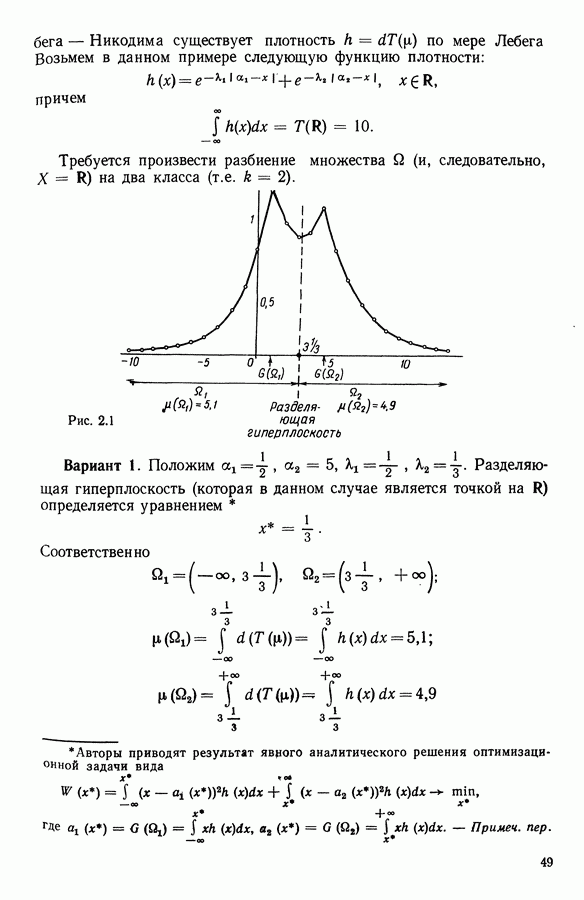
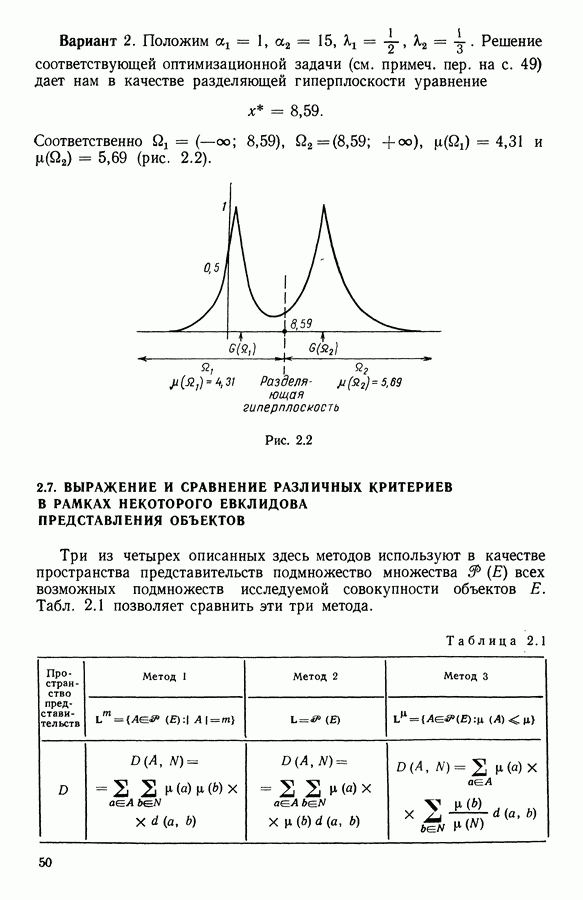
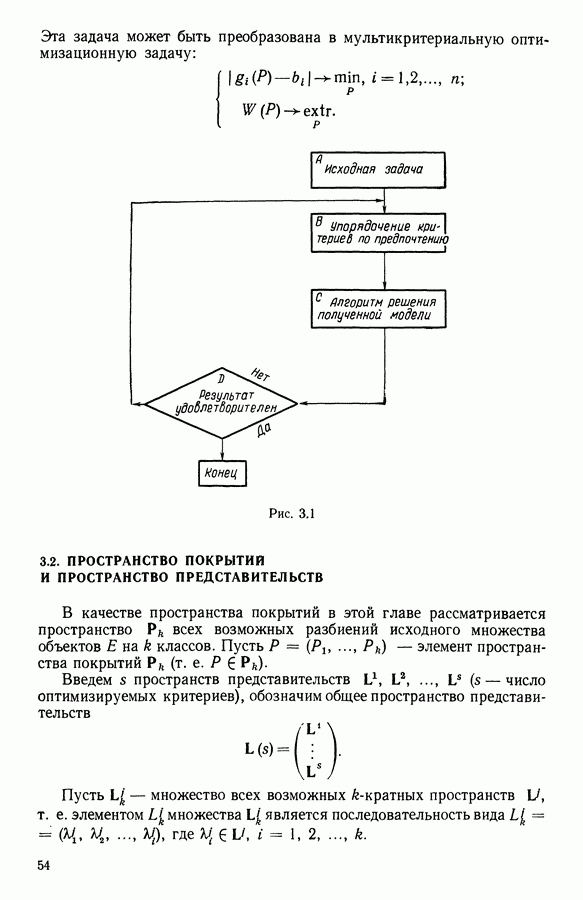
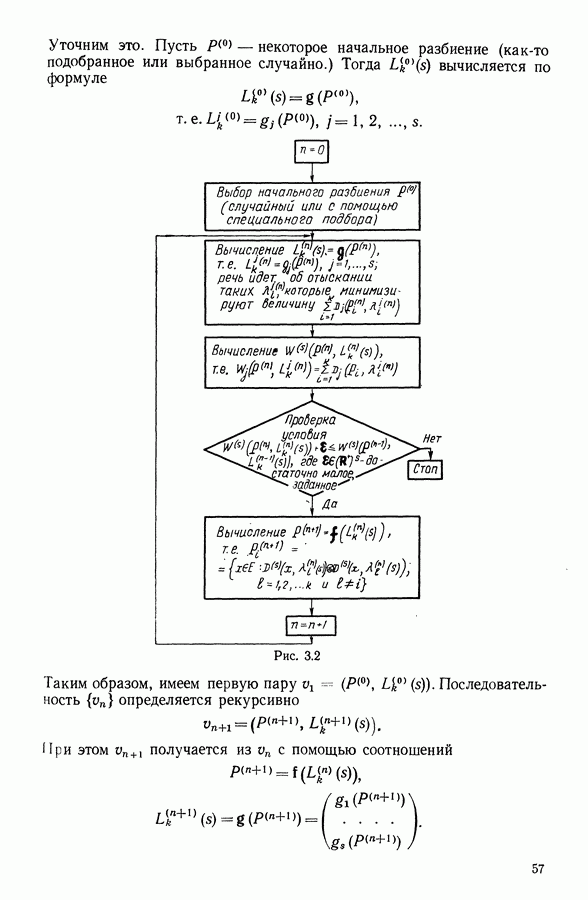
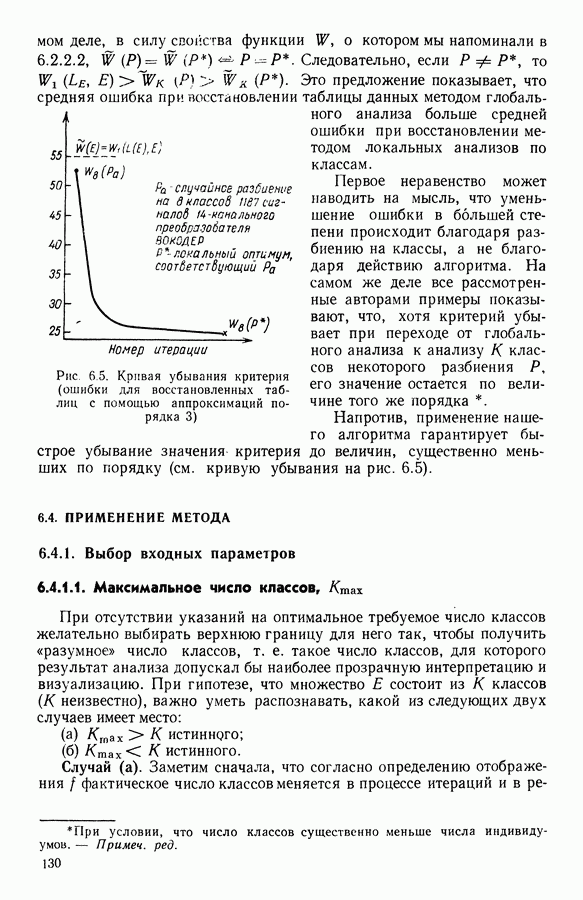
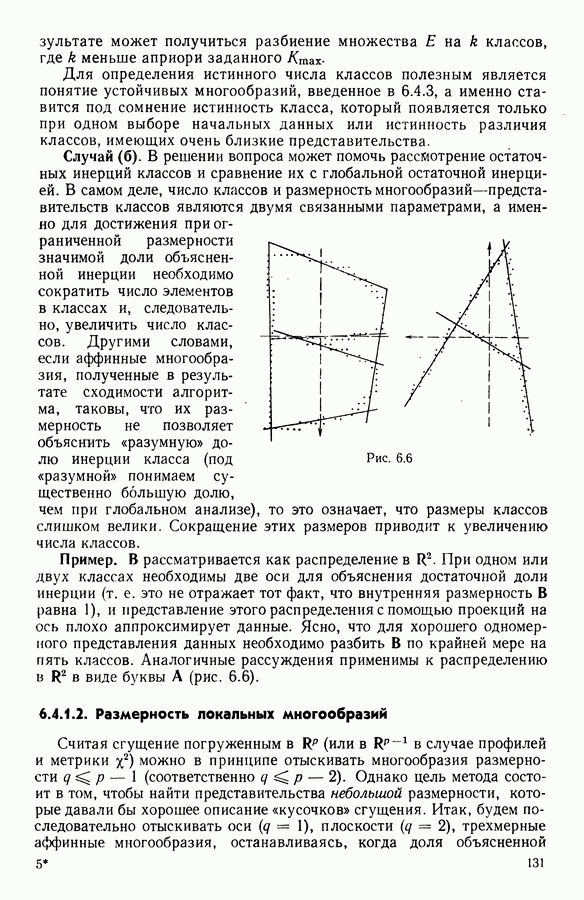
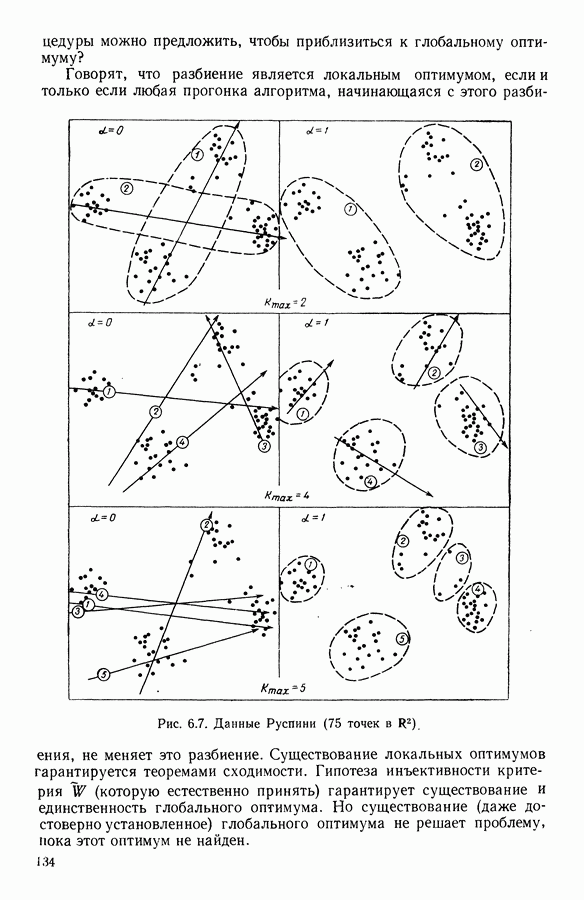
