Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
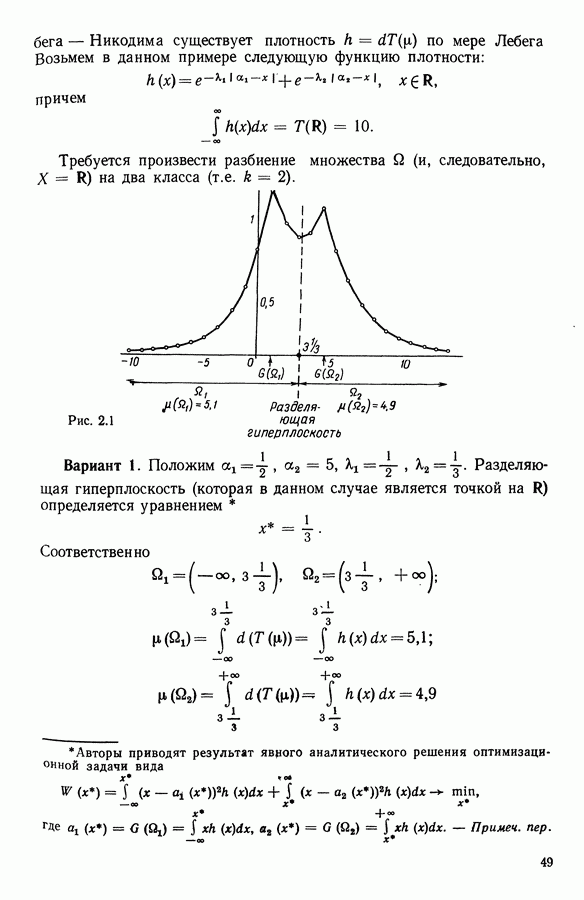
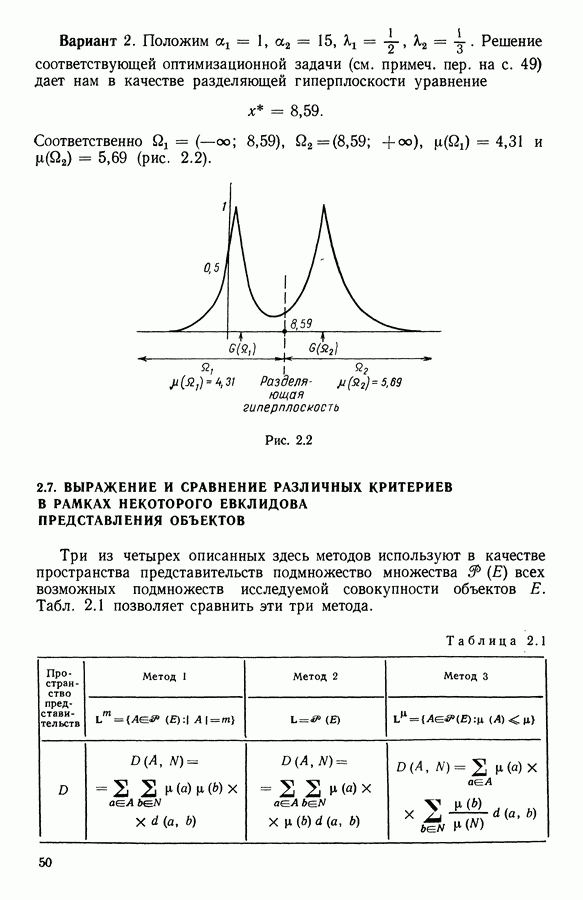
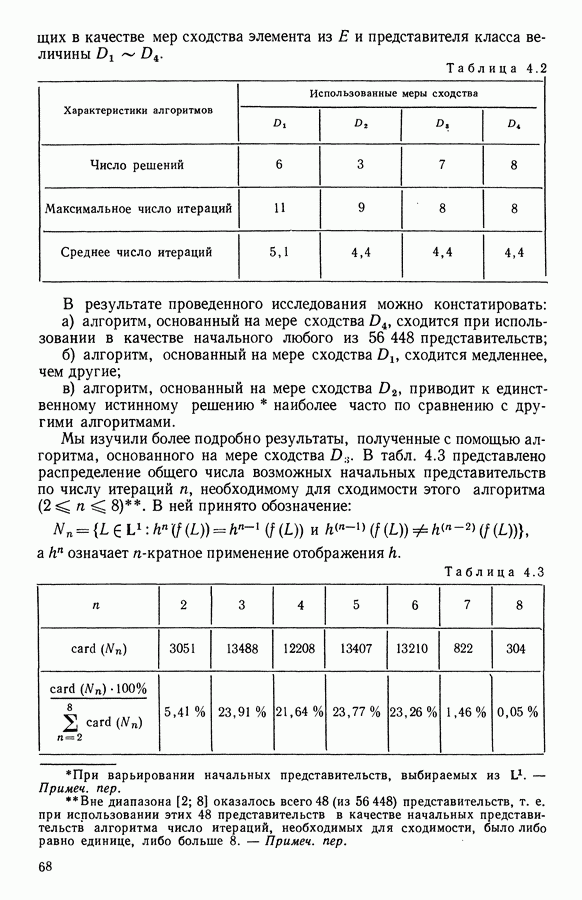
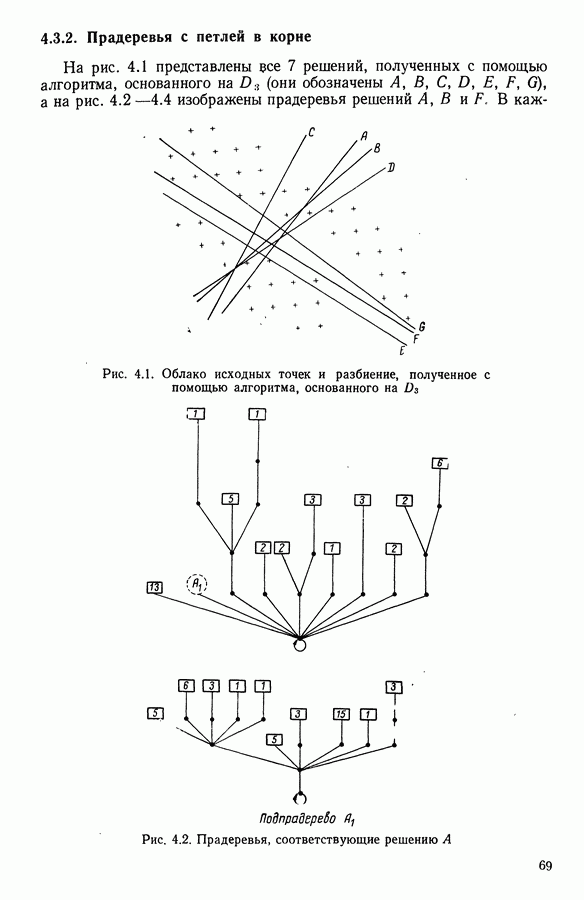
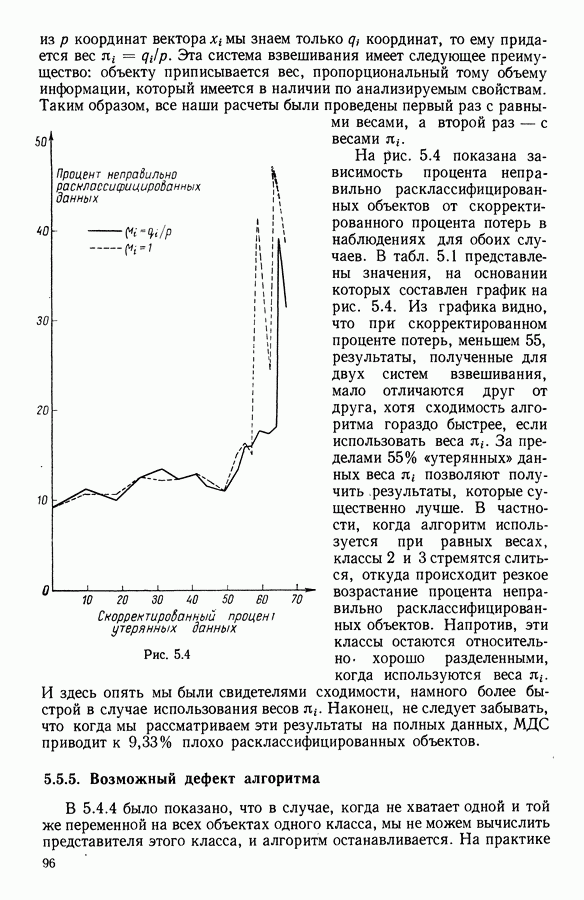
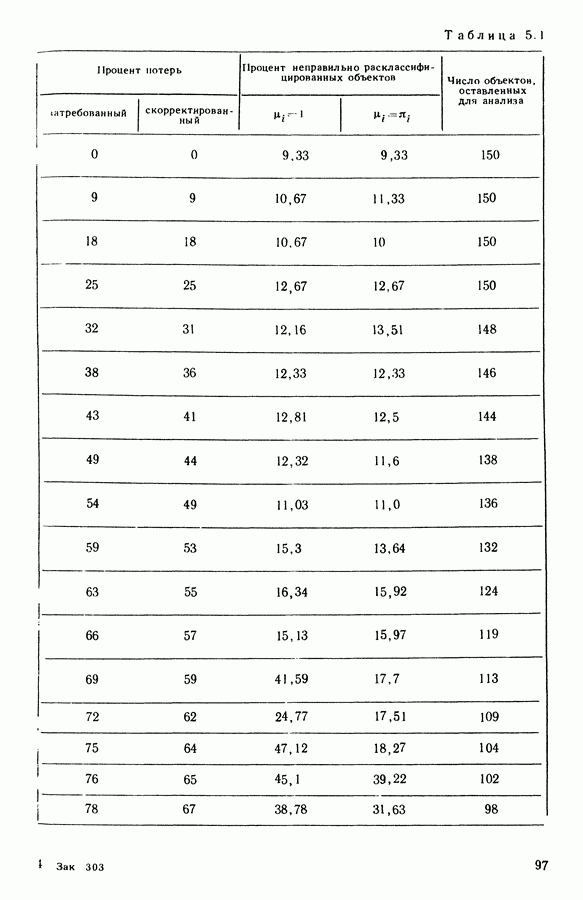
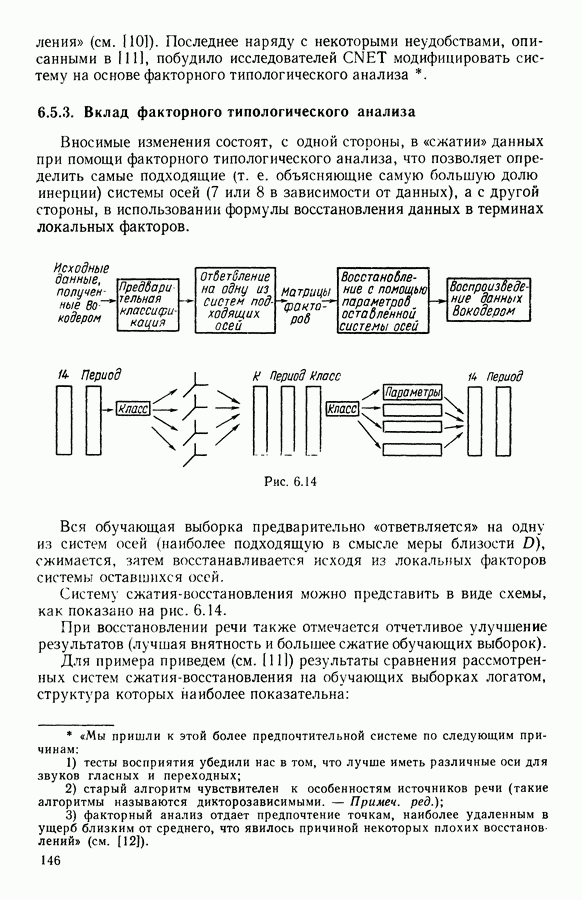
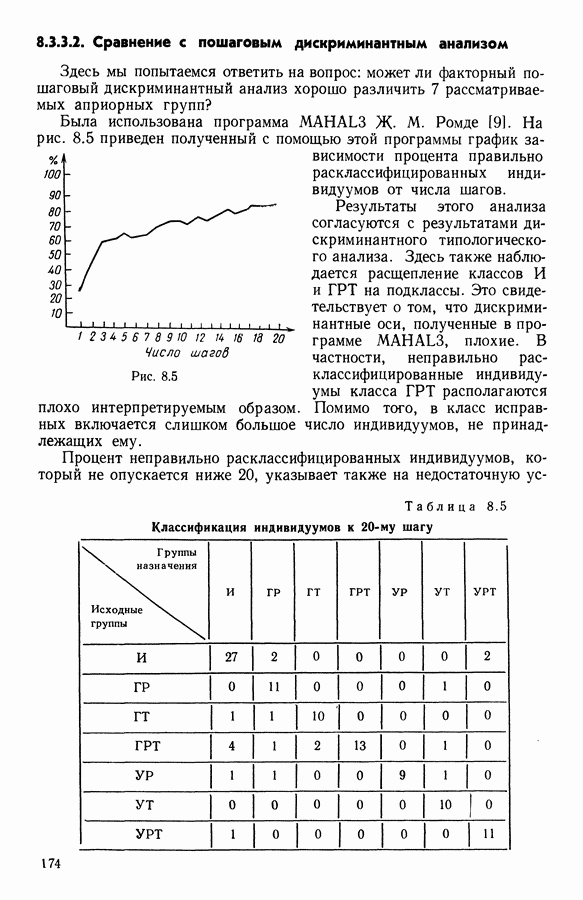
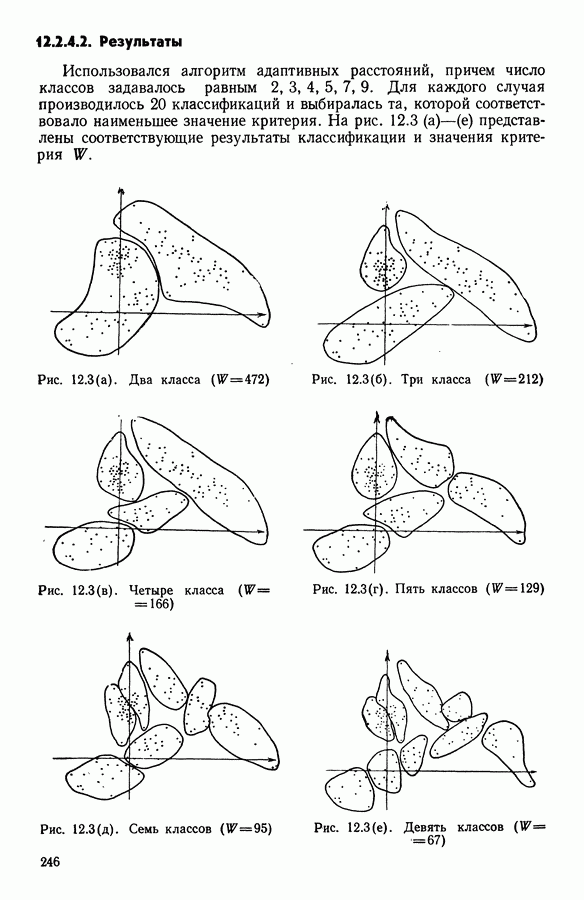
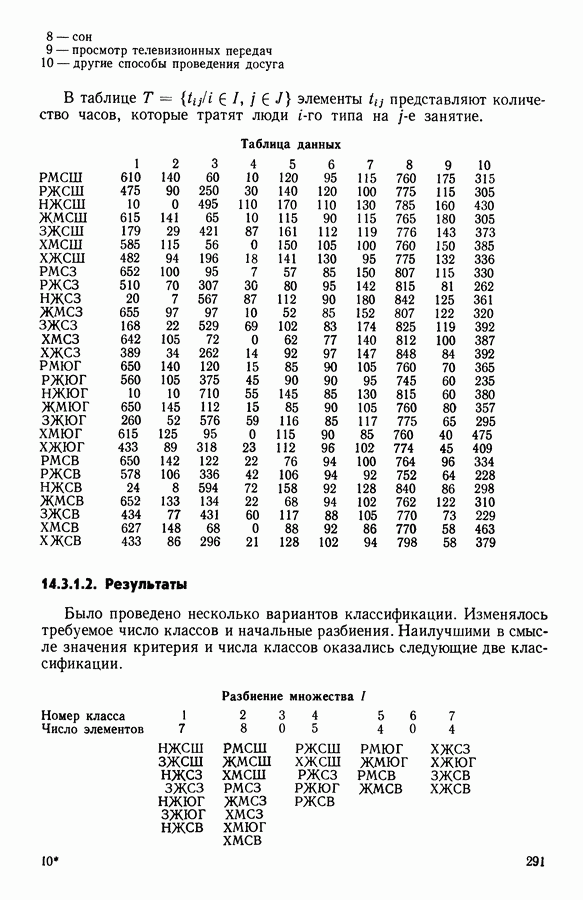
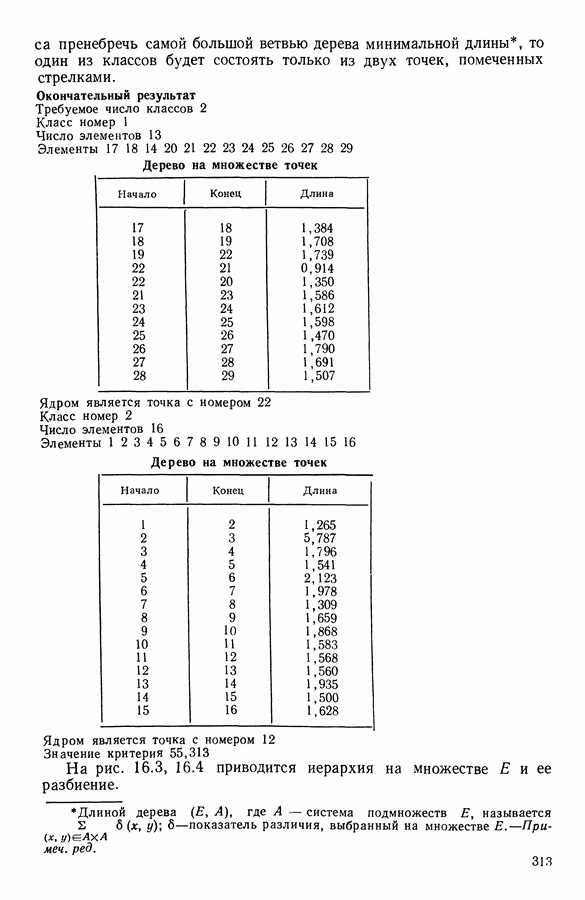
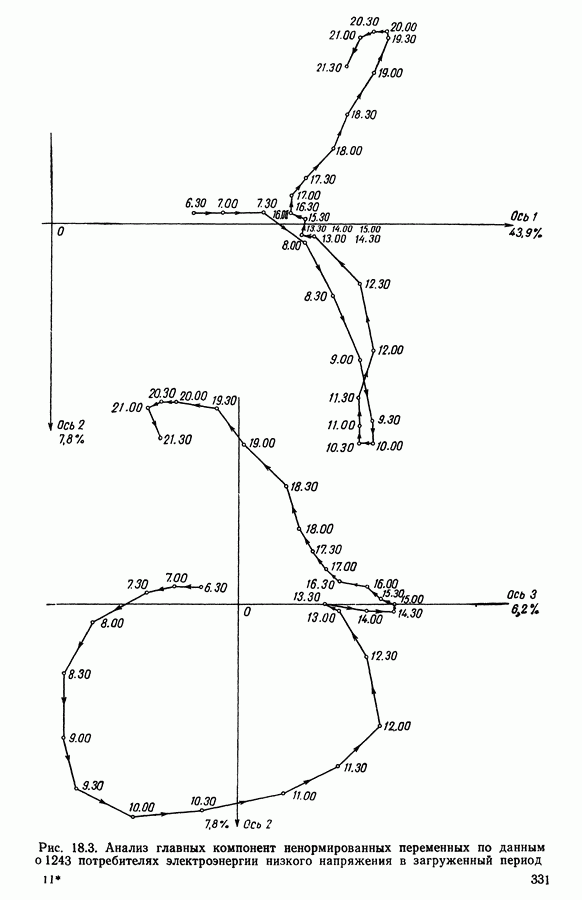
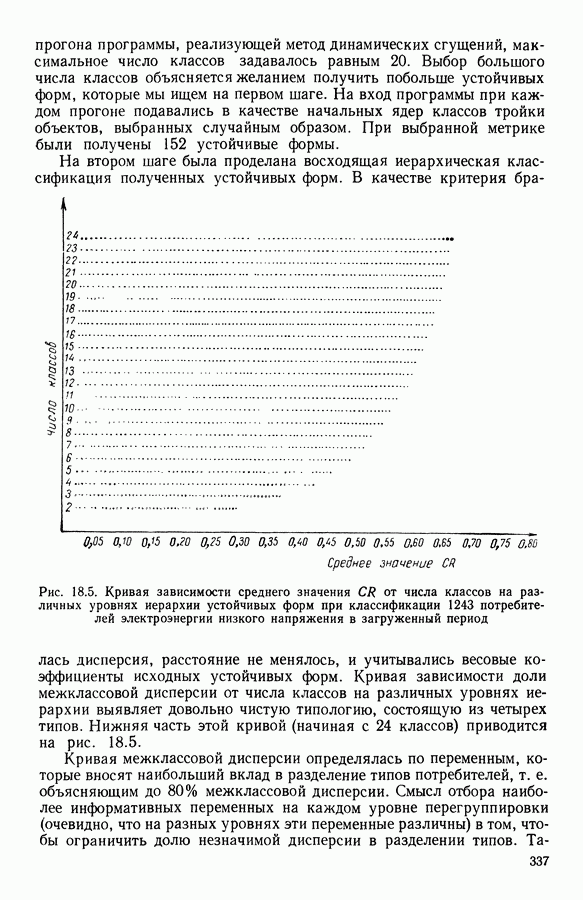
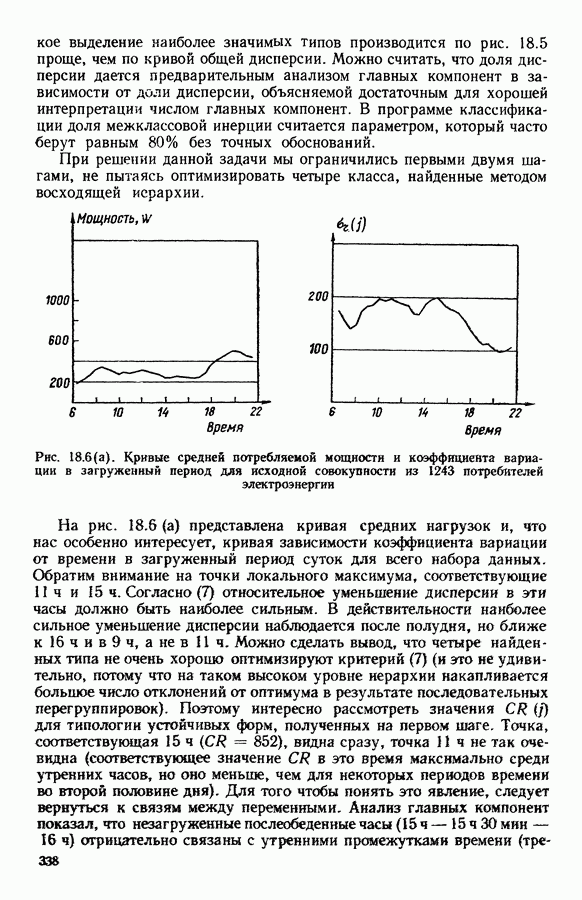
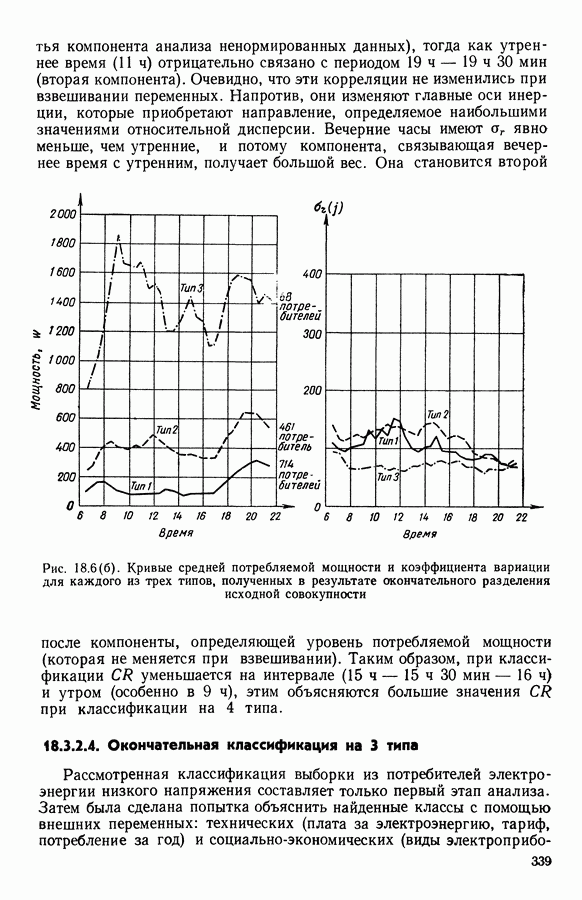
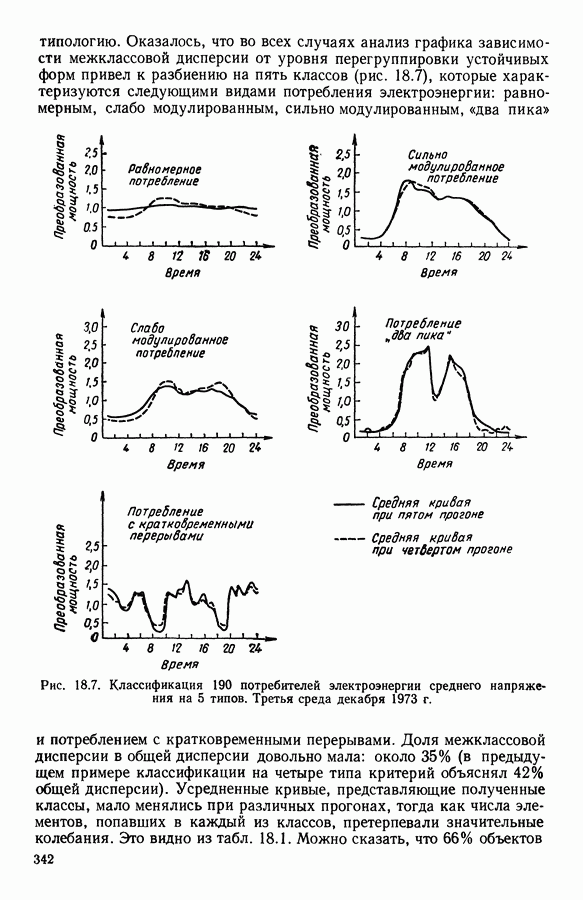
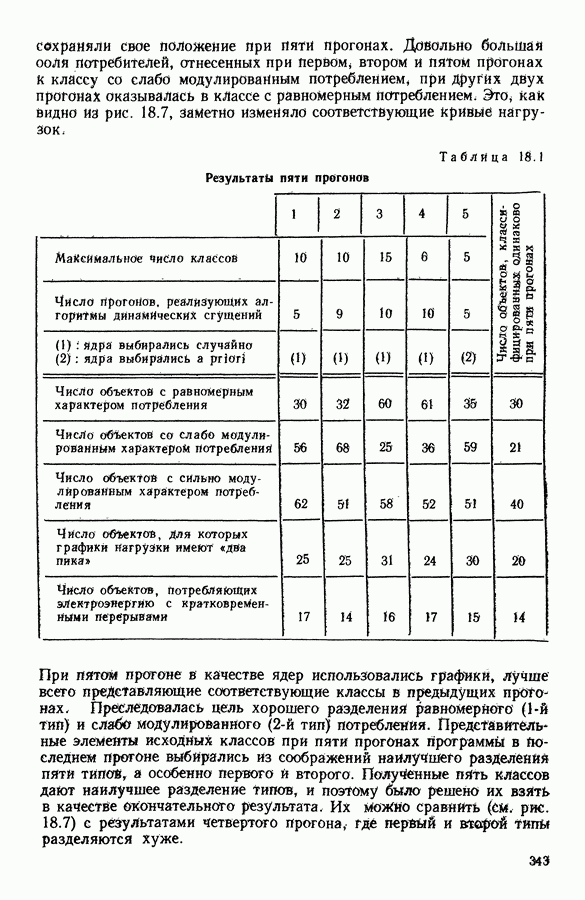
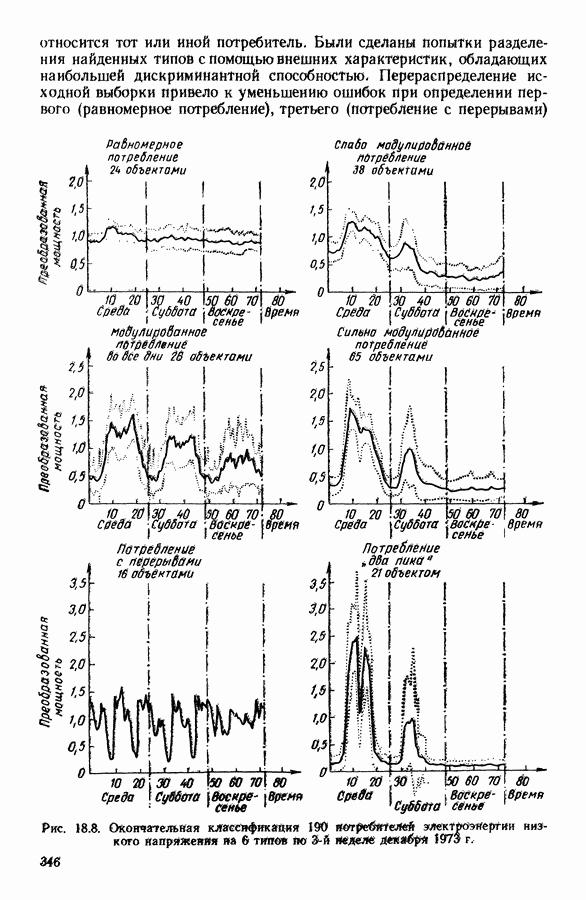
8.3. ПРИМЕНЕНИЕ ДИСКРИМИНАНТНОГО ТИПОЛОГИЧЕСКОГО АНАЛИЗА8.3.1. МетодологияЦель дискриминантного анализа состоит в том, чтобы для исследуемой совокупности найти решающее правило, которое дало бы возможность различать априори заданные группы. Это правило должно позволять