Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
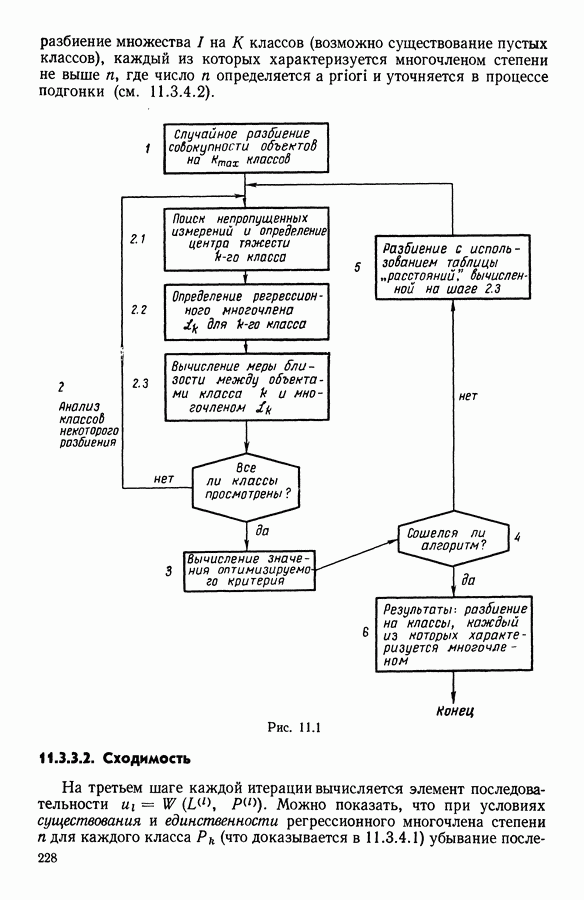
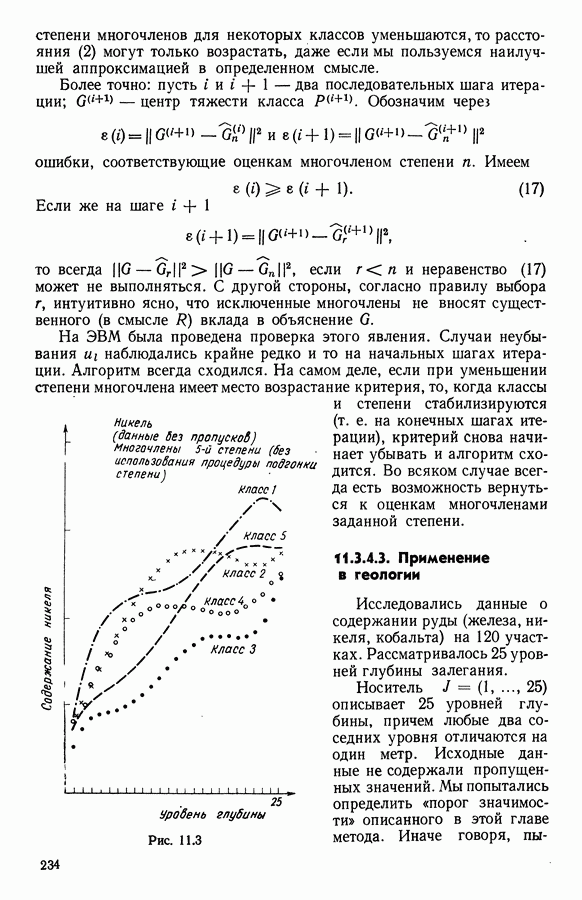
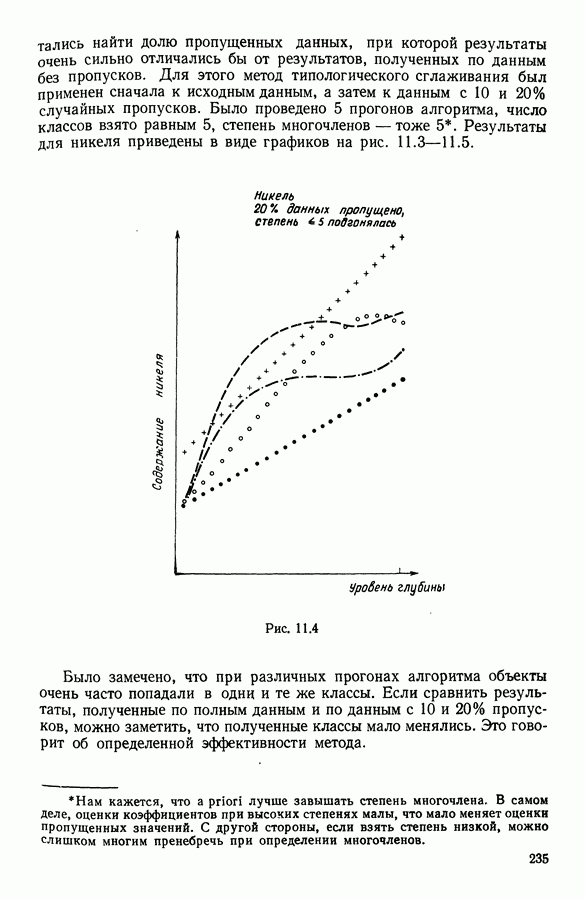
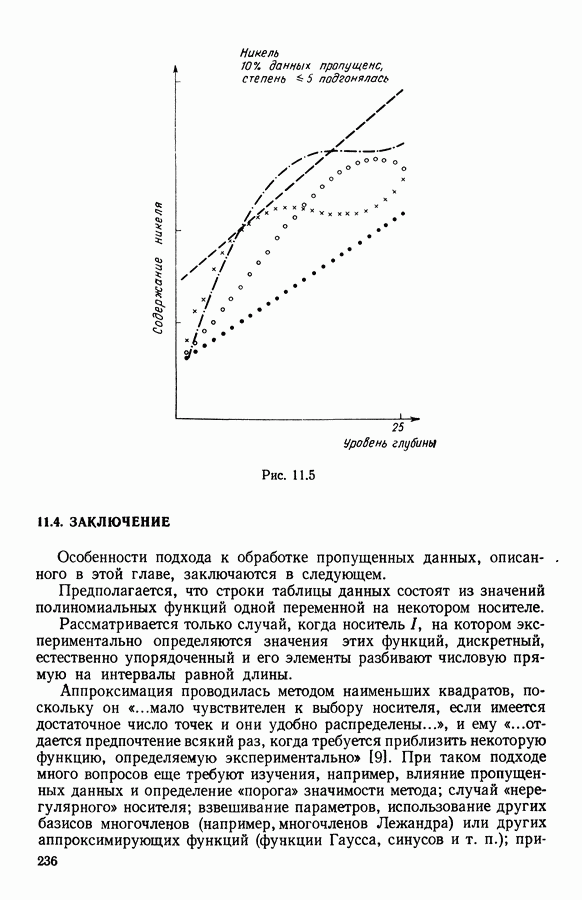
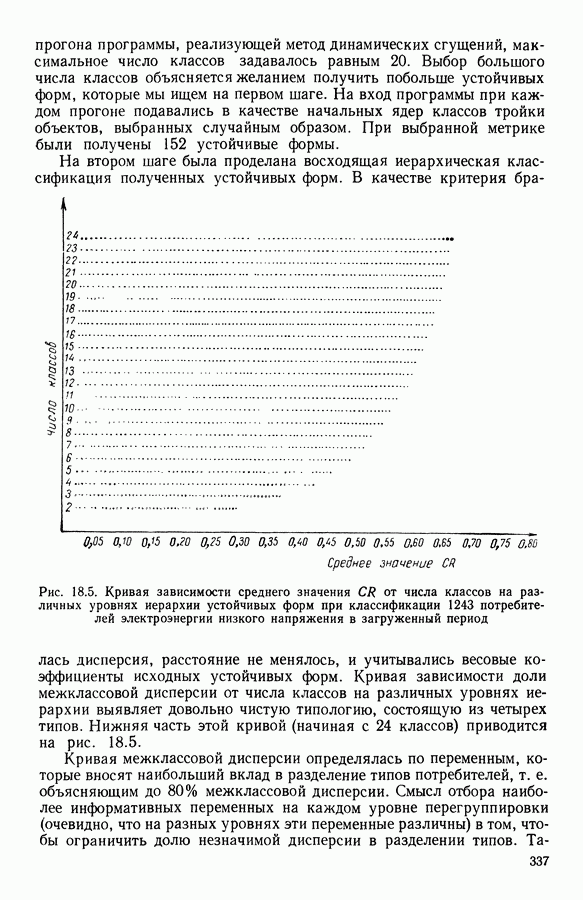
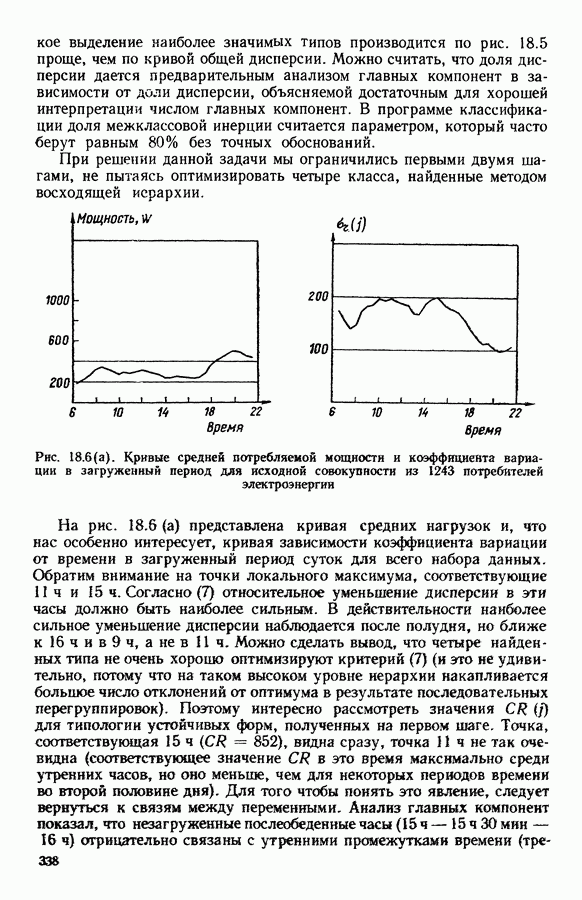
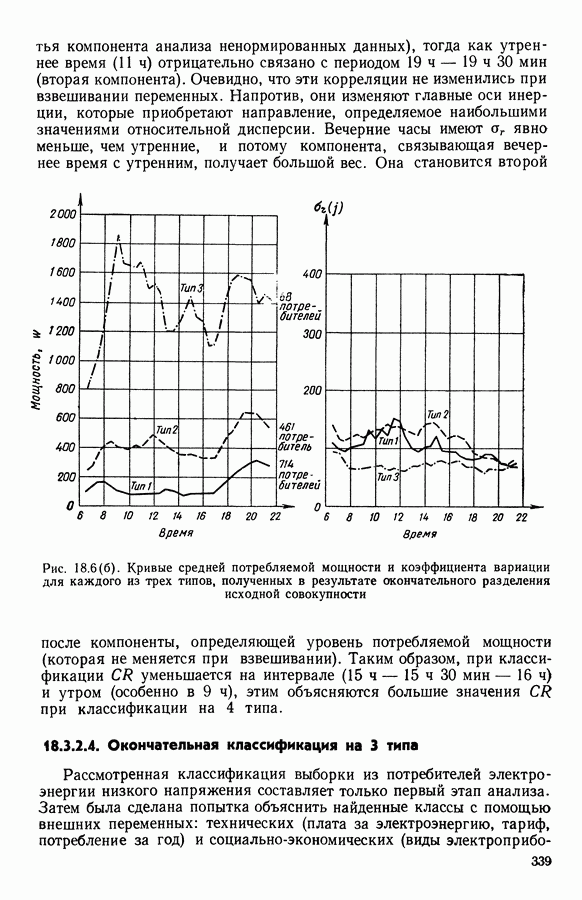
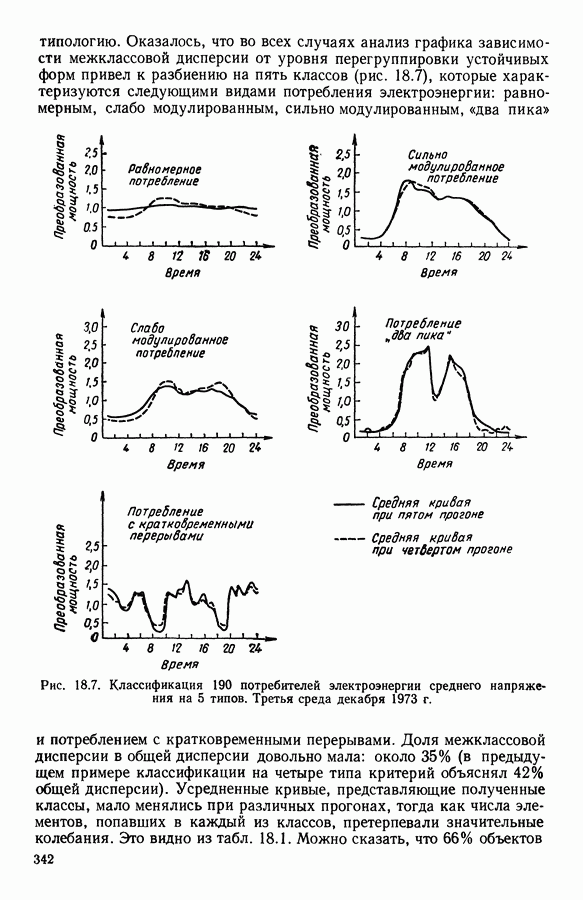
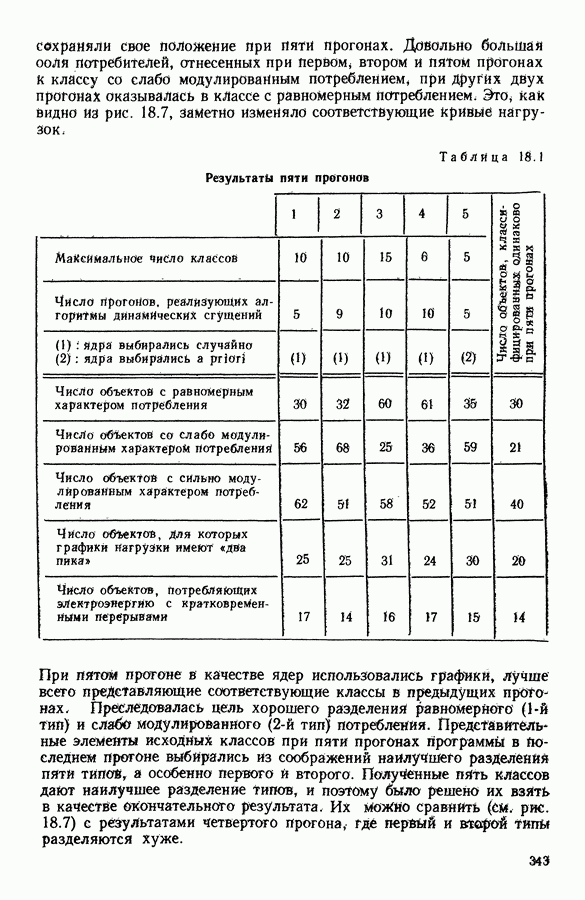
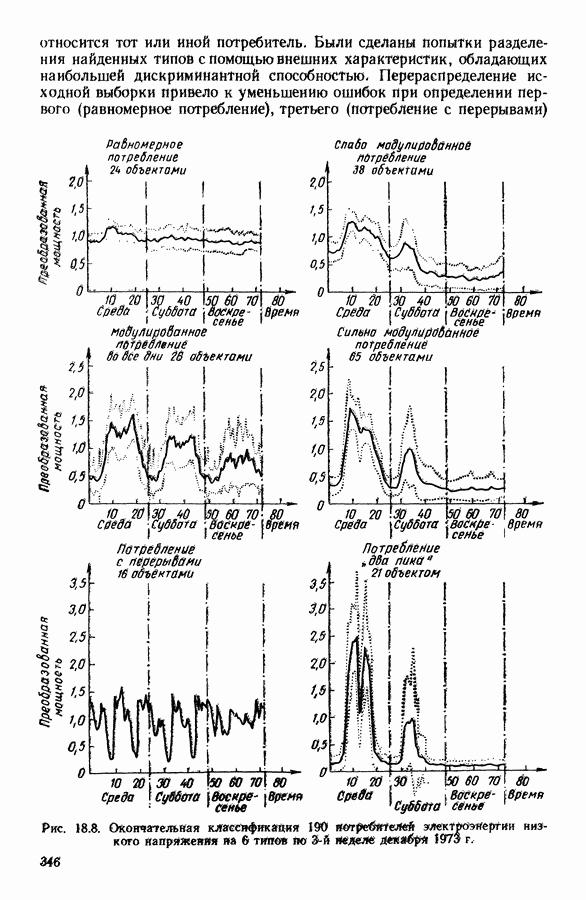
ПРЕДИСЛОВИЕЦель анализа данных, реализация которой возможна лишь благодаря применению ЭВМ, состоит в создании средств, позволяющих охватывать содержание таблиц данных значительного объема через представления (предпочтительно визуальные), которые легко доступны для понимания пользователя. Перспективы использования анализа данных весьма широкие, поскольку редко встречаются области, в которых не было бы таблиц, охватывающих огромное число объектов, характеризуемых одновременно многими переменными. Безусловно, анализ данных составляет важную часть человеческого мышления и опыта, накопленного в контакте с «многомерной реальностью»: от Аристотеля с его деревом «вещей жизни», через Адансона [1] с его первой иерархией, основанной на понятии сходства (XVIII в.), до основ факторного анализа Пирсона (начало XX в.) и метода главных компонент Хотеллинга (30-е годы нашего столетия). Огромный объем вычислений, которые необходимо производить при обработке данных, обусловил тот факт, что именно ЭВМ была главным инструментом, которого недоставало в этой области. Благодаря работам таких ученых, как Л. Гуттман [7], С. Хаяши [15], Р. Шепард [18], Дж. Крускал [10], в начале 60-х годов появились первые визуальные представления многомерных данных, полученные посредством метода многомерного шкалирования, реализованного с помощью ЭВМ. Во Франции к середине 60-х годов в этой области стали известны работы Ж. Бэнзекри и его коллег (см. [4], [9]), которые получили первые визуальные