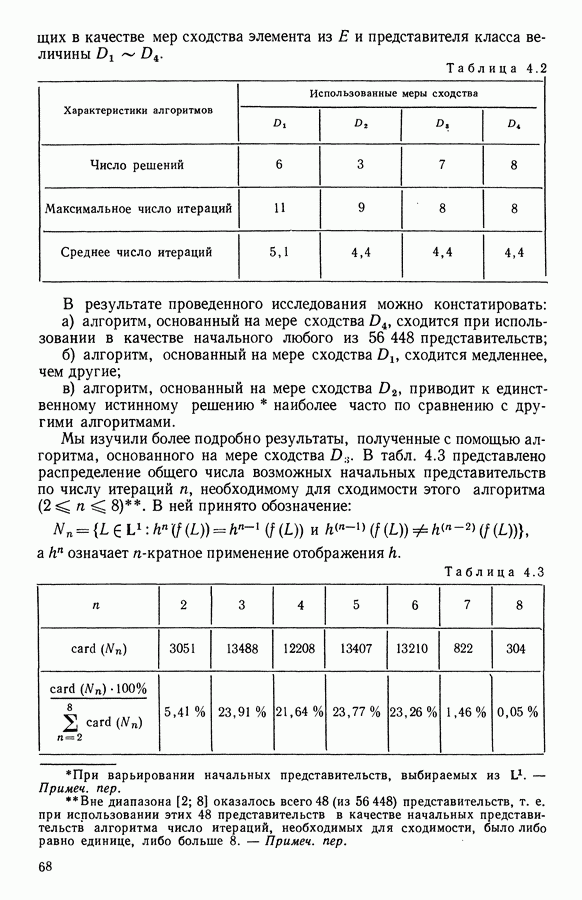
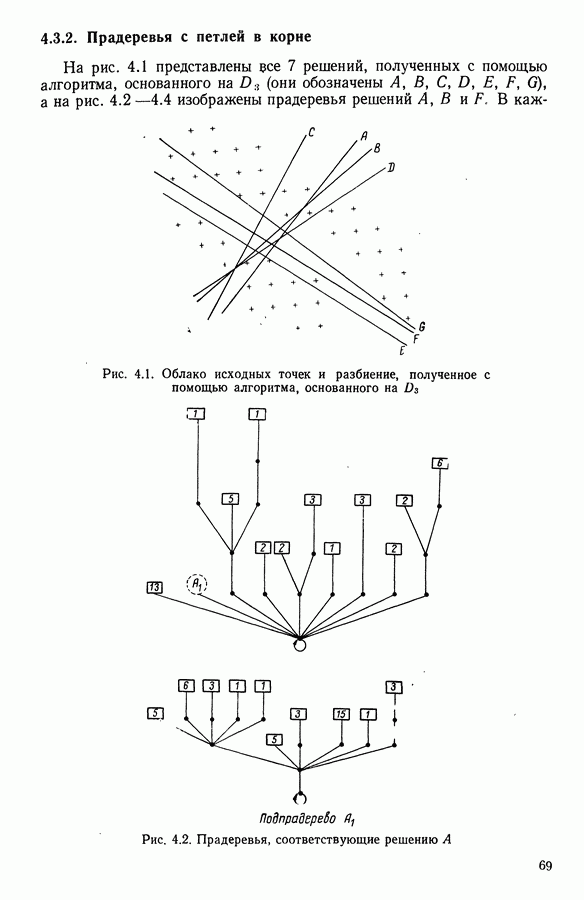
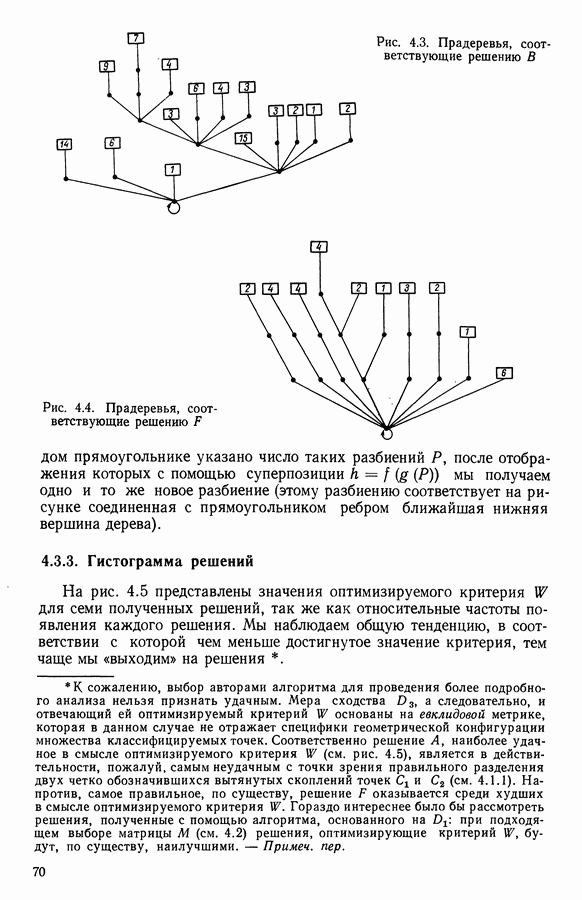
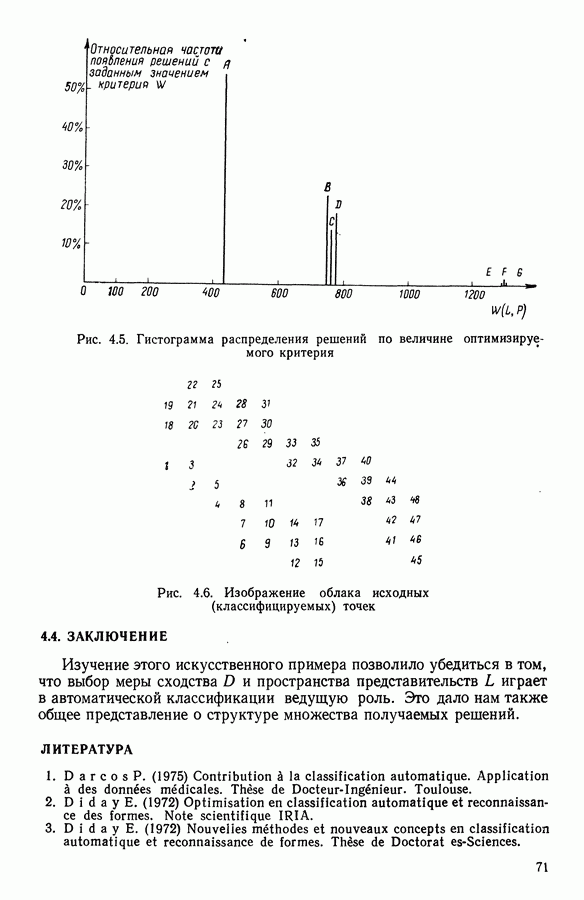
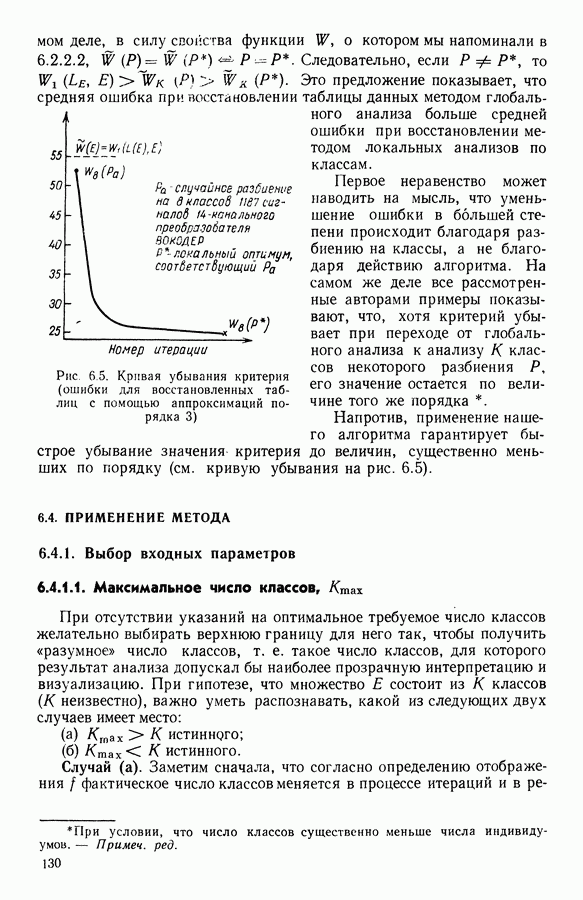
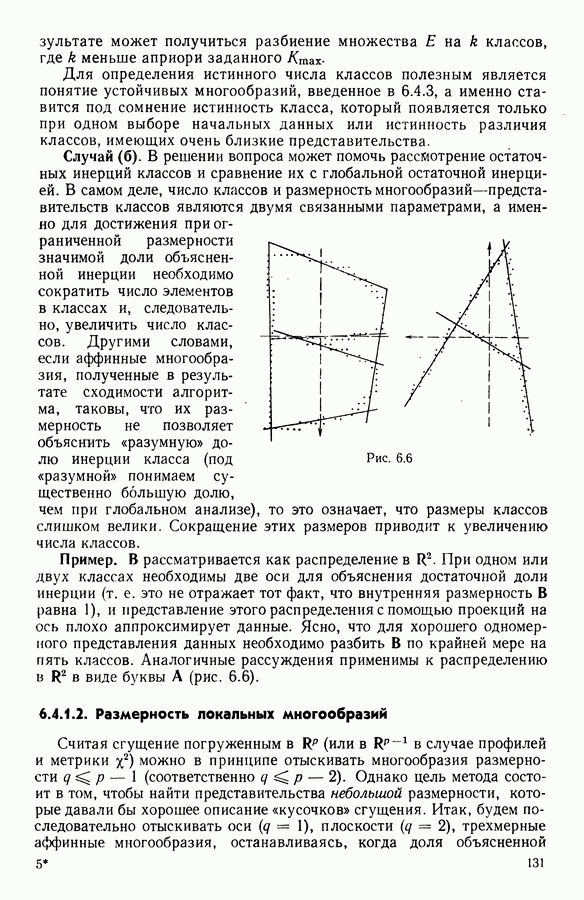
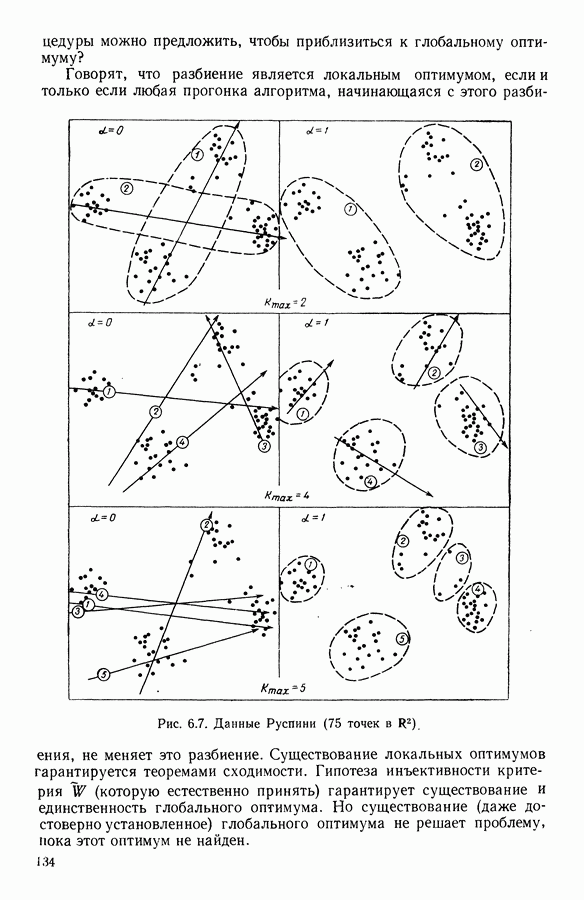
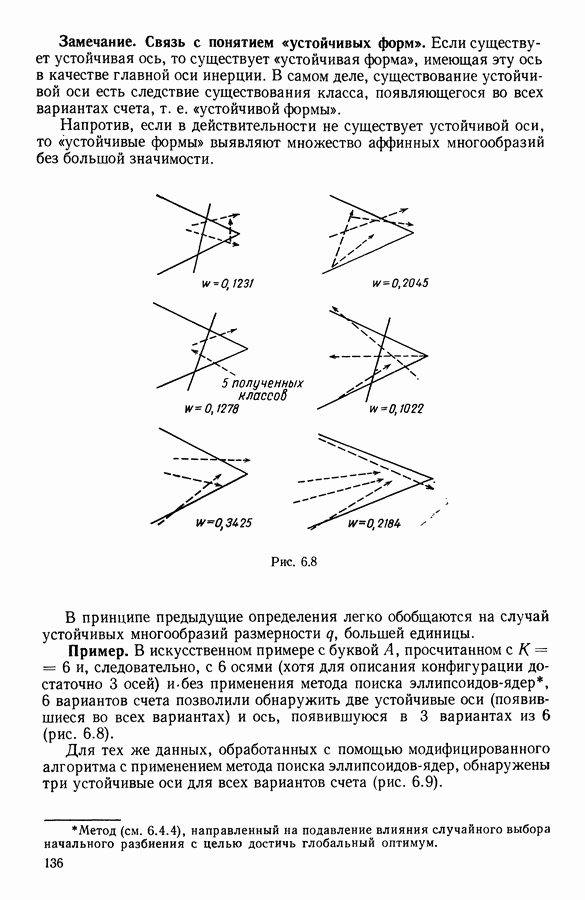
