Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
КомментарииК ГЛАВЕ 1 § 1.1. Методам идентификации посвящено необозримое число работ. Поэтому здесь мы укажем лишь монографии и обзоры, которые могут дать представление о достигнутых к настоящему времени результатах и которые содержат обширную библиографию. Общим вопросам идентификации разнообразных технических систем посвящены книги Эйкхоффа [1-1], Брикмана и Кристникова [1.1], Ли [1-1], Райбмана и Чадеева [1.1], Дейча [1.1], Химмельблау [1.1], Сейджа и Мелзы [1.1], Гропа [1.1], Гудвина и Пейна [1.1], Перельмана [1.1], Льюнга [1.4]. Идентификация динамических систем рассматривается в книгах Мендела [1.1], Арбачаускене и др. [1,1], Каминскаса и Немуры [1.1], Острёма [1.1], Саридиса [1.1], Ландау [1.2], посвященных рассмотрению также и адаптивных систем управления, в которых используются результаты идентификации. В книгах Фишера [11], Маленао [1.1], [1-2], Греяджераи Хатанака [1.1] рассмотрены вопросы идентификации экономических систем. Большое внимание в этих книгах уделяется изучению временных рядов. Идентификация, трактуемая как оценивание параметров, излагается в обширной литературе по статистике, включая книги Кендалла и Стьюарта [1-1] - [1.3], Андерсона [1.1], Хеннана [1.1], [1-2], Кокса и Хинкли [1.1], [1.2], Бартлетта [1.1] и др. Укажем также на обзоры, посвященные задачам идентификации, Острёма и Эйкхоффа [1.1], Густавсона [1.1], Густавсоиа, Льюнга и Содерстрёма [1.1], Янга [1.1], Стрейца [1.1], Райбмана [1.2]. В этих обзорах подведен определенный итог результатов, полученных к настоящему времени и изложенных в журнальных публикациях. Регулярно статьи по идентификации публикуются в журналах: Автоматика и телемеханика, Техническая кибернетика, Automatica, IEEE Transactions on Automatic Control, International Journal of Control, International Journal of Systems Science, а также в журналах биологического и экономического направлений. Теории и технике идентификации посвящаются специальные симпозиумы. К настоящему времени состоялось девять симпозиумов: Прага (1967), Прага (1970), Гаага — Дельфт (1973), Тбилиси (1976), Дармштадт (1979), Вашингтон (1982), Йорк (1985), Пекин (1988), Будапешт (1991). Изданы труди этих симпозиумов - Identification and System Parameter Estimation. В результате усилий ведущих специалистов мира по идентификации создан под редакцией Эйкхоффа обзор современного состояния теории идентификации. Идентификация как пример оптимизации в условиях неопределенности рассматривалась в предыдущих книгах автора (Цыпкин [1-1], [1.2]). Знакомство со всеми этими публикациями показывает § 1.2. Описание динамического объекта линейным разностным уравнением было использовано во многих работах по идентификации и адаптивному управлению: см., например, Острём и Болин [1.1], Острём [1.1], Эйкхофф [1.1], Острём и Эйкхофф [1.1], Сейдж и Мелза [1.1], Райбман и Чадеев [1.1], Саридис [1.1], Ландау [1.1], Частные случаи этого разностного уравнения охватывают регрессионные и авторегрессионные задачи. Регрессионные задачи особенно подробно рассмотрены в статистике: см., например, Крамер [1.1], Рао [1.1], Шметтерер [1.1], Кендалл и Стьюарт Мы не останавливаемся на методах определения порядка разностных уравнений динамических объектов. Этой задаче посвящено большое число работ. Отметим лишь недавно появившиеся работы, посвященные определению порядка разностных уравнений АР-объектов: Инагаки [1.1], Стоица и Содерстрём [1.1]. Интересующийся читатель в библиографии этих работ найдет указание на прежние работы в этой области. При записи уравнений идентифицируемых динамических объектов в операторной форме в литературе встречаются различные обозначения оператора сдвига: § 1.3. В задачах идентификации линейных динамических объектов используются, как правило, два типа прогнозирующих или настраиваемых моделей — статические и динамические. Обычно прогнозирующие или настраиваемые модели выбирались, исходя из различных интуитивных соображений. Часто оказывалось, что эти модели не удовлетворяли ряду требований. Тогда в них вводилось то или иное видоизменение. Так, метод инструментальных переменных (Янг [1.1], [1.2]), расширенный матричный метод (Пануска [11], [1-2]) были предложены с целью устранения смещенности оценок параметров динамических объектов; см. также Содерстрём [1.2]. Эти методы, как правило, приводили к видоизменению первоначально принятой настраиваемой модели. Задача о выборе наилучшей, оптимальной предсказывающей или настраиваемой модели до сих пор не рассматривалась. Эта задача была поставлена и решена в работе Цылкина [1.3]. В § 1.3 излагаются результаты этой работы в несколько более простой форме. Для минимально-фазового по помехе объекта оптимальную настраиваемую модель можно также получить на основании следующих простых соображений. Перепишем уравнение объекта в виде
или
Обозначая
получим
Таким образом,
где
и есть уравнение оптимальной настраиваемой модели при Оптимальная настраиваемая модель минимизирует второй момент невязки Введение понятие оптимальной прогнозирующей, или настраиваемой модели устраняет существовавшую ранее неопределенность и приводит к выбору модели, которая наилучшим образом предсказывает выходную величину объекта. Отметим, что оптимальней! прогнозирующая модель связана, как нам кажется, с оптимальными наблюдателями и предсказателями на один шаг (см., например, Острём [1.1]). Но эту связь мы вскрывать не будем. § 1.4. Как правило, критерий качества идентификации выбирался квадратичным. Это было связано не только с простотой критерия, но и с тем, что оптимальное решение § 1.5. Рекуррентным алгоритмам типа стохастической аппроксимации посвящена огромная и разнообразная литература. Эти алгоритмы были положены в основу теории адаптивных и обучающихся систем в книгах Цыпкина [1.1] и [1.2], Фу [1.1], Мен дела и Фу [1.1], Айзермана, Бравермана и Розоноэра [1.1], Катковника [1.1], Коростелева также статьи Соло [1.1] — [1.3], посвященные сходимости алгоритмов идентификации линейных динамических систем типа стохастической аппроксимации. § 1.6. Асимптотическая скорость сходимости рекуррентных алгоритмов стохастической аппроксимации изучалась в работах Чжуна [1.1], Сакса [1.1], Фабиана [1,1], [1.2], в книге Каниовского, Кнопова и Некрыловой [1.1]. Были найдены условия справедливости теоремы об асимптотической нормальности, при которых случайная величина Теорема об асимптотической нормальности излагалась, усиливалась и обобщалась Острёмом и Болином [1.1], Невельсоном и Хасьминским [1,1], Гудвином и Пейном [1,1], Репиным и Тартаковским Оценкам скорости сходимости алгоритмов стохастической аппроксимации посвящены работы Кашнера [1.1] и книга Кашнера и Кларка Различные способы получения матричного уравнения относительно АМКО приведены у Сакса [1.1], Невельсона и Хасьминского [1.1], Репина и Тартаковского [1.1]. Часто в литературе это матричное уравнение называют матрнчным уравнением Ляпунова или матрнчным уравнением Риккати. Изучению свойств подобных матричных уравнений и способов их решения посвящена огромная литература. Укажем на работы Дэвисона и Манна [1.1], Гудорзи [1.1], Зайдана [1.1], Шапиро [1.1], Квона и Пирсона [1.1], Хоскинса, Мика и Уолтона [1.1], Нейтела и Тоды [1,1], Мори, Фукума и Кувахара [1.1], Биаласа [1,1], Каранама [1,1], Они могут оказаться полезными для читателей, специально интересующихся этим кругом вопросов. Вывод уравнения, определяющего АМКО, строго говоря, справедлив, когда § 1-7. Вопросам оптимизации рекуррентных алгоритмов с разных точек зрения посвящено довольно большое число работ. К ним относятся работы Чжуна [1.1], Дворецкого [1-1], Кестена [1.1]- Наглядное изложение этих результатов содержится в гл. 6 превосходной книги Уайльда [1.1]; см. также книги Невельсона и Хасьминского [1.1] и Цыпкнна [1.1]. Оптимальные алгоритмы с точки зрения асимптотической скорости сходимости, которые получаются путем надлежащего выбора матрицы усиления, впервые были предложены и исследованы Саксом [1,1]. Эти оптимальные алгоритмы и их различные варианты исследовались Вентерем [1.1], Цыпкиным [1.1], [1.2], Стратоновичем [1.1], Репиным и Тартаковским [1-1]. Невельсоном и Хасьминским [1.1] и др. с несколько отличных друг от друга точек эреннл. Оптимальным или, точнее, асимптотически оптимальным алгоритмам посвящены специальные обзоры Фабнана [1.1], [1.2]. Любопытно, что до сих пор продолжается публикация работ по улучшению алгоритмов типа стохастической аппроксимации, начало которому было положено Кестеном [1.1] (см., например, Саридис [1.1], Унтон [1.1], [1-2]), хотя предельные асимптотические свойства подобных алгоритмов при фиксированной произвольной функции потерь известны со времени появления статьи Сакса [1.1]. Фигурирующая в асимптотически оптимальных алгоритмах нормированная информационная матрица Приемы построения реализуемых оптимальных алгоритмов, связанные с заменой в матрице усиления оптимального решения с его оценкой К ГЛАВЕ 2 § 2.1. Эмпирические средние потери и оценки оптимального решения, порождаемые ими для регрессионных задач, т. е. Р-объектов с простой помехой, довольно подробно изучены в работах по статистике. Их также называют оценками минимального эмпирического риска (минимального контраста). Одной из первых работ в этом направлении была статья Хьюбера [2.1]. Методу минимизации эмпирического риска посвящена книга Вапника [2.1]. Применительно к идентификации нелинейных Р-объектов с простои помехой при произвольной функции потерь см. Цыбаков [2.1]. Айвазян, Бнюков и Мешалкин [2.1] приводят многочисленные примеры задач, в которых применяются оценки минимального эмпирического риска. § 2.2. Асимптотические свойства оценок метода наименьших квадратов и метода максимального правдоподобия Р-объектов с простой помехой рассмотрены в книгах по статистике: Крамер [1.1], Уилкс [2.1], Закс [1.1], Ибрагимов и Хасьминский [2.1]; см. также статью Холево [2.1]. Для иных видов объектов Чтобы как-то утешить математически настроенного читателя, приведем вывод соотношения (2.2.22). В силу определения матрица
где
Следовательно,
Таким образом,
§ 2.3, Вывод неравенства Крамера-Pao для регрессионных задач § 2.4. Выбор критерия качества идентификации сводится к выбору функции потерь Нет решительно никаких общих оснований для предпочтения одного критерия другому. Критерий квадратичного уклонения применяется особенно часто потому, что при пользовании им получаются, как правило, сравнительно простые выкладки» (Харкевич [2.1]). «Выбор самого критерия оптимальности произволен. Выбор всегда представляет собой компромисс между стремлением приблизиться к реальности и стремлением к математической простоте» (Миддлтон [2.1]). Выбор критерия приближения всегда является трудным и сложным вопросом. Случаи, когда можно с должным основанием указать, какого рода приближение необходимо, являются скорее исключением из правила» (Вакман и Седлецкий [2.1]). Подобные цитаты из самых разнообразных источников можно продолжить, но и этих достаточно, чтобы охарактеризовать состояние этого вопроса не только в задачах идентификации. Конечно, следует иметь в виду, что здесь речь идет о критериях, характеризующих качество аппроксимации, а не о технико-экономических или физических критериях, которые, как правило, имеют определенный технический, экономический или физический смысл. К таким критериям относятся размеры или вес устройств, коэффициент полезного действия силовой установки, прибыль предприятия и т. п. В этих случаях неопределенности в выборе критерия не возникает или, по крайней мере, не должно возникать, если не иметь в виду многокритериальных задач (см., например, Красненкер [2.1]). В книге критерии подобного типа не рассматриваются. Для определения оптимальной функции потерь можно также воспользоваться неравенством Коши — Бундовского, как это было сделано в работе Цыпкина и Поляка [2.1]. Сейчас, однако, нам кажется, что такой прием несколько искусствен, и мы предпочли иной, более прямой подход, который был использован в статье Цыпкина [2.1]. § 2,5. Здесь использованы понятия шенноновской информации (Шеннон [2.1]) и кульбаковской информации (Кульбак [2.1]). Неравенство, связанное с энтропией, встречается во многих работах по теории информации и статистике {см., например, Кульбак [2.1], Ченцов [2.1], Уилкс Найденная оптимальная функция потерь Задача выбора наилучшей скалярной функции потерь для матричной невязки — Метод максимального правдоподобия предложен Фишером [2.1]. Для временных рядов, описываемых разностными уравнениями первого порядка, и нормального распределения помехи этот метод изложен в книге Кендалла и Стьюарта [1.3]. Там же имеются ссылки на прежние работы. Применению и исследованию метода максимального правдоподобия для идентификации динамических систем посвящены работы Кал мани [2,1], Острёма [2.1], Острёма и Содерстрёма [2.1], Гертлера и Баньлша [2.1], Ворчнка [2.1], Содерстрёма [2,1], Катнапа [2.1]. Большое число различных плотностей распределения и в частности интересующих нас симметричных плотностей распределения, содержится в справочнике Хастннгса и Пикока [2.1]. К ГЛАВЕ 3 § 3.1. Как правило, во всех известных нам работах, связанных с исследованием семейств рекуррентных алгоритмов, структура алгоритма постулируется, т. е. задается заранее. Затем рассматривается задача выбора матрицы усиления (см., например, Сакс Асимптотическое поведение оценок § 3.2. Здесь используются приемы формирования реализуемых рекуррентных оптимальных алгоритмов, развитые в § 3.1 применительно к абсолютно оптимальным алгоритмам. Впервые абсолютно-оптимальный алгоритм для § 3.3. Настройка параметра масштаба в абсолютно оптимальных алгоритмах по существу в литературе не рассматривалась. Может быть, оправданием этому служило то, что для линейных алгоритмов, которые чаще всего встречались, в этом не было необходимости. § 3.4. Одномерные абсолютно оптимальные алгоритмы оценивания параметра сдвига были подробно исследованы Анбаром [3.1] и Абдельхамидом [3.1]. В последней работе рассматривались также одномерные поисковые алгоритмы. Свойства таких алгоритмов исследовались Фабианом [3.1], [3.2]. § 3.5. Многомерные абсолютно оптимальные алгоритмы идентификации, или оценивания параметров К ГЛАВЕ 4 § 4.1. Часть из приведенных классов распределений довольно популярна среди статистиков. Особенно это относится к классу § 4.2. Понятие оптимальности на классе тесно связано с понятиями нечувствительности, грубости, робастности, хотя полностью и не совпадает с ними. Для задач оптимизации в условиях неопределенности понятие оптимальности на классе было введено Поляком и Цыпкиным [4.1]. § 4.3. Принцип оптимальности для частного случал оценивания одномерного параметра сдвига соответствует минимаксному принципу Хьюбера [4.1], [4.7]. В связи с общим минимаксным принципом см. книги Гермейера [4.1], Демьянова и Малоземова [4.1], Карлина [4.1], Федорова [4.1]. Отметим также статьи Бхата и Дораисвамн [4.1] и Дораисвами [4.1]. Минимаксный подход в последнее время получил развитие для построения гарантированных оценок параметров § 4.4. Вариационные задачи минимизации комбинаций фишеровскон информации § 4.5. Оптимальные на классах функции потерь для [4.1]). Примеры иных функций потерь можно найти в работах Эндрюса, Бикела, Хэмпела, Хьюбера, Роджерса и Тьюки [4.1], Гильбо и Челпанова [4.1] — [4.4], Демиденко [1.1]. В книге Хэмпела, Рончетти, Рауссеу и Штаэля [4.1] приводятся разнообразные функции потерь, полученные на основе подхода, использующего функции влияния. Оптимальная на классе функция потерь определяется по наименее благоприятной на данном классе плотности распределения, т. е. плотности распределения, минимизирующей фишеровскую информацию. При обсуждении наименее благоприятных, или наименее предпочтительных, плотностей распределения встречаются иногда и неточные гипотезы. Так, Репин и Тартаковскнй [1.1] замечают в своей книге, что (во всех предыдущих примерах наименее предпочтительное распределение вероятностей § 4.6. Для АР-объектов аналитическое решение вариационной задачи может быть получено для класса Методы исследования асимптотики решения дифференциальных уравнений, подобных уравнению (4.6.7), описаны, например, в книге Федорюка [4.1]. § 4.7. Для § 4.8, 4.9. Впервые термин (робастный) («robust» (англ.) — крепкий, стойкий, сильный) появился в работах Бокса [4.1] и Бокса и Андерсона [4.1]. Робастной называлась (статистическая процедура, нечувствительная к отклонениям от предложений, лежащих в ее основе». Обычно в русской литературе используются термины: «устойчивые», (помехоустойчивые», (стабильные», (Свободные от распределения» и, наконец, »робастные» оценки. Последний термин уже получил право гражданства и постепенно вытесняет слишком перегруженные и неадекватные термины, перечисленные выше. Большую роль в пропаганде необходимости робастных оценок сыграли работы Тьюки [4.1], [4.2]. Тьюки [4.2] цитирует высказывание Джери [4.1]: (Нормальность — это миф. В реальном мире никогда не было и не будет нормального распределения». Можно еще к этому прибавить высказывание Пуанкаре: «В нормальном законе должно быть что-то таинственное, так как математики считают его законом природы, тогда как физики убеждены в том, что он доказан математически». Хэмпел [4.1] в своем обзоре приводит многочисленные примеры практических задач, в которых встречаются выбросы. Так, в инженерных измерениях по данным Олмстеда обычно содержится 10% выбросов (см. Тьюки [4.1]), а по данным Даниелл [4,1] — от 1 до 20% (4.3] — [4.5], Бикела [4.1], Хогга [4.1], Демпстера [4.1], монографии Хьюбера [4.5], 4.8], Барнетта и Льюиса [4.1], Рея [4.1], Такеухи [4.1], Смоляка и Титаренко [4.1] и сборники под редакцией Лаунера и Уилкннсона [4.1], Новака и Зентграфа [4.1]. В практике обработки статистической информации уже давно применялись различные эмпирические приемы устранения влияния выбросов. Описание таких приемов можно найти, например, в книгах Дейвида [4.1], Барнетта и Льюиса [4.1]. Очень любопытное сравнение различных методов оценивания параметра сдвига, таких, как среднее, медиана, цензурирование, а также методов, основанных на нелинейных преобразованиях типа насыщения, гармонического, параболического преобразований и т. п., приведено в статье Стигдера Теория робастного оценивания первоначально развивалась в направлении, связанном с оценкой одномерных параметров сдвига и масштаба и со смежными вопросами. Традиционно рассматривались нерекуррентные оценки. Достижения этого периода наиболее полно изложены в книге Хьюбера [4.8]. В ней отражены результаты, полученные до 1975-1976 гг. Обобщение основных результатов теории робастного оценивания на задачу регрессии, а затем на более широкую задачу оптимизации в условиях неопределенности было сделано в работах Поляка и Цыпкина [3.1], [3.2], Понятие качественной робастности, наиболее близкое к понятию грубости, нечувствительности, было разработано Хэмпелом [4.1] (см. также Папантони-Каэакос [4.1]). Отметим также работы по робастной фильтрации (Масрелиэ [4.1], Масрелиэ и Мартин [4.1], Ершов и Липцер [4.1], Мартин [4.2]), по робастному оцениванию при асимметричных помехах (Коллинз [4.1]), при коррелированных помехах (Цыпкин и Позняк [4.1]) и по робастной непараметрической регрессии (Хьюбер [4.7], Цыбаков Довольно полная библиография по робастным методам оценивания приведена в обзоре Ершова [4.1] и несколько позже появившемся обзоре Стогова, Макшанова и Мусаева [4.1], который сильно пересекается с обзором Ершова, но не содержит ссылки на него. Быть может, причина этого состоит в том, что в «Зарубежной радиоэлектронике не принято ссылаться на отечественных авторов даже тогда, когда они являются авторами обзоров. Более поздние работы зарубежных авторов частично отражены в библиографии к книге Хьюбера [4.7] и в сборниках под редакцией Лаунера и Уилкннсона [4.1] и Новака и Зентграфа [4.1]. К ГЛАВЕ 5 § 5.1, 5.2. Исследованию рекуррентных абсолютно оптимальных на классе алгоритмов идентификации § 5,3. Нерекуррентные оценки с настройкой параметра масштаба рассматривали Бикел [5.1], Иохаи и Маронна [5.1], Маронна 5 5.4. Робастные алгоритмы оценивания одномерного параметра сдвига рассматривали Мартин [5.1], Мартин и Масрелнэ [4.1], Цыпкин и Поляк [2.1], Прайс и Ванделинде [5.1]. Релейные алгоритмы исследовались Бедельбаевой [5.1]. Отметим здесь различные применения робаетных алгоритмов: в радиолокации — Фелер и Мак-Карти [5.1], в метеорологии — Кливленд и Гуарино [5.1], в управлении энергосистемами — Хандшин, Швеппе, Колас и Фихтер [5.1], Гамм [5.1]. В книге Гамма [5.1] читатель найдет дополнительные ссылки на работы по робастному оцениванию. § 5.5. Частные случаи многомерных робаетных алгоритмов исследовались Поляком и Цыпкииым [3.1], [4.2], Клейнером, Мартином и Томсоном [5.1]. К ГЛАВЕ 6 § 6.1. Неминимально-фазовые системы изучаются в курсах теории линейных цепей и теории автоматического управления § 6.2. Особенности оптимальной настраиваемой модели для неминимально-фазового по возмущению объекта были выяснены в статье Цыпкина [1.3]. § 0.3. Задача нахождения распределения случайной величины после преобразования ее линейным дискретным фильтром в общем случае не имеет аналитического решения. В частных случаях так называемых устойчивых распределений закон распределения при этом не меняется. Из симметричных устойчивых плотностей, выражаемых в элементарных функциях, известны лишь нормальная плотность § 6.4. Сколь-нибудь полное рассмотрение задач по определению оптимальных и оптимальных на классе функций потерь пока наталкивается на непреодолимые препятствия. § 6,5. Сходимость линейных алгоритмов идентификации неминимально фазовых по возмущению объектов изучалась в работе Цыпкина, Аведьяна и Тулинского [6.1]. С несколько иной точки зрения идентификация неминимально-фазовых по возмущению объектов рассматривалась в работе Бен вен Иста, Гурса и Руже § 6.6, Строгое обоснование нелинейных абсолютно оптимальных и абсолютно оптимальных на классе алгоритмов к настоящему времени отсутствует. Однако приведенные примеры иллюстрируют не только работоспособность этих алгоритмов, но и их оптимальность на классе. К ГЛАВЕ 7 § 7.1. Акселериэация оценок тесно связана с регуляризацией решений так называемых некорректных обратных задач. См. книги Тихонова и Арсенина [7.1], Иванова и Васина [7.1], Федорова [7.1], а также обзор Морозова [7.1]. § 7,2. Физическая рандомизация широко применяется при решении самых разнообразных задач. Укажем на задачи суммирования расходящихся рядов (Харди [7.1], Кеменн и Снелл [7.1]), аппроксимации плохо определенных функций (Гюнтер [7.1], Хеннан [7.1]), ускорения сходимости итерационных процессов (Боголюбов и Митропольский [7.1]), поиска экстремума мкогоэкстремальных функций (Хась-минский [7.1], Катковник [1.1]), случайного поиска (Растригин [7.1]). Рандомиэация оптимального решения фигурирует в итерационных методах решений задач теории игр (Браун [7.1], Евтушенко и Жадан [7.1]), задачах векторной оптимизации (Красненкер [7.1]), задачах оптимизации в условиях неопределенности (Кап-линский, Красненкер и Цыпкин [7.1], приближенных методах решения задач дискретного программирования (Гарусин и Каплинский [7.1]). Рассматриваемая здесь рандомизация связанаспреднамеренным введением случайности. Она представляет собой искусственное рассмотрение оптимального решения как случайного, характеризуемого так называемой фидуциальной плотностью распределения («fiducial» (англ.) — основанный на вере, доверии). Кендалл и Стьюарт [1.2] пишут по этому поводу: «Фидуциальное распределение не является частотным распределением в том смысле, а каком использовалось это выражение до сих пор. Это новое понятие, выражающее интенсивность нашей веры в различные возможные значения параметра...». Фидуцнальное распределение «...можно рассматривать как распределение вероятностей в смысле степеней убежденности». Фидуциальное распределение можно также рассматривать как новое понятие, дающее формальное выражение некоторым интуитивным идеям относительно величины нашего доверия к различным значениям параметрам. О фидуциальной плотности распределения см. также § 7.3. Возможные методы учета априорной информации об оптимальном решении рассматривались в работах Жуковского и Морозова [7.1], Успенского и Федорова [7.1], Поляка и Цыпкина [7.1], Цыпкина [7.1], а также в ранее упомянутом обзоре Морозова [7.1], Эти методы, по существу, сводились к байесовскому методу или методу максимума апостериорной вероятности. § 7.6. Различные способы получения акселерантных линейных, т. е. соответствующих МНК, алгоритмов были описаны в работах Жуковского [7.1] — [7.3], Мелешко [7.1] — [7.4], Жуковского и Мелешко [7.1], Поляка и Цыпкина [7.1], Цыпкина [7.1]; см. также Моррис [7.1]. Иной путь получения акселерантных алгоритмов как линейных, так и нелинейных, основан на использовании переключающейся матрицы усиления
Такие алгоритмы обладают при Термин «акселерантный алгоритм» предложен И. § 7.7. Выбор оптимальных входных воздействий тесно связан с методами планирования эксперимента и, в частности, с последовательными рекуррентными методами планирования. Эти методы и их применения описаны в книгах Гудвина и Пейна [1.1], Круг, Сосулина и Фатеева [7.1], Хартмана, Лецкого и Шефера [7.1], а также в статьях Соколова [7.1], Аримото и Кимура [7.1], Мехры [7.1], [7.2], Аоки и Стейли [7.1], Лопес-Толедо и Атанса [7,1]. Обычно в теории планирования эксперимента используются различные скалярные функционалы матрицы типа определителя: К ГЛАВЕ 8 § 8.2. Оптимальные и оптимальные на классе алгоритмы со скалярной матрицей усиления рассматривались Поляком и Цыпкиным [3.1]. Рекуррентный способ оценивания минимальных собственных значений информационных матриц предложен и исследован Ждановым § 8.3. Усредненные алгоритмы со скалярной матрицей усиления относятся к классу двухшаговых алгоритмов. Обычно рассматриваемые двухшаговые алгоритмы не оправдали надежд на ускорение сходимости, высказанных Фу и Николичем [8.1]. Более того, их сходимость оказалась более медленной, чем для одношаговых алгоритмов. Этот факт был отмечен в работах Цыпкина [1.2], [8.1] — [8-3] и Поляка [8.1]. Эффект ускорения сходимости, достигаемый за счет надлежащего выбора коэффициента усиления основного алгоритма, изменяющегося медленнее, чем § 8.4. Алгоритмы с упрощенными градиентом и скалярной, но не оптимальной матрицей усиления, впервые рассматривались Пануской [1.1], [1.2], [8.1], Янгом [8.1], однако вне связи с абсолютно оптимальными алгоритмами. § 8.5. Алгоритмы стохастической аппроксимации при наличии коррелированных помех исследовались Портным [8.1], Девлином, Гнанадесиканом и Кеттенрингом [8.1], Фарденом [8.1], Пануской [8.2], Бородиным [8.1], Кашнером и Хуангом [1.1], Немировскнм § 8.6. Описание нелинейных систем при помощи функциональных рядов Вольтерра довольно широко используется в литературе по идентификации (см., например, книгу Ван Триса [2.1] и статью Биллингс и Факхури [8.1], а также библиографию в этих работах). Идентификации нелинейных систем посвящены, например, работы Нетравали и Фигуеиредо [8.1], Каминскаса и Яницкене [8.1] — [8.3]. § 8.8. Любопытно отметить, что на начальной стадии развития робастных рекуррентных алгоритмов часто матрица усиления Только недавно были поняты акселерантные свойства подобных алгоритмов. Численный эксперимент подтверждает эти свойства. Более того, как установлено Платоновым, Позняком, Тихоновым и Шабатиным, функцию 5 8.9. Задачи оптимизации, как это неоднократно отмечалось в литературе (см., например, Цыпкнн [8.4], Тихонов и Арсенин [7.1], Цирлин [8.1]), подразделяются на два типа. В задачах первого типа, которые естественно назвать аргументными, основной целью является нахождение точки минимума, которая предполагается единственной, а минимизируемый функционал здесь играет роль меры отличия оценки В большинстве работ по оптимизации рассматриваются задачи аргументной оптимиэаиии. Интересно отметить, что вопрос о критериальной, а не аргументной сходимости рассматривался в одной из первых работ по обоснованию детерминированных алгоритмов оптимизации Канторовичем [8.1]. Для стохастических алгоритмов критериальная сходимость исследовалась Литваковым [8.1], Девятериковым, Каплинским и Цыпкиным [8.1], Айзерманом, Браверманом и Розоноэром [1.1], Ермольевым [1.1]. Задача построения оптимальных критериальных алгоритмов оптимизации сравнительно нова. Она была поставлена и решена в работах Поляка и Цыпкина [8.1], [8.2] для непоисковых алгоритмов и в работе Цыпкина, Познлка и Песина [8.1] для поисковых алгоритмов. Задачи идентификации до последнего времени безоговорочно относились к аргументным задачам. Оптимальные критериальные алгоритмы идентификации здесь приводятся впервые. В обосновании этих алгоритмов принимали участие Б. Т. Поляк и А. В. Назин. К ГЛАВЕ 9 5 9.1. Задачи, связанные с анализом и оцениванием нестационарных объектов, возникают во многих областях человеческой деятельности. К задачам идентификации линейных объектов вида (9.1.1) относится большое число задач, связанных с изучением временных рядов в экономике (см., например, Гренджер и Хатзнака [1.1], Льюис [9.1], Лукашин [9.1], Четыркин [9.1]). Разичные модели дрейфов анализируются у Кендалла и Стьюарта [1.3]. В обзоре Цыпкина и Поляка [9.1] рассмотрены различные постановки нестационарных задач и пути их решения, приведена подробная библиография. § 9.2. Задание законов изменения параметров, т. е. дрейфа в явной и неявной формах, широко использовалось при описании нестационарных объектов. Эти описания использовались в задачах динамической стохастической аппроксимации, введенной в работах Дупача [9.1], [9.2]. Развитию этого направления посвящены работы Фигуеиредо [9.1], Чиена и Фу [9.1], Цыпкина [9.1], Цыпкина, Каплинского и Ларионова [9.1], Катковника и Хейсина [9.1], Хейсина [9.1], Рупперта [9.1], Сугиява и Уосаки [9.1], Станковича [9.1], Теодореску и Вольфа [9.1] и др. Используемые в этом параграфе понятия согласованной настраиваемой модели и вектора чувствительности были введены в гл. 1. Условие оптимальности (9.2.16) и алгоритмы идентификации нестационарных объектов вида (9.2.17) были получены в статье Цыпкина [9.2]. §9.3. Оптимальные алгоритмы в форме (9.3.31) были введены в работе Цыпкина [9.1]. Сходимость различных частных случаев линейных алгоритмов, соответствующих § 9.4. Оптимальные и абсолютно оптимальные алгоритмы идентификации нестационарных объектов введены Цыпкиным и Поляком [9.1] и Цыпкиным [9.1]. Там же вводится термин <многошаговые алгоритмы). Алгоритмы типа расширенного фильтра Калмана рассматривались в работах Катковника и Хейсина [9.1], Не и Янга [9-1]. В статье Миянага, Мики и Наган [9.1] авторы применяют алгоритм типа расширенного фильтра Калмана для оценивания нестационарных параметров и входных возбуждений в ARMA-системе при синтезе речевых сигналов. Доказательству сходимости и асимптотической нормальности линейных алгоритмов посвящена статья Бондаренко и Лозняка [9.1]. Другой подход, не требующий использования в явном виде модели дрейфа, может быть основан на выборе постоянного коэффициента усиления в алгоритме идентификации. Этому направлению посвящены работы Бенвениста и Руже [7.1], Назина и Юдицкого [9.1] и § 9.5. Многошаговые алгоритмы особенно эффективно работают при полиномиальных дрейфах параметра. В связи с этим вызывает интерес работа Женга [9.1], в которой применяется локальная аппроксимация нестационарностей полиномами Тейлора. § 9.6. Скалярные упрощенные алгоритмы в литературе ранее не рассматривались. В связи с приведенным в этом параграфе примером заслуживают внимания работы Аленгрина, Барло и Менеза [9.1] и Чанга, Янга и Ванга [9.1], в которых предложено представлять нелинейный дрейф в виде разложения по полной ортогональной системе функций (полиномы Тейлора, Лежандра, ряды Фурье и др.). § 9.7. При негауссовеких помехах алгоритмы (9.7.6) становятся робастными. Робастные алгоритмы рассматривались в работе Ковачевича и Станковича [9.1], однако полученные в этой работе алгоритмы не являются оптимальными. К ГЛАВЕ 10 § 10.1. Среди большого числа работ, заложивших основы теории искусственных нейронных сетей, отметим работу Мак-Кулочаи Питса [10.1] и книги Хебба § 10.2. Структуры нейронных сетей довольно подробно описаны в работе Нарендры и Партасарати [10.1], в которой основное внимание уделяется статическим и динамическим многослойным нейронным сетям. Различные подходы к описанию структур нейронных сетей можно найти в работе Хопфилда [10.1], в трудах международного симпозиума «Модели нейронных структур» (см. Трапезников [10.1]), в книге Свечникова и Шквар [10-1] и др. § 10.3. Процедура расчета в обратном направлении (Back Propagation) была предложена в работе Румельхарта, Хинтона и Вильяме [10.1]. Ее обобщение на случай комплексных коэффициентов и сигналов приведено в работе Леунга и Хайкина [10.1]. Эта процедура в некотором смысле сходна с вычислениями, возникающими в условиях оптимальности дискретных систем (см., например, Пропой [3 0.1]). § 10.4. Обычно применяемые алгоритмы настройки нейронных сетей представляют собой алгоритмы типа стохастической аппроксимации со скалярным коэффициентом усиления вида
|
 |
Оглавление
|