относить каждого нового индивидуума к одной из групп. Задание априорного разбиения на классы, необходимое для применения методов классического дискриминантного анализа, фактически предопределяет результаты. С другой стороны, очень часто оказывается, что разбиение совокупности на классы имеет элементы субъективизма или даже случайно. Дискриминантный типологический анализ сходен с дискриминант-ным анализом с точки зрения построения решающего правила, однако в процессе работы итеративного алгоритма он позволяет ставить под сомнение априорные группы. Алгоритм, начинаясь с некоторого априорного разбиения, определяет дискриминантное подпространство, затем относит каждого индивидуума к тому классу, чей центр тяжести в проекции на дискриминантное подпространство является самым близким. Полученное к моменту сходимости алгоритма разбиение будет устойчивым в смысле применяемого правила отнесения индивидуумов к классам. Если выбор начального разбиения удачный, то для новых индивидуумов этот алгоритм даст правило отнесения, незначительно отличающееся от правил факторного дискриминантного анализа. Если, напротив, классы начального разбиения размыты и недостаточно однородны, то алгоритм даст правило отнесения, которое приведет к еще менее надежным классам, чем заданные априори. Прежде чем описать результаты, полученные с помощью дискриминантного типологического анализа, приведем несколько основных предположений, при которых он использовался. Пусть Пространство В программе разбиение требуемое число классов требуемое число дискриминантных осей Далее мы приводим некоторые соображения, позволяющие наилучшим образом выбирать эти три параметра. Обычно разбиение Подобной опасности, Кто существу, нет в дискриминантном типологическом анализе, где в качестве начального выбирается разбиение, составленное из априорных классов. Действительно, даже если это разбиение вызывает сомнение, классы не лишены смысла. Более того, пользователь все равно должен проверить, не являются ли априорные классы (или хотя бы некоторые из них) хорошо распознаваемыми — случай, когда применимы методы классического дискриминантного анализа. По