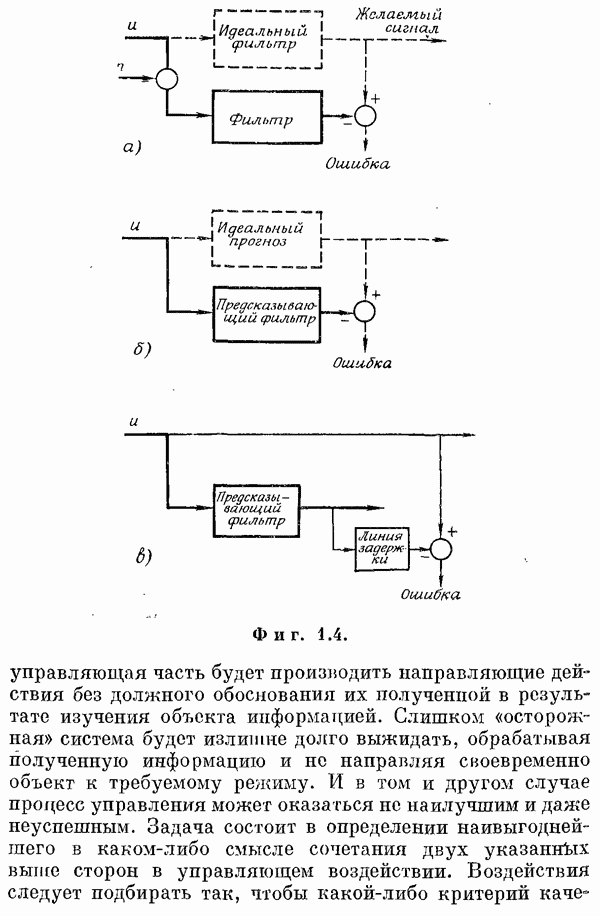
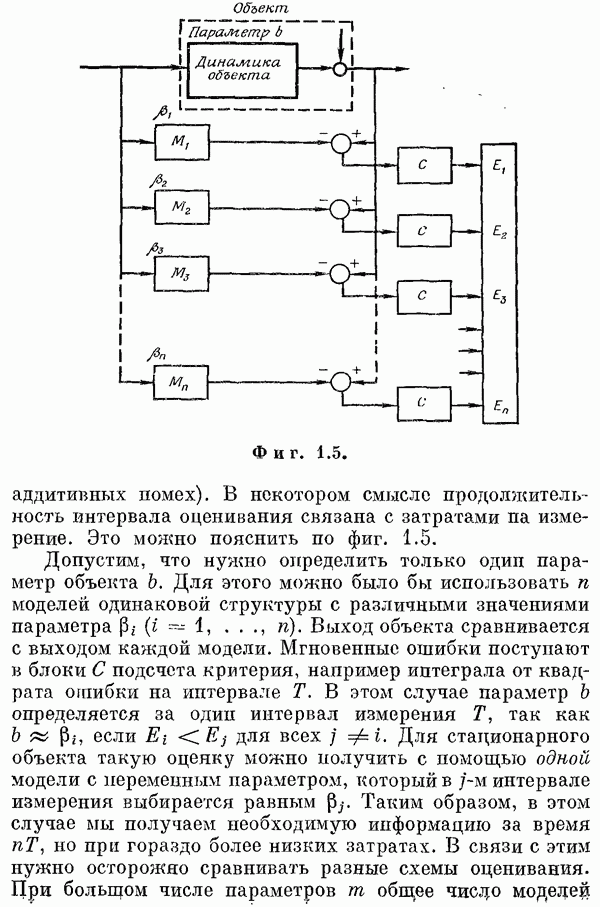
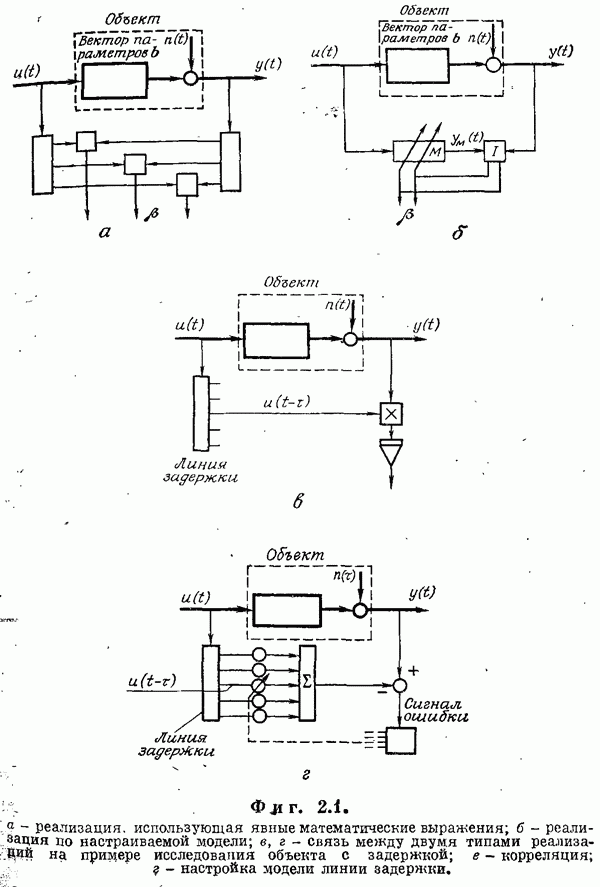
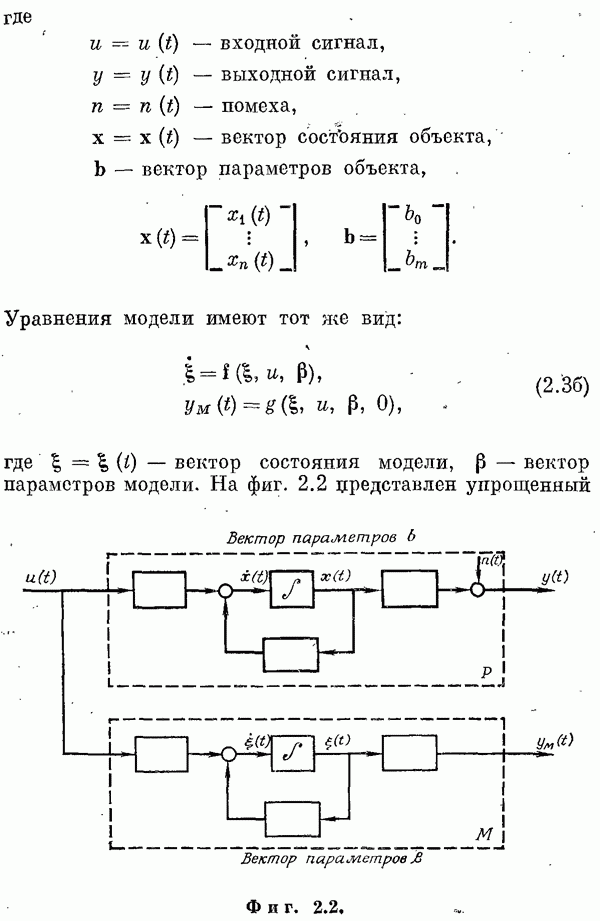
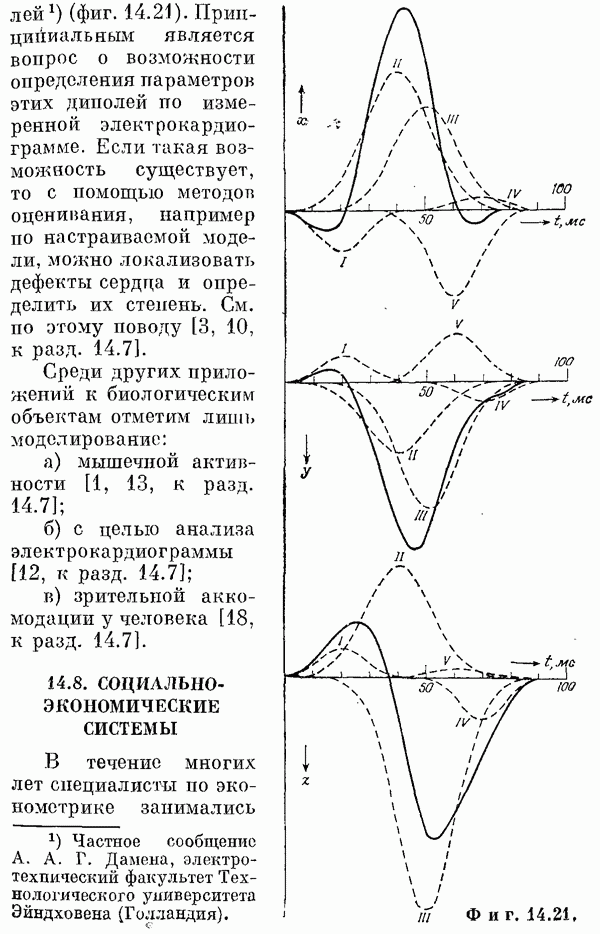
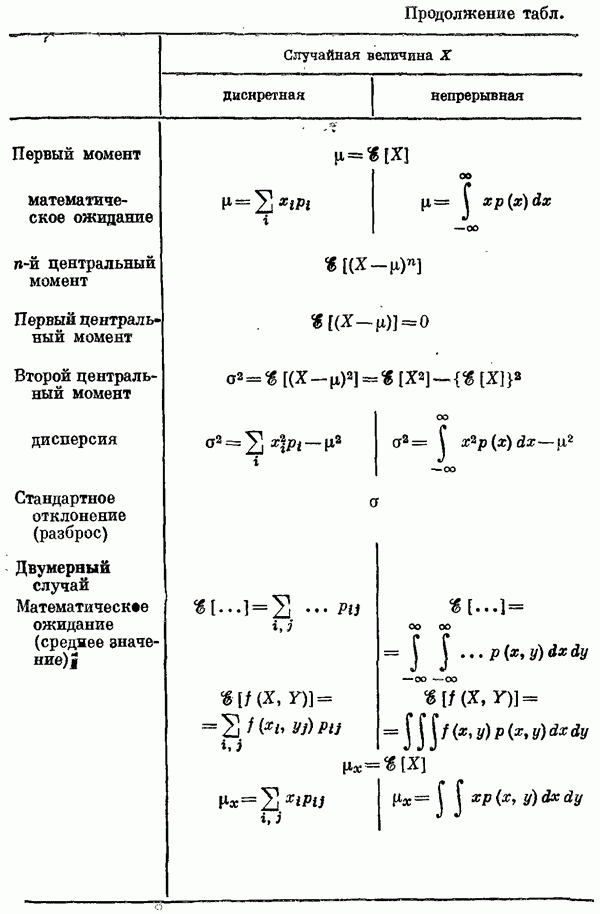
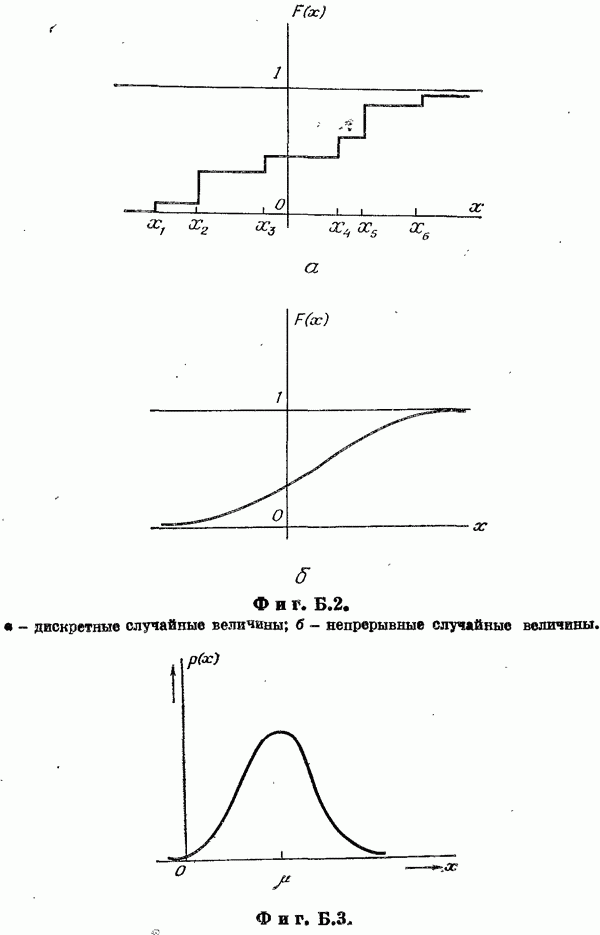
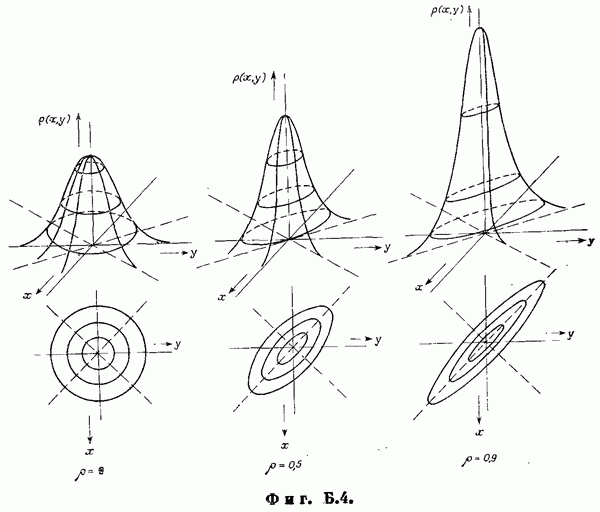
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
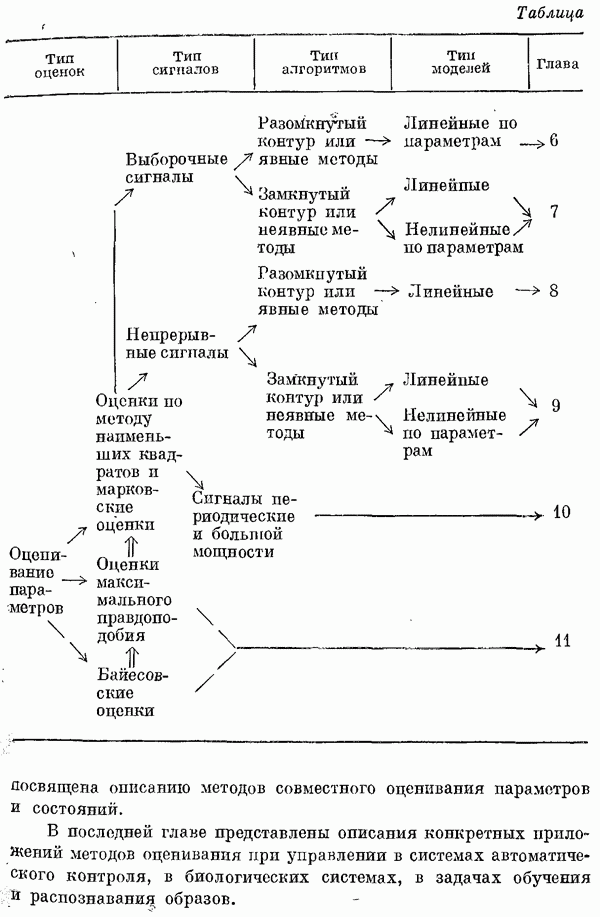
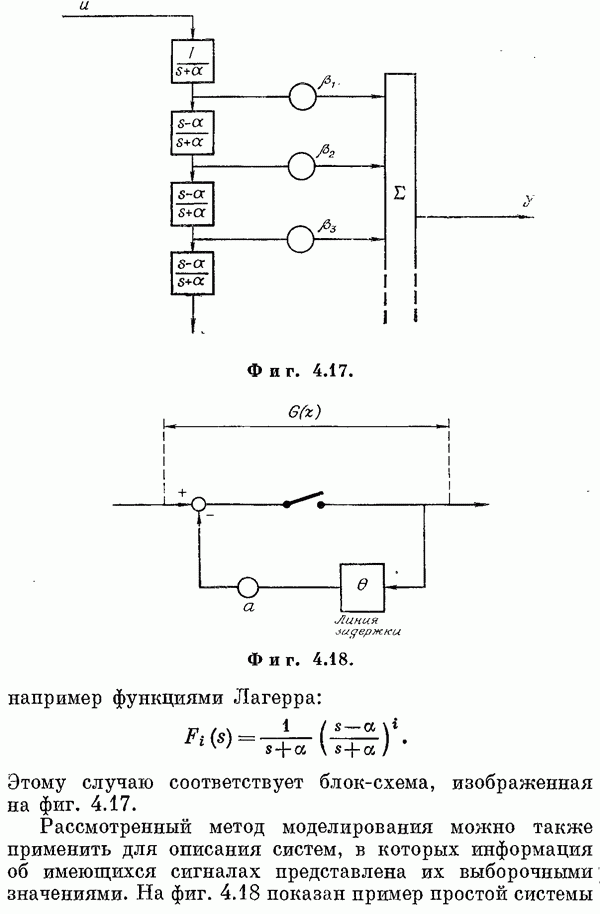
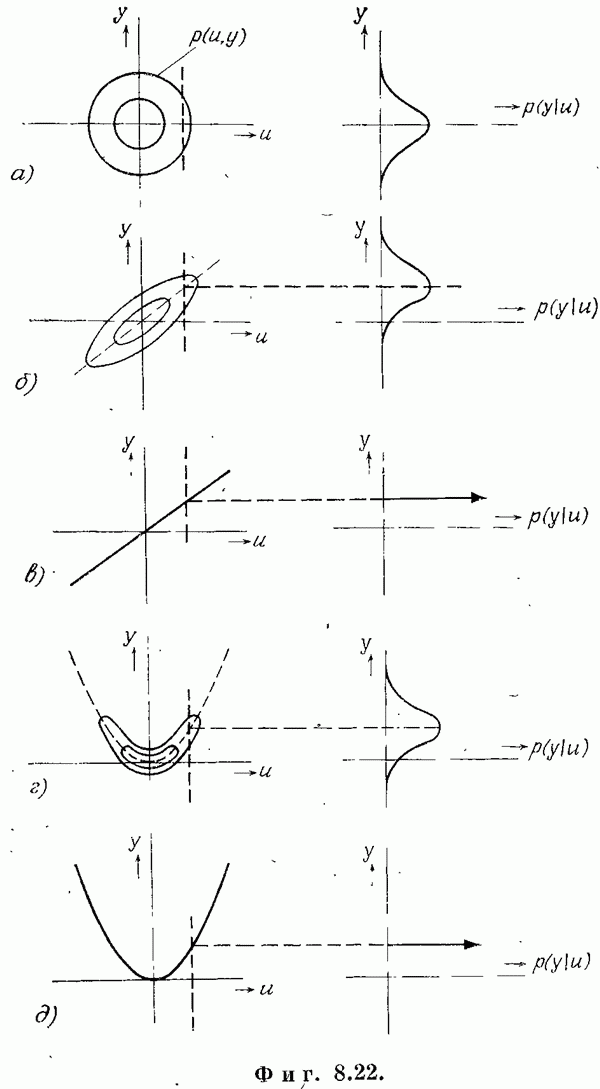
6.1. РЕГРЕССИОННЫЙ АНАЛИЗЛинии и плоскости регрессииЭлементарным введением в регрессионный анализ может служить случай двух переменных [1, 8]. Пусть х и у — случайные величины с совместной плотностью вероятности
По этой функции необходимо определить функциональные зависимости, например условное математическое ожидание у при фиксированном х
Эта функция называется линией регрессии у по х. Можно показать ([1], стр. 96), что линия регрессии дает наилучшую оценку у в смысле минимума среднеквадратической ошибки. Точно так же определяется любая функциональная зависимость без ограничений на
Однако можно потребовать, чтобы эта функция принадлежала к какому-то классу функций, например к классу всех линейных функций или к классу полипомов заданной степени. Выбор такого класса и минимизация среднеквадратической ошибки ведут к среднеквадратическим линиям регрессии. Пример. Пусть нужно найти наилучшую аппроксимацию у линейной функцией
Такая аппроксимация называется линейной регрессионной моделью, а
где оператор математического ожидания
Дифференцирование (6.4) по
Отсюда следует, что
Подстановка этих выражений для
Читатель может самостоятельно записать формулу для случая двумерного нормального распределения Эти идеи можно использовать для отыскания наилучших нелинейных регрессионных моделей, папример полиномиальных моделей вида
где
представляет собой маргинальную плотность распределения вероятностей х. Если теперь положить
то нужно минимизировать
Дифференцируя по получаем
Приравнивая производные нулю при
Таким образом, не нужно решать систему линейных алгебраических уравнений. Это особенно удобно, так как по мере увеличения порядка модели система линейных уравнений часто становится почти вырожденной. Эти идеи можно распространить на многомерный случай, когда условная плотность вероятности имеет вид
Класс функций точно так же может быть ограничен, например, классом линейных функций. В этом случае выбор
приводит к среднеквадратической гиперплоскости регрессии для у как функции
Если все случайные величины предполагаются центрированными, то коэффициент а может быть опущен. Дифференцирование по
Если ковариациоппая матрица иевырождена, то эту систему линейных алгебраических уравнепий можно решить относительно коэффициентов регрессии Оценивание по конечному числу наблюденийДо сих пор предполагалось, что все математические ожидания могут быть вычислены, т. е. известна совместная плотность распределения Излагаемые методы имеют длинную историю. Уже в 1795 г. Гаусс использовал их при исследовании движения планет. В наши дни они применяются, например, при определении параметров орбит спутников. Следует отметить, что, помимо обычных регрессионных моделей
Где
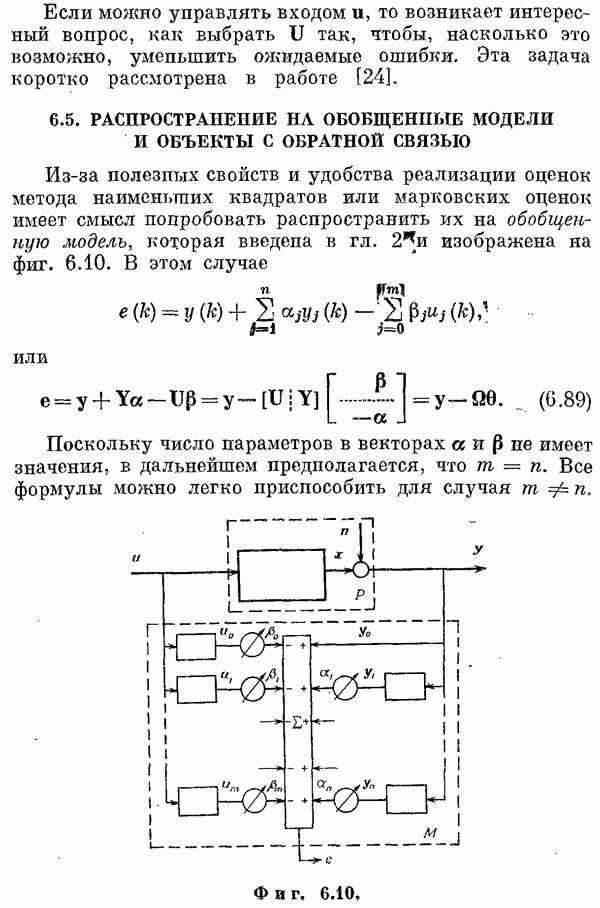
и обобщенная регрессионная модель
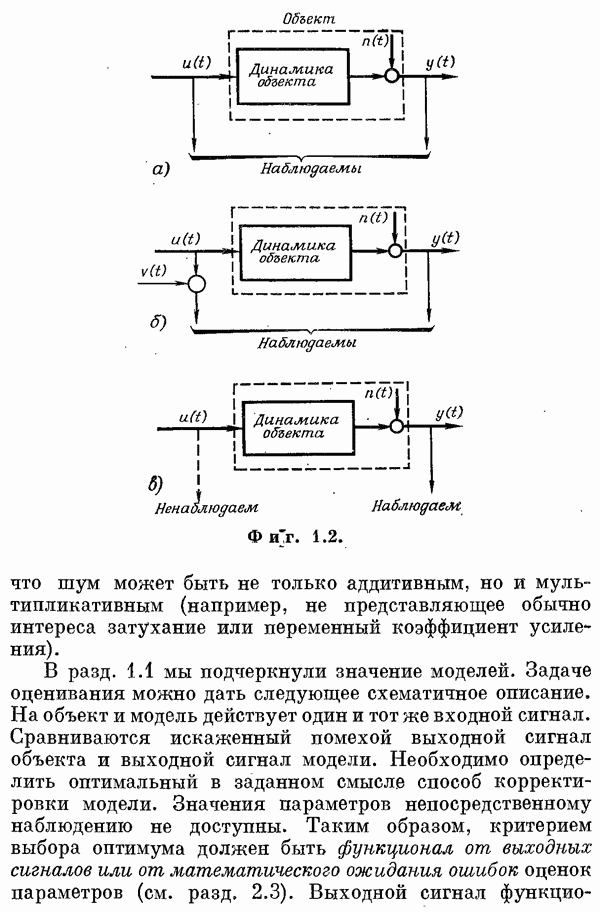
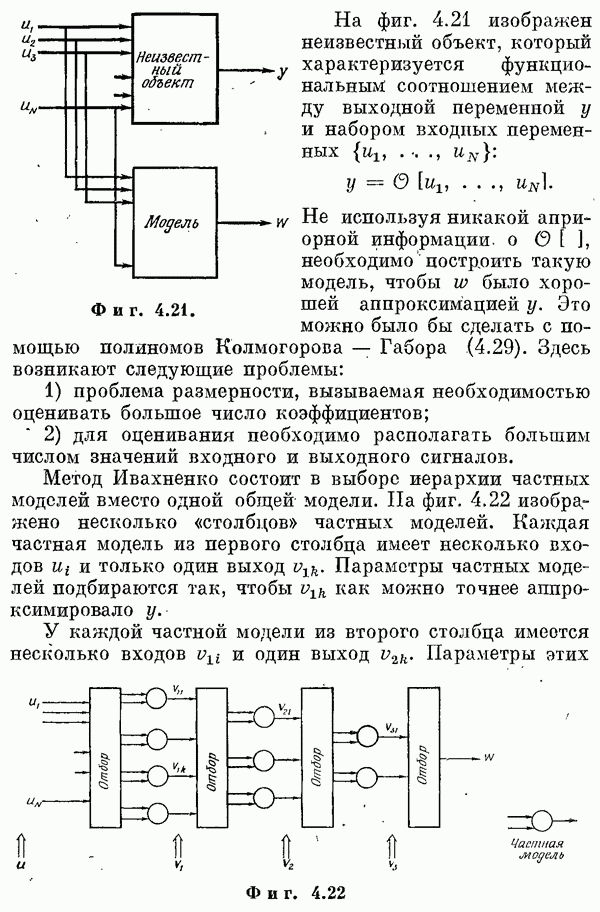
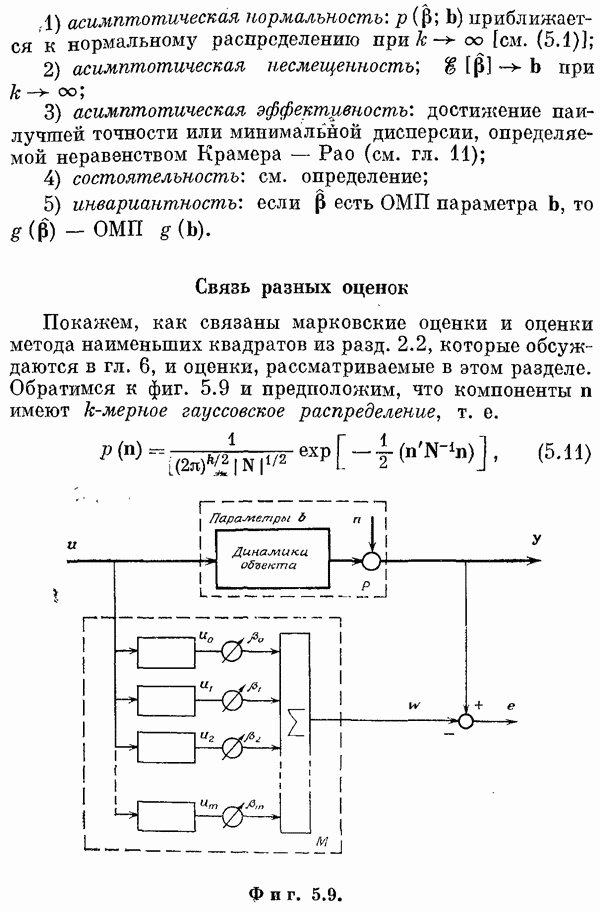
(См. также [9, 11, 14, 16, 17].) Обозначения. Теперь посмотрим, как получаются оценки. Пусть наблюдается выходной сигнал объекта у. Как и в гл. 2, у состоит из отклика на входное воздействие и, шума объекта и ошибок измерений. В момент
Вектором
Шум зададим его математическим ожиданием и ковариационной матрицей:
Задача состоит в том, чтобы определить оценку
где
где