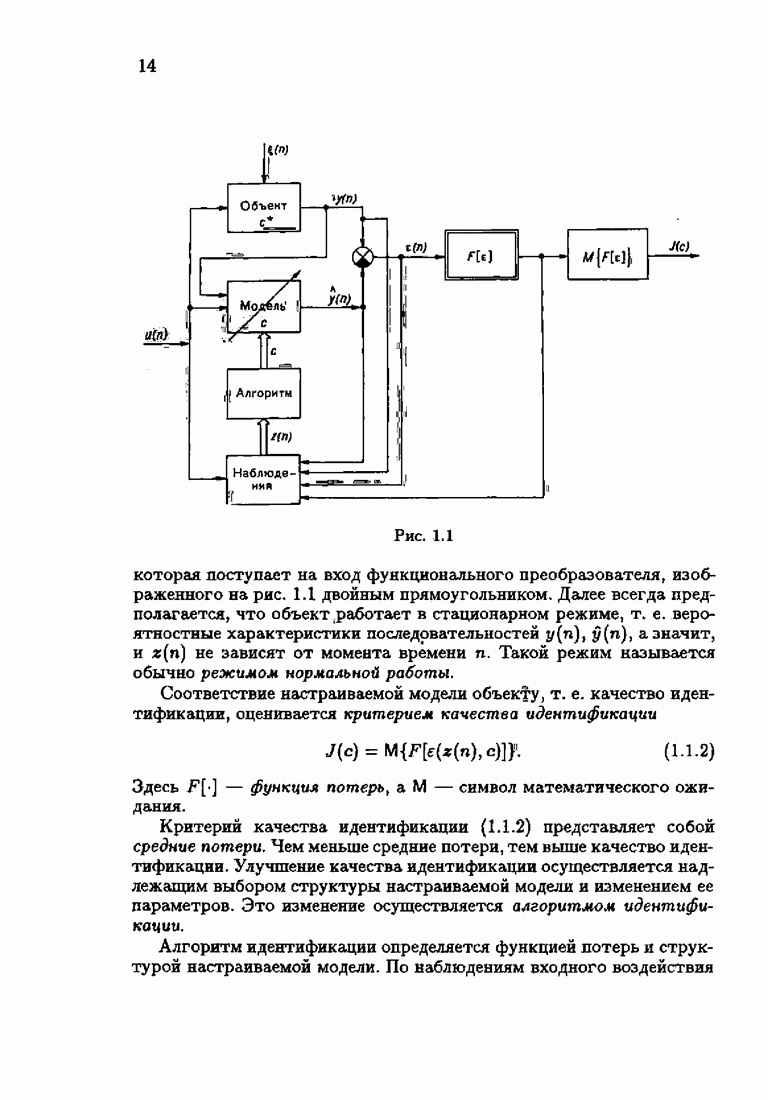
















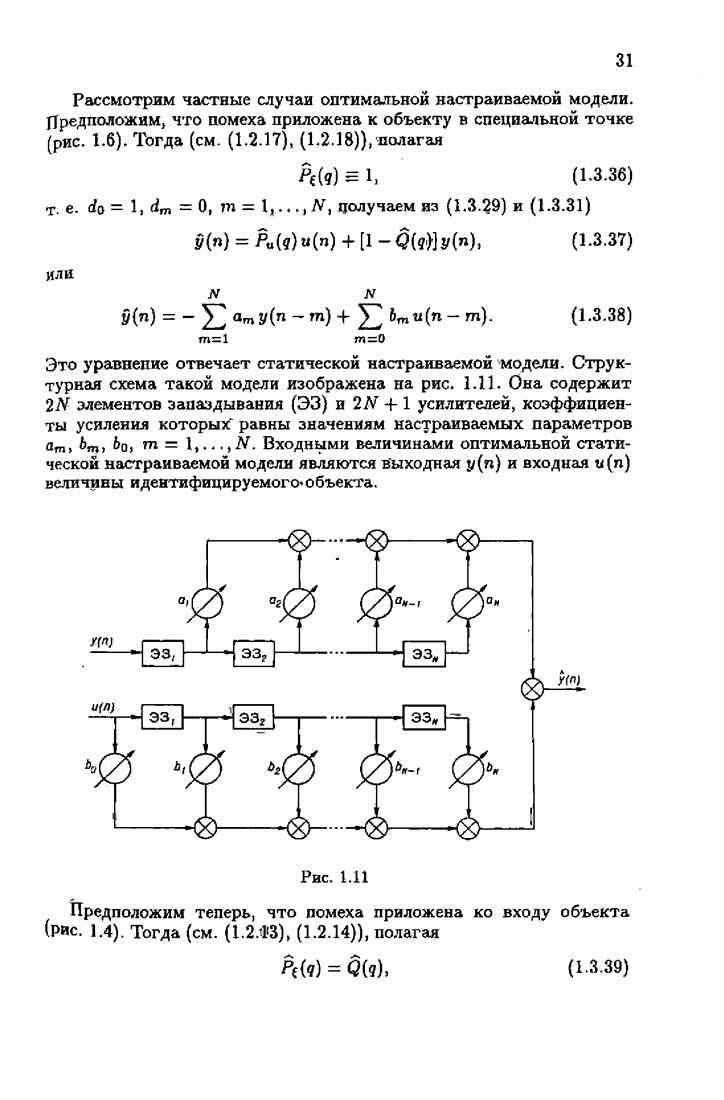
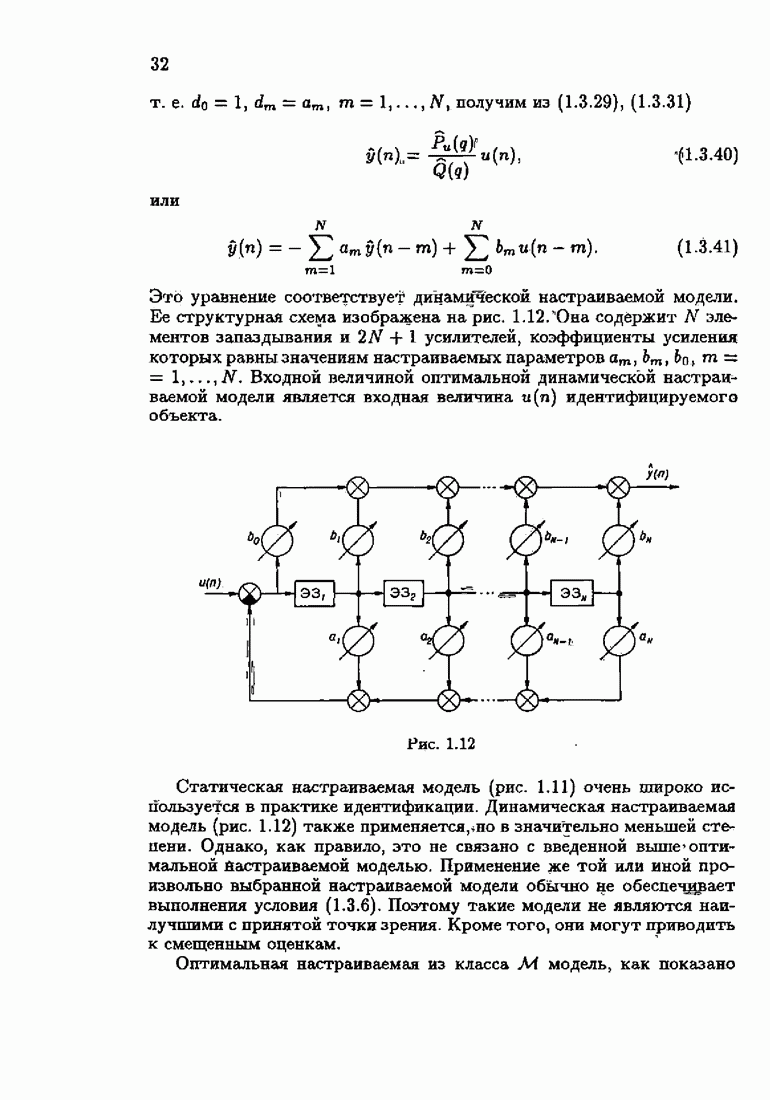






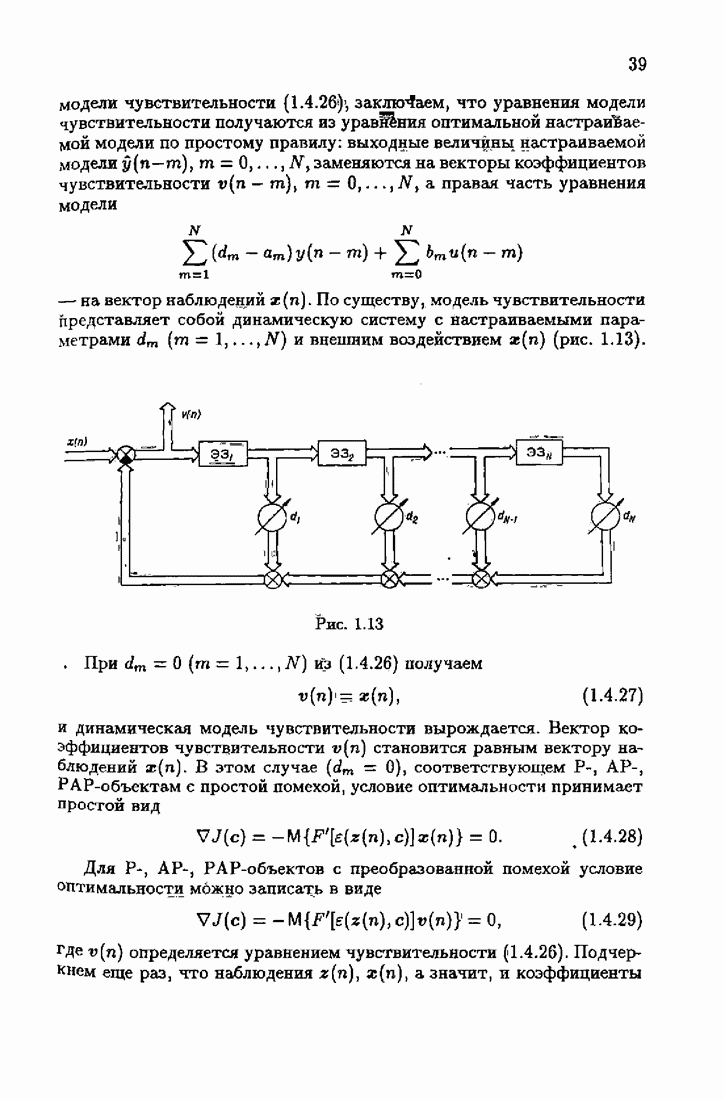













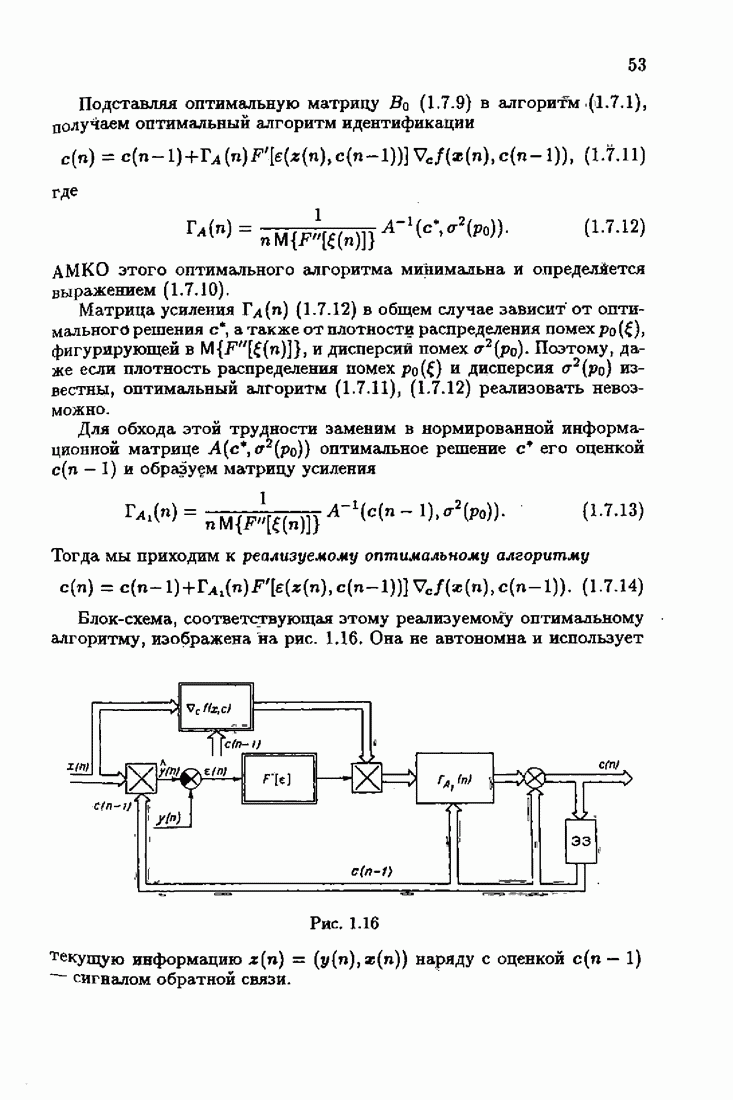


















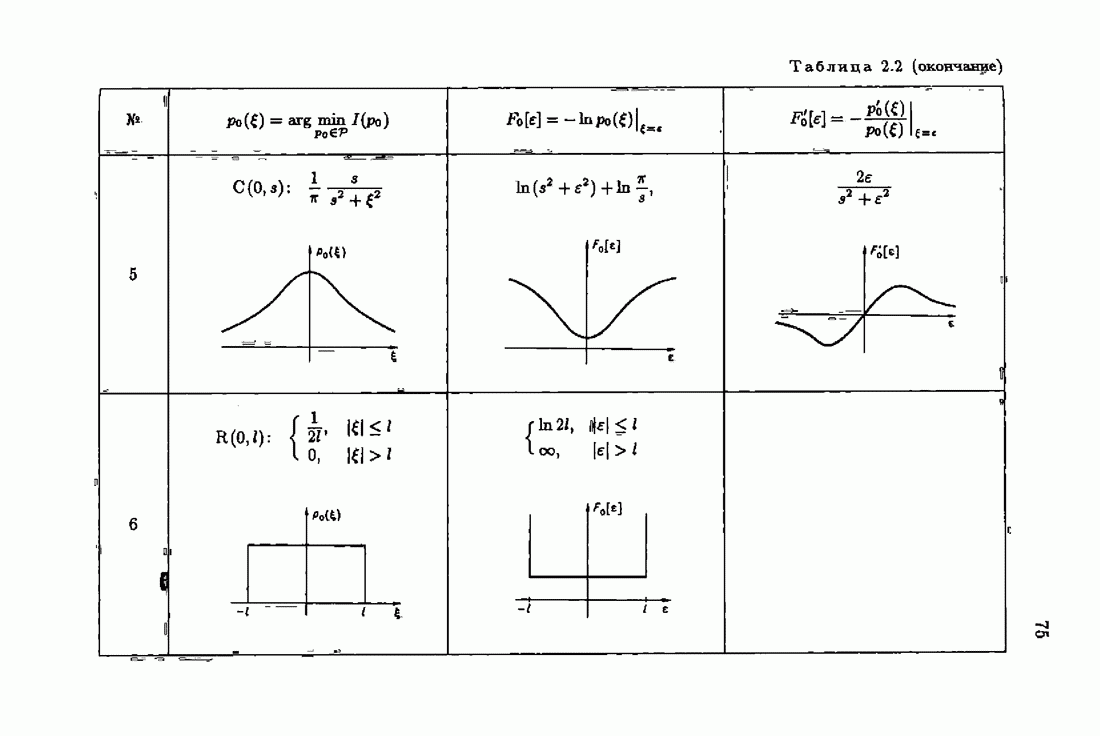








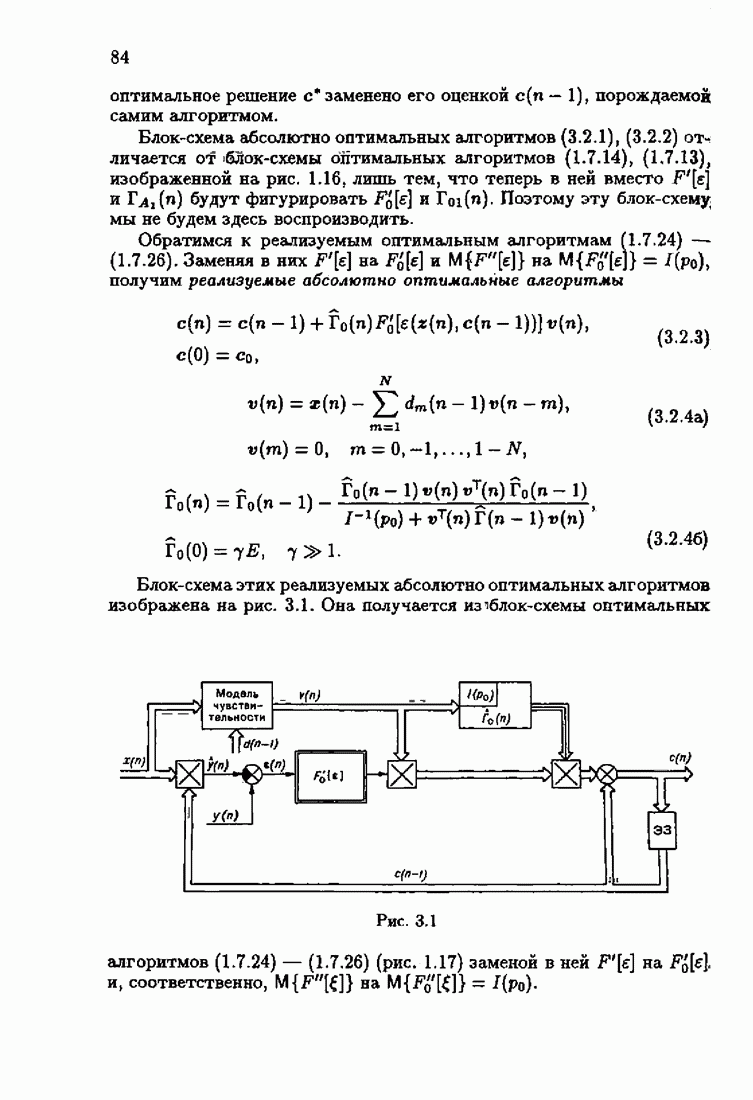
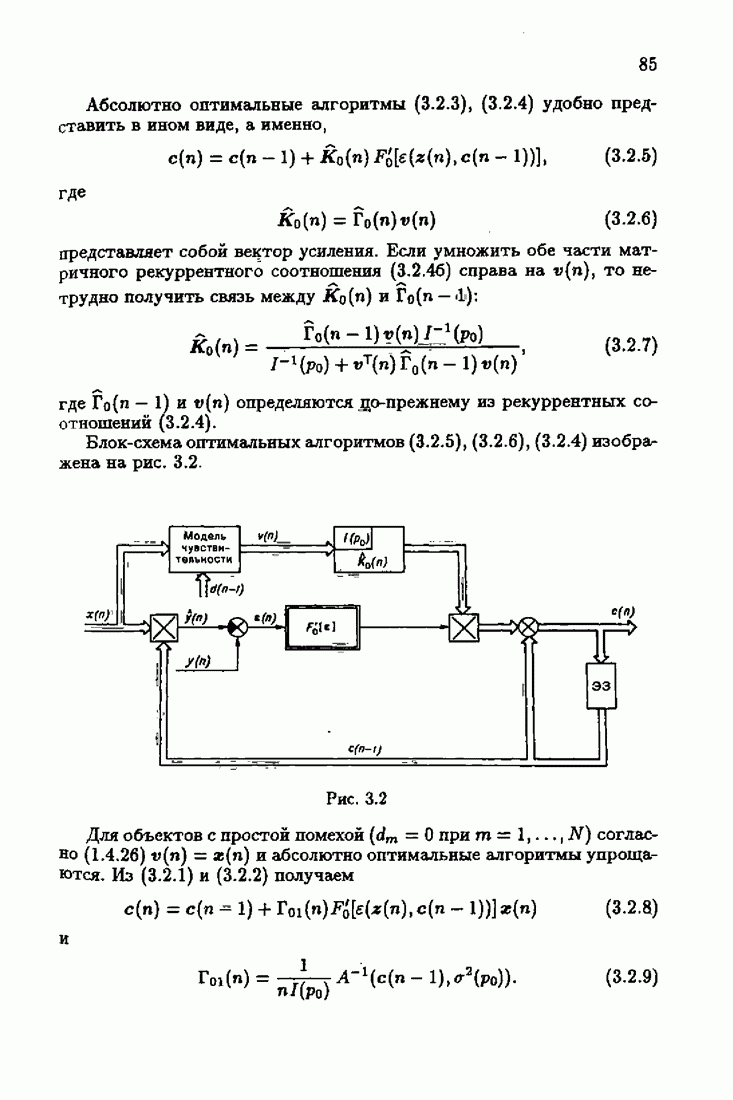
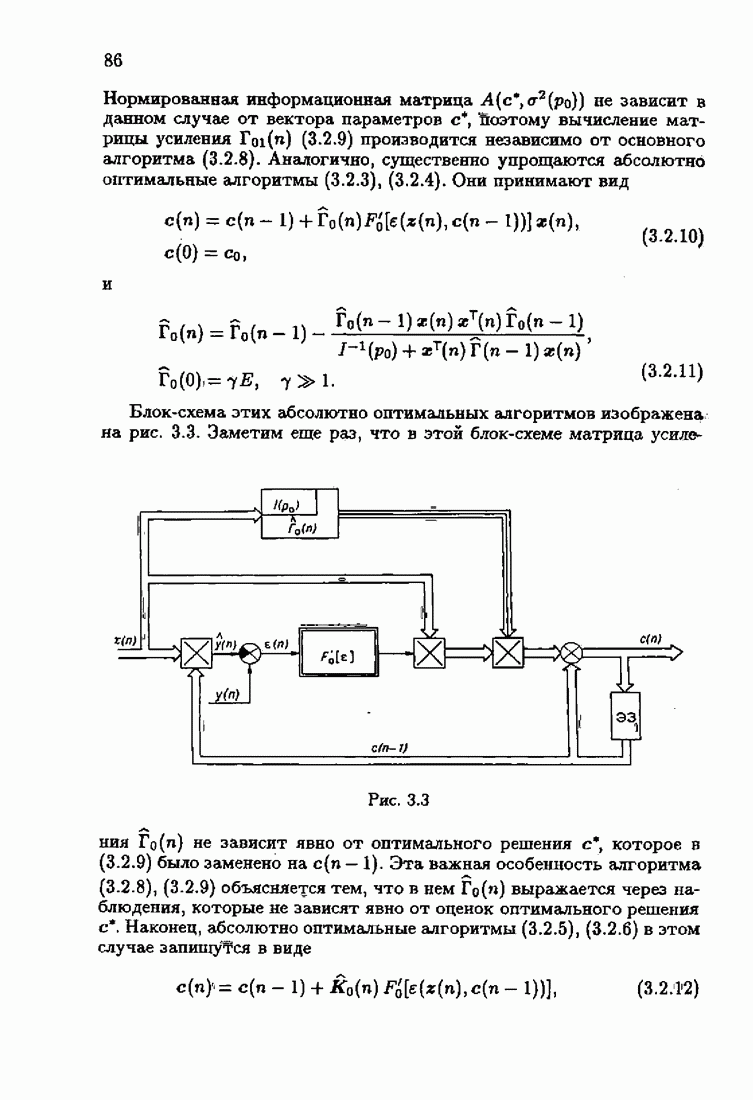
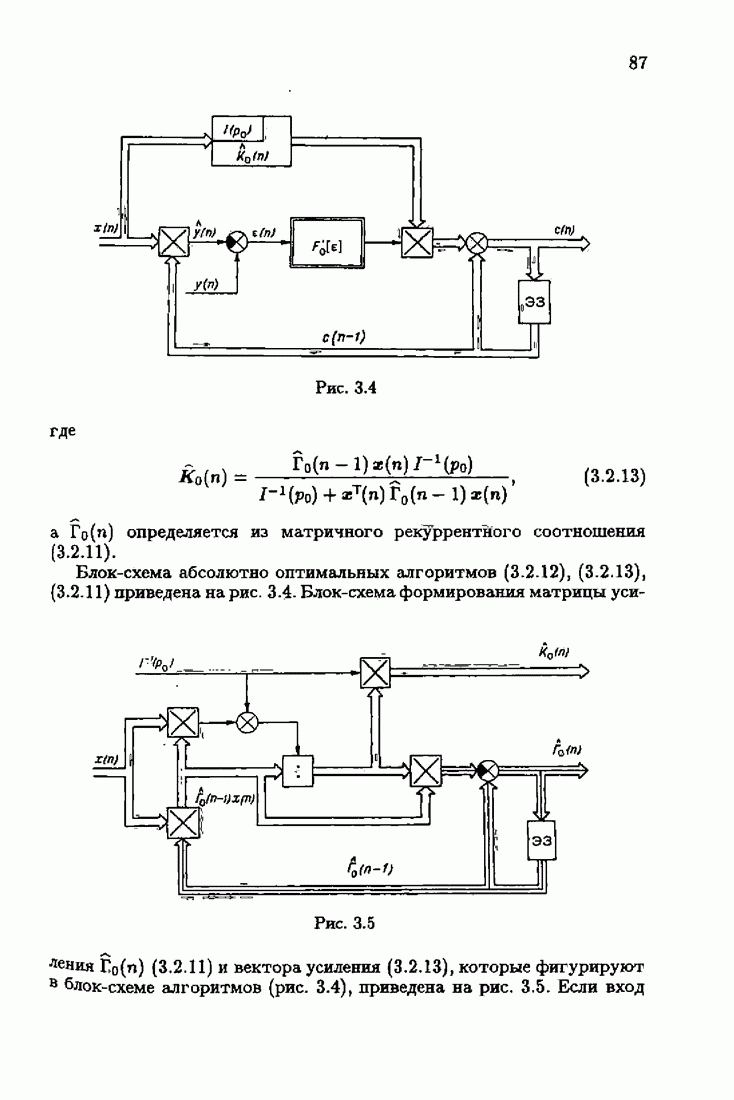