этому поводу заметим, что если в качестве начального выбирается разбиение на априорные классы, то первая итерация типологического дискриминантного анализа приводит к тем же результатам, что и факторный дискриминантный анализ. Во всяком случае, какими бы ни были результаты первого анализа, именно они подсказывают, как естественным образом проводить последующую обработку. В частности, если классы начального разбиения плохо распознаваемы (это тот случай, когда дискриминантный типологический анализ применяется в полной мере), то результаты такого анализа подсказывают, как надо перегруппировать, расщепить, смешать классы и получить начальное разбиение для второго этапа алгоритма. Результаты этого этапа позволят аналогичным образом начать возможный третий этап и т. д. Указанный процесс останавливается, когда выбранное разбиение оказывается устойчивым. Выбор числа Необходимое число 8.3.2. РезультатыПервый этап анализа. Анализ с начальным разбиением, заданным априори. Анализ начинается с разбиения на 7 классов Согласно табл. 8.1 установим соответствие: (см. скан) Алгоритм останавливается на 5-й итерации и дает разбиение Таблица 8.2 (см. скан) Начальное разбиение Представление центров тяжести (ЦТ) классов
Рис. 8.1
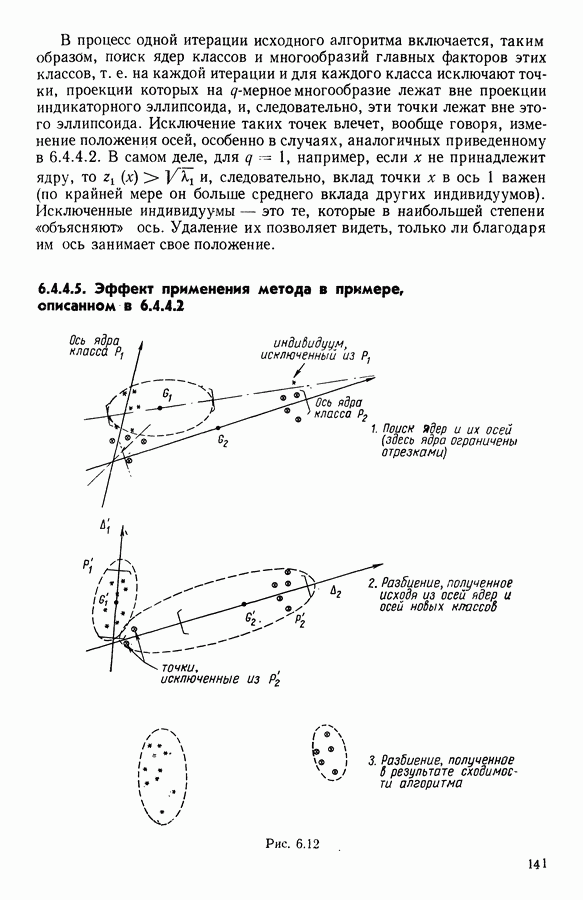
Рис. 8.2 Комментарии. Как и можно было предвидеть, априорное разбиение на 7 классов оказалось неустойчивым. Точнее: класс «исправных» распался на два; класс классы Изучение представления центров тяжести привело к интересным результатам (аналогично представлению на плоскости в факторном анализе совокупность элементов тем лучше представлена, чем больше разброс ее по осям). Ось 1 отделяет класс Малая стабильность класса
Введение класса
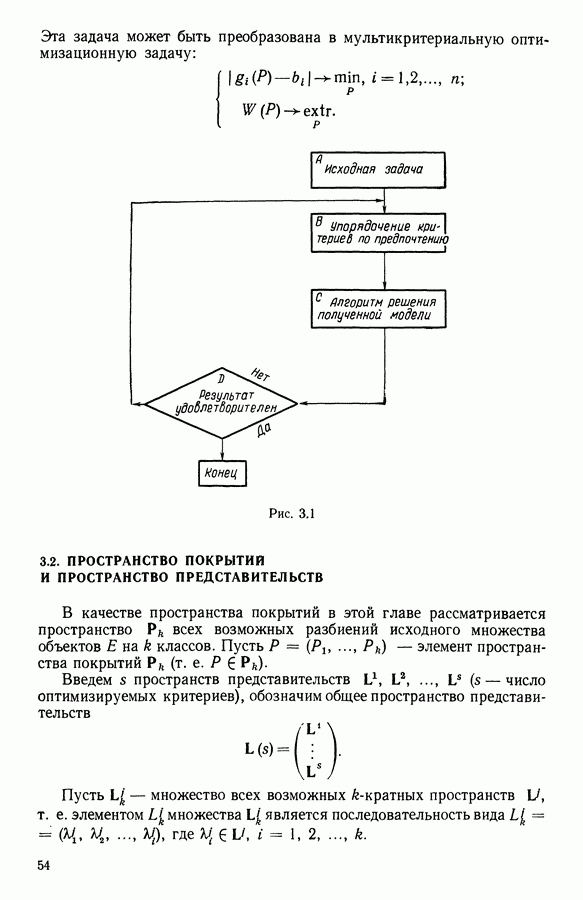
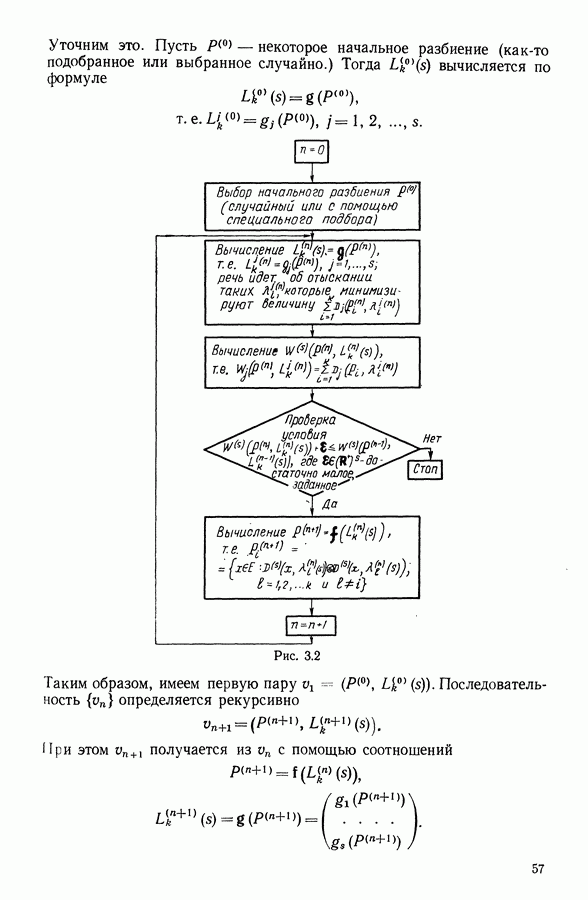
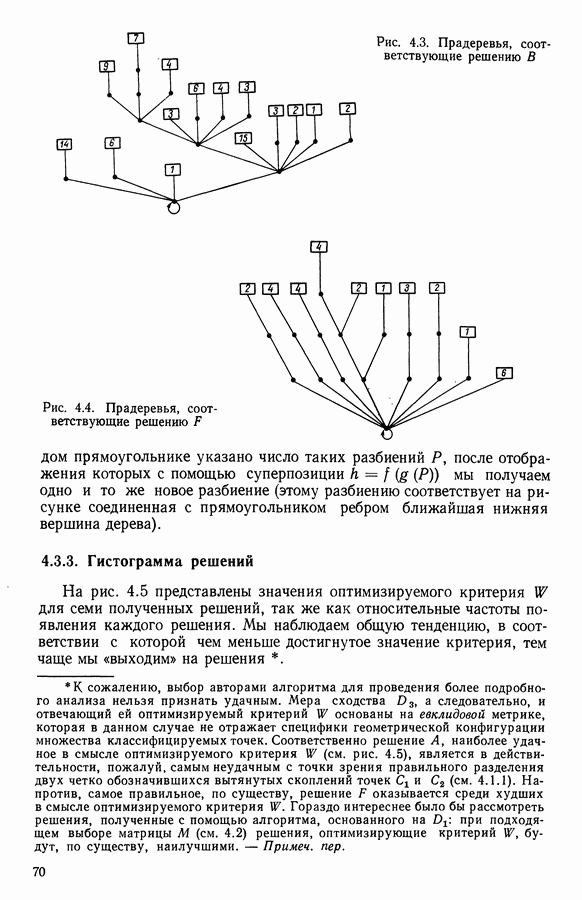
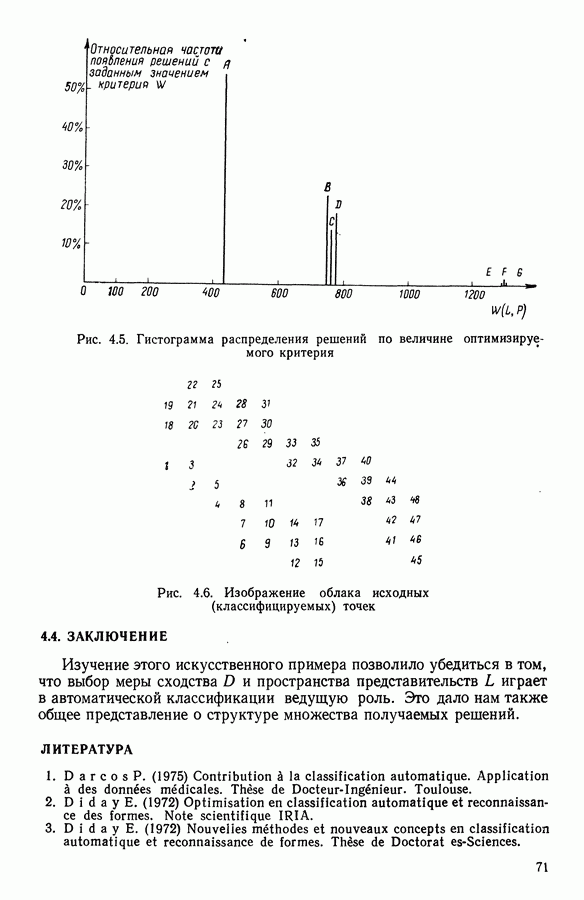
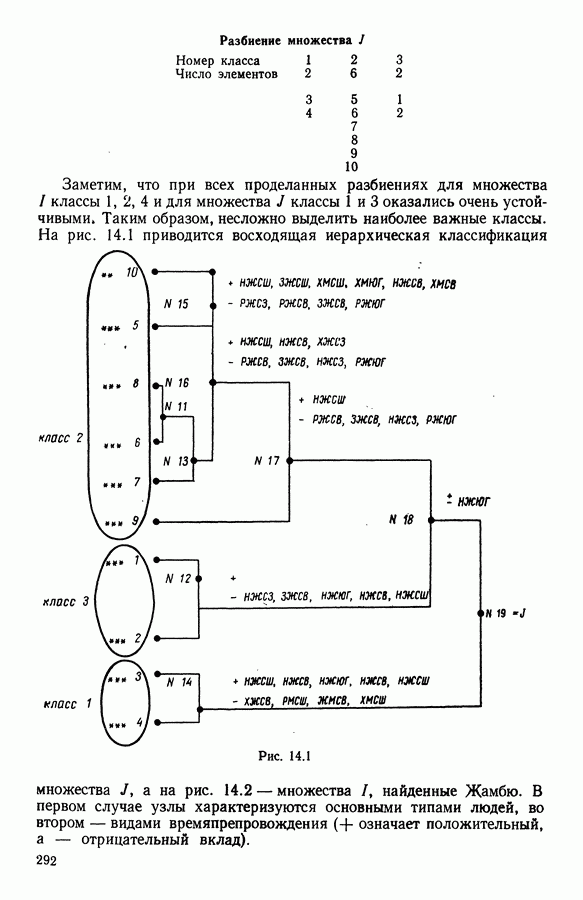
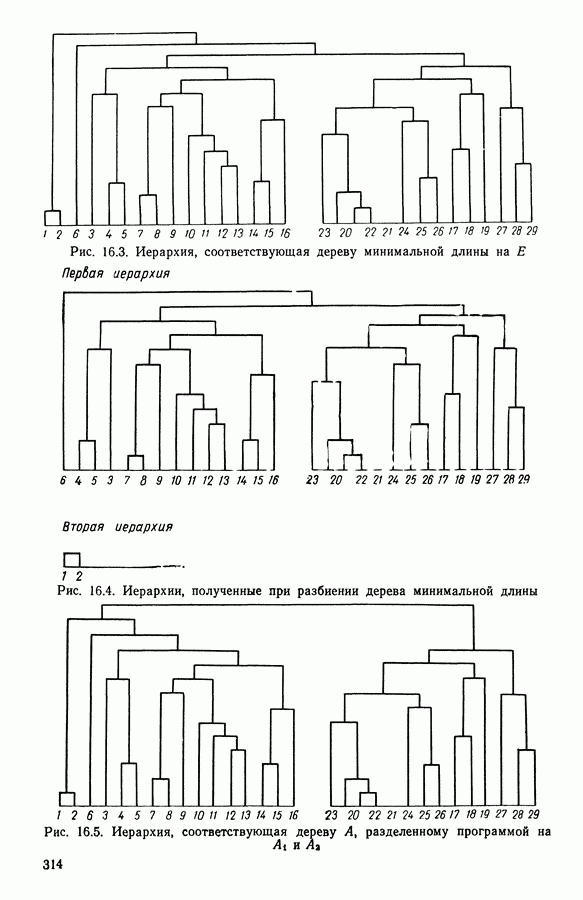
В классе Второй этап анализа. Дискриминантный типологический анализ начинается с разбиения Алгоритм сходится за 2 итерации к разбиению Представление центров тяжести классов.
