Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Предисловие к русскому изданиюНаша книга не названа «Теория нечетких множеств», хотя в различных ее главах речь неизменно идет об этой теории. Мы хотели выделить здесь особый случай применения нечетких множеств, продолжив тем самым высказанную Л. А. Заде в 1977 году идею о том, что функцию принадлежности можно в некоторых случаях интерпретировать как распределение возможностей. Это означает, что произвольное множество может рассматриваться как ограничение на возможные значения некоторой переменной. Преимушество данного подхода состоит в гармоничном сочетании теоретико-множественного и логического способов представления неточности знаний с методами количественного описания неопреде лен ности, вписывающимися в обобщенную теорию меры. Так, распределение возможностей можно одновременно рассматривать как обобщение понятия множества и как «плотность» меры неопределенности. Эта двойственность, допустимая в теории возможностей и отражающая противоречие между неопределенностью и неточностью, используется для единообразного представления неточной и неопределенной информации — идет ли речь о вычислении нечетких величин, об их сравнении, об использовании баз неполных знаний или о рассуждениях на их основе. В этом плане теория возможностей проводит четкое различие между степенью истинности и мерой неопределенности. К тому же нечетко-множественный подход предоставляет очень богатые возможности для комбинирования гибких критериев и для единого описания неточных и неопределенных данных. Исследования советских ученых в области нечетких множеств имеют богатую традицию и носят фундаментальный характер. Мы полагаем, что эта книга может особенно заинтересовать советских исследователей и