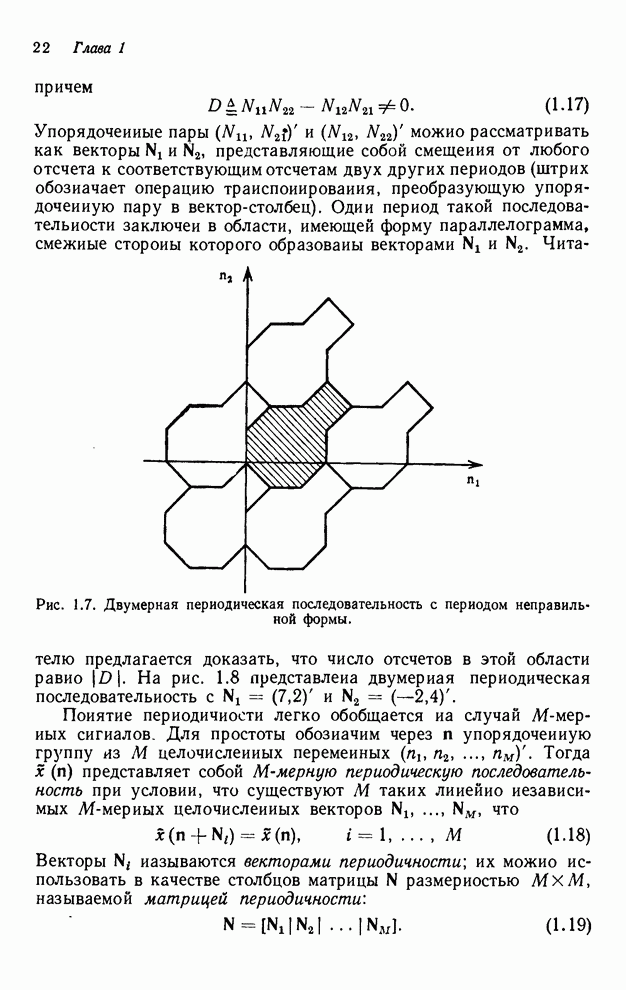
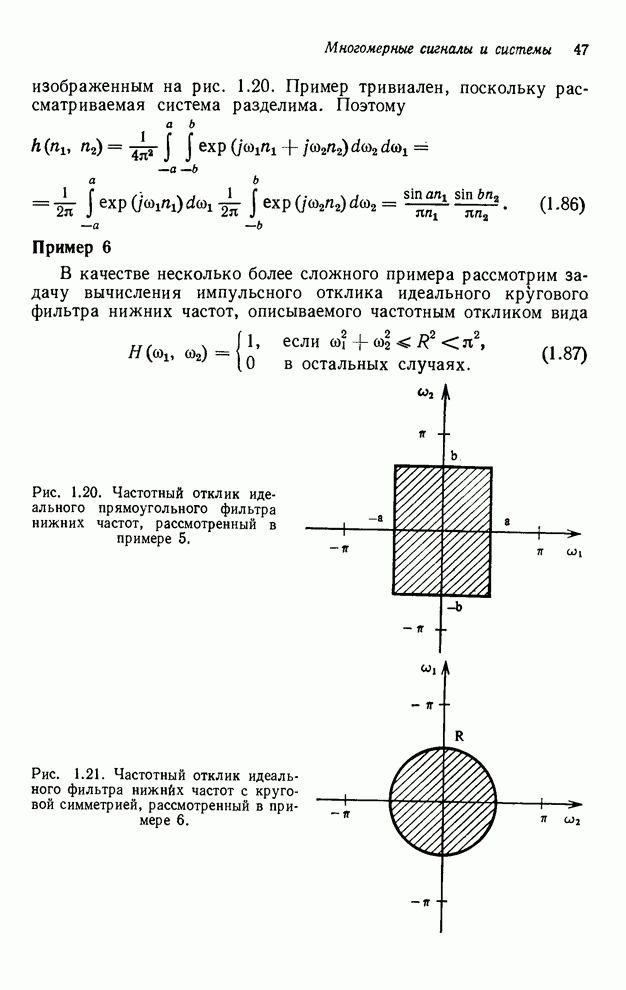
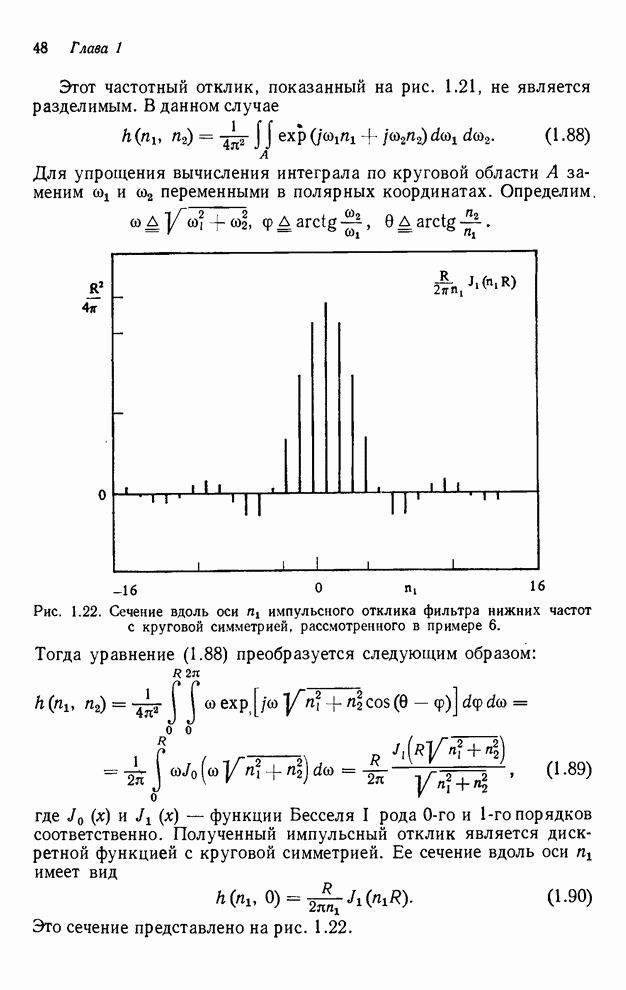
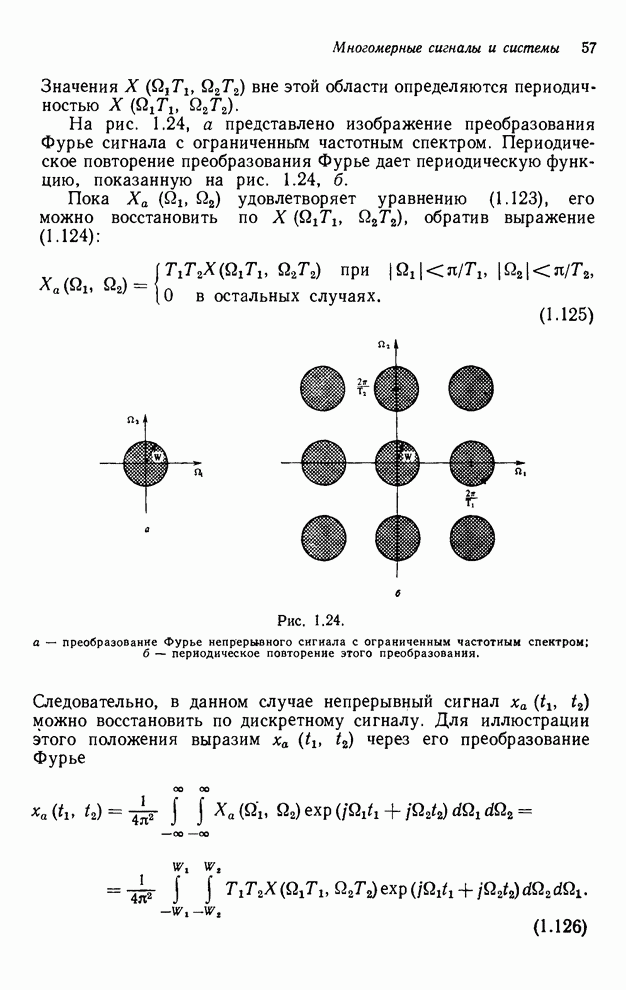
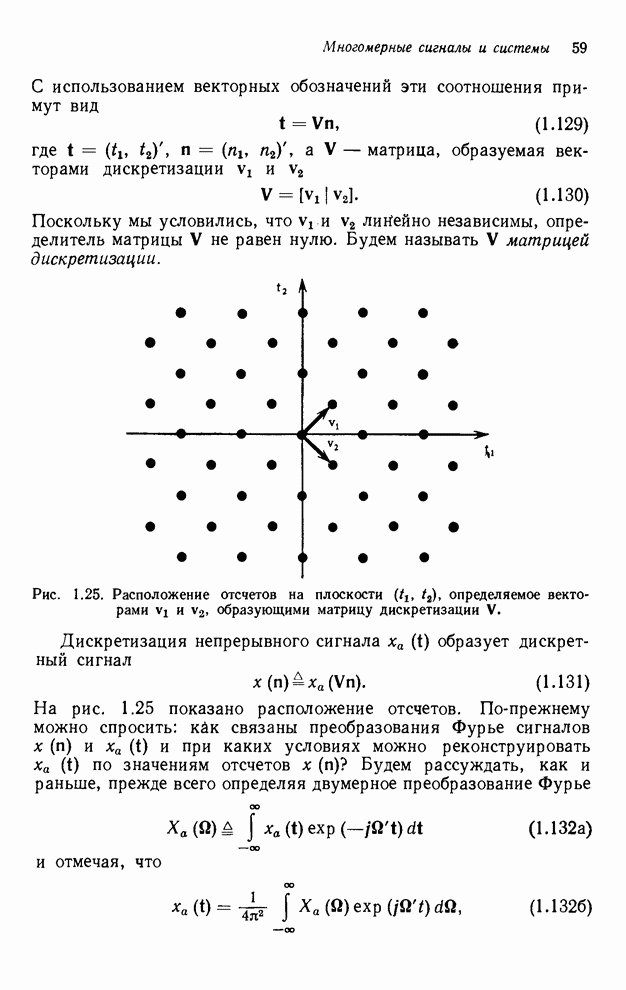
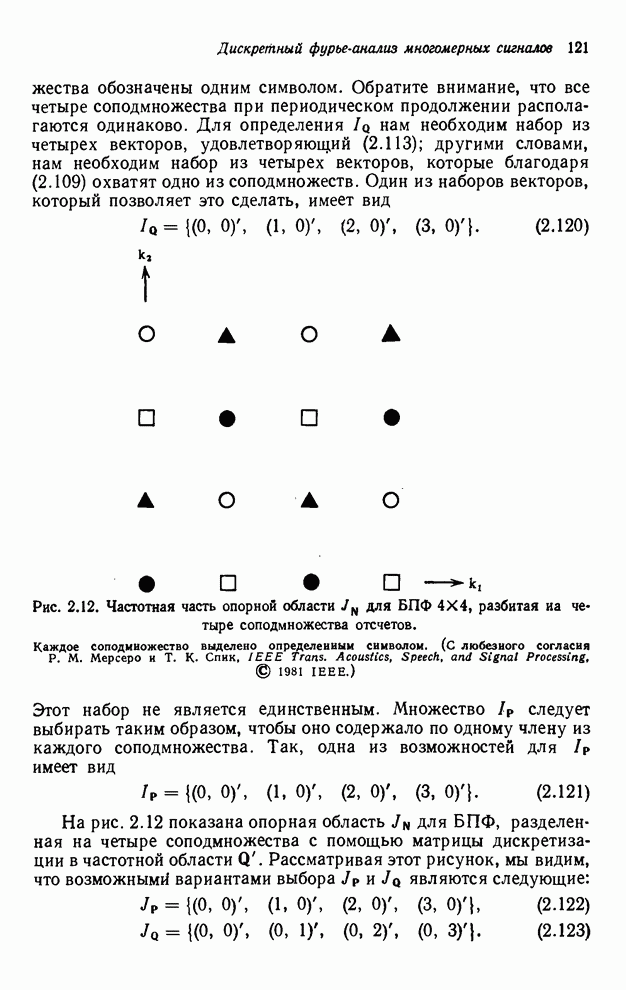
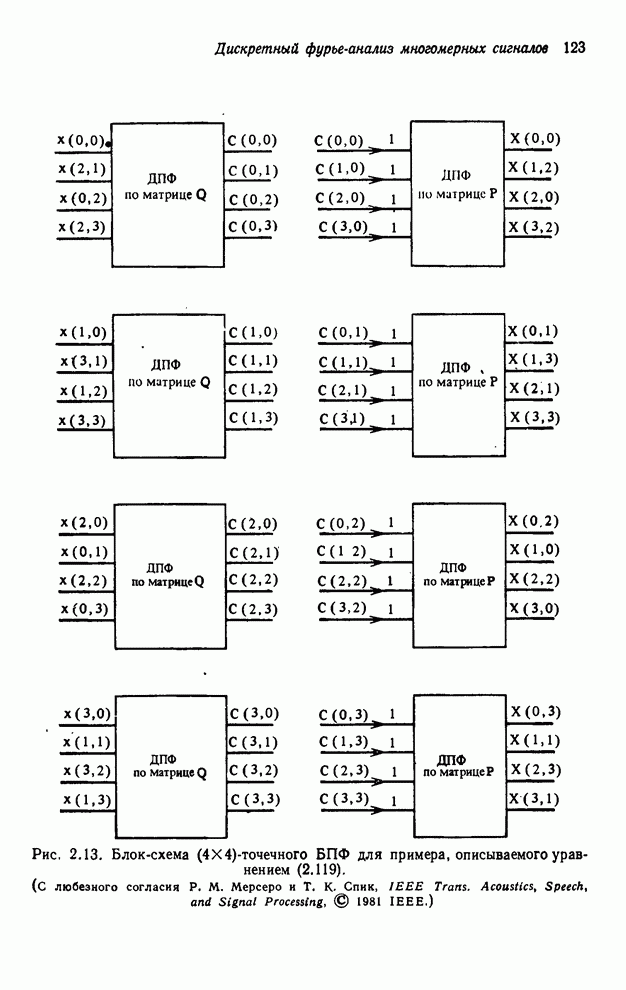
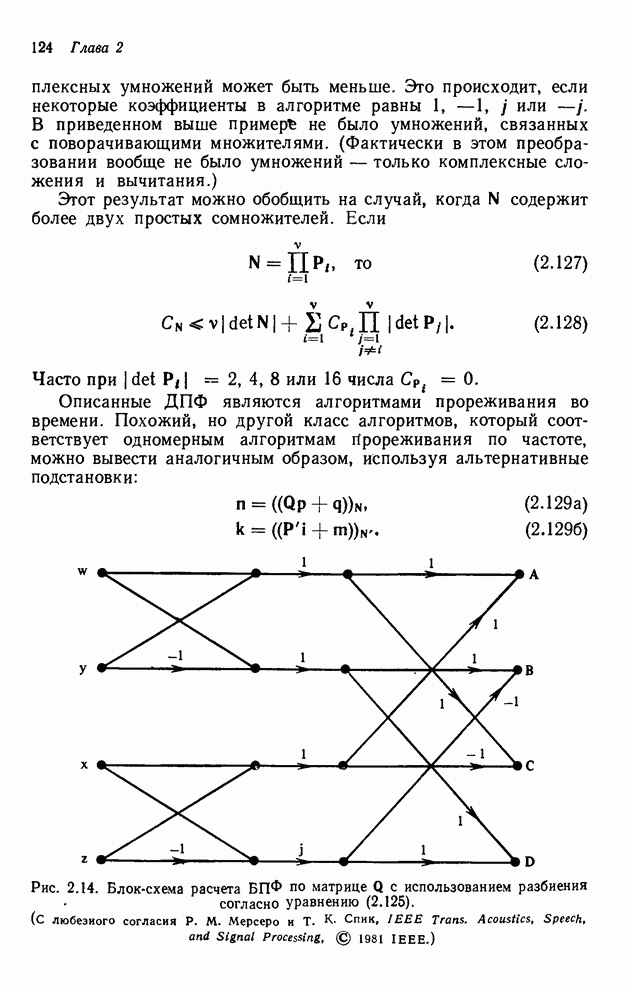
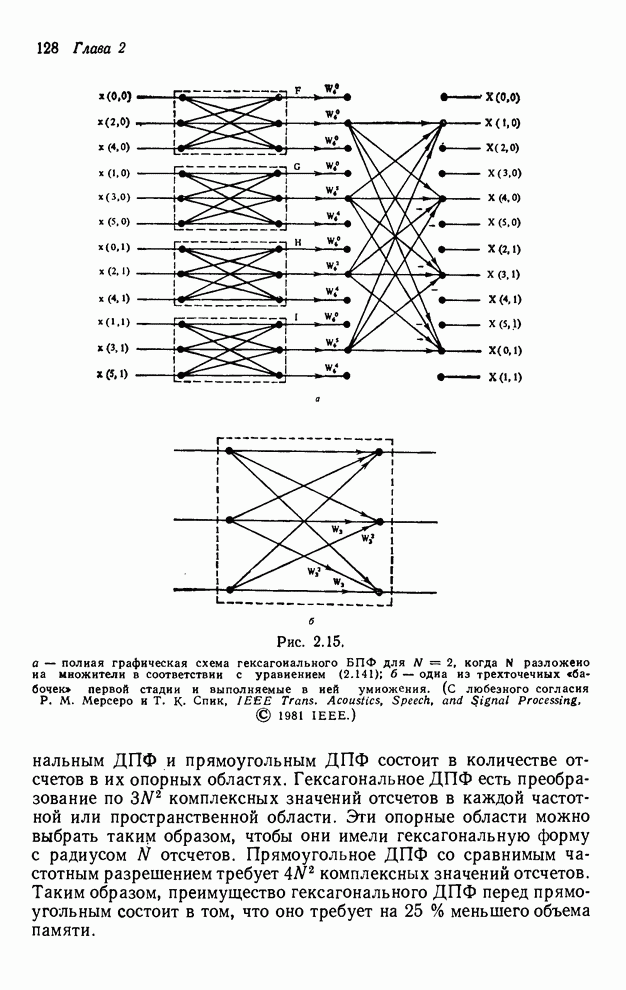
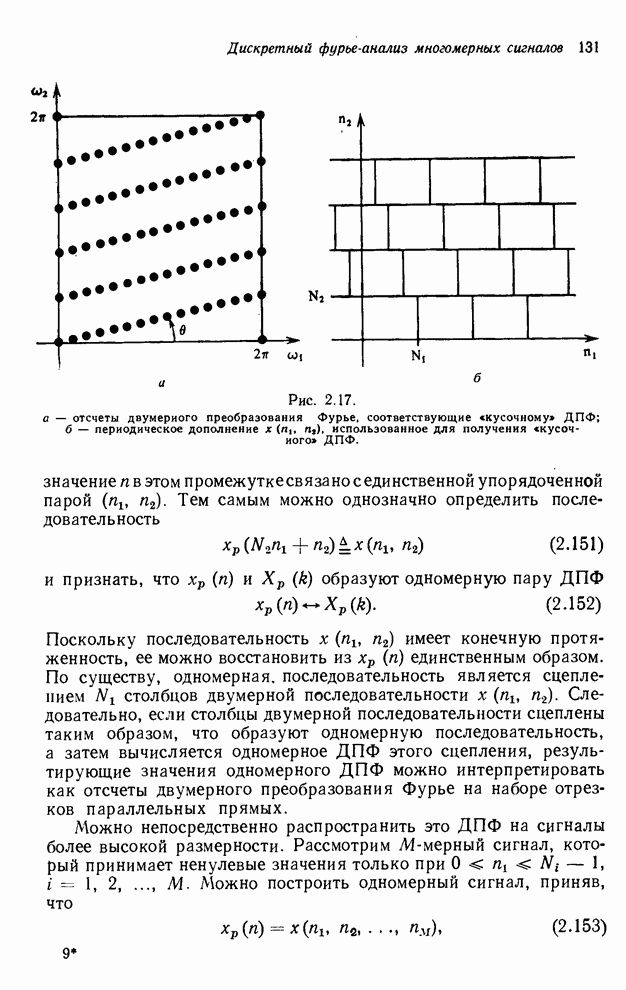
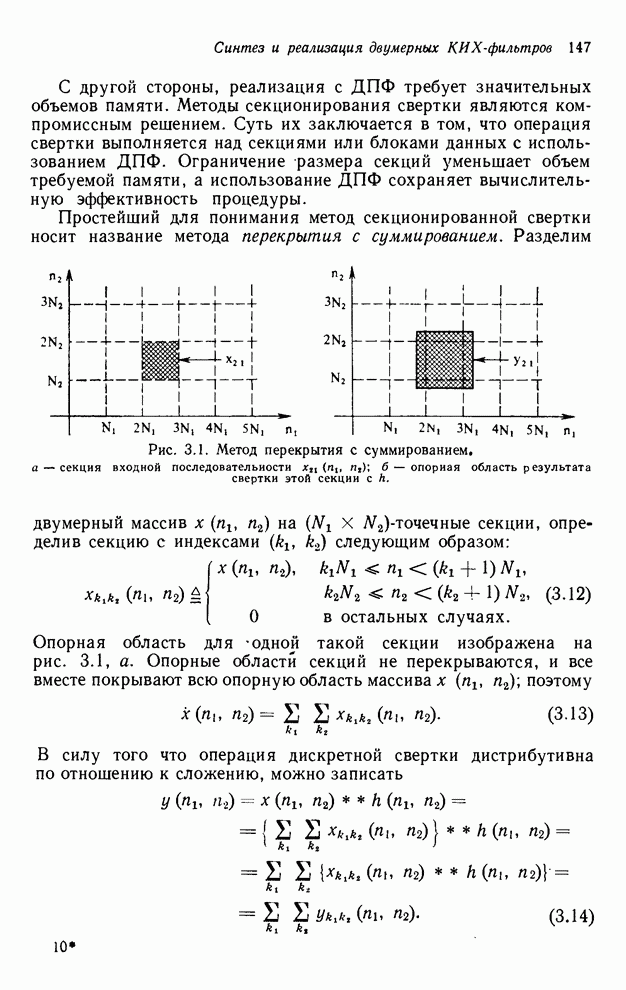