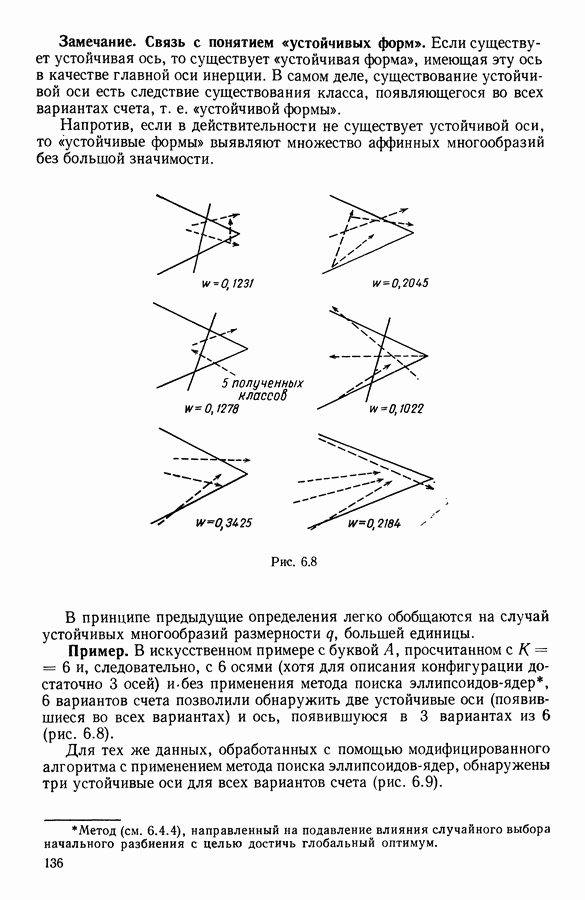
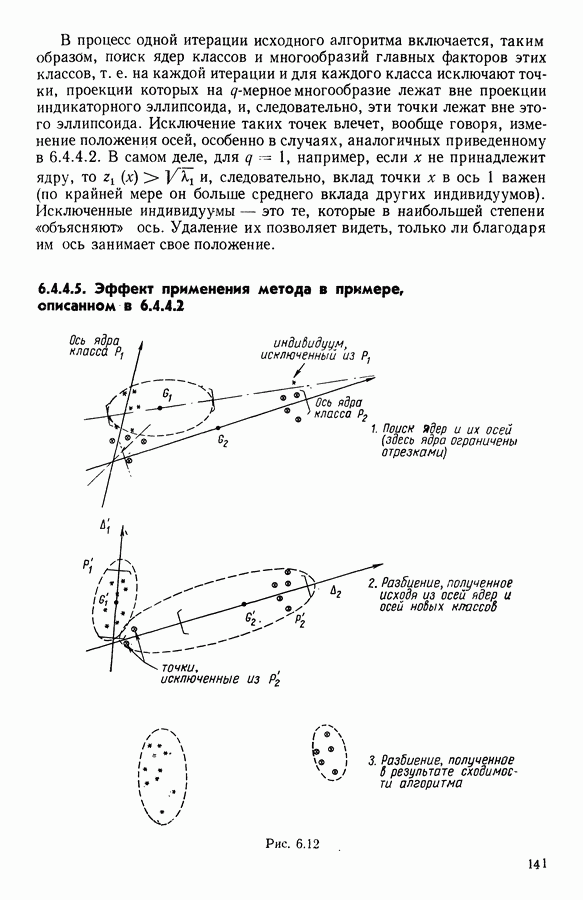
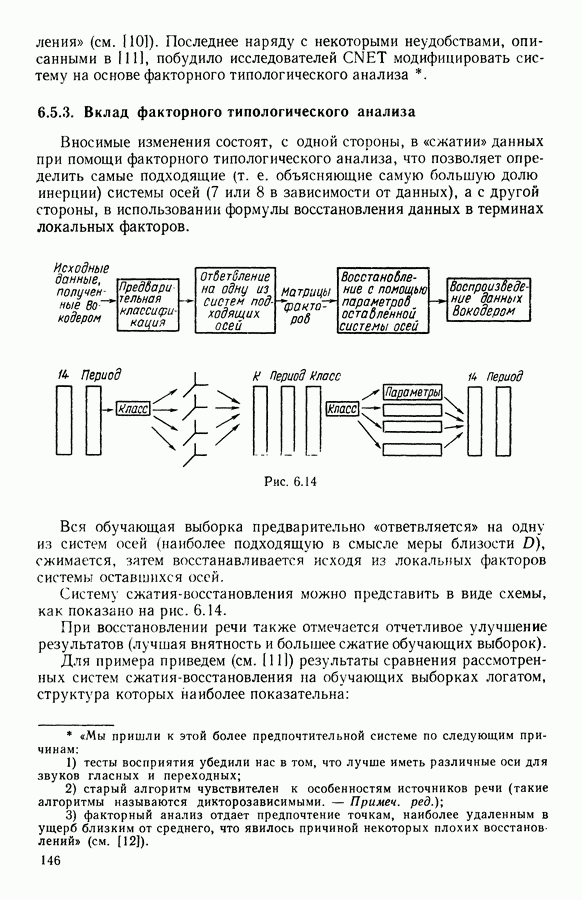
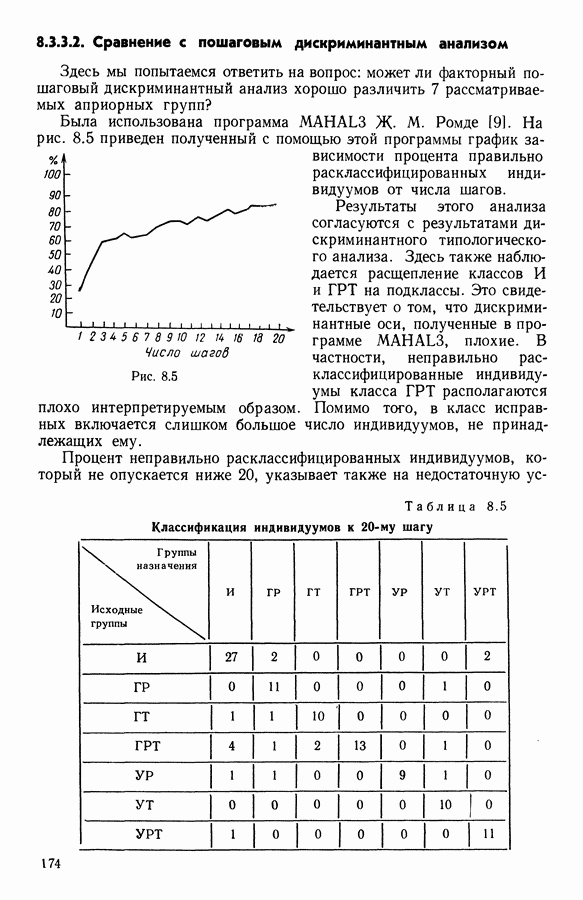
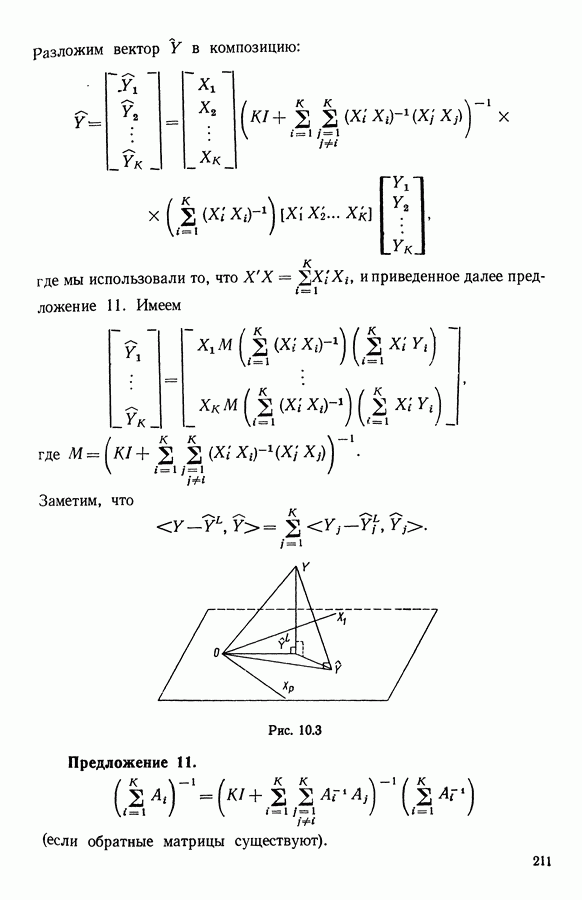
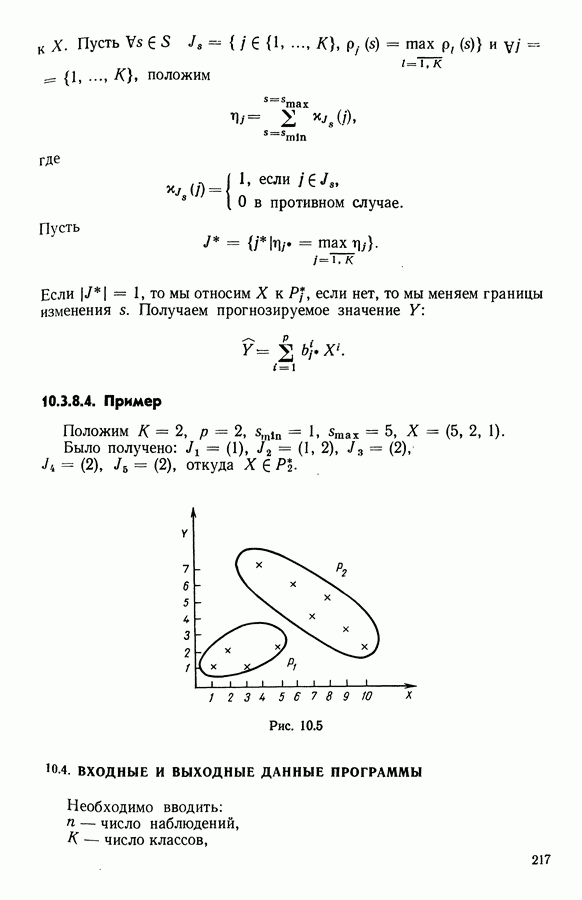
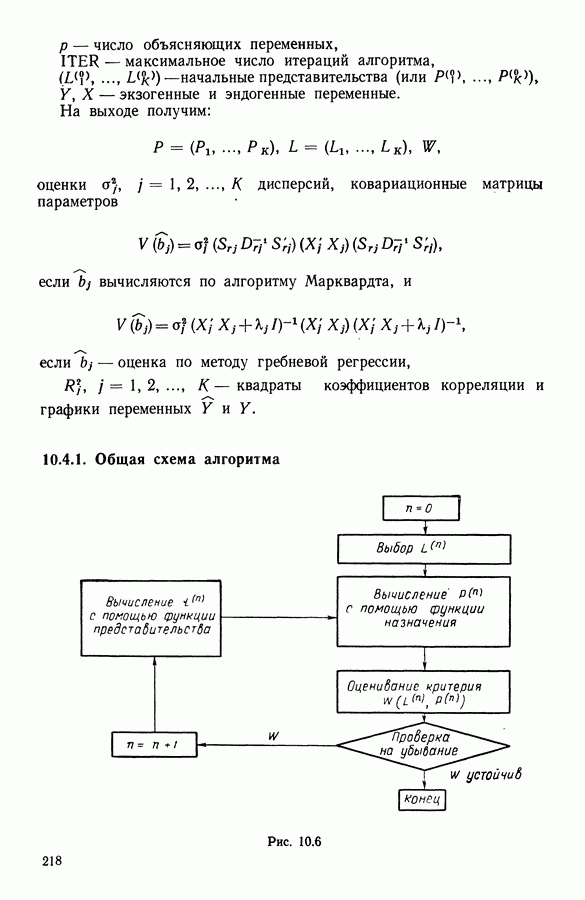
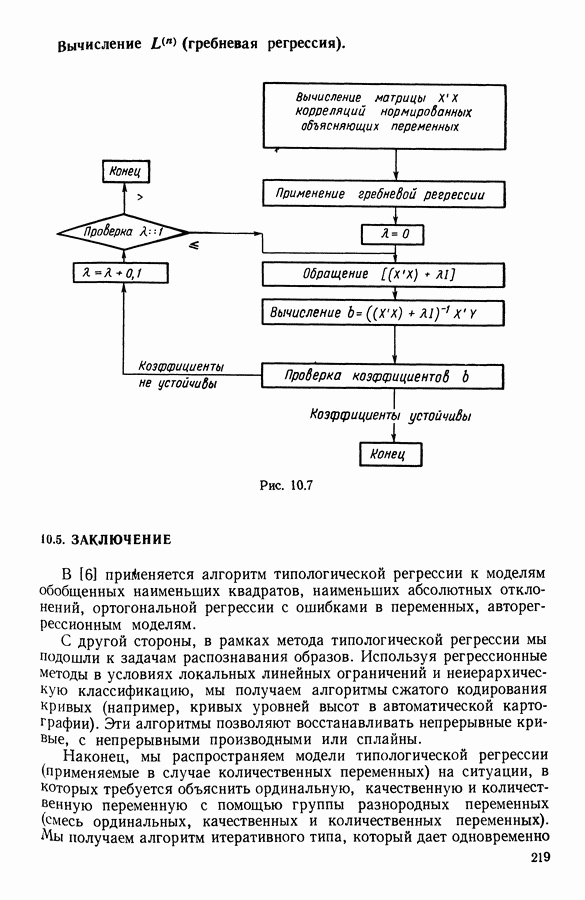
