6.4. КРИТЕРИИ ОПТИМИЗАЦИИ
В этом разделе рассмотрим критерии оптимизации, которые используются при оценке вектора изображения методом, основанным на применении разложения функции в ряд. Хотя об этом не будет сказано в явной форме, многое из того, что будет изложено ниже, применимо при оценке изображений алгоритмами, основанными на преобразованиях.
В выражении (6.24) вектор  не известен. В лучшем случае мы можем считать, что вектор
не известен. В лучшем случае мы можем считать, что вектор  является выборкой случайной переменной. Однако в большинстве случаев это невозможно. Простой подход в попытке решить (6.24) состоит в том, чтобы принять в качестве первого приближения, что
является выборкой случайной переменной. Однако в большинстве случаев это невозможно. Простой подход в попытке решить (6.24) состоит в том, чтобы принять в качестве первого приближения, что  есть нулевой вектор. Это чревато опасностью:
есть нулевой вектор. Это чревато опасностью:  может не иметь решения или может иметь много решений, ни одно из которых не является подходящим для рассматриваемой практической задачи. Тем не менее были выработаны некоторые критерии, указывающие, какой вектор
может не иметь решения или может иметь много решений, ни одно из которых не является подходящим для рассматриваемой практической задачи. Тем не менее были выработаны некоторые критерии, указывающие, какой вектор  должен быть выбран в качестве решения (6.24).
должен быть выбран в качестве решения (6.24).
Критерии, которые были использованы при решении задач реконструкции, обычно имеют следующий вид. В качестве решения (6.24) выбираем такой вектор изображения  для которого значение функции
для которого значение функции  минимально, а если имеется более чем один вектор, который минимизирует
минимально, а если имеется более чем один вектор, который минимизирует  то выбирают из них тот, для которого минимально значение некоторой другой функции
то выбирают из них тот, для которого минимально значение некоторой другой функции  . В данном разделе мы изложим некоторые из предложенных методов выборов функций
. В данном разделе мы изложим некоторые из предложенных методов выборов функций  .
.
С теоретической точки зрения заманчивым является подход, заключающийся в следующем. Пусть как вектор изображения  так и вектор ошибки
так и вектор ошибки  являются выборками случайных переменных, которые обозначим соответственно буквами
являются выборками случайных переменных, которые обозначим соответственно буквами  Так как обсуждение в разд. 1.2 ограничено рассмотрением только дискретных случайных переменных (т.е. с конечным числом возможных исходов), а в качестве возможных исходов рассматриваются векторы-столбцы из вещественных чисел, то здесь необходимы дополнительные пояснения. [Читатель, который не имеет желания знакомиться с основными положениями теории оценок Байеса, может без ущерба пропустить этот текст до (6.33).]
Так как обсуждение в разд. 1.2 ограничено рассмотрением только дискретных случайных переменных (т.е. с конечным числом возможных исходов), а в качестве возможных исходов рассматриваются векторы-столбцы из вещественных чисел, то здесь необходимы дополнительные пояснения. [Читатель, который не имеет желания знакомиться с основными положениями теории оценок Байеса, может без ущерба пропустить этот текст до (6.33).]
Случайная переменная X определяется функцией плотности вероятности  которая представляет собой вещественную функцию от
которая представляет собой вещественную функцию от  -мерных векторов из вещественных чисел, являющихся возможными исходами
-мерных векторов из вещественных чисел, являющихся возможными исходами  Эта функция плотности вероятности определена так, чтобы для любых
Эта функция плотности вероятности определена так, чтобы для любых  пар чисел
пар чисел  было справедливо следующее утверждение. Вероятность того, что выборка
было справедливо следующее утверждение. Вероятность того, что выборка  из X будет иметь свойство
из X будет иметь свойство  для
для  равна
равна

Для удобства обозначения интегралы такого рода будут иногда обозначаться сокращенно:

В соответствии с понятиями среднего значения и дисперсии, как они были определены в (1.4) и (1.5), введем понятия средний вектор  и матрица ковариации
и матрица ковариации  которые определены следующим образом:
которые определены следующим образом:

где  означает вектор-строку, который равен транспонированному
означает вектор-строку, который равен транспонированному
вектору-столбцу  вектор-строке,
вектор-строке,  элемент которой равен
элемент которой равен  Эти интегралы вычисляют покомпонентно. Например, если
Эти интегралы вычисляют покомпонентно. Например, если  обозначает
обозначает  компоненту вектора
компоненту вектора  то
то  компонента матрицы
компонента матрицы  равна
равна

Наиболее часто используемой случайной переменной с векторами в качестве возможных исходов является многопараметрическое распределение Гаусса, для которого функция плотности вероятности однозначно определяется средним вектором и ее матрицей ковариации следующим образом:

Отметим, что для того, чтобы  имело смысл, детерминант матрицы ковариации
имело смысл, детерминант матрицы ковариации  должен быть положительным. Нетрудно проверить, что соотношения (6.28), (6.29) и (6.31) являются совместимыми. Функция плотности вероятности многопараметрического распределения Гаусса достигает максимума при среднем значении.
должен быть положительным. Нетрудно проверить, что соотношения (6.28), (6.29) и (6.31) являются совместимыми. Функция плотности вероятности многопараметрического распределения Гаусса достигает максимума при среднем значении.
Важность многопараметрического распределения Гаусса определяется двумя фактами. Во-первых, многие распределения, встречающиеся на практике, аппроксимируются многопараметрическим распределением Гаусса. Во-вторых, предположение о том, что неизвестное распределение является многопараметрическим распределением Гаусса, делает задачу с математической точки зрения гораздо проще, чем в остальных случаях.
Вернемся к случайным переменным  связанным с
связанным с  соотношением (6.24). В этом случае
соотношением (6.24). В этом случае  называется функцией плотности априорной вероятности, так как
называется функцией плотности априорной вероятности, так как  указывает правдоподобие случайно встретить вектор изображения, близкий к
указывает правдоподобие случайно встретить вектор изображения, близкий к  . В реконструктивной томографии имеет смысл связывать
. В реконструктивной томографии имеет смысл связывать  с той областью тела пациента, которую мы отображаем; вероятности того, что то же самое изображение представляет сечение головы или грудной клетки пациента, будут различными. Наше рассмотрение
с той областью тела пациента, которую мы отображаем; вероятности того, что то же самое изображение представляет сечение головы или грудной клетки пациента, будут различными. Наше рассмотрение  раздельно само по себе является упрощающим предположением, так как на практике
раздельно само по себе является упрощающим предположением, так как на практике  не является независимым от X, как это следует из обсуждения, приведенного в разд. 3.1. Теория, которую мы здесь излагаем, может быть развита без этого предположения, однако при этом она становится более сложной.
не является независимым от X, как это следует из обсуждения, приведенного в разд. 3.1. Теория, которую мы здесь излагаем, может быть развита без этого предположения, однако при этом она становится более сложной.
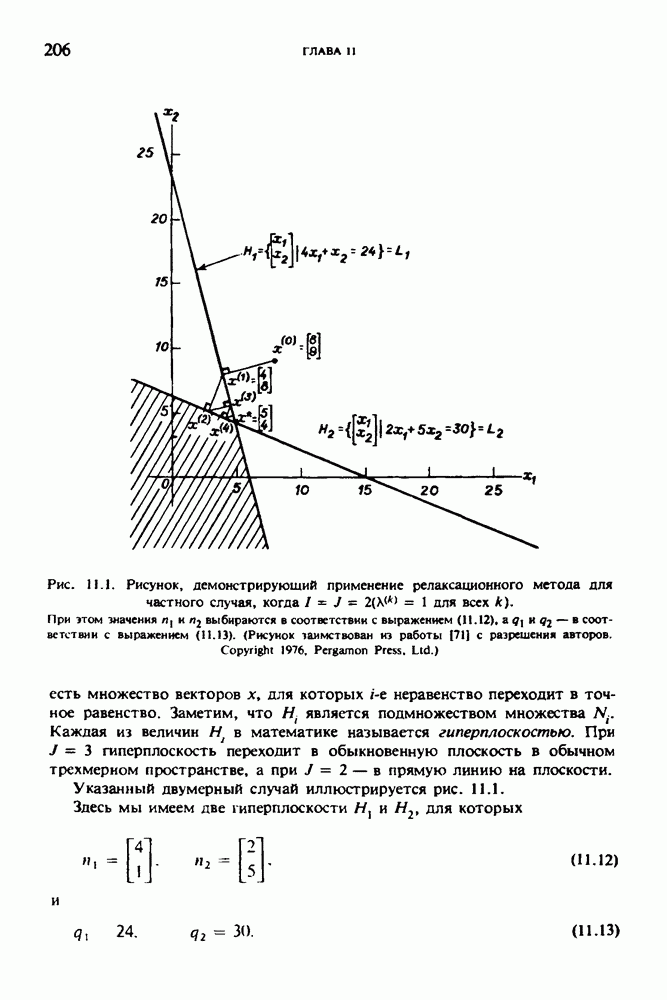
Наконец, мы можем сформулировать критерий оптимизации в предположении, что  известны: по заданным значениям у выбрать вектор изображения
известны: по заданным значениям у выбрать вектор изображения  такой, чтобы величина
такой, чтобы величина

имела по возможности большее значение. Заметим, что второй сомножитель
в этом произведении становится большим при значениях  которые имеют большую априорную вероятность, тогда как первый сомножитель становится большим при тех значениях
которые имеют большую априорную вероятность, тогда как первый сомножитель становится большим при тех значениях  которые совместимы с исходными данными, по крайней мере если
которые совместимы с исходными данными, по крайней мере если  имеет пик при векторе нуль. Относительное значение каждого из этих множителей зависит от природы
имеет пик при векторе нуль. Относительное значение каждого из этих множителей зависит от природы  Если
Если  имеет плоское распределение и поэтому многие векторы изображения имеют равную вероятность и если
имеет плоское распределение и поэтому многие векторы изображения имеют равную вероятность и если  имеет большее значение вблизи вектора нуль, то с помощью нашего критерия можно получить вектор изображения
имеет большее значение вблизи вектора нуль, то с помощью нашего критерия можно получить вектор изображения  который соответствует измеренным данным в том смысле, что
который соответствует измеренным данным в том смысле, что  будет иметь почти такие же значения, что и
будет иметь почти такие же значения, что и  . С другой стороны, если
. С другой стороны, если  имеет плоское распределение и поэтому большие значения ошибок имеют почти такую же вероятность, что и малые, однако если при этом
имеет плоское распределение и поэтому большие значения ошибок имеют почти такую же вероятность, что и малые, однако если при этом  имеет явно выраженный максимум, выполненные наши измерения будут иметь лишь небольшое влияние на наши предварительные представления о том, какой вектор изображения должен быть выбран.
имеет явно выраженный максимум, выполненные наши измерения будут иметь лишь небольшое влияние на наши предварительные представления о том, какой вектор изображения должен быть выбран.
Те значения  которые максимизируют (6.32), называются оценкой Байеса (байесовской оценкой).
которые максимизируют (6.32), называются оценкой Байеса (байесовской оценкой).
Трудность, связанная с нахождением байесовской оценки, связана с тем, что должны быть заранее известны величины  Полная информация об истинном априорном распределении векторов изображения и ошибки, как правило, отсутствует. Вторая трудность состоит в том, что для многихрх
Полная информация об истинном априорном распределении векторов изображения и ошибки, как правило, отсутствует. Вторая трудность состоит в том, что для многихрх  нахождение значений, которые максимизируют (6.32), может быть не столь простой задачей.
нахождение значений, которые максимизируют (6.32), может быть не столь простой задачей.
Если считать, что  подчиняются многопараметрическим распределениям Гаусса, то задача оптимизации существенно упрощается. В таком случае из выражения (6.31) легко видеть, что в предположении, что
подчиняются многопараметрическим распределениям Гаусса, то задача оптимизации существенно упрощается. В таком случае из выражения (6.31) легко видеть, что в предположении, что  является нулевым вектором, значения
является нулевым вектором, значения  которые соответствуют максимуму (6.32), равны тем же значениям
которые соответствуют максимуму (6.32), равны тем же значениям  которые минимизируют
которые минимизируют

Менее изящный подход состоит в использовании метода наименьших квадратов для получения решения (6.24), т.е. для нахождения  которые минимизируют
которые минимизируют

