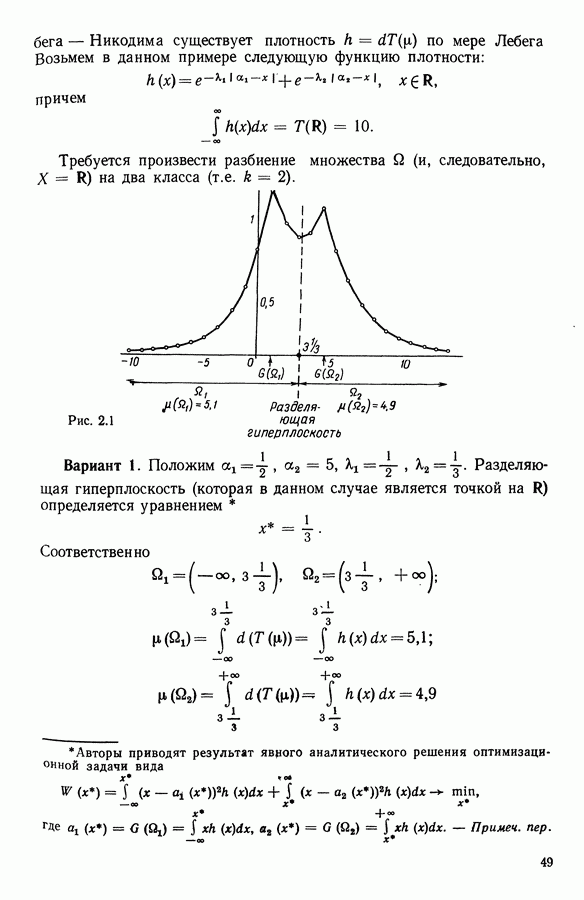
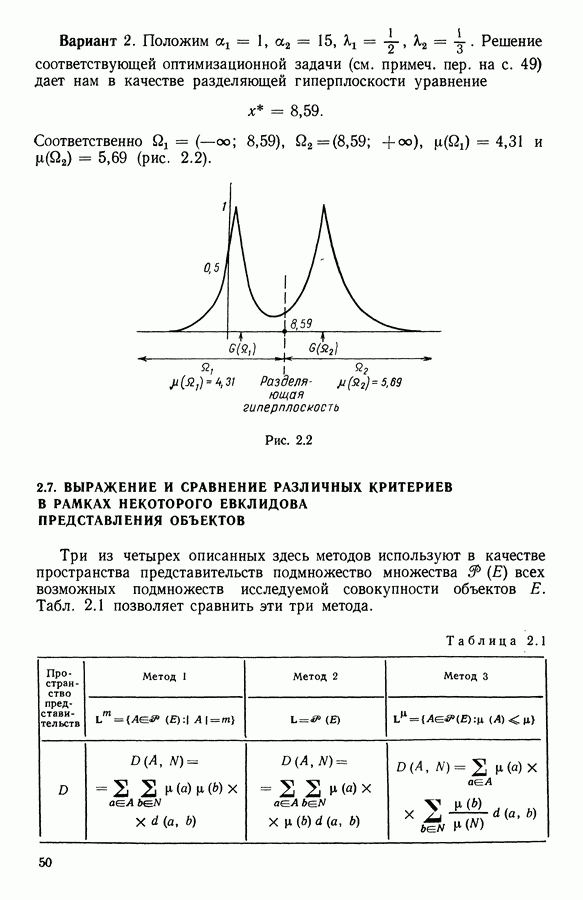
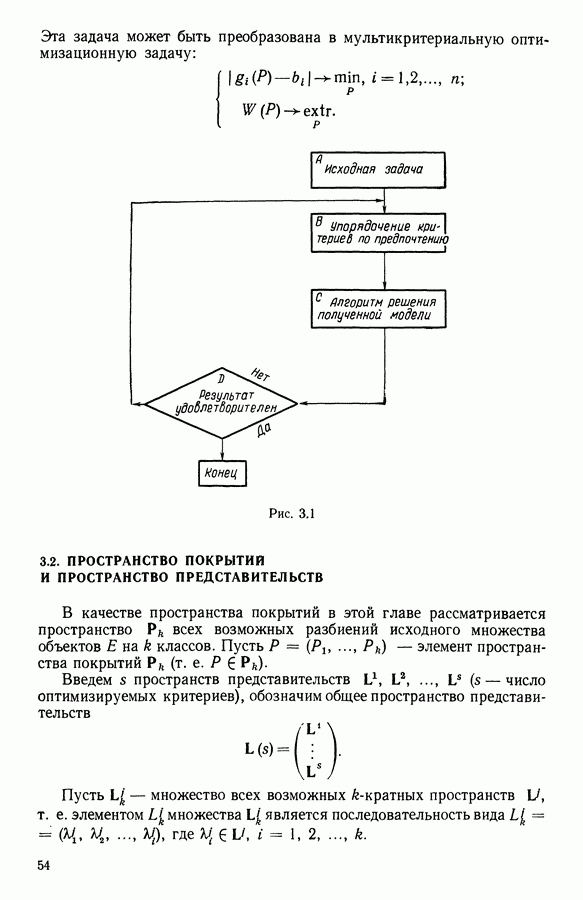
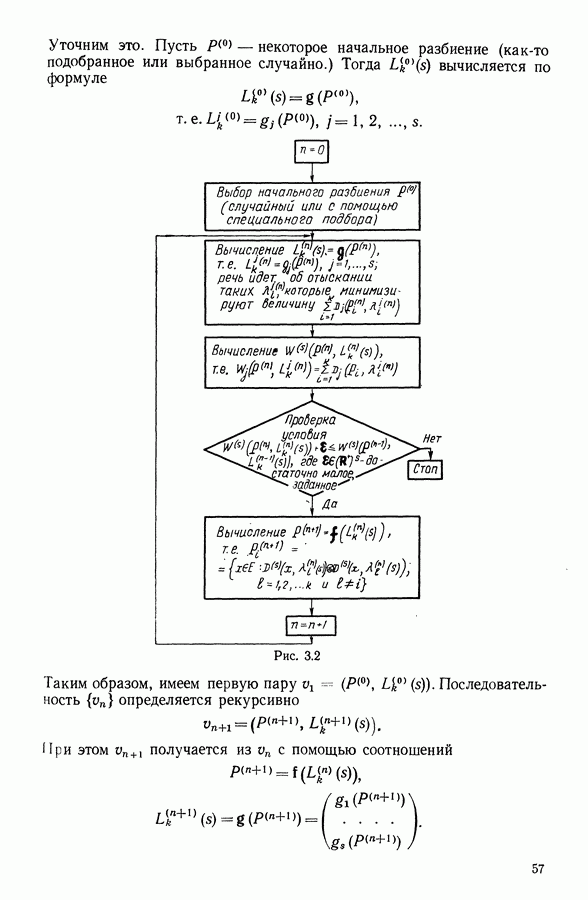
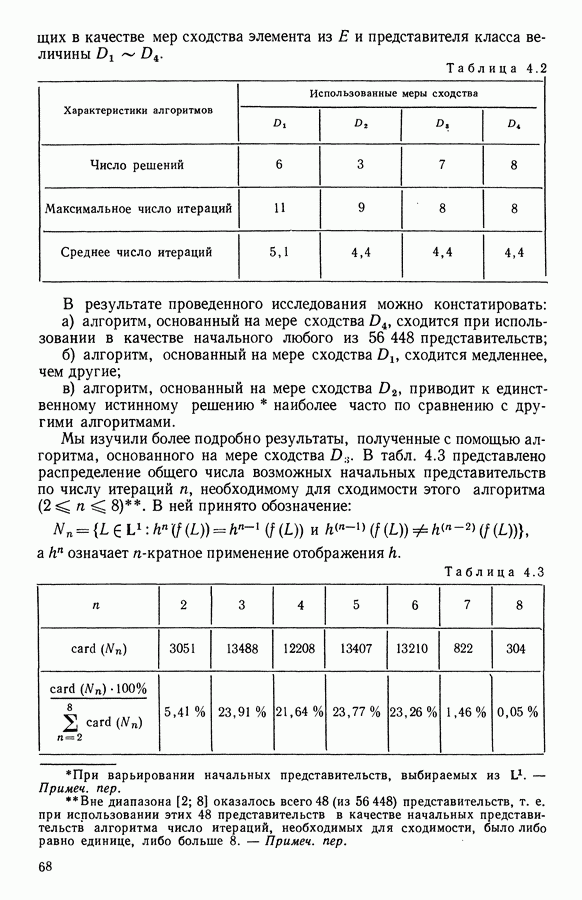
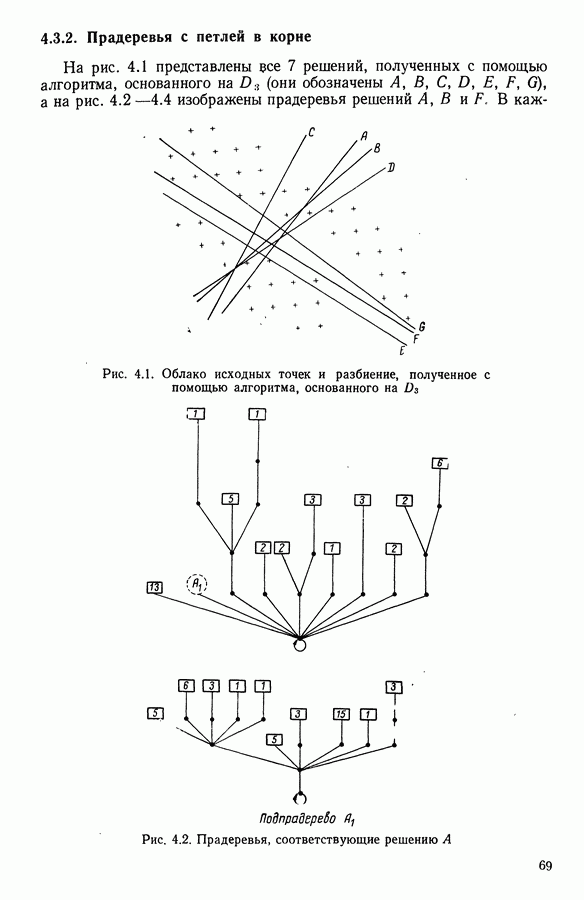
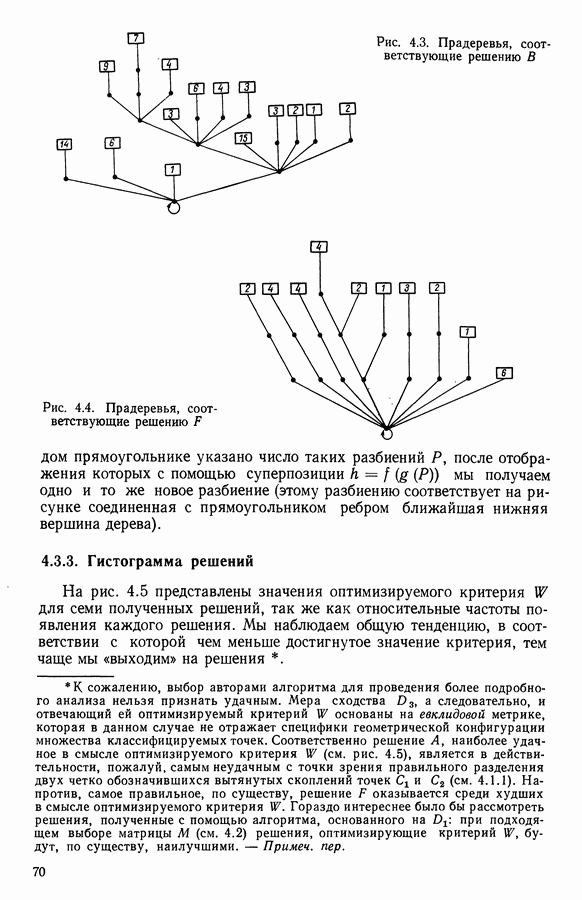
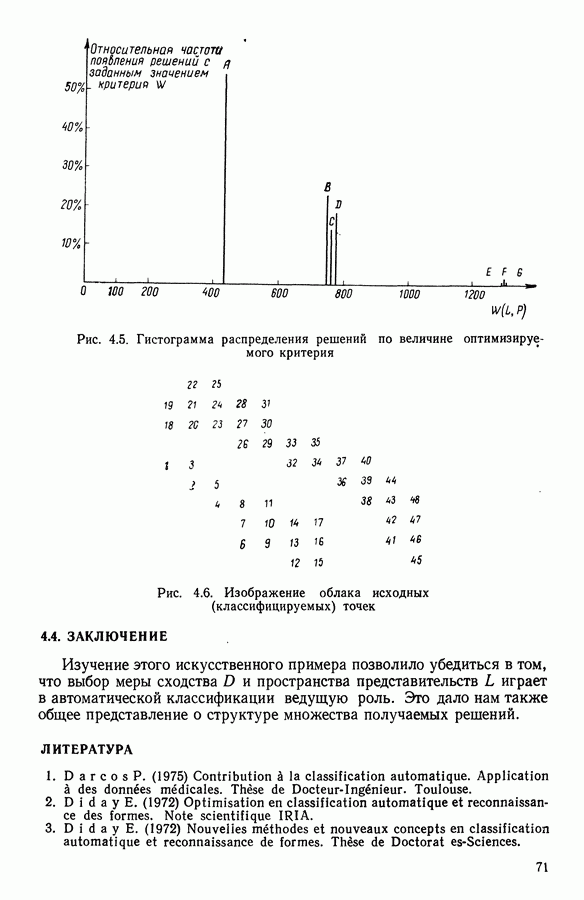
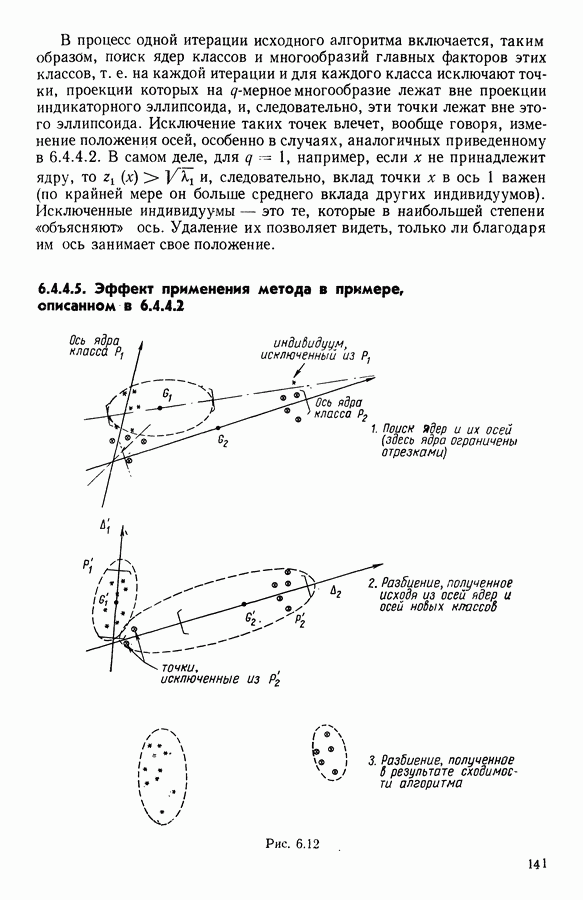
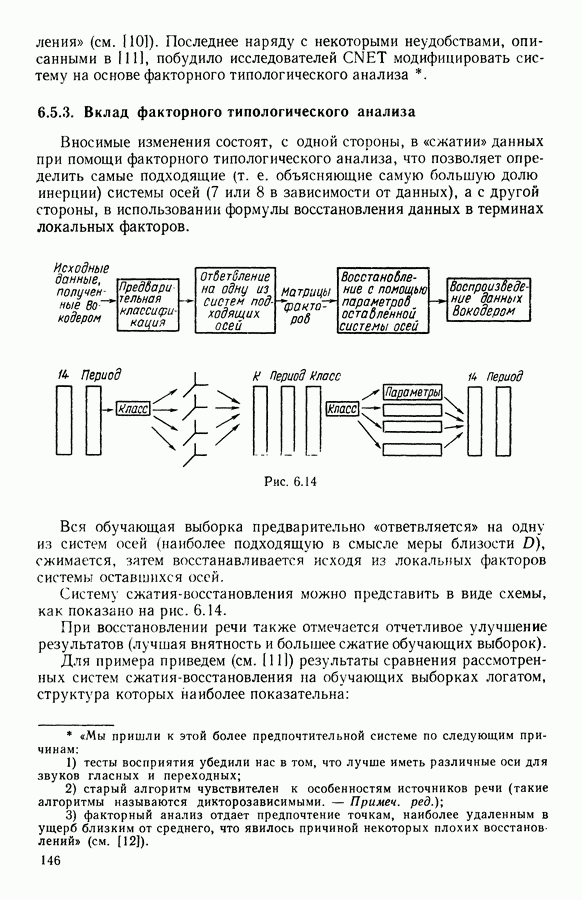
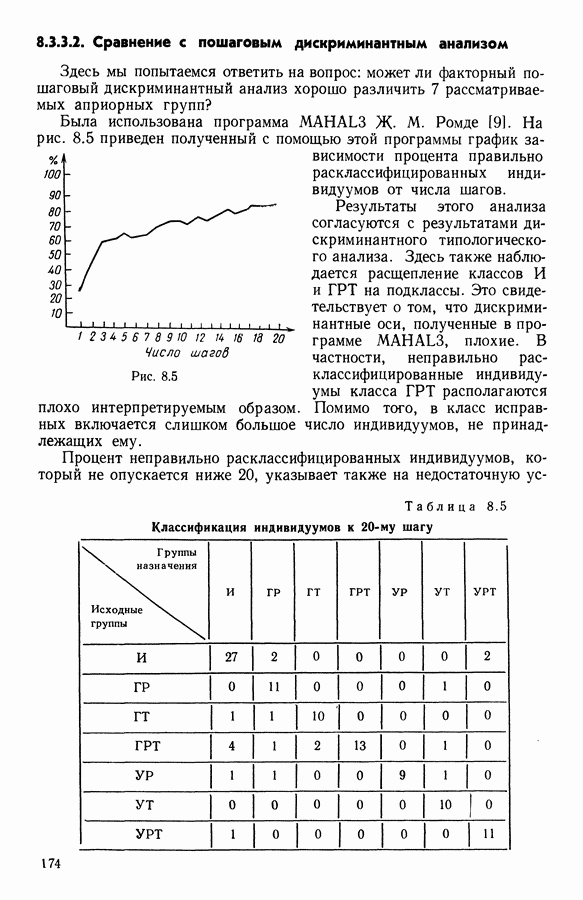
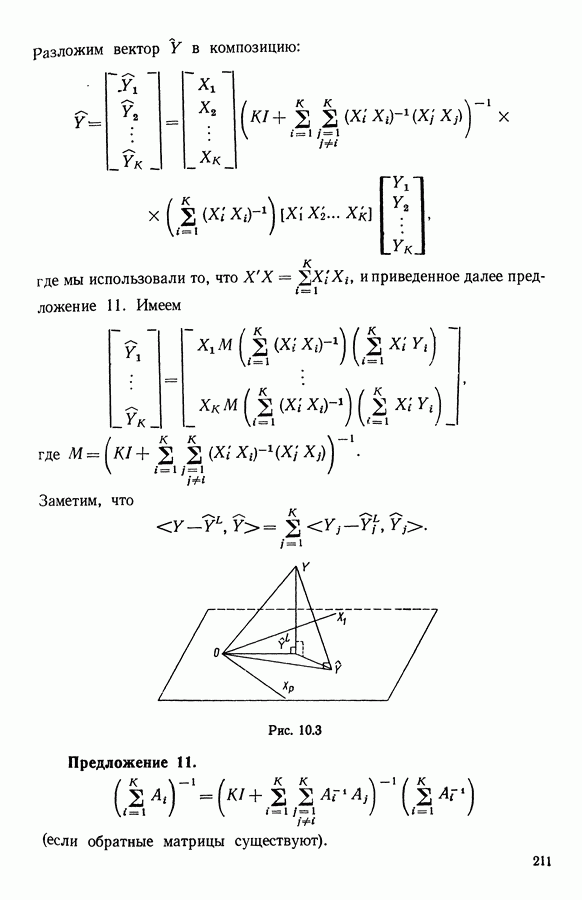
