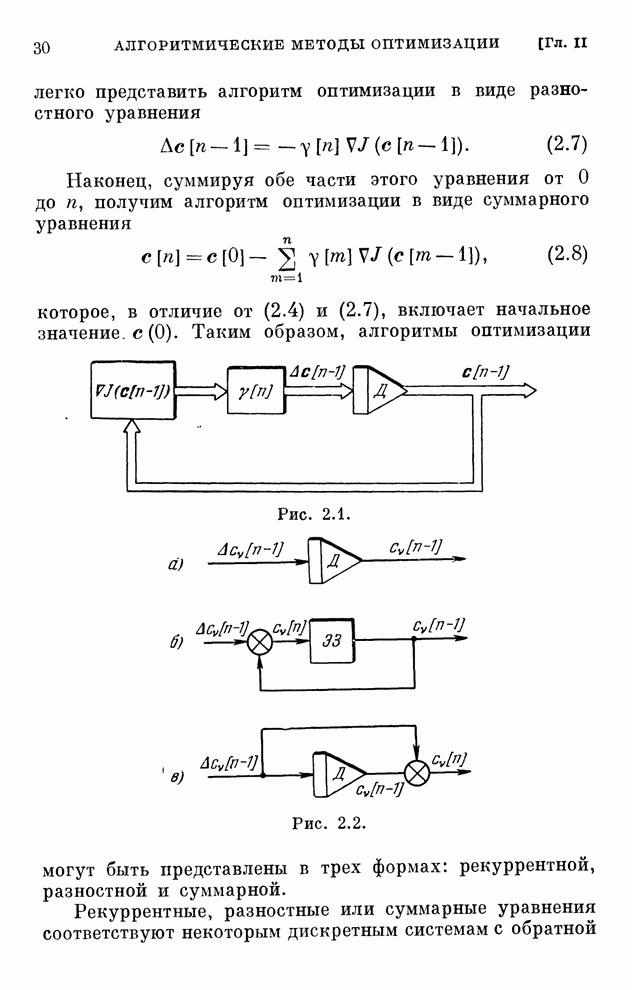
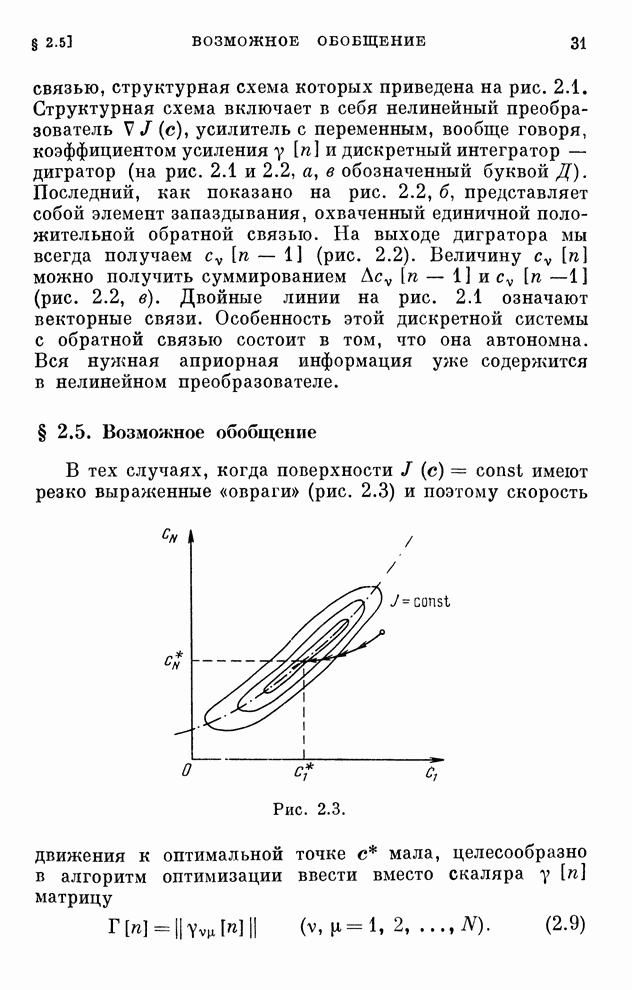
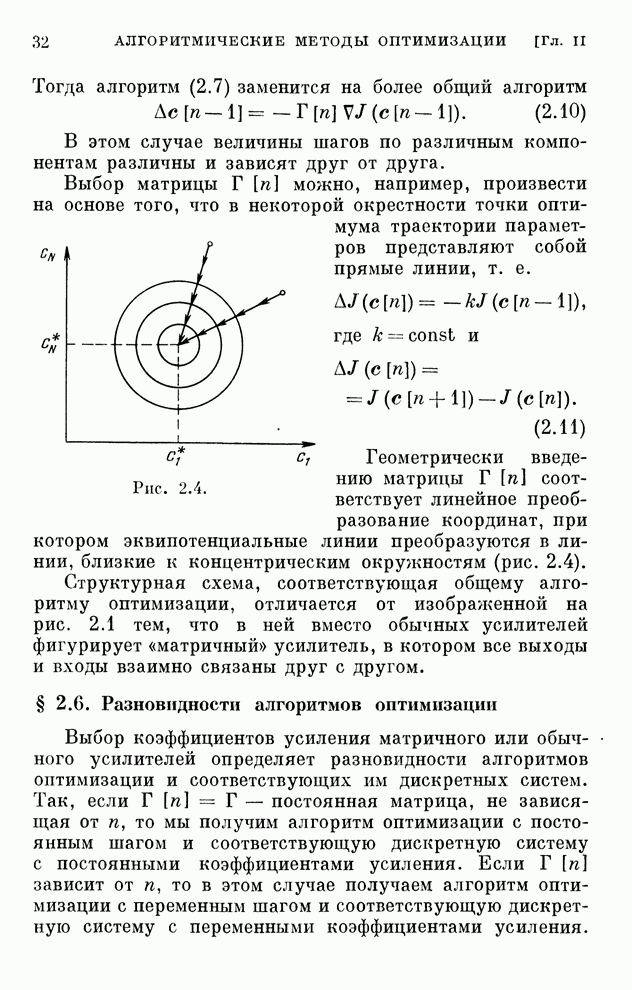
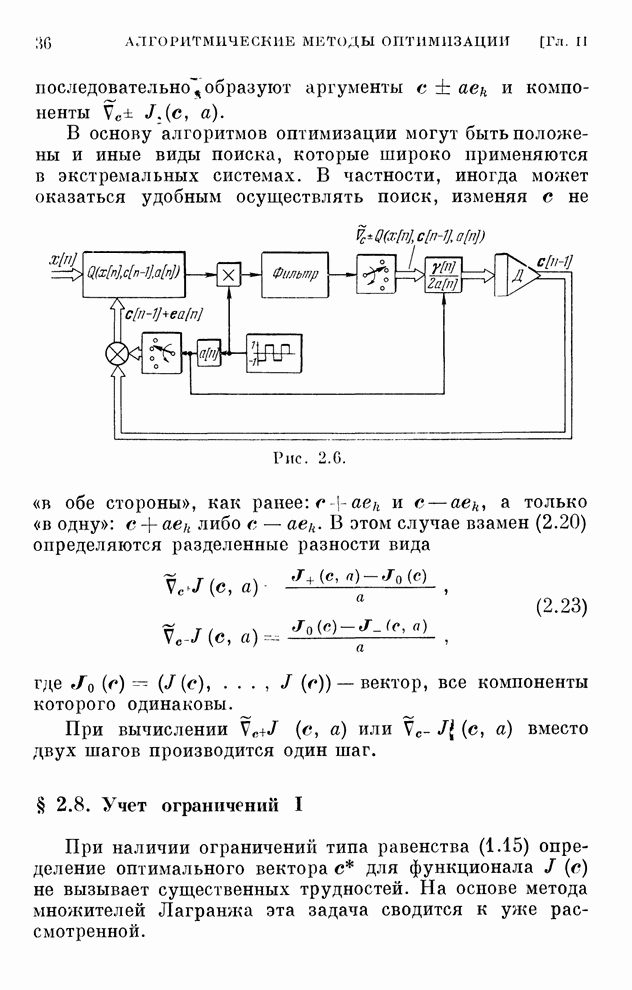
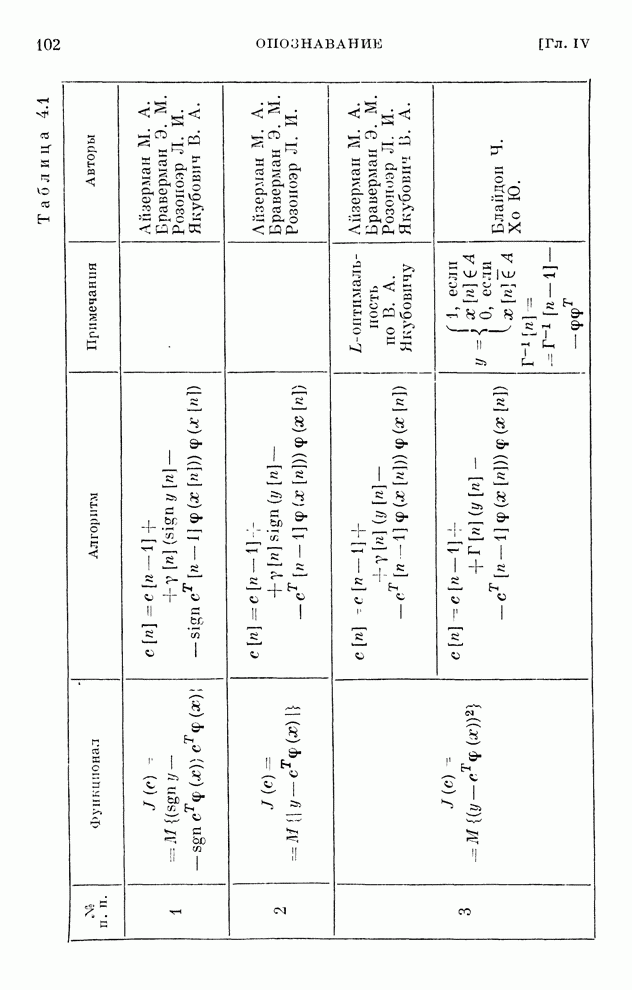
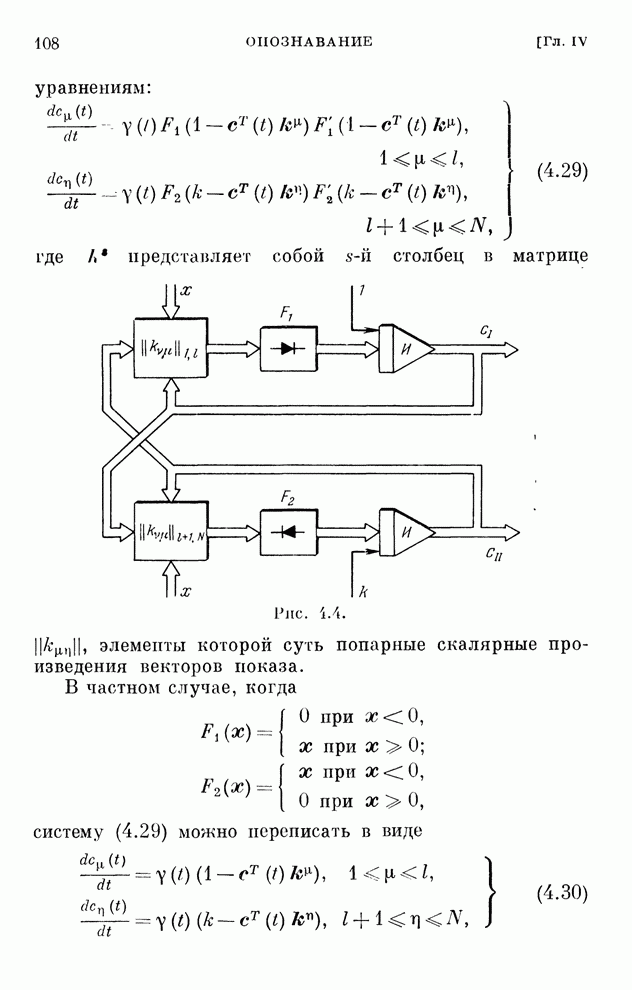
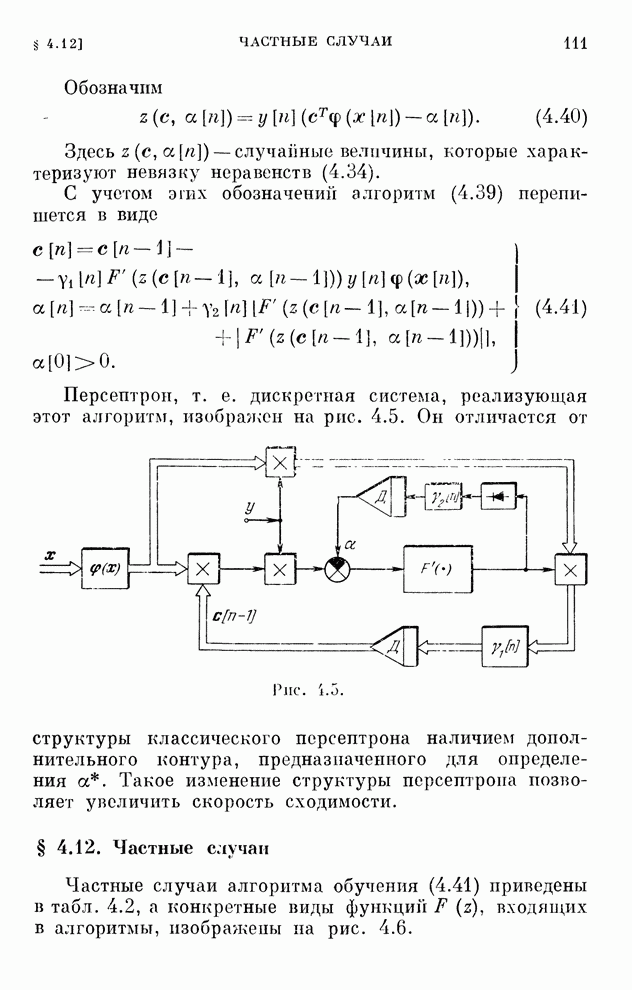
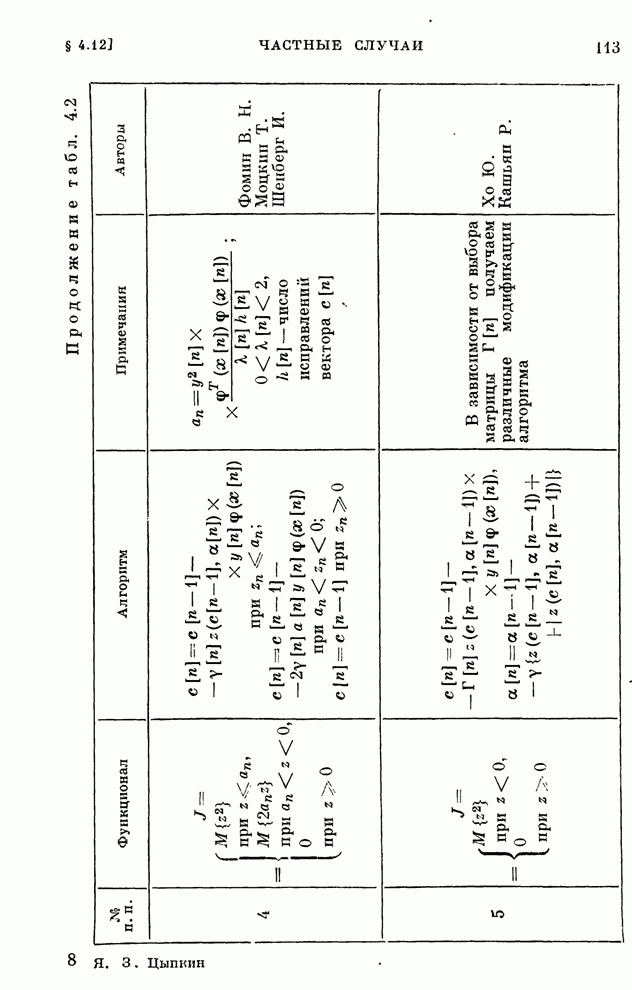
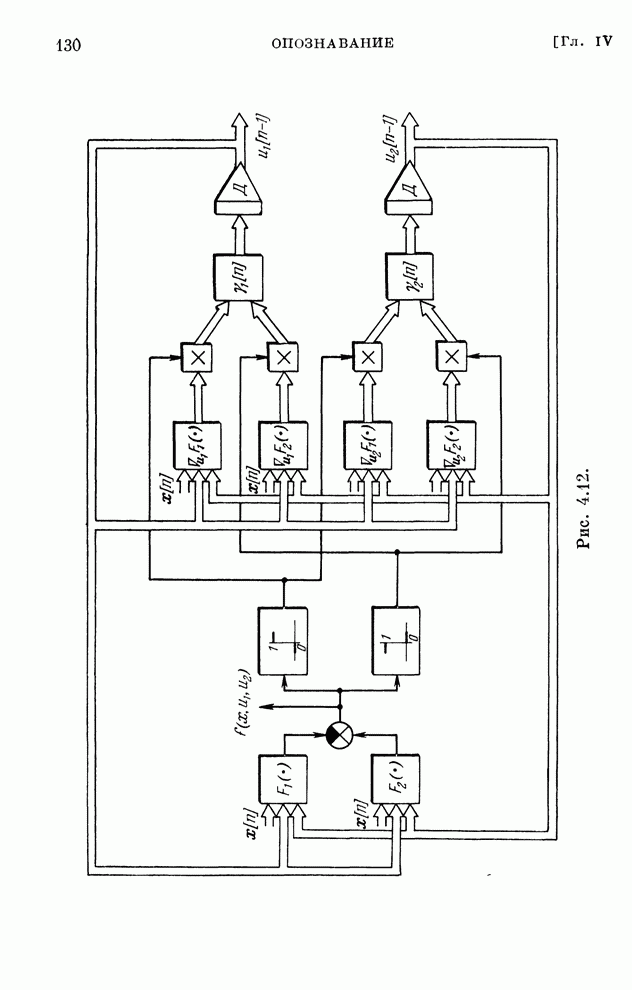
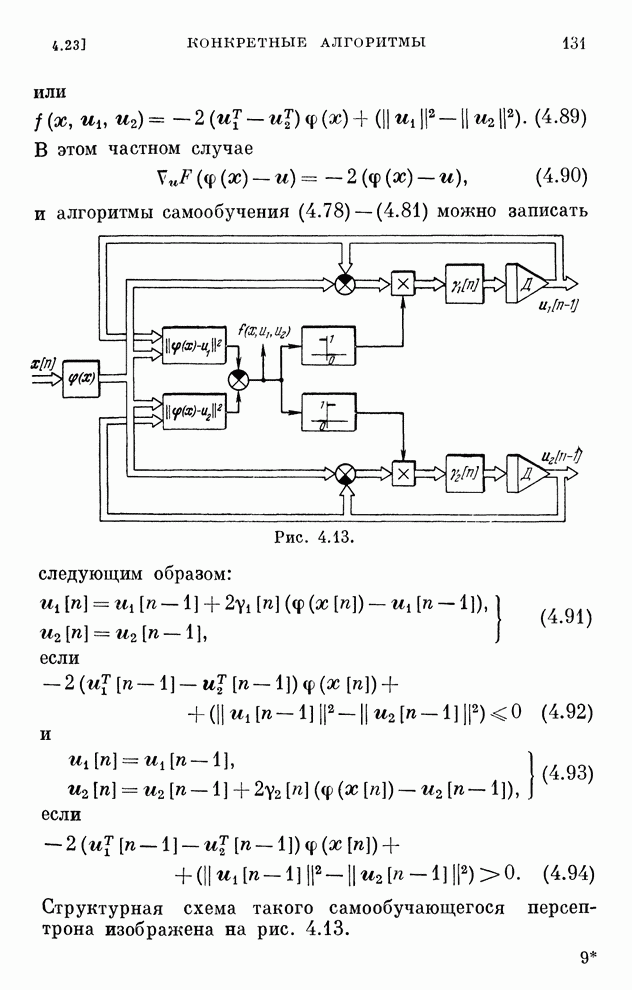
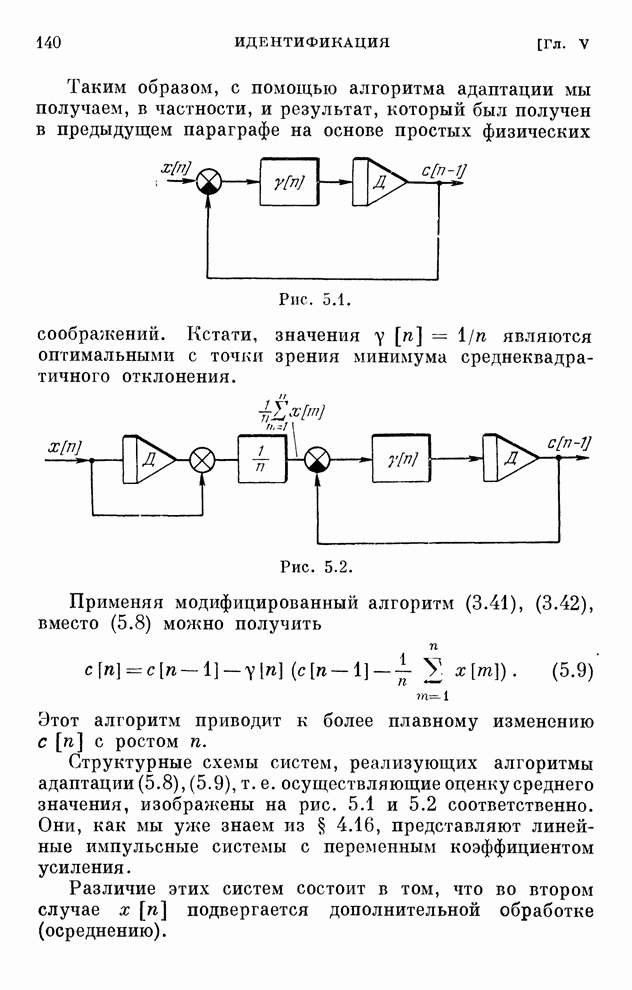
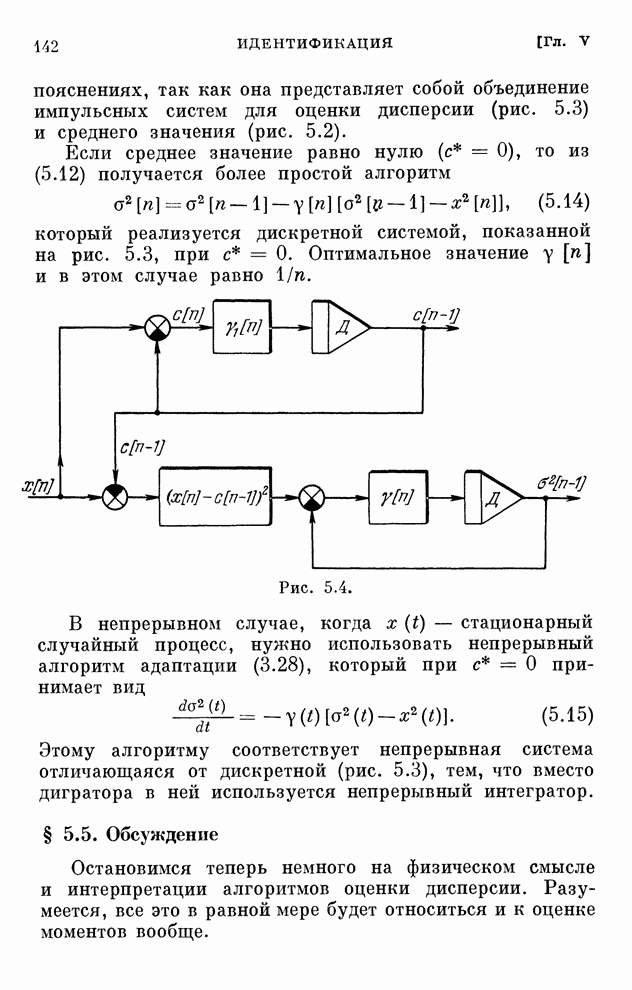
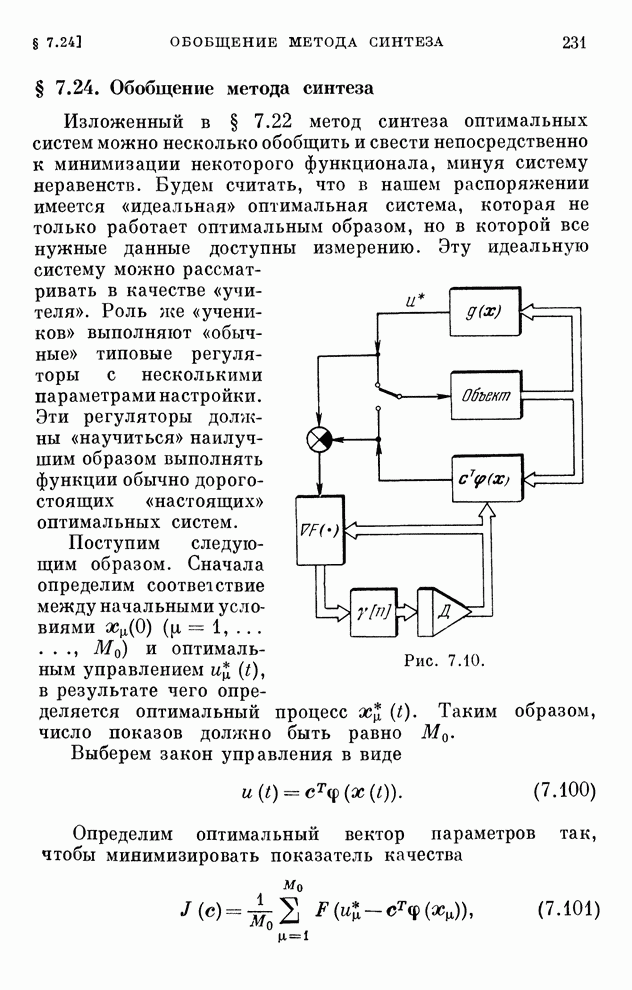
