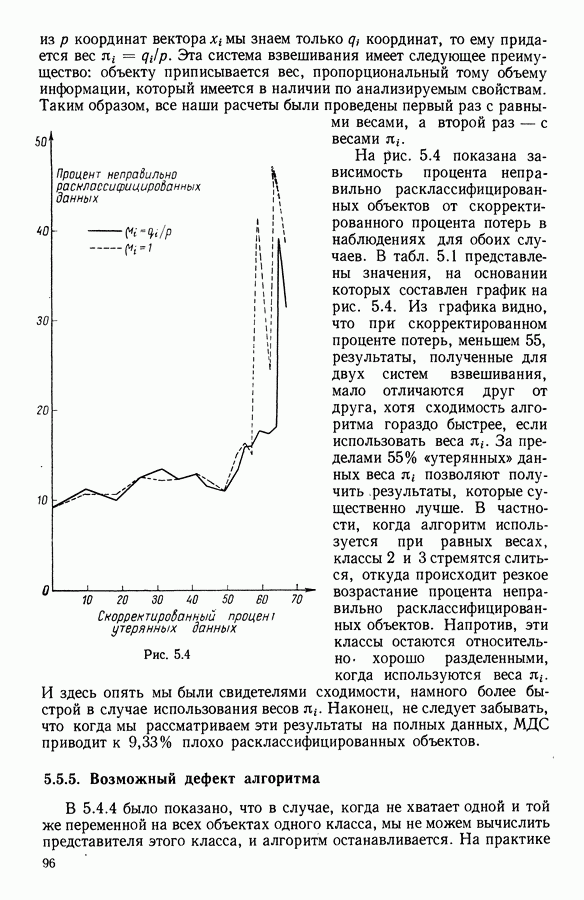
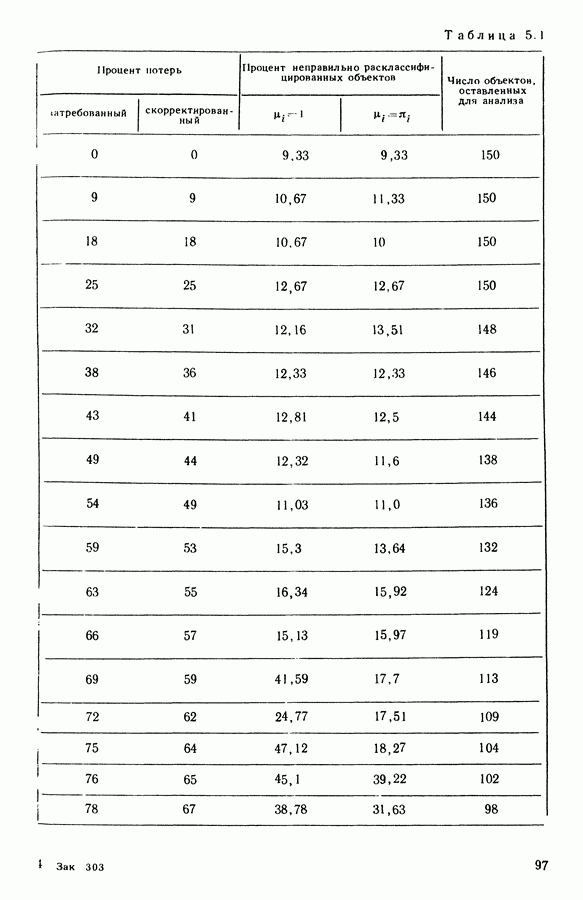
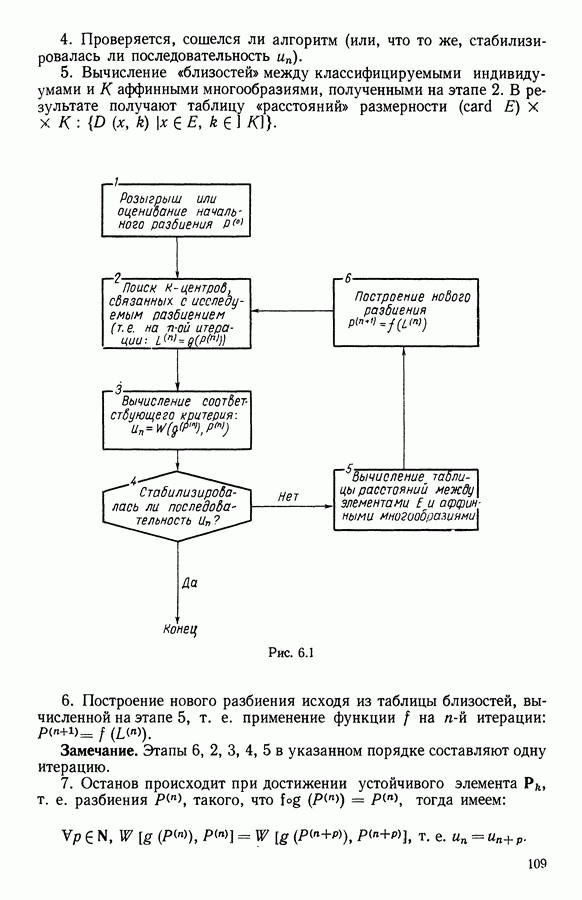
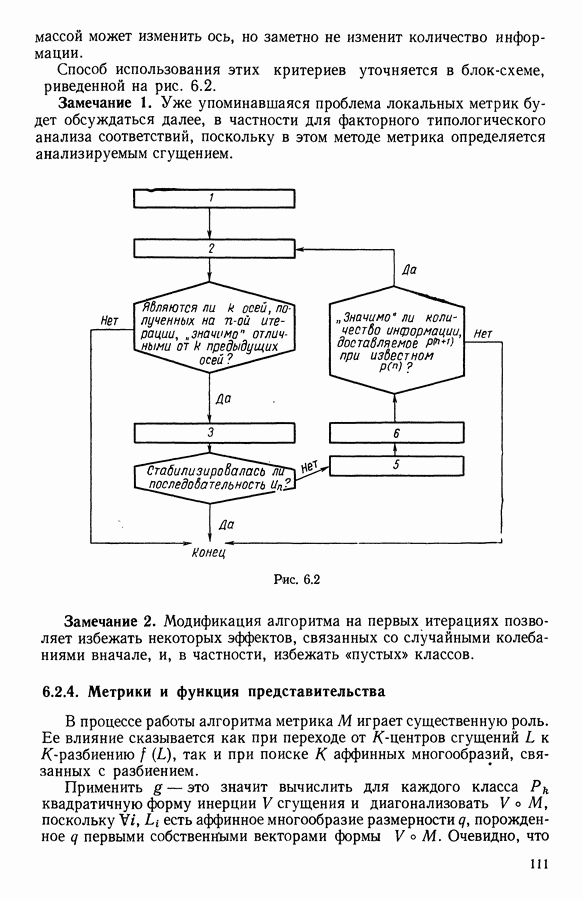
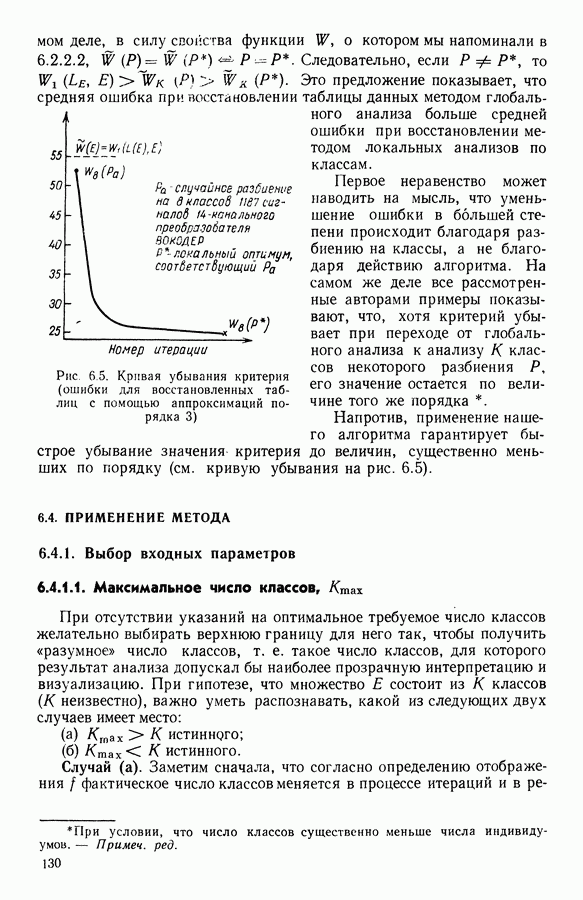
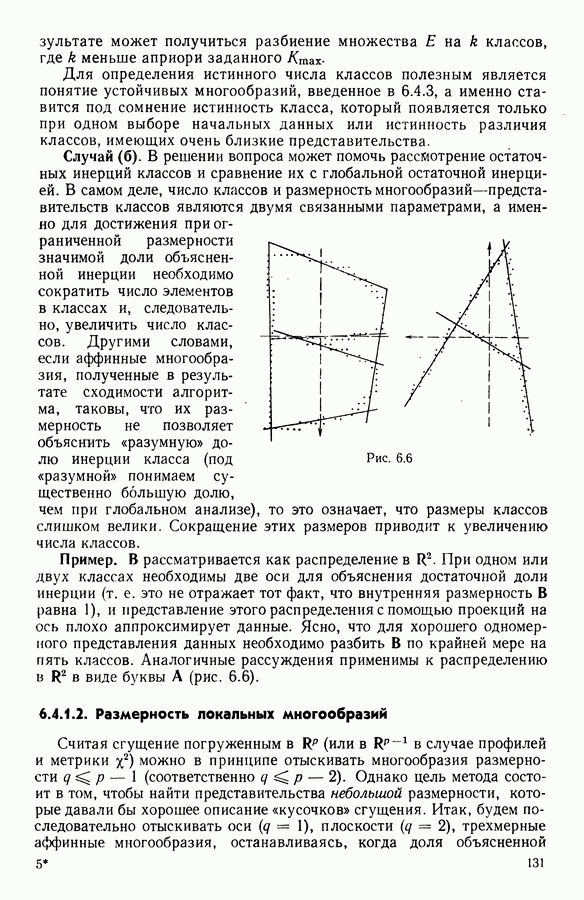
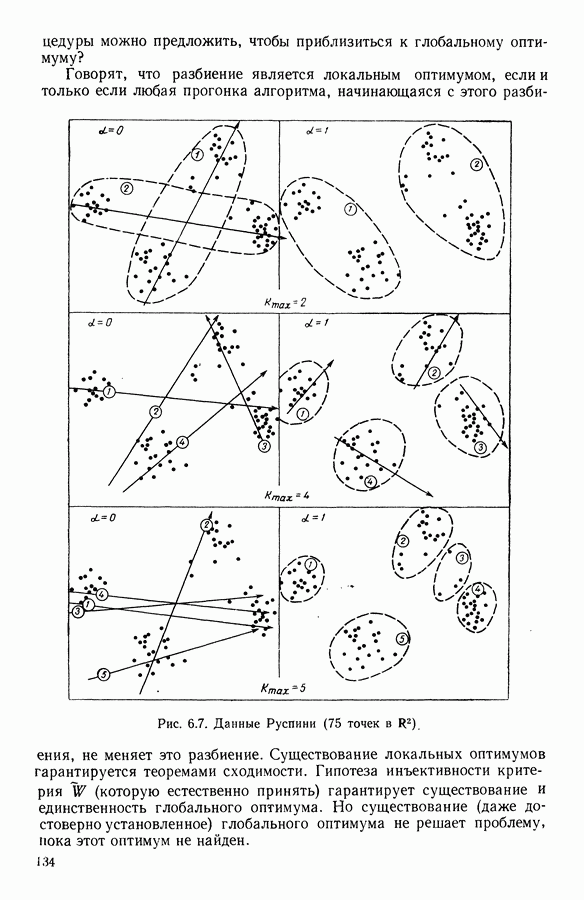
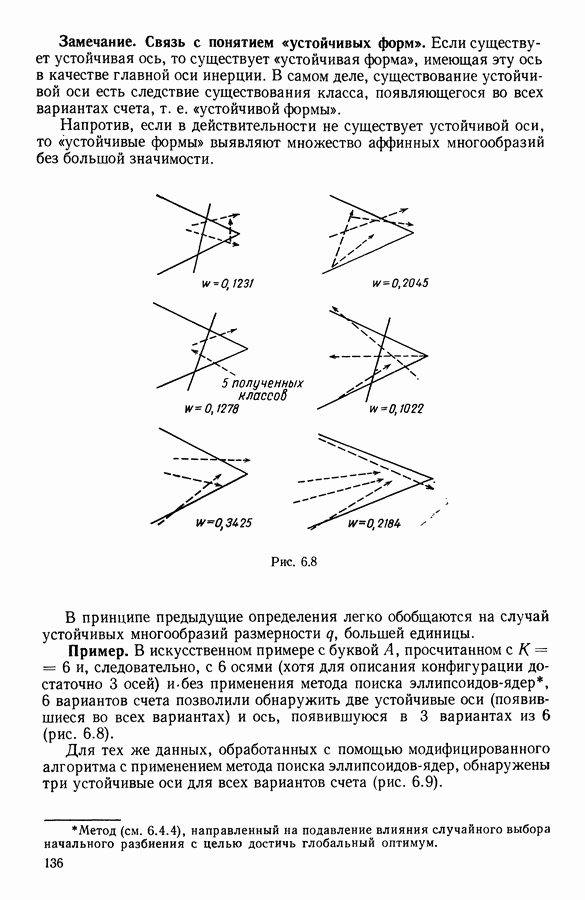
