панорамного приемника или какого-либо другого приемника автоматизированного типа эти параметры измерены и известны в точке приема [91]. В этом случае принятый сигнал после переноса в область видеочастот превращается в видеочастотную двоичную кодовую последовательность, которая и поступает на вход исследуемого обнаружителя. Таким образом, будем считать, что на входе обнаружителя может быть или двоичная псевдослучайная последовательность (ПСП) в виде М-последовательности, искаженная с вероятностью ошибки в одном двоичном символе  или случайная последовательность (СП).
или случайная последовательность (СП).
Обозначим через  простую гипотезу о том, что принятая последоватепьность носит случайный характер, альтернативной гипотезой для которой является сложная гипотеза
простую гипотезу о том, что принятая последоватепьность носит случайный характер, альтернативной гипотезой для которой является сложная гипотеза  состоящая в том, что принята ПСП, образованная примитивным многочленом степени
состоящая в том, что принята ПСП, образованная примитивным многочленом степени  Обнаружитель принимает либо решение
Обнаружитель принимает либо решение  о том, что справедлива гипотеза
о том, что справедлива гипотеза  либо решение
либо решение  означающее принятие гипотезы Ни причем решение
означающее принятие гипотезы Ни причем решение  принимается совместно с оценкой параметра
принимается совместно с оценкой параметра  принятого сигнала.
принятого сигнала.
При решении подобной задачи необходимо задаться свойствами сигнала, на основе которых будет производиться обнаружение, и построить оптимальный с точки зрения выбранного критерия обнаружитель при заданной совокупности свойств сигнала.
Рассмотрим блоковую структуру исследуемых сигналов. Будем называть нулевым блоком последовательность нулевых символов, а единичным блоком — последовательность единичных символов. На рис. 14.10 сплошной линией показано распределение вероятности появления нулевого блока в СП, штриховой линией — аналогичное распределение для неискаженной ПСП, образованной примитивным многочленом степени  Вероятность появления нулевого блока длины
Вероятность появления нулевого блока длины  в случайной последовательности
в случайной последовательности

и совпадает при  с вероятностью появления блока такой же длины в ПСП. При
с вероятностью появления блока такой же длины в ПСП. При  распределения вероятностей появления блоков определенной длины в СП и ПСП будут существенно различаться.
распределения вероятностей появления блоков определенной длины в СП и ПСП будут существенно различаться.
При построении структуры обнаружителя будем использовать то, что для любой ПСП, образованной примитивным многочленом степени  вероятность появления нулевого блока длины
вероятность появления нулевого блока длины  равна нулю, а вероятность появления нулевого блока длины
равна нулю, а вероятность появления нулевого блока длины  в 2 раза больше, чем в случайной последовательности.
в 2 раза больше, чем в случайной последовательности.
Пусть за время наблюдения Т принято  двоичных символов. Среднее число блоков равно
двоичных символов. Среднее число блоков равно 
Предположим, что  где
где  минимально возможная степень;
минимально возможная степень;  максимально возможная степень примитивного многочлена. Сформируем в конце интервала наблюдения вектор
максимально возможная степень примитивного многочлена. Сформируем в конце интервала наблюдения вектор

где  число принятых за интервал наблюдения нулевых блоков длины
число принятых за интервал наблюдения нулевых блоков длины  и построим обнаружитель, принимающий решение на основе анализа компонентов вектора
и построим обнаружитель, принимающий решение на основе анализа компонентов вектора 
Будем характеризовать два соседних компонента вектора  кодовой группой
кодовой группой  Тогда произвольный элемент кодовой группы соответствует элементу
Тогда произвольный элемент кодовой группы соответствует элементу  если принята СП или
если принята СП или  элементу
элементу  если принята
если принята
 и элементу
и элементу  , если принята
, если принята  Из рис. 14.10 видно, что два соседних компонента
Из рис. 14.10 видно, что два соседних компонента  вектора
вектора  могут характеризоваться одной из кодовых групп
могут характеризоваться одной из кодовых групп 
Обнаружитель принимает решение  если существует такое —1,
если существует такое —1,
«2—1]. для которого два соседних компонента  вектора
вектора  соответствуют кодовой группе
соответствуют кодовой группе  причем величина
причем величина  считается в этом случае степенью примитивного многочлена, характеризующей класс используемых сигналов
считается в этом случае степенью примитивного многочлена, характеризующей класс используемых сигналов  В противном случае принимается решение
В противном случае принимается решение 