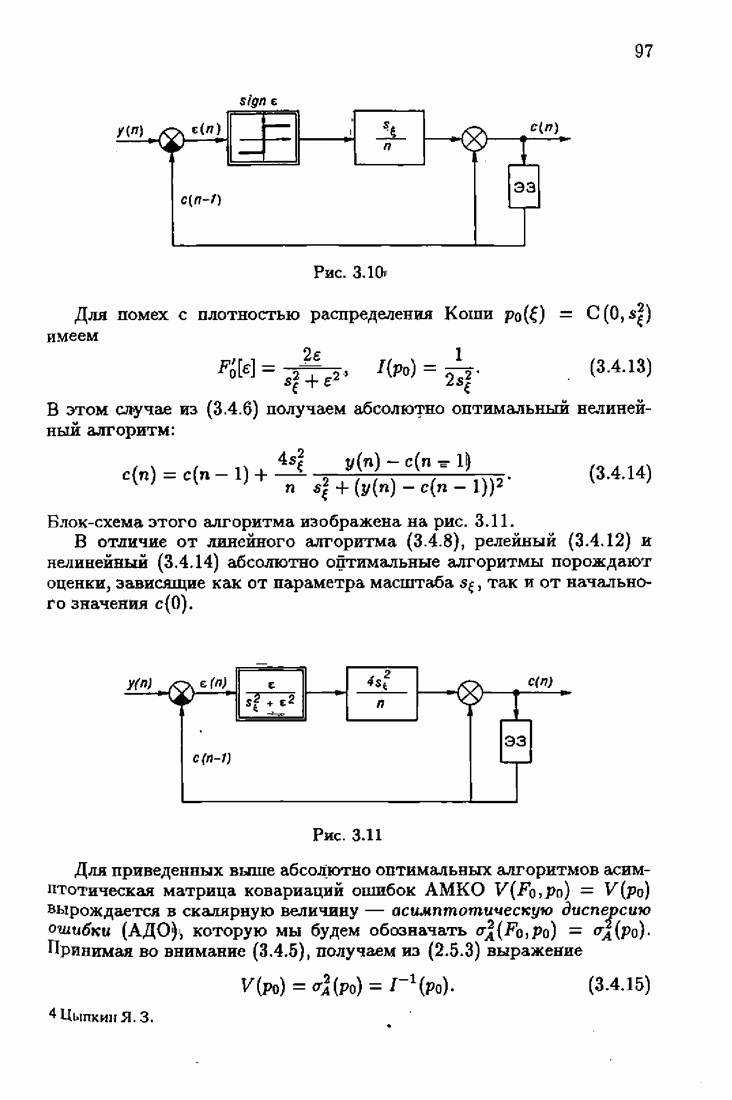



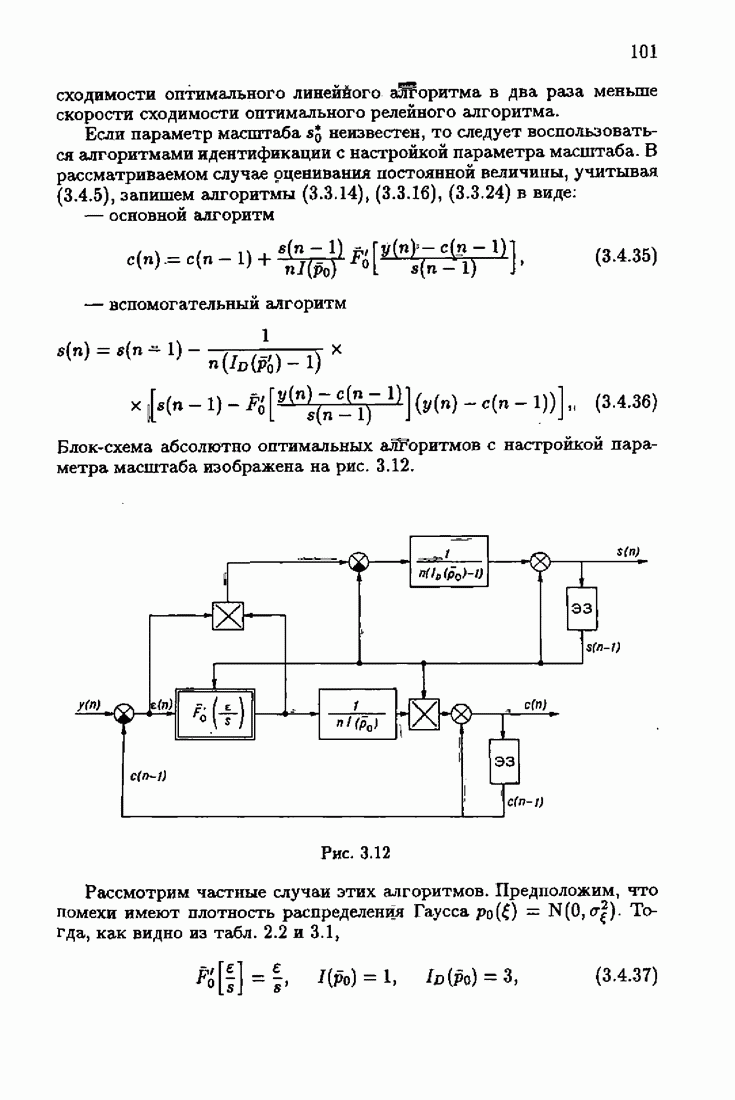
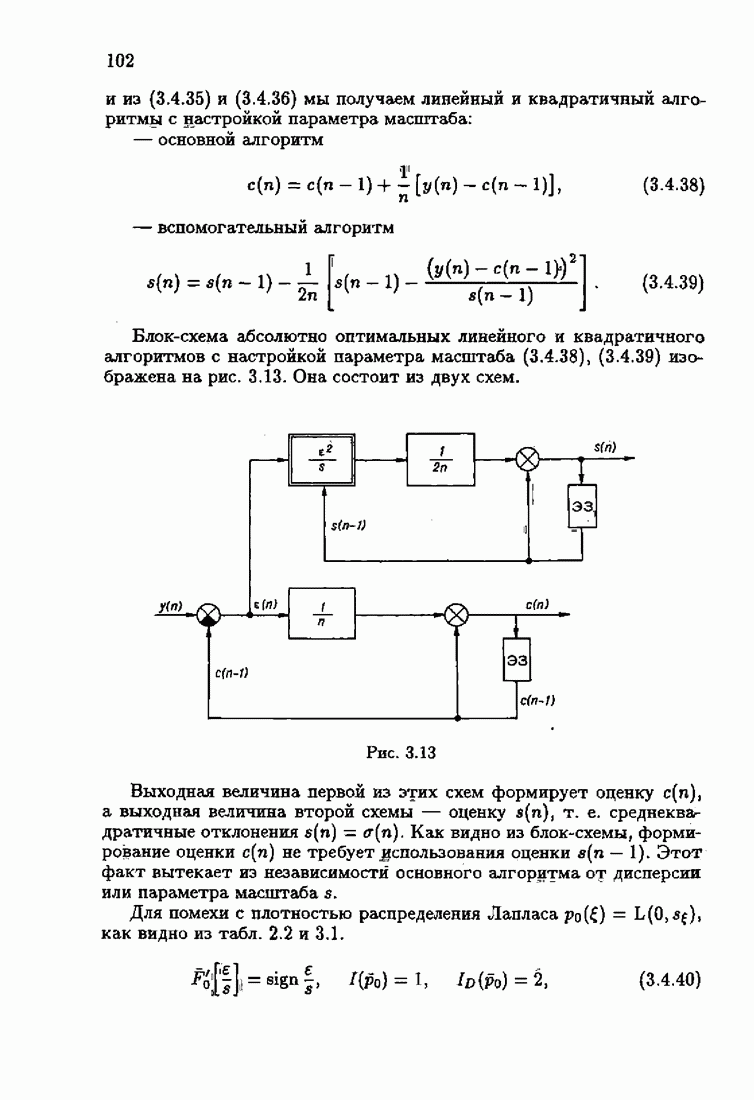
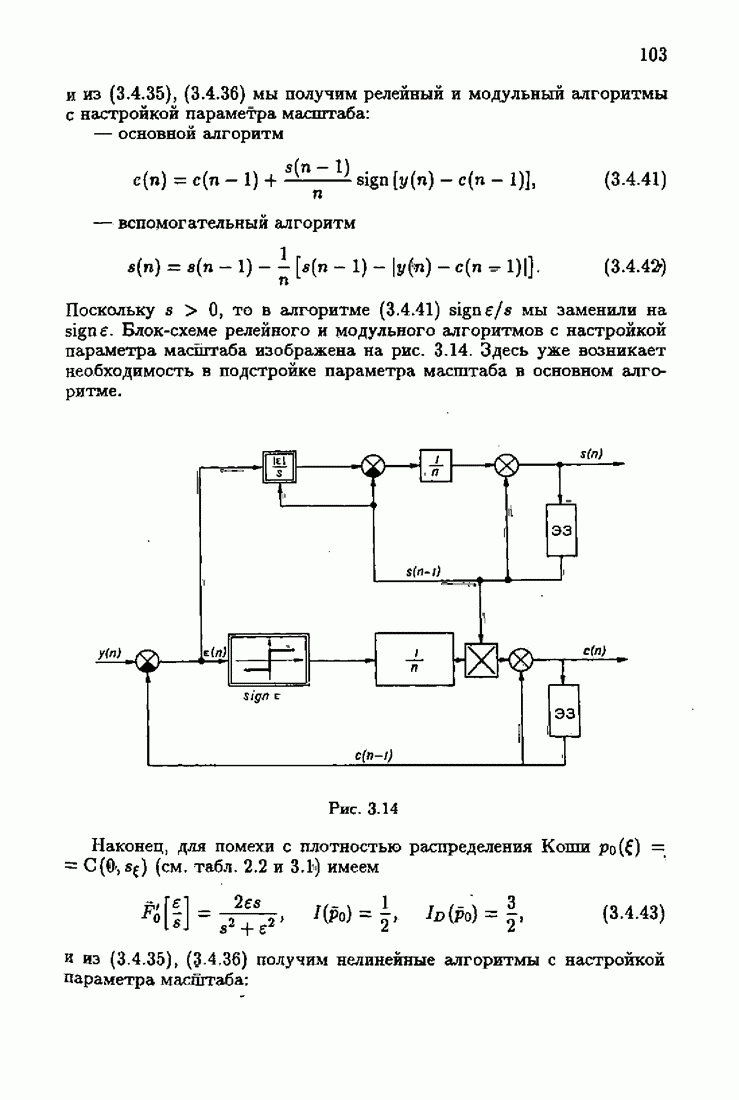
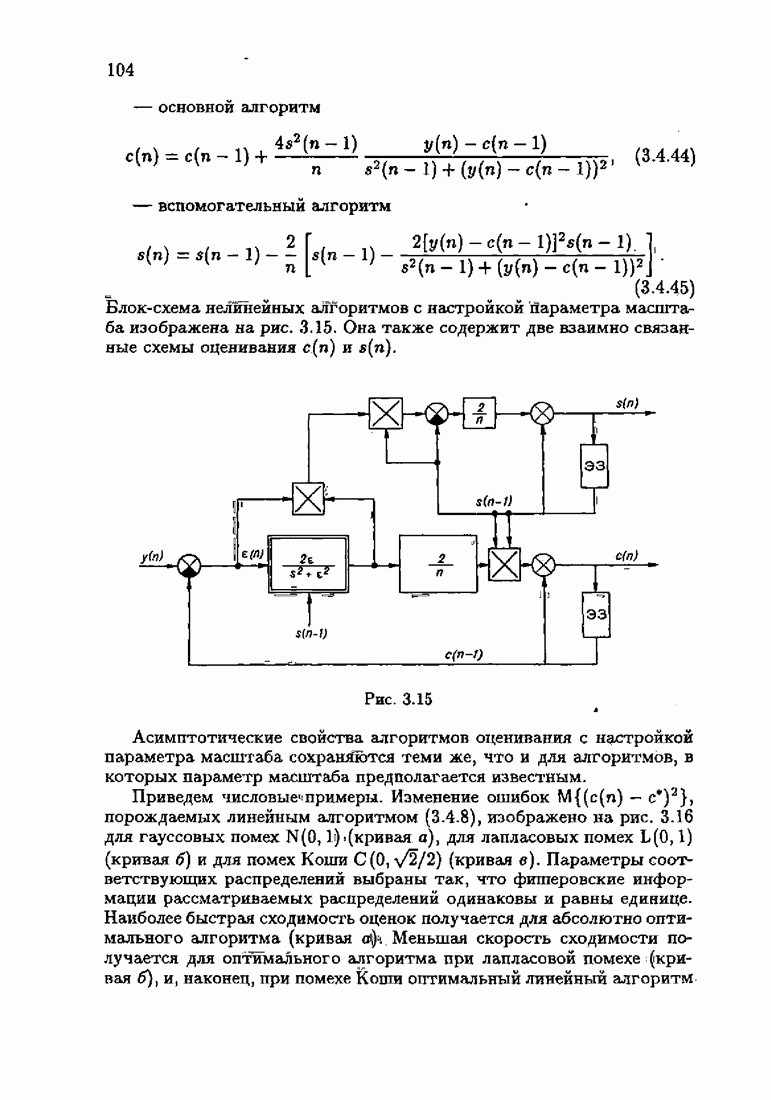



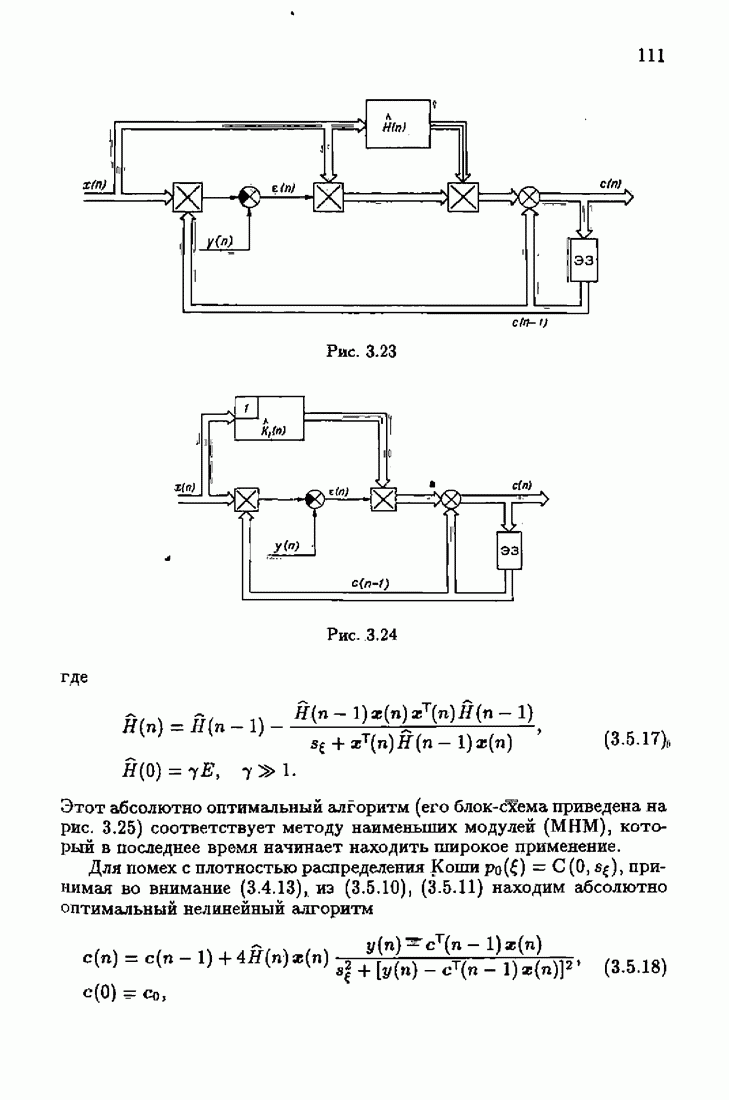
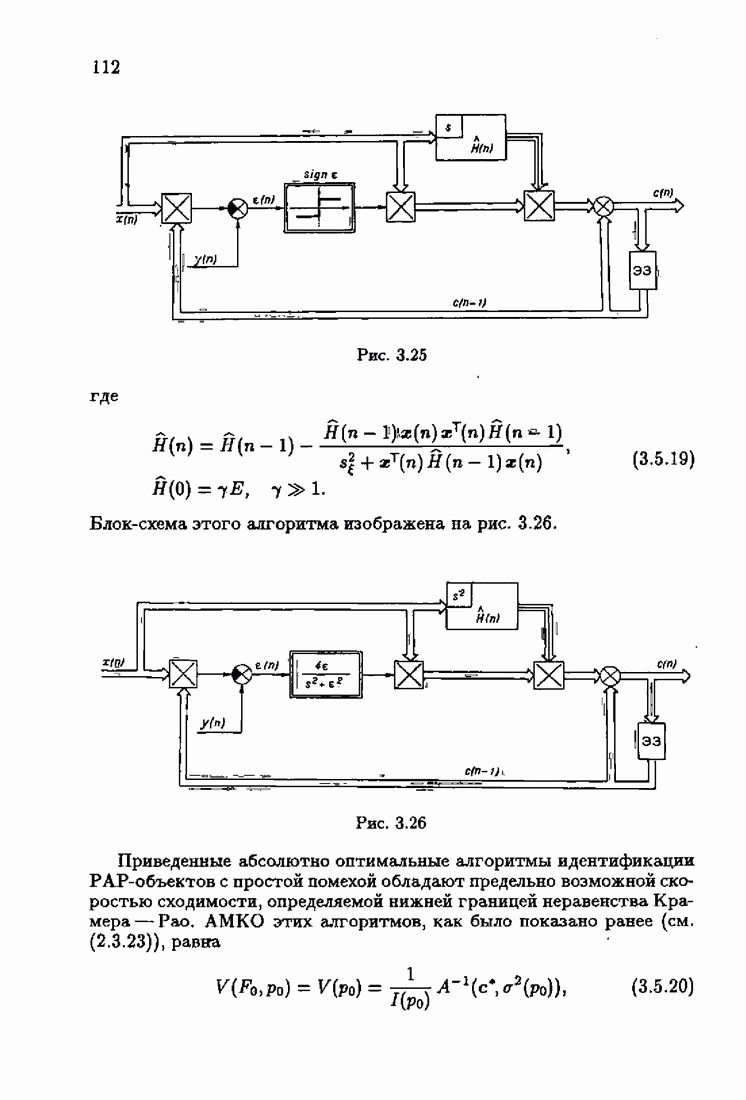



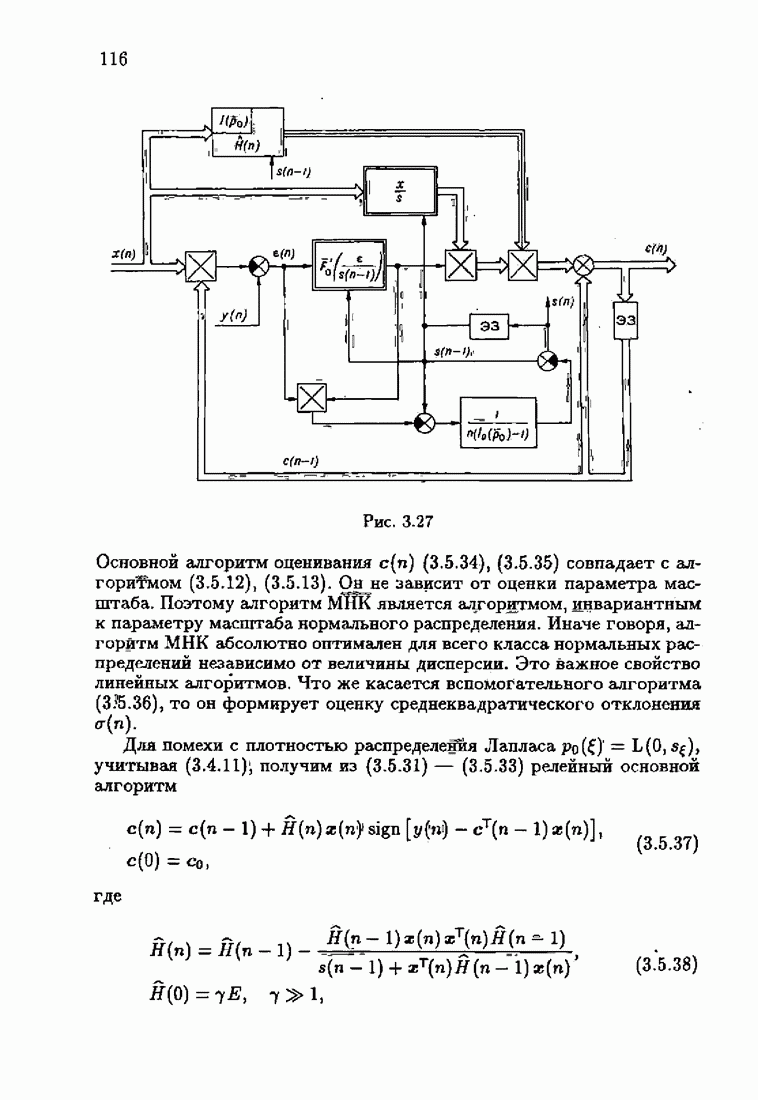
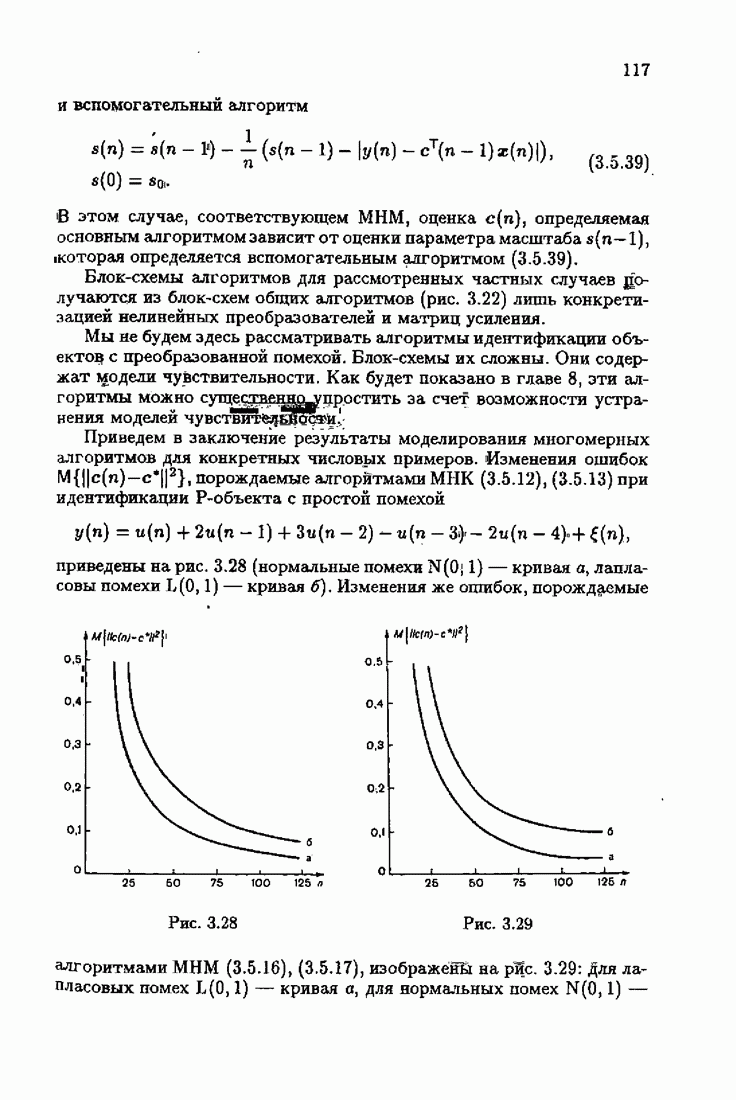
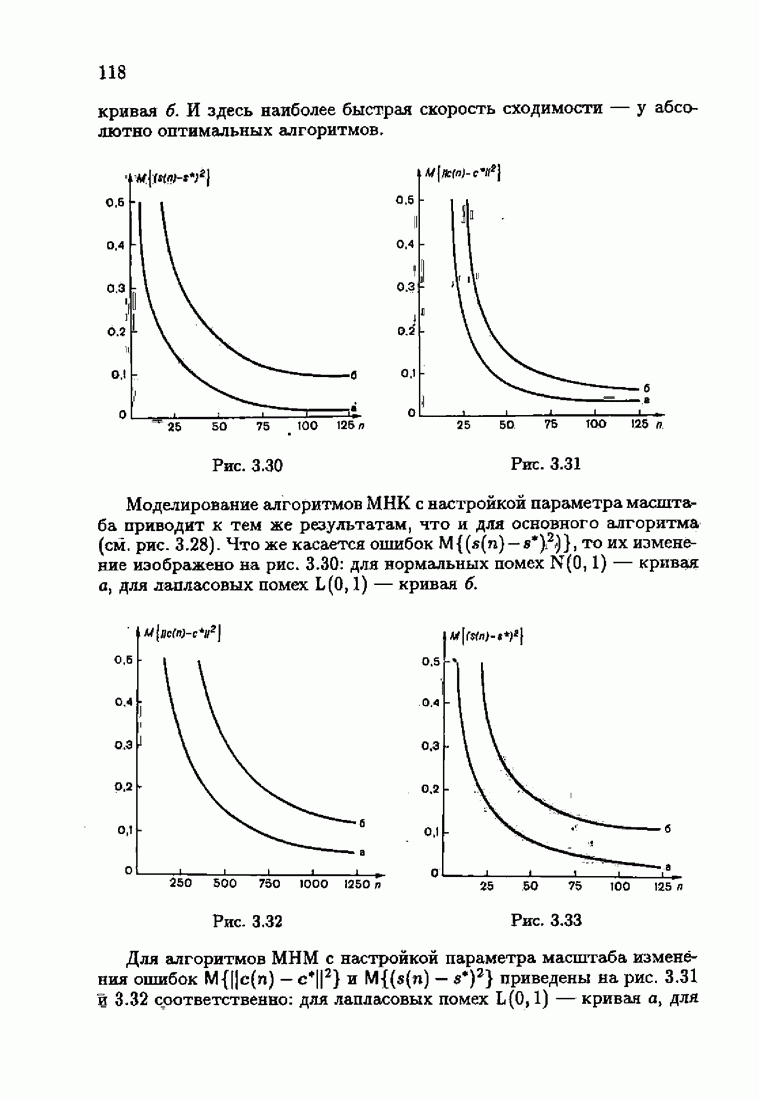




























