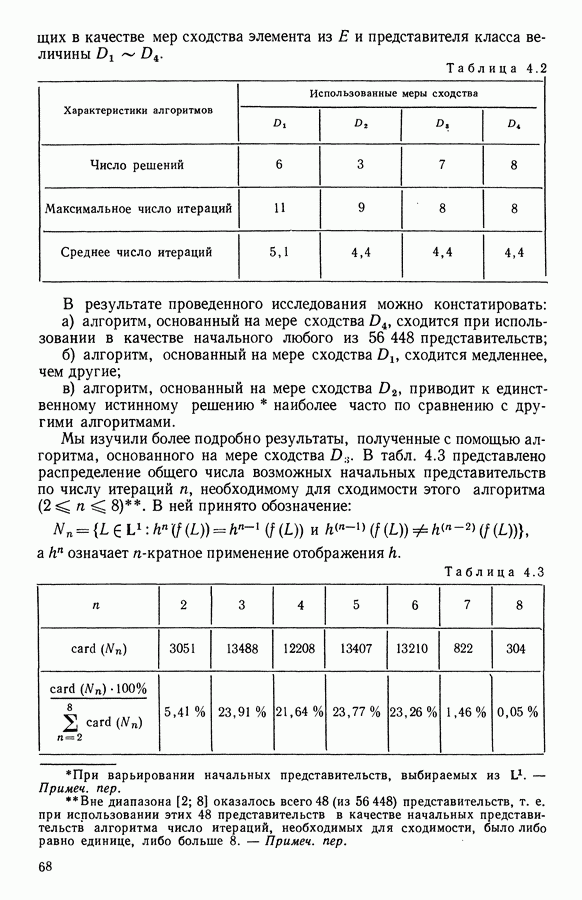
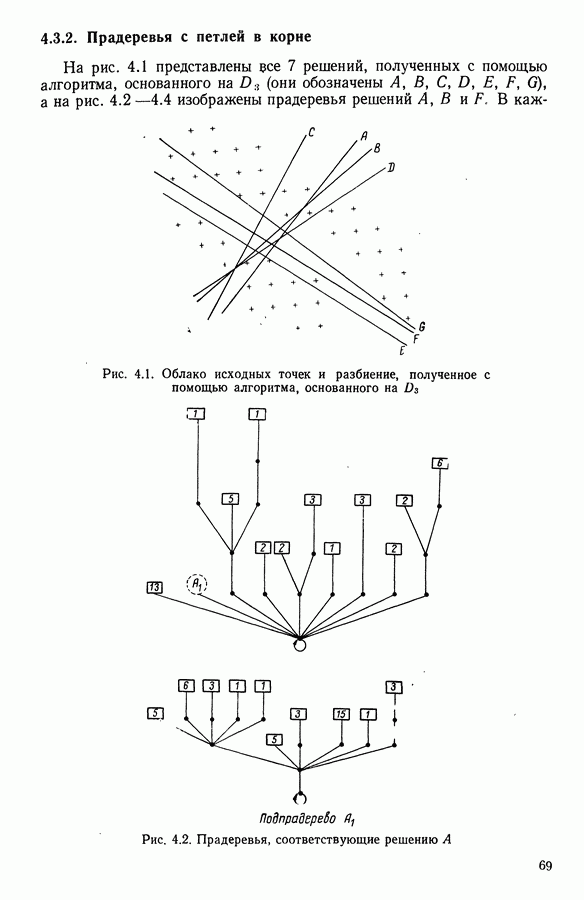
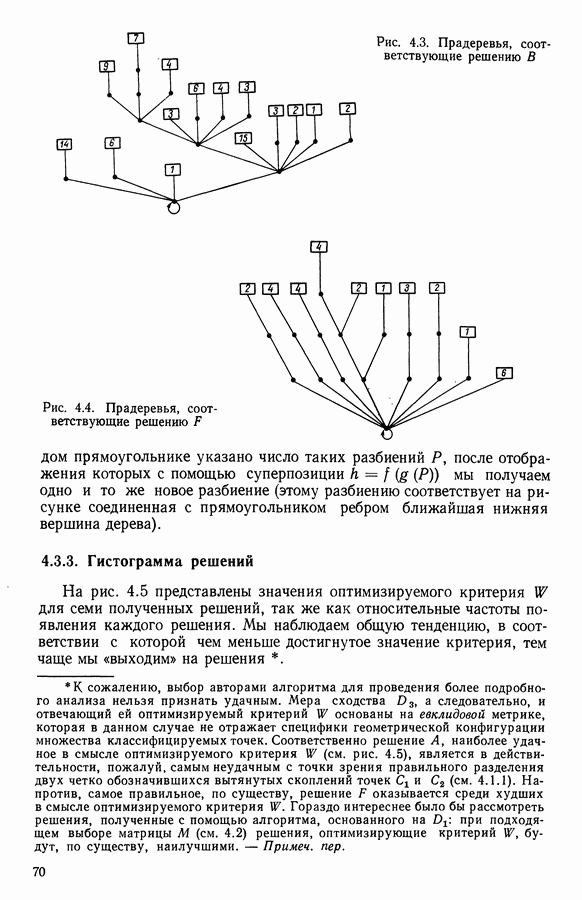
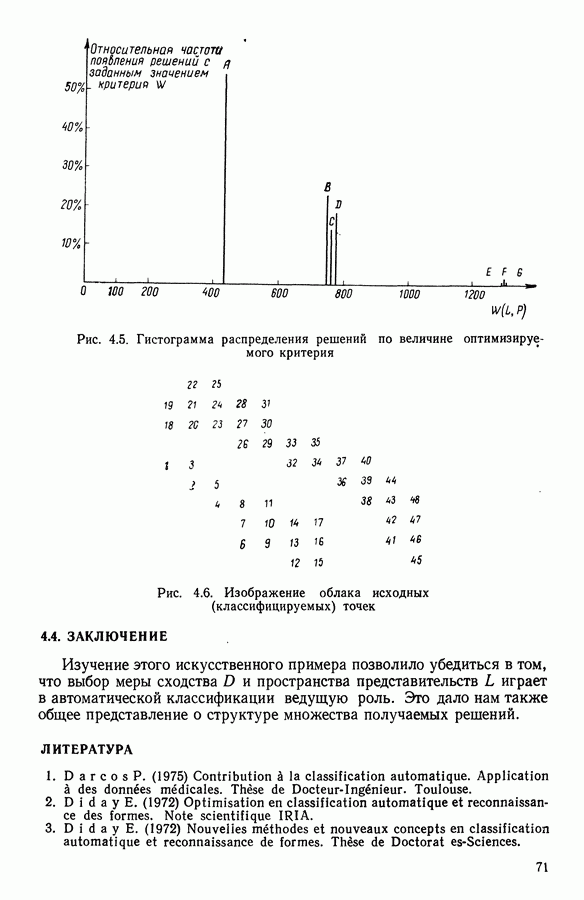
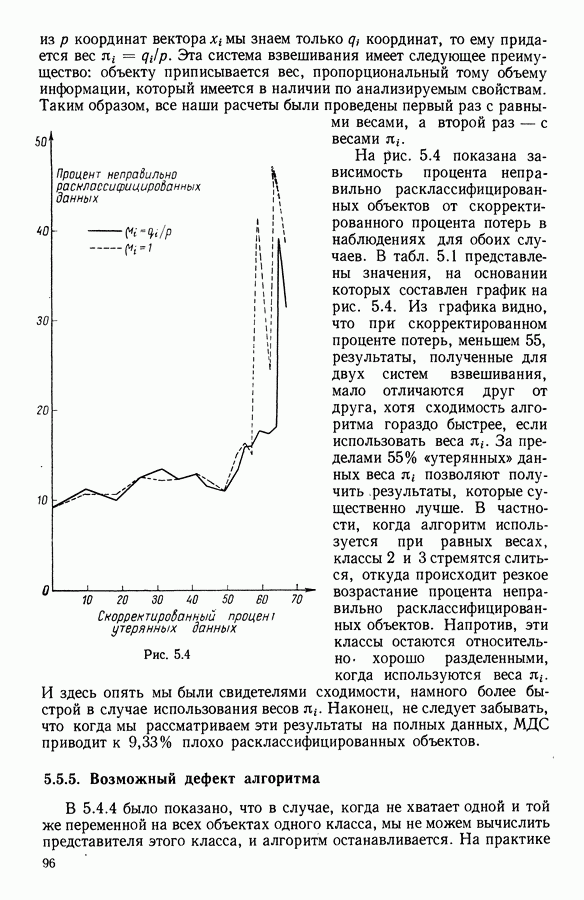
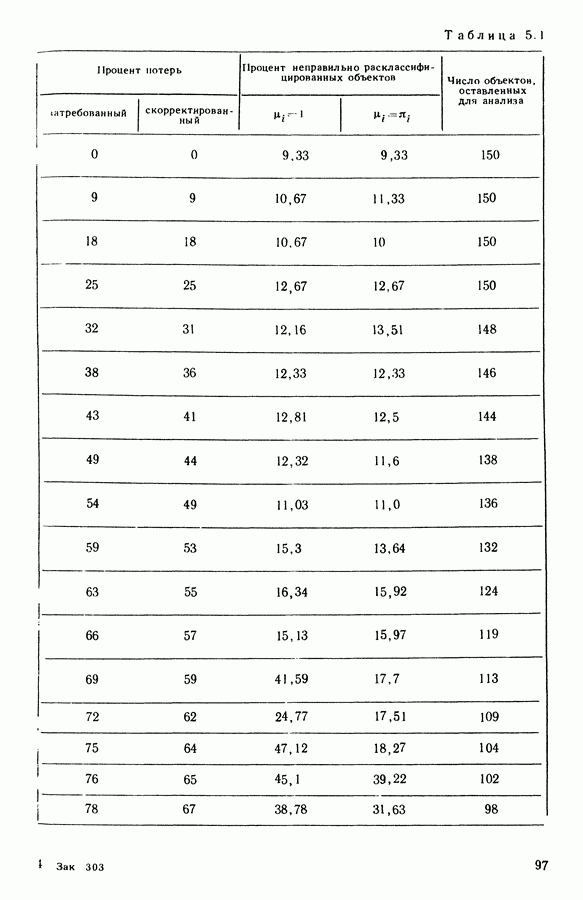
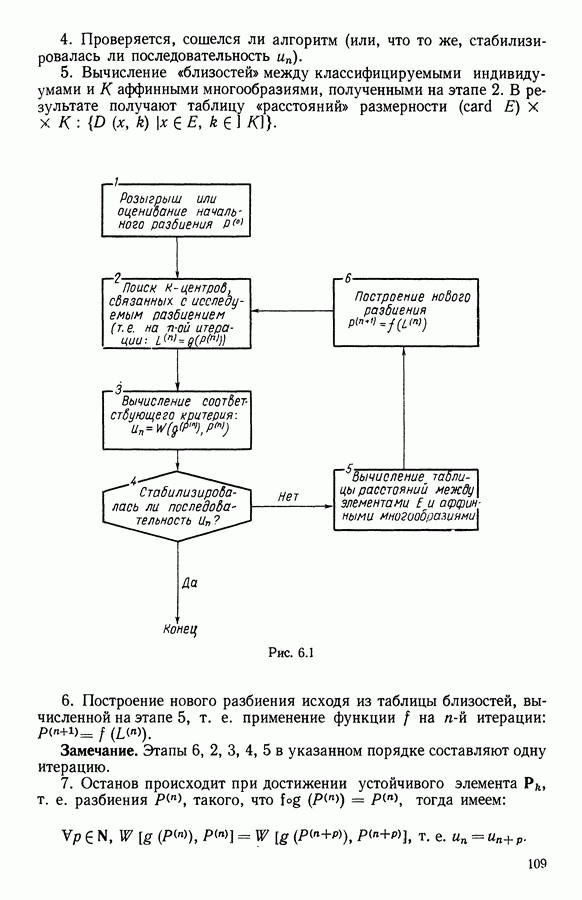
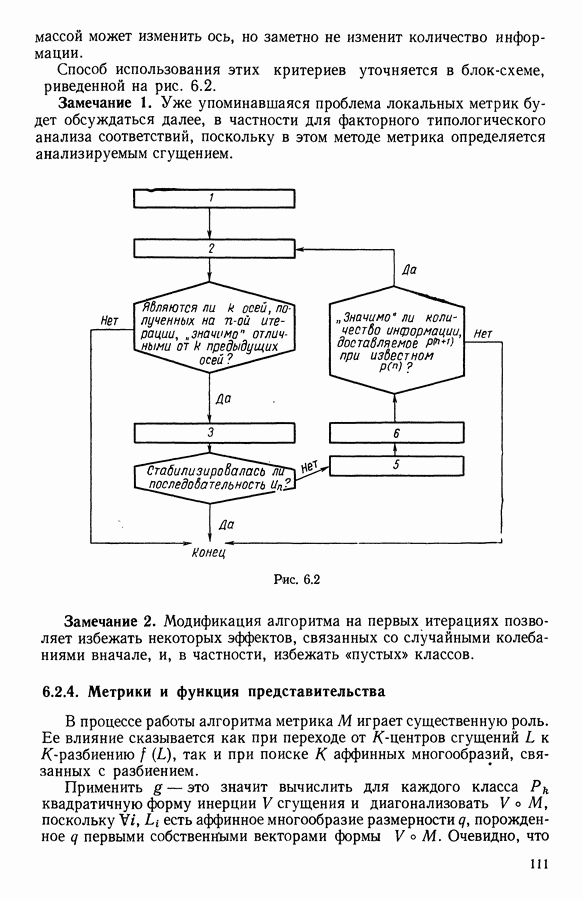
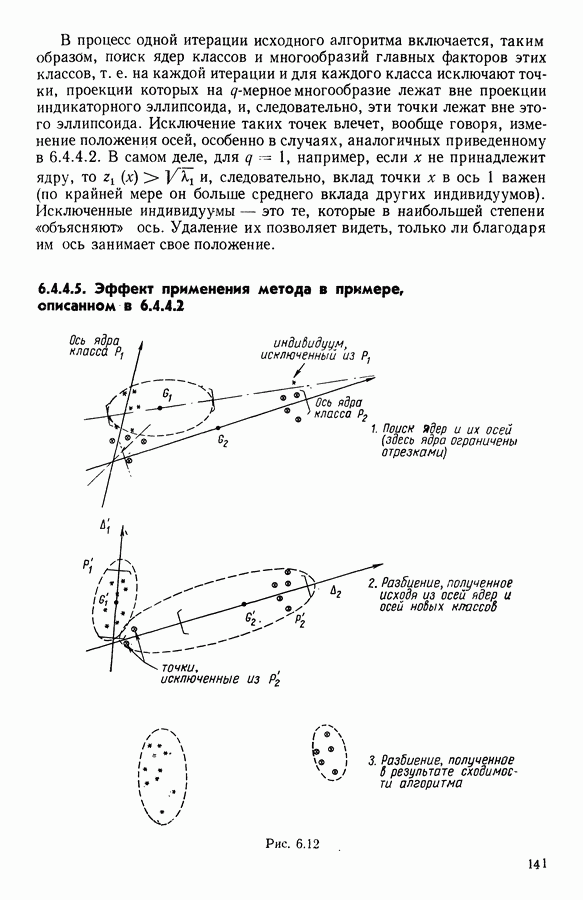
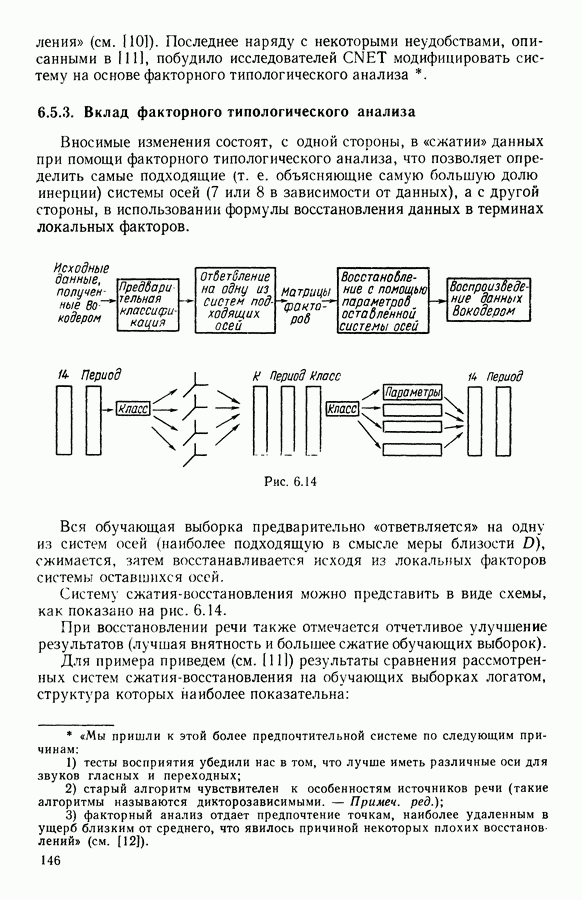
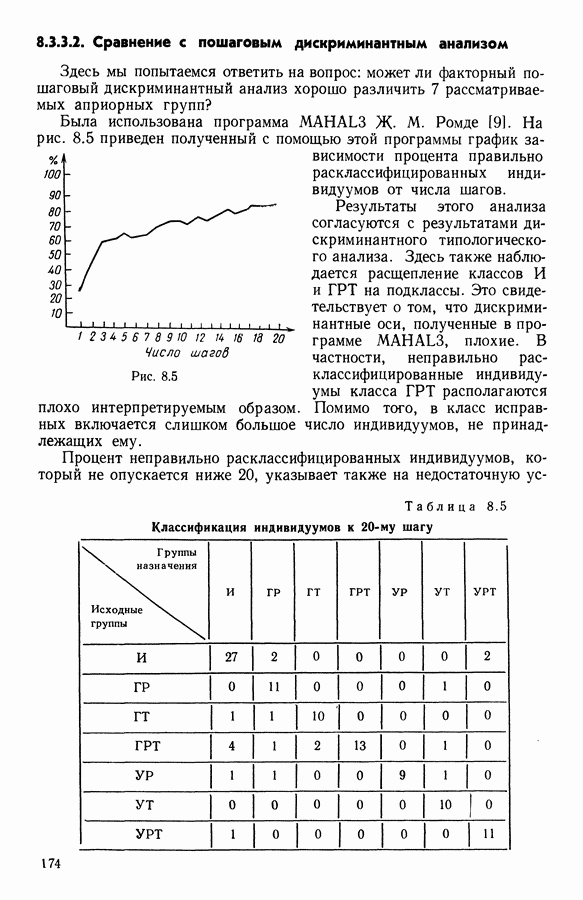
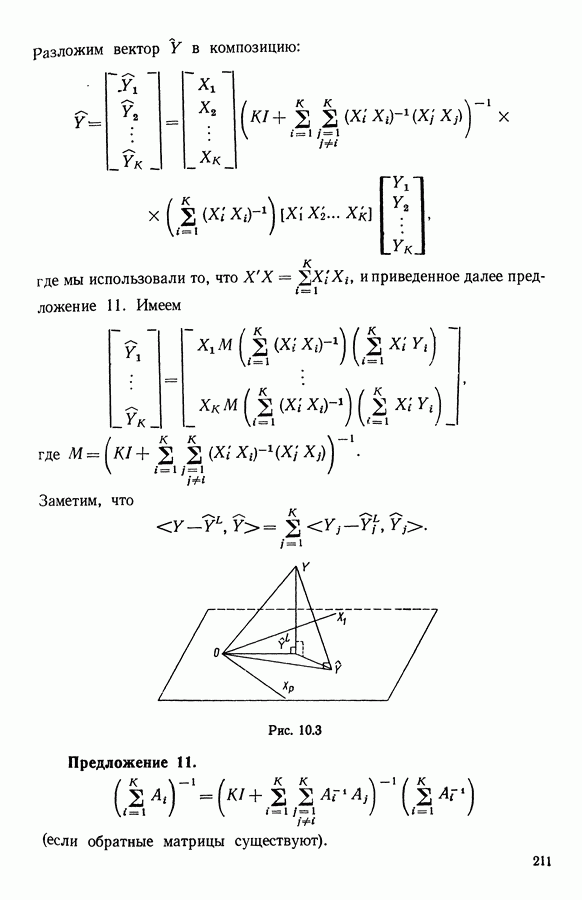
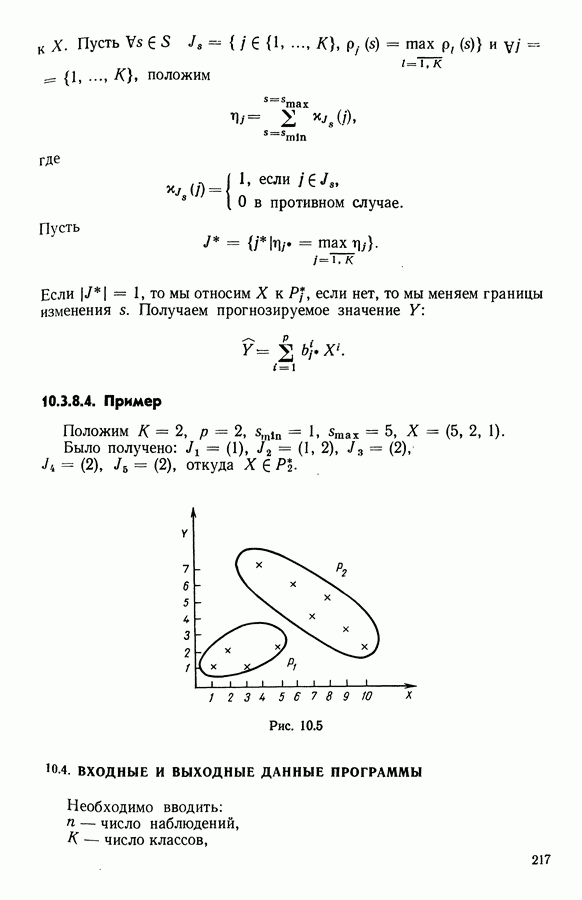
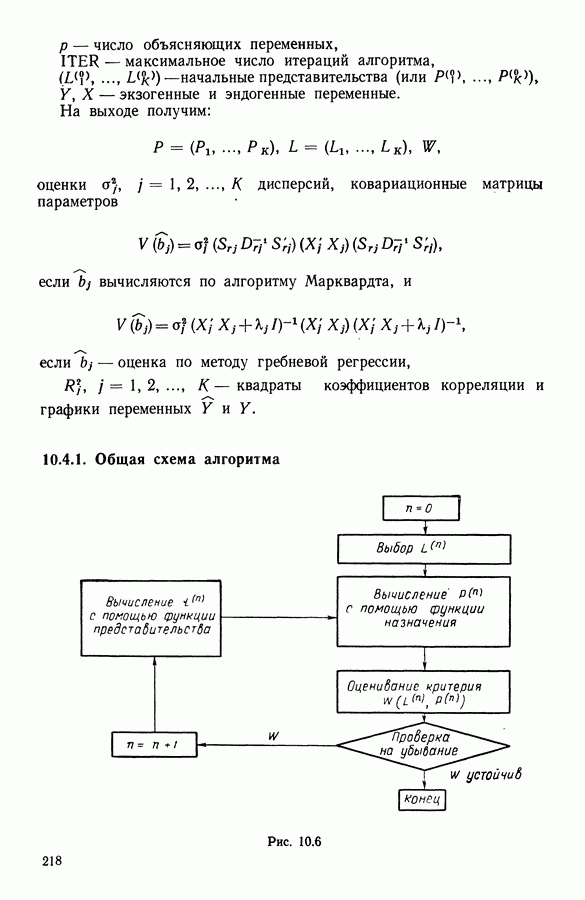
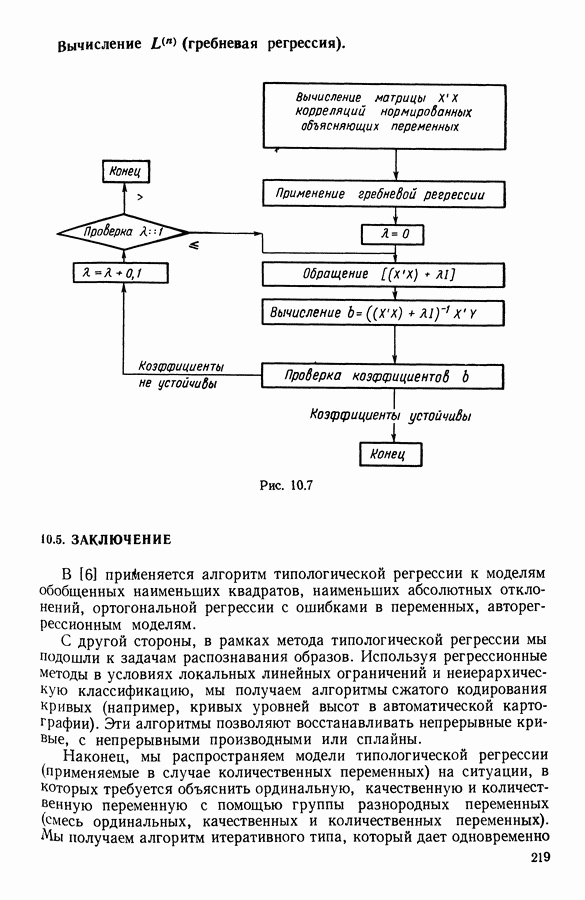
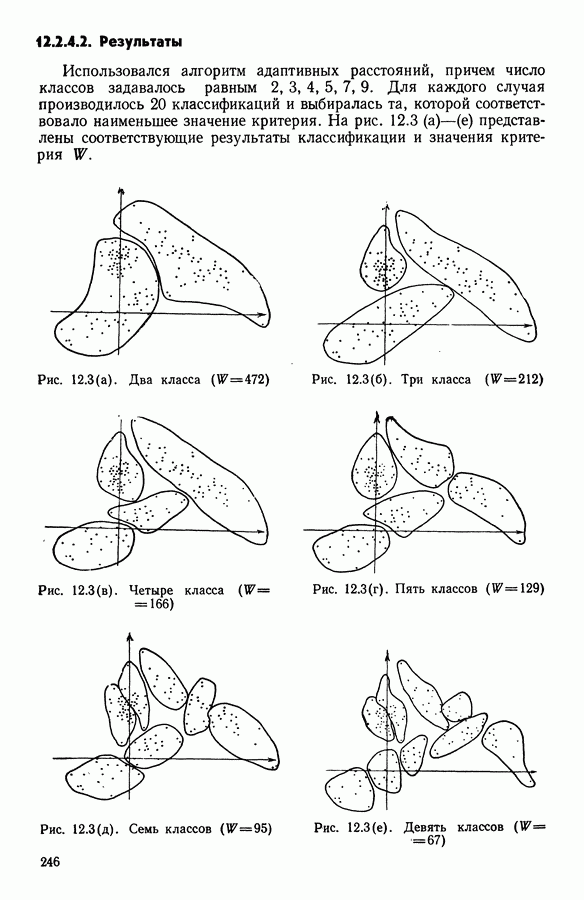
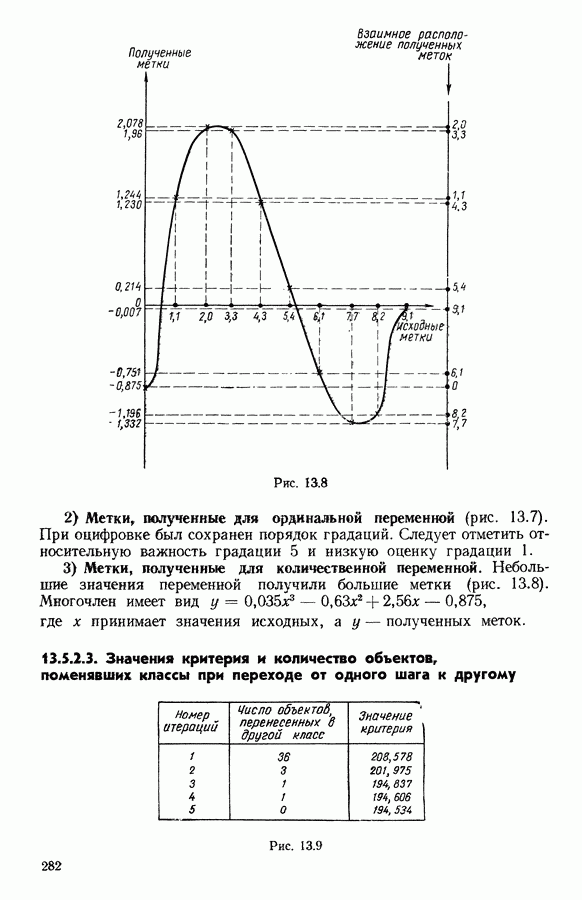
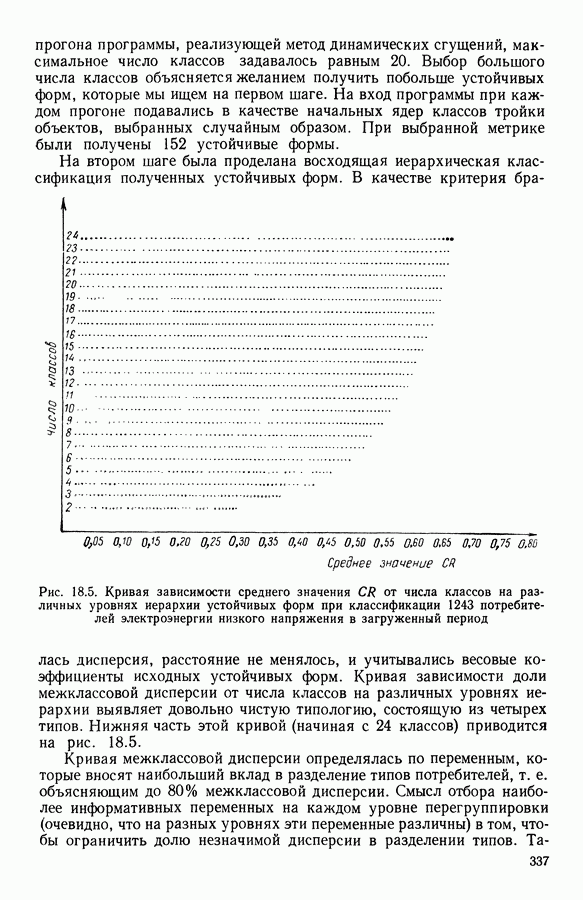
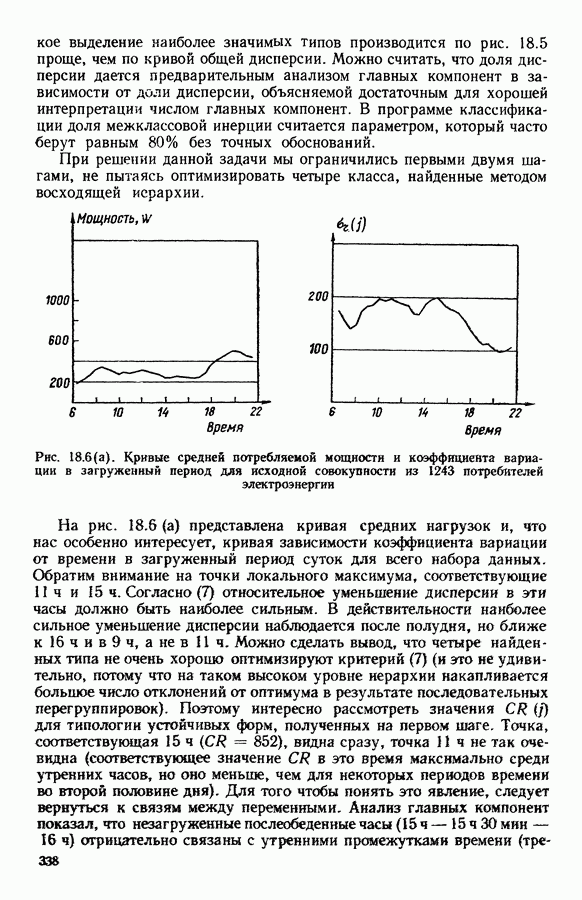