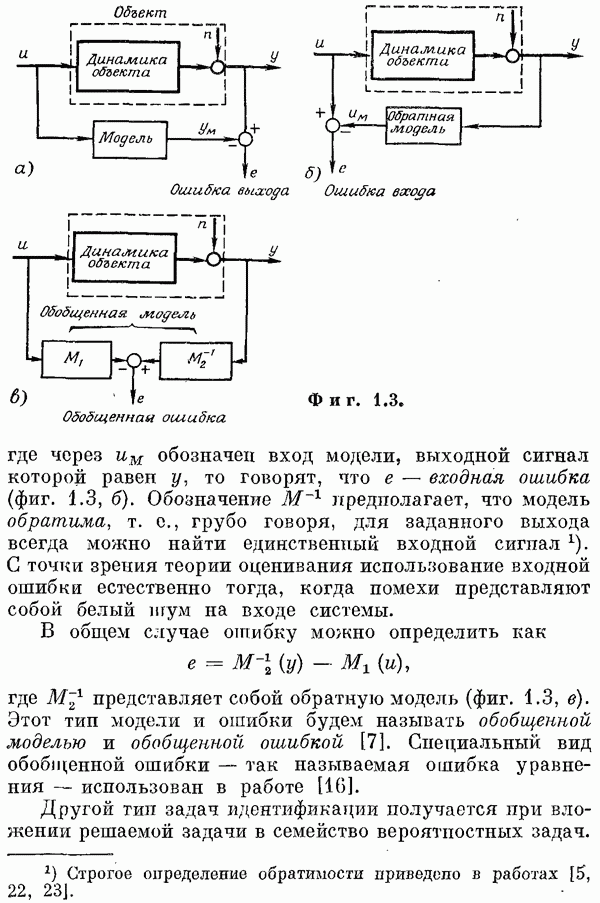
Снова заметим, что такой выбор линейной связи между Линейные несмещенные оценкиКласс линейных несмещенных оценок определяется следующими свойствами:
где
Предполагается, что равенство (6.20) может дать полное описание объекта, т. е.
Допустим сначала, что
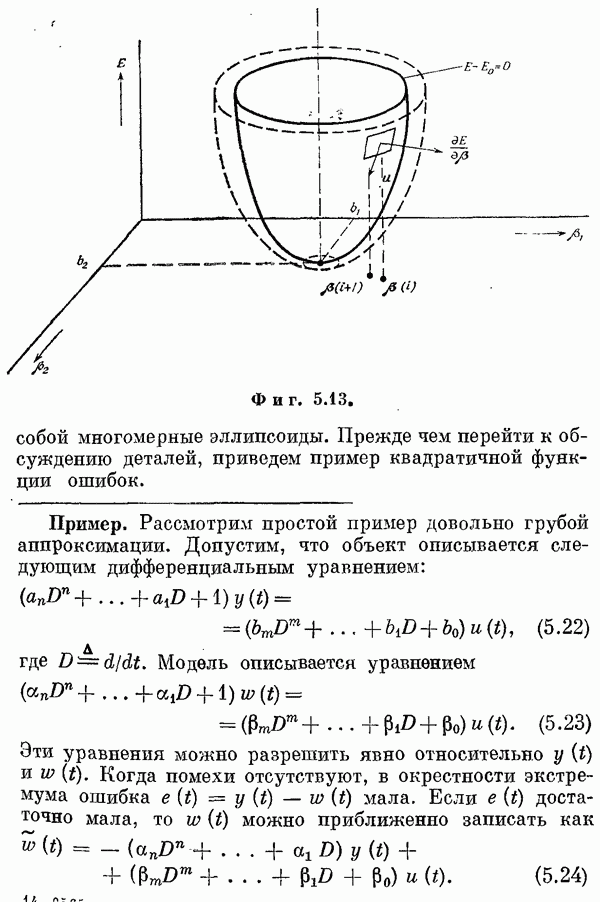
В качестве фупкции ошибок или функции потерь можно выбрать положительно определенную форму
где
Так как
Дифференцирование этого выражения по
Последнее выражение можно записать в виде
При некотором
Эту систему называют системой нормальных уравнений. Если
Нетрудно показать, что при Здесь уместно сделать несколько замечаний: 1) Конечно, уравнение (6.31) можно решить методами вариационного исчисления:
или
при произвольном 2) Прямое доказательство того, что анализа членов второго порядка по
Очевидно, что при 3) В качестве мнемонического правила может оказаться удобным использовать то, что
умножается на
Так как второе слагаемое неизвестно, не измеряется и предполагается, что Эта оценка обладает свойством линейности, поскольку
Из формул (6.31) и (6.24) следует, что
Поскольку входной сигнал и шум статистически независимы,
А так как уже предполагалось, что
Отсюда следует, что
т. е. математическое ожидание выхода модели равно выходу объекта без аддитивного шума. Желательно определить еще одну характеристику оценки
По-прежнему предполагается, что справедливо соотношение (6.24) и
Следовательно,
Будет показано, что в нескольких практически интересных случаях это выражение можно существенно упростить. Главная диагональ матрицы состоит из оценок дисперсий оцениваемых параметров. Оценки по методу наименьших квадратов [26, 27]При использовании метода наименьших квадратов минимизируется выражение
Таким образом, в уравнении (6.26) и вытекающих из него уравнениях
И из формул (6.30), (6.31) и (6.35) получаем
или
и
Если имеет обратную, то
откуда
С инженерпой точки зрения этот случай не представляет особого интереса, поскольку случайные возмущения не учитываются. Для уменьшения влияния шумов размер выборки должен быть гораздо больше числа параметров. Если в уравнении (6.37) выразить все величины через
Ортогональпость или ортонормальность пробных сигналов может привести к существенным упрощениям (см. гл. 4). В случае ортонормальности
и
или
Можно дать простую геометрическую интерпретацию оценок метода наименьших квадратов для случая двумерного вектора параметров
Фиг. 6.1. Если вектор
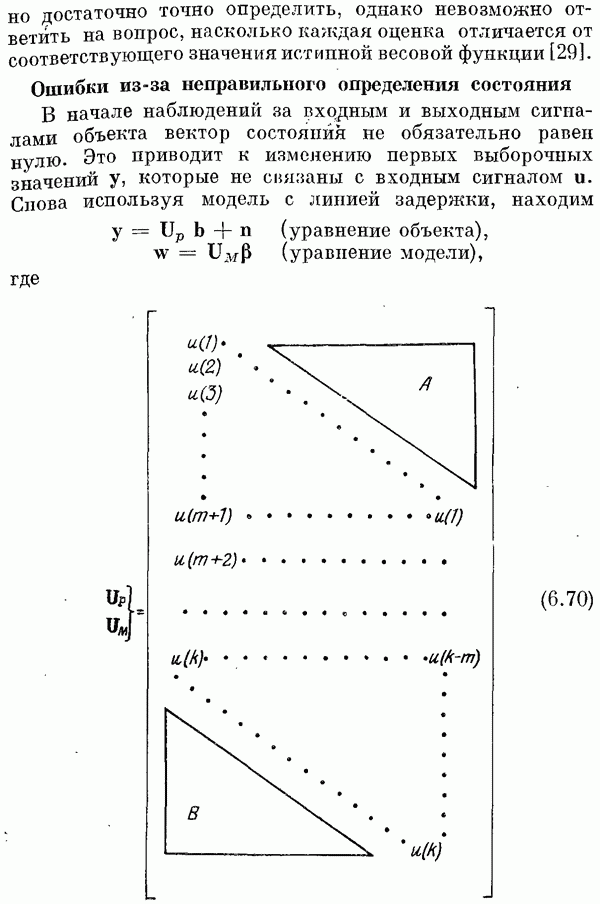
Следовательно,
или
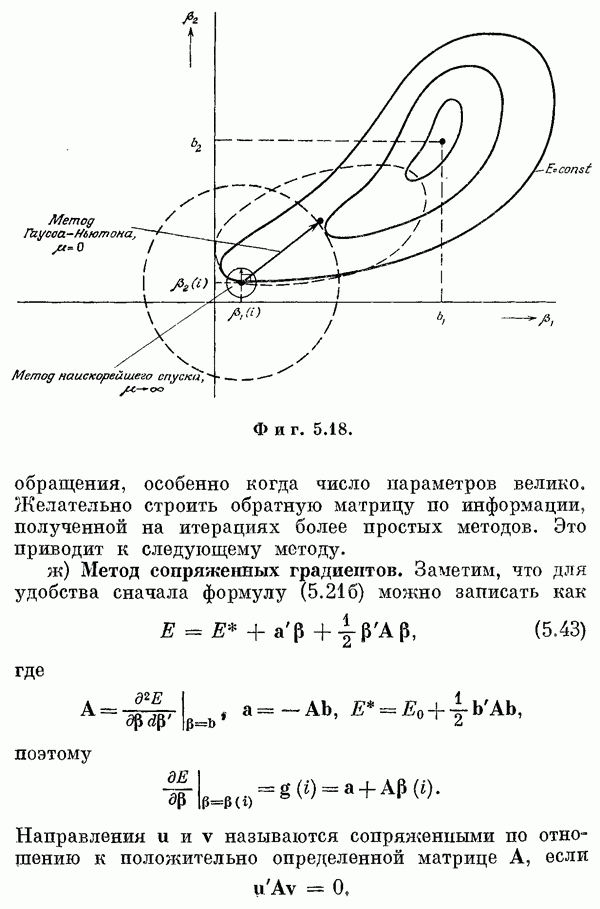
т. е. имеем уравнение (6.37). Марковские оценки (оценки обобщенного метода наименьших квадратов)При использовании марковских оценок минимизируется выражение
Следовательно,
и из формул (6.30), (6.31) и (6.35) находим
или
и
Так как ковариационная матрица (6.46) входит в формулу для оценки (6.45), оценка и ковариация определяются одновременно. Диагональные элементы (6.46) представляют собой дисперсии оценок параметров, остальные элементы матрицы — коэффициенты корреляции между оценками разных параметров. Если к Используя матричное неравенство Шварца (см. приложение В), можно легко показать, что эта линейная несмещенная оценка обладает минимальной дисперсией. Неравенство Шварца имеет вид
Выбирая
Так как
или
т. е. матрица
не отрицательно определена. Здесь Из предыдущих разделов ясно, что если аддитивная помеха — белый шум, т. е.
то
и
Как отмечалось в гл. 5, для гауссовских шумов оценки метода наименьших квадратов и марковские оценки совпадают с оценками максимального правдоподобия, все они обладают минимальной дисперсией в классе несмещенных оценок. Класс линейных несмещенных оценок порождается минимизацией положительно определенной формы
Таким образом, выбор
где
|
 |
Оглавление
|





























