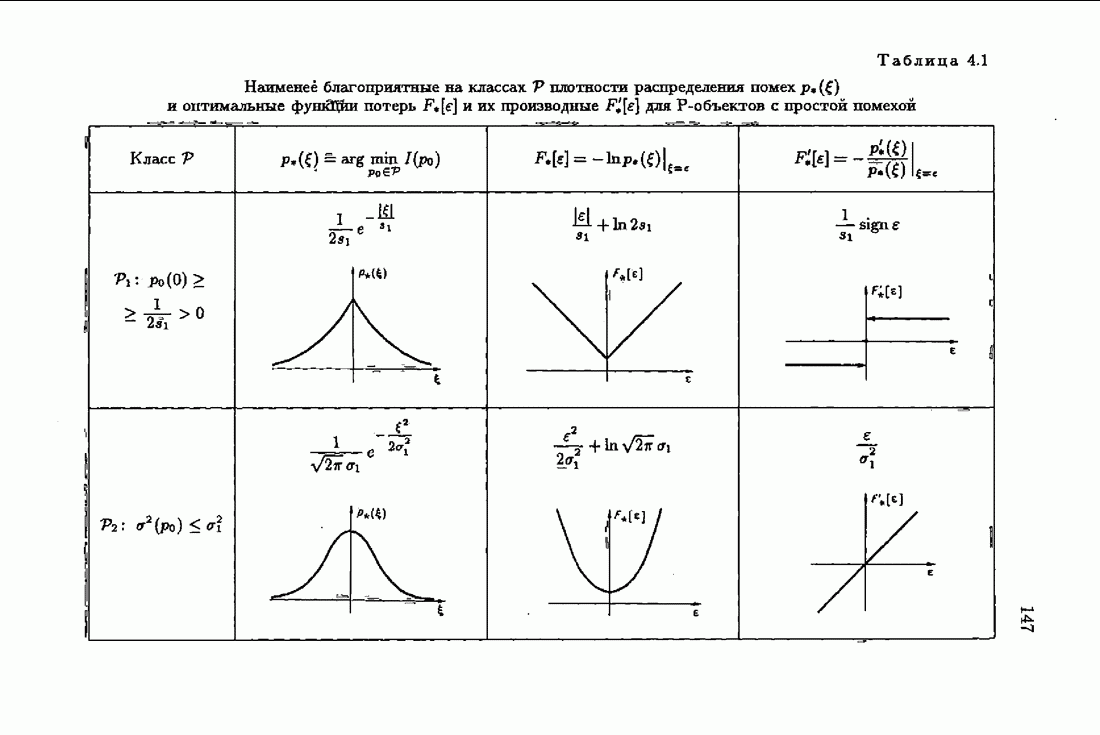



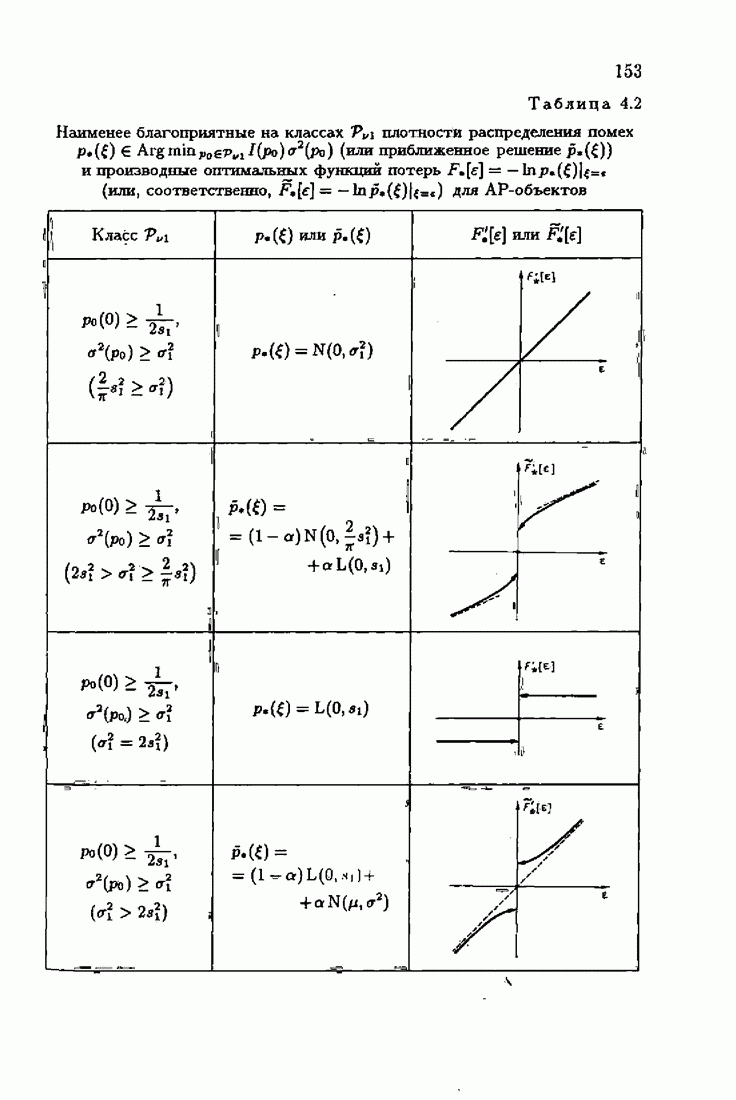
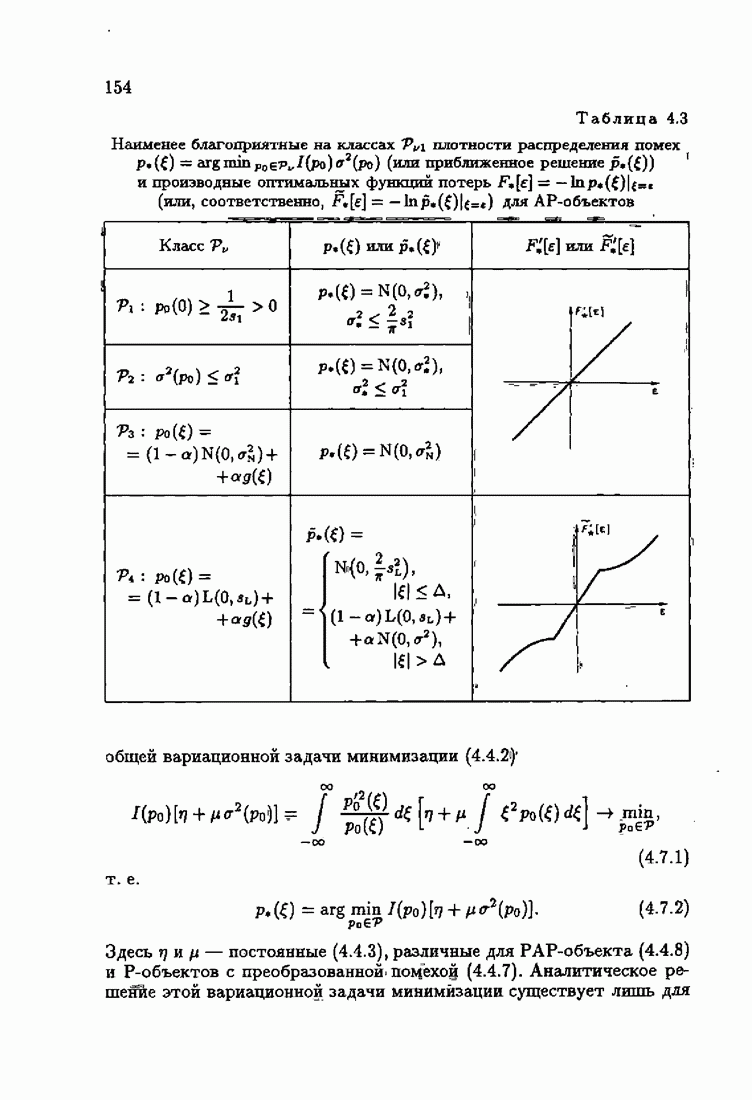


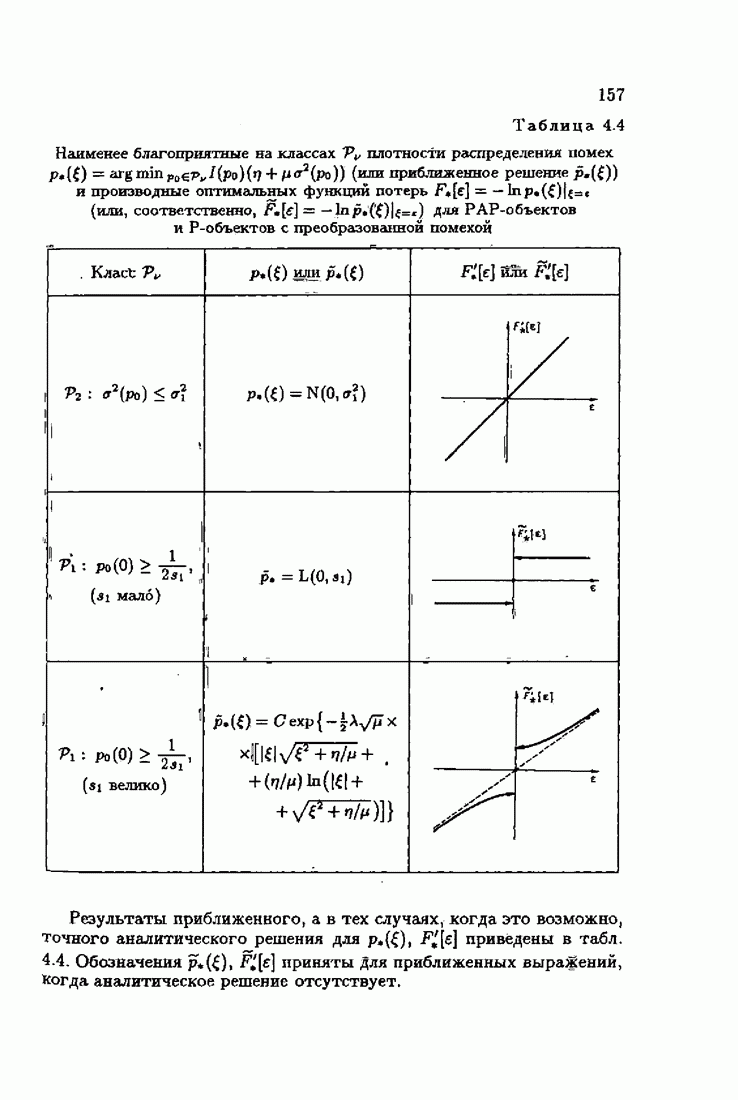











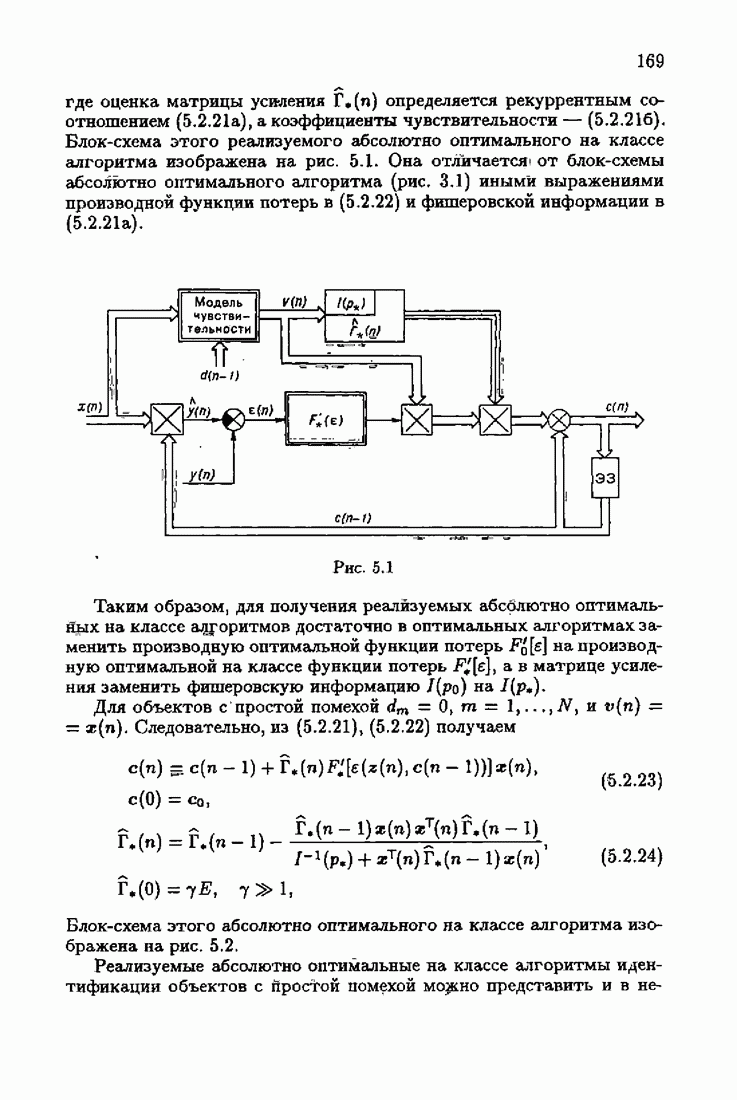
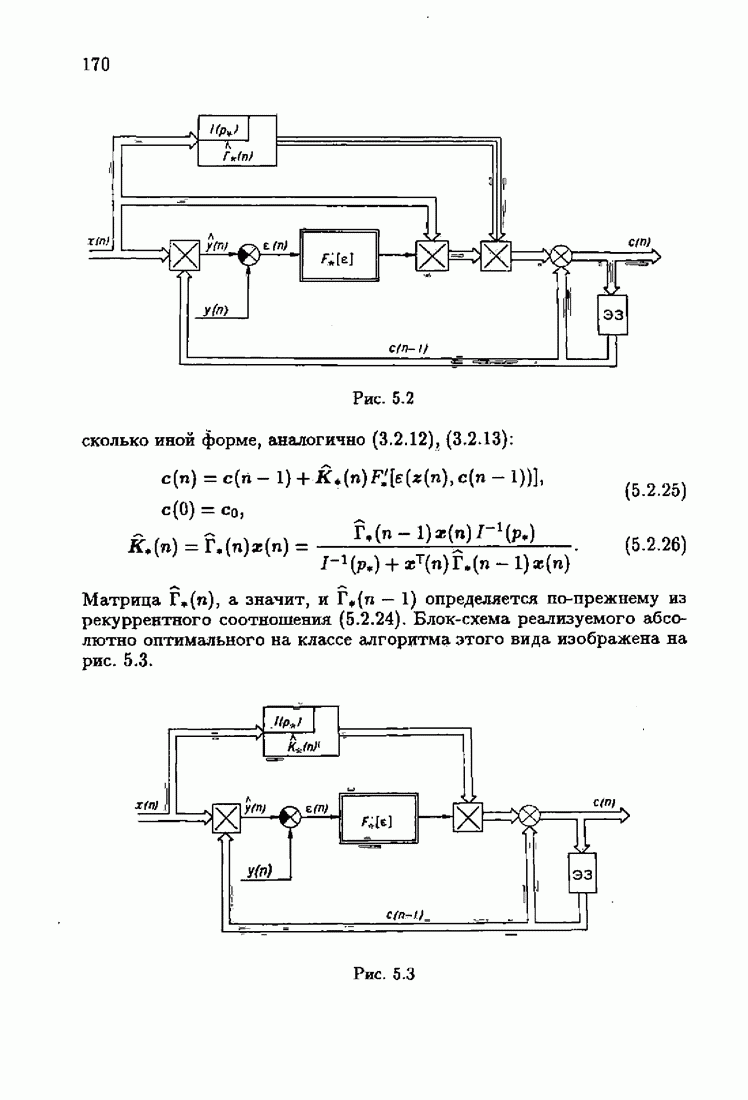

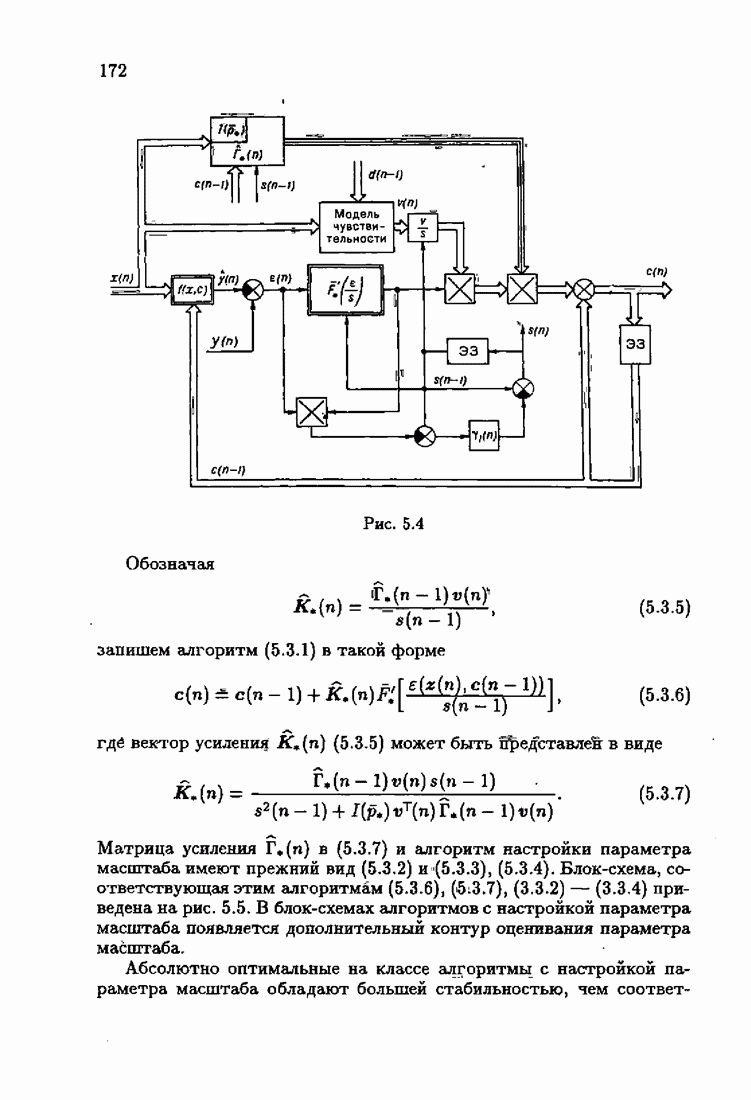
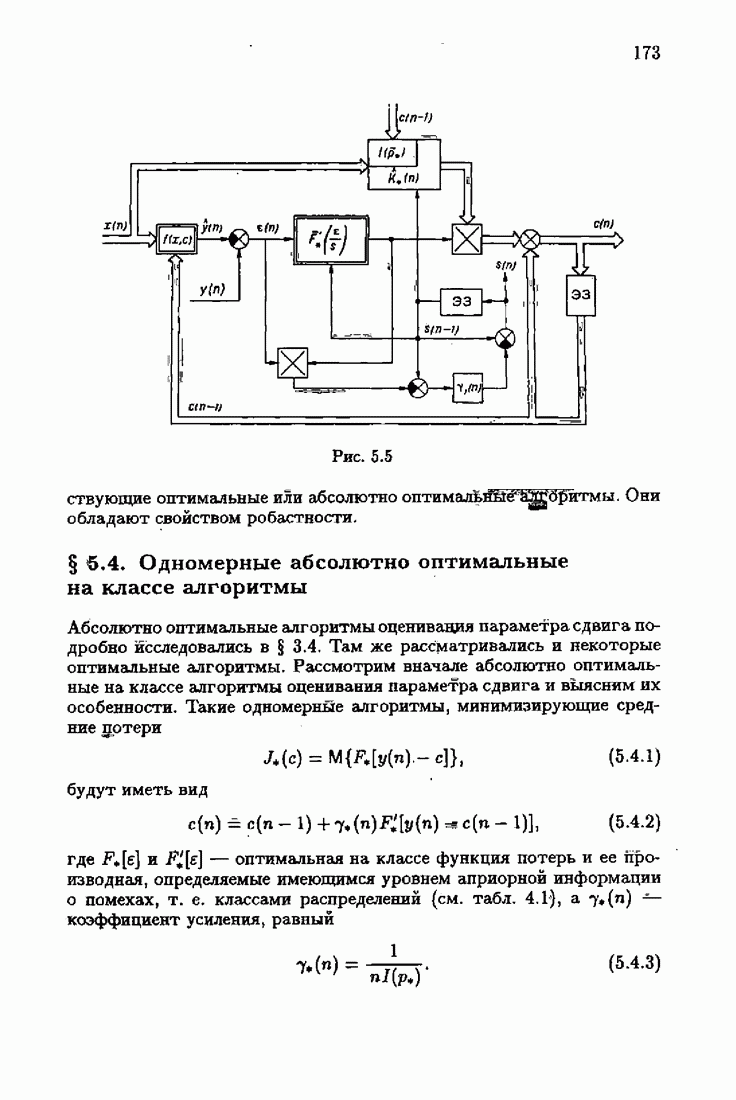




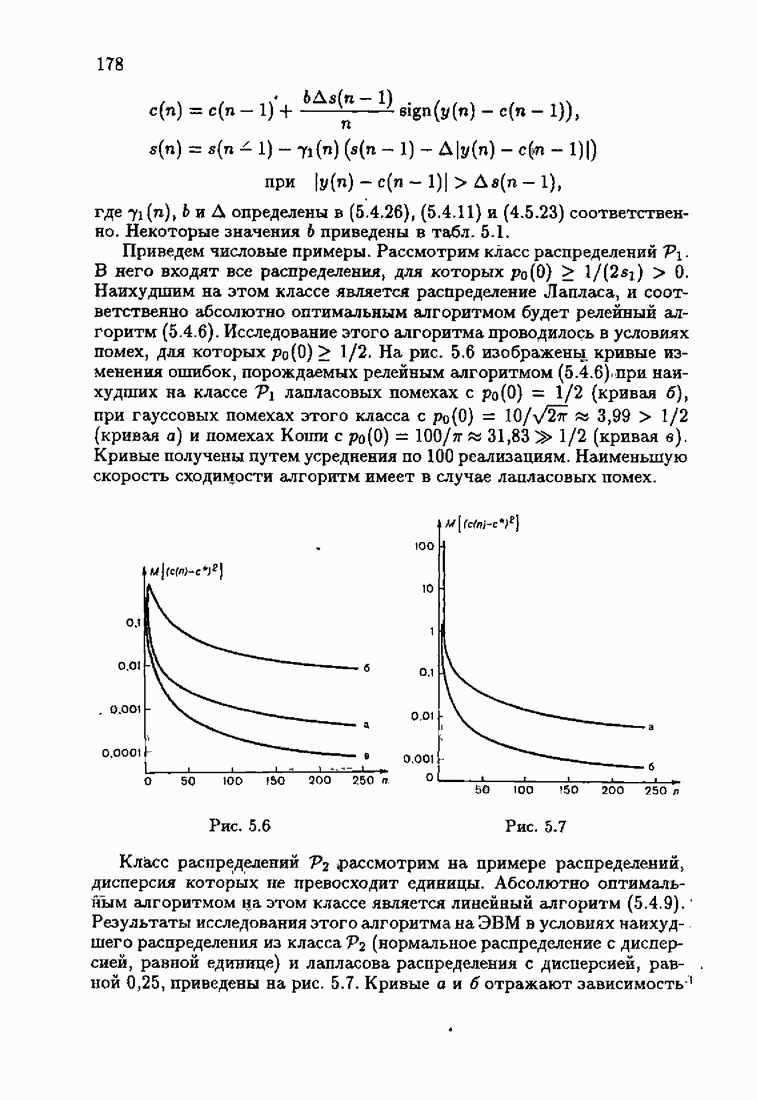
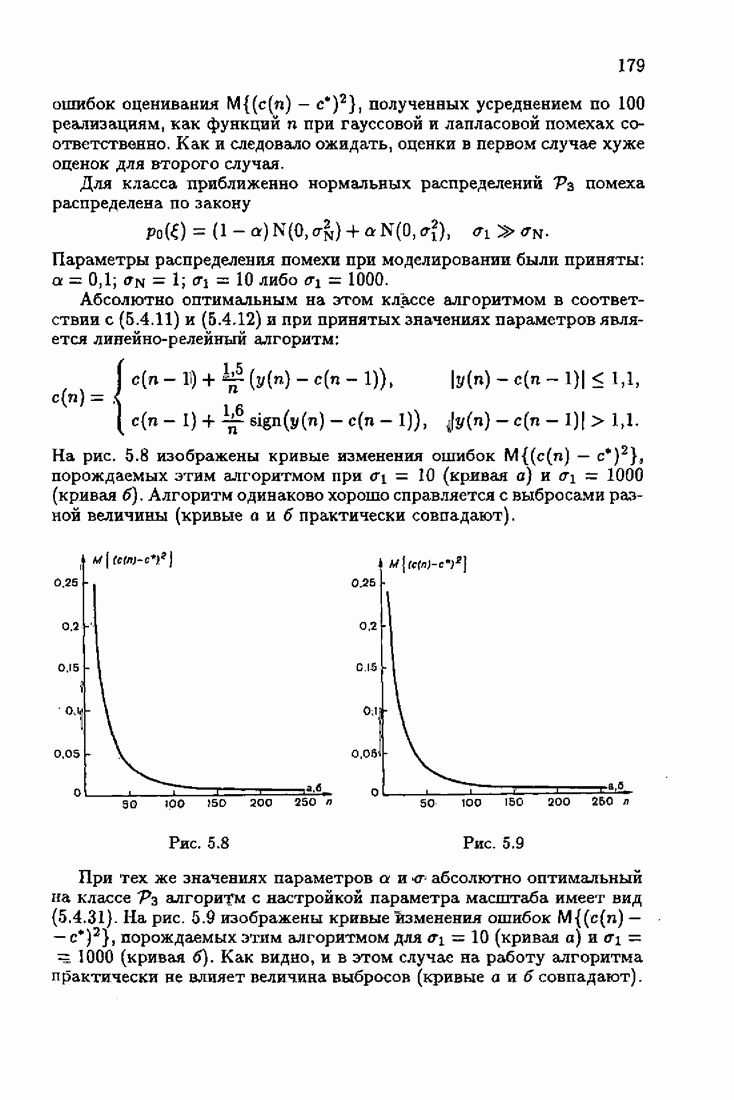
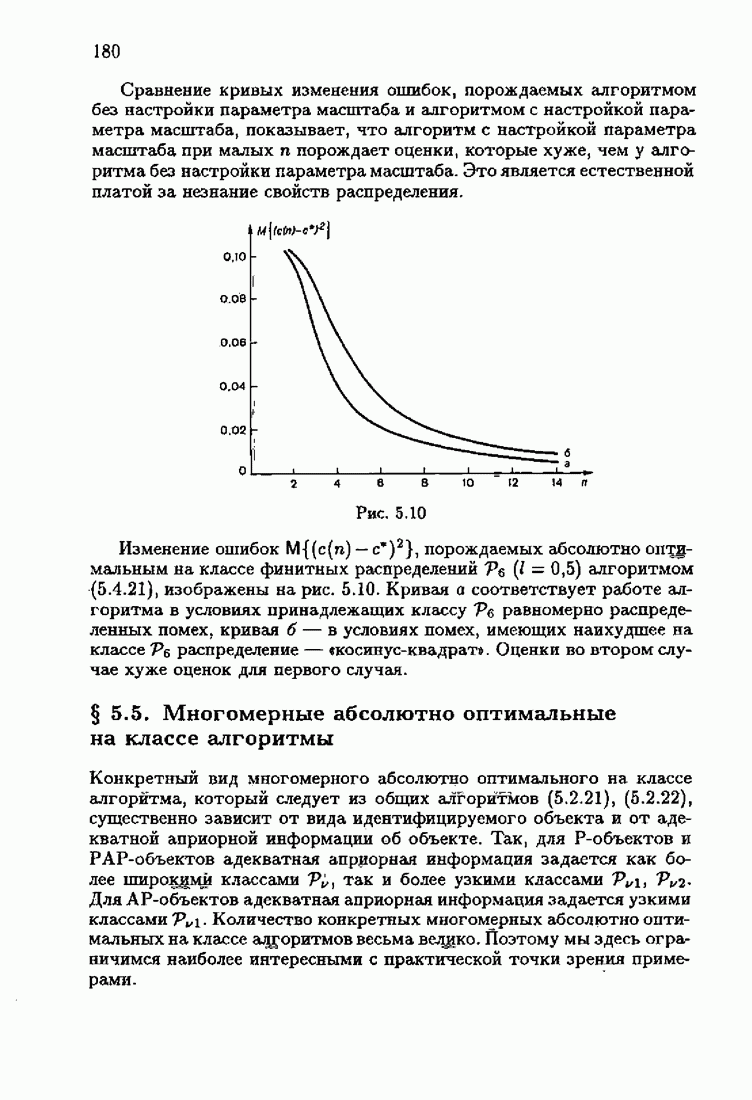

