Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.4.3 Обобщенный алгоритм свертки в виде дерева для расчета сетей МООписанные в п. 3.4.2 методы реконфигурации сети МО позволяют лишь частично снизить затраты времени счета и памяти, но, очевидно, не могут решить проблему точного расчета сетей МО большой размерности. Действительно, анализ базовой сети передачи данных средних размеров требует исследования модели сети МО, включающей до М = 50 центров обслуживания, Поэтому в настоящем разделе описывается новый вычислительный алгоритм свертки в виде дерева (или просто алгоритм дерева), частичный случай которого для расчета сетей древовидной структуры приведен в [41], а общий случай разработан в [242]. В отличие от традиционного алгоритма свертки (алгоритма последовательной свертки) и метода средних значений, алгоритм дерева использует информацию о маршрутах сообщений каждого класса. Использование этой информации позволяет существенно сократить затраты времени и памяти при расчете сетей МО с большим числом центров обслуживания и классов сообщений, в которых сообщения каждого класса в среднем посещают лишь небольшую долю от имеющихся в сети центров обслуживания (свойство разряженности сети. Если в сети, обладающей свойством разряженности, отдельные классы сообщений группируются в некоторых частях сети (свойство локализации), то сокращение времени счета и затрат памяти для реализации вычислительного алгоритма может быть еще более значительным. Алгоритм дерева, являющийся обобщением традиционного алгоритма последовательной свертки, реализуется для замкнутых сетей МО с мультипликативной формой вероятностей состояний (3.22)
где
Нормализующая константа отыскивается с помощью вспомогательной функции
В отличие от алгоритма последовательной свертки, предусматривающего использование операции свертки (3.49) последовательно для номеров Обозначим Будем говорить, что класс Предположим, что массив Разделим множество классов
Заметим, что для дальнейшего вычисления
Таблица 3.7
Пусть Для сетей МО, обладающих свойством разряженности, экономия памяти при использовании частично покрываемых массивов вместо массивов размерности R может быть очень существенной. Языки программирования, допускающие динамическое распределение памяти (такие, как Пусть Q распадается на два подмножества:
Говорят, что класс
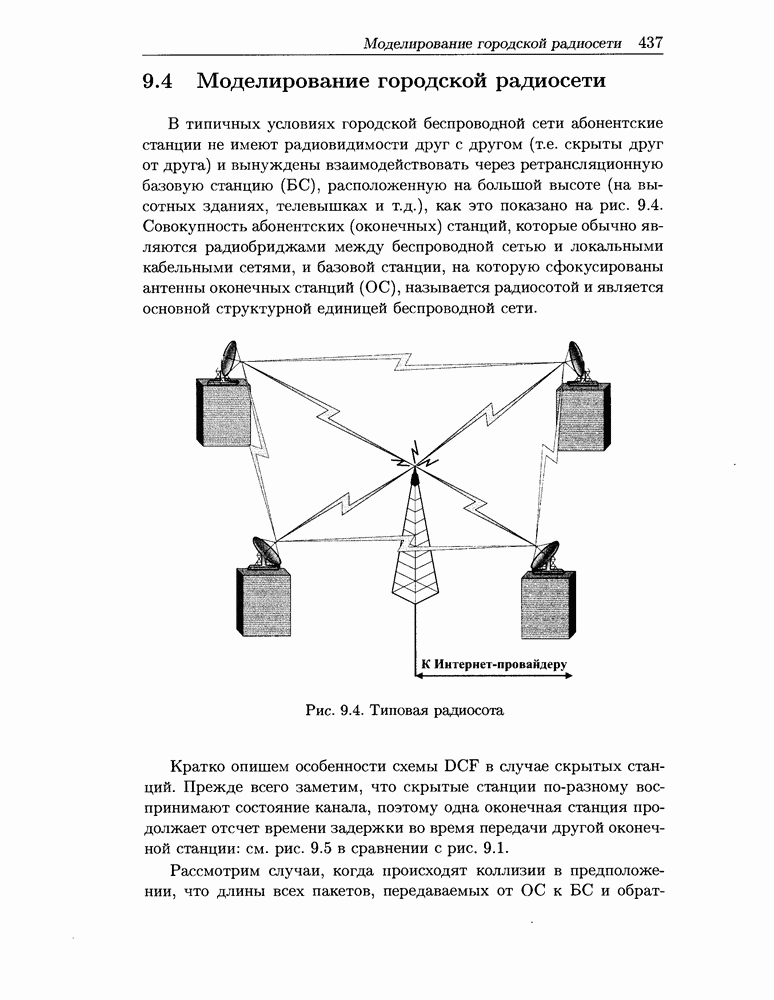
операций умножения и почти такое же количество операций сложения: количество операций сложения меньше, чем умножений, на величину Выражение (3.51) может использоваться как мера времени для реализации операции свертки по формуле (3.50). Таким образом, при частично покрываемых массивах операция свертки (3.50) может быть выполнена с существенной экономией памяти и времени, если имеется несколько частично покрытых классов в При применении описанных выше соображений в алгоритме последовательной свертки можно также достигнуть некоторой экономии памяти и времени. В этом случае алгоритм начинается с подсети 1, состоящей из обслуживающего центра с номером 1, а затем последовательно «сливает» эту подсеть с другими центрами обслуживания. Когда все центры будут соединены, алгоритм заканчивает работу. Основная цель алгоритма дерева отыскать последовательность сверток («слияния»), минимизирующую число частично покрываемых классов в промежуточных подсетях, используя информацию о маршрутах сообщений. Для реализации этой цели служит бинарное дерево (рис. 3.1).
Рис. 3.1
Рис. 3.2 Обслуживающие центры сети МО размещаются в листьях бинарного дерева. Каждый узел дерева соответствует подмножеству центров обслуживания (подсети), которые сходятся к этому узлу. Таким образом, корень дерева соответствует сети в целом. Осуществим обход всех узлов дерева в соответствии с некоторым правилом. Корень дерева посещается в последнюю очередь. Промежуточный узел посещается только после обхода всех узлов нижнего уровня, сходящихся к нему. Посещение узла соответствует вычислению массива g по формуле (3.50) исходя из известных массивов g узлов нижнего уровня. При достижении корневого узла находится нормализующая константа Заметим, что алгоритм последовательной свертки является частным случаем алгоритма дерева и соответствует дереву, представленному на рис. 3.2. Пусть