представления на машине с помощью факторного анализа соответствий. В этой же связи следует упомянуть работы Л. Лебара и его коллег (см. [11], [12]). Читателю, интересующемуся историческими сведениями, можно рекомендовать книгу Ж. Бэнзекри [3]. В этом развитии методов и идей автоматическая классификация (АК), конечно же, должна была заявить о себе. Какое же место занимает автоматическая классификация в рамках анализа данных? Автоматическая классификация объединяет весь набор методов и алгоритмов, предназначенных для разбиения совокупности объектов, каждый из которых описан набором переменных, на какое-то число однородных (в определенном смысле) классов. Эти классы могут быть в той или иной степени связаны между собой, например в форме графа, или дерева, каждая вершина которого представляет один класс. Следует отличать методы автоматической классификации от методов дискриминантного анализа и методов упорядочения, потому что последние предполагают обязательное знание априорно заданных классов объектов (обучающих выборок). Именно в связи с необходимостью классифицировать растения В настоящее время имеется обширная литература по методам автоматической классификации. Приведем некоторые работы, полностью посвященные автоматической классификации: Бэнзекри [4], Лерман [13], Андерберг [21, Хартиган [8], а также недавние исследования, такие, как Жамбю [9], Шандон и Пэнсон [6]. Существенная часть книги Пажеса и Кайеза [51 также связана с данной тематикой. Как и в любой начинающей научной дисциплине, в автоматической классификации были созданы и использованы разнообразные, в той или иной степени экспериментальные и эвристические, методы. Этим объясняется тот факт, что зачастую пользователь оказывается перед лицом огромного количества алгоритмов, часто описывающих плохо сформулированные или вообще не поставленные задачи! В результате для некоторых пользователей автоматическая классификация является амальгамой