Рис. 8.3
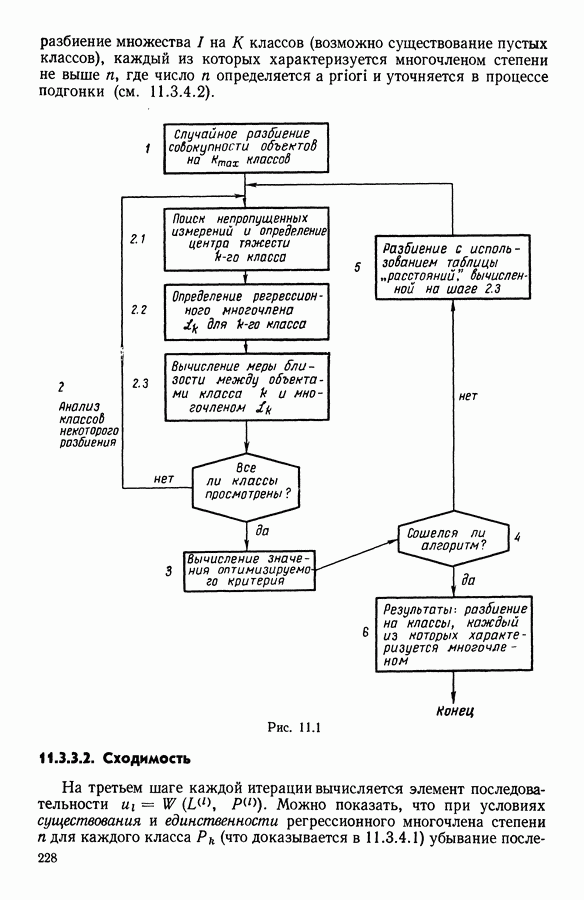
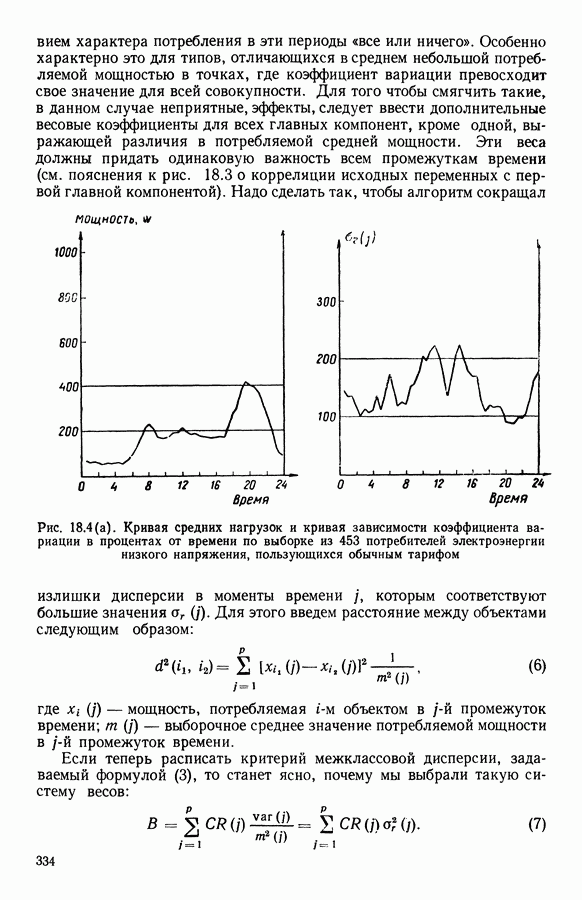
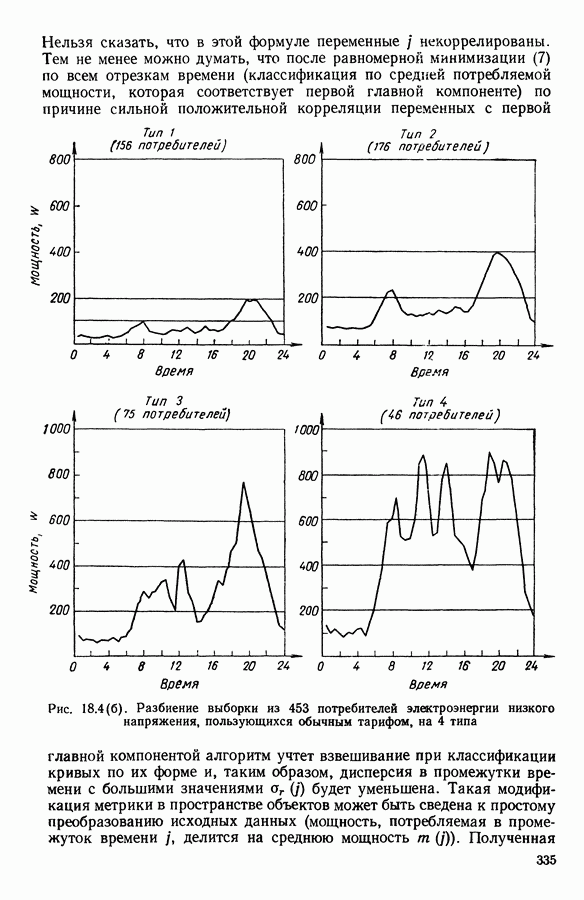
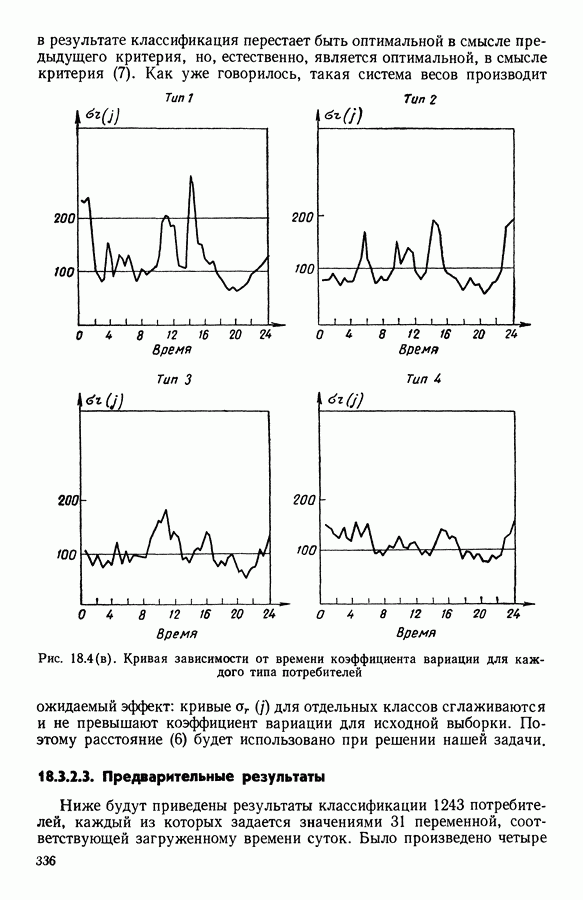
Рис. 8.4 Комментарии. Как уже отмечалось, алгоритм сходится за 2 итерации к разбиению Таблица 8.3 (см. скан) Графическое представление показывает, что: первая дискриминантная ось позволяет выделить Табл. 8.4 помогает сравнить классификацию нашей совокупности, полученную в результате дискриминантного типологического анализа с априорной классификацией. Таблица 8.4 (см. скан) Объединения Класс Диагноз относительно семейства исправных машин может показаться слишком строгим, но, как оказалось, он не удивляет специалистов и определенным образом подтверждается метрологической экспертизой. Напротив, объединение семейств Интересно было посмотреть, проведя новый анализ, можно ли различить семейства Начальное разбиение для этого анализа соответствовало разбиению Полученный результат при этом не заслуживает большого доверия. В самом деле, 3 из 12 элементов класса Нам показалось разумным ограничиться результатами, полученными на В наших исследованиях мы рассматривали вместе режимы разгона и торможения. Однако переменные, соответствующие режиму торможения, являются мешающими для распознавания семейств, которые различаются по переменным, соответствующим режиму разгона. Кроме того, чтобы разделить семейства Дополнительные исследования. Эти исследования учитывали работу машины только в режиме разгона, цель их — выяснить, можно ли разделить: группы группы группу Наиболее убедительными оказались результаты следующего анализа. Выбрано было (см. скан) Индивидуумы групп напротив, оказалось возможным построить исходя из этого анализа второй уровень дискриминации, позволяющий расщепить класс разделение групп напротив, границы семейства исправных машин очень нечеткие. В частности, тщетно пытаться отделить подгруппу исправных анализ показывает, что можно ввести второй уровень дискриминации и добиться разделения классов «гул» и «удар» при разгоне.
