Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
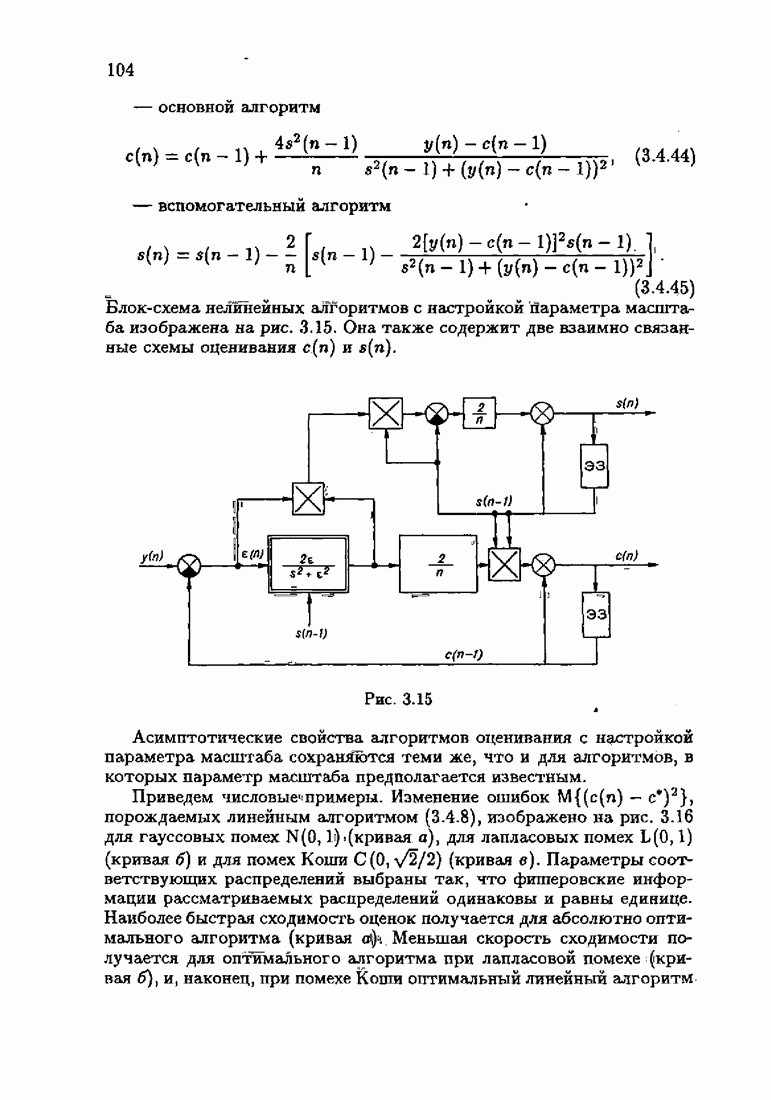
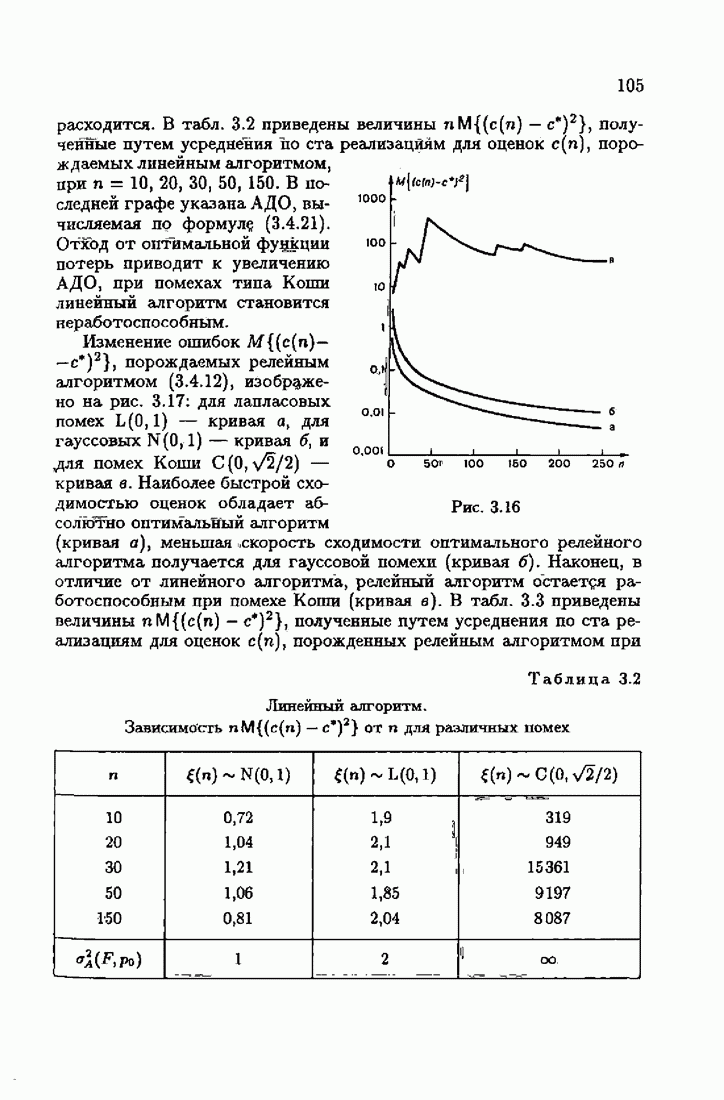
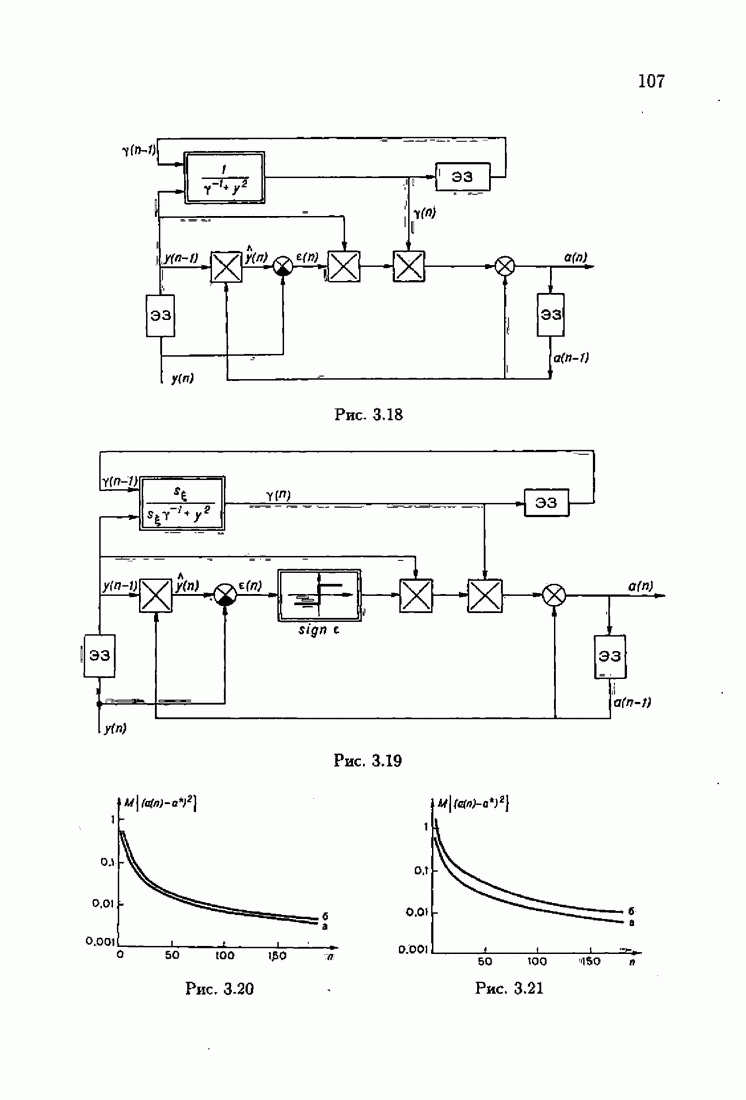
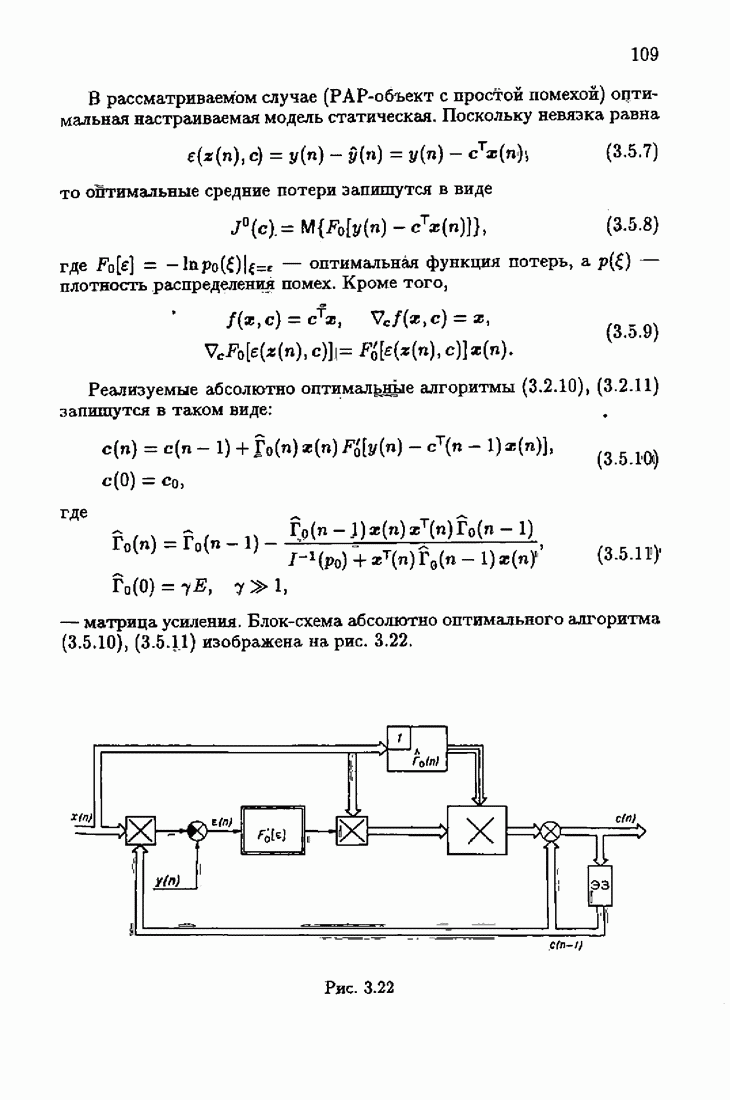
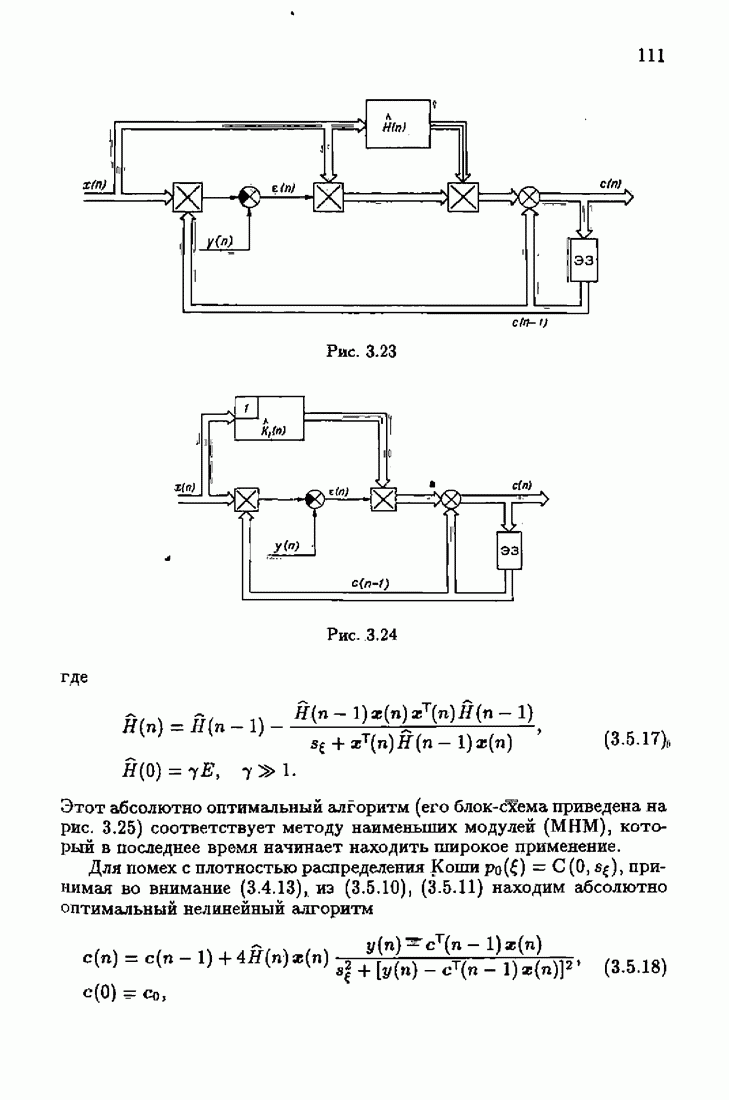
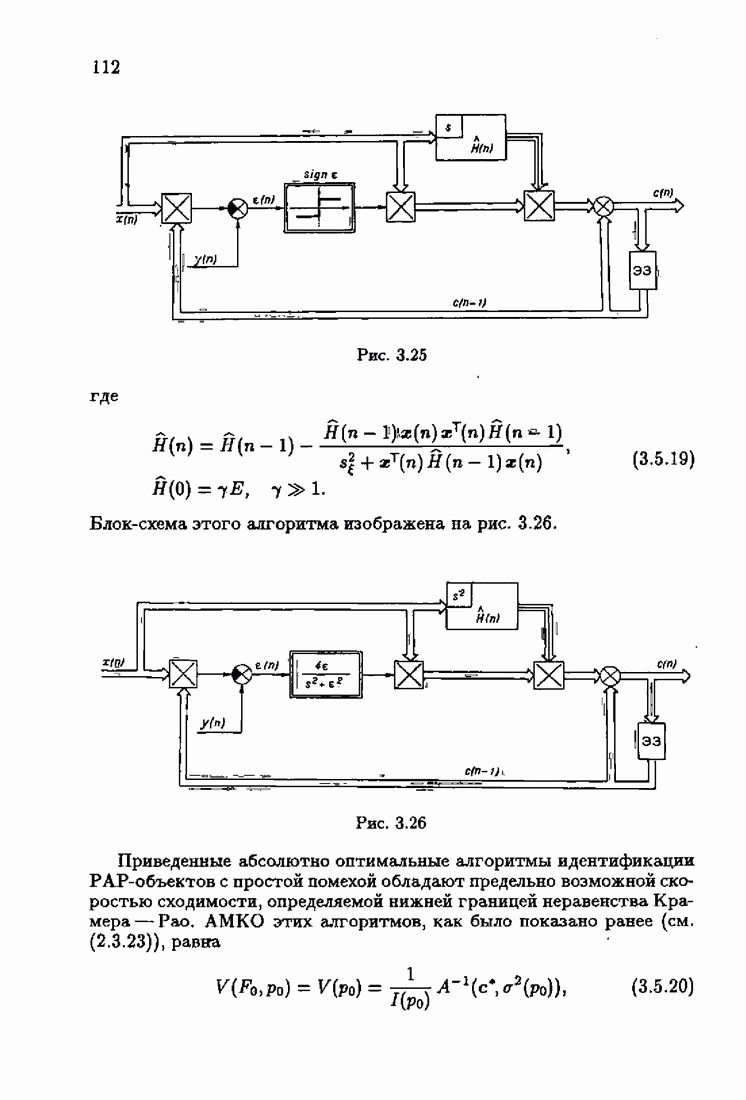
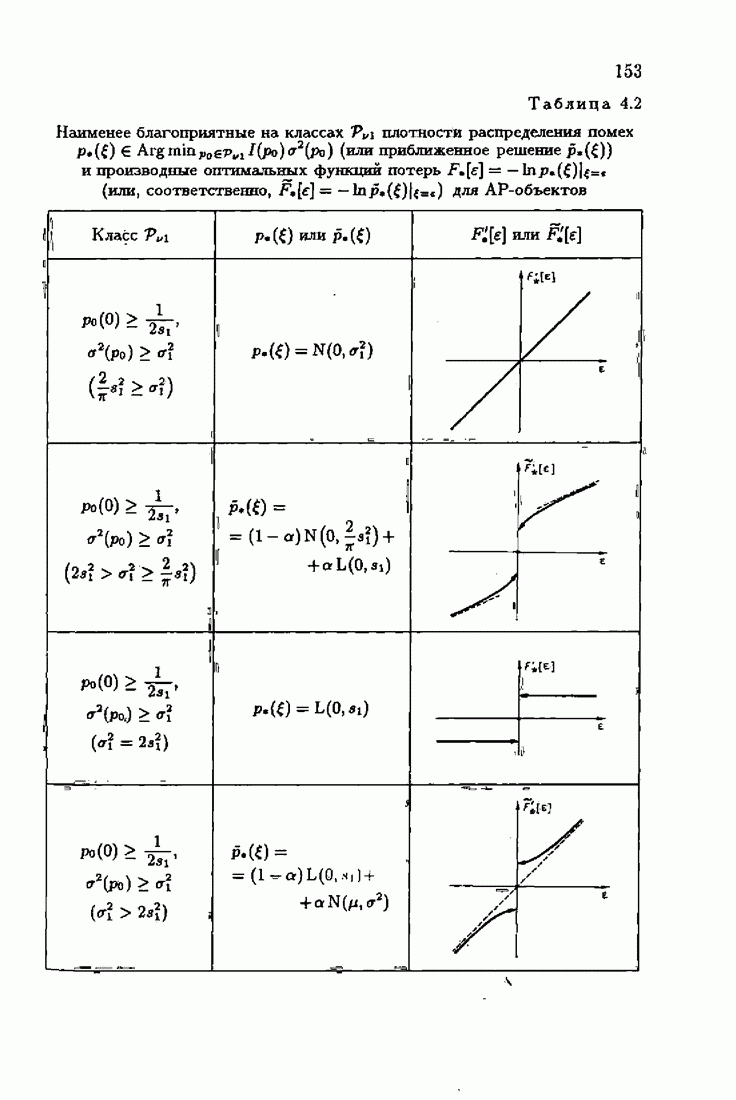
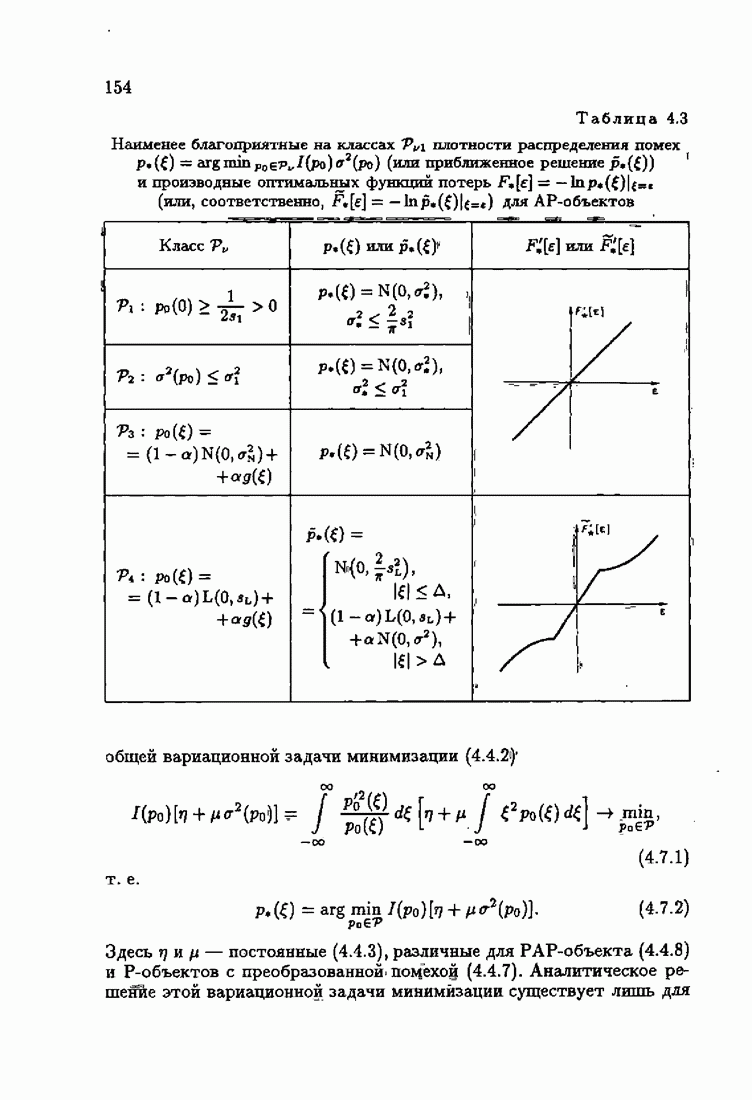
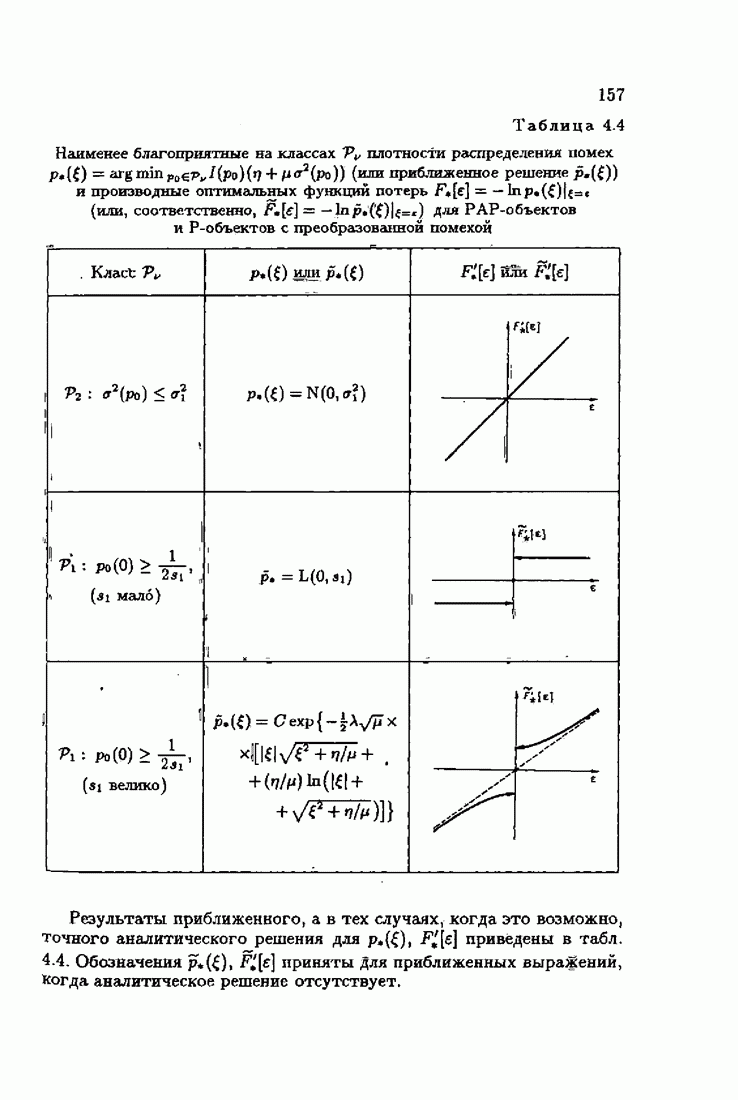
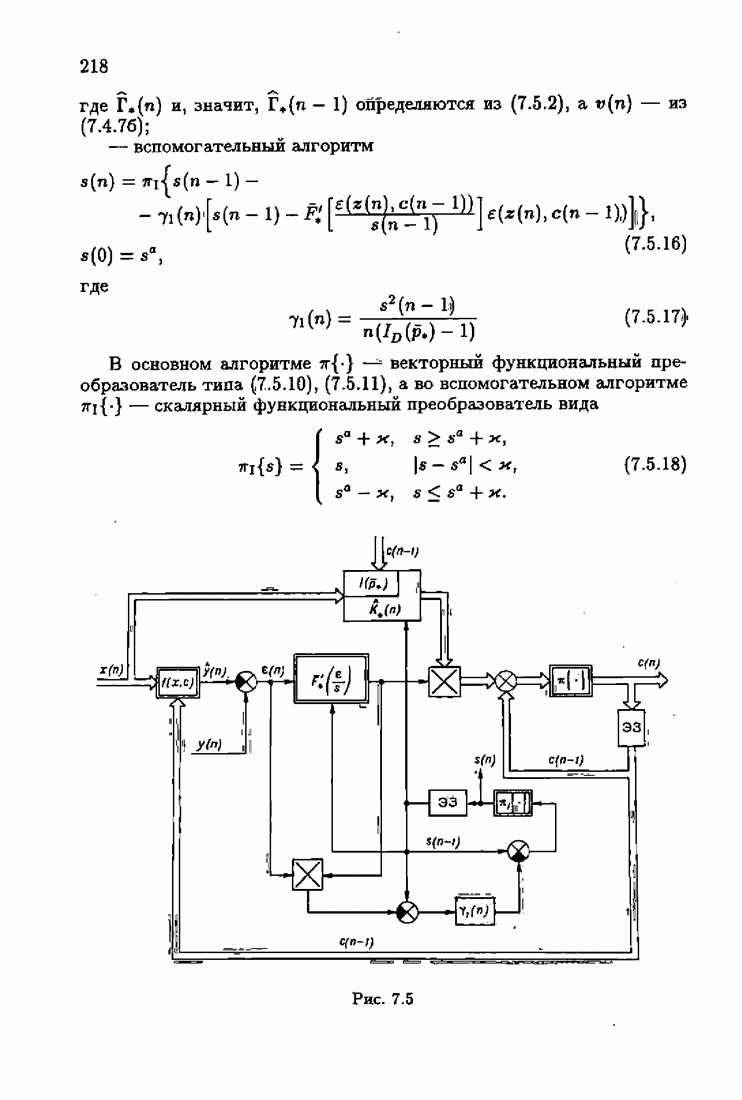
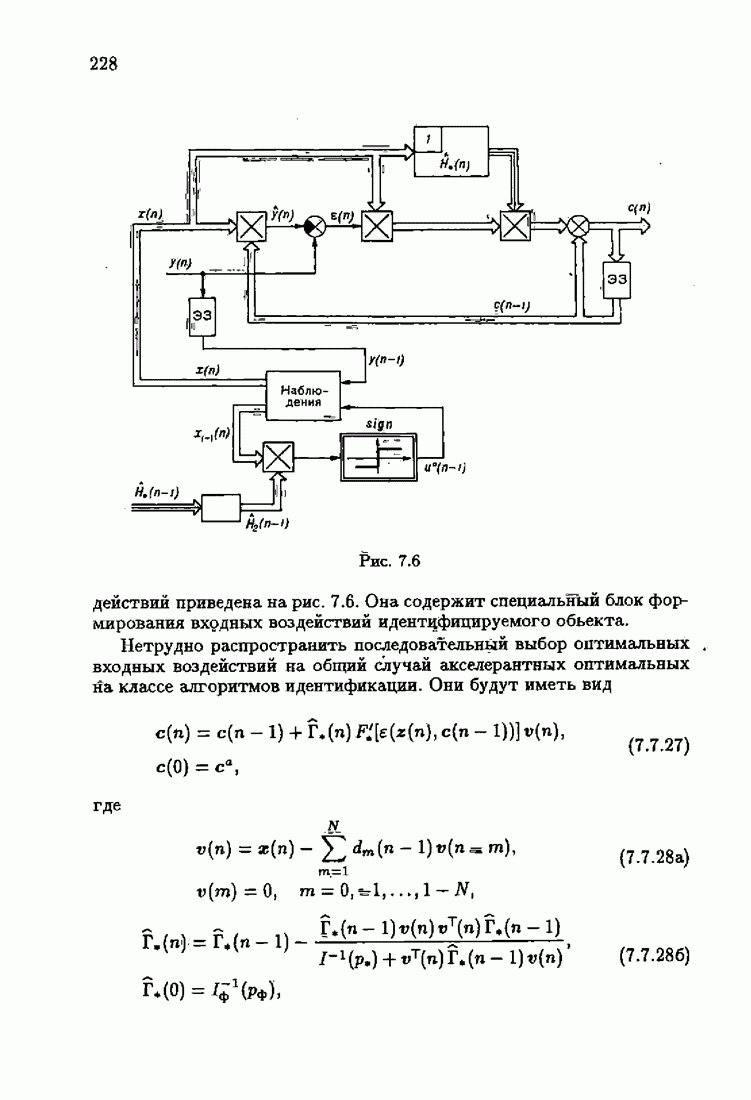
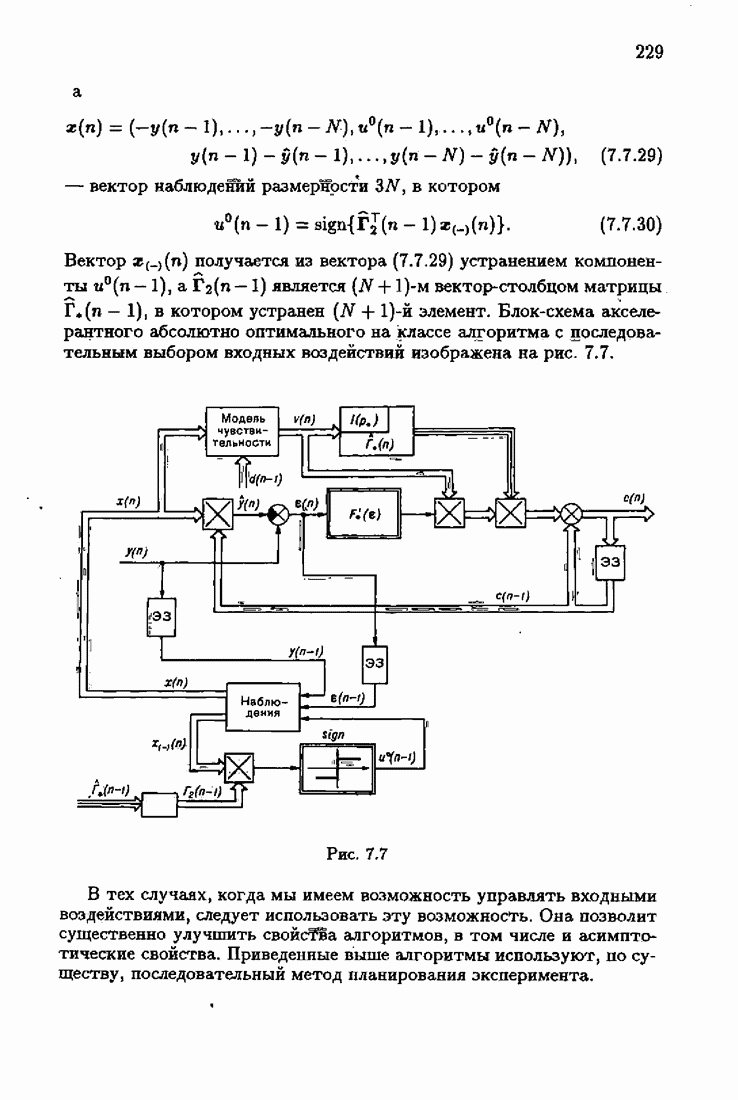
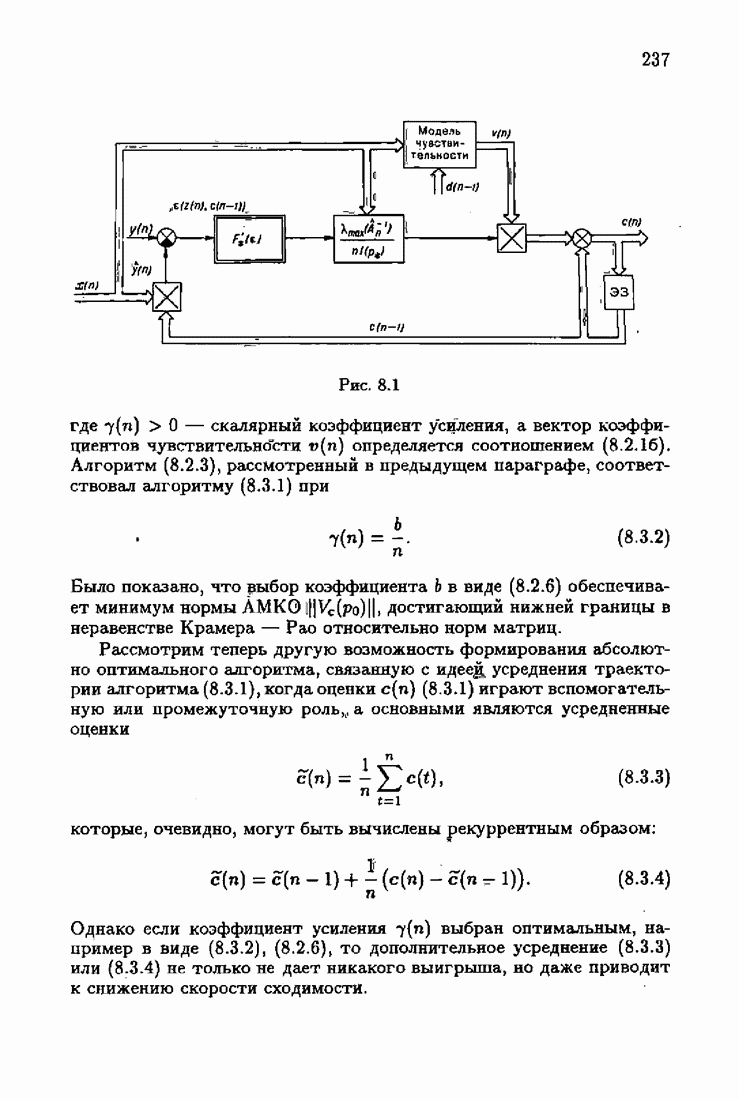
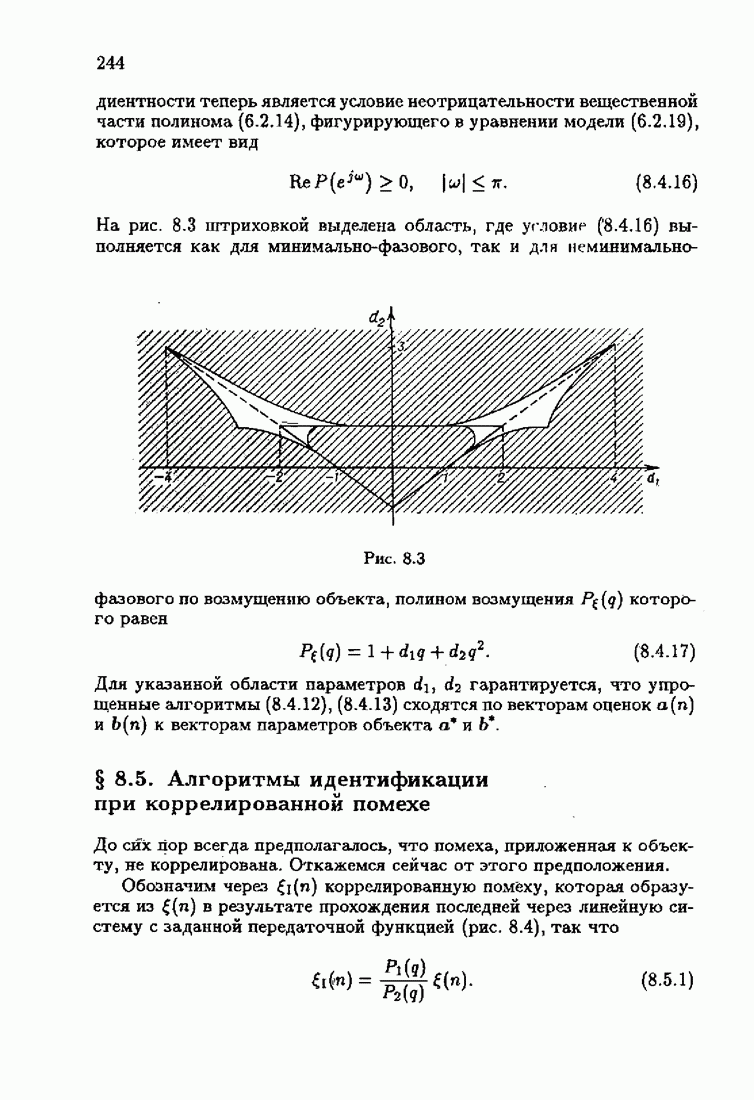
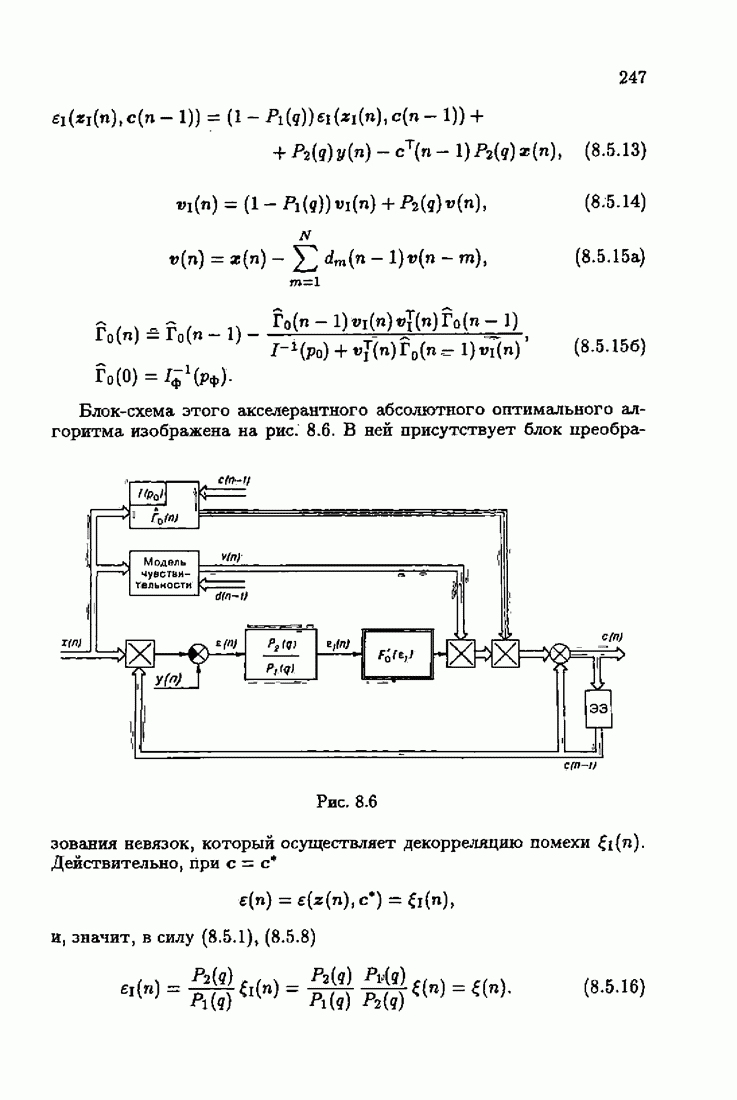
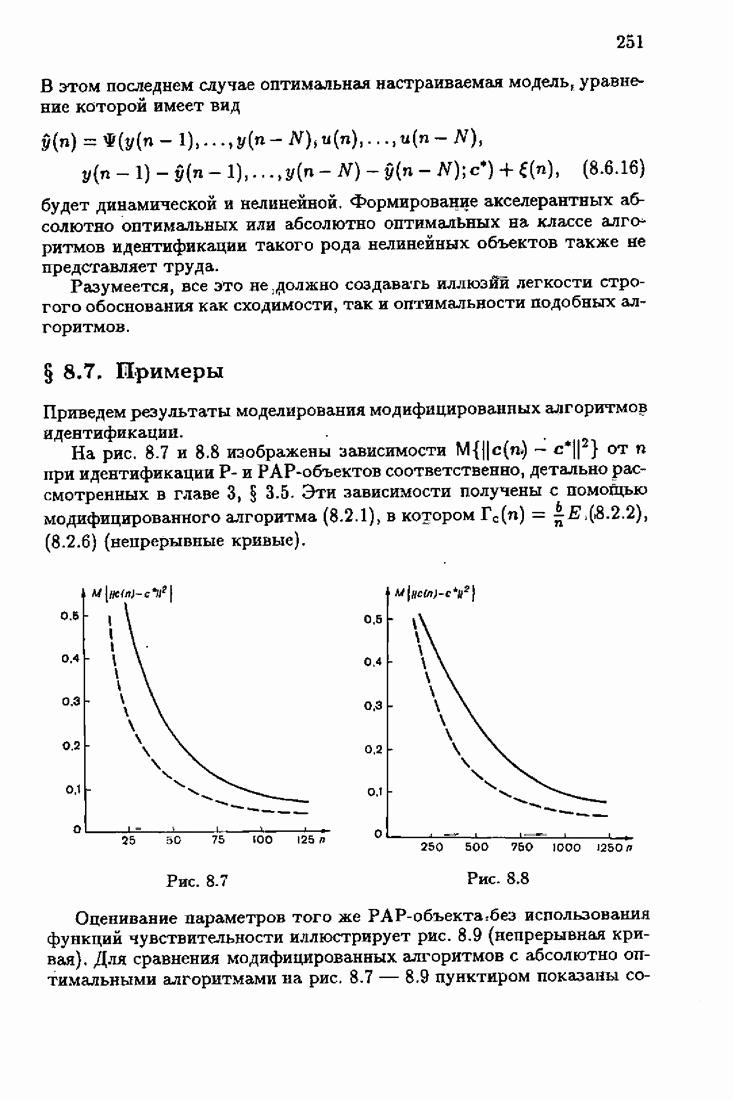
§ 8.8. Еще о возможности акселериэации алгоритмовАкселеризация алгоритмов путем учета априорной информации о решении, как было показано в главе 7, сводилась к определению начальных условий алгоритмов Естественно, чем ближе начальное условие Абсолютно оптимальные алгоритмы идентификации, обладающие предельно возможной асимптотической скоростью сходимости, имеют вид (3.1.15), (3.2.4а), (3.1.16)
где
Для получения реализуемых алгоритмов мы в предыдущих главах широко использовали замену в матрице усиления
что, в частности, приводило к оценке обратной матрицы усиления
Отсюда, в свою очередь, вытекало рекуррентное представление оценки матрицы усиления