алгоритмов, основная цель которых — получить классы. Нас же в первую очередь интересуют постановки задач, решение которых дается этими алгоритмами. Другими словами, до того как начать сравнивать алгоритмы, необходимо сравнить задачи (выраженные математическим языком), которые эти алгоритмы стремятся решить. На типичный вопрос неофита, спрашивающего: «Какой алгоритм наилучший?», - мы отвечаем: «Какова конкретная математическая постановка задачи, решаемой при обработке ваших данных?» Действительно, если быть более наблюдательным, то мы можем констатировать, что еще редко встречаются различные алгоритмы, которые решали бы одну и ту же задачу и оптимизировали один и тот же критерий. В данной работе мы покажем, что очень большая группа задач АК может быть выражена в форме оптимизации критерия, хорошо определенного с математической точки зрения. Излагаемый в книге метод динамических сгущений (МДС) позволяет построить необходимый базис для формулировки этих задач и получения алгоритмов, дающих их приближенные решения. Основное свойство МДС состоит в том, что он вводит новую проблематику. Речь идет об оптимизации критерия, который оценивает согласованность между покрытием множества объектов, подлежащих классификации, и способом представительства классов этого покрытия. В таком случае задача оптимизации может быть сформулирована как задача одновременного отыскания покрытия и представительства его классов среди множества возможных покрытий и представительств, которые оптимизируют заданный критерий. Множество разбиений и множество иерархий дают два классических примера множеств покрытий. Каждый класс разбиения или каждую ступень иерархии можно «представить» с помощью «центра тяжести»; множество таких центров является классическим примером множества представительств. Термин «представительства» будет уточнен в гл. 1. С учетом конкретных задач, которые ставятся пользователями, можно вообразить большое число других множеств покрытий