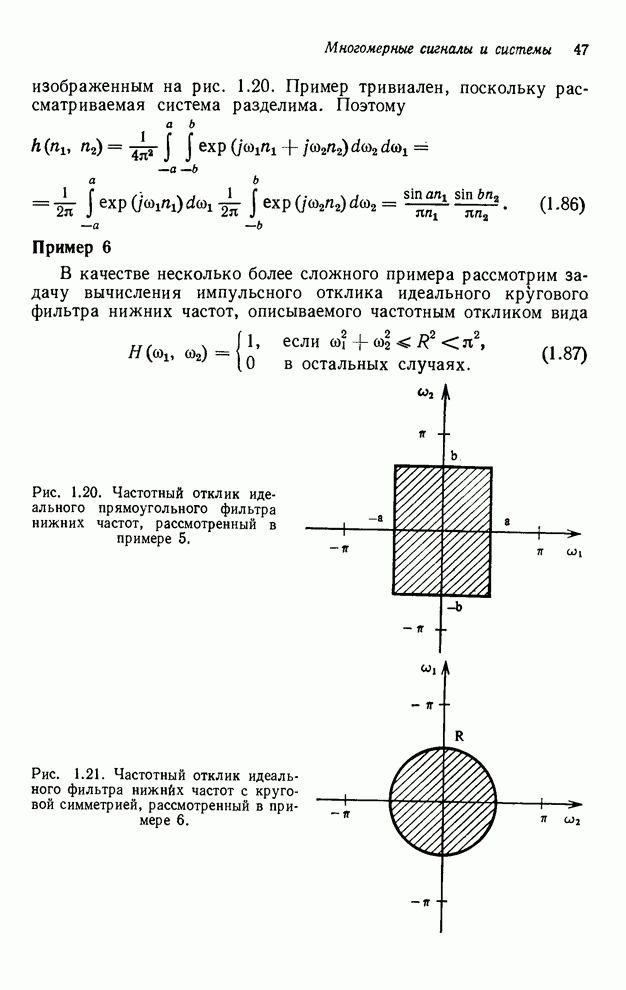
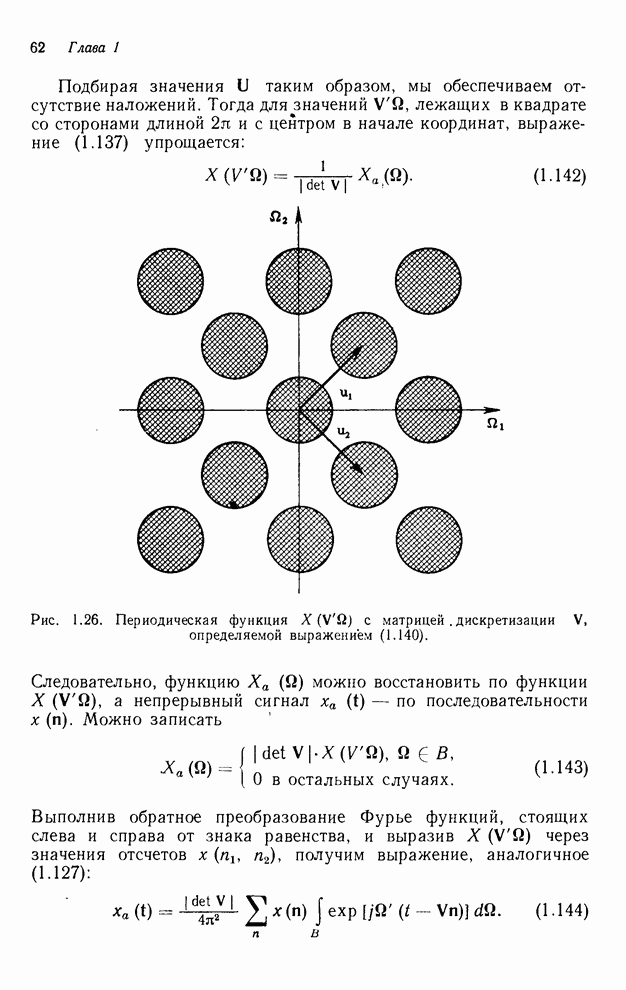
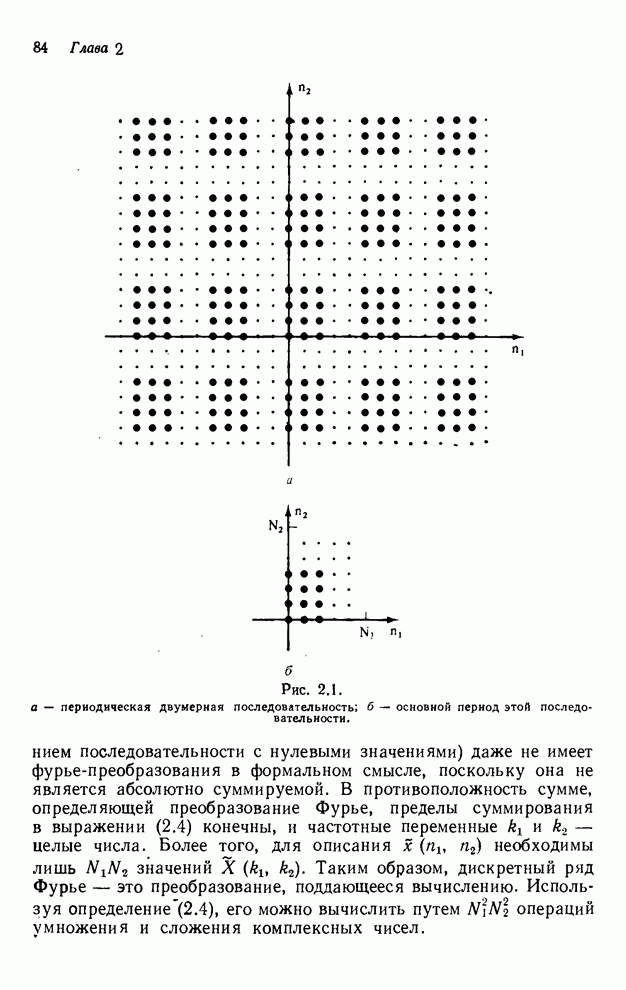
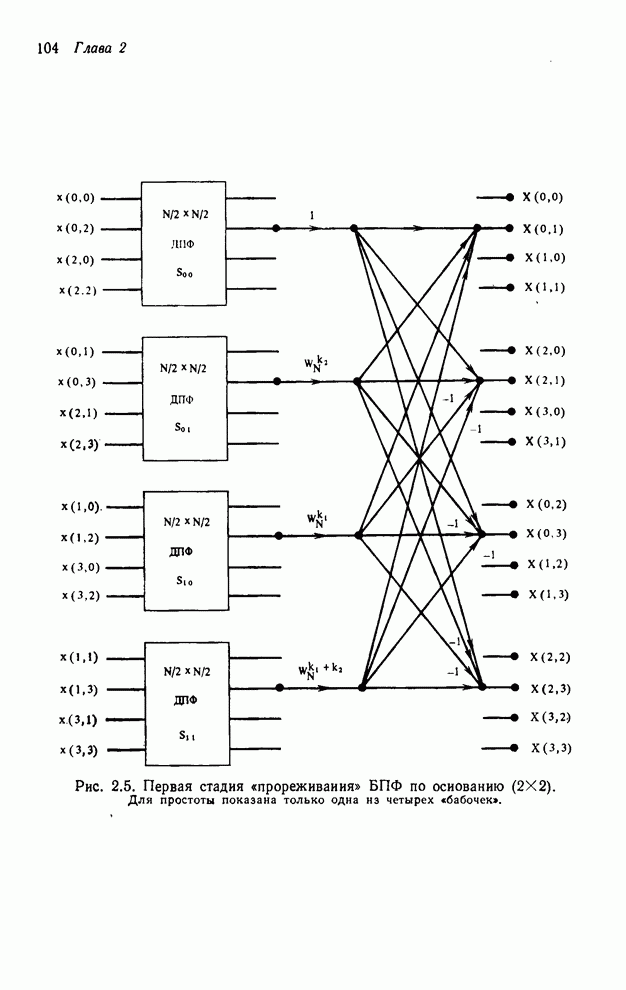
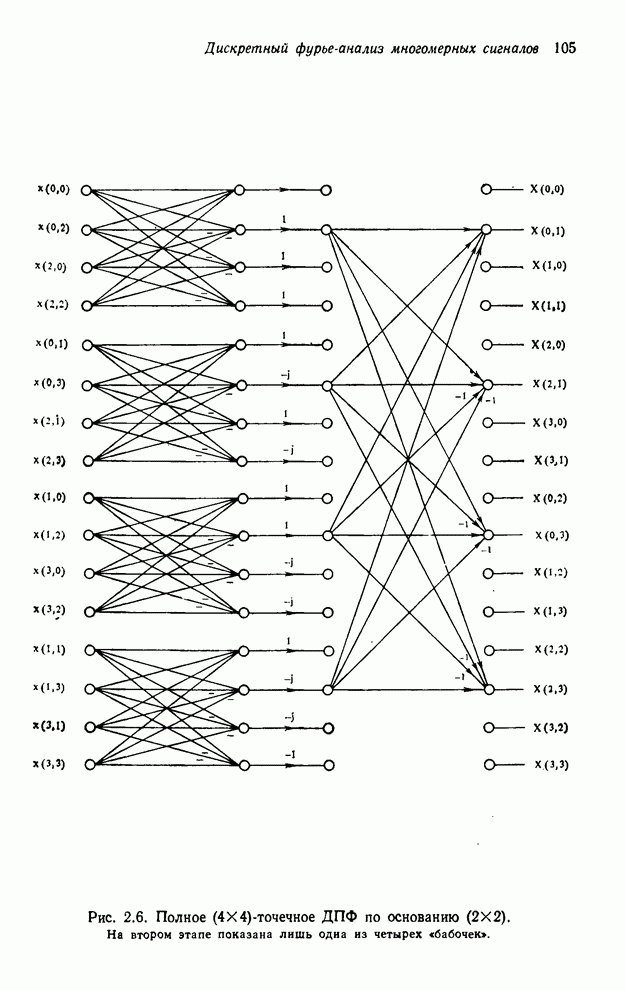
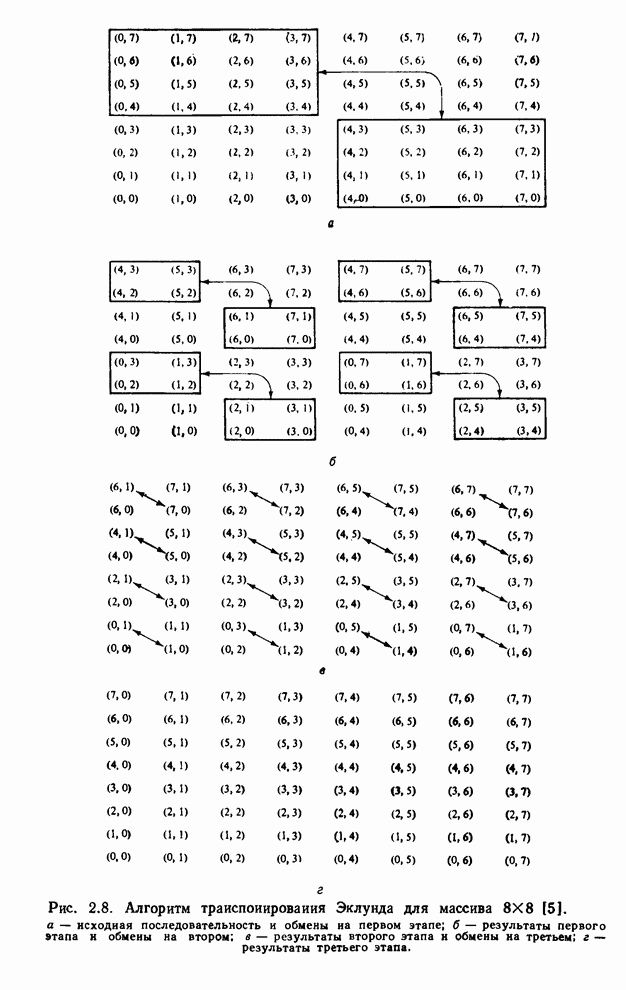
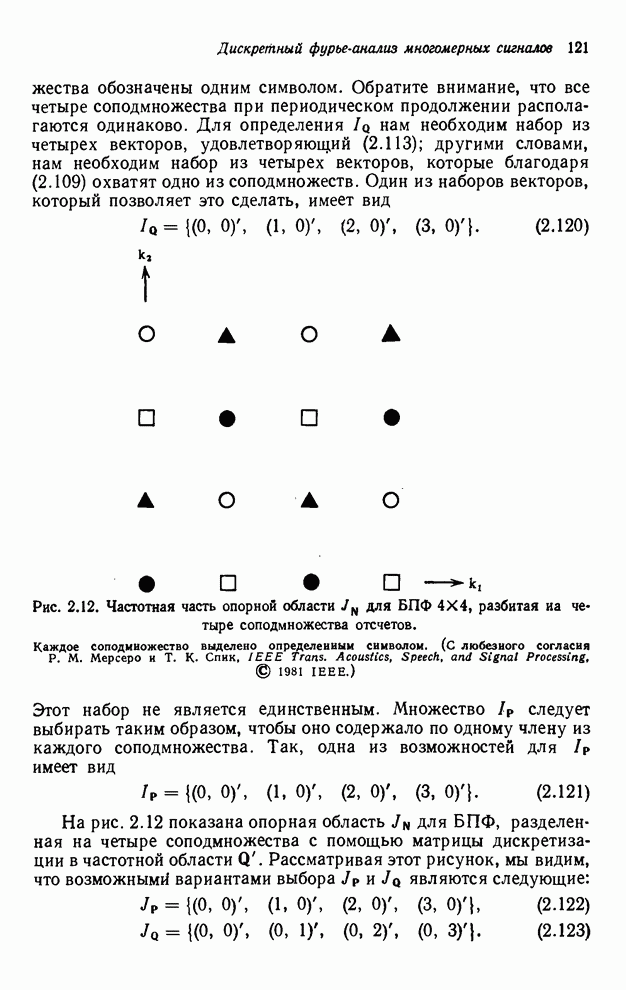
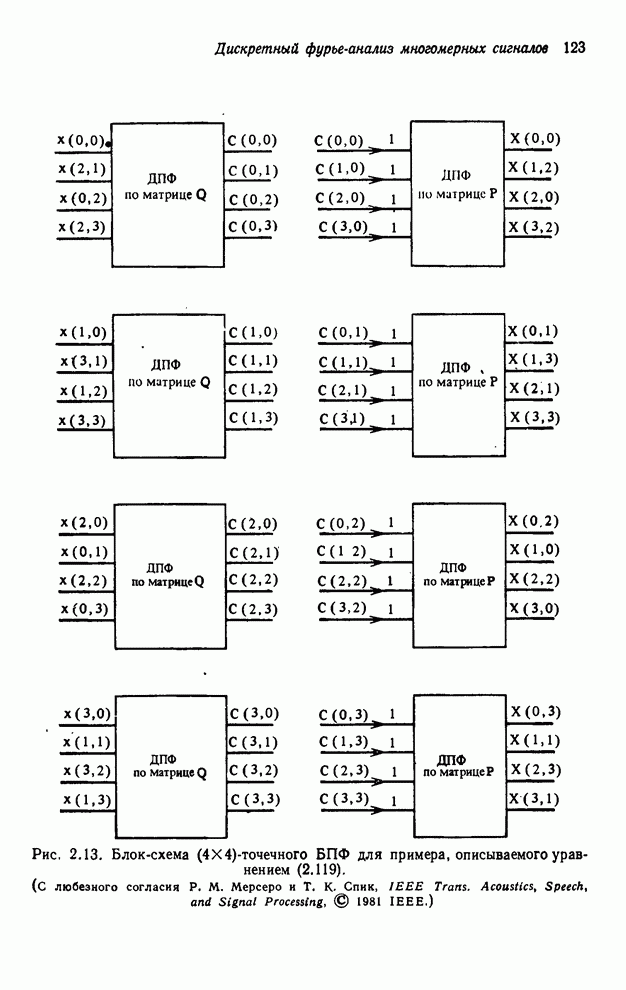
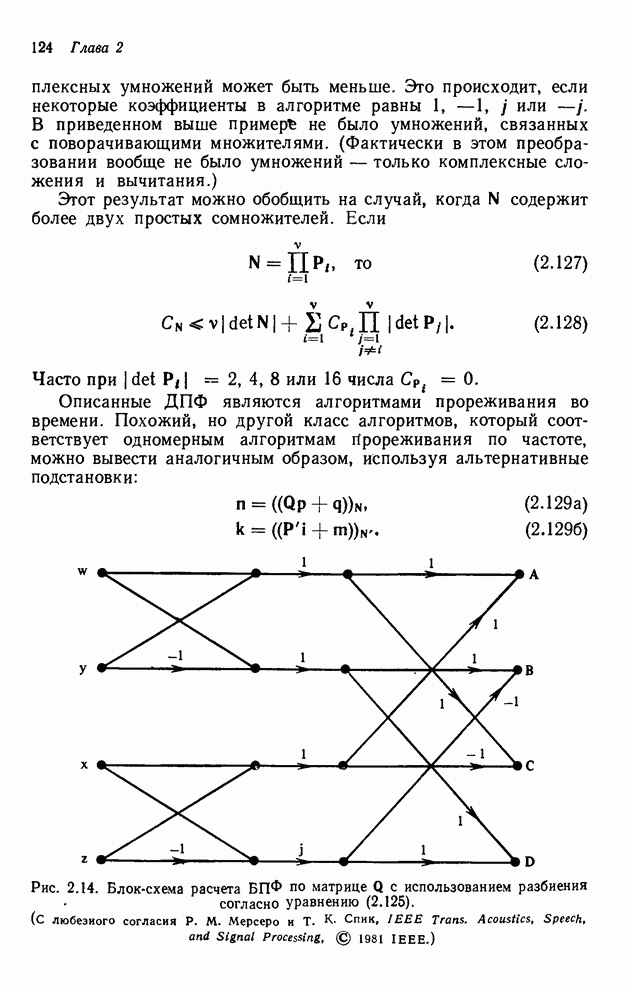
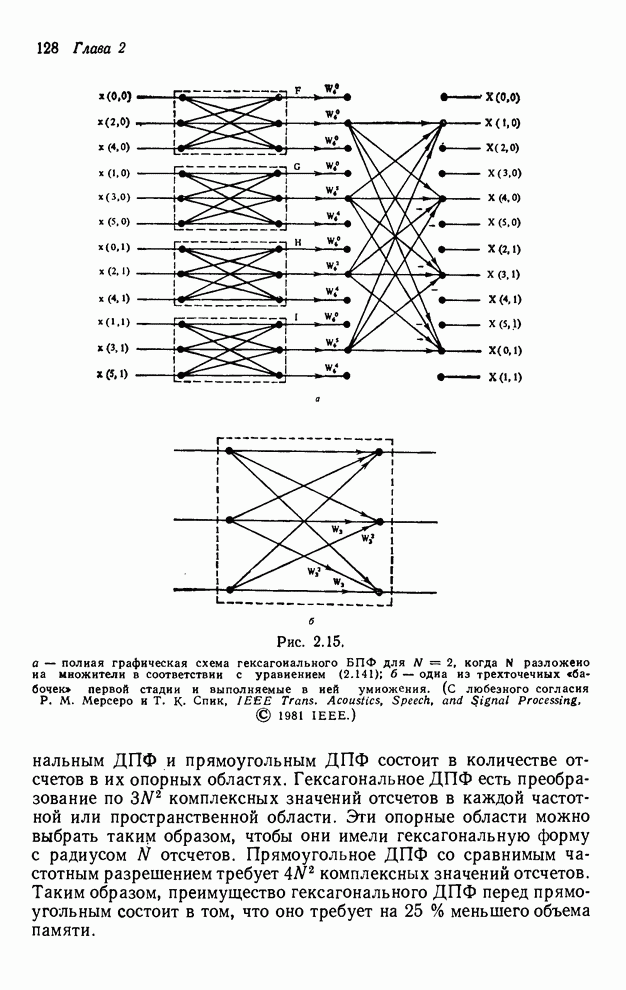
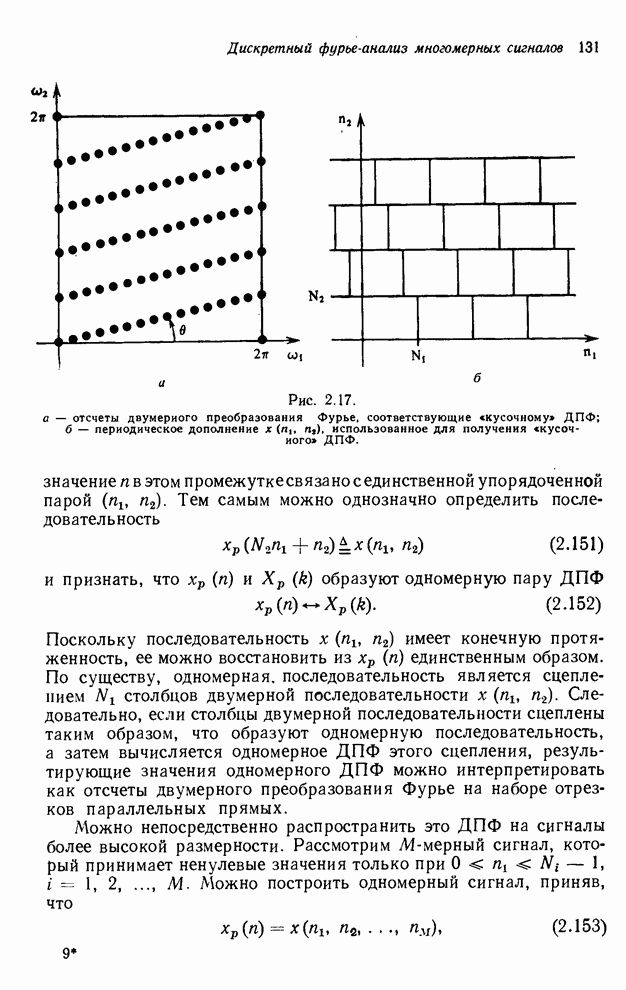
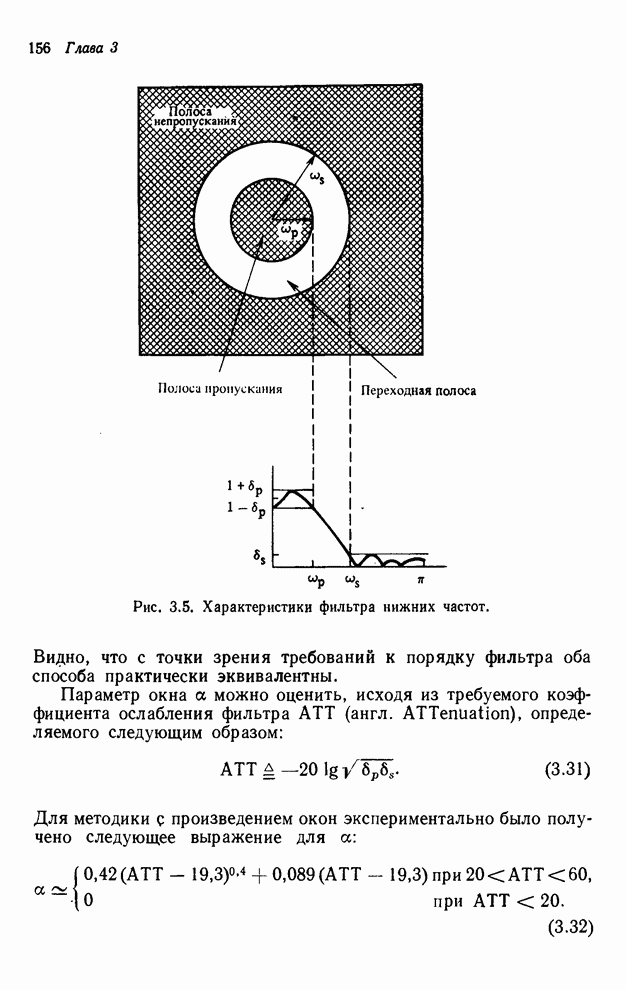
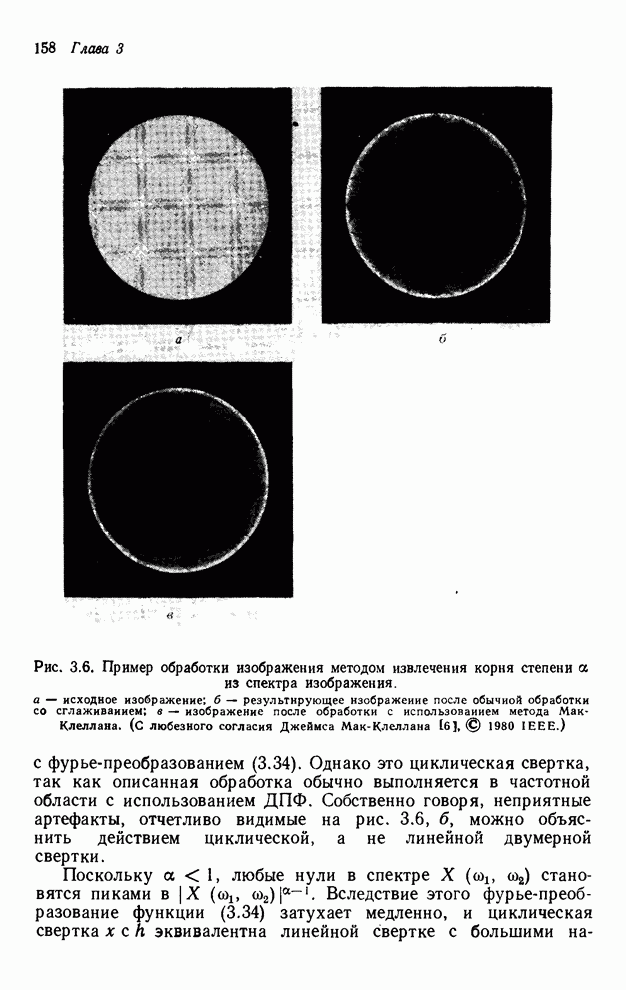
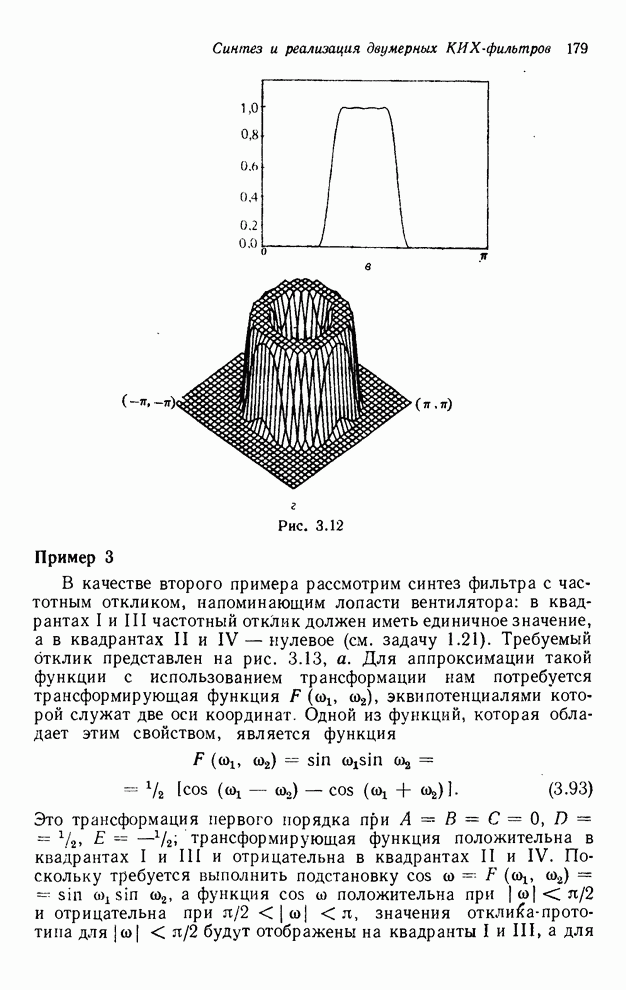
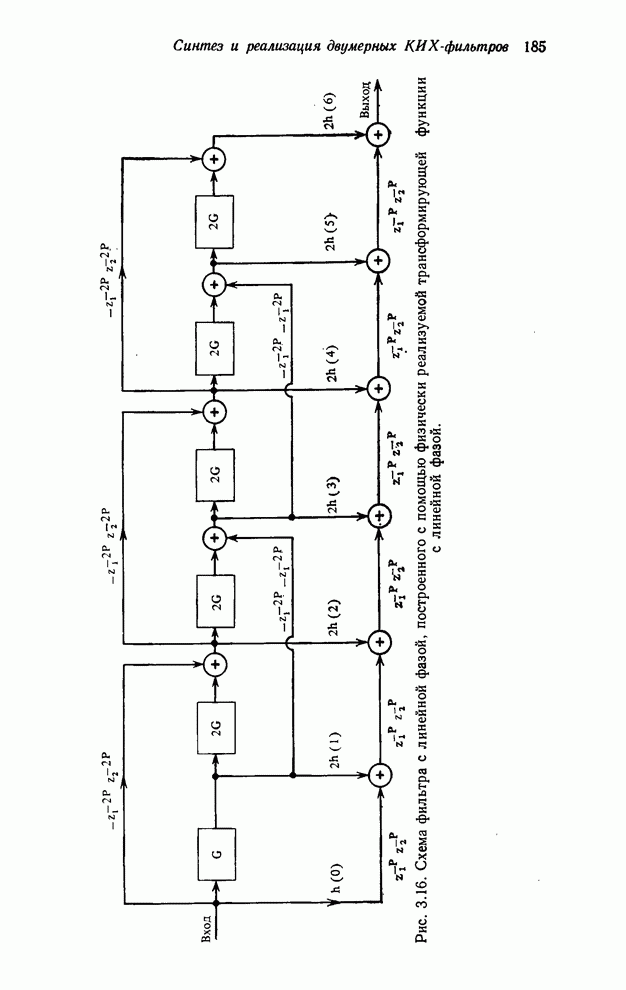
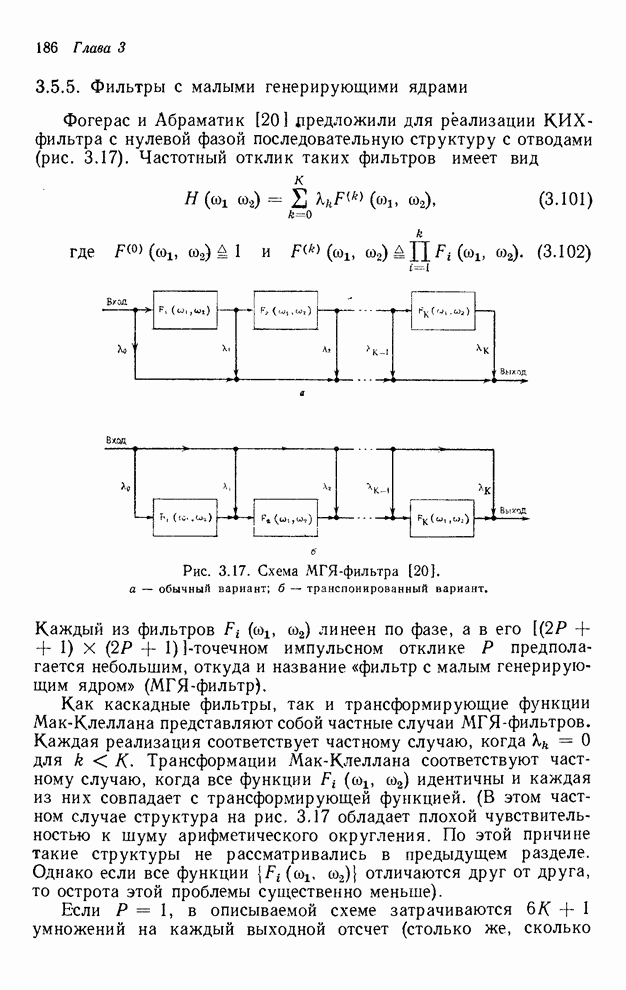
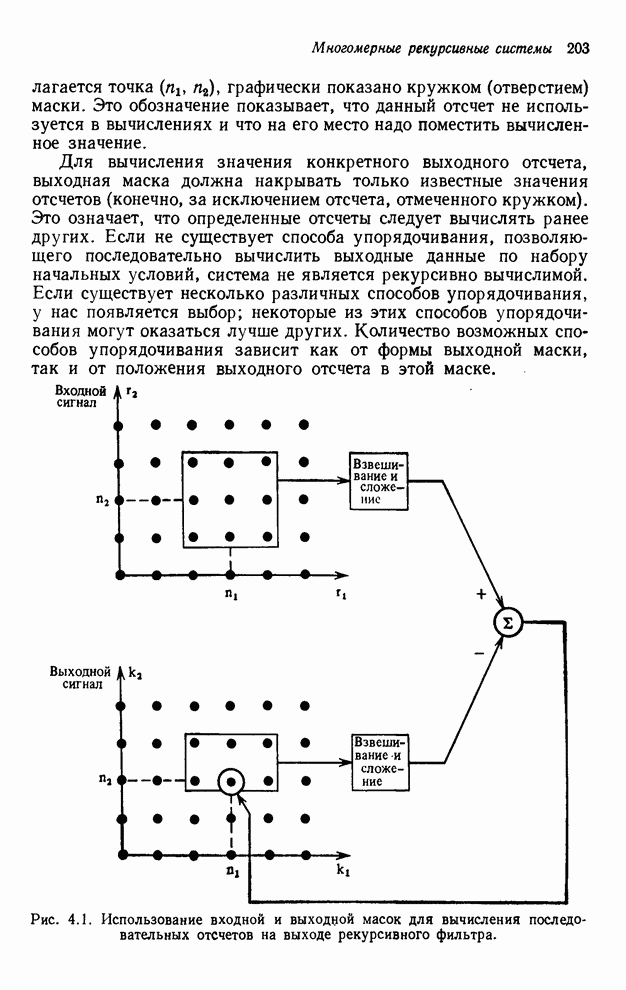
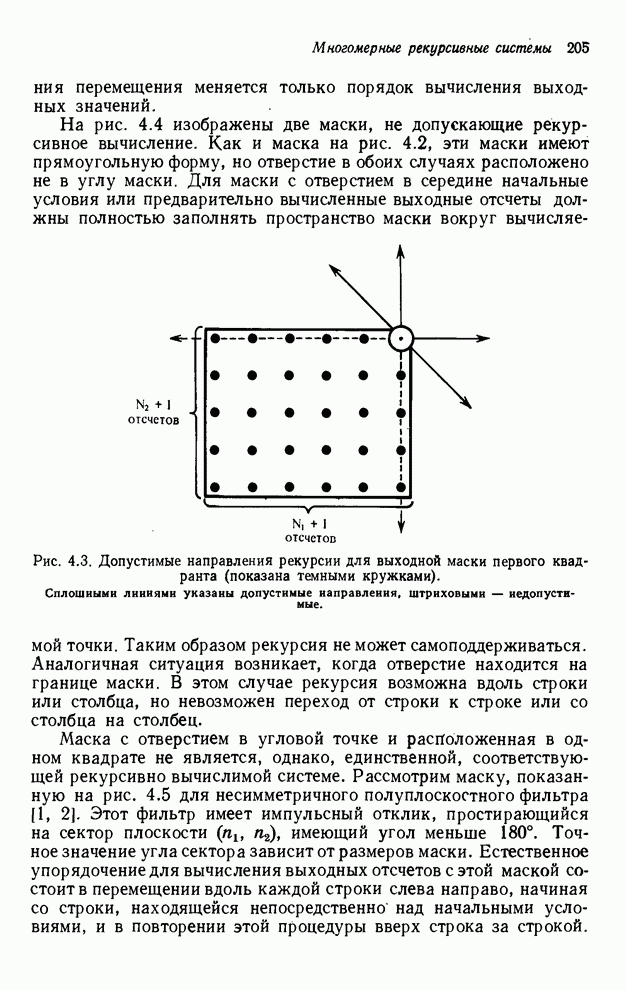
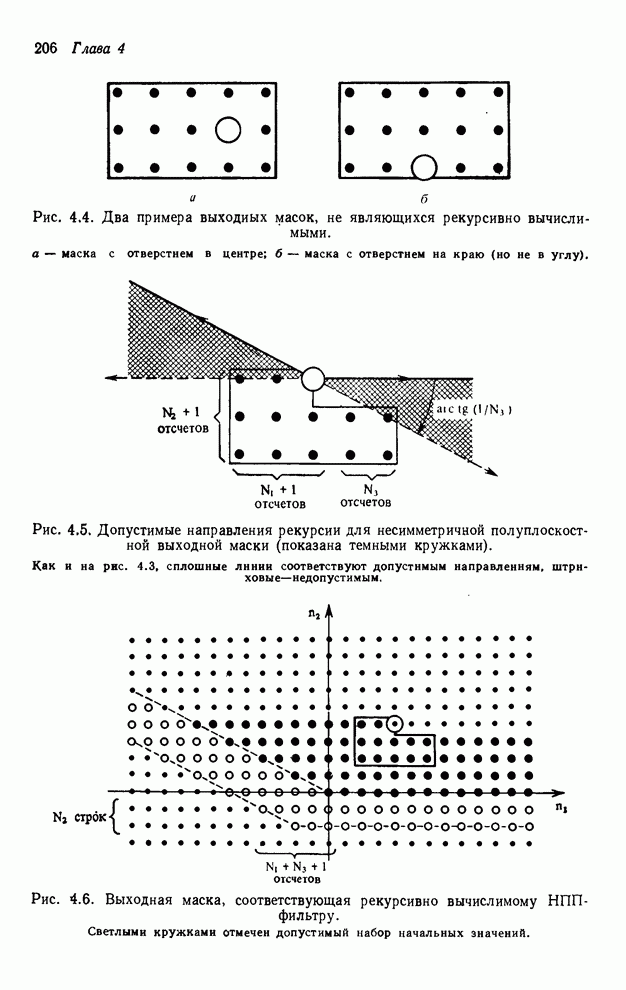
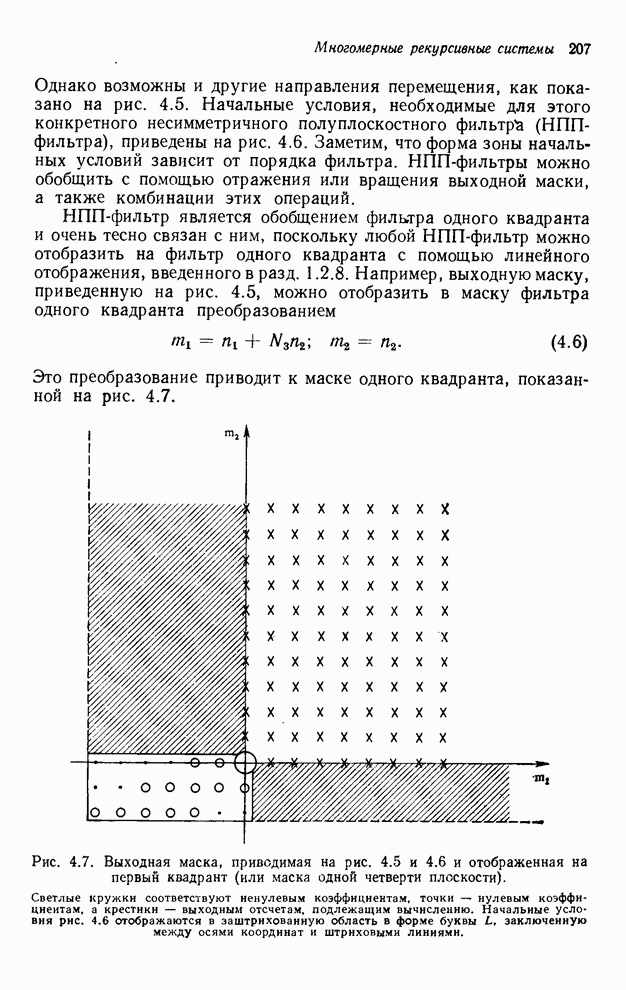
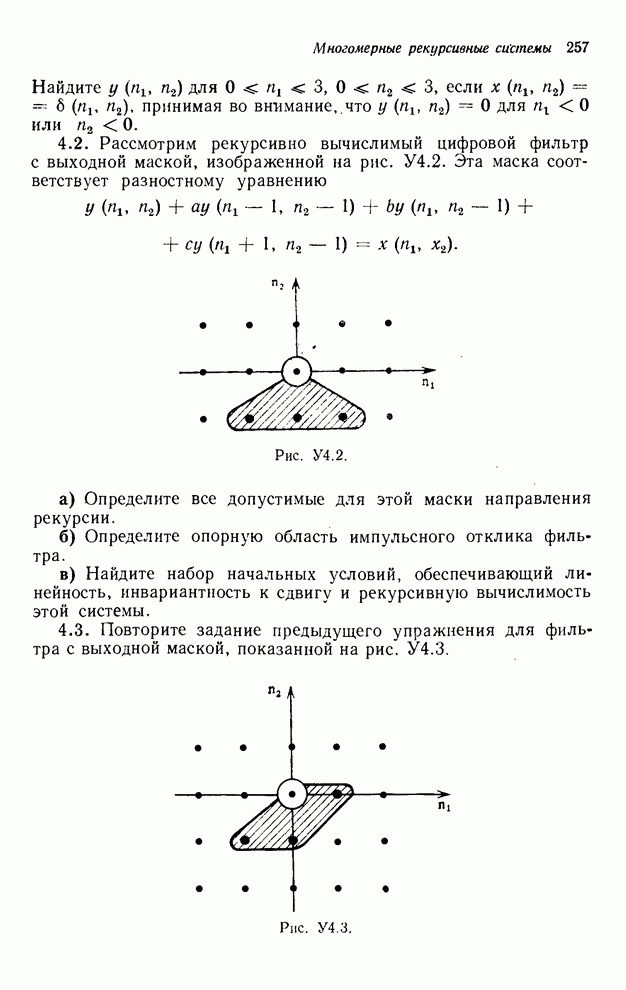
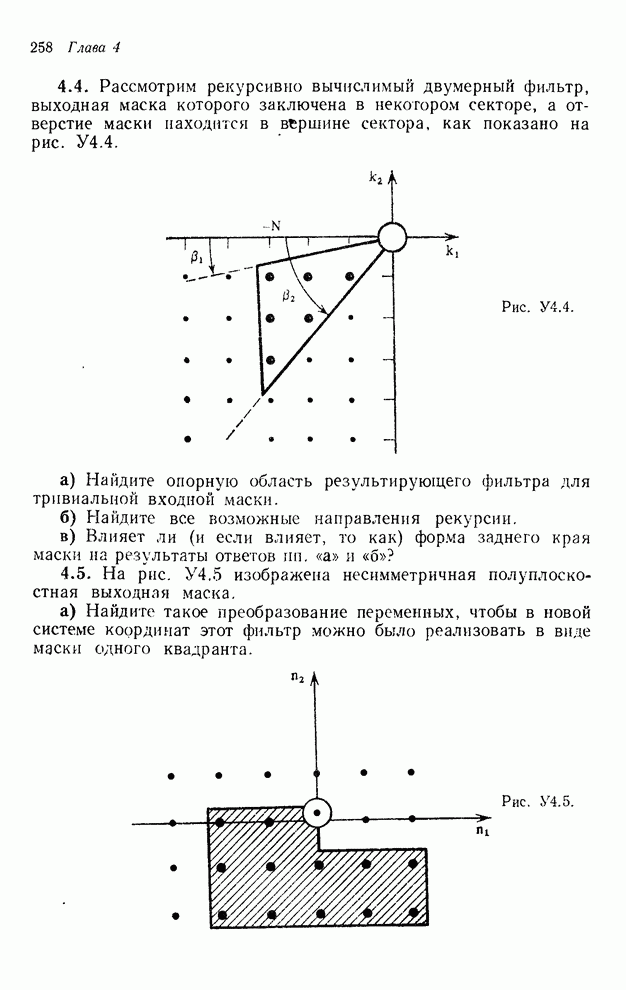
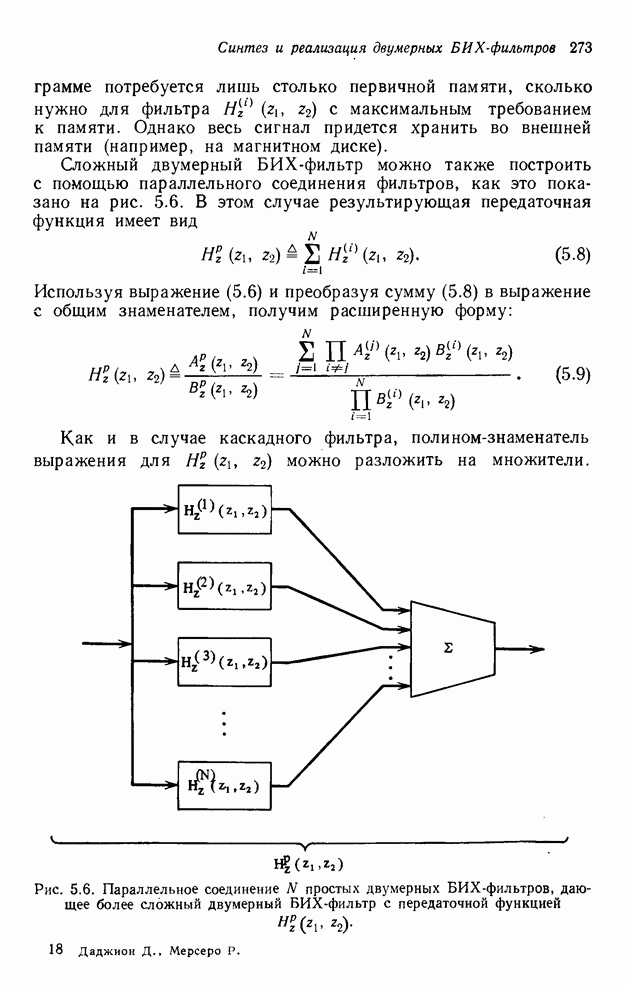