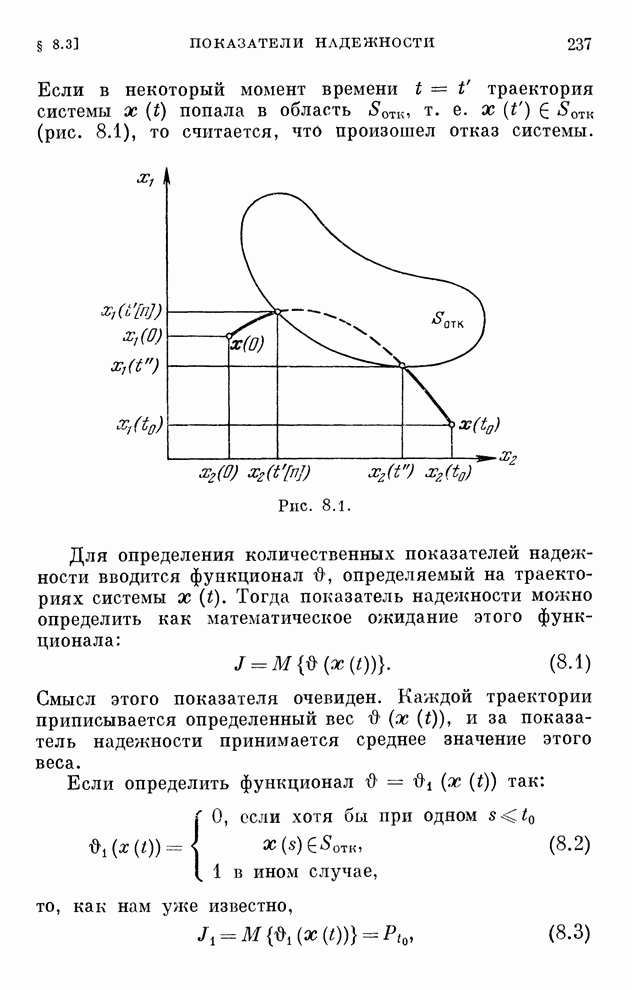
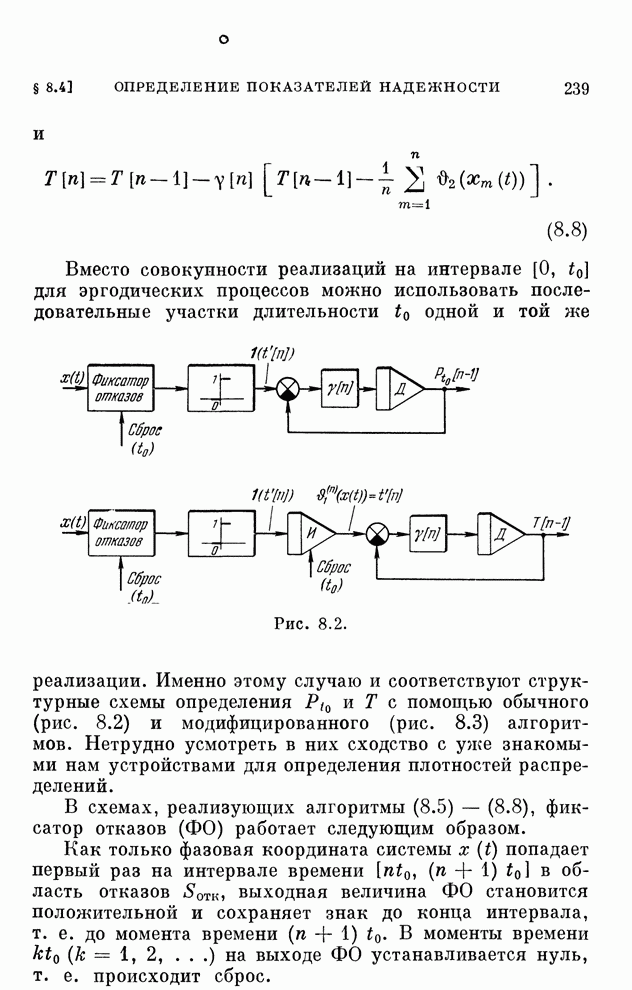
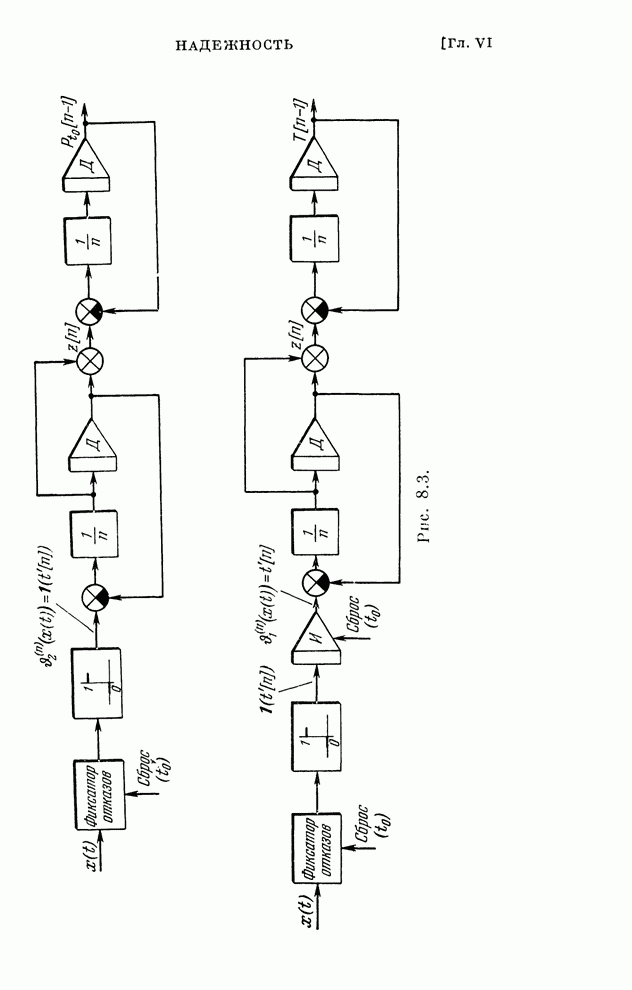
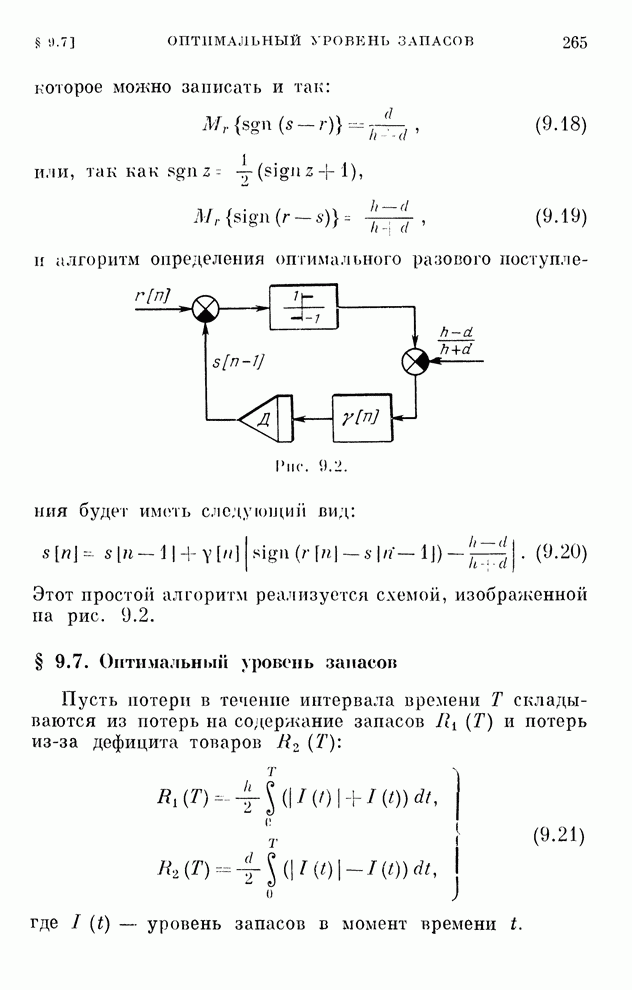
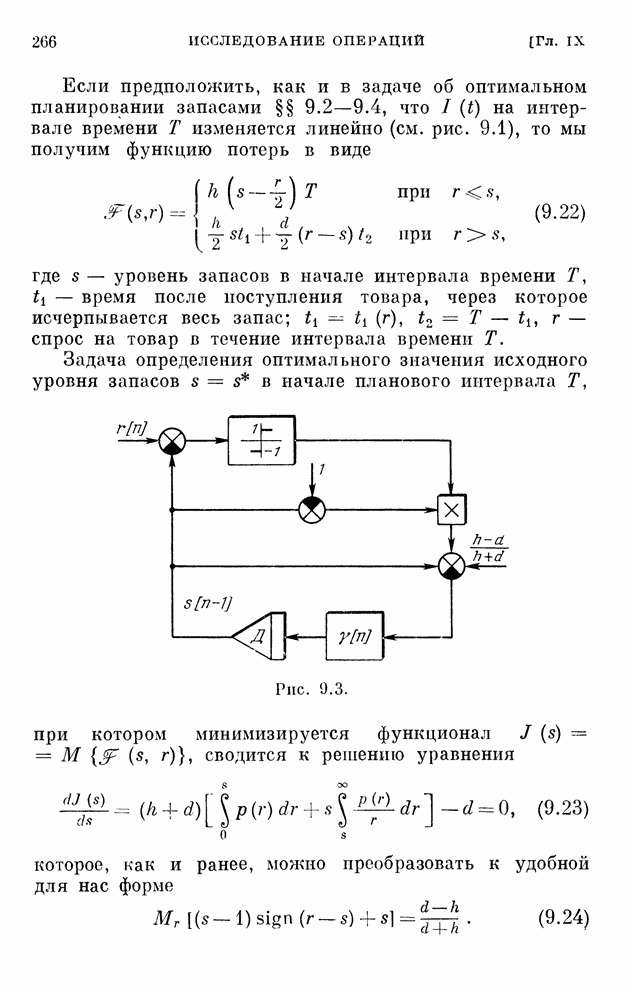
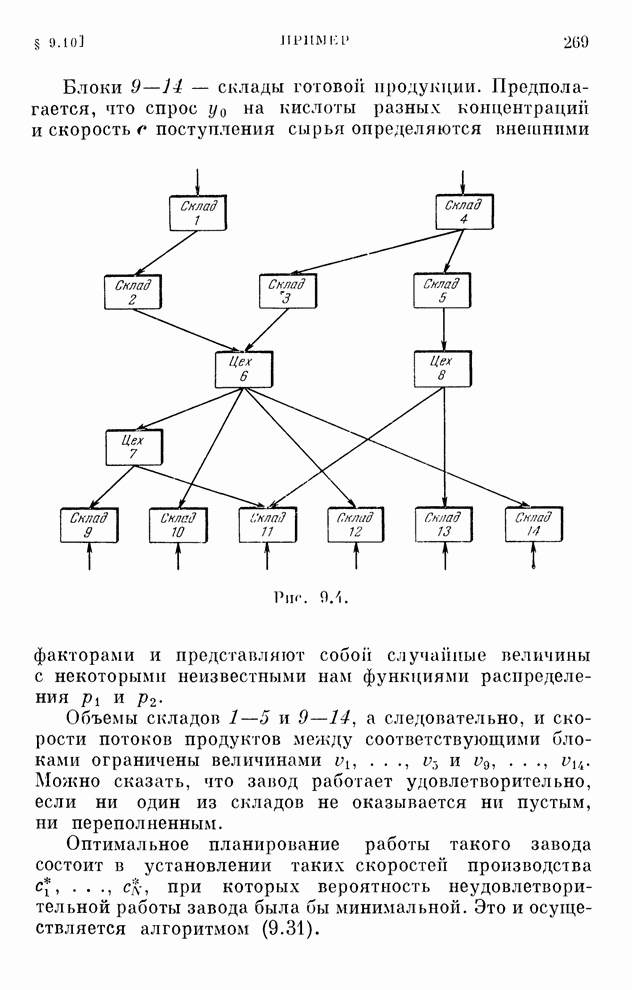
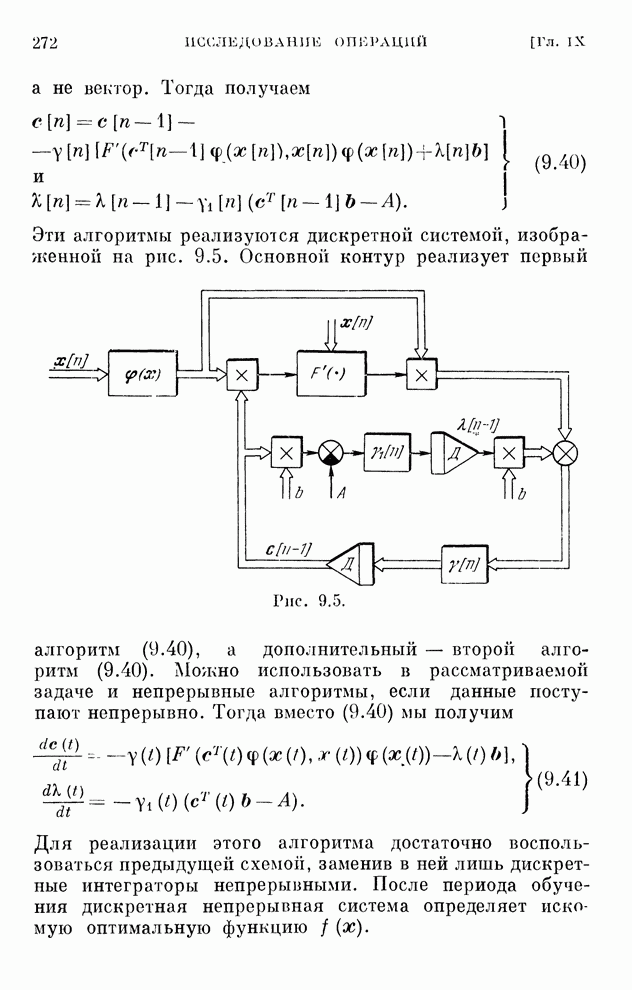
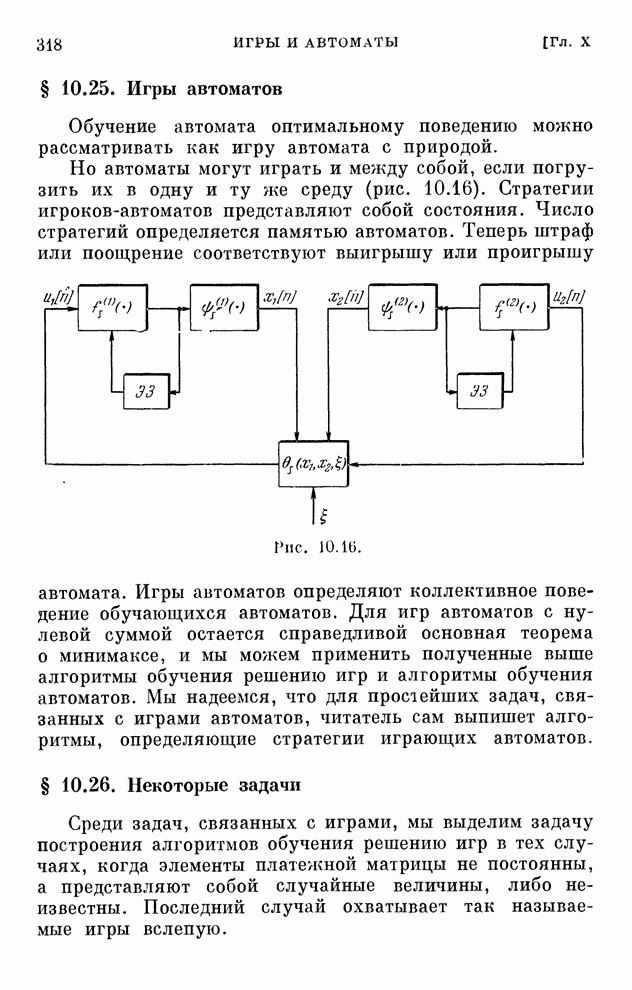
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
§ 3.21. Связь с байесовским методом
Байесовский метод приводит при конечном
числе наблюдений к наилучшим оценкам оптимального вектора  с точки зрения минимума