и представительств; некоторые из них будут рассмотрены далее. Другое важное свойство МДС состоит в том, что он позволяет построить семейство алгоритмов, при некоторых условиях гарантирующих убывание минимизируемого критерия. Не следует придавать чрезмерного значения самим алгоритмам. Наиболее важными, с нашей точки зрения, являются четкая формулировка задачи оптимизации (а хорошо поставить задачу — это дать, по существу, половину ее решения) и способность метода ввести концепцию и аппарат автоматической классификации во многие области. Более того, в будущем может оказаться, что алгоритмы, не обладающие общностью метода динамических сгущений, но лучше приспособленные к какой-то специальной области, могут лучше решать задачи, о которых мы говорим в этой работе. В основных своих чертах метод динамических сгущений был разработан в конце 60-х годов сотрудниками IRIA-LABORIA. На с. 2 диссертации Э. Дидэ (1972 г.) можно прочесть: «Среди всех разбиений на К классов следует найти разбиение, относительно каждого класса которого заданное «ядро» оказалось бы наиболее представительным. Понятие ядра (оно будет уточнено математически) имеет самый широкий смысл: ядро класса (т. е. группы точек) может быть подгруппой точек, центром тяжести, осью, случайной переменной и т. д.» Впоследствии мы привыкли вместо «ядра» употреблять слово «представитель». Некоторые задачи классификации, формулируемые в рамках схемы МДС, являются совершенно новыми, для других — в соответствующей главе приведена библиография. В гл. 1 мы старались представить «формализм» МДС таким образом, чтобы выразить в первую очередь основную идеологию, на которой базируются все главы; для этого мы сознательно устранили некоторые интересные аспекты МДС, например связь с задачами распознавания образов; некоторые аспекты этой проблематики имеются у Ж. Симона [19]. Другие главы связаны с первой, но их можно читать и независимо друг от друга; их можно сгруппировать