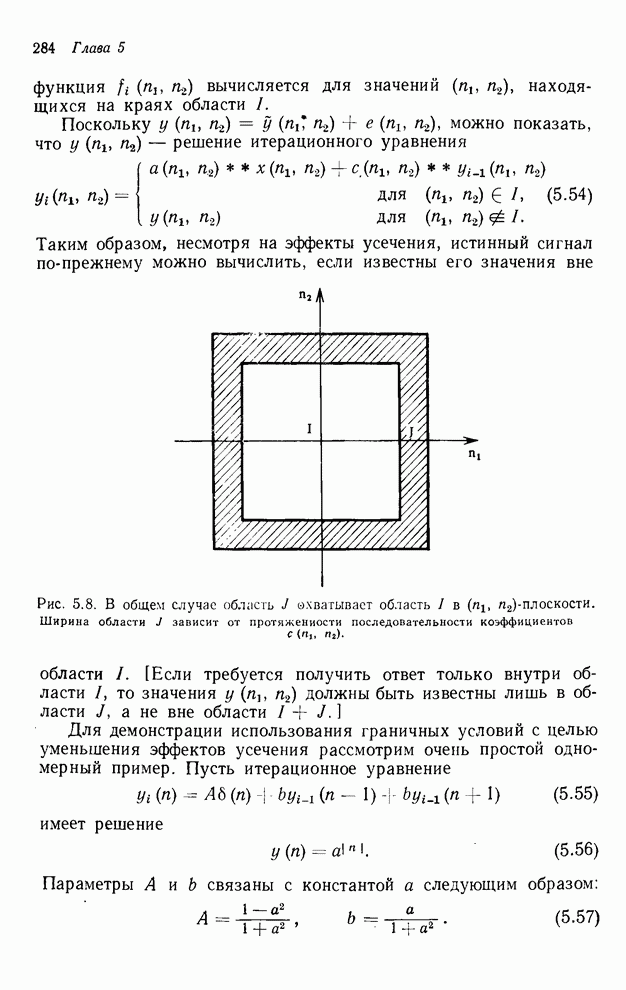
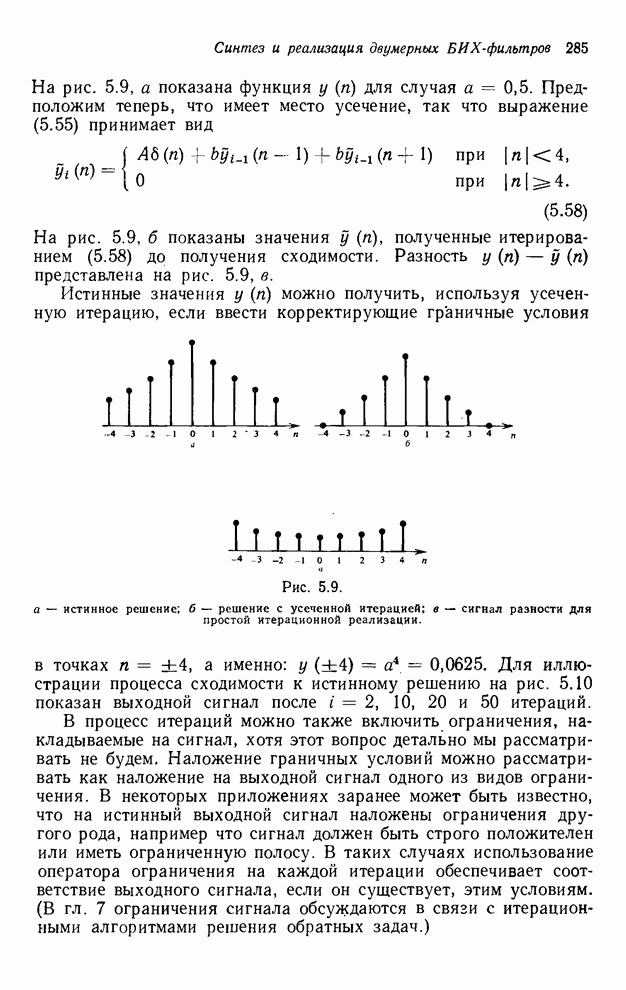
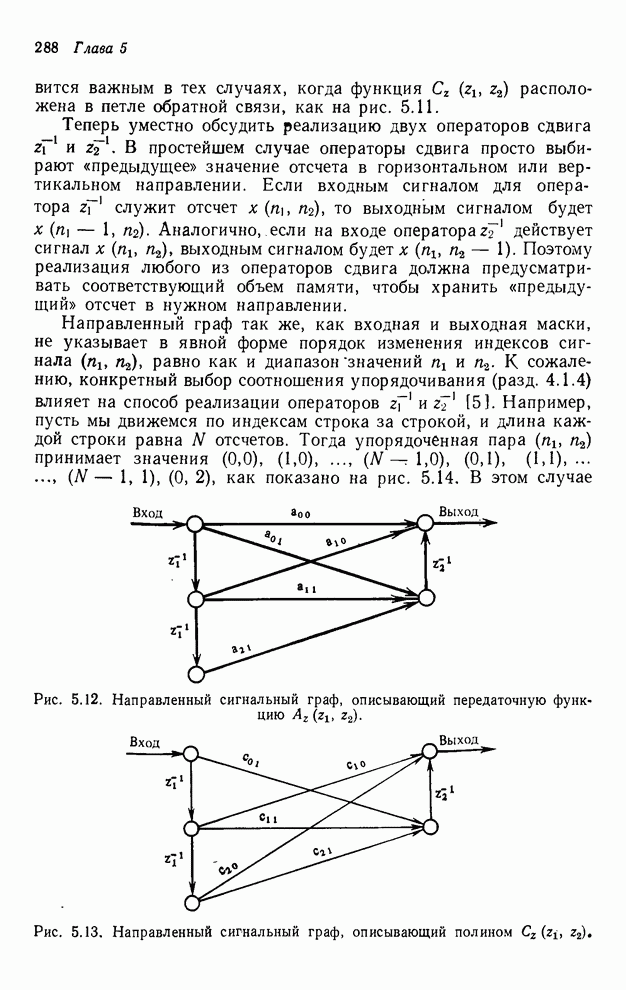
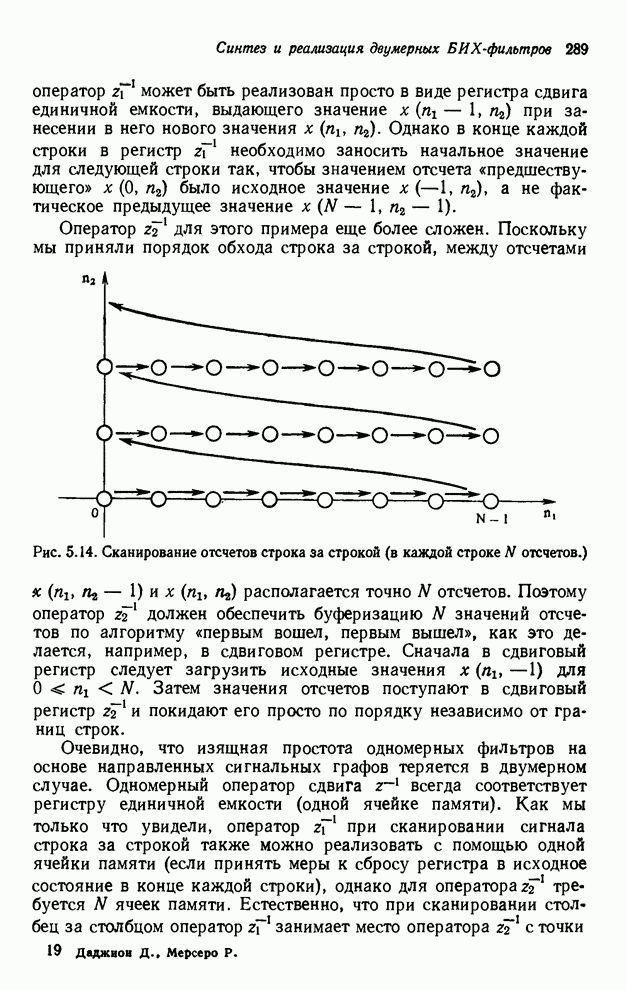
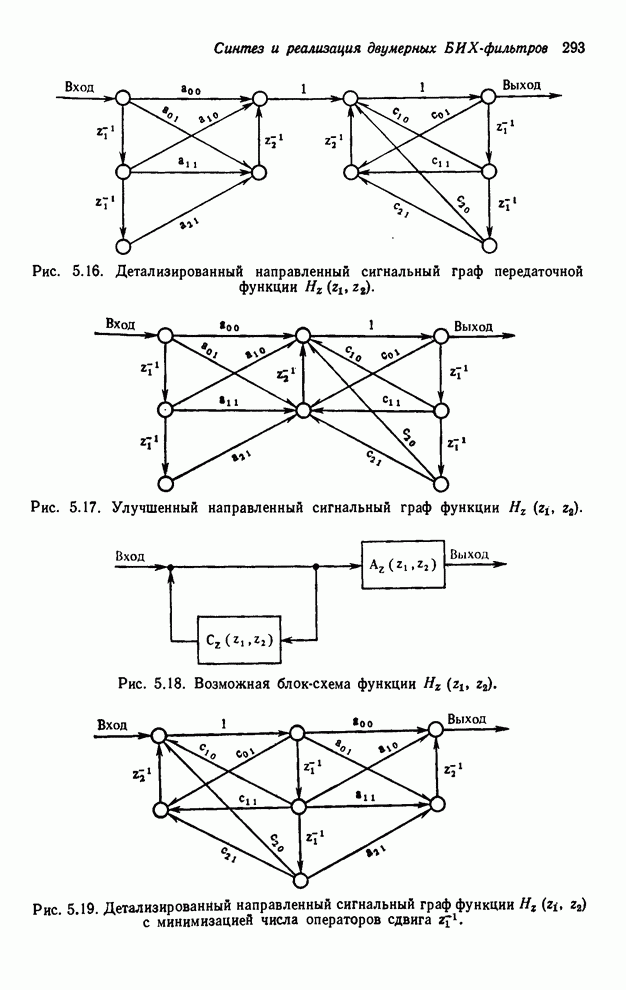
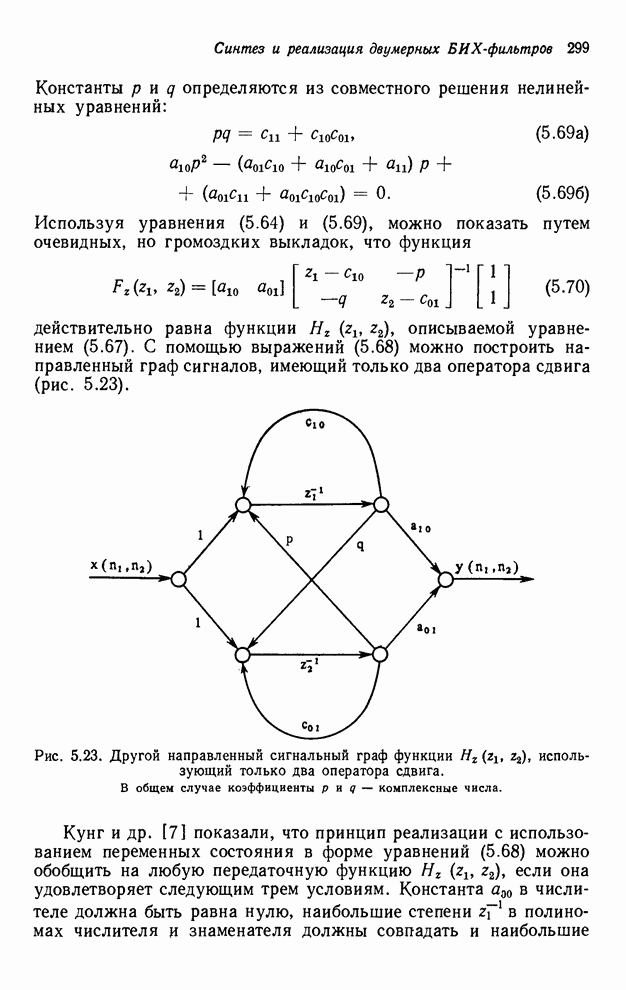
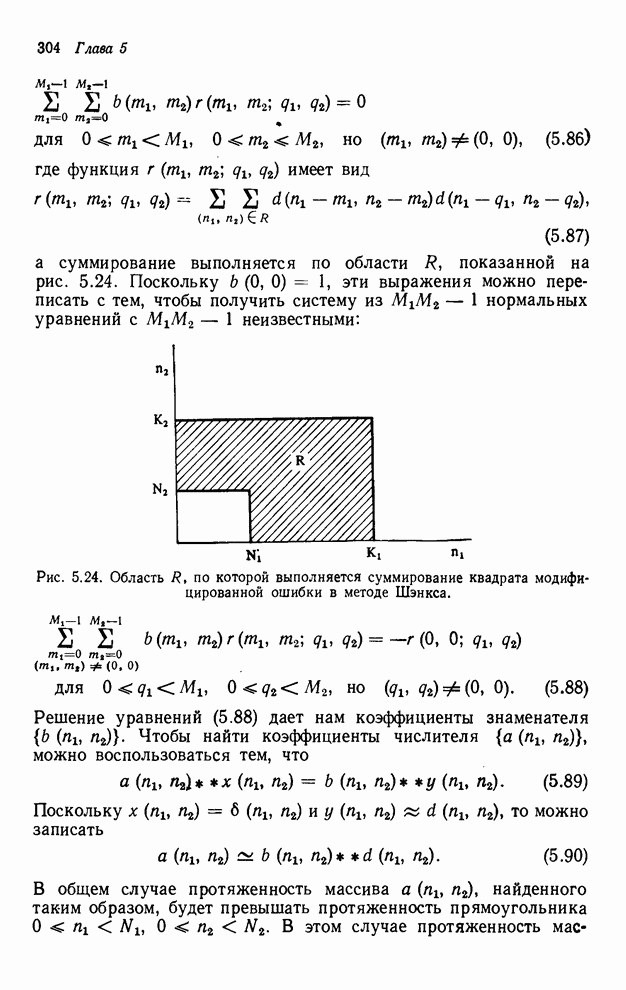
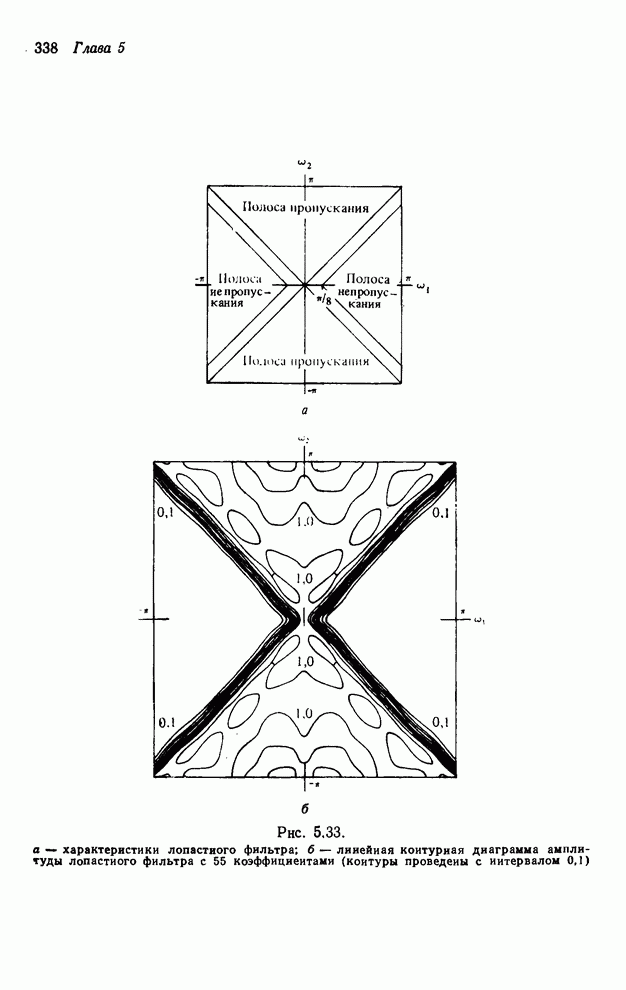
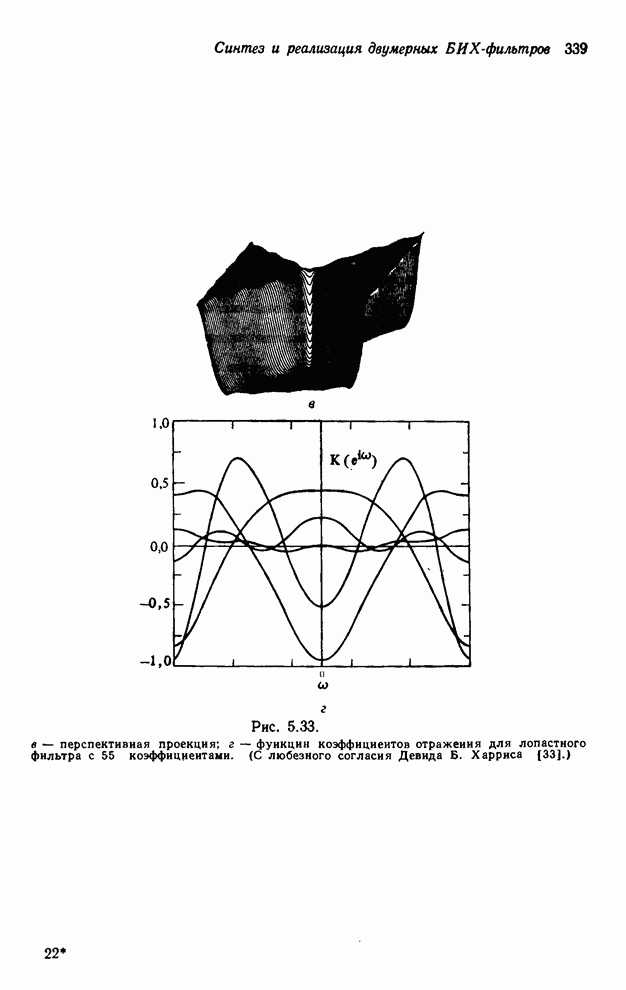
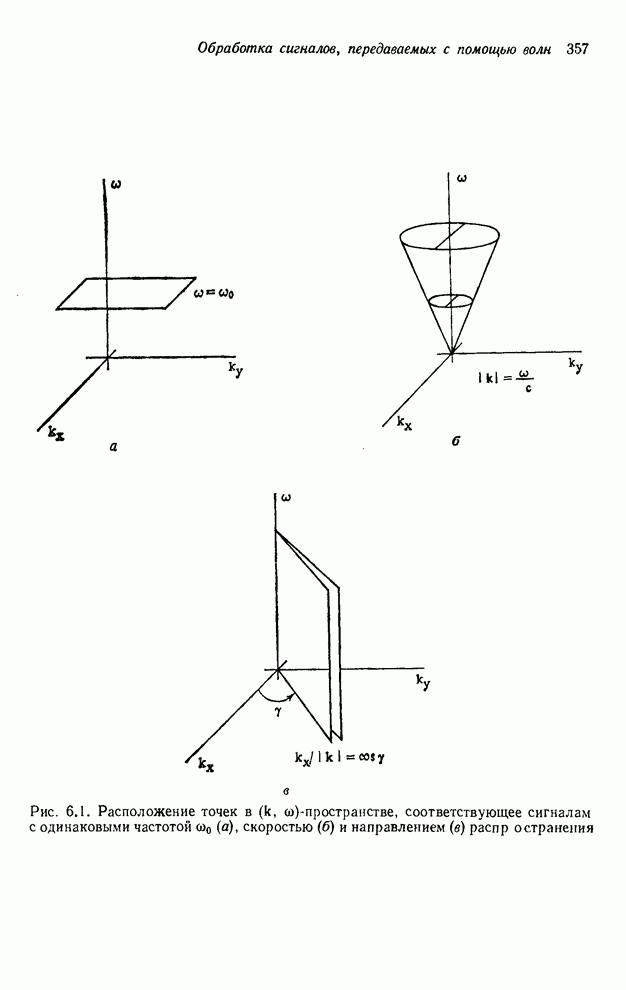
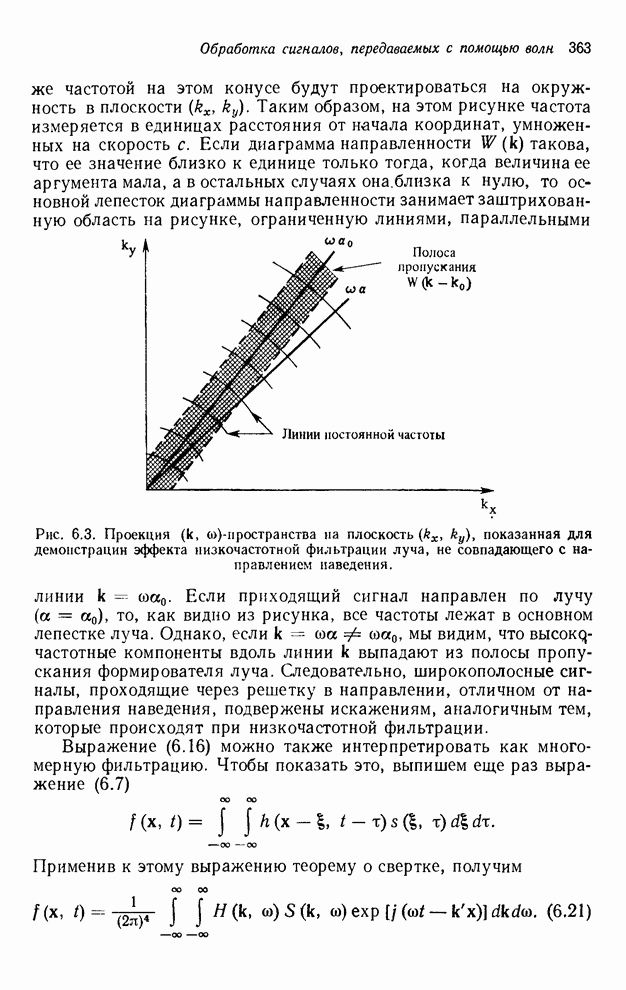
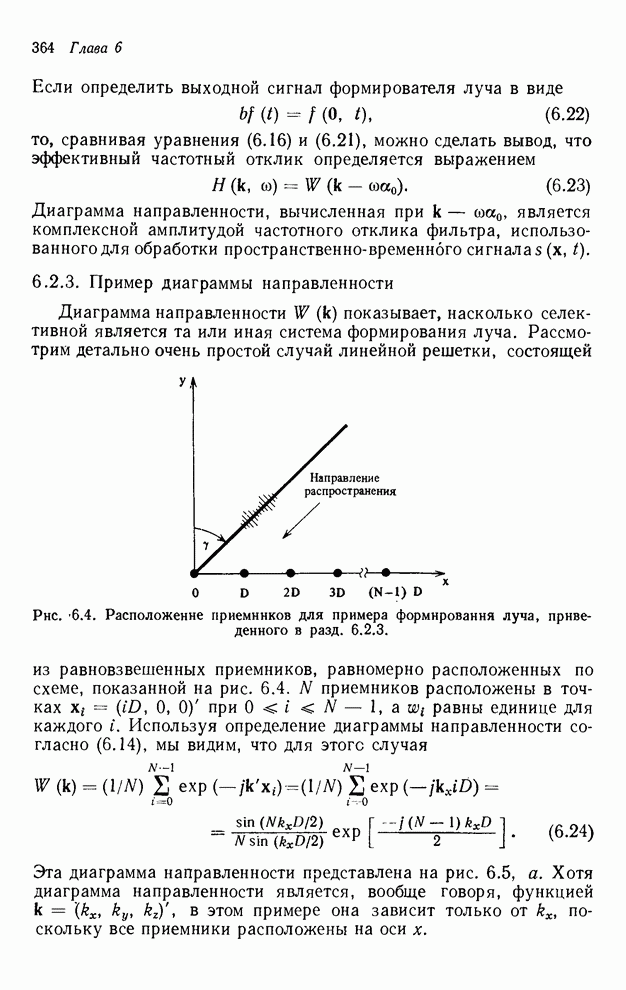
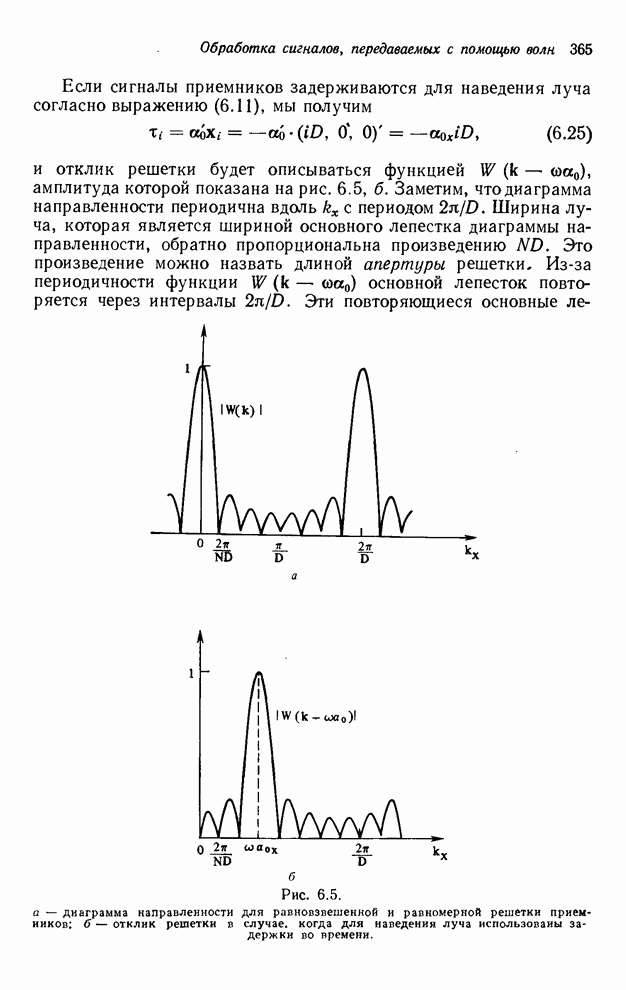
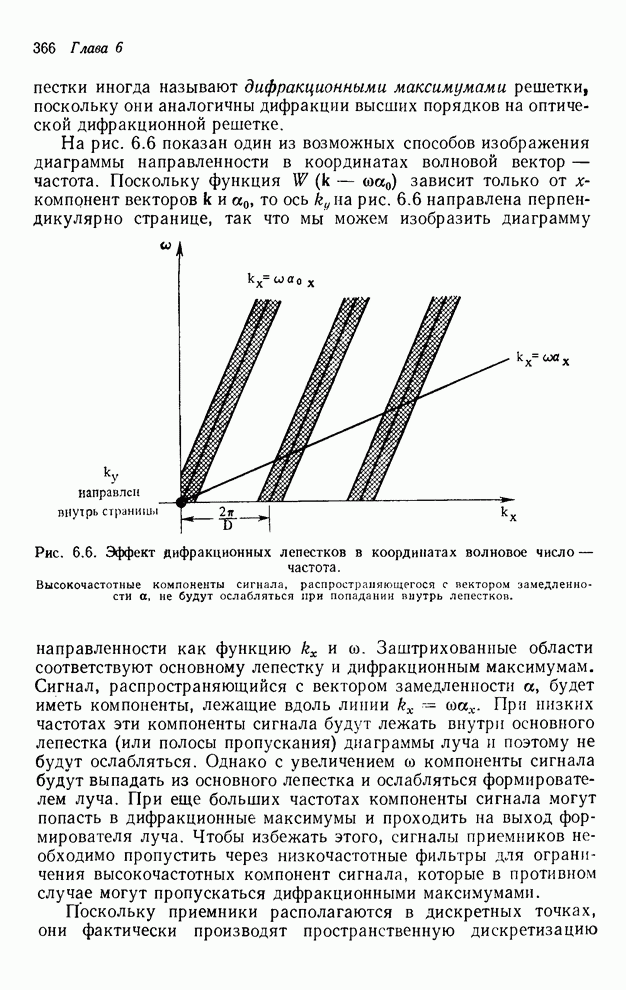
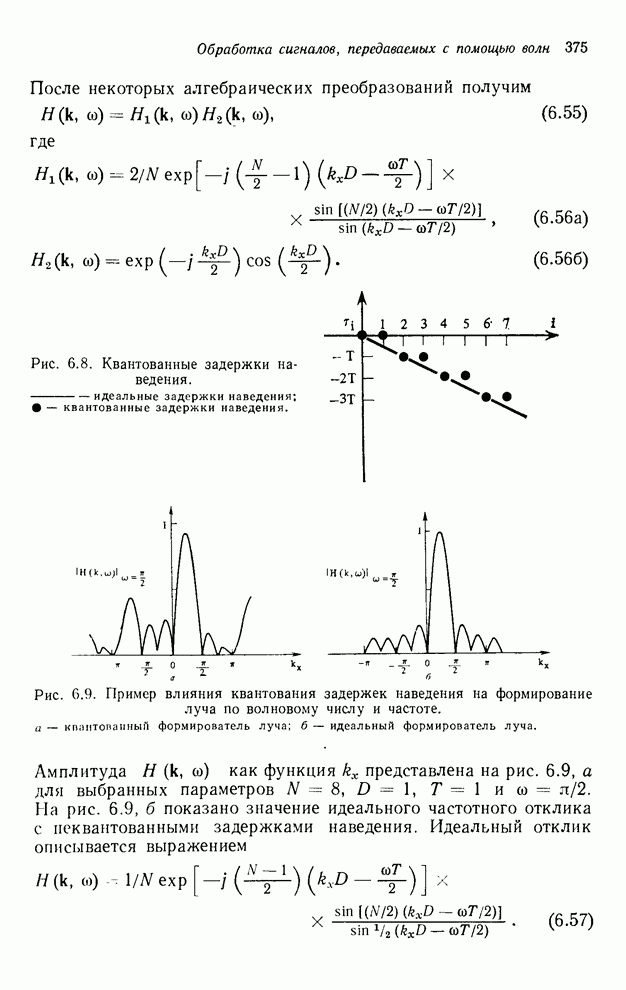
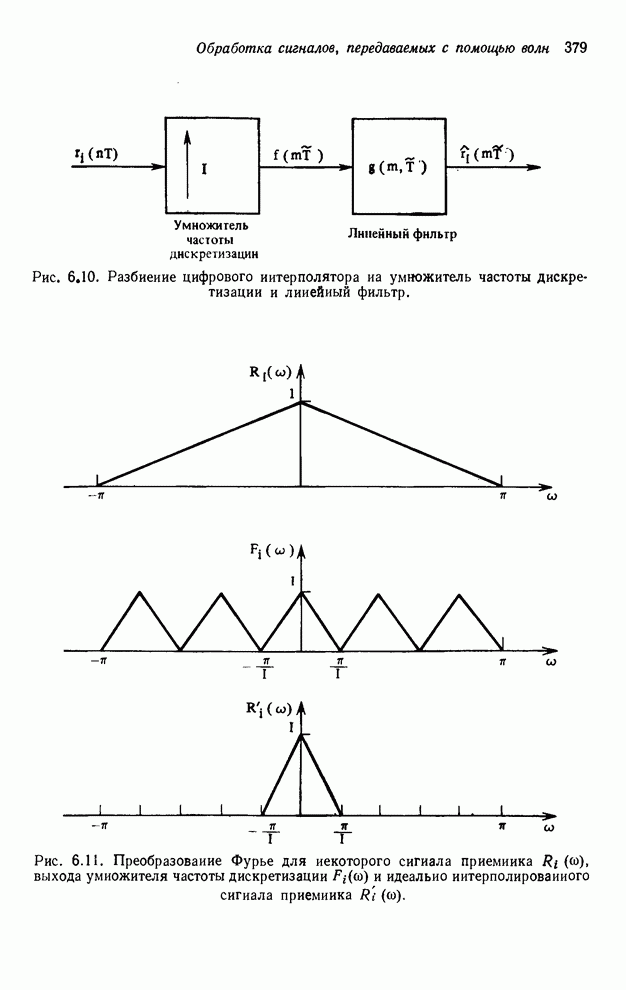
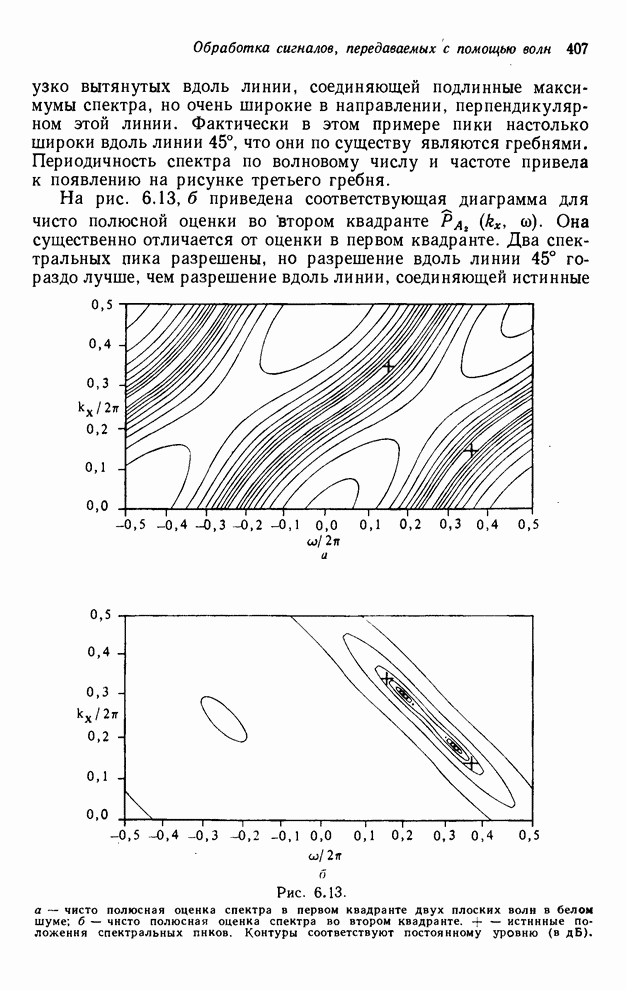
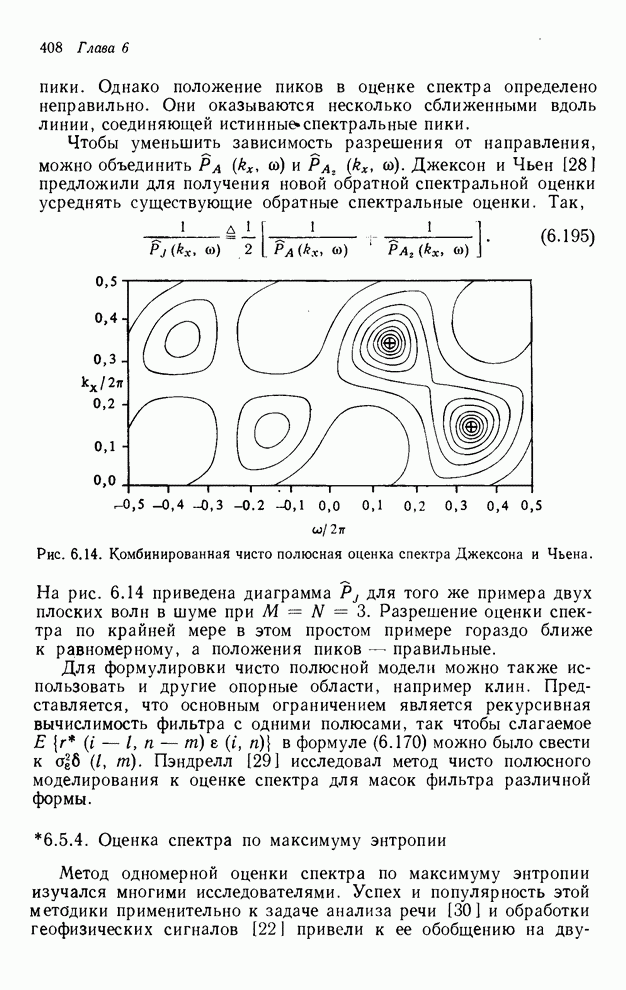
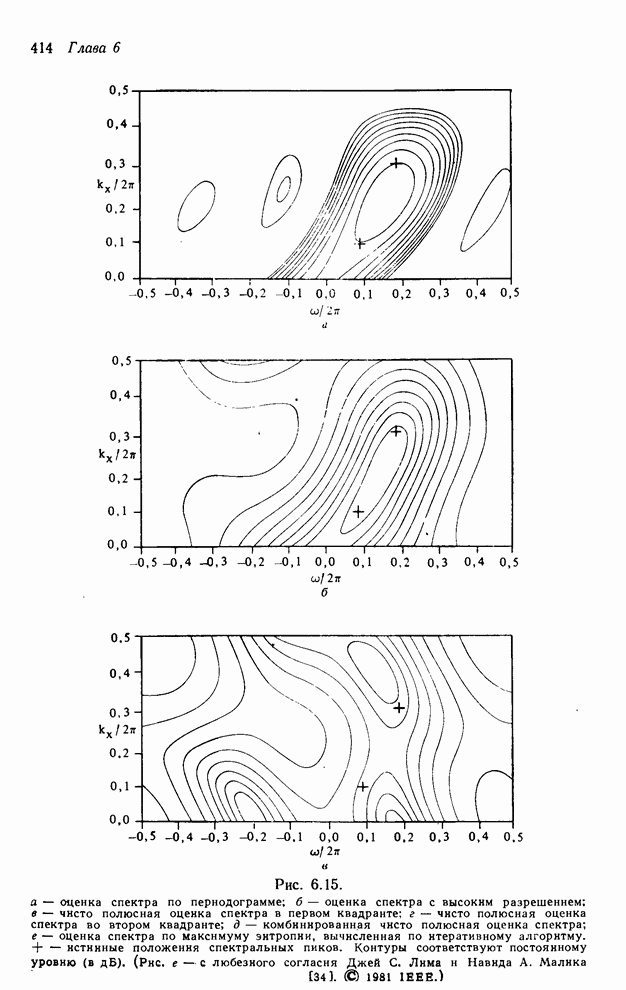
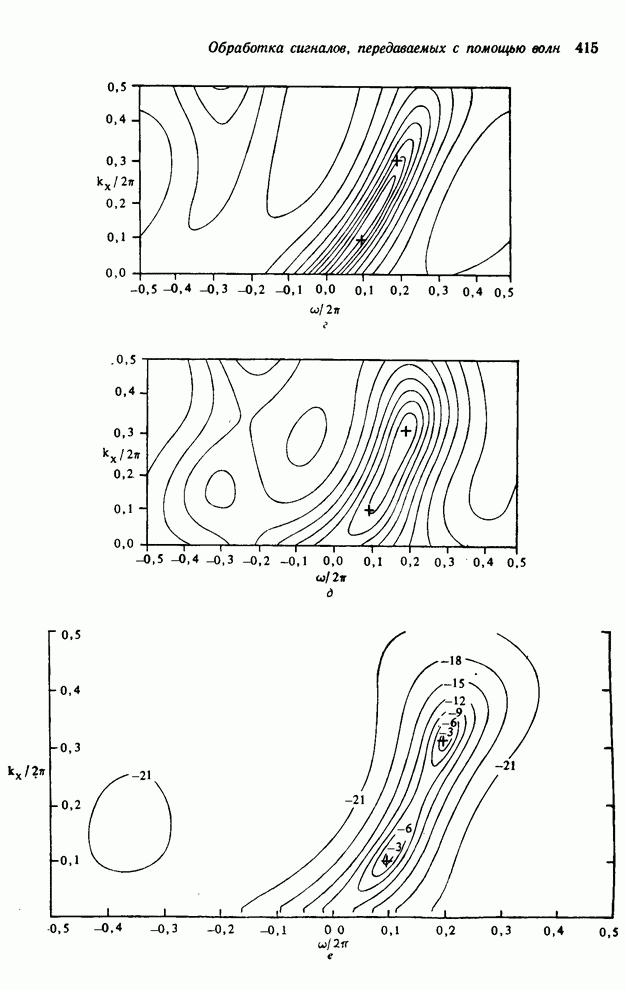
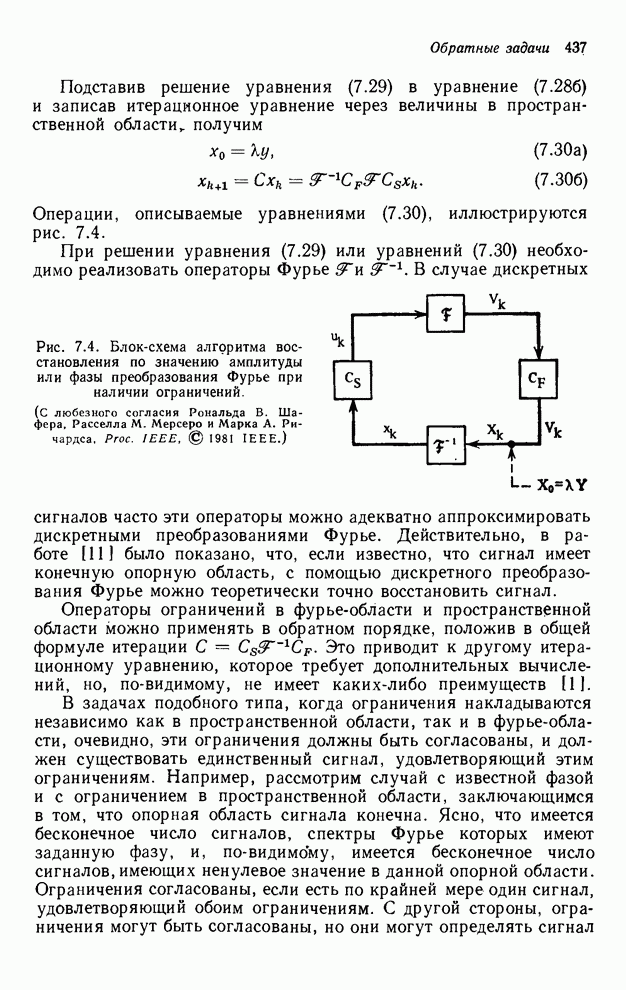
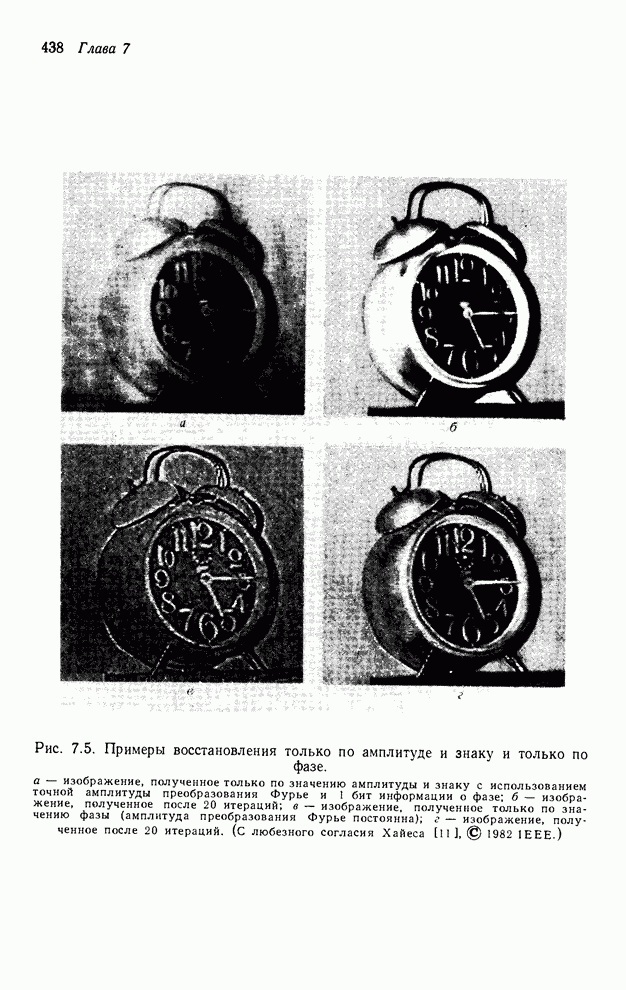
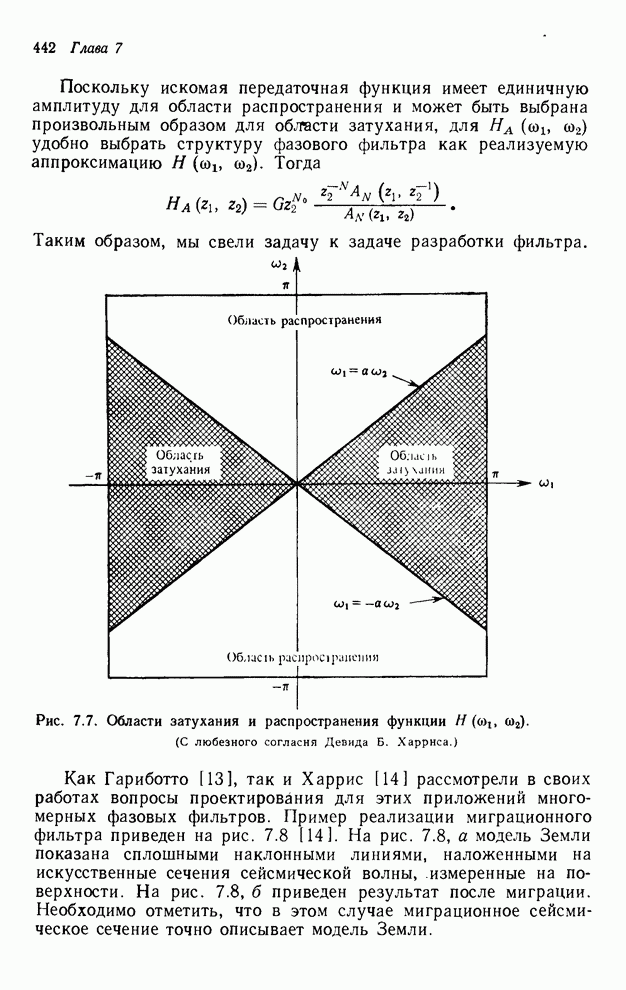
