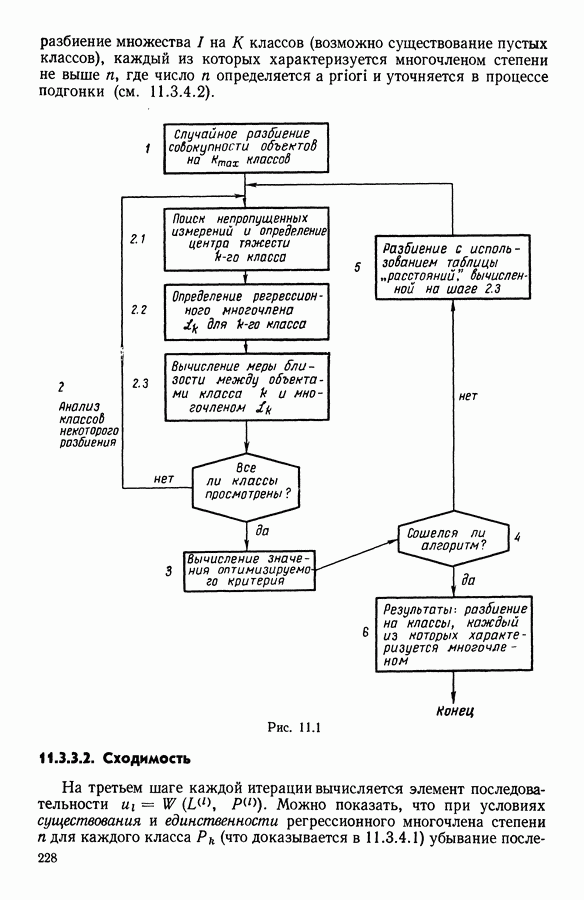
Пред.
След.
Макеты страниц
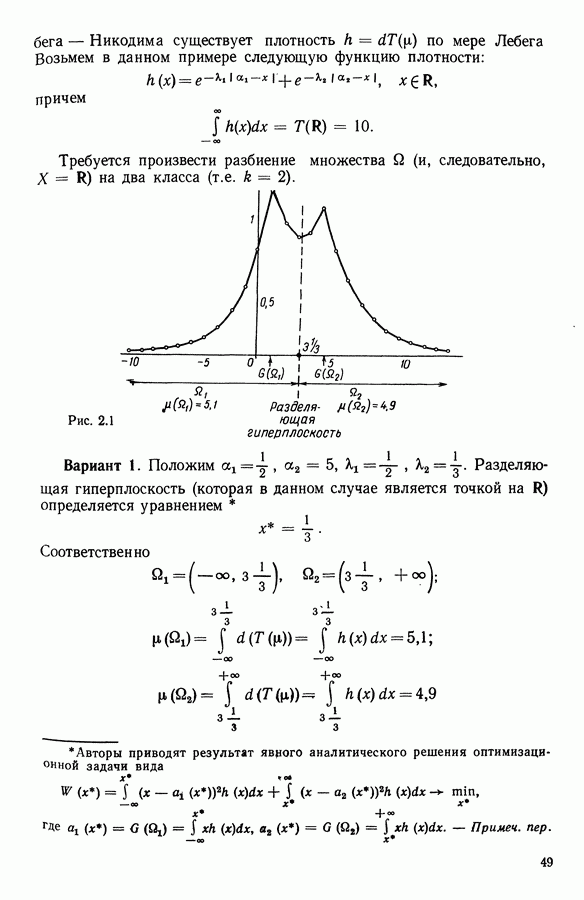
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Глава 12. АДАПТИВНЫЕ РАССТОЯНИЯ12.1. ВВЕДЕНИЕВ большинстве существующих алгоритмов используется единая мера сходства для всего множества 12.2. МЕТОД АДАПТИВНЫХ РАССТОЯНИЙ12.2.1. Пространство представительствОпределим пространство представительств
Мера сходства между подмножеством
Если 12.2.2. АлгоритмИспользуется общий алгоритм, описанный в гл. 1, применительно к введенному выше пространству представительств 12.2.2.1. Функция назначенияСледуя 1.2.4, определим функцию назначения Если
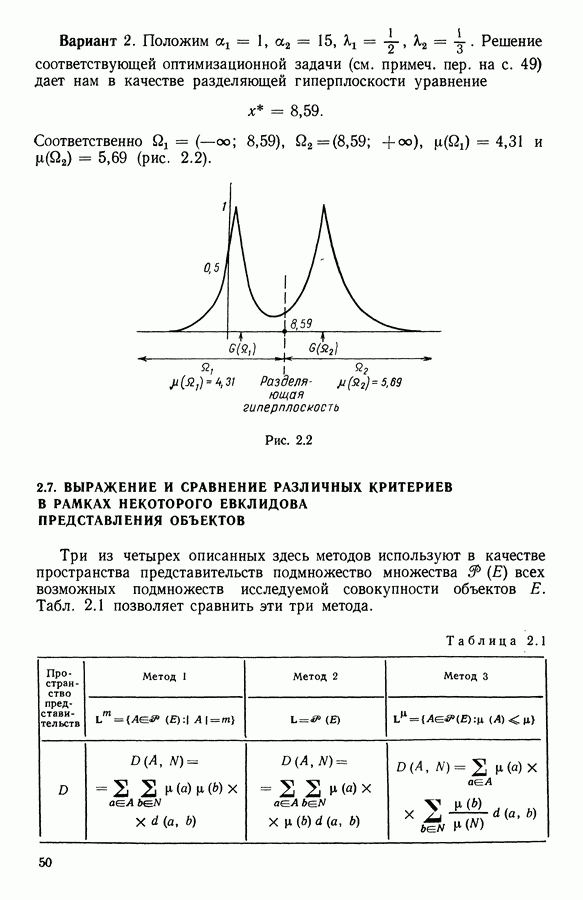
Поскольку
Таким образом, каждый класс 12.2.2.2. Функция представительстваСледуя 1.2.3, определим функцию представительства Если
Ниже будет раскрыт смысл пары Предложение. Если В — конечное подмножество
единственная, причем Это утверждение является следствием двух классических результатов. 1. Квадратичная метрика 2. Точка, относительно которой инерция множества В минимальна, совпадает с центром тяжести В. Это утверждение является следствием теоремы Гюйгенса. Отсюда, в частности, следует, что функция представительства будет ставить в соответствие разбиению 12.2.2.3. Свойства алгоритмаСходимость доказана для общего случая (см. 1.3.6). Критерий имеет вид