специалистов в области искусственного интеллекта, разработки баз данных и исследования операций. Д. Дюбуа, А. Прад Тулуза, 10 июня 1987 г. Предисловие ко второму изданиюДля второго издания текст книги в некоторых местах был переработан, а порой существенно дополнен. Основные изменения касаются гл. 4, меньше добавлений и вставок было сделано в гл. 1, 3 и 6; гл. 2, 5 остались без изменений (за исключением обновленных ссылок на литературу). Эти изменения отражают уровень развития наших работ, а также работ других авторов, особенно в области автоматизированного логического вывода в условиях неопределенности. Наши дополнения относятся к следующим темам. Глава 1. Понятие мощности нечеткого множества, возможностные аппроксимации неточных статистических данных, связи нечеткости с интервальным анализом. Глава 3. Нечеткие кванторы и их использование для свертывания критериев, применение нечетких интервалов к анализу временных окон в задаче планирования работ. Глава 4. Моделирование одновременно как неточной, так и неопределенной информации, «логический» подход к обусловливанию, обсуждение вариантов комбинирования неточно определенной информации, описание неопределенности с помощью матричного исчисления и расширенного принципа резолюции, вывод с нечеткими кванторами, интерпретация нечетких правил, нечеткая фильтрация. Кроме того, программа, реализующая машину вывода SPII, предложенная в приложении 2 к гл. 4, написана заново, а сопровождающее ее приложение 1 было полностью переписано, чтобы лучше была понятна методика применения обобщенного правила «модус поненс» к нечетким предикатам. Глава 6. Обработка взвешенных размытых вопросников с помощью нечеткой фильтрации и метода, уже использованного в гл. 3, классификация результатов, полученных