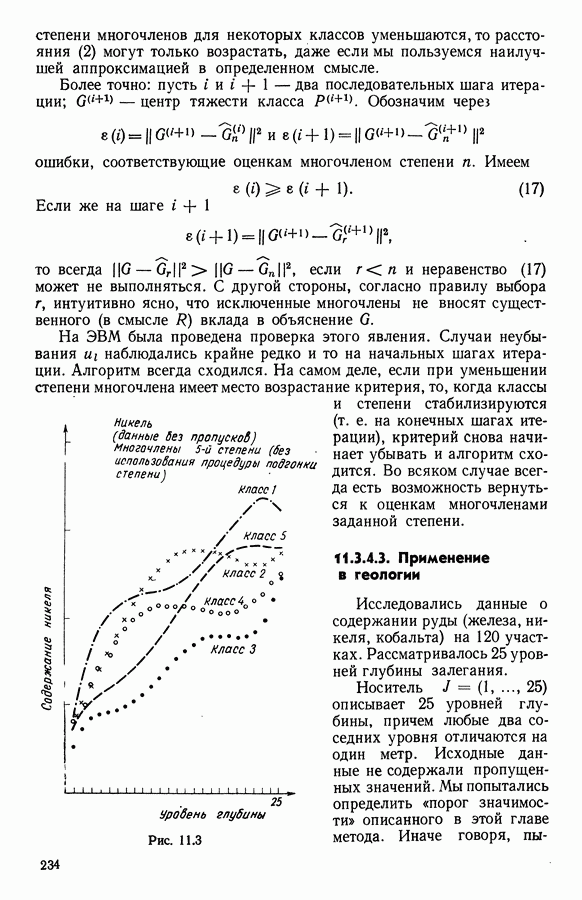
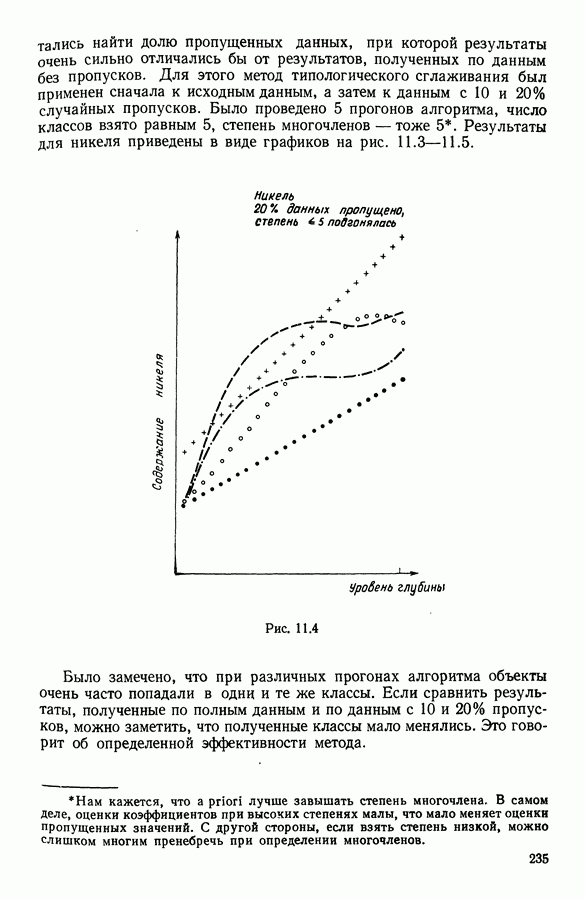
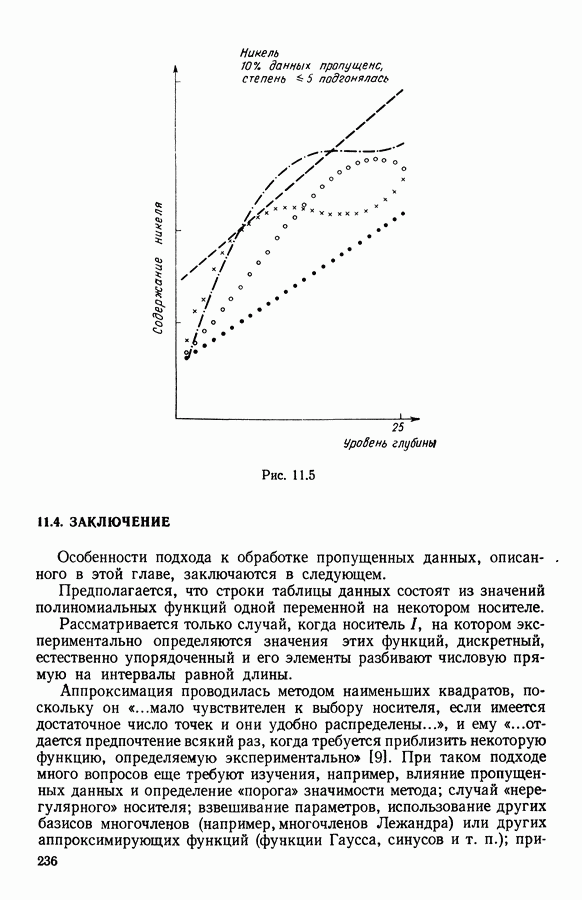
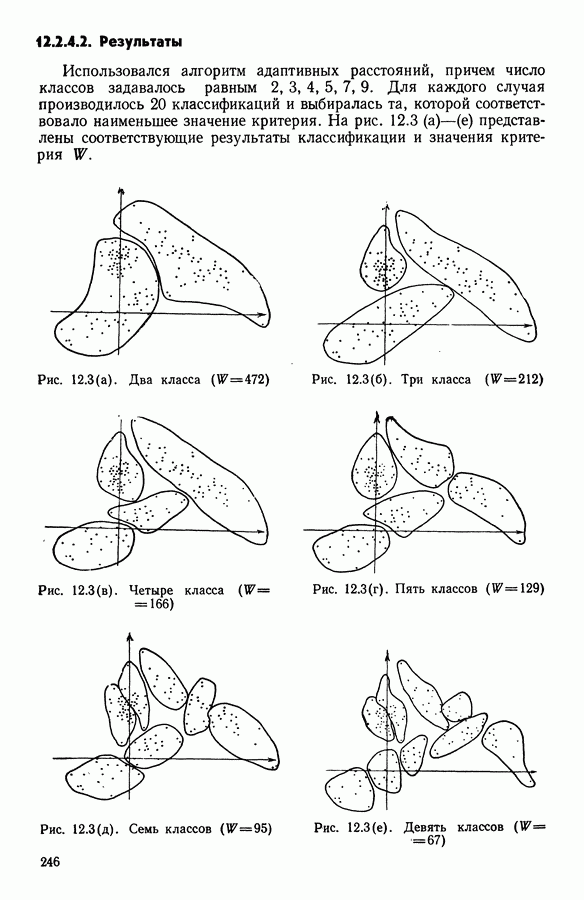
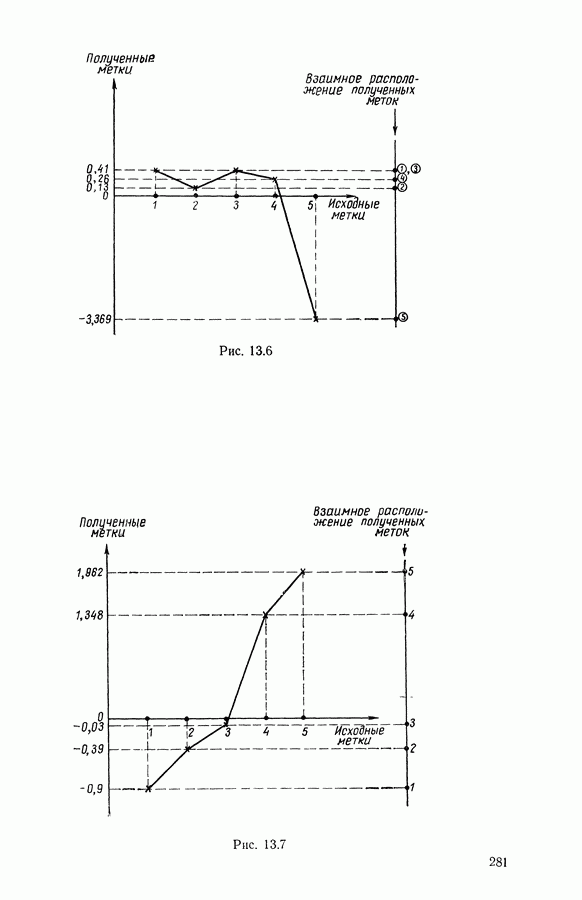
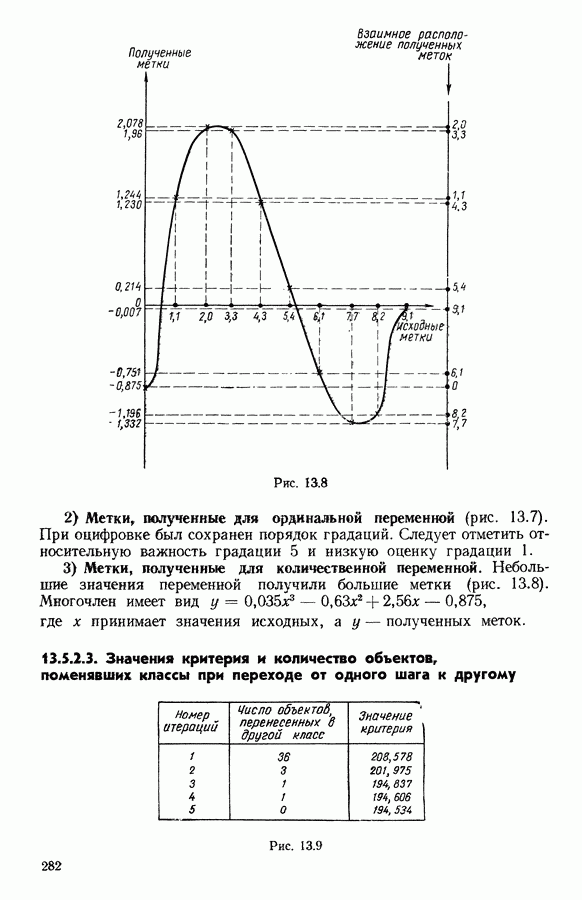
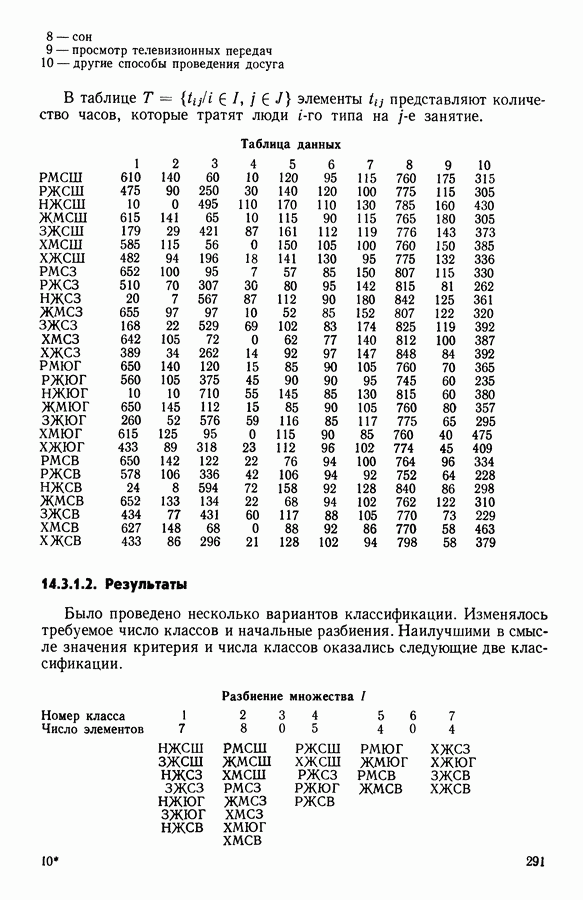