где Очевидно, что метрика не выбрана раз и навсегда, а определяется для каждого класса заново. Приведем другие выражения критерия. Используя свойства расстояния Махаланобиса, можно доказать следующие предложения. Предложение 1. Критерий (2) может быть записан в виде
где Доказательство. Критерий (2) является суммой инерций, а каждая инерция в метрике Махаланобиса равна Предложение 2. С помощью описанной процедуры определяются такие классы, для каждого из которых произведение дисперсий по главным осям инерции минимально. Доказательство. Можно заменить матрицы
Свойство инвариантности Предложение 3. Последовательность разбиений Доказательство. Известно, что при преобразовании базиса, задаваемом невырожденной матрицей 12.2.3. Случай необратимой ковариационной матрицы12.2.3.1. Постановка задачиОписываемый алгоритм на всех шагах итерации для каждого класса требует обращения соответствующей ковариационной матрицы. Это возможно тогда и только тогда, когда подпространство, порожденное каждым классом, имеет размерность Пусть на некотором шаге
Вклад Предложение 4. Если
Доказательство. Обозначим через X и вектор-столбцы пространства
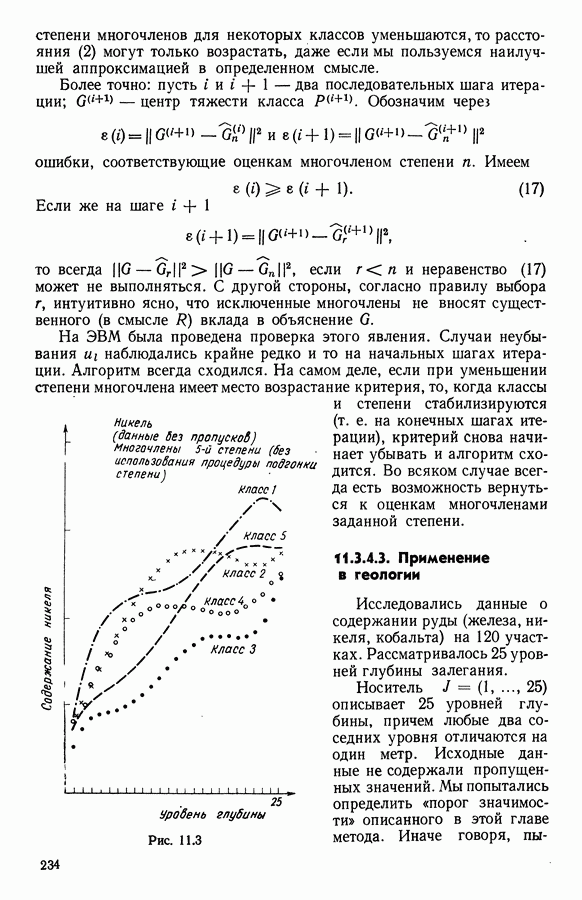
где
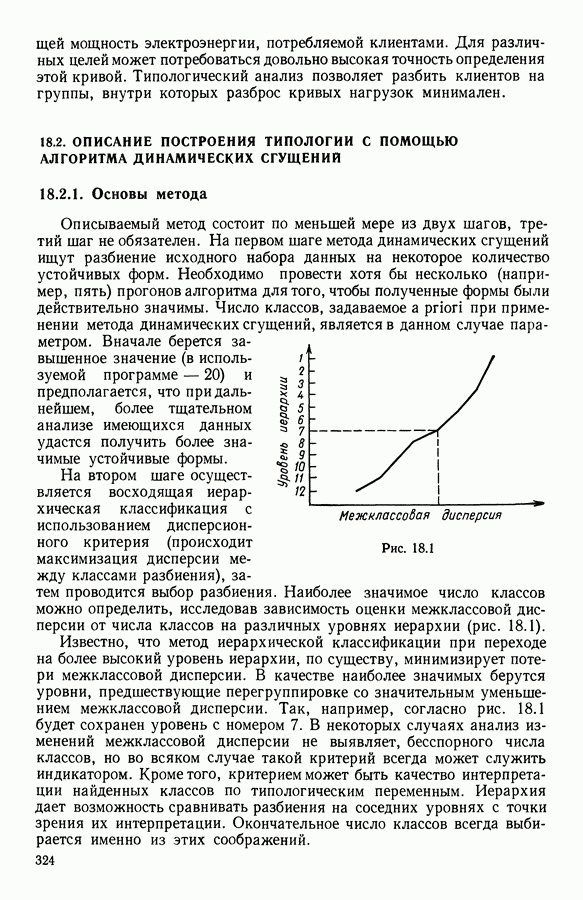
Согласно предположению матрица
С другой стороны, последние
Из равенства Следствие. Если матрица 12.2.3.2. РешениеПоскольку не существует расстояния, минимизирующего величину На предыдущем шаге вклад
Достаточно выбрать такое
и вклад
Будем действовать как при доказательстве предложения 4: заменяя