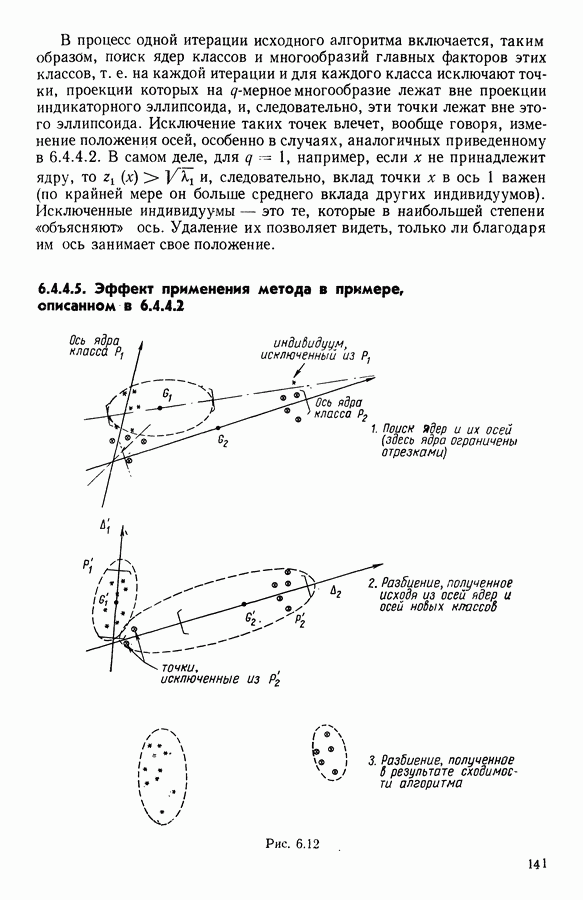
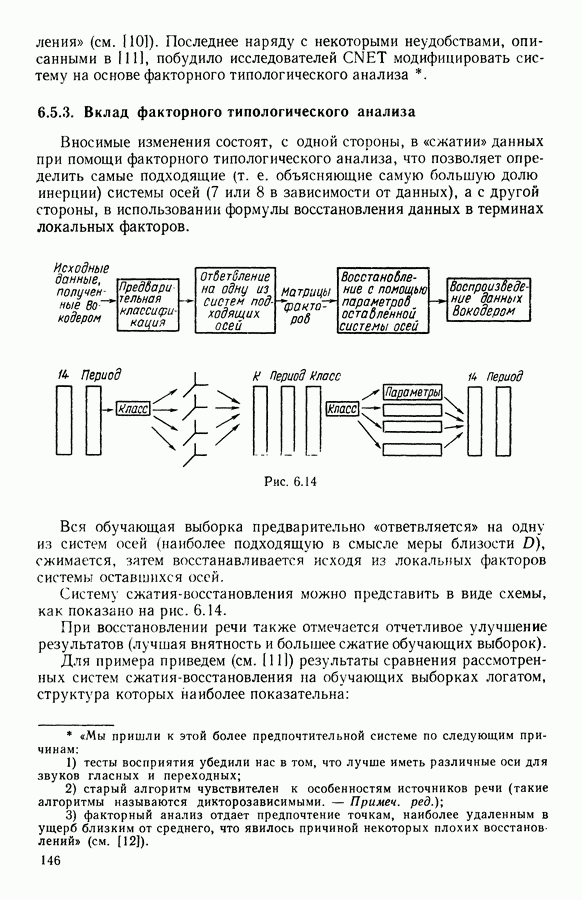
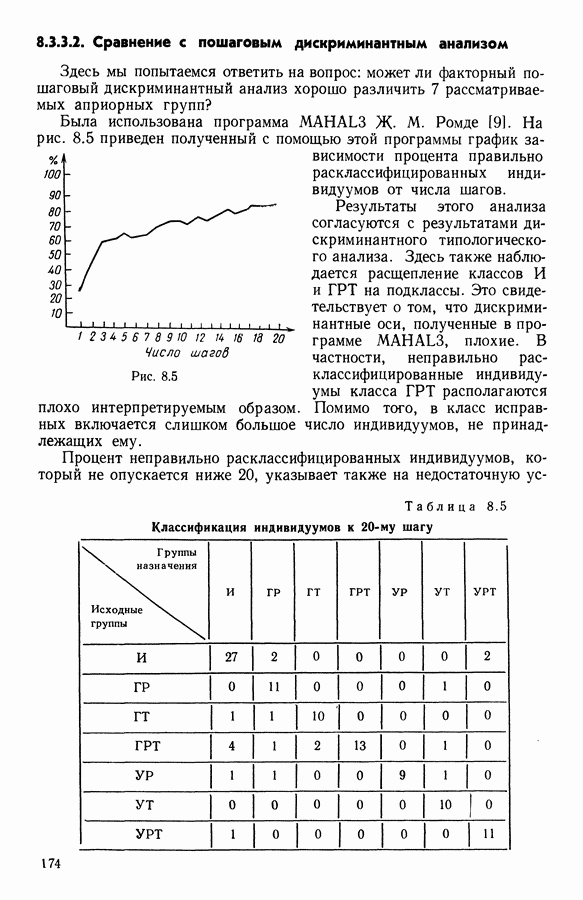
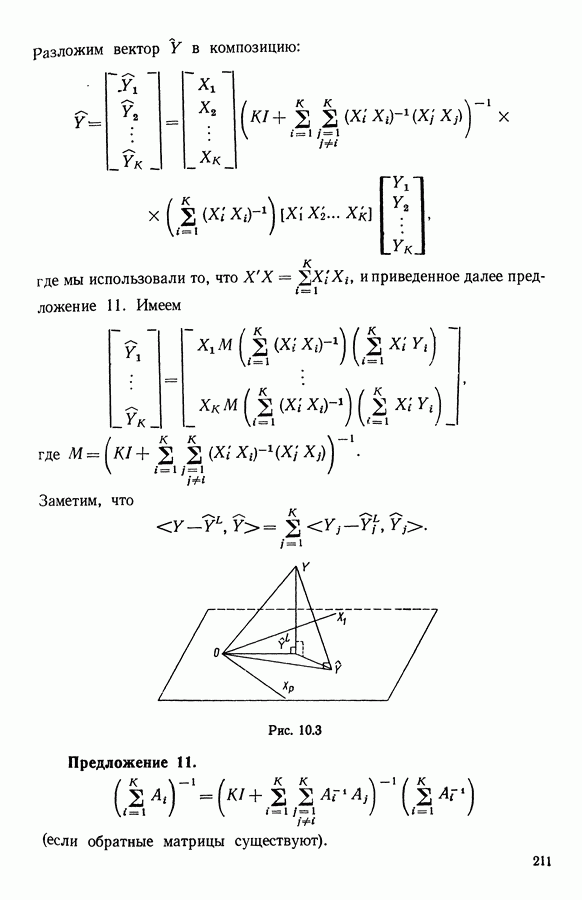
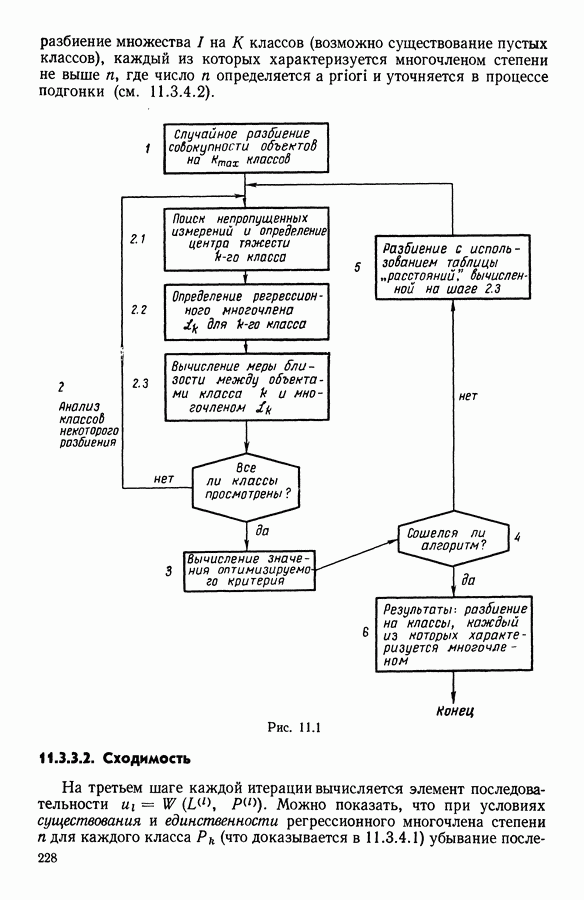
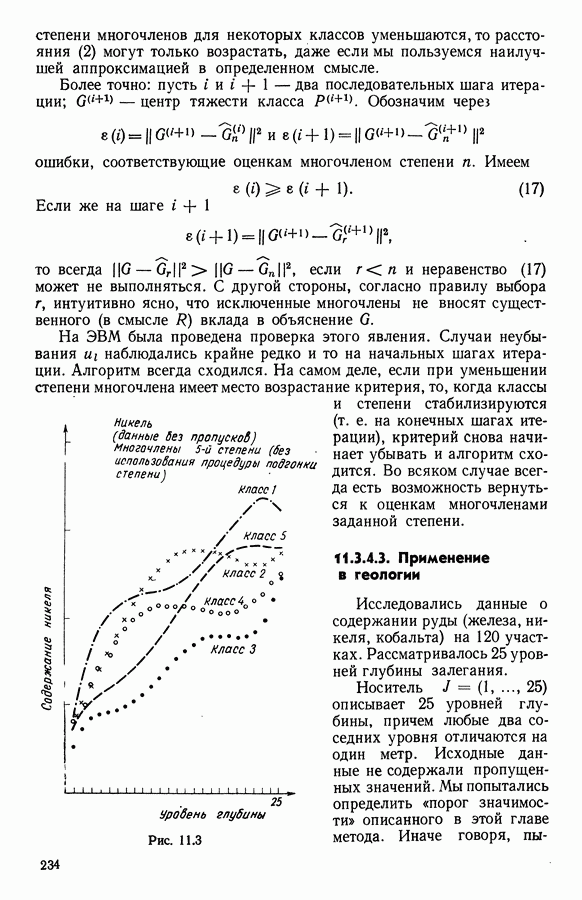
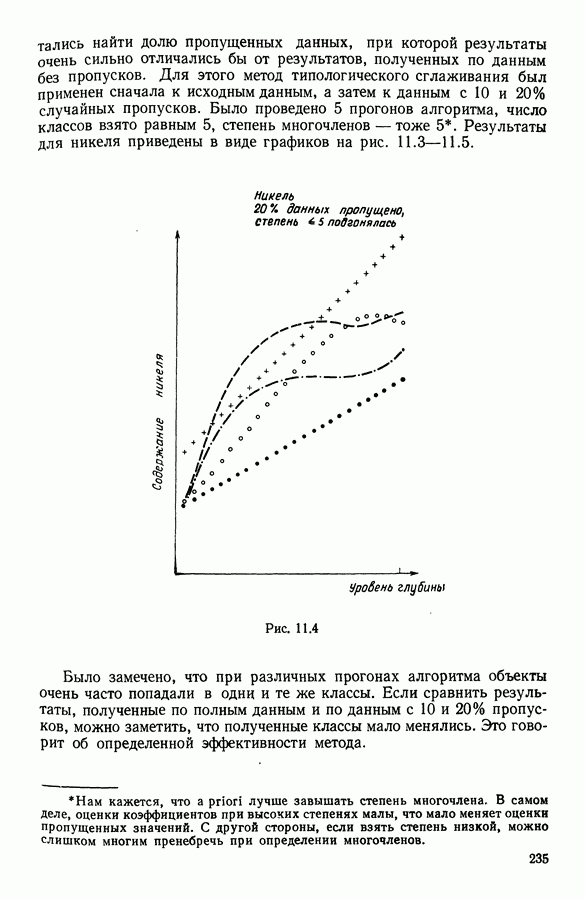
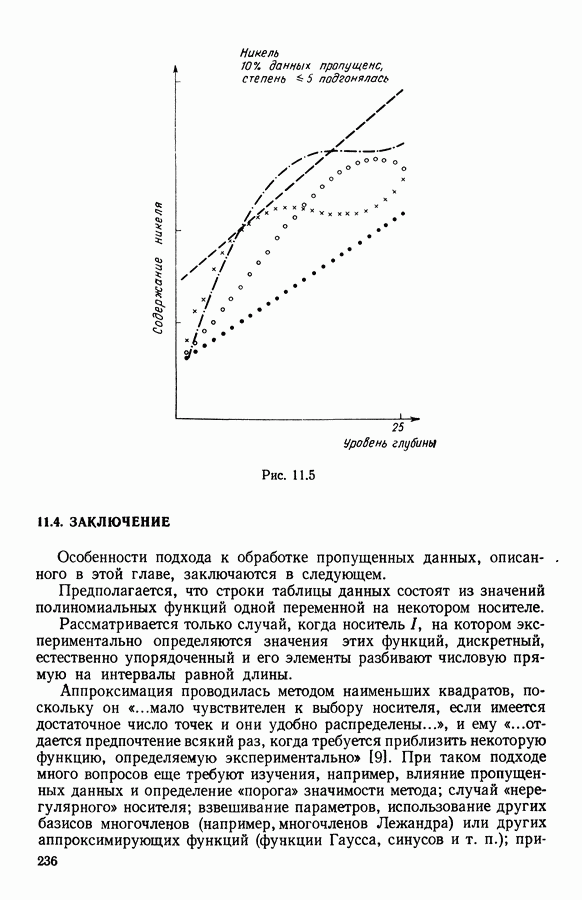