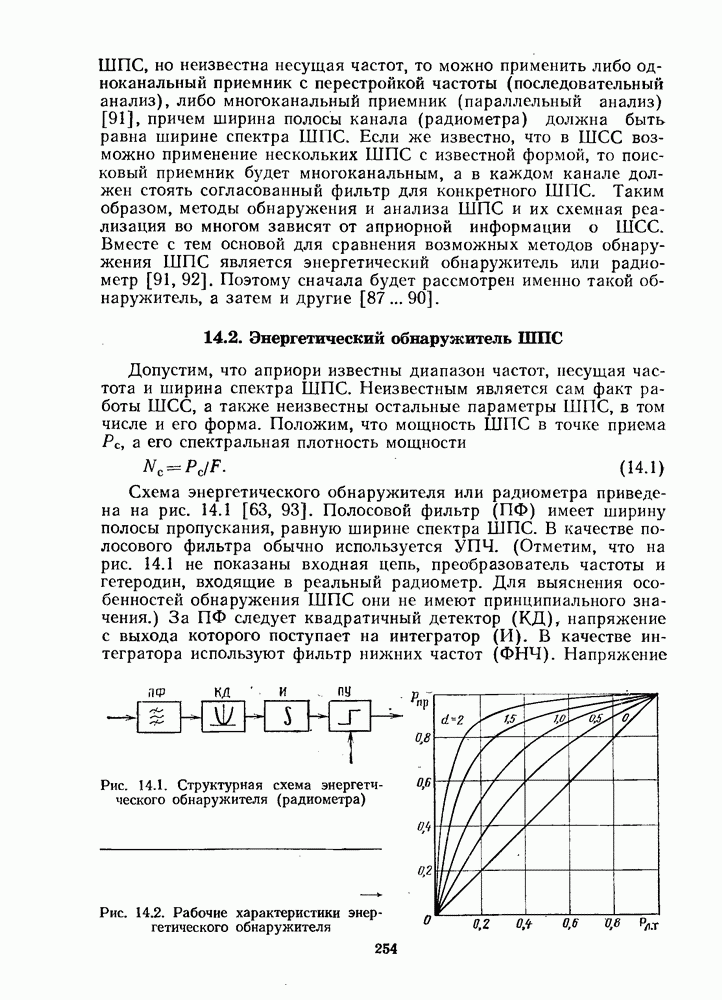
Рис. 14.10. Вероятности появления блоков

Рис. 14.11. Плотности вероятности
Таким образом, исследуемый обнаружитель должен оптимальным образом отличать кодовую группу  от кодовых групп
от кодовых групп 
Рассмотрим произвольную составляющую  вектора
вектора  и запишем выражение для условных распределений
и запишем выражение для условных распределений 
Распределение  -распределение числа нулевых блоков длины
-распределение числа нулевых блоков длины  в СП при условии, что принято
в СП при условии, что принято  двоичных символов. Распределение
двоичных символов. Распределение  биномиальное, однако, предполагая интервал наблюдения достаточно большим и используя теорему Муавра — Лапласа, запишем его нормальную аппроксимацию
биномиальное, однако, предполагая интервал наблюдения достаточно большим и используя теорему Муавра — Лапласа, запишем его нормальную аппроксимацию

где  величина
величина  определяется выражением (14.15),
определяется выражением (14.15),  Распределение
Распределение  числа нулевых блоков длины
числа нулевых блоков длины  при приеме ПСП существенно зависит от вероятности ошибки в одном двоичном символе
при приеме ПСП существенно зависит от вероятности ошибки в одном двоичном символе  Примерный вид распределения для различных значений
Примерный вид распределения для различных значений  показан на рис. 14.11 (кривые 1, 2). При
показан на рис. 14.11 (кривые 1, 2). При  в любой принятой ПСП нет нулевых блоков длины
в любой принятой ПСП нет нулевых блоков длины  (рис. 14.11) и распределение
(рис. 14.11) и распределение  имеет
имеет  -образный характер
-образный характер  При этом считается, что вероятность образования блока такой длины на стыке двух сигналов чрезвычайно мала.
При этом считается, что вероятность образования блока такой длины на стыке двух сигналов чрезвычайно мала.
С увеличением вероятности ошибки  распределение
распределение  расплывается. Это связано с тем, что блоки такой длины могут быть образованы из блоков меньшей длины за счет ошибочных символов, содержащихся в принятой последовательности. Рассматривая реализацию ПСП при заданной символьной вероятности ошибки
расплывается. Это связано с тем, что блоки такой длины могут быть образованы из блоков меньшей длины за счет ошибочных символов, содержащихся в принятой последовательности. Рассматривая реализацию ПСП при заданной символьной вероятности ошибки  и перечисляя всевозможные варианты образования нулевых
и перечисляя всевозможные варианты образования нулевых
блоков длины  , получим выражение для вероятности появления нулевого блока длины
, получим выражение для вероятности появления нулевого блока длины  в ПСП, аналогичное выражению (14.15) для СП
в ПСП, аналогичное выражению (14.15) для СП