Обозначим через —
Будем искать матрицу
где
Матрица Определим расстояние где
Тогда
Таким образом, расстояние 12.2.4. Пример применения метода адаптивных расстояний12.2.4.1. Исходные данныеМы будем использовать данные из [4] и [8] для решения задачи оценивания смеси распределений. Имеется 150 точек, взятых из 3 двумерных нормальных распределений, определяемых средними
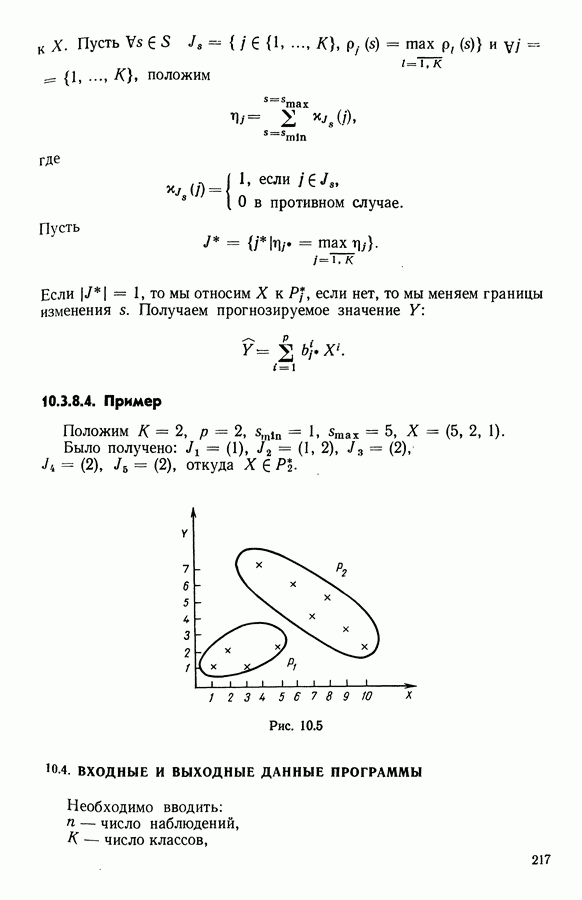
и ковариационными матрицами
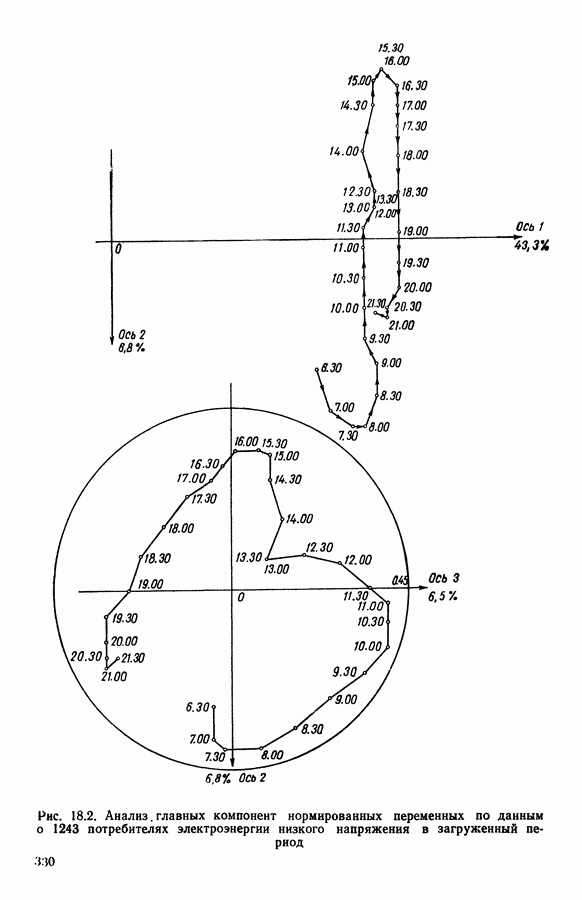
На рис. 12.2 представлено геометрическое изображение данных, на рис. 12.1 приводятся координаты элементов выборки. Первые 50 точек принадлежат первому распределению, точки с номерами 51—100 имеют распределение со средним
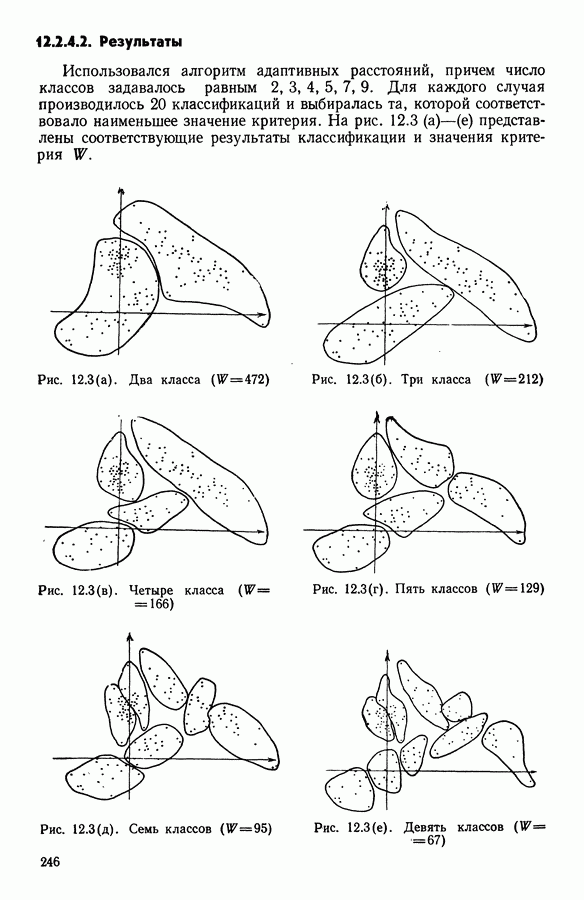
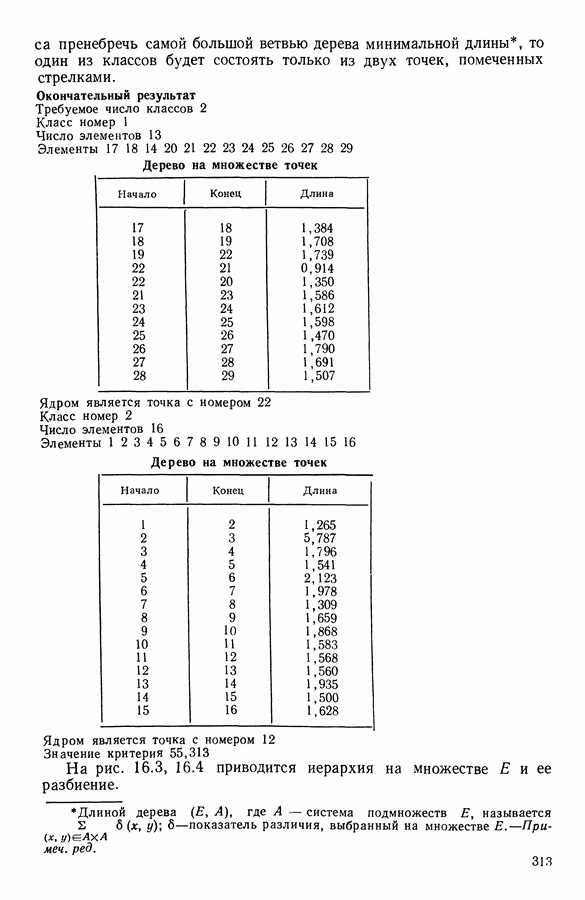
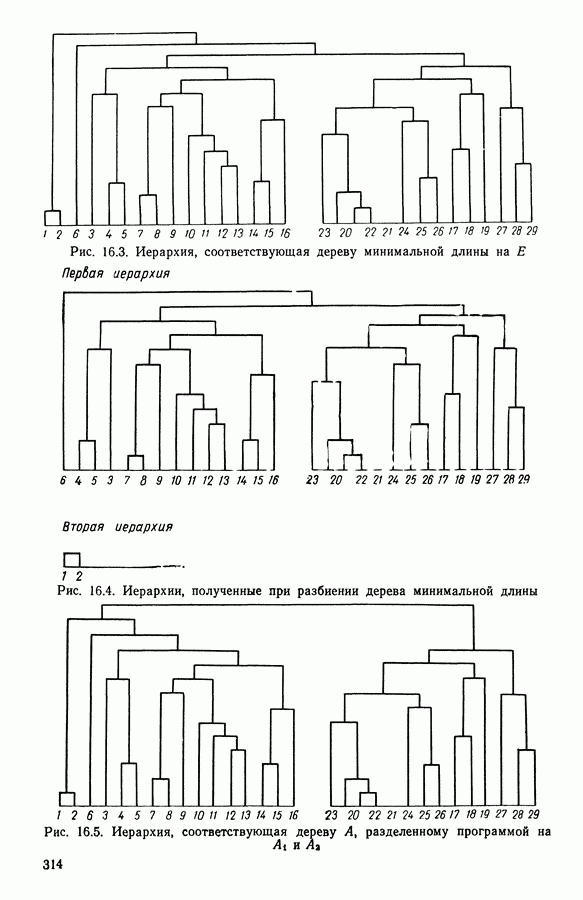
(кликните для просмотра скана) 12.2.4.2. РезультатыИспользовался алгоритм адаптивных расстояний, причем число классов задавалось равным 2, 3, 4, 5, 7, 9. Для каждого случая производилось 20 классификаций и выбиралась та, которой соответствовало наименьшее значение критерия. На рис. 12.3 (а)-(е) представлены соответствующие результаты классификации и значения критерия
Рис. 12.3(a). Два класса
Рис. 12.3(6). Три класса
Рис. 12.3(b). Четыре класса
Рис. 12.3(г). Пять классов
Рис. 12.3(д). Семь классов
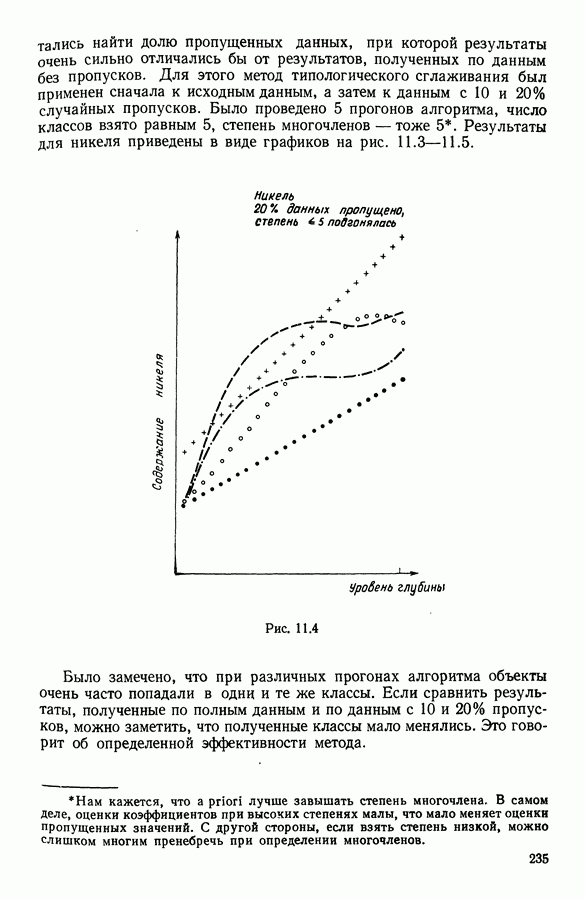
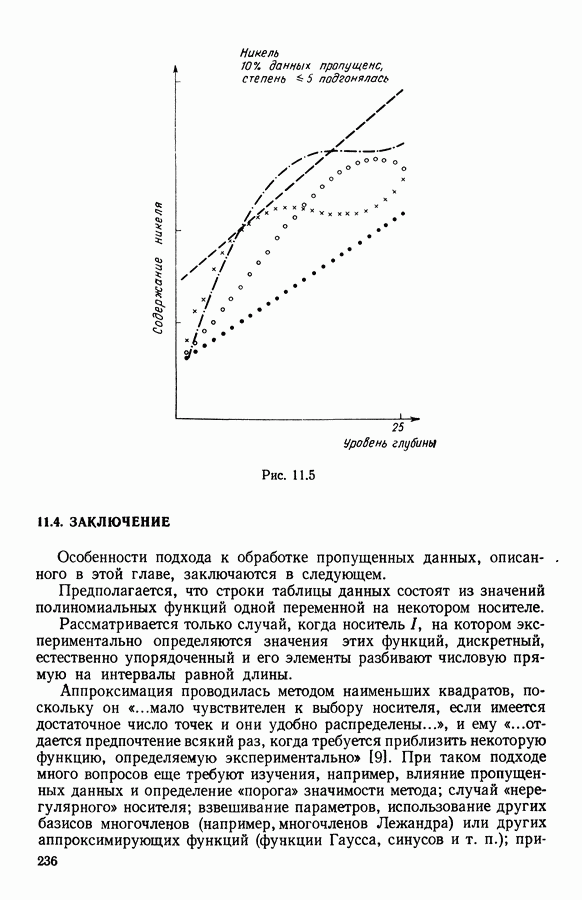