где Если Затраты времени и памяти ЭВМ, необходимые для вычисления нормализующей константы В настоящее время не решена задача оптимального построения дерева, минимизирующего затраты памяти и времени ЭВМ. Однако найдены эффективные эвристические подходы для решения этой задачи. Алгоритм дерева использует две процедуры. Первая из них, называемая препроцессором, применяется для построения дерева; вторая реализует основные функции алгоритма - обход дерева и свертку массивов. Процедура построения дерева требует значительно меньше памяти и времени ЭВМ, чем реализация операций свертки. Препроцессор позволяет получить точные априорные оценки объема памяти и времени, необходимые для расчета конкретной сети МО. Указанные оценки позволяют осуществлять сравнение с другими вычислительными алгоритмами и, что не менее важно, определять возможность использования данного класса ЭВМ для реализации алгоритма (не превышают ли требования алгоритма, например, объемов оперативной памяти ЭВМ). Как уже отмечалось, возможны различные способы построения бинарного дерева. Однако все эти способы имеют общие черты, основанные на следующем базовом алгоритме. Алгоритм 1. Основная процедура построения дерева. Инициализация. Делать, пока существуют две подсети: выполнить слияние; отсортировать подсети согласно критерию размера; выделить две подсети для слияния по критерию стоимости; слить две подсети в одну; Конец; Конец. Первоначально имеется М подсетей, каждая из которых соответствует центру обслуживания. Алгоритм определения последовательности слияния состоит в следующем. Во-первых, определяются отношения между подсетями. Такое отношение существует, если множество частично покрываемых классов одной подсети принадлежит множеству частично покрываемых классов другой подсети. Подсети, между которыми существует такое отношение, сливаются. В противном случае для слияния выбираются две подсети на основании критерия, условно названного стоимостью. Выбор облегчается первичной сортировкой в соответствии с критерием размера. Указанный критерий определяется следующим образом. Пусть Q - массив подмножества номеров центров обслуживания;
где Далее рассмотрим один из возможных конкретных алгоритмов построения дерева, в соответствии с которым первоначально каждый центр обслуживания представляет собой подсеть нижнего уровня дерева и осуществляется наращивание дерева по одному уровню за каждый шаг. Алгоритм 2. Инициализация. Для каждого уровня дерева от листьев к корню делать: сортировать подсети по весу в порядке убывания; пометить все подсети; Делать пока остались помеченные подсети: выбрать подсеть с максимальным весом в качестве первого кандидата к слиянию; выбрать из оставшихся помеченных подсетей другого кандидата для слияния с минимальной стоимостью; осуществить процедуру слияния выбранных двух подсетей. Конец. Конец. Конец. Для построенного дерева препроцессор вычисляет необходимые объемы памяти и времени. Время вычисления После того как вычислена нормализующая константа, можно перейти к расчету других характеристик сети. Например, пропускная способность центра
Для расчета средней длины очереди сообщений
Нормализующие константы
|
 |
Оглавление
|
















































































































































































































































































































































































































































































































