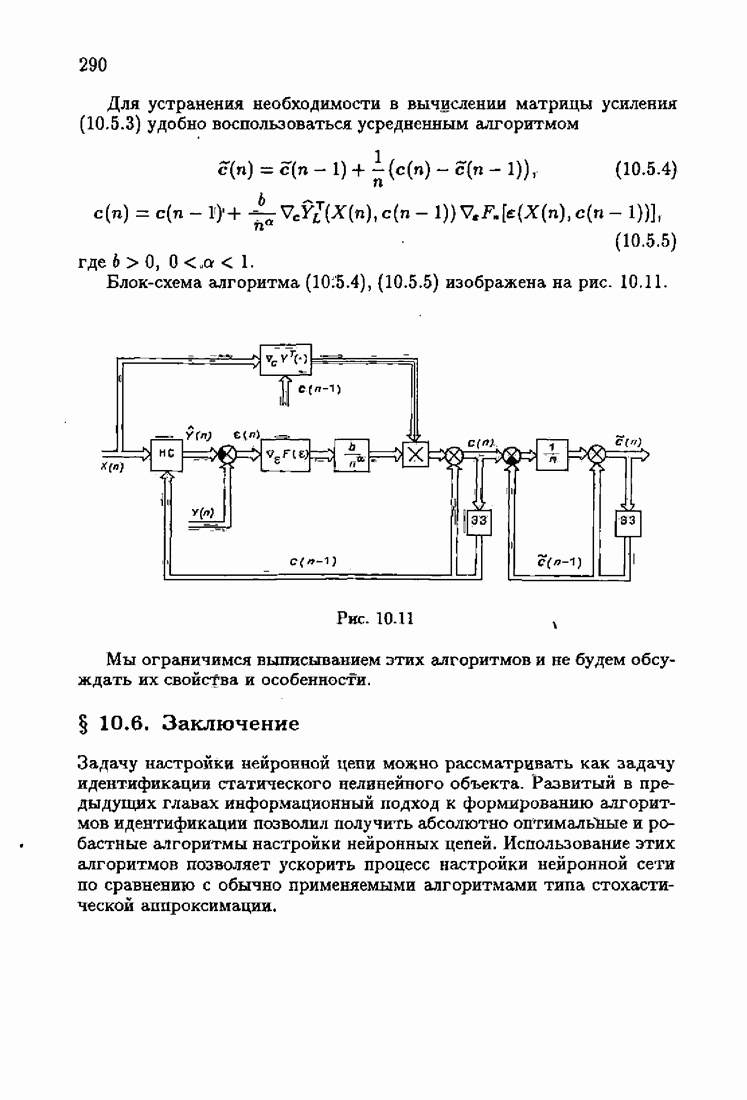
ПослесловиеПроблеме идентификации посвящено необозримое число работ. В них используются различные настраиваемые или прогнозирующие модели, те или иные критерии качества идентификации и большое число различных алгоритмов идентификации. Многие работы посвящены как разработке новых алгоритмов идентификации, так и сравнению разных алгоритмов между собой. Большое внимание уделяется рекуррентным алгоритмам, осуществляющим, по существу, адаптацию прогнозирующей модели к идентифицируемому объекту на основе получения и надлежащей обработки текущей информации о состоянии объекта. По мере развития теории идентификации возникали и новые задачи, связанные, в частности, с формированием оптимальных, с той или иной точки зрения, рекуррентных алгоритмов. Наиболее естественным критерием оптимальности алгоритмов, очевидно, является скорость адаптации, т. е. скорость сходимости алгоритмов. Аналогично тому, как в теории линейных автоматических систем их качество оценивалось быстротой затухания свободного процесса — степенью устойчивости, в теории идентификации эту роль играет асимптотическая скорость сходимости алгоритмов. Несмотря на то, что понятие асимптотической скорости сходимости возникло давно в теории стохастической аппроксимации, эта оценка качества рекуррентных алгоритмов долгое время не привлекала внимание специалистов. Может быть, причина этого состояла в том, что усилия были в основном направлены на обоснование а доказательство сходимости алгоритмов. Сравнительно недавно было попято, что оптимизация рекуррентных алгоритмов идентификации тесно связана с учетом в них априорной информации об объекте и о статистических свойствах приложенных к нему помех. Учет априорной информации в алгоритмах, обрабатывающих текущую информацию, лежит в основе информационной теории идентификации. Эта теория при заданном уровне априорной информации позволяет однозначно определить оптимальную прогнозирующую модель, оптимальную функцию потерь и оптимальные алгоритмы идентификации. При этом априорная информация о структуре динамического объекта определяет оптимальную прогнозирующую модель, обладающую тем свойством, что при совпадении параметров этой модели (оценок) с параметрами объекта второй момент невязки достигает минимально возможного значения. Априорная информация о помехе, задаваемая ее плотностью распределения, однозначно определяет оптимальную функцию потерь, т. е. критерий качества идентификации (средние потери), и абсолютно оптимальные алгоритмы, обладающие предельно возможной асимптотической скоростью сходимости. Эта скорость сходимости не может быть превзойдена никакими иными алгоритмами, как рекуррентными, так и нерекуррентными. Неполная априорная информация о помехе, задаваемая классом принадлежности неизвестной плотности распределения, также однозначно определяет критерий качества идентификации и абсолютно оптимальные на классе алгоритмы идентификации, обладающие скоростью сходимости, не меньшей некоей гарантированной. Эти алгоритмы характеризуются грубостью, нечувствительностью по отношению к отклонению от принятых априори предположений; они называются робастными. Априорная информация об области принадлежности параметров идентифицируемого объекта, задаваемая в виде так называемой фидуциальной плотности распределения, позволяет подобрать начальные значения алгоритмов идентификации, приводящие к акселеризации оценок, т. е. ускоряющие получение оценок заданной точности. Такие абсолютно оптимальные на классе алгоритмы, осуществляющие регуляризацию оценок, можно назвать акселерантными. Абсолютно оптимальные на классе алгоритмы идентификации допускают упрощение путем замены полной матрицы усиления на скалярную, а градиента средних потерь — на псевдоградиент, а также при использовании дополнительного усреднения в алгоритмах со скалярной матрицей усиления. Это позволяет получить различные модификации алгоритмов, удобные в тех или иных конкретных ситуациях. С другой стороны, возможно