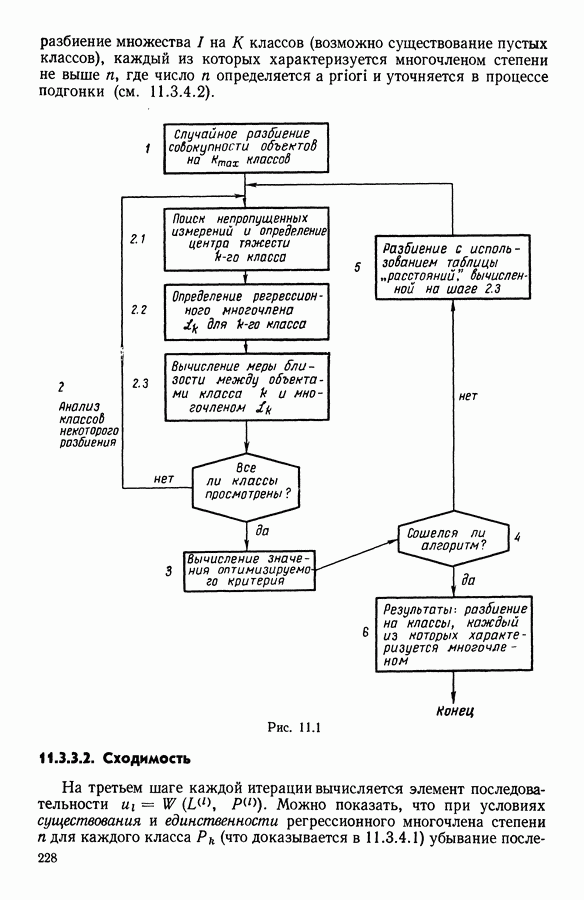
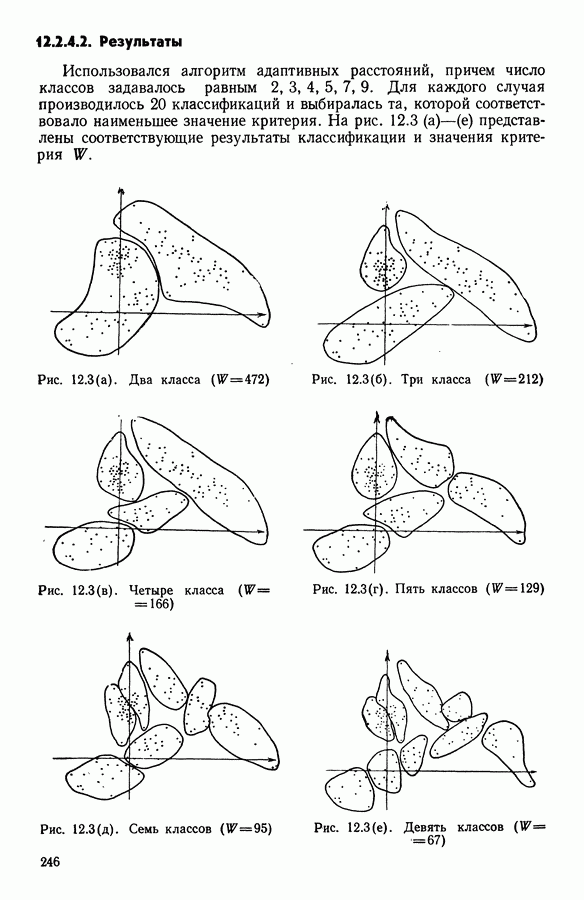
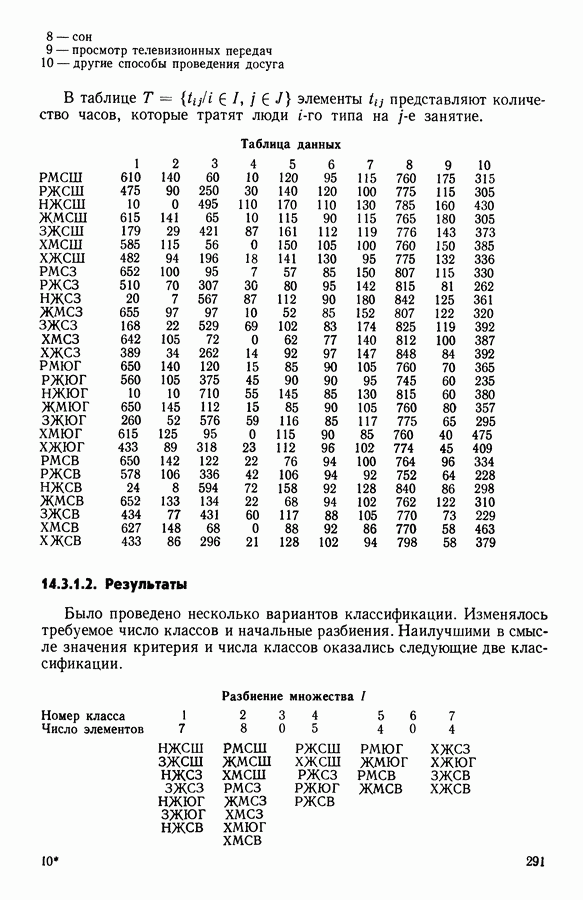
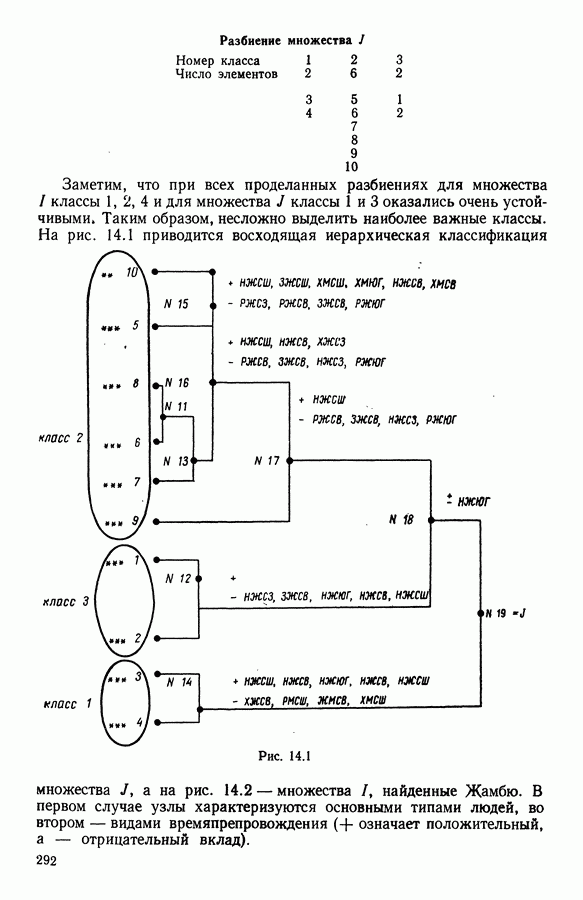
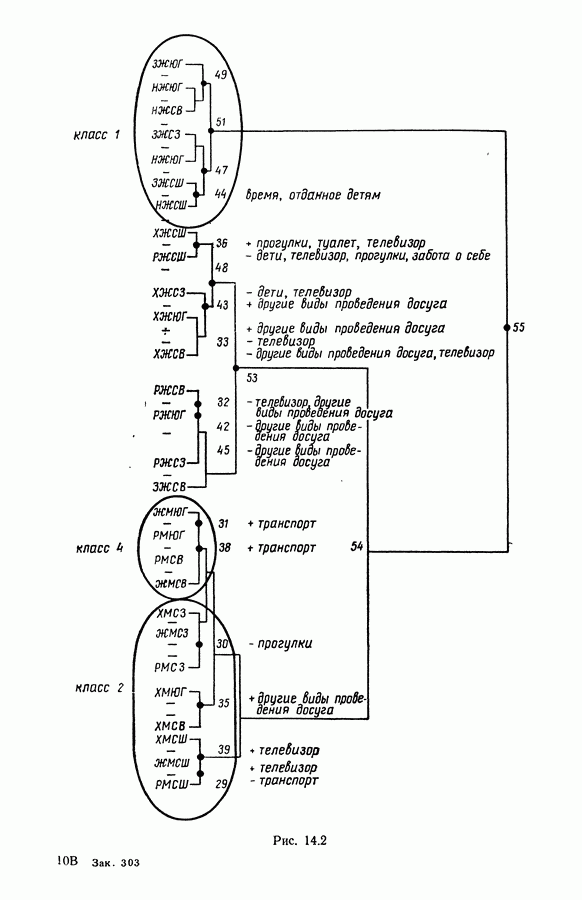
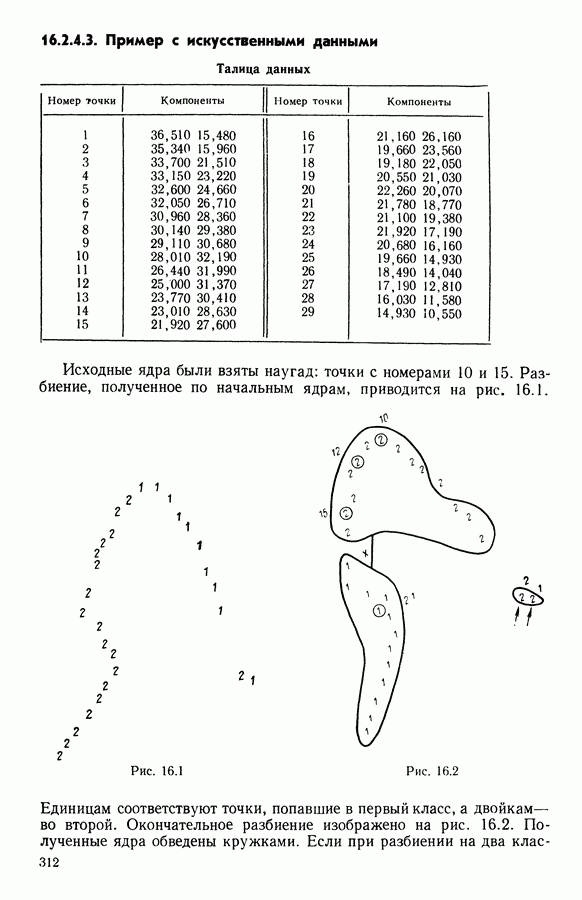
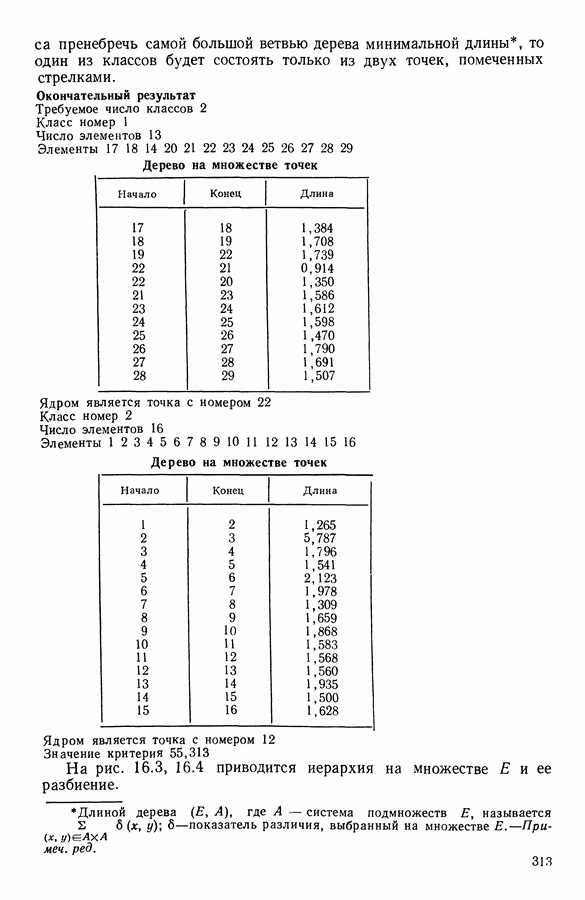
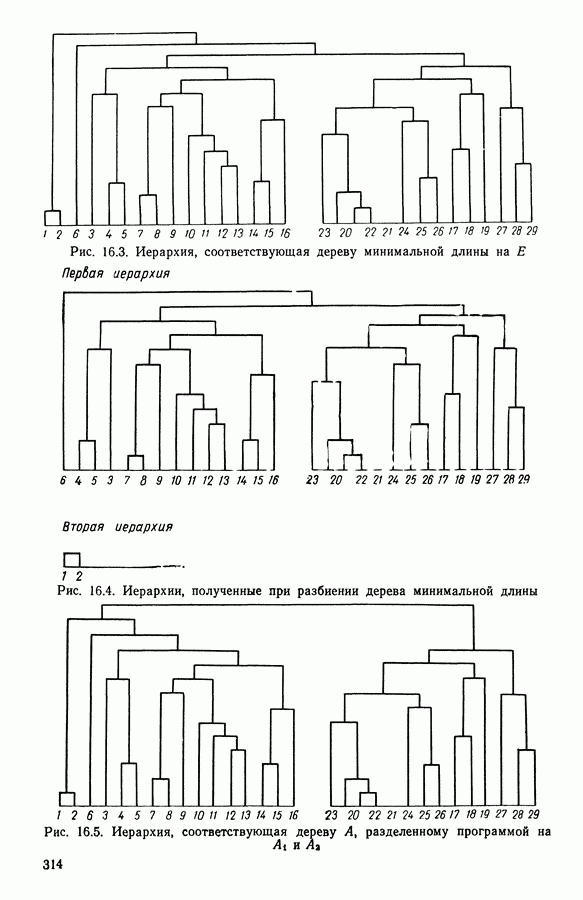
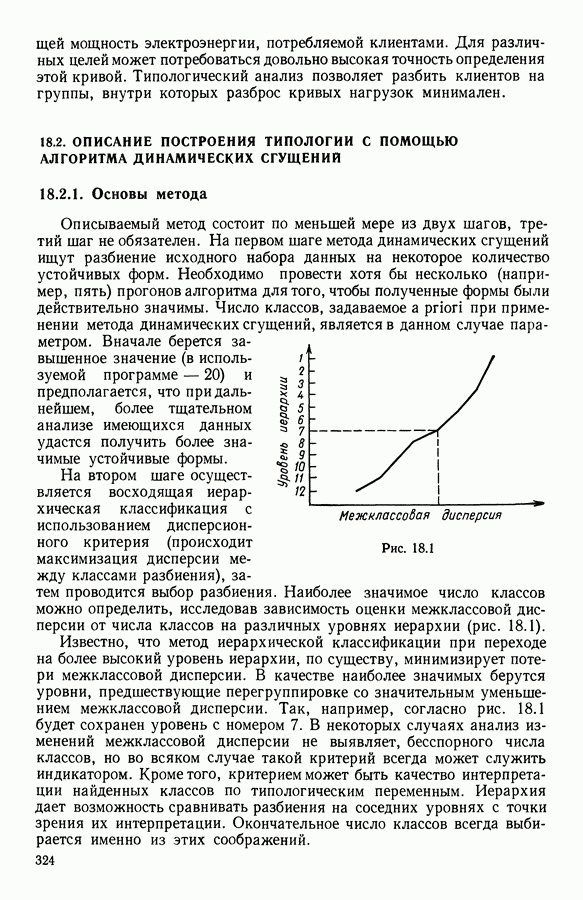
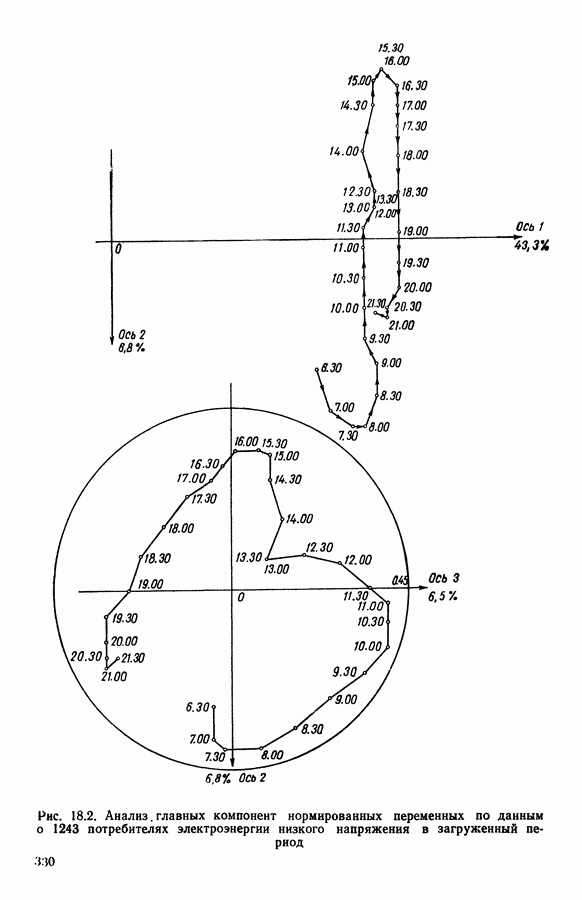
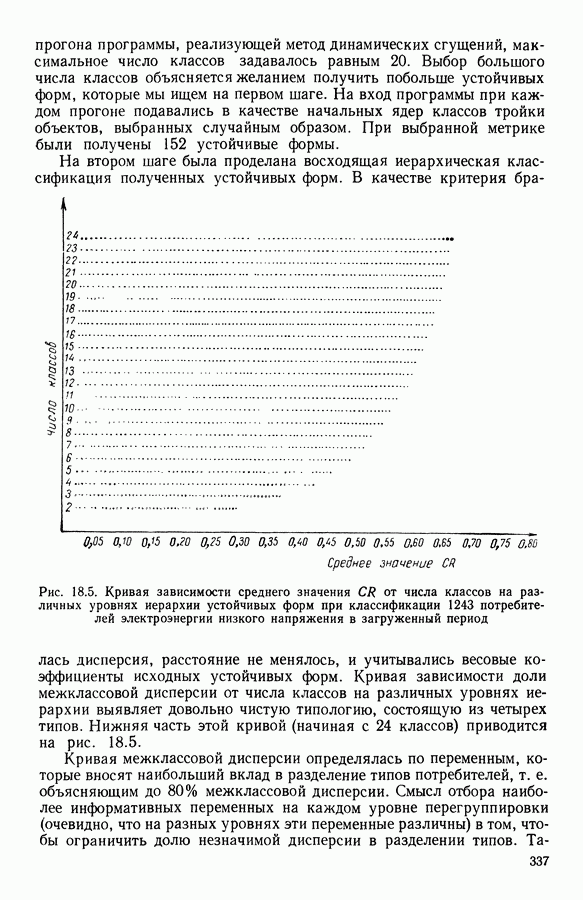
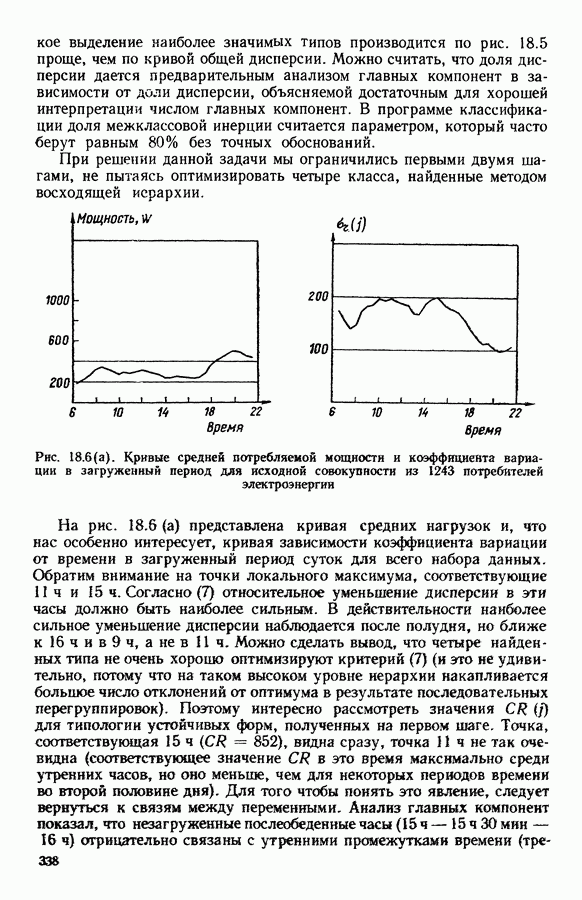