с помощью нечеткой фильтрации. Д. Дюбуа, А. Прад Тулуза, 2 июня 1987 г. Предисловие к первому изданиюНаступление эры вычислительных машин, породив стремление решать новые практические задачи, исходя из все более и более сложных моделей, ускорило потребность в получении и обработке все более сложной и неточной информации. Значительная часть этой информации недоступна в форме точных, четко определенных чисел, и чисто символьная обработка данных может быть недостаточной. По разным причинам — из-за несовершенства измерительных устройств или вследствие того, что во многих случаях человек (эксперт) представляет собой единственный источник сведений, — информация является неточной, противоречивой, неполной. Поэтому с появлением информатики разработка теорий, средств и методов представления и анализа неточности и неопределенности (в том числе субъективной неопределенности) становится важной целью, отчасти обусловливающей прогресс как самой информатики, так и использующих ее дисциплин. При измерениях получить точную информацию практически невозможно, а если и возможно, то она чаще всего оказывается малополезной и трудно-интерпретируемой. Это как раз тот случай, когда анализируется функционирование сложной или многомерной системы. Упрощенная модель обеспечивает порой более понятную информацию, чем детальная и более точная модель. Заде подчеркивает: ”По мере возрастания сложности системы наша способность формулировать точные, содержащие смысл утверждения о ее поведении уменьшается вплоть до некоторого порога, за которым точность и смысл становятся взаимоисключающими” [9]. Этот принцип несовместимости связан со способом восприятия и рассуждений человека. В его основе лежат обобщенные, схематизированные, а следовательно, неточные