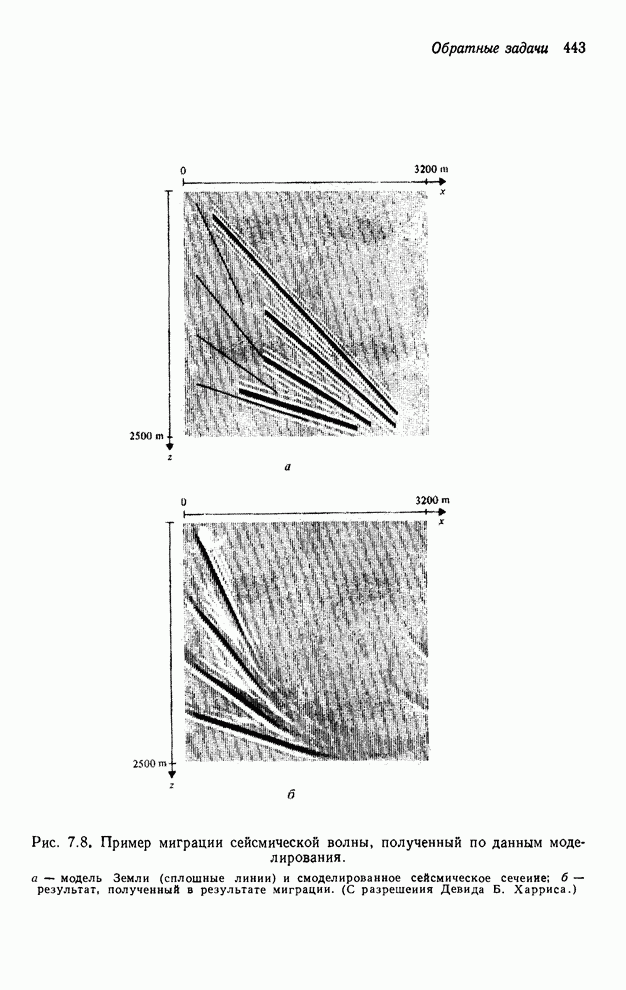
4.1.4. Упорядочивание вычислений выходных отсчетов
В предыдущих разделах мы видели,
что существенная разница между одномерными и  -мерными разностными уравнениями состоит
в том порядке, в котором могут быть вычислены выходные отсчеты. Для одномерной
системы с заданной выходной маской имеется самое большее один способ
упорядочивания, с помощью которого можно определить выходные отсчеты, и
вычисления, таким образом, являются полностью упорядоченными. Однако в
двумерном случае выходные отсчеты можно найти с помощью любого из нескольких
возможных способов упорядочивания, и вычисления в этом случае являются лишь
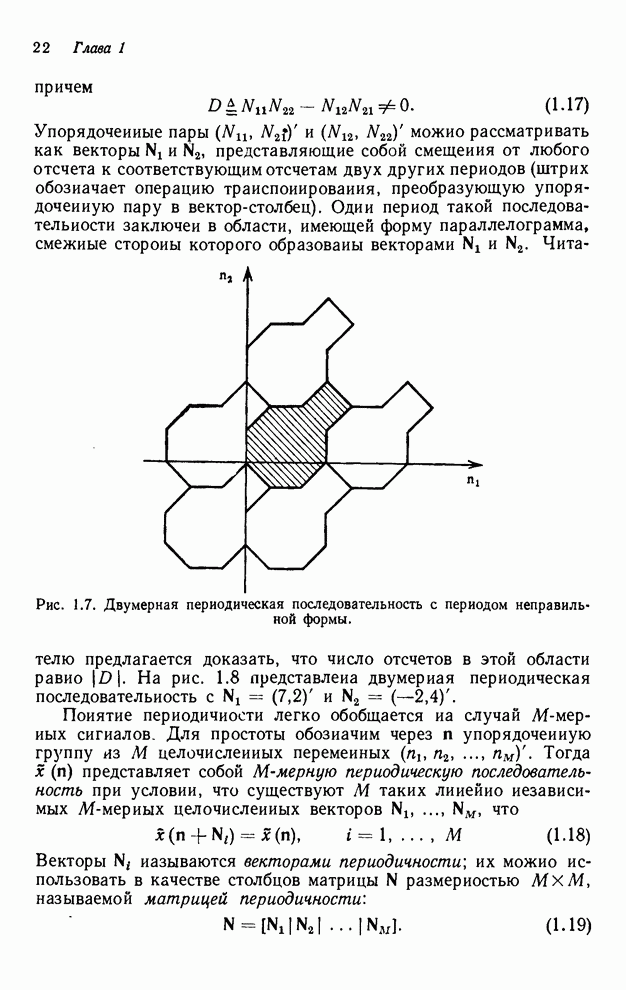
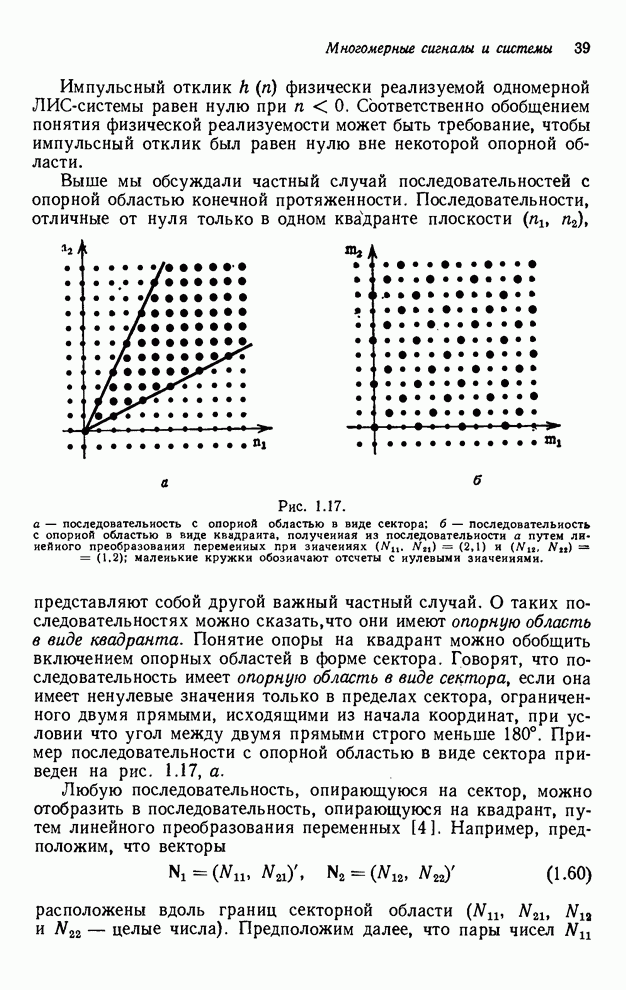
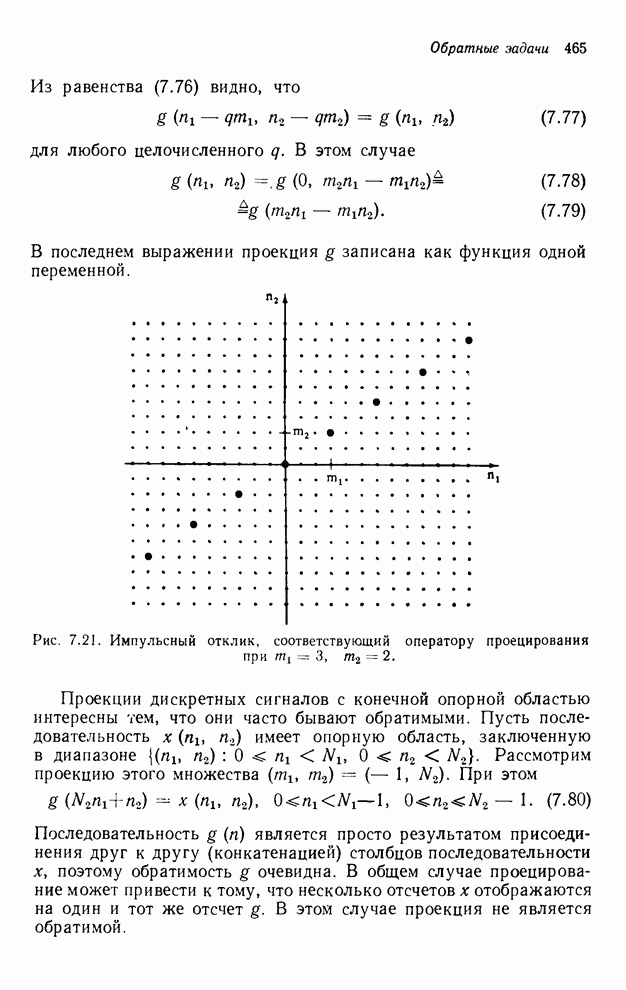
частично упорядоченными. Это частичное упорядочивание может быть представлено с
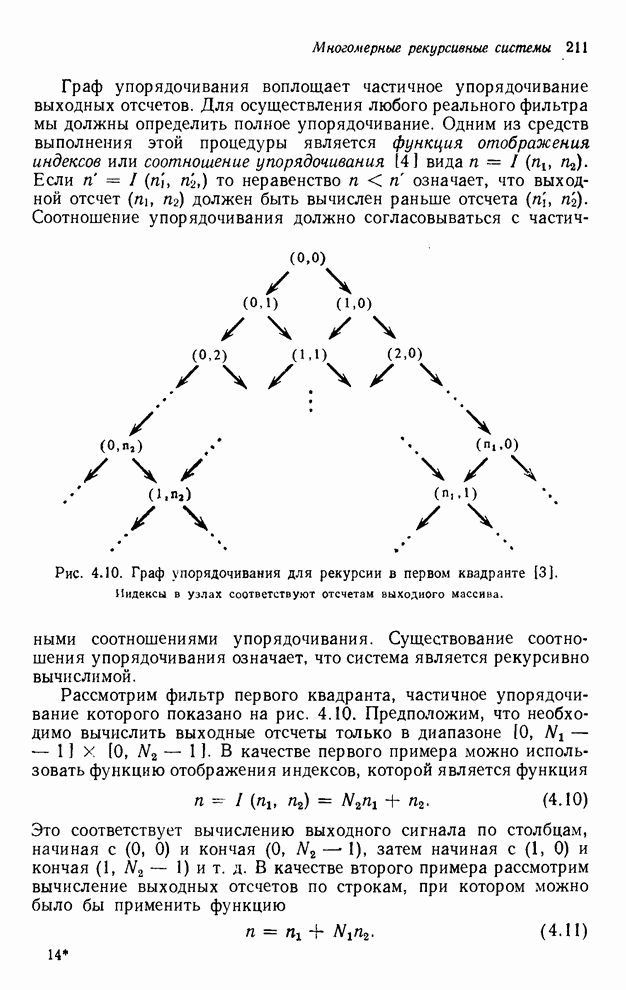