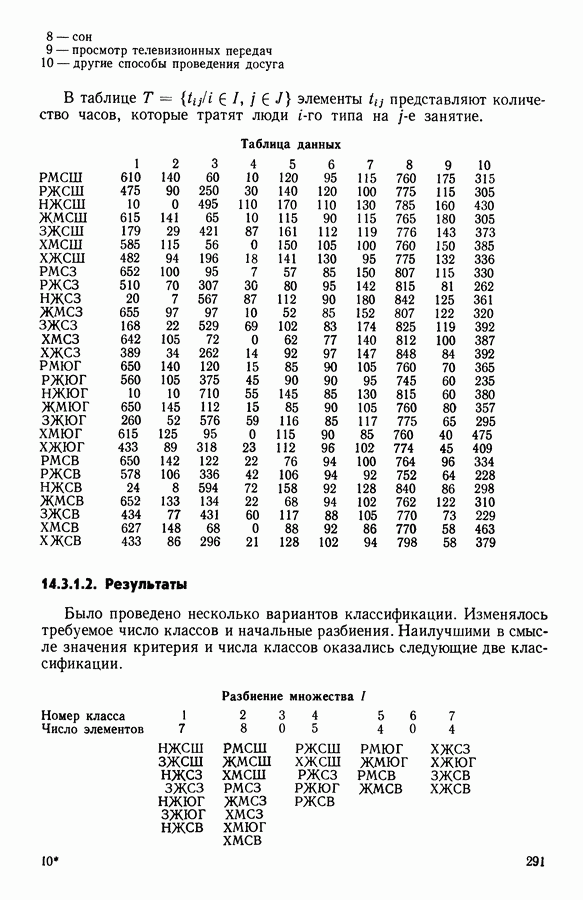
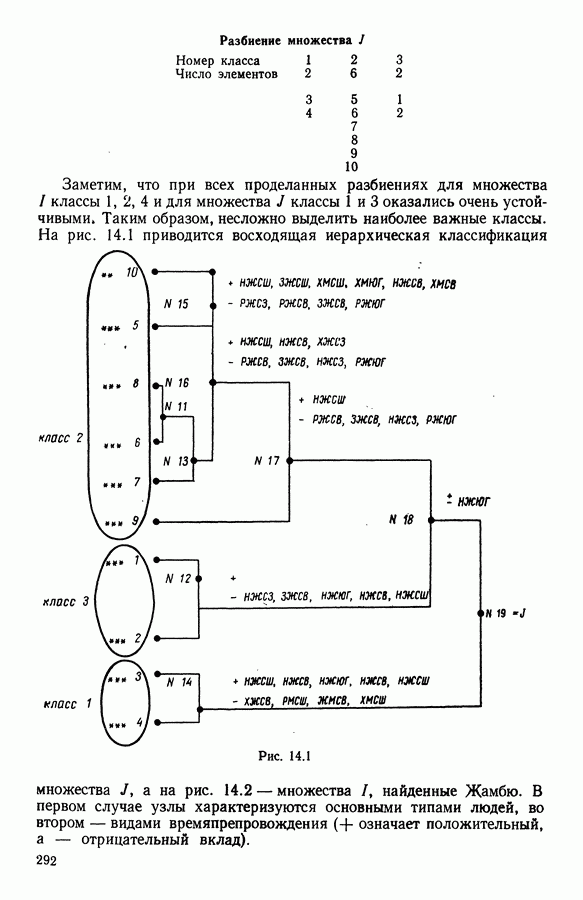
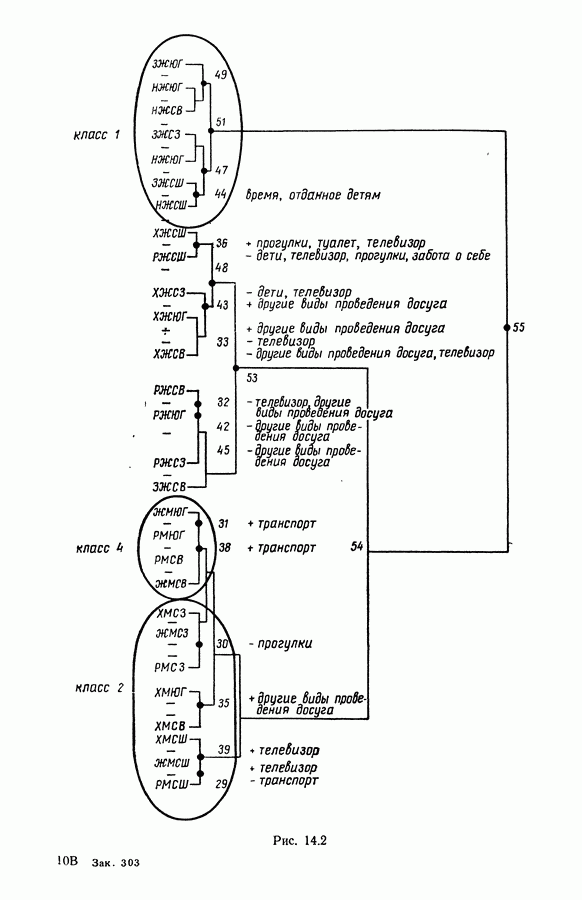
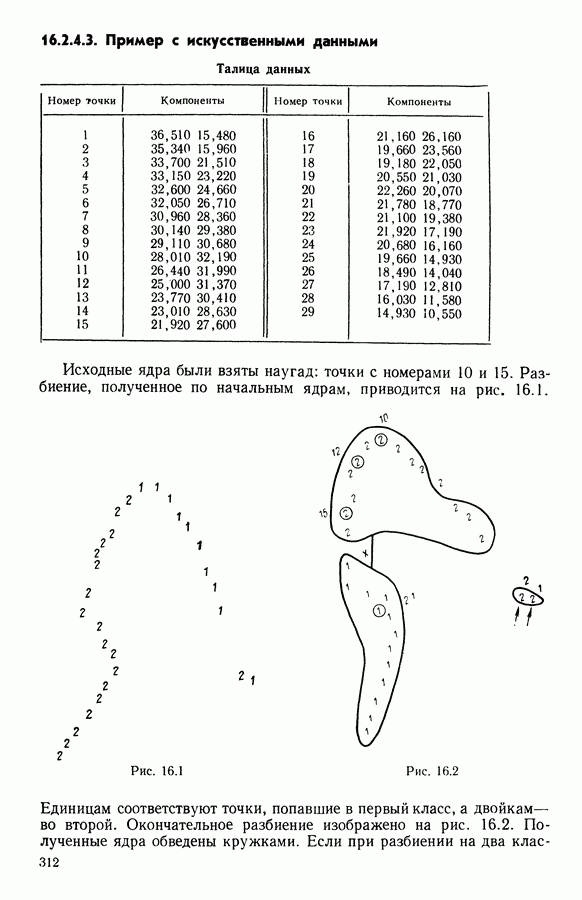
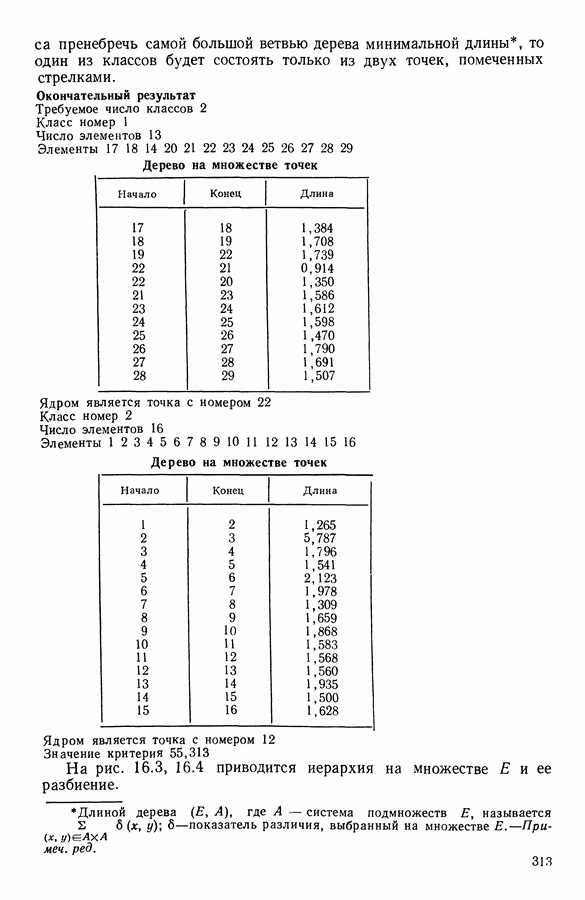
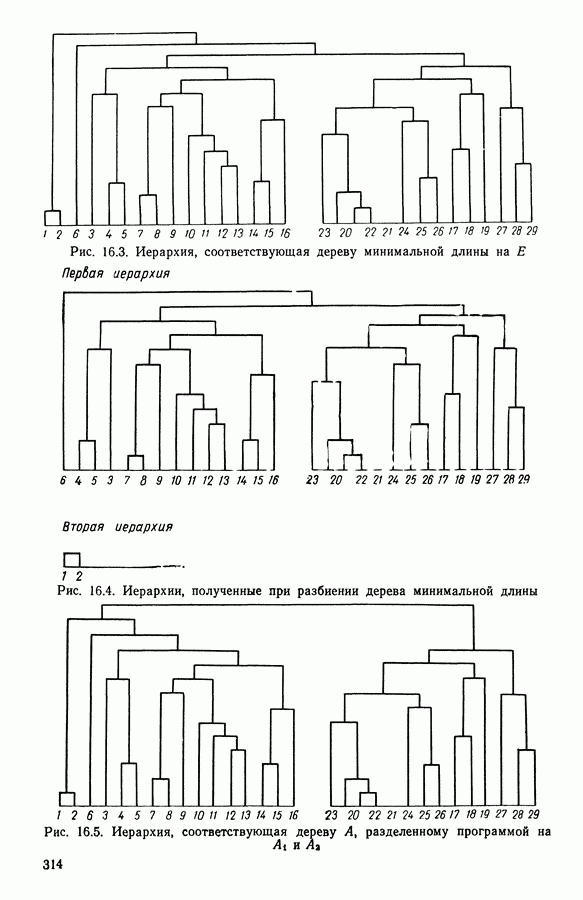
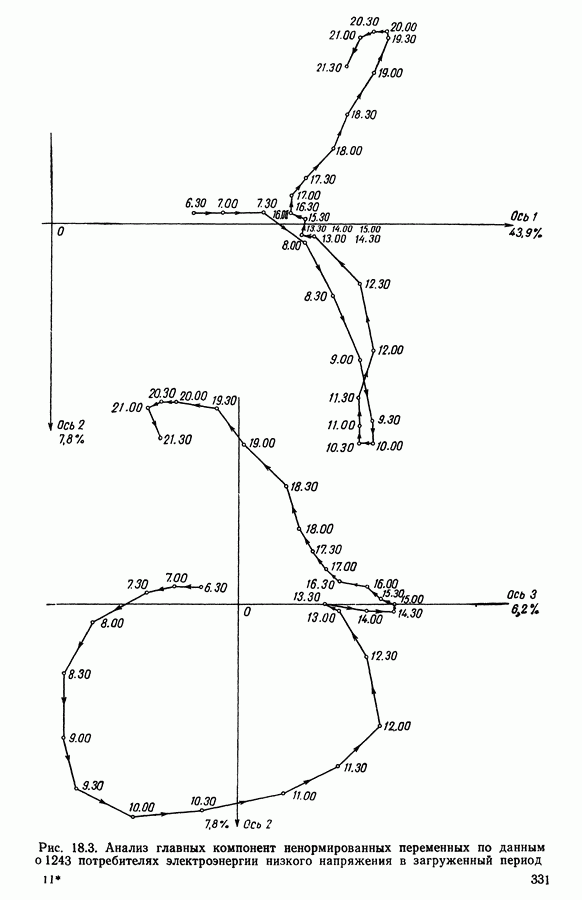
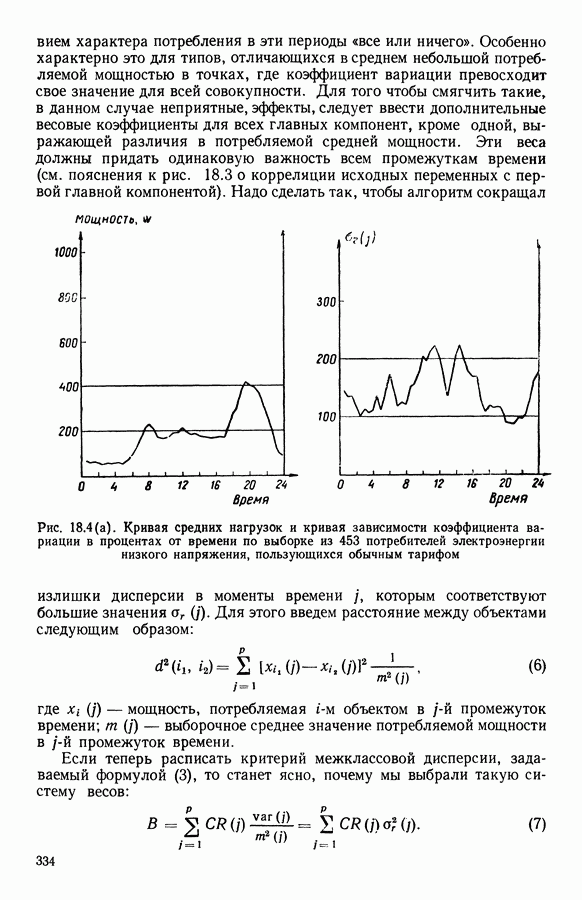
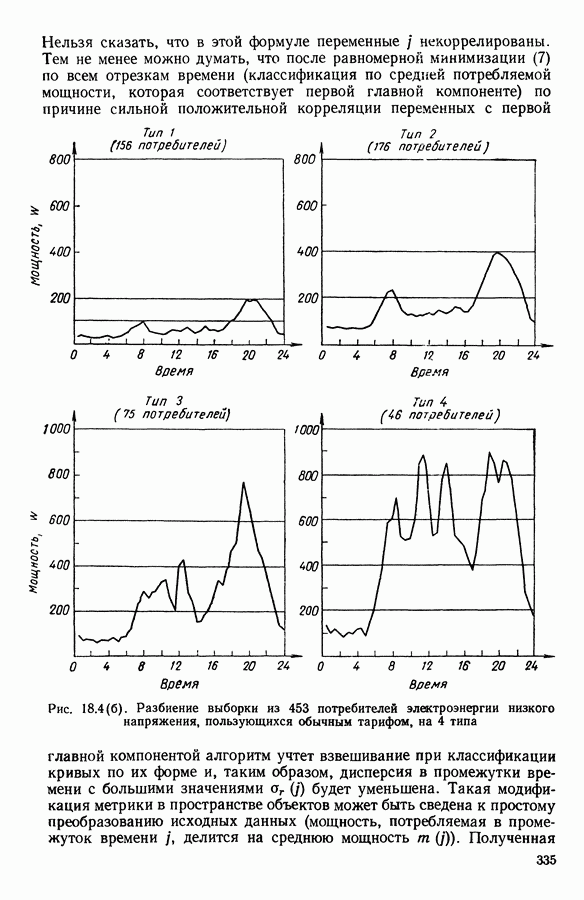