Пойдем еще дальше по этому пути. Поскольку, как это видно из (8.8.3), (8.8.4) и (2.5.7),
то, переходя в (8.8.8) от математического ожидания к его эмпирической оценке, получим
Применяя к (8.8.9) формулу обращения матрицы (1.7.18) и заменяя затем
Сопоставляя (8.8.10) и (8.8.7), замечаем, что
Заменяя в (8.8.11) и
Эти абсолютно оптимальные на классе алгоритмы можно также назвать акселерантными. В них матрица усиления зависит от невязки
Отсюда вытекает, что при большой величине невязки, а именно при Разумеется, изложенный путь акселеризации применим не только к абсолютно оптимальным и абсолютно оптимальным на классе алгоритмам, но и к их модификациям, описанным в настоящей главе. Отметим, что замена в рекуррентных формах матрицы усиления (8.8.7) фишеровской информации Рассмотрим простейший пример акселеризации алгоритма оценки среднего значения. Абсолютно оптимальный на классе алгоритм оценки среднего значения, как было показано в § 5-4, может быть записан в виде
где
Из равенства
эквивалентного (8.8.19), вытекает, что
Акселерантный алгоритм получается из (8.8.21) после замены
и
Легко видеть, что при Физический смысл таких акселерантных алгоритмов состоит в том, что благодаря постоянству или даже возрастанию коэффициента усиления на некоторых участках процесса адаптации быстрее устанавливаются асимптотические свойства оценок. При этом устраняется существенное влияние начальных условий.
|
 |
Оглавление
|