в пять частей. Первая часть включает гл. 2—5, она посвящена развитию МДС. Вторая часть содержит описание преобразования с помощью МДС классических задач анализа данных (гл. 6, 7, 8) и математической статистики (гл. 9, 10, И) в задачи автоматической классификации. Во всех случаях МДС позволяет по-новому взглянуть на анализируемые задачи, трансформируя проблему «глобальной оптимизации» на всей анализируемой совокупности объектов в аналогичную задачу «локальной оптимизации» на множестве возможных покрытий. Интерес «локальной» точки зрения объясняется по крайней мере двумя следующими причинами: а) может оказаться, что представительство, рассматриваемое среди множества всех возможных представительств, окажется посредственным, но будет вполне удовлетворительным на надлежащих частях анализируемой совокупности; б) отнесение («назначение» в один из классов) нового объекта исходя из локального представительства классов может оказаться более точным. Например, две хорошо выбранные локальные факторные плоскости будут иметь «инерцию» лучше, чем единая глобальная факторная плоскость Третья часть (гл. 12, 13, 14) касается проблем «редактирования» и предварительного анализа исходной таблицы данных. Известно, насколько это важная задача, задача, которую исследователь, анализирующий данные, стремится решить до того, как применить основной метод. Эта задача прежде всего касается пересмотра состава анализи руемой выборки, состава набора переменных, привилегированности некоторых из них или модификации меры подобия (или сходства) объектов, априорно заданных пользователем. Здесь показано, каким образом эта задача может быть реализована «адаптивно» с учетом возможностей автоматической классификации и МДС. Четвертая часть (гл. 15 и 16) связана с изучением иных (чем разбиения) покрытий. Речь идет о получении удовлетворительной адекватности между покрытием и представителями, которые выбираются для каждой его части. Тогда можно