субъективные представления о реальности. Действительно, «хорошая модель» должна реализовывать некоторый компромисс без всякого избытка точности (которая может привноситься произвольным образом и вызывать неопределенность) или избытка неточности (в результате чего модель может стать малоинформативной). Наши предыдущие размышления не претендуют на критику традиционного научного подхода: со времени открытия Гейзенбергом соотношений неопределенности принципиально неустранимая неточность стала привычным явлением. Но учет неточности, даже порождаемой ограниченными возможностями человеческого разума, не отменяет требований к строгости, которая должна быть в еще большей степени, чем поиск точности, присущей научному подходу. Теория ошибок, с одной стороны, и теория вероятностей — с другой, суть два классических подхода к представлению неполноты информации. Но они оказываются недостаточными при столкновении с новыми потребностями. В самом деле, ограниченность теории ошибок состоит в том,что она не отражает огтенки и применима лишь к числовым величинам. А теория вероятностей предлагает, по-видимому, чересчур нормативные рамки для учета субъективных суждений. Последнее обсуждается в гл. 1. Постановка вопроса о применимости аддитивных вероятностей в моделях субъективных суждений отнюдь не нова. В своей замечательной статье по истории наук Шейфер [7] напоминает, что вплоть до конца XVII века понятия «шанс», связанное со случайностью, к «вероятность», как атрибут суждения рассматривались независимо друг от друга. Первоначально теория шансов и теория вероятностей развивалась порознь, причем последняя — без аксиомы аддитивности. Шейфер [7] показал, что немалая часть трудов Бернулли посвящена рассмотрению неаддитивных вероятностей. Успех