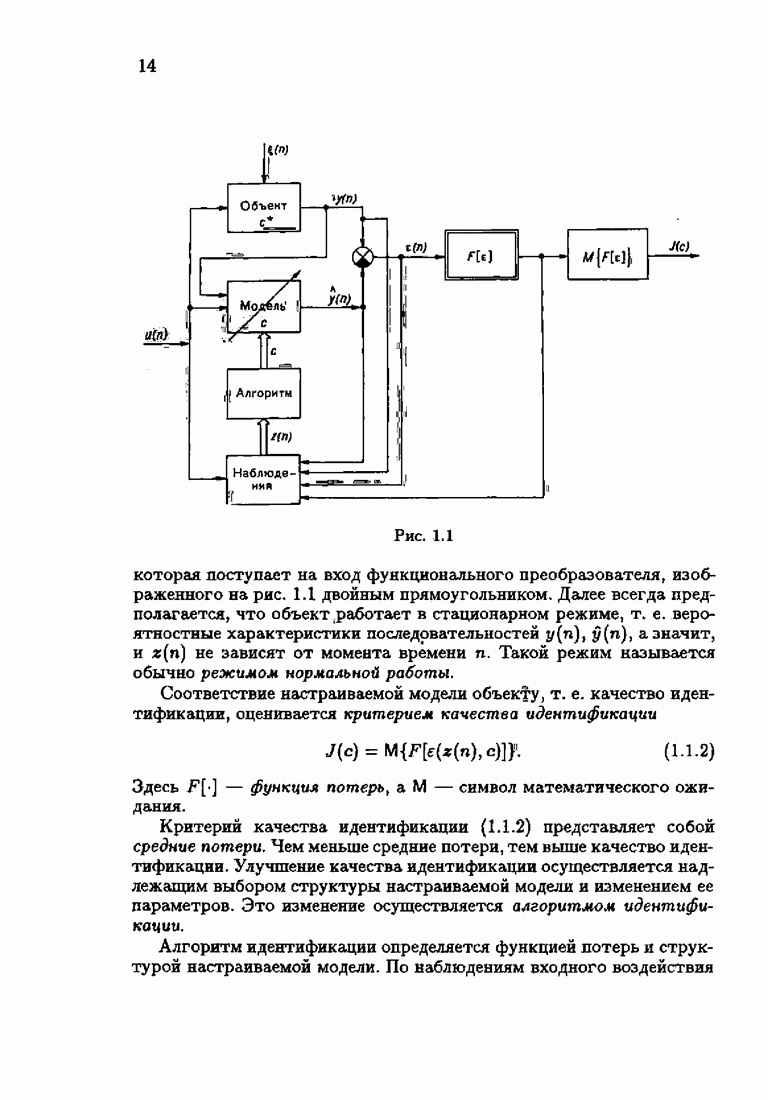
















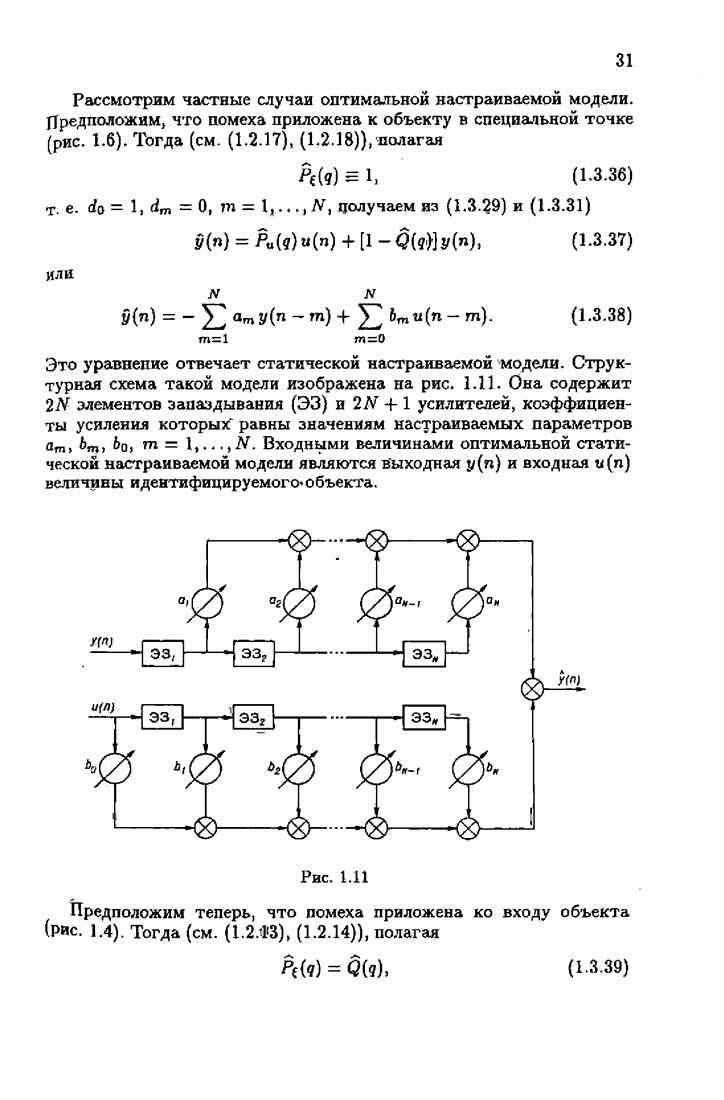
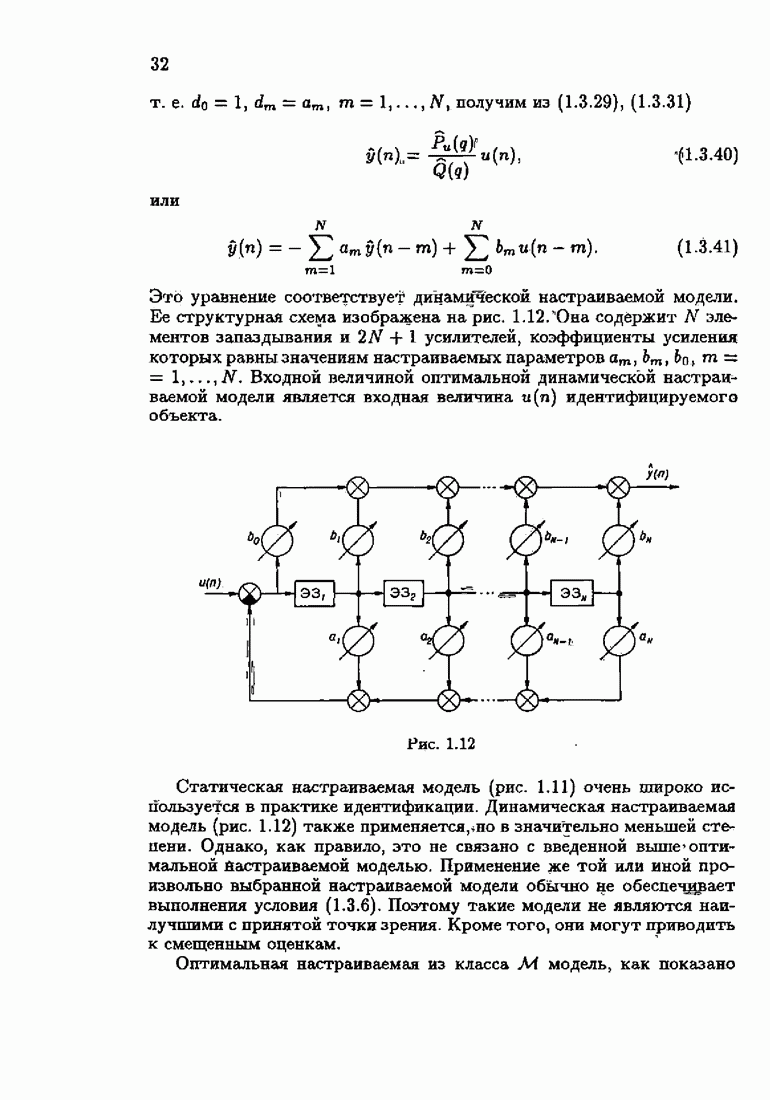






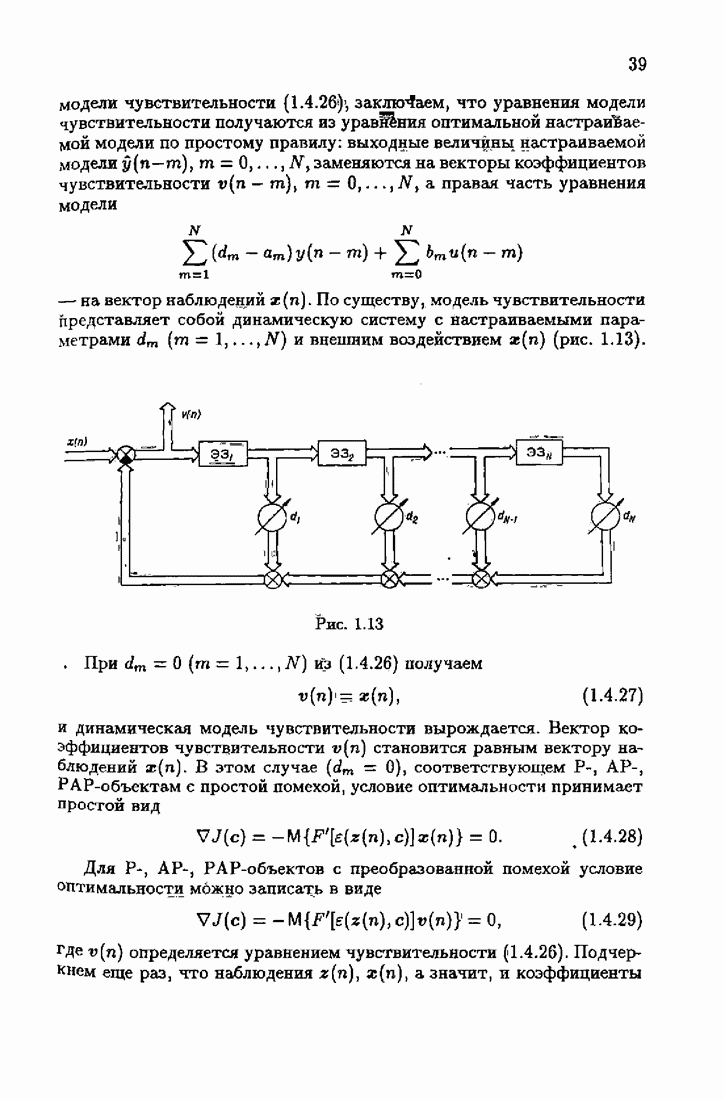













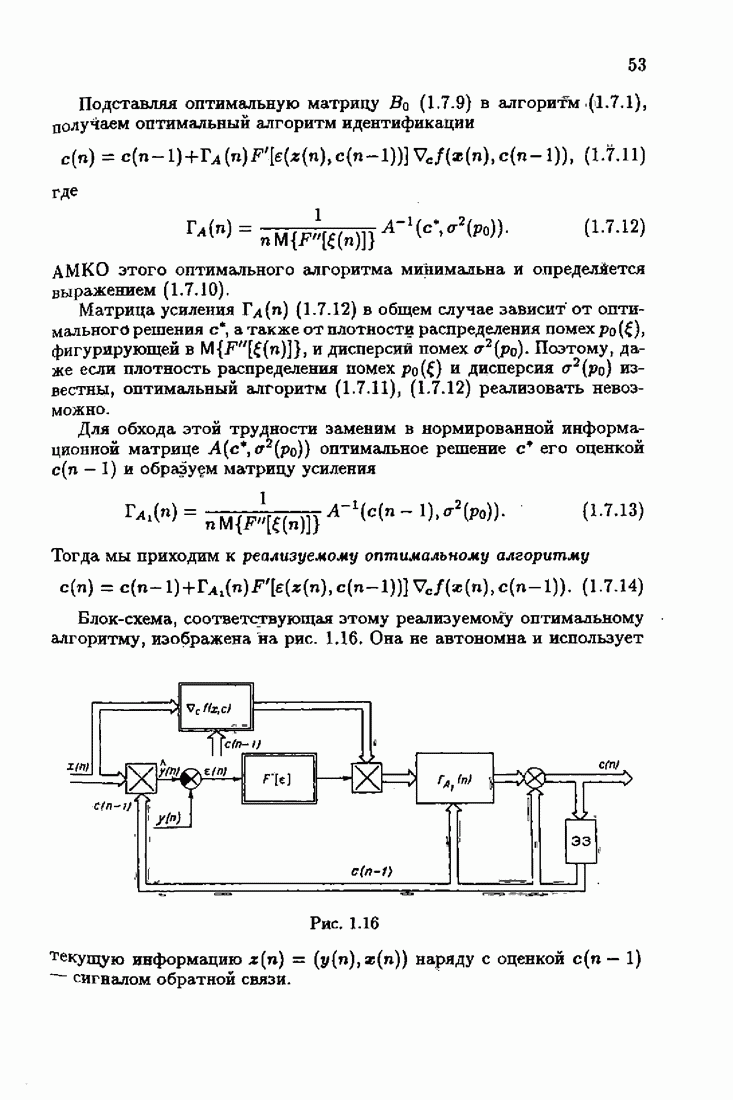















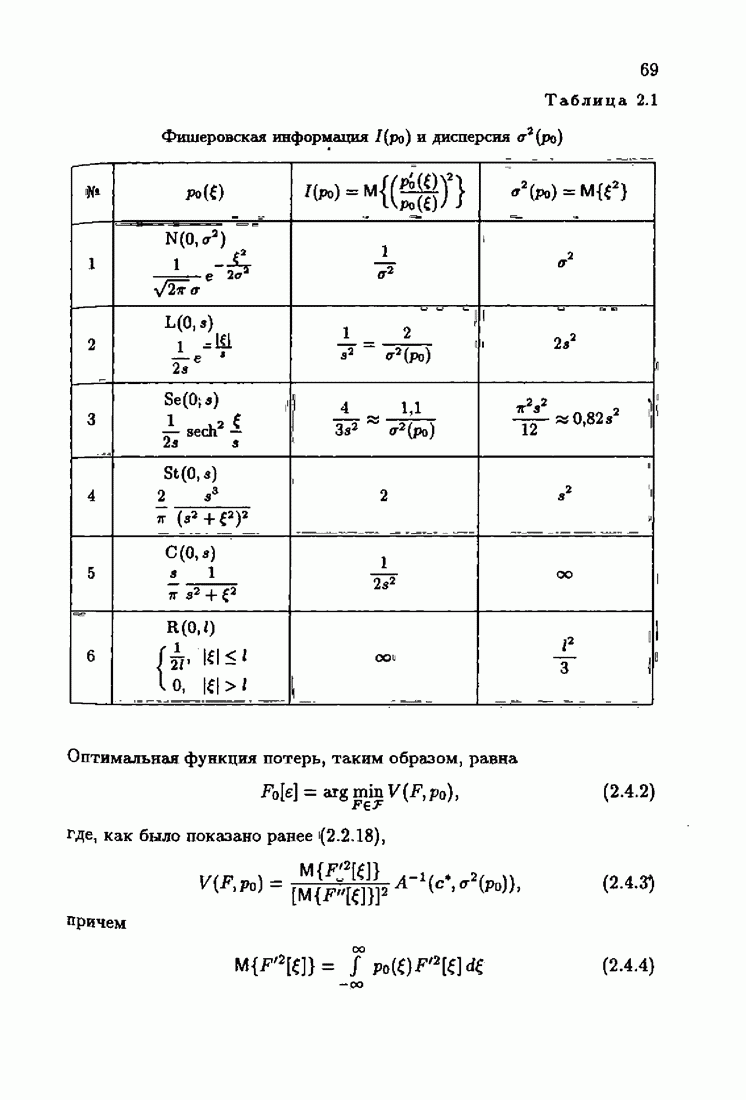



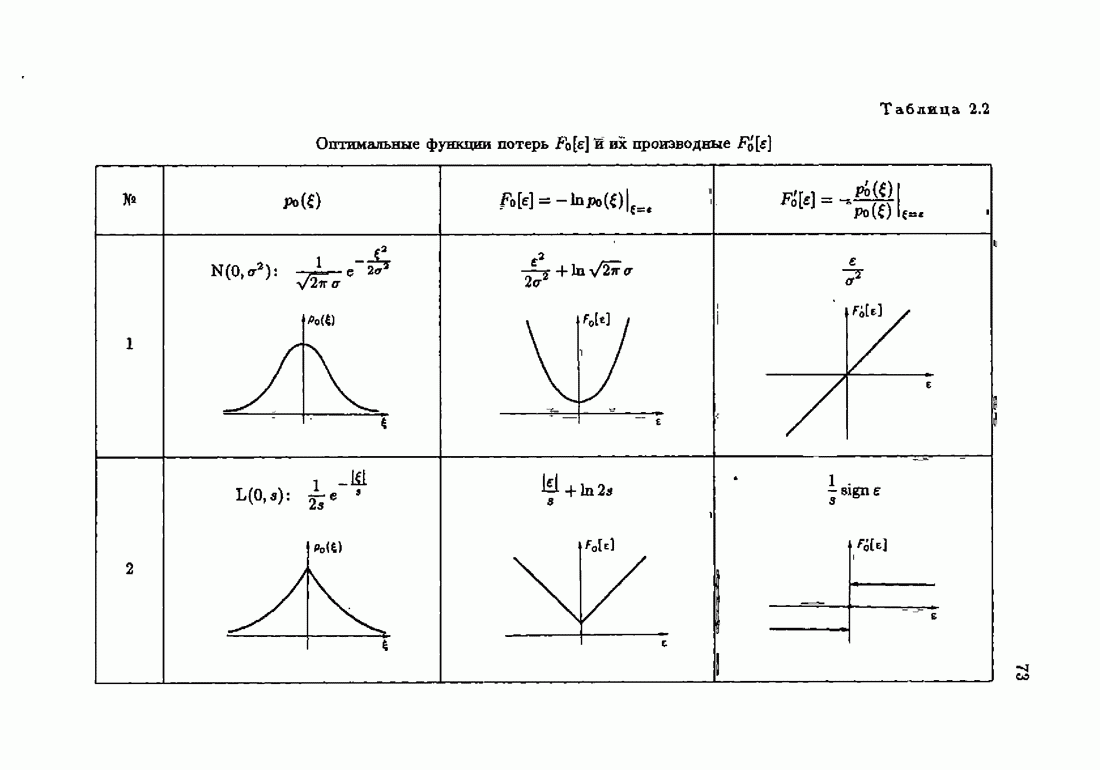
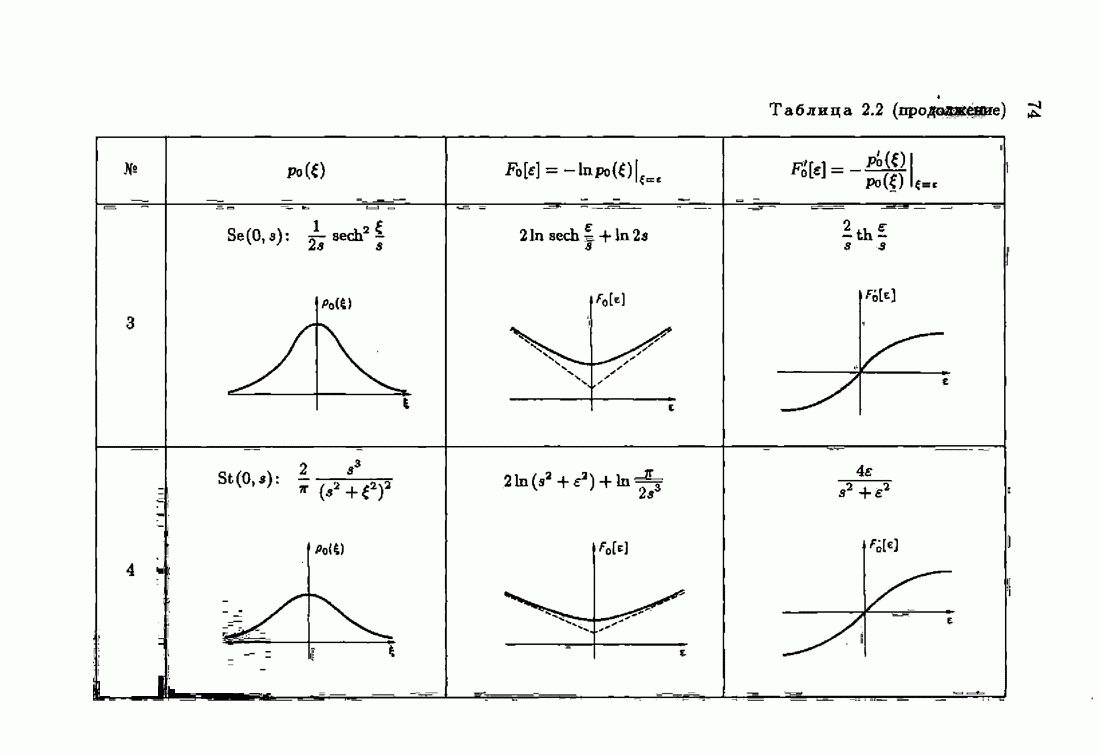
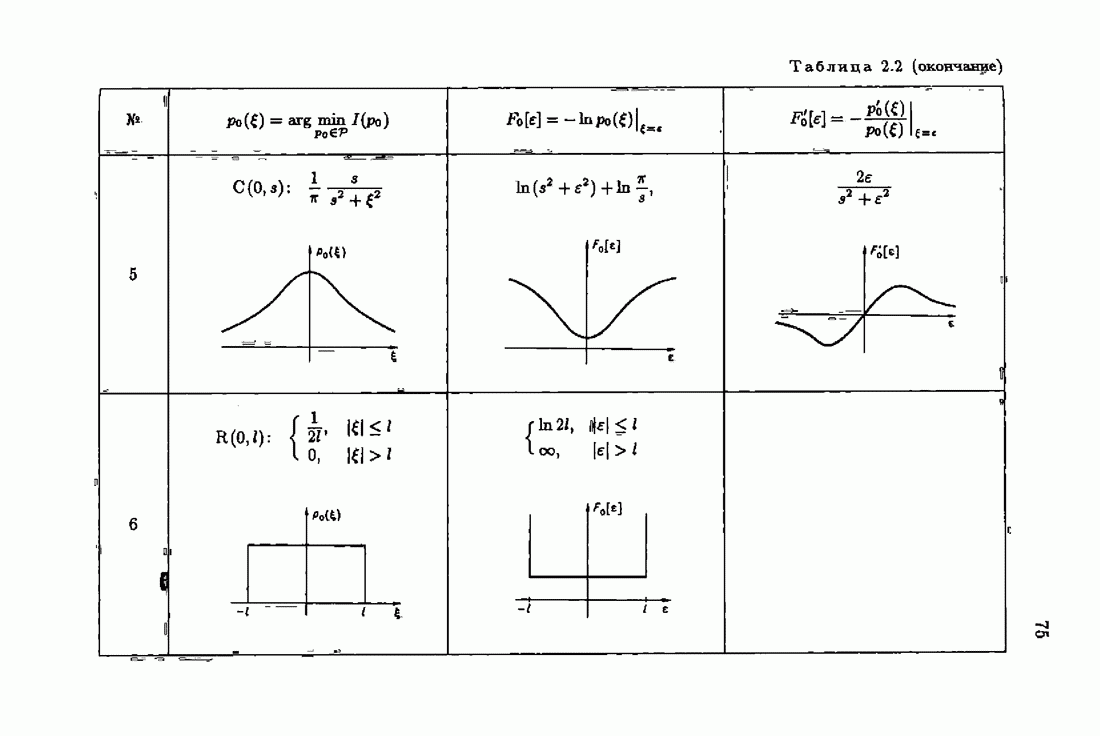








