Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
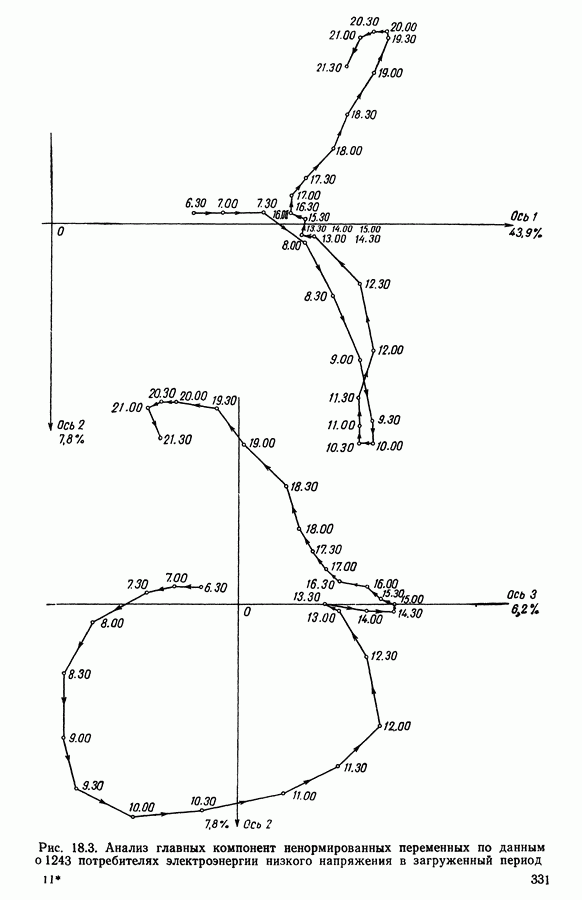
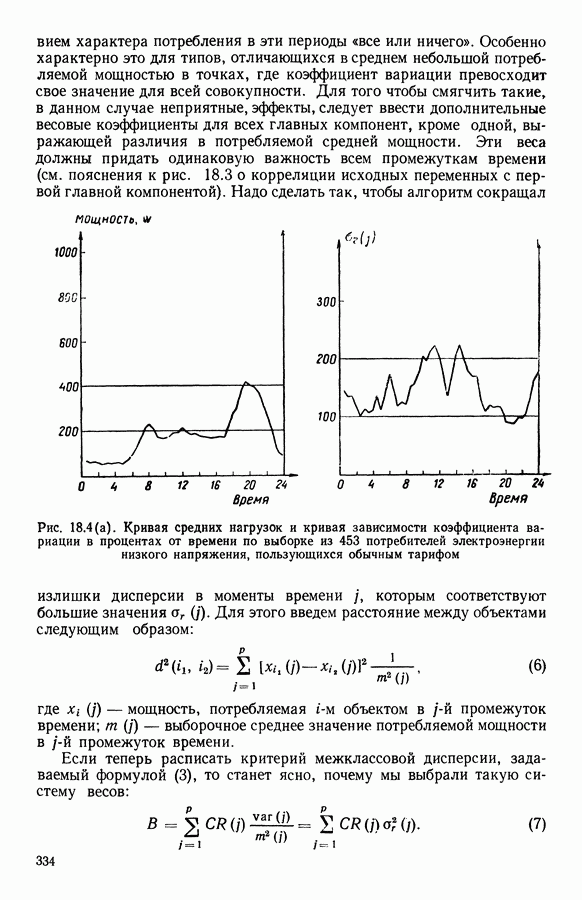
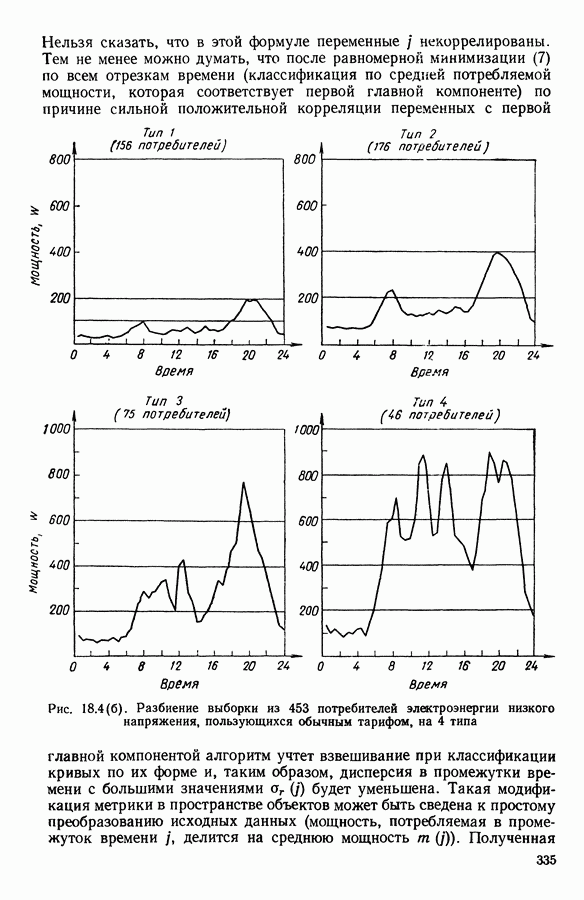
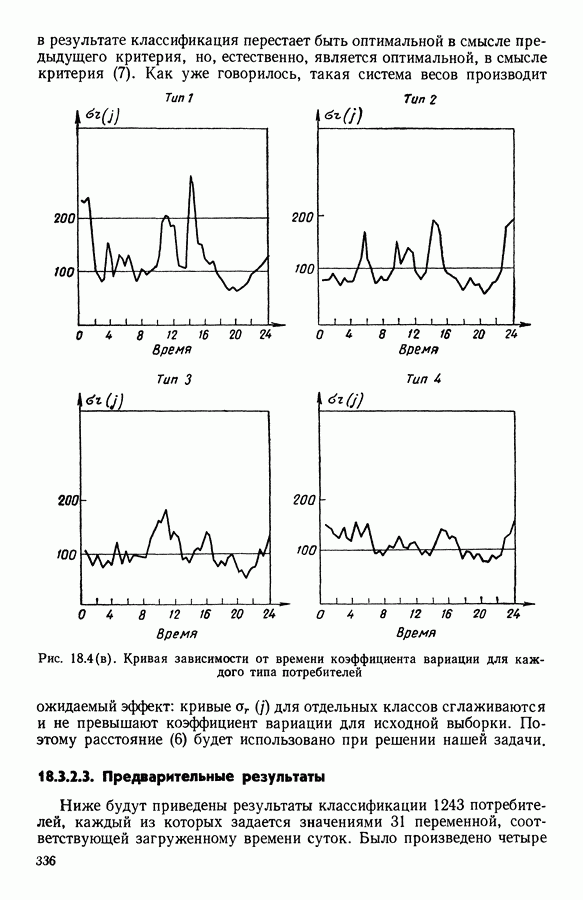
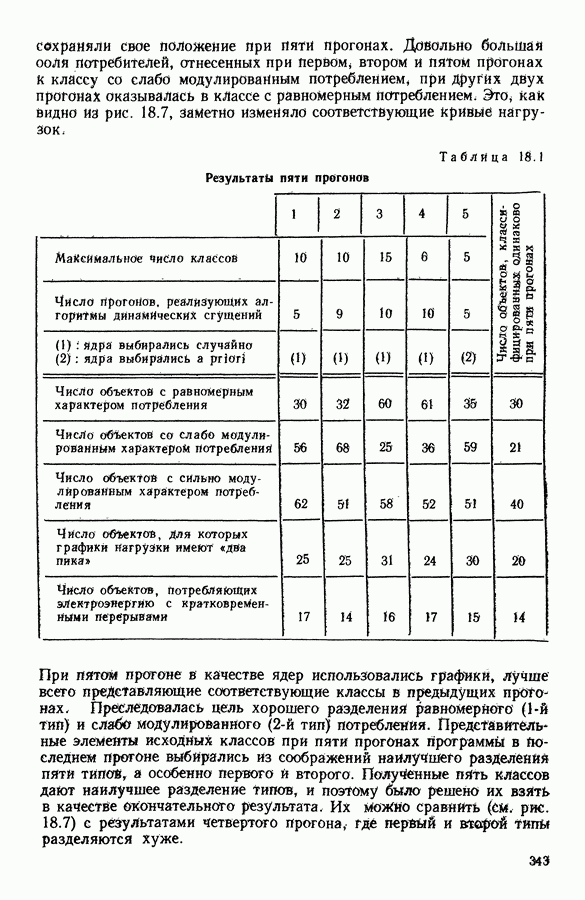
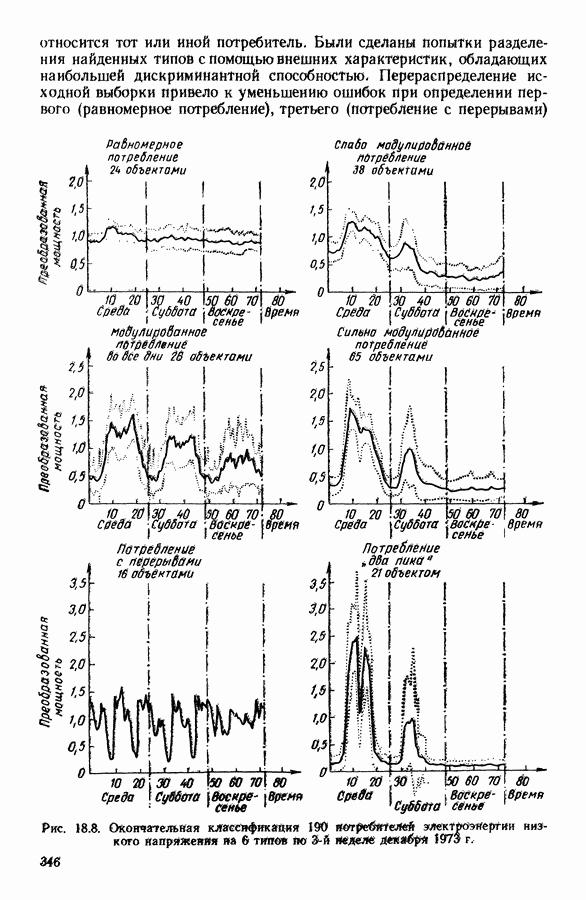
АНАЛИЗ ДАННЫХ, ПРИКЛАДНАЯ СТАТИСТИКА И ПОСТРОЕНИЕ ОБЩЕЙ ТЕОРИИ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ1. ЗАДАЧИ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ ДАННЫХ И МЕТОД ДИНАМИЧЕСКИХ СГУЩЕНИЙРекомендуя к изданию на русском языке коллективную монографию французских коллег «Методы анализа данных. Подход, основанный на методе динамических сгущений», мы в какой-то мере отдавали себе отчет в том, какие трудности нас ожидают. Главная из них — значительная отдаленность содержания и формы данной книги от принятых в литературе по методам статистической обработки данных большинством советских, американских и английских авторов. Однако как раз первый компонент «отдаленности» (оригинальность содержания) и явился решающим доводом в пользу целесообразности русского издания этого труда. Что касается второго компонента (особенность стиля подачи материала, заключающаяся в увлечении, до некоторой степени традиционном для французской математической литературы, сухим лаконичным формализмом), то переводчики и редакторы постарались, по возможности, облегчить читателю адаптацию к принятой авторами форме изложения. Предлагаемая читателю книга посвящена изложению и развитию одного общего подхода (названного авторами «методом динамических сгущений»: МДС - Methode des Nuees Dinamiques: MND) к статистической обработке данных (гл. 1—4, 12), способного генерировать методы решения таких задач, как: 1. Разбиение обследованной совокупности объектов или признаков на некоторое число (известное заранее или нет) однородных классов — собственно проблема автоматической классификации в различных постановках (гл. 5, 7, 15, 16). 2. Снижение размерности (числа анализируемых показателей) исследуемого массива исходных данных, отбор наиболее информативных показателей и визуализация (удобное наглядное представление) исходных многомерных данных и полученных статистических выводов 3. Статистический анализ предпочтений, задача их типологизации и агрегирования 4. Статистический анализ линейных моделей регрессионного типа 5. Оптимальная (в рамках решаемой конкретной задачи) оцифровка анализируемых переменных 6. Статистический анализ «двухвходовых» таблиц сопряженности Работоспособность описанных приемов статистической обработки продемонстрирована на иллюстративных и самостоятельных реальных задачах (гл. 8, 17, 18). Используемые методы сопровождаются комментариями, относящимися