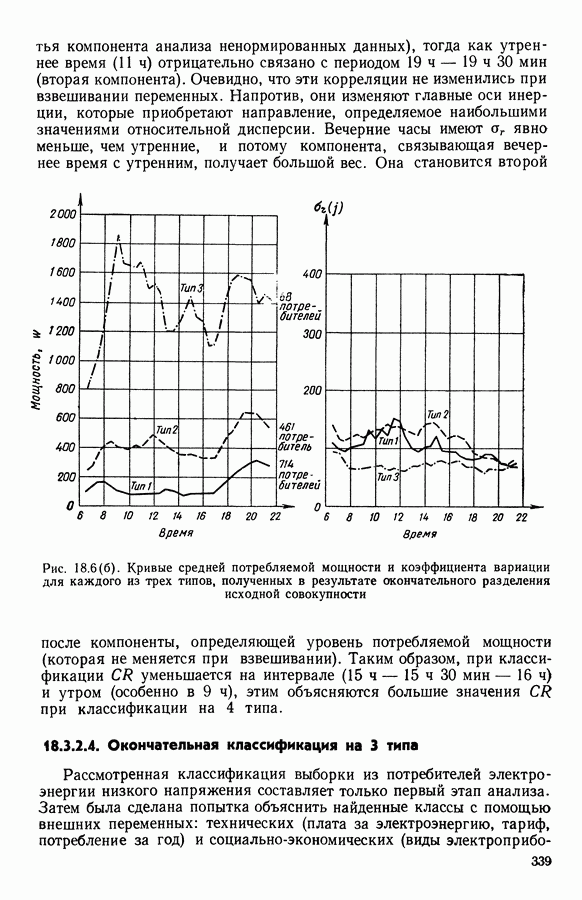
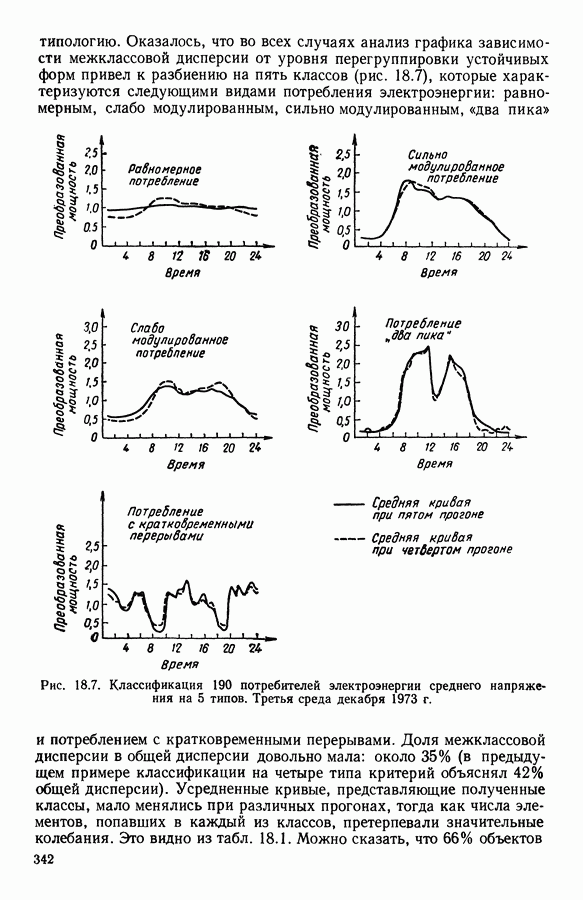
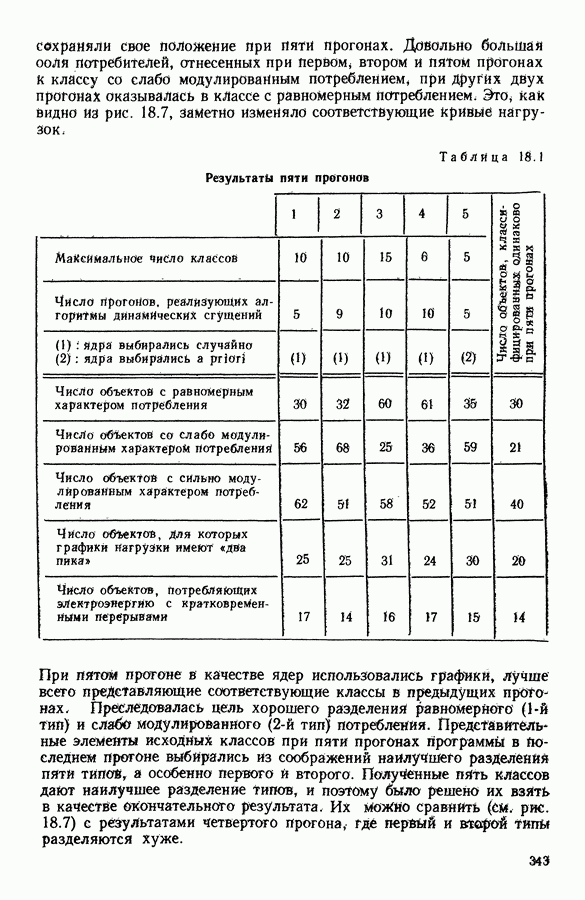
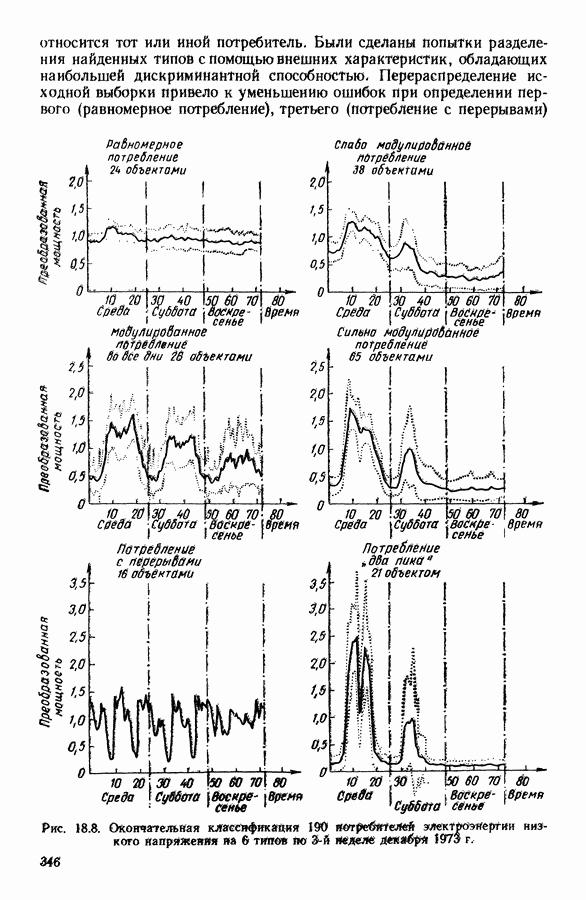
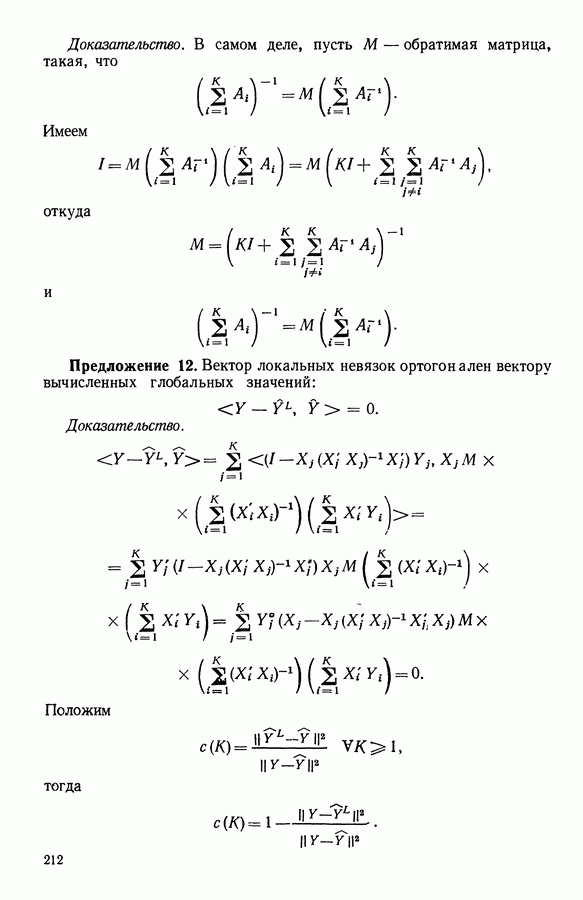Глава 13. ОПТИМАЛЬНАЯ АДАПТИВНАЯ ОЦИФРОВКА
13.1. ВВЕДЕНИЕ
Пусть  конечное множество из
конечное множество из  объектов, характеризуемых
объектов, характеризуемых  переменными различных типов (количественными, номинальными или ординальными). Такому множеству соответствует таблица разнородных данных. Для статистика таблица данных является «промежуточным продуктом», который следует видоизменить так, чтобы можно было получить некоторые содержательные результаты и выводы. Как правило, в случае таблицы разнородных данных трудно выявить информацию, которую несут некоторые переменные, поскольку