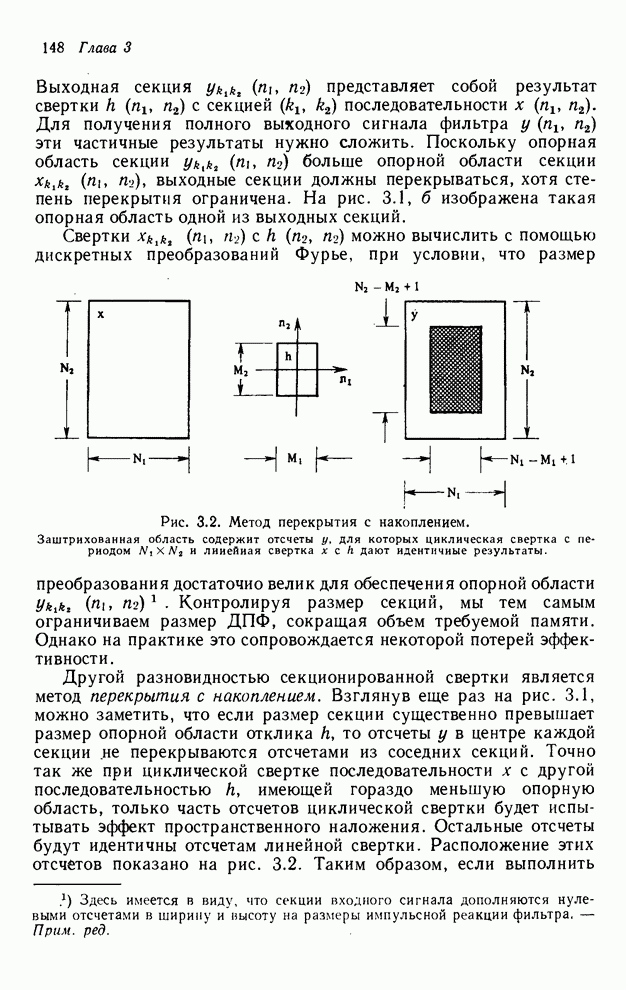
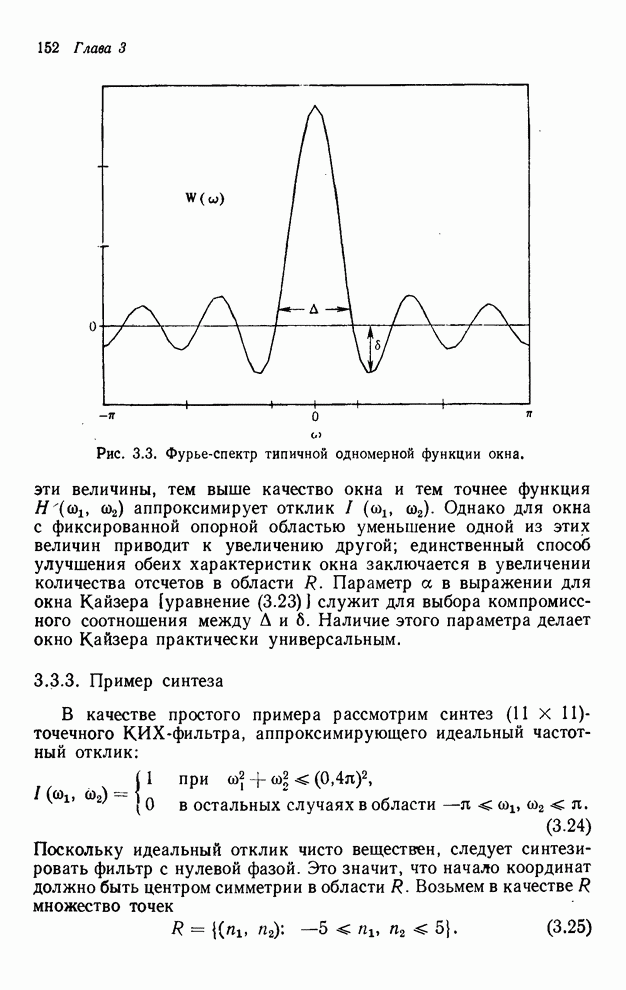
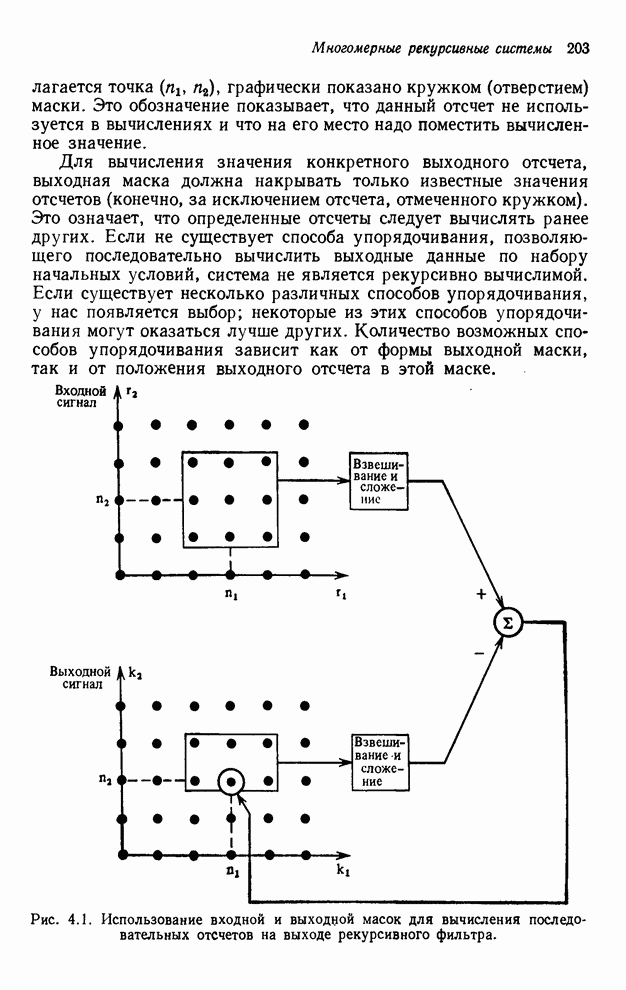
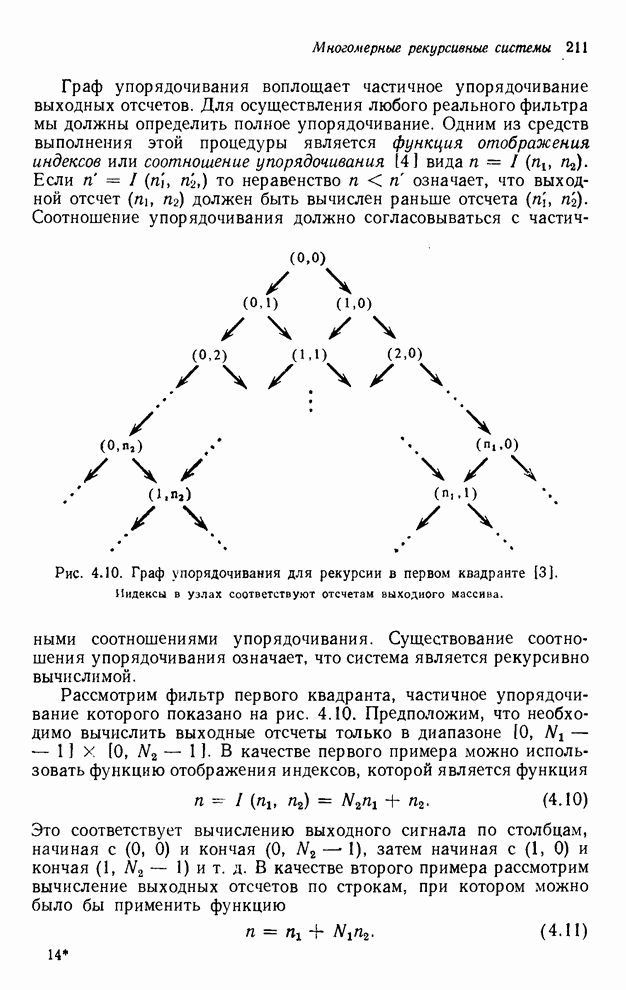
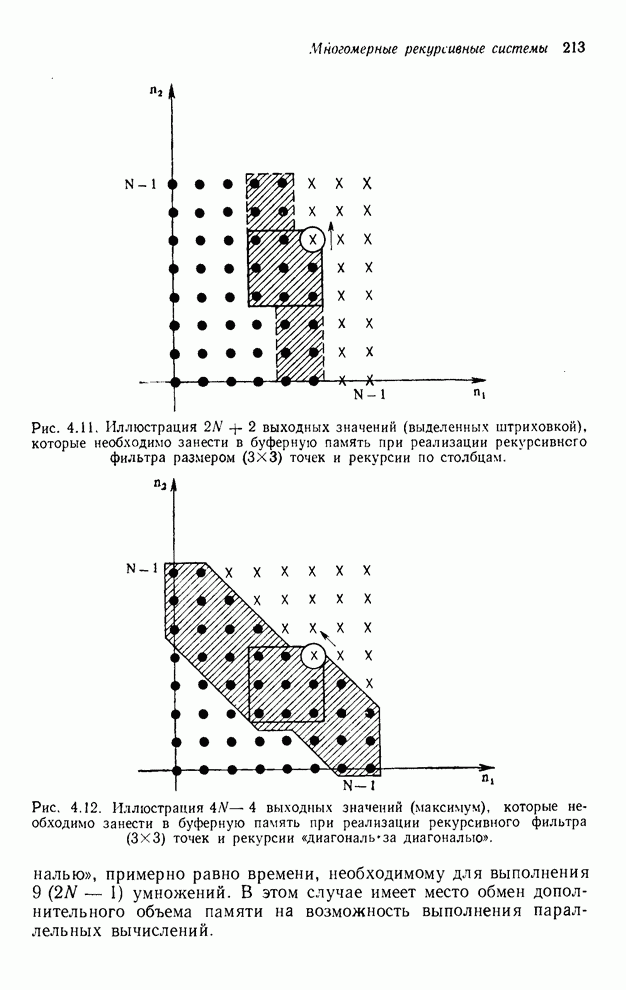
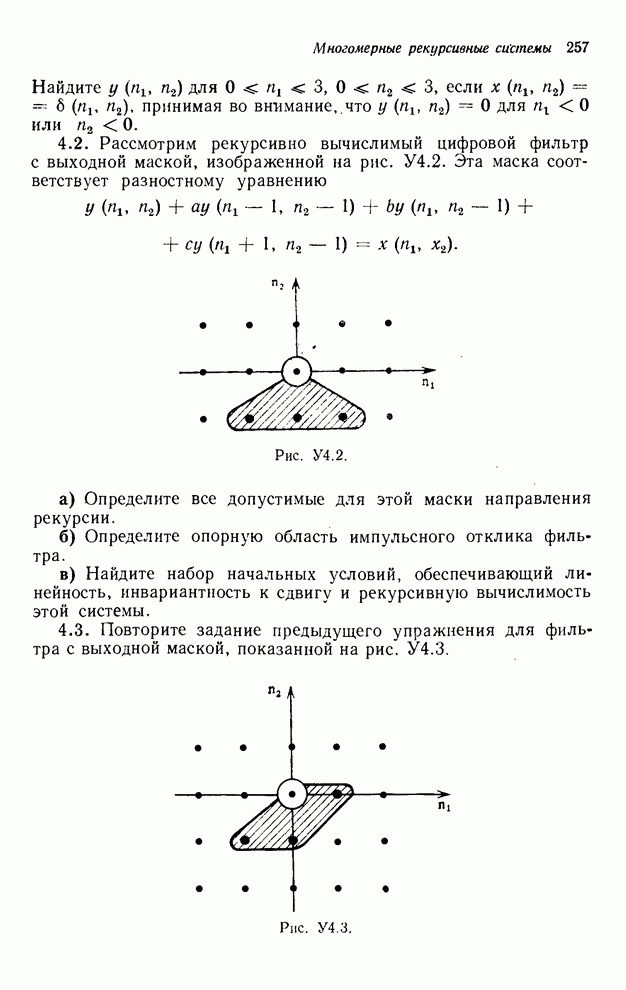
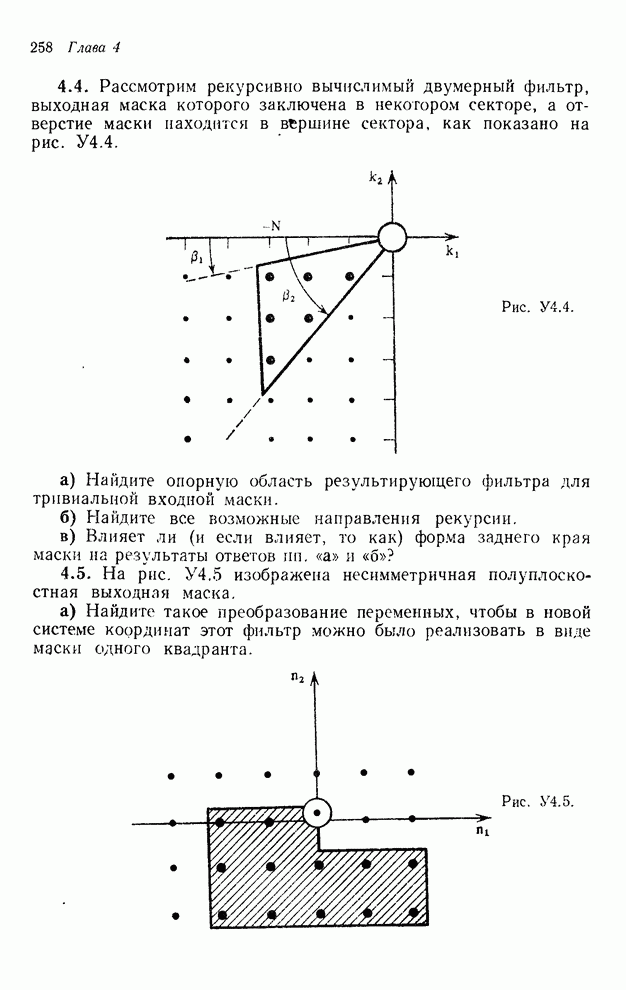
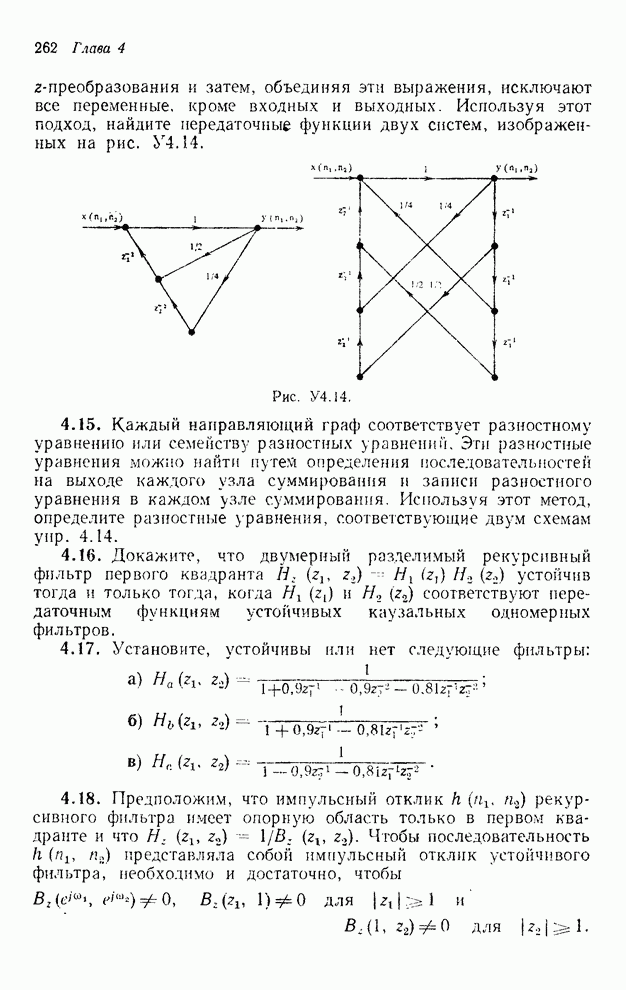
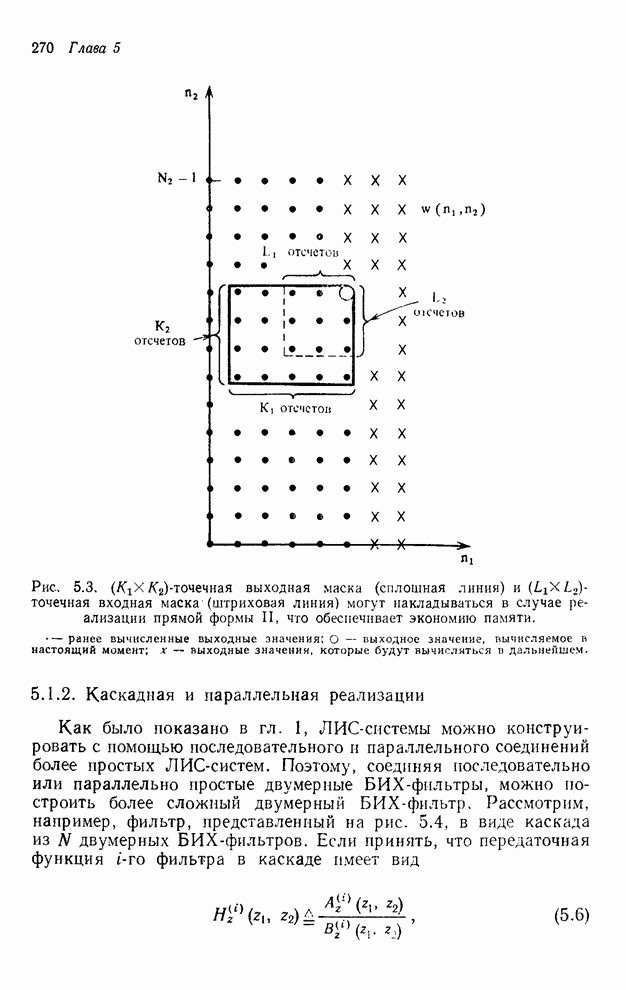
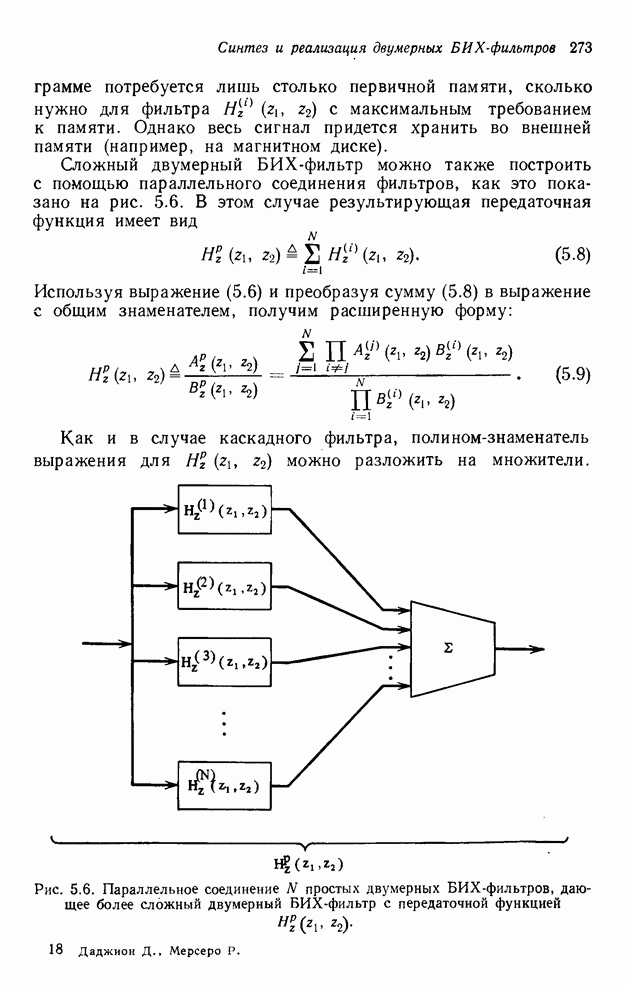
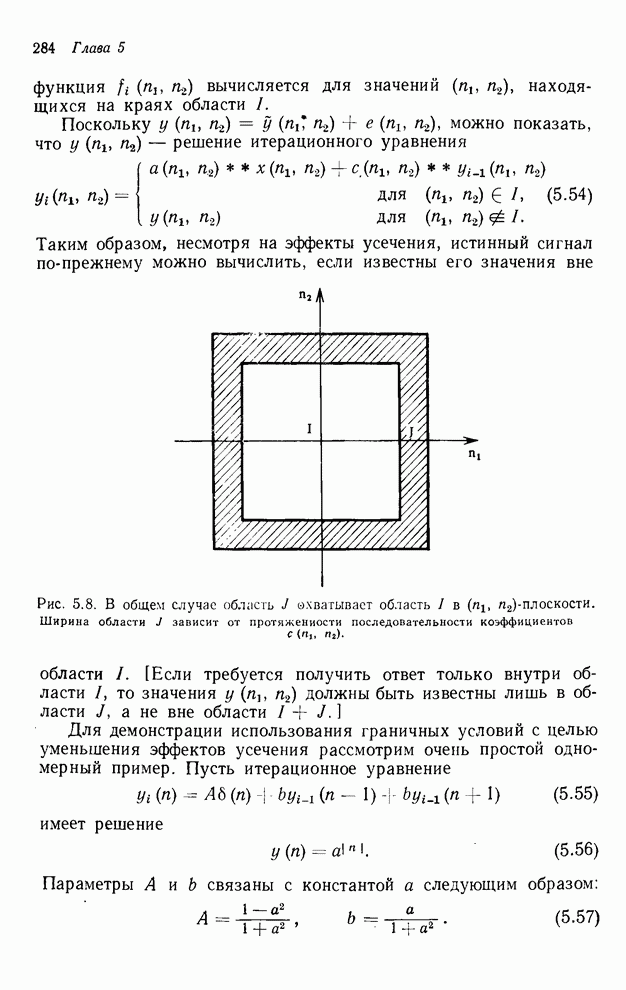