Заметим, что при  вероятность
вероятность  и распределение приближается к распределению таких блоков в СП, т. е. к распределению
и распределение приближается к распределению таких блоков в СП, т. е. к распределению  Отсюда следует, что нормальная аппроксимация распределения
Отсюда следует, что нормальная аппроксимация распределения  имеет вид
имеет вид

где 
Аналогичные рассуждения можно привести и для распределения  т. е. распределения нулевых блоков длины
т. е. распределения нулевых блоков длины  в ПСП при вероятности ошибки в одном двоичном символе
в ПСП при вероятности ошибки в одном двоичном символе 
Нормальная аппроксимация распределения имеет вид  где
где  При
При  распределение
распределение  также имеет
также имеет  -образный характер
-образный характер  а при
а при  совпадает с распределением
совпадает с распределением  нулевых блоков в
нулевых блоков в  Примерный вид распределения
Примерный вид распределения  представлен на рис. 14.11 (кривые 3).
представлен на рис. 14.11 (кривые 3).
Перейдем к рассмотрению структуры обнаружителя, оптимальным образом отличающего кодовую группу  от кодовых групп
от кодовых групп  Зададимся произвольным значением
Зададимся произвольным значением  и запишем отношение правдоподобия [73] для кодовых
и запишем отношение правдоподобия [73] для кодовых  групп
групп 

В случае, если  число нулевых блоков длины
число нулевых блоков длины  в СП, то так как длина нулевого блока не зависит от длины предшествующих нулевых блоков, случайные величины
в СП, то так как длина нулевого блока не зависит от длины предшествующих нулевых блоков, случайные величины  независимы. Если
независимы. Если  -число нулевых блоков соответствующей длины в искаженной ПСП, то, считая преобразование блока длины
-число нулевых блоков соответствующей длины в искаженной ПСП, то, считая преобразование блока длины  в блок длины
в блок длины  или блока длины
или блока длины  в блок длины
в блок длины  маловероятным, приходим к независимости компонентов
маловероятным, приходим к независимости компонентов  вектора
вектора 

В качестве критерия оптимальности используем критерий Неймана — Пирсона, согласно которому величину  надо сравнить с некоторым порогом,
надо сравнить с некоторым порогом,

Пользуясь независимостью составляющих  учитывая выражение (14.19), представим решающее правило (14.20) в виде системы двух независимых решающих правил:
учитывая выражение (14.19), представим решающее правило (14.20) в виде системы двух независимых решающих правил:

где величины  выбираются из требований к статистическим характеристикам обнаружителя.
выбираются из требований к статистическим характеристикам обнаружителя.
В [94] доказано, что решающие правила (14.21), (14.22) полностью определяют структуру исследуемого обнаружителя, а алгоритм обнаружения
сводится к формированию на основе входной двоичной последовательности вектора  и последовательному анализу пар компонентов
и последовательному анализу пар компонентов  вектора по решающим правилам (14.21), (14.22) для всех
вектора по решающим правилам (14.21), (14.22) для всех  Если существует такое
Если существует такое  для которого будут одновременно выполнены оба неравенства, обнаружитель принимает решение, что принята ПСП, образованная примитивным многочленом степени
для которого будут одновременно выполнены оба неравенства, обнаружитель принимает решение, что принята ПСП, образованная примитивным многочленом степени  В противном случае принятая последовательность считается случайной. Отметим, что предлагаемый алгоритм обнаружения псевдослучайных последовательностей легко реализуем на ЭВМ.
В противном случае принятая последовательность считается случайной. Отметим, что предлагаемый алгоритм обнаружения псевдослучайных последовательностей легко реализуем на ЭВМ.
В [94] показано, что для обнаружения  -последовательности с неизвестным
-последовательности с неизвестным  необходимо принять
необходимо принять

