Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
6.1.2. СХОДСТВО И ОТЛИЧИЕ ОТ ДРУГИХ ПОДХОДОВ К ПРЕДСТАВЛЕНИЮ НЕЧЕТКОЙ ИНФОРМАЦИИ В БАЗЕ ДАННЫХИдея использования функций распределения возможностей или родственных им построений при моделировании неполноты или нечеткости информации в базах данных уже рассматривалась в работах [6 - 8, 27, 37 - 39]. Так, в работе [37] Тахани использует нечеткие термы исключительно с целью формулирования нечетких запросов с точных данных, при этом ответ на вопрос состоит из нечеткого множества данных. В свою очередь, Баклс и Петри [6 - 8] ввели нечеткое отношение подобия, связанное с каждой областью значений атрибута, имея в виду описание степени взаимозаменяемости элементов этой области. Таким образом, возможные значения атрибута представляются с помощью (обычных) множеств элементов, которые считаются взаимозаменяемыми по отношению подобия и фиксированному порогу, зависящему от области значений Умано в работе [38] предлагает модель, в явном виде основанную на понятии функции распределения возможностей. В нашем подходе предлагается вариант обобщения этого способа представления информации за счет введения дополнительного элемента, который позволяет нам учитывать ситуации, когда имеется ненулевая вероятность неприменимости данного атрибута. Однако сам метод, разработанный для оценки вопросов (см. разд 6.2), отличаемся от метода Умано: он основан на двойственных понятиях мер возможности и необходимости, тогда как подход Умано в работе [38] опирается, скорее, на специальную логику, разработанную для этой цели. Другой способ представления нечеткой информации состоит в связывании с каждой гранулой информации о некотором объекте нечеткого значения истинности (т. е. числа, принадлежащего интервалу [0,1]) (см. работы [2,3, 16, 20, 21, 26]). Фрекса [16] использует, скорее, лингвистические значения истинности, характеризуемые функциями распределения возможностей на интервале [0, 1] (так же как и Умано в [39]). В реляционной базе данных этот способ представления нечеткой информации приводит к использованию наборов из Отметим, что Умано в своей более поздней статье [39] комбинирует оба этих представления и получает наборы в виде упорядоченных семейств нечетких множеств, которые к тому же характеризуются и некоторой «степенью истинности” (в случае необходимости определяемой некоторой функцией распределения возможностей на интервале [0, 1]). Однако при этом не дается никакого указания относительно интерпретации этих степеней истинности в рамках теории возможностей, следовательно, и определение их значений, и способ их учета в оценке запросов остаются сугубо эмпирическими. Заде в работе [44] (см также разд 4 1) предложил свой подход к оценке высказывания, частично определяющего значение атрибута, с помощью лингвистического значения истинности. Этот подход позволяет перейти к простому распределению возможностей, заданному на возможных значениях атрибута; как нам кажется, это в корне отличается от подхода, избранного Умано в [39]. Тем не менее интересно заметить, что в том случае, когда все наборы из Болдуин [2] также использует смешанный подход: представление объектов на основе функций распределения возможностей с нечеткими множествами, ограничивающими возможные значения атрибутов и представление нечетких взаимосвязей между объектами на основе значений истинности. Однако он достигает однородности своего описания, придавая каждой строке из все строки которого будут наборами нечетких множеств, как это видно из следующего примера Нечеткое отношение
преобразуется в отношение
где область значений атрибута ТИП задается в виде Примечание В ряде случаев может оказаться естественным использовать плотности распределения вероятностей при моделировании неопределенной информации (см [41]) Как уже упоминалось в разд. 1,6 2, можно определить взаимно однозначное соответствие между распределением вероятностей
|
 |
Оглавление
|




























































































































