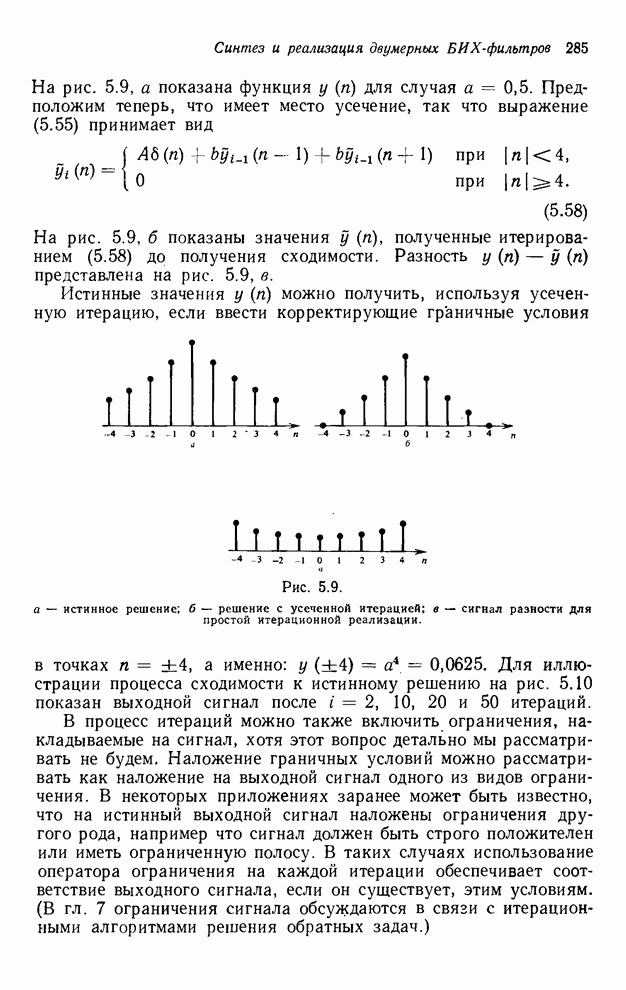
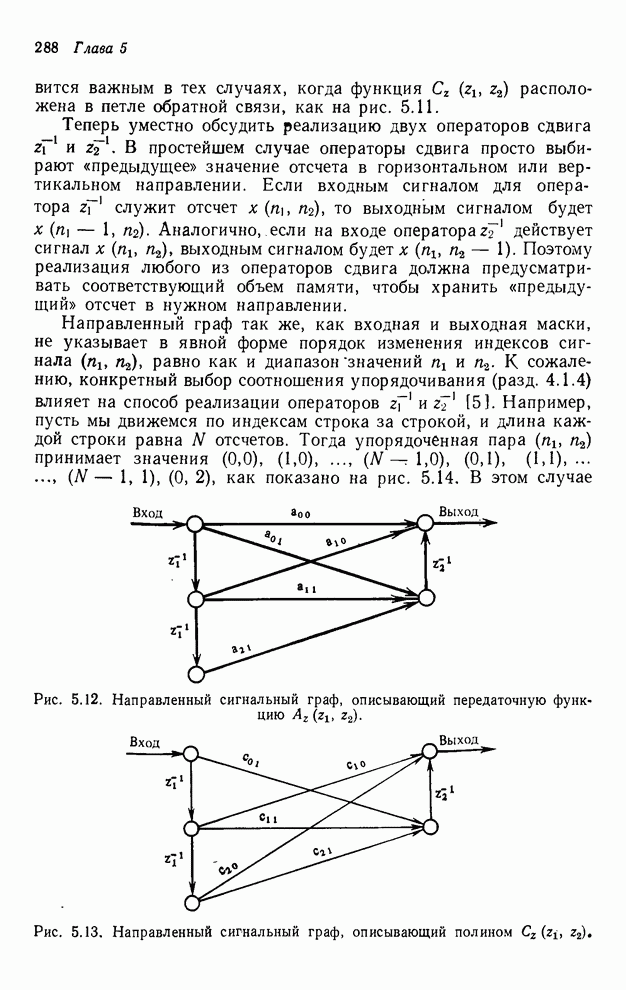
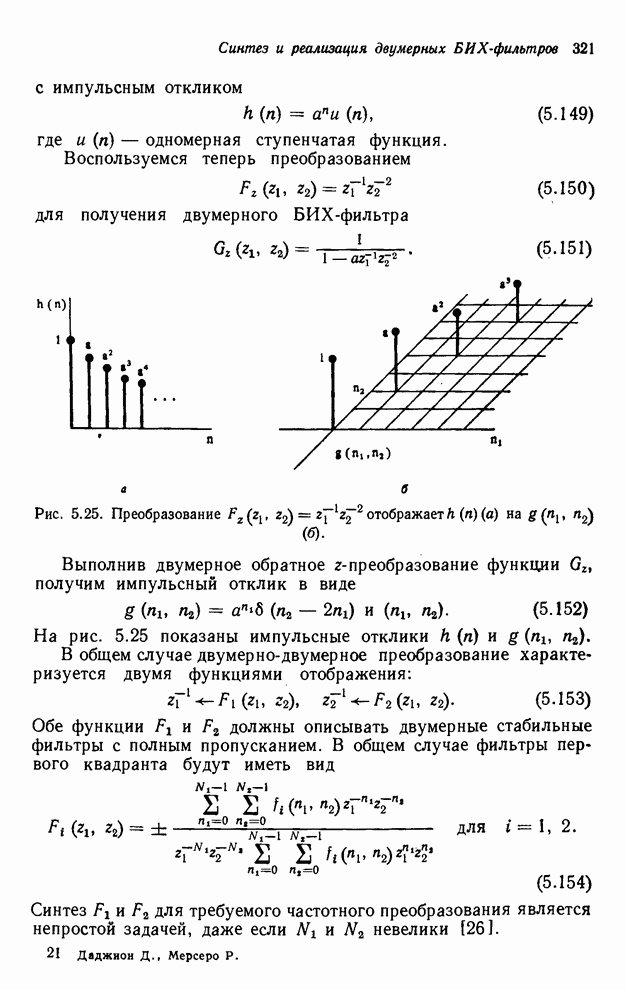
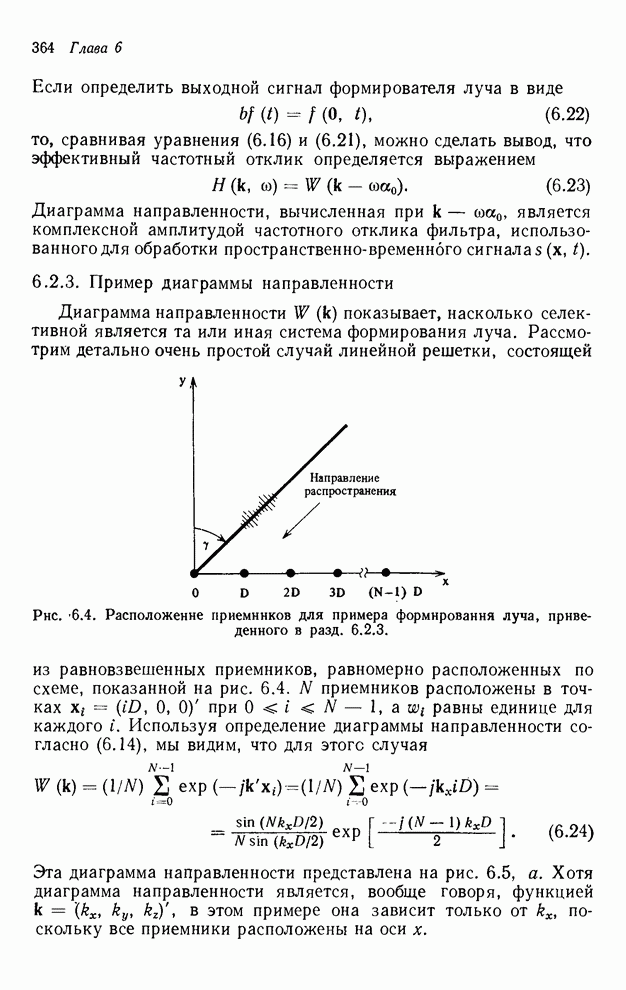
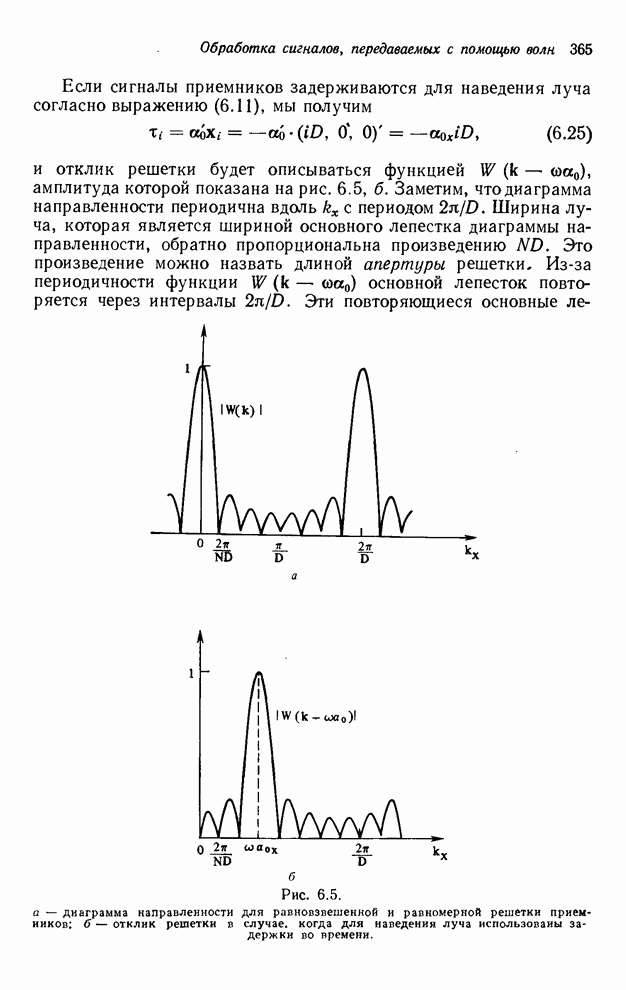
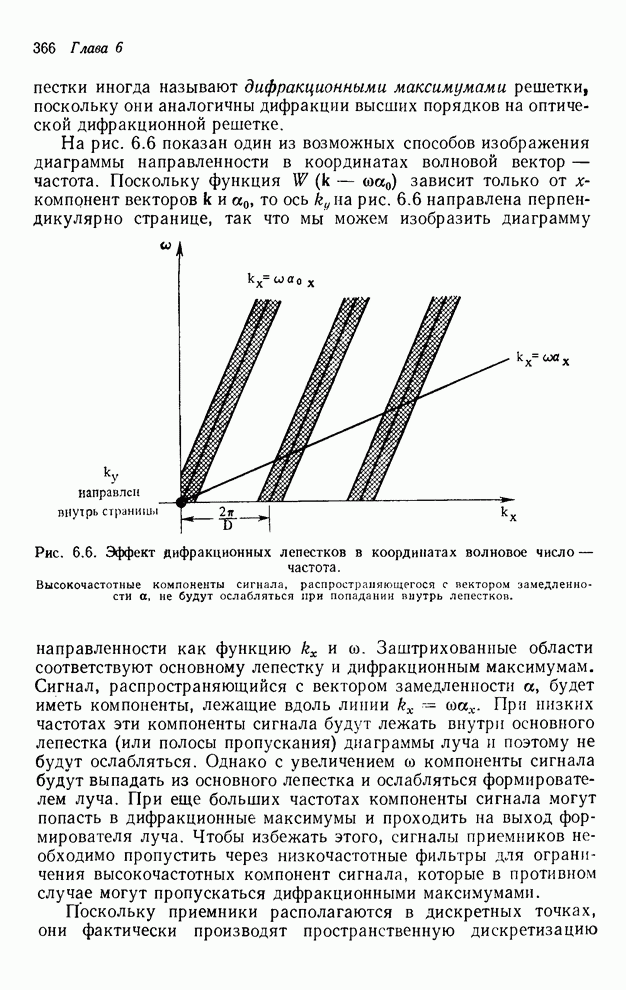
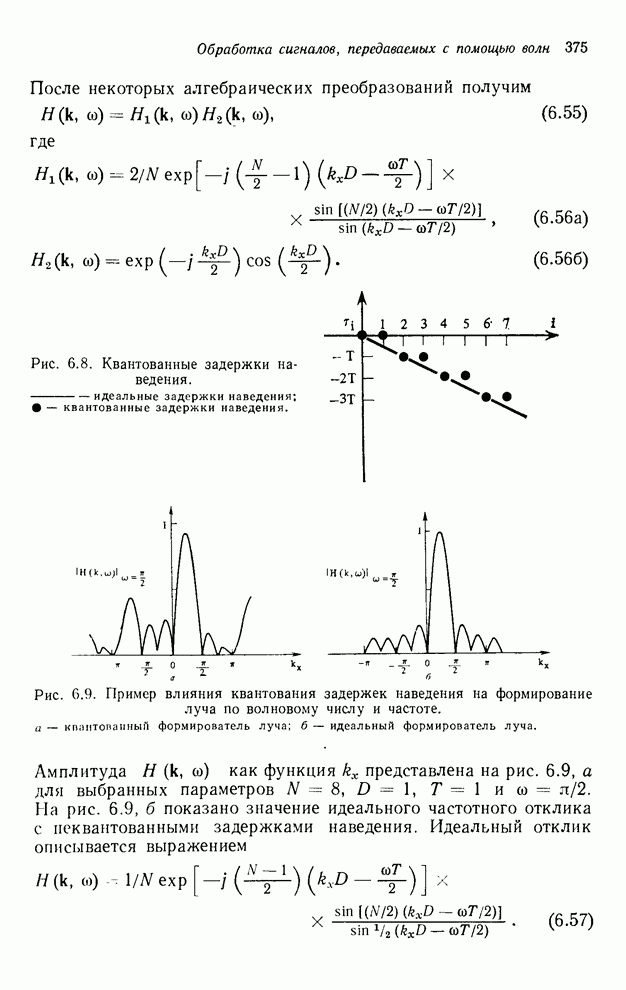
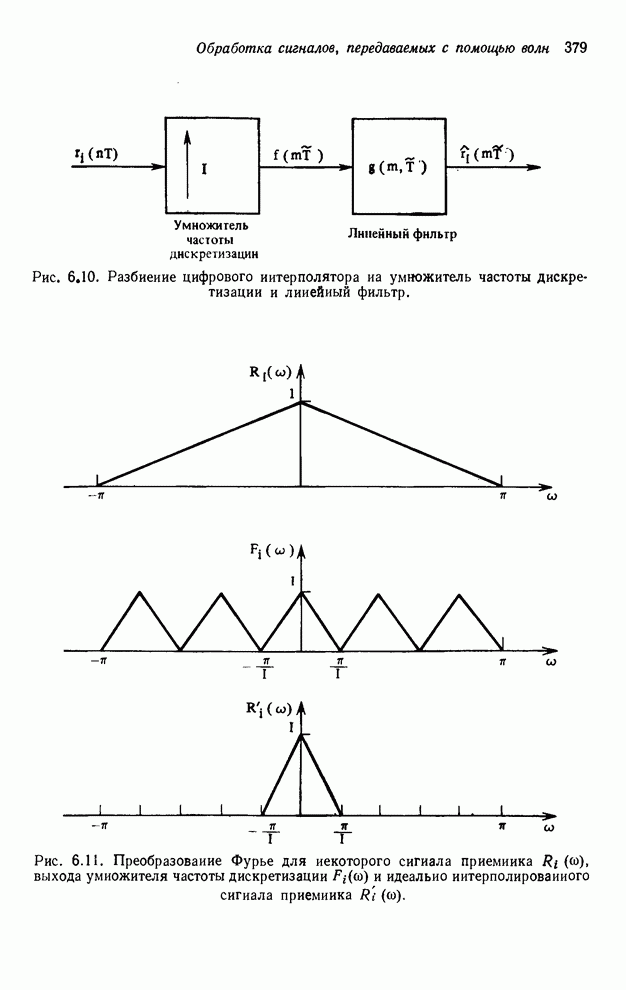
2.3.4. Вычислительная сложность ДПФ
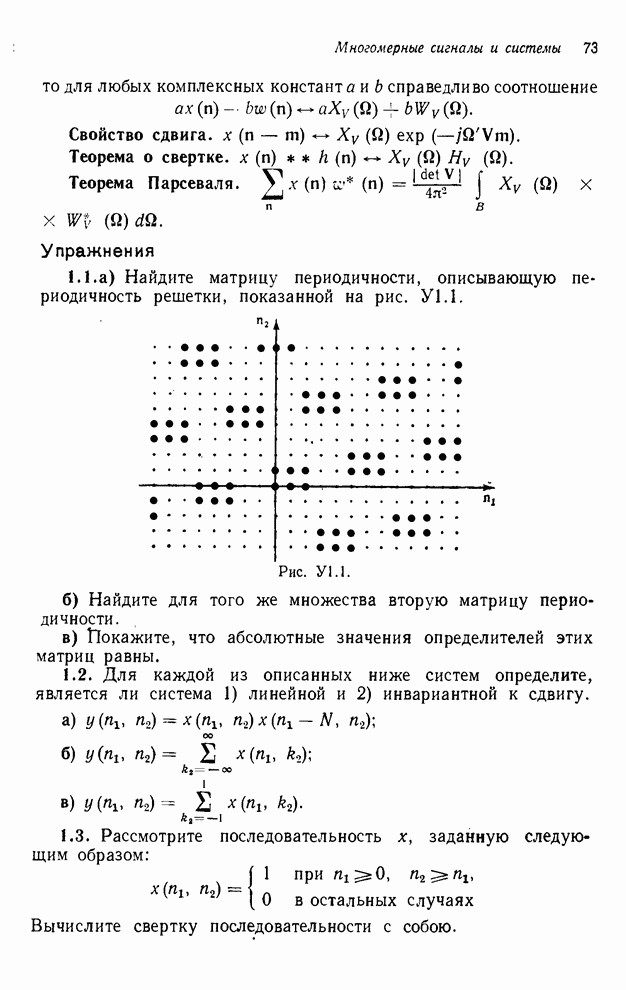
Существует ряд методов измерения
сложности алгоритма  -мерного
БПФ. Можно, например, подсчитать количество умножений и сложений, измерить
объем памяти или машинное время, необходимое для выполнения конкретного ДПФ.
Последнее, пожалуй, наиболее информативно, но оно зависит от типа ЭВМ и от
программиста. Вместо поиска единой определяющей меры сложности мы просто
сравним алгоритм по нескольким разным мерам. Для целей анализа предположим, что
нам необходимо выполнить -мерное ДПФ
-мерного
БПФ. Можно, например, подсчитать количество умножений и сложений, измерить
объем памяти или машинное время, необходимое для выполнения конкретного ДПФ.
Последнее, пожалуй, наиболее информативно, но оно зависит от типа ЭВМ и от
программиста. Вместо поиска единой определяющей меры сложности мы просто
сравним алгоритм по нескольким разным мерам. Для целей анализа предположим, что
нам необходимо выполнить -мерное ДПФ  -точечного множества, где
-точечного множества, где  - некоторая степень
2.