к их вычислительной реализации. Научный редактор книги профессор Эдвин Дидэ — один из ведущих специалистов в области так называемого «анализа данных». Он руководит подразделением в Национальном институте исследований по информатике и автоматике (INRIA) и одновременно преподает в университете Париж-IX. Характеризуя анализ данных как область исследований, следует сказать, что до последнего времени развитие теории, методологии и практики статистической обработки анализируемых данных шло, по существу, в двух параллельных направлениях. Одно из них представлено методами, предусматривающими возможность вероятностной интерпретации обрабатываемых данных и полученных в результате обработки статистических выводов. Эту систему понятий, определений и методов принято называть математической статистикой. Другое направление представлено методами анализа данных и основано на следующей логической схеме: подлежащие статистической обработке исходные данные не могут интерпретироваться как выборка из генеральной совокупности, и, следовательно, использование вероятностных моделей при построении и выборе наилучших методов статистической обработки и последующая вероятностная интерпретация статистических выводов оказываются неправомерными; из множества возможных методов, реализующих поставленную цель статистической обработки данных, наилучший метод выбирается с помощью оптимизации некоторого экзогенно заданного критерия (функционала) качества метода. Разработанный Э. Дидэ и его сотрудниками метод динамических сгущений (МДС) хотя и формулируется в терминах общей задачи классификации, но, по существу, при соответствующем подборе управляемых параметров метода индуцирует разнообразные методы решения задач типов 1—6. Основная идея МДС (являющаяся далеким обобщением идеи известного ранее метода дует найти разбиение, относительно каждого класса которого заданное «ядро» оказалось бы наиболее представительным. Понятие ядра Именно степени свободы, предоставляемые исследователю возможностью выбора типа ядра, вида оптимизируемого функционала качества метода и связанных с ними параметров, и позволяют вкладывать в рамки описываемого в книге метода широкий спектр приемов статистической обработки данных. Это и составляет главную ценность МДС, обусловливает теоретический и прикладной интерес данного метода для нашего читателя. Дело втом, что сама по себе идея формулировки и решения основных задач прикладной статистики в качестве специальных оптимизационных задач предлагалась и последовательно реализовывалась и в работах других авторов ([1], [4], [5]). Однако авторам МДС впервые удалось сформулировать различные типы задач статистической обработки данных в рамках единой