использовать МДС, либо чтобы улучшить результаты, полученные другими методами (например, результаты иерархической классификации могут быть улучшены путем минимизации критерия, охватывающего глобально все иерархии, см. гл. 16), либо чтобы изучать новые типы покрытий (например, мультиразбиения Г. Броссье, см, гл. 15 и 16). В каждой из четырех частей перспективы расширения сферы применения МДС весьма многообразны, что достигается, например, с помощью варьирования пространства покрытий или представительств. Но всегда ли они полезны? Априорно трудно ответить на этот вопрос. Так, например, мы намеревались сначала использовать факторный типологический анализ Пятая часть книги (гл. 17, 18) посвящена разнообразным приложениям МДС. Наиболее интересными из них являются, с нашей точки зрения: 1) совершенствование информационной системы путем адаптации программ в пронумерованной среде; 2) изучение и типологизация кривых спроса электромощностей. Другие работы, касающиеся вопросов оптимизации в автоматической классификации, публиковались в виде диссертаций, статей или рабочих отчетов LABORIA, а также в трудах Международных конференций (1977 и 1979 гг.) по анализу данных и информатике. Данная монография — результат коллективной работы, в которой авторы старались использовать один и тот же язык. Это дает по крайней мере два преимущества. Во-первых, возможность «погрузить» свою задачу в общие рамки МДС позволяет часто получить более глубокое понимание содержательной сущности решаемой задачи. Для пояснения этой мысли приведем пример с анализом смеси распределений вероятностей: возможность поставить задачу в рамках МДС позволяет (путем простого изменения пространства представительств) обрабатывать смесь вероятностных распределений иначе, чем это делается в случае нормальных компонент смеси; в частности, при нашем подходе рассматриваемое семейство законов входит только как параметр программы. Во-вторых, исследователь зачастую теряется