- некоторая степень
2.
Преобразование с использованием
разбиения по строкам и столбцам требует выполнения  -точечных одномерных ДПФ. В
приложениях, где применяется матричный процессор, это является критической мерой.
Если для вычисления преобразований с разбиением по строкам и столбцам будет
использован одномерный алгоритм БПФ по основанию 2, мы получим всего
-точечных одномерных ДПФ. В
приложениях, где применяется матричный процессор, это является критической мерой.
Если для вычисления преобразований с разбиением по строкам и столбцам будет
использован одномерный алгоритм БПФ по основанию 2, мы получим всего
 комплексных
умножений и (2.80)
комплексных
умножений и (2.80)
 комплексных
сложений. (2.81)
комплексных
сложений. (2.81)
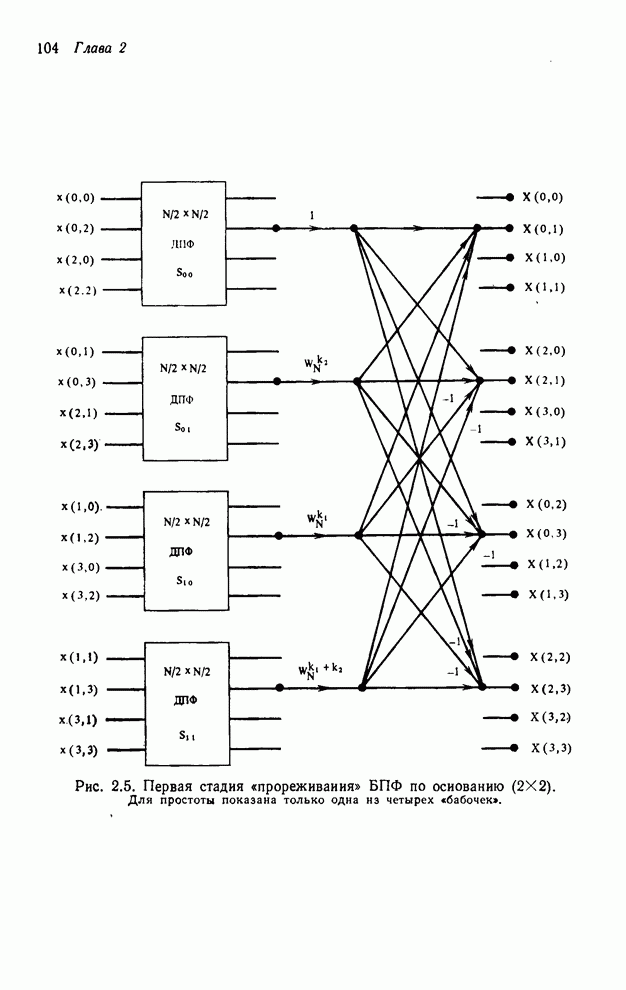
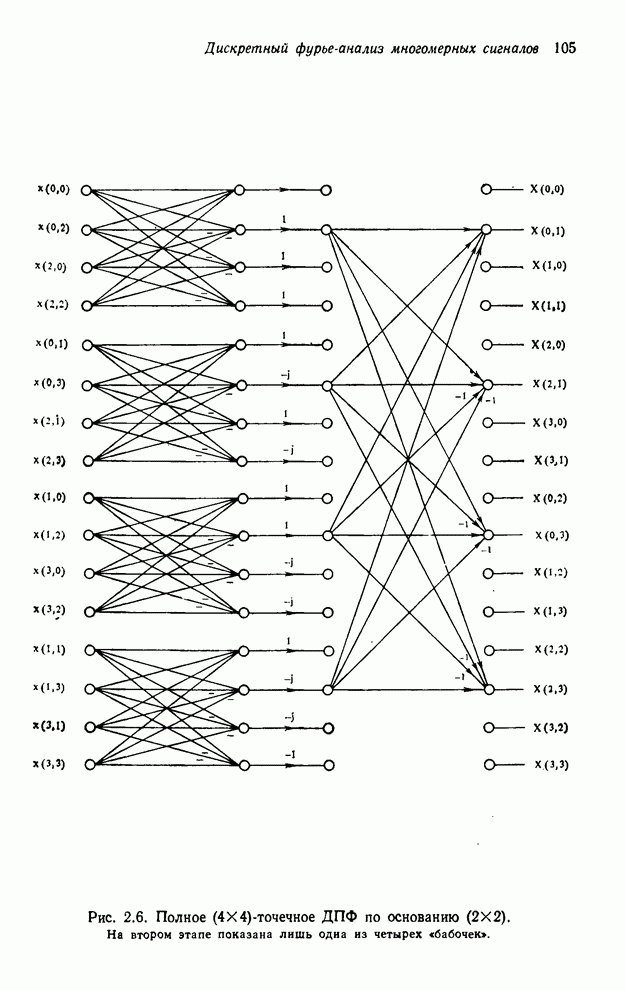
Для
преобразования по векторному основанию  каждая «бабочка» требует
каждая «бабочка» требует  умножений, и на
каждой стадии имеется
умножений, и на
каждой стадии имеется  «бабочек». Это дает
«бабочек». Это дает
 (2.82)
(2.82)
комплексных
умножений и
 (2.83)
(2.83)
комплексных
сложений. Таким образом, алгоритм по векторному основанию требует столько же
сложений, но меньше умножений. Выигрыш как функция приведен в табл. 2.1.
Таблица 2.1. Сравнение количества
комплексных умножений, необходимых для -мерных алгоритмов БПФа)
|
|

|
|
2
|
0,75
|
|
3
|
0,58
|
|
4
|
0,47
|
|
5
|
0,39
|
|
а)
Предполагается, что опорная область рассматриваемого множества – гиперкуб.
|
Количество операций, необходимых
для вычисления -мерного
ДПФ, можно также несколько уменьшить путем применения большего основания.
Например, если представляет
собой степень числа 4, то можно использовать разложения строка-столбец с
основанием 4 или алгоритм вектор-основания  для вычисления
для вычисления  -точечного ДПФ. «Бабочки» этих
алгоритмов будут включать лишь тривиальные умножения на
-точечного ДПФ. «Бабочки» этих
алгоритмов будут включать лишь тривиальные умножения на  ,
,  ,
,  и
и  , и, поскольку количество «бабочек»
уменьшено по сравнению с алгоритмом по векторному основанию 2, общее количество
операций также уменьшится (см. упр. 2.13).
, и, поскольку количество «бабочек»
уменьшено по сравнению с алгоритмом по векторному основанию 2, общее количество
операций также уменьшится (см. упр. 2.13).
Для обоих алгоритмов БПФ
количество комплексных чисел, размещаемых в памяти, равно размеру массива
данных, т. е.  .
Для многих практических задач, представляющих интерес, эта величина превышает
объем основной (оперативной) памяти мини-ЭВМ. Следовательно, сигнал должен
располагаться на дополнительном устройстве памяти, например на диске, и
восприниматься по частям. Возникающие проблемы ввода-вывода очень сильно влияют
на эффективность алгоритма БПФ.
.
Для многих практических задач, представляющих интерес, эта величина превышает
объем основной (оперативной) памяти мини-ЭВМ. Следовательно, сигнал должен
располагаться на дополнительном устройстве памяти, например на диске, и
восприниматься по частям. Возникающие проблемы ввода-вывода очень сильно влияют
на эффективность алгоритма БПФ.
Рассмотрим в качестве примера
обработку с помощью двумерного алгоритма с разбиением по строкам и столбцам БПФ
 -точечного
изображения на мини-компьютере с объемом памяти, доступным для записи данных,
16К (
-точечного
изображения на мини-компьютере с объемом памяти, доступным для записи данных,
16К ( )
комплексных слов. Допустим, что полный сигнал записан на диске и что, хотя
«блоки» диска могут располагаться произвольно, при обмене данными между диском
и памятью ЭВМ должен быть записан или считан по крайней мере один полный блок.
В нашем примере блок будет иметь размер в 1024 комплексных слов. В
действительности блоки могут быть и короче, но практически все дисковые ЗУ
имеют такое свойство, что количество переданных слов должно быть не меньше
некоторой величины. (Даже если это не так, наложение подобного ограничения
поможет заметно уменьшить накладные расходы на ввод-вывод - одну из самых емких
по времени операций.)
)
комплексных слов. Допустим, что полный сигнал записан на диске и что, хотя
«блоки» диска могут располагаться произвольно, при обмене данными между диском
и памятью ЭВМ должен быть записан или считан по крайней мере один полный блок.
В нашем примере блок будет иметь размер в 1024 комплексных слов. В
действительности блоки могут быть и короче, но практически все дисковые ЗУ
имеют такое свойство, что количество переданных слов должно быть не меньше
некоторой величины. (Даже если это не так, наложение подобного ограничения
поможет заметно уменьшить накладные расходы на ввод-вывод - одну из самых емких
по времени операций.)
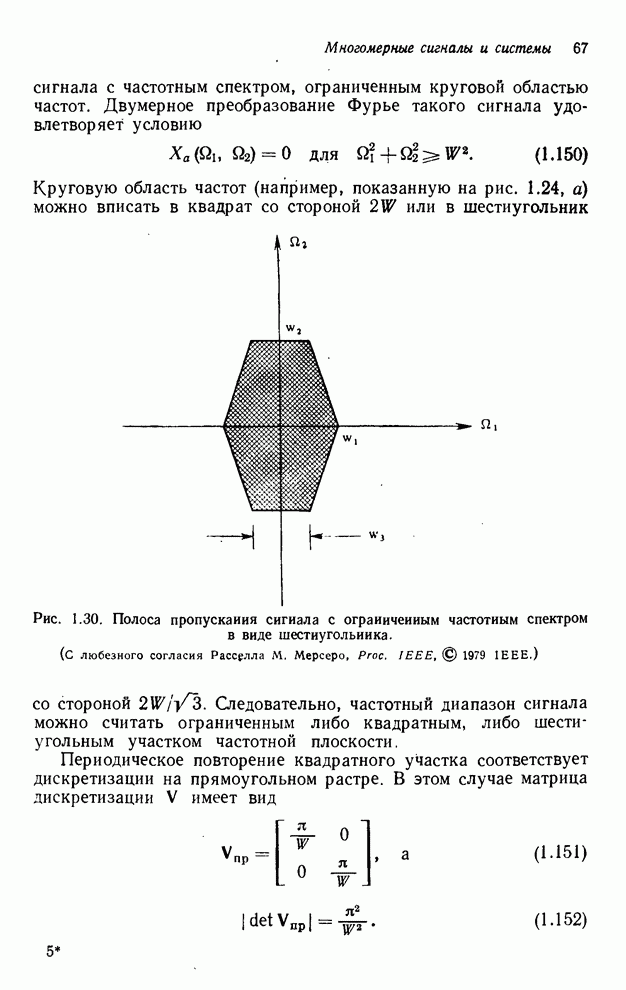
Если сигнал запоминается строка
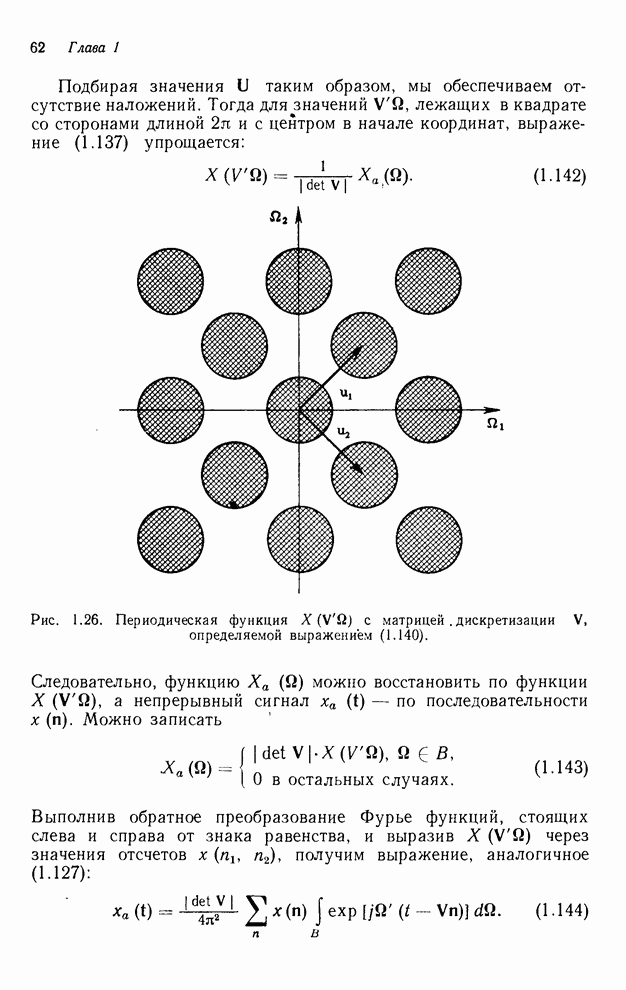
за строкой, т. е. отсчеты сигнала для  строки следуют непосредственно за
строки следуют непосредственно за  -й строкой, можно
считывать строки поодиночке, выполнять БПФ для строки и затем записывать
результат обратно на диск. В нашем конкретном случае, поскольку у нас имеется
память на 16К слов, мы можем одновременно разместить в памяти 16 строк данных.