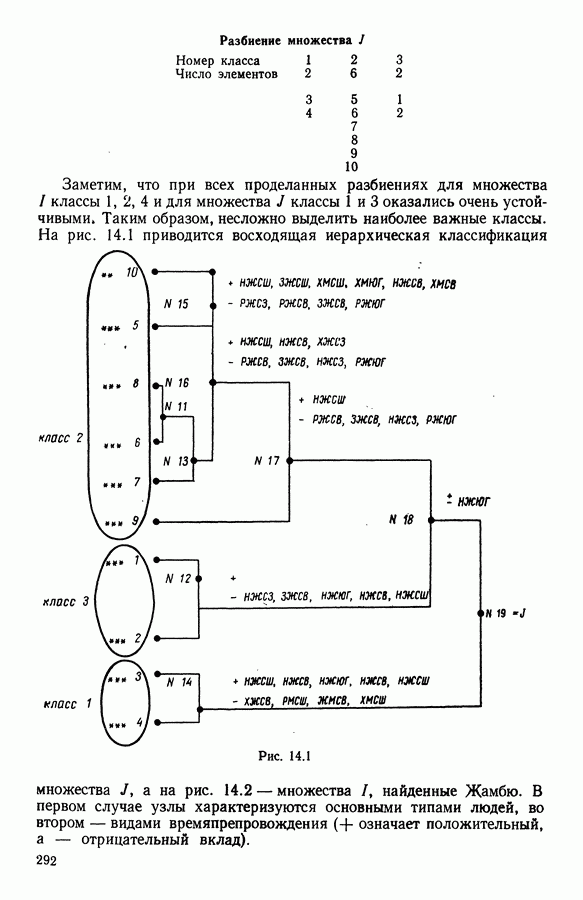
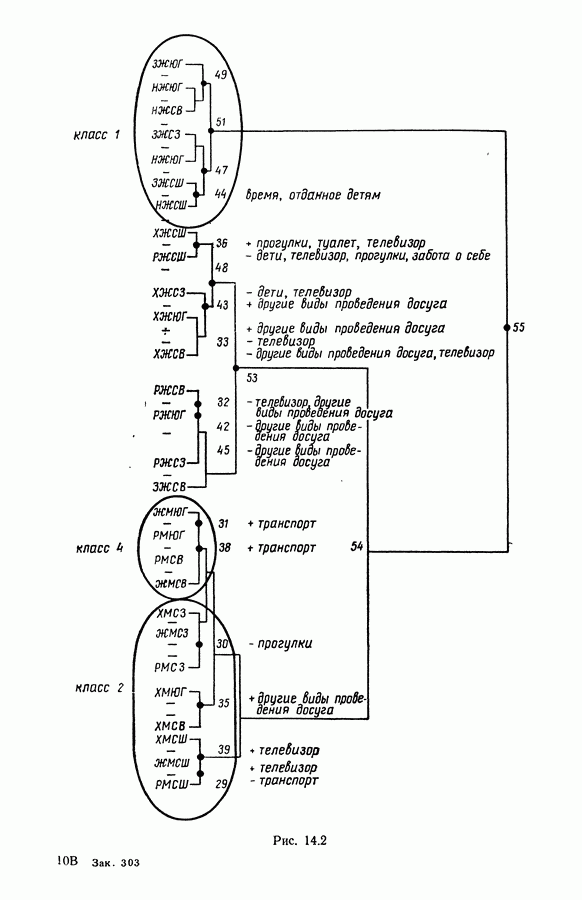
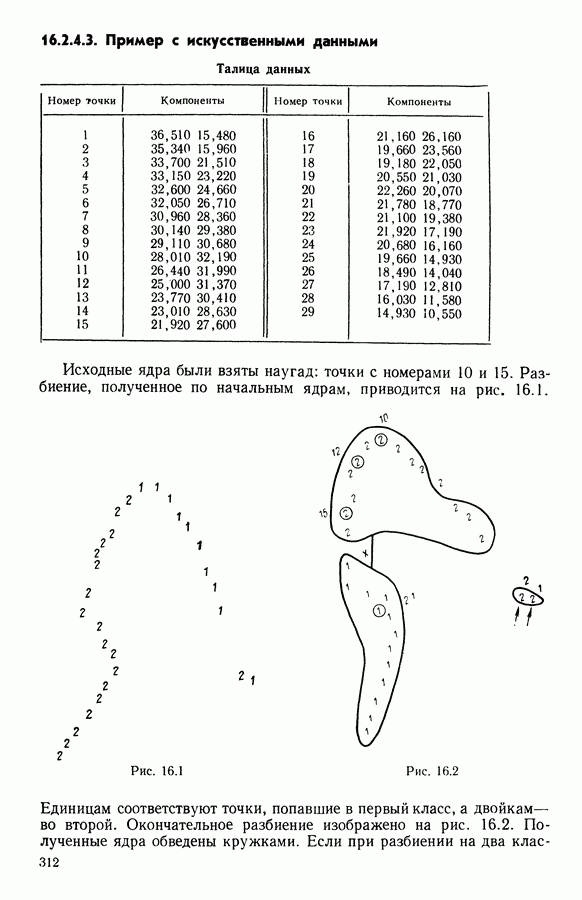
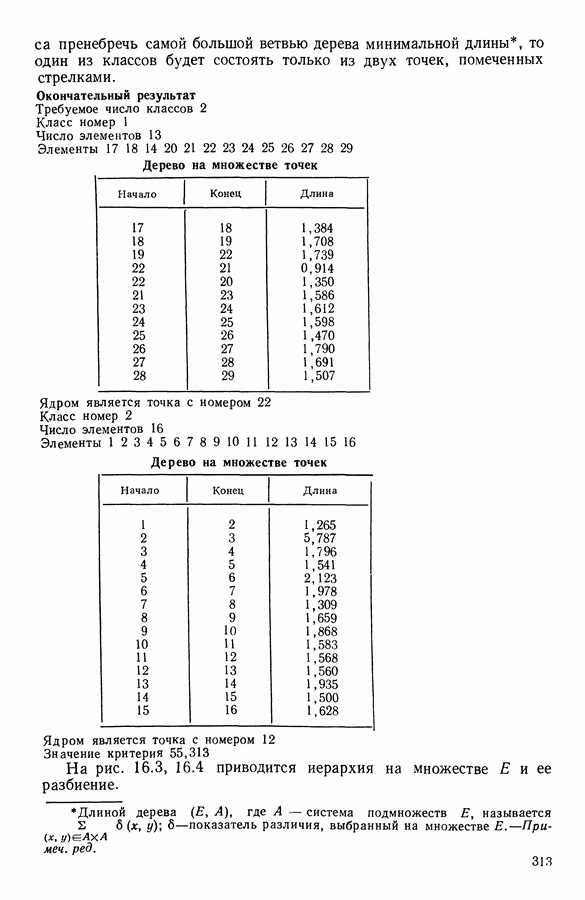
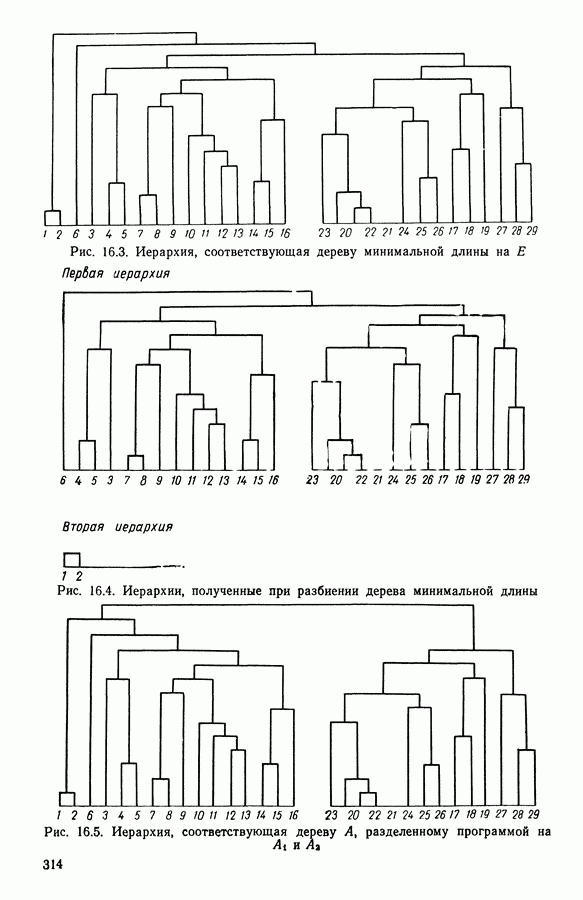
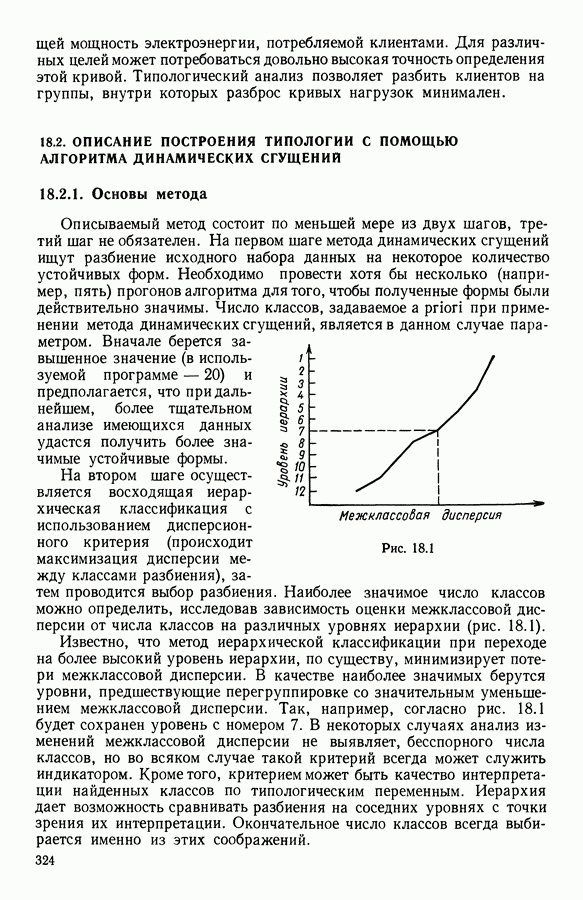
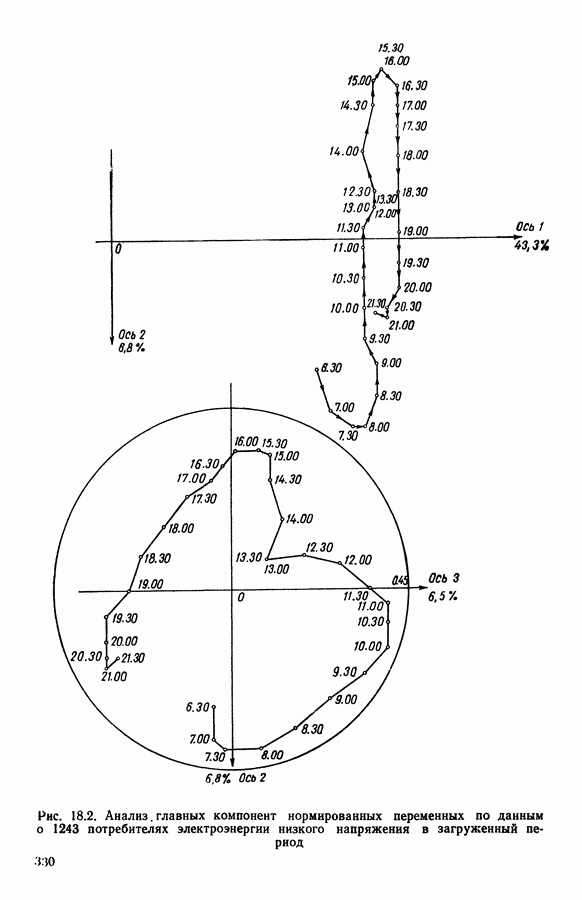
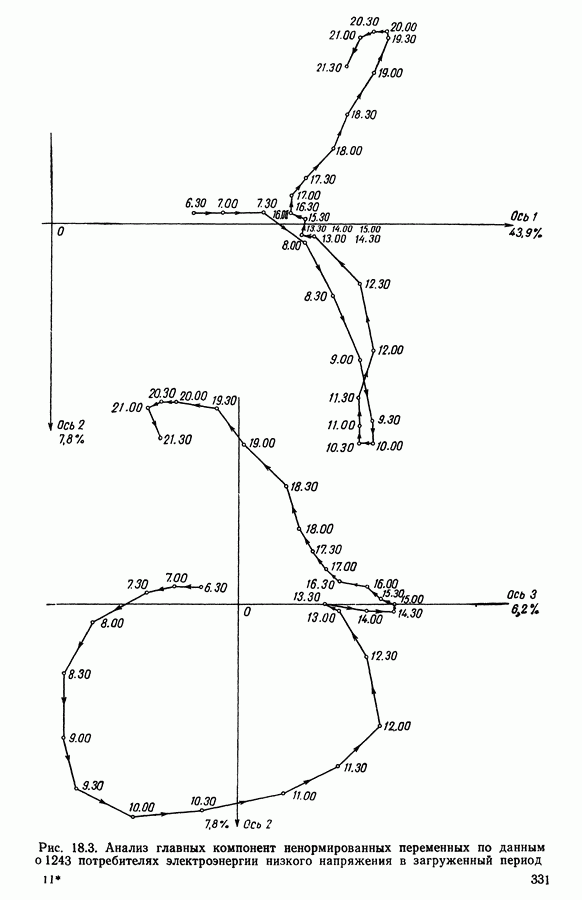