Рис. 12.3(e). Девять классов 12.2.4.3. Результаты, полученные методом динамических сгущений с использованием единого расстоянияЧисло классов было взято равным трем. Каждое представительство состояло из трех точек исходного множества. Использовалось евклидово расстояние. На рис. 12.4 приводится наилучшая из 20 классификаций.
Рис. 12.4. Метод динамических сгущений (расстояние фиксировано) 12.2.4.4. ЗаключениеСравним результаты двух методов. В случае адаптивного расстояния 3 элемента были ошибочно классифицированы, тогда как при применении обычного метода динамических сгущений число таких элементов равнялось 23 (точка считается ошибочно классифицированной, если после работы алгоритма она относится не к тому классу, из которого она выбрана). Здесь виден недостаток методов, в которых дисперсия вычисляется в единой метрике. Такие методы имеют склонность к выделению классов сферической формы. В описываемом примере данные сформированы из классов другого вида. Результаты показывают, что использование адаптивных расстояний помогает преодолеть этот недостаток. Заметим, что метод разделения смеси распределений [8] дает примерно те же результаты, что и метод адаптивных расстояний. В самом Деле, разница между двумя алгоритмами невелика и заключается только в вычислении расстояний: водном случае в качестве расстояния между точкой и парой
где
|
 |
Оглавление
|




























