 классов с числом сообщений
классов с числом сообщений  в каждом. Формулы (3.46) - (3.48) показывают, что затраты ресурсов ЭВМ, необходимые для расчета таких сетей МО, превышают возможности современных ЭВМ.
в каждом. Формулы (3.46) - (3.48) показывают, что затраты ресурсов ЭВМ, необходимые для расчета таких сетей МО, превышают возможности современных ЭВМ.

 - нормализующая константа;
- нормализующая константа;

 [см. формулу (3.23)], определяющей соотношение свертки
[см. формулу (3.23)], определяющей соотношение свертки

 от 1 до М, в алгоритме дерева операция свертки осуществляется с помощью бинарного дерева, для построения которого используется информация о маршрутах сообщений каждого класса. В результате этого в операции свертки участвуют множества, размерность которых меньше размерности R множеств, используемых в алгоритме последовательной свертки.
от 1 до М, в алгоритме дерева операция свертки осуществляется с помощью бинарного дерева, для построения которого используется информация о маршрутах сообщений каждого класса. В результате этого в операции свертки участвуют множества, размерность которых меньше размерности R множеств, используемых в алгоритме последовательной свертки.
 массив номеров обслуживающих центров, которые могут посещаться сообщениями класса
массив номеров обслуживающих центров, которые могут посещаться сообщениями класса  , a Q - подмножество номеров всех обслуживающих центров сети.
, a Q - подмножество номеров всех обслуживающих центров сети.
 полностью покрывает Q, если
полностью покрывает Q, если  , не покрывается множеством Q, если
, не покрывается множеством Q, если  в остальных случаях частично покрывается множеством Q. Пусть
в остальных случаях частично покрывается множеством Q. Пусть  Тогда
Тогда 
 был уже получен на промежуточной стадии вычисления нормализующей константы
был уже получен на промежуточной стадии вычисления нормализующей константы  . Тогда, если часть классов из множества (1,2, либо не покрыта Q, либо полностью покрыта Q, для дальнейшего вычисления
. Тогда, если часть классов из множества (1,2, либо не покрыта Q, либо полностью покрыта Q, для дальнейшего вычисления  необходимы лишь некоторые элементы массива
необходимы лишь некоторые элементы массива  При этом объем памяти, необходимой для запоминания этих элементов, может быть значительно меньше, чем
При этом объем памяти, необходимой для запоминания этих элементов, может быть значительно меньше, чем  . Этот факт является ключевым в алгоритме дерева.
. Этот факт является ключевым в алгоритме дерева.
 по отношению к Q на три подмножества:
по отношению к Q на три подмножества:

 необходимы только те элементы массива
необходимы только те элементы массива  индексы которых удовлетворяют условиям:
индексы которых удовлетворяют условиям:


 означает размерность массива а. Для вычисления
означает размерность массива а. Для вычисления  достаточно запоминать
достаточно запоминать  размерности
размерности  с индексами
с индексами  . Такой массив называется частично покрываемым. Объем памяти для запоминания этого массива пропорционален
. Такой массив называется частично покрываемым. Объем памяти для запоминания этого массива пропорционален  (дополнительно небольшой объем памяти требуется для запоминания элементов множества
(дополнительно небольшой объем памяти требуется для запоминания элементов множества  ).
).
 ), позволяют эффективно использовать частично покрываемые массивы. Однако экономия памяти возможна даже при статическом распределении памяти.
), позволяют эффективно использовать частично покрываемые массивы. Однако экономия памяти возможна даже при статическом распределении памяти.
 Тогда
Тогда

 перекрыт, если он частично покрыт и
перекрыт, если он частично покрыт и  Разобьем множество классов
Разобьем множество классов  на четыре подмножества:
на четыре подмножества:  Принадлежность класса к одному из подмножеств в зависимости от его отношения к Q (частично перекрыт или нет), а также к
Принадлежность класса к одному из подмножеств в зависимости от его отношения к Q (частично перекрыт или нет), а также к  (перекрыт или нет) определяется по таблице 3.7. Для выполнения операции (3.50) необходимо
(перекрыт или нет) определяется по таблице 3.7. Для выполнения операции (3.50) необходимо


 .
.