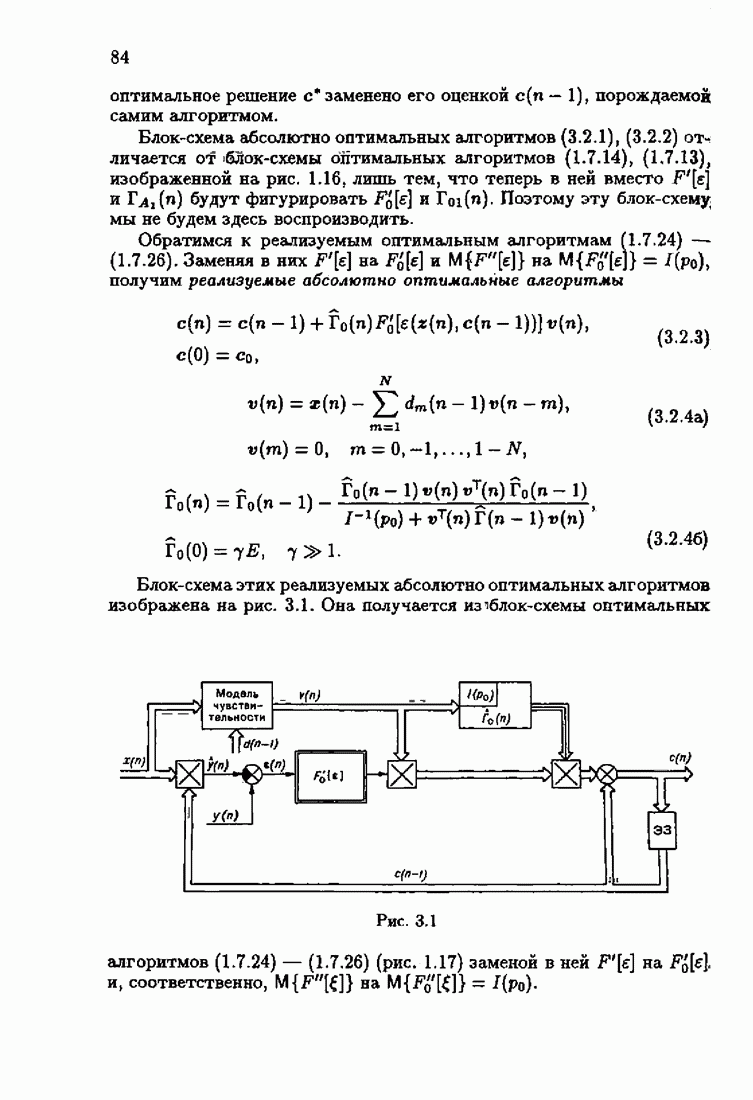
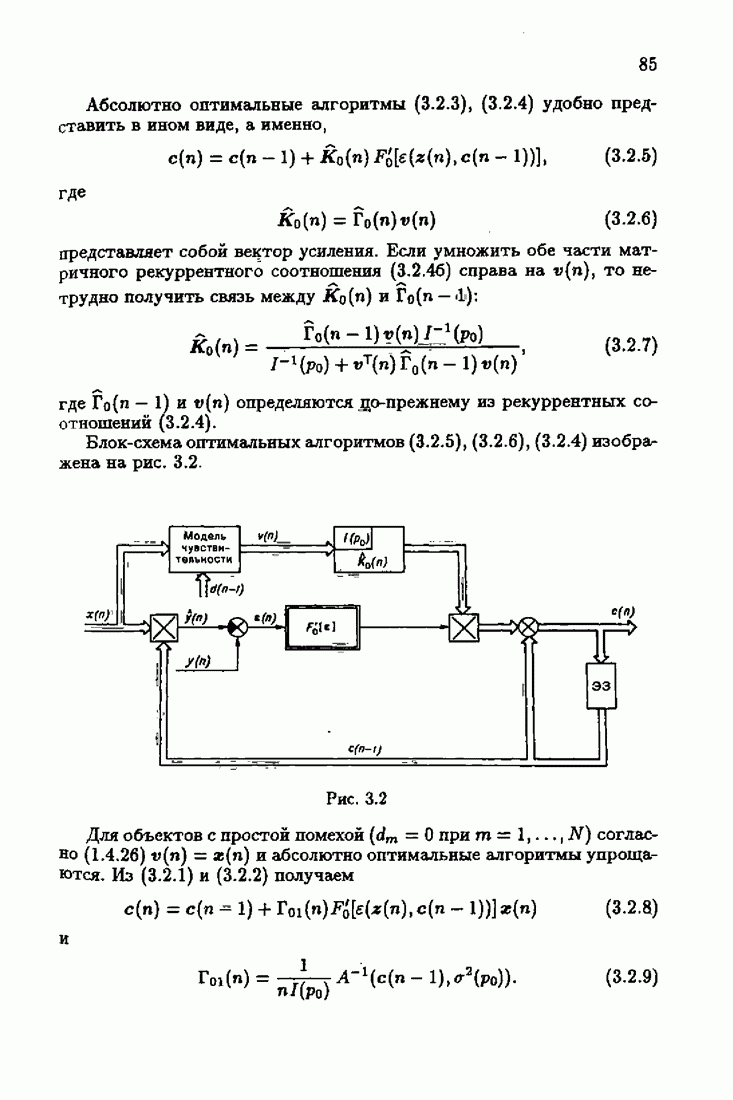
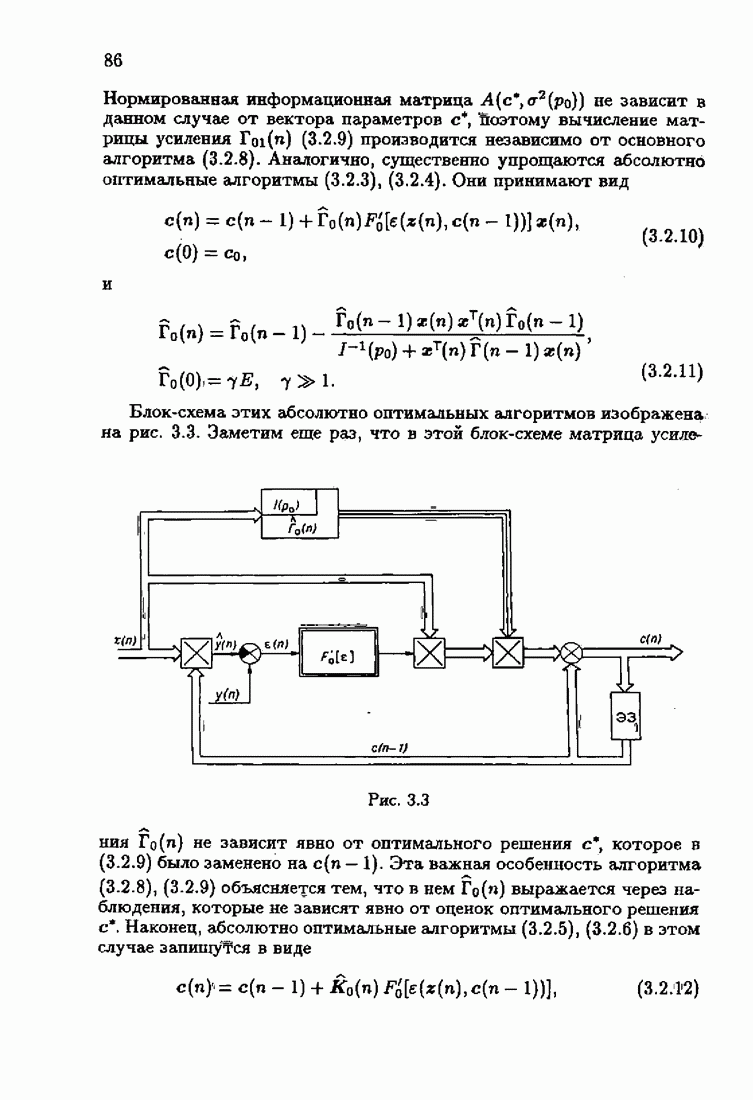
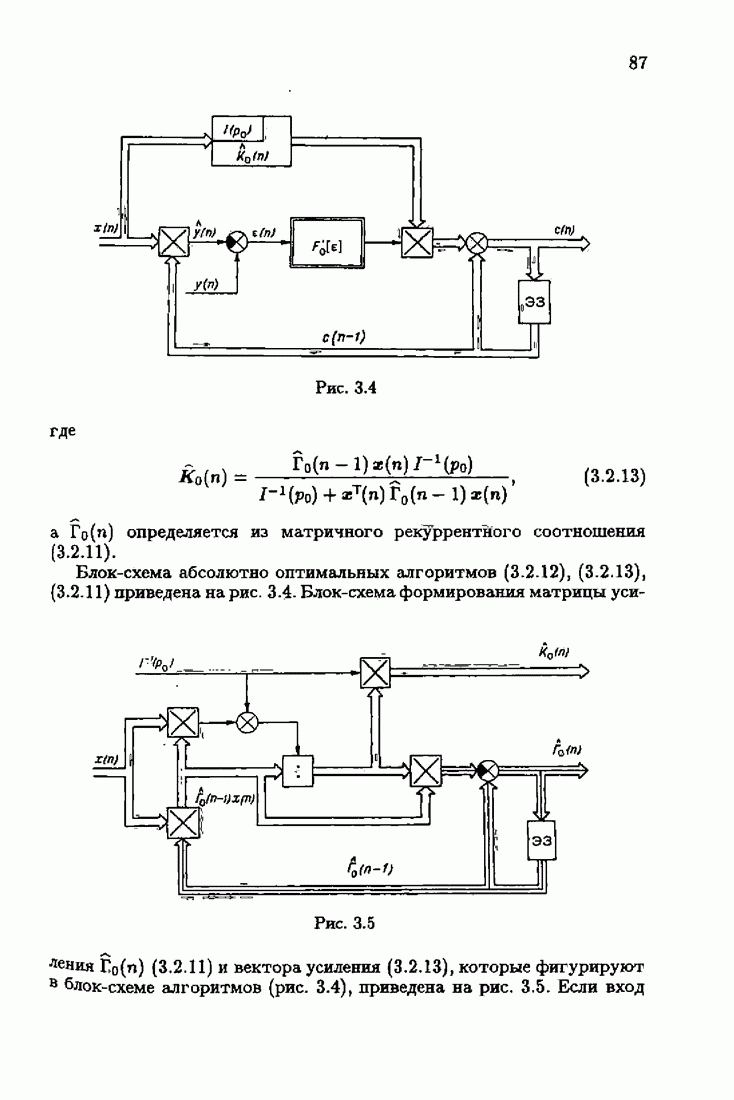




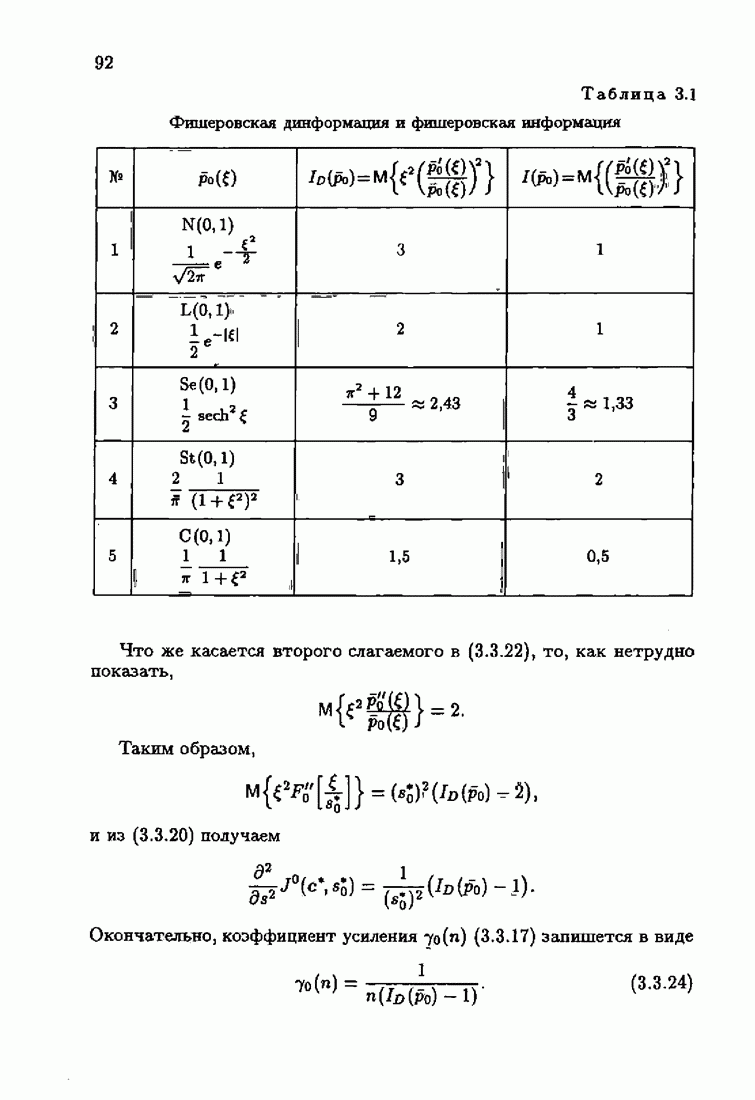
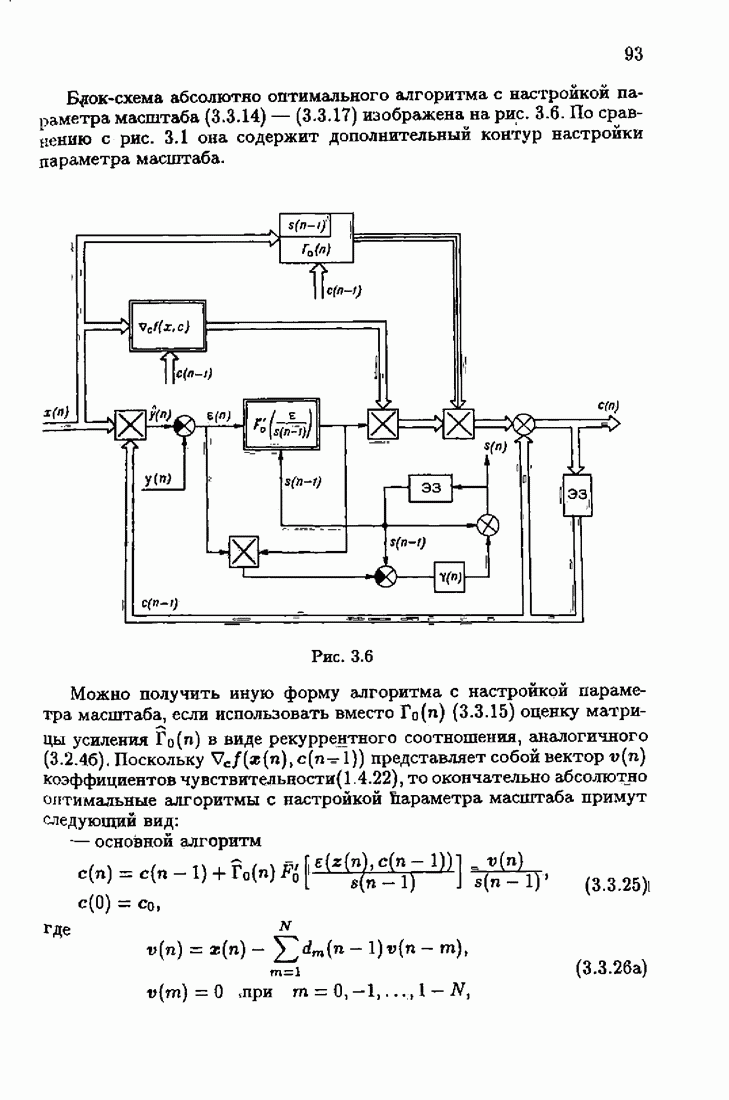
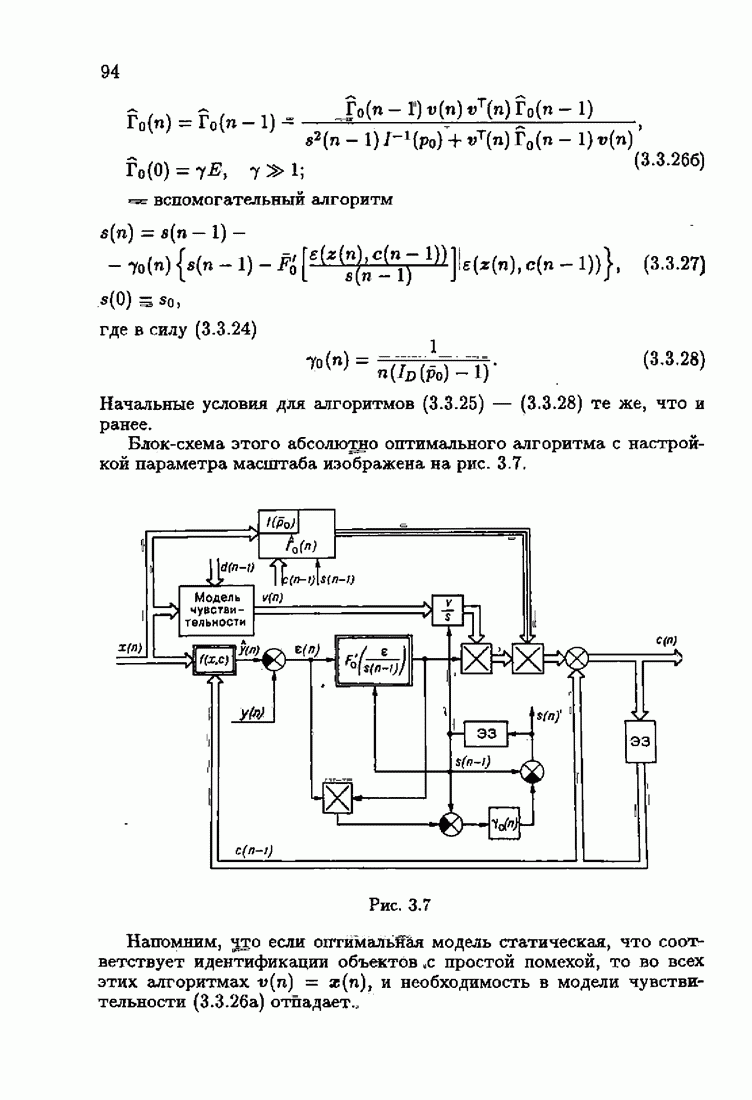