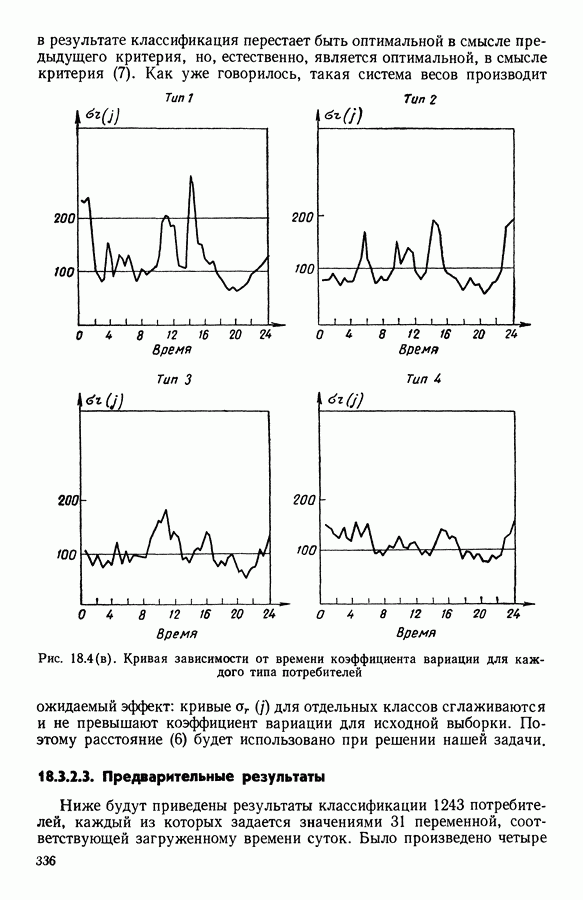
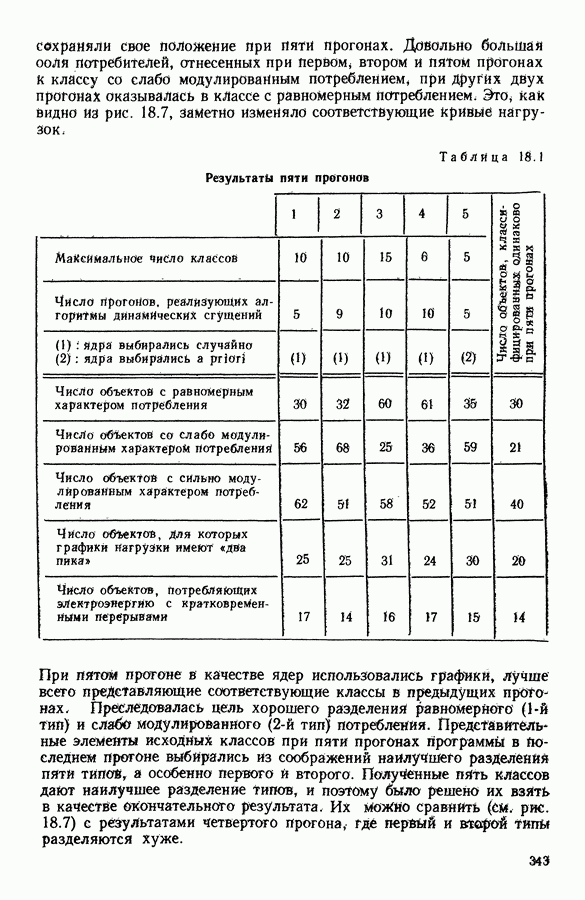
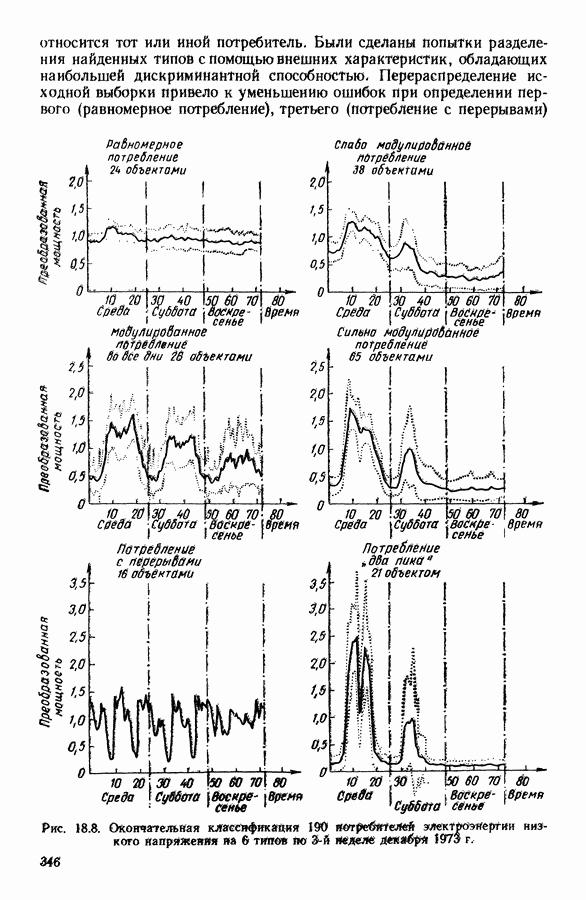
Глава 6. ФАКТОРНЫЙ ТИПОЛОГИЧЕСКИЙ АНАЛИЗ
6.1. ВВЕДЕНИЕ
Статистик, располагающий набором данных, из которых он желает извлечь максимально возможное количество информации, часто отдает предпочтение методам факторного анализа. Результаты, полученные этими методами, в самом деле обладают тем преимуществом, что они дают синтетическое описание данных, упрощая исходное описание и одновременно минимизируя потерянную информацию. Более того, они могут быть использованы (см. II, т. II В, с. 262]) на конечных этапах классификации: исследование аппроксимирующих плоских образов, полученных проецированием анализируемого сгущения на одну или несколько плоскостей главных осей, позволяет перегруппировать в классы близкие элементы с учетом качества их представлений. Нам кажется, что, действуя подобным образом, сталкиваются со следующими неудобствами:
1) при составлении классов частью информации пренебрегают. Используемые плоскости являются наиболее значимыми, однако они значимы с глобальной точки зрения и это не обязательно для каждого отдельного класса;
2) то, что главные факторы ортогональны, не позволяет обнаружить локальные тенденции, например обнаружить направления вытянутости в неортогональных направлениях.