Передача данных с диска и обратно может быть осуществлена секциями длиной по 16
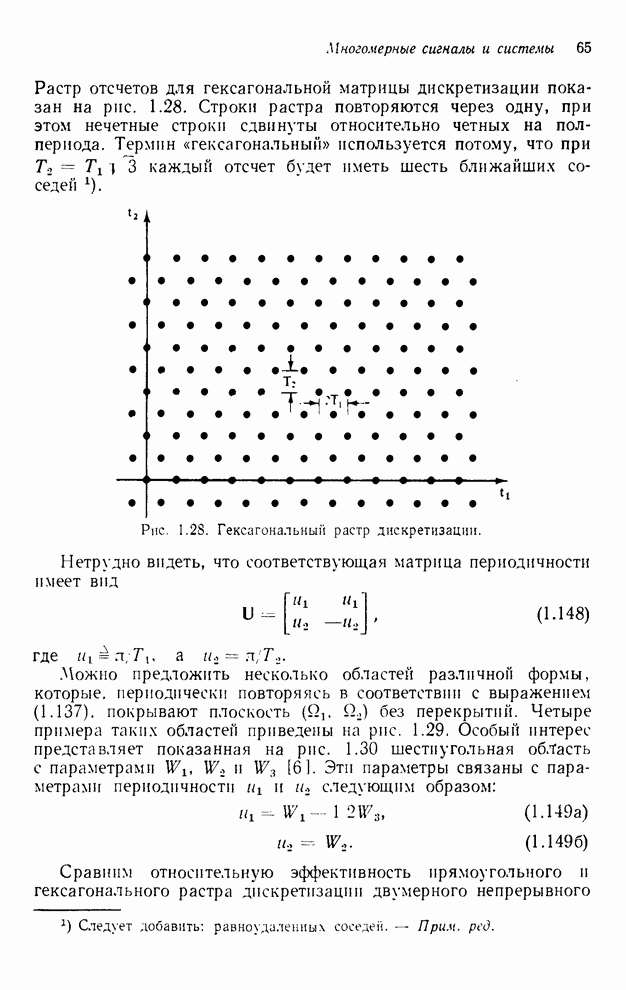
блоков. Часть программы, которая вычисляет БПФ по строкам, будет состоять из
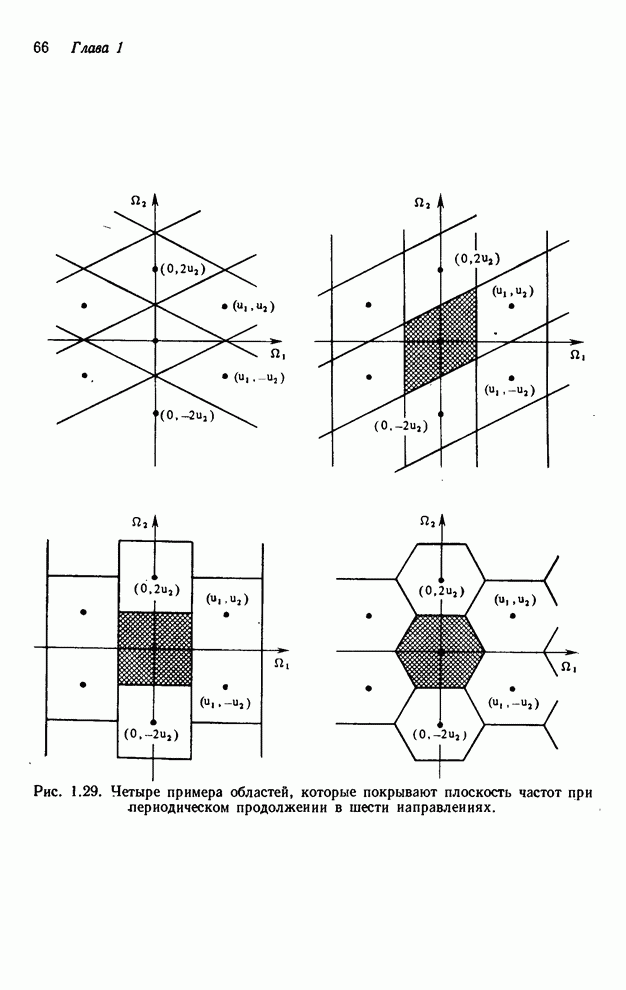
повторяющегося 64 раза цикла: считывание 16 строк с диска, выполнение 16
одномерных БПФ и записи результатов обратно на диск.
-й строкой, можно
считывать строки поодиночке, выполнять БПФ для строки и затем записывать
результат обратно на диск. В нашем конкретном случае, поскольку у нас имеется
память на 16К слов, мы можем одновременно разместить в памяти 16 строк данных.
Передача данных с диска и обратно может быть осуществлена секциями длиной по 16
блоков. Часть программы, которая вычисляет БПФ по строкам, будет состоять из
повторяющегося 64 раза цикла: считывание 16 строк с диска, выполнение 16
одномерных БПФ и записи результатов обратно на диск.
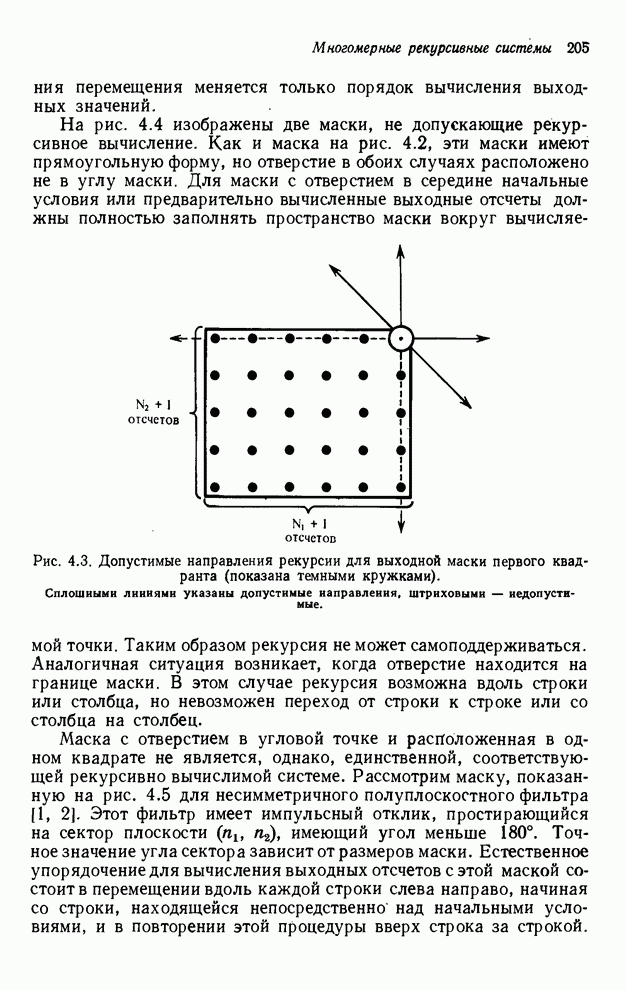
Однако здесь возникает серьезная
проблема. После этого необходимо выполнить преобразование по столбцам, но,
поскольку данные записаны строками, выделение  -го столбца означает выделение только -го слова из каждого
блока размером 1К, что запрещено. К счастью, существует эффективный алгоритм
Эклунда [5] транспонирования матрицы, записанной во внешней памяти. После
выполнения преобразования строк массив промежуточных данных транспонируется, в
результате чего получается массив данных, организованный в виде столбцов, по
которому может быть произведено вычисление столбцовой части ДПФ. Теперь массив
результатов получится в виде столбцов. Если это неудобно, можно выполнить транспонирование
еще раз.
-го столбца означает выделение только -го слова из каждого
блока размером 1К, что запрещено. К счастью, существует эффективный алгоритм
Эклунда [5] транспонирования матрицы, записанной во внешней памяти. После
выполнения преобразования строк массив промежуточных данных транспонируется, в
результате чего получается массив данных, организованный в виде столбцов, по
которому может быть произведено вычисление столбцовой части ДПФ. Теперь массив
результатов получится в виде столбцов. Если это неудобно, можно выполнить транспонирование
еще раз.
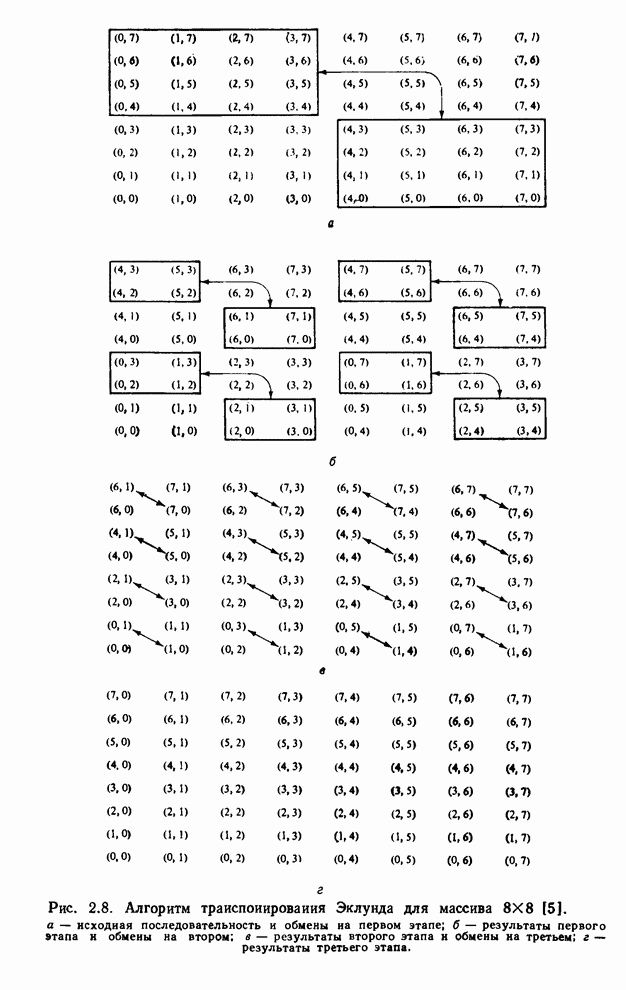
Алгоритм транспонирования Эклунда
основан на стратегии divide et impera. Обозначим двумерную последовательность,
подлежащую транспонированию, через  . Если по размеру занимает
. Если по размеру занимает  точек, ее можно разбить на 4
меньшие последовательности размером
точек, ее можно разбить на 4
меньшие последовательности размером  точек каждая:
точек каждая:
 . (2.84)
. (2.84)
( представляет собой
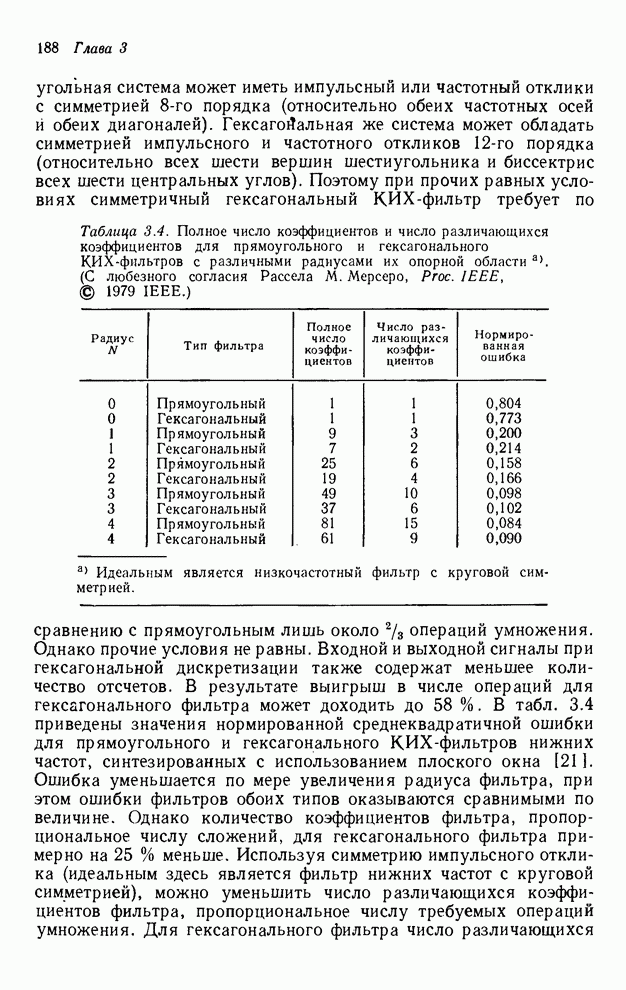
двумерную последовательность, поэтому ее начало располагается в левом нижнем
углу).