помощью графа упорядочивания [3], например, показанного на рис. 4.10 для нашего
первого примера с фильтром первого квадранта. Каждый выходной отсчет,
подлежащий определению, соответствует вершине графа. Каждый отсчет можно
вычислить в том случае, если уже вычислены два отсчета, лежащие над ним. Так,
для фильтра первого квадранта первым должен быть вычислен отсчет
-мерными разностными уравнениями состоит
в том порядке, в котором могут быть вычислены выходные отсчеты. Для одномерной
системы с заданной выходной маской имеется самое большее один способ
упорядочивания, с помощью которого можно определить выходные отсчеты, и
вычисления, таким образом, являются полностью упорядоченными. Однако в
двумерном случае выходные отсчеты можно найти с помощью любого из нескольких
возможных способов упорядочивания, и вычисления в этом случае являются лишь
частично упорядоченными. Это частичное упорядочивание может быть представлено с
помощью графа упорядочивания [3], например, показанного на рис. 4.10 для нашего
первого примера с фильтром первого квадранта. Каждый выходной отсчет,
подлежащий определению, соответствует вершине графа. Каждый отсчет можно
вычислить в том случае, если уже вычислены два отсчета, лежащие над ним. Так,
для фильтра первого квадранта первым должен быть вычислен отсчет  . Если его значение
известно, можно вычислить отсчет
. Если его значение
известно, можно вычислить отсчет  , или
, или  , или, если позволяет аппаратура, оба
отсчета одновременно. То же утверждение справедливо и для других уровней графа.
, или, если позволяет аппаратура, оба
отсчета одновременно. То же утверждение справедливо и для других уровней графа.

Рис. 4.10. Граф упорядочивания
для рекурсии в первом квадранте [3]. Индексы в узлах соответствуют отсчетам
выходного массива.
Граф упорядочивания воплощает
частичное упорядочивание выходных отсчетов. Для осуществления любого реального