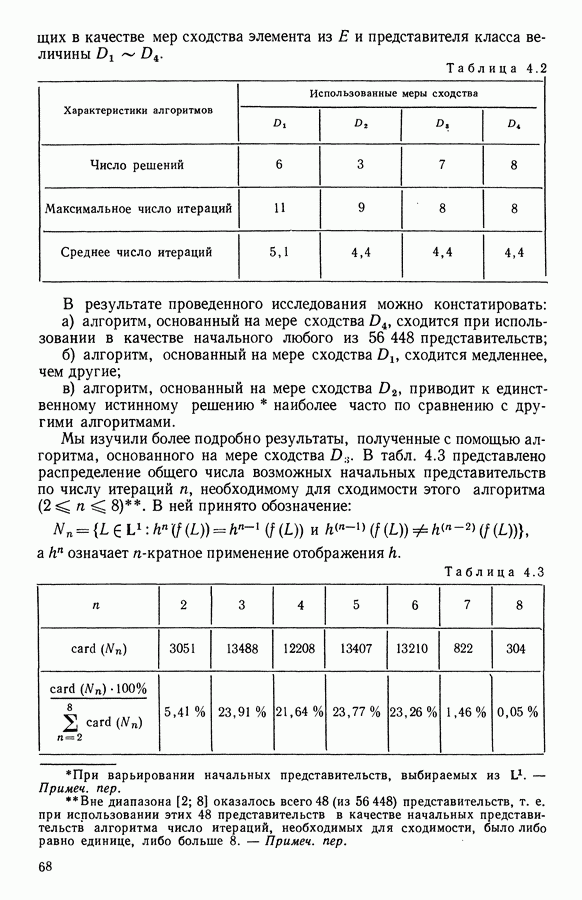
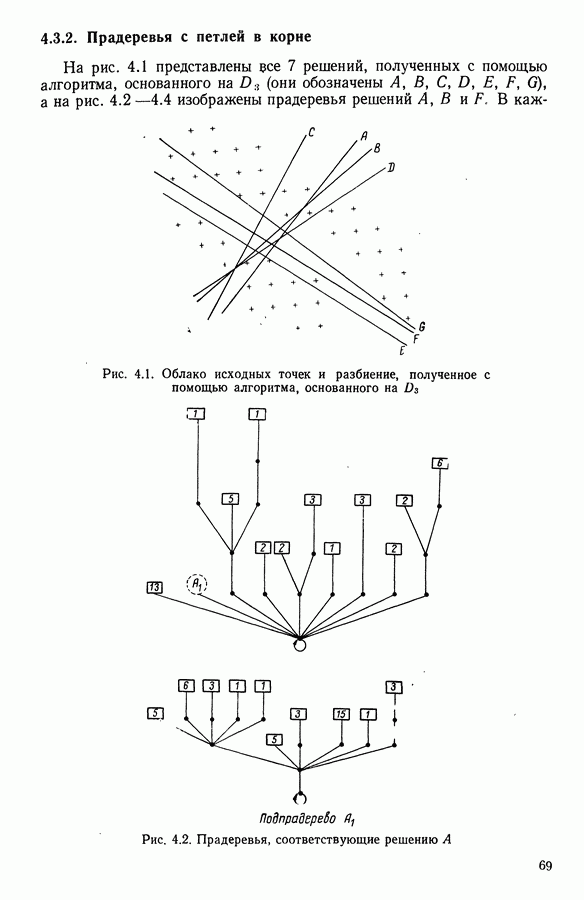
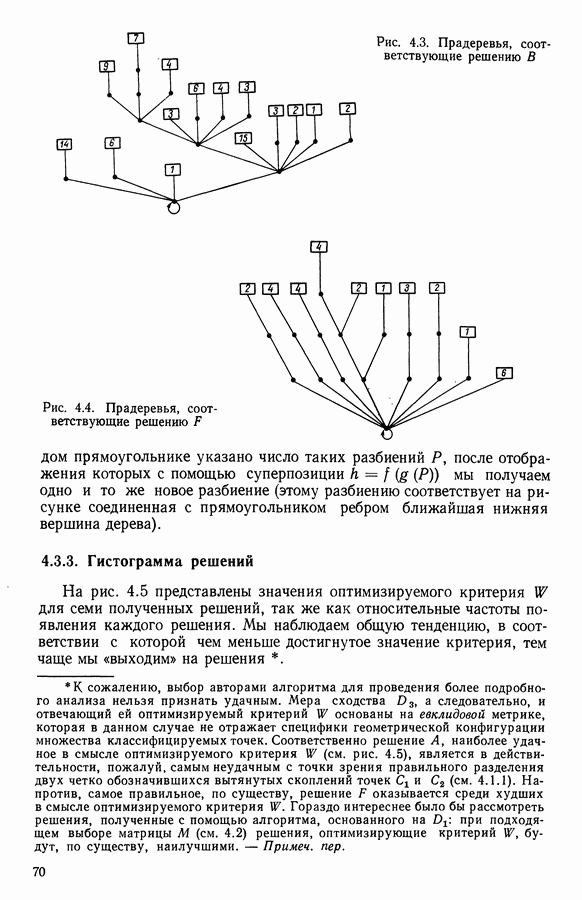
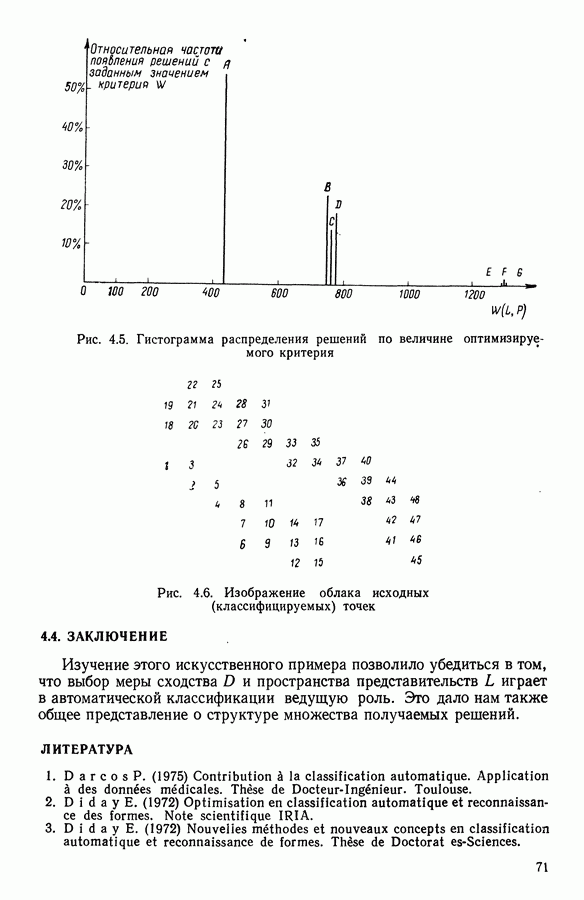





























