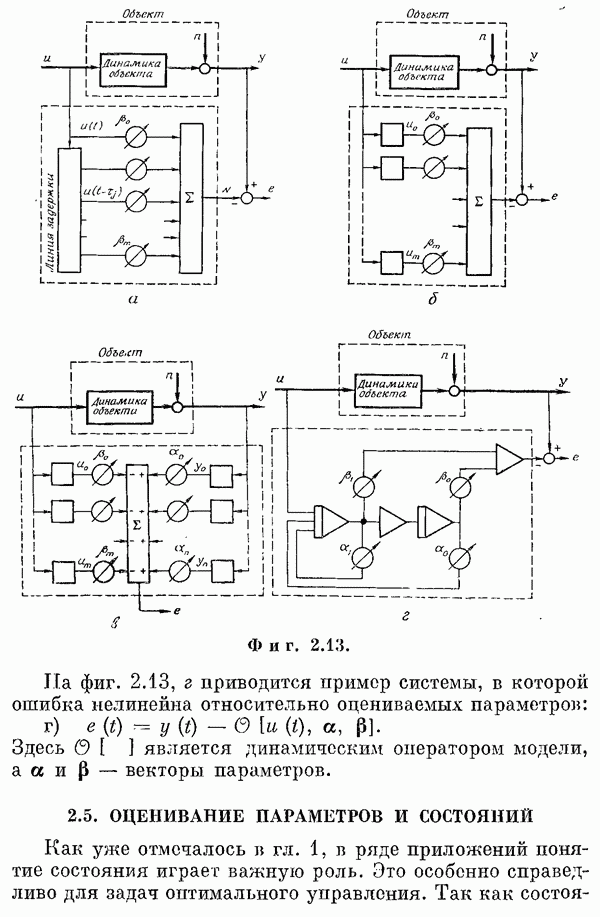



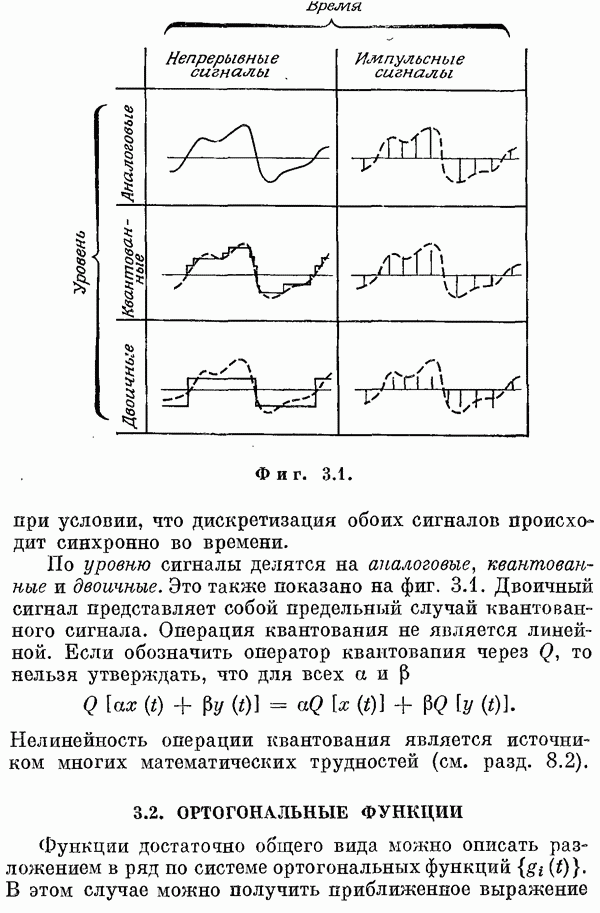






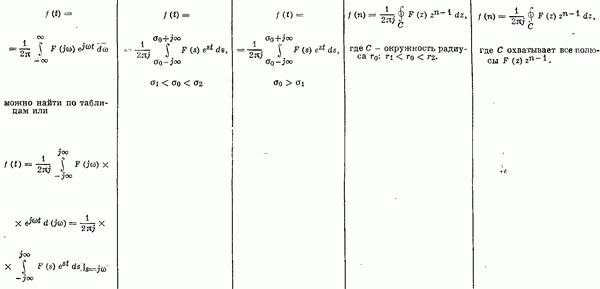
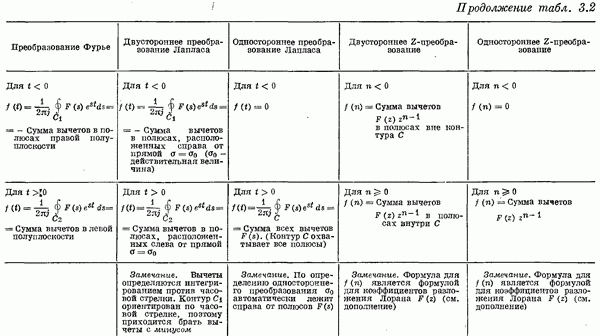





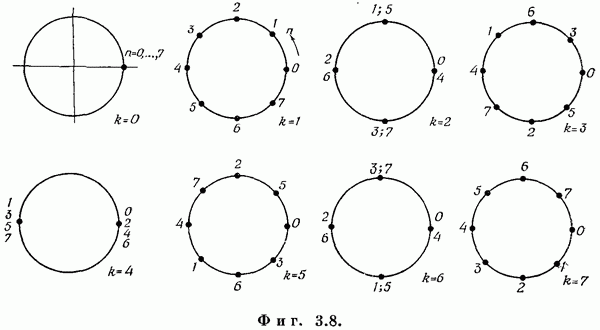














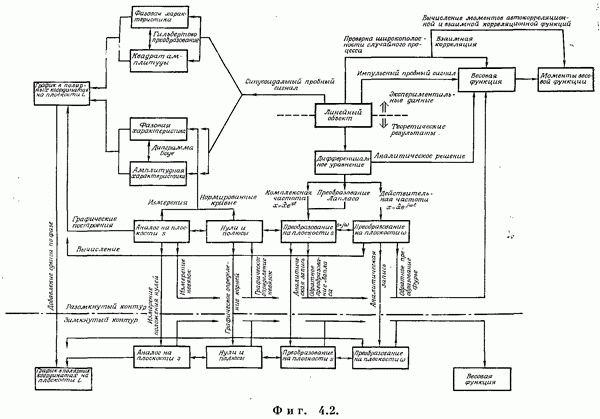



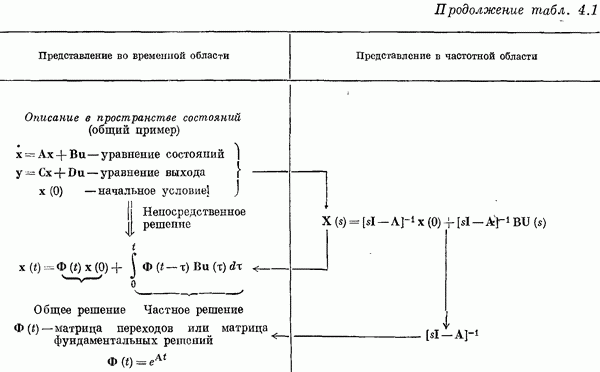


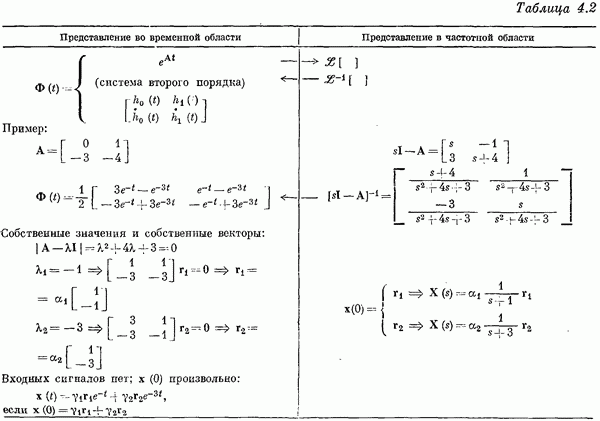

















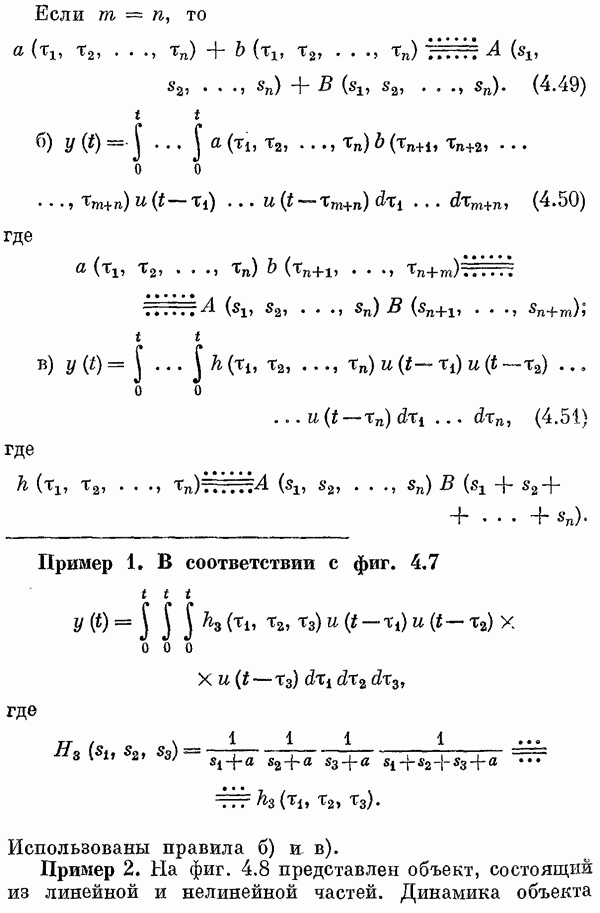
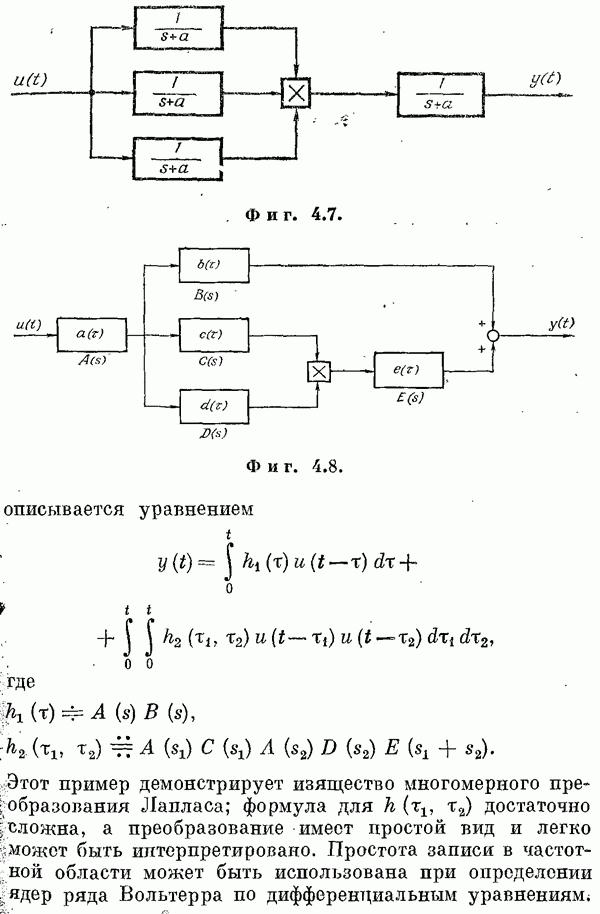



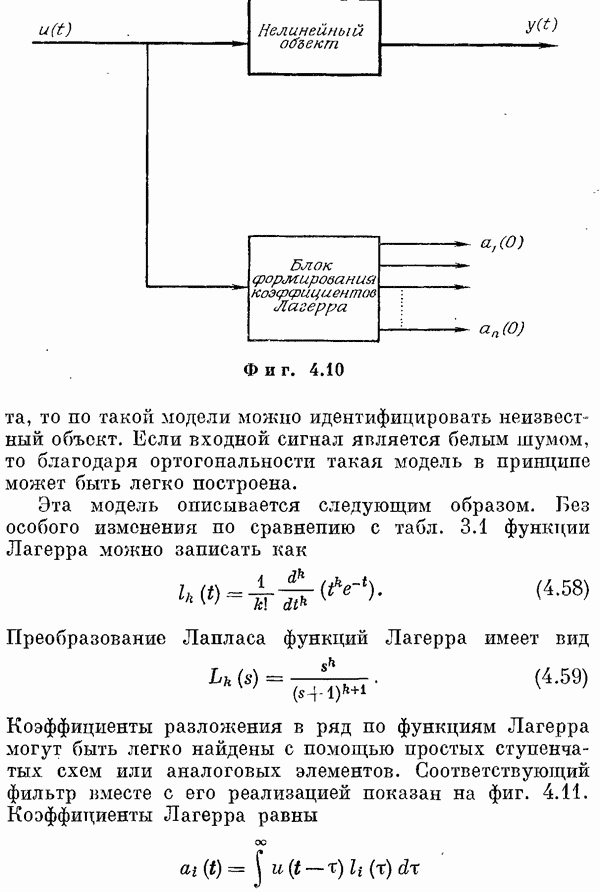




















































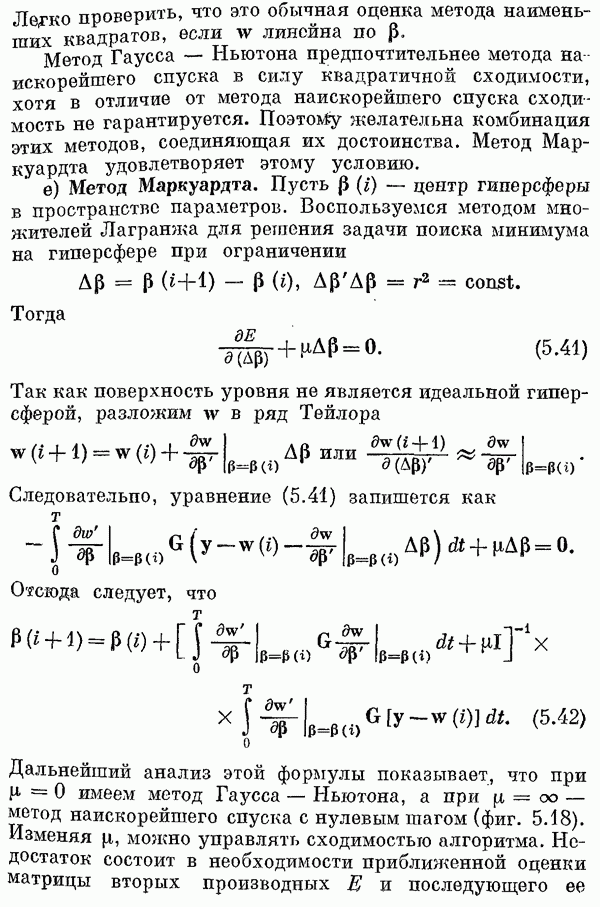













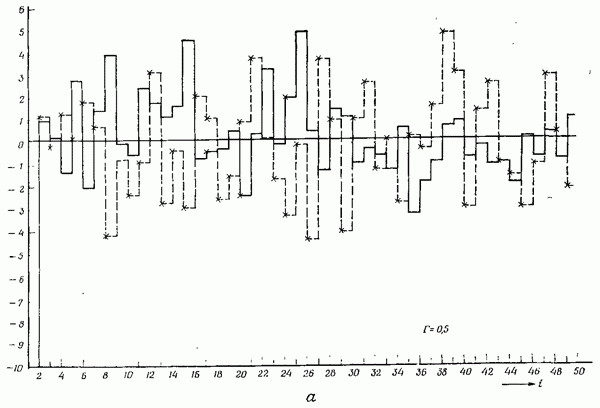
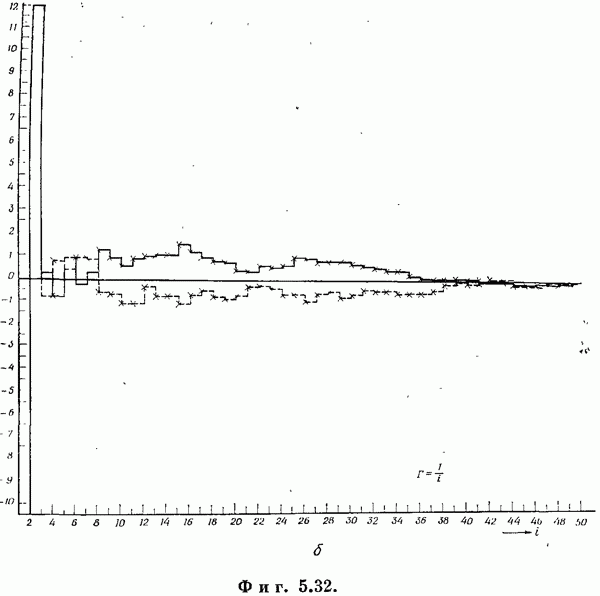


