Такой критерий не обязательно должен определять  однозначно; возможно, что имеется более чем один вектор
однозначно; возможно, что имеется более чем один вектор  который минимизирует (6.34). В подобном случае для определения значения следует использовать второй критерий, ыборы которого описаны ниже.
который минимизирует (6.34). В подобном случае для определения значения следует использовать второй критерий, ыборы которого описаны ниже.
Другая причина, по которой решение, полученное методом наименьших квадратов, не обязательно будет достаточно хорошим, состоит в том, что критерий, выраженный (6.34), не содержит никакой информации относительно природы «желаемого» решения  При использовании байесовского
При использовании байесовского
подхода при помощи выражения (6.33) такая информация содержится в априорно заданной матрице ковариации 
Разумно считать, что желаемым свойством решения (6.24) является то, что дисперсия

где

должна быть малой. [Если базисные изображения выбраны согласно (6.17), то  соответствует средней плотности в дискретизированном изображении.] Можно показать, что если
соответствует средней плотности в дискретизированном изображении.] Можно показать, что если  считать фиксированным для всех приемлемых решений (6.24), то значение
считать фиксированным для всех приемлемых решений (6.24), то значение  которое минимизирует (6.35), равно тому значению
которое минимизирует (6.35), равно тому значению  которое минимизирует норму
которое минимизирует норму  от
от  где
где

Иными словами, в таком случае решения, соответствующие минимуму дисперсии и минимуму нормы, совпадают.
Критерии, которые выражены формулами (6.35) и (6.37), не следует использовать как «первичные» для реконструкции изображений, т.е., если пользоваться терминологией, введенной в начале этого раздела, не естественно определять  выражением (6.35). Это, как правило, приводит к «решению», в котором все компоненты
выражением (6.35). Это, как правило, приводит к «решению», в котором все компоненты  имеют одно и то же значение, а именно
имеют одно и то же значение, а именно  Выражение (6.35) следует использовать либо в качестве вторичного критерия, либо в качестве составляющей части первичного критерия, в котором другие компоненты заставляют какое-то определенное «решение» соответствовать данным измерениям или выражать другие качества желаемого решения (6.24).
Выражение (6.35) следует использовать либо в качестве вторичного критерия, либо в качестве составляющей части первичного критерия, в котором другие компоненты заставляют какое-то определенное «решение» соответствовать данным измерениям или выражать другие качества желаемого решения (6.24).
Например, в том случае, когда базисные изображения выбраны в соответствии с (6.17), «желательными» могут быть те значения  относящиеся к соседним элементам изображения, которые были близки друг к другу в среднем. Такой критерий может быть выражен (разд. 12.3) утверждением: мы хотим минимизировать
относящиеся к соседним элементам изображения, которые были близки друг к другу в среднем. Такой критерий может быть выражен (разд. 12.3) утверждением: мы хотим минимизировать  , где В — соответствующим образом выбранная матрица. Это в сочетании с желанием минимизировать (6.34) и (6.37) одновременно приводит нас к утверждению, что искомое решение
, где В — соответствующим образом выбранная матрица. Это в сочетании с желанием минимизировать (6.34) и (6.37) одновременно приводит нас к утверждению, что искомое решение  уравнения (6.24) минимизирует выражение
уравнения (6.24) минимизирует выражение

где а и b - соответствующим образом выбранные положительные числа, указывающие относительный вес, который мы приписываем различным выражениям, рассмотренным выше, при минимизации,  единичная матрица.
единичная матрица.
Все рассмотренные выше условия минимизации [(6.33) - (6.35), (6.37) и (6.38)] являются частными случаями задачи квадратичной оптимизации, которую можно сформулировать следующим образом:
ищут  которое минимизирует выражение
которое минимизирует выражение

где А — симметричная  -матрица,
-матрица,  -матрицы,
-матрицы,  с — неотрицательные вещественные числа, а
с — неотрицательные вещественные числа, а  есть
есть  -мерный вектор. (Другие подробности о свойствах этих матриц, постоянных чисел и векторов приводятся в разд. 12.1, в котором объяснено, почему второе слагаемое
-мерный вектор. (Другие подробности о свойствах этих матриц, постоянных чисел и векторов приводятся в разд. 12.1, в котором объяснено, почему второе слагаемое  имеет такую сложную форму.)
имеет такую сложную форму.)
Имеются другие пути введения априорной информации об интересующем нас изображении в процесс выбора выражения для решения (6.24). Одним из примеров является использование того факта, что лгу должны находиться внутри определенного диапазона значений. Во многих применениях все возможные изображения  которые могут встречаться, характеризуются только неотрицательными значениями. Поэтому разумно потребовать, чтобы вектор изображения
которые могут встречаться, характеризуются только неотрицательными значениями. Поэтому разумно потребовать, чтобы вектор изображения  основанный на процессе дискретизации (6.17), удовлетворял как решение (6.24) только тогда, когда
основанный на процессе дискретизации (6.17), удовлетворял как решение (6.24) только тогда, когда  для
для  Фактически можно пойти дальше и, кроме этого, потребовать, чтобы для любого решения (6.24) погрешность находилась в определенных пределах, т.е. указать положительные числа
Фактически можно пойти дальше и, кроме этого, потребовать, чтобы для любого решения (6.24) погрешность находилась в определенных пределах, т.е. указать положительные числа  такие, чтобы принимать в качестве решения только те компоненты
такие, чтобы принимать в качестве решения только те компоненты  для которых
для которых

для  . Могут быть введены и другие ограничивающие условия в виде неравенств.
. Могут быть введены и другие ограничивающие условия в виде неравенств.
Используя подобные рассуждения, мы может заменить систему уравнений (6.24), содержащих неопределенное  на неравенство, ограничивающее с одной стороны, вида
на неравенство, ограничивающее с одной стороны, вида 

которое моокно переписать, используя матричное обозначение, как

а затем переформулировать задачу реконструкции в задачу нахождения вектора
изображения  который удовлетворяет выражению (6.42). При этом следует иметь в виду, что может возникнуть следующая ситуация: когда может не существовать
который удовлетворяет выражению (6.42). При этом следует иметь в виду, что может возникнуть следующая ситуация: когда может не существовать  который бы удовлетворял всем неравенствам (6.42), или когда имеется одно соответствующее значение
который бы удовлетворял всем неравенствам (6.42), или когда имеется одно соответствующее значение  то, как правило, имеется и много других значений. Точно так же, как и в случае, когда имеется более чем один вектор, минимизирующий вектор выражения (6.39), требуется ввести дополнительный критерий минимизации, для того чтобы отобрать один из этих векторов в качестве нужного решения.
то, как правило, имеется и много других значений. Точно так же, как и в случае, когда имеется более чем один вектор, минимизирующий вектор выражения (6.39), требуется ввести дополнительный критерий минимизации, для того чтобы отобрать один из этих векторов в качестве нужного решения.
В литературе по реконструктивной томографии предложены два вида таких дополнительных критериев оптимизации.
Один из них основан на минимизации нормы  который был рассмотрен выше. В более общей формулировке единственное решение существует, если из этих всех векторов изображения, которые удовлетворя
который был рассмотрен выше. В более общей формулировке единственное решение существует, если из этих всех векторов изображения, которые удовлетворя  основным условиям, выбираем такой, который минимизирует выраже ние
основным условиям, выбираем такой, который минимизирует выраже ние

где  положительно определенная, симметричная
положительно определенная, симметричная  -матрица. Напо мним, что матрица
-матрица. Напо мним, что матрица  называется положительно определенной, если
называется положительно определенной, если  для всех отличных от нуля векторов. Как будет показано ниже, некоторые алгоритмы реконструкции используют минимизацию вида (6.43) при других матрицах.
для всех отличных от нуля векторов. Как будет показано ниже, некоторые алгоритмы реконструкции используют минимизацию вида (6.43) при других матрицах.
Если известно среднее значение компонент равное  то можно использовать следующий дополнительный критерий. В таком случае имеется по крайней мере один вектор, для которого
то можно использовать следующий дополнительный критерий. В таком случае имеется по крайней мере один вектор, для которого  при
при  который имеет среднее значение
который имеет среднее значение  и который максимизирует выражение
и который максимизирует выражение 