они могут быть измерены в довольно специфичных шкалах. Поэтому перед любым статистическим анализом таких данных исследователь вынужден приводить их к однородному виду с тем, чтобы можно было воспользоваться нужным методом (в нашем случае — методом автоматической классификации).
переменными различных типов (количественными, номинальными или ординальными). Такому множеству соответствует таблица разнородных данных. Для статистика таблица данных является «промежуточным продуктом», который следует видоизменить так, чтобы можно было получить некоторые содержательные результаты и выводы. Как правило, в случае таблицы разнородных данных трудно выявить информацию, которую несут некоторые переменные, поскольку они могут быть измерены в довольно специфичных шкалах. Поэтому перед любым статистическим анализом таких данных исследователь вынужден приводить их к однородному виду с тем, чтобы можно было воспользоваться нужным методом (в нашем случае — методом автоматической классификации).
Следует заметить, что информация, содержащаяся в любой переменной из рассматриваемой таблицы данных, сохраняется при различных преобразованиях, удовлетворяющих некоторым ограничениям, которые накладываются согласно природе самой переменной [14]. Если в результате получается переменная, принимающая вещественные значения, то соответствующее преобразование называется оцифровкой. Эта задача рассматривалась такими авторами, как Кайе и Пажес [1], Де Леев, Янг, Такане [91, Сапорта [16], Массон [11], Тененос [18].