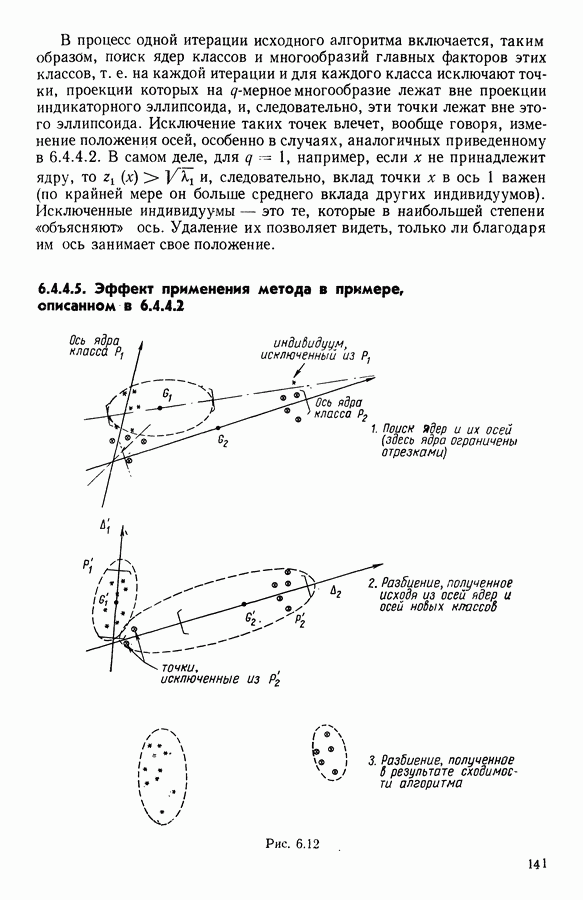
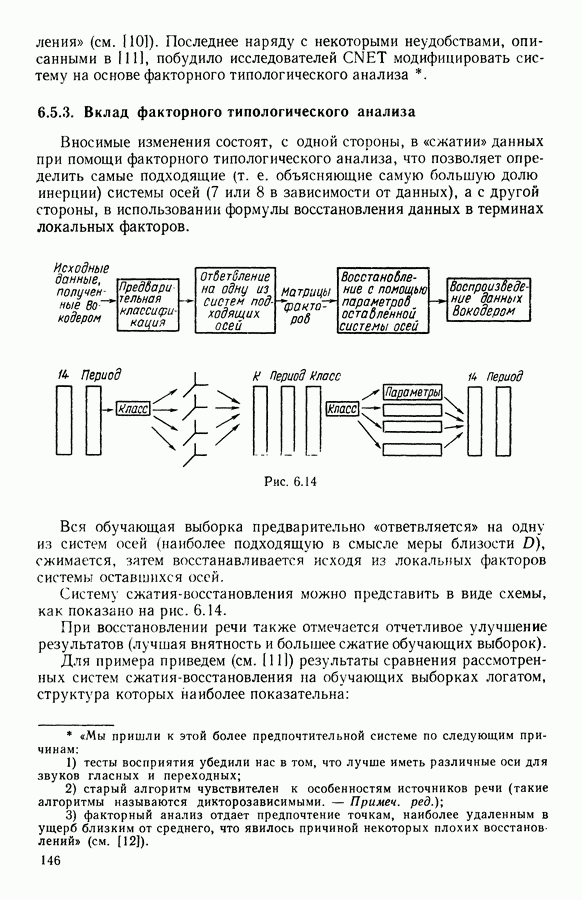
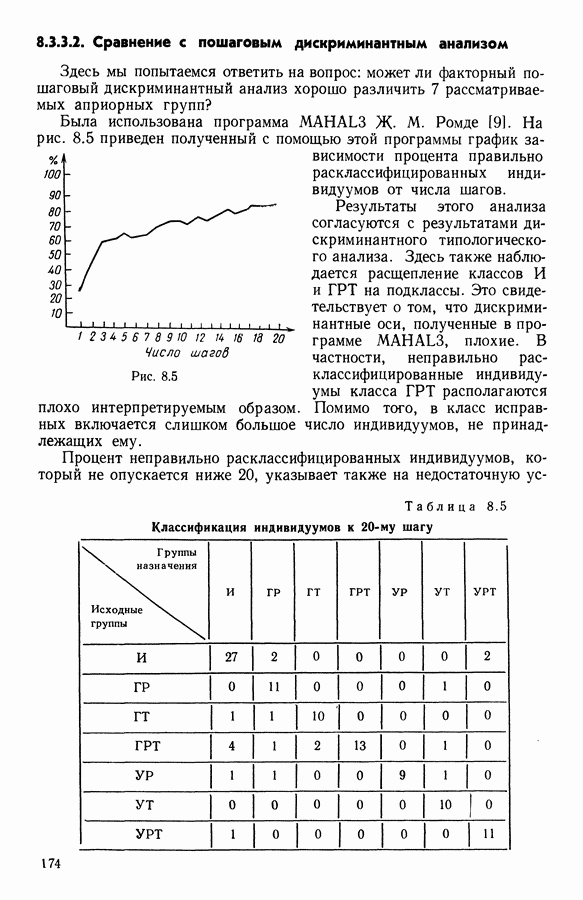
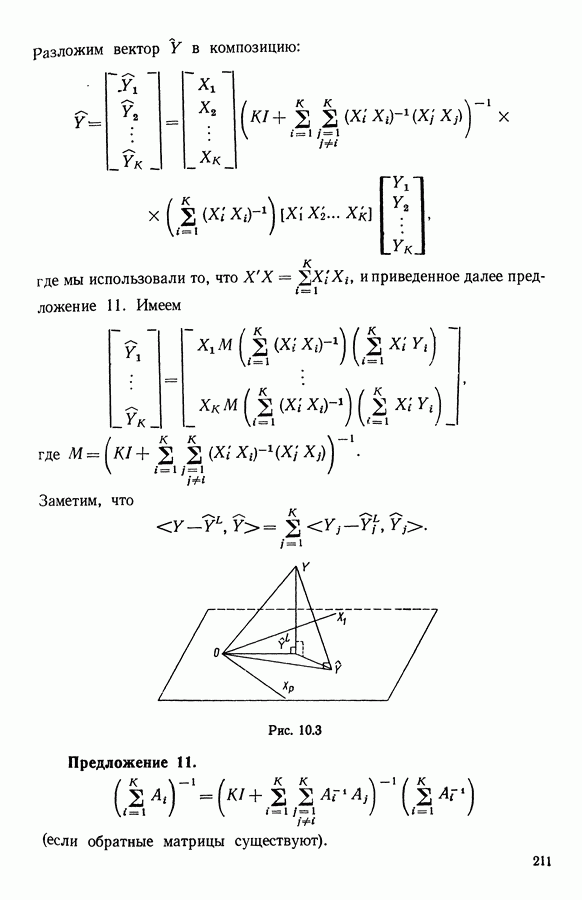
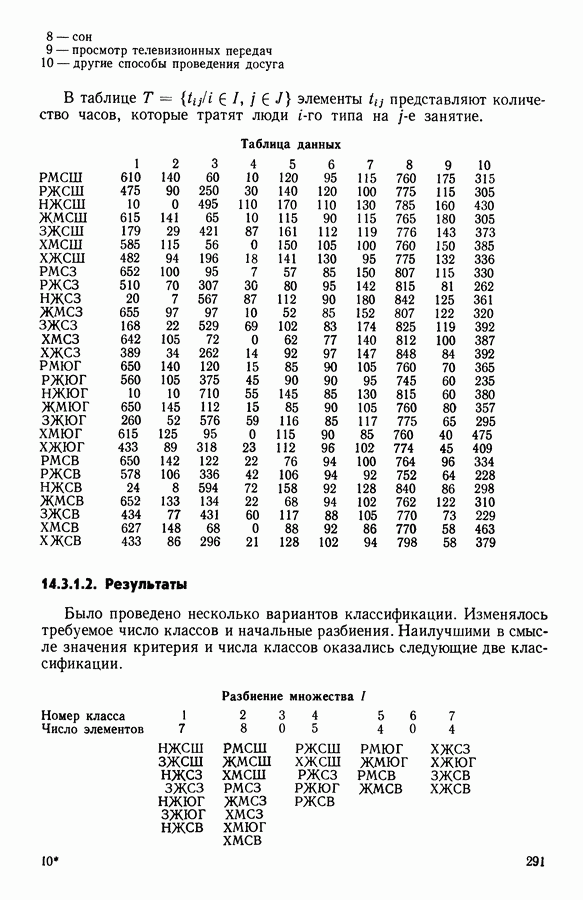
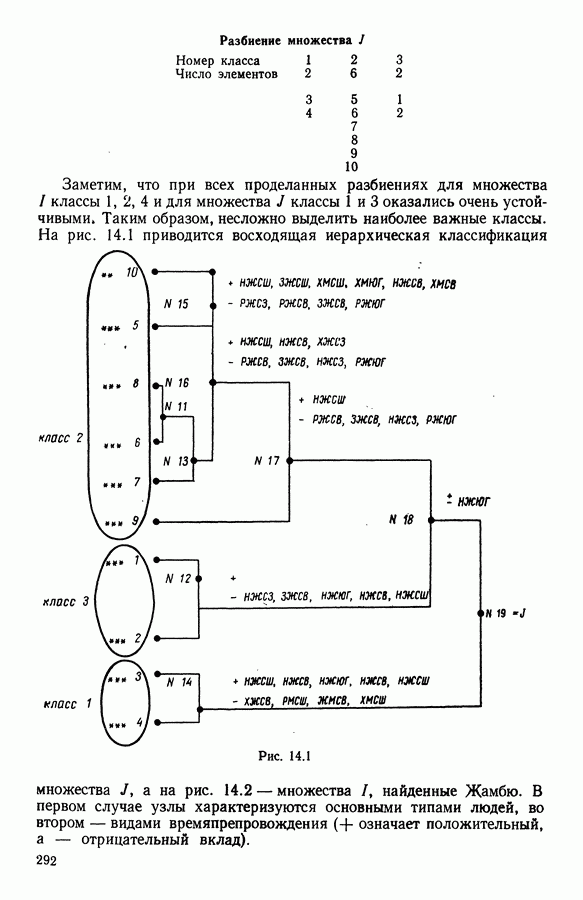
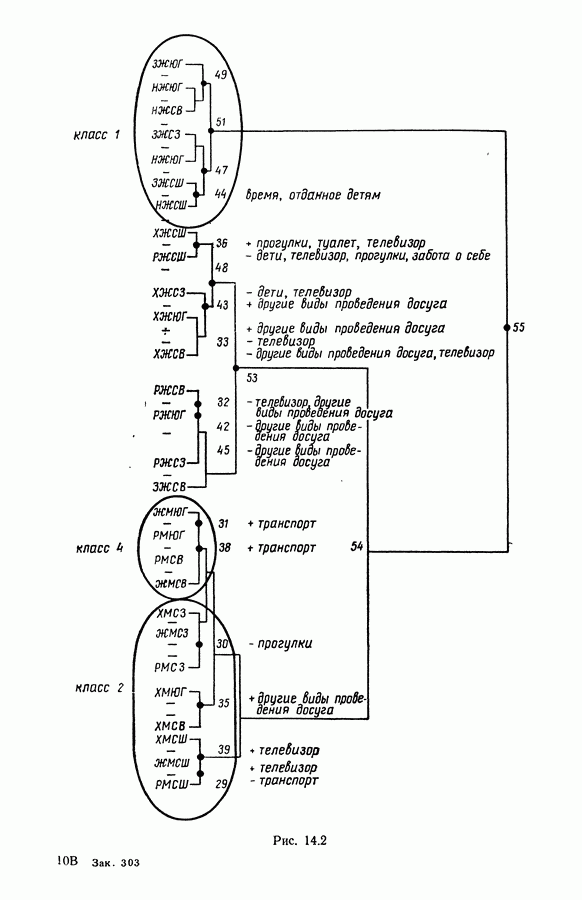
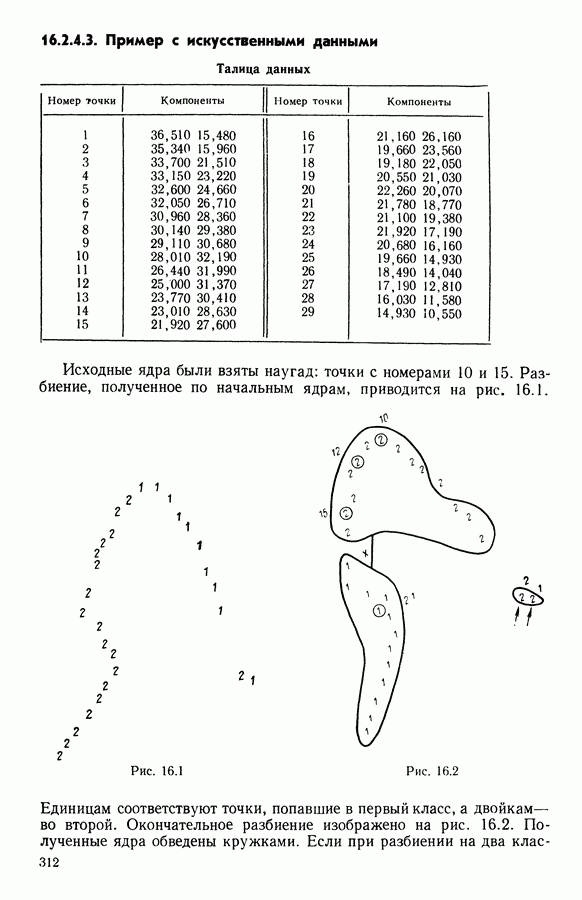