Этот критерий называется критерием максимума энтропии. Использование подобного критерия оправдывают доводами, которые слишком длинны, чтобы их здесь приводить; их цель состоит в том, что из всех изображений, удовлетворяющих основному критерию, решение, соответствующее максимуму энтропии, имеет наименьшее количество информации и поэтому с наименьшей вероятностью вводит в заблуждение наличием артефактов.
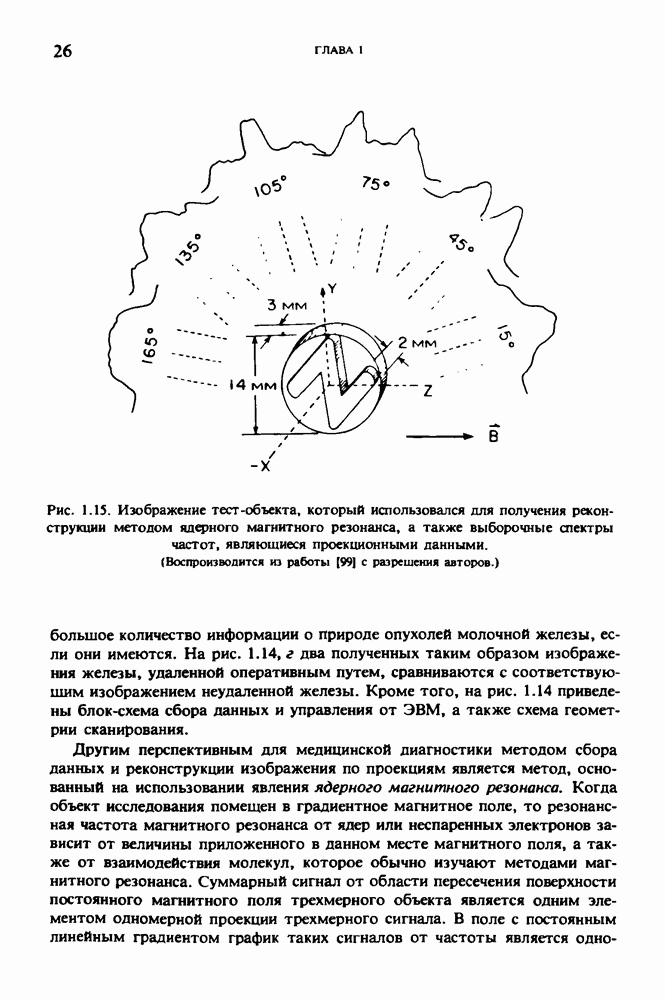
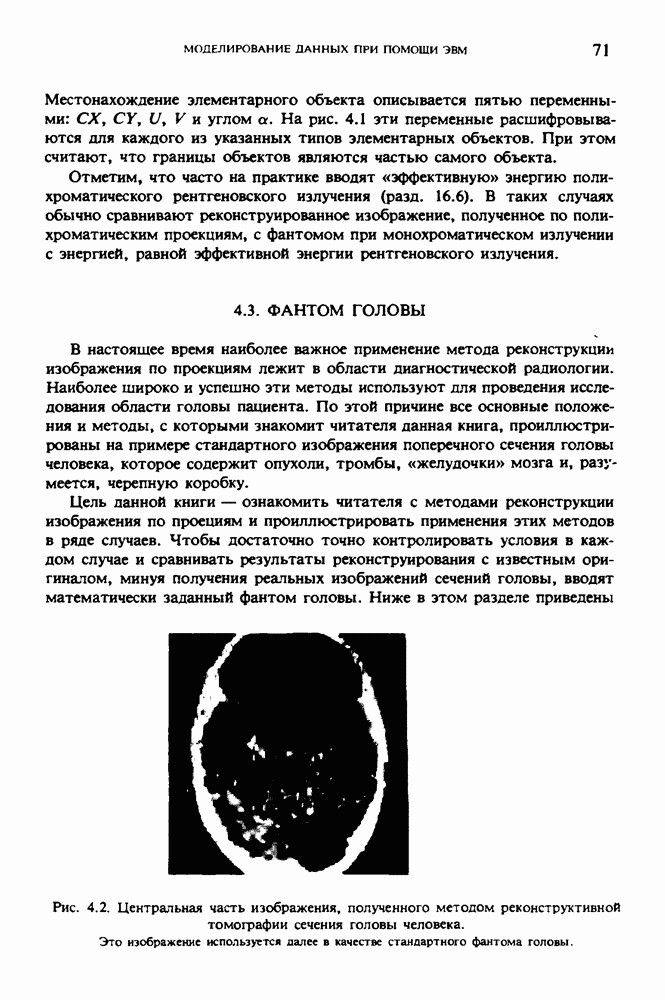
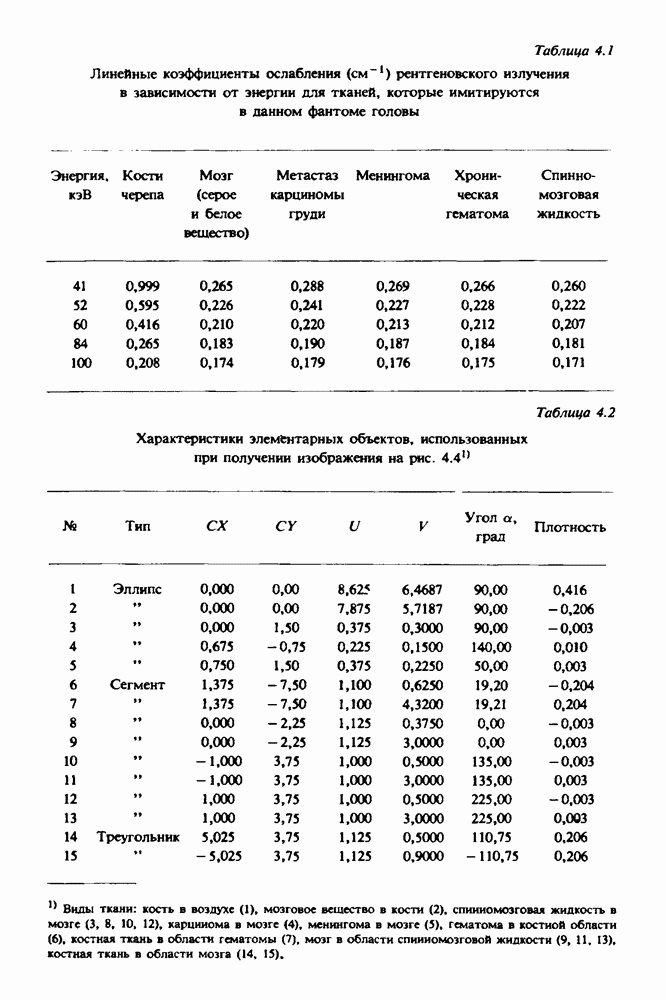
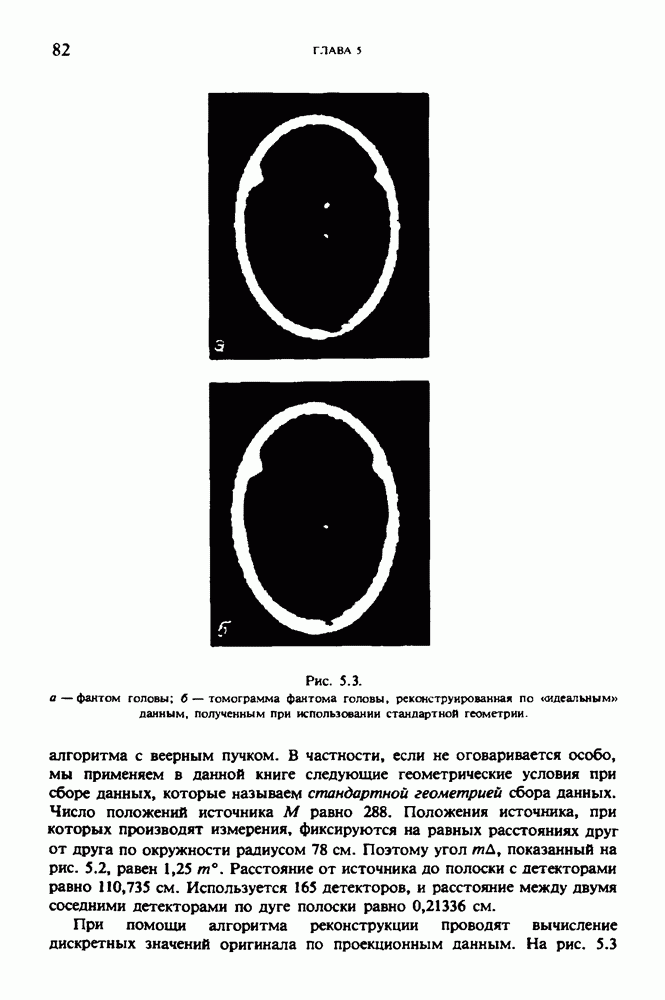
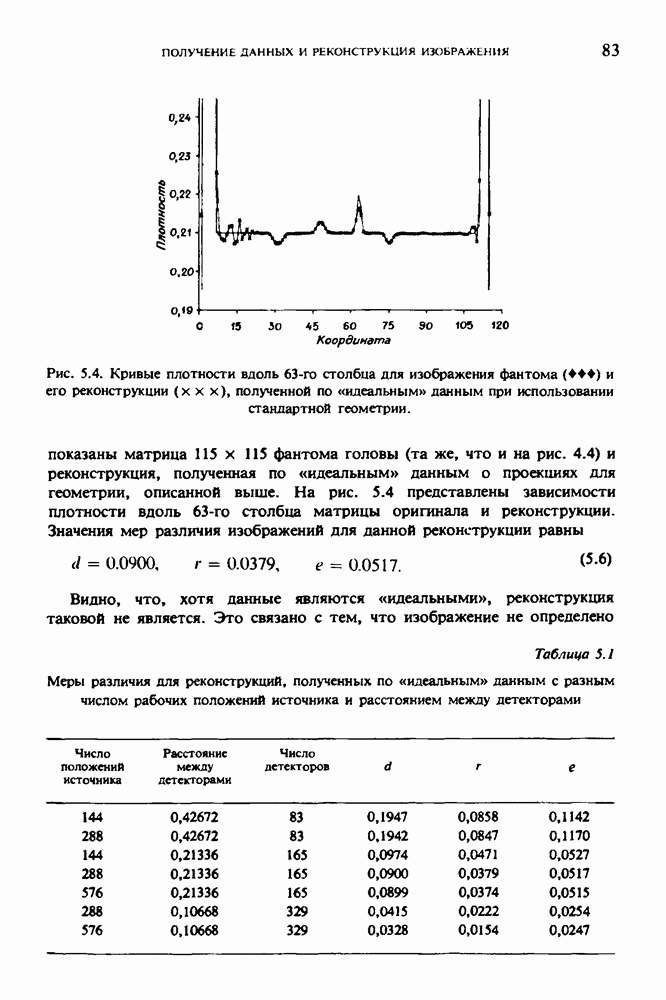
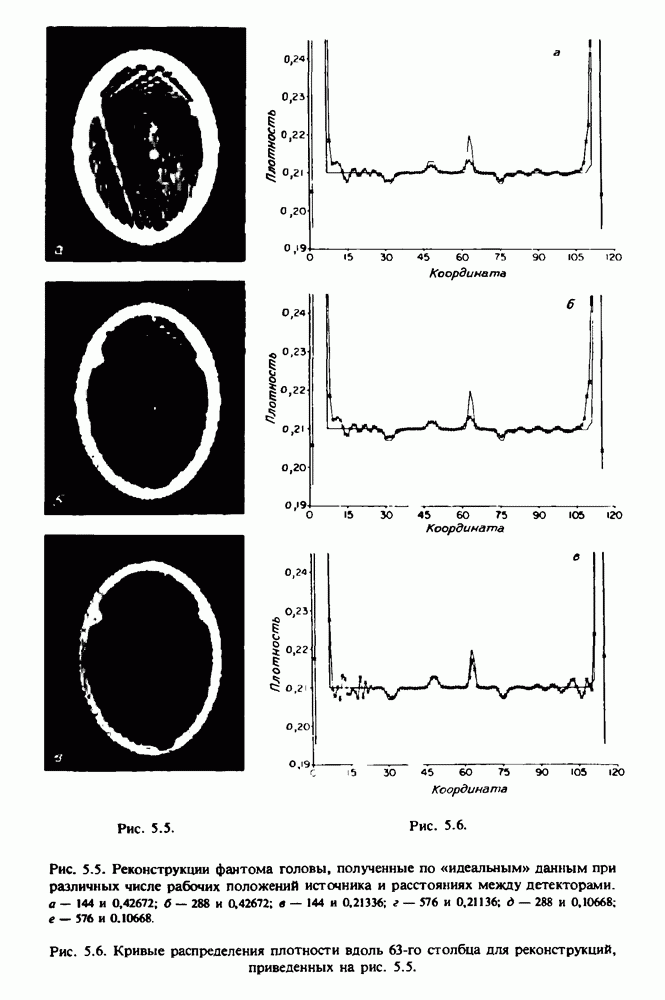
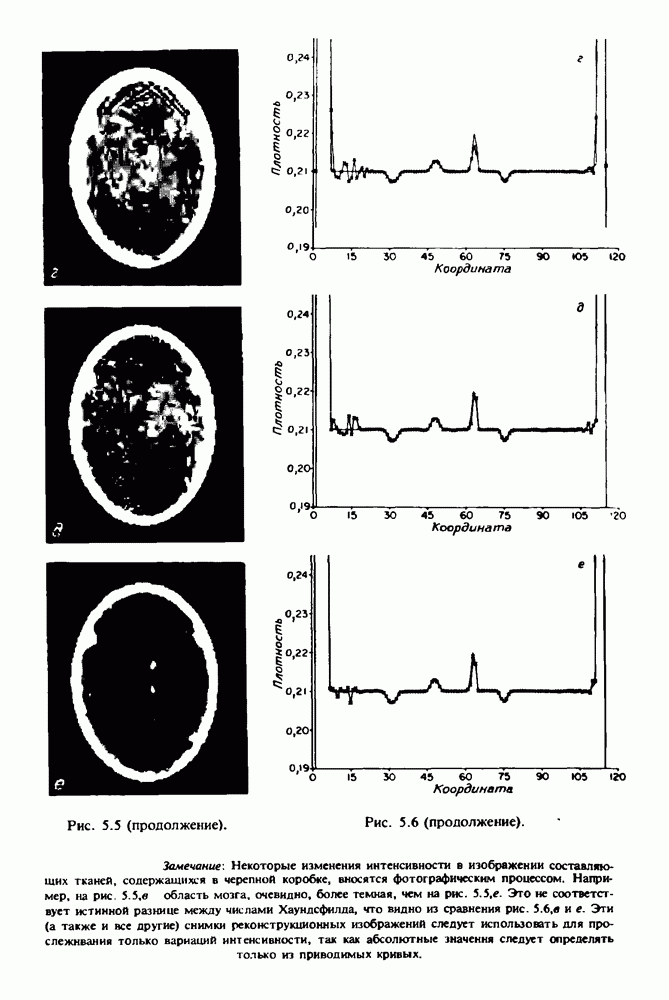
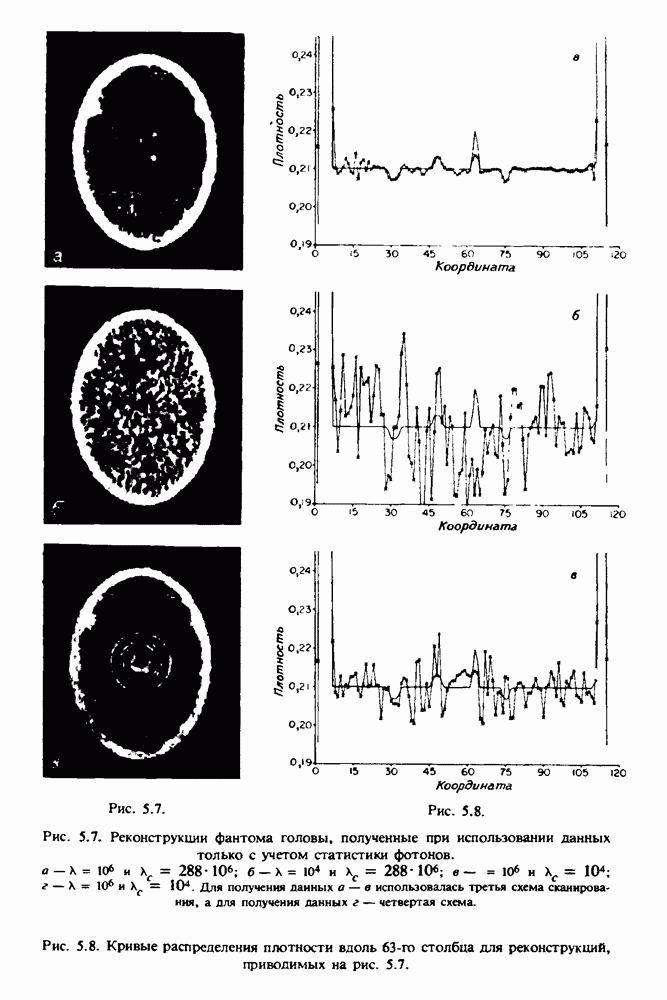
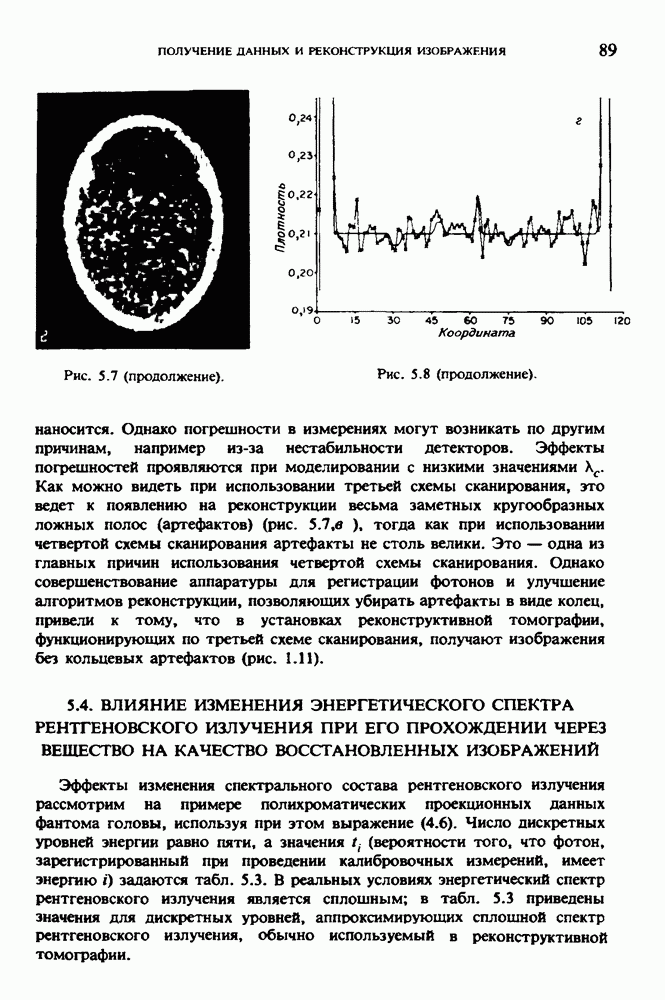
Причина, по которой мы можем считать, что величина  известна, состоит в следующем. Рассмотрим рис. 2.8. Для любой пары источник — детектор лучевая сумма, деленная на длину отрезка луча, пересекающего кадр изображения (или поле реконструкции), представляет собой оценку среднего относительного линейного коэффициента ослабления данного луча. Если рассмотреть большое число лучей, которые достаточно равномерно и плотно покрывают кадр реконструкции, то сумма всех лучевых сумм, деленная на сумму длин пересечений, является вполне разумной оценкой величины
известна, состоит в следующем. Рассмотрим рис. 2.8. Для любой пары источник — детектор лучевая сумма, деленная на длину отрезка луча, пересекающего кадр изображения (или поле реконструкции), представляет собой оценку среднего относительного линейного коэффициента ослабления данного луча. Если рассмотреть большое число лучей, которые достаточно равномерно и плотно покрывают кадр реконструкции, то сумма всех лучевых сумм, деленная на сумму длин пересечений, является вполне разумной оценкой величины  Например, для рассмотренного нами выше стандартного фантома головы
Например, для рассмотренного нами выше стандартного фантома головы  Оценка
Оценка  полученная по стандартным проекционным данным (разд. 5.6) методом, описанным выше, равна 0,1461. И это несмотря на то, что стандартные проекционные данные
полученная по стандартным проекционным данным (разд. 5.6) методом, описанным выше, равна 0,1461. И это несмотря на то, что стандартные проекционные данные















































