аддитивных вероятностей связан с быстрым развитием физики, которая отодвинула на второй план задачи моделирования субъективных суждений. В работах XX в. доминирует представление об аддитивности степеней доверия, особенно в теории принятия решений. Однако в 50-е годы английский экономист Шейкл [5] предложил невероятностный подход к принятию решений, в котором этот процесс анализировался в терминах «возможностей». В 60-е годы исследователи в области математической статистики, в частности Демпстер [1], ввели понятие уже неаддитивных верхних и нижних вероятностей для учета неполноты наблюдений. Взяв за основу модель Демпстера, Шейфер [6] определил эти верхние и нижние вероятности соответственно через степени правдоподобности и степени доверия в теории принятия решений. С прогрессом информатики и с развитием методов искусственного интеллекта возникла настоятельная потребность в теории субъективных суждений, выходящей за рамки теории вероятности, о чем свидетельствуют работы по экспертным системам, таким как MYCIN (Шортлифф и Бьюкенен [8]), а также возрастающий интерес специалистов по искусственному интеллекту к работам, подобным работам Шейфера. Теория возможностей, сформулированная Заде в 1977 г., предлагает некоторую модель количественного описания суждений, которая позволяет также провести каноническое обобщение теории ошибок. В этом плане неопределенность некоторого события описывается одновременно степенью возможности этого события и степенью возможности противоположного события, причем эти две степени возможности слабо связаны между собой. Дополнение к единице степени возможности противоположного события может интерпретироваться как степень необходимости (определенности). Этот способ представления неопределенности в