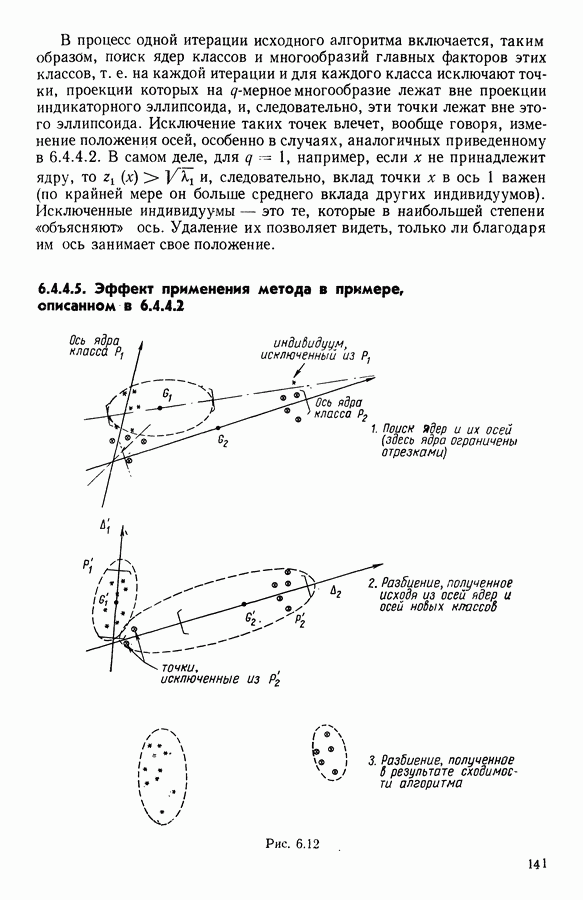




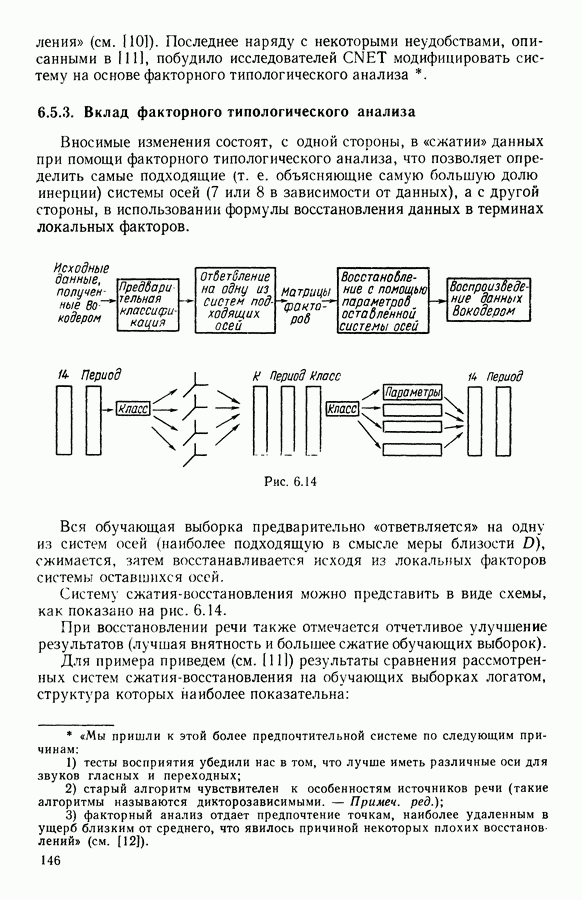



























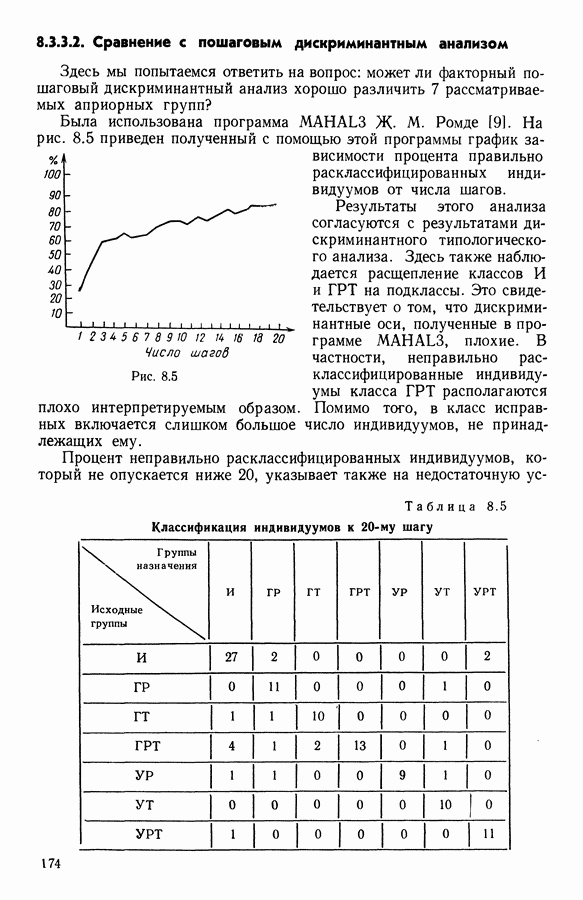




































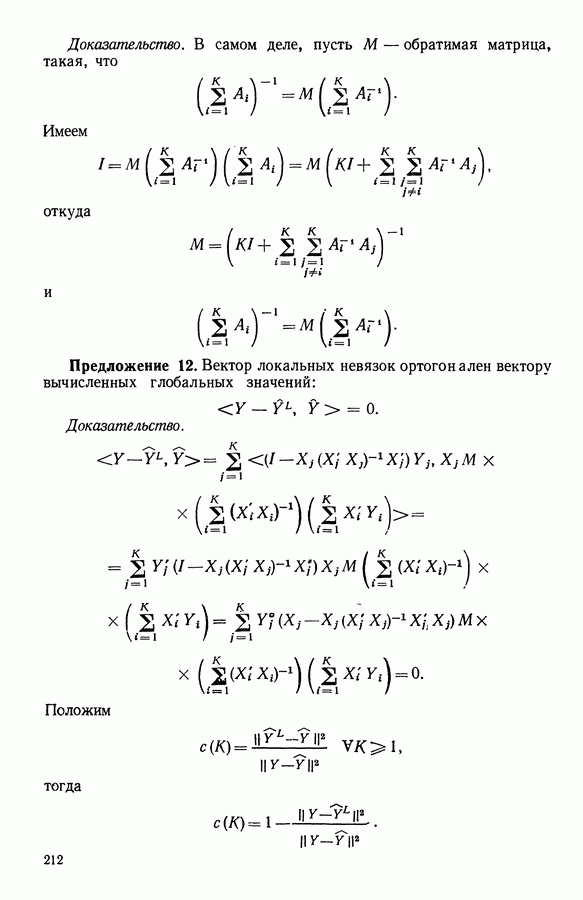



































































































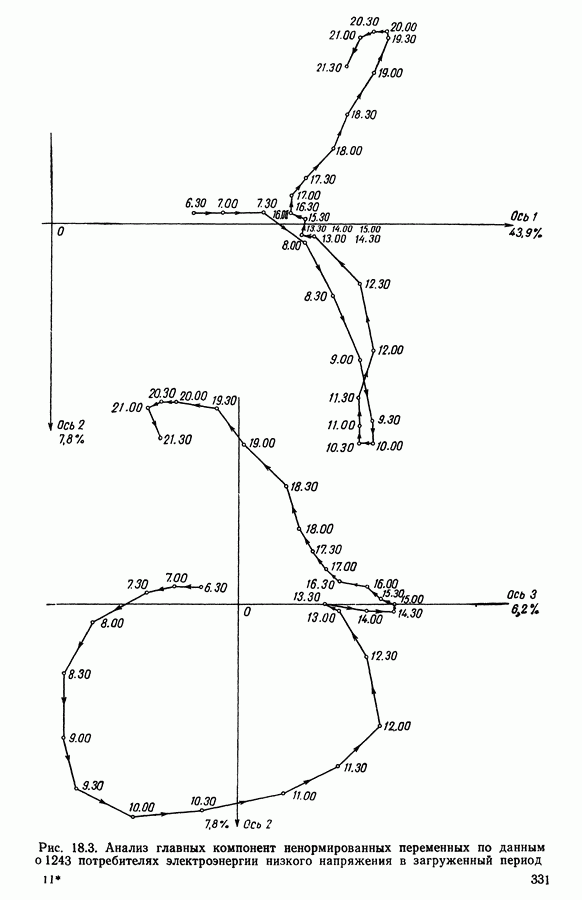


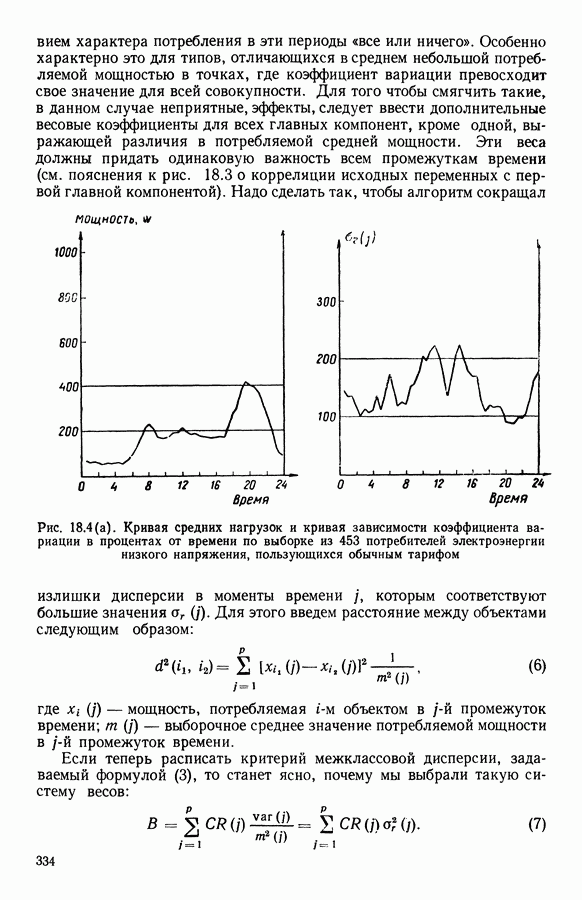
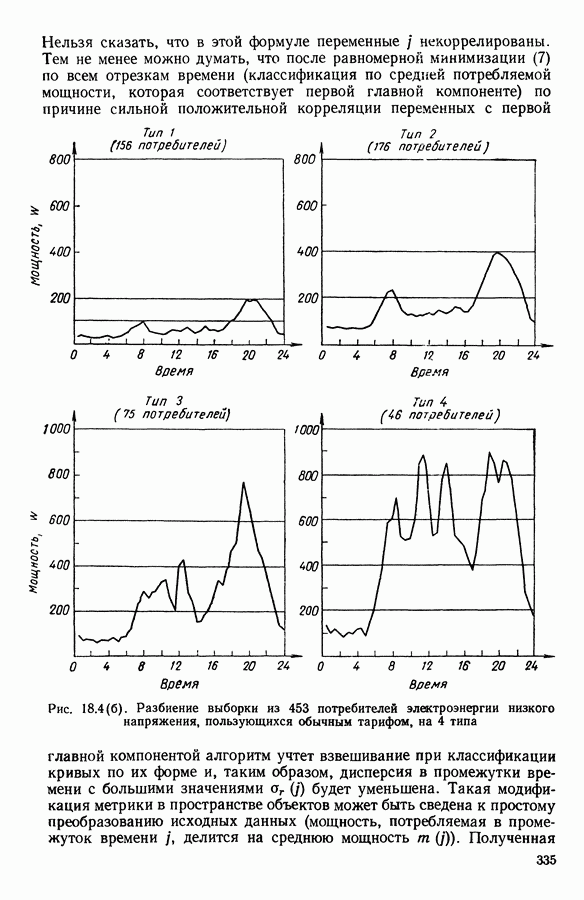
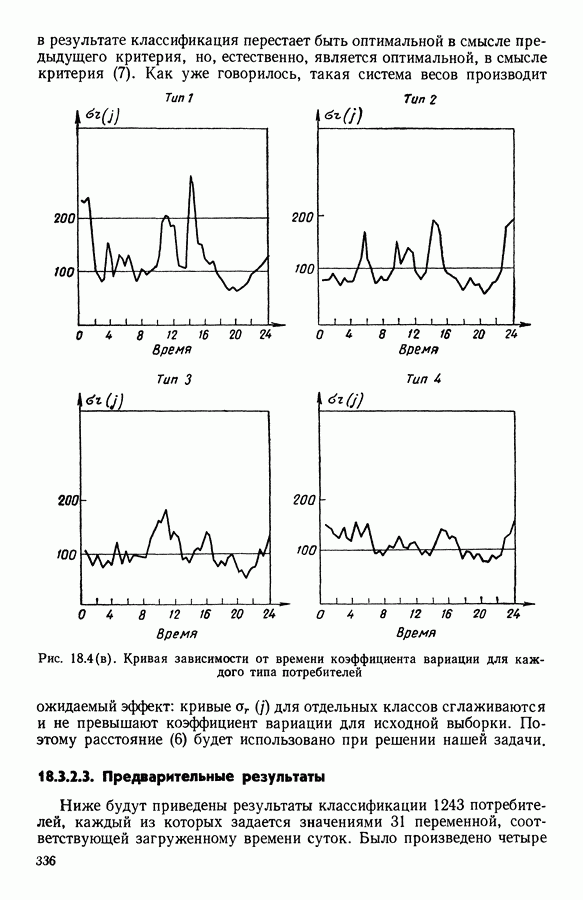







 и она не меняется во время работы алгоритма. В этой главе будет описан метод, в котором мера сходства локально приспосабливается к структуре пространства
и она не меняется во время работы алгоритма. В этой главе будет описан метод, в котором мера сходства локально приспосабливается к структуре пространства  оптимизируя некоторый критерий, выражающий степень этой приспособленности. При этом мера остается квадратичной функцией. Далее, в рамках более общего алгоритма в качестве расстояний рассматриваются и другие семейства функций.
оптимизируя некоторый критерий, выражающий степень этой приспособленности. При этом мера остается квадратичной функцией. Далее, в рамках более общего алгоритма в качестве расстояний рассматриваются и другие семейства функций.
 как прямое произведение:
как прямое произведение:  где
где  — множество квадратичных функций
— множество квадратичных функций  определяющих расстояния в
определяющих расстояния в  таких, что определители соответствующих матриц равны единице. Мера сходства
таких, что определители соответствующих матриц равны единице. Мера сходства  между элементами
между элементами  определяется соотношением
определяется соотношением

 состоящим из конечного числа элементов, и
состоящим из конечного числа элементов, и  задается соотношением
задается соотношением

 квадрат расстояния от точки а и элементы множества В имеют массу 1, то
квадрат расстояния от точки а и элементы множества В имеют массу 1, то  инерция множества В относительно точки а.