Цель настоящей главы состоит в том, чтобы поставить задачи оптимизации и описать алгоритмы, позволяющие преобразовывать метки, приписанные категориям переменных так, чтобы получить наилучшие, в смысле некоторых математически определенных критериев, разбиения. Одновременно получаются новые метки, которые должны быть «эквивалентными» исходными или «совместимыми» с ними. Говоря о преобразовании значений некоторой переменной, принадлежащей неоднородной таблице данных, которое осуществляется с помощью вещественного отображения, мы будем пользоваться следующими понятиями: 1) если мы имеем дело с инъективным отображением, будем говорить, что набор полученных значений эквивалентен рассматриваемой переменной; любые два различные значения переменной оцифровываются разными числами; 2) если при используемом отображении различные значения переменной могут быть оцифрованы одинаково, то полученные метки лишь совместимы с исходными.
В этой главе мы рассмотрим основные этапы метода динамических лущений применительно к разнородной таблице данных (см. также
[3], [17]). Вначале определяется пространство покрытий для разбиения на фиксированное число классов, затем пространство представительств, в общем случае зависящее от прямого произведения пространства мер сходства на пространство допустимых оцифровок и, наконец, вводится критерий, выражающий меру адекватности между оцифровкой, совместимой с начальными значениями, и разбиением имеющихся объектов на  однородных классов. Смысл меры адекватности в том, что сумма инерций внутри классов должна быть минимальна. Таким образом, осуществляется адаптивная оцифровка данных, имеющих различную природу.