|
 |
Оглавление
|





















































































































































































































































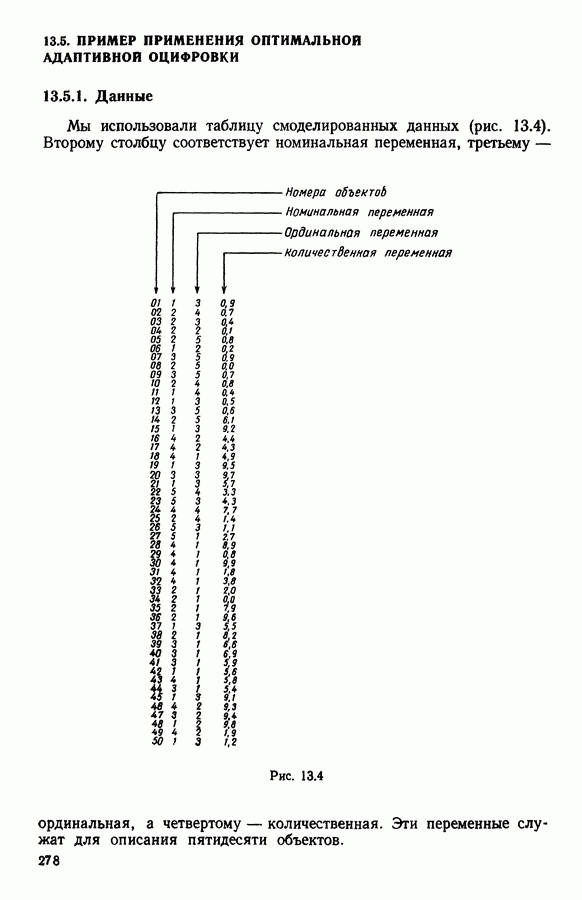


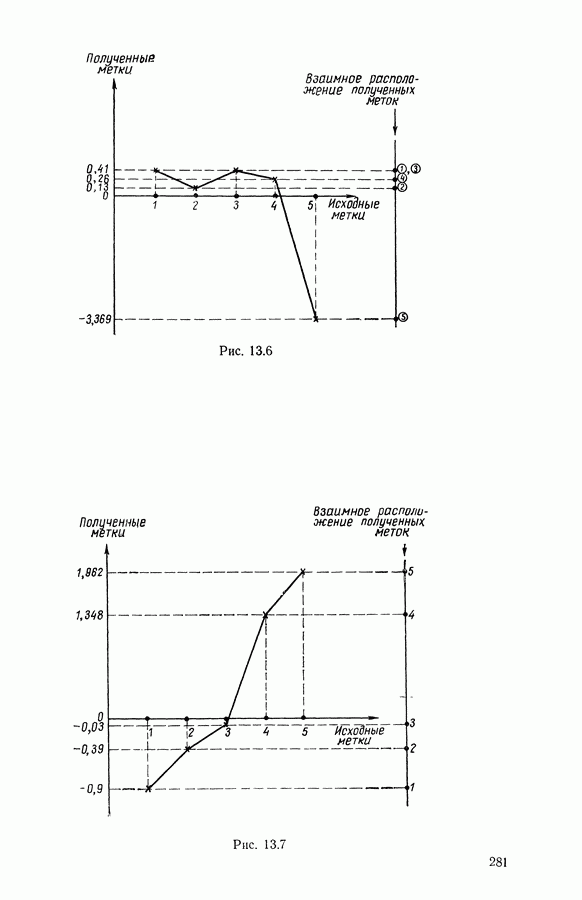
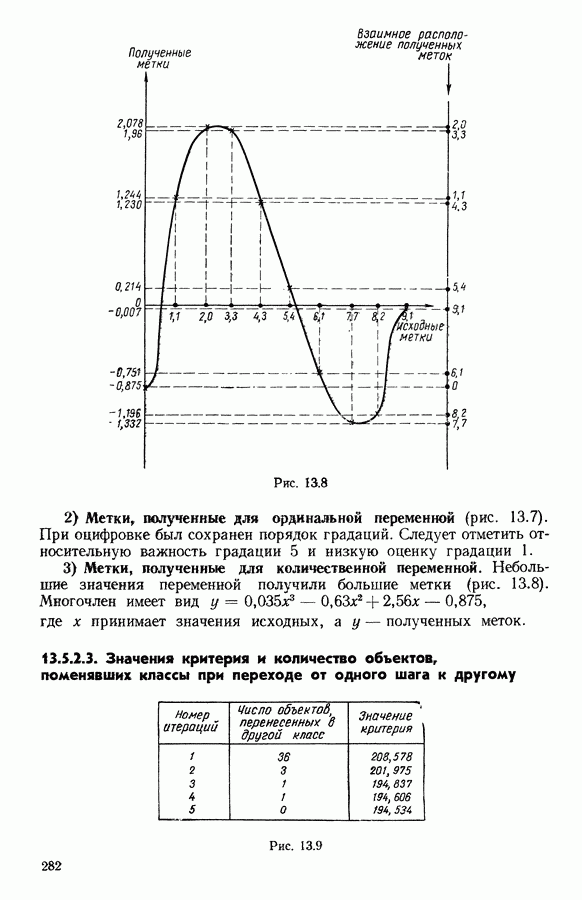

















































 множество из
множество из  индивидуумов, характеризуемых
индивидуумов, характеризуемых  числовыми параметрами. С помощью дискриминантного типологического анализа отыскивается разбиение
числовыми параметрами. С помощью дискриминантного типологического анализа отыскивается разбиение  множества
множества  на
на  классов
классов  фиксировано) и подпространство
фиксировано) и подпространство  размерности
размерности  фиксировано), которое минимизирует внутриклассовую инерцию, объясняемую
фиксировано), которое минимизирует внутриклассовую инерцию, объясняемую 
 снабжено метрикой
снабжено метрикой  (задаваемой матрицей, обратной к матрице ковариаций множества
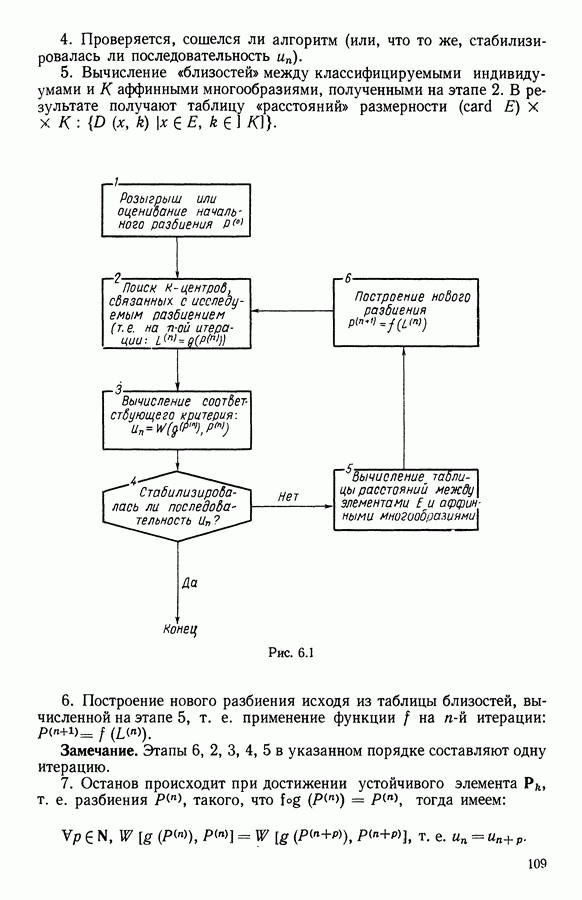
(задаваемой матрицей, обратной к матрице ковариаций множества  Этот поиск осуществляется с помощью алгоритма типа динамических сгущений.
Этот поиск осуществляется с помощью алгоритма типа динамических сгущений.
 (дискриминантного типологического анализа) пользователем определяются три входных параметра:
(дискриминантного типологического анализа) пользователем определяются три входных параметра:
 с которого начинает работу алгоритм;
с которого начинает работу алгоритм;


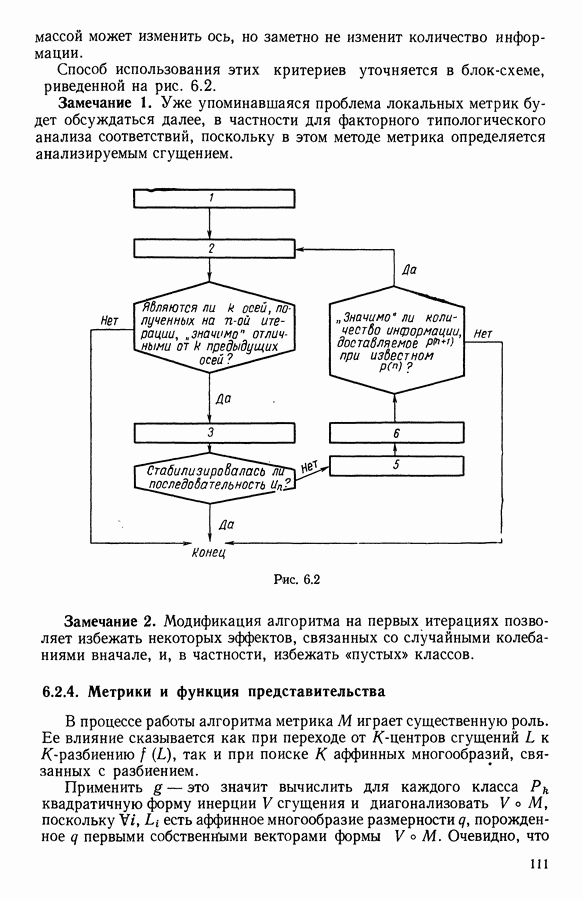
 либо оценивается, либо выбирается случайным образом. Во всех алгоритмах классификации, когда начальное разбиение выбирается случайным образом, есть опасность, что алгоритм сойдется к неинтересным решениям. Вот почему в алгоритмах этого типа рекомендуется делать множество прогонок, меняя начальное разбиение. С другой стороны, существуют методы, позволяющие частично преодолеть это неудобство (например, использование сильных форм, см. 1.3.7, а также [3]).