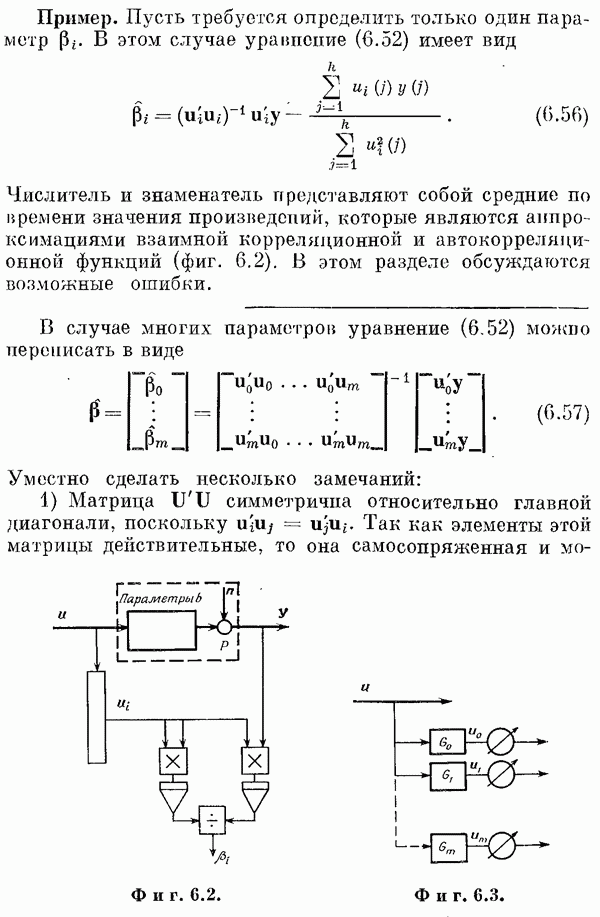









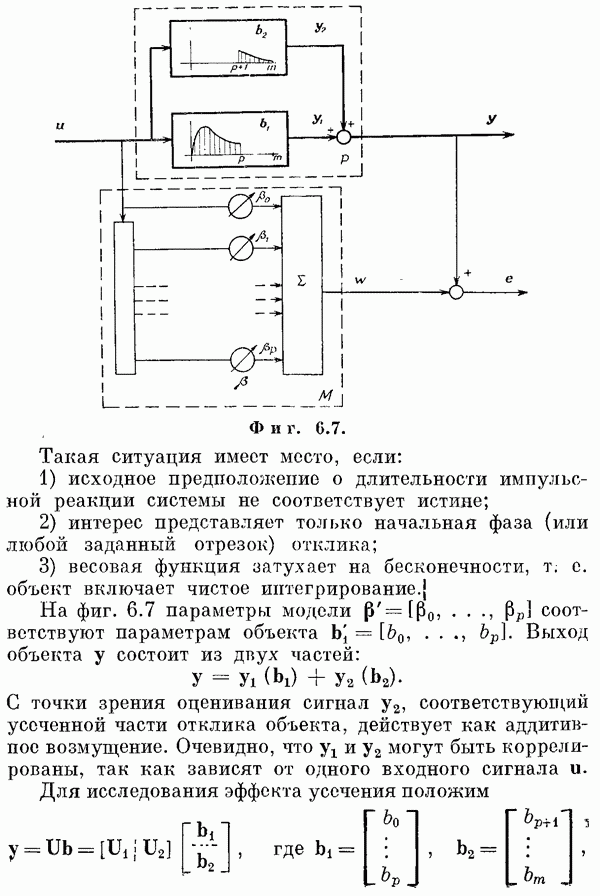










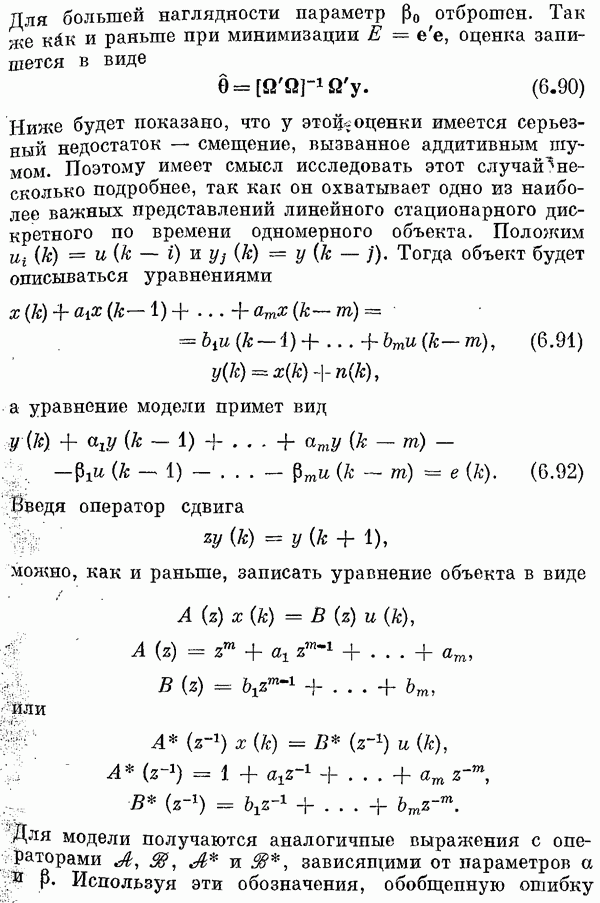





































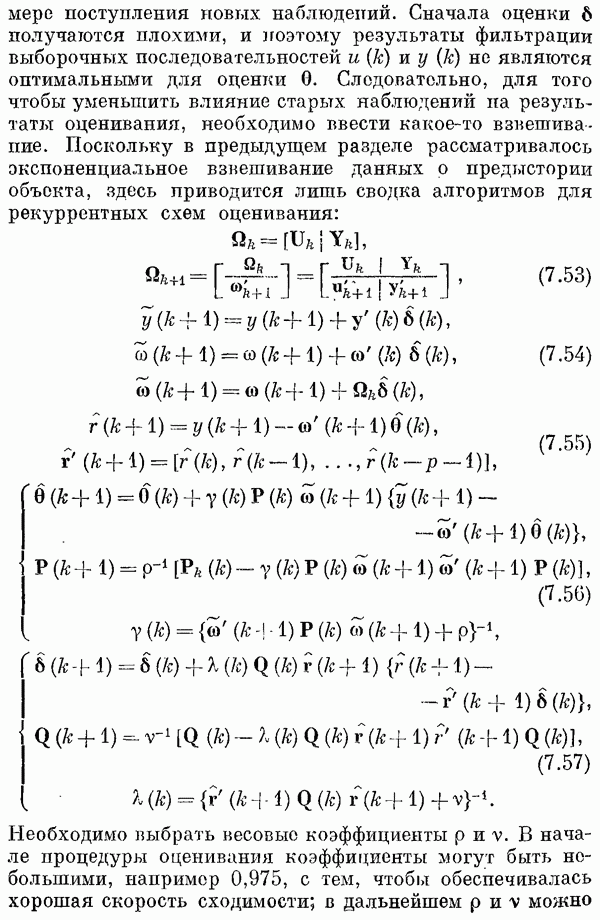





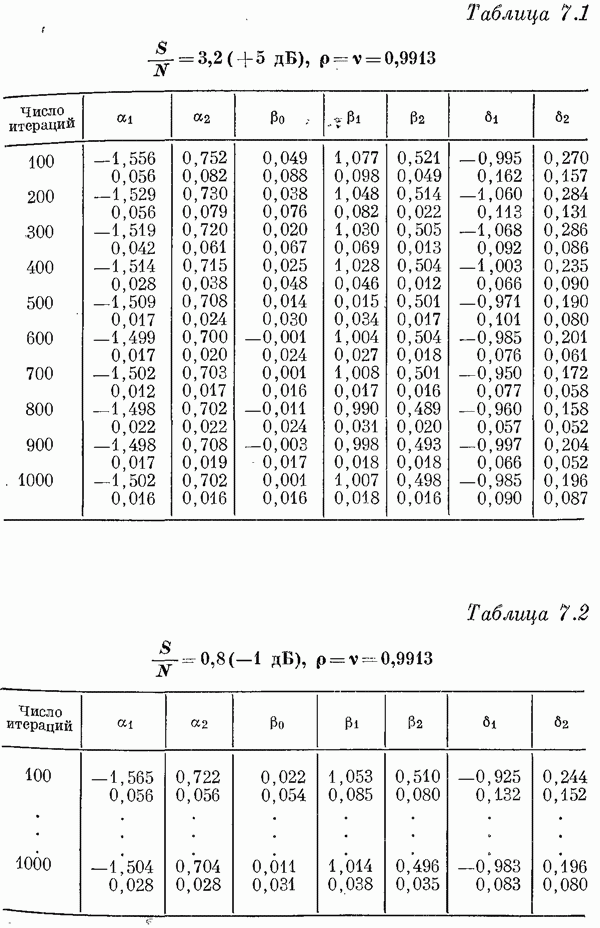
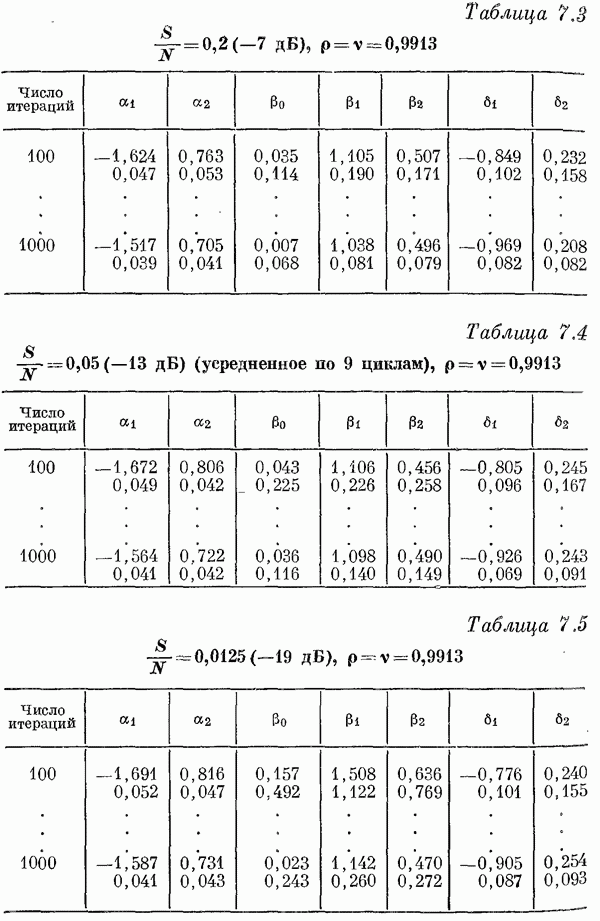
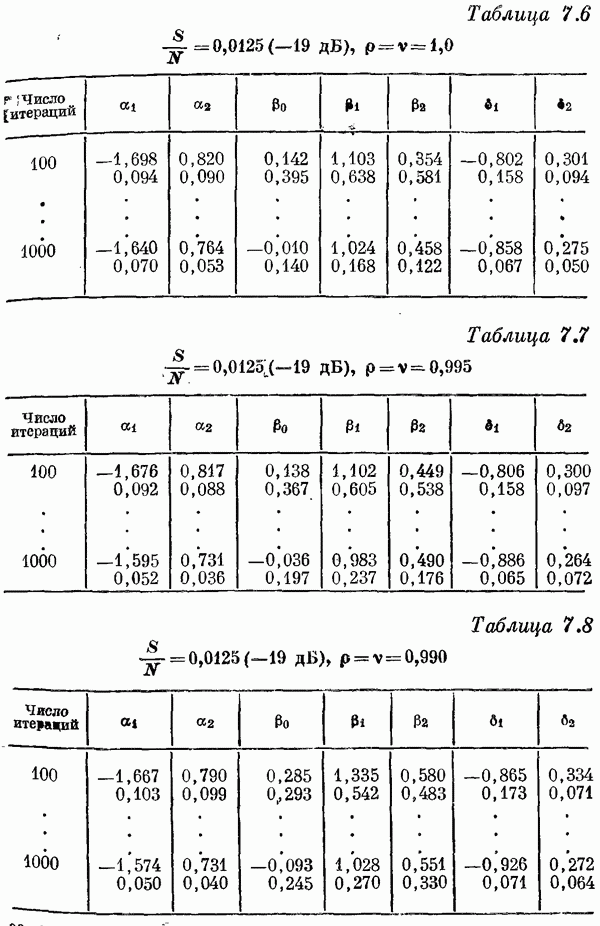
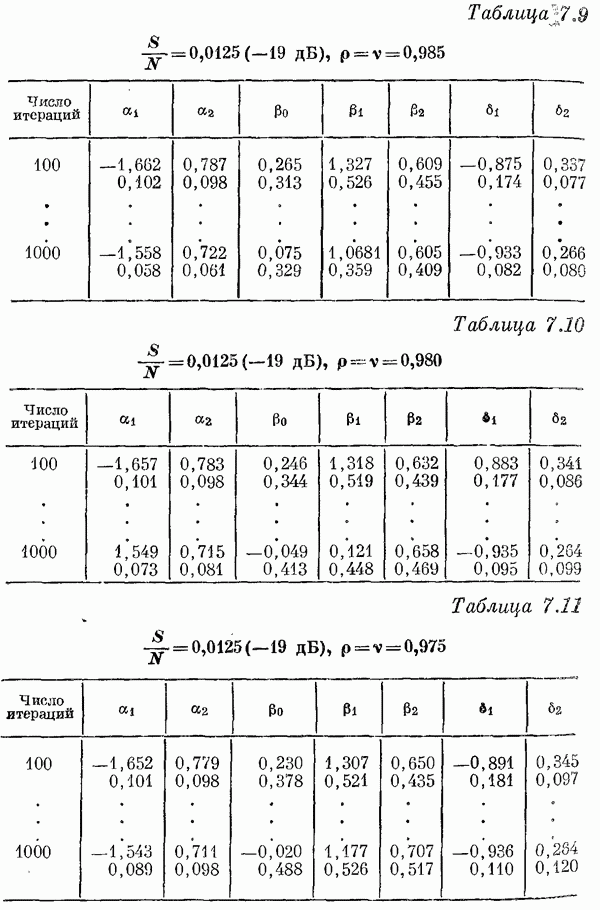