распространение абсолютно оптимальных на классе алгоритмов на более общие случаи, охватывающие коррелированные помехи, а также нелинейные объекты. Недавно обнаружена еще одна возможность улучшения оценок при небольшом числе наблюдений, связанная с заменой фишеровской информации в матрице усиления ее простейшей оценкой. Это делает оценку матрицы усиления зависимой от невязки и благодаря этому замедляет убывание компонент этой матрицы с ростом числа наблюдений. Дальнейшее улучшение оценок также и в асимптотике может быть достигнуто путем надлежащего выбора входных воздействий, если это допустимо условиями, при которых осуществляется идентификация объекта. Информационная теория идентификации вносит однозначность как в формулировку, так и в решение задачи идентификации динамических объектов. Сейчас уже очевидны некоторые обобщения информационной теории идентификации на случаи идентификации неустойчивого динамического объекта путем охвата его стабилизирующей обратной связью. По-видимому, обратную связь можно использовать и при идентификации неминимально-фазового объекта, устранив тем самым неудобства, вызванные неминимально-фазовостью. Дальнейшее развитие информационной теории идентификации, с одной стороны, состоит в обосновании построения упрощенных прогнозирующих моделей, обеспечивающих минимально возможное для них значение средних потерь и упрощение оптимальных на классе алгоритмов идентификации, а с другой стороны — в распространении идей информационной теории идентификации на более сложные случаи динамических систем с несколькими помехами, как линейных, так и нелинейных. При этом важно охватить случай идентификации динамических систем при наличии помех, не обладающих свойством независимости, которое лежит в основе изложенной выше информационной теории. Информационный подход позволяет также формировать оптимальные и оптимальные на классе алгоритмы идентификации нестационарных динамических систем. В последнем случае форма алгоритмов идентификации зависит от моделей нестационарности, которые могут быть весьма разнообразными. В изложенной информационной теории идентификации рассматривались алгоритмы, которые можно назвать аргументными; они обеспечивают наибольшую скорость сходимости оценок (параметров прогнозирующей модели) к истинным значениям (параметрам динамического объекта). Во многих случаях, однако, нас могут интересовать алгоритмы иного типа — называемые критериальными, — которые должны обеспечивать сходимость средних потерь к минимальным средним потерям; при этом сами оценки могут сходиться к произвольным значениям. В частности, оказалось, что после надлежащего обобщения такие алгоритмы могут применяться для настройки параметров нейронных сетей. Небезынтересно отметить, что до последнего времени использование нейронных сетей было основано на простейших алгоритмах типа алгоритмов стохастической аппроксимации. Применение оптимальных на классе алгоритмов настройки нейронных сетей существенно повышает их эффективность и позволяет осуществить идентификацию сложных нелинейных систем. Алгоритмы идентификации, как аргументные, так и критериальные, являются основой для решения более общей задачи адаптивного управления динамическими объектами, т. е. задачи управления в условиях неопределенности, а также различных задач оптимизации в условиях неполной информации. Очевидно, информационная теория идентификации может сыграть важную роль и в теории адаптивных систем управления. Она позволит не только устранить неоднозначность в выборе алгоритмов адаптации, но и оптимизировать контуры настройки параметров в адаптивных системах. Благодаря этому могут быть созданы не просто адаптивные системы, а адаптивные системы, оптимальные по скорости адаптации. Создание информационной теории идентификации свидетельствует о завершении эпохи поиска алгоритмов идентификации методом «проб и ошибок и наступлении эпохи сознательного формирования оптимальных или оптимальных на классе алгоритмов на основе априорной информации.
|
 |
Оглавление
|