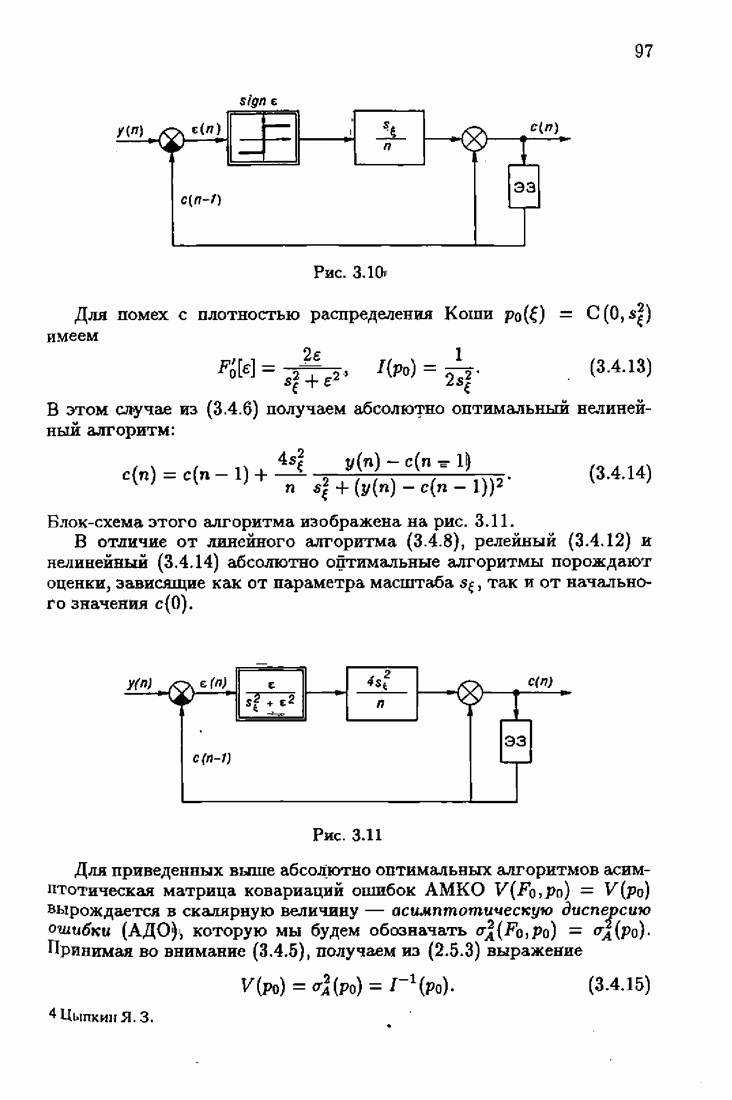



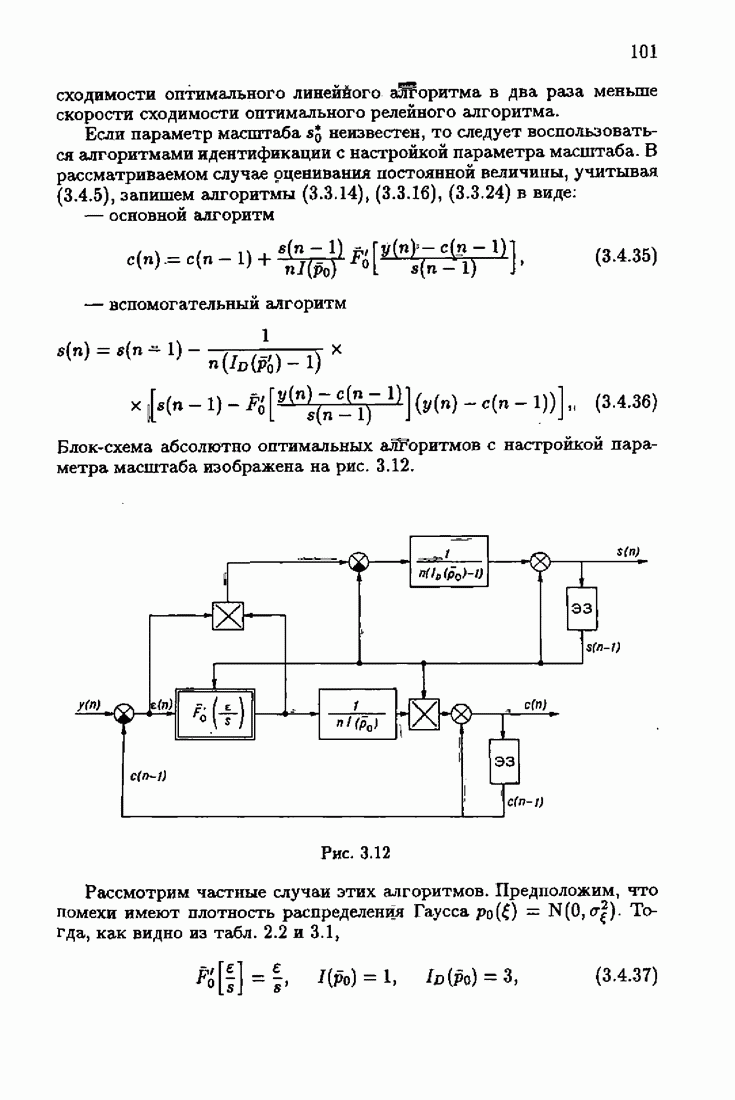
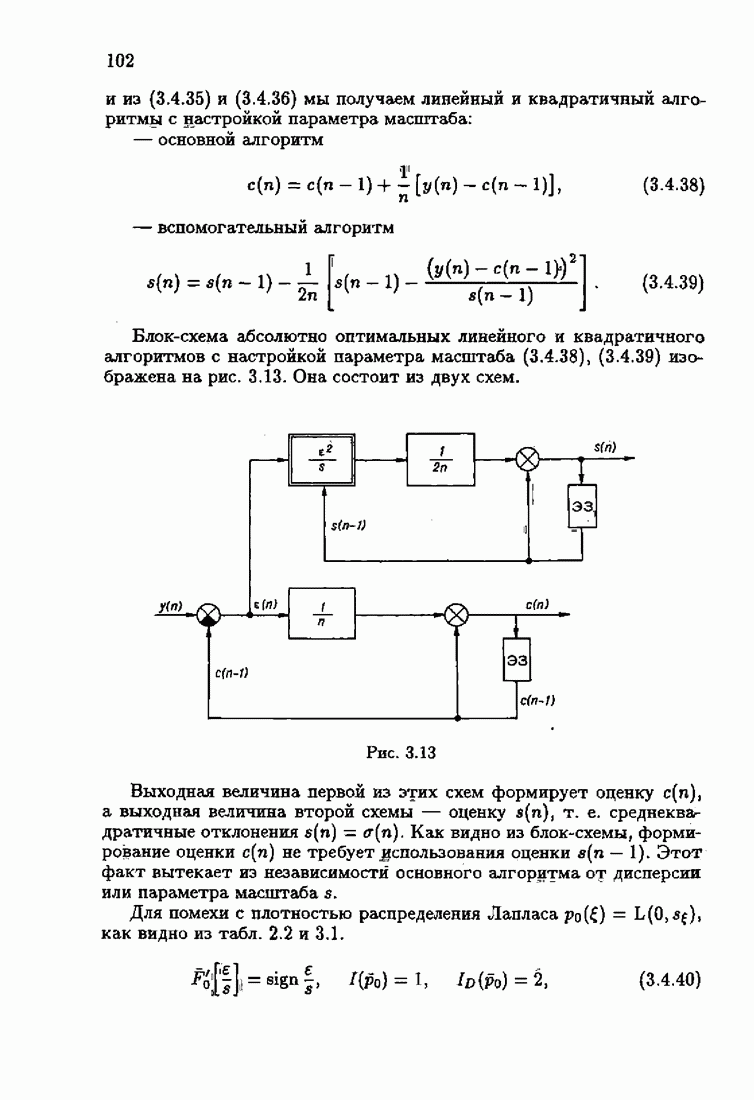
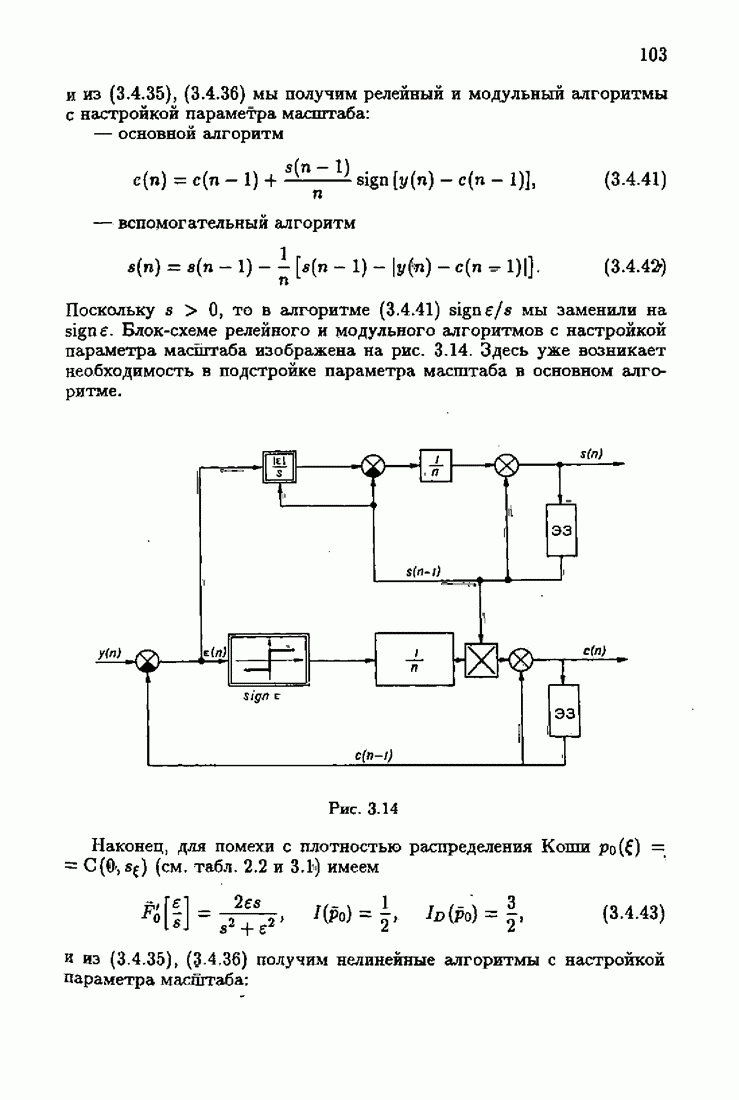






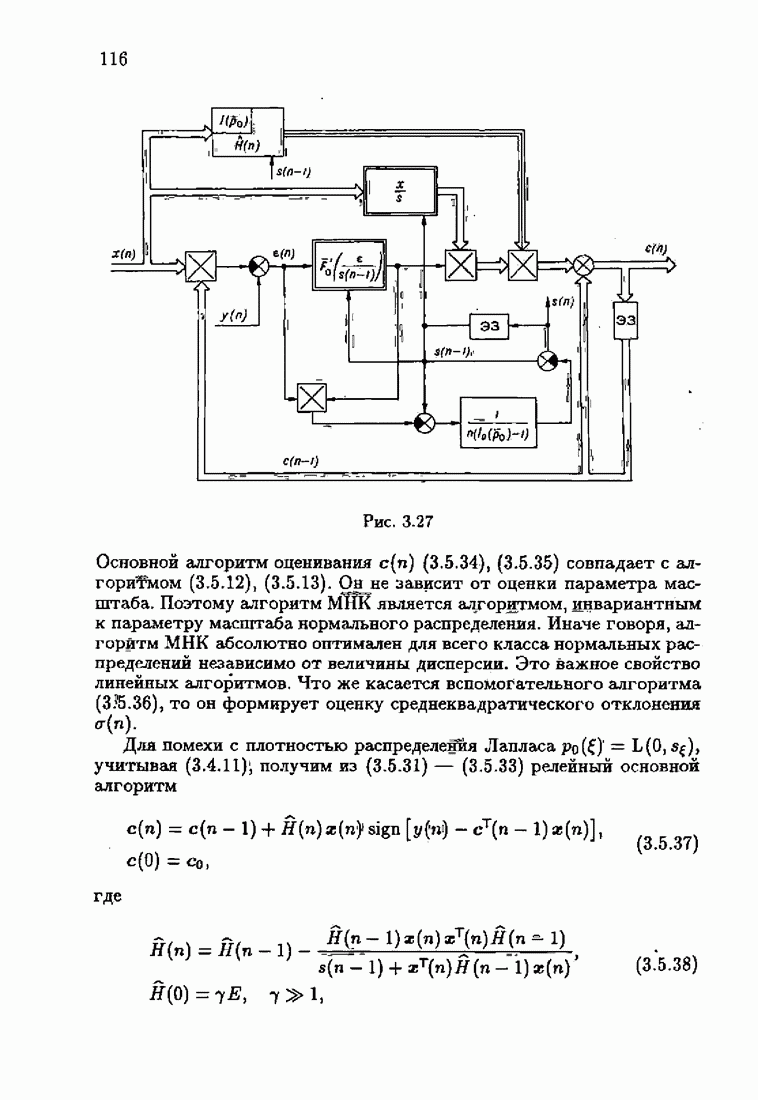
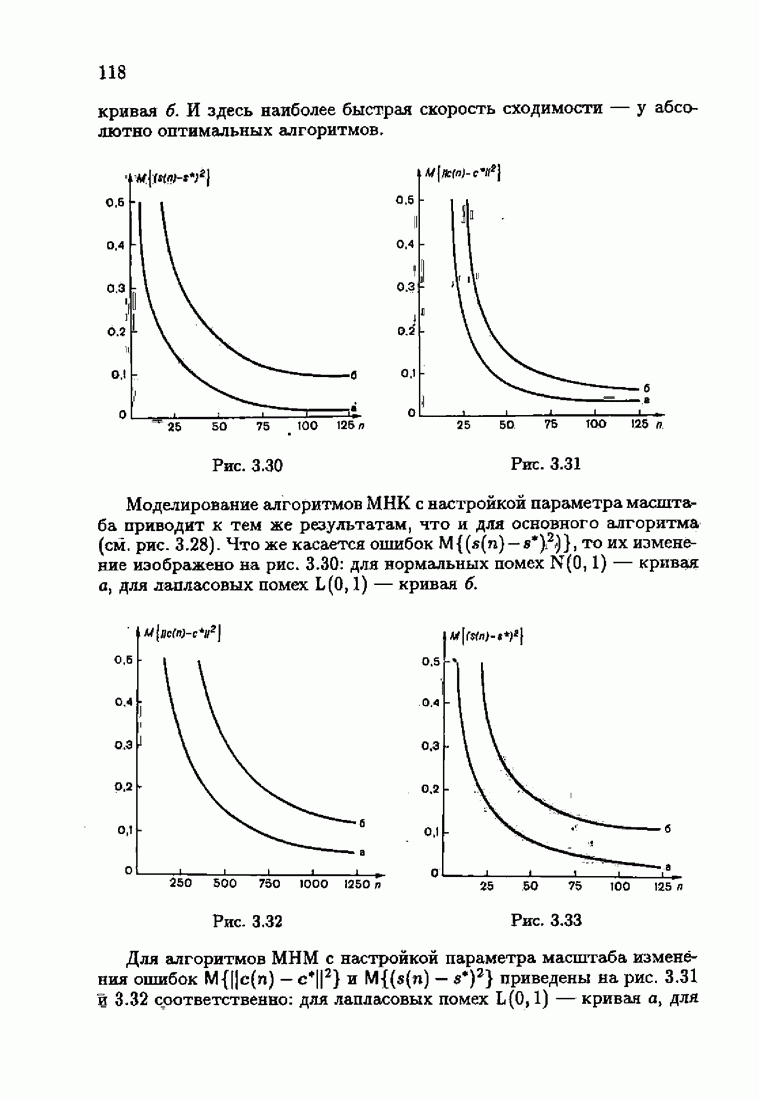












































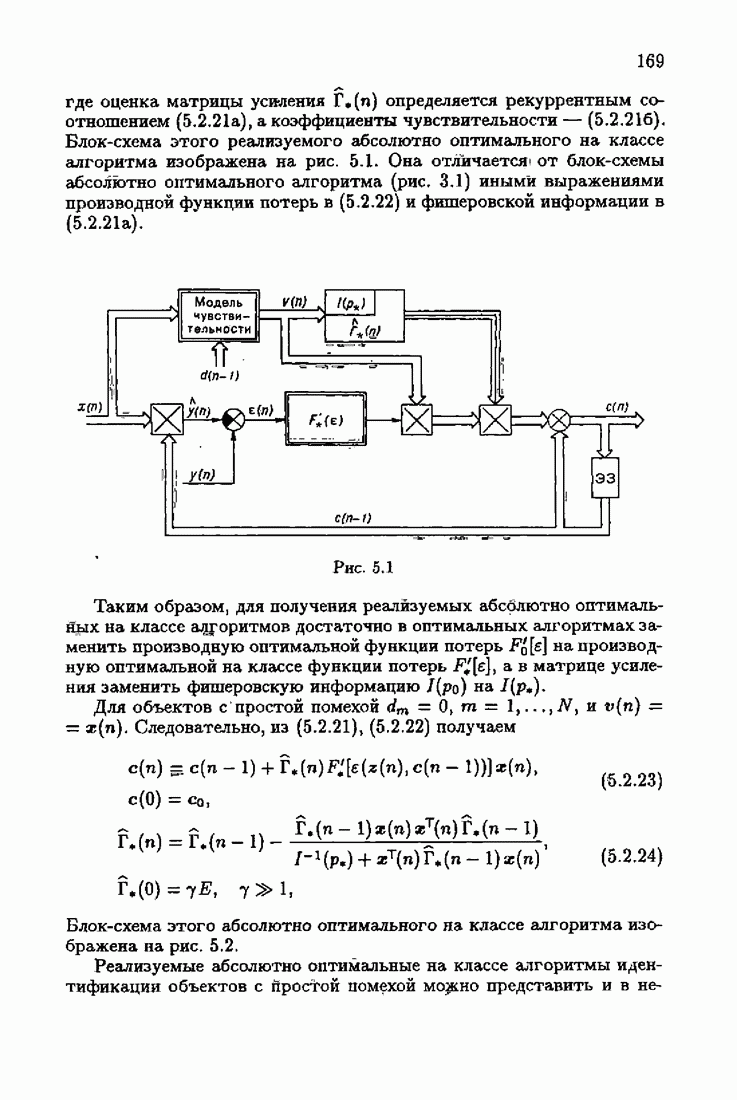
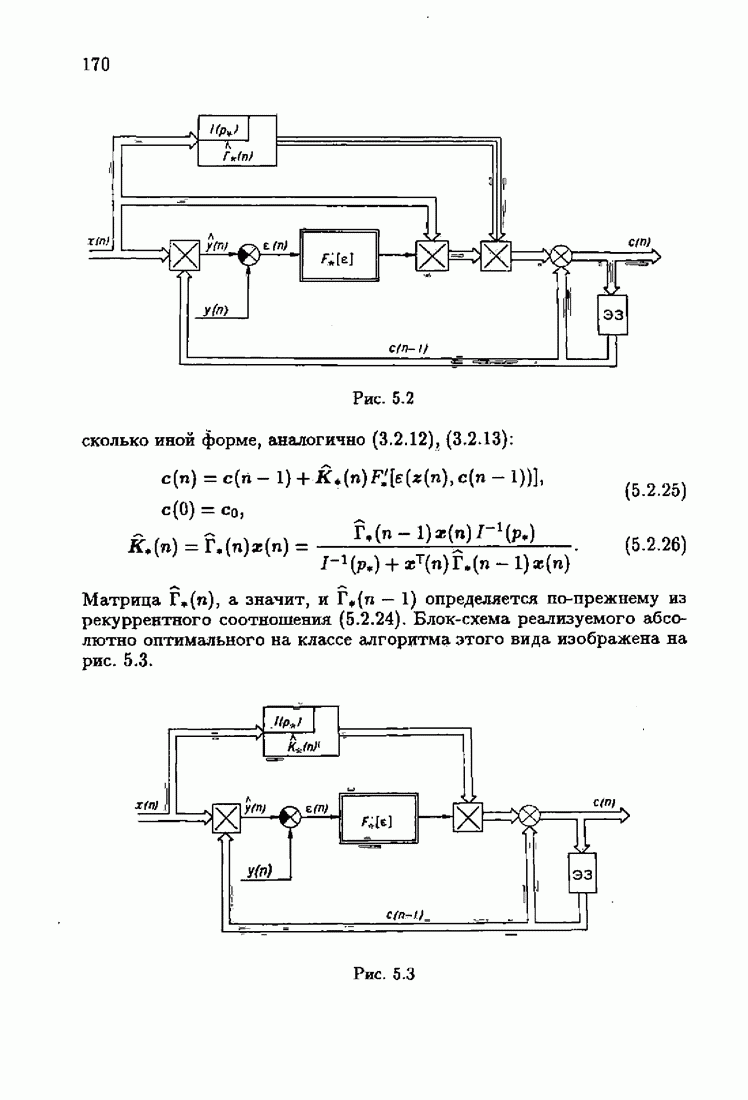