фильтра мы должны определить полное упорядочивание. Одним из средств выполнения
этой процедуры является функция отображения индексов или соотношение
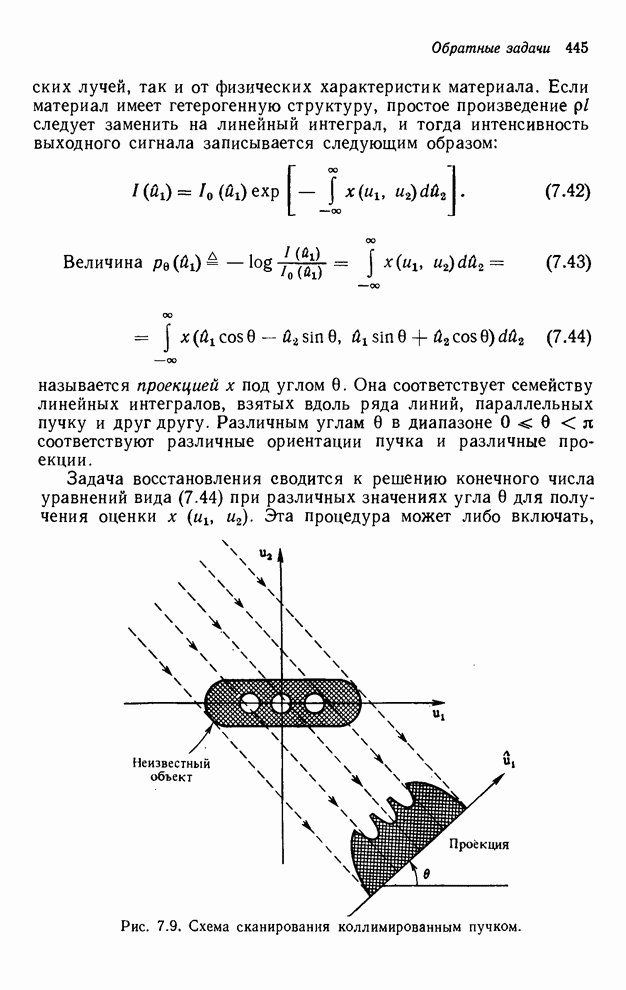
упорядочивания [4] вида  . Если
. Если  , то неравенство
, то неравенство  означает, что выходной отсчет
означает, что выходной отсчет  должен быть вычислен
раньше отсчета
должен быть вычислен
раньше отсчета  .
Соотношение упорядочивания должно согласовываться с частичными соотношениями
упорядочивания. Существование соотношения упорядочивания означает, что система
является рекурсивно вычислимой.
.
Соотношение упорядочивания должно согласовываться с частичными соотношениями
упорядочивания. Существование соотношения упорядочивания означает, что система
является рекурсивно вычислимой.
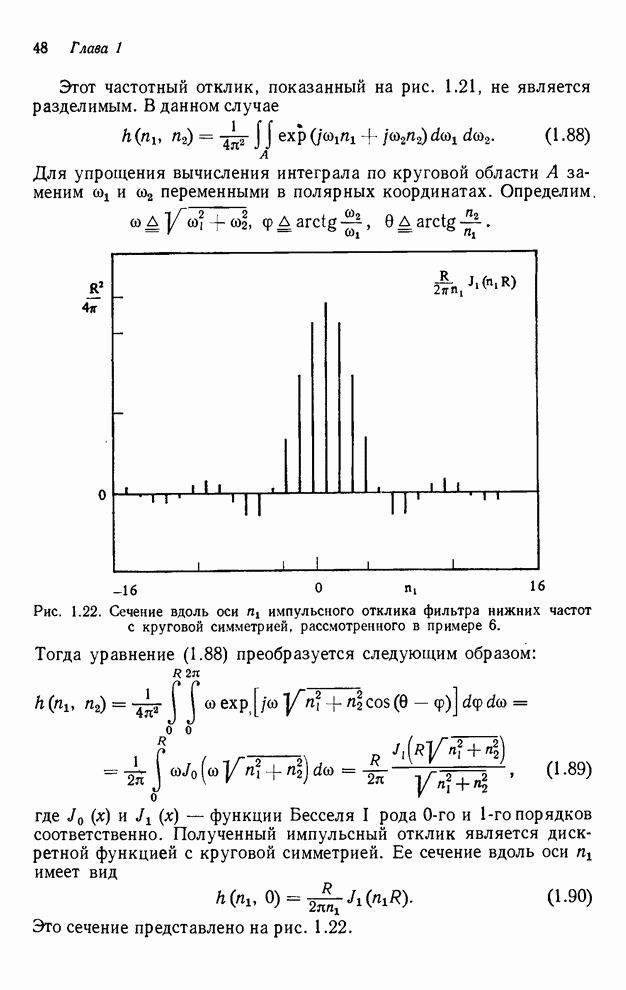
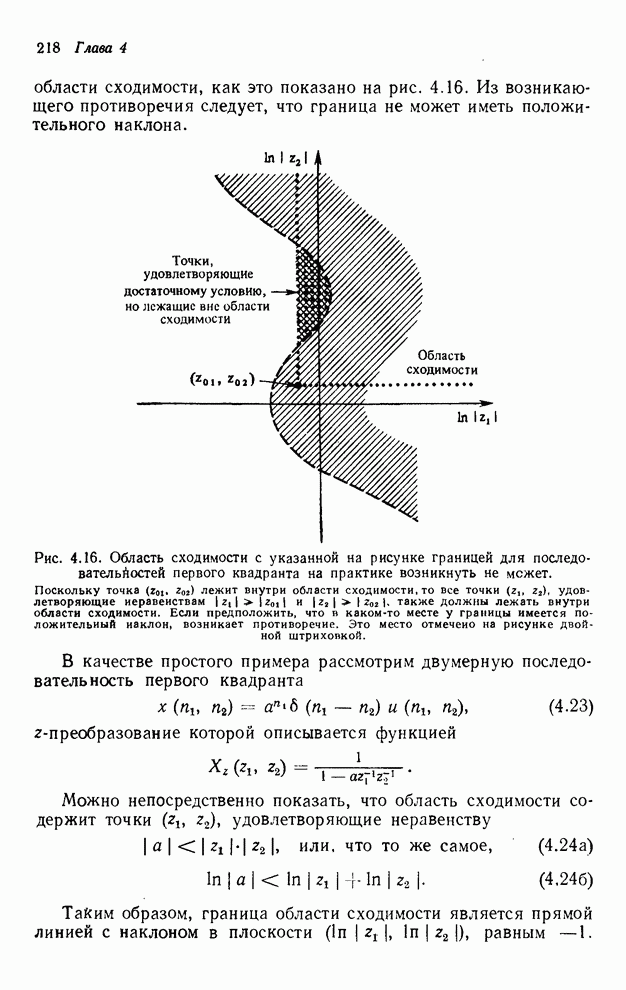
Рассмотрим фильтр первого
квадранта, частичное упорядочивание которого показано на рис. 4.10.