оптимизационной задачи автоматической классификации (АК). Сами авторы разделяют содержание своего двухтомника на 5 частей. Особое место занимает гл. 1, в которой введены основные понятия, сформулирована математическая идея метода и дана общая схема доказательства сходимости алгоритмов, основанных на МДС. Подчеркнем, что сходимость алгоритма авторы понимают в смысле «анализа данных», а не в смысле классической математической статистики, т. е. утверждается стабилизация алгоритма только на данной выборке. Остальные главы первой (теоретической) части монографии (гл. 2— 4) посвящены детализации и углублению МДС. Эти главы можно считать теоретической базой всех последующих частей. Здесь хотелось бы выделить гл. 3 «Мультикритериальная классификация», которая особенно выпукло демонстрирует возможности МДС. Вторая часть посвящена изложению и дальнейшему развитию на базе метода МДС классических задач анализа данных, математической статистики и численного анализа (гл. 5, 6, 7, 10, И). Здесь наибольшее впечатление производит гл. 6 «Факторный типологический анализ», в которой показано, что МДС позволяет создать алгоритм, синтезирующий достоинства классического факторного анализа и автоматической классификации, реализуемой с помощью метода Третья часть посвящена разработке адаптивных алгоритмов (гл. 12, 13) и проблемам статистической обработки так называемых таблиц сопряженности признаков Четвертая часть (глава 15) посвящена задачам получения разбиения выборки на классы с дополнительной структурой либо на классы, Удовлетворяющие некоторым априорным ограничениям. Самостоятельный интерес представляют главы, посвященные изложению результатов решения прикладных задач с использованием различных вариантов МДС (пятая часть). Так, в гл. 8 описывается применение дискриминантного типологического анализа (ДТА) к решению проблемы автоматизации контроля качества функционирования вращающихся механизмов. С помощью ДТА удалось формализовать и автоматизировать ранее субъективно оцениваемые понятия «хорошее качество» и разные типы дефектных режимов функционирования. Метод основан на статистической обработке (с использованием ДТА) частотных характеристик режима вращения. В гл. 9 демонстрируются возможности МДС при статистическом анализе множества предпочтений, высказанных относительно одной и той же совокупности объектов, намечены конкретные области применений такого анализа в маркетинге, в управлении (в частности, при решении проблемы мультикритериального выбора), в статистической обработке экспертиз. Гл. 17 и 18 целиком посвящены описанию решения конкретных задач соответственно при исследовании информационных систем и при типологическом анализе так называемых «нагрузочных