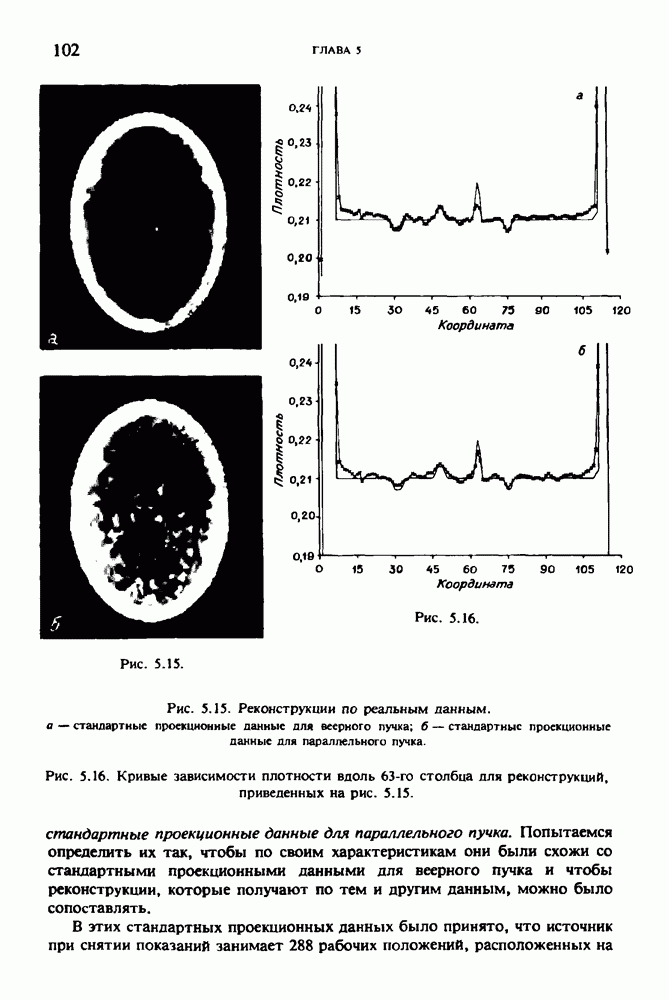





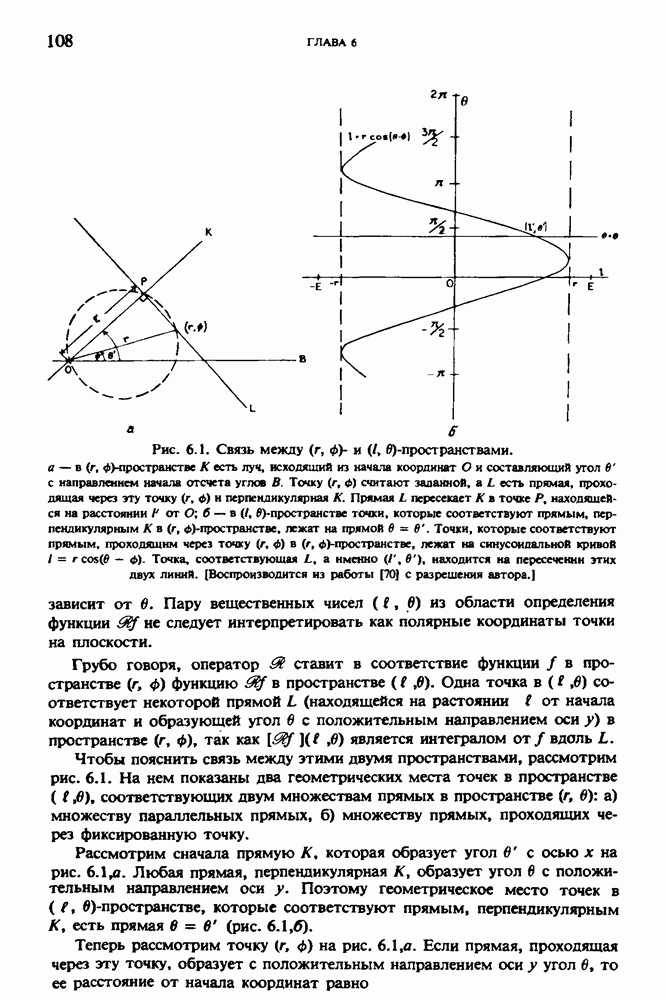



















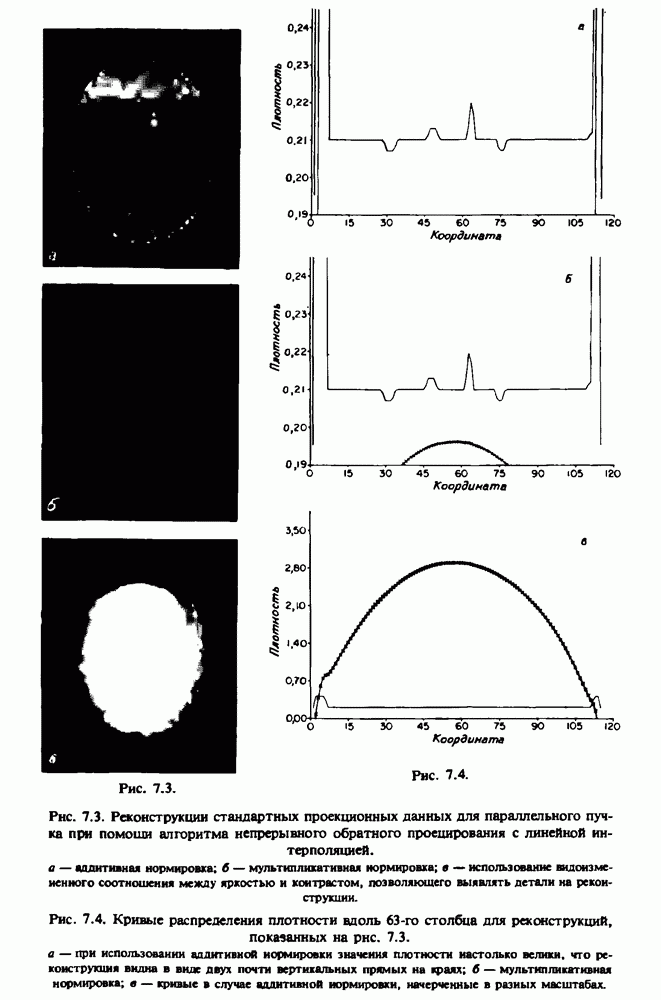


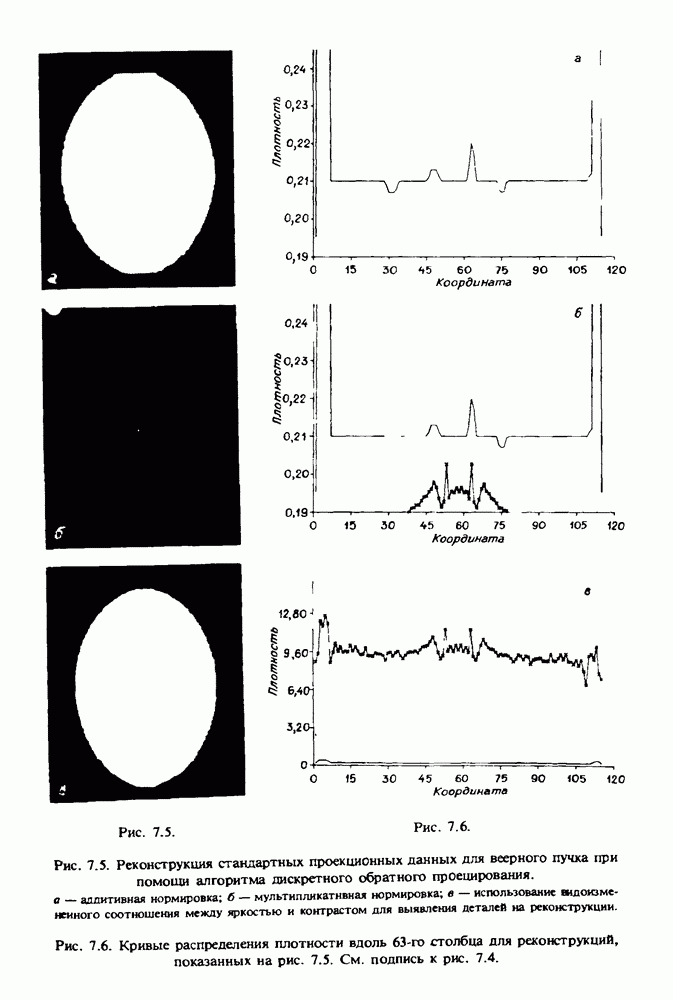


















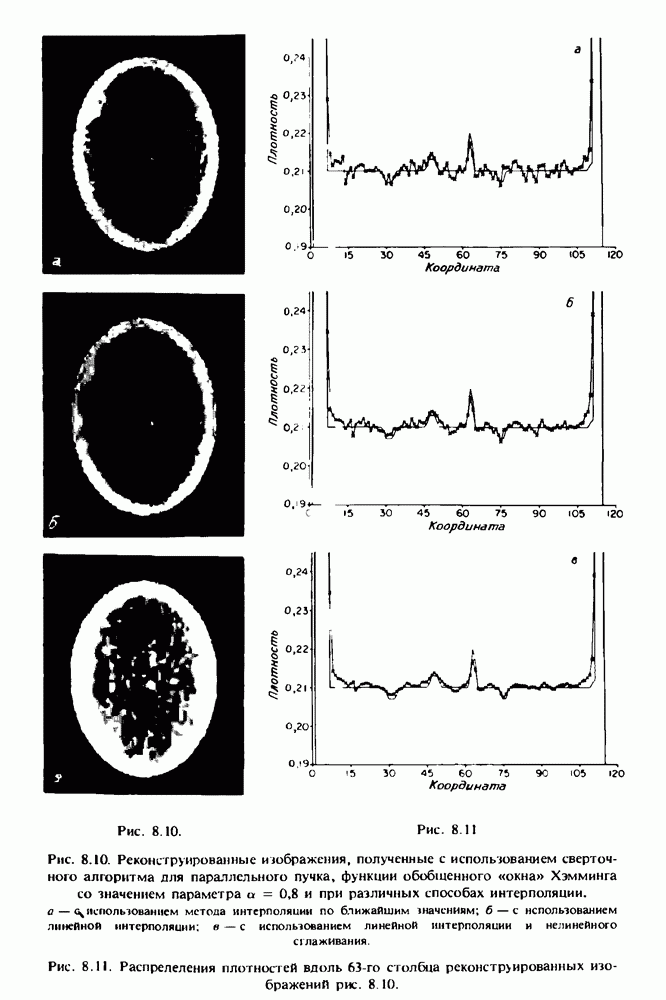











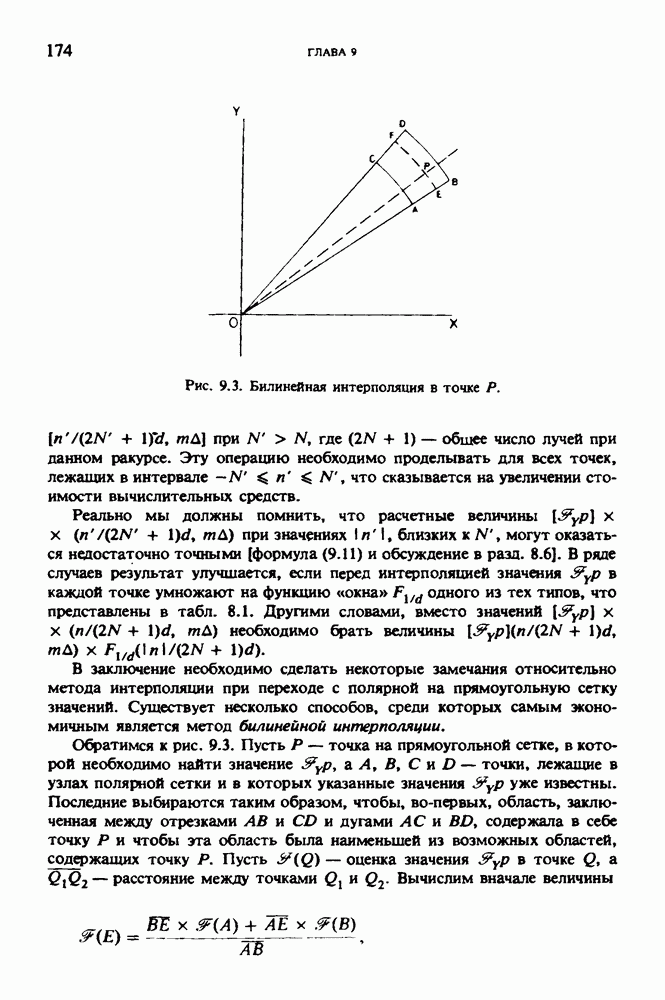

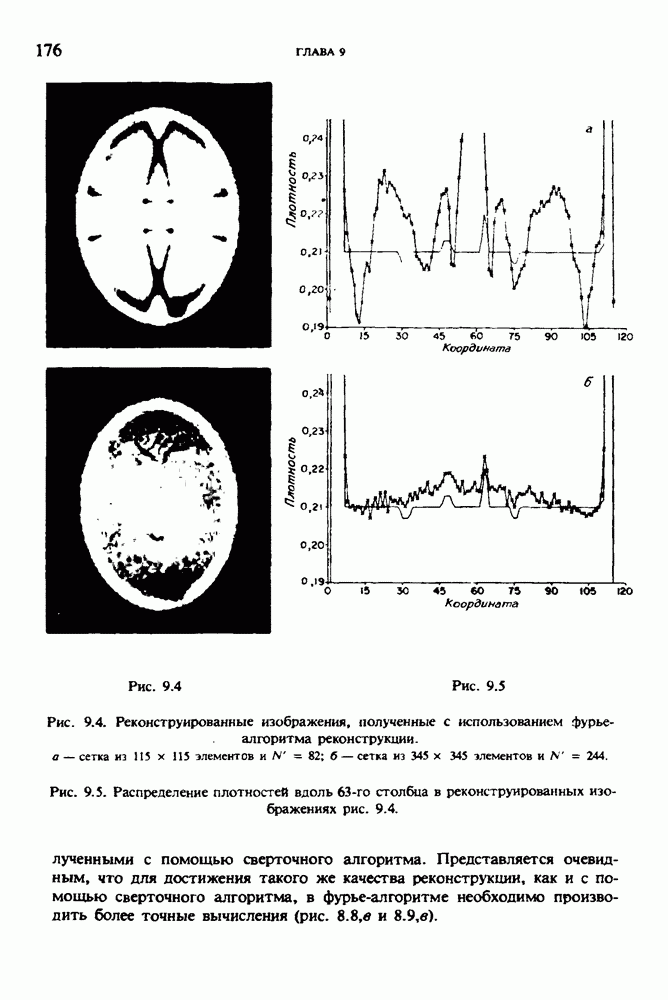
