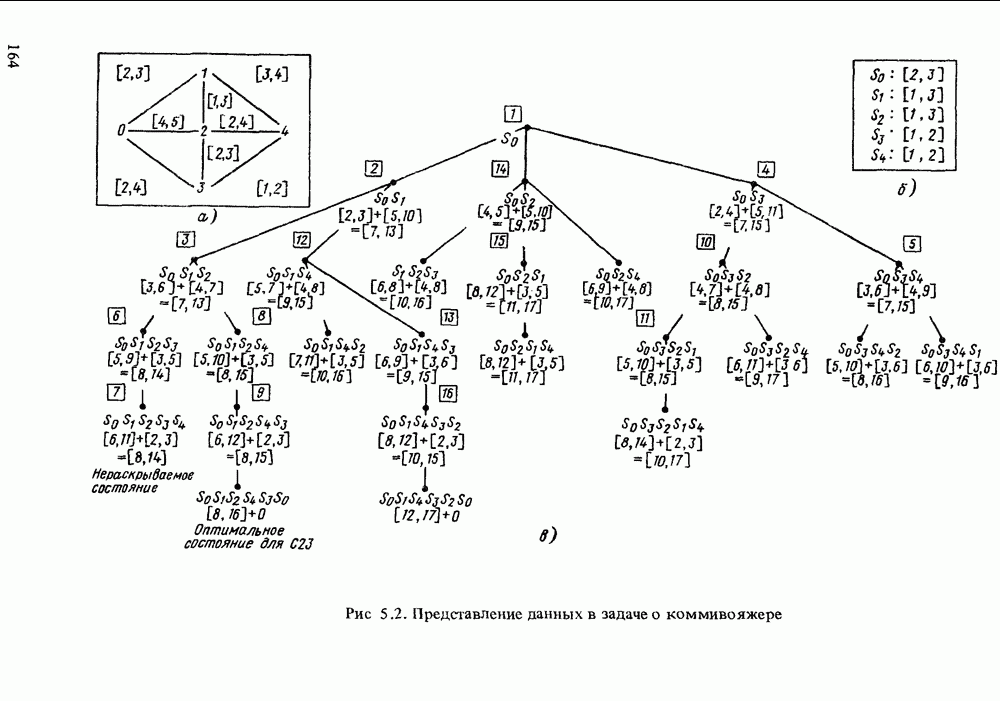








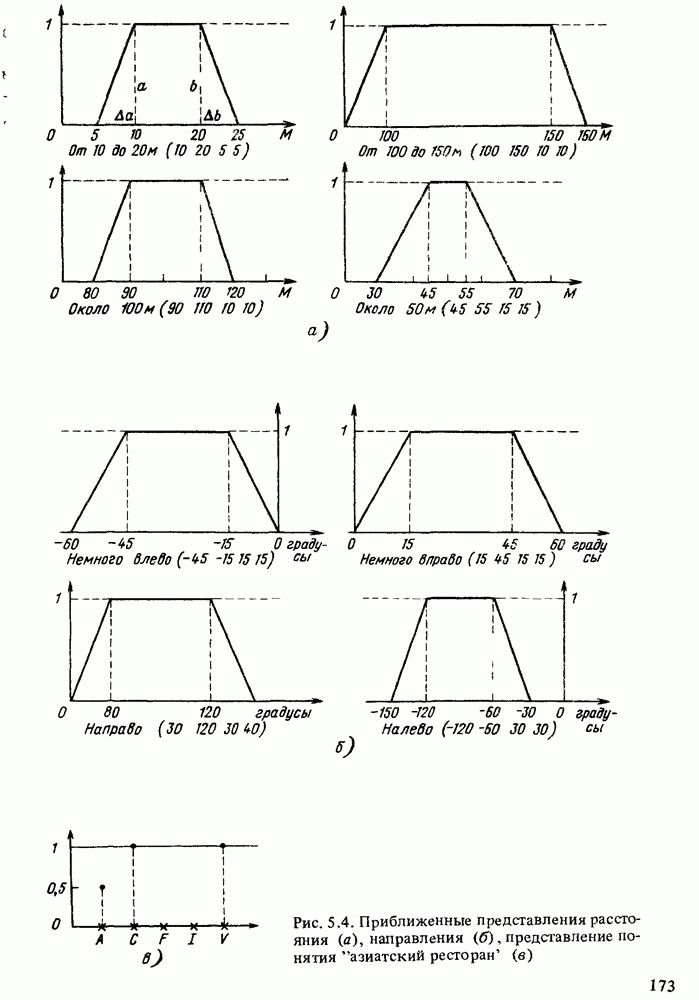


































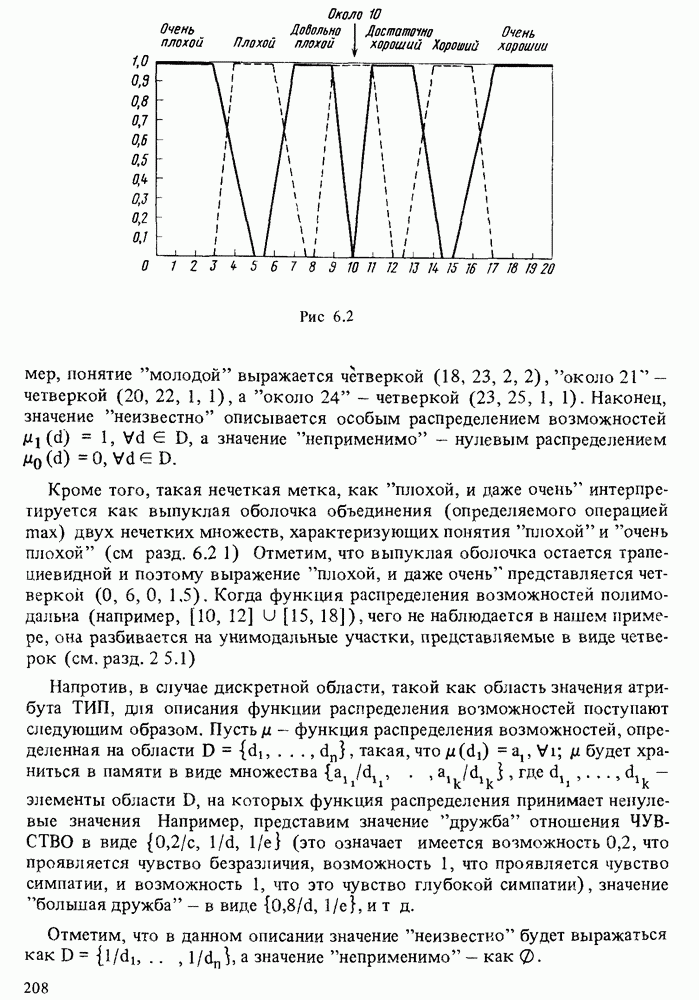









































































 значений атрибутов, причем каждый набор характеризуется функцией распределения возможностей на [0, 1] (в известных случаях сводящейся к числу, заключенному между 0 и 1). Такой способ представления информации соответствует нечеткому отношению и отличается от подхода, основанного на функциях распределения возможностей, где каждый набор из элементов уопрядочен и содержит, возможно, и нечеткие значения атрибута, а значение истинности не рассматривается.
значений атрибутов, причем каждый набор характеризуется функцией распределения возможностей на [0, 1] (в известных случаях сводящейся к числу, заключенному между 0 и 1). Такой способ представления информации соответствует нечеткому отношению и отличается от подхода, основанного на функциях распределения возможностей, где каждый набор из элементов уопрядочен и содержит, возможно, и нечеткие значения атрибута, а значение истинности не рассматривается.
 элементов характеризуются значением 1, метод оценки запросов, предложенный Умано в [39], дает в результате нечеткое множество, степени принадлежности которого, в свою очередь, являются функциями распределения возможностей на интервале [0, 1] На основе этого нечеткого множества можно получить такой же результат при ответе на тот же запрос, что и в рамках нашего подхода, однако нам представляется более предпочтительным прямо и в явном виде работать с функциями распределения возможностей и необходимости.
элементов характеризуются значением 1, метод оценки запросов, предложенный Умано в [39], дает в результате нечеткое множество, степени принадлежности которого, в свою очередь, являются функциями распределения возможностей на интервале [0, 1] На основе этого нечеткого множества можно получить такой же результат при ответе на тот же запрос, что и в рамках нашего подхода, однако нам представляется более предпочтительным прямо и в явном виде работать с функциями распределения возможностей и необходимости.