либо оценивается, либо выбирается случайным образом. Во всех алгоритмах классификации, когда начальное разбиение выбирается случайным образом, есть опасность, что алгоритм сойдется к неинтересным решениям. Вот почему в алгоритмах этого типа рекомендуется делать множество прогонок, меняя начальное разбиение. С другой стороны, существуют методы, позволяющие частично преодолеть это неудобство (например, использование сильных форм, см. 1.3.7, а также [3]).
 требуемых классов диктуется числом классов начального разбиения.
требуемых классов диктуется числом классов начального разбиения.
 дискриминантных осей, по-видимому, разумно выбирать близким к
дискриминантных осей, по-видимому, разумно выбирать близким к  например
например  или
или 
 заданного априори. Выбрано
заданного априори. Выбрано 
 В табл. 8.2 приведено разложение классов разбиения
В табл. 8.2 приведено разложение классов разбиения  по классам исходного разбиения
по классам исходного разбиения 
 и разбиение к моменту сходимости алгоритма
и разбиение к моменту сходимости алгоритма 


 также распался на два, часть его сгруппировалась с классом
также распался на два, часть его сгруппировалась с классом  образуя новый класс;
образуя новый класс;
 и
и  относительно устойчивы; классы
относительно устойчивы; классы  и
и  оказались более размытыми и наблюдается тенденция смешивания их.
оказались более размытыми и наблюдается тенденция смешивания их.
 от других; несомненно, здесь мы имеем дело с устойчивым классом. Аналогично классы
от других; несомненно, здесь мы имеем дело с устойчивым классом. Аналогично классы  и Ту, хорошо представленные по осям 2 и 3, должны быть устойчивыми. Отметим, наконец, что в случае использования 4 осей классы
и Ту, хорошо представленные по осям 2 и 3, должны быть устойчивыми. Отметим, наконец, что в случае использования 4 осей классы  и
и  ведут себя сходным образом. Согласно табл. 8.2 объединение классов
ведут себя сходным образом. Согласно табл. 8.2 объединение классов  интерпретируется как объединение априорных классов
интерпретируется как объединение априорных классов  Эти два последних класса определяются наличием дефекта соударения соответственно при торможении и в обоих режимах одновременно. Объединение классов
Эти два последних класса определяются наличием дефекта соударения соответственно при торможении и в обоих режимах одновременно. Объединение классов  интерпретируется просто как множество объектов из имеющих дефект соударения по крайней мере в режиме торможения. Специалисты указали, что класс
интерпретируется просто как множество объектов из имеющих дефект соударения по крайней мере в режиме торможения. Специалисты указали, что класс  (входящий в
(входящий в  представляет собой множество машин из
представляет собой множество машин из  имеющих характерный дефект производства (напомним, что априорное разбиение на типы определялось только по особенностям функционирования).
имеющих характерный дефект производства (напомним, что априорное разбиение на типы определялось только по особенностям функционирования).
 (машины без дефекта) отражает то, что понятие исправной машины является «размытым». Перечисленные результаты и их интерпретация подсказывают следующее новое разбиение множества
(машины без дефекта) отражает то, что понятие исправной машины является «размытым». Перечисленные результаты и их интерпретация подсказывают следующее новое разбиение множества  на 5 классов:
на 5 классов:

 оправдано определениями априорных классов
оправдано определениями априорных классов  и
и 
 — гул только при торможении;
— гул только при торможении;
 — гул при разгоне и торможении.
— гул при разгоне и торможении.
 объединены машины, имеющие небольшой (с точки зрения специалиста) дефект — гул или удар — только в режиме разгона, что соответствует классам
объединены машины, имеющие небольшой (с точки зрения специалиста) дефект — гул или удар — только в режиме разгона, что соответствует классам  Машины, рассматриваемые априори как бездефектные, но не попавшие в
Машины, рассматриваемые априори как бездефектные, но не попавшие в  естественно объединять с этими машинами, имеющими небольшой дефект.
естественно объединять с этими машинами, имеющими небольшой дефект.
 определенного выше. Выбрано
определенного выше. Выбрано 
 аналогичному разбиению С с точки зрения интерпретации классов.
аналогичному разбиению С с точки зрения интерпретации классов.


 . Табл. 8.3 подтверждает устойчивость разбиения, выбранного в качестве начального для нашего алгоритма.
. Табл. 8.3 подтверждает устойчивость разбиения, выбранного в качестве начального для нашего алгоритма.
 вторая ось разделяет классы
вторая ось разделяет классы  четвертая ось позволяет разделить классы
четвертая ось позволяет разделить классы  . Пять полученных классов, помимо устойчивости, допускают содержательную интерпретацию.
. Пять полученных классов, помимо устойчивости, допускают содержательную интерпретацию.
 не удивительны, они соответствуют дефекту одного типа и, по-видимому, отражают следующий факт. Когда оператор слышит аномалию, более ярко выраженную при торможении, чем при разгоне, он имеет тенденцию забывать аномалию при разгоне (в самом деле, прослушивание при торможении осуществляется после прослушивания при разгоне).
не удивительны, они соответствуют дефекту одного типа и, по-видимому, отражают следующий факт. Когда оператор слышит аномалию, более ярко выраженную при торможении, чем при разгоне, он имеет тенденцию забывать аномалию при разгоне (в самом деле, прослушивание при торможении осуществляется после прослушивания при разгоне).
 выделившийся из класса
выделившийся из класса  соответствует, как мы видели, дефекту, достаточно хорошо объясняемому метрологически. Метрологический анализ показал, что 11 машин обладают резко выраженным доминирующим дефектом. Эти машины вошли в класс
соответствует, как мы видели, дефекту, достаточно хорошо объясняемому метрологически. Метрологический анализ показал, что 11 машин обладают резко выраженным доминирующим дефектом. Эти машины вошли в класс  насчитывающий 13 элементов.
насчитывающий 13 элементов.
 в класс
в класс  не столь удовлетворительно, хотя довольно естественно назвать класс С классом «небольшого дефекта в режиме разгона».
не столь удовлетворительно, хотя довольно естественно назвать класс С классом «небольшого дефекта в режиме разгона».
 в задаче разбиения на 6 вместо пяти классов.
в задаче разбиения на 6 вместо пяти классов.
 в том случае, когда группа
в том случае, когда группа  не отделяется от класса
не отделяется от класса  образуя 6-й класс.
образуя 6-й класс.
 начального разбиения присоединились к классу
начального разбиения присоединились к классу 
 этапе анализа, давшем разбиение на пять «естественных» классов. Отметим, кстати, что, по нашему мнению, неуместно требование любой ценой разделить группы методом дискриминантного типологического анализа. Поступая так, теряют большую часть преимуществ этого метода, а устойчивость полученных результатов в итоге оказывается сомнительной.
этапе анализа, давшем разбиение на пять «естественных» классов. Отметим, кстати, что, по нашему мнению, неуместно требование любой ценой разделить группы методом дискриминантного типологического анализа. Поступая так, теряют большую часть преимуществ этого метода, а устойчивость полученных результатов в итоге оказывается сомнительной.
 и
и  нам кажется разумным ввести второй уровень дискриминации, проводя исследования только по переменным в режиме разгона.
нам кажется разумным ввести второй уровень дискриминации, проводя исследования только по переменным в режиме разгона.
 и
и  входящие в
входящие в 
 и
и  входящие в
входящие в 
 и подгруппу
и подгруппу  входящие в
входящие в 
 Начальное разбиение следующее:
Начальное разбиение следующее:
 и
и  рассматриваются при этом как анонимные: они не участвуют в анализе, но распределяются затем по классам, полученным к моменту сходимости алгоритма. Результаты этого анализа можно резюмировать так: он недвусмысленно показал, что нельзя разделить классы
рассматриваются при этом как анонимные: они не участвуют в анализе, но распределяются затем по классам, полученным к моменту сходимости алгоритма. Результаты этого анализа можно резюмировать так: он недвусмысленно показал, что нельзя разделить классы  и
и 
 Те элементы из
Те элементы из  и
и  которые расположены в одном и том же классе, неправильно классифицируются;
которые расположены в одном и том же классе, неправильно классифицируются;
 и
и  исходя из результатов этого анализа также возможно. Лишь элементы
исходя из результатов этого анализа также возможно. Лишь элементы  в классе
в классе  в классе 2 неправильно классифицируются;
в классе 2 неправильно классифицируются;
 от группы
от группы 