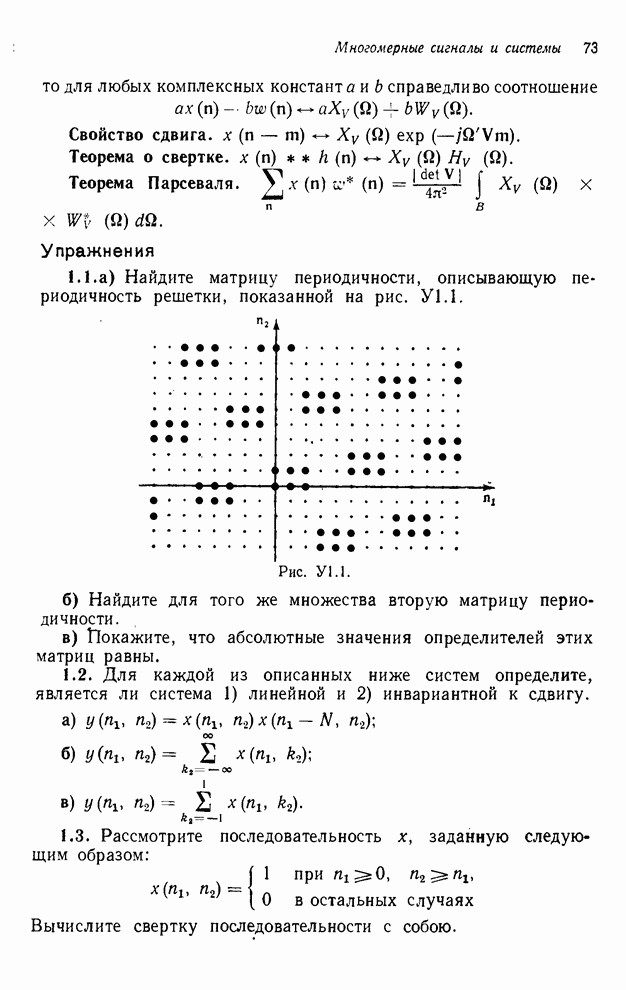
Предположим, что необходимо вычислить выходные отсчеты только в диапазоне  . В качестве первого
примера можно использовать функцию отображения индексов, которой является
функция
. В качестве первого
примера можно использовать функцию отображения индексов, которой является
функция
 . (4.10)
. (4.10)
Это
соответствует вычислению выходного сигнала по столбцам, начиная с и кончая  , затем начиная с и кончая
, затем начиная с и кончая  и т. д. В качестве
второго примера рассмотрим вычисление выходных отсчетов по строкам, при котором
можно было бы применить функцию
и т. д. В качестве
второго примера рассмотрим вычисление выходных отсчетов по строкам, при котором
можно было бы применить функцию
 . (4.11)
. (4.11)
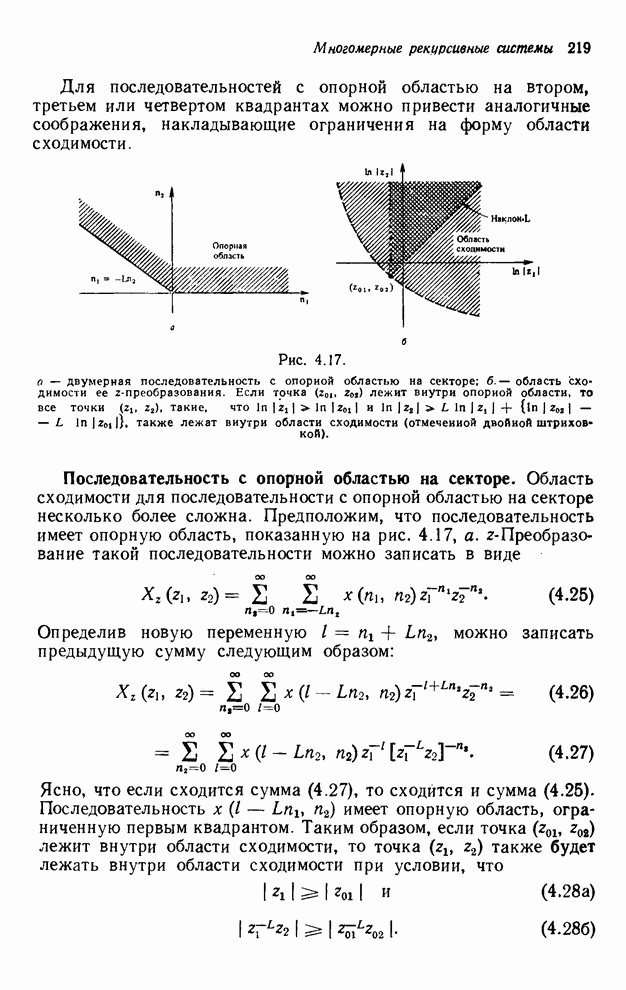
В качестве третьего примера можно
рассмотреть вычисление выходных значений вдоль диагоналей  . Соответствующей этому случаю
функцией отображения индексов будет функция
. Соответствующей этому случаю
функцией отображения индексов будет функция
 . (4.12)
. (4.12)
Эта
функция отображения будет порождать такой порядок индексов: , , ,  ,
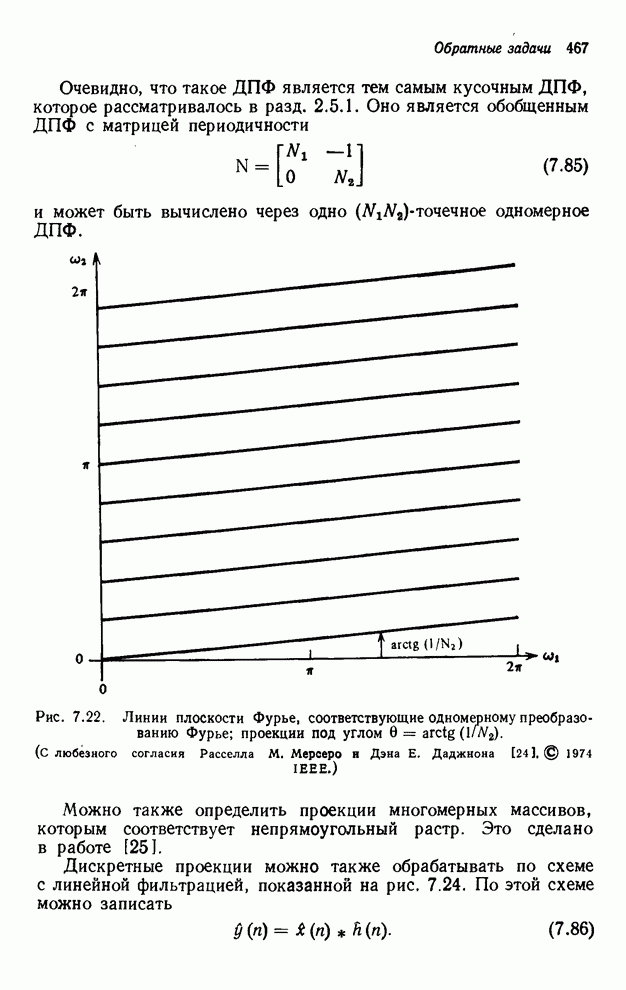
,  ,
,  ,
,  ,
,  ,
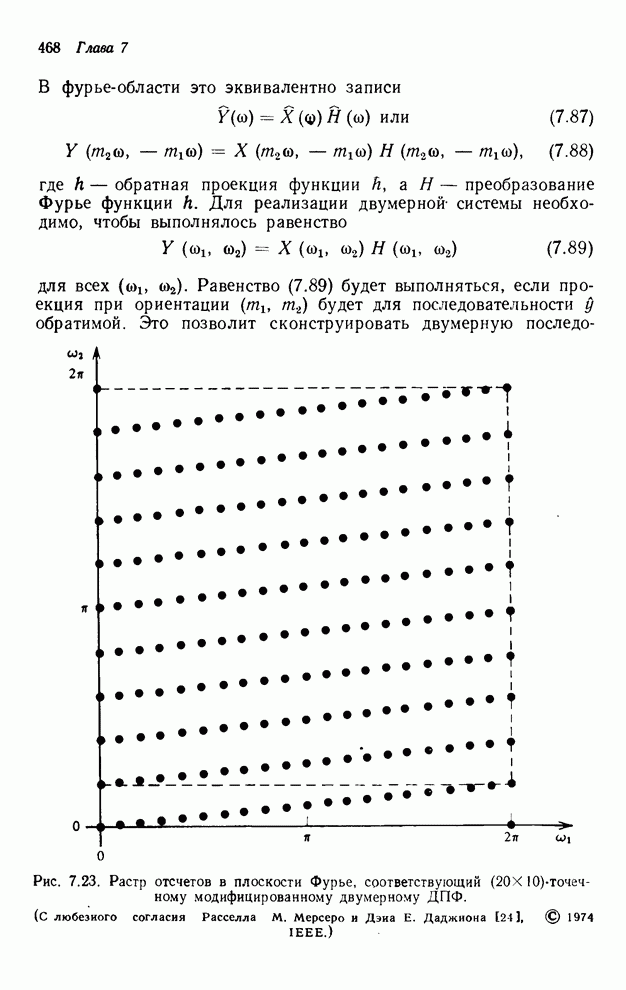
,  , …. Кажется очевидным, что для одного
разностного уравнения часто можно использовать несколько различных функций
отображения индексов. Однако различные полные упорядочивания могут иметь
существенные преимущества или недостатки по сравнению друг с другом. Поясним
это утверждение рассмотрением двух наиболее общепринятых упорядочиваний:
«столбец за столбцом» (или строка за строкой) и «диагональ за диагональю».
Чтобы сделать пример максимально конкретным, допустимым, что мы хотим
реализовать фильтр первого квадранта с квадратной
, …. Кажется очевидным, что для одного
разностного уравнения часто можно использовать несколько различных функций
отображения индексов. Однако различные полные упорядочивания могут иметь
существенные преимущества или недостатки по сравнению друг с другом. Поясним
это утверждение рассмотрением двух наиболее общепринятых упорядочиваний:
«столбец за столбцом» (или строка за строкой) и «диагональ за диагональю».
Чтобы сделать пример максимально конкретным, допустимым, что мы хотим
реализовать фильтр первого квадранта с квадратной  -точечной выходной маской и с
-точечной выходной маской и с  -точечной входной
маской. Пусть, далее, нам необходимо получить выходные данные в квадратной
области
-точечной входной
маской. Пусть, далее, нам необходимо получить выходные данные в квадратной
области  .
.
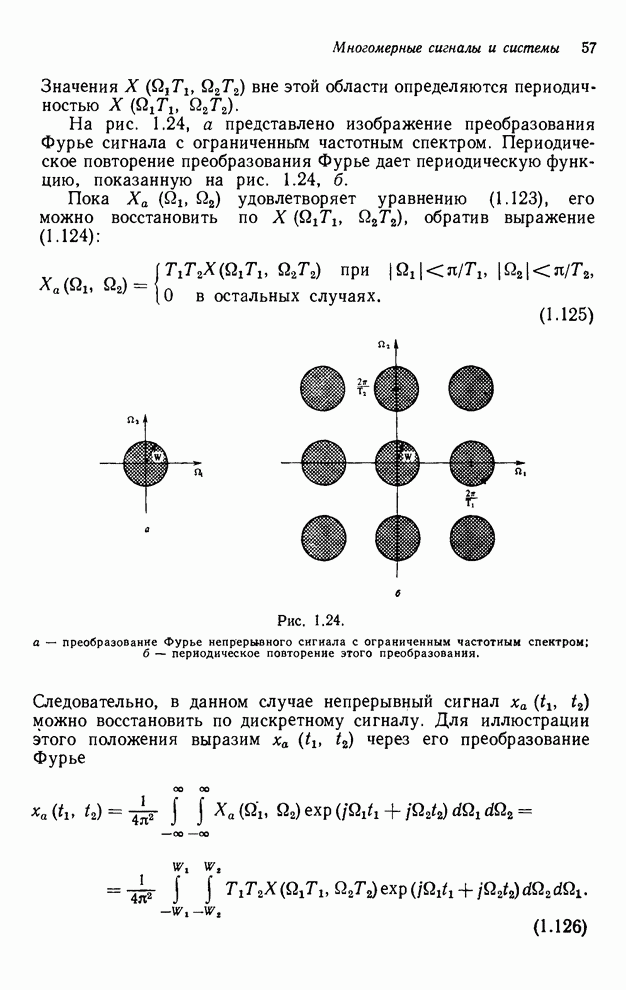
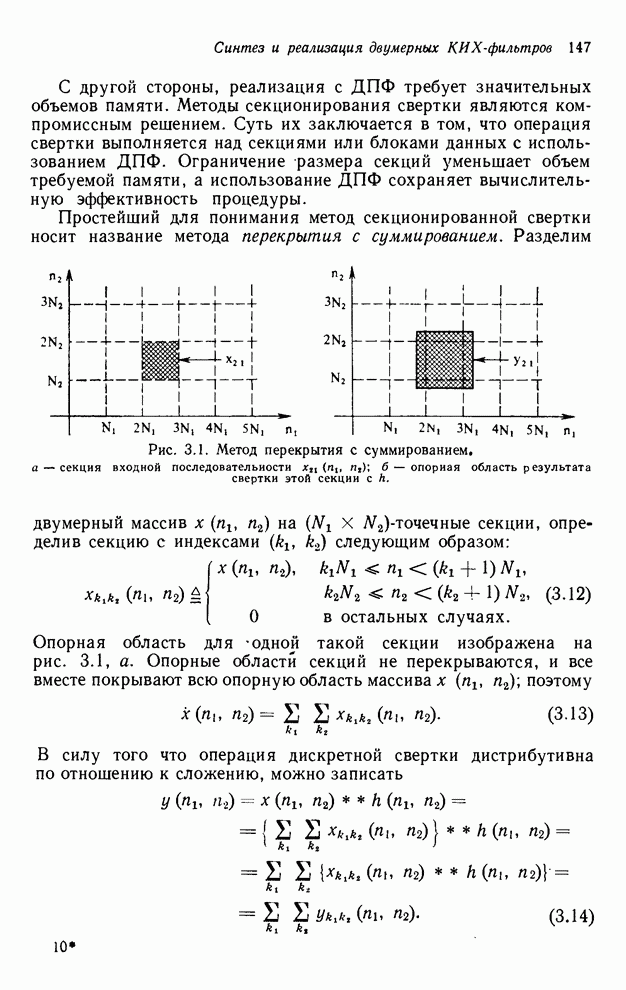
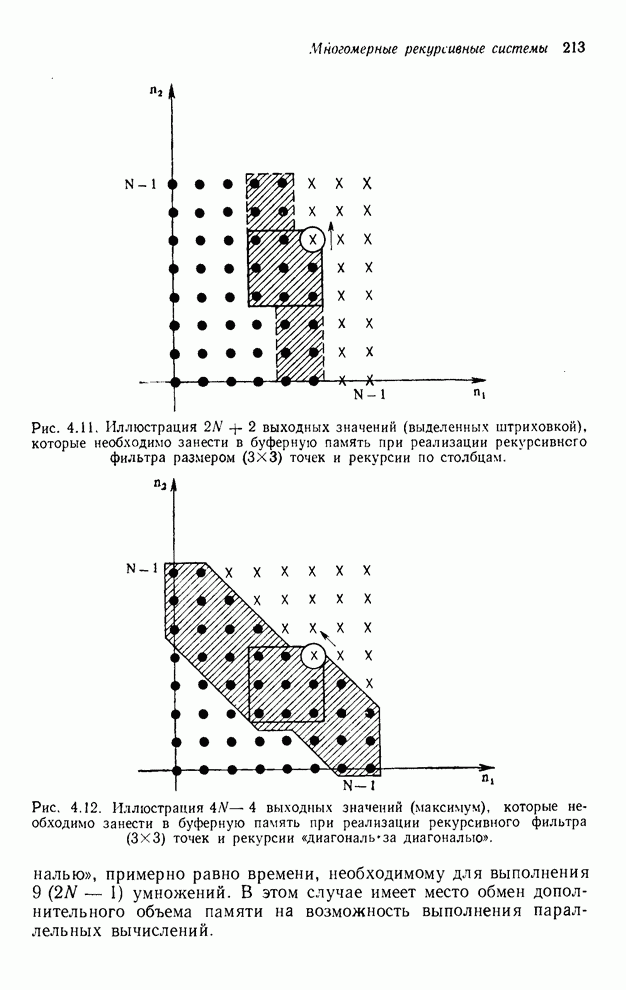
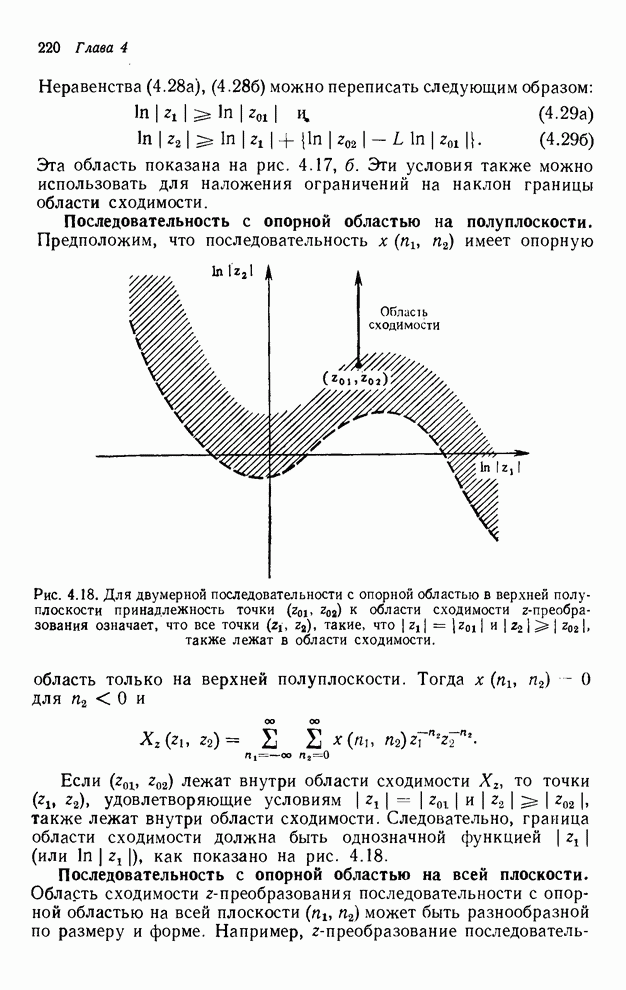
При реализации упорядочивания
«столбец за столбцом» нам необходимо помнить значения текущего столбца, лежащие
ниже выходной точки, вычисляемой в настоящий момент, выходные значения
предыдущего столбца и те выходные значения столбца, предшествующего предыдущему,
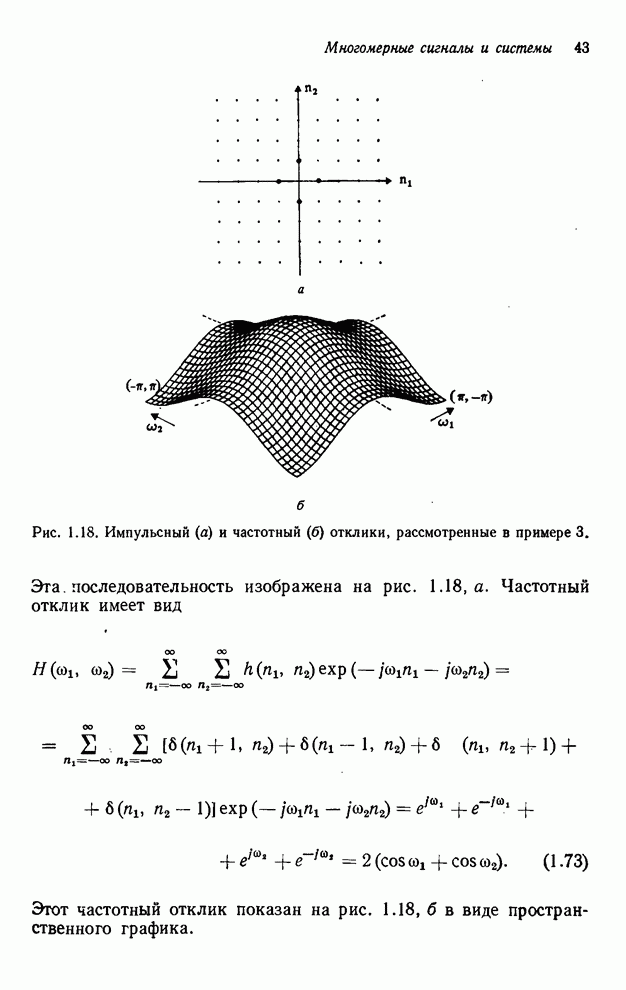
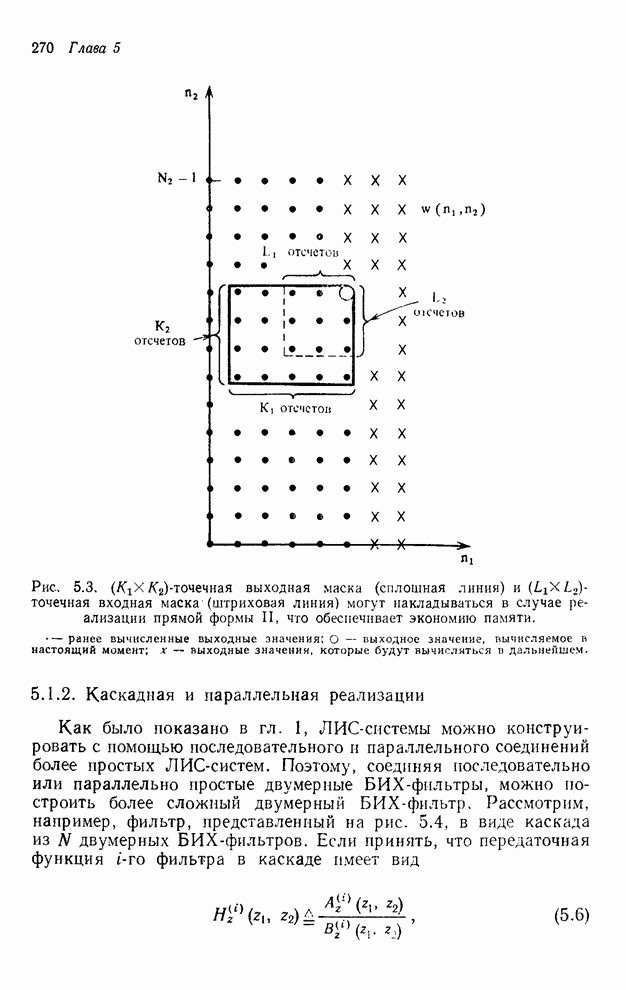
которые накрываются выходной маской или лежат выше ее. Как показано на рис.