терминах более или менее возможных и более или менее достоверных событий выглядит естественным и, по-видимому, широко используется человеком. Такая точка зрения вполне отражает интуитивное представление Шейкла, формализованное в рамках теории возможности. Более того, можно показать (см. гл. 1 и 4), что дихотомия «возможность — необходимость» в математическом смысле есть частный случай дихотомии «правдоподобность - доверие», предложенной Шейфером. Теория возможностей основана на идее нечеткого множества, развиваемой Заде начиная с 60-х годов. Нечеткое множество позволяет учитывать тот факт, что любой объект может более или менее соответствовать некоторой категории, к которой его хотели бы отнести. Когда степени возможности принимают лишь значения 0 или 1, теория возможности в точности совпадает с теорией ошибок, в которой неточная информация представлена в виде множеств возможных значений (вместо точных значений). В общем случае в теории возможностей эти множества становятся нечеткими. Данные замечания подчеркивают наличие взаимосвязей между теорией возможностей и «наивной» теорией множеств, а также между понятиями возможности и меры (в том смысле, как ее понимают в теории меры). К тому же известно, что, с одной стороны, нечеткие множества связаны с многозначными логиками, разработанными "польской школой” в 30-е годы, а с другой стороны, как отмечали Кампе де Ферье [4], а также Форте и Камбузиа [3], функции принадлежности нечеткого множества можно интерпретировать через функции правдоподобности Шейфера или характеристические функции случайных множеств. Одно из преимуществ теории возможностей заключается в том, что она позволяет одновременно моделировать неточность (в форме нечетких множеств) и количественно характеризовать