некоторой функции потерь. Это достигается благодаря полному использованию
достаточной априорной информации о распределениях и, к сожалению, довольно
громоздким вычислениям.
с точки зрения минимума
некоторой функции потерь. Это достигается благодаря полному использованию
достаточной априорной информации о распределениях и, к сожалению, довольно
громоздким вычислениям.
Для отдельных классов распределений
критерий оптимальности вида условного математического ожидания можно
представить как выборочное среднее, так, что
 . (3.81)
. (3.81)
Это
равенство справедливо, в частности, для экспоненциальных распределений.
Таким образом, алгоритм адаптации (3.62)
одновременно минимизирует условное математическое ожидание (3.81); при этом он
является приближенно наилучшим. Если же  — квадратичная функция
относительно
— квадратичная функция
относительно  ,
то алгоритм становится наилучшим без всяких приближений. Отсюда можно сделать
заключение, что при специальном выборе
,
то алгоритм становится наилучшим без всяких приближений. Отсюда можно сделать
заключение, что при специальном выборе  вероятностные итеративные методы в случае
квадратичных функций потерь приводят к тем же результатам, что и байесовский.
Найденное значение
вероятностные итеративные методы в случае
квадратичных функций потерь приводят к тем же результатам, что и байесовский.
Найденное значение  зависит
от всех имеющихся в нашем распоряжении значений векторов
зависит
от всех имеющихся в нашем распоряжении значений векторов  , получившихся при конечном
числе наблюдений
, получившихся при конечном
числе наблюдений  .
Заметим, однако, что с ростом размерности вектора