инерция множества В относительно точки а.

 как отображение
как отображение
 то
то  является разбиением
является разбиением  где
где

 можно записать так:
можно записать так:

 состоит из элементов
состоит из элементов  расстояние от которых до а, измеренное функцией
расстояние от которых до а, измеренное функцией  меньше, чем до любой другой точки
меньше, чем до любой другой точки  измеренное с помощью
измеренное с помощью 
 как отображение
как отображение 
 некоторое разбиение
некоторое разбиение  на
на  классов, то
классов, то  где
где  такое, что
такое, что


 то пара
то пара  определяемая из условия
определяемая из условия

 центр тяжести
центр тяжести  расстояние Махаланобиса, определяемое матрицей
расстояние Махаланобиса, определяемое матрицей  где
где  ковариационная матрица элементов В (в дальнейшем будем называть
ковариационная матрица элементов В (в дальнейшем будем называть  расстоянием Махаланобиса, ассоциированным с В).
расстоянием Махаланобиса, ассоциированным с В).
 определяемая матрицей с единичным определителем и минимизирующая инерцию множества В, состоящего из элементов
определяемая матрицей с единичным определителем и минимизирующая инерцию множества В, состоящего из элементов  является расстоянием Махаланобиса, ассоциированным с В, и задается матрицей
является расстоянием Махаланобиса, ассоциированным с В, и задается матрицей  (доказательство приводится в приложении 1.
(доказательство приводится в приложении 1.
 последовательность
последовательность  в которой
в которой  где
где  центр тяжести класса
центр тяжести класса  расстояние Махаланобиса, ассоциированное с
расстояние Махаланобиса, ассоциированное с 

 Минимизация (2) сводится к поиску пары
Минимизация (2) сводится к поиску пары  минимизирующей сумму инерций классов относительно точек а, измеренных в метриках
минимизирующей сумму инерций классов относительно точек а, измеренных в метриках 