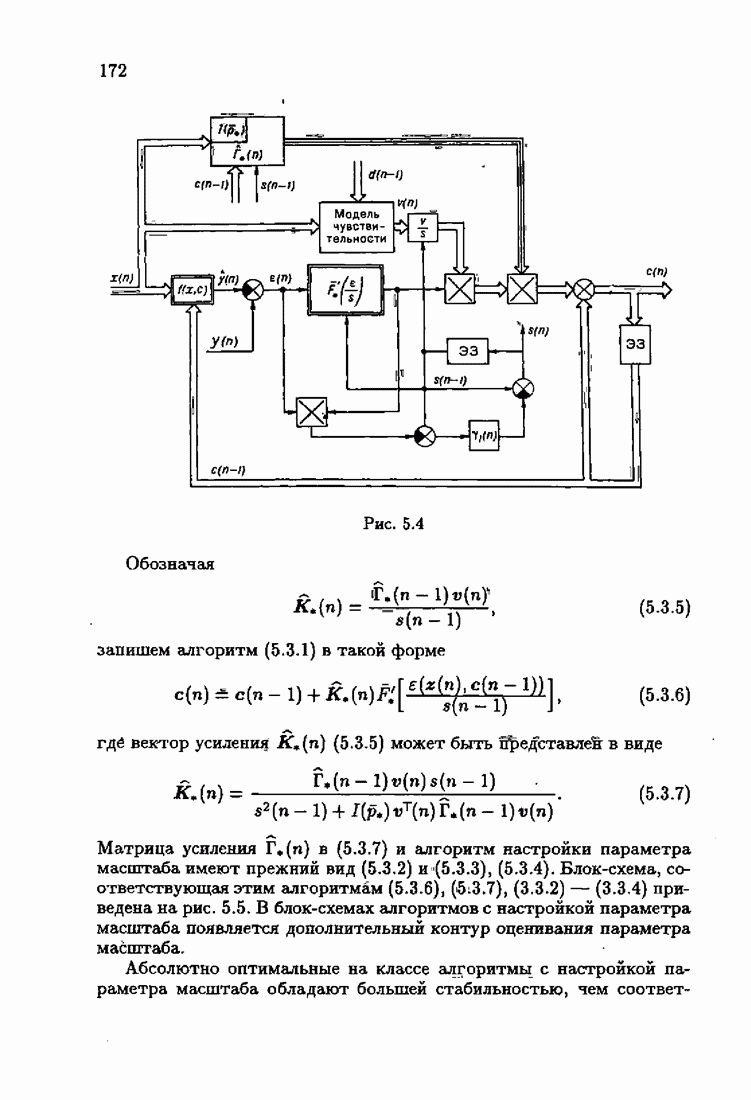
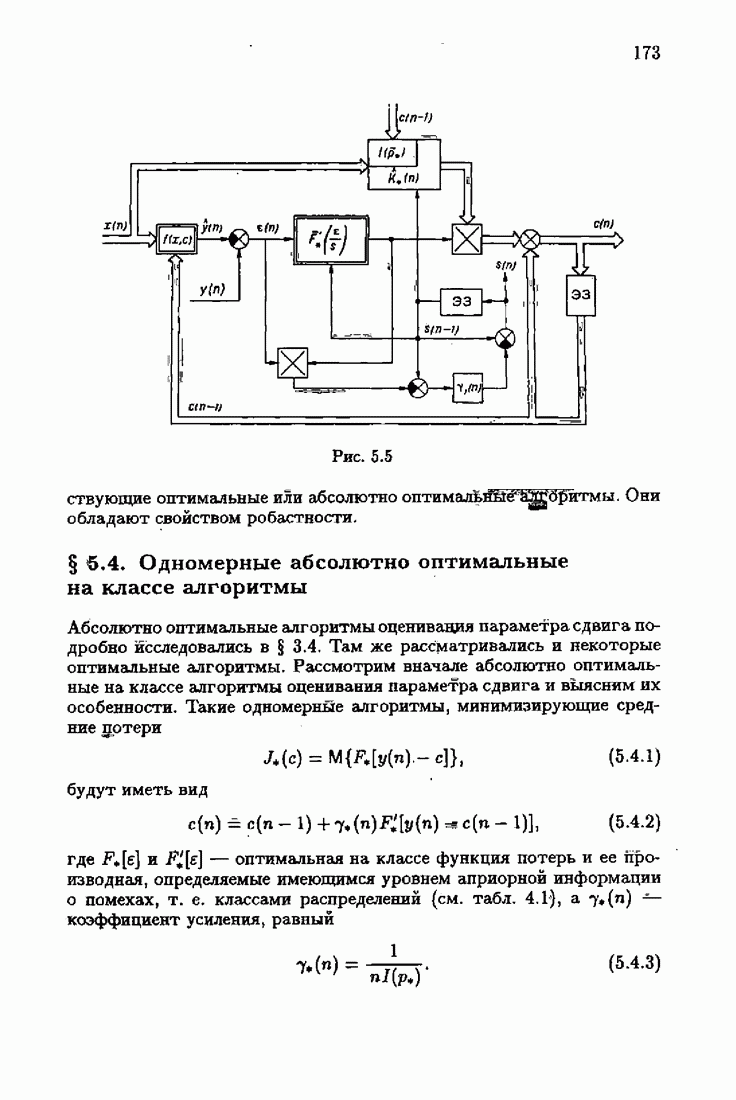




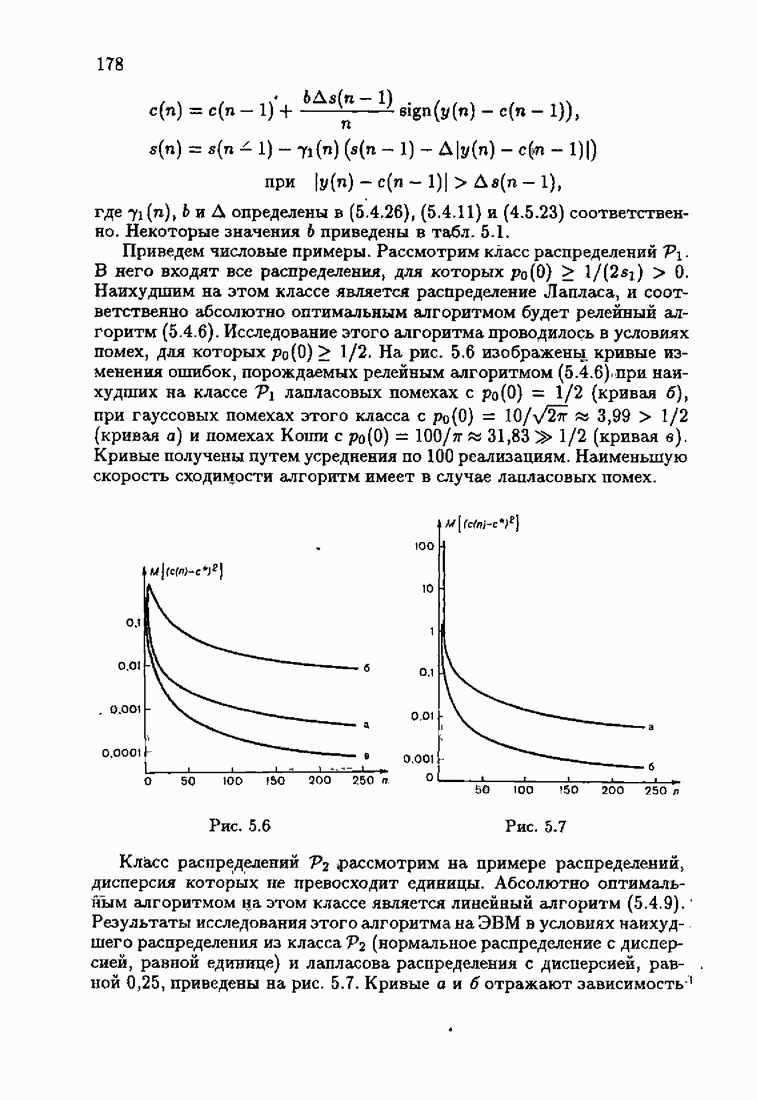
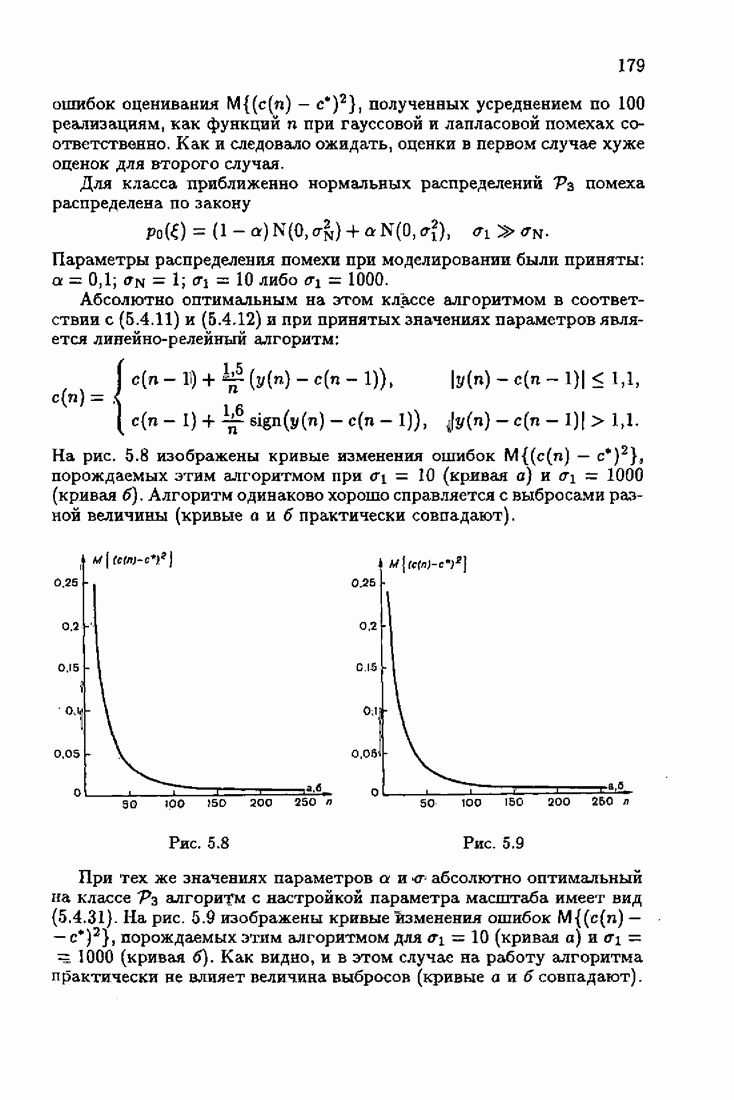
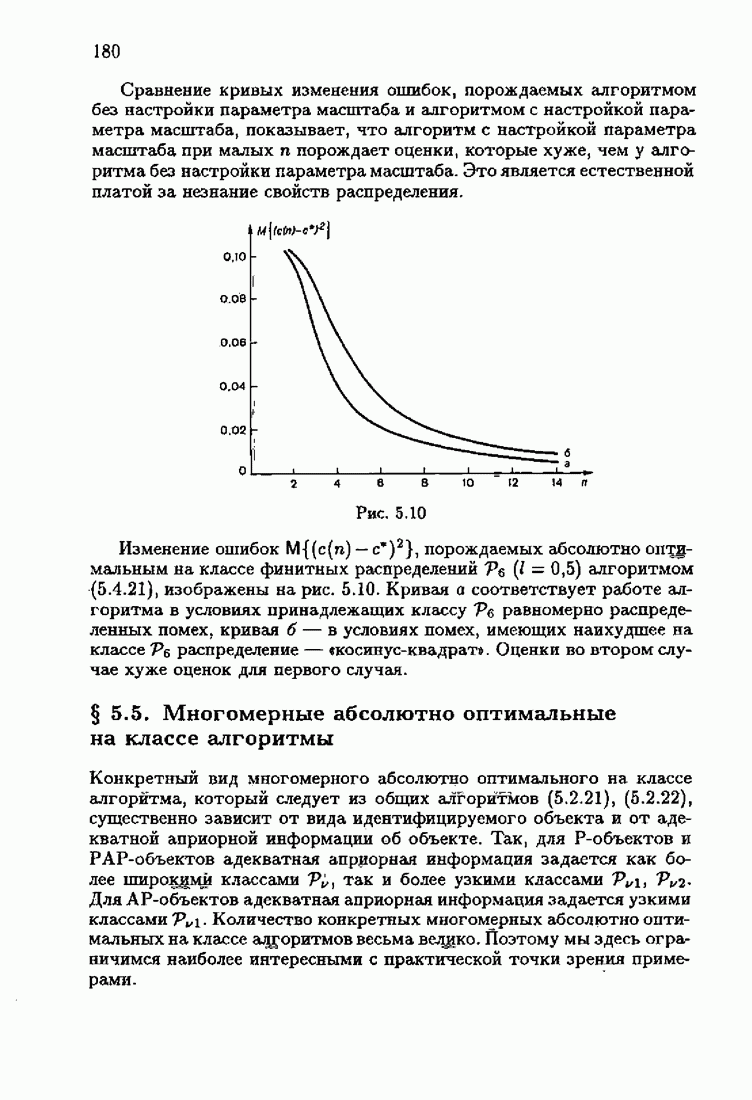

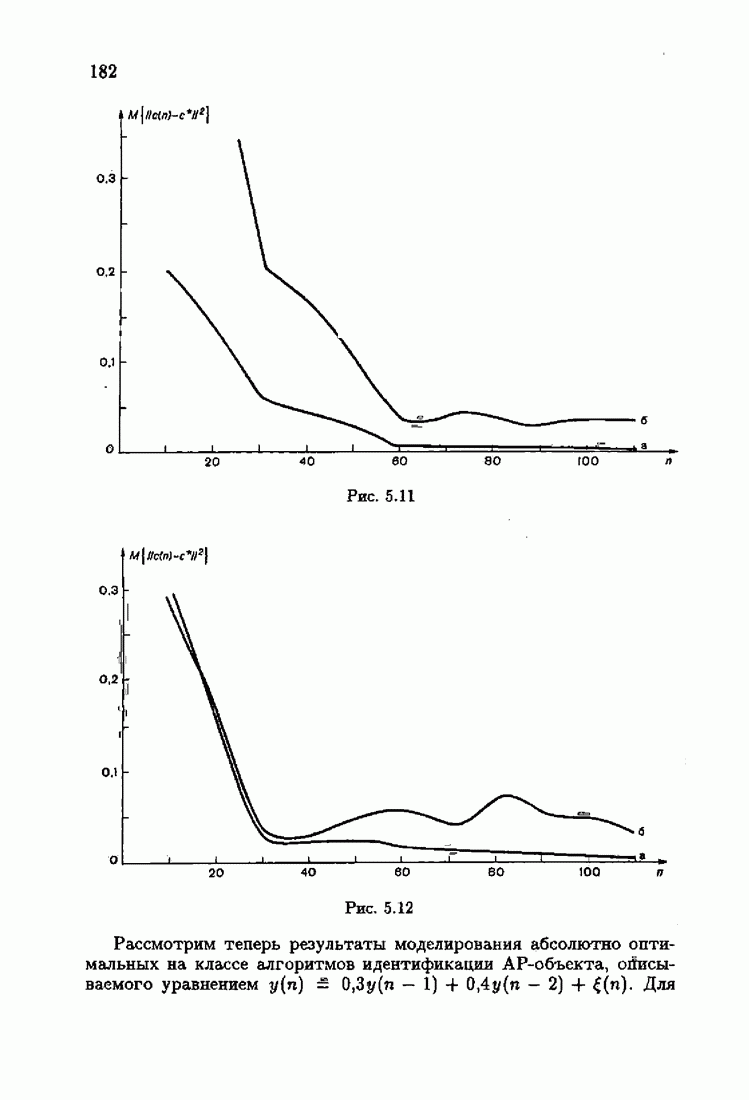
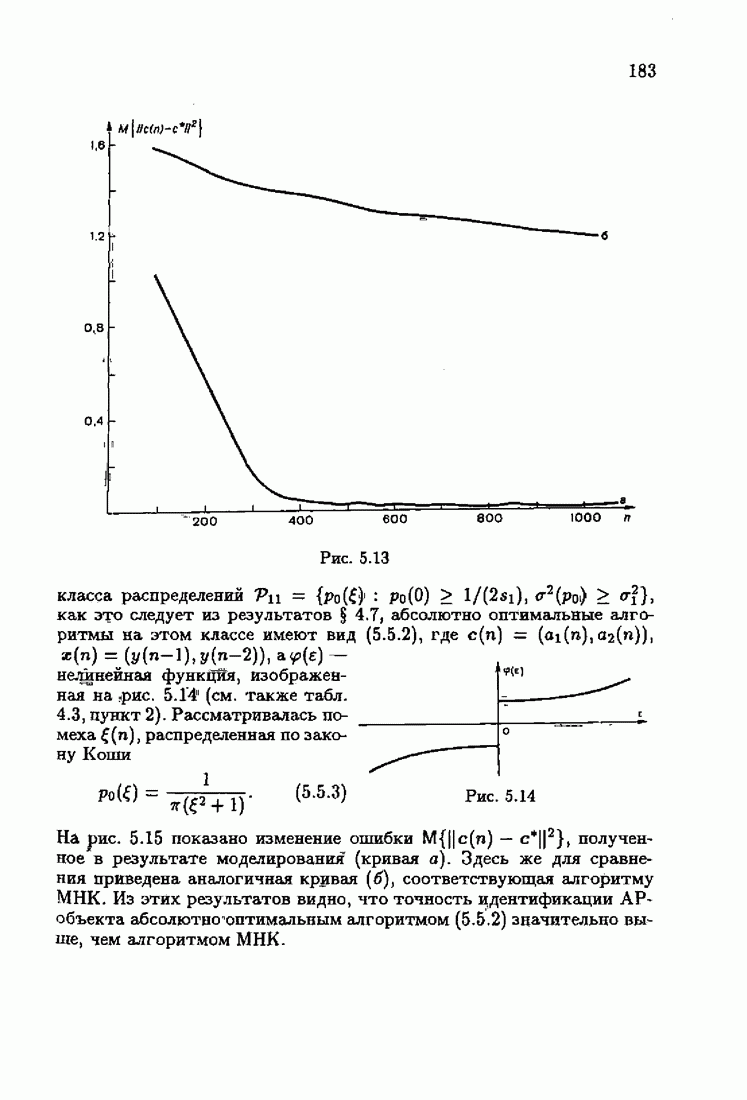









