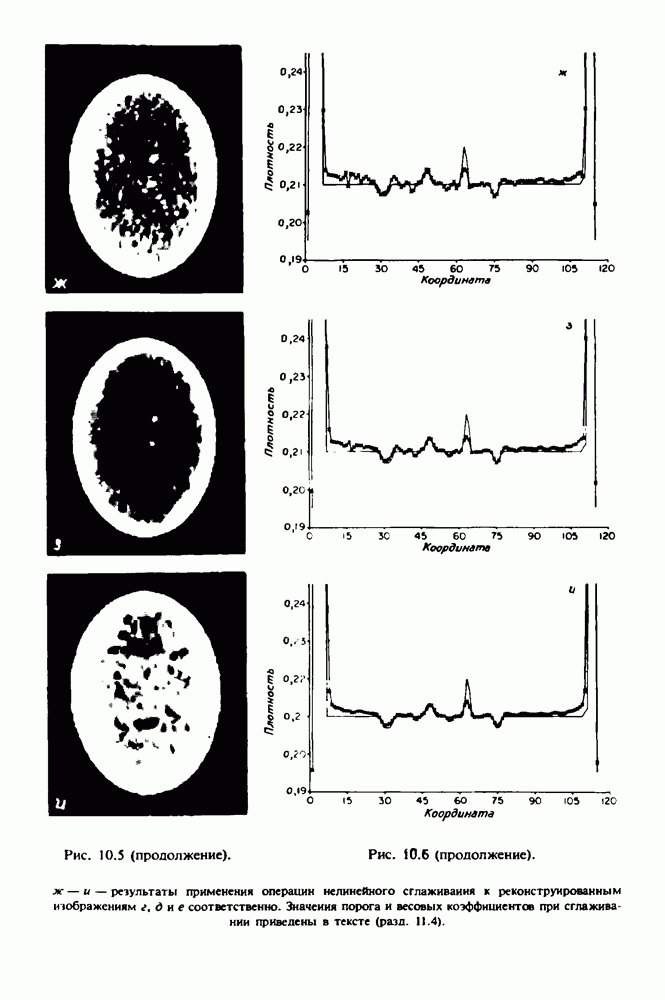




















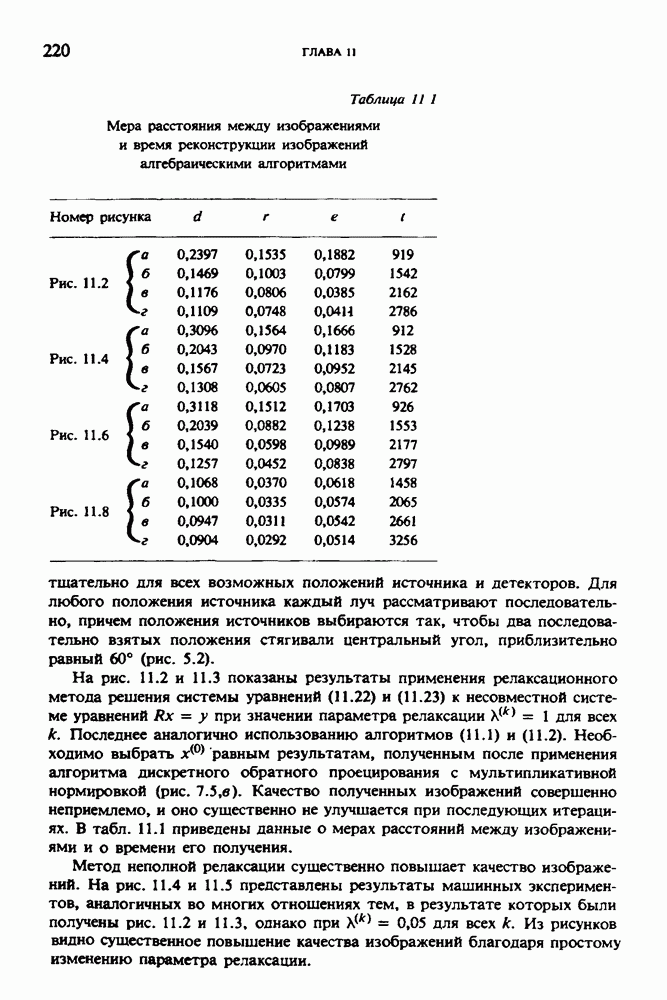
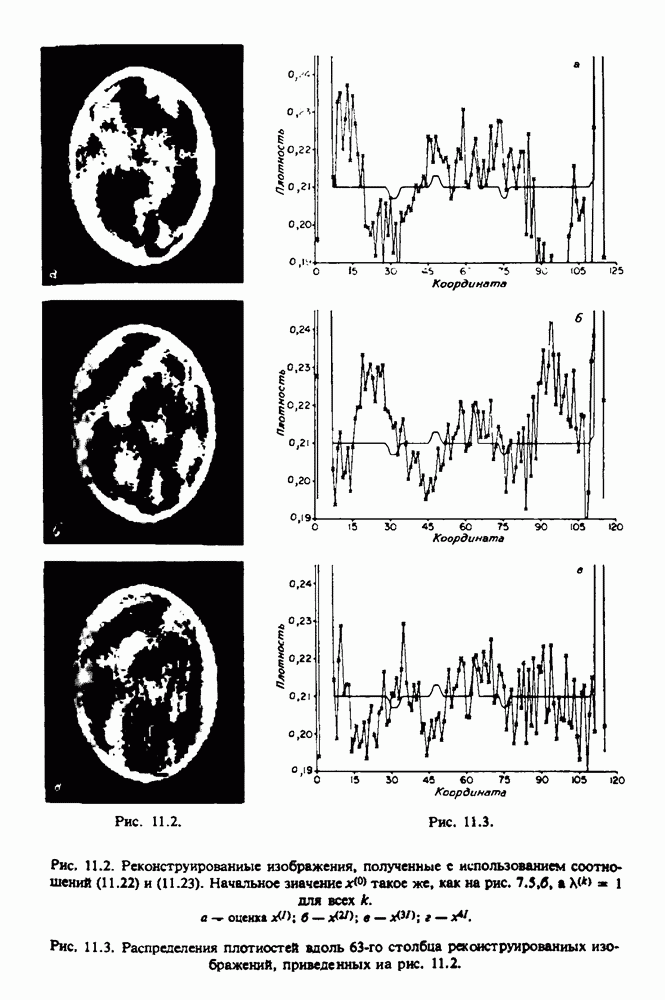
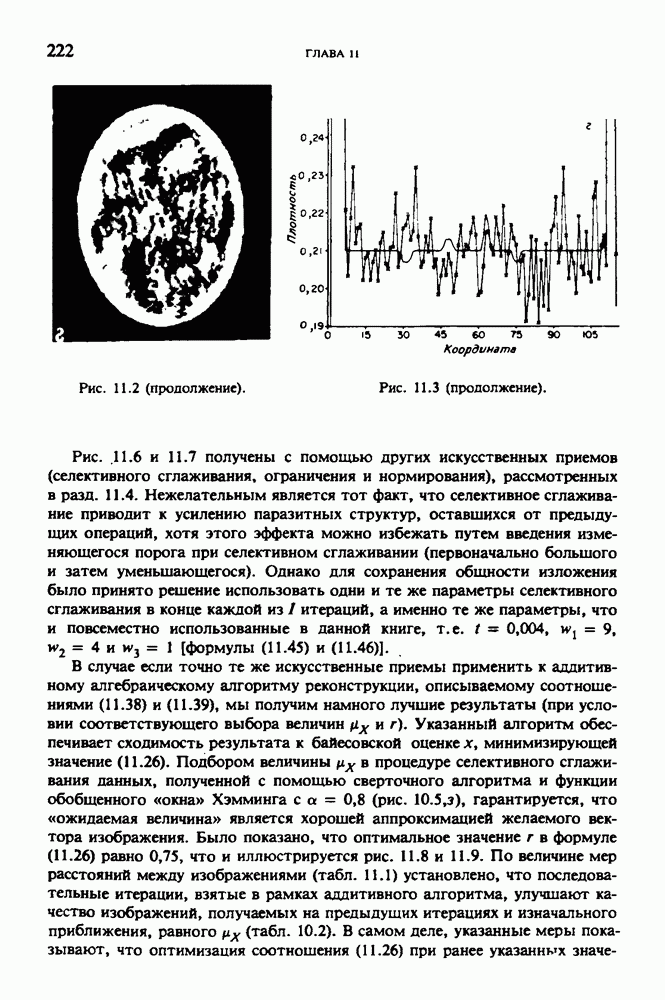
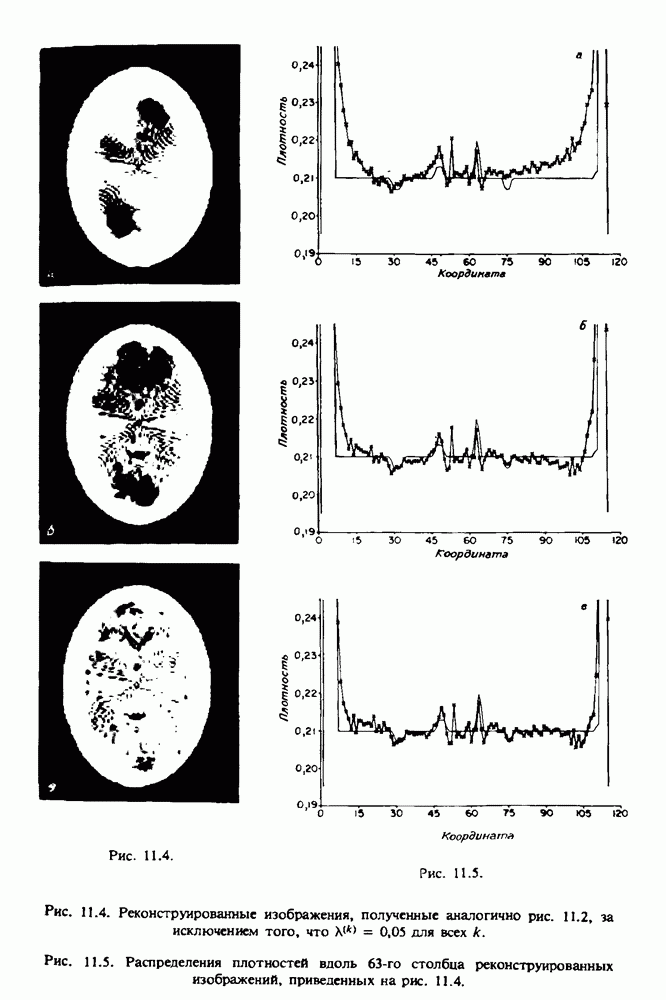
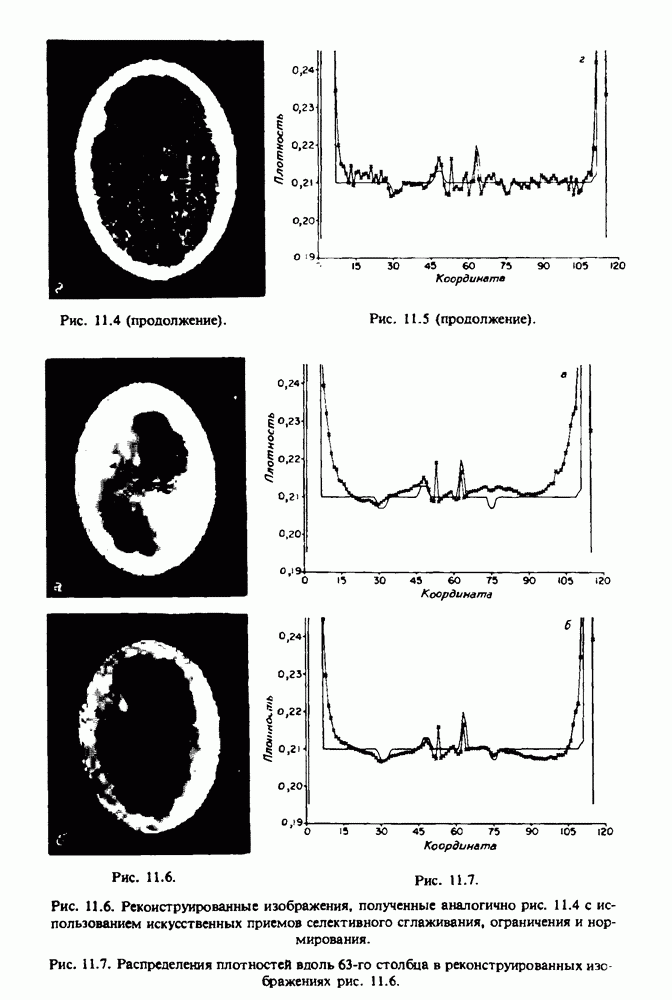
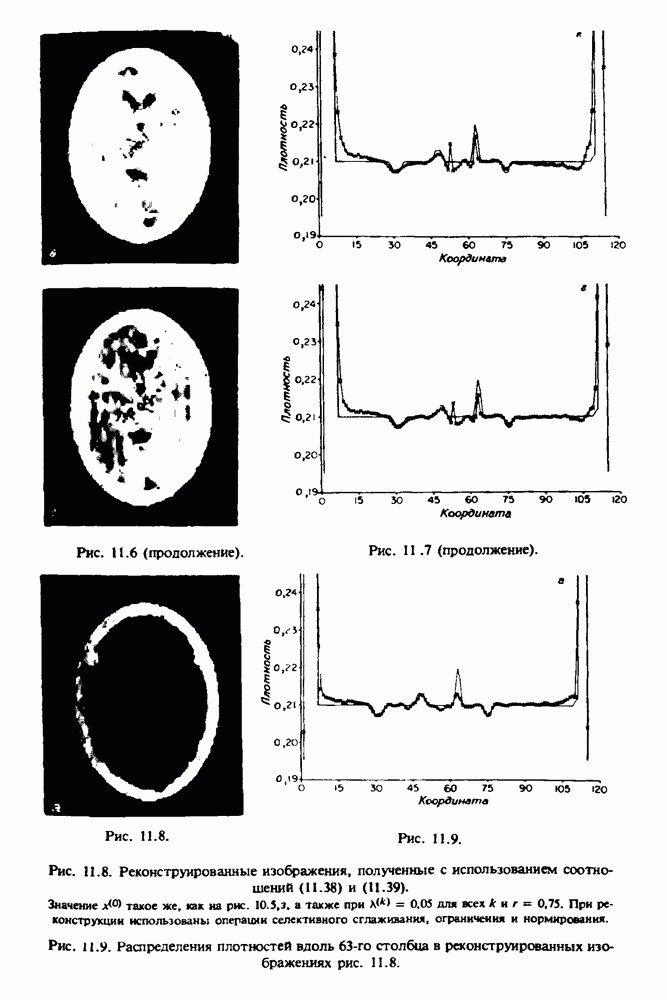
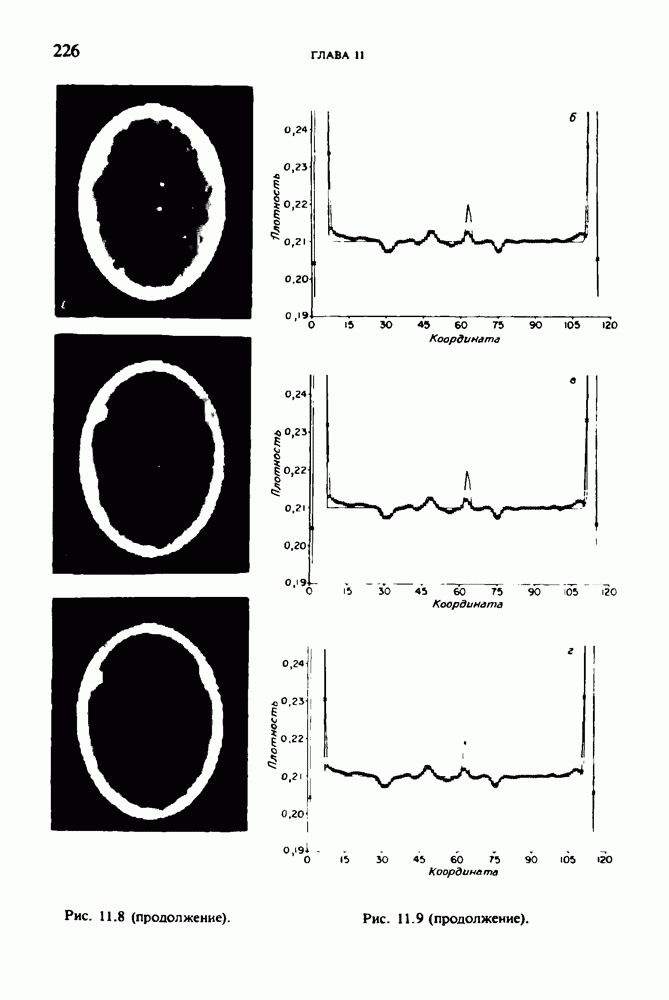
