4.11, количество выходных значений, которые необходимо занести в буферную
память, составляет  .
Если входные отсчеты поступают столбец за столбцом, никакого промежуточного
хранения входных отсчетов не требуется. Для вычисления всех
.
Если входные отсчеты поступают столбец за столбцом, никакого промежуточного
хранения входных отсчетов не требуется. Для вычисления всех  выходных значений требуется
выходных значений требуется  умножений. В выходной
маске выполняется восемь умножений на одну выходную точку, а девятое требуется
для нормировки входных значений.
умножений. В выходной
маске выполняется восемь умножений на одну выходную точку, а девятое требуется
для нормировки входных значений.

Рис. 4.11. Иллюстрация выходных значений
(выделенных штриховкой), которые необходимо занести в буферную память при
реализации рекурсивного фильтра размером точек и рекурсии по столбцам.
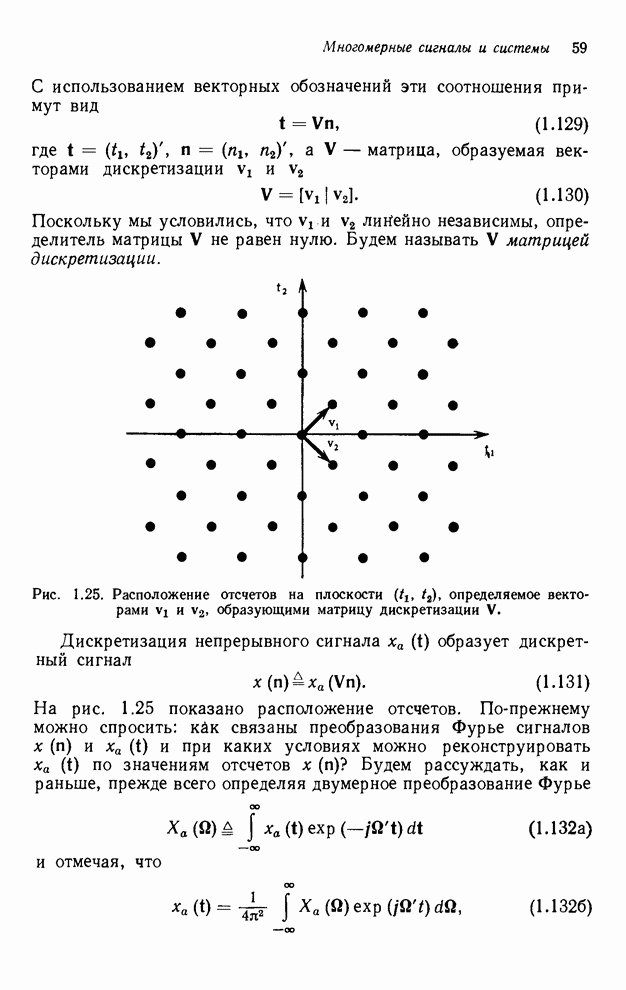
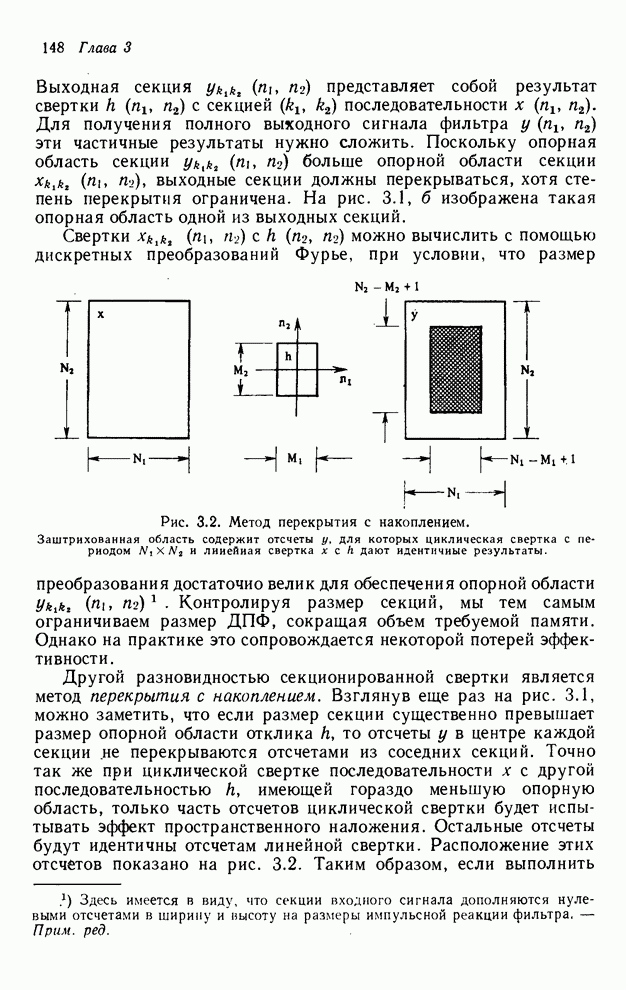
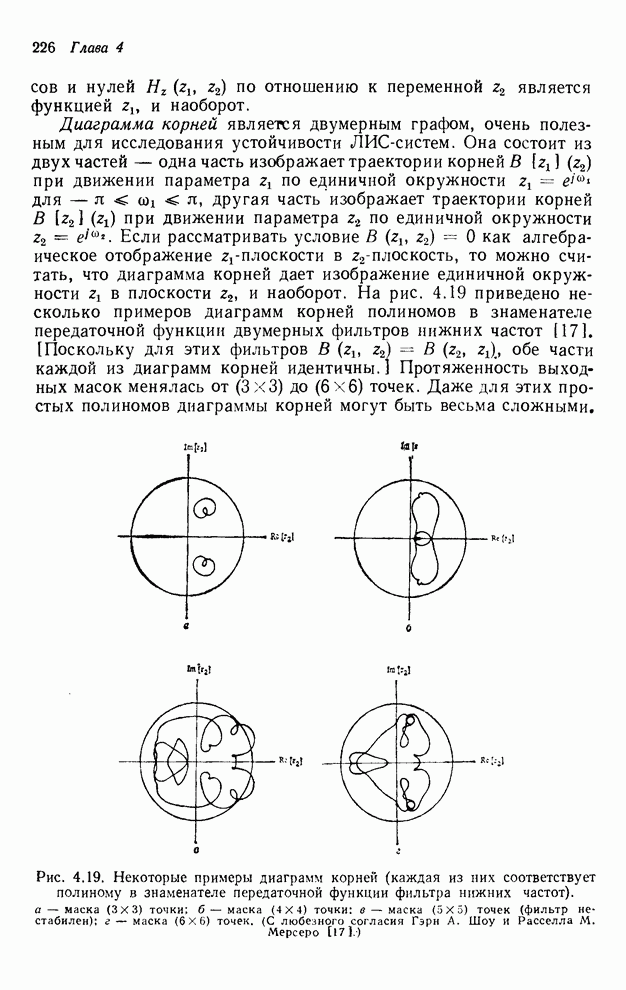
При
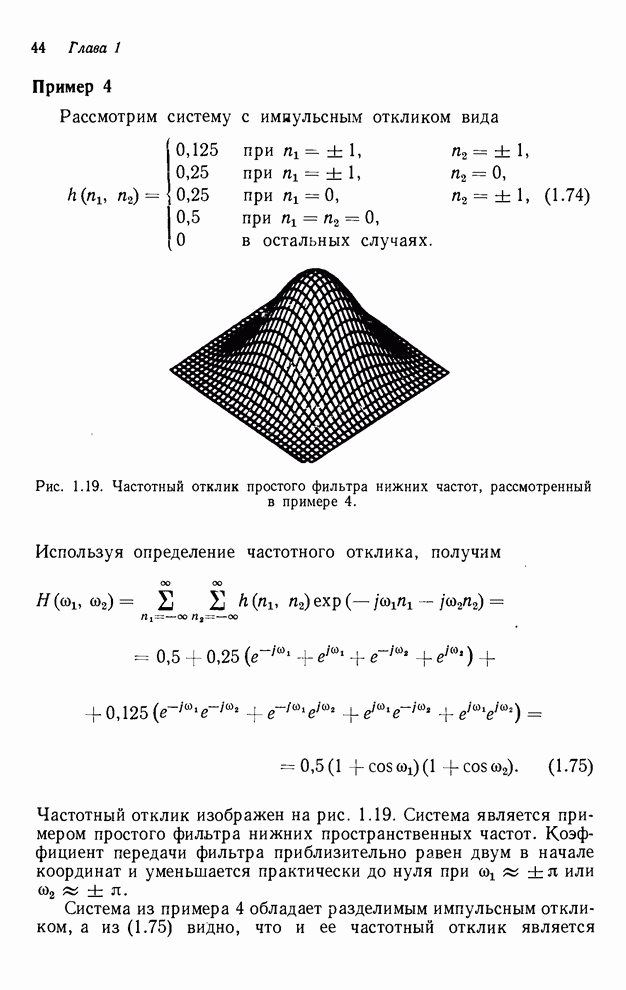
реализации упорядочивания «диагональ за диагональю» необходимо помнить четыре
вычисленные перед этим диагонали. Детальный подсчет согласно рис. 4.12
показывает, что в самом худшем случае необходимо занести в буферную память  выходных значения.
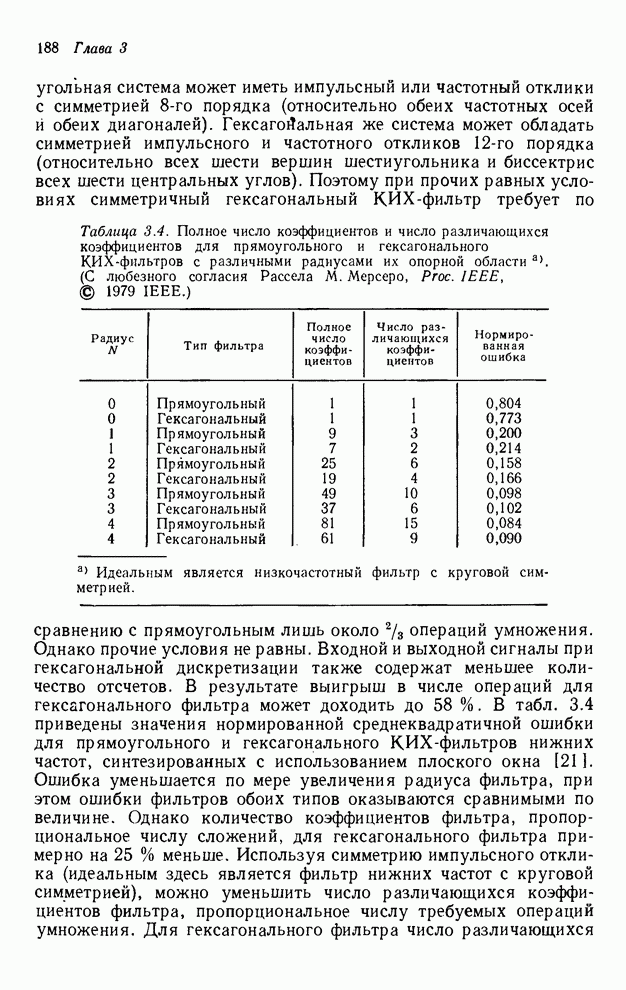
Хотя эта реализация требует большего объема памяти, чем реализация
упорядочивания «столбец за столбцом», ее важное преимущество состоит в том, что
выходные отсчеты вдоль любой диагонали можно вычислять независимо.
Следовательно, если позволяют технические возможности, все выходные отсчеты
вдоль каждой диагонали можно вычислять одновременно. Хотя по-прежнему
необходимо выполнить умножений, в том случае, если имеется
выходных значения.
Хотя эта реализация требует большего объема памяти, чем реализация
упорядочивания «столбец за столбцом», ее важное преимущество состоит в том, что
выходные отсчеты вдоль любой диагонали можно вычислять независимо.
Следовательно, если позволяют технические возможности, все выходные отсчеты
вдоль каждой диагонали можно вычислять одновременно. Хотя по-прежнему
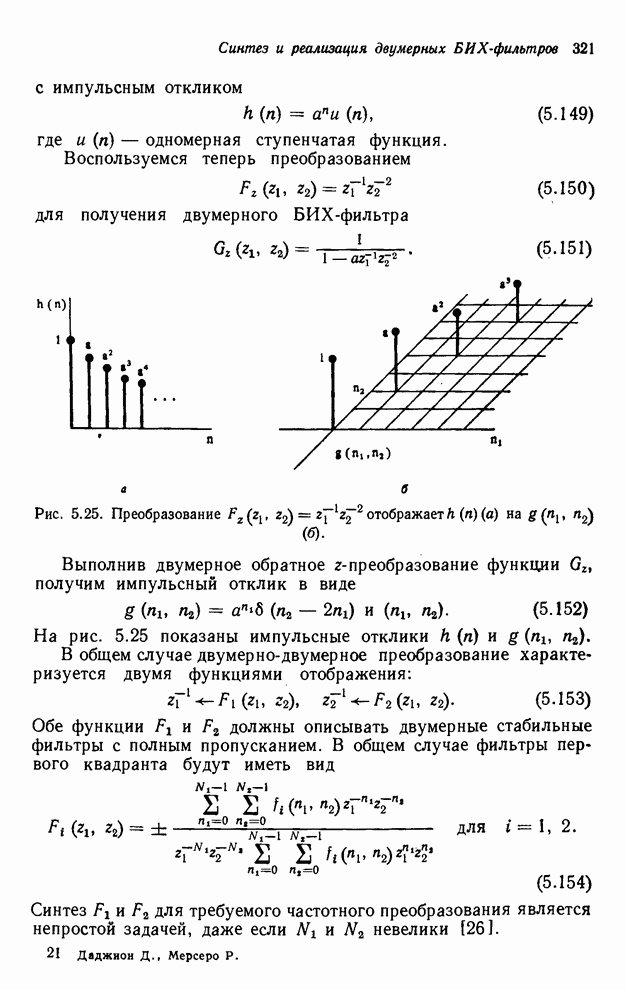
необходимо выполнить умножений, в том случае, если имеется  параллельных
процессоров, время, необходимое для реализации упорядочивания «диагональ за
диагональю», примерно равно времени, необходимому для выполнения
параллельных
процессоров, время, необходимое для реализации упорядочивания «диагональ за
диагональю», примерно равно времени, необходимому для выполнения  умножений. В этом
случае имеет место обмен дополнительного объема памяти на возможность
выполнения параллельных вычислений.
умножений. В этом
случае имеет место обмен дополнительного объема памяти на возможность
выполнения параллельных вычислений.

Рис. 4.12. Иллюстрация выходных значений
(максимум), которые необходимо занести в буферную память при реализации
рекурсивного фильтра точек и рекурсии «диагональ за
диагональю».