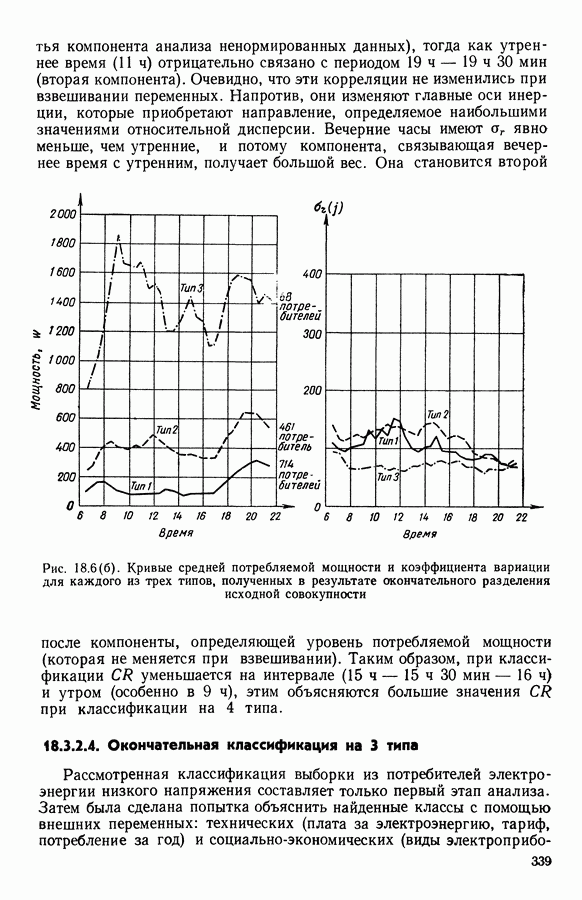
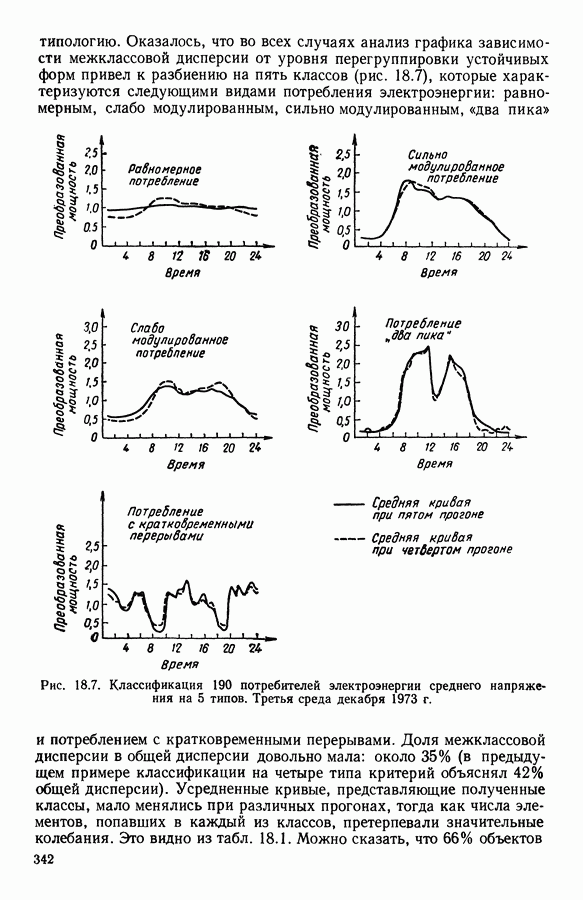
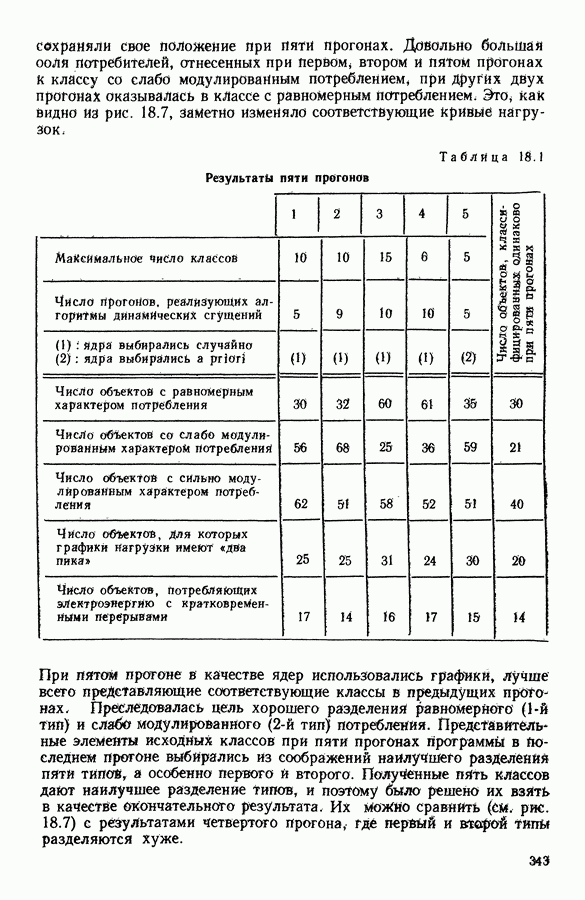
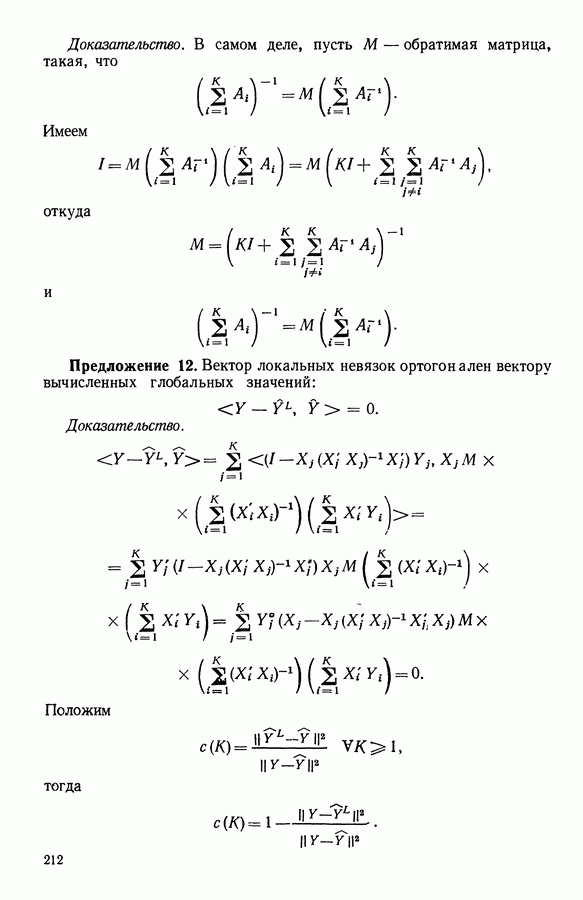6.4.2. Выбор меры близости D
6.4.2.1. Определение D и «стратегия объединения»
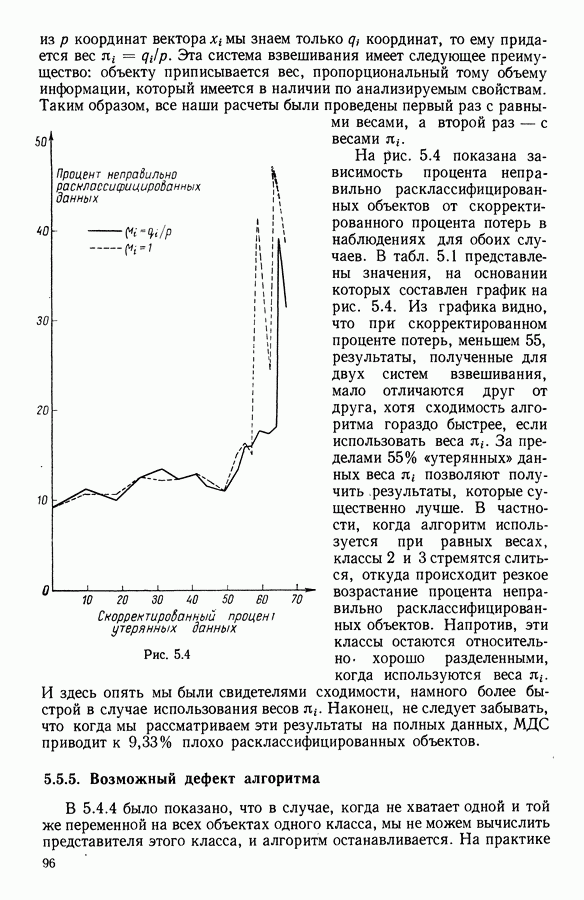
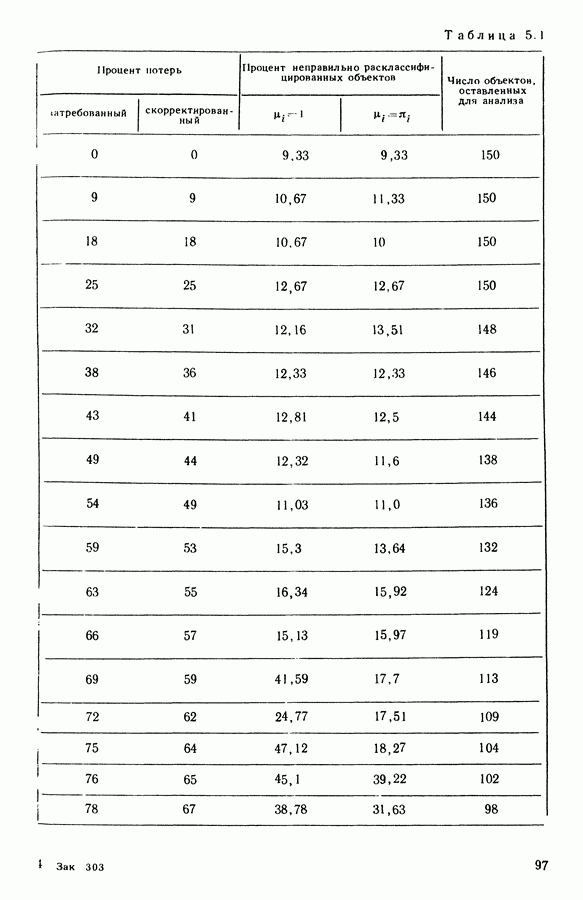
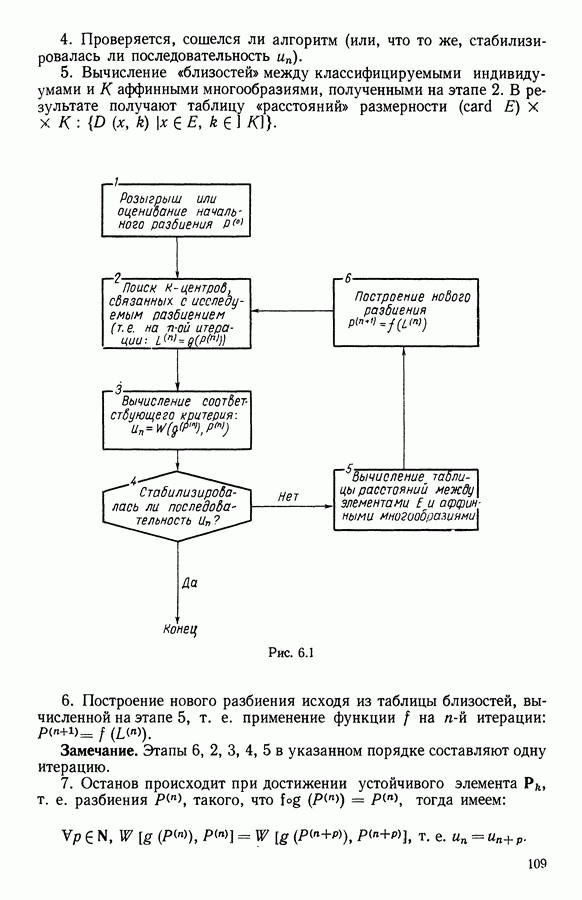
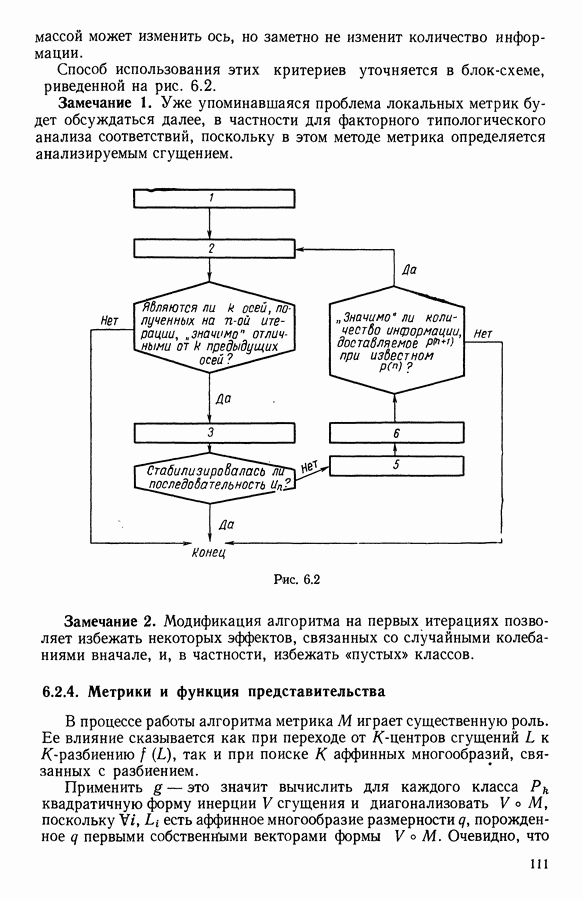
В факторном типологическом анализе стратегия объединения, т. е. правило, по которому индивидуумы множества  