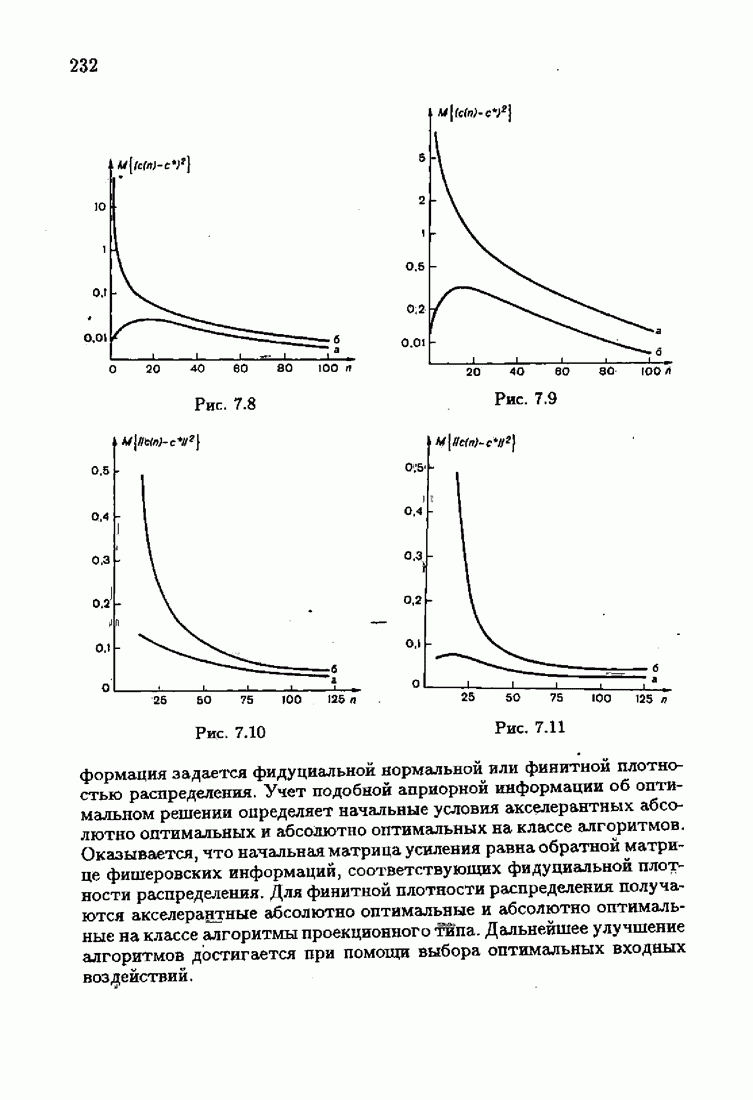















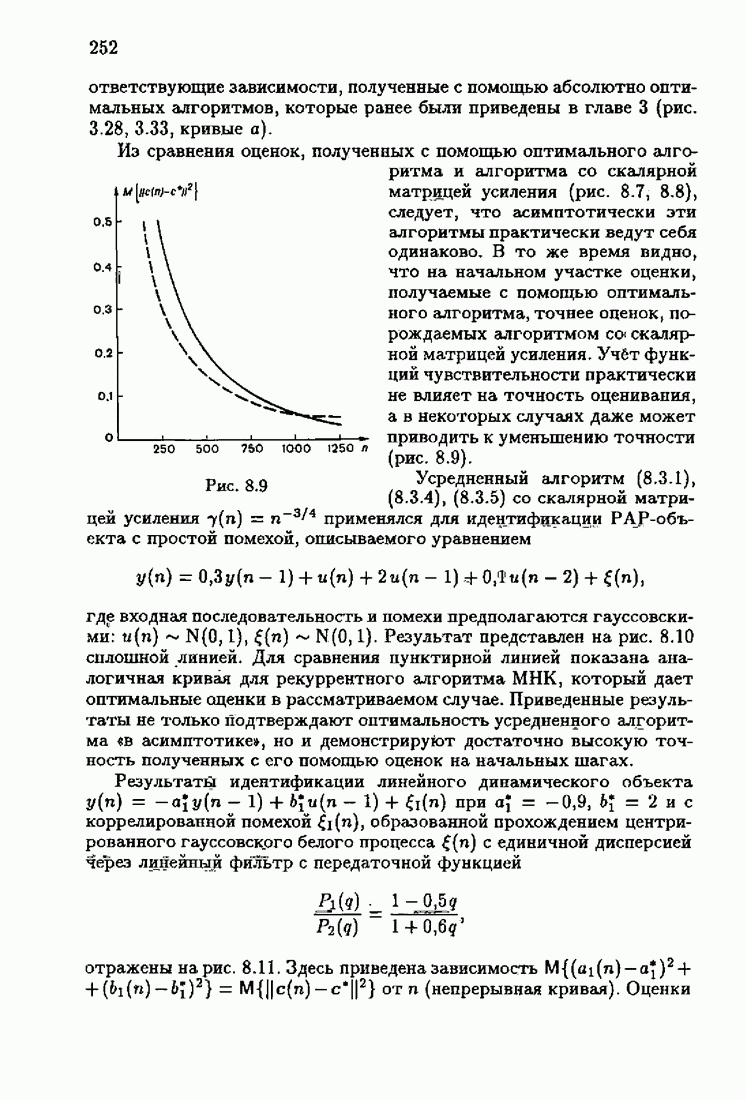
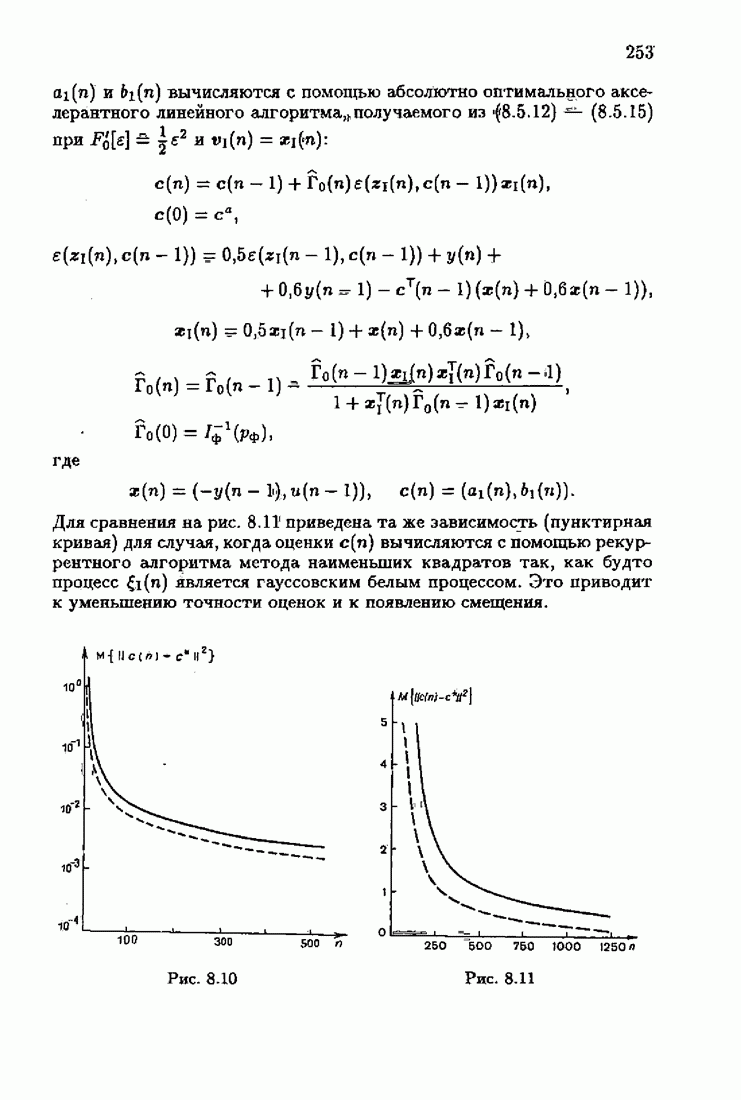





















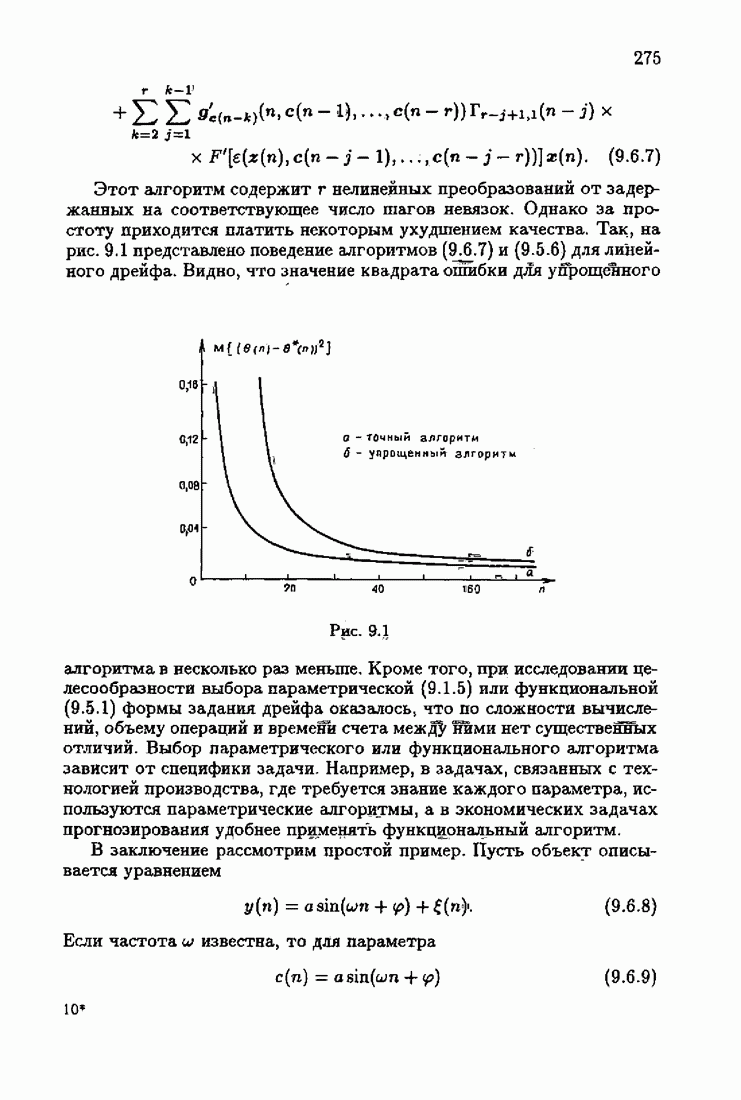
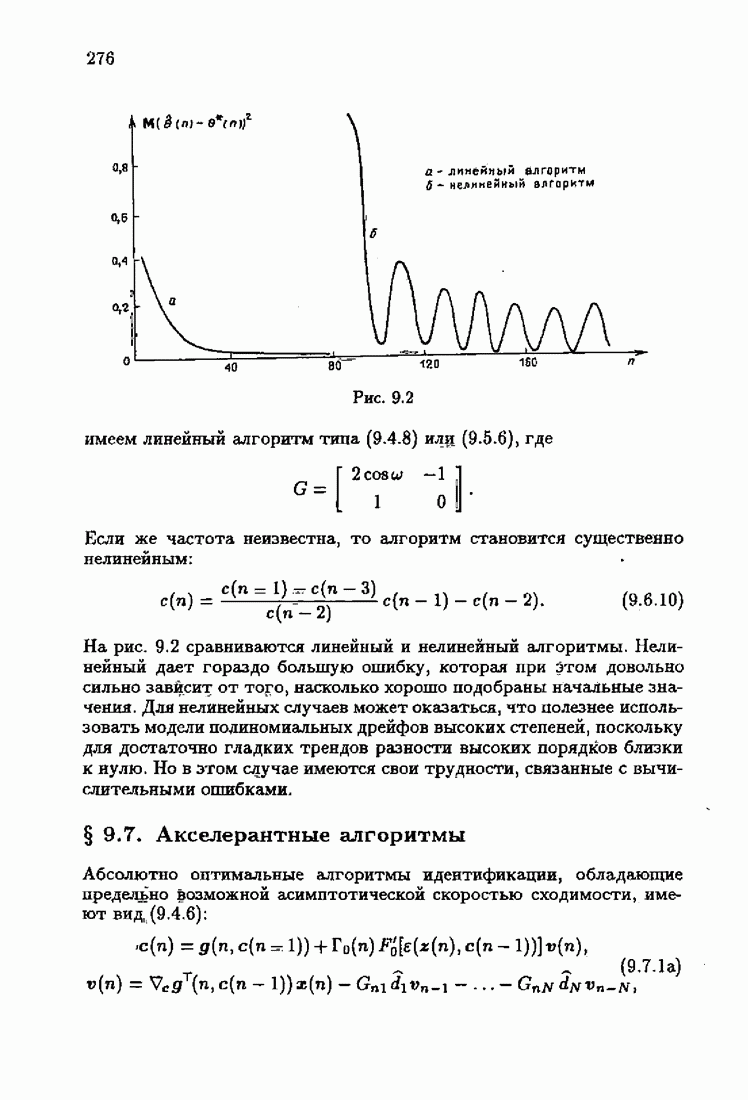

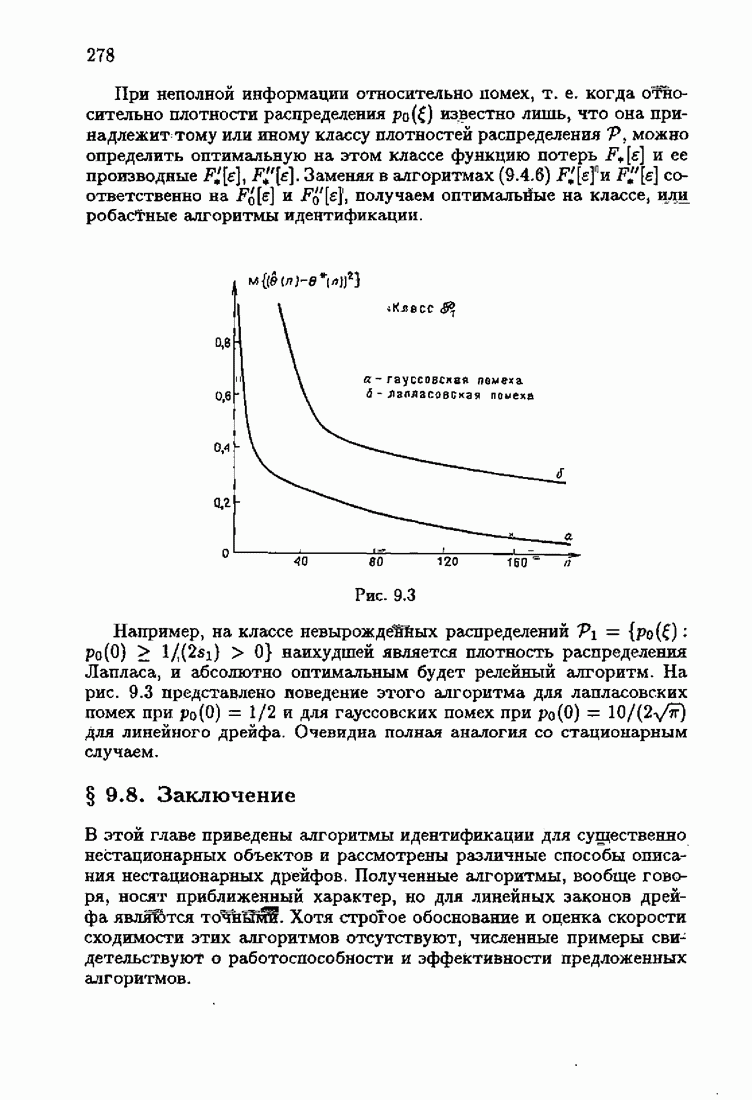


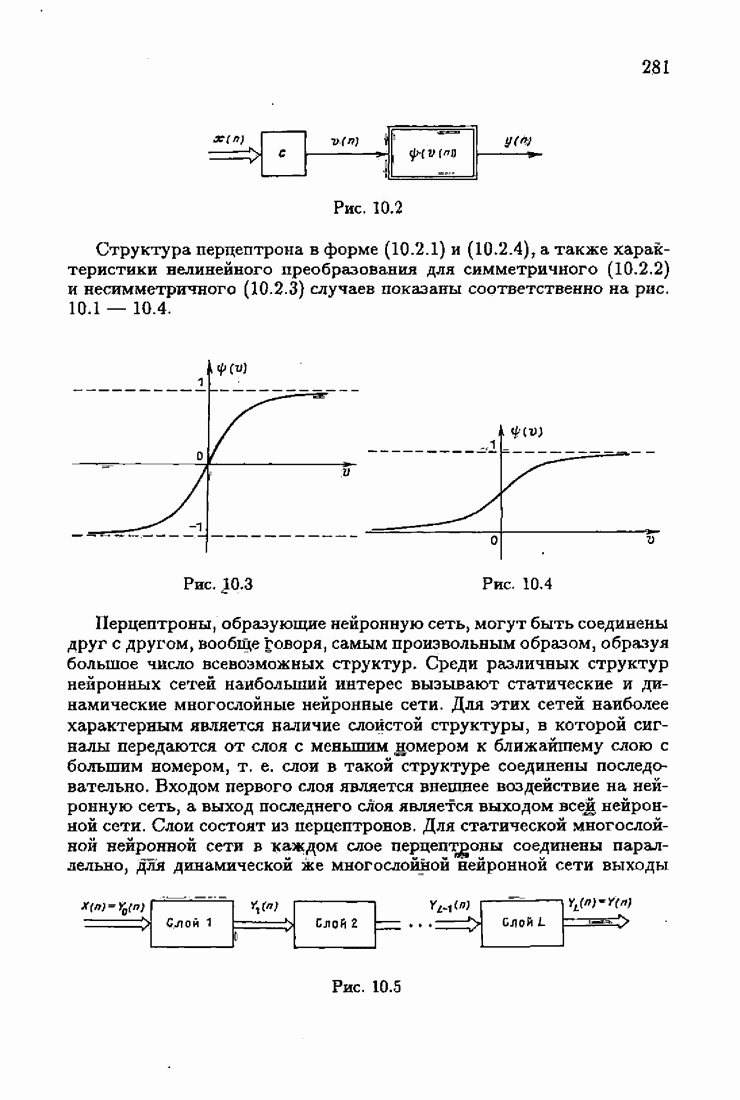
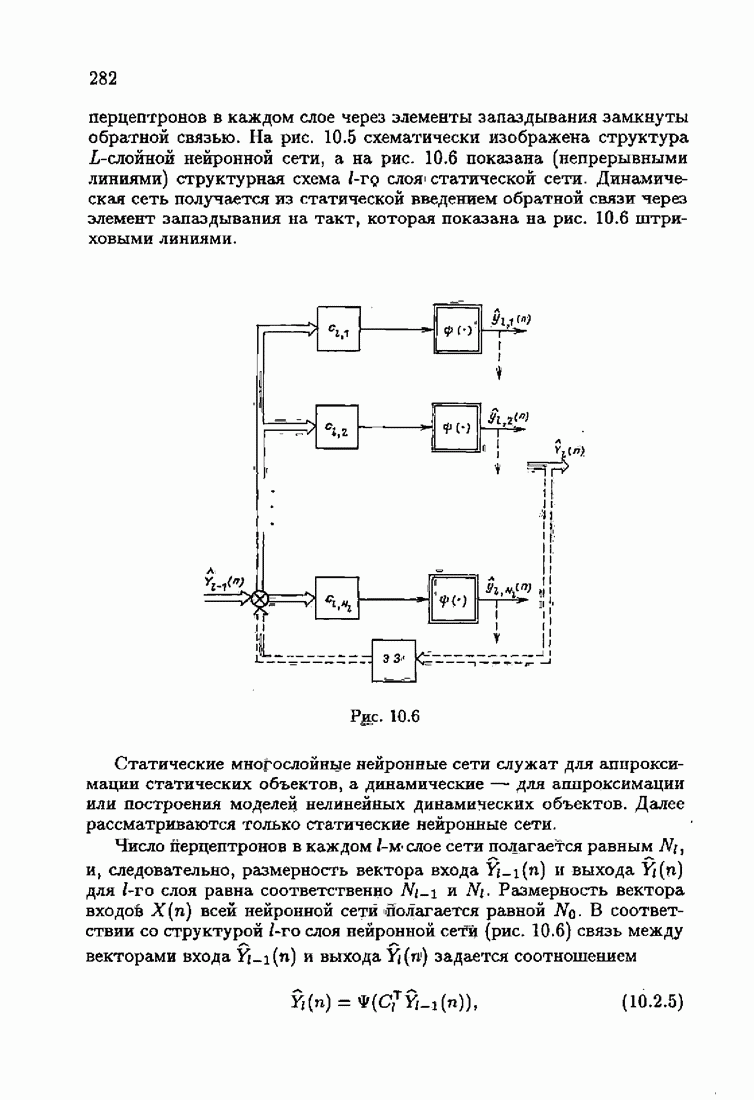