перед растущей массой алгоритмов автоматической классификации. Предлагаемый в книге МДС является как бы путеводной нитью, позволяющей осмыслить семейство алгоритмов автоматической классификации в рамках единой точно сформулированной оптимизационной задачи и общего языка. В заключение мы выражаем свою признательность директору Национального института исследований по информатике и автоматике профессору Лионсу, благодаря которому мы обрели научную среду, благоприятную для формирования основных идей, представленных в данном труде, а также профессору Ж. К. Симону за его советы и поддержку. Мы благодарны профессорам Ж. П. Обэну, Ж. Леви и А. Ситбону за их дружескую поддержку в Парижском университете — IX («Дофин»), господину Борну, мадемуазель де ля Фабрэг, которые способствовали практической реализации данного издания; мадам Беллиа и мадам Корнелис за их постоянную помощь в техническом оформлении рукописи. ЛИТЕРАТУРА(см. скан) (см. скан)
|
 |
Оглавление
|













































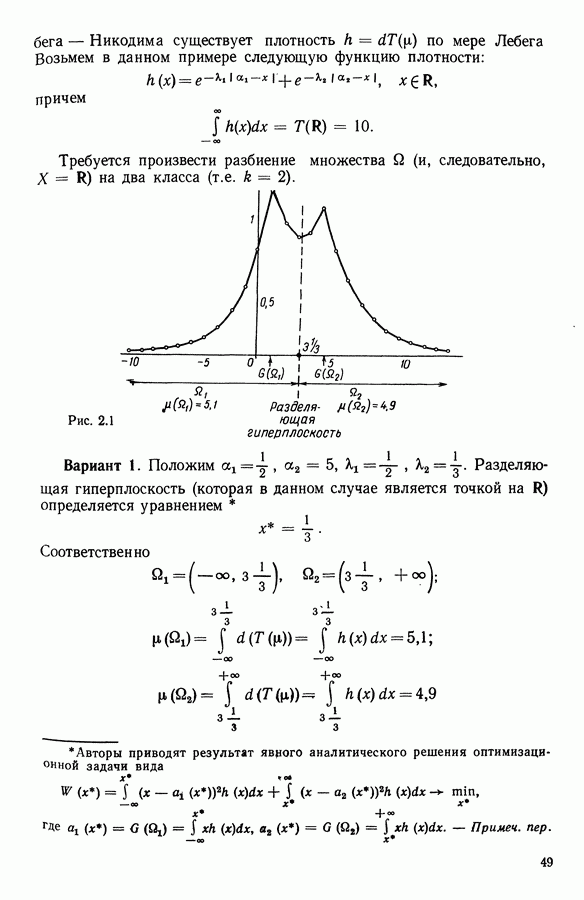
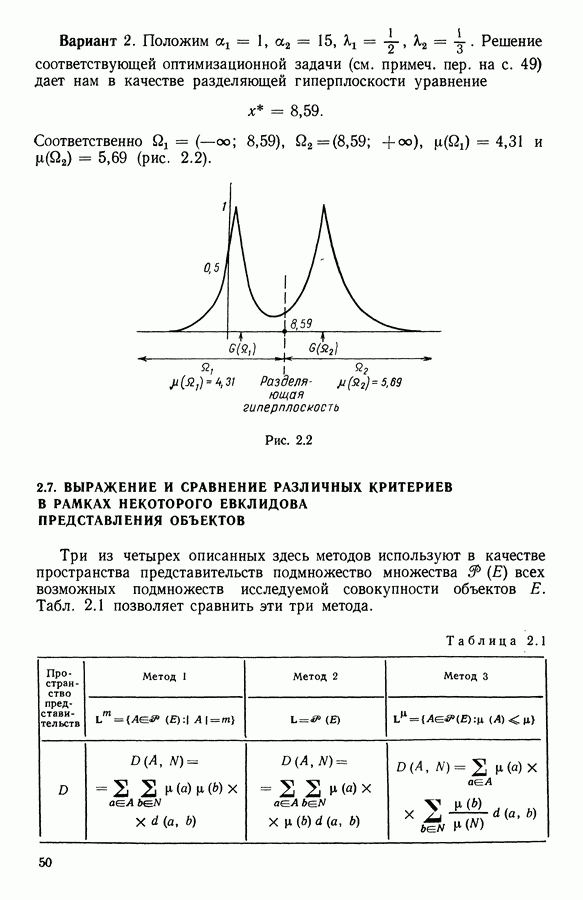















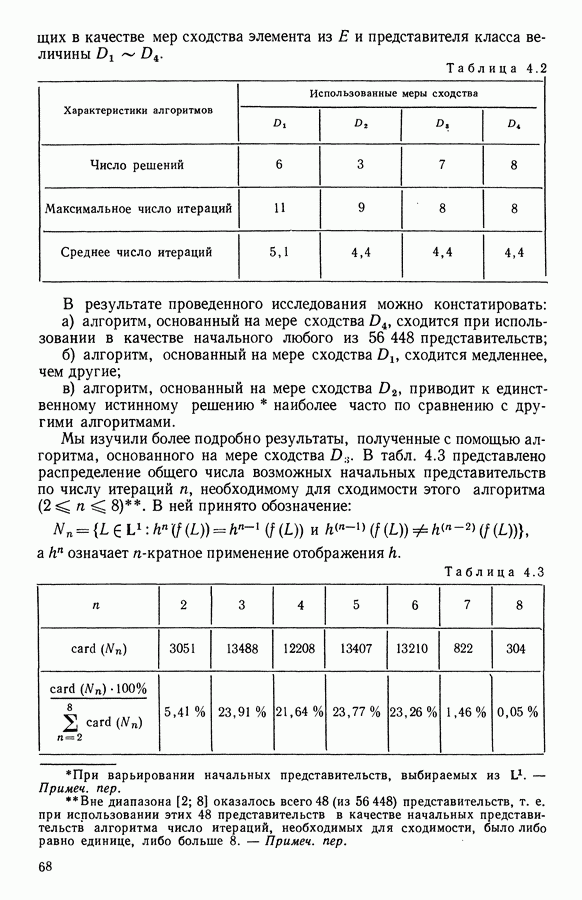
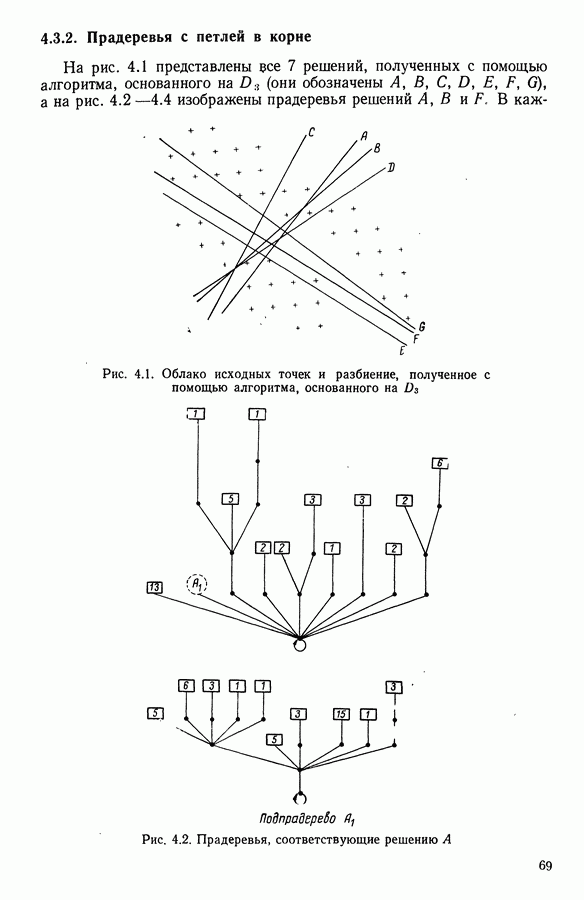
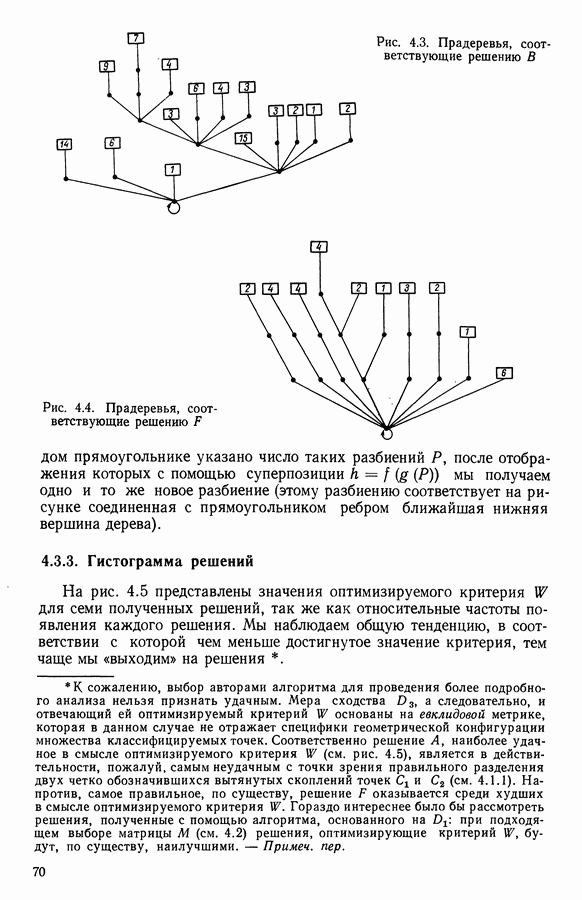
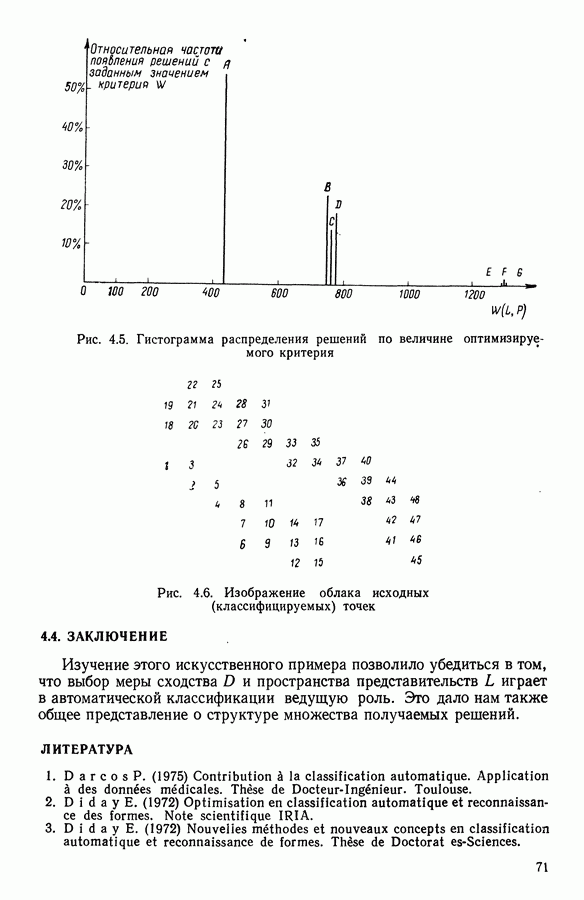
































































































































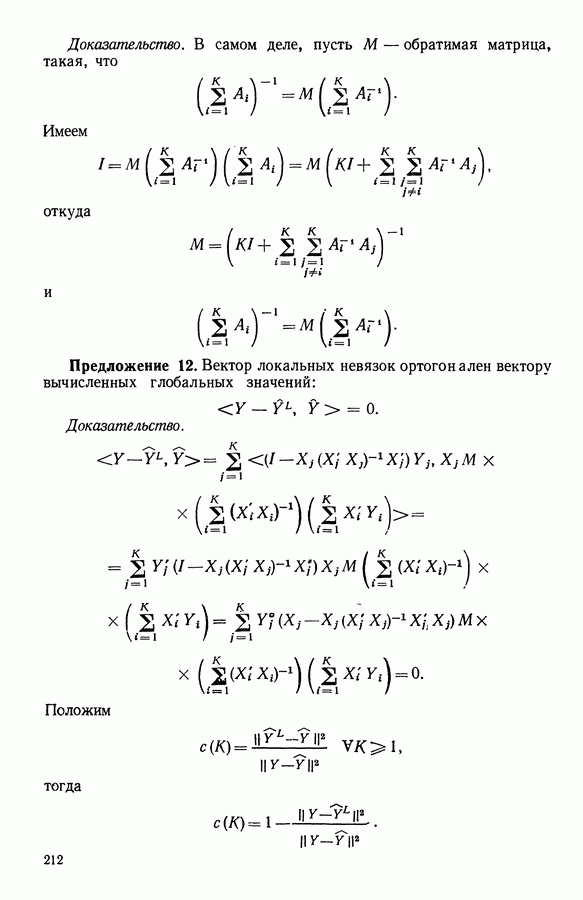



































































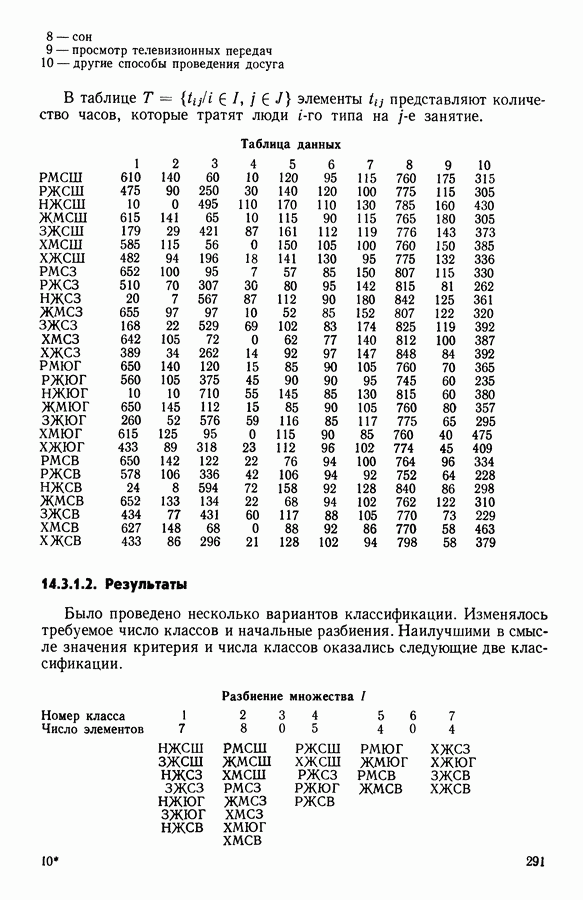
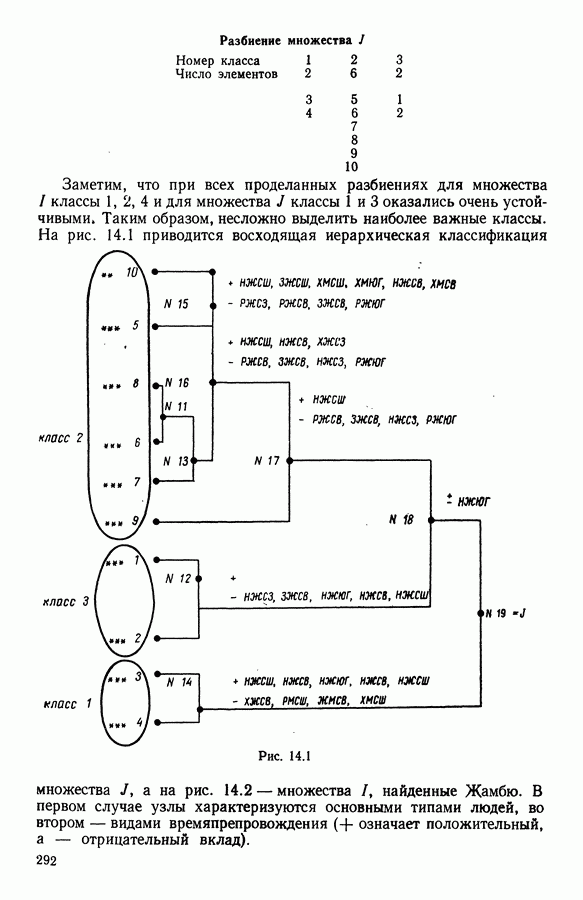
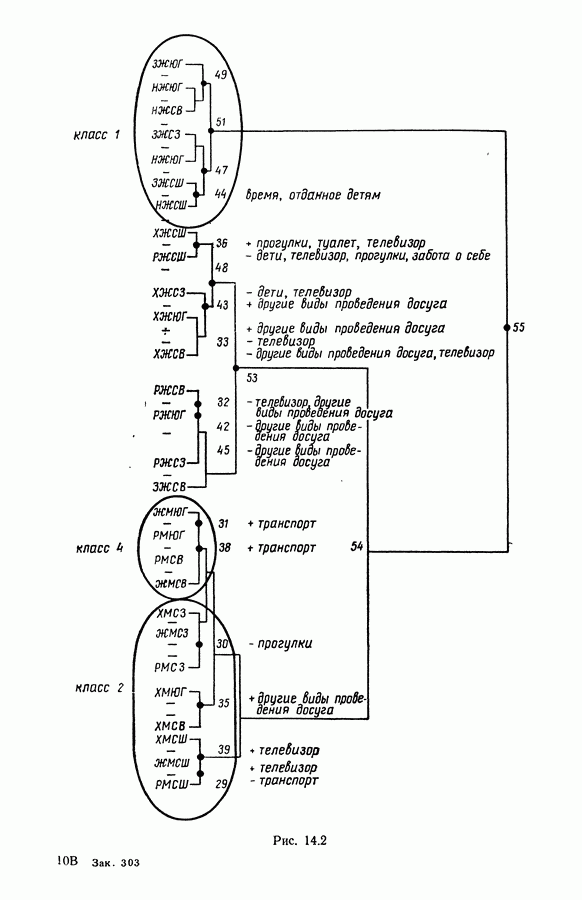


















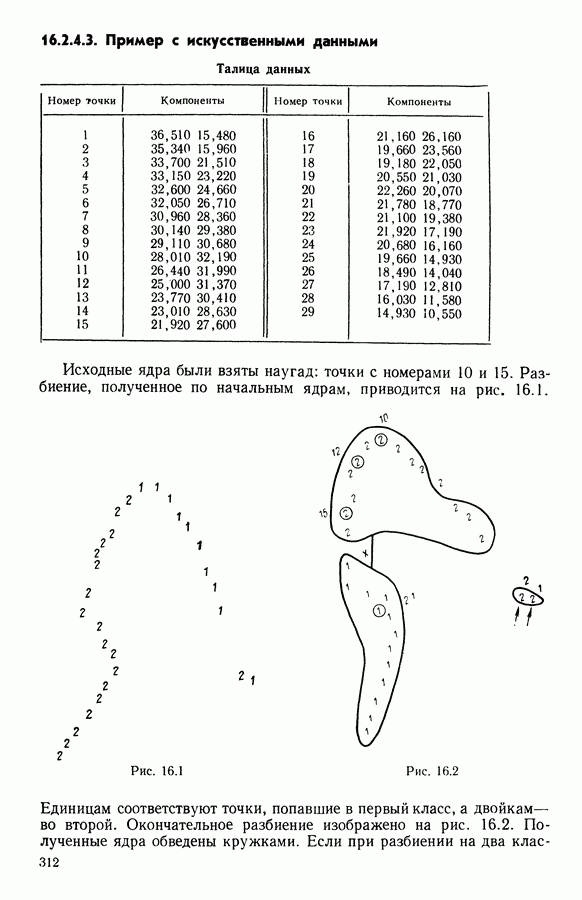














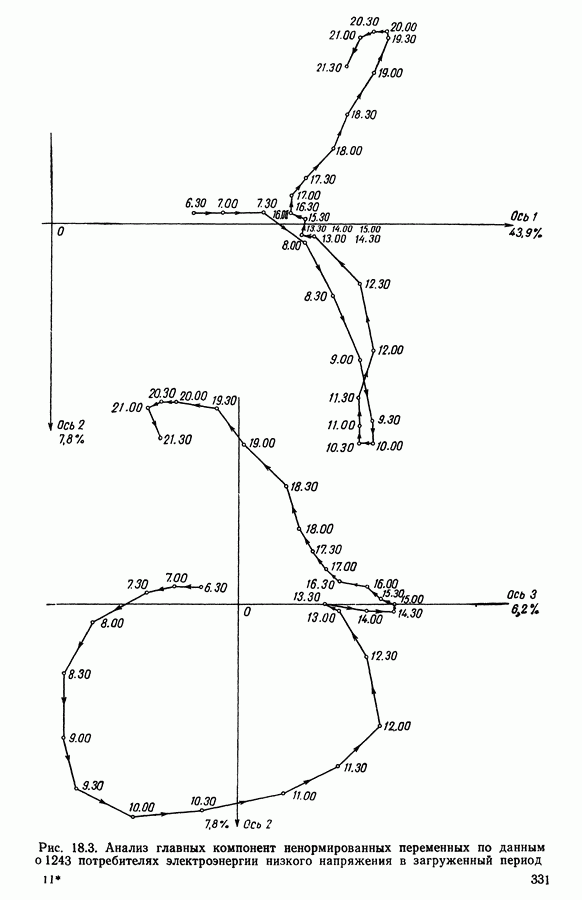


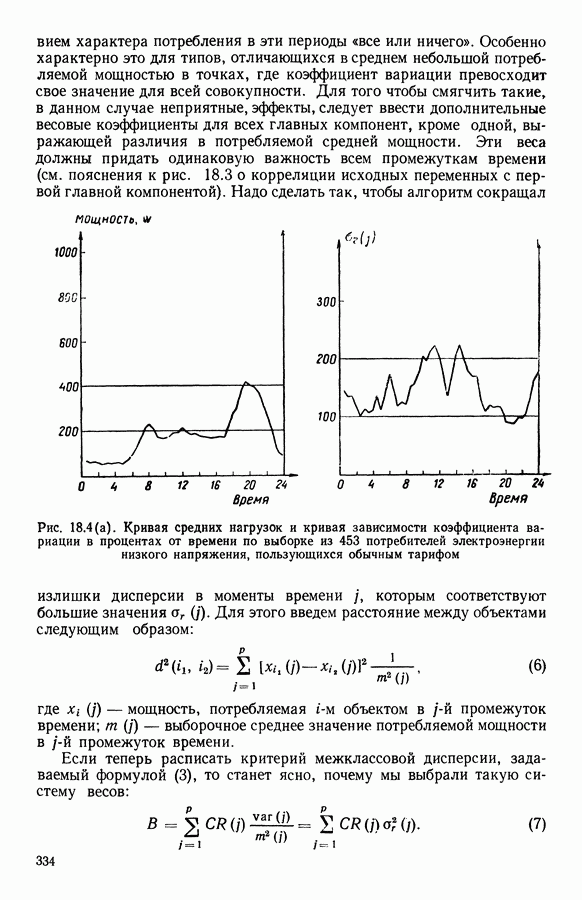
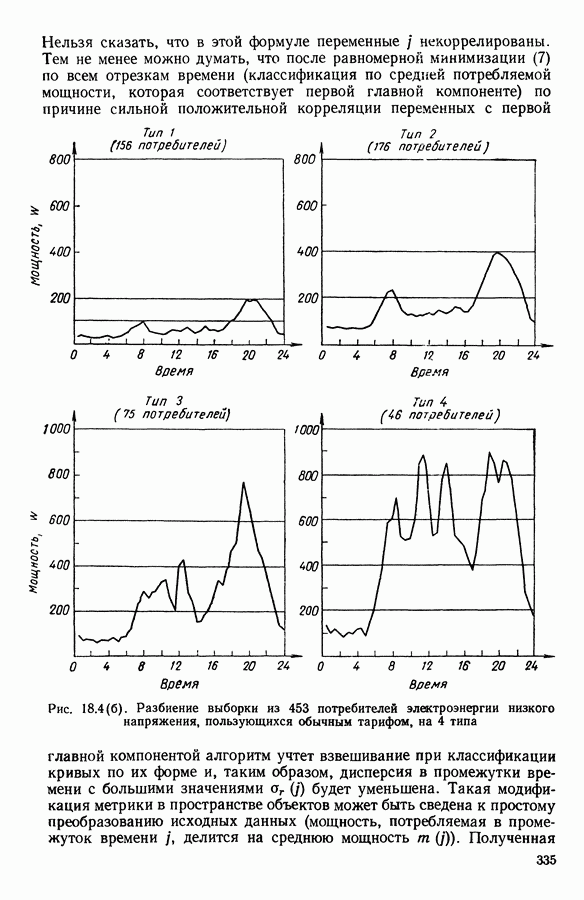
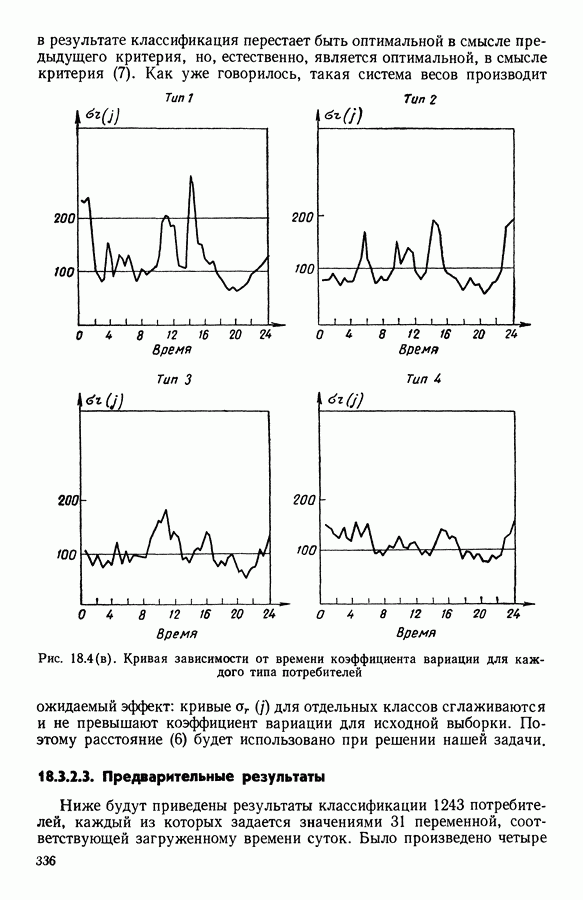