импульсов, где

где  некоторые константы, определяемые заданными вероятностями ложных тревог
некоторые константы, определяемые заданными вероятностями ложных тревог  и правильного обнаружения
и правильного обнаружения  вероятность ошибки при приеме одного импульса. Обратимся к случаю, когда анализируемая двоичная последовательность получена в результате посимвольного приема входного ФМ сигнала, и на конкретном примере рассмотрим числовые характеристики предлагаемого метода обнаружения. Предположим, что
вероятность ошибки при приеме одного импульса. Обратимся к случаю, когда анализируемая двоичная последовательность получена в результате посимвольного приема входного ФМ сигнала, и на конкретном примере рассмотрим числовые характеристики предлагаемого метода обнаружения. Предположим, что  На рис. 14.12 представлена зависимость числа сигналов
На рис. 14.12 представлена зависимость числа сигналов  которые необходимо принять для достижения требуемых статистических характеристик обнаружителя, от базы ФМ сигналов, испльзуемых в системе при различных отношениях сигнал-шум
которые необходимо принять для достижения требуемых статистических характеристик обнаружителя, от базы ФМ сигналов, испльзуемых в системе при различных отношениях сигнал-шум  Так, при базе сигнала
Так, при базе сигнала  и отношении сигнал-шум
и отношении сигнал-шум  для достижения
для достижения  необходимо принять 38 сигналов, а при
необходимо принять 38 сигналов, а при  необходимо принять 55 сигналов. При больших значениях В зависимость числа сигналов
необходимо принять 55 сигналов. При больших значениях В зависимость числа сигналов  от величины базы можно аппроксимировать выражением
от величины базы можно аппроксимировать выражением  из которого следует, что при увеличении базы сигнала или при уменьшении отношения сигнал-шум случайная и псевдослучайная последовательности становятся неразличимыми.
из которого следует, что при увеличении базы сигнала или при уменьшении отношения сигнал-шум случайная и псевдослучайная последовательности становятся неразличимыми.

Рис. 4.12. Характеристики обнаружения
Из приведенных выше результатов видно, что для снижения вероятности обнаружения сигнала в условиях априорной неопределенности необходимо увеличивать его базу, что равносильно увеличению степени примитивного многочлена, соответствующего сигналу. Кроме того, снижение вероятности обнаружения может быть достигнуто за счет усложнения алгоритма формирования используемых сигналов, в частности путем использования нелинейных законоз формирования модулирующей последовательности.
Заметим, что аналогичный обнаружитель может быть построен и на основе анализа распределения единичных блоков в принятой последовательности. Объединение двух указанных методов позволяет улучшить статистические характеристики обнаружителя.




























































































































































































































































































































































































 -последовательностей [7]. Это объясняется тем, что в настоящее время во многих системах связи с шумоподобными сигналами в качестве носителя информации используются фазо-манипулированные сигналы (ФМ), модулированные усеченными М-последовательностями [7]. Основной характеристикой М-последовательностей является степень примитивных многочленов
-последовательностей [7]. Это объясняется тем, что в настоящее время во многих системах связи с шумоподобными сигналами в качестве носителя информации используются фазо-манипулированные сигналы (ФМ), модулированные усеченными М-последовательностями [7]. Основной характеристикой М-последовательностей является степень примитивных многочленов  Если величина
Если величина  известна, то длина сигнала (его база) определяется выражением
известна, то длина сигнала (его база) определяется выражением  и для обнаружения можно применить методы, используемые при обнаружении сигналов с точно известными параметрами. Однако представляет интерес исследование методов обнаружения и анализа таких сигналов при априорной неопределенности относительно степени примитивного многочлена принимаемого сигнала.
и для обнаружения можно применить методы, используемые при обнаружении сигналов с точно известными параметрами. Однако представляет интерес исследование методов обнаружения и анализа таких сигналов при априорной неопределенности относительно степени примитивного многочлена принимаемого сигнала.
 М-последовательности. Приведем основные результаты [94]. Пусть на вход приемника поступает ФМ сигнал с несущей частотой
М-последовательности. Приведем основные результаты [94]. Пусть на вход приемника поступает ФМ сигнал с несущей частотой  и тактовой частотой
и тактовой частотой  Допустим, что при помощи
Допустим, что при помощи