Транспонирование можно записать через
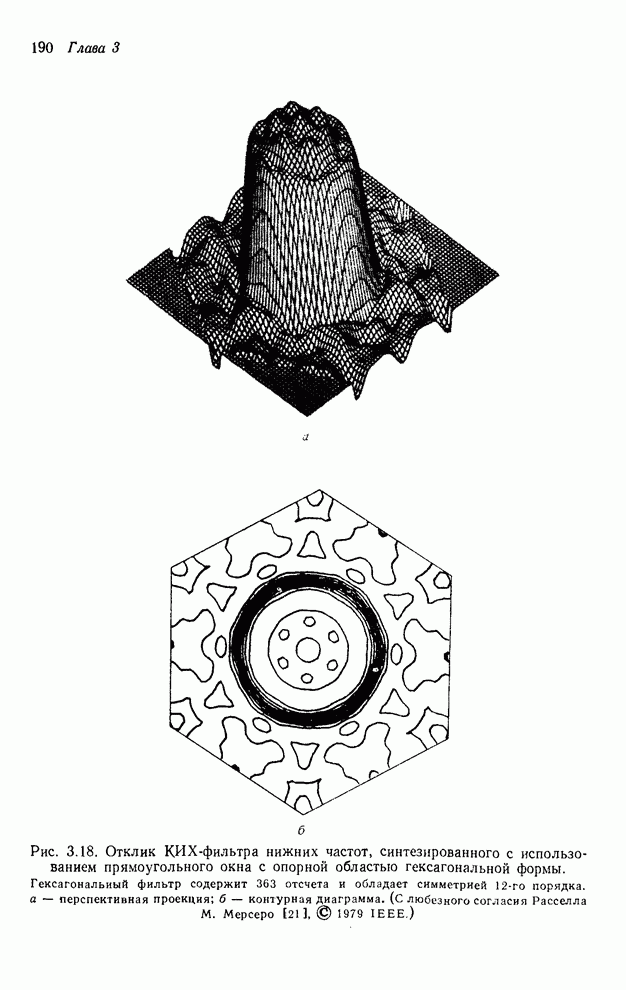
составляющие в виде
 . (2.85)
. (2.85)
Каждая
из составляющих сама транспонирована, а верхняя левая и правая нижняя
составляющие поменялись местами. Каждое из меньших транспонирований теперь
можно выполнить путем повторения того же алгоритма. Очевидно, что полный
алгоритм потребует  подобных
разбиений. Этапы транспонирования массива
подобных
разбиений. Этапы транспонирования массива  показаны на рис. 2.8.
показаны на рис. 2.8.

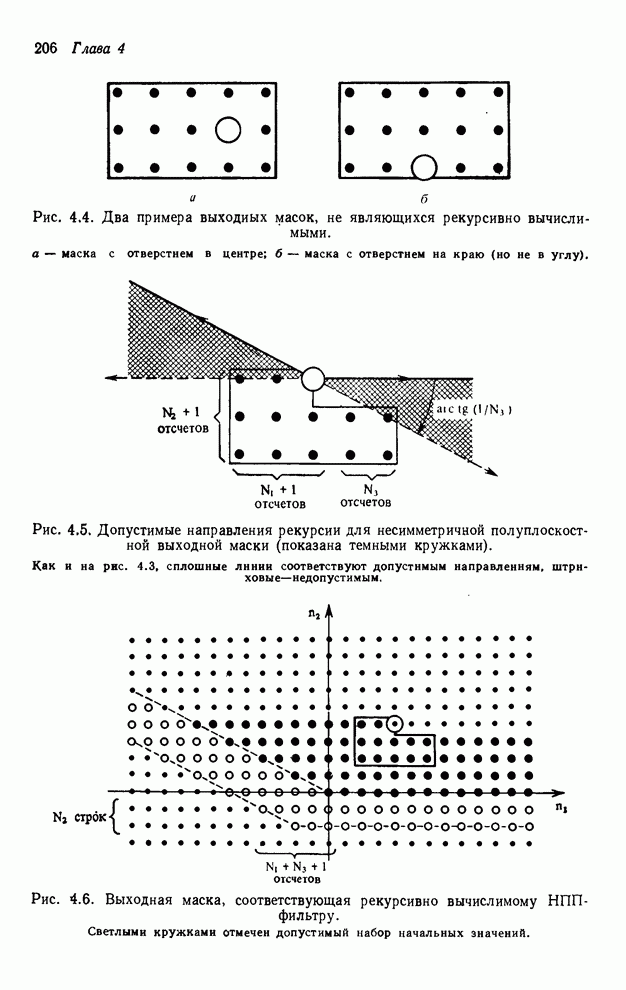
Рис. 2.8. Алгоритм транспонирования
Эклунда для массива [5]:
а - исходная последовательность и обмены на первом этапе; б - результаты
первого этапа и обмены на втором; в - результаты второго этапа и обмены на
третьем; г - результаты третьего этапа.
Главное требование этого
алгоритма состоит в том, что в памяти должно хватить места по крайней мере на
две полные строки данных. В этом случае надо будет прочесть и записать полный
массив раз.
БПФ по строкам можно объединить с первым этапом алгоритма транспонирования, а
БПФ по столбцам - с последним этапом, так что потребуется  циклов записи-считывания для
полного двумерного БПФ, причем результаты будут записаны столбцами. Количество
проходов данных, конечно, можно уменьшить, если в памяти хватает места для
одновременной записи более чем двух строк. Например, пусть число
циклов записи-считывания для
полного двумерного БПФ, причем результаты будут записаны столбцами. Количество
проходов данных, конечно, можно уменьшить, если в памяти хватает места для
одновременной записи более чем двух строк. Например, пусть число  будет наибольшей
степенью числа 2, такой что строк данных можно одновременно разместить
в оперативной памяти ЭВМ. Тогда количество проходов, необходимых для
транспонирования массива
будет наибольшей
степенью числа 2, такой что строк данных можно одновременно разместить
в оперативной памяти ЭВМ. Тогда количество проходов, необходимых для
транспонирования массива  , можно снизить до наименьшего целого
числа, большего
, можно снизить до наименьшего целого
числа, большего  .
.
Выше рассмотрен случай
транспонирования массива , где представляет собой степень 2. В общем
случае можно аналогичным образом вывести алгоритм для числа , являющегося степенью
произвольного основания  . Если не является степенью целого числа,
можно, как и в случае БПФ, представить себе составной алгоритм
транспонирования, основанный на факторизации по простым множителям .
. Если не является степенью целого числа,
можно, как и в случае БПФ, представить себе составной алгоритм
транспонирования, основанный на факторизации по простым множителям .
Проблема транспонирования массивов
становится еще более серьезной для -мерного разбиения по строкам и столбцам.
Рассмотрим конечную стадию такого алгоритма, на которой выполняется  -мерное ДПФ. Данные
должны быть организованы таким образом, чтобы последние
-мерное ДПФ. Данные
должны быть организованы таким образом, чтобы последние  одномерных ДПФ можно вычислить
из данных, расположенных в последовательных ячейках внешней памяти. Эта
перегруппировка требует
одномерных ДПФ можно вычислить
из данных, расположенных в последовательных ячейках внешней памяти. Эта
перегруппировка требует  двумерных транспонирований, как показано
на рис. 2.9 для трехмерного случая. Если обозначить через
двумерных транспонирований, как показано
на рис. 2.9 для трехмерного случая. Если обозначить через  количество двумерных
транспонирований, необходимых для выполнения -мерного ДПФ, то должно удовлетворяться
следующее рекурсивное соотношение:
количество двумерных
транспонирований, необходимых для выполнения -мерного ДПФ, то должно удовлетворяться
следующее рекурсивное соотношение:
 (2.86)
(2.86)
с
начальным условием  .
.

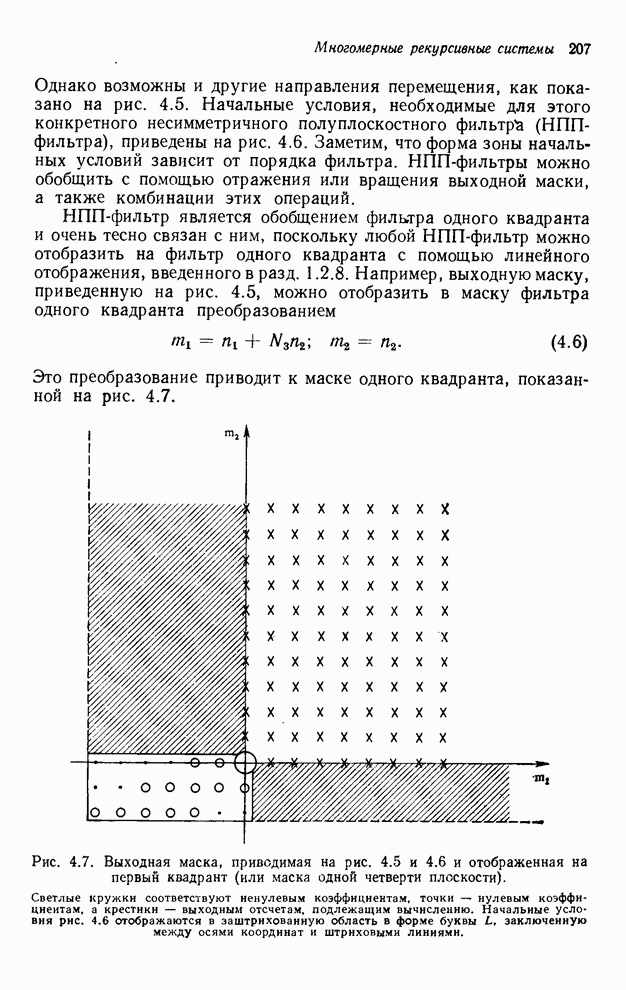
Рис. 2.9. Иллюстрация
необходимости двумерных
транспонирований для выполнения БПФ по строкам для трехмерного БПФ  с разбиением по
строкам и столбцам.
с разбиением по
строкам и столбцам.
Решая
это рекурсивное уравнение, получим, что общее количество двумерных транспонирований,
необходимых для -мерного
БПФ по алгоритму строка-столбец, составляет
 . (2.87)
. (2.87)
Поскольку
для каждого двумерного транспонирования доступно только  отсчетов данных, число циклов
записи-считывания полного массива данных ( точек), необходимых для -мерного разбиения
строка-столбец, равно
отсчетов данных, число циклов
записи-считывания полного массива данных ( точек), необходимых для -мерного разбиения
строка-столбец, равно
 , (2.88)
, (2.88)
где,
как и раньше, -
количество строк, которые одновременно можно расположить в памяти.
Многомерное БПФ по векторному
основанию требует одного цикла записи-считывания полного массива данных для
выполнения двоичной инверсии данных и, кроме того,  дополнительных циклов
записи-считывания для выполнения стадий прореживания по алгоритму
векторного основания, что в сумме дает
дополнительных циклов
записи-считывания для выполнения стадий прореживания по алгоритму
векторного основания, что в сумме дает  циклов записи-считывания. Однако -мерное БПФ по
векторному основанию требует также, чтобы одновременно в оперативной памяти ЭВМ
были размещены
циклов записи-считывания. Однако -мерное БПФ по
векторному основанию требует также, чтобы одновременно в оперативной памяти ЭВМ
были размещены  строк
данных с тем, чтобы эффективно вычислить «бабочку». Если этот объем памяти
доступен для БПФ по алгоритму строка-столбец, мы можем положить
строк
данных с тем, чтобы эффективно вычислить «бабочку». Если этот объем памяти
доступен для БПФ по алгоритму строка-столбец, мы можем положить  выражении (2.88),
подразумевая, что для выполнения БПФ по алгоритму строка-столбец необходимо
только циклов
записи-считывания, что меньше, чем количество, необходимое для выполнения БПФ
по векторному основанию. В зависимости от значений преобразуемых параметров,
относительной скорости выполнения арифметических операций и операций
ввода-вывода конкретной ЭВМ вычислительные преимущества разбиения по векторному
основанию могут быть сведены на нет необходимостью выполнения дополнительных
циклов записи-считывания.
выражении (2.88),
подразумевая, что для выполнения БПФ по алгоритму строка-столбец необходимо
только циклов
записи-считывания, что меньше, чем количество, необходимое для выполнения БПФ
по векторному основанию. В зависимости от значений преобразуемых параметров,
относительной скорости выполнения арифметических операций и операций
ввода-вывода конкретной ЭВМ вычислительные преимущества разбиения по векторному
основанию могут быть сведены на нет необходимостью выполнения дополнительных
циклов записи-считывания.