неопределенность Настоящая книга состоит из шести глав. Основные понятия вводятся и обсуждаются в гл. 1. Особое внимание здесь уделяется связям между мерами возможности и вероятностными мерами. Математический аппарат изложен в основном в гл. 1, 2 с дополнениями в гл. 3, 4. В гл. 2 - 6 с помощью кратких примеров иллюстрируется применение теории возможностей в различных областях, таких как исследование операций, искусственный интеллект, построение баз данных, а в приложениях к этим главам приводятся соответствующие программы для ЭВМ. Главы следуют друг за другом в порядке, удобном для чтения, однако гл. 4 - 6 относительно независимы друг от друга. Программы, помещенные в приложениях, показывают реализуемость представленных методов на ЭВМ, но отнюдь не оптимальны по их выполнению на на ЭВМ. Выбор языка программирования Бейсик для некоторых из них объясняется широкой распространенностью этого языка программирования; характер других примеров обусловил использование язык? программирования Лисп. Здесь охвачены не все области применения теории возможностей. Например, в этой книге не рассматриваются вопросы автоматической классификации, управления, оптимизации и ряд других, в которых теория возможностей или нечеткие множества уже нашли успешное применение. Более полная, хотя и несколько устаревшая, картина исследований по нечетким множествам и их применению имеется в предыдущей книге авторов [2]. Главы 4—6 были задуманы и написаны совместно с Р. Мартэн-Клуэром, А. Фаррени и К. Тестмаль соответственно. Они написали имеющиеся в этих главах программы на языке Лисп. Программы на языке Бейсик созданы Ф. Шаталиком. Рисунки 3.2 — 3.13 нам любезно предоставил К. Тессье. Перепечатку рукописи с большой тщательностью и терпением осуществила мадам Л. Фресс. Д. Дюбуа, А. Прад Тулуза, ноябрь 1984 г. СПИСОК ЛИТЕРАТУРЫ К ПРЕДИСЛОВИЮ(см. скан) ДОПОЛНИТЕЛЬНЫЙ СПИСОК ЛИТЕРАТУРЫ(см. скан)