Факторный типологический анализ помогает исключить эти неудобства. Его цель — выявить локальные тенденции и охарактеризовать их. В области анализа многомерных данных он лежит в пересечении линейного анализа и автоматической классификации. Его можно рассматривать с двух точек зрения:
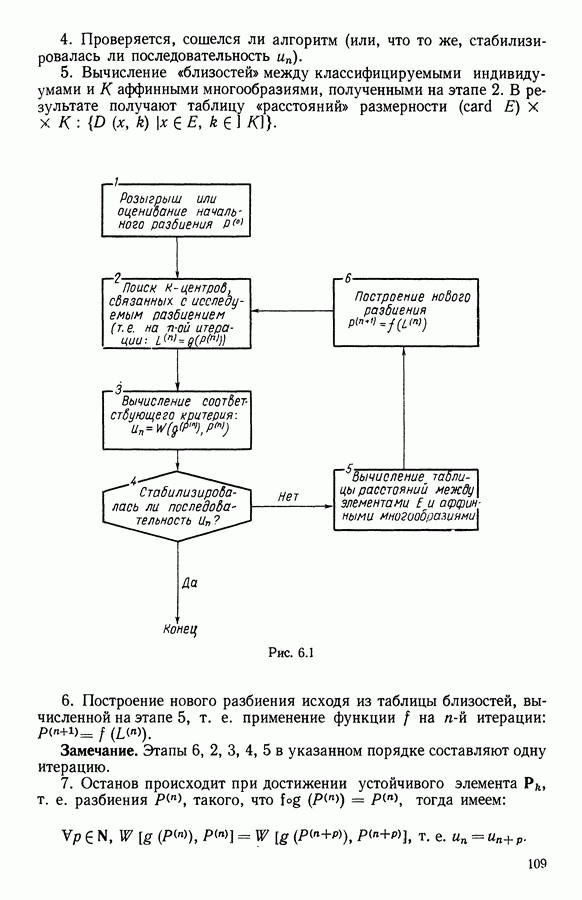
с одной стороны, это метод автоматической классификации, который посредством итерационного сходящегося процесса на каждом шаге улучшает, в смысле заданного критерия, разбиение анализируемого множества и позволяет в результате получить локальные оптимумы, т. е. наилучшие разбиения, достижимые при выбранных начальных разбиениях. Его оригинальность по сравнению с другими алгоритмами типа «динамических сгущений» состоит в использовании метода факторного анализа (анализа главных компонент (см. [5]) или анализа соответствий [I, т. II] для нахождения по разбиению множества на классы новых «представительств», являющихся в данном случае аффинными многообразиями, вокруг которых затем агрегируются новые классы; алгоритм состоит из последовательных итераций вплоть до нахождения подмножеств, сконцентрированных вокруг аффинного многообразия;
он может, следовательно, приводить к распознаванию некоторых сложных форм, составленных из таких многообразий и сгущений около них. Как метод классификации этот метод обогащается вкладом факторного анализа: распознавание формы сгущений, глобальные и локальные визуализации конфигурации, описываемой таблицей данных, интерпретация с помощью небольшого числа информативных признаков, восстановление данных с помощью небольшого числа факторов и т. д., что позволяет более полно описать полученную классификацию;
с другой стороны, можно считать, что это метод факторного анализа, получивший благодаря алгоритму динамических сгущений возможность учитывать специфику данных. В самом деле, он подходит к основной задаче факторного анализа в некотором смысле наиболее общим образом. Вместо того чтобы искать аффинную прямую, плоскость или  -мерное аффинное многообразие, наиболее «близкие» к анализируемому сгущению, и считать удовлетворительным упрощенное описание его в подпространстве пространства
-мерное аффинное многообразие, наиболее «близкие» к анализируемому сгущению, и считать удовлетворительным упрощенное описание его в подпространстве пространства  объясняющем достаточный процент дисперсии, ищут аффинные многообразия размерности
объясняющем достаточный процент дисперсии, ищут аффинные многообразия размерности  наиболее близкие к отдельным локальным агломератам данного сгущения, и спрашивают себя, можно ли считать это сгущение состоящим из классов, сконцентрированных вокруг этих многообразий. (Для этого используют показатель, оценивающий близость «класс-многообразие» и близость между исходным сгущением и совокупностью из К аффинных многообразий (критерий
наиболее близкие к отдельным локальным агломератам данного сгущения, и спрашивают себя, можно ли считать это сгущение состоящим из классов, сконцентрированных вокруг этих многообразий. (Для этого используют показатель, оценивающий близость «класс-многообразие» и близость между исходным сгущением и совокупностью из К аффинных многообразий (критерий 
Если ответ отрицательный, то метод, который предполагает априори существование К классов, ищет новые многообразия и с их помощью разбивает данное сгущение на новые локальные агломераты до тех пор, пока не осуществляется «хорошая» аппроксимация данного сгущения К аффинными многообразиями небольшой размерности.
В результате действия алгоритма получается совокупность аффинных многообразий, составляющих «скелет», аппроксимирующий сгущения точек лучше, чем одно аффинное многообразие, определяемое обычным факторным анализом, который, впрочем, можно рассматривать как частный случай факторного типологического анализа при К 1.
Такое применение алгоритма динамических сгущений позволяет еще обнаружить и проанализировать локальные подпопуляции, которые выявляются таким образом не произвольно, а в результате более точной аппроксимации данных. Это интересно, в частности, в случае больших таблиц, когда метод напоминает применение увеличительного стекла вдоль отдельных направлений или на отдельных плоскостях, замечательных тем, что они дают хорошее локальное представление для исследуемого сгущения.