 ковариационная матрица класса
ковариационная матрица класса 
 (см. [6]).
(см. [6]).
 в выражении (3) на
в выражении (3) на  полученные диагонализацией
полученные диагонализацией  так как
так как  Каждый элемент
Каждый элемент  матрицы
матрицы  равен дисперсии класса
равен дисперсии класса  относительно
относительно  главной оси инерции, т. е.
главной оси инерции, т. е.  (см. приложение 2). Следовательно,
(см. приложение 2). Следовательно,

 полученная в результате применения описываемого алгоритма к некоторому начальному разбиению
полученная в результате применения описываемого алгоритма к некоторому начальному разбиению  инвариантна относительно выбора базиса в пространстве
инвариантна относительно выбора базиса в пространстве  содержащем множество классифицируемых объектов
содержащем множество классифицируемых объектов 
 значение расстояния Махаланобиса, ассоциированного с некоторым подмножеством из
значение расстояния Махаланобиса, ассоциированного с некоторым подмножеством из  умножается на
умножается на  Доказательство этого факта приводится в приложении 3. Таким образом, в процессе работы описываемого алгоритма значения всех расстояний умножаются на
Доказательство этого факта приводится в приложении 3. Таким образом, в процессе работы описываемого алгоритма значения всех расстояний умножаются на  но это не меняет получаемых разбиений.
но это не меняет получаемых разбиений.
 иначе говоря, линейная оболочка векторов, принадлежащих любому из классов, должна совпадать с
иначе говоря, линейная оболочка векторов, принадлежащих любому из классов, должна совпадать с  Если, например, какой-нибудь класс состоит меньше чем из
Если, например, какой-нибудь класс состоит меньше чем из  элементов, то это условие не выполняется. Мы покажем, что в таком случае не существует расстояния, минимизирующего критерий, и что при некоторых дополнительных ограничениях задача может быть решена с сохранением сходимости алгоритма.
элементов, то это условие не выполняется. Мы покажем, что в таком случае не существует расстояния, минимизирующего критерий, и что при некоторых дополнительных ограничениях задача может быть решена с сохранением сходимости алгоритма.
 имеется разбиение и требуется вычислить
имеется разбиение и требуется вычислить  Если
Если  то
то  где — центр тяжести класса
где — центр тяжести класса  а расстояние
а расстояние  определяется матрицей
определяется матрицей  Критерий может быть записан в виде
Критерий может быть записан в виде

 класса в значение критерия на предыдущем шаге равен
класса в значение критерия на предыдущем шаге равен  Если матрица
Если матрица  обратима, то функция
обратима, то функция  классу
классу  ставит в соответствие пару
ставит в соответствие пару  минимизирующую
минимизирующую  В этом случае можно быть уверенным в уменьшении вклада
В этом случае можно быть уверенным в уменьшении вклада  класса в значение минимизируемого критерия.
класса в значение минимизируемого критерия.
 нельзя обратить, то
нельзя обратить, то  такое, что
такое, что

 соответствующие
соответствующие  Пусть
Пусть  тогда имеем
тогда имеем

 матрица, определяющая
матрица, определяющая  По определению
По определению

 необратима, значит, векторы
необратима, значит, векторы  принадлежат некоторому векторному подпространству
принадлежат некоторому векторному подпространству  размерности
размерности  Введем с помощью матрицы
Введем с помощью матрицы  такое преобразование базиса, чтобы первые
такое преобразование базиса, чтобы первые  векторов составляли базис в
векторов составляли базис в  а оставшиеся
а оставшиеся  были
были  -ортогональны первым. Пусть
-ортогональны первым. Пусть  и X в новом базисе соответствуют
и X в новом базисе соответствуют  т. е.
т. е.  Метрика
Метрика  в новом базисе будет задаваться матрицей
в новом базисе будет задаваться матрицей  В силу того, что векторы нового базиса образуют два ортогональных подпространства, матрица
В силу того, что векторы нового базиса образуют два ортогональных подпространства, матрица  состоит из двух блоков:
состоит из двух блоков:

 координат у всех векторов
координат у всех векторов  равны нулю, поскольку такие векторы принадлежат
равны нулю, поскольку такие векторы принадлежат  Следовательно, при использовании формулы (5) для нового базиса действие
Следовательно, при использовании формулы (5) для нового базиса действие  сводится к блоку В. Расстояние можно задать матрицей
сводится к блоку В. Расстояние можно задать матрицей  где
где

 следует
следует  а значит,
а значит,  Отсюда вытекает (4).
Отсюда вытекает (4).
 не является обратимой, то не существует расстояния, минимизирующего
не является обратимой, то не существует расстояния, минимизирующего 
 возьмем в качестве
возьмем в качестве  расстояние из
расстояние из  улучшающее вклад
улучшающее вклад  класса в критерий. Таким образом, мы ограничиваемся подпространством
класса в критерий. Таким образом, мы ограничиваемся подпространством  порожденным классом
порожденным классом  и выбираем в
и выбираем в  наилучшее расстояние с определителем, равным определителю матрицы, индуцирующей расстояние
наилучшее расстояние с определителем, равным определителю матрицы, индуцирующей расстояние  Затем мы продолжаем такое расстояние на все пространство
Затем мы продолжаем такое расстояние на все пространство  так, чтобы определитель полученной матрицы был равен единице.
так, чтобы определитель полученной матрицы был равен единице.
 класса в критерий был равен
класса в критерий был равен  Везде будем полагать
Везде будем полагать  равным центру тяжести класса
равным центру тяжести класса  Таким образом,
Таким образом,

 чтобы
чтобы

 класса в критерий будет улучшен. Имеем
класса в критерий будет улучшен. Имеем

 на воспользуемся таким преобразованием
на воспользуемся таким преобразованием  базиса, при котором
базиса, при котором  будет определяться матрицей
будет определяться матрицей  представимой в виде
представимой в виде

 -мерный вектор, состоящий только из
-мерный вектор, состоящий только из  первых координат — X (оставшиеся
первых координат — X (оставшиеся  координат равны нулю):
координат равны нулю):

 минимизирующую выражение (6). Согласно приложению 1 имеем
минимизирующую выражение (6). Согласно приложению 1 имеем


 обратима, поскольку линейная оболочка векторов
обратима, поскольку линейная оболочка векторов  совпадает с
совпадает с 
 такой матрицей
такой матрицей  что
что 


 улучшает вклад
улучшает вклад  класса в критерий.
класса в критерий.


 и второй ковариационной матрицей, а последние 50 точек принадлежат третьему классу.
и второй ковариационной матрицей, а последние 50 точек принадлежат третьему классу.















 берется
берется  а в другом —
а в другом —

 матрица, определяющая расстояние
матрица, определяющая расстояние  Однако применение этих двух методов, во-первых, к неквадратичным расстояниям (например
Однако применение этих двух методов, во-первых, к неквадратичным расстояниям (например  во-вторых, к распределениям, не являющимся нормальными (к гамма-распределению), приводит к совершенно различным результатам.
во-вторых, к распределениям, не являющимся нормальными (к гамма-распределению), приводит к совершенно различным результатам.