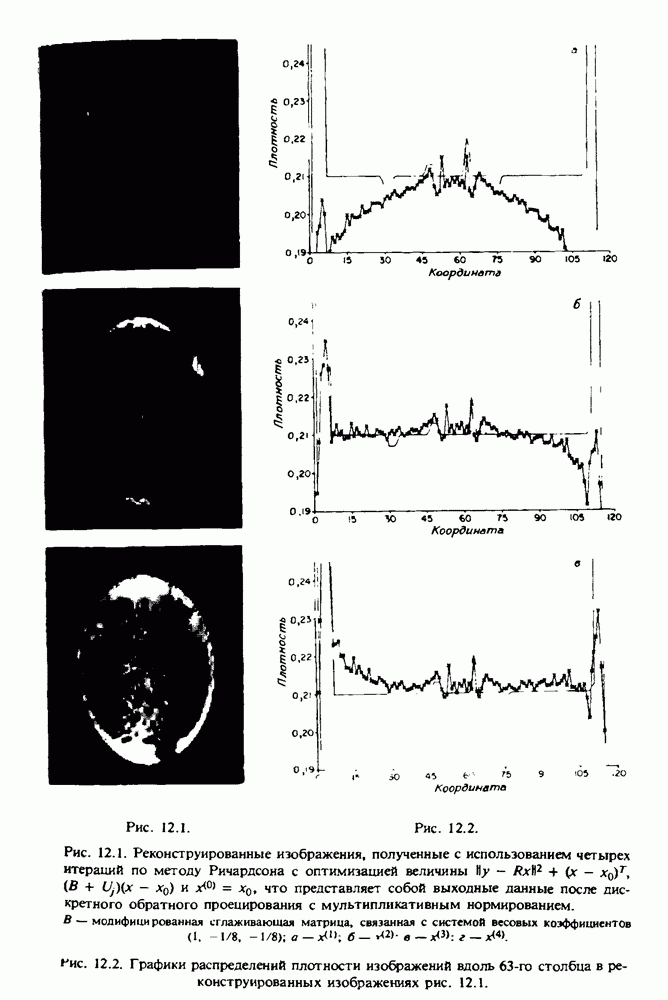
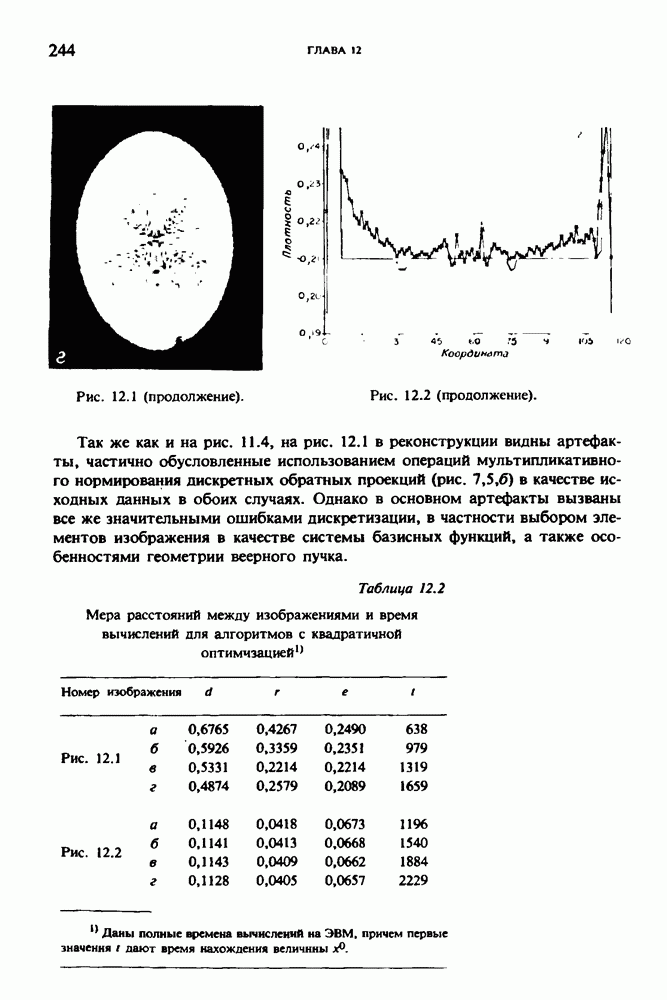
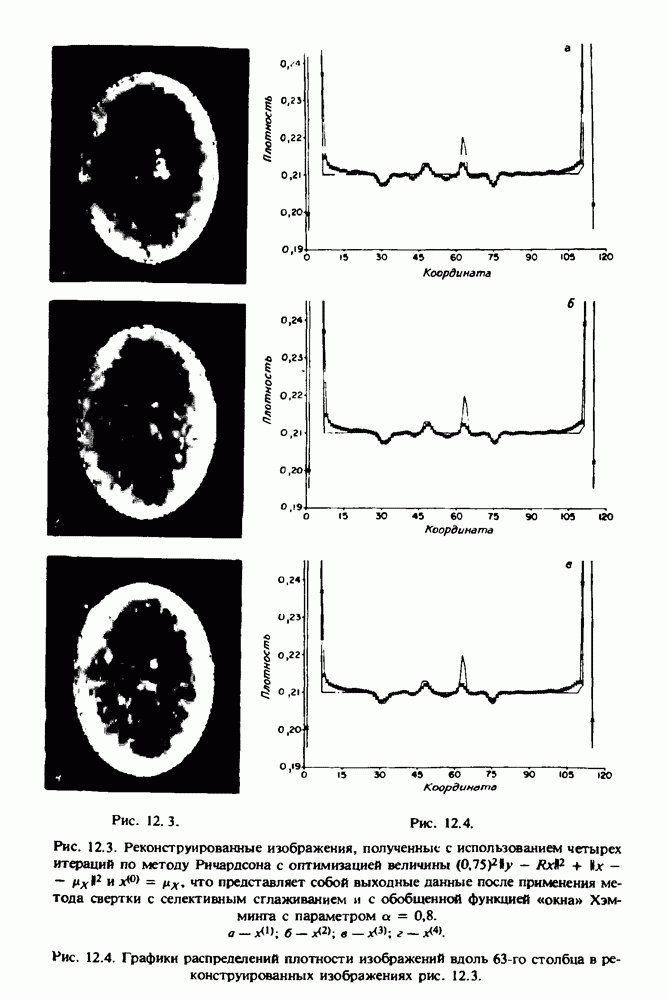
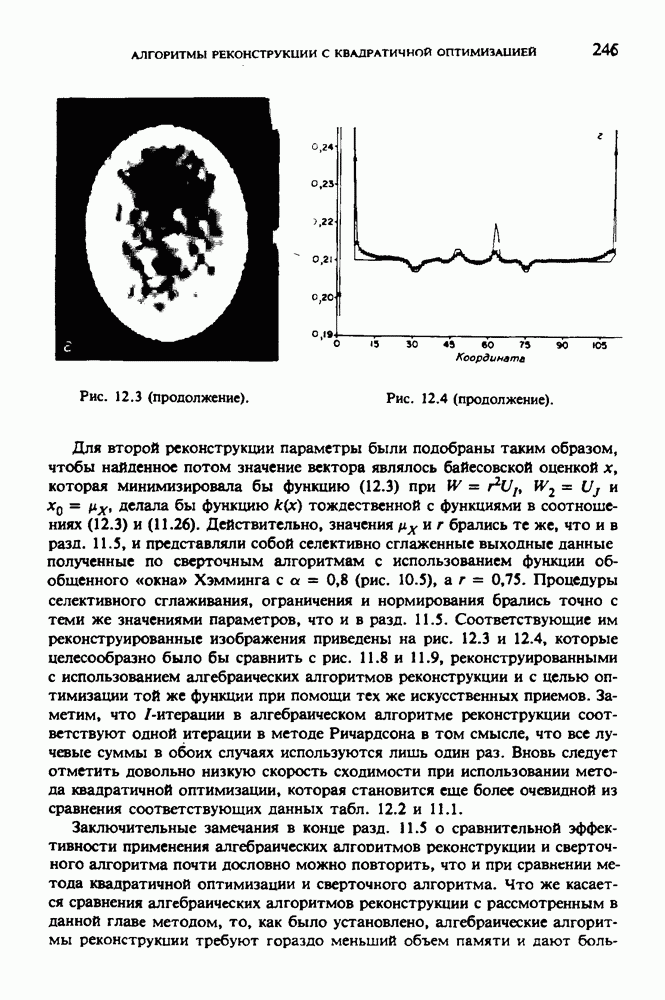
















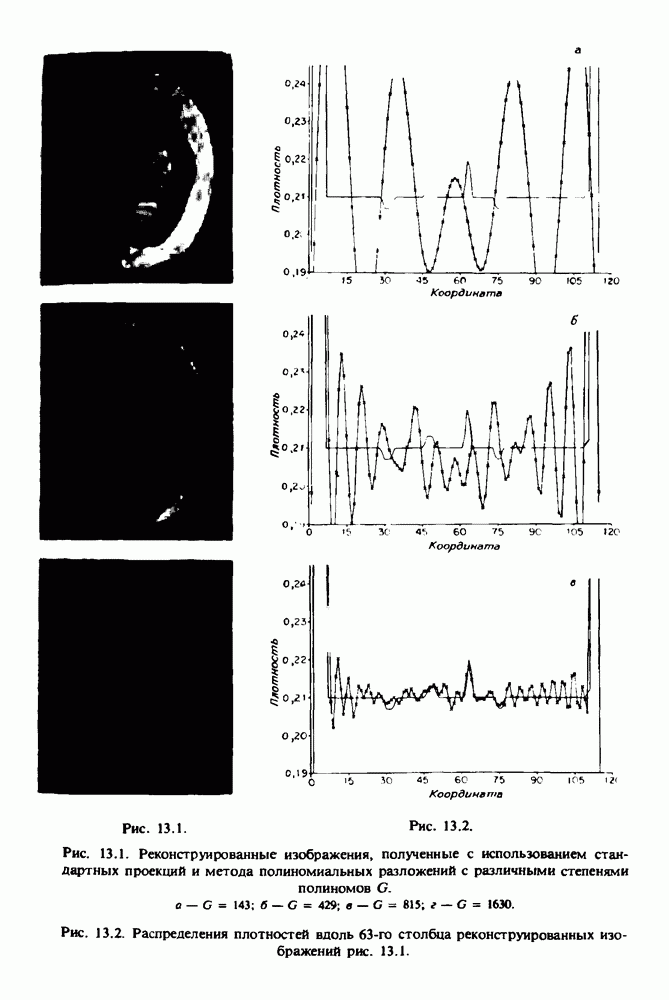
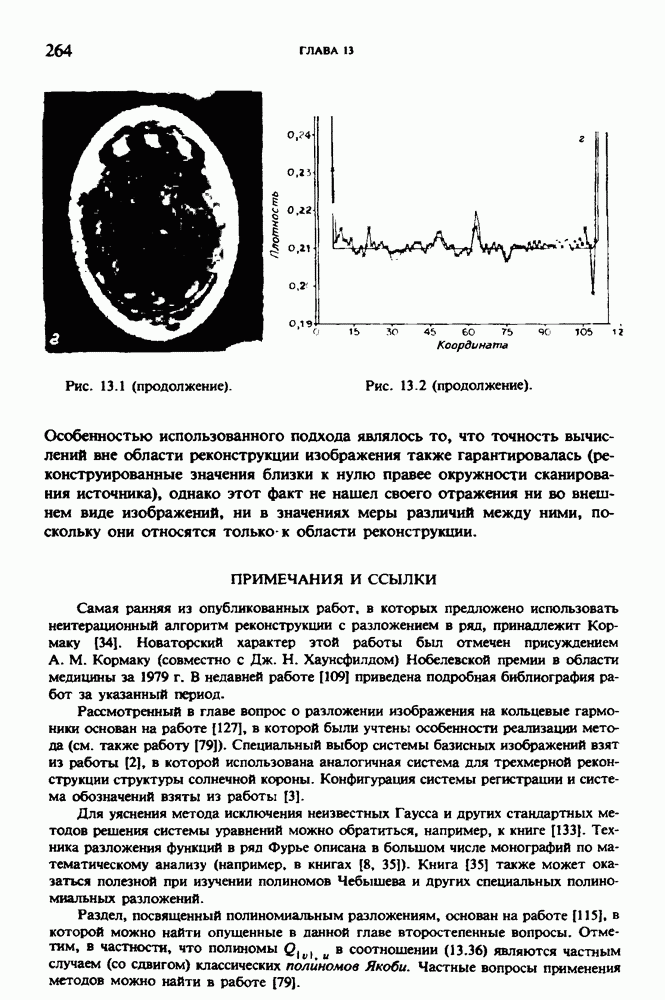




