кривых» (последовательностей, описывающих суточную динамику потребляемой электроэнергии). Оценивая монографию в целом, следует отметить широту диапазона практической применимости описанного в ней подхода, его работоспособность при решении широкого спектра задач типа 1—6. Обратим внимание читателя на тот факт, что множество алгоритмов, построение которых возможно на базе МДС, не исчерпывается алгоритмами, описанными в предлагаемой работе (как отмечают сами авторы, подбор алгоритмов, представленных в монографии, осуществлялся ими с ориентацией в первую очередь на их прикладную актуальность). Необходимо подчеркнуть также, что предлагаемая вниманию читателя книга — одна из очень немногих (если не единственная), полностью посвященная проблеме автоматической классификации (наша точка зрения относительно подобной ситуации изложена в разделе II данного предисловия). Говоря о недостатках монографии, следует отметить относительно слабо представленный аспект вероятностного моделирования и вероятностной интерпретации при конструировании и использовании методов статистической обработки данных. Список цитируемых работ явно не полон и сильно отражает пристрастия авторов. Например, в монографии нет ссылок на опубликованные на английском языке работы Фукунаги и, в частности, на его книгу [22], хотя алгоритм Фукунаги решения задачи автоматической классификации с максимизацией разделимости классов, по существу, совпадает с алгоритмом дискриминантного типологического анализа, описанного в гл. 7. Книга сильно выиграла бы, если бы авторы уделили внимание сравнительному анализу эффективности предлагаемого ими МДС и другим возможным методам решений тех же задач. По согласованию с авторами в русском издании книги произведены некоторые сокращения. В основном они коснулись текстов программного обеспечения ЭВМ. Дело в том, что советский читатель не смог бы им воспользоваться, в частности, из-за невозможности непосредственной адаптации ряда стандартных модулей, наличие которых является необходимым условием применения описываемых программ. Несмотря на отмеченные недостатки, мы не сомневаемся в том, что знакомство советского читателя с книгой Э. Дидэ и соавторов будет способствовать распространению в статистической практике новых актуальных и эффективных методов анализа многомерных данных, проводимого с целью получения научных или практических выводов. В следующей части предисловия мы постарались описать соотношение между изложенными в книге результатами французских коллег и достижениями советских специалистов в данной области, связь с задачей построения общей теории автоматической классификации. С этой частью предисловия можно познакомиться и после прочтения книги.