|
 |
Оглавление
|





























































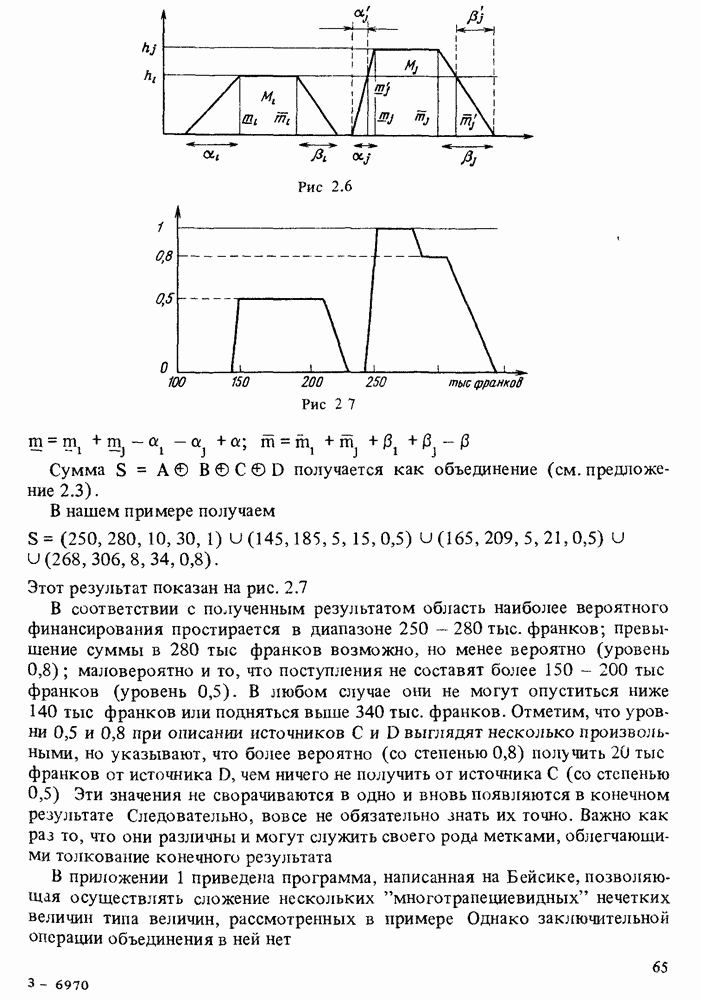

















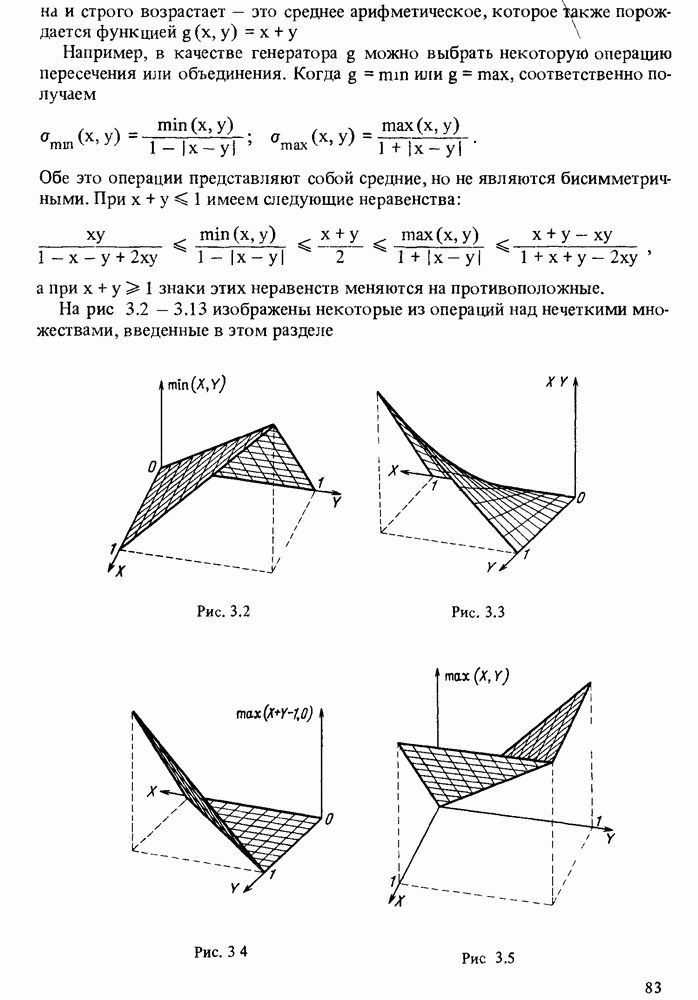
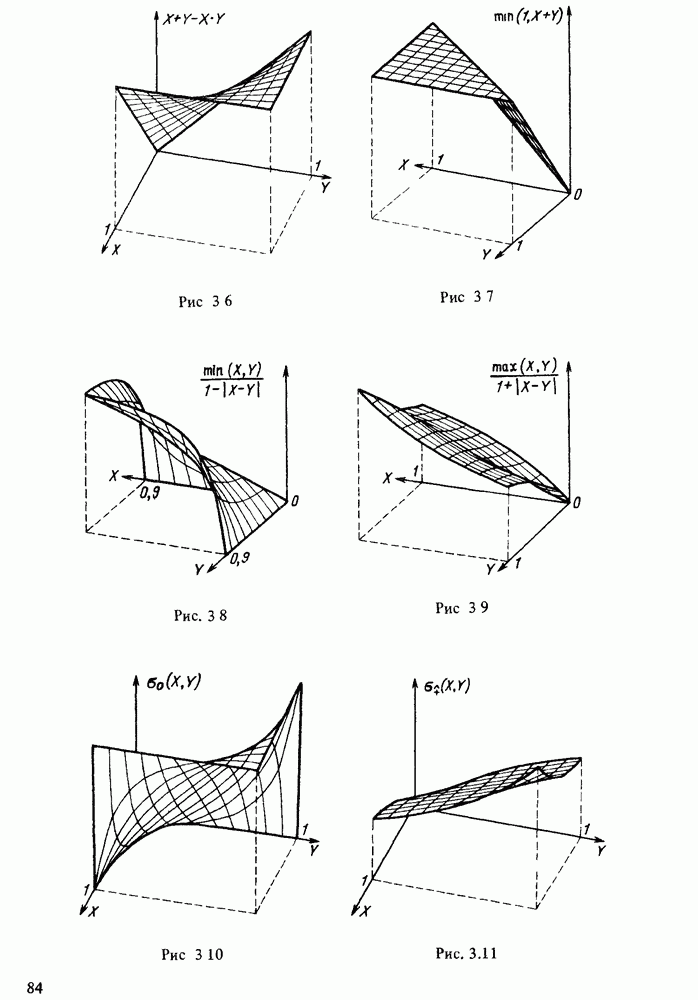












































































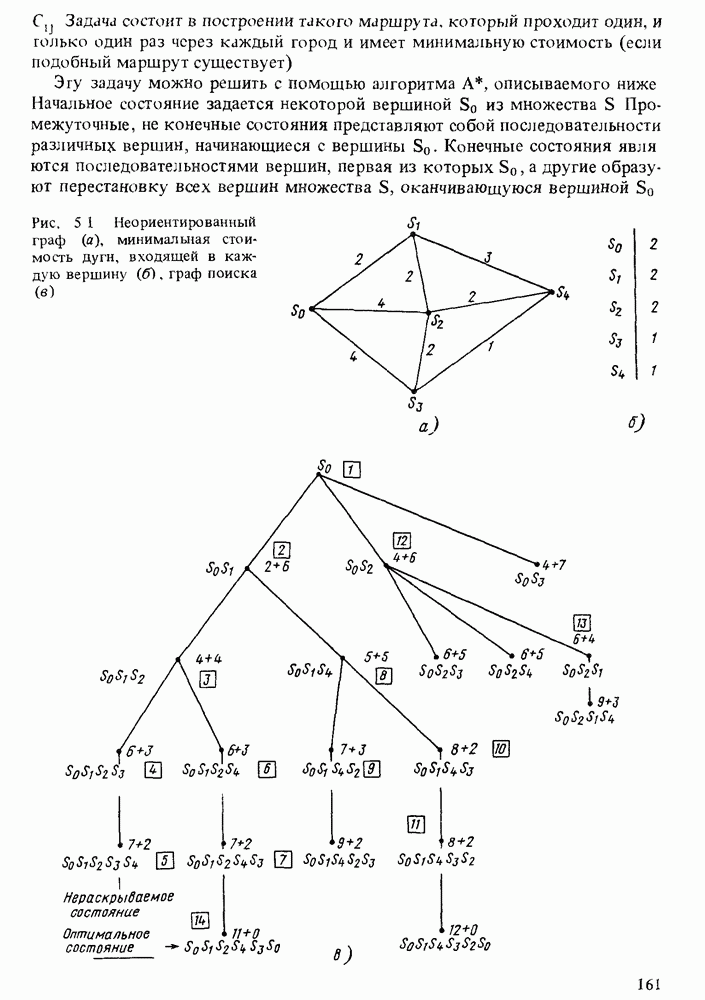


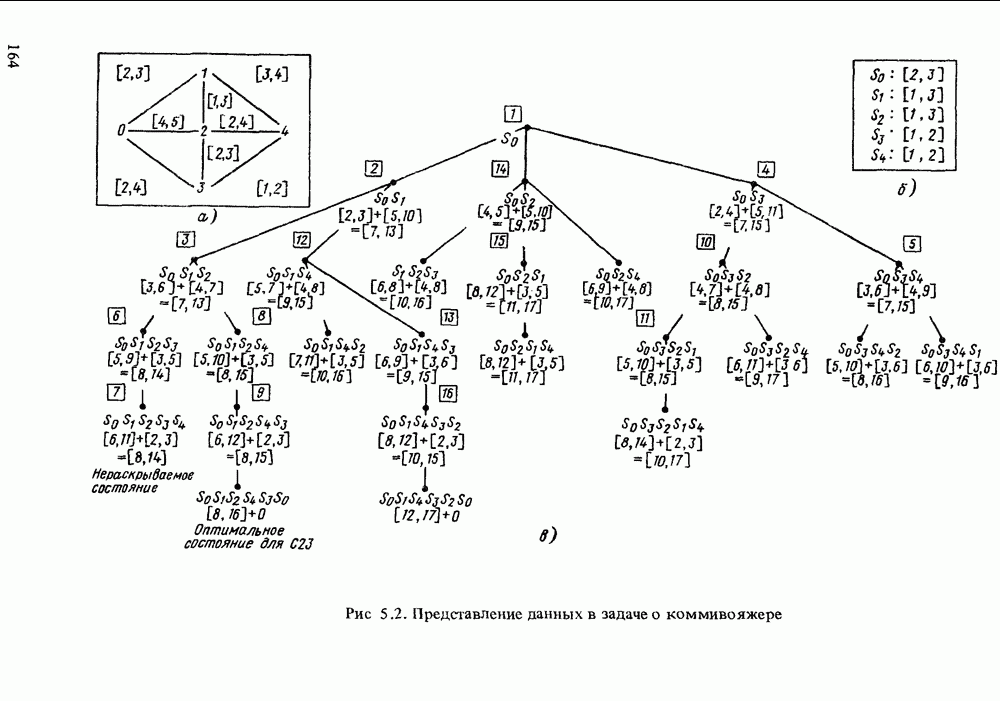








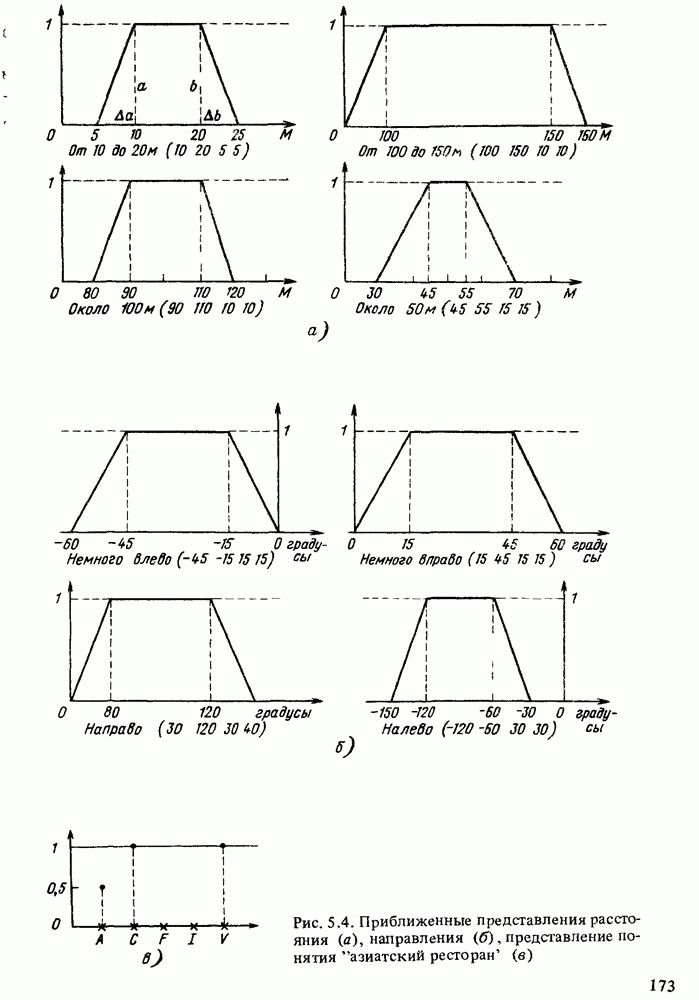


































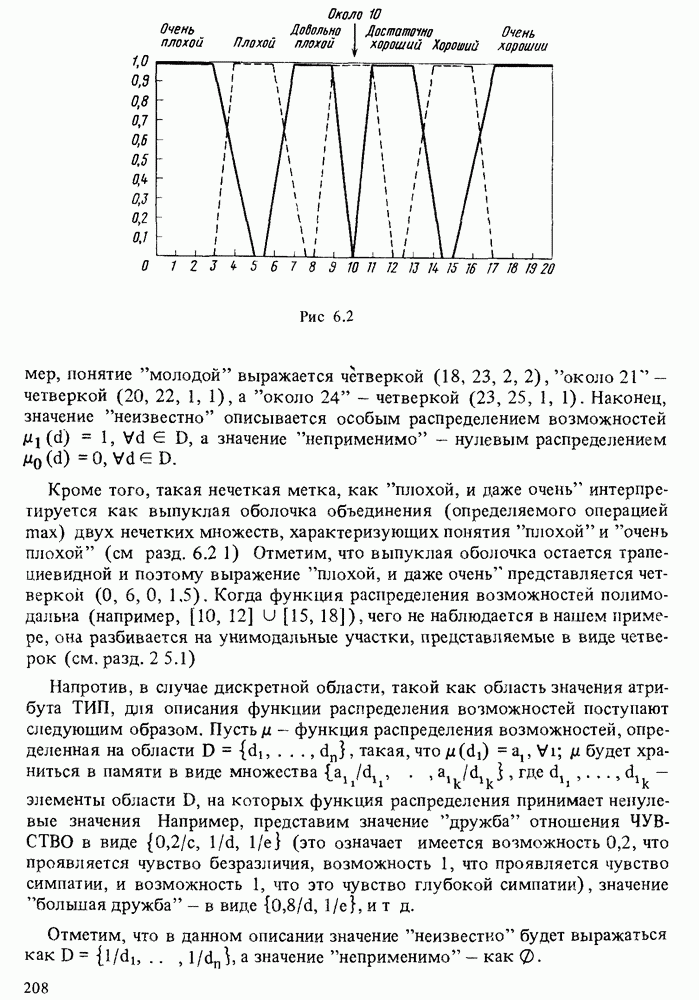






















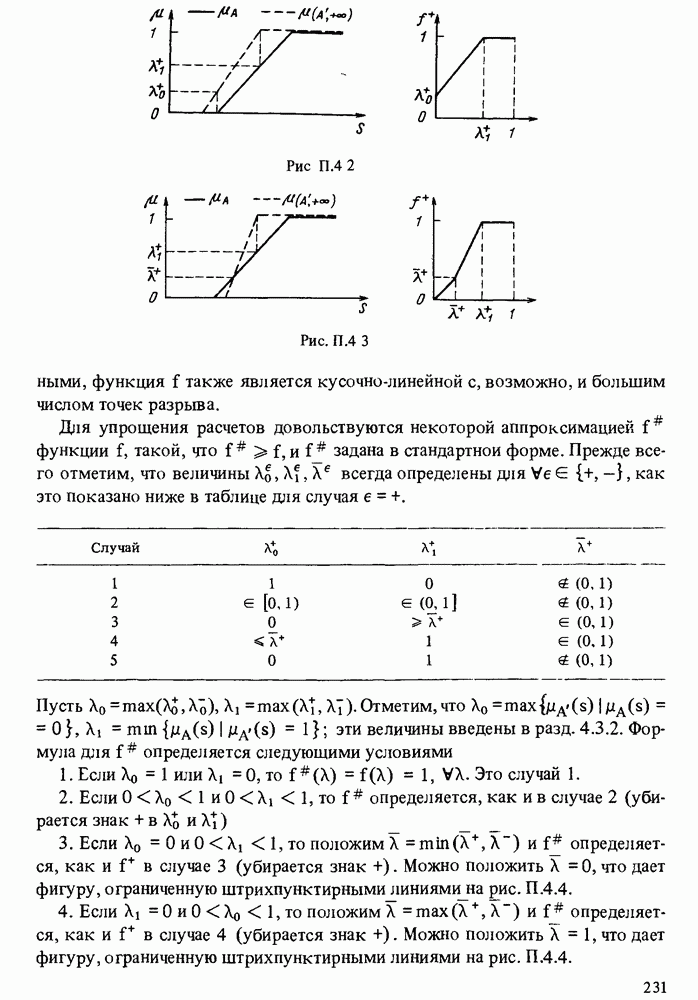



















































 в форме пары чисел «возможность — необходимость»). Однако в данной теории количественные описания выражаются, пожалуй, наиболее качественным способом, так как для вычислений в ней используются в основном операторы минимума и максимума. В определенном смысле теория возможностей опровергает знаменитую формулу Резерфорда: "Качественное есть не что иное, как бедное количественное”. Принцип теории возможностей, наоборот, состоит в рассмотрении количественного как предельного случая качественного.
в форме пары чисел «возможность — необходимость»). Однако в данной теории количественные описания выражаются, пожалуй, наиболее качественным способом, так как для вычислений в ней используются в основном операторы минимума и максимума. В определенном смысле теория возможностей опровергает знаменитую формулу Резерфорда: "Качественное есть не что иное, как бедное количественное”. Принцип теории возможностей, наоборот, состоит в рассмотрении количественного как предельного случая качественного.