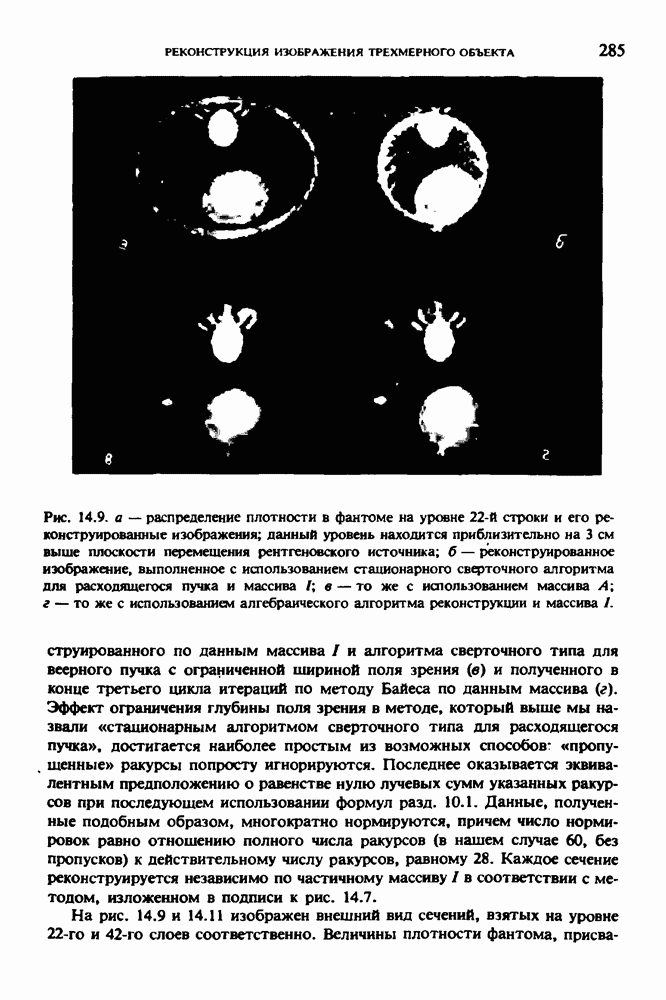
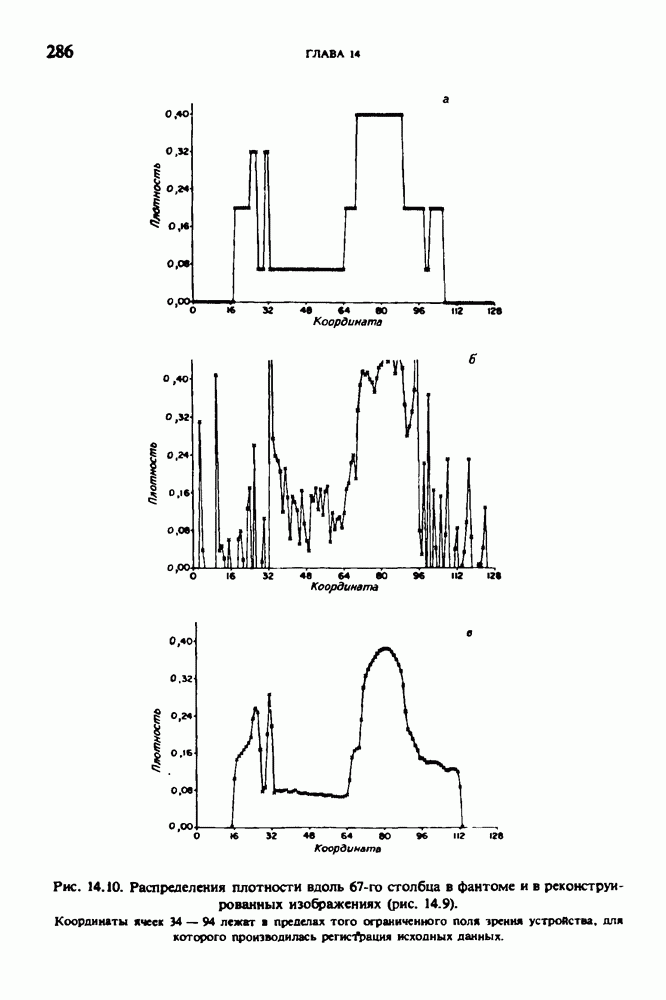
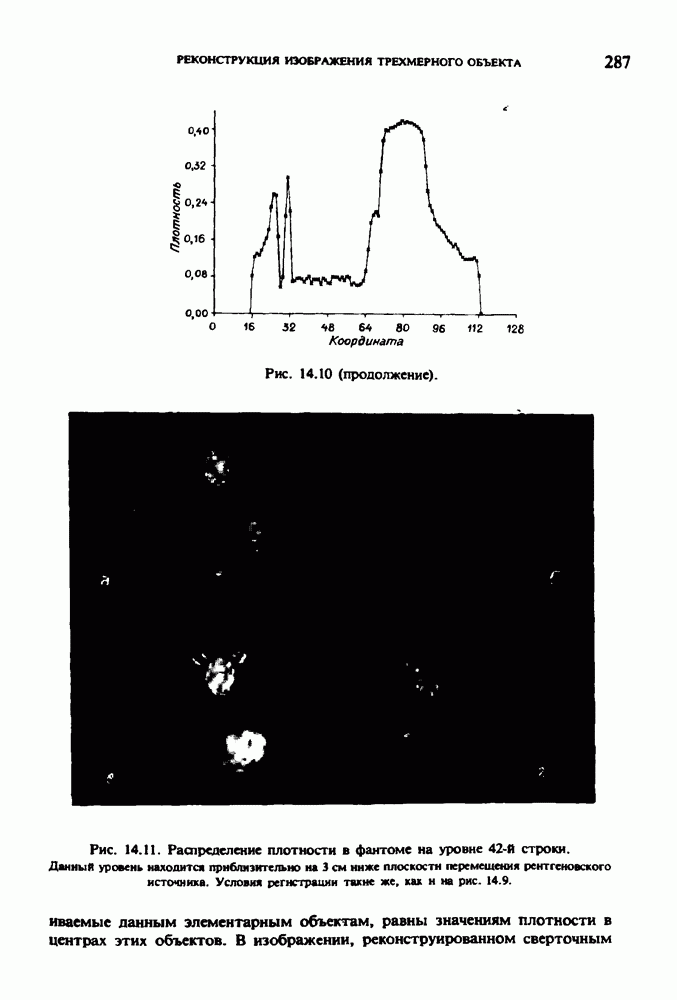
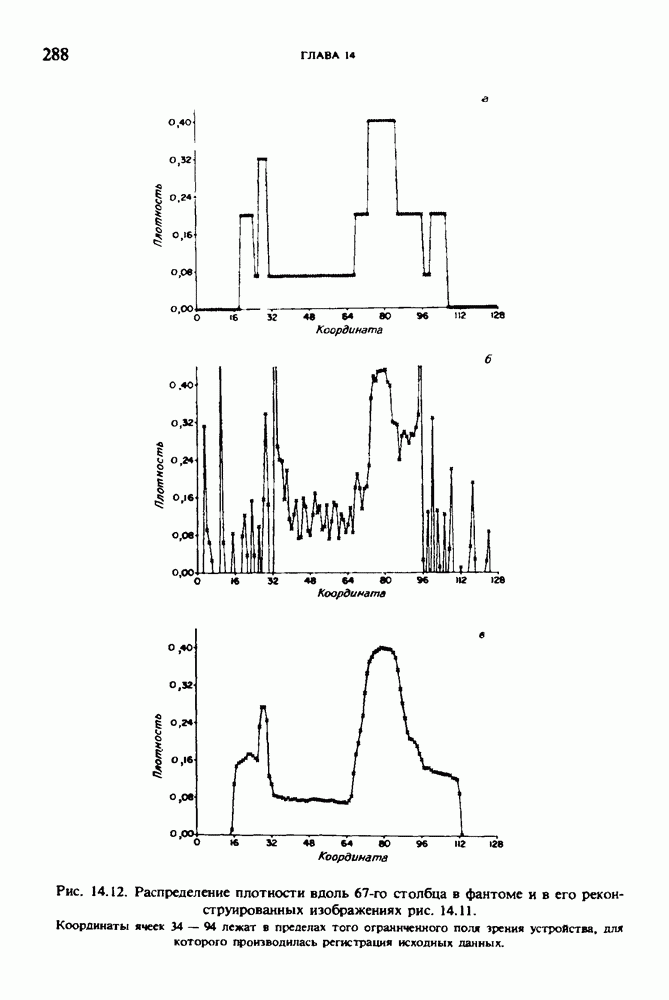
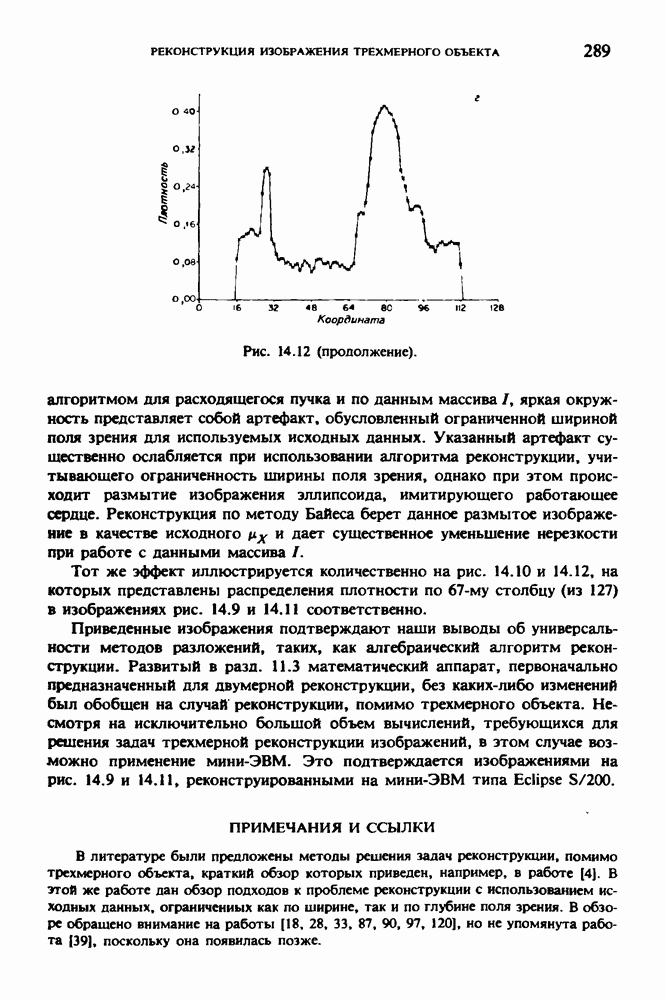














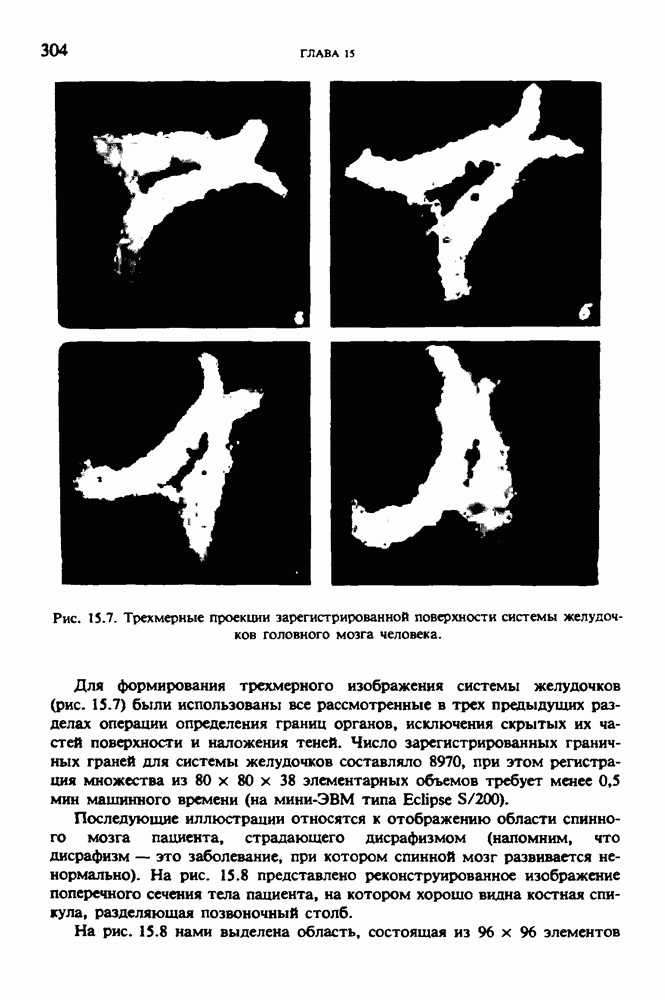



































 по стандартным проекционным данным для параллельного пучка, и тогда мы приходим к значению
по стандартным проекционным данным для параллельного пучка, и тогда мы приходим к значению  Эти данные указывают, что имеются основания для использования методов, описанных выше, для оценки
Эти данные указывают, что имеются основания для использования методов, описанных выше, для оценки  при использовании критериев оптимизации, таких, как максимум энтропии или минимум дисперсии.
при использовании критериев оптимизации, таких, как максимум энтропии или минимум дисперсии.