|
 |
Оглавление
|




























































































































































































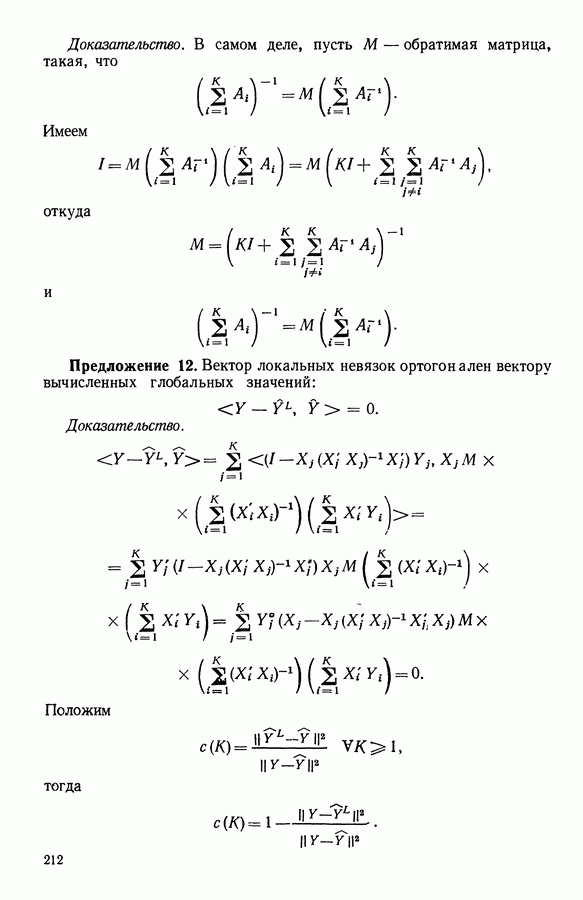



































































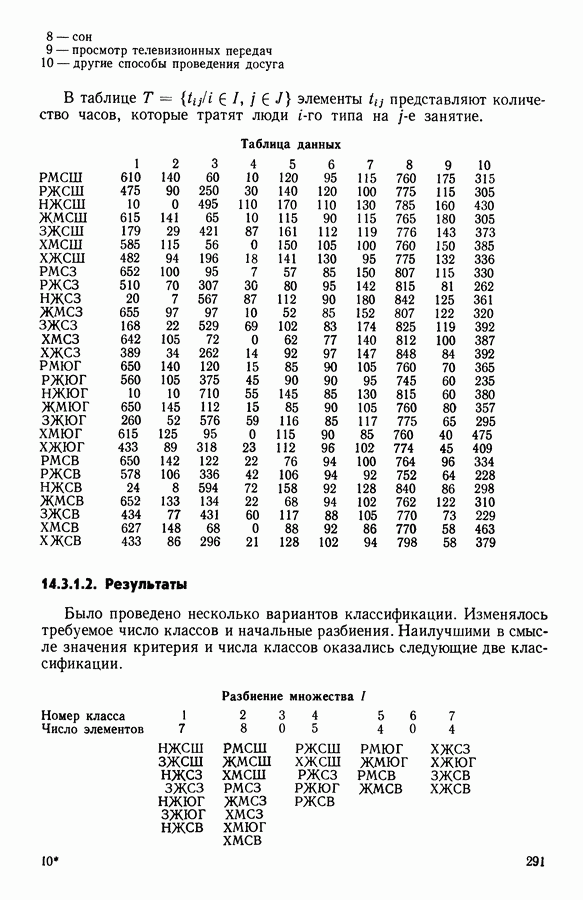
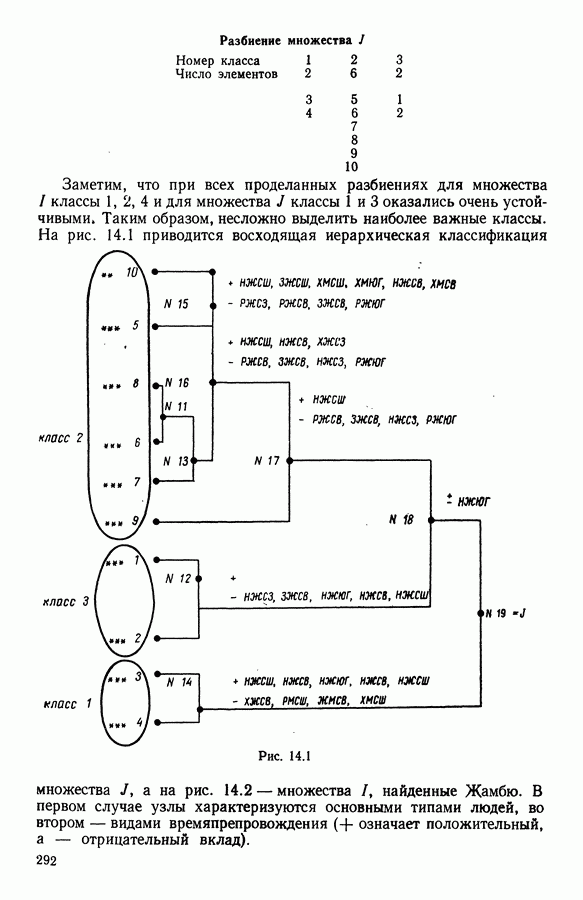