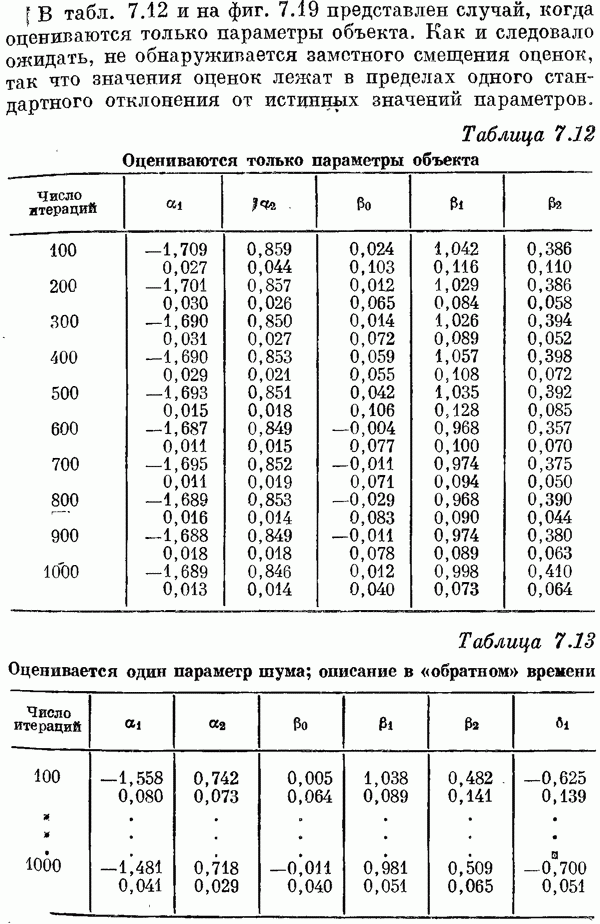
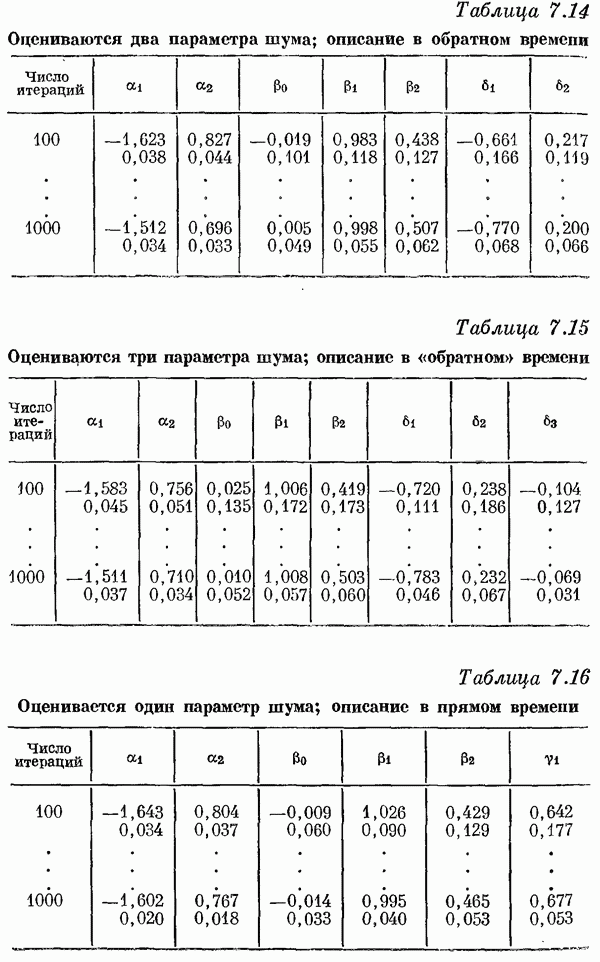
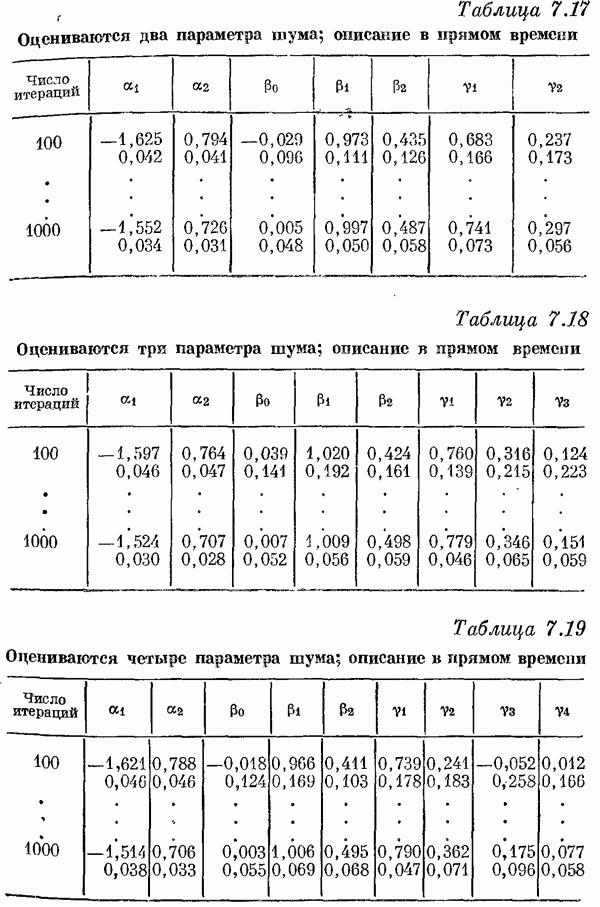
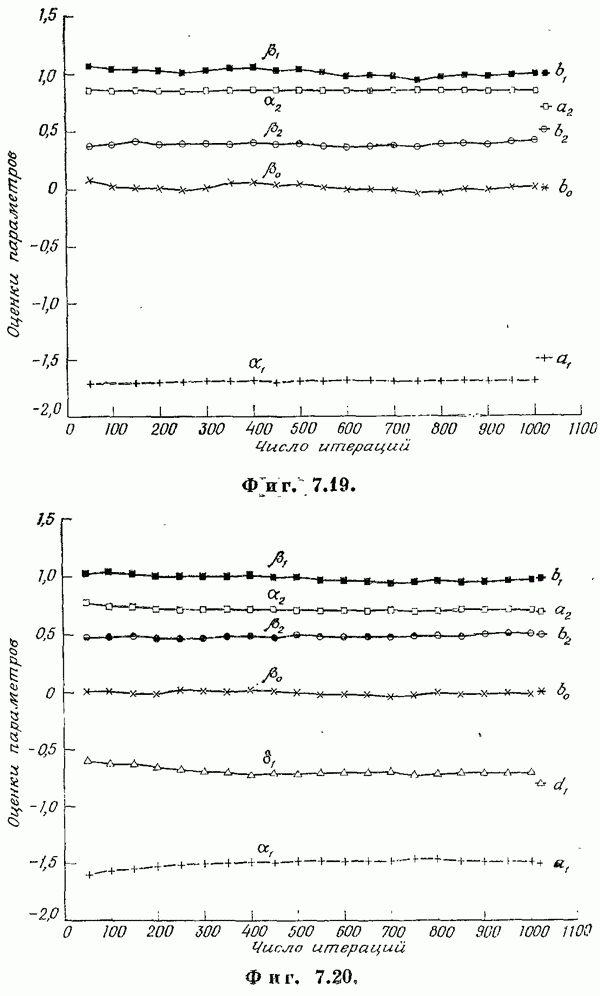
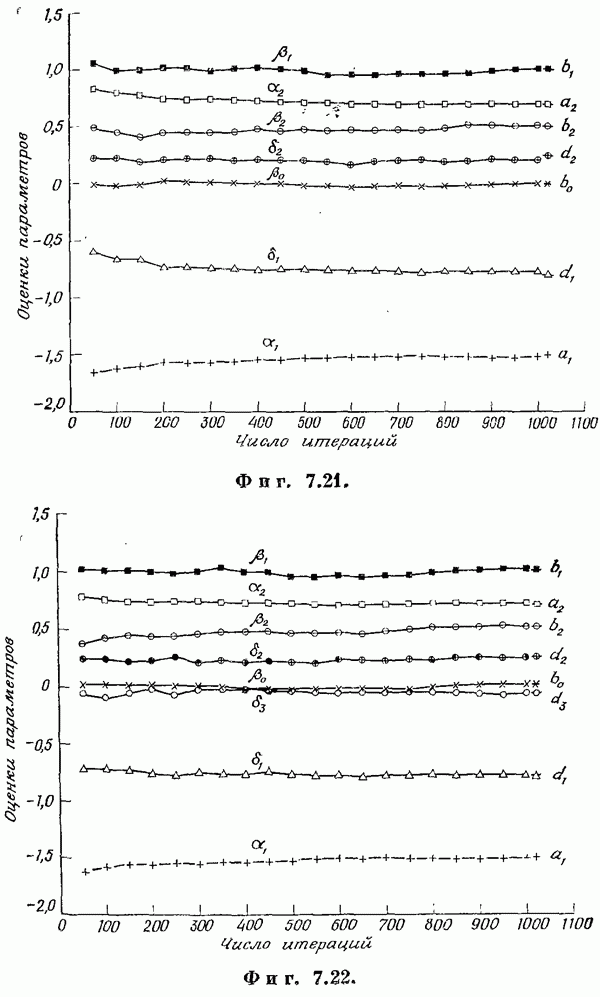

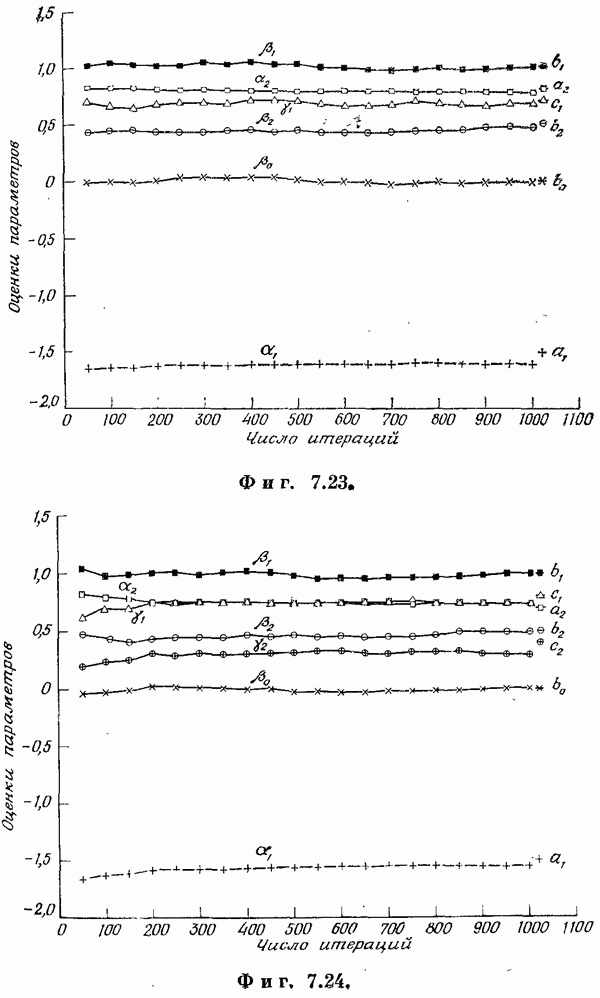
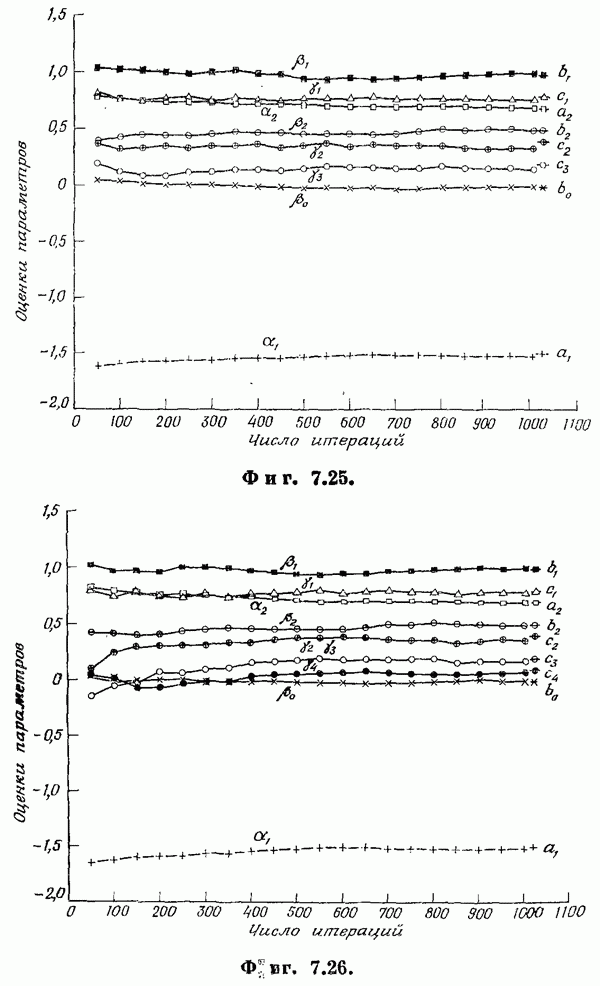

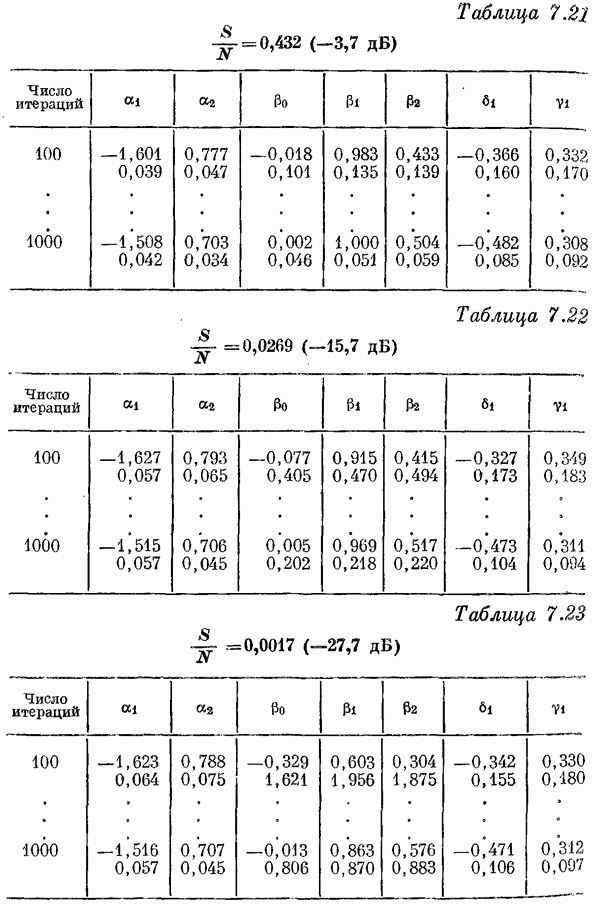
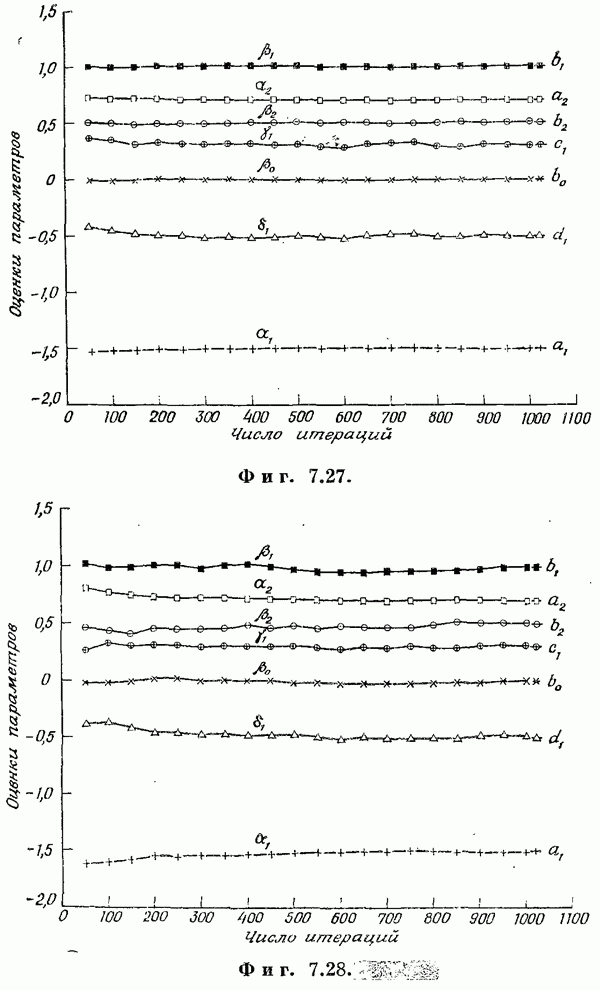
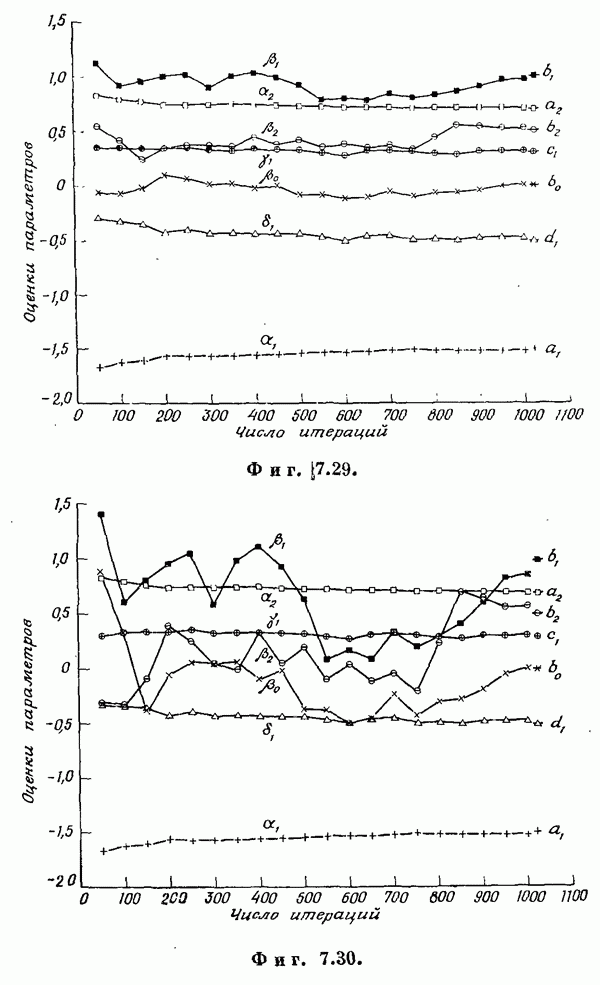
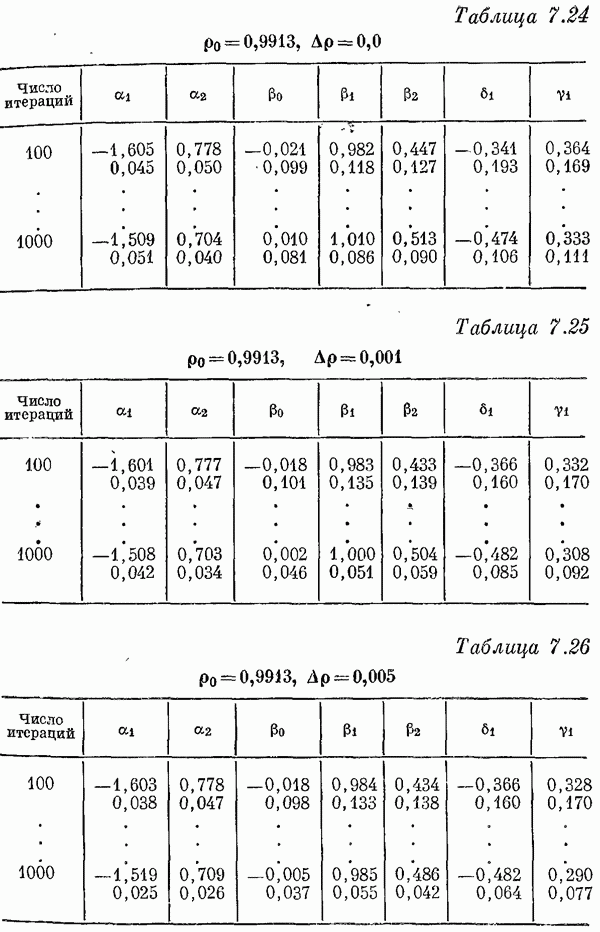