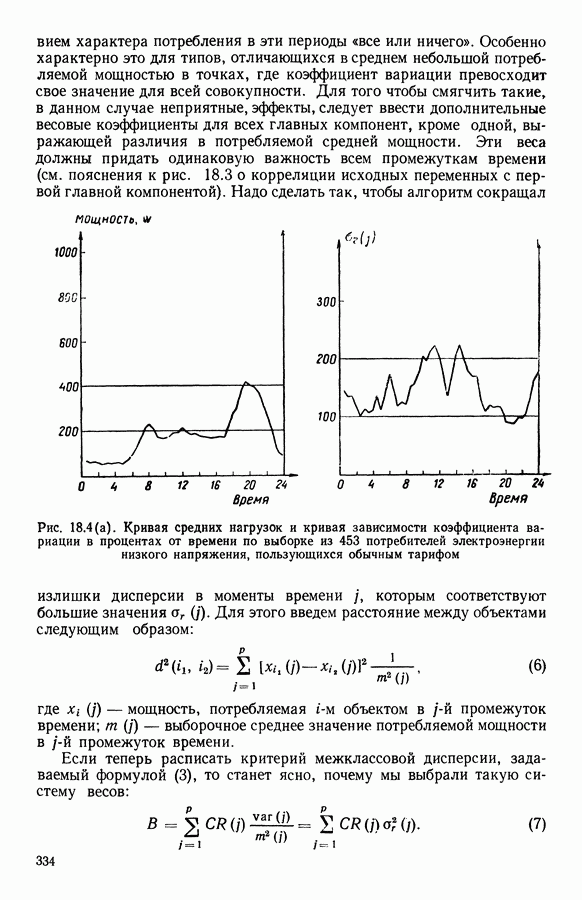
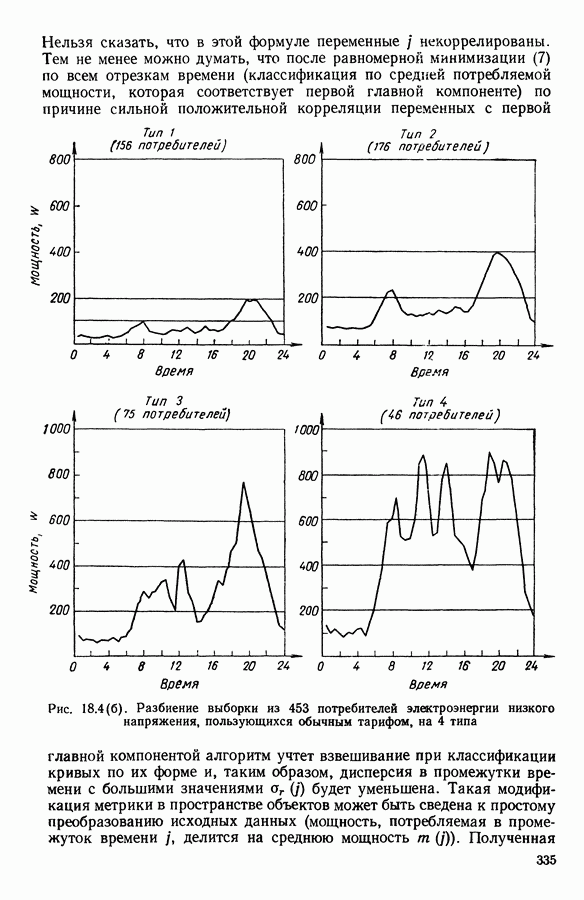
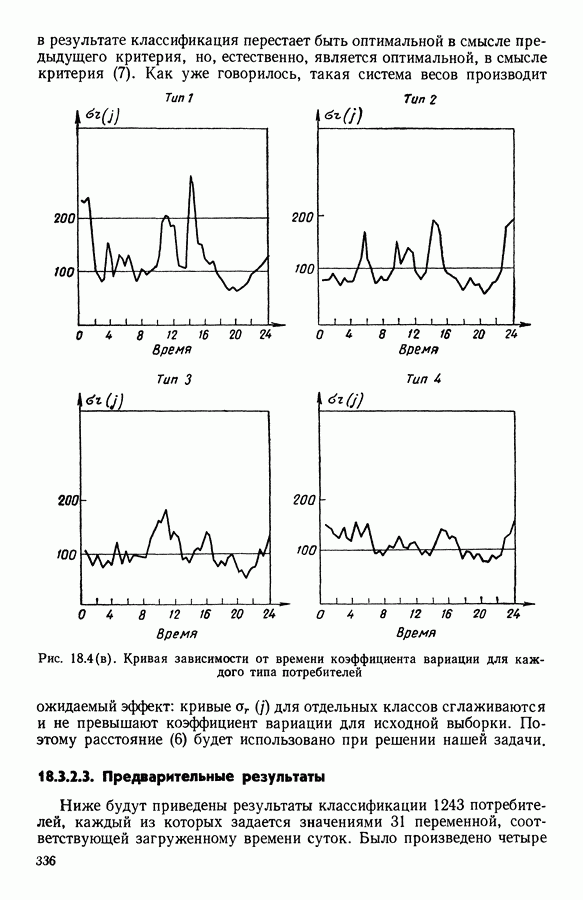
5.6. ЗАКЛЮЧЕНИЕ
Построенный нами вариант алгоритма МДС в большинстве случаев используется при классификации неполных количественных данных без их восстановления, а лишь на базе имеющейся информации.