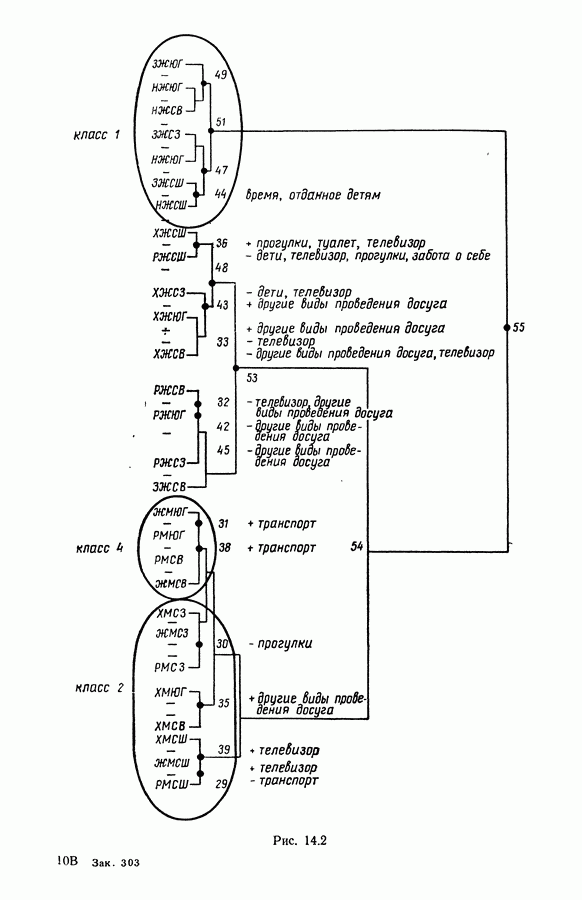


















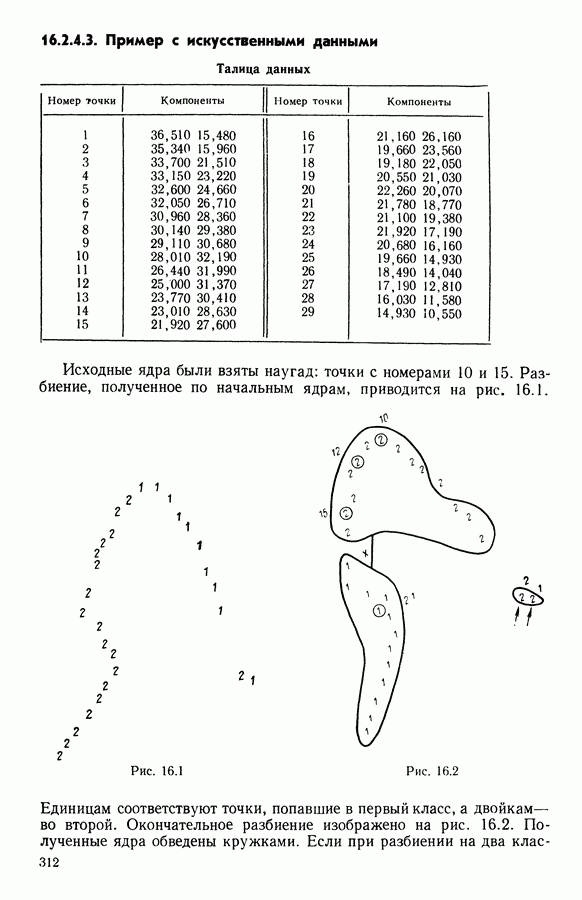
















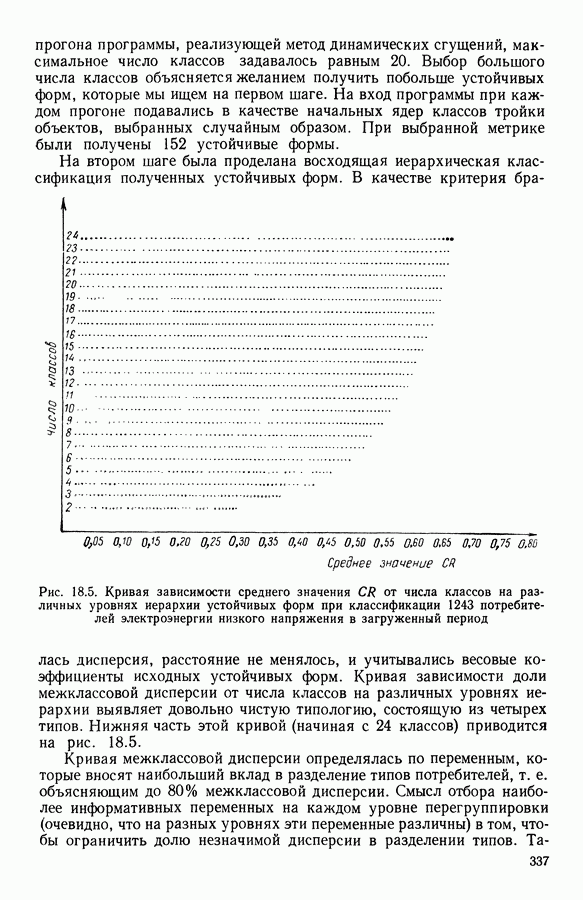
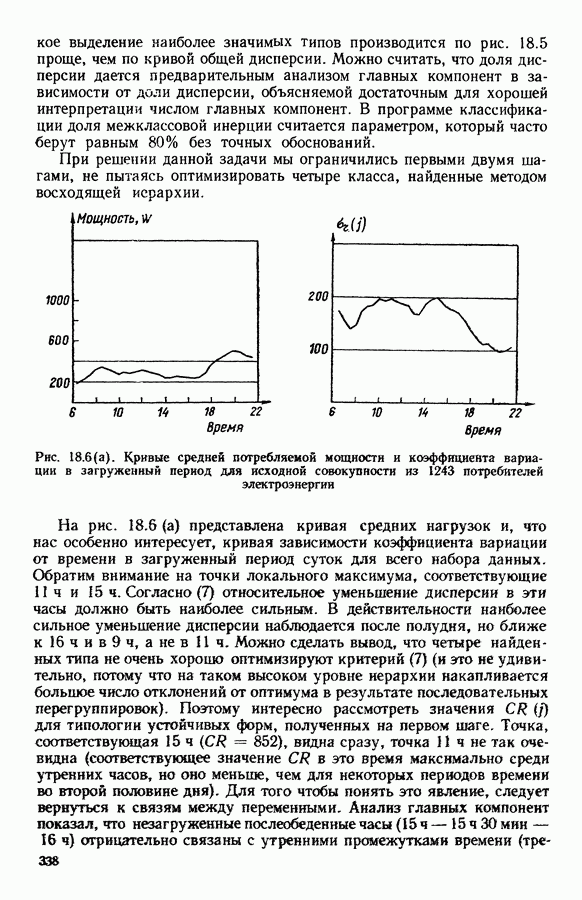
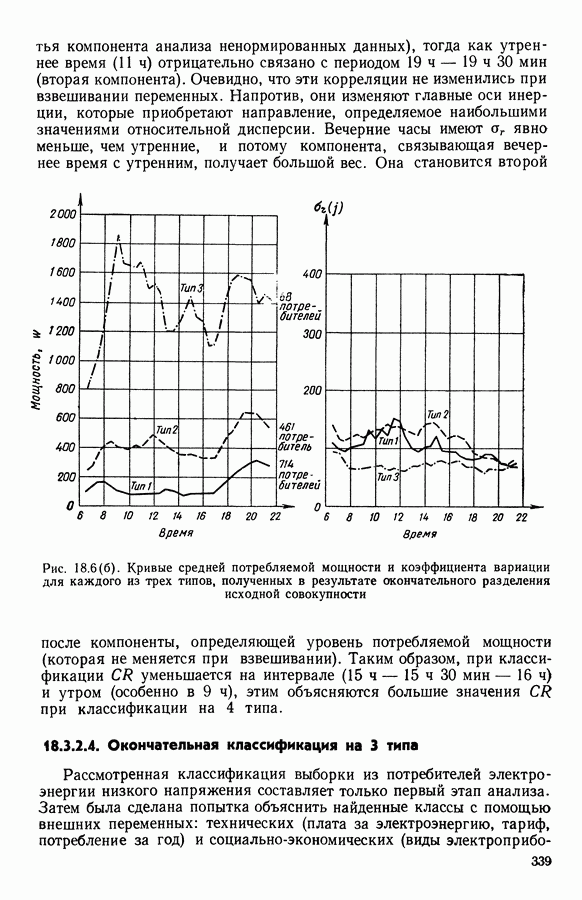


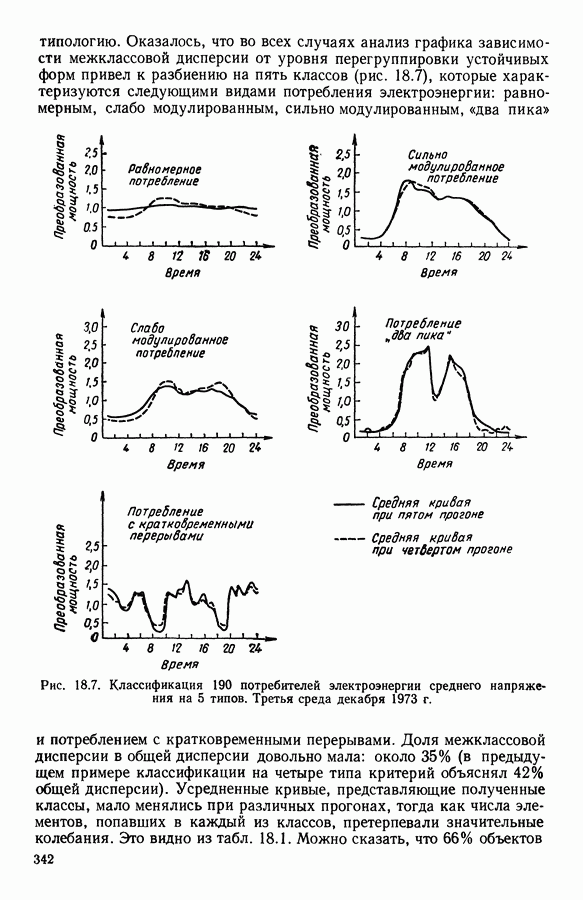










 -средних», примерно в одно и то же время предложенного Себастианом (США, [17]), Мак Куином (США, [25]) и Шлезингером (СССР, [23])) может быть достаточно отчетливо выражена словами Э. Дидэ: «Среди всех разбиений на К классов еле.
-средних», примерно в одно и то же время предложенного Себастианом (США, [17]), Мак Куином (США, [25]) и Шлезингером (СССР, [23])) может быть достаточно отчетливо выражена словами Э. Дидэ: «Среди всех разбиений на К классов еле.
 имеет самый широкий смысл (курсив наш.- С. А. и В. Б.): ядро класса (т. е. группы точек) может быть подгруппой точек, центром тяжести, осью, случайной переменной и т. д.» (см. с. 25).
имеет самый широкий смысл (курсив наш.- С. А. и В. Б.): ядро класса (т. е. группы точек) может быть подгруппой точек, центром тяжести, осью, случайной переменной и т. д.» (см. с. 25).
 -средних.
-средних.