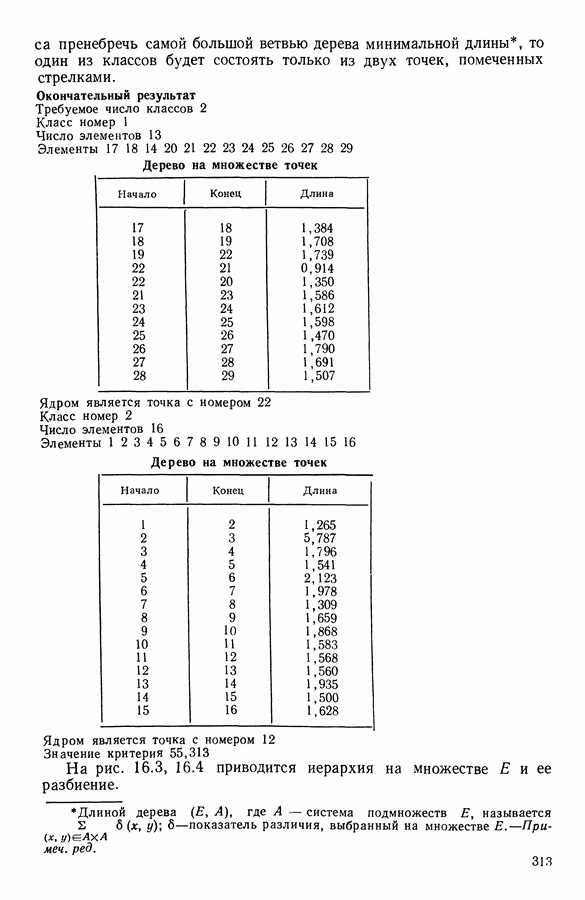
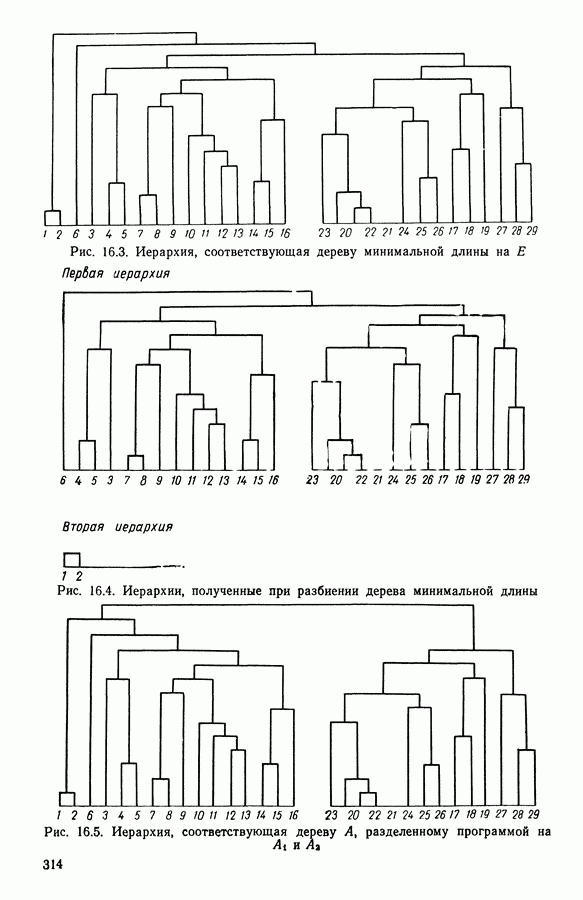
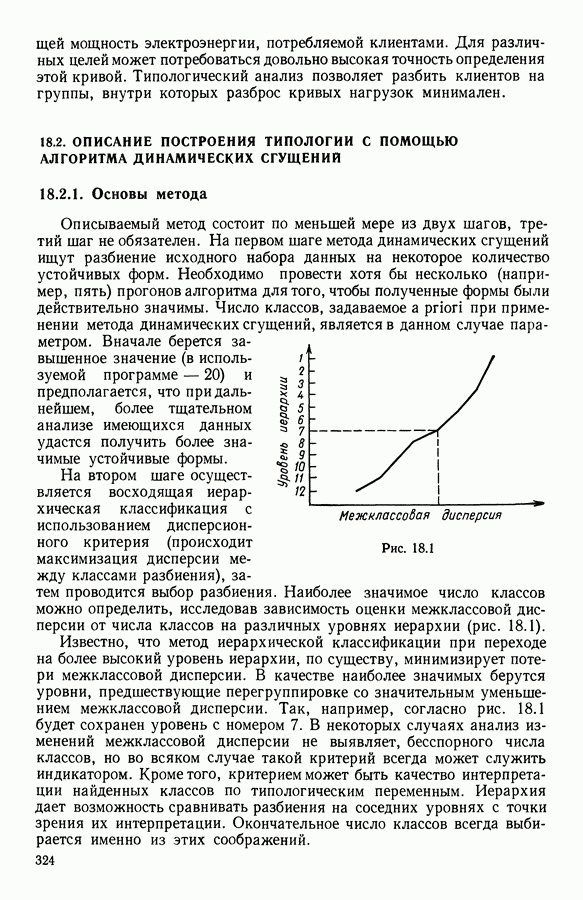
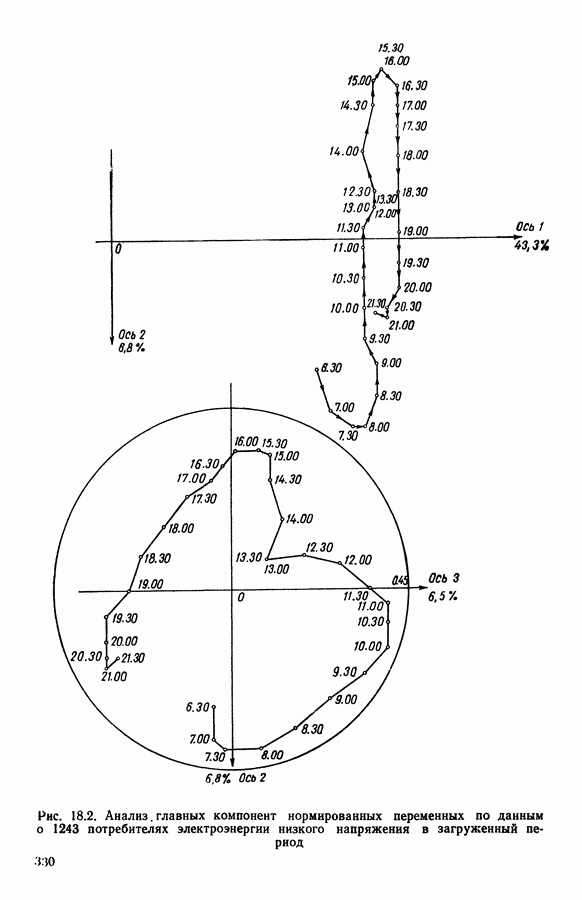
Глава 1. ОСНОВНЫЕ ПОНЯТИЯ И ФОРМАЛЬНЫЕ ПОСТРОЕНИЯ
1.1. ОБЪЕКТЫ, ПЕРЕМЕННЫЕ И МЕРА СХОДСТВА
При решении большинства задач автоматической классификации необходимо заранее