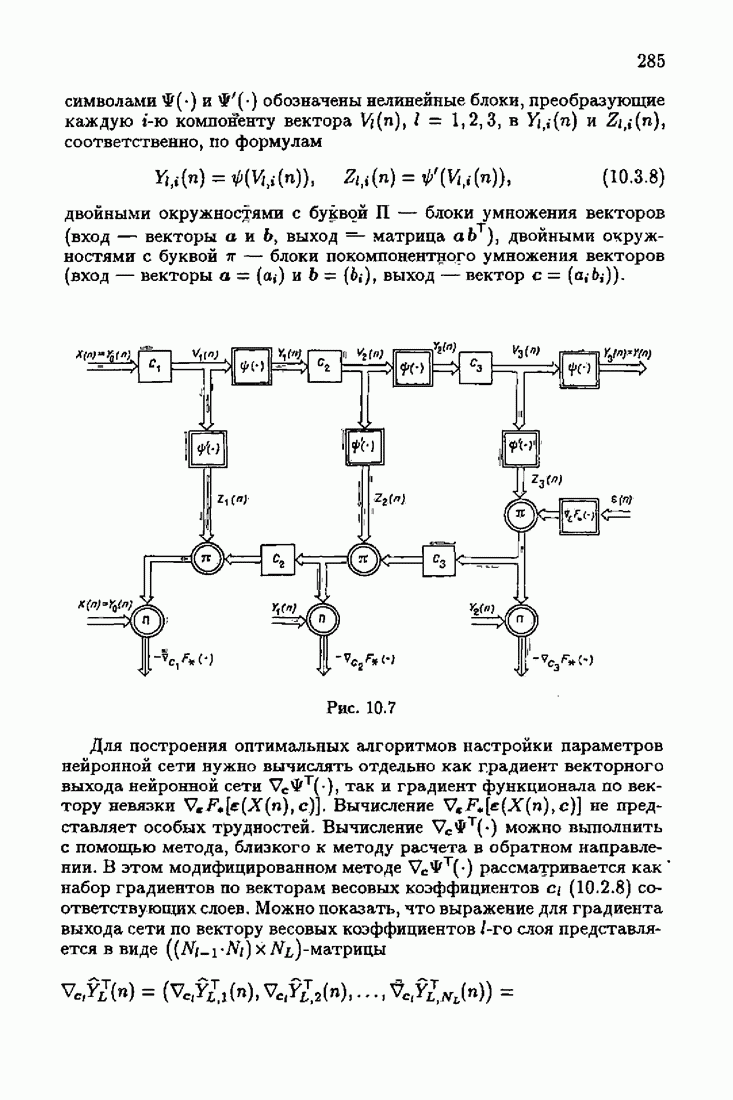
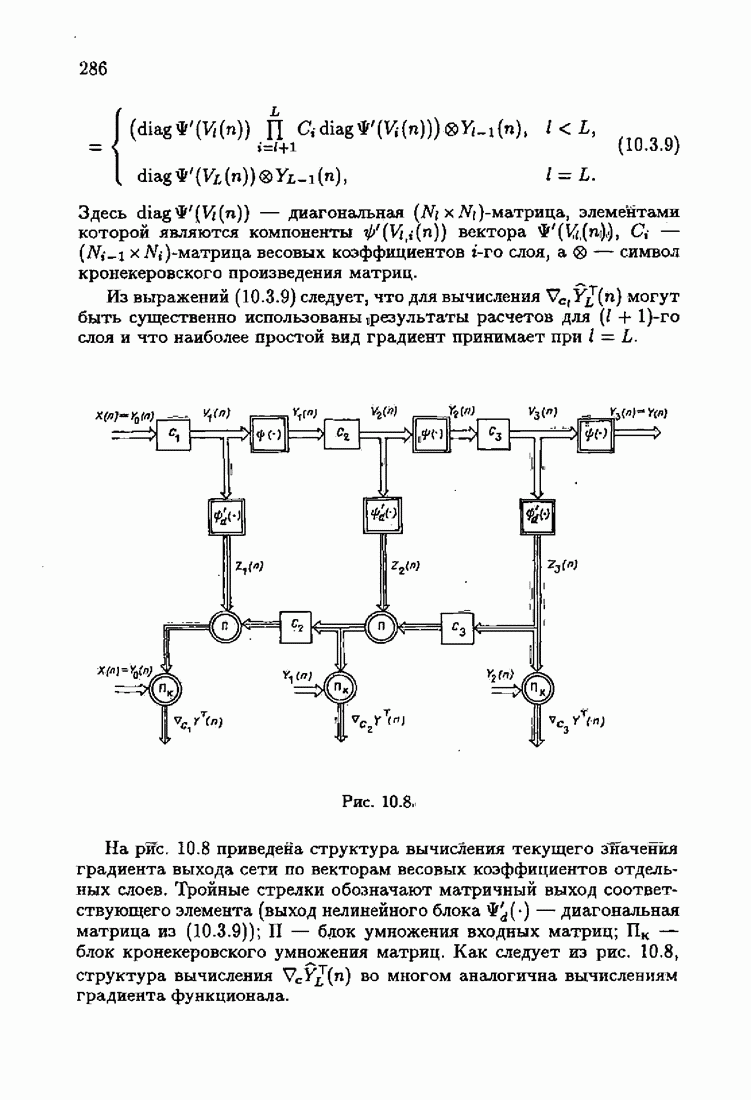
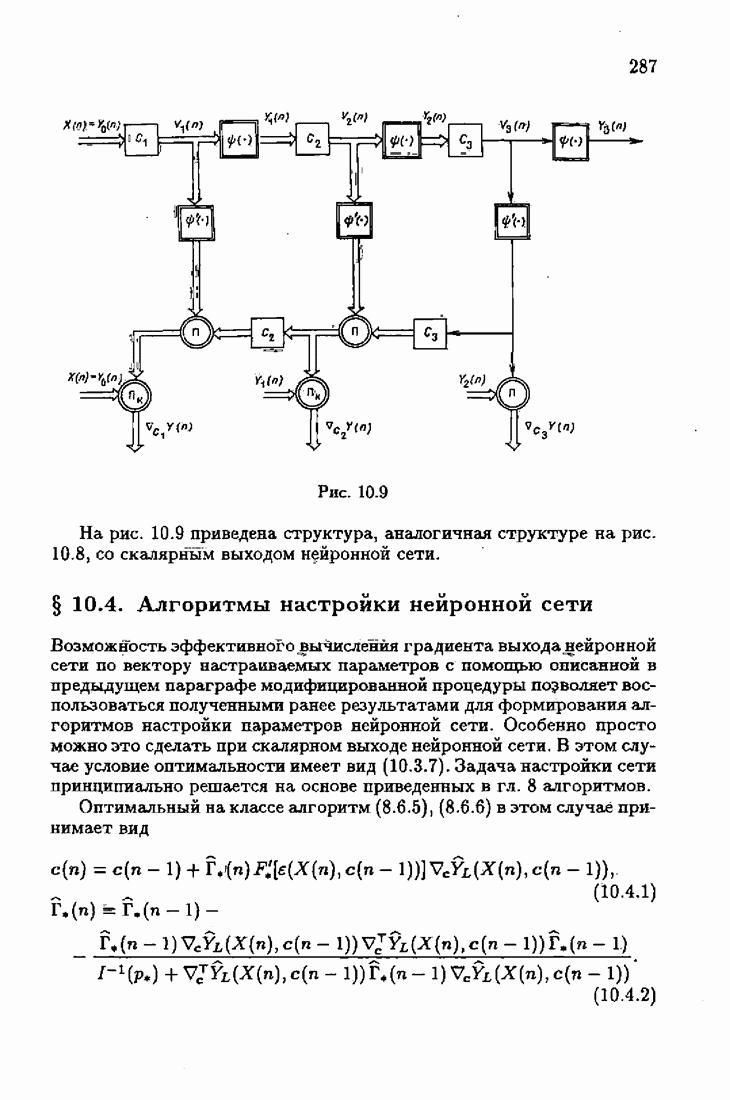


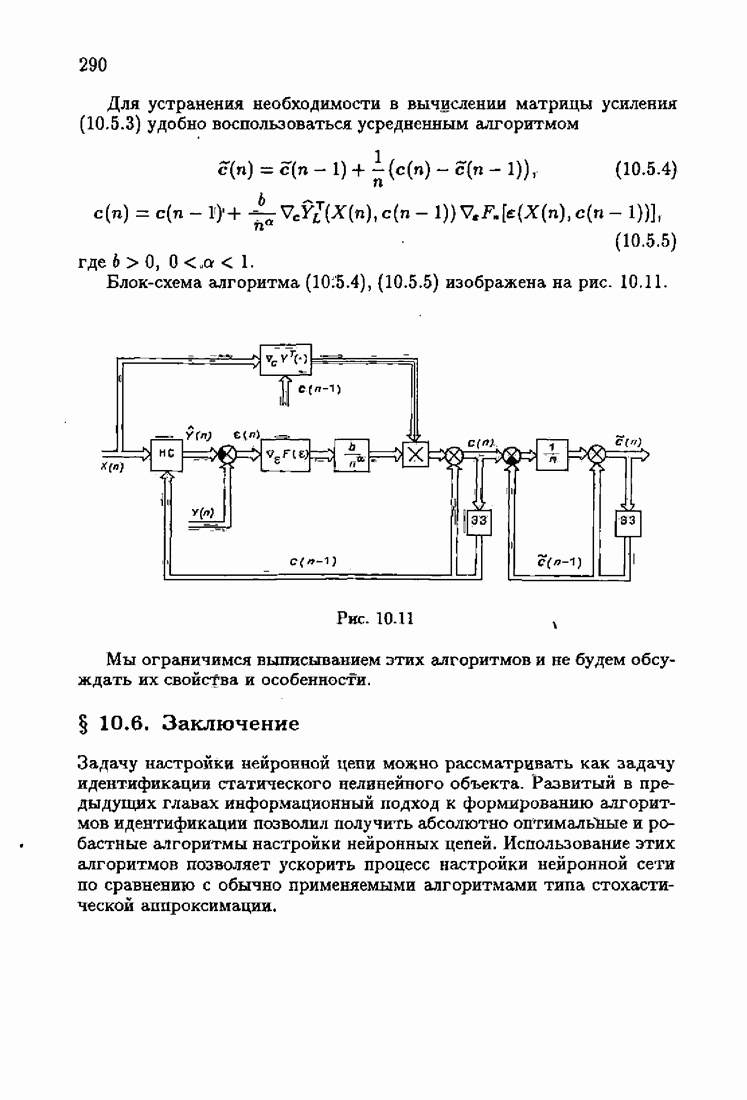














































 При этом начальное значение матрицы усиления оказалось равным значению обратной фишеровской информационной матрицы, определенной фидуциальной плотностью распределения.
При этом начальное значение матрицы усиления оказалось равным значению обратной фишеровской информационной матрицы, определенной фидуциальной плотностью распределения.
 к с, тем быстрее оценки, порождаемые абсолютно оптимальным алгоритмом, достигают своего асимптотического, а значит, и оптимального поведения. При отсутствии такой априорной информации абсолютно оптимальные алгоритмы на конечных шагах
к с, тем быстрее оценки, порождаемые абсолютно оптимальным алгоритмом, достигают своего асимптотического, а значит, и оптимального поведения. При отсутствии такой априорной информации абсолютно оптимальные алгоритмы на конечных шагах  могут приводить, вообще говоря, к оценкам
могут приводить, вообще говоря, к оценкам  очень далеким от с. Возникает задача такой модификации абсолютно оптимальных алгоритмов, которая, не изменяя их асимптотических свойств, позволила бы при конечном
очень далеким от с. Возникает задача такой модификации абсолютно оптимальных алгоритмов, которая, не изменяя их асимптотических свойств, позволила бы при конечном  получить лучшие оценки, мало зависящие от произвольного выбора начальных условий. Обсуждению этой возможности мы и посвятим настоящий параграф книги.
получить лучшие оценки, мало зависящие от произвольного выбора начальных условий. Обсуждению этой возможности мы и посвятим настоящий параграф книги.


 вектора оптимального решения с оценкой
вектора оптимального решения с оценкой  также нормированной информационной матрицы
также нормированной информационной матрицы  оценкой
оценкой





 на
на  запишем матрицу усиления
запишем матрицу усиления  в виде рекуррентного соотношения
в виде рекуррентного соотношения

 получается из
получается из  путем замены фишеровской информации
путем замены фишеровской информации  величиной
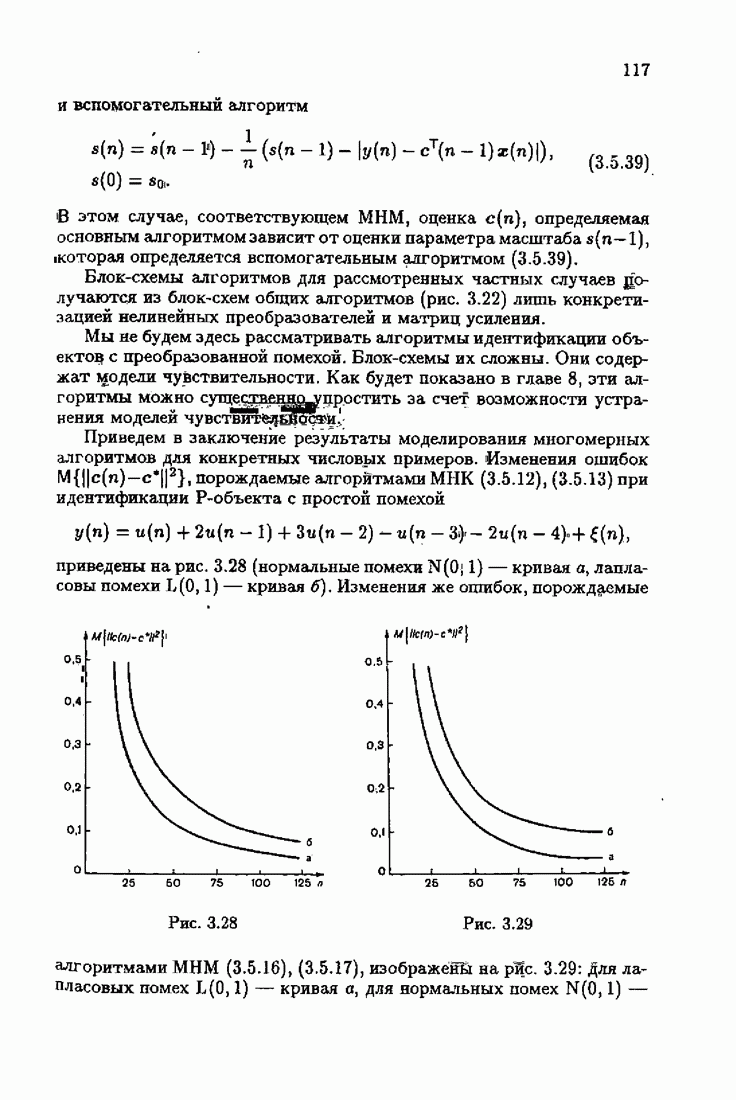
величиной  Таким образом, из абсолютно оптимальных алгоритмов (3.2.3), (3.2.4) заменой в матрице усиления математического ожидания эмпирическим средним мы приходим к абсолютно оптимальным алгоритмам
Таким образом, из абсолютно оптимальных алгоритмов (3.2.3), (3.2.4) заменой в матрице усиления математического ожидания эмпирическим средним мы приходим к абсолютно оптимальным алгоритмам

 на получаем абсолютно оптимальные на классе алгоритмы
на получаем абсолютно оптимальные на классе алгоритмы


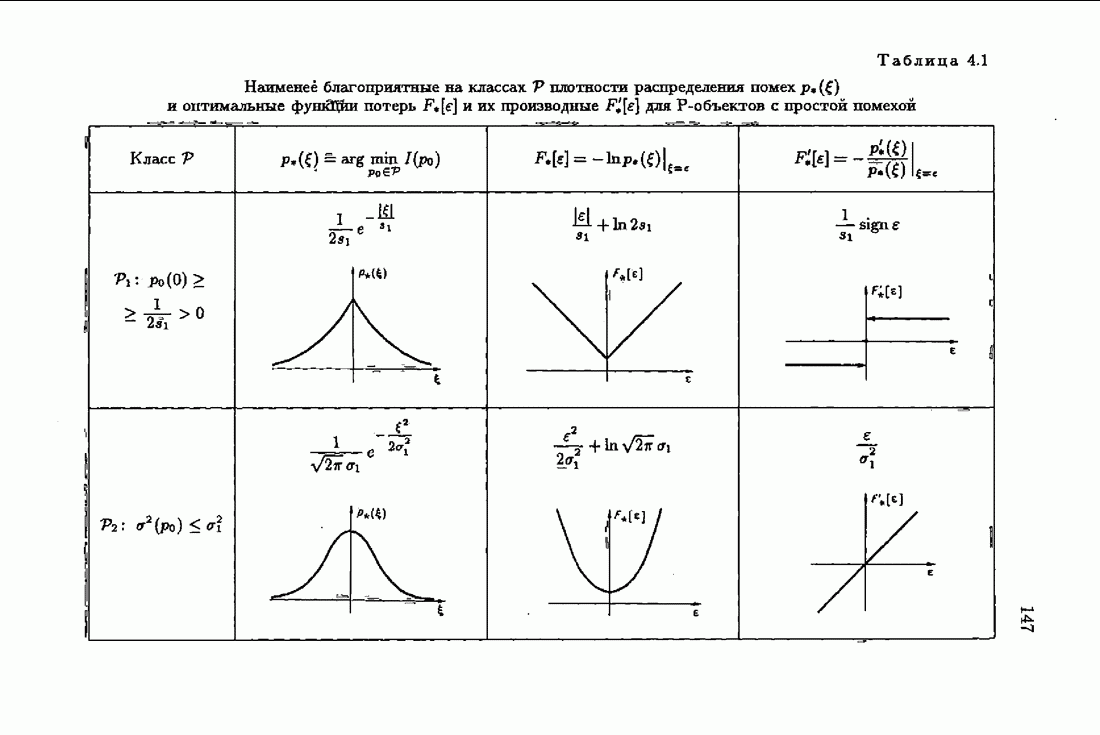
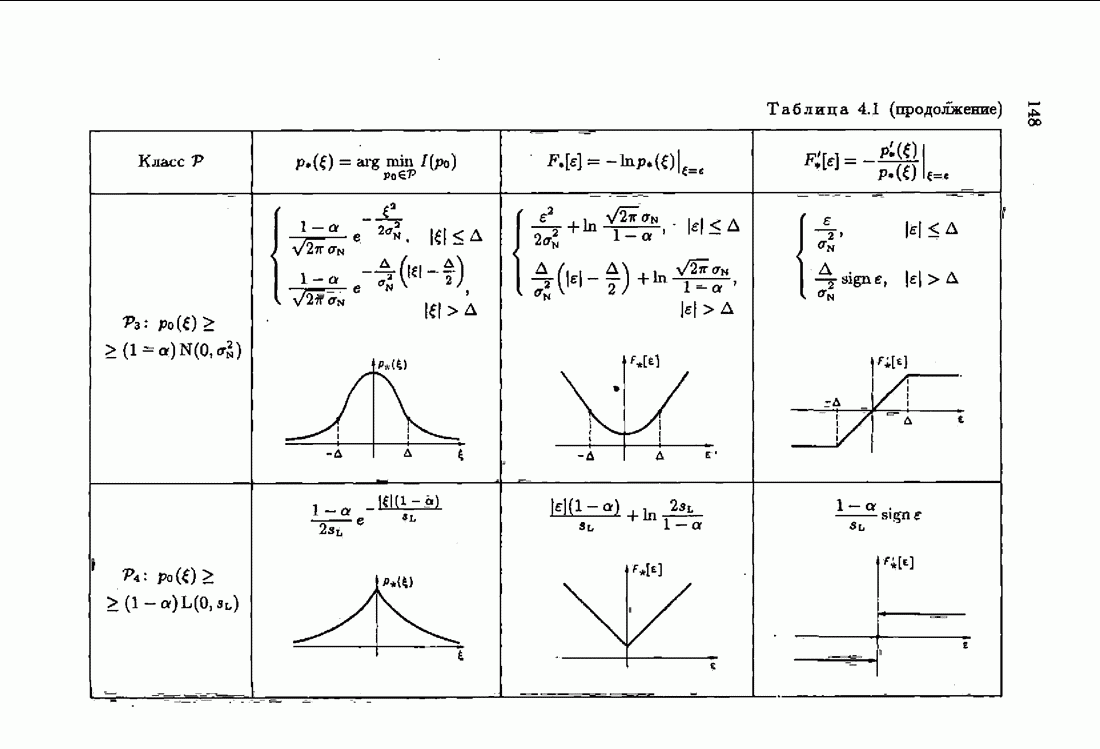
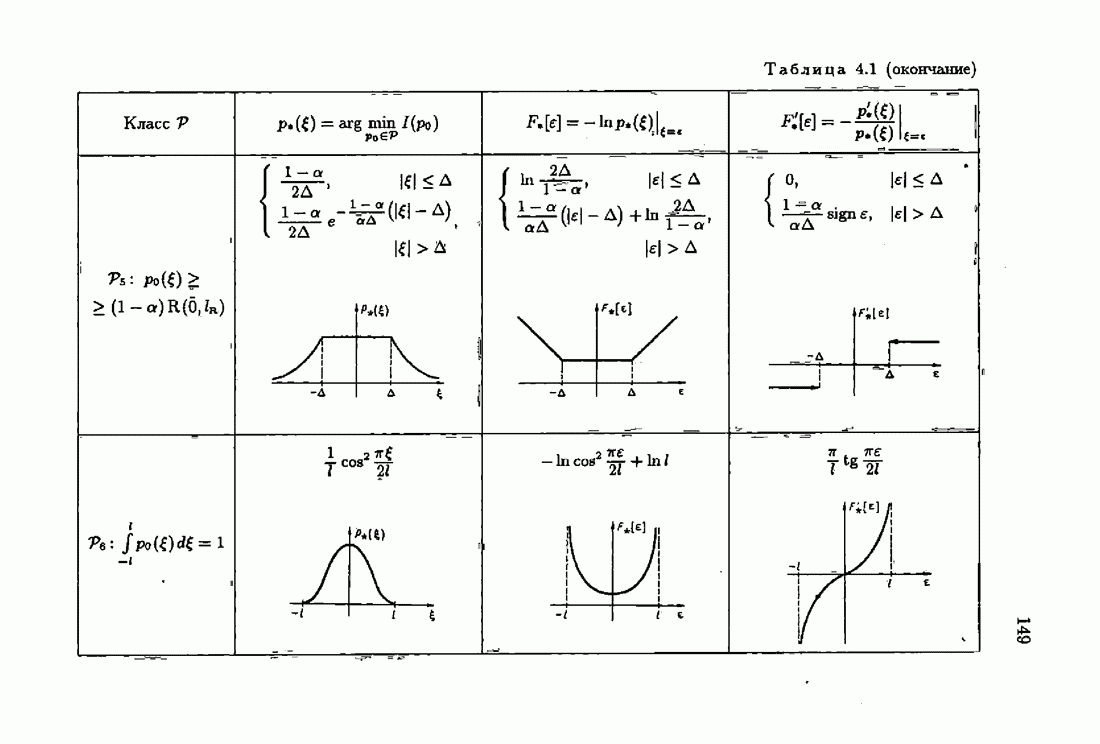
 и это обстоятельство приводит к акселеризации. Чтобы убедиться в этом, рассмотрим два класса распределений:
и это обстоятельство приводит к акселеризации. Чтобы убедиться в этом, рассмотрим два класса распределений:  класс распределений с ограниченной дисперсией
класс распределений с ограниченной дисперсией  класс приближенно нормальных распределений (см. табл. 4.1). Для класса
класс приближенно нормальных распределений (см. табл. 4.1). Для класса  имеем
имеем  и из (8.8.14) — (8.8.16) следуют алгоритмы метода наименьших квадратов. Для класса
и из (8.8.14) — (8.8.16) следуют алгоритмы метода наименьших квадратов. Для класса 

 второе слагаемое в (8.8.16) обращается в нуль и, значит, матрица усиления остается неизменной, а не уменьшается монотонно с ростом
второе слагаемое в (8.8.16) обращается в нуль и, значит, матрица усиления остается неизменной, а не уменьшается монотонно с ростом  как это имеет место в алгоритмах (8.8.1) — (8.8.3). Постоянство матрицы
как это имеет место в алгоритмах (8.8.1) — (8.8.3). Постоянство матрицы  при
при  ускоряет сходимость алгоритма при малых
ускоряет сходимость алгоритма при малых 
 на
на  позволяет не только ускорить сходимость, но и обеспечить сходимость в тех случаях, когда при матрицах усиления вида (8.8.7) она может нарушаться для отдельных реализаций.
позволяет не только ускорить сходимость, но и обеспечить сходимость в тех случаях, когда при матрицах усиления вида (8.8.7) она может нарушаться для отдельных реализаций.



 можно представить в рекуррентной форме:
можно представить в рекуррентной форме:

 на
на


 коэффициент усиления
коэффициент усиления  не изменяет своего значения, т. е.
не изменяет своего значения, т. е. 