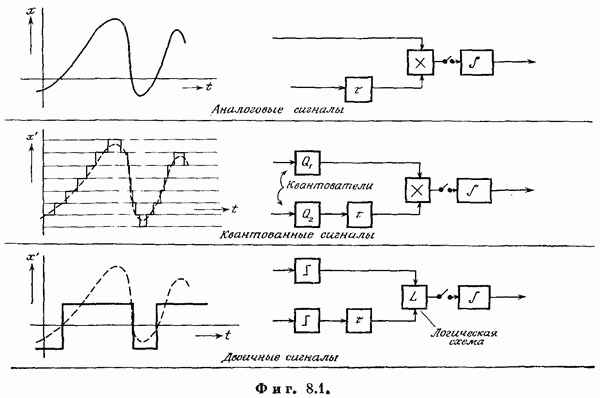




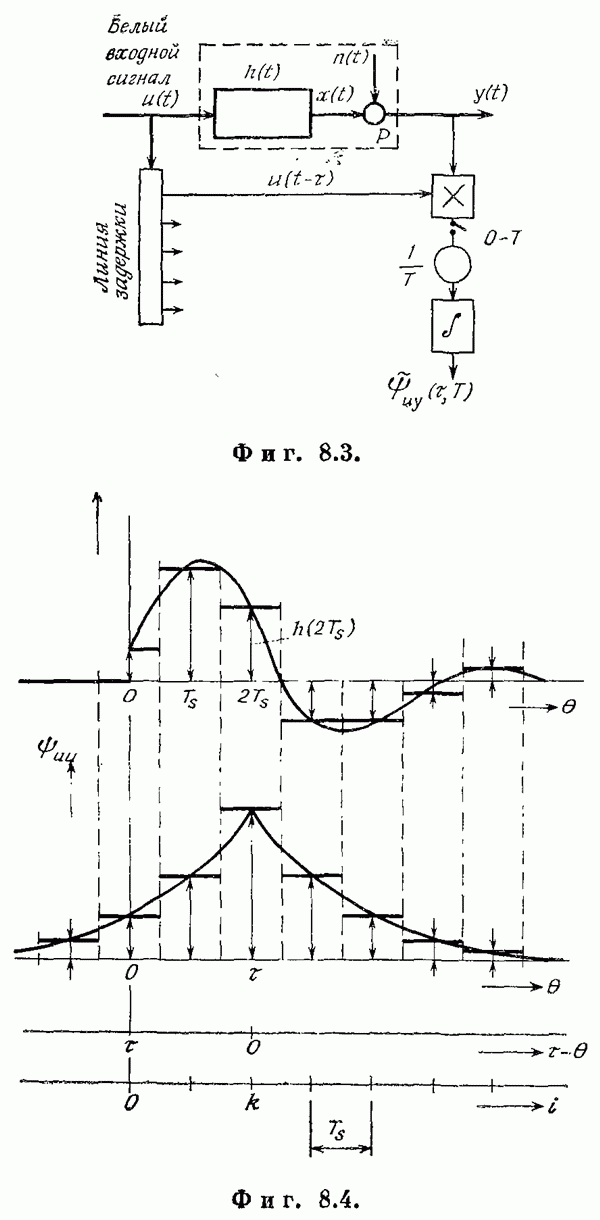

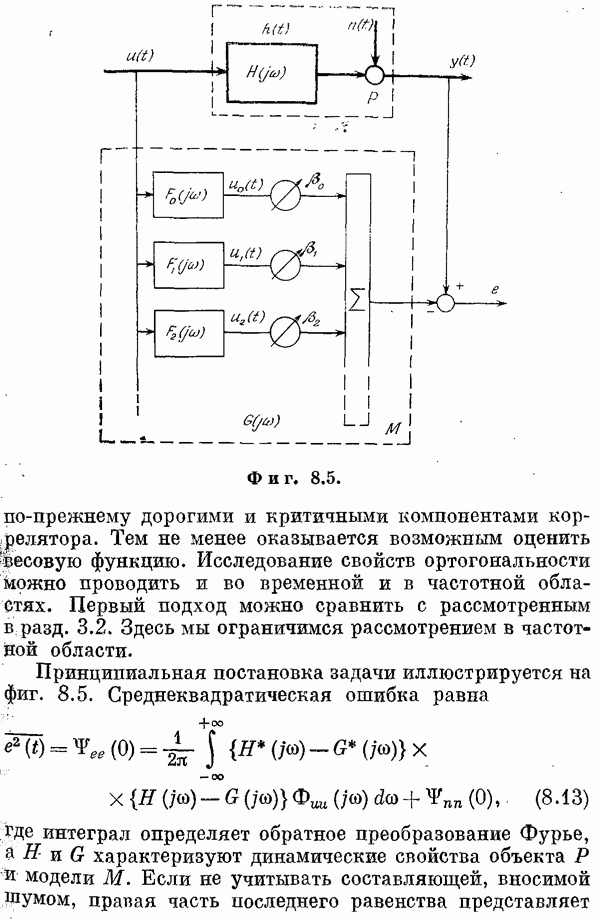

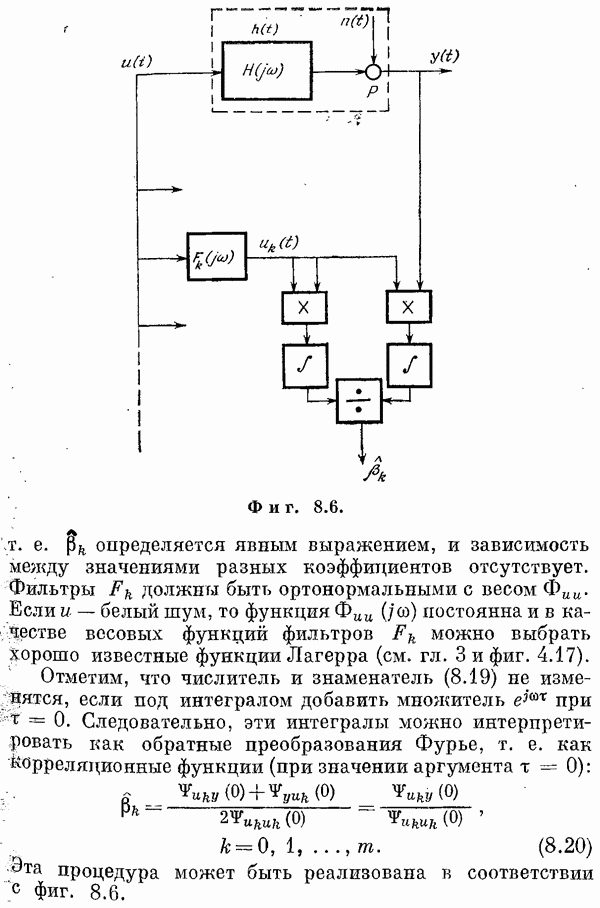



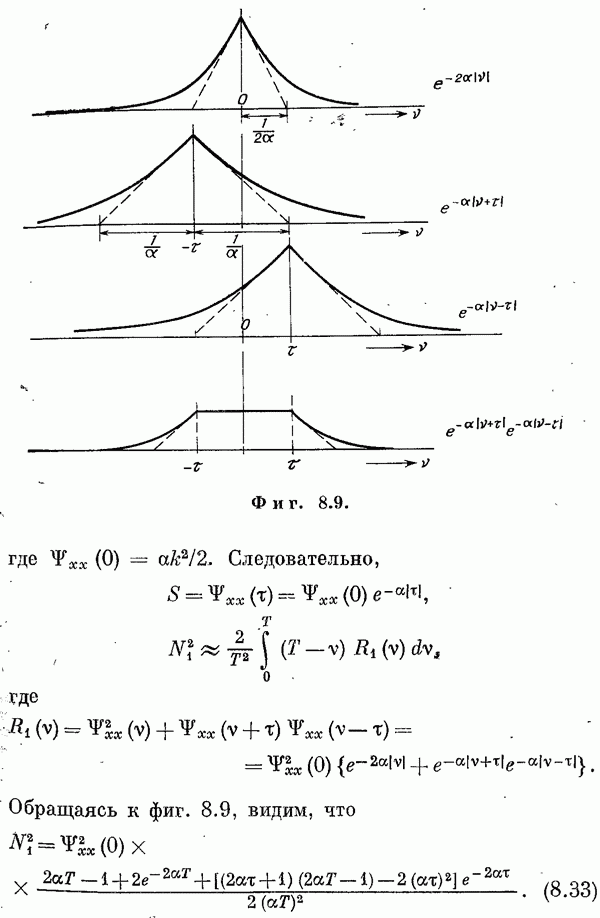


























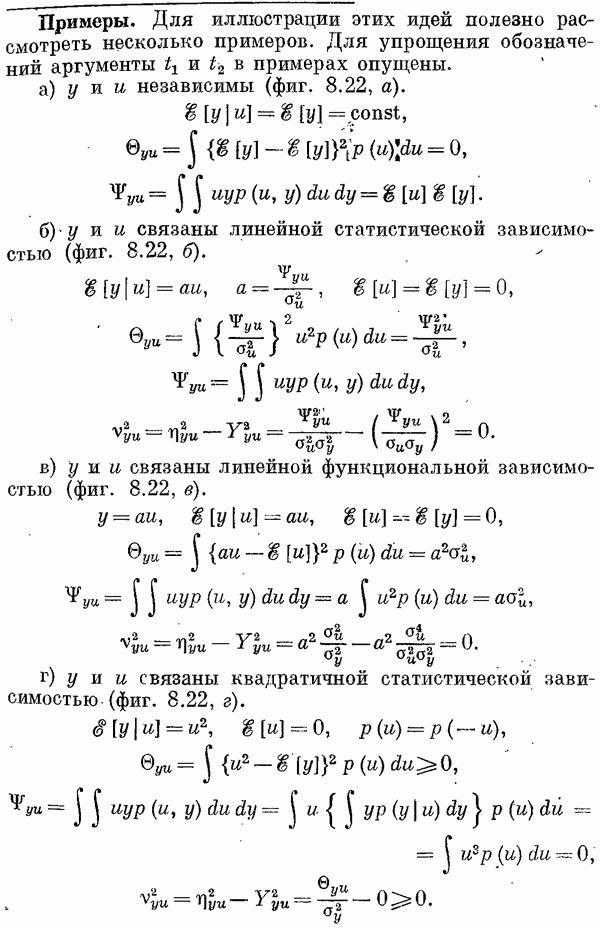



























































































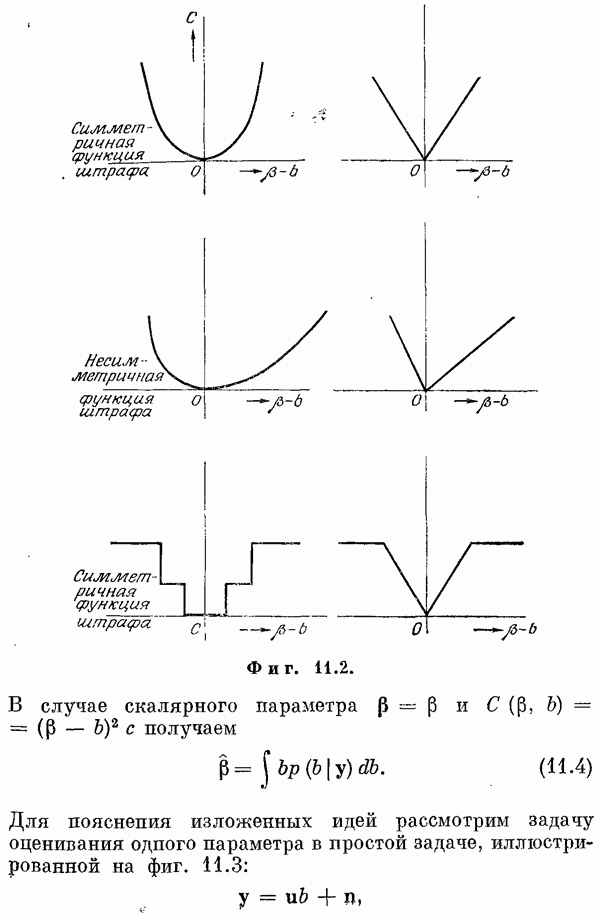







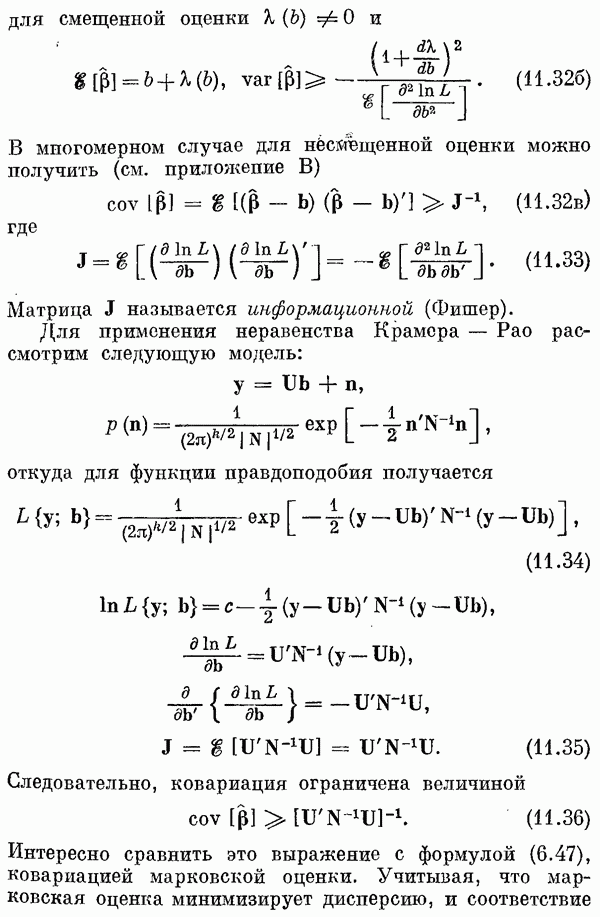

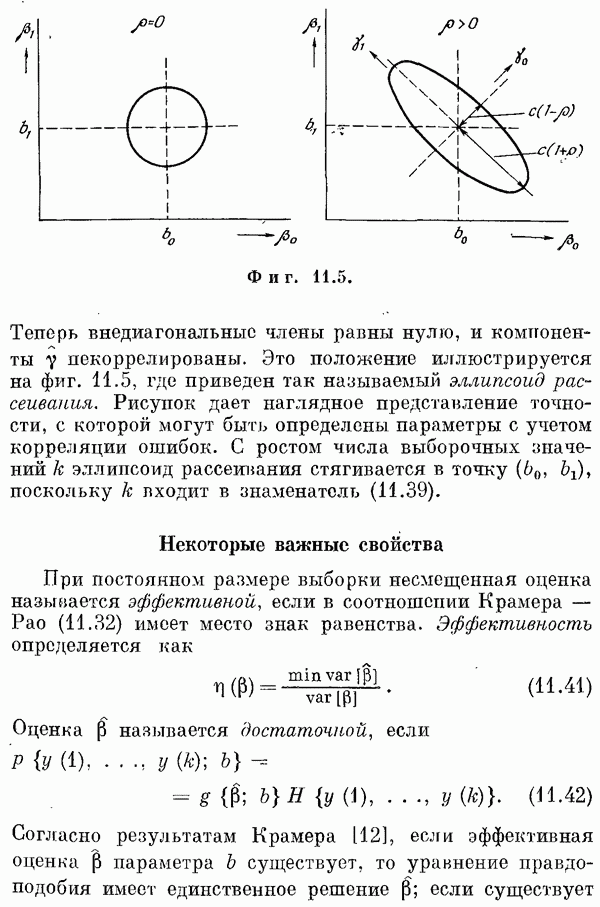

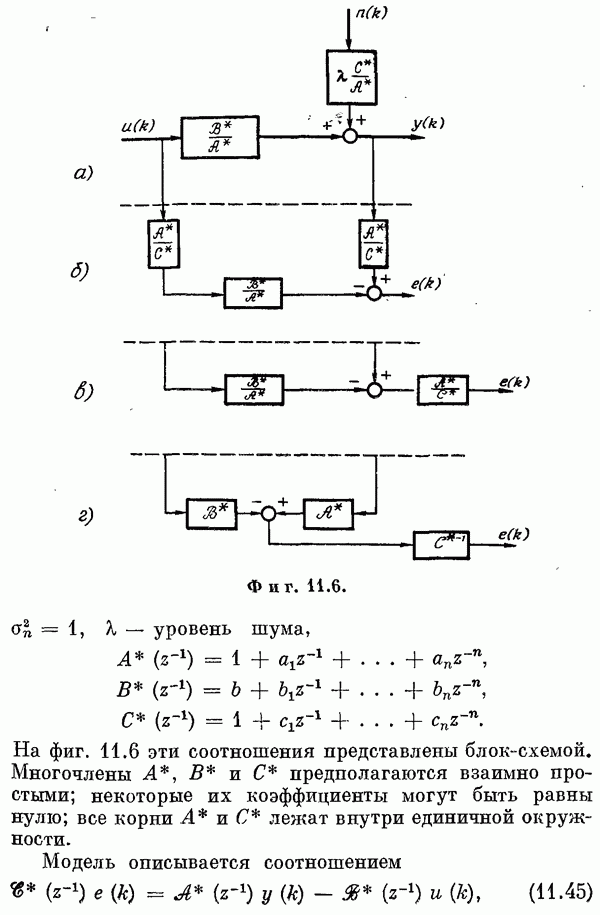

























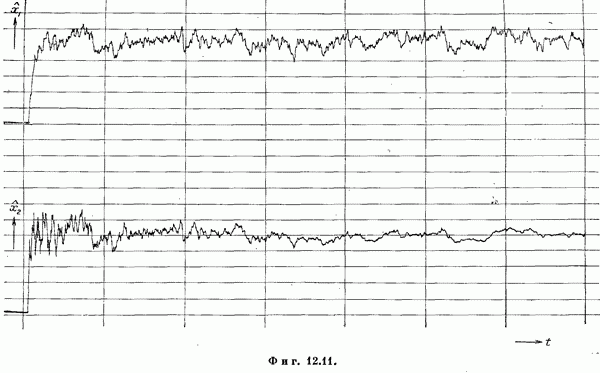








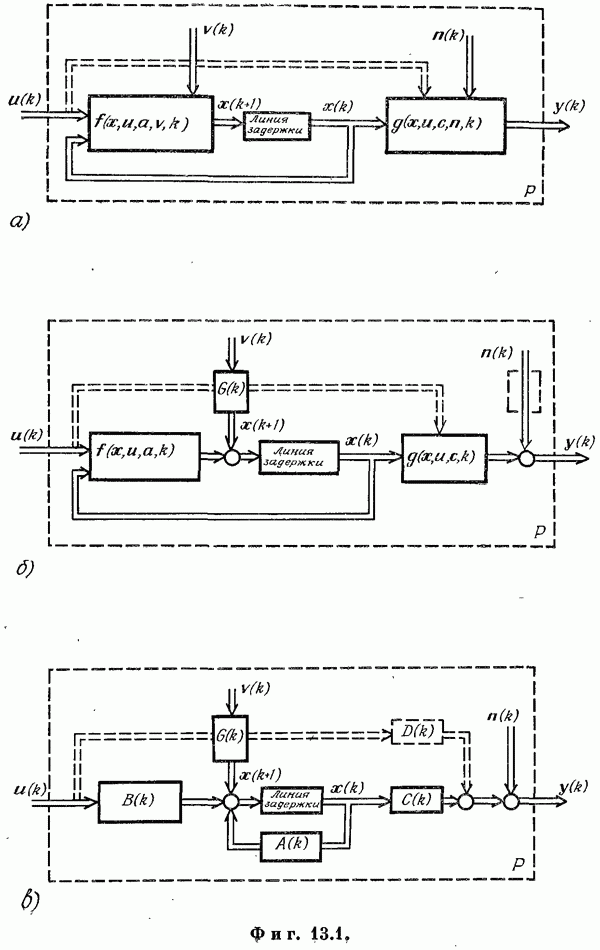














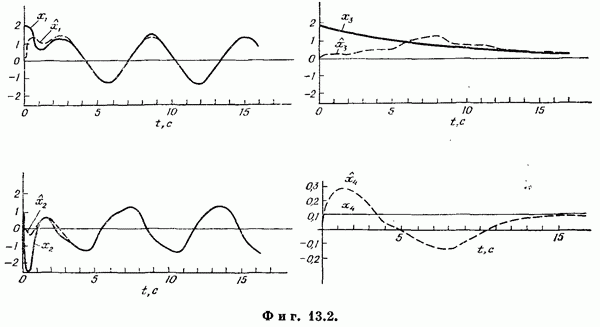







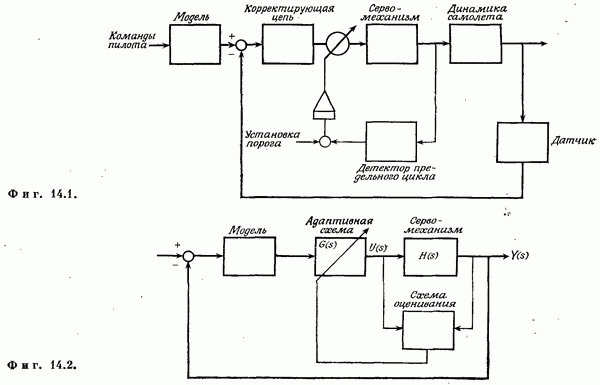

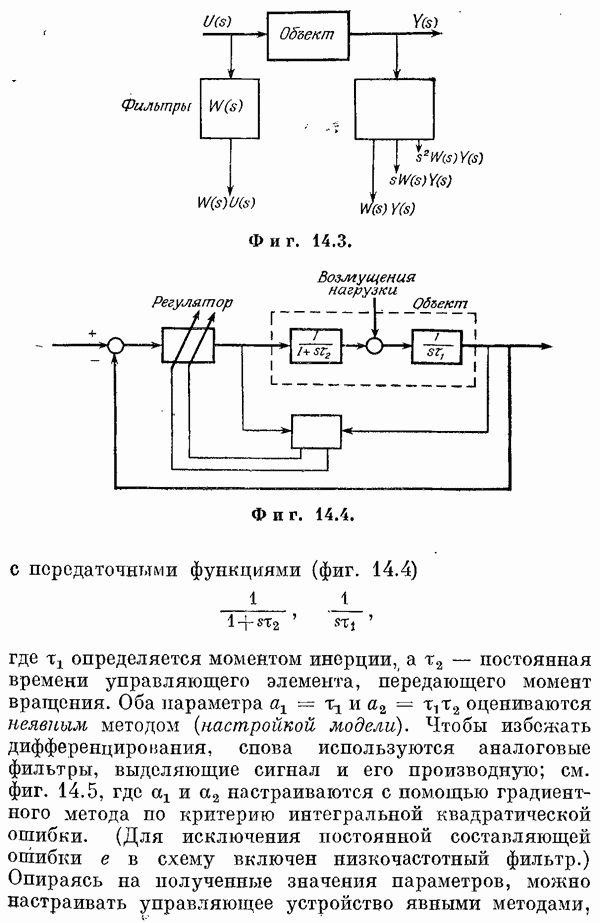
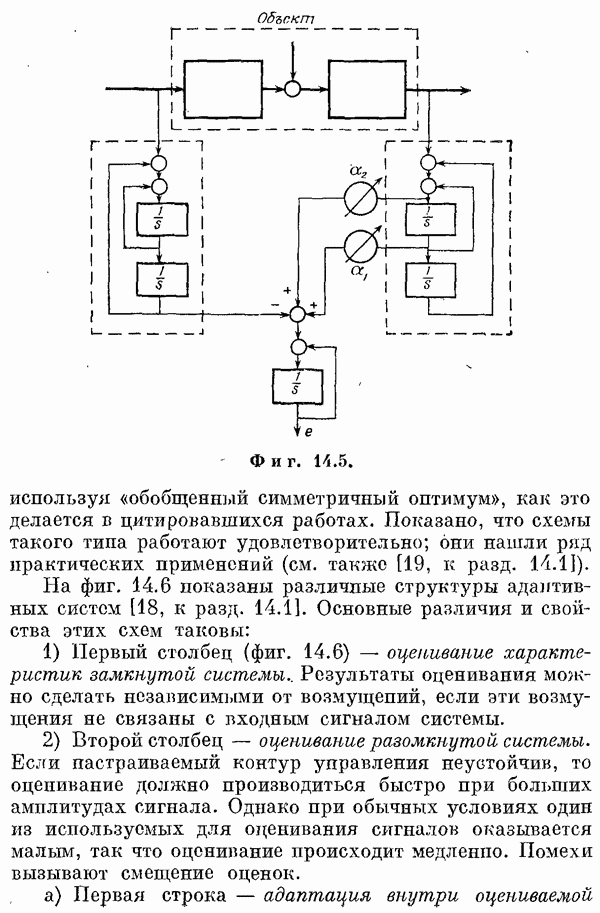
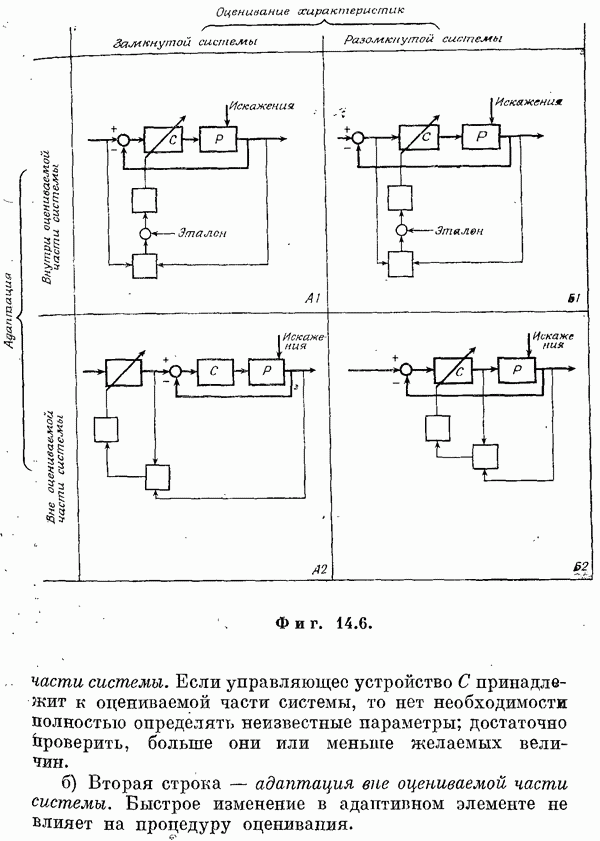








































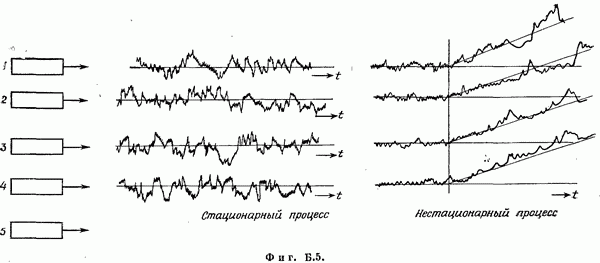
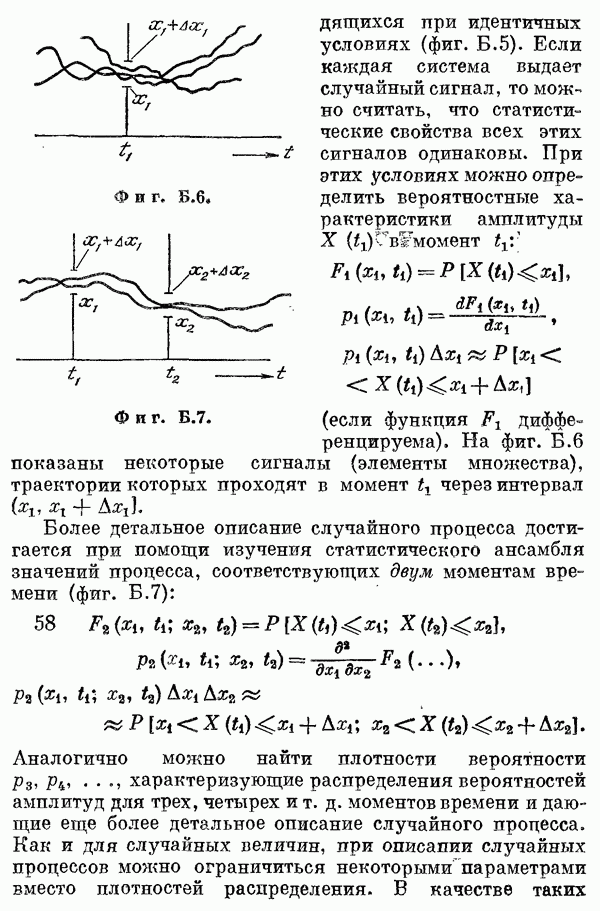



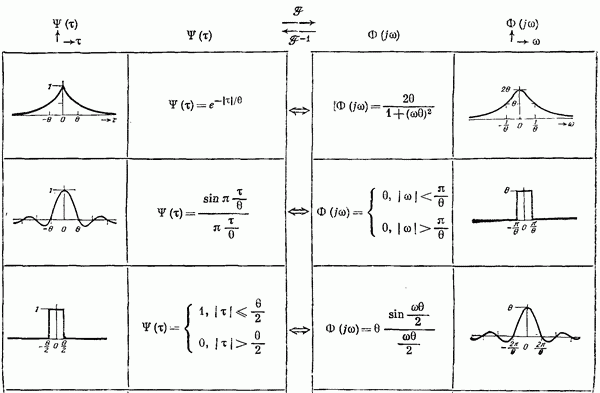
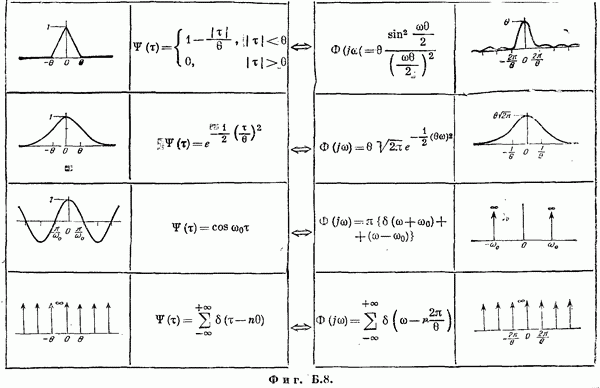












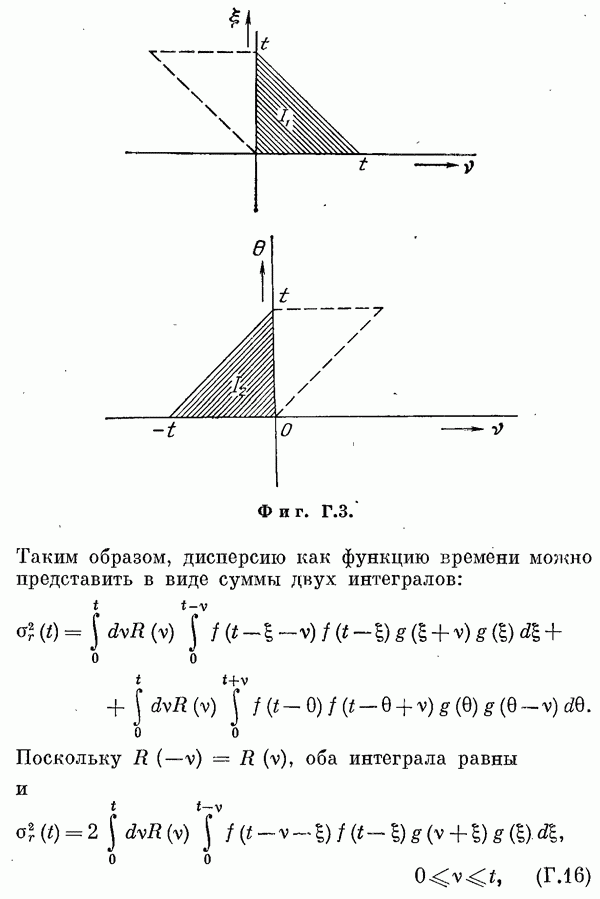


 Если эта функция непрерывна по у, то условную плотность вероятности у по х можно записать
Если эта функция непрерывна по у, то условную плотность вероятности у по х можно записать





 коэффициентами регрессии. Нужно минимизировать
коэффициентами регрессии. Нужно минимизировать

 означает интеграл
означает интеграл  В дальнейшем будут использоваться следующие обозначения (см. приложение
В дальнейшем будут использоваться следующие обозначения (см. приложение  :
:

 с приравниванием полученных результатов нулю дает
с приравниванием полученных результатов нулю дает


 в (6.3) приводит к уравнению линии регрессии
в (6.3) приводит к уравнению линии регрессии


 Может оказаться полезным набор ортонормальных полиномов (см. [1], стр. 115). Это полиномы х, степени
Может оказаться полезным набор ортонормальных полиномов (см. [1], стр. 115). Это полиномы х, степени  для которых выполняются условия ортогональности
для которых выполняются условия ортогональности





 силу ортонормальности будем иметь
силу ортонормальности будем иметь



 если минимизируется математическое ожидание
если минимизируется математическое ожидание

 и приравнивание производных нулю при
и приравнивание производных нулю при  приводят к следующей системе уравнений:
приводят к следующей системе уравнений:

 Если же
Если же  сложпее полинома (например, включает экспоненты), то соответствующую систему уравнений трудно разрешить относительно коэффициентов регрессии.
сложпее полинома (например, включает экспоненты), то соответствующую систему уравнений трудно разрешить относительно коэффициентов регрессии.
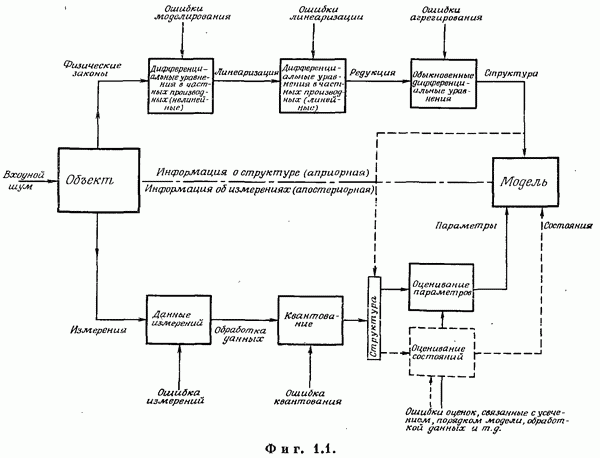
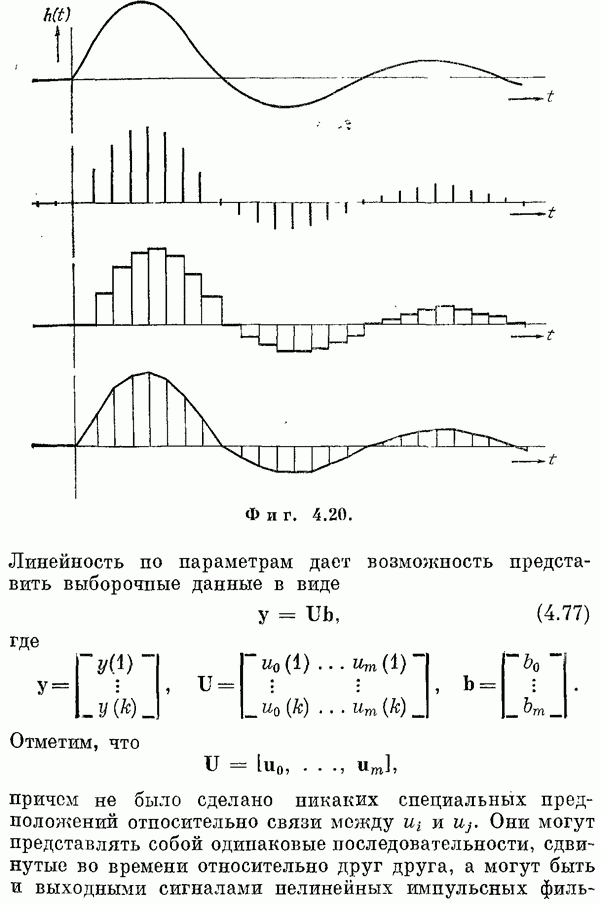
 Так бывает довольно редко. Обычно необходимо оценивать параметры, используя конечное число наблюдений, а именно выборочные значения. Таким образом, оценка должна быть функцией этих выборочных значений, которые фактически представляют собой наблюдаемые значения реализаций случайных величин. Это означает, что оценка тоже случайная величина и может быть охарактеризована плотностью вероятности. Качество оценки зависит от этой фупкции и, в частности, от среднего значения и дисперсии.
Так бывает довольно редко. Обычно необходимо оценивать параметры, используя конечное число наблюдений, а именно выборочные значения. Таким образом, оценка должна быть функцией этих выборочных значений, которые фактически представляют собой наблюдаемые значения реализаций случайных величин. Это означает, что оценка тоже случайная величина и может быть охарактеризована плотностью вероятности. Качество оценки зависит от этой фупкции и, в частности, от среднего значения и дисперсии.

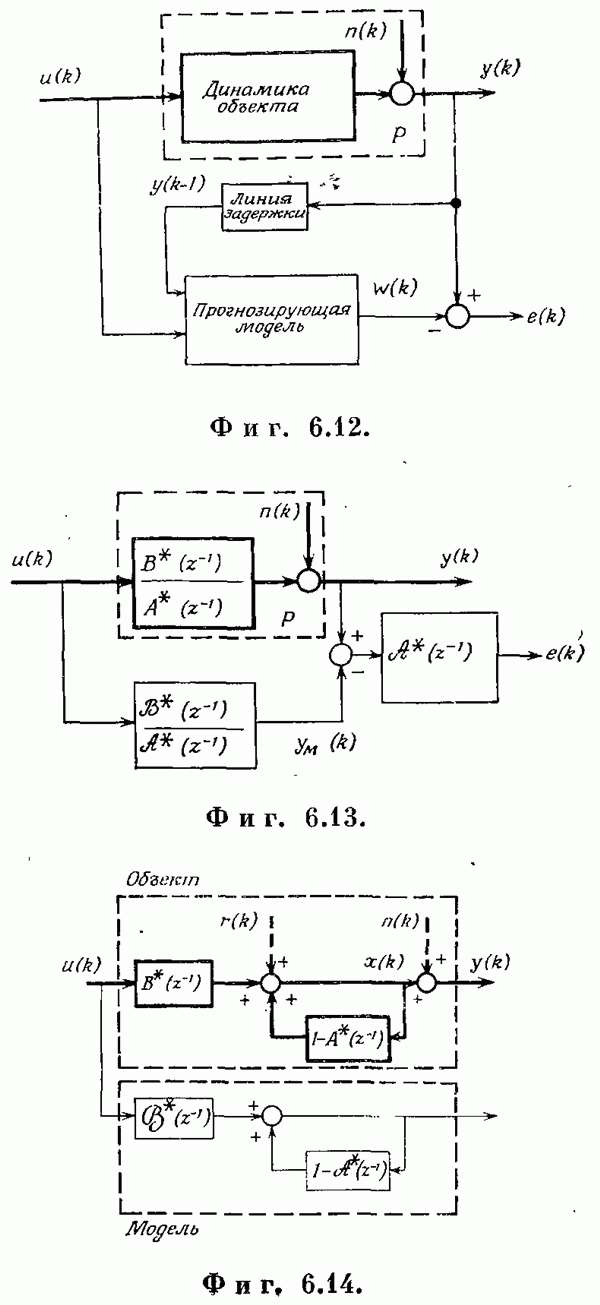
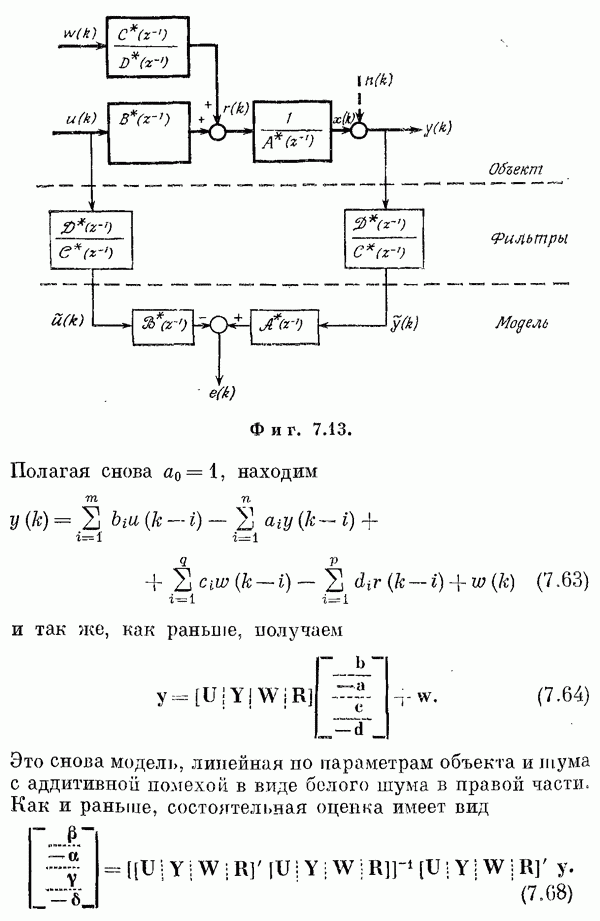
 случайная величипа, в литературе [12, 13] рассматриваются также авторегрессионная модель
случайная величипа, в литературе [12, 13] рассматриваются также авторегрессионная модель


 измерения выходной сигнал имеет вид
измерения выходной сигнал имеет вид

 обозначена зависимость выборочных значений от компонент вектора параметров объекта
обозначена зависимость выборочных значений от компонент вектора параметров объекта  Определим
Определим


 вектора параметров
вектора параметров  Для этого используется теоретически предсказываемый выходной сигнал
Для этого используется теоретически предсказываемый выходной сигнал  т. е. выход модели, который зависит от вектора коэффициентов
т. е. выход модели, который зависит от вектора коэффициентов  Эта функциональная зависимость может быть выбрана различными способами. Простейшей является
Эта функциональная зависимость может быть выбрана различными способами. Простейшей является
 линейная функциональная связь между
линейная функциональная связь между  и
и  (линейная по параметрам модель, см. разд. 4.6)
(линейная по параметрам модель, см. разд. 4.6)

 известные линейно независимые функции. Запишем
известные линейно независимые функции. Запишем  в виде
в виде


 и
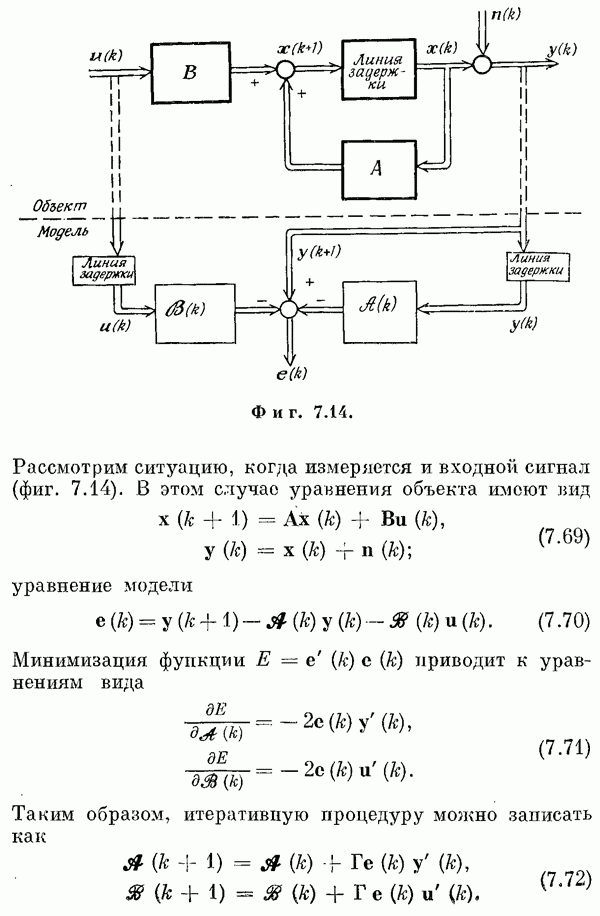
и  не означает того, что связь между входом и выходом модели должна быть линейной, Предполагается, что матрица
не означает того, что связь между входом и выходом модели должна быть линейной, Предполагается, что матрица  полностью известна, т. е. может быть измерена без ошибок. Кроме того, предполагается, что число наблюдений к превышает число
полностью известна, т. е. может быть измерена без ошибок. Кроме того, предполагается, что число наблюдений к превышает число  неизвестных параметров.
неизвестных параметров.


 -матрица, и
-матрица, и


 статистически независимы. Теперь вектор ошибки
статистически независимы. Теперь вектор ошибки  можно определить как
можно определить как


 матрица весовых коэффициентов
матрица весовых коэффициентов  Без потери общности можно предположить, что эта матрица симметрична. Функция ошибок может быть записана в виде
Без потери общности можно предположить, что эта матрица симметрична. Функция ошибок может быть записана в виде

 симметричная матрица, то
симметричная матрица, то

 дает (см. приложение В)
дает (см. приложение В)


 выражение (6.29) обращается в нуль. Отсюда находим
выражение (6.29) обращается в нуль. Отсюда находим  обеспечивающее экстремум функции ошибок Е:
обеспечивающее экстремум функции ошибок Е:

 невырожденная матрица, то
невырожденная матрица, то

 функций ошибок
функций ошибок  принимает минимальное зпачение. Это значение
принимает минимальное зпачение. Это значение  называется остаточной ошибкой (основанной на к наблюдениях).
называется остаточной ошибкой (основанной на к наблюдениях).


 (припцип ортогональности).
(припцип ортогональности).
 достигает минимума, может быть основано на стандартном приеме
достигает минимума, может быть основано на стандартном приеме
 Из формулы (6.27) имеем
Из формулы (6.27) имеем

 удовлетворяющем уравнению (6.31),
удовлетворяющем уравнению (6.31),  достигает минимума.
достигает минимума.



 статистически независимы, то это слагаемое отбрасывается. В результате получается оценка
статистически независимы, то это слагаемое отбрасывается. В результате получается оценка  истинного значения
истинного значения  [см. формулу (6.30)]. Естественно, такой способ вывода уравнения (6.31) не показывает, в каком смысле оценка оптимальна.
[см. формулу (6.30)]. Естественно, такой способ вывода уравнения (6.31) не показывает, в каком смысле оценка оптимальна.



 то оценка является и несмещенной:
то оценка является и несмещенной:


 [формула (6.31)] — ее дисперсию. Интересно также оценить корреляцию между компонентами вектора (3. Все эти характеристики можно определить с помощью ковариационной матрицы
[формула (6.31)] — ее дисперсию. Интересно также оценить корреляцию между компонентами вектора (3. Все эти характеристики можно определить с помощью ковариационной матрицы

 статистически независимы. Тогда, используя формулу (6.32), находим
статистически независимы. Тогда, используя формулу (6.32), находим







 квадратная матрица, т. е. если размер выборки равен числу оцениваемых параметров, и если матрица
квадратная матрица, т. е. если размер выборки равен числу оцениваемых параметров, и если матрица 


 то нетрудно получить
то нетрудно получить




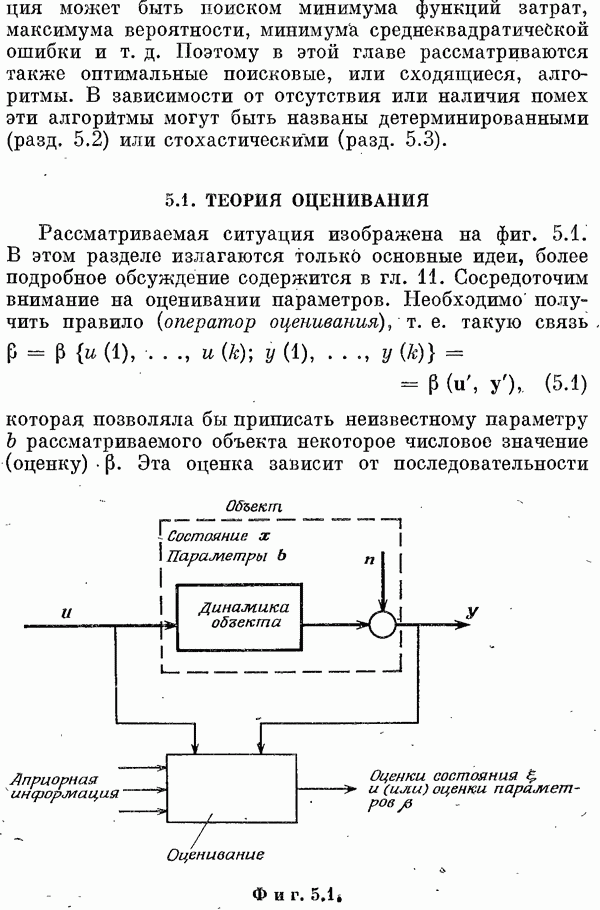
 (фиг. 6.1). Необходимо минимизировать длину вектора
(фиг. 6.1). Необходимо минимизировать длину вектора


 ортогонален к
ортогонален к  и
и 








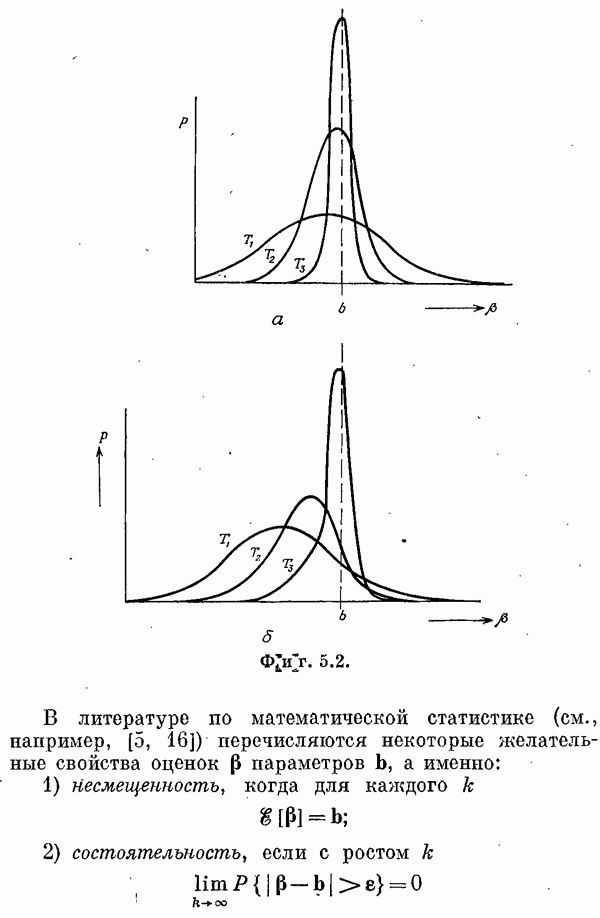
 то дисперсии оценок стремятся к нулю и, следовательно, оценки являются состоятельными (см. разд. 5.1).
то дисперсии оценок стремятся к нулю и, следовательно, оценки являются состоятельными (см. разд. 5.1).

 получаем
получаем





 любая другая линейная оценка. Это означает, что оценка эффективна (см. разд. 5.1).
любая другая линейная оценка. Это означает, что оценка эффективна (см. разд. 5.1).




 приводит к оценкам метода наименьших квадратов и марковским оценкам. Можно было бы выбрать
приводит к оценкам метода наименьших квадратов и марковским оценкам. Можно было бы выбрать  иначе, например, как матрицу весовых коэффициентов, учитывающую возможную нестационарную аддитивную помеху. В этом случае необходимо минимизировать следующую функцию ошибок:
иначе, например, как матрицу весовых коэффициентов, учитывающую возможную нестационарную аддитивную помеху. В этом случае необходимо минимизировать следующую функцию ошибок:

 дисперсия шума в момент времени
дисперсия шума в момент времени 