 и виды встал вопрос об автоматической классификации. Это проявилось, в частности, в работах Адансона [1], выполненных под руководством Бюффона (1747 г.)., И первой книгой, полностью посвященной автоматической классификации (после появления ЭВМ), мы обязаны натуралистам Сокалу и Сниту (1963 г.). Сдерживаемая в своем развитии громоздкостью вычислений автоматическая классификация должна была занять свое место в общем развитии методов анализа данных в связи с появлением ЭВМ. Сфера ее применения должна быть очень широкой, поскольку она охватывает все области, в которых аккумулируются большие объемы данных.
и виды встал вопрос об автоматической классификации. Это проявилось, в частности, в работах Адансона [1], выполненных под руководством Бюффона (1747 г.)., И первой книгой, полностью посвященной автоматической классификации (после появления ЭВМ), мы обязаны натуралистам Сокалу и Сниту (1963 г.). Сдерживаемая в своем развитии громоздкостью вычислений автоматическая классификация должна была занять свое место в общем развитии методов анализа данных в связи с появлением ЭВМ. Сфера ее применения должна быть очень широкой, поскольку она охватывает все области, в которых аккумулируются большие объемы данных.
 Отнесение нового объекта к объектам одной из двух плоскостей (к той, к которой они ближе) дает возможность приписать ему соответствующие новые координаты (их число равно числу выбранных факторных осей), более точные, чем те, что он имел бы в глобальной факторной плоскости.
Отнесение нового объекта к объектам одной из двух плоскостей (к той, к которой они ближе) дает возможность приписать ему соответствующие новые координаты (их число равно числу выбранных факторных осей), более точные, чем те, что он имел бы в глобальной факторной плоскости.
 в распознавании рукописных букв; в действительности же он нашел себе применение при распознавании слов и в геологии.
в распознавании рукописных букв; в действительности же он нашел себе применение при распознавании слов и в геологии.