относятся к одному центров, зависит существенно от выбранной меры близости
относятся к одному центров, зависит существенно от выбранной меры близости  в самом деле, с представительством
в самом деле, с представительством  связано разбиение
связано разбиение  на полиэдральные выпуклые области
на полиэдральные выпуклые области  определяемые следующим образом:
определяемые следующим образом:

Границы этих областей состоят из частей гиперплоскостей  где
где

Разбиение сгущения  индуцируется разбиением пространства
индуцируется разбиением пространства 
Различный выбор  приводит к различным разбиениям и как следствие к различным стратегиям объединения точек.
приводит к различным разбиениям и как следствие к различным стратегиям объединения точек.
В основном алгоритме «расстояние» между индивидуумами и центрами равно:

моменту инерции индивидуума х относительно аффинного многообразия 
Исходную стратегию модифицируют:
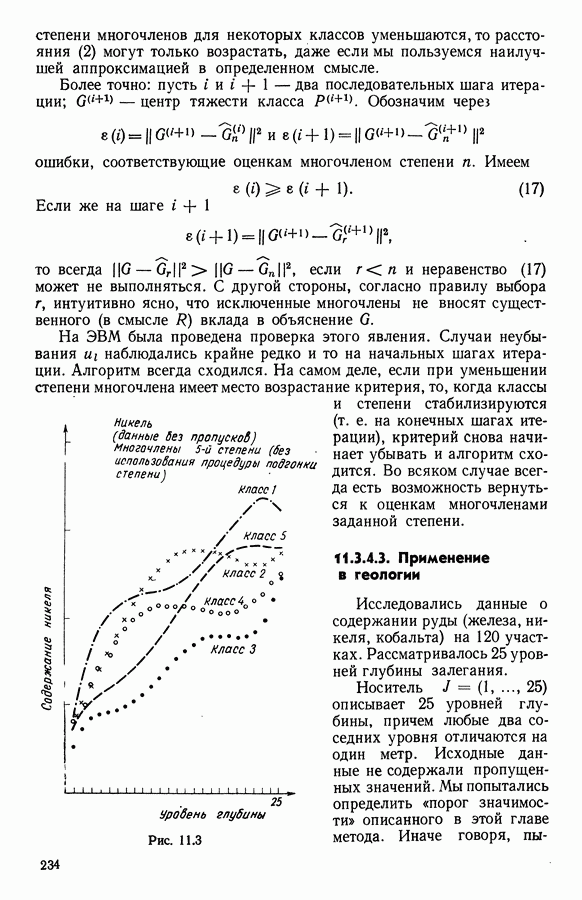