однородных классов. Смысл меры адекватности в том, что сумма инерций внутри классов должна быть минимальна. Таким образом, осуществляется адаптивная оцифровка данных, имеющих различную природу.
В большинстве алгоритмов автоматической классификации используется одна и та же мера сходства во всем пространстве рассматриваемых объектов и найденные метки не меняются в процессе работы алгоритма. В этой главе будет описан алгоритм нового типа. В нем мера сходства и метки меняются локально приспосабливаясь к структуре пространства объектов, по мере того как алгоритм сходится. Степень адаптации выражается определенным критерием, который уменьшается при каждом изменении меры сходства или меток.
Описываемые алгоритмы адаптивной оцифровки относятся к группе методов динамических сгущений и обладают двумя преимуществами:
1) они позволяют разбить объекты, характеризуемые разнородными переменными, на однородные классы;
2) полученные метки, совместимые с начальными, позволяют дать следующую интерпретацию: для каждой переменной две метки тем ближе, чем более похожи ответы, соответствующие этим меткам для других переменных.
Одна из оригинальных черт настоящей работы заключается в доказательстве того, что адаптивную оцифровку можно рассматривать как частный случай метода адаптивных расстояний (см. 13.4.7, а также [171). Однако для облегчения чтения этой главы мы будем идти от частного к общему. Вначале будет рассмотрена адаптивная оцифровка при фиксированном расстоянии, а потом задача будет распространена на случай адаптивного расстояния.