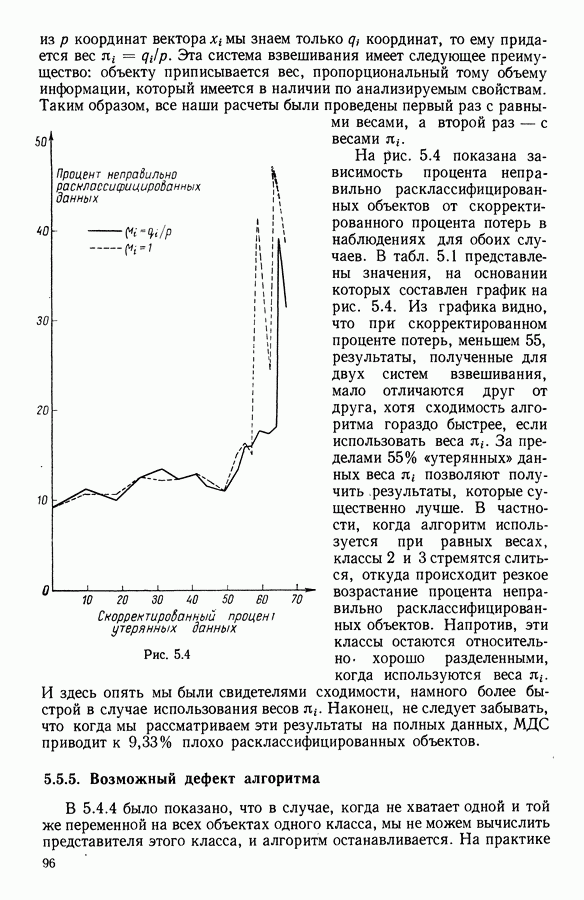
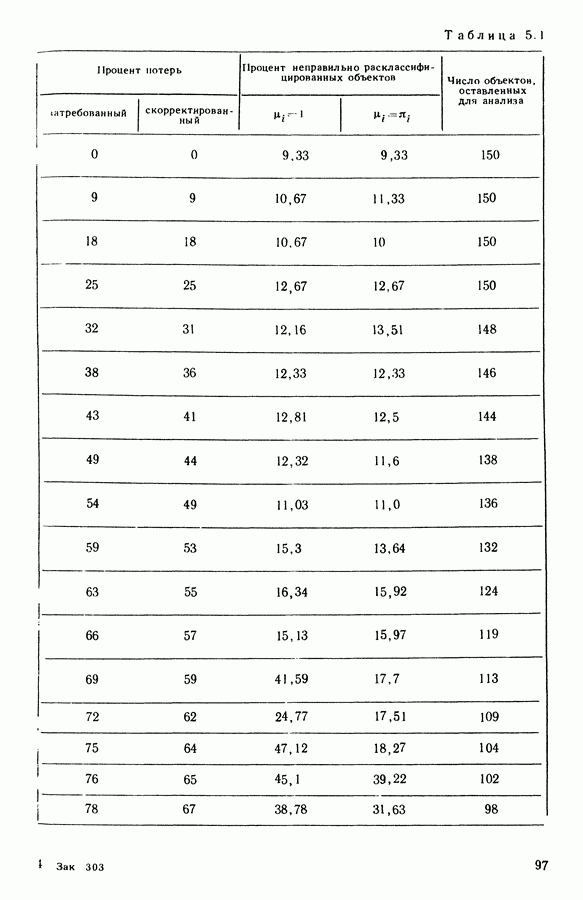
Конечно, алгоритм не претендует на то, чтобы быть универсальным средством в случае неполных данных, с одной стороны, потому, что он может оказаться с дефектом (неожиданная остановка алгоритма), а с другой — потому, что качество классификации падает по мере возрастания количества недостающих данных.
Классификационный анализ оставшихся данных показывает тем не менее, что объект оказывается среди плохо расклассифицированных объектов чаще всего потому, что его координаты, обладающие
наибольшей дискриминирующей способностью, являются утерянными («стертыми»); если же судить по оставшимся в целости координатам, то такие объекты кажутся более близкими к классу, к которому они были приписаны в ходе алгоритма, чем к классу, в котором они должны были бы находиться в действительности.
ЛИТЕРАТУРА
(см. скан)