 сети.
сети.
 означает подсеть, состоящую только из центра с номером
означает подсеть, состоящую только из центра с номером  - множество его частично покрываемых классов;
- множество его частично покрываемых классов;  - множество его полностью покрываемых классов. Тогда массив g подсети
- множество его полностью покрываемых классов. Тогда массив g подсети  имеет вид
имеет вид


 то последнее произведение в (3.52) равно 1. Расчет по формуле (3.52) требует порядка
то последнее произведение в (3.52) равно 1. Расчет по формуле (3.52) требует порядка  операций умножения.
операций умножения.
 по алгоритму дерева, зависят от последовательности слияния подсетей, которая определяется конфигурацией дерева, расположением обслуживающих центров в листьях дерева и порядком обхода дерева.
по алгоритму дерева, зависят от последовательности слияния подсетей, которая определяется конфигурацией дерева, расположением обслуживающих центров в листьях дерева и порядком обхода дерева.
 - множество его частично покрываемых классов. Тогда вес Q определяется выражением
- множество его частично покрываемых классов. Тогда вес Q определяется выражением

 определяет число элементов, имеющихся в множестве А, но отсутствующих в В. Первый кандидат для слияния выбирается по минимальному весу, следующий - по критерию стоимости. Стоимость слияния двух подсетей А и В вычисляется следующим образом. Для любого
определяет число элементов, имеющихся в множестве А, но отсутствующих в В. Первый кандидат для слияния выбирается по минимальному весу, следующий - по критерию стоимости. Стоимость слияния двух подсетей А и В вычисляется следующим образом. Для любого  если
если  то цена класса равна
то цена класса равна  если
если  , то цена класса равна -2, если
, то цена класса равна -2, если  то цена класса равна -1. Очевидно, что выбор подсети меньшей стоимости делает алгоритм слияния более эффективным.
то цена класса равна -1. Очевидно, что выбор подсети меньшей стоимости делает алгоритм слияния более эффективным.
 складывается из времени расчета массива
складывается из времени расчета массива  для листьев дерева и времени реализации
для листьев дерева и времени реализации  слияний. Объем памяти для расчета
слияний. Объем памяти для расчета  совпадает с объемом памяти, необходимой для запоминания массивов
совпадает с объемом памяти, необходимой для запоминания массивов  . Число массивов
. Число массивов  , одновременно сохраняемых при расчете
, одновременно сохраняемых при расчете  зависит от порядка обхода дерева. Например, при использовании алгоритма 2 максимальное число одновременно запоминаемых массивов равно
зависит от порядка обхода дерева. Например, при использовании алгоритма 2 максимальное число одновременно запоминаемых массивов равно  . Однако заметим, что массивы имеют различные размеры, поэтому число одновременно запоминаемых массивов неоднозначно определяет требуемый объем памяти.
. Однако заметим, что массивы имеют различные размеры, поэтому число одновременно запоминаемых массивов неоднозначно определяет требуемый объем памяти.
 для сообщений класса
для сообщений класса  в соответствии с (3.32) имеет вид
в соответствии с (3.32) имеет вид

 класса в
класса в  центре по формуле (3.35) необходимо предварительно рассчитывать маргинальные вероятности
центре по формуле (3.35) необходимо предварительно рассчитывать маргинальные вероятности  определяемые из (3.29) как
определяемые из (3.29) как

 входящие в последние выражения, вычисляются с помощью соответствующих модификаций бинарного дерева [242]. В частности,
входящие в последние выражения, вычисляются с помощью соответствующих модификаций бинарного дерева [242]. В частности,  отыскивается из исходного дерева для сети МО с числом сообщений, определяемым вектором
отыскивается из исходного дерева для сети МО с числом сообщений, определяемым вектором  , а для расчета
, а для расчета  используется бинарное дерево, отличающееся от исходного отсутствием центра обслуживания с номером
используется бинарное дерево, отличающееся от исходного отсутствием центра обслуживания с номером  .
.