либо используя другое определение  (см. замечание 4 из 6.2.1), для которого доказывают следующее предложение:
(см. замечание 4 из 6.2.1), для которого доказывают следующее предложение:
пусть  задано следующим образом, где
задано следующим образом, где 

 задано, как в 6.2.1. Тогда, если отображение
задано, как в 6.2.1. Тогда, если отображение  сопоставляет сгущению подпространство, натянутое на
сопоставляет сгущению подпространство, натянутое на  первых факторов этого сгущения, то алгоритм сходится;
первых факторов этого сгущения, то алгоритм сходится;
либо дополняя стратегию так называемым методом эллипсоидов-ядер для исключения влияния резко выделяющихся точек (см. 6.4.4) и влияния случайного выбора начального разбиения множества 
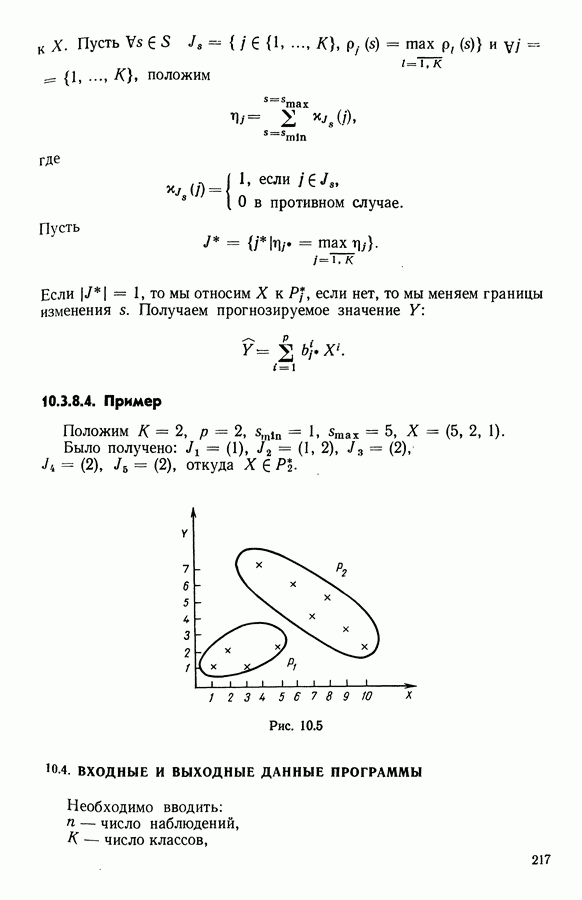
6.4.2.2. Эффект выбора параметра a
Правильный выбор этого параметра может способствовать более эффективному распознаванию структуры данных. Этот выбор может быть обусловлен либо априорной информацией о данных, либо предпочтениями пользователя.