.
Заметим, однако, что с ростом размерности вектора  возрастают и вычислительные трудности,
зачастую лишающие нас возможности использовать даже современные вычислительные
машины с их большой, но все же ограниченной оперативной памятью. Нельзя ли
преодолеть эти трудности? Оказывается, можно.
возрастают и вычислительные трудности,
зачастую лишающие нас возможности использовать даже современные вычислительные
машины с их большой, но все же ограниченной оперативной памятью. Нельзя ли
преодолеть эти трудности? Оказывается, можно.
Будем в интервалах между поступлением
текущих данных использовать в вероятностных итеративных алгоритмах простые
выражения  типа
типа
 , а необходимое
для этих алгоритмов бесконечное число наблюдений заменим периодическим
повторением имеющегося в нашем распоряжении конечного числа наблюдений. При
этом вероятностные итеративные алгоритмы будут приводить к такой же наилучшей
оценке вектора
, а необходимое
для этих алгоритмов бесконечное число наблюдений заменим периодическим
повторением имеющегося в нашем распоряжении конечного числа наблюдений. При
этом вероятностные итеративные алгоритмы будут приводить к такой же наилучшей
оценке вектора  ,
как и наилучшие алгоритмы при
,
как и наилучшие алгоритмы при  . Разумеется, эта периодизация наблюдений
должна вестись в ускоренном масштабе времени так, чтобы успевать определять
оценку внутри
каждого интервала между
. Разумеется, эта периодизация наблюдений
должна вестись в ускоренном масштабе времени так, чтобы успевать определять
оценку внутри
каждого интервала между  -м и -м наблюдениями.
-м и -м наблюдениями.