задать некоторые величины; наиболее существенным в этом отношении является выбор самих объектов, переменных и меры сходства между объектами. Обозначим:
Е - анализируемое конечное множество объектов. Мы предполагаем, что  и что эти объекты обозначаются соответственно
и что эти объекты обозначаются соответственно 
F - конечное множество переменных, характеризующих эти объекты. Мы предполагаем, что  и что эти переменные обозначаются
и что эти переменные обозначаются 
Обозначим:
 значение, принимаемое переменной
значение, принимаемое переменной  на объекте
на объекте  — мера сходства между объектами, которая есть отображение
— мера сходства между объектами, которая есть отображение  такое, что
такое, что  для любых
для любых  принадлежащих
принадлежащих 
Для улучшения анализа данных полезно исследовать вопрос о пересмотре нашего выбора величин. Так, например, можно из множеств  выделить подмножества, затем произвести замену переменных, изменить меру сходства так, чтобы наилучшим образом «приспособиться» к структуре искомых классов. С этой целью следует определить пространство допустимых изменений и найти в этом пространстве такое изменение, которое было бы наилучшим в смысле определенного критерия, зависящего от типа искомой классификации (см. гл. 4, 8).
выделить подмножества, затем произвести замену переменных, изменить меру сходства так, чтобы наилучшим образом «приспособиться» к структуре искомых классов. С этой целью следует определить пространство допустимых изменений и найти в этом пространстве такое изменение, которое было бы наилучшим в смысле определенного критерия, зависящего от типа искомой классификации (см. гл. 4, 8).