В наиболее часто встречающейся ситуации, когда структура данных априори неизвестна, мера близости  может быть модифицирована после получения предварительных результатов, оцениваемых как малоудовлетворительные.
может быть модифицирована после получения предварительных результатов, оцениваемых как малоудовлетворительные.
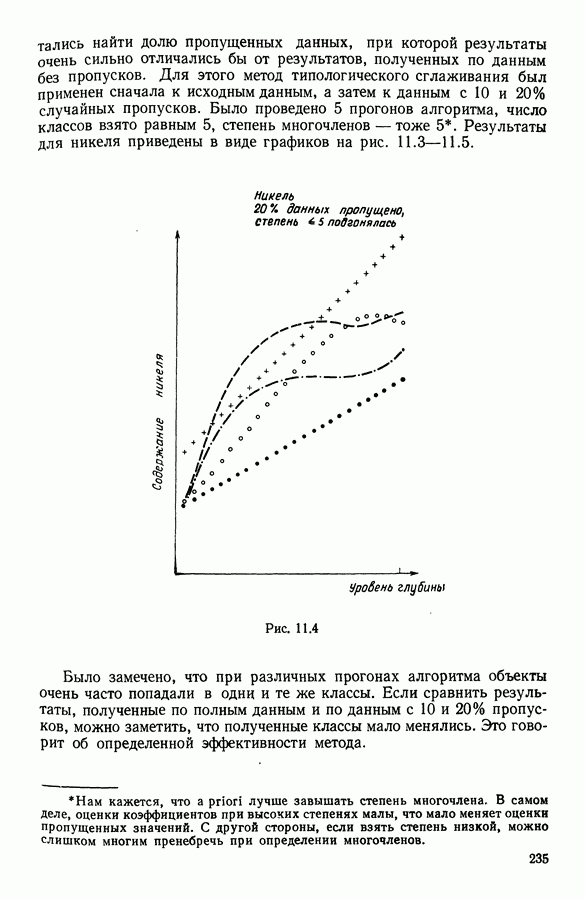
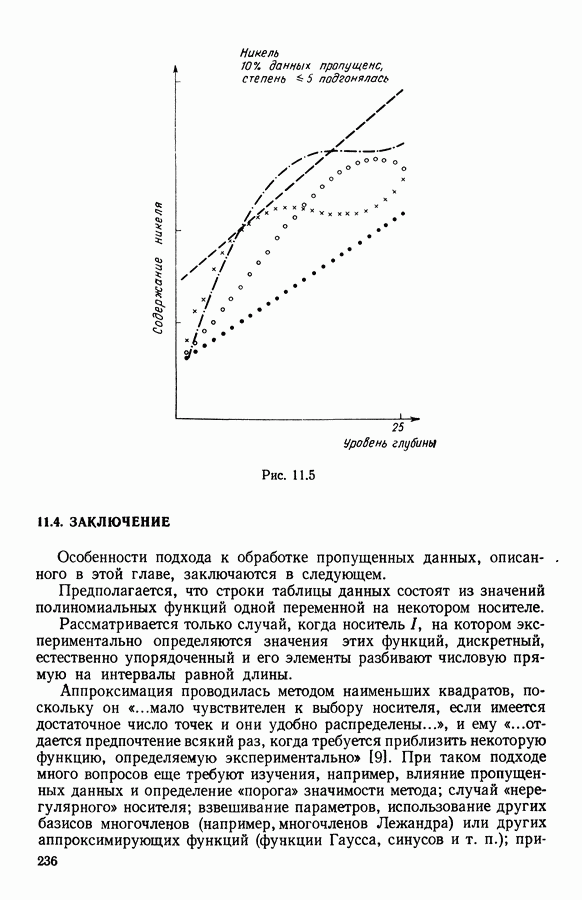
Две крайние возможности  и
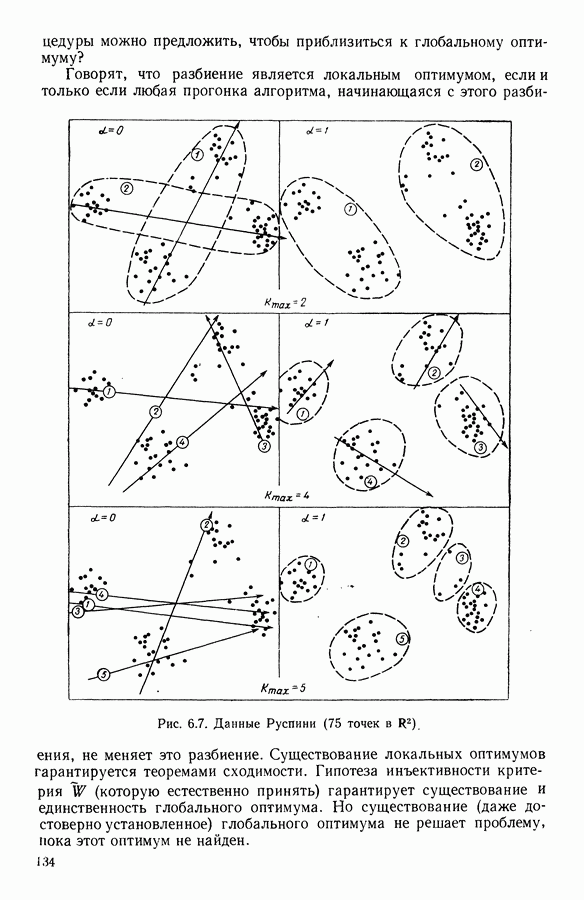
и  были проверены на различных данных. Полученные результаты проиллюстрированы на рис. 6.7. Вывод таков, что при
были проверены на различных данных. Полученные результаты проиллюстрированы на рис. 6.7. Вывод таков, что при  алгоритм обнаруживает направления вытянутости, тогда как при
алгоритм обнаруживает направления вытянутости, тогда как при  он обнаруживает, в большей степени, концентрацию массы.
он обнаруживает, в большей степени, концентрацию массы.
Если ищут направления вытянутости (т. е.  то во всех вариантах появляются 2 одинаковые оси, т. е. в этом искусственном примере
то во всех вариантах появляются 2 одинаковые оси, т. е. в этом искусственном примере  является оптимальным числом направлений. Напротив, с
является оптимальным числом направлений. Напротив, с  появляются естественные разбиения, соответствующие требуемому числу классов.
появляются естественные разбиения, соответствующие требуемому числу классов.