 элементов отношения, определяющего объект, значение истинности, равное 1. С другой стороны, представляется возможным преобразовать нечеткое отношение
элементов отношения, определяющего объект, значение истинности, равное 1. С другой стороны, представляется возможным преобразовать нечеткое отношение  характеризующее некоторую взаимосвязь, в обычное отношение,
характеризующее некоторую взаимосвязь, в обычное отношение,


 .причем каждая буква соответствует характерному проявлению взаимных чувств двух лиц, причем элемент а — соответствует «крайней ненависти”, а
.причем каждая буква соответствует характерному проявлению взаимных чувств двух лиц, причем элемент а — соответствует «крайней ненависти”, а  - «большой любви” Здесь сказуемое «любит” рассматривается как нечеткое подмножество области значений атрибута ТИП, функция принадлежности которого задается на примерах, т. е. для набора
- «большой любви” Здесь сказуемое «любит” рассматривается как нечеткое подмножество области значений атрибута ТИП, функция принадлежности которого задается на примерах, т. е. для набора  Очевидно, что в общем случае любое нечеткое подмножество, определенное на области значений атрибута ТИП, допускается в качестве значения атрибута в столбце ТИП. Это позволяет отразить неполноту информации относительно взаимных чувств двух лиц, что довольно-таки сложно сделать в модели с использованием единственного значения истинности.
Очевидно, что в общем случае любое нечеткое подмножество, определенное на области значений атрибута ТИП, допускается в качестве значения атрибута в столбце ТИП. Это позволяет отразить неполноту информации относительно взаимных чувств двух лиц, что довольно-таки сложно сделать в модели с использованием единственного значения истинности.
 и распределением воз можностей
и распределением воз можностей  (см формулы (158) и (159)) Так, помимо обычной вероятностной интерпретации можно дать возможностную интерпретацию частотных
(см формулы (158) и (159)) Так, помимо обычной вероятностной интерпретации можно дать возможностную интерпретацию частотных  стограмм Другими словами, статистические данные можио также представлять с помощью распределений возможностей
стограмм Другими словами, статистические данные можио также представлять с помощью распределений возможностей