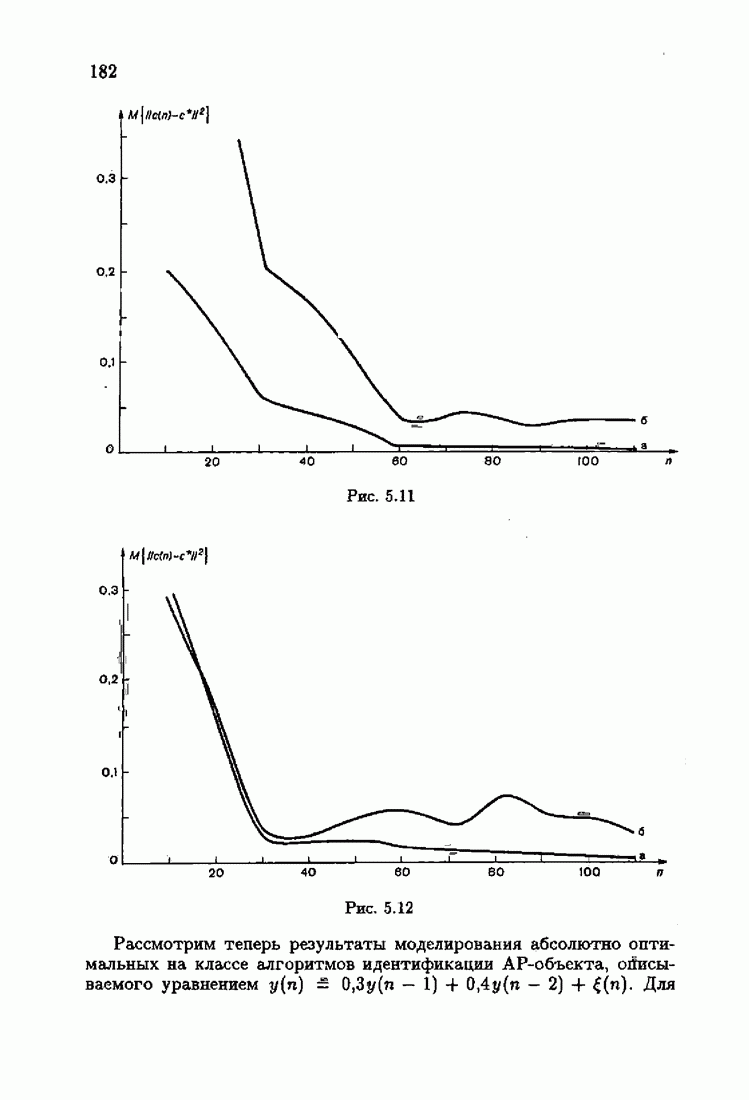
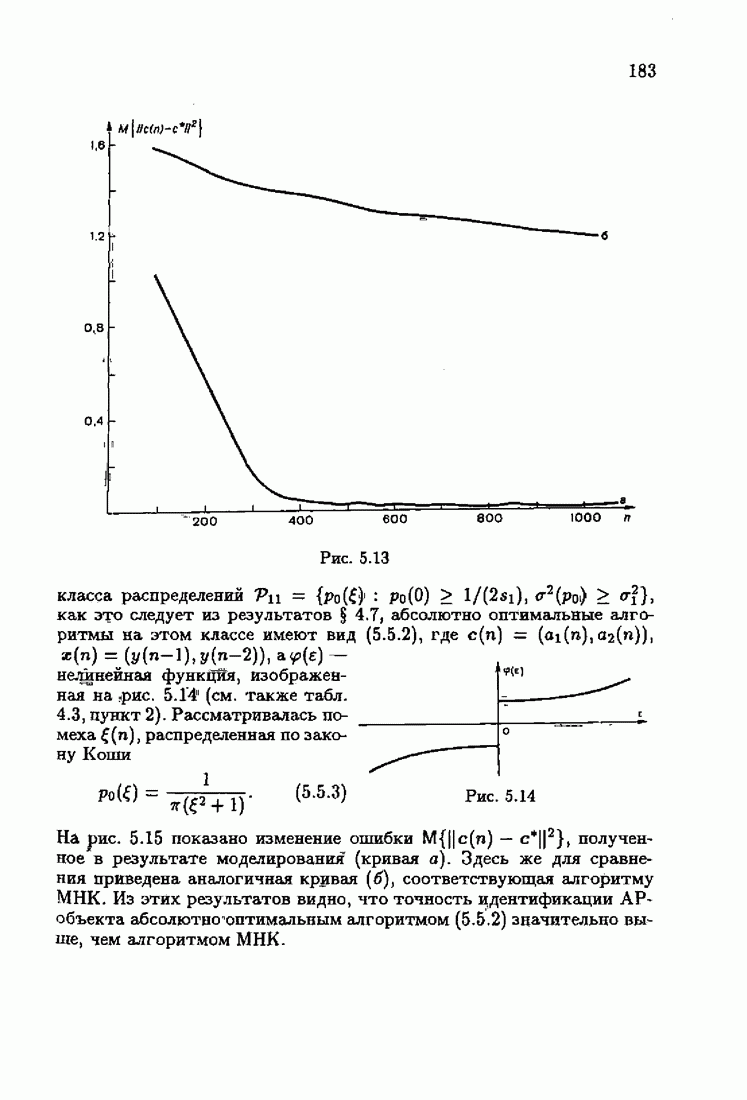
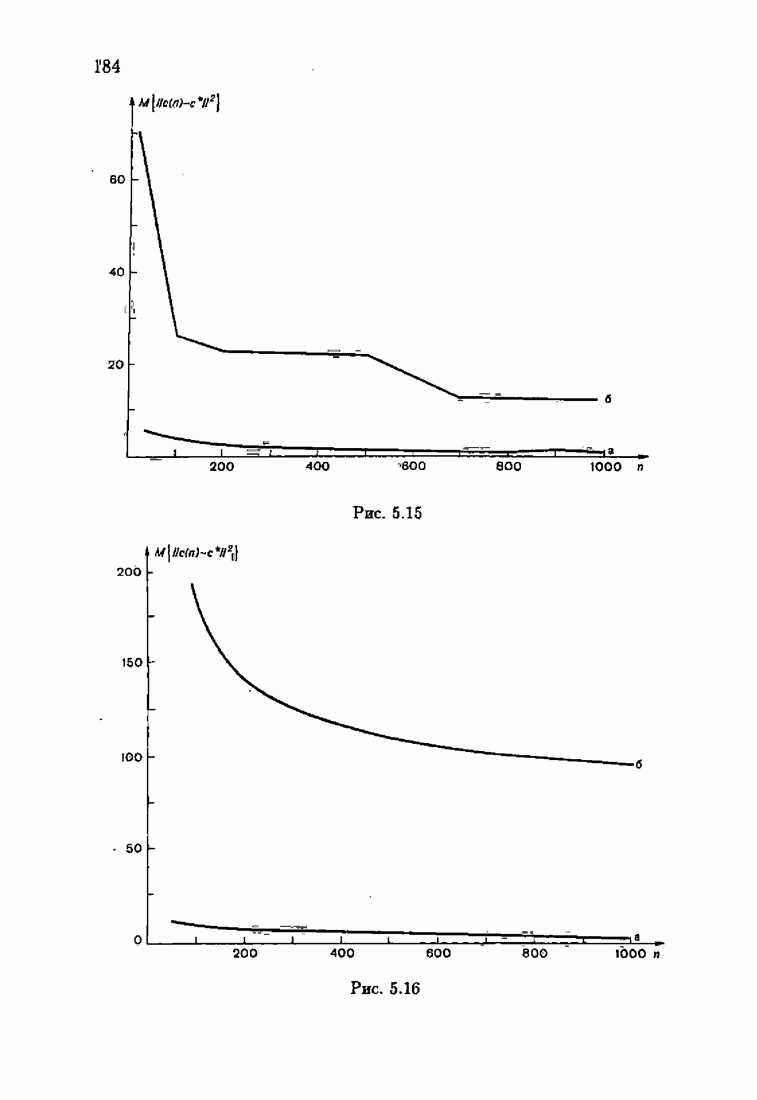















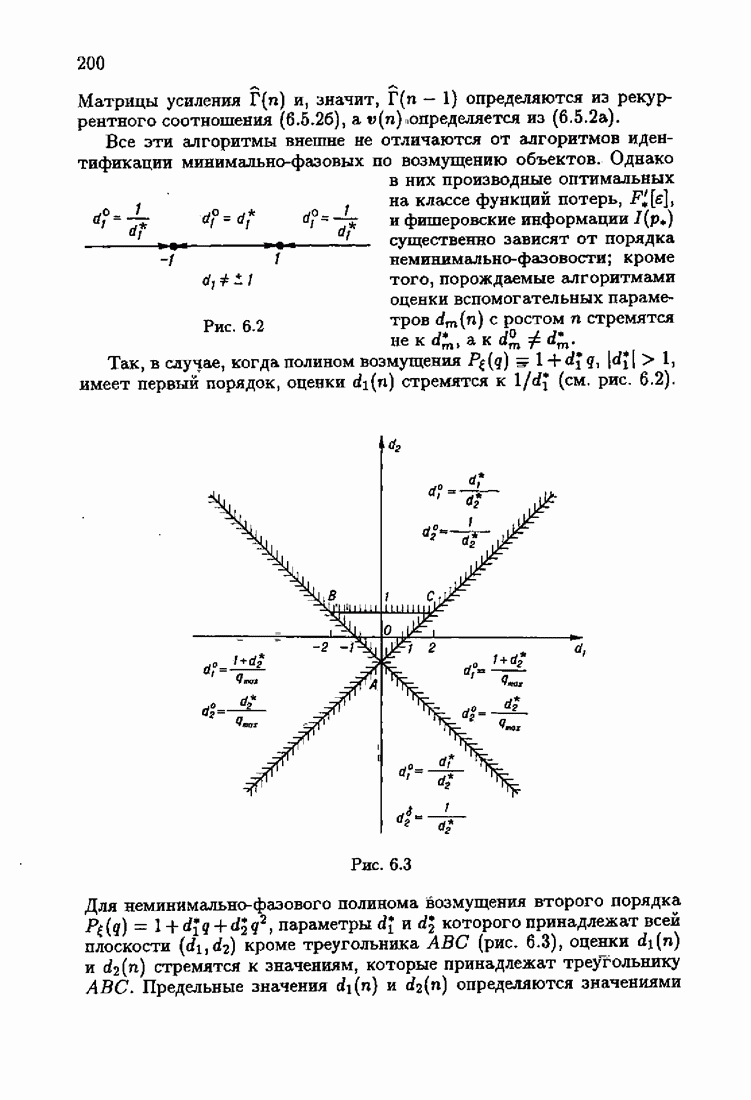

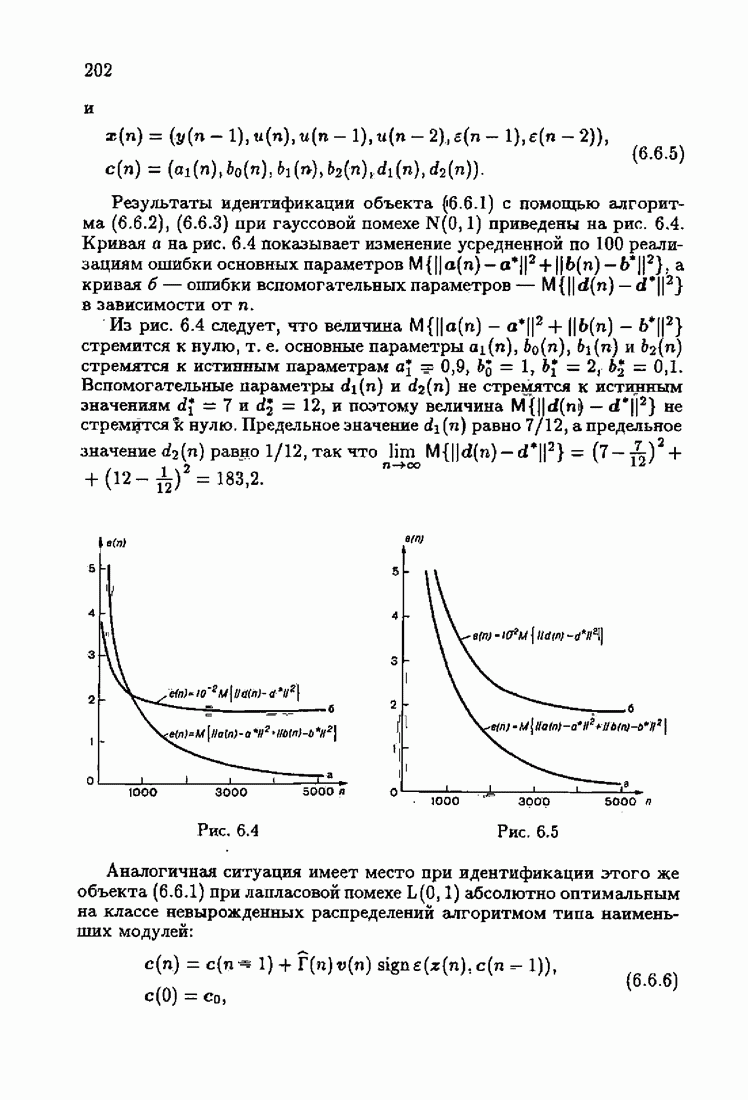














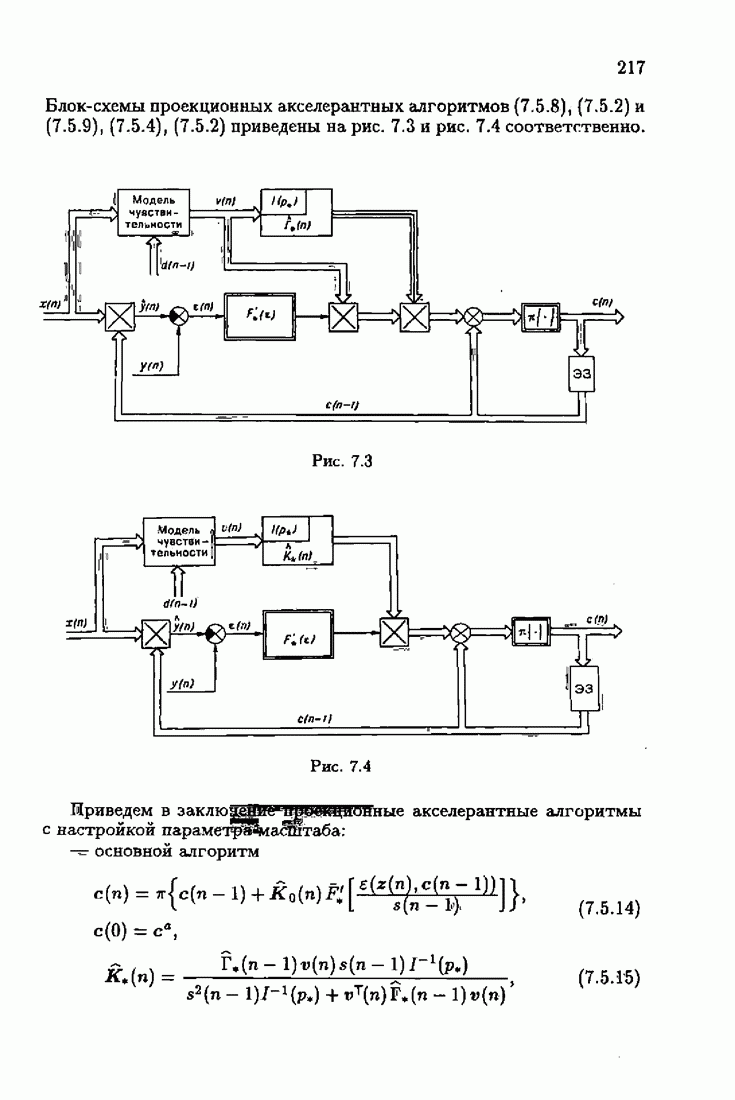
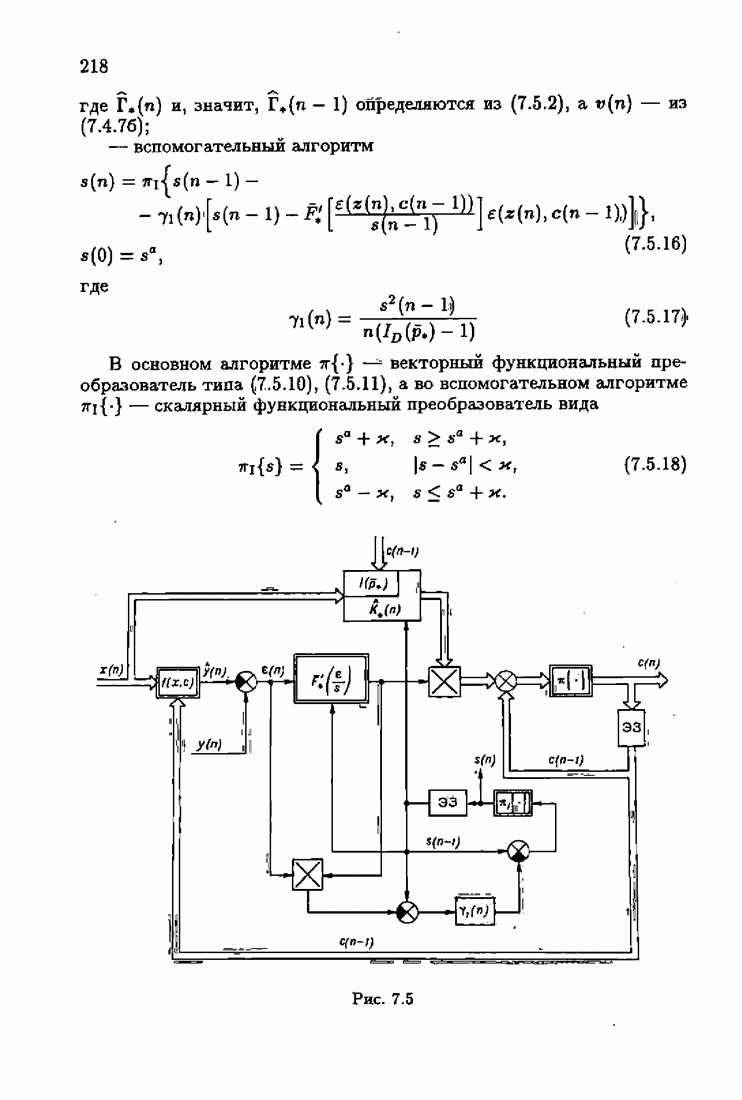









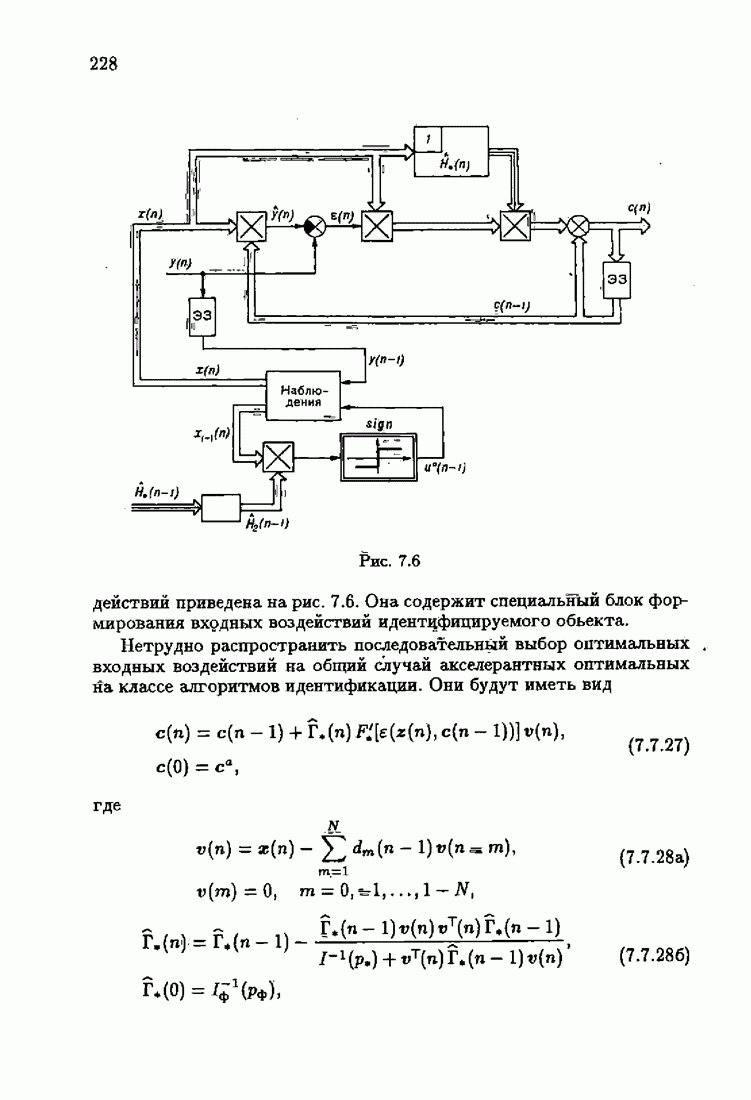
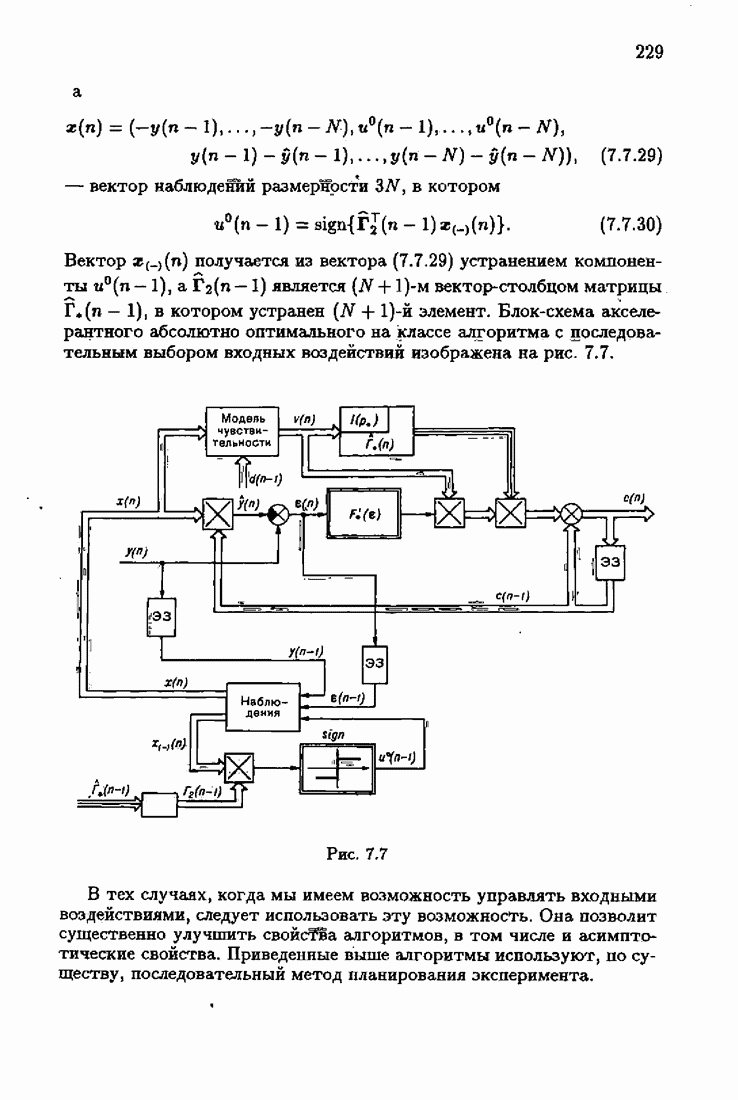


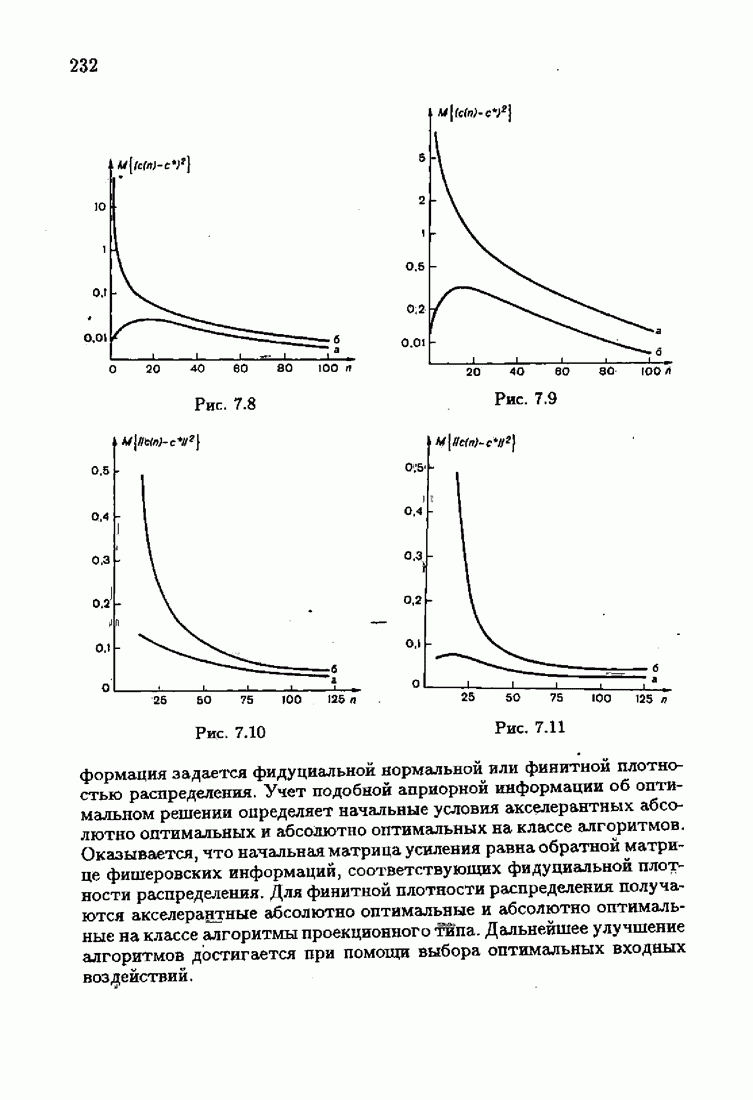




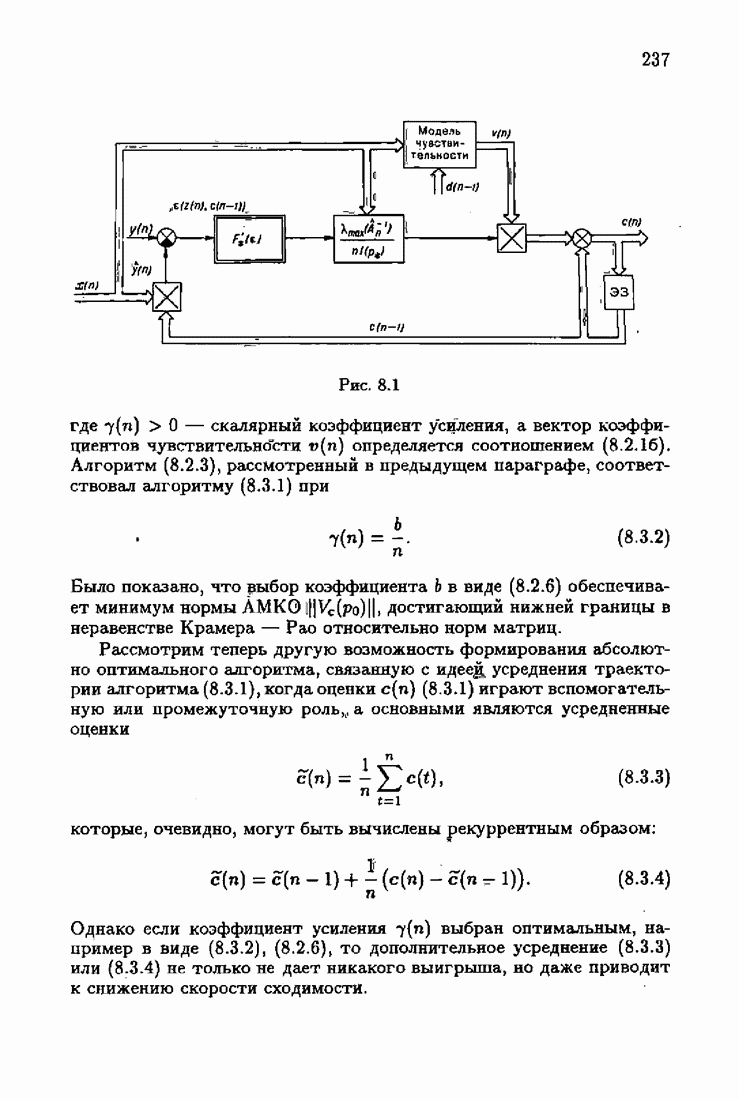






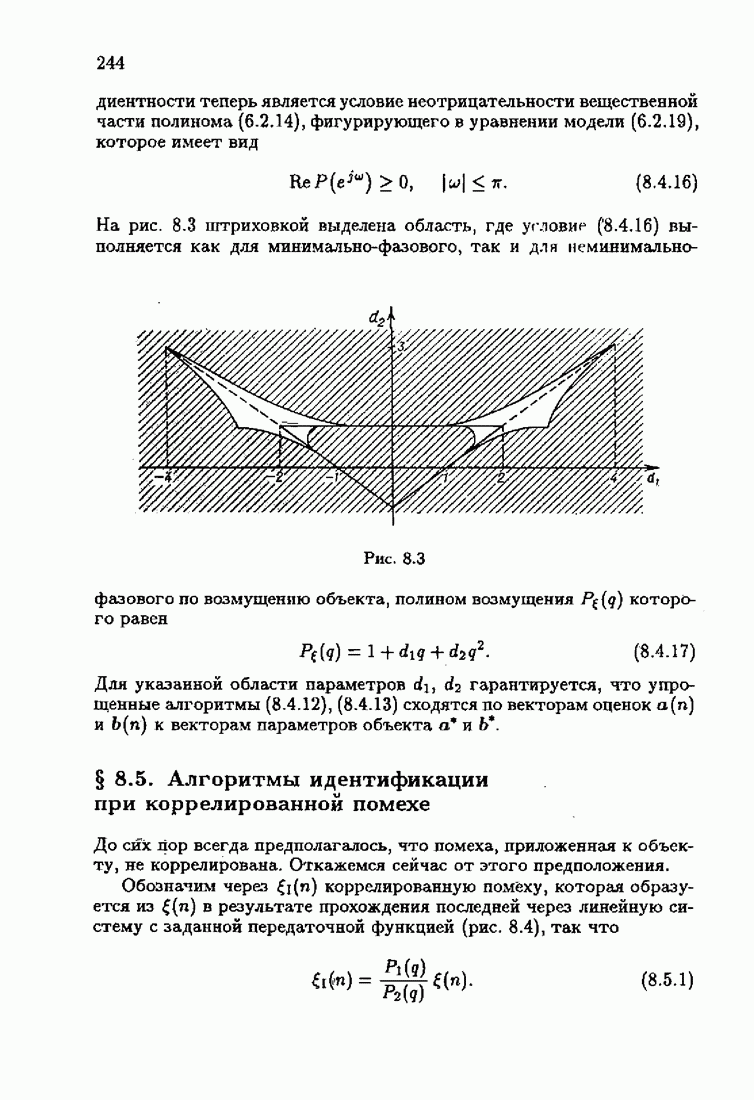


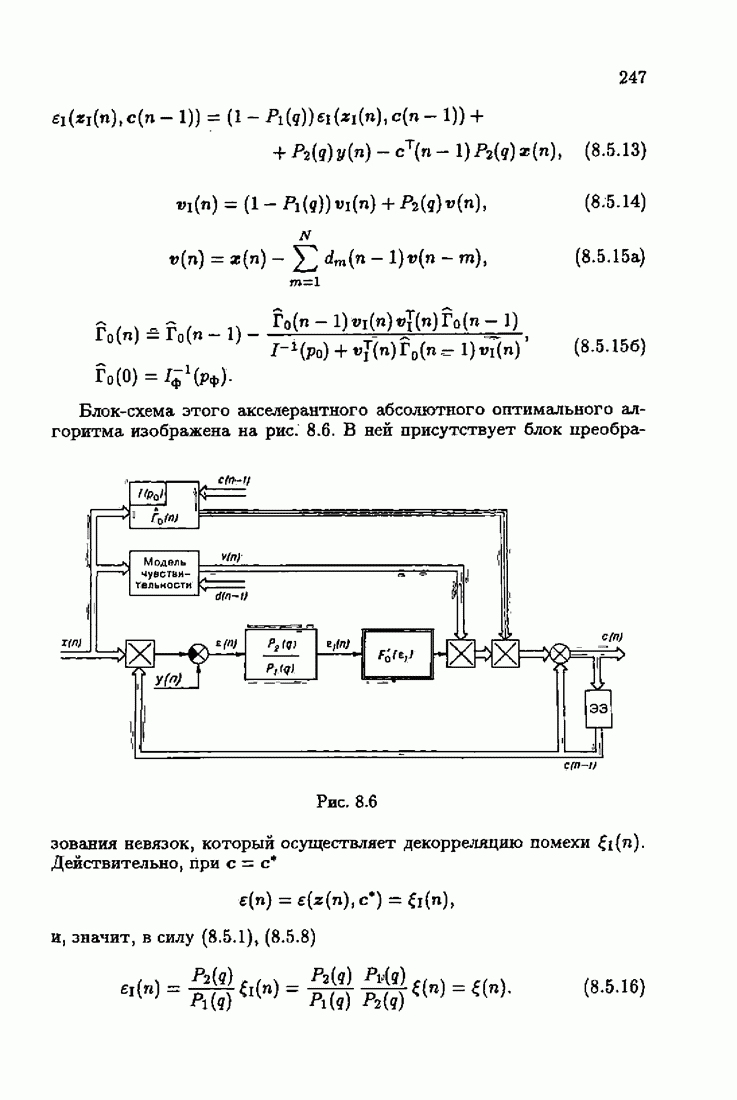



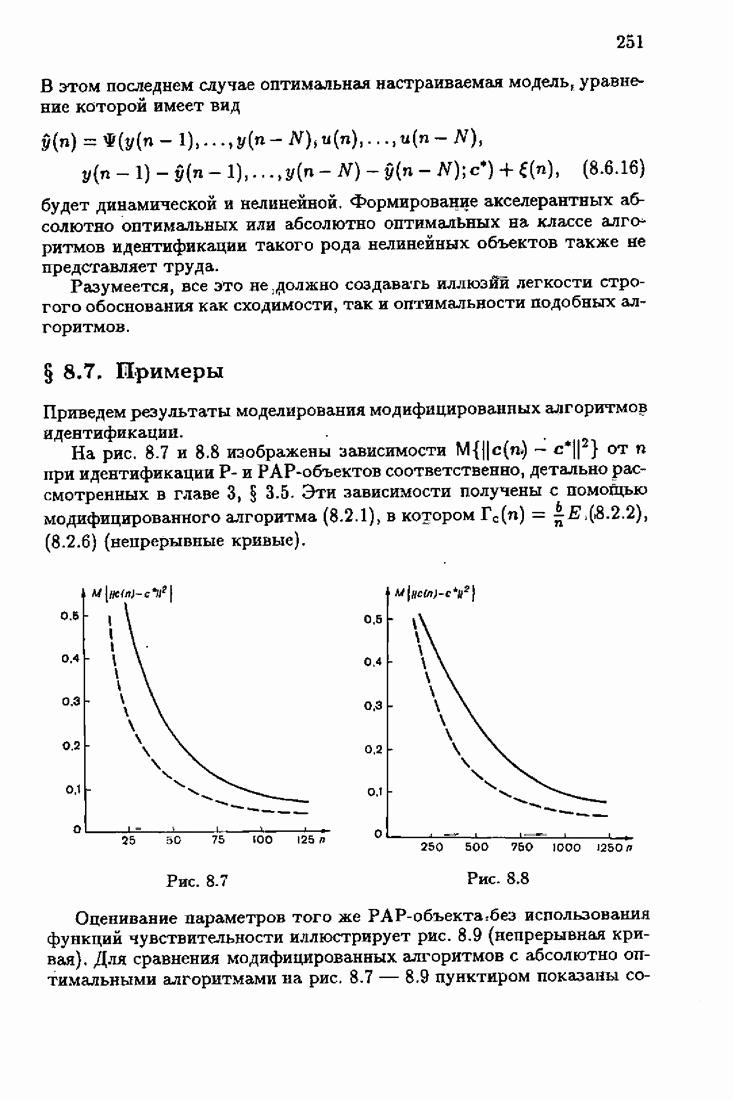
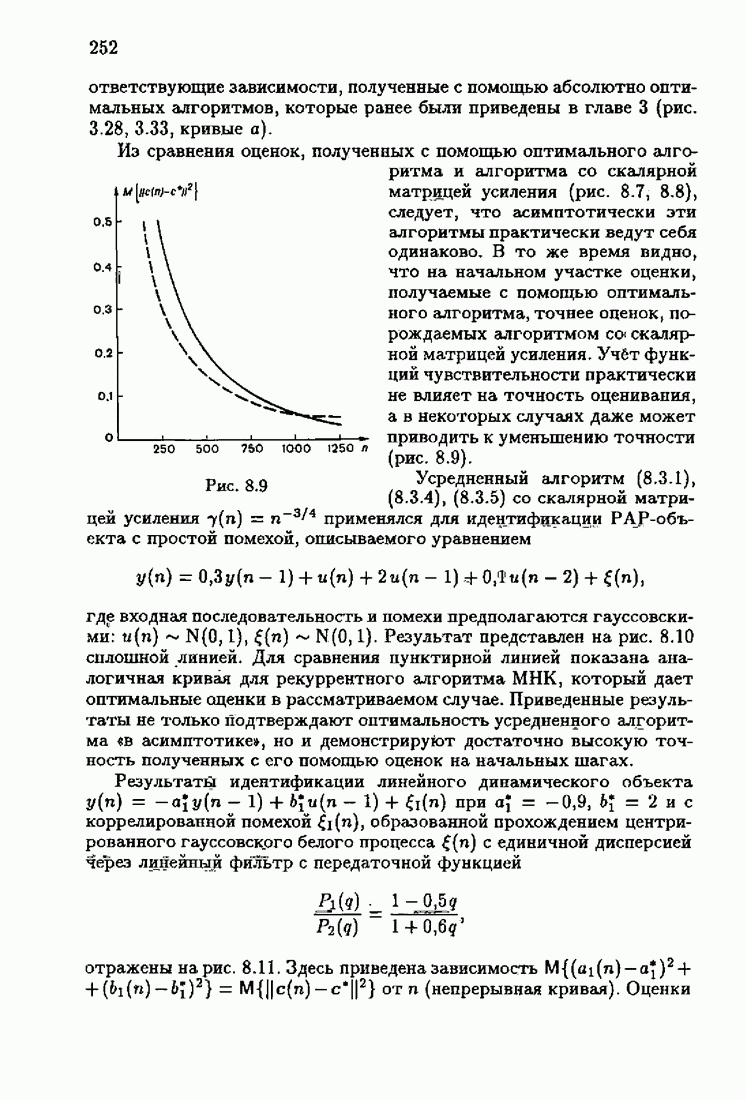
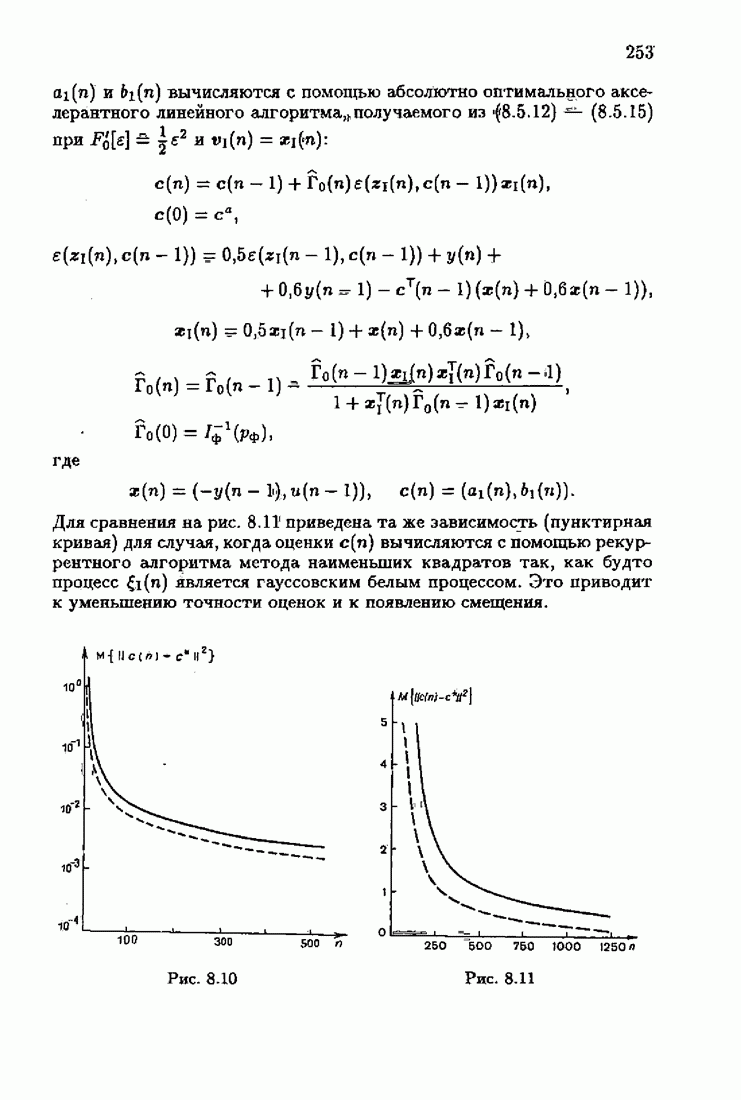





















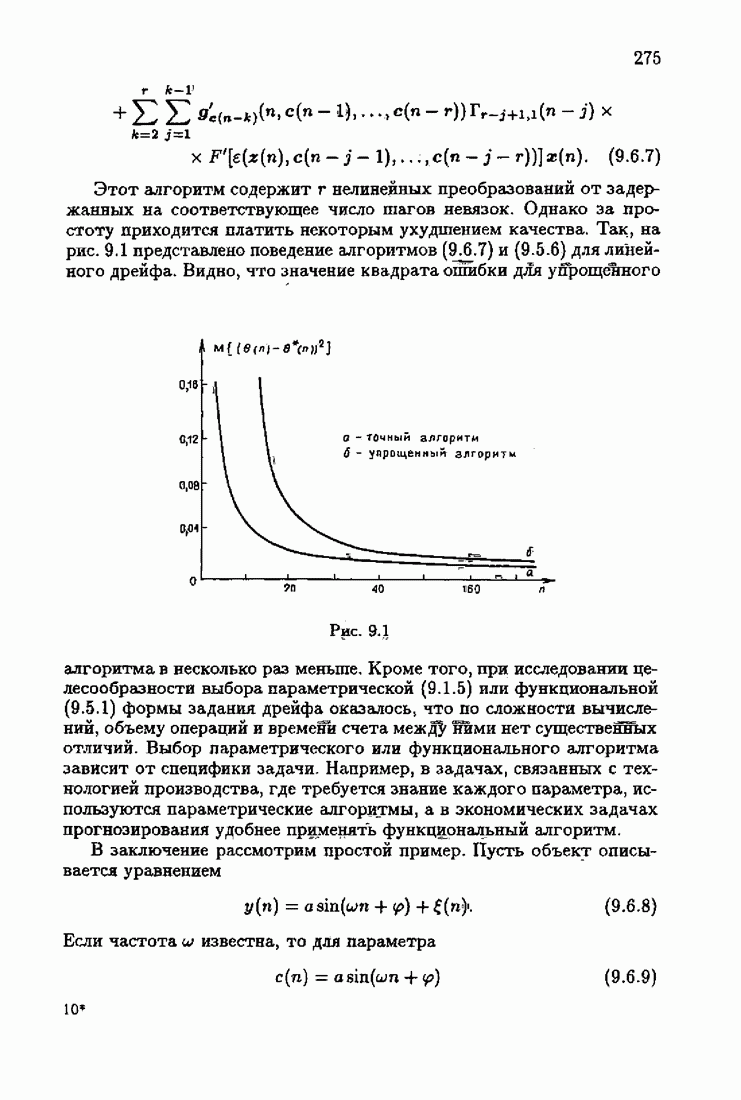
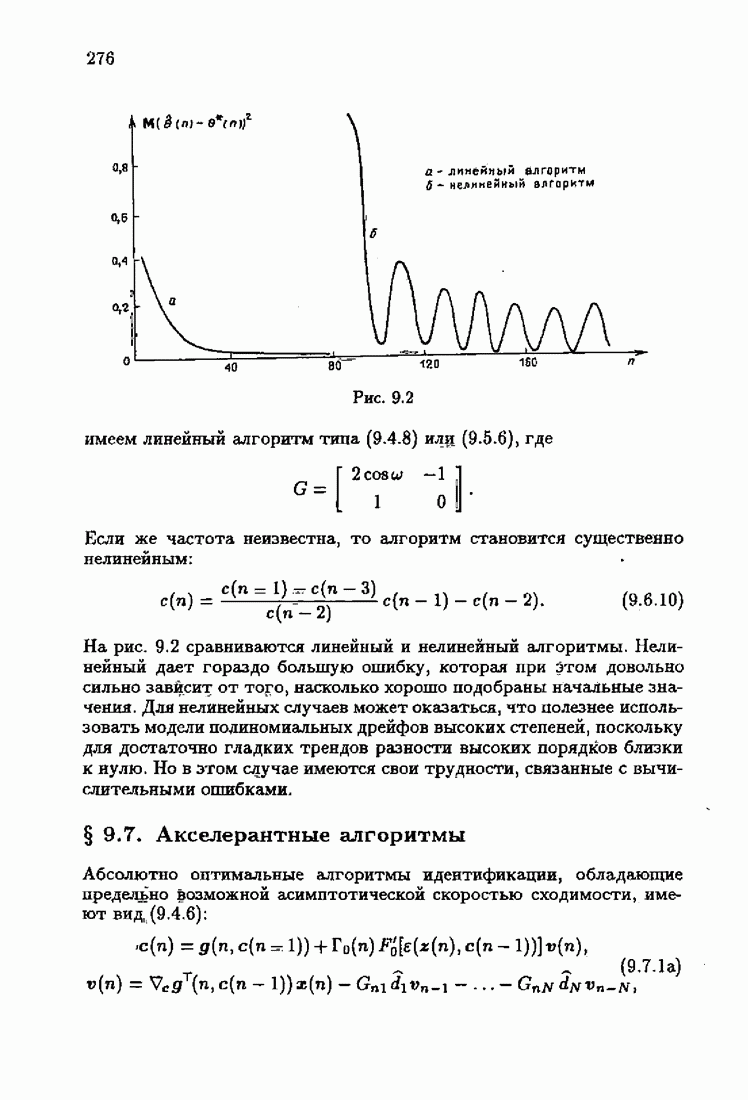

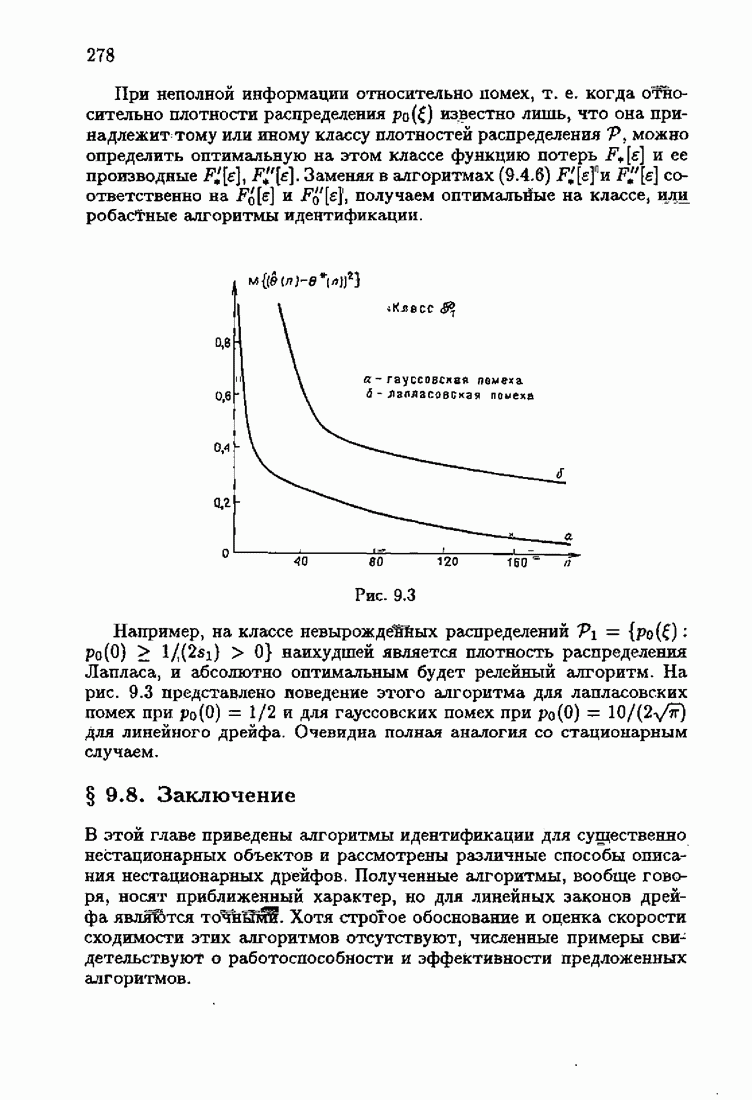


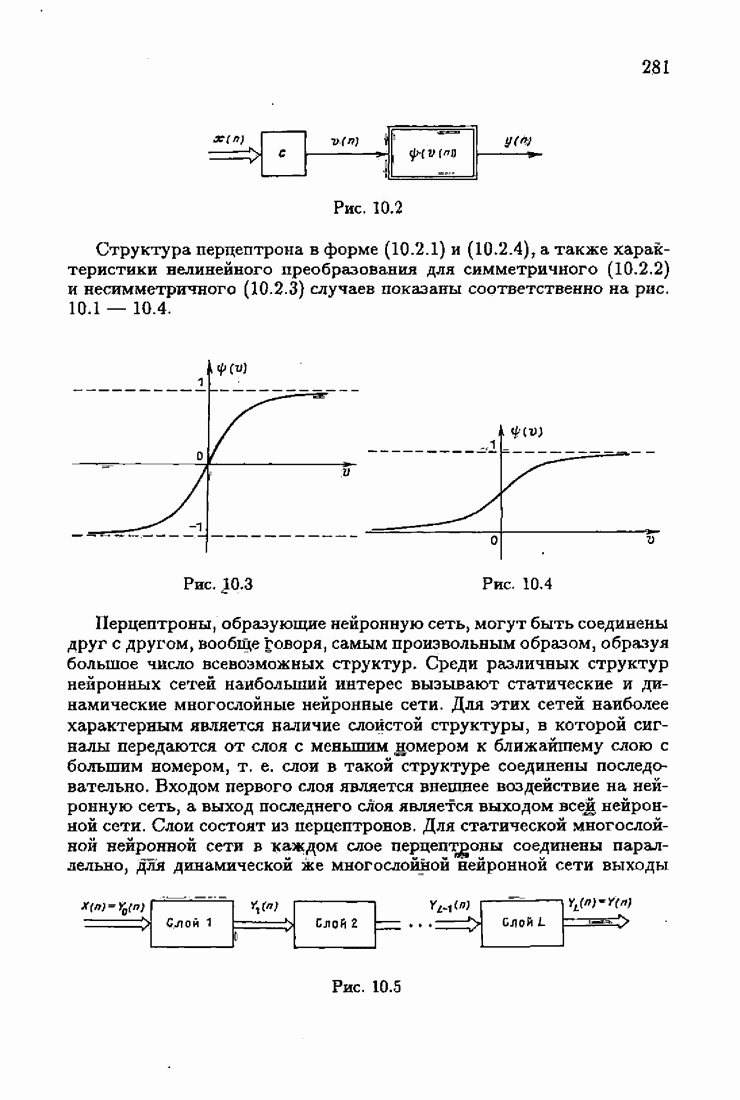
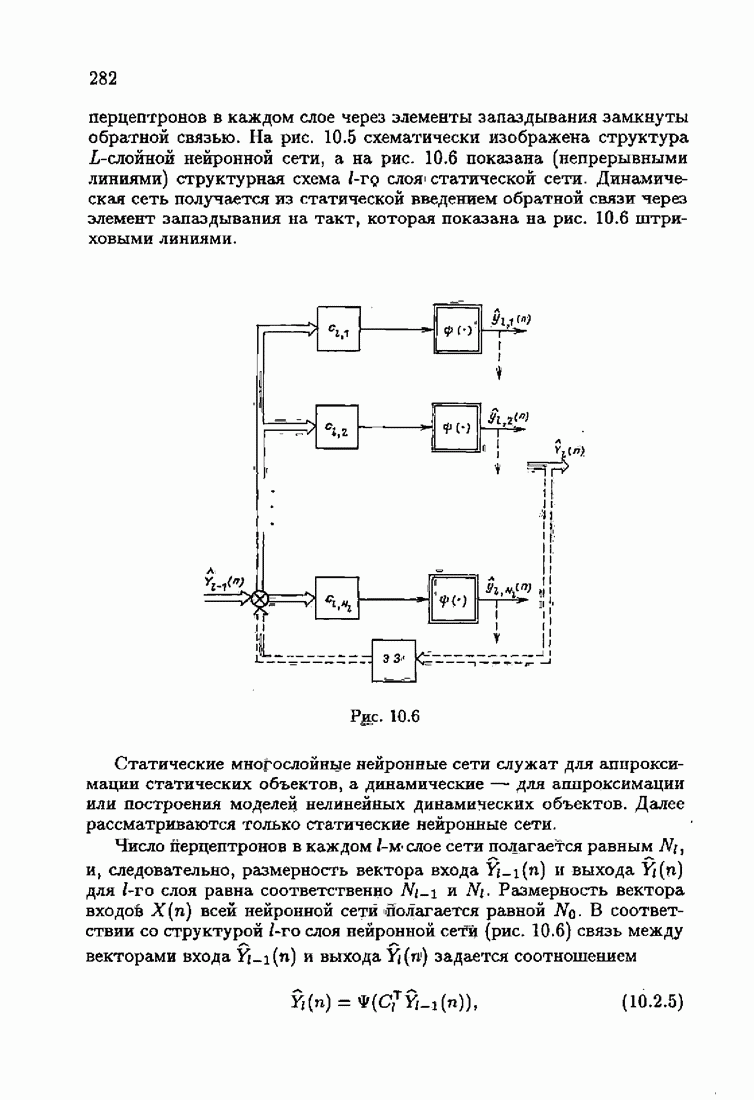


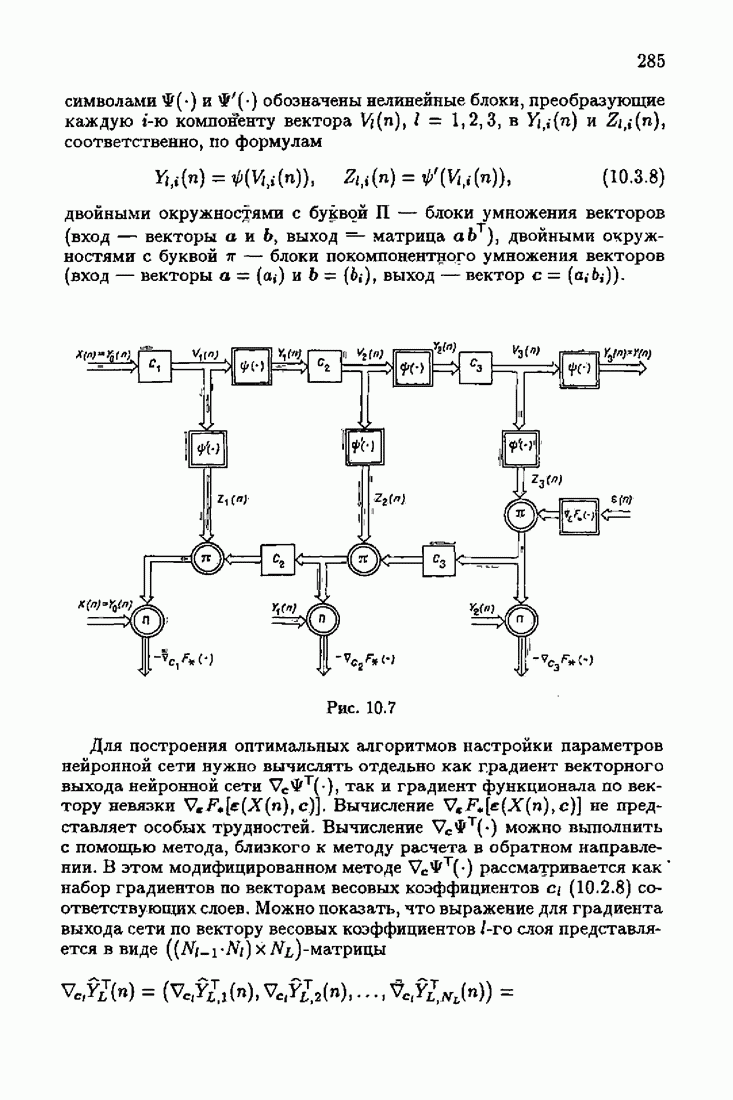
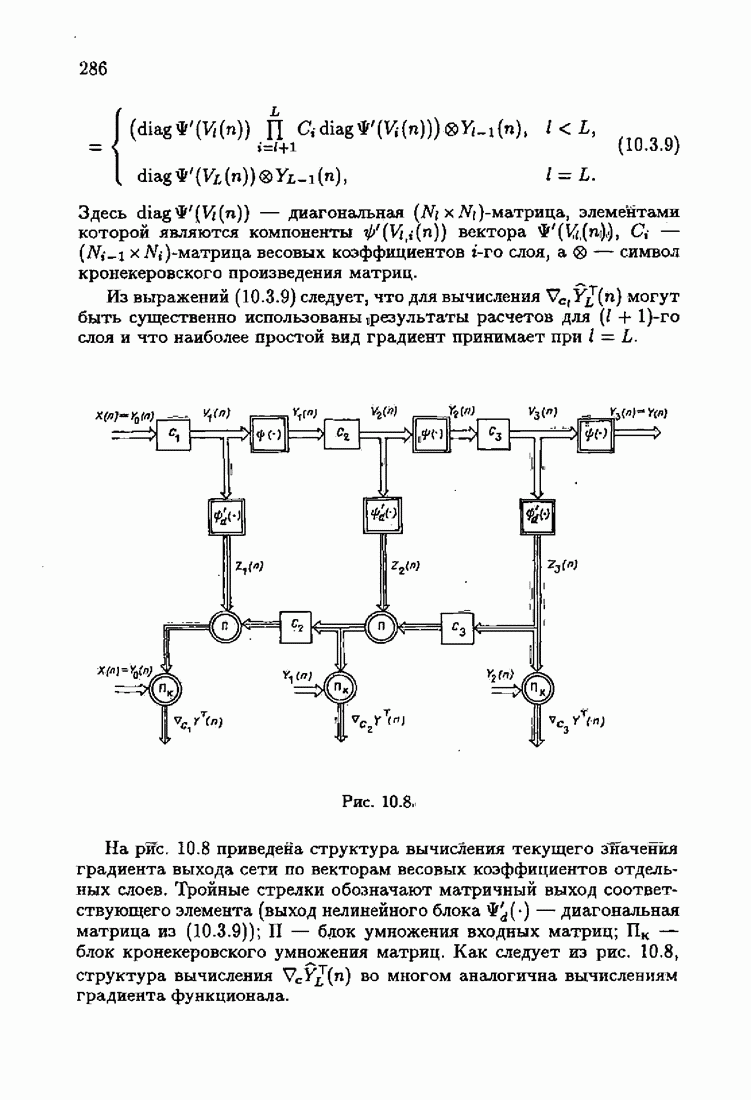
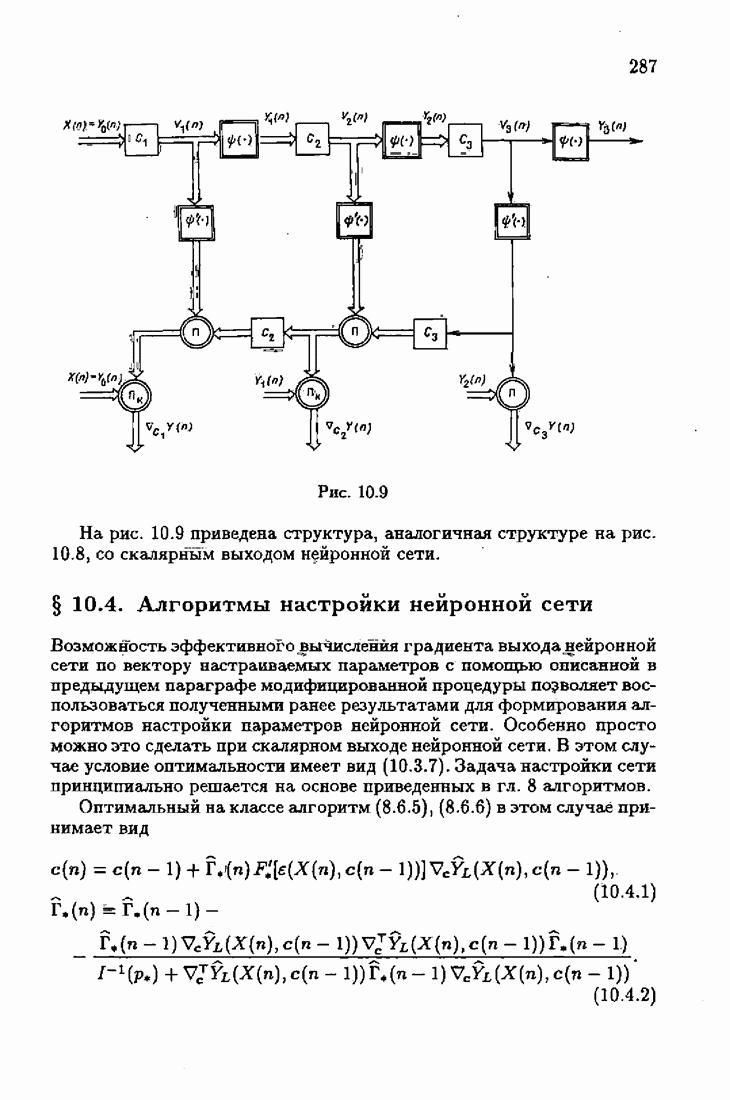


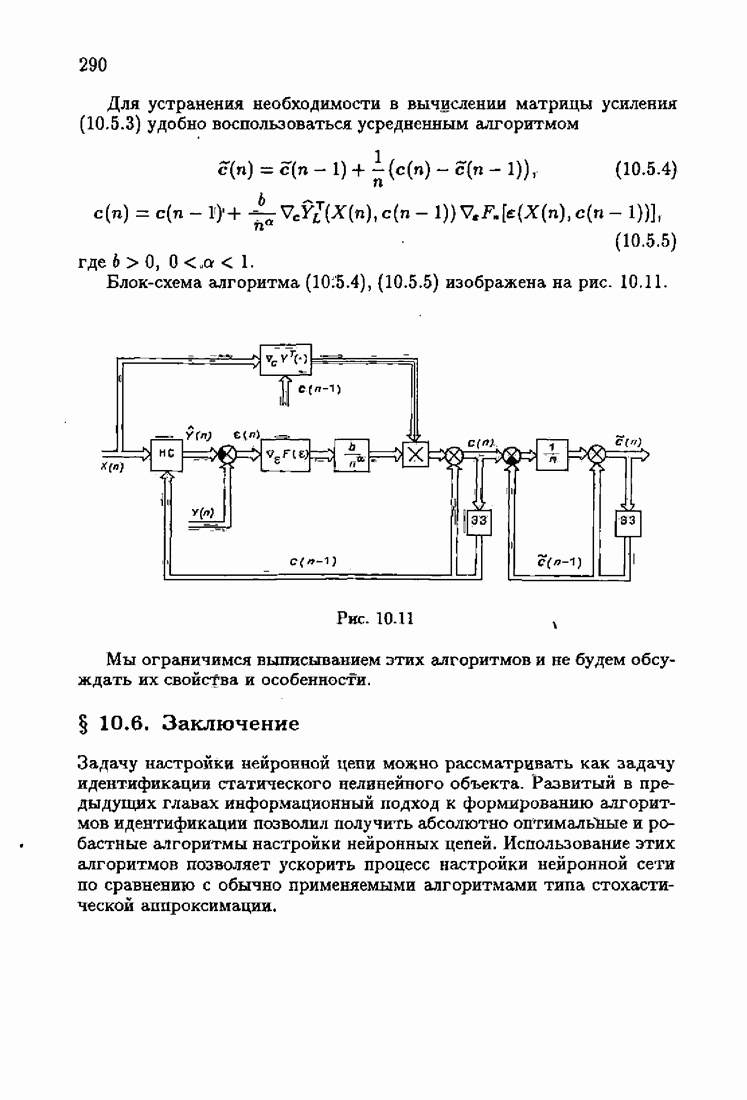














































 что существует огромное число методов идентификации, отличающихся не только типами идентифицируемых объектов, но и прогнозирующими или настраиваемыми моделями, отчасти критериями качества идентификации и особенно алгоритмами идентификации. Какая-либо определенная единая классификация постановок задач идентификации и методов их решения к настоящему времени по существу отсутствует.
что существует огромное число методов идентификации, отличающихся не только типами идентифицируемых объектов, но и прогнозирующими или настраиваемыми моделями, отчасти критериями качества идентификации и особенно алгоритмами идентификации. Какая-либо определенная единая классификация постановок задач идентификации и методов их решения к настоящему времени по существу отсутствует.
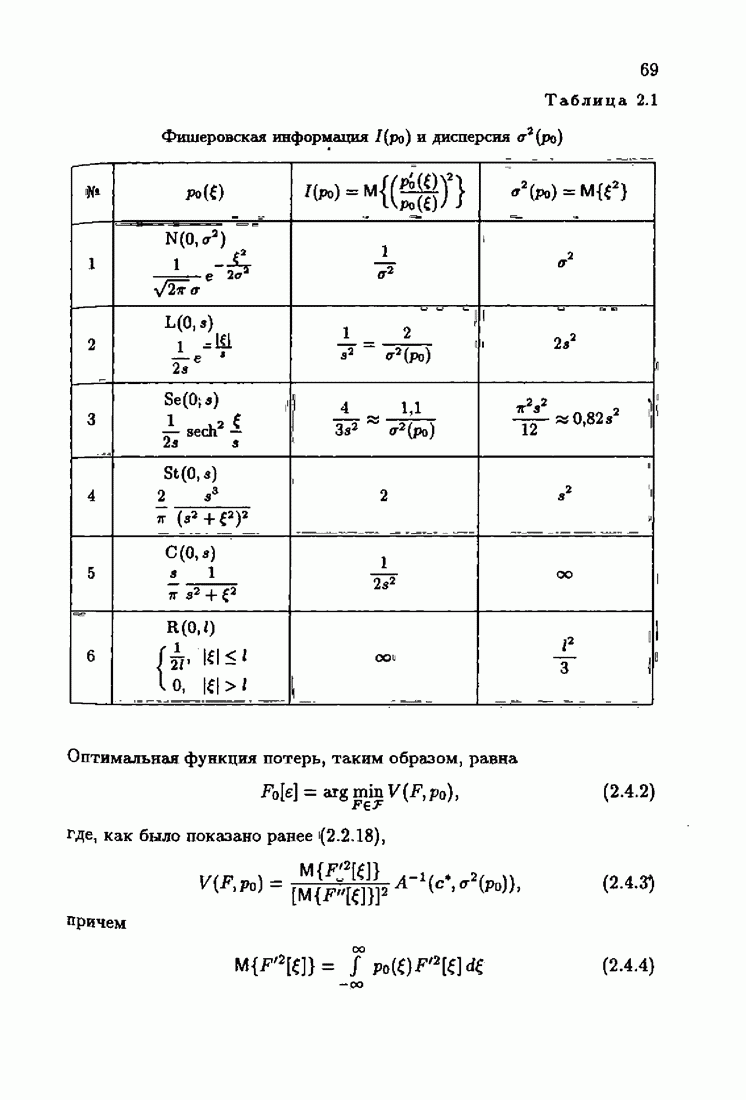
 Закс [1.1]. Современное состояние методов регрессионного анализа описано Демиденко [1.1]. Авторегрессионные задачи и тесно связанные с ними задачи обработки временных рядов, определения скользящих средних рассмотрены в книгах Бокса и Дженкинса [1.1], Андерсона [1.1], Хеннана [1.1], [1.2], Кендалла и Стьюарта [1.3], Вриллинджера [1.1] и др. В литературе авторегресеиониые задачи в тех случаях, когда в уравнении фигурирует помеха при различных моментах времени
Закс [1.1]. Современное состояние методов регрессионного анализа описано Демиденко [1.1]. Авторегрессионные задачи и тесно связанные с ними задачи обработки временных рядов, определения скользящих средних рассмотрены в книгах Бокса и Дженкинса [1.1], Андерсона [1.1], Хеннана [1.1], [1.2], Кендалла и Стьюарта [1.3], Вриллинджера [1.1] и др. В литературе авторегресеиониые задачи в тех случаях, когда в уравнении фигурирует помеха при различных моментах времени  часто называют задачами авторегрессии — скользящего среднего (АРСС); см., например, Бокс и Дженкинс [1.1]. Возможность идентификации неустойчивого авторегрессионного объекта методом наименьших квадратов обоснована Барабановым [1.1].
часто называют задачами авторегрессии — скользящего среднего (АРСС); см., например, Бокс и Дженкинс [1.1]. Возможность идентификации неустойчивого авторегрессионного объекта методом наименьших квадратов обоснована Барабановым [1.1].
 (Бокс и Дженкинс [1.1]),
(Бокс и Дженкинс [1.1]),  (Эйкхофф [1.1]),
(Эйкхофф [1.1]),  (Острём [1.1]). Наиболее простое обозначение оператора сдвига —
(Острём [1.1]). Наиболее простое обозначение оператора сдвига —  так что
так что  и в общем случае
и в общем случае 







 и она по существу является оптимальным экстраполятором выходной величины объекта на один шаг. Эти простые соображения становятся непригодными в том случае, когда объект неминимально-фазовый по помехе. Поэтому мы предпочли общий подход, охватывающий все интересующие нас случаи.
и она по существу является оптимальным экстраполятором выходной величины объекта на один шаг. Эти простые соображения становятся непригодными в том случае, когда объект неминимально-фазовый по помехе. Поэтому мы предпочли общий подход, охватывающий все интересующие нас случаи.
 не зависит от конкретного вида симметричной выпуклой функции потерь (см., например, Витерби [1.1], Сейдж и Мелза [1.1]). Мы к этому вопросу еще вернемся. Функции чувствительности, фигурирующие в условии оптимальности, являются объектом исследования теории чувствительности (см., например, монографию Роэенвассера и Юсупова [1.1] и библиографию к ней).
не зависит от конкретного вида симметричной выпуклой функции потерь (см., например, Витерби [1.1], Сейдж и Мелза [1.1]). Мы к этому вопросу еще вернемся. Функции чувствительности, фигурирующие в условии оптимальности, являются объектом исследования теории чувствительности (см., например, монографию Роэенвассера и Юсупова [1.1] и библиографию к ней).
 статье Сакрисона [1.1]. Они использовались также в качестве алгоритмов идентификации а книгах, перечисленных в комментарии к § 1.2. Математическим вопросам теории алгоритмов стохастической аппроксимации посвящены специальные монографин Вазана [11], Невельсона и Хасьминского [1.1], Альберта и Гарднера [1.1], Гудвина и Пейна [1.1], Бенвениста, Метивье и Приоре [1.1]. В зтих монографиях также приводятся и примеры применения рекуррентных алгоритмов. Все упомянутые выше книги содержат обширную библиографию как по свойствам рекуррентных алгоритмов, так и по их применениям в задачах адаптации и обучения, задачах оптимизации в условиях неопределенности. См.
статье Сакрисона [1.1]. Они использовались также в качестве алгоритмов идентификации а книгах, перечисленных в комментарии к § 1.2. Математическим вопросам теории алгоритмов стохастической аппроксимации посвящены специальные монографин Вазана [11], Невельсона и Хасьминского [1.1], Альберта и Гарднера [1.1], Гудвина и Пейна [1.1], Бенвениста, Метивье и Приоре [1.1]. В зтих монографиях также приводятся и примеры применения рекуррентных алгоритмов. Все упомянутые выше книги содержат обширную библиографию как по свойствам рекуррентных алгоритмов, так и по их применениям в задачах адаптации и обучения, задачах оптимизации в условиях неопределенности. См.
 с, где
с, где  порождается алгоритмом стохастической аппроксимации, при
порождается алгоритмом стохастической аппроксимации, при  имеет нормальное распределение с нулевым средним и матрицей ковариаций, характеризующей асимптотическую скорость сходимости.
имеет нормальное распределение с нулевым средним и матрицей ковариаций, характеризующей асимптотическую скорость сходимости.
 Содерстрёмом и Стоицей [1.1], Каниовским, Кноповым и Некрыловой [1.1]. Специально теореме об асимптотической нормальности для задач идентификации динамических систем посвящена работа Льюнга и Кайнеса [1.1], в которой приведена подробная библиография. Подход Льюнга и Кайнеса получил дальнейшее развитие в работах Содерстрёма и Стонцы [1.2] и Стоицы и Содерстрёма [1.3].
Содерстрёмом и Стоицей [1.1], Каниовским, Кноповым и Некрыловой [1.1]. Специально теореме об асимптотической нормальности для задач идентификации динамических систем посвящена работа Льюнга и Кайнеса [1.1], в которой приведена подробная библиография. Подход Льюнга и Кайнеса получил дальнейшее развитие в работах Содерстрёма и Стонцы [1.2] и Стоицы и Содерстрёма [1.3].
 См. также: Катковннк [1.1], Цыпкин и Поляк [1.1], Поляк [1.1], [1.2], Шнльман и Ястребов
См. также: Катковннк [1.1], Цыпкин и Поляк [1.1], Поляк [1.1], [1.2], Шнльман и Ястребов  Альбер и Шнльман
Альбер и Шнльман  Каниовский, Кнопов и Некрылова [1.1]. Мы не приводим точные формулировки и доказательства теорем об асимптотической нормальности, Для нашей цели достаточно знать лишь вид АМКО, характеризующей скорость сходимости.
Каниовский, Кнопов и Некрылова [1.1]. Мы не приводим точные формулировки и доказательства теорем об асимптотической нормальности, Для нашей цели достаточно знать лишь вид АМКО, характеризующей скорость сходимости.
 Если же представляет собой полином, то
Если же представляет собой полином, то  является функционалом от последовательности
является функционалом от последовательности  значит, и
значит, и  представляет собой также функционал последовательности
представляет собой также функционал последовательности  Поэтому рассуждения, связанные с алгоритмом для АМКО, не могут претендовать на какую-либо строгость, если
Поэтому рассуждения, связанные с алгоритмом для АМКО, не могут претендовать на какую-либо строгость, если  Да они и не претендуют на это. Цель здесь состояла в получении АМКО из эвристических соображений. Для строгого математического вывода уравнения АМКО нужна иная техника, отличная от той, которая хорошо работала для регрессионных задач. Строгому обоснованию уравнения АМКО в различных частных случаях посвящены упомянутые выше работы.
Да они и не претендуют на это. Цель здесь состояла в получении АМКО из эвристических соображений. Для строгого математического вывода уравнения АМКО нужна иная техника, отличная от той, которая хорошо работала для регрессионных задач. Строгому обоснованию уравнения АМКО в различных частных случаях посвящены упомянутые выше работы.
 может быть записана в различной форме как через корни характеристического уравнения (см., например, Бокс и Дженкинс [1.1]), так и через коэффициенты разностного уравнения
может быть записана в различной форме как через корни характеристического уравнения (см., например, Бокс и Дженкинс [1.1]), так и через коэффициенты разностного уравнения  (см., например, Острём [1.1])- Приведенные в тексте выражения нормированных информационных матриц
(см., например, Острём [1.1])- Приведенные в тексте выражения нормированных информационных матриц  были получены А. В. Наэиным.
были получены А. В. Наэиным.
 давно применялись в алгоритмах стохастической аппроксимации, см., например, Вентер [1.1], Невельсон и Хасьминский [1.1].
давно применялись в алгоритмах стохастической аппроксимации, см., например, Вентер [1.1], Невельсон и Хасьминский [1.1].
 -объектов с преобразованной помехой, РАР-объектов и АР-объектов) различные частные случаи теоремы об асимптотической нормальности приведены у Кокса и Хинкли [1.2] (АР-объект произвольного порядка и квадратичная функция потерь), КаЙнеса и Риссанена [2.1], Гудвнна и Пейна [1.1], Содерстрёман Стоицы [1,1] (РАР-Объект и квадратичная функция потерь), Руссана [2.1], Льюнга и КаЙнеса [1.1], Огата [2.1], Басавы, Фейджина и Хейде [2.1] (РАР-объект и произвольная функция потерь). Отметим, в частности, работы по асимптотическим свойствам оценок МНК: Манн и Вальд [2.1] (АР-объекты с простой помехой), Дурбин [2.2]
-объектов с преобразованной помехой, РАР-объектов и АР-объектов) различные частные случаи теоремы об асимптотической нормальности приведены у Кокса и Хинкли [1.2] (АР-объект произвольного порядка и квадратичная функция потерь), КаЙнеса и Риссанена [2.1], Гудвнна и Пейна [1.1], Содерстрёман Стоицы [1,1] (РАР-Объект и квадратичная функция потерь), Руссана [2.1], Льюнга и КаЙнеса [1.1], Огата [2.1], Басавы, Фейджина и Хейде [2.1] (РАР-объект и произвольная функция потерь). Отметим, в частности, работы по асимптотическим свойствам оценок МНК: Манн и Вальд [2.1] (АР-объекты с простой помехой), Дурбин [2.2]  -объекты с преобразованной помехой), Дурбин [2.1] (РАР-объекты с простой помехой); см. также Маленво [1.2], Андерсон [1.1],
-объекты с преобразованной помехой), Дурбин [2.1] (РАР-объекты с простой помехой); см. также Маленво [1.2], Андерсон [1.1],
 симметрична. Поэтому существует ортогональная матрица
симметрична. Поэтому существует ортогональная матрица  такая, что
такая, что  диагональная матрица. Обозначая
диагональная матрица. Обозначая  и пользуясь свойствами диагональных матриц, получим
и пользуясь свойствами диагональных матриц, получим

 обозначает след матрицы В. Принимая во внимание обозначение
обозначает след матрицы В. Принимая во внимание обозначение  получаем
получаем



 -объектов с простой помехой) содержится в книгах по статистике. Помимо упомянутых ранее книг, укажем еще на книги Левина [2.1], Хелстрёма [2.1], Ван Триса [2.2]. В последней из них и в книге Ибрагимова и Хасьминского [2.1] приведена матричная форма неравенства Крамера-Рао. Для динамических задач (охватывающих
-объектов с простой помехой) содержится в книгах по статистике. Помимо упомянутых ранее книг, укажем еще на книги Левина [2.1], Хелстрёма [2.1], Ван Триса [2.2]. В последней из них и в книге Ибрагимова и Хасьминского [2.1] приведена матричная форма неравенства Крамера-Рао. Для динамических задач (охватывающих  -объекты с преобразованной помехой, РАР-объекты и АР-объекты) неравенства Крамера-Рао приводятся в книге Кашиапа и Рао [2.1] и статьях Галдоеа [2.1], Острёма [1.1], Вобровски и Закаи [2.1], Чанга [2.1]. Информационные неравенства, аналогичные неравенству Крамера — Рао, были получены и для других, близких к идентификации задач: для задач стохастической аппроксимации и стохастической оптимизации — Фабианом [2,1] и Назиным [2.1], планирования эксперимента — Малютовым [2.1], адаптивного управления — Немировским и Цылкиным [2.1], Назиным и Юдицким [2.1], Назиным [2.2].
-объекты с преобразованной помехой, РАР-объекты и АР-объекты) неравенства Крамера-Рао приводятся в книге Кашиапа и Рао [2.1] и статьях Галдоеа [2.1], Острёма [1.1], Вобровски и Закаи [2.1], Чанга [2.1]. Информационные неравенства, аналогичные неравенству Крамера — Рао, были получены и для других, близких к идентификации задач: для задач стохастической аппроксимации и стохастической оптимизации — Фабианом [2,1] и Назиным [2.1], планирования эксперимента — Малютовым [2.1], адаптивного управления — Немировским и Цылкиным [2.1], Назиным и Юдицким [2.1], Назиным [2.2].
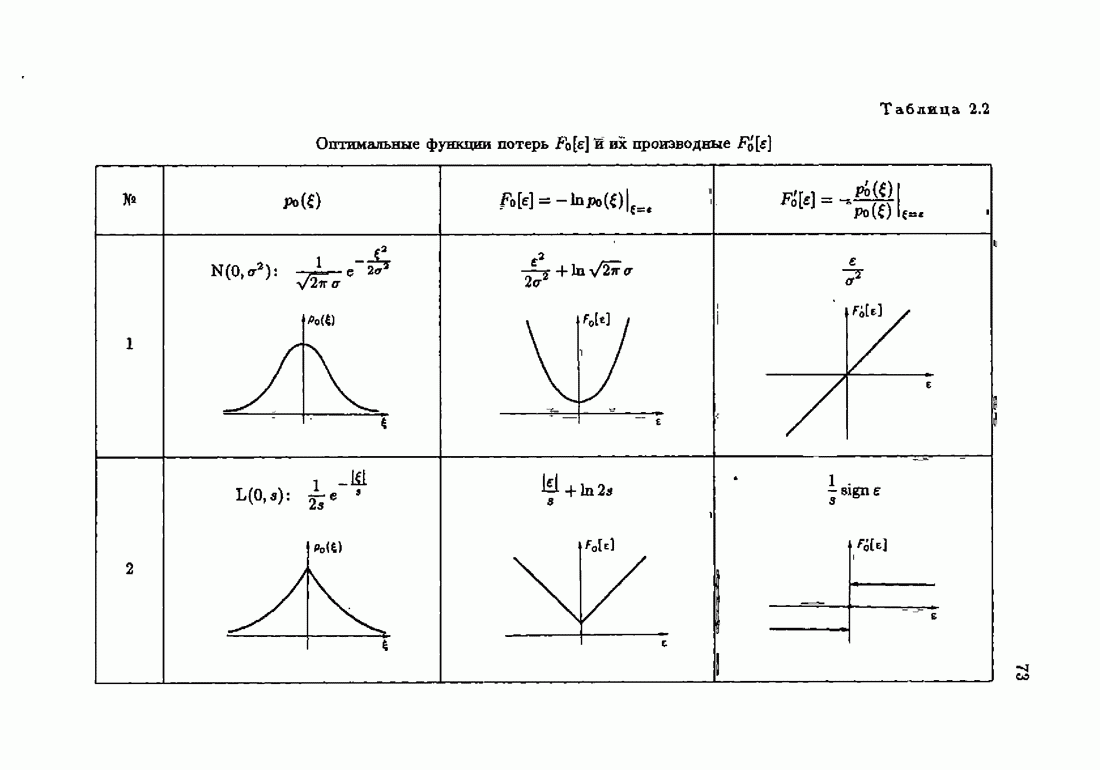
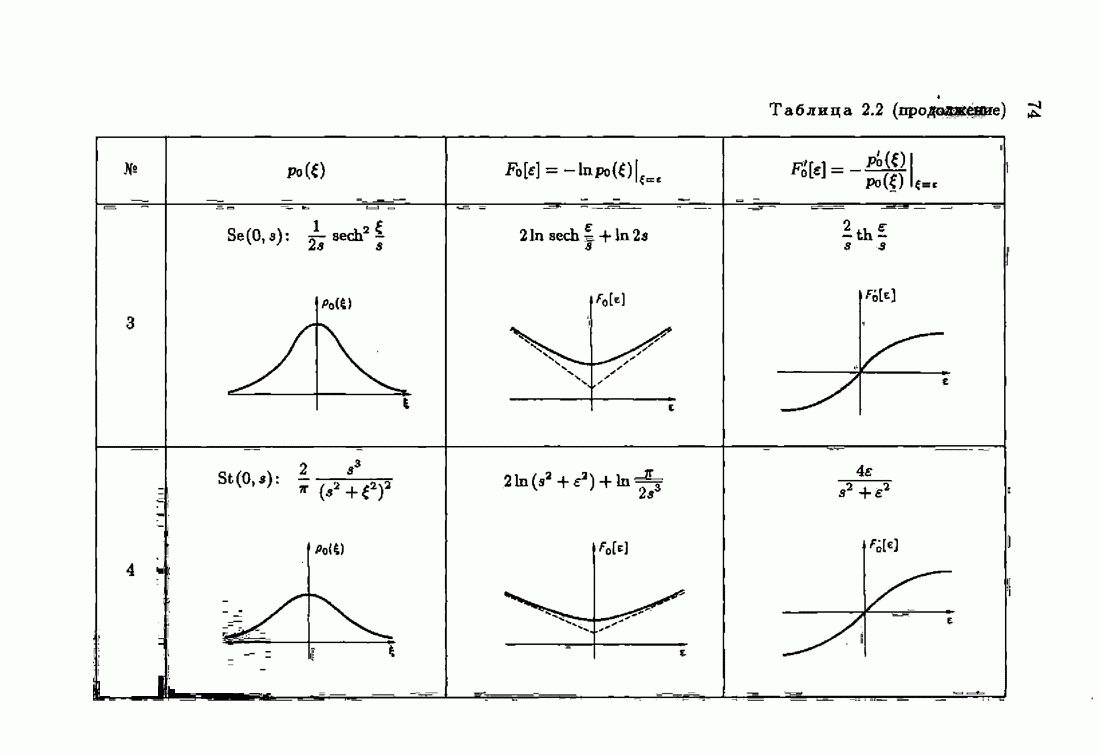
 До сих пор этот выбор был в значительной мере произвольным, и поэтому предпочитали квадратичную функцию потерь, которая приводит к задаче, допускающей аналитическое решение. Этот произвол, как правило, оправдывается тем, что для всех симметричных унимодальных плотностей распределения помехи и симметричной выпуклой функции потерь оптимальное решение с одно и то же. Интересно Познакомиться с различными мнениями по этому поводу, разбросанными по литературе. Приведем некоторые из них.
До сих пор этот выбор был в значительной мере произвольным, и поэтому предпочитали квадратичную функцию потерь, которая приводит к задаче, допускающей аналитическое решение. Этот произвол, как правило, оправдывается тем, что для всех симметричных унимодальных плотностей распределения помехи и симметричной выпуклой функции потерь оптимальное решение с одно и то же. Интересно Познакомиться с различными мнениями по этому поводу, разбросанными по литературе. Приведем некоторые из них.
 Отметим также статьи Линдли [2.1] и Сакагучи [2.1] по использованию шенноновскои информации в качестве меры информативности экспериментов и Фразера [2.1], Шютценбергера [2.1] по применению информации в статистике. Связь шенноновскои информации — энтропии — с информационными процессами подробно рассмотрен в монографиях Шамбадаля [2.1], Поплавского [2.1] и Стратоновича [2.1].
Отметим также статьи Линдли [2.1] и Сакагучи [2.1] по использованию шенноновскои информации в качестве меры информативности экспериментов и Фразера [2.1], Шютценбергера [2.1] по применению информации в статистике. Связь шенноновскои информации — энтропии — с информационными процессами подробно рассмотрен в монографиях Шамбадаля [2.1], Поплавского [2.1] и Стратоновича [2.1].
 по существу представляет собой логарифмическую функцию правдоподобия с обратным знаком, т. е. логарифмическую функцию неправдоподобия.
по существу представляет собой логарифмическую функцию правдоподобия с обратным знаком, т. е. логарифмическую функцию неправдоподобия.
 рассматривалась в интересной работе Содерстрёма и Стоицы [1.2]. Оказалось, что наилучшей функцией потерь является определитель матричной невязки, т. е.
рассматривалась в интересной работе Содерстрёма и Стоицы [1.2]. Оказалось, что наилучшей функцией потерь является определитель матричной невязки, т. е. 
 а в ряде случаев и функции потерь или, точнее, ее производной (см., например, Сакрисон [3.1]), при которых максимизируется асимптотическая скорость сходимости. В отличие от установившейся традиции, в основном тексте книги оптимальные и абсолютно оптимальные рекуррентные алгоритмы идентификации синтезируются, или формируются. Одновременно с этим устраняется водораздел между изучением свойств оценок
а в ряде случаев и функции потерь или, точнее, ее производной (см., например, Сакрисон [3.1]), при которых максимизируется асимптотическая скорость сходимости. В отличие от установившейся традиции, в основном тексте книги оптимальные и абсолютно оптимальные рекуррентные алгоритмы идентификации синтезируются, или формируются. Одновременно с этим устраняется водораздел между изучением свойств оценок  минимизирующих эмпирические средние потери, и оценок
минимизирующих эмпирические средние потери, и оценок  порождаемых оптимальными рекуррентными алгоритмами, т. е. алгоритмами типа стохастической аппроксимации.
порождаемых оптимальными рекуррентными алгоритмами, т. е. алгоритмами типа стохастической аппроксимации.
 характеризуемое АМКО, одинаково. Термин «абсолютно оптимальный алгоритм" предложен О. А. Цыпкиной и навеян далекой аналогией с термином «абсолютной устойчивости», введенным в теорию управления А. И. Лурье. Под абсолютно оптимальным понимается алгоритм, наилучший в смысле выбора функции потерь среди всех оптимальных алгоритмов.
характеризуемое АМКО, одинаково. Термин «абсолютно оптимальный алгоритм" предложен О. А. Цыпкиной и навеян далекой аналогией с термином «абсолютной устойчивости», введенным в теорию управления А. И. Лурье. Под абсолютно оптимальным понимается алгоритм, наилучший в смысле выбора функции потерь среди всех оптимальных алгоритмов.
 -объекта с простой помехой был предложен Сакрисоном [3.1] — [3.3], Иные итеративные методы рассматривались Кейлом [3.1], [3.2].
-объекта с простой помехой был предложен Сакрисоном [3.1] — [3.3], Иные итеративные методы рассматривались Кейлом [3.1], [3.2].
 -объектов, предложенные Сакрисоном [3.1], исследовались Хасьминским [3.1], Невельсоном и Хасьминским [1.1], Поляком и Цыпкиным [3.1], Цыпкиным [3.1]. Абсолютно оптимальные алгоритмы идентификации АР-объектов рассматривались Немировским [3.1], Поляком и Цыпкиным [3.2]. Отметим здесь также абсолютно оптимальные алгоритмы оптимизации, предложенные и исследованные Цыпкиным и Поляком [2.1] и Поляком и Цыпкиным [3.1], [3.2] (непоисковые алгоритмы) и Цыпкиным и Позняком [3.1] (поисковые алгоритмы).
-объектов, предложенные Сакрисоном [3.1], исследовались Хасьминским [3.1], Невельсоном и Хасьминским [1.1], Поляком и Цыпкиным [3.1], Цыпкиным [3.1]. Абсолютно оптимальные алгоритмы идентификации АР-объектов рассматривались Немировским [3.1], Поляком и Цыпкиным [3.2]. Отметим здесь также абсолютно оптимальные алгоритмы оптимизации, предложенные и исследованные Цыпкиным и Поляком [2.1] и Поляком и Цыпкиным [3.1], [3.2] (непоисковые алгоритмы) и Цыпкиным и Позняком [3.1] (поисковые алгоритмы).
 почти нормальных распределений. Этот класс был введен Тьюки [4,1]. Он широко использовался Хьюбером [4.1], [4.2] и его последователями (см. обзоры Хэмпела [4.3] и Бикела [4.1] по робастному оцениванию). Классы
почти нормальных распределений. Этот класс был введен Тьюки [4,1]. Он широко использовался Хьюбером [4.1], [4.2] и его последователями (см. обзоры Хэмпела [4.3] и Бикела [4.1] по робастному оцениванию). Классы  финитных и приближенно финитных распределений рассматривались в работах Мартина и Масрелиза [4.1], Сакса и Илвисакера [4.1] и Хьюбера [4.4]. Известны и другие классы, в которых имеет место близость не плотностей, а функций распределения (см. Хьюбер [4.1]). Мы, однако, такие классы не рассматриваем.
финитных и приближенно финитных распределений рассматривались в работах Мартина и Масрелиза [4.1], Сакса и Илвисакера [4.1] и Хьюбера [4.4]. Известны и другие классы, в которых имеет место близость не плотностей, а функций распределения (см. Хьюбер [4.1]). Мы, однако, такие классы не рассматриваем.
 -объектов при ограниченности помех или их матриц ковариацнй в работах Эльясберга. Он подробно изложен в монографиях Эльясберга [4.1], Бахшияна, Назирова и Эльясберга [4.1].
-объектов при ограниченности помех или их матриц ковариацнй в работах Эльясберга. Он подробно изложен в монографиях Эльясберга [4.1], Бахшияна, Назирова и Эльясберга [4.1].
 и дисперсии
и дисперсии  в общем случае ранее не рассматривались. Оки являются сравнительно новыми. Их частный случай — минимизация
в общем случае ранее не рассматривались. Оки являются сравнительно новыми. Их частный случай — минимизация  рассматривался в литературе по характериэационным задачам математической статистики (Каган, Линник и Рао [4.1] — класс
рассматривался в литературе по характериэационным задачам математической статистики (Каган, Линник и Рао [4.1] — класс  а также в связи с робастным оцениванием (Хьюбер [4.1] — класс
а также в связи с робастным оцениванием (Хьюбер [4.1] — класс  Сакс и Илвисакер [4.1], Хьюбер [4.4], Мартин и Масрелиз [4.1] — классы
Сакс и Илвисакер [4.1], Хьюбер [4.4], Мартин и Масрелиз [4.1] — классы  Решение задачи минимизации
Решение задачи минимизации  на классах
на классах  получено Цыпкиным и Поляком [2.1],
получено Цыпкиным и Поляком [2.1],
 -объектов с простой помехой были найдены Поляком и Цыпкиным [3.1]. Ранее часто предлагались не оптимальные, но близкие к ним функции потерь. При этом обычно исходили из интуитивных соображений. Так, функция потерь
-объектов с простой помехой были найдены Поляком и Цыпкиным [3.1]. Ранее часто предлагались не оптимальные, но близкие к ним функции потерь. При этом обычно исходили из интуитивных соображений. Так, функция потерь  рассмотрена Форсайтом [4.1]. При
рассмотрена Форсайтом [4.1]. При  мы приходим к методу наименьших модулей (МНМ), подробное исследование которого приведено в книге Мудрова и Кушко [4.1] и в статьях Епишина [4,1], Бассета и Коенкера [4.1]. Мерилл и Швеппе [4.1] предлагают
мы приходим к методу наименьших модулей (МНМ), подробное исследование которого приведено в книге Мудрова и Кушко [4.1] и в статьях Епишина [4,1], Бассета и Коенкера [4.1]. Мерилл и Швеппе [4.1] предлагают  при
при  при
при  где
где  Близкая по форме функция потерь получается из логарифмической функции неправдоподобия при смеси двух нормальных распределений (см. Колас
Близкая по форме функция потерь получается из логарифмической функции неправдоподобия при смеси двух нормальных распределений (см. Колас
 обладает характерной особенностью — оно является распределением с максимальной для заданного класса энтропией», и далее: (Можно высказать гипотезу, что и в других случаях наименее предпочтительным распределением является распределение с максимальной энтропией. Хотя доказать такую гипотезу или установить условия, при которых она справедлива, довольно затруднительно, она обладает большой степенью правдоподобия». Аналогичная точка зрения высказывалась Гольдманом [4.1]. Эта гипотеза в общем случае, очевидно, неверна.
обладает характерной особенностью — оно является распределением с максимальной для заданного класса энтропией», и далее: (Можно высказать гипотезу, что и в других случаях наименее предпочтительным распределением является распределение с максимальной энтропией. Хотя доказать такую гипотезу или установить условия, при которых она справедлива, довольно затруднительно, она обладает большой степенью правдоподобия». Аналогичная точка зрения высказывалась Гольдманом [4.1]. Эта гипотеза в общем случае, очевидно, неверна.
 и для классов
и для классов  но при дополнительном ограничении
но при дополнительном ограничении  либо при малых олибо при фиксированных значениях
либо при малых олибо при фиксированных значениях  В иных случаях соответствующую задачу приходится решать численно. Задачи идентификации АР-объектов и их особенности рассмотрены в статье Поляка и Цыпкина [4.1]. Оцениванием параметров АР-объектов интенсивно занимались Мартин [4.1], [4.4], [4.5], Денби и Мартин [4.1].
В иных случаях соответствующую задачу приходится решать численно. Задачи идентификации АР-объектов и их особенности рассмотрены в статье Поляка и Цыпкина [4.1]. Оцениванием параметров АР-объектов интенсивно занимались Мартин [4.1], [4.4], [4.5], Денби и Мартин [4.1].
 -объектов и
-объектов и  -объектов с преобразованной помехой вариационная задача может быть решена лишь численно на ЭВМ. Примеры такого решения, приведенные в тексте (табл. 4.4), были получены А. С. Красненкером.
-объектов с преобразованной помехой вариационная задача может быть решена лишь численно на ЭВМ. Примеры такого решения, приведенные в тексте (табл. 4.4), были получены А. С. Красненкером.
 При обработке сейсмограмм, как отмечает Фридман [4.1], возникает 5—7% выбросов. В клинических условиях наблюдаемая медицинская информация, по данным Порта, содержит 8—12% выбросов (см. Хэмпел [4.1]). Примеры подобного рода приводятся Боксом и Андерсоном [4.1], Тьюки
При обработке сейсмограмм, как отмечает Фридман [4.1], возникает 5—7% выбросов. В клинических условиях наблюдаемая медицинская информация, по данным Порта, содержит 8—12% выбросов (см. Хэмпел [4.1]). Примеры подобного рода приводятся Боксом и Андерсоном [4.1], Тьюки  Романовски и Грином [4.1], Демиденко [1.1], а также в наиболее полном обзоре по робастным методам оценивания Ершова [4.1]. См. также обзоры Хэмпела
Романовски и Грином [4.1], Демиденко [1.1], а также в наиболее полном обзоре по робастным методам оценивания Ершова [4.1]. См. также обзоры Хэмпела
 Это сравнение проведено на реальных данных Галлея по определению параллакса Солнца, Кевендиша по определению плотности Земли и Майкельсона и Ыьюкомба по определению скорости света. Заинтересованному читателю рекомендуется познакомиться с дискуссией, следующей за этой статьей.
Это сравнение проведено на реальных данных Галлея по определению параллакса Солнца, Кевендиша по определению плотности Земли и Майкельсона и Ыьюкомба по определению скорости света. Заинтересованному читателю рекомендуется познакомиться с дискуссией, следующей за этой статьей.
 этих работах также показано, что робастные рекуррентные алгоритмы, обладающие большей простотой реализации, чем нерекуррентные оценки, не уступают последним по асимптотической скорости сходимости. Что же касается АР-объектов, то они рассматривались в статьях, связанных с обработкой временных рядов; Бокс [4,1], Мартин [4.1], [4.4], [4.5], Денби и Мартин [4.1], но с несколько иных позиций, чем это сделано в тексте.
этих работах также показано, что робастные рекуррентные алгоритмы, обладающие большей простотой реализации, чем нерекуррентные оценки, не уступают последним по асимптотической скорости сходимости. Что же касается АР-объектов, то они рассматривались в статьях, связанных с обработкой временных рядов; Бокс [4,1], Мартин [4.1], [4.4], [4.5], Денби и Мартин [4.1], но с несколько иных позиций, чем это сделано в тексте.

 -объектов с простой помехой или, как их называют, робастных алгоритмов, посвящено небольшое число работ. Укажем на работы Мартина [5.1], Мартина и Масрелиза [4.1], Поляка и Цыпкина [3.1], [4.3]. Некоторые из рекуррентных абсолютно оптимальных на классе алгоритмов идентификации АР-объектов рассмотрены Мартином [4.1] —
-объектов с простой помехой или, как их называют, робастных алгоритмов, посвящено небольшое число работ. Укажем на работы Мартина [5.1], Мартина и Масрелиза [4.1], Поляка и Цыпкина [3.1], [4.3]. Некоторые из рекуррентных абсолютно оптимальных на классе алгоритмов идентификации АР-объектов рассмотрены Мартином [4.1] —  Денби и Мартином [4.1], Несколько иные алгоритмы подобного типа, основанные на ранговых статистиках, содержатся в статье Эванса, Керстейна и Курца [5.1]; см. также обзоры Хогга [4.1] и Ершова [4.1].
Денби и Мартином [4.1], Несколько иные алгоритмы подобного типа, основанные на ранговых статистиках, содержатся в статье Эванса, Керстейна и Курца [5.1]; см. также обзоры Хогга [4.1] и Ершова [4.1].
 Хьюбер [4.8]. Итеративные алгоритмы для вычисления этих оценок описаны Хьюбером [4.8]. Иной подход см. в работах Джонсона, Мак-Гуире и Милликена [5.1], Кэрролла [5.1].
Хьюбер [4.8]. Итеративные алгоритмы для вычисления этих оценок описаны Хьюбером [4.8]. Иной подход см. в работах Джонсона, Мак-Гуире и Милликена [5.1], Кэрролла [5.1].
 например, книги Карни [6.1], Боде [6.1], Цылкина [6.1]). В теории идентификации, как правило, неминимально-фазовые по возмущению объекты исключались из рассмотрения. Почему-то все считали, что идентифицировать неминимально-фазовый по возмущению объект невозможно. Но вслух об этом говорили немногие. Может быть, это было связано с желанием получать оценки не только основных коэффициентов
например, книги Карни [6.1], Боде [6.1], Цылкина [6.1]). В теории идентификации, как правило, неминимально-фазовые по возмущению объекты исключались из рассмотрения. Почему-то все считали, что идентифицировать неминимально-фазовый по возмущению объект невозможно. Но вслух об этом говорили немногие. Может быть, это было связано с желанием получать оценки не только основных коэффициентов  но и вспомогательных коэффициентов
но и вспомогательных коэффициентов  На принципиальную возможность идентификации неминимально-фазового по возмущению объекта, состоящую в оценке коэффициентов
На принципиальную возможность идентификации неминимально-фазового по возмущению объекта, состоящую в оценке коэффициентов  коэффициентовявляющихся функциями d впервые указал
коэффициентовявляющихся функциями d впервые указал  Аведьян.
Аведьян.
 и плотность Коши
и плотность Коши  Об устойчивых плотностях распределения см. Гнеденко и Колмогоров [6.1], Петров [6.1], Лукач [6.1].
Об устойчивых плотностях распределения см. Гнеденко и Колмогоров [6.1], Петров [6.1], Лукач [6.1].

 Климов [7.1]. Искусственная рандомизация тесно связана с регуляризацией решений, см. Цыпкин [7.1].
Климов [7.1]. Искусственная рандомизация тесно связана с регуляризацией решений, см. Цыпкин [7.1].

 повышенной скоростью сходимости в окрестность оптимального решения, и можно ожидать, что это позволит более быстро выходить на режим, при котором наиболее полно используются асимптотические свойства алгоритмов. Мы, однако, здесь эту возможность не будем рассматривать. Отметим, что в последнее время интерес к алгоритмам с постоянной матрицей усиления возрос. Их исследованию посвящены работы Кашнера и
повышенной скоростью сходимости в окрестность оптимального решения, и можно ожидать, что это позволит более быстро выходить на режим, при котором наиболее полно используются асимптотические свойства алгоритмов. Мы, однако, здесь эту возможность не будем рассматривать. Отметим, что в последнее время интерес к алгоритмам с постоянной матрицей усиления возрос. Их исследованию посвящены работы Кашнера и  анга [7.1], Бенвеииста и Руже [7.1].
анга [7.1], Бенвеииста и Руже [7.1].
 Белоглаэовым.
Белоглаэовым.
 т. е.
т. е. 
 следа:
следа:  или максимального собственного числа:
или максимального собственного числа:  На основании результатов Содерстрёма и Стоицы [7.1] можно показать, что в рассматриваемом случае имеют место неравенства
На основании результатов Содерстрёма и Стоицы [7.1] можно показать, что в рассматриваемом случае имеют место неравенства  Эти неравенства могут служить оправданием выбора в качестве предпочтительного скалярного функционала не
Эти неравенства могут служить оправданием выбора в качестве предпочтительного скалярного функционала не  и не
и не 

 обнаружен Поляком [8-2]. Им подробно исследованы усредненные линейные
обнаружен Поляком [8-2]. Им подробно исследованы усредненные линейные  алгоритмы со скалярной матрицей усиления на основе матричных лемм. Скалярный алгоритм типа стохастической аппроксимации рассматривался Руппертом [8.1]. Продолжение исследования усредненных алгоритмов идентификации со скалярной матрицей усиления читатель может найти в работах Поляка и Юдицкого [8.1] и Йина [8.1]. Кроме того, отметим работу Юдицкого и Наэина [8.1], посвященную использованию этого подхода в задачах адаптивного управления.
алгоритмы со скалярной матрицей усиления на основе матричных лемм. Скалярный алгоритм типа стохастической аппроксимации рассматривался Руппертом [8.1]. Продолжение исследования усредненных алгоритмов идентификации со скалярной матрицей усиления читатель может найти в работах Поляка и Юдицкого [8.1] и Йина [8.1]. Кроме того, отметим работу Юдицкого и Наэина [8.1], посвященную использованию этого подхода в задачах адаптивного управления.
 [1.2], Соло [8.1], а оптимальные алгоритмы оптимизации — Цыпкиным и Позняком [8.1].
[1.2], Соло [8.1], а оптимальные алгоритмы оптимизации — Цыпкиным и Позняком [8.1].
 или, в одномерном случае, коэффициент усиления
или, в одномерном случае, коэффициент усиления  выписывались в виде (8.8.10) или (8.8.23) (см., например, Цыпкнн и Поляк [2.1], Поляк и Цыпкин [4.1], Ершов [4.1]). Основной алгоритм (8.7.11) при таких
выписывались в виде (8.8.10) или (8.8.23) (см., например, Цыпкнн и Поляк [2.1], Поляк и Цыпкин [4.1], Ершов [4.1]). Основной алгоритм (8.7.11) при таких  относили к асимптотически оптимальным на классе алгоритмам.
относили к асимптотически оптимальным на классе алгоритмам.
 в (8.8.13) или
в (8.8.13) или  в (8.8.16) можно заменять иными функциями, удовлетворяющими определенным условиям, при которых гарантирована сходимость алгоритмов и обеспечивается их акселеризаиия.
в (8.8.16) можно заменять иными функциями, удовлетворяющими определенным условиям, при которых гарантирована сходимость алгоритмов и обеспечивается их акселеризаиия.
 от истинного решения с. В задачах второго типа — их можно назвать критериальными — основной целью является нахождение любой точки, в которой значение функционала минимально.
от истинного решения с. В задачах второго типа — их можно назвать критериальными — основной целью является нахождение любой точки, в которой значение функционала минимально.
 для линейных дрейфов исследовалась в работах Цыпкина, Каплинского, Ларионова [9.1], Бенвениста и Фухс [9.1], Ковачевича и Станковича [9.1], Хианя и Эванса [9.1], [9.2]. Нелинейный одномерный алгоритм был введен Уосаки [9.1]. Им же показано, что введение нелинейного преобразования невязки может привести к ускорению скорости сходимости алгоритма.
для линейных дрейфов исследовалась в работах Цыпкина, Каплинского, Ларионова [9.1], Бенвениста и Фухс [9.1], Ковачевича и Станковича [9.1], Хианя и Эванса [9.1], [9.2]. Нелинейный одномерный алгоритм был введен Уосаки [9.1]. Им же показано, что введение нелинейного преобразования невязки может привести к ускорению скорости сходимости алгоритма.

 и Розенблата [10.1]. Применению нейронных сетей для решения задач распознавания образов посвящены работы Бурра [10.1], Гормана и Сейновски [10.1], Сейновскии Роэенберга [10.1], Уидроу, Винтера и Бакстера [10.1] и многие другие. Кроме того, искусственные нейронные сети применялись, в частности, Хопфилдом и Танком [10.1], Раухом и Винарске [10.1] для решения задач оптимизации, Ченом, Биллингсом и Грантом [10.1], Нарендрой и Партасзрати [10.1] для идентификации и управления динамическими объектами. См. такжеобзор Хорна, Лмшиди и Вадк [10.1].
и Розенблата [10.1]. Применению нейронных сетей для решения задач распознавания образов посвящены работы Бурра [10.1], Гормана и Сейновски [10.1], Сейновскии Роэенберга [10.1], Уидроу, Винтера и Бакстера [10.1] и многие другие. Кроме того, искусственные нейронные сети применялись, в частности, Хопфилдом и Танком [10.1], Раухом и Винарске [10.1] для решения задач оптимизации, Ченом, Биллингсом и Грантом [10.1], Нарендрой и Партасзрати [10.1] для идентификации и управления динамическими объектами. См. такжеобзор Хорна, Лмшиди и Вадк [10.1].
 (см., например, Станкович и Милосавлиевич [10.1]). Скорость сходимости этих алгоритмов весьма медленная. Замена их на двухшаговые алгоритмы с усреднением позволяет существенно повысить скорость сходимости.
(см., например, Станкович и Милосавлиевич [10.1]). Скорость сходимости этих алгоритмов весьма медленная. Замена их на